15 ਜੂਨ 2025·8 ਮਿੰਟ
ਕਿਵੇਂ ਡੇਟਾਬੇਸ ਕੰਮ ਵਿੱਚ ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਬਣ ਜਾਂਦੇ ਹਨ
ਸਿੱਖੋ ਕਿ ਸੰਸਥਾਵਾਂ ਕਿਵੇਂ ਗਵਰਨੈਂਸ, ਮਾਡਲਿੰਗ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਡੇਟਾ ਗੁਣਵੱਤਾ ਅਭਿਆਸਾਂ ਰਾਹੀਂ ਡੇਟਾਬੇਸ ਨੂੰ ਕੰਮ ਵਿੱਚ ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਸਿੱਖੋ ਕਿ ਸੰਸਥਾਵਾਂ ਕਿਵੇਂ ਗਵਰਨੈਂਸ, ਮਾਡਲਿੰਗ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਡੇਟਾ ਗੁਣਵੱਤਾ ਅਭਿਆਸਾਂ ਰਾਹੀਂ ਡੇਟਾਬੇਸ ਨੂੰ ਕੰਮ ਵਿੱਚ ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਇੱਕ ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ (SSOT) ਉਹ ਸਾਂਝੀ ਰੀਤੀ ਹੈ ਜਿਸ ਨਾਲ ਇੱਕ ਸੰਸਥਾ ਬੁਨਿਆਦੀ ਸਵਾਲਾਂ ਦਾ ਇੱਕੋ ਜਿਹਾ ਜਵਾਬ ਦੇ ਸਕਦੀ ਹੈ—ਜਿਵੇਂ “ਸਾਡੇ ਕਿੰਨੇ ਸਰਗਰਮ ਗਾਹਕ ਹਨ?” ਜਾਂ “ਰੈਵਨਿਊ ਵਿਚ ਕੀ ਗਿਣਿਆ ਜਾਂਦਾ ਹੈ?”—ਅਤੇ ਟੀਮਾਂ ਵੱਲੋਂ ਇੱਕੋ ਜਵਾਬ ਮਿਲਦਾ ਹੈ।
ਇਹ ਸੋਚਣਾ ਆਸਾਨ ਹੈ ਕਿ SSOT ਦਾ ਮਤਲਬ “ਇੱਕ ਥਾਂ ਜਿੱਥੇ ਡੇਟਾ ਰਹਿੰਦਾ ਹੈ।” ਅਸਲ ਵਿੱਚ, SSOT ਇੱਕ ਇਕੱਠੇ ਹੋਣ ਵਾਲੀ ਰੀਤ ਹੈ: ਹਰ ਕੋਈ ਉਹੀ ਪਰਿਭਾਸ਼ਾਵਾਂ, ਨਿਯਮ ਅਤੇ ਪਛਾਣਕਰਤਾ ਵਰਤਦਾ ਹੈ ਜਦੋਂ ਉਹ ਰਿਪੋਰਟ ਬਣਾਉਂਦੇ, ਓਪਰੇਸ਼ਨ ਚਲਾਉਂਦੇ ਜਾਂ ਫੈਸਲੇ ਲੈਂਦੇ ਹਨ।
ਤੁਸੀਂ SSOT ਨੂੰ ਕਿਸੇ ਡੇਟਾਬੇਸ, ਇਕੱਠੇ ਹੋਏ ਸਿਸਟਮਾਂ ਜਾਂ ਡੇਟਾ ਪਲੇਟਫਾਰਮ 'ਤੇ ਤਿਆਰ ਕਰ ਸਕਦੇ ਹੋ—ਪਰ “ਸੱਚ” ਤਤਕਾਲ ਉਸ ਵੇਲੇ ਹੀ ਠੀਕ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ ਲੋਕ ਹੇਠਾਂ ਦਿੱਤੇ ਮਾਮਲਿਆਂ 'ਤੇ ਸਹਿਮਤ ਹੋਣ:
ਬਿਨਾਂ ਇਸ ਸਹਿਮਤੀ ਦੇ, ਸਭ ਤੋਂ ਵਧੀਆ ਡੇਟਾਬੇਸ ਵੀ ਟਕਰਾਉਂਦੇ ਨੰਬਰ ਦੇ ਸਕਦਾ ਹੈ।
SSOT ਸੰਦਰਭ ਵਿੱਚ, “ਸੱਚ” ਬਹੁਤ ਘੱਟ ਫ਼ਿਲਾਸਫ਼ੀਕਲ ਪੱਕੇ ਪੱਕੇ ਮਾਨਨ ਦਾ ਮਤਲਬ ਹੈ। ਇਹ ਉਹ ਡੇਟਾ ਹੁੰਦਾ ਹੈ ਜੋ:
ਜੇ ਤੁਸੀਂ ਕਿਸੇ ਨੰਬਰ ਨੂੰ ਉਸਦੇ ਸਰੋਤ ਅਤੇ ਲਾਜਿਕ ਤੱਕ ਵਾਪਸ ਟਰੇਸ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਭੀ ਭਰੋਸਾ ਕਰਨਾ ਔਖਾ ਹੁੰਦਾ ਹੈ—ਚਾਹੇ ਉਹ ਸਹੀ ਲੱਗੇ।
SSOT ਦਾ ਮਤਲਬ ਹੈ ਸੰਗਤ ਡੇਟਾ + ਸੰਗਤ ਮਿਆਨ + ਸੰਗਤ ਪ੍ਰਕਿਰਿਆਵਾਂ।
ਟਕਰਾਉਂਦਾ ਡੇਟਾ ਆਮ ਤੌਰ 'ਤੇ “ਖਰਾਬ ਲੋਕ” ਜਾਂ “ਖਰਾਬ ਟੂਲ” ਕਾਰਨ ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਵਿਕਾਸ ਦਾ ਕੁਦਰਤੀ ਨਤੀਜਾ ਹੈ: ਟੀਮਾਂ ਸਥਾਨਕ ਸਮੱਸਿਆਵਾਂ ਲਈ ਨਵੇਂ ਸਿਸਟਮ ਜੋੜ ਦਿੰਦੇ ਹਨ, ਅਤੇ ਸਮੇਂ ਨਾਲ-ਨਾਲ ਉਹ ਸਿਸਟਮ ਇਕ-ਦੂਜੇ ਦੇ ਨਾਲ ਓਵਰਲੈਪ ਕਰਨ ਲੱਗਦੇ ਹਨ।
ਜ਼ਿਆਦਾਤਰ ਸੰਸਥਾਵਾਂ ਇੱਕੋ ਗਾਹਕ, ਆਰਡਰ ਜਾਂ ਉਤਪਾਦ ਦੀ ਜਾਣਕਾਰੀ ਕਈ ਸਿਸਟਮਾਂ ਵਿੱਚ ਸਟੋਰ ਕਰ ਲੈਂਦੀਆਂ ਹਨ—CRM, ਬਿਲਿੰਗ, ਸਪੋਰਟ, ਮਾਰਕੀਟਿੰਗ, ਸਪ੍ਰੈਡਸ਼ੀਟਾਂ, ਅਤੇ ਕਈ ਵਾਰੀ ਕਿਸੇ ਨਿਰਦੀਸ਼ ਟੀਮ ਦਾ ਕਸਟਮ ਐਪ। ਹਰ ਸਿਸਟਮ ਇੱਕ ਆਛੇ ਪਾਰਸ਼ੀਅਲ ਸੱਚ ਬਣ ਜਾਂਦਾ ਹੈ, ਜੋ ਆਪਣੀ ਅਪਡੇਟ ਸ਼ਡਿਊਲ 'ਤੇ, ਆਪਣੇ ਯੂਜ਼ਰਾਂ ਵੱਲੋਂ ਅੱਪਡੇਟ ਹੁੰਦਾ ਹੈ।
ਗਾਹਕ CRM ਵਿੱਚ ਆਪਣਾ ਕੰਪਨੀ ਨਾਂ ਬਦਲਦਾ ਹੈ, ਪਰ ਬਿਲਿੰਗ ਕੋਲ ਪੁਰਾਣਾ ਨਾਂ ਰਹਿ ਜਾਂਦਾ ਹੈ। ਸਪੋਰਟ ਇੱਕ “ਨਵਾਂ” ਗਾਹਕ ਬਣਾਉਂਦਾ ਹੈ ਕਿਉਂਕਿ ਉਹ ਮੌਜੂਦਾ ਨੁਹੀਂ ਲੱਭ ਪਾਉਂਦਾ। ਕਾਰੋਬਾਰ ਨੇ ਜ਼ਰੂਰੀ ਤੌਰ 'ਤੇ ਗਲਤੀ ਨਹੀਂ ਕੀਤੀ—ਡੇਟਾ ਸਿਰਫ਼ ਡੁਪਲੀਕੇਟ ਹੋ ਗਿਆ।
ਹਾਲਾਂਕਿ ਮੁੱਲ ਮਿਲਦੇ ਹਨ, ਅਰਥ ਅਕਸਰ ਮਿਲਦਾ ਨਹੀਂ। ਇੱਕ ਟੀਮ ਦੀ “ਸਰਗਰਮ ਗਾਹਕ” ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ “30 ਦਿਨਾਂ ਵਿੱਚ ਲੌਗਇਨ ਕੀਤਾ”, ਜਦਕਿ ਦੂਜੀ ਦੀ ਵਿਆਖਿਆ ਹੋ ਸਕਦੀ ਹੈ “ਇਸ ਚੌਥਾਇ ਵਿੱਚ ਇਨਵੌਇਸ ਭਰੀ।” ਦੋਹਾਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਵਾਜ਼ਬ ਹੋ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਰਿਪੋਰਟਾਂ ਵਿੱਚ ਉਨ੍ਹਾਂ ਦਾ ਮਿਲਾਉਣ ਬਹਿਸ ਪੈਦਾ ਕਰਦਾ ਹੈ।
ਇਸੇ ਕਰਕੇ ਵਿਸ਼ਲੇਸ਼ਣ ਇੱਕਸਾਰਤਾ ਮੁਸ਼ਕਲ ਹੈ: ਨੰਬਰ ਵੱਖ-ਵੱਖ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਬੁਨਿਆਦੀ ਪਰਿਭਾਸ਼ਾਵਾਂ ਵੱਖ-ਵੱਖ ਹੁੰਦੀਆਂ ਹਨ।
ਮੈਨੁਅਲ ਐਕਸਪੋਰਟ, ਸਪ੍ਰੈਡਸ਼ੀਟ ਨਕਲਾਂ, ਅਤੇ ਈਮੇਲ ਜੁੜਤੀਆਂ ਡੇਟਾ ਸਕੈਪਸ਼ਾਟ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ ਤੁਰੰਤ ਬੁਢ਼ੀਆਂ ਹੋਣ ਲੱਗਦੀਆਂ ਹਨ। ਇੱਕ ਸਪ੍ਰੈਡਸ਼ੀਟ ਇੱਕ ਛੋਟੀ ਡੇਟਾਬੇਸ ਬਣ ਜਾਂਦੀ ਹੈ ਜਿਸ ਵਿੱਚ ਆਪਣੀਆਂ ਸੁਧਾਰਾਂ ਅਤੇ ਨੋਟਸ ਹੁੰਦੀਆਂ ਹਨ—ਜੋ ਕੰਮ ਦੇ ਦਿਨ-ਬਦ-ਦਿਨ ਸਿਸਟਮਾਂ ਵੱਲ ਵਾਪਸ ਨਹੀਂ ਆਉਂਦੀਆਂ।
###ਅਸਲ ਲਾਗਤ: ਭਰੋਸਾ ਅਤੇ ਤੇਜ਼ੀ
ਨਤੀਜੇ ਤੇਜ਼ੀ ਨਾਲ ਦਿਖਾਈ ਦਿੰਦੇ ਹਨ:
ਜਦ ਤੱਕ ਸੰਸਥਾ ਇਹ ਫੈਸਲਾ ਨਹੀਂ ਕਰਦੀ ਕਿ ਅਧਿਕਾਰਿਕ ਵਰਜਨ ਕਿੱਥੇ ਰਹੇਗਾ—ਅਤੇ ਅਪਡੇਟਾਂ ਨੂੰ ਕਿਵੇਂ ਗਵਰਨ ਕੀਤਾ ਜਾਵੇ—ਟਕਰਾਉਂਦਾ ਡੇਟਾ ਮੂਲ ਰੂਪ ਹੈ।
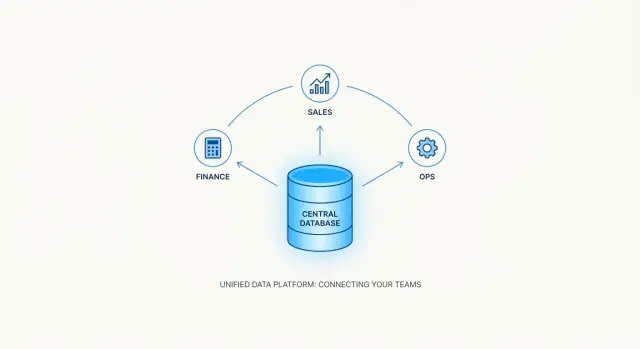
“ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ” ਸਾਂਝੀ ਸਪ੍ਰੈਡਸ਼ੀਟ ਜਾਂ ਚੰਗੇ ਮਨ ਵਾਲੇ ਡੈਸ਼ਬੋਰਡ ਤੋਂ ਵੱਧ ਚਾਹੀਦਾ ਹੈ। ਇਸਨੂੰ ਉਸ ਥਾਂ ਦੀ ਲੋੜ ਹੈ ਜਿੱਥੇ ਡੇਟਾ ਨਿਯਮਤ ਢੰਗ ਨਾਲ ਰੱਖਿਆ ਜਾਵੇ, ਆਟੋਮੈਟਿਕ ਤਰੀਕੇ ਨਾਲ ਵੈਰੀਫਾਇ ਕੀਤਾ ਜਾਵੇ, ਅਤੇ ਕਈ ਟੀਮਾਂ ਵੱਲੋਂ ਇੱਕਸਾਰ ਤਰੀਕੇ ਨਾਲ ਰੀਟਰਿਵ ਕੀਤਾ ਜਾ ਸਕੇ। ਇਸੇ ਲਈ ਸੰਸਥਾਵਾਂ ਆਮ ਤੌਰ 'ਤੇ ਆਪਣੇ SSOT ਦੇ ਕੇਂਦਰ ਵਿੱਚ ਇੱਕ ਡੇਟਾਬੇਸ ਰੱਖਦੀਆਂ ਹਨ—ਭਲੇ ਹੀ ਕਈ ਐਪਸ ਅਤੇ ਟੂਲ ਉਸਦੇ ਚਾਰੋਂ ਪਾਸੇ ਹੋਣ।
ਡੇਟਾਬੇਸ ਸਿਰਫ਼ ਜਾਣਕਾਰੀ ਸਟੋਰ ਨਹੀਂ ਕਰਦੇ; ਉਹ ਇਹ ਵੀ ਬਰਾਬਰ ਕਰ ਸਕਦੇ ਹਨ ਕਿ ਜਾਣਕਾਰੀ ਕਿਵੇਂ ਮੌਜੂਦ ਰਹੇ।
ਜਦੋਂ ਗਾਹਕ ਰਿਕਾਰਡ, ਆਰਡਰ ਅਤੇ ਉਤਪਾਦ ਸੰਰਚਿਤ ਸਕੀਮਾ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ, ਤੁਸੀਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰ ਸਕਦੇ ਹੋ:
ਇਸ ਨਾਲ ਉਹ ਧੀਰਾ ਡ੍ਰਿਫਟ ਘੱਟ ਹੁੰਦਾ ਹੈ ਜੋ ਟੀਮਾਂ ਆਪਣੇ ਖੇਤਰ, ਨਾਂ-ਕਨਵੈੰਸ਼ਨ ਜਾਂ “ਅਸਲ” ਵਰਕਅਰਾਊਂਡ ਬਣਾਉਂਦਿਆਂ ਕਰਦੀਆਂ ਹਨ।
ਓਪਰੇਸ਼ਨਲ ਡੇਟਾ ਲਗਾਤਾਰ ਬਦਲਦਾ ਰਹਿੰਦਾ ਹੈ: ਇਨਵੌਇਸ ਬਣਦੇ ਹਨ, ਸ਼ਿਪਮੈਂਟ ਅਪਡੇਟ ਹੁੰਦੇ ਹਨ, ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਰਿਨਿਊ ਹੁੰਦੇ ਹਨ, ਰੀਫੰਡ ਹੁੰਦੇ ਹਨ। ਡੇਟਾਬੇਸ ਇਸ ਕਿਸਮ ਦੇ ਕੰਮ ਲਈ ਬਣਾਏ ਗਏ ਹਨ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨਾਲ, ਡੇਟਾਬੇਸ ਇੱਕ ਬਹੁ-ਕਦਮ ਅਪਡੇਟ ਨੂੰ ਇੱਕ ਇਕਾਈ ਵਜੋਂ ਇਸਤेमाल ਕਰ ਸਕਦਾ ਹੈ: ਜਾਂ ਤਾਂ ਸਾਰੇ ਬਦਲਾਅ ਸਫਲ ਹੋਣ ਜਾਂ ਫੇਲ—ਇਸਦਾ ਅਰਥ ਹੈ ਘੱਟ ਸਥਿਤੀਆਂ ਜਿੱਥੇ ਇੱਕ ਸਿਸਟਮ ਭੁਗਤਾਨ ਨੂੰ ਕੈਪਚਰ ਕੀਤਾ ਦਿਖਾਵੇ ਤੇ ਦੂਜਾ ਫੇਲ ਦੱਸੇ। ਜਦੋਂ ਟੀਮ ਪੁੱਛਦੀ ਹੈ, “ਹੁਣ ਇਸ ਵੇਲੇ ਸੱਚ ਕੀ ਹੈ?” ਡੇਟਾਬੇਸ ਤਣਾਅ ਹਾਲਤਾਂ ਵਿੱਚ ਇਸ ਦਾ ਸਹੀ ਜਵਾਬ ਦੇਣ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ।
SSOT ਉਸ ਵੇਲੇ ਲਾਭਦਾਇਕ ਨਹੀਂ ਜਦੋਂ ਸਿਰਫ਼ ਇੱਕ ਵਿਅਕਤੀ ਹੀ ਇਸਨੂੰ ਸਮਝ ਸਕਦਾ ਹੋਵੇ। ਡੇਟਾਬੇਸ ਕੈਵਰੀਆਂ ਰਾਹੀਂ ਡੇਟਾ ਐਕਸੈਸਬਲ ਬਣਾਉਂਦੇ ਹਨ, ਤਾਂ ਕਿ ਵੱਖ-ਵੱਖ ਟੂਲ ਇੱਕੋ ਪਰਿਭਾਸ਼ਾਵਾਂ ਤੋਂ ਖਿੱਚ ਸਕਣ:
ਇਹ ਸਾਂਝੀ ਐਕਸੈਸ ਵਿਸ਼ਲੇਸ਼ਣ ਇਕਸਾਰਤਾ ਵਲ ਇੱਕ ਵੱਡਾ ਕਦਮ ਹੈ—ਕਿਉਂਕਿ ਲੋਕ ਹੋਰ ਅਲੱਗ-ਅਲੱਗ ਡੇਟਾ ਦੀ ਕਾਪੀ ਅਤੇ ਰੀਸ਼ੇਪ ਨਹੀਂ ਕਰ ਰਹੇ।
ਆਖਿਰਕਾਰ, ਡੇਟਾਬੇਸ ਪ੍ਰਾਇਕਟਿਕਲ ਗਵਰਨੈਂਸ ਨੂੰ ਸਹਾਰਾ ਦਿੰਦੇ ਹਨ: ਰੋਲ-ਅਧਾਰਿਤ ਐਕਸੈਸ, ਚੇਂਜ ਕੰਟਰੋਲ, ਅਤੇ ਜੋ ਬਦਲਿਆ ਉਸਦੀ ਆਡੀਟ-ਫ੍ਰੈਂਡਲੀ ਹਿਸਟਰੀ। ਇਹ “ਸੱਚ” ਨੂੰ ਸਿਰਫ਼ ਇੱਕ ਸਹਿਮਤੀ ਤੋਂ ਓਸ ਚੀਜ਼ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ ਜੋ ਲਾਗੂ ਹੋ ਸਕਦੀ ਹੈ—ਜਿੱਥੇ ਪਰਿਭਾਸ਼ਾਵਾਂ ਡਾਟਾ ਮਾਡਲ ਵਿੱਚ ਲਾਗੂ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਸਿਰਫ਼ ਕਿਸੇ ਦਸਤਾਵੇਜ਼ ਵਿੱਚ ਨਹੀਂ।
ਟੀਮਾਂ ਅਕਸਰ “ਸਿੰਗਲ ਸੋਰਸ ਆਫ ਟਰੂਥ” ਦਾ ਮਤਲਬ “ਉਹ ਥਾਂ ਜਿਸਤੇ ਮੈਂ ਭਰੋਸਾ ਕਰਦਾ ਹਾਂ” ਸਮਝਦੀਆਂ ਹਨ। ਅਸਲ ਵਿੱਚ, ਇਹ ਤਿੰਨ ਜੁੜੀਆਂ ਪਰ ਪਰਅਲੱਗ ਸਮਝਾਂ ਨੂੰ ਵੱਖ ਕਰਨਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ: ਸਿਸਟਮ ਆਫ਼ ਰਿਕਾਰਡ (SoR), ਸਿਸਟਮ ਆਫ਼ ਐਨਗੇਜਮੈਂਟ, ਅਤੇ ਐਨਾਲਿਟਿਕਲ ਸਟੋਰ (ਅਕਸਰ ਡੇਟਾ ਵేర్ਹਾਊਸ)। ਇਹ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਓਵਰਲੈਪ ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਲਾਜ਼ਮੀ ਨਹੀਂ।
A system of record (SoR) ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਕੋਈ ਤੱਥ ਅਧਿਕਾਰਿਕ ਤੌਰ 'ਤੇ ਬਣਾਇਆ ਜਾਂਦਾ ਅਤੇ ਰੱਖਿਆ ਜਾਂਦਾ ਹੈ। ਸੋਚੋ: ਗਾਹਕ ਦਾ ਕਾਨੂੰਨੀ ਨਾਂ, ਇਨਵੌਇਸ ਸਥਿਤੀ, ਕਰਮਚਾਰੀ ਦੀ ਸ਼ੁਰੂਆਤ ਦੀ ਤਾਰੀਖ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਦੈਨੀਕ ਓਪਰੇਸ਼ਨਾਂ ਅਤੇ ਸਹੀਤਾ ਲਈ optimize ਕੀਤਾ ਹੁੰਦਾ ਹੈ।
ਇੱਕ SoR ਡੋਮੇਨ-ਨਿਰਧਾਰਿਤ ਹੁੰਦਾ ਹੈ। ਤੁਹਾਡਾ CRM ਲੀਡਸ ਅਤੇ ਮੌਕੇ ਲਈ SoR ਹੋ ਸਕਦਾ ਹੈ, ਜਦਕਿ ਤੁਹਾਡਾ ERP ਇਨਵੌਇਸ ਅਤੇ ਭੁਗਤਾਨ ਲਈ SoR। ਇੱਕ ਅਸਲੀ SSOT ਅਕਸਰ ਡੋਮੇਨ ਵੱਖ-ਵੱਖ ਸਹਿਮਤ “ਸੱਚ” ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ ਹੀ ਐਪਲੀਕੇਸ਼ਨ।
A system of engagement ਉਹ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਇੰਟਰੈੱਕਟ ਕਰਦੇ ਹਨ—ਸੇਲਜ਼ ਟੂਲ, ਸਪੋਰਟ ਡੈਸਕ, ਪ੍ਰੋਡਕਟ ਐਪਸ। ਇਹ ਸਿਸਟਮ SoR ਤੋਂ ਡੇਟਾ ਦਿਖਾ ਸਕਦੇ ਹਨ, ਇਸਨੂੰ enriich ਕਰ ਸਕਦੇ ਹਨ, ਜਾਂ ਅਸਥਾਈ ਸੋਧ ਰੱਖ ਸਕਦੇ ਹਨ। ਉਹ ਵਰਕਫਲੋ ਅਤੇ ਤੇਜ਼ੀ ਲਈ ਬਣੇ ਹੁੰਦੇ ਹਨ, ਸਦਾ ਅਧਿਕਾਰਕ ਪ੍ਰਮਾਣ ਲਈ ਨਹੀਂ।
ਇੱਥੇ ਟਕਰਾਅ ਸ਼ੁਰੂ ਹੁੰਦੇ ਹਨ: ਦੋ ਟੂਲ ਦੋਹਾਂ ਹੀ ਕਿਸੇ ਖੇਤਰ ਨੂੰ “ਮਾਲਕ” ਮੰਨ ਲੈਂਦੇ ਹਨ, ਜਾਂ ਉਹ ਮਿਲਦੀ-ਜੁਲਦੀ ਜਾਣਕਾਰੀ ਵੱਖ-ਵੱਖ ਪਰਿਭਾਸ਼ਾਵਾਂ ਨਾਲ ਇਕੱਠੀ ਕਰਦੇ ਹਨ।
A ਡੇਟਾ ਵేర్ਹਾਊਸ (ਜਾਂ ਐਨਾਲਿਟਿਕਲ ਸਟੋਰ) ਇਸ ਲਈ ਬਣਿਆ ਹੈ ਕਿ ਪ੍ਰਸ਼ਨਾਂ ਦੇ ਇੱਕਸਾਰ ਜਵਾਬ ਦਿੱਤੇ ਜਾਣ: ਸਮੇਂ ਦੇ ਨਾਲ ਰੈਵਨਿਊ, ਚਰਨ ਬਾਈ ਸੈਗਮੈਂਟ, ਵਿਭਾਗਾਂ ਦੇ ਬੀਚ ਓਪਰੇਸ਼ਨਲ ਰਿਪੋਰਟਿੰਗ। ਇਹ ਅਕਸਰ ਐਨਾਲਿਟਿਕਲ (OLAP) ਹੁੰਦਾ ਹੈ, ਜੋ ਕੈਵਰੀ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਮਹੱਤਵ ਦਿੰਦਾ ਹੈ।
ਇੱਕ SSOT ਹੋ ਸਕਦਾ ਹੈ:
ਹਰ ਇੱਕ ਲੋਡ ਨੂੰ ਇੱਕ ਡੇਟਾਬੇਸ ਵਿੱਚ ਫੋਰਸ ਕਰਨਾ ਪਿੱਛੇ ਲੱਗ ਸਕਦਾ ਹੈ: ਓਪਰੇਸ਼ਨਲ ਲੋੜਾਂ (ਤੇਜ਼ ਲਿਖਾਈ, ਕੜੀ ਪਾਬੰਦੀਆਂ) ਐਨਾਲਿਟਿਕਸ (ਵੱਡੇ ਸਕੈਨ, ਲੰਮੇ ਕੈਵਰੀ) ਨਾਲ ਟਕਰਾਉਂਦੀਆਂ ਹਨ। ਇੱਕ ਸਿਹਤਮੰਦ ਰਵੱਈਆ ਇਹ ਹੈ ਕਿ ਹਰ ਡੋਮੇਨ ਲਈ ਕਿਹੜਾ ਸਿਸਟਮ ਅਧਿਕਾਰਕ ਹੈ ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਡੇਟਾ ਇੰਟੀਗ੍ਰੇਟ ਅਤੇ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ ਤਾਂ ਕਿ ਸਭ ਇੱਕੋ ਪਰਿਭਾਸ਼ਾਵਾਂ ਪੜ੍ਹਨ—ਭਾਵੇਂ ਡੇਟਾ ਕਈ ਥਾਵਾਂ 'ਤੇ ਰਹੇ।
ਡੇਟਾਬੇਸ صرف ਉਹ ਸਮਰਥ ਹੋ ਸਕਦਾ ਹੈ ਜੋ SSOT ਹੈ ਜੇ ਲੋਕ ਇਹ ਤੈਅ ਕਰਨ 'ਤੇ ਸਹਿਮਤ ਹੋਣ ਕਿ “ਸੱਚ” ਕੀ ਹੈ। ਉਹ ਸਹਿਮਤੀ ਡੇਟਾ ਮਾਡਲ ਵਿੱਚ ਬੰਨੀ ਹੁੰਦੀ ਹੈ: ਮੁੱਖ ਐਂਟੀਟੀਆਂ, ਉਹਨਾਂ ਦੀਆਂ ਪਛਾਣਾਂ, ਅਤੇ ਉਹ ਇਕ-ਦੂਜੇ ਨਾਲ ਕਿਵੇਂ ਜੁੜਦੀਆਂ ਹਨ। ਜਦ ਮਾਡਲ ਸਪਸ਼ਟ ਹੋਵੇ, ਵਿਸ਼ਲੇਸ਼ਣ ਇਕਸਾਰਤਾ ਸੁਧਰਦੀ ਹੈ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਰਿਪੋਰਟਿੰਗ ਵਾਦ-ਵਿਵਾਦ ਬਣਨ ਤੋਂ ਰੁਕ ਜਾਂਦੀ ਹੈ।
ਉਸ ਬਿਜ਼ਨੈਸ ਦੀਆਂ ਨਾਊਂ ਛੇਤੀ ਨਾਂ ਲਿਖੋ—ਆਮ ਤੌਰ 'ਤੇ ਗਾਹਕ, ਉਤਪਾਦ, ਕਰਮਚਾਰੀ, ਅਤੇ ਸਪਲਾਇਰ—ਅਤੇ ਹਰ ਇੱਕ ਦਾ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਮਤਲਬ ਵਿਆਖਿਆ ਕਰੋ। ਉਦਾਹਰਣ ਵਜੋਂ, “ਗਾਹਕ” ਇੱਕ ਬਿਲਿੰਗ ਖਾਤਾ ਹੈ, ਇੱਕ ਅੰਤ-ਯੂਜ਼ਰ ਹੈ, ਜਾਂ ਦੋਹਾਂ? ਜਵਾਬ ਹਰ ਡਾਊਨਸਟਰੀਮ ਰਿਪੋਰਟ ਅਤੇ ਇੰਟਿਗ੍ਰੇਸ਼ਨ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਉਂਦਾ ਹੈ।
ਹਰ ਕੋਰ ਐਂਟੀਟੀ ਨੂੰ ਇੱਕ ਸਥਿਰ, ਯੂਨੀਕ ਪਹਿਚਾਨ ਜ਼ਰੂਰੀ ਹੈ (ਜਿਵੇਂ customer_id, product SKU, employee ID)। “ਸਮਾਰਟ” IDs ਜੋ ਮਤਲਬ encode ਕਰਦੇ ਹਨ (ਜਿਵੇਂ ਰੀਜਨ ਜਾਂ ਸਾਲ) ਤੋਂ ਬਚੋ ਕਿਉਂਕਿ ਉਹ ਗੁਣਾ-ਬਦਲ ਸਕਦੇ ਹਨ। ਕੀਜ਼ ਅਤੇ ਸੰਬੰਧ ਵਰਤਕੇ ਇਹ ਦਰਸਾਓ ਕਿ ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਜੁੜਦੀਆਂ ਹਨ:
ਸਪਸ਼ਟ ਸੰਬੰਧ ਡੁਪਲਿਕੇਟ ਰਿਕਾਰਡ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਸਿਸਟਮਾਂ ਵਿਚਕਾਰ ਡੇਟਾ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਨੂੰ ਸਧਾਰਨ ਬਣਾਉਂਦੇ ਹਨ।
ਚੰਗਾ ਡੇਟਾ ਮਾਡਲ ਇੱਕ ਛੋਟੀ ਡੇਟਾ ਡਿਕਸ਼ਨਰੀ ਸ਼ਾਮਲ ਕਰਦਾ ਹੈ: ਬਿਜ਼ਨੈਸ ਪਰਿਭਾਸ਼ਾਵਾਂ, ਉਦਾਹਰਣ ਅਤੇ ਅਹਿਮ ਖੇਤਰਾਂ ਲਈ ਮਨਜ਼ੂਰ ਕੀਤੇ ਮੁੱਲ। ਜੇ “status” active, paused, ਜਾਂ closed ਹੋ ਸਕਦਾ ਹੈ, ਤਾਂ ਇਹ ਲਿਖੋ—ਅਤੇ ਦਰਜ ਕਰੋ ਕਿ ਨਵੇਂ ਮੁੱਲ ਕੌਣ ਬਣਾ ਸਕਦਾ ਹੈ। ਇਹ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਡੇਟਾਬੇਸ ਗਵਰਨੈਂਸ ਪ੍ਰਾਇਕਟਿਕਲ ਬਣਦੀ ਹੈ: ਘੱਟ ਹੈਰਾਨੀਆਂ, ਘੱਟ “ਰਾਜ਼” ਸ਼੍ਰੇਣੀਆਂ।
ਸੱਚ ਬਦਲਦਾ ਹੈ। ਗਾਹਕ ਜਗ੍ਹਾ ਬਦਲਦੇ ਹਨ, ਉਤਪਾਦ ਰੀਬਰੈਂਡ ਹੁੰਦੇ ਹਨ, ਕਰਮਚਾਰੀ ਵਿਭਾਗ ਬਦਲਦੇ ਹਨ। ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ ਕਿ ਤੁਸੀਂ ਇਤਿਹਾਸ ਕਿਵੇਂ ਟ੍ਰੈਕ ਕਰੋਗੇ: ਪ੍ਰਭਾਵੀ ਤਰੀਖਾਂ, “ਮੌਜੂਦਾ” ਫ਼ਲੈਗ, ਜਾਂ ਵੱਖ-ਵੱਖ ਇਤਿਹਾਸ ਟੇਬਲ।
ਜੇ ਤੁਹਾਡਾ ਮਾਡਲ ਬਦਲਾਅ ਨੂੰ ਸਾਫ਼-ਸੁਥਰੇ ਢੰਗ ਨਾਲ ਦਰਸਾ ਸਕਦਾ ਹੈ ਤਾਂ ਤੁਹਾਡੀ ਆਡੀਟ ਟ੍ਰੇਲ ਆਸਾਨ ਹੋ ਜਾਂਦੀ ਹੈ, ਡੇਟਾ ਗੁਣਵੱਤਾ ਨਿਯਮ ਲਾਗੂ ਕਰਨਾ ਸਾਦਾ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਟੀਮਾਂ ਵਿਸ਼ਵਾਸ ਨਾਲ ਸਮਾਂ-ਅਧਾਰਿਤ ਰਿਪੋਰਟਿੰਗ ਤੇ ਨਿਰਭਰ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਜੇ ਕੋਈ ਨਹੀਂ ਜਾਣਦਾ ਕਿ ਕਿਸਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਕੀ ਹੈ, ਕੌਣ ਬਦਲ ਸਕਦਾ ਹੈ, ਜਾਂ ਫੀਲਡਾਂ ਦਾ ਮਤਲਬ ਕੀ ਹੈ, ਤਾਂ ਡੇਟਾਬੇਸ ਇੱਕ SSOT ਨਹੀਂ ਬਣ ਸਕਦਾ। ਗਵਰਨੈਂਸ ਉਹ ਰੋਜ਼ਾਨਾ ਨਿਯਮ ਹਨ ਜੋ “ਸੱਚ” ਨੂੰ ਕਾਫ਼ੀ ਸਥਿਰ ਬਣਾ ਦਿੰਦੇ ਹਨ ਤਾਂ ਕਿ ਟੀਮਾਂ ਉਸ 'ਤੇ ਨਿਰਭਰ ਕਰ ਸਕਣ—ਬਿਨਾਂ ਹਰ ਫੈਸਲੇ ਨੂੰ ਕਮੇਟੀ ਵਿੱਚ ਦਿਓ।
ਹਰ ਡੋਮੇਨ ਲਈ ਡੇਟਾ ਓਨਰ ਅਤੇ ਡੇਟਾ ਸਟੀਵਰਡ ਨਿਰਧਾਰਤ ਕਰੋ (ਉਦਾਹਰਣ: Customers, Products, Orders, Employees)। ਓਨਰ ਡੋਮੇਨ ਲਈ ਦਰਸਤ ਉਪਯੋਗ ਅਤੇ ਮਤਲਬ ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਹੁੰਦੇ ਹਨ। ਸਟੀਵਰਡ ਦਿੱਤੇ ਕੰਮ ਨੂੰ ਸੰਭਾਲਦੇ ਹਨ: ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਪਡੇਟ ਰੱਖਣਾ, ਗੁਣਵੱਤਾ ਨਿਗਰਾਨੀ, ਅਤੇ ਸੁਧਾਰਾਂ ਦੀ ਕੋਆਰਡੀਨੇਸ਼ਨ।
ਇਹ ਆਮ ਫੇਲ੍ਹ ਹੋਣ ਵਾਲਾ ਮੋਡ ਰੋਕਦਾ ਹੈ ਜਿਥੇ ਡੇਟਾ ਸਮੱਸਿਆਵਾਂ IT, ਐਨਾਲਿਟਿਕਸ ਅਤੇ ਓਪਰੇਸ਼ਨਸ ਵਿੱਚ ਝੱਲਦੀਆਂ ਰਹਿੰਦੀਆਂ ਹਨ ਬਿਨਾਂ ਕਿਸੇ ਸੁਪਟੇ ਫੈਸਲੇ-ਕਰਤਾ ਦੇ।
ਜੇ “ਸਰਗਰਮ ਗਾਹਕ” ਦਾ ਮਤਲਬ Sales ਵਿੱਚ ਇਕ ਹੋਵੇ ਅਤੇ Support ਵਿੱਚ ਦੂਜਾ, ਤਾਂ ਤੁਹਾਡੇ ਰਿਪੋਰਟ ਕਦੇ ਮਿਲ ਕੇ ਨਹੀਂ ਚੱਲਣਗੇ। ਇੱਕ ਡੇਟਾ ਕੈਟਾਲੌਗ/ਗਲਾਸਰੀ ਰੱਖੋ ਜੋ ਟੀਮਾਂ ਵਾਸਤੇ ਅਸਲ ਵਿੱਚ ਵਰਤੀ ਜਾਵੇ:
ਇਸਨੂੰ ਲੱਭਣਾ ਆਸਾਨ ਅਤੇ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰਨਾ ਮੁਸ਼ਕਲ ਬਣਾਓ—ਡੈਸ਼ਬੋਰਡ, ਟਿਕਟਸ ਅਤੇ ਓਨਬੋਰਡਿੰਗ ਡੌਕਸ ਵਿੱਚ ਲਿੰਕ ਸ਼ਾਮਲ ਕਰਕੇ।
ਡੇਟਾਬੇਸ ਵਿਕਸਿਤ ਹੁੰਦੇ ਰਹਿੰਦੇ ਹਨ। 목표 ਇਹ ਨਹੀਂ ਕਿ ਸਕੀਮਾ ਫ੍ਰੋਜ਼ ਕਰ ਦਿੱਤੀ ਜਾਵੇ—ਇਸਦਾ ਮਕਸਦ ਬਦਲਾਅ ਨੂੰ ਸੋਚ-ਸਮਝ ਕੇ ਕਰਨਾਂ ਹੈ। ਖਾਸ ਕਰਕੇ ਹੇਠਾਂਲੀਆਂ ਚੀਜ਼ਾਂ ਲਈ ਸਕੀਮਾ ਅਤੇ ਪਰਿਭਾਸ਼ਾ ਬਦਲਾਅ ਲਈ ਮਨਜ਼ੂਰੀ ਵਰਕਫਲੋ ਸੈੱਟ ਕਰੋ:
ਇੱਕ ਹਲਕਾ ਜਿਹਾ ਪ੍ਰਕਿਰਿਆ (ਪਰਸਤਾਵ → ਸਮੀਖਿਆ → ਸ਼ਡਿਊਲਡ ਰਿਲੀਜ਼ ਨੋਟ) ਡਾਊਨਸਟਰੀਮ ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਇੰਟਿਗ੍ਰੇਸ਼ਨਾਂ ਦੀ ਰੱਖਿਆ ਕਰਦੀ ਹੈ।
ਸੱਚ ਭਰੋਸੇ 'ਤੇ ਵੀ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਐਕਸੈਸ ਨਿਯਮ ਰੋਲ ਅਤੇ ਸੰਵੇਦਨਸ਼ੀਲਤਾ ਅਨੁਸਾਰ ਸੈੱਟ ਕਰੋ:
ਸਪਸ਼ਟ ਮਲਕੀਅਤ, ਨਿਯੰਤਰਿਤ ਬਦਲਾਅ, ਅਤੇ ਸਾਂਝੀਆਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਨਾਲ, ਡੇਟਾਬੇਸ ਇੱਕ ਉਹ ਸਰੋਤ ਬਣ ਜਾਂਦਾ ਹੈ ਜਿਸ 'ਤੇ ਲੋਕ ਨਿਰਭਰ ਕਰ ਸਕਦੇ ਹਨ—ਸਿਰਫ਼ ਇਕ ਥਾਂ ਜਿੱਥੇ ਡੇਟਾ ਕੈਦਾ ਹੀ ਨਹੀਂ ਹੋ ਰਿਹਾ।
ਡੇਟਾਬੇਸ ਉਹ ਹੀ SSOT ਹੋ ਸਕਦਾ ਹੈ ਜਦ ਲੋਕ ਇਸ 'ਤੇ ਅਸਲੀ ਤਰੀਕੇ ਨਾਲ ਭਰੋਸਾ ਕਰਨ। ਉਹ ਭਰੋਸਾ ਡੈਸ਼ਬੋਰਡ ਜਾਂ ਸੋਚ-ਵਿੱਚਾਰ ਵਾਲੀ ਨੋਟ ਨਾਲ ਨਹੀਂ ਬਣਦਾ—ਇਹ ਬਾਰ-ਬਾਰ ਹੋਣ ਵਾਲੇ ਡੇਟਾ ਗੁਣਵੱਤਾ ਨਿਯੰਤਰਣਾਂ ਰਾਹੀਂ ਕਮਾਇਆ ਜਾਂਦਾ ਹੈ ਜੋ ਖਰਾਬ ਡੇਟਾ ਨੂੰ ਆਉਣ ਤੋਂ ਰੋਕਦੇ, ਮੁੱਦਿਆਂ ਨੂੰ ਜਲਦੀ ਦਰਸਾਉਂਦੇ, ਅਤੇ ਸੁਧਾਰਾਂ ਨੂੰ ਦਿਖਾਉਂਦੇ ਹਨ।
ਸਭ ਤੋਂ ਸਸਤਾ ਡੇਟਾ ਸਮੱਸਿਆ ਉਹ ਹੈ ਜਿਸਨੂੰ ingest ਹੋਣ ਵਕਤ ਰੋਕਿਆ ਜਾਵੇ। ਪ੍ਰੈਕਟੀਕਲ ਵੈਰੀਫਿਕੇਸ਼ਨ ਨਿਯਮਾਂ ਸ਼ਾਮਲ ਹਨ:
ਚੰਗੀ ਵੈਰੀਫਿਕੇਸ਼ਨ ਨੂੰ “ਪੂਰਾ” ਹੋਣਾ ਜ਼ਰੂਰੀ ਨਹੀਂ—ਇਹ ਲਾਜ਼ਮੀ ਹੈ ਕਿ ਇਹ ਸਥਿਰ ਹੋਵੇ ਅਤੇ ਸਾਂਝੀਆਂ ਪਰਿਭਾਸ਼ਾਵਾਂ ਨਾਲ ਮਿਲਦੀ ਹੋਵੇ ਤਾਂ ਕਿ ਵਿਸ਼ਲੇਸ਼ਣ ਇਕਸਾਰਤਾ ਸਮੇਂ ਨਾਲ ਸੁਧਰੇ।
ਡੁਪਲਿਕੇਟ ਭਰੋਸਾ ਨੁਕਸਾਨ ਕਰਦੇ ਹਨ: ਇੱਕੋ ਗਾਹਕ ਦੀਆਂ ਵੱਖ-ਵੱਖ ਸਪੈਲਿੰਗਾਂ, ਕੰਨ ਸਪਲਾਇਰ ਇੰਟ੍ਰੀ, ਜਾਂ ਇੱਕ ਸੰਪਰਕ ਦੋ ਵਿਭਾਗਾਂ ਦੇ ਹੇਠਾਂ ਦਿੱਤਾ ਹੋਣਾ। ਇਹ ਓਥੇ ਹੈ ਜਿੱਥੇ “ਮਾਸਟਰ ਡੇਟਾ ਮੈਨੇਜਮੈਂਟ” ਸਿਰਫ਼ ਉਹੇ ਮਿਲਣ ਵਾਲੇ ਨਿਯਮ ਹਨ ਜਿਨ੍ਹਾਂ 'ਤੇ ਸਭ ਸਹਿਮਤ ਹੋਣ।
ਆਮ ਅਪ੍ਰੋਚ:
ਇਹ ਨਿਯਮ ਡੇਟਾਬੇਸ ਗਵਰਨੈਂਸ ਦਾ ਹਿੱਸਾ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾ ਕਿ ਇੱਕ ਵਾਰੀ ਦੀ ਸਫਾਈ।
ਇਨਪੁਟਿੰਗ ਰੋਕਣ ਦੇ ਬਾਵਜੂਦ, ਡੇਟਾ ਡ੍ਰਿਫਟ ਕਰਦਾ ਹੈ। ਚਲਦੇ ਸਥਿਤੀ-ਨਿਗਰਾਨੀ ਮੁੱਦਿਆਂ ਨੂੰ ਦਰਸਾਉਂਦੀ ਹੈ ਜਿਵੇਂ:
ਇੱਕ ਸਧਾਰਣ ਸਕੋਰਕਾਰਡ ਅਤੇ ਅਲਰਟਿੰਗ ਥ੍ਰੈਸ਼ਹੋਲਡ ਆਮ ਤੌਰ 'ਤੇ ਗੁਣਵੱਤਾ 'ਤੇ ਧਿਆਨ ਬਣਾਈ ਰੱਖਣ ਲਈ ਕਾਫੀ ਹੁੰਦੇ ਹਨ।
ਜਦੋਂ ਕੋਈ ਸਮੱਸਿਆ ਮਿਲਦੀ ਹੈ, ਤਾ ਸੁਧਾਰ ਦਾ ਰਸਤਾ ਸਪੱਸ਼ਟ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਕੌਣ ਇਸ ਦਾ ਮਾਲਕ ਹੈ, ਇਹ ਕਿਵੇਂ ਲੌਗ ਕੀਤਾ ਗਿਆ, ਅਤੇ ਇਹ ਕਿਵੇਂ ਹੱਲ ਕੀਤਾ ਜਾਵੇਗਾ। ਗੁਣਵੱਤਾ ਮੁੱਦਿਆਂ ਨੂੰ ਸਪੋਰਟ ਟਿਕਟਾਂ ਵਾਂਗ ਸੰਭਾਲੋ—ਪ੍ਰਭਾਵ ਅਨੁਸਾਰ ਤਰਜੀਹ, ਇੱਕ ਡੇਟਾ ਸਟੀਵਰਡ ਨਿਰਧਾਰਤ ਕਰੋ, ਸਰੋਤ 'ਤੇ ਠੀਕ ਕਰੋ, ਅਤੇ ਬਦਲਾਅ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ। ਸਮੇਂ ਨਾਲ ਇਹ ਸੁਧਾਰਾਂ ਦੀ ਆਡੀਟ ਟ੍ਰੇਲ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ “ਡੇਟਾਬੇਸ ਗਲਤ ਹੈ” ਨੂੰ “ਅਸੀਂ ਜਾਣਦੇ ਹਾਂ ਕੀ ਹੋਇਆ ਤੇ ਇਸਨੂੰ ਠੀਕ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ” ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ।
ਜੇ ਅਪਡੇਟ ਦੇਰੀ ਨਾਲ ਆਉਂਦੇ ਹਨ, ਦੋ ਵਾਰੀ ਆਉਂਦੇ ਹਨ, ਜਾਂ ਗਾਇਆ ਹੋ ਜਾਂਦੇ ਹਨ, ਤਾਂ ਡੇਟਾਬੇਸ SSOT ਨਹੀਂ ਰਹਿੰਦਾ। ਤੁਸੀਂ ਜੋ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਪੈਟਰਨ ਚੁਣਦੇ ਹੋ—ਬੈਚ ਜਾਬ, APIs, ਇਵੇਂਟ ਸਟ੍ਰੀਮ, ਜਾਂ ਮੈਨੇਜਡ ਕਨੇਕਟਰ—ਉਸ ਨਾਲ ਇਹ ਨਿਰਧਾਰਤ ਹੁੰਦਾ ਹੈ ਕਿ ਟੀਮਾਂ ਲਈ ਤੁਹਾਡੀ “ਸੱਚਾਈ” ਕਿਵੇਂ ਲੱਗੇਗੀ।
ਬੈਚ ਸਿੰਕਿੰਗ ਡੇਟਾ ਨੂੰ ਸਕੈਜੂਲ ਤੇ ਮੂਵ ਕਰਦੀ ਹੈ (ਘੰਟੇ, ਰਾਤੀ, ਹਫਤਾਵਾਰ)। ਇਹ ਉਹਥੇ ਚੰਗੀ ਹੈ ਜਦ:
ਰੀਅਲ-ਟਾਈਮ ਸਿੰਕਿੰਗ (ਜਾਂ ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ) ਬਦਲਾਅ ਨੂੰ ਜਿਵੇਂ ਹੀ ਹੁੰਦੇ ਹਨ ਧੱਕਦੀ ਹੈ। ਇਹ ਲਾਇਕ ਹੈ ਜਦ:
ਟ੍ਰੇਡਆਫ਼ complexity ਹੈ: ਰੀਅਲ-ਟਾਈਮ ਨੂੰ ਮਜ਼ਬੂਤ ਨਿਗਰਾਨੀ ਅਤੇ ਸਪਸ਼ਟ ਨਿਯਮਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਕਿ ਜਦ ਸਿਸਟਮ ਵਿਰੋਧ ਕਰਦੇ ਹਨ ਤਾਂ ਕੀ ਕਰਨਾ।
ETL/ELT ਪਾਇਪਲਾਈਨ ਉਹਨਾਂ ਜਗ੍ਹਾਂ ਹਨ ਜਿੱਥੇ ਇੱਕਸਾਰਤਾ ਜਿੱਤ ਜਾਂ ਹਾਰਦੀ ਹੈ। ਦੋ ਆਮ ਫ਼ੇਲ:
ਇਕ ਪ੍ਰੈਕਟੀਕਲ ਅਪ੍ਰੋਚ ਹੈ ਟ੍ਰਾਂਸਫ਼ੋਰਮੇਸ਼ਨਾਂ ਨੂੰ ਕੇਂਦਰੀਕ੍ਰਿਤ ਅਤੇ ਵਰਜਨ-ਕੰਟਰੋਲਡ ਰੱਖਣਾ, ਤਾਂ ਜੋ ਇੱਕੋ ਬਿਜ਼ਨੈਸ ਨਿਯਮ (ਉਦਾਹਰਣ: “active customer”) ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਓਪਰੇਸ਼ਨ ਦੋਹਾਂ ਵਿੱਚ ਇੱਕਸਾਰ ਲਾਗੂ ਹੋਵੇ।
ਲਕਸ਼ ਇੱਕੋ ਹੀ ਹੈ: ਘੱਟ ਮੈਨੁਅਲ ਐਕਸਪੋਰਟ/ਇੰਪੋਰਟ, ਘੱਟ “ਕਿਸੇ ਨੇ ਫਾਈਲ ਚਲਾਉਣ ਭੁੱਲ ਗਿਆ” ਸੀਨ, ਅਤੇ ਘੱਟ ਖਾਮੋਸ਼ ਡੇਟਾ ਸੋਧ।
ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਫੇਲ ਹੁੰਦੇ ਹਨ—ਨੈੱਟਵਰਕ ਡਿੱਗਦੇ ਹਨ, ਸਕੀਮਾ ਬਦਲ ਜਾਂਦੇ ਹਨ, ਰੇਟ ਲਿਮਿਟਸ ਲੱਗਦੇ ਹਨ। ਉਸ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ:
ਜਦ ਫੇਲਿਅਰ ਵਿਖੇਲੇ ਅਤੇ ਰੀਕਵਰੇਬਲ ਹੋਣ, ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਖਰਾਬ ਦਿਨਾਂ 'ਤੇ ਵੀ ਭਰੋਸੇਯੋਗ ਰਹਿੰਦਾ ਹੈ।
ਮਾਸਟਰ ਡੇਟਾ ਮੈਨੇਜਮੈਂਟ (MDM) ਸਿਰਫ਼ ਉਹ ਅਭਿਆਸ ਹੈ ਜੋ “ਮੁੱਖ ਚੀਜ਼ਾਂ” ਨੂੰ ਹਰ ਜਗ੍ਹਾ ਸੰਗਤ ਰੱਖਦਾ ਹੈ—ਗਾਹਕ, ਉਤਪਾਦ, ਸਥਾਨਕ, ਸਪਲਾਇਰ—ਤਾਂ ਜੋ ਟੀਮਾਂ ਇਸ ਗੱਲ 'ਤੇ ਨਹੀਂ ਲੜਨ ਕਿ ਕਿਹੜਾ ਰਿਕਾਰਡ ਸਹੀ ਹੈ।
ਜਦ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਇੱਕ ਪ੍ਰਮੁੱਖ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਹੈ, MDM ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਡੁਪਲਿਕੇਟ, ਮਿਲਦਾ-ਜੁਲਦਾ ਨਾਂ, ਅਤੇ ਟਕਰਾਉਂਦੇ ਗੁਣ ਲਾਹੇ ਵਿੱਚ ਰਿਪੋਰਟਾਂ ਅਤੇ ਦੈਨੀਕ ਓਪਰੇਸ਼ਨਾਂ ਵਿੱਚ ਨਹੀਂ ਆਉਣ ਦੇ ਰਾਹ ਧਾਰੋ।
ਸਿਸਟਮਾਂ ਨੂੰ aligned ਰੱਖਣ ਦਾ ਸਭ ਤੋਂ ਆਸਾਨ ਰਸਤਾ ਹੈ ਇਕ ਪਛਾਣ ਨੀਤੀ ਦੀ ਵਰਤੋਂ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼।
ਉਦਾਹਰਣ ਵਜੋਂ, ਜੇ ਹਰ ਸਿਸਟਮ ਵਿੱਚ ਇੱਕੋ customer_id ਹੋਵੇ (ਕੇਵਲ ਈਮੇਲ ਜਾਂ ਨਾਂ ਨਹੀਂ), ਤਾਂ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਜੋੜ ਸਕਦੇ ਹੋ ਅਤੇ ਅਚਾਨਕ ਡੁਪਲਿਕੇਟ ਤੋਂ ਬਚ ਸਕਦੇ ਹੋ। ਜਦੋਂ ਸਾਂਝਾ ID ਸੰਭਵ ਨਹੀਂ, ਡੇਟਾਬੇਸ ਵਿੱਚ ਮੈਪਿੰਗ ਟੇਬਲ ਰੱਖੋ (ਉਦਾਹਰਣ: CRM customer key ↔ billing customer key) ਅਤੇ ਇਸਨੂੰ ਪਹਿਲ-ਸ਼੍ਰੇਣੀ ਸੰਪਤੀ ਵਾਂਗੋ ਸਮਝੋ।
ਗੋਲਡਨ ਰਿਕਾਰਡ ਉਹ ਸਭ ਤੋਂ ਵਧੀਆ-ਜਾਣਿਆ ਵਰਜ਼ਨ ਹੁੰਦਾ ਹੈ ਇੱਕ ਗਾਹਕ ਜਾਂ ਉਤਪਾਦ ਦਾ, ਜੋ ਕਈ ਸਰੋਤਾਂ ਤੋਂ ਇਕੱਠਾ ਕੀਤਾ ਗਿਆ ਹੋਵੇ। ਇਸਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਇੱਕ ਸਿਸਟਮ ਸਭ ਕੁਝ ਮਾਲਕ ਹੋਵੇ; ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਡੇਟਾਬੇਸ ਇੱਕ curated ਮਾਸਟਰ ਦ੍ਰਿਸ਼ ਬਣਾਕੇ ਰੱਖਦਾ ਹੈ ਜਿਸ 'ਤੇ ਡਾਊਨਸਟਰੀਮ ਸਿਸਟਮ ਅਤੇ ਐਨਾਲਿਟਿਕਸ ਨਿਰਭਰ ਕਰ ਸਕਦੇ ਹਨ।
ਟਕਰਾਅ ਆਮ ਹਨ। ਮਿਹਨੇ ਜ਼ਰੂਰੀ ਇਹ ਹੈ ਕਿ ਹਰ ਖੇਤਰ ਲਈ ਇਹ ਨਿਯਮ ਸਪਸ਼ਟ ਹੋ ਕਿ ਕਿਹੜੇ ਸਿਸਟਮ ਦੀ ਵੈਲਿਊ ਜਿੱਤਦੀ ਹੈ।
ਉਦਾਹਰਣ:
ਇਹ ਨਿਯਮ ਲਿਖੋ ਅਤੇ ਆਪਣੀ ਡੇਟਾ ਪਾਈਪਲਾਈਨ ਜਾਂ ਡੇਟਾਬੇਸ ਲਾਜਿਕ ਵਿੱਚ ਲਾਗੂ ਕਰੋ ਤਾਂ ਜੋ ਨਤੀਜਾ بار-ਬਾਰ ਸੁਚਾਰੂ ਹੋਵੇ, ਮੈਨੁਅਲ ਨਾ ਹੋਵੇ।
ਨਿਯਮਾਂ ਦੇ ਬਾਵਜੂਦ, ਕੁਝ ਐਜ ਕੇਸ ਆਉਣਗੇ: ਦੋ ਰਿਕਾਰਡ ਜੋ ਇੱਕੋ ਗਾਹਕ ਵਰਗੇ ਲੱਗਦੇ ਹਨ, ਜਾਂ ਕੋਈ ਉਤਪਾਦ ਕੋਡ ਗਲਤ ਵਰਤਿਆ ਗਿਆ।
ਇਨ ਉਦਾਹਰਣਾਂ ਲਈ ਇੱਕ ਸਕਿਆ ਪ੍ਰਕਿਰਿਆ ਬਣਾਓ:
MDM ਸਭ ਤੋਂ ਵਧੀਆ ਉਦਾਸੀ ਭਰਿਆ ਹੋਇਆ ਹੁੰਦਾ ਹੈ: ਪੇਸ਼ਗੀ IDs, ਸਪਸ਼ਟ ਗੋਲਡਨ ਰਿਕਾਰਡ, ਵਿਵਾਦ-ਸਪੱਸ਼ਟ ਸਰਵਾਇਵਰਸ਼ਿਪ, ਅਤੇ ਡਿੱਗੀਆਂ ਹਾਲਤਾਂ ਨੂੰ ਹੱਲ ਕਰਨ ਲਈ ਹਲਕਾ ਰਸਤਾ।
ਡੇਟਾਬੇਸ ਉਸ ਵੇਲੇ ਹੀ ਇੱਕ ਸਿੰਗਲ ਸੋਰਸ ਆਫ ਟਰੂਥ ਹੋ ਸਕਦਾ ਹੈ ਜਦ ਲੋਕ ਦੇਖ ਸਕਣ ਕਿ ਉਹ ਸੱਚ ਸਮੇਂ ਦੇ ਨਾਲ ਕਿਵੇਂ ਬਦਲਦਾ ਹੈ—ਅਤੇ ਭਰੋਸਾ ਕਰਨ ਕਿ ਬਦਲਾਅ ਜਾਣਬੂਝ ਕੇ ਹੋਏ। ਆਡੀਟਿੰਗ, ਲਾਈਨਿਏਜ਼, ਅਤੇ ਚੇਂਜ ਮੈਨੇਜਮੈਂਟ ਉਹ ਪ੍ਰੈਕਟਿਕਲ ਟੂਲ ਹਨ ਜੋ “ਡੇਟਾਬੇਸ ਸਹੀ ਹੈ” ਨੂੰ ਵੈਰੀਫਾਇ ਕਰਨਯੋਗ ਚੀਜ਼ ਬਣਾਉਂਦੇ ਹਨ।
ਘੱਟੋ-ਘੱਟ ਇਹ ਟ੍ਰੈਕ ਕਰੋ ਕਿ ਕਿਸ ਨੇ ਬਦਲਿਆ, ਕੀ ਬਦਲਿਆ (ਪੁਰਾਣੀ ਵੈਲਿਊ বনਾਮ ਨਵੀਂ ਵੈਲਿਊ), ਕਦੋਂ ਹੋਇਆ, ਅਤੇ ਕਿਉਂ (ਛੋਟਾ ਕਾਰਨ ਜਾਂ ਟਿਕਟ ਰੈਫਰੈਂਸ)।
ਇਹ ਡੇਟਾਬੇਸ-ਨੈਟਿਵ ਆਡੀਟ ਫੀਚਰਾਂ, ਟ੍ਰਿਗਰਾਂ, ਜਾਂ ਐਪਲੀਕੇਸ਼ਨ-ਲੈਅਰ ਇਵੈਂਟ ਲੌਗ ਨਾਲ ਲਾਗੂ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਮੁੱਖ ਅਹਿਮ ਐਂਟੀਟੀਆਂ (ਗਾਹਕ, ਉਤਪਾਦ, ਕੀਮਤ, ਐਕਸੈਸ ਰੋਲ) 'ਤੇ ਹਮੇਸ਼ਾ ਆਡੀਟ ਟ੍ਰੇਲ ਰਹਿਣੀ ਚਾਹੀਦੀ ਹੈ।
ਸਵਾਲ ਉਠਣ 'ਤੇ—“ਇਸ ਗਾਹਕ ਨੂੰ ਕਦੋਂ ਮਰਜ ਕੀਤਾ ਗਿਆ?” ਜਾਂ “ਦਾਮ ਕਦੋਂ ਬਦਲਾ?”—ਆਡੀਟ ਲੌਗ ਤਰਕ-ਤਲਾਸ਼ ਨੂੰ ਤੇਜ ਖੋਜ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ।
ਸਕੀਮਾ ਬਦਲਾਅ ਅਟੱਲ ਹਨ। ਜੋ ਭਰੋਸਾ ਤੋੜਦਾ ਹੈ ਉਹ ਚੁਪਚਾਪ ਬਦਲਾਅ ਹੁੰਦਾ ਹੈ।
ਸਕੀਮਾ ਵਰਜਨਿੰਗ ਅਭਿਆਸ ਵਰਤੋ ਜਿਵੇਂ:
ਜੇ ਤੁਸੀਂ ਸਾਂਝੇ ਡੇਟਾਬੇਸ ਆਬਜੈਕਟ (ਵਿਊਜ਼, ਟੇਬਲ, APIs) ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਪੀਰੀਅਡ ਲਈ ਬੈਕਵਰਡ-ਕੰਪੈਟਿਬਲ ਵਿਊਜ਼ ਰੱਖਣ 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਇੱਕ ਛੋਟਾ “ਡੀਪਰੀਕੇਸ਼ਨ ਵਿੰਡੋ” ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਇੱਕ ਰਾਤ ਵਿੱਚ ਟੁੱਟਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਲਾਈਨਿਏਜ਼ ਦਾ ਜਵਾਬ ਹੁੰਦਾ ਹੈ: “ਇਸ ਨੰਬਰ ਦਾ ਸਰੋਤ ਕਿੱਥੋਂ ਹੈ?” ਸਰੋਤ ਸਿਸਟਮਾਂ ਤੋਂ, ਟ੍ਰਾਂਸਫ਼ੋਰਮੇਸ਼ਨਾਂ ਰਾਹੀਂ, ਡੇਟਾਬੇਸ ਟੇਬਲਾਂ 'ਚ, ਅਤੇ ਆਖ਼ਿਰਕਾਰ ਡੈਸ਼ਬੋਰਡਾਂ ਵਿੱਚ ਪਹੁੰਚਣ ਤੱਕ ਦਾ ਰਾਸ਼ਟਾ ਦਰਜ ਕਰੋ।
ਹਲਕਾ ਜਿਹਾ ਲਾਈਨਿਏਜ਼—wiki, ਡੇਟਾ ਕੈਟਾਲੌਗ, ਜਾਂ repo README ਵਿੱਚ—ਟੀਮਾਂ ਨੂੰ ਗੜਬੜ ਠੀਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਅਤੇ metrics ਨੂੰ align ਕਰਨ ਵਿੱਚ ਸਹਾਇਕ ਹੋਂਦਾ ਹੈ। ਇਹ ਨਿੱਜੀ ਡੇਟਾ ਫਲੋ ਵੀ ਦਰਸਾਉਂਦਾ ਹੈ ਤਾਂ ਕਿ ਅਨੁਕੂਲਤਾ ਕੰਮ ਆਸਾਨ ਹੋਵੇ।
ਸਮੇਂ ਦੇ ਨਾਲ, ਬਿਨਾ ਵਰਤੋਂ ਵਾਲੇ ਟੇਬਲ ਅਤੇ ਫੀਲਡਾਂ ਉਲਝਣ ਬਣਾਉਂਦੇ ਹਨ ਅਤੇ ਅਕਸਮਾਤ ਗਲਤ ਵਰਤੋਂ ਕਰਵਾਉਂਦੇ ਹਨ। ਨਿਯਮਤ ਸਮੀਖਿਆਵਾਂ ਸ਼ੈਡਿਊਲ ਕਰੋ ਤਾਂ ਕਿ:
ਇਹ ਘਰਕਾਮ ਡੇਟਾਬੇਸ ਨੂੰ ਸਮਝਣਯੋਗ ਰੱਖਦਾ ਹੈ, ਜੋ ਵਿਸ਼ਲੇਸ਼ਣ ਇਕਸਾਰਤਾ ਅਤੇ ਭਰੋਸੇਯੋਗ ਓਪਰੇਸ਼ਨਲ ਰਿਪੋਰਟਿੰਗ ਲਈ ਲਾਜ਼ਮੀ ਹੈ।
“ਇੱਕ ਹੀ ਸੱਚਾਈ ਦਾ ਸਰੋਤ” ਤਦ ਹੀ ਸਫਲ ਹੁੰਦਾ ਹੈ ਜਦ ਇਹ ਰੋਜ਼ਾਨਾ ਫੈਸਲਿਆਂ ਨੂੰ ਬਦਲ ਦੇਵੇ, ਨਾ ਕਿ ਸਿਰਫ਼ ਡਾਇਗ੍ਰਾਮਾਂ ਨੂੰ। ਸ਼ੁਰੂ ਕਰਨ ਦਾ ਆਸਾਨ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਇਸਨੂੰ ਇੱਕ ਪ੍ਰੋਡਕਟ ਲਾਂਚ ਵਾਂਗ ਹੀ ਸੌਂਪੋ: ਪਹਿਰਾ הביטੇ ਕਿ “ਬਿਹਤਰ” ਕੀ ਲੱਗੇਗਾ, ਇੱਕ ਖੇਤਰ 'ਚ ਸਾਬਤ ਕਰੋ, ਫਿਰ ਸਕੇਲ ਕਰੋ।
ਉਹ ਨਤੀਜੇ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਇੱਕ ਮਹੀਨੇ ਜਾਂ ਦੋ ਵਿੱਚ ਸਬੂਤ ਕਰ ਸਕੋ। ਉਦਾਹਰਣ:
ਬੇਸਲਾਈਨ ਅਤੇ ਲਕ਼ਸ਼ ਲਿਖੋ। ਜੇ ਤੁਹਾਡਾ ਸੁਧਾਰ ਮਾਪ ਨਹੀਂ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਭਰੋਸਾ ਸਾਬਤ ਨਹੀਂ ਕਰ ਸਕੋਗੇ।
ਉਹ ਡੋਮੇਨ ਚੁਣੋ ਜਿੱਥੇ ਟਕਰਾਅ ਦਰਦਨਾਕ ਅਤੇ ਵੱਧ ਆਮ ਹਨ—ਆਮ ਤੌਰ 'ਤੇ ਗਾਹਕ, ਆਰਡਰ, ਜਾਂ ਇਨਵੈਂਟਰੀ। ਸਕੋਪ ਤੰਗ ਰੱਖੋ: 10–20 ਅਹਿਮ ਫੀਲਡ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਉਹ ਟੀਮਾਂ ਜੋ ਵਰਤਦੀਆਂ ਹਨ, ਅਤੇ ਉਹ ਫੈਸਲੇ ਜੋ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਹਨ।
ਪਾਇਲਟ ਡੋਮੇਨ ਲਈ:
ਪਾਇਲਟ ਨੂੰ ਦੇਖਣਯੋਗ ਬਣਾਓ: ਇੱਕ ਸਧਾਰਨ “ਕੀ ਬਦਲਿਆ” ਨੋਟ ਅਤੇ ਇੱਕ ਛੋਟੀ ਗਲੋਸਰੀ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ।
ਟੀਮ ਅਤੇ ਯੂਜ਼ ਕੇਸ ਵਾਰ ਰੋਲ ਆਊਟ ਨਕਸ਼ਾ ਬਣਾਓ। ਫੈਸਲੇ ਲਈ ਇੱਕ ਡੇਟਾ ਓਨਰ ਨਿਯੁਕਤ ਕਰੋ ਅਤੇ ਪਰਿਭਾਸ਼ਾਵਾਂ ਅਤੇ ਐਕਸਪਸ਼ਨ ਲਈ ਇੱਕ ਸਟੀਵਰਡ ਨਿਯੁਕਤ ਕਰੋ। ਚੇਂਜ ਰਿਕਵੈਸਟ ਲਈ ਇੱਕ ਹਲਕਾ ਪ੍ਰਕਿਰਿਆ ਸੈੱਟ ਕਰੋ, ਅਤੇ ਨਿਯਮਤ ਤੌਰ 'ਤੇ ਗੁਣਵੱਤਾ ਮੈਟਰਿਕ ਦੀ ਸਮੀਖਿਆ ਕਰੋ।
ਇੱਕ ਪ੍ਰਯੋਗਕਾਰੀ ਤਜ਼ੀਨਕ ਹੋ ਸਕਦਾ ਹੈ ਕਿ SSOT ਦੇ ਆਸ-ਪਾਸ ਦੇ “ਗਲੂ” ਟੂਲਾਂ ਨੂੰ ਬਣਾਉਣ ਵਿੱਚ friction ਘਟਾਓ—ਅੰਦਰੂਨੀ ਸਟੀਵਰਡਸ਼ਿਪ UIs, ਐਕਸਪਸ਼ਨ ਰਿਊ ਕ੍ਯੂਜ਼, ਜਾਂ ਲਾਈਨਿਏਜ਼ ਪੇਜ਼। ਟੀਮਾਂ ਕਈ ਵਾਰੀ Koder.ai ਵਰਤ ਕੇ ਚੈਟ ਇੰਟਰਫੇਸ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਇਹ ਅੰਦਰੂਨੀ ਐਪ ਕੋਡ ਕਰ ਲੈਂਦੀਆਂ ਹਨ, ਫਿਰ ਉਹਨਾਂ ਨੂੰ PostgreSQL-backed SSOT ਨਾਲ ਜੋੜਦੀਆਂ ਹਨ, snapshots/rollback ਨਾਲ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਸ਼ਿਪ ਕਰਦੀਆਂ ਹਨ, ਅਤੇ ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਤਾਂ ਸਰੋਤ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰ ਲੈਂਦੀਆਂ ਹਨ।
ਮਕਸਦ ਬੇ-ਮਿਸਾਲੀ ਨਹੀਂ ਹੈ—ਇਹ ਟਕਰਾਅ ਵਾਲੇ ਨੰਬਰ, ਮੈਨੁਅਲ ਕੰਮ, ਅਤੇ ਅਚਾਨਕ ਡੇਟਾ ਬਦਲਾਅ ਨੂੰ ਕਦਮ-ਦਰ-ਕਦਮ ਘਟਾਉਣਾ ਹੈ।
An SSOT is shared agreement on definitions, identifiers, and rules so different teams answer the same questions with the same results.
It’s not necessarily a single tool; it’s consistency in meaning + process + data access across systems.
A database can store data with schemas, constraints, relationships, and transactions that reduce “close enough” records and partial updates.
It also supports consistent querying by many teams, which reduces spreadsheet copies and metric drift.
Because data is duplicated across CRMs, billing systems, support tools, and spreadsheets—each updated on different schedules.
Conflicts also come from definition drift (e.g., two meanings of “active customer”) and manual exports that create outdated snapshots.
A system of record is where a fact is officially created and maintained (e.g., invoices in ERP).
An SSOT is broader: the organization-wide standard for definitions and how data should be used—often spanning multiple systems of record by domain.
A data warehouse is optimized for analytics and history (OLAP): consistent metrics, long time ranges, and cross-system reporting.
An SSOT can be operational, analytical, or both—but many teams use a warehouse as the “truth for reporting” while operational systems remain the sources of record.
Start by defining core entities (customer, product, order) in plain language.
Then enforce:
This captures “agreement” directly in the schema.
Assign clear accountability:
Pair that with a living glossary/catalog and lightweight change control so definitions don’t drift silently.
Focus on controls that prevent issues early and make them visible:
Trust grows when fixes are repeatable, not heroic.
Choose based on business latency needs:
Whichever you use, design for failure with retries, dead-letter handling, and freshness/error-rate alerts (not just “job succeeded”).
A practical path is to pilot one painful domain (like customers or orders) and prove measurable improvement.
Steps:
Scale domain by domain once the pilot is stable.