07 ਮਈ 2025·8 ਮਿੰਟ
ਡੇਟਾਬੇਸ ਸ਼ਾਰਡਿੰਗ ਕਿਵੇਂ ਕੰਮ ਕਰਦੀ ਹੈ — ਅਤੇ ਇਸ ਬਾਰੇ ਸੋਚਣਾ ਕਿਉਂ ਔਖਾ ਹੈ
ਸ਼ਾਰਡਿੰਗ ਡੇਟਾ ਨੂੰ ਨੋਡਾਂ ਵਿੱਚ ਵੰਡ ਕੇ ਡੇਟਾਬੇਸ ਨੂੰ ਸਕੇਲ ਕਰਦੀ ਹੈ, ਪਰ ਇਹ ਰੂਟਿੰਗ, ਰੀਬੈਲੈਂਸਿੰਗ ਅਤੇ ਨਵੇਂ ਫੇਲਯੂਰ ਮੋਡ ਲਿਆਉਂਦੀ ਹੈ ਜੋ ਸਿਸਟਮ ਨੂੰ ਸੋਚਣ ਵਿੱਚ ਔਖਾ ਬਣਾਉਂਦੇ ਹਨ।
ਸ਼ਾਰਡਿੰਗ ਡੇਟਾ ਨੂੰ ਨੋਡਾਂ ਵਿੱਚ ਵੰਡ ਕੇ ਡੇਟਾਬੇਸ ਨੂੰ ਸਕੇਲ ਕਰਦੀ ਹੈ, ਪਰ ਇਹ ਰੂਟਿੰਗ, ਰੀਬੈਲੈਂਸਿੰਗ ਅਤੇ ਨਵੇਂ ਫੇਲਯੂਰ ਮੋਡ ਲਿਆਉਂਦੀ ਹੈ ਜੋ ਸਿਸਟਮ ਨੂੰ ਸੋਚਣ ਵਿੱਚ ਔਖਾ ਬਣਾਉਂਦੇ ਹਨ।
ਸ਼ਾਰਡਿੰਗ (ਜਿਸਨੂੰ ਹੋਰਾਈਜ਼ਾਂਟਲ ਪਾਰਟੀਸ਼ਨਿੰਗ ਵੀ ਕਿਹਾ ਜਾਂਦਾ ਹੈ) ਦਾ ਮਤਲਬ ਹੈ ਇੱਕ ਐਸੀ ਡੇਟਾਬੇਸ ਜੋ ਐਪ ਲਈ ਇੱਕ ਲੱਗਦੀ ਹੈ, ਉਸ ਦੇ ਡੇਟਾ ਨੂੰ ਕਈ ਮਸ਼ੀਨਾਂ ਵਿੱਚ ਵੰਡਣਾ, ਜਿਨ੍ਹਾਂ ਨੂੰ ਸ਼ਾਰਡ ਕਿਹਾ ਜਾਂਦਾ ਹੈ। ਹਰ ਸ਼ਾਰਡ ਸਿਰਫ ਰਿਕਾਰਡਾਂ ਦਾ ਇੱਕ ਹਿੱਸਾ ਰੱਖਦਾ ਹੈ, ਪਰ ਮਿਲ ਕੇ ਉਹ ਪੂਰਾ ਡੇਟਾਸੈੱਟ ਬਣਾਉਂਦੇ ਹਨ.
ਇੱਕ ਨੁਕਸਾਨੀ ਮਾਨਸਿਕ ਮਾਡਲ ਹੈ ਲੌਜਿਕਲ ਬਣਤਰ ਅਤੇ ਭੌਤਿਕ ਰੱਖ-ਰਖਾਵ ਵਿੱਚ ਫ਼ਰਕ.
ਐਪ ਦੀ ਨਜ਼ਰ ਵਿੱਚ, ਤੁਸੀਂ ਕਵੈਰੀਆਂ ਓਹਦੇ ਨਾਲ ਚਲਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਜਿਵੇਂ ਇਹ ਇੱਕ ਟੇਬਲ ਹੋਵੇ. ਪਰ ਅੰਦਰੋਂ, ਸਿਸਟਮ ਨੂੰ ਨਿਰਧਾਰਨ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ ਕਿਹੜੇ shard(ਸ) ਨਾਲ ਗੱਲ ਕਰਨੀ ਹੈ.
ਸ਼ਾਰਡਿੰਗ ਰੈਪਲਿਕੇਸ਼ਨ ਤੋਂ ਵੱਖ ਹੈ। ਰੈਪਲਿਕੇਸ਼ਨ ਇੱਕੋ ਡੇਟਾ ਦੀਆਂ ਨਕਲਾਂ ਬਣਾਉਂਦੀ ਹੈ ਕਈ ਨੋਡਾਂ 'ਤੇ, ਜ਼ਿਆਦਾਤਰ ਉਪਲਬਧਤਾ ਅਤੇ ਰੀਡ ਸਕੇਲਿੰਗ ਲਈ। ਸ਼ਾਰਡਿੰਗ ਡੇਟਾ ਨੂੰ ਵੰਡਦੀ ਹੈ ਤਾਂ ਜੋ ਹਰ ਨੋਡ ਵੱਖ ਰਿਕਾਰਡ ਰਖੇ।
ਇਹ ਵਰਟਿਕਲ ਸਕੇਲਿੰਗ ਤੋਂ ਵੀ ਵੱਖ ਹੈ, ਜਿਸ ਵਿੱਚ ਤੁਸੀਂ ਇੱਕ ਡੇਟਾਬੇਸ ਹੀ ਰੱਖਦੇ ਹੋ ਪਰ ਉਨ੍ਹਾਂ ਨੂੰ ਵੱਡੀ ਮਸ਼ੀਨ ਤੇ ਲਿਆ ਜਾਂਦੇ ਹੋ (ਵੱਧ CPU/RAM/ਤੇਜ਼ ਡਿਸਕ). ਵਰਟਿਕਲ ਸਕੇਲਿੰਗ ਸਧਾਰਣ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਹੱਦਾਂ ਹਨ ਅਤੇ ਜ਼ਲਦੀ ਮਹਿੰਗੀ ਹੋ ਸਕਦੀ ਹੈ।
ਸ਼ਾਰਡਿੰਗ ਸਮਰੱਥਾ ਵਧਾਉਂਦੀ ਹੈ, ਪਰ ਇਹ ਆਪਣੇ ਆਪ ਤੁਹਾਡੀ ਡੇਟਾਬੇਸ ਨੂੰ "ਆਸਾਨ" ਨਹੀਂ ਬਣਾਉਂਦੀ ਜਾਂ ਹਰ ਕਵੈਰੀ ਨੂੰ ਤੇਜ਼ ਨਹੀਂ ਕਰਦੀ।
ਇਸ ਲਈ ਸ਼ਾਰਡਿੰਗ ਨੂੰ ਸਮਝਣਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਇਹ ਸਟੋਰੇਜ ਅਤੇ throughput ਨੂੰ ਸਕੇਲ ਕਰਦੀ ਹੈ—ਨਾ ਕਿ ਡੇਟਾਬੇਸ ਦੇ ਹਰ ਪਹਿਲੂ ਨੂੰ ਮੁਫ਼ਤ ਵਿੱਚ ਸੁਧਾਰ ਦੇਵੇ।
ਸ਼ਾਰਡਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲਾ ਚੋਣ ਨਹੀਂ ਹੁੰਦੀ। ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਵੱਲ ਜਾਣਦੀਆਂ ਹਨ ਜਦੋਂ ਸਿਸਟਮ ਨੇ ਸਫਲਤਾ ਦੇ ਬਾਅਦ ਫਿਜ਼ਿਕਲ ਹੱਦਾਂ ਨੂੰ ਛੂਹ ਲਿਆ ਹੋਵੇ—ਜਾਂ ਜਦੋਂ ਓਪਰੇਸ਼ਨਲ ਦਰਦ ਇੰਨਾ ਵੱਧ ਜਾਵੇ ਕਿ ਉਹ ਨਜ਼ਰਅੰਦਾਜ਼ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ। ਮਕਸਦ ਘੱਟੋ-ਘੱਟ "ਸਾਨੂੰ ਸ਼ਾਰਡਿੰਗ ਚਾਹੀਦੀ ਹੈ" ਨਹੀਂ ਹੁੰਦਾ, ਸਗੋਂ "ਸਾਨੂੰ ਅਜਿਹਾ ਤਰੀਕਾ ਚਾਹੀਦਾ ਹੈ ਜਿਸ ਨਾਲ ਇੱਕ ਡੇਟਾਬੇਸ ਇਕੱਲਾ ਬਿੰਦੂ ਨਾ ਬਣੇ।"
ਇੱਕ ਸਿੰਗਲ ਡੇਟਾਬੇਸ ਨੋਡ ਕਈ ਤਰੀਕਿਆਂ ਨਾਲ ਕਮ ਰੱਖ ਸਕਦਾ ਹੈ:
ਜੇ ਇਹ ਮੁੱਦੇ ਰੈਗੂਲਰ ਢੰਗ ਨਾਲ ਆਉਂਦੇ ਹਨ, ਤਾਂ ਅਕਸਰ ਮੁੱਦਾ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਇੱਕ ਮਸ਼ੀਨ ਬਹੁਤ ਜ਼ਿਆਦਾ ਜ਼ਿੰਮੇਵਾਰੀ ਢੋ ਰਹੀ ਹੈ।
ਡੇਟਾਬੇਸ ਸ਼ਾਰਡਿੰਗ ਡੇਟਾ ਅਤੇ ਟ੍ਰੈਫਿਕ ਨੂੰ ਕਈ ਨੋਡਾਂ ਵਿੱਚ ਫੈਲਾਉਂਦੀ ਹੈ ਤਾਂ ਕਿ ਸਮਰੱਥਾ ਮਸ਼ੀਨਾਂ ਜੋੜ ਕੇ ਵਧੇ. ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੀਤੀ ਗਈ ਸ਼ਾਰਡਿੰਗ workloads ਨੂੰ ਅਲੱਗ-ਅਲੱਗ ਕਰ ਸਕਦੀ ਹੈ (ਇਕ ਟੀਨੈਂਟ ਦੇ spike ਨਾਲ ਹੋਰਾਂ ਦੀ ਲੈਟੈਂਸੀ ਖਰਾਬ ਨਾ ਹੋਵੇ) ਅਤੇ ਲਾਗਤ ਨੂੰ ਨਿਯੰਤਰਿਤ ਕਰ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਹਰ ਵਾਰ ਮਹਿੰਗੀਆਂ ਪ੍ਰੀਮੀਅਮ ਇੰਸਟੇਂਸਾਂ ਖਰੀਦਣ ਦੀ ਥਾਂ ਨਵੇਂ ਨੋਡ ਜੋੜ ਸਕਦੇ ਹੋ।
ਦੋਹਰਾਈਆਂ ਰੈਪੈਟਰਨਿੰਗ ਪੈਟਰਨਾਂ ਵਿੱਚ ਚਰਮ ਤੇ p95/p99 ਦਾ ਵੱਧਣਾ, replication lag ਵਧਣਾ, ਬੈਕਅੱਪ/ਰਿਸਟੋਰ ਤੁਹਾਡੇ ਮਨਜ਼ੂਰਵੇ ਹਿੱਸੇ ਤੋਂ ਵੱਧ ਹੋਣਾ ਅਤੇ "ਛੋਟੀ" ਸਕੀਮਾ ਬਦਲਾਵ ਇੱਕ ਵੱਡਾ ਸਮਰੱਥਾ ਘਟਨਾ ਬਣ ਜਾਣਾ ਸ਼ਾਮਿਲ ਹੈ।
ਇਸ ਨੂੰ ਅਪਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਣ ਵਿਕਲਪ ਖਤਮ ਕਰਦੀਆਂ ਹਨ: ਇੰਡੈਕਸਿੰਗ ਅਤੇ ਕਵੈਰੀ ਫਿਕਸ, ਕੈਸ਼ਿੰਗ, ਰੀਡ ਰੈਪਲਿਕਾਜ਼, ਇੱਕ ਨੋਡ ਦੇ ਅੰਦਰ ਪਾਰਟੀਸ਼ਨਿੰਗ, ਬੁਰੇ ਡੇਟਾ ਦਾ ਆਰਕੀਵ, ਅਤੇ ਹਾਰਡਵੇਅਰ ਅੱਪਗਰੇਡ. ਸ਼ਾਰਡਿੰਗ ਸਮਰੱਥਾ ਹੱਲ ਕਰ ਸਕਦੀ ਹੈ, ਪਰ ਇਹ ਕੋਆਰਡੀਨੇਸ਼ਨ, ਓਪਰੇਸ਼ਨਲ ਜਟਿਲਤਾ, ਅਤੇ ਨਵੇਂ ਫੇਲਯੂਰ ਮੋਡ ਲਿਆਉਂਦੀ ਹੈ—ਇਸ ਲਈ ਬਹੁਤ ਸੋਚ-ਵਿਚਾਰ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
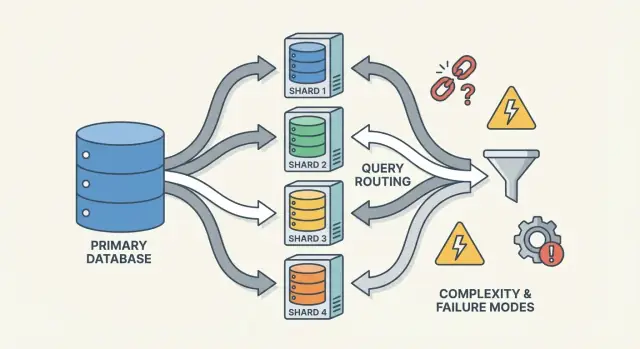
ਇੱਕ ਸ਼ਾਰਡਡ ਡੇਟਾਬੇਸ ਇੱਕ ਚੀਜ਼ ਨਹੀਂ—ਇਹ ਥੋੜ੍ਹੇ ਭਾਗਾਂ ਦਾ ਇੱਕ ਛੋਟਾ ਸਿਸਟਮ ਹੁੰਦਾ ਹੈ ਜੋ ਮਿਲ ਕੇ ਕੰਮ ਕਰਦਾ ਹੈ। ਸ਼ਾਰਡਿੰਗ "ਸੋਚਣਾ ਮੁਸ਼ਕਿਲ" ਮਹਿਸੂਸ ਹੋਣ ਦਾ ਕਾਰਣ ਇਹ ਹੈ ਕਿ ਸਹੀਪਣ ਅਤੇ ਪੈਰਫਾਰਮੈਂਸ ਇਨ੍ਹਾਂ ਟੁਕੜਿਆਂ ਦੇ ਅੰਤਰਕਿਰਿਆ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ, ਸਿਰਫ ਡੇਟਾਬੇਸ ਇੰਜਨ 'ਤੇ ਨਹੀਂ।
ਇੱਕ ਸ਼ਾਰਡ ਡੇਟਾ ਦਾ ਇੱਕ ਉਪਸੈੱਟ ਹੁੰਦਾ ਹੈ, ਆਮ ਤੌਰ 'ਤੇ ਆਪਣੇ ਸਰਵਰ ਜਾਂ ਕਲੱਸਟਰ 'ਤੇ ਸਟੋਰ ਕੀਤਾ. ਹਰੇਕ shard ਆਮ ਤੌਰ 'ਤੇ ਰੱਖਦਾ ਹੈ:
ਐਪ্লਿਕੇਸ਼ਨ ਦੀ ਨਜ਼ਰ ਵਿੱਚ, ਇੱਕ ਸ਼ਾਰਡਡ ਸੈਟਅਪ ਅਕਸਰ ਇੱਕ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਵਰਗਾ ਦਿਖਾਈ ਦੇਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ. ਪਰ ਅੰਦਰੋਂ, ਇੱਕ ਕਵੈਰੀ ਜੋ ਸਿੰਗਲ-ਨੋਡ ਡੇਟਾਬੇਸ ਵਿੱਚ "ਇੱਕ ਇੰਡੈਕਸ ਲੁੱਕਅੱਪ" ਹੁੰਦੀ, ਉਹ ਹੁਣ "ਸਹੀ shard ਲੱਭੋ, ਫਿਰ ਲੁੱਕਅੱਪ ਕਰੋ" ਬਣ ਸਕਦੀ ਹੈ।
ਇੱਕ ਰਾਊਟਰ (ਕਦੇ-ਕਦੇ ਕੋਆਰਡੀਨੇਟਰ, ਕਵੈਰੀ ਰਾਊਟਰ, ਜਾਂ ਪ੍ਰਾਕਸੀ) ਟ੍ਰੈਫਿਕ ਦਾ ਪੋਲੀਸ ਹੈ. ਇਹ ਪ੍ਰੈਕਟਿਕਲ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦਿੰਦਾ ਹੈ: ਇਸ ਬੇਨਤੀ ਦੀ ਸਥਿਤੀ ਦੇਖ ਕੇ, ਕਿਹੜਾ shard ਇਸਨੂੰ ਹੇਠਾਂ ਲੈ ਲਏਗਾ?
ਦੋ ਆਮ ਡਿਜ਼ਾਈਨ ਪੈਟਰਨ ਹਨ:
ਰਾਊਟਰ ਐਪ ਵਿੱਚ ਕੰਪਲੇਕਸਿਟੀ ਘਟਾਉਂਦੇ ਹਨ, ਪਰ ਜੇ ਧਿਆਨ ਨਾਲ ਨਹੀਂ ਬਣਾਏ ਗਏ ਤਾਂ ਉਹ ਬੌਤਲਨੈਕ ਜਾਂ ਨਵਾਂ ਫੇਲਯੂਰ ਪੁਆਇੰਟ ਵੀ ਬਣ ਸਕਦੇ ਹਨ।
ਸ਼ਾਰਡਿੰਗ ਮੈਟਾਡੇਟਾ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ—ਇੱਕ ਸੋਸ ਨਾਲ ਆਫ ਸਚ ਜੋ ਦਰਸਾਉਂਦਾ ਹੈ:
ਇਹ ਜਾਣਕਾਰੀ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਕੰਫਿਗ ਸਰਵਿਸ (ਜਾਂ ਇੱਕ ਛੋਟੀ "ਕੰਟਰੋਲ ਪਲੇਨ" ਡੇਟਾਬੇਸ) ਵਿੱਚ ਰਹਿੰਦੀ ਹੈ. ਜੇ ਮੈਟਾਡੇਟਾ ਸਟੇਲ ਜਾਂ ਅਨਕਨਸਿਸਟੈਂਟ ਹੋਵੇ, ਤਾਂ ਰਾਊਟਰ ਗਲਤ ਥਾਂ ਟਰੈਫਿਕ ਭੇਜ ਸਕਦੇ ਹਨ—ਚਾਹੇ ਹਰ shard ਪੂਰੀ ਤਰ੍ਹਾਂ ਸਿਹਤਮੰਦ ਹੋਵੇ।
ਅਖੀਰਕਾਰ, ਸ਼ਾਰਡਿੰਗ ਪਿੱਠ-ਭੂਮੀ ਪ੍ਰਕਿਰਿਆਵਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਜੋ ਸਿਸਟਮ ਨੂੰ ਸਮੇਂ ਨਾਲ ਵਰਤਣਯੋਗ ਰੱਖਦੀਆਂ ਹਨ:
ਇਹ ਜਾਬਜ਼ ਸ਼ੁਰੂ ਵਿੱਚ ਅਣਦੇਖੀਆਂ ਰਹਿ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਉਹੀ ਉਹਨਾਂ ਥਾਵਾਂ ਹਨ ਜਿੱਥੇ ਕਈ ਪ੍ਰੋਡਕਸ਼ਨ ਅਚਾਨਕੀ ਨਿਰਾਸ਼ਾਵਾਂ ਹੁੰਦੀਆਂ ਹਨ—ਕਿਉਂਕਿ ਉਹ ਸਿਸਟਮ ਦਾ ਆਕਾਰ ਬਦਲ ਰਹੇ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਇਹ ਸੇਵਾ ਦਿੰਦੀ ਹੈ।
ਸ਼ਾਰਡ ਕੀ ਉਹ ਫੀਲਡ (ਜਾਂ ਫੀਲਡਾਂ ਦਾ ਜੋੜ) ਹੁੰਦੀ ਹੈ ਜੋ ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ ਇੱਕ ਰੋ ਕਿਹੜੇ shard 'ਤੇ ਸਟੋਰ ਹੋਵੇਗੀ. ਇਹ ਇਕੱਲਾ ਚੋਣ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ ਪੈਰਫਾਰਮੈਂਸ, ਲਾਗਤ, ਅਤੇ ਉਹ ਫੀਚਰ ਕਿੰਨੇ ਆਸਾਨ ਮਹਿਸੂਸ ਹੋਣਗੇ—ਕਿਉਂਕਿ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ ਬੇਨਤੀਆਂ ਇੱਕ shard ਨੂੰ ਰੂਟ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਕਈ ਨੂੰ ਫੈਨ-ਆਉਟ ਕਰਦੀਆਂ ਹਨ.
ਚੰਗੀ ਕੀ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਰੱਖਦੀ ਹੈ:
user_id ਦੇ ਮੁਕਾਬਲੇ ਦੇਸ਼)\n- ਬਰਾਬਰ ਵੰਡ: ਮੁੱਲ shards ਤੇ ਲਿਖਤਾਂ ਅਤੇ ਪੜ੍ਹਨਾਂ ਨੂੰ ਫੈਲਾਉਣਏਕ ਆਮ ਉਦਾਹਰਨ tenant_id ਦੁਆਰਾ ਸ਼ਾਰਡਿੰਗ ਹੈ: ਜ਼ਿਆਦਾਤਰ ਇੱਕ ਟੇਨੈਂਟ ਲਈ ਰੀਡ ਅਤੇ ਰਾਈਟ ਇੱਕ shard 'ਤੇ ਰਹਿੰਦੀਆਂ ਹਨ, ਅਤੇ ਟੇਨੈਂਟਾਂ ਕਾਫੀ ਹਨ ਤਾਂ ਲੋਡ ਫੈਲ ਜਾਂਦਾ ਹੈ।
ਕੁਝ ਕੁੰਜੀਆਂ ਲਗਭਗ ਪੱਕੇ ਤੌਰ 'ਤੇ ਸਮੱਸਿਆ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ:
ਇਹ ਅਕਸਰ ਰੁਟੀਨ ਕਵੈਰੀਆਂ ਨੂੰ scatter-gather ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ, ਕਿਉਂਕਿ ਮਿਲਦੇ-ਜੁਲਦੇ ਰਿਕਾਰਡ ਹਰ ਜਗ੍ਹਾ ਹੋ ਸਕਦੇ ਹਨ।
ਲੋਡ ਬੈਲੈਂਸਿੰਗ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ shard ਕੀ ਸਦਾ ਉਤਨੀ ਹੀ ਚੰਗੀ ਨਹੀਂ ਹੁੰਦੀ ਜਿੰਨੀ ਕਿ ਉਤਨੀ ਕਵੈਰੀ ਸੁਵਿਧਾ ਲਈ।
user_id), ਤਾਂ ਕੁਝ "ਗਲੋਬਲ" ਕਵੈਰੀਆਂ (ਜਿਵੇਂ ਐਡਮਿਨ ਰਿਪੋਰਟਿੰਗ) ਧੀਮੀ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਵੱਖਰੇ ਪਾਈਪਲਾਈਨਾਂ ਦੀ ਲੋੜ ਪਵੇਗੀ।region), ਤਾਂ ਤੁਸੀਂ ਹਾਟਸਪੌਟਾਂ ਅਤੇ ਅਸਮਾਨ ਸਮਰੱਥਾ ਦੇ ਖਤਰੇ ਵਿੱਚ ਹੁੰਦੇ ਹੋ।ਕਈ ਟੀਮ ਇਸ ਟਰੇਡ-ਆਫ ਦੇ ਆਸ-ਪਾਸ ਡਿਜ਼ਾਈਨ ਕਰਦੀਆਂ ਹਨ: shard ਕੀ ਨੂੰ ਸਭ ਤੋਂ ਘੱਟ latency-ਸੰਵੇਦੀ ਆਪਰੇਸ਼ਨਾਂ ਲਈ optimize ਕਰੋ—ਅਤੇ ਬਾਕੀ ਨੂੰ ਇੰਡੈਕਸ, ਡੇਨੋਰਮਲਾਈਜੇਸ਼ਨ, ਰੈਪਲਿਕਾ, ਜਾਂ ਸਮਰਪਿਤ ਐਨਾਲਿਟਿਕਸ ਟੇਬਲਾਂ ਨਾਲ ਸਾਂਭੋ।
ਇੱਕ "ਸਭ ਤੋਂ ਵਧੀਆ" ਤਰੀਕਾ ਨਹੀਂ ਹੈ. ਜੋ ਰਣਨੀਤੀ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ ਉਹ ਰੂਟਿੰਗ ਕਿੰਨੀ ਆਸਾਨ ਹੋਵੇਗੀ, ਡੇਟਾ ਕਿੰਨਾ ਬਰਾਬਰ ਵੰਡੇਗਾ, ਅਤੇ ਕਿਹੜੇ ਐਕਸੈਸ ਪੈਟਰਨ ਦੁੱਖਦਾਇਕ ਹੋਣਗੇ—ਇਸ ਨੂੰ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ.
ਰੇਂਜ ਸ਼ਾਰਡਿੰਗ ਵਿੱਚ ਹਰ ਸ਼ਾਰਡ ਕੁੰਜੀ ਸਪੇਸ ਦਾ ਐੱਕ ਲਗਾਤਾਰ ਟੁਕੜਾ ਹੁੰਦਾ ਹੈ—ਉਦਾਹਰਣ:
ਰੂਟਿੰਗ ਸਿੱਧੀ ਹੈ: ਕੀ ਵੇਖੋ, ਸ਼ਾਰਡ ਚੁਣੋ.
ਫੜ ਹੈ ਹਾਟਸਪੌਟ: ਜੇ ਨਵੇਂ ਯੂਜ਼ਰ ਹਰ ਵਾਰੀ ਵਧਦੇ ਹੋਏ IDs ਪਾਉਂਦੇ ਹਨ, ਤਾਂ "ਆਖਰੀ" shard ਲਿਖਾਈ ਬੋਤਲਨੈਕ ਬਣ ਸਕਦਾ ਹੈ. ਰੇਂਜ ਕਵੈਰੀਆਂ ("ਸਾਰੇ ਆਰਡਰ Oct 1–Oct 31") ਲਾਭਦਾਇਕ ਹੋ سکتیਆਂ ਹਨ ਕਿਉਂਕਿ ਡੇਟਾ ਭੌਤਿਕ ਤੌਰ 'ਤੇ ਗਰੁੱਪ ਹੈ।
ਹੈਸ਼ ਸ਼ਾਰਡਿੰਗ shard ਕੀ ਨੂੰ ਹੈਸ਼ ਫੰਕਸ਼ਨ ਵਿੱਚ ਦਾਲ ਕੇ shard ਚੁਣਦੀ ਹੈ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਡੇਟਾ ਨੂੰ ਹੋਰ ਬਰਾਬਰ ਵੰਡਦੀ ਹੈ, ਜਿਸ ਨਾਲ "ਨਵਾਂ ਸਭ ਕੁਛ ਨਵੇਂ shard 'ਤੇ" ਸਮੱਸਿਆ ਘੱਟ ਹੁੰਦੀ ਹੈ।
ਟ੍ਰੇਡ-ਆਫ: ਰੇਂਜ ਕਵੈਰੀਆਂ ਮੁਸ਼ਕਿਲ ਹੋ ਜਾਂਦੀਆਂ ਹਨ—ਉਦਾਹਰਣ ਲਈ "ID X ਤੋਂ Y" ਕਵੈਰੀ ਹੁਣ ਕਈ shards ਨੂੰ ਛੂਹ ਸਕਦੀ ਹੈ।
ਵਰਤੋਂ ਵਿੱਚ, ਕਈ ਸਿਸਟਮconsistent hashing ਵਰਤਦੇ ਹਨ ਅਤੇ "ਵਰਚੁਅਲ ਨੋਡਸ" ਤਕਨੀਕ ਨਾਲ shards ਨੂੰ ਵਧਾਉਣ ਤੇ ਸਬ ਕੁਝ ਮੁੜ-ਰਾਸ਼ਨ ਤੋਂ ਬਚਾਉਂਦੇ ਹਨ।
ਡਾਇਰੈਕਟਰੀ ਸ਼ਾਰਡਿੰਗ ਇੱਕ ਵਿਸ਼ੇਸ਼ ਨਕਸ਼ਾ (key → shard) ਰੱਖਦੀ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਲਚਕੀਲਾ ਹੈ: ਤੁਸੀਂ ਖਾਸ ਟੇਨੈਂਟਾਂ ਨੂੰ ਡੈਡੀਕੇਟੇਡ shards 'ਤੇ ਰੱਖ ਸਕਦੇ ਹੋ, ਇੱਕ ਗਾਹਕ ਨੂੰ ਹਿਲਾ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਸਭ ਨੂੰ ਮੂਵ ਕੀਤੇ, ਅਤੇ ਅਸਮਾਨ shard ਆਕਾਰ ਸਹਿਯੋਗ ਕਰ ਸਕਦੇ ਹੋ.
ਨੁਕਸਾਨ: ਹੋਰ ਇੱਕ ਨਿਰਭਰਤਾ—ਜੇ ਡਾਇਰੈਕਟਰੀ ਹੌਲੀ, ਸਟੇਲ ਜਾਂ ਅਣਉਪਲਬਧ ਹੋਵੇ, ਤਾਂ ਰੂਟਿੰਗ ਪ੍ਰਭਾਵਿਤ ਹੋ ਸਕਦੀ ਹੈ।
ਅਸਲ ਸਿਸਟਮ ਅਕਸਰ ਤਰੀਕੀਆਂ ਮਿਲਾ ਦਿੰਦੇ ਹਨ। ਇੱਕ ਕੰਪੋਜ਼ਿਟ shard ਕੀ (ਉਦਾਹਰਣ tenant_id + user_id) ਟੇਨੈਂਟਾਂ ਨੂੰ ਅਲੱਗ ਰੱਖਦਾ ਹੈ ਅਤੇ ਇੱਕ ਟੇਨੈਂਟ ਦੇ ਅੰਦਰ ਲੋਡ ਫੈਲਾਉਂਦਾ ਹੈ। ਸਬ-ਸ਼ਾਰਡਿੰਗ ਮਿਲਦੀ ਜੁਲਦੀ ਹੈ: ਪਹਿਲਾਂ ਟੇਨੈਂਟ ਦੁਆਰਾ ਰੂਟ ਕਰੋ, ਫਿਰ ਉਸ ਟੇਨੈਂਟ ਦੇ ਗਰੁੱਪ ਵਿੱਚ ਹੈਸ਼ ਕਰੋ ਤਾਂ ਕਿ ਇੱਕ "ਬੜਾ ਟੇਨੈਂਟ" ਇਕੱਲਾ shard ਨੂੰ ਕਬਜ਼ਾ ਨਾ ਕਰੇ।
ਸ਼ਾਰਡਡ ਡੇਟਾਬੇਸ ਵਿੱਚ ਦੋ ਬਹੁਤ ਵੱਖਰੇ "ਕਵੈਰੀ ਪਾਥ" ਹੁੰਦੇ ਹਨ। ਇਹ ਸਮਝਣਾ ਕਿ ਤੁਸੀਂ ਕਿਹੜੇ ਰਸਤੇ 'ਤੇ ਹੋ ਜ਼ਿਆਦਾਤਰ ਪ੍ਰਦਰਸ਼ਨ ਦੇ ਹੈਰਾਨੀਆਂ ਅਤੇ ਯੋਗ ਸ਼ਾਰਡਿੰਗ ਦਾ ਅਨੁਭਵ ਵੀ ਸਮਝਾਊਂਦਾ ਹੈ।
ਆਦਰਸ਼ ਨਤੀਜਾ ਇਹ ਹੈ ਕਿ ਕਵੈਰੀ ਨਿਰਧਾਰਤ ਰੂਪ ਵਿੱਚ ਸਿਰਫ ਇੱਕ shard ਨੂੰ ਭੇਜੀ ਜਾਵੇ। ਜੇ ਬੇਨਤੀ shard ਕੀ ਸ਼ਾਮਿਲ ਕਰਦੀ ਹੈ (ਜਾਂ ਰਾਊਟਰ ਕੁਝ ਐਸੀ ਚੀਜ਼ ਦਾ ਨਕਸ਼ਾ ਕਰ ਸਕਦਾ ਹੈ), ਤਾਂ ਸਿਸਟਮ ਸੀਧਾ ਸਹੀ ਥਾਂ ਭੇਜ ਸਕਦਾ ਹੈ।
ਇਸ ਲਈ ਟੀਮਾਂ ਅਕਸਰ ਆਮ ਪੜ੍ਹਨਾਂ ਨੂੰ "shard-key ਅਨੁਕੂਲ" ਬਣਾਉਣ ਦਾ ਧਿਆਨ ਰੱਖਦੀਆਂ ਹਨ। ਇੱਕ shard ਦਾ ਮਤਲਬ ਘੱਟ ਨੈੱਟਵਰਕ ਹੋਪ, ਸਿੱਧਾ ਇਜੈਕਿਊਸ਼ਨ, ਘੱਟ ਲਾਕ, ਅਤੇ ਕਮ ਸੰਯੋਜਨ—ਲੈਟੈਂਸੀ ਬਹੁਤ ਘੱਟ ਹੁੰਦੀ ਹੈ।
ਜਦੋਂ ਇੱਕ ਕਵੈਰੀ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਰੂਟ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ, ਤਾਂ ਸਿਸਟਮ ਇਸਨੂੰ ਬਹੁਤ ਸਾਰਿਆਂ shards ਨੂੰ ਭੇਜ ਸਕਦਾ ਹੈ। ਹਰ shard ਲੋਕਲੀ ਕਵੈਰੀ ਚਲਾਉਂਦਾ ਹੈ, ਫਿਰ ਰਾਊਟਰ (ਜਾਂ ਕੋਆਰਡੀਨੇਟਰ) ਨਤੀਜੇ ਜੋੜਦਾ—ਸੋਰਟ, ਡਿਡੁਪਲੀਕੇਟ, ਲਿਮਿਟ ਲਗਾਉਣ ਅਤੇ ਹਿੱਸਾ-ਕਲੈਕਸ਼ਨ ਨੂੰ ਮਿਲਾਉਂਦਾ।
ਇਹ ਫੈਨ-ਆਉਟ ਟੇਲ ਲੇਟੈਂਸੀ ਨੂੰ ਵਧਾਉਂਦਾ ਹੈ: ਜੇ 9 shards ਜਲਦੀ ਜਵਾਬ ਦੇਣ, ਇੱਕ ਸੁਸਤ shard ਪੂਰੀ ਬੇਨਤੀ ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ. ਇਹ ਲੋਡ ਨੂੰ ਵੀ ਗੁਣਾ ਕਰਦਾ ਹੈ: ਇਕ ਯੂਜ਼ਰ ਬੇਨਤੀ N shard ਬੇਨਤੀਆਂ ਵਿੱਚ ਬਦਲ ਸਕਦੀ ਹੈ।
ਸ਼ਾਰਡਸ 'ਤੇ ਜੋਇਨਾਂ ਮਹਿੰਗੇ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਜੋ ਡੇਟਾ ਅੰਦਰ ਹੀ ਮਿਲ ਸਕਦਾ ਸੀ, ਹੁਣ shards ਵਿਚੋਂ ਇੱਕ ਦੂਜੇ ਨੂੰ ਭੇਜਣਾ ਪੈਂਦਾ ਹੈ (ਜਾਂ ਕੋਆਰਡਿਨੇਟਰ ਦੇ ਕੋਲ). ਸਧਾਰਨ ਏਗਰੇਗੇਸ਼ਨ (COUNT, SUM, GROUP BY) ਵੀ ਦੋ-ਚਰਣੀ ਯੋਜ਼ਨਾ ਮੰਗ ਸਕਦੇ ਹਨ: ਹਰ shard 'ਤੇ ਹਿੱਸਾ-ਨਤੀਜੇ ਕੱਢੋ, ਫਿਰ ਉਨ੍ਹਾਂ ਨੂੰ ਮਿਲਾਓ।
ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ ਡੀਫਾਲਟ ਤੌਰ 'ਤੇ ਲੋਕਲ ਇੰਡੈਕਸ ਵਰਤਦੇ ਹਨ: ਹਰ shard ਆਪਣਾ ਡੇਟਾ ਹੀ ਇੰਡੈਕਸ ਕਰਦਾ ਹੈ। ਇਹ ਮੇਂਟੇਨ ਕਰਨ ਲਈ ਸਸਤੇ ਹਨ, ਪਰ ਰੂਟਿੰਗ ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦੇ—ਇਸ ਲਈ ਕਵੈਰੀਆਂ ਅਜੇ ਵੀ scatter ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਗਲੋਬਲ ਇੰਡੈਕਸ ਨਾਨ-ਸ਼ਾਰਡ-ਕੀ ਫੀਲਡਾਂ 'ਤੇ ਨਿਸ਼ਾਨਾ ਲੱਗਾ ਕੇ ਟਾਰਗੇਟ ਰੂਟਿੰਗ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ, ਪਰ ਉਹ ਲਿਖਤ ਓਵਰਹੈਡ, ਵਾਧੂ ਕੋਆਰਡੀਨੇਸ਼ਨ, ਅਤੇ ਆਪਣੀ ਸਕੇਲਿੰਗ ਅਤੇ ਕਨਸਿਸਟੈਂਸੀ ਮੁਸ਼ਕਿਲਾਂ ਲਿਆਉਂਦੇ ਹਨ।
ਲਿਖਤਾਂ ਉਹ ਜਗ੍ਹਾ ਹਨ ਜਿੱਥੇ ਸ਼ਾਰਡਿੰਗ "ਸਿਰਫ ਸਕੇਲ" ਮਹਿਸੂਸ ਕਰਨਾ ਬੰਦ ਕਰ ਦਿੰਦੀ ਹੈ ਅਤੇ ਫੀਚਰ ਡਿਜ਼ਾਈਨ ਨੂੰ ਬਦਲ ਦਿੰਦੀ ਹੈ। ਇਕ ਲਿਖਤ ਜੋ ਇੱਕ shard ਨੂੰ ਛੂਹਦੀ ਹੈ ਤੇਜ਼ ਅਤੇ ਸਧਾਰਣ ਹੋ ਸਕਦੀ ਹੈ। ਪਰ ਇੱਕ ਲਿਖਤ ਜੋ ਕਈ shards ਨੂੰ ਛੂਹਦੀ ਹੈ, ਉਹ ਧੀਮੀ, ਫੇਲ-ਪ੍ਰੋਨ, ਅਤੇ ਸਹੀ ਬਣਾਉਣ ਵਿੱਚ ਹੈਰਾਨ ਕਰਨ ਵਾਲੀ ਹੋ ਸਕਦੀ ਹੈ।
ਜੇ ਹਰ ਬੇਨਤੀ ਨੂੰ ਸਹੀ shard 'ਤੇ ਰੂਟ ਕੀਤਾ ਜਾ ਸਕੇ (ਆਮ ਤੌਰ 'ਤੇ shard ਕੀ ਰਾਹੀਂ), ਤਾਂ ਡੇਟਾਬੇਸ ਆਪਣੀ ਨਾਰਮਲ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਮਸ਼ੀਨਰੀ ਵਰਤ ਸਕਦਾ ਹੈ। ਤੁਸੀਂ atomicity ਅਤੇ isolation shard ਦੇ ਅੰਦਰ ਪਾਓਗੇ ਅਤੇ ਬਹੁਤ ਸਾਰੇ ਓਪਰੇਸ਼ਨਲ ਮੁੱਦੇ ਜਾਣ ਦੇ ਤਰੀਕੇ ਇੱਕੋ ਜਿਹੇ ਰਹਿੰਦੇ ਹਨ—ਸਿਰਫ N ਵਾਰੀ ਦੁਹਰਾਏ ਹੋਏ।
ਜਦੋਂ ਤੁਹਾਨੂੰ ਦੋ shards 'ਤੇ ਇੱਕ ਹੀ "ਲੌਜਿਕਲ ਕਾਰਵਾਈ" ਵਿੱਚ ਅੱਪਡੇਟ ਕਰਨ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ (ਉਦਾਹਰਣ ਲਈ ਪੈਸਾ ਟ੍ਰਾਂਸਫਰ ਕਰਨਾ, ਇੱਕ ਆਰਡਰ ਕਿਸੇ ਹੋਰ ਗ੍ਰਾਹਕ 'ਤੇ ਮੂਵ ਕਰਨਾ, ਜਾਂ ਕੋਈ ਏਗਰੇਗੇਟ ਜੋ ਦੂਜੇ ਥਾਂ ਸਟੋਰ ਹੈ ਨੂੰ ਨਵੀਨ ਕਰਨਾ), ਤੁਸੀਂ ਵੰਡੇ ਹੋਏ ਟਰਾਂਜ਼ੈਕਸ਼ਨਜ਼ ਵਾਲੇ ਖੇਤਰ ਵਿੱਚ ਆ ਜਾਦੇ ਹੋ।
ਵੰਡੇ ਹੋਏ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਮੁਸ਼ਕਿਲ ਹਨ ਕਿਉਂਕਿ ਉਹ ਮਸ਼ੀਨਾਂ ਵਿਚਕਾਰ ਕੋਆਰਡੀਨੇਸ਼ਨ ਮੰਗਦੇ ਹਨ ਜੋ ਧੀਮੇ, ਪਾਰਟੀਸ਼ਨਡ, ਜਾਂ ਰੀਸਟਾਰਟ ਹੋ ਸਕਦੇ ਹਨ। two-phase commit-ਜਿਹੇ ਪ੍ਰੋਟੋਕੋਲ ਵਾਧੂ ਰਾਉਂਡ ਟ੍ਰਿਪ ਲੈਂਦੇ ਹਨ, ਟਾਈਮਆਉਟ 'ਤੇ ਬਲਾਕ ਕਰ ਸਕਦੇ ਹਨ, ਅਤੇ ਫੇਲਯੂਰ ਅਸਪષ્ટ ਬਣਾਉਂਦੇ ਹਨ: ਕੀ shard B ਨੇ ਚੇਂਜ ਲਾਗੂ ਕੀਤਾ ਸੀ ਪਹਿਲਾਂ coordinator ਮਰ ਗਿਆ? ਜੇ client ਰੀਟ੍ਰਾਈ ਕਰਦਾ ਹੈ ਤਾਂ ਕੀ ਤੁਸੀਂ ਦੋਹਰਾ ਲਾਗੂ ਕਰੋਂਗੇ? ਜੇ ਨਹੀਂ ਕਰਦੇ ਤਾਂ ਕੀ ਡੇਟਾ ਗੁੰਮ ਹੋ ਜਾਵੇਗਾ?
ਕੁਝ ਆਮ ਤਰਕੇ ਜੋ ਮਲਟੀ-ਸ਼ਾਰਡ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੀ ਲੋੜ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ:
ਸ਼ਾਰਡਡ ਸਿਸਟਮਾਂ ਵਿੱਚ ਰੀਟ੍ਰਾਈ ਆਖ਼ਤਰੀ ਨਹੀਂ—ਉਹ ਜਰੂਰੀ ਹਨ। ਲਿਖਤਾਂ ਨੂੰ idempotent ਬਣਾਓ: ਸਥਿਰ ਓਪਰੇਸ਼ਨ IDs (ਜਿਵੇਂ idempotency key) ਵਰਤੋ ਅਤੇ ਡੇਟਾਬੇਸ ਵਿੱਚ "ਪਹਿਲਾਂ ਹੀ ਲਾਗੂ ਹੋ ਚੁੱਕਾ" ਮਾਰਕਰ ਸਟੋਰ ਕਰੋ। ਇਸ ਤਰ੍ਹਾਂ, ਜੇ ਟਾਈਮਆਉਟ ਹੋਵੇ ਅਤੇ ਕਲਾਇਂਟ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰੇ, ਦੂਜੀ ਕੋਸ਼ਿਸ਼ ਨੋ-ਓਪ ਹੋ ਜਾਵੇਗੀ बजाय ਦੋਹਰਾ-ਲਾਗੂ ਕਰਨ ਦੇ।
ਸ਼ਾਰਡਿੰਗ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਕਈ ਮਸ਼ੀਨਾਂ 'ਤੇ ਵੰਡਦਾ ਹੈ, ਪਰ ਇਸ ਨਾਲ redundancy ਦੀ ਲੋੜ ਨਹੀਂ ਘੱਟਦੀ। ਰੈਪਲਿਕੇਸ਼ਨ ਉਹ ਹੈ ਜੋ ਇੱਕ shard ਨੂੰ ਉਪਲਬਧ ਰੱਖਦੀ ਹੈ ਜਦੋਂ ਇਕ ਨੋਡ ਡਾਅਉਨ ਹੋ ਜਾਏ—ਪਰ ਇਹ ਵੀ ਇਹ ਸਵਾਲ ਲਿਆਉਂਦਾ ਹੈ: "ਹੁਣੇ ਕੀ ਸਹੀ ਹੈ?"
ਜ਼ਿਆਦਾਤਰ ਸਿਸਟਮ ਹਰ shard ਦੇ ਅੰਦਰ ਰੈਪਲਿਕੇਸ਼ਨ ਕਰਦੇ ਹਨ: ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਲੀਡਰ ਲਿਖਤਾਂ ਨੂੰ ਮਨਜ਼ੂਰ ਕਰਦਾ ਹੈ ਅਤੇ ਇਕ ਜਾਂ ਵੱਧ ਰੈਪਲਿਕਾ ਉਹਨਾਂ ਨੂੰ ਨਕਲ ਕਰਦੇ ਹਨ। ਜੇ ਪ੍ਰਾਇਮਰੀ ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾੰ ਸਿਸਟਮ ਇੱਕ ਰੈਪਲਿਕਾ ਨੂੰ ਪ੍ਰਮੋਟ ਕਰਦਾ ਹੈ (failover). ਰੈਪਲਿਕਾ ਪੜ੍ਹਨਾਂ ਲਈ ਵੀ ਸੇਵਾ ਦੇ ਸਕਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਲੋਡ ਘਟੇ।
ਟਰੇਡ-ਆਫ ਸਮੇਂ 'ਤੇ ਹੈ: ਇਕ ਰੀਡ ਰੈਪਲਿਕਾ ਕੁਝ ਮਿਲੀ-ਸੈਕਿੰਡ ਜਾਂ ਸਕਿੰਟ ਪਿੱਛੇ ਹੋ ਸਕਦੀ ਹੈ। ਇਹ ਫਰਕ ਆਮ ਹੈ ਪਰ ਜਦੋਂ ਯੂਜ਼ਰ ਉਮੀਦ ਕਰਦਾ ਹੈ "ਮੈਂ ਹੁਣੀ ਅਪਡੇਟ ਕੀਤਾ, ਮੈਨੂੰ ਵੇਖਣਾ ਚਾਹੀਦਾ" ਤਾਂ ਮਹੱਤਵਪੂਰਨ ਹੋ ਜਾਂਦਾ ਹੈ।
ਸ਼ਾਰਡਡ ਸੈਟਅਪ ਵਿੱਚ, ਤੁਸੀਂ ਅਕਸਰ ਇੱਕ shard ਦੇ ਅੰਦਰ strong consistency ਅਤੇ ਸ਼ਾਰਡਾਂ ਵਿਚਕਾਰ ਕਮਜ਼ੋਰ ਗਾਰੰਟੀਜ਼ ਦੇ ਨਾਲ ਜਾਵੋਗੇ, ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਮਲਟੀ-ਸ਼ਾਰਡ ਓਪਰੇਸ਼ਨ ਸ਼ਾਮਿਲ ਹੋਣ।
ਸ਼ਾਰਡਿੰਗ ਵਿੱਚ, "ਇੱਕ ਸੂਤਰ-ਇਨ-ਤੱਥ" ਅਕਸਰ ਇਸਦਾ ਮਤਲਬ ਹੁੰਦਾ ਹੈ: ਹਰ ਇੱਕ ਡੇਟਾ ਟੁਕੜੇ ਲਈ ਇੱਕ ਅਧਿਕਾਰਕ ਲਿਖਣੀ ਥਾਂ ਹੁੰਦੀ ਹੈ (ਆਮ ਤੌਰ 'ਤੇ shard ਦਾ ਲੀਡਰ). ਪਰ ਗਲੋਬਲ ਤੌਰ 'ਤੇ, ਕੋਈ ਐਸੀ ਮਸ਼ੀਨ ਨਹੀਂ ਜਿਸਨੂੰ ਪੂਰੇ ਸਿਸਟਮ ਦੀ ਤੁਰੰਤ ਸਥਿਤੀ ਦੀ ਪੁਸ਼ਟੀ ਹੋਵੇ। ਤੁਹਾਡੇ ਕੋਲ ਕਈ ਲੋਕਲ ਸੱਚਾਈਆਂ ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਰੈਪਲਿਕੇਸ਼ਨ ਰਾਹੀਂ ਸਮਨਵਿਤ ਕੀਤੀਆਂ ਜਾਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ।
ਜਦੋਂ ਡੇਟਾ ਵੱਖ-ਵੱਖ shards 'ਤੇ ਹੋਵੇ, ਤਾਂ ਬੰਧਨਾਂ ਦੀਆਂ ਪੁਸ਼ਟੀਆਂ ਮੁਸ਼ਕਿਲ ਹੋ ਜਾਂਦੀਆਂ ਹਨ:
ਇਹ ਚੋਣਾਂ ਸਿਰਫ ਇੰਪਲਿਮੈਂਟੇਸ਼ਨ ਦੇ ਵਿਸਥਾਰ ਨਹੀਂ ਹਨ—ਉਹ ਤੁਹਾਡੇ ਉਤਪਾਦ ਲਈ "ਸਹੀ" ਕੀ ਹੈ, ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦੀਆਂ ਹਨ।
ਰੀਬੈਲੈਂਸਿੰਗ ਉਹ ਹੈ ਜੋ ਧੀਰੇ-ਧੀਰੇ ਇੱਕ ਸ਼ਾਰਡਡ ਡੇਟਾਬੇਸ ਨੂੰ ਵਰਤਣਯੋਗ ਬਣਾਈ ਰੱਖਦੀ ਹੈ। ਡੇਟਾ ਅਸਮਾਨ ਵਧਦਾ ਹੈ, shard-key ਸਕਿਊ ਹੋ ਸਕਦੀ ਹੈ, ਤੁਸੀਂ ਨਵੇਂ ਨੋਡ ਜੋੜਦੇ ਹੋ, ਜਾਂ ਹਾਰਡਵੇਅਰ retire ਕਰਨਾ ਪੈਂਦਾ—ਇਹ ਸਾਰਾ ਕੁੱਝ ਕਿਸੇ ਵੀ ਸਮੇਂ ਇੱਕ shard ਨੂੰ ਬੌਤਲਨੈਕ ਬਣਾ ਸਕਦਾ ਹੈ—ਭਾਵੇਂ ਅੰਦਰੋਂ ਡਿਜ਼ਾਈਨ ਸ਼ੁਰੂ ਵਿੱਚ ਠੀਕ ਦਿੱਸਦਾ ਹੋਵੇ।
ਇੱਕ ਸਿੰਗਲ ਡੇਟਾਬੇਸ ਦੇ ਉਲਟ, ਸ਼ਾਰਡਿੰਗ ਰੂਟਿੰਗ ਲਾਜਿਕ ਵਿੱਚ ਡੇਟਾ ਦੀ ਟਿਕਾਣਾ ਬੇ ਵਿਚਾਰ ਰੱਖਦੀ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਡੇਟਾ ਮੂਵ ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਸਿਰਫ ਬਾਈਟ ਨਹੀਂ ਕਾਪੀ ਕਰ ਰਹੇ—ਤੁਸੀਂ ਇਹ ਬਦਲ ਰਹੇ ਹੋ ਕਿ ਕਿਵੇਂ ਬੇਨਤੀਆਂ ਨੂੰ ਭੇਜਿਆ ਜਾਵੇ। ਇਸ ਲਈ ਰੀਬੈਲੈਂਸਿੰਗ metadata ਅਤੇ ਕਲਾਇੰਟਸ ਬਾਰੇ ਵੀ ਹੋਰ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇੱਕ ਆਨਲਾਈਨ ਵਰਕਫਲੋ ਚਾਹੁੰਦੀਆਂ ਹਨ ਜੋ ਇੱਕ ਵੱਡੇ "stop the world" ਜ਼ਮਾਨੇ ਨੂੰ ਟਾਲੇ:
ਜੇ ਕਲਾਇੰਟ ਰੂਟਿੰਗ ਫੈਸਲਿਆਂ ਨੂੰ cache ਕਰਦਾ ਹੈ, ਤਾਂ shard ਮੈਪ تبدیلی ਏਕ ਬ੍ਰੇਕਿੰਗ ਇਵੈਂਟ ਹੋ ਸਕਦੀ ਹੈ। ਚੰਗੇ ਸਿਸਟਮ ਰੂਟਿੰਗ metadata ਨੂੰ configuration ਵਾਂਗ ਵਰਤਦੇ ਹਨ: ਉਸਨੂੰ ਵਰਜ਼ਨ ਕਰੋ, ਅਕਸਰ ਰਿਫ੍ਰੇਸ਼ ਕਰੋ, ਅਤੇ ਇਸ ਗੱਲ 'ਤੇ ਸਪੱਸ਼ਟ ਰਹੋ ਕਿ ਜਦੋਂ ਕਲਾਇੰਟ moved key 'ਤੇ ਲੱਗਦਾ ਹੈ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ (redirect, retry, ਜਾਂ proxy)।
ਰੀਬੈਲੈਂਸਿੰਗ ਅਕਸਰ ਅਸਥਾਈ ਪੈਰਫਾਰਮੈਂਸ ਡਿੱਪ (ਵਾਧੂ ਲਿਖਤ, cache churn, ਬੈਕਗਰਾਊਂਡ ਕਾਪੀ ਲੋਡ) ਦਾ ਕਾਰਨ ਬਣਦੀ ਹੈ। ਹਿੱਸੇ-ਹਿੱਸੇ moves ਆਮ ਹਨ—ਕੁਝ ਰੇਂਜ ਪਹਿਲਾਂ migrate ਹੁੰਦੀਆਂ ਹਨ—ਇਸ ਲਈ ਤੁਹਾਨੂੰ ਸਪੱਸ਼ਟ ਦਰਸ਼ਕਤਾ ਅਤੇ ਰੋਲਬੈਕ ਯੋਜਨਾ ਚਾਹੀਦੀ ਹੈ (ਉਦਾਹਰਣ: ਮੈਪ ਨੂੰ ਵਾਪਸ ਫਲਿੱਪ ਕਰਨਾ ਅਤੇ ਡ੍ਰੇਨਿੰਗ dual-writes) ਪਹਿਲਾਂ cuts over ਸ਼ੁਰੂ ਕਰਨ ਤੋਂ।
ਸ਼ਾਰਡਿੰਗ ਇਹ ਮੰਨ ਕੇ ਚਲਦੀ ਹੈ ਕਿ ਕੰਮ ਫੈਲ ਜਾਵੇਗਾ। ਹੈਰਾਨੀ ਇਹ ਹੈ ਕਿ ਕਲੱਸਟਰ ਕਾਗਜ਼ਾਂ 'ਤੇ "ਬਰਾਬਰ" ਦਿਖਾਈ ਦੇ ਸਕਦਾ ਹੈ (ਹਰ shard 'ਤੇ ਇੱਕੋ ਰੋਜ਼ ਦੀ ਗਿਣਤੀ), ਪਰ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਬਹੁਤ ਅਸਮਾਨ ਵਿਹਾਰ ਕਰ ਸਕਦਾ ਹੈ।
ਹਾਟਸਪੌਟ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਕੀ-ਸਪੇਸ ਦਾ ਇਕ ਛੋਟਾ ਹਿੱਸਾ ਜ਼ਿਆਦਾਤਰ ਟ੍ਰੈਫਿਕ ਪ੍ਰਾਪਤ ਕਰ ਲੈਂਦਾ ਹੈ—ਚੁਣੋ ਇੱਕ ਪ੍ਰਸਿੱਧ ਖਾਤਾ, ਇੱਕ ਬੇਚ ਜੋ ਭਾਰੀ ਹੈ, ਜਾਂ ਉਹ ਟਾਈਮ-ਅਧਾਰਿਤ ਕੁੰਜੀ ਜਿੱਥੇ "ਅੱਜ" ਸਾਰੀਆਂ ਲਿਖਤਾਂ ਖਿੱਚਦਾ ਹੈ. ਜੇ ਉਹ keys ਇੱਕ shard 'ਤੇ ਹੋਣ, ਤਾਂ ਉਹ shard ਬੌਤਲਨੈਕ ਬਣ ਜਾਦਾ ਹੈ ਭਲੇ ਬਾਕੀ ਸਾਰੇ shards ਸੁੱਥਰੇ ਹੋਣ।
"ਸਕਿਊ" ਇਕੋ ਚੀਜ਼ ਨਹੀਂ ਹੈ:
ਉਹਨਾਂ ਦੋਹਾਂ ਦੇ ਮਿਲਣ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ—ਇੱਕ shard ਘੱਟ ਡੇਟਾ ਰੱਖ ਕੇ ਵੀ ਸਭ ਤੋਂ ਹਾਟ ਹੋ ਸਕਦਾ ਹੈ ਜੇ ਉਹ ਸਭ ਤੋਂ ਮੰਗ ਵਾਲੀਆਂ ਕੁੰਜੀਆਂ ਦਾ ਮਾਲਕ ਹੋਵੇ।
ਫੈਂਸੀ ਟ੍ਰੇਸਿੰਗ ਦੀ ਲੋੜ ਨਹੀਂ—per-shard ਡੈਸ਼ਬੋਰਡ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਜੇ ਇੱਕ shard ਦੀ ਲੇਟੈਂਸੀ ਉਸਦੇ QPS ਨਾਲ ਵੱਧਦੀ ਹੈ ਜਦਕਿ ਹੋਰਾਂ ਦੀ ਕਦੇ ਨਹੀਂ, ਤਾਂ ਤੁਹਾਨੂੰ ਹਾਟਸਪੌਟ ਦਾ ਸਾਹਮਣਾ ਹੈ।
ਠੀਕ ਕਰਨ ਵਾਲੇ ਹਲ ਸਧਾਰਣਤਾ ਨੂੰ ਬੈਲੈਂਸ ਦੇਣਗੇ:
ਸ਼ਾਰਡਿੰਗ ਕੇਵਲ ਹੋਰ ਸਰਵਰਾਂ ਨਹੀਂ ਜੋੜਦੀ—ਇਹ ਹੋਰ ਤਰੀਕੇ ਜੋ ਚੀਜ਼ਾਂ ਗਲਤ ਹੋ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਹੋਰ ਥਾਵਾਂ ਜਿਥੇ ਵੇਖਣਾ ਪੈਂਦਾ ਹੈ, ਜੋੜਦੀ ਹੈ। ਕਈ ਘਟਨਾਵਾਂ "ਡੇਟਾਬੇਸ ਡਾਊਨ ਹੈ" ਤੋਂ ਵੱਖ-ਵੱਖ ਹੁੰਦੀਆਂ ਹਨ—"ਇੱਕ shard ਡਾਊਨ ਹੈ" ਜਾਂ "ਸਿਸਟਮ ਇਹਨੂੰ ਨਹੀਂ ਜਾਣਦਾ ਕਿ ਡੇਟਾ ਕਿੱਥੇ ਹੈ"।
ਕੁਝ ਆਮ ਪੈਟਰਨ:
ਇੱਕ-ਨੋਡ ਡੇਟਾਬੇਸ ਵਿੱਚ ਤੁਸੀਂ ਇਕ ਲੋਗ ਟੇਲ ਕਰਦੇ ਹੋ ਅਤੇ metrics ਵੇਖਦੇ ਹੋ। ਇੱਕ ਸ਼ਾਰਡਡ ਸਿਸਟਮ ਵਿੱਚ, ਤੁਹਾਨੂੰ ਇੱਕ ਬੇਨਤੀ ਨੂੰ shards ਦੇ ਆਲੇ-ਦੁਆਲੇ follow ਕਰਨ ਵਾਲੀ observability ਚਾਹੀਦੀ ਹੈ।
ਹਰ ਬੇਨਤੀ ਵਿੱਚ correlation IDs ਰੱਖੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ API ਲੇਅਰ ਤੋਂ ਰਾਊਟਰਾਂ ਅਤੇ ਹਰ shard ਤੱਕ propagate ਕਰੋ। ਇਸਨੂੰ distributed tracing ਨਾਲ ਜੋੜੋ ਤਾਂ ਕਿ ਇੱਕ scatter-gather ਕਵੈਰੀ ਇਹ ਦਿਖਾ ਸਕੇ ਕਿ ਕਿਹੜਾ shard ਸੁਸਤ ਸੀ ਜਾਂ ਫੇਲ ਹੋਇਆ। ਮੈਟਰਿਕਸ ਪ੍ਰਤੀ shard (ਲੇਟੈਂਸੀ, ਕਤਾਰ ਡੈਪਥ, ਐਰਰ ਦਰ) ਵਰਗੇ ਟੁੱਟੇ ਹੋਏ ਵਿਸ਼ਲੇਸ਼ਣ ਨਹੀਂ ਵਰਗੇ, ਨਹੀਂ ਤਾਂ ਹਾਟ shard ਫਲੀਟ-ਸਰਸਤ ਵਿੱਚ ਲੁਕ ਜਾਵੇਗਾ।
ਸ਼ਾਰਡਿੰਗ ਫੇਲਯੂਰ ਆਮ ਤੌਰ 'ਤੇ correctness ਬੱਗਾਂ ਵਜੋਂ ਸਾਹਮਣੇ ਆਉਂਦੀਆਂ ਹਨ:
"ਡੇਟਾਬੇਸ ਦੁਬਾਰਾ ਬਹਾਲ ਕਰੋ" ਹੁਣੋਂ ਬਣ ਜਾਂਦਾ ਹੈ "ਕਈ ਹਿੱਸਿਆਂ ਨੂੰ ਸਹੀ ਕ੍ਰਮ ਵਿੱਚ ਰੀਸਟੋਰ ਕਰੋ"। ਤੁਹਾਨੂੰ ਸ਼ਾਇਦ ਪਹਿਲਾਂ ਮੈਟਾਡੇਟਾ ਨੂੰ ਰੀਸਟੋਰ ਕਰਨਾ ਪਵੇ, ਫਿਰ ਹਰ shard ਨੂੰ, ਫਿਰ ਯਕੀਨੀ ਬਣਾਉਣਾ ਕਿ shard ਬਾਊਂਡਰੀਆਂ ਅਤੇ ਰੂਟਿੰਗ ਨਿਯਮ ਬਹਾਲ ਪੁਆਇੰਟ-ਇਨ-ਟਾਈਮ ਨਾਲ ਮਿਲਦੇ ਹਨ। DR ਯੋਜਨਾਵਾਂ ਵਿੱਚ ਅਭਿਆਸ ਵੀ ਸ਼ਾਮਿਲ ਹੋਣ: ਇਹ ਸਾਬਤ ਕਰਨਾ ਕਿ ਤੁਸੀਂ ਇਕ ਸੰਗਠਿਤ ਕਲੱਸਟਰ ਬਣਾਕੇ ਵਾਪਸ ਲਿਆ ਸਕਦੇ ਹੋ—ਸਿਰਫ ਅਲੱਗ ਨੋਡਾਂ ਨੂੰ recover ਕਰਨ ਨਾਲ ਕਾਮ ਨਹੀਂ ਚੱਲਦਾ।
ਸ਼ਾਰਡਿੰਗ ਨੂੰ ਅਕਸਰ "ਸਕੇਲਿੰਗ ਸਵਿੱਚ" ਵਾਂਗ ਲਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਇਹ ਇਕ ਸਥਾਈ ਵਾਧਾ ਹੈ ਸਿਸਟਮ ਦੀ ਜਟਿਲਤਾ ਵਿੱਚ। ਜੇ ਤੁਸੀਂ ਆਪਣੇ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਭਰੋਸੇਯੋਗਤਾ ਲਕੜਾਂ ਨੂੰ ਵੰਡੇ ਬਿਨਾਂ ਪੂਰੇ-ਸਿਸਟਮ ਦੇ ਭੀਤਰੀ ਹਿੱਸੇ ਨੂੰ ਵਿਭਾਜਿਤ ਕੀਤੇ ਹੱਲ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਇੱਕ ਸਧਾਰਣ ਆਰਕੀਟੈਕਚਰ, ਆਸਾਨ ਡੀਬੱਗਿੰਗ, ਅਤੇ ਘੱਟ ਓਪਰੇਸ਼ਨਲ ਐਜ ਕੇਸ ਪ੍ਰਾਪਤ ਕਰੋਗੇ।
ਸ਼ਾਰਡਿੰਗ 'ਤੇ ਜਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਉਹ ਵਿਕਲਪ ਅਜ਼ਮਾਓ ਜੋ ਇਕੋ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਨੂੰ ਬਰਕਰਾਰ ਰੱਖਦੇ ਹਨ:
ਸ਼ਾਰਡਿੰਗ ਦਾ ਜੋਖਮ ਘਟਾਉਣ ਲਈ ਇੱਕ ਪ੍ਰਯੋਗਤਮਕ ਤਰੀਕਾ ਪਲੰਬਿੰਗ (routing boundaries, idempotency, migration workflows, observability) ਦਾ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾਉਣਾ ਹੈ।
ਉਦਾਹਰਣ ਵਜੋਂ, Koder.ai ਦੇ ਨਾਲ ਤੁਸੀਂ ਛੇਤੀ ਇੱਕ ਛੋٽي, ਹਕੀਕਤੀ ਸੇਵਾ ਚੈਟ ਤੋਂ ਸਪਿਨ ਅੱਪ ਕਰ ਸਕਦੇ ਹੋ—ਅਕਸਰ ਇੱਕ React ਐਡਮਿਨ UI ਨਾਲ Go ਬੈਕਐਂਡ ਅਤੇ PostgreSQL—ਅਤੇ shard-key-aware APIs, idempotency keys, ਅਤੇ "cutover" ਵਿਹਾਰਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਸੈਂਡਬਾਕਸ ਵਿੱਚ ਪ੍ਰਯੋਗ ਕਰ ਸਕਦੇ ਹੋ। Koder.ai planning mode, snapshots/rollback, ਅਤੇ source code export ਸਹਾਇਤਾ ਦਿੰਦਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਸ਼ਾਰਡਿੰਗ-ਸਬੰਧੀ ਡਿਜ਼ਾਈਨ ਫੈਸਲੇ (ਜਿਵੇਂ ਰੂਟਿੰਗ ਅਤੇ ਮੈਟਾਡੇਟਾ ਆਕਾਰ) 'ਤੇ ਇਟਰੈਟ ਕਰ ਸਕੋ ਅਤੇ ਫਿਰ ਨਤੀਜਾ ਕੋਡ ਅਤੇ ਰਨਬੁੱਕ ਆਪਣੀ ਮੁੱਖ ਸਟੈੱਕ ਵਿੱਚ ਲੈ ਜਾ ਸਕੋ ਜਦੋਂ ਤੁਸੀਂ ਨਿਸ਼ਚਿਤ ਹੋਵੋ।
ਸ਼ਾਰਡਿੰਗ ਉਸ ਵੇਲੇ ਬਿਹਤਰ ਫਿੱਟ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਤੁਹਾਡਾ ਡੇਟਾਸੈੱਟ ਜਾਂ ਲਿਖਤ throughput ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਇਕ ਨੋਡ ਦੀਆਂ ਸੀਮਾਵਾਂ ਤੋਂ ਵੱਧ ਚਲਾ ਗਿਆ ਹੋਵੇ ਅਤੇ ਤੁਹਾਡੇ ਅਹਿਮ ਕਵੈਰੀ ਪੈਟਰਨ shard key ਦੁਆਰਾ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਰੂਟ ਹੋ ਸਕਦੇ ਹੋ (ਘੱਟ ਕ੍ਰਾਸ-ਸ਼ਾਰਡ ਜੋਇਨ, ਘੱਟ scatter-gather ਕਵੈਰੀਆਂ).
ਇਹ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚੰਗਾ ਫਿੱਟ ਨਹੀਂ ਜਦੋਂ:
ਪੂਛੋ:
ਚਾਹੇ ਤੁਸੀਂ ਸ਼ਾਰਡਿੰਗ ਨੂੰ ਡਿਲੇ ਕਰੋ, ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ ਪਾਥ ਤਿਆਰ ਕਰੋ: ਉਹ identifiers ਚੁਣੋ ਜੋ ਭਵਿੱਖ ਦੇ shard key ਵਿੱਚ ਰੁਕਾਵਟ ਨਾ ਬਣਣ, single-node ਧਾਰਣਾ ਨੂੰ ਹਾਰਡ-ਕੋਡ ਨਾ ਕਰੋ, ਅਤੇ ਅਭਿਆਸ ਕਰੋ ਕਿ ਤੁਸੀਂ ਡਾਟਾ ਕਿਵੇਂ ਘੱਟ ਡਾਊਨਟਾਈਮ ਨਾਲ ਮੂਵ ਕਰੋਗੇ। ਸਭ ਤੋਂ ਵਧੀਆ ਸਮਾਂ resharding ਦੀ ਯੋਜਨਾ ਬਣਾਉਣ ਲਈ ਉਹ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਅਜੇ ਤਿਆਰ ਹੋ।
ਸ਼ਾਰਡਿੰਗ (ਹੋਰਾਈਜ਼ਾਂਟਲ ਪਾਰਟੀਸ਼ਨਿੰਗ) ਇੱਕ ਹੀ ਲੌਜਿਕਲ ਡੇਟਾਸੈੱਟ ਨੂੰ ਕਈ ਮਸ਼ੀਨਾਂ ("ਸ਼ਾਰਡ") ਵਿੱਚ ਵੰਡ ਦਿੰਦੀ ਹੈ, ਜਿੱਥੇ ਹਰ ਸ਼ਾਰਡ ਵੱਖਰੇ ਰਿਕਾਰਡ ਰੱਖਦਾ ਹੈ.
ਇਸ ਦੇ ਉਲਟ, ਰੈਪਲਿਕੇਸ਼ਨ ਇੱਕੋ ਡੇਟਾ ਦੀਆਂ ਨਕਲਾਂ ਕਈ ਨੋਡਾਂ 'ਤੇ ਰੱਖਦੀ ਹੈ—ਜ਼ਿਆਦਾਤਰ ਉਪਲਬਧਤਾ ਅਤੇ ਰੀਡ ਸਕੇਲਿੰਗ ਲਈ।
ਵਰਟਿਕਲ ਸਕੇਲਿੰਗ ਦਾ ਮਤਲਬ ਹੈ ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ ਸਰਵਰ ਨੂੰ ਅੱਪਗ੍ਰੇਡ ਕਰਨਾ (ਵਧੇਰੇ CPU/RAM/ਤੇਜ਼ ਡਿਸਕ). ਇਹ ਆਪਰੇਸ਼ਨਲ ਤੌਰ `ਤੇ ਸਧਾਰਣ ਹੈ, ਪਰ ਅੱਡੇ ਸੀਮਾਵਾਂ ਵਿਚ ਪਹੁੰਚ ਜਾਂਤੀ ਹੈ (ਅਤੇ ਮਹਿੰਗਾ ਹੋ ਸਕਦਾ ਹੈ).
ਸ਼ਾਰਡਿੰਗ ਮਸ਼ੀਨਾਂ ਨੂੰ ਵਧਾ ਕੇ ਆਊਟਸਕੇਲ ਕਰਦੀ ਹੈ, ਪਰ ਇਹ ਰੂਟਿੰਗ, ਰੀਬੈਲੈਂਸਿੰਗ ਅਤੇ ਕ੍ਰਾਸ-ਸ਼ਾਰਡ ਸਹੀਪਣ ਸਮੱਸਿਆਵਾਂ ਲਿਆਉਂਦੀ ਹੈ।
ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਾਰਡ ਕਰਦੀਆਂ ਹਨ ਜਦੋਂ ਇੱਕ ਨੋਡ ਮੁੜ-ਮੁੜ ਬੋਤਲਨੈਕ ਬਣ ਜਾਂਦਾ ਹੈ, ਜਿਵੇਂ ਕਿ:
ਸ਼ਾਰਡਿੰਗ ਡੇਟਾ ਅਤੇ ਟ੍ਰੈਫਿਕ ਫੈਲਾਉਂਦੀ ਹੈ ਤਾਂ ਕਿ ਸਮਰੱਥਾ ਮਸ਼ੀਨਾਂ ਜੋੜ ਕੇ ਵਧੇ।
ਇੱਕ ਆਮ ਸ਼ਾਰਡਿੰਗ ਸਿਸਟਮ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹੁੰਦਾ ਹੈ:
ਪੈਰਫਾਰਮੈਂਸ ਅਤੇ ਸਹੀਪਣ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਕਿ ਇਹ ਹਿੱਸੇ ਇਕੱਠੇ ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ।
ਸ਼ਾਰਡ ਕੀ ਉਹ ਫੀਲਡ(ਜਾਂ ਫੀਲਡਾਂ ਦੀ ਜੋੜੀ) ਹੁੰਦੀ ਹੈ ਜੋ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ ਇਕ ਰੋ ਕਿੱਥੇ ਰਹੇਗੀ. ਇਹ ਬਹੁਤ ਹੱਦ ਤੱਕ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ ਕਿ ਬੇਨਤੀ ਇਕ.shard ਤੇ ਜਾਏਗੀ (ਤੇਜ਼ ਰਸਤਾ) ਜਾਂ ਕਈ ਸ਼ਾਰਡਸ ਨੂੰ ਫੈਨ-ਆਉਟ ਕਰੇਗੀ (ਧੀਮੀਆਂ ਕਵੈਰੀਆਂ).
ਚੰਗੀ shard ਕੁੰਜੀ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਗੁਣ ਰੱਖਦੀ ਹੈ:
user_id)ਕੁਝ shard ਕੁੰਜੀਆਂ ਨੁਕਸਾਨ ਦੇਣ ਵਾਲੀਆਂ ਹੁੰਦੀਆਂ ਹਨ:
ਇਹਨਾਂ ਕਾਰਨਾਂ ਨਾਲ ਰੁਟੀਨ ਕਵੈਰੀਆਂ scatter-gather ਫੈਨ-ਆਉਟ ਬਣ ਸਕਦੀਆਂ ਹਨ।
ਤਿੰਨ ਆਮ ਰਣਨੀਤੀਆਂ ਹਨ:
ਰੇਂਜ ਸ਼ਾਰਡਿੰਗ: ਹਰ ਸ਼ਾਰਡ ਇੱਕ ਲਗਾਤਾਰ ਕੀ ਰੇਂਜ ਦਾ ਮਾਲਕ ਹੁੰਦਾ ਹੈ (ਉਦਾਹਰਣ: customer_id 1–1,000,000). ਰੂਟਿੰਗ ਸਧਾਰਨ ਹੁੰਦੀ ਹੈ, ਪਰ ਨਵਾਂ ਡੇਟਾ monotonic ਆਈਡੀਜ਼ ਨਾਲ ਹਾਟਸਪੌਟ ਬਣ ਸਕਦਾ ਹੈ। ਰੇਂਜ ਕਵੈਰੀਆਂ ਲਈ ਇਹ ਚੰਗਾ ਹੈ।
ਸ਼ਾਰਡ ਕੀ (ਜਾਂ ਉਸ ਦੇ ਕੁਝ ਹਿੱਸੇ) ਰੂਟਿੰਗ ਲਈ ਮੌਜੂਦ ਹੋਵੇ ਤਾਂ ਕਵੈਰੀ ਸਿੱਧਾ ਇੱਕ ਸ਼ਾਰਡ 'ਤੇ ਜਾ ਸਕਦੀ ਹੈ—ਇਹ ਤੇਜ਼ ਰਸਤਾ ਹੈ.
ਜਦੋਂ ਰੂਟਿੰਗ ਨਿਰਧਾਰਿਤ ਨਹੀਂ ਹੋ ਸਕਦੀ (ਉਦਾਹਰਣ ਲਈ non-shard-key ਫੀਲਡ 'ਤੇ ਫਿਲਟਰ), ਤਾਂ ਸਿਸਟਮ ਕਈ/ਸਾਰੇ shards ਨੂੰ ਕਵੈਰੀ ਭੇਜ ਸਕਦਾ ਹੈ। ਹਰ ਸ਼ਾਰਡ ਲੋਕਲੀ ਕਵੈਰੀ ਚਲਾਉਂਦਾ ਹੈ ਅਤੇ ਫਿਰ ਨਤੀਜੇ ਜੋੜੇ ਜਾਂਦੇ ਹਨ—ਇਸ ਨੂੰ scatter-gather ਕਹਿੰਦੇ ਹਨ।
ਇਸ ਫੈਨ-ਆਉਟ ਨਾਲ ਟੇਲ ਲੇਟੈਂਸੀ ਵੱਧਦੀ ਹੈ: 9 shards ਜਲਦੀ ਜਵਾਬ ਦੇਣ ਤਾਂ ਵੀ ਇੱਕ ਸੁਸਤ shard ਪੂਰੇ ਬੇਨਤੀ ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ।
ਜੇ ਹਰ ਬੇਨਤੀ ਨੂੰ ਸਹੀ shard 'ਤੇ ਰੂਟ ਕੀਤਾ ਜਾ ਸਕੇ, ਤਾਂ ਲਿਖਤ ਆਮ ਤੌਰ 'ਤੇ ਉਸ shard ਦੀ ਸਧਾਰਣ ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਮਸ਼ੀਨਰੀ ਵਰਤ ਸਕਦੀ ਹੈ—ਇਹ ਤੇਜ਼ ਅਤੇ ਸਧਾਰਣ ਹੁੰਦਾ ਹੈ.
ਪਰ ਜਦੋਂ ਇੱਕ ਲਾਜ਼ਮੀ ਕਾਰਵਾਈ ਦੋ shards 'ਤੇ ਬਦਲ-ਬਦਲ ਕੇ ਹੋਣੀ ਪਏ, ਤਾਂ ਤੁਸੀਂ ਵੰਡੇ ਹੋਏ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਜਾਣੇ ਵਾਲੇ ਇਲਾਕੇ ਵਿੱਚ ਆ ਜਾਂਦੇ ਹੋ. ਦੂ-ਪੜਾਅ ਵਾਲੇ ਕਮਿੱਟ ਪ੍ਰੋਟੋਕੋਲ (two-phase commit) ਵੱਧ round-trips ਲੈਂਦੇ ਹਨ, ਟਾਈਮਆਉਟ 'ਤੇ ਬਲੌਕ ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ ਫੇਲਯੂਰ ਅਸਪಷ್ಟ ਹੋ ਸਕਦੇ ਹਨ (ਕੀ ਲਾਗਤ ਲੱਗ ਚੁੱਕੀ ਹੈ ਜਾਂ ਨਹੀਂ?).
ਅਮਲਾਤਮਕ ਹੱਲਾਂ ਵਿੱਚ ਸ਼ਾਮਿਲ ਹਨ:
ਸ਼ਾਰਡਿੰਗ ਵਿੱਚ replication ਨੇ shard ਦੇ ਅੰਦਰ ਉਪਲਬਧਤਾ ਲਈ ਨਕਲ ਰੱਖਣੀ ਪੈਂਦੀ ਹੈ. ਆਮ ਤੌਰ 'ਤੇ ਹਰ shard ਵਿੱਚ ਇੱਕ ਲੀਡਰ (ਪ੍ਰਾਇਮਰੀ) ਹੁੰਦਾ ਹੈ ਜੋ ਲਿਖਤਾਂ ਮਨਜ਼ੂਰ ਕਰਦਾ ਹੈ ਅਤੇ ਰੈਪਲਿਕਾ ਉਨ੍ਹਾਂ ਨੂੰ ਨਕਲ ਕਰਦੇ ਹਨ.
ਇਸ ਨਾਲ ਸਮਾਂ-ਗੈਪ ਆ ਸਕਦੀ ਹੈ—ਰੀਡ ਰੈਪਲਿਕਾ ਕੁਝ ਮਿਲੀ-ਸੈਕਿੰਡ ਜਾਂ ਸਕਿੰਟ ਪਿੱਛੇ ਹੋ ਸਕਦੀ ਹੈ।
ਸਧਾਰਨ ਤੌਰ 'ਤੇ ਤੁਸੀਂ shard ਦੇ ਅੰਦਰ strong consistency ਅਤੇ shards ਦੇ ਅਕਸਰ weaker ਗਾਰੰਟੀਜ਼ ਦੇ ਮਿਸ਼ਰਨ ਨਾਲ ਕੰਮ ਕਰਦੇ ਹੋ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਕ੍ਰਾਸ-ਸ਼ਾਰਡ ਆਪਰੇਸ਼ਨ ਸ਼ਾਮਿਲ ਹੋਣ।
ਰੀਬੈਲੈਂਸਿੰਗ ਦਾ ਮਤਲਬ ਹੈ ਸਮੇਂ ਦੇ ਨਾਲ ਸਿਸਟਮ ਨੂੰ ਵਰਤਣਯੋਗ ਬਣਾਈ ਰੱਖਣਾ—ਡੇਟਾ ਅਸਮਾਨ ਵਧ ਸਕਦੀ ਹੈ, shard-key ਸਕਿਊ ਹੋ ਸਕਦੀ ਹੈ, ਨਵੇਂ ਨੋਡ ਜੋੜੇ ਜਾਂ ਹਟਾਏ ਜਾਣੇ ਹੋ ਸਕਦੇ ਹਨ.
ਆਨਲਾਈਨ ਮਾਈਗ੍ਰੇਸ਼ਨ ਦਾ ਆਮ ਪੈਟਰਨ ਇਹ ਹੈ:
ਹਾਟਸਪੌਟ ਉਹ ਸਮਾਂ ਹੈ ਜਦੋਂ ਕੁੰਜੀ ਦਾ ਇੱਕ ਛੋਟਾ ਹਿੱਸਾ ਜ਼ਿਆਦਾ ਟ੍ਰੈਫਿਕ ਖਾ ਲੈਂਦਾ ਹੈ—ਉਦਾਹਰਣ ਲਈ ਇੱਕ ਸਲੈਬਰਿਟੀ ਅਕਾਉਂਟ, ਪ੍ਰਸਿੱਧ ਉਤਪਾਦ, ਜਾਂ "ਅੱਜ" ਵਾਲੀ ਟਾਇਮ-ਅਧਾਰਿਤ ਕੁੰਜੀ. ਜੇ ਇਹਾਂ ਕੁੰਜੀਆਂ ਇੱਕ ਹੀ shard ਨੂੰ ਮੈਪ ਹੋਣ, ਤਾਂ ਉਹ shard ਬੋਤਲਨੈਕ ਬਣ ਜਾਂਦਾ ਹੈ.
ਸਕਿਊ ਦੋ ਤਰ੍ਹਾਂ ਦੀ ਹੁੰਦੀ ਹੈ:
ਉਹਨਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪਤਾ ਕਰਨ ਲਈ per-shard ਡੈਸ਼ਬੋਰਡ ਦੇਖੋ: p95 latency ਪ੍ਰਤੀ shard, QPS ਪ੍ਰਤੀ shard, ਸਟੋਰੇਜ ਵਰਤੋਂ.
ਮੁਕਾਬਲੇ:
ਸ਼ਾਰਡਿੰਗ ਨਾਲ ਗਲਤੀਆਂ ਦੇ ਹੋਰ ਰਸਤੇ ਆ ਜਾਂਦੇ ਹਨ ਅਤੇ ਡੀਬੱਗਿੰਗ ਵੀ ਵੱਖਰੇ ਹੋ ਜਾਂਦੀ ਹੈ.
ਆਮ ਫੇਲਯੂਰ ਮੋਡ:
ਸ਼ਾਰਡਿੰਗ ਇਕ ਪੱਕਾ ਬਰਧੀ ਹੋਈ ਜਟਿਲਤਾ ਹੈ—ਇਸ ਲਈ ਪਹਿਲਾਂ ਇਹ ਵਿਕਲਪਾਂ ਆਜ਼ਮਾਓ ਜੋ ਇੱਕ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਨੂੰ ਬਰਕਰਾਰ ਰੱਖਣ:
ਖਤਰਨਾਕ-ਕਮੀ ਦੂਰ ਕਰਨ ਲਈ, ਸ਼ਾਰਡਿੰਗ ਦਾ ਪਲੰਬਿੰਗ (ਰਾਊਟਿੰਗ, idempotency, ਮਾਈਗ੍ਰੇਸ਼ਨ ਵਰਕਫਲੋਜ਼, ਦੇਖਰੇਖ) ਪਹਿਲਾਂ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰਨਾ ਚੰਗਾ ਹੁੰਦਾ ਹੈ—Koder.ai ਇਸ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ Koder.ai ਨਾਂਵ ਜਾਂ ਡੋਮੇਨ ਨਾਲ ਜੁੜੇ ਲੇਖਾਂ ਨੂੰ ਬਦਲਣਾ ਨਹੀਂ।
ਉਦਾਹਰਣ: ਮਲਟੀ-ਟੇਨੈਂਟ ਐਪ ਵਿੱਚ tenant_id ਦੁਆਰਾ ਸ਼ਾਰਡਿੰਗ ਅਕਸਰ ਵਧੀਆ ਹੁੰਦੀ ਹੈ—ਅਕਸਰ ਇੱਕ ਹੀ ਟੇਨੈਂਟ ਦੀਆਂ ਰੀਡ/ਰਾਈਟਸ ਇੱਕ ਸ਼ਾਰਡ 'ਤੇ ਰਹਿੰਦੀਆਂ ਹਨ।
ਹੈਸ਼ ਸ਼ਾਰਡਿੰਗ: ਕੀ ਨੂੰ ਹੈਸ਼ ਕਰਕੇ shard ਚੁਣਿਆ ਜਾਂਦਾ ਹੈ—ਇਸ ਨਾਲ ਡੇਟਾ ਜ਼ਿਆਦਾ ਬਰਾਬਰ ਵੰਡਦਾ ਹੈ। ਪਰ ਰੇਂਜ ਕਵੈਰੀਆਂ ਮਹਿਲਕ ਹੋ ਜਾਂਦੀਆਂ ਹਨ। ਕਨਸਿਸਟੈਂਟ ਹੈਸ਼ਿੰਗ ਵਰਤਕੇ shards ਨੂੰ ਵੱਧਾਇਆ ਜਾਣ 'ਤੇ ਸਾਰੇ ਕੁੰਜੀਆਂ ਦੀ ਮੁੜ-ਵੰਡ ਘੱਟ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ।
ਡਾਇਰੈਕਟਰੀ (ਲੁੱਕਅੱਪ) ਸ਼ਾਰਡਿੰਗ: ਇੱਕ ਐਕਸਪਲਿਸਿਟ ਨਕਸ਼ਾ key → shard ਰੱਖਦਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਲਚਕੀਲਾ ਹੈ—ਅਲੱਗ-ਅਲੱਗ ਟੇਨੈਂਟਾਂ ਨੂੰ ਡੈਡੀਕੇਟੇਡ ਸ਼ਾਰਡਾਂ 'ਤੇ ਰੱਖ ਸਕਦੇ ਹੋ—ਪਰ ਇਹ ਨਕਸ਼ੇ (ਡਾਇਰੈਕਟਰੀ) 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
ਇਸ ਮੁਕਾਬਲੇ metadata ਅਤੇ clients ਨੂੰ ਵੀ ਅਪਡੇਟ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ—ਇਸ ਲਈ shard ਮੈਪ ਦਾ ਵਰਜ਼ਨਿੰਗ, ਅਕਸਰ ਰਿਫ੍ਰੇਸ਼ ਅਤੇ ਕਲੀਅਰ ਰੋਲਬੈਕ ਯੋਜਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਡੈਬੱਗਿੰਗ ਲਈ correlation IDs ਅਤੇ distributed tracing ਵਰਤੋ ਤਾਂ ਕਿ ਹਰ ਬੇਨਤੀ ਕਿਹੜੇ shards 'ਤੇ ਗਈ, ਕਿਹੜਾ ਸੁਸਤ ਸੀ—ਇਹ ਦੇਖ ਸਕੋ. ਮੈਟਰਿਕਸ ਪ੍ਰਤੀ shard ਤੋੜ ਕੇ ਦਿੱਖਾਓ, ਨਹੀਂ ਤਾਂ ਹਾਟ shard ਫਲੀਟ-ਅਵਰੇਜ ਵਿੱਚ ਲੁਕ ਜਾਵੇਗਾ.
ਬੈਕਅੱਪ/ਰਿਸਟੋਰ ਲਈ: ਪਹਿਲਾਂ metadata ਬਹਾਲ ਕਰੋ, ਫਿਰ ਹਰ shard ਨੂੰ, ਅਤੇ ਯਕੀਨ ਪਕ ਕਰੋ ਕਿ shard ਬਾਊਂਡਰੀਆਂ ਅਤੇ ਰੂਟਿੰਗ ਨਿਯਮ ਕਿੱਤੇ ਗਏ ਪੁਆਇੰਟ-ਇਨ-ਟਾਈਮ ਨਾਲ ਮਿਲਦੇ ਹਨ. ਡਿਜਾਸਟਰ ਰਿਕਵਰੀ ਯੋਜਨਾਵਾਂ ਦੀ ਰੀਹਰਸਲ ਕਰੋ।