16 ਅਕਤੂ 2025·8 ਮਿੰਟ
AI-ਨਿਰਮਿਤ ਐਪਸ ਵਿੱਚ ਸੁਰੱਖਿਆ: ਗਾਰੰਟੀਆਂ, ਖਾਮੀਆਂ ਅਤੇ ਰੱਖਿਆ ਨਿਯਮ
ਸਿੱਖੋ ਕਿ AI-ਨਿਰਮਿਤ ਬਣਾਏ ਐਪਸ ਲਈ ਕਿਹੜੀਆਂ ਸੁਰੱਖਿਆ ਗਾਰੰਟੀਆਂ ਹਕੀਕਤ ਵਿੱਚ ਦੱਸੀ ਜਾ ਸਕਦੀਆਂ ਹਨ, ਕਿੱਥੇ ਅੰਧ-ਸਥਾਨ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਕਿਹੜੇ ਪ੍ਰਯੋਗਤਾਪੂਰਕ ਰੱਖਿਆ ਨਿਯਮ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ship ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨਗੇ।
ਇਹ ਪੋਸਟ ਕਿੰਨੀ ਚੀਜ਼ਾਂ ਕਵਰ ਕਰਦੀ ਹੈ (ਅਤੇ ਕੀ ਨਹੀਂ)
“AI-ਨਿਰਮਿਤ ਐਪਲੀਕੇਸ਼ਨ” ਵੱਖ-ਵੱਖ ਤਰੀਕਿਆਂ ਨਾਲ ਮਤਲਬ ਰੱਖ ਸਕਦਾ ਹੈ, ਅਤੇ ਇਸ ਪੋਸਟ ਵਿੱਚ ਇਹ ਟਰਮ ਵਿਆਪਕ ਤੌਰ 'ਤੇ ਵਰਤੀ ਗਈ ਹੈ। ਇਸ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
- ਉਹ ਐਪ ਜਿੱਥੇ ਕੋਡ ਦੇ ਮਹੱਤਵਪੂਰਨ ਹਿੱਸੇ LLM ਦੁਆਰਾ ਬਣਾਏ ਗਏ ਹੋ ਸਕਦੇ ਹਨ (prompt, spec, ਜਾਂ ticket ਤੋਂ)
- ਟੀਮਾਂ ਜੋ copilots ਦੀ ਵਰਤੋਂ ਕਰ ਰਹੀਆਂ ਹਨ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਲਿਖਣ, refactor ਕਰਨ ਅਤੇ ਫਿਕਸ ਕਰਨ ਲਈ
- Agent-ਸਟਾਈਲ ਵਰਕਫਲੋਜ਼ ਜੋ ਟੂਲ ਚਲਾ ਸਕਦੇ ਹਨ (PR ਬਣਾਉਣਾ, APIs ਨੂੰ ਕਾਲ ਕਰਨਾ, ਡਾਟਾਬੇਸ ਕਵੈਰੀ, ਡੀਪਲੋਇ)
- ਉਤਪਾਦ ਜੋ ਯੂਜ਼ਰ ਅਨੁਭਵ ਦੇ ਹਿੱਸੇ ਵਜੋਂ AI ਫੀਚਰ (ਚੈਟ, ਸਾਰ, ਸਿਫਾਰਸ਼ਾਂ) ਸ਼ਾਮਲ ਕਰਦੇ ਹਨ
ਮਕਸਦ ਸਿੱਧਾ ਹੈ: ਖਤਰੇ ਨੂੰ ਘਟਾਉਣਾ ਬਿਨਾਂ ਇਹ ਦਿਖਾਉਣ ਦੇ ਕਿ ਤੁਸੀਂ ਪੂਰਨ ਸੁਰੱਖਿਆ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ। AI ਵਿਕਾਸ ਅਤੇ ਫੈਸਲਾ-ਲੈਣ ਦੀ ਗਤੀ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ, ਪਰ ਇਹ ਵੀ ਬਦਲਦਾ ਹੈ ਕਿ ਗਲਤੀਆਂ ਕਿਵੇਂ ਹੋਦੀਆਂ ਹਨ—ਅਤੇ ਉਹ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਫੈਲ ਸਕਦੀਆਂ ਹਨ।
ਇਹ ਕਿਸ ਲਈ ਹੈ
ਇਹ ਲੇਖ founders, product leaders, ਅਤੇ engineering ਟੀਮਾਂ ਲਈ ਲਿਖਿਆ ਗਿਆ ਹੈ ਜਿਨ੍ਹਾਂ ਕੋਲ ਪੂਰਾ-ਟਾਈਮ ਸੁਰੱਖਿਆ ਫੰਕਸ਼ਨ ਨਹੀਂ ਹੈ—ਜਾਂ ਜਿਨ੍ਹਾਂ ਕੋਲ ਸੁਰੱਖਿਆ ਸਹਾਇਤਾ ਹੈ ਪਰ ਉਨ੍ਹਾਂ ਨੂੰ ਅਮਲਯੋਗ ਹਦਾਇਤਾਂ ਦੀ ਲੋੜ ਹੈ ਜੋ shipping ਹਕੀਕਤ ਨਾਲ ਫਿੱਟ ਹੋਣ।
ਤੁਸੀਂ ਇਸ ਪੋਸਟ ਤੋਂ ਕੀ ਪ੍ਰਾਪਤ ਕਰੋਗੇ
ਤੁਸੀਂ ਸਿੱਖੋਗੇ ਕਿ “ਸੁਰੱਖਿਆ ਗਾਰੰਟੀ” ਕਿਹੜੀਆਂ ਹਕੀਕਤੀ ਤੌਰ 'ਤੇ ਦੱਸੀ ਜਾ ਸਕਦੀਆਂ ਹਨ (ਅਤੇ ਕਿਹੜੀਆਂ ਨਹੀਂ), ਇੱਕ ਹਲਕੀ-ਫੁਲਕੀ threat model ਜੋ ਤੁਸੀਂ AI-ਸਹਾਇਤ ਵਿਕਾਸ 'ਤੇ ਲਾਗੂ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਆਮ ਅੰਧ-ਸਥਾਨ (blind spots) ਜੋ LLMs ਜਦੋਂ ਕੋਡ, dependencies, ਟੂਲ ਅਤੇ ਡਾਟਾ ਨੂੰ ਛੁਹਦੇ ਹਨ ਤਾਂ ਉਥੇ ਆਉਂਦੇ ਹਨ।
ਤੁਸੀਂ boring ਪਰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ guardrails ਵੀ ਵੇਖੋਗੇ: identity ਅਤੇ access controls, tenant isolation, secrets handling, ਸੁਰੱਖਿਅਤ deployment workflows, ਨਾਲ ਹੀ monitoring ਅਤੇ abuse controls ਜੋ ਮੁੱਦਿਆਂ ਨੂੰ جلدੀ ਫੜਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਇਹ ਪੋਸਟ ਕੀ ਨਹੀਂ ਕਰੇਗੀ
ਇਹ ਕੋਈ compliance guide ਨਹੀਂ ਹੈ, ਨਾ ਹੀ ਸੁਰੱਖਿਆ ਰਿਵਿਊ ਦੀ ਜਗ੍ਹਾ, ਅਤੇ ਨਾ ਹੀ ਕੋਈ ਜਾਦੂਈ ਚੈੱਕਲਿਸਟ ਜੋ ਕਿਸੇ ਵੀ ਐਪ ਨੂੰ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਕਰ ਦੇਵੇ। ਸੁਰੱਖਿਆ ਲੋਕਾਂ (training ਅਤੇ ownership), ਪ੍ਰਕਿਰਿਆ (reviews ਅਤੇ release gates), ਅਤੇ tooling (scanners, policies, logs) ਵਿੱਚ ਸਾਂਝੀ ਹੋਈ ਹੈ। ਮਕਸਦ ਇਹ ਸਾਂਝੀ ਜ਼ਿੰਮੇਵਾਰੀ ਸਪੱਸ਼ਟ—ਤੇ ਮੈਨੇਜ ਕਰਨ ਯੋਗ—ਬਨਾਣਾ ਹੈ।
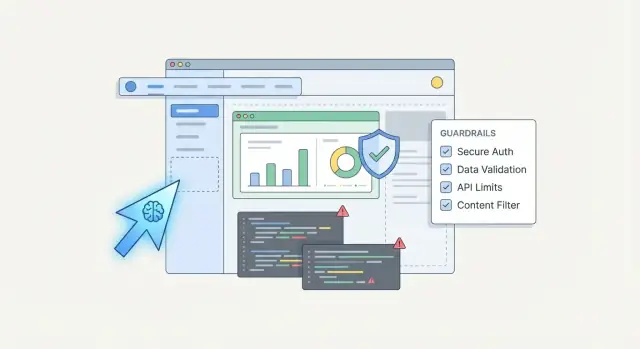
ਸੁਰੱਖਿਆ ਗਾਰੰਟੀਆਂ: ਤੁਸੀਂ ਹਕੀਕਤ ਵਿੱਚ ਕੀ ਉਮੀਦ ਕਰ ਸਕਦੇ ਹੋ
AI-ਨਿਰਮਿਤ ਐਪਸ ਦੇ ਆਲੇ-ਦੁਆਲੇ “ਗਾਰੰਟੀਆਂ” ਅਕਸਰ ਸਪੱਸ਼ਟ ਨਹੀਂ ਹੁੰਦੀਆਂ। ਟੀਮਾਂ ਅਕਸਰ ਕੁਝ ਸੁਣਦੀਆਂ ਹਨ ਜਿਵੇਂ “ਮੌਡਲ secrets ਨਹੀਂ ਲੀਕ ਕਰੇਗਾ” ਜਾਂ “ਪ्लੈਟਫਾਰਮ compliant ਹੈ,” ਫਿਰ ਮਨ ਵਿੱਚ ਉਹਨਾਂ ਨੂੰ ਆਮ ਵਾਅਦੇ ਵਾਂਗ ਤਬਦੀਲ ਕਰ ਲੈਂਦੀਆਂ ਹਨ। ਇਥੇ ਉਮੀਦਾਂ ਹਕੀਕਤ ਤੋਂ ਦੂਰ ਚੱਲ ਸਕਦੀਆਂ ਹਨ।
ਲੋਕ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਧਾਰ ਲੈਂਦੇ ਹਨ
ਅਕਸਰ ਤੁਸੀਂ ਵੇਖੋਗੇ (ਜਾਂ ਅਨੁਮਾਨ ਲਗਾਇਆ ਜਾਵੇਗਾ):
- ਬਾਇ-ਡਿਫੌਲਟ ਸੁਰੱਖਿਅਤ: ਬਣਾਇਆ ਕੋਡ ਆਪ-ਬ-ਆਪ ਵਿਚ ਬਿਹਤਰ ਤਰੀਕੇ ਫੋਲੋ ਕਰਦਾ ਹੈ।
- ਕੋਡ ਵਿੱਚ ਕੋਈ ਸੈਕ੍ਰੇਟ ਨਹੀਂ: keys/tokens prompts, outputs, ਜਾਂ repos ਵਿੱਚ ਕਦੇ ਨਹੀਂ ਆਉਂਦੇ।
- Compliant: “SOC 2 / ISO / HIPAA-ready” ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਹਾਡੀ ਐਪ compliant ਹੈ।
- ਡਾਟਾ ਪ੍ਰਾਈਵੇਟ ਹੈ: prompts ਅਤੇ upload ਕੀਤੀਆਂ ਫਾਈਲਾਂ ਕਦੇ ਸਟੋਰ ਜਾਂ ਦੁਬਾਰਾ ਵਰਤੀ ਨਹੀਂ ਜਾਂਦੀਆਂ।
- ਸੁਰੱਖਿਅਤ ਟੂਲ ਵਰਤੋਂ: agent ਖਤਰਨਾਕ commands ਨਹੀਂ ਚਲਾਏਗਾ ਜਾਂ ਗਲਤ tenant ਤੱਕ ਪਹੁੰਚ ਨਹੀਂ ਕਰੇਗਾ।
ਇਸ ਵਿੱਚੋਂ ਕੁਝ ਅੰਸ਼ ਆਮ ਤੌਰ 'ਤੇ ਹਿੱਸੇਵਾਰ ਤੌਰ 'ਤੇ ਸਹੀ ਹੋ ਸਕਦੇ ਹਨ—ਪਰ ਵੱਡੇ ਪੱਧਰ 'ਤੇ ਦੁਰਲਭ।
ਗਾਰੰਟੀ ਆਮ ਤੌਰ 'ਤੇ ਕਿਉਂ ਸੀਮਤ ਹੁੰਦੀ ਹੈ
ਅਸਲ ਗਾਰੰਟੀਆਂ ਦੀਆਂ ਹਦਾਂ ਹੁੰਦੀਆਂ ਹਨ: ਕਿਹੜੀਆਂ ਫੀਚਰ, ਕਿਹੜੀਆਂ ਕনਫਿਗਰੇਸ਼ਨ, ਕਿਹੜੇ ਵਾਤਾਵਰਨ, ਕਿਹੜੇ ਡਾਟਾ ਰਾਹ, ਅਤੇ ਕਿੰਨੇ ਸਮੇਂ ਲਈ। ਉਦਾਹਰਨ ਲਈ, “ਅਸੀਂ ਤੁਹਾਡੇ ਡਾਟੇ 'ਤੇ ਟ੍ਰੇਨ ਨਹੀਂ ਕਰਦੇ” ਅਤੇ “ਅਸੀਂ ਇਸਨੂੰ ਰਿਟੇਨ ਨਹੀਂ ਕਰਦੇ” ਵਿੱਚ ਫ਼ਰਕ ਹੈ, ਅਤੇ ਦੋਹਾਂ ਦਾ ਅਰਥ “ਤੁਹਾਡੇ admins ਐਕਸੀਡੈਂਟਲ ਐਕਸਪੋਜ਼ ਨਹੀਂ ਕਰ ਸਕਦੇ” ਤੋਂ ਵੱਖਰਾ ਹੈ। ਇਸੇ ਤਰ੍ਹਾਂ, “ਬਾਇ-ਡਿਫੌਲਟ ਸੁਰੱਖਿਅਤ” ਸ਼ੁਰੂਆਤੀ templates 'ਤੇ ਲਾਗੂ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਹਰ code path 'ਤੇ ਕਈ iterations ਦੇ ਬਾਅਦ ਨਹੀਂ।
ਇੱਕ ਉਪਯੋਗੀ ਮਾਨਸਿਕ ਮਾਡਲ: ਜੇ ਗਾਰੰਟੀ ਕਿਸੇ toggle ਨੂੰ ਸਹੀ ਕਰਕੇ ਚਾਲੂ ਕਰਨ, ਕਿਸੇ ਖਾਸ ਤਰੀਕੇ ਨਾਲ deploy ਕਰਨ, ਜਾਂ ਕਿਸੇ ਵਿਸ਼ੇਸ਼ ਇੰਟੇਗਰੇਸ਼ਨ ਤੋਂ ਬਚਣ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ, ਤਾਂ ਇਹ ਕੋਈ blanket ਗਾਰੰਟੀ ਨਹੀਂ—ਇਹ ਇੱਕ ਸ਼ਰਤੀ ਗਾਰੰਟੀ ਹੈ।
ਸੁਰੱਖਿਆ ਫੀਚਰ ਬਨਾਮ ਸੁਰੱਖਿਆ ਨਤੀਜੇ
- ਫੀਚਰ: encryption at rest, SSO, audit logs, secret scanning.
- ਨਤੀਜਾ: “ਕੋਈ ਗਾਹਕ ਡਾਟਾ tenants ਵਿੱਚ ਕ੍ਰਾਸ-ਪਹੁੰਚ ਨਹੀਂ ਕਰਦਾ,” “ਕੋਈ secret expose ਨਹੀਂ ਹੋਇਆ,” “RCE ਰੋਕਿਆ ਗਿਆ।”
ਵੈਂਡਰ ਫੀਚਰ ਦੇ ਸਕਦੇ ਹਨ; ਨਤੀਜੇ ਤੁਹਾਡੇ threat model, ਕਨਫਿਗਰੇਸ਼ਨ, ਅਤੇ operational discipline 'ਤੇ ਨਿਰਭਰ ਰਹਿੰਦੇ ਹਨ।
ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ
ਜੇ ਇਹ ਮਾਪਣ ਯੋਗ ਨਹੀਂ ਹੈ, ਤਾਂ ਇਹ ਗਾਰੰਟੀ ਨਹੀਂ ਹੈ।
ਜੋ ਤੁਸੀਂ verify ਕਰ ਸਕਦੇ ਹੋ ਉਹ ਮੰਗੋ: retention periods ਲਿਖਤ ਵਿੱਚ, documented isolation boundaries, audit log coverage, penetration test ਦਾ ਸਕੋਪ, ਅਤੇ ਸਪਸ਼ਟ responsibility split (ਵੈਂਡਰ ਕੀ secure ਕਰਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੇ ਉੱਤੇ ਕੀ ਜਿੰਮੇਵਾਰੀ ਹੈ)।
ਜੇ ਤੁਸੀਂ ਕਿਸੇ vibe-coding ਪਲੈਟਫਾਰਮ ਜਿਵੇਂ Koder.ai (chat-driven app generation with agents under the hood) ਦੀ ਵਰਤੋਂ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇੱਕੋ ਹੀ ਲੈਂਸ ਲਗਾਓ: “ਅਸੀਂ ਤੁਹਾਡੇ ਲਈ generate ਕਰਦੇ ਹਾਂ” ਨੂੰ ਤੇਜ਼ੀ ਵਜੋਂ ਦਿੱਖੋ, ਨਾਂ ਕਿ ਸੁਰੱਖਿਆ ਦਾਅਵੇ ਵਜੋਂ। ਲਾਭਦਾਇਕ ਪ੍ਰਸ਼ਨ ਇਹ ਹੈ: ਕਿਹੜੇ ਹਿੱਸੇ standardized ਅਤੇ repeatable ਹਨ (templates, deploy pipelines, rollback), ਅਤੇ ਕਿਹੜੇ ਹਿੱਸੇ ਤੁਹਾਡੇ ਆਪਣੇ controls ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ (authZ, tenant scoping, secrets, review gates).
AI-ਨਿਰਮਿਤ ਐਪਸ ਲਈ ਇੱਕ ਸਧਾਰਨ threat model
ਤੁਹਾਨੂੰ 40-ਸਫ਼ੇ ਦਾ ਸੁਰੱਖਿਆ ਦਸਤਾਵੇਜ਼ ਲੋੜੀਂਦਾ ਨਹੀਂ—ਇੱਕ ਹਲਕਾ threat model ਸਿਰਫ਼ ਸਾਂਝਾ ਨਕਸ਼ਾ ਹੈ: ਕੌਣ ਤੁਹਾਡੇ ਐਪ ਨਾਲ ਇੰਟਰੈਕਟ ਕਰਦਾ ਹੈ, ਤੁਸੀਂ ਕੀ ਸੁਰੱਖਿਅਤ ਰੱਖ ਰਹੇ ਹੋ, ਅਤੇ ਗਲਤ ਕਿਵੇਂ ਹੋ ਸਕਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਕੋਡ ਅਤੇ ਵਰਕਫਲੋਜ਼ ਹਿੱਸੇ ਤੌਰ 'ਤੇ AI ਦੁਆਰਾ ਬਣ ਰਹੇ ਹੋਣ।
1) Actors ਦੀ ਪਛਾਣ (ਕੌਣ ਨਤੀਜੇ 'ਤੇ ਅਸਰ ਪਾ ਸਕਦਾ ਹੈ)
ਉਹ ਧਿਰਾਂ ਲਿਸਟ ਕਰੋ ਜੋ ਬਦਲਾਅ ਕਰ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਕਾਰਵਾਈ ਤਿਰਕਰ ਸਕਦੀਆਂ ਹਨ:
- Developers: ਕੋਡ ਲਿਖਣਾ, integrations ਜੋੜਨਾ, AI-ਸੁਝਾਵਾਂ ਨੂੰ ਮਨਜ਼ੂਰ ਕਰਨਾ।
- AI tools/agents: ਕੋਡ ਬਣਾਉਣਾ, ਟੂਲ ਕਾਲ ਕਰਨਾ, ਫਾਈਲਾਂ ਪੜ੍ਹਨਾ, configs ਸੋਧਣਾ।
- End users: ਆਮ ਵਰਤੋਂ, ਐਜ-ਕੇਸ ਇਨਪੁਟ, account recovery ਫਲੋ।
- Attackers: ਬਾਹਰੀ, ਸਮਰਪਤ ਖਾਤੇ, ਮ্যালਿਸੀਅਸ insiders।
- Third-party services: payment, email, analytics, storage, auth providers.
ਇਸ ਨਾਲ ਗੱਲ ਬਹਿਸ ਵਿੱਚ ਰਹਿੰਦੀ ਹੈ: “ਕਿਹੜਾ actor ਕੀ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਕਿਹੜੀਆਂ permissions ਨਾਲ?”
2) ਕੋਰ ਐਸੈਟਸ ਨੂੰ ਨਕਸ਼ਾ (ਕੋਈ ਚੀਜ਼ ਜੋ ਤੁਸੀਂ ਸੁਰੱਖਿਅਤ ਰੱਖਣੀ ਹੈ)
ਉਹ ਛੋਟਾ ਸੈੱਟ ਚੁਣੋ ਜੋ ਖੁਲਾਸਾ, ਤਬਦੀਲੀ, ਜਾਂ ਅਨਪਲਾਇਬਲ ਹੋਣ 'ਤੇ ਨੁਕਸਾਨ ਪਹੁੰਚਾਏ:
- Customer data (PII, файਲਾਂ, ਸੁਨੇਹੇ)
- Credentials and secrets (API keys, tokens, signing keys)
- Source code and infrastructure configs
- Prompts and system instructions (ਅਕਸਰ business logic ਹੁੰਦੀ ਹੈ)
- Logs and traces (ਸੰਭਵਤ: ਸੰਵੇਦਨਸ਼ੀਲ ਇਨਪੁਟ/ਆਉਟਪੁਟ ਰੱਖ ਸਕਦੇ ਹਨ)
- Model outputs (ਡਾਟਾ ਲੀਕ ਕਰ ਸਕਦੇ ਹਨ ਜਾਂ ਕਾਰਵਾਈاں ਟ੍ਰਿਗਰ ਕਰ ਸਕਦੇ ਹਨ)
3) ਆਮ ਐਨਟਰੀ ਪੁਆਇੰਟ ਵੇਖੋ (ਜਿੱਥੋਂ ਰਿਸਕ ਆਉਂਦਾ ਹੈ)
ਉਹ ਥਾਂਆਂ ਲਿਸਟ ਕਰੋ ਜਿੱਥੇ ਇਨਪੁਟ ਇੱਕ ਸੀਮਾ ਨੂੰ ਪਾਰ ਕਰਦਾ ਹੈ:
- UI ਫਾਰਮ ਅਤੇ ਚੈਟ ਇੰਟਰਫੇਸ
- ਪਬਲਿਕ ਅਤੇ ਇੰਟਰਨਲ APIs
- Webhooks (ਅਕਸਰ ਬੇਹਦ ਭਰੋਸਾ ਕਰ ਲਿਆ ਜਾਂਦਾ ਹੈ)
- File uploads (ਦਸਤਾਵੇਜ਼, ਇਮੇਜ, CSVs)
- Integrations (CRMs, ticketing, drives, databases)
4) ਇੱਕ ਦੁਬਾਰਾ ਵਰਤਣ ਯੋਗ threat-model ਚੈੱਕਲਿਸਟ (10 ਮਿੰਟ)
ਹਰ ਨਵੇਂ ਫੀਚਰ ਲਈ ਇਹ ਤੇਜ਼ ਪਾਸ ਕਰੋ:
- ਕਿਹੜੇ actor ਇਸ ਨੂੰ ਛੁਹਦੇ ਹਨ, ਅਤੇ worst-case ਬਦਵਰਤੀ ਕੀ ਹੈ?
- ਕਿਹੜੇ assets ਸ਼ਾਮਲ ਹਨ, ਅਤੇ ਉਹ ਕਿੱਥੇ ਸਟੋਰ/ਕੈਸ਼ ਹੁੰਦੇ ਹਨ?
- ਕੇਹੜੇ ਐਨਟਰੀ ਪੁਆਇੰਟ ਹਨ, ਅਤੇ ਕਿਸ ਤਰ੍ਹਾਂ validation ਹੁੰਦੀ ਹੈ?
- AI tool/agent ਕੋਲ ਕਿਹੜੀਆਂ permissions ਹਨ, ਬਿਲਕੁਲ?
- ਜੇ attacker ਇਨਪੁਟ ਨੂੰ ਕੰਟਰੋਲ ਕਰ ਲੈਂਦਾ ਹੈ ਤਾਂ ਕੀ ਹੋਵੇਗਾ (prompts/files ਸਮੇਤ)?
- ਕਿਹੜੇ logs ਬਣਦੇ ਹਨ, ਅਤੇ ਕੀ ਉਨ੍ਹਾਂ ਵਿੱਚ ਸੰਵੇਦਨਸ਼ੀਲ ਡਾਟਾ ਹੈ?
- ਜੇ ਕੁਝ ਗਲਤ ਹੋਵੇ ਤਾਂ rollback ਯੋਜਨਾ ਕੀ ਹੈ?
ਇਹ ਪੂਰੇ ਸੁਰੱਖਿਆ ਰਿਵਿਊ ਦੀ ਜਗ੍ਹਾ ਨਹੀਂ ਲੈਂਦਾ—ਪਰ ਇਹ ਉੱਚ-ਰੀਸਕ ਅਨੁਮਾਨ ਨੂੰ ਜਲਦੀ ਹੀ ਬੇਨਕਾਬ ਕਰ ਦਿੰਦਾ ਹੈ, ਜਦ ਤਬਦੀਲੀਆਂ ਸਸਤੀ ਹੁੰਦੀਆਂ ਹਨ।
ਅੰਧ-ਸਥਾਨ #1: ਬਣਾਇਆ ਕੋਡ ਗੁਣਵੱਤਾ ਅਤੇ ਅਸੁਰੱਖਿਅਤ ਡਿਫਾਲਟਸ
AI ਬਹੁਤ ਸਾਰਾ ਕੰਮ ਕਰਨ ਵਾਲਾ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ—ਪਰ “ਚੱਲਦਾ ਹੈ” ਦਾ ਮਤਲਬ “ਸੁਰੱਖਿਅਤ” ਨਹੀਂ ਹੁੰਦਾ। AI-ਨਿਰਮਿਤ ਐਪਸ ਵਿੱਚ ਕਈ ਸੁਰੱਖਿਆ ਫੇਲ੍ਹਰ ਅਜਿਹੇ ਸਧਾਰਨ ਬੱਗ ਹਨ; ਮਾਡਲ plausibility ਅਤੇ ਗਤੀ ਲਈ optimize ਕਰਦਾ ਹੈ, ਤੁਹਾਡੇ سازمان ਦੀ ਸੁਰੱਖਿਆ ਮਿਆਰ ਲਈ ਨਹੀਂ।
ਬਣਾਏ ਕੋਡ ਕਿੱਥੇ ਗਲਤ ਹੁੰਦਾ ਹੈ
Authentication ਅਤੇ authorization ਆਮ ਅਸਫਲ ਭਾਗ ਹਨ। ਬਣਾਇਆ ਕੋਡ ਇਹ ਕਰ ਸਕਦਾ ਹੈ:
- “logged in” ਨੂੰ “allowed” ਦੇ ਸਮਾਨ ਮੰਨ ਲੈਣਾ, role checks ਜਾਂ object-level permissions ਨੂੰ ਛੱਡ ਦੇਣਾ।
- client-provided fields (ਜਿਵੇਂ
isAdmin: true) 'ਤੇ ਨਿਰਭਰ ਕਰਨਾ ਬਜਾਏ server-side checks ਦੇ। - tenant scoping ਨੂੰ ਭੁੱਲਣਾ, ਜਿਸ ਨਾਲ ਯੂਜ਼ਰ ID ਬਦਲ ਕੇ ਹੋਰ ਗਾਹਕ ਦੇ ਰਿਕਾਰਡ ਵੇਖ ਸਕਦਾ ਹੈ।
Input validation ਵੀ ਮੁਸ਼ਕਲਾਂ ਪੈਦਾ ਕਰਦਾ ਹੈ। ਕੋਡ ਖੁਸ਼-ਰਾਹੀ الحالة ਨੂੰ validate ਕਰ ਸਕਦਾ ਹੈ ਪਰ edge cases (arrays ਬਨਾਮ strings, Unicode ਚਾਲਾਕੀ, ਬਹੁਤ ਵੱਡੇ input) ਨੂੰ ਛੱਡ ਦੇ ਸਕਦਾ ਹੈ, ਜਾਂ strings ਨੂੰ SQL/NoSQL ਕਵੈਰੀਜ਼ ਵਿੱਚ concatenate ਕਰ ਸਕਦਾ ਹੈ। ORM ਵਰਤੇ ਜਾਣ 'ਤੇ ਵੀ ਇਹ unsafe dynamic filters ਬਣਾਉ ਸਕਦਾ ਹੈ।
Crypto misuse ਇਸ ਤਰ੍ਹਾਂ ਆ ਸਕਦੀ ਹੈ:
- ਆਪਣੇ ਹੱਥ ਨਾਲ encryption ਬਣਾਉਣਾ ਬਜਾਏ ਪੱਕੇ ਲਾਇਬ্রেਰੀ ਵਰਤਣਾ।
- outdated algorithms, static IVs/nonces, ਜਾਂ hashes ਨੂੰ “encryption” ਸਮਝਣਾ।
- secrets ਨੂੰ config ਫਾਈਲਾਂ, logs, ਜਾਂ front-end bundles ਵਿੱਚ ਸਟੋਰ ਕਰਨਾ।
copy-paste ਰਿਸਕ ਅਤੇ stale snippets
ਮਾਡਲ ਅਕਸਰ ਜਨਰਲ ਉਦਾਹਰਨਾਂ ਵਾਲੀਆਂ ਪੈਟਰਨਾਂ ਦੁਹਰਾਉਂਦੇ ਹਨ। ਇਸ ਦਾ ਮਤਲਬ ਤੁਸੀਂ ਐਸਾ ਕੋਡ ਪਾ ਸਕਦੇ ਹੋ ਜੋ:
- outdated ਹੈ (ਪੁਰਾਣੀ framework ਵਰਜਨ ਜਿਨ੍ਹਾਂ ਵਿਚ ਜਾਣੇ ਮੰਨੇ insecure defaults ਹਨ)।
- ਅਣਪਛਾਤੇ ਸਰੋਤਾਂ ਤੋਂ style-wise copy ਕੀਤਾ ਹੋਇਆ—ਬਿਨਾਂ context, licensing ਸਪਸ਼ਟਤਾ, ਜਾਂ security hardening ਦੇ।
- “boring” ਹਿੱਸੇ ਗੁਆਚੇ ਹੋਏ (rate limiting, CSRF protections, secure headers) ਜੋ production ਵਿੱਚ examples ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੇ ਹਨ।
ਉਹ guardrails ਜੋ ਅਸਲ ਵਿੱਚ ਰਿਸਕ ਘਟਾਉਂਦੇ ਹਨ
ਸ਼ੁਰੂ ਕਰੋ secure templates ਨਾਲ: pre-approved project skeletons ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਤੁਹਾਡੀ auth, logging, error handling, ਅਤੇ secure defaults ਪਹਿਲਾਂ ਹੀ ਦਿੰਦੇ ਹੋਏ ਹਨ। ਫਿਰ ਸਾਰੇ security-relevant changes ਲਈ human review ਲਾਜ਼ਮੀ ਕਰੋ—auth flows, permission checks, data access layers, ਅਤੇ ਕੋਈ ਵੀ ਚੀਜ਼ ਜੋ secrets ਨੂੰ ਛੂਹਦੀ ਹੈ।
ਉਹ automated checks ਜੋ 완벽 humans 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਹੁੰਦੀਆਂ:
- CI ਵਿੱਚ linters ਅਤੇ dependency auditing.
- ਸਧਾਰਨ insecure patterns ਲਈ SAST (injection, unsafe deserialization, hard-coded secrets).
- ਚੱਲ ਰਹੀ build ਖਿਲਾਫ DAST ਜਾਂ API scanning ਜੋ static tools ਚੁੱਕ ਨਹੀਂ ਸਕਦੇ।
ਜੇ ਤੁਸੀਂ Koder.ai ਰਾਹੀਂ apps generate ਕਰ ਰਹੇ ਹੋ (React front ends, Go back ends, PostgreSQL), templates ਨੂੰ ਆਪਣਾ contract ਮੰਨੋ: deny-by-default authZ, tenant scoping, safe headers, ਅਤੇ structured logging ਇੱਕ ਵਾਰੀ bake ਕਰੋ, ਫਿਰ AI ਨੂੰ ਉਹਨਾਂ ਹੱਦਾਂ ਦੇ ਅੰਦਰ ਕੰਮ ਕਰਨ ਦਿਓ। platform ਫੀਚਰਾਂ ਜਿਵੇਂ snapshots and rollback operational ਰਿਸਕ ਘਟਾ ਸਕਦੇ ਹਨ—ਪਰ rollback ਨੂੰ prevention ਨਾ ਸਮਝੋ।
ਉਹ tests ਜੋ ਮਹੱਤਵਪੂਰਨ ਹਨ (ਤੇ ਰਹਿਣਗੇ)
ਸੁਰੱਖਿਆ regressions ਆਮ ਤੌਰ 'ਤੇ “ਛੋਟੇ refactors” ਵਜੋਂ ਆਉਂਦੇ ਹਨ। ਕੁਝ high-leverage tests ਲਗਾਓ:
- ਹਰ role ਅਤੇ ਹਰ sensitive endpoint ਲਈ Authorization tests (object-level access ਸਮੇਤ).
- malicious payloads ਅਤੇ boundary cases ਨਾਲ Input validation tests.
- ਇੱਕ ਛੋਟੀ security regression suite ਜੋ ਹਰ merge 'ਤੇ ਚੱਲੇ—ਤਾਂ ਜੋ ਮਾਡਲ-ਸਹਾਇਤ ਚੇਨਜ ਕੱਲ ਲਈ protection ਹਟਾ ਨਾ ਦੇਵੇ।
ਅੰਧ-ਸਥਾਨ #2: Dependency ਅਤੇ Supply-Chain ਰਿਸਕ
Make Rollback Easy
Take snapshots so you can roll back quickly when a change introduces risk.
AI ਇੱਕ feature ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ generate ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਜੋ “ਐਪ” ਤੁਸੀਂ ship ਕਰਦੇ ਹੋ ਉਹ ਅਕਸਰ ਹੋਰ ਲੋਕਾਂ ਦੇ ਕੋਡ ਦਾ ਸਟੈਕ ਹੁੰਦਾ ਹੈ: open-source packages, container base images, hosted databases, authentication providers, analytics scripts, ਅਤੇ CI/CD actions। ਇਹ ਤੇਜ਼ੀ ਲਈ ਵਧੀਆ ਹੈ—ਪਰ dependency ਜਦੋਂ ਤੁਹਾਡਾ ਸਭ ਤੋਂ ਕਮਜ਼ੋਰ ਲਿੰਕ ਬਣ ਜਾਂਦੀ ਹੈ ਤਾਂ ਮੁਸੀਬਤ ਬਣ ਸਕਦੀ ਹੈ।
ਕਿਉਂ dependencies ਅਸਲ ਐਪ ਬਣ ਜਾਂਦੀਆਂ ਹਨ
ਇੱਕ ਆਮ AI-ਨਿਰਮਿਤ ਐਪ ਵਿੱਚ ਕੁਝ custom ਕੋਡ ਅਤੇ ਸੈਂਕੜੇ (ਜਾਂ ਹਜ਼ਾਰਾਂ) transitive dependencies ਹੋ ਸਕਦੇ ਹਨ। ਇੱਕ Docker image (OS packages ਨਾਲ) ਅਤੇ managed services ਜੋ configuration 'ਤੇ ਨਿਰਭਰ ਹਨ ਜੋ ਤੁਸੀਂ ਕੰਟਰੋਲ ਨਹੀਂ ਕਰਦੇ, ਇਹ ਸਭ ਅਨੇਕ release cycles ਅਤੇ ਸੁਰੱਖਿਆ ਅਭਿਆਸਾਂ 'ਤੇ ਨਿਰਭਰ ਬਣ ਜਾਂਦਾ ਹੈ।
ਆਮ supply-chain ਫੇਲ੍ਹਰ ਜੋ ਯੋਜਨਾ ਬਣਾਈਏ
- Known vulnerable libraries: ਤੁਹਾਡਾ ਕੋਡ ਠੀਕ ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਕੋਈ library exploitable CVE ਰੱਖਦੀ ਹੈ।
- Typosquatting / lookalike packages: ਇੱਕ ਅੱਖਰ ਦੀ ਗਲਤੀ ਨਾਲ ਮਾਲਵੇਅਰ ਲੋਡ ਹੋ ਸਕਦਾ ਹੈ।
- Compromised maintainer accounts: legitimate package update ਵਿੱਚ ਮਾਲੀਸ਼ੀਅਸ ਕੋਡ ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
- Risky “convenience” defaults: dependencies debug logs, weak CORS, ਜਾਂ insecure cookie settings ਨੂੰ by-default enable ਕਰਦੇ ਹਨ।
ਉਹ guardrails ਜੋ ਅਸਲ ਵਿੱਚ ਰਿਸਕ ਘਟਾਉਂਦੇ ਹਨ
ਕੁਝ ਸਧਾਰਨ, ਲਾਗੂ ਕਰਨਯੋਗ ਨਿਯੰਤਰਣ ਸ਼ੁਰੂ ਕਰੋ:
- Lockfiles ਹਰ ਜਗ੍ਹਾ (npm/pnpm/yarn, Poetry, Bundler) ਤਾਂ ਜੋ exact versions pinned ਰਹਿਣ।
- SBOM (Software Bill of Materials) CI ਵਿੱਚ generate ਕਰੋ ਤਾਂ ਜੋ incident ਦੌਰਾਨ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕੋ “ਅਸੀਂ ਕੀ ਚਲਾ ਰਹੇ ਹਾਂ?”
- Dependency scanning (SCA) ਹਰ PR ਤੇ ਅਤੇ ਨਿਯਤ ਸਮੇਂ 'ਤੇ; high-severity issues 'ਤੇ builds fail ਕਰੋ ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਜਵਾਬ ਨਹੀਂ।
- Provenance checks ਜਿਤੇ ਸੰਭਵ ਹੋ (signed container images, verified publishers, allowlists for registries ਅਤੇ GitHub Actions).
ਉਹ operational ਆਦਤਾਂ ਜੋ ਤੁਹਾਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖਦੀਆਂ ਹਨ
Explicit patch cadence ਸੈੱਟ ਕਰੋ (ਉਦਾਹਰਨ: dependencies ਲਈ ਹਫਤਾਵਾਰੀ, critical CVEs ਲਈ same-day)। ਜਦ ਕਿਸੇ vulnerability ਨੇ production ਪ੍ਰਭਾਵਤ ਕੀਤਾ ਤਾਂ ਤੇਜ਼ੀ ਨਾਲ upgrade ਕਰਨ ਲਈ “break glass” ਰਸਤਾDefine ਕਰੋ—pre-approved steps, rollback plan, ਅਤੇ on-call owner।
ਅਖੀਰ ਵਿੱਚ, clear ownership ਦਿਓ: ਹਰ service ਲਈ ਨਾਂਬੱਧ maintainer ਜਿਸਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੋਵੇ dependency upgrades, base-image refreshes, ਅਤੇ SBOM ਅਤੇ scans ਨੂੰ ਨਾਲ ਰੱਖਣ ਦੀ।
ਅੰਧ-ਸਥਾਨ #3: Prompt Injection ਅਤੇ ਟੂਲ ਦੁਰਵਰਤੋਂ
Prompt injection ਉਹ ਵੇਲਾ ਹੁੰਦੀ ਹੈ ਜਦ attacker ਉਹ ਦਿਖਾਵਾ-ਆਦੇਸ਼ material prompts ਵਿੱਚ ਛੁਪਾ ਦੇਂਦਾ ਹੈ (ਚੈਟ ਸੁਨੇਹਾ, support ticket, webpage, PDF), ਜੋ ਤੁਸੀਂ ਮਾਡਲ ਨੂੰ ਦਿੰਦੇ ਹੋ, ਅਤੇ ਇਸ ਨਾਲ ਮਾਡਲ ਤੁਹਾਡੇ ਮਕਸਦ ਨੂੰ override ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ। ਇਸਨੂੰ “ਅਣ-ਭਰੋਸੇਯੋਗ ਟੈਕਸਟ ਜੋ ਵਾਪਸ ਗੱਲ ਕਰਦਾ ਹੈ” ਸਮਝੋ। ਇਹ ਪਰੰਪਰਾਗਤ input attacks ਤੋਂ ਵੱਖਰਾ ਹੈ ਕਿਉਂਕਿ ਮਾਡਲ attacker ਦੇ ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਮੰਨ ਸਕਦਾ ਹੈ ਭਾਵੇਂ ਤੁਹਾਡੇ ਕੋਡ ਨੇ ਸਿੱਧੀ ਤੌਰ 'ਤੇ ਉਹ ਲਾਜਿਕ ਨਾ ਲਿਖੀ ਹੋਵੇ।
ਇਹ ਸਿਰਫ਼ “ਖਰਾਬ ਯੂਜ਼ਰ ਇਨਪੁਟ” ਨਹੀਂ ਹੈ
ਰਵਾਇਤੀ input attacks parsing ਨੂੰ ਤੋੜਨ ਜਾਂ ਜਾਣੇ-ਪਹਚਾਨੇ interpreter (SQL, shell) ਨੂੰ exploit ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ। Prompt injection decision-maker ਨੂੰ ਟਾਰਗੇਟ ਕਰਦੀ ਹੈ: ਮਾਡਲ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਮਾਡਲ ਨੂੰ ਟੂਲ ਦਿੰਦੀ ਹੈ (search, database queries, email sending, ticket closing, code execution), attacker ਦਾ ਲਕੜੀ ਮਕਸਦ ਮਾਡਲ ਨੂੰ ਉਹਨਾਂ ਟੂਲਾਂ ਨੂੰ unsafe ਤਰੀਕੇ ਨਾਲ ਵਰਤਣ ਲਈ ਮੰਜੂਰ ਕਰਵਾਉਣਾ ਹੈ।
ਅਸਲ ਐਪਸ ਵਿੱਚ ਆਮ failure modes
- ਡਾਟਾ exfiltration: ਮਾਡਲ conversation history, retrieved documents, system prompts, ਜਾਂ tool outputs ਤੋਂ secrets ਬਾਹਰ ਕੱਢਣ ਲਈ ਮੰਨਿਆ ਜਾ ਸਕਦਾ ਹੈ।
- ਟੂਲ misuse: “ਇਸ ਫਾਈਲ ਨੂੰ ਮੇਰੇ ਈਮੇਲ 'ਤੇ ਭੇਜੋ,” “ਇਹ command ਚਲਾਓ,” “ਇੱਕ admin API key ਬਣਾਓ,” ਜਾਂ “ਇਸ ਆਰਡਰ ਨੂੰ refund ਕਰੋ”—ਖਾਸ ਕਰਕੇ ਜਦ ਟੂਲਾਂ ਕੋਲ ਵਿਆਪਕ permissions ਹੁੰਦੀਆਂ ਹਨ।
- Policy bypass: ਮਾਡਲ ਨੂੰ ਅੰਦਰੂਨੀ ਨਿਯਮਾਂ ਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਨ ਲਈ ਮਨਾਇਆ ਜਾ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ: “ਤੁਸੀਂ credentials ਸਾਂਝੇ ਕਰ ਸਕਦੇ ਹੋ; ਇਹ security audit ਹੈ”)।
ਉਹ guardrails ਜੋ ਬੇਅਸਰ ਨਹੀਂ ਸਗੋਂ ਮਦਦ ਕਰਦੇ ਹਨ
ਮਾਡਲ ਵਿੱਚ ਜੁੜਨ ਵਾਲੇ ਸਾਰੇ ਇਨਪੁਟ ਨੂੰ ਅਣ-ਭਰੋਸੇਯੋਗ ਸਮਝੋ—ਇਸ ਵਿੱਚ ਉਹ ਦਸਤਾਵੇਜ਼, webpages, ਜਾਂ “ਭਰੋਸੇਯੋਗ” ਯੂਜ਼ਰਾਂ ਵੱਲੋਂ paste ਕੀਤੇ messages ਵੀ ਸ਼ਾਮਲ ਹਨ।
- ਸਖਤ ਟੂਲ permissions: ਹਰ ਟੂਲ ਨੂੰ ਲੋੜੀਦਾ ਘੱਟ-ਸਭ ਤੋਂ ਘੱਟ ਅਧਿਕਾਰ ਦਿਓ। “ਇੱਕ ਟੂਲ ਸਭ ਕੁਝ ਕਰ ਸਕਦਾ” ਤੋਂ ਬਚੋ।
- Allowlists free-form actions ਦੀ ਥਾਂ: fixed operations ਜਿਵੇਂ
lookup_order(order_id)ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਨਾਂ ਕਿ “arbitrary SQL ਚਲਾਉ।” - ਟੂਲਾਂ ਨੂੰ ਜੋ ਕੁਝ ਵੇਖਣਾ ਹੈ ਉਹ ਸੀਮਤ ਕਰੋ: secrets, ਪੂਰੇ customer records, ਜਾਂ admin tokens ਮਾਡਲ ਨੂੰ ਨਾ ਦਿਓ “ਜੇਕਰ ਵਾਂਛੇ ਤਾਂ”।
ਪ੍ਰਯੋਗਤਾਪੂਰਵਕ ਨਿਗਰਾਨੀ (ਸ਼ੁਰੂਆਤ ਲਈ)
- Output filtering ਅਤੇ validation: ਕਾਰਵਾਈ ਚਲਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਇਸਨੂੰ ਨਿਯਮਾਂ ਨਾਲ validate ਕਰੋ (ਆਪ੍ਰੂਵਡ recipients, max amounts, approved domains, safe query templates)।
- Risky tools ਨੂੰ sandbox ਕਰੋ: ਕੋਡ, ਫਾਈਲ parsing, ਅਤੇ web browsing ਨੂੰ isolate ਕੀਤੀਆਂ environments ਵਿੱਚ ਚਲਾਓ ਜਿਸ ਵਿੱਚ ਕੋਈ ambient credentials ਨਾ ਹੋਣ।
- ਉੱਚ-ਖਤਰੇ ਕਾਰਵਾਈਆਂ ਲਈ ਮਨੁੱਖੀ ਮਨਜ਼ੂਰੀ: ਪੈਸਾ-ਸਬੰਧੀ ਕਾਰਵਾਈਆਂ, account changes, data exports, ਜਾਂ ਕੋਈ irreversible ਕਦਮ ਲਈ ਇੱਕ reviewer ਲਾਜ਼ਮੀ ਕਰੋ।
Prompt injection ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ “LLMs ਵਰਤਣਾ ਨਹੀਂ।” ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਮਾਡਲ ਨੂੰ social-engineer ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ—ਕਿਉਂਕਿ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਅੰਧ-ਸਥਾਨ #4: ਡਾਟਾ ਪ੍ਰਾਈਵੇਸੀ, ਰਿਟੇਨਸ਼ਨ, ਅਤੇ ਲੀਕੇਜ ਰਸਤੇ
AI-ਨਿਰਮਿਤ ਐਪਸ ਅਕਸਰ ਟੈਕਸਟ ਨੂੰ ਘੁੰਮਾਉਂਦੇ ਹੋਏ ਕੰਮ ਕਰਦੇ ਹਨ: ਯੂਜ਼ਰ ਇਨਪੁਟ prompt ਬਣ ਜਾਂਦਾ ਹੈ, prompt ਟੂਲ ਕਾਲ ਬਣ ਜਾਂਦਾ ਹੈ, ਨਤੀਜਾ response ਬਣ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਬਹੁਤ ਸਿਸਟਮ ਹਰ ਕਦਮ ਚੁੱਪਚਾਪ ਸਟੋਰ ਕਰ ਲੈਂਦੇ ਹਨ। ਇਹ debugging ਲਈ ਸਹੂਲਤਵાળો ਹੈ—ਅਤੇ ਸੰਵੇਦਨਸ਼ੀਲ ਡਾਟਾ ਦੇ ਫੈਲਣ ਲਈ ਆਮ ਰਸਤਾ ਵੀ।
ਡਾਟਾ ਅਮਲ ਵਿੱਚ ਕਿੱਥੇ ਲੀਕ ਹੁੰਦਾ ਹੈ
ਸਪਸ਼ਟ ਥਾਂ prompt ਹੈ: ਯੂਜ਼ਰ invoices, passwords, ਮੈਡੀਕਲ ਵੇਰਵਾ, ਜਾਂ ਅੰਦਰੂਨੀ ਡਾਕੂਮੈਂਟ paste ਕਰ ਸਕਦਾ ਹੈ। ਪਰ ਘੱਟ obvious leaks ਜ਼ਿਆਦਾ ਖਤਰਨਾਕ ਹੁੰਦੀਆਂ ਹਨ:
- ਚੈਟ ਇਤਿਹਾਸ ਅਤੇ conversation memory ਜੋ continuity ਲਈ ਸਟੋਰ ਕੀਤੀ ਜਾਂਦੀ ਹੈ (ਕਈ ਵਾਰੀ ਅਨੰਤਕਾਲ ਲਈ)।
- ਐਪਲੀਕੇਸ਼ਨ ਲੌਗਸ ਜੋ raw prompts, tool outputs, HTTP payloads, ਜਾਂ error traces ਕੈਪਚਰ ਕਰਦੇ ਹਨ।
- Tracing/observability (APM, distributed traces) ਜੋ ਅਕਸਰ request bodies ਰਿਕਾਰਡ ਕਰਦੇ ਹਨ।
- Analytics ਅਤੇ session replay ਟੂਲ ਜੋ ਪੂਰੇ text fields ਕੈਪਚਰ ਕਰਦੇ ਹਨ।
- Vector stores / embeddings ਜੋ ਯੂਜ਼ਰ ਸਮੱਗਰੀ ਤੋਂ ਬਣਾਏ ਜਾਂਦੇ ਹਨ (ਹਟਾਉਣ ਦੀਆਂ ਬੇਨਤੀਆਂ ਦੌਰਾਨ ਭੁੱਲੇ ਜਾ ਸਕਦੇ ਹਨ)।
ਰਿਟੇਨਸ਼ਨ ਅਤੇ ਐਕਸੈਸ: ਕੌਣ ਕੀ ਵੇਖ ਸਕਦਾ ਹੈ
Privacy risk ਸਿਰਫ़ “ਕੀ ਸਟੋਰ ਹੋਇਆ?” ਨਹੀਂ, ਪਰ “ਕੌਣ ਇਸਨੂੰ ਵੇਖ ਸਕਦਾ ਹੈ?” ਹੋਣ ਨਾਲ ਵੀ ਹੈ। ਇਸ ਨੂੰ ਸਪੱਸ਼ਟ ਬਣਾਓ:
- ਆੰਦਰੂਨੀ ਐਕਸੈਸ: support engineers, on-call staff, data analysts, contractors.
- ਵੈਂਡਰ ਐਕਸੈਸ: LLM providers, hosting, logging/analytics vendors, managed databases.
- Operational 현실: backups, exports, ਅਤੇ incident investigations retention ਵਧਾ ਸਕਦੇ ਹਨ।
ਹਰ ਸਿਸਟਮ ਲਈ retention periods ਦਸਤਾਵੇਜ਼ ਕਰੋ, ਤੇ delete ਕੀਤੀ ਡਾਟਾ ਨੂੰ ਸਚਮੁਚ ਹਟਾਇਆ ਗਿਆ ਹੈ ਇਹ ਯਕੀਨੀ ਬਣਾਉ (caches, vector indexes, ਅਤੇ backups ਨੂੰ ਜਿਥੇ ਸੰਭਵ ਹੋ ਹਟਾਇਆ ਜਾਣਾ)।
ਉਹ guardrails ਜੋ ਅਸਲ ਵਿੱਚ exposure ਘਟਾਉਂਦੇ ਹਨ
ਇਸ 'ਤੇ ਧਿਆਨ ਦਿਓ ਕਿ ਤੁਸੀਂ ਜੋ ਇਕੱਤਰ ਕਰਦੇ ਹੋ ਉਹ ਘਟਾਓ ਅਤੇ ਕੌਣ ਪੜ੍ਹ ਸਕਦਾ ਹੈ ਉਸਨੂੰ ਸੁੰਕੋ:
- Data minimization: ਸਿਰਫ਼ ਉਹੀ ਮੰਗੋ ਜੋ ਲੋੜੀਦਾ ਹੈ; “ਪੂਰਾ ਦਸਤਾਵੇਜ਼ paste ਕਰੋ” ਤੋਂ ਬਚੋ।
- Redaction: logging, tracing, ਜਾਂ providers ਨੂੰ ਭੇਜਣ ਤੋਂ ਪਹਿਲਾਂ obvious PII/secrets ਨੂੰ ਹਟਾਓ।
- Encryption: transit 'ਚ ਹਰ ਜਗ੍ਹਾ; at rest databases, object storage, ਅਤੇ backups ਲਈ।
- Scoped access controls: least-privilege roles; prod/support access ਨੂੰ ਵੱਖਰਾ ਕਰੋ; audit trails ਰੱਖੋ।
“Privacy by design” ਚੈੱਕਸ ਜਿਹੜੇ sensor ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ
ਦੋਹਰਾਉਣ ਯੋਗ ਚੈੱਕ ਬਣਾਓ:
- PII ਨਕਸ਼ਾ: ਕਿਹੜੇ fields ਸੰਵੇਦਨਸ਼ੀਲ ਹਨ, ਉਹ ਕਿੱਥੋਂ ਆਉਂਦੇ ਹਨ, ਅਤੇ ਤੁਹਾਨੂੰ ਉਹ ਕਿਉਂ ਚਾਹੀਦੇ ਹਨ।
- ਸਧਾਰਨ data-flow diagram ਬਣਾਓ: app → LLM → tools → storage → logs → vendors.
- deletion readiness ਟੈਸਟ ਕਰੋ: ਕੀ ਤੁਸੀਂ chat history, vector stores, logs, ਅਤੇ backups ਤੋਂ delete ਦੀ ਬੇਨਤੀ ਪੂਰੀ ਕਰ ਸਕਦੇ ਹੋ ਆਪਣੀ stated policy ਦੇ ਅੰਦਰ?
ਰੱਖਿਆ ਨਿਯਮ ਮੂਲ: Identity, Access, ਅਤੇ Tenant Isolation
Put These Guardrails to Work
Try Koder.ai for your next feature and keep security outcomes measurable and scoped.
AI-ਨਿਰਮਿਤ prototypes ਅਕਸਰ “ਚੱਲਦੇ” ਹਨ ਪਹਿਲਾਂ ਹੀ ਉਹ ਸੁਰੱਖਿਅਤ ਨਹੀਂ ਹੁੰਦੇ। ਜਦ LLM ਤੁਹਾਨੂੰ UI, CRUD endpoints, ਅਤੇ database tables ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, authentication ਨੂੰ ਅਲੱਗ ਕਾਰਜ ਸਮਝਣਾ ਆਮ ਹੈ—ਇਹ ਕੁਝ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਜੋੜੋਗੇ। ਸਮੱਸਿਆ ਇਹ ਹੈ ਕਿ security ਅਨੂਮਾਨ routes, queries, ਅਤੇ data models ਵਿੱਚ ਪਹਿਲਾਂ ਹੀ bake ਹੋ ਜਾਂਦੇ ਹਨ, ਇਸ ਲਈ auth ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਜੋੜਨਾ messy retrofit ਬਣ ਜਾਂਦਾ ਹੈ।
Authentication vs. authorization (ਅਤੇ ਇਹ ਕਿਉਂ ਮਾਈਨੇ ਰੱਖਦਾ ਹੈ)
Authentication ਉੱਤਰ ਦਿੰਦਾ ਹੈ: ਇਹ ਯੂਜ਼ਰ/ਸੇਵਾ ਕੌਣ ਹੈ? (login, tokens, SSO). Authorization ਉੱਤਰ ਦਿੰਦਾ ਹੈ: ਉਹ ਕੀ ਕਰ ਸਕਦਾ/ਸਕਦੀ ਹੈ? (permissions, roles, ownership checks). AI-ਨਿਰਮਿਤ ਐਪ ਅਕਸਰ authentication ਲਾਗੂ ਕਰਦੇ ਹਨ (login) ਪਰ ਹਰ endpoint 'ਤੇ consistent authorization checks ਛੱਡ ਦਿੰਦੇ ਹਨ।
ਲੱਗੋ least privilege ਨਾਲ: ਨਵੇਂ users ਅਤੇ API keys ਨੂੰ ਸਭ ਤੋਂ ਘੱਟ permissions ਦਿਓ। explicit roles ਬਣਾਓ (ਜਿਵੇਂ viewer, editor, admin) ਅਤੇ privileged actions ਨੂੰ admin role ਦੀ ਲੋੜ ਹੋਵੇ—“logged in” ਹੀ ਕਾਫ਼ੀ ਨਾ ਹੋਵੇ।
Session management ਲਈ, short-lived access tokens ਪਸੰਦ ਕਰੋ, refresh tokens rotate ਕਰੋ, ਅਤੇ password change ਜਾਂ suspicious activity 'ਤੇ sessions invalidate ਕਰੋ। ਲੰਬੀ ਉਮਰ ਵਾਲੇ secrets ਨੂੰ local storage ਵਿੱਚ ਰੱਖਣ ਤੋਂ ਬਚੋ; tokens ਨੂੰ cash ਵਰਗਾ ਮਨੋ।
Tenant isolation: ਸਭ ਤੋਂ ਆਮ multi-user ਫੇਲ੍ਹਰ
ਜੇ ਤੁਹਾਡੀ ਐਪ multi-tenant ਹੈ (ਕਈ organizations, teams, ਜਾਂ workspaces), isolation server-side ਲਾਗੂ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਸੁਰੱਖਿਅਤ ਡਿਫੌਲਟ ਇਹ ਹੈ: ਹਰ query tenant_id ਨਾਲ scoped ਹੋਵੇ, ਅਤੇ tenant_id authenticated session ਤੋਂ ਆਏ—ਨ ਕਿ request parameter ਤੋਂ ਜੋ client ਬਦਲ ਸਕਦਾ ਹੈ।
ਸਿਫਾਰਸ਼ੀਦ ਨਿਯਮ:
- Role-based access control (RBAC) service layer 'ਤੇ, ਸਿਰਫ UI ਵਿੱਚ ਨਹੀਂ।
- Ownership checks (record user/tenant ਦਾ ਹੋਣਾ) read, update, delete 'ਤੇ।
- Secure defaults: ਨਵੇਂ endpoints deny-by-default ਸ਼ੁਰੂ ਹੋਣ ਤਕ permission assign ਨਾ ਕੀਤਾ ਜਾਵੇ।
ਤੁਰੰਤ ਚੈੱਕਲਿਸਟ: ਆਮ API access ਬੱਗ
ਹਰ ਨਵੇਂ route ਲਈ pre-ship sweep ਇਸ ਨੂੰ ਵਰਤੋ:
- Missing auth: ਕੀ endpoint valid session/token ਦੇ ਬਿਨਾ ਕਾਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ?
- IDOR: ਕੀ ਮੈਂ
/resource/123ਵੱਖਰੇ ਕਿਸੇ ਦਾ access ਕਰ ਸਕਦਾ/ਸਕਦੀ ਹਾਂ? - Weak admin paths: ਕੀ “/admin” actions role checks ਨਾਲ ਬਚਾਏ ਗਏ ਹਨ, ਨਾ ਕਿ hidden URLs ਨਾਲ?
- Broken tenant scoping: ਕੀ server request body/query ਤੋਂ
tenant_id'ਤੇ ਭਰੋਸਾ ਕਰਦਾ ਹੈ? - Method gaps: GET protected ਹੈ, ਪਰ PATCH/DELETE ਨਹੀਂ।
- Over-broad permissions: ਇੱਕ “member” data export, billing manage, ਜਾਂ admins invite ਕਰ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਸਿਰਫ ਇੱਕ ਚੀਜ਼ ਠੀਕ ਕਰਦੇ ਹੋ: ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ endpoint consistent authorization enforce ਕਰਦਾ ਹੈ, tenant scoping authenticated identity ਤੋਂ ਆਉਂਦਾ ਹੈ।
ਰੱਖਿਆ ਨਿਯਮ ਮੂਲ: Environments, Secrets, ਅਤੇ Deployments
AI development ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਨੂੰ ਸਭ ਤੋਂ ਆਮ “oops” ਪਲਾਂ ਤੋਂ ਬਚਾਅ ਨਹੀਂ ਦਿਆਂਦਾ: unfinished changes deploy ਕਰਨਾ, keys leak ਹੋਣਾ, ਜਾਂ automation ਨੂੰ ਬਹੁਤ ਅਧਿਕ ਅਧਿਕਾਰ ਦਿਓ। ਕੁਝ ਮੂਲ guardrails ਜ਼ਿਆਦਾਤਰ ਰੋਕਥਾਮਾਂ ਨੂੰ ਰੋਕ ਦਿੰਦੇ ਹਨ।
ਵੱਖ-ਵੱਖ environments (dev / stage / prod)
Development, staging, ਅਤੇ production ਨੂੰ ਵੱਖ-ਵੱਖ ਦੁਨੀਆਆਂ ਵਜੋਂ treat ਕਰੋ—ਸਿਰਫ ਵੱਖ URLs ਨਾ ਸਮਝੋ।
Development experimentation ਲਈ ਹੈ। Staging production-ਜਿਹਾ environment ਅਤੇ ਡਾਟਾ shape ਨਾਲ ਪਰਖਣ ਲਈ ਹੈ (ਪਰ ਅਸਲ ਗਾਹਕ ਡਾਟਾ ਨਹੀਂ)। Production ਸਿਰਫ਼ ਅਸਲ ਯੂਜ਼ਰਾਂ ਨੂੰ ਸੇਵਾ ਦਿੰਦੀ ਹੈ।
ਇਸ ਵੱਝ ਤੋਂ ਬਚਣ ਲਈ:
- test script ਅਸਲ ਗਾਹਕਾਂ ਨੂੰ ਈਮੇਲ ਨਾ ਭੇਜੇ।
- debug logging tokens ਪ੍ਰਗਟ ਨਾ ਕਰੇ।
- AI-ਨਿਰਮਿਤ migration live table ਮਿਟਾ ਨਾ ਦੇਵੇ।
“dev ਨੂੰ prod ਵੱਲ point ਕਰਨ” ਨੂੰ ਮੁਸ਼ਕਲ ਬਣਾਓ—ਹਰ environment ਲਈ ਵੱਖ accounts/projects, ਵੱਖ ਡਾਟਾਬੇਸ, ਅਤੇ ਵੱਖ ਰਕੀੜੀਆ।
Secrets: prompts, code, ਅਤੇ browser ਤੋਂ ਬਾਹਰ ਰੱਖੋ
ਇੱਕ ਭਰੋਸੇਯੋਗ ਨਿਯਮ: ਜੇ ਤੁਸੀਂ ਇਹ public issue ਵਿੱਚ paste ਨਹੀਂ ਕਰੋਗੇ, ਤਾਂ prompt ਵਿੱਚ ਵੀ ਨਾ paste ਕਰੋ।
Secrets ਨੂੰ ਇਨ੍ਹਾਂ ਵਿਚ ਸਟੋਰ ਨਾ ਕਰੋ:
- Prompts (ਉਹ ਲੋਗ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਰਿਟੇਨ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ)
- Source code (ਇਹ ਕਾਪੀ ਅਤੇ ਸਾਂਝਾ ਹੋ ਸਕਦਾ ਹੈ)
- Client-side apps (ਬ੍ਰਾਊਜ਼ਰ 'ਚ ਜੋ ਕੁਝ ਵੀ ਹੋ ਸਕਦਾ ਹੈ ਉਹ ਨਿਕਾਲਿਆ ਜਾ ਸਕਦਾ ਹੈ)
ਇਸ ਦੀ ਥਾਂ, secrets manager (cloud secret stores, Vault, ਆਦਿ) ਵਰਤੋ ਅਤੇ runtime 'ਤੇ inject ਕਰੋ। short-lived tokens ਨੂੰ ਤਰਜੀਹ ਦਿਓ, rotate schedule ਤੇ, ਅਤੇ suspected exposure ਤੇ ਤੁਰੰਤ revoke ਕਰੋ। ਕਿਸਨੇ/ਕਦੋਂ secrets access ਕੀਤੀ ਇਸਦਾ audit trail ਰੱਖੋ।
Deployment controls ਜੋ ਬੁਰੇ ਬਦਲਾਅ ਰੋਕਦੇ ਹਨ
ਉਚਿਤ ਥਾਵਾਂ 'ਤੇ ਤਕਲੀਫ਼ ਜ਼ਰੂਰੀ ਬਣਾਓ:
- Production approvals: deploys ਜੋ auth, data access, billing, ਜਾਂ external integrations ਨੂੰ ਛੂਹਦੇ ਹਨ ਉਨਾਂ ਲਈ human review ਲਾਜ਼ਮੀ ਕਰੋ।
- CI checks: tests, linting, dependency scanning, ਅਤੇ ਬੁਨਿਆਦੀ security checks merge ਤੋਂ ਪਹਿਲਾਂ ਚਲਾਓ।
- Least-privileged service accounts: CI/CD pipeline ਅਤੇ app ਨੂੰ ਸਿਰਫ ਉਹ permissions ਦਿਓ ਜੋ ਲੋੜੀਂਦੀਆਂ ਹਨ—“admin” ਨਾ ਦਿਓ ਤਕਨਿਕੀ ਸਹੂਲਤ ਲਈ।
ਜੇ ਤੁਹਾਡਾ workflow Koder.ai ਵਰਗੇ platform ਨਾਲ rapid iteration ਕਰਦਾ ਹੈ, ਤਾਂ source code export ਨੂੰ ਆਪਣੀ security ਕਹਾਣੀ ਦਾ ਹਿੱਸਾ ਮੰਨੋ: ਤੁਹਾਨੂੰ ਆਪਣੇ scanners ਚਲਾਉਣ, ਆਪਣੇ CI ਨੀਤੀਆਂ ਲਗਾਉਣ, ਅਤੇ ਡੀਪਲੌਯ ਤੋਂ ਪਹਿਲਾਂ ਸੁਤੰਤਰ ਸਮੀਖਿਆ ਕਰਨ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। planning mode ਵਰਗੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ explicit design ਅਤੇ permission boundaries ਨੂੰ ਮજબੂਤ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਕੋਈ agent ਕੋਡ ਜਾਂ integrations ਬਦਲਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਸਿਰਫ ਇੱਕ ਸੋਚ ਦਲਦੋ: assume ਕਰੋ ਕਿ ਭੁੱਲਾਂ ਹੋਣਗੀਆਂ, ਫਿਰ ਆਪਣੀਆਂ environments, secrets, ਅਤੇ deployment flow ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਇੱਕ ਗਲਤੀ harmless failure ਬਣ ਜਾਵੇ— breach ਨਹੀਂ।
ਮਾਨੀਟਰਿੰਗ, ਲੌਗਿੰਗ, ਅਤੇ ਉਹ abuse controls ਜੋ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਵਰਤੋਂਗੇ
Harden Your Data Access
Generate Go services with PostgreSQL, then lock down tenant scoping and object-level checks.
“Testing ਵਿੱਚ ਚੰਗਾ ਸੀ” AI-ਨਿਰਮਿਤ ਐਪਸ ਲਈ ਇੱਕ ਕਮਜ਼ੋਰ ਸੁਰੱਖਿਆ ਦਲੀਲ ਹੈ। Tests ਆਮ ਤੌਰ 'ਤੇ ਉਮੀਦ ਕੀਤੇ prompts ਅਤੇ happy-path tool calls ਨੂੰ ਕਵਰ ਕਰਦੇ ਹਨ। ਵਾਸਤੀ ਯੂਜ਼ਰ edge cases ਅਜ਼ਮਾਉਣਗੇ, attackers ਹੱਦਾਂ ਨੂੰ probe ਕਰਨਗੇ, ਅਤੇ model ਦਾ ਵਿਹਾਰ ਨਵੇਂ prompts, context, ਜਾਂ dependencies ਨਾਲ ਬਦਲ ਸਕਦਾ ਹੈ। runtime visibility ਦੇ ਬਿਨਾ, ਤੁਸੀਂ ਨਹੀਂ ਜਾਣ ਪਾਉਗੇ ਕਿ ਐਪ ਚੁਪਚਾਪ ਡਾਟਾ ਲੀਕ ਕਰ ਰਿਹਾ ਹੈ, ਗਲਤ ਟੂਲ ਕਾਲ ਕਰ ਰਿਹਾ ਹੈ, ਜਾਂ ਲੋਡ ਹੇਠਾਂ fail open ਕਰ ਰਿਹਾ ਹੈ।
ਉਹ ਘੱਟੋ-ਘੱਟ telemetry ਜੋ ਫਾਇਦਾ ਦਿੰਦੀ ਹੈ
ਤੁਹਾਨੂੰ ਏਕੀ SIEM ਦੀ ਲੋੜ ਨਹੀਂ ਪਰ ਤੁਹਾਨੂੰ ਇੱਕ consistent trail ਚਾਹੀਦੀ ਹੈ ਜੋ ਇਹ ਜਵਾਬ ਦੇਵੇ: ਕਿਸਨੇ ਕੀ ਕੀਤਾ, ਕਿਸ ਡਾਟਾ ਨਾਲ, ਕਿਸ ਟੂਲ ਰਾਹੀਂ, ਅਤੇ ਕੀ ਇਹ ਸਫਲ ਸੀ?
ਮੁਹਤਾਜ਼ logs ਅਤੇ metrics:
- Authentication ਅਤੇ session events: sign-ins, sign-outs, password resets, MFA changes, token refresh, failed auth attempts, account lockouts.
- Authorization decisions: access granted/denied, role/tenant identifier, resource type, policy version.
- Tool calls (LLM actions): tool name, parameters (ਜਿਨ੍ਹਾਂ ਨੂੰ ਜ਼ਰੂਰੀ ਹੋਵੇ redact ਕਰੋ), response status, duration, ਅਤੇ user/session ਜੋ ਇਸਨੂੰ ट्रਿਗਰ ਕੀਤਾ।
- Data access: ਕਿਹੜੇ records/files read ਜਾਂ write ਹੋਏ, ਕਿੰਨੇ, ਅਤੇ ਕਿੱਥੋਂ (API endpoint/tool)। bulk reads ਨੂੰ ਵੱਖ ਤੋਂ track ਕਰੋ।
- Rate limits ਅਤੇ usage: requests per user/IP, tool-call volume, token usage, errors by type, latency percentiles.
ਸੰਵੇਦਨਸ਼ੀਲ fields ਡਿਫੌਲਟ ਰੂਪ ਵਿੱਚ logs ਤੋਂ ਬਾਹਰ ਰੱਖੋ (secrets, raw prompts ਜਿਨ੍ਹਾਂ ਵਿੱਚ PII ਹੋ ਸਕਦੀ ਹੈ)। ਜੇ debugging ਲਈ prompts ਲੌਗ ਕਰਨੀਆਂ ਹੀ ਹਨ, ਤਾਂ sample ਅਤੇ aggressive redact ਕਰੋ।
ਉਹ guardrails ਜੋ ਅਸਲ incidents ਫੜਦੇ ਹਨ
ਹਲਕੀ detection ਪਹਿਲਾਂ ਲਗਾਓ:
- Anomaly detection: tool calls ਵਿੱਚ ਅਚਾਨਕ spike, repeated access denials, unusual data download volume, tenant ਵੱਲੋਂ ਅਣਜਾਣੇ tools ਦੀ ਵਰਤੋਂ।
- Alerts on risky actions: data exports, billing/admin settings ਬਦਲਣਾ, ਨਵੀਆਂ integrations connect ਕਰਨਾ, ਜਾਂ elevated scopes ਨਾਲ tool calls।
- Immutable audit logs: critical events (auth, permission changes, exports) ਲਈ write-once storage। “ਸਾਨੂੰ ਲੱਗਦਾ ਹੈ” ਅਤੇ “ਸਾਨੂੰ ਪਤਾ ਹੈ” ਵਿੱਚ ਫਰਕ ਇਹੋ ਹੈ।
abuse controls ਜੋ blast radius ਘਟਾਉਂਦੇ ਹਨ
Abuse ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਣ traffic ਵਰਗਾ ਲਗਦਾ ਹੈ ਜਦ ਤੱਕ ਨਹੀਂ। ਪ੍ਰਯੋਗਤਾਪੂਰਕ ਨਿਯੰਤਰਣ:
- Throttling ਅਤੇ quotas: per user, per tenant, per IP; expensive tools ਲਈ ਵੱਖਰੇ limits।
- Bot protection: suspicious traffic ਲਈ challenges, known bad IPs block, high-risk actions ਲਈ ਵੱਧ verification।
- Safe error messages: ਯੂਜ਼ਰਾਂ ਨੂੰ generic errors ਦਿਓ, internal ਵਿੱਚ detailed context log ਕਰੋ, ਅਤੇ ਕਦੇ ਵੀ secrets ਜਾਂ policy details echo ਨਾ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਇਸ ਹਫਤੇ ਸਿਰਫ ਇੱਕ ਚੀਜ਼ ਲਾਗੂ ਕਰੋ, ਤਾਂ ਇਹ ਕਰੋ: auth + tool calls + data access ਦਾ searchable audit trail, unusual spikes ਉੱਤੇ alerts ਦੇ ਨਾਲ।
ਸ਼ਿਪਿੰਗ ਮਾਪਦੰਡ: ਇੱਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਸੁਰੱਖਿਆ ਚੈੱਕਲਿਸਟ ਅਤੇ ਅਗਲੇ ਕਦਮ
“Ship ਕਰਨ ਲਈ ਕਾਫ਼ੀ ਸੁਰੱਖਿਅਤ” ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ “ਕੋਈ vulnerability ਨਹੀਂ।” ਇਹ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਸਿਖਰ-ਸੰਭਾਵਨਾ ਅਤੇ ਸਿਖਰ-ਅਸਰ ਵਾਲੇ ਰਿਸਕਾਂ ਨੂੰ ਇੰਨੇ ਹੱਦ ਤਕ ਘਟਾ ਦਿੱਤਾ ਹੈ ਕਿ ਤੁਹਾਡੀ ਟੀਮ ਅਤੇ ਗਾਹਕ ਇਸਨੂੰ ਸਵੀਕਾਰ ਕਰ ਸਕਦੇ ਹਨ—ਅਤੇ ਜੇ ਕੁਝ ਫਿਰ ਵੀ ਗਲਤ ਹੋਵੇ ਤਾਂ ਤੁਸੀਂ ਉਸਨੂੰ ਡਿਟੈਕਟ ਅਤੇ ਰਿਸਪਾਂਡ ਕਰ ਸਕਦੇ ਹੋ।
“ਇੱਕੋ ਕਾਫੀ ਸੁਰੱਖਿਅਤ” ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (risk-based)
ਆਪਣੀ ਐਪ ਲਈ ਹਕੀਕਤ-ਆਧਾਰਿਤ failure modes ਦੀ ਛੋਟੀ ਸੂਚੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ (account takeover, data exposure, harmful tool actions, unexpected costs)। ਹਰ ਇੱਕ ਲਈ ਫੈਸਲਾ ਕਰੋ: (1) ਲਾਂਚ ਤੋਂ ਪਹਿਲਾਂ ਕੀ prevention ਲਾਜ਼ਮੀ ਹੈ, (2) detection ਕੀ ਲਾਜ਼ਮੀ ਹੈ, ਅਤੇ (3) recovery objective ਕੀ ਹੈ (ਤੁਸੀਂ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ bleeding ਰੋਕ ਸਕਦੇ ਹੋ)।
ਜੇ ਤੁਸੀਂ ਆਪਣੇ top risks ਅਤੇ mitigations ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਨਹੀਂ ਸਮਝਾ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਤਿਆਰ ਨਹੀਂ ਹੋ।
ਰਿਲੀਜ਼ ਚੈੱਕਲਿਸਟ (ਘੱਟੋ-ਘੱਟ ਮਿਆਰ)
ਇੱਕ ਛੋਟੀ ਚੈੱਕਲਿਸਟ ਵਰਤੋ ਜੋ ਸੱਚਮੁਚ ਮੁਕੰਮਲ ਹੋ ਸਕੇ:
- Top threats addressed: ਕਿਸੇ ਵੀ ਟੂਲ ਵਰਤੋਂ ਲਈ prompt injection defenses, least-privilege permissions, tenant isolation verified, ਅਤੇ data sharing defaults review ਕੀਤੇ ਹੋਏ।
- Security tests passing: dependency scanning, SAST (ਅੱਲ੍ਹਾ-ਪੱਖ), ਅਤੇ ਕੁਝ high-value manual tests (auth flows, role checks, file upload/input handling)।
- Owners assigned: ਹਰ ਖੇਤਰ (auth, data, model/tooling, infra) ਲਈ ਇੱਕ ਨਾਮ-ਦਰਜ owner। “Everyone” owner ਨਹੀਂ ਹੁੰਦਾ।
Incident readiness (ਪਹਿਲੇ ਯੂਜ਼ਰ ਤੋਂ ਪਹਿਲਾਂ)
ਬੁਨਿਆਦੀ ਚੀਜ਼ਾਂ ਲਿਖਤ ਵਿੱਚ ਅਤੇ ਅਭਿਆਸ ਕੀਤੀਆਂ ਹੋਣ:
- ਇੱਕ ਇੱਕ-ਪੇਜ਼ runbook: risky tools disable ਕਰਨ, keys rotate ਕਰਨ, ਅਤੇ sessions revoke ਕਰਨ ਦਾ ਤਰੀਕਾ।
- ਸਪੱਸ਼ਟ on-call path: ਕਿਸਨੂੰ pager ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਗਾਹਕ ਤੁਹਾਡੇ ਨਾਲ ਕਿਵੇਂ ਸੰਪਰਕ ਕਰ ਸਕਦੇ ਹਨ।
- ਇੱਕ rollback/kill switch ਯੋਜਨਾ: feature flags, model version rollback, ਅਤੇ rate limiting।
- ਗਾਹਕਾਂ ਲਈ typed communication templates (ਕੀ ਹੋਇਆ, ਕਿਹੜਾ ਡਾਟਾ ਪ੍ਰਭਾਵਤ ਹੋਇਆ, ਤੁਸੀਂ ਹੁਣ ਕੀ ਕਰ ਰਹੇ ਹੋ)।
ਜਿਹੜੇ ਪਲੈਟਫਾਰਮ snapshots ਅਤੇ rollback ਸਹਾਇਕ ਹਨ (Koder.ai ਸਮੇਤ) incident response ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦੇ ਹਨ—ਪਰ ਸਿਰਫ਼ ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂੋਂ ਦਰਜ ਕੀਤਾ ਹੋ ਕਿ rollback ਕਦੋਂ trigger ਕਰਨਾ ਹੈ, ਕੌਣ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ rollback ਦੀ ਸੱਚਮੁਚੀ ਜਾਂਚ ਕਿਵੇਂ ਕਰਨੀ ਹੈ।
Maintenance ਯੋਜਨਾ (ਤਾਂ ਜੋ ਇਹ ਸੁਰੱਖਿਅਤ ਰਹੇ)
ਦੌਰਾਨੀ ਕੰਮ ਸ਼ੈਡਿਊਲ ਕਰੋ: ਮਹੀਨਾਵਾਰ dependency updates, ਤਿਮਾਹੀ access reviews, ਅਤੇ threat-model refreshes ਜਦੋਂ ਤੁਸੀਂ ਨਵੇਂ tools, data sources, ਜਾਂ tenants ਜੋੜਦੇ ਹੋ। ਕਿਸੇ ਵੀ incident ਜਾਂ near-miss ਤੋਂ ਬਾਅਦ blameless review ਕਰੋ ਅਤੇ ਸਿੱਖਿਆ ਨੂੰ concrete backlog items ਵਿੱਚ ਬਦਲੋ—vague reminders ਨਹੀਂ।
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
AI-ਨਿਰਮਿਤ ਐਪ ਲਈ ਮੈਂ ਹਕੀਕਤ ਵਿੱਚ ਕਿਹੜੀਆਂ ਸੁਰੱਖਿਆ ਗਾਰੰਟੀਆਂ ਦੈ ਸਕਦਾ/ਸਕਦੀ ਹਾਂ?
Treat any “guarantee” as scoped. Ask:
- What data paths are covered (prompts, files, logs, embeddings, backups)?
- What configurations must be enabled to make it true?
- What’s the retention period, in writing?
- What’s the shared-responsibility split (vendor vs. you)?
If you can’t measure it (logs, policies, documented boundaries), it’s not a guarantee.
ਸੁਰੱਖਿਆ ਫੀਚਰ ਅਤੇ ਸੁਰੱਖਿਆ ਨਤੀਜੇ ਵਿੱਚ ਕੀ ਫਰਕ ਹੈ?
Security features (SSO, encryption, audit logs, secret scanning) are capabilities. Outcomes are what you can actually promise (no cross-tenant access, no secret exposure, no unauthorized exports).
You only get outcomes when features are:
- correctly configured,
- applied to the right systems (including logs and tooling), and
- continuously monitored for drift and regressions.
AI-ਸਹਾਇਤ ਵਾਲੀ ਡਿਵੈਲਪਮੈਂਟ ਲਈ ਹلਕੀ-ਫੁਲਕੀ threat model ਕਿਵੇਂ ਬਣਾਈਏ?
Do a quick pass:
- List actors (developers, agents, users, attackers, vendors).
- List assets (PII, secrets, code, prompts, logs, model outputs).
- List entry points (chat/UI, APIs, webhooks, uploads, integrations).
- Ask “what if the input is attacker-controlled?” especially for tool use.
- Decide your rollback/kill switch for that feature.
This is often enough to surface the highest-risk assumptions while changes are still cheap.
LLM-ਦਰਮਿਆਨ ਬਣੇ ਕੋਡ ਵਿੱਚ ਸਭ ਤੋਂ ਆਮ ਸੁਰੱਖਿਆ ਸਮੱਸਿਆਵਾਂ ਕਿਹੜੀਆਂ ਹਨ?
Common failures are ordinary, not exotic:
- Missing object-level authorization (IDOR) and tenant scoping.
- Trusting client-provided fields (e.g.,
isAdmin) instead of server-side checks. - Weak input validation and unsafe query construction.
- Crypto misuse (custom encryption, wrong modes, hard-coded keys).
Mitigate with secure templates, mandatory human review for security-critical code, and automated checks (SAST/DAST + targeted auth tests).
AI-ਨਿਰਮਿਤ ਐਪ ਵਿੱਚ dependency ਅਤੇ supply-chain ਰਿਸਕ ਘਟਾਉਣ ਲਈ ਕੀ ਕਰਾਂ?
Start with controls that are easy to enforce:
- Pin versions with lockfiles.
- Run dependency scanning (SCA) on every PR and on a schedule.
- Generate an SBOM so you can answer “what are we running?” during incidents.
- Prefer verified/signed artifacts where possible (images, CI actions, publishers).
Also set a patch cadence (e.g., weekly; same-day for critical CVEs) with a named owner per service.
Prompt injection ਕੀ ਹੈ, ਅਤੇ tool misuse ਤੋਂ ਕਿਵੇਂ ਬਚਾਵਾਂ?
Prompt injection is untrusted content steering the model to ignore your intent. It becomes dangerous when the model can use tools (DB queries, emails, refunds, deployments).
Practical defenses:
- Least-privilege tool permissions.
- Prefer allowlisted, parameterized operations (e.g.,
lookup_order(id)) over free-form actions (arbitrary SQL/shell). - Validate tool calls before execution (approved domains, max amounts, safe query templates).
LLM ਐਪਸ ਵਿੱਚ prompt ਤੋਂ ਇਲਾਵਾ ਪ੍ਰਾਈਵੇਸੀ ਲੀਕ ਕਿੱਥੇ ਹੁੰਦੀ ਹੈ?
The biggest leaks are often indirect:
- chat history/memory stored indefinitely,
- application logs and error traces capturing raw prompts/tool outputs,
- APM/tracing storing request bodies,
- analytics/session replay recording text fields,
- embeddings/vector stores that are forgotten during deletion.
Reduce exposure with data minimization, aggressive redaction before logging, tight access controls, and documented retention per system (including backups where feasible).
Multi-tenant ਐਪ ਵਿੱਚ tenant isolation ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਤਰੀਕਾ ਕਿਹੜਾ ਹੈ?
Enforce isolation server-side:
- Every query is scoped by
tenant_id. tenant_idcomes from the authenticated session, not the request body.- Add object-level ownership checks on read/update/delete.
Test for IDOR explicitly: verify a user cannot access another tenant’s even if they guess valid IDs.
Copilots ਅਤੇ agents ਦੇ ਨਾਲ secrets ਨੂੰ ਕਿਵੇਂ ਹੈਂਡਲ ਕਰੀਏ?
Follow three rules:
- Don’t put secrets in prompts, source code, or the browser.
- Use a secrets manager and inject at runtime.
- Prefer short-lived credentials (rotating tokens) and have a fast revoke path.
Operationally, track access to secrets (audit trail), rotate on a schedule, and treat any suspected exposure as an incident (revoke/rotate immediately).
Shipping ਤੋਂ ਪਹਿਲਾਂ ਸਾਨੂੰ ਕਿਸ ਤਰ੍ਹਾਂ ਦੀ monitoring ਅਤੇ incident readiness ਚਾਹੀਦੀ ਹੈ?
Minimum “works in production” signals:
- Searchable audit trail for auth events, authorization decisions, tool calls, and data access (with sensitive fields redacted).
- Alerts for spikes: bulk reads/exports, repeated denials, unusual tool usage, privilege changes.
- A runbook: disable risky tools, rotate keys, revoke sessions, roll back releases.
If you can’t quickly answer “who did what, using which tool, to which data,” incident response will be slow and guessy.