03 ਅਕਤੂ 2025·8 ਮਿੰਟ
ਬਾਹਰ ਵਾਲਾ vs ਅੰਦਰ ਵਾਲਾ ਡੇਟਾ — Pat Helland ਦੀਆਂ ਸਿੱਖਿਆਵਾਂ ਐਪ ਲਈ
Pat Helland ਦੇ "ਬਾਹਰ vs ਅੰਦਰ" ਡੇਟਾ ਸਿੱਧਾਂਤ ਸਿੱਖੋ — ਸਪਸ਼ਟ ਸੀਮਾਵਾਂ ਬਣਾਓ, idempotent ਕਾਲਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਅਤੇ ਨੈੱਟਵਰਕ ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਸਟੇਟ ਨੂੰ ਮੇਲ ਕਰੋ।
Pat Helland ਦੇ "ਬਾਹਰ vs ਅੰਦਰ" ਡੇਟਾ ਸਿੱਧਾਂਤ ਸਿੱਖੋ — ਸਪਸ਼ਟ ਸੀਮਾਵਾਂ ਬਣਾਓ, idempotent ਕਾਲਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਅਤੇ ਨੈੱਟਵਰਕ ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਸਟੇਟ ਨੂੰ ਮੇਲ ਕਰੋ।
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਐਪ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਆਸਾਨੀ ਨਾਲ ਸੋਚਦੇ ਹੋ ਕਿ ਰਿਕਵੇਸਟ ਠੀਕ ਢੰਗ ਨਾਲ, ਇੱਕ-ਇੱਕ ਕਰਕੇ, ਸਹੀ ਕ੍ਰਮ ਵਿੱਚ ਆ ਰਹੀਆਂ ਹਨ। ਹਕੀਕਤ ਵਿੱਚ ਨੈੱਟਵਰਕ ਅਜਿਹਾ ਨਹੀਂ ਹੁੰਦਾ। ਉਪਭੋਗਤਾ ਸਕ੍ਰੀਨ ਫ੍ਰੀਜ਼ ਹੋਣ ਕਾਰਨ “Pay” ਨੂੰ ਦੋ ਵਾਰੀ ਟੈਪ ਕਰ ਦਿੰਦਾ ਹੈ। ਇੱਕ ਮੋਬਾਈਲ ਕਨੈਕਸ਼ਨ ਬਟਨ ਦਬਾਉਣ ਤੋਂ ਬਾਅਦ ਹੀ ਡਰੌਪ ਹੋ ਸਕਦਾ ਹੈ। ਇੱਕ webhook ਦੇਰ ਨਾਲ ਆ ਸਕਦਾ ਹੈ, ਜਾਂ ਵਾਰ-ਵਾਰ ਆ ਸਕਦਾ ਹੈ। ਕਈ ਵਾਰੀ ਇਹ ਕਦੇ ਨਹੀਂ ਆਉਂਦਾ।
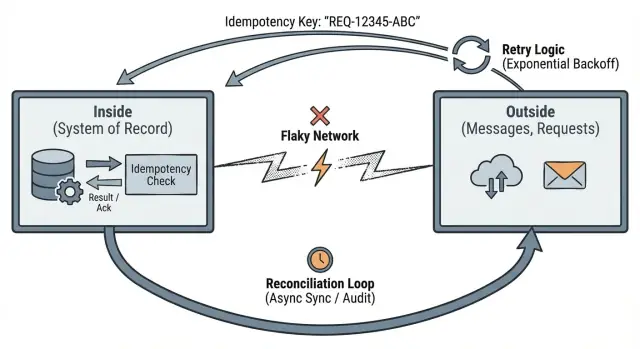
Pat Helland ਦਾ ਵਿਚਾਰ ਬਾਹਰ vs ਅੰਦਰ ਡੇਟਾ ਇਸ ਗੜਬੜ ਦੇ ਬਾਰੇ ਸੋਚਣ ਦਾ ਇੱਕ ਸਾਫ਼ ਤਰੀਕਾ ਹੈ।
"ਬਾਹਰ" ਉਹ ਸਭ ਹੈ ਜੋ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਅਧੀਨ ਨਹੀਂ ਹੈ। ਇਹ ਓਥੇ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਹੋਰ ਲੋਕਾਂ ਅਤੇ ਸਿਸਟਮਾਂ ਨਾਲ ਗੱਲ-ਬਾਤ ਕਰਦੇ ਹੋ, ਅਤੇ ਜਿੱਥੇ ਡਿਲਿਵਰੀ ਅਣਨਿਸ਼ਚਿਤ ਹੁੰਦੀ ਹੈ: ਬ੍ਰਾਊਜ਼ਰ ਅਤੇ ਮੋਬਾਈਲ ਐਪ ਤੋਂ HTTP ਰਿਕਵੇਸਟਾਂ, ਕਿਊਜ਼ ਤੋਂ ਸੁਨੇਹੇ, ਤੀਜੀ-ਪਾਰਟੀ webhook (ਪੇਮੈਂਟ, ਈਮੇਲ, ਸ਼ਿਪਿੰਗ), ਅਤੇ ਕਲਾਇੰਟ, ਪ੍ਰੌਕਸੀ ਜਾਂ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਦੁਆਰਾ ਟ੍ਰਿਗਰ ਕੀਤੇ ਗਏ ਰੀਟ੍ਰਾਈਜ਼।
ਬਾਹਰ ਨੂੰ ਮੰਨੋ ਕਿ ਸੁਨੇਹੇ ਦੇਰ ਨਾਲ ਆ ਸਕਦੇ ਹਨ, ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਗਲਤ ਕ੍ਰਮ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ। ਭਾਵੇਂ ਕੁਝ “ਆਮ ਤੌਰ 'ਤੇ ਭਰੋਸੇਯੋਗ” ਹੋਵੇ, ਉਸ ਦਿਨ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ ਜਦੋਂ ਉਹ ਨਹੀਂ ਹੋਵੇਗਾ।
"ਅੰਦਰ" ਉਹ ਹੈ ਜੋ ਤੁਹਾਡਾ ਸਿਸਟਮ ਭਰੋਸੇਯੋਗ ਬਣਾ ਸਕਦਾ ਹੈ। ਇਹ ਉਹ ਡਿਊਰੇਬਲ ਸਟੇਟ ਹੈ ਜੋ ਤੁਸੀਂ ਸਟੋਰ ਕਰਦੇ ਹੋ, ਤੁਹਾਡੇ ਲਾਗੂ ਕੀਤੇ ਜਾ ਰਹੇ ਨਿਯਮ, ਅਤੇ ਉਹ ਤੱਥ ਜੋ ਤੁਸੀਂ ਬਾਦ ਵਿੱਚ ਸਾਬਤ ਕਰ ਸਕਦੇ ਹੋ:
ਅੰਦਰ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ invariants ਦੀ ਰੱਖਿਆ ਕਰਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ "ਹਰ ਆਰਡਰ ਲਈ ਇੱਕ ਹੀ ਭੁਗਤਾਨ" ਦਾ ਵਾਅਦਾ ਕਰਦੇ ਹੋ, ਉਹ ਵਾਅਦਾ ਅੰਦਰ ਲਾਗੂ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਕਿਉਂਕਿ ਬਾਹਰ ਭਰੋਸੇਯੋਗ ਨਹੀਂ ਹੈ।
ਮਨੋ-ਬਦਲੀ ਸਧਾਰਨ ਹੈ: ਪਰਫੈਕਟ ਡਿਲਿਵਰੀ ਜਾਂ ਸਮਾਂ-ਮੁਹੱਈਆ ਹੋਣ ਦੀ ਉਮੀਦ ਨਾ ਕਰੋ। ਹਰ ਬਾਹਰੀ ਇੰਟਰੈਕਸ਼ਨ ਨੂੰ ਇੱਕ ਅਣ-ਭਰੋਸੇਯੋਗ ਸੁਝਾਅ ਵਜੋਂ ਲੋ ਜੋ ਮੁੜ-ਦੋਹਰਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਅਤੇ ਅੰਦਰ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰਨ ਲਈ ਬਣਾਓ।
ਇਹ ਛੋਟੀ ਟੀਮਾਂ ਅਤੇ ਸਜੇ-ਸਧਾਰਨ ਐਪਾਂ ਲਈ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਜਦੋਂ ਪਹਿਲੀ ਵਾਰੀ ਨੈੱਟਵਰਕ ਗਲਤੀ ਡੁਪਲਿਕੇਟ ਚਾਰਜ ਜਾਂ ਫਸਿਆ ਹੋਇਆ ਆਰਡਰ ਬਣਾਉਂਦੀ ਹੈ, ਤਾਂ ਇਹ ਥਿਊਰੀ ਨਹੀਂ ਰਹਿ ਜਾਂਦੀ—ਇਹ ਰਿਫੰਡ, ਸਪੋਰਟ ਟਿਕਟ ਅਤੇ ਭਰੋਸੇ ਦੀ ਘਾਟ ਬਣ ਜਾਂਦੀ ਹੈ।
ਇੱਕ ਠੋਸ ਉਦਾਹਰਨ: ਉਪਭੋਗਤਾ "Place order" ਟੈਪ ਕਰਦਾ ਹੈ, ਐਪ ਇੱਕ ਰਿਕਵੇਸਟ ਭੇਜਦੀ ਹੈ, ਅਤੇ ਕਨੈਕਸ਼ਨ ਡ੍ਰੌਪ ਹੋ ਜਾਂਦਾ ਹੈ। ਉਪਭੋਗਤਾ ਮੁੜ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ। ਜੇ ਤੁਹਾਡੇ ਅੰਦਰ ਦਾ ਕੋਈ ਤਰੀਕਾ ਨਹੀਂ ਕਿ 'ਇਹ ਇੱਕੋ ਕੋਸ਼ਿਸ਼ ਹੈ', ਤਾਂ ਤੁਸੀਂ ਦੋ ਆਰਡਰ ਬਣਾ ਸਕਦੇ ਹੋ, ਇਕੋ ਇਨਵੈਂਟਰੀ ਦੋ ਵਾਰੀ ਰਿਜ਼ਰਵ ਕਰ ਸਕਦੇ ਹੋ ਜਾਂ ਦੋ ਈਮੇਲ ਭੇਜ ਸਕਦੇ ਹੋ।
Helland ਦੀ ਗੱਲ ਸਿੱਧੀ ਹੈ: ਬਾਹਰੀ ਦੁਨੀਆ ਅਣਨਿਸ਼ਚਿਤ ਹੈ, ਪਰ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦਾ ਅੰਦਰੂਨੀ ਹਿੱਸਾ ਸਥਿਰ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ। ਨੈੱਟਵਰਕ ਪੈਕਟ ਡ੍ਰੌਪ ਕਰਦੇ ਹਨ, ਫੋਨ ਸਿਗਨਲ ਗੁਆਚਦੇ ਹਨ, ਕਲਾਕ ਡਰਿਫਟ ਕਰਦੇ ਹਨ, ਅਤੇ ਯੂਜ਼ਰ refresh ਦਬਾਉਂਦੇ ਹਨ। ਤੁਹਾਡੀ ਐਪ ਇਹਨਾਂ ਨੂੰ ਨਿਯੰਤਰਿਤ ਨਹੀਂ ਕਰ ਸਕਦੀ। ਪਰ ਇਹ ਨਿਯੰਤਰਿਤ ਕਰ ਸਕਦੀ ਹੈ ਕਿ ਇਕ ਸਾਫ ਬਾਊਂਡਰੀ ਪਾਰ ਹੋਕੇ ਆਉਣ ਵਾਲੇ ਡੇਟਾ 'ਨੂੰ ਕਿਹੜਾ ਸੱਚ ਮੰਨਣਾ ਹੈ।'
ਇੱਕ ਵਿਅਕਤੀ ਨੂੰ ਸਮਝੋ ਜੋ ਖਰਾਬ Wi‑Fi ਵਾਲੀ ਇਮਾਰਤ ਵਿੱਚ ਫਿਰਦੇ ਹੋਏ ਆਪਣੇ ਫ਼ੋਨ ਤੋਂ ਕੌਫੀ ਆਰਡਰ ਕਰ ਰਿਹਾ ਹੈ। ਉਹ "Pay" ਟੈਪ ਕਰਦਾ ਹੈ। ਸਪਿਨਰ ਚੱਲਦਾ ਹੈ। ਨੈੱਟਵਰਕ ਕੱਟ ਜਾਂਦਾ ਹੈ। ਉਹ ਮੁੜ ਟੈਪ ਕਰਦਾ ਹੈ।
ਸਾਇਦ ਪਹਿਲੀ ਰਿਕਵੇਸਟ ਤੁਹਾਡੇ ਸਰਵਰ ਤੱਕ ਪਹੁੰਚ ਗਈ ਸੀ, ਪਰ ਰਿਸਪਾਂਸ ਵਾਪਸ ਨਹੀਂ ਪਹੁੰਚਿਆ। ਜਾਂ ਸਾਇਦ ਕੋਈ ਵੀ ਰਿਕਵੇਸਟ ਨਹੀਂ ਪਹੁੰਚੀ। ਉਪਭੋਗਤਾ ਦੇ ਨਜ਼ਰੀਏ ਤੋਂ ਦੋਹਾਂ ਸੰਭਾਵਨਾਵਾਂ ਇੱਕੋ ਜਿਹੀਆਂ ਦਿੱਸਦੀਆਂ ਹਨ।
ਇਹ ਹੈ ਸਮਾਂ ਅਤੇ ਅਣਨਿਸ਼ਚਿਤਤਾ: ਤੁਸੀਂ ਅਜੇ ਨਹੀਂ ਜਾਣਦੇ ਕਿ ਕੀ ਹੋਇਆ, ਅਤੇ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ ਪਤਾ ਲੱਗ ਸਕਦਾ ਹੈ। ਤੁਹਾਡਾ ਸਿਸਟਮ ਇਸ ਦੇਰ ਦੌਰਾਨ ਸਮਝਦਾਰੀ ਨਾਲ ਕੰਮ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਮਨ ਲੈਂਦੇ ਹੋ ਕਿ ਬਾਹਰ ਅਣਨਿਸ਼ਚਿਤ ਹੈ, ਤਾਂ ਕੁਝ "ਅਜੀਬ" ਚੀਜ਼ਾਂ ਆਮ ਹੋ ਜਾਂਦੀਆਂ ਹਨ:
ਬਾਹਰੀ ਡੇਟਾ ਇੱਕ ਦਾਵਾ ਹੈ, ਤੱਥ ਨਹੀਂ। "ਮੈਂ ਭੁਗਤਾਨ ਕੀਤਾ" ਸਿਰਫ਼ ਇੱਕ ਬਿਆਨ ਹੈ ਜੋ ਇੱਕ ਅਣਨਿਸ਼ਚਿਤ ਚੈਨਲ ਰਾਹੀਂ ਭੇਜਿਆ ਗਿਆ। ਇਹ ਤੱਥ ਵਜੋਂ ਉਸ ਵੇਲੇ ਬਣਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਉਸਨੂੰ ਆਪਣੇ ਸਿਸਟਮ ਵਿੱਚ ਡਿਊਰੇਬਲੀ ਅਤੇ ਸਥਿਰ ਤਰੀਕੇ ਨਾਲ ਦਰਜ਼ ਕਰ ਲੈਹੁ।
ਇਹ ਤੁਹਾਨੂੰ ਤਿੰਨ ਪ੍ਰੈਟਿਕਲ ਆਦਤਾਂ ਵੱਲ ਧੱਕੇਗਾ: ਸਪਸ਼ਟ ਸੀਮਾ ਨਿਰਧਾਰਿਤ ਕਰੋ, ਰੀਟ੍ਰਾਈਜ਼ ਸੁਰੱਖਿਅਤ ਬਣਾਉਣ ਲਈ idempotency ਲਾਗੂ ਕਰੋ, ਅਤੇ ਜਦੋਂ ਹਕੀਕਤ ਮਿਲਦੀ ਨਹੀਂ ਤਾਂ reconciliation ਯੋਜਨਾ ਬਣਾਓ।
"ਬਾਹਰ vs ਅੰਦਰ" ਵਿਚਾਰ ਇੱਕ ਪ੍ਰੈਕਟਿਕਲ ਸਵਾਲ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ: ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੀ ਸੱਚਾਈ ਕਿੱਥੇ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ ਅਤੇ ਕਿੱਥੇ ਖਤਮ ਹੁੰਦੀ ਹੈ?
ਬਾਊਂਡਰੀ ਦੇ ਅੰਦਰ ਤੁਸੀਂ ਮਜ਼ਬੂਤ ਗਾਰੰਟੀ ਦੇ ਸਕਦੇ ਹੋ ਕਿਉਂਕਿ ਤੁਸੀਂ ਡੇਟਾ ਅਤੇ ਨਿਯਮਾਂ ਨੂੰ ਨਿਯੰਤਰਿਤ ਕਰਦੇ ਹੋ। ਬਾਊਂਡਰੀ ਦੇ ਬਾਹਰ ਤੁਸੀਂ ਬੇਸਟ‑ਐਫ਼ੋਰਟ ਕੋਸ਼ਿਸ਼ਾਂ ਕਰਦੇ ਹੋ ਅਤੇ ਮੰਨੀਦਾ ਹੈ ਕਿ ਸੁਨੇਹੇ ਗੁੰਮ, ਡੁਪਲੀਕੇਟ, ਦੇਰ ਨਾਲ ਜਾਂ ਗਲਤ ਕ੍ਰਮ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ।
ਅਸਲ ਐਪਾਂ ਵਿੱਚ, ਉਹ ਬਾਊਂਡਰੀ ਅਕਸਰ ਇੱਥੇ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ:
ਇੱਕ ਵਾਰੀ ਤੁਸੀਂ ਉਸ ਰੇਖਾ ਖਿੱਚ ਲੈਂਦੇ ਹੋ, ਫੇਰ ਫੈ਼ਸਲਾ ਕਰੋ ਕਿ ਅੰਦਰ ਕਿਹੜੀਆਂ invariants ਗੈਰ-ਰੱਥ ਹੋਣਗੀਆਂ। ਉਦਾਹਰਣ:
created -> paid -> shipped)।ਬਾਊਂਡਰੀ ਲਈ "ਅਸੀਂ ਕਿਸ ਸਥਿਤੀ 'ਚ ਹਾਂ" ਦਾ ਸਪਸ਼ਟ ਭਾਸ਼ਾ ਵੀ ਲਾਜ਼ਮੀ ਹੈ। ਕਈ ਫੇਲਿਅਰ 'ਸਾਡੀ ਫੀਲਿੰਗ' ਅਤੇ 'ਅਸੀਂ ਮੁਕੰਮਲ ਕੀਤਾ' ਦੇ ਗੈਰ‑ਸਾਫ਼ੀ ਵਿੱਚ ਵੱਸਦੇ ਹਨ। ਇੱਕ ਲਾਭਦਾਇਕ ਪੈਟਰਨ ਹੈ ਤਿੰਨ ਅਰਥਨੂੰ ਵੱਖ ਕਰਨਾ:
ਜਦੋਂ ਟੀਮਾਂ ਇਹ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ, ਉਹ ਅਜਿਹੇ ਬੱਗ ਪੈਦਾ ਹੋ ਜਾਂਦੇ ਹਨ ਜੋ ਸਿਰਫ਼ ਲੋਡ ਜਾਂ ਅੰਸ਼ਿਕ ਆਊਟੇਜ ਦੌਰਾਨ ਹੀ ਆਉਂਦੇ ਹਨ। ਇੱਕ ਸਿਸਟਮ "paid" ਨੂੰ ਮਤਲਬ ਪੈਸਾ ਕੈਪਚਰ ਹੋਣਾ ਸਮਝਦਾ ਹੈ; ਦੂਜਾ ਇਸਨੂੰ payment attempt ਸ਼ੁਰੂ ਹੋਣਾ ਸਮਝਦਾ ਹੈ। ਇਹ ਮਿਲਾਉਂਦਿਆਂ duplicates, ਫਸੇ ਆਰਡਰ ਅਤੇ ਹੇਠਾਂ ਨਹੀਂ ਆਉਣ ਵਾਲੀਆਂ ਸਪੋਰਟ ਟਿਕਟਾਂ ਬਣ ਜਾਂਦੀਆਂ ਹਨ।
Idempotency ਦਾ ਮਤਲਬ ਹੈ: ਜੇ ਇਕੋ ਰਿਕਵੇਸਟ ਦੋ ਵਾਰੀ ਭੇਜੀ ਜਾਂਦੀ ਹੈ, ਸਿਸਟਮ ਉਸਨੂੰ ਇੱਕੋ ਰਿਕਵੇਸਟ ਵਾਂਗ ਸਮਝੇ ਅਤੇ ਇਕੋ ਨਤੀਜਾ ਵੇਰੇ।
ਰੀਟ੍ਰਾਈਜ਼ ਆਮ ਗੱਲ ਹਨ। ਟਾਈਮਆਉਟ ਹੁੰਦਾ ਹੈ। ਕਲਾਇੰਟ ਆਪਣੇ ਆਪ ਨੂੰ ਦੁਹਰਾਉਂਦੇ ਹਨ। ਜੇ ਬਾਹਰ ਦੁਹਰਾਓ ਕਰ ਸਕਦਾ ਹੈ, ਤਾਂ ਅੰਦਰ ਉਸਨੂੰ ਸਥਿਰ ਸਟੇਟ ਚੇਂਜ ਵਿੱਚ ਤਬਦੀਲ ਕਰਨਾ ਪਵੇਗਾ।
ਸਧਾਰਨ ਉਦਾਹਰਨ: ਇੱਕ ਮੋਬਾਈਲ ਐਪ "pay $20" ਭੇਜਦੀ ਹੈ ਅਤੇ ਕਨੈਕਸ਼ਨ ਡ੍ਰੌਪ ਹੋ ਜਾਂਦਾ ਹੈ। ਐਪ ਰੀਟ੍ਰਾਈ ਕਰਦੀ ਹੈ। ਬਿਨਾਂ idempotency ਦੇ, ਗਾਹਕ ਤੋਂ ਦੋ ਵਾਰੀ ਚਾਰਜ ਹੋ ਸਕਦਾ ਹੈ। idempotency ਨਾਲ, ਦੂਜੀ ਰਿਕਵੇਸਟ ਪਹਿਲੇ ਚਾਰਜ ਦੇ ਨਤੀਜੇ ਨੂੰ ਵਾਪਸ ਕਰੇਗੀ।
ਅਕਸਰ ਟੀਮਾਂ ਇਹਨਾਂ ਪੈਟਰਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਵਰਤਦੀਆਂ ਹਨ (ਕਈ ਵਾਰੀ ਮਿਕਸ ਵੀ):
Idempotency-Key: ...). ਸਰਵਰ key ਅਤੇ ਅੰਤਿਮ ਰਿਸਪਾਂਸ ਨੂੰ ਰਿਕਾਰਡ ਕਰਦਾ ਹੈ।(client_id, key) ਜਾਂ (order_id, operation) ਨਾਲ ਇਕ ਰੋ ਜੋੜੋ ਅਤੇ ਦੂਜੀ ਵਾਰੀ ਸਾਈਡ-ਇਫੈਕਟ ਮਨਾਉਣ ਤੋਂ ਇਨਕਾਰ ਕਰੋ।ਜਦੋਂ ڈੁਪਲਿਕੇਟ ਆਉਂਦਾ ਹੈ, ਸਭ ਤੋਂ ਵਧੀਆ ਵਰਤਾਓ ਆਮ ਤੌਰ 'ਤੇ "409 conflict" ਜਾਂ ਕਿਸੇ ਜਨਰਿਕ error ਨਾ ਹੋ ਕੇ ਉਹੀ ਨਤੀਜਾ ਵਾਪਸ ਕਰਨਾ ਹੁੰਦਾ ਹੈ ਜੋ ਪਹਿਲੀ ਵਾਰੀ ਦਿੱਤਾ ਗਿਆ ਸੀ, ਜਿਸ ਵਿੱਚ ਉਹੀ resource ID ਅਤੇ status ਸ਼ਾਮਲ ਹੋ। ਇਹ ਹੀ ਰੀਟ੍ਰਾਈਜ਼ ਨੂੰ ਕਲਾਇੰਟ ਅਤੇ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਲਈ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦਾ ਹੈ।
idempotency ਰਿਕਾਰਡ ਤੁਹਾਡੇ ਬਾਊਂਡਰੀ ਦੇ ਅੰਦਰ ਡਿਊਰੇਬਲ ਸਟੋਰੇਜ ਵਿੱਚ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ, ਮੈਮੋਰੀ ਵਿੱਚ ਨਹੀਂ। ਜੇ API ਰੀਸਟਾਰਟ ਹੁੰਦੀ ਹੈ ਅਤੇ ਭੁੱਲ ਜਾਉਂਦੀ ਹੈ, ਤਾਂ ਸੁਰੱਖਿਆ ਗੁਮ ਹੋ ਜਾਂਦੀ ਹੈ।
ਰਿਕਾਰਡ ਉਹ ਸਮਾਂ ਰੱਖੋ ਜੋ ਯਥਾਰਥਿਕ ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਡੀਲੇਡ ਡਿਲਿਵਰੀ ਕਵਰ ਕਰ ਸਕੇ। ਵਿੰਡੋ ਬਿਜ਼ਨਸ ਰਿਸਕ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ: ਘੱਟ-ਖਤਰੇ ਵਾਲੇ creations ਲਈ ਮਿੰਟ-ਘੰਟੇ, ਪੇਮੈਂਟ/ਈਮੇਲ/ਸਪਾਈਨਮੈਂਟ ਲਈ ਦਿਨ, ਅਤੇ ਜੇ ਭਾਈਦਾਰੀ ਲੰਮੀ ਰੀਟ੍ਰਾਈ ਪਹੁੰਚ ਰੱਖਦੀ ਹੈ ਤਾਂ ਹੋਰ ਵੀ ਲੰਬਾ।
Distributed transactions ਸੁਣਨ ਵਿੱਚ ਆਸਾਨ ਲਗਦੇ ਹਨ: ਸੇਵਾਵਾਂ, ਕਿਊਜ਼ ਅਤੇ ਡੇਟਾਬੇਸ 'ਤੇ ਇੱਕ ਵੱਡਾ commit। ਪਰ ਅਮਲ ਵਿੱਚ ਇਹ ਅਕਸਰ ਅਣਉਪਲਬਧ, ਧੀਮੇ ਜਾਂ ਬਹੁਤ ਨਾਜ਼ੁਕ ਹੁੰਦੇ ਹਨ। ਜਦੋਂ ਵੀ ਨੈੱਟਵਰਕ ਹੋਪ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ, ਤੁਸੀਂ ਇਹ ਮੰਨ ਕੇ ਨਹੀਂ ਚੱਲ ਸਕਦੇ ਕਿ ਸਭ ਕੁਝ ਇੱਕੱਠੇ commit ਹੋ ਜਾਵੇ।
ਅਕਸਰ ਜਾਲ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇੱਕ workflow ਬਣਾਉਂਦੇ ਹੋ ਜੋ ਸਿਰਫ਼ ਤਦ ਹੀ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਹਰ ਕਦਮ ਹੁਣੇ-ਹੁਣੇ ਸਫਲ ਹੋ ਜਾਵੇ: order save, charge card, reserve inventory, send confirmation. ਜੇ ਤੀਸਰਾ ਕਦਮ timeout ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਕੀ ਉਹ fail ਹੋਇਆ ਜਾਂ success? ਜੇ ਤੁਸੀਂ retry ਕਰੋਗੇ, ਕੀ double-charge ਹੋ ਜਾਵੇਗਾ ਜਾਂ double-reserve?
ਦੋ ਪ੍ਰੈਕਟਿਕਲ ਤਰੀਕੇ ਇਸ ਤੋਂ ਬਚਦੇ ਹਨ:
ਹਰ workflow ਲਈ ਇੱਕ ਸਟਾਈਲ ਚੁਣੋ ਅਤੇ ਉਸੇ 'ਤੇ ਟਿਕੇ ਰਹੋ। "ਕਦੇ-ਕਦੇ ਆਊਟਬਾਕਸ ਕਰਦੇ ਹਾਂ" ਅਤੇ "ਕਦੇ-ਕਦੇ sync ਸਫਲ ਮੰਨ ਲਈਦਾ ਹਾਂ" ਮਿਲਾਉਣ ਨਾਲ ਐਜੇ edge-cases ਬਣਦੇ ਹਨ ਜੋ ਟੈਸਟ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: ਜੇ ਤੁਸੀਂ ਬਾਊਂਡਰੀਆਂ 'ਤੇ ਐਟੋਮਿਕ ਕਮਿਟ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਰੀਟ੍ਰਾਈਜ਼, ਡੁਪਲੀਕੇਟ ਅਤੇ ਦੇਰ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ।
ਰਿਕਨਸੀਲੇਸ਼ਨ ਇੱਕ ਮੂਲ ਸਚਾਈ ਮੰਨਣ ਹੈ: ਜਦੋਂ ਤੁਹਾਡੀ ਐਪ ਦੂਜੇ ਸਿਸਟਮਾਂ ਨਾਲ ਨੈੱਟਵਰਕ ਰਾਹੀਂ ਗੱਲ ਕਰਦੀ ਹੈ, ਤਾਂ ਕਈ ਵਾਰੀ ਤੁਸੀਂ ਇਹ ਸੋਚ ਨਹੀਂ ਸਕਦੇ ਕਿ ਕੀ ਹੋਇਆ। ਰਿਕਨਸੀਲੇਸ਼ਨ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ mismatch ਨੂੰ ਪਛਾਣਦੇ ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ ਠੀਕ ਕਰਦੇ ਹੋ।
ਬਾਹਰੀ ਸਿਸਟਮਾਂ ਨੂੰ ਸੁਤੰਤਰ ਸਰੋਤ-ਅਫ਼-ਟ੍ਰੂਥ ਮੰਨੋ। ਤੁਹਾਡੀ ਐਪ ਆਪਣਾ ਅੰਦਰੂਨੀ ਰਿਕਾਰਡ ਰੱਖਦੀ ਹੈ, ਪਰ ਉਸਨੂੰ ਇਹ ਤਰੀਕਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਉਹ ਆਪਣੇ ਰਿਕਾਰਡ ਦੀ ਤੁਲਨਾ ਪ੍ਰੋਵਾਈਡਰਾਂ, ਪਾਰਟਨਰਾਂ ਅਤੇ ਯੂਜ਼ਰਾਂ ਦੀ ਹਕੀਕਤ ਨਾਲ ਕਰ ਸਕੇ।
ਅਕਸਰ ਟੀਮਾਂ ਮਿੱਠੇ ਅਤੇ ਸਧਾਰਨ ਔਜ਼ਾਰ ਵਰਤਦੀਆਂ ਹਨ (ਸਧਾਰਨ ਚੰਗਾ ਹੁੰਦਾ ਹੈ): ਇੱਕ worker ਜੋ pending actions ਨੂੰ ਦੁਬਾਰਾ ਟ੍ਰਾਈ ਕਰਦਾ ਅਤੇ ਬਾਹਰੀ status ਨੂੰ ਰੀ-ਚੈੱਕ ਕਰਦਾ, ਇੱਕ ਨਿਯਮਿਤ ਸਕੈਨ ਜੋ inconsistencies ਲੱਭਦਾ, ਅਤੇ ਇੱਕ ਛੋਟਾ admin repair action ਜੋ support ਲਈ retry, cancel ਜਾਂ mark as reviewed ਦੀ ਆਸਾਨੀ ਦਿੰਦਾ ਹੈ।
ਰਿਕਨਸੀਲੇਸ਼ਨ ਉਸ ਵੇਲੇ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਜਾਣਦੇ ਹੋ ਕਿ ਕੀ ਤੁਲਨਾ ਕਰਨੀ ਹੈ: ਅੰਦਰੂਨੀ ਲੈਜਰ ਵਿਰੁੱਧ ਪ੍ਰੋਵਾਇਡਰ ਲੈਜਰ (payments), order state ਵਿਰੁੱਧ shipment state (fulfillment), subscription state ਵਿਰੁੱਧ billing state।
ਸਟੇਟਾਂ ਨੂੰ repairable ਬਣਾਓ। "created" ਤੋਂ ਸਿੱਧਾ "completed" ਵਿੱਚ ਛਾਲ ਮਾਰਨ ਦੀ ਬਜਾਏ, ਹੋਲਡਿੰਗ states ਵਰਗੇ pending, on hold, ਜਾਂ needs review ਵਰਤੋ। ਇਸ ਨਾਲ ਇਹ ਕਹਿਣਾ ਸੁਰੱਖਿਅਤ ਹੁੰਦਾ ਹੈ "ਅਸੀਂ ਪੱਕੇ ਨਹੀਂ ਹਾਂ" ਅਤੇ ਰਿਕਨਸੀਲੇਸ਼ਨ ਲਈ ਇੱਕ ਸਾਫ਼ ਲੈਂਡਿੰਗ ਪਲੇਸ ਮਿਲਦਾ ਹੈ।
ਮਹੱਤਵਪੂਰਨ ਬਦਲਾਵਾਂ 'ਤੇ ਇੱਕ ਛੋਟਾ audit trail ਕੈਪਚਰ ਕਰੋ:
ਉਦਾਹਰਨ: ਜੇ ਤੁਹਾਡੀ ਐਪ shipment label ਲਈ ਬੇਨਤੀ ਕਰਦੀ ਹੈ ਅਤੇ ਨੈੱਟਵਰਕ ਡ੍ਰੌਪ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਡੇ ਅੰਦਰੂਨੀ ਰਿਕਾਰਡ 'no label' ਦਿਖਾ ਸਕਦੇ ਹਨ ਜਦਕਿ ਕੈਰੀਅਰ ਨੇ ਅਸਲ ਵਿੱਚ ਇੱਕ ਲੇਬਲ ਬਣਾਇਆ ਹੋ ਸਕਦਾ ਹੈ। ਇਕ recon worker correlation ID ਰਾਹੀਂ ਲਭ ਕੇ ਲੇਬਲ ਮਿਲਾ ਸਕਦਾ ਹੈ ਅਤੇ ਆਰਡਰ ਨੂੰ ਅੱਗੇ ਵਧਾ ਸਕਦਾ ਹੈ (ਜਾਂ ਅਗਰ ਡੇਟਾ ਮੇਲ ਨਹੀਂ ਖਾਂਦਾ ਤਾਂ review ਲਈ ਨਿਸ਼ਾਨਾ ਕਰੇ)।
ਜਦੋਂ ਤੁਸੀਂ ਮੰਨ ਲੈਂਦੇ ਹੋ ਕਿ ਨੈੱਟਵਰਕ ਫੇਲ੍ਹ ਹੋਏਗਾ, ਤਾਂ ਟੀਚਾ ਬਦਲ ਜਾਂਦਾ ਹੈ। ਤੁਸੀਂ ਹਰ ਕਦਮ ਨੂੰ ਇਕ ਵਾਰੀ ਵਿੱਚ ਸਫਲ ਬਣਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਹੀਂ ਕਰ ਰਹੇ; ਤੁਸੀਂ ਹਰ ਕਦਮ ਨੂੰ ਦੁਹਰਾਉਣ ਲਈ ਸੁਰੱਖਿਅਤ ਅਤੇ ਠੀਕ ਕਰਨ ਲਈ ਆਸਾਨ ਬਣਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੇ ਹੋ।
ਇੱਕ ਇੱਕ-ਪੰਗਤੀ ਬਾਊਂਡਰੀ ਬਿਆਨ ਲਿਖੋ। ਸਪੱਸ਼ਟ ਹੋਵੋ ਕਿ ਤੁਹਾਡਾ ਸਿਸਟਮ ਕੀ ਮਾਲਕ ਹੈ (source of truth), ਕੀ ਉਹ ਮਿਰਰ ਕਰਦਾ ਹੈ, ਅਤੇ ਕੀ ਉਹ ਸਿਰਫ਼ ਹੋਰਾਂ ਤੋਂ ਬੇਨਤੀ ਕਰਦਾ ਹੈ।
ਖੁਸ਼ੀ ਮਾਰਗ ਤੋਂ ਪਹਿਲਾਂ ਫੇਲਿਅਰ ਮੋਡਾਂ ਦੀ ਸੂਚੀ ਬਣਾਓ। ਘੱਟੋ-ਘੱਟ: timeouts (ਤੁਹਾਨੂੰ ਪਤਾ ਨਹੀਂ ਕਿ ਇਹ ਕੰਮ ਹੋਇਆ), duplicate requests, partial success (ਇੱਕ ਕਦਮ ਹੋਇਆ, ਅਗਲਾ ਨਹੀਂ), ਅਤੇ out-of-order events।
ਹਰ ਇਨਪੁੱਟ ਲਈ idempotency ਰਣਨੀਤੀ ਚੁਣੋ। synchronous APIs ਲਈ ਇਹ ਅਕਸਰ idempotency key + ਸਟੋਰ ਕੀਤਾ ਨਤੀਜਾ ਹੁੰਦਾ ਹੈ। messages/events ਲਈ ਇਹ ਆਮ ਤੌਰ 'ਤੇ unique message ID ਅਤੇ "ਕੀ ਮੈਂ ਇਸਨੂੰ ਪ੍ਰੋਸੈਸ ਕੀਤਾ ਹੈ?" ਰਿਕਾਰਡ ਹੁੰਦਾ ਹੈ।
ਇਰਾਦਾ ਸਟੋਰ ਕਰੋ, ਫਿਰ ਕਾਰਵਾਈ ਕਰੋ। ਪਹਿਲਾਂ ਕੁਝ ਡਿਊਰੇਬਲ ਸਟੋਰ ਕਰੋ ਜਿਵੇਂ PaymentAttempt: pending ਜਾਂ ShipmentRequest: queued, ਫਿਰ ਬਾਹਰੀ ਕਾਲ ਕਰੋ, ਫਿਰ outcome ਸਟੋਰ ਕਰੋ। ਇੱਕ ਸਥਿਰ reference ID ਵਾਪਸ ਕਰੋ ਤਾਂ ਜੋ ਰੀਟ੍ਰਾਈਜ਼ ਇੱਕੋ ਇਰਾਦੇ ਵੱਲ ਇਸ਼ਾਰਾ ਕਰਨ ਨਾ ਕਿ ਨਵਾਂ ਬਣਾਉਣ।
ਰਿਕਨਸੀਲੇਸ਼ਨ ਅਤੇ ਇੱਕ repair path ਬਣਾਓ, ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਵਿਖਾਈ ਦੇਣਯੋਗ ਬਣਾਓ। ਰਿਕਨਸੀਲੇਸ਼ਨ ਇੱਕ job ਹੋ ਸਕਦੀ ਹੈ ਜੋ "ਪੈਂਡਿੰਗ ਬਹੁਤ ਦੇਰ" ਵਾਲੀਆਂ ਰਿਕਾਰਡਾਂ ਨੂੰ ਸਕੈਨ ਕਰਦੀ ਅਤੇ ਬਾਹਰੀ ਸਿਸਟਮ ਨੂੰ ਦੁਬਾਰਾ ਚੈੱਕ ਕਰਦੀ। repair path ਇੱਕ ਸੁਰੱਖਿਅਤ admin action ਹੋ ਸਕਦੀ ਹੈ ਜਿਵੇਂ "retry", "cancel" ਜਾਂ "mark resolved" ਨਾਲ ਇੱਕ audit note। ਬੇਸਿਕ observability ਜੋੜੋ: correlation IDs, ਸਪਸ਼ਟ status fields, ਅਤੇ ਕੁਝ ਗਿਣਤੀਆਂ (pending, retries, failures)।
ਉਦਾਹਰਨ: ਜੇ checkout ਤੁਹਾਡੇ payment provider ਨੂੰ ਕਾਲ ਕਰਨ ਦੇ ਤੁਰੰਤ ਬਾਅਦ timeout ਹੋ ਜਾਂਦਾ ਹੈ, ਅਨੁਮਾਨ ਨਾ ਲਗਾਓ। attempt ਸਟੋਰ ਕਰੋ, attempt ID ਵਾਪਸ ਕਰੋ, ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ ਉਹੀ idempotency key ਨਾਲ ਮੁੜ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਦਿਓ। ਬਾਅਦ ਵਿੱਚ reconciliation ਇਹ ਪੁਸ਼ਟੀ ਕਰ ਸਕਦੀ ਹੈ ਕਿ provider ਨੇ charge ਕੀਤਾ ਜਾਂ ਨਹੀਂ ਅਤੇ attempt ਨੂੰ ਬਿਨਾਂ ਡਬਲ-ਚਾਰਜ ਕੀਤੇ ਅਪਡੇਟ ਕਰ ਸਕਦੀ ਹੈ।
ਗਾਹਕ "Place order" ਟੈਪ ਕਰਦਾ ਹੈ। ਤੁਹਾਡੀ ਸੇਵਾ payment ਲਈ provider ਨੂੰ ਬੇਨਤੀ ਭੇਜਦੀ ਹੈ, ਪਰ ਨੈੱਟਵਰਕ ਢਿੱਲ ਹੈ। ਪ੍ਰੋਵਾਇਡਰ ਦਾ ਆਪਣਾ ਸੱਚ ਹੈ, ਅਤੇ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਦਾ ਆਪਣਾ। ਜੇ ਤੁਸੀਂ ਇਸਦੇ ਅਨੁਕੂਲ ਡਿਜ਼ਾਈਨ ਨਹੀਂ ਕਰੋਗੇ ਤਾਂ ਉਹ ਦੂਰ ਹੋ ਜਾਣਗੇ।
ਤੁਹਾਡੇ ਨਜ਼ਰੀਏ ਤੋਂ, ਬਾਹਰ ਸੁਨੇਹਿਆਂ ਦਾ ਇੱਕ ਸਟ੍ਰੀਮ ਹੈ ਜੋ ਦੇਰ ਨਾਲ, ਵਾਰ-ਵਾਰ ਜਾਂ ਗੈਰਮੌਜੂਦ ਹੋ ਸਕਦਾ ਹੈ:
ਇਨ੍ਹਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ ਕਦਮ "ਬਿਲਕੁਲ ਇੱਕ ਵਾਰੀ" ਦੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦਿੰਦੇ। ਓਹ ਸਿਰਫ਼ "ਸੰਭਵ" ਹਨ।
ਆਪਣੇ ਬਾਊਂਡਰੀ ਦੇ ਅੰਦਰ, ਡਿਊरेਬਲ ਤੱਥ ਅਤੇ ਬਾਹਰੀ ਘਟਨਾਵਾਂ ਨੂੰ ਉਹਨਾਂ ਤੱਥਾਂ ਨਾਲ ਜੋੜਨ ਲਈ ਘੱਟੋ-ਘੱਟ ਚੀਜ਼ਾਂ ਸਟੋਰ ਕਰੋ।
ਜਦੋਂ ਗਾਹਕ ਪਹਿਲੀ ਵਾਰੀ ਆਰਡਰ ਰੱਖਦਾ ਹੈ, ਇੱਕ order ਰਿਕਾਰਡ ਬਣਾਓ ਇੱਕ ਸਪਸ਼ਟ ਸਟੇਟ ਵਿੱਚ ਜਿਵੇਂ pending_payment। ਨਾਲ ਹੀ payment_attempt ਰਿਕਾਰਡ ਬਣਾਓ ਜਿਸ ਵਿੱਚ ਯੂਨੀਕ provider reference ਅਤੇ ਗਾਹਕ ਕਾਰਵਾਈ ਨਾਲ ਜੁੜਿਆ idempotency_key ਹੋਵੇ।
ਜੇ client timeout ਹੋ ਦੇ ਕੇ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ, ਤੁਹਾਡੀ API ਨੂੰ ਦੂਜਾ ਆਰਡਰ ਨਹੀਂ ਬਣਾਉਣਾ ਚਾਹੀਦਾ। ਇਹਨੂੰ idempotency_key ਨਾਲ ਲੁੱਕ ਕਰਨਾ ਅਤੇ ਉਹੀ order_id ਅਤੇ ਮੌਜੂਦਾ ਸਟੇਟ ਵਾਪਸ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ। ਇਹ ਚੋਣ ਡੁਪਲਿਕੇਟ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ।
ਹੁਣ webhook ਦੋ ਵਾਰੀ ਆਉਂਦਾ ਹੈ। ਪਹਿਲੀ callback payment_attempt ਨੂੰ authorized 'ਤੇ ਅਪਡੇਟ ਕਰਦੀ ਹੈ ਅਤੇ order ਨੂੰ paid ਵਿੱਚ ਲਾਂਦੀ ਹੈ। ਦੂਜੀ callback ਉਸੇ ਹੈਂਡਲਰ ਨੂੰ ਮਾਰਦੀ ਹੈ, ਪਰ ਤੁਹਾਨੂੰ ਪਤਾ ਹੈ ਕਿ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਉਸ provider event ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰ ਚੁੱਕੇ ਹੋ (provider event ID ਸਟੋਰ ਕਰਕੇ, ਜਾਂ ਮੌਜੂਦਾ ਸਟੇਟ ਚੈੱਕ ਕਰਕੇ) ਅਤੇ ਕੁਛ ਨਹੀਂ ਕਰਦੇ। ਤੂੰ ਫਿਰ ਵੀ 200 OK ਵਾਪਸ ਕਰ ਸਕਦੇ ਹੋ, ਕਿਉਂਕਿ ਨਤੀਜਾ ਪਹਿਲਾਂ ਹੀ ਸੱਚ ਹੈ।
ਅੰਤ ਵਿੱਚ, reconciliation ਗੁੰਝਲਦਾਰ ਮਾਮਲਿਆਂ ਨੂੰ ਹੈਂਡਲ ਕਰਦਾ ਹੈ। ਜੇ order pending_payment ਬਾਅਦ ਵੀ ਦੇਰ ਨਾਲ ਰਹਿ ਜਾਂਦਾ ਹੈ, ਇੱਕ background job ਸਟੋਰ ਕੀਤੇ reference ਨੂੰ ਵਰਤ ਕੇ provider ਨੂੰ ਪੁੱਛਦਾ ਹੈ। ਜੇ provider "authorized" ਕਹਿੰਦਾ ਹੈ ਪਰ ਤੁਸੀਂ webhook ਮਿਸ ਕਰ ਦਿੱਤਾ, ਤੁਸੀਂ ਆਪਣੇ ਰਿਕਾਰਡ ਅਪਡੇਟ ਕਰੋਗੇ। ਜੇ provider "failed" ਕਹਿੰਦਾ ਹੈ ਪਰ ਤੁਸੀਂ ਉਸਨੂੰ paid ਚਿੰਨ੍ਹਿਤ ਕੀਤਾ ਸੀ, ਤੁਸੀਂ review ਲਈ ਫਲੈਗ ਕਰ ਸਕਦੇ ਹੋ ਜਾਂ compensating action ਜਿਵੇਂ refund ਟ੍ਰਿਗਰ ਕਰ ਸਕਦੇ ਹੋ।
ਅਧਿਕਤਮ duplicates ਅਤੇ "ਫਸਿਆ ਹੋਇਆ" ਵਰਕਫਲੋਜ਼ ਇਸ ਗਲਤੀ ਕਾਰਨ ਹੁੰਦੇ ਹਨ ਕਿ ਬਾਹਰ ਹੋਈ ਘਟਨਾ (ਇੱਕ ਰਿਕਵੇਸਟ ਆਈ, ਇੱਕ ਸੁਨੇਹਾ ਮਿਲਿਆ) ਨੂੰ ਤੁਸੀਂ ਅੰਦਰ ਜੋ ਕੁਝ durable commit ਕੀਤਾ ਉਸ ਨਾਲ ਗੁਲਮਿਲ ਕਰ ਦਿੰਦੇ ਹੋ।
ਕਲਾਸਿਕ ਫੇਲ: ਇੱਕ ਕਲਾਇੰਟ "place order" ਭੇਜਦਾ ਹੈ, ਤੁਹਾਡਾ ਸਰਵਰ ਕੰਮ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, ਨੈੱਟਵਰਕ ਡ੍ਰੌਪ ਹੋ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਕਲਾਇੰਟ ਮੁੜ ਰੀਟ੍ਰਾਈ ਕਰਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਹਰ retry ਨੂੰ ਨਵੀਂ ਸੱਚਾਈ ਮੰਨੋਗੇ, ਤਾਂ ਤੁਹਾਨੂੰ ਡਬਲ ਚਾਰਜ, ਡੁਪਲਿਕੇਟ ਆਰਡਰ ਜਾਂ ਕਈ ਈਮੇਲ ਮਿਲਣਗੀਆਂ।
ਆਮ ਕਾਰਨ:
ਇੱਕ ਮਸਲਾ ਸਭ ਕੁਝ ਹੋਰ ਬੁਰਾ ਕਰ ਦਿੰਦਾ: ਕੋਈ audit trail ਨਹੀਂ। ਜੇ ਤੁਸੀਂ ਫੀਲਡਾਂ ਨੂੰ overwrite ਕਰਦੇ ਹੋ ਅਤੇ ਸਿਰਫ਼ ਆਖਰੀ ਸਟੇਟ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਉਹ ਸਬੂਤ ਗਵਾ ਬੈਠਦੇ ਹੋ ਜੋ ਬਾਅਦ 'ਚ reconcile ਕਰਨ ਲਈ ਲੋੜੀਂਦੇ ਹਨ।
ਇੱਕ ਚੰਗੀ sanity ਚੈਕ: "ਜੇ ਮੈਂ ਇਸ handler ਨੂੰ ਦੋ ਵਾਰੀ ਚਲਾਂਦਾਂ, ਕੀ ਨਤੀਜਾ ਇਕੋ ਆਵੇਗਾ?" ਜੇ ਜਵਾਬ 'ਨਹੀਂ' ਹੈ, ਤਾਂ duplicates ਕਦੇ-ਕਦੇ ਵਾਲਾ ਮਾਮਲਾ ਨਹੀਂ — ਉਹ ਗਾਰੰਟੀ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਗੱਲ ਯਾਦ ਰੱਖੋ: ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਠੀਕ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ ਭਾਵੇਂ ਸੁਨੇਹੇ ਦੇਰ ਨਾਲ ਆਉਣ, ਦੋ ਵਾਰੀ ਆਉਣ ਜਾਂ ਕਭੀ ਨਹੀਂ ਆਉਣ।
ਇਸ ਚੈਕਲਿਸਟ ਤੋਂ ਵਰਤੋਂ ਕਰੋ ਤਾਂ ਕਿ ਕਮਜ਼ੋਰੀਆਂ ਤਦ ਬਚੀਆਂ ਰਹਿਣ:
ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਇਕ ਦਾ ਜਲਦੀ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਇਹ ਉਪਯੋਗੀ ਹੈ—ਇਸਦਾ ਮਤਲਬ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਬਾਊਂਡਰੀ fuzzy ਹੈ ਜਾਂ ਇੱਕ ਸਟੇਟ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਗਾਇਬ ਹੈ।
ਪ੍ਰੈਕਟਿਕਲ ਅਗਲੇ ਕਦਮ:
ਪਹਿਲਾਂ ਬਾਊਂਡਰੀਆਂ ਅਤੇ ਸਟੇਟਾਂ ਦਾ ਸਕੈਚ ਬਣਾਓ। ਹਰ workflow ਲਈ ਛੋਟੇ state ਸੈੱਟ define ਕਰੋ (ਉਦਾਹਰਨ: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed)।
ਸਭ ਤੋਂ ਜ਼ਰੂਰੀ ਥਾਵਾਂ ਤੇ idempotency ਜੋੜੋ। ਉੱਚ-ਝੋਖਮ ਵਾਲੀਆਂ ਲਿਖਤਾਂ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ: create order, capture payment, issue refund. Idempotency keys PostgreSQL ਵਿੱਚ unique constraint ਨਾਲ store ਕਰੋ ਤਾਂ ਕਿ duplicates ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਰੱਦ ਹੋ ਜਾਣ।
reconciliation ਨੂੰ ਇੱਕ ਸਧਾਰਨ ਫੀਚਰ ਸਮਝੋ। ਇੱਕ job schedule ਕਰੋ ਜੋ "ਪੈਂਡਿੰਗ ਬਹੁਤ ਦੇਰ" ਵਾਲੀਆਂ ਰਿਕਾਰਡਾਂ ਨੂੰ ਲੱਭ ਕੇ ਬਾਹਰੀ ਸਿਸਟਮ ਨੂੰ ਫਿਰ ਚੈੱਕ ਕਰੇ ਅਤੇ ਸਥਾਨਿਕ ਸਟੇਟ ਨੂੰ repair ਕਰੇ।
ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ iterate ਕਰੋ। transitions ਅਤੇ retry ਨੀਤੀਆਂ ਨੂੰ ਢਾਲੋ, ਫਿਰ ਜਾਣ-ਬੁਝ ਕੇ ਇੱਕੋ ਹੀ ਰਿਕਵੇਸਟ ਨੂੰ ਦੁਬਾਰਾ ਭੇਜ ਕੇ ਅਤੇ ਇੱਕੋ ਹੀ ਇਵੈਂਟ ਨੂੰ ਫਿਰ-ਪ੍ਰੋਸੈਸ ਕਰਕੇ ਟੈਸਟ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਖ਼ੁੱਬ ਤੇਜ਼ੀ ਨਾਲ Koder.ai (koder.ai) ਜਿਹੇ chat-ਚਲਿਤ ਪਲੇਟਫਾਰਮ 'ਤੇ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਫੇਰ ਵੀ ਇਹ ਨੀਤੀਆਂ ਜਲਦੀ ਹੀ ਆਪਣਾ ਅਸਰ ਦਿਖਾਈ ਦੇਣਗੀਆਂ: automation ਤੋਂ ਗਤੀ ਮਿਲਦੀ ਹੈ, ਪਰ ਭਰੋਸੇਯੋਗਤਾ ਸਪਸ਼ਟ ਸੀਮਾਵਾਂ, idempotent handlers ਅਤੇ reconciliation ਤੋਂ ਆਉਂਦੀ ਹੈ।
"ਬਾਹਰ" ਉਹ ਸਭ ਕੁਝ ਹੈ ਜੋ ਤੁਸੀਂ ਨਿਯੰਤਰਣ ਨਹੀਂ ਕਰਦੇ: ਬ੍ਰਾਉਜ਼ਰ, ਮੋਬਾਈਲ ਨੈੱਟਵਰਕ, ਕਿਊਜ਼, ਥਰਡ‑ਪਾਰਟੀ webhook, ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਟਾਈਮਆਉਟ। ਸੋਚੋ ਕਿ ਮੇਸੇਜ ਦਿੱਲੇ ਹੋ ਸਕਦੇ ਹਨ, ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ, ਗੁੰਮ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਅਲੱਗ ਕ੍ਰਮ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ।
"ਅੰਦਰ" ਉਹ ਹੈ ਜੋ ਤੁਸੀਂ ਨਿਯੰਤਰਿਤ ਕਰਦੇ ਹੋ: ਤੁਹਾਡਾ ਸਟੋਰ ਕੀਤਾ ਹੋਇਆ ਸਟੇਟ, ਤੁਹਾਡੇ ਨਿਯਮ ਅਤੇ ਉਹ ਤੱਥ ਜੋ ਤੁਸੀਂ ਬਾਦ ਵਿੱਚ ਸਬੂਤ ਕਰ ਸਕਦੇ ਹੋ (ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਵਿੱਚ)।
ਕਿਉਂਕਿ ਨੈੱਟਵਰਕ ਤੁਹਾਡੇ ਨਾਲ ਸੱਚ ਨਹੀਂ ਬੋਲਦਾ।
ਕਲਾਇੰਟ ਦਾ ਟਾਈਮਆਉਟ ਇਹ ਨਹੀਂ ਦੱਸਦਾ ਕਿ ਤੁਹਾਡਾ ਸਰਵਰ ਰੀਕਵੇਸਟ ਪ੍ਰੋਸੈਸ ਕਰ ਚੁੱਕਾ ਸੀ ਜਾਂ ਨਹੀਂ। ਇੱਕ webhook ਦੋ ਵਾਰੀ ਆ ਸਕਦੀ ਹੈ ਪਰ ਇਸਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਪ੍ਰొਵਾਇਡਰ ਨੇ ਕਾਰਵਾਈ ਦੋ ਵਾਰੀ ਕੀਤੀ। ਜੇ ਤੁਸੀਂ ਹਰ ਮੈਸੇਜ ਨੂੰ "ਨਵਾਂ ਸਚ" ਸਮਝੋਗੇ, ਤਾਂ ਤੁਸੀਂ ਡੁਪਲਿਕੇਟ ਆਰਡਰ, ਡਬਲ-ਚਾਰਜ ਜਾਂ ਫਸੇ ਹੋਏ ਵਰਕਫਲੋ ਬਣਾ ਲਵੋਗੇ।
ਸਪੱਸ਼ਟ ਬਾਊਂਡਰੀ ਉਹ ਬਿੰਦੂ ਹੈ ਜਿੱਥੇ ਇੱਕ ਅਣ-ਭਰੋਸੇਯੋਗ ਸੁਨੇਹਾ ਇੱਕ ਡਿਊਰੇਬਲ ਤੱਥ ਬਣ ਜਾਂਦਾ ਹੈ।
ਆਮ ਬਾਊਂਡਰੀਜ਼:
ਜਦੋਂ ਡੇਟਾ ਬਾਊਂਡਰੀ پار ਕਰ ਲੈਂਦਾ ਹੈ, ਤੁਹਾਨੂੰ ਅੰਦਰੂਨੀ ਨਿਯਮ ਲੱਗੂ ਕਰਨੇ ਹਨ (ਜਿਵੇਂ "ਆਰਡਰ ਇੱਕ ਵਾਰੀ ਹੀ ਭੁਗਤਾਨ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ").
ਇਡੀੰਪੋਟੈਂਸੀ ਦਾ ਮਤਲਬ ਹੈ: ਜੇ ਇੱਕੋ ਰਿਕਵੇਸਟ ਦੋ ਵਾਰੀ ਭੇਜੀ ਜਾਂਦੀ ਹੈ, ਪਰ ਸਿਸਟਮ ਉਸਨੂੰ ਇੱਕ ਹੀ ਗਿਣੇ ਅਤੇ ਇਕੋ ਨਤੀਜਾ ਦੇਵੇ।
ਪ੍ਰੈਕਟਿਕਲ ਪੈਟਰਨ:
ਇਸ ਤਰ੍ਹਾਂ ਰੀਟ੍ਰਾਈਜ਼ ਸੁਰੱਖਿਅਤ ਬਣ ਜਾਂਦੇ ਹਨ ਅਤੇ ਕਲਾਇੰਟ ਨੂੰ ਬੇਵਜਹ ਚਾਰਜ ਨਹੀਂ ਹੁੰਦੇ।
ਇਸਨੂੰ ਕੇਵਲ ਮੈਮੋਰੀ ਵਿੱਚ ਨਾ ਰੱਖੋ। idempotency ਰਿਕਾਰਡ ਤੁਹਾਡੇ ਬਾਊਂਡਰੀ ਵਿੱਚ ਡਿਊਰੇਬਲ ਸਟੋਰੇਜ (ਉਦਾਹਰਨ ਲਈ PostgreSQL) ਵਿੱਚ ਰਹਿਣੇ ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਕਿ ਰੀਸਟਾਰਟ ਵੀ ਸੁਰੱਖਿਅਤ ਰਹੇ।
ਰਿਟੇਨਸ਼ਨ ਲਈ ਸਧਾਰਨ ਨਿਯਮ:
ਰੱਖੋ ਇਹਨਾ ਨੂੰ ਕਿੱਥੇ ਤੱਕ ਕਿ ਯਥਾਰਥਿਕ ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਡੀਲੇਡ ਕਾਲਬੈਕ ਕਵਰ ਹੋ ਜਾਣ।
ਅਜਿਹੇ states ਵਰਤੋ ਜੋ ਅਣਿਸ਼ਚਿਤਤਾ ਦੀ ਆਗਿਆ ਦਿੰਦੇ ਹਨ।
ਸਧਾਰਨ ਅਤੇ ਕਾਰਗਰ ਸੈੱਟ:
pending_* (ਇਰਾਦਾ ਸਵੀਕਾਰ ਕੀਤਾ ਗਿਆ ਪਰ ਨਤੀਜਾ ਪਤਾ ਨਹੀਂ)succeeded / failed (ਅਸੀਂ ਅੰਤਿਮ ਨਤੀਜਾ ਦਰਜ ਕਰ ਲਿਆ)needs_review (ਕਿਸੇ ਗਲਤ-ਮੈਚ ਜਾਂ ਮਨੁੱਖੀ ਜਾਂ ਖਾਸ ਜਬ ਦੀ ਲੋੜ)ਇਸ ਨਾਲ ਟਾਈਮਆਉਟ ਦੌਰਾਨ ਅਨੁਮਾਨ ਲੱਗਾਉਣਾ ਬਚਦਾ ਹੈ ਅਤੇ ਰਿਕਨਸੀਲੇਸ਼ਨ ਆਸਾਨ ਹੁੰਦੀ ਹੈ।
ਕਿਉਂਕਿ ਤੁਹਾਡੀ ਕੋਸ਼ਿਸ਼ ਇਹ ਹੈ ਕਿ ਕਈ ਪ੍ਰਣਾਲੀਆਂ 'ਤੇ ਨੈੱਟਵਰਕ ਰਾਹੀਂ ਏਕਠੇ commit ਕਰ ਲਿਆ ਜਾਵੇ — ਪਰ ਨੈੱਟਵਰਕ ਹੋਪ ਹੋਣ 'ਤੇ ਤੁਸੀਂ ਸਭ ਕੁਝ ਇੱਕੱਠੇ commit ਨਹੀਂ ਕਰ ਸਕਦੇ।
ਸਿੰਕ੍ਰੋਨਸ ਵਰਕਫਲੋਜ਼ (save order → charge card → reserve inventory) ਪਾਕੇ-ਟਿਕੇ ਨਹੀਂ ਹੁੰਦੇ: ਜੇ ਦੂਜਾ ਕਦਮ timeout ਹੋ ਜਾਂਦਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਨਹੀਂ ਜਾਣਦੇ ਕਿ retry ਕਰਨਾ ਹੈ ਜਾਂ ਨਹੀਂ — ਜੋ duplicates/ਛੱਡੀਆਂ-ਰਹੀਆਂ ਕਾਰਵਾਈਆਂ ਬਣਾਉਂਦਾ ਹੈ।
ਇਸ ਲਈ partial success ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ: ਪਹਿਲਾਂ intent ਸਟੋਰ ਕਰੋ, ਫਿਰ ਬਾਹਰਲੀ ਕਾਰਵਾਈ ਕਰੋ, ਫਿਰ outcome ਦਰਜ ਕਰੋ।
outbox/inbox ਪੈਟਰਨ ਬਿਨਾਂ ਨੈੱਟਵਰਕ ਨੂੰ ਪੂਰੀ ਤਰ੍ਹਾਂ ਭਰੋਸੇਯੋਗ ਮਨਣ ਦੇ ਕ੍ਰਾਸ-ਸਿਸਟਮ ਮੇਸੇਜਿੰਗ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦਾ ਹੈ:
ਰਿਕਨਸੀਲੇਸ਼ਨ ਉਹ ਪ੍ਰਕਿਰਿਆ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ ਉਸ ਸਮੇਂ ਬਹਾਲੀ ਕਰਦੇ ਹੋ ਜਦੋਂ ਤੁਹਾਡੇ ਰਿਕਾਰਡ ਅਤੇ ਬਾਹਰੀ ਸਿਸਟਮ ਵਿਚ ਅਸਮੰਜ਼ਸ ਪੈਦਾ ਹੋ ਜਾਵੇ।
ਅਚ্ছে ਡਿਫਾਲਟ:
needs_review ਨਿਸ਼ਾਨਾਇਹ payments, fulfillment, subscriptions ਜਾਂ ਕਿਸੇ ਵੀ webhook ਵਾਲੀ ਚੀਜ਼ ਲਈ ਜ਼ਰੂਰੀ ਹੈ।
ਹਾਂ। ਤੇਜ਼ ਤਰੀਕੇ ਨਾਲ ਬਣਾਉਣਾ ਨੈੱਟਵਰਕ ਫੇਲ੍ਹ ਨੂੰ ਖ਼ਤਮ ਨਹੀਂ ਕਰਦਾ—ਸਿਰਫ਼ ਤੁਹਾਨੂੰ ਉਨ੍ਹਾਂ ਮੁੱਦਿਆਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਮਿਲਵਾਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਗੇ ਚੈਟ‑ਡਰਿਵਨ ਪਲੇਟਫਾਰਮ 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਸੇਵਾਵਾਂ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਇਹ ਨੀਤੀ ਮੁਢਲੇ ਹੀ ਸ਼ਾਮਲ ਕਰੋ:
ਇਸ ਨਾਲ, ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਡੁਪਲਿਕੇਟ ਕਾਲਬੈਕ ਬੋਰੀੰਗ ਹੋ ਜਾਂਦੇ ਹਨ ਨਾ ਕਿ ਮਹਿੰਗੇ।