08 ਜੂਨ 2025·8 ਮਿੰਟ
ACID ਗਾਰੰਟੀਆਂ ਕਿਵੇਂ ਭਰੋਸੇਯੋਗ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਸਿਸਟਮ ਬਣਾਉਂਦੀਆਂ ਹਨ
ਸਿੱਖੋ ਕਿ ACID ਗਾਰੰਟੀਆਂ ਡੇਟਾਬੇਸ ਡਿਜ਼ਾਈਨ ਅਤੇ ਐਪ ਵਿਹਾਰ ਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਤ ਕਰਦੀਆਂ ਹਨ। Atomicity, Consistency, Isolation, Durability, ਟਰੇਡ-ਆਫ ਅਤੇ ਅਸਲ ਉਦਾਹਰਨਾਂ ਦੀ ਜਾਂਚ ਕਰੋ।
ਸਿੱਖੋ ਕਿ ACID ਗਾਰੰਟੀਆਂ ਡੇਟਾਬੇਸ ਡਿਜ਼ਾਈਨ ਅਤੇ ਐਪ ਵਿਹਾਰ ਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਤ ਕਰਦੀਆਂ ਹਨ। Atomicity, Consistency, Isolation, Durability, ਟਰੇਡ-ਆਫ ਅਤੇ ਅਸਲ ਉਦਾਹਰਨਾਂ ਦੀ ਜਾਂਚ ਕਰੋ।
ਜਦੋਂ ਤੁਸੀਂ ਰਾਸ਼ਨ ਲਈ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ, ਉਡਾਣ ਬੁੱਕ ਕਰਦੇ ਹੋ, ਜਾਂ ਖਾਤਿਆਂ ਵਿਚੋਂ ਪੈਸੇ ਘੁਮਾਉਂਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਨਤੀਜਾ ਸਪਸ਼ਟ ਹੋਵੇ: ਜਾਂ ਤਾਂ ਇਹ ਸਫਲ ਹੋਇਆ, ਜਾਂ ਫੇਲ। ਡੇਟਾਬੇਸ ਵੀ ਇਨ੍ਹਾਂ ਹੀ ਉਮੀਦਾਂ ਨੂੰ ਪੂਰਾ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ—ਭਲੇ ਹੀ ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰ ਇਕੱਠੇ ਸਿਸਟਮ ਵਰਤ ਰਹੇ ਹੋਣ, ਸਰਵਰ ਕ੍ਰੈਸ਼ ਹੋ ਰਹੇ ਹੋਣ, ਜਾਂ ਨੈਟਵਰਕ ਹਿੱਚਕਸ ਹੋ ਰਹੇ ਹੋਣ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇੱਕ ਇਕੱਲਾ ਕੰਮ ਦਾ ਯੂਨਿਟ ਹੁੰਦਾ ਹੈ ਜਿਸਨੂੰ ਡੇਟਾਬੇਸ ਇੱਕ “ਪੈਕੇਜ” ਵਜੋਂ ਲੈਂਦਾ ਹੈ। ਇਹ ਕਈ ਕਦਮ ਹੋ ਸਕਦੇ ਹਨ—ਇਨਵੈਂਟਰੀ ਘਟਾਉਣਾ, ਆਰਡਰ ਰਿਕਾਰਡ ਬਣਾਉਣਾ, ਕਾਰਡ ਚਾਰਜ ਕਰਨਾ, ਅਤੇ ਰਸੀਦ ਲਿਖਣਾ—ਪਰ ਇਹ ਇੱਕ ਸੰਗਠਿਤ ਕਾਰਵਾਈ ਵਾਂਗ ਵਰਤਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜੇ ਕਿਸੇ ਵੀ ਕਦਮ ਵਿੱਚ ਨਾਕਾਮੀ ਆਉਂਦੀ ਹੈ, ਤਾਂ ਸਿਸਟਮ ਨੂੰ ਇੱਕ ਸੁਰੱਖਿਅਤ ਬਿੰਦੂ 'ਤੇ ਵਾਪਸ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਨਾ ਕਿ ਅਧੂਰਾ ਕੰਮ ਛੱਡਣਾ ਚਾਹੀਦਾ ਹੈ।
ਅਧੂਰੀ ਅਪਡੇਟ ਸਿਰਫ ਤਕਨੀਕੀ ਗਲਤੀਆਂ ਨਹੀਂ ਹਨ; ਇਹ ਗਾਹਕ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਅਤੇ ਵਿੱਤੀ ਖਤਰਿਆਂ ਵਿੱਚ ਬਦਲ ਜਾਂਦੇ ਹਨ। ਉਦਾਹਰਨ ਲਈ:
ਇਹ ਫੇਲ੍ਹ-ਅਵਸਥਾਵਾਂ ਡਿਬੱਗ ਕਰਨ ਵਾਸਤੇ ਮੁਸ਼ਕਲ ਹੁੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਵੱਧਤਰ ਚੀਜ਼ਾਂ “ਜ਼ਿਆਦਾ-ਕਿਰਪਾ” ਠੀਕ ਲੱਗਦੀਆਂ ਹਨ, ਪਰ ਨੰਬਰ ਮਿਲਦੇ ਨਹੀਂ।
ACID ਚਾਰ ਗਾਰੰਟੀਆਂ ਲਈ ਛੋਟਾ-ਸੰਕੇਤ ਹੈ ਜੋ ਕਈ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲਈ ਦੇ ਸਕਦੇ ਹਨ:
ਇਹ ਕੋਈ ਖ਼ਾਸ ਡੇਟਾਬੇਸ ਬਰਾਂਡ ਜਾਂ ਇੱਕ ਫੀਚਰ ਨਾ ਹੀ ਹੈ ਜਿਸਨੂੰ ਤੁਸੀਂ ਟੌਗਲ ਕਰੋ—ਇਹ ਵਿਹਾਰ ਬਾਰੇ ਇੱਕ ਵਾਅਦਾ ਹੈ।
ਮਜ਼ਬੂਤ ਗਾਰੰਟੀਆਂ ਅਕਸਰ ਮਤਲਬ ਹਨ ਕਿ ਡੇਟਾਬੇਸ ਨੂੰ ਹੋਰ ਕੰਮ ਕਰਨਾ ਪੈਂਦਾ ਹੈ: ਵਾਧੂ ਕੋਆਰਡੀਨেশਨ, ਲਾਕਾਂ ਲਈ ਉਡੀਕ, ਵਰਜ਼ਨਾਂ ਦਾ ਟ੍ਰੈਕ ਰੱਖਣਾ, ਅਤੇ ਲੌਗਾਂ ਵਿੱਚ ਲਿਖਣਾ। ਇਸ ਨਾਲ ਭਾਰੀ ਲੋਡ ਹੇਠ throughput ਘਟ ਸਕਦੀ ਹੈ ਜਾਂ latency ਵਧ ਸਕਦੀ ਹੈ। ਮਕਸਦ ਹਰ ਵੇਲੇ “ਅਧਿਕਤਮ ACID” ਨਹੀਂ, ਬਲਕਿ ਉਹ ਗਾਰੰਟੀਆਂ ਚੁਣਨਾ ਹੈ ਜੋ ਤੁਹਾਡੇ ਵਾਸਤੇ ਅਸਲ ਕਾਰੋਬਾਰੀ ਖਤਰਿਆਂ ਨਾਲ ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ।
ਅਟੋਮਿਕਤਾ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਇੱਕ ਇਕੱਲੇ ਯੂਨਿਟ ਵਜੋਂ Treat ਕੀਤਾ ਜਾਂਦਾ ਹੈ: ਇਹ ਜਾਂ ਤਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਮੁਕੰਮਲ ਹੁੰਦੀ ਹੈ ਜਾਂ ਇਸਦਾ ਕੋਈ ਪ੍ਰਭਾਵ ਨਹੀਂ ਹੁੰਦਾ। ਡੇਟਾਬੇਸ ਵਿੱਚ ਤੁਸੀਂ ਕਦੇ ਵੀ “ਹਾਫ-ਅਪਡੇਟ” ਨਹੀਂ ਵੇਖੋਗੇ।
ਕਲਪਨਾ ਕਰੋ ਐਲਿਸ ਤੋਂ ਬੌਬ ਵਿੱਚ $50 ਟ੍ਰਾਂਸਫਰ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ। ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਕਮ-ਵੇ-ਕਮ ਦੋ ਬਦਲਾਵ ਵਿਚ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ:
ਅਟੋਮਿਕਤਾ ਨਾਲ, ਇਹ ਦੋਵੇਂ ਬਦਲਾਵ ਇਕੱਠੇ ਸਫਲ ਹੋ ਜਾਂਦੇ ਹਨ ਜਾਂ ਇਕੱਠੇ ਫੇਲ। ਜੇ ਸਿਸਟਮ ਦੋਹਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ ਨਹੀਂ ਕਰੇਗਾ। ਇਹ ਉਸ ਭਿਆਨਕ ਨਤੀਜੇ ਨੂੰ ਰੋਕਦਾ ਹੈ ਜਿੱਥੇ ਐਲਿਸ ਤੋਂ ਪੈਸਾ ਕੱਟਿਆ ਗਿਆ ਪਰ ਬੌਬ ਨੂੰ ਨਹੀਂ ਮਿਲਿਆ (ਜਾਂ ਬੌਬ ਨੂੰ ਮਿਲ ਗਿਆ ਬਿਨਾਂ ਐਲਿਸ ਚਾਰਜ ਹੋਏ)।
ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਦੋ ਰਾਹ ਦਿੰਦੇ ਹਨ:
ਇੱਕ ਉਪਯੋਗੀ ਮਾਨਸਿਕ ਮਾਡਲ ਹੈ “ਡ੍ਰਾਫਟ vs. ਪਬਲਿਸ਼।” ਜਦੋਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਚੱਲ ਰਿਹਾ ਹੁੰਦਾ ਹੈ, ਤਬਦੀਲੀਆਂ ਅਸਥਾਈ ਹੁੰਦੀਆਂ ਹਨ। ਕੇਵਲ commit ਹੀ ਉਨ੍ਹਾਂ ਨੂੰ ਪਬਲਿਸ਼ ਕਰਦਾ ਹੈ।
ਅਟੋਮਿਕਤਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਫੇਲ੍ਹ ਹੋਣਾ ਅਸਧਾਰਣ ਨਹੀਂ:
ਜੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ commit ਤੋਂ ਪਹਿਲਾਂ ਹੋ ਜਾਂਦਾ ਹੈ, ਅਟੋਮਿਕਤਾ ਯਕੀਨੀ ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਡੇਟਾਬੇਸ rollback ਕਰ ਸਕਦਾ ਹੈ ਤਾਂ ਕਿ ਅਧੂਰਾ ਕੰਮ ਸਥਾਈ ਸਟੇਟ ਵਿੱਚ ਨਾ ਆਵੇ।
ਅਟੋਮਿਕਤਾ ਡੇਟਾਬੇਸ ਸਟੇਟ ਦੀ ਰੱਖਿਆ ਕਰਦੀ ਹੈ, ਪਰ ਤੁਹਾਡੀ ਐਪਲੀਕੇਸ਼ਨ ਨੂੰ ਅਜਿਹੀਆਂ ਅਣਿਸ਼ਚਿਤਤਾਵਾਂ ਨੂੰ ਵੀ ਸੰਭਾਲਣਾ ਚਾਹੀਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਨੈਟਵਰਕ ਡ੍ਰੌਪ ਕਾਰਨ ਪਤਾ ਨਹੀਂ ਚਲਦਾ ਕਿ commit ਹੋਇਆ ਸੀ।
ਦੋ ਪ੍ਰਯੋਗਿਕ ਪੂਰਕ:
ਇੱਕਠੇ ਹੋ ਕੇ, ਅਟੋਮਿਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਅਤੇ idempotent retries ਤੁਹਾਨੂੰ ਅਧੂਰੇ ਅਪਡੇਟ ਅਤੇ ਗਲਤੀ ਨਾਲ ਦੁੱਗਣੇ ਚਾਰਜ/ਲਿਖਤ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ।
ACID ਵਿੱਚ Consistency ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ “ਡੇਟਾ ਠੀਕ ਲੱਗੇ” ਜਾਂ “ਸਾਰੇ ਰੇਪ্লਿਕਾ ਮਿਲਦੇ ਹਨ।” ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਤੁਹਾਡੇ ਦੁਆਰਾ ਨਿਰਧਾਰਿਤ ਨਿਯਮਾਂ ਅਨੁਸਾਰ ਇੱਕ ਵੈਧ ਸਟੇਟ ਤੋਂ ਦੂਜੇ ਵੈਧ ਸਟੇਟ ਵਿੱਚ ਲੈ ਕੇ ਜਾਂਦਾ ਹੈ।
ਡੇਟਾਬੇਸ ਸਿਰਫ਼ ਉਹਨਾਂ explicit constraints, triggers ਅਤੇ invariants ਦੇ ਸੰਦਰਭ ਵਿੱਚ ਹੀ ਡੇਟਾ ਨੂੰ consistent ਰੱਖ ਸਕਦਾ ਹੈ ਜੋ “ਵੈਧ” ਦਾ ਮਤਲਬ ਦੱਸਦੇ ਹਨ। ACID ਇਹ ਨਿਯਮ ਨਹੀਂ ਬਣਾਉਂਦਾ; ਇਹ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਦੌਰਾਨ ਉਨ੍ਹਾਂ ਨੂੰ ਲਾਗੂ ਕਰਦਾ ਹੈ।
ਆਮ ਉਦਾਹਰਨਾਂ:
order.customer_id ਨੂੰ ਮੌਜੂਦ customer ਕੋਲ ਦਿਖਣਾ ਚਾਹੀਦਾ ਹੈ।ਜੇ ਇਹ ਨਿਯਮ ਲਾਗੂ ਹਨ, ਡੇਟਾਬੇਸ ਕਿਸੇ ਵੀ ਐਸੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ reject ਕਰੇਗਾ ਜੋ ਉਨ੍ਹਾਂ ਦੀ ਉਲੰਘਣਾ ਕਰੇ—ਇਸ ਤਰ੍ਹਾਂ ਤੁਸੀਂ “ਹਾਫ-ਵੈਧ” ਡੇਟਾ ਨਾਲ ਨਹੀਂ ਰਹਿ ਜਾਓਗੇ।
ਐਪ-ਲੈਵਲ ਵੈਲੀਡੇਸ਼ਨ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਪਰ ਇੱਕੱਲੀ ਉਹ ਕਾਫ਼ੀ ਨਹੀਂ:
ਕਲਾਸਿਕ ਫੇਲਯੋਰ ਮੋਡ ਉਹ ਹੈ ਜਿੱਥੇ ਐਪ ‘email ਉਪਲਬਧ ਹੈ’ ਚੈੱਕ ਕਰਦਾ ਹੈ ਅਤੇ ਫਿਰ row insert ਕਰਦਾ ਹੈ। ਕਨਕਰਨਸੀ ਹੇਠ ਦੋ ਬੇਨਤੀਆਂ ਇੱਕੋ ਸਮੇਂ ਚੈੱਕ ਪਾਸ ਕਰ ਸਕਦੀਆਂ ਹਨ—ਇਸ ਲਈ ਡੇਟਾਬੇਸ ਵਿੱਚ unique constraint ਹੀ ਆਖਰੀ ਸੁਰੱਖਿਆ ਹੈ।
ਜੇ ਤੁਸੀਂ “ਬੈਲੰਸ ਨਕਾਰਾਤਮਕ ਨਹੀਂ ਹੋ ਸਕਦਾ” ਨੂੰ ਇੱਕ constraint ਵਜੋਂ encode ਕਰਦੇ ਹੋ (ਜਾਂ ਇੱਕ ਹੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਇਸਨੂੰ ਭਰੋਸੇਯੋਗ ਢੰਗ ਨਾਲ ਲਾਗੂ ਕਰਦੇ ਹੋ), ਤਾਂ ਕੋਈ ਵੀ ਟ੍ਰਾਂਜ਼ਫਰ ਜੋ ਖਾਤਾ ਓਵਰਡ੍ਰਾਫਟ ਕਰੇਗੀ, ਸਾਰੇ ਤੌਰ 'ਤੇ fail ਹੋ ਜਾਣੀ ਚਾਹੀਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਹ ਨਿਯਮ ਕਿਵੇਂ ਵੀ encode ਨਹੀਂ ਕਰਦੇ, ਤਾਂ ACID ਇਸਦੀ ਰੱਖਿਆ ਨਹੀਂ ਕਰ ਸਕਦਾ—ਕਿਉਂਕਿ ਲਾਗੂ ਕਰਨ ਲਈ ਕੁਝ ਵੀ ਮੌਜੂਦ ਨਹੀਂ।
Consistency ਆਖ਼ਿਰਕਾਰ ਸਪਸ਼ਟ ਹੋਣ ਬਾਰੇ ਹੈ: ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇਹ ਯਕੀਨੀ ਬਣਾਉਣ।
Isolation ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਇਕ ਦੂਜੇ 'ਤੇ ਖਰਾਬ ਪ੍ਰਭਾਵ ਨਹੀਂ ਪਾਉਂਦੀਆਂ। ਜਦੋਂ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਚੱਲ ਰਿਹਾ ਹੁੰਦਾ ਹੈ, ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਅਧੂਰੇ ਕੰਮ ਨਹੀਂ ਦੇਖਣੇ ਚਾਹੀਦੇ। ਮਕਸਦ ਸਧਾਰਨ ਹੈ: ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਚਲਨਾ ਚਾਹੀਦਾ ਹੈ ਜਿਵੇਂ ਉਹ ਅਕੇਲਾ ਚੱਲ ਰਿਹਾ ਹੋਵੇ, ਭਾਵੇਂ ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰ ਇੱਕ ਸਾਥ ਹੀ ਸਿਸਟਮ ਵਰਤ ਰਹੇ ਹੋਣ।
ਅਸਲ सिस्टम ਸਿਆਣੇ ਹਨ: ਗਾਹਕ ਆਰਡਰ ਰੱਖਦੇ ਹਨ, ਸਪੋਰਟ ਏਜੰਟ ਪ੍ਰੋਫਾਈਲ ਅਪਡੇਟ ਕਰਦੇ ਹਨ, ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਭੁਗਤਾਨ reconcile ਕਰਦੇ ਹਨ—ਸਭ ਇਕੱਠੇ। ਇਹ ਕਾਰਵਾਈਆਂ ਸਮੇਂ ਵਿੱਚ ਓਵਰਲੈਪ ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਅਕਸਰ ਇੱਕੋ ਹੀ rows ਨੂੰ ਛੂਹਦੀਆਂ ਹਨ (ਇਕ ਖਾਤਾ ਬੈਲੰਸ, ਇਨਵੈਂਟਰੀ ਗਿਣਤੀ, ਜਾਂ ਬੁਕਿੰਗ ਸਲੋਟ)।
ਇਸੋਲੇਸ਼ਨ ਦੇ ਬਿਨਾਂ, timing ਤੁਹਾਡੇ ਬਿਜ਼ਨਸ ਲਾਜਿਕ ਦਾ ਹਿੱਸਾ ਬਣ ਜਾਂਦਾ ਹੈ। “ਸਟਾਕ ਘਟਾਓ” ਅਪਡੇਟ ਦੂਜੇ ਚੈੱਕਆਉਟ ਨਾਲ ਰੇਸ ਕਰ ਸਕਦੀ ਹੈ, ਜਾਂ ਰਿਪੋਰਟ ਕਿਸੇ ਅਧੂਰੇ ਬਦਲਾਅ ਨੂੰ ਪੜ੍ਹ ਕੇ ਅਜਿਹਾ ਨਤੀਜਾ ਦਿਖਾ ਸਕਦੀ ਜੋ ਕਦੇ ਇਸਤਿਰ ਨਹੀਂ ਸੀ।
ਪੂਰੀ “ਤੁਸੀਂ ਇਕਲੇ ਹੋ” ਵਰਗੀ isolation ਮਹਿੰਗੀ ਹੋ ਸਕਦੀ ਹੈ। ਇਹ throughput ਘਟਾ ਸਕਦੀ ਹੈ, ਉਡੀਕ (ਲਾਕ) ਵਧਾ ਸਕਦੀ ਹੈ, ਜਾਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਰੀਟ੍ਰਾਈਜ਼ ਲਿਆ ਸਕਦੀ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਵਰਕਫ਼ਲੋ ਸਭ ਤੋਂ ਕਠੋਰ ਰੱਖਿਆ ਦੀ ਲੋੜ ਨਹੀਂ ਰੱਖਦੇ—ਉਦਾਹਰਨ ਲਈ, ਕੱਲ ਦੇ ਐਨਾਲਿਟਿਕਸ ਹਲਕੀਆਂ ਅਸਮਰਥਤਾਵਾਂ ਨੂੰ ਸਹਿਮਤੀ ਦੇ ਸਕਦੇ ਹਨ।
ਇਸ ਲਈ ਡੇਟਾਬੇਸ configurable isolation levels ਦਿੰਦੇ ਹਨ: ਤੁਸੀਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ performance ਅਤੇ ਘੱਟ conflicts ਦੇ ਬਦਲੇ ਵਿੱਚ ਕਿੰਨੀ concurrency ਖ਼ਤਰਾ ਸਹਿਣਾ ਚਾਹੁੰਦੇ ਹੋ।
ਜਦੋਂ isolation ਤੁਹਾਡੇ ਵਰਕਲੋਡ ਲਈ ਬਹੁਤ ਕਮਜ਼ੋਰ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਕਲਾਸਿਕ anomalies ਦੇ ਸ਼ਿਕਾਰ ਹੋ ਸਕਦੇ ਹੋ:
ਇਹ ਫੇਲ੍ਹ-ਮੋਡਸ ਨੂੰ ਸਮਝਣ ਨਾਲ ਇਹ ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਕਿ isolation level ਕਿਵੇਂ ਚੁਣਨਾ ਹੈ ਜੋ ਤੁਹਾਡੇ product ਦੇ ਵਾਅਦੇ ਨਾਲ ਮਿਲਦਾ ਹੋਵੇ।
Isolation ਇਹ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਦੇਖਣ ਦੀ ਆਗਿਆ ਕੀ ਹੈ ਜਦੋਂ ਤੁਹਾਡੀ ਚੱਲ ਰਹੀ ਹੁੰਦੀ ਹੈ। ਜਦੋਂ isolation ਤੁਹਾਡੇ ਵਰਕਲੋਡ ਲਈ ਕਮਜ਼ੋਰ ਹੁੰਦੀ ਹੈ, ਤੁਸੀਂ ਅਸਧਾਰਣ ਵਿਹਾਰ (anomalies) ਦੇਖੋਗੇ—ਜੋ ਤਕਨੀਕੀ ਤੌਰ 'ਤੇ ਸੰਭਵ ਹਨ ਪਰ ਯੂਜ਼ਰਾਂ ਲਈ ਹੈਰਾਨੀਜਨਕ ਹੋ ਸਕਦੇ ਹਨ।
Dirty read ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਉਸ ਡੇਟਾ ਨੂੰ ਪੜ੍ਹ ਲੈਂਦੇ ਹੋ ਜੋ ਕਿਸੇ ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੇ ਲਿਖਿਆ ਹੈ ਪਰ commit ਨਹੀਂ ਕੀਤਾ।
ਸਿਨਾਰਿਓ: ਐਲੈਕਸ $500 ਇਕ ਅਕਾਉਂਟ ਵਿੱਚੋਂ ਕੱਦ ਰਿਹਾ ਹੈ, ਬੈਲੰਸ ਅਲਵਾ $200 ਬਣ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਉਹ $200 ਪੜ੍ਹ ਲੈਂਦੇ ਹੋ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਐਲੈਕਸ ਦੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਬਾਅਦ ਵਿਚ fail ਹੋ ਕੇ rollback ਹੋ ਜਾਏ।
ਯੂਜ਼ਰ ਨਤੀਜਾ: ਗਾਹਕ ਨੇ ਗਲਤ ਘੱਟ ਬੈਲੰਸ ਵੇਖਿਆ, ਇਕ fraud rule ਗਲਤ ਤਰੀਕੇ ਨਾਲ trigger ਹੋ ਸਕਦਾ ਹੈ, ਜਾਂ ਸਹਾਇਤਾ ਏਜੰਟ ਗਲਤ ਜਵਾਬ ਦੇ ਸਕਦਾ ਹੈ।
Non-repeatable read ਜਿਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਇਕੋ row ਨੂੰ ਦੋ ਵਾਰ ਪੜ੍ਹਦੇ ਹੋ ਅਤੇ ਵੱਖਰੇ ਮੁੱਲ ਮਿਲਦੇ ਹਨ ਕਿਉਂਕਿ ਦਰਮਿਆਨ ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ commit ਹੋ ਗਿਆ।
ਸਿਨਾਰਿਓ: ਤੁਸੀਂ ਇੱਕ ਆਰਡਰ ਟੋਟਲ ($49.00) ਲੋਡ ਕਰਦੇ ਹੋ, ਫੇਰ ਥੋੜ੍ਹੇ ਪਲ ਬਾਅਦ ਰਿਫრੈਸ਼ ਕਰਦੇ ਹੋ ਅਤੇ $54.00 ਵੇਖਦੇ ਹੋ ਕਿਉਂਕਿ ਕੋਈ discount line ਹਟਾਈ ਗਈ।
ਯੂਜ਼ਰ ਨਤੀਜਾ: “ਮੇਰਾ ਟੋਟਲ ਚੈੱਕਆਊਟ ਦੌਰਾਨ ਬਦਲ ਗਿਆ,” ਜਿਸ ਨਾਲ ਭਰੋਸਾ ਘਟ ਸਕਦਾ ਹੈ ਜਾਂ ਕਾਰਟ ਛੱਡਣ ਵਾਲੇ ਬਰਹਾਂ ਹੋ ਸਕਦੇ ਹਨ।
Phantom read non-repeatable read ਵਰਗੀ ਹੈ, ਪਰ rows ਦੇ ਸੈੱਟ ਨਾਲ: ਇੱਕ ਦੂਜੀ ਕਵੈਰੀ ਵੱਖਰਾ ਰਿਕਾਰਡ ਸੈੱਟ ਵਾਪਸ ਕਰਦੀ ਹੈ ਕਿਉਂਕਿ ਕਿਸੇ ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੇ matching ਰਿਕਾਰਡ insert/delete ਕੀਤੇ।
ਸਿਨਾਰਿਓ: ਹੋਟਲ ਦੀ ਖੋਜ “3 ਕਮਰੇ ਉਪਲਬਧ” ਦਿਖਾਉਂਦੀ ਹੈ, ਫਿਰ ਬੁਕਿੰਗ ਦੌਰਾਨ ਸਿਸਟਮ ਦੁਬਾਰਾ ਜਾਂਚਦਾ ਹੈ ਅਤੇ ਪਾਇਆ ਕਿ ਕੋਈ ਵੀ ਨਹੀਂ ਬਚੇ ਕਿਉਂਕਿ ਨਵੀਆਂ ਰਿਜ਼ਰਵੇਸ਼ਨਾਂ ਜੋੜੀ ਗਈਆਂ।
ਯੂਜ਼ਰ ਨਤੀਜਾ: ਡਬਲ-ਬੁਕਿੰਗ ਕੋਸ਼ਿਸ਼ਾਂ, ਅਸਮਰਥ availability ਸਕ੍ਰੀਨ, ਜਾਂ overselling।
Lost update ਉਸ ਵੇਲੇ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਦੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੇ ਇਕੋ value ਪੜ੍ਹੀ ਅਤੇ ਦੋਵੇਂ ਅਪਡੇਟ ਲਿਖਦੇ ਹਨ, ਜਿਸ ਨਾਲ ਇਕ ਦੀ ਲਿਖਤ ਮਿਟ ਜਾਂਦੀ ਹੈ।
ਸਿਨਾਰਿਓ: ਦੋ ਐਡਮਿਨ ਇੱਕੋ product price edit ਕਰਦੇ ਹਨ। ਦੋਵੇਂ $10 ਤੋਂ ਸ਼ੁਰੂ ਕਰਦੇ ਹਨ; ਇੱਕ $12 ਸੇਵ ਕਰਦਾ ਹੈ, ਦੂਜਾ ਆਖਿਰ ਵਿੱਚ $11 ਸੇਵ ਕਰਦਾ ਹੈ।
ਯੂਜ਼ਰ ਨਤੀਜਾ: ਕਿਸੇ ਦਾ change ਖਤਮ ਹੋ ਜਾਂਦਾ ਹੈ; totals ਅਤੇ ਰਿਪੋਰਟਾਂ ਗਲਤ ਹੋ ਜਾਂਦੀਆਂ ਹਨ।
Write skew ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਦੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਬਦਲਾਅ ਕਰਦੇ ਹਨ ਜੋ ਅਲੱਗ-ਅਲੱਗ ਤੌਰ 'ਤੇ ਵੈਧ ਹਨ, ਪਰ ਇਕੱਠੇ ਹੋ ਕੇ ਕਿਸੇ ਨਿਯਮ ਨੂੰ ਤੋੜ ਦਿੰਦੇ ਹਨ।
ਸਿਨਾਰਿਓ: ਨਿਯਮ: “ਘੱਟੋ-ਘੱਟ ਇੱਕ on-call ਡਾਕਟਰ ਸ਼ੈਡਿਊਲ 'ਤੇ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।” ਦੋ ਡਾਕਟਰ ਆਪਣਾ on-call ਹਟਾਉਂਦੇ ਹਨ ਬਿਨਾਂ ਕਿਸੇ ਨੇ ਚੈੱਕ ਕੀਤਾ ਕਿ ਦੂਜਾ ਅਜੇ ਵੀ on-call ਹੈ।
ਯੂਜ਼ਰ ਨਤੀਜਾ: ਤੁਸੀਂ ਅੰਤ ਵਿੱਚ ਜ਼ੀਰੋ ਕੋਵਰੇਜ ਵਾਲੀ ਸਥਿਤੀ ਵਿੱਚ ਖੜੇ ਹੋ ਜਾਂਦੇ ਹੋ, ਹੋਣ ਕੇ ਕਿ ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਆਪਣੇ ਚੈੱਕ ਵਿੱਚ ਠੀਕ ਸੀ।
ਮਜ਼ਬੂਤ isolation anomalies ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ ਪਰ ਉਡੀਕ, ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਲਾਗਤ ਵਧਾ ਸਕਦੀ ਹੈ। ਅਨੇਕ ਸਿਸਟਮ read-heavy analytics ਲਈ ਕਮਜ਼ੋਰ isolation ਚੁਣਦੇ ਹਨ, ਜਦੋਂ ਕਿ ਪੈਸੇ-ਸਬੰਧੀ ਕਾਯਮੀਆਂ, ਬੁਕਿੰਗ ਅਤੇ ਹੋਰ correctness-critical flows ਲਈ ਕਠੋਰ ਸੈਟਿੰਗਾਂ ਵਰਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
Isolation ਇਹ ਬਤਾਉਂਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੌਰਾਨ ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਤੁਸੀਂ ਕੀ ਦੇਖ ਸਕਦੇ ਹੋ। ਡੇਟਾਬੇਸ ਇਹਨੂੰ isolation levels ਵਜੋਂ ਦਰਸਾਉਂਦੇ ਹਨ: ਉੱਚ ਪੱਧਰ ਅਣਉਮੀਦ ਵਿਹਾਰਾਂ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ, ਪਰ throughput ਘਟਾ ਸਕਦਾ ਹੈ ਜਾਂ ਉਡੀਕ ਵਧਾ ਸਕਦਾ ਹੈ।
ਟੀਮ ਆਮ ਤੌਰ 'ਤੇ Read Committed ਨੂੰ ਬਹੁਤ ਸਾਰੀਆਂ user-facing ਐਪ ਲਈ ਇੱਕ ਡਿਫਾਲਟ ਰੱਖਦੇ ਹਨ: ਚੰਗੀ ਕਾਰਗੁਜ਼ਾਰੀ, ਅਤੇ “ਕੋਈ dirty reads ਨਹੀਂ” ਜ਼ਿਆਦਾਤਰ ਉਮੀਦਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ।
Repeatable Read ਵਰਤੋ ਜਦੋਂ ਤੁਹਾਨੂੰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ ਅੰਦਰ ਨਤੀਜਿਆਂ ਦੀ ਸਥਿਰਤਾ ਚਾਹੀਦੀ ਹੋਵੇ (ਉਦਾਹਰਨ: line items ਤੋਂ invoice ਜਨਰੇਟ ਕਰਨਾ) ਅਤੇ ਤੁਸੀਂ ਕੁਝ ਓਵਰਹੈੱਡ ਸਹਿ ਸਕਦੇ ਹੋ।
Serializable ਵਰਤੋ ਜਦੋਂ correctness concurrency ਨਾਲੋਂ ਜਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੋ (ਉਦਾਹਰਨ: inventory oversell ਤੋਂ ਬਚਾਉਣਾ), ਜਾਂ ਜਦੋਂ ਤੁਸੀਂ race conditions ਨੂੰ ਐਪ ਕੋਡ ਵਿੱਚ ਆਸਾਨੀ ਨਾਲ ਨਹੀਂ ਸਮਝ ਸਕਦੇ।
Read Uncommitted OLTP ਸਿਸਟਮਾਂ ਵਿੱਚ ਕਮੀ ਲਈ ਹੁੰਦਾ ਹੈ; ਇਹ ਕੁਝ ਨਿਗਰਾਨੀ ਜਾਂ ਅਕਸਰ ਅਨੁਮਾਨੀ ਰਿਪੋਰਟਿੰਗ ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ ਜਿਥੇ ਚੁਣ-ਚੁਣ ਕੇ ਗਲਤ ਪੜ੍ਹਾਈਆਂ ਸਹੀ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਨਾਂ ਸਟੈਂਡਰਡ ਹਨ, ਪਰ ਸਹੀ ਗਾਰੰਟੀਆਂ ਡੇਟਾਬੇਸ ਇੰਜਨ ਅਨੁਸਾਰ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦੀਆਂ ਹਨ (ਅਤੇ ਕਈ ਵਾਰੀ configuration ਅਨੁਸਾਰ ਵੀ)। ਆਪਣੀ ਡੇਟਾਬੇਸ ਡੌਕਯੂਮੈਂਟੇਸ਼ਨ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ ਅਤੇ ਉਸ anomaly ਨੂੰ ਟੈਸਟ ਕਰੋ ਜੋ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹਨ।
Durability ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਜਦੋਂ ਕੋਈ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ committed ਹੋ ਜਾਂਦੀ ਹੈ, ਉਸਦੇ ਨਤੀਜੇ ਨੂੰ ਇੱਕ crash—ਪਾਵਰ ਲੌਸ, ਪ੍ਰੋਸੈਸ ਰੀਸਟਾਰਟ ਜਾਂ ਮਸ਼ੀਨ ਰੀਬੂਟ—ਬਾਅਦ ਵੀ ਯਾਦ ਰੱਖਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਗਾਹਕ ਨੂੰ “ਭੁਗਤਾਨ ਸਫਲ” ਦੱਸਦੀ ਹੈ, ਤਾਂ durability ਉਹ ਵਾਅਦਾ ਹੈ ਕਿ ਡੇਟਾਬੇਸ ਅਗਲੇ ਫੇਲ੍ਹ ਤੋਂ ਬਾਅਦ ਵੀ ਉਸ ਗੱਲ ਨੂੰ ਭੁੱਲੇਗਾ ਨਹੀਂ।
ਜ਼ਿਆਦਾਤਰ relational ਡੇਟਾਬੇਸ durability ਨੂੰ write-ahead logging (WAL) ਨਾਲ ਹਾਸਲ ਕਰਦੇ ਹਨ। ਉੱਚ-ਸਤਰ ਤੇ, ਡੇਟਾਬੇਸ commit ਮੰਨਣ ਤੋਂ ਪਹਿਲਾਂ ਤਬਦੀਲੀਆਂ ਦਾ ਕ੍ਰਮਬੱਧ “ਰਸਿੱਟ” ਇੱਕ ਲੌਗ 'ਤੇ ਡਿਸਕ 'ਤੇ ਲਿਖਦਾ ਹੈ। ਜੇ ਡੇਟਾਬੇਸ crash ਕਰਦਾ ਹੈ, ਤਾਂ startup ਤੇ ਇਹ ਲੌਗ replay ਕਰਕੇ committed ਤਬਦੀਲੀਆਂ ਨੂੰ ਰੀਸਟੋਰ ਕਰ ਸਕਦਾ ਹੈ।
ਰਿਕਵਰੀ ਸਮਾਂ ਨੂੰ reasonable ਰੱਖਣ ਲਈ, ਡੇਟਾਬੇਸ checkpoint ਵੀ ਬਣਾਉਂਦਾ ਹੈ। ਇੱਕ checkpoint ਉਹ ਸਮਾਂ ਹੈ ਜਦੋਂ ਡੇਟਾਬੇਸ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਕਾਫੀ ਹਾਲੀਆ ਬਦਲਾਵ ਮੁੱਖ ਡੇਟਾ ਫਾਇਲਾਂ ਵਿੱਚ ਲਿਖੇ ਗਏ ਹਨ, ਤਾਂ ਕਿ ਰਿਕਵਰੀ ਨੂੰ ਅਣੰਤ ਲੌਗ ਇਤਿਹਾਸ ਨੂੰ replay ਨਾ ਕਰਨਾ ਪਵੇ।
Durability ਕੋਈ ਇਕ on/off ਸੁਵਿਧਾ ਨਹੀ; ਇਹ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਡੇਟਾਬੇਸ ਡੇਟਾ ਨੂੰ ਸਥਾਈ ਸਟੋਰੇਜ 'ਤੇ ਕਿੰਨੀ ਜ਼ੋਰ ਨਾਲ ਫ਼ੋਰਸ ਕਰਦਾ ਹੈ।
fsync ਰਾਹੀਂ)। ਇਹ ਸੁਰੱਖਿਅਤ ਹੈ, ਪਰ latency ਵਧਾ ਸਕਦਾ ਹੈ।ਅਧਾਰਭੂਤ hardware ਵੀ ਅਹਮ ਹੈ: SSDs, RAID controllers ਨਾਲ write caches, ਅਤੇ cloud volumes failures ਹੇਠ ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ ਦਰਜ ਹੋ ਸਕਦੇ ਹਨ।
ਬੈਕਅੱਪ ਅਤੇ replication ਤੁਹਾਨੂੰ recover ਕਰਨ ਜਾਂ downtime ਘਟਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ, ਪਰ ਇਹ durability ਦੇ ਬਰਾਬਰ ਨਹੀਂ ਹੁੰਦੇ। ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ primary ਤੇ durable ਹੋ ਸਕਦੀ ਹੈ ਹਾਲਾਂਕਿ ਉਹ ਹਜੇ replica 'ਤੇ ਨਹੀਂ ਪੁੱਜੀ, ਅਤੇ ਬੈਕਅੱਪ ਆਮ ਤੌਰ 'ਤੇ point-in-time snapshots ਹੁੰਦੇ ਹਨ ਨਾਂ ਕਿ ਹਰ commit-ਵਾਰ ਦੀ ਗਾਰੰਟੀ।
ਜਦੋਂ ਤੁਸੀਂ BEGIN ਕਰਦੇ ਹੋ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਤੇ ਬਾਅਦ COMMIT, ਡੇਟਾਬੇਸ ਕਈ ਹਿੱਸਿਆਂ ਦਾ ਕੋਆਰਡੀਨੇਸ਼ਨ ਕਰਦਾ ਹੈ: ਕੌਣ ਕਿਹੜੇ rows ਪੜ੍ਹ ਸਕਦਾ/ਲਿਖ ਸਕਦਾ ਹੈ, ਕੌਣ ਉਨ੍ਹਾਂ ਨੂੰ ਅਪਡੇਟ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਦੋ ਲੋਕ ਇਕੋ record ਨੂੰ ਬਦਲਣਾ ਚਾਹੁੰਦੇ ਹਨ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਮੁੱਖ “ਅੰਦਰੋਂ” ਚੋਣ ਇਹ ਹੈ ਕਿ conflicts ਨੂੰ ਕਿਵੇਂ ਹੇਠ-ਲਿਆ ਜਾਵੇ:
ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ workload ਅਤੇ isolation level ਦੇ ਅਧਾਰ 'ਤੇ ਦੋਹਾਂ ਵਿਚਲੀਆਂ ਤਕਨੀਕਾਂ ਨੂੰ ਮਿਲਾਉਂਦੇ ਹਨ।
ਆਧੁਨਿਕ ਡੇਟਾਬੇਸ ਅਕਸਰ MVCC (Multi-Version Concurrency Control) ਵਰਤਦੇ ਹਨ: ਇੱਕ row ਦੀ ਇਕੋ ਨਕਲ ਰੱਖਣ ਦੀ ਬਜਾਏ, ਡੇਟਾਬੇਸ ਕਈ ਵਰਜਨਾਂ ਰੱਖਦਾ ਹੈ।
ਇਸ ਨਾਲ ਕਈ ਵਾਰ reads ਅਤੇ writes concurrent ਤੌਰ 'ਤੇ ਘੱਟ blocking ਨਾਲ ਚੱਲ ਸਕਦੇ ਹਨ—ਪਰ write/write conflicts ਦਾ ਹੱਲ ਫਿਰ ਵੀ ਲਾਜ਼ਮੀ ਹੁੰਦਾ ਹੈ।
ਲਾਕਾਂ deadlocks ਪੈਦਾ ਕਰ ਸਕਦੀਆਂ ਹਨ: Transaction A B ਵੱਲੋਂ ਰੱਖੇ ਲਾਕ ਲਈ ਉਡੀਕ ਕਰਦਾ ਹੈ, ਜਦਕਿ B A ਦੇ ਲਾਕ ਲਈ ਉਡੀਕ ਕਰ ਰਿਹਾ ਹੈ।
ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ cycle detect ਕਰਕੇ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ abort ਕਰ ਦਿੰਦੇ ਹਨ ("deadlock victim"), ਤਾਂ ਜੋ ਐਪਲੀਕੇਸ਼ਨ retry ਕਰ ਸਕੇ।
ਜੇ ACID ਦੀ ਰੱਖਿਆ friction ਪੈਦਾ ਕਰ ਰਹੀ ਹੈ, ਤੁਸੀਂ ਅਕਸਰ ਵੇਖੋਗੇ:
ਇਹ ਲੱਛਣ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਦਰਸਾਉਂਦੇ ਹਨ ਕਿ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਆਕਾਰ, ਇੰਡੈਕਸਿੰਗ, ਜਾਂ isolation/locking ਰਣਨੀਤੀ 'ਤੇ ਦੁਬਾਰਾ ਵਿਚਾਰ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
ACID ਗਾਰੰਟੀਆਂ ਸਿਰਫ ਡੇਟਾਬੇਸ ਸਿਧਾਂਤ ਨਹੀਂ ਹਨ—ਉਹ ਇਹ ਤੈਅ ਕਰਦੀਆਂ ਹਨ ਕਿ ਤੁਸੀਂ APIs, ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ, ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ UI flows ਨੂੰ ਕਿਵੇਂ ਡਿਜ਼ਾਈਨ ਕਰੋ। ਮੁੱਖ ਵਿਚਾਰ ਸਧਾਰਨ ਹੈ: ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕਿਹੜੇ ਕਦਮ ਇਕੱਠੇ ਸਫਲ ਹੋਣਾ ਲਾਜ਼ਮੀ ਹੈ, ਅਤੇ ਫਿਰ ਸਿਰਫ ਉਹੀ ਕਦਮ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰੱਖੋ।
ਇੱਕ ਚੰਗੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ API ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਭਾਰਤੀ ਕਾਰਵਾਈ ਦੇ ਨਾਲ ਮਿਲਦੀ ਹੈ, ਭਾਵੇਂ ਇਹ ਕਈ ਟੇਬਲਾਂ ਨੂੰ ਛੂਹੇ। ਉਦਾਹਰਨ ਲਈ, /checkout ਓਪਰੇਸ਼ਨ ਸ਼ਾਇਦ: ਇੱਕ ਆਰਡਰ ਬਣਾਏ, ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਕਰੇ, ਅਤੇ ਭੁਗਤਾਨ ਇਰਾਦਾ ਰਿਕਾਰਡ ਕਰੇ। ਇਹਨਾਂ ਡੇਟਾਬੇਸ ਲਿਖਤਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰੱਖਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਜੇ ਕੋਈ validation fail ਹੋਵੇ ਤਾਂ ਸਾਰੇ rollback ਹੋ ਜਾ ਸਕਣ।
ਇੱਕ ਆਮ ਪੈਟਰਨ:
ਇਸ ਨਾਲ atomicity ਅਤੇ consistency ਬਣੀ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ ਕਿ slow, ਨਾਜੁਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੀਮਾ ਕਿੱਥੇ ਰੱਖੀ ਜਾਵੇ ਇਹ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ “ਇੱਕ ਯੂਨਿਟ ਆਫ ਵਰਕ” ਦਾ ਮਤਲਬ ਕੀ ਹੈ:
ACID ਮਦਦ ਕਰਦਾ ਹੈ, ਪਰ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਫਿਰ ਵੀ ਫੇਲਿਅਰਾਂ ਨੂੰ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਹੱਲ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ:
Avoid ਲੰਮੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ, ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ ਅੰਦਰ external APIs ਕਾਲ ਕਰਨਾ, ਅਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ ਅੰਦਰ user think time (ਉਦੇਹਰਨ: “cart row ਲਾਕ ਕਰੋ, ਯੂਜ਼ਰ ਤੋਂ confirmation ਦੀ ਉਡੀਕ ਕਰੋ”)। ਇਹ contention ਵਧਾਉਂਦੇ ਹਨ ਅਤੇ isolation conflicts ਨੂੰ ਬਹੁਤ ਮਸਲੇਦਾਰ ਬਣਾਉਂਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਟਰਾਂਜ਼ੈਕਸ਼ਨਲ ਸਿਸਟਮ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਂ ਰਹੇ ਹੋ, ਸਭ ਤੋਂ ਵੱਡਾ ਖ਼ਤਰਾ ਆਮ ਤੌਰ 'ਤੇ “ACID ਨਾ ਜਾਣਣਾ” ਨਹੀਂ—ਇਹ ਇੱਕ ਕਾਰੋਬਾਰੀ ਕਾਰਵਾਈ ਨੂੰ ਕਈ endpoints, ਜੌਬਾਂ, ਜਾਂ ਟੇਬਲਾਂ 'ਤੇ ਬੇਤਰਤੀਬੀ ਨਾਲ ਫੈਲਾਉਣਾ ਹੈ ਬਿਨਾਂ ਸਪਸ਼ਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੀਮਾ ਤੋਂ।
ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਆਗੇ ਵਧਣ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ ਜਦਕਿ ACID ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹਨ: ਤੁਸੀਂ ਇੱਕ ਵਰਕਫਲੋ ਵਰਣਨ ਕਰ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਨ: “checkout with inventory reservation and payment intent”) ਇੱਕ planning-first聊天 ਵਿੱਚ, React UI ਅਤੇ Go + PostgreSQL ਬੈਕਇੰਡ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ schema/transaction boundary ਬਦਲਣ 'ਤੇ snapshots/rollback ਨਾਲ iterate ਕਰ ਸਕਦੇ ਹੋ। ਡੇਟਾਬੇਸ ਫਿਰ ਵੀ ਗਾਰੰਟੀਆਂ ਲਾਗੂ ਕਰੇਗਾ; ਇਸ ਦਾ ਮੁੱਲ ਇੱਕ ਸਹੀ ਡਿਜ਼ਾਇਨ ਤੋਂ ਕੰਮ ਕਰਨ ਵਾਲੀ ਇੰਪਲੀਮੈਂਟੇਸ਼ਨ ਤੱਕ ਰাস্তਾ ਤੇਜ਼ ਕਰਨਾ ਹੈ।
ਇਕ ਇਕਲੌਤਾ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੀਮਾ ਦੇ ਅੰਦਰ ACID ਗਾਰੰਟੀ ਦੇ ਸਕਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਕੰਮ ਨੂੰ ਕਈ ਸਰਵਿਸਾਂ (ਅਕਸਰ ਕਈ ਡੇਟਾਬੇਸ) ਵਿੱਚ ਫੈਲਾ ਦਿੰਦੇ ਹੋ, ਉਹੀ ਗਾਰੰਟੀਆਂ ਰੱਖਣਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ—ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹੋ ਤਾਂ ਮਹਿੰਗਾ ਵੀ।
ਕਠੋਰ consistency ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਹਰ ਪੜ੍ਹਾਈ “ਤਾਜ਼ਾ committed ਸੱਚ” ਵੇਖਦੀ ਹੈ। High availability ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸਿਸਟਮ ਜਵਾਬ ਦਿੰਦਾ ਰਹੇ ਭਾਵੇਂ ਕੁਝ ਹਿੱਸੇ धीਮੇ ਜਾਂ ਅਣਪਹੁੰਚੇ ਹੋਣ।
ਬਹੁ-ਸਰਵਿਸ ਸੈਟਅਪ ਵਿੱਚ, ਇੱਕ ਆਰਥਿਕ ਨੈਟਵਰਕ ਸਮੱਸਿਆ ਤੁਹਾਨੂੰ ਚੋਣ ਕਰਵਾਉਂਦੀ ਹੈ: ਸਾਰੇ ਭਾਗਾਂ ਦੇ ਸਹਿਮਤ ਹੋਣ ਤੱਕ ਬਲਾਕ ਕਰਨ ਜਾਂ request fail ਕਰਨਾ (ਜ਼ਿਆਦਾ consistent, ਘੱਟ available), ਜਾਂ ਇਹ ਸਵੀਕਾਰ ਕਰਨਾ ਕਿ ਸਰਵਿਸਾਂ ਥੋੜ੍ਹੀ ਦੇਰ ਲਈ unsynced ਹੋ ਸਕਦੀਆਂ ਹਨ (ਜ਼ਿਆਦਾ available, ਘੱਟ consistent)। ਦੋਹਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ “ਹਮੇਸ਼ਾ ਠੀਕ” ਨਹੀਂ—ਇਹ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰ ਵੱਲੋਂ ਸਹਿਤ ਕੀਤੇ ਜਾ ਸਕਣ ਵਾਲੇ ਗਲਤੀਆਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
ਵੰਡੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਉਹਨਾਂ ਸਰਹੱਦਾਂ 'ਤੇ ਸਹਿਯੋਗ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਜੋ ਤੁਸੀਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਨਿਯੰਤਰਿਤ ਨਹੀਂ ਕਰਦੇ: ਨੈੱਟਵਰਕ ਦੇਰੀ, ਰੀਟ੍ਰਾਈਜ਼, ਟਾਈਮਆਉਟ, ਸਰਵਿਸ ਕ੍ਰੈਸ਼, ਅਤੇ ਅਧੂਰੇ ਫੇਲਿਅਰ।
ਭਾਵੇਂ ਹਰ ਸਰਵਿਸ ਸਹੀ ਹੋਵੇ, ਨੈੱਟਵਰਕ ਅਸਪਸ਼ਟਤਾ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ: ਕੀ payment service commit ਕਰ ਚੁੱਕੀ ਹੈ ਪਰ order service ਨੂੰ acknowledgment ਨਹੀਂ ਮਿਲੀ? ਇਸਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਹੱਲ ਕਰਨ ਲਈ ਸਿਸਟਮ ਕੋਆਰਡੀਨੇਸ਼ਨ ਪ੍ਰੋਟੋਕੋਲ ਵਰਤਦੇ ਹਨ (ਜਿਵੇਂ two-phase commit), ਜੋ ਧੀਮੇ, ਫੇਲਿਅਰ ਦੌਰਾਨ availability ਘਟਾ ਸਕਦੇ ਹਨ ਅਤੇ ਆਪਰੇਸ਼ਨਲ ਜਟਿਲਤਾ ਵਧਾ ਸਕਦੇ ਹਨ।
Sagas ਇੱਕ ਵਰਕਫਲੋ ਨੂੰ ਕਦਮਾਂ ਵਿੱਚ ਤੋੜਦੇ ਹਨ, ਹਰ ਕਦਮ ਨੂੰ ਲੋਕਲ ਤੌਰ 'ਤੇ commit ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਜੇ بعد ਵਾਲਾ ਕਦਮ fail ਹੋ ਜਾਵੇ, ਤਾਂ ਪਹਿਲੇ ਕਦਮਾਂ ਨੂੰ compensating actions ਨਾਲ undone ਕੀਤਾ ਜਾਂਦਾ ਹੈ (ਉਦਾਹਰਨ: charge refund)।
Outbox/inbox ਪੈਟਰਨ event publishing ਅਤੇ consumption ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੇ ਹਨ। ਇੱਕ ਸਰਵਿਸ ਬਿਜ਼ਨਸ ਡੇਟਾ ਅਤੇ “publish ਕਰਨ ਲਈ event” ਰਿਕਾਰਡ ਨੂੰ ਇੱਕੋ ਲੋਕਲ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ (outbox) ਵਿੱਚ ਲਿਖਦਾ ਹੈ। Consumers processed message IDs (inbox) ਰਿਕਾਰਡ ਕਰਦੇ ਹਨ ਤਾਂ ਕਿ retries ਦੇ ਸਮੇਂ duplication ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
Eventual consistency ਛੋਟੇ ਖਿਡਾਰੀਆਂ ਨੂੰ ਸਵੀਕਾਰ ਕਰਦੀ ਹੈ ਜਿੱਥੇ ਸਰਵਿਸਾਂ ਵਿਚਕਾਰ ਦਾ ਡੇਟਾ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ reconciliation ਲਈ ਇੱਕ ਸਾਫ਼ ਯੋਜਨਾ ਹੁੰਦੀ ਹੈ।
ਤੁਸੀਂ ਗਾਰੰਟੀਆਂ ਢੀਲ ਕਰਦੇ ਹੋ ਜਦੋਂ:
ਜੋਖਮ ਨਿਯੰਤਰਿਤ ਕਰਨ ਲਈ invariants define ਕਰੋ (ਕੀ ਕਦੇ ਵੀ ਤੋੜਿਆ ਨਹੀਂ ਜਾਣਾ ਚਾਹੀਦਾ), operations idempotent ਬਣਾਓ, timeouts ਅਤੇ retries ਲਈ backoff ਵਰਤੋ, ਅਤੇ drift (stuck sagas, repeated compensations, outbox tables ਦਾ ਵੱਧਣਾ) ਲਈ ਮਾਨੀਟਰਿੰਗ ਰੱਖੋ। ਸੱਚਮੁਚ ਨਾਜ਼ੁਕ invariants (ਉਦਾਹਰਨ: "ਕਦੇ ਵੀ ਖਾਤੇ ਤੋਂ ਜ਼ਿਆਦਾ ਖਰਚ ਨਾ ਕਰੋ") ਲਈ ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਹੀ ਸਰਵਿਸ ਅਤੇ ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ ਅੰਦਰ ਰੱਖੋ ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ।
ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਯੂਨਿਟ ਟੈਸਟ ਵਿੱਚ “ਸਹੀ” ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਅਸਲ ਟ੍ਰੈਫਿਕ, ਰੀਸਟਾਰਟ ਅਤੇ concurrency ਹੇਠ ਫੇਲ ਹੋ ਸਕਦਾ ਹੈ। ਇਸ ਚੈਕਲਿਸਟ ਨੂੰ ਵਰਤੋ ਤਾਂ ਕਿ ACID ਗਾਰੰਟੀਆਂ ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿਵਹਾਰ ਨਾਲ aligned ਰਹਿਣ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਲਿਖੋ ਕਿ ਕੀ ਹਮੇਸ਼ਾਂ ਸਹੀ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ (ਤੁਹਾਡੇ ਡੇਟਾ invariants)। ਉਦਾਹਰਨ: “account balance ਕਦੇ negative ਨਹੀਂ ਹੋ ਸਕਦਾ,” “order total line items ਦੇ ਜੋੜ ਦੇ ਬਰਾਬਰ ਹੋਵੇ,” “inventory zero ਤੋਂ ਘੱਟ ਨਹੀਂ ਹੋ ਸਕਦੀ,” “ਇੱਕ payment ਇੱਕ order ਨਾਲ ਹੀ linked ਹੋਵੇ।” ਇਹਨਾਂ ਨੂੰ product rule ਸਮਝੋ, ਨਾ ਕਿ ਡੇਟਾਬੇਸ trivia।
ਫਿਰ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਜ਼ਰੂਰੀ ਹੈ ਇਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰੱਖਣਾ ਤੇ ਕੀ defer ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਛੋਟਾ ਰੱਖੋ: ਘੱਟ rows ਛੂਹੋ, ਘੱਟ ਕੰਮ ਕਰੋ (ਕੋਈ external API calls ਨਹੀਂ), ਤੇ ਤੇਜ਼ੀ ਨਾਲ commit ਕਰੋ।
Concurrency ਨੂੰ ਇੱਕ ਮੁੱਖ ਟੈਸਟ dimension ਬਣਾਓ।
ਜੇ ਤੁਸੀਂ retries ਸਹਾਇਤਾ ਕਰਦੇ ਹੋ, ਤਾਂ ਇੱਕ idempotency key ਜੁਤਾਇਆ ਅਤੇ “request repeated after success” ਟੈਸਟ ਸ਼ਾਮਲ ਕਰੋ।
ਉਹ ਇੰਡਿਕੇਟਰ ਦੇਖੋ ਜੋ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿ ਤੁਹਾਡੀਆਂ ਗਾਰੰਟੀਆਂ ਮਹਿੰਗੀਆਂ ਜਾਂ ਨਾਜ਼ੁਕ ਹੋ ਰਹੀਆਂ ਹਨ:
trend 'ਤੇ ਅਲਰਟ ਕਰੋ, ਸਿਰਫ spikes 'ਤੇ ਨਹੀਂ, ਅਤੇ metrics ਨੂੰ ਉਹ endpoints ਜਾਂ jobs ਨਾਲ ਜੋੜੋ ਜੋ ਉਨ੍ਹਾਂ ਦਾ ਕਾਰਨ ਹਨ।
ਉਹ ਸਭ ਤੋਂ ਕਮਜ਼ੋਰ isolation ਵਰਤੋ ਜੋ ਤੁਹਾਡੇ invariants ਨੂੰ ਬਚਾਉਂਦਾ ਹੈ; by default “max it out” ਨਾ ਕਰੋ। ਜਦੋਂ ਤੁਹਾਨੂੰ ਇੱਕ ਛੋਟੀ critical section ਲਈ ਸਖ਼ਤ correctness ਲੋੜੀਦੀ ਹੈ (pennies movement, inventory decrement), ਤਾਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਸਿਰਫ ਉਸੇ section ਤੱਕ ਸੀਮਿਤ ਕਰੋ ਅਤੇ ਬਾਕੀ ਸਾਰਾ ਕੰਮ ਬਾਹਰ ਰੱਖੋ।
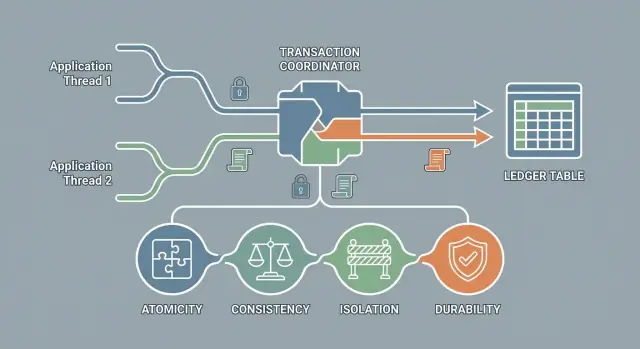
ACID ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਗਾਰੰਟੀਆਂ ਦਾ ਇੱਕ ਸੇਟ ਹੈ ਜੋ ਡੇਟਾਬੇਸਾਂ ਨੂੰ ਫੇਲਿਅਰਾਂ ਅਤੇ ਸਮਕਾਲੀ ਕੰਮ ਦੇ ਦਰਮਿਆਨ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦਾ ਹੈ:
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇੱਕ ਇਕੱਲਾ “ਯੂਨਿਟ ਆਫ ਵਰਕ” ਹੈ ਜਿਸ ਨੂੰ ਡੇਟਾਬੇਸ ਇੱਕ ਪੈਕੇਜ ਵਜੋਂ ਸੰਭਾਲਦਾ ਹੈ। ਭਾਵੇਂ ਇਹ ਕਈ SQL ਬਿਆਨਾਂ ਨੂੰ ਚਲਾਏ (ਉਦਾਹਰਨ: order ਬਣਾਉਣਾ, ਇਨਵੈਂਟਰੀ ਘਟਾਉਣਾ, ਭੁਗਤਾਨ ਇਰਾਦਾ ਰਿਕਾਰਡ ਕਰਨਾ), ਇਸ ਦੇ ਸਿਰਫ ਦੋ ਨਤੀਜੇ ਹੋ ਸਕਦੇ ਹਨ:
ਅਧੂਰੀਅਪਡੇਟਸ ਅਸਲ ਦੁਨੀਆ ਵਿੱਚ تضادات ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ ਜਿਹਨਾਂ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਠੀਕ ਕਰਨਾ ਮਹਿੰਗਾ ਹੁੰਦਾ ਹੈ—ਉਦਾਹਰਨ:
ACID (ਖਾਸ ਕਰਕੇ atomicity + consistency) ਇਨ੍ਹਾਂ “ਅਧੂਰੇ” ਸਥਿਤੀਆਂ ਨੂੰ ਸੱਚਾਈ ਵਜੋਂ ਵਿਖਣ ਤੋਂ ਰੋਕਦਾ ਹੈ।
ਅਟੋਮਿਕਤਾ ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਡੇਟਾਬੇਸ ‘ਹਾਫ-ਕੰਪਲੀਟ’ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਕਦੇ ਵੀ ਦਰਸਾਉਂਦਾ ਨਹੀਂ। ਜੇ commit ਤੋਂ ਪਹਿਲਾਂ ਕੁਝ ਵੀ ਫੇਲ ਹੁੰਦਾ ਹੈ—ਐਪ ਕ੍ਰੈਸ਼, ਨੈਟਵਰਕ ਡ੍ਰੌਪ, DB ਰੀਸਟਾਰਟ—ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ rollback ਹੋ ਜਾਂਦਾ ਹੈ ਤਾਂ ਕਿ ਪਹਿਲੇ ਕਦਮ ਸਥਾਈ ਸਟੇਟ ਵਿੱਚ ਲीक ਨਾ ਹੋਣ।
ਅਮਲ ਵਿੱਚ, ਅਟੋਮਿਕਤਾ ਉਹੀ ਚੀਜ਼ ਹੈ ਜੋ ਕਈ-ਕਦਮ ਬਦਲਾਵਾਂ (ਜਿਵੇਂ ਦੋ ਬੈਲੰਸਾਂ ਨੂੰ ਅਪਡੇਟ ਕਰਨ ਵਾਲੀ ਟ੍ਰਾਂਜ਼ਫਰ) ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੀ ਹੈ।
ਤੁਹਾਨੂੰ ਹਮੇਸ਼ਾਂ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ ਕਿ commit ਹੋਇਆ ਸੀ ਕਿ ਨਹੀਂ ਜਦੋਂ ਕਲਾਇੰਟ response ਖੋ ਦਿੰਦਾ ਹੈ (ਉਦਾਹਰਨ: commit ਦੇ ਬਾਅਦ ਨੈਟਵਰਕ ਟਾਈਮਆਉਟ)। ACID ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਇਹਨਾਂ ਨਾਲ ਜੋੜੋ:
ਇਸ ਤਰ੍ਹਾਂ ਅਟੋਮਿਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਤੇ idempotent ਰੀਟ੍ਰਾਈਜ਼ ਮਿਲ ਕੇ ਅਧੂਰੇ ਅਪਡੇਟ ਅਤੇ ਦੋਹਰਾਈ ਹੋਈ ਚਾਰਜਿੰਗ ਦੋਹਾਂ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ।
ACID ਵਿੱਚ “Consistency” ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਡੇਟਾ ਸਿਰਫ ਠੀਕ ਲੱਗੇ—ਇਸ ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਤੁਹਾਡੇ ਦੁਆਰਾ ਪਰਿਭਾਸ਼ਿਤ ਨਿਯਮਾਂ ਅਨੁਸਾਰ ਇੱਕ ਵੈਧ ਸਟੇਟ ਤੋਂ ਦੂਜੇ ਵੈਧ ਸਟੇਟ ਵਿੱਚ ਲੈ ਕੇ ਜਾਂਦਾ ਹੈ—ਜਿਹੜੇ ਨਿਯਮ ਤੁਸੀਂ ਤਿਆਰ ਕਰਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਨਿਯਮ ਨੂੰ ਕਿਤੇ ਵੀ ਦਰਜ ਨਹੀਂ ਕੀਤਾ (ਜਿਵੇਂ “ਬੈਲੰਸ ਨਕਾਰਾਤਮਕ ਨਹੀਂ ਹੋ ਸਕਦਾ”), ਤਾਂ ACID ਉਸਨੂੰ ਆਪ ਹੀ ਲਾਗੂ ਨਹੀਂ ਕਰ ਸਕਦਾ। ਡੇਟਾਬੇਸ ਲਈ ਸਪੱਸ਼ਟ invariants ਲਿਖੋ ਤਾਂ ਜੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਟੁੱਟਣ ਤੋਂ ਰੋਕ ਸਕਣ।
ਐਪ-ਲੈਵਲ ਵੈਲੀਡੇਸ਼ਨ UX ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ ਪਰ ਇੱਕੱਲੀ ਉਹ ਕਾਫ਼ੀ ਨਹੀਂ।
ਕлассਿਕ ਫੇਲਯੋਰ ਮੋਡ: ਐਪ ਵਿੱਚ ਚੈੱਕ ਕਰਨਾ (“email ਲਭਿਆ”) ਅਤੇ ਫਿਰ row insert ਕਰਨਾ—ਕਨਕਰਨਸੀ ਹੋਣ 'ਤੇ ਦੋ ਰਿਕਵੇਸਟ ਇੱਕੋ ਸਮੇਂ ਚੈੱਕ ਪਾਸ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਡੇਟਾਬੇਸ ਵਿੱਚ unique constraint ਹੀ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਕੇਵਲ ਇੱਕ insert ਕਾਮਯਾਬ ਹੋਵੇ।
Isolation ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਇੱਕ ਦੂਜੇ 'ਤੇ ਖਰਾਬ ਪ੍ਰਭਾਵ ਨਹੀਂ ਪਾਉਂਦੀਆਂ। ਜਦੋਂ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਚੱਲ ਰਿਹਾ ਹੁੰਦਾ ਹੈ, ਹੋਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਧੂਰੇ ਕੰਮ ਨੂੰ ਨਹੀਂ ਵੇਖਣੇ ਚਾਹੀਦੇ ਜਾਂ ਅੰਨੇ-ਵੱਖਰੇ ਤਰੀਕੇ ਨਾਲ overwrite ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ।
ਕੁਝ ਆਮ anomalies ਜੋ ਆ ਸਕਦੀਆਂ ਹਨ:
ਅਟੋਮਿਕਤਾ, Consistency, Isolation ਅਤੇ Durability ਲਾਗੂ ਕਰਨ ਲਈ ਡੇਟਾਬੇਸ ਕਈ ਭਾਗਾਂ ਨੂੰ ਸਮਨਵਯ ਕਰਦਾ ਹੈ: ਕਿਸ ਨੂੰ ਕਿਹੜੇ rows ਪੜ੍ਹਣੇ/ਲਿਖਣੇ ਦੇ ਅਧਿਕਾਰ ਹਨ, ਕਦੋਂ ਲਾਕ ਲਾਉਣੇ ਨੇ, ਅਤੇ ਵਿਵਾਦਾਂ ਦਾ ਕਿਵੇਂ ਨਿਵਾਰਣ ਹੋਵੇ।
ਕੁਝ ਮੁੱਖ ਤਕਨੀਕਾਂ:
Durability ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਜਦੋਂ ਕੋਈ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ committed ਹੋ ਚੱਕੀ ਹੈ, ਉਸ ਦਾ ਨਤੀਜਾ crash—ਪਾਵਰ ਲੌਸ, ਪ੍ਰੋਸੈੱਸ ਰੀਸਟਾਰਟ ਜਾਂ ਮਸ਼ੀਨ ਰੀਬੂਟ—ਤੋਂ ਬਾਦ ਵੀ ਕਾਇਮ ਰਹੇ।
ਅਧਿਕਤਰ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਇਸਨੂੰ write-ahead logging (WAL) ਨਾਲ ਹਾਸਲ ਕਰਦੇ ਹਨ: ਬਦਲਾਵ ਇੱਕ ਕ੍ਰਮਬੱਧ ਲੌਗ ਤੇ ਡਿਸਕ 'ਤੇ ਲਿਖੇ ਜਾਂਦੇ ਹਨ ਪਹਿਲਾਂ ਕਿ ਡੇਟਾਬੇਸ commit ਵਜੋਂ ਮੰਨਣ। ਕਿੱਤੇ ਦੇ ਤੋੜ 'ਤੇ DB restart ਤੇ ਲੌਗ replay ਕਰਕੇ committed ਬਦਲਾਵ ਮੁੜ ਲਾਇਆ ਜਾਂਦਾ ਹੈ।
Durability storage ਅਤੇ configuration 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ—synchronous fsync ਵਗੈਰਾ ਲੈਟੈਂਸੀ ਵਧਾ ਸਕਦੇ ਹਨ ਪਰ ਸੁਰੱਖਿਆ ਵਧਾਉਂਦੇ ਹਨ।
ਇਹਨਾਂ anomaly ਨੂੰ ਰੋਕਣ ਲਈ ਡੇਟਾਬੇਸ isolation levels ਦਿੰਦੇ ਹਨ, ਜਿੱਥੇ ਤੁਸੀਂ ਕਾਰਗੁਜ਼ਾਰੀ ਅਤੇ ਸੁਰੱਖਿਆ ਵਿਚ ਵਪਾਰ ਕਰਦੇ ਹੋ।
ਲਾਕਿੰਗ deadlocks ਵੀ ਬਣ ਸਕਦੇ ਹਨ; ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ cycle detect ਕਰਕੇ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ abort ਕਰ ਦਿੰਦਾ (deadlock victim) ਤਾਂ ਜੋ ਅਰਜੀ ਰੀਟ੍ਰਾਈ ਕੀਤੀ ਜਾ ਸਕੇ।