01 ਮਾਰਚ 2025·8 ਮਿੰਟ
ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਦੀ ਅਪਣਾਉਣ ਟਰੈਕ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਇਨ ਅਤੇ ਬਣਾਈਏ ਜੋ ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਦੀ ਅਪਣਾਉਣ ਨੂੰ ਸਪਸ਼ਟ ਮੈਟ੍ਰਿਕਸ, ईਵੈਂਟ ਟਰੈਕਿੰਗ, ਡੈਸ਼ਬੋਰਡ, ਪ੍ਰਾਈਵੇਸੀ ਅਤੇ ਰੋਲਆਉਟ ਕਦਮਾਂ ਨਾਲ ਨਾਪੇ।
Define Goals, Audience, and Success Criteria
Before you build anything, align on what “adoption” actually means inside your organization. Internal tools don’t “sell” themselves—adoption is usually a mix of access, behavior, and habit.
Define “adoption” in plain terms
Pick a small set of definitions everyone can repeat:
- Activation: the first meaningful moment of value. Example: “Submitted a first request,” “Ran the first report,” or “Completed onboarding checklist.”
- Usage: ongoing activity that signals the tool is being used for real work (not just logging in). Example: “Created a ticket,” “Approved a purchase,” “Published a dashboard.”
- Retention: continued use over time. Example: “Active in 3 of the last 4 weeks” for weekly tools, or “Used at least once per month” for monthly workflows.
Write these down and treat them as product requirements, not analytics trivia.
Decide what decisions the app must support
A tracking app is valuable only if it changes what you do next. List the decisions you want to make faster or with fewer debates, such as:
- Where to focus training (which teams struggle after activation)
- What to prioritize on the roadmap (features used vs. avoided)
- Whether to change access (who needs the tool, who doesn’t, who needs admin rights)
- When to invest in support (spikes in errors, repeated retries, stalled workflows)
If a metric won’t drive a decision, it’s optional for the MVP.
Identify stakeholders and their questions
Be explicit about audiences and what each needs:
- IT / Security: who accessed what, when; compliance-friendly audit signals
- Ops / Enablement: where people get stuck; which teams need coaching
- Tool owners: feature adoption, drop-offs, and feedback loops
- Managers: team-level progress without exposing individual performance
- End users: transparency about what’s tracked and why
Set success criteria and an MVP timeline
Define success criteria for the tracking app itself (not the tool being tracked), for example:
- 90%+ of target workflows emit the required events
- A weekly adoption report is generated automatically and trusted by stakeholders
- Key questions can be answered in under 2 minutes
Set a simple timeline: Week 1 definitions + stakeholders, Weeks 2–3 MVP instrumentation + basic dashboard, Week 4 review, fix gaps, and publish a repeatable cadence.
Choose Adoption Metrics That Actually Help
Internal tool analytics only works when the numbers answer a decision. If you track everything, you’ll drown in charts and still won’t know what to fix. Start with a small set of adoption metrics that map to your rollout goals, then layer on engagement and segmentation.
Start with four core adoption metrics
Activated users: the count (or %) of people who completed the minimum “setup” needed to get value. For example: signed in via SSO and successfully completed their first workflow.
WAU/MAU: weekly active users vs monthly active users. This quickly tells you whether usage is habitual or occasional.
Retention: how many new users keep using the tool after their first week or month. Define the cohort (e.g., “first used the tool in October”) and a clear “active” rule.
Time-to-first-value (TTFV): how long it takes a new user to reach the first meaningful outcome. Shorter TTFV usually correlates with better long-term adoption.
Add engagement metrics that point to product changes
After you have core adoption, add a small set of engagement measures:
- Feature usage: which key features are used and by whom (not every click—just the actions that matter).
- Task completion: success rate for the tool’s main jobs (e.g., “submitted request,” “approved invoice”).
- Frequency and depth: number of sessions per week, and how many meaningful actions happen per session.
Segment without creating a privacy or interpretation trap
Break down the metrics by department, role, location, or team, but avoid overly granular cuts that encourage “scoreboarding” individuals or tiny groups. The goal is to find where enablement, training, or workflow design needs help—not to micromanage.
Define “healthy adoption” and alerts
Write down thresholds like:
- WAU/MAU ≥ 0.55 for target teams
- Retention ≥ 60% at week 4
- TTFV ≤ 2 days
Then add alerts for sharp drops (e.g., “feature X usage down 30% week-over-week”) so you can investigate quickly—release issues, permission problems, or process changes usually show up here first.
Map User Journeys and Create an Event Taxonomy
Before you add tracking code, get clear on what “adoption” looks like in day-to-day work. Internal tools often have fewer users than customer apps, so every event should earn its keep: it should explain whether the tool is helping people complete real tasks.
Document the journeys that matter
Start with 2–4 common workflows and write them as short, step-by-step journeys. For example:
- Get started: open tool → sign in → land on home → complete first required setup
- Core task: create → edit → submit → approve/reject
- Output: export → share link → send to another system
For each journey, mark the moments you care about: first success, handoffs (e.g., submit → approve), and bottlenecks (e.g., validation errors).
Decide what to capture: events, page views, or backend logs
Use events for meaningful actions (create, approve, export) and for state changes that define progress.
Use page views sparingly—helpful for understanding navigation and drop-offs, but noisy if treated as a proxy for usage.
Use backend logs when you need reliability or coverage across clients (e.g., approvals triggered via API, scheduled jobs, bulk imports). A practical pattern is: track the UI click as an event, and track the actual completion in the backend.
Create a naming convention and required properties
Pick a consistent style and stick to it (e.g., verb_noun: create_request, approve_request, export_report). Define required properties so events stay usable across teams:
user_id(stable identifier)tool_id(which internal tool)feature(optional grouping, likeapprovals)timestamp(UTC)
Add helpful context when it’s safe: org_unit, role, request_type, success/error_code.
Plan for versioning
Tools change. Your taxonomy should tolerate that without breaking dashboards:
- Add
schema_version(orevent_version) to payloads. - Deprecate events instead of silently reusing names with new meaning.
- Keep a simple changelog so analysts know when definitions shifted.
Design the Data Model and Identifiers
A clear data model prevents reporting headaches later. Your goal is to make every event unambiguous: who did what in which tool, and when, while keeping the system easy to maintain.
Core tables to start with
Most internal adoption tracking apps can begin with a small set of tables:
- users: stable user record, plus references to your identity source
- teams/departments: the org structure you want to report by
- tools: the internal tools you’re measuring (name, owner, status)
- sessions (optional): helpful for “active users” and time-based analysis
- events: the activity log (the heart of analytics)
- permissions/roles: what a user can see and administer inside your tracking app
Keep the events table consistent: event_name, timestamp, user_id, tool_id, and a small JSON/properties field for details you’ll filter on (e.g., feature, page, workflow_step).
Identifiers: make them stable and boring
Use stable internal IDs that won’t change when someone updates their email or name:
- user_id: your app’s UUID, mapped to an immutable IdP identifier (e.g.,
idp_subject) - tool_id: a UUID for each tool (don’t use tool name as a key)
- anonymous_id (optional): only if you truly need pre-login tracking; otherwise skip it for internal apps
Retention, rollups, and performance
Define how long you keep raw events (e.g., 13 months), and plan daily/weekly rollup tables (tool × team × date) so dashboards stay fast.
Data ownership and sources
Document which fields come from where:
- HRIS/IdP: department, manager, employment status, canonical identity
- Your app: tool metadata, tool owners, permissions within the tracking app
This avoids “mystery fields” and makes it clear who can fix bad data.
Instrument Data Collection (Front End and Back End)
Instrumentation is where adoption tracking becomes real: you translate user activity into reliable events. The key decision is where events are generated—on the client, the server, or both—and how you make that data dependable enough to trust.
Pick the right tracking methods
Most internal tools benefit from a hybrid approach:
- Client-side SDK events capture UI interactions (button clicks, page views, filter changes) and user context at the moment it happens.
- Server-side events capture authoritative actions (record created, approval submitted, export generated) even if the UI changes.
- Both is often best: the UI can log “attempted,” while the server logs “completed,” which helps you spot friction.
Keep client-side tracking minimal: don’t log every keystroke. Focus on moments that indicate progress through a workflow.
Make delivery reliable (retries + batching)
Network hiccups and browser constraints will happen. Add:
- Batching to send multiple events in one request (lower overhead, fewer failures).
- Retries with backoff for failed requests, with a reasonable cap to avoid endless loops.
- A small local queue (e.g., in memory or localStorage) so events aren’t lost if a tab closes.
On the server side, treat analytics ingestion as non-blocking: if event logging fails, the business action should still succeed.
Validate payloads to keep data clean
Implement schema checks at ingestion (and ideally in the client library too). Validate required fields (event name, timestamp, actor ID, org/team ID), data types, and allowed values. Reject or quarantine malformed events so they don’t silently pollute dashboards.
Separate environments so test data doesn’t leak
Always include environment tags like env=prod|stage|dev and filter reports accordingly. This prevents QA runs, demos, and developer testing from inflating adoption metrics.
If you need a simple rule: start with server-side events for core actions, then add client-side events only where you need more detail about user intent and UI friction.
Add Authentication, Roles, and Access Control
Turn learnings into credits
Earn credits by sharing what you build with Koder.ai and how you shipped it.
If people don’t trust how adoption data is accessed, they won’t use the system—or they’ll avoid tracking altogether. Treat auth and permissions as a first-class feature, not an afterthought.
Prefer SSO and avoid passwords
Use your company’s existing identity provider so access matches how employees already sign in.
- Implement SSO via OIDC (common with Okta, Azure AD) or SAML when required.
- Minimize password handling: ideally, don’t store passwords at all. If you must, use a proven auth library and strong hashing, but default to SSO.
Define roles and scope-based access
A simple role model covers most internal adoption use cases:
- Admin: manages org-wide settings, identity connections, and global permissions.
- Tool owner: manages a specific tool’s tracking settings, dashboards, and alerts.
- Manager: can view adoption for their team/org unit only (needs a team mapping source).
- Viewer: read-only access to approved dashboards.
Make access scope-based (by tool, department, team, or location) so “tool owner” doesn’t automatically mean “see everything.” Restrict exports the same way—data leaks often happen through CSV.
Audit logs and safe defaults
Add audit logs for:
- permission/role changes
- edits to tracking settings (event mappings, filters)
- dashboard sharing changes
- data exports and API token creation
Document least-privilege defaults (e.g., new users start as Viewer) and an approval flow for Admin access—link to your internal request page or a simple form at /access-request. This reduces surprises and makes reviews painless.
Address Privacy, Compliance, and Trust
Tracking internal tool adoption involves employee data, so privacy can’t be an afterthought. If people feel monitored, they’ll resist the tool—and the data will be less reliable. Treat trust as a product requirement.
Set clear rules for what you track
Start by defining “safe” events. Track actions and outcomes, not the content employees type.
- Prefer events like
report_exported,ticket_closed,approval_submitted. - Avoid text fields, message bodies, free-form notes, search queries, attachments, and anything that could contain personal data.
- Don’t record full URLs if they can embed IDs or sensitive parameters; store a route template (for example,
/orders/:id).
Write these rules down and make them part of your instrumentation checklist so new features don’t accidentally introduce sensitive capture.
Align with internal policy (and the law)
Work with HR, Legal, and Security early. Decide the purpose of tracking (e.g., training needs, workflow bottlenecks) and explicitly prohibit certain uses (e.g., performance evaluation without a separate process). Document:
- Data retention (how long raw events are kept)
- Who can access employee-level views and under what approvals
- Where data is stored and whether it leaves your region
Anonymize and aggregate by default
Most stakeholders don’t need person-level data. Provide team/org aggregation as the default view, and only allow identifiable drill-down for a small set of admins.
Use small-group suppression thresholds so you don’t expose behavior of tiny groups (for example, hide breakdowns where the group size is < 5). This also reduces re-identification risk when combining filters.
Be transparent: notices + an internal FAQ
Add a short notice in the app (and in onboarding) explaining what is collected and why. Maintain a living internal FAQ that includes examples of tracked vs. not tracked data, retention timelines, and how to raise concerns. Link it from the dashboard and settings page (e.g., /internal-analytics-faq).
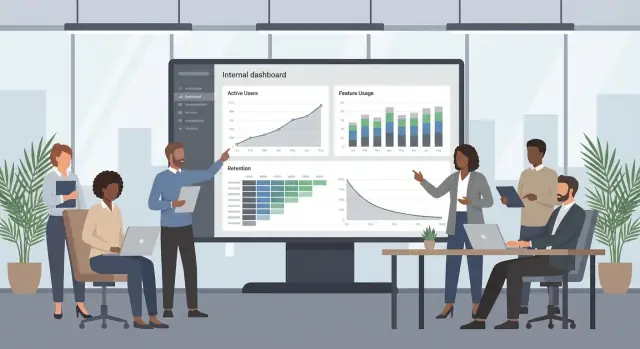
Design Dashboards and Reports for Action
Run a focused pilot
Pilot with one tool and one team, then expand once your reports are trusted.
Dashboards should answer one question: “What should we do next?” If a chart is interesting but doesn’t lead to a decision (nudge training, fix onboarding, retire a feature), it’s noise.
Start with overview dashboards
Create a small set of overview views that work for most stakeholders:
- Adoption funnel: eligible users → invited → first use → activated (your definition) → power users. Show conversion rates and where people drop off.
- Trend lines: daily/weekly active users, key event counts, and activation rate over time. Pair each trend with a comparison period.
- Retention cohorts: for users who started in the same week/month, how many return in week 2, week 4, etc. This helps separate “trial” from real adoption.
Keep the overview clean: 6–10 tiles max, consistent time ranges, and clear definitions (e.g., what counts as “active”).
Add drill-downs that explain the “why”
When a metric moves, people need quick ways to explore:
- By tool: compare adoption across tools (or modules) with the same funnel and retention view.
- By segment: department, location, role, seniority band, or “new hires vs. tenured.”
Make filters obvious and safe: date range, tool, team, and segment, with sensible defaults and reset built in.
Surface “top opportunities,” not just charts
Add a short list that updates automatically:
- Teams with low activation despite high eligibility
- Features that are underused among activated users
- Sudden drops in usage after a release
Each item should link to a drill-down page and a suggested next step.
Exports and scheduled reports (with permission checks)
Exports are powerful—and risky. Only allow exporting data the viewer is allowed to see, and avoid row-level employee data by default. For scheduled reports, include:
- Audience and scope (who receives it, what segments)
- Delivery cadence
- A clear summary plus a link to the live dashboard (e.g., /reports/adoption)
Manage Tools, Owners, and Metadata
Adoption data gets hard to interpret when you can’t answer basic questions like “Who owns this tool?”, “Who is it for?”, and “What changed last week?”. A lightweight metadata layer turns raw events into something people can act on—and makes your tracking web app useful beyond the analytics team.
Build a simple Tool Catalog
Start with a Tool Catalog page that acts as the source of truth for every internal tool you track. Keep it readable and searchable, with just enough structure to support reporting.
Include:
- Tool name + short description (what it’s for, in plain language)
- Owner(s) (primary and backup), plus an owning team or cost center
- Target users (roles, departments, locations if relevant)
- Expected workflows (a short list like “Create request → Approve → Export”) so metrics can be interpreted against intended usage
This page becomes the hub you link to from dashboards and runbooks, so anyone can quickly understand what “good adoption” should look like.
Let owners manage key events and feature notes
Give tool owners an interface to define or refine key events/features (e.g., “Submitted expense report”, “Approved request”), and attach notes about what counts as success. Store change history for these edits (who changed what, when, and why), because event definitions evolve as tools evolve.
A practical pattern is to store:
- Event name + description
- Status (draft/active/deprecated)
- Related workflow step
- Owner notes (examples, edge cases, “don’t count test accounts”)
Track rollout context alongside usage
Usage spikes and dips often correlate with rollout activity—not product changes. Store rollout metadata per tool:
- Rollout dates (pilot start, general availability)
- Training links (recordings, decks)
- Support channels (Slack channel, ticket queue, office hours)
Add a checklist link right in the tool record, such as /docs/tool-rollout-checklist, so owners can coordinate measurement and change management in one place.
Select a Practical Architecture and Tech Stack
Your goal isn’t to build the “perfect” analytics platform—it’s to ship something reliable that your team can maintain. Start by matching the stack to your existing skills and deployment environment, then make a few deliberate choices about storage and performance.
Choose a stack that fits your team
For many teams, a standard web stack is enough:
- React + Node (Express/NestJS) if you already ship JavaScript/TypeScript and want shared types across client/server.
- Django if you want fast CRUD, strong admin tooling, and mature auth integrations.
- Rails if you value convention, quick iteration, and a strong ecosystem for background jobs.
Keep the ingestion API boring: a small set of endpoints like /events and /identify with versioned payloads.
If you’re trying to get to an MVP quickly, a vibe-coding approach can work well for internal apps like this—especially for CRUD-heavy screens (tool catalog, role management, dashboards) and the first pass at ingestion endpoints. For example, Koder.ai can help teams prototype a React-based web app with a Go + PostgreSQL backend from a chat-driven spec, then iterate using planning mode, snapshots, and rollback while you refine your event taxonomy and permissions model.
Pick event storage and analytics storage intentionally
You typically need two “modes” of data:
- Raw events (high volume, append-only)
- Aggregations (fast dashboards)
Common approaches:
- Relational DB (Postgres) for both, using time-based partitions for the events table. This is often the simplest path.
- Columnar store (ClickHouse/BigQuery/Snowflake) when event volume is high and queries are heavy. Pair it with a small relational DB for app config, users, and permissions.
Plan background jobs early
Dashboards should not recompute everything on every page load. Use background jobs for:
- Daily/weekly rollups (active users, feature usage, retention)
- Scheduled email/Slack reports
- Backfills when you change taxonomy or fix bugs
Tools: Sidekiq (Rails), Celery (Django), or a Node queue like BullMQ.
Set performance goals and monitor them
Define a few hard targets (and measure them):
- Dashboard load time (e.g., p95 under 2s)
- Ingest throughput (events/sec at peak)
- Queue lag for aggregation jobs
Instrument your own app with basic tracing and metrics, and add a simple status page at /health so operations stays predictable.
Ensure Data Quality, Testing, and Monitoring
Own the source code
Keep full control by exporting source code when your tracker moves into a standard pipeline.
Adoption numbers are only useful if people trust them. A single broken event, a renamed property, or a double-send bug can make a dashboard look busy while the tool is actually unused. Build quality checks into your tracking system so issues are caught early and fixed with minimal disruption.
Validate events before they hit production
Treat your event schema like an API contract.
- Test event schemas with automated checks and sample payloads: keep a canonical JSON schema (or similar) per event, and run it in CI when code changes. Include “good” and “bad” payloads so failures are obvious.
- Add lightweight runtime validation: if required fields are missing (e.g.,
user_id,tool,action), log and quarantine the event rather than polluting analytics.
Monitor data health, not just uptime
Dashboards can stay online while data quietly degrades. Add monitors that alert you when tracking behavior changes.
- Add data quality monitors: missing properties, spikes/drops, duplicate events. Examples: sudden 80% drop in
tool_opened, a new spike inerrorevents, or an unusual rise in identical events per user minute. - Track “unknown” values (like
feature = null) as a first-class metric. If it rises, something is broken.
Create a safe place to demo and verify
- Create staging dashboards and seed data for safe demos: a staging workspace with seeded “fake employees” and predictable activity lets you validate charts, filters, and role-based visibility without exposing real usage.
- Add a simple checklist for each release: “event fired,” “properties populated,” “appears in dashboard,” “no duplicates.”
Define escalation and ownership
When tracking fails, adoption reporting becomes a blocker for leadership reviews.
- Document an on-call or escalation path for tracking outages: who owns instrumentation, who owns pipelines/warehouse, and who owns dashboards.
- Put the runbook in a shared place (e.g., /handbook/analytics) with common fixes, rollback steps, and how to reprocess events if needed.
Roll Out, Drive Adoption, and Iterate
Shipping the tracker isn’t the finish line—your first rollout should be designed to learn quickly and earn trust. Treat internal adoption like a product: start small, measure, improve, then expand.
Start with an MVP (and a repeatable onboarding)
Pick 1–2 high-impact tools and a single department to pilot. Keep scope tight: a few core events, a simple dashboard, and one clear owner who can act on findings.
Create an onboarding checklist you can reuse for each new tool:
- Confirm the tool’s primary workflows and “success moments” (e.g., request submitted, report exported)
- Add required events and properties to the taxonomy
- Validate identities (SSO user IDs, teams) and permissions
- Publish a short “how we measure” note so teams understand what’s tracked and why
If you’re iterating fast, make it easy to ship incremental improvements safely: snapshots, rollback, and clean environment separation (dev/stage/prod) reduce the risk of breaking tracking in production. Platforms like Koder.ai support that workflow while also allowing source code export if you later move the tracker into a more traditional pipeline.
Pair metrics with enablement
Adoption improves when measurement is tied to support. When you see low activation or drop-offs, respond with enablement:
- Schedule short training sessions for common workflows
- Hold weekly office hours for questions and setup help
- Add in-app tips or lightweight prompts where people get stuck
Turn insights into actions
Use the data to remove friction, not to score employees. Focus on actions like simplifying approval steps, fixing broken integrations, or rewriting confusing docs. Track whether changes reduce time-to-complete or increase successful outcomes.
Share outcomes and iterate
Run a recurring adoption review (biweekly or monthly). Keep it practical: what changed, what moved, what will we try next. Publish a small iteration plan and close the loop with teams so they see progress—and stay engaged.
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
How should we define “adoption” for an internal tool?
Adoption is usually a mix of activation, usage, and retention.
- Activation: the first meaningful moment of value (e.g., “submitted first request”).
- Usage: ongoing actions that represent real work (not just logins).
- Retention: continued use over time (e.g., active in 3 of last 4 weeks).
Write these definitions down and use them as requirements for what your app must measure.
What decisions should an internal adoption tracking app support?
Start by listing the decisions the tracking app should make easier, such as:
- Where to focus training/enablement (who stalls after activation)
- What to prioritize on the roadmap (features used vs. avoided)
- Whether to change access/permissions (who needs the tool, who doesn’t)
- When to invest in (error spikes, retries, stalled workflows)
Which metrics should we start with for adoption tracking?
A practical MVP set is:
- Activated users (count or % who reached first value)
- WAU/MAU (habitual vs. occasional use)
- Retention (cohorts returning in week 2, week 4, etc.)
- Time-to-first-value (TTFV) (how long to reach first meaningful outcome)
These four cover the funnel from first value to sustained use without drowning you in charts.
Should we track events, page views, or backend logs?
Track meaningful workflow actions, not everything.
- Use for actions/state changes like , , .
What does a good event taxonomy look like for internal tools?
Use a consistent event naming convention (e.g., verb_noun) and require a small set of properties.
Minimum recommended fields:
event_nametimestamp(UTC)- (stable)
How should we handle user IDs and tool identifiers?
Make identifiers stable and non-semantic.
- Use a UUID
user_idmapped to an immutable IdP identifier (e.g., OIDC subject). - Use a UUID
tool_id(don’t key off tool names). - Avoid
anonymous_idunless you truly need pre-login tracking.
This prevents dashboards from breaking when emails, names, or tool labels change.
What’s the best way to instrument data collection reliably?
Use a hybrid model for reliability:
- Client-side events for UI intent (clicks, filter changes) with minimal noise.
- Server-side events for authoritative actions (record created, approval completed).
Add batching, retry with backoff, and a small local queue to reduce event loss. Also ensure analytics failures don’t block business actions.
How do we implement roles and access control without creating trust issues?
Keep roles simple and scope-based:
- Admin: global settings and identity connections
- Tool owner: manages tracking/dashboards for a specific tool
- Manager: views only their org unit/team
- Viewer: read-only dashboards
Restrict exports the same way (CSV is a common leak path), and add audit logs for role changes, settings edits, sharing, exports, and API token creation.
How do we address employee privacy and compliance in internal analytics?
Design for privacy by default:
- Track actions and outcomes, not content employees type.
- Avoid free-form text, message bodies, attachments, search queries, and full URLs with sensitive parameters.
- Provide aggregated views by default and require approvals for identifiable drill-down.
- Use small-group suppression (e.g., hide breakdowns where group size is < 5).
Publish a clear notice and an internal FAQ (e.g., at /internal-analytics-faq) explaining what’s tracked and why.
What dashboards and reports actually drive action (not just charts)?
Start with a few action-oriented views:
- Adoption funnel: eligible → invited → first use → activated → power users
- Trends: WAU/MAU, activation rate, key event counts (with comparison periods)
- Retention cohorts: week 2/week 4 return rates by start cohort
Add drill-downs by tool and segment (department/role/location), and surface “top opportunities” like low activation teams or post-release drops. Keep exports permission-checked and avoid row-level employee data by default.