05 ਮਈ 2025·8 ਮਿੰਟ
Datadog ਅਤੇ ਪਲੇਟਫਾਰਮ ਬਦਲਾਅ: ਟੈਲੀਮੇਟਰੀ, ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ, ਵਰਕਫਲੋਜ਼
ਜਾਣੋ ਕਿ Datadog ਕਿਵੇਂ ਇੱਕ ਪਲੇਟਫਾਰਮ ਬਣਦਾ ਹੈ ਜਦੋਂ ਟੈਲੀਮੇਟਰੀ, ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ, ਅਤੇ ਵਰਕਫਲੋਜ਼ ਪ੍ਰੋਡਕਟ ਬਣ ਜਾਂਦੇ ਹਨ—ਅਤੇ ਇਨ੍ਹਾਂ ਵਿਚੋਂ ਆਪਣੇ ਸਟੈਕ ਲਈ ਲਾਗੂ ਕਰਨਯੋਗ ਪ੍ਰਯੋਗਿਕ ਵਿਚਾਰ।
ਜਾਣੋ ਕਿ Datadog ਕਿਵੇਂ ਇੱਕ ਪਲੇਟਫਾਰਮ ਬਣਦਾ ਹੈ ਜਦੋਂ ਟੈਲੀਮੇਟਰੀ, ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ, ਅਤੇ ਵਰਕਫਲੋਜ਼ ਪ੍ਰੋਡਕਟ ਬਣ ਜਾਂਦੇ ਹਨ—ਅਤੇ ਇਨ੍ਹਾਂ ਵਿਚੋਂ ਆਪਣੇ ਸਟੈਕ ਲਈ ਲਾਗੂ ਕਰਨਯੋਗ ਪ੍ਰਯੋਗਿਕ ਵਿਚਾਰ।
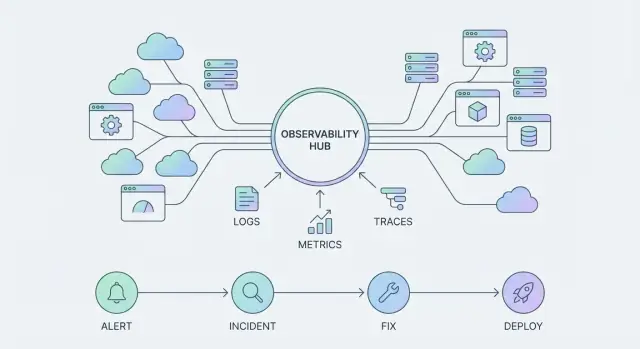
ਇੱਕ observability ਟੂਲ ਤੁਹਾਨੂੰ ਸਿਸਟਮ ਬਾਰੇ ਖਾਸ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ—ਆਮ ਤੌਰ 'ਤੇ ਚਾਰਟ, ਲੋਗ, ਜਾਂ ਇੱਕ ਕਵੇਰੀ ਨਤੀਜੇ ਦੇ ਕੇ। ਇਹ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਤੁਸੀਂ ਮੁੱਦੇ ਹੋਣ 'ਤੇ "ਵਰਤਦੇ" ਹੋ।
ਇੱਕ observability ਪਲੇਟਫਾਰਮ ਵੱਧ ਚੌੜਾ ਹੁੰਦਾ ਹੈ: ਇਹ ਟੈਲੀਮੇਟਰੀ ਇਕੱਠਾ ਕਰਨ ਦੇ ਢੰਗ, ਟੀਮਾਂ ਦੇ ਇਸ ਨੂੰ ਖੋਜਣ ਦੇ ਢੰਗ, ਅਤੇ incidents ਨੂੰ end-to-end ਸੰਭਾਲਣ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਦਾ ਹੈ। ਇਹ ਉਹ ਚੀਜ਼ ਬਣ ਜਾਂਦੀ ਹੈ ਜੋ ਤੁਹਾਡੀ 조직 ਹਰ ਰੋਜ਼ ਚਲਾਂਦੀ ਹੈ, ਕਈ ਸੇਵਾਵਾਂ ਅਤੇ ਟੀਮਾਂ ਵਿੱਚ।
ਅਕਸਰ ਟੀਮ ਡੈਸ਼ਬੋਰਡ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ: CPU ਚਾਰਟ, error-rate ਗ੍ਰਾਫ, ਸ਼ਾਇਦ ਕੁਝ ਲੋਗ ਸੋਰਚਾਂ। ਇਹ ਲਾਭਦਾਇਕ ਹੈ, ਪਰ ਅਸਲ ਮਕਸਦ ਸੁੰਦਰ ਚਾਰਟ ਨਹੀਂ—ਇਹ ਹੈ ਤੇਜ਼ ਪਛਾਣ ਅਤੇ ਤੇਜ਼ ਰਿਜ਼ੋਲੂਸ਼ਨ।
ਇੱਕ ਪਲੇਟਫਾਰਮ ਬਦਲਾਅ ਉਦੋਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਪੁੱਛਣਾ ਛੱਡ ਦਿੰਦੇ ਹੋ, “ਕੀ ਅਸੀਂ ਇਸ ਨੂੰ ਗ੍ਰਾਫ ਕਰ ਸਕਦੇ ਹਾਂ?” ਅਤੇ ਸ਼ੁਰੂ ਕਰ ਦਿੰਦੇ ਹੋ:
ਇਹ ਨਤੀਜਾ-ਕੇਂਦਰਤ ਸਵਾਲ ਹਨ, ਅਤੇ ਇਹਨਾਂ ਲਈ ਸਿਰਫ਼ ਵਿਜ਼ੂਅਲਾਈਜ਼ੇਸ਼ਨ ਨਹੀਂ ਚਾਹੀਦੀ। ਇਹ ਸਾਂਝੇ ਡਾਟਾ ਮਿਆਰ, ਸਥਿਰ ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ, ਅਤੇ ਐਸੇ ਵਰਕਫਲੋਜ਼ ਮੰਗਦੇ ਹਨ ਜੋ ਟੈਲੀਮੇਟਰੀ ਨੂੰ ਕਾਰਵਾਈ ਨਾਲ ਜੋੜਦੇ ਹਨ।
ਜਿਵੇਂ ਕਿ Datadog observability platform ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਵਿਕਸਤ ਹੁੰਦੇ ਹਨ, “ਪ੍ਰੋਡਕਟ ਸਤਹ” ਸਿਰਫ਼ ਡੈਸ਼ਬੋਰਡ ਨਹੀਂ ਰਹਿੰਦੀ। ਇਹ ਤਿੰਨ ਆਪਸ ਵਿੱਚ ਜੁੜੇ ਸਤੰਭ ਹਨ:
ਇੱਕ ਇਕੱਲਾ ਡੈਸ਼ਬੋਰਡ ਇੱਕ ਟੀਮ ਦੀ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ। ਇੱਕ ਪਲੇਟਫਾਰਮ ਹਰੇਕ ਸੇਵਾ ਦੇ onboard ਹੋਣ, ਹਰ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਦੇ ਜੁੜਨ, ਅਤੇ ਹਰ ਵਰਕਫਲੋ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਨ ਨਾਲ ਹੋਰ ਮਜ਼ਬੂਤ ਹੁੰਦਾ ਹੈ। ਸਮੇਂ ਦੇ ਨਾਲ, ਇਹ ਘੱਟ ਅਗਾਹੀ, ਘੱਟ ਡੁਪਲੀਕੇਟ ਟੂਲਿੰਗ, ਅਤੇ ਛੋਟੇ ਇੰਸੀਡੈਂਟਾਂ ਵਿੱਚ ਰੂਪਾਂਤਰੀਤ ਹੋ ਜਾਂਦਾ ਹੈ—ਕਿਉਂਕਿ ਹਰ ਸੁਧਾਰ ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਬਣ ਜਾਂਦਾ ਹੈ, ਇੱਕ-ਵਾਰ ਦਾ ਨਹੀਂ।
ਜਦੋਂ observability “ਇੱਕ ਟੂਲ ਜੋ ਅਸੀਂ ਕਵੇਰੀ ਕਰਦੇ ਹਾਂ” ਤੋਂ “ਇੱਕ ਪਲੇਟਫਾਰਮ ਜਿਸ 'ਤੇ ਅਸੀਂ ਬਣਾਉਂਦੇ ਹਾਂ” ਵੱਲ ਵੱਧਦੀ ਹੈ, ਟੈਲੀਮੇਟਰੀ ਕੱਚੇ ਬਰਬਾਦੀ (exhaust) ਰਹਿਣਾ ਬੰਦ ਕਰ ਦਿੰਦੀ ਅਤੇ ਪ੍ਰੋਡਕਟ ਸਤਹ ਵੱਜੋਂ ਕੰਮ ਕਰਨ ਲੱਗਦੀ ਹੈ। ਤੁਸੀਂ ਕੀ emit ਕਰਦੇ ਹੋ—ਅਤੇ ਕਿੰਨੀ 一ਸਤੀ ਦਰ ਨਾਲ—ਇਹ ਤੈਅ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀਆਂ ਟੀਮਾਂ ਕੀ ਦੇਖ ਸਕਦੀਆਂ ਹਨ, ਆਟੋਮੇਟ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਅਤੇ ਭਰੋਸਾ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਅਕਸਰ ਟੀਮ ਨੀਚੇ ਦਿੱਤੇ ਸੰਕੇਤਾਂ ਦੇ ਆਸ-ਪਾਸ ਸਟੈਂਡਰਡ ਕਰਦੀਆਂ ਹਨ:
ਅਲੱਗ-ਅਲੱਗ, ਹਰ ਸਿਗਨਲ ਲਾਭਦਾਇਕ ਹੈ। ਇਕੱਠੇ, ਇਹ ਤੁਹਾਡੇ ਸਿਸਟਮਾਂ ਲਈ ਇੱਕ ਇੰਟਰਫੇਸ ਬਣ ਜਾਂਦੇ ਹਨ—ਜਿਹੜਾ ਤੁਸੀਂ ਡੈਸ਼ਬੋਰਡਾਂ, ਅਲਰਟਸ, incident ਟਾਈਮਲਾਈਨਜ਼, ਅਤੇ postmortems ਵਿੱਚ ਦੇਖਦੇ ਹੋ।
ਇੱਕ ਆਮ ਗਲਤੀ ਇਹ ਹੈ ਕਿ “ਸਭ ਕੁਝ” ਇਕੱਠਾ ਕਰ ਲਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਨਾਮਕਰਨ inconsistent ਹੁੰਦਾ ਹੈ। ਜੇ ਇੱਕ ਸੇਵਾ userId ਵਰਤਦੀ ਹੈ, ਦੂਜੀ uid, ਅਤੇ ਤੀਜੀ ਕੁਝ ਵੀ ਲੋਗ ਨਹੀਂ ਕਰਦੀ, ਤਾਂ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਡੇਟਾ ਨੂੰ ਸਲਾਈਸ, ਸਥਾਪਿਤ ਜਾਂ reusable मॉਨੀਟਰ ਬਣਾਉਣ ਲਈ ਜੋੜ ਨਹੀਂ ਸਕਦੇ।
ਟੀਮਾਂ ਨੂੰ ਵਧੇਰੇ ਮੂਲ ਮਿਲਦਾ ਹੈ ਜਦੋਂ ਉਹ ਕੁਝ conventions 'ਤੇ ਸਹਿਮਤ ਹੁੰਦੀਆਂ ਹਨ—service names, environment tags, request IDs, ਅਤੇ ਇੱਕ ਮਿਆਰੀ attributes—ਬਜਾਏ ingestion ਵਾਧੇ ਕਰਨ ਦੇ।
High-cardinality ਫੀਲਡ ਉਹ ਹਨ ਜਿੰਨ੍ਹਾਂ ਦੀਆਂ ਬਹੁਤ ਸਾਰੀਆਂ ਸੰਭਾਵਨਾਵਾਂ ਹਨ (ਜਿਵੇਂ user_id, order_id, ਜਾਂ session_id)। ਇਹ debugging ਲਈ ਬਲਦਾਰ ਹਨ “ਸਿਰਫ਼ ਇੱਕ ਗਾਹਕ ਲਈ ਹੁੰਦਾ” ਮੁੱਦਿਆਂ ਲਈ, ਪਰ ਜੇ ਹਰ ਜਗ੍ਹਾ ਵਰਤੇ ਜਾਣ ਤਾਂ ਖਰਚ ਵਧਾ ਸਕਦੇ ਹਨ ਅਤੇ ਕਵੇਰੀਆਂ ਨੂੰ ਧੀਮਾ ਕਰ ਸਕਦੇ ਹਨ।
ਪਲੇਟਫਾਰਮ ਤਰੀਕਾ ਇਰਾਦੇ ਨਾਲ ਹੁੰਦਾ ਹੈ: high-cardinality ਉਹੀ ਰੱਖੋ ਜਿੱਥੇ ਇਹ ਖੋਜ਼ ਲਈ ਸਪਸ਼ਟ ਮੁੱਲ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਉਨ੍ਹਾਂ ਥਾਵਾਂ ਤੋਂ ਬਚੋ ਜਿੱਥੇ ਗਲੋਬਲ aggregates ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ।
ਫਾਇਦਾ ਤੇਜ਼ੀ ਹੈ। ਜਦੋਂ metrics, logs, traces, events, ਅਤੇ profiles ਇਕੋ ਸੰਦਰਭ (service, version, region, request ID) ਸਾਂਝੇ ਕਰਦੇ ਹਨ, ਤਾਂ ਇੰਜੀਨੀਅਰ ਸਬੂਤ ਨੂੰ ਜੋੜਨ ਵਿੱਚ ਘੱਟ ਸਮਾਂ ਲਗਾਉਂਦੇ ਹਨ ਅਤੇ ਅਸਲ ਸਮੱਸਿਆ ਨੂੰ ਠੀਕ ਕਰਨ ਵਿੱਚ ਵਧੇਰੇ ਸਮਾਂ ਲਗਾਉਂਦੇ ਹਨ। ਟੂਲਾਂ ਵਿੱਚ ਜੰਪ ਕਰਨ ਅਤੇ ਅਨੁਮਾਨ ਲਗਾਉਣ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਇੱਕ ਥ੍ਰੈੱਡ ਦੀ ਪਾਲਣਾ ਕਰਦੇ ਹੋ ਨਿਸ਼ਾਨੀ ਤੋਂ root cause ਤੱਕ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮ observability ਨੂੰ "ਡੇਟਾ ਪਾਉਣ" ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ। ਇਹ ਲਾਜ਼ਮੀ ਹੈ, ਪਰ ਇਹ ਇੱਕ ਰਣਨੀਤੀ ਨਹੀਂ ਹੈ। ਇੱਕ ਟੈਲੀਮੇਟਰੀ ਰਣਨੀਤੀ ਉਹ ਹੈ ਜੋ onboarding ਤੇਜ਼ ਰੱਖਦੀ ਹੈ ਅਤੇ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਇੰਨਾ consistent ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਸਾਂਝੇ ਡੈਸ਼ਬੋਰਡ, ਭਰੋਸੇਯੋਗ ਅਲਰਟਸ, ਅਤੇ ਮਾਨੇਯੋਗ SLOs ਤਿਆਰ ਹੋ ਸਕਣ।
Datadog ਆਮ ਤੌਰ 'ਤੇ ਟੈਲੀਮੇਟਰੀ ਕੁਝ ਪ੍ਰਾਇਗਟਿਕ ਰਸਤੇ ਰਾਹੀਂ ਲੈਂਦਾ ਹੈ:
ਸ਼ੁਰੂ ਵਿੱਚ, ਤੇਜ਼ੀ ਜਿੱਤਦੀ ਹੈ: ਟੀਮ agent install ਕਰਦੀ ਹੈ, ਕੁਝ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਚਾਲੂ ਕਰਦੀ ਹੈ, ਅਤੇ ਤੁਰੰਤ ਮੁੱਲ ਵੇਖਦੀ ਹੈ। ਰਿਸਕ ਇਹ ਹੈ ਕਿ ਹਰ ਟੀਮ ਆਪਣੀ tagging, service names, ਅਤੇ log formats ਖੋਜ ਲੈ—ਜੋ cross-service views ਗੰਦੇ ਅਤੇ alerts ਭਰੋਸੇਯੋਗ ਨਹੀਂ ਬਣਾਉਂਦੇ।
ਸਰਲ ਨਿਯਮ: "quick start" onboarding ਦੀ ਆਗਿਆ ਦਿਓ, ਪਰ 30 ਦਿਨਾਂ ਵਿੱਚ standardize ਲਾਜ਼ਮੀ ਕਰੋ। ਇਸ ਨਾਲ ਟੀਮਾਂ ਨੂੰ ਗਤੀ ਮਿਲਦੀ ਹੈ ਬਿਨਾਂ ਅਫਰਾਤਫਰੀ ਨੂੰ ਲਾਕ-ਇਨ ਕੀਤਾ।
ਤੁਹਾਨੂੰ ਇੱਕ ਵੱਡੀ taxonomੀ ਦੀ ਲੋੜ ਨਹੀਂ। ਇਕ ਛੋਟੀ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਹਰ ਸਿਗਨਲ (logs, metrics, traces) ਨੂੰ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:\n\n- service: ਛੋਟਾ, ਸਥਿਰ, lowercase (ਉਦਾਹਰਨ: checkout-api)\n- env: prod, staging, dev\n- team: ਮਾਲਕ ਟੀਮ ਦੀ ਪਛਾਣ (ਉਦਾਹਰਨ: payments)\n- version: deploy ਵਰਜਨ ਜਾਂ git SHA\n\nਜੇ ਤੁਸੀਂ ਇੱਕ ਹੋਰ ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਜਲਦੀ ਰਿਟਰਨ ਦੇਵੇ, ਤਾਂ tier (frontend, backend, data) ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਜੋ ਫਿਲਟਰਿੰਗ ਸੌਖੀ ਹੋ ਜਾਵੇ।
ਖਰਚ ਆਮ ਤੌਰ 'ਤੇ ਉਹਨਾਂ ਡਿਫੌਲਟਸ ਤੋਂ ਆਉੰਦਾ ਹੈ ਜੋ ਬਹੁਤ ਦਿਆਲੂ ਹੁੰਦੇ ਹਨ:\n\n- Traces: high-volume endpoints ਲਈ head-based sampling ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ; ਮਹੱਤਵਪੂਰਨ ਫਲੋ ਲਈ 100% ਰੱਖੋ।\n- Logs: ਡਿਫੌਲਟ "error + important business events" ਰੱਖੋ, ਫਿਰ ਸਮੇਂ-ਬੱਕਸ retention ਨਾਲ info/debug ਲਾਗਾਂ ਨੂੰ ਚੁਣਦਾਰ ਤਰੀਕੇ ਨਾਲ ਸ਼ਾਮਿਲ ਕਰੋ।\n- Retention: high-resolution ਡੇਟਾ ਨੂੰ ਛੋਟੇ ਸਮੇਂ ਲਈ ਰੱਖੋ (ਦਿਨ), ਅਤੇ ਕੁੰਜ aggregates ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਰੱਖੋ (ਹਫ਼ਤੇ/ਮਹੀਨੇ)।
ਹੇਠਾਂ ਦਾ ਮਕਸਦ ਘੱਟ collect ਕਰਨਾ ਨਹੀਂ—ਇਹ ਹੈ ਸਹੀ ਡੇਟਾ ਲਗਾਤਾਰ ਇਕੱਠਾ ਕਰਨਾ, ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਿਨਾਂ ਅਚਾਨਕਤਾਵਾਂ ਦੇ ਵਰਤੋਂ ਦੇ ਨਾਲ ਸਕੇਲ ਕਰ ਸਕੋ।
ਅਧਿਕਾਂ ਲੋਕ observability ਟੂਲਾਂ ਨੂੰ "ਕੋਈ ਚੀਜ਼ ਜਿਸਨੂੰ ਤੁਸੀਂ install ਕਰੋ" ਸਮਝਦੇ ਹਨ। ਅਸਲ ਵਿਚ, ਉਹ ਇੱਕ ਸੰਸਥਾ ਵਿੱਚ ਉਸ ਤਰ੍ਹਾਂ ਫੈਲਦੇ ਹਨ ਜਿਵੇਂ ਚੰਗੇ ਕਨੈਕਟਰ ਫੈਲਦੇ ਹਨ: ਇੱਕ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਇੱਕ ਸਮੇਂ 'ਤੇ।
ਇਕ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਸਿਰਫ਼ ਡਾਟਾ ਪਾਈਪ ਨਹੀਂ ਹੈ। ਇਸ ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਹਿੱਸੇ ਹੁੰਦੇ ਹਨ:\n\n- Data sources: वह ਸਿਸਟਮਾਂ ਤੋਂ ਮੈਟਰਿਕਸ, ਲੋਗ, ਟਰੇਸ, ਇਵੈਂਟਸ, ਅਤੇ topology ਖਿੱਚਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਚਲਾ ਰਹੇ ਹੋ (ਕਲਾਉਡ ਸੇਵਾਵਾਂ, Kubernetes, ਡੇਟਾਬੇਸ, CI/CD, SaaS ਟੂਲ)।\n- Enrichment: ਸੰਦਰਭ ਜੋੜਣਾ ਤਾ ਕਿ ਟੈਲੀਮੇਟਰੀ ਤੁਰੰਤ ਵਰਤਣਯੋਗ ਬਣ ਜਾਏ—service names, environments, ownership tags, team routing, deployment versions, ਅਤੇ cloud metadata।\n- Actions: ਜੋ ਤੁਸੀਂ ਸਿੱਖਦੇ ਹੋ ਉਸ ਨਾਲ ਕੁਝ ਕਰਨਾ—ਟਿਕਟ ਬਣਾਉਣਾ, on-call ਨੂੰ paging ਕਰਨਾ, deploys annotate ਕਰਨਾ, resources scale ਕਰਨਾ, ਜਾਂ runbooks trigger ਕਰਨਾ।
ਉਹ ਆਖਰੀ ਹਿੱਸਾ ਹੀ ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ ਨੂੰ distribution ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਟੂਲ ਸਿਰਫ਼ "ਪੜ੍ਹਦਾ" ਹੈ, ਤਾਂ ਉਹ ਸਿਰਫ਼ ਡੈਸ਼ਬੋਰਡ ਮੰਜ਼ਿਲ ਹੈ। ਜੇ ਇਹ "ਲਿਖਦਾ" ਵੀ ਹੈ, ਤਾਂ ਇਹ ਦੈਨੀਕ ਕੰਮ ਦਾ ਹਿੱਸਾ ਬਣ ਜਾਂਦਾ ਹੈ।
ਵਧੀਆ ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ setup ਸਮਾ ਘਟਾਉਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ sensible defaults ਨਾਲ ਆਉਂਦੀਆਂ ਹਨ: ਪ੍ਰੀਬਿਲਟ ਡੈਸ਼ਬੋਰਡ, ਸਿਫ਼ਾਰਸ਼ੀ ਮਾਨੀਟਰਸ, parsing rules, ਅਤੇ ਆਮ tags। ਹਰ ਟੀਮ ਆਪਣਾ "CPU dashboard" ਜਾਂ "Postgres alerts" ਨਹੀਂ ਬਣਾਉਂਦੀ—ਤੁਸੀਂ ਇੱਕ ਸਰਬ-ਅਧਾਰ ਮਿਲਦਾ ਹੈ ਜੋ ਬੈਸਟ ਪ੍ਰੈਕਟਿਸਜ਼ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ।
ਟੀਮਾਂ ਫਿਰ ਵੀ ਆਪਣੀ ਕਸਟਮਾਈਜ਼ ਕਰਦੀਆਂ ਹਨ—ਪਰ ਉਹ ਸਾਂਝੇ ਬੇਸਲਾਈਨ ਤੋਂ ਤਬਦੀਲ ਕਰਦੀਆਂ ਹਨ। ਜਦੋਂ ਤੁਸੀਂ ਟੂਲ consolidate ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇਹ ਸਟੈਂਡਰਡਾਈਜ਼ੇਸ਼ਨ ਮੱਤਵਪੂਰਨ ਹੁੰਦੀ ਹੈ: ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ ਪੈਟਰਨ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ ਨਵੀਂ ਸੇਵਾਵਾਂ ਨਕਲ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਜਿਸ ਨਾਲ ਵਿਕਾਸ ਸੰਭਾਲਯੋਗ ਰਹਿੰਦਾ ਹੈ।
ਚੋਣ ਕਰਦਿਆਂ, ਪੁਛੋ: ਕੀ ਇਹ signals ingest ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ ਕਾਰਵਾਈ ਕਰ ਸਕਦੇ ਹਨ? ਉਦਾਹਰਣਾਂ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ: ਆਪਣੇ ticketing system ਵਿੱਚ incidents ਖੋਲ੍ਹਣਾ, incident channels ਨੂੰ update ਕਰਨਾ, ਜਾਂ ਇੱਕ trace ਲਿੰਕ ਨੂੰ PR ਜਾਂ deploy view ਨਾਲ attach ਕਰਨਾ। ਬਾਈ-ਡਾਇਰੈਕਸ਼ਨਲ ਸੈਟਅੱਪਸ ਉਹ ਥਾਂ ਹਨ ਜਿੱਥੇ workflows "ਨੇਟਿਵ" ਮਹਿਸੂਸ ਹੋਣ ਲੱਗਦੇ ਹਨ।
ਛੋਟੇ ਅਤੇ ਭਰੋਸੇਯੋਗ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:\n\n1. ਮਹੱਤਵਪੂਰਨ infrastructure ਪਹਿਲਾਂ (cloud provider, Kubernetes, load balancers, core databases)।\n2. ਫਿਰ deploy pipeline (CI/CD, feature flags, release tracking) ਤਾ ਕਿ ਟੈਲੀਮੇਟਰੀ ਚੇਂਜਾਂ ਨਾਲ ਲਾਈਨ ਵਿੱਚ ਆ ਜਾਏ।\n3. ਇੱਕ ਵਾਰੀ tagging ਅਤੇ ownership conventions ਸਥਿਰ ਹੋ ਜਾਣ, ਫਿਰ ਟੀਮ-ਡਵਾਈਜ਼ SaaS (queues, caches, auth, payments) ਸ਼ਾਮਿਲ ਕਰੋ।
ਨਿਯਮ-ਹੱਥ-ਨਿਯਮ: ਉਹ ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ ਤਰਜੀਹ ਦਿਓ ਜੋ ਤੁਰੰਤ incident response ਸੁਧਾਰਦੇ ਹਨ, ਨਾ ਕਿ ਜੋ ਸਿਰਫ਼ ਹੋਰ ਚਾਰਟ ਜੋੜਦੇ ਹਨ।
ਸਟੈਂਡਰਡ ਦ੍ਰਿਸ਼ ਉਹ ਹਨ ਜਿੱਥੇ ਇੱਕ observability ਪਲੇਟਫਾਰਮ ਦਿਨ-ਪ੍ਰਤੀ-ਦਿਨ ਯੂਜ਼ਬਲ ਬਣ ਜਾਂਦਾ ਹੈ। ਜਦੋਂ ਟੀਮਾਂ ਸੇਮੇ ਮਨੋਵਿਜ਼ਨ ਸਾਂਝੀਆਂ ਕਰਦੀਆਂ ਹਨ—ਕੀ "service" ਹੈ, "healthy" ਕਿਵੇਂ ਦਿਸਦਾ ਹੈ, ਅਤੇ ਪਹਿਲਾ ਕਿੱਥੇ ਕਲਿੱਕ ਕਰਨਾ ਹੈ—ਤਾਂ ਡਿਬੱਗ ਤੇਜ਼ ਹੁੰਦਾ ਹੈ ਅਤੇ ਹੈਂਡੋਫਸ ਸਾਫ ਹੁੰਦੇ ਹਨ।
ਛੋਟੇ "golden signals" ਦੀ ਚੋਣ ਕਰੋ ਅਤੇ ਹਰ ਇੱਕ ਲਈ ਇੱਕ ਕੰਕਰੀਟ, ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਡੈਸ਼ਬੋਰਡ ਨਕਸ਼ਾ ਬਣਾਓ। ਬਹੁਤ ਸੇ ਸੇਵਾਵਾਂ ਲਈ, ਇਹ ਹਨ:\n\n- Latency (key endpoints ਲਈ p95/p99)\n- Traffic (requests per second, jobs processed)\n- Errors (ਰੈਟ ਅਤੇ top error types)\n- Saturation (CPU, memory, queue depth, DB connections)\n\nਕੁੰਜੀ ਗੱਲ consistency ਹੈ: ਇੱਕੋ ਡੈਸ਼ਬੋਰਡ ਲੇਆਉਟ ਜੋ ਸੇਵਾਵਾਂ 'ਤੇ ਕੰਮ ਕਰੇ, ਦਸ ਵੱਖ-ਵੱਖ bespoke ਡੈਸ਼ਬੋਰਡਾਂ ਨਾਲੋਂ ਬੇਹਤਰ ਹੈ।
ਇੱਕ service catalog (ਸਧਾਰਨ ਵੀ ਹੋ ਸਕਦਾ) "ਕਿਸੇ ਨੂੰ ਇਹ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ" ਨੂੰ ਬਦਲ ਦਿੰਦਾ ਹੈ "ਇਸ ਟੀਮ ਦਾ ਇਹ ਮਾਲਕ ਹੈ"। ਜਦੋਂ ਸੇਵਾਵਾਂ ਨਾਲ owners, environments, ਅਤੇ dependencies tag ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਤਾਂ ਪਲੇਟਫਾਰਮ ਮੁੱਖ ਸਵਾਲਾਂ ਦੇ ਤੁਰੰਤ ਜਵਾਬ ਦੇ ਸਕਦਾ ਹੈ: ਇਹ ਮਾਨੀਟਰ ਇਸ ਸੇਵਾ 'ਤੇ ਲਾਗੂ ਹੁੰਦੇ ਹਨ? ਮੈਨੂੰ ਕਿਹੜੇ ਡੈਸ਼ਬੋਰਡ ਖੋਲ੍ਹਣੇ ਚਾਹੀਦੇ ਹਨ? ਕੌਣ page ਹੋਵੇਗਾ?
ਇਹ ਸਪਸ਼ਟਤਾ incidents ਦੌਰਾਨ Slack ping-pong ਘਟਾਉਂਦੀ ਹੈ ਅਤੇ ਨਵੇਂ ਇੰਜੀਨੀਅਰਾਂ ਨੂੰ self-serve ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
ਹੇਠਾਂ ਦਿੱਤੇ ਆਈਟਮਾਂ ਨੂੰ ਸਧਾਰਤ ਆਰਟੀਫੈਕਟ ਸਮਝੋ, ਨਾ ਕਿ ਵਿਕਲਪਿਕ:
Vanity dashboards (ਸਿਰਫ਼ ਸੁੰਦਰ ਚਾਰਟ ਬਿਨਾਂ ਕਿਸੇ ਫੈਸਲੇ ਦੀ بنیاد), ਇਕ-ਬਾਰੀ alerts (ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਇਆ ਗਿਆ ਅਤੇ ਕਦੇ ਟਿਊਨ ਨਹੀਂ ਕੀਤਾ ਗਿਆ), ਅਤੇ undocumented queries (ਕੇਵਲ ਇੱਕ ਵਿਅਕਤੀ ਹੀ ਜਾਦੂਈ ਫਿਲਟਰ ਸਮਝਦਾ ਹੈ) ਪਲੇਟਫਾਰਮ ਸ਼ੋਰ ਬਣਾਉਂਦੇ ਹਨ। ਜੇ ਇੱਕ ਕਵੇਰੀ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਸੇਵ ਕਰੋ, ਨਾਮ ਦਿਓ, ਅਤੇ ਇੱਕ service view ਨਾਲ ਜੋੜੋ ਤਾਂ ਜੋ ਹੋਰ ਲੋੜਮੰਦ ਲੱਭ ਸਕਣ।
Observability ਤਦ ਹੀ "ਅਸਲ" ਬਿਜ਼ਨਸ ਲਈ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਇਹ ਸਮੱਸਿਆ ਅਤੇ ਇਕ ਪੱਕਾ ਹੱਲ ਦਰਮਿਆਨ ਵਕਤ ਘਟਾਉਂਦੀ ਹੈ। ਇਹ ਵਰਕਫਲੋਜ਼ ਰਾਹੀਂ ਹੁੰਦਾ ਹੈ—ਉਹ ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਰਸਤੇ ਜੋ ਤੁਹਾਨੂੰ signal ਤੋਂ ਕਾਰਵਾਈ ਤੱਕ ਅਤੇ ਕਾਰਵਾਈ ਤੋਂ ਸਿੱਖਿਆ ਤੱਕ ਲੈ ਜਾਂਦੇ ਹਨ।
ਇੱਕ ਸਕੇਲਯੋਗ ਵਰਕਫਲੋ ਸਿਰਫ਼ ਕਿਸੇ ਨੂੰ page ਕਰਨ ਤੋਂ ਵੱਧ ਹੁੰਦੀ ਹੈ।
ਇੱਕ alert ਨੂੰ ਇੱਕ ਕੇਂਦਰਿਤ triage ਲੂਪ ਖੋਲ੍ਹਣਾ ਚਾਹੀਦਾ ਹੈ: ਪ੍ਰਭਾਵ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ, ਪ੍ਰਭਾਵਿਤ ਸੇਵਾ ਦੀ ਪਛਾਣ ਕਰੋ, ਅਤੇ ਸਬ ਤੋਂ ਸੰਬੰਧਤ ਸੰਦਰਭ (ਹਾਲੀਆ deploys, dependency ਹਾਲਤ, error spikes, saturation ਸੰਕੇਤ) ਖਿੱਚੋ। ਉਸ ਦੌਰਾਨ, ਸੰਚਾਰ ਇੱਕ ਤਕਨੀਕੀ ਘਟਨਾ ਨੂੰ ਇੱਕ ਕੋਆਰਡੀਨੇਟ ਸਿੰਘਣਾ ਵਿੱਚ ਬਦਲਦਾ ਹੈ—ਕੌਣ incident ਦਾ ਮਾਲਕ ਹੈ, ਉਪਭੋਗਤਾ ਕੀ ਦੇਖ ਰਹੇ ਹਨ, ਅਤੇ ਅਗਲਾ ਅਪਡੇਟ ਕਦੋਂ ਆਏਗਾ।
Mitigation ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ “safe moves” ਆਪਣੀ ਉਂਗਲੀ ਦੇ ਪਾਸ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ: feature flags, traffic shifting, rollback, rate limits, ਜਾਂ ਇੱਕ ਜਾਣਿਆ-ਪਛਾਣਿਆ workaround। ਅਖੀਰ ਵਿੱਚ, learning ਇੱਕ ਹਲਕੀ-ਫੁਲਕੀ review ਨਾਲ ਲੂਪ ਨੂੰ ਬੰਦ ਕਰਦਾ ਹੈ ਜੋ ਕਿ ਕੀ ਬਦਲਿਆ, ਕੀ ਕੰਮ ਕੀਤਾ, ਅਤੇ ਅਗਲੇ ਕਦਮ ਆਟੋਮੇਟ ਕਰਨ ਹਨ, ਇਹ ਦਰਜ ਕਰਦਾ ਹੈ।
Datadog observability platform ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਮੁੱਲ ਵਧਾਉਂਦੇ ਹਨ ਜਦੋਂ ਉਹ ਸਾਂਝਾ ਕੰਮ ਸਹਿਯੋਗ ਕਰਦੇ ਹਨ: incident channels, status updates, handoffs, ਅਤੇ consistent timelines। ChatOps ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ alerts ਨੂੰ ਢਾਂਚਾਬੱਧ conversations ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨ—incident ਬਣਾਉਣਾ, ਰੋਲ ਅਸਾਈਨ ਕਰਨਾ, ਅਤੇ ਮੁੱਖ ਗ੍ਰਾਫ ਅਤੇ ਕਵੇਰੀਆਂ ਸਿੱਧਾ thread ਵਿੱਚ ਪੋਸਟ ਕਰਨਾ ਤਾਂ ਜੋ ਹਰ ਕੋਈ ਇਕੋ ਸਬੂਤ ਵੇਖੇ।
ਇੱਕ ਉਪਯੋਗੀ runbook ਛੋਟਾ, ਰਾਏ-ਭਰਿਆ, ਅਤੇ ਸੁਰੱਖਿਅਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਲਕੜੀ (goal) (service ਨੂੰ بحال ਕਰਨਾ), ਸਪਸ਼ਟ ਮਾਲਕ/ਨੋ-ਕਲੋਟੇਸ਼ਨ, ਕਦਮ-ਦਰ-ਕਦਮ ਜਾਂਚਾਂ, ਸਹੀ ਡੈਸ਼ਬੋਰਡ/ਮਾਨੀਟਰਾਂ ਦੇ ਲਿੰਕ, ਅਤੇ “safe actions” ਜੋ ਜੋਖਮ ਘਟਾਉਂਦੇ ਹਨ (rollback steps ਦੇ ਨਾਲ)। ਜੇ ਇਹ 3 ਵਜੇ ਰਾਤ ਨੂੰ ਚਲਾਉਣ ਲਈ ਸੁਰੱਖਿਅਤ ਨਹੀਂ, ਤਾਂ ਇਹ ਮੁਕੰਮਲ ਨਹੀਂ।
Root cause ਤੇਜ਼ ਮਿਲਦੀ ਹੈ ਜਦੋਂ incidents ਨੂੰ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ deploys, config changes, ਅਤੇ feature flag flips ਨਾਲ correlate ਕੀਤਾ ਜਾਵੇ। "ਕੀ ਬਦਲਿਆ?" ਨੂੰ ਪਹਿਲੀ-ਕਲਾਸ ਦ੍ਰਿਸ਼ ਬਣਾਓ ਤਾਂ ਜੋ triage ਸਬੂਤ ਨਾਲ ਸ਼ੁਰੂ ਹੋਵੇ, ਅਨੁਮਾਨ ਨਾਲ ਨਹੀਂ।
ਇੱਕ SLO (Service Level Objective) ਇੱਕ ਸਾਦਾ ਵਾਅਦਾ ਹੈ ਉਪਭੋਗਤਾ ਅਨੁਭਵ ਬਾਰੇ ਇੱਕ ਸਮੇਂ ਦੀ ਝਿੜਕੀ 'ਤੇ—ਜਿਵੇਂ "30 ਦਿਨਾਂ ਵਿੱਚ 99.9% ਰਿਕਵੈਸਟ ਸਫਲ" ਜਾਂ "p95 ਪੇਜ ਲੋਡ 2 ਸਕਿੰਟ ਤੋਂ ਘੱਟ"।
ਇਹ "green dashboard" ਨਾਲੋਂ ਵਧੀਆ ਹੈ ਕਿਉਂਕਿ ਡੈਸ਼ਬੋਰਡ ਅਕਸਰ ਸਿਸਟਮ ਹੈਲਥ (CPU, ਮੈਮੋਰੀ, queue depth) ਦਿਖਾਉਂਦੇ ਹਨ ਨਾ ਕਿ ਗਾਹਕ ਪ੍ਰਭਾਵ। ਇੱਕ ਸੇਵਾ green ਦਿਸ ਸਕਦੀ ਹੈ ਪਰ ਫਿਰ ਵੀ ਯੂਜ਼ਰਾਂ ਨੂੰ ਨਿਰਾਸ਼ਾ ਹੋ ਸਕਦੀ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਇੱਕ dependency timeout ਕਰ ਰਿਹਾ ਹੈ, ਜਾਂ errors ਇੱਕ ਖੇਤਰ 'ਚ ਇਕੱਠੇ ਹਨ)। SLOs ਟੀਮ ਨੂੰ ਉਹ ਮਾਪਣ ਲਈ ਮਜ਼ਬੂਰ ਕਰਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ ਅਸਲ ਵਿੱਚ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ।
ਇੱਕ error budget ਉਹ ਪ੍ਰਮਾਣ ਹੈ ਜੋ ਤੁਹਾਡੀ SLO ਦੁਆਰਾ ਮਨਜ਼ੂਰ ਕੀਤੀ ਗਲਤੀ ਦੀ ਰਕਮ ਦਰਸਾਉਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ 30 ਦਿਨਾਂ 'ਤੇ 99.9% ਸਫਲਤਾ ਦਾ ਵਾਅਦਾ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਲਗਭਗ 43 ਮਿੰਟ ਦੀ errors ਦੀ ਇਜਾਜ਼ਤ ਰੱਖਦੇ ਹੋ।
ਇਹ ਫੈਸਲਿਆਂ ਲਈ ਇੱਕ ਵਰਤੋ-ਯੋਗ ਓਐਸ ਬਣਾਉਂਦਾ ਹੈ:\n\n- Budget healthy: ਫੀਚਰ ਸ਼ਿਪ ਕਰੋ, experiments ਚਲਾਓ, ਵਾਜਬ ਜੋਖਮ ਲਵੋ।\n- Budget burning: ਰੀਲੀਜ਼ ਨੂੰ ਧੀਮਾ ਕਰੋ, ਰਿਲਾਇਬਿਲਟੀ ਕੰਮ 'ਤੇ ਧਿਆਨ ਦਿਓ, ਬਦਲਾਅ ਘਟਾਓ।\n- Budget exhausted: ਜੋਖਿਮ ਵਾਲੀ deploys ਰੋਕੋ ਅਤੇ ਮੁੱਖ ਫੇਲਯਰ ਸਰੋਤਾਂ ਨੂੰ ਸਹੀ ਕਰੋ।
ਇੱਕ release ਮੀਟਿੰਗ ਵਿੱਚ ਰਾਏਆਂ 'ਤੇ ਬਹਿਸ ਕਰਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਉਹ ਨੰਬਰ ਵਿਚਾਰ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹੋ ਜੋ ਹਰ ਕੋਈ ਦੇਖ ਸਕਦਾ ਹੈ।
SLO alerting ਸਭ ਤੋਂ ਵਧੀਆ ਤਦ ਹੈ ਜਦੋਂ ਤੁਸੀਂ burn rate (ਕਿਵੇਂ ਤੇਜ਼ੀ ਨਾਲ error budget ਖ਼ਤਮ ਹੋ ਰਿਹਾ ਹੈ) 'ਤੇ alert ਕਰਦੇ ਹੋ, ਨਾ ਕਿ ਕੱਚੇ error counts 'ਤੇ। ਇਸ ਨਾਲ noise ਘਟਦਾ ਹੈ:\n\n- ਇੱਕ ਛੋਟਾ spike ਜੋ ਆਪਣੇ ਆਪ ਠੀਕ ਹੋ ਜਾਂਦਾ ਹੈ, ਕਿਸੇ ਨੂੰ page ਨਹੀਂ ਕਰੇਗਾ।\n- ਇੱਕ ਲੰਬੇ ਸਮੇਂ ਵਾਲੀ ਸਮੱਸਿਆ ਜੋ ਜਲਦੀ error budget ਖ਼ਤਮ ਕਰ ਦੇਵੇਗੀ, ਸਪਸ਼ਟ, ਕਾਰਵਾਈਯੋਗ ਅਲਰਟ ਥ੍ਰਿਗਰ ਕਰੇਗੀ।
ਕਈ ਟੀਮ ਦੋ ਵਿੰਡੋ ਵਰਤਦੀਆਂ ਹਨ: fast burn (ਤੇਜ਼ੀ ਨਾਲ page) ਅਤੇ slow burn (ticket/notify)।
ਛੋਟੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ—2–4 SLOs ਜੋ ਤੁਸੀਂ ਵਾਸਤਵ ਵਿੱਚ ਵਰਤੋਂਗੇ:\n\n- Availability: 30 ਦਿਨਾਂ 'ਤੇ % successful requests (ਉਦਾਹਰਨ: HTTP 2xx/3xx)।\n- Latency: p95 request latency ਇੱਕ ਥ੍ਰੇਸ਼ਹੋਲਡ ਤੋਂ ਘੱਟ।\n- Checkout / critical endpoint: ਦਾ success rate ਜਿਸ ਰਾਹੀ ਕਾਰੋਬਾਰ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਚਿੰਤਤ ਹੈ।\n- Freshness (ਜੇ ਲਾਗੂ ਹੁੰਦਾ): background jobs X ਮਿੰਟਾਂ ਦੇ ਅੰਦਰ ਮੁਕੰਮਲ ਹੋਣ।
ਇਹ ਸਥਿਰ ਹੋਣ 'ਤੇ ਤੁਸੀਂ ਵਧਾ ਸਕਦੇ ਹੋ—ਨਹੀਂ ਤਾਂ ਤੁਸੀਂ ਸਿਰਫ਼ ਹੋਰ ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਦੀ ਦੀਵਾਰ ਬਣਾਉਣਗੇ। ਵਧੇਰੇ ਲਈ, ਦੇਖੋ /blog/slo-monitoring-basics.
ਅਲਰਟਿੰਗ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੇ observability ਕਾਰਜ ਰੁਕ ਜਾਂਦੇ ਹਨ: ਡੇਟਾ ਉੱਥੇ ਹੈ, ਡੈਸ਼ਬੋਰਡ ਚੰਗੇ ne, ਪਰ on-call ਅਨੁਭਵ ਨੌਇਜ਼ੀ ਅਤੇ ਅਣਭਰੋਸੇਯੋਗ ਬਣ ਜਾਂਦਾ ਹੈ। ਜੇ ਲੋਕ alerts ਨੂੰ ignore ਕਰਨਾ ਸਿਖ ਜਾਣ, ਤੁਹਾਡਾ ਪਲੇਟਫਾਰਮ ਕਾਰੋਬਾਰ ਦੀ ਰੱਖਿਆ ਕਰਨ ਦੀ ਸਮਰੱਥਾ ਗੁਆ ਬੈਠੇਗਾ।
ਅਕਸਰ ਕਾਰਨ ਇਕੋ-ਜੇਹੇ ਹੁੰਦੇ ਹਨ:\n\n- ਬਹੁਤ ਸਾਰੇ “FYI” alerts ਜੋ ਕਾਰਵਾਈ ਨਹੀਂ ਮੰਗਦੇ\n- Thresholds ਵੱਖ-ਵੱਖ ਸੇਵਾਵਾਂ ਲਈ ਬਿਨਾਂ ਪਰਿਸ਼ਰਤ ਦੇ ਕੌਪੀ ਕੀਤੇ ਜਾਂਦੇ ਹਨ\n- ਇੱਕੋ ਲੱਛਣ 'ਤੇ ਵੱਖ-ਵੱਖ ਟੂਲ/ਟੀਮਾਂ ਦੁਆਰਾ paging—ਉਦਾਹਰਣ ਲਈ, APM error-rate monitor ਅਤੇ ਇੱਕ log-based error monitor ਦੋਹਾਂ ਇੱਕੋ incident ਲਈ page ਕਰ ਰਹੇ ਹਨ\n- Noisy metrics (spiky latency percentiles, autoscaling ਪ੍ਰਭਾਵ) ਜੋ ਹਕੀਕੀ ਸਮੱਸਿਆ ਦੀ ਥਾਂ ਉਤਾਰ-ਚੜ੍ਹਾਅ trigger ਕਰਦੇ ਹਨ
Datadog ਸੰਦਰਭ ਵਿੱਚ, duplicated signals ਅਕਸਰ ਉਸ ਵੇਲੇ ਵੇਖੇ ਜਾਂਦੇ ਹਨ ਜਦੋਂ monitors ਵੱਖ-ਵੱਖ "surfaces" (metrics, logs, traces) ਤੋਂ ਬਣਾਏ ਜਾਂਦੇ ਹਨ ਬਿਨਾਂ ਇਹ ਫੈਸਲਾ ਕਰਨ ਦੇ ਕਿ canonical page ਕੌਣ ਹੈ।
ਅਲਰਟਿੰਗ ਨੂੰ ਸਕੇਲ ਕਰਨ ਦੀ ਸ਼ੁਰੂਆਤ routing ਨਿਯਮਾਂ ਨਾਲ ਹੁੰਦੀ ਹੈ ਜੋ ਮਨੁੱਖਾਂ ਲਈ ਸਮਝਦਾਰ ਹੋਣ:
ਇੱਕ ਲਾਭਦਾਇਕ ਡਿਫੌਲਟ: signsptoms 'ਤੇ alert ਕਰੋ, ਹਰ metric change 'ਤੇ ਨਹੀਂ। ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰਨ ਵਾਲੀਆਂ ਚੀਜ਼ਾਂ (error rate, failed checkouts, sustained latency, SLO burn) 'ਤੇ page ਕਰੋ, ਨਾ ਕਿ "inputs" (CPU, pod count) 'ਤੇ ਜੇ ਉਹ ਪ੍ਰਭਾਵ ਦੀ ਭਵਿੱਖਬਾਣੀ ਨਹੀਂ ਕਰਦੇ।
operations ਦਾ ਹਿੱਸਾ ਬਣਾਉ: ਮਾਸਿਕ monitor pruning ਅਤੇ tuning। ਜਿਹੜੇ monitors ਕਦੇ ਫਾਇਰ ਨਹੀਂ ਹੁੰਦੇ, ਉਹਨਾਂ ਨੂੰ ਹਟਾਓ; ਜਿਹੜੇ ਬਹੁਤ ਮਹਾਂ ਫਾਇਰ ਹੁੰਦੇ ਹਨ ਉਹ thresholds adjust ਕਰੋ; duplicates merge ਕਰੋ ਤਾਂ ਕਿ ਹਰ incident ਦਾ ਇੱਕ primary page ਹੋਵੇ ਨਾਲ ਹੀ supportive context।
ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੀਤਾ ਹੋਵੇ ਤਾਂ, alerting ਇੱਕ ਐਸਾ workflow ਬਣ ਜਾਂਦਾ ਹੈ ਜਿਸ 'ਤੇ ਲੋਕ ਭਰੋਸਾ ਕਰਦੇ ਹਨ—ਨਹੀਂ ਤਾਂ ਇੱਕ ਪਿਛੋਕੜ ਸ਼ੋਰ ਜਨਰੇਟਰ।
observability ਨੂੰ "ਪਲੇਟਫਾਰਮ" ਕਹਿਣਾ ਸਿਰਫ਼ ਲੋਗ, ਮੈਟਰਿਕਸ, ਟਰੇਸ ਅਤੇ ਕਈ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਹੋਣ ਬਾਰੇ ਨਹੀਂ ਹੈ। ਇਹ governance ਨੂੰ ਵੀ ਦਰਸਾਉਂਦਾ ਹੈ: consistency ਅਤੇ guardrails ਜੋ ਪ੍ਰਣਾਲੀ ਨੂੰ ਯੂਜ਼ਬਲ ਰੱਖਦੀਆਂ ਹਨ ਜਦੋਂ ਟੀਮਾਂ, ਸੇਵਾਵਾਂ, ਡੈਸ਼ਬੋਰਡ, ਅਤੇ alerts ਦੀ ਗਿਣਤੀ ਵਧਦੀ ਹੈ।
ਬਿਨਾਂ governance, Datadog (ਜਾਂ ਕੋਈ ਵੀ observability ਪਲੇਟਫਾਰਮ) ਇੱਕ ਸ਼ੋਰ ਭਰਿਆ scrapbook ਬਣ ਸਕਦੀ ਹੈ—ਸੈਂਕੜੇ ਥੋੜ੍ਹੇ-ਫਰਕ ਵਾਲੇ ਡੈਸ਼ਬੋਰਡ, inconsistent tags, unclear ownership, ਅਤੇ alerts ਜੋ ਕਿਸੇ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕਰਦੇ।
ਚੰਗੀ governance ਸਪਸ਼ਟ ਕਰਦੀ ਹੈ ਕਿ ਕੌਣ ਕੀ ਫੈਸਲਾ ਕਰਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ پਲੇਟਫਾਰਮ ਗੰਦਾ ਹੋ ਜਾਵੇ ਤਾਂ किस 'ਤੇ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ:\n\n- Platform team: standards (tagging, naming, dashboard patterns) define ਕਰਦਾ ਹੈ, ਸਾਂਝੇ components ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ, ਅਤੇ integrations maintain ਕਰਦਾ ਹੈ।\n- Service owners: ਆਪਣੀਆਂ ਸੇਵਾਵਾਂ ਲਈ telemetry quality ਦੇ ਮਾਲਕ ਹਨ ਅਤੇ monitors ਨੂੰ meaningful ਰੱਖਦੇ ਹਨ।\n- Security & compliance: ਡੇਟਾ ਹੈਂਡਲਿੰਗ ਨੀਤੀਆਂ (PII, retention, access boundaries) ਸੈੱਟ ਕਰਦਾ ਹੈ ਅਤੇ high-risk integrations ਦੀ review ਕਰਦਾ ਹੈ।\n- Leadership: governance ਨੂੰ ਬਿਜ਼ਨਸ प्राथमिकਤਾਂ (reliability targets, incident response ਉਮੀਦਾਂ) ਨਾਲ align ਕਰਦਾ ਹੈ ਅਤੇ ਇਸ ਕੰਮ ਨੂੰ ਫੰਡ ਕਰਦਾ ਹੈ।
ਕੁਝ ਹਲਕੇ-ਫੁਲਕੇ ਨਿਯੰਤਰਣ ਲੰਬੇ ਨੀਤੀ ਦਸਤਾਵੇਜ਼ਾਂ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹਨ:\n\n- Templates by default: starter dashboards ਅਤੇ monitor packs per service type (API, queue worker, database) ਤਾਂ ਕਿ ਟੀਮਾਂ consistent ਸ਼ੁਰੂ ਕਰਨ\n- Tagging policy: ਇੱਕ ਛੋਟੀ ਲੋੜੀਂਦੀ ਸੈੱਟ (ਉਦਾਹਰਨ: service, env, team, tier) ਨਾਲ ਸਾਫ਼ ਨੀਤੀਆਂ; ਜਿੱਥੇ ਸੰਭਵ ਹੋ CI ਵਿੱਚ enforce ਕਰੋ\n- Access and ownership: sensitive ਡੇਟਾ ਲਈ role-based access ਅਤੇ dashboards/monitors ਲਈ owner ਲਾਜ਼ਮੀ ਕਰੋ\n- Approval flows for high-impact changes: monitors ਜੋ ਲੋਕਾਂ ਨੂੰ page ਕਰਦੇ ਹਨ، log pipelines ਜੋ ਖਰਚ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ، ਅਤੇ integrations ਜੋ sensitive ਡੇਟਾ ਖਿੱਚਦੀਆਂ ਹਨ، ਉਹਨਾਂ ਲਈ review steps ਰੱਖੋ
ਗੁਣਵੱਤਾ ਨੂੰ ਸਕੇਲ ਕਰਨ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਇਹ ਹੈ ਕੇ ਜੋ ਚੰਗਾ ਕੰਮ ਕੀਤਾ, ਉਸਨੂੰ ਸਾਂਝਾ ਕਰਨਾ:\n\n- Shared libraries: ਅੰਦਰੂਨੀ packages ਜਾਂ snippets ਜੋ logging fields, trace attributes, ਅਤੇ ਆਮ metrics ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਦੇ ਹਨ\n- Reusable dashboards ਅਤੇ monitors: ਇੱਕ ਕੇਂਦਰੀ ਕੈਟਾਲੌਗ "golden" ਡੈਸ਼ਬੋਰਡਾਂ ਅਤੇ monitor templates ਦਾ, ਜੋ ਟੀਮਾਂ clone ਕਰ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਅਨੁਕੂਲਿਤ ਕਰ ਸਕਦੀਆਂ ਹਨ\n- Versioned standards: ਮੁੱਖ assets ਨੂੰ ਕੋਡ ਵਾਂਗ ਟ੍ਰੀਟ ਕਰੋ—ਬਦਲਾਅ ਦਸਤਾਵੇਜ਼ ਕਰੋ, ਪੁਰਾਣੇ patterns ਨੂੰ deprecated ਕਰੋ, ਅਤੇ ਇੱਕ ਸਥਾਨ 'ਚ ਅੱਪਡੇਟ ਜ਼ਾਹਰ ਕਰੋ
ਜੇ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਇਹ ਲਗੇ ਰਹੇ, ਤਾਂ governed path ਨੂੰ ਆਸਾਨ ਰੱਖੋ—ਘੱਟ ਕਲਿਕ, ਤੇਜ਼ setup, ਅਤੇ ਸਪਸ਼ਟ ownership।
ਜਦੋਂ observability ਇੱਕ ਪਲੇਟਫਾਰਮ ਵਾਂਗ ਵਰਤਾਉਂਦਾ ਹੈ, ਇਹ ਪਲੇਟਫਾਰਮ ਅਰਥਸ਼ਾਸਤ੍ਰੀ ਦੀ ਪਾਲਨਾ ਕਰਨ ਲੱਗਦਾ ਹੈ: ਜਿੰਨਾ ਜ਼ਿਆਦਾ ਟੀਮਾਂ ਇਸਨੂੰ ਅਪਨਾਉਂਦੀਆਂ ਹਨ, ਓਨੀ ਨਿੱਕੀ-ਟੈਲੀਮੇਟਰੀ ਉਤਪੰਨ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਓਨਾ ਤੋਂ ਜ਼ਿਆਦਾ ਇਹ ਜ਼ਿਆਦਾ ਲਾਭਦਾਇਕ ਬਣਦਾ ਹੈ।
ਇਸ ਨਾਲ ਇੱਕ ਫਲਾਈਵ੍ਹੀਲ ਬਣਦਾ ਹੈ:\n\n- ਵਧੇਰੇ ਸੇਵਾਵਾਂ onboard → ਬਿਹਤਰ cross-service visibility ਅਤੇ correlation\n- ਬਿਹਤਰ visibility → ਤੇਜ਼ ਡਾਇਗਨੋਸਿਸ, ਘੱਟ ਦੁਹਰਾਏ incidents, ਸੰਦ 'ਤੇ ਵਧਦਾ ਵਿਸ਼ਵਾਸ\n- ਵਧਦਾ ਵਿਸ਼ਵਾਸ → ਹੋਰ ਟੀਮਾਂ instrument ਅਤੇ integrate ਕਰਦੀਆਂ ਹਨ → ਹੋਰ ਡੇਟਾ
ਕੰਚਾ ਇਹ ਹੈ ਕਿ ਇੱਕੋ ਲੂਪ ਖ਼ਰਚ ਵੀ ਵਧਾਉਂਦਾ ਹੈ। ਵਧੇਰੇ hosts, containers, l߀ਗਸ, ਟਰੇਸਸ, synthetics, ਅਤੇ ਕਸਟਮ ਮੈਟਰਿਕਸ ਤੁਹਾਡੇ ਬਜਟ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਵਧ ਸਕਦੇ ਹਨ ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਧਿਆਨ ਨਾਲ manage ਨਾ ਕਰੋ।
ਤੁਹਾਨੂੰ "ਸਭ ਬੰਦ" ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ: ਡੇਟਾ ਨੂੰ shape ਕਰਕੇ ਸ਼ੁਰੂ ਕਰੋ:\n\n- Sampling: ਮਹੱਤਵਪੂਰਨ endpoints ਲਈ high-fidelity traces ਰੱਖੋ, ਹੋਰ ਥਾਂ ਤੇ ਜ਼ਿਆਦਾ aggressive sampling ਕਰੋ।\n- Retention tiers: ਕੱਚੇ high-volume logs ਲਈ ਛੋਟੀ retention; curated security/audit streams ਲਈ ਲੰਬੀ retention।\n- Log filtering & parsing: health checks, static asset requests ਵਰਗੇ ਨੌਇਜ਼ ਨੂੰ ਪਹਿਲਾਂ ਹੀ_DROP_ ਕਰੋ ਅਤੇ parsing ਸਟੈਂਡਰਡ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ attributes ਅਧਾਰ 'ਤੇ route ਕਰ ਸਕੋ।\n- Metric aggregation: per-user ID ਵਰਗੀਆਂ ਅਨੰਤ cardinality ਦੀ ਥਾਂ percentiles, rates, ਅਤੇ rollups ਵਰਤੋ।
ਛੋਟੀ ਸੈੱਟ ਦੇ ਮਾਪਦੰਡ ਟਰੈਕ ਕਰੋ ਜੋ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿ ਪਲੇਟਫਾਰਮ ਵਾਪਸੀ ਕਰ ਰਿਹਾ ਹੈ ਕਿ ਨਹੀਂ:\n\n- MTTD (mean time to detect)\n- MTTR (mean time to resolve)\n- Incident count ਅਤੇ repeat incidents (ਉਹੀ root cause)\n- Deploy frequency (ਅਤੇ change failure rate ਜੇ ਤੁਸੀਂ ਟ੍ਰੈਕ ਕਰਦੇ ਹੋ)
ਇਸ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਰਿਵਿਊ ਬਣਾਉ, ਨਾਂ ਕਿ ਇਕ ਆਡੀਟ। platform owners, ਕੁਝ service teams, ਅਤੇ finance ਨੂੰ ਲਿਆਓ। ਰਿਵਿਊ ਕਰੋ:\n\n- ਟੀਮ-ਵਾਰ ਅਤੇ ਡੇਟਾ ਕਿਸਮ-ਵਾਰ ਸਭ ਤੋਂ ਵੱਡੇ ਖਰਚ ਡ੍ਰਾਈਵਰ\n- ਸਭ ਤੋਂ ਵੱਡੀ ਜਿੱਤ: incidents ਜੋ ਛੋਟੇ ਹੋਏ, outages ਉਦੋਂ ਬਚਾਏ ਗਏ, toil ਘਟਾਇਆ ਗਿਆ\n- 2–3 ਸਮਝੌਤੇ ਕਾਰਵਾਈਆਂ (ਉਦਾਹਰਨ: sampling ਨਿਯਮ adjust, retention tier add, noisy integration ਸਹੀ ਕਰਨੀ)
ਲਕੜੀ ਮਕਸਦ ਸਾਂਝੀ ਮਾਲਕੀਅਤ ਹੈ: ਖਰਚ ਇੱਕ input ਬਣਦਾ ਹੈ ਬਿਹਤਰ instrumentation ਫੈਸਲੇ ਲਈ, ਨਾਂ ਕਿ observing ਨੂੰ ਰੋਕਣ ਲਈ ਕਾਰਨ।
ਜੇ observability ਪਲੇਟਫਾਰਮ ਬਣ ਰਹੀ ਹੈ, ਤਾਂ ਤੁਹਾਡਾ “ਟੂਲ ਸਟੈਕ” ਇੱਕ ਸਿਰਫ਼ ਬਿੰਦੂ ਸਮਾਧਾਨਾਂ ਦਾ ਸੰਗ੍ਰਹਿ ਨਹੀਂ ਰਹਿੰਦਾ—ਇਹ ਸਾਂਝੇ ਇਨਫ੍ਰਾਸਟ੍ਰਕਚਰ ਵਾਂਗ ਕੰਮ ਕਰਨ ਲੱਗਦਾ ਹੈ। ਇਹ ਬਦਲਾਅ ਟੂਲ ਸਪ੍ਰੋਅਲ ਨੂੰ ਇੱਕ ਤਕਲੀਫ਼ ਤੋਂ ਵੱਧ ਕਰ ਦਿੰਦਾ: ਇਹ ਨਕਲ ਕੀਤਾ instrumentation, inconsistent definitions (error ਕੀ ਗਿਣਤੀ ਹੈ?), ਅਤੇ ਉੱਚ on-call ਬੋਝ ਪੈਦਾ ਕਰਦਾ ਹੈ ਕਿਉਂਕਿ signals logs, metrics, traces, ਅਤੇ incidents ਵਿੱਚ align ਨਹੀਂ ਹੁੰਦੇ।
Consolidation ਦਾ ਮਤਲਬ ਅਜੇ ਵੀ “ਹਰ ਚੀਜ਼ ਲਈ ਇੱਕ vendor” ਨਹੀਂ ਹੁੰਦਾ। ਮਤਲਬ ਹੈ—telemetry ਅਤੇ response ਲਈ ਘੱਟ ਸਿਸਟਮ ਐਕਠੇ, ਸਪਸ਼ਟ ownership, ਅਤੇ ਓਹਨਾ ਥਾਂ ਦੀ ਗਿਣਤੀ ਘੱਟ ਜਿੱਥੇ ਲੋਕ outage ਦੌਰਾਨ ਵੇਖਣੇ ਪੈਂਦੇ ਹਨ।
ਟੂਲ ਸਪ੍ਰੋਅਲ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਥਾਵਾਂ 'ਚ ਲੁਕਿਆ ਖਰਚ ਸਾਜ਼ਦਾ ਹੈ: UI ਵਿੱਚ ਵਿਆਪਕ hops, brittle integrations ਜੋ ਤੁਹਾਨੂੰ ਰੱਖਣੀਆਂ ਪੈਂਦੀਆਂ ਹਨ, ਅਤੇ fragmented governance (ਨਾਮ, tags, retention, access)।
ਇੱਕ ਵੱਧ ਇਕਸਾਰ ਪਲੇਟਫਾਰਮ approach context switching ਘਟਾ ਦਿੰਦਾ ਹੈ, ਸੇਵਾ ਦ੍ਰਿਸ਼ਾਂ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਦਾ ਹੈ, ਅਤੇ incident workflows ਨੂੰ ਦੁਹਰਾਏ ਜਾ ਸਕਦੇ ਬਣਾਂਦਾ ਹੈ।
ਆਪਣੇ ਸਟੈਕ ਨੂੰ (Datadog ਸਮੇਤ) ਮੁਲਾਂਕਣ ਕਰਦੇ ਸਮੇਂ ਇਹਨਾਂ 'ਤੇ ਦਬਾਅ ਪਾਓ:\n\n- Must-have integrations: cloud provider, Kubernetes, CI/CD, incident management, paging, ਅਤੇ ਕੁਝ "ਬਿਨਾਂ ਇਸ ਦੇ ਅਸੀਂ ਸ਼ਿਪ ਨਹੀਂ ਕਰ ਸਕਦੇ" ਬਿਜ਼ਨਸ ਸਿਸਟਮ।\n- Workflows: alert → owner → runbook → timeline → postmortem ਬਿਨਾਂ manual copy/paste ਜਾਂਦਾ ਹੈ?\n- Governance: tagging standards, access controls, retention, ਅਤੇ guardrails dashboard/monitor sprawl ਲਈ ਹਨ?\n- Pricing model: ਕੀ ਚੀਜ਼ ਖਰਚ ਚਲਾਉਂਦੀ ਹੈ (hosts, containers, ingested logs, indexed traces)? ਕੀ ਤੁਸੀਂ ਵਿਕਾਸ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਅਚਾਨਕਤਾਵਾਂ ਦੇ?
ਇੱਕ ਜਾਂ ਦੋ ਸੇਵਾਵਾਂ ਚੁਣੋ ਜੋ ਅਸਲੀ traffic ਤੇ ਹਨ। ਇੱਕ ਸਫਲਤਾ ਮੈਟਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ—"root cause ਪਛਾਣਣ ਦਾ ਸਮਾਂ 30 ਮਿੰਟ ਤੋਂ 10 ਮਿੰਟ ਹੋ ਜਾਵੇ" ਜਾਂ "ਨੌਇਜ਼ੀ alerts 40% ਘਟ ਜਾਣ"—ਸਿਰਫ਼ ਜਰੂਰੀ ਇਨਸਟਰੂਮੈਂਟਸ਼ਨ ਕਰੋ, ਅਤੇ ਦੋ ਹਫਤਿਆਂ ਬਾਅਦ ਨਤੀਜੇ ਰਿਵਿਊ ਕਰੋ।
ਅੰਦਰੂਨੀ docs centralized ਰੱਖੋ ਤਾਂ ਜੋ ਸਿੱਖਿਆ ਸੰਘਣੀ ਬਣੇ—pilot runbook, tagging rules, ਅਤੇ dashboards ਨੂੰ ਇੱਕ ਥਾਂ ਤੋਂ ਲਿੰਕ ਕਰੋ (ਉਦாஃਰਨ ਲਈ, /blog/observability-basics ਅੰਦਰੂਨੀ ਸ਼ੁਰੂਆਤ ਲਈ)।
ਤੁਸੀਂ "Datadog ਨੂੰ ਇਕ ਵਾਰੀ roll out" ਨਹੀਂ ਕਰਦੇ। ਤੁਸੀਂ ਛੋਟੇ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ, ਸ਼ੁਰੂ ਵਿੱਚ ਮਿਆਰ ਬਣਾਉਂਦੇ ਹੋ, ਫਿਰ ਜੋ ਕੰਮ ਕਰਦਾ ਹੈ ਉਸਨੂੰ ਸਕੇਲ ਕਰਦੇ ਹੋ।
ਦਿਨ 0–30: Onboard (ਤੇਜ਼ ਲਾਭ ਸਾਬਤ ਕਰੋ)
1–2 critical services ਅਤੇ ਇੱਕ customer-facing journey ਚੁਣੋ। ਲੋਗਸ, ਮੈਟਰਿਕਸ, ਅਤੇ ਟਰੇਸਸ ਤਰਤੀਬ ਨਾਲ instrument ਕਰੋ, ਅਤੇ ਉਹ ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਵਰਤਦੇ ਹੋ (cloud, Kubernetes, CI/CD, on-call) ਜੋੜੋ।
ਦਿਨ 31–60: Standardize (ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਬਣਾਓ)
ਜੋ ਸਿੱਖਿਆ ਮਿਲੀ ਉਸਨੂੰ defaults ਵਿੱਚ ਤਬਦੀਲ ਕਰੋ: service naming, tagging, dashboard templates, monitor naming, ਅਤੇ ownership। "golden signals" ਵਿਊਜ਼ ਬਣਾਓ (latency, traffic, errors, saturation) ਅਤੇ ਮਹੱਤਵਪੂਰਨ endpoints ਲਈ ਇੱਕ ਘੱਟੋ-ਘੱਟ SLO ਸੈੱਟ ਬਣਾਓ।
ਦਿਨ 61–90: Scale (ਬਿਨਾਂ ਅਫਰਾਤਫਰੀ ਦੇ ਫੈਲਾਓ)
ਉਹੀ templates ਵਰਤ ਕੇ ਹੋਰ ਟੀਮਾਂ onboard ਕਰੋ। governance ਲਾਗੂ ਕਰੋ (tag rules, required metadata, ਨਵੇਂ monitors ਲਈ review ਪ੍ਰਕਿਰਿਆ) ਅਤੇ platform ਸਿਹਤ ਰੱਖਣ ਲਈ cost vs usage ਟਰੈਕ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰੋ।
ਜਦੋਂ ਤੁਸੀਂ observability ਨੂੰ ਪਲੇਟਫਾਰਮ ਵਜੋਂ ਦੇਖਦੇ ਹੋ, ਤਾਂ ਅਕਸਰ ਤੁਹਾਨੂੰ ਇਸਦੇ ਆਲੇ-ਦੁਆਲੇ ਛੋਟੇ "glue" ਐਪ ਚਾਹੀਦੇ ਹਨ: ਇੱਕ service catalog UI, ਇੱਕ runbook hub, ਇੱਕ incident timeline ਪੰਨਾ, ਜਾਂ ਇੱਕ ਅੰਦਰੂਨੀ ਪੋਰਟਲ ਜੋ owners → dashboards → SLOs → playbooks ਨੂੰ ਜੋੜਦਾ ਹੈ।
ਇਹ ਉਹ ਹਲਕੇ-ਫੁਲਕੇ ਅੰਦਰੂਨੀ ਟੂਲ ਹਨ ਜੋ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ Koder.ai ਉੱਤੇ ਬਣਾਉਂ ਸਕਦੇ ਹੋ—ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਜੋ chat ਰਾਹੀਂ ਵੈਬ ਐਪ ਜੈਨਰੇਟ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ (ਅਕਸਰ React frontend, Go + PostgreSQL backend), ਅਤੇ ਸਰੋਤ ਕੋਡ ਐਕਸਪੋਰਟ ਅਤੇ deployment/hosting ਸਹਾਇਤਾ ਦਿੰਦਾ ਹੈ। ਅਮਲ ਵਿੱਚ, ਟੀਮਾਂ ਇਸਨੂੰ ਉਹਨਾਂ operational surfaces ਨੂੰ ਪ੍ਰੋਟੋਟਾਈਪ ਅਤੇ ਸ਼ਿਪ ਕਰਨ ਲਈ ਵਰਤਦੀਆਂ ਹਨ ਜੋ governance ਅਤੇ workflows ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੀਆਂ ਹਨ ਬਿਨਾਂ ਪੂਰੇ ਉਤਪਾਦ ਟੀਮ ਨੂੰ ਰੋਡਮੈਪ ਤੋਂ ਹਟਾਉਣ ਦੇ।
ਦੋ 45- ਮਿੰਟ ਦੇ ਸੈਸ਼ਨ ਚਲਾਓ: (1) “ਅਸੀਂ ਇੱਥੇ ਕਿਵੇਂ ਕਵੇਰੀ ਕਰਦੇ ਹਾਂ” ਨਾਲ ਸਾਂਝੇ ਕਵੇਰੀ ਪੈਟਰਨ (service, env, region, version), ਅਤੇ (2) “Troubleshooting playbook” ਇੱਕ ਸਧਾਰਨ ਫਲੋ ਨਾਲ: ਪ੍ਰਭਾਵ ਦੀ ਪੁਸ਼ਟੀ → deploy markers ਚੈੱਕ ਕਰੋ → service ਤੱਕ 좁੍ਹੋ → traces ਦੇਖੋ → dependency health ਪੁਸ਼ਟੀ ਕਰੋ → rollback/mitigation ਦਾ ਫੈਸਲਾ ਕਰੋ।
ਇੱਕ observability ਟੂਲ ਉਹ ਚੀਜ਼ ਹੈ ਜਿਹੀਨੂੰ ਤੁਸੀਂ ਮੱਸਲੇ ਦੇ ਸਮੇਂ ਸਲਾਹ-ਮਸ਼ਵਰੇ ਲਈ ਦੇਖਦੇ ਹੋ (ਡੈਸ਼ਬੋਰਡ, ਲੋਗ ਸੁਰਚ, ਇੱਕ ਕਵੇਰੀ)। ਇੱਕ observability ਪਲੇਟਫਾਰਮ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਤੁਸੀਂ ਲਗਾਤਾਰ ਚਲਾਉਂਦੇ ਹੋ: ਇਹ ਟੈਲੀਮੇਟਰੀ, ਇੰਟਿਗ੍ਰੇਸ਼ਨ, ਪਹੁੰਚ, ਮਾਲਕੀਅਤ, ਅਲਰਟਿੰਗ ਅਤੇ incident ਵਰਕਫਲੋਜ਼ ਨੂੰ ਟੀਮਾਂ ਵਿੱਚ ਸਟੈਂਡਰਡ ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਨਤੀਜੇ ਸੁਧਰਣ (ਜਿਵੇਂ ਤੇਜ਼ ਡਿਟੈਕਸ਼ਨ ਅਤੇ ਰਿਜ਼ੋਲੂਸ਼ਨ)।
ਕਿਉਂਕਿ ਸਭ ਤੋਂ ਵੱਡੇ ਨਤੀਜੇ ਨਤੀਜਿਆਂ ਤੋਂ ਆਉਂਦੇ ਹਨ, ਨਾਂ ਕਿ ਸਿਰਫ਼ ਵਿਜ਼ੂਅਲ ਤੋਂ:
ਚਾਰਟ ਮਦਦ ਕਰਦੇ ਹਨ, ਪਰ ਤੁਹਾਨੂੰ MTTD/MTTR ਘਟਾਉਣ ਲਈ ਸਾਂਝੇ ਮਿਆਰ ਅਤੇ ਵਰਕਫਲੋਜ਼ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਸ਼ੁਰੂ ਕਰੋ ਇੱਕ ਲਾਜ਼ਮੀ ਬੇਸਲਾਈਨ ਨਾਲ ਜੋ ਹਰ ਸਿਗਨਲ ਤੋਂ ਲੱਗਦਾ ਹੋਵੇ:
serviceenv (prod, staging, )High-cardinality ਫੀਲਡ (ਜਿਵੇਂ user_id, order_id, session_id) ਇੱਕ-ਇਕ ਗ੍ਰਾਹਕ ਨਾਲ ਸੰਬੰਧਤ ਪ੍ਰਾਬਲਮਾਂ ਲਈ ਸ਼ਾਨਦਾਰ ਹਨ, ਪਰ ਜੇਹੜੇ ਥਾਵਾਂ ਤੇ ਇਹ ਹਰ ਜਗ੍ਹਾ ਵਰਤੇ ਜਾਣ ਤਾਂ ਖਰਚ ਵੱਧ ਸਕਦਾ ਹੈ ਅਤੇ ਕਵੇਰੀਆਂ ਧੀਮੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਉਨ੍ਹਾਂ ਨੂੰ ਇਰਾਦੇ ਨਾਲ ਵਰਤੋ:
ਅਕਸਰ ਟੀਮ ਹੇਠਾਂ ਦੇ ਸਿਗਨਲਾਂ 'ਤੇ ਸਟੈਂਡਰਡ ਕਰਦੀਆਂ ਹਨ:
ਇੱਕ ਕਰਿਆਤਮਕ ਡਿਫੌਲਟ ਹੈ:
ਦੋਹਾਂ ਕਰੋ:
ਇਸ ਨਾਲ ਅਡਾਪਸ਼ਨ ਦੀ ਰਫ਼ਤਾਰ ਬਣੀ ਰਹਿੰਦੀ ਹੈ ਬਿਨਾਂ ਹਰ ਟੀਮ ਦੇ ਆਪਣੇ ਸਕੀਮਾ ਨੂੰ ਲਾਕ-ਇਨ ਕੀਤੇ।
ਕਿਉਂਕਿ integrations ਸਿਰਫ਼ ਡਾਟਾ ਪਾਈਪ ਨਹੀਂ ਹੁੰਦੀਆਂ—ਉਹ ਸ਼ਾਮਿਲ ਹਨ:
ਉਹਨਾਂ bidirectional ਇੰਟਿਗ੍ਰੇਸ਼ਨਸ ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਜੋ ਸੰਕੇਤ ਲੈਂਦੀਆਂ ਅਤੇ ਕਾਰਵਾਈ ਵੀ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਜੋ observability ਦਿਨ-ਚਰਿਆ ਦਾ ਹਿੱਸਾ ਬਣ ਜਾਵੇ, ਸਿਰਫ਼ ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਨਹੀਂ।
ਇੱਕ ਸੇਵਾ ਕਿਸਮ ਲਈ ਇੱਕ “golden signals” layout ਤੈਅ ਕਰੋ ਅਤੇ ਇੱਕ ਸੰਗਠਿਤ ਡੈਸ਼ਬੋਰਡ ਨਾਲ ਜੋੜੋ:
ਇੱਕ ਹੀ ਡੈਸ਼ਬੋਰਡ ਲੇਆਉਟ ਜੋ ਸਾਰੀਆਂ ਸੇਵਾਵਾਂ ਲਈ ਕੰਮ ਕਰੇ, ਕਈ ਵਿਅਕਤੀਗਤ ਡੈਸ਼ਬੋਰਡਾਂ ਨਾਲੋਂ ਬਿਹਤਰ ਹੈ।
SLO ਇੱਕ ਸادہ ਵਾਅਦਾ ਹੈ ਜੋ ਇੱਕ ਸਮੇਂ ਦੀ ਖਿੜਕੀ 'ਤੇ ਉਪਭੋਗਤਾ ਅਨੁਭਵ ਬਾਰੇ ਹੁੰਦਾ ਹੈ—ਜਿਵੇਂ “30 ਦਿਨਾਂ ਵਿੱਚ 99.9% ਰਿਕਵੈਸਟ ਸਫਲ” ਜਾਂ “p95 ਪੇਜ ਲੋਡ 2 ਸਕਿੰਟ ਤੋਂ ਘੱਟ”।
ਇਹ “green dashboard” ਨਾਲੋਂ ਵਧੀਆ ਹੈ ਕਿਉਂਕਿ ਡੈਸ਼ਬੋਰਡ ਅਕਸਰ ਸਿਸਟਮ ਹੈਲਥ ਦਿਖਾਉਂਦੇ ਹਨ (CPU, ਮੈਮੋਰੀ), ਨਾ ਕਿ ਗਾਹਕ ਪ੍ਰਭਾਵ। SLOs ਟੀਮ ਨੂੰ ਇਹ ਮਾਪਣ ਲਈ ਮਜਬੂਰ ਕਰਦੇ ਹਨ ਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ ਕੀ ਮਹਿਸੂਸ ਹੋ ਰਿਹਾ ਹੈ।
ਅਲਰਟਿੰਗ ਉਸ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰਾ observability ਪ੍ਰੋਗਰਾਮ ਰੁਕ ਜਾਂਦੇ ਹਨ: ਡਾਟਾ ਹੈ, ਡੈਸ਼ਬੋਰਡ ਵਧੀਆ ਨੇ, ਪਰ on-call ਅਨੁਭਵ ਸ਼ੋਰ ਅਤੇ ਅਣਭਰੋਸੇਮੰਦ ਹੋ ਜਾਂਦਾ ਹੈ। ਜੇ ਲੋਕ ਅਲਰਟਾਂ ਨੂੰ ਅਣਦੇਖਾ ਕਰਨਾ ਸਿਖ ਲੈਂਦੇ ਹਨ, ਤਾਂ ਤੁਹਾਡਾ ਪਲੇਟਫਾਰਮ ਕਾਰੋਬਾਰ ਦੀ ਰੱਖਿਆ ਕਰਨ ਦੀ ਸਮਰੱਥਾ ਗੁੰਵਾ ਬੈਠਦਾ ਹੈ।
ਅਲਰਟ fatigue ਆਮ ਤੌਰ 'ਤੇ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ:
ਸਰਲ ਨਿਯਮ: ਲੋਕੀ ਮਹਿਸੂਸ ਕਰਨ ਵਾਲੀ ਸਮੱਸਿਆ 'ਤੇ ਅਲਰਟ ਕਰੋ (error rate, failed checkouts, sustained latency, SLO burn) ਨਾ ਕਿ ਹਰ input metric 'ਤੇ, ਜੇਕਰ ਉਹ ਪ੍ਰਭਾਵ ਦੀ ਭਵਿੱਖਵਾਣੀ ਨਹੀਂ ਕਰਦੇ।
ਸਰਲ ਨਿਯਮ ਇਹ ਹਨ:
ਇਕ ਕਾਰਗਰ ਡਿਫੌਲਟ: symptoms 'ਤੇ alert ਕਰੋ, ਹਰ metric ਬਦਲਾਅ 'ਤੇ ਨਹੀਂ।
Governance ਦਰਅਸਲ ਲੋਕ-ਅਤੇ-ਪਰਕਿਰਿਆ ਦੀ ਸਮੱਸਿਆ ਹੈ:
ਕੁਝ ਹਲਕੇ-ਫੁਲਕੇ ਨਿਯੰਤਰਣ ਲੰਮੇ ਨੀਤੀ ਦਸਤਾਵੇਜ਼ਾਂ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਫਾਇਦਾ ਕਰਦੇ ਹਨ:
ਕੁਝ ਮੁੱਖ KPIs ਜੋ ਖਰਚ ਨੂੰ ਨਤੀਜਿਆਂ ਨਾਲ ਜੋੜਦੇ ਹਨ:
ਇਹ ਮੈਟਰਿਕਸ ਦਿਖਾਉਂਦੀਆਂ ਹਨ ਕਿ ਪਲੇਟਫਾਰਮ ਵਿਸ਼ਵਾਸ ਨੂੰ ਕਿਵੇਂ ਵਾਪਸ ਕਰ ਰਿਹਾ ਹੈ।
ਕੁਝ ਕਾਰਗਰ ਖਰਚ-ਕਮ ਕਰਨ ਵਾਲੇ ਉਪਾਅ ਜੋ signal ਨੂੰ ਘਟਾਉਂਦੇ ਬਿਨਾਂ ਕੰਮ ਦੇ ਰੁਚੀ ਨੂੰ ਖਤਮ ਕੀਤੇ ਬਿਨਾਂ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ:
ਟੂਲ ਸਪ੍ਰੋਅਲ ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਥਾਵਾਂ 'ਚ ਲੁਕਿਆ ਖਰਚ ਦਿਖਾਉਂਦਾ ਹੈ: UI ਵਿਚ hop ਕਰਨ 'ਤੇ ਲੱਗਣ ਵਾਲਾ ਸਮਾਂ, brittle integrations ਦੀ ਰਖਤ, ਅਤੇ fragmented governance (ਨਾਮਕਰਨ, tags, retention, access)।
ਇਕ ਅਧਿਕ ਇਕਸਾਰ platform approach context switching ਘਟਾ ਦਿੰਦਾ ਹੈ, ਸੇਵਾ ਦ੍ਰਿਸ਼ਾਂ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਦਾ ਹੈ ਅਤੇ incident workflows ਨੂੰ ਦੁਹਰਾਏ ਜਾਣ ਯੋਗ ਬਣਾਂਦਾ ਹੈ।
ਪੈਲਟਫਾਰਮ ਜਾਂ alternatives ਦੀ ਮੁਲਾਂਕਣ ਕਰਦੇ ਸਮੇਂ ਇਹਨਾਂ 'ਤੇ ਦਬਾਅ ਪਾਓ:
ਇੱਕ ਜਾਂ ਦੋ ਸੇਵਾਵਾਂ ਚੁਣੋ ਜਿਨ੍ਹਾਂ ਦਾ ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਹੋਵੇ। ਇੱਕ ਸਪਸ਼ਟ ਸਫਲਤਾ ਮੈਟਰਿਕ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਜਿਵੇਂ “root cause ਪਛਾਣਣ ਦਾ ਸਮਾਂ 30 ਮਿੰਟ ਤੋਂ 10 ਮਿੰਟ ਹੋ ਜਾਵੇ” ਜਾਂ “ਨੌਇਜ਼ੀ alerts 40% ਘਟ ਜਾਵਣ।” ਸਿਰਫ਼ ਜਰੂਰੀ ਜਾਣਕਾਰੀ instrument ਕਰੋ ਅਤੇ ਦੋ ਹਫ਼ਤਿਆਂ ਬਾਅਦ ਨਤੀਜੇ ਰਿਵਿਊ ਕਰੋ।
devteamversion (deploy ਵਰਜਨ ਜਾਂ git SHA)ਜੇਕਰ ਤੁਸੀਂ ਤੇਜ਼ ਲਾਭ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ tier (frontend, backend, data) ਇੱਕ ਛੋਟਾ ਵਾਧੂ ਫਿਲਟਰ ਹੈ ਜੋ ਜਲਦੀ ਲਾਭ ਦਿੰਦਾ ਹੈ।
ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਸਿਗਨਲ ਇੱਕੋ ਸੰਦਰਭ (service/env/version/request ID) ਸਾਂਝੇ ਕਰਨ ਤਾਂ ਜੋ correlation ਤੇਜ਼ ਹੋਵੇ।
ਉਹ ਰਾਹ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਕੰਟਰੋਲ ਦੀ ਲੋੜ ਨਾਲ ਮਿਲਦਾ ਹੋਵੇ, ਫਿਰ ਉਹਨਾਂ ਸਾਰਿਆਂ 'ਤੇ ਇਕੋ ਨਾਮ/ਟੈਗ ਨੀਤੀਆਂ ਲਾਗੂ ਕਰੋ।
service, env, team, tier) ਅਤੇ ਸੀਧੀਆਂ ਨੀਤੀਆਂ