17 ਅਗ 2025·8 ਮਿੰਟ
ਡਾਟਾ ਮਾਡਲਿੰਗ ਦੇ ਫੈਸਲੇ ਤੁਹਾਡੀ ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਲਾਕ‑ਇਨ ਕਿਵੇਂ ਕਰਦੇ ਹਨ
ਡਾਟਾ ਮਾਡਲਿੰਗ ਦੇ ਫੈਸਲੇ ਸਾਲਾਂ ਤੱਕ ਤੁਹਾਡੇ ਡਾਟਾ ਸਟੈਕ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ। ਵੇਖੋ ਕਿੱਥੇ ਲਾਕ‑ਇਨ ਹੁੰਦਾ ਹੈ, ਤਰਜੀਹਾਂ ਕਿਹੜੀਆਂ ਹਨ, ਅਤੇ ਵਿਕਲਪ ਖੁੱਲੇ ਰੱਖਣ ਦੇ ਕਾਰਗਰ ਤਰੀਕੇ।
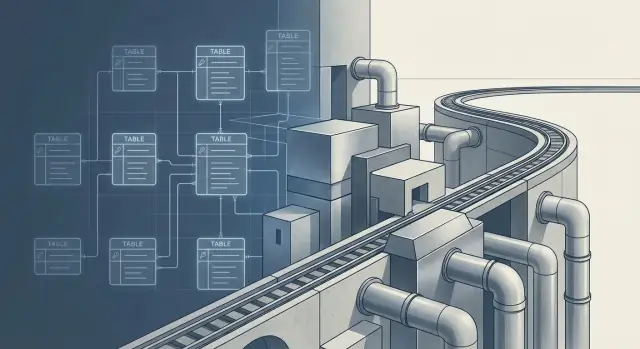
ਡਾਟਾ ਮਾਡਲਿੰਗ ਦੇ ਫੈਸਲੇ ਸਾਲਾਂ ਤੱਕ ਤੁਹਾਡੇ ਡਾਟਾ ਸਟੈਕ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ। ਵੇਖੋ ਕਿੱਥੇ ਲਾਕ‑ਇਨ ਹੁੰਦਾ ਹੈ, ਤਰਜੀਹਾਂ ਕਿਹੜੀਆਂ ਹਨ, ਅਤੇ ਵਿਕਲਪ ਖੁੱਲੇ ਰੱਖਣ ਦੇ ਕਾਰਗਰ ਤਰੀਕੇ।
“ਲਾਕ‑ਇਨ” ਸਿਰਫ਼ ਵੇਂਡਰਾਂ ਜਾਂ ਟੂਲਾਂ ਬਾਰੇ ਨਹੀਂ ਹੈ। ਇਹ ਉਸ ਸਮੇਂ ਵਾਪਰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਆਪਣਾ ਸਕੀਮਾ ਬਦਲਣਾ ਇਨਾ ਖ਼ਤਰਨਾਕ ਜਾਂ ਮਹਿੰਗਾ ਸਮਝੋ ਕਿ ਤੁਸੀਂ ਸਟਾਪ ਕਰ ਦਿਓ—ਕਿਉਂਕਿ ਇਹ dashboards, reports, ML ਫੀਚਰ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਡਾਟਾ ਦੇ ਸਾਂਝੇ ਅਰਥ ਨੂੰ ਤੋੜ ਦੇਵੇਗਾ।
ਇੱਕ ਡਾਟਾ ਮਾਡਲ ਉਹਨਾਂ ਕਈ ਫੈਸਲਿਆਂ ਵਿੱਚੋਂ ਇੱਕ ਹੈ ਜੋ ਹੋਰ ਹਰ ਚੀਜ਼ ਤੋਂ ਬਾਅਦ ਵੀ ਰਹਿੰਦਾ ਹੈ। ਵੇਅਰਹਾਊਸ ਬਦਲ ਜਾਦੇ ਹਨ, ETL ਟੂਲ ਤਬਦੀਲ ਹੁੰਦੇ ਹਨ, ਟੀਮਾਂ ਦੁਬਾਰਾ ਬਣਦੀਆਂ ਹਨ, ਅਤੇ ਨਾਮਕਰਨ ਰੀਤੀਆਂ drift ਕਰਦੀਆਂ ਹਨ। ਪਰ ਜਦੋਂ ਡਾਊਨਸਟਰੀਮ ਉਪਭੋਗਤਾਵਾਂ ਸੈਂਕੜਿਆਂ ਦੀ ਗਿਣਤੀ ਕਿਸੇ ਟੇਬਲ ਦੇ column, key ਅਤੇ grain 'ਤੇ ਨਿਰਭਰ ਹੋਣ ਲਗਦੇ ਹਨ, ਤਾਂ ਮਾਡਲ ਇੱਕ ਠੇਕਾ ਬਣ ਜਾਂਦਾ ਹੈ। ਇਸਨੂੰ ਬਦਲਣਾ ਸਿਰਫ਼ ਤਕਨੀਕੀ ਮਾਈਗ੍ਰੇਸ਼ਨ ਨਹੀਂ, ਬਲਕਿ ਲੋਕਾਂ ਅਤੇ ਪ੍ਰਕਿਰਿਆਵਾਂ ਵਿੱਚ ਸਹਯੋਗ ਦਾ ਮੁੱਦਾ ਬਣ ਜਾਂਦਾ ਹੈ।
ਟੂਲ ਬਦਲੇ ਜਾ ਸਕਦੇ ਹਨ; dependencies ਨਹੀਂ। ਇੱਕ ਮੈਟ੍ਰਿਕ ਜੋ ਇਕ ਮਾਡਲ ਵਿੱਚ “revenue” ਹੈ, ਦੂਜੇ ਵਿੱਚ “gross” ਹੋ ਸਕਦੀ ਹੈ। ਇੱਕ customer key ਇਕ ਸਿਸਟਮ ਵਿੱਚ “billing account” ਨੂੰ ਦਰਸਾ ਸਕਦੀ ਹੈ ਅਤੇ ਦੂਜੇ ਵਿੱਚ “person” ਨੂੰ। ਇਹ ਅਰਥ-ਸਤਹ ਦੇ ਫੈਸਲੇ ਇੱਕ ਵਾਰ ਫੈਲ ਜਾਣ ਤੋਂ ਬਾਅਦ ਵਾਪਸ ਲੈਣਾ ਔਖਾ ਹੁੰਦਾ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਲੰਬੀ ਮਿਆਦ ਦੇ ਲਾਕ‑ਇਨ ਇੱਕ-ਦੋ ਸ਼ੁਰੂਆਤੀ ਚੋਣਾਂ ਨਾਲ ਜੁੜੇ ਹੁੰਦੇ ਹਨ:
Trade-offs ਸਧਾਰਨ ਹਨ। ਉਦੇਸ਼ ਇਹ ਨਹੀਂ ਕਿ ਕਮਿਟਮੈਂਟ ਨਾ ਹੋਵੇ—ਬਲਕਿ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਕਮਿਟਮੈਂਟ ਸੋਚ-ਸਮਝ ਕੇ ਕਰੋ, ਅਤੇ ਬਾਕੀ ਜਿੰਨਾ ਸੰਭਵ ਹੋਵੇ ਉਨ੍ਹें reversible ਰੱਖੋ। ਬਾਅਦ ਵਾਲੇ ਭਾਗ ਤਬਦੀਲੀ ਅਣਿਵਾਰਯ ਹੋਣ 'ਤੇ ਨੁਕਸਾਨ ਘੱਟ ਕਰਨ ਦੇ ਵਿਹਾਰਿਕ ਤਰੀਕੇ ਦੱਸਦੇ ਹਨ।
ਡਾਟਾ ਮਾਡਲ ਸਿਰਫ਼ ਟੇਬਲਾਂ ਦਾ ਸੈੱਟ ਨਹੀਂ ਹੈ। ਇਹ ਉਹ ਠੇਕਾ ਬਣ ਜਾਂਦਾ ਹੈ ਜਿਸ 'ਤੇ ਕਈ ਸਿਸਟਮ ਨਿਰਭਰ ਹੋ ਜਾਂਦੇ ਹਨ—ਅਕਸਰ ਪਹਿਲੀ ਸੰਸਕਰਣ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਹੀ ਜਿੱਥੇ ਉਹ ਫੈਲ ਜਾਂਦਾ ਹੈ।
ਜਦੋਂ ਕੋਈ ਮਾਡਲ “ਮੰਨਿਆ” ਜਾ ਲੈਂਦਾ ਹੈ ਤਾਂ ਇਹ ਅਕਸਰ ਫੈਲਦਾ ਹੈ:
ਹਰ ਇੱਕ dependency ਬਦਲਾਅ ਦੀ ਲਾਗਤ ਨੂੰ ਗੁਣਾ ਕਰਦਾ ਹੈ: ਹੁਣ ਤੁਸੀਂ ਇੱਕ schema ਨਹੀਂ ਬਦਲ ਰਹੇ—ਤੁਸੀਂ ਬਹੁਤ ਸਾਰਿਆਂ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ coordinate ਕਰ ਰਹੇ ਹੋ।
ਇੱਕ ਪ੍ਰਕਾਸ਼ਿਤ ਮੈਟ੍ਰਿਕ (ਜਿਵੇਂ “Active Customer”) ਅਕਸਰ ਕੇਂਦਰੀ ਨਹੀਂ ਰਹਿੰਦਾ। ਕਿਸੇ ਨੇ ਇਸਨੂੰ BI ਟੂਲ ਵਿੱਚ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ, ਦੂਜੇ ਟੀਮ ਨੇ dbt ਵਿੱਚ ਦੁਬਾਰਾ ਬਣਾਇਆ, growth analyst ਨੇ notebook ਵਿੱਚ hardcode ਕੀਤਾ, ਅਤੇ product dashboard ਵਿੱਚ ਥੋੜ੍ਹਾ ਵੱਖਰਾ filter ਲਾ ਕੇ ਦੋਬਾਰਾ ਵਰਤਿਆ।
ਕੁਝ ਮਹੀਨਿਆਂ ਦੇ ਬਾਅਦ, “ਇੱਕ ਮੈਟ੍ਰਿਕ” ਅਸਲ ਵਿੱਚ ਕਈ ਸਮਾਨ ਮੈਟਰਿਕ ਵੱਲ ਵੰਡ ਜਾਂਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਦੇ edge-case ਨਿਯਮ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ। ਮਾਡਲ ਬਦਲਣ ਨਾਲ ਹੁਣ ਵਿਸ਼ਵਾਸ ਟੁੱਟਣ ਦਾ ਖਤਰਾ ਹੁੰਦਾ ਹੈ, ਸਿਰਫ਼ queries ਨਹੀਂ।
ਲਾਕ‑ਇਨ ਅਕਸਰ ਇਨ੍ਹਾਂ ਵਿੱਚ ਛੁਪਦਾ ਹੈ:
*_id, created_at)ਮਾਡਲ ਦੀ shape ਰੋਜ਼ਾਨਾ ਓਪਰੇਸ਼ਨ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ: wide tables scan ਖਰਚ ਵਧਾਉਂਦੇ ਹਨ, high-grain event ਮਾਡਲ ਲੇਟੇੰਸੀ ਵਧਾ ਸਕਦੇ ਹਨ, ਅਤੇ unclear lineage incidents ਨੂੰ triage ਕਰਨਾ ਔਖਾ ਬਣਾ ਦਿੰਦੀ ਹੈ। ਜਦੋਂ metrics drift ਜਾਂ pipelines fail ਹੁੰਦੇ ਹਨ, ਤੁਹਾਡੀ on-call response ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਮਾਡਲ ਕਿੰਨਾ ਸਮਝਣਯੋਗ—ਅਤੇ ਟੈਸਟ ਕਰਨ ਯੋਗ—ਹੈ।
“Grain” ਇਸ ਗੱਲ ਦੀ ਪੱਧਰ ਹੈ ਕਿ ਇੱਕ ਟੇਬਲ ਇੱਕ ਰੋ ਨੂੰ ਕਿਹੜੀ ਚੀਜ਼ ਦੀ ਨੁਮਾਇندگی ਦਿੰਦਾ ਹੈ—ਅਪਣਾ row ਕਿਸ ਲਈ ਹੈ। ਇਹ ਛੋਟੀ ਗੱਲ ਲੱਗਦੀ ਹੈ, ਪਰ ਅਕਸਰ ਇਹ ਪਹਿਲਾ ਫੈਸਲਾ ਹੁੰਦਾ ਹੈ ਜੋ ਚੁਪਚਾਪ ਤੁਹਾਡੀ ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਫਿਕਸ ਕਰ ਦਿੰਦਾ ਹੈ।
order_id). ਆਰਡਰ ਟੋਟਲ, ਸਥਿਤੀ ਅਤੇ ਉੱਚ-ਸਤਰ ਦੀ ਰਿਪੋਰਟਿੰਗ ਲਈ ਵਧੀਆ।order_id + product_id + line_number). ਪ੍ਰੋਡਕਟ ਮਿਕਸ, ਪ੍ਰਤੀ ਆਈਟਮ ਛੂਟ, SKU ਦੁਆਰਾ ਵਾਪਸੀ ਲਈ ਜ਼ਰੂਰੀ।session_id). ਫਨਲ ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ attribution ਲਈ ਉਪਯੋਗੀ।ਮੁੱਦਾ ਓਦੋਂ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਐਸਾ grain ਚੁਣ ਲੈਂਦੇ ਹੋ ਜੋ ਬਾਕੀ ਕਾਰੋਬਾਰਿਕ ਸਵਾਲਾਂ ਦਾ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦਾ।
ਜੇ ਤੁਸੀਂ ਸਿਰਫ਼ orders ਸਟੋਰ ਕਰਦੇ ਹੋ ਪਰ ਬਾਅਦ ਵਿੱਚ “revenue ਅਨੁਸਾਰ top products” ਦੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਤੁਸੀਂ ਮਜ਼ਬੂਰ ਹੋ ਕੇ:
order_items ਟੇਬਲ ਬਣਾਉ ਜੀ ਤੇ backfill ਕਰੋ (migration ਦਰਦ), ਜਾਂorders_by_product, orders_with_items_flat) ਜੋ ਸਮੇਂ ਨਾਲ drift ਕਰ ਜਾਂਦੀਆਂ ਹਨ।ਇਸੇ ਤਰ੍ਹਾਂ, ਜੇ ਤੁਸੀਂ ਮੁੱਖ fact grain ਵਜੋਂ sessions ਚੁਣਦੇ ਹੋ ਤਾਂ “net revenue by day” awkward ਬਣ ਸਕਦਾ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ purchases ਨੂੰ sessions ਨal ਸ ਠੀਕ ਜੋੜ ਨਹੀਂ ਲੈਂਦੇ। brittle joins, double-counting ਦੇ ਖਤਰੇ, ਅਤੇ “special” metric ਪਰਿਭਾ ਸ਼ਨ ਹੋ ਸਕਦੇ ਹਨ।
Grain relationship ਨਾਲ ਘਿੜਿਆ ਹੁੰਦਾ ਹੈ:
ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ stakeholders ਤੋਂ ਅਜਿਹੇ ਸਵਾਲ ਪੁੱਛੋ ਜੋ ਉਹ ਜਵਾਬ ਦੇ ਸਕਣ:
Keys ਇਹ ਤੈਅ ਕਰਦੇ ਹਨ ਕਿ “ਇਹ ਰੋ ਉਹੀ ਹਕੀਕਤੀ ਚੀਜ਼ ਹੈ ਜੋ ਉਸ ਰੋ ਨਾਲ ਮਿਲਦੀ ਹੈ।” ਇਹ ਗਲਤ ਹੋਵੇ ਤਾਂ joins ਗੱਦਮੱਥੇ ਹੋ ਜਾਂਦੇ ਹਨ, incremental loads ਸੁਸਤੀ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਅਤੇ ਨਵੀਆਂ ਸਿਸਟਮਾਂ ਨੂੰ ਜੋੜਨਾ ਇਕ مذاکراتੀ ਪ੍ਰਕਿਰਿਆ ਬਣ ਜਾਂਦੀ ਹੈ।
Natural key ਇੱਕ ਐਸਾ ID ਹੈ ਜੋ ਕਾਰੋਬਾਰ ਜਾਂ ਸਰੋਤ ਸਿਸਟਮ ਵਿੱਚ ਪਹਿਲਾਂ ਤੋਂ ਮੌਜੂਦ ਹੁੰਦਾ ਹੈ—ਜਿਵੇਂ invoice number, SKU, email, ਜਾਂ CRM customer_id। Surrogate key ਇੱਕ ਅੰਦਰੂਨੀ ID ਹੈ ਜੋ ਤੁਸੀਂ ਬਣਾਉਂਦੇ ਹੋ (ਅਕਸਰ integer ਜਾਂ generated hash) ਅਤੇ ਵੇਅਰਹਾਊਸ ਤੋਂ ਬਾਹਰ ਕੋਈ ਮਤਲਬ ਨਹੀਂ ਰੱਖਦੀ।
Natural keys ਆਕਰਸ਼ਕ ਹਨ ਕਿਉਂਕਿ ਉਹ ਪਹਿਲਾਂ ਹੀ ਹਨ ਅਤੇ ਸਮਝਣ ਵਿੱਚ ਆਉਂਦੇ ਹਨ। Surrogate keys ਆਕਰਸ਼ਕ ਹਨ ਕਿਉਂਕਿ ਉਹ ਸਥਿਰ ਹੋ ਸਕਦੇ ਹਨ—ਜੇ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ manage ਕਰੋ।
ਲਾਕ‑ਇਨ ਉਸ ਸਮੇਂ ਮਿਲਦਾ ਹੈ ਜਦੋ ਸਰੋਤ ਸਿਸਟਮ ਬਦਲਦਾ ਹੈ:
customer_id namespace ਲਿਆ ਸਕਦੀ ਹੈ।ਜੇ ਤੁਹਾਡਾ ਵੇਅਰਹਾਊਸ ਸਰੋਤ natural keys ਹਰ ਥਾਂ ਵਰਤਦਾ ਹੈ, ਤਾਂ ਇਹ ਬਦਲਾਵ facts, dimensions ਅਤੇ ਡਾਊਨਸਟਰੀਮ dashboards 'ਤੇ ਲਹਿਰਾਂ ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ। ਤੁਰੰਤ, historical metrics shift ਹੋ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ “customer 123” ਪਹਿਲਾਂ ਇੱਕ ਵਿਅਕਤੀ ਨੂੰ ਦਰਸਾਉਂਦਾ ਸੀ ਅਤੇ ਹੁਣ ਦੂਜਾ।
Surrogate keys ਨਾਲ, ਤੁਸੀਂ ਨਵੇਂ ਸਰੋਤ IDs ਨੂੰ ਮੌਜੂਦਾ surrogate identity ਨਾਲ ਮੈਪ ਕਰਕੇ ਸਥਿਰ ਵੇਅਰਹਾਊਸ ਪਛਾਣ ਰੱਖ ਸਕਦੇ ਹੋ।
ਅਸਲ ਡੇਟਾ ਨੂੰ merge ਨੀਤੀਆਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: “ਉਹੀ email + ਉਹੀ phone = ਉਹੀ customer,” ਜਾਂ “ਸਭ ਤੋਂ ਨਵਾਂ record ਪ੍ਰਾਥਮਿਕਤਾ ਹੈ,” ਜਾਂ “ਤਕਦੀਰ ਤੱਕ ਦੋਹਾਂ ਰੱਖੋ।” ਉਹ dedup policy ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ:
ਆਮ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਇੱਕ ਟੁੱਟਾ mapping table ਰੱਖੋ (ਕਈ ਵਾਰੀ identity map ਕਿਹਾ ਜਾਂਦਾ ਹੈ) ਜੋ ਦਰਸਾਉਂਦਾ ਹੈ ਕਿ ਕਿਵੇਂ ਕਈ ਸਰੋਤ keys ਇੱਕ ਵੇਅਰਹਾਊਸ identity ਵਿੱਚ roll up ਹੁੰਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਡਾਟਾ ਭਾਈਚਾਰੇ ਨਾਲ ਸਾਂਝਾ ਕਰਦੇ ਹੋ ਜਾਂ ਨਵੀਂ ਖਰੀਦੀ ਕੰਪਨੀ ਨੂੰ ਜੋੜਦੇ ਹੋ, ਤਾਂ key strategy mehnat ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ। ਸਰੋਤ natural keys ਅਕਸਰ ਅਚੰਗੇ ਸਿਸਟਮਾਂ ਵਿੱਚ travel ਨਹੀਂ ਕਰਦੀਆਂ। Surrogate keys ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ travel ਕਰ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਜੇ ਹੋਰਾਂ ਨੂੰ join ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇ ਤਾਂ ਇੱਕ consistent crosswalk ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਨ ਦੀ ਲੋੜ ਬਣਦੀ ਹੈ।
ਕਿਸੇ ਰੂਪ ਵਿੱਚ, keys ਇੱਕ ਕਮਿਟਮੈਂਟ ਹਨ: ਤੁਸੀਂ ਸਿਰਫ਼ ਕਾਲਮ ਨਹੀਂ ਚੁਣ ਰਹੇ—ਤੁਸੀਂ ਨਿਰਣਾ ਕਰ ਰਹੇ ਹੋ ਕਿ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰੀ ਇ@Entityies ਬਦਲ ਚਾਲੂ ਹੋਣ 'ਤੇ ਕਿਵੇਂ ਰਹਿਣਗੇ।
ਸਮਾਂ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ “ਸਰਲ” ਮਾਡਲ ਮਹਿੰਗੇ ਬਣ ਜਾਂਦੇ ਹਨ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇੱਕ current-state ਟੇਬਲ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ (ਹਰ customer/order/ticket ਲਈ ਇੱਕ ਰੋ)। ਇਹ ਛਣੀ-ਛੜੀ ਸੋਧ ਲਾਇਕ ਹੈ, ਪਰ ਇਹ ਅਹੰਕਾਰਕ ਤੌਰ 'ਤੇ ਉਹ ਸਵਾਲ ਹਟਾ ਦਿੰਦੀ ਹੈ ਜੋ ਬਾਅਦ ਵਿੱਚ ਲੋੜ ਪਏ।
ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਡੇ ਕੋਲ ਤਿੰਨ ਵਿਕਲਪ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਹਰ ਇੱਕ ਵੱਖਰੀ tooling ਅਤੇ ਲਾਗਤਾਂ ਨੂੰ ਲਾਕ ਕਰਦਾ ਹੈ:
effective_start, effective_end, ਅਤੇ is_current flag ਨਾਲ।ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਵੀ ਸਮੇਂ “ਉਸ ਵੇਲੇ ਸਾਨੂੰ ਕੀ ਪਤਾ ਸੀ?” ਦੇ ਸਵਾਲ ਦੀ ਸੰਭਾਵਨਾ ਹੋਵੇ—ਤਾਂ overwrite ਤੋਂ ਵੱਧ ਚੁਣੋ।
ਟੀਮਾਂ ਅਕਸਰ ਇਸ ਗੱਲ ਨੂੰ ਪਛਾਣਦੀਆਂ ਹਨ:
ਇਹ ਬਾਅਦ ਵਿੱਚ reconstruct ਕਰਨਾ ਦਰਦਨਾਕ ਹੈ ਕਿਉਂਕਿ upstream ਸਿਸਟਮ ਪਹਿਲਾਂ ਹੀ ਸੱਚਾਈ overwrite ਕਰ ਚੁੱਕੇ ਹੋ ਸਕਦੇ ਹਨ।
ਟਾਈਮ ਮਾਡਲਿੰਗ ਸਿਰਫ਼ ਇੱਕ timestamp ਕਾਲਮ ਨਹੀਂ ਹੈ।
ਇਤਿਹਾਸ ਸਟੋਰੇਜ ਅਤੇ compute ਵਧਾਉਂਦਾ ਹੈ, ਪਰ ਬਾਅਦ ਵਿੱਚ complexity ਘਟਾ ਸਕਦਾ ਹੈ। Append-only logs ingestion ਨੂੰ ਸਸਤਾ ਅਤੇ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੇ ਹਨ, ਜਦ ਕਿ SCD tables ਆਮ “as of” queries ਨੂੰ ਸਪੱਸ਼ਟ ਬਣਾਉਂਦੇ ਹਨ। ਉਹ ਪੈਟਰਨ ਚੁਣੋ ਜੋ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰ ਦੇ ਸਵਾਲਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੋ—ਸਿਰਫ਼ ਅੱਜ ਦੇ ਡੈਸ਼ਬੋਰਡਾਂ ਨਾਲ ਨਹੀਂ।
Normalization ਅਤੇ dimensional modeling ਸਿਰਫ਼ “ਸਟਾਈਲ” ਨਹੀਂ ਹਨ। ਉਹ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ ਕਿ ਤੁਹਾਡਾ ਸਿਸਟਮ ਕਿਸ ਲਈ ਮਿੱਤਰ ਹੈ—pipeline maintainers ਲਈ ਜਾਂ ਉਹਨਾਂ ਲਈ ਜੋ ਹਰ ਰੋਜ਼ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦੈ ਹਨ।
Normalized ਮਾਡਲ (ਅਕਸਰ 3rd normal form) ਡੇਟਾ ਨੂੰ ਛੋਟੇ, ਸੰਬੰਧਿਤ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡਦਾ ਹੈ ਤਾਂ ਕਿ ਹਰ fact ਇੱਕ ਵਾਰੀ ਹੀ ਰੱਖਿਆ ਜਾਵੇ। ਲਕਸ਼ ਹੈ duplication ਅਤੇ ਇਸ ਨਾਲ ਜੁੜੀਆਂ ਸਮੱਸਿਆਵਾਂ ਤੋਂ ਬਚਣਾ:
ਇਹ ਰਚਨਾ data integrity ਅਤੇ ਅਪਡੇਟਸ ਵਾਲੀਆਂ ਸਥਿਤੀਆਂ ਲਈ ਵਧੀਆ ਹੈ। ਇਹ engineering-heavy ਟੀਮਾਂ ਲਈ ਢੁਕਵਾਂ ਹੁੰਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ ownership boundaries ਅਤੇ predictable data quality ਚਾਹੀਦੀ ਹੈ।
Dimensional modeling ਡੇਟਾ ਨੂੰ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਦੁਬਾਰਾ ਰੂਪ ਦਿੰਦਾ ਹੈ। ਆਮਤੌਰ 'ਤੇ star schema ਵਿੱਚ:
ਇਹ ਲੇਆਊਟ ਤੇਜ਼ ਅਤੇ ਸੌਖਾ ਹੈ: analysts dimensions ਨਾਲ filter ਅਤੇ group ਕਰ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਜਟਿਲ joins ਦੇ, ਅਤੇ BI ਟੂਲ ਆਮ ਤੌਰ 'ਤੇ ਇਸਨੂੰ ਅਚਾਨਕ ਸਮਝਦੇ ਹਨ। Product ਟੀਮਾਂ ਨੂੰ ਵੀ ਲਾਹਾ ਮਿਲਦਾ ਹੈ—self-serve exploration ਜ਼ਿਆਦਾ ਹਕੀਕਤੀ ਬਣ ਜਾਂਦੀ ਹੈ ਜਦੋਂ ਆਮ ਮੈਟਰਿਕ ਸੌਖੇ ਤੌਰ 'ਤੇ ਕਵੇਰੀ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
Normalized models optimize ਲਈ:
Dimensional models optimize ਲਈ:
ਲਾਕ‑ਇਨ ਅਸਲੀ ਹੁੰਦੀ ਹੈ: ਜਦੋਂ ਦਰਜਨੋਂ dashboards ਇੱਕ star schema 'ਤੇ ਨਿਰਭਰ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਤਾਂ grain ਜਾਂ dimensions ਬਦਲਣਾ ਰਾਜਨੀਤਿਕ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ ਮਹਿੰਗਾ ਹੋ ਜਾਂਦਾ ਹੈ।
ਇੱਕ ਆਮ drama-ਕਮ ਕਰਨ ਵਾਲਾ ਤਰੀਕਾ ਦੋਹਾਂ ਲੇਅਰਾਂ ਨੂੰ ਰੱਖਣਾ ਹੈ ਜਿਸ ਵਿੱਚ ਸਪੱਸ਼ਟ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਹੋਣ:
ਇਹ ਹਾਈਬ੍ਰਿਡ ਤੁਹਾਡੀ “system of record” ਨੂੰ ਲਚਕੀਲਾ ਰੱਖਦਾ ਹੈ ਜਦ ਕਿ ਕਾਰੋਬਾਰ ਨੂੰ ਉਹ speed ਅਤੇ usability ਮਿਲਦੀ ਹੈ ਜੋ ਉਮੀਦ ਹੁੰਦੀ—ਬਿਨ੍ਹਾਂ ਇਕ ਮਾਡਲ ਨੂੰ ਹਰ ਕੰਮ ਕਰਨ ਲਈ ਮਜ਼ਬੂਰ ਕੀਤੇ।
Event-centric ਮਾਡਲ ਦੱਸਦੇ ਹਨ ਕਿ ਕੀ ਹੋਇਆ: ਇੱਕ click, payment attempt, shipment update, support ticket reply। Entity-centric ਮਾਡਲ ਦੱਸਦੇ ਹਨ ਕਿ ਚੀਜ਼ ਕੀ ਹੈ: customer, account, product, contract।
Entity-centric (customers, products, subscriptions with “current state” columns) operational reporting ਅਤੇ ਸਧਾਰਨ ਪ੍ਰਸ਼ਨਾਂ ਲਈ ਵਧੀਆ ਹੈ—“ਅਸੀਂ ਕਿੰਨੇ active accounts ਦੇਖਦੇ ਹਾਂ?” ਜਾਂ “ਹਰ customer ਦੀ ਮੌਜੂਦਾ ਯੋਜਨਾ ਕੀ ਹੈ?”। ਇਹ ਸੌਖਾ ਹੈ: ਇੱਕ ਚੀਜ਼ ਲਈ ਇੱਕ ਰੋ।
Event-centric (append-only facts) ਸਮੇਂ-ਅਧਾਰਿਤ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ optimize ਕਰਦਾ ਹੈ: “ਕੀ ਬਦਲਿਆ?” ਅਤੇ “ਕਿਵੇਂ ਕ੍ਰਮ ਵਿੱਕੀ?” ਇਹ ਸਰੋਤ ਸਿਸਟਮਾਂ ਦੇ ਨੇੜੇ ਹੁੰਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਨਵੇਂ ਸਵਾਲਾਂ ਨੂੰ ਬਿਨਾਂ ਮੁੜ-ਮਾਡਲਿੰਗ ਦੇ ਜੋੜਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਵੈਂਟਾਂ ਦੀ ਇੱਕ ਚੰਗੀ ਤਰ੍ਹਾਂ ਵਿਆਖਿਆ ਕੀਤੀ ਸਰੜੀ ਰੱਖਦੇ ਹੋ—ਹਰ ਇਕ timestamp, actor, object, ਅਤੇ context ਨਾਲ—ਤਾਂ ਤੁਸੀਂ ਨਵੇਂ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਤਿਆਰ ਕੀਤੇ ਬਿਨਾਂ ਦੇ ਸਕਦੇ ਹੋ। ਉਦਾਹਰਨ ਲਈ, ਜੇ ਬਾਅਦ ਵਿੱਚ ਤੁਹਾਨੂੰ “first value moment”, “drop-off between steps”, ਜਾਂ “trial start ਤੋਂ ਪਹਿਲਾ ਪਹਿਲੀ payment ਤੱਕ ਦਾ ਸਮਾਂ” ਦੀ ਲੋੜ ਹੋਵੇ, ਉਹ ਮੌਜੂਦਾ events ਤੋਂ ਨਿਕਲ ਸਕਦੇ ਹਨ।
ਹਦਾਂ ਹਨ: ਜੇ event payload ਨੇ ਕਦੇ ਇੱਕ ਮੁੱਖ attribute ਰਿਕਾਰਡ ਨਹੀਂ ਕੀਤਾ (ਉਦਾਹਰਨ ਲਈ, ਕਿਹੜੀ marketing campaign ਲਾਗੂ ਹੋਈ), ਤਾਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਉਸਨੂੰ ਬਣਾਉਂ ਨਹੀਂ ਸਕਦੇ।
Event models ਭਾਰੀ ਹੁੰਦੇ ਹਨ:
ਇਵੈਨਟ-ਪਹਿਲਾ ਆਰਕੀਟੈਕਚਰ ਵੀ ਅਮੂਕ stable entity tables ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ—accounts, contracts, product catalog ਅਤੇ ਹੋਰ reference data। Events ਕਹਾਣੀ ਦੱਸਦੇ ਹਨ; entities ਕਿਰਦਾਰ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ। ਫੈਸਲਾ ਇਹ ਹੈ ਕਿ ਕਿੰਨਾ ਮਤਲਬ ਤੁਸੀਂ “current state” ਵਿੱਚ encode ਕਰੋਗੇ ਬਜਾਏ ਇਸ ਦੇ ਕਿ ਇਤਿਹਾਸ ਤੋਂ ਨਿਕਾਲੋ।
ਇੱਕ semantic layer (ਕਦੇ ਕਦੇ metrics layer) raw tables ਅਤੇ ਉਹਨਾਂ ਅੰਕਾਂ ਦਰਮਿਆਨ “translation sheet” ਹੈ ਜੋ ਲੋਕ ਅਸਲ ਵਿੱਚ ਵਰਤਦੇ ਹਨ। ਹਰ dashboard (ਜਾਂ analyst) ਨੂੰ “Revenue” ਜਾਂ “Active customer” ਵਰਗਾ logic ਵੱਖ-ਵੱਖ implement ਕਰਨ ਦੀ ਬਜਾਏ, semantic layer ਉਹ ਸ਼ਬਦ ਇੱਕ ਵਾਰੀ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ—ਉਨ੍ਹਾਂ dimensions ਨਾਲ ਜੋ ਤੁਸੀਂ slice ਕਰ ਸਕਦੇ ਹੋ (date, region, product) ਅਤੇ ਉਹ filters ਜੋ ਸਦਾ ਲਾਗੂ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।
ਜਦੋਂ ਕੋਈ ਮੈਟ੍ਰਿਕ ਵਿਆਪਕ ਤੌਰ 'ਤੇ ਅਪਨਾਈ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਇਹ ਕਾਰੋਬਾਰ ਲਈ API ਵਰਗੀ ਬਣ ਜਾਂਦੀ ਹੈ। ਸੈਂਕੜੇ reports, alerts, experiments, forecasts, ਅਤੇ bonus plans ਇਸ ਉੱਤੇ ਨਿਰਭਰ ਹੋ ਸਕਦੇ ਹਨ। ਬਦਲਣ ਨਾਲ ਭਰੋਸਾ ਟੁੱਟ ਸਕਦਾ ਹੈ ਭਾਵੇਂ SQL ਚਲਦਾ ਰਹੇ।
ਲਾਕ‑ਇਨ ਸਿਰਫ਼ ਤਕਨੀਕੀ ਨਹੀਂ—ਇਹ ਸਮਾਜਕ ਵੀ ਹੈ। ਜੇ “Revenue” ਹਮੇਸ਼ਾਂ refunds ਨੂੰ exclude ਕਰਦਾ ਆ ਰਿਹਾ ਹੈ, ਤਾਂ ਇੱਕ ਅਚਾਨਕ switch net revenue ਤੇ overnight trends ਨੂੰ ਗਲਤ ਦਿਖਾ ਦੇਵੇਗਾ। ਲੋਕ ਪਹਿਲਾਂ ਹੀ ਡਾਟੇ 'ਤੇ ਭਰੋਸਾ ਵੀ ਕਰਨਾ ਬੰਦ ਕਰ ਦੇਣਗੇ ਪਹਿਲਾਂ ਕਿ ਪੁੱਛਣ ਕਿ ਕੀ ਬਦਲਿਆ।
ਛੋਟੀ ਚੋਣਾਂ ਜਲਦੀ ਕਠੋਰ ਹੋ ਜਾਂਦੀਆਂ ਹਨ:
orders ਨਾਮ ਮਤਲਬ ਆਮ ਤੌਰ 'ਤੇ orders ਦੀ ਗਿਣਤੀ ਦਿਖਾਉਂਦਾ ਹੈ, line items ਨਹੀਂ। ਅਸਪਸ਼ਟ ਨਾਂ inconsistent ਵਰਤੋਂ ਨੂੰ ਦਾਵਤ ਦਿੰਦੇ ਹਨ।order_date ਨਾਲ group ਕਰ ਸਕਦੇ ਹੋ ਜਾਂ ship_date ਨਾਲ, narratives ਅਤੇ operational ਫੈਸਲੇ ਬਦਲ ਦਿੰਦਾ ਹੈ।ਮੈਟ੍ਰਿਕ ਬਦਲਾਵਾਂ ਨੂੰ product releases ਵਾਂਗੋ ਟ੍ਰੀਟ ਕਰੋ:
revenue_v1, revenue_v2, ਅਤੇ ਦੋਹਾਂ ਨੂੰ transition ਦੌਰਾਨ ਉਪਲਬਧ ਰੱਖੋ।ਜੇ ਤੁਸੀਂ semantic layer ਇरਾਦੇ ਨਾਲ ڈਿਜ਼ਾਈਨ ਕਰੋਗੇ ਤਾਂ ਤੁਸੀਂ meaning ਨੂੰ ਬਦਲਣ ਯੋਗ ਬਣਾਉਂਦੇ ਹੋ ਬਿਨਾਂ ਸਭ ਨੂੰ ਹੈਰਾਨ ਕੀਤੇ।
ਸਕੀਮਾ ਬਦਲਾਅ ਸਾਰੇ ਇਕੋ ਜਿਹਾ ਨਹੀਂ ਹੁੰਦੇ। ਨਵਾਂ nullable column ਜੋੜਨਾ ਆਮ ਤੌਰ 'ਤੇ ਘੱਟ ਜੋਖ਼ਿਮ ਹੈ: ਮੌਜੂਦਾ queries ਇਸਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਦੇ ਰਹਿੰਦੇ ਹਨ, downstream jobs ਚਲਦੇ ਰਹਿੰਦੇ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ backfill ਕਰ ਸਕਦੇ ਹੋ।
ਇੱਕ ਮੌਜੂਦਾ column ਦੇ ਅਰਥ ਨੂੰ ਬਦਲਣਾ ਸਭ ਤੋਂ ਮਹਿੰਗਾ ਹੈ। ਜੇ status ਪਹਿਲਾਂ “payment status” ਦਾ ਮਤਲਬ ਹੁੰਦਾ ਸੀ ਅਤੇ ਹੁਣ “order status” ਬਣ ਗਿਆ, ਤਾਂ ਹਰ dashboard, alert, ਅਤੇ join ਜੋ ਇਸ 'ਤੇ ਨਿਰਭਰ ਸੀ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਗਲਤ ਹੋ ਜਾਵੇਗਾ—ਭਾਵੇਂ ਕੁਝ ਮਕੈਨਿਕਲ ਠੀਕ ਰਹਿਣ। ਮਤਲਬ ਬਦਲਣ ਹੋਰ ਨੂੰ ਖੁਫੀਆ bugs ਬਣਾਉਂਦਾ ਹੈ, ਉੱਚਾ failure ਨਹੀਂ।
ਜੋ ਟੇਬਲ ਕਈ ਟੀਮਾਂ ਦੁਆਰਾ ਖਪਤ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਉਹਨਾਂ ਲਈ ਇੱਕ ਸਪੱਸ਼ਟ contract ਅਤੇ tests ਬਨਾਓ:
pending|paid|failed) ਅਤੇ ਸੰਖਿਆਤਮਕ ਮੈਦਾਨਾਂ ਲਈ ranges।ਇਹ ਮੂਲ ਤੌਰ 'ਤੇ ਡੇਟਾ ਲਈ contract testing ਹੈ। ਇਹ випадਾਕੀ drift ਰੋਕਦਾ ਹੈ ਅਤੇ “breaking change” ਨੂੰ ਇੱਕ ਸਪੱਸ਼ਟ ਵਰਗ ਬਣਾਉਂਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ Debates ਦਾ ਵਿਸ਼ਾ।
ਜਦੋਂ ਤੁਸੀਂ ਮਾਡਲ evolve ਕਰ ਰਹੇ ਹੋ, ਉਮੀਦ ਕਰੋ ਕਿ ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ consumers ਇਕ ਤੇ ਹੀ ਲੰਮ੍ਹੇ ਸਮੇਂ ਲਈ co-exist ਕਰ ਸਕਣ:
Shared tables ਲਈ ਸਪੱਸ਼ਟ ownership ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ: ਕੌਣ changes approve ਕਰੇਗਾ, ਕੌਣ notify ਹੋਵੇਗਾ, ਅਤੇ rollout ਪ੍ਰਕਿਰਿਆ ਕੀ ਹੈ। ਇੱਕ ਥੋੜ੍ਹਾ ਜਿਹਾ change policy (owner + reviewers + deprecation timeline) breakage ਤੋਂ ਰੋਕਣ ਵਿੱਚ ਕਿਸੇ ਵੀ ਟੂਲ ਤੋਂ ਜ਼ਿਆਦਾ ਪ੍ਰਭਾਵੀ ਹੈ।
ਡਾਟਾ ਮਾਡਲ ਸਿਰਫ਼ ਤਰਕੀਬੀ ਡਾਇਗ੍ਰਾਮ ਨਹੀਂ—ਇਹ ਭੌਤਿਕ ਨਿਯਮਾਂ ਦੇ ਪੈਸੇ ਹੁੰਦੇ ਹਨ ਕਿ queries ਕਿਵੇਂ ਚਲਣਗੀਆਂ, ਕਿੰਨੀ ਖ਼ਰਚ ਹੋਵੇਗੀ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਕੀ ਦਿਖੇਗਾ।
Partitioning (ਅਕਸਰ date ਦੇ ਆਧਾਰ ਤੇ) ਅਤੇ clustering (ਆਮ ਤੌਰ 'ਤੇ filtered keys ਜਿਵੇਂ customer_id ਜਾਂ event_type ਦੇ ਅਧਾਰ ਤੇ) ਕੁਝ query patterns ਨੂੰ reward ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਦੂਜੇ punish।
ਜੇ ਤੁਸੀਂ partition by event_date ਕਰਦੇ ਹੋ, ਤਾਂ “last 30 days” filters ਸਸਤੇ ਅਤੇ ਤੇਜ਼ ਰਹਿਣਗੇ। ਪਰ ਜੇ ਕਈ ਯੂਜ਼ਰ ਲੰਬੇ ਸਮੇਂ-ਦਾਇਰੇ ਵਿੱਚ account_id ਨਾਲ slice ਕਰਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਕਈ partitions scan ਕਰ ਦਿਓਗੇ—ਖ਼ਰਚ ਫੁੱਟੇਗਾ, ਅਤੇ ਟੀਮਾਂ summary tables ਜਾਂ extracts ਵਰਗੀਆਂ workarounds ਬਣਾਉਣ ਲੱਗਦੀਆਂ ਹਨ ਜੋ ਹੋਰ model entrench ਕਰਦੀਆਂ ਹਨ।
Wide tables (denormalized) BI ਟੂਲਾਂ ਲਈ ਦੋਸਤਾਨਾ ਹੁੰਦੇ ਹਨ: ਘੱਟ joins, ਘੱਟ ਹੈਰਾਨੀ, ਤੇਜ਼ “time to first chart।” ਉਹ queries ਨੂੰ ਸਸਤਾ ਵੀ ਰੱਖ ਸਕਦੇ ਹਨ ਜਦੋਂ repeated joins ਨੂੰ ਬਚਾਇਆ ਜਾਵੇ।
ਟਰੇਡ‑ਆਫ਼: wide tables ਡੇਟਾ duplicate ਕਰਦੇ ਹਨ। ਇਹ storage ਵਧਾਉਂਦਾ, updates ਨੂੰ ਸੰਕੁਚਿਤ ਕਰਦਾ, ਅਤੇ consistent definitions enforce ਕਰਨਾ ਔਖਾ ਕਰਦਾ ਹੈ।
ਬਹੁਤ normalized models duplication ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ data integrity ਨੂੰ ਸੁਧਾਰਦੇ ਹਨ, ਪਰ repeated joins queries ਨੂੰ ਸੁਸਤ ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ non-technical users ਲਈ ਖਰਾਬ UX ਬਣ ਸਕਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਉਹ ਆਪਣੀ ਰਿਪੋਰਟਾਂ ਬਣਾਉਂਦੇ ਹਨ।
ਜ਼ਿਆਦਾਤਰ pipelines incremental ਲੋਡ ਕਰਦੇ ਹਨ (ਨਵੇਂ rows ਜਾਂ बदਲੇ ਹੋਏ rows)। ਇਹ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ stable keys ਅਤੇ append-friendly structure ਹੋਵੇ। ਉਹ ਮਾਡਲ ਜਿਹਨਾਂ ਨੂੰ ਅਕਸਰ “ਪਿਛਲੇ ਸਮੇਂ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖੋ” ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ (ਉਦਾਹਰਨ ਲਈ, bahut derived columns rebuild) ਮਹਿੰਗੇ ਅਤੇ ਅਪਰੇਸ਼ਨਲ ਤੌਰ ਤੇ ਜੋਖ਼ਿਮ ਭਰੇ ਹੋ ਜਾਂਦੇ ਹਨ।
ਤੁਹਾਡਾ ਮਾਡਲ ਇਹ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕੀ validate ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਕੀ fix ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਮੈਟਰਿਕs complex joins 'ਤੇ ਨਿਰਭਰ ਹਨ, ਤਾਂ quality checks ਨੂੰ localize ਕਰਨਾ ਔਖਾ ਹੋ ਜਾਂਦਾ ਹੈ। ਜੇ tables ਉਹ ਤਰੀਕੇ ਨਾਲ partition ਨਹੀਂ ਕੀਤੀਆਂ ਜੋ ਤੁਸੀਂ backfill (by day, by source batch) ਲਈ ਵਰਤਦੇ ਹੋ, ਤਾਂ reprocessing ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ ਕਦੇ ਕਈ ਵਧੇ ਡੇਟਾ ਨੂੰ scan ਅਤੇ rewrite ਕਰਨਾ—ਜੋ routine corrections ਨੂੰ ਵੱਡੇ incidents ਬਣਾਉਂਦਾ ਹੈ।
ਡਾਟਾ ਮਾਡਲ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਬਦਲਣਾ ਸਧਾਰਨ “refactor” ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਉਸ ਸ਼ਹਿਰ ਨੂੰ ਘੁਮਾਉਣ ਵਾਂਗ ਹੈ ਜਿੱਥੇ ਲੋਕ ਅਜੇ ਵੀ ਰਹਿ ਰਹੇ ਹਨ: reports ਚਲਦੇ ਰਹਿਣੇ, definitions ਸਥਿਰ ਰਹਿਣੇ, ਅਤੇ ਪੁਰਾਣੀਆਂ ਸੋਚਾਂ dashboards, pipelines, ਅਤੇ ਇਨਸੈਂਟਿਵ ਵਿੱਚ ਦਰਜ ਹੋ ਚੁੱਕੀਆਂ ਹੁੰਦੀਆਂ ਹਨ।
ਕੁਝ ਤਰੱਕੀ بار-ਬਾਰ ਉਭਰ ਕੇ ਆਉਂਦੀ ਹੈ:
ਘੱਟ-ਜੋਖ਼ਮ ਵਾਲਾ ਤਰੀਕਾ ਮਾਈਗ੍ਰੇਸ਼ਨ ਨੂੰ engineering ਅਤੇ change-management ਦੋਹਾਂ ਪ੍ਰੋਜੈਕਟ ਵਾਂਗ ਟ੍ਰੀਟ ਕਰਨਾ ਹੈ।
ਲਾਕ‑ਇਨ ਉਸ ਸਮੱਸਿਆ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ ਜਦੋਂ ਟੇਬਲਾਂ ਨੂੰ ਬਦਲਣਾ ਬਹੁਤ ਜੋਖ਼ਿਮਭਰਿਆ ਜਾਂ ਮਹਿੰਗਾ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਬਹੁਤ ਸਾਰੇ ਡਾਊਨਸਟਰੀਮ ਉਪਭੋਗਤਾ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ।
ਭਾਵੇਂ ਤੁਸੀਂ ਵੇਅਰਹਾਊਸ ਜਾਂ ETL ਟੂਲ ਬadalੋ, ਜੇਕਰ ਤੁਸੀਂ ਜੋ ਮਤਲਬ encode ਕਰਦੇ ਹੋ—ਜਿਵੇਂ grain, keys, history ਅਤੇ metric definitions—ਉਹ ਰਹਿ ਜਾਂਦੇ ਹਨ ਅਤੇ dashboards, ML ਫੀਚਰ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਸਾਂਝੀ ਕਾਰੋਬਾਰੀ ਭਾਸ਼ਾ ਵਿੱਚ ਇੱਕ ਠੋਸ ਠਹਿਰਾਅ ਬਣ ਜਾਂਦਾ ਹੈ।
ਹਰ ਵਿਆਪਕ ਟੇਬਲ ਨੂੰ ਇੱਕ ਦਾ ਇੰਟਰਫੇਸ ਸਮਝੋ:
ਉਦੇਸ਼ “ਕਦੇ ਵੀ ਨਾ ਬਦਲਣਾ” ਨਹੀਂ, ਸਗੋਂ “ਬਿਨਾਂ ਹੈਰਾਨੀ ਦੇ ਬਦਲਣਾ” ਹੈ।
ਉਹ grain ਚੁਣੋ ਜੋ ਭਵਿੱਖ ਵਿੱਚ ਪੱਛੇ ਲੈ ਕੇ ਆਉਣ ਵਾਲੇ ਸਵਾਲਾਂ ਨੂੰ ਬਿਨਾਂ ਗੁੰਝਲ ਦਿਤੇ ਜਵਾੱਬ ਦੇ ਸਕੇ।
ਇੱਕ ਕਾਰਗਰ ਚੈੱਕ:
ਜੇ ਤੁਸੀਂ ਇੱਕ one-to-many ਰਿਸ਼ਤੇ ਦੀ “one” ਪਾਸੇ ਹੀ ਮਾਡਲ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਬਾਅਦ ਵਿੱਚ backfills ਜਾਂ ਨਕਲ ਕੀਤੀਆਂ derived tables ਦੇ ਰਾਹ ਵਿੱਚ ਖਰਚ ਆਵੇਗਾ।
Natural keys (ਜਿਵੇਂ invoice number, SKU, source customer_id) ਸਮਝਣ ਵਿੱਚ ਆਉਂਦੇ ਹਨ ਪਰ ਬਦਲ ਸਕਦੇ ਜਾਂ systems ਵਿੱਚ ਟਕਰਾਅ ਕਰ ਸਕਦੇ ਹਨ।
Surrogate keys ਅੰਦਰੂਨੀ ਸਥਿਰ ਪਛਾਣ ਦੇ ਸਕਦੇ ਹਨ ਜੇ ਤੁਸੀਂ ਸਰੋਤ ID ਤੋਂ ਵੇਅਰਹਾਊਸ ID ਤੱਕ ਮੈਪਿੰਗ ਰੱਖਦੇ ਹੋ।
ਜੇ CRM মਾਈਗ੍ਰੇਸ਼ਨ, M&A, ਜਾਂ ਬਹੁਤ ਸਾਰੇ ID namespaces ਦੀ ਉਮੀਦ ਹੈ, ਤਾਂ ਯੋਜਨਾ ਬਣਾਓ:
ਜੇ ਤੁਹਾਨੂੰ ਕਿਸੇ ਵੀ ਸਮੇਂ “ਸਾਡੇ ਕੋਲ ਉਸ ਵੇਲੇ ਕੀ ਜਾਣਕਾਰੀ ਸੀ?” ਜਵਾਬ ਲੈਣ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ, ਤਾਂ overwrite-only ਮਾਡਲ ਤੋਂ ਬਚੋ।
ਆਮ ਵਿਕਲਪ:
ਟਾਈਮ ਸਮੱਸਿਆਵਾਂ ਅਕਸਰ ambiguity ਵੱਜੋਂ ਆਉਂਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਕੁਝ ਕਾਲਮ ਦੇ ਨਾ ਹੋਣ ਕਾਰਨ।
ਪ੍ਰਯੋਗੀ defaults:
ਇੱਕ semantic (metrics) layer ਨਕਲ-ਚੋਲੀ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ ਪਰ ਜੇ ਪਰਿਭਾਸ਼ਾ ਵਿਆਪਕ ਹੋ ਜਾਵੇ ਤਾਂ ਉਹ ਇੱਕ API ਵਰਗੀ ਬਣ ਜਾਂਦੀ ਹੈ।
ਕਰਨ ਲਈ:
orders vs order_items)।ਉਹ ਤਰੀਕੇ ਜਿਹੜੇ ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਇਕੱਠੇ ਕੰਮ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ:
ਸਭ ਤੋਂ ਖ਼ਤਰਨਾਕ ਬਦਲਾਅ ਕਿਸੇ ਕਾਲਮ ਦੇ ਮਤਲਬ ਨੂੰ ਉਸੇ ਨਾਮ ਨਾਲ ਬਦਲਣਾ ਹੈ—ਕੋਈ ਹੰਗਾਮਾ ਨਹੀਂ, ਪਰ ਸਭ ਕੁਝ ਸੁਤੰਤਰ ਰੂਪ ਵਿੱਚ ਗਲਤ ਹੋ ਜਾਂਦਾ ਹੈ।
ਜਿਸ ਪੰਜਾਬੀ ਤਰੀਕੇ ਨਾਲ ਤੁਸੀਂ partitioning/ clustering ਕਰਨਦੇ ਹੋ, ਉਹ ਕੁਝ ਕੁ filter ਪੈਟਰਨਾਂ ਨੂੰ ਫਾਈਦਾ ਦੇਂਦੇ ਅਤੇ ਦੂਜੇ ਨੂੰ ਸਜ਼ਾ ਦੇਂਦੇ ਹਨ।
ਆਪਣੇ ਪ੍ਰਮੁੱਖ access patterns (ਅਖੀਰਲੇ 30 ਦਿਨ, account_id ਆਦਿ) ਦੇ ਅਨੁਸਾਰ ਆਕਾਰ ਅਤੇ partitioning ਚੁਣੋ, ਅਤੇ ਆਪਣੇ backfill/ reprocessing ਤਰੀਕੇ ਨਾਲ align ਕਰੋ ਤਾਂ ਕਿ ਮਹਿੰਗੇ rewrites ਤੋਂ ਬਚੋ।
“Big bang” swap ਉੱਚ ਜੋਖ਼ਿੰਮ ਵਾਲਾ ਹੈ ਕਿਉਂਕਿ consumers, definitions, ਅਤੇ ਭਰੋਸਾ ਸਥਿਰ ਰਹਿਣੇ ਲਾਜ਼ਮੀ ਹਨ।
ਸੁਰੱਖਿਅਤ ਤਰੀਕਾ:
ਦੋਹਾਂ ਚੱਲਣ ਵਾਲੀ compute ਅਤੇ stakeholder sign-off ਲਈ ਬਜਟ ਜ਼ਰੂਰੀ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ trade-offs ਅਤੇ ਟਾਈਮਲਾਈਨਾਂ ਰੂਪ ਵਿੱਚ ਫਰੇਮ ਕਰਨ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਦੇਖੋ /pricing।
effective_starteffective_endਆਡੀਟ, ਫਾਇਨੈਨਸ, ਸਪੋਰਟ ਜਾਂ ਕੰਪਲਾਇੰਸ ਵੱਲੋਂ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲਾਂ ਦੇ ਅਧਾਰ 'ਤੇ ਨਿਰਣੈ ਲਵੋ—ਸਿਰਫ ਅੱਜ ਦੇ ਡੈਸ਼ਬੋਰਡਾਂ ਦੀ ਨਹੀਂ।
revenue_v1, revenue_v2) ਅਤੇ ਮਾਈਗ੍ਰੇਸ਼ਨ ਦੌਰਾਨ ਦੋਹਾਂ ਚਲਾਓ।ਇਸ ਨਾਲ lock-in ਵਿਕਰਾਲ SQL ਤੋਂ ਇੱਕ ਪ੍ਰਬੰਧਤ, ਡੌਕਯੂਮੈਂਟ ਕੀਤੀ ਨੀਤੀ ਵੱਲ ਲਿਆਉਂਦੇ ਹੋ।