23 ਦਸੰ 2025·8 ਮਿੰਟ
ਛੋਟੀ ਟੀਮਾਂ ਲਈ ਗਲਤੀ ਬਜਟ: ਹਕੀਕਤੀ SLOs ਅਤੇ ਰੀਤੀਆਂ
ਛੋਟੀ ਟੀਮਾਂ ਲਈ ਗਲਤੀ ਬਜਟ ਸਿੱਖੋ: ਸ਼ੁਰੂਆਤੀ ਉਤਪਾਦਾਂ ਲਈ ਹਕੀਕਤੀ SLOs ਸੈੱਟ ਕਰੋ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜੇ ਇਨਸੀਡੈਂਟ ਗੱਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਇੱਕ ਸਧਾਰਣ ਹਫਤਾਵਾਰੀ ਰਿਲਾਇਬਟੀ ਰੀਤ ਚਲਾਓ।
ਛੋਟੀ ਟੀਮਾਂ ਲਈ ਗਲਤੀ ਬਜਟ ਸਿੱਖੋ: ਸ਼ੁਰੂਆਤੀ ਉਤਪਾਦਾਂ ਲਈ ਹਕੀਕਤੀ SLOs ਸੈੱਟ ਕਰੋ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜੇ ਇਨਸੀਡੈਂਟ ਗੱਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਇੱਕ ਸਧਾਰਣ ਹਫਤਾਵਾਰੀ ਰਿਲਾਇਬਟੀ ਰੀਤ ਚਲਾਓ।
ਛੋਟੀ ਟੀਮਾਂ ਤੇਜ਼ੀ ਨਾਲ ਸ਼ਿਪ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਨ੍ਹਾਂ ਨੂੰ ਕਰਨਾ ਪੈਂਦਾ ਹੈ। ਖਤਰਾ ਆਮ ਤੌਰ 'ਤੇ ਕੋਈ ਵੱਡਾ ਬਰੇਕਡਾਊਨ ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਉਹੀ ਛੋਟਾ ਫੇਲਰ ਹੈ ਜੋ ਦੁਹਰਾਉਂਦਾ ਰਹਿੰਦਾ ਹੈ: ਇੱਕ ਫਲੇਕੀ ਸਾਈਨਅਪ, ਕਦੇ-ਕਦੇ ਫੇਲ ਹੋਣ ਵਾਲਾ ਚੈਕਆਉਟ, ਇੱਕ ਡਿਪਲੌਇ ਜੋ ਕਈ ਵਾਰੀ ਇੱਕ ਸਕ੍ਰੀਨ ਤੋੜ ਦੇਂਦਾ ਹੈ। ਹਰ ਇੱਕ ਘੰਟੇ ਚੁਰਾ ਲੈਂਦਾ ਹੈ, ਭਰੋਸੇ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ, ਅਤੇ ਰਿਲੀਜ਼ਾਂ ਨੂੰ ਕੋਇਨ-ਫ਼ਲਿਪ ਬਣਾ ਦਿੰਦਾ ਹੈ।
ਗਲਤੀ ਬਜਟ ਛੋਟੀ ਟੀਮਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਅੱਗੇ ਵਧਣ ਦਾ ਸਧਾਰਣ ਤਰੀਕਾ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਇਹ ਜ਼ਾਹਿਰ ਕੀਤੇ ਕਿ ਰਿਲਾਇਬਿਲਟੀ "ਆਪਣੇ ਆਪ" ਹੋ ਜਾਵੇਗੀ।
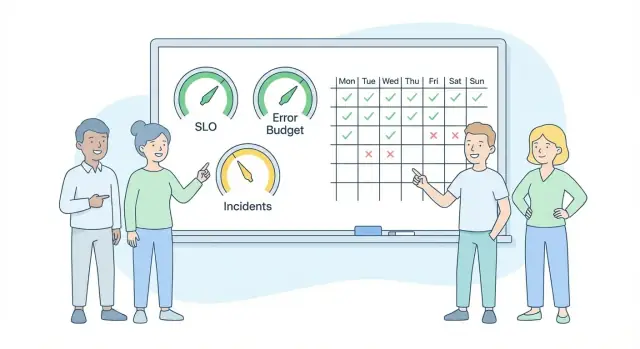
SLO (service level objective) ਇਕ ਸਾਫ਼ ਵਾਅਦਾ ਹੁੰਦਾ ਹੈ ਜੋ ਉਪਭੋਗਤਾ ਦੇ ਤਜ਼ੁਰਬੇ ਬਾਰੇ ਨੰਬਰ ਦੇ ਰੂਪ ਵਿੱਚ वक्त ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਅਤੇ ਇੱਕ ਸਮੇਂ ਦੀ ਖਿੜਕੀ ਤੇ ਮਾਪਿਆ ਜਾਂਦਾ ਹੈ। ਉਦਾਹਰਨ: “ਅਖੀਰਲੇ 7 ਦਿਨਾਂ ਵਿੱਚ ਸਫਲ ਚੈਕਆਉਟ ਘੱਟੋ-ਘੱਟ 99.5% ਹੋਣ।” ਗਲਤੀ ਬਜਟ ਉਸ ਵਾਅਦੇ ਅੰਦਰ "ਖ਼ਰਾਬ" ਦੀ ਇਜਾਜ਼ਤ ਕੀਤੀ ਮਾਤਰਾ ਹੈ। ਜੇ ਤੁਹਾਡਾ SLO 99.5% ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਹਫਤਾਵਾਰੀ ਬਜਟ 0.5% ਅਸਫਲ ਚੈਕਆਉਟ ਹਨ।
ਇਹ ਪਰਫ਼ੈਕਸ਼ਨ ਜਾਂ uptime ਥੀਏਟਰ ਬਾਰੇ ਨਹੀਂ ਹੈ। ਇਹ ਭਾਰੀ ਪ੍ਰਕਿਰਿਆ, ਬੇਅੰਤ ਮੀਟਿੰਗਾਂ ਜਾਂ ਕਿਸੇ ਐਕਸਲ ਸ਼ੀਟ ਬਾਰੇ ਨਹੀਂ ਹੈ ਜੋ ਕੋਈ ਅਪਡੇਟ ਨਹੀਂ ਕਰਦਾ। ਇਹ ਇਹ ਤੇ ਫੈਸਲਾ ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ ਕਿ "ਕਾਫ਼ੀ ਚੰਗਾ" ਕੀ ਹੈ, ਜਦੋਂ ਤੁਸੀਂ ਘੁਸਪੈਠ ਕਰ ਰਹੇ ਹੋ ਤਾਂ ਨਿਯਮਤ ਤੌਰ 'ਤੇ ਧਿਆਨ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਅਗਲੇ ਕਦਮ ਬਾਰੇ ਠੰਢੇ ਦਿਲ ਨਾਲ ਫੈਸਲਾ ਕਰਨ ਲਈ ਮਦਦ ਕਰਦਾ ਹੈ।
ਛੋਟੇ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ: 1 ਤੋਂ 3 ਯੂਜ਼ਰ-ਸਾਮਣੇ ਵਾਲੇ SLOs ਚੁਣੋ ਜੋ ਤੁਹਾਡੀਆਂ ਮਹੱਤਵਪੂਰਨ ਯਾਤਰਾਵਾਂ ਨਾਲ ਜੁੜੇ ਹੋਣ, ਉਹਨਾਂ ਨੂੰ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਮੌਜੂਦ ਸੰਕੇਤਾਂ ਨਾਲ ਮਾਪੋ (ਏਰਰਜ਼, ਲੇਟੰਸੀ, ਅਸਫਲ ਭੁਗਤਾਨ), ਅਤੇ ਹਰ ਹਫਤੇ ਇੱਕ ਛੋਟੀ ਸਮੀਖਿਆ ਕਰੋ ਜਿੱਥੇ ਤੁਸੀਂ ਬਜਟ ਬਰਨ ਵੇਖਦੇ ਹੋ ਅਤੇ ਇੱਕ ਅਗਲਾ ਕੰਮ ਚੁਣਦੇ ਹੋ। ਆਦਤ ਸਾਜ਼ੋ-ਸਮਾਨ ਤਕਨੀਕ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ।
ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਇੱਕ ਡਾਇਟ ਪਲਾਨ ਵਾਂਗ ਸੋਚੋ। ਤੁਹਾਨੂੰ ਪੂਰਨ ਦਿਨਾਂ ਦੀ ਲੋੜ ਨਹੀਂ। ਤੁਹਾਨੂੰ ਇੱਕ ਟਾਰਗੇਟ, ਉਸਨੂੰ ਮਾਪਣ ਦਾ ਤਰੀਕਾ ਅਤੇ ਅਸਲ ਜ਼ਿੰਦਗੀ ਲਈ ਇਕ ਛੋਟਾ ਰੁਕਸਾਨ ਦੀ ਆਗਿਆ ਚਾਹੀਦੀ ਹੈ।
SLI (service level indicator) ਉਹ ਨੰਬਰ ਹੈ ਜੋ ਤੁਸੀਂ ਦੇਖਦੇ ਹੋ, ਜਿਵੇਂ “ਕਿੰਨੇ ਪ੍ਰਤੀਸ਼ਤ ਰਿਕਵੈਸਟ ਸਫਲ ਹੁੰਦੇ ਹਨ” ਜਾਂ “p95 ਪੇਜ਼ ਲੋਡ ਸਮਾਂ 2 ਸਕਿੰਟ ਤੋਂ ਘੱਟ”। SLO ਉਸ ਨੰਬਰ ਦਾ ਟਾਰਗੇਟ ਹੈ, ਜਿਵੇਂ “99.9% ਰਿਕਵੈਸਟ ਸਫਲ ਹੋਣ।” ਗਲਤੀ ਬਜਟ ਉਹ ਮਾਤਰਾ ਹੈ ਜਿਸ ਤੱਕ ਤੁਸੀਂ SLO ਨੂੰ ਚੁੱਕ ਸਕਦੇ ਹੋ ਅਤੇ ਫਿਰ ਵੀ ਟਰੈੱਕ 'ਤੇ ਰਹਿੰਦੇ ਹੋ।
ਉਦਾਹਰਨ: ਜੇ ਤੁਹਾਡਾ SLO 99.9% ਉਪਲਬਧਤਾ ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਬਜਟ 0.1% ਡਾਊਨਟਾਈਮ ਹੈ। ਇੱਕ ਹਫਤੇ (10,080 ਮਿੰਟ) ਵਿੱਚ 0.1% ਲਗਭਗ 10 ਮਿੰਟ ਹੁੰਦੇ ਹਨ। ਇਸਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਤੁਹਾਨੂੰ ਖਾਸ ਤੌਰ 'ਤੇ 10 ਮਿੰਟ "ਵਰਤਣੀ" ਚਾਹੀਦੀ ਹੈ। ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਜਦੋਂ ਤੁਸੀਂ ਇਹ ਵਰਤਦੇ ਹੋ, ਤੁਸੀਂ ਜਾਗਰੂਕ ਤੌਰ 'ਤੇ ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਤੇਜ਼ੀ ਜਾਂ ਐਕਸਪੇਰਿਮੈਂਟ ਲਈ ਤਿਆਗ ਰਹੇ ਹੋ।
ਮੁਲ ਹੈ: ਇਹ ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਰਿਪੋਰਟਿੰਗ ਕਸਰਤ ਨਹੀਂ ਬਣਾ ਦਿੰਦਾ, ਸਗੋਂ ਇੱਕ ਫੈਸਲਾ ਕਰਨ ਵਾਲਾ ਔਜ਼ਾਰ ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਅੱਧੇ ਹਫਤੇ ਤੱਕ ਬਹੁਤ ਸਾਰਾ ਬਜਟ ਸੜ ਗਿਆ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਖਤਰਨਾਕ ਬਦਲਾਅ ਰੋਕਦੇ ਹੋ ਅਤੇ ਜੋ ਟੁੱਟ ਰਿਹਾ ਹੈ ਉਹ ਠੀਕ ਕਰਦੇ ਹੋ। ਜੇ ਬਹੁਤ ਘੱਟ ਬਜਟ ਵਰਤ ਰਹੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਬੇਫਿਕਰ ਹੋ ਕੇ ਹੋਰ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹੋ।
ਹਰ ਚੀਜ਼ ਲਈ ਉੱਠੇ SLO ਜ਼ਰੂਰੀ ਨਹੀਂ। ਇੱਕ ਪਬਲਿਕ ਗਾਹਕ-ਸਮੁਖ ਐਪ ਨੂੰ 99.9% ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ। ਇਕ ਅੰਦਰੂਨੀ ਐਡਮਿਨ ਟੂਲ ਆਮ ਤੌਰ 'ਤੇ ਢੀਲਾ ਹੋ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਘੱਟ ਲੋਕ ਨੋਟਿਸ ਕਰਦੇ ਹਨ ਅਤੇ ਪ੍ਰਭਾਵ ਛੋਟਾ ਹੁੰਦਾ ਹੈ।
ਹਰ ਚੀਜ਼ ਮਾਪਣ ਨਾਲ ਸ਼ੁਰੂ ਨਾ ਕਰੋ। ਉਹ ਪਲ ਰੱਖੋ ਜਿੱਥੇ ਯੂਜ਼ਰ ਫੈਸਲਾ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਉਤਪਾਦ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਨਹੀਂ।
1 ਤੋਂ 3 ਯੂਜ਼ਰ ਯਾਤਰਾਵਾਂ ਚੁਣੋ ਜੋ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਭਰੋਸਾ ਲੈਂਦੀਆਂ ਹਨ। ਜੇ ਉਹ ਠੀਕ ਹਨ ਤਾਂ ਬਾਕੀ ਅਕਸਰ ਛੋਟੇ ਲੱਗਦੇ ਹਨ। ਚੰਗੇ ਉਮੀਦਵਾਰ ਹਨ: ਪਹਿਲਾ ਟੱਚ (signup ਜਾਂ login), ਪੈਸੇ ਵਾਲਾ ਪਲ (checkout ਜਾਂ upgrade), ਅਤੇ ਮੁੱਖ ਕਾਰਵਾਈ (publish, create, send, upload, ਜਾਂ ਇਕ ਮਹੱਤਵਪੂਰਨ API ਕਾਲ)।
ਸਪਸ਼ਟ ਸ਼ਬਦਾਂ ਵਿੱਚ ਲਿਖੋ ਕਿ “ਸਫਲਤਾ” ਦਾ ਮਤਲਬ ਕੀ ਹੈ। ਜੇ ਤੁਹਾਡੇ ਯੂਜ਼ਰ ਡਿਵੈਲਪਰ ਨਹੀਂ ਹਨ ਤਾਂ “200 OK” ਵਰਗਾ ਤਕਨੀਕੀ ਸ਼ਬਦ ਨਾ ਵਰਤੋ।
ਕੁਝ ਉਦਾਹਰਨ ਜੋ ਤੁਸੀਂ ਅਨੁਕੂਲ ਕਰ ਸਕਦੇ ਹੋ:
ਉਹ ਮਾਪਣ ਦੀ ਵਿੰਡੋ ਚੁਣੋ ਜੋ ਇਸ ਗੱਲ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹੋ ਕਿ ਤੁਸੀਂ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਚੀਜ਼ਾਂ ਬਦਲਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਰੋਜ਼ਾਨਾ ਸ਼ਿਪ ਕਰਦੇ ਹੋ ਅਤੇ ਤੁਰੰਤ ਫੀਡਬੈਕ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ 7-ਦਿਨ ਵਿੰਡੋ ਚੰਗੀ ਹੈ। ਜੇ ਰਿਲੀਜ਼ ਘੱਟ ਹਨ ਜਾਂ ਡੇਟਾ ਸ਼ੋਰ ਵਾਲਾ ਹੈ ਤਾਂ 28-ਦਿਨ ਸ਼ਾਂਤ ਰਹਿਣ ਵਾਲੀ ਹੈ।
ਸ਼ੁਰੂਆਤੀ ਉਤਪਾਦਾਂ ਦੇ ਸੀਮਤੀਆਂ ਹੁੰਦੀਆਂ ਹਨ: ਟ੍ਰੈਫਿਕ ਘੱਟ ਹੋ ਸਕਦਾ ਹੈ (ਇੱਕ ਖਰਾਬ ਡਿਪਲੌਇ ਤੁਹਾਡੇ ਨੰਬਰ ਤੋੜ ਸਕਦਾ ਹੈ), ਫਲੋਜ਼ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦੇ ਹਨ, ਅਤੇ ਟੈਲੀਮੇਟਰੀ ਘੱਟ ਹੋ ਸਕਦੀ ਹੈ। ਠੀਕ ਹੈ। ਸਧਾਰਣ ਗਿਣਤੀਆਂ (ਕੋਸ਼ਿਸ਼ਾਂ ਬਨਾਮ ਸਫਲਤਾਵਾਂ) ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਪਰਿਭਾਸ਼ਾਵਾਂ ਨੂੰ ਉਸ ਸਮੇਂ ਤੱਕ ਤੰਗ ਕਰੋ ਜਦੋਂ ਯਾਤਰਾ ਖੁਦ ਬਦਲਣਾ ਬੰਦ ਕਰ ਦੇਵੇ।
ਆਪ ਜੋ ਅੱਜ ਸ਼ਿਪ ਕਰਦੇ ਹੋ ਉਸ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਉਹ ਨਹੀ ਜੋ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ। ਇੱਕ ਜਾਂ ਦੋ ਹਫ਼ਤਿਆਂ ਲਈ ਹਰ ਮੁੱਖ ਯਾਤਰਾ ਦਾ ਬੇਸਲਾਈਨ ਲਵੋ: ਕਿੰਨੀ ਵਾਰ ਇਹ ਸਫਲ ਹੁੰਦੀ ਹੈ ਅਤੇ ਕਿੰਨੀ ਵਾਰ ਫੇਲ। ਜੇ ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਹੈ ਤਾਂ ਉਸਨੇ ਵਰਤੋ। ਜੇ ਨਹੀਂ, ਤਾਂ ਆਪਣੇ ਟੈਸਟ, ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਅਤੇ ਲੌਗਾਂ ਵਰਤੋ। ਤੁਸੀਂ “ਨਾਰਮਲ” ਦੀ ਇੱਕ ਖ਼ਾਕਾ ਤਿਆਰ ਕਰ ਰਹੇ ਹੋ।
ਤੁਹਾਡਾ ਪਹਿਲਾ SLO ਉਹ ਹੋਣਾ ਚਾਹੀਦਾ ਜੋ ਤੁਸੀਂ ਜਿਆਦਾਤਰ ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਪੱਕਾ ਕਰ ਸਕੋ ਅਤੇ ਫਿਰ ਵੀ ਸ਼ਿਪ ਕਰ ਸਕੋ। ਜੇ ਤੁਹਾਡਾ ਬੇਸਲਾਈਨ 98.5% ਹੈ, ਤਾਂ 99.9% ਨਾ ਰੱਖੋ ਅਤੇ ਉਮੀਦ ਕਰੋ। 98% ਜਾਂ 98.5% ਰੱਖੋ, ਫਿਰ ਬਾਅਦ ਵਿੱਚ ਕਸੋ।
ਲੇਟੰਸੀ ਆਕਰਸ਼ਕ ਹੈ, ਪਰ ਸ਼ੁਰੂ ਵਿੱਚ ਇਹ ਧਿਆਨ ਭਟਕਾ ਸਕਦੀ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਪਹਿਲਾਂ सफल-ਦਰ SLO ਤੋਂ ਜ਼ਿਆਦਾ ਮੁੱਲ ਪ੍ਰਾਪਤ ਕਰਦੀਆਂ ਹਨ (ਰਿਕਵੈਸਟ ਬਿਨਾਂ ਗਲਤੀਆਂ ਪੂਰੀ ਹੁੰਦੀ ਹੈ)। ਜਦੋਂ ਯੂਜ਼ਰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਇਹ ਮਹਿਸੂਸ ਕਰਨ, ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਅਪਨੇ ਅੰਕੜੇ ਥੋੜੇ ਸਥਿਰ ਹੋਣ, ਤਾਂ ਲੇਟੰਸੀ ਸ਼ਾਮਲ ਕਰੋ।
ਇੱਕ ਮਦਦਗਾਰ ਫਾਰਮੈਟ: ਹਰ ਯਾਤਰਾ ਲਈ ਇੱਕ ਲਾਈਨ: ਕਿਸ ਨੇ, ਕੀ, ਟਾਰਗੇਟ, ਅਤੇ ਸਮੇਂ ਦੀ ਵਿੰਡੋ।
ਪੈਸਾ ਅਤੇ ਭਰੋਸੇ ਵਾਲੇ ਮੋਮੈਂਟ ਲਈ ਵਿੰਡੋ ਲੰਮੀ ਰੱਖੋ (ਬਿਲਿੰਗ, auth). ਰੋਜ਼ਾਨਾ ਫਲੋਜ਼ ਲਈ ਛੋਟੀ ਰੱਖੋ। ਜਦੋਂ ਤੁਸੀਂ SLO ਆਸਾਨੀ ਨਾਲ ਮਿਲਾ ਲੈਂਦੇ ਹੋ, ਤਾਂ ਥੋੜ੍ਹਾ ਉੱਪਰ ਕਰੋ ਅਤੇ ਅੱਗੇ ਵਧੋ।
ਛੋਟੀ ਟੀਮਾਂ ਬਹੁਤ ਵਕਤ ਗੁਆਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਹਰ ਛੋਟੀ ਗੜਬੜ ਨੂੰ ਅੱਗ ਲਗਾਉਣ ਵਾਲੀ ਮਿਸ਼ਨ ਸਮਝ ਲੈਂਦੀਆਂ ਹਨ। ਮਕਸਦ ਸਧਾਰਣ ਹੈ: ਯੂਜ਼ਰ-ਨਜ਼ਰ ਆਉਣ ਵਾਲਾ ਦਰਦ ਬਜਟ ਖਰਚ ਕਰਦਾ ਹੈ; ਬਾਕੀ ਸਧਾਰਨ ਕੰਮ ਵਜੋਂ ਸੰਭਾਲਿਆ ਜਾਵੇ।
ਇੱਕ ਛੋਟਾ ਸੈੱਟ ਇਨਸੀਡੈਂਟ ਕਿਸਮਾਂ ਕਾਫ਼ੀ ਹੁੰਦੀਆਂ ਹਨ: ਫੁੱਲ ਆਉਟੇਜ, ਪਾਰਸ਼ੀਅਲ ਆਉਟੇਜ (ਇੱਕ ਮੁੱਖ ਫਲੋ ਤੱਟੀ), ਘਟਿਆ ਪ੍ਰਦਰਸ਼ਨ (ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਪਰ ਧੀਮਾ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ), ਖ਼ਰਾਬ ਡਿਪਲੌਇ (ਰਿਲੀਜ਼ ਕਾਰਨ ਫੇਲ), ਅਤੇ ਡੇਟਾ ਮੁੱਦੇ (ਗਲਤ, ਮਿਸਿੰਗ, ਡੁਪਲੀਕੇਟ)।
ਸਕੇਲ ਛੋਟੀ ਰੱਖੋ ਅਤੇ ਹਰ ਵਾਰੀ ਵਰਤੋਂ।
ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਬਜਟ ਦੇ ਖਿਲਾਫ਼ ਗਿਣਿਆ ਜਾਵੇ। ਯੂਜ਼ਰ-ਨਜ਼ਰੀਏ ਵਾਲੀ ਅਸਫਲਤਾ ਨੂੰ ਖਰਚ ਵਜੋਂ ਸਲੂਕੀਟ ਕਰੋ: ਟੁੱਟਿਆ signup ਜਾਂ checkout, ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰਨ ਵਾਲੇ timeout, 5xx spikes ਜੋ ਯਾਤਰਾਵਾਂ ਨੂੰ ਰੋਕਦੇ ਹਨ। ਯੋਜਨਾ ਬਣਾ ਕੇ ਕੀਤਾ ਗਿਆ ਰੱਖ-ਰਖਾਅ ਗਿਣਿਆ ਨਹੀਂ ਜਾਣਾ ਚਾਹੀਦਾ ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਸੂਚਿਤ ਕੀਤਾ ਸੀ ਅਤੇ ਐਪ ਉਸ ਖਿੜਕੀ ਦੌਰਾਨ ਉਮੀਦ ਮੁਤਾਬਕ ਵਰਤਿਆ ਗਿਆ।
ਇੱਕ ਨਿਯਮ ਜ਼ਿਆਦਾਤਰ ਬਹਸ ਖ਼ਤਮ ਕਰਦਾ ਹੈ: ਜੇ ਇੱਕ ਅਸਲੀ ਬਾਹਰੀ ਯੂਜ਼ਰ ਨੋਟਿਸ ਕਰੇਗਾ ਅਤੇ ਇਕ ਸੰਰੱਖਿਤ ਯਾਤਰਾ ਪੂਰੀ ਨਹੀਂ ਹੋ ਸਕੇਗੀ, ਤਾਂ ਇਹ ਗਿਣਿਆ ਜਾਂਦਾ ਹੈ। ਨਹੀਂ ਤਾਂ ਨਹੀਂ।
ਇਹ ਨਿਯਮ ਆਮ ਧੁੰਧਲੇ ਹਾਲਾਤਾਂ ਨੂੰ ਵੀ ਕਵਰ ਕਰਦਾ ਹੈ: ਕੋਈ ਤੀਸਰੀ-ਧਿਰ ਦਾ ਆਉਟੇਜ ਸਿਰਫ਼ ਤਾਂ ਗਿਣਿਆ ਜਾਂਦਾ ਹੈ ਜੇ ਇਹ ਤੁਹਾਡੀ ਯੂਜ਼ਰ ਯਾਤਰਾ ਨੂੰ ਤੱਡਦਾ ਹੈ; ਘੱਟ-ਟ੍ਰੈਫਿਕ ਘੰਟਿਆਂ ਵਿੱਚ ਵੀ ਗਿਣਿਆ ਜਾਵੇਗਾ ਜੇ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵਿਤ ਹੋ ਰਹੇ ਹਨ; ਅਤੇ ਸਿਰਫ਼ ਅੰਦਰੂਨੀ ਟੈਸਟ ਕਰਨ ਵਾਲੇ ਗਿਣੇ ਨਹੀਂ ਜਾਣਗੇ ਜਦੋਂ ਤੱਕ ਡੌਗਫੂਡਿੰਗ ਮੁੱਖ ਵਰਤੋਂ ਨਹੀਂ ਹੈ।
ਲਕੜੀ ਪਰਫ਼ੈਕਸ਼ਨ ਨਹੀਂ। ਮਕਸਦ ਇਕ ਸਾਂਝਾ, ਦੁਹਰਾਊ ਨਿਸ਼ਾਨਾ ਹੈ ਜੋ ਦੱਸਦਾ ਹੈ ਕਿ ਰਿਲਾਇਬਿਲਟੀ ਮਹਿੰਗੀ ਹੋ ਰਹੀ ਹੈ ਕਿ ਨਹੀਂ।
ਹਰ SLO ਲਈ ਇੱਕ ਸੋਰਸ-ਆਫ-ਟ੍ਰੂਥ ਚੁਣੋ ਅਤੇ ਉਸੇ ਨਾਲ ਰਹੋ: ਇੱਕ ਮਾਨੀਟਰਿੰਗ ਡੈਸ਼ਬੋਰਡ, ਐਪ ਲੌਗਸ, ਇੱਕ ਸਿੰਥੇਟਿਕ ਚੈਕ ਜੋ ਇੱਕ endpoint ਨੂੰ ਹਿੱਟ ਕਰਦਾ ਹੈ, ਜਾਂ ਇੱਕ ਸਿੰਗਲ ਮੈਟ੍ਰਿਕ ਜਿਵੇਂ ਸਫਲ ਚੈਕਆਉਟ ਪ੍ਰਤੀ ਮਿੰਟ। ਜੇ ਤੁਸੀਂ ਮਾਪਣ ਦੀ ਵਿਧੀ ਬਦਲਦੇ ਹੋ, ਤਾਰੀਖ ਲਿਖੋ ਅਤੇ ਉਸਨੂੰ ਰੀਸੈੱਟ ਵਜੋਂ ਟ੍ਰੀਟ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਸੇਬਾਂ ਅਤੇ ਸੰਤਰੇ ਨਹੀਂ ਜੋੜ ਰਹੇ।
ਅਲਰਟਸ ਨੂੰ ਹਰ ਛੋਟੀ ਗੜਬੜ ਲਈ ਨਹੀਂ, ਬਲਕੀ ਬਜਟ ਬਰਨ ਲਈ ਰੱਖੋ। ਇੱਕ ਛੋਟਾ ਪੈਟਰਨ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ: “ਫਾਸਟ ਬਰਨ” ਤੇ ਅਲਰਟ (ਤੁਸੀਂ ਇੱਕ ਦਿਨ ਵਿੱਚ ਮਹੀਨੇ ਦਾ ਬਜਟ ਬਰਨ ਕਰ ਰਹੇ ਹੋ) ਅਤੇ “ਸਲੋ ਬਰਨ” ਤੇ ਨਰਮ ਅਲਰਟ (ਹਫਤੇ ਵਿੱਚ ਬਜਟ ਬਰਨ ਹੋ ਜਾਵੇ)।
ਇੱਕ ਛੋਟੀ ਰਿਲਾਇਬਿਲਟੀ ਲੌਗ ਰੱਖੋ ਤਾਂ ਕਿ ਯਾਦ 'ਤੇ ਨਿਰਭਰ ਨਾ ਰਹੋ। ਇਕ ਲਾਈਨ ਪ੍ਰਤੀ ਇਨਸੀਡੈਂਟ ਕਾਫੀ ਹੈ: ਤਾਰੀਖ ਅਤੇ ਦੌਰਾਨ, ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ, ਸੰਭਵ ਕਾਰਨ, ਤੁਸੀਂ ਕੀ ਬਦਲਿਆ, ਅਤੇ ਇਕ ਫਾਲੋ-ਅਪ ਮਲਿਕ ਜਿਸਦੀ ਮਿਆਦ ਹੈ।
ਉਦਾਹਰਨ: ਇੱਕ ਦੋ-ਵਿਆਕਤੀ ਟੀਮ ਨੇ ਇੱਕ ਨਵਾਂ API ਮੋਬਾਇਲ ਐਪ ਲਈ ਸ਼ਿਪ ਕੀਤਾ। ਉਨ੍ਹਾਂ ਦਾ SLO "99.5% ਸਫਲ ਰਿਕਵੈਸਟ" ਇੱਕ ਕਾਊਂਟਰ ਤੋਂ ਮਾਪਿਆ ਗਿਆ। ਇੱਕ ਖ਼ਰਾਬ ਡਿਪਲੌਇ ਨੇ ਸਫਲਤਾ 97% ਤੱਕ 20 ਮਿੰਟ ਲਈ ਘਟਾ ਦਿੱਤੀ। ਫਾਸਟ-ਬਰਨ ਅਲਰਟ ਟ੍ਰਿਗਰ ਹੋਇਆ, ਉਨ੍ਹਾਂ ਨੇ ਰੋਲਬੈਕ ਕੀਤਾ, ਅਤੇ ਫਾਲੋ-ਅਪ "ਡਿਪਲੌਇ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਕੈਨਰੀ ਚੈਕ ਸ਼ਾਮਲ ਕਰੋ" ਬਣਿਆ।
ਤੁਹਾਨੂੰ ਭਾਰੀ ਪ੍ਰਕਿਰਿਆ ਨਹੀਂ ਚਾਹੀਦੀ। ਤੁਹਾਨੂੰ ਇੱਕ ਛੋਟੀ ਆਦਤ ਚਾਹੀਦੀ ਹੈ ਜੋ ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਦਿਖਾਏ ਬਿਨਾਂ ਬਿਲਡ ਸਮੇਂ ਨੂੰ ਚੁਰਾਏ। 20-ਮਿੰਟ ਚੈਕ-ਇਨ ਕੰਮ ਕਰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਸਾਰੀਆਂ ਚੀਜ਼ਾਂ ਨੂੰ ਇਕ ਸਵਾਲ ਵਜੋਂ ਬਦਲ ਦਿੰਦਾ ਹੈ: ਕੀ ਅਸੀਂ ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਆਪਣੀ ਯੋਜਨਾ ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਖਰਚ ਕਰ ਰਹੇ ਹਾਂ?
ਹਰ ਹਫਤੇ ਇੱਕੋ ਕੈਲੰਡਰ ਸਲੌਟ ਵਰਤੋ। ਇੱਕ ਸਾਂਝਾ ਨੋਟ ਰੱਖੋ ਜਿਸਨੂੰ ਤੁਸੀਂ ਐਪੈਂਡ ਕਰਦੇ ਹੋ (ਦੋਬਾਰਾ ਨਾ ਲਿਖੋ)। ਲਗਾਤਾਰਤਾ ਵੇਰਵੇ ਤੋਂ ਬੇਹਤਰ ਹੈ।
ਸਰਲ ਏਜੰਡਾ:
ਫਾਲੋ-ਅਪ ਅਤੇ ਕਮੇਟਮੈਂਟਾਂ ਦੇ ਵਿਚਕਾਰ, ਹਫਤੇ ਲਈ ਆਪਣਾ ਰਿਲੀਜ਼ ਨਿਯਮ ਫੈਸਲਾ ਕਰੋ ਅਤੇ ਸਧਾਰਣ ਰੱਖੋ:
ਜੇ ਤੁਹਾਡੇ ਸਾਈਨਅਪ ਫਲੋ ਵਿੱਚ ਦੋ ਛੋਟੀ ਆਉਟੇਜ ਹੋਈਆਂ ਅਤੇ ਬਹੁਤ ਬਜਟ ਬਰਨ ਹੋ ਗਿਆ, ਤੁਸੀਂ ਸਿਰਫ਼ ਸਾਈਨਅਪ ਸਬੰਧੀ ਬਦਲਾਅ ਨੂੰ ਫ੍ਰੀਜ਼ ਕਰ ਸਕਦੇ ਹੋ ਪਰ ਹੋਰ ਅਣਸੰਬੰਧਿਤ ਕੰਮ ਜਾਰੀ ਰੱਖ ਸਕਦੇ ਹੋ।
ਗਲਤੀ ਬਜਟ ਸਿਰਫ਼ ਤਾਂ ਮਹੱਤਵਪੂਰਕ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਤੈਅ ਕਰਦਾ ਹੈ ਕਿ ਅਗਲੇ ਹਫ਼ਤੇ ਤੁਸੀਂ ਕੀ ਕਰੋਗੇ। ਮਕਸਦ ਪੂਰਨ ਅਪਟਾਈਮ ਨਹੀਂ। ਇਹ ਇਹ ਸਪੱਸ਼ਟ ਤਰੀਕਾ ਹੈ ਕਿ ਫੈਸਲਾ ਕਰੋ: ਅਸੀਂ ਫੀਚਰਾਂ ਸ਼ਿਪ ਕਰੀਏ ਜਾਂ ਰਿਲਾਇਬਿਲਟੀ ਕਰਜ਼ਾ ਵਾਪਸ ਚੁਕਾਈਏ?
ਇੱਕ ਪਾਲਿਸੀ ਜੋ ਤੁਸੀਂ ਆਵਾਜ਼ ਨਾਲ ਕਹਿ ਸਕੋ:
ਇਹ ਸਜ਼ਾ ਨਹੀਂ ਹੈ। ਇਹ ਸਰਜਨਕ ਤੌਰ 'ਤੇ ਉਹਨਾਂ ਫੈਸਲਿਆਂ ਨੂੰ ਜਨਤਕ ਬਣਾਉਂਦਾ ਹੈ ਤਾਂ ਕਿ ਯੂਜ਼ਰ ਬਾਅਦ ਵਿੱਚ ਇਸਦਾ ਭੁਗਤਾਨ ਨਾ ਕਰਨ।
ਜਦੋਂ ਤੁਸੀਂ ਧੀਮੇ ਹੋ, vague ਟਾਸਕਾਂ ਤੋਂ ਬਚੋ ਜਿਵੇਂ “ਸਥਿਰਤਾ ਸੁਧਾਰੋ।” ਉਹ ਬਦਲਾਅ ਚੁਣੋ ਜੋ ਅਗਲੇ ਨਤੀਜੇ 'ਤੇ ਅਸਰ ਪਾਉਂਦੇ: ਇੱਕ ਗਾਰਡਰੇਲ (timeouts, input validation, rate limits) ਜੋੜੋ, ਇੱਕ ਟੈਸਟ ਸੁਧਾਰੋ ਜੋ ਬਗ ਫੜ ਲੈਂਦਾ, rollback ਨੂੰ ਆਸਾਨ ਬਣਾਓ, ਸਭ ਤੋਂ ਵੱਡੇ error source ਨੂੰ ਠੀਕ ਕਰੋ, ਜਾਂ ਇੱਕ ਅਲਰਟ ਜੋ ਯੂਜ਼ਰ ਯਾਤਰਾ ਨਾਲ ਜੁੜਿਆ ਹੋਵੇ ਸ਼ਾਮਲ ਕਰੋ।
ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਦੋਸ਼ ਸੈੱਟਿੰਗ ਤੋਂ ਅਲੱਗ ਰੱਖੋ। ਤੇਜ਼ ਇਨਸੀਡੈਂਟ ਲਿਖਾਈ ਨੂੰ ਇਨਾਮ ਦਿਓ, ਭਾਵੇਂ ਵੇਰਵੇ ਗੁੰਦੇ ਹੋਣ। ਇਕੋ ਗਲਤ ਇਨਸੀਡੈਂਟ ਰਿਪੋਰਟ ਉਹ ਹੈ ਜੋ ਦੇਰ ਨਾਲ ਆਉਂਦੀ ਹੈ ਜਿਸ 'ਚ ਕੋਈ ਯਾਦ ਨਹੀਂ ਰੱਖਦਾ ਕਿ ਕੀ ਬਦਲਿਆ ਸੀ।
ਇੱਕ ਆਮ ਫਾਂਦਾ ਹੈ ਦਿਨ-ਇੱਕ 'ਤੇ ਸੋਨੇ ਉੱਤੇ SLO ਰੱਖਣਾ (99.99% ਵਧੀਆ ਲਗਦਾ ਹੈ) ਅਤੇ ਫਿਰ ਹਕੀਕਤ ਆਉਣ 'ਤੇ ਚੁੱਪ ਚਾਪ ਇਸਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰ ਦੇਣਾ। ਤੁਹਾਡਾ ਸ਼ੁਰੂਆਤੀ SLO ਤੁਹਾਡੇ ਮੌਜੂਦਾ ਲੋਕਾਂ ਅਤੇ ਟੂਲਾਂ ਨਾਲ ਪਹੁੰਚਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਹੀਂ ਤਾਂ ਇਹ ਬੈਕਗ੍ਰਾਊਂਡ ਸ਼ੋਰ ਬਣ ਜਾਵੇਗਾ।
ਦੂਜੀ ਗਲਤੀ ਗਲਤ ਚੀਜ਼ ਮਾਪਣਾ ਹੈ। ਟੀਮਾਂ ਪੰਜ ਸਰਵਿਸز ਅਤੇ ਡੇਟਾਬੇਸ ਗਰਾਫ ਵੇਖਦੀਆਂ ਹਨ, ਪਰ ਉਹ ਯਾਤਰਾ ਨੂੰ ਮਿਸ ਕਰਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰਦਾ ਹੈ: signup, checkout, ਜਾਂ “save changes.” ਜੇ ਤੁਸੀਂ ਯੂਜ਼ਰ ਦੇ ਨਜ਼ਰੀਏ ਤੋਂ SLO ਇੱਕ ਵਾਕ ਵਿੱਚ ਸਮਝਾ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਇਹ ਅਕਸਰ ਬਹੁਤ ਅੰਦਰੂਨੀ ਹੁੰਦਾ ਹੈ।
ਅਲਰਟ ਫੈਟਿਗ ਇੱਕ ਐਸਾ ਕਾਰਨ ਹੈ ਜੋ ਉਨ੍ਹਾਂ ਇੱਕ ਵਿਅਕਤੀ ਨੂੰ ਥਕਾ ਦਿੰਦਾ ਹੈ ਜੋ ਪ੍ਰੋਡਕਸ਼ਨ ਸਹੀ ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਹਰ ਛੋਟੀ spike ਕਿਸੇ ਨੂੰ paging ਕਰੇਗੀ, ਤਾਂ paging "ਨਾਰਮਲ" ਬਣ ਜਾਂਦਾ ਹੈ ਅਤੇ ਅਸਲ ਬੜੇ ਅੱਗ ਨੂੰ ਛੱਡ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ। ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ 'ਤੇ ਪੇਜ ਕਰੋ। ਬਾਕੀ ਚੀਜ਼ਾਂ ਨੂੰ ਰੋਜ਼ਾਨਾ ਚੈਕ ਦੁਆਰਾ ਰੂਟ ਕਰੋ।
ਇੱਕ ਚੌਪੜਾ ਕਤਲਕਾਰੀ ਹੈ ਗਣਨਾ ਵਿੱਚ ਅਸਥਿਰਤਾ। ਇਕ ਹਫਤੇ ਤੁਸੀਂ 2 ਮਿੰਟ ਦੀ slowdown ਨੂੰ ਇਨਸੀਡੈਂਟ ਗਿਣਦੇ ਹੋ, ਅਗਲੇ ਹਫਤੇ ਨਹੀਂ। ਫਿਰ ਬਜਟ ਇਕ ਬਹਿਸ ਬਣ ਜਾਂਦਾ ਹੈ ਨਾ ਕਿ ਨਿਸ਼ਾਨਾ। ਨਿਯਮ ਇੱਕ ਵਾਰੀ ਲਿਖੋ ਅਤੇ ਇਸਨੂੰ ਲਗਾਤਾਰ ਲਾਗੂ ਕਰੋ।
ਮਦਦਗਾਰ ਗਾਰਡਰੇਲ:
ਜੇ ਇੱਕ ਡਿਪਲੌਇ ਲੌਗਿਨ ਨੂੰ 3 ਮਿੰਟ ਲਈ ਤੋੜ ਦੇਵੇ, ਹਰ ਵਾਰੀ ਇਸਨੂੰ ਗਿਣੋ, ਭਾਵੇਂ ਜਲਦੀ ਠੀਕ ਹੋ ਜਾਵੇ। ਲਗਾਤਾਰਤਾ ਉਹ ਗੁਣ ਹੈ ਜੋ ਬਜਟ ਨੂੰ ਉਪਯੋਗੀ ਬਣਾਉਂਦੀ ਹੈ।
10-ਮਿੰਟ ਟਾਈਮਰ ਲਗਾਓ, ਇੱਕ ਸਾਂਝਾ ਡੌਕ ਖੋਲ੍ਹੋ, ਅਤੇ ਇਹ 5 ਸਵਾਲ ਜਵਾਬ ਦਿਓ:
ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਚੀਜ਼ ਨੂੰ ਅਜੇ ਮਾਪ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਇੱਕ ਪ੍ਰਾਕਸੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਦੇਖ ਸਕਦੇ ਹੋ: ਅਸਫਲ ਭੁਗਤਾਨ, 500 errors, ਜਾਂ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਜੋ "checkout" ਨਾਲ ਟੈੱਗ ਕੀਤੀਆਂ ਹਨ। ਪ੍ਰਾਕਸੀ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਚੰਗਾ ਬਣਾਓ।
ਉਦਾਹਰਨ: ਇਕ ਦੋ-ਅੱਦਦ ਟੀਮ ਨੇ ਇਸ ਹਫਤੇ 3 “password reset ਨਹੀਂ ਹੋ ਸਕਿਆ” ਸੁਨੇਹੇ ਵੇਖੇ। ਜੇ password reset ਇੱਕ ਸੰਰੱਖਿਤ ਯਾਤਰਾ ਹੈ, ਤਾਂ ਇਹ ਇਕ ਇਨਸੀਡੈਂਟ ਹੈ। ਉਹ ਇੱਕ ਛੋਟੀ ਨੋਟ ਲਿਖਦੇ ਹਨ (ਕੀ ਹੋਇਆ, ਕਿੰਨੇ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵਿਤ, ਉਹਨਾਂ ਨੇ ਕੀ ਕੀਤਾ) ਅਤੇ ਇੱਕ ਫਾਲੋ-ਅਪ ਚੁਣਦੇ ਹਨ: reset ਫੇਲ ਚੈੱਕ 'ਤੇ ਅਲਰਟ ਜੋੜੋ ਜਾਂ ਰੀ-ਟ੍ਰਾਈ ਸ਼ਾਮਲ ਕਰੋ।
Maya ਅਤੇ Jon ਇੱਕ ਦੋ-ਵਿਆਕਤੀ ਸਟਾਰਟਅਪ ਚਲਾਉਂਦੇ ਹਨ ਅਤੇ ਹਰ ਸ਼ੁੱਕਰਵਾਰ ਸ਼ਿਪ ਕਰਦੇ ਹਨ। ਉਹ ਤੇਜ਼ੀ ਨਾਲ ਹਿੱਲਦੇ ਹਨ, ਪਰ ਉਹਨਾਂ ਦੇ ਪਹਿਲੇ ਪੈਡ ਯੂਜ਼ਰ ਇੱਕ ਗੱਲ ਦੀ ਪਰਵਾਹ ਕਰਦੇ ਹਨ: ਕੀ ਉਹ ਪ੍ਰੋਜੈਕਟ ਬਣਾਂ ਸਕਦੇ ਹਨ ਅਤੇ ਟੀਮਮੈਂਬਰ ਨੂੰ ਨਿਯੋਤਾ ਭੇਜ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਟੁੱਟਣ ਦੇ?
ਪਿਛਲੇ ਹਫਤੇ ਉਨ੍ਹਾਂ ਕੋਲ ਇੱਕ ਅਸਲੀ ਆਉਟੇਜ ਸੀ: “Create project” ਇੱਕ ਖਰਾਬ ਮਾਈਗ੍ਰੇਸ਼ਨ ਤੋਂ ਬਾਅਦ 22 ਮਿੰਟ ਲਈ ਫੇਲ ਹੋ ਗਿਆ। ਉਨ੍ਹਾਂ ਕੋਲ ਤਿੰਨ "ਧੀਮੀਆਂ ਪਰ ਮੁੰਨ੍ਹਾ ਨਹੀਂ" ਘੜੀਆਂ ਵੀ ਸਨ ਜਿੱਥੇ ਸਕ੍ਰੀਨ 8 ਤੋਂ 12 ਸਕਿੰਟ ਲਈ ਘੁੰਮਦੀ ਰਹੀ। ਯੂਜ਼ਰ ਸ਼ਿਕਾਇਤ ਕੀਤੇ, ਪਰ ਟੀਮ ਇਹ ਬਹਿਸ ਕਰ ਰਹੀ ਸੀ ਕਿ ਕੀ ਧੀਮਾ "ਡਾਊਨ" ਗਿਣਿਆ ਜਾਵੇ।
ਉਹ ਇੱਕ ਯਾਤਰਾ ਚੁਣਦੇ ਹਨ ਅਤੇ ਇਸਨੂੰ ਮਾਪਯੋਗ ਬਣਾਉਂਦੇ ਹਨ:
ਸੋਮਵਾਰ ਨੂੰ ਉਹ 20-ਮਿੰਟ ਰੀਤ ਚਲਾਉਂਦੇ ਹਨ। ਇਕੋ ਸਮਾਂ, ਇਕੋ ਡੌਕ। ਉਹ ਚਾਰ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ: ਕੀ ਹੋਇਆ, ਕਿੰਨਾ ਬਜਟ ਸੜ ਗਿਆ, ਕੀ ਦੁਹਰਾਇਆ, ਅਤੇ ਇਕੋ ਬਦਲਾਅ ਕੀ ਹੈ ਜੋ ਦੁਹਰਾਅ ਰੋਕ ਸਕੇ।
ਟ੍ਰੇਡ-ਆਫ਼ ਸਪੱਸ਼ਟ ਹੋ ਜਾਂਦਾ ਹੈ: ਆਉਟੇਜ ਅਤੇ ਧੀਮੀਆਂ ਘੜੀਆਂ ਨੇ ਹਫਤਾਵਾਰ ਬਜਟ ਦਾ ਬਹੁਤ ਹਿੱਸਾ ਬੁਰਨ ਕਰ ਦਿੱਤਾ। ਤਾਂ ਅਗਲੇ ਹਫਤੇ ਦਾ "ਇੱਕ ਵੱਡਾ ਫੀਚਰ" ਬਣਨ ਦੀ ਬਜਾਏ "DB index ਜੋੜੋ, ਮਾਈਗਰੇਸ਼ਨਾਂ ਨੂੰ ਸੇਫ਼ ਬਣਾਓ, ਅਤੇ create-project ਫੇਲ 'ਤੇ ਅਲਰਟ ਜੋੜੋ"।
ਨਤੀਜਾ ਪੂਰੀ ਤਰ੍ਹਾਂ ਰਿਲਾਇਬਿਲਟੀ ਨਹੀਂ ਹੈ। ਇਹ ਘੱਟ ਦੁਹਰਾਉਂਦੀਆਂ ਸਮੱਸਿਆਵਾਂ, ਸਪੱਸ਼ਟ ਹਾਂ/ਨਹੀਂ ਫੈਸਲੇ, ਅਤੇ ਘੱਟ ਦੇਰ ਰਾਤ ਵਾਲੇ ਘਬਰਾਏ ਹਾਲਾਤ ਹਨ ਕਿਉਂਕਿ ਉਨ੍ਹਾਂ ਨੇ ਪਹਿਲਾਂ ਹੀ ਫੈਸਲਾ ਕਰ ਲਿਆ ਕਿ "ਕਾਫੀ ਨੁਕਸান" ਕੀ ਹੈ।
ਇੱਕ ਯੂਜ਼ਰ ਯਾਤਰਾ ਚੁਣੋ ਅਤੇ ਉਸ 'ਤੇ ਸਧਾਰਣ ਰਿਲਾਇਬਿਲਟੀ ਵਾਅਦਾ ਕਰੋ। ਗਲਤੀ ਬਜਟ ਸਭ ਤੋਂ ਵਧੀਆ ਤਰ੍ਹਾਂ ਉਦਾਸ ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਹੋਣ ਤੇ ਕੰਮ ਕਰਦੇ ਹਨ, ਨਾ ਕਿ ਪੂਰੇ-ਪਰਫੈਕਸ਼ਨ 'ਤੇ।
ਇੱਕ SLO ਅਤੇ ਇੱਕ ਹਫਤਾਵਾਰੀ ਰੀਤ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਜੇ ਇੱਕ ਮਹੀਨੇ ਬਾਅਦ ਇਹ ਅਜੇ ਵੀ ਅਸਾਨ ਲੱਗੇ, ਤਾਂ ਦੂਜਾ SLO ਜੋੜੋ। ਜੇ ਭਾਰੀ ਲੱਗੇ, ਤਾਂ ਇਸਨੂੰ ਘਟਾਓ।
ਹਿਸਾਬ ਸਧਾਰਣ ਰੱਖੋ (ਹਫਤੇ ਜਾਂ ਮਹੀਨੇ)। ਟਾਰਗੇਟ ਉਹੀ ਰੱਖੋ ਜੋ ਤੁਹਾਡੇ ਮੌਜੂਦਾ ਹਾਲਾਤ ਲਈ ਯਥਾਰਥ ਹੈ। ਇੱਕ ਇਕ-ਪੇਜ਼ ਰਿਲਾਇਬਿਲਟੀ ਨੋਟ ਲਿਖੋ ਜਿਸ 'ਚ ਇਹ ਸਭ ਹੋਵੇ: SLO ਅਤੇ ਇਸਦਾ ਮਾਪਣ, ਕੀ ਗਿਣਿਆ ਜਾਣਾ ਹੈ ਇਨਸੀਡੈਂਟ ਵਜੋਂ, ਇਸ ਹਫਤੇ ਕੌਣ ਜਵਾਬਦੇਹ ਹੈ, ਚੈਕ-ਇਨ ਕਦੋਂ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਬਜਟ ਤੀਜ਼ੀ ਨਾਲ ਬਰਨ ਹੋਵੇ ਤਾਂ ਡਿਫ਼ਾਲਟ ਵਿੱਚ ਕੀ ਕਰਦੇ ਹੋ।
If you’re building on a platform like Koder.ai (koder.ai), it can help to pair fast iteration with safety habits, especially snapshots and rollback, so “revert to last good state” stays a normal, practiced move.
ਲੂਪ ਘੱਟ ਰੱਖੋ: ਇੱਕ SLO, ਇੱਕ ਨੋਟ, ਇੱਕ ਛੋਟੀ ਹਫਤਾਵਾਰੀ ਚੈਕ-ਇਨ। ਮਕਸਦ ਇਨਸੀਡੈਂਟਾਂ ਨੂੰ ਖਤਮ ਕਰਨਾ ਨਹੀਂ। ਮਕਸਦ ਹੈ ਜਲਦੀ ਨੋਟਿਸ ਕਰਨਾ, ਠੰਢੇ ਦਿਲ ਨਾਲ ਫੈਸਲਾ ਕਰਨਾ, ਅਤੇ ਉਹ ਕੁਝ ਚੀਜ਼ਾਂ ਬਚਾਉਣਾ ਜੋ ਯੂਜ਼ਰ ਹਕੀਕਤ ਵਿੱਚ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ।
An SLO is a reliability promise about a user experience, measured over a time window (like 7 or 30 days).
Example: “99.5% of checkouts succeed over the last 7 days.”
An error budget is the allowed amount of “bad” within your SLO.
If your SLO is 99.5% success, your budget is 0.5% failures in that window. When you burn the budget too fast, you slow risky changes and fix the causes.
Start with 1–3 journeys users notice immediately:
If those are reliable, most other issues feel smaller and are easier to prioritize later.
Pick a baseline you can actually meet most weeks.
If you’re at 98.5% today, starting at 98–98.5% is more useful than declaring 99.9% and ignoring it.
Use simple counting: attempts vs. successes.
Good starter data sources:
Don’t wait for perfect observability; start with a proxy you trust and keep it consistent.
Count it if an external user would notice and fail to complete a protected journey.
Common “counts against budget” examples:
Don’t count internal-only inconvenience unless internal use is the main product usage.
A simple rule: page on budget burn, not on every blip.
Two useful alert types:
This reduces alert fatigue and focuses attention on issues that will change what you ship next.
Keep it to 20 minutes, same time, same doc:
End with a release mode for the week: Normal, Cautious, or Freeze (only that area).
Use a default policy that’s easy to say out loud:
The goal is a calm trade-off, not blame.
A few practical guardrails help:
If you’re building on a platform like Koder.ai, make “revert to last good state” a routine move, and treat repeated rollbacks as a signal to invest in tests or safer deploy checks.