30 ਨਵੰ 2025·8 ਮਿੰਟ
ਕਲਾਉਡ ਲਾਗਤ ਅਤੇ ਉਪਯੋਗ ਵੰਡ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਜਾਣੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਈਨ ਅਤੇ ਬਣਾਉਣਾ ਹੈ ਜੋ ਕਲਾਉਡ ਬਿੱਲਿੰਗ ਡੇਟਾ ਲੈਂਦਾ ਹੈ, ਉਪਯੋਗ ਨੂੰ ਟੀਮਾਂ ਨੂੰ ਵੰਡਦਾ ਹੈ, ਅਤੇ ਡੈਸ਼ਬੋਰਡ, ਬਜਟ ਅਤੇ ਕਾਰਵਾਈਯੋਗ ਰਿਪੋਰਟਾਂ ਦਿੰਦਾ ਹੈ।
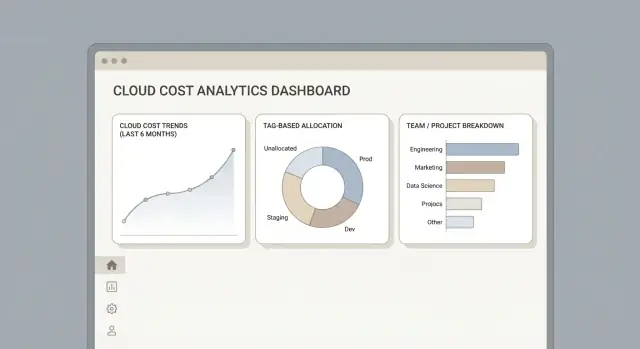
ਜਾਣੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਈਨ ਅਤੇ ਬਣਾਉਣਾ ਹੈ ਜੋ ਕਲਾਉਡ ਬਿੱਲਿੰਗ ਡੇਟਾ ਲੈਂਦਾ ਹੈ, ਉਪਯੋਗ ਨੂੰ ਟੀਮਾਂ ਨੂੰ ਵੰਡਦਾ ਹੈ, ਅਤੇ ਡੈਸ਼ਬੋਰਡ, ਬਜਟ ਅਤੇ ਕਾਰਵਾਈਯੋਗ ਰਿਪੋਰਟਾਂ ਦਿੰਦਾ ਹੈ।
ਸਕ੍ਰੀਨ ਜਾਂ ਪਾਈਪਲਾਈਨ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਕਿਹੜੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣੇ ਹੋਣਗੇ। “ਕਲਾਉਡ ਲਾਗਤ” ਦਾ मतलब ਇੱਕ ਇਨਵਾਇਸ ਟੋਟਲ, ਇੱਕ ਟੀਮ ਦਾ ਮਹੀਨਾਵਾਰ ਖਰਚ, ਇੱਕ ਸੇਵਾ ਦੀ ਯੂਨਿਟ ਆਰਥਿਕਤਾ, ਜਾਂ ਕਿਸੇ ਕਸਟਮਰ-ਮੁੱਖ ਫੀਚਰ ਦੀ ਲਾਗਤ ਹੋ ਸਕਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਸਮੱਸਿਆ ਨਿਰਧਾਰਿਤ ਨਹੀਂ ਕਰੋਗੇ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਅਜਿਹੇ ਡੈਸ਼ਬੋਰਡ ਬਣ ਜਾਣਗੇ ਜੋ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਲੱਗਦੇ ਹਨ ਪਰ ਵਿਵਾਦ ਹੱਲ ਨਹੀਂ ਕਰਦੇ।
ਇੱਕ ਮਦਦਗਾਰ ਫਰੇਮਿੰਗ: ਤੁਹਾਡੀ ਪਹਿਲੀ ਡਿਲੀਵਰੇਬਲ “ਇੱਕ ਡੈਸ਼ਬੋਰਡ” ਨਹੀਂ, ਇੱਕ ਸਾਂਝੀ ਸੱਚਾਈ ਦੀ ਪਰਿਭਾਸ਼ਾ ਹੈ (ਆਖੜੇ ਕੀ ਮਤਲਬ ਹਨ, ਉਹ ਕਿਵੇਂ ਗਣੇ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕਿਸ ਨੂੰ ਇਨ੍ਹਾਂ 'ਤੇ ਕਾਰਵਾਈ ਕਰਨ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ)।
ਪਹਿਲਾਂ ਮੁੱਖ ਉਪਭੋਗਤਾਂ ਦੇ ਨਾਮ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਫੈਸਲਾ ਕਰਨ ਲਈ ਕੀ ਚਾਹੀਦਾ ਹੈ—ਲਿਖੋ:
ਵੱਖ-ਵੱਖ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਡੀਟੇਲ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। Finance ਨੂੰ ਸਥਿਰ, ਆਡੀਟਯੋਗ ਮਹੀਨਾਵਾਰ ਨੰਬਰ ਚਾਹੀਦੇ ਹੋ ਸਕਦੇ ਹਨ; ਇੰਜੀਨੀਅਰਜ਼ ਨੂੰ ਰੋਜ਼ਾਨਾ ਗਰੈਨੁਲੈਰਿਟੀ ਅਤੇ ਡ੍ਰਿੱਲ-ਡਾਊਨ ਚਾਹੀਦਾ ਹੈ।
ਸਪਸ਼ਟ ਹੋਵੋ ਕਿ ਤੁਸੀਂ ਪਹਿਲਾਂ ਕਿਹੜੇ ਨਤੀਜੇ ਦੇ ਰਹੇ ਹੋ:
ਵਿਆਵਹਾਰਿਕ ਤਰੀਕਾ: ਇੱਕ “ਪ੍ਰਾਇਮਰੀ ਨਤੀਜੇ” ਚੁਣੋ ਅਤੇ ਬਾਕੀਆਂ ਨੂੰ ਫੋਲੋ-ਆਨ ਸਮਝੋ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ showback ਅਤੇ ਬੁਨਿਆਦੀ anomaly detection ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ, ਫਿਰ chargeback ਵੱਲ ਵੱਧਦੀਆਂ ਹਨ।
ਉਹ ਕਲਾਉਡ ਅਤੇ ਬਿਲਿੰਗ ਇਕਾਈਆਂ ਲਿਸਟ ਕਰੋ ਜੋ ਦਿਨ ਇੱਕ ਤੋਂ ਸਮਰਥਿਤ ਹੋਣੀ ਚਾਹੀਦੀ ਹਨ: AWS payer accounts, Azure subscriptions ਅਤੇ management groups, GCP billing accounts/projects, ਨਾਲ ਹੀ shared services (logging, networking, security)। ਫ਼ੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਤੁਸੀਂ marketplace charges ਅਤੇ ਤੀਜੇ-ਪਾਰਟੀ SaaS ਦੀ ਸ਼ਾਮਲ ਹੋਣਾ ਚਾਹੁੰਦੇ ਹੋ।
ਇੱਕ ਟਾਰਗੇਟ ਅਪਡੇਟ ਕੈਡੈਂਸ ਚੁਣੋ: ਰੋਜ਼ਾਨਾ finance ਅਤੇ ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਲਈ ਕਾਫੀ ਹੈ; near-real-time ਇਨਸੀਡੈਂਟ ਰਿਸਪਾਂਸ ਲਈ ਅਤੇ ਤੇਜ਼-ਗਤੀ ਵਾਲੀਆਂ ਸੰਸਥਾਵਾਂ ਲਈ ਲਾਭਕਾਰੀ ਹੈ ਪਰ ਇਹ ਜਟਿਲਤਾ ਅਤੇ ਲਾਗਤ ਵਧਾਉਂਦਾ ਹੈ। ਰਿਟੇਨਸ਼ਨ (ਉਦਾਹਰਨ: 13–24 ਮਹੀਨੇ) ਅਤੇ ਕਿ ਕੀ ਤੁਹਾਨੂੰ ਆਡੀਟ ਲਈ ਅਟੱਲ “month close” ਸਨੇਪਸ਼ਾਟ ਚਾਹੀਦੇ ਹਨ—ਇਹ ਵੀ ਨਿਰਧਾਰਿਤ ਕਰੋ।
ਇੱਕ ਵੀ CSV ਇੰਪੋਰਟ ਜਾਂ ਬਿੱਲਿੰਗ API ਕੱਲ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਨਿਰਧਾਰਿਤ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਐਪ ਵਿੱਚ “ਸੱਚ” ਕਿਵੇਂ ਦਿੱਸਦਾ ਹੈ। ਇੱਕ ਸਾਫ਼ ਮੈਜ਼ਰਮੈਂਟ ਮਾਡਲ ਬਾਅਦ ਦੀਆਂ ਬਹਿਸਾਂ ਰੋਕਦਾ ਹੈ (“ਇਹ ਇਨਵਾਇਸ ਨਾਲ ਕਿਉਂ ਨਹੀਂ ਮਿਲਦਾ?”) ਅਤੇ ਮਲਟੀ-ਕਲਾਉਡ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਪੇਸ਼ਗੋਈਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਘੱਟੋ-ਘੱਟ, ਹਰੇਕ ਬਿੱਲਿੰਗ ਲਾਈਨ ਨੂੰ ਇੱਕ ਰਿਕਾਰਡ ਵਜੋਂ ਰੱਖੋ ਜਿਸ ਵਿੱਚ ਇੱਕ ਸਥਿਰ ਸੈੱਟ ਮਾਪਦੰਡ ਹੋਣ:
ਵਿਆਵਹਾਰਿਕ ਨਿਯਮ: ਜੇ ਇੱਕ ਮੁੱਲ ਫਾਇਨੈਂਸ ਦੇ ਭੁਗਤਾਨ ਜਾਂ ਟੀਮ ਦੇ ਚਾਰਜ ਨੂੰ ਬਦਲ ਸਕਦਾ ਹੈ, ਤਾਂ ਉਨ੍ਹਾਂ ਲਈ ਆਪਣਾ ਮੈਟਰਿਕ ਬਣਾਓ।
ਡਾਇਮੈਨਸ਼ਨ ਖਰਚਾਂ ਨੂੰ ਖੋਜਯੋਗ ਅਤੇ ਵੰਡ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ। ਆਮ ਡਾਇਮੈਨਸ਼ਨਾਂ:
ਡਾਇਮੈਨਸ਼ਨਾਂ ਨੂੰ ਲਚਕੀਲਾ ਰੱਖੋ: ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਹੋਰ ਜੋੜੋਗੇ (ਉਦਾਹਰਨ: “cluster”, “namespace”, “vendor”)।
ਅਕਸਰ ਤੁਹਾਨੂੰ ਕਈ ਸਮੇਂ ਵਾਲੀਆਂ ਸੰਕਲਪਾਂ ਦੀ ਲੋੜ ਹੋਵੇਗੀ:
ਇੱਕ ਸਖਤ ਪਰਿਭਾਸ਼ਾ ਲਿਖੋ:
ਇਹ ਇੱਕਪਰਾਰੇ ਪਰਿਭਾਸ਼ਾ ਤੁਹਾਡੇ ਡੈਸ਼ਬੋਰਡ, ਅਲਰਟ ਅਤੇ ਨੰਬਰਾਂ 'ਤੇ ਭਰੋਸਾ ਬਣਾਉਂਦੀ ਹੈ।
ਬਿੱਲਿੰਗ ਇਨਜੈਸ਼ਨ ਇੱਕ ਕਲਾਉਡ ਲਾਗਤ ਪ੍ਰਬੰਧਨ ਐਪ ਦੀ ਨੀਂਹ ਹੈ: ਜੇ ਕੱਚਾ ਇਨਪੁੱਟ ਅਧੂਰਾ ਜਾਂ ਦੁਹਰਾਇਆ ਜਾ ਸਕਦਾ ਨਹੀਂ, ਤਾਂ ਹਰ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਵੰਡ ਨਿਯਮ ਬਹਿਸ ਦਾ ਵਿਸ਼ਾ ਬਣ ਜਾਂਦੇ ਹਨ।
ਹਰ ਕਲਾਉਡ ਲਈ “ਨੈਟਿਵ ਸੱਚ” ਨੂੰ ਸਮਰਥਨ ਦੇ ਕੇ ਸ਼ੁਰੂ ਕਰੋ:
ਹਰ ਕਨੈਕਟਰ ਨੂੰ ਇੱਕੋ ਹੀ ਮੁੱਖ ਨਿਕਾਸਾਂ ਦਾ ਉਤਪਾਦ ਬਣਾਉਣ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ: ਕੁਝ raw files/rows, ਅਤੇ ਇਕ ingestion log (ਕੀ ਲਿਆ, ਕਦੋਂ, ਤੇ ਕਿੰਨੇ ਰਿਕਾਰਡ)।
ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਦੋ ਪੈਟਰਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਚੁਣੋਗੇ:
ਅਕਸਰ ਟੀਮਾਂ ਹਿਬ੍ਰਿਡ ਚਲਾਉਂਦੀਆਂ ਹਨ: freshness ਲਈ push, ਅਤੇ missed files ਲਈ ਰੋਜ਼ਾਨਾ pull sweeper।
Ingestion ਪ੍ਰੋਵਾਇਡਰ ਦੀ ਮੁਢਲੀ ਮੁਦਰਾ, ਟਾਈਮ ਜ਼ੋਨ, ਅਤੇ ਬਿਲਿੰਗ ਪੀਰੀਅਡ semantics ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖੇ। ਹੁਣੇ ਹੀ “ਸਹੀ” ਨਾ ਕਰੋ—ਸਿਰਫ ਪ੍ਰੋਵਾਇਡਰ ਜੋ ਕਹਿੰਦਾ ਹੈ ਉਹ ਕੈਪਚਰ ਕਰੋ ਅਤੇ provider ਦੇ period start/end ਨੂੰ ਸਟੋਰ ਕਰੋ ਤਾਂ ਕਿ late adjustments ਸਹੀ ਮਹੀਨੇ 'ਚ ਆ ਸਕਣ।
ਕੱਚੇ exports ਨੂੰ ਇੱਕ immutable, versioned staging bucket/container/dataset ਵਿੱਚ ਸਟੋਰ ਕਰੋ। ਇਸ ਨਾਲ auditability ਮਿਲਦੀ ਹੈ, parsing logic ਬਦਲਣ 'ਤੇ reprocessing ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਹੋ ਸਕਦੀ ਹੈ, ਅਤੇ ਵਿਵਾਦ ਸੁਲਝਾਉਣਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ ਉਹ exact source file ਦਿਖਾ ਸਕਦੇ ਹੋ ਜਿਸਨੇ ਇੱਕ ਨੰਬਰ ਬਣਾਇਆ।
ਜੇ ਤੁਸੀਂ AWS CUR, Azure exports, ਅਤੇ GCP Billing ਡੇਟਾ ਨੂੰ ਜਿਵੇਂ-ਹੀ ਲਿਆਉਂਦੇ ਹੋ, ਤਾਂ ਤੁਹਾਡੀ ਐਪ inconsistent ਮਹਿਸੂਸ ਹੋਵੇਗੀ: ਇੱਕੋ ਚੀਜ਼ ਇੱਕ ਜਗ੍ਹਾ “service” ਕਹਿੰਦੇ ਹਨ, ਦੂਜੇ 'ਚ “meter”, ਅਤੇ ਕਿਸੇ ਹੋਰ 'ਚ “SKU”। ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਉਥੇ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਉਹ ਪ੍ਰੋਵਾਇਡਰ-ਖਾਸ ਟਰਮਜ਼ ਇਕ predictable ਸਕੀਮਾ ਵਿੱਚ ਬਦਲਦੇ ਹੋ ਤਾਂ ਕਿ ਹਰ ਚਾਰਟ, ਫਿਲਟਰ, ਅਤੇ allocation rule ਇਕੋ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰੇ।
ਮੁੱਢ ਤੋਂ provider ਫੀਲਡਸ ਨੂੰ ਇੱਕ ਆਮ ਸੈੱਟ ਡਾਇਮੈਨਸ਼ਨਾਂ 'ਚ ਮੈਪ ਕਰੋ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ ਹਰ ਜਗ੍ਹਾ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹੋ:
ਪਰ provider-native IDs ਵੀ ਰੱਖੋ (ਜਿਵੇਂ AWS ProductCode ਜਾਂ GCP SKU ID) ਤਾਂ ਕਿ ਕਿਸੇ ਵਿਵਾਦ ਦੇ ਸਮੇਂ ਆਸਾਨੀ ਨਾਲ original record ਤੱਕ trace ਕੀਤਾ ਜਾ ਸਕੇ।
Normalization ਸਿਰਫ columns ਦਾ ਨਾਮ ਬਦਲਣਾ ਨਹੀਂ—ਇਹ ਡੇਟਾ ਸਫਾਈ ਵੀ ਹੈ।
ਹਰ normalized row ਨੂੰ lineage metadata ਨਾਲ ਰੱਖੋ: source file/export, import time, ਅਤੇ transformation version (ਉਦਾਹਰਨ: norm_v3)। ਜਦੋ mapping rules ਬਦਲਦੇ ਹਨ, ਤੁਸੀਂ ਦਰੁਸਤ ਤਰੀਕੇ ਨਾਲ reprocess ਕਰਕੇ ਫਰਕ ਸਮਝਾ ਸਕਦੇ ਹੋ।
ਟੌਟਲਜ਼ ਬਾਇ ਡੇ, ਨੈਗੇਟਿਵ-ਕਾਸਟ ਨਿਯਮ, ਮੁਦਰਾ ਸਥਿਰਤਾ, ਅਤੇ “ਖਰਚ ਖਾਤਾ/ਸਬਸਕ੍ਰਿਪਸ਼ਨ/ਪ੍ਰੋਜੈਕਟ ਦੁਆਰਾ” ਵਰਗੇ automated checks ਬਣਾਓ। ਫਿਰ UI ਵਿੱਚ ਇੱਕ import summary ਦਿਖਾਓ: ingested rows, rejected rows, time coverage, ਅਤੇ provider totals ਦੇ ਨਾਲ delta। ਜਦੋਂ ਉਪਭੋਗਤਾ ਵੇਖ ਸਕਣ ਕਿ ਕੀ ਹੋਇਆ, ਤਾਂ ਭਰੋਸਾ ਬਣਦਾ ਹੈ—ਕੇਵਲ ਆਖਰੀ ਨੰਬਰ ਨਹੀਂ।
ਖਰਚ ਡੇਟਾ ਤਦ ਹੀ полез ਹੈ ਜਦੋਂ ਕੋਈ ਕਹਿ ਸਕੇ “ਇਸ ਦਾ ਮਾਲਕ ਕੌਣ ਹੈ?” ਲਗਾਤਾਰ। Tagging (AWS), labels (GCP), ਅਤੇ resource tags (Azure) ਸਭ ਤੋਂ ਸਧਾਰਨ ਤਰੀਕੇ ਹਨ spend ਨੂੰ ਟੀਮਾਂ, ਐਪਾਂ, ਅਤੇ ਵਾਤਾਵਰਨ ਨਾਲ ਜੋੜਨ ਲਈ—ਪਰ ਸਿਰਫ਼ ਜੇ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ product ਡੇਟਾ ਵਾਂਗ ਸਮਝਦੇ ਹੋ, ਨਾ ਕਿ ਇੱਕ ਬਿਹਤਰ-ਕੋਸ਼ਿਸ਼ ਆਦਤ ਵਾਂਗ।
ਇੱਕ ਛੋਟਾ ਸੈੱਟ required keys ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਕੇ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਤੁਹਾਡਾ allocation engine ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਭਰੋਸਾ ਕਰਨਗੇ:
teamappcost-centerenv (prod/stage/dev)ਨਿਯਮ ਸਪਸ਼ਟ ਬਣਾਓ: ਕਿਹੜੀਆਂ resources ਨੂੰ ਟੈਗ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹੈ, ਕਿਹੜੇ tag formats ਮਨਜ਼ੂਰ ਹਨ (ਉਦਾਹਰਨ: lowercase kebab-case), ਅਤੇ ਟੈਗ ਗਾਇਬ ਹੋਣ 'ਤੇ ਕੀ ਹੁੰਦਾ ਹੈ (ਉਦਾਹਰਨ: “Unassigned” ਬੱਕੇਟ ਨਾਲ ਇੱਕ ਅਲਰਟ)। ਇਹ ਨੀਤੀ ਐਪ ਦੇ ਅੰਦਰ ਦਿਖਾਓ ਅਤੇ deeper guidance ਲਈ /blog/tagging-best-practices ਦੀ ਸੂਚਨਾ ਦਿਓ।
ਨਿਯਮਾਂ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਤੁਹਾਨੂੰ drift ਮਿਲੇਗਾ: TeamA, team-a, team_a, ਜਾਂ ਟੀਮ ਦਾ ਨਾਂ ਬਦਲਿਆ ਹੋ ਸਕਦਾ ਹੈ। ਇੱਕ ਹਲਕਾ mapping ਲੇਅਰ ਜੋੜੋ ਤਾਂ ਕਿ finance ਅਤੇ platform owners ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖੇ ਬਿਨਾਂ ਵੈਲਿਊਜ਼ ਨਾਰਮਲਾਈਜ਼ ਕਰ ਸਕਣ:
TeamA, team-a → team-a)ਇਹ mapping UI ਉਹ ਜਗ੍ਹਾ ਵੀ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ enrichment ਕਰ ਸਕਦੇ ਹੋ: ਜੇ app=checkout ਹੈ ਪਰ cost-center ਗਾਇਬ ਹੈ, ਤਾਂ ਤੁਸੀਂ app registry ਤੋਂ ਅਨੁਮਾਨ ਲਗਾ ਸਕਦੇ ਹੋ।
ਕੁਝ ਖਰਚ ਆਸਾਨੀ ਨਾਲ ਟੈਗ ਨਹੀਂ ਹੁੰਦੀ:
ਇਨ੍ਹਾਂ ਨੂੰ owned “shared services” ਵਜੋਂ ਮਾਡਲ ਕਰੋ ਅਤੇ ਸਪਸ਼ਟ allocation rules ਬਣਾਓ (ਉਦਾਹਰਨ: headcount, usage metrics, ਜਾਂ ਅਨੁਪਾਤਿਕ ਖਰਚ ਨਾਲ ਵੰਡ). ਲਕੜੀ-ਮਕਸਦ ਇਹ ਨਹੀਂ ਕਿ attribution ਪਰਫੈਕਟ ਹੋਵੇ—ਬਲਕਿ ਹਰੇਕ ਡਾਲਰ ਲਈ ਇੱਕ ਘਰ ਅਤੇ ਇੱਕ ਵਿਅਕਤੀ ਹੋਵੇ ਜੋ ਉਸਨੂੰ ਸਮਝਾ ਸਕੇ।
ਇੱਕ allocation engine normalized billing lines ਨੂੰ “ਇਹ ਖਰਚ ਕਿਸ ਦਾ ਹੈ, ਅਤੇ ਕਿਉਂ” ਵਿੱਚ ਬਦਲਦਾ ਹੈ। ਲਕੜੀ-ਮਕਸਦ ਸਿਰਫ਼ ਗਣਿਤ ਨਹੀਂ—ਇਹ ਐਸੇ ਨਤੀਜੇ ਬਣਾਉਣ ਹੈ ਜੋ ਸਟੇਕਹੋਲਡਰ ਸਮਝ ਸਕਣ, ਚੁਣੌਤੀ ਦੇ ਸਕਣ, ਅਤੇ ਸੁਧਾਰ ਸਕਣ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਨੂੰ ਮਿਲੇ-ਜੁਲੇ ਤਰੀਕੇ ਚਾਹੀਦੇ ਹਨ ਕਿਉਂਕਿ ਹਰ ਖਰਚ ਸਾਫ ownership ਨਾਲ ਨਹੀਂ ਆਉਂਦੀ:
Allocation ਨੂੰ ordered rules ਨਾਲ ਮਾਡਲ ਕਰੋ ਜੋ priority ਅਤੇ effective dates ਰੱਖਦੇ ਹਨ। ਇਸ ਨਾਲ ਤੁਸੀਂ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹੋ: “ਕਿਹੜਾ rule March 10 ਨੂੰ ਲਾਗੂ ਹੋਇਆ?” ਅਤੇ ਨੀਤੀ ਨੂੰ ਸੁਰਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਅਪਡੇਟ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ-ਲਿਖੇ।
ਇਕ ਪ੍ਰਯੋਗਿਕ rule schema ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਾਮਲ ਕਰਦਾ ਹੈ:
Shared costs—Kubernetes clusters, networking, data platforms—ਅਕਸਰ ਇਕ-ਗੁਣਾ ਟੀਮ ਨਾਲ ਨਹੀਂ ਜੁੜਦੇ। ਪਹਿਲਾਂ ਉਨ੍ਹਾਂ ਨੂੰ “pools” ਵਜੋਂ ਮਾਡਲ ਕਰੋ, ਫਿਰ distribute ਕਰੋ।
ਉਦਾਹਰਨ:
before/after views ਦਿਓ: original vendor line items vs. allocated results by owner। ਹਰ allocated row ਲਈ, ਇੱਕ “explanation” (rule ID, match fields, driver values, split percentages) ਸਟੋਰ ਕਰੋ। ਇਹ audit trail ਵਿਵਾਦ ਘਟਾਉਂਦੀ ਹੈ ਅਤੇ ਭਰੋਸਾ ਬਣਾਉਂਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ chargeback ਅਤੇ showback ਦੌਰਾਨ।
ਕਲਾਉਡ ਬਿੱਲਿੰਗ exports ਤੇਜ਼ੀ ਨਾਲ ਵੱਡੇ ਹੋ ਜਾਂਦੇ ਹਨ: ਹਰ resource ਲਈ ਲਾਈਨ ਆਈਟਮ, ਪ੍ਰਤੀ ਘੰਟਾ, ਕਈ account ਅਤੇ ਪ੍ਰੋਵਾਇਡਰਾਂ 'ਚ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਸਲੋ ਮਹਿਸੂਸ ਹੋਏ, ਉਪਭੋਗਤਾ ਭਰੋਸਾ ਘਟਾ ਦੇਣਗੇ—ਇਸ ਲਈ ਸਟੋਰੇਜ ਡਿਜ਼ਾਈਨ product ਡਿਜ਼ਾਈਨ ਹੈ।
ਆਮ ਸੈੱਟਅਪ ਇੱਕ ਰਿਲੇਸ਼ਨਲ ਵੇਅਰਹਾਊਸ ਹੁੰਦਾ ਹੈ (ਛੋਟੇ deployments ਲਈ Postgres; ਜਦੋਂ ਵੋਲਿਊਮ ਵਧੇ ਤਾਂ BigQuery ਜਾਂ Snowflake), ਨਾਲ OLAP-ਸ਼ੈਲੀ views/materializations analytics ਲਈ।
raw billing line items ਨੂੰ ਉਹੀ ਢੰਗ ਨਾਲ ਸਟੋਰ ਕਰੋ ਜਿਵੇਂ ਮਿਲਿਆ (ਨਾਲ ਕੁੱਝ ingestion fields ਜਿਵੇਂ import time ਅਤੇ source file)। ਫਿਰ curated tables ਬਣਾਓ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਹਾਡੀ ਐਪ query ਕਰੇ। ਇਸ ਨਾਲ “ਕਿੱਦਾਂ ਮਿਲਿਆ” ਅਤੇ “ਅਸੀਂ ਕਿਵੇਂ ਰਿਪੋਰਟ ਕਰਦੇ ਹਾਂ” ਵੱਖਰੇ ਰਹਿੰਦੇ ਹਨ, ਜੋ audits ਅਤੇ reprocessing ਨੂੰ ਸੁਰਖਿਅਤ ਬਣਾਉਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਹ scratch ਤੋਂ बना ਰਹੇ ਹੋ, ਤਾਂ ਪਹਿਲੀ iteration ਨੂੰ ਤੇਜ਼ ਕਰਨ ਲਈ ਇੱਕ ਪਲੇਟਫਾਰਮ ਦੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰਨ 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਉਦਾਹਰਨ ਲਈ, Koder.ai (vibe-coding ਪਲੇਟਫਾਰਮ) ਟੀਮਾਂ ਨੂੰ chat ਰਾਹੀਂ ਕੰਮ ਕਰਦੀ ਐਪ ਜਨਰੇਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ—ਅਕਸਰ React frontend, Go backend, ਅਤੇ PostgreSQL ਨਾਲ—ਤਾਂ ਜੋ ਤੁਸੀਂ ਡੇਟਾ ਮਾਡਲ ਅਤੇ allocation logic 'ਤੇ ਵੱਧ ਸਮਾਂ ਬਿਤਾ ਸਕੋ (ਇਹ ਭਰੋਸੇ ਦੀਆਂ ਚੀਜ਼ਾਂ ਹਨ) ਨਾ ਕਿ boilerplate ਦੁਹਰਾਉਣ 'ਤੇ।
ਜ਼ਿਆਦਾਤਰ queries ਸਮਾਂ ਅਤੇ ਬਾਉਂਡਰੀ (cloud account/subscription/project) ਨਾਲ ਫਿਲਟਰ ਹੁੰਦੀਆਂ ਹਨ। ਇਸ ਲਈ partition ਅਤੇ cluster/index accordingly:
ਇਸ ਨਾਲ “ਪਿਛਲੇ 30 ਦਿਨਾਂ ਲਈ Team A” ਤੇਜ਼ ਰਹਿੰਦਾ ਹੈ ਭਾਵੇਂ ਕੁੱਲ ਇਤਿਹਾਸ ਵੱਡਾ ਹੋਵੇ।
ਡੈਸ਼ਬੋਰਡ raw line items ਨੂੰ ਸ੍ਕੈਨ ਨਹੀਂ ਕਰਨੇ ਚਾਹੀਦੇ। ਉਪਭੋਗਤਾ ਜੋ ਅਨੁਸੰਦੇ ਕਰਦੇ ਹਨ ਉਨ੍ਹਾਂ ਗਰੇਨ 'ਤੇ aggregated tables ਬਣਾਓ:
ਇਹ tables ਆਪਣੇ ਨਿਯਤ ਸਮੇਂ ਤੇ (ਜਾਂ incremental) materialize ਕਰੋ ਤਾਂ ਕਿ charts ਸਕਿੰਨਡਾਂ ਵਿੱਚ ਲੋਡ ਹੋਣ।
Allocation rules, tagging mappings, ਅਤੇ ownership definitions ਬਦਲਣਗੇ। ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਗਣਨਾ ਕਰਨ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ:
ਇਹ ਲਚੀਲਾਪਣ ਹੀ ਇੱਕ cost dashboard ਨੂੰ ਇੱਕ ਸਿਸਟਮ ਬਣਾਉਂਦਾ ਹੈ ਜਿਸ 'ਤੇ ਲੋਕ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ।
ਇੱਕ cost allocation ਐਪ ਤਦ ਹੀ ਕਾਮਯਾਬ ਹੁੰਦਾ ਹੈ ਜਦ ਲੋਕ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਸੈਕਿੰਡਾਂ ਵਿੱਚ ਲੱਭ ਸਕਣ: “ਖਰਚ ਕਿਉਂ ਵਧਿਆ?”, “ਇਸਦਾ ਮਾਲਕ ਕੌਣ ਹੈ?”, ਅਤੇ “ਅਸੀਂ ਇਸ ਬਾਰੇ ਕੀ ਕਰ ਸਕਦੇ ਹਾਂ?” ਤੁਹਾਡਾ UI totals ਤੋਂ details ਤੱਕ ਇੱਕ ਸਪਸ਼ਟ ਕਹਾਣੀ ਦੱਸੇ, ਬਿਨਾਂ ਇਸਦੇ ਕਿ ਉਪਭੋਗਤਾ ਨੂੰ ਬਿੱਲਿੰਗ ਜਾਰਗਨ ਸਮਝਣਾ ਪਏ।
ਛੋਟੇ, ਪੇਸ਼ਗੋਈਯੋਗ ਨਿਰੀਖਣਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਹਰ ਥਾਂ ਇੱਕੋ filter bar ਵਰਤੋ: date range, cloud, team, project, ਅਤੇ environment (prod/stage/dev)। ਫਿਲਟਰ ਬਿਹੇਵਿਅਰ ਸਥਿਰ ਰੱਖੋ (ਇਕੋ defaults, ਇਕੋ “applies to all charts”), ਅਤੇ active filters ਦਿਖਾਓ ਤਾਂ ਜੋ ਸਹਿ-ਸ਼ੇਅਰ ਕੀਤੇ ਸਕ्रीनਸ਼ੌਟ ਅਤੇ links ਸਪਸ਼ਟ ਰਹਿਣ।
ਇੱਕ ਇਰਾਦੇ ਵਾਲਾ ਰਸਤਾ ਡਿਜ਼ਾਈਨ ਕਰੋ:
Invoice total → allocated total → service/category → account/project → SKU/line items。
ਹਰ ਕਦਮ 'ਤੇ ਨੰਬਰ ਦੇ ਨਾਲ “ਕਿਉਂ” ਦਿਖਾਓ: ਲਾਗੂ allocation rules, ਵਰਤੇ ਗਏ tags, ਅਤੇ ਕੋਈ ਅਨੁਮਾਨ। ਜਦੋ ਉਪਭੋਗਤਾ ਇੱਕ line item 'ਤੇ ਆਵੇ, ਤੁਰੰਤ ਕਾਰਵਾਈ ਲਈ ਬਟਨ ਦਿਓ ਜਿਵੇਂ “view owner mapping” (see /settings/ownership) ਜਾਂ “report missing tags” (see /governance/tagging)।
ਹਰ ਟੇਬਲ ਤੋਂ CSV exports ਦਿਓ, ਪਰ ਨਾਲ ਹੀ shareable links ਦਿਓ ਜੋ filters ਨੂੰ ਬਚਾਉਂਦੇ ਹਨ। Links ਨੂੰ reports ਵਾਂਗ ਵਰਤੋ: ਉਹ role-based access ਨੂੰ ਮੰਨਣ, audit trail ਰੱਖਣ, ਅਤੇ ਚਾਹੇ ਤਾਂ expire ਵੀ ਕਰਨ। ਇਸ ਨਾਲ ਸਹਿਯੋਗ ਆਸਾਨ ਬਣਦਾ ਹੈ ਅਤੇ ਸੰਵੇਦਨਸ਼ੀਲ ਖਰਚ ਡੇਟਾ ਨਿਯੰਤਰਿਤ ਰਹਿੰਦਾ ਹੈ।
ਡੈਸ਼ਬੋਰਡ ਦੱਸਦੇ ਹਨ ਕਿ ਕੀ ਹੋਇਆ। ਬਜਟ ਅਤੇ ਅਲਰਟ ਦੱਸਦੇ ਹਨ ਕਿ ਹੁਣ ਕੀ ਹੋਣਾ ਚਾਹੀਦਾ।
ਜੇ ਤੁਹਾਡੀ ਐਪ ਟੀਮ ਨੂੰ ਨਹੀ ਦੱਸ ਸਕਦੀ “ਤੂੰ ਆਪਣਾ ਮਹੀਨਾਵਾਰ ਬਜਟ ਤੋੜਣ ਵਾਲਾ ਹੈ”, ਅਤੇ ਸਹੀ ਵਿਅਕਤੀ ਨੂੰ ਸੂਚਿਤ ਨਹੀਂ ਕਰ ਸਕਦੀ, ਤਾਂ ਇਹ ਸਿਰਫ ਇੱਕ ਰਿਪੋਰਟਿੰਗ ਟੂਲ ਹੀ ਰਹਿ ਜਾਂਦੀ—Nਹੀਂ ਕਿ ਇੱਕ ਆਪਰੇਸ਼ਨਲ ਟੂਲ।
ਵੋਹੀ ਲੈਵਲ ਚੁਣੋ ਜਿਸ 'ਤੇ ਤੁਸੀਂ costs allocate ਕਰਦੇ ਹੋ: team, project, environment, ਜਾਂ product। ਹਰ budget ਵਿੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
UI ਸਧਾਰਤ ਰੱਖੋ: amount + scope + owner ਸੈੱਟ ਕਰਨ ਲਈ ਇੱਕ ਸਕਰੀਨ, ਅਤੇ “ਇਸ scope ਵਿੱਚ ਪਿਛਲਾ ਮਹੀਨਾ ਖਰਚ” ਦਾ preview sanity-check ਲਈ।
ਬਜਟ slow drift ਨੂੰ ਕੈਚ ਕਰਦੇ ਹਨ, ਪਰ ਟੀਮਾਂ ਨੂੰ ਤੁਰੰਤ ਸਿਗਨਲ ਵੀ ਚਾਹੀਦੇ ਹਨ:
Alerts actionable ਬਣਾਓ: top drivers (service, region, project), ਇੱਕ ਛੋਟੀ ਵਿਆਖਿਆ, ਅਤੇ explorer view ਵਿੱਚ link (see /costs?scope=team-a&window=7d)।
Machine learning ਦੇ ਪਹਿਲਾਂ, ਅਜਿਹੇ baseline comparisons ਲਾਗੂ ਕਰੋ ਜੋ debug ਕਰਨ ਵਿੱਚ ਆਸਾਨ ਹੋਣ:
ਇਸ ਨਾਲ ਛੋਟੇ spend categories 'ਤੇ noisy alerts ਤੋਂ ਬਚਣ ਵਿੱਚ ਮਦਦ ਮਿਲਦੀ ਹੈ।
ਹਰ alert event ਨੂੰ ਸਟੋਰ ਕਰੋ ਅਤੇ status ਰੱਖੋ: acknowledged, muted, false positive, fixed, ਜਾਂ expected। ਕਿਸ ਨੇ ਕਾਰਵਾਈ ਕੀਤੀ ਅਤੇ ਲੱਗੇ ਸਮੇਂ ਨੂੰ ਟ੍ਰੈਕ ਕਰੋ।
ਸਮੇਂ ਦੇ ਨਾਲ, ਇਸ ਇਤਿਹਾਸ ਨੂੰ noise ਘਟਾਉਣ ਲਈ ਵਰਤੋ: repeat alerts auto-suppress ਕਰੋ, thresholds ਪ੍ਰਤੀ scope ਸੁਧਾਰੋ, ਅਤੇ “ਹਮੇਸ਼ਾਂ untagged” ਟੀਮਾਂ ਦੀ ਪਛਾਣ ਕਰੋ ਜਿਨ੍ਹਾਂ ਨੂੰ workflow ਸੁਧਾਰ ਦੀ ਲੋੜ ਹੈ ਨਾ ਕਿ ਹੋਰ ਨੋਟੀਫਿਕੇਸ਼ਨ।
ਖਰਚ ਡੇਟਾ ਸੰਵੇਦਨਸ਼ੀਲ ਹੁੰਦਾ ਹੈ: ਇਹ vendor pricing, ਅੰਦਰੂਨੀ ਪ੍ਰੋਜੈਕਟ, ਅਤੇ ਕੁਝ ਵਾਰੀ ਗਾਹਕ ਕੰਮ-ਕਰਾਰ ਦਾ ਪਤਾ ਦਿਵਾ ਸਕਦਾ ਹੈ। ਆਪਣੇ cost ਐਪ ਨੂੰ ਫਾਇਨੈਂਸ਼ੀਅਲ ਸਿਸਟਮ ਵਾਂਗ ਵਰਤੋ—ਕਿਉਂਕਿ ਕਈ ਟੀਮਾਂ ਲਈ ਇਹ ਦੇਸ਼ੀ ਰੂਪ ਵਿੱਚ ਇੱਕ ਵਿੱਤੀ ਸਿਸਟਮ ਹੁੰਦਾ ਹੈ।
ਛੋਟਾ roles ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਸਪਸ਼ਟ ਰੱਖੋ:
ਇਨ੍ਹਾਂ ਨੂੰ API ਵਿੱਚ enforce ਕਰੋ (ਕੇਵਲ UI 'ਚ ਨਹੀਂ), ਅਤੇ resource-level scoping ਜੋੜੋ (ਉਦਾਹਰਨ: ਇੱਕ team lead ਹੋਰ ਟੀਮਾਂ ਦੇ projects ਨਹੀਂ ਵੇਖ ਸਕਦਾ)।
ਕਲਾਉਡ ਬਿੱਲਿੰਗ exports ਅਤੇ usage APIs ਲਈ credentials ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। Secrets dedicated secret manager (ਜਾਂ KMS ਨਾਲ encrypted at rest) ਵਿੱਚ ਰੱਖੋ, ਕਦੇ ਵੀ plain database fields ਵਿੱਚ ਨਹੀਂ। rotation ਸੁਲਝਾਉਣ ਲਈ multiple active credentials per connector ਸਮਰਥਨ ਕਰੋ ਜਿਸਦੇ ਨਾਲ “effective date” ਹੋਵੇ, ਤਾਂ ingestion key swaps ਦੌਰਾਨ ਬਰਕਰਾਰ ਰਹੇ।
UI ਵਿੱਚ ਪ੍ਰਾਇਗਟਿਕ ਤੱਥ ਦਿਖਾਓ: last successful sync time, permission scope warnings, ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ “re-authenticate” flow।
Append-only audit logs ਸ਼ਾਮਲ ਕਰੋ:
ਲੋਗ searchable ਅਤੇ exportable (CSV/JSON) ਹੋਣ, ਅਤੇ ਹਰ log entry ਨੂੰ ਪ੍ਰਭਾਵਤ object ਨਾਲ ਲਿੰਕ ਕਰੋ।
UI 'ਚ retention ਅਤੇ privacy settings ਦਸਤਾਵੇਜ਼ ਕਰੋ: ਕੱਚੇ billing files ਕਿੰਨੀ ਦੇਰ ਰੱਖੇ ਜਾਣਗੇ, ਕਦੋਂ aggregated tables raw data ਦੀ ਥਾਂ ਲੈਣਗੇ, ਅਤੇ ਕੌਣ ਡੇਟਾ ਮਿਟਾ ਸਕਦਾ ਹੈ। ਇੱਕ ਸਧਾਰਨ “Data Handling” ਪੰਨਾ (see /settings/data-handling) support tickets ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ finance/ security teams ਨਾਲ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ。
ਇੱਕ cost allocation ਐਪ ਤਦ ਹੀ ਬਦਲਾਅ ਲਿਆਉਂਦੀ ਹੈ ਜਦੋਂ ਇਹ ਉਹਨਾਂ ਥਾਵਾਂ 'ਤੇ ਪ੍ਰਗਟ ਹੁੰਦੀ ਹੈ ਜਿੱਥੇ ਲੋਕ ਪਹਿਲਾਂ ਕੰਮ ਕਰਦੇ ਹਨ। ਇੰਟਿਗ੍ਰੇਸ਼ਨ "ਰਿਪੋਰਟਿੰਗ ਓਵਰਹੈਡ" ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ cost ਡੇਟਾ ਨੂੰ ਸਾਂਝਾ, ਆਪਰੇਸ਼ਨਲ ਸੰਦਰਭ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ—finance, engineering, ਅਤੇ leadership ਤਿੰਨੋਂ ਇਕੋ ਨੰਬਰ ਵੇਖਦੇ ਹਨ।
ਸ਼ੁਰੂਆਤ notifications ਨਾਲ ਕਰੋ ਕਿਉਂਕਿ ਉਹ ਤੁਰੰਤ ਕਾਰਵਾਈ ਚਲਾਉਂਦੀਆਂ ਹਨ। ਸੰਖੇਪ ਸੁਨੇਹੇ ਭੇਜੋ ਜਿਸ ਵਿੱਚ owner, service, delta, ਅਤੇ ਤੁਹਾਡੇ ਐਪ ਵਿੱਚ ਸਹੀ view ਲਈ link ਸ਼ਾਮਲ ਹੋਵੇ (filtered to team/project and time window)।
ਆਮ alerts:
ਜੇ access ਮੁਸ਼ਕਿਲ ਹੈ ਤਾਂ ਲੋਕ adopt ਨਹੀਂ ਕਰਨਗੇ। SAML/OIDC SSO ਸਮਰਥਨ ਕਰੋ ਅਤੇ identity groups ਨੂੰ cost “owners” (teams, cost centers) ਨਾਲ ਮੈਪ ਕਰੋ। ਇਸ ਨਾਲ offboarding ਸਧਾਰਨ ਹੁੰਦਾ ਹੈ ਅਤੇ permissions org changes ਨਾਲ aligned ਰਹਿੰਦੇ ਹਨ।
ਇੱਕ stable API ਦਿਓ ਤਾਂ ਕਿ ਅੰਦਰੂਨੀ ਸਿਸਟਮ “cost by team/project” ਨੂੰ screen-scraping ਬਿਨਾਂ fetch ਕਰ ਸਕਣ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਰੂਪ:
GET /api/v1/costs?team=payments&start=2025-12-01&end=2025-12-31&granularity=dayRate limits, caching headers, ਅਤੇ idempotent query semantics ਦਸਤਾਵੇਜ਼ ਕਰੋ ਤਾਂ ਕਿ consumers ਭਰੋਸੇਯੋਗ pipeline ਬਣਾ ਸਕਣ।
Webhooks ਤੁਹਾਡੇ ਐਪ ਨੂੰ ਪ੍ਰਤੀਕਿਰਿਆਸ਼ੀਲ ਬਣਾਉਂਦੇ ਹਨ। budget.exceeded, import.failed, anomaly.detected, ਅਤੇ tags.missing ਵਰਗੇ events fire ਕਰੋ ਤਾਂ ਜੋ ਹੋਰ ਸਿਸਟਮਾਂ ਵਿੱਚ workflow trigger ਹੋ ਸਕੇ।
ਆਮ ਮੰਜ਼ਿਲਾਂ ਵਿੱਚ Jira/ServiceNow ਟਿਕਟ ਬਣਾਉਣਾ, incident tools, ਜਾਂ custom runbooks ਸ਼ਾਮਲ ਹਨ।
ਕੁਝ ਟੀਮਾਂ ਆਪਣੀਆਂ ਰਿਪੋਰਟਾਂ ਬਣਾਉਣੀ ਚਾਹੁੰਦੀਆਂ ਹਨ। ਇੱਕ governed export (ਜਾਂ read-only warehouse schema) ਦਿਓ ਤਾਂ ਕਿ BI reports ਇੰਨੇ allocation logic ਨੂੰ ਵਰਤਣ—ਨਾ ਕਿ formulas ਨੂੰ ਦੁਬਾਰਾ ਲਿਖਣ।
ਜੇ ਤੁਸੀਂ integrations ਨੂੰ add-ons ਵਜੋਂ ਪੈਕੇਜ ਕਰਦੇ ਹੋ, ਤਾਂ ਯੂਜ਼ਰਾਂ ਨੂੰ /pricing ਬਾਰੇ ਜਾਣਕਾਰੀ ਦਿਖਾਓ।
ਇੱਕ cost allocation ਐਪ ਤਦ ਹੀ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ। ਭਰੋਸਾ ਦੁਹਰਾਏ ਜਾਂਦੇ ਟੈਸਟਿੰਗ, ਦਿੱਖਣਯੋਗ data quality checks, ਅਤੇ ਇੱਕ ਰੋਲਆਉਟ ਜੋ ਟੀਮਾਂ ਨੂੰ ਤੁਸੀਂ ਦੇ ਰਹੇ ਨੰਬਰਾਂ ਨਾਲ ਤੁਲਨਾ ਕਰਨ ਦਿੰਦਾ ਹੈ—ਇਸ ਨਾਲ ਮਿਲਦਾ ਹੈ।
ਆਰੰਭ ਕਰੋ ਇੱਕ ਛੋਟੀ ਲਾਇਬ੍ਰੇਰੀ provider exports ਅਤੇ invoices ਦੀ ਜੋ ਆਮ edge cases ਦਰਸਾਉਂਦੇ ਹਨ: credits, refunds, taxes/VAT, reseller fees, free tiers, committed-use discounts, ਅਤੇ support charges। ਇਹ samples ਸੰਭਾਲ ਕੇ ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ parser ਜਾਂ allocation logic ਵਿੱਚ ਕੋਈ ਬਦਲਾਵ ਕਰਦਿਆਂ ਉਹ tests ਦੁਬਾਰਾ ਚਲਾ ਸਕੋ।
ਟੈਸਟ outcomes 'ਤੇ ਕੇਂਦਰਿਤ ਕਰੋ, ਸਿਰਫ parsing 'ਤੇ ਨਹੀਂ:
ਆਪਣੇ ਹਿਸਾਬ-ਕਿਤਾਬ ਵਾਲੇ totals ਨੂੰ provider-reported totals ਨਾਲ ਇੱਕ tolerance ਅੰਦਰ reconcile ਕਰਨ ਵਾਲੇ automated checks ਜੋੜੋ (ਉਦਾਹਰਨ: rounding ਜਾਂ timing ਫਰਕ ਕਾਰਨ)। ਸਮੇਂ ਦੇ ਨਾਲ ਇਹ checks track ਕਰੋ ਤਾਂ ਕਿ ਜਵਾਬ ਦਿੱਤਾ ਜਾ ਸਕੇ: “ਇਹ drift ਕਦੋਂ ਸ਼ੁਰੂ ਹੋਇਆ?”
ਲਾਭਦਾਇਕ assertions:
ingestion failures, stalled pipelines, ਅਤੇ “data not updated since” thresholds ਲਈ alerts ਸੈੱਟ ਕਰੋ। slow queries ਅਤੇ dashboard load times ਮਨਿitor ਕਰੋ, ਅਤੇ ਕਿਹੜੇ reports heavy scans ਚਲਾਉਂਦੇ ਹਨ ਇਹ ਲਾਗ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਸਹੀ tables optimize ਕਰ ਸਕੋ।
ਪਹਿਲਾਂ ਕੁਝ ਟੀਮਾਂ ਨਾਲ pilot ਚਲਾਓ। ਉਨ੍ਹਾਂ ਨੂੰ ਉਨ੍ਹਾਂ ਦੀਆਂ ਮੌਜੂਦਾ spreadsheets ਨਾਲ তুলਨात्मक view ਦਿਓ, definitions 'ਤੇ ਸਹਿਮਤ ਹੋਵੋ, ਫਿਰ ਛੋਟੀ ਟ੍ਰੇਨਿੰਗ ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ feedback channel ਨਾਲ ਬਰਾਡ ਰੋਲਆਉਟ ਕਰੋ। ਇੱਕ change log (ਸਧਾਰਨ /blog/changelog) ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ ਤਾਂ ਕਿ ਸਟੇਕਹੋਲਡਰ ਵੇਖ ਸਕਣ ਕਿ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕਿਉਂ।
ਜੇ ਤੁਸੀਂ pilot ਦੌਰਾਨ product requirements 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ iteration ਕਰ ਰਹੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗੇ ਟੂਲ UI flows (filters, drill-down paths, allocation rule editors) prototype ਕਰਨ ਵਿੱਚ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ ਅਤੇ ਕਨੂੰਨੀ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ source code export, deployment, ਅਤੇ rollback 'ਤੇ ਕਾਬੂ ਦਿੰਦੇ ਹਨ ਜਿਵੇਂ ਐਪ ਮੈਚੂਰ ਹੁੰਦੀ ਹੈ।
ਐਪ ਨੂੰ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਉਸ ਫੈਸਲੇ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਐਪ ਨੂੰ ਸਹਿਯੋਗ ਕਰਨਾ ਹੈ (ਵੈਰੀਐਂਸ ਸਪਸ਼ਟੀकरण, ਫਜਾ ਘਟਾਉਣਾ, ਬਜਟ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ, ਫੋਰਕਾਸਟਿੰਗ)। ਫਿਰ ਮੱਖੀ ਉਪਭੋਗਤਾਵਾਂ (Finance/FinOps, Engineering, ਟੀਮ ਲੀਡ, ਐਗਜ਼ੈਕ੍ਯੂਟਿਵ) ਅਤੇ ਪਹਿਲਾਂ ਜੋ ਨਤੀਜੇ ਤੁਸੀਂ ਦੇਣਗੇ (showback, chargeback, forecasting, budget control) 'ਤੇ ਸਹਿਮਤੀ ਬਣਾਓ。
ਡੈਸ਼ਬੋਰਡ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਲਿਖੋ ਕਿ “ਅਚਛਾ” ਕਿਵੇਂ ਦਿਖਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਪ੍ਰੋਵਾਇਡਰ ਇਨਵਾਇਸ ਨਾਲ ਕਿਵੇਂ ਇਕਰਾਰ ਕਰਵਾਓਗੇ।
Showback ਐਡਾ ਦੇਖਾਊ ਹੈ ਕਿ ਕੌਣ ਕਿੰਨਾ ਖਰਚ ਕਰ ਰਿਹਾ ਹੈ ਬਿਨਾਂ ਅੰਦਰੂਨੀ ਇਨਵੌਇਸ ਜਾਰੀ ਕੀਤੇ। Chargeback ਉਹ ਹੈ ਜਿਥੇ ਅੰਦਰੂਨੀ ਇਨਵੌਇਸ ਬਣਦੇ ਹਨ ਅਤੇ ਵੰਡ ਬਜਟਾਂ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਂਦੀ ਹੈ—ਇਸ ਨੂੰ ਅਕਸਰ ਮঞ্জੂਰੀ ਤੇ audit trails ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ。
ਜੇ ਤੁਹਾਨੂੰ ਕਠੋਰ ਜ਼ਿੰਮੇਵਾਰੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ chargeback ਲਈ ਪਹਿਲਾਂ ਹੀ ਡਿਜ਼ਾਈਨ ਸ਼ੁਰੂ ਕਰੋ (immutable month-close snapshots, explainable rules, formal exports), ਹਾਲਾਂਕਿ ਤੁਸੀਂ ਪਹਿਲਾਂ showback UI ਨਾਲ ਲਾਂਚ ਕਰ ਸਕਦੇ ਹੋ।
ਹਰ ਪ੍ਰੋਵਾਇਡਰ ਲਾਈਨ ਆਈਟਮ ਨੂੰ ਇੱਕ ਰਿਕਾਰਡ ਵਜੋਂ ਮਾਡਲ ਕਰੋ ਜਿਸ ਵਿੱਚ ਏਹ ਮੈਟਰਿਕਸ ਸ਼ਾਮਲ ਹੋਣ:
ਨਿਯਮ: ਜੇ ਇੱਕ ਵੈليਅਰ ਫਾਇਨੈਂਸ ਦੇ ਭੁਗਤਾਨ ਜਾਂ ਟੀਮ ਨੂੰ ਚਾਰਜ ਕਰਨ 'ਤੇ ਅਸਰ ਪਾ ਸਕਦੀ ਹੈ, ਉਸਨੂੰ ਪਹਿਲ-ਕਲਾਸ ਮੈਟਰਿਕ ਬਣਾਓ।
ਉਹ ਡਾਇਮੈਨਸ਼ਨਾਂ ਜੋ ਲੋਕ ਅਕਸਰ ਗਰੁੱਪ ਕਰਦੇ ਹਨ, ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਡਾਇਮੈਨਸ਼ਨਾਂ ਨੂੰ ਲਚਕੀਲਾ ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ cluster/namespace/vendor ਜੋੜ ਸਕੋ ਬਿਨਾਂ ਰਿਪੋਰਟ ਤੋੜੇ।
ਕੰਮ ਕਰਨ ਲਈ ਕਈ ਸਮਾਂ-ਕੰਸੈਪਟ ਸੁਰੱਖਿਅਤ ਰੱਖੋ:
ਸਾਥ ਹੀ ਪ੍ਰੋਵਾਇਡਰ ਦੀ ਮੁਢਲੀ ਟਾਈਮ ਜ਼ੋਨ ਅਤੇ ਬਿਲਿੰਗ ਬਾਉਂਡਰੀਜ਼ ਸਟੋਰ ਕਰੋ ਤਾਂ ਕਿ ਲੇਟ adjustments ਠੀਕ ਮਹੀਨੇ 'ਚ ਪੈ ਸਕਣ।
Near-real-time INCIDENT response ਅਤੇ ਤੇਜ਼ੀ ਵਾਲੀਆਂ Organizations ਲਈ ਉਪਯੋਗੀ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਦੁਹਰਾਅ, ਅਧੂਰੇ-ਦਿਨ ਪਰਿਸਥਿਤੀਆਂ ਅਤੇ ਲਾਗਤ ਵਧਾਉਂਦਾ ਹੈ।
ਅਕਸਰ ਰੋਜ਼ਾਨਾ ਅਪਡੇਟ ਫਾਇਨੈਂਸ ਅਤੇ ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਲਈ ਕਾਫੀ ਹੁੰਦਾ ਹੈ। ਆਮ ਹਿਬ੍ਰਿਡ ਪੈਟਰਨ: freshness ਲਈ event-driven ingestion ਅਤੇ ਛੁਟਕਾਰੀ ਲਈ ਰੋਜ਼ਾਨਾ sweeper।
ਕੱਚੇ ਪ੍ਰੋਵਾਇਡਰ ਐਕਸਪੋਰਟਾਂ ਨੂੰ ਇੱਕ immutable, versioned staging area 'ਚ ਰੱਖੋ (S3/Blob/BigQuery)। ਹਰ ਇੰਟਕਸ਼ਨ ਲਈ ਇਕ ingestion log ਰੱਖੋ: ਕੀ ਫੈਚ ਕੀਤਾ, ਕਦੋਂ, ਅਤੇ ਕਿੰਨੇ ਰਿਕਾਰਡ।
ਇਸ ਨਾਲ audits ਸੁਗਮ ਹੁੰਦੇ ਹਨ, parser ਬਦਲੇ ਜਾਣ 'ਤੇ reprocessing ਹੋ ਸਕਦੀ ਹੈ, ਅਤੇ ਵਿਵਾਦਾਂ ਦੌਰਾਨ ਇੱਕ ਸਕੂਪਲ ਸਰੋਤ ਦਿਖਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
ਪ੍ਰੋਵਾਇਡਰ ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਇੱਕ ਯੂਨਿਫਾਈਡ ਸਕੀਮਾ (ਜਿਵੇਂ: Service, SKU, Usage Type) 'ਚ ਤਬਦੀਲ ਕਰੋ, ਅਤੇ traceability ਲਈ provider-native IDs (AWS ProductCode, GCP SKU ID) ਵੀ ਰੱਖੋ।
ਫਿਰ data hygiene ਲਾਗੂ ਕਰੋ:
ਛੋਟਾ ਸੈੱਟ required keys ਪਰਕਾਸ਼ਿਤ ਕਰੋ ਜੋ allocation engine ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਵਰਤਣਗੇ:
teamappcost-centerenv (prod/stage/dev)ਪਾਲਿਸੀ ਸਪਸ਼ਟ ਕਰੋ: ਕਿਹੜੀਆਂ resources ਨੂੰ ਟੈਗ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹੈ, ਸਵੀਕਾਰਯੋਗ ਫਾਰਮੇਟ (lowercase kebab-case ਆਦਿ), ਅਤੇ ਟੈਗ ਗਾਇਬ ਹੋਣ 'ਤੇ ਕੀ ਹੁੰਦਾ (ਉਦਾਹਰਨ: “Unassigned” ਬੱਕੇਟ + ਅਲਰਟ)। ਇਸ ਪਾਲਿਸੀ ਨੂੰ ਐਪ ਦੇ ਅੰਦਰ ਦਿਖਾਓ ਅਤੇ deeper guidance ਦੇ ਲਈ /blog/tagging-best-practices ਦੀ ਸੂਚਨਾ ਦਿਓ।
Allocation ਨਿਯਮਾਂ ਨੂੰ priority ਅਤੇ effective dates ਨਾਲ ordered rules ਵਜੋਂ ਮਾਡਲ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਉੱਤਰ ਦੇ ਸਕੋ: “ਕਿਹੜਾ rule March 10 ਨੂੰ ਲਾਗੂ ਹੋਇਆ?” ਅਤੇ ਨੈਤਿਕ ਤੌਰ 'ਤੇ ਨਿਯਮ ਬਦਲ ਸਕੋਂ ਬਿਨਾਂ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ-ਲਿਖੇ।
ਰੂਲ ਸਕੀਮਾ ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ: