12 ਸਤੰ 2025·8 ਮਿੰਟ
ਦਿਨ-ਇਕ ਮਾਨੀਟਰਿੰਗ ਲਈ ਪ੍ਰੋਡਕਸ਼ਨ ਨਿਰੀਖਣ ਸਟਾਰਟਰ ਪੈਕ
ਦਿਨ-ਇਕ ਲਈ production ਨਿਗਰਾਨੀ: ਘੱਟੋ-ਘੱਟ ਲੌਗ, ਮੈਟਰਿਕਸ, ਅਤੇ ਟਰੇਸ ਜੋ ਜੋੜਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾਲ ਹੀ “it’s slow” ਰਿਪੋਰਟਾਂ ਲਈ ਸਧਾਰਨ triage ਫਲੋ।
ਦਿਨ-ਇਕ ਲਈ production ਨਿਗਰਾਨੀ: ਘੱਟੋ-ਘੱਟ ਲੌਗ, ਮੈਟਰਿਕਸ, ਅਤੇ ਟਰੇਸ ਜੋ ਜੋੜਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾਲ ਹੀ “it’s slow” ਰਿਪੋਰਟਾਂ ਲਈ ਸਧਾਰਨ triage ਫਲੋ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਟੁੱਟਣ ਵਾਲੀ ਚੀਜ਼ ਬਹੁਤ ਕਦਾਚਿਤ ਪੂਰੀ ਐਪ ਨਹੀਂ ਹੁੰਦੀ। ਆਮ ਤੌਰ ਤੇ ਇਹ ਇੱਕ ਕਦਮ ਹੁੰਦਾ ਹੈ ਜੋ ਅਚਾਨਕ ਬਹੁਤਾਂ ਸਮੇਂ ਲਈ ਵਿਅਸਤ ਹੋ ਜਾਂਦਾ ਹੈ, ਇੱਕ ਕੁਐਰੀ ਜੋ ਟੈਸਟਾਂ ਵਿੱਚ ਠੀਕ ਸੀ, ਜਾਂ ਕੋਈ ਡਿਪੈਂਡੈਂਸੀ ਜੋ timeout ਹੋਣ ਲੱਗਦੀ ਹੈ। ਅਸਲੀ ਉਪਭੋਗਤਿਆਂ ਨਾਲ ਅਸਲੀ ਵਿਵਿਧਤਾ ਆਉਂਦੀ ਹੈ: ਹੌਲੀ ਫੋਨ, ਠੰਭ-ਠੱਲ ਪネットਵਰਕ, ਅਜੀਬ ਇਨਪੁਟ ਅਤੇ ਟ੍ਰੈਫਿਕ ਦੇ ਅਚਾਨਕ spike।
ਜਦ ਕੋਈ ਕਹਿੰਦਾ ਹੈ “it’s slow”, ਉਹ ਕਈ ਵੱਖ-ਵੱਖ ਗੱਲਾਂ ਨੂੰ ਮਤਲਬ ਰੱਖ ਸਕਦਾ ਹੈ। ਪੇਜ ਲੋਡ ਹੋਣ ਵਿੱਚ ਜ਼ਿਆਦਾ ਸਮਾਂ ਲੱਗ ਰਿਹਾ ਹੋ ਸਕਦਾ ਹੈ, interactions lag ਹੋ ਰਹੇ ਹੋ ਸਕਦੇ ਹਨ, ਇੱਕ API ਕਾਲ timeout ਹੋ ਰਹੀ ਹੋ ਸਕਦੀ ਹੈ, background jobs ਪਾਈਲ ਹੋ ਰਹੇ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਕੋਈ third-party ਸਰਵਿਸ ਸਭ ਕੁਝ ਧੀਮਾ ਕਰ ਰਿਹਾ ਹੋ ਸਕਦੀ ਹੈ।
ਇਸ ਲਈ ਤੁਹਾਨੂੰ ਡੈਸ਼ਬੋਰਡ ਤੋਂ ਪਹਿਲਾਂ ਸਿਗਨਲ ਚਾਹੀਦੇ ਹਨ। ਦਿਨ-ਇਕ 'ਤੇ ਤੁਹਾਨੂੰ ਹਰ ਏਂਡਪਾਇੰਟ ਲਈ ਪੂਰੇ ਪਰਫੈਕਟ ਚਾਰਟ ਦੀ ਲੋੜ ਨਹੀਂ। ਤੁਹਾਨੂੰ ਇੰਨੇ ਲੌਗ, ਮੈਟਰਿਕਸ, ਅਤੇ ਟਰੇਸ ਚਾਹੀਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਇੱਕ ਸਵਾਲ ਜਲਦੀ ਜਵਾਬ ਦੇ ਸਕੋ: ਸਮਾਂ ਕਿੱਥੇ ਲੱਗ ਰਿਹਾ ਹੈ?
ਜਿਆਂਦਾ ਇੰਸਟ੍ਰੂਮੈਂਟੇਸ਼ਨ ਦੇ ਵੀ ਖਤਰੇ ਹੁੰਦੇ ਹਨ। ਬਹੁਤ ਸਾਰੇ ਘਟਨਾਵਾਂ ਸ਼ੋਰ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ, ਖਰਚ ਵਧਾਉਂਦੀਆਂ ਹਨ, ਅਤੇ ਐਪ ਨੂੰ ਵੀ ਧੀਮਾ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਸਭ ਤੋਂ ਵੱਧ, ਟੀਮਾਂ ਟੈਲੀਮੇਟਰੀ 'ਤੇ ਭਰੋਸਾ ਕਰਨਾ ਛੱਡ ਦਿੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਗੰਦਗੀ ਅਤੇ ਅਸਥਿਰ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਯਥਾਰਥਿਕ ਦਿਨ-ਇਕ ਲਕਸ਼ ਸਧਾਰਨ ਹੈ: ਜਦ ਤੁਸੀਂ “it’s slow” ਰਿਪੋਰਟ ਪਾਉ, ਤਾਂ 15 ਮਿੰਟ ਤੋਂ ਘੱਟ ਵਿੱਚ ਤੁਹਾਨੂੰ ਸਲੋ ਕਦਮ ਲੱਭਣਾ ਚਾਹੀਦਾ ਹੈ। ਤੁਸੀਂ ਬਤਾਂ ਸਕੋ ਕਿ bottleneck client rendering ਵਿੱਚ ਹੈ, API handler ਅਤੇ ਉਸਦੀ dependencies ਵਿੱਚ ਹੈ, database ਜਾਂ cache ਵਿੱਚ ਹੈ, ਜਾਂ background worker ਜਾਂ external service ਵਿੱਚ ਹੈ।
ਉਦਾਹਰਣ: ਨਵਾਂ checkout flow ਧੀਮਾ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਟੂਲਾਂ ਦੇ ਬਿਨਾਂ ਵੀ, ਤੁਸੀਂ ਇਹ ਕਹਿ ਸਕਣਾ ਚਾਹੁੰਦੇ ਹੋ: “95% ਸਮਾਂ payment provider calls 'ਚ ਲੰਘਦਾ ਹੈ,” ਜਾਂ “cart query ਬਹੁਤ ਜ਼ਿਆਦਾ rows ਸਕੈਨ ਕਰ ਰਿਹਾ ਹੈ।” ਜੇ ਤੁਸੀਂ Koder.ai ਵਰਗੇ ਟੂਲਾਂ ਨਾਲ ਤੇਜ਼ੀ ਨਾਲ ਐਪ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਇਹ ਦਿਨ-ਇਕ ਬੇਸਲਾਈਨ ਹੋਰ ਵੀ ਮਹੱਤਵਪੂਰਨ ਬਣ ਜਾਂਦੀ ਹੈ, ਕਿਉਂਕਿ ਤੇਜ਼ ਡਿਲਿਵਰੀ ਮਦਦ ਕਰਦੀ ਹੈ ਸਿਵਾਏ ਇਸਦੇ ਕਿ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਡੀਬੱਗ ਵੀ ਕਰ ਸਕੋ।
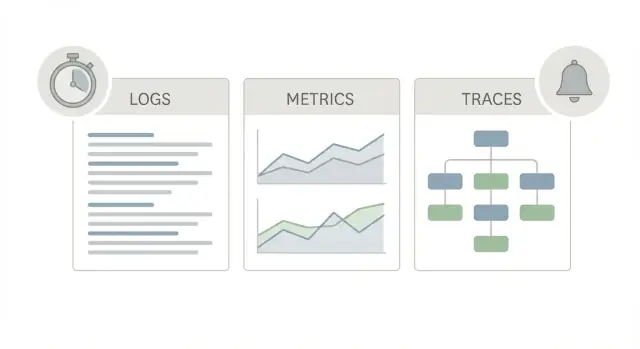
ਇੱਕ ਚੰਗਾ production observability starter pack ਤਿੰਨ ਵੱਖ-ਵੱਖ “ਦ੍ਰਿਸ਼” ਵਰਤਦਾ ਹੈ, ਕਿਉਂਕਿ ਹਰ ਇੱਕ ਵੱਖਰਾ ਸਵਾਲ ਜਵਾਬ ਦਿੰਦਾ ਹੈ।
ਲੌਗਸ ਵੀਹਲਾ ਬਿਆਨ ਦਿੰਦੀਆਂ ਹਨ। ਉਹ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਇੱਕ request, ਇੱਕ user, ਜਾਂ ਇੱਕ background job ਲਈ ਕੀ ਵਾਪਰਾ। ਇੱਕ ਲੌਗ ਲਾਇਨ ਕਹਿ ਸਕਦੀ ਹੈ “payment failed for order 123” ਜਾਂ “DB timeout after 2s,” ਨਾਲੇ request ID, user ID ਅਤੇ error message ਵਰਗੀਆਂ ਜਾਣਕਾਰੀਆਂ। ਜਦ ਕੋਈ ਅਜੀਬ ਇਕਲੋਤਾ issue ਰਿਪੋਰਟ ਕਰਦਾ ਹੈ, ਤਦ ਲੌਗਸ ਅਕਸਰ ਇਸਨੂੰ ਪੁਸ਼ਟੀ ਕਰਨ ਦਾ ਸਭ ਤੋਂ ਤੇਜ਼ ਤਰੀਕਾ ਹੁੰਦੇ ਹਨ।
ਮੈਟਰਿਕਸ ਸਕੋਰਬੋਰਡ ਹਨ। ਉਹ ਨੰਬਰ ਹਨ ਜਿਨ੍ਹਾਂ 'ਤੇ ਤੁਸੀਂ trend ਅਤੇ alert ਕਰ ਸਕਦੇ ਹੋ: request rate, error rate, latency percentiles, CPU, queue depth। ਮੈਟਰਿਕਸ ਦੱਸਦੀਆਂ ਹਨ ਕਿ ਕੋਈ ਚੀਜ਼ ਕਿੰਨੀ ਵਿਸ਼ਾਲ ਹੈ ਅਤੇ ਕੀ ਇਹ ਖਰਾਬ ਹੋ ਰਹੀ ਹੈ। ਜੇ latency 10:05 'ਤੇ ਸਭ ਲਈ ਵੱਧ ਗਿਆ, ਮੈਟਰਿਕਸ ਇਹ ਦਿਖਾਵੇਗੀ।
ਟਰੇਸਿਜ਼ ਨਕਸ਼ਾ ਹਨ। ਇੱਕ trace ਇੱਕ request ਨੂੰ ਹੇਠਾਂ-ਉਪਰ ਤੁਹਾਡੇ ਸਿਸਟਮ ਰਾਹੀਂ follow ਕਰਦਾ ਹੈ (web -> API -> database -> third-party)। ਇਹ ਦਿਖਾਉਂਦਾ ਹੈ ਕਿ ਸਮਾਂ ਕਿੱਥੇ ਲੱਗਿਆ, ਕਦਮ-ਬ-ਕਦਮ। ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ “it’s slow” ਬਹੁਤ ਵਾਰੀ ਇੱਕ ਵੱਡੇ ਰਹੱਸ ਵਾਂਗ ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਅਕਸਰ ਇੱਕ ਸਲੋ ਹੌਪ ਹੁੰਦਾ ਹੈ।
ਇੰਸੀਡੈਂਟ ਦੌਰਾਨ ਇੱਕ ਯੁਕਤ flow ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦਾ ਹੈ:
ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: ਜੇ ਕੁਝ ਮਿੰਟਾਂ 'ਚ ਤੁਸੀਂ ਇੱਕ bottleneck ਨੁਹੀਂ ਪਤਾ ਲਗਾ ਪਾ ਰਹੇ, ਤਾਂ ਤੁਹਾਨੂੰ ਹੋਰ alerts ਦੀ ਲੋੜ ਨਹੀਂ। ਤੁਹਾਨੂੰ ਬਿਹਤਰ traces ਅਤੇ ਓਹ ID ਚਾਹੀਦੇ ਹਨ ਜੋ traces ਨੂ ਲੌਗਸ ਨਾਲ ਜੋੜਦੇ ਹਨ।
ਜ਼ਿਆਦਾਤਰ “ਅਸੀਂ ਇਸਨੂੰ ਲੱਭ ਨਹੀਂ ਪਾ ਰਹੇ” ਵਾਂਗ incidents ਗੁੰਮ ਹੋਏ ਡੇਟਾ ਕਾਰਨ ਨਹੀਂ ਹੁੰਦੇ। ਇਹ ਇਸ ਕਾਰਨ ਹੁੰਦੇ ਹਨ ਕਿ ਇੱਕੋ ਚੀਜ਼ ਸੇਵਾਵਾਂ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਦਰਜ ਹੁੰਦੀ ਹੈ। ਦਿਨ-ਇਕ 'ਤੇ ਕੁਝ ਸਾਂਝੇ ਰਵਾਇਆਂ ਲੌਗਸ, ਮੈਟਰਿਕਸ ਅਤੇ ਟਰੇਸ ਨੂੰ ਇਕੱਠਾ ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਤੁਹਾਨੂੰ ਜਦ ਜਵਾਬ ਚਾਹੀਦਾ ਹੋਵੇ ਉਹ ਮਿਲ ਜਾਏ।
ਸ਼ੁਰੂਆਤ ਕਰੋ ਇਕ ਸੇਵਾ ਨਾਮ ਪਸੰਦ ਕਰਕੇ ਹਰ deployable unit ਲਈ ਅਤੇ ਇਸਨੂੰ ਸਥਿਰ ਰੱਖੋ। ਜੇ “checkout-api” ਅੱਧੇ ਡੈਸ਼ਬੋਰਡ ਵਿੱਚ “checkout” ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇਤਿਹਾਸ ਗੁਆ ਦੇਂਦੇ ਹੋ ਅਤੇ alerts ਟੁੱਟ ਜਾਂਦੇ ਹਨ। environment labels ਲਈ ਵੀ ਇਹੋ ਹੀ ਕਰੋ। ਛੋਟਾ ਸੈੱਟ ਚੁਣੋ ਜਿਵੇਂ prod ਅਤੇ staging ਅਤੇ ਹਰ ਥਾਂ ਵਰਤੋ।
ਅਗਲਾ, ਹਰ request ਨੂੰ follow ਕਰਨਾ ਆਸਾਨ ਬਣਾਓ। edge 'ਤੇ (API gateway, web server ਜਾਂ ਪਹਿਲਾ handler) ਇੱਕ request ID ਬਣਾਓ ਅਤੇ ਇਸਨੂੰ HTTP calls, message queues, ਅਤੇ background jobs 'ਚ ਪਾਸ ਕਰੋ। ਜੇ ਇਕ support ticket ਕਹਿੰਦੀ ਹੈ “10:42 'ਤੇ ਧੀਮਾ ਸੀ,” ਤਾਂ ਇੱਕ ID ਤੁਹਾਨੂੰ ਸਹੀ logs ਅਤੇ trace ਤੁਰੰਤ ਖਿੱਚ ਕੇ ਦੇਵੇਗੀ।
ਇੱਕ ਦਿਨ-ਇਕ ਰਵਾਇਆਂ ਜੋ ਚੰਗਾ ਕੰਮ ਕਰਦੀਆਂ ਹਨ:
ਸਮੇਂ ਇਕਾਈਆਂ 'ਤੇ ਪਹਿਲਾਂ ਹੀ ਸਹਿਮਤ ਹੋ ਜਾਓ। API latency ਲਈ milliseconds ਅਤੇ ਲੰਮੇ jobs ਲਈ seconds ਚੁਣੋ ਅਤੇ ਉਸੇ ਨਾਲ ਚੱਲੋ। ਮਿਲੀ ਜੁੱਟ ਏਕਾਈਆਂ ਵਾਲੀਆਂ ਚਾਰਟਸ ਵੇਖਣ ਵਿੱਚ ਠੀਕ ਲੱਗਦੀਆਂ ਹਨ ਪਰ ਗਲਤ ਕਹਾਣੀ ਦਸਦੀਆਂ ਹਨ।
ਉਦਾਹਰਣ: ਜੇ ਹਰ API duration_ms, route, status ਅਤੇ request_id ਲੌਗ ਕਰਦਾ ਹੈ, ਤਾਂ “tenant 418 ਲਈ checkout ਧੀਮਾ ਹੈ” ਵਰਗਾ ਰਿਪੋਰਟ ਇਕ ਤੇਜ਼ ਫਿਲਟਰ ਬਣ ਜਾਂਦਾ ਹੈ, ਨਾ ਕਿ ਰਾਹਾ-ਰਾਹੀ ਕਥਾ।
ਜੇ ਤੁਸੀਂ ਸਿਰਫ ਇੱਕ ਗੱਲ ਕਰੋ production observability starter pack 'ਚ, ਤਾਂ ਲੌਗਸ ਨੂੰ ਖੋਜਯੋਗ ਬਣਾਓ। ਇਹ structured logs (ਅਮੂਮਨ JSON) ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ ਅਤੇ ਹਰ ਸੇਵਾ 'ਚ ਇਕੋ ਫੀਲਡ ਹੋਣ ਚਾਹੀਦੇ ਹਨ। ਲੋਕਲ ਡਿਵ 'ਚ ਸਧਾਰਨ ਟੈਕਸਟ ਲੌਗ ਠੀਕ ਹਨ, ਪਰ ਜਦ ਤੁਹਾਡੇ ਕੋਲ ਅਸਲੀ ਟ੍ਰੈਫਿਕ, retries ਅਤੇ ਕਈ instance ਹੁੰਦੇ ਹਨ, ਉਹ ਸ਼ੋਰ ਬਣ ਜਾਂਦੇ ਹਨ।
ਚੰਗਾ ਨਿਯਮ: ਉਹੀ ਲੌਗ ਕਰੋ ਜਿਸ ਦੀ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ incident ਦੌਰਾਨ ਵਰਤੋਂ ਕਰੋਗੇ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਨੂੰ ਇਹ ਸਵਾਲ ਜਵਾਬ ਦੇਣੇ ਹੁੰਦੇ ਹਨ: ਇਹ ਕਿਹੜੀ request ਸੀ? ਇਹ ਕਿਸਨੇ ਕੀਤੀ? ਕਿੱਥੇ fail ਹੋਇਆ? ਇਸਨੇ ਕਿੰਨ੍ਹ-ਕਿੰਨ੍ਹ ਚੀਜ਼ਾਂ ਨੂੰ ਛੂਹਿਆ? ਜੇ ਕੋਈ ਲੌਗ ਲਾਈਨ ਆਉਂਦੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕਿਸੇ ਨੂੰ ਵੀ ਮਦਦ ਨਹੀਂ ਕਰਦੀ, ਤਾਂ ਉਹ ਸਾਇਦ ਹੀ ਮੌਜੂਦ ਰਹੇ।
ਦਿਨ-ਇਕ ਲਈ ਇੱਕ ਛੋਟਾ ਪਰ consistent ਫੀਲਡ ਸੈੱਟ ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਸੇਵਾਵਾਂ ਦੇ events ਨੂੰ filter ਅਤੇ join ਕਰ ਸਕੋ:
ਜਦ error ਹੋਵੇ, ਉਸਨੂੰ ਇੱਕ ਵਾਰੀ ਲੌਗ ਕਰੋ, ਸੰਦਰਭ ਦੇ ਨਾਲ। ਇੱਕ error type (ਜਾਂ code), ਇੱਕ ਛੋਟਾ message, server errors ਲਈ stack trace, ਅਤੇ upstream dependency ਸ਼ਾਮਲ ਕਰੋ (ਉਦਾਹਰਨ: postgres, payment provider, cache)। retries 'ਤੇ ਹਰੇਕ ਵਾਰੀ ਇੱਕੋ ਹੀ stack trace ਨਾ ਦਿਓ। ਉਸਦੀ ਥਾਂ request_id ਜੋੜੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਚੇਨ follow ਕਰ ਸਕੋ।
ਉਦਾਹਰਣ: ਇੱਕ ਯੂਜ਼ਰ ਰਿਪੋਰਟ ਕਰਦਾ ਹੈ ਕਿ ਉਹ settings ਸੇਵ ਨਹੀਂ ਕਰ ਸਕਦਾ। ਇੱਕ search request_id ਲਈ ਦਿੱਖਾਉਂਦਾ ਹੈ ਕਿ PATCH /settings 'ਤੇ 500 ਆ ਰਿਹਾ ਹੈ, ਫਿਰ downstream Postgres timeout duration_ms ਨਾਲ। ਤੁਹਾਨੂੰ ਪੂਰਾ payload ਦੀ ਲੋੜ ਨਹੀਂ ਸੀ, ਸਿਰਫ ਰੂਟ, user/session, ਅਤੇ dependency name।
ਪ੍ਰਾਈਵੇਸੀ logging ਦਾ ਹਿੱਸਾ ਹੈ, ਨਾ ਕਿ ਬਾਅਦ ਦੀ ਟਾਸਕ। passwords, tokens, auth headers, ਪੂਰੇ request bodies ਜਾਂ ਸੰਵੇਦਨਸ਼ੀਲ PII ਨੂੰ ਲੌਗ ਨਾ ਕਰੋ। ਜੇ ਤੁਹਾਨੂੰ user ਨੂੰ ਪਛਾਣਨਾ ਹੈ, ਤਾਂ ਇਕ stable ID (ਜਾਂ hashed value) ਲੌਗ ਕਰੋ email ਜਾਂ phone number ਦੀ ਥਾਂ।
ਜੇ ਤੁਸੀਂ Koder.ai (React, Go, Flutter) 'ਤੇ ਐਪ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਇਹ ਫੀਲਡ ਹਰ generated ਸੇਵਾ ਵਿੱਚ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਸ਼ਾਮਲ ਕਰਨ ਯੋਗ ਹਨ ਤਾਂ ਕਿ ਤੁਹਾਨੂੰ ਆਪਣੇ ਪਹਿਲੇ incident ਦੌਰਾਨ “ਲੌਗਿੰਗ ਠੀਕ ਕਰਨ” ਦੀ ਲੋੜ ਨਾ ਪਏ।
ਛੋਟਾ ਸੈੱਟ ਮੈਟਰਿਕਸ ਜੋ ਤੇਜ਼ੀ ਨਾਲ ਇਕ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦੇਣ: ਕੀ ਸਿਸਟਮ ਹੁਣ ਸਿਹਤਮੰਦ ਹੈ, ਅਤੇ ਜੇ ਨਹੀਂ ਤਾਂ ਕਿੱਥੇ ਦਰਦ ਹੈ?
ਜ਼ਿਆਦਾਤਰ production ਮੁੱਦੇ ਚਾਰ “golden signals” ਦੇ ਰੂਪ ਵਿੱਚ ਆਉਂਦੇ ਹਨ: latency (responses ਧੀਮੇ), traffic (ਲੋਡ ਬਦਲਿਆ), errors (ਚੀਜ਼ਾਂ fail ਹੋ ਰਹੀਆਂ), ਅਤੇ saturation (ਕੋਈ ਸਾਂਝਾ ਸ੍ਰੋਤ ਮੈਕਸ ਹੋ ਗਿਆ)। ਜੇ ਤੁਸੀਂ ਇਹ ਚਾਰ ਸਿਗਨਲ ਪ੍ਰਮੁੱਖ ਹਿੱਸੇ ਲਈ ਦੇਖ ਸਕਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਬਿਨਾਂ ਅਨੁਮਾਨ ਲਗਾਏ ਜਿਆਦਾਤਰ incidents triage ਕਰ ਸਕਦੇ ਹੋ।
Latency percentiles ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, averages ਨਹੀਂ। p50, p95 ਅਤੇ p99 ਟ੍ਰੈਕ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਵੇਖ ਸਕੋ ਕਿ ਇਕ ਛੋਟੇ ਗਰੁੱਪ ਦੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਕੋਈ ਮਸਲਾ ਹੋ ਰਿਹਾ ਹੈ। Traffic ਲਈ requests per second (ਜਾਂ workers ਲਈ jobs per minute) ਸ਼ੁਰੂ ਕਰੋ। Errors ਲਈ 4xx ਅਤੇ 5xx ਨੂੰ ਵੱਖਰਾ ਰੱਖੋ: 4xx ਵਿੱਚ ਵਾਧਾ ਅਕਸਰ client behaviour ਜਾਂ validation changes ਵੱਲ ਸੰकेत ਕਰਦਾ ਹੈ; 5xx ਵਾਧਾ ਤੁਹਾਡੇ ਐਪ ਜਾਂ ਉਸਦੀ dependencies ਵੱਲ ਦਰਸਾਉਂਦਾ ਹੈ। Saturation ਉਹ signal ਹੈ ਜਦੋਂ “ਸਾਡੇ ਕੋਲ ਕੁਝ ਖਤਮ ਹੋਣ ਲੱਗਾ ਹੈ” (CPU, memory, DB connections, queue backlog)।
ਬਹੁਤ ਸਾਰੀਆਂ ਐਪ ਲਈ ਘੱਟੋ-ਘੱਟ ਸੈੱਟ:
ਉਦਾਹਰਣ: ਜੇ users ਕਹਿੰਦੇ ਹਨ “it’s slow” ਅਤੇ API p95 latency spike ਹੋ ਜਾਂਦੀ ਹੈ ਪਰ traffic ਸਥਿਰ ਰਹਿੰਦੀ ਹੈ, ਤਾਂ saturation ਚੈੱਕ ਕਰੋ। ਜੇ DB pool usage ਲਗਾਤਾਰ max ਕੋਲ ਪਿੰਡ ਹੈ ਅਤੇ timeouts ਵੱਧ ਰਹੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਸੰਭਾਵਤ bottleneck ਲੱਭ ਲਈ।
ਜੇ ਤੁਸੀਂ Koder.ai 'ਤੇ ਐਪ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਇਸ ਚੈਕਲਿਸਟ ਨੂੰ ਦਿਨ-ਇਕ ਦੀ definition of done ਵਜੋਂ ਰੱਖੋ। ਐਪ ਛੋਟੀ ਹੋਣ ਵੇਲੇ ਇਹ ਮੈਟਰਿਕਸ ਜੋੜਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਬਜਾਏ ਪਹਿਲੇ ਵੱਡੇ incident ਦੌਰਾਨ ਜੋੜਨ ਦੇ।
ਜਦ user ਕਹਿੰਦਾ ਹੈ “it’s slow”, ਲੌਗਸ ਅਕਸਰ ਦੱਸਦੇ ਹਨ ਕਿ ਕੀ ਵਾਪਰਾ ਅਤੇ ਮੈਟਰਿਕਸ ਦੱਸਦੇ ਹਨ ਕਿ ਕਿੰਨੀ ਵਾਰ। ਟਰੇਸ ਇਹ ਦੱਸਦੇ ਹਨ ਕਿ ਇੱਕ request ਦੇ ਅੰਦਰ ਸਮਾਂ ਕਿੱਥੇ ਲੱਗਿਆ। ਉਹ ਇਕ timeline ਖਾਣਾ vague ਸ਼ਿਕਾਇਤ ਨੂੰ ਸਪੱਸ਼ਟ ਫਿਕਸ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ।
ਸਰਵਰ-ਸਾਈਡ 'ਤੇ ਸ਼ੁਰੂ ਕਰੋ। ਉਦੋਂ instrument inbound requests app ਦੇ edge (ਪਹਿਲਾ handler) 'ਤੇ ਕਰੋ ਤਾਂ ਕਿ ਹਰ request ਇੱਕ trace ਪੈਦਾ ਕਰ ਸਕੇ। Client-side tracing ਬਾਅਦ 'ਚ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਚੰਗੀ ਦਿਨ-ਇਕ trace ਵਿੱਚ spans ਉਹ ਹਿੱਸੇ ਹੋਣ ਚਾਹੀਦੇ ਹਨ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਸਲੋ ਹੁੰਦੇ ਹਨ:
ਟਰੇਸ ਨੂ searchable ਅਤੇ comparable ਬਣਾਉਣ ਲਈ ਕੁਝ ਕੁੰਜੀ attributes consistent ਰੱਖੋ।
ਇਨਬਾਊਂਡ request span ਲਈ route (ਟੈਂਪਲੇਟ ਜਿਵੇਂ /orders/:id), HTTP method, status code, ਅਤੇ latency ਰੱਖੋ। DB spans ਲਈ DB system (PostgreSQL, MySQL), operation type (select, update) ਅਤੇ table name ਜੇ ਆਸਾਨ ਹੋ ਤਾਂ ਜੋੜੋ। External calls ਲਈ dependency name (payments, email, maps), target host, ਅਤੇ status ਰੱਖੋ।
Sampling ਦਿਨ-ਇਕ 'ਤੇ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਨਹੀਂ ਤਾਂ ਲਾਗਤ ਅਤੇ ਸ਼ੋਰ ਤੇਜ਼ੀ ਨਾਲ ਵੱਧਦਾ ਹੈ। ਇੱਕ ਸਧਾਰਨ head-based ਨਿਯਮ ਵਰਤੋ: errors ਅਤੇ slow requests ਨੂੰ 100% trace ਕਰੋ (ਜੇ SDK ਸਮਰਥਨ ਕਰਦਾ ਹੋਵੇ), ਅਤੇ ਆਮ ਟ੍ਰੈਫਿਕ ਦਾ ਛੋਟਾ ਪ੍ਰਤੀਸ਼ਤ (1-10%) sample ਕਰੋ। ਘੱਟ ਟ੍ਰੈਫਿਕ 'ਚ high sampling ਰੱਖੋ ਅਤੇ ਜਿਵੇਂ ਵਰਤੋਂ ਵੱਧੇ ਘਟਾਓ।
“ਚੰਗੀ” trace ਇਹ ਹੈ: ਇੱਕ trace ਜਿਸਨੂੰ ਤੁਸੀਂ ਉਪਰੋਂ ਹੇਠਾਂ ਕਹਾਣੀ ਵਾਂਗ ਪੜ੍ਹ ਸਕੋ। ਉਦਾਹਰਣ: GET /checkout 2.4s ਲੱਗਿਆ, DB ਨੇ 120ms ਲਿਆ, cache 10ms, ਅਤੇ external payment call 2.1s ਲਿਆ ਜਿਸ 'ਚ retry ਸੀ। ਹੁਣ ਤੁਸੀਂ ਜਾਣਦੇ ਹੋ ਕਿ ਸਮੱਸਿਆ dependency ਵਿੱਚ ਹੈ, ਨਾਂ ਕਿ ਤੁਹਾਡੇ ਕੋਡ ਵਿੱਚ। ਇਹ production observability starter pack ਦੀ ਮੁੱਖ ਗੱਲ ਹੈ।
ਜਦ ਕੋਈ ਕਹਿੰਦਾ ਹੈ “it’s slow”, ਸਭ ਤੋਂ ਤੇਜ਼ ਜਿੱਤ ਇਹ ਹੈ ਕਿ ਉਹ vague ਮਹਿਸੂਸ ਨੂੰ ਕੁਝ ਠੋਸ ਸਵਾਲਾਂ 'ਚ ਬਦਲ ਦੇਵੇ। ਇਹ production observability starter pack triage flow ਨਵੇਂ ਐਪ ਲਈ ਵੀ ਕੰਮ ਕਰਦੀ ਹੈ।
ਪਰਬੰਧ ਤੋਂ ਸਮੱਸਿਆ ਨੂੰ ਸੀਮਿਤ ਕਰੋ, ਫਿਰ ਸਬੂਤ ਦੇ ਅਨੁਸਾਰ ਅੱਗੇ ਵਧੋ। ਸਿੱਧਾ database 'ਤੇ ਨਾ ਛਾਲ ਮਾਰੋ।
ਸਥਿਰ ਕਰਨ ਤੋਂ ਬਾਅਦ ਇੱਕ ਛੋਟੀ ਸੁਧਾਰ ਕਰੋ: ਜੋ ਕੁਝ ਹੋਇਆ ਉਸਨੂੰ ਲਿਖੋ ਅਤੇ ਇੱਕ ਗੁਮ ਸਿਗਨਲ ਜੋੜੋ। ਉਦਾਹਰਣ ਲਈ, ਜੇ ਤੁਸੀਂ ਇਹ ਨਹੀਂ ਦੱਸ ਸਕੇ ਕਿ slowdown ਸਿਰਫ ਇੱਕ region 'ਚ ਸੀ, latency metrics 'ਚ region tag ਜੋੜੋ। ਜੇ trace 'ਚ ਲੰਮਾ DB span ਸੀ ਪਰ ਕਿਸ query ਦਾ ਪਤਾ ਨਹੀਂ, ਤਾਂ ਹੌਲੀ-ਹੌਲੀ query labels ਜੋੜੋ ਜਾਂ ਇੱਕ "query name" ਫੀਲਡ ਸ਼ਾਮਲ ਕਰੋ।
ਛੋਟੀ ਉਦਾਹਰਣ: ਜੇ checkout p95 400ms ਤੋਂ 3s ਹੋ ਜਾਂਦਾ ਹੈ ਅਤੇ traces ਇੱਕ payment call ਵਿੱਚ 2.4s ਦਿਖਾਉਂਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਕੋਡ ਦੀ ਚਰਚਾ ਰੋਕਕੇ payment provider, retries ਅਤੇ timeouts 'ਤੇ ਧਿਆਨ ਦੇ ਸਕਦੇ ਹੋ।
ਜਦ ਕੋਈ ਕਹਿੰਦਾ ਹੈ “it’s slow”, ਤੁਸੀਂ ਇੱਕ ਘੰਟਾ ਵੀ ਖਾਲੀ ਕਰ ਸਕਦੇ ਹੋ ਸਿਰਫ ਇਸ ਨੂੰ ਸਮਝਣ ਲਈ ਕਿ ਉਹ ਕੀ ਮਤਲਬ ਰੱਖਦਾ। ਇੱਕ production observability starter pack ਤਦ ਹੀ ਲਾਭਕਾਰੀ ਹੈ ਜਦ ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਸਮੱਸਿਆ ਨੂੰ ਸੀਮਿਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰੇ।
ਪਹਿਲਾਂ ਤਿੰਨ ਸਵਾਲ ਪੁੱਛੋ:
ਫਿਰ ਕੁਝ ਨੰਬਰਾਂ 'ਤੇ ਇੱਕ ਨਜ਼ਰ ਮਾਰੋ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਦੱਸਦੇ ਹਨ ਕਿ ਅੱਗੇ ਕਿਹੜੀ ਰਾਹ ਲੈਣੀ ਹੈ। ਪੂਰੇ ਡੈਸ਼ਬੋਰਡ ਦੀ ਤਲਾਸ਼ ਨਾ ਕਰੋ—ਤੁਹਾਨੂੰ ਸਿਰਫ “ਨਾਰਮਲ ਤੋਂ ਬੁਰਾ” ਸਿਗਨਲ ਚਾਹੀਦਾ ਹੈ।
ਜੇ p95 ਵੱਧ ਗਿਆ ਪਰ errors ਸਥਿਰ ਹਨ, ਤਦ ਆਖਰੀ 15 ਮਿੰਟਾਂ ਲਈ slow route ਦਾ ਇੱਕ trace ਖੋਲ੍ਹੋ। ਇੱਕ trace ਅਕਸਰ ਦਿਖਾਉਂਦਾ ਹੈ ਕਿ ਸਮਾਂ DB, external API, ਜਾਂ locks 'ਤੇ ਖਰਚ ਹੋ ਰਿਹਾ ਹੈ।
ਫਿਰ ਇੱਕ ਲੌਗ search ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਖਾਸ user report ਹੈ, ਤਾਂ ਉਹਨਾਂ ਦੇ request_id (ਜਾਂ correlation ID) 'ਤੇ search ਕਰੋ ਅਤੇ timeline ਪੜ੍ਹੋ। ਜੇ ਨਹੀਂ, ਤਾਂ ਇੱਕ ਆਮ error message ਲਈ ਉਸੇ time window 'ਚ search ਕਰੋ ਅਤੇ ਵੇਖੋ ਕਿ ਕੀ ਉਹ slowdown ਨਾਲ align ਕਰਦਾ ਹੈ।
ਅਖੀਰ 'ਚ ਫੈਸਲਾ ਕਰੋ ਕਿ ਅਜੇ mitigate ਕਰਨਾ ਹੈ ਜਾਂ ਹੋਰ ਖੋਜ ਕਰਨੀ ਹੈ। ਜੇ users blocked ਹਨ ਅਤੇ saturation high ਹੈ, ਤਾਂ ਇੱਕ ਤੁਰੰਤ mitigation (scale up, rollback, ਜਾਂ non-essential feature flag disable) ਸਮਾਂ ਖਰੀਦ ਸਕਦੀ ਹੈ। ਜੇ ਪ੍ਰਭਾਵ ਛੋਟਾ ਹੈ ਅਤੇ ਸਿਸਟਮ ਸਥਿਰ ਹੈ, ਤਾਂ traces ਅਤੇ slow query logs ਨਾਲ deeper investigation ਜਾਰੀ ਰੱਖੋ।
ਕੁਝ ਘੰਟਿਆਂ ਬਾਅਦ release ਤੋਂ, support tickets ਆਉਣੀਆਂ ਸ਼ੁਰੂ ਹੁੰਦੀਆਂ ਹਨ: “Checkout 20 ਤੋਂ 30 ਸਕਿੰਟ ਲੈਂਦਾ ਹੈ।” ਕੋਈ ਆਪਣੀ ਲੈਪਟਾਪ 'ਤੇ reproduce ਨਹੀਂ ਕਰ ਪਾਉਂਦਾ, ਇਸ ਲਈ ਅਨੁਮਾਨ ਲਗਾਉਣ ਦੀ ਸ਼ੁਰੂਆਤ ਹੁੰਦੀ ਹੈ। ਇੱਥੇ production observability starter pack ਕਾਰਗਰ ਸਾਬਤ ਹੁੰਦਾ ਹੈ।
ਪਹਿਲਾਂ metrics 'ਤੇ ਜਾਓ ਅਤੇ ਲੱਛਣ Verify ਕਰੋ। HTTP requests ਲਈ p95 latency chart ਇੱਕ ਸਪਸ਼ਟ spike ਦਿਖਾਂਦੀ ਹੈ, ਪਰ ਸਿਰਫ POST /checkout ਲਈ। ਹੋਰ routes ਸਧਾਰਨ ਲੱਗਦੇ ਹਨ ਅਤੇ error rate ਸਥਿਰ ਹੈ। ਇਹ ਗੱਲ “ਸਾਈਟ ਪੂਰੀ ਤਰ੍ਹਾਂ slow” ਤੋਂ “ਇੱਕ endpoint release ਤੋਂ ਬਾਅਦ slow ਹੋ ਗਿਆ” ਤੱਕ ਸੀਮਿਤ ਕਰ ਦਿੰਦੀ ਹੈ।
ਅਗਲੇ ਕਦਮ 'ਚ slow POST /checkout request ਲਈ ਇੱਕ trace ਖੋਲ੍ਹੋ। trace waterfall culprit ਸਭ ਨੂੰ ਆਸਾਨੀ ਨਾਲ ਦਿਖਾ ਦਿੰਦਾ ਹੈ। ਦੋ ਆਮ ਨਤੀਜੇ:
ਹੁਣ logs ਨਾਲ ਪੁਸ਼ਟੀ ਕਰੋ, trace ਤੋਂ ਉਹੀ request ID ਵਰਤ ਕੇ (ਜਾਂ ਜੇ ਤੁਸੀਂ logs 'ਚ trace ID ਸਟੋਰ ਕਰਦੇ ਹੋ ਤਾਂ trace ID)। ਉਸ request ਲਈ logs ਵਿੱਚ ਤੁਸੀਂ repeated warnings ਵੇਖਦੇ ਹੋ ਜਿਵੇਂ “payment timeout reached” ਜਾਂ “context deadline exceeded”, ਨਾਲੇ retries ਜੋ ਨਵੀਂ release ਵਿੱਚ ਸ਼ਾਮਲ ਕੀਤੇ ਗਏ ਸਨ। ਜੇ ਇਹ database ਪਾਸ ਹੈ, logs lock wait messages ਜਾਂ slow query statements ਦਿਖਾ ਸਕਦੇ ਹਨ।
ਤਿੰਨੋ ਸਿਗਨਲ ਮਿਲ ਕੇ, ਫਿਕਸ ਸਧਾਰਨ ਬਣ ਜਾਂਦਾ ਹੈ:
ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ hunt ਨਹੀਂ ਕੀਤਾ। metrics endpoint ਨੂੰ ਨਿਰਧਾਰਤ ਕੀਤੇ, traces slow step ਨੂੰ ਦਿਖਾਉਂਦੇ, ਅਤੇ logs failure mode ਨੂੰ ਪੁਸ਼ਟੀ ਕਿੱਤੀ ਜਿਸ ਨਾਲ ਤੁਹਾਡੇ ਕੋਲ ਠੀਕ request ਸੀ।
ਜ਼ਿਆਦਾਤਰ incident ਸਮਾਂ avoidable gaps ਤੇ ਖ਼ਰਚ ਹੁੰਦਾ ਹੈ: ਡੇਟਾ ਮੌਜੂਦ ਹੁੰਦੀ ਹੈ, ਪਰ ਉਹ noisy, risky, ਜਾਂ ਉਹ ਇਕੋ ਕੁੰਜੀ ਵੇਰਵਾ ਲੁੱਕਦੀ ਹੈ ਜੋ ਤੁਸੀਂ symptoms ਨੂੰ cause ਨਾਲ ਜੋੜ ਸਕੋ। production observability starter pack ਤਦ ਹੀ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦ ਇਹ ਤਣਾਅ ਹੇਠਾਂ ਵਰਤਣ ਯੋਗ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ ਆਮ ਫੰਸ: ਬਹੁਤ ਜ਼ਿਆਦਾ ਲੌਗ ਕਰਨਾ, ਖਾਸ ਕਰਕੇ raw request bodies। ਇਹ ਸੁਣਨ ਵਿੱਚ ਮਦਦਗਾਰ ਲੱਗਦਾ ਹੈ ਪਰ ਜਦ ਤੁਸੀਂ ਵੱਡਾ ਸਟੋਰੇਜ ਭਰ ਰਹੇ ਹੋ, search slow ਹੋ ਜਾਂਦੀ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਗਲਤੀ ਨਾਲ passwords, tokens ਜਾਂ ਨਿੱਜੀ ਡੇਟਾ capture ਕਰ ਲੈਂਦੇ ਹੋ। structured fields (route, status code, latency, request_id) ਪਸੰਦ ਕਰੋ ਅਤੇ input ਦੇ ਛੋਟੇ, ਸਪਸ਼ਟ ਅਨੁਭਾਗ ਹੀ ਲੌਗ ਕਰੋ।
ਹੋਰ ਸਮਾਂ ਖ਼ਰਚ ਕਰਨ ਵਾਲੀ ਗਲਤੀ ਉਹ metrics ਹੋ ਸਕਦੀਆਂ ਹਨ ਜੋ ਵਿਸਥਾਰ ਦਿਖਦੀਆਂ ਹਨ ਪਰ aggregate ਨਹੀਂ ਹੋ ਸਕਦੀਆਂ। ਉੱਚ-cardinality labels ਜਿਵੇਂ ਪੂਰੇ user IDs, emails ਜਾਂ unique order numbers ਤੁਹਾਡੇ metric series ਦੀ ਗਿਣਤੀ ਖਤਿਰੀ ਤੌਰ 'ਤੇ ਵਧਾ ਦਿੰਦੀਆਂ ਹਨ ਅਤੇ dashboards ਗੈਰ-ਭਰੋਸੇਯੋਗ ਬਣ ਜਾਂਦੀਆਂ ਹਨ। ਬਦلے coarse labels ਵਰਤੋ (route name, HTTP method, status class, dependency name) ਅਤੇ user-specific ਚੀਜ਼ਾਂ logs ਵਿੱਚ ਰੱਖੋ।
ਇਹ ਗਲਤੀਆਂ ਜੋ ਵਾਰ-ਵਾਰ ਤੇਜ਼ ਨਿਧਾਨ ਨੂੰ ਅਵਰੋਧ ਕਰਦੀਆਂ ਹਨ:
ਛੋਟੀ ਪ੍ਰਾਇਕਟਿਕ ਉਦਾਹਰਣ: ਜੇ checkout p95 800ms ਤੋਂ 4s ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਮਿੰਟਾਂ ਵਿੱਚ ਦੋ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਚਾਹੁੰਦੇ ਹੋ: ਕੀ ਇਹ deploy ਤੋਂ ਬਾਅਦ ਸ਼ੁਰੂ ਹੋਇਆ, ਅਤੇ ਕੀ ਸਮਾਂ ਤੁਹਾਡੇ ਐਪ ਵਿੱਚ ਖਰਚ ਹੋ ਰਿਹਾ ਹੈ ਜਾਂ dependency (DB, payment provider, cache) ਵਿੱਚ? percentiles, release tag, ਅਤੇ traces ਜਿਨ੍ਹਾਂ ਵਿੱਚ route ਅਤੇ dependency names ਹੋਣ ਨਾਲ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਪਹੁੰਚ ਜਾ ਸਕਦੇ ਹੋ। ਨਹੀਂ ਤਾਂ incident window ਵਿੱਚ ਤੁਸੀਂ ਗਲਤ ਅਨੁਮਾਨਾਂ 'ਤੇ ਸਮਾਂ ਗਵਾਂਦੇ ਹੋ।
ਅਸਲੀ ਜਿੱਤ consistency ਹੈ। production observability starter pack ਸਿਰਫ ਤਾਂ ਮਦਦ ਕਰਦਾ ਹੈ ਜਦ ਹਰ ਨਵੀਂ ਸੇਵਾ ਨਾਲ ਇੱਕੋ ਹੀ ਬੁਨਿਆਦੀ ਚੀਜ਼ਾਂ ਸ਼ਿਪ ਕੀਤੀਆਂ ਜਾਣ ਅਤੇ ਉਹਨਾਂ ਦਾ ਨਾਮ ਇਕੋ ਰਿਹਾ ਜਾਵੇ ਤਾਂ ਜੋ ਕੁਝ ਟੁੱਟਣ 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਲੱਭਿਆ ਜਾ ਸਕੇ।
ਆਪਣੀਆਂ ਦਿਨ-ਇਕ ਚੋਣਾਂ ਨੂੰ ਇੱਕ ਛੋਟੇ template ਵਿੱਚ ਤਬਦੀਲ ਕਰੋ ਜੋ ਟੀਮ ਦੁਹਰਾਏ। ਇਸਨੂੰ ਛੋਟਾ ਰੱਖੋ, ਪਰ ਨਿਰਧਾਰਤ।
ਇੱਕ “home” view ਬਣਾਓ ਜੋ ਕੋਈ ਵੀ incident ਦੌਰਾਨ ਖੋਲ੍ਹ ਸਕੇ। ਇੱਕ ਸਕ੍ਰੀਨ requests per minute, error rate, p95 latency, ਅਤੇ ਤੁਹਾਡਾ ਮੁੱਖ saturation metric ਦਿਖਾਵੇ, environment ਅਤੇ version ਲਈ filter ਦੇ ਨਾਲ।
ਸ਼ੁਰੂ ਵਿੱਚ alerting ਨਿੱਕਾ ਰੱਖੋ। ਦੋ alerts ਬਹੁਤ ਕੁਝ ਕਵਰ ਕਰਦੇ ਹਨ: ਇੱਕ key route 'ਤੇ error rate spike, ਅਤੇ ਉਹੀ route 'ਤੇ p95 latency spike। ਜੇ ਤੁਸੀਂ ਹੋਰ ਜੋੜਦੇ ਹੋ, ਤਾਂ ਇਹ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ alert ਦਾ ਇੱਕ ਰੁਕਾਵਟ ਵਾਲਾ ਕਾਰਵਾਈ ਨਿਰਧਾਰਿਤ ਹੋਵੇ।
ਅੰਤ ਵਿੱਚ, ਮਹੀਨਾਵਾਰ ਸਮੀਖਿਆ ਨਿਰਧਾਰਿਤ ਕਰੋ। noisy alerts ਹਟਾਓ, naming ਸਖਤ ਕਰੋ, ਅਤੇ ਇੱਕ ਗੁਮ ਸਿਗਨਲ ਜੋੜੋ ਜੋ ਪਿਛਲੇ incident ਵਿੱਚ ਸਮਾਂ ਬਚਾਉਂਦਾ।
ਇਸਨੂੰ ਆਪਣੇ build ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਬਾਉਂਡ ਕਰਨ ਲਈ, ਆਪਣੀ release checklist ਵਿੱਚ ਇੱਕ “observability gate” ਸ਼ਾਮਲ ਕਰੋ: बिना request IDs, version tags, home view, ਅਤੇ ਦੋ ਬੇਸਲਾਈਨ alerts ਦੇ deploy ਨਾ ਕਰੋ। ਜੇ ਤੁਸੀਂ Koder.ai ਨਾਲ ship ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ deployment ਤੋਂ ਪਹਿਲਾਂ planning mode 'ਚ ਇਹ ਦਿਨ-ਇਕ signals ਪਰਿਭਾਸ਼ਿਤ ਕਰ ਸਕਦੇ ਹੋ, ਫਿਰ snapshots ਅਤੇ rollback ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਤੇਜ਼ੀ ਨਾਲ iterate ਕਰੋ।
ਸ਼ੁਰੂਆਤ edge ਨੰੂ ਆਉਂਦੇ ਸਿਸਟਮ ਦੇ ਪਹਿਲੇ ਸਥਾਨ ਤੋਂ ਕਰੋ: web server, API gateway ਜਾਂ ਪਹਿਲਾ handler।
request_id ਜੋੜੋ ਅਤੇ ਉਸਨੂੰ ਹਰ ਅੰਦਰੂਨੀ ਕਾਲ 'ਚ ਪਾਸ ਕਰੋ।route, method, status, ਅਤੇ duration_ms ਲੌਗ ਕਰੋ।ਇਨ੍ਹਾਂ ਨਾਲ ਤੁਹਾਨੂੰ ਜਿਆਦਾਤਰ ਵਾਰ ਇੱਕ ਖਾਸ ਐਂਡਪਾਇੰਟ ਅਤੇ ਸਮਾਂ-ਵਿੰਡੋ ਤੁਰੰਤ ਮਿਲ ਜਾਏਗੀ।
ਇਸ ਨੂੰ ਡੈਫੌਲਟ ਨਿਸ਼ਾਨ ਵੇਖੋ: ਤੁਸੀਂ 15 ਮਿੰਟ ਦੇ ਅੰਦਰ ਸਲੋ ਕਦਮ ਪਛਾਣ ਸਕਣੇ ਹੋ।
ਦਿਨ-ਇਕ ਤੇ ਤੁਹਾਨੂੰ ਪਰਫੈਕਟ ਡੈਸ਼ਬੋਰਡ ਦੀ ਲੋੜ ਨਹੀਂ; ਤੁਹਾਨੂੰ ਇਹ ਜਾਣਨ ਲਈ ਕਾਫ਼ੀ ਸਿਗਨਲ ਚਾਹੀਦੇ ਹਨ:
ਇੱਕ incident ਦੌਰਾਨ: metrics ਨਾਲ ਪ੍ਰਭਾਵ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ, traces ਨਾਲ bottleneck ਲੱਭੋ, ਅਤੇ logs ਨਾਲ ਉਸਦੀ ਵਿਆਖਿਆ ਕਰੋ।
ਛੋਟੀ ਪਰ ਸਾਫ਼ ਰਵਾਇਆਂ ਦੀ ਇੱਕ ਨਿਯਤੀ ਬਣਾਓ ਅਤੇ ਹਰ ਥਾਂ ਲਾਗੂ ਕਰੋ:
ਡਿਫ਼ਾਲਟ ਤੌਰ 'ਤੇ structured logs (ਆਮ ਤੌਰ 'ਤੇ JSON) ਵਰਤੋ ਅਤੇ ਹਰ ਥਾਂ ਇਕੋ ਹੀ keys ਰੱਖੋ।
ਤੁਰੰਤ ਲਾਭ ਦੇਣ ਵਾਲੇ ਘੱਟੋ-ਘੱਟ ਫੀਲਡ:
ਹਰ ਪ੍ਰਮੁੱਖ ਹਿੱਸੇ ਲਈ ਥੋੜੇ ਜਿਹੇ metrics ਜੋ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦਿੰਦੀਆਂ ਹਨ:
-Latency: p50/p95/p99 (average ਤੋਂ ਬਚੋ) -Traffic: requests/sec (workers ਲਈ jobs/min) -Errors: 4xx vs 5xx ਦਰ -Saturation: ਕੋਈ resource limit (CPU, memory, DB connections, queue depth)
ਚੋਟੀ ਦੇ ਹਿੱਸੇ ਲਈ ਮਿਨੀਮਮ ਚੈੱਕਲਿਸਟ:
ਸਰਵਰ-ਪਾਰਟੀ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ। ਹਰ inbound request 'ਤੇ instrument ਕਰੋ ਤਾਂ ਕਿ ਹਰ request ਇੱਕ trace ਪੈਦਾ ਕਰ ਸਕੇ।
ਇੱਕ ਚੰਗੀ ਦਿਨ-ਇਕ trace ਵਿੱਚ spans ਉਹਨਾਂ ਹਿੱਸਿਆਂ ਨੂੰ ਦਰਸਾਉਣੇ ਚਾਹੀਦੇ ਹਨ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਸਲੋ ਹੁੰਦੇ ਹਨ:
Spans ਨੂੰ searchable ਬਣਾਉਣ ਲਈ ਕੁਝ ਕੋਮਲ attributes ਜਿਵੇਂ route (ਟੈਂਪਲੇਟ), HTTP method, status code ਅਤੇ latency ਰੱਖੋ।
ਇੱਕ ਸਧਾਰਨ ਅਤੇ ਸੁਰੱਖਿਅਤ ਡਿਫੋਲਟ:
ਟ੍ਰੈਸਿੰਗ ਦੀ मात्रा ਘੱਟ ਰੱਖਣ ਲਈ ਇਹ ਸ਼ੁਰੂਆਤੀ ਨੀਤੀ ਮਦਦਗਾਰ ਹੈ: ਜਦ ਟ੍ਰੈਫਿਕ ਘੱਟ ਹੋ, sample ਜ਼ਿਆਦਾ ਰੱਖੋ; ਜਿਵੇਂ ਵਾਧਾ ਹੋਵੇ, ਘਟਾਓ।
ਇਕ ਦੁਹਰਾਈਯੋਗ ਫਲੋ ਵਰਤੋ ਜੋ ਸਬੂਤ ਦੇ ਅਨੁਸਾਰ ਚੱਲੇ:
ਫਿਕਸ ਕਰਨ ਤੋਂ ਬਾਦ ਇੱਕ ਛੋਟੀ ਸੁਧਾਰ ਲਿਖੋ ਅਤੇ ਇੱਕ ਗੁਮ ਸਿਗਨਲ ਜੋੜੋ ਜੋ ਅੱਗੇ ਸਮਾਂ ਬਚਾਏਗਾ।
ਇਹ ਗੱਲਾਂ ਸਭ ਤੋਂ ਵੱਧ ਸਮਾਂ ਵਿਅਰਥ ਕਰਦੀਆਂ ਹਨ:
ਸਾਡਾ ਸਲਾਹ: ਸਧਾਰਨ ਰੱਖੋ—stable IDs, percentiles, ਸਾਫ਼ dependency names, ਅਤੇ version tags ਹਰ ਥਾਂ।
service_name, environment (ਜਿਵੇਂ prod/staging) ਅਤੇ versionrequest_id ਜੋ ਕਾਲਾਂ ਅਤੇ ਜੌਬਾਂ 'ਚ propagate ਹੋਵੇroute, method, status_code, ਅਤੇ tenant_id (ਜੇ multi-tenant)duration_ms)ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਇੱਕ ਹੀ ਫਿਲਟਰ ਸੇਵਾਵਾਂ ਵਿੱਚ ਕਾਮ ਕਰੇ ਨਾ ਕਿ ਹਰ ਵਾਰੀ ਮੁੜ ਸ਼ੁਰੂ ਕਰਨ ਦੀ ਲੋੜ ਪਵੇ।
timestamp, level, service_name, environment, versionrequest_id (ਅਤੇ ਜੇ ਉਪਲਬਧ ਹੋਵੇ ਤਾਂ trace_id)route, method, status_code, duration_msuser_id ਜਾਂ session_id (ਇੱਕ stable ID, email ਨਾ)Errors ਨੂੰ ਇਕ ਵਾਰੀ ਹੀ ਲੌਗ ਕਰੋ ਸੰਦਰਭ ਦੇ ਨਾਲ (error type/code + message + dependency name)। retries 'ਤੇ ਇੱਕੋ ਹੀ stack trace ਦੁਹਰਾਉਣ ਤੋਂ ਬਚੋ।
Sampling: 100% errors ਅਤੇ slow requests trace ਕਰੋ (ਜੇ SDK ਸਹਾਇਕ ਹੋਵੇ), ਅਤੇ ਆਮ ਟ੍ਰੈਫਿਕ ਦਾ 1–10% sample ਕਰੋ।