18 ਅਗ 2025·8 ਮਿੰਟ
Chris Lattner ਦਾ LLVM: ਆਧੁਨਿਕ ਟੂਲਚੇਨਾਂ ਦੇ ਪਿੱਛੇ ਸ਼ਾਂਤ ਇੰਜਨ
ਜਾਣੋ ਕਿ Chris Lattner ਦਾ LLVM ਕਿਵੇਂ ਭਾਸ਼ਾਵਾਂ ਅਤੇ ਟੂਲਾਂ ਦੇ ਪਿੱਛੇ ਮਾਡਿਊਲਰ ਕੰਪਾਇਲਰ ਪਲੇਟਫਾਰਮ ਬਣਿਆ—ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ, ਬਿਹਤਰ ਡਾਇਗਨੋਸਟਿਕਸ ਅਤੇ ਤੇਜ਼ ਬਿਲਡ ਲਈ ਇੱਕ ਸਾਂਝਾ ਕੋਰ।
##LLVM ਕੀ ਹੈ, ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ
LLVM ਨੂੰ ਉਹ “ਇੰਜਿਨ ਰੂਮ” ਸਮਝੋ ਜੋ ਕਈ ਕੰਪਾਇਲਰਾਂ ਅਤੇ ਡਿਵੈਲਪਰ ਟੂਲਾਂ ਨੇ ਸਾਂਝਾ ਕੀਤਾ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ C, Swift, ਜਾਂ Rust ਵਰਗੀ ਭਾਸ਼ਾ ਵਿੱਚ ਕੋਡ ਲਿਖਦੇ ਹੋ, ਤਾਂ ਕੁਝ ਨਾ ਕੁਝ ਉਸ ਕੋਡ ਨੂੰ ਉਹਨਾਂ ਹਦਾਇਤਾਂ ਵਿੱਚ ਬਦਲਣਾ ਪੈਂਦਾ ਹੈ ਜੋ ਤੁਹਾਡਾ CPU ਚਲਾਉ ਸਕੇ। ਰਵਾਇਤੀ ਕੰਪਾਇਲਰ ਅਕਸਰ ਪੂਰੀ ਪਾਈਪਲਾਈਨ ਖੁਦ ਬਣਾਉਂਦੇ ਸਨ। LLVM ਵੱਖਰੀ ਰਾਹ ਲੈਂਦਾ ਹੈ: ਇਹ ਇੱਕ ਉੱਚ ਗੁਣਵੱਤਾ ਵਾਲਾ, ਮੁੜ-ਵਰਤੋਂਯੋਗ ਕੋਰ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ ਜੋ ਸਖ਼ਤ, ਮਹਿੰਗੇ ਹਿੱਸਿਆਂ — ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ, ਵਿਸ਼ਲੇਸ਼ਣ, ਅਤੇ ਵੱਖ-ਵੱਖ ਪ੍ਰੋਸੈਸਰਾਂ ਲਈ ਮਸ਼ੀਨ ਕੋਡ ਬਣਾਉਣਾ — ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ।
ਕਈ ਭਾਸ਼ਾਵਾਂ ਲਈ ਇੱਕ ਸਾਂਝੀ ਨੀਵ
ਬਹੁਤ ਵਾਰ LLVM ਇੱਕ ਇਕੱਲਾ ਕੰਪਾਇਲਰ ਨਹੀਂ ਹੁੰਦਾ ਜੋ ਤੁਸੀਂ ਸਿੱਧਾ ਵਰਤਦੇ ਹੋ। ਇਹ ਕੰਪਾਇਲਰ ਢਾਂਚਾ ਹੈ: ਜਿਨ੍ਹਾਂ ਨੀਮਾਂ ਤੋਂ ਭਾਸ਼ਾ ਟੀਮਾਂ ਇਕ ਟੂਲਚੇਨ ਬਣਾਉਂਦੀਆਂ ਹਨ। ਇੱਕ ਟੀਮyntax, semantics, ਅਤੇ ਵਿਕਾਸਕਾਰ-ਮੁੱਖ ਫੀਚਰਾਂ 'ਤੇ ਧਿਆਨ ਦੇ ਸਕਦੀ ਹੈ, ਫਿਰ ਭਾਰੀ ਕੰਮ LLVM ਨੂੰ ਦੇ ਸਕਦੀ ਹੈ।
ਇਹ ਸਾਂਝੀ ਨੀਵ ਇਸ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿ ਆਧੁਨਿਕ ਭਾਸ਼ਾਵਾਂ ਤੇਜ਼, ਸੁਰੱਖਿਅਤ ਟੂਲਚੇਨ ਬਿਨਾਂ ਪਿਛਲੇ ਦਹਾਕਿਆਂ ਦੀ ਕੰਪਾਇਲਰ ਮਿਹਨਤ ਨੂੰ ਦੁਹਰਾਏ ਬਗੈਰ ਰਲੀਜ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ ਕੰਪਾਇਲਰ ਵਿਸ਼ੇ ਨਹੀਂ ਜਾਣਦੇ ਤਾਂ ਭੀ ਇਹ ਮਹੱਤਵ ਰੱਖਦਾ ਹੈ
LLVM ਰੋਜ਼ਾਨਾ ਵਿਕਾਸਕਾਰ ਅਨੁਭਵ ਵਿੱਚ ਇਸ ਤਰ੍ਹਾਂ ਮੌਜੂਦ ਹੈ:
- ਰੇਖਾ: ਇਹ ਉੱਚ-ਸਤਰ ਦੇ ਕੋਡ ਨੂੰ ਵੱਖ-ਵੱਖ ਪਲੇਟਫਾਰਮਾਂ 'ਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਮਸ਼ੀਨ ਕੋਡ ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ।
- ਵਧੀਆ ਐਰਰ ਅਤੇ ਡੀਬੱਗਿੰਗ: LLVM ਦੇ ਆਸਪਾਸ ਦਾ ਇੱਕੋਸਿਸਟਮ ਰਿਚ ਡਾਇਗਨੋਸਟਿਕ ਅਤੇ ਬੇਹਤਰ ਟੂਲਿੰਗ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
- ਸਿਰਫ "ਸੰਪਾਇਲ" ਹੀ ਨਹੀਂ: ਸਟੈਟਿਕ ਵਿਸ਼ਲੇਸ਼ਣ, ਸੇਨੀਟਾਈਜ਼ਰ, ਕੋਡ ਕਵਰੇਜ, ਅਤੇ ਹੋਰ ਡਿਵੈਲਪਰ ਸਹਾਇਕ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕੋ ਹੀ ਮੱਧਵਰਤਨ ਅਤੇ ਲਾਇਬ੍ਰੇਰੀਆਂ 'ਤੇ ਬਣਦੇ ਹਨ।
ਇਹ ਲੇਖ ਕੀ ਦਿਖਾਏਗਾ (ਅਤੇ ਕੀ ਨਹੀਂ)
ਇਹ Chris Lattner ਦੁਆਰਾ ਸ਼ੁਰੂ ਕੀਤੀਆਂ ਵਿਚਾਰਧਾਰਾਵਾਂ ਦਾ ਇੱਕ ਗਾਈਡਡ ਟੂਰ ਹੈ: LLVM ਕਿਵੇਂ ਰਚਿਆ ਗਿਆ, ਮੱਧ ਲੇਅਰ ਕੌਣ ਸੀ, ਅਤੇ ਇਹ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਅਤੇ ਮਲਟੀ-ਪਲੇਟਫਾਰਮ ਸਹਾਇਤਾ ਨੂੰ ਕਿਵੇਂ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ। ਇਹ ਕਿਸੇ ਟੈਕਸਟਬੁੱਕ ਵਰਗਾ ਨਹੀਂ—ਅਸੀਂ ਸਿਧਾਂਤਾਂ ਦੀ ਬਜਾਏ ਭਾਵਨਾ ਅਤੇ ਵਾਸਤਵਿਕ ਪ੍ਰਭਾਵ 'ਤੇ ਧਿਆਨ ਰਖਾਂਗੇ।
Chris Lattner ਦੀ ਮੂਲ ਦ੍ਰਿਸ਼ਟੀ
Chris Lattner ਇੱਕ ਕੰਪਿਊਟਰ ਵਿਗਿਆਨੀ ਅਤੇ ਇੰਜੀਨੀਅਰ ਹਨ ਜੋ 2000 ਦੇ ਆਰੰਭ ਵਿੱਚ ਗ੍ਰੈਜੂਏਟ ਸਟੂਡੈਂਟ ਦੇ ਤੌਰ 'ਤੇ LLVM ਸ਼ੁਰੂ ਕਰਦੇ ਸਮੇਂ ਇਕ ਵਿਆਵਹਾਰਿਕ ਨਿਰਾਸ਼ਾ ਨਾਲ ਸ਼ੁਰੂ ਹੋਏ: ਕੰਪਾਇਲਰ ਤਕਨਾਲੋਜੀ ਸ਼ਕਤੀਸ਼ਾਲੀ ਸੀ, ਪਰ ਮੁੜ ਵਰਤੋਂ ਲਈ ਕਠਿਨ। ਨਵੀਂ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ ਬਣਾਉਣ ਜਾਂ ਨਵੇਂ CPU ਲਈ ਸਹਾਇਤਾ ਦਿਣ ਲਈ ਅਕਸਰ ਤੁਹਾਨੂੰ ਇਕ ਕਠੋਰ-ਜੁੜੇ "ਆਲ-ਇਨ-ਵਨ" ਕੰਪਾਇਲਰ ਨਾਲ ਛੇਡ-ਛਾੜ ਕਰਨੀ ਪੈਂਦੀ ਸੀ ਜਿਥੇ ਹਰ ਬਦਲਾਅ ਦੇ ਸਾਈਡ ਇਫੈਕਟ ਸਨ।
ਜਿਸ ਸਮੱਸਿਆ ਨੂੰ ਉਸਨੇ ਹੱਲ ਕਰਨਾ ਕੀਤਾ
ਉਸ ਸਮੇਂ, ਬਹੁਤ ਸਾਰੇ ਕੰਪਾਇਲਰ ਇਕ ਵੱਡੀ ਮਸ਼ੀਨ ਵਾਂਗ ਬਣੇ ਹੋਏ ਸਨ: ਭਾਸ਼ਾ ਸਮਝਣ ਵਾਲਾ ਹਿੱਸਾ, ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਹਿੱਸਾ, ਅਤੇ ਮਸ਼ੀਨ ਕੋਡ ਬਣਾਉਣ ਵਾਲਾ ਹਿੱਸਾ ਗਹਿਰਾਈ ਨਾਲ ਇਕੱਠੇ ਸਨ। ਇਸ ਨਾਲ ਉਹ ਆਪਣੇ ਮੌਲਿਕ ਉਦੇਸ਼ ਲਈ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੋ ਸਕਦੇ ਸਨ, ਪਰ ਅਨੁਕੂਲ ਕਰਨ ਵਿੱਚ ਮਹਿੰਗੇ ਸਾਬਿਤ ਹੁੰਦੇ ਸਨ।
Lattner ਦਾ ਲੱਕੜਾ ਇਹ ਨਹੀਂ ਸੀ ਕਿ "ਇੱਕ ਭਾਸ਼ਾ ਲਈ ਕੰਪਾਇਲਰ" ਬਣਾਇਆ ਜਾਵੇ। ਇਹ ਇੱਕ ਸਾਂਝਾ ਨੀਵ ਬਣਾਉਣ ਦਾ ਟੀਕਾ ਸੀ ਜੋ ਕਈ ਭਾਸ਼ਾਵਾਂ ਅਤੇ ਟੂਲਾਂ ਨੂੰ ਚਲਾ ਸਕੇ—ਟੁੱਟ-ਫੁੱਟ ਹਿੱਸਿਆਂ ਨੂੰ ਹਰ ਵਾਰੀ ਦੁਬਾਰਾ ਨਹੀਂ ਲਿਖਣਾ ਪਵੇ। ਬੀਟ ਇਹ ਸੀ ਕਿ ਜੇ ਤੁਸੀਂ ਪਾਈਪਲਾਈਨ ਦੇ ਮੱਧ ਨੂੰ ਮਿਆਰੀਕ੍ਰਿਤ ਕਰਨ ਵਿੱਚ ਸਫਲ ਹੋ ਗਏ, ਤਾਂ ਕਿਨਾਰੇ ਤੇ ਨਵੀਨਤਾ ਤੇਜ਼ੀ ਨਾਲ ਹੋ ਸਕਦੀ ਸੀ।
"ਮੋਡੀਊਲਰ ਇੰਫ੍ਰਾਸਟ੍ਰਕਚਰ" کیوں ਤਾਜ਼ਾ ਵਿਚਾਰ ਸੀ
ਮੁੱਖ ਬਦਲਾਅ ਇਹ ਸੀ ਕਿ ਕੰਪਿਲੇਸ਼ਨ ਨੂੰ ਵੱਖ-ਵੱਖ ਵੱਖਰੇ ਬਲਾਕਾਂ ਦੇ ਤੌਰ 'ਤੇ ਦੇਖਿਆ ਗਿਆ ਜਿਨ੍ਹਾਂ ਦੇ ਸਾਫ਼ ਸਰਹੱਦ ਹੁੰਦੇ ਹਨ। ਇੱਕ ਮੋਡੀਊਲਰ ਦੁਨੀਆ ਵਿੱਚ:
- ਇੱਕ ਭਾਸ਼ਾ ਟੀਮ পারਸਿੰਗ ਅਤੇ ਡਿਵੈਲਪਰ-ਮੁੱਖ ਫੀਚਰਾਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਕਰ ਸਕਦੀ ਹੈ,
- ਇੱਕ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਟੀਮ ਇੱਕ ਵਾਰੀ ਬਿਹਤਰੀ ਕਰਕੇ ਉਸਨੂੰ ਚੌੜੇ ਪੱਧਰ 'ਤੇ ਸਾਂਝਾ ਕਰ ਸਕਦੀ ਹੈ,
- ਹਾਰਡਵੇਅਰ ਸਹਾਇਤਾ ਨੂੰ ਉੱਪਸਟ੍ਰੀਮ ਨੂੰ ਦੁਬਾਰਾ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਬਿਨਾਂ ਜੋੜਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਹੁਣ ਇਹ ਗੱਲ ਸਪਸ਼ਟ ਲੱਗਦੀ ਹੈ ਪਰ ਉਸ ਸਮੇਂ ਇਹ ਬਹੁਤ ਸਾਰੀਆਂ ਉਤਪਾਦਕ ਕੰਪਾਇਲਰਾਂ ਦੀ ਵਿਕਾਸ ਰੀਤ ਦੇ ਵਿਰੋਧ ਸੀ।
ਖੁੱਲ੍ਹਾ ਸਰੋਤ, ਦੂਜਿਆਂ ਵੱਲੋਂ ਵਰਤਣ ਲਈ ਬਣਾਇਆ ਗਿਆ
LLVM ਨੂੰ ਸ਼ੁਰੂ ਵਿੱਚ ਹੀ ਖੁੱਲ੍ਹਾ ਸਰੋਤ ਰਿਹਾ ਗਿਆ, ਜੋ ਮਹੱਤਵਪੂਰਨ ਸੀ ਕਿਉਂਕਿ ਇੱਕ ਸਾਂਝਾ ਢਾਂਚਾ ਤਦੋਂ ਹੀ ਕਾਰਗਰ ਹੁੰਦਾ ਹੈ ਜਦ ਕਈ ਗਰੁੱਪ ਉਸ 'ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਣ, ਜਾਂਚ ਕਰ ਸਕਣ, ਅਤੇ ਵਧਾ ਸਕਣ। ਸਮੇਂ ਨਾਲ, ਯੂਨੀਵਰਸਿਟੀਆਂ, ਕੰਪਨੀਆਂ, ਅਤੇ ਖੁਦਮੁਖਤਾਰ ਯੋਗਦਾਨਕਾਰੀਆਂ ਨੇ ਪ੍ਰਾਜੈਕਟ ਨੂੰ ਨਵੇਂ ਟарਗੇਟ, ਕੋਨਰ ਕੇਸਾਂ ਦੀ ਠੀਕ-ਥਾਕ, ਪ੍ਰਦਰਸ਼ਨ ਸੁਧਾਰ ਅਤੇ ਨਵੇਂ ਟੂਲ ਬਣਾਕੇ ਸੰਵਾਰਿਆ।
ਇਹ ਕਮੀਉਨਿਟੀ ਪਹਲੂ ਸਿਰਫ਼ ਭਲਾਈ ਨਹੀਂ ਸੀ—ਇਹ ਡਿਜ਼ਾਈਨ ਦਾ ਹਿੱਸਾ ਸੀ: ਕੋਰ ਨੂੰ ਚੌੜੇ ਪੱਧਰ 'ਤੇ ਉਪਯੋਗੀ ਬਣਾਓ, ਤੇ ਇਹ ਇਕੱਠੇ ਸੰਭਾਲਣ ਯੋਗ ਬਣ ਜਾਵੇਗਾ।
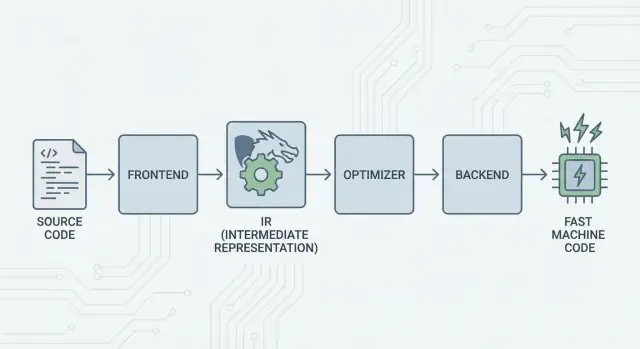
ਵੱਡਾ ਖ਼ਿਆਲ: ਫਰੰਟਏਂਡ, ਸਾਂਝਾ ਕੋਰ, ਅਤੇ ਬੈਕਏਂਡ
LLVM ਦਾ ਮੁੱਖ ਖ਼ਿਆਲ ਸਾਦਾ ਹੈ: ਇਕ ਕੰਪਾਇਲਰ ਨੂੰ ਤਿੰਨ ਮੁੱਖ ਹਿੱਸਿਆਂ ਵਿੱਚ ਵੰਡੋ ਤਾਂ ਕਿ ਕਈ ਭਾਸ਼ਾਵਾਂ ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਕੰਮ ਸਾਂਝੇ ਕਰ ਸਕਣ।
1) ਫਰੰਟਏਂਡ: "ਪ੍ਰੋਗ੍ਰਾਮਰ ਦਾ ਕੀ ਅਰਥ ਸੀ?"
ਇੱਕ ਫਰੰਟਏਂਡ ਇੱਕ ਨਿਰਧਾਰਿਤ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ ਨੂੰ ਸਮਝਦਾ ਹੈ। ਇਹ ਤੁਹਾਡੇ ਸਰੋਤ ਕੋਡ ਨੂੰ ਪੜ੍ਹਦਾ ਹੈ, ਨਿਯਮ (syntax ਅਤੇ types) ਦੀ ਜਾਂਚ ਕਰਦਾ ਹੈ, ਅਤੇ ਉਸਨੂੰ ਇੱਕ ਸੰਰਚਿਤ ਪ੍ਰਤੀਨਿਧਤਾ ਵਿੱਚ ਬਦਲਦਾ ਹੈ।
ਮੁੱਖ ਗੱਲ: ਫਰੰਟਏਂਡਜ਼ ਨੂੰ ਹਰ CPU ਵੇਰਵੇ ਦੀ ਜਾਣਕਾਰੀ ਰੱਖਣ ਦੀ ਲੋੜ ਨਹੀਂ। ਉਨ੍ਹਾਂ ਦਾ ਕੰਮ ਭਾਸ਼ਾ ਸੰਕਲਪਾਂ—ਫੰਕਸ਼ਨਾਂ, ਲੂਪਾਂ, ਵੈਰੀਏਬਲਾਂ—ਨੂੰ ਇੱਕ ਜਿਆਦਾ ਸਰਬ-ਭਾਸ਼ਾਈ ਰੂਪ ਵਿੱਚ ਤਬਦੀਲ ਕਰਨਾ ਹੈ।
2) ਸਾਂਝਾ ਮੱਧ: N×M ਕੰਮ ਦੀ ਬਜਾਏ ਇੱਕ ਆਮ ਕੋਰ
ਰਵਾਇਤੀ ਤੌਰ 'ਤੇ, ਇੱਕ ਕੰਪਾਇਲਰ ਬਣਾਉਣ ਦਾ ਮਤਲਬ ਇੱਕੋ ਕੰਮ ਨੂੰ ਵਾਰ-ਵਾਰ ਕਰਨਾ ਸੀ:
- N ਭਾਸ਼ਾਵਾਂ ਅਤੇ M ਚਿਪ ਟਾਰਗੇਟਾਂ ਨਾਲ, ਤੁਹਾਡੇ ਕੋਲ N×M ਸੰਯੋਜਨਾਂ ਦੀ ਲਿਸਟ ਹੋ ਜਾਂਦੀ ਸੀ।
LLVM ਇਸਨੂੰ ਘਟਾ ਕੇ:
- N ਫਰੰਟਏਂਡ ਜੋ ਇੱਕ ਸਾਂਝੇ ਰੂਪ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦੇ ਹਨ,
- M ਬੈਕਏਂਡ ਜੋ ਉਸ ਸਾਂਝੇ ਰੂਪ ਤੋਂ ਮਸ਼ੀਨ ਕੋਡ ਬਣਾਉਂਦੇ ਹਨ।
ਇਹ "ਸਾਂਝਾ ਰੂਪ" LLVM ਦਾ ਕੇਂਦਰ ਹੈ: ਇੱਕ ਆਮ ਪਾਈਪਲਾਈਨ ਜਿੱਥੇ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਰਹਿੰਦੇ ਹਨ। ਮੱਧ ਵਿੱਚ ਸੁਧਾਰ (ਉਦਾਹਰਨ ਵਜੋਂ ਬਿਹਤਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਜਾਂ ਡੀਬੱਗ ਇੰਫੋ) ਕਈ ਭਾਸ਼ਾਵਾਂ ਨੂੰ ਇਕੱਠੇ ਲਾਭ ਦੇ ਸਕਦੇ ਹਨ।
3) ਬੈਕਏਂਡ: "ਇਸਨੂੰ ਕਿਸ ਤਰ੍ਹਾਂ ਉਸ CPU 'ਤੇ ਤੇਜ਼ ਚਲਾਵਾਂ?"
ਇੱਕ ਬੈਕਏਂਡ ਸਾਂਝੇ ਪ੍ਰਤੀਨਿਧੀ ਨੂੰ ਲੈ ਕੇ ਮਸ਼ੀਨ-ਵਿਸ਼ੇਸ਼ ਆਉਟਪੁੱਟ ਤਿਆਰ ਕਰਦਾ ਹੈ: x86, ARM ਆਦਿ ਲਈ ਹੁਕਮ। ਇਥੇ ਰਜਿਸਟਰ, ਕਾਲਿੰਗ ਕਨਵੇਂਸ਼ਨ, ਅਤੇ ਨਿਰਦੇਸ਼ ਚੋਣ ਵਰਗੀਆਂ ਵਿਸਥਾਰ ਭੂਮਿਕਾ ਨਿਭਾਉਂਦੇ ਹਨ।
ਪਾਈਪਲਾਈਨ ਦੀ ਇੱਕ ਬੁਨਿਆਦੀ ਤਸਵੀਰ
ਕੰਪਾਇਲਸ਼ਨ ਨੂੰ ਇਕ ਯਾਤਰਾ ਰਸਤੇ ਵਾਂਗ ਸੋਚੋ:
- ਸਰੋਤ ਕੋਡ ਇੱਕ ਭਾਸ਼ਾ-ਖਾਸਦੇਸ਼ (frontend) ਵਿੱਚ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ।
- ਇਹ ਇੱਕ ਸਾਂਝੇ, ਮਿਆਰੀਕ੍ਰਿਤ "ਮੱਧ ਭਾਸ਼ਾ" (LLVM ਦਾ ਕੋਰ) ਵਿੱਚ ਚਾਲੂ ਹੁੰਦਾ ਹੈ।
- ਫਿਰ ਇਹ ਇੱਕ ਵੀਸ਼ੇਸ਼ ਦਿਸ਼ਾ (ਟਾਰਗੇਟ ਮਸ਼ੀਨ ਲਈ ਬੈਕਏਂਡ) 'ਤੇ ਪੁੱਜਦਾ ਹੈ।
ਨਤੀਜਾ: ਇੱਕ ਮੋਡੀਊਲਰ ਟੂਲਚੇਨ—ਭਾਸ਼ਾਵਾਂ ਵਿਚਾਰ ਪ੍ਰਗਟ ਕਰਨ 'ਤੇ ਧਿਆਨ ਰੱਖ ਸਕਦੀਆਂ ਹਨ, ਜਦਕਿ LLVM ਦਾ ਸਾਂਝਾ ਕੋਰ ਉਹਨਾਂ ਵਿਚਾਰਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਪਲੇਟਫਾਰਮਾਂ 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਚਲਾਉਣਾ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ।
LLVM IR: ਉਹ ਮੱਧ ਪਰਤ ਜੋ ਮੁੜ-ਵਰਤੋਂ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ
LLVM IR (Intermediate Representation) ਉਹ "ਆਮ ਭਾਸ਼ਾ" ਹੈ ਜੋ ਇੱਕ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ ਅਤੇ ਤੁਹਾਡੇ CPU ਦੁਆਰਾ ਚਲਾਏ ਜਾਣ ਵਾਲੇ ਮਸ਼ੀਨ ਕੋਡ ਦੇ ਵਿਚਕਾਰ ਬੈਠਦੀ ਹੈ।
ਇੱਕ ਕੰਪਾਇਲਰ ਫਰੰਟਏਂਡ (ਜਿਵੇਂ Clang C/C++ ਲਈ) ਤੁਹਾਡੇ ਸਰੋਤ ਕੋਡ ਨੂੰ ਇਸ ਸਾਂਝੇ ਰੂਪ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ। ਫਿਰ LLVM ਦੇ ਅਪਟੀਮਾਈਜ਼ਰ ਅਤੇ ਕੋਡ ਜਨਰੇਟਰ IR 'ਤੇ ਕੰਮ ਕਰਦੇ ਹਨ, ਨਾ ਕਿ ਮੂਲ ਭਾਸ਼ਾ 'ਤੇ। ਆਖ਼ਰਕਾਰ, ਇੱਕ ਬੈਕਏਂਡ IR ਨੂੰ ਕਿਸੇ ਖ਼ਾਸ ਟਾਰਗੇਟ ਲਈ ਨਿਰਦੇਸ਼ਾਂ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ (x86, ARM ਆਦਿ)।
ਟੂਲਾਂ ਅਤੇ CPUs ਦੇ ਵਿਚਕਾਰ ਇੱਕ ਆਮ ਭਾਸ਼ਾ
LLVM IR ਨੂੰ ਇੱਕ ਸੋਚ-ਵਿਖਿਆਤ ਪੁਲ ਸਮਝੋ:
- ਉਪਰ: ਕਈ ਸਰੋਤ ਭਾਸ਼ਾਵਾਂ ਜੁੜ ਸਕਦੀਆਂ ਹਨ (C, C++, Rust, Swift, Julia ਆਦਿ)।
- ਥੱਲੇ: ਕਈ CPUs ਟਾਰਗੇਟ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
- ਦਰਮਿਆਨ: ਇੱਕੋ ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਟੂਲ ਮੁੜ-ਵਰਤੋਂ ਯੋਗ ਹੁੰਦੇ ਹਨ।
ਇਸੇ ਲਈ ਲੋਕ ਅਕਸਰ LLVM ਨੂੰ "ਕੰਪਾਇਲਰ ਢਾਂਚਾ" ਕਹਿੰਦੇ ਹਨ ਨਾ ਕਿ ਸਿਰਫ਼ "ਇੱਕ ਕੰਪਾਇਲਰ"। IR ਉਹ ਸਾਂਝਾ ਅਨੁਬੰਧ ਹੈ ਜੋ ਇਸ ਢਾਂਚੇ ਨੂੰ ਮੁੜ-ਵਰਤੋਂਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
IR ਮੁੜ-ਵਰਤੋਂ ਨੂੰ ਕਿਵੇਂ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ
ਜਦੋਂ ਕੋਡ LLVM IR ਵਿੱਚ ਆ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਜ਼ਿਆਦਾਤਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪਾਸਾਂ ਨੂੰ ਇਹ ਜਾਣਣ ਦੀ ਲੋੜ ਨਹੀਂ ਕਿ ਉਹ ਕੋਡ ਕਿਹੜੀ ਭਾਸ਼ਾ ਵਿੱਚ ਲਿਖਿਆ ਗਿਆ ਸੀ। ਉਹ ਆਮ ਆਇਡੀਆਜ਼ 'ਤੇ ਧਿਆਨ ਦਿੰਦੇ ਹਨ:
- "ਇਹ ਮੁੱਲ ਇੱਕ ਸੰਤਤ ਹੈ।"
- "ਇਹ ਹਿਸਾਬ ਬਾਰ-ਬਾਰ ਹੋ ਰਿਹਾ ਹੈ; ਕੀ ਅਸੀਂ ਨਤੀਜਾ ਦੁਬਾਰਾ ਵਰਤ ਸਕਦੇ ਹਾਂ?"
- "ਇਸ ਮੈਮੋਰੀ ਲੋਡ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਹਟਾਇਆ ਜਾਂ ਸਕਦਾ ਹੈ।"
ਇਸ ਲਈ ਭਾਸ਼ਾ ਟੀਮਾਂ ਨੂੰ ਆਪਣਾ ਪੂਰਾ ਅਪਟੀਮਾਈਜ਼ਰ ਸਟੈਕ ਬਣਾਉਣ ਅਤੇ ਸੰਭਾਲਣ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ। ਉਹ ਫਰੰਟਏਂਡ—ਪਾਰਸਿੰਗ, ਟਾਈਪ ਚੈੱਕਿੰਗ, ਭਾਸ਼ਾ-ਖਾਸ ਨਿਯਮ—'ਤੇ ਧਿਆਨ ਕਰਕੇ LLVM ਨੂੰ ਭਾਰੀ ਕੰਮ ਦੇ ਸਕਦੀਆਂ ਹਨ।
ਇਹ ਸੰਕਲਪਾਤਮਕ ਤੌਰ 'ਤੇ ਕਿਵੇਂ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ
LLVM IR ਮਸ਼ੀਨ ਕੋਡ ਨਾਲ ਸਾਫ਼ ਨਕਸ਼ਾ ਬਣਾਉਣ ਲਈ ਨੀਚਾ-ਸਤਰ ਦਾ ਹੁੰਦਾ ਹੈ, ਪਰ ਫਿਰ ਵੀ ਇਨਾ ਬਨਿਆਦੀ ਹੈ ਕਿ ਉਸ 'ਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਕੀਤੀ ਜਾ ਸਕੇ। ਇਹ ਸਧਾਰਨ ਨਿਰਦੇਸ਼ਾਂ (ਜੋੜ, তুলਨਾ, ਲੋਡ/ਸਟੋਰ), ਸਪੱਸ਼ਟ ਕੰਟਰੋਲ ਫ਼ਲੋ (ਸ਼ਾਖਾਂ), ਅਤੇ ਮਜ਼ਬੂਤ-ਟਾਇਪ ਕੀਤੀ ਕੀਮਤਾਂ ਤੋਂ ਬਣਿਆ ਹੋਇਆ—ਇੱਕ ਸਾਫ-ਸੁਥਰਾ ਅਸੈmbler-ਸਹਿਰੂਪ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਮਨੁੱਖਾਂ ਵੱਲੋਂ ਨਹੀਂ ਲਿਖਿਆ ਜਾਂਦਾ।
ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀਆਂ ਹਨ (ਗਣਿਤ ਤੋਂ ਬਿਨਾਂ)
ਜਦੋਂ ਲੋਕ "ਕੰਪਾਇਲਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ" ਸੁਣਦੇ ਹਨ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਰਹਸਮੀ ਤਰੀਕਿਆਂ ਦੀ ਸੋਚ ਕਰਦੇ ਹਨ। LLVM ਵਿੱਚ, ਜ਼ਿਆਦਾਤਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਨੂੰ ਇੱਕ-ਜਹੇ, ਸੁਰੱਖਿਅਤ, ਮਕੈਨਿਕਲ ਰੀਰਾਈਟਸ ਵਾਂਗ ਦੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ—ਟ੍ਰਾਂਸਫਾਰਮੇਸ਼ਨ ਜੋ ਕੋਡ ਦਾ ਅਰਥ ਬਰਕਰਾਰ ਰੱਖਦੇ ਹਨ ਪਰ ਉਸਨੂੰ ਤੇਜ਼ (ਜਾਂ ਛੋਟਾ) ਬਣਾਉਂਦੇ ਹਨ।
ਇਸਨੂੰ ਇਕ ਸੰਪਾਦਨ ਵਾਂਗ ਸੋਚੋ, ਨਾ ਕਿ ਨਵੀਨਤਾ
LLVM ਤੁਹਾਡੇ ਕੋਡ (LLVM IR ਵਿੱਚ) ਨੂੰ ਲੈ ਕੇ ਛੋਟੀ-ਛੋਟੀ ਸੁਧਾਰਾਂ ਨੂੰ ਬਾਰ-ਬਾਰ ਲਗਾਉਂਦਾ ਹੈ, ਬਿਲਕੁਲ ਇੱਕ ਡਰਾਫਟ ਨੂੰ ਪੋਲਿਸ਼ ਕਰਨ ਵਾਂਗ:
- ਨਕਲਵਾਰ ਕੰਮ ਹਟਾਓ: ਜੇ ਕੋਈ ਕੀਮਤ ਦੋ ਵਾਰੀ ਗਣਨਾ ਹੁੰਦੀ ਹੈ ਤੇ ਦਰਮਿਆਨ ਕੁਝ ਨਹੀਂ ਬਦਲਦਾ, LLVM ਇੱਕ ਵਾਰੀ ਗਣਨਾ ਕਰਕੇ ਨਤੀਜਾ ਦੁਬਾਰਾ ਵਰਤ ਸਕਦਾ ਹੈ।
- ਸਾਹਮਣੇ ਲੋジਕ ਸਧਾਰੋ: ਨਿਰੰਤਰ ਅਭਿਵਿਆਕਤੀਆਂ ਪਹਿਲਾਂ ਹੀ ਜੋੜ ਕੇ (ਉਦਾਹਰਨ ਲਈ
3 * 4ਨੂੰ12), CPU ਨੂੰ ਰਨਟਾਈਮ ਤੇ ਘੱਟ ਕੰਮ ਕਰਨਾ ਪੈਂਦਾ ਹੈ। - ਲੂਪ ਸਧਾਰਨਾ: ਲੂਪ-ਸਬੰਧੀ ਪਾਸ ਲੂਪ-ਚਾਲੂ ਕੰਮ ਨੂੰ ਘਟਾ ਸਕਦੇ ਹਨ, ਅਸਥਿਰ ਕੰਮ ਨੂੰ ਲੂਪ ਤੋਂ ਬਾਹਰ ਖਿਚ ਸਕਦੇ ਹਨ, ਜਾਂ ਪੈਟਰਨਾਂ ਨੂੰ ਪ੍ਰਤੀਚਿਤ ਕਰ ਸਕਦੇ ਹਨ ਜੋ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਚਲਦੇ ਹਨ।
ਇਹ ਬਦਲਾਅ ਜ਼ਿਮਮੇਵਾਰ ਹਨ—ਇੱਕ ਪਾਸ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਬਦਲ ਕਰਦਾ ਹੈ ਜਦ ਇਹ ਸਾਬਤ ਕੀਤਾ ਜਾ ਸਕੇ ਕਿ ਕੋਡ ਦਾ ਅਰਥ ਨਹੀਂ ਬਦਲੇਗਾ।
ਰੁਝਾਨੀ ਉਦਾਹਰਣਾਂ
ਜੇ ਤੁਹਾਡੇ ਪ੍ਰੋਗਰਾਮ ਵਿੱਚ ਇਹ ਅਕਸਰ ਹੁੰਦਾ ਹੈ:
- ਹਰ ਇਟਰੈਸ਼ਨ ਵਿੱਚ ਇੱਕੋ ਕੰਫਿਗਰੇਸ਼ਨ ਮੁੱਲ ਨੂੰ ਪੜ੍ਹਨਾ
- ਇੱਕੋ ਇਨਪੁੱਟ 'ਤੇ ਇੱਕੋ ਗਣਨਾ ਕਈ ਥਾਵਾਂ ਤੇ ਕਰਨਾ
- ਇੱਕ ਸ਼ਰਤ ਜੋ ਕਿਸੇ ਸੰਦਰਭ ਵਿੱਚ ਹਮੇਸ਼ਾ ਸੱਚ/ਝੂਠ ਹੈ
…ਤਾ LLVM ਇਸਨੂੰ "ਇੱਕ ਵਾਰੀ ਸੈਟਅੱਪ ਕਰੋ," "ਨਤੀਜੇ ਨੂੰ ਦੁਬਾਰਾ ਵਰਤੋਂ," ਅਤੇ "ਮੁਰੱਛੇ ਹੋਏ ਸ਼ਾਖਾਂ ਨੂੰ ਮਿਟਾਓ" ਵਿੱਚ ਬਦਲਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੇਗਾ। ਇਹ ਜਾਦੂ ਤੋਂ ਘੱਟ ਅਤੇ ਘਰੇਲੂ ਸਫਾਈ ਵਾਂਗ ਹੈ।
ਅਸਲ ਟਰੇਡ-ਆਫ: ਕੰਪਾਈਲ ਸਮਾਂ ਵਿਰੁੱਧ ਰਨਟਾਈਮ
ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਮੁਫ਼ਤ ਨਹੀਂ ਹੁੰਦੀ: ਹੋਰ ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਪਾਸ ਆਮ ਤੌਰ 'ਤੇ ਕੰਪਾਇਲੇਸ਼ਨ ਨੂੰ ਢੀਲਾ ਕਰਦੇ ਹਨ, ਭਾਵੇਂ ਆਖ਼ਰੀ ਪ੍ਰੋਗਰਾਮ ਤੇਜ਼ ਚੱਲੇ। ਇਸੀ ਲਈ ਟੂਲਚੇਨ ਵੱਖ-ਵੱਖ ਸਤਰਾਂ ਦੀ ਪੇਸ਼ਕਸ਼ ਕਰਦੇ ਹਨ—"ਥੋੜ੍ਹਾOptimize" ਜਾਂ "ਜਬਰਦਸਤOptimize".
ਪ੍ਰੋਫਾਈਲਸ ਇੱਥੇ ਸਹਾਇਕ ਹੁੰਦੇ ਹਨ। profile-guided optimization (PGO) ਨਾਲ ਤੁਸੀਂ ਪ੍ਰੋਗਰਾਮ ਚਲਾਕੇ ਅਸਲੀ ਵਰਤੋਂ ਡੇਟਾ ਇਕੱਤਰ ਕਰਦੇ ਹੋ, ਫਿਰ ਦੁਬਾਰਾ ਕੰਪਾਇਲ ਕਰਕੇ LLVM ਨੂੰ ਉਹ ਰਸਤੇ ਤੇ ਧਿਆਨ ਦੇਣ ਲਈ ਕਹਿੰਦੇ ਹੋ ਜੋ ਅਸਲ ਵਿੱਚ ਮਹੱਤਵਪੂਰਨ ਹਨ—ਇਸ ਤਰ੍ਹਾਂ ਟਰੇਡ-ਆਫ਼ ਨਿੱਤ ਪ੍ਰਾਪਤੀਯੋਗ ਬਣ ਜਾਂਦਾ ਹੈ।
ਬੈਕਏਂਡ: ਬਿਨਾਂ ਹਰ ਚੀਜ਼ ਨੂੰ ਮੁੜ-ਲਿਖੇ ਕਈ CPUs ਤੱਕ ਪਹੁੰਚ
ਇੱਕ ਕੰਪਾਇਲਰ ਦੇ ਦੋ ਹੋਰ ਵੱਖ-ਵੱਖ ਕੰਮ ਹੁੰਦੇ ਹਨ। ਪਹਿਲਾ, ਇਹ ਤੁਹਾਡੇ ਸਰੋਤ ਕੋਡ ਨੂੰ ਸਮਝਦਾ ਹੈ। ਦੂਜਾ, ਇਹ ਖ਼ਾਸ CPU ਲਈ ਐਸਾ ਮਸ਼ੀਨ ਕੋਡ ਤਿਆਰ ਕਰਦਾ ਹੈ ਜੋ ਚਲ ਸਕੇ। LLVM ਬੈਕਏਂਡਾਂ ਉਸ ਦੂਜੇ ਕੰਮ 'ਤੇ ਧਿਆਨ ਕਰਦੀਆਂ ਹਨ।
ਇੱਕ ਬੈਕਏਂਡ ਅਸਲ ਵਿੱਚ ਕੀ ਕਰਦਾ ਹੈ
LLVM IR ਨੂੰ "ਯੂਨੀਵਰਸਲ ਰੈਸਪੀ" ਸਮਝੋ ਜੋ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਕੀ ਕਰਨਾ ਹੈ ਦੱਸਦੀ ਹੈ। ਇੱਕ ਬੈਕਏਂਡ ਉਸ ਰੈਸਪੀ ਨੂੰ ਕਿਸੇ ਨਿਰਧਾਰਿਤ ਪ੍ਰੋਸੈਸਰ ਪਰਿਵਾਰ ਲਈ ਅਨੁਕੂਲ ਹੁਕਮਾਂ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ—x86-64 ਡੈਸਕਟਾਪ/ਸਰਵਰ ਲਈ, ARM64 ਫੋਨ/ਨਵੇਂ ਲੈਪਟਾਪ ਲਈ, ਜਾਂ WebAssembly ਵਰਗੇ ਵਿਸ਼ੇਸ਼ ਟਾਰਗੇਟ ਲਈ।
ਠੋਸ ਤੌਰ 'ਤੇ, ਇੱਕ ਬੈਕਏਂਡ ਜ਼ਿੰਮੇਵਾਰ ਹੁੰਦਾ ਹੈ:
- ਨਿਰਦੇਸ਼ ਚੋਣ: IR ਓਪਰੇਸ਼ਨਾਂ ਨੂੰ ਅਸਲ CPU ਨਿਰਦੇਸ਼ਾਂ ਨਾਲ ਮੈਪ ਕਰਨਾ
- ਰਜਿਸਟਰ ਅਲੋਕੇਸ਼ਨ: ਕਿਹੜੀਆਂ ਕੀਮਤਾਂ ਤੇਜ਼ CPU ਰਜਿਸਟਰਾਂ ਵਿੱਚ ਰਹਿਣੀਆਂ ਹਨ ਅਤੇ ਕਿਹੜੀਆਂ ਮੈਮੋਰੀ ਵਿੱਚ
- ਸ਼ੈਡਿਊਲਿੰਗ: ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਕਤਾਰਬੱਧ ਕਰਨਾ ਕਿ CPU ਉਹਨਾਂ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਚਲਾ ਸਕੇ
- ਅਸੈਂਬਲੀ/ਆਬਜੈਕਟ ਆਉਟਪੁੱਟ: ਕੋਡ ਨੂੰ ਉਤਪਾਦ ਕਰਨਾ ਜੋ ਲਿੰਕਰ ਅਤੇ OS ਸਮਝ ਸਕਦੇ ਹਨ
ਸਾਂਝੇ ਢਾਂਚੇ ਨਾਲ ਨਵੇਂ ਹਾਰਡਵੇਅਰ ਸਹਾਇਤਾ ਕਿਉਂ ਆਸਾਨ ਹੁੰਦੀ ਹੈ
ਸਾਂਝਾ ਕੋਰ ਨਾ ਹੋਏ ਤਾਂ ਹਰ ਭਾਸ਼ਾ ਨੂੰ ਹਰ CPU ਲਈ ਇਹ ਸਭ ਮੁੜ-ਲਿਖਣਾ ਪੈਂਦਾ—ਇੱਕ ਵੱਡਾ ਕੰਮ ਅਤੇ ਲਗਾਤਾਰ ਮੇਨਟੇਨੈਂਸ।
LLVM ਇਸਨੂੰ ਉਲਟ ਕਰਦਾ ਹੈ: ਫਰੰਟਏਂਡ (ਜਿਵੇਂ Clang) ਇੱਕ ਵਾਰੀ LLVM IR ਬਣਾਉਂਦੀ ਹੈ, ਅਤੇ ਬੈਕਏਂਡ ਹਰ ਟਾਰਗੇਟ ਲਈ "ਆਖਰੀ ਦੌੜ" ਸੰਭਾਲਦਾ ਹੈ। ਨਵੇਂ CPU ਲਈ ਸਹਾਇਤਾ ਜੋੜਨੀ ਹੋਵੇ ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਬੈਕਏਂਡ ਲਿਖਨੀ ਪੈਂਦੀ ਹੈ (ਜਾਂ ਮੌਜੂਦਾ ਨੂੰ ਵਧਾਇਆ ਜਾਂਦਾ ਹੈ), ਨਾ ਕਿ ਹਰ ਕੰਪਾਇਲਰ ਨੂੰ ਮੁੜ-ਲਿਖਣਾ ਪਵੇ।
ਬਹੁ-ਪਲੇਟਫਾਰਮ ਟੀਮਾਂ ਲਈ ਪੋਰਟੇਬਿਲਟੀ
ਜਿਨ੍ਹਾਂ ਪ੍ਰੋਜੈਕਟਾਂ ਨੂੰ Windows/macOS/Linux, x86 ਅਤੇ ARM, ਜਾਂ ਇੱਪਟੇ ਬਰਾਊਜ਼ਰ 'ਚ ਚਲਾਉਣਾ ਹੋਵੇ, LLVM ਦਾ ਬੈਕਏਂਡ ਮਾਡਲ ਵਰਤਣਯੋਗ ਫਾਇਦਾ ਦਿੰਦਾ ਹੈ। ਤੁਸੀਂ ਇੱਕ ਕੋਡਬੇਸ ਅਤੇ ਮੁੱਖ ਤੌਰ 'ਤੇ ਇੱਕ ਬਿਲਡ ਪਾਈਪਲਾਈਨ ਰੱਖ ਸਕਦੇ ਹੋ, ਫਿਰ ਵੱਖ-ਵੱਖ ਬੈਕਏਂਡ ਚੁਣ ਕੇ ਨਿਸ਼ਾਨ ਇਮਤਿਹਾਨ ਕਰ ਸਕਦੇ ਹੋ।
ਇਹ ਪੋਰਟੇਬਿਲਟੀ LLVM ਦੇ ਹਰ ਥਾਂ ਹੋਣ ਦਾ ਕਾਰਨ ਹੈ: ਇਹ ਸਿਰਫ਼ ਤੇਜ਼ੀ ਬਾਰੇ ਨਹੀਂ—ਇਹ ਉਹ ਕੰਮ ਦੁਹਰਾਉਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ ਜੋ ਟੀਮਾਂ ਨੂੰ ਹੌਲਾ ਕਰਦਾ ਹੈ।
Clang: ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੇ ਡਿਵੈਲਪਰ ਪਹਿਲਾਂ LLVM ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ
ਸੁਰੱਖਿਅਤ ਅਦਾਇਗੀ
ਵੱਡੇ ਬਦਲਾਅ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਚੈਕਪੋਇੰਟ ਸੇਵ ਕਰੋ ਤਾਂ ਜੋ ਤੁਹਾਨੂੰ ਆਰਾਮ ਨਾਲ ਵਾਪਸ ਜਾਣ ਦੀ ਸਹੂਲਤ ਹੋਵੇ।
Clang C, C++, ਅਤੇ Objective-C ਲਈ ਫਰੰਟਏਂਡ ਹੈ ਜੋ LLVM ਵਿੱਚ ਪਲੱਗ ਹੁੰਦਾ ਹੈ। ਜੇ LLVM ਸਾਂਝਾ ਇੰਜਿਨ ਹੈ ਜੋ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਅਤੇ ਮਸ਼ੀਨ ਕੋਡ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ, ਤਾਂ Clang ਉਹ ਹਿੱਸਾ ਹੈ ਜੋ ਤੁਹਾਡੇ ਸਰੋਤ ਫਾਈਲਾਂ ਨੂੰ ਪੜ੍ਹਦਾ, ਭਾਸ਼ਾ ਨਿਯਮ ਸਮਝਦਾ, ਅਤੇ ਜੋ ਤੁਸੀਂ ਲਿਖਿਆ ਹੈ ਉਸਨੂੰ LLVM ਲਈ ਸਮਝਣਯੋਗ ਰੂਪ ਵਿੱਚ ਬਦਲਦਾ ਹੈ।
Clang ਨੂੰ ਕਿਉਂ ਨੋਟਿਸ ਮਿਲੀ
ਬਹੁਤ ਸਾਰੇ ਡਿਵੈਲਪਰਾਂ ਨੇ LLVM ਨੂੰ ਪੇਪਰ ਪੜ੍ਹ ਕੇ ਨਹੀਂ ਮਿਲਿਆ—ਉਹ ਪਹਿਲੀ ਵਾਰੀ ਜਦੋਂ ਉਨ੍ਹਾਂ ਨੇ ਕੰਪਾਇਲਰ ਬਦਲਿਆ ਅਤੇ ਫ਼ੀਡਬੈਕ ਅਚਾਨਕ ਬਹਤਰ ਹੋ ਗਿਆ।
Clang ਦੀਆਂ ਡਾਇਗਨੋਸਟਿਕਸ ਨੂੰ ਵਧੀਆ, ਵਧੇਰੇ ਨਿਰਦਿਸ਼ਟ ਮਨਿਆ ਜਾਂਦਾ ਹੈ। ਧੁੰਦਲੇ ਗਲਤੀ ਸੁਨੇਹਿਆਂ ਦੀ ਥਾਂ, ਇਹ ਅਕਸਰ ਉਸ ਟੋਕਨ ਤੱਕ ਇਸ਼ਾਰਾ ਕਰਦਾ ਹੈ ਜਿਸ ਨੇ ਮੁੱਦਾ ਖੜਾ ਕੀਤਾ, ਸਬੰਧਤ ਲਾਈਨ ਦਿਖਾਉਂਦਾ, ਅਤੇ ਕਿਹਾ ਕਿ ਕੀ ਉਮੀਦ ਸੀ। ਇਹ ਦਿਨ-ਪਰ-ਦਿਨ ਦੇ ਕੰਮ ਵਿੱਚ ਅਹੰਕਾਰਪੂਰਕ ਹੈ ਕਿਉਂਕਿ "ਕੰਪਾਇਲ, ਠੀਕ ਕਰੋ, ਦੁਹਰਾਓ" ਲੂਪ ਘੱਟ ਪਰੇਸ਼ਾਨ ਕਰਨ ਲੱਗਦਾ ਹੈ।
Clang ਸਾਫ, ਵਧੀਆ ਦਸਤਾਵੇਜ਼ ਕੀਤੇ ਇੰਟਰਫੇਸ ਵੀ ਐਕਸਪੋਜ਼ ਕਰਦਾ ਹੈ (ਲਾਹਿਰਿ libclang ਅਤੇ ਵੱਡੇ Clang ਟੂਲਿੰਗ ਇਕੋਸਿਸਟਮ ਰਾਹੀਂ)। ਇਸ ਨਾਲ ਐਡੀਟਰ, IDEs, ਅਤੇ ਹੋਰ ਡਿਵੈਲਪਰ ਟੂਲਾਂ ਲਈ ਗਹਿਰੀ ਭਾਸ਼ਾ ਸਮਝਿਆਉਣ ਨੂੰ ਇਕੱਠੇ ਕੀਤੇ ਬਿਨਾਂ ਇੰਟੈਗਰੇਟ ਕਰਨਾ ਆਸਾਨ ਹੋ ਗਿਆ।
ਰੋਜ਼ਾਨਾ ਵਰਕਫ਼ਲੋ ਵਿੱਚ ਇਹ ਕਿਵੇਂ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ
ਜਦੋਂ ਇੱਕ ਟੂਲ ਤੁਹਾਡੀ ਕੋਡ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਪਾਰਸ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਉਹ ਫੀਚਰਾਂ ਲੈ ਸਕਦੇ ਹੋ ਜੋ ਟੈਕਸਟ ਸੰਪਾਦਨ ਤੋਂ ਵਧ ਕੇ ਸਰਚੀਤ ਕਾਰਜਬਲ ਬਣਾਉਂਦੇ ਹਨ:
- ਵੱਡੇ, macro-ਭਰੇ C++ ਪ੍ਰੋਜੈਕਟਾਂ ਵਿੱਚ ਵੀ ਸਹੀ ਕੋਡ ਨੈਵੀਗੇਸ਼ਨ ("ਜਿੱਥੇ ਪਰਿਭਾਸ਼ਾ ਹੈ ਉੱਠੇ ਜਾਓ," "ਰੈਫਰੰਸ ਲੱਭੋ")
- ਰੀਫੈਕਟਰਿੰਗ ਸਹਾਇਤਾ ਜੋ ਚਿੰਨ੍ਹਾਂ ਅਤੇ ਸਕੋਪਾਂ ਨੂੰ ਸਮਝਦੀ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ ਖੋਜ-ਅਤੇ-ਬਦਲ ਕਰਦੀ ਹੈ
- ਇਨਲਾਈਨ ਸੁਝਾਅ ਅਤੇ ਤੇਜ਼ fixes ਜੋ ਅਸਲੀ ਸਿੰਟੈਕਸ ਅਤੇ ਟਾਈਪ ਜਾਣਕਾਰੀ 'ਤੇ ਆਧਾਰਤ ਹੁੰਦੇ ਹਨ
ਇਸ ਲਈ Clang ਅਕਸਰ LLVM ਲਈ ਪਹਿਲਾ "ਟਚ ਪੌਇੰਟ" ਹੁੰਦਾ ਹੈ: ਇਹ ਓਥੇ ਹੈ ਜਿੱਥੇ ਪ੍ਰਯੋਗਿਕ ਵਿਕਾਸਕਾਰ ਅਨੁਭਵ ਵਿਚ ਸੁਧਾਰ ਆਉਂਦੇ ਹਨ। ਭਾਵੇਂ ਤੁਸੀਂ ਕਦੇ LLVM IR ਜਾਂ ਬੈਕਏਂਡ ਬਾਰੇ ਨਹੀਂ ਸੋਚਦੇ, ਤੁਸੀਂ ਫਿਰ ਵੀ ਲਾਭ ਉਠਾਉਂਦੇ ਹੋ ਜਦੋਂ ਤੁਹਾਡਾ ਐਡਟਰAutocomplete ਤੇਜ਼ ਹੋ ਜਾਂਦਾ, ਤੁਹਾਡੇ ਸਟੈਟਿਕ ਚੈਕਸ ਸਹੀ ਹੋ ਜਾਂਦੇ, ਅਤੇ ਬਿਲਡ ਤ੍ਰੁੱਟੀਆਂ ਨੂੰ ਜ਼ਿਆਦਾ ਆਸਾਨੀ ਨਾਲ ਠੀਕ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਕਿਉਂ ਕਈ ਆਧੁਨਿਕ ਭਾਸ਼ਾਵਾਂ LLVM 'ਤੇ ਬਣਦੀਆਂ ਹਨ
LLVM ਭਾਸ਼ਾ ਟੀਮਾਂ ਲਈ ਸਹੀ ਹੈ ਕਿਉਂਕਿ ਇਹ ਉਨ੍ਹਾਂ ਨੂੰ ਭਾਸ਼ਾ ਤੇ ਧਿਆਨ ਕਰਨ ਦਿੰਦਾ ਹੈ ਨ ਕਿ ਇਕ ਪੂਰੇ-ਪੂਰੇ ਅਪਟੀਮਾਈਜ਼ਿੰਗ ਕੰਪਾਇਲਰ ਨੂੰ ਸਫਲ ਕਰਨ ਵਿੱਚ ਸਾਲ ਖਰਚ ਕਰਨ ਦੀ ਲੋੜ ਪਏ।
ਤੇਜ਼ ਟਾਈਮ-ਟੂ-ਮਾਰਕੀਟ
ਨਵੀਂ ਭਾਸ਼ਾ ਬਨਾਉਣਾ ਪਹਿਲਾਂ ਹੀ ਪਾਰਸਿੰਗ, ਟਾਈਪ-ਚੈੱਕਿੰਗ, ਡਾਇਗਨੋਸਟਿਕਸ, ਪੈਕੇਜ ਟੂਲਿੰਗ, ਦਸਤਾਵੇਜ਼, ਅਤੇ ਕਮਿਊਨਿਟੀ ਸਹਾਇਤਾ ਦੀ ਮੰਗ ਕਰਦਾ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਇੱਕ ਪ੍ਰੋਡਕਸ਼ਨ-ਗਰੇਡ ਅਪਟੀਮਾਈਜ਼ਰ, ਕੋਡ ਜਨਰੇਟਰ, ਅਤੇ ਪਲੇਟਫਾਰਮ ਸਹਾਇਤਾ ਵੀ ਸ਼ੁਰੂ ਤੋਂ ਤਿਆਰ ਕਰਨੀ ਪਏ, ਤਾਂ ਸ਼ਿਪਿੰਗ ਵਿੱਚ ਸਾਲ ਲੱਗ ਜਾਂਦੇ ਹਨ।
LLVM ਇੱਕ ਤਿਆਰ-ਮਾਇਆ ਕੰਪਾਇਲਰ ਕੋਰ ਦਿੰਦਾ ਹੈ: ਰਜਿਸਟਰ ਅਲੋਕੇਸ਼ਨ, ਨਿਰਦੇਸ਼ ਚੋਣ, ਪਰਿਪੱਕ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪਾਸ, ਅਤੇ ਆਮ CPU ਟਾਰਗੇਟ। ਟੀਮਾਂ ਇੱਕ ਫਰੰਟਏਂਡ ਪਲੱਗ ਕਰਕੇ ਆਪਣੀ ਭਾਸ਼ਾ ਨੂੰ LLVM IR ਵਿੱਚ ਘਟਾਕੇ ਨੈਟਿਵ ਕੋਡ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਉੱਚ ਪ੍ਰਦਰਸ਼ਨ (ਬਿਨਾਂ ਬਹਾਦੁਰੀਆਂ)
LLVM ਦਾ ਅਪਟੀਮਾਈਜ਼ਰ ਅਤੇ ਬੈਕਏਂਡ ਲੰਬੇ ਸਮੇਂ ਦੀ ਇੰਜੀਨੀਅਰਿੰਗ ਅਤੇ ਨਿਰੰਤਰ ਰੀਅਲ-ਵਰਲਡ ਪਰੀਖਣ ਦਾ ਨਤੀਜਾ ਹਨ। ਇਸ ਦਾ ਅਰਥ ਇਹ ਹੈ ਕਿ LLVM ਅਪਨਾਉਣ ਵਾਲੀਆਂ ਭਾਸ਼ਾਵਾਂ ਲਈ ਮਜਬੂਤ ਬੇਸਲਾਈਨ ਪ੍ਰਦਰਸ਼ਨ ਮਿਲਦਾ ਹੈ—ਕੋਈ ਨਿਰਾਸ਼ਕ ਸੰਘਰਸ਼ ਨਹੀਂ, ਅਤੇ ਜਿਵੇਂ-जਿਵੇਂ LLVM ਸੁਧਰੇਗਾ, ਉਨ੍ਹਾਂ ਦੀਆਂ ਭਾਸ਼ਾਵਾਂ ਵੀ ਲਾਭ ਉਠਾ ਸਕਦੀਆਂ ਹਨ।
ਇਸੇ ਲਈ ਕਈ ਜਾਣੇ-ਮਾਣੇ ਭਾਸ਼ਾਵਾਂ ਨੇ ਇਸ 'ਤੇ ਆਧਾਰ ਕੀਤਾ:
- Swift Apple ਪਲੇਟਫਾਰਮਾਂ 'ਤੇ ਉੱਚ-ਅਪਟੀਮਾਈਜ਼ਡ ਨੈਟਿਵ ਬਿਨਰੀਜ਼ ਬਣਾਉਣ ਲਈ LLVM ਵਰਤਦਾ ਹੈ।
- Rust ਕੋਡ ਜਨਰੇਸ਼ਨ ਅਤੇ ਕਈ ਆਰਕੀਟੈਕਚਰ ਟਾਰਗੇਟ ਲਈ LLVM 'ਤੇ ਨਿਰਭਰ ਹੈ।
- Julia ਤੇਜ਼ ਗਣਿਤੀ ਕੋਡ ਅਤੇ runtime compilation ਲਈ LLVM ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ।
ਹਰ ਭਾਸ਼ਾ ਨੂੰ LLVM ਦੀ ਲੋੜ ਨਹੀਂ
LLVM ਚੁਣਨਾ ਇੱਕ ਟਰੇਡ-ਆਫ਼ ਹੈ, ਲਾਜ਼ਮੀ ਨਹੀਂ। ਕੁਝ ਭਾਸ਼ਾਵਾਂ ਛੋਟੀ ਬਿਨਰੀਆਂ, ਬਹੁਤ ਤੇਜ਼ ਕੰਪਾਈਲ ਸਮਾਂ, ਜਾਂ ਪੂਰੀ ਟੂਲਚੇਨ 'ਤੇ ਕਾਬੂ ਰੱਖਣ ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੀਆਂ ਹਨ। ਹੋਰਾਂ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਸਥਾਪਿਤ ਕੰਪਾਇਲਰ ਹਨ (ਜਿਵੇਂ GCC-ਅਧਾਰਿਤ ਪਰਿਵਾਰ) ਜਾਂ ਉਹ ਸਧਾਰਨ ਬੈਕਏਂਡ ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹਨ।
LLVM ਲੋਕਪ੍ਰਿਯ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਮਜ਼ਬੂਤ ਡਿਫਾਲਟ ਹੈ—ਨਾ ਕਿ ਕਿਹੜਾ ਇਕੱਲਾ ਸਹੀ ਰਸਤਾ।
JIT ਅਤੇ ਰਨਟਾਈਮ ਕੰਪਾਇਲੇਸ਼ਨ: ਤੇਜ਼ ਫੀਡਬੈਕ ਲੂਪ
ਆਪਣੀ ਰਫ਼ਤਾਰ 'ਤੇ ਸਕੇਲ ਕਰੋ
ਤੁਸੀਂ ਕਿੰਨਾ ਅੱਗੇ ਜਾਣਾ ਚਾਹੁੰਦੇ ਹੋ ਉਸ ਅਨੁਸਾਰ Free, Pro, Business ਜਾਂ Enterprise ਚੁਣੋ।
"Just-in-time" (JIT) ਕੰਪਾਇਲੇਸ਼ਨ ਨੂੰ ਸਭ ਤੋਂ ਆਸਾਨੀ ਨਾਲ "ਜਦੋਂ ਤੁਸੀਂ ਚਲਾਉਂਦੇ ਹੋ ਤਦੋਂ ਕੰਪਾਇਲ" ਦੇ ਤੌਰ 'ਤੇ ਸੋਚੋ। ਸਾਰੀ ਕੋਡ ਨੂੰ ਪਹਿਲਾਂ ਤੋਂ ਤਿਆਰ ਕਰਨ ਬਜਾਏ, ਇੱਕ JIT ਇੰਜਿਨ ਉਸ ਟੁਕੜੇ ਨੂੰ ਤਬ ਕੰਪਾਇਲ ਕਰਦਾ ਹੈ ਜਦੋਂ ਉਹ ਸੱਚ-ਮੁੱਚ ਲੋੜੀਂਦਾ ਹੁੰਦਾ ਹੈ—ਅਕਸਰ ਰਨਟਾਈਮ ਜਾਣਕਾਰੀ (ਜਿਵੇਂ ਕਿ ਨਿਰਧਾਰਿਤ ਕਿਸਮਾਂ ਅਤੇ ਡੇਟਾ ਦੇ ਆਕਾਰ) ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਬਿਹਤਰ ਫੈਸਲੇ ਲੈਂਦਾ ਹੈ।
JIT ਤੇਜ਼ ਕਿਉਂ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ
ਕਿਉਂਕਿ ਤੁਹਾਨੂੰ ਸਭ ਕੁਝ ਪਹਿਲਾਂ ਤੋਂ ਕੰਪਾਇਲ ਨਹੀਂ ਕਰਨਾ ਪੈਂਦਾ, JIT ਸਿਸਟਮ ਇੰਟਰੇਕਟਿਵ ਕੰਮ ਲਈ ਤੁਰੰਤ ਫੀਡਬੈਕ ਦੇ ਸਕਦੇ ਹਨ। ਤੁਸੀਂ ਥੋੜ੍ਹਾ ਕੋਡ ਲਿਖਦੇ/ਜਨਰੇਟ ਕਰਦੇ ਹੋ, ਤੁਰੰਤ ਚਲਾਉਂਦੇ ਹੋ, ਅਤੇ ਸਿਸਟਮ ਸਿਰਫ਼ ਜਰੂਰੀ ਹਿੱਸੇ ਨੂੰ ਹੀ ਉਸ ਸਮੇਂ ਕੰਪਾਇਲ ਕਰਦਾ ਹੈ। ਜੇ ਉਹੀ ਕੋਡ ਵਾਰ-ਵਾਰ ਚਲਦਾ ਹੈ, ਤਾਂ JIT ਕੰਪਾਇਲ ਕੀਤੀ ਨਤੀਜਾ ਨੂੰ ਕੈਸ਼ ਕਰ ਸਕਦਾ ਹੈ ਜਾਂ "ਹੌਟ" ਹਿੱਸਿਆਂ ਨੂੰ ਜ਼ਿਆਦਾ ਤੀਬਰਤਾ ਨਾਲ ਮੁੜ-ਕੰਪਾਇਲ ਕਰ ਸਕਦਾ ਹੈ।
ਰਨਟਾਈਮ ਕੰਪਾਇਲੇਸ਼ਨ ਵਾਸਤੇ ਹਕੀਕਤੀ ਫਾਇਦੇ
JIT ਉਦਾਹਰਣਾਂ ਵਿੱਚ ਚਮਕਦਾ ਹੈ ਜਦ ਵਰਕਲੋਡ ਡਾਇਨਾਮਿਕ ਜਾਂ ਇੰਟਰੇਕਟਿਵ ਹੁੰਦੇ ਹਨ:
- REPLs ਅਤੇ ਨੋਟਬੁੱਕਸ: ਟੁਕੜੇ ਤੁਰੰਤ ਮੁਲਾਂਕਣ ਕਰੋ ਜਦੋਂ ਕਿ ਭਾਰੀ ਲੂਪਾਂ ਲਈ ਨੈਟਿਵ-ਸਪੀਡ ਐਗਜ਼ਿਕਿਊਸ਼ਨ ਮਿਲਦੀ ਹੈ।
- ਪਲੱਗਇਨ ਅਤੇ ਐਕਸਟੇਂਸ਼ਨ: ਐਪਲੀਕੇਸ਼ਨਾਂ ਦੇ ਨੇੜੇ ਯੂਜ਼ਰ ਕੋਡ ਲੋਡ ਕਰਕੇ ਉਸਨੂੰ ਹੋਸਟ CPU ਦੇ ਅਨੁਸਾਰ ਕੰਪਾਇਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
- ਡਾਇਨਾਮਿਕ ਵਰਕਲੋਡ: ਜਦ ਇਨਪੁੱਟਜ਼ ਬਹੁਤ ਵੱਖ-ਵੱਖ ਹੁੰਦੇ ਹਨ, ਰਨਟਾਈਮ ਪ੍ਰੋਫਾਈਲਿੰਗ ਇਹ ਦੱਸ ਸਕਦੀ ਹੈ ਕਿ ਕਿਹੜੇ ਰਸਤੇ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਲਈ ਯੋਗ ਹਨ।
- ਸਾਇੰਟਿਫਿਕ ਕੰਪਿਊਟਿੰਗ: ਜਨਰੇਟ ਕੀਤਾ ਗਇਆ ਕੋਡ (ਕਿਸੇ ਖ਼ਾਸ ਮੈਟ੍ਰਿਕਸ ਸਾਈਜ਼, ਮਾਡਲ ਆਕਾਰ, ਜਾਂ ਹਾਰਡਵੇਅਰ ਫੀਚਰ) ਮੰਗ 'ਤੇ ਕੰਪਾਇਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
LLVM ਦੀ ਭੂਮਿਕਾ (ਹਾਈਪ ਤੋਂ ਬਿਨਾਂ)
LLVM ਹਰโปรਗ੍ਰਾਮ ਨੂੰ ਜਾਦੂਈ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਨਹੀਂ ਬਣਾਉਂਦਾ, ਅਤੇ ਇਹ ਆਪਣੇ ਆਪ ਵਿੱਚ ਪੂਰਾ JIT ਨਹੀਂ ਹੁੰਦਾ। ਜੋ ਇਹ ਦਿੰਦਾ ਹੈ ਉਹ ਇੱਕ ਟੂਲਕਿਟ ਹੈ: ਇੱਕ ਪਰਿਭਾਸ਼ਿਤ IR, ਬਹੁਤ ਸਾਰੇ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪਾਸ, ਅਤੇ ਕਈ CPU ਲਈ ਕੋਡ ਜਨਰੇਸ਼ਨ। ਪ੍ਰੋਜੈਕਟ ਇਨ੍ਹਾਂ ਬਿਲਡਿੰਗ ਬਲਾਕਾਂ 'ਤੇ JIT ਇੰਜਿਨ ਬਣਾ ਸਕਦੇ ਹਨ, ਅਤੇ ਸ਼ੁਰੂਆਤੀ ਸਮਾਂ, ਚੋਟੀ ਪ੍ਰਦਰਸ਼ਨ, ਅਤੇ ਜਟਿਲਤਾ ਦਰਮਿਆਨ ਠੀਕ ਟਰੇਡ-ਆਫ਼ ਚੁਣ ਸਕਦੇ ਹਨ।
ਪ੍ਰਦਰਸ਼ਨ, ਪੇਸ਼ਗੋਈਯੋਗਤਾ, ਅਤੇ ਹਕੀਕਤੀ ਟਰੇਡ-ਆਫ਼
LLVM-ਅਧਾਰਿਤ ਟੂਲਚੇਨ ਤੇਜ਼ ਕੋਡ ਤਿਆਰ ਕਰ ਸਕਦੇ ਹਨ—ਪਰ "ਤੇਜ਼" ਇੱਕ ਇਕੱਲਾ ਸਥਿਰ ਗੁਣ ਨਹੀਂ ਹੈ। ਇਹ ਨਤੀਜਾ ਕੰਪਾਇਲਰ ਵਰਜਨ, ਟਾਰਗੇਟ CPU, ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਸੈਟਿੰਗ ਅਤੇ ਇੱਥੇ ਤੱਕ ਕਿ ਤੁਸੀਂ ਕੰਪਾਇਲਰ ਨੂੰ ਕੀ ਮਾਨ ਲੈਂਦੇ ਹੋ, ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
"ਉਸੀ ਸਰੋਤ, ਵੱਖ-ਵੱਖ ਨਤੀਜੇ" ਕਿਉਂ ਹੁੰਦਾ ਹੈ
ਦੋ ਕੰਪਾਇਲਰ ਇੱਕੋ ਸਰੋਤ ਨੂੰ ਪੜ੍ਹਕੇ ਵੀ ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨ ਕੋਡ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹਨ। ਕੁਝ ਇਸ ਲਈ ਕਿ ਹਰ ਕੰਪਾਇਲਰ ਦੇ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪਾਸ, ਹਿਊਰੀਸਟਿਕਸ, ਅਤੇ ਡਿਫਾਲਟ ਸੈਟਿੰਗ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ। LLVM ਅੰਦਰ ਵੀ, Clang 15 ਅਤੇ Clang 18 ਵੱਖ-ਵੱਖ ਇਨਲਾਈਨ ਫੈਸਲੇ, ਵੈਕਟਰਾਈਜ਼ੇਸ਼ਨ ਦੇ ਵੱਖਰੇ ਪੈਸੇ, ਜਾਂ ਨਿਰਦੇਸ਼ ਦੀ ਸ਼ੈਡਿਊਲਿੰਗ ਵੱਖਰੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਅਕਸਰ ਅਣਪਹਿਚਾਣਿਆ ਵਿਹਾਰ (undefined behavior) ਜਾਂ ਅਣਨਿਰ্ধਾਰਤ ਵਿਹਾਰ (unspecified behavior) ਕਾਰਨ ਵੀ ਹੁੰਦਾ ਹੈ। ਜੇ ਤੁਹਾਡਾ ਪਰੋਗਰਾਮ ਕਿਸੇ ਚੀਜ਼ 'ਤੇ ਨਿਰਭਰ ਕਰ ਰਿਹਾ ਹੈ ਜੋ ਭਾਸ਼ਾ ਸਟੈਂਡਰਡ ਵਿੱਚ ਗਾਰੰਟੀ ਨਹੀਂ, ਤਾਂ ਵੱਖ-ਵੱਖ ਕੰਪਾਇਲਰ—ਜਾਂ ਵੱਖ-ਵੱਖ ਫਲੈਗ—ਨਤੀਜੇ ਬਦਲ ਸਕਦੇ ਹਨ।
ਨਿਰਛਲਤਾ, ਡੀਬੱਗ ਬਿਲਡ ਅਤੇ ਰਿਲੀਜ਼ ਬਿਲਡ
ਲੋਕ ਆਮ ਤੌਰ 'ਤੇ ਉਮੀਦ ਕਰਦੇ ਹਨ ਕਿ ਕੰਪਾਇਲਸ਼ਨ ਨਿਰਛਲ ਹੋਵੇ: ਇੱਕੋ ਇਨਪੁੱਟ, ਇੱਕੋ ਆਊਟਪੁੱਟ। ਅਮਲ ਵਿੱਚ ਤੁਸੀਂ ਕਰੀਬ-ਕਰੀਬ ਇਸਦੇ ਨੇੜੇ ਜਾ ਸਕਦੇ ਹੋ, ਪਰ ਹਮੇਸ਼ਾ ਇੱਕੋ ਹੀ ਬਿਨਰੀ ਨਹੀਂ ਮਿਲਦੀ। ਬਿਲਡ ਰਸਤੇ, ਟਾਈਮਸਟੈਂਪ, ਲਿੰਕ ਆਰਡਰ, ਪ੍ਰੋਫਾਈਲ-ਗਾਇਡਡ ਡੇਟਾ, ਅਤੇ LTO ਚੋਣਾਂ ਆਖ਼ਰੀ ਆਰਟੀਫੈਕਟ ਨੂੰ ਪ੍ਰਭਾਵਤ ਕਰ ਸਕਦੇ ਹਨ।
ਵੱਡਾ ਵਿਵੇਕਸ਼ੀਲ ਅੰਤਰ ਡੀਬੱਗ ਅਤੇ ਰਿਲੀਜ਼ builds ਵਿੱਚ ਹੁੰਦਾ ਹੈ। ਡੀਬੱਗ builds ਆਮ ਤੌਰ 'ਤੇ ਬਹੁਤ ਸਾਰੀਆਂ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨਾਂ ਨੂੰ ਅਪਹਿSTਿਤ ਕਰਦੇ ਹਨ ਤਾਂ ਕਿ ਸਟੀਪ-ਬਾਈ-ਸਟੀਪ ਡੀਬੱਗਿੰਗ ਅਤੇ ਪੜ੍ਹਨਯੋਗ ਸਟੈਕ ਟ੍ਰੇਸਜ਼ ਮਿਲ ਸਕਣ। ਰਿਲੀਜ਼ builds ਜਬਰਦਸਤ ਤਬਦੀਲੀਆਂ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ ਜੋ ਕੋਡ ਨੂੰ ਦੁਬਾਰਾ-ਕ੍ਰਮਬੱਧ, ਫੰਕਸ਼ਨਾਂ ਨੂੰ ਇਨਲਾਈਨ, ਅਤੇ ਵੈਰੀਏਬਲ-ਹਟਾਉਂਦੇ ਹਨ—ਪਰ ਇਹ ਡੀਬੱਗ ਕਰਨ ਨੂੰ ਔਖਾ ਕਰ ਸਕਦਾ ਹੈ।
ਵਾਸਤਵਿਕ ਸਲਾਹ: ਅਨੁਮਾਨ نہ ਲਗਾਓ, ਮਾਪੋ
ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਇਕ ਮਾਪਣ ਦੀ ਸਮੱਸਿਆ ਵਜੋਂ ਲਓ:
- ਜਿਸ ਹਾਰਡਵੇਅਰ ਅਤੇ ਹਕੀਕਤੀ ਡੇਟਾਸੇਟ 'ਤੇ ਕੋਈ ਪ੍ਰਤੀਨਿਧਿਮਕ ਹੈ, ਉੱਥੇ ਬੈਂਚਮਾਰਕ ਕਰੋ।
- caches ਨੂੰ ਗਰਮ ਕਰੋ ਅਤੇ ਕਈ ਇਤਰਾਏਸ਼ਨ ਚਲਾਓ।
- ਖੁੱਲ੍ਹੇ ਫਲੈਗਾਂ ਨਾਲ builds ਦੀ ਤੁਲਨਾ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ
-O2vs-O3, LTO ਚਾਲੂ/ਬੰਦ, ਜਾਂ-marchਨਾਲ ਟਾਰਗੇਟ ਸਿਲੈਕਟ ਕਰਕੇ)।
ਛੋਟੇ ਫਲੈਗ ਬਦਲਾਅ ਕੁਝ ਵੀ ਪ੍ਰਭਾਵਤ ਕਰ ਸਕਦੇ ਹਨ। ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਦਿਸ਼ਾ: ਇੱਕ ਹਿਪੋਥੈਸਿਸ ਚੁਣੋ, ਉਸਨੂੰ ਮਾਪੋ, ਅਤੇ ਬੈਂਚਮਾਰਕ ਉਹੀ ਰੱਖੋ ਜੋ ਤੁਹਾਡੇ ਉਪਭੋਗੀਆਂ ਚਲਾਉਂਦੇ ਹਨ।
ਕੰਪਾਇਲੇਸ਼ਨ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਟੂਲਿੰਗ: ਵਿਸ਼ਲੇਸ਼ਣ, ਡੀਬੱਗਿੰਗ, ਅਤੇ ਸੁਰੱਖਿਆ
LLVM ਨੂੰ ਅਕਸਰ ਇਕ ਕੰਪਾਇਲਰ ਟੂਲਕਿੱਟ ਵਜੋਂ ਵਰਣਨ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਬਹੁਤ ਸਾਰੇ ਡਿਵੈਲਪਰ ਇਸਦਾ ਪ੍ਰਭਾਵ ਉਨ੍ਹਾਂ ਟੂਲਾਂ ਰਾਹੀਂ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ ਜੋ ਕੰਪਾਇਲੇਸ਼ਨ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਬੈਠਦੇ ਹਨ: ਵਿਸ਼ਲੇਸ਼ਕ, ਡੀਬੱਗਰ, ਅਤੇ ਸੁਰੱਖਿਆ-ਚੈੱਕ ਜੋ ਬਿਲਡ ਅਤੇ ਟੈਸਟ ਦੌਰਾਨ ਚਾਲੂ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਇੰਸਟਰੂਮੈਂਟੇਸ਼ਨ ਨੂੰ "ਐਡ-ਆਨ" ਬਣਾਉਣਾ
ਕਿਉਂਕਿ LLVM ਇੱਕ ਪਰਿਭਾਸ਼ਿਤ IR ਅਤੇ ਪਾਸ ਪਾਈਪਲਾਈਨ ਦਿੰਦਾ ਹੈ, ਇਹ ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਕਿ ਹੋਰ ਕਦਮ ਬਣਾਏ ਜਾਣ ਕਿ ਜੋ ਕੋਡ ਨੂੰ ਤੇਜ਼ ਕਰਨ ਦੀ ਬਜਾਏ ਜਾਂਚਣ ਜਾਂ ਦੁਬਾਰਾ ਲਿਖਣ ਲਈ ਹੁੰਦੇ ਹਨ। ਇੱਕ ਪਾਸ ਪ੍ਰੋਫਾਈਲਿੰਗ ਲਈ ਕਾਊਂਟਰ ਇਨਸਰਟ ਕਰ ਸਕਦੀ ਹੈ, ਸ਼ੱਕੀ ਮੈਮੋਰੀ ਓਪਰੇਸ਼ਨਾਂ ਨੂੰ ਨਿਸ਼ਾਨ ਲਾ ਸਕਦੀ ਹੈ, ਜਾਂ ਕਵਰੇਜ ਡੇਟਾ ਇਕੱਠਾ ਕਰ ਸਕਦੀ ਹੈ।
ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਫੀਚਰ ਇਕੱਤਰ ਰੂਪ ਵਿੱਚ ਇੰਟੈਗਰੇਟ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਹਰ ਭਾਸ਼ਾ ਟੀਮ ਨੂੰ ਉਹੀ ਪਲੰਬਿੰਗ ਦੁਬਾਰਾ ਲਿਖਣ ਦੀ ਲੋੜ ਹੋਵੇ।
ਸੈਨਿਟਾਈਜ਼ਰ: ਸੋਧ ਸਮੇਂ ਗਲਤੀਆਂ ਫੜਨ
Clang ਅਤੇ LLVM ਨੇ ਰਨਟਾਈਮ "ਸੈਨਿਟਾਈਜ਼ਰਜ਼" ਦੀ ਇੱਕ ਪਰਿਵਾਰ ਪ੍ਰਚਲਿਤ ਕੀਤਾ ਜੋ ਟੈਸਟ ਦੇ ਦੌਰਾਨ ਆਮ ਕਿਸਮ ਦੀਆਂ ਗਲਤੀਆਂ ਨੂੰ ਪਤਾ ਲਾਉਂਦੇ ਹਨ—ਜਿਵੇਂ ਬਾਊਂਡ ਤੋਂ ਬਾਹਰ ਮੈਮੋਰੀ ਐਕਸੈਸ, use-after-free, ਡੇਟਾ ਰੇਸ, ਅਤੇ undefined behavior ਪੈਟਰਨ। ਇਹ ਜਾਦੂਈ ਢਾਲ ਨਹੀਂ ਹਨ, ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਸੁਸਤ ਕਰਦੇ ਹਨ, ਇਸ ਲਈ ਇਹ ਆਮ ਤੌਰ 'ਤੇ CI ਅਤੇ ਪ੍ਰੀ-ਰਿਲੀਜ਼ ਟੈਸਟਿੰਗ ਵਿੱਚ ਵਰਤੇ ਜਾਂਦੇ ਹਨ। ਪਰ ਜਦ ਇਹ ਟ੍ਰਿਗਰ ਹੁੰਦੇ ਹਨ, ਤਾਂ ਅਕਸਰ ਇਹ ਇਕ ਠੀਕ ਸਰੋਤ ਸਥਾਨ ਅਤੇ ਪੜ੍ਹਨਯੋਗ ਵਿਆਖਿਆ ਦਿੰਦੇ ਹਨ, ਜੋ ਦਰਮਿਆਨੀ ਤੌਰ 'ਤੇ ਘੁਮਢੇ ਕ੍ਰੈਸ਼ਜ਼ ਦੀ ਪਹਿਚਾਣ ਲਈ ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੈ।
ਵਧੀਆ ਡਾਇਗਨੋਸਟਿਕ = ਤੇਜ਼ onboarding
ਟੂਲਿੰਗ ਗੁਣਵੱਤਾ ਦਾ ਇਕ аспект ਸੰਚਾਰ ਵੀ ਹੈ। ਸਾਫ਼ ਚੇਤਾਵਨੀਆਂ, ਕਾਰਗਰ ਗਲਤੀ ਸੁਨੇਹੇ, ਅਤੇ ਸਥਿਰ ਡੀਬੱਗ ਇੰਫੋ ਨਵਿਆਂ ਲਈ "ਰਹੱਸ ਫੈਕਟਰ" ਘਟਾਉਂਦੇ ਹਨ। ਜਦ ਟੂਲਚੇਨ ਇਹ ਵਿਆਖਿਆ ਕਰਦਾ ਹੈ ਕਿ ਕੀ ਹੋਇਆ ਅਤੇ ਉਹਨੂੰ ਕਿਵੇਂ ਠੀਕ ਕਰਨਾ ਹੈ, ਵਿਕਾਸਕਾਰ ਸ Compiler quirks ਯਾਦ ਕਰਨ ਦੀ ਬਜਾਏ ਕੋਡਬੇਸ ਸਿੱਖਣ 'ਤੇ ਵਧੇਰੇ ਸਮਾਂ ਲਾਉਂਦੇ ਹਨ।
LLVM ਆਪਣੇ ਆਪ ਵਿੱਚ ਪੂਰਨ ਡਾਇਗਨੋਸਟਿਕ ਜਾਂ ਸੁਰੱਖਿਆ ਦੀ ਗਾਰੰਟੀ ਨਹੀਂ ਦਿੰਦਾ, ਪਰ ਇਹ ਇੱਕ ਆਮ ਨੀਵ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ ਜੋ ਇਹਨਾਂ ਡਿਵੈਲਪਰ-ਮੁੱਖ ਟੂਲਾਂ ਨੂੰ ਬਣਾਉਣਾ, ਸੰਭਾਲਣਾ, ਅਤੇ ਸਾਂਝਾ ਕਰਨਾ ਅਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਕਦੋਂ LLVM ਵਰਤਣਾ (ਅਤੇ ਕਦੋਂ ਨਹੀ)
ਤੇਜ਼ ਸੁਧਾਰ ਕਰੋ
ਗਲਤ ਬਦਲਾਅ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਉਲਟੋ ਅਤੇ ਬਿਨਾਂ ਰੁਕੇ ਅੱਗੇ ਵਧੋ।
LLVM ਨੂੰ "ਆਪਣੇ-ਆਪਣੇ ਕੰਪਾਇਲਰ ਅਤੇ ਟੂਲਿੰਗ ਕਿਟ ਬਣਾਉ" ਵਜੋਂ ਸੋਚੋ। ਇਹ ਲਚਕੀਲੇਪਣ ਹੀ ਕਾਰਨ ਹੈ ਕਿ ਇਹ ਬਹੁਤ ਸਾਰੇ ਆਧੁਨਿਕ ਟੂਲਚੇਨਾਂ ਨੂੰ ਚਲਾਉਂਦਾ—ਪਰ ਇਹ ਹਰ ਪ੍ਰोजੈਕਟ ਲਈ ਸਹੀ ਉੱਤਰ ਨਹੀਂ ਹੁੰਦਾ।
ਜਦੋਂ LLVM ਬਿਹਤਰ ਹੈ
LLVM ਉਸ ਵੇਲੇ ਚਮਕਦਾ ਹੈ ਜਦ ਤੁਸੀਂ ਗੰਭੀਰ ਕੰਪਾਇਲਰ ਇੰਜੀਨੀਅਰਿੰਗ ਨੂੰ ਮੁੜ-ਵਰਤਣਾ ਚਾਹੁੰਦੇ ਹੋ।
- ਜੇ ਤੁਸੀਂ ਇੱਕ ਨਵੀਂ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਭਾਸ਼ਾ ਬਣਾ ਰਹੇ ਹੋ, LLVM ਤੁਹਾਨੂੰ ਇੱਕ ਸਾਬਤ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਪਾਈਪਲਾਈਨ, ਮੈਚੂਰ ਕੋਡ ਜਨਰੇਸ਼ਨ, ਅਤੇ ਚੰਗੇ ਡੀਬੱਗਿੰਗ ਸਹਾਇਤਾ ਦਿੰਦਾ ਹੈ।
- ਜੇ ਤੁਸੀਂ ਕ੍ਰਾਸ-ਪਲੇਟਫਾਰਮ ਐਪਲੀਕੇਸ਼ਨ ਸ਼ਿਪ ਕਰ ਰਹੇ ਹੋ, LLVM ਦਾ ਬੈਕਏਂਡ ਇਕੋ-ਵਾਰ ਕੰਮ ਘਟਾਉਂਦਾ ਹੈ।
- ਜੇ ਤੁਹਾਡਾ ਲਕਸ਼ ਡਿਵੈਲਪਰ ਟੂਲਿੰਗ (ਲਿੰਟਰ, ਸਟੈਟਿਕ ਵਿਸ਼ਲੇਸ਼ਣ, ਕੋਡ ਨੈਵੀਗੇਸ਼ਨ) ਹੈ, ਤਾਂ LLVM ਅਤੇ ਉਸਦੇ ਗਿਰਦੇ ਇਕੋਸਿਸਟਮ ਇੱਕ ਮਜ਼ਬੂਤ ਬੁਨਿਆਦ ਦਿੰਦੇ ਹਨ।
ਜਦੋਂ ਇਹ ਓਵਰਕਿਲ ਹੋ ਸਕਦਾ ਹੈ
ਜੇ ਤੁਸੀਂ ਬਹੁਤ ਛੋਟੇ ਐਂਬੈੱਡੇਡ ਸਿਸਟਮਾਂ ਤੇ ਕੰਮ ਕਰ ਰਹੇ ਹੋ ਜਿੱਥੇ ਬਿਲਡ ਆਕਾਰ, ਮੈਮੋਰੀ, ਅਤੇ ਕੰਪਾਈਲ ਸਮਾਂ ਬਹੁਤ ਕੱਟ ਹਨ, ਤਾਂ LLVM ਵੱਡਾ ਹੋ ਸਕਦਾ ਹੈ।
ਇਹ ਉਹਨਾਂ ਵਿਸ਼ੇਸ਼ ਪਾਈਪਲਾਈਨਾਂ ਲਈ ਵੀ ਘੱਟ ਢਿੱਲਾ ਹੋ ਸਕਦਾ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਸਧਾਰਨ ਡਾਇਰੈਕਟ-ਟੂ-ਮਸ਼ੀਨ ਕੋਡ ਮੈਪਿੰਗ ਚਾਹੁੰਦੇ ਹੋ।
ਇੱਕ ਸਧਾਰਣ ਚੈਕਲਿਸਟ
ਇਹ ਤਿੰਨ ਸਵਾਲ ਪੁੱਛੋ:
- ਕੀ ਸਾਨੂੰ ਹੁਣ ਜਾਂ ਜਲਦੀ ਕਈ ਪਲੇਟਫਾਰਮ/CPU ਟਾਰਗੇਟ ਕਰਨ ਦੀ ਲੋੜ ਹੈ?
- ਕੀ ਅਸੀਂ ਮੌਜੂਦਾ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਅਤੇ ਡੀਬੱਗ ਇੰਫੋ ਤੋਂ ਲਾਭ ਲੈਣਾ ਚਾਹੁੰਦੇ ਹਾਂ, ਨਾ ਕਿ ਆਪਣਾ ਬਣਾਉਣਾ?
- ਕੀ ਅਸੀਂ ਇੱਕ ਇਕੋਸਿਸਟਮ ਰਸਤਾ (ਟੂਲਿੰਗ, ਇੰਟੇਗ੍ਰੇਸ਼ਨ, ਭਰਤੀ) ਚਾਹੁੰਦੇ ਹਾਂ ਜ਼ਿਆਦਾ ਕਿ ਇਕ ਨਿਊਨਤਮ ਕਸਟਮ ਕੰਪਾਇਲਰ?
ਜੇ ਤੁਸੀਂ ਬਹੁਤੇ ਸਵਾਲਾਂ ਦਾ "ਹਾਂ" ਕਹਿੰਦੇ ਹੋ, ਤਾਂ LLVM ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਚੋਣ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਮੁੱਖ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਛੋਟਾ, ਸਧਾਰਨ ਕੰਪਾਇਲਰ ਚਾਹੀਦਾ ਹੈ ਜੋ ਇਕ ਤੇਜ਼ ਸਮੱਸਿਆ ਹੱਲ ਕਰਦਾ ਹੈ, ਤਾਂ ਹਲਕਾ ਪਹੁੰਚ ਜ਼ਿਆਦਾ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ।
ਪ੍ਰੋਡਕਟ ਟੀਮਾਂ ਲਈ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਨੋਟ: LLVM ਦੇ ਫਾਇਦੇ ਬਿਨਾਂ ਕੰਪਾਇਲਰ-ਮਾਹਿਰ ਬਣੇ
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ "LLVM ਗ੍ਰਹਿਣ" ਨਹੀਂ ਕਰਦੇ—ਉਹ ਨਤੀਜੇ ਚਾਹੁੰਦੇ ਹਨ: ਕ੍ਰਾਸ-ਪਲੇਟਫਾਰਮ ਬਿਲਡ, ਤੇਜ਼ ਬਿਨਰੀ, ਚੰਗੇ ਡਾਇਗਨੋਸਟਿਕ, ਅਤੇ ਭਰੋਸੇਯੋਗ ਟੂਲਿੰਗ।
ਇਸੇ ਲਈ Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਰੁਚਿਕਰ ਹਨ। ਜੇ ਤੁਹਾਡਾ ਵਰਕਫਲੋ ਵੱਧਦੇ ਹੋਏ ਉੱਚ-ਪੱਧਰੀ ਆਟੋਮੇਸ਼ਨ (ਪਲਾਨਿੰਗ, ਸਕੈਫੋਲਡਿੰਗ ਜਨਰੇਸ਼ਨ, ਤੀਬਰ ਇਟਰੇਸ਼ਨ) ਨਾਲ ਚੱਲ ਰਿਹਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਅਮਲ ਵਿੱਚ LLVM ਤੋਂ ਅਪਰੋਕਸ਼ ਲਾਭ ਪਾਉਂਦੇ ਹੋ—ਚਾਹੇ ਤੁਸੀਂ React ਵੈੱਬ ਐਪ, Go ਬੈਕਐਂਡ ਨਾਲ PostgreSQL, ਜਾਂ Flutter ਮੋਬਾਈਲ ਕਲਾਇੰਟ ਬਣਾ ਰਹੇ ਹੋ। Koder.ai ਦੀ chat-driven "vibe-coding" ਰਵਾਇਤ ਉਤਪਾਦ ਤੇਜ਼ੀ ਨਾਲ ਭੇਜਣ 'ਤੇ ਧਿਆਨ ਰੱਖਦੀ ਹੈ, ਜਦਕਿ ਆਧੁਨਿਕ ਕੰਪਾਇਲਰ ਇੰਫ੍ਰਾਸ਼ਟਰਕਚਰ (LLVM/Clang ਅਤੇ ਮਿੱਤਰ, ਜਿੱਥੇ ਲਾਗੂ) ਪਿੱਠ-ਪ੍ਰੇਖ ਵਿੱਚ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ, ਡਾਇਗਨੋਸਟਿਕ, ਅਤੇ ਪੋਰਟੇਬਿਲਟੀ ਜਿਹਾ ਅਨਗਿਨਤ ਕੰਮ ਕਰਦਾ ਰਹਿੰਦਾ ਹੈ।