15 ਨਵੰ 2025·8 ਮਿੰਟ
ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਓ ਜੋ ਐਪ ਦੀ ਸਿਹਤ ਅਤੇ ਕਾਰੋਬਾਰੀ KPI ਟਰੈਕ ਕਰੇ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਈਏ ਜੋ uptime, latency ਅਤੇ errors ਨੂੰ revenue, conversions ਅਤੇ churn ਨਾਲ ਇਕਠਾ ਕਰਦਾ ਹੈ—ਸਿਹਾੜੇ ਸਾਥੀ ਡੈਸ਼ਬੋਰਡ, ਅਲਰਟ ਅਤੇ ਡਾਟਾ ਡਿਜ਼ਾਈਨ ਦੇ ਨਾਲ।
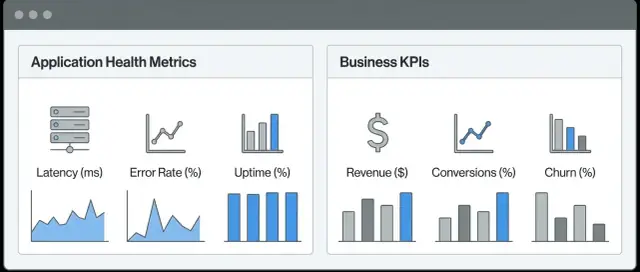
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਈਏ ਜੋ uptime, latency ਅਤੇ errors ਨੂੰ revenue, conversions ਅਤੇ churn ਨਾਲ ਇਕਠਾ ਕਰਦਾ ਹੈ—ਸਿਹਾੜੇ ਸਾਥੀ ਡੈਸ਼ਬੋਰਡ, ਅਲਰਟ ਅਤੇ ਡਾਟਾ ਡਿਜ਼ਾਈਨ ਦੇ ਨਾਲ।
ਇੱਕ ਮਿਗ੍ਰੇਟ "ਐਪ ਸਿਹਤ + ਕਾਰੋਬਾਰੀ KPI" ਦਰਸ਼ਨ ਉਹ ਇਕ ਹੀ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਟੀਮਾਂ ਵੇਖ ਸਕਦੀਆਂ ਹਨ ਕਿ ਸਿਸਟਮ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਅਤੇ ਪ੍ਰੋਡਕਟ ਕਾਰੋਬਾਰ ਲਈ ਚਾਹੀਦੇ ਨਤੀਜੇ ਦੇ ਰਿਹਾ ਹੈ। ਇਨਸਪੈਕਸ਼ਨ ਟੂਲ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਟੂਲ ਵਿਚ ਬਾਊਂਸ ਕਰਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਇੱਕ ਹੀ ਵਰਕਫਲੋ ਵਿੱਚ ਨਕਸ਼ੇ ਜੋੜਦੇ ਹੋ।
ਤਕਨੀਕੀ ਮੈਟਰਿਕਸ ਤੁਹਾਡੇ ਸਾਫਟਵੇਅਰ ਅਤੇ ਇੰਫਰਾਸਟਰੱਕਚਰ ਦੇ ਸਲੂਕ ਦਾ ਵਰਣਨ ਕਰਦੀਆਂ ਹਨ। ਇਹ ਸਵਾਲਾਂ ਦੇਂਦੀਆਂ ਹਨ: ਐਪ ਜਵਾਬ ਦੇ ਰਹੀ ਹੈ? ਕੀ ਇਸ ਵਿੱਚ errors ਆ ਰਹੇ ਹਨ? ਕੀ ਇਹ slow ਹੈ? ਆਮ ਉਦਾਹਰਣਾਂ ਵਿੱਚ latency, error rate, throughput, CPU/memory ਉਪਯੋਗ, queue depth, ਅਤੇ dependency availability ਸ਼ਾਮਿਲ ਹਨ.
ਕਾਰੋਬਾਰੀ ਮੈਟਰਿਕਸ (KPIs) ਯੂਜ਼ਰ ਅਤੇ ਰੈਵਨਿਊ ਨਤੀਜਿਆਂ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ। ਇਹ ਸਵਾਲਾਂ ਦੇਂਦੀਆਂ ਹਨ: ਕੀ ਯੂਜ਼ਰ ਸਫਲ ਹੋ ਰਹੇ ਹਨ? ਕੀ ਅਸੀਂ ਪੈਸਾ ਕਮਾ ਰਹੇ ਹਾਂ? ਉਦਾਹਰਣਾਂ ਵਿੱਚ sign-ups, activation rate, conversion, checkout completion, average order value, churn, refunds, ਅਤੇ support ticket ਦੀ ਗਿਣਤੀ ਸ਼ਾਮਿਲ ਹੈ।
ਮਕਸਦ ਕਿਸੇ ਇੱਕ ਸ਼੍ਰੇਣੀ ਨੂੰ ਬਦਲਣਾ ਨਹੀਂ—ਮੇਰਾ ਹੈ ਕਿ ਉਨ੍ਹਾਂ ਨੂੰ ਜੋੜਿਆ ਜਾਵੇ, ਤਾਂ ਜੋ 500 errors ਦਾ spike ਸਿਰਫ "ਚਾਰਟ ਤੇ ਲਾਲ" ਨਾ ਹੋਵੇ, ਪਰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ "checkout conversion 12% ਘਟਿਆ" ਨਾਲ ਜੁੜਿਆ ਹੋਵੇ।
ਜਦੋਂ ਸਿਹਤ ਦੇ ਸਿਗਨਲ ਅਤੇ KPIs ਇੱਕੋ ਇੰਟਰਫੇਸ ਅਤੇ ਸਮਾਂ ਖਿੜਕੀ ਸਾਂਝੇ ਕਰਦੇ ਹਨ, ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਪ੍ਰਾਪਤ ਕਰਦੀਆਂ ਹਨ:
ਇਹ ਗਾਈਡ ਸੰਰਚਨਾ ਅਤੇ ਫੈਸਲਿਆਂ 'ਤੇ ਧਿਆਨ ਦਿੰਦੀ ਹੈ: ਮੈਟਰਿਕਸ ਕਿਵੇਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨੇ ਹਨ, ਪਹਚਾਣਕਾਰੀਆਂ (identifiers) ਕਿਵੇਂ ਜੋੜਣੀਆਂ ਹਨ, ਡਾਟਾ ਕਿੱਥੇ ਰੱਖਣੀ ਹੈ ਅਤੇ ਕਿਵੇਂ ਪੁੱਛਗਿੱਛ ਕਰਨੀ ਹੈ, ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਅਲਰਟ ਕਿਵੇਂ ਪੇਸ਼ ਕਰਨੇ ਹਨ। ਇਹ ਕਿਸੇ ਖ਼ਾਸ ਵੇਂਡਰ ਨਾਲ ਜੁੜੀ ਨਹੀਂ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇਹ ਪਹੁੰਚ ਚਾਹੇ off-the-shelf ਟੂਲਾਂ ਨਾਲ ਕਰੋ, ਆਪਣਾ ਬਣਾਓ, ਜਾਂ ਦੋਨਾਂ ਮਿਲਾ ਕੇ ਵਰਤੋਂ।
ਜੇ ਤੁਸੀਂ ਸਭ ਕੁਝ ਟਰੈਕ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋਗੇ ਤਾਂ ਇੱਕ ਐਸਾ ਡੈਸ਼ਬੋਰਡ ਬਣ ਜਾਵੇਗਾ ਜਿਸ 'ਤੇ ਕੋਈ ਭਰੋਸਾ ਨਹੀਂ ਕਰੇਗਾ। ਦਰਅਸਲ, ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਮਾਨੀਟਰਿੰਗ ਐਪ ਨੂੰ ਦਬਾਅ ਹੇਠ ਕੀ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨ ਦੀ ਲੋੜ ਹੈ: ਇਨਸਿਡੈਂਟ ਦੌਰਾਨ ਤੇਜ਼, ਸਹੀ ਫੈਸਲੇ ਕਰਨੇ ਅਤੇ ਹਫ਼ਤੇ ਵਾਰੀ ਤਰੱਕੀ ਟਰੈਕ ਕਰਨੇ।
ਕਿਸੇ ਗੜਬੜ ਹੋਣ 'ਤੇ, ਤੁਹਾਡੇ ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਤੁਰੰਤ ਇਹਨਾਂ ਦਾ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ:
ਜੇ ਕੋਈ ਚਾਰਟ ਇਨ੍ਹਾਂ ਵਿੱਚੋਂ ਕਿਸੇ ਦੇ ਜਵਾਬ ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦਾ, ਤਾਂ ਉਹ ਹਟਾਉਣ ਲਈ ਉਮੀਦਯੋਗ ਉਮੀਦਵਾਰ ਹੈ।
ਮੂਲ ਸੈੱਟ ਛੋਟਾ ਅਤੇ ਟੀਮਾਂ ਵੱਲੋਂ ਸਥਿਰ ਰੱਖੋ। ਸ਼ੁਰੂਆਤ ਲਈ ਇੱਕ ਚੰਗੀ ਸੂਚੀ:
ਇਹ ਆਮ ਫੇਲ੍ਹ ਹੋਣ ਵਾਲੀਆਂ ਸਥਿਤੀਆਂ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਮੈਪ ਹੁੰਦੇ ਹਨ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਅਲਰਟ ਲਈ ਆਸਾਨ ਹਨ।
ਉਹ ਮੈਟਰਿਕਸ ਚੁਣੋ ਜੋ ਗਾਹਕ ਫਨਲ ਅਤੇ ਰੈਵਨਿਊ ਹਕੀਕਤ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ:
ਹਰ ਮੈਟਰਿਕ ਲਈ ਇੱਕ ਮਾਲਕ, ਇੱਕ definition/source of truth, ਅਤੇ ਇੱਕ review cadence (ਹਫ਼ਤਾਵਾਰ ਜਾਂ ਮਹੀਨਾਵਾਰ) ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਜੇ ਕਿਸੇ ਮੈਟਰਿਕ ਦਾ ਕੋਈ ਮਾਲਕ ਨਹੀਂ ਹੈ ਤਾਂ ਉਹ ਚੁੱਪਚਾਪ ਗਲਤ ਹੋ ਜਾਵੇਗਾ—ਅਤੇ ਤੁਹਾਡੇ ਇਨਸਿਡੈਂਟ ਫੈਸਲੇ ਪ੍ਰਭਾਵਤ ਹੋਣਗੇ।
ਜੇ ਤੁਹਾਡੇ health charts ਇੱਕ ਟੂਲ ਵਿੱਚ ਹਨ ਅਤੇ ਕਾਰੋਬਾਰੀ KPI ਡੈਸ਼ਬੋਰਡ ਦੂਜੇ ਵਿੱਚ, ਤਾਂ ਇਨਸਿਡੈਂਟ ਦੌਰਾਨ "ਕੀ ਹੋਇਆ" 'ਤੇ ਆਸਾਨੀ ਨਾਲ ਤਰਕ-ਵਿਵਾਦ ਹੋ ਸਕਦਾ ਹੈ। ਨਿਗਰਾਨੀ ਨੂੰ ਉਹਨਾਂ ਕੁਝ ਗਾਹਕ ਯਾਤਰਾ ਦੇ ਆਸ-ਪਾਸ ਲਗਾਓ ਜਿੱਥੇ ਪ੍ਰਦਰਸ਼ਨ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਨਤੀਜਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ।
ਉਹ ਫਲੋਜ਼ ਚੁਣੋ ਜੋ ਸਿੱਧੇ revenue ਜਾਂ retention ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ, ਜਿਵੇਂ onboarding, search, checkout/payment, account login, ਜਾਂ content publishing। ਹਰ ਯਾਤਰਾ ਲਈ ਮੁੱਖ ਕਦਮ ਅਤੇ "ਸਫਲਤਾ" ਦੀ ਪਰਿਭਾਸ਼ਾ ਕਰੋ।
ਉਦਾਹਰਣ (checkout):
ਉਹ ਤਕਨੀਕੀ ਸਿਗਨਲ ਨਕਸ਼ੇ ਜੋ ਹਰ ਕਦਮ 'ਤੇ ਸਭ ਤੋ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵ ਪਾਉਂਦੇ ਹਨ:
ਚੈਕਆਊਟ ਲਈ, ਇੱਕ leading indicator ਹੋ ਸਕਦਾ ਹੈ “payment API p95 latency,” ਜਦਕਿ lagging indicator ਹੈ “checkout conversion rate.” ਇਕੋ ਟਾਈਮਲਾਈਨ 'ਤੇ ਦੋਹਾਂ ਦੇਖਣ ਨਾਲ ਕਾਰਨ-ਨਤੀਜਾ ਸਪਸ਼ਟ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਮੈਟਰਿਕ ਡਿਕਸ਼ਨਰੀ ਗੁੰਝਲਦਾਰੀਆਂ ਅਤੇ "ਉਹੀ KPI, ਵੱਖਰਾ ਗਣਿਤ" ਦੀਆਂ बहਸਾਂ ਰੋਕਦੀ ਹੈ। ਹਰ ਮੈਟਰਿਕ ਲਈ ਦਸਤਾਵੇਜ਼ ਕਰੋ:
Page views, raw signups ਜਾਂ "ਟੋਟਲ sessions" ਸੰਦਰਭ ਦੇ ਬਿਨਾਂ ਸ਼ੋਰ ਦੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਫੈਸਲੇ ਨਾਲ ਜੁੜੀਆਂ ਮੈਟਰਿਕਸ ਨੂੰ ਤਰਜੀਹ ਦਿਓ (completion rate, error budget burn, revenue per visit). ਨਾਲ ਹੀ KPIs ਨੂੰ deduplicate ਕਰੋ: ਇੱਕ ਸਰਕਾਰੀ ਪਰਿਭਾਸ਼ਾ ਤੀਨ ਮੁਕਾਬਲਤੀਆਂ ਤੋਂ ਵਧੀਆ ਹੈ ਜੋ 2% ਦੇ ਅੰਦਰ ਵੱਖ-ਵੱਖ ਨਤੀਜੇ ਦਿੰਦੀਆਂ ਹਨ।
UI ਕੋਡ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਅਸਲ ਵਿਚ ਕੀ ਬਣਾਉਣ ਜਾ ਰਹੇ ਹੋ। ਇੱਕ "health + KPIs" ਐਪ ਆਮ ਤੌਰ 'ਤੇ ਪੰਜ ਮੁੱਖ ਘਟਕਾਂ ਦੇ ਨਾਲ ਹੁੰਦਾ ਹੈ: collectors (metrics/logs/traces ਅਤੇ product events), ingestion (queues/ETL/streaming), storage (time-series + warehouse), ਇਕ data API (consistent queries ਅਤੇ permissions ਲਈ), ਅਤੇ ਇੱਕ UI (ਡੈਸ਼ਬੋਰਡ + drill-down). Alerting UI ਦਾ ਹਿੱਸਾ ਹੋ ਸਕਦਾ ਹੈ, ਜਾਂ ਮੌਜੂਦਾ on-call ਸਿਸਟਮ ਨੂੰ ਸੌਂਪਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ UI ਅਤੇ ਵਰਕਫਲੋ ਦਾ ਪ੍ਰੋਟੋਟਾਈਪ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗਾ vibe-coding ਪਲੇਟਫਾਰਮ ਤੁਹਾਡੇ ਲਈ React-ਆਧਾਰਤ ਡੈਸ਼ਬੋਰਡ ਸ਼ੈਲ ਨੂੰ Go + PostgreSQL ਬੈਕਐਂਡ ਨਾਲ chat-driven spec ਤੋਂ ਉਤਪੰਨ ਕਰਨ ਵਿੱਚ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ, ਫਿਰ ਡ੍ਰਿਲ-ਡਾਊਨ ਨੈਵੀਗੇਸ਼ਨ ਅਤੇ ਫਿਲਟਰਾਂ 'ਤੇ ਇਟਰੇਟ ਕਰੋ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਪੂਰੇ ਡਾਟਾ ਪਲੇਟਫਾਰਮ ਰਿਰਾਈਟ ਲਈ ਵਚਨਬੱਧ ਹੋਵੋ।
ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਵੱਖਰੇ ਵਾਤਾਵਰਨ ਯੋਜਨਾ ਬਣਾਓ: production ਡੇਟਾ ਨੂੰ staging/dev ਨਾਲ ਮਿਲਾਉਣ ਦੀ ਆਗਿਆ ਨਾ ਦਿਓ। ਵੱਖਰੇ project IDs, API keys, ਅਤੇ storage buckets/tables ਰੱਖੋ। ਜੇ ਤੁਸੀਂ "prod vs staging ਦੀ ਤੁਲਨਾ" ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਇਹ API ਵਿੱਚ ਇੱਕ ਨਿਯੰਤਰਤ ਦ੍ਰਿਸ਼ ਦੇ ਰਾਹੀਂ ਕਰੋ—ਕੱਚੇ ਪਾਈਪਲਾਈਨਾਂ ਸਾਂਝੇ ਕਰਕੇ ਨਹੀਂ।
ਇੱਕ single pane ਦਾ ਮਤਲਬ ਹਰ visualization ਨੂੰ ਮੁੜ-ਲਿਖਣਾ ਨਹੀਂ। ਤੁਸੀਂ:
ਜੇ ਤੁਸੀਂ embedding ਚੁਣਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਸਪਸ਼ਟ ਨੈਵੀਗੇਸ਼ਨ ਮਿਆਰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਉਦਾਹਰਣ: “KPI ਕਾਰਡ ਤੋਂ trace view ਤੱਕ”) ਤਾਂ ਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ ਟੂਲਾਂ ਵਿਚ ਛੱਡ-ਭੱਜ ਮਹਿਸੂਸ ਨਾ ਹੋਵੇ।
ਤੁਹਾਡੇ ਡੈਸ਼ਬੋਰਡਸ ਪਿਛੇ ਨਾਲ ਡਾਟਾ ਹੀ ਉਹਨਾ ਦੀ ਭਰੋਸੇਯੋਗਤਾ ਨਿਰਧਾਰਤ ਕਰੇਗਾ। ਪਾਈਪਲਾਈਨਾਂ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਉਹ ਸਿਸਟਮਾਂ ਦੀ ਸੂਚੀ ਬਣਾਓ ਜੋ ਪਹਿਲਾਂ ਹੀ "ਕੀ ਹੋ ਰਿਹਾ ਹੈ" ਨੂੰ ਜਾਣਦੇ ਹਨ, ਫਿਰ ਫੈਸਲਾ ਕਰੋ ਕਿ ਹਰ ਇੱਕ ਨੂੰ ਕਿਨੀ ਤੇਜ਼ੀ ਨਾਲ ਰਿਫ਼੍ਰੈਸ਼ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
ਸੇਰੋਤਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਭਰੋਸੇਯੋਗਤਾ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਸਮਝਾਉਂਦੇ ਹਨ:
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਨਿਯਮ: health signals ਨੂੰ ਡਿਫਾਲਟ ਰੂਪ ਵਿੱਚ near-real-time ਮੰਨੋ, ਕਿਉਂਕਿ ਇਹ ਅਲਰਟਸ ਅਤੇ ਇਨਸਿਡੈਂਟ ਰਿਸਪਾਂਸ ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ।
ਕਾਰੋਬਾਰੀ KPIs ਅਕਸਰ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਦੇ ਟੂਲਾਂ ਵਿੱਚ ਰਹਿੰਦੀਆਂ ਹਨ:
ਹਰ KPI ਨੂੰ ਸੈਕਿੰੜ-ਦਰ-ਸੈਕਿੰੜ ਅਪਡੇਟ ਦੀ ਲੋੜ ਨਹੀਂ ਹੁੰਦੀ। ਰੋਜ਼ਾਨਾ ਰੈਵਨਿਊ ਬੈਚ ਹੋ ਸਕਦੀ ਹੈ; checkout conversion ਹੋਰ ਤਾਜ਼ਾ ਡਾਟਾ ਦੀ ਲੋੜ ਰੱਖ ਸਕਦੀ ਹੈ।
ਹਰ KPI ਲਈ ਇੱਕ ਸਧਾਰਾ ਲੈਟੈਂਸੀ ਉਮੀਦ ਲਿਖੋ: “1 ਮਿੰਟ ਵਿੱਚ ਅਪਡੇਟ”, “ਘੰਟਾਵਾਰ”, ਜਾਂ “ਅਗਲੇ ਕਾਰੋਬਾਰੀ ਦਿਨ”। ਫਿਰ ਇਹ UI ਵਿੱਚ ਸਿੱਧਾ ਦਰਸਾਓ (ਉਦਾਹਰਣ: “Data as of 10:35 UTC”). ਇਹ ਮਿਸਅਲਰਟਾਂ ਨੂੰ ਰੋਕਦਾ ਹੈ ਅਤੇ "ਗਲਤ" ਨੰਬਰਾਂ ਬਾਰੇ ਹੋਣ ਵਾਲੀਆਂ बहਸਾਂ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ।
errors ਨੂੰ lost revenue ਨਾਲ ਜੋੜਨ ਲਈ ਤੁਹਾਨੂੰ consistent IDs ਦੀ ਲੋੜ ਹੈ:
ਹਰ identifier ਲਈ ਇੱਕ “source of truth” ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ ਸਿਸਟਮ ਇਸਨੂੰ ਸੰਭਾਲਦਾ ਹੈ (analytics events, logs, billing records). ਜੇ ਸਿਸਟਮ ਵੱਖ-ਵੱਖ ਕੁੰਜੀਆਂ ਵਰਤਦੇ ਹਨ, ਤਾਂ ਪਹਿਲਾਂ ਹੀ ਇੱਕ mapping table ਜੋੜੋ—ਪਿਛੋਂ stitch ਕਰਨਾ ਮਹਿੰਗਾ ਅਤੇ ਗਲਤ ਹੋ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਸਭ ਕੁਝ ਇੱਕ ਡੇਟਾਬੇਸ ਵਿਚ ਰੱਖਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋਗੇ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ slow dashboards, ਮਹਿੰਗੇ queries, ਜਾਂ ਦੋਹਾਂ ਨਾਲ ਜੂਝੋਗੇ। ਇੱਕ ਸਾਫ਼ ਪਹੁੰਚ ਇਹ ਹੈ ਕਿ app health telemetry ਅਤੇ business KPIs ਨੂੰ ਵੱਖ-ਵੱਖ ਡਾਟਾ ਆਕਾਰ ਅਤੇ ਪੜ੍ਹਨ ਦੇ ਰੂਪਾਂ ਵਜੋਂ ਮੰਨਿਆ ਜਾਵੇ।
Health metrics (latency, error rate, CPU, queue depth) high-volume ਹੁੰਦੇ ਹਨ ਅਤੇ ਸਮੇਂ ਦੀ ਰੇਂਜ ਅਨੁਸਾਰ ਪੁੱਛੇ ਜਾਂਦੇ ਹਨ: “last 15 minutes,” “compare to yesterday,” “p95 by service.” ਇੱਕ time-series database (ਜਾਂ metrics backend) ਤੇਜ਼ rollups ਅਤੇ range scans ਲਈ ਅਨੁਕੂਲ ਹੁੰਦਾ ਹੈ।
ਟੈਗਸ/ਲੇਬਲਸ ਨੂੰ ਸੀਮਿਤ ਅਤੇ consistent ਰੱਖੋ (service, env, region, endpoint group). ਬਹੁਤ ਜ਼ਿਆਦਾ unique labels cardinality ਨੂੰ explode ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ ਖ਼ਰਚ ਵੱਧਾ ਸਕਦੇ ਹਨ।
ਕਾਰੋਬਾਰੀ KPIs (signups, paid conversions, churn, revenue, orders) ਅਕਸਰ joins, backfills ਅਤੇ “as-of” ਰਿਪੋਰਟਿੰਗ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ। ਇੱਕ warehouse/lake ਇਹਨਾਂ ਲਈ ਬਿਹਤਰ ਹੈ:
ਤੁਹਾਡੀ ਵੈੱਬ ਐਪ ਬ੍ਰੌਜ਼ਰ ਤੋਂ ਦੋਨੋਂ stores ਨਾਲ ਸਿੱਧਾ ਗੱਲਬਾਤ ਨਹੀਂ ਕਰਨੀ ਚਾਹੀਦੀ। ਇੱਕ ਬੈਕਐਂਡ API ਬਣਾਓ ਜੋ ਹਰ ਸਟੋਰ ਨੂੰ ਪੁੱਛਦਾ ਹੈ, permissions ਲਾਗੂ ਕਰਦਾ ਹੈ, ਅਤੇ ਇੱਕ consistent schema ਵਾਪਸ ਕਰਦਾ ਹੈ। ਆਮ ਪੈਟਰਨ: health panels time-series store ਨੂੰ ਪੁੱਛਦੇ ਹਨ; KPI panels warehouse ਨੂੰ; drill-down endpoints ਦੋਹਾਂ ਨੂੰ ਫੈੱਚ ਕਰਕੇ ਸਮਾਂ ਖਿੜਕੀ ਨਾਲ ਮਰਜ ਕਰ ਸਕਦੇ ਹਨ।
ਸਾਫ਼ ਟਿਅਰ ਬਣਾੋ:
ਆਮ ਡੈਸ਼ਬੋਰਡ views ਲਈ ਪ੍ਰੀ-ਅਗ੍ਰੀਗੇਟ ਕਰੋ (ਘੰਟਾਵਾਰ/ਰੋਜ਼ਾਨਾ) ਤਾਂ ਕਿ ਜ਼ਿਆਦਾਤਰ ਯੂਜ਼ਰ ਮਹਿੰਗੀਆਂ "ਸਾਰੇ-ਸਕੈਨ" queries ਨਾ ਚਲਾਓ।
ਤੁਹਾਡੀ UI ਉਸ API ਜਿੰਨੀ ਵਰਤਣਯੋਗ ਹੋਵੇਗੀ, ਉਨੀ ਹੀ ਵਰਤਣਯੋਗ ਹੋਵੇਗੀ। ਇੱਕ ਚੰਗਾ ਡਾਟਾ API ਆਮ ਡੈਸ਼ਬੋਰਡ ਵਿਊਜ਼ ਨੂੰ ਤੇਜ਼ ਅਤੇ ਪੇਸ਼ਗੋਈਯੋਗ ਬਣਾਉਂਦਾ ਹੈ, ਤੇ ਲੋਕਾਂ ਨੂੰ detail 'ਚ ਕਲਿਕ ਕਰਨ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਵੱਖਰੇ ਉਤਪਾਦ ਲੋਡ ਕਰਨ ਦੇ।
ਮੁੱਖ ਨੈਵੀਗੇਸ਼ਨ ਦੇ ਅਨੁਕੂਲ endpoints ਡਿਜ਼ਾਈਨ ਕਰੋ, ਨਾ ਕਿ ਅਧਾਰਭੂਤ ਡੇਟਾਬੇਸ:
GET /api/dashboards ਅਤੇ GET /api/dashboards/{id} ਸੇਵਡ ਲੇਆਉਟ, ਚਾਰਟ ਪਰਿਭਾਸ਼ਾਵਾਂ, ਅਤੇ ਡੀਫਾਲਟ ਫਿਲਟਰ ਲੈਣ ਲਈ।GET /api/metrics/timeseries health ਅਤੇ KPI ਚਾਰਟਾਂ ਲਈ from, to, interval, timezone, ਅਤੇ filters ਨਾਲ।GET /api/drilldowns (ਜਾਂ /api/events/search) "ਮੈਨੂੰ ਇੱਕ ਚਾਰਟ ਸੈਗਮੈਂਟ ਦੇ ਪਿੱਛੇ ਅੰਦਰਲੀ requests/orders/users ਦਿਖਾਓ" ਲਈ।GET /api/filters enumerations (regions, plans, environments) ਅਤੇ typeaheads ਲਈ।ਡੈਸ਼ਬੋਰਡ ਕਦਾਚਿਤ raw data ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ; ਉਹਨਾਂ ਨੂੰ summaries ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
ਦੋਹਰਾਈ ਵਾਲੀਆਂ ਬੇਨਤੀਆਂ ਲਈ caching ਜੋੜੋ (ਉਹੀ ਡੈਸ਼ਬੋਰਡ, ਉਹੀ ਸਮਾਂ ਰੇਂਜ) ਅਤੇ ਵਿਅਪਕ queries ਲਈ rate limits ਲਗਾਓ। ਇੰਟਰਐਕਟਿਵ drill-downs ਬਨਾਮ scheduled refreshes ਲਈ ਵੱਖ-ਵੱਖ ਲਿਮਿਟ ਸੋਚੋ।
ਚਾਰਟਾਂ ਨੂੰ ਤੁਲਨਾਤਮਕ ਬਣਾਉਣ ਲਈ ਸਦਾ ਉਹੀ ਬੱਬਲ ਬਾਉਂਡਰੀਆਂ ਅਤੇ ਯੂਨਿਟ ਵਾਪਸ ਕਰੋ: ਚੁਣੇ ਗਏ interval 'ਤੇ timestamps align ਹੋਣ, unit ਖੇਤਰ (ms, %, USD) ਸਪਸ਼ਟ ਹੋਣ, ਅਤੇ stable rounding ਰੀਤੀਆਂ। consistency chart jumps ਨੂੰ ਰੋਕਦੀ ਹੈ ਜਦ ਯੂਜ਼ਰ ਫਿਲਟਰ ਬਦਲਦੇ ਹਨ ਜਾਂ environment ਤੁਲਨਾ ਕਰਦੇ ਹਨ।
ਇੱਕ ਡੈਸ਼бੋਰਡ ਉਸ ਵੇਲੇ ਕਾਮਯਾਬ ਹੁੰਦਾ ਹੈ ਜਦ ਉਹ ਇੱਕ ਸਵਾਲ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇਵੇ: "ਕੀ ਅਸੀਂ ਠੀਕ ਹਾਂ?" ਅਤੇ "ਜੇ ਨਹੀਂ, ਤਾਂ ਅਗਲੇ ਕਿੱਥੇ ਵੇਖਾਂ?" ਫੈਸਲਿਆਂ ਦੇ ਆਧਾਰ 'ਤੇ ਡਿਜ਼ਾਈਨ ਕਰੋ, ਨਾ ਕਿ ਉਸ ਸਭ ਕੁਝ 'ਤੇ ਜੋ ਤੁਸੀਂ ਮਾਪ ਸਕਦੇ ਹੋ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਕੁਝ ਮਕਸਦਪੂਰਕ ਵਿਊਜ਼ ਨਾਲ ਚੰਗਾ ਕਰਦੀਆਂ ਹਨ ਬਜਾਏ ਇਕ ਮਹਾ਼-ਡੈਸ਼ਬੋਰਡ ਦੇ:
ਹਰ ਪੰਨੇ ਦੇ ਉੱਪਰ ਇਕ ਇਕਲੋ-ਟਾਈਮ ਪਿਕਰ ਰੱਖੋ, ਅਤੇ ਇਸਨੂੰ ਇੱਕਸਾਰ ਰੱਖੋ। ਗਲੋਬਲ ਫਿਲਟਰ ਜੋ ਲੋਕ ਅਸਲ ਵਿੱਚ ਵਰਤਦੇ ਹਨ—region, plan, platform, ਅਤੇ ਹੋ ਸਕਦਾ ਹੈ customer segment—ਸ਼ਾਮਿਲ ਕਰੋ। ਲਕੜੀ ਮੇਰਾ ਹੈ ਕਿ ਤੁਸੀਂ "US + iOS + Pro plan" ਨੂੰ "EU + Web + Free" ਨਾਲ ਤੁਲਨਾ ਕਰ ਸਕੋ ਬਿਨਾਂ ਚਾਰਟਾਂ ਨੂੰ ਮੁੜ ਬਣਾਏ।
ਹਰ ਪੰਨੇ 'ਤੇ ਘੱਟੋ-ਘੱਟ ਇਕ correlation ਪੈਨਲ ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ ਤਕਨੀਕੀ ਅਤੇ ਕਾਰੋਬਾਰੀ ਸਿਗਨਲਾਂ ਨੂੰ ਇੱਕੋ ਤਾਂ-ਧੁਰੇ 'ਤੇ overlay ਕਰਦਾ ਹੈ। ਉਦਾਹਰਣ:
ਇਸ ਨਾਲ ਗੈਰ-ਤਕਨੀਕੀ ਹਿੱਸੇਦਾਰ ਪ੍ਰਭਾਵ ਵੇਖ ਸਕਦੇ ਹਨ, ਅਤੇ ਇੰਜੀਨੀਅਰ ਉਹ ਫਿਕਸ ਪ੍ਰਾਥਮਿਕਤਾ ਦੇ ਸਕਦੇ ਹਨ ਜੋ ਨਤੀਜੇ ਬਚਾਉਂਦੇ ਹਨ।
ਭਾਰਭਰਕ ਤੋਂ ਬਚੋ: ਘੱਟ ਚਾਰਟ, ਵੱਡੇ ਫ਼ੋਂਟ, ਸਾਫ਼ ਲੇਬਲ। ਹਰੇਕ ਮੁੱਖ ਚਾਰਟ ਨੂੰ ਥਰੈਸ਼ਹੋਲਡ (good / warning / bad) ਦਿਖਾਉਣੇ ਚਾਹੀਦੇ ਹਨ ਅਤੇ ਮੌਜੂਦਾ ਸਥਿਤੀ hover ਕਰਨ ਬਿਨਾਂ ਪੜ੍ਹੀ ਜਾ ਸਕਣੀ ਚਾਹੀਦੀ ਹੈ। ਜੇ ਕਿਸੇ ਮੈਟਰਿਕ ਲਈ ਮਨਾ ਗਿਆ ਚੰਗਾ/ਬੁਰਾ ਰੇਂਜ ਨਹੀਂ ਹੈ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਹੋਮਪੇਜ ਲਈ ਤਿਆਰ ਨਹੀਂ ਹੁੰਦਾ।
ਮਾਨੀਟਰਿੰਗ तभी਼ ਲਾਭਕਾਰੀ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਇਹ ਸਹੀ ਕਾਰਵਾਈ ਨੂੰ ਚਲਾਉਂਦੀ ਹੈ। Service Level Objectives (SLOs) ਤੁਹਾਨੂੰ "ਠੀਕ-ਠਾਕ" ਦੀ ਪਰਿਭਾਸ਼ਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ ਅਨੁਭਵ ਨਾਲ ਮਿਲਦੀ ਹੈ—ਅਤੇ alerts ਤੁਹਾਨੂੰ ਗਾਹਕ ਦੇ ਨੋਟਿਸ ਤੋਂ ਪਹਿਲਾਂ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਉਹ SLIs ਚੁਣੋ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ ਅਸਲ ਵਿੱਚ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ: errors, latency, ਅਤੇ availability ਮੁੱਖ ਯਾਤਰਾ ਜਿਵੇਂ login, search, ਅਤੇ payment 'ਤੇ—ਅੰਦਰੂਨੀ ਮੈਟਰਿਕਸ ਨਹੀਂ।
ਜਿਤਨਾ ਸੰਭਵ ਹੋਵੇ, ਪਹਿਲਾਂ ਉਪਭੋਗਤਾ ਪ੍ਰਭਾਵ ਦੇ ਲੱਛਣਾਂ 'ਤੇ alert ਕਰੋ, ਫਿਰ ਕਾਰਨਾਂ 'ਤੇ:
ਕਾਰਨ alerts ਅਜੇ ਵੀ ਕੀਮਤੀ ਹਨ, ਪਰ ਲੱਛਣ-ਅਧਾਰਤ alerts ਸ਼ੋਰ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਟੀਮ ਨੂੰ ਗਾਹਕ ਦੇ ਅਨੁਭਵ 'ਤੇ ਧਿਆਨ ਦੇਣ ਲਈ ਪ੍ਰੇਰਿਤ ਕਰਦੇ ਹਨ।
ਸਿਹਤ ਮਾਨੀਟਰਿੰਗ ਨੂੰ ਕਾਰੋਬਾਰੀ KPIs ਨਾਲ ਜੋੜਣ ਲਈ, ਕਈ ਛੋਟੇ ਅਲਰਟ ਜੋ ਅਸਲ ਰੈਵਨਿਊ ਜਾਂ ਵਿਕਾਸ ਖਤਰੇ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ ਸ਼ਾਮਿਲ ਕਰੋ, ਜਿਵੇਂ:
ਹਰ ਅਲਰਟ ਨੂੰ ਇੱਕ “ਉਮੀਦ ਕੀਤੀ ਕਾਰਵਾਈ” ਨਾਲ ਜੋੜੋ: investigate, roll back, provider switch, ਜਾਂ support ਨੂੰ ਸੂਚਿਤ ਕਰੋ।
ਪਹਿਲਾਂ severity ਲੈਵਲ ਅਤੇ routing ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਹਰ ਅਲਰਟ ਇਹ ਜਵਾਬ ਦੇਵੇ: ਕੀ ਪ੍ਰਭਾਵਿਤ ਹੈ, ਕਿੰਨਾ ਗੰਭੀਰ ਹੈ, ਅਤੇ ਕੀ ਅਗਲਾ ਕਦਮ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ?
ਐਪ ਸਿਹਤ ਮਾਨੀਟਰਿੰਗ ਨੂੰ ਕਾਰੋਬਾਰੀ KPI ਡੈਸ਼ਬੋਰਡ ਨਾਲ ਮਿਲਾਉਣ ਨਾਲ ਸਟੇਕਿੰਗ ਵਧ ਜਾਂਦੀ ਹੈ: ਇੱਕ ਸਕ੍ਰੀਨ ਵਿੱਚ errors ਕੰਨੀ revenue, churn, ਜਾਂ ਗਾਹਕ ਨਾਂ ਦੇ ਨਾਲ ਦਿੱਸ ਸਕਦੇ ਹਨ। ਜੇ permissions ਅਤੇ privacy ਬਾਅਦ ਵਿੱਚ ਜੋੜੀਆਂ ਗਈਆਂ, ਤਾਂ ਤੁਸੀਂ ਜਾਂ ਤਾਂ ਉਤਪਾਦ ਨੂੰ ਬਹੁਤ ਜ਼ਿਆਦਾ ਰੋਕ ਦੇਵੋਗੇ (ਕੋਈ ਵੀ ਇਸਦੀ ਵਰਤੋਂ ਨਹੀਂ ਕਰੇਗਾ) ਜਾਂ ਡੇਟਾ ਬਹੁਤ ਖੁੱਲ੍ਹਾ ਹੋ ਜਾਵੇਗਾ (ਇੱਕ ਅਸਲ ਖਤਰਾ)।
ਸ਼ੁਰੂ ਵਿੱਚ ਰੋਲ ਸੰਰਚਨਾ ਫੈਸਲੇ ਵਾਰ ਬਣਾਓ, ਨਾ ਕਿ ਆਰਗ ਚਾਰਟ ਦੇ ਆਧਾਰ 'ਤੇ। ਉਦਾਹਰਣ ਲਈ:
ਫਿਰ least-privilege defaults ਲਾਗੂ ਕਰੋ: ਯੂਜ਼ਰਾਂ ਨੂੰ ਘੱਟੋ-ਘੱਟ ਡੇਟਾ ਦਿਖਾਓ ਜੋ ਲੋੜੀਦਾ ਹੈ, ਅਤੇ ਜ਼ਰੂਰਤ ਹੋਣ 'ਤੇ ਵੱਡੀ ਪਹੁੰਚ ਦੀ ਬੇਨਤੀ ਕਰਨ ਦਿਓ।
PII ਨੂੰ ਇੱਕ ਵੱਖਰੀ ਸ਼੍ਰੇਣੀ ਵਜੋਂ ਨਿਭਾਓ ਜਿਸ ਦੀ ਕਠੋਰ ਹੈਂਡਲਿੰਗ ਹੋਵੇ:
ਜੇ ਤੁਹਾਨੂੰ observability sinais ਨੂੰ customer records ਨਾਲ ਜੋੜਨਾ ਲਾਜ਼ਮੀ ਹੈ, ਤਾਂ ਇਹ stable, non-PII identifiers (tenant_id, account_id) ਨਾਲ ਕਰੋ ਅਤੇ mapping tighter access controls ਦੇ ਪਿੱਛੇ ਰੱਖੋ।
ਟੀਮਾਂ ਭਰੋਸਾ ਗੁਆ ਸਕਦੀਆਂ ਹਨ ਜਦ KPI ਫਾਰਮੂਲ ਚੁਪਚਾਪ ਬਦਲ ਜਾਂਦੇ ਹਨ। ਟਰੈਕ ਕਰੋ:
ਇਸਨੂੰ ਇੱਕ audit log ਵਜੋਂ ਦਿਖਾਓ ਅਤੇ ਮੁੱਖ ਵਿਜੇਟਾਂ ਨਾਲ ਜੋੜੋ।
ਜੇ ਕਈ ਟੀਮਾਂ ਜਾਂ ਕਲਾਇੰਟ ਐਪ ਵਰਤਦੇ ਹਨ, ਤਾਂ tenancy ਲਈ ਪਹਿਲਾਂ ਤੋਂ ਡਿਜ਼ਾਈਨ ਕਰੋ: scoped tokens, tenant-aware queries, ਅਤੇ default ਤੌਰ 'ਤੇ ਕਠੋਰ ਇਕੱਲਾਪਨ। ਇਹ analytics ਇੰਟੇਗ੍ਰੇਸ਼ਨ ਅਤੇ incident response ਪਹਿਲਾਂ ਹੀ ਲਾਈਵ ਹੋਣ ਤੋਂ ਬਾਅਦ retrofit ਕਰਨ ਤੋਂ ਕਾਫੀ ਆਸਾਨ ਹੈ।
"ਐਪ सਿਹਤ + KPI" ਉਤਪਾਦ ਦੀ ਜਾਂਚ ਸਿਰਫ ਇਹ ਨਹੀਂ ਕਿ ਚਾਰਟ ਲੋਡ ਹੋ ਰਹੇ ਹਨ। ਇਹ ਜਾਂਚਣ ਬਾਰੇ ਵੀ ਹੈ ਕਿ ਲੋਕ ਨੰਬਰਾਂ ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ ਅਤੇ ਉਹਨਾਂ 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਕਾਰਵਾਈ ਕਰ ਸਕਦੇ ਹਨ। ਕਿਸੇ ਵੀ ਬਾਹਰੀ ਵਰਤੋਂਕਾਰ ਨੂੰ ਵੇਖਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, correctness ਅਤੇ speed ਨੂੰ ਹਕੀਕਤ-ਨੁਮਾਇਆ ਸਥਿਤੀਆਂ ਵਿੱਚ ਪ੍ਰਮਾਣਿਤ ਕਰੋ।
ਆਪਣੀ ਮਾਨੀਟਰਿੰਗ ਐਪ ਨੂੰ ਇੱਕ ਪਹਿਲੀ-ਕਲਾਸ ਉਤਪਾਦ ਵਜੋਂ ਟ੍ਰੀਟ ਕਰੋ ਅਤੇ ਆਪਣੇ ਨਿਸ਼ਾਨ ਨਿਰਧਾਰਤ ਕਰੋ ਜਿਵੇਂ:
ਇਹ ਟੈਸਟ "ਅਸਲੀ ਬੁਰੇ ਦਿਨ" ਨਾਲ ਵੀ ਚਲਾਓ—ਉੱਚ-ਕਾਰਡਿਨੈਲਿਟੀ ਮੈਟਰਿਕਸ, ਵੱਡੇ ਸਮਾਂ ਰੇਂਜ, ਅਤੇ peak traffic windows।
ਇਕ ਡੈਸ਼ਬੋਰਡ ਠੀਕ ਦਿਖ ਸਕਦਾ ਹੈ ਜਦ ਕਿ ਪਾਈਪਲਾਈਨ ਚੁੱਪਚਾਪ ਫੇਲ ਹੋ ਰਹੀ ਹੋਵੇ। automated checks ਜੋੜੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਅੰਦਰੂਨੀ ਦ੍ਰਿਸ਼ ਵਿੱਚ ਉਪਰ ਉਤਾਰੋ:
ਇਹ checks staging ਵਿੱਚ ਜ਼ੋਰ ਨਾਲ fail ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਕਿ ਤੁਸੀਂ production ਵਿੱਚ ਸਮੱਸਿਆਵਾਂ ਨੂਂ ਪਤਾ ਨਾ ਲਗੋ।
ਏਜ ਕੇਸਾਂ ਨੂੰ ਸ਼ਾਮਿਲ ਕਰਨ ਵਾਲੀ synthetic datasets ਬਣਾਓ: ਜੀਰੋ, spikes, refunds, duplicated events, ਅਤੇ timezone ਬਾਰਡਰ। ਫਿਰ production traffic ਦੇ ਨਮੂਨੇ (identifiers anonymized) ਨੂੰ staging ਵਿੱਚ replay ਕਰੋ ਤਾਂ ਕਿ ਡੈਸ਼ਬੋਰਡ ਅਤੇ alerts ਨੂੰ ਜ਼indaba-ਖ਼ਤਰੇ ਤੋਂ ਬਿਨਾਂ ਵੈਰੀਫਾਈ ਕੀਤਾ ਜਾ ਸਕੇ।
ਹਰ ਮੁੱਖ KPI ਲਈ ਇੱਕ ਦੁਹਰਾਉਣਯੋਗ correctness routine ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਜੇ ਤੁਸੀਂ ਇੱਕ ਗੈਰ-ਤਕਨੀਕੀ ਹਿੱਸੇਦਾਰ ਨੂੰ ਇੱਕ ਨੰਬਰ ਇਕ ਮਿੰਟ ਅੰਦਰ ਸਮਝਾ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਇਹ ship ਕਰਨ ਲਈ ਤਿਆਰ ਨਹੀਂ ਹੈ।
ਇੱਕ ਮਿਲੀ-ਜੁਲੀ "health + KPIs" ਐਪ ਸਿਰਫ ਤਦ ਹੀ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ, ਵਰਤਦੇ ਹਨ, ਅਤੇ ਇਸ ਨੂੰ ਅਪਡੇਟ ਰੱਖਦੇ ਹਨ। ਰੋਲਆਊਟ ਨੂੰ ਇਕ ਉਤਪਾਦ ਲਾਂਚ ਵਜੋਂ ਟ੍ਰੀਟ ਕਰੋ: ਛੋਟੇ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਮੁੱਲ ਸਾਬਤ ਕਰੋ, ਅਤੇ ਆਦਤਾਂ ਬਣਾਓ।
ਇੱਕ ਇਕੱਲੀ customer journey ਚੁਣੋ ਜੋ ਸਭ ਦੀ ਫਿਕਰ ਹੈ (ਉਦਾਹਰਣ: checkout) ਅਤੇ ਉਸ ਲਈ ਸਭ ਤੋਂ ਜ਼ਿੰਮੇਵਾਰ backend service। ਉਸ ਪਤਲੇ ਟੁਕੜੇ ਲਈ ship ਕਰੋ:
ਇਹ "ਇੱਕ ਯਾਤਰਾ + ਇੱਕ ਸਰਵਿਸ" ਨਜ਼ਰੀਆ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਐਪ ਕਿਸ ਲਈ ਹੈ, ਅਤੇ ਸ਼ੁਰੂਆਤੀ ਵਿਚਾਰ-ਵਟਾਂਦਰੇ "ਕਿਹੜੇ ਮੈਟਰਿਕਸ ਮਹੱਤਵਪੂਰਨ ਹਨ" ਬਾਰੇ ਸੰਭਾਲਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਉਤਪਾਦ, support, ਅਤੇ engineering ਨਾਲ ਇੱਕ ਦੁਹਰਾਉਣਯੋਗ 30–45 ਮਿੰਟ ਦੀ ਹਫ਼ਤਾਵਾਰ ਸਮੀਖਿਆ ਰੱਖੋ। ਇਸਨੂੰ ਪ੍ਰਯੋਗਿਕ ਰੱਖੋ:
Unused ਡੈਸ਼ਬੋਰਡਸ ਨੂੰ ਸਧਾਰਨ ਕਰਨ ਦਾ ਇਸ਼ਾਰਾ ਮੰਨੋ। noisy alerts ਨੂੰ bugs ਵਜੋਂ ਮੰਨੋ।
ਮਾਲਿਕੀ ਨਿਰਧਾਰਤ ਕਰੋ (ਭਾਵੇਂ ਇਹ ਸਾਂਝਾ ਹੋਵੇ) ਅਤੇ ਇੱਕ ਨਰਮ ਚੈਕਲਿਸਟ ਮਹੀਨਾਵਾਰ ਰੂਪ ਵਿੱਚ ਚਲਾਓ:
ਜਦ ਪਹਿਲਾ ਸਲਾਈਸ ਸਥਿਰ ਹੋ ਜਾਵੇ, ਉਹੇ ਪੈਟਰਨ ਨਾਲ ਅਗਲੀ ਯਾਤਰਾ ਜਾਂ ਸਰਵਿਸ ਵਧਾਓ।
ਜੇ ਤੁਸੀਂ ਇੰਪਲੀਮੈਂਟੇਸ਼ਨ ਵਿਚਾਰ ਅਤੇ ਉਦਾਹਰਣ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ browse /blog. ਜੇ ਤੁਸੀਂ build vs. buy ਦਾ ਮੁਕਾਬਲਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ options ਅਤੇ scope /pricing 'ਤੇ ਤੁੱਲ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਪਹਿਲੀ ਵਰਕਿੰਗ ਵਰਜਨ (ਡੈਸ਼ਬੋਰਡ UI + API ਲੇਅਰ + auth) ਨੂੰ ਤੇਜ਼ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਇਕ ਵਿਤੀਅਕ ਸ਼ੁਰੂਆਤ ਹੋ ਸਕਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ ਉਹ ਟੀਮਾਂ ਲਈ ਜੋ React frontend, Go + PostgreSQL backend ਚਾਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ ਜਦੋਂ ਤਿਆਰ ਹੋਵੋਗੇ ਤਾਂ ਸਰੋਤ ਕੋਡ export ਕਰਨ ਦਾ ਵਿਕਲਪ ਵੀ ਚਾਹੁੰਦੀਆਂ ਹਨ।
ਇਹ ਇਕ ਇਕਲ-ਫਲੋ (ਅਕਸਰ ਇਕ ਡੈਸ਼ਬੋਰਡ + ਡ੍ਰਿਲ-ਡਾਊਨ ਅਨੁਭਵ) ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਇਕੋ ਸਮੇਂ ਤਕਨੀਕੀ ਸਿਹਤ ਸਿਗਨਲ (ਲੈਟੈਂਸੀ, errors, saturation) ਅਤੇ ਕਾਰੋਬਾਰੀ ਨਤੀਜੇ (conversion, revenue, churn) ਦੇਖ ਸਕਦੇ ਹੋ।
ਮਕਸਦ correlation ਕਰਨਾ ਹੈ: ਨਾ ਸਿਰਫ "ਕੁਝ ਟੁੱਟਿਆ ਹੈ," ਬਲਕਿ "checkout errors ਵਧੇ ਤੇ conversion ਘਟਿਆ," ਤਾਂ ਜੋ ਤੁਸੀਂ ਪ੍ਰਭਾਵ ਦੇ ਆਧਾਰ ਤੇ ਠੀਕ ਤਰਤੀਬ ਨਾਲ ਫਿਕਸ ਕਰ ਸਕੋ।
ਕਿਉਂਕਿ ਜਦੋਂ ਤੁਸੀਂ turant ਹੀ ਗਾਹਕ ਪ੍ਰਭਾਵ ਦੀ ਪੁਸ਼ਟੀ ਕਰ ਸਕਦੇ ਹੋ ਤਾਂ ਘਟਨਾਵਾਂ triage ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਲੈਟੈਂਸੀ spike ਮਹੱਤਵਪੂਰਨ ਹੈ ਜਾਂ ਨਹੀਂ, ਇਹ ਅਨੁਮਾਨ ਦੀ ਥਾਂ KPIs ਜਿਵੇਂ purchases/minute ਜਾਂ activation rate ਨਾਲ ਤੁਹਾਨੂੰ ਸਿੱਧਾ ਦੱਸ ਸਕਦਾ ਹੈ ਅਤੇ ਫੈਸਲਾ ਕਰਨ ਦਿੰਦਾ ਹੈ ਕਿ page ਕਰੋ, roll back ਕਰੋ ਜਾਂ ਨਿਗਰਾਨੀ ਕਰੋ।
Incident ਸਵਾਲਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਫਿਰ 5–10 health metrics ਚੁਣੋ (availability, latency, error rate, saturation, traffic) ਅਤੇ 5–10 KPIs (signups, activation, conversion, revenue, retention). ਹੋਮਪੇਜ ਨੂੰ ਨਿਆਣਾ ਰੱਖੋ।
3–5 ਆਹਮੀ journeys ਚੁਣੋ ਜੋ ਸਿੱਧੇ revenue ਜਾਂ retention ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ (checkout/payment, login, onboarding, search, publishing).
ਹਰ journey ਲਈ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਇਸ ਤਰ੍ਹਾਂ ਡੈਸ਼ਬੋਰਡ ਨਤੀਜਿਆਂ ਵਾਲੇ ਹੋਂਦੇ ਹਨ ਨਾ ਕਿ ਬਸ ਇੰਫਰਾਸਟਰੱਕਚਰ ਦੇ ਵੇਰਵੇ।
ਇੱਕ metric dictionary “same KPI, different math” ਵਾਲੀਆਂ ਸਮੱਸਿਆਵਾਂ ਰੋਕਦਾ ਹੈ। ਹਰ ਮੈਟਰਿਕ ਲਈ ਦਸਤਾਵੇਜ਼ ਕਰੋ:
ਜਿਨ੍ਹਾਂ ਮੈਟਰਿਕਾਂ ਦੇ ਮਾਲਕ ਨਹੀਂ ਹੁੰਦੇ ਉਹਨਾਂ ਨੂੰ deprecated ਮੰਨੋ ਜਦ ਤੱਕ ਕੋਈ ਉਸਨੂੰ maintain ਨਾ ਕਰੇ।
ਜੇ ਸਿਸਟਮ consistent identifiers ਨਹੀਂ ਸਾਂਝੇ ਕਰਦੇ ਤਾਂ ਤੁਸੀਂ errors ਨੂੰ outcomes ਨਾਲ reliably ਜੋੜ ਨਹੀਂ ਸਕੋਗੇ.
ਸਧਾਰਨ ਕਰੋ (ਤੇ ਹਰ ਥਾਂ ਲਿਜਾਓ):
user_idaccount_id/org_idorder_id/invoice_idਜੇ ਟੂਲਾਂ ਵਿੱਚ ਕੁੰਜੀਆਂ ਵੱਖ-ਵੱਖ ਹਨ, ਤਾਂ ਜਲ्दी ਹੀ ਇਕ mapping table ਬਣਾਓ; ਪਿੱਛੇ ਤੋਂ ਸਿਲਾਈ ਕਰਨਾ ਮਹਿੰਗਾ ਅਤੇ ਅਸਹੀਹ ਹੋ ਸਕਦਾ ਹੈ।
ਇਕ ਪ੍ਰੈਕਟਿਕਲ ਵੰਡ ਇਹ ਹੈ:
ਇੱਕ backend data API ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ ਦੋਨੋਂ ਤੋਂ ਪੁੱਛਗਿੱਛ ਕਰੇ, permissions ਲਾਗੂ ਕਰੇ ਅਤੇ UI ਨੂੰ ਇੱਕਜੈਹ schema ਫਰਾਹਮ ਕਰੇ।
ਇਸ ਨਿਯਮ ਨੂੰ ਵਰਤੋਂ:
"Single pane" ਦਾ ਮਤਲਬ ਹਰ visualization ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਉਣਾ ਨਹੀਂ ਹੈ।
ਲੱਛਣ ਤੇ ਫਿਰ ਕਾਰਨ 'ਤੇ ਅਲਰਟ ਕਰੋ:
ਜਿੰਨਾ ਸੰਭਵ ਹੋ ਸਕੇ, ਪਹਿਲਾਂ ਉਪਭੋਗਤਾ ਪ੍ਰਭਾਵ ਦੇ ਲੱਛਣ ਤੇ ਅਲਰਟ ਕਰੋ, ਫਿਰ ਕਾਰਨਾਂ ਤੇ:
ਲੱਛਣ-ਅਧਾਰਤ ਅਲਰਟ ਸ਼ੋਰ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਟੀਮ ਨੂੰ ਗਾਹਕ ਅਨੁਭਵ 'ਤੇ ਕੇਂਦਰਿਤ ਕਰਦੇ ਹਨ।
ਰੇਵਨਿਊ/KPI ਨਾਲ operational ਡੇਟਾ ਮਿਲਾਉਣਾ ਪਰਾਇਵੇਸੀ ਅਤੇ ਭਰੋਸੇ ਦੇ ਖਤਰੇ ਵਧਾ ਦਿੰਦਾ ਹੈ।
ਲਾਗੂ ਕਰੋ:
ਜੋੜਨ ਲਈ stable non-PII IDs (ਜਿਵੇਂ ) ਨੂੰ ਤਰਜੀਹ ਦਿਓ।
account_id