ਲਕਸ਼ ਅਤੇ ਸਕੋਪ ਤੈਅ ਕਰੋ (ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਲਈ)
ਕੋਈ ਮੈਟ੍ਰਿਕ ਚੁਣਨ ਜਾਂ ਡੈਸ਼ਬੋਰਡ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਫ਼ੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਰਿਲਾਇਬਿਲਟੀ ਐਪ ਕਿਨ੍ਹਾਂ ਚੀਜ਼ਾਂ ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਹੈ — ਅਤੇ ਕਿਹੜੀਆਂ ਚੀਜ਼ਾਂ ਲਈ ਨਹੀਂ। ਇੱਕ ਸਪਸ਼ਟ ਸਕੋਪ ਟੂਲ ਨੂੰ ਹਰ ਚੀਜ਼ ਦਾ “ops portal” ਬਣਨ ਤੋਂ ਰੋਕਦਾ ਹੈ ਜਿਸ 'ਤੇ ਕੋਈ ਭਰੋਸਾ ਨਹੀਂ ਕਰਦਾ।
ਤੁਸੀਂ ਕੀ ਟ੍ਰੈਕ ਕਰ ਰਹੇ ਹੋ ਇਹ ਪਰਿਭਾਸ਼ਤ ਕਰੋ
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਉਹਨਾਂ اندرੂਨੀ ਟੂਲਾਂ ਦੀ ਲਿਸਟ बनਾਓ ਜਿਨ੍ਹਾਂ ਨੂੰ ਐਪ ਕਵਰ ਕਰੇਗੀ (ਉਦਾਹਰਨ: ticketing, payroll, CRM ਇਨਟਿਗ੍ਰੇਸ਼ਨ, ਡੇਟਾ ਪਾਈਪਲਾਈਨ) ਅਤੇ ਉਹ ਟੀਮਾਂ ਜੋ ਇਹਨਾਂ ਦੀ ਮਾਲਕੀ ਜਾਂ ਨਿਰਭਰਤਾ ਰੱਖਦੀਆਂ ਹਨ। ਸਰਹੱਦਾਂ ਬਾਰੇ ਸਪਸ਼ਟ ਹੋਵੋ: “customer-facing website” ਹੋ ਸਕਦਾ ਹੈ ਬਾਹਰ-ਦੇ-ਸਕੋਪ ਹੋਵੇ, ਜਦਕਿ “internal admin console” ਅੰਦਰ ਹੋਵੇ।
ਇੱਥੇ “ਰਿਲਾਇਬਿਲਟੀ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਇਹ ਨਾਲ ਸਹਿਮਤੀ ਕਰੋ
ਵੱਖ-ਵੱਖ ਸੰਗਠਨਾਂ ਵਿੱਚ ਇਸ ਸ਼ਬਦ ਦਾ ਵੱਖਰਾ ਅਰਥ ਹੁੰਦਾ ਹੈ। ਆਪਣੀ ਕਾਰਜਕਾਰੀ ਪਰਿਭਾਸ਼ਾ ਸਧੀ ਭਾਸ਼ਾ ਵਿੱਚ ਲਿਖੋ—ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਮਿਲਾਝੁਲ ਹੁੰਦੀ ਹੈ:\n\n- Availability: ਕੀ ਲੋਕ ਇਸਨੂੰ ਜ਼ਰੂਰਤ ਵੇਲੇ ਪੁੱਜ ਸਕਦੇ ਹਨ?\n- Latency: ਕੀ ਇਹ ਯੂਜ਼ ਕਰਨ ਲਈ ਪਰਯਾਪਤ ਤੇਜ਼ ਹੈ?\n- Errors: ਕੀ ਇਹ ਐਸੇ ਤਰੀਕੇ ਨਾਲ ਫੇਲ ਹੁੰਦਾ ਹੈ ਜੋ ਯੂਜ਼ਰ ਨੋਟਿਸ ਕਰਦੇ ਹਨ (ਟਾਈਮਆਉਟ, ਜੌਬ ਫੇਲ, ਗਲਤ ਰਿਸਪਾਂਸ)?\n\nਜੇ ਟੀਮਾਂ ਸਹਿਮਤ ਨਹੀਂ ਹੁੰਦੀਆਂ ਤਾਂ ਤੁਹਾਡੀ ਐਪ ਸੇਬਦੀਆਂ ਨਾਲ ਬਦਲੀਆਂ ਹੋਇਆਂ ਮਿਆਦਾਂ ਦੀ ਤੁਲਨਾ ਕਰੇਗੀ।
ਉਹ ਨਤੀਜੇ ਤੈਅ ਕਰੋ ਜੋ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ
1–3 ਮੁੱਖ ਨਤੀਜੇ ਚੁਣੋ, ਉਦਾਹਰਨ ਲਈ:\n\n- ਮੁੱਦਿਆਂ ਦੀ ਤੇਜ਼ੀ ਨਾਲ ਪਹਿਚਾਣ (ਨੋਟਿਸ ਕਰਨ ਦਾ ਸਮਾਂ ਘੱਟ ਹੋਵੇ)\n- ਮੈਨੇਜਰਾਂ ਅਤੇ ਹਿੱਸੇਦਾਰਾਂ ਲਈ ਵਧੇਰੇ ਸਪਸ਼ਟ ਰਿਪੋਰਟਿੰਗ\n- ਬਿਹਤਰ ਫਾਲੋ-ਅਪ ਰਾਹੀਂ ਦੁਹਰਾਈ ਗਈਆਂ ਘਟਨਾਵਾਂ ਘੱਟ ਹੋਣ\n\nਇਹ ਨਤੀਜੇ ਬਾਅਦ ਵਿੱਚ ਇਹ ਚੁਣਨਗੇ ਕਿ ਤੁਸੀਂ ਕੀ ਮਾਪਦੇ ਹੋ ਅਤੇ ਇਹ ਕਿਵੇਂ ਪੇਸ਼ ਕੀਤਾ ਜਾਵੇ।
ਯੂਜ਼ਰਾਂ ਅਤੇ ਭੂਮਿਕਾਵਾਂ ਦੀ ਪਛਾਣ ਕਰੋ
ਲਿਸਟ ਬਣਾਓ ਕਿ ਕੌਣ ਐਪ ਵਰਤੇਗਾ ਅਤੇ ਉਹ ਉਹਨਾਂ ਦੇ ਫੈਸਲੇ ਕੀ ਹਨ: ਇੰਜੀਨੀਅਰ ਜੋ ਇਨਸਿਡੈਂਟ ਦੀ ਜਾਂਚ ਕਰਦੇ ਹਨ, ਸਪੋਰਟ ਜੋ ਮੁੱਦੇ escalate ਕਰਦਾ ਹੈ, ਮੈਨੇਜਰ ਜੋ ਰੁਝਾਨ ਵੇਖਦੇ ਹਨ, ਅਤੇ ਹਿੱਸੇਦਾਰ ਜੋ ਸਥਿਤੀ ਅਪਡੇਟ ਚਾਹੁੰਦੇ ਹਨ। ਇਹ ਟਰਮੀਨੋਲੋਜੀ, permissions, ਅਤੇ ਹਰ ਦ੍ਰਿਸ਼ ਵਿਚ ਦਿੱਖ ਦੇ ਪੱਧਰ ਨੂੰ ਆਕৃত ਕਰੇਗਾ।
ਉਹ ਰਿਲਾਇਬਿਲਟੀ ਮੈਟ੍ਰਿਕ ਚੁਣੋ ਜੋ ਮਾਇਨੇ ਰੱਖਦੇ ਹਨ (SLIs/SLOs)
ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਸਿਰਫ਼ ਤਾਂ ਹੀ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਹਰ ਕੋਈ ਇਹ ਸਮਝਦਾ ਹੈ ਕਿ “ਚੰਗਾ” ਕੀ ਹੈ। ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਤਿੰਨ ਸਮਾਨ-ਸੁਨ੍ਹੇ ਹੋਏ ਸ਼ਬਦਾਂ ਨੂੰ ਵੱਖਰਾ ਕਰੋ।
SLI vs SLO vs SLA (ਸਧਾਰਨ ਭਾਸ਼ਾ)
ਇੱਕ SLI (Service Level Indicator) ਇਕ ਮਾਪ ਹੈ: “ਕਿੰਨੇ ਪ੍ਰਤੀਸ਼ਤ ਰਿਕੁਐਸਟ ਸਫਲ ਹੋਏ?” ਜਾਂ “ਪੰਨੇ ਲੋਡ ਹੋਣ ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਿਆ?”
ਇੱਕ SLO (Service Level Objective) ਉਸ ਮਾਪ ਲਈ ਲਕਸ਼ ਹੈ: “30 ਦਿਨਾਂ ਵਿੱਚ 99.9% ਸਫਲਤਾ।”
ਇੱਕ SLA (Service Level Agreement) ਇੱਕ ਵਾਅਦਾ ਹੁੰਦਾ ਹੈ ਜਿਸ ਦੇ ਨਤੀਜੇ ਹੁੰਦੇ ਹਨ, ਆਮ ਤੌਰ 'ਤੇ ਬਾਹਰੀ-ਚੁਕਤ (ਕ੍ਰੈਡਿਟ, ਪੈਨਲਟੀ)। ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਲਈ, ਤੁਸੀਂ ਅਕਸਰ SLOs ਸੈਟ ਕਰੋਗੇ ਬਿਨਾਂ ਰਸਮੀ SLAs ਦੇ—ਇਸ ਨਾਲ ਉਮੀਦੇ ਮਿਲਦੀਆਂ ਹਨ ਬਿਨਾਂ ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਕਾਨੂਨੀ ਢਾਂਚੇ ਵਿੱਚ ਬਦਲੇ।
ਹਰ ਟੂਲ ਲਈ ਛੋਟਾ, ਸਥਿਰ SLI ਸੈੱਟ ਚੁਣੋ
ਇਸਨੂੰ ਟੂਲਾਂ ਵਿੱਚ ਤੁਲਨਾਤਮਕ ਅਤੇ ਸਮਝਣ ਵਿੱਚ ਆਸਾਨ ਰੱਖੋ। ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਬੇਸਲਾਈਨ ਇਹ ਹੈ:\n\n- Uptime/availability: ਕੀ ਟੂਲ ਪਹੁੰਚਯੋਗ ਸੀ?\n- Response time: ਮੁੱਖ ਪੰਨੇ ਜਾਂ endpoints ਕਿੰਨੇ ਤੇਜ਼ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰਦੇ ਹਨ?\n- Error rate: ਚੈਕਾਂ ਜਾਂ ਰਿਕੁਐਸਟਾਂ ਦਾ ਕਿਹੜਾ ਹਿੱਸਾ ਫੇਲ ਹੋਇਆ (5xx, ਟਾਈਮਆਉਟ, ਜਾਣੇ-ਪਛਾਣੇ ਫੇਲ ਸਟੇਟ)?\n\nਜੋੜੋ ਨਾ ਜਦ ਤੱਕ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕਣ: “ਇਹ ਮੈਟ੍ਰਿਕ ਕਿਹੜਾ ਫੈਸਲਾ ਚਲਾਏਗੀ?”
ਲੋਕ ਜਿਵੇਂ ਸੋਚਦੇ ਹਨ ਉਸ ਅਨੁਸਾਰ ਵਕਤ ਖਿੜਕੀਆਂ ਚੁਣੋ
ਰੋਲਿੰਗ ਵਿੰਡੋ ਵਰਤੋ ਤਾਂ ਜੋ ਸਕੋਰਕਾਰਡ ਲਗਾਤਾਰ ਅਪਡੇਟ ਹੁੰਦੇ ਰਹਿਣ:\n\n- 7 days: ਰੈਗਰੇਸ਼ਨ ਤੇਜ਼ੀ ਨਾਲ ਪਕੜੇ ਜਾਣ\n- 30 days: ਮਹੀਨਾਵਾਰ ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਰੁਝਾਨ\n- 90 days: ਤਿਮਾਹੀਵਾਰ ਸਥਿਰਤਾ\n
ਇਨਸਿਡੈਂਟਾਂ ਨੂੰ ਸਪਸ਼ਟ ਸੈਵਿਰਟੀ ਪੱਧਰਾਂ ਨਾਲ ਪਰਿਭਾਸ਼ਤ ਕਰੋ
ਤੁਹਾਡੀ ਐਪ ਮੈਟ੍ਰਿਕਸ ਨੂੰ ਕਾਰਵਾਈ ਵਿੱਚ ਬਦਲ ਦੇਣੀ ਚਾਹੀਦੀ ਹੈ। ਸੈਵਿਰਟੀ ਪੱਧਰ (ਉਦਾਹਰਨ: Sev1–Sev3) ਅਤੇ ਸਪਸ਼ਟ ਟ੍ਰਿੱਗਰ ਜਿਵੇਂ ਕਿ:\n\n- Sev1: ਟੂਲ ਡਾਊਨ ਜਾਂ ਨੁਕਸਾਨਪ੍ਰਦ ਵਰਕਫਲੋ X ਮਿੰਟ ਲਈ ਰੁਕਿਆ ਹੋਇਆ\n- Sev2: ਵੱਡੀ ਪੈਮਾਨੇ ਉੱਤੇ ਘਟਾਅ (ਉਦਾਹਰਨ: ਐਰਰ ਰੇਟ Y% ਤੋਂ ਉੱਪਰ Z ਮਿੰਟ ਲਈ)\n- Sev3: ਨਕਾਸ਼ੀ ਸਮੱਸਿਆਵਾਂ ਜਾਂ ਅੰਤਰਾਲੀ ਫੇਲਯੁਰ\n\nਇਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਲਰਟਿੰਗ, ਇਨਸਿਡੈਂਟ ਟਾਈਮਲਾਈਨ, ਅਤੇ ਐਰਰ ਬਜਟ ਟ੍ਰੈਕਿੰਗ ਨੂੰ ਟੀਮਾਂ ਵਿੱਚ ਸੰਗਤ ਬਨਾਉਂਦੀਆਂ ਹਨ।
ਡਾਟਾ ਸੋਰਸ ਅਤੇ ਇੰਜੈਸਟਸ਼ਨ ਨਿਯੋਜਨ ਯੋਜਨਾ ਬਣਾਓ
ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਐਪ ਦੇ ਨਾਲ ਖਾਡੇ ਡਾਟਾ ਦੀ ਭਰੋਸੇਯੋਗਤਾ ਮੁਖ ਹੈ। ਇੰਜੈਸਟਸ਼ਨ ਪਾਈਪਲਾਈਨਾਂ ਤਿਆਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਹਰ ਸਿਗਨਲ ਦਾ ਨਕਸ਼ਾ ਬਣਾਓ ਜਿਸਨੂੰ ਤੁਸੀਂ “ਸੱਚ” ਮੰਨੋਗੇ ਅਤੇ ਲਿਖੋ ਕਿ ਉਹ ਕਿਹੜਾ ਸਵਾਲ ਜਵਾਬ ਦੇਂਦਾ ਹੈ (ਉਪਲਬਧਤਾ, ਲੇਟੈਂਸੀ, ਐਰਰ, ਡਿਪਲੌਇ ਇੰਪੈਕਟ, ਇਨਸਿਡੈਂਟ ਰਿਸਪਾਂਸ)।
ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਮੌਜੂਦ ਡਾਟਾ ਸੋਰਸ ਮੈਪ ਕਰੋ
ਅਕਸਰ ਟੀਮ ਬੇਸਿਕ ਨੂੰ ਇਹਨਾਂ ਨਾਲ ਕਵਰ ਕਰ ਸਕਦੀਆਂ ਹਨ:\n\n- Status checks / synthetic probes (ਅਪਟਾਈਮ ਅਤੇ ਬੇਸਿਕ ਰਿਸਪਾਂਸ ਟਾਈਮ)\n- Metrics (ਲੇਟੈਂਸੀ percentiles, ਐਰਰ ਰੇਟ, ਸੈਚੂਰੇਸ਼ਨ)\n- Logs (ਐਰਰ ਗਿਣਤ, ਟੌਪ ਫੇਲ ਹੋਣ ਵਾਲੇ endpoints)\n- Traces (ਕਿੱਥੇ ਲੇਟੈਂਸੀ ਡੁੱਬਦਾ ਹੈ dependencies ਵਿੱਚ)\n- Ticketing/incident tools (ਇਨਸਿਡੈਂਟ ਸ਼ੁਰੂ/ਅੰਤ, ਸੈਵਿਰਟੀ, ਮਾਲਿਕ, ਪੋਸਟਮੋਰਟਮ ਲਿੰਕ)
ਉਹ ਸਿਸਟਮ ਸਪਸ਼ਟ ਕਰੋ ਜੋ ਪ੍ਰਮਾਣਿਕ ਹਨ। ਉਦਾਹਰਨ ਲਈ, ਤੁਹਾਡਾ “uptime SLI” ਸਿਰਫ synthetic probes ਤੋਂ ਆ ਸਕਦਾ ਹੈ, ਨਾ ਕਿ ਸਰਵਰ ਲੌਗਸ ਤੋਂ।
ਪੂਸ਼ ਬਨਾਮ ਪੁੱਲ ਫੈਸਲਾ ਕਰੋ (ਅਤੇ ਕਿੰਨੀ ਵਾਰ)
- Pull APIs ਲਈ (Prometheus, cloud monitoring, ticketing): ਐਪ ਨਿਯਮਤ ਤੌਰ 'ਤੇ ਪੋਲ ਕਰੇ।\n- Push ਉੱਚ-ਵਾਲੀਉਮ ਇਵੈਂਟਾਂ ਲਈ ਭੇਜਣ ਵਧੀਆ ਹੁੰਦਾ ਹੈ (deploys, incidents, alerts): ਸਿਸਟਮ ਵੈਬਹੁਕ/ਇਵੈਂਟ ਭੇਜਦੇ ਹਨ।
ਉਪਦੇਸ਼ ਵਾਰੰਟੀ ਅਨੁਸਾਰ ਅਪਡੇਟ ਫ੍ਰੀਕਵੈਂਸੀ ਰੱਖੋ: ਡੈਸ਼ਬੋਰਡ 1–5 ਮਿੰਟ 'ਚ ਰਿਫ੍ਰੈਸ਼ ਹੋ ਸਕਦੇ ਹਨ, ਜਦਕਿ ਸਕੋਰਕਾਰਡ ਘੰਟੇਵਾਰ/ਰੋਜ਼ਾਨਾ ਗਣਨਾ ਕੀਤੇ ਜਾਣ।
ਆਈਡੀਫਾਇਰ ਅਤੇ ਮਾਲਕੀ ਨੂੰ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ
Tools/services, environments (prod/stage), ਅਤੇ owners ਲਈ ਇਕਸਾਰ IDs ਬਣਾਓ। ਪਹਿਲਾਂ ਹੀ naming ਨਿਯਮਾਂ 'ਤੇ ਸਹਿਮਤੀ ਕਰੋ ਤਾਂ ਕਿ “Payments-API”, “payments_api”, ਅਤੇ “payments” ਤਿੰਨ ਵੱਖਰੇ ਇਕਾਈਆਂ ਨਾ ਬਣ ਜਾਣ।
ਰਿਟੇਨਸ਼ਨ ਅਤੇ ਪ੍ਰਾਈਵੇਸੀ
ਇਹ ਯੋਜਨਾ ਬਣਾਓ ਕਿ ਕਿੰਨਾ ਸਮਾਂ ਕੁਝ ਰੱਖਣਾ ਹੈ (ਉਦਾਹਰਨ: ਰੌ ਕੁਈ ਇਵੈਂਟ 30–90 ਦਿਨ, ਡੇਲੀ ਐਗਰੀਗੇਟ 12–24 ਮਹੀਨੇ). ਸੰਵੇਦਨਸ਼ੀਲ ਪੇਲੋਡ ਇੰਜੈਸਟ ਨਾ ਕਰੋ; ਸਿਰਫ ਉਹ ਮੈਟਾਡੇਟਾ ਰੱਖੋ ਜੋ ਰਿਲਾਇਬਿਲਟੀ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਲੋੜੀਂਦਾ ਹੈ (ਟਾਈਮਸਟੈਂਪ, ਸਟੇਟਸ ਕੋਡ, ਲੇਟੈਂਸੀ ਬਕੇਟ, ਇਨਸਿਡੈਂਟ ਟੈਗ).
ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਡੇਟਾਬੇਸ ਸਕੀਮਾ ਡਿਜ਼ਾਇਨ ਕਰੋ
ਤੁਹਾਡਾ ਸਕੀਮਾ ਦੋ ਚੀਜ਼ਾਂ ਆਸਾਨ ਬਣਾਉਣੇ ਚਾਹੀਦੇ ਹਨ: ਰੋਜ਼ਾਨਾ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦੇਣਾ (“ਕੀ ਇਹ ਟੂਲ ਸਿਹਤਮੰਦ ਹੈ?”) ਅਤੇ ਇਨਸਿਡੈਂਟ ਦੌਰਾਨ ਕੀ ਹੋਇਆ ਇਹ ਦੁਬਾਰਾ ਤਿਆਰ ਕਰਨਾ (“ਲੱਛਣ ਕਦੋਂ ਸ਼ੁਰੂ ਹੋਏ, ਕਿਸ ਨੇ ਕੀ ਬਦਲਿਆ, ਕਿਸ ਅਲਰਟ ਨੇ ਫਾਇਰ ਕੀਤਾ?”)। ਇੱਕ ਛੋਟਾ ਕੋਰ ਐਂਟਿਟੀ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਰਿਸ਼ਤੇ ਸਪਸ਼ਟ ਰੱਖੋ।
ਕੋਰ ਐਂਟਿਟੀਜ਼ (ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਨਿਊਨਤਮ)
- Tool/Service: ਟਰੇਕ ਕੀਤਾ ਜਾ ਰਿਹਾ اندرੂਨੀ ਟੂਲ (name, description, environment, criticality).\n- Check: ਇੱਕ ਖਾਸ uptime ਜਾਂ synthetic check ਜੋ ਇਕ ਟੂਲ ਨਾਲ ਜੁੜਿਆ ਹੈ (type, target URL, schedule, enabled).\n- Metric: ਟਾਈਮ-ਸੀਰੀਜ਼ ਡਾਟਾਪੌਇੰਟ (ਲੇਟੈਂਸੀ, success rate, error count) ਜੋ ਟੂਲ ਜਾਂ check ਨਾਲ ਜੁੜੇ ਹੁੰਦੇ ਹਨ.\n- SLO: ਟਾਰਗੇਟ ਅਤੇ ਮੁਲਾਂਕਣ ਵਿੰਡੋ (ਉਦਾਹਰਨ: 30 ਦਿਨ 'ਤੇ 99.9%) ਨਾਲ error budget settings.\n- Incident: ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਪ੍ਰਭਾਵਤ ਘਟਨਾ (severity, status, start/end, summary).\n- Event: ਇਨਸਿਡੈਂਟ ਲਈ ਟਾਈਮਲਾਈਨ ਰਿਕਾਰਡ (ਸਟੇਟਸ ਚੇਂਜ, ਨੋਟਸ, ਅਲਰਟ ਪ੍ਰਾਪਤ, mitigation ਲਾਗੂ).\n- Owner: ਟੀਮ ਜਾਂ ਵਿਅਕਤੀ ਜੋ ਟੂਲ ਲਈ ਜਿੰਮੇਵਾਰ ਹੈ।
ਰਿਸ਼ਤੇ ਜੋ ਕਵੈਰੀਆਂ ਨੂੰ ਸਧਾਰਨ ਰੱਖਣ
ਇੱਕ ਕਾਰਗਰ ਬੇਸਲਾਈਨ ਇਹ ਹੈ:\n\n- Tool has many Checks (ਅਤੇ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਕਈ SLOs ਹੋਣ)।\n- Check has many Metrics (ਜਾਂ metric streams)।\n- Incident belongs to Tool, ਅਤੇ Incident has many Events ਲਈ ਟਾਈਮਲਾਈਨ।\n- Tool belongs to Owner (ਜਾਂ many-to-many ਜੇ ਸ਼ੇਅਰਡ ਮਾਲਕੀ ਆਮ ਹੋਵੇ)।
ਇਹ structure ਡੈਸ਼ਬੋਰਡਸ ("tool → current status → recent incidents") ਅਤੇ ਡ੍ਰਿੱਲ-ਡਾਊਨ ("incident → events → related checks and metrics") ਨੂੰ ਸਹਾਇਕ ਬਣਾਉਂਦੀ ਹੈ।
ਆਡਿਟ ਫੀਲਡਸ ਅਤੇ ਟੈਗਿੰਗ
ਜਿੱਥੇ ਤੁਹਾਨੂੰ ਜਵਾਬਦੇਹੀ ਅਤੇ ਇਤਿਹਾਸ ਦੀ ਲੋੜ ਹੋਵੇ ਓਥੇ ਆਡਿਟ ਫੀਲਡਸ ਸ਼ਾਮਿਲ ਕਰੋ:\n\n- created_by, created_at, updated_at\n- status ਨਾਲ status change tracking (Event table ਜਾਂ dedicated history table ਵਿੱਚ)
ਅੰਤ ਵਿੱਚ, ਫਿਲਟਰਿੰਗ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਲਈ ਲਚਕੀਲੇ tags ਸ਼ਾਮਿਲ ਕਰੋ (ਉਦਾਹਰਨ: team, criticality, system, compliance). ਇੱਕ tool_tags join table (tool_id, key, value) ਟੈਗਿੰਗ ਨੂੰ ਸਥਿਰ ਰੱਖਦੀ ਹੈ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਸਕੋਰਕਾਰਡ ਅਤੇ ਰੋਲਅੱਪਸ ਸੌਖੇ ਬਣਾਉਂਦੀ ਹੈ।
ਟੈਕ ਸਟੈਕ ਤੇ ਡਿਪਲੌਇਮੈਂਟ ਮਾਡਲ ਚੁਣੋ
ਤੁਹਾਡਾ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਰ "ਸਧਾਰਨ" ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਚਲਾਉਣ ਵਿੱਚ ਆਸਾਨ, ਬਦਲਣ ਵਿੱਚ ਆਸਾਨ, ਅਤੇ ਸਮਰਥਨ ਕਰਨ ਵਿੱਚ ਆਸਾਨ। "ਸਹੀ" ਸਟੈਕ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਹੁੰਦਾ ਹੈ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਨਰਮ ਦਿਲ ਨਾਲ ਰੱਖ ਸਕੇ।
ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਪਹਿਲਾਂ ਹੀ ਸ਼ਿਪ ਕਰਦੀ ਹੈ ਉਸ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
ਆਪਣੀ ਟੀਮ ਨੂੰ ਜਾਣੂ mainstream web framework ਚੁਣੋ—Node/Express, Django, ਜਾਂ Rails ਸਭ ਵਧੀਆ ਵਿਕਲਪ ਹਨ। ਤਰਜੀਹ ਦਿਓ:\n\n- ਸਪਸ਼ਟ convention (ਤਾਂ ਜੋ ਨਵੇਂ ਯੋਗਦਾਤਾ ਖੋ ਜਾ ਨਾ ਕਰਨ)\n- auth, background jobs, ਅਤੇ charts ਲਈ ਵਧੀਆ libraries\n- predictable upgrade paths
ਜੇ ਤੁਸੀਂ ਅੰਦਰੂਨੀ ਸਿਸਟਮਾਂ (SSO, ticketing, chat) ਨਾਲ ਇੰਟਿਗ੍ਰੇਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਉਹ ecosystem ਚੁਣੋ ਜਿੱਥੇ ਉਹ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਸਭ ਤੋਂ ਆਸਾਨ ਹੋਣ।
ਜੇ ਤੁਸੀਂ ਪਹਿਲੀ iteration ਤੇ ਤੇਜ਼ੀ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗਾ vibe-coding ਪਲੇਟਫਾਰਮ ਇੱਕ ਪ੍ਰਾਇਗਟਿਕ ਸ਼ੁਰੂਆਤ ਹੋ ਸਕਦਾ ਹੈ: ਤੁਸੀਂ ਆਪਣੀਆਂ ਐਂਟਿਟੀਜ਼ (tools, checks, SLOs, incidents), ਵਰਕਫਲੋ (alert → incident → postmortem), ਅਤੇ ਡੈਸ਼ਬੋਰਡਸ ਚੈਟ ਵਿੱਚ ਵੇਰਵਾ ਕਰਕੇ ਇੱਕ ਕੰਮ ਕਰਦੀਆਂ ਵੈੱਬ ਐਪ scaffold ਜਨਰੇਟ ਕਰਵਾ ਸਕਦੇ ਹੋ। Koder.ai ਆਮ ਤੌਰ 'ਤੇ frontend 'ਤੇ React ਅਤੇ backend 'ਤੇ Go + PostgreSQL ਨਿਸ਼ਾਨਾ ਰੱਖਦਾ ਹੈ, ਜੋ ਕਿ ਬਹੁਤ ਟੀਮਾਂ ਲਈ “ਸਧਾਰਨ, ਰੱਖ-ਰਖਾਅ ਯੋਗ” ਡਿਫਾਲਟ ਸਟੈਕ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ—ਅਤੇ ਤੁਸੀਂ ਜਦੋਂ ਚਾਹੋ ਸਰੋਤ ਕੋਡ ਐਕਸਪੋਰਟ ਵੀ ਕਰ ਸਕਦੇ ਹੋ।
ਪਹਿਲਾਂ ਡੇਟਾਬੇਸ, ਫਿਰ ਸਹਾਇਕ ਪੀਸੇ ਜੋੜੋ
ਅਕਸਰ اندرੂਨੀ ਰਿਲਾਇਬਿਲਟੀ ਐਪਾਂ ਲਈ PostgreSQL ਡੀਫਾਲਟ ਲਈ ਠੀਕ ਰਹਿੰਦਾ ਹੈ: ਇਹ ਰਿਲੇਸ਼ਨਲ ਰਿਪੋਰਟਿੰਗ, ਸਮੇਂ-ਆਧਾਰਿਤ ਕਵੈਰੀਆਂ, ਅਤੇ ਆਡੀਟਿੰਗ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸੰਭਾਲਦਾ ਹੈ।
ਅਤਿਰਿਕਤ ਕੰਪੋਨੈਂਟ ਉਸ ਵੇਲੇ ਜੋੜੋ ਜਦੋਂ ਉਹ ਅਸਲ ਸਮੱਸਿਆ ਹੱਲ ਕਰਨ:
- Cache (ਉਦਾਹਰਨ: Redis) ਜੇ ਡੈਸ਼ਬੋਰਡ ਧੀਮਾ ਹੋ ਜਾਂ upstream APIs ਨਾਲ rate-limited ਹੋ\n- Queue/background jobs (Redis + worker, Sidekiq, Celery, BullMQ) uptime polling, notifications ਭੇਜਣ ਅਤੇ رپورਟਸ ਬਣਾਉਣ ਲਈ
ਹੋਸਟਿੰਗ ਅਤੇ ਡਿਪਲੌਇਮੈਂਟ ਮਾਡਲ
ਚੁਣੋ:\n\n- Internal cloud / Kubernetes ਜਦੋਂ ਤੁਹਾਨੂੰ ਅੰਦਰੂਨੀ ਸੇਵਾਵਾਂ ਤੱਕ ਗਹਿਰੀ ਨੈੱਟਵਰਕ ਪਹੁੰਚ ਦੀ ਲੋੜ ਹੋਵੇ\n- PaaS ਜਦੋਂ ਤੁਸੀਂ ਸਾਦਾ ਓਪਰੇਸ਼ਨ ਅਤੇ ਤੇਜ਼ iteration ਚਾਹੁੰਦੇ ਹੋ
ਜੋ ਵੀ ਤੁਹਾੰ ਚੁਣੋ, dev/staging/prod ਨੂੰ استاندਰਡ ਕਰੋ ਅਤੇ deployments ਨੂੰ automate (CI/CD) ਕਰੋ, ਤਾਂ ਜੋ ਬਦਲਾਅ ਸੁਚੇਤ ਰੀਤੀ ਨਾਲ ਨੰਬਰਾਂ ਨੂੰ ਬਦਲਣ ਨਾ ਦੇਵੇ। ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਪਲੇਟਫਾਰਮ ਪਹੁੰਚ (ਤਿੰਨਾਂ ਸ਼ਾਮਿਲ Koder.ai) ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋ, ਤਾਂ environment separation, deployment/hosting, ਅਤੇ fast rollback (snapshots) ਵਰਗੀ ਖੂਬੀਆਂ ਦੇਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ tracker ਨੂੰ ਬਿਨਾਂ ਤਬਾਹ ਕੀਤੇ iterate ਕਰ ਸਕੋ।
ਕਨਫਿਗਰੇਸ਼ਨ ਪ੍ਰਬੰਧਨ ਜੋ ਤੁਸੀਂ ਭਰੋਸਾ ਕਰ ਸਕੋ
ਇੱਕ ਥਾਂ 'ਤੇ configuration ਦਸਤਾਵੇਜ਼ ਬਣਾਓ: environment variables, secrets, ਅਤੇ feature flags. ਇੱਕ ਸਪਸ਼ਟ “local ਚਲਾਉਣ ਲਈ ਕਿਵੇਂ” ਗਾਈਡ ਅਤੇ ਇਕ ਘੱਟੋ-ਘੱਟ ਰਨਬੁੱਕ (ਜੇ ingestion ਰੁਕ ਜਾਏ, queue ਭਰ ਜਾਏ, ਜਾਂ ਡੀਬੀ ਲਿਮਿਟਸ ਹਿੱਟ ਹੋਣ) ਰੱਖੋ। ਇੱਕ ਛੋਟੀ ਪੇਜ਼ docs ਵਿੱਚ ਅਕਸਰ ਕਾਫੀ ਹੁੰਦੀ ਹੈ।
UX ਡਿਜ਼ਾਇਨ: ਡੈਸ਼ਬੋਰਡ, ਡ੍ਰਿੱਲ-ਡਾਊਨ, ਅਤੇ ਵਰਕਫਲੋ
Deploy and share internally
Host your app with built-in deployment, then add a custom domain when you're ready.
ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਐਪ ਤਦ ਹੀ ਸਫਲ ਹੁੰਦੀ ਹੈ ਜਦ ਲੋਕ ਦੋ ਸਵਾਲ ਸਕੇਤੀ ਸੈਕਿੰਡਾਂ ਵਿੱਚ ਜਵਾਬ ਦੇ ਸਕਣ: “ਕੀ ਅਸੀਂ ਠੀਕ ਹਾਂ?” ਅਤੇ “ਅਗਲਿਆ ਕਦਮ ਕੀ ਹੈ?” ਇਸ ਲਈ ਅਵਲੋਕਨ-ਪ੍ਰਧਾਨ ਸਕਰੀਨਾਂ ਬਣਾਓ: overview → specific tool → specific incident.
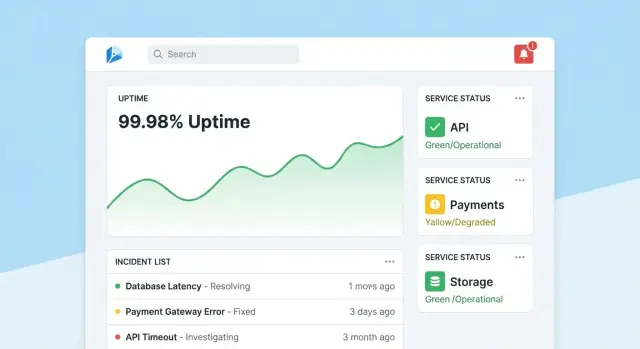
ਹੋਮਪੇਜ: ਤੇਜ਼ ਸਿਹਤ ਰੀਡ
ਹੋਮਪੇਜ ਨੂੰ ਇੱਕ ਸੰਕੁਚਿਤ command center ਬਣਾਓ। ਮੁੱਖ ਰੱਖੋ overall health summary (ਉਦਾਹਰਨ: SLO ਪੂਰੇ ਕਰਨ ਵਾਲੇ ਟੂਲਾਂ ਦੀ ਗਿਣਤੀ, active incidents, ਸਭ ਤੋਂ ਵੱਡੇ ਰਿਸਕ), ਫਿਰ ਤਾਜ਼ਾ ਇਨਸਿਡੈਂਟ ਅਤੇ ਅਲਰਟ ਦਿਖਾਓ status badges ਨਾਲ।
ਡਿਫਾਲਟ ਵਿਉ ਸ਼ਾਂਤ ਰੱਖੋ: ਸਿਰਫ਼ ਉਹੀ ਚੀਜ਼ ਹਾਈਲਾਈਟ ਕਰੋ ਜਿਸ ਨੂੰ ਧਿਆਨ ਦੀ ਲੋੜ ਹੈ। ਹਰ ਟਾਈਲ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਟੂਲ ਜਾਂ ਇਨਸਿਡੈਂਟ ਦਾ ਸਿੱਧਾ ਡ੍ਰਿੱਲ-ਡਾਊਨ ਦਿਓ।
ਟੂਲ ਪੇਜ਼: ਸਥਿਤੀ ਤੋਂ ਕਾਰਵਾਈ ਤੱਕ
ਹਰ ਟੂਲ ਪੇਜ਼ ਨੂੰ ਇਹ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ “ਕੀ ਇਹ ਟੂਲ ਕਾਫੀ ਭਰੋਸੇਯੋਗ ਹੈ?” ਅਤੇ “ਕਿਉਂ/ਕਿਉਂ ਨਹੀਂ?” ਸ਼ਾਮਿਲ ਕਰੋ:\n\n- ਮੌਜੂਦਾ SLO ਸਥਿਤੀ ਸਾਫ਼ pass/fail ਅਤੇ ਬਚੀ ਹੋਈ error budget ਨਾਲ\n- ਚਾਰਟਸ uptime, latency, ਜਾਂ error rate ਲਈ ਚੁਣੇ ਹੋਏ WIndows ਨਾਲ\n- ਹਾਲੀਆ ਬਦਲਾਅ (deploys, config edits, check updates) ਤਾਂ ਜੋ ਪੈਟਰਨ ਸਪਸ਼ਟ ਹੋਣ\n- ਰਨਬੁੱਕਸ ਅਤੇ ਮਾਲਿਕ: ਇੱਕ ਸਪਸ਼ਟ “ਕੀ ਕਰਨਾ” ਸੈਕਸ਼ਨcontacts ਨਾਲ\n
ਚਾਰਟ ਅਜਿਹੇ ਬਣਾਓ ਜੋ non-experts ਲਈ ਸਪਸ਼ਟ ਹੋਣ: ਯੂਨਿਟਾਂ ਨੂੰ ਲੇਬਲ ਕਰੋ, SLO thresholds ਮਾਰਕ ਕਰੋ, ਅਤੇ ਛੋਟੇ tooltip ਵਿਆਖਿਆਵਾਂ ਜੋੜੋ ਨਾ ਕਿ ਭਾਰੀ ਤਕਨੀਕੀ ਕੰਟਰੋਲ।
ਇਨਸਿਡੈਂਟ ਪੇਜ਼: ਸਾਂਝਾ ਸੰਦਰਭ ਅਤੇ ਟਾਈਮਲਾਈਨ
ਇਨਸਿਡੈਂਟ ਪੇਜ਼ ਇੱਕ ਜੀਵੰਤ ਰਿਕਾਰਡ ਹੈ। ਇਕ ਟਾਈਮਲਾਈਨ ਸ਼ਾਮਿਲ ਕਰੋ (auto-captured events ਜਿਵੇਂ alert fired, acknowledged, mitigated), ਮਨੁੱਖੀ ਅਪਡੇਟ, ਪ੍ਰਭਾਵਿਤ ਯੂਜ਼ਰ, ਅਤੇ ਕੀ ਕੀਤੇ ਗਏ ਕਾਰਵਾਈ।
ਅਪਡੇਟਸ ਪਬਲਿਸ਼ ਕਰਨਾ ਆਸਾਨ ਬਣਾਓ: ਇੱਕ ਟੈਕਸਟ ਬਾਕਸ, ਪੂਰਵ ਨਿਰਧਾਰਤ ਸਥਿਤੀਆਂ (Investigating/Identified/Monitoring/Resolved), ਅਤੇ ਵਿਕਲਪਿਕ ਅੰਦਰੂਨੀ ਨੋਟਸ. ਜਦ ਇਨਸਿਡੈਂਟ ਬੰਦ ਹੋ ਜਾਵੇ, “Start postmortem” ਕਾਰਵਾਈ timeline ਤੋਂ ਤੱਥਾਂ ਨੂੰ prefill ਕਰੇ।
ਐਡਮਿਨ ਪੇਜ਼: ਮਾਲਕੀ ਅਤੇ ਇਕਸਾਰਤਾ
Admins ਲਈ ਸਾਦੇ ਸਕਰੀਨ ਬਣਾਓ ਤਾਂ ਜੋ tools, checks, SLO targets, ਅਤੇ owners manage ਕਰ ਸਕਣ। correctness ਤੇ optimize ਕਰੋ: sensible defaults, validation, ਅਤੇ warnings ਜਦੋਂ ਬਦਲਾਅ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰੇ। ਇਕ ਵਿਸ਼ੇਸ਼ “last edited” ਟ੍ਰੇਲ ਦਿਖਾਓ ਤਾਂ ਜੋ ਲੋਕ ਨੰਬਰਾਂ 'ਤੇ ਭਰੋਸਾ ਕਰਨ।
authentication, permissions, ਅਤੇ audit trails ਲਾਗੂ ਕਰੋ
ਰਿਲਾਇਬਿਲਟੀ ਡਾਟਾ ਤਦ ਹੀ ਕਾਇਮ ਰਹਿੰਦਾ ਹੈ ਜਦੋਂ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਹਰ ਸੋਧ ਨੂੰ ਇੱਕ ਪਛਾਣ ਨਾਲ ਜੋੜਨਾ, ਉੱਚ-ਪ੍ਰਭਾਵ ਵਾਲੀ ਸੋਧਾਂ ਨੂੰ ਸੀਮਿਤ ਕਰਨਾ, ਅਤੇ ਸਪਸ਼ਟ ਇਤਿਹਾਸ ਰੱਖਣਾ ਜੋ ਸਮੀਖਿਆ ਦੌਰਾਨ ਵੇਖਿਆ ਜਾ ਸਕੇ।
Authentication: ਜੋ ਤੁਹਾਡੀ ਕੰਪਨੀ ਪਹਿਲਾਂ ਵਰਤਦੀ ਹੈ ਵਰਤੋ
ਇੱਕ ਅੰਦਰੂਨੀ ਟੂਲ ਲਈ, ਡੀਫਾਲਟ SSO (SAML) ਜਾਂ OAuth/OIDC ਦੀ ਵਰਤੋਂ ਕਰੋ ਆਪਣੇ identity provider (Okta, Azure AD, Google Workspace) ਰਾਹੀਂ। ਇਸ ਨਾਲ password management ਘੱਟ ਹੁੰਦਾ ਹੈ ਅਤੇ onboarding/offboarding ਆਟੋਮੈਟਿਕ ਹੁੰਦਾ ਹੈ।
ਪ੍ਰਾਇਕਟਿਕ ਡੀਟੇਲ:\n\n- IdP ਰਾਹੀਂ MFA ਲਾਜ਼ਮੀ ਕਰੋ (ਫਿਰ ਤੋਂ ਨਵਾਂ ਨ ਬਣਾਓ)\n- IdP groups ਨੂੰ app roles 'ਤੇ login ਤੇ map ਕਰੋ\n- ਛੋਟੀਆਂ session lifetimes ਅਤੇ manual sign-out ਸਹਿਯੋਗ ਕਰੋ
Permissions: role-based access with “protected actions”
ਸਧਾਰਨ roles ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਜ਼ਰੂਰਤ ਤੇ finer-grained ਨਿਯਮ ਜੋੜੋ:\n\n- Viewer: stakeholders ਲਈ read-only dashboards ਅਤੇ scorecards\n- Editor: checks, incidents, ਅਤੇ notes ਬਣਾਉਣ/ਅਪਡੇਟ ਕਰਨ ਵਾਲਾ\n- Admin: SLO definitions, thresholds, integrations, ਅਤੇ user/role mappings manage ਕਰਨ ਵਾਲਾ\n
ਉਹ ਕਾਰਵਾਈਆਂ ਜੋ ਰਿਲਾਇਬਿਲਟੀ ਨਤੀਜਿਆਂ ਜਾਂ ਰਿਪੋਰਟਿੰਗ ਨੈਰੇਟਿਵ ਨੂੰ ਬਦਲ ਸਕਦੀਆਂ ਹਨ ਉਨ੍ਹਾਂ ਨੂੰ ਰੱਖੋ:\n\n- ਕੇਵਲ Admins SLO targets, alert thresholds, ਜਾਂ data-source mappings ਬਦਲ ਸਕਦੇ ਹਨ।\n- ਕਿਸੇ ਨੂੰ ਵੀ ਇਨਸਿਡੈਂਟ ਬੰਦ ਕਰਨ ਜਾਂ "resolved" ਚਿੰਨ੍ਹਨ ਦੀ ਆਗਿਆ ਸੀਮਿਤ ਕਰੋ, ਅਤੇ resolution summary ਲਾਜ਼ਮੀ ਕਰੋ।
Audit trails: ਅਟੱਲ ਇਤਿਹਾਸ
ਹਰ SLO, check, ਅਤੇ incident ਫੀਲਡ ਦੀ ਸੋਧ ਲਈ ਲਾਗ ਰੱਖੋ:\n\n- ਕਿਸਨੇ ਕੀਤਾ (user + role)\n- ਕਦੋਂ ਕੀਤਾ (timestamp)\n- ਕੀ ਬਦਲਿਆ (before/after values)\n- ਕਿੱਥੋਂ ਆਇਆ (UI, API, automation)\n
ਆਡਿਟ ਲੋਗਸ searchable ਅਤੇ relevant detail pages ਤੋਂ ਦਰਸ਼ਾਈਏ (ਉਦਾਹਰਨ: ਇਕ incident ਪੇਜ਼ ਆਪਣੇ ਪੂਰੇ change history ਦਿਖਾਵੇ). ਇਸ ਨਾਲ ਸਮੀਖਿਆਆਂ ਵਾਸਤੇ ਤੱਥ ਆਧਾਰਤ ਰਹਿਣਗੇ ਅਤੇ postmortems ਦੌਰਾਨ ਘੁੰਮਾਫਿਰ ਘੱਟ ਹੋਵੇਗੀ।
ਮਾਨੀਟਰਿੰਗ ਚੈੱਕ ਅਤੇ ਅਪਟਾਈਮ ਸੰਗ੍ਰਹਿ ਬਣਾਓ
ਮਾਨੀਟਰਿੰਗ "ਸੈਂਸਰ ਲੇਅਰ" ਹੈ: ਇਹ ਅਸਲ ਵਿਹਾਰ ਨੂੰ ਡਾਟਾ ਵਿੱਚ ਬਦਲਦਾ ਹੈ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹੋ। ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਲਈ synthetic checks ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਤੇਜ਼ ਰਸਤਾ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਤੁਸੀਂ ਨਿਰਧਾਰਤ ਕਰ ਸਕਦੇ ਹੋ ਕਿ "ਹੈਲਥੀ" ਕੀ ਹੈ।
ਹਰ ਟੂਲ ਲਈ synthetic checks ਪਰਿਭਾਸ਼ਤ ਕਰੋ
ਚਾਰ ਟਾਈਪਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਜਿਆਦਾਤਰ اندرੂਨੀ ਐਪਸ ਨੂੰ ਕਵਰ ਕਰਦੇ ਹਨ:\n\n- HTTP ping: ਸੇਵਾ ਦਾ ਜਵਾਬ ਪੁਸ਼ਟੀ ਕਰੋ (status code, TLS, basic headers).\n- Endpoint validation: ਜਾਣਿਆ ਹੋਇਆ URL ਹਿੱਟ ਕਰੋ ਅਤੇ ਕੁਝ ਮੈਨੀਨਿੰਗਫੁਲ ਵੈਰੀਫਾਈ ਕਰੋ (ਉਮੀਦ ਕੀਤੀ JSON ਰੂਪਰੇਖਾ, HTML ਵਿੱਚ ਮੁੱਖ ਸਤਰ, ਜਾਂ ਜੀਵੰਤ health endpoint payload).\n- Login-free “smoke” path: ਜੇ ਸੰਭਵ ਹੋਵੇ, ਇੱਕ read-only flow ਟੈਸਟ ਕਰੋ ਜੋ ਯੂਜ਼ਰ ਅਨੁਭਵ ਦਰਸਾਉਂਦਾ ਹੈ (ਉਦਾਹਰਨ: ਡੈਸ਼ਬੋਰਡ ਪੇਜ਼ ਲੋਡ ਕਰਕੇ ਦੇਖੋ ਕਿ ਇਹ ਰੈਂਡਰ ਹੁੰਦਾ ਹੈ)।
ਚੈੱਕ deterministic ਰੱਖੋ। ਜੇ ਵੈਰੀਫਿਕੇਸ਼ਨ ਐਸੇ ਕਾਰਨਾਂ ਕਰਕੇ ਫੇਲ ਹੋ ਸਕਦੀ ਹੈ ਜੋ ਕਨਟੈਂਟ ਬਦਲਣ ਨਾਲ ਹੁੰਦੀ ਹੈ ਤਾਂ ਤੁਸੀਂ ਸ਼ੋਰ ਬਣਾ ਦਿਓਗੇ ਅਤੇ ਭਰੋਸਾ ਘਟੇਗਾ।
ਅਪਟਾਈਮ ਅਤੇ ਲੇਟੈਂਸੀ ਇਕੱਠੇ ਕਰੋ (ਅਤੇ ਸਾਂਝਾ ਤਰੀਕੇ ਨਾਲ ਸਟੋਰ ਕਰੋ)
ਹਰ ਚੈਕ ਰਨ ਲਈ capture ਕਰੋ:\n\n- Timestamp (start ਅਤੇ end)\n- Result: up/down/unknown\n- Latency: ਕੁੱਲ ਸਮਾਂ (ਤੇ ਅਨਿੱਚਿਤ ਤੌਰ 'ਤੇ DNS/connect/TTFB ਜੇ ਮਾਪੋ)\n- Reason: error code, timeout, validation failure, ਜਾਂ exception message
ਡਾਟਾ ਨੂੰ ਜਾਂ ਤਾਂ time-series events (ਹਰ ਚੈਕ ਰਨ ਲਈ ਇੱਕ ਰੋ) ਵਜੋਂ ਰੱਖੋ ਜਾਂ aggregated intervals (ਉਦਾਹਰਨ: ਪ੍ਰਤੀ ਮਿੰਟ ਰੋਲਅੱਪਸ counts ਅਤੇ p95 latency) ਵਜੋਂ। ইਵੈਂਟ ਡਾਟਾ ਡੀਬੱਗਿੰਗ ਲਈ ਵਧੀਆ ਹੈ; ਰੋਲਅੱਪ ਸਪੀਡੀ ਡੈਸ਼ਬੋਰਡਸ ਲਈ ਵਧੀਆ। ਕਈ ਟੀਮ ਦੋਹਾਂ ਕਰਦੀਆਂ ਹਨ: ਕਚਾ ਇਵੈਂਟ 7–30 ਦਿਨ ਲਈ ਰੱਖੋ ਅਤੇ ਲੰਬੇ ਸਮੇਂ ਲਈ ਰੋਲਅੱਪਸ ਰੱਖੋ।
ਆਉਟੇਜ ਤੇ ਮਿਸਿੰਗ ਡਾਟਾ ਨੂੰ ਸਪਸ਼ਟ ਰੱਖੋ
ਮਿਸਿੰਗ ਚੈਕ ਨਤੀਜਾ ਨੂੰ ਆਟੋਮੈਟਿਕ "ਡਾਊਨ" ਨਾ ਮੰਨੋ। ਇਕ ਵੱਖਰਾ unknown ਸਟੇਟ ਸ਼ਾਮਿਲ ਕਰੋ ਜਿਵੇਂ:\n\n- checker worker ਰੁਕਿਆ ਹੋਇਆ\n- ਚੈੱਕਰ ਅਤੇ ਟਾਰਗੇਟ ਵਿਚਕਾਰ ਨੈੱਟਵਰਕ partitions\n- ਕਨਫਿਗ ਮਿਡ-ਰਣ ਬਦਲਿਆ ਗਿਆ
ਇਸ ਨਾਲ ਜ਼ਰੂਰਤੀ ਨਹੀਂ ਕਿ downtime ਫਰਜ਼ੀ ਤਰੀਕੇ ਨਾਲ ਵਧੇ ਅਤੇ ਮਾਨੀਟਰਨਿੰਗ ਗੇਪਸ ਵੀ ਅਲੱਗ ਤੌਰ 'ਤੇ ਦਿਖਾਈ ਦੇਣ।
background jobs ਨਾਲ ਨਿਯਮਤ ਤਰੀਕੇ ਨਾਲ ਚੈੱਕ ਚਲਾਓ
ਚੈਕਸ fixed intervals ਤੇ ਚਲਾਉਣ ਲਈ background workers (cron-like scheduling, queues) ਵਰਤੋ (ਉਦਾਹਰਨ: critical tools ਲਈ 30–60 ਸਕਿੰਟ). timeouts, retries with backoff, ਅਤੇ concurrency limits ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਕਿ checker internal ਸੇਵਾਵਾਂ ਨੂੰ overload ਨਾ ਕਰੇ। ਹਰ ਰਨ ਨਤੀਜੇ ਨੂੰ ਸੰਭਾਲੋ—ਭਾਵੇਂ ਫੇਲ—ਤਾਂ ਜੋ ਤੁਹਾਡਾ uptime ਮਾਨੀਟਰਿੰਗ ਡੈਸ਼ਬੋਰਡ ਮੌਜੂਦਾ ਸਥਿਤੀ ਅਤੇ ਭਰੋਸੇਯੋਗ ਇਤਿਹਾਸ ਦਿਖਾ ਸਕੇ।
ਅਲਰਟਿੰਗ ਅਤੇ ਨੋਟੀਫਿਕੇਸ਼ਨ ਫਲੋ ਬਣਾਓ
Share your build, get credits
Join the earn credits program when you publish what you built with Koder.ai.
ਅਲਰਟਸ ਉਹ ਸਥਾਨ ਹਨ ਜਿੱਥੇ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਕਾਰਵਾਈ ਵਿੱਚ ਬਦਲਦੀ ਹੈ। ਮਕਸਦ ਸਧਾਰਨ ਹੈ: ਸਹੀ ਲੋਕਾਂ ਨੂੰ, ਸਹੀ ਸੰਦਰਭ ਨਾਲ, ਸਹੀ ਸਮੇਂ 'ਤੇ ਸੂਚਿਤ ਕਰੋ—ਬਿਨਾਂ ਹਰ ਕਿਸੇ ਨੂੰ ਹੱਲਾ ਕਰਨ ਦੇ।
SLOs ਨਾਲ ਅਲਰਟ ਜੋੜੋ (ਸਿਰਫ thresholds ਨਹੀਂ)
SLIs/SLOs ਨਾਲ ਸਿੱਧਾ ਨਕਸ਼ਾਬੰਦੀ ਵਾਲੇ alert rules ਤੈਅ ਕਰੋ। ਦੋ ਪ੍ਰਾਇਕਟਿਕ ਪੈਟਰਨ:\n\n- Burn-rate alerts: ਜਦਿਕਿ error budget ਇਤਨੀ ਤੇਜ਼ੀ ਨਾਲ ਘੱਟ ਹੋ ਰਿਹਾ ਹੋ ਕਿ ਤੁਸੀਂ SLO ਮੀਸ ਕਰ ਜਾਵੋਗੇ ਜੇ ਕੁਝ ਨਾ ਕੀਤਾ ਗਿਆ।\n- Threshold breaches: ਜਦੋਂ ਕੋਈ ਮੈਟਰਿਕ ਇੱਕ ਸਪਸ਼ਟ ਸੀਮਾ ਪਾਰ ਕਰਦਾ ਹੈ (ਉਦਾਹਰਨ: availability 15 ਮਿੰਟ 'ਚ 99.5% ਤੋਂ ਘੱਟ)।\n\nਹਰ rule ਲਈ “why” ਨੂੰ “what” ਦੇ ਨਾਲ ਸਟੋਰ ਕਰੋ: ਕਿਹੜਾ SLO ਪ੍ਰਭਾਵਿਤ ਹੋ ਰਿਹਾ, evaluation window, ਅਤੇ ਨਿਰਧਾਰਿਤ ਸੈਵਿਰਟੀ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਕਾਰਵਾਈਯੋਗ ਬਣਾਓ
ਸੂਚਨਾ ਉਹਨਾਂ ਚੈਨਲਾਂ ਰਾਹੀਂ ਭੇਜੋ ਜਿੱਥੇ ਟੀਮ ਰਹਿੰਦੀ ਹੈ (email, Slack, Microsoft Teams). ਹਰ ਸੁਨੇਹੇ ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:\n\n- ਇੱਕ ਇਕ-ਪੰਗਤੀ ਸਾਰਾਂਸ਼ (service + symptom + severity)\n- ਸਬੰਧਤ ਡੈਸ਼ਬੋਰਡ ਵਿਊ ਦਾ ਸਪਸ਼ਟ ਟੈਕਸਟ ਸੰਦਰਭ (ਉਦਾਹਰਨ: services/payments?window=1h)\n- ਇਕ ਇਨਸਿਡੈਂਟ ਪੇਜ਼ ਦੇ ਸੰਦਰਭ ਦਾ ਟੈਕਸਟ (ਉਦਾਹਰਨ: incidents/123)\n\nਕੱਚੇ ਮੈਟ੍ਰਿਕ ਨੂੰ ਨਾ ਡੰਪ ਕਰੋ। ਇੱਕ ਛੋਟਾ “ਅਗਲਾ ਕਦਮ” ਦਿਓ ਜਿਵੇਂ “ਹਾਲੀਆ deploys ਚੈੱਕ ਕਰੋ” ਜਾਂ “logs ਖੋਲੋ।”
ਸ਼ੋਰ ਘਟਾਓ: dedupe, grouping, ਅਤੇ quiet hours
ਲਾਗੂ ਕਰੋ:\n\n- Deduplication (ਇੱਕੋ alert fingerprint → ਮੌਜੂਦਾ ਥ੍ਰੈਡ ਅਪਡੇਟ)\n- Grouping (ਇੱਕ ਇਨਸਿਡੈਂਟ ਕਈ ਸਬੰਧਿਤ ਅਲਰਟ ਇਕੱਠੇ ਕਰ ਸਕਦਾ ਹੈ)\n- Quiet hours ਅਤੇ routing rules ਤਾਂ ਜੋ ਘੱਟ-ਸੈਵਿਰਟੀ ਅਲਰਟ on-call ਨੂੰ ਜਾਗ ਨਾ ਕਰਨ
ਐਸਕਲੇਸ਼ਨ ਅਤੇ on-call routing ਸਹਿਯੋਗ ਕਰੋ
ਭਾਵੇਂ ਇਹ ਇੱਕ ਅੰਦਰੂਨੀ ਟੂਲ ਹੈ, ਲੋਕਾਂ ਨੂੰ ਕੰਟਰੋਲ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਅਲਰਟ/ਇਨਸਿਡੈਂਟ ਪੇਜ਼ ਤੇ manual escalation ਬਟਨ ਜੋੜੋ ਅਤੇ ਜੇ ਉਪਲਬਧ ਹੋਵੇ ਤਾਂ on-call tooling ਨਾਲ ਇੰਟਿਗ੍ਰੇਟ ਕਰੋ (PagerDuty/Opsgenie ਵਰਗੇ), ਜਾਂ ਘੱਟੋ-ਘੱਟ ਇੱਕ configurable rotation list ਆਪਣੀ ਐਪ ਵਿੱਚ ਰੱਖੋ।
ਇਨਸਿਡੈਂਟ ਮੈਨੇਜਮੈਂਟ ਅਤੇ ਪੋਸਟਮੋਰਟਮ ਫੀਚਰ ਜੋੜੋ
ਇਨਸਿਡੈਂਟ ਮੈਨੇਜਮੈਂਟ “ਅਸੀਂ ਅਲਰਟ ਵੇਖਿਆ” ਨੂੰ ਸੰਯੁਕਤ, ਟਰੇਕ-ਯੋਗ ਪ੍ਰਤੀਕਿਰਿਆ ਵਿੱਚ ਬਦਲਦਾ ਹੈ। ਇਸਨੂੰ ਆਪਣੇ ਰਿਲਾਇਬਿਲਟੀ ਐਪ ਵਿੱਚ ਬਿਲਟ ਕਰੋ ਤਾਂ ਜੋ ਲੋਕ signal ਤੋਂ coordination ਤੱਕ ਬਿਨਾਂ ਟੂਲ ਬਦਲਣ ਦੇ ਜਾ ਸਕਣ।
ਇਕ-ਕਲਿੱਕ ਇਨਸਿਡੈਂਟ ਬਣਾਉਣਾ
ਅਲਰਟ, ਸੇਵਾ ਪੇਜ਼, ਜਾਂ uptime chart ਤੋਂ ਸਿੱਧਾ ਇਨਸਿਡੈਂਟ ਬਣਾਉਣ ਯੋਗ ਬਣਾਓ। ਮੁੱਖ ਫੀਲਡ ਪ੍ਰੀ-fill ਕਰੋ (service, environment, alert source, first seen time) ਅਤੇ ਇੱਕ unique incident ID ਐਸਾਈਨ ਕਰੋ।
ਚੰਗੇ ਡਿਫਾਲਟ ਫੀਲਡਸ ਹਲਕਾ ਰੱਖੋ: severity, customer impact (ਅੰਦਰੂਨੀ ਟੀਮਾਂ ਪ੍ਰਭਾਵਿਤ), current owner, ਅਤੇ triggering alert ਦੇ ਲਿੰਕ. (ਨੋਟ: ਲਿੰਕ ਟਾਰਗੇਟ ਹਟਾਏ ਗਏ — ਕਿਰਪਾ ਕਰਕੇ ਸੰਦਰਭ ਦੀ ਟੈਕਸਟ ਦਿਓ ਜਿਵੇਂ runbooks/payments-retries ਜਾਂ tickets/INC-1234)
ਸਥਿਤੀ ਲਾਈਫਸਾਈਕਲ ਅਤੇ ਸਹਿਯੋਗ
ਇਕ ਸਧਾਰਨ ਲਾਈਫਸਾਈਕਲ ਵਰਤੋ ਜੋ ਹਕੀਕਤ ਵਿੱਚ ਟੀਮਾਂ ਵਰਤਦੀਆਂ ਹਨ:\n\n- Open → Investigating → Mitigated → Resolved\n\nਹਰ ਸਥਿਤੀ ਬਦਲਣ ਨਾਲ ਕਿਸਨੇ ਅਤੇ ਕਦੋਂ ਬਦਲਿਆ ਦਰਜ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਟਾਈਮਲਾਈਨ ਅਪਡੇਟ (ਛੋਟੇ, timestamped ਨੋਟਸ), attachments, ਅਤੇ runbooks ਅਤੇ tickets ਲਈ links ਸ਼ਾਮਿਲ ਕਰੋ (ਉਦਾਹਰਨ: runbooks/payments-retries ਜਾਂ tickets/INC-1234) ਤਾਂ ਜੋ ਇਹ "ਕੀ ਹੋਇਆ ਅਤੇ ਕੀ ਕੀਤਾ ਗਿਆ" ਦੀ ਇਕ ਸੀਧੀ ਧਾਗਾ ਬਣ ਜਾਵੇ।
ਪੋਸਟਮੋਰਟਮਸ ਨਾਲ action items
ਪੋਸਟਮੋਰਟਮਜ਼ ਤੇਜ਼ ਸ਼ੁਰੂ ਕੀਤੇ ਜਾਣ ਅਤੇ ਸਮੀਖਿਆ ਲਈ ਸਥਿਰ ਬਿਨਾਂ ਹੋਣ ਚਾਹੀਦੇ ਹਨ। templates ਦਿਓ ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹੋਵੇ:\n\n- Summary, impact, detection, ਅਤੇ root cause\n- Contributing factors (ਭਰਤੀ ਪ੍ਰਕਿਰਿਆ ਦੀਆਂ ਖਾਮੀਆਂ ਸਮੇਤ)\n- ਕੀ ਚੰਗਾ/ਕੀ ਖਰਾਬ ਰਿਹਾ\n- Follow-ups owners ਅਤੇ due dates ਨਾਲ
Action items ਨੂੰ incident ਨਾਲ ਜੋੜੋ, completion track ਕਰੋ, ਅਤੇ overdue items ਨੂੰ ਟੀਮ ਡੈਸ਼ਬੋਰਡਸ 'ਤੇ ਉਠਾਓ। ਜੇ ਤੁਸੀਂ “learning reviews” ਸਹਾਇਤ ਕਰਦੇ ਹੋ, ਤਾਂ “blameless” ਮੋਡ ਦਿਓ ਜੋ ਵਿਅਕਤੀਗਤ ਗਲਤੀਆਂ ਦੀ ਬਜਾਏ ਸਿਸਟਮ ਅਤੇ ਪ੍ਰਕਿਰਿਆ ਬਦਲਾਅ 'ਤੇ ਧਿਆਨ ਦੇਵੇ।
ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਰਿਲਾਇਬਿਲਟੀ ਸਕੋਰਕਾਰਡਸ
Turn SLOs into dashboards
Build React views for scorecards and drill-downs with Go and PostgreSQL generated for you.
ਰਿਪੋਰਟਿੰਗ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਫੈਸਲੇ ਬਣਾਉਂਦੀ ਹੈ। ਡੈਸ਼ਬੋਰਡਸ ਆਪਰੇਟਰਾਂ ਦੀ ਮਦਦ ਕਰਦੇ ਹਨ; ਸਕੋਰਕਾਰਡਸ ਨੇਤਾਵਾਂ ਨੂੰ ਸਮਝਾਉਂਦੇ ਹਨ ਕਿ اندرੂਨੀ ਟੂਲ ਸੁਧਰ ਰਹੇ ਹਨ ਜਾਂ ਨਹੀਂ, ਕਿਹੜੇ ਖੇਤਰ ਵਿੱਚ ਨਿਵੇਸ਼ ਦੀ ਲੋੜ ਹੈ, ਅਤੇ "ਚੰਗਾ" ਕੀ ਦਿਖਦਾ ਹੈ।
ਸਕੋਰਕਾਰਡ ਵਿੱਚ ਕੀ ਸ਼ਾਮਿਲ ਹੋਵੇ
ਹਰ ਟੂਲ (ਅਤੇ ਜਰੂਰੀ ਹੋਵੇ ਤਾਂ ਹਰ ਟੀਮ) ਲਈ ਇੱਕ ਨਿਯਮਤ, ਦੁਹਰਾਓਯੋਗ ਵਿਉ ਬਣਾਓ ਜੋ ਇਹਨਾਂ ਸਵਾਲਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇਵੇ:\n\n- SLO compliance over time: ਮੌਜੂਦਾ 기간 (ਹਫ਼ਤਾ/ਮਹੀਨਾ/ਤਿਮਾਹੀ) ਅਤੇ SLO ਟਾਰਗੇਟ ਦੇ ਖਿਲਾਫ ਰੁਝਾਨ ਲਾਈਨ.\n- Top unreliable tools: missed SLO, ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ downtime ਮਿੰਟ, ਜਾਂ worst error-budget burn ਆਧਾਰ 'ਤੇ rank.\n- MTTR: median ਅਤੇ p90 time-to-restore, ਤਾਂ ਜੋ ਇੱਕ ਲੰਬਾ ਇਨਸਿਡੈਂਟ pattern ਨੂੰ ਛੁਪਾਉਂ ਨਾ ਦੇਵੇ।\n- Incident counts: ਕੁੱਲ ਇਨਸਿਡੈਂਟਾਂ ਦੀ ਗਿਣਤੀ ਅਤੇ ਸੈਵਿਰਟੀ breakdown (Sev1–Sev3), ਤੌਲਨਾ ਪਿਛਲੇ ਪੀਰੀਅਡ ਨਾਲ।
ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ, ਹਲਕਾ ਸੰਦਰਭ ਸ਼ਾਮਿਲ ਕਰੋ: “SLO missed due to 2 deployments” ਜਾਂ “Most downtime from dependency X”, ਬਿਨਾਂ ਰਿਪੋਰਟ ਨੂੰ ਪੂਰੇ ਇਨਸਿਡੈਂਟ ਰਿਵਿਊ ਵਿੱਚ ਬਦਲੇ।
ਫਿਲਟਰ ਜੋ ਲੀਡਰਸ਼ਿਪ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਉਪਯੋਗੀ ਬਣਾਉਂਦੇ ਹਨ
ਲੈਡਰਸ਼ਿਪ ਅਕਸਰ “ਸਭ ਕੁਝ” ਨਹੀਂ ਚਾਹੁੰਦੇ। ਟੀਮ, tool criticality (Tier 0–3), ਅਤੇ time window ਲਈ ਫਿਲਟਰ ਜੋੜੋ। ਸੁਨਿਸ਼ਚਿਤ ਕਰੋ ਕਿ ਇੱਕ ਟੂਲ ਕਈ ਰੋਲਅੱਪਸ ਵਿੱਚ ਆ ਸਕਦਾ ਹੈ (platform team owns it, finance relies on it)।
ਸੰਖੇਪ ਅਤੇ ਨਿਰਯਾਤ
ਹਫਤੇਵਾਰ ਅਤੇ ਮਹੀਨਾਵਾਰ ਸੰਖੇਪ ਦਿਓ ਜੋ ਐਪ ਦੇ ਬਾਹਰ ਵੀ ਸਾਂਝੇ ਕੀਤੇ ਜਾ ਸਕਣ:\n\n- ਇਕ-ਕਲਿੱਕ CSV export spreadsheets ਲਈ\n- ਸਾਫ਼ PDF export status reviews ਲਈ\n
ਨੈਰੇਟਿਵ ਸੰਗਤ ਰੱਖੋ (“ਪਿਛਲੇ ਪੀਰੀਅਡ ਤੋਂ ਕੀ ਬਦਲਿਆ?” “ਕਿੱਥੇ ਅਸੀਂ ਬਜਟ ਤੋਂ ਉਪਰ ਹਾਂ?”). ਜੇ stakeholders ਲਈ ਇੱਕ ਪ੍ਰਾਇਮਰ ਦੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਇੱਕ ਛੋਟੀ gids ਜਿਵੇਂ blog/sli-slo-basics ਦਾ ਹਵਾਲਾ ਦਿਖਾਓ (ਲਿੰਕ ਹਟਾਇਆ ਗਿਆ)।
ਸੁਰੱਖਿਆ, ਡਾਟਾ ਗੁਣਵੱਤਾ, ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਮਜ਼ਬੂਤੀ
ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਰ ਜਲਦੀ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਬਣ ਜਾਂਦਾ ਹੈ। ਇਸਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਸਿਸਟਮ ਵਾਂਗ ਵਰਤੋ: default ਤੌਰ 'ਤੇ secure, ਖਰਾਬ ਡਾਟਾ ਦੇ ਪ੍ਰਤੀ ਰੋਧੀ, ਅਤੇ ਆਸਾਨੀ ਨਾਲ recover ਕਰਨ ਯੋਗ।
ਐਪ ਸਰਫੇਸ ਏਰੀਆ ਨੂੰ ਸੁਰੱਖਿਅਤ ਕਰੋ
ਹਰ endpoint ਨੂੰ lockdown ਕਰੋ—ਭਾਵੇਂ ਉਹ “ਅੰਦਰੂਨੀ-ਕੇਵਲ” ਹੋਵੇ।\n\n- ਬਾਊਂਡਰੀ ਤੇ inputs validate ਕਰੋ (types, ranges, allowed enums, max payload sizes) ਅਤੇ unknown fields reject ਕਰੋ।\n- per user/service token rate limiting ਜੋੜੋ ਤਾਂ ਕਿ noisy clients ingestion ਜਾਂ ਡੈਸ਼ਬੋਰਡ ਨੂੰ overwhelm ਨਾ ਕਰਨ।\n- injection issues ਤੋਂ ਬਚਣ ਲਈ parameterized queries ਅਤੇ safe ORM ਪੈਟਰਨ ਵਰਤੋ।
Secrets ਅਤੇ access control
ਕੋਡ ਅਤੇ ਲੌਗਸ ਵਿੱਚ credentials ਨਾ ਰੱਖੋ।\n\nSecrets secret manager ਵਿੱਚ ਰੱਖੋ ਅਤੇRotate ਕਰੋ। ਵੈੱਬ ਐਪ ਨੂੰ least-privilege ਡੀਬੀ ਐਕਸੈਸ ਦਿਓ: read/write roles ਵੱਖ-ਵੱਖ, ਸਿਰਫ਼ ਲੋੜੀਂਦੇ ਟੇਬਲਾਂ ਤੱਕ ਪੁੱਜ, ਅਤੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ short-lived credentials ਵਰਤੋ। browser↔app ਅਤੇ app↔database ਵਿਚ TLS ਨਾਲ ਡਾਟਾ encrypt ਕਰੋ।
ਡਾਟਾ ਗੁਣਵੱਤਾ guardrails
ਰਿਲਾਇਬਿਲਟੀ ਮੈਟਰਿਕਸ ਤਦ ਹੀ ਉਪਯੋਗੀ ਹੁੰਦੇ ਹਨ ਜਦ underlying events ਭਰੋਸੇਯੋਗ ਹੋਣ।\n\n- server-side checks ਜੋ timestamps (timezone/clock skew), required fields, ਅਤੇ idempotency keys ਦੀ ਜਾਂਚ ਕਰਦੇ ਹਨ ਤਾਂ retries ਨੂੰ deduplicate ਕੀਤਾ ਜਾ ਸਕੇ।\n- ingestion errors ਨੂੰ dead-letter queue ਜਾਂ “quarantine” table ਵਿੱਚ ਰੱਖੋ ਤਾਂ ਕਿ ਖਰਾਬ events ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਪ੍ਰਦੂਸ਼ਿਤ ਨਾ ਕਰਨ।
ਓਪਰੇਸ਼ਨਲ ਬੇਸਿਕਸ (ਛੱਡੋ ਨਾ)
ਡੈਟਾਬੇਸ migrations automate ਕਰੋ ਅਤੇ rollbacks ਦੀ ਜਾਂਚ ਕਰੋ। ਬੈਕਅੱਪ ਸਕੈਜ਼ਿੂਲ ਕਰੋ, ਆਮ ਤੌਰ 'ਤੇ restore-test ਕਰੋ, ਅਤੇ ਇੱਕ ਨਿਯੂਨਤਮ disaster recovery ਯੋਜਨਾ ਦਸਤਾਵੇਜ਼ ਕਰੋ (ਕੌਣ, ਕੀ, ਕਿੰਨਾ ਸਮਾਂ)।
ਅੰਤ ਵਿੱਚ, ਰਿਲਾਇਬਿਲਟੀ ਐਪ ਨੂੰ ਖੁਦ ਭਰੋਸੇਯੋਗ ਬਣਾਓ: health checks, queue lag ਅਤੇ DB latency ਲਈ ਬੇਸਿਕ ਮਾਨੀਟਰਿੰਗ, ਅਤੇ ingestion ਜਦੋਂ ਖਾਮੋਸ਼ੀ ਨਾਲ ਜ਼ੀਰੋ ਤੱਕ ਘਟੇ ਤਦ alert ਕਰੋ।
ਰੋਲਆਊਟ ਯੋਜਨਾ ਅਤੇ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲਾ ਰੋਡਮੈਪ
ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਟ੍ਰੈਕਿੰਗ ਐਪ ਤਦ ਹੀ ਸਫਲ ਹੁੰਦੀ ਹੈ ਜਦ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ ਅਤੇ ਅਸਲ ਵਿੱਚ ਇਸਨੂੰ ਵਰਤਦੇ ਹਨ। ਪਹਿਲੀ ਰਿਲੀਜ਼ ਨੂੰ ਇਕ ਸਿੱਖਣ ਵਾਲਾ ਲੂਪ ਸਮਝੋ, ਨਾ ਕਿ "ਬੜਾ ਬੈਂਗ" ਲਾਂਚ।
ਫੋਕਸਡ ਪਾਇਲਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ
2–3 اندرੂਨੀ ਟੂਲਾਂ ਦੀ ਚੋਣ ਕਰੋ ਜੋ ਚੌੜੇ ਪੱਧਰ 'ਤੇ ਵਰਤੇ ਜਾਂਦੇ ਹਨ ਅਤੇ ਜਿਨ੍ਹਾਂ ਦੇ ਸਪਸ਼ਟ ਮਾਲਕ ਹਨ। ਇੱਕ ਛੋਟਾ ਸੈੱਟ checks ਲਾਗੂ ਕਰੋ (ਉਦਾਹਰਨ: homepage availability, login success, ਅਤੇ ਇੱਕ ਮੁੱਖ API endpoint) ਅਤੇ ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਪਬਲਿਸ਼ ਕਰੋ ਜੋ ਇਹ ਜਵਾਬ ਦਿੰਦਾ: "ਕੀ ਇਹ ਉੱਪ ਹੈ? ਜੇ ਨਹੀਂ, ਤਾਂ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕੌਣ ਮਾਲਿਕ ਹੈ?"
ਪਾਇਲਟ ਨੂੰ ਨਜ਼ਰਅंदਾਜ਼ ਨਾ ਕਰੋ: ਇਕ ਟੀਮ ਜਾਂ ਕੁਝ ਪਾਵਰ ਯੂਜ਼ਰ ਹੀ MVP ਦੀ ਯੋਗਤਾ ਪ੍ਰਮਾਣਿਤ ਕਰਨ ਲਈ ਕਾਫੀ ਹੁੰਦੇ ਹਨ।
ਫੀਡਬੈਕ ਇਕੱਤਰ ਕਰੋ ਜਿੱਥੇ ਦਰਦ ਹੁੰਦਾ ਹੈ
ਪਹਿਲੇ 1–2 ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਸਰਗਰਮ ਫੀਡਬੈਕ ਲਵੋ:\n\n- ਕੀ ਗੁਲਲਤ ਲੱਗਦਾ ਹੈ (metric names, charts, filters, definitions)\n- ਕੀ ਸ਼ੋਰ ਕਰ ਰਿਹਾ ਹੈ (alerts ਜੋ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ)\n- ਕੀ ਗੁੰਢ ਹੋ ਰਿਹਾ ਹੈ (ownership, runbooks, links to incidents)
ਫੀਡਬੈਕ ਨੂੰ ਸਪਸ਼ਟ backlog items ਵਿੱਚ ਬਦਲੋ। ਹਰ chart 'ਤੇ ਇੱਕ ਸਾਦਾ “Report an issue with this metric” ਬਟਨ ਅਕਸਰ ਸਭ ਤੋਂ ਤੇਜ਼ insights ਲੈ ਕੇ ਆਉਂਦਾ ਹੈ।
ਇੰਟੀਗ੍ਰੇਸ਼ਨਸ ਅਤੇ ਆਟੋਮੇਸ਼ਨ ਨਾਲ ਦੁਹਰਾਓ
ਹਰ ਵਾਰੀ ਕੀਮਤੀ ਵਧਾਉ: chat tool ਲਈ notifications, ਫਿਰ incident tool ਲਈ automatic ticket creation, ਫਿਰ CI/CD ਲਈ deploy markers. ਹਰ ਇਕ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਮੈਨੂਅਲ ਕੰਮ ਘਟਾਏ ਜਾਂ time-to-diagnose ਘੱਟ ਕਰੇ—ਨਹੀਂ ਤਾਂ ਇਹ ਕੇਵਲ ਜਟਿਲਤਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ ਪ੍ਰੋਟੋਟਾਇਪ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Koder.ai ਦੀ planning mode ਇੱਕ ਸਧਾਰਨ ਤਰੀਕਾ ਹੈ ਪਹਿਲੀ scope (entities, roles, workflows) ਨੂੰ ਨਕਸ਼ਾ ਬਣਾਉਣ ਲਈ ਪਹਿਲਾਂ build ਜਨਰੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ। ਇਹ MVP ਨੂੰ ਟਾਇਟ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ—ਅਤੇ ਤੁਸੀਂ snapshot/rollback ਕਰਕੇ ingestion ਅਤੇ alerts 'ਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ iterate ਕਰ ਸਕਦੇ ਹੋ ਜਿਵੇਂ ਹੀ ਟੀਮ definitions ਨੂੰ ਸੁਧਾਰਦੀ ਹੈ।
ਸਫਲਤਾ ਮੈਟਰਿਕ ਤੈਅ ਕਰੋ ਅਤੇ ਫੈਲਾਓ
ਹੋਰ ਟੀਮਾਂ ਨੂੰ rollout ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਸਫਲਤਾ ਮੈਟਰਿਕ ਤੈਅ ਕਰੋ ਜਿਵੇਂ dashboard weekly active users, reduced time-to-detect, fewer duplicate alerts, ਜਾਂ consistent SLO reviews. ਇਕ ਹਲਕਾ ਰੋਡਮੈਪ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ (reliability-tracking-roadmap) ਅਤੇ ਟੂਲ-ਬਾਈ-ਟੂਲ ਫੈਲਾਓ ਸਾਫ਼ ਮਾਲਕਾਂ ਅਤੇ ਟਰੇਨਿੰਗ ਸੈਸ਼ਨਸ ਦੇ ਨਾਲ।