21 ਅਗ 2025·8 ਮਿੰਟ
6 SQL JOINs ਜੋ ਤੁਹਾਨੂੰ ਪਤਾ ਹੋਣੇ ਚਾਹੀਦੇ (ਸਰਲ, ਸਪਸ਼ਟ ਉਦਾਹਰਨਾਂ)
INNER, LEFT, RIGHT, FULL OUTER, CROSS ਅਤੇ SELF ਸਮੇਤ 6 ਅਹੰਕਾਰਪੂਰਕ SQL JOINs ਸਿੱਖੋ—ਸਰਲ ਉਦਾਹਰਨਾਂ ਅਤੇ ਆਮ pitfalls ਨਾਲ।
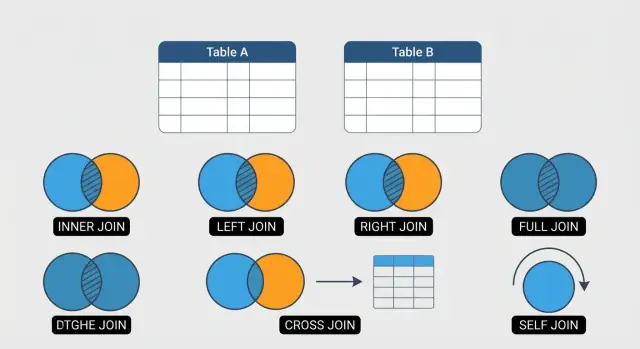
INNER, LEFT, RIGHT, FULL OUTER, CROSS ਅਤੇ SELF ਸਮੇਤ 6 ਅਹੰਕਾਰਪੂਰਕ SQL JOINs ਸਿੱਖੋ—ਸਰਲ ਉਦਾਹਰਨਾਂ ਅਤੇ ਆਮ pitfalls ਨਾਲ।
SQL JOIN ਤੁਹਾਨੂੰ ਦੋ (ਜਾਂ ਵੱਧ) ਟੇਬਲਾਂ ਦੀਆਂ ਕਤਾਰਾਂ ਨੂੰ ਇੱਕ ਨਤੀਜੇ ਵਿੱਚ ਮਿਲਾ ਕੇ ਵੇਖਣ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ, ਬਹੁਤ ਵਾਰੀ ਇੱਕ ਸੰਬੰਧਿਤ ਕਾਲਮ — ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ID — ਦੇ ਆਧਾਰ 'ਤੇ।
ਅਧਿਕਤਰ ਅਸਲ ਡੇਟਾਬੇਸ ਸੂਚਨਾ ਨੂੰ ਵੱਖ-ਵੱਖ ਟੇਬਲਾਂ ਵਿੱਚ ਤੋੜ ਕੇ ਰੱਖਦੇ ਹਨ ਤਾਂ ਕਿ ਇੱਕੋ ਹੀ ਜਾਣਕਾਰੀ ਬਾਰ-ਬਾਰ ਨਾਂ ਲਿਖਨੀ ਪਏ। ਉਦਾਹਰਨ ਵਜੋਂ, ਗਾਹਕ ਦਾ ਨਾਮ customers ਟੇਬਲ ਵਿੱਚ ਹੁੰਦਾ ਹੈ, ਜਦਕਿ ਉਸਦੇ ਖਰੀਦ orders ਵਿੱਚ ਹੁੰਦੇ ਹਨ। JOINs ਉਹ ਤਰੀਕਾ ਹਨ ਜਿਹੜੇ ਤੁਹਾਨੂੰ ਜਵਾਬ ਲੱਭਣ ਲਈ ਇਹਨਾਂ ਹਿੱਸਿਆਂ ਨੂੰ ਮੁੜ ਜੋੜਨ ਦਿੰਦੇ ਹਨ।
ਇਸ ਲਈ JOINs ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਵਿੱਚ ਹਰ ਜਗ੍ਹਾ ਵਰਤੀ ਜਾਂਦੀਆਂ ਹਨ:
JOINs ਦੇ ਬਗੈਰ, ਤੁਹਾਨੂੰ ਵੱਖ-ਵੱਖ ਕੁਏਰੀਆਂ ਚਲਾਕੇ ਨਤੀਜੇ ਮੈਨੂਅਲੀ ਤਰੀਕੇ ਨਾਲ ਮਿਲਾਉਣੇ ਪੈਂਦੇ—ਧੀਮਾ, ਗਲਤੀਆਂ ਵਾਲਾ ਅਤੇ ਦੁਹਰਾਉਣਾ ਮੁਸ਼ਕਲ।
ਜੇ ਤੁਸੀਂ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਦੇ ਉੱਪਰ ਪ੍ਰੋਡਕਟ ਬਣਾ ਰਹੇ ਹੋ (ਡੈਸ਼ਬੋਰਡ, ਐਡਮਿਨ ਪੈਨਲ, ਇੰਟਰਨਲ ਟੂਲ, ਕਸਟਮਰ ਪੋਰਟਲ), JOINs ਉਹੀ ਹਨ ਜੋ “ਕੱਚੀਆਂ ਟੇਬਲਾਂ” ਨੂੰ ਯੂਜ਼ਰ-ਫੇਸਿੰਗ ਵਿਊਜ਼ ਵਿੱਚ ਬਦਲਦੇ ਹਨ। Platforms ਜਿਵੇਂ Koder.ai (ਜੋ chat ਤੋਂ React + Go + PostgreSQL ਐਪਜ ਬਣਾਉਂਦਾ ਹੈ) ਵੀ ਸਹੀ ਲਿਸਟ ਪੇਜ, ਰਿਪੋਰਟ ਅਤੇ reconciliation ਸਕ੍ਰੀਨਾਂ ਲਈ JOIN ਮੁੱਢ-ਸਿਧਾਂਤਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ—ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ ਲਾਜ਼ਮਤ ਨਹੀਂ ਗੁੰਮ ਹੁੰਦੀ, ਭਾਵੇਂ ਡਿਵੈਲਪਮੈਂਟ ਤੇਜ਼ ਹੋਵੇ।
ਇਹ ਗਾਈਡ ਛੇ JOINs 'ਤੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਕਰਦੀ ਹੈ ਜੋ ਰੋਜ਼ਾਨਾ SQL ਕੰਮ ਦਾ ਵੱਧਾ ਹਿੱਸਾ ਕਵਰ ਕਰਦੇ ਹਨ:
JOIN syntax ਬਹੁਤ ਜ਼ਿਆਦਾ SQL ਡੇਟਾਬੇਸਾਂ (PostgreSQL, MySQL, SQL Server, SQLite) ਵਿੱਚ ਸਮਾਨ ਹੁੰਦੀ ਹੈ। ਕੁਝ ਫਰਕ ਹੋ ਸਕਦੇ ਹਨ—ਖ਼ਾਸ ਕਰਕੇ FULL OUTER JOIN ਸਮਰਥਨ ਅਤੇ ਕੁਝ ਏਜ-ਕੇਸ ਵਿਵਹਾਰਾਂ 'ਤੇ—ਪਰ ਅਸਲੀ ਧਾਰਣਾ ਅਤੇ ਮੁੱਖ ਨਮੂਨੇ ਆਮ ਤੌਰ 'ਤੇ ਅਨੁਵਾਦ ਲਾਇਕ ਹਨ।
JOIN ਉਦਾਹਰਣਾਂ ਨੂੰ ਸਧਾਰਨ ਰੱਖਣ ਲਈ, ਅਸੀਂ ਤਿੰਨ ਛੋਟੀ ਟੇਬਲਾਂ ਵਰਤਾਂਗੇ ਜੋ ਆਮ ਵਰਲਡ ਸੈਟਅਪ ਦਰਸਾਉਂਦੀਆਂ ਹਨ: customers ਆਰਡਰ ਕਰਦੇ ਹਨ, ਅਤੇ ਆਰਡਰਾਂ ਦੇ ਭੁਗਤਾਨ ਹੋ ਸਕਦੇ ਹਨ (ਜਾਂ ਨਹੀਂ ਵੀ)।
ਇੱਕ ਨੋਟ: ਹੇਠਾਂ ਦਿੱਤੀਆਂ ਨਮੂਨਾ ਟੇਬਲਾਂ 'ਚ ਸਿਰਫ ਕੁਝ ਕਾਲਮ ਦਿਖਾਏ ਗਏ ਹਨ, ਪਰ ਕੁਝ ਕੁਏਰੀਆਂ ਬਾਅਦ ਵਿੱਚ ਹੋਰ ਫੀਲਡਾਂ (ਜਿਵੇਂ order_date, created_at, status, ਜਾਂ paid_at) ਨੂੰ ਦਰਸਾਉਂਦੀਆਂ ਹਨ ਤਾ ਕਿ ਆਮ ਪੈਟਰਨ ਦਿਖਾਏ ਜਾ ਸਕਣ। ਉਹਨਾਂ ਕਾਲਮਾਂ ਨੂੰ ਉਤਪਾਦਨ ਸਕੀਮਾਂ ਵਿੱਚ ਆਮ ਫੀਲਡਾਂ ਵਜੋਂ ਸਮਝੋ।
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
ਧਿਆਨ ਦਿਓ order_id = 104 customer_id = 5 ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ, ਜੋ customers ਵਿੱਚ ਮੌਜੂਦ ਨਹੀਂ ਹੈ। ਇਹ “ਗਾਇਬ ਮੈਚ” ਇਹ ਵੇਖਣ ਲਈ ਉਪਯੋਗੀ ਹੈ ਕਿ LEFT, RIGHT ਅਤੇ FULL OUTER JOIN ਕਿਵੇਂ ਵਿਹਾਰ ਕਰਦੇ ਹਨ।
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
ਇੱਥੇ ਦੋ ਮਹੱਤਵਪੂਰਨ ਸਿਖਲਾਈ ਵਾਲੀਆਂ ਗੱਲਾਂ ਹਨ:
order_id = 102 ਦੇ ਦੋ payment rows ਹਨ (split payment). ਜਦੋਂ ਤੁਸੀਂ orders ਨੂੰ payments ਨਾਲ join ਕਰੋਗੇ, ਉਹ order ਦੋ ਵਾਰੀ ਦਿਖੇਗਾ—ਇਹ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ duplicates ਲੋਕਾਂ ਨੂੰ ਆਸ਼ਚਰਜ ਵਿੱਚ ਪਾ ਸਕਦੇ ਹਨ।payment_id = 9004 order_id = 999 ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ, ਜੋ orders ਵਿੱਚ ਮੌਜੂਦ ਨਹੀਂ ਹੈ। ਇਹ ਇਕ ਹੋਰ “unmatched” ਮਾਮਲਾ ਬਣਾਉਂਦਾ ਹੈ।orders ਨੂੰ payments ਨਾਲ join ਕਰਨ 'ਤੇ order 102 ਦੁਹਰਾਇਆ ਜਾਵੇਗਾ ਕਿਉਂਕਿ ਇਸਦੇ ਦੋ ਸੰਬੰਧਿਤ payments ਹਨ।INNER JOIN ਸਿਰਫ ਉਹੀ ਕਤਾਰਾਂ ਵਾਪਸ ਕਰਦਾ ਹੈ ਜਿੱਥੇ ਦੋਹਾਂ ਟੇਬਲਾਂ ਵਿੱਚ ਮੈਚ ਹੋਵੇ। ਜੇ ਕਿਸੇ ਗਾਹਕ ਦਾ ਕੋਈ ਆਰਡਰ ਨਹੀਂ, ਤਾਂ ਉਹ ਨਤੀਜੇ ਵਿੱਚ ਨਹੀਂ ਆਉਣਾ। ਜੇ ਕੋਈ ਆਰਡਰ ਕਿਸੇ ਮੌਜੂਦ ਗਾਹਕ ਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਦਾ ਹੈ (ਖ਼ਰਾਬ ਡੇਟਾ), ਉਹ ਵੀ ਨਤੀਜੇ ਤੋਂ ਬਾਹਰ ਰਹੇਗਾ।
ਤੁਸੀਂ ਇੱਕ “ਖੱਬੀ” ਟੇਬਲ ਚੁਣਦੇ ਹੋ, ਇੱਕ “ਸੱਜੀ” ਟੇਬਲ ਨੂੰ join ਕਰਦੇ ਹੋ, ਅਤੇ ON ਕਲਾਸ ਵਿੱਚ ਉਨ੍ਹਾਂ ਨੂੰ ਜੁੜਦੇ ਹੋ।
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
ਮੁੱਖ ਵਿਚਾਰ ON o.customer_id = c.customer_id ਲਾਈਨ ਹੈ: ਇਹ SQL ਨੂੰ ਦਸਦੀ ਹੈ ਕਿ ਕਿਵੇਂ ਕਤਾਰਾਂ ਸੰਬੰਧਿਤ ਹਨ।
ਜੇ ਤੁਸੀਂ ਉਹ ਗਾਹਕਾਂ ਦੀ ਲਿਸਟ ਚਾਹੁੰਦੇ ਹੋ ਜਿਨ੍ਹਾਂ ਨੇ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਆਰਡਰ ਦਿੱਤਾ (ਅਤੇ ਆਰਡਰ ਵੇਰਵੇ), ਤਾਂ INNER JOIN ਕੁਜ਼ੀ-ਛੁਟੀ ਚੋਣ ਹੈ:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
ਇਹ ਵਰਤੋਂਗੀਆਂ ਚੀਜ਼ਾਂ ਜਿਵੇਂ “order follow-up email ਭੇਜੋ” ਜਾਂ “revenue per customer ਗਣਨਾ” ਲਈ ਮਦਦਗਾਰ ਹੈ (ਜਦੋਂ ਤੁਸੀਂ ਸਿਰਫ ਖਰੀਦਦਾਰਾਂ 'ਤੇ ਧਿਆਨ ਦੇ ਰਹੇ ਹੋ)।
ਜੇ ਤੁਸੀਂ ON ਸ਼ਰਤ ਭੁੱਲ ਜਾਂ ਗਲਤ ਕਾਲਮ 'ਤੇ join ਕਰ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਗਲਤੀ ਨਾਲ ਇੱਕ Cartesian product (ਹਰ ਗਾਹਕ ਹਰ ਆਰਡਰ ਨਾਲ) ਬਣਾ ਸਕਦੇ ਹੋ ਜਾਂ ਨਰਮ matches ਬਣ ਸਕਦੇ ਹਨ।
ਬੁਰਾ (ਇਹ ਨਾ ਕਰੋ):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
ਹਮੇਸ਼ਾ ਸੁਨਿਸ਼ਚਿਤ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਕੋਲ ON (ਜਾਂ ਜਿੱਥੇ ਲਾਗੂ ਹੋਵੇ USING) ਵਿੱਚ ਸਪਸ਼ਟ join ਸ਼ਰਤ ਹੋਵੇ।
LEFT JOIN ਖੱਬੀ ਟੇਬਲ ਦੀਆਂ ਸਾਰੀ ਕਤਾਰਾਂ ਵਾਪਸ ਕਰਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਮੈਚ ਮਿਲੇ ਤਾਂ ਸੱਜੀ ਟੇਬਲ ਤੋਂ ਡੇਟਾ ਜੋੜਦਾ ਹੈ। ਜੇ ਮੈਚ ਨਹੀਂ ਮਿਲਦਾ, ਤਾਂ ਸੱਜੇ ਪਾਸੇ ਵਾਲੇ ਕਾਲਮ NULL ਦਿਖਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਆਪਣੀ ਪ੍ਰਾਇਮਰੀ ਟੇਬਲ ਦੀ ਪੂਰੀ ਲਿਸਟ ਚਾਹੁੰਦੇ ਹੋ ਅਤੇ ਸਬੰਧਿਤ ਵੱਕਲ ਡੇਟਾ ਜੇ ਉਪਲੱਬਧ ਹੋਵੇ ਤਾਂ ਸ਼ਾਮਲ ਕਰਨਾ ਹੋਵੇ।
ਉਦਾਹਰਨ: “ਮੇਨੂੰ ਸਾਰੇ ਗਾਹਕ ਦਿਖਾਓ, ਅਤੇ ਜੇ ਉਹਨਾਂ ਕੋਲ ਕੋਈ ਆਰਡਰ ਹੋਵੇ ਤਾਂ ਉਹ ਵੀ ਦਿਖਾਓ।”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (ਅਤੇ ਹੋਰ orders ਕਾਲਮ) NULL ਹੋਵੇਗਾ।LEFT JOIN ਵਰਤੋਂ ਦਾ ਇੱਕ ਬਹੁਤ ਆਮ ਕਾਰਨ ਉਹ ਆਈਟਮ ਲੱਭਣਾ ਹੈ ਜਿਹੜਿਆਂ ਦੇ ਸਬੰਧੀ ਰਿਕਾਰਡ ਨਹੀਂ ਹਨ।
ਉਦਾਹਰਨ: “ਕਿਹੜੇ ਗਾਹਕਾਂ ਨੇ ਕਦੇ ਵੀ ਆਰਡਰ ਨਹੀਂ ਕੀਤਾ?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
ਉਹ WHERE ... IS NULL ਸ਼ਰਤ ਸਿਰਫ ਉਹ ਖੱਬੇ-ਟੇਬਲ ਦੀਆਂ ਕਤਾਰਾਂ ਰੱਖਦੀ ਹੈ ਜਿੱਥੇ JOIN ਨੂੰ ਕੋਈ ਮੈਚ ਨਹੀਂ ਮਿਲਿਆ।
LEFT JOIN ਖੱਬੇ-ਟੇਬਲ ਦੀਆਂ ਕਤਾਰਾਂ ਨੂੰ ਅਕਸਰ ਦੁਹਰਾਉਂਦਾ ਹੈ ਜਦੋਂ ਸੱਜੇ ਪਾਸੇ ਕਈ ਮਿਲਦੇ ਹਨ।
ਜੇ ਇੱਕ ਗਾਹਕ ਕੋਲ 3 ਆਰਡਰ ਹਨ, ਤਾਂ ਉਹ ਗਾਹਕ 3 ਵਾਰੀ ਆਵੇਗਾ—ਹਰ ਆਰਡਰ ਲਈ ਇੱਕ ਵਾਰੀ। ਇਹ ਉਮੀਦਯੋਗ ਹੈ, ਪਰ ਜੇ ਤੁਸੀਂ ਗਾਹਕਾਂ ਨੂੰ ਗਿਣ ਰਹੇ ਹੋ ਤਾਂ ਇਹ ਹੈਰਾਨੀ ਵਾਲੀ ਗੱਲ ਹੋ ਸਕਦੀ ਹੈ।
ਉਦਾਹਰਨ ਲਈ, ਇਹ orders ਗਿਣਦਾ ਹੈ (customers ਨਹੀਂ):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
ਜੇ ਤੁਹਾਡਾ ਟੀਚਾ ਗਾਹਕਾਂ ਦੀ ਗਿਣਤੀ ਹੈ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ customer key ਗਿਣੋਗੇ (ਅਕਸਰ COUNT(DISTINCT c.customer_id)), ਇਸ ਗੱਲ ਤੇ ਨਿਰਭਰ ਕਰਕੇ ਕਿ ਤੁਸੀਂ ਕੀ ਮੈਪ ਕਰ ਰਹੇ ਹੋ।
RIGHT JOIN ਸੱਜੀ ਟੇਬਲ ਦੀਆਂ ਸਾਰੀਆਂ ਕਤਾਰਾਂ ਰੱਖਦਾ ਹੈ, ਅਤੇ ਖੱਬੇ ਟੇਬਲ ਤੋਂ ਸਿਰਫ਼ ਮਿਲਣ ਵਾਲੀਆਂ ਕਤਾਰਾਂ। ਜੇ ਮੈਚ ਨਹੀਂ ਮਿਲਦਾ, ਤਾਂ ਖੱਬੇ-ਟੇਬਲ ਦੇ ਕਾਲਮ NULL ਦਿਖਦੇ ਹਨ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ LEFT JOIN ਦਾ ਉਲਟਾ ਹੈ।
ਸਾਡੀਆਂ ਉਦਾਹਰਨ ਟੇਬਲਾਂ ਵਰਤ ਕੇ, ਸੋਚੋ ਕਿ ਤੁਸੀਂ ਹਰ ਭੁਗਤਾਨ ਨੂੰ ਲਿਸਟ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਚਾਹੇ ਉਹ ਕਿਸੇ ਆਰਡਰ ਨਾਲ ਜੋੜਿਆ ਜਾ ਸਕਦਾ ਹੋਵੇ ਜਾਂ ਨਹੀਂ (ਸ਼ਾਇਦ ਆਰਡਰ ਮਿਟ ਗਿਆ ਹੋਵੇ, ਜਾਂ ਡੇਟਾ ਗੰਦਗੀ ਹੋਵੇ)।
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
ਤੁਹਾਨੂੰ ਕੀ ਮਿਲਦਾ ਹੈ:
payments ਸੱਜੀ ਵੱਲ ਹਨ)।o.order_id ਅਤੇ o.customer_id NULL ਹੋਉਣਗੇ।ਜ਼ਿਆਦਾਤਰ ਵਾਰ, ਤੁਸੀਂ RIGHT JOIN ਨੂੰ LEFT JOIN ਵਿੱਚ ਦੁਬਾਰਾ ਲਿਖ ਸਕਦੇ ਹੋ ਉਸ ਟੇਬਲ ਦੇ ਅਨੁਕੂਲ ਕਰਕੇ:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
ਇਹੋ ਨਤੀਜਾ ਦੇਵੇਗਾ, ਪਰ ਬਹੁਤ ਲੋਕ ਇਸਨੂੰ ਪੜ੍ਹਨ ਵਿੱਚ ਆਸਾਨ ਪਾਉਂਦੇ ਹਨ: ਤੁਸੀਂ ਸ਼ੁਰੂ ਵਿੱਚ “ਮੁੱਖ” ਟੇਬਲ ਲੈਂਦੇ ਹੋ (ਇੱਥੇ payments) ਅਤੇ ਫਿਰ ਸਬੰਧਿਤ ਡੇਟਾ "ਓਪਸ਼ਨਲ" ਤੌਰ 'ਤੇ ਜੋੜਦੇ ਹੋ।
ਕਈ SQL ਸਟਾਈਲ ਗਾਈਡ RIGHT JOIN ਨੂੰ ਨਕਾਰਾਂਦਿਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਪਾਠਕਾਂ ਨੂੰ ਆਮ ਪੈਟਰਨ ਨੂੰ ਅਲਟਾ ਸੋਚਣ 'ਤੇ ਮਜਬੂਰ ਕਰਦਾ ਹੈ:
ਜਦੋਂ optional relationships ਲਗਾਤਾਰ LEFT JOIN ਵੱਜੋਂ ਲਿਖੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਕੁਏਰੀਆਂ ਤੁਰੰਤ ਸਕੈਨ ਕਰਨ ਵਿੱਚ ਸੌਖੀਆਂ ਹੁੰਦੀਆਂ ਹਨ।
RIGHT JOIN ਉਸ ਸਮੇਂ ਸਹਾਇਕ ਹੋ ਸਕਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਮੌਜੂਦਾ ਲੰਬੀ ਕੁਏਰੀ ਸੋਧ ਰਹੇ ਹੋ ਅਤੇ ਪਤਾ ਲੱਗੇ ਕਿ “ਹਰ-ਰੱਖਣ ਵਾਲੀ” ਟੇਬਲ ਹੁਣ ਸੱਜੀ ਵੱਲ ਹੈ। ਸਾਰੇ ਕੁਏਰੀ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ ਦੀ ਥਾਂ, ਇੱਕ JOIN ਨੂੰ RIGHT JOIN 'ਤੇ ਬਦਲਣਾ ਇੱਕ ਤੇਜ਼ ਅਤੇ ਘੱਟ-ਖ਼ਤਰੇ ਵਾਲਾ ਬਦਲਾਵ ਹੋ ਸਕਦਾ ਹੈ।
FULL OUTER JOIN ਦੋਹਾਂ ਟੇਬਲਾਂ ਦੀਆਂ ਸਾਰੀਆਂ ਕਤਾਰਾਂ ਵਾਪਸ ਕਰਦਾ ਹੈ।
INNER JOIN)।NULL ਨਾਲ।NULL ਨਾਲ।ਇੱਕ ਕਲਾਸਿਕ ਬਿਜ਼ਨਸ ਕੇਸ orders vs. payments ਦੀ reconciliation ਹੈ:
ਉਦਾਹਰਨ:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN PostgreSQL, SQL Server, ਅਤੇ Oracle ਵਿੱਚ ਸਪੋਰਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਇਹ MySQL ਅਤੇ SQLite ਵਿੱਚ ਉਪਲੱਧ ਨਹੀਂ ਹੈ (ਤੁਹਾਨੂੰ ਵਰਕਅਰਾਉਂਡ ਦੀ ਲੋੜ ਪਵੇਗੀ)।
ਜੇ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਵਿੱਚ FULL OUTER JOIN ਦੀ ਸਹਾਇਤਾ ਨਹੀਂ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇਸਨੂੰ ਏਸ ਤਰੀਕੇ ਨਾਲ ਨੱਕਲ ਕਰ ਸਕਦੇ ਹੋ:
ਇੱਕ ਆਮ ਨਮੂਨਾ:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
ਟਿਪ: ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਪਾਸੇ NULLs ਵੇਖਦੇ ਹੋ, ਉਹ ਸਿਗਨਲ ਹੁੰਦਾ ਹੈ ਕਿ ਰਿਕਾਰਡ ਦੂਜੇ ਪਾਸੇ “ਗਾਇਬ” ਸੀ — ਬਿਲਕੁਲ ਉਹੀ ਜੋ ਤੁਸੀਂ ਆਡੀਟ ਅਤੇ reconciliation ਲਈ ਚਾਹੁੰਦੇ ਹੋ।
CROSS JOIN ਦੋ ਟੇਬਲਾਂ ਦੀਆਂ ਹਰ ਸੰਭਵ ਜੋੜੀਆਂ ਵਾਪਸ ਕਰਦਾ ਹੈ। ਜੇ ਟੇਬਲ A ਕੋਲ 3 ਕਤਾਰਾਂ ਹਨ ਤੇ ਟੇਬਲ B ਕੋਲ 4, ਤਾਂ ਨਤੀਜਾ 3 × 4 = 12 ਕਤਾਰਾਂ ਵਾਲਾ ਹੋਵੇਗਾ। ਇਸਨੂੰ Cartesian product ਵੀ ਕਹਿੰਦੇ ਹਨ।
ਇਹ ਡਰਾਉਣਾ ਲੱਗ ਸਕਦਾ ਹੈ—ਅਤੇ ਕਈ ਵਾਰੀ ਹੁੰਦਾ ਵੀ ਹੈ—ਪਰ ਇਹ ਓਦੋਂ ਬਹੁਤ ਉਪਯੋਗੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਜਾਣ-ਬੁਝ ਕੇ combinations ਬਣਾਉਣੇ ਹੋ।
ਕਲਪਨਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਉਤਪਾਦ ਵਿਕਲਪ ਵੱਖ-ਵੱਖ ਟੇਬਲਾਂ ਵਿੱਚ ਰੱਖਦੇ ਹੋ:
sizes: S, M, Lcolors: Red, BlueCROSS JOIN ਸਾਰੀਆਂ ਸੰਭਵ variants ਬਣਾਉ ਸਕਦਾ ਹੈ (SKU ਬਣਾਉਣ, ਕੈਟਾਲੌਗ ਪ੍ਰੀਬਿਲਡ ਕਰਨ ਜਾਂ ਟੈਸਟਿੰਗ ਲਈ):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
ਨਤੀਜਾ (3 × 2 = 6 ਕਤਾਰਾਂ):
ਕਿਉਂਕਿ ਕਤਾਰਾਂ ਗੁਣਾ ਹੁੰਦੀਆਂ ਹਨ, CROSS JOIN ਤੇਜ਼ੀ ਨਾਲ ਖਤਰਨਾਕ ਹੋ ਸਕਦਾ ਹੈ:
ਇਹ ਕੁਏਰੀਆਂ ਨੂੰ ਸੁਸਤ ਕਰ ਸਕਦਾ ਹੈ, ਮੈਮੋਰੀ overwhelm ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਵਰਤੋਂਯੋਗ ਨਤੀਜਾ ਨਹੀਂ ਦਿੰਦਾ। ਜੇ ਤੁਹਾਨੂੰ combinations ਚਾਹੀਦੇ ਹਨ, ਤਾਂ ਇਨਪੁਟ ਟੇਬਲਾਂ ਛੋਟੀਆਂ ਰੱਖੋ ਅਤੇ ਲਿਮਿਟ ਜਾਂ ਫਿਲਟਰਜ਼ ਲਾਉਣ 'ਤੇ ਵਿਚਾਰ ਕਰੋ।
SELF JOIN ਉਹੀ ਹੈ ਜੋ ਲੱਗਦਾ ਹੈ: ਤੁਸੀਂ ਇੱਕ ਟੇਬਲ ਨੂੰ ਆਪਣੇ ਆਪ ਨਾਲ ਜੋੜਦੇ ਹੋ। ਇਹ ਉਪਯੋਗੀ ਹੈ ਜਦੋਂ ਟੇਬਲ ਵਿੱਚ ਇੱਕ ਕਤਾਰ ਦੂਜੇ ਕਤਾਰ ਨਾਲ ਸੰਬੰਧਿਤ ਹੋਵੇ—ਸਭ ਤੋਂ ਆਮ ਹੈ employees ਅਤੇ ਉਹਨਾਂ ਦੇ managers ਵਾਲੀ ਹਾਇਰਾਰਕੀ।
ਕਿਉਂਕਿ ਤੁਸੀਂ ਇੱਕੋ ਟੇਬਲ ਦੋ ਵਾਰ ਵਰਤ ਰਹੇ ਹੋ, ਹਰ “ਕਾਪੀ” ਨੂੰ ਇੱਕ ਵੱਖਰਾ alias ਦੇਣਾ ਜਰੂਰੀ ਹੁੰਦਾ ਹੈ। aliases ਕੁਏਰੀ ਨੂੰ ਪੜ੍ਹਨਯੋਗ ਬਣਾਉਂਦੇ ਹਨ ਅਤੇ SQL ਨੂੰ ਦੱਸਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਕਿਸ ਸਾਈਡ ਦੀ ਗੱਲ ਕਰ ਰਹੇ ਹੋ।
ਆਮ ਤਰੀਕਾ:
e ਕਰਮਚਾਰੀ ਲਈm ਮੈਨੇਜਰ ਲਈਸੋਚੋ ਇੱਕ employees ਟੇਬਲ ਹੈ:
idnamemanager_id (ਕਿਸੇ ਹੋਰ ਕਰਮਚਾਰੀ ਦੇ id ਨੂੰ ਦਰਸਾਉਂਦਾ)ਹਰ ਕਰਮਚਾਰੀ ਨਾਲ ਉਹਨਾਂ ਦੇ ਮੈਨੇਜਰ ਦਾ ਨਾਮ ਲਿਸਟ ਕਰਨ ਲਈ:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
ਧਿਆਨ ਦੇਓ ਕਿ ਕੁਐਰੀ LEFT JOIN ਵਰਤਦੀ ਹੈ, ਨਾ ਕਿ INNER JOIN। ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਕੁਝ ਕਰਮਚਾਰੀ (ਜਿਵੇਂ CEO) ਦਾ ਕੋਈ ਮੈਨੇਜਰ ਨਹੀਂ ਹੁੰਦਾ। ਉਹਨਾਂ ਮਾਮਲਿਆਂ ਵਿੱਚ manager_id ਆਮ ਤੌਰ ਤੇ NULL ਹੁੰਦਾ ਹੈ, ਅਤੇ LEFT JOIN ਕਰਮਚਾਰੀ ਦੀ ਕਤਾਰ ਨੂੰ ਰੱਖਦਾ ਹੈ ਜਦੋਂ ਕਿ manager_name NULL ਦਿਖਾਉਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ INNER JOIN ਵਰਤਦੇ ਤਾਂ ਉਹ top-level ਕਰਮਚਾਰੀ ਨਤੀਜੇ ਵਿੱਚੋਂ ਲਾਪਤਾ ਹੋ ਜਾਣਗੇ ਕਿਉਂਕਿ ਉਹਨਾਂ ਦਾ ਕੋਈ matching manager row ਨਹੀਂ ਹੁੰਦਾ।
JOIN "ਆਪਣੇ ਆਪ" ਨਹੀਂ ਜਾਣਦਾ ਕਿ ਦੋ ਟੇਬਲ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਕਿਵੇਂ ਜੁੜਦੇ ਹਨ—ਤੁਹਾਨੂੰ ਇਹ ਦੱਸਣਾ ਪੈਂਦਾ ਹੈ। ਉਹ ਸੰਬੰਧ join ਸ਼ਰਤ ਵਿੱਚ ਦੱਸਿਆ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਇਹ JOIN ਦੇ ਬਗਲ ਵਿੱਚ ਹੀ ਰਹਣਾ ਚਾਹੀਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਦਰਸਾਉਂਦਾ ਹੈ ਕਿ ਟੇਬਲਾਂ ਕਿਵੇਂ ਮਿਲਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਅੰਤੀਮ ਨਤੀਜੇ ਨੂੰ ਕਿਵੇਂ ਛਾਂਟਣਾ ਹੈ।
ON: ਸਭ ਤੋਂ ਲਚਕੀਲਾ (ਅਤੇ ਸਭ ਤੋਂ ਆਮ)ON ਉਪਯੋਗ ਕਰੋ ਜਦੋਂ ਤੁਸੀਂ ਪੂਰੀ ਕੰਟਰੋਲ ਚਾਹੁੰਦੇ ਹੋ—ਵੱਖ-ਵੱਖ ਕਾਲਮ ਨਾਮ, ਇੱਕ ਤੋਂ ਵੱਧ ਸ਼ਰਤਾਂ, ਜਾਂ ਹੋਰ ਕਦਮ।
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON ਓਥੇ ਵੀ ਵਰਤੋਂ ਜਿੱਥੇ ਤੁਸੀਂ ਕਈ-ਕਾਲਮ_MATCH ਜਾਂ ਹੋਰ ਜਟਿਲ ਮੈਚਿੰਗ ਲਾਜਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ।
USING: ਛੋਟਾ, ਪਰ ਸਿਰਫ਼ ਇੱਕੋ-ਨਾਂ ਦੇ ਕਾਲਮਾਂ ਲਈਕੁਝ ਡੇਟਾਬੇਸ (ਜਿਵੇਂ PostgreSQL ਅਤੇ MySQL) USING ਨੂੰ ਸਹਿਯੋਗ ਕਰਦੇ ਹਨ। ਇਹ ਉਸ ਵੇਲੇ ਇੱਕ ਸੁਖਾਦ ਸੰਖੇਪ ਹੈ ਜਦੋਂ ਦੋਹਾਂ ਟੇਬਲਾਂ ਵਿੱਚ ਇੱਕੋ ਨਾਂ ਵਾਲਾ ਕਾਲਮ ਹੋਵੇ ਅਤੇ ਤੁਸੀਂ ਉਸ 'ਤੇ JOIN ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ।
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
ਇਕ ਲਾਭ ਇਹ ਹੈ ਕਿ USING ਆਮ ਤੌਰ 'ਤੇ ਆਊਟਪੁੱਟ ਵਿੱਚ ਸਿਰਫ਼ ਇੱਕ customer_id ਕਾਲਮ ਦਿੰਦਾ ਹੈ (ਦੋ ਨਕਲਾਂ ਦੀ ਥਾਂ)।
ਜਦੋਂ ਤੁਸੀਂ tables join ਕਰਦੇ ਹੋ, ਕਈ ਵਾਰੀ ਕਾਲਮ ਨਾਮ ਇੱਕੋ-ਝੈ ਹੁੰਦੇ ਹਨ (id, created_at, status). ਜੇ ਤੁਸੀਂ SELECT id ਲਿਖਦੇ ਹੋ, ਡੇਟਾਬੇਸ “ambiguous column” error ਦੇ ਸਕਦਾ ਹੈ—ਜਾਂ ਤੁਹਾਨੂੰ ਗਲਤ id ਮਿਲ ਸਕਦਾ ਹੈ।
ਸਪਸ਼ਟਤਾ ਲਈ table prefixes (ਜਾਂ aliases) ਵਰਤੋ:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * ਛੱਡੋਜੋੜੀਆਂ ਕੁਏਰੀਆਂ ਵਿੱਚ SELECT * ਤੇਜ਼ੀ ਨਾਲ ਗੰਦੀਆਂ ਬਣ ਜਾਂਦੀਆਂ ਹਨ: ਤੁਸੀਂ ਬੇਕਾਰ ਕਾਲਮ ਖਿੱਚ ਲੈਂਦੇ ਹੋ, duplicate ਨਾਮਾਂ ਦਾ ਖਤਰਾ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਇਹ ਵੇਖਣਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿ ਕੁਏਰੀ ਦਾ ਮਕਸਦ ਕੀ ਹੈ।
ਇਸ ਦੀ ਬਜਾਏ, ਜਰੂਰੀ ਕਾਲਮਾਂ ਹੀ ਚੁਣੋ। ਨਤੀਜਾ ਸਾਫ਼, ਰੱਖ-ਰਖਾਵ ਵਿੱਚ ਆਸਾਨ ਅਤੇ ਅਕਸਰ ਜ਼ਿਆਦਾ ਕੁਸ਼ਲ ਹੁੰਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਟੇਬਲ ਚੌੜੀਆਂ ਹੁੰਦੀਆਂ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਟੇਬਲ join ਕਰਦੇ ਹੋ, WHERE ਅਤੇ ON ਦੋਹਾਂ "ਫਿਲਟਰ" ਕਰਦੇ ਹਨ, ਪਰ ਵੱਖ-ਵੱਖ ਸਮੇਂ ਤੇ।
ਉਹ ਸਮੇਂ-ਫਰਕ ਉਹ ਕਾਰਨ ਹੈ ਕਿ ਲੋਕ ਅਕਸਰ ਇੱਕ LEFT JOIN ਨੂੰ ਗਲਤੀ ਨਾਲ INNER JOIN ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ।
ਕਹੋ ਕਿ ਤੁਸੀਂ ਸਾਰੇ ਗਾਹਕ ਚਾਹੁੰਦੇ ਹੋ, ਭਾਵੇਂ ਉਹਨਾਂ ਕੋਲ ਹਾਲੀਆ ਭੁਗਤਾਨ ਕੀਤੇ ਗਏ ਆਰਡਰ ਨਾ ਹੋਣ।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
ਸਮੱਸਿਆ: ਜਿਨ੍ਹਾਂ ਗਾਹਕਾਂ ਦੇ ਕੋਈ matching order ਨਹੀਂ ਹਨ, ਉਹਨਾਂ ਲਈ o.status ਅਤੇ o.order_date NULL ਹੁੰਦੇ ਹਨ। WHERE ਸ਼ਰਤ ਉਹਨਾਂ ਕਤਾਰਾਂ ਨੂੰ ਨਕਾਰ ਦਿੰਦੀ ਹੈ—ਤਾਂ ਤੁਹਾਡਾ LEFT JOIN ਅਸਲ ਵਿੱਚ INNER JOIN ਵਰਗਾ ਵਿਹਾਰ ਕਰਨ ਲੱਗਦਾ ਹੈ।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
ਹੁਣ ਉਹ ਗਾਹਕ ਜਿਨ੍ਹਾਂ ਦੇ ਪਾਸ qualifying orders ਨਹੀਂ, ਉਹ ਫਿਰ ਵੀ (NULL order ਕਾਲਮਾਂ ਨਾਲ) ਦਿਖਦੇ ਹਨ—ਜੋ ਆਮ ਤੌਰ 'ਤੇ LEFT JOIN ਦਾ ਮਕਸਦ ਹੁੰਦਾ ਹੈ।
LEFT JOIN + ON ਨੂੰ ਤਰਜੀਹ ਦਿਓ।INNER JOIN (ਜਾਂ ਸਪਸ਼ਟ WHERE o.order_id IS NOT NULL) ਵਰਤੋ।JOINs ਸਿਰਫ ਕਾਲਮ ਨਹੀਂ ਜੋੜਦੇ—ਉਹ ਕਤਾਰਾਂ ਨੂੰ ਵੀ ਗੁਣਾ ਕਰ ਸਕਦੇ ਹਨ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਸਹੀ ਹੁੰਦਾ ਹੈ, ਪਰ ਜਦੋਂ ਸੰਖਿਆਵਾਂ ਅਚਾਨਕ ਦੋਹਰੀਆਂ (ਜਾਂ ਹੋਰ) ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਤਾਂ ਇਹ ਲੋਕਾਂ ਨੂੰ ਹੈਰਾਨ ਕਰਦਾ ਹੈ।
ਇੱਕ join ਹਰ ਜੋੜੇ ਮੈਚ ਲਈ ਇੱਕ ਆਉਟਪੁਟ ਰਿਕਾਰਡ ਦਿੰਦਾ ਹੈ।
customers ਨੂੰ orders ਨਾਲ join ਕਰੋ, ਤਾਂ ਹਰ ਆਰਡਰ ਲਈ ਉਹ ਗਾਹਕ ਵੱਖਰੀ ਵਾਰੀ ਆਵੇਗਾ।orders ਨੂੰ payments ਨਾਲ join ਕਰਦੇ ਹੋ ਅਤੇ ਹਰ order ਦੇ ਇਕ ਤੋਂ ਵੱਧ payments ਹਨ, ਤਾਂ ਇੱਕ order ਲਈ ਕਈ ਕਤਾਰਾਂ ਆ ਸਕਦੀਆਂ ਹਨ। ਜੇ ਤੁਸੀਂ ਹੋਰ “many” ਟੇਬਲ (ਜਿਵੇਂ order_items) ਨੂੰ ਵੀ join ਕਰੋਗੇ, ਤਾਂ payments × items ਵਰਗਾ multiplication ਪ੍ਰਭਾਵ ਬਣ ਸਕਦਾ ਹੈ।ਜੇ ਤੁਹਾਡਾ ਟੀਚਾ “ਇੱਕ ਕਤਾਰ ਪ੍ਰਤੀ ਗਾਹਕ” ਜਾਂ “ਇੱਕ ਕਤਾਰ ਪ੍ਰਤੀ ਆਰਡਰ” ਹੈ, ਤਾਂ ਪਹਿਲਾਂ "many" ਪਾਸੇ ਨੂੰ summarize ਕਰੋ, ਫਿਰ join ਕਰੋ।
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
ਇਸ ਨਾਲ join ਦਾ "shape" ਪੇਸ਼ਗੀ ਤਰ੍ਹਾਂ ਰਹਿੰਦਾ ਹੈ: ਇੱਕ order ਦੀ ਇਕ ਕਤਾਰ ਹੀ ਇੱਕ order ਰਿਹਾ।
SELECT DISTINCT duplicates ਨੂੰ ਦੁਰੁਸਤ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਅਸਲੀ ਸਮੱਸਿਆ ਨੂੰ ਛੁਪਾ ਸਕਦਾ ਹੈ:
ਜਦੋਂ ਤੁਸੀਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਜਾਣਦੇ ਹੋ ਕਿ duplicates ਬਿਲਕੁਲ ਅਣਚਾਹੇ ਹਨ ਅਤੇ ਉਹਨਾਂ ਦਾ ਕਾਰਨ ਸਮਝਦੇ ਹੋ ਤਾਂ ਹੀ ਇਸ ਨੂੰ ਵਰਤੋ।
ਨਤੀਜਿਆਂ 'ਤੇ ਭਰੋਸਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ row counts ਦੀ ਤੁਲਨਾ ਕਰੋ:
JOINs ਨੂੰ ਅਕਸਰ “ਢੀਲੀ ਕੁਏਰੀ” ਲਈ ਦੋਸ਼ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਅਸਲ ਕਾਰਨ ਅਕਸਰ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਡੇਟਾ ਦੀ ਕਿੰਨੀ ਮਾਤਰਾ ਨੂੰ ਜੋੜਨ ਦੀ ਬੇਨਤੀ ਕਰ ਰਹੇ ਹੋ, ਅਤੇ ਉਹ ਕਿੰਨੀ ਅਸਾਨੀ ਨਾਲ ਇਸਨੂੰ ਲੱਭ ਸਕਦਾ ਹੈ।
ਇੱਕ index ਨੂੰ ਇਕ ਕਿਤਾਬ ਦੀ table of contents ਦੀ ਤਰ੍ਹਾਂ ਸੋਚੋ। ਬਿਨਾ index ਦੇ, ਡੇਟਾਬੇਸ ਨੂੰ JOIN ਸ਼ਰਤ ਲਈ ਬਹੁਤ ਸਾਰੀਆਂ ਕਤਾਰਾਂ ਸਕੈਨ ਕਰਨੀ ਪੈ ਸਕਦੀਆਂ ਹਨ। join key (ਜਿਵੇਂ customers.customer_id ਅਤੇ orders.customer_id) 'ਤੇ index ਹੋਣ ਨਾਲ ਡੇਟਾਬੇਸ ਤੇਜ਼ੀ ਨਾਲ ਸੰਬੰਧਿਤ ਕਤਾਰਾਂ 'ਤੇ jump ਕਰ ਸਕਦਾ ਹੈ।
ਤੁਹਾਨੂੰ ਅੰਦਰੂਨੀ ਵੇਰਵੇ ਜਾਣਨ ਦੀ ਲੋੜ ਨਹੀਂ—ਜੇ ਕੋਈ ਕਾਲਮ ਅਕਸਰ JOIN ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ, ਉਹ ਇੱਕ ਚੰਗਾ ਉਮੀਦਵਾਰ ਹੈ ਕਿ ਉਸ 'ਤੇ index ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜਿੰਨ੍ਹਾਂ ਕਾਲਮਾਂ ਨੂੰ stable, unique identifiers ਬਣਾਇਆ ਗਿਆ ਹੈ ਉਨ੍ਹਾਂ 'ਤੇ JOIN ਕਰੋ:
customers.customer_id = orders.customer_idcustomers.email = orders.email ਜਾਂ customers.name = orders.nameਨਾਂ ਬਦਲ ਸਕਦੇ ਹਨ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਦੇ ਹਨ। IDs ਮੁਕੰਮਲ ਮਿਲਾਪ ਲਈ ਤਿਆਰ ਹੁੰਦੇ ਹਨ ਅਤੇ ਆਮ ਤੌਰ ਤੇ indexed ਹੁੰਦੇ ਹਨ।
ਦੋ ਆਦਤਾਂ JOINs ਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਨ ਯੋਗ ਤੇਜ਼ ਬਣਾ ਦਿੰਦੀਆਂ ਹਨ:
SELECT * ਤੋਂ ਬਚੋ—ਵਾਧੂ ਕਾਲਮ ਮੇਮੋਰੀ ਅਤੇ ਨੈੱਟਵਰਕ ਬਰ੍ਹਾਉਂਦੇ ਹਨ।ਉਦਾਹਰਨ: ਪਹਿਲਾਂ orders ਨੂੰ ਸੀਮਤ ਕਰੋ, ਫਿਰ join:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
ਜੇ ਤੁਸੀਂ ਇਹਨਾਂ ਕੁਏਰੀਆਂ 'ਤੇ ਐਪ ਬਣਾਉਣ ਦੌਰਾਨ ਦੁਹਰਾਈ ਕਰ ਰਹੇ ਹੋ (ਉਦਾਹਰਨ ਲਈ, PostgreSQL ਦੇ ਨਾਲ ਇੱਕ ਰਿਪੋਰਟਿੰਗ ਪੇਜ਼ ਬਣਾਉਣਾ), ਤਾਂ Tools ਜਿਵੇਂ Koder.ai scaffold ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦੇ ਹਨ—schema, endpoints, UI—ਜਦਕਿ ਤੁਸੀਂ JOIN ਲਾਜ਼ਮਤਾਂ 'ਤੇ ਪੂਰਾ ਕਬੂ ਰੱਖਦੇ ਹੋ ਜੋ ਸਹੀਤ ਨਤੀਜੇ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ।
NULL ਬਣਦੇ)NULL ਜਦੋਂ ਗਾਇਬ)NULL ਵੇਖਾਉਂਦੇ ਹਨSQL JOIN ਦੋ (ਜਾਂ ਵੱਧ) ਟੇਬਲਾਂ ਦੀਆਂ ਕਤਾਰਾਂ ਨੂੰ ਇੱਕ ਨਤੀਜੇ ਸੈੱਟ ਵਿੱਚ ਜੋੜਦਾ ਹੈ, ਜਿੱਥੇ ਸੰਬੰਧਤ ਕਾਲਮ ਮਿਲਦੇ ਹਨ—ਅਕਸਰ ਇੱਕ primary key ਨੂੰ foreign key ਨਾਲ ਜੋੜ ਕੇ (ਉਦਾਹਰਨ ਵਜੋਂ customers.customer_id = orders.customer_id). ਇਹ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ normalized ਟੇਬਲਾਂ ਨੂੰ ਰਿਪੋਰਟਾਂ, ਆਡੀਟਾਂ ਜਾਂ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਦੁਬਾਰਾ ਕਨੈਕਟ ਕਰਦੇ ਹੋ।
ਜਦੋਂ ਤੁਸੀਂ ਸਿਰਫ ਉਹੀ ਕਤਾਰਾਂ ਚਾਹੁੰਦੇ ਹੋ ਜਿੱਥੇ ਦੋਨੋਂ ਟੇਬਲਾਂ ਵਿੱਚ ਰਿਸ਼ਤਾ ਮੌਜੂਦ ਹੋਵੇ, ਤਾਂ INNER JOIN ਵਰਤੋਂ।
ਇਹ “ਪੱਕੇ ਰਿਸ਼ਤਿਆਂ” ਲਈ ਵਧੀਆ ਹੈ, ਉਦਾਹਰਨ ਲਈ ਸਿਰਫ ਉਹ ਗਾਹਕ ਲਿਸਟ ਕਰਨਾ ਜਿਨ੍ਹਾਂ ਨੇ ਅਸਲ ਵਿੱਚ ਆਰਡਰ ਕੀਤੇ।
ਜਦੋਂ ਤੁਹਾਨੂੰ ਆਪਣੀ ਮੁੱਖ (ਲੈਫਟ) ਟੇਬਲ ਦੀ ਸਾਰੀ ਲਿਸਟ ਚਾਹੀਦੀ ਹੋਵੇ ਅਤੇ ਦੂਜੇ ਪਾਸੇ ਦਾ ਡੇਟਾ ਜੇ ਮਿਲੇ ਤਾਂ ਜੋੜਨਾ ਹੋਵੇ, ਤਾਂ LEFT JOIN ਵਰਤੋਂ।
“ਕੋਨ-ਕੋਣ ਸੇ ਗਾਹਕ ਨੇ ਕਦੇ ਆਰਡਰ ਨਹੀਂ ਦਿੱਤਾ?” ਲੱਭਣ ਲਈ, JOIN ਕਰਕੇ ਫਿਰ ਸੱਜੇ ਪਾਸੇ ਨੂੰ NULL ਲਈ ਫਿਲਟਰ ਕਰੋ:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN ਸੱਜੀ ਟੇਬਲ ਦੀ ਹਰ ਕਤਾਰ ਨੂੰ ਰੱਖਦਾ ਹੈ ਅਤੇ ਜੇ ਮੈਚ ਨਹੀਂ ਮਿਲਦਾ ਤਾਂ ਖੱਬੇ ਟੇਬਲ ਦੇ ਕਾਲਮ NULL ਹੁੰਦੇ ਹਨ। ਇਹ ਅਕਸਰ ਪਠਨ ਦੇ ਤਰੀਕੇ ਕਾਰਨ ਟਾਲਿਆ ਜਾਂਦਾ ਹੈ।
ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਇਸ ਨੂੰ LEFT JOIN ਨਾਲ ਬਦਲ ਸਕਦੇ ਹੋ ਬੱਸ ਟੇਬਲ ਦੇ ਹੁਕਮ ਨੂੰ ਉਲਟ ਕੇ:
FROM payments p
LEFT JOIN orders o o.order_id p.order_id
FULL OUTER JOIN ਉਨ੍ਹਾਂ ਮਾਮਲਿਆਂ ਲਈ ਵਧੀਆ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ reconciliations ਕਰ ਰਹੇ ਹੋ: ਤੁਹਾਨੂੰ ਮਿਲਦੇ ਹੋਏ ਰਿਕਾਰਡ, ਸਿਰਫ ਖੱਬੇ-ਪਾਸੇ ਵਾਲੇ ਰਿਕਾਰਡ ਅਤੇ ਸਿਰਫ ਸੱਜੇ-ਪਾਸੇ ਵਾਲੇ ਰਿਕਾਰਡ ਸਭ ਇੱਕ ਨਤੀਜੇ ਵਿੱਚ ਚਾਹੀਦੇ ਹਨ।
ਇਹ audits ਲਈ ਧੰਨਵਾਦੀ ਹੈ, ਜਿਵੇਂ “ਆਰਡਰ ਬਿਨਾਂ ਭੁਗਤਾਨ” ਅਤੇ “ਭੁਗਤਾਨ ਬਿਨਾਂ ਆਰਡਰ” ਨੂੰ ਇੱਕੱਠੇ ਵੇਖਣਾ।
ਕੁਝ ਡੇਟਾਬੇਸ (ਖਾਸ ਕਰਕੇ MySQL ਅਤੇ SQLite) ਸਿੱਧੇ FULL OUTER JOIN ਨੂੰ ਸਹਾਇਤਾ ਨਹੀਂ ਦਿੰਦੇ। ਇੱਕ ਆਮ ਵਰਕਅਰਾਉਂਡ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਦੋ ਕੁਏਰੀਆਂ ਨੂੰ ਜੋੜੋ:
orders LEFT JOIN paymentsਅਕਸਰ ਇਹ UNION (ਜਾਂ UNION ALL ਨਾਲ ਧਿਆਨ) ਨਾਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ ਦੋਹਾਂ “left-only” ਅਤੇ “right-only” ਰਿਕਾਰਡ ਰੱਖ ਸਕੋ।
CROSS JOIN ਦੋ ਟੇਬਲਾਂ ਦੇ ਹਰ ਸੰਭਵ ਜੋੜੇ ਨੂੰ ਵਾਪਸ ਕਰਦਾ ਹੈ (Cartesian product). ਇਹ ਸੈਨੇਰਿਓ ਜਨਰੇਸ਼ਨ ਜਾਂ ਛੋਟੀ ਇਨਪੁਟ ਲਈ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ—ਉਦਾਹਰਨ ਲਈ sizes × colors।
ਸਾਵਧਾਨ ਰਹੋ: ਕਿਉਂਕਿ ਕਤਾਰਾਂ ਗੁਣਾ ਹੋ ਕੇ ਵਧਦੀਆਂ ਹਨ, ਨਤੀਜਾ ਤੇਜ਼ੀ ਨਾਲ ਵੱਡਾ ਹੋ ਸਕਦਾ ਹੈ ਅਤੇ ਕੁਏਰੀ ਨੂੰ ਸਲੋ ਕਰ ਸਕਦਾ ਹੈ।
Self join ਉਹ ਹੁੰਦੀ ਹੈ ਜਿਸ ਵਿੱਚ ਇੱਕ ਟੇਬਲ ਨੂੰ ਆਪਣੇ ਆਪ ਨਾਲ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ, ਜਿਵੇਂ ਕਿਰਿਆਸ਼ੀਲ ਸੰਬੰਧ ਜਿਹੜੇ ਟੇਬਲ ਦੇ ਅੰਦਰ ਹੋਣ (ਉਦਾਹਰਣ ਲਈ employee → manager)।
ਤੁਸੀਂ ਦੋਨਾ “ਕਾਪੀਆਂ” ਲਈ alias ਦੀ ਲੋੜ ਹੋਵੇਗੀ ਤਾਂ ਕਿ ਸਪਸ਼ਟ ਹੋਵੇ ਕਿ ਤੁਹਾਡੀ ਕੋਰੀ ਕਿਹੜੇ ਸਾਈਡ ਦਾ ਹਵਾਲਾ ਦੇ ਰਹੀ ਹੈ:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON ਇਹ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਕਿ JOIN ਦੌਰਾਨ ਕਿਹੜੀਆਂ ਕਤਾਰਾਂ ਮੈਚ ਹੋਣਗੀਆਂ; WHERE ਆਖਿਰਕਾਰ ਨਤੀਜੇ 'ਤੇ ਫਿਲਟਰ ਲਗਾਂਦਾ ਹੈ।
LEFT JOIN ਦੇ ਨਾਲ, ਜੇ ਤੁਸੀਂ ਸੱਜੇ ਪਾਸੇ ਦੀਆਂ ਸ਼ਰਤਾਂ WHERE ਵਿੱਚ ਰੱਖਦੇ ਹੋ ਤਾਂ ਉਹ NULL ਵਾਲੀਆਂ (ਮੈਚ ਨਾ ਹੋਈਆਂ) ਕਤਾਰਾਂ ਨੂੰ ਹਟਾ ਦੇਵੇਗੀ ਅਤੇLEFT JOIN ਅਸਰਤੌਰ 'ਤੇ INNER JOIN ਬਣ ਜਾਵੇਗੀ।
ਜੇ ਤੁਸੀਂ ਸਾਰੇ ਖੱਬੇ ਰਿਕਾਰਡ ਰੱਖਣੇ ਹਨ ਪਰ ਸੱਜੇ ਪਾਸੇ ਦੀਆਂ ਕਤਾਰਾਂ ਨੂੰ ਸੀਮਿਤ ਕਰਨਾ ਹੈ, ਤਾਂ ਉਹ ਸ਼ਰਤਾਂ ਵਿੱਚ ਰੱਖੋ।
ਜਦੋਂ ਰਿਲੇਸ਼ਨ one-to-many ਜਾਂ many-to-many ਹੋਵੇ ਤਾਂ joins ਕਤਾਰਾਂ ਨੂੰ ਗੁਣਾ ਕਰ ਦਿੰਦੇ ਹਨ—ਇਸ ਲਈ ਤੁਸੀਂ ਡਬਲ-ਕਾਉਂਟਿੰਗ ਦੇ ਫਾਇਲ ਹੋ ਸਕਦੇ ਹੋ। ਉਦਾਹਰਨ ਵਜੋਂ, ਇੱਕ ਆਰਡਰ ਦੇ ਦੋ ਭੁਗਤਾਨ ਹੋਣ 'ਤੇ orders ਨੂੰ payments ਨਾਲ join ਕਰਨ ਤੇ ਉਹ ਆਰਡਰ ਦੋ ਵਾਰੀ ਆਵੇਗਾ।
ਇਸ ਨੂੰ ਰੋਕਣ ਲਈ, “many” ਪਾਸੇ ਨੂੰ ਪਹਿਲਾਂ aggregate ਕਰੋ (ਜਿਵੇਂ SUM(amount) grouped by order_id) ਅਤੇ ਫਿਰ join ਕਰੋ, ਤਾਂ ਜੋ ਇੱਕ ਆਰਡਰ ਇੱਕ ਸਤਰ ਹੀ ਰੱਖੇ।
DISTINCT ਅੰਤਿਮ ਵਿਕਲਪ ਵਜੋਂ ਵਰਤੋ ਕਿਉਂਕਿ ਇਹ ਅਸਲੀ ਸਮੱਸਿਆ ਨੂੰ ਛੁਪਾ ਸਕਦਾ ਹੈ ਅਤੇ ਟੋਟਲਾਂ ਨੂੰ ਗਲਤ ਕਰ ਸਕਦਾ ਹੈ।
ON