18 ਅਕਤੂ 2025·8 ਮਿੰਟ
ਡੇਟਾ ਇੰਪੋਰਟ, ਐਕਸਪੋਰਟ ਅਤੇ ਵੈਲੀਡੇਸ਼ਨ ਲਈ ਵੈਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈਬ ਐਪ ਡਿਜ਼ਾਇਨ ਕਰਨੀ ਹੈ ਜੋ CSV/Excel/JSON ਨੂੰ ਇੰਪੋਰਟ ਅਤੇ ਐਕਸਪੋਰਟ ਕਰੇ, ਸਪਸ਼ਟ ਐਰਰਾਂ ਨਾਲ ਡੇਟਾ ਵੈਲੀਡੇਟ ਕਰੇ, ਰੋਲਸ, ਆਡਿਟ ਲੌਗ ਅਤੇ ਭਰੋਸੇਯੋਗ ਪ੍ਰੋਸੈਸਿੰਗ ਸਮਰਥਤ ਕਰੇ।
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈਬ ਐਪ ਡਿਜ਼ਾਇਨ ਕਰਨੀ ਹੈ ਜੋ CSV/Excel/JSON ਨੂੰ ਇੰਪੋਰਟ ਅਤੇ ਐਕਸਪੋਰਟ ਕਰੇ, ਸਪਸ਼ਟ ਐਰਰਾਂ ਨਾਲ ਡੇਟਾ ਵੈਲੀਡੇਟ ਕਰੇ, ਰੋਲਸ, ਆਡਿਟ ਲੌਗ ਅਤੇ ਭਰੋਸੇਯੋਗ ਪ੍ਰੋਸੈਸਿੰਗ ਸਮਰਥਤ ਕਰੇ।
ਸਕ੍ਰੀਨਾਂ ਡਿਜ਼ਾਇਨ ਕਰਨ ਜਾਂ ਕਿਸੇ ਫਾਇਲ ਪਾਰਸਰ ਦੀ ਚੋਣ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਵਜ੍ਹੀ ਤਰੀਕੇ ਨਾਲ ਜਾਣ ਲਓ ਕਿ ਕੌਣ ਤੁਹਾਡੇ ਉਤਪਾਦ ਵਿੱਚ ਡੇਟਾ ਲਿਆ/ਭੇਜ ਰਿਹਾ ਹੈ ਅਤੇ ਕਿਉਂ. ਇੱਕ ਡੇਟਾ ਇੰਪੋਰਟ ਵੈਬ ਐਪ ਜੋ ਅੰਦਰੂਨੀ ਓਪਰੇਟਰਾਂ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ, ਉਹ ਕਿਸੇ self-serve Excel ਇੰਪੋਰਟ ਟੂਲ ਤੋਂ ਬਹੁਤ ਵੱਖਰਾ ਲੱਗੇਗਾ ਜੋ ਗਾਹਕ ਵਰਤਦੇ ਹਨ.
ਉਹ ਰੋਲ ਲਿਸਟ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਇੰਪੋਰਟ/ਐਕਸਪੋਰਟ ਨੂੰ ਛੂਹਣਗੇ:
ਹਰ ਰੋਲ ਲਈ, ਉਮੀਦ ਕੀਤੀ ਕਿਸਮ ਦੀ ਹੁਨਰ-ਪੱਧਰ ਅਤੇ ਜਟਿਲਤਾ ਸਹਿਣਸ਼ੀਲਤਾ ਨਿਰਧਾਰਤ ਕਰੋ। ਗਾਹਕਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਘੱਟ ਵਿਕਲਪ ਅਤੇ ਬਹੁਤ ਵਧੀਆ ਇਨ-ਪ੍ਰੋਡਕਟ ਸਮਝਾਏ ਜਾਣੇ ਚਾਹੀਦੇ ਹਨ।
ਆਪਣੇ ਟੌਪ ਦ੍ਰਿਸ਼ਾਂ ਨੂੰ ਲਿਖੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਤਰਜੀਹ ਦਿਓ। ਆਮ ਹਨ:
ਫਿਰ ਸਫਲਤਾ ਮੈਟ੍ਰਿਕਸ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਤੁਸੀਂ ਮੈਪ ਕਰ ਸਕਦੇ ਹੋ। ਉਦਾਹਰਨਾਂ: ਘੱਟ ਫੇਲਡ ਇੰਪੋਰਟ, ਗਲਤੀਆਂ ਲਈ ਤੇਜ਼ ਸਮਾਂ-ਦੂਰ ਕਰਨਾ, ਅਤੇ “ਮੇਰੀ ਫਾਇਲ ਅਪਲੋਡ ਨਹੀਂ ਹੋ ਰਹੀ” ਬਾਰੇ ਕਮ ਸਹਾਇਤਾ ਟਿਕਟਾਂ। ਇਹ ਮੈਟ੍ਰਿਕਸ ਤੁਹਾਨੂੰ ਬਾਅਦ ਵਿੱਚ ਟ੍ਰੇਡਆਫ਼ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨਗੇ (ਜਿਵੇਂ ਸਪਸ਼ਟ ਐਰਰ ਰਿਪੋਰਟਿੰਗ ਵਿੱਚ ਨਿਵੇਸ਼ ਬਣਾਮ ਵਧੇਰੇ ਫਾਇਲ ਫਾਰਮੈਟ ਦੇ ਸਮਰਥਨ)।
ਪਹਿਲੇ ਦਿਨ ਤੇ ਤੁਸੀਂ ਕੀ ਸਮਰਥਨ ਕਰੋਗੇ ਇਸ ਬਾਰੇ ਸਪਸ਼ਟ ਹੋਵੋ:
ਆਖਿਰ ਵਿੱਚ, compliance ਲੋੜਾਂ ਜਲਦੀ ਪਛਾਣੋ: ਕੀ ਫਾਇਲਾਂ ਵਿੱਚ PII ਹੈ, retention ਲੋੜਾਂ (ਕਿੰਨਾ ਸਮਾਂ uploads ਸਟੋਰ ਕਰਨੇ ਹਨ), ਅਤੇ ਆਡਿਟ ਲੋੜਾਂ (ਕੌਣ ਕੀ ਇੰਪੋਰਟ ਕੀਤਾ, ਕਦੋਂ, ਅਤੇ ਕੀ ਬਦਲਿਆ)। ਇਹ ਫੈਸਲੇ ਸਟੋਰੇਜ, ਲੌਗਿੰਗ, ਅਤੇ permission ਨੂੰ ਸਿਸਟਮ ਭਰ ਵਿੱਚ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
ਕਿਸੇ fancy column mapping UI ਜਾਂ CSV ਇੰਪੋਰਟ ਵੈਲੀਡੇਸ਼ਨ ਨਿਯਮ ਬਾਰੇ ਸੋਚਣ ਤੋਂ ਪਹਿਲਾਂ, ਇੱਕ ਐਸਾ ਆਰਕੀਟੈਕਚਰ ਚੁਣੋ ਜਿਸ ਨੂੰ ਤੁਹਾਡੀ ਟੀਮ ਭਰੋਸੇ ਨਾਲ ship ਅਤੇ operate ਕਰ ਸਕੇ। ਇੰਪੋਰਟ ਅਤੇ ਐਕਸਪੋਰਟ “ਬੋਰਿੰਗ” infrastructure ਹਨ—ਤਿਹਰਾਈ ਦੀ ਰਫ਼ਤਾਰ ਅਤੇ ਡੀਬੱਗ ਕਰਨ ਦੀ ਆਸਾਨੀ ਨੋਵਲਟੀ ਤੋਂ ਵਧ ਕੇ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਕੋਈ ਵੀ mainstream web stack ਇੱਕ ਡੇਟਾ ਇੰਪੋਰਟ ਵੈਬ ਐਪ ਚਲਾ ਸਕਦੀ ਹੈ। ਚੁਣੋ ਮੌਜੂਦਾ ਹੁਨਰ ਅਤੇ hiring ਹਕੀਕਤਾਂ ਦੇ ਆਧਾਰ 'ਤੇ:
ਕੁੰਜੀ consistency ਹੈ: ਸਟੈਕ ਨੂੰ ਨਵੀਨਤਮ ਕਿਸੇ rewrite ਤੋਂ ਬਿਨਾਂ ਨਵੇਂ import ਪ੍ਰਕਾਰ, ਨਵੇਂ ਡੇਟਾ ਵੈਲੀਡੇਸ਼ਨ ਨਿਯਮ, ਅਤੇ ਨਵੇਂ ਐਕਸਪੋਰਟ ਫਾਰਮੈਟ ਐਡ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇੱਕ one-off prototype ਦੇ ਵਜ੍ਹੇ ਤੇ scaffolding ਤੇਜ਼ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ Koder.ai ਵਰਗਾ vibe-coding ਪਲੇਟਫਾਰਮ ਮਦਦਗਾਰ ਸਕਦਾ ਹੈ: ਤੁਸੀਂ ਆਪਣੇ ਇੰਪੋਰਟ ਫਲੋ (upload → preview → mapping → validation → background processing → history) ਨੂੰ ਚੈਟ ਵਿਚ ਵਰਣਨ ਕਰ ਸਕਦੇ ਹੋ, ਇੱਕ React UI ਨਾਲ Go + PostgreSQL ਬੈਕਐਂਡ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ planning mode ਅਤੇ snapshots/rollback ਵਰਤ ਕੇ ਤੇਜ਼ iteration ਕਰ ਸਕਦੇ ਹੋ।
ਸੰਰਚਿਤ ਰਿਕਾਰਡਾਂ, upserts, ਅਤੇ ਆਡਿਟ ਲੌਗ ਲਈ relational database (Postgres/MySQL) ਵਰਤੋ।
ਅਸਲ uploads (CSV/Excel) ਨੂੰ object storage (S3/GCS/Azure Blob) ਵਿੱਚ ਸਟੋਰ ਕਰੋ। Raw ਫਾਇਲਾਂ ਰੱਖਣਾ support ਲਈ ਅਮੂਲ ਹੈ: ਤੁਸੀਂ parsing ਮੁੱਦਿਆਂ ਨੂੰ ਦੁਹਰਾਅ ਸਕਦੇ ਹੋ, ਨੌਕਰੀਆਂ ਨੂੰ ਫਿਰ ਤੋਂ ਚਲਾ ਸਕਦੇ ਹੋ, ਅਤੇ ਐਰਰ ਹੈਂਡਲਿੰਗ ਫੈਸਲਿਆਂ ਦੀ ਵਿਆਖਿਆ ਕਰ ਸਕਦੇ ਹੋ।
ਛੋਟੀ ਫਾਇਲਾਂ ਨੂੰ synchronously ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ (upload → validate → apply) ਇੱਕ ਚੁਸਤ UX ਲਈ। ਵੱਡੀਆਂ ਫਾਇਲਾਂ ਲਈ ਕੰਮ ਨੂੰ background jobs ਵਿੱਚ ਸਥਾਨਾਂਤਰਿਤ ਕਰੋ:
ਇਸ ਨਾਲ retries ਅਤੇ rate-limited writes ਲਈ ਵੀ ਸਹੂਲਤ ਮਿਲਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ SaaS ਬਣਾ ਰਹੇ ਹੋ ਤਾਂ ਸ਼ੁਰੂ ਵਿੱਚ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ tenant ਡੇਟਾ ਨੂੰ ਕਿਵੇਂ ਵੱਖ ਕਰੋਗੇ (row-level scoping, separate schemas, ਜਾਂ separate databases)। ਇਹ ਚੋਣ ਤੁਹਾਡੇ ਡੇਟਾ ਐਕਸਪੋਰਟ API, permissions, ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ।
Uptime ਟਿੱਪਣੀਆਂ, maximum file size, expected rows per import, time-to-complete, ਅਤੇ cost limits ਲਿਖੋ। ਇਹ ਨੰਬਰ job queue ਚੋਣ, batching ਰਣਨੀਤੀ, ਅਤੇ indexing ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ—UI ਸੋਝਾ ਕਰਨ ਤੋਂ ਕਾਫੀ ਪਹਿਲਾਂ।
ਇੰਟੇਕ ਫਲੋ ਹਰ ਇੰਪੋਰਟ ਲਈ ਟੋਨ ਸੈਟ ਕਰਦਾ ਹੈ। ਜੇ ਇਹ predictable ਅਤੇ forgiving ਮਹਿਸੂਸ ਹੋਵੇ ਤਾਂ ਯੂਜ਼ਰ ਖ਼ਰਾਬ ਹੋਣ 'ਤੇ ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰਨਗੇ—ਅਤੇ ਸਪੋਰਟ ਟਿਕਟ ਘਟਣਗੇ।
ਵੈਬ UI ਲਈ drag-and-drop ਜ਼ੋਨ ਅਤੇ ਇੱਕ classic file picker ਦੋਹਾਂ ਦਿਓ। Drag-and-drop ਪਾਵਰ ਯੂਜ਼ਰ ਲਈ ਤੇਜ਼ ਹੈ, ਜਦਕਿ file picker ਜ਼ਿਆਦਾ accessible ਅਤੇ ਜਾਣੀ-ਪਹਚਾਣੀ ਹੁੰਦੀ ਹੈ।
ਜੇ ਤੁਹਾਡੇ ਗਾਹਕ ਹੋਰ ਸਿਸਟਮਾਂ ਤੋਂ ਇੰਪੋਰਟ ਕਰਦੇ ਹਨ, ਤਾਂ ਇੱਕ API endpoint ਵੀ ਸ਼ਾਮਲ ਕਰੋ। ਇਹ multipart uploads (file + metadata) ਜਾਂ ਵੱਡੀਆਂ ਫਾਇਲਾਂ ਲਈ pre-signed URL flow ਨੂੰ ਸਵੀਕਾਰ ਕਰ ਸਕਦਾ ਹੈ।
ਅਪਲੋਡ 'ਤੇ, ਡੇਟਾ ਨੂੰ commit ਕਰਣ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਹਲਕੀ parsing ਕਰੋ ਤਾਂ ਕਿ ਇੱਕ “preview” ਬਣ ਜਾਏ:
ਇਹ preview ਬਾਅਦ ਦੇ ਕਦਮਾਂ ਲਈ column mapping ਅਤੇ validation ਨੂੰ ਪਾਵਰ ਕਰਦਾ ਹੈ।
ਹਮੇਸ਼ਾਂ ਅਸਲ ਫਾਇਲ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਸਟੋਰ ਕਰੋ (object storage ਆਮ ਹੈ)। ਇਸਨੂੰ immutable ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ:
ਹਰ upload ਨੂੰ ਇੱਕ first-class record ਸਮਝੋ। uploader, timestamp, source system, file name, ਅਤੇ checksum (duplicates ਦਾ ਪਤਾ ਕਰਨ ਅਤੇ ਇੰਟੈਗ੍ਰਿਟੀ ਨਿਸ਼ਚਿਤ ਕਰਨ ਲਈ) ਵਰਗੇ ਮੈਟਾਡੇਟਾ ਸੰਭਾਲੋ। ਇਹ ਆਡਿਟੇਬਿਲਟੀ ਅਤੇ ਡੀਬੱਗਿੰਗ ਲਈ ਬੇਹਦ ਕੀਮਤੀ ਹੁੰਦਾ ਹੈ।
ਤੇਜ਼ ਪ੍ਰੀ-ਚੈਕ ਤੁਰੰਤ ਚਲਾਓ ਅਤੇ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ ਜਣੇ early fail ਕਰੋ:
ਜੇ ਪ੍ਰੀ-ਚੈਕ ਫੇਲ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਸਪਸ਼ਟ ਸੁਨੇਹਾ ਵਾਪਸ ਕਰੋ ਅਤੇ ਦਿਖਾਓ ਕਿ ਕੀ ਠੀਕ ਕਰਨਾ ਹੈ। ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਬਿਲਕੁਲ ਬੁਰੇ ਫਾਇਲਾਂ ਨੂੰ ਜਲਦੀ ਰੋਕਿਆ ਜਾਵੇ—ਬਿਨਾਂ ਉਹਨਾਂ ਵੈਧ ਪਰ ਅਪਰਿਪਕਟ ਡੇਟਾ ਨੂੰ ਰੋਕੇ ਜੋ ਬਾਅਦ ਵਿੱਚ ਮੈਪ ਅਤੇ ਸਾਫ਼ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
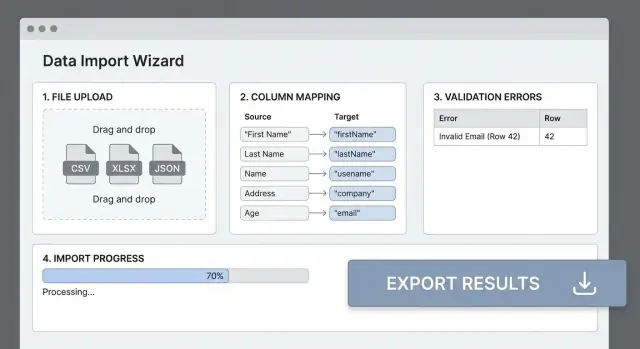
ਜ਼ਿਆਦਾਤਰ ਇੰਪੋਰਟ ਫੇਲ੍ਹਰ ਇਸ ਲਈ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਫਾਇਲ ਦੇ headers ਤੁਹਾਡੇ ਐਪ ਦੇ ਫੀਲਡਾਂ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ। ਇੱਕ ਸਪਸ਼ਟ column mapping ਕਦਮ “messy CSV” ਨੂੰ ਪੇਸ਼ਗੀ ਇਨਪੁੱਟ ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ ਅਤੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਟ੍ਰਾਇ-ਅਤੇ-ਏਰਰ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਇੱਕ ਸਧਾਰਣ ਟੇਬਲ ਦਿਖਾਓ: Source column → Destination field। ਸੰਭਾਵਤ ਮੈਚ ਆਟੋ-ਡਿਟੈਕਟ (case-insensitive header matching, synonyms ਜਿਵੇਂ “E-mail” → email), ਪਰ ਹਮੇਸ਼ਾ ਯੂਜ਼ਰਾਂ ਨੂੰ override ਕਰਨ ਦਿਓ।
ਕੁਝ ਸੁਵਿਧਾਵਾਂ ਸ਼ਾਮਿਲ ਕਰੋ:
ਜੇ ਗਾਹਕ ਹਰ ਹਫ਼ਤੇ ਇੱਕੋ ਫਾਰਮੈਟ ਇੰਪੋਰਟ ਕਰਦੇ ਹਨ, ਤਾਂ ਇੱਕ-ਕਲਿੱਕ ਉਪਲਬਧ ਕਰੋ। ਉਨ੍ਹਾਂ ਨੂੰ ਟੈਮਪਲੇਟ ਸੇਵ ਕਰਨ ਦਿਓ ਜੋ scoped ਹੋ ਸਕਦੇ ਹਨ:
ਜਦੋਂ ਨਵੀਂ ਫਾਇਲ ਅਪਲੋਡ ਹੁੰਦੀ ਹੈ, ਤਾਂ column overlap ਦੇ ਆਧਾਰ 'ਤੇ ਟੈਮਪਲੇਟ ਸੁਝਾਓ। ਵਰਜਨਿੰਗ ਵੀ ਸਹਾਇਤਾ ਦਿਓ ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਇੱਕ ਟੈਮਪਲੇਟ ਨੂੰ ਅੱਪਡੇਟ ਕਰ ਸਕਣ ਬਿਨਾਂ ਪੁਰਾਣੀਆਂ ਰਨਾਂ ਨੂੰ ਤੋੜੇ।
Mapped field ਪ੍ਰਤੀ ਹਲਕੀ ਟ੍ਰਾਂਸਫਾਰਮਸ ਸ਼ਾਮਿਲ ਕਰੋ:
MM/DD/YYYY vs. DD.MM.YYYY) ਟਾਈਮਜ਼ੋਨ ਵਿਕਲਪਾਂ ਨਾਲACTIVE)ਟ੍ਰਾਂਸਫਾਰਮ explicit UI ਵਿੱਚ ਰੱਖੋ (“Applied: Trim → Parse Date”) ਤਾਂ ਕਿ ਆਉਟਪੁੱਟ ਸਮਝਾਏ ਜਾਣਯੋਗ ਹੋਵੇ।
ਪੂਰੀ ਫਾਇਲ ਨੂੰ ਪ੍ਰੋਸੈਸ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ (ਮਿਸਾਲ ਵਜੋਂ) 20 rows ਦਾ mapped results preview ਦਿਖਾਓ। ਮੂਲ ਵੈਲਯੂ, ਟ੍ਰਾਂਸਫਾਰਮ ਕੀਤੀ ਵੈਲਯੂ, ਅਤੇ ਵਾਰਨਿੰਗ (ਜਿਵੇਂ “Could not parse date”) ਦਿਖਾਓ। ਇੱਥੇ ਯੂਜ਼ਰ ਪਹਿਲਾਂ ਹੀ ਮੁੱਦੇ ਫੜ ਲੈਂਦੇ ਹਨ।
ਯੂਜ਼ਰਾਂ ਨੂੰ ਇੱਕ key field (email, external_id, SKU) ਚੁਣਨ ਲਈ ਕਹੋ ਅਤੇ ਸਮਝਾਓ ਕਿ duplicates 'ਤੇ ਕੀ ਹੁੰਦਾ ਹੈ। ਭਾਵੇਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ upserts ਸੰਭਾਲੋ, ਇਹ ਕਦਮ ਉਮੀਦਾਂ ਸੈੱਟ ਕਰਦਾ ਹੈ: ਤੁਸੀਂ ਫਾਇਲ ਵਿੱਚ ਡਿਊਪਲਿਕੇਟ ਕੀਜ਼ ਬਾਰੇ ਵਾਰਨਿੰਗ ਦੇ ਸਕਦੇ ਹੋ ਅਤੇ ਸੁਝਾਅ ਦੇ ਸਕਦੇ ਹੋ ਕਿ ਕਿਹੜਾ ਰਿਕਾਰਡ “ਜਿੱਤੇਗਾ” (first, last, ਜਾਂ error)।
ਵੈਲੀਡੇਸ਼ਨ ਇੱਕ “file uploader” ਅਤੇ ਇੱਕ ਐਸੇ import ਫੀਚਰ ਵਿਚਕਾਰ ਫਰਕ ਬਣਾਉਂਦੀ ਜਿਸ 'ਤੇ ਲੋਕ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ। ਮਕਸਦ ਸਖ਼ਤ ਹੋਣਾ ਨਹੀਂ—ਮਕਸਦ ਬੁਰੇ ਡੇਟਾ ਨੂੰ ਫੈਲਣ ਤੋਂ ਰੋਕਣਾ ਹੈ ਜਦਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ ਸਪਸ਼ਟ, actionable ਫੀਡਬੈਕ ਦਿੱਤਾ ਜਾਵੇ।
ਵੈਲੀਡੇਸ਼ਨ ਨੂੰ ਤਿੰਨ ਵੱਖਰੇ ਚੈਕਾਂ ਵਜੋਂ ਇਲਹਾਮ ਕਰੋ, ਹਰ ਇੱਕ ਦਾ ਮਕਸਦ ਵੱਖਰਾ ਹੈ:
email a string?”, “Is amount a number?”, “Is customer_id present?” ਇਹ ਤੇਜ਼ ਹਨ ਅਤੇ parsing ਤੋਂ ਬਾਅਦ ਤੁਰੰਤ ਚਲਾਈ ਜਾ ਸਕਦੀ ਹੈ।country=US, state is required”, “end_date must be after start_date”, “Plan name must exist in this workspace.” ਇਹ ਆਮ ਤੌਰ 'ਤੇ context (ਦੂਜੇ ਕਾਲਮ ਜਾਂ DB lookups) ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ।ਇਨ੍ਹਾਂ ਲੇਅਰਾਂ ਨੂੰ ਵੱਖ ਵੱਖ ਰੱਖਣ ਨਾਲ ਸਿਸਟਮ ਨੂੰ ਵਧਾਉਣਾ ਅਤੇ UI ਵਿੱਚ ਸਮਝਾਉਣਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਲਹਿਰੋਂ ਪਹਿਲਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਇਕ ਇੰਪੋਰਟ:
ਤੁਸੀਂ ਦੋਹਾਂ ਸਹਾਇਤ ਕਰ ਸਕਦੇ ਹੋ: strict default ਤੇ, admins ਲਈ “Allow partial import” ਚੋਣ।
ਹਰ ਗਲਤੀ ਨੂੰ ਇਹ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ: ਕੀ ਹੋਇਆ, ਕਿੱਥੇ, ਅਤੇ ਕਿਵੇਂ ਠੀਕ ਕਰਾਂ।
ਉਦਾਹਰਨ: “Row 42, Column ‘Start Date’: must be a valid date in YYYY-MM-DD format.”
ਫਰਕ ਕਰੋ:
ਯੂਜ਼ਰ ਵਿਰਲੇ ਹੀ ਸਭ ਕੁਝ ਇੱਕ ਹੀ ਪਾਸ ਵਿੱਚ ਠੀਕ ਕਰਦੇ ਹਨ। validation ਨਤੀਜਿਆਂ ਨੂੰ ਇੱਕ import کوشش ਨਾਲ ਜੋੜਿਆ ਰੱਖ ਕੇ re-uploads ਨੂੰ ਆਸਾਨ ਬਣਾਓ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ downloadable error reports ਦੇ ਨਾਲ ਜੋੜੋ ਤਾਂ ਜੋ ਉਹ ਬਲਕ ਵਿੱਚ ਮੁੱਦਿਆਂ ਨੂੰ ਹੱਲ ਕਰ ਸਕਣ।
ਇੱਕ عملي ਢੰਗ ਹਾਈਬ੍ਰਿਡ ਹੈ:
ਇਸ ਨਾਲ validation ਲਚਕੀਲਾ ਬਣਿਆ ਰਹੇਗਾ ਬਿਨਾਂ ਇਸਨੂੰ ਇੱਕ ਮੁਸ਼ਕਿਲ-ਡਿਬੱਗ “settings ਭੁੱਠੇ” ਵਿੱਚ ਬਦਲਣ ਦੇ।
ਇੰਪੋਰਟ ਆਮ ਤੌਰ 'ਤੇ ਠਹਿਰਾਉਂਦੇ ਕਾਰਨਾਂ ਕਰਕੇ ਫੇਲ ਹੁੰਦੇ ਹਨ: ਹੌਲੀ ਡੇਟਾਬੇਸ, ਪੀਕ ਸਮੇਂ ਫਾਇਲ ਸਪਾਈਕ, ਜਾਂ ਇੱਕ single “ਬਦ” ਰੋ ਜੋ ਸਾਰੇ ਬੈਚ ਨੂੰ ਰੋਕ ਦਿੰਦਾ ਹੈ। ਭਰੋਸੇਯੋਗਤਾ ਬਹੁਤ ਹੱਦ ਤਕ ਕੰਮ ਨੂੰ request/response ਪਾਥ ਤੋਂ ਬਾਹਰ ਲਿਜਾਣ ਅਤੇ ਹਰ ਕਦਮ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾਉਣ ਯੋਗ ਬਣਾਉਣ ਦੇ ਬਾਰੇ ਹੈ।
Parsing, validation, ਅਤੇ writes ਨੂੰ background jobs (queues/workers) ਵਿੱਚ ਚਲਾਓ ਤਾਂ ਕਿ uploads ਵੈਬ timeout ਦਾ ਸਾਹਮਣਾ ਨਾ ਕਰਨ। ਇਸ ਨਾਲ ਦੇਖਭਾਲ ਲਈ retries ਅਤੇ workers ਨੂੰ ਅਲੱਗ scale ਕਰਨ ਦੀ ਆਗਿਆ ਮਿਲਦੀ ਹੈ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਪੈਟਰਨ ਹੈ chunks ਵਿੱਚ ਕੰਮ ਵੰਡਣਾ (ਉਦਾਹਰਨ: 1,000 rows ਪ੍ਰਤੀ job). ਇੱਕ “parent” import job chunk jobs ਨੂੰ schedule ਕਰਦਾ ਹੈ, ਨਤੀਜੇ aggregate ਕਰਦਾ ਹੈ, ਅਤੇ ਪ੍ਰੋਗਰੈਸ ਨੂੰ ਅਪਡੇਟ ਕਰਦਾ ਹੈ।
ਇੰਪੋਰਟ ਨੂੰ state machine ਵਜੋਂ ਮਾਡਲ ਕਰੋ ਤਾਂ ਕਿ UI ਅਤੇ ops ਟੀਮ ਹਮੇਸ਼ਾ ਜਾਣ ਸਕਣ ਕਿ ਕੀ ਹੋ ਰਿਹਾ ਹੈ:
ਰਾਜ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਪ੍ਰਤੀ timestamps ਅਤੇ attempt counts ਸਟੋਰ ਕਰੋ ਤਾਂ ਕਿ “ਇਹ ਕਦੋਂ ਸ਼ੁਰੂ ਹੋਇਆ?” ਅਤੇ “ਕਿੰਨੀ retries ਹੋਈਆਂ?” ਜਵਾਬ ਬਿਨਾ ਲੋਗز ਖੰਗਾਲੇ ਦਿੱਤੇ ਜਾ ਸਕਣ।
ਮਾਪਯੋਗ ਪ੍ਰੋਗਰੈਸ ਦਿਖਾਓ: process ਕੀਤੀਆਂ rows, ਬਚੀਆਂ rows, ਅਤੇ ਹੁਣ ਤੱਕ ਮਿਲੀਆਂ ਗਲਤੀਆਂ। ਜੇ ਤੁਸੀਂ throughput ਅੰਦਾਜ਼ਾ ਲਗਾ ਸਕਦੇ ਹੋ ਤਾਂ ਇੱਕ ਕਰੀਬਨ ETA ਦਿਓ—ਪਰ ਸਹੀ countdown ਨਾਲੋਂ “~3 min” ਵਰਗਾ ਅੰਦਾਜ਼ਾ ਠੀਕ ਹੈ।
Retries ਤੋਂ duplicates ਜਾਂ double-apply ਨਾ ਹੋਣ:
import_id + row_number (ਜਾਂ row hash) ਵਰਗਾ stable idempotency key ਵਰਤੋ।external_id) ਨਾਲ upsert ਕਰੋ ਬਜਾਏ “ਹਮੇਸ਼ਾ insert” ਦੇ।Per workspace concurrent imports ਨੂੰ rate-limit ਕਰੋ ਅਤੇ write-heavy ਕਦਮਾਂ (ਉਦਾਹਰਨ: max N rows/sec) ਨੂੰ throttle ਕਰੋ ਤਾਂ ਕਿ ਡੇਟਾਬੇਸ overwhelm ਨਾ ਹੋਵੇ ਅਤੇ ਹੋਰ ਯੂਜ਼ਰਾਂ ਦਾ ਤਜਰਬਾ ਪ੍ਰਭਾਵਿਤ ਨਾ ਹੋਵੇ।
ਜੇ ਲੋਗ ਨਹੀਂ ਸਮਝ ਸਕਦੇ ਕਿ ਕੀ ਗਲਤ ਹੋਇਆ, ਫਿਰ ਉਹ ਇੱਕੋ ਜਿਹੀ ਫਾਇਲ ਨੂੰ ਦੁਹਰਾਉਂਦੇ ਰਹਿਣਗੇ ਜਦ ਤਕ ਉਹ ਹਾਰ ਨਾ ਮੰਨ ਲੈਂ। ਹਰ import ਨੂੰ ਇੱਕ first-class "run" ਸਮਝੋ ਜਿਸਦਾ ਇੱਕ ਸਪਸ਼ਟ ਪੇਪਰ ਟਰੇਲ ਹੋਵੇ ਅਤੇ actionable errors ਹੋਣ।
ਜਦੋਂ ਫਾਇਲ ਸਬਮਿਟ ਹੁੰਦੀ ਹੈ ਤਾਂ ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ import run ਐਂਟੀਟੀ ਬਣਾਓ। ਇਹ ਰਿਕਾਰਡ ਮੁੱਖ ਚੀਜ਼ਾਂ ਕੈਪਚਰ ਕਰੇ:
ਇਹ ਤੁਹਾਡੀ import history ਸਕ੍ਰੀਨ ਬਣੇਗੀ: ਰਨਾਂ ਦੀ ਇੱਕ ਸਾਦਾ ਲਿਸਟ status, counts, ਅਤੇ “view details” ਪੇਜ ਨਾਲ।
ਐਪਲਿਕੇਸ਼ਨ ਲੌਗਜ਼ engineers ਲਈ ਵਧੀਆ ਹਨ, ਪਰ ਯੂਜ਼ਰਾਂ ਨੂੰ ਕੁਐਰੀਏਬਲ error ਚਾਹੀਦੀ ਹੈ। errors ਨੂੰ ਢਾਂਚਾਬੱਧ ਰਿਕਾਰਡ ਵਜੋਂ import run ਨਾਲ ਜੋੜ ਕੇ ਰੱਖੋ, ਆਦਰਸ਼ ਤੌਰ 'ਤੇ ਦੋ ਲੈਵਲਾਂ ਤੇ:
ਇਸ ਢਾਂਚੇ ਨਾਲ ਤੁਸੀਂ ਤੇਜ਼ ਫਿਲਟਰਿੰਗ ਅਤੇ aggregate insights (ਜਿਵੇਂ “ਇਸ ਹਫਤੇ Top 3 error types”) ਨੂੰ ਪਾਵਰ ਕਰ ਸਕਦੇ ਹੋ।
Run details ਪੇਜ ਵਿੱਚ type, column, ਅਤੇ severity ਦੁਆਰਾ ਫਿਲਟਰ ਅਤੇ ਇੱਕ search ਬਾਕਸ ਦੇਓ (ਉਦਾਹਰਨ: “email”)। ਫਿਰ ਇੱਕ downloadable CSV error report ਦਿਓ ਜਿਸ ਵਿੱਚ original row ਨਾਲ error_columns ਅਤੇ error_message ਵਰਗੇ ਵਾਧੂ ਕਾਲਮ ਹੋਣ, ਅਤੇ ਸਪਸ਼ਟ ਦਿਸ਼ਾ-ਨਿਰਦੇਸ਼ ਹੋਣ ਜਿਵੇਂ “Fix date format to YYYY-MM-DD.”
ਇੱਕ “dry run” ਹਰ ਚੀਜ਼ ਨੂੰ ਉਹੀ mapping ਅਤੇ ਨਿਯਮਾਂ ਨਾਲ validate ਕਰਦਾ ਹੈ, ਪਰ ਡੇਟਾ ਨਹੀਂ ਲਿਖਦਾ। ਇਹ ਪਹਿਲੀ ਵਾਰੀ ਇੰਪੋਰਟ ਲਈ ਉਤਮ ਹੈ ਅਤੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਬਿਨਾਂ commit ਕੀਤੇ iterate ਕਰਨ ਦਿੰਦਾ ਹੈ।
ਇੰਪੋਰਟਾਂ ਨੂੰ “ਮੁੱਕ” ਤਦ ਹੀ ਲੱਗਦਾ ਹੈ ਜਦ ਰੋਜ਼ ਤੁਹਾਡੇ DB ਵਿੱਚ ਆ ਜਾਂਦੇ ਹਨ—ਪਰ ਲੰਬੇ ਸਮੇਂ ਦਾ ਖ਼ਰਚਾ ਆਮ ਤੌਰ 'ਤੇ ਗੁੰਝਲਦਾਰ ਅਪਡੇਟ, duplicates, ਅਤੇ ਅਸਪਸ਼ਟ ਚੇਂਜ ਹਿਸਟਰੀ ਵਿੱਚ ਹੁੰਦਾ ਹੈ। ਇਹ ਸੈਕਸ਼ਨ ਤੁਹਾਡੇ ਡੇਟਾ ਮਾਡਲ ਬਾਰੇ ਹੈ ਤਾਂ ਜੋ ਇੰਪੋਰਟ predictable, reversible, ਅਤੇ explainable ਹੋਣ।
ਸ਼ੁਰੂ ਵਿੱਚ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ ਇੱਕ imported row ਤੁਹਾਡੇ ਡੋਮੇਨ ਮਾਡਲ ਨੂੰ ਕਿਵੇਂ ਮੇਪ ਕਰਦਾ ਹੈ। ਹਰ entity ਲਈ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਇੰਪੋਰਟ:
ਇਹ ਫੈਸਲਾ import setup UI ਵਿੱਚ explicit ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ import job ਨਾਲ ਸਟੋਰ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਵਿਹਾਰ repeatable ਹੋਵੇ।
ਜੇ ਤੁਸੀਂ “create or update” ਸਮਰਥਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਸਥਿਰ upsert keys ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ—ਉਹ ਫੀਲਡ ਜੋ ਹਰ ਵਾਰ ਇੱਕੋ ਰਿਕਾਰਡ ਨੂੰ ਪਛਾਣਦੇ ਹਨ। ਆਮ ਚੋਣਾਂ:
external_id (ਜਦੋਂ ਦੂਜੇ ਸਿਸਟਮ ਤੋਂ ਆਉਂਦਾ ਹੈ ਇਹ ਵਧੀਆ ਹੈ)account_id + sku)collision ਹੇਠਾਂ ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਜੇ ਦੋ rows ਇੱਕੋ key ਸਾਂਝਾ ਕਰਦੇ ਹਨ ਜਾਂ key ਕਈ ਰਿਕਾਰਡਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ ਤਾਂ ਕੀ ਹੁੰਦਾ? ਚੰਗੇ defaults ਹਨ “ਸਪਸ਼ਟ ਤੌਰ ਤੇ row fail ਕਰੋ” ਜਾਂ “last row wins”, ਪਰ ਸੋਚ-ਸਮਝ ਕੇ ਚੁਣੋ।
ਜਿੱਥੇ consistency ਦੀ ਰੱਖਿਆ ਕਰਦੀ ਹੋਵੇ ਉੱਥੇ transactions ਵਰਤੋਂ (ਉਦਾਹਰਨ: ਮਾਂ-ਬੱਚੇ ਬਣਾਉਂਦੇ ਸਮੇਂ)। 200k-row ਫਾਇਲ ਲਈ ਇੱਕ ਵੱਡਾ transaction ਵਰਤਣ ਤੋਂ ਬਚੋ; ਇਹ tables ਨੂੰ lock ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ retries ਨੂੰ ਦੁਖਦਾਈ ਬਣਾ ਸਕਦਾ ਹੈ। chunks ਵਾਲੀਆਂ ਲਿਖਾਈਆਂ ਪਸੰਦ ਕਰੋ (ਉਦਾਹਰਨ: 500–2,000 rows ਪ੍ਰਤੀ batch) idempotent upserts ਨਾਲ।
ਇੰਪੋਰਟਸ ਰਿਸ਼ਤਿਆਂ ਦਾ ਆਦਰ ਕਰਣੇ ਚਾਹੀਦੇ ਹਨ: ਜੇ ਇੱਕ row ਕਿਸੇ parent record ਨੂੰ reference ਕਰਦਾ ਹੈ (ਜਿਵੇਂ Company), ਤਾਂ ਜਾਂ ਤਾਂ ਇਸਨੂੰ ਮੌਜੂਦ ਹੋਣਾ ਲਾਜ਼ਮੀ ਕਰੋ ਜਾਂ controlled step ਵਿੱਚ ਇਸਨੂੰ ਬਣਾਓ। “missing parent” errors ਨਾਲ ਪਹਿਲੇ ਹੀ fail ਹੋਣਾ ਅੱਧ-ਜੁੜੇ ਡੇਟੇ ਨੂੰ ਰੋਕਦਾ ਹੈ।
ਇੰਪੋਰਟ-ਚਲਿਤ ਬਦਲਾਅ ਲਈ audit logs ਸ਼ਾਮਿਲ ਕਰੋ: ਕੌਣ import ਤਰਕੀਬੀ ਰੂਪ ਵਿੱਚ ਚਲਾਇਆ, ਕਦੋਂ, source file, ਅਤੇ ਪ੍ਰਤੀ-ਰਿਕਾਰਡ ਸਾਰ (old vs new)। ਇਹ support ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ, ਯੂਜ਼ਰ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ, ਅਤੇ rollbacks ਨੂੰ ਸਧਾਰਨ ਕਰਦਾ ਹੈ।
ਐਕਸਪੋਰਟ ਸਾਦਾ ਲੱਗਦੇ ਹਨ ਜਦ ਤਕ ਗਾਹਕ deadline ਤੋਂ ਪਹਿਲਾਂ “ਸਭ ਕੁਝ” ਡਾਊਨਲੋਡ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਾ ਕਰਨ। ਇੱਕ ਸਕੇਲ ਕਰਨਯੋਗ ਐਕਸਪੋਰਟ ਸਿਸਟਮ ਵੱਡੇ datasets ਨੂੰ ਹਲਕਾ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਬਿਨਾਂ ਤੁਹਾਡੀ ਐਪ ਨੂੰ slowing down ਕੀਤੇ ਜਾਂ inconsistent ਫਾਇਲਾਂ ਤਿਆਰ ਕੀਤੇ।
ਤਿੰਨ ਵਿਕਲਪਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
Incremental exports ਇੰਟੀਗ੍ਰੇਸ਼ਨਾਂ ਲਈ ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹਨ ਅਤੇ ਮੁੜ-ਮੁੜ full dumps ਦੇ ਮੁਕਾਬਲੇ ਲੋਡ ਘਟਾਉਂਦੇ ਹਨ।
ਜੋ ਵੀ ਤੁਸੀਂ ਚੁਣੋ, consistent headers ਅਤੇ ਕਾਲਮ ਆਰਡਰ ਰੱਖੋ ਤਾਂ downstream processes ਟੁੱਟਣ।
ਵੱਡੇ ਐਕਸਪੋਰਟ ਸਾਰੇ rows ਨੂੰ memory ਵਿੱਚ ਲੋਡ ਨਹੀਂ ਕਰਨੇ ਚਾਹੀਦੇ। rows ਨੂੰ ਫੈਚ ਕਰਦਿਆਂ ਲਿਖਣ ਲਈ pagination/streaming ਵਰਤੋ। ਇਹ timeouts ਰੋਕਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੀ ਵੈਬ ਐਪ responsive ਰੱਖਦਾ ਹੈ।
ਵੱਡੇ datasets ਲਈ exports ਨੂੰ background job ਵਿੱਚ ਜਨਰੇਟ ਕਰੋ ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ ਤਿਆਰ ਹੋਣ 'ਤੇ notify ਕਰੋ। ਆਮ ਪੈਟਰਨ:
ਇਹ ਤੁਹਾਡੇ imports ਲਈ background jobs ਪੈਟਰਨ ਅਤੇ error reports ਲਈ ਇੱਕੋ “run history + downloadable artifact” ਪੈਟਰਨ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਮਿਲਦਾ ਹੈ।
ਐਕਸਪੋਰਟ ਆਮ ਤੌਰ 'ਤੇ ਆਡਿਟ ਹੋਂਦੇ ਹਨ। ਹਮੇਸ਼ਾ ਸ਼ਾਮਿਲ ਕਰੋ:
ਇਹ ਵੇਰਵਿਆਂ ਨਾਲ ਗ਼ਲਤਫਹਿਮੀਆਂ ਘਟਦੀਆਂ ਹਨ ਅਤੇ ਭਰੋਸੇਯੋਗ reconciliation ਸਹਾਇਤਾ ਮਿਲਦੀ ਹੈ।
ਇੰਪੋਰਟ ਅਤੇ ਐਕਸਪੋਰਟ ਸ਼ਕਤੀਸ਼ਾਲੀ ਫੀਚਰ ਹਨ ਕਿਉਂਕਿ ਇਹ ਤੁਰੰਤ ਬਹੁਤ ਸਾਰਾ ਡੇਟਾ ਘੁਮਾ ਸਕਦੇ ਹਨ। ਇਸ ਨਾਲ ਉਹਨਾਂ ਵਿੱਚ ਅਕਸਰ ਸੁਰੱਖਿਆ ਦੀਆਂ ਖ਼ਤਰੇ ਉभरਦੀਆਂ ਹਨ: ਇੱਕ ਜ਼ਿਆਦਾ-ਲੋੜੀਪੂਰਕ ਰੋਲ, ਕੋਈ leaked file URL, ਜਾਂ ਇੱਕ ਲੌਗ ਲਾਈਨ ਜੋ ਗਲਤੀ ਨਾਲ personal data ਸ਼ਾਮਿਲ ਕਰਦੇ ਹਨ।
ਉਹੀ authentication ਵਰਤੋਂ ਜੋ ਤੁਸੀਂ ਐਪ ਭਰ ਵਿੱਚ ਵਰਤਦੇ ਹੋ—imports ਲਈ ਇੱਕ “ਖ਼ਾਸ” auth path ਨਾ ਬਣਾਓ।
ਜੇ ਤੁਹਾਡੇ ਯੂਜ਼ਰ browser ਵਿੱਚ ਕੰਮ ਕਰਦੇ ਹਨ ਤਾਂ session-based auth (ਨਾਲ optional SSO/SAML) ਆਮ ਤੌਰ 'ਤੇ ਠੀਕ ਹੈ। ਜੇ imports/exports automated ਹਨ (ਰਾਤਾਨ ਵਾਲੀ ਨੌਕਰੀਆਂ, integration partners) ਤਾਂ API keys ਜਾਂ OAuth tokens ਨੂੰ ਸਪਸ਼ਟ scoping ਅਤੇ rotation ਨਾਲ ਵਿਚਾਰੋ।
ਇੱਕ عملي ਨਿਯਮ: import UI ਅਤੇ import API ਦੋਹਾਂ ਨੂੰ ਇੱਕੋ permissions ਲਾਗੂ ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ, ਭਾਵੇਂ ਉਹ ਵੱਖ-ਵੱਖ ਦਰਸ਼ਕਾਂ ਵਲੋਂ ਵਰਤੇ ਜਾਣ।
ਇੰਪੋਰਟ/ਐਕਸਪੋਰਟ ਸਮਰੱਥਾਵਾਂ ਨੂੰ explicit privileges ਵਜੋਂ ਰੱਖੋ। ਆਮ ਰੋਲ ਹਨ:
“download files” ਨੂੰ ਇੱਕ ਵਿਛੋੜੀ permission ਬਣਾਉ। ਬਹੁਤ ਸਾਰੇ ਸੰਵੇਦਨਸ਼ੀਲ leaks ਉਸ ਵੇਲੇ ਹੁੰਦੇ ਹਨ ਜਦ ਕਿਸੇ ਕੋਲ run ਵੇਖਣ ਦੀ permission ਹੋਵੇ ਅਤੇ ਸਿਸਟਮ ਮੰਨ ਲੈ ਕਿ ਉਹ original spreadsheet ਵੀ ਡਾਊਨਲੋਡ ਕਰ ਸਕਦਾ ਹੈ।
ਇਸ ਤੋਂ ਇਲਾਵਾ row-level ਜਾਂ tenant-level boundaries ਵਿਚਾਰੋ: ਇੱਕ ਯੂਜ਼ਰ ਨੂੰ ਸਿਰਫ਼ ਉਸ account/workspace ਦਾ ਡੇਟਾ import/export ਕਰਨ ਦੀ ਆਗਿਆ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਜਿਸ ਨਾਲ ਉਹ ਸੰਬੰਧਤ ਹੈ।
ਸਟੋਰ ਕੀਤੀਆਂ ਫਾਇਲਾਂ (uploads, generated error CSVs, export archives) ਲਈ private object storage ਅਤੇ short-lived download links ਵਰਤੋ। ਜੇ ਤੁਹਾਡੇ compliance ਦੀ ਲੋੜ ਹੈ ਤਾਂ at-rest encryption ਯਕੀਨੀ ਬਣਾਓ, ਅਤੇ consistent ਰਹੋ: original upload, processed staging file, ਅਤੇ generated reports ਸਭ ਨੂੰ ਇੱਕੋ ਨੀਤੀਆਂ ਬੋਲਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ।
ਲੌਗਜ਼ 'ਤੇ ਧਿਆਨ ਰੱਖੋ। ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡਜ਼ (emails, phone numbers, IDs, addresses) ਨੂੰ redact ਕਰੋ ਅਤੇ ਡੀਫਾਲਟ ਰੂਪ ਵਿੱਚ raw rows ਨੂੰ ਕਦੇ ਵੀ ਲੌਗ ਨਾ ਕਰੋ। ਜਦ debugging ਜ਼ਰੂਰੀ ਹੋਵੇ, “verbose row logging” ਨੂੰ admin-only settings ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਇਹ ਅਸਤੀ-ਮਿਆਦ ਵਾਲਾ ਹੈ।
ਹਰ upload ਨੂੰ untrusted input ਸਮਝੋ:
ਉਸੇ ਸਮੇਂ structure ਨੂੰ early validate ਕਰੋ: ਜ਼ਹਿਰੀਲਾ malformed files background jobs ਤੱਕ ਪਹੁੰਚਣ ਤੋਂ ਪਹਿਲਾਂ reject ਕਰੋ, ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ ਸਪਸ਼ਟ ਸੁਨੇਹਾ ਦਿਓ ਕਿ ਕੀ ਗਲਤ ਹੈ।
ਉਹ events record ਕਰੋ ਜੋ ਤੁਸੀਂ ਜਾਂਚ ਦੌਰਾਨ ਚਾਹੋਗੇ: ਕਿਸਨੇ ਫਾਇਲ upload ਕੀਤਾ, ਕਿਸਨੇ import ਸ਼ੁਰੂ ਕੀਤਾ, ਕਿਸਨੇ export ਡਾਊਨਲੋਡ ਕੀਤਾ, permission changes, ਅਤੇ failed access attempts।
Audit entries ਵਿੱਚ actor, timestamp, workspace/tenant, ਅਤੇ ਪ੍ਰਭਾਵਤ object (import run ID, export ID) ਸ਼ਾਮਿਲ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਪਰ ਸੰਵੇਦਨਸ਼ੀਲ ਰੋ ਡੇਟਾ ਸਟੋਰ ਨਾ ਕਰੋ। ਇਹ import history UI ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਜੁੜਦਾ ਹੈ ਅਤੇ ਤੁਹਾਨੂੰ ਜਲਦੀ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ: “ਕੌਣ ਕੀ ਬਦਲਿਆ, ਅਤੇ ਕਦੋਂ?”
ਜੇ imports ਅਤੇ exports ਗਾਹਕ ਡੇਟਾ ਨੂੰ ਛੂਹਦੇ ਹਨ, ਤੁਹਾਨੂੰ ਆਖ਼ਿਰਕਾਰ edge cases ਮਿਲਣਗੇ: ajeeb encodings, merged cells, ਅਧੂਰੇ ਰੋਜ਼, duplicates, ਅਤੇ “ਕੱਲ੍ਹ ਚੱਲਦਾ ਸੀ” ਹਾਦਸੇ। Operability ਉਹੀ ਹੈ ਜੋ ਇਨ੍ਹਾਂ ਮੁੱਦਿਆਂ ਨੂੰ support nightmares ਵਿੱਚ ਨਹੀਂ ਬਦਲਣ ਦਿੰਦੀ।
ਸਭ ਤੋਂ failure-prone ਹਿੱਸਿਆਂ (parsing, mapping, validation) ਦੇ ਆਲੇ-ਦੁਆਲੇ ਕੇਂਦਰਿਤ tests ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਫਿਰ ਘੱਟੋ-ਘੱਟ ਇੱਕ end-to-end test ਸ਼ਾਮਿਲ ਕਰੋ: upload → background processing → report generation। ਇਹ UI, API, ਅਤੇ workers ਵਿਚਕਾਰ contract mismatches ਫੜਦੇ ਹਨ (ਉਦਾਹਰਨ: job payload ਵਿੱਚ mapping configuration ਗ਼ਾਇਬ ਹੋਣਾ)।
ਉਹ signals ਟ੍ਰੈਕ ਕਰੋ ਜੋ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ:
ਸੁਨੇਹੇ (alerts) ਨੂੰ ਲਕੜੀ ਦੀ ਥਾਂ ਲੱਛਣਾਂ ਤੋਂ ਜੋੜੋ (increased failures, growing queue depth) ਨਾ ਕਿ ਹਰ exception ਤੇ।
ਅੰਦਰੂਨੀ ਟੀਮਾਂ ਨੂੰ ਕੁਝ admin ਸਰਫੇਸ ਦਿਓ ਤਾਂ ਕਿ ਉਹ jobs ਨੂੰ ਰੀ-ਰਨ, stuck imports cancel, ਅਤੇ failures inspect ਕਰ ਸਕਣ (input file metadata, mapping used, error summary, ਅਤੇ logs/traces ਲਈ ਲਿੰਕ)।
ਯੂਜ਼ਰਾਂ ਲਈ preventable errors ਨੂੰ inline tips, downloadable sample templates, ਅਤੇ error screens ਵਿੱਚ ਸਪਸ਼ਟ next steps ਨਾਲ ਘਟਾਓ। ਇੱਕ ਕੇਂਦਰੀ help page ਰੱਖੋ ਅਤੇ import UI ਤੋਂ ਇਸ ਨੂੰ ਲਿੰਕ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ: /docs)।
ਇੰਪੋਰਟ/ਐਕਸਪੋਰਟ ਸਿਸਟਮ ਨੂੰ ship ਕਰਨਾ ਸਿਰਫ़ “production 'ਤੇ push” ਨਹੀਂ ਹੁੰਦਾ। ਇਸਨੂੰ ਇੱਕ product ਫੀਚਰ ਵਜੋਂ ਸਭ ਵਰਗੀਆਂ safe defaults, ਸਾਫ਼ recovery paths, ਅਤੇ ਵਿਕਾਸ ਲਈ ਜਗ੍ਹਾ ਨਾਲ treat ਕਰੋ।
ਅਲੱਗ dev/staging/prod ਵਾਤਾਵਰਣ ਸੈਟਅੱਪ ਕਰੋ ਜਿਸ ਵਿੱਚ ਅਲੱਗ ਡੇਟਾਬੇਸ ਅਤੇ uploaded files ਤੇ generated exports ਲਈ ਅਲੱਗ object storage buckets (ਜਾਂ prefixes) ਹੋਣ। ਹਰ ਵਾਤਾਵਰਣ ਲਈ ਵੱਖਰੇ encryption keys ਅਤੇ credentials ਰੱਖੋ, ਅਤੇ ਯਕੀਨੀ ਬਣਾਓ ਕਿ background job workers ਸਹੀ queues ਵੱਲ point ਕਰ ਰਹੇ ਹਨ।
Staging ਨੂੰ production ਨਾਲ ਮਿਲਦਾ-जुलਦਾ ਰੱਖੋ: ਇੱਕੋ ਜਿਹੀ job concurrency, timeouts, ਅਤੇ file size limits। ਓਥੇ ਤੁਸੀਂ performance ਅਤੇ permissions validate ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਅਸਲੀ ਗਾਹਕ ਡੇਟਾ ਦੇ ਖਤਰੇ ਦੇ।
ਇੰਪੋਰਟ ਲੰਮੇ ਸਮੇਂ ਤੱਕ “ਰਿਹਿੰਦੇ” ਹਨ ਕਿਉਂਕਿ ਗਾਹਕ ਪੁਰਾਣੀਆਂ spreadsheets ਰੱਖਦੇ ਹਨ। ਕਾਨੂੰਨੀ migration ਪ੍ਰਕਿਰਿਆ ਵਰਤੋ, ਪਰ ਆਪਣੀਆਂ import templates ਨੂੰ ਵੀ version ਕਰੋ (ਅਤੇ mapping presets)। ਇਸ ਤਰ੍ਹਾਂ schema change ਪਿਛਲੇ ਕਾਲ ਦੀ CSV ਨੂੰ ਨਹੀਂ ਤੋੜਦਾ।
ਇੱਕ عملي ਅਭਿਗਮ ਇਹ ਹੈ ਕਿ ਹਰ import run ਨਾਲ template_version ਸਟੋਰ ਕਰੋ ਅਤੇ ਪੁਰਾਣੀ ਵਰਜਨਾਂ ਲਈ compatibility ਕੋਡ ਰੱਖੋ ਜਦ ਤੱਕ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਡਿਪ੍ਰੇਕੇਟ ਨਹੀਂ ਕਰ ਸਕਦੇ।
ਤਬਦੀਲੀਆਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ship ਕਰਨ ਲਈ feature flags ਵਰਤੋ:
Flags ਤੁਹਾਨੂੰ ਨਵੀਆਂ ਚੀਜ਼ਾਂ ਨੂੰ ਪਹਿਲਾਂ ਆਂਤਰਿਕ ਯੂਜ਼ਰਾਂ ਜਾਂ ਇੱਕ ਛੋਟੇ ਗਾਹਕ ਕੋਹੋਰਟ ਤੇ ਟੈਸਟ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦੀਆਂ ਹਨ।
ਸਪੋਰਟ ਨੂੰFailures ਦੀ ਜਾਂਚ ਕਰਨ ਦਾ ਤਰੀਕਾ ਦਸਤਾਵੇਜ਼ ਕਰੋ: import history, job IDs, ਅਤੇ logs। ਇੱਕ ਸਧਾਰਨ ਚੈੱਕਲਿਸਟ ਮਦਦਗਾਰ ਹੁੰਦੀ ਹੈ: template version ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ, ਪਹਿਲੀ failing row ਦੀ ਸਮੀਖਿਆ ਕਰੋ, storage access ਜਾਂਚੋ, ਫਿਰ worker logs ਦੇਖੋ। ਇਸਨੂੰ ਆਪਣੇ internal runbook ਵਿੱਚ ਲਿੰਕ ਕਰੋ ਅਤੇ ਜਿੱਥੇ ਉਪਯੋਗ ਹੋਵੇ admin UI ਤੋਂ ਵੀ ਲਿੰਕ ਦਿਓ (ਉਦਾਹਰਨ ਲਈ: /admin/imports)।
ਜਦੋਂ core workflow ਸਥਿਰ ਹੋ ਜਾਏ, ਤਾਂ ਇਸਨੂੰ uploads ਤੋਂ ਅੱਗੇ ਵਧਾਓ:
ਇਹ ਅੱਪਗਰੇਡ manual ਕੰਮ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਤੁਹਾਡੇ ਡੇਟਾ ਇੰਪੋਰਟ ਵੈਬ ਐਪ ਨੂੰ ਗਾਹਕਾਂ ਦੇ ਮੌਜੂਦਾ ਪ੍ਰਕਿਰਿਆਵਾਂ ਵਿੱਚ ਨੈਟਿਵ ਮਹਿਸੂਸ ਕਰਾਉਂਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਇੱਕ product ਫੀਚਰ ਵਜੋਂ ਬਣਾ ਰਹੇ ਹੋ ਅਤੇ “ਪਹਿਲੀ ਉਪਯੋਗੀ ਸੰਜਨ” ਨੂੰ ਘਟਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ Koder.ai ਵਰਤ ਕੇ import wizard, job status ਪੇਜਜ਼, ਅਤੇ run history ਸਕ੍ਰੀਨਾਂ end-to-end prototype ਕਰਨ ਤੇ ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਬੇਨਤੀ ਹੋ ਸਕਦੀ ਹੈ, ਫਿਰ source code conventional engineering workflow ਲਈ export ਕਰੋ। ਇਹ ਅਭਿਗਮ ਖਾਸ ਕਰਕੇ ਪ੍ਰਯੋਗੀ ਹੈ ਜਦ ਲਕਸ਼ reliability ਅਤੇ iteration speed ਹੁੰਦਾ ਹੈ (ਸਭ ਤੋਂ ਪਹਿਲਾਂ bespoke UI perfection ਨਹੀਂ)।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਸਪੱਸ਼ਟ ਕਰੋ ਕਿ ਕੌਣ ਇੰਪੋਰਟ/ਐਕਸਪੋਰਟ ਕਰ ਰਿਹਾ ਹੈ (admins, operators, customers) ਅਤੇ ਤੁਹਾਡੇ ਮੁੱਖ ਵਰਕੇਸ ਕੇਹੜੇ ਹਨ (onboarding bulk load, periodic sync, one-off exports)।
ਦਿਨ-ਨੂੰ ਦੀਆਂ ਸੀਮਾਵਾਂ ਲਿਖੋ:
ਇਹ ਫੈਸਲੇ ਆਰਕੀਟੈਕਚਰ, UI ਜਟਿਲਤਾ ਅਤੇ ਸਹਾਇਤਾ ਲੋਡ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
ਸਿੰਕ੍ਰੋਨਸ ਪ੍ਰੋਸੈਸਿੰਗ ਉਹਨਾਂ ਮਾਮਲਿਆਂ ਲਈ ਵਰਤੋ ਜਦੋਂ ਫਾਇਲਾਂ ਛੋਟੀ ਹੁੰਦੀਆਂ ਹਨ ਅਤੇ ਵੈਬ ਰਿਕਵੇਸਟ ਟਾਈਮਆਉਟ ਵਿੱਚ ਵੈਲੀਡੇਸ਼ਨ + ਲਿਖਾਈ ਪੂਰੀ ਹੋ ਜਾਂਦੀ ਹੈ।
ਬੈਕਗ੍ਰਾਊਂਡ ਜਾਬਜ਼ ਵਰਤੋਂ ਜਦੋਂ:
ਇੱਕ ਆਮ ਪੈਟਰਨ ਹੈ: upload → enqueue → show run status/progress → notify on completion.
ਦੋਨੋਂ ਲਈ ਮੌਕੇ ਹਨ:
Raw upload ਨੂੰ immutable ਰੱਖੋ ਅਤੇ ਇਸਨੂੰ ਇੱਕ import run ਰਿਕਾਰਡ ਨਾਲ ਜੋੜੋ।
ਅਪਲੋਡ 'ਤੇ ਪ੍ਰੀਵਿਊ ਸਟੈਪ ਬਣਾਓ ਜੋ ਹੈਡਰ ਡਿਟੈਕਟ ਕਰਦਾ ਹੈ ਅਤੇ ਕੋਈ ਵੀ ਚੀਜ਼ ਕਮਿਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਛੋਟਾ ਨਮੂਨਾ (ਉਦਾਹਰਨ ਲਈ 20–100 ਰੋਜ਼) ਪਾਰਸ ਕਰਦਾ ਹੈ।
ਆਮ ਵੈਰੀਏਬਿਲਿਟੀ ਨੂੰ ਹੇਠਾਂ ਹਨਡਲ ਕਰੋ:
ਸੱਚੇ ਬਲਾਕਰਾਂ (unreadable file, missing required columns) 'ਤੇ ਫੇਲ ਤੇਜ਼ੀ ਨਾਲ ਕਰੋ, ਪਰ ਉਹ ਡੇਟਾ reject ਨਾ ਕਰੋ ਜੋ ਮੈਪ ਜਾਂ ਟ੍ਰਾਂਸਫਾਰਮ ਹੋ ਸਕਦਾ ਹੈ।
ਸਧਾਰਣ ਮੈਪਿੰਗ ਟੇਬਲ ਵਰਤੋਂ: Source column → Destination field।
ਸਰਵੋਤਮ ਅਭਿਆਸ:
ਹਮੇਸ਼ਾ mapped preview ਦਿਖਾਓ ਤਾਂ ਕਿ ਯੂਜ਼ਰ ਪੂਰੀ ਫਾਇਲ ਪ੍ਰੋਸੈਸ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਗਲਤੀਆਂ ਫੜ ਸਕਣ।
ਹੇਠਾਂ ਹਲਕੀ-ਫੁਲਕੀ ਟ੍ਰਾਂਸਫਾਰਮਾਂ ਦਾ ਸਹਾਰਾ ਦਿਓ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ schema ਨਾਲ ਮੇਲ ਖਾਣ ਵਿੱਚ ਮਦਦ ਕਰਣ:
ACTIVE)ਪ੍ਰੀਵਿਊ ਵਿੱਚ “original → transformed” ਦਿਖਾਓ ਤੇ ਜਦੋਂ ਕੋਈ ਟ੍ਰਾਂਸਫਾਰਮ ਲਾਗੂ ਨਹੀਂ ਹੋ ਸਕਦਾ ਤਾਂ ਵਾਰਨਿੰਗ ਦਿਖਾਓ।
ਵੈਲੀਡੇਸ਼ਨ ਨੂੰ ਤਿੰਨ ਤਹਾਂ ਵਿੱਚ ਵੰਡੋ:
UI ਵਿੱਚ actionable ਸੁਨੇਹੇ ਦਿਓ ਜਿਹੜੇ row/column ਰਿਫਰੈਂਸ ਨਾਲ ਹੋਣ (ਉਦਾਹਰਨ: “Row 42, Start Date: must be YYYY-MM-DD”).
ਤੈਅ ਕਰੋ ਕਿ ਇੰਪੋਰਟ (ਸਾਰੀ ਫਾਇਲ fail) ਹੋਣਗੇ ਜਾਂ (ਵੈਧ ਰੋਜ਼ ਸਵੀਕਾਰ ਕੀਤੇ ਜਾਣ)। admins ਲਈ ਦੋਹਾਂ ਚੋائس ਦਿਓ।
ਪ੍ਰੋਸੈਸਿੰਗ ਨੂੰ retry-safe ਬਨਾਓ:
import_id + row_number ਜਾਂ row hash)external_id) ਨਾਲ upserts ਪਸੰਦ ਕਰੋ insert always ਦੀ ਥਾਂਫਾਇਲ ਜਮ੍ਹਾਂ ਹੋਣ ਦੇ ਨਾਲ ਹੀ ਇੱਕ import run ਰਿਕਾਰਡ ਬਣਾਓ ਅਤੇ ਲਾਗਜ਼ ਤੋਂ ਇਲਾਵਾ ਢਾਂਚਾਬੱਧ, ਕ੍ਵੈਰੀਏਬਲ ਐਰਰ ਸਟੋਰ ਕਰੋ।
ਉਪਯੋਗੀ ਫੀਚਰ:
ਇਹ “ਦੋਹਰੇ ਜੋੜ ਕੇ ਤੱਕ ਰਹੋ” ਵਰਤੇ ਜਾਣ ਵਾਲੀ ਹਠ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਘਟਾਉਂਦਾ ਹੈ।
Import/export قوي permissions ਵਾਲੇ ਕੰਮ ਹਨ:
ਜੇ ਤੁਸੀਂ PII ਸੰਭਾਲਦੇ ਹੋ ਤਾਂ retention ਅਤੇ deletion ਨਿਯਮ ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ ਤਾਂ ਕਿ ਸੰਵੇਦਨਸ਼ੀਲ ਫਾਇਲਾਂ ਇਕੱਠੀਆਂ ਨਾ ਹੋਣ।
ਇਸ ਤੋਂ ਇਲਾਵਾ, ਡੇਟਾਬੇਸ ਅਤੇ ਹੋਰ ਯੂਜ਼ਰਾਂ ਦੀ ਰੱਖਿਆ ਲਈ workspace ਪ੍ਰਤੀ concurrent imports ਨੂੰ throttle ਕਰੋ।