02 ਅਕਤੂ 2025·8 ਮਿੰਟ
Brendan Burns ਅਤੇ Kubernetes: ਉਹ ਵਿਚਾਰ ਜਿਨ੍ਹਾਂ ਨੇ ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਨੂੰ ਰੂਪ ਦਿੱਤਾ
Brendan Burns ਦੇ Kubernetes-ਕਾਲ ਦੇ ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਵਿਚਾਰਾਂ ਦਾ ਪ੍ਰਯੋਗਿਕ ਨਜ਼ਰੀਆ—ਘੋਸ਼ਣਾਤਮਕ ਹਾਲਤ, ਕੰਟਰੋਲਰ, ਸਕੇਲਿੰਗ ਅਤੇ ਸੇਵਾ ਓਪਰੇਸ਼ਨ—ਅਤੇ ਇਹ ਕਿਉਂ ਮਿਆਰੀ ਬਣ ਗਏ।
Brendan Burns ਦੇ Kubernetes-ਕਾਲ ਦੇ ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਵਿਚਾਰਾਂ ਦਾ ਪ੍ਰਯੋਗਿਕ ਨਜ਼ਰੀਆ—ਘੋਸ਼ਣਾਤਮਕ ਹਾਲਤ, ਕੰਟਰੋਲਰ, ਸਕੇਲਿੰਗ ਅਤੇ ਸੇਵਾ ਓਪਰੇਸ਼ਨ—ਅਤੇ ਇਹ ਕਿਉਂ ਮਿਆਰੀ ਬਣ ਗਏ।
Kubernetes ਸਿਰਫ਼ ਇੱਕ ਨਵਾਂ ਟੂਲ ਨਹੀਂ ਲਿਆਇਆ—ਇਸਨੇ “ਦਿਨ-ਪ੍ਰਤੀ ਦਿਨ ਓਪਰੇਸ਼ਨ” ਦਾ ਰੂਪ ਹੀ ਬਦਲ ਦਿੱਤਾ ਜਦੋਂ ਤੁਸੀਂ ਦਹਾਈਆਂ (ਜਾਂ ਸੈਂਕੜਿਆਂ) ਸਰਵਿਸਾਂ ਚਲਾ ਰਹੇ ਹੋ। ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਪਹਿਲਾਂ, ਟੀਮਾਂ ਅਕਸਰ ਸਕ੍ਰਿਪਟਾਂ, ਹੱਥ-ਚਲਾਏ ਜਾਂ ਰਨਬੁਕ ਅਤੇ ਟ੍ਰਾਇਬਲ ਨੋਲੇਜ ਨੂੰ ਜੋੜ ਕੇ ਉਹੀ ਮੁੜ-ਮੁੜ ਆਉਣ ਵਾਲੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਲੱਭਦੀਆਂ ਸਨ: ਇਹ ਸਰਵਿਸ ਕਿੱਥੇ ਚੱਲੀ? ਕਿਸ ਤਰੀਕੇ ਨਾਲ ਸੁਰੱਖਿਅਤ ਤੌਰ ਤੇ ਬਦਲ ਅਪਨਾਇਆ ਜਾਵੇ? ਜੇ ਨੋਡ ਰਾਤ 2 ਵਜੇ ਫੇਲ ਹੋ ਜਾਵੇ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ?
ਮੂਲ ਤੌਰ 'ਤੇ, ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਤੁਹਾਡੇ ਇਰਾਦੇ (“ਇਸ ਤਰ੍ਹਾਂ ਇਹ ਸੇਵਾ ਚੱਲੇ”) ਅਤੇ ਮਸ਼ੀਨਾਂ ਦੇ ਫੇਲ ਹੋਣ, ਟ੍ਰੈਫਿਕ ਹਿਲ ਜਾਣ ਅਤੇ ਲਗਾਤਾਰ ਡਿਪਲੋਇਮੈਂਟ ਵਸਤੀ ਹਕੀਕਤ ਦੇ ਵਿੱਚ ਇਕ ਕੋਆਰਡੀਨੇਸ਼ਨ ਲੇਅਰ ਹੈ। ਹਰ ਸਰਵਰ ਨੂੰ ਖ਼ਾਸ ਸਮਝਣ ਦੀ ਥਾਂ, ਆਰਕੀਸਟ੍ਰੇਸ਼ਨ ਕਮਪਿਊਟ ਨੂੰ ਇਕ ਪੂਲ ਸਮਝਦਾ ਹੈ ਅਤੇ ਵਰਕਲੋਡ ਨੂੰ ਐਸੇ ਯੂਨਿਟ ਵਜੋਂ ਜੋ ਸ਼ਿਡਿਊਲ ਹੋ ਸਕਦੇ ਹਨ।
Kubernetes ਇੱਕ ਮਾਡਲ ਨੂੰ ਲੋਕਪ੍ਰਿਯ ਬਣਾਉਂਦਾ ਹੈ ਜਿੱਥੇ ਟੀਮਾਂ ਦਰਸਾਉਂਦੀਆਂ ਹਨ ਕਿ ਉਹ ਕੀ ਚਾਹੁੰਦੇ ਹਨ, ਅਤੇ ਸਿਸਟਮ ਲਗਾਤਾਰ ਹੁੰਦਾ ਹੈ ਕਿ ਹਕੀਕਤ ਉਸ ਵਰਣਨ ਨਾਲ ਮਿਲੇ। ਇਹ ਬਦਲਾਅ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਇਹ ਓਪਰੇਸ਼ਨਜ਼ ਨੂੰ ਹੀਰੋਇਕ ਕਾਰਜਾਂ ਤੋਂ ਘਟਾ ਕੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਪ੍ਰਕਿਰਿਆਵਾਂ ਵਲ ਵਧਾਉਂਦਾ ਹੈ।
Kubernetes ਉਹ ਓਪਰੇਸ਼ਨਲ ਨਤੀਜੇ ਨਿਯਮਿਤ ਕੀਤੇ ਜੋ ਜ਼ਿਆਦਾਤਰ ਸਰਵਿਸ ਟੀਮਾਂ ਨੂੰ ਚਾਹੀਦੇ ਹੁੰਦੇ ਹਨ:
ਇਹ ਲੇਖ Kubernetes ਨਾਲ ਜੁੜੀਆਂ ਵਿਚਾਰਧਾਰਾਵਾਂ ਅਤੇ ਪੈਟਰਨਾਂ 'ਤੇ ਕੇਂਦਰਿਤ ਹੈ (ਅਤੇ Brendan Burns ਵਰਗੇ ਨੇਤਾਵਾਂ), ਨਾਕਿ ਨਿੱਜੀ ਜੀਵਨੀ 'ਤੇ। ਅਤੇ ਜਦੋਂ ਅਸੀਂ “ਇਹ ਕਿਵੇਂ ਸ਼ੁਰੂ ਹੋਇਆ” ਜਾਂ “ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਿਉਂ ਕੀਤਾ ਗਿਆ” ਬਾਰੇ ਗੱਲ ਕਰਦੇ ਹਾਂ, ਉਹ ਦਾਵੇ ਲੋਕ-ਪ੍ਰਕਾਸ਼ਿਤ ਸਰੋਤਾਂ — ਕਾਨਫਰੰਸ ਟਾਕਸ, ਡਿਜ਼ਾਈਨ ਡੌਕ, ਅਤੇ ਅੱਪਸਟਰੀਮ ਡਾਕੂਮੈਂਟੇਸ਼ਨ — 'ਤੇ ਆਧਾਰਿਤ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਤਾਂ ਜੋ ਕਹਾਣੀ ਦ੍ਰਿੜ੍ਹ ਹੋਵੇ ਨਾ ਕਿ ਰਹੱਸਮੀ।
Brendan Burns ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ Kubernetes ਦੇ ਤਿੰਨ ਮੂਲ ਸਹਿ-ਸੰਸਥਾਪਕਾਂ ਵਿੱਚੋਂ ਇੱਕ ਵਜੋਂ ਮਾਣਿਆ ਜਾਂਦਾ ਹੈ,Joe Beda ਅਤੇ Craig McLuckie ਦੇ ਨਾਲ। Google ਵਿੱਚ ਸ਼ੁਰੂਆਤੀ Kubernetes ਕੰਮ ਦੌਰਾਨ, Burns ਨੇ ਤਕਨੀਕੀ ਦਿਸ਼ਾ ਅਤੇ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਵਰਤੋਂਕਾਰਾਂ ਨੂੰ ਸਮਝਾਉਣ ਦੇ ਢੰਗ ਨੂੰ ਸਾਰਥਕ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕੀਤੀ—ਖ਼ਾਸ ਕਰਕੇ “ਤੁਸੀਂ ਸਾਫਟਵੇਅਰ ਕਿਵੇਂ ਚਲਾਉਂਦੇ ਹੋ” ਬਾਰੇ, ਨਾ ਕਿ ਸਿਰਫ਼ “ਕੰਟੇਨਰ ਕਿਵੇਂ ਚਲਦੇ ਹਨ।” (ਸਰੋਤ: Kubernetes: Up & Running, O’Reilly; Kubernetes ਪ੍ਰੋਜੈਕਟ ਰਿਪੋਜ਼ਟਰੀ AUTHORS/maintainers ਲਿਸਟ)
Kubernetes ਸਿਰਫ਼ ਅੰਦਰੂਨੀ ਪੂਰਨ ਸਿਸਟਮ ਵਜੋਂ “ਰੀਲੀਜ਼” ਨਹੀਂ ਕੀਤਾ ਗਿਆ; ਇਹ ਸਭ ਦੇਖਣ ਵਾਲੇ ਤਰੀਕੇ ਨਾਲ ਵਿਕਸਤ ਹੋਇਆ ਜਿੱਥੇ ਯੋਗਦਾਨਕਾਰਾਂ, ਵਰਤੋਂਕੇਸ ਅਤੇ ਸੀਮਾਵਾਂ ਵਧਦੀਆਂ ਗਈਆਂ। ਇਸ ਖੁੱਲ੍ਹਣ ਵਾਲੇ ਤਣਾਅ ਨੇ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਐਸੇ ਇੰਟਰਫੇਸਾਂ ਵੱਲ ਧੱਕਿਆ ਜਿਹੜੇ ਵੱਖ-ਵੱਖ ਵਾਤਾਵਰਨਾਂ ਵਾਸਤੇ ਟਿਕ ਸਕਦੇ ਹਨ:
ਇਹ ਸਹਿਯੋਗੀ ਦਬਾਅ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਇਹ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ ਕਿ Kubernetes ਕਿਸ ਲਈ optimize ਕਰਦਾ ਹੈ: ਸਾਂਝੇ ਪ੍ਰਿਮਿਟਿਵ ਅਤੇ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ ਪੈਟਰਨ ਜਿਹੜੇ ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਸਹਿਮਤ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਜਦੋਂ ਲੋਕ ਕਹਿੰਦੇ ਹਨ ਕਿ Kubernetes ਨੇ ਡਿਪਲੋਇਮੈਂਟ ਅਤੇ ਓਪਰੇਸ਼ਨ “ਸਟੈਂਡਰਡ” ਕੀਤਾ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਨਹੀਂ ਮਤਲਬ ਰਖਦੇ ਕਿ ਹਰ ਸਿਸਟਮ ਇੱਕੋ ਜਿਹਾ ਹੋ ਗਿਆ। ਉਹ ਮਤਲਬ ਰੱਖਦੇ ਹਨ ਕਿ ਇਹ ਇੱਕ ਸਾਂਝੀ ਸ਼ਬਦਾਵਲੀ ਅਤੇ ਕਾਰਜ-ਵਿਧੀਆਂ ਦੇ ਸੈੱਟ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ ਜੋ ਟੀਮਾਂ ਵੱਲੋਂ ਦੁਹਰਾਏ ਜਾ ਸਕਦੇ ਹਨ:
ਇਹ ਸਾਂਝਾ ਮਾਡਲ ਦਸਤਾਵੇਜ਼, ਟੂਲਿੰਗ ਅਤੇ ਟੀਮ ਪ੍ਰੈਕਟਿਸ ਨੂੰ ਇੱਕ ਕੰਪਨੀ ਤੋਂ ਦੂਜੀ ਕੰਪਨੀ ਤਕ ਆਸਾਨੀ ਨਾਲ ਟਰਾਂਸਫਰ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਇਹ ਲਾਭਪ੍ਰਦ ਹੈ ਕਿ Kubernetes (ਓਪਨ-ਸੋਰਸ ਪ੍ਰੋਜੈਕਟ) ਅਤੇ Kubernetes ਇਕੋਸਿਸਟਮ ਨੂੰ ਵੱਖ ਕਰਕੇ ਵੇਖਿਆ ਜਾਵੇ।
ਪ੍ਰੋਜੈਕਟ ਕੋਰ API ਅਤੇ ਕੰਟਰੋਲ-ਪਲੇਨ ਕੰਪੋਨੈਂਟ ਹਨ ਜੋ ਪਲੇਟਫਾਰਮ ਨੂੰ ਲਾਗੂ ਕਰਦੇ ਹਨ। ਇਕੋਸਿਸਟਮ ਉਹ ਸਾਰਾ ਕੁਝ ਹੈ ਜੋ ਇਸਦੇ ਆਲੇ-ਦੁਆਲੇ ਵਧਿਆ—ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ, ਮੈਨੇਜਡ ਸਰਵਿਸ, ਐਡ-ਆਨ, ਅਤੇ CNCF ਪ੍ਰੋਜੈਕਟ। ਕਈ ਅਸਲ-ਦੁਨੀਆ “Kubernetes ਫੀਚਰ” ਜਿਹੜਿਆਂ 'ਤੇ ਲੋਕ ਭਰੋਸਾ ਕਰਦੇ ਹਨ (ਲਾਇਬ੍ਰੇਰਿਟੀ ਸਟੈਕ, ਪਾਲਸੀ ਇੰਜਨ, GitOps ਟੂਲ) ਉਨ੍ਹਾਂ ਵਿੱਚ ਇਕੋਸਿਸਟਮ ਵਿਚਲੇ ਹਨ, ਕੋਰ ਪ੍ਰੋਜੈਕਟ ਵਿੱਚ ਨਹੀਂ।
ਘੋਸ਼ਣਾਤਮਕ ਕੰਫਿਗਰੇਸ਼ਨ ਇਹ ਦਰਸਾਉਂਦੀ ਹੈ ਕਿ ਤੁਸੀਂ ਪ੍ਰਣਾਲੀ ਤੋਂ ਕੀ ਅੰਤਿਮ ਨਤੀਜਾ ਚਾਹੁੰਦੇ ਹੋ: ਬਦਲੇ ਵਿੱਚ ਕਦਮ-ਦਰ-ਕਦਮ ਦੀ ਲਿਸਟ ਦੇਣ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਨਤੀਜੇ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹੋ।
ਕੁਬਰਨੇਟਿਸ ਸ਼ਬਦਾਂ ਵਿੱਚ, ਤੁਸੀਂ ਪਲੇਟਫਾਰਮ ਨੂੰ ਨਹੀਂ ਦੱਸਦੇ “ਇਕ ਕੰਟੇਨਰ ਸ਼ੁਰੂ ਕਰੋ, ਫਿਰ ਪੋਰਟ ਖੋਲ੍ਹੋ, ਫਿਰ ਇਹ ਰੀਸਟਾਰਟ ਕਰੋ ਜੇ ਇਹ ਕਰੈਸ਼ ਹੋਵੇ।” ਤੁਸੀਂ ਘੋਸ਼ਣਾ ਕਰਦੇ ਹੋ “ਇਸ ਐਪ ਦੀ 3 ਨਕਲ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ, ਇਹ ਪੋਰਟ 'ਤੇ ਪਹੁੰਚਯੋਗ ਹੋਵੇ, ਇਸ ਕੰਟੇਨਰ ਇਮੇਜ ਦਾ ਉਪਯੋਗ ਕਰੇ।” Kubernetes ਇਸ ਗੱਲ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਲੈਂਦਾ ਹੈ ਕਿ ਹਕੀਕਤ ਉਸ ਵਰਣਨ ਨੂੰ ਮਿਲੇ।
ਇੰਪੇਰੇਟਿਵ ਓਪਰੇਸ਼ਨਜ਼ ਇੱਕ ਰਨਬੁਕ ਵਾਂਗ ਹੁੰਦੇ ਹਨ: ਕਮਾਂਡਾਂ ਦੀ ਇੱਕ ਲੜੀ ਜੋ ਪਿਛਲੀ ਵਾਰੀ ਚੱਲੀ, ਜਦੋਂ ਕੁਝ ਬਦਲਦਾ ਹੈ ਉਸੇ ਤਰੀਕੇ ਨਾਲ ਫਿਰ ਚਲਾਈ ਜਾਂਦੀ ਹੈ।
ਚਾਹੀਦੀ ਹਾਲਤ ਇਕ ਠੇਕੇ ਵਾਂਗ ਹੈ। ਤੁਸੀਂ ਇਰਾਦਾ ਇਕ ਕੰਫਿਗਰੇਸ਼ਨ ਫਾਇਲ ਵਿੱਚ ਰਿਕਾਰਡ ਕਰਦੇ ਹੋ, ਅਤੇ ਸਿਸਟਮ ਲਗਾਤਾਰ ਉਸ ਨਤੀਜੇ ਵੱਲ ਕੰਮ ਕਰਦਾ ਹੈ। ਜੇ ਕੁਝ ਭਟਕਦਾ ਹੈ—ਇੱਕ ਇੰਸਟੈਂਸ ਮਰ ਜਾਂਦਾ, ਨੋਡ ਗਾਇਬ ਹੋ ਜਾਂਦਾ, ਜਾਂ ਕੋਈ ਮਨੁੱਖੀ ਬਦਲਾਅ ਕਰਦਾ ਹੈ—ਪਲੇਟਫਾਰਮ ਮਿਸ਼ਮੈਚ ਪਛਾਣਦਾ ਹੈ ਅਤੇ ਉਸਨੂੰ ਸਹੀ ਕਰਦਾ ਹੈ।
ਪਹਿਲਾਂ (ਇੰਪੇਰੇਟਿਵ ਰਨਬੁਕ ਸੋਚ):
ਇਹ ਤਰੀਕਾ ਕੰਮ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਆਸਾਨੀ ਨਾਲ “ਸਨੋਫਲੇਕ” ਸਰਵਰ ਅਤੇ ਲੰਬੀ ਚੈੱਕਲਿਸਟ ਹੋ ਸਕਦੀ ਹੈ ਜਿਸ 'ਤੇ ਕੇਵਲ ਕੁਝ ਲੋਕ ਵਿਸ਼ਵਾਸ ਕਰਦੇ ਹਨ।
ਬਾਅਦ (ਘੋਸ਼ਣਾਤਮਕ ਚਾਹੀਦੀ ਹਾਲਤ):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
ਤੁਸੀਂ ਫਾਇਲ ਨੂੰ ਬਦਲਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ, image ਜਾਂ replicas ਅਪਡੇਟ ਕਰੋ), apply ਕਰੋ, ਅਤੇ Kubernetes ਦੇ ਕੰਟਰੋਲਰ ਇਹਦੇ ਚੱਲ ਰਹੇ ਹਾਲਤ ਨੂੰ ਦਰਸ਼ਾਏ ਹੋਏ ਨਾਲ ਮਿਲਾਉਣ ਲਈ ਕੰਮ ਕਰਦੇ ਹਨ।
ਘੋਸ਼ਣਾਤਮਕ ਚਾਹੀਦੀ ਹਾਲਤ ਓਪਰੇਸ਼ਨਲ toil ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ ਕਿਉਂਕਿ ਇਹ “ਇਹ 17 ਕਦਮ ਕਰੋ” ਨੂੰ “ਇਸ ਤਰ੍ਹਾਂ ਰੱਖੋ” ਵਿੱਚ ਬਦਲ ਦਿੰਦੀ ਹੈ। ਇਹ ਸੰਰਚਨਾ ਡ੍ਰਿਫਟ ਨੂੰ ਵੀ ਘਟਾਉਂਦੀ ਹੈ ਕਿਉਂਕਿ ਸਚਾਈ ਦਾ ਸਰੋਤ ਸਪਸ਼ਟ ਅਤੇ ਰਿਵਿਊਯੋਗ ਹੁੰਦਾ ਹੈ—ਅਕਸਰ ਵਰਜ਼ਨ ਕੰਟਰੋਲ ਵਿੱਚ—ਇਸ ਲਈ ਅਚਾਨਕਤਾਵਾਂ ਨੂੰ ਦੇਖਣਾ, ਆਡੀਟ ਕਰਨਾ ਅਤੇ ਸਥਿਰਤਾ ਨਾਲ ਰੋਲਬੈਕ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
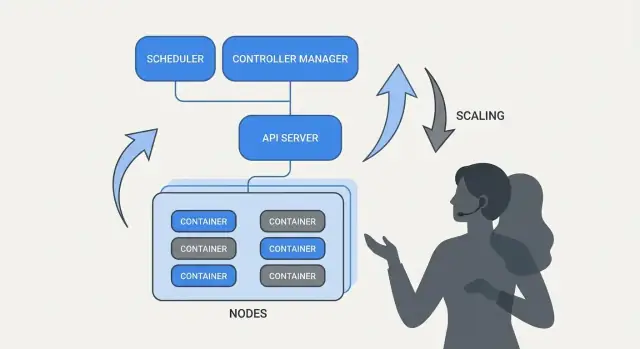
Kubernetes “ਆਪਣੇ ਆਪ ਸੰਭਾਲਨ ਵਾਲਾ” ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇਕ ਸਧਾਰਣ ਪੈਟਰਨ 'ਤੇ ਨਿਰਭਰ ਹੈ: ਤੁਸੀਂ ਜੋ ਚਾਹੁੰਦੇ ਹੋ ਦਰਸਾਉਂਦੇ ਹੋ, ਅਤੇ ਸਿਸਟਮ ਲਗਾਤਾਰ ਹਕੀਕਤ ਨੂੰ ਉਸ ਵਰਣਨ ਨਾਲ ਮਿਲਾਉਂਦਾ ਰਹਿੰਦਾ ਹੈ। ਇਸ ਪੈਟਰਨ ਦਾ ਇੰਜਨ ਕੰਟਰੋਲਰ ਹੁੰਦਾ ਹੈ।
ਕੰਟਰੋਲਰ ਇੱਕ ਲੂਪ ਹੈ ਜੋ ਕਲੱਸਟਰ ਦੀ ਮੌਜੂਦਾ ਹਾਲਤ ਨੂੰ ਵੇਖਦਾ ਅਤੇ YAML (ਜਾਂ API ਕਾਲ) ਵਿੱਚ ਦਰਸ਼ਾਈ ਗਈ ਚਾਹੀਦੀ ਹਾਲਤ ਨਾਲ ਤੁਲਨਾ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਇਹ ਇੱਕ ਫਰਕ ਵੇਖਦਾ ਹੈ, ਇਹ ਉਸ ਫਰਕ ਨੂੰ ਘਟਾਉਣ ਲਈ ਕਾਰਵਾਈ ਕਰਦਾ ਹੈ।
ਇਹ ਕੋਈ ਇਕ-ਵਾਰੀ ਦਾ ਸਕ੍ਰਿਪਟ ਨਹੀਂ ਹੈ ਅਤੇ ਇਹ ਕਿਸੇ ਮਨੁੱਖ ਦਾ ਬਟਨ ਦਬਾਉਣ ਦੀ ਉਡੀਕ ਵੀ ਨਹੀਂ ਕਰਦਾ। ਇਹ ਕਈ ਵਾਰੀ ਦੌੜਦਾ ਹੈ—ਦੇਖੋ, ਫੈਸਲਾ ਕਰੋ, ਕੁਝ ਕਰੋ—ਤਾਂ ਜੋ ਇਹ ਕਿਸੇ ਵੀ ਸਮੇਂ ਬਦਲਾਵ ਨੂੰ ਸੰਭਾਲ ਸਕੇ।
ਉਹ ਦੁਹਰਾਇਆ ਪਕੜੋ-ਅਤੇ-ਸੁਧਾਰੋ ਵਿਹਾਰ ਰੀਕਨਸੀਲੀਏਸ਼ਨ ਕਿਹਾ ਜਾਂਦਾ ਹੈ। ਇਹ “ਸਵੈ-ਮਰੰਮਤੀ” ਦੇ ਆਮ ਵਾਅਦੇ ਦੇ ਪਿੱਛੇ ਮਕੈਨਿਜ਼ਮ ਹੈ। ਪ੍ਰਣਾਲੀ ਫੇਲਿਅਰਾਂ ਨੂੰ ਰੋਕਣ ਦਾ ਜਾਦੂ ਨਹੀਂ ਕਰਦੀ; ਪਰ ਇਹ ਡ੍ਰਿਫ਼ਟ ਨੂੰ ਨੋਟਿਸ ਕਰਦੀ ਅਤੇ ਠੀਕ ਕਰਦੀ ਹੈ।
ਡ੍ਰਿਫਟ ਸਧਾਰਨ ਕਾਰਨਾਂ ਕਰਕੇ ਹੁੰਦੀ ਹੈ:
ਰੀਕਨਸੀਲੀਏਸ਼ਨ ਦਾ ਮਤਲਬ ਹੈ ਕਿ Kubernetes ਉਹਨਾਂ ਘਟਨਾਵਾਂ ਨੂੰ ਇਕ ਨਿਸ਼ਾਨ ਵਜੋਂ ਲੈਂਦਾ ਹੈ ਕਿ ਤੁਹਾਡੇ ਇਰਾਦੇ ਨੂੰ ਦੁਬਾਰਾ ਚੈੱਕ ਕਰਨਾ ਅਤੇ ਉਸਨੂੰ بحال ਕਰਨਾ।
ਕੰਟਰੋਲਰ ਸਧਾਰਨ ਓਪਰੇਸ਼ਨਲ ਨਤੀਜਿਆਂ ਵਿੱਚ ਬਦਲ ਜਾਂਦੇ ਹਨ:
ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਲੱਛਣਾਂ ਦਾ ਪਿੱਛਾ ਨਹੀਂ ਕਰ ਰਹੇ—ਤੁਸੀਂ ਟਾਰਗੇਟ ਦਰਸਾਉਂਦੇ ਹੋ ਅਤੇ ਕੰਟਰੋਲ ਲੂਪ ਲਗਾਤਾਰ “ਇਹਨੂੰ ਓਸੇ ਤਰ੍ਹਾਂ ਰੱਖੋ” ਕੰਮ ਕਰਦੇ ਹਨ।
ਇਹ ਤਰੀਕਾ ਕਿਸੇ ਇੱਕ ਰਿਸੋਰਸ ਕਿਸਮ ਤੱਕ ਸੀਮਿਤ ਨਹੀਂ ਹੈ। Kubernetes ਇਹੀ ਕੰਟਰੋਲਰ-ਅਤੇ-ਰੀਕਨਸੀਲੀਏਸ਼ਨ ਵਿਚਾਰਧਾਰਾ ਕਈ ਔਬਜੈਕਟਾਂ 'ਤੇ ਲਾਗੂ ਕਰਦਾ ਹੈ—Deployments, ReplicaSets, Jobs, Nodes, Endpoints ਆਦਿ। ਇਹ ਲਗਾਤਾਰਤਾ ਇੱਕ ਵੱਡਾ ਕਾਰਨ ਹੈ ਕਿ Kubernetes ਇੱਕ ਪਲੇਟਫਾਰਮ ਬਣ ਗਿਆ: ਜਦੋਂ ਤੁਸੀਂ ਪੈਟਰਨ ਨੂੰ ਸਮਝ ਲੈਂਦੇ ਹੋ, ਤੁਸੀਂ ਅਨੁਮਾਨ ਲਗਾ ਸਕਦੇ ਹੋ ਕਿ ਜਦੋਂ ਤੁਸੀਂ ਨਵੀਆਂ ਸੁਵਿਧਾਵਾਂ ਜੋੜੋਗੇ (ਕਸਟਮ ਰਿਸੋਰਸ ਸਮੇਤ) ਤਾਂ ਪ੍ਰਣਾਲੀ ਕਿਵੇਂ ਵਰਤਾਓ ਹੋਵੇਗੀ।
ਜੇ Kubernetes ਸਿਰਫ਼ “ਕੰਟੇਨਰ ਚਲਾਉਂਦਾ” ਹੀ ਹੁੰਦਾ, ਤਾਂ ਵੀ ਟੀਮਾਂ ਕੋਲ ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਹਿੱਸਾ ਰਹਿੰਦਾ: ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਕਿ ਹਰ ਵਰਕਲੋਡ ਕਿੱਥੇ ਚੱਲੇगा। ਸ਼ੈਡੀਊਲਿੰਗ ਉਹ ਬਿਲਟ-ਇਨ ਸਿਸਟਮ ਹੈ ਜੋ Pods ਨੂੰ ਸਹੀ ਨੋਡਾਂ 'ਤੇ ਆਪੋਂ-ਆਪ ਰੱਖਦਾ ਹੈ, ਰਿਸੋਰਸ ਲੋੜਾਂ ਅਤੇ ਤੁਸੀਂ ਪਰਿਭਾਸ਼ਿਤ ਨਿਯਮਾਂ ਦੇ ਆਧਾਰ 'ਤੇ।
ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਪਲੇਸਮੈਂਟ ਫੈਸਲੇ ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਅਪਟਾਈਮ ਅਤੇ ਲਾਗਤ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਉਂਦੇ ਹਨ। ਇੱਕ ਵੈੱਬ API ਇੱਕ ਭੀੜ-ਭਰੇ ਨੋਡ 'ਤੇ ਫਸ ਜਾਣ ਨਾਲ ਧੀਮਾ ਹੋ ਜਾਂਦਾ ਜਾਂ ਕਰੈਸ਼ ਕਰ ਸਕਦਾ ਹੈ। Kubernetes ਇਸਨੂੰ ਇੱਕ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੀ ਉਤਪਾਦ ਸਮਰੱਥਾ ਬਣਾਉਂਦਾ ਹੈ ਬਜਾਏ ਕਿ spreadsheet-ਅਤੇ-SSH ਰੂਟੀਨ।
ਬੁਨਿਆਦੀ ਤੌਰ 'ਤੇ, ਸ਼ੈਡੀਊਲਰ ਉਹ ਨੋਡ ਲਭਦਾ ਹੈ ਜੋ ਤੁਹਾਡੇ Pod ਦੀਆਂ ਬੇਨਤੀਆਂ ਪੂਰੀਆਂ ਕਰ ਸਕਦਾ ਹੈ।
ਇਹ ਇਕ ਆਦਤ—ਵਾਸਤਵਿਕ requests ਸੈਟ ਕਰਨ ਦੀ—ਅਕਸਰ “ਰੈਂਡਮ” ਅਸਥਿਰਤਾ ਨੂੰ ਘਟਾ ਦਿੰਦੀ ਹੈ ਕਿਉਂਕਿ ਆਵਸ਼ਕ ਸਰਵਿਸ ਹੋਰ ਸਭ ਨਾਲ ਮੁਕਾਬਲਾ ਕਰਨਾ ਰੋਕਦੀ ਹੈ।
ਰਿਸੋਰਸਾਂ ਤੋਂ ਇਲਾਵਾ, ਵੱਧਤਰ ਪ੍ਰੋਡਕਸ਼ਨ ਕਲੱਸਟਰ ਕੁਝ ਪ੍ਰੈਕਟਿਕਲ ਨਿਯਮਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ:
ਸ਼ੈਡੀਊਲਿੰਗ ਫੀਚਰ ਟੀਮਾਂ ਨੂੰ ਉਸ ਅਪਰੈਸ਼ਨਲ ਇਰਾਦੇ ਨੂੰ ਏਨਕੋਡ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ:
ਮੁੱਖ ਨਤੀਜਾ: ਸ਼ੈਡੀਊਲਿੰਗ ਨਿਯਮਾਂ ਨੂੰ ਉਤਪਾਦ ਦੀਆਂ ਲੋੜਾਂ ਵਾਂਗ ਲਿਖੋ, ਸਮੀਖਿਆ ਕਰੋ, ਅਤੇ ਲਗਾਤਾਰ ਲਾਗੂ ਕਰੋ—ਤਾਂ ਜੋ ਭਰੋਸਾ ਨਾ ਹੋਵੇ ਕਿ ਕਿਸੇ ਨੂੰ ਰਾਤ 2 ਵਜੇ “ਸਹੀ ਨੋਡ” ਯਾਦ ਰਹੇ।
Kubernetes ਦਾ ਇੱਕ ਸਭ ਤੋਂ ਵਰਤੋਂਯੋਗ ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ ਸਕੇਲਿੰਗ ਲਈ ਐਪ ਕੋਡ ਬਦਲਣ ਜਾਂ ਨਵਾਂ ਡਿਪਲੋਇਮੈਂਟ ਤਰੀਕਾ ਬਣਾਉਣ ਦੀ ਲੋੜ ਨਹੀਂ ਹੋਣੀ ਚਾਹੀਦੀ। ਜੇ ਐਪ ਇੱਕ ਕੰਟੇਨਰ ਵਜੋਂ ਚੱਲ ਸਕਦੀ ਹੈ, ਉਹੀ ਵਰਕਲੋਡ ਡਿਫ਼ਿਨੀਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਸੌਂਕੜੇ ਜਾਂ ਹਜ਼ਾਰਾਂ ਨਕਲਾਂ ਤੱਕ ਵਧ ਸਕਦੀ ਹੈ।
Kubernetes ਸਕੇਲਿੰਗ ਨੂੰ ਦੋ ਸੰਬੰਧਿਤ ਫੈਸਲਿਆਂ ਵਿੱਚ ਵੰਡਦਾ ਹੈ:
ਇਹ ਵੰਡ ਮਹੱਤਵਪੂਰਨ ਹੈ: ਤੁਸੀਂ 200 pods ਮੰਗ ਸਕਦੇ ਹੋ, ਪਰ ਜੇ ਕਲੱਸਟਰ ਵਿੱਚ ਸਿਰਫ਼ 50 ਲਈ ਕਮਰਾ ਹੈ, ਤਾਂ “ਸਕੇਲ” ਕਰਨ ਦਾ ਕੰਮ pending ਰਿਹਾ।
Kubernetes ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਆਟੋਸਕੇਲਰ ਵਰਤਦਾ ਹੈ, ਹਰ ਇਕ ਵੱਖਰੇ ਲੀਵਰ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ:
ਇਹਨਾਂ ਨੂੰ ਇਕੱਠੇ ਵਰਤ ਕੇ, ਸਕੇਲਿੰਗ ਨੀਤੀ ਬਣ ਜਾਂਦੀ ਹੈ: “ਲੇਟੈਂਸੀ ਸਥਿਰ ਰੱਖੋ” ਜਾਂ “CPU X% ਦੇ ਆਸ-ਪਾਸ ਰੱਖੋ,” ਨਾਂ ਕਿ ਹੱਥ-ਚਲਾਉਣ ਵਾਲੀ paging ਰੂਟੀਨ।
ਸਕੇਲਿੰਗ ਸਿਰਫ਼ ਉਹਨਾਂ ਇਨਪੁੱਟਾਂ ਦੀ ਤਰ੍ਹਾਂ ਚੰਗੀ ਹੁੰਦੀ ਹੈ:
ਦੋ ਗਲਤੀਆਂ ਬਾਰ-ਬਾਰ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ: ਗਲਤ ਮੈਟ੍ਰਿਕ 'ਤੇ ਸਕੇਲਿੰਗ (CPU ਘੱਟ ਹੈ ਪਰ ਰਿਕਵੇਸਟ ਟਾਈਮਆਊਟ) ਅਤੇ ਰੀਕੁਐਸਟ ਪੂਰਨ ਨਾ ਹੋਣਾ (ਆਟੋਸਕੇਲਰ ਸਮਰਥਾ ਦੀ ਪੇਸ਼ਗੋਈ ਨਹੀਂ ਕਰ ਸਕਦਾ, pods ਬਹੁਤ ਘਨੇਰੇ ਪੈਕ ਹੋ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਅਸਥਿਰ ਹੋ ਜਾਂਦਾ ਹੈ)।
Kubernetes ਨੇ ਪ੍ਰਸਿੱਧ ਕੀਤਾ ਇੱਕ ਵੱਡਾ ਤਬਦੀਲੀ-ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ “ਡਿਪਲੋਇਮੈਂਟ” ਨੂੰ ਇਕ ਲਗਾਤਾਰ ਕੰਟਰੋਲ ਸਮੱਸਿਆ ਵਜੋਂ ਦੇਖਿਆ ਜਾਵੇ, ਨਾ ਕਿ ਸ਼ੁੱਕਰਵਾਰ ਦੀ 5 ਵਜੇ ਦੀ ਇੱਕ ਵਾਰੀ ਚੱਲਾਈ ਜਾਣ ਵਾਲੀ ਸਕ੍ਰਿਪਟ। ਰੋਲਆਊਟ ਅਤੇ ਰੋਲਬੈਕ ਫਰਸਟ-ਕਲਾਸ ਵਿਹਾਰ ਹਨ: ਤੁਸੀਂ ਕਿਹੜਾ ਵਰਜ਼ਨ ਚਾਹੁੰਦੇ ਹੋ ਇਹ ਦਰਸਾਉਂਦੇ ਹੋ ਅਤੇ Kubernetes ਪ੍ਰਣਾਲੀ ਨੂੰ ਉਸ ਵੱਲ ਕਦਮ-ਦਰ-ਕਦਮ ਲੈ ਜਾਂਦਾ ਹੈ ਜਦੋਂ ਤੱਕ ਬਦਲਾਅ ਸੁਰੱਖਿਅਤ ਨਹੀਂ ਪਾਖਿਆ ਜਾਂਦਾ।
Deployment ਨਾਲ, ਰੋਲਆਊਟ ਪੁਰਾਣੇ Pods ਨੂੰ ਨਵੇਂ ਨਾਲ ਕਦਮਬਦਲ ਕਰਦਾ ਹੈ। ਸਾਰੇ ਕੁਝ ਰੋਕ ਕੇ ਨਾ ਹੀ ਸਾਰਾ ਮੁੜ-ਸ਼ੁਰੂ ਹੁੰਦਾ, Kubernetes ਕਦਮ-ਦਰ-ਕਦਮ ਅਪਡੇਟ ਕਰ ਸਕਦਾ ਹੈ—ਟਿਕਾਉ ਰੱਖਦੇ ਹੋਏ ਜਦੋਂ ਨਵਾਂ ਵਰਜ਼ਨ ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਨੂੰ ਸੰਭਾਲਣ ਦੀ ਸਮਰੱਥਾ ਸਾਬਤ ਕਰਦਾ ਹੈ।
ਜੇ ਨਵਾਂ ਵਰਜ਼ਨ ਫੇਲ ਹੋਣਾ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, ਰੋਲਬੈਕ ਐਕਸਾਈਤੀ ਰੂਪ ਦੀ ਕਾਰਵਾਈ ਨਹੀਂ ਰਹਿੰਦੀ। ਤੁਸੀਂ ਪਿਛਲੇ ReplicaSet (ਜਾਣਿਆ-ਚੰਗਾ ਵਰਜ਼ਨ) 'ਤੇ ਵਾਪਸ ਜਾ ਸਕਦੇ ਹੋ ਅਤੇ ਕੰਟਰੋਲਰ ਪੁਰਾਣੀ ਹਾਲਤ ਮੁੜ-ਸਥਾਪਿਤ ਕਰ ਦੇਵੇਗਾ।
ਹੈਲਥ ਚੈੱਕ ਰੋਲਆਊਟਾਂ ਨੂੰ “ਆਸ-ਆਧਾਰਿਤ” ਤੋਂ ਮਾਪਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
ਚੰਗੀ ਤਰ੍ਹਾਂ ਵਰਤੀਆਂ ਗਈਆਂ ਪ੍ਰੋਬ deployment ਦੀਆਂ ਗਲਤ-ਸਫਲਤਾਵਾਂ ਨੂੰ ਘਟਾਉਂਦੀਆਂ ਹਨ—ਉਹ ਡਿਪਲੋਇਮੈਂਟ ਜਿਹੜੇ Pods ਸ਼ੁਰੂ ਹੋਣ ਕਰਕੇ “ਠੀਕ” ਲੱਗਦੇ ਹਨ ਪਰ ਅਸਲ ਵਿੱਚ ਰਿਕਵੇਸਟ ਫੇਲ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹਨ।
Kubernetes ਬਾਕਸ ਤੋਂ ਬਾਹਰ rolling update ਨੂੰ ਸਹਿਯੋਗ ਦਿੰਦਾ ਹੈ, ਪਰ ਟੀਮਾਂ ਅਕਸਰ ਉਪਰਲੇ ਪੈਟਰਨ ਵੀ ਲਾਈਅਰ ਕਰਦੀਆਂ ਹਨ:
ਸੁਰੱਖਿਅਤ ਡਿਪਲੋਇਮੈਂਟ ਸਿਗਨਲਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ: error rate, latency, saturation, ਅਤੇ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ। ਬਹੁਤੀਆਂ ਟੀਮਾਂ rollout ਫੈਸਲਿਆਂ ਨੂੰ SLOs ਅਤੇ error budgets ਨਾਲ ਜੋੜਦੀਆਂ ਹਨ—ਜੇ ਇੱਕ canary ਬਹੁਤ ਜ਼ਿਆਦਾ ਬਜਟ ਖ਼ਰਚ ਕਰਦਾ ਹੈ, ਤਾਂ ਪ੍ਰੋਮੋਸ਼ਨ ਰੁਕ ਜਾਦਾ ਹੈ।
ਮਕਸਦ ਆਟੋਮੈਟਿਕ ਰੋਲਬੈਕ ਟ੍ਰਿੱਗਰ ਬਣਾਉਣਾ ਹੈ ਜਿਹੜੇ ਅਸਲ ਇੰਡਿਕੇਟਰਾਂ (failed readiness, ਵੱਧ 5xx, latency spike) 'ਤੇ ਆਧਾਰਿਤ ਹਨ, ਤਾਂ ਜੋ “ਰੋਲਬੈਕ” ਇਕ ਅਟਕਾਉਣ ਯੋਗ ਪ੍ਰਣਾਲੀਕ੍ਰਿਤ ਜਵਾਬ ਬਣ ਜਾਵੇ—ਨਾਕਾਮ-ਰਾਤੀ ਹੀਰੋਇਕ ਘਟਨਾ ਨਹੀਂ।
ਇੱਕ ਕੰਟੇਨਰ ਪਲੇਟਫਾਰਮ ਸਿਰਫ਼ “ਆਟੋਮੈਟਿਕ” ਮਹਿਸੂਸ ਨਹੀਂ ਕਰਦਾ ਜਦ ਤਕ ਸਿਸਟਮ ਦੇ ਹੋਰ ਹਿੱਸੇ ਵੀ ਤੁਹਾਡੇ ਐਪ ਨੂੰ ਉਸ ਦੇ ਹਿਲਦੇ-ਡੁਲਦੇ ਸਮੇਂ ਵਿਚ ਲੱਭ ਸਕਣ। ਅਸਲ ਪ੍ਰੋਡਕਸ਼ਨ ਕਲੱਸਟਰਾਂ ਵਿੱਚ, pods ਬਣਾਏ ਜਾਂਦੇ ਹਨ, ਮਿਟਾਏ ਜਾਂਦੇ ਹਨ, ਰੀ-ਸੈਡਿਊਲ ਹੋਏ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਲਗਾਤਾਰ ਸਕੇਲ ਕੀਤੇ ਜਾਂਦੇ ਹਨ। ਜੇ ਹਰ ਤਬਦੀਲੀ ਲਈ IP ਐਡਰੈੱਸਜ਼ ਨੂੰ configs ਵਿੱਚ ਅੱਪਡੇਟ ਕਰਨ ਦੀ ਲੋੜ ਪੈਂਦੀ, ਤਾਂ ਓਪਰੇਸ਼ਨਜ਼ ਲਗਾਤਾਰ ਕਮਵੇਸ਼ਨ ਬਣ ਜਾਂਦੇ ਅਤੇ ਆਊਟੇਜ ਆਮ ਹੋ ਜਾਣੇ।
Service discovery ਇਸ ਅਭਿਆਸ ਨੂੰ ਕਹਿੰਦਾ ਹੈ ਕਿ ਕਲਾਇੰਟਾਂ ਨੂੰ ਬਦਲ ਰਹੇ ਬੈਕਐਂਡਾਂ ਤੱਕ ਪਹੁੰਚਣ ਦਾ ਇੱਕ ਭਰੋਸੇਮੰਦ ਤਰੀਕਾ ਦਿੱਤਾ ਜਾਵੇ। Kubernetes ਵਿੱਚ ਮੁੱਖ ਬਦਲਾਅ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇੰਸਟੈਂਸ-ਨੂੰ ਟਾਰਗੇਟ ਕਰਨਾ ਛੱਡ ਦਿੰਦੇ (“10.2.3.4 ਨੂੰ ਕਾਲ ਕਰੋ”) ਅਤੇ ਨਾਂਮੀ ਸੇਵਾ ਟਾਰਗੇਟ ਕਰਦੇ ਹੋ (“checkout ਨੂੰ ਕਾਲ ਕਰੋ”)। ਪਲੇਟਫਾਰਮ ਇਹ ਸੰਭਾਲਦਾ ਹੈ ਕਿ ਇਸ ਨਾਮ ਦੇ ਪਿੱਛੇ ਕਿਹੜੇ pods ਸੇਵਾ ਕਰ ਰਹੇ ਹਨ।
ਇੱਕ Service ਇੱਕ ਸਥਿਰ ਦਰਵਾਜ਼ਾ ਹੈ ਇੱਕ ਗਰੁੱਪ pods ਲਈ। ਇਹ ਕਲੱਸਟਰ ਦੇ ਅੰਦਰ ਇੱਕ ਲਗਾਤਾਰ ਨਾਮ ਅਤੇ ਵਰਚੁਅਲ ਐਡਰੈੱਸ ਰੱਖਦਾ ਹੈ, ਭਾਵੇਂ ਅਧਾਰਭੂਤ pods ਬਦਲ ਰਹੇ ਹਨ।
Selector ਇਹ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਕਿ Service ਦੇ ਪਿੱਛੇ ਕਿਹੜੇ pods ਹਨ—ਜ਼ਿਆਦਾਤਰ cases ਵਿੱਚ ਇਹ labels (ਜਿਵੇਂ app=checkout) ਨਾਲ ਮਿਲਦਾ ਹੈ।
Endpoints (ਜਾਂ EndpointSlices) ਉਹ ਸਚੀ ਸੂਚੀ ਹਨ ਜੋ ਉਸ ਸਮੇਂ ਮੈਚ ਕਰਨ ਵਾਲੀਆਂ pod IPs ਦਾ ਜੀਵੰਤ ਲਿਸਟ ਰੱਖਦੀਆਂ ਹਨ। ਜਦੋਂ pods ਸਕੇਲ ਹੁੰਦੇ ਹਨ, ਰੋਲਆਊਟ ਹੁੰਦਾ ਹੈ ਜਾਂ ਰੀ-ਸੈਡਿਊਲ ਹੁੰਦੇ ਹਨ, ਇਹ ਸੂਚੀ ਆਪੋ-ਆਪ ਅਪਡੇਟ ਹੁੰਦੀ ਹੈ—ਕਲਾਇੰਟ ਉਹੀ Service ਨਾਂਮ ਉਪਯੋਗ ਕਰਦੇ ਰਹਿੰਦੇ ਹਨ।
ਆਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ, ਇਹ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ:
ਬਾਹਰਲੇ ਟ੍ਰੈਫਿਕ (north–south) ਲਈ, Kubernetes ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ Ingress ਜਾਂ ਨਵੇਂ Gateway ਤਰੀਕੇ ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ। ਦੋਹਾਂ ਇੱਕ ਨਿਯੰਤ੍ਰਿਤ ਐਂਟਰੀ ਪોઇਂਟ ਮੁਹੱਈਆ ਕਰਦੇ ਹਨ ਜਿਥੇ ਤੁਸੀਂ hostname ਜਾਂ path ਅਨੁਸਾਰ ਰੂਟ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਅਕਸਰ TLS ਟਰਮੀਨੇਸ਼ਨ ਵਰਗੀਆਂ ਚਿੰਤਾਵਾਂ ਕੇਂਦਰਿਤ ਕਰ ਸਕਦੇ ਹੋ। ਮੁੱਖ ਵਿਚਾਰ ਇਕੋ ਹੀ ਹੈ: ਬਾਹਰੀ ਪਹੁੰਚ ਸਥਿਰ ਰੱਖੋ ਜਦੋਂ ਕਿ ਬੈਕਐਂਡ ਹੇਠਾਂ-ਵਿੱਚ ਬਦਲ ਰਹੇ ਹਨ।
Kubernetes ਵਿੱਚ “ਸਵੈ-ਮਰੰਮਤੀ” ਜਾਦੂ ਨਹੀਂ ਹੈ। ਇਹ ਫੇਲਿਅਰ 'ਤੇ ਆਟੋਮੇਟਿਕ ਪ੍ਰਤਿਕਿਰਿਆਵਾਂ ਦਾ ਸੈੱਟ ਹੈ: ਰੀਸਟਾਰਟ, ਰੀ-ਸੈਡਿਊਲ, ਅਤੇ ਬਦਲਾਵ। ਪਲੇਟਫਾਰਮ ਉਹ ਚੀਜ਼ਾਂ ਵੇਖਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਚਾਹੀਦਾ ਹੋ (ਚਾਹੀਦੀ ਹਾਲਤ) ਅਤੇ ਹਕੀਕਤ ਨੂੰ ਉਸ ਵੱਲ ਧਕੇਲਦਾ ਰਹਿੰਦਾ ਹੈ।
ਜੇਕਰ ਕੋਈ ਪ੍ਰੋਸੈਸ ਬੰਦ ਹੋ ਜਾਂਦਾ ਜਾਂ ਕੰਟੇਨਰ ਅਨਹੈਲਥੀ ਹੋ ਜਾਂਦਾ ਹੈ, Kubernetes ਇਸਨੂੰ ਉਸੇ ਨੋਡ 'ਤੇ ਰੀਸਟਾਰਟ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਨਿਰਦੇਸ਼ਤ ਹੁੰਦਾ ਹੈ:
ਇੱਕ ਆਮ ਪ੍ਰੋਡਕਸ਼ਨ ਪੈਟਰਨ: ਇੱਕ ਹੀ ਕੰਟੇਨਰ ਕਰੈਸ਼ → Kubernetes ਇਸਨੂੰ ਰੀਸਟਾਰਟ ਕਰਦਾ → ਤੁਹਾਡੀ Service ਸਿਰਫ਼ ਸਿਹਤਮੰਦ Pods ਨੂੰ ਰੂਟ ਕਰਦੀ ਰਹਿੰਦੀ ਹੈ।
ਜੇ ਪੂਰਾ ਨੋਡ ਡਾਊਨ ਹੋ ਜਾਂਦਾ (ਹਾਰਡਵੇਅਰ ਮੁੱਦਾ, kernel panic, ਨੈੱਟਵਰਕ ਖੋ ਜਾਣ), Kubernetes ਉਸ ਨੋਡ ਨੂੰ unavailable ਦਰਸਾਉਂਦਾ ਅਤੇ ਕੰਮ ਹੋਰ ਥਾਂ ਚੱਲਾਉਂਦਾ ਹੈ। ਉੱਚ-ਪੱਧਰੀ ਦ੍ਰਿਸ਼ਟੀਕੋਣ:
ਇਹ ਕਲੱਸਟਰ-ਸਤਹ 'ਤੇ “ਸਵੈ-ਮਰੰਮਤੀ” ਹੈ: ਪ੍ਰਣਾਲੀ ਸਮਰਥਾ ਨੂੰ ਬਦਲਦੀ ਹੈ, ਨਾ ਕਿ ਕਿਸੇ ਮਨੁੱਖ ਦੇ SSH ਕਰਨ ਦੀ ਉਡੀਕ ਕਰਦੀ ਹੈ।
ਸਵੈ-ਮਰੰਮਤੀ ਤਦ ਹੀ ਮੀਨਿੰਗਫੁਲ ਹੁੰਦੀ ਹੈ ਜਦ ਤੁਸੀਂ ਇਸਨੂੰ ਪੜਚੋਲ ਸਕੋ। ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਦੇਖਦੀਆਂ ਹਨ:
Kubernetes ਹੋਣ ਦੇ ਬਾਵਜੂਦ ਵੀ, “ਹੀਲਿੰਗ” ਫੇਲ ਹੋ ਸਕਦੀ ਹੈ ਜੇ ਗਾਰਡਰੇਲ ਸਹੀ ਨਹੀਂ ਹਨ:
ਜਦ ਸਵੈ-ਮਰੰਮਤੀ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸੈੱਟ ਹੋਵੇ, ਆਊਟੇਜ ਛੋਟੇ ਅਤੇ ਛੇਤੀ ਹੋ ਜਾਂਦੇ ਹਨ—ਤੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ, ਮਾਪੇ ਜਾ ਸਕਣ।
Kubernetes ਸਿਰਫ਼ ਇਸ ਲਈ ਜਿੱਤਿਆ ਨਹੀਂ ਕਿ ਇਹ ਕੰਟੇਨਰ ਚਲਾ ਸਕਦਾ ਸੀ। ਇਹ ਇਸ ਲਈ ਜਿੱਤਿਆ ਕਿ ਇਸਨੇ ਸਭ ਤੋਂ ਆਮ ਓਪਰੇਸ਼ਨਲ ਜ਼ਰੂਰਤਾਂ—ਡਿਪਲੋਇਮੈਂਟ, ਸਕੇਲਿੰਗ, ਨੈਟਵਰਕਿੰਗ, ਅਤੇ ਨਿਰੀਖਣ—ਲਈ ਮਿਆਰੀ APIs ਮੁਹੱਈਆ ਕੀਤੇ। ਜਦ ਟੀਮਾਂ ਇੱਕੋ “ਆਕਾਰ” ਦੇ ਅਬਜੈਕਟਾਂ (Deployments, Services, Jobs) 'ਤੇ ਸਹਿਮਤ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਤੋਟੇ-ਫਰੇਮ ਵਰਕ ਸ਼ੇਅਰ ਕੀਤੇ ਜਾ ਸਕਦੇ, ਟਰੇਨਿੰਗ ਸਧਾਰਨ ਹੁੰਦੀ, ਅਤੇ dev-ops ਦੇ ਹੂਫੇ tribal knowledge 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਰਹਿੰਦੇ।
ਇੱਕ ਲਗਾਤਾਰ API ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡਾ ਡਿਪਲੋਇਮੈਂਟ ਪਾਈਪਲਾਈਨ ਹਰ ਐਪ ਦੀਆਂ ਖ਼ਾਸੀਅਤਾਂ ਨੂੰ ਜਾਣਨ ਦੀ ਲੋੜ ਨਹੀਂ ਰੱਖਦੀ। ਇਹ ਇਕੋ ਕਾਰਵਾਈਆਂ—create, update, roll back, ਅਤੇ check health—ਉਹਨਾਂ Kubernetes ਧਾਰਨਾਵਾਂ ਨਾਲ ਕਰ ਸਕਦੀ ਹੈ।
ਇਸ ਨਾਲ ਸੰਮੀਲਨ ਵੀ ਸੁਧਰਦਾ ਹੈ: ਸੁਰੱਖਿਆ ਟੀਮ ਗਾਰਡਰੇਲ ਨੀਤੀਆਂ ਵਜੋਂ ਪ੍ਰਗਟ ਕਰ ਸਕਦੀਆਂ ਹਨ; SREs ਆਮ ਹੈਲਥ ਸਿਗਨਲਾਂ 'ਤੇ ਰਨਬੁਕਾਂ ਨੂੰ ਮਾਪ ਸਕਦੇ ਹਨ; ਵਿਕਾਸਕਾਰ ਸਾਂਝੇ ਸ਼ਬਦਾਵਲੀ ਨਾਲ ਰਿਲੀਜ਼ਾਂ ਬਾਰੇ ਸੋਚ ਸਕਦੇ ਹਨ।
ਪਲੇਟਫਾਰਮ ਬਦਲਾਅ CRDs ਨਾਲ ਸਪੱਸ਼ਟ ਹੁੰਦਾ ਹੈ। ਇੱਕ CRD ਤੁਹਾਨੂੰ ਕਲੱਸਟਰ ਵਿੱਚ ਨਵਾਂ ਆਬਜੈਕਟ (ਜਿਵੇਂ Database, Cache, ਜਾਂ Queue) ਜੋੜਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਅਤੇ ਇਸਨੂੰ ਉਸੇ API ਪੈਟਰਨਾਂ ਨਾਲ ਪ੍ਰਬੰਧਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਜੋ ਬਿਲਟ-ਇਨ ਸਰੋਤਾਂ ਲਈ ਹਨ।
ਇੱਕ Operator ਉਨ੍ਹਾਂ ਕਸਟਮ ਆਬਜੈਕਟਾਂ ਨੂੰ ਇਕ ਕੰਟਰੋਲਰ ਨਾਲ ਜੋੜਦਾ ਹੈ ਜੋ ਲਗਾਤਾਰ ਹਕੀਕਤ ਨੂੰ ਚਾਹੀਦੀ ਹਾਲਤ ਨਾਲ ਮਿਲਾਉਂਦੀ ਹੈ—ਉਹ ਕਾਰਜ ਜੋ ਪਹਿਲਾਂ ਮੈਨੁਅਲ ਹੁੰਦੇ ਸਨ, ਜਿਵੇਂ ਬੈਕਅਪ, failover, ਜਾਂ ਵਰਜ਼ਨ ਅਪਗਰੇਡ। ਮੁੱਖ ਲਾਭ ਜਾਦੂ ਨਹੀਂ, ਬਲਕਿ ਉਸੀ ਕੰਟਰੋਲ ਲੂਪ ਪਹੁੰਚ ਦਾ ਦੁਹਰਾਵ ਹੈ ਜੋ Kubernetes ਹਰ ਚੀਜ਼ 'ਤੇ ਲਗਾਉਂਦਾ ਹੈ।
ਕਿਉਂਕਿ Kubernetes API-ਡ੍ਰਿਵਨ ਹੈ, ਇਹ ਆਧੁਨਿਕ ਵਰਕਫਲੋਜ਼ ਨਾਲ ਸਾਫ਼-ਸੁਥਰਾ ਇੰਟਗਰੇਟ ਹੁੰਦਾ ਹੈ:
ਜੇ ਤੁਸੀਂ ਇਨ੍ਹਾਂ ਵਿਚਾਰਾਂ 'ਤੇ ਆਧਾਰਿਤ ਹੋਰ ਪ੍ਰਯੋਗਿਕ ਡਿਪਲੋਇਮੈਂਟ ਅਤੇ ਓਪਸ ਗਾਈਡਸ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ /blog ਨੂੰ ਵੇਖੋ।
Kubernetes ਦੇ ਸਭ ਤੋਂ ਵੱਡੇ ਵਿਚਾਰ—ਜੋ Brendan Burns ਦੇ ਸ਼ੁਰੂਆਤੀ ਫਰੇਮ 'ਤੇ ਬਹੁਤ ਨਿਰਭਰ ਹਨ—ਸਭ ਵੱਧ ਵਧੀਆ ਤਰੀਕੇ ਨਾਲ ਤਰਜਮਾ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ ਭਾਵੇਂ ਤੁਸੀਂ VMs, serverless, ਜਾਂ ਛੋਟੀ container ਸੈਟਅੱਪ 'ਤੇ ਚੱਲ ਰਹੇ ਹੋ।
“ਚਾਹੀਦੀ ਹਾਲਤ” ਲਿਖੋ ਅਤੇ ਆਟੋਮੇਸ਼ਨ ਨੂੰ ਇਸਨੂੰ ਦਿੱਤਾ ਕਰੋ। ਚਾਹੇ Terraform, Ansible, ਜਾਂ CI ਪਾਈਪਲਾਈਨ ਹੋਵੇ, ਕੰਫਿਗਰੇਸ਼ਨ ਨੂੰ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਮੰਨੋ। ਨਤੀਜਾ ਘੱਟ ਮੈਨੁਅਲ ਡਿਪਲੋਇਮੈਂਟ ਕਦਮ ਅਤੇ ਘੱਟ “ਮੇਰੇ ਮਸ਼ੀਨ 'ਤੇ ਚਲਿਆ” ਹੈਰਾਨੀ।
ਰੀਕਨਸੀਲੀਏਸ਼ਨ ਵਰਤੋ, ਇਕ-ਵਾਰੀ ਸਕ੍ਰਿਪਟਾਂ ਨਹੀਂ। ਇੱਕ-ਵਾਰੀ ਚੱਲਣ ਵਾਲੀਆਂ ਸਕ੍ਰਿਪਟਾਂ ਦੀ ਥਾਂ, ਅਜਿਹੇ ਲੂਪ ਬਣਾਓ ਜੋ ਲਗਾਤਾਰ ਮੁੱਖ ਗੁਣਾਂ (ਵਰਜ਼ਨ, ਕੰਫਿਗ, ਇੰਸਟੈਂਸ ਗਿਣਤੀ, ਸਿਹਤ) ਦੀ ਜਾਂਚ ਕਰਕੇ ਠੀਕ ਕਰਦੇ ਰਹਿਣ। ਇਹ ਹੀ ਤੁਹਾਨੂੰ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਓਪਸ ਅਤੇ ਫੇਲਿਅਰ ਤੋਂ ਬਾਅਦ ਭਰੋਸੇਯੋਗ ਰਿਕਵਰੀ ਦਿੰਦਾ ਹੈ।
ਸ਼ੈਡੀਊਲਿੰਗ ਅਤੇ ਸਕੇਲਿੰਗ ਨੂੰ ਸਪੱਸ਼ਟ ਉਤਪਾਦ ਫੀਚਰ ਬਣਾਓ। ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਤੁਸੀਂ ਕਦੋਂ ਅਤੇ ਕਿਉਂ کپੈਸਿਟੀ ਵਧਾਉਂਦੇ ਹੋ (CPU, queue depth, latency SLOs)। Kubernetes ਆਟੋਸਕੇਲਿੰਗ ਨਾ ਹੋਣ 'ਤੇ ਵੀ, ਟੀਮਾਂ ਸਕੇਲ ਨਿਯਮ ਸਟੈਂਡਰਡ ਕਰ ਸਕਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਵਾਧਾ ਐਪ ਦੁਬਾਰਾ ਲਿਖਣ ਜਾਂ ਕਿਸੇ ਨੂੰ ਜਗਾਉਣ ਦੀ ਲੋੜ ਨਾ ਬਣੇ।
ਰੋਲਆਊਟ ਸਧਾਰਨ ਕਰੋ। ਰੋਲਿੰਗ ਅੱਪਡੇਟ, ਹੈਲਥ ਚੈੱਕ ਅਤੇ ਤੇਜ਼ ਰੋਲਬੈਕ ਕਾਰਜ ਬਦਲਾਵਾਂ ਦੇ ਖ਼ਤਰੇ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ। ਤੁਸੀਂ ਇਹ ਲੋਡ ਬੈਲੈਂਸਰ, ਫੀਚਰ ਫਲੈਗ, ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ ਪਾਈਪਲਾਈਨਾਂ ਨਾਲ ਲਾਗੂ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਰੀਲੀਂਜ਼ਾਂ ਨੂੰ ਅਸਲੀ ਸਿਗਨਲਾਂ 'ਤੇ ਗੇਟ ਕਰਦੇ ਹਨ।
ਇਹ ਪੈਟਰਨ ਖਰਾਬ ਐਪ ਡਿਜ਼ਾਈਨ, ਅਸੁਰੱਖਿਅਤ ਡੇਟਾ ਮਾਈਗ੍ਰੇਸ਼ਨ, ਜਾਂ ਲਾਗਤ ਨਿਯੰਤਰਣ ਨੂੰ ਖ਼ੁਦ ਹੀ ਠੀਕ ਨਹੀਂ ਕਰਦੇ। ਤੁਹਾਨੂੰ ਹਾਲੇ ਵੀ ਵਰਜ਼ਨਡ APIs, ਮਾਈਗ੍ਰੇਸ਼ਨ ਯੋਜਨਾਵਾਂ, ਬਜਟਿੰਗ/ਹੱਦਾਂ, ਅਤੇ ਡਿਪਲੋਇਮੈਂਟਾਂ ਨੂੰ ਗ੍ਰਾਹਕ ਪ੍ਰਭਾਵ ਨਾਲ ਜੋੜਨ ਵਾਲੀ ਨਿਰੀਖਣਯੋਗਤਾ ਦੀ ਲੋੜ ਹੈ।
ਇੱਕ ਗਾਹਕ-ਸਮ੍ਹਣਾ ਸਰਵਿਸ ਚੁਣੋ ਅਤੇ ਚੈੱਕਲਿਸਟ ਨੂੰ end-to-end ਲਾਗੂ ਕਰੋ, ਫਿਰ ਵਧਾਓ।
ਜੇ ਤੁਸੀਂ ਨਵੀਆਂ ਸਰਵਿਸਾਂ ਬਣਾ ਰਹੇ ਹੋ ਅਤੇ “ਤਿਆਰ ਤੈਨਾਤ ਕਰਨ ਯੋਗ” ਤੇਜ਼ੀ ਨਾਲ ਪਹੁੰਚਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਤੁਹਾਡੀ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: ਇਹ ਚੈਟ-ਚਲਿਤ ਸਪੈੱਕ ਤੋਂ ਪੂਰਾ ਵੈੱਬ/ਬੈਕਐਂਡ/ਮੋਬਾਈਲ ਐਪ ਜਨਰੇਟ ਕਰਦਾ—ਆਮ ਤੌਰ 'ਤੇ React ਫਰੰਟਐਂਡ, Go PostgreSQL ਨਾਲ ਬੈਕਐਂਡ, ਅਤੇ Flutter ਮੋਬਾਈਲ—ਫਿਰ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰਦਾ ਤਾਂ ਜੋ ਤੁਸੀਂ ਇੱਥੇ ਵਰਣਿਤ Kubernetes ਪੈਟਰਨ (ਘੋਸ਼ਣਾਤਮਕ ਕਨਫਿਗ, ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਰੋਲਆਊਟ, ਅਤੇ ਰੋਲਬੈਕ-ਮਿੱਤਰ ਓਪਰੇਸ਼ਨ) ਨੂੰ ਲਾਗੂ ਕਰ ਸਕੋ। ਲਾਗਤ ਅਤੇ ਗਵਰਨੈਂਸ ਮੁੱਲਾਂਕਣ ਕਰਨ ਵਾਲੀਆਂ ਟੀਮਾਂ ਲਈ, ਤੁਸੀਂ /pricing ਨੂੰ ਵੇਖ ਸਕਦੇ ਹੋ।
Orchestration ਤੁਹਾਡੇ ਇरਾਦੇ (ਕੋਈ ਸੇਵਾ ਕਿੱਥੇ ਅਤੇ ਕਿਵੇਂ ਚੱਲਣੀ ਚਾਹੀਦੀ ਹੈ) ਨੂੰ ਅਸਲੀ ਦੁਨੀਆ ਦੇ ਬਦਲਾਅ (ਨੋਡ ਫੇਲ ਹੋਣਾ, ਰੋਲਿੰਗ ਡਿਪਲੋਇਮੈਂਟ, ਸਕੇਲਿੰਗ) ਨਾਲ ਜੋੜਦਾ ਹੈ।
ਪ੍ਰੈਕਟਿਕਲੀ, ਇਹ ਘਟਾਉਂਦਾ ਹੈ:
ਘੋਸ਼ਣਾਤਮਕ ਕੰਫਿਗਰੇਸ਼ਨ ਉਸ ਨਤੀਜੇ ਨੂੰ ਦਰਸਾਉਂਦੀ ਹੈ ਜੋ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ: “ਇਸ ਇਮੇਜ ਦੇ 3 ਨਕਲ, ਇਸ ਪੋਰਟ 'ਤੇ ਪ੍ਰਾਪਤਯੋਗ”)—ਬਦਲੇ ਵਿੱਚ ਤੁਸੀਂ ਕਦਮ-ਦਰ-ਕਦਮ ਨਹੀਂ ਦੱਸਦੇ।
ਤੁਰੰਤ ਫਾਇਦੇ:
ਕੰਟਰੋਲਰ ਲਗਾਤਾਰ ਚੱਲਣ ਵਾਲੇ ਲੂਪ ਹੁੰਦੇ ਹਨ ਜੋ ਮੌਜੂਦਾ ਹਾਲਤ ਨੂੰ ਚਾਹੀਦੀ ਹਾਲਤ ਨਾਲ ਤੁਲਨਾ ਕਰਦੇ ਹਨ ਅਤੇ ਫੇਰ ਅੰਤਰ ਨੂੰ ਘਟਾਉਣ ਲਈ ਕਾਰਵਾਈ ਕਰਦੇ ਹਨ।
ਇਸ ਕਰਕੇ Kubernetes ਆਮ ਨਤੀਜਿਆਂ ਨੂੰ “ਆਪਣੇ ਆਪ ਸੰਭਾਲਣ” ਵਾਲਾ ਬਣਾਉਂਦਾ ਹੈ:
ਕਰੈਸ਼ ਹੋਣ ਤੋਂ ਬਾਦ Pods ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਉਣਾ
ਫੇਲਿਅਰ ਦੌਰਾਨ ਰੈਪਲਿਕਾ ਗਿਣਤੀ ਨੂੰ ਕਾਇਮ ਰੱਖਣਾ
ਸ਼ੈਡੀਊਲਰ ਇਹ ਫ਼ੈਸਲਾ ਕਰਦਾ ਹੈ ਕਿ ਹਰ Pod ਕਿੱਥੇ ਚੱਲੇਗਾ, ਨੋਡ ਦੀ ਉਪਲਬਧਤਾ ਅਤੇ ਨਿਯਮਾਂ ਦੇ ਆਧਾਰ 'ਤੇ। ਬਿਨਾਂ ਸਹੀ ਦਿਸ਼ਾ-ਨਿਰਦੇਸ਼ ਦੇ, ਤੁਸੀਂ ਹੋ ਸਕਦਾ ਹੈ ਕਿ noisy neighbors, hotspots ਜਾਂ ਇਕੋ ਨੋਡ 'ਤੇ ਸਾਰੀਆਂ ਰੈਪਲਿਕਾ ਰੱਖਣ ਜਿਹੇ ਸਮੱਸਿਆਵਾਂ ਦਾ ਸਾਹਮਣਾ ਕਰੋ।
ਆਮ ਨਿਯਮ ਜੋ ਆਪਰੇਸ਼ਨਲ ਇਰਾਦਾ ਨੂੰ ਐਂਕੋਡ ਕਰਦੇ ਹਨ:
Requests ਸਚੇਤ ਕਰਦੇ ਹਨ ਕਿ ਇਕ Pod ਨੂੰ ਕੀ ਲੋੜ ਹੈ; limits ਇਹ ਸੀਮਾ ਨਿਧਾਰਤ ਕਰਦੇ ਹਨ ਕਿ ਉਹ ਕਿੰਨਾ ਵਰਤ ਸਕਦਾ ਹੈ। ਬਿਨਾਂ ਵਾਸਤਵਿਕ requests ਦੇ, ਸ਼ੈਡੀਊਲਰ ਲਈ ਪਲੇਸਮੈਂਟ ਅੰਦਾਜ਼ 'ਤੇ ਆ ਜਾਦਾ ਹੈ ਅਤੇ ਸਥਿਰਤਾ ਪ੍ਰਭਾਵਿਤ ਹੁੰਦੀ ਹੈ।
ਪ੍ਰੈਕਟਿਕਲ ਸ਼ੁਰੂਆਤ ਲਈ:
Deployment ਰੋਲਆਊਟ ਪੁਰਾਣੀਆਂ Pods ਨੂੰ ਨਵੇਂ ਨਾਲ ਕਦਮ-ਦਰ-ਕਦਮ ਬਦਲਦਾ ਹੈ ਜਦੋਂ ਕਿ ਉਪਲਬਧਤਾ ਬਰਕਰਾਰ ਰੱਖਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਹੁੰਦੀ ਹੈ।
ਰੋਲਆਊਟ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਣ ਲਈ:
Service ਇੱਕ ਟਿਕਾਊ ਦਰਵਾਜ਼ਾ ਹੁੰਦੀ ਹੈ ਜੋ ਬਦਲ ਰਹੀਆਂ Pods ਦੇ ਗਰੁੱਪ ਲਈ ਇੱਕ ਸਥਿਰ ਨਾਮ ਅਤੇ ਵਿਰਚੁਅਲ ਐਡਰੈੱਸ ਦਿੰਦੀ ਹੈ। Labels/selectors ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ ਕਿ ਕਿਹੜੇ Pods ਉਸ ਸੇਵਾ ਦੇ ਪਿੱਛੇ ਹਨ, ਅਤੇ EndpointSlices ਉਹਨਾਂ Pods ਦੀ ਸਚੀ IP ਸੂਚੀ ਰੱਖਦੇ ਹਨ।
ਆਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ, ਇਸਦਾ ਮਤਲਬ ਹੈ:
service-name ਨੂੰ ਕਾਲ ਕਰਦੇ ਹਨ ਨਾ ਕਿ Pod IPs ਨੂੰਹੋਰੋਂ ਤੇ ਤਿੰਨਣੇ ਲੇਅਰਾਂ ਹੈ ਜਿਨ੍ਹਾਂ ਦਾ ਸਾਅਧਾਰਕ ਕੰਮ ਵੱਖਰਾ ਹੈ:
ਆਮ ਗਲਤੀਆਂ:
CRDs ਤੁਹਾਨੂੰ ਨਵੇਂ API ਆਬਜੈਕਟ (ਉਦਾਹਰਣ: Database, Cache) ਜੋੜਨ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦੇ ਹਨ ਤਾਂ ਜੋ ਤੁਸੀਂ ਉੱਚ-ਸਤਹ ਸਿਸਟਮਾਂ ਨੂੰ ਇੱਕੋ Kubernetes API ਦੇ ਰੂਪ ਵਿੱਚ ਪ੍ਰਬੰਧ ਕਰ ਸਕੋ।
Operators ਉਹਨਾਂ CRDs ਨਾਲ controllers ਨੂੰ ਜੋੜਦੇ ਹਨ ਜੋ ਚਾਹੀਦੀ ਹਾਲਤ ਨੂੰ ਹਕੀਕਤ ਨਾਲ ਮਿਲਾਉਂਦੇ ਹਨ ਅਤੇ ਆਮ ਰੁਟੀਨੀ ਕਾਰਜ ਆਟੋਮੇਟ ਕਰਦੇ ਹਨ—ਜਿਵੇਂ:
ਉਹਨਾਂ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਸੋਫਟਵੇਅਰ ਵਾਂਗ ਹੀ ਸੋਚੋ: maturity, observability, ਅਤੇ failure modes ਦੀ ਮੁਲਾਂਕਣ ਕਰੋ ਪਹਿਲਾਂ ਕਿ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਹੋਵੋ।
ਹੇਲਥ ਸੰਕੇਤਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਰੋਲਆਊਟ ਨੂੰ ਅੱਗੇ ਵਧਾਉਣਾ ਜਾਂ ਰੋਕਣਾ