27 ਜੁਲਾ 2025·8 ਮਿੰਟ
ਭਾਸ਼ਾਵਾਂ, ਡੇਟਾਬੇਸ ਅਤੇ ਫਰੇਮਵਰਕ ਇਕੱਠੇ ਇੱਕ ਸਿਸਟਮ ਵਾਂਗ ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਭਾਸ਼ਾਵਾਂ, ਡੇਟਾਬੇਸ, ਅਤੇ ਫਰੇਮਵਰਕ ਇੱਕ ਸਿਸਟਮ ਵਜੋਂ ਕੰਮ ਕਰਦੇ ਹਨ। ਟਰੇਡ-ਆਫ, ਇੰਟੀਗਰੇਸ਼ਨ ਪੁਆਇੰਟ, ਅਤੇ ਇੱਕ ਮੇਲ ਖਾਣ ਵਾਲਾ ਸਟੈਕ ਚੁਣਨ ਦੇ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕੇ ਜਾਣੋ।
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਭਾਸ਼ਾਵਾਂ, ਡੇਟਾਬੇਸ, ਅਤੇ ਫਰੇਮਵਰਕ ਇੱਕ ਸਿਸਟਮ ਵਜੋਂ ਕੰਮ ਕਰਦੇ ਹਨ। ਟਰੇਡ-ਆਫ, ਇੰਟੀਗਰੇਸ਼ਨ ਪੁਆਇੰਟ, ਅਤੇ ਇੱਕ ਮੇਲ ਖਾਣ ਵਾਲਾ ਸਟੈਕ ਚੁਣਨ ਦੇ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕੇ ਜਾਣੋ।
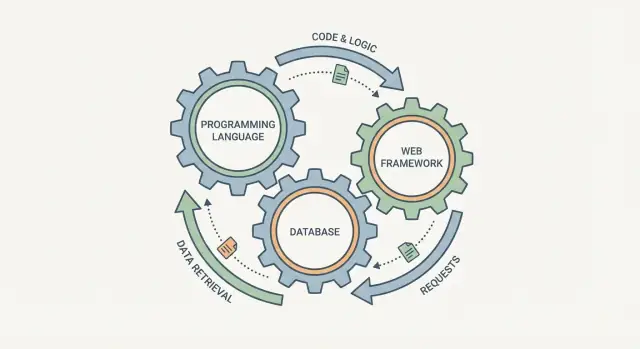
ਇੱਕ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ, ਡੇਟਾਬੇਸ, ਅਤੇ ਵੇਬ ਫਰੇਮਵਰਕ ਨੂੰ ਤਿੰਨ ਅਲੱਗ ਚੈੱਕਬਾਕਸ ਵਾਂਗ ਚੁਣਨਾ ਆਸਾਨ ਲੱਗਦਾ ਹੈ। ਹਕੀਕਤ ਵਿੱਚ, ਇਹ ਇਕ ਦੂਜੇ ਨਾਲ ਜੁੜੇ ਗੀਅਰ ਵਾਂਗ ਕੰਮ ਕਰਦੇ ਹਨ: ਇੱਕ ਬਦਲੋ, ਤੇ ਹੋਰ ਦਿਲ ਦੇ ਨਾਲ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ।
ਇੱਕ ਫਰੇਮਵਰਕ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰਦਾ ਹੈ ਕਿ ਬੇਨਤੀ ਕਿਵੇਂ ਸੰਭਾਲੀ ਜਾਂਦੀ ਹੈ, ਡਾਟਾ ਕਿਵੇਂ ਵੈਲੀਡੇਟ ਹੁੰਦਾ ਹੈ, ਅਤੇ error ਕਿਵੇਂ surface ਹੁੰਦੇ ਹਨ। ਡੇਟਾਬੇਸ ਇਹ ਤਿਆਰ ਕਰਦਾ ਹੈ ਕਿ „ਆਸਾਨ ਸਟੋਰ ਕਰਨ ਯੋਗ“ ਕੀ ਹੈ, ਤੁਸੀਂ ਕਿਵੇਂ ਪੁੱਛਗਿੱਛ ਕਰੋਗੇ, ਅਤੇ ਜਦੋਂ ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰ ਇਕੱਠੇ ਕੰਮ ਕਰਦੇ ਹਨ ਤਾਂ ਕਿਹੜੀਆਂ ਗਾਰੰਟੀ ਮਿਲਦੀਆਂ ਹਨ। ਭਾਸ਼ਾ ਵਿਚਕਾਰ ਬੈਠਦੀ ਹੈ: ਇਹ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ ਕਿ ਤੁਸੀਂ ਨਿਯਮ ਕਿੰਨੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਬਿਆਨ ਕਰ ਸਕਦੇ ਹੋ, concurrency ਕਿਵੇਂ ਮੈਨੇਜ ਕਰਦੇ ਹੋ, ਅਤੇ ਕਿਹੜੀਆਂ ਲਾਇਬ੍ਰੇਰੀਆਂ ਅਤੇ ਟੂਲਿੰਗ ਉਪਲਬਧ ਹਨ।
ਸਟੈਕ ਨੂੰ ਇਕੱਲਾ ਸਿਸਟਮ ਸਮਝਣਾ ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਹਰ ਹਿੱਸੇ ਨੂੰ ਅਲੱਗ-ਅਲੱਗ optimise ਨਹੀਂ ਕਰਦੇ। ਤੁਸੀਂ ਇੱਕ ਐਸੀ ਕੁੰਬੀਨੇਸ਼ਨ ਚੁਣਦੇ ਹੋ ਜੋ:
ਇਹ ਲੇਖ ਪ੍ਰਯੋਗਿਕ ਅਤੇ ਜਾਣ-ਬੁਝ ਕੇ ਗੈਰ-ਟੈਕਨੀਕਲ ਰੱਖਿਆ ਗਿਆ ਹੈ। ਤੁਹਾਨੂੰ ਡੇਟਾਬੇਸ ਥਿਊਰੀ ਜਾਂ ਭਾਸ਼ਾ ਇੰਟਰਨਲਜ਼ ਯਾਦ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ—ਸਿਰਫ ਵੇਖੋ ਕਿ ਚੋਣਾਂ ਪੂਰੇ ਐਪਲੀਕੇਸ਼ਨ 'ਤੇ ਕਿਵੇਂ ਪ੍ਰਭਾਵ ਪਾਉਂਦੀਆਂ ਹਨ।
ਇੱਕ ਛੋਟੀ ਉਦਾਹਰਣ: ਬਹੁਤ ਹੀ ਸੰਰਚਿਤ, ਰਿਪੋਰਟ-ਭਰਪੂਰ ਬਿਜਨੈਸ ਡੇਟਾ ਲਈ schema-less ਡੇਟਾਬੇਸ ਵਰਤਣਾ ਅਕਸਰ ਐਪ ਕੋਡ ਵਿੱਚ ਫੈਲੀਆਂ ਨਿਯਮਾਂ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਉਲਝਣ ਭਰੀਆਂ ਐਨਾਲਿਟਿਕਸ ਨੂੰ ਜਨਮ ਦਿੰਦਾ ਹੈ। ਇਕ ਵਧੀਆ ਮੇਲ ਇਹ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਉਸੇ ਡੋਮੇਨ ਨੂੰ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਅਤੇ ਐਸੇ ਫਰੇਮਵਰਕ ਨਾਲ ਜੋ consistent validation ਅਤੇ migrations ਨੂੰ ਉਤਸ਼ਾਹਿਤ ਕਰਦਾ ਹੋਵੇ, ਜੋ ਤੁਹਾਡੇ ਡਾਟਾ ਨੂੰ ਉਤਪਾਦ ਦੀ ਵਿਕਾਸ ਦੇ ਨਾਲ coherent ਰੱਖੇ।
ਜਦ ਤੁਸੀਂ ਸਟੈਕ ਨੂੰ ਇੱਕਠੇ ਰੂਪ ਵਿੱਚ ਯੋਜਨਾ ਬਣਾਉਂਦੇ ਹੋ, ਤੁਸੀਂ ਤਿੰਨ ਵੱਖ-ਵੱਖ ਦਾਉਆਂ ਦੀ ਬਜਾਏ ਇਕ ਹੀ ਟਰੇਡ-ਆਫ ਡਿਜ਼ਾਈਨ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹੋ।
ਸਟੈਕ ਬਾਰੇ ਸੋਚਣ ਦਾ ਮਦਦਗਾਰ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ ਇਕ ਪਾਈਪਲਾਈਨ ਵਜੋਂ ਵੇਖੋ: ਇੱਕ ਯੂਜ਼ਰ ਦੀ ਬੇਨਤੀ ਤੁਹਾਡੇ ਸਿਸਟਮ ਵਿੱਚ ਦਾਖਿਲ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਇਕ ਜਵਾਬ (ਨਾਲ ਹੀ ਸੇਵ ਕੀਤੇ ਡਾਟਾ) ਬਾਹਰ ਆਉਂਦਾ ਹੈ। ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ, ਵੇਬ ਫਰੇਮਵਰਕ, ਅਤੇ ਡੇਟਾਬੇਸ ਅਲੱਗ ਚੋਣਾਂ ਨਹੀਂ—ਇਹ ਇੱਕ ਹੀ ਯਾਤਰਾ ਦੇ ਤਿੰਨ ਹਿੱਸੇ ਹਨ।
ਇਕ ਗਾਹਕ ਆਪਣਾ ਸ਼ਿਪਿੰਗ ਐਡਰੈੱਸ ਅਪਡੇਟ ਕਰਦਾ ਹੈ, ਇਹ ਸੋਚੋ:
/account/address)। Validation ਦਿਖਦੀ ਹੈ ਕਿ ਇਨਪੁੱਟ ਪੂਰਾ ਅਤੇ ਸਹੀ ਹੈ।ਜਦ ਇਹ ਤਿੰਨ ਇਕੱਠੇ ਮਿਲਦੇ ਹਨ, ਇੱਕ ਬੇਨਤੀ ਸੁਚੱਜੇ ਤਰੀਕੇ ਨਾਲ ਵਗਦੀ ਹੈ। ਜਦ ਇਹ ਮਿਲਦੇ ਨਹੀਂ, ਤਾਂ friction ਆਉਂਦੀ ਹੈ: ਅਜੀਬ ਡਾਟਾ ਐਕਸੈੱਸ, ਲੀਕੀ validation, ਅਤੇ ਨਾਜੁਕ consistency ਬੱਗ।
ਜ਼ਿਆਦਾਤਰ “ਸਟੈਕ” ਵਾਲੀਆਂ बहਸਾਂ ਭਾਸ਼ਾ ਜਾਂ ਡੇਟਾਬੇਸ ਬਰਾਂਡ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੀਆਂ ਹਨ। ਬੇਹਤਰ ਸ਼ੁਰੂਆਤ ਤੁਹਾਡੇ ਡੇਟਾ ਮਾਡਲ ਨਾਲ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ—ਕਿਉਂਕਿ ਇਹ ਚੁਪਚਾਪ ਨਿਸ਼ਚਿਤ ਕਰਦਾ ਹੈ ਕਿ ਹੋਰ ਥਾਵਾਂ 'ਤੇ ਕੀ ਕੁਦਰਤੀ (ਜਾਂ ਦਰਦਨਾਕ) ਮਹਿਸੂਸ ਹੋਵੇਗਾ: validation, queries, APIs, migrations, ਅਤੇ ਟੀਮ ਵਰਕਫਲੋ ਤੱਕ।
ਐਪਲੀਕੇਸ਼ਨਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇਕੱਠੇ ਚਾਰ ਰੂਪ ਨਿਭਾਉਂਦੇ ਹਨ:
ਚੰਗਾ ਮੇਲ ਉਹ ਹੈ ਜਦ ਤੁਸੀਂ ਦਿਨ ਭਰ ਇਹ ਰੂਪ ਤਬਦੀਲ ਕਰਨ ਵਿਚ ਨਹੀਂ ਲੱਗਦੇ। ਜੇ ਤੁਹਾਡਾ ਕੋਰ ਡਾਟਾ ਬਹੁਤ ਜੁੜਿਆ ਹੋਇਆ ਹੈ (users ↔ orders ↔ products), ਤਾਂ rows ਅਤੇ joins ਲੇਾਜਿਕ ਨੂੰ ਸਧਾਰਨ ਰੱਖ ਸਕਦੇ ਹਨ। ਜੇ ਡਾਟਾ ਮੁੱਖਤੌਰ 'ਤੇ “ਹਰ ਏਨਟੀਟੀ ਲਈ ਇੱਕ ਬਲੌਬ” ਹੈ ਜਿਸ ਵਿੱਚ ਬਦਲਦੇ ਫੀਲਡ ਹਨ, ਤਾਂ documents ceremony ਨੂੰ ਘਟਾ ਸਕਦੇ ਹਨ—ਜਦ ਤੱਕ ਤੁਹਾਨੂੰ cross-entity reporting ਦੀ ਲੋੜ ਨਹੀਂ ਪੈਂਦੀ।
ਜਦ ਡੇਟਾਬੇਸ ਵਿੱਚ ਮਜ਼ਬੂਤ ਸਕੀਮਾ ਹੋਵੇ, ਤਾਂ ਕਈ ਨਿਯਮ ਡਾਟਾ ਦੇ ਨੇੜੇ ਰਹਿ ਸਕਦੇ ਹਨ: ਟਾਈਪ, constraints, foreign keys, uniqueness। ਇਸ ਨਾਲ ਅਕਸਰ ਸੇਵਾਵਾਂ ਵਿੱਚ ਨਕਲ ਕੀਤੀਆਂ ਜਾਂ ਵਿਖਰੀਆਂ ਜਾਂਚਾਂ ਘੱਟ ਹੁੰਦੀਆਂ ਹਨ।
ਲਚਕੀਲੇ ਢਾਂਚਿਆਂ ਨਾਲ, ਨਿਯਮ ਉੱਪਰਲੇ ਪੱਧਰ ਤੇ ਐਪਲੀਕੇਸ਼ਨ ਵਿੱਚ ਚਲੇ ਜਾਂਦੇ ਹਨ: validation ਕੋਡ, versioned payloads, backfills, ਅਤੇ ਸੰਭਾਲ ਕੇ ਪੜ੍ਹਨ ਵਾਲੀ ਲਾਜਿਕ ("ਜੇ ਫੀਲਡ ਮੌਜੂਦ ਹੈ, ਤਾਂ...")। ਇਹ ਉਹ ਸਮੇਂ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦ ਉਤਪਾਦ ਦੀਆਂ ਲੋੜਾਂ ਹਫ਼ਤੇਵਾਰ ਬਦਲਦੀਆਂ ਰਹਿੰਦੀਆਂ ਹਨ, ਪਰ ਇਹ ਤੁਹਾਡੇ ਫਰੇਮਵਰਕ ਅਤੇ ਟੈਸਟਿੰਗ 'ਤੇ ਭਾਰ ਵਧਾ ਦਿੰਦਾ ਹੈ।
ਤੁਹਾਡੇ ਮਾਡਲ ਨੇ ਇਹ ਨਿਰਧਾਰਿਤ ਕੀਤਾ ਕਿ ਤੁਹਾਡਾ ਕੋਡ ਮੁੱਖਤੌਰ 'ਤੇ:
ਇਸ ਨਾਲ ਭਾਸ਼ਾ ਅਤੇ ਫਰੇਮਵਰਕ ਦੀਆਂ ਲੋੜਾਂ ਪ੍ਰਭਾਵਿਤ ਹੁੰਦੀਆਂ ਹਨ: ਮਜ਼ਬੂਤ ਟਾਈਪਿੰਗ JSON ਫੀਲਡਸ ਵਿੱਚ ਨਾਜੁਕ ਡ੍ਰਿਫਟ ਨੂੰ ਰੋਕ ਸਕਦੀ ਹੈ, ਜਦਕਿ ਮੈਚੋਰ ਮਾਈਗ੍ਰੇਸ਼ਨ ਟੂਲਿੰਗ ਵਧਦੀ ਹੈ ਜਦ ਸਕੀਮਾ ਬਾਰ-ਬਾਰ ਬਦਲਦੇ ਹਨ।
ਮਾਡਲ ਪਹਿਲਾਂ ਚੁਣੋ; "ਸਹੀ" ਫਰੇਮਵਰਕ ਅਤੇ ਡੇਟਾਬੇਸ ਚੋਣ ਅਕਸਰ ਉਸ ਤੋਂ ਬਾਅਦ ਸਪਸ਼ਟ ਹੋ ਜਾਂਦੀ ਹੈ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਉਹ "ਸਭ-ਜਾਂ ਕੁਝ ਨਹੀਂ" ਗਾਰੰਟੀ ਹਨ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਹਾਡੀ ਐਪ ਚੁਪਚਾਪ ਨਿਰਭਰ ਕਰਦੀ ਹੈ। ਜਦ ਚੈਕਆਊਟ ਸਫਲ ਹੁੰਦਾ ਹੈ, ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ ਕਿ ਆਰਡਰ ਰਿਕਾਰਡ, ਭੁਗਤਾਨ ਦੀ ਸਥਿਤੀ, ਅਤੇ ਇਨਵੈਂਟਰੀ ਅਪਡੇਟ ਜਾਂ ਤਾਂ ਸਾਰੇ ਹੋਣਗੇ—ਜਾਂ ਬਿਲਕੁਲ ਵੀ ਨਹੀਂ। ਇਸ ਵਾਦੇ ਤੋਂ ਬਿਨਾਂ, ਤੁਹਾਨੂੰ ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਕਿਸਮ ਦੇ ਬੱਗ ਮਿਲਦੇ ਹਨ: ਕਦੇ-ਕਦੇ, ਮਹਿੰਗੇ, ਅਤੇ ਦੁਹਰਾਉਣਾ ਔਖਾ।
ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਕਈ ਡੇਟਾਬੇਸ ਆਪਰੇਸ਼ਨਾਂ ਨੂੰ ਇੱਕ ਯੂਨਿਟ ਆਫ ਵਰਕ ਵਿੱਚ ਗਰੁੱਪ ਕਰਦਾ ਹੈ। ਜੇ ਕੁਝ ਮਧ੍ਯ ਵਿੱਚ fails (ਵੈਲੀਡੇਸ਼ਨ ਐਰਰ, ਟਾਇਮਆਊਟ, ਪ੍ਰੋਸੈਸ ਕਰੈਸ਼), ਡੇਟਾਬੇਸ ਪਿਛਲੇ ਸੁਰੱਖਿਅਤ ਹਾਲਤ ਤੇ ਰੋਲਬੈਕ ਕਰ ਸਕਦਾ ਹੈ।
ਇਹ ਪੈਸੇ ਦੇ ਫਲੋ ਤੋਂ ਬਾਹਰ ਵੀ ਮਾਇਨੇ ਰਖਦਾ ਹੈ: ਖਾਤਾ ਬਣਾਉਣਾ (user row + profile row), ਸਮੱਗਰੀ ਪ੍ਰਕਾਸ਼ਨ (post + tags + search index pointers), ਜਾਂ ਕੋਈ ਵੀ ਵਰਕਫਲੋ ਜੋ ਇੱਕ ਤੋਂ ਵੱਧ ਟੇਬਲ ਨੂੰ ਛੂਹਦਾ ਹੈ।
Consistency ਦਾ ਮਤਲਬ ਹੈ “ਰੀਡਸ ਹਕੀਕਤ ਨਾਲ ਮੈਚ ਕਰਦੇ ਹਨ।” Speed ਦਾ ਮਤਲਬ ਹੈ “ਕੁਝ ਛੇਤੀ ਵਾਪਸ ਕਰੋ।” ਕਈ ਪ੍ਰਣਾਲੀਆਂ ਇੱਥੇ ਟਰੇਡ-ਆਫ ਕਰਦੀਆਂ ਹਨ:
ਆਮ ਨਾਕامی ਦਾ ਪੈਟਰਨ ਹੈ ਇੱਕ eventually consistent ਸੈਟਅਪ ਚੁਣਨਾ, ਫਿਰ ਉਸੇ ਤਰੀਕੇ ਨਾਲ ਕੋਡ ਲਿਖਣਾ ਜਿਵੇਂ ਉਹ strong consistent ਹੋਵੇ।
ਫਰੇਮਵਰਕ ਅਤੇ ORMs ਆਪਣੇ-ਆਪ ਵਿੱਚ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨਹੀਂ ਬਣਾਉਂਦੇ ਸਿਰਫ ਇਸਲਈ ਕਿ ਤੁਸੀਂ ਕਈ "save" ਮੈਥਡਾਂ ਨੂੰ ਕਾਲ ਕੀਤਾ। ਕੁਝ explicit transaction blocks ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ; ਹੋਰ ਪ੍ਰਤੀ-ਰਿਕਵੇਸਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸ਼ੁਰੂ ਕਰਦੇ ਹਨ, ਜੋ ਪ੍ਰਦਰਸ਼ਨ ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਛੁਪਾ ਸਕਦਾ ਹੈ।
Retries ਵੀ ਨਾਜੁਕ ਹੁੰਦੀਆਂ ਹਨ: ORMs deadlocks ਜਾਂ transient failures 'ਤੇ retry ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਤੁਹਾਡੇ ਕੋਡ ਨੂੰ ਦੋ ਵਾਰੀ ਚੱਲਣ ਲਈ ਸੁਰੱਖਿਅਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਪਾਰਸ਼ਲ ਰਾਈਟਸ ਉਸ ਸਮੇਂ ਹੁੰਦੀਆਂ ਹਨ ਜਦ ਤੁਸੀਂ A ਅਪਡੇਟ ਕਰੋ ਅਤੇ ਫੇਲ ਹੋ ਜਾਏ ਬਿਨਾਂ B ਅਪਡੇਟ ਕਰਨ ਦੇ। duplicate actions ਉਸ ਵੇਲੇ ਹੁੰਦੇ ਹਨ ਜਦ ਇਕ ਬੇਨਤੀ ਟਾਇਮਆਊਟ ਦੇ ਬਾਅਦ retry ਕੀਤੀ ਜਾਂਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ ਜੇ ਤੁਸੀਂ ਕਾਰਡ ਨੂੰ ਚਾਰਜ ਜਾਂ ਈਮੇਲ ਭੇਜਦੇ ਹੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਕਮਿਟ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ।
ਇੱਕ ਸਧਾਰਣ ਨਿਯਮ ਮਦਦ ਕਰਦਾ ਹੈ: ਸਾਈਡ-ਇਫੈਕਟਸ (ਈਮੇਲ, ਵੈੱਬਹੁੱਕ) ਨੂੰ ਕਮਿਟ ਤੋਂ ਬਾਅਦ ਕਰੋ, ਅਤੇ ਕਾਰਵਾਈਆਂ ਨੂੰ idempotent ਬਣਾਓ (ਯੂਨਿਕ constraints ਜਾਂ idempotency keys ਦੀ ਵਰਤੋਂ ਕਰਕੇ)।
ਇਹ ਤੁਹਾਡੇ ਐਪਲੀਕੇਸ਼ਨ ਕੋਡ ਅਤੇ ਡੇਟਾਬੇਸ ਦਰਮਿਆਨ "ਅਨੁਵਾਦ ਪਰਤ" ਹੈ। ਇੱਥੇ ਚੋਣਾਂ ਅਕਸਰ ਦਿਨ-प्रतिदिन ਦੇ ਕੰਮਾਂ ਵਿੱਚ ਡੇਟਾਬੇਸ ਬਰਾਂਡ ਤੋਂ ਵੀ ਵੱਧ ਅਹਮ ਹੁੰਦੀਆਂ ਹਨ।
ORM (Object-Relational Mapper) ਤੁਹਾਨੂੰ ਟੇਬਲਾਂ ਨੂੰ ਆਬਜੈਕਟ ਵਾਂਗ ਵਰਤਣ ਦਿੰਦਾ: ਇੱਕ User ਬਣਾਓ, ਇੱਕ Post ਅਪਡੇਟ ਕਰੋ, ਅਤੇ ORM ਪਿੱਛੇ SQL ਜੈਨਰੇਟ ਕਰਦਾ ਹੈ। ਇਹ ਉਤਪਾਦਕਤਾ ਲਈ ਚੰਗਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਆਮ ਕਾਰਜਾਂ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਦਾ ਅਤੇ ਰੀਪੀਟੀਟਿਵ ਪਲੰਬਿੰਗ ਨੂੰ ਛੁਪਾ ਦਿੰਦਾ ਹੈ।
Query builder ਹੋਰ explicit ਹੈ: ਤੁਸੀਂ ਕੋਡ ਦੀ ਵਰਤੋਂ ਕਰਕੇ SQL-ਵਾਂਗ ਕੁਏਰੀ ਬਣਾਉਂਦੇ ਹੋ (ਚੇਨਜ਼ ਜਾਂ ਫੰਕਸ਼ਨਾਂ)। ਤੁਸੀਂ ਹਜੇ ਵੀ “joins, filters, groups” ਵਿਚ ਸੋਚਦੇ ਹੋ, ਪਰ ਤੁਹਾਡੇ ਕੋਲ parameter safety ਅਤੇ composability ਹੁੰਦੀ ਹੈ।
Raw SQL ਅਸਲ SQL ਆਪਣੇ ਆਪ ਲਿਖਣਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਸਿੱਧਾ ਅਤੇ ਅਕਸਰ ਜਟਿਲ ਰਿਪੋਰਟਿੰਗ ਕੁਏਰੀਆਂ ਲਈ ਸਭ ਤੋਂ ਸਪਸ਼ਟ ਹੁੰਦਾ ਹੈ—ਪਰ ਇਸਦਾ ਕੀਮਤ ਵਧੇਰੇ ਮੈਨੁਅਲ ਕੰਮ ਅਤੇ conventions ਦੀ ਲੋੜ ਹੈ।
ਟਾਈਪ-ਸਮਰੱਥ ਭਾਸ਼ਾਵਾਂ (TypeScript, Kotlin, Rust) ਅਕਸਰ ਤੁਹਾਨੂੰ ਐਸੇ ਟੂਲਾਂ ਵੱਲ ਧੱਕਦੀਆਂ ਹਨ ਜੋ ਕੁਏਰੀਆਂ ਅਤੇ ਨਤੀਜੇ ਦੇ ਆਕਾਰਾਂ ਨੂੰ ਪਹਿਲਾਂ validate ਕਰ ਸਕਦੇ ਹਨ। ਇਸ ਨਾਲ runtime ਇਹੋਂ-ਇਹੋਂ surprises ਘਟ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਇਹ ਟੀਮਾਂ ਨੂੰ data access ਨੂੰ centralize ਕਰਨ ਦਾ ਦਬਾਅ ਵੀ ਦਿੰਦਾ ਹੈ ਤਾਂ ਕਿ types drift ਨਾ ਕਰਣ।
ਲਚਕੀਲੇ ਮੈਟਾਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਵਾਲੀਆਂ ਭਾਸ਼ਾਵਾਂ (Ruby, Python) ਅਕਸਰ ORMs ਨੂੰ ਕੁਦਰਤੀ ਅਤੇ ਤੇਜ਼ iteration ਲੱਗਦੇ ਹਨ—ਜਦ ਤੱਕ ਲੁਕੀਆਂ ਕੁਏਰੀਆਂ ਜਾਂ implicit ਵਿਵਹਾਰ ਸਮਝਣਾ ਔਖਾ ਨਹੀਂ ਹੋ ਜਾਂਦਾ।
ਮਾਈਗਰੇਸ਼ਨ ਤੁਹਾਡੇ ਸਕੀਮਾ ਲਈ ਵਰਜ਼ਨਡ ਚੇੰજર ਸਕ੍ਰਿਪਟ ਹਨ: ਇੱਕ ਕਾਲਮ ਜੋੜੋ, ਇੱਕ ਇੰਡੈਕਸ ਬਣਾਓ, ਡਾਟਾ backfill ਕਰੋ। ਮੁੱਖ ਮਕਸਦ ਸਧਾਰਣ ਹੈ: ਕੋਈ ਵੀ ਐਪ deploy ਕਰੇ ਅਤੇ ਇਕੋ ਡੇਟਾਬੇਸ ਸਟਰਕਚਰ ਮਿਲੇ। ਮਾਈਗਰੇਸ਼ਨਾਂ ਨੂੰ ਉਹਨਾ ਕੋਡ ਵਾਂਗ treat ਕਰੋ ਜੋ ਤੁਸੀ review, test, ਅਤੇ roll back ਕਰਦੇ ਹੋ ਜਦ ਜ਼ਰੂਰਤ ਪਏ।
ORMs quietly N+1 queries ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹਨ, ਵੱਡੇ rows fetch ਕਰ ਸਕਦੇ ਹਨ ਜੋ ਤੁਹਾਨੂੰ ਚਾਹੀਦੇ ਨਹੀਂ, ਜਾਂ joins awkward ਬਣਾ ਸਕਦੇ ਹਨ। Query builders unreadable “chains” ਬਣ ਸਕਦੇ ਹਨ। Raw SQL duplicate ਅਤੇ inconsistent ਹੋ ਸਕਦਾ ਹੈ।
ਇੱਕ ਚੰਗਾ ਨਿਯਮ: ਉਹ ਸਰਲ ਟੂਲ ਵਰਤੋ ਜੋ ਇਰਾਦਾ ਨੂੰ ਸਪੱਸ਼ਟ ਰੱਖੇ—ਅਤੇ critical paths ਲਈ ਹਮੇਸ਼ਾਂ ਅਸਲ SQL ਵੇਖੋ ਜੋ ਚੱਲ ਰਹੀ ਹੈ।
ਲੋਕ ਅਕਸਰ "ਡੇਟਾਬੇਸ" ਨੂੰ ਦੋਸ਼ੀ ਠਹਿਰਾਉਂਦੇ ਹਨ ਜਦ ਇੱਕ ਪੇਜ਼ ਸਲੋ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਪਰ ਜ਼ਿਆਦਾਤਰ ਯੂਜ਼ਰ-ਦ੍ਰਿਸ਼ਟੀ latency ਅਨੇਕ ਨਿੱਕੇ ਇੰਤਜ਼ਾਰਾਂ ਦਾ ਜੋੜ ਹੁੰਦੀ ਹੈ ਜੋ ਸਾਰੀ ਰਿਕਵੇਸਟ-ਪਾਥ 'ਤੇ ਹਨ।
ਇੱਕ ਇਕਲ ਰਿਕਵੇਸਟ ਆਮ ਤੌਰ 'ਤੇ ਇਹਨਾਂ ਤੱਤਾਂ ਲਈ ਭੁਗਤਾਨ ਕਰਦੀ ਹੈ:
ਚਾਹੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ 5 ms ਵਿੱਚ ਜਵਾਬ ਦੇਵੇ, ਜੇ ਐਪ ਇਕ ਰਿਕਵੇਸਟ ਲਈ 20 ਕੁਏਰੀਆਂ ਕਰਦਾ ਹੈ, I/O ਤੇ ਰੁਕਦਾ ਹੈ, ਅਤੇ 30 ms ਵੱਡੇ response ਨੂੰ ਸੀਰੀਅਲਾਈਜ਼ ਕਰਨ ਵਿੱਚ ਲਗਾਉਂਦਾ ਹੈ ਤਾਂ ਫੀਲ ਸਲੋ ਰਹੇਗਾ।
ਨਵਾਂ DB ਕਨੈਕਸ਼ਨ ਖੋਲ੍ਹਣਾ ਮਹਿੰਗਾ ਹੁੰਦਾ ਹੈ ਅਤੇ لوਡ ਹੇਠ ਡੇਟਾਬੇਸ ਨੂੰ overwhelm ਕਰ ਸਕਦਾ ਹੈ। ਇੱਕ ਕਨੈਕਸ਼ਨ ਪੂਲ ਮੌਜੂਦਾ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਦੁਬਾਰਾ ਵਰਤਦਾ ਹੈ ਤਾਂ ਜੋ ਰਿਕਵੇਸਟਾਂ ਨੂੰ ਹਰ ਵਾਰ ਉਹ setup ਖਰਚ ਨਾ ਭੁਗਤਣਾ ਪਏ।
ਪਕੜ: “ਸਹੀ” ਪੂਲ ਸਾਈਜ਼ ਤੁਹਾਡੇ ਰਨਟਾਈਮ ਮਾਡਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਇੱਕ high-concurrency async ਸਰਵਰ massive simultaneous demand ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ; ਬਿਨਾਂ pool limits ਦੇ ਤੁਸੀਂ queueing, timeouts, ਅਤੇ noisy failures ਦੇਖੋਗੇ। ਬਹੁਤ ਕਠੋਰ pool limits ਨਾਲ, ਤੁਹਾਡੀ ਐਪ ਬੋਤਲਨੈਕ ਬਣ ਸਕਦੀ ਹੈ।
ਕੈਸ਼ਿੰਗ ਬਰਾਊਜ਼ਰ, CDN, in-process cache, ਜਾਂ shared cache (ਜਿਵੇਂ Redis) ਵਿੱਚ ਹੋ ਸਕਦੀ ਹੈ। ਇਹ ਉਸ ਵੇਲੇ ਮਦਦ ਕਰਦੀ ਹੈ ਜਦ ਬਹੁਤ ਸਾਰੀਆਂ ਬੇਨਤੀਆਂ ਨੂੰ ਉਸੇ ਨਤੀਜੇ ਦੀ ਲੋੜ ਹੋਵੇ।
ਪਰ ਕੈਸ਼ਿੰਗ ਇਹਨਾਂ ਨੂੰ ਠੀਕ ਨਹੀਂ ਕਰੇਗੀ:
ਤੁਹਾਡੇ ਭਾਸ਼ਾ ਰਨਟਾਈਮ throughput ਨੂੰ shape ਕਰਦਾ ਹੈ। thread-per-request ਮਾਡਲ I/O ਦੀ ਉਡੀਕ ਦੌਰਾਨ ਸਾਧਨ ਗਵਾਉਂ ਸਕਦਾ ਹੈ; async ਮਾਡਲ concurrency ਵਧਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਸ ਨਾਲ backpressure (ਜਿਵੇਂ pool limits) ਜਰੂਰੀ ਬਣ ਜਾਂਦਾ ਹੈ। ਇਸੀ ਲਈ performance tuning ਇੱਕ ਸਟੈਕ ਫੈਸਲਾ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ ਡੇਟਾਬੇਸ ਫੈਸਲਾ।
ਸੁਰੱਖਿਆ ਕੋਈ checbox plugin ਨਹੀਂ ਹੈ ਜੋ ਤੁਸੀਂ ਜੋੜ ਦਿੰਦੇ ਹੋ। ਇਹ ਤੁਸੀਂ, ਤੁਹਾਡੀ ਭਾਸ਼ਾ/ਰੰਟਾਈਮ, ਫਰੇਮਵਰਕ, ਅਤੇ ਡੇਟਾਬੇਸ ਵਿਚਕਾਰ ਉਹ ਸਮਝੌਤਾ ਹੈ ਜੋ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰਦਾ ਹੈ ਕਿ ਕੀ ਹਮੇਸ਼ਾਂ ਸੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ—ਚਾਹੇ ਕੋਈ ਡਿਵੈਲਪਰ ਗਲਤੀ ਕਰੇ ਜਾਂ ਕੋਈ ਨਵਾਂ endpoint ਜੋੜਿਆ ਜਾਵੇ।
Authentication (ਕੌਣ ਹੈ?) ਆਮ ਤੌਰ 'ਤੇ ਫਰੇਮਵਰਕ ਦੇ ਏਜ ਤੇ ਹੁੰਦੀ ਹੈ: sessions, JWTs, OAuth callbacks, middleware। Authorization (ਉਹ ਕੀ ਕਰਨ ਦੀ ਆਗਿਆ ਰੱਖਦਾ ਹੈ?) ਜ਼ਬਰਦਸਤ ਢੰਗ ਨਾਲ ਐਪ ਲੌਜਿਕ ਅਤੇ ਡੇਟਾ ਨਿਯਮਾਂ ਦੋਹਾਂ ਵਿੱਚ ਲਾਗੂ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਆਮ ਪੈਟਰਨ: ਐਪ ਇਰਾਦਾ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ ("ਯੂਜ਼ਰ ਇਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ edit ਕਰ ਸਕਦਾ ਹੈ"), ਅਤੇ ਡੇਟਾਬੇਸ ਸੀਮਾਵਾਂ ਨੂੰ enforce ਕਰਦਾ ਹੈ (tenant IDs, ownership constraints, ਅਤੇ ਜਿਥੇ ਲੋੜ ਹੋਵੇ row-level policies)। ਜੇ authorization ਸਿਰਫ controllers ਵਿੱਚ ਹੋਵੇ, ਤਾਂ background jobs ਅਤੇ ਅੰਦਰੂਨੀ ਸਕ੍ਰਿਪਟਾਂ ਅਕਸਰ ਇਸਨੂੰ ਬਾਈਪਾਸ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਫਰੇਮਵਰਕ validation ਤੇਜ਼ ਫੀਡਬੈਕ ਅਤੇ ਚੰਗੇ error messages ਦਿੰਦਾ ਹੈ। ਡੇਟਾਬੇਸ constraints ਆਖਰੀ safety net ਦਿੰਦੇ ਹਨ।
ਜਦ ਲੋੜ ਹੋਵੇ ਦੋਹਾਂ ਵਰਤੋ:
CHECK constraints, NOT NULLਇਸ ਨਾਲ “ਅਸੰਭਵ ਸਥਿਤੀਆਂ” ਘੱਟ ਹੁੰਦੀਆਂ ਹਨ ਜਦ ਦੋ ਰਿਕਵੇਸਟ race ਕਰਦੀਆਂ ਹਨ ਜਾਂ ਨਵਾਂ ਸਰਵਿਸ ਡਾਟਾ ਵੱਖਰੇ ਢੰਗ ਨਾਲ ਲਿਖਦਾ ਹੈ।
Secrets ਨੂੰ ਰਨਟਾਈਮ ਅਤੇ deployment ਵਰਕਫਲੋ (env vars, secret managers) ਦੁਆਰਾ ਹੈਂਡਲ ਕਰੋ—ਕੋਡ ਜਾਂ migrations ਵਿੱਚ hardcode ਨਾ ਕਰੋ। ਇਨਕ੍ਰਿਪਸ਼ਨ ਐਪ ਵਿੱਚ (field-level encryption) ਅਤੇ/ਜਾਂ ਡੇਟਾਬੇਸ (at-rest encryption, managed KMS) ਦੋਹਾਂ ਤਰੀਕਿਆਂ ਨਾਲ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਇਹ ਸਪਸ਼ਟ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਕੀ key rotate ਕਰੇਗਾ ਅਤੇ recovery ਕਿਵੇਂ ਹੋਵੇਗਾ।
ਆਡੀਟਿੰਗ ਵੀ ਸਾਂਝੀ ਹੈ: ਐਪ ਨੂੰ ਮਾਨੇਯੋਗ ਇਵੈਂਟ ਜਾਰੀ ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ; ਡੇਟਾਬੇਸ immutable ਲਾਗ ਰੱਖੇ ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ (ਉਦਾਹਰਣ: append-only audit tables, restricted access)।
ਐਪ ਲੌਜਿਕ 'ਤੇ ਅਤਿ-ਭਰੋਸਾ ਸਭ ਤੋਂ ਆਮ ਸਮੱਸਿਆ ਹੈ: ਘੱਟ constraints, silent nulls, "admin" flags ਬਿਨਾਂ ਚੈੱਕਾਂ ਦੇ। ਸੁਧਾਰ ਸਧਾਰਣ ਹੈ: ਧਾਰਨਾ ਕਰੋ ਕਿ ਬੱਗ ਹੋਣਗੇ, ਅਤੇ ਸਟੈਕ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਡੇਟਾਬੇਸ ਤੁਹਾਡੇ ਆਪਣੇ ਕੋਡ ਤੋਂ ਵੀ unsafe writes ਨੂੰ ਨਾਕਾਰ ਸਕੇ।
ਸਕੇਲਿੰਗ ਅਕਸਰ ਇਸ ਲਈ ਫੇਲ ਹੁੰਦੀ ਹੈ ਕਿ "ਡੇਟਾਬੇਸ ਨਹੀਂ ਸੰਭਾਲ ਸਕਦਾ"—ਇਸ ਲਈ ਨਹੀਂ ਕਿ ਪੂਰਾ ਸਟੈਕ ਲੋਡ ਦੇ ਹੋਣ 'ਤੇ ਬੁਰੇ ਤਰੀਕੇ ਨਾਲ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰਦਾ ਹੈ: ਇਕ endpoint ਲੋਕਪ੍ਰਿਯ ਹੋ ਜਾਂਦਾ ਹੈ, ਇਕ ਕੁਏਰੀ hot ਹੋ ਜਾਂਦੀ ਹੈ, ਜਾਂ ਇਕ ਵਰਕਫਲੋ retries ਸ਼ੁਰੂ ਕਰ ਦਿੰਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਪਹਿਲੇ ਹੀ ਉਹੀ ਬੋਤਲਨੈਕ ਵੇਖਦੀਆਂ ਹਨ:
ਕੀ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹੋ ਇਹ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡੇ ਫਰੇਮਵਰਕ ਅਤੇ ਡੇਟਾਬੇਸ ਟੂਲਿੰਗ query plans, migrations, connection pooling, ਅਤੇ safe caching patterns ਨੂੰ ਕਿੰਨਾ ਸਪਸ਼ਟ ਕਰਦੇ ਹਨ।
ਆਮ ਸਕੇਲਿੰਗ ਕਦਮ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਕ੍ਰਮ ਵਿੱਚ ਆਉਂਦੇ ਹਨ:
ਇੱਕ ਸਕੇਲੇਬલ ਸਟੈਕ ਨੂੰ background tasks, scheduling, ਅਤੇ safe retries ਲਈ ਪਹਿਲ-ਕਲਾਸ ਸਹਾਇਤਾ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਜੇ ਤੁਹਾਡਾ job system idempotency enforce ਨਹੀਂ ਕਰ ਸਕਦਾ (ਉਹੀ job ਦੋ ਵਾਰੀ ਚੱਲੇ ਬਿਨਾਂ double-charging ਜਾਂ double-sending), ਤਾਂ ਤੁਸੀਂ "scale" ਕਰ ਕੇ ਡਾਟਾ corruption ਦੀ ਓਰ ਵਧ ਜਾਵੋਗੇ। ਸ਼ੁਰੂਆਤੀ ਚੋਣਾਂ—ਜਿਵੇਂ implicit transactions 'ਤੇ ਨਿਰਭਰ, ਕਮਜ਼ੋਰ uniqueness constraints, ਜਾਂ opaque ORM behaviors—ਸਾਫ਼ ਪਾਥਾਂ (outbox patterns, exactly-once-ish workflows) ਨੂੰ ਲਾਗੂ ਕਰਨ ਵਿੱਚ ਬਾਧਾ ਪਹੁੰਚਾ ਸਕਦੀਆਂ ਹਨ।
ਸ਼ੁਰੂ ਵਿੱਚ ਸਹੀ ਮੇਲ ਮਿਲਾਪ ਲਾਭਦਾਇਕ ਹੈ: ਉਹ ਡੇਟਾਬੇਸ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ consistency ਦੀਆਂ ਲੋੜਾਂ ਨਾਲ ਮਿਲਦਾ ਹੋਵੇ, ਅਤੇ ਐਸਾ ਫਰੇਮਵਰਕ ecosystem ਚੁਣੋ ਜੋ ਅਗਲਾ ਸਕੇਲਿੰਗ ਕਦਮ (replicas, queues, partitioning) ਨੂੰ ਇੱਕ ਸਹਾਇਕ ਰਾਹ ਬਣਾਏ ਨਾ ਕਿ rewrite ਦੀ ਲੋੜ ਪਵੇ।
ਇੱਕ ਸਟੈਕ "ਆਸਾਨ" ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ ਜਦ ਡਿਵੈਲਪਮੈਂਟ ਅਤੇ ਆਪਰੇਸ਼ਨ ਇੱਕੋ ਹੀ ਧਾਰਨਾਵਾਂ ਸਾਂਝੀਆਂ ਕਰਦੇ ਹਨ: ਤੁਸੀਂ ਐਪ ਕਿਵੇਂ ਸਟਾਰਟ ਕਰਦੇ ਹੋ, ਡਾਟਾ ਕਿਵੇਂ ਬਦਲਦਾ ਹੈ, ਟੈਸਟ ਕਿਵੇਂ ਚਲਦੇ ਹਨ, ਅਤੇ ਜਦ ਕੁਝ ਖਰਾਬ ਹੁੰਦਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਕਿਵੇਂ ਪਤਾ ਲਗਾਉਂਦੇ ਹੋ। ਜੇ ਇਹ ਟੁਕੜੇ ਇਕ-ਦੂਜੇ ਨਾਲ ਨਹੀਂ ਮਿਲਦੇ, ਟੀਮਾਂ glue code, brittle scripts, ਅਤੇ manual runbooks 'ਤੇ ਸਮਾਂ ਗੁਆਂਢ ਕਰਦੀਆਂ ਹਨ।
ਤੇਜ਼ ਲੋਕਲ ਸੈਟਅਪ ਇੱਕ ਫੀਚਰ ਹੈ। ਇੱਕ ਨਵੇਂ ਸਾਥੀ ਲਈ ਵਰਕਫਲੋ ਪਸੰਦ ਕਰੋ ਜਿੱਥੇ ਕੋਇ clone ਕਰਕੇ, install ਕਰਕੇ, migrations ਚਲਾ ਕੇ, ਅਤੇ vast-ਮੋਤਾਬਿਕ ਟੈਸਟ ਡੇਟਾ ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ ਮਿਲ ਜਾਏ—ਨ੍ਹੀਂ ਤਾਂ ਘੰਟਿਆਂ ਵਿੱਚ ਨਹੀਂ।
ਇਸਦਾ ਅਰਥ ਆਮ ਤੌਰ 'ਤੇ:
ਜੇ ਤੁਹਾਡਾ ਫਰੇਮਵਰਕ ਦੀ migration tooling ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਚੋਣ ਨਾਲ ਲੜਦੀ ਹੈ, ਤਾਂ ਹਰ ਸਕੀਮਾ ਬਦਲਾਉਂ ਇੱਕ ਛੋਟੀ ਪ੍ਰੋਜੈਕਟ ਬਣ ਸਕਦੀ ਹੈ।
ਤੁਹਾਡੇ ਸਟੈਕ ਨੂੰ ਇਹ ਲਿਖਣਾ ਕੁਦਰਤੀ ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ:
ਆਮ ਨਾਕਾਮੀ: ਟੀਮਾਂ integration tests ਤੋਂ ਹਟ ਕੇ unit tests 'ਤੇ ਜ਼ਿਆਦਾ ਨਿਰਭਰ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ integration tests slow ਜਾਂ setup ਲਈ painful ਹਨ। ਇਹ ਅਕਸਰ ਇੱਕ stack/ops mismatch ਹੁੰਦਾ ਹੈ—ਟੈਸਟ ਡੇਟਾਬੇਸ provisioning, migrations, ਅਤੇ fixtures streamline ਨਹੀਂ ਹੁੰਦੇ।
ਜਦ latency spike ਹੁੰਦਾ ਹੈ, ਤੁਹਾਨੂੰ ਇੱਕ ਰਿਕਵੇਸਟ ਨੂੰ ਫਰੇਮਵਰਕ ਤੋਂ ਲੈ ਕੇ ਡੇਟਾਬੇਸ ਤੱਕ follow ਕਰਨ ਲਈ ਸਮਰੱਥ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
consistent structured logs, ਬੇਸਿਕ metrics (request rate, errors, DB time), ਅਤੇ traces ਜੋ query timing ਸ਼ਾਮਲ ਕਰਦੀਆਂ ਹਨ ਇਹ ਸਹਾਇਕ ਹਨ। ਇੱਕ correlation ID ਜੋ ਐਪ ਲੌਗਾਂ ਅਤੇ ਡੇਟਾਬੇਸ ਲੌਗਾਂ ਵਿੱਚ ਮੌਜੂਦ ਹੋਵੇ guessing ਨੂੰ finding ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ।
ਆਪਰੇਸ਼ਨ ਵਿਕਾਸ ਤੋਂ ਵਿਭਾਜਤ ਨਹੀਂ; ਇਹ ਉਸ ਦਾ ਜਾਰੀ ਰੂਪ ਹੈ।
ਉਹ ਟੂਲਿੰਗ ਚੁਣੋ ਜੋ ਸਹਾਇਤਾ ਕਰਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ restore ਜਾਂ migration ਨੂੰ ਲੋਕਲ ਰੂਪ ਵਿੱਚ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ rehearsal ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ tekanan ਹੇਠ ਤੁਸੀਂ ਭਲਕੇ ਨਹੀਂ ਕਰੋਂਗੇ।
ਸਟੈਕ ਚੁਣਨਾ "ਸਰਵੋਤਮ" ਟੂਲ ਚੁਣਨ ਬਾਰੇ ਨਹੀਂ, ਬਲਕਿ ਉਹ ਟੂਲ ਚੁਣਨ ਬਾਰੇ ਹੈ ਜੋ ਤੁਹਾਡੇ ਅਸਲੀ ਸੀਮਾਵਾਂ 'ਤੇ ਇਕੱਠਾ ਫਿੱਟ ਬੈਠਦੇ ਹਨ। ਓਸ ਚੈਕਲਿਸਟ ਨੂੰ ਵਰਤੋ ਤਾਂ ਜੋ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਸੁਮੇਲ ਹੋਵੇ।
Time-box ਕਰੋ 2–5 ਦਿਨ। ਇੱਕ پتਲਾ vertical slice ਬਣਾਓ: ਇਕ ਕੋਰ ਵਰਕਫਲੋ, ਇਕ background job, ਇਕ report-ਜੈਸੀ ਕੁਏਰੀ, ਅਤੇ ਬੁਨਿਆਦੀ auth। developer friction, migration ergonomics, query clarity, ਅਤੇ ٹੈਸਟ ਕਰਨ ਦੀ ਅਸਾਨੀ ਨੂੰ measure ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਇਸ ਕਦਮ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਕਰਨਾ ਚਾਹੋ, ਤਾਂ Koder.ai ਵਰਗੇ vibe-coding ਟੂਲ ਛੇਤੀ ਇੱਕ ਵਰਟਿਕਲ ਸਲਾਈਸ ਤਿਆਰ ਕਰਨ ਵਿੱਚ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ (UI, API, ਅਤੇ ਡੇਟਾਬੇਸ) ਜੋ ਚੈਟ-ਡਰਿਵਨ spec ਤੋਂ ਬਣਦਾ ਹੈ—ਫਿਰ snapshots/rollback ਨਾਲ iterate ਕਰੋ ਅਤੇ ਜਦ ਤੱਕ ਦਿਸ਼ਾ ਫਿਕਸ ਹੋ ਜਾਵੇ source code export ਕਰੋ।
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
ਬਿਹਤਰ ਟੀਮਾਂ ਵੀ ਸਟੈਕ mismatches ਦਾ ਸ਼ਿਕਾਰ ਹੋ ਜਾਂਦੀਆਂ ਹਨ—ਚੋਣਾਂ ਜੋ ਅਲੱਗ-ਅਲੱਗ ਠੀਕ ਲੱਗਦੀਆਂ ਹਨ ਪਰ ਸਿਸਟਮ ਬਣਨ 'ਤੇ friction ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ। ਚੰਗੀ ਖ਼ਬਰ: ਜ਼ਿਆਦਾਤਰ ਪੇਸ਼ੀਨਜ਼ اندازੇਯੋਗ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਕੁਝ checks ਨਾਲ ਉਨ੍ਹਾਂ ਤੋਂ ਬਚ ਸਕਦੇ ਹੋ।
ਇੱਕ ਪੁਰਾਣਾ ਸੁਗੰਧ ਹੈ ਕਿਸੇ ਡੇਟਾਬੇਸ ਜਾਂ ਫਰੇਮਵਰਕ ਨੂੰ trending ਹੋਣ ਕਰਕੇ ਚੁਣਨਾ ਜਦੋਂ ਕਿ ਤੁਹਾਡਾ ਅਸਲੀ ਡੇਟਾ ਮਾਡਲ ਅਜੇ ਵੀ ਅਸਪਸ਼ਟ ਹੋ। ਇੱਕ ਹੋਰ ਹੈ premature scaling: ਦਸਲੱਖ ਯੂਜ਼ਰਾਂ ਲਈ optimize ਕਰਨਾ ਪਹਿਲਾਂ ਜਦੋਂ ਤੁਸੀਂ ਸੌਂ-ਸੌ ਯੂਜ਼ਰਾਂ ਨੂੰ ਭੀ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ handle ਨਹੀਂ ਕਰ ਸਕਦੇ—ਇਸ ਨਾਲ ਅਕਸਰ ਵਾਧੂ infrastructure ਅਤੇ ਹੋਰ failure modes ਆ ਜਾਂਦੇ ਹਨ।
ਇਸ ਤੋਂ ਇਲਾਵਾ ਉਹ ਸਟੈਕ ਦੇਖੋ ਜਿੱਥੇ ਟੀਮ ਹਰ ਮੁੱਖ ਹਿੱਸੇ ਦਾ ਕਾਰਨ ਸਮਝ ਨਹੀਂ ਸਕਦੀ। ਜੇ ਜਵਾਬ ਹੈ “ਸਾਰਾਂ ਲੋਕਾਂ ਨੇ ਇਸਨੂੰ ਵਰਤਿਆ”, ਤਾਂ ਤੁਸੀਂ ਜੋਖਮ ਇਕੱਤਰ ਕਰ ਰਹੇ ਹੋ।
ਕਈ ਸਮੱਸਿਆਵਾਂ seams 'ਤੇ ਆਉਂਦੀਆਂ ਹਨ:
ਇਹ ਨਾ ਤਾਂ “ਡੇਟਾਬੇਸ ਸਮੱਸਿਆਵਾਂ” ਹਨ ਨਾਂ ਹੀ “ਫਰੇਮਵਰਕ ਸਮੱਸਿਆਵਾਂ”—ਇਹ ਸਿਸਟਮ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਹਨ।
ਘੱਟ moving parts ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਅਤੇ ਆਮ ਟਾਸਕਾਂ ਲਈ ਇੱਕ ਸਾਫ਼ ਰਾਹ: ਇਕ migration approach, ਇਕ query style ਜ਼ਿਆਦਾਤਰ features ਲਈ, ਅਤੇ ਸੇਵਾਵਾਂ ਵਿੱਚ consistent conventions। ਜੇ ਫਰੇਮਵਰਕ ਇੱਕ ਪੈਟਰਨ (request lifecycle, dependency injection, job pipeline) ਨੂੰ ਉਤਸ਼ਾਹਦਾ ਹੈ, ਤਾਂ ਉਸ ਤੇ ਭਰੋਸਾ ਕਰੋ ਨਾ ਕਿ ਸ਼ੈਲੀਆਂ ਨੂੰ ਮਿਲਾਉਣ।
ਜਦ ਤੁਸੀਂ production incidents ਦੇ ਰੀਕਰਿੰਗ, ਲਗਾਤਾਰ ਡਿਵੈਲਪਰ friction, ਜਾਂ ਨਵੇਂ ਉਤਪਾਦ ਦੀਆਂ ਲੋੜਾਂ ਜੋ ਬੁਨਿਆਦੀ ਤੌਰ 'ਤੇ ਤੁਹਾਡੇ ਡਾਟਾ ਐਕਸੈੱਸ ਪੈਟਰਨਾਂ ਨੂੰ ਬਦਲ ਦਿੰਦੇ ਹਨ, ਤਦ ਫੈਸਲੇ ਮੁੜ-ਵਿਚਾਰੋ।
ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਬਦਲੋ: seam ਨੂੰ isolate ਕਰੋ, adapter layer ਦਾਖਲ ਕਰੋ, incremental migrate (dual-write ਜਾਂ backfill ਜਿੱਥੇ ਲੋੜ), ਅਤੇ traffic ਫਲਿਪ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ automated tests ਨਾਲ parity ਸਾਬਤ ਕਰੋ।
ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ, ਵੇਬ ਫਰੇਮਵਰਕ, ਅਤੇ ਡੇਟਾਬੇਸ ਚੁਣਨਾ ਤਿੰਨ ਅਲੱਗ ਫੈਸਲੇ ਨਹੀਂ—ਇਹ ਇੱਕ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਫੈਸਲਾ ਹੈ ਜੋ ਤਿੰਨ ਥਾਵਾਂ 'ਤੇ ਦਰਸਾਇਆ ਜਾਂਦਾ ਹੈ। "ਸਭ ਤੋਂ ਵਧੀਆ" ਵਿਕਲਪ ਉਹ ਕੁੰਬੀਨੇਸ਼ਨ ਹੈ ਜੋ ਤੁਹਾਡੇ ਡੇਟਾ ਆਕਾਰ, consistency ਦੀਆਂ ਲੋੜਾਂ, ਟੀਮ ਦੇ ਵਰਕਫਲੋ, ਅਤੇ ਉਤਪਾਦ ਦੇ ਵਧਣ ਦੇ ਢੰਗ ਨਾਲ ਮਿਲਦਾ ਹੈ।
ਆਪਣੀਆਂ ਚੋਣਾਂ ਦੇ ਕਾਰਨ ਲਿਖੋ: ਉਮੀਦ ਕੀਤੀ ਟ੍ਰੈਫਿਕ ਪੈਟਰਨ, ਮਨਜ਼ੂਰ latency, ਡੇਟਾ ਰੂਟ ਅਨੇਕ, failure modes ਜੋ ਤੁਸੀਂ ਸਹਿ ਰਹੇ ਹੋ, ਅਤੇ ਉਹ ਚੀਜ਼ਾਂ ਜਿਨ੍ਹਾਂ ਲਈ ਤੁਸੀਂ ਖੁੱਲ੍ਹਾ ਤੌਰ 'ਤੇ optimize ਨਹੀਂ ਕਰ ਰਹੇ। ਇਹ ਟਰੇਡ-ਆਫਜ਼ ਨੂੰ ਵਿਖਾਵਾਂਦਾ ਬਣਾਉਂਦਾ ਹੈ, ਭਵਿੱਖ ਦੇ ਸਾਥੀਆਂ ਨੂੰ “ਕਿਉਂ” ਸਮਝਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, ਅਤੇ requirements ਬਦਲਣ 'ਤੇ accidental architecture drift ਨੂੰ ਰੋਕਦਾ ਹੈ।
ਆਪਣੇ ਮੌਜੂਦਾ ਸੈਟਅਪ ਨੂੰ ਚੈਕਲਿਸਟ ਰਾਹੀਂ ਚਲਾਓ ਅਤੇ ਨੋਟ ਕਰੋ ਕਿ ਕਿੱਥੇ ਫੈਸਲੇ ਮਿਲਦੇ ਨਹੀਂ (ਉਦਾਹਰਣ: ਇੱਕ ਸਕੀਮਾ ਜੋ ORM ਨਾਲ ਲੜਦਾ ਹੈ, ਜਾਂ ਇਕ ਫਰੇਮਵਰਕ ਜੋ background work ਨੂੰ awkward ਬਣਾਉਂਦਾ)।
ਜੇ ਤੁਸੀਂ ਨਵੀਂ ਦਿਸ਼ਾ ਖੋਜ ਰਹੇ ਹੋ, ਤਦ Koder.ai ਵਰਗੇ ਟੂਲ ਤੁਹਾਨੂੰ जल्दी ਦੋ-ਤਿੰਨ ਬੇਸਲਾਈਨ ਐਪ ਜਨਰੇਟ ਕਰਕੇ ਸਟੈਕ ਅਨੁਮਾਨਾਂ ਦੀ ਤੁਲਨਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ—ਇੱਕ ਆਮ ਕੰਬੋ (ਅਕਸਰ React web, Go services ਨਾਲ PostgreSQL, ਅਤੇ Flutter mobile) ਜੋ ਤੁਸੀਂ ਇੰსპੈਕਟ, export, ਅਤੇ evolve ਕਰ ਸਕਦੇ ਹੋ—ਨੋ commitments ਤੋਂ ਪਹਿਲਾਂ।
ਗਹਿਰਾਈ ਵਾਲੀ follow-up ਲਈ, /blog 'ਤੇ ਸਬੰਧਤ ਗਾਈਡਾਂ ਵੇਖੋ, implementation details ਲਈ /docs ਚੈਕ ਕਰੋ, ਜਾਂ /pricing 'ਤੇ support ਅਤੇ deployment ਵਿਕਲਪਾਂ ਦੀ ਤੁਲਨਾ ਕਰੋ।
ਇਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਪਾਈਪਲਾਈਨ ਵਜੋਂ ਸਮਝੋ: ਫਰੇਮਵਰਕ → ਕੋਡ (ਭਾਸ਼ਾ) → ਡੇਟਾਬੇਸ → ਰਿਸਪਾਂਸ। ਜੇ ਇੱਕ ਟੁਕੜਾ ਹੋਰਾਂ ਦੇ ਖਿਲਾਫ ਪੈਟਰਨ ਪ੍ਰੇਰਿਤ ਕਰੇ (ਜਿਵੇਂ schema-less ਸਟੋਰੇਜ + ਭਾਰੀ ਰਿਪੋਰਟਿੰਗ), ਤਾਂ ਤੁਸੀਂ ਗਲੂ ਕੋਡ, ਨਕਲ ਕੀਤੀਆਂ ਨਿਯਮਾਂ, ਅਤੇ ਮੁਸ਼ਕਲ ਸਮਝ ਆਉਣ ਵਾਲੀਆਂ ਸੰਗਤੀਆਂ ਨਾਲ ਸਮਾਂ ਗੁਆਂਢ ਕਰੋਗੇ।
ਆਪਣੇ ਮੁੱਖ ਡੇਟਾ ਮਾਡਲ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਉਹ ਆਪਰੇਸ਼ਨ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਬਾਰੰਬਾਰ ਕਰੋਗੇ:
ਜਦ ਮਾਡਲ ਸਾਫ਼ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਕਿਸ ਡੇਟਾਬੇਸ ਅਤੇ ਫਰੇਮਵਰਕ ਫੀਚਰ ਦੀ ਲੋੜ ਹੈ ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਸਪਸ਼ਟ ਹੋ ਜਾਂਦੇ ਹਨ।
ਜੇ ਡੇਟਾਬੇਸ ਇੱਕ ਮਜ਼ਬੂਤ ਸਕੀਮਾ ਲਗੂ ਕਰਦਾ ਹੈ ਤਾਂ ਕਈ ਨਿਯਮ ਡਾਟਾ ਦੇ ਨੇੜੇ ਰਹਿ ਸਕਦੇ ਹਨ:
NOT NULL, uniquenessCHECK constraints ਕਈ ਵੈਲੀਡ ਰੈਂਜ/ਸਟੇਟ ਨਾਲਲਚਕੀਲੇ ਡਾਟਾ ਸਟਰਕਚਰ ਨਾਲ, ਹੋਰ ਨਿਯਮ ਐਪਲੀਕੇਸ਼ਨ ਕੋਡ ਵਿੱਚ ਸਕਿਫਟ ਹੋ ਜਾਂਦੇ ਹਨ (ਵੈਲੀਡੇਸ਼ਨ, ਵਰਜ਼ਨਡ ਪੇਲੋਡ, ਬੈਕਫਿਲ)। ਇਹ ਸ਼ੁਰੂਆਤੀ ਤਬਦੀਲੀ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ ਪਰ ਟੈਸਟਿੰਗ ਭਾਰ ਅਤੇ ਸਰਵਿਸਾਂ ਵਿੱਚ ਡ੍ਰਿਫਟ ਦਾ ਖਤਰਾ ਵadhata hai.
ਜਦ ਵੀ ਕਈ ਰਾਈਟਸ ਨੂੰ ਇਕੱਠੇ ਸਫਲ ਹੋਣਾ ਲਾਜ਼ਮੀ ਹੋਵੇ (ਉਦਾਹਰਣ: ਆਰਡਰ + ਭੁਗਤਾਨ ਸਥਿਤੀ + ਇਨਵੈਂਟਰੀ ਅਪਡੇਟ), ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਰਤੋ। ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨਾ ਹੋਣ 'ਤੇ ਤੁਹਾਨੂੰ ਮਿਲ ਸਕਦਾ ਹੈ:
ਜ਼ਰੂਰੀ ਹੈ ਕਿ ਸਾਈਡ-ਇਫੈਕਟ (ਈਮੇਲ/ਵੈੱਬਹੁੱਕ) ਕਮਿਟ ਤੋਂ ਬਾਅਦ ਹੋਣ ਅਤੇ ਆਪਰੇਸ਼ਨਾਂ ਨੂੰ idoempotent ਬਣਾਇਆ ਜਾਵੇ (ਦੁਬਾਰਾ ਚਲਾਉਣ ਤੇ ਨੁਕਸਾਨ ਨਾ ਹੋਵੇ)।
ਸਿੱਧਾ ਨਿਯਮ: ਉਹ ਸਭ ਤੋਂ ਸਧਾਰਣ ਟੂਲ ਚੁਣੋ ਜੋ ਇਰਾਦਾ ਸਪੱਸ਼ਟ ਰੱਖੇ:
ਮਹੱਤਵਪੂਰਨ ਏਂਡਪੋਇੰਟ ਲਈ ਹਮੇਸ਼ਾਂ ਵੇਖੋ ਕਿ ਅਸਲ ਵਿੱਚ ਕਿਹੜੀ SQL ਚੱਲ ਰਹੀ ਹੈ।
Schema ਅਤੇ ਕੋਡ ਨੂੰ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਸਿੰਕ ਰੱਖੋ ਅਤੇ ਮਾਈਗਰੇਸ਼ਨਾਂ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਕੋਡ ਵਾਂਗ ਰਵੱਈਆ ਦਿਓ:
ਜੇ ਮਾਈਗਰੇਸ਼ਨ ਮੈਨੂਅਲ ਜਾਂ flaky ਹਨ, ਤਾਂ ਵਾਤਾਵਰਨ drift ਕਰਦੇ ਹਨ ਅਤੇ deploy ਖਤਰਨਾਕ ਬਣ ਜਾਂਦੇ ਹਨ।
ਪੂਰੇ ਰਿਕਵੇਸਟ ਪੱਥ ਨੂੰ ਪ੍ਰੋਫਾਈਲ ਕਰੋ, ਸਿਰਫ਼ ਡੇਟਾਬੇਸ ਨੂੰ ਨਹੀਂ:
ਜੇ ਡੇਟਾਬੇਸ 5ms ਵਿੱਚ ਜਵਾਬ ਦੇ ਰਿਹਾ ਹੈ, ਪਰ ਐਪ 20 ਕੁਏਰੀਆਂ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ I/O 'ਤੇ ਰੁਕਿਆ ਹੈ ਤਾਂ ਪੇਜ਼ ਫੀਲ ਸਲੋ ਹੀ ਰਹੇਗਾ।
ਇੱਕ ਕਨੈਕਸ਼ਨ ਪੂਲ ਨਵੇਂ ਕਨੈਕਸ਼ਨ ਦੇ ਸੈਟਅੱਪ ਖਰਚ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ ਲੋਡ ਹੇਠ ਡੇਟਾਬੇਸ ਨੂੰ ਬਚਾਉਂਦਾ ਹੈ.
ਪ੍ਰਯੋਗਿਕ ਸਲਾਹ:
ਗਲਤ ਸਾਈਜ਼ਡ ਪੂਲਜ਼ ਆਮ ਤੌਰ 'ਤੇ ਟਾਈਮਆਊਟ ਅਤੇ noisy failures ਵਜੋਂ ਨਜ਼ਰ ਆਉਂਦੇ ਹਨ।
ਦੋਹਾਂ ਤਹਾਂ ਵਰਤੋ:
NOT NULL, CHECK)ਇਸ ਨਾਲ “ਅਸੰਭਵ ਸਥਿਤੀਆਂ” ਘੱਟ ਹੁੰਦੀਆਂ ਹਨ ਜਦ ਦੋ ਰਿਕਵੇਸਟ race ਕਰਦੀਆਂ ਹਨ, background jobs ਡਾਟਾ ਲਿਖਦੀਆਂ ਹਨ, ਜਾਂ ਕੋਈ ਨਵਾਂ endpoint ਇਕ ਚੈੱਕ ਭੁੱਲ ਜਾਂਦਾ ਹੈ।
2–5 ਦਿਨ ਦੇ time-box ਵਿੱਚ ਇੱਕ ਛੋਟਾ proof of concept ਬਣਾਓ ਜੋ ਅਸਲ seams ਦੀ ਪਰਖ ਕਰੇ:
ਫਿਰ ਇੱਕ ਪੰਨੇ ਦਾ decision record ਲਿਖੋ ਤਾਂ ਜੋ ਭਵਿੱਖ ਵਿੱਚ ਤਬਦੀਲੀਆਂ ਇਰਾਦੇ ਨਾਲ ਹੋਣ।