12 ਨਵੰ 2025·8 ਮਿੰਟ
AI ਕ੍ਰਾਲਰਾਂ ਅਤੇ LLM ਇੰਡੈਕਸਿੰਗ ਲਈ ਤਿਆਰ ਵੈਬਸਾਈਟ ਬਣਾਓ
ਸਿੱਖੋ ਕਿ ਸਮੱਗਰੀ, ਮੈਟਾਡੇਟਾ, crawl ਨਿਯਮ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਕਿਵੇਂ ਬਣਾਇਆ ਜਾਵੇ ਤਾਂ ਕਿ AI ਕ੍ਰਾਲਰ ਅਤੇ LLM ਟੂਲ ਤੁਹਾਡੇ ਪੰਨਿਆਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਖੋਜ, ਪਾਰਸ ਅਤੇ ਉਧਰਣ ਕਰ ਸਕਣ।
ਸਿੱਖੋ ਕਿ ਸਮੱਗਰੀ, ਮੈਟਾਡੇਟਾ, crawl ਨਿਯਮ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਕਿਵੇਂ ਬਣਾਇਆ ਜਾਵੇ ਤਾਂ ਕਿ AI ਕ੍ਰਾਲਰ ਅਤੇ LLM ਟੂਲ ਤੁਹਾਡੇ ਪੰਨਿਆਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਖੋਜ, ਪਾਰਸ ਅਤੇ ਉਧਰਣ ਕਰ ਸਕਣ।
“AI-optimized” ਅਕਸਰ ਇੱਕ ਬਜ਼ਵਰਡ ਵਜੋਂ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਅਮਲ ਵਿੱਚ ਇਸਦਾ ਅਰਥ ਹੈ ਕਿ ਤੁਹਾਡੀ ਵੈਬਸਾਈਟ automated ਸਿਸਟਮਾਂ ਲਈ ਆਸਾਨੀ ਨਾਲ ਖੋਜੀ, ਪੜ੍ਹੀ ਅਤੇ ਸਹੀ ਢੰਗ ਨਾਲ ਦੁਬਾਰਾ ਵਰਤੀ ਜਾ ਸਕੇ।
ਜਦੋਂ ਲੋਕ AI ਕ੍ਰਾਲਰਾਂ ਦੀ ਗੱਲ ਕਰਦੇ ਹਨ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਬੋਟ ਮੰਨਦੇ ਹਨ ਜੋ ਖੋਜ ਇੰਜਨਾਂ, AI ਉਤਪਾਦਾਂ ਜਾਂ ਡਾਟਾ ਪ੍ਰੋਵਾਈਡਰਾਂ ਦੁਆਰਾ ਚਲਾਏ ਜਾਂਦੇ ਹਨ ਅਤੇ ਜਿਹੜੇ ਸੰਖੇਪ, ਜਵਾਬ, ਟ੍ਰੇਨਿੰਗ ਡੇਟਾਸੈੱਟ ਜਾਂ retrieval ਸਿਸਟਮਾਂ ਵਾਸਤੇ ਵੈਬ ਪੇਜ਼ ਫੈਚ ਕਰਦੇ ਹਨ। LLM ਇੰਡੈਕਸਿੰਗ ਅਕਸਰ ਉਹ ਪ੍ਰਕਿਰਿਆ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡੇ ਪੰਨੇ searchable knowledge store ਵਿੱਚ ਬਦਲੇ ਜਾਂਦੇ ਹਨ (ਅਕਸਰ “chunked” ਟੈਕਸਟ ਮੈਟਾਡੇਟਾ ਸਮੇਤ) ਤਾਂ ਜੋ AI ਸਹਾਇਕ ਸਹੀ ਪੈਸੇਜ ਰੀਟਰਾਈਵ ਕਰਕੇ ਉਧਰਣ ਦੇ ਸਕੇ।
AI ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਜ਼ਿਆਦਾ “ਰੈਂਕਿੰਗ” ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੀ, ਬਲਕਿ ਚਾਰ ਨਤੀਜਿਆਂ ਬਾਰੇ ਹੈ:
ਕੋਈ ਵੀ ਕਿਸੇ ਖਾਸ AI ਇੰਡੈਕਸ ਜਾਂ ਮਾਡਲ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹੋਣ ਦੀ ਗਰੰਟੀ ਨਹੀਂ ਦੇ ਸਕਦਾ। ਵੱਖ-ਵੱਖ ਪ੍ਰੋਵਾਇਡਰ ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ ਕ੍ਰਾਲ ਕਰਦੇ ਹਨ, ਵੱਖ-ਵੱਖ ਨੀਤੀਆਂ ਦੀ ਪਾਲਣਾ ਕਰਦੇ ਹਨ, ਅਤੇ ਵੱਖ-ਵੱਖ ਸੂਚੀਆਂ 'ਤੇ ਤਾਜ਼ਾ ਕਰਦੇ ਹਨ।
ਤੁਸੀਂ ਜੋ ਨਿਯੰਤਰਿਤ ਕਰ ਸਕਦੇ ਹੋ ਉਹ ਇਹ ਹੈ ਕਿ ਆਪਣੀ ਸਮੱਗਰੀ ਨੂੰ ਐਸਾ ਬਣਾਓ ਕਿ ਉਹ ਪਹੁੰਚਣਯੋਗ, ਨਿਕਾਲਣ ਯੋਗ ਅਤੇ attribution ਯੋਗ ਹੋਵੇ—ਤਾਂ ਜੋ ਜੇ ਉਹ ਵਰਤੀ ਜਾਵੇ, ਤਾਂ ਠੀਕ ਢੰਗ ਨਾਲ ਵਰਤੀ ਜਾਵੇ।
llms.txt ਫਾਈਲ ਜੋ LLM-ਫੋਕਸਡ discovery ਨੂੰ ਗਾਈਡ ਕਰੇਜੇ ਤੁਸੀਂ ਨਵੇਂ ਪੰਨੇ ਤੇ ਫਲੋਜ਼ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉ ਰਹੇ ਹੋ, ਤਾਂ ਉਹ tooling ਚੁਣੋ ਜੋ ਇਹ ਲੋੜਾਂ ਨਾਲ ਟਕਰਾਉਂਦਾ ਨਹੀਂ। ਉਦਾਹਰਨ ਲਈ, ਟੀਮਾਂ ਜੋ Koder.ai ਵਰਤ ਰਹੀਆਂ ਹਨ (ਇੱਕ chat-driven vibe-coding ਪਲੇਟਫਾਰਮ ਜੋ React frontends ਅਤੇ Go/PostgreSQL backends ਜਨਰੇਟ ਕਰਦਾ ਹੈ) ਅਕਸਰ SSR/SSG-ਮਿਤ੍ਰ ਟੈਮਪਲੇਟ, ਸਥਿਰ ਰੂਟ, ਅਤੇ ਲਗਾਤਾਰ ਮੈਟਾਡੇਟਾ ਸ਼ੁਰੂ ਵਿੱਚ ਹੀ ਸ਼ਾਮਿਲ ਕਰ ਲੈਂਦੀਆਂ ਹਨ—ਇਸ ਤਰ੍ਹਾਂ “AI-ready” ਇੱਕ ਡਿਫਾਲਟ ਬਣ ਜਾਂਦਾ ਹੈ, ਰਿਟ੍ਰੋਫਿਟ ਨਹੀਂ।
LLMs ਅਤੇ AI ਕ੍ਰਾਲਰ ਪੇਜ ਨੂੰ ਇਨਸਾਨਾਂ ਵਾਂਗ ਨਹੀਂ ਸਮਝਦੇ। ਉਹ ਟੈਕਸਟ ਨਿਕਾਲਦੇ ਹਨ, ਵਿਚਾਰਾਂ ਦਰਮਿਆਨ ਰਿਸ਼ਤੇ ਅਨੁਮਾਨ ਕਰਦੇ ਹਨ, ਅਤੇ ਤੁਹਾਡੇ ਪੇਜ ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਇਰਾਦੇ ਨਾਲ ਨਕਸ਼ਾ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ। ਜਿੰਨੀ ਜ਼ਿਆਦਾ ਤੁਹਾਡੀ ਬਣਤਰ predictable ਹੋਵੇਗੀ, ਉਸੀ ਘੱਟ ਗਲਤ ਅਨੁਮਾਨ ਲੱਗਣਗੇ।
ਪੇਜ ਨੂੰ ਸਧਾ_plain ਟੈਕਸਟ ਵਿੱਚ ਸਕੈਨ ਕਰਨ ਯੋਗ ਬਣਾਓ:
ਇੱਕ ਉਪਯੋਗੀ ਪੈਟਰਨ ਹੈ: ਵਾਅਦਾ → ਸੰਖੇਪ → ਵਿਆਖਿਆ → ਸਬੂਤ → ਅਗਲੇ ਕਦਮ।
ਸ਼ੁਰੂ ਵਿੱਚ ਇੱਕ ਛੋਟਾ ਸਾਰ (2–5 ਲਾਈਨਾਂ) ਰੱਖੋ। ਇਸ ਨਾਲ AI ਸਿਸਟਮ ਪੰਨੇ ਨੂੰ ਜਲਦੀ ਵਰਗੀਕ੍ਰਿਤ ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ ਮੁੱਖ ਦਾਵਿਆਂ ਨੂੰ ਕੈਪਚਰ ਕਰ ਸਕਦੇ ਹਨ।
Example TL;DR:
TL;DR: ਇਹ ਪੰਨਾ ਦੱਸਦਾ ਹੈ ਕਿ ਕਿਵੇਂ ਸਮੱਗਰੀ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਬਣਾਇਆ ਜਾਵੇ ਕਿ AI ਕ੍ਰਾਲਰ ਮੁੱਖ ਵਿਸ਼ਾ, ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਤੇ ਮੁੱਖ ਨਤੀਜੇ ਭਰੋਸੇਯੋਗ ਢੰਗ ਨਾਲ ਨਿਕਾਲ ਸਕਣ।
LLM ਇੰਡੈਕਸਿੰਗ ਤਦੋਂ ਸਭ ਤੋਂ ਚੰਗੀ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਹਰ URL ਇੱਕ ਇਰਾਦੇ ਦਾ ਜਵਾਬ ਦੇਵੇ। ਜੇ ਤੁਸੀਂ ਗੈਰ-ਸੰਬੰਧਤ ਮਕਸਦ ਮਿਲਾ ਦਿਉ (ਜਿਵੇਂ “pricing”, “integration docs”, ਅਤੇ “company history” ਇੱਕੇ ਪੇਜ 'ਤੇ), ਪੇਜ ਕਰਨ ਦੀ ਵਰਗੀਕ੍ਰਿਤੀ ਔਖੀ ਹੋ ਜਾਵੇਗੀ ਅਤੇ ਗਲਤ ਕਵੈਰੀਜ਼ ਲਈ surfaced ਹੋ ਸਕਦੀ ਹੈ।
ਸੰਬੰਧਤ ਪਰ ਵੱਖ-ਵੱਖ ਇਰਾਦਿਆਂ ਨੂੰ ਕਵਰ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇ ਤਾਂ, ਉਹਨਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਪੰਨਿਆਂ ਵਿੱਚ ਵੰਡੋ ਅਤੇ ਅੰਦਰੂਨੀ ਲਿੰਕ ਨਾਲ ਜੁੜੋ (ਉਦਾਹਰਣ: /pricing, /docs/integrations)।
ਜੇ ਤੁਹਾਡਾ ਦਰਸ਼ਕ ਕਿਸੇ ਸ਼ਬਦ ਨੂੰ ਕਈ ਤਰੀਕੇ ਨਾਲ ਸਮਝ ਸਕਦਾ ਹੈ, ਉਸਨੂੰ ਸ਼ੁਰੂ ਵਿੱਚ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ।
Example:
AI crawler optimization: ਸਾਈਟ ਸਮੱਗਰੀ ਅਤੇ ਪਹੁੰਚ ਨਿਯਮਾਂ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਤਿਆਰ ਕਰਨਾ ਕਿ automated ਸਿਸਟਮ ਪੰਨਿਆਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਖੋਜ, ਪੜ੍ਹ ਅਤੇ ਸਮਝ ਸਕਣ।
ਹਰ ਉਤਪਾਦ, ਫੀਚਰ, ਯੋਜਨਾ ਅਤੇ ਮੁੱਖ ਸੰਕਲਪ ਲਈ ਇੱਕ ਨਾਮ ਚੁਣੋ—ਅਤੇ ਹਰ ਜਗ੍ਹਾ ਉਸੇ ਨਾਮ ਨੂੰ ਵਰਤੋ। ਇਹ consistency extraction ਵਿੱਚ ਸੁਧਾਰ ਲਿਆਉਂਦਾ ਹੈ ("Feature X" ਹਮੇਸ਼ਾ ਉਸੇ ਚੀਜ਼ ਨੂੰ ਦਰਸਾਂਦਾ ਹੈ) ਅਤੇ ਕੰਪੈਰ/ਸੰਖੇਪ ਕਰਦਿਆਂ ਏਨਟਿਟੀ confusion ਘਟਾਉਂਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ AI ਇੰਡੈਕਸਿੰਗ ਪਾਈਪਲਾਈਨ ਪੰਨਿਆਂ ਨੂੰ ਟੁਕੜਿਆਂ ਵਿੱਚ ਵੰਡਦੇ ਹਨ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਸਭ ਤੋਂ ਮਿਲਦਾ-ਜੁਲਦਾ ਹਿੱਸਾ ਸਟੋਰ/ਰੀਟਰਾਈਵ ਕਰਦੇ ਹਨ। ਤੁਹਾਡਾ ਕੰਮ ਇਹ ਹੈ ਕਿ ਉਹ ਚੰਕ ਸਪਸ਼ਟ, self-contained ਅਤੇ ਕੋਟ ਕਰਨ ਯੋਗ ਹੋਣ।
ਹਰ ਪੇਜ 'ਤੇ ਇੱਕ H1 ਰੱਖੋ (ਪੇਜ ਦਾ ਵਾਅਦਾ), ਫਿਰ ਮਹੱਤਵਪੂਰਨ ਸੈਕਸ਼ਨਾਂ ਲਈ H2 ਅਤੇ ਸਬਟੌਪਿਕਸ ਲਈ H3 ਵਰਤੋ।
ਸਧਾਰਨ ਨਿਯਮ: ਜੇ ਤੁਸੀਂ ਆਪਣੇ H2s ਨੂੰ ਇਕ table of contents ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹੋ ਜੋ ਪੂਰੇ ਪੇਜ ਦਾ ਵਰਣਨ ਕਰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਸਹੀ ਕਰ ਰਹੇ ਹੋ। ਇਹ ਬਣਤਰ retrieval ਸਿਸਟਮਾਂ ਨੂੰ ਹਰ ਚੰਕ ਨਾਲ ਸਹੀ ਪ੍ਰਸੰਗ ਲਗਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
"Overview" ਜਾਂ "More info" ਵਰਗੇ ਅਸਪਸ਼ਟ ਲੇਬਲਾਂ ਤੋਂ ਬਚੋ। ਇਸਦੀ ਥਾਂ, ਹੈਡਿੰਗਾਂ ਉਪਭੋਗਤਾ ਦੇ ਇਰਾਦੇ ਦਾ ਜਵਾਬ ਦੇਣ ਵਾਲੀਆਂ ਹੋਣ:
ਜਦੋਂ ਇੱਕ ਚੰਕ ਸੰਦਰਭ ਤੋਂ ਕੱਢਿਆ ਜਾਂਦਾ ਹੈ, ਹੈਡਿੰਗ ਅਕਸਰ ਉਸਦੀ “title” ਬਣ ਜਾਂਦੀ ਹੈ। ਇਸਨੂੰ ਮਾਇਨੇਦਾਰ ਬਣਾਓ।
ਪੜ੍ਹਨ ਯੋਗਤਾ ਅਤੇ ਚੰਕ ਫੋਕਸ ਬਣਾਈ ਰੱਖਣ ਲਈ ਛੋਟੇ ਪੈਰਾਗ੍ਰਾਫ (1–3 ਵਾਕ) ਵਰਤੋ।
ਬੁਲੇਟ ਲਿਸਟਾਂ requirements, ਕਦਮ, ਅਤੇ ਫੀਚਰ ਹਾਈਲਾਈਟਸ ਲਈ ਚੰਗੀਆਂ ਹਨ। ਟੇਬਲ ਤੁਲਨਾਵਾਂ ਲਈ ਵਧੀਆ ਹਨ ਕਿਉਂਕਿ ਉਹ ਬਣਤਰ ਨੂੰ ਰੱਖਦੇ ਹਨ।
| Plan | Best for | Key limit |
|---|---|---|
| Starter | Trying it out | 1 project |
| Team | Collaboration | 10 projects |
ਛੋਟੀ FAQ ਸੈਕਸ਼ਨ ਜੋ ਸਿੱਧੇ, ਪੂਰੇ ਜਵਾਬ ਦਿੰਦੀ ਹੈ extractability ਨੂੰ ਬਿਹਤਰ ਬਣਾਉਂਦੀ ਹੈ:
Q: Do you support CSV uploads?
A: Yes—CSV up to 50 MB per file.
ਮੁੱਖ ਪੰਨਿਆਂ ਨੂੰ navigation blocks ਨਾਲ ਬੰਦ ਕਰੋ ਤਾਂ ਜੋ ਉਭੋਗਤਾ ਅਤੇ ਕ੍ਰਾਲਰ ਦੋਹਾਂ ਇਰਾਦੇ-ਅਧਾਰਤ ਰਾਹ ਫਾਲੋ ਕਰ ਸਕਣ:
AI ਕ੍ਰਾਲਰ ਸਾਰਿਆਂ ਹੀ ਇੱਕ ਪੂਰੇ ਬ੍ਰਾਊਜ਼ਰ ਵਾਂਗ ਨਹੀਂ ਚਲਦੇ। ਬਹੁਤ ਸਾਰੇ ਤੇਜ਼ੀ ਨਾਲ ਕੱਚ HTML ਨੂੰ ਫੈਚ ਅਤੇ ਪੜ੍ਹ ਲੈਂਦੇ ਹਨ, ਪਰ JavaScript ਚਲਾਉਣ, API calls ਦੀ ਉਡੀਕ ਕਰਨ ਅਤੇ hydration ਤੋਂ ਬਾਅਦ ਪੇਜ ਤਿਆਰ ਕਰਨ ਵਿੱਚ ਮੁਸ਼ਕਲ ਹੋ ਸਕਦੀ ਹੈ। ਜੇ ਤੁਹਾਡੀ ਮੁੱਖ ਸਮੱਗਰੀ ਸਿਰਫ਼ client-side rendering ਤੋਂ ਬਾਅਦ ਦਿਖਾਈ ਦਿੰਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ LLM ਇੰਡੈਕਸਿੰਗ ਕਰਨ ਵਾਲੇ ਸਿਸਟਮਾਂ ਨੂੰ ਅਦ੍ਰਿਸ਼ਯ ਕਰ ਸਕਦੇ ਹੋ।
ਇੱਕ ਪਰੰਪਰਾਗਤ HTML ਪੇਜ ਨਾਲ, ਕ੍ਰਾਲਰ document ਡਾਊਨਲੋਡ ਕਰਦਾ ਹੈ ਅਤੇ ਸਿਰਫ਼ headings, paragraphs, links ਅਤੇ metadata ਨੂੰ ਤੁਰੰਤ ਨਿਕਾਲ ਸਕਦਾ ਹੈ।
JS-ਭਾਰੀ ਪੇਜ ਦੇ ਨਾਲ, ਪਹਿਲਾ ਰਿਸਪਾਂਸ ਇਕ patla shell ਹੋ ਸਕਦੀ ਹੈ (ਕੁਝ divs ਅਤੇ ਸਕ੍ਰਿਪਟ)। ਮਹੱਤਵਪੂਰਨ ਟੈਕਸਟ ਸਿਰਫ਼ ਸਕ੍ਰਿਪਟ ਚਲਣ ਤੋਂ ਬਾਅਦ ਹੀ ਦਿਖਾਈ ਦੇ ਸਕਦਾ ਹੈ। ਇਸ ਦੂਜੇ ਕਦਮ 'ਤੇ ਕਵਰੇਜ ਘਟਦੀ ਹੈ: ਕੁਝ ਕ੍ਰਾਲਰ ਸਕ੍ਰਿਪਟ ਨਹੀਂ ਚਲਾਉਂਦੇ; ਹੋਰ ਲੋਕ ਟਾਈਮਆਊਟਾਂ ਜਾਂ ਹਿੱਸੇਦਾਰੀ ਸਮਰਥਨ ਨਾਲ ਚਲਾਉਂਦੇ ਹਨ।
ਜਿਹੜੇ ਪੰਨਿਆਂ ਨੂੰ ਤੁਸੀਂ ਇੰਡੈਕਸ ਕਰਵਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ—ਉਦਾਹਰਣ ਲਈ product descriptions, pricing, FAQs, docs—ਉਹਨਾਂ ਲਈ پسند ਕਰੋ:
ਲਕਸ਼ ਇਹ ਨਹੀਂ ਕਿ “ਕੋਈ JavaScript ਨਹੀਂ.” ਇਹ ਹੈ ਮਹੱਤਵਪੂਰਨ HTML ਪਹਿਲਾਂ, JS ਬਾਦ ਵਿੱਚ।
Tabs, accordions, "read more" control ਠੀਕ ਹਨ ਜੇ text DOM ਵਿੱਚ ਮੌਜੂਦ ਹੈ। ਸਮੱਸਿਆ ਉਦੋਂ ਹੁੰਦੀ ਹੈ ਜਦੋਂ tab ਸਮੱਗਰੀ ਸਿਰਫ਼ ਕਲਿੱਕ 'ਤੇ ਫੈਚ ਕੀਤੀ ਜਾਂਦੀ ਹੈ ਜਾਂ client-side request ਨਾਲ inject ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਜੇ ਉਹ ਸਮੱਗਰੀ AI ਖੋਜ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਤਾਂ ਉਸਨੂੰ initial HTML ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰੋ ਅਤੇ visibility ਲਈ CSS/ARIA ਵਰਤੋ।
ਇਹ ਦੋ ਚੈੱਕ ਵਰਤੋ:
ਜੇ ਤੁਹਾਡੇ headings, ਮੁੱਖ ਕਾਪੀ, ਅੰਦਰੂਨੀ ਲਿੰਕ ਜਾਂ FAQ ਜਵਾਬ ਸਿਰਫ਼ Inspect Element ਵਿੱਚ ਹਨ ਪਰ View Source ਵਿੱਚ ਨਹੀਂ, ਤਾਂ ਉਹ rendering risk ਹੈ ਅਤੇ ਉਸ ਸਮੱਗਰੀ ਨੂੰ server-rendered output ਵਿੱਚ ਲਿਜਾਓ।
AI ਕ੍ਰਾਲਰ ਅਤੇ ਰਵਾਇਤੀ search bots ਦੋਹਾਂ ਨੂੰ ਸਾਫ ਤੇ ਲਗਾਤਾਰ access ਨਿਯਮ ਚਾਹੀਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਅਕਸਮਾਤ ਮਹੱਤਵਪੂਰਨ ਸਮੱਗਰੀ ਨੂੰ ਬਲਾਕ ਕਰ ਦਿੰਦੇ ਹੋ—ਜਾਂ ਬੇਸੁਰਕੀ ਜਾਂ "ਗੰਦੀ" ਖੇਤਰਾਂ ਨੂੰ ਅਨੁਮਤ ਕਰ ਦਿੰਦੇ ਹੋ—ਤਾਂ ਤੁਸੀਂ crawl budget ਖ਼ਰਚ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਜੋ ਇੰਡੈਕਸ ਹੋ ਰਿਹਾ ਹੈ ਉਸ ਵਿੱਚ ਗੱਲਤ ਸਮੱਗਰੀ ਆ ਸਕਦੀ ਹੈ।
robots.txt ਦਾ ਇਸਤੇਮਾਲ ਵਿਆਪਕ ਨਿਯਮਾਂ ਲਈ ਕਰੋ: ਕੀ ਖੋਲ੍ਹਿਆ ਜਾਂ ਨਾ ਕੀਤਾ ਜਾਵੇ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਬੇਸਲਾਈਨ:
/admin/, /account/, internal search results, ਜਾਂ parameter-heavy URLs ਜੋ near-infinite combinations ਬਣਾਉਂਦੇ ਹਨ।Example:
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
ਮਹੱਤਵਪੂਰਨ: robots.txt ਨਾਲ ਬਲਾਕ ਕਰਨ ਨਾਲ crawling ਰੁਕਦੀ ਹੈ, ਪਰ ਇਹ ਹਮੇਸ਼ਾ ਯਕੀਨੀ ਨਹੀਂ ਬਣਾਉਂਦਾ ਕਿ ਕਿਸੇ URL ਨੂੰ index ਤੋਂ ਹਟਾਇਆ ਜਾਵੇਗਾ ਜੇ ਉਹ ਕਿਸੇ ਹੋਰ ਸਥਾਨ ਤੋਂ refer ਕੀਤਾ ਗਿਆ ਹੋਵੇ। ਇੰਡੈਕਸ ਨਿਯੰਤਰਣ ਲਈ page-level directives ਵਰਤੋ।
HTML ਪੰਨਿਆਂ ਵਿੱਚ meta name="robots" ਅਤੇ non-HTML ਫਾਈਲਾਂ (PDFs, feeds, generated exports) ਲਈ X-Robots-Tag headers ਵਰਤੋ।
ਆਮ ਪੈਟਰਨ:
noindex,follow ਤਾਂ ਕਿ links ਫਿਰ ਵੀ ਪਾਸ ਹੋ ਸਕਣ ਪਰ ਪੰਨਾ index ਵਿੱਚ ਨਾ ਜਾਵੇ।noindex 'ਤੇ ਨਿਰਭਰ ਨਾ ਰਹੋ—authentication ਨਾਲ ਸੁਰੱਖਿਆ ਕਰੋ, ਅਤੇ ਸੋਚੋ ਕਿ crawl ਨੂੰ ਵੀ disallow ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।noindex ਨਾਲ proper canonicalization ਜੋੜੋ (ਬਾਅਦ ਵਿੱਚ ਕਵਰ ਕੀਤਾ ਗਿਆ)।ਹਰ ਵਾਤਾਵਰਣ ਲਈ ਨਿਯਮ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਅਤੇ ਲਾਗੂ ਕਰੋ:
noindex जोड़ੋ (header-based ਆਸਾਨ) ।ਜੇ ਤੁਹਾਡੇ access controls ਉਪਭੋਗਤਾ ਡੇਟਾ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ, ਤਾਂ ਯਕੀਨੀ ਬਣਾਓ ਕਿ user-facing ਨੀਤੀ ਹਕੀਕਤ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹੈ (ਜਦੋਂ ਮੋਹਰ /privacy ਅਤੇ /terms ਲਾਗੂ ਹੁੰਦੇ ਹਨ)।
ਜੇ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ AI ਸਿਸਟਮ (ਅਤੇ search crawlers) ਭਰੋਸੇਯੋਗ ਢੰਗ ਨਾਲ ਤੁਹਾਡੇ ਪੰਨਿਆਂ ਨੂੰ ਸਮਝਣ ਅਤੇ ਉਧਰਣ ਕਰ ਸਕਣ, ਤਾਂ ਤੁਹਾਨੂੰ "ਇੱਕੋ ਸਮੱਗਰੀ, ਬਹੁਤ ਸਾਰੇ URLs" ਦੀ ਸਥਿਤੀ ਘਟਾਉਣ ਦੀ ਲੋੜ ਹੈ। duplicates crawl budget ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੇ ਹਨ, ਸਿਗਨਲਾਂ ਨੂੰ ਵੰਡ ਦਿੰਦੇ ਹਨ, ਅਤੇ ਗਲਤ ਵਰਜਨ ਇੰਡੈਕਸ ਹੋ ਸਕਦਾ ਹੈ।
ਉਹ URLs ਲਕੜੀ ਜੋ ਸਾਲਾਂ ਲਈ ਵੈਧ ਰਹਿਣ। session IDs, sorting options, ਜਾਂ tracking codes ਜਿਹੜੇ ਅਣਚਾਹੇ ਹਨ, ਉਹ indexable URLs ਵਿੱਚ ਪ੍ਰਗਟ ਨਾ ਕਰੋ (ਉਦਾਹਰਣ: ?utm_source=..., ?sort=price, ?ref=)। ਜੇ parameters functionality ਲਈ ਲਾਜ਼ਮੀ ਹਨ (filters, pagination, internal search), ਤਾਂ ਇਹ ਯਕੀਨੀ ਬਣਾਓ ਕਿ “main” ਵਰਜਨ ਇੱਕ ਸਥਿਰ, ਸਾਫ URL ਤੇ ਵੀ ਪਹੁੰਚਯੋਗ ਹੈ।
ਸਥਿਰ URLs ਲੰਬੇ ਸਮੇਂ ਲਈ citations ਨੂੰ ਸੁਧਾਰਦੇ ਹਨ: ਜਦੋਂ ਇੱਕ LLM ਇੱਕ ਸੰਦਰਭ ਸਿੱਖਦਾ ਜਾਂ ਸਟੋਰ ਕਰਦਾ ਹੈ, ਇਸਨੂੰ ਇੱਕੋ ਪੇਜ ਵੱਲ ਮੁੜ-ਆਉਣ ਦੀ ਸੰਭਾਵਨਾ ਵੱਧ ਹੁੰਦੀ ਹੈ ਜੇ ਤੁਹਾਡੀ URL ਸਟ੍ਰਕਚਰ ਡਿਜ਼ਾਈਨ ਸੋਧਾਂ ਵਿੱਚ ਬਦਲਦੀ ਨਹੀਂ।
ਉਹਨਾਂ ਪੰਨਿਆਂ 'ਤੇ \u003clink rel=\"canonical\"\u003e ਜੋੜੋ ਜਿੱਥੇ duplicates ਉਮੀਦ ਕੀਤੇ ਜਾਂਦੇ ਹਨ:
Canonical tags ਨੂੰ preferred, indexable URL ਵੱਲ ਇੰਗੇ ਕਰੋ (ਅਤੇ ideally ਉਹ canonical URL 200 status ਰਿਟਰਨ ਕਰਦੀ ਹੋਵੇ)।
ਜਦੋਂ ਕੋਈ ਪੇਜ permanently move ਹੁੰਦਾ ਹੈ, ਤਦ 301 redirect ਵਰਤੋ। redirect chains (A → B → C) ਤੇ loops ਤੋਂ ਬਚੋ; ਇਹ ਕ੍ਰਾਲਰਾਂ ਨੂੰ ਹੌਲੀ ਕਰਦੇ ਹਨ ਅਤੇ ਅੰਕੜਿਆਂ ਨੂੰ ਅਧੂਰਾ ਛੱਡ ਸਕਦੇ ਹਨ। ਪੁਰਾਣੇ URLs ਨੂੰ ਸਿੱਧੇ ਅੰਤਿਮ ਮੰਜ਼ਿਲ ਤੇ redirect ਕਰੋ, ਅਤੇ HTTP/HTTPS ਅਤੇ www/non-www ਦੇ across redirects consistent ਰੱਖੋ।
hreflang ਸਿਰਫ਼ ਉਹਦੋਂ ਲਾਗੂ ਕਰੋ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਸੱਚਮੁਚ localized equivalents ਹੋਣ (ਸਿਰਫ਼ ਅਨੁਵਾਦਿਕ snippets ਨਹੀਂ)। ਗਲਤ hreflang ਇਹ ਦਿਖਾ ਸਕਦੀ ਹੈ ਕਿ ਕਿਹੜਾ ਪੇਜ ਕਿਸ ਦਰਸ਼ਕ ਲਈ ਉਚਿਤ ਹੈ, ਜਿਸ ਨਾਲ citation ਬਾਰੇ ਗੜਬੜ ਹੋ ਸਕਦੀ ਹੈ।
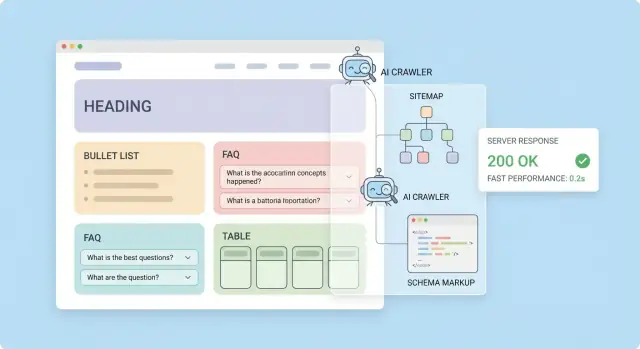
Sitemaps ਅਤੇ ਅੰਦਰੂਨੀ ਲਿੰਕ ਤੁਹਾਡੇ ਖੋਜ ਲਈ "ਡਿਲਿਵਰੀ ਸਿਸਟਮ" ਹਨ: ਇਹ ਕ੍ਰਾਲਰਾਂ ਨੂੰ ਦੱਸਦੇ ਹਨ ਕਿ ਕੀ ਮੌਜੂਦ ਹੈ, ਕੀ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਅਤੇ ਕੀ ਨਜਰਅੰਦਾਜ਼ ਕਰਨਾ ਹੈ। AI ਕ੍ਰਾਲਰਾਂ ਅਤੇ LLM ਇੰਡੈਕਸਿੰਗ ਲਈ ਲਕਸ਼ ਸਧਾਰਨ ਹੈ—ਤੁਹਾਡੇ ਸਭ ਤੋਂ ਵਧੀਆ, ਸਾਫ਼ URLs ਨੂੰ ਲੱਭਣਾ ਆਸਾਨ ਅਤੇ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਨਾ ਮੁਸ਼ਕਲ ਬਣਾਉ।
ਤੁਹਾਡੇ sitemap ਵਿੱਚ ਸਿਰਫ਼ canonical, indexable URLs ਹੋਣ ਚਾਹੀਦੇ ਹਨ। ਜੇ ਕੋਈ ਪੰਨਾ robots.txt ਨਾਲ block ਹੈ, noindex ਹੈ, redirect ਹੈ, ਜਾਂ canonical ਵਰਜਨ ਨਹੀਂ ਹੈ, ਤਾਂ ਉਹ sitemap ਵਿੱਚ ਨਹੀਂ ਜਾਣਾ ਚਾਹੀਦਾ। ਇਸ ਨਾਲ crawler budget ਕੇਂਦਰਿਤ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਇੱਕ LLM ਨੂੰ duplicate ਜਾਂ outdated ਵਰਜਨ ਚੁਣਨ ਦੀ ਸੰਭਾਵਨਾ ਘਟਦੀ ਹੈ।
URL ਫਾਰਮੈਟਾਂ (trailing slashes, lowercase, HTTPS) ਨਾਲ consistent ਰਹੋ ਤਾਂ sitemap ਤੁਹਾਡੇ canonical ਨਿਯਮਾਂ ਨੂੰ mirror ਕਰੇ।
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਬਹੁਤ ਸਾਰੇ URLs ਹਨ, ਉਹਨਾਂ ਨੂੰ ਕਈ sitemap ਫਾਈਲਾਂ ਵਿੱਚ ਵੰਡੋ (ਆਮ limit: 50,000 URLs ਫਾਈਲ ਪ੍ਰਤੀ) ਅਤੇ ਹਰ ਇੱਕ sitemap ਨੂੰ ਲਿਸਟ ਕਰਨ ਵਾਲਾ ਇੱਕ sitemap index ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ। ਸਮੱਗਰੀ ਕਿਸਮ ਅਨੁਸਾਰ ਵਿਭਾਜਨ ਰੱਖੋ ਜੇ ਇਹ ਮਦਦਗਾਰ ਹੋਵੇ, ਉਦਾਹਰਣ:
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xmlਇਸ ਨਾਲ ਰਖ-ਰਖਾਅ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਜੋ ਖੋਜ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ ਉਸਨੂੰ ਨਿਗਰਾਨੀ ਕਰ ਸਕਦੇ ਹੋ।
lastmod ਨੂੰ trust signal ਵਜੋਂ ਵਰਤੋਂ, deployment timestamp ਵਜੋਂ ਨਹੀਂlastmod ਨੂੰ ਸੋਚ-ਸਮਝ ਕੇ ਅਪਡੇਟ ਕਰੋ—ਸਿਰਫ਼ ਜਦੋਂ ਪੰਨਾ ਅਰਥਪੂਰਨ ਤੌਰ 'ਤੇ ਬਦਲਦਾ ਹੈ (ਸਮੱਗਰੀ, ਕੀਮਤ, ਨੀਤੀ, ਮੁੱਖ ਮੈਟਾਡੇਟਾ)। ਜੇ ਹਰ deploy ਤੇ ਹਰ URL ਅਪਡੇਟ ਹੁੰਦੀ ਰਹੇ, ਤਾਂ ਕ੍ਰਾਲਰ ਇਸ ਫੀਲਡ ਨੂੰ ਅਣਡਿੱਠਾ ਕਰ ਦੇਵੇਗਾ, ਅਤੇ ਅਸਲੀ ਮਹੱਤਵਪੂਰਨ ਅਪਡੇਟ ਦੇਖਣ ਵਿੱਚ ਦੇਰੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇੱਕ ਮਜ਼ਬੂਤ hub-and-spoke ਬਣਤਰ ਉਪਭੋਗੀਆਂ ਅਤੇ ਮਸ਼ੀਨਾਂ ਦੋਹਾਂ ਦੀ ਮਦਦ ਕਰਦੀ ਹੈ। hubs (category, product, ਜਾਂ topic pages) ਬਣਾਓ ਜੋ ਮਹੱਤਵਪੂਰਨ spoke pages ਨੂੰ ਲਿੰਕ ਕਰਦੇ ਹਨ, ਅਤੇ ਹਰ spoke ਤੋਂ ਵਾਪਸ hub ਨੂੰ ਲਿੰਕ ਹੋਵੇ। copy ਵਿੱਚ context-based links ਸ਼ਾਮਿਲ ਕਰੋ, ਕੇਵਲ menus ਵਿੱਚ ਨਹੀਂ।
ਜੇ ਤੁਸੀਂ ਸਿੱਖਿਆਤਮਕ ਸਮੱਗਰੀ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਆਪਣੇ ਮੁੱਖ ਪਰਵੇਸ਼-ਬਿੰਦੂ ਸਪਸ਼ਟ ਰੱਖੋ—ਲੇਖਾਂ ਲਈ /blog ਅਤੇ ਡੀਪ ਨਹੀਂ ਜਾਣ ਵਾਲੇ reference материал ਲਈ /docs।
Structured data ਇੱਕ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਪੰਨੇ "ਕੀ ਹੈ" ਨੂੰ (article, product, FAQ, organization) ਐਸੇ ਫਾਰਮੈਟ ਵਿੱਚ ਲੇਬਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਜੋ ਮਸ਼ੀਨਾਂ ਆਸਾਨੀ ਨਾਲ ਪੜ੍ਹ ਸਕਦੀਆਂ ਹਨ। ਖੋਜ ਇੰਜਨ ਅਤੇ AI ਸਿਸਟਮ ਨੂੰ ਇਹ ਗੱਲ ਫ਼ਿੱਕਰ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ ਕਿ ਕਿਹੜਾ ਟੈਕਸਟ ਸਿਰਲੇਖ ਹੈ, ਕੌਣ ਲਿਖਿਆ, ਜਾਂ ਮੁੱਖ ਏਨਟਿਟੀ ਕੀ ਹੈ—ਉਹ ਇਸਨੂੰ ਸਿੱਧਾ ਪਾਰਸ ਕਰ ਸਕਦੇ ਹਨ।
ਉਹ Schema.org ਕਿਸਮਾਂ ਵਰਤੋ ਜੋ ਤੁਹਾਡੇ ਸਮੱਗਰੀ ਨਾਲ ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ:
ਹਰ ਪੰਨੇ ਲਈ ਇੱਕ ਪ੍ਰਾਈਮਰੀ ਟਾਈਪ ਚੁਣੋ, ਫਿਰ ਸਹਾਇਕ properties ਜੋੜੋ (ਉਦਾਹਰਣ, ਇੱਕ Article publisher ਵਜੋਂ Organization ਨੂੰ refer ਕਰ ਸਕਦਾ ਹੈ)।
AI ਕ੍ਰਾਲਰ ਅਤੇ ਖੋਜ ਇੰਜਨਾਂ structured data ਨੂੰ visible page ਨਾਲ ਮਿਲਾ ਕੇ ਵੇਖਦੇ ਹਨ। ਜੇ ਤੁਹਾਡਾ ਮਾਰਕਅਪ ਉਸ FAQ ਦਾ ਦਾਅਵਾ ਕਰਦਾ ਹੈ ਜੋ ਅਸਲ ਵਿੱਚ ਪੇਜ 'ਤੇ ਨਹੀਂ ਹੈ, ਜਾਂ ਲੇਖਕ ਨਾਮ ਜੋ ਦਿੱਖ ਨਹੀਂ ਰਿਹਾ, ਤਾਂ ਇਹ ਗਲਤਫਹਮੀ ਪੈਦਾ ਕਰਦਾ ਹੈ ਅਤੇ ਮਾਰਕਅਪ ignore ਹੋ ਸਕਦਾ ਹੈ।
ਸਮੱਗਰੀ ਪੰਨਿਆਂ ਲਈ author, datePublished ਅਤੇ dateModified ਸ਼ਾਮਿਲ ਕਰੋ ਜਦੋਂ ਉਹ ਅਸਲ ਅਤੇ ਅਰਥਪੂਰਨ ਹੋਣ। ਇਹ freshness ਅਤੇ accountability ਨੂੰ ਸਪਸ਼ਟ ਕਰਦਾ—ਇਹ ਦੋ ਚੀਜ਼ਾਂ LLMs ਅਕਸਰ ਭਰੋਸਾ ਕਰਨ ਵੇਲੇ ਦੇਖਦੇ ਹਨ।
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਅਧਿਕਾਰਤ ਪ੍ਰੋਫਾਈਲ ਹਨ, Organization schema ਵਿੱਚ sameAs links (ਉਦਾਹਰਣ, ਤੁਹਾਡੀ ਕੰਪਨੀ ਦੇ verified social profiles) ਸ਼ਾਮਿਲ ਕਰੋ।
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
ਅਖੀਰ ਵਿੱਚ, ਆਮ ਟੈਸਟਿੰਗ ਟੂਲ (Google’s Rich Results Test, Schema Markup Validator) ਨਾਲ validate ਕਰੋ। errors ਠੀਕ ਕਰੋ, ਅਤੇ warnings ਨੂੰ ਪ੍ਰਾਇਰਿਟੀ ਦੇ ਕੇ ਹੱਲ ਕਰੋ: ਉਹ warnings ਜਿਹੜੀਆਂ ਤੁਹਾਡੇ ਚੁਣੇ ਕਿਸਮ ਅਤੇ ਕੁੰਜੀ properties (title, author, dates, product info) ਨਾਲ ਸੰਬੰਧਿਤ ਹਨ ਉਹਨਾਂ ਨੂੰ ਪਹਿਲਾਂ ਦਿੱਖੋ।
llms.txt ਫਾਈਲ ਇੱਕ ਛੋਟੀ, ਮਨੁੱਖ-ਪੜ੍ਹਨਯੋਗ “index card” ਹੈ ਜੋ language-model-ਫੋਕਸਡ ਕ੍ਰਾਲਰਾਂ (ਅਤੇ ਉਹਨਾਂ ਲੋਕਾਂ ਲਈ ਜੋ ਉਨ੍ਹਾਂ ਨੂੰ ਕਨਫਿਗਰ ਕਰਦੇ ਹਨ) ਨੂੰ ਤੁਹਾਡੀ ਸਾਈਟ ਦੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਐਂਟਰੀ-ਪਾਇੰਟਾਂ ਵੱਲ ਇਸ਼ਾਰਾ ਕਰਦੀ: ਤੁਹਾਡੀਆਂ docs, ਮੁੱਖ product pages, ਅਤੇ ਕੋਈ ਸੰਦਰਭ material ਜੋ ਤੁਹਾਡੀ ਸ਼ਬਦਾਵਲੀ ਨੂੰ ਸਮਝਾਉਂਦੀ ਹੈ।
ਇਹ ਕੋਈ ਸਟੈਂਡਰਡ ਨਹੀਂ ਹੈ ਜਿਸਦਾ ਹਰ ਕ੍ਰਾਲਰ ਹਰ ਢੰਗ ਨਾਲ ਪਾਲਣ ਕਰੇਗਾ, ਅਤੇ ਇਸਨੂੰ sitemaps, canonicals, ਜਾਂ robots controls ਦੀ ਥਾਂ ਨਾ ਸਮਝੋ। ਇਸਨੂੰ ਖੋਜ ਲਈ ਉਪਯੋਗ ਛੋਟਾ ਸਹਾਇਕ ਸਮਝੋ।
ਇਸਨੂੰ ਸਾਈਟ ਰੂਟ 'ਤੇ ਰੱਖੋ ਤਾਂ ਕਿ ਲਭਨਾ ਆਸਾਨ ਹੋਵੇ:
/llms.txtਇਹ robots.txt ਦੇ ਇੱਕੋ ਹੀ ਵਿਚਾਰ ਨਾਲ ਹੈ: predictable location, quick fetch।
ਇਸਨੂੰ ਛੋਟਾ ਅਤੇ curated ਰੱਖੋ। ਚੰਗੇ ਉਮੀਦਵਾਰ:
ਛੋਟੇ style notes ਵੀ ਸ਼ਾਮਿਲ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਅਸਪਸ਼ਟਤਾ ਘਟਾਉਂਦੇ ਹਨ (ਉਦਾਹਰਣ, “ਅਸੀਂ UI ਵਿੱਚ customers ਨੂੰ ‘workspaces’ ਕਹਿੰਦੇ ਹਾਂ”)। ਲੰਬਾ marketing copy, ਪੂਰਾ URL dump, ਜਾਂ ਕੁਝ ਵੀ ਜੋ ਤੁਹਾਡੇ canonical URLs ਨਾਲ ਟਕਰਾਉਂਦਾ ਹੋ, ਉਹਨਾਂ ਤੋਂ ਬਚੋ।
ਇੱਕ ਸਧਾਰਨ ਉਦਾਹਰਨ:
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
Consistency volume ਤੋਂ ਵੱਧ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ:
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਰੁਟੀਨ ਜੋ manageable ਰਹੇ:
ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੀਤਾ ਗਿਆ llms.txt ਛੋਟੀ, ਸਹੀ ਅਤੇ ਵਾਸਤਵ ਵਿੱਚ ਉਪਯੋਗ ਰਹਿੰਦੀ ਹੈ—ਬਿਨਾਂ ਕਿਸੇ ਇਹ ਗਾਰੰਟੀ ਦਿੱਤੇ ਕਿ ਕੋਈ ਖਾਸ ਕ੍ਰਾਲਰ ਕਿਵੇਂ ਵਤੀਰੇਗਾ।
ਕ੍ਰਾਲਰ (ਅਤੇ AI-ਫੋਕਸਡ ਉਹ) ਬਹੁਤ ਹੱਦ ਤੱਕ ਬੇਸਬਰੀ ਉਪਭੋਗੀਆਂ ਵਾਂਗ ਵਰਤੋਂ ਕਰਦੇ ਹਨ: ਜੇ ਤੁਹਾਡੀ ਸਾਈਟ ਧੀਮੀ ਜਾਂ ਫ್ಲੇਕੀ ਹੋਵੇ, ਉਹ ਘੱਟ ਪੰਨੇ ਫੈਚ ਕਰਾਂਗੇ, ਘੱਟ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰਾਂਗੇ, ਅਤੇ ਆਪਣੀ ਇੰਡੈਕਸ ਤਾਜ਼ਗੀ ਘੱਟ ਕਰ ਦੇਣਗੇ। ਚੰਗਾ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਭਰੋਸੇਯੋਗ ਸਰਵਰ ਜਵਾਬ ਇਹ ਸੰਭਾਵਨਾ ਵਧਾਉਂਦੇ ਹਨ ਕਿ ਤੁਹਾਡੀ ਸਮੱਗਰੀ ਖੋਜੀ, ਮੁੜ-ਕ੍ਰਾਲ ਕੀਤੀ ਅਤੇ ਅਪਡੇਟ ਰੱਖੀ ਜਾਵੇ।
ਜੇ ਤੁਹਾਡਾ ਸਰਵਰ ਅਕਸਰ timeout ਜਾਂ errors ਰਿਟਰਨ ਕਰਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਕ੍ਰਾਲਰ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਬੈਕ-ਆਫ ਕਰ ਸਕਦਾ ਹੈ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਨਵੇਂ ਪੰਨੇ ਆਉਣ ਵਿੱਚ ਜ਼ਿਆਦਾ ਸਮਾਂ ਲੈ ਸਕਦੇ ਹਨ, ਅਤੇ ਅਪਡੇਟ ਵੇਖਣ ਵਿੱਚ ਵੀ ਦੇਰੀ ਹੋ ਸਕਦੀ ਹੈ।
ਉੱਚ ਪ੍ਰਭਾਵ ਵਾਲੇ ਕੁਝ ਫਿਕਸ:
ਹਾਲਾਂਕਿ ਕ੍ਰਾਲਰ images ਨੂੰ ਇਨਸਾਨਾਂ ਵਾਂਗ ਨਹੀਂ ਵੇਖਦੇ, ਵੱਡੀਆਂ ਫਾਈਲਾਂ ਵੀ crawl ਸਮਾਂ ਅਤੇ bandwidth ਨੂੰ ਵਿਅਰਥ ਖਰਚ ਕਰਦੀਆਂ ਹਨ।
ਕ੍ਰਾਲਰ status codes 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਇਹ ਫੈਸਲਾ ਕਰਨ ਲਈ ਕਿ ਕੀ ਰੱਖਣਾ ਹੈ ਅਤੇ ਕੀ ਹਟਾਉਣਾ ਹੈ:
ਜੇ ਮੁੱਖ ਲੇਖ متن authentication ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ, ਕਈ ਕ੍ਰਾਲਰ ਸਿਰਫ਼ shell ਨੂੰ ਹੀ ਇੰਡੈਕਸ ਕਰਨਗੇ। ਮੁੱਖ ਪੜ੍ਹਨ ਯੋਗੀ ਪ੍ਰਵਾਨਗੀ ਨੂੰ public ਰੱਖੋ, ਜਾਂ ਇੱਕ crawlable preview ਦਿਓ ਜਿਸ ਵਿੱਚ key content ਸ਼ਾਮਿਲ ਹੋਵੇ।
ਆਪਣੀ ਸਾਈਟ ਨੂੰ abuse ਤੋਂ ਬਚਾਓ, ਪਰ ਸਖ਼ਤ ਬਲਾਕਾਂ ਤੋਂ ਬਚੋ। ਪ੍ਰਿਫਰ ਕਰੋ:
Retry-After headersਇਸ ਨਾਲ ਤੁਹਾਡੀ ਸਾਈਟ ਸੁਰੱਖਿਅਤ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਜਵਾਬਦੇਹ ਕ੍ਰਾਲਰ ਕੰਮ ਕਰ ਸਕਦੇ ਹਨ।
“E‑E‑A‑T” ਵੱਡੇ ਦਾਅਵੇ ਜਾਂ ਸ਼ਾਨਦਾਰ ਬੈਜਾਂ ਦੀ ਲੋੜ ਨਹੀਂ ਰੱਖਦਾ। AI ਕ੍ਰਾਲਰਾਂ ਅਤੇ LLMs ਲਈ ਇਹ ਮੁੱਖ ਤੌਰ 'ਤੇ ਇਹ ਹੈ ਕਿ ਤੁਹਾਡੀ ਸਾਈਟ ਸਪਸ਼ਟ ਦੱਸੇ ਕਿ ਕਿਸਨੇ ਕੁਝ ਲਿਖਿਆ, ਕਿੱਥੋਂ ਤੱਥ ਆਏ, ਅਤੇ ਕੌਣ ਇਸਦੀ ਰਖ-ਰਖਾਅ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਕੋਈ ਤੱਥ ਦੱਸੋ, ਉਸ ਦਾਅਵੇ ਦੇ ਨਜ਼ਦੀਕ ਸਰੋਤ ਜ਼ਰੂਰ ਜੋੜੋ। ਪ੍ਰਾਇਰਿਟੀ primary ਤੇ official references (ਕਾਨੂੰਨ, standards bodies, vendor docs, peer-reviewed papers) ਨੂੰ ਦਿਓ ਨਾ ਕਿ ਦੂਜੀ-ਹਥੀਂ ਦੇ summaries ਨੂੰ।
ਉਦਾਹਰਣ ਲਈ, ਜੇ ਤੁਸੀਂ structured data ਬਾਰੇ ਗੱਲ ਕਰਦੇ ਹੋ, ਤਾਂ Google ਦੀ ਦਸਤਾਵੇਜ਼ ("Google Search Central — Structured Data") ਅਤੇ ਜਦੋਂ ਲੋੜ ਹੋ Schema.org ਦੀ ਪਰਿਭਾਸ਼ਾ ਦਾ ਹਵਾਲਾ ਦਿਓ। ਜੇ ਤੁਸੀਂ robots directives ਬਾਰੇ ਗੱਲ ਕਰਦੇ ਹੋ, ਤਾਂ ਸੰਬੰਧਿਤ ਮਿਆਰ ਅਤੇ official crawler docs (ਉਦਾਹਰਣ: "RFC 9309: Robots Exclusion Protocol") ਦੀ ਗੱਲ ਕਰੋ। ਯਾਦ ਰਹੇ ਕਿ ਹਰ ਜਗ੍ਹਾ ਲਿੰਕ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ—ਪਰ ਪਰਯਾਪਤ ਵੇਰਵਾ ਦਿਓ ਤਾਂ ਕਿ ਪਾਠਕ ਅਸਲ ਦਸਤਾਵੇਜ਼ ਲੱਭ ਸਕੇ।
ਲੇਖਕ ਦੀ ਬਾਈਲਾਈਨ, ਛੋਟੀ bio, ਅਤੇ ਉਹ ਕੀ ਜਿੰਮੇਵਾਰੀ ਰੱਖਦਾ ਹੈ ਇਹ ਜੋੜੋ। ਫਿਰ ਮਲਕੀਅਤ ਨੂੰ ਸਪਸ਼ਟ ਕਰੋ:
“Best” ਜਾਂ “guaranteed” ਵਰਗਾ ਭੜਕਾਊ ਭਾਸ਼ਾ ਨਾ ਵਰਤੋ। ਇਸ ਦੀ ਥਾਂ, ਦੱਸੋ ਕਿ ਤੁਸੀਂ ਕੀ ਟੈਸਟ ਕੀਤਾ, ਕੀ ਬਦਲਿਆ, ਅਤੇ ਸੀਮਾਵਾਂ ਕੀ ਹਨ। ਮੁੱਖ ਪੰਨਿਆਂ 'ਤੇ update notes ਜੋੜੋ (ਉਦਾਹਰਣ: “Updated 2025-12-10: clarified canonical handling for redirects”)। ਇਹ maintenance trail ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਮਨੁੱਖਾਂ ਅਤੇ ਮਸ਼ੀਨਾਂ ਦੋਹਾਂ ਲਈ ਸਮਝਯੋਗ ਹੈ।
ਆਪਣੇ ਮੁੱਖ ਸ਼ਬਦਾਂ ਨੂੰ ਇੱਕ ਵਾਰੀ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਸਾਰੀ ਸਾਈਟ ਵਿੱਚ ਉਹੀ ਵਰਤੋਂ (ਉਦਾਹਰਣ: “AI crawler,” “LLM indexing,” “rendered HTML”)। ਇੱਕ ਹਲਕੀ glossary ਪੰਨਾ (ਉਦਾਹਰਨ: /glossary) ਅਸਪਸ਼ਟਤਾ ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੀ ਸਮੱਗਰੀ ਨੂੰ summarize ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
AI-ready ਸਾਈਟ ਇਕ ਇਕ-ਵਾਰ ਦਾ ਪ੍ਰੋਜੈਕਟ ਨਹੀਂ। ਛੋਟੇ ਬਦਲਾਅ—ਜਿਵੇਂ CMS ਅਪਡੇਟ, ਨਵਾਂ redirect, ਜਾਂ navigation redesign—ਅਕਸਮਾਤ ਖੋਜ ਅਤੇ ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦੇ ਹਨ। ਇੱਕ ਸਧਾਰਨ ਟੈਸਟਿੰਗ ਰੁਟੀਨ ਤੁਹਾਨੂੰ ਅਟਕਾਉਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਬੁਨਿਆਦੀ ਗੱਲਾਂ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ: crawl errors, index coverage, ਅਤੇ top-linked pages track ਕਰੋ। ਜੇ ਕ੍ਰਾਲਰ ਮਹੱਤਵਪੂਰਨ URLs ਫੈਚ ਨਹੀਂ ਕਰ ਪा ਰਹੇ (timeouts, 404s, blocked resources), LLM ਇੰਡੈਕਸਿੰਗ ਤੇਜ਼ੀ ਨਾਲ ਘਟ ਸਕਦੀ ਹੈ।
ਹੋਰ ਵੀ ਨਿਗਰਾਨੀ ਕਰੋ:
ਲਾਂਚਾਂ (ਭੀ "ਛੋਟੇ" ਸਮਝੀਆਂ ਜਾਣ ਵਾਲੀਆਂ) ਤੋਂ ਬਾਅਦ, ਇਹ ਵੇਖੋ ਕਿ ਕੀ ਬਦਲਿਆ:
15 ਮਿੰਟ ਦੀ post-release audit ਅਕਸਰ ਮੁੱਦੇ ਫੜ ਲੈਂਦੀ ਹੈ ਜਿਸ ਨੂੰ ਲੰਮੇ ਸਮੇਂ ਦੀ visibility ਘਾਟ ਤੋਂ ਪਹਿਲਾਂ ਠੀਕ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਕੁਝ high-value ਪੰਨਿਆਂ ਚੁਣੋ ਅਤੇ ਵੇਖੋ ਕਿ AI ਟੂਲ ਜਾਂ ਆਧਾਰਕ summarization ਸਕ੍ਰਿਪਟ ਉਹਨਾਂ ਨੂੰ ਕਿਵੇਂ ਸੰਖੇਪ ਕਰਦੇ ਹਨ। ਧਿਆਨ ਰੱਖੋ:
ਜੇ ਸੰਖੇਪ vague ਹਨ, ਤਾਂ ਸੁਧਾਰ ਆਮ ਤੌਰ 'ਤੇ ਸੰਪਾਦਕੀ ਹੁੰਦਾ ਹੈ: ਮਜ਼ਬੂਤ H2/H3 ਹੈਡਿੰਗਾਂ, ਸਪਸ਼ਟ ਪਹਿਲੇ ਪੈਰਾਗ੍ਰਾਫ, ਅਤੇ ਵੱਧ explicit terminology।
ਜੋ ਤੁਸੀਂ ਸਿੱਖਦੇ ਹੋ ਉਸਨੂੰ ਇੱਕ ਬਾਰਿਕੀ ਵਾਲੀ ਚੈਕਲਿਸਟ ਵਿੱਚ ਬਦਲੋ ਅਤੇ ਇੱਕ ਜ਼ਿੰਮੇਵਾਰ ਨਿਯੁਕਤ ਕਰੋ (ਅਸਲ ਨਾਮ, “marketing” ਨਹੀਂ)। ਇਸਨੂੰ ਜੀਵੰਤ ਅਤੇ ਕਾਰਜਯੋਗ ਰੱਖੋ—ਫਿਰ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਨਵੀਨਤਮ ਵਰਜਨ ਲਿੰਕ ਕਰੋ ਤਾਂ ਸਾਰੀ ਟੀਮ ਇੱਕੋ playbook ਵਰਤੇ। ਇੱਕ ਹਲਕਾ ਹਵਾਲਾ ਜਿਵੇਂ /blog/ai-seo-checklist ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ ਅਤੇ ਜਿਵੇਂ ਤੁਸੀਂ ਸਾਈਟ ਅਤੇ tooling ਨੂੰ ਅਪਡੇਟ ਕਰੋ ਇਸਨੂੰ ਅਪਡੇਟ ਕਰੋ।
ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਤੇਜ਼ੀ ਨਾਲ ship ਕਰਦੀ ਹੈ (ਖਾਸ ਕਰਕੇ AI-ਸਹਾਇਕ ਵਿਕਾਸ ਨਾਲ), ਤਾਂ ਸੋਚੋ ਕਿ "AI readiness" checks ਨੂੰ सीधे build/release workflow ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰੋ: ਟੈਮਪਲੇਟ ਜੋ ਹਮੇਸ਼ਾ canonical tags, consistent author/date fields, ਅਤੇ server-rendered core content ਨਿਕਲਣ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ। Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਇੱਥੇ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਇਹ defaults ਨਵੇਂ React ਪੰਨਿਆਂ ਅਤੇ ਐਪ ਸਤਹਾਂ 'ਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਬਣਾਉਂਦੇ ਹਨ—ਅਤੇ planning mode, snapshot, ਅਤੇ rollback ਦੇ ਨਾਲ ਤੁਸੀਂ ਜਦੋਂ ਕੋਈ ਬਦਲਾਅ ਕ੍ਰਾਲਬਿਲਟੀ 'ਤੇ ਅਸਰ ਪਾਂਦਾ ਹੈ ਤਾਂ ਉਸਨੂੰ ਪਿੱਛੇ ਲੈ ਜਾ ਸਕਦੇ ਹੋ।
ਛੋਟੇ, ਲਗਾਤਾਰ ਸੁਧਾਰ ਮਿਲ ਕੇ ਵੱਡੇ ਨਤੀਜੇ ਦਿੰਦੇ ਹਨ: ਘੱਟ crawl failures, ਸਾਫ਼ ਇੰਡੈਕਸਿੰਗ, ਅਤੇ ਸਮੱਗਰੀ ਜੋ ਮਨੁੱਖਾਂ ਅਤੇ ਮਸ਼ੀਨਾਂ ਦੋਹਾਂ ਲਈ ਸਮਝਣਯੋਗ ਹੋਵੇ।
ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡੀ ਸਾਈਟ automated ਸਿਸਟਮਾਂ ਲਈ ਖੋਜਣ, ਪਾਰਸ ਕਰਨ ਅਤੇ ਸਹੀ ਢੰਗ ਨਾਲ ਮੁੜ ਵਰਤਣ ਲਈ ਆਸਾਨ ਹੋਵੇ।
ਅਮਲ ਵਿੱਚ, ਇਹ crawlable URLs, ਸਾਫ਼ HTML ਬਣਤਰ, ਸਪੱਸ਼ਟ attribution (ਲੇਖਕ / ਤਰੀਖ / ਸਰੋਤ) ਅਤੇ ਖੁਦ-ਮੁਕੰਮਲ ਟੁਕੜਿਆਂ ਵਿੱਚ ਲਿਖੀ ਸਮੱਗਰੀ ਉਤੇ ਟਿਕਿਆ ਹੁੰਦਾ ਹੈ, ਜਿਸਨੂੰ retrieval ਸਿਸਟਮ ਖਾਸ ਪ੍ਰਸ਼ਨਾਂ ਨਾਲ ਮਿਲਾ ਸਕਣ।
ਨਹੀਂ—ਇਹ ਨਿਰਧਾਰਤ ਤੌਰ 'ਤੇ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ। ਵੱਖ-ਵੱਖ ਪ੍ਰੋਵਾਈਡਰ ਵੱਖ-ਵੱਖ ਸਮਿਆਂ 'ਤੇ ক্রਾਲ ਕਰਦੇ ਹਨ, ਵੱਖ-ਵੱਖ ਨੀਤੀਆਂ ਦੀ ਪਾਲਣਾ ਕਰਦੇ ਹਨ, ਅਤੇ ਹੋ ਸਕਦਾ ਹੈ ਉਹ ਤੁਹਾਨੂੰ ਕਦੇ ਵੀ ਕਰਾਲ ਨਾ ਕਰਨ।
ਉਸ ਦੀ ਬਜਾਏ, ਉਨ੍ਹਾਂ ਚੀਜ਼ਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ ਜੋ ਤੁਸੀਂ ਨਿਯੰਤਰਿਤ ਕਰ ਸਕਦੇ ਹੋ: ਆਪਣੇ ਪੰਨਿਆਂ ਨੂੰ ਪਹੁੰਚਯੋਗ, ਸਪਸ਼ਟ, ਤੇਜ਼ ਫੈਚ ਕਰਨ ਵਾਲੇ ਅਤੇ attribution ਦੇ ਯੋਗ ਬਣਾਓ ਤਾਂ ਕਿ ਜੇ ਉਹ ਵਰਤੇ ਜਾਂ, ਤਾਂ ਸਹੀ ਢੰਗ ਨਾਲ ਵਰਤੇ ਜਾਣ।
ਮੁੱਖ ਰੂਪ ਵਿੱਚ ਪਹਿਲੇ ਰਿਸਪਾਂਸ ਵਿੱਚ ਮਹੱਤਵਪੂਰਨ HTML ਹੋਵੇ।
ਜ਼ਰੂਰੀ ਪੰਨਿਆਂ (pricing, docs, FAQs) ਲਈ SSR/SSG/hybrid rendering ਵਰਤੋ, ਅਤੇ ਫੇਰ interactivity ਲਈ JavaScript ਜੋੜੋ। ਜੇ ਮੁੱਖ ਟੈਕਸਟ ਸਿਰਫ਼ hydration ਜਾਂ API calls ਤੋਂ ਬਾਦ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ, ਤਾਂ ਬਹੁਤ ਸਾਰੇ ਕ੍ਰਾਲਰ ਉਸਨੂੰ ਮਿਸ ਕਰ ਸਕਦੇ ਹਨ।
ਤੁਲਨਾ ਕਰੋ:
ਜੇ ਮੁੱਖ headings, ਮੁੱਖ ਨਕਲ, ਲਿੰਕ ਜਾਂ FAQ ਸਿਰਫ਼ Inspect Element ਵਿੱਚ ਆ ਰਹੇ ਹਨ ਪਰ View Source ਵਿੱਚ ਨਹੀਂ, ਤਾਂ ਉਹ rendering risk ਹੈ—ਉਹ ਸਮੱਗਰੀ ਸਰਵਰ-ਰੇਂਡਰਡ HTML ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰੋ।
robots.txt ਦਾ ਇਸਤੇਮਾਲ ਵਿਆਪਕ crawl ਨਿਯਮਾਂ ਲਈ ਕਰੋ (ਜਿਵੇਂ /admin/ ਨੂੰ ਬਲਾਕ ਕਰਨਾ), ਤੇ meta robots / X-Robots-Tag ਪੰਨਾ-ਸਤਰ ਦੇ index ਫੈਸਲੇ ਲਈ ਵਰਤੋ।
ਇੱਕ ਆਮ ਰੁਝਾਨ ਇਹ ਹੈ ਕਿ thin utility ਪੰਨਿਆਂ ਲਈ noindex,follow ਵਰਤਿਆ ਜਾਵੇ, ਅਤੇ private areas ਲਈ authentication ਨੂੰ ਮੂਲ ਰੱਖੋ (ਸਿਰਫ਼ noindex 'ਤੇ ਨਿਰਭਰ ਨਾ ਕਰੋ)।
ਹਰ piece of content ਲਈ ਇੱਕ ਸਥਿਰ, indexable canonical URL ਰੱਖੋ।
rel="canonical" ਜੋੜੋ (filters, parameters, variants)।ਇਸ ਨਾਲ split-signals ਘਟਦੇ ਹਨ ਅਤੇ citation ਲੰਬੇ ਸਮੇਂ ਲਈ ਸਥਿਰ ਰਹਿੰਦੇ ਹਨ।
ਸਿਰਫ਼ canonical, indexable URLs ਸ਼ਾਮਿਲ ਕਰੋ।
ਜੋ URLs redirect, noindex, robots.txt ਨਾਲ block ਕੀਤੇ ਜਾਂ non-canonical duplicates ਹਨ, ਉਹ sitemap ਵਿੱਚ ਨਹੀਂ ਜਾਣੇ ਚਾਹੀਦੇ। ਫਾਰਮੈਟ consistent ਰੱਖੋ (HTTPS, trailing slash ਨੀਤੀਆਂ, lowercase) ਅਤੇ lastmod ਨੂੰ ਸਿਰਫ਼ ਅਸਲੀ, ਮਹੱਤਵਪੂਰਨ ਬਦਲਾਅ ਤੇ ਹੀ ਅਪਡੇਟ ਕਰੋ।
ਇਸਨੂੰ ਇੱਕ curated “index card” ਵਜੋਂ ਵਰਤੋ ਜੋ ਤੁਹਾਡੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਐਂਟਰੀ-ਪਾਇੰਟਾਂ (docs hubs, getting started, glossary, policies) ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ।
ਛੋਟਾ ਰੱਖੋ—ਸਿਰਫ਼ ਉਹ URLs ਲਿਸਟ ਕਰੋ ਜੋ ਤੁਸੀਂ ਖੋਜਵੀਂ ਅਤੇ ਉദ്ധਰਣ ਲਈ ਚਾਹੁੰਦੇ ਹੋ, ਅਤੇ ਯਕੀਨ ਕਰੋ ਕਿ ਹਰ ਲਿੰਕ 200 ਰਿਟਰਨ ਕਰਦਾ ਹੈ ਅਤੇ ਸਹੀ canonical ਹੋਵੇ। ਇਸ ਨੂੰ sitemap, canonicals ਜਾਂ robots ਫੰਕਸ਼ਨਜ਼ ਦਾ ਬਦਲ ਨਹੀਂ ਸਮਝੋ।
ਪੰਨੇ ਇਸ ਤਰ੍ਹਾਂ ਲਿਖੋ ਕਿ ਚੰਕ ਆਪਣੇ ਆਪ ਵਿਚ ਖੜੇ ਹੋ ਸਕਣ:
ਇਸ ਨਾਲ retrieval ਸਹੀ ਹੋਵੇਗੀ ਅਤੇ ਗਲਤ summaries ਘੱਟ ਹੋਣਗੀਆਂ।
ਨਿਸ਼ਚਿਤ ਅਤੇ ਦ੍ਰਿਸ਼ਟੀਯੋਗ trust signals ਜੋ attribution ਨੂੰ ਸੁਧਾਰਦੇ ਹਨ:
datePublished ਅਤੇ ਅਰਥਪੂਰਨ dateModifiedਇਹ ਚੀਜ਼ਾਂ ਕ੍ਰਾਲਰਾਂ ਅਤੇ LLMs ਲਈ attribution ਅਤੇ citation ਨੂੰ ਹੋਰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ।