30 ਨਵੰ 2025·8 ਮਿੰਟ
CRUD ਐਪ ਲਈ AI: ਕੀ ਆਟੋਮੇਟ ਹੁੰਦਾ ਹੈ ਅਤੇ ਕੀ ਮਨੁੱਖਾਂ ਦੀ ਲੋੜ ਹੈ
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਗਾਈਡ: CRUD ਐਪਾਂ ਵਿੱਚ AI ਕਿਹੜੇ ਕੰਮ ਭਰੋਸੇਯੋਗ ਤੌਰ 'ਤੇ ਆਟੋਮੇਟ ਕਰ ਸਕਦਾ ਹੈ (scaffolding, queries, tests) ਅਤੇ ਕਿੱਥੇ ਮਨੁੱਖੀ ਫੈਸਲੇ ਜ਼ਰੂਰੀ ਹਨ (models, rules, security)।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਗਾਈਡ: CRUD ਐਪਾਂ ਵਿੱਚ AI ਕਿਹੜੇ ਕੰਮ ਭਰੋਸੇਯੋਗ ਤੌਰ 'ਤੇ ਆਟੋਮੇਟ ਕਰ ਸਕਦਾ ਹੈ (scaffolding, queries, tests) ਅਤੇ ਕਿੱਥੇ ਮਨੁੱਖੀ ਫੈਸਲੇ ਜ਼ਰੂਰੀ ਹਨ (models, rules, security)।
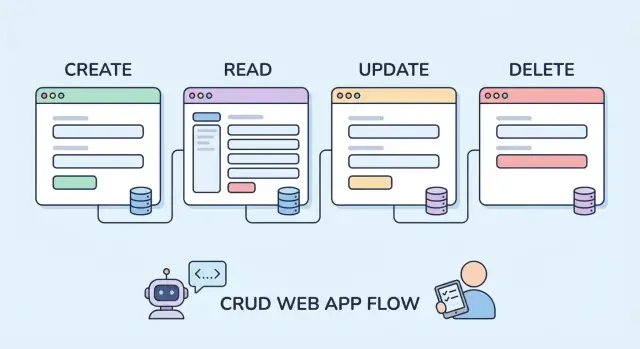
CRUD ਐਪ ਉਹ ਰੋਜ਼ਾਨਾ ਟੂਲ ਹਨ ਜੋ ਲੋਕਾਂ ਨੂੰ ਡੇਟਾ Create, Read, Update, ਅਤੇ Delete ਕਰਨ ਦਿੰਦੀਆਂ ਹਨ — ਸੋਚੋ customer ਲਿਸਟਾਂ, inventory ਟ੍ਰੈਕਰ, appointment ਸਿਸਟਮ, ਇੰਟਰਨਲ ਡੈਸ਼ਬੋਰਡ ਅਤੇ admin ਪੈਨਲ। ਇਹ ਆਮ ਹਨ ਕਿਉਂਕਿ ਜ਼ਿਆਦਾਤਰ ਵਿਅਵਸਾਯ ਸੰਰਚਿਤ ਰਿਕਾਰਡ ਅਤੇ ਦੁਹਰਾਉਂਦੇ ਵਰਕਫਲੋਜ਼ 'ਤੇ ਚੱਲਦੇ ਹਨ।
ਜਦ ਲੋਕ ਕਹਿੰਦੇ ਹਨ "AI for CRUD apps," ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਐਸੇ ਸਹਾਇਕ ਦੀ ਗੱਲ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹਨ ਜੋ routine ਇੰਜੀਨੀਅਰਿੰਗ ਕੰਮ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ ਅਤੇ ਡ੍ਰਾਫਟ ਤਿਆਰ ਕਰਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਐਡਿਟ, ਸਮੀਖਿਆ ਅਤੇ ਮਜ਼ਬੂਤ ਕਰ ਸਕਦੇ ਹੋ।
ਅਮਲ ਵਿੱਚ, AI ਆਟੋਮੇਸ਼ਨ ਇਸ ਤਰ੍ਹਾਂ ਹੈ:
ਇਹ boilerplate 'ਤੇ ਘੰਟੇ ਬਚਾ ਸਕਦਾ ਹੈ — ਖਾਸ ਕਰਕੇ CRUD ਪ੍ਰਾਜੈਕਟਾਂ 'ਚ ਜੋ patterns ਫਾਲੋ ਕਰਦੇ ਹਨ।
AI ਤੁਹਾਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਨਤੀਜੇ ਨੂੰ ਆਪਣੇ ਆਪ ਸਹੀ ਨਹੀਂ ਬਣਾਉਂਦਾ। ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ:
ਸਹੀ ਉਮੀਦ ਹੈ: ਤੇਜ਼ੀ, ਨਾ ਕਿ ਪੱਕੀ ਗੈਰੰਟੀ। ਤੁਸੀਂ ਹਾਲੇ ਵੀ review, test ਅਤੇ ਫੈਸਲਾ ਕਰੋਗੇ।
AI ਉਸ ਥਾਂ ਸਭ ਤੋਂ ਭਲੂ ਹੈ ਜਿੱਥੇ ਕੰਮ patterned ਹੈ ਅਤੇ "ਸਹੀ ਜਵਾਬ" ਜ਼ਿਆਦਾਤਰ ਮਾਮਲਿਆਂ ਵਿੱਚ ਸਟੈਂਡਰਡ ਹੁੰਦਾ ਹੈ: scaffolding, CRUD endpoints, ਮੁੱਢਲੇ ਫਾਰਮ ਅਤੇ predictable ਟੈਸਟ।
ਜਿੱਥੇ ਮਨੁੱਖ ਅਜੇ ਵੀ ਜ਼ਰੂਰੀ ਹਨ: ਡੇਟਾ ਦਾ ਅਰਥ, access control, security/privacy, edge cases, ਅਤੇ ਉਹ ਨਿਯਮ ਜੋ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਵਿਲੱਖਣ ਬਣਾਉਂਦੇ ਹਨ।
CRUD ਐਪ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕੋ ਜਿਹੇ LEGO ਬਲਾਕਾਂ ਤੋਂ ਬਣਦੇ ਹਨ: ਡੇਟਾ ਮਾਡਲ, ਮਾਈਗ੍ਰੇਸ਼ਨ, ਫਾਰਮ, ਵੈਲਿਡੇਸ਼ਨ, list/detail ਪੇਜ਼, ਟੇਬਲ ਅਤੇ ਫਿਲਟਰ, endpoints (REST/GraphQL/RPC), search ਅਤੇ pagination, auth, ਅਤੇ permissions। ਇਹ ਦੋਹਰਾਉਂਦੀਆਂ ਸਾਂਝੀਆਂ ਬਣਤਰਾਂ ਬਨਾਉਂਦੀਆਂ ਹਨ — ਇਸੀ ਲਈ AI-ਸਹਾਇਤ ਜਨਰੇਸ਼ਨ ਤੇਜ਼ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ।
ਪੈਟਰਨ ਹਰ ਜਗ੍ਹਾ ਨਜ਼ਰ ਆਉਂਦੇ ਹਨ:
ਇਨ੍ਹਾਂ patterns ਦੀ ਲਗਾਤਾਰਤਾ ਕਾਰਨ, AI ਇੱਕ ਪਹਿਲਾ ਡ੍ਰਾਫਟ ਪੈਦਾ ਕਰਨ ਵਿੱਚ ਚੰਗਾ ਹੈ: ਮੁੱਢਲੇ ਮਾਡਲ, scaffolded routes, simple controllers/handlers, standard UI forms, ਅਤੇ starter tests। ਇਹ frameworks ਅਤੇ code generators ਵਰਗੇ ਹੀ ਹੈ—AI ਸਿਰਫ਼ ਤੁਹਾਡੇ naming ਅਤੇ conventions ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਅਡਾਪਟ ਕਰਦਾ ਹੈ।
CRUD ਐਪ “ਸਟੈਂਡਰਡ” ਹੋਣਾ ਬੰਦ ਕਰ ਦਿੰਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਉਸ ਵਿੱਚ ਅਰਥ ਪਾਉਂਦੇ ਹੋ:
ਇਹ ਉਹ ਖੇਤਰ ਹਨ ਜਿੱਥੇ ਇੱਕ ਛੋਟੀ ਗਲਤੀ ਵੱਡੇ ਮੁੱਦੇ ਪੈਦਾ ਕਰਦੀ ਹੈ: unauthorized access, irreversible deletions, ਜਾਂ records ਜੋ reconcile ਨਹੀਂ ਹੁੰਦੇ।
AI ਨੂੰ patterns ਆਟੋਮੇਟ ਕਰਨ ਲਈ ਵਰਤੋ, ਫਿਰ ਨਤੀਜਿਆਂ ਦੀ ਨਿਯਤ ਤੌਰ 'ਤੇ ਸਮੀਖਿਆ ਕਰੋ। ਜੇ ਨਿਕਾਸੀ ਦੇ ਨਤੀਜੇ यह ਦਰਸਾਉਂਦੇ ਹਨ ਕਿ ਕੌਣ ਵੇਖ ਸਕਦਾ/ਬਦਲ ਸਕਦਾ ਹੈ ਜਾਂ ਡੇਟਾ ਸਮੇਂ ਦੇ ਨਾਲ ਸਹੀ ਰਹਿੰਦਾ ਹੈ, ਤਾਂ ਉਸਨੂੰ high-risk ਸਮਝੋ ਅਤੇ production-critical ਕੋਡ ਵਾਂਗ verify ਕਰੋ।
AI ਉਸ ਵੇਲੇ ਸਭ ਤੋਂ ਵਧੀਆ ਹੈ ਜਦ ਕੰਮ repetitive, structurally predictable, ਅਤੇ ਆਸਾਨੀ ਨਾਲ verify ਕੀਤੇ ਜਾ ਸਕਦੇ ਹੋ। CRUD ਐਪ ਵਿੱਚ ਇਹ ਮੌਕਿਆਂ ਭਰਪੂਰ ਹਨ: ਇੱਕੋ ਜਿਹੇ patterns ਮੁੱਖ ਮਾਡਲਾਂ, endpoints, ਅਤੇ ਸਕਰੀਨਾਂ 'ਚ ਦੋਹਰਾਏ ਜਾਂਦੇ ਹਨ। ਇਸ ਤਰੀਕੇ ਨਾਲ AI ਘੰਟੇ ਬਚਾ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਉਤਪਾਦ ਦੀ ਮਾਲਕੀ ਲਈ ਦਾਅਵਾ ਕੀਤੇ।
ਜੇ ਤੁਸੀਂ ਕਿਸੇ entity (ਫੀਲਡਾਂ, ਰਿਸ਼ਤਿਆਂ, ਅਤੇ ਬੁਨਿਆਦੀ ਐਕਸ਼ਨਾਂ) ਦੀ ਵਿਆਖਿਆ ਸਾਫ਼ ਦਿੰਦੇ ਹੋ, ਤਾਂ AI ਤੇਜ਼ੀ ਨਾਲ ਲਕੜੀ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ: ਮਾਡਲ ਪਰਿਭਾਸ਼ਾਵਾਂ, controllers/handlers, routes, ਅਤੇ ਮੁੱਢਲੇ ਪੇਜ। ਤੁਸੀਂ ਹਾਲੇ ਵੀ naming, ਡੇਟਾ ਟਾਈਪ, ਅਤੇ ਰਿਸ਼ਤਿਆਂ ਦੀ ਪੁਸ਼ਟੀ ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਹੈ—ਪਰ ਮੁਕੰਮਲ ਡ੍ਰਾਫਟ ਤੋਂ ਸ਼ੁਰੂ ਕਰਨਾ ਹਰ ਫਾਇਲ ਨੂੰ scratch ਤੋਂ ਬਣਾਉਣ ਨਾਲੋਂ ਤੇਜ਼ ਹੈ।
ਆਮ operations — list, detail, create, update, delete — ਲਈ AI convention ਅਨੁਸਾਰ handler ਕੋਡ ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ: input parse ਕਰੋ, data-access layer ਨੂੰ ਬੁਲਾਓ, response ਵਾਪਸ ਕਰੋ।
ਜਦੋਂ ਤੁਸੀਂ ਬਹੁਤ ਸਾਰੇ ਮਿਲਦੇ-ਜੁਲਦੇ endpoints ਇਕੱਠੇ ਸੈਟਅੱਪ ਕਰ ਰਹੇ ਹੋ, ਇਹ ਜ਼ਿਆਦਾ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ। ਤਾਂਦੀ key ਗੱਲਾਂ ਦੀ ਸਮੀਖਿਆ ਕਰੋ: filtering, pagination, error codes, ਅਤੇ ਉਹ "special cases" ਜੋ ਸਟੈਂਡਰਡ ਨਹੀਂ ਹੁੰਦੇ।
CRUD ਅਕਸਰ internal tooling ਲੋੜੀਂਦਾ ਹੈ: list/detail ਪੇਜ, ਬੇਸਿਕ ਫਾਰਮ, ਟੇਬਲ ਵੇਖਾਏ, ਅਤੇ admin-ਸਟਾਈਲ navigation। AI ਪਹਿਲੇ ਵਰਜ਼ਨ ਤੇਜ਼ੀ ਨਾਲ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ।
ਇਨ੍ਹਾਂ ਨੂੰ prototype ਸਮਝੋ ਅਤੇ harden ਕਰੋ: empty states, loading states, ਅਤੇ ਇਹ ਦੇਖੋ ਕਿ UI ਲੋਕਾਂ ਦੇ ਖੋਜ ਅਤੇ ਸਕੈਨ ਕਰਨ ਦੇ ਅੰਦਾਜ਼ ਨਾਲ ਮਿਲਦੀ ਹੈ ਜਾਂ ਨਹੀਂ।
AI ਮਕੈਨੀਕਲ refactors—ਫਾਇਲਾਂ 'ਚ ਫੀਲਡਾਂ ਦਾ ਨਾਮ ਬਦਲਨਾ, ਮੋਡੀਊਲਸ ਹਿਲਾਉਣਾ, helpers ਕੱਢਣਾ, ਜਾਂ patterns standardize ਕਰਨ—ਚ ਹੈਰਾਨੀਜਨਕ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹੈ। ਇਹ ਸੁਝਾ ਸਕਦਾ ਹੈ ਕਿ duplication ਕਿੱਥੇ ਹੈ।
ਫਿਰ ਵੀ, tests ਚਲਾਓ ਅਤੇ diffs ਦੀ ਸਮੀਖਿਆ ਕਰੋ—ਕਿਉਂਕਿ ਰਿਫੈਕਟੋਰ ਕੁਝ ਸੁਖੜੇ ਤਰੀਕੇ ਨਾਲ fail ਕਰ ਸਕਦਾ ਹੈ ਜਦ ਦੋ "ਇਕੋ ਜਿਹੇ" ਕੇਸ ਸਚਮੁਚ ਇਕੋ ਜਿਹੇ ਨਹੀਂ ਹੁੰਦੇ।
AI README ਭਾਗ, endpoint ਵੇਰਵੇ, ਅਤੇ inline comments ਦਾ ਡ੍ਰਾਫਟ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਇਰਾਦੇ ਨੂੰ ਸਮਝਾਉਂਦੇ ਹਨ। ਇਹ onboarding ਅਤੇ code reviews ਲਈ ਲਾਭਦਾਇਕ ਹੈ—ਪਰ ਤੁਸੀਂ ਹਰ ਦਾਓਂ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ। ਪੁਰਾਣੇ ਜਾਂ ਗਲਤ docs ਹੋਣਾ ਕਿਸੇ ਚੀਜ਼ ਤੋਂ ਵਧ ਕੇ ਨੁਕਸਾਨਦਾਇਕ ਹੁੰਦਾ ਹੈ।
AI ਡੇਟਾ ਮਾਡਲਿੰਗ ਦੀ ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਵਾਸਤਵ ਵਿੱਚ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ plain-language entities ਨੂੰ ਪਹਿਲੇ-ਪਾਸ ਸਕੀਮਾ ਵਿੱਚ ਬਦਲਣ ਵਿੱਚ ਚੰਗਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਕਹੋ "Customer, Invoice, LineItem, Payment", ਇਹ ਟੇਬਲ/ਕਲੇਕਸ਼ਨ, ਆਮ ਫੀਲਡ, ਅਤੇ منطقی defaults (IDs, timestamps, status enums) ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ।
ਸਧਾਰਨ ਬਦਲਾਵਾਂ ਲਈ AI ਨਿਰਾਸ਼ਾ-ਭਰੇ ਹਿੱਸਿਆਂ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ:
tenant_id + created_at, status, email), ਪਰ ਇਹਨਾਂ ਨੂੰ ਅਸਲ queries ਦੇ ਖਿਲਾਫ਼ ਜਾਂਚੋਜਦ ਤੁਹਾਨੂੰ model explore ਕਰਨਾ ਹੋਵੇ, ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹੈ: ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਟਰੇਟ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਫਿਰ workflow ਸਪਸ਼ਟ ਹੋਣ 'ਤੇ tighten ਕਰੋ।
ਡੇਟਾ ਮਾਡਲ ਵਿੱਚ ਉਹ "gotchas" ਹੁੰਦੇ ਹਨ ਜੋ AI ਛੋਟੇ prompt ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਨਿਰਧਾਰਤ ਨਹੀਂ ਕਰ ਸਕਦਾ:
ਇਹ ਸਿੰਟੈਕਸ ਸਮੱਸਿਆਵਾਂ ਨਹੀਂ ਹਨ; ਇਹਾਂ ਵਪਾਰ ਅਤੇ ਜੋਖਿਮ ਫੈਸਲੇ ਹਨ।
ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ ਜੋ "ਸਹੀ" ਹੈ ਉਹ ਫਿਰ ਵੀ ਅਸੁਰੱਖਿਅਤ ਹੋ ਸਕਦੀ ਹੈ। ਕਿਸੇ ਵੀ ਚੀਜ਼ ਨੂੰ ਅਸਲ ਡੇਟਾ 'ਤੇ ਚਲਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਤੁਸੀਂ ਫੈਸਲਾ ਕਰੋ:
AI migration ਅਤੇ rollout ਯੋਜਨਾ ਦਾ ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਯੋਜਨਾ ਇੱਕ ਪ੍ਰਸਤਾਵ ਵਾਂਗ ਮੰਨੋ—ਤੁਹਾਡੀ ਟੀਮ ਨਤੀਜਿਆਂ ਦੀ ਮਾਲਕੀ ਕਰਦੀ ਹੈ।
ਫਾਰਮ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ CRUD ਐਪ ਮਨੁੱਖਾਂ ਨਾਲ ਮਿਲਦੇ ਹਨ। AI ਇੱਥੇ ਸੱਚਮੁਚ ਮਦਦਗਾਰ ਹੈ ਕਿਉਂਕਿ ਕੰਮ ਦੁਹਰਾਉਂਦਾ ਹੈ: schema ਨੂੰ inputs ਵਿੱਚ ਬਦਲਣਾ, ਬੁਨਿਆਦੀ ਵੈਲਿਡੇਸ਼ਨ ਵਾਇਰ ਕਰਨਾ, ਅਤੇ client ਅਤੇ server ਨੂੰ sync ਰੱਖਣਾ।
ਕਿਸੇ ਡੇਟਾ ਮਾਡਲ (ਜਾਂ ਉਦਾਹਰਣ JSON payload) ਤੋਂ, AI ਤੇਜ਼ੀ ਨਾਲ ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ:
ਇਹ ਸ਼ੁਰੂਆਤੀ ਵਰਜ਼ਨ ਲਈ ਤੇਜ਼ੀ ਨਾਲ ਵਰਕ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ, ਖਾਸ ਕਰਕੇ admin-ਸਟਾਈਲ ਸਕਰੀਨਾਂ ਲਈ।
Validation ਸਿਰਫ਼ ਗਲਤ ਡੇਟਾ ਰੋਕਣ ਬਾਰੇ ਨਹੀਂ ਹੈ; ਇਹ ਇਰਾਦੇ ਨੂੰ ਪ੍ਰਗਟ ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ। AI ਤੁਹਾਡੇ ਯੂਜ਼ਰਾਂ ਲਈ "ਚੰਗਾ" ਕੀ ਹੈ, ਇਹ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਅਨੁਮਾਨ ਨਹੀਂ ਲਗਾ ਸਕਦਾ।
ਤੁਹਾਨੂੰ ਫੈਸਲਾ ਕਰਨਾ ਹੋਵੇਗਾ:
ਆਮ ਨੁਕਸਾਨੀ ਮੋਡ ਇਹ ਹੈ ਕਿ AI ਐਸੇ ਨਿਯਮ ਲਗਾ ਦੇਵੇ ਜੋ ਤਰਕਸੰਗਤ ਲੱਗਦੇ ਹਨ ਪਰ ਤੁਹਾਡੇ ਵਪਾਰ ਲਈ ਗਲਤ ਹਨ (ਉਦਾਹਰਨ: ਫੋਨ ਫਾਰਮੈਟ ਕੜੇ ਤੌਰ 'ਤੇ ਲੱਗੂ ਕਰਨਾ ਜਾਂ ਨਾਂਵਾਂ ਵਿੱਚ apostrophes ਨੂੰ ਰੱਦ ਕਰਨਾ)।
AI ਵਿਕਲਪ ਸੁਝਾ ਸਕਦਾ ਹੈ, ਪਰ ਸੱਚਾਈ ਤੁਹਾਡੇ ਕੋਲ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ:
ਇੱਕ ਪ੍ਰ效ਕਟਿਕਲ ਤਰੀਕਾ: AI ਨੂੰ ਪਹਿਲਾ ਪਾਸ ਬਣਾਉਣ ਦਿਓ, ਫਿਰ ਹਰ ਨਿਯਮ ਦੀ ਸਮੀਖਿਆ ਕਰੋ ਅਤੇ ਪੁੱਛੋ, "ਕੀ ਇਹ ਯੂਜ਼ਰ ਸੁਵਿਧਾ ਹੈ, API contract ਹੈ, ਜਾਂ ਕਠੋਰ ਡੇਟਾ invariant?"
CRUD APIs ਆਮ ਤੌਰ 'ਤੇ repeatable patterns ਫਾਲੋ ਕਰਦੀਆਂ ਹਨ: list records, fetch one by ID, create, update, delete, ਅਤੇ ਕਦੇ-ਕਦੇ search. ਇਹ AI ਸਹਾਇਤਾ ਲਈ ਖਾਸ ਵਧੀਆ ਖੇਤਰ ਹਨ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਹਾਨੂੰ ਕਈ resources ਲਈ ਮਿਲਦੇ-ਜੁਲਦੇ endpoints ਚਾਹੀਦੇ ਹੋਣ।
AI ਆਮ ਤੌਰ 'ਤੇ standard list/search/filter endpoints ਅਤੇ ਉਨ੍ਹਾਂ ਦੇ ਆਲੇ-ਦੁਆਲੇ "glue code" ਦਾ ਡ੍ਰਾਫਟ ਬਣਾਉਣ ਵਿੱਚ ਚੰਗਾ ਹੁੰਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ:
GET /orders, GET /orders/:id, POST /orders, ਆਦਿ)ਇਹ ਆਖਰੀ ਗੱਲ ਤਅਕਤ ਵਿੱਚੋਂ ਵੱਧ ਅਹਿਮ ਹੈ: inconsistent API shapes front-end ਟੀਮਾਂ ਅਤੇ ਇੰਟੇਗ੍ਰੇਸ਼ਨਾਂ ਲਈ ਛੁਪਾ ਕੰਮ ਬਣਾਉਂਦੇ ਹਨ। AI ਝਲਕ ਸਕਦਾ ਹੈ ਕਿ responses ਹਮੇਸ਼ਾ { data, meta } ਵਾਂਗ ਹੋਣ ਜਾਂ dates ਸਦਾ ISO-8601 ਰਹਿਣ।
AI pagination ਅਤੇ sorting ਜੁੜ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਡੇ ਡੇਟਾ ਲਈ ਸਹੀ ਰਣਨੀਤੀ ਚੁਣਨ ਦੀ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਨਹੀ ਕਰੇਗਾ।
Offset pagination (?page=10) ਸਧਾਰਨ ਹੈ, ਪਰ ਵੱਡੇ ਅਤੇ ਬਦਲਦੇ datasets ਲਈ slow ਅਤੇ inconsistent ਹੋ ਸਕਦੀ ਹੈ। Cursor pagination ("next cursor" token) ਸਕੇਲ 'ਤੇ ਵਧੀਆ ਪ੍ਰਦਰਸ਼ਨ ਦਿੰਦੀ ਹੈ, ਪਰ ਇਹ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਲਾਗੂ ਕਰਨੀ ਮੁਸ਼ਕਲ ਹੈ—ਖਾਸ ਕਰਕੇ ਜਦ ਯੂਜ਼ਰ ਕਈ ਫੀਲਡਾਂ ਦੁਆਰਾ sort ਕਰ ਸਕਦੇ ਹਨ।
ਤੁਸੀਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਉਤਪਾਦ ਲਈ "ਸਹੀ" ਕੀ ਹੈ: stable ordering, ਉਪਭੋਗਤਾ ਕਿੰਨੀ ਪਿੱਛੇ ਦੇਖ ਸਕਦੇ ਹਨ, ਅਤੇ ਕੀ expensive counts ਸਹਿਣਯੋਗ ਹਨ।
Query ਕੋਡ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਛੋਟੀyaan ਗਲਤੀਆਂ ਵੱਡੀਆਂ ਆਉਟੇਜ਼ ਬਣ ਸਕਦੀਆਂ ਹਨ। AI-ਜਨਰੇਟ ਕੀਤਾ API logic ਅਕਸਰ ਸਮੀਖਿਆ ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ:
ਜਨਰੇਟ ਕੋਡ ਨੂੰ ਸਵੀਕਾਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, realistic data volumes ਦੇ ਵਿਰੁੱਧ sanity-check ਕਰੋ। ਆਮ ਗ੍ਰਾਹਕ ਕੋਲ ਕਿੰਨੇ records ਹੋਣਗੇ? "search" 10k vs 10M rows 'ਤੇ ਕੀ ਮਤਲਬ ਰੱਖੇਗਾ? ਕਿਹੜੇ endpoints ਨੂੰ indexes, caching, ਜਾਂ ਸਖ਼ਤ rate limits ਦੀ ਲੋੜ ਹੈ?
AI patterns ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਮਨੁੱਖਾਂ ਨੂੰ guardrails: performance budgets, safe query rules, ਅਤੇ ਕੀ API load ਹੇਠਾਂ ਕਰਨ ਦੇ ਅਧਿਕਾਰ ਦਿੱਤੇ ਜਾਣਗੇ — ਇਹ ਸੈੱਟ ਕਰਨੇ ਪੈਣਗੇ।
AI ਹੈਰਾਨੀਜਨਕ ਤੌਰ 'ਤੇ ਬਹੁਤ ਟੈਸਟ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ CRUD apps ਲਈ ਜਿੱਥੇ patterns ਦੋਹਰਾਏ ਜਾਂਦੇ ਹਨ। ਜਾਲ ਇਹ ਸੋਚਣਾ ਕਿ "ਵੱਧ ਟੈਸਟ" ਆਪਣੇ ਆਪ ਨੂੰ "ਉਤਪਾਦ ਗੁਣਵੱਤਾ" ਨਹੀਂ ਬਣਾਉਂਦਾ। AI ਓਅਵਰਨੁਮਬਰ ਪੈਦਾ ਕਰਦਾ ਹੈ; ਤੁਸੀਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਜੇ ਤੁਸੀਂ AI ਨੂੰ function signature, ਕੁਝ ਵੇਰਵਾ ਅਤੇ ਕੁਝ ਉਦਾਹਰਣ ਦਿੰਦੇ ਹੋ, ਇਹ unit tests ਤੇਜ਼ੀ ਨਾਲ ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਖੁਸ਼-ਰਸਤੇ integration tests ਬਣਾਉਣ ਵਿੱਚ ਵੀ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੈ ("create → read → update → delete" ਵਰਗੇ) - request wiring, status codes asserting, response shapes ਦੀ ਜਾਂਚ ਸਮੇਤ।
ਇੱਕ ਹੋਰ ਮਜਬੂਤ ਉਪਯੋਗ: test data scaffolding। AI factories/fixtures (users, records, related entities) ਅਤੇ mocking patterns (time, UUIDs, external calls) ਦਾ ਖਾਕਾ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਹਰ ਵਾਰੀ repetitive setup ਨਾ ਲਿਖੋ।
AI ਅਕਸਰ coverage numbers ਅਤੇ ਸਾਫ scenarios ਲਈ ਫੋਕਸ ਕਰਦਾ ਹੈ। ਤੁਹਾਡੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ ਮਹੱਤਵਪੂਰਨ ਕੇਸ ਚੁਣਨਾ:
ਇੱਕ ਪ੍ਰੌਗਮੈਟਿਕ ਨਿਯਮ: AI ਨੂੰ ਪਹਿਲਾ ਪਾਸ ਬਣਾਉਣ ਦਿਓ, ਫਿਰ ਹਰ ਟੈਸਟ ਨੂੰ ਪੁੱਛੋ "ਇਹ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਕਿਹੜੀ failure ਰੋਕੇਗਾ?" ਜੇ ਜਵਾਬ "ਕੋਈ ਨਹੀਂ", ਤਾਂ ਉਸਨੂੰ ਹਟਾਓ ਜਾਂ ਮੁੜ-ਲਿਖੋ।
Authentication (ਕੌਣ ਯੂਜ਼ਰ ਹੈ) ਆਮ ਤੌਰ 'ਤੇ ਸਿੱਧੀ ਹੁੰਦੀ ਹੈ। Authorization (ਉਹ ਕੀ ਕਰ ਸਕਦਾ/ਨਹੀਂ) ਉਸ ਸਮੇਂ ਉੱਤੇ ਪ੍ਰਾਜੈਕਟ breach/ਆਡੀਟ/ਡਾਟਾ ਲੀਕ ਹੋ ਜਾਂਦੇ ਹਨ। AI mechanics ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਜੋਖਿਮ ਲਈ ਜ਼ਿੰਮੇਵਾਰੀ ਮਨੁੱਖੀ ਟੀਮ ਦੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ AI ਨੂੰ ਸਾਫ਼ requirements ਦਿਓ ("Managers can edit any order; customers can only view their own; support can refund but not change addresses"), ਇਹ RBAC/ABAC ਨਿਯਮਾਂ ਦਾ ਪਹਿਲਾ ਡ੍ਰਾਫਟ ਬਣਾ ਸਕਦਾ ਹੈ ਅਤੇ roles, attributes, resources ਨੂੰ ਮੈਪ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਇੱਕ ਸ਼ੁਰੂਆਤੀ ਸਕੈਚ ਵਾਂਗ ਲਓ, ਫੈਸਲੇ ਵਾਂਗ ਨਹੀਂ।
AI inconsistent authorization ਦੀ ਖੋਜ ਵਿੱਚ ਵੀ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ—ਕੋਡਬੇਸ ਵਿੱਚ ਜਿੱਥੇ ਕਈ handlers/controllers ਹੋਣ, ਇਹ endpoints ਦੀ ਸਕੈਨ ਕਰਕੇ ਓਹੇ ਜਗ੍ਹਾ ਜਿੱਥੇ authentication ਹੇਠਾਂ permissions enforce ਹੋ ਰਹੇ ਹਨ ਜਾਂ ਨਹੀਂ, ਇਹ ਦਿਖਾ ਸਕਦਾ ਹੈ।
ਅੰਤ ਵਿੱਚ, ਇਹ plumbing ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ: middleware stubs, policy files, decorators/annotations, ਅਤੇ boilerplate checks।
ਤੁਸੀਂ threat model define ਕਰੋ (ਕੌਣ ਸਿਸਟਮ ਨਾਲ ਨੁਕਸਾਨ ਕਰ ਸਕਦਾ), least-privilege defaults (ਜਦ role ਗਾਇਬ ਹੋਵੇ ਤਾਂ ਕੀ ਹੋਵੇ), ਅਤੇ audit ਲੋੜਾਂ (ਕੀ log/retain/ਸਮੀਖਿਆ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ)। ਇਹ ਚੋਣਾਂ ਤੁਹਾਡੇ ਵਪਾਰ 'ਤੇ ਆਧਾਰਤ ਹਨ, framework 'ਤੇ ਨਹੀਂ।
AI ਤੁਹਾਨੂੰ "implemented" ਪੱਧਰ 'ਤੇ ਲੈ ਜਾ ਸਕਦਾ ਹੈ। "Safe" ਪੱਧਰ ਤੱਕ ਪਹੁੰਚਣਾ ਮਨੁੱਖਾਂ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ।
AI ਇੱਥੇ ਮਦਦਗਾਰ ਹੈ ਕਿਉਂਕਿ error handling ਅਤੇ observability ਪਛਾਣਯੋਗ patterns ਦਿਖਾਉਂਦੇ ਹਨ। ਇਹ ਤੇਜ਼ੀ ਨਾਲ "ਚੰਗੇ ਕਾਫੀ" ਡਿਫਾਲਟ ਸੈਟ ਕਰ ਸਕਦਾ ਹੈ—ਫਿਰ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰੋ ਆਪਣੇ ਉਤਪਾਦ, ਜੋਖਿਮ ਪ੍ਰੋਫਾਈਲ, ਅਤੇ ਉਸ ਟੀਮ ਦੀ ਲੋੜਾਂ ਅਨੁਸਾਰ ਸਧਾਰੋ ਜੋ ਰਾਤ 2 ਵਜੇ ਦੇਖਦੀ ਹੈ।
AI ਬੁਨਿਆਦੀ ਪ੍ਰੈਕਟਿਸਿਸ ਸੁਝਾ ਸਕਦਾ ਹੈ:
API error format ਦਾ ਇੱਕ ਆਮ AI-ਜਨਰੇਟ ਕੀਤਾ starting point ਇਸ ਤਰ੍ਹਾਂ ਹੋ ਸਕਦਾ ਹੈ:
{
"error": {
"code": "VALIDATION_ERROR",
"message": "Email is invalid",
"details": [{"field": "email", "reason": "format"}],
"request_id": "..."
}
}
ਉਹ consistency client apps ਬਣਾਉਣਾ ਅਤੇ support ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦੀ ਹੈ।
AI metric names ਅਤੇ starter dashboard ਸੁਝਾ ਸਕਦਾ ਹੈ: request rate, latency (p50/p95), error rate by endpoint, queue depth, ਅਤੇ database timeouts। ਇਹਨਾਂ ਨੂੰ initial ideas ਸਮਝੋ, ਨਾ ਕਿ ਇੱਕ ਤਿਆਰ monitoring ਰਣਨੀਤੀ।
ਖਤਰਨਾਕ ਹਿੱਸਾ ਇਹ ਨਹੀਂ ਕਿ logs ਜੋੜੋ—ਬਲਕਿ ਇਹ ਚੁਣੋ ਕਿ ਕੀ capture ਕਰਨਾ ਹੈ ਅਤੇ ਕੀ ਨਹੀਂ।
ਤੁਸੀਂ ਨਿਰਧਾਰਤ ਕਰੋ:
ਅਖ਼ੀਰ ਵਿੱਚ, "healthy" ਦਾ ਮਤਲਬ ਕਿ ਹੈ ਇਹ define ਕਰੋ: "successful checkouts", "projects created", "emails delivered"—ਨਾ ਕਿ ਸਿਰਫ਼ "servers up"। ਇਹ definition alerts ਨੂੰ ਉਹ signalse ਬਣਾਉਂਦੀ ਹੈ ਜੋ ਅਸਲ user impact ਦੱਸਦੇ ਹਨ, ਨਾ ਕਿ ਸ਼ੋਰ।
CRUD ਐਪ ਸਾਦੀਆਂ ਲੱਗਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਸਕ੍ਰੀਨ ਮੋਡਲ ਰੋਜ਼ਾਨਾ ਵਰਗੇ ਹਨ: record ਬਣਾਓ, ਫੀਲਡ ਅਪਡੇਟ ਕਰੋ, search, delete। ਮੁਸ਼ਕਲ ਗੱਲ ਉਹ ਸਾਰਾ ਕੁਝ ਹੈ ਜੋ ਤੁਹਾਡੀ ਸੰਸਥਾ ਉਸ ਕਾਰਵਾਈ ਨਾਲ ਮਤਲਬ ਰੱਖਦੀ ਹੈ।
AI controllers, forms, ਅਤੇ ਡੇਟਾਬੇਸ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਂਦਾ ਹੈ—ਪਰ ਉਹ ਉਹ ਨਿਯਮ ਨਹੀਂ ਜਾਣ ਸਕਦਾ ਜੋ ਤੁਹਾਡੇ ਉਤਪਾਦ ਨੂੰ ਸਹੀ ਬਣਾਉਂਦੇ ਹਨ। ਉਹ ਨਿਯਮ policy documents, tribal knowledge, ਅਤੇ ਦਿਨ-ਪ੍ਰਤੀਦਿਨ ਫੈਸਲਿਆਂ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ।
ਇੱਕ ਭਰੋਸੇਯੋਗ CRUD workflow ਅਕਸਰ ਇੱਕ decision tree ਨੂੰ ਛੁਪਾਉਂਦਾ ਹੈ:
Approvals ਇੱਕ ਚੰਗਾ ਉਦਾਹਰਣ ਹਨ। "Manager approval required" ਸਲਾਹ ਦਿੰਦਾ ਹੈ ਪਰ ਤਫਸੀਲਾਂ ਜ਼ਰੂਰੀ ਹਨ: manager ਛੁੱਟੀ 'ਤੇ ਹੋਵੇ ਤਾਂ, amount approval ਤੋਂ ਬਾਅਦ ਬਦਲੇ, ਜਾਂ request ਦੋ departments ਵਿਚ ਫੈਲਿਆ ਹੋਵੇ—AI approvals state machine scaffold ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਨਿਯਮ ਤੁਹਾਨੂੰ define ਕਰਨੇ ਪੈਣਗੇ।
Stakeholders ਅਕਸਰ ਬਿਨਾਂ ਸਮਝੌਤੇ ਦੇ ਵੱਖ-ਵੱਖ ਮੰਗਾਂ ਰੱਖਦੇ ਹਨ: ਇੱਕ ਟੀਮ "ਤੇਜ਼ ਪ੍ਰੋਸੈਸਿੰਗ" ਚਾਹੁੰਦੀ ਹੈ, ਦੂਜੀ "ਕਠੋਰ ਨਿਯੰਤਰਣ"। AI ਜਿਸ ਹਦ ਤੱਕ ਸਭ ਤੋਂ ਹੱਲ਼ਾ ਹੁੰਦਾ ਹੈ ਉਹ ਸਭ ਤੋਂ ਅਖ਼ੀਰਾ, ਸਭ ਤੋਂ explicit ਜਾਂ ਸਭ ਤੋਂ ਆਤਮ ਵਿਸ਼ਵਾਸ ਵਾਲੇ ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਲਾਗੂ ਕਰੇਗਾ।
ਮਨੁੱਖਾਂ ਨੂੰ ਟੱਕਰਾਂ ਨੂੰ ਮਿਲਾ ਕੇ ਇੱਕ single source of truth ਲਿਖਣੀ ਚਾਹੀਦੀ ਹੈ: ਨਿਯਮ ਕੀ ਹੈ, ਕਿਉਂ ਹੈ, ਅਤੇ ਸਫਲਤਾ ਕਿਵੇਂ ਨਾਪੀ ਜਾਏਗੀ।
ਛੋਟੀ naming choices downstream ਵੱਡੇ ਪ੍ਰਭਾਵ ਪਾ ਸਕਦੀਆਂ ਹਨ। ਕੋਡ ਜਨਰੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇਸ 'ਤੇ ਸਹਿਮਤੀ ਕਰੋ:
ਬਿਜ਼ਨੈਸ ਨਿਯਮ trade-offs ਲਿਆਉਂਦੇ ਹਨ: simplicity ਵੱਸਤੇ flexibility ਤੋਂ ਘੱਟ, strictness ਵੱਸਤੇ speed ਤੋਂ ਘੱਟ। AI ਵਿਕਲਪ ਸੁਝਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਡੇ risk tolerance ਨੂੰ ਨਹੀਂ ਜਾਣਦਾ।
ਪ੍ਰੈਕਟਿਕਲ ਤਰੀਕਾ: 10–20 rule examples plain language ਵਿੱਚ ਲਿਖੋ (exceptions ਸਮੇਤ), ਫਿਰ AI ਨੂੰ ਕਹੋ ਕਿ ਉਹਨਾਂ ਨੂੰ validations, transitions, constraints ਵਿੱਚ ਬਦਲ ਦਿਓ—ਤੁਸੀਂ ਹਰ edge condition ਦੀ ਸਮੀਖਿਆ ਕਰੋ ਤਾਂ ਕਿ ਅਣਚਾਹੀਆਂ ਨਤੀਜਿਆਂ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
AI CRUD ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾ ਸਕਦਾ ਹੈ, ਪਰ security ਅਤੇ compliance "ਠੀਕ ਹੈ" ਦੇ ਉਤਪਾਦ ਨਹੀਂ ਹਨ। ਇੱਕ ਜਨਰੇਟ ਕੀਤਾ ਕੰਟਰੋਲਰ ਜੋ ਰਿਕਾਰਡ ਸੇਵ ਕਰਦਾ ਅਤੇ JSON ਵਾਪਸ ਕਰਦਾ ਦਿਖਾਈ ਦੇ ਸਕਦਾ ਹੈ—ਅਤੇ ਫਿਰ ਵੀ production ਵਿੱਚ breach ਕਰਾ ਸਕਦਾ ਹੈ। AI ਆਉਟਪੁੱਟ ਨੂੰ ਤੱਕੜੀ ਸਮੀਖਿਆ ਤੱਕ ਅਣ-ਟ੍ਰੱਸਟਡ ਮੰਨੋ।
role=admin, isPaid=true)।CRUD apps ਅਕਸਰ seams 'ਤੇ fail ਹੁੰਦੀਆਂ ਹਨ: list endpoints, "export CSV", admin views, ਅਤੇ multi-tenant filtering। AI query scope (ਉਦਾਹਰਨ: account_id ਨਾਲ) ਭੁੱਲ ਸਕਦਾ ਹੈ ਜਾਂ UI ਨੂੰ access ਰੋਕਣ ਵਾਲਾ ਮੰਨ ਸਕਦਾ ਹੈ। ਮਨੁੱਖਾਂ ਨੂੰ verify ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ:
Data residency, audit trails, ਅਤੇ consent ਵਰਗੀਆਂ ਲੋੜਾਂ ਤੁਹਾਡੇ ਵਪਾਰ, ਜਿਓਗ੍ਰਾਫੀ, ਅਤੇ contracts 'ਤੇ ਨਿਰਭਰ ਕਰਦੀਆਂ ਹਨ। AI patterns ਸੁਝਾ ਸਕਦਾ ਹੈ, ਪਰ ਤੁਸੀਂ define ਕਰੋ ਕਿ "compliant" ਦਾ ਮਤਲਬ ਕੀ ਹੈ: ਕੀ log/retain ਕੀਤਾ ਜਾਂਦਾ, retention ਕਿੰਨੀ ਹੈ, ਕੌਣ access ਰੱਖੇਗਾ, ਅਤੇ deletion requests ਕਿਵੇਂ ਸੰਭਾਲੇ ਜਾਣ।
ਸੁਰੱਖਿਆ ਸਮੀਖਿਆ ਕਰੋ, dependencies ਦੀ ਜਾਂਚ ਕਰੋ, ਅਤੇ incident response ਯੋਜਨਾ ਬਣਾਓ (alerts, secrets rotation, rollback steps)। "Stop the line" release criteria ਨਿਰਧਾਰਤ ਕਰੋ: ਜੇ access rules ambiguous ਹਨ, sensitive data handling verify ਨਹੀਂ ਹੈ, ਜਾਂ auditability ਮੌਜੂਦ ਨਹੀਂ, ਤਾਂ release ਰੁਕ ਜਾਵੇ।
AI CRUD ਕੰਮ ਵਿਚ ਸਭ ਤੋਂ ਵੱਧ ਮੂਲਾਂਕਣਤ ਹੈ ਜਦ ਤੁਸੀਂ ਇਸਨੂੰ ਤੇਜ਼ ڈ੍ਰਾਫਟ ਸਾਥੀ ਸਮਝਦੇ ਹੋ—ਲਿਖਾਰਥਾ ਨਹੀਂ। ਲਕ੍ਹਾ ਸਧਾਰਨ ਹੈ: idea ਤੋਂ ਕੰਮ ਕਰਦਾ ਕੋਡ ਤੱਕ ਰਸਤਾ ਘੱਟ ਕਰੋ ਪਰ correctness, security, ਅਤੇ product intent ਲਈ ਅਕਾਊਂਟਬਿਲਟੀ ਰੱਖੋ।
ਉਹ ਟੂਲ ਜਿਵੇਂ Koder.ai ਇਸ ਮਾਡਲ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਫਿੱਟ ਕਰਦੇ ਹਨ: ਤੁਸੀਂ ਇੱਕ CRUD ਫੀਚਰ ਦਾ ਵਰਣਨ ਚੈਟ ਵਿੱਚ ਦੱਸ ਸਕਦੇ ਹੋ, UI ਅਤੇ API ਦੋਹਾਂ ਲਈ ਵਰਕਿੰਗ ਡ੍ਰਾਫਟ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਫਿਰ guardrails (planning mode, snapshots, rollback) ਨਾਲ iterate ਕਰ ਸਕਦੇ ਹੋ ਜਿੱਥੇ ਮਨੁੱਖ permissions, migrations, ਅਤੇ business rules ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਰੱਖਦੇ ਹਨ।
"user management CRUD" ਪੁੱਛਣ ਦੀ ਥਾਂ ਨਿਰਧਾਰਤ ਬਦਲਾਅ ਸੱਵਾਲ ਕਰੋ।
ਸ਼ਾਮਿਲ ਕਰੋ: framework/version, ਮੌਜੂਦਾ conventions, ਡੇਟਾ constraints, ਐਰਰ ਬਿਹੇਵਿਅਰ, ਅਤੇ "done" ਦਾ ਮਤਲਬ। ਉਦਾਹਰਨ acceptance criteria: "Reject duplicates, return 409", "Soft-delete only", "Audit log required", "No N+1 queries", "Must pass existing test suite." ਇਹ plausible-but-wrong ਕੋਡ ਘਟਾਉਂਦਾ ਹੈ।
AI ਨੂੰ 2–3 approaches ਪ੍ਰਸਤਾਵਿਤ ਕਰਨ ਲਈ ਕਹੋ (ਉਦਾਹਰਨ: "single table vs join table", "REST vs RPC endpoint shape"), ਅਤੇ trade-offs ਲਿਖਵਾਓ: performance, complexity, migration risk, permission model. ਇੱਕ ਵਿਕਲਪ ਚੁਣੋ ਅਤੇ PR/ਟਿਕਟ 'ਤੇ ਕਾਰਨ ਦਰਜ ਕਰੋ ਤਾਂ ਕਿ ਭਵਿੱਖ ਵਿੱਚ drift ਨਾ ਹੋਵੇ।
ਕੁਝ ਫਾਇਲਾਂ ਨੂੰ "ਹਮੇਸ਼ਾ ਮਨੁੱਖ-ਸਮੀਖਿਆ" ਮੰਨੋ:
ਇਸਨੂੰ PR ਟੈਮਪਲੇਟ (ਜਾਂ /contributing) ਵਿੱਚ ਚੈੱਕਲਿਸਟ ਬਣਾਕੇ ਲਾਗੂ ਕਰੋ।
ਛੋਟੀ, editable spec (module README, ADR, ਜਾਂ /docs) ਰੱਖੋ core entities, validation rules, ਅਤੇ permission decisions ਲਈ। ਪ੍ਰੰਪਟਾਂ ਵਿੱਚ ਸਬੰਧਤ ਹਿੱਸੇ ਪੇਸਟ ਕਰੋ ਤਾਂ ਜੋ generated ਕੋਡ aligned ਰਹੇ ਨਾ ਕਿ "ਨਿਯਮ ਬਣਾਉਣ" ਲੱਗੇ।
Outcome track ਕਰੋ: CRUD changes ਲਈ cycle time, bug rate (ਖਾਸ ਕਰਕੇ permission/validation defects), support tickets, ਅਤੇ user success metrics (task completion, ਘੱਟ manual workarounds). ਜੇ ਇਹ ਸੁਧਰ ਨਹੀਂ ਰਹੇ, ਤਾਂ prompts ਤਿੱਖੇ ਕਰੋ, gates ਵਧਾਓ, ਜਾਂ AI scope ਘਟਾਓ।
"AI for CRUD" ਆਮ ਤੌਰ 'ਤੇ ਮਤਲਬ ਹੈ ਕਿ AI ਨੂੰ ਵਰਤ ਕੇ ਦੋਹਰਾਏ ਜਾਣ ਵਾਲੇ ਕੰਮਾਂ—ਮਾਡਲ, ਮਾਈਗ੍ਰੇਸ਼ਨ, ਐਂਡਪੌਇੰਟ, ਫਾਰਮ ਅਤੇ ਸ਼ੁਰੂਆਤੀ ਟੈਸਟ—ਦੇ ਡ੍ਰਾਫਟ ਬਣਾਏ ਜਾਂਦੇ ਹਨ ਜੋ ਤੁਹਾਡੇ ਵੇਰਵੇ ਦੇ ਆਧਾਰ 'ਤੇ ਤਿਆਰ ਹੁੰਦੇ ਹਨ。
ਇਹ boilerplate ਲਈ ਤੇਜ਼ੀ ਵਜੋਂ ਵਰਤਣਾ ਸਭ ਤੋਂ ਵਧੀਆ ਹੈ—ਇਹ ਸੁਚੇਤਨਾ ਜਾਂ ਪ੍ਰੋਡਕਟ ਫੈਸਲਿਆਂ ਦੀ ਥਾਂ ਨਹੀਂ ਲੈਂਦਾ।
ਜਿੱਥੇ ਕੰਮ ਪੈਟਰਨ-ਅਧਾਰਿਤ ਅਤੇ ਆਸਾਨੀ ਨਾਲ ਜਾਂਚਯੋਗ ਹੋਵੇ, ਉੱਥੇ AI ਵਰਤੋਂ ਲਈ ਬਿਹਤਰ ਹੈ:
ਜੋਖਿਮ-ਭਰਪੂਰ ਫੈਸਲਿਆਂ — ਜਿਵੇਂ ਕਿ ਪਹੁੰਚ ਨਿਯੰਤਰਣ, ਡੇਟਾ ਅਰਥ, ਅਤੇ ਖਤਰਨਾਕ ਮਾਈਗ੍ਰੇਸ਼ਨ—ਨੂੰ ਬਿਨਾਂ ਸਮੀਖਿਆ ਦੇ ਸੌਂਪੋ ਨਾ।
ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ ਇਹ ਕਰ ਸਕਦਾ ਹੈ:
ਆਉਟਪੁੱਟ ਨੂੰ ਸਮੀਖਿਆ ਅਤੇ ਟੈਸਟ ਬਿਨਾਂ ਭਰੋਸਾ ਨਾ ਕਰੋ।
ਫੀਚਰ ਨਾਮ ਦੇਣ ਦੀ ਥਾਂ ਪਾਬੰਦੀਵਾਰ acceptance criteria ਅਤੇ ਸੀਮਾਵਾਂ ਦਿਓ। ਸ਼ਾਮਿਲ ਕਰੋ:
ਜਿੰਨੀ ਜ਼ਿਆਦਾ "definition of done" ਦਿਓਗੇ, ਉਤਨੇ ਘੱਟ plausible-but-wrong ਡ੍ਰਾਫਟ ਮਿਲਣਗੇ।
AI ਪਹਿਲੀ-ਪਾਸ ਸਕੀਮਾ (ਟੇਬਲ, ਫੀਲਡ, enums, timestamps) ਸੁਝਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਨਹੀਂ ਨਿਰਧਾਰਤ ਕਰ ਸਕਦਾ:
AI ਨੂੰ ਵਿਕਲਪਾਂ ਲਈ ਵਰਤੋ, ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਅਸਲ ਵਰਕਫ਼ਲੋਜ਼ ਅਤੇ ਫੇਲਿਅਰ ਸੈਨਾਰਿਓਜ਼ ਦੇ ਵਿਰੁੱਧ ਜਾਂਚੋ।
ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ syntax ਤੌਰ 'ਤੇ ਠੀਕ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਫਿਰ ਵੀ ਖਤਰਨਾਕ ਹੋ ਸਕਦੀ ਹੈ। ਪ੍ਰੋਡਕਸ਼ਨ 'ਤੇ ਚਲਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਚੈੱਕ ਕਰੋ:
AI ਮਾਈਗ੍ਰੇਸ਼ਨ ਅਤੇ ਰੋਲਆਉਟ ਯੋਜਨਾ ਦਾ ਡ੍ਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਰਿਸ਼ਕ ਸਮੀਖਿਆ ਅਤੇ ਅਮਲ ਤੁਹਾਡੇ ਹੱਥ ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
AI schema ਤੋਂ ਫਾਰਮ ਫੀਲਡਾਂ ਬਣਾਉਣ ਅਤੇ ਮੁੱਢਲੀ ਵੈਲਿਡੇਸ਼ਨ ਜਨਰੇਟ ਕਰਨ ਵਿੱਚ ਮਹਾਨ ਹੈ:required, min/max, length, email/URL format ਆਦਿ। ਪਰ ਸੈਮੈਂਟਿਕ ਖਤਰੇ ਹਨ:
AI ਪਹਿਲਾ ਪਾਸ ਤਿਆਰ ਕਰੇ—ਤੁਸੀਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜਾ rule UX ਸੁਵਿਧਾ ਹੈ, API contract ਹੈ ਜਾਂ ਸਖ਼ਤ ਡੇਟਾ invariant ਹੈ।
AI ਆਮ ਤੌਰ 'ਤੇ list/search/filter endpoints ਅਤੇ ਉਨ੍ਹਾਂ ਦੇ ਆਲੇ-ਦੁਆਲੇ glue code ਦਾ ਡ੍ਰਾਫਟ ਬਣਾਉਣ 'ਚ ਵਧੀਆ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ:
GET /orders, GET /orders/:id, POST /orders ਆਦਿ)ਪਰ ਸਮੀਖਿਆ ਕਰੋ:
AI ਤੇਜ਼ੀ ਨਾਲ ਬਹੁਤ ਸਾਰੇ ਟੈਸਟ ਕੋਡ ਲਿਖ ਸਕਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ CRUD ਜਿੱਥੇ patterns ਤੇਹਰਾਉਂਦੇ ਹਨ। ਪਰ "ਜ਼ਿਆਦਾ ਟੈਸਟ" = "ਉੱਚ ਗੁਣਵੱਤਾ" ਨਹੀਂ।
ਤੁਹਾਡਾ ਕੰਮ ਹੈ ਮਹੱਤਵਪੂਰਨ ਕੇਸ ਚੁਣਨਾ:
ਆਓ AI ਨੂੰ ਪਹਿਲਾ ਪਾਸ ਬਣਾਉਣ ਦਿਓ, ਫਿਰ ਹਰ ਟੈਸਟ ਨੂੰ ਪੁੱਛੋ: "ਕੀ ਇਹ ਪ੍ਰੋਡਕਸ਼ਨ ਫੇਲਿਅਰ ਨੂੰ ਰੋਕੇਗਾ?" ਜੇ ਨਹੀਂ ਤਾਂ ਉਸਨੂੰ ਦੁਰੁਸਤ ਕਰੋ ਜਾਂ ਹਟਾਓ।
Authentication ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਨ ਹੈ; authorization (ਕੌਣ ਕੀ ਕਰ ਸਕਦਾ ਹੈ) ਜ਼ਿਆਦਾ ਜੋਖਿਮ ਵਾਲੀ ਗੱਲ ਹੈ। AI mechanics ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ ਪਰ ਜੋਖਿਮ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਮਨੁੱਖੀ ਟੀਮ ਦੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ。
ਤੁਸੀਂ AI ਨੂੰ requirements ਦਿਓ (ਉਦਾਹਰਨ: "Managers can edit any order; customers can only view their own; support can refund but not change addresses")—AI ਪਹਿਲਾ ਡ੍ਰਾਫਟ RBAC/ABAC ਨੀਤੀ ਅਤੇ ਪਲੰਬਿੰਗ (middleware stubs, policy files) ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ।
ਪਰ ਮਨੁੱਖੀ ਟੀਮ ਨੇ threat model, least-privilege defaults ਅਤੇ audit ਲੋੜਾਂ ਨਿਰਧਾਰਤ ਕਰਨੀਆਂ ਹਨ।
AI error handling ਅਤੇ observability ਲਈ ਚੰਗੀਆਂ ਡਿਫਾਲਟ ਪ੍ਰੈਕਟਿਸਿਸ ਸੁਝਾ ਸਕਦਾ ਹੈ:
AI metrics ਅਤੇ dashboard ਲਈ ਵੀ starter ਸੁਝਾਵ ਦੇ ਸਕਦਾ ਹੈ: request rate, latency (p50/p95), error rate by endpoint ਆਦਿ। ਪਰ ਇਹਨਾਂ ਨੂੰ ਆਪਣੀ ਦਿਨਚਰੀ ਅਤੇ 2am ਆਲਰਟ ਪ੍ਰਾਇਰਟੀਆਂ ਦੇ ਅਨੁਸਾਰ ਸਧਾਰੋ।
ਹਰ ਲੌਗ ਵਿਚ PII ਲੈਣਾ ਸੁਰਖਸ਼ਿਤ ਨਹੀਂ—ਤੁਸੀਂ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕੀ redact/ਹੈਸ਼/ਬਚਾਉਣਾ ਹੈ ਅਤੇ retention ਕਿੰਨੀ ਹੋਵੇਗੀ।
CRUD ਸਕਰੀਨਾਂ ਸਾਦੀਆਂ ਲੱਗਦੀਆਂ ਹਨ, ਪਰ ਅਸਲ ਨਿਰਣੈ ਉਹਨਾਂ ਅੰਦਰ ਲੁਕੇ ਹੁੰਦੇ ਹਨ। AI controllers, forms ਅਤੇ ਡੇਟਾਬੇਸ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਂਦਾ ਹੈ ਪਰ ਉਹ ਉਹ ਨੀਤੀ ਨਹੀਂ ਜਾਣ ਸਕਦਾ ਜੋ ਤੁਹਾਡੇ ਵਿਅਵਸਾਯ ਨੂੰ ਸਹੀ ਬਣਾਦੇ।
ਅਮਲਿਕ ਤਰੀਕਾ: 10–20 ਨਿਯਮ ਉਦਾਹਰਣ plain language ਵਿੱਚ ਲਿਖੋ (exceptions ਸਮੇਤ), ਫਿਰ AI ਨੂੰ ਕਹੋ ਕਿ ਉਹਨਾਂ ਨੂੰ validations, transitions, constraints ਵਿੱਚ ਤਬਦੀਲ ਕਰੇ—ਤੁਸੀਂ ਹਰ edge condition ਦੀ ਸਮੀਖਿਆ ਕਰੋ।
AI ਤੇਜ਼ੀ ਨਾਲ CRUD ਕੋਡ ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ security ਅਤੇ compliance "ਚੰਗਾ ਕਾਫੀ" ਨਹੀਂ ਚਲਦੇ। AI ਆਉਟਪੁੱਟ ਨੂੰ ਤੱਕੜੀ ਸਮੀਖਿਆ ਤੱਕ ਅਣ-ਟ੍ਰੱਸਟਡ ਮਾਨੋ।
ਸੰਭਾਵਤ ਖਾਮੀਆਂ:
ਨਿਯਮ: ਹਰ read/write path ਸਾਈਡ ਤੇ ਖਤਰੇ ਲਈ ਜਾਂਚੋ; logs/ਐਰਰ messages sensitive data ਨਾ ਲੀਕ ਕਰਨ। Compliance (data residency, audit trails, consent) ਕੋਡ ਸਨਿੱਪੇਟ ਨਹੀਂ—ਤੁਹਾਡੇ ਵਪਾਰ ਅਤੇ ਕਾਨੂਨੀ ਲੋੜਾਂ ਖ਼ਾਸ ਹੁੰਦੀਆਂ ਹਨ।
Pagination ਰਣਨੀਤੀ (offset vs cursor) ਨੂੰ ਵੀ ਧਿਆਨ ਨਾਲ ਚੁਣੋ।