15 ਸਤੰ 2025·8 ਮਿੰਟ
ਡੇਵਿਡ ਪੈਟਰਸਨ, RISC ਸੋਚ ਅਤੇ ਕੋ‑ਡਿਜ਼ਾਈਨ ਦਾ ਦਾਇਮੀ ਪ੍ਰਭਾਵ
ਜਾਣੋ ਕਿ ਡੇਵਿਡ ਪੈਟਰਸਨ ਦੀ RISC ਸੋਚ ਅਤੇ ਹਾਰਡਵੇਅਰ-ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਨੇ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਨੂੰ ਕਿਵੇਂ ਸੁਧਾਰਿਆ, CPUs ਨੂੰ ਕਿਵੇਂ ਆਕਾਰ ਦਿੱਤਾ, ਅਤੇ RISC-V 'ਤੇ ਕਿਸ ਤਰ੍ਹਾਂ ਅਸਰ ਪਾਇਆ।
ਜਾਣੋ ਕਿ ਡੇਵਿਡ ਪੈਟਰਸਨ ਦੀ RISC ਸੋਚ ਅਤੇ ਹਾਰਡਵੇਅਰ-ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਨੇ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਨੂੰ ਕਿਵੇਂ ਸੁਧਾਰਿਆ, CPUs ਨੂੰ ਕਿਵੇਂ ਆਕਾਰ ਦਿੱਤਾ, ਅਤੇ RISC-V 'ਤੇ ਕਿਸ ਤਰ੍ਹਾਂ ਅਸਰ ਪਾਇਆ।
ਡੇਵਿਡ ਪੈਟਰਸਨ ਨੂੰ ਅਕਸਰ “RISC ਪਾਇਨੀਆਂਰ” ਵਜੋਂ ਜਾਣਿਆ ਜਾਂਦਾ ਹੈ, ਪਰ ਉਹਨਾਂ ਪ੍ਰਭਾਵ ਇੱਕ ਹੀ CPU ਡਿਜ਼ਾਈਨ ਤੋਂ ਕਾਫੀ ਵਿਆਪਕ ਹੈ। ਉਹਨਾਂ ਨੇ ਕੰਪਿਊਟਰਾਂ ਬਾਰੇ ਇੱਕ عملي ਸੋਚ ਪ੍ਰਚਲਿਤ ਕੀਤੀ: ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਮਾਪੋ, ਸਧਾਰਨ ਬਣਾਓ, ਤੇ ਅੰਤ-ਤੱਕ ਸੁਧਾਰੋ—ਚਿੱਪ ਦੇ ਸਮਝਣ ਵਾਲੇ ਨਿਰਦੇਸ਼ਾਂ ਤੋਂ ਲੈ ਕੇ ਉਹਨਾਂ ਸੌਫਟਵੇਅਰ ਟੂਲਾਂ ਤੱਕ ਜੋ ਉਹ ਨਿਰਦੇਸ਼ ਬਣਾਉਂਦੇ ਹਨ।
RISC (Reduced Instruction Set Computing) ਇਹ ਵਿਚਾਰ ਹੈ ਕਿ ਜਦੋਂ ਪ੍ਰੋਸੈਸਰ ਘੱਟ ਪਰ ਸਧਾਰਨ ਹਦਾਇਤਾਂ 'ਤੇ ਧਿਆਨ ਦੇਂਦਾ ਹੈ ਤਾਂ ਉਹ ਤੇਜ਼ ਅਤੇ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਚੱਲ ਸਕਦਾ ਹੈ। ਵੱਡੇ ਤੇ ਜਟਿਲ ਆਪਰੇਸ਼ਨਾਂ ਦੀ ਬਜਾਏ ਤੁਸੀਂ ਆਮ ਆਪਰੇਸ਼ਨਾਂ ਨੂੰ ਤੇਜ਼, ਨਿਯਮਤ ਅਤੇ ਪਾਈਪਲਾਈਨ ਲਈ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹੋ। ਨਤੀਜਾ “ਘੱਟ ਸਮਰੱਥਾ” ਨਹੀਂ—ਇਹ ਹੈ ਕਿ ਸਧਾਰਨ ਨਿਰਦੇਸ਼ਕ ਬਲਾਕ ਜੇਕਰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਚਲਾਏ ਜਾਣ ਤਾਂ ਅਸਲ ਵਰਕਲੋਡ ਵਿੱਚ ਅਕਸਰ ਜਿੱਤ ਹੁੰਦੀ ਹੈ।
ਪੈਟਰਸਨ ਨੇ ਹਾਰਡਵੇਅਰ–ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਨੂੰ ਵੀ ਬਰਾਬਰ ਸੰਜਾਬਾ ਕੀਤਾ: ਇਹ ਇੱਕ ਫੀਡਬੈਕ ਲੂਪ ਹੈ ਜਿੱਥੇ ਚਿਪ ਆਰਕੀਟੈਕਟ, ਕੰਪਾਇਲਰ ਲਿਖਨ ਵਾਲੇ ਅਤੇ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨਰ ਇਕੱਠੇ ਇਟਰੇਟ ਕਰਦੇ ਹਨ।
ਜੇਕਰ ਇੱਕ ਪ੍ਰੋਸੈਸਰ ਸਧਾਰਨ ਪੈਟਰਨਾਂ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਚਲਾਉਣ ਲਈ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਹੈ, ਤਾਂ ਕੰਪਾਇਲਰ ਭਰੋਸੇਯੋਗ ਢੰਗ ਨਾਲ ਉਹ ਪੈਟਰਨ ਬਣਾਉਣਗੇ। ਜਦੋਂ ਕੰਪਾਇਲਰ ਦਰਸਾਉਂਦੇ ਹਨ ਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮ ਕਿਸੇ ਖਾਸ ਆਪਰੇਸ਼ਨਾਂ (ਜਿਵੇਂ ਮੈਮੋਰੀ ਪਹੁੰਚ) 'ਚ ਸਮਾਂ ਲਗਾਉਂਦੇ ਹਨ, ਤਾਂ ਹਾਰਡਵੇਅਰ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਲਈ ਢੁੰਗ ਅਨੁਸਾਰ ਢਾਲਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਇਸੀ ਲਈ ISA ਦੀਆਂ ਚਰਚਾਵਾਂ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਕੰਪਾਇਲਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ, ਕੈਸ਼ਿੰਗ ਅਤੇ ਪਾਈਪਲਾਈਨਿੰਗ ਨਾਲ ਜੁੜਦੀਆਂ ਹਨ।
ਤੁਸੀਂ ਜਾਣੋਗੇ ਕਿ RISC ਵਿਚਾਰਧਾਰਾ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਨਾਲ ਕਿਵੇਂ ਜੁੜਦੀ ਹੈ (ਸਿਰਫ਼ ਕੱਚਾ ਤੇਜ਼ੀ ਨਹੀਂ), ਕਿਵੇਂ “ਪੇਸ਼ਗੀ” ਆਧੁਨਿਕ CPU ਅਤੇ ਮੋਬਾਈਲ ਚਿਪਸ ਨੂੰ ਬਚਤਯੋਗ ਬਣਾਉਂਦੀ ਹੈ, ਅਤੇ ਇਹ ਸਿਧਾਂਤ ਅੱਜ ਦੇ ਡਿਵਾਈਸ—ਲੈਪਟਾਪ ਤੋਂ ਕਲਾਉਡ ਸਰਵਰ ਤੱਕ—ਵਿੱਚ ਕਿਵੇਂ ਪ੍ਰਗਟ ਹੁੰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਕੁੰਜੀ ਧਾਰਾਵਾਂ ਦਾ ਨਕਸ਼ਾ ਪਹਿਲਾਂ ਹੀ ਵੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ /blog/key-takeaways-and-next-steps ਤੇ ਸਿੱਧਾ ਜਾ ਸਕਦੇ ਹੋ।
ਸ਼ੁਰੂਆਤੀ ਮਾਈਕ੍ਰੋਪ੍ਰੋਸੈਸਰ ਸਖਤ ਸੀਮਾਵਾਂ ਹੇਠ ਬਣਾਏ ਗਏ ਸਨ: ਚਿਪ ਵਿੱਚ ਸਰਕਿਊਟਰੀ ਲਈ ਥੋੜੀ ਜਗ੍ਹਾ, ਮਹਿੰਗੀ ਮੈਮੋਰੀ, ਅਤੇ ਧੀਮੀ ਸਟੋਰੇਜ। ਡਿਜ਼ਾਈਨਰ ਸਸਤੇ ਅਤੇ “ਕਾਫੀ ਤੇਜ਼” ਕੰਪਿਊਟਰ ਪ੍ਰਦਾਨ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੇ ਸਨ—ਅਕਸਰ ਛੋਟੀਆਂ ਕੈਸ਼ਾਂ (ਜਾਂ ਬਿਨਾਂ), ਨਿਯਮਤ ਕਲਾਕ ਸਪੀਡ ਅਤੇ ਮੁੱਖ ਮੈਮੋਰੀ ਜੋ ਸਾਫ਼ਟਵੇਅਰ ਦੀਆਂ ਮੰਗਾਂ ਨਾਲੋਂ ਕਾਫੀ ਘੱਟ ਹੁੰਦੀ ਸੀ।
ਉਸ ਸਮੇਂ ਇੱਕ ਪ੍ਰਚਲਿਤ ਵਿਚਾਰ ਸੀ ਕਿ ਜੇ CPU ਵਧੇਰੇ ਸ਼ਕਤੀਸ਼ਾਲੀ, ਉੱਚ-ਸਤਰ ਦੀਆਂ ਹਦਾਇਤਾਂ ਦੇਵੇ—ਜਿਹੜੀਆਂ ਇੱਕ ਹੀ ਵਿਰਤਾਂ ਵਿੱਚ ਕਈ ਕਦਮ ਕਰ ਸਕਦੀਆਂ—ਤਾਂ ਪ੍ਰੋਗਰਾਮ ਤੇਜ਼ ਚੱਲਣਗੇ ਅਤੇ ਲਿਖਣ ਲਈ ਆਸਾਨ ਹੋਣਗੇ। ਜੇ ਇਕ ਹਦਾਇਤ “ਕਈ ਦੇ ਕੰਮ” ਕਰ ਸਕਦੀ, ਤਾਂ ਸੋਚ ਇਹ ਸੀ ਕਿ ਕੁੱਲ ਮਿਲਾ ਕੇ ਘੱਟ ਹਦਾਇਤਾਂ ਲੱਗਣਗੀਆਂ, ਸਮਾਂ ਅਤੇ ਮੈਮੋਰੀ ਬਚੇਗੀ।
ਇਹੀ ਧਾਰਨਾ ਬਹੁਤ ਸਾਰੇ CISC ਡਿਜ਼ਾਈਨਾਂ ਦੇ ਪਿੱਛੇ ਸੀ: ਪ੍ਰੋਗਰਾਮਰਾਂ ਅਤੇ ਕੰਪਾਇਲਰਾਂ ਨੂੰ ਇੱਕ ਵੱਡਾ ਅਤੇ ਸ਼ਿੰਗਾਰਭਰਿਆ ਟੂਲਬਾਕਸ ਦਿਓ।
ਪੈਕੇਟ ਇਹ ਸੀ ਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮ (ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਤਰਜਮਾ ਕਰਨ ਵਾਲੇ ਕੰਪਾਇਲਰ) ਉਸ ਜਟਿਲਤਾ ਨੂੰ ਲਗਾਤਾਰ ਫਾਇਦਾਕਾਰੀ ਢੰਗ ਨਾਲ ਵਰਤਦੇ ਨਹੀਂ ਸਨ। ਬਹੁਤ ਸਾਰੀਆਂ ਸਭ ਤੋਂ ਜਟਿਲ ਹਦਾਇਤਾਂ ਘੱਟ ਹੀ ਵਰਤੀਆਂ ਜਾਂਦੀਆਂ ਸਨ, ਜਦਕਿ ਸਧਾਰਨ ਆਪਰੇਸ਼ਨਾਂ ਦਾ ਇੱਕ ਛੋਟਾ ਸੈੱਟ—ਡਾਟਾ ਲੋਡ, ਡਾਟਾ ਸਟੋਰ, ਜੋੜ, ਤੁਲਨਾ, ਬ੍ਰਾਂਚ—ਅਕਸਰ ਮਿਲਦਾ ਸੀ।
ਇਸਦੇ ਨਾਲ, ਹੀਰ-ਬਾਜ਼ ਜਟਿਲ ਹਦਾਇਤਾਂ ਦਾ ਸਹਾਰਾ ਲੈਣਾ CPUs ਨੂੰ ਬਣਾਉਣਾ ਮੁਸ਼ਕਲ ਅਤੇ ਅਪਟੀਮਾਈਜ਼ ਕਰਨਾ ਔਖਾ ਬਣਾਉਂਦਾ ਸੀ। ਜਟਿਲਤਾ ਚਿਪ ਥਾਂ ਅਤੇ ਡਿਜ਼ਾਈਨ ਕੋਸ਼ਿਸ਼ ਖ਼ਰਚ ਕਰਦੀ ਸੀ ਜੋ ਆਮ ਰਾਹਾਂ ਨੂੰ ਤੇਜ਼ ਬਣਾਉਣ ਵਿੱਚ ਲੱਗ ਸਕਦੀ ਸੀ।
RISC ਨੇ ਉਸ ਖਾਈ ਨੂੰ ਭਰ੍ਹਨ ਲਈ ਪ੍ਰਤੀਸ਼ੋਧ ਦਿੱਤਾ: CPU ਨੂੰ ਉਹਨਾਂ ਗਤੀਵਿਧੀਆਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦ੍ਰਿਤ ਕਰੋ ਜੋ ਸੌਫਟਵੇਅਰ ਅਸਲ ਵਿੱਚ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਕਰਦਾ ਹੈ, ਅਤੇ ਉਹ ਰਸਤਿਆਂ ਨੂੰ ਤੇਜ਼ ਬਣਾਓ—ਅਤੇ ਕੰਪਾਇਲਰ ਨੂੰ ਵੱਧ “ਆਰਕੈਸਟਰ” ਬਣਨ ਦਿਓ।
ਇੱਕ ਸਧਾਰਨ ਤਰੀਕਾ CISC ਅਤੇ RISC ਦੀ ਤੁਲਨਾ ਕਰਨ ਦੀ ਹੈ ਉਹਨਾਂ ਦੇ ਟੂਲਕਿਟਾਂ ਵਰਗੋ।
CISC (Complex Instruction Set Computing) ਇੱਕ ਵਰਕਸ਼ਾਪ ਵਾਂਗ ਹੈ ਜੋ ਬਹੁਤ ਸਾਰੇ ਵਿਸ਼ੇਸ਼, ਸ਼ਿੰਗਾਰ ਭਰੇ ਟੂਲਾਂ ਨਾਲ ਭਰਿਆ ਹੋਇਆ ਹੈ—ਹਰ ਇਕ ਇੱਕ ਵੱਡਾ ਕੰਮ ਇੱਕ ਕਦਮ ਵਿੱਚ ਕਰ ਸਕਦਾ ਹੈ। ਇਕ ہی “ਹਦਾਇਤ” ਸਮੇਂ ਵਿੱਚ ਮੈਮੋਰੀ ਤੋਂ ਡਾਟਾ ਲੋਡ ਕਰ ਸਕਦੀ ਹੈ, ਗਣਿਤ ਕਰ ਸਕਦੀ ਹੈ, ਅਤੇ ਨਤੀਜਾ ਸਟੋਰ ਕਰ ਸਕਦੀ ਹੈ।
RISC (Reduced Instruction Set Computing) ਇੱਕ ਛੋਟੇ, ਭਰੋਸੇਯੋਗ ਟੂਲਕਿਟ ਵਾਂਗ ਹੈ—ਜਿਹੜੇ ਤੁਹਾਨੂੰ ਨਿੱਯਮਤ ਤੌਰ 'ਤੇ ਵਰਤਣੇ ਚਾਹੀਦੇ ਹਨ—ਅਤੇ ਹਰ ਚੀਜ਼ ਨਿਰਧਾਰਿਤ, ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ ਕਦਮਾਂ ਤੋਂ ਬਣਾਈ ਜਾਂਦੀ ਹੈ। ਹਰ ਹਦਾਇਤ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਛੋਟਾ, ਸਪਸ਼ਟ ਕੰਮ ਕਰਦੀ ਹੈ।
ਜਦੋਂ ਹਦਾਇਤਾਂ ਸਧਾਰਨ ਅਤੇ ਹੋਰ ਇੱਕਸਾਰ ਹੁੰਦੀਆਂ ਹਨ, CPU ਉਹਨਾਂ ਨੂੰ ਇੱਕ ਸਾਫ਼ ਐਸੈਂਬਲੀ ਲਾਈਨ (ਪਾਈਪਲਾਈਨ) ਵਿੱਚ ਚਲਾ ਸਕਦਾ ਹੈ। ਇਹ assembly line ਢਾਂਚਾ ਡਿਜ਼ਾਈਨ ਕਰਨਾ, ਉੱਚ ਘੰਟਾਕ ਸਪੀਡ 'ਤੇ ਚਲਾਉਣਾ ਅਤੇ ਲਗਾਤਾਰ ਰੱਖਣਾ ਆਸਾਨ ਬਣ ਜਾਂਦਾ ਹੈ।
CISC-ਸ਼ੈਲੀ ਦੀਆਂ “ਕਰ-ਬਹੁਤ” ਹਦਾਇਤਾਂ ਨਾਲ, CPU ਅਕਸਰ ਇੱਕ ਜਟਿਲ ਹਦਾਇਤ ਨੂੰ ਡਿਕੋਡ ਕਰਕੇ ਅੰਦਰੂਨੀ ਛੋਟੇ ਕਦਮਾਂ ਵਿੱਚ ਬਾਂਟਣਾ ਪੈਂਦਾ ਹੈ। ਇਸ ਨਾਲ ਜਟਿਲਤਾ ਵਧਦੀ ਹੈ ਅਤੇ ਪਾਈਪਲਾਈਨ ਨੂੰ ਸੁਚਾਰੂ ਰੱਖਣਾ ਔਖਾ ਹੋ ਜਾਂਦਾ ਹੈ।
RISC ਦਾ ਉਦੇਸ਼ ਹਦਾਇਤ ਸਮੇਂ ਵਿੱਚ ਪੇਸ਼ਗੀ ਹੈ—ਕਈ ਹਦਾਇਤਾਂ ਲਗਭਗ ਇੱਕੋ ਜਿਹਾ ਸਮਾਂ ਲੈਂਦੀਆਂ ਹਨ। ਪੇਸ਼ਗੀ CPU ਨੂੰ ਕੰਮ ਨਿਯੋਜਿਤ ਕਰਨ ਵਿੱਚ ਸਹਾਇਕ ਹੁੰਦੀ ਹੈ ਅਤੇ ਕੰਪਾਇਲਰ ਨੂੰ ਕੋਡ ਜਨਰੇਟ ਕਰਨ ਲਈ ਮਦਦ ਕਰਦੀ ਹੈ ਜੋ ਪਾਈਪਲਾਈਨ ਨੂੰ ਭਰਿਆ ਰੱਖਦਾ ਹੈ ਨਾ ਕਿ ਰੁਕਾਉਂਦਾ।
RISC ਆਮ ਤੌਰ 'ਤੇ ਇੱਕੋ ਕੰਮ ਕਰਨ ਲਈ ਜ਼ਿਆਦਾ ਹਦਾਇਤਾਂ ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ। ਇਸ ਦਾ ਮਤਲਬ ਹੋ ਸਕਦਾ ਹੈ:
ਪਰ ਇਹ ਫਾਇਦੇਮੰਦ ਹੋ ਸਕਦਾ ਹੈ ਜੇ ਹਰੇਕ ਹਦਾਇਤ ਤੇਜ਼ ਹੋਵੇ, ਪਾਈਪਲਾਈਨ ਸਧਾਰਨ ਰਹੇ, ਅਤੇ ਸਮੁੱਚੇ ਡਿਜ਼ਾਈਨ ਨੂੰ ਸੀਧੇ ਰੂਪ ਵਿੱਚ ਅਸਮਾਨ ਰੱਖਿਆ ਜਾਵੇ। ਪ੍ਰਤੀਯੋਗੀ ਕੰਪਾਇਲਰ ਅਤੇ ਚੰਗੀ ਕੈਸ਼ਿੰਗ ਅਕਸਰ “ਜ਼ਿਆਦਾ ਹਦਾਇਤਾਂ” ਦੀ ਕੋਲ ਹਨਮਾਰੀਆਂ ਨੁਕਸਾਨ ਨੂੰ ਪੂਰਾ ਕਰ ਦਿੰਦੀਆਂ ਹਨ—ਅਤੇ CPU ਲਗਭਗ ਜ਼ਿਆਦਾ ਸਮਾਂ ਫਾਲਤੂ ਕੰਮ ਨਹੀਂ ਕਰ ਰਿਹਾ ਹੁੰਦਾ।
Berkeley RISC ਸਿਰਫ਼ ਨਵਾਂ ISA ਨਹੀਂ ਸੀ। ਇਹ ਇੱਕ ਖੋਜੀ ਰਵੱਈਆ ਸੀ: ਕਾਗਜ਼ 'ਤੇ ਜੋ ਸੁੰਦਰ ਲੱਗੇ ਉਸ ਤੋਂ ਸ਼ੁਰੂ ਨਾ ਕਰੋ—ਉਹਨਾਂ ਪ੍ਰੋਗਰਾਮਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਅਸਲ ਵਿੱਚ ਕਰਦੇ ਹਨ, ਫਿਰ CPU ਨੂੰ ਉਸ ਹਕੀਕਤ ਦੇ ਆਸਪਾਸ ਡਿਜ਼ਾਈਨ ਕਰੋ।
Berkeley ਟੀਮ ਨਿਰਧਾਰਤ ਤੌਰ 'ਤੇ ਇੱਕ ਐਸਾ CPU ਕੋਰ ਚਾਹੁੰਦੀ ਸੀ ਜੋ ਕਾਫੀ ਸਧਾਰਨ ਹੋਵੇ ਤਾਂ ਕਿ ਬਹੁਤ ਤੇਜ਼ ਤੇ ਪੇਸ਼ਗੀਯੋਗ ਚੱਲੇ। ਬਹੁਤ ਸਾਰੇ ਹਾਰਡਵੇਅਰ-ਅੰਦਰੂਨੀ “ਚਾਲਾਂ” ਹੋਣ ਦੀ ਬਜਾਏ, ਉਹਾਂ ਨੇ ਕੰਪਾਇਲਰ 'ਤੇ ਵੱਧ ਕੰਮ ਛੱਡਿਆ: ਸਧਾਰਨ ਹਦਾਇਤਾਂ ਚੁਣਨਾ, ਉਨ੍ਹਾਂ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸ਼ੈਡਿਊਲ ਕਰਨਾ, ਅਤੇ ਡੇਟਾ ਨੂੰ ਜ਼ਿਆਦਾਤਰ ਰਜਿਸਟਰਾਂ ਵਿੱਚ ਰੱਖਣਾ।
ਇਹ ਕੰਮ ਦੇ ਵੰਡਣ ਨਾਲ ਫਰਕ ਪਿਆ। ਛੋਟਾ, ਸਾਫ਼ ਕੋਰ ਪਾਈਪਲਾਈਨਿੰਗ ਲਈ ਆਸਾਨ ਹੁੰਦਾ ਹੈ, ਸੋਝੀ ਨਾਲ ਸਮਝਣ ਲਈ ਆਸਾਨ, ਅਤੇ ਪ੍ਰਤੀ ਟਰਾਂਜ਼ਿਸਟਰ ਤੇ ਅਕਸਰ ਤੇਜ਼ ਹੁੰਦਾ ਹੈ। ਕੰਪਾਇਲਰ, ਜੋ ਸਮੂਹ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਵੇਖਦਾ ਹੈ, ਅਜਿਹੀਆਂ ਯੋਜਨਾਵਾਂ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਹਾਰਡਵੇਅਰ ਅਕਸਰ ਤਤਕਾਲ ਨਹੀਂ ਕਰ ਸਕਦਾ।
ਡੇਵਿਡ ਪੈਟਰਸਨ ਨੇ ਮਾਪਣ 'ਤੇ ਜ਼ੋਰ ਦਿੱਤਾ ਕਿਉਂਕਿ ਕੰਪਿਊਟਰ ਡਿਜ਼ਾਈਨ ਭਰਮਾਂ ਨਾਲ ਭਰਪੂਰ ਹੈ—ਉਹ ਫੀਚਰ ਜੋ ਸੁਣਨ 'ਚ ਵਰਤੇਲੱਗਦੇ ਹਨ ਪਰ ਅਸਲ ਕੋਡ ਵਿੱਚ ਕਦੇ-ਕਦੇ ਹੀ ਮਿਲਦੇ ਹਨ। Berkeley RISC ਨੇ ਬੈਂਚਮਾਰਕ ਅਤੇ ਵਰਕਲੋਡ ਟ੍ਰੇਸ ਵਰਤਣ ਲਈ ਦਬਾਅ ਕੀਤਾ ਤਾਂ ਕਿ ਗਰਮ ਰਾਹ (ਲੂਪ, ਫੰਕਸ਼ਨ ਕਾਲ, ਅਤੇ ਮੈਮੋਰੀ ਐਕਸੈਸ) ਮਿਲ ਸਕਣ ਜੋ ਰਨਟਾਈਮ ਦਾ ਬਹੁਤ ਹਿੱਸਾ ਘੇਰਦੇ ਹਨ।
ਇਹ ਸਿੱਧਾ “ਆਮ ਕੇਸ ਨੂੰ ਤੇਜ਼ ਬਣਾਓ” ਸਿਧਾਂਤ ਨਾਲ ਜੁੜਦਾ ਹੈ। ਜੇ ਬਹੁਤ ਸਾਰੀਆਂ ਹਦਾਇਤਾਂ ਸਧਾਰਨ ਆਪਰੇਸ਼ਨ ਹਨ ਅਤੇ ਲੋਡ/ਸਟੋਰ ਆਮ ਹਨ, ਤਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਅਪਟੀਮਾਈਜ਼ ਕਰਨਾ ਦਰਅਸਲ ਵਧੀਆ ਨਤੀਜੇ ਦਿੰਦਾ ਹੈ ਬਣਿਸਪਤ ਕਿ ਰੇਅਰ ਜਟਿਲ ਹਦਾਇਤਾਂ ਨੂੰ ਤੇਜ਼ ਕਰਨਾ।
ਲੰਬੇ ਸਮੇਂ ਦੀ ਸ਼ਿੱਖ ਇਹ ਹੈ ਕਿ RISC ਨਾ ਸਿਰਫ਼ ਇੱਕ ਆਰਕੀਟੈਕਚਰ ਸੀ, ਬਲਕਿ ਇੱਕ ਮਨਸੂਬਾ ਵੀ ਸੀ: ਜੋ ਆਮ ਹੈ ਉਸ ਨੂੰ ਸਧਾਰਨ ਕਰੋ, ਡੇਟਾ ਨਾਲ ਸੱਚਾਉ, ਅਤੇ ਹਾਰਡਵੇਅਰ ਅਤੇ ਸੌਫਟਵੇਅਰ ਨੂੰ ਇਕੱਠੇ ਇੱਕ ਸਿਸਟਮ ਵਜੋਂ ਦੇਖੋ ਜੋ ਇਕੱਠੇ ਟਿਊਨ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
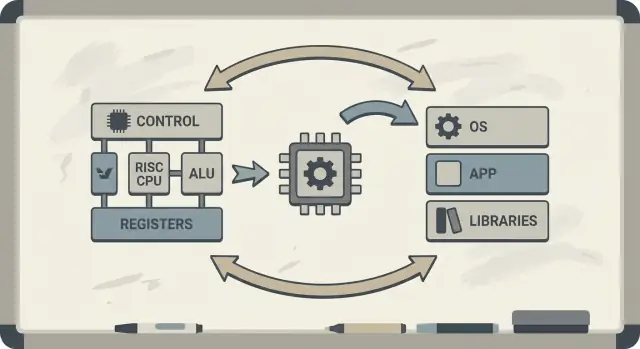
ਹਾਰਡਵੇਅਰ–ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਇਹ ਵਿਚਾਰ ਹੈ ਕਿ ਤੁਸੀਂ CPU ਨੂੰ ਅਲੱਗ ਨਹੀਂ ਡਿਜ਼ਾਈਨ ਕਰਦੇ। ਤੁਸੀਂ ਚਿਪ ਅਤੇ ਕੰਪਾਇਲਰ (ਅਤੇ ਕਈ ਵਾਰ ਓਐਸ) ਇਕੱਠੇ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਜੋ ਅਸਲ ਪ੍ਰੋਗਰਾਮ ਤੇਜ਼ ਅਤੇ ਕੁਸ਼ਲ ਚੱਲਣ—ਸਿਰਫ਼ ਸੁੱਕੇ “ਬੈਸਟ ਕੇਸ” ਸਿੱਖੇ ਟੁਕੜੇ ਨਹੀਂ।
ਕੋ‑ਡਿਜ਼ਾਈਨ ਇੰਜੀਨੀਅਰਿੰਗ ਲੂਪ ਵਾਂਗ ਕੰਮ ਕਰਦਾ ਹੈ:
ISA ਚੋਣਾਂ: instruction set architecture (ISA) ਇਹ ਤੈਅ ਕਰਦੀ ਹੈ ਕਿ CPU ਕੀ ਆਸਾਨੀ ਨਾਲ ਜ਼ਾਹਿਰ ਕਰ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਣ ਲਈ, “load/store” ਮੈਮੋਰੀ ਐਕਸੈਸ, ਕਈ ਰਜਿਸਟਰ, ਸਧਾਰਨ ਐਡ੍ਰੈਸਿੰਗ ਮੋਡ)।
ਕੰਪਾਇਲਰ ਰਣਨੀਤੀਆਂ: ਕੰਪਾਇਲਰ ਅਨੁਕੂਲ ਹੁੰਦਾ ਹੈ—ਗਰਮ ਵੇਰੀਏਬਲ ਰਜਿਸਟਰਾਂ ਵਿੱਚ ਰੱਖਣਾ, ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਦੁਹਰਾਵਾਂ ਤੋਂ ਬਚਾਉਣਾ, ਅਤੇ ਕਾਲਿੰਗ ਕੰਵੇਂਸ਼ਨਾਂ ਚੁਣਨਾ ਜੋ ਓਵਰਹੈਡ ਘਟਾਉਂਦੇ ਹਨ।
ਵਰਕਲੋਡ ਨਤੀਜੇ: ਤੁਸੀਂ ਅਸਲ ਪ੍ਰੋਗਰਾਮਾਂ (ਕੰਪਾਇਲਰ, ਡੇਟਾਬੇਸ, ਗ੍ਰਾਫਿਕਸ, OS ਕੋਡ) ਨੂੰ ਮਾਪਦੇ ਹੋ ਅਤੇ ਵੇਖਦੇ ਹੋ ਕਿ ਸਮਾਂ ਅਤੇ ਊਰਜਾ ਕਿੱਥੇ ਜਾ ਰਹੀ ਹੈ।
ਅਗਲਾ ਡਿਜ਼ਾਈਨ: ਤੁਸੀਂ ਉਹ IAS ਜਾਂ ਮਾਈਕ੍ਰੋਆਰਕੀਟੈਕਚਰ (ਪਾਈਪਲਾਈਨ ਦੀ ਗਹਿਰਾਈ, ਰਜਿਸਟਰਾਂ ਦੀ ਗਿਣਤੀ, ਕੈਸ਼ ਸਾਈਜ਼) ਉਨਾਂ ਮਾਪਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਤਿੱਕੀ ਕਰਦੇ ਹੋ।
ਇੱਥੇ ਇੱਕ ਛੋਟਾ C ਲੂਪ ਹੈ ਜੋ ਇਹ ਸੰਬੰਧ ਰੋਸ਼ਨ ਕਰਦਾ ਹੈ:
for (int i = 0; i \u003c n; i++)
sum += a[i];
RISC-ਸ਼ੈਲੀ ISA 'ਤੇ, ਕੰਪਾਇਲਰ ਆਮ ਤੌਰ 'ਤੇ sum ਅਤੇ i ਨੂੰ ਰਜਿਸਟਰਾਂ ਵਿੱਚ ਰੱਖਦਾ ਹੈ, a[i] ਲਈ ਸਧਾਰਨ load ਨਿਰਦੇਸ਼ਾਂ ਦਾ ਉਪਯੋਗ ਕਰਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਲੋਡ ਰਾਹ 'ਚ ਹੋਵੇ ਤਾਂ CPU ਨੂੰ ਰੁਜ਼ਗਾਰ ਰੱਖਣ ਲਈ instruction scheduling ਕਰਦਾ ਹੈ।
ਜੇ ਇੱਕ ਚਿਪ ਅਜਿਹੀਆਂ ਜਟਿਲ ਹਦਾਇਤਾਂ ਜਾਂ ਖਾਸ ਹਾਰਡਵੇਅਰ ਜੋ ਕੰਪਾਇਲਰ ਘੱਟ ਹੀ ਵਰਤਦਾ ਹੈ ਜੋੜਦਾ ਹੈ, ਤਾਂ ਉਹ ਖੇਤਰ ਫਿਰ ਵੀ ਪਾਵਰ ਅਤੇ ਡਿਜ਼ਾਈਨ ਕੋਸ਼ਿਸ਼ ਖਪਾਏਗਾ। ਇਸਨਾਂ ਦੇ ਬਦਲੇ, ਉਹ “ਨਾਂਚਾਹੀਆਂ” ਚੀਜ਼ਾਂ ਜਿਹਨ ਤੇ ਕੰਪਾਇਲਰ ਨਿਰਭਰ ਕਰਦਾ ਹੈ—ਪੂਰੇ ਰਜਿਸਟਰ, ਪੇਸ਼ਗੀਯੋਗ ਪਾਈਪਲਾਈਨ, ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਕਾਲਿੰਗ ਕੰਵੇਂਸ਼ਨ—ਕੁਝ ਹੋਰ ਉਪਯੋਗੀ ਢੰਗ ਨਾਲ ਘੱਟ ਲੋੜ ਪੈਂਦੇ ਹਨ।
ਪੈਟਰਸਨ ਦੀ RISC ਸੋਚ ਇਹ ਜ਼ੋਰ ਦਿੰਦੀ ਸੀ ਕਿ ਸਿਲਿਕਾਨ ਉਨ੍ਹਾਂ ਥਾਵਾਂ ਤੇ ਖਰਚੋ ਜਿੱਥੇ ਅਸਲ ਸੌਫਟਵੇਅਰ ਲਾਭ ਉਠਾ ਸਕੇ।
RISC ਦਾ ਇੱਕ ਮੁੱਖ ਵਿਚਾਰ CPU ਦੇ “ਅਸੈਂਬਲੀ ਲਾਈਨ” ਨੂੰ ਬਹੁਤ ਹੀ ਹਲਕਾ ਰੱਖਣਾ ਸੀ। ਇਹ assembly line ਪਾਈਪਲਾਈਨ ਹੈ: ਇੱਕ ਨਿਰਦੇਸ਼ ਨੂੰ ਪੂਰੀ ਤਰ੍ਹਾਂ ਮੁਕੰਮਲ ਕਰਨ ਦੀ ਬਜਾਏ, ਪ੍ਰੋਸੈਸਰ ਕੰਮ ਨੂੰ ਸਟੇਜਾਂ (fetch, decode, execute, write-back) ਵਿੱਚ ਵੰਡਦਾ ਹੈ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਓਵਰਲੈਪ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਸਭ ਕੁਝ ਸਹੀ ਚੱਲਦਾ ਹੈ, ਤੁਸੀਂ ਲਗਭਗ ਇੱਕ ਨਿਰਦੇਸ਼ ਪ੍ਰਤੀ ਸਾਈਕਲ ਮੁਕੰਮਲ ਕਰ ਸਕਦੇ ਹੋ—ਜਿਵੇਂ ਇੱਕ ਫੈਕਟਰੀ ਵਿੱਚ ਕਾਰਾਂ ਬਹੁਤ ਸਟੇਸ਼ਨਾਂ ਤੋਂ ਗੁਜ਼ਰਦੀਆਂ ਹਨ।
ਪਾਈਪਲਾਈਨ ਉਸ ਵਕਤ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਹਰ ਇਕ ਆਈਟਮ ਲਾਈਨ ਵਿੱਚ ਮਿਲਦਾ-ਜੁਲਦਾ ਹੋਵੇ। RISC ਹਦਾਇਤਾਂ ਨਿਸ਼ਚਿਤ ਤੌਰ 'ਤੇ ਇਕਸਾਰ ਅਤੇ ਪੇਸ਼ਗੀਯੋਗ (ਅਕਸਰ ਫਿਕਸਡ ਲੰਬਾਈ, ਸਧਾਰਨ ਐਡਰੈਸਿੰਗ) ਦੇ ਤੌਰ 'ਤੇ ਡਿਜ਼ਾਈਨ ਕੀਤੀਆਂ ਗਈਆਂ ਸਨ। ਇਹ “ਖਾਸ ਕੇਸ” ਘੱਟ ਕਰਦਾ ਹੈ ਜਿੱਥੇ ਇਕ ਹਦਾਇਤ ਨੂੰ ਵੱਧ ਸਮਾਂ ਜਾਂ ਅਸਾਮਾਨ ਸਰੋਤਾਂ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ।
ਅਸਲ ਪ੍ਰੋਗਰਾਮ ਸਦਾ ਸਿਖਰੇ ਨਹੀਂ ਹੁੰਦੇ। ਕਈ ਵਾਰੀ ਇੱਕ ਨਿਰਦੇਸ਼ ਪਿਛਲੇ ਨਿਰਦੇਸ਼ ਦੇ ਨਤੀਜੇ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ (ਤੁਸੀਂ ਮੁੱਲ ਤੋਂ ਪਹਿਲਾਂ ਉਸਨੂੰ ਵਰਤ ਨਹੀਂ ਸਕਦੇ)। ਕਈ ਵਾਰੀ CPU ਨੂੰ ਮੈਮੋਰੀ ਤੋਂ ਡੇਟਾ ਦੀ ਉਡੀਕ ਰਹਿੰਦੀ ਹੈ, ਜਾਂ ਉਨਾਂ ਨੂੰ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ ਕਿ ਕੋਈ ਬ੍ਰਾਂਚ ਕਿਹੜੀ ਰਾਹ ਲਵੇਗੀ।
ਇਹ ਸਥਿਤੀਆਂ ਸਟਾਲ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ—ਛੋਟੇ ਰੁਕਾਅ ਜਿੱਥੇ ਪਾਈਪਲਾਈਨ ਦਾ ਹਿੱਸਾ ਨਿਸ਼ਕ੍ਰિય ਹੋ ਜਾਂਦਾ ਹੈ। ਅਨੁਮਾਨ ਸਧਾਰਨ ਹੈ: ਜਦੋਂ ਅਗਲਾ ਸਟੇਜ ਲੋੜੀ ਦੀ ਚੀਜ਼ ਦੀ ਉਡੀਕ ਕਰ ਰਿਹਾ ਹੁੰਦਾ ਹੈ ਤਾਂ ਸਟਾਲ ਹੁੰਦਾ ਹੈ।
ਇੱਥੇ ਹਾਰਡਵੇਅਰ–ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਸਾਫ਼ ਤੌਰ 'ਤੇ ਦਿਸਦਾ ਹੈ। ਜੇ ਹਾਰਡਵੇਅਰ ਪੇਸ਼ਗੀਯੋਗ ਹੈ, ਤਾਂ ਕੰਪਾਇਲਰ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ ਨਿਰਦੇਸ਼ਾਂ ਦੇ ਕ੍ਰਮ ਨੂੰ (ਪ੍ਰੋਗਰਾਮ ਦਾ ਅਰਥ ਬਦਲੇ ਬਿਨਾਂ) ਦੁਬਾਰਾ ਸੇਡਿਊਲ ਕਰਕੇ “ਖਾਲੀਆਂ ਥਾਂਵਾਂ” ਭਰ ਦੇਣ ਲਈ। ਉਦਾਹਰਨ ਲਈ, ਜਦੋਂ ਇੱਕ ਮੁੱਲ ਬਣਨ ਦੀ ਉਡੀਕ ਹੈ, ਕੰਪਾਇਲਰ ਕੋਈ ਅਜਿਹੀ ਮੁਕਤ ਹਦਾਇਤ ਤਜਵੀਜ਼ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਉਸ ਮੁੱਲ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਕਰਦੀ।
ਲਾਭ ਇਹ ਹੈ ਕਿ ਦਾਇਤ ਸਾਂਝੀ ਜ਼ਿੰਮੇਵਾਰੀ ਕਰਦੇ ਹਨ: CPU ਆਮ ਕੇਸ ਤੇ ਸਧਾਰਨ ਤੇਜ਼ ਰਹਿੰਦਾ ਹੈ, ਜਦਕਿ ਕੰਪਾਇਲਰ ਵੱਧ ਯੋਜਨਾ ਬਣਾਉਂਦਾ ਹੈ। ਇਕੱਠੇ, ਉਹ ਸਟਾਲ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਥਰੂਪੁਟ ਵਧਾਉਂਦੇ ਹਨ—ਅਕਸਰ ਅਸਲ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਬਿਨਾਂ ਹੋਰ ਜਟਿਲ ਹਾਰਡਵੇਅਰ ਜੋੜਣ ਦੇ ਸੁਧਾਰਨ ਵਾਲਾ ਨਤੀਜਾ ਮਿਲਦਾ ਹੈ।
CPU ਕੁਛ ਚੱਕਰਾਂ ਵਿੱਚ ਸਧਾਰਨ ਆਪਰੇਸ਼ਨਾਂ ਨੂੰ ਚਲਾ ਸਕਦਾ ਹੈ, ਪਰ ਮੈਨ ਮੈਮੋਰੀ (DRAM) ਤੋਂ ਡੇਟਾ ਲੈਣਾ ਸੈਂਕੜੇ ਚੱਕਰ ਲੈ ਸਕਦਾ ਹੈ। ਇਹ ਫਰਕ ਇਸ ਲਈ ਹੈ ਕਿਉਂਕਿ DRAM ਭੌਤਿਕ ਤੌਰ 'ਤੇ ਦੂਰ ਹੈ, ਨਾਮਾਤਰ ਲਾਗਤ-ਕੁਸ਼ਲਤਾ ਲਈ ਅਨੁਕੂਲ ਹੈ, ਅਤੇ ਲੇਟੈਂਸੀ (ਇੱਕ ਬੇਨਤੀ ਦੀ ਲੰਬਾਈ) ਅਤੇ ਬੈਂਡਵਿਡਥ (ਕਿੰਨੀ ਬਾਈਟ ਪ੍ਰਤੀ ਸਕਿੰਟ) ਨਾਲ ਸੀਮਤ ਹੈ।
ਜਦੋਂ CPUs ਤੇਜ਼ ਹੋਏ, ਮੈਮੋਰੀ ਇੱਕੋ ਗਤੀ ਨਾਲ ਨਹੀਂ ਚਲੀ—ਇਹ ਵਧਦਾ ਫਰਕ ਅਕਸਰ memory wall ਕਿਹਾ ਜਾਂਦਾ ਹੈ।
ਕੈਸ਼ ਛੋਟੀ, ਤੇਜ਼ ਮੈਮੋਰੀਆਂ ਹਨ ਜੋ CPU ਦੇ ਕੋਲ ਰੱਖੀਆਂ ਜਾਂਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਹਰ ਐਕਸੈਸ 'ਤੇ DRAM ਜ਼ਿਆਦਾ ਮਹਿੰਗਾ ਸਜ਼ਾ ਨਾ ਭੁਗਤੀਏ। ਇਹ ਕੰਮ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮਾਂ ਵਿੱਚ ਲੋਕੈਲਿਟੀ ਹੁੰਦੀ ਹੈ:
ਆਧੁਨਿਕ ਚਿਪ ਕੈਸ਼ਾਂ (L1, L2, L3) ਨੂੰ ਸਟੈਕ ਕਰਦੇ ਹਨ, ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹੋਏ ਕਿ ਕੋਡ ਅਤੇ ਡੇਟਾ ਦੀ “ਵਰਕਿੰਗ ਸੈਟ” ਕੋਰ ਦੇ ਨੇੜੇ ਰਹਿ ਜਾਵੇ।
ਇੱਥੇ ਹਾਰਡਵੇਅਰ–ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਆਪਣੀ ਅਸਲ ਯੋਗਤਾ ਦਿਖਾਉਂਦਾ ਹੈ। ISA ਅਤੇ ਕੰਪਾਇਲਰ ਮਿਲ ਕੇ ਇਹ ਤੈਅ ਕਰਦੇ ਹਨ ਕਿ ਕਿਸ ਪ੍ਰੋਗਰਾਮ ਨਾਲ ਕਿੰਨਾ ਕੈਸ਼ ਦਬਾਅ ਬਣਦਾ ਹੈ।
ਰੋਜ਼ਾਨਾ ਬੋਲਚਾਲ ਵਿੱਚ, memory wall ਇਸ ਲਈ ਹੈ ਕਿ ਇੱਕ ਤੇਜ਼ ਕਲਾਕ ਸਪੀਡ ਵਾਲਾ CPU ਵੀ ਅਕਸਰ ਸੁਸਤ ਮਹਿਸੂਸ ਕਰ ਸਕਦਾ ਹੈ: ਇੱਕ ਵੱਡਾ ਐਪ ਖੋਲ੍ਹਣਾ, ਡੇਟਾਬੇਸ ਕੁਏਰੀ ਚਲਾਉਣਾ, ਫੀਡ ਸਕ੍ਰੋਲ ਕਰਨਾ, ਜਾਂ ਵੱਡੇ ਡੇਟਾਸੈਟ ਨੂੰ ਪ੍ਰਕਿਰਿਆ ਕਰਨਾ ਅਕਸਰ ਕੈਸ਼ ਮਿਸਜ਼ ਅਤੇ ਮੈਮੋਰੀ ਬੈਂਡਵਿਡਥ 'ਤੇ ਰੁਕਦਾ ਹੈ—ਕੱਚੀ ਗਣਿਤੀ ਦੋੜ ਤੇ ਨਹੀਂ।
ਕਾਫ਼ੀ ਸਮੇਂ ਤੱਕ CPU ਚਰਚਾ ਇੱਕ ਦੌੜ ਵਰਗੀ ਲੱਗਦੀ ਸੀ: ਜਿਸ ਚਿੱਪ ਨੇ ਇੱਕ ਟਾਸਕ ਸਭ ਤੋਂ ਤੇਜ਼ ਕੀਤਾ “ਉਹ ਜਿੱਤ ਗਿਆ।” ਪਰ ਅਸਲ ਕੰਪਿਊਟਰ ਭੌਤਿਕ ਸੀਮਾਵਾਂ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ—ਬੈਟਰੀ ਸਮਰੱਥਾ, ਗਰਮੀ, ਫੈਨ ਸ਼ੋਰ, ਅਤੇ ਬਿਜਲੀ ਦਾ ਬਿੱਲ।
ਇਸ ਲਈ ਪਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਇੱਕ ਮੁੱਖ ਮੈਟ੍ਰਿਕ ਬਣ ਗਿਆ: ਤੁਸੀਂ ਜੋ ਕੰਮ ਕਰ ਰਹੇ ਹੋ ਉਸ ਲਈ ਲਗਣ ਵਾਲੀ ਊਰਜਾ।
ਇਸਨੂੰ ਪ੍ਰਭਾਵਸ਼ੀਲਤਾ ਸਮਝੋ, ਨਾ ਕਿ ਚੋਟੀ ਦੀ ਤਾਕਤ। ਦੋ ਪ੍ਰੋਸੈਸਰ ਹੋ ਸਕਦੇ ਹਨ ਜੋ ਦਿਨਚਰਿਆ ਵਰਤੋਂ ਵਿੱਚ ਮਿਲਦੇ-ਜੁਲਦੇ ਤੇਜ਼ ਮਹਿਸੂਸ ਹੋਣ, ਪਰ ਇਕ ਹੋਰ ਥੋੜ੍ਹੀ ਘੱਟ ਪਾਵਰ ਖਾਂਦਾਂ ਹੋ ਸਕਦਾ ਹੈ, ਠੰਡਾ ਰਹਿੰਦਾ ਹੈ, ਅਤੇ ਇਕੋ ਬੈਟਰੀ 'ਤੇ ਵੱਧ ਚੱਲਦਾ ਹੈ।
ਲੈਪਟਾਪ ਅਤੇ ਫੋਨਾਂ ਵਿੱਚ, ਇਹ ਸਿੱਧਾ ਬੈਟਰੀ ਲਾਈਫ ਅਤੇ ਆਰਾਮ ਤੇ ਅਸਰ ਕਰਦਾ ਹੈ। ਡੇਟਾ-ਸੈਂਟਰਾਂ ਵਿੱਚ, ਇਹ ਹਜ਼ਾਰਾਂ ਮਸ਼ੀਨਾਂ ਨੂੰ ਪਾਵਰ ਅਤੇ ਕੂਲ ਕਰਨ ਦੀ ਲਾਗਤ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਸਰਵਰਾਂ ਨੂੰ ਘਣਤਾਪੂਰਵਕ ਰੱਖ ਸਕਦੇ ਹੋ ਯਾ ਨਹੀਂ।
RISC ਸੋਚ CPU ਡਿਜ਼ਾਈਨ ਨੂੰ ਇਸਤਰਫ਼ ਧੁਕੇ ਕਿ ਹਾਰਡਵੇਅਰ ਵਿੱਚ ਘੱਟ ਚੀਜ਼ਾਂ ਕਰੋ ਅਤੇ ਅਧਿਕ ਪੇਸ਼ਗੀਯੋਗ ਬਣਾਓ। ਸਧਾਰਨ ਕੋਰ ਕੁਝ ਕਾਰਨਾਂ ਕਰਕੇ ਊਰਜਾ ਘੱਟ ਕਰ ਸਕਦਾ ਹੈ:
ਮਕਸਦ ਇਹ ਨਹੀਂ ਕਿ “ਸਧਾਰਨ ਹਮੇਸ਼ਾ ਬਿਹਤਰ” ਹੈ। ਮੰਤਵ ਇਹ ਹੈ ਕਿ ਜਟਿਲਤਾ ਦੀ ਆਪਣੀ ਊਰਜਾ ਲਾਗਤ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਇੱਕ ਚੰਗੀ ISA ਅਤੇ ਮਾਈਕ੍ਰੋਆਰਕੀਟੈਕਚਰ ਸਥਾਪਨਾ ਕੁਝ ਚਤੁਰਾਈ ਦੇ ਬਦਲੇ ਵਿਚ ਡੂੰਘੀ ਕੁਸ਼ਲਤਾ ਦੇ ਸਕਦੀ ਹੈ।
ਫੋਨ ਬੈਟਰੀ ਅਤੇ ਗਰਮੀ ਦੀ ਪਰਵਾ ਕਰਦੇ ਹਨ; ਸਰਵਰ ਪਾਵਰ ਡਿਲਿਵਰੀ ਅਤੇ ਕੂਲਿੰਗ ਦੀ ਪਰਵਾ ਕਰਦੇ ਹਨ। ਵੱਖ-ਵੱਖ ਵਾਤਾਵਰਣ, ਪਰ ਸਬਕ ਇੱਕੋ: ਸਭ ਤੋਂ ਤੇਜ਼ ਚਿਪ ਹਮੇਸ਼ਾ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਪਿਊਟਰ ਨਹੀਂ ਹੁੰਦੀ। ਜਿੱਤਣ ਵਾਲੇ ਉਹ ڈਿਜ਼ਾਈਨ ਹੁੰਦੇ ਹਨ ਜੋ ਠੰਡਾ ਹੋ ਕੇ ਜਾਂ ਬਿਨਾਂ ਵੱਧ ਊਰਜਾ ਖਰਚੇ steady throughput ਦੇ ਸਕਦੇ ਹਨ।
RISC ਨੂੰ ਅਕਸਰ “ਸਧਾਰਨ ਹਦਾਇਤਾਂ ਜਿੱਤਦੀਆਂ ਹਨ” ਵਜੋਂ ਸੰਖੇਪ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਦਰਅਸਲ ਸਬਕ ਧੀਰਜ ਨਾਲ ਹੈ: ISA ਮਹੱਤਵਪੂਰਨ ਹੈ, ਪਰ ਕਈ ਅਸਲ-ਦੁਨੀਆ ਫਾਇਦੇ ਉਸ ਤਰੀਕੇ ਤੋਂ ਆਉਂਦੇ ਹਨ ਕਿ ਚਿਪ ਬਣਾਏ ਗਏ—ਨਾ ਕਿ ਸਿਰਫ਼ ISA ਦੀ ਦਿਖਾਈ ਦਿਓ।
ਪਹਿਲੇ RISC ਦਲੀਲਾਂ ਇਹ ਸੁਝਾਉੰਦੀਆਂ ਸਨ ਕਿ ਇੱਕ ਸਾਫ਼ ਅਤੇ ਛੋਟਾ ISA ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਕੰਪਿਊਟਰ ਨੂੰ ਤੇਜ਼ ਕਰ ਦੇਵੇਗਾ। ਅਮਲੀ ਵਿੱਚ, ਸਭ ਤੋਂ ਵੱਡੇ ਤੇਜ਼ ਹੋਣ ਅਕਸਰ RISC ਨੇ ਜੋ ਆਸਾਨ ਬਣਾਇਆ—ਸਪਲਾਈ ਕੀਤੇ ਡਿਕੋਡਿੰਗ ਦੀ ਸਧਾਰਤਾ, ਡੀਪਰ ਪਾਈਪਲਾਈਨ, ਉੱਚ ਘੰਟਾਕ ਘੰਨਾਂ, ਅਤੇ ਕੰਪਾਇਲਰ ਜੋ ਕੰਮ ਨਿਯਮਤ ਤਰੀਕੇ ਨਾਲ ਸ਼ੈਡਿਊਲ ਕਰ ਸਕਦੇ—ਇਨ੍ਹਾਂ ਤੋਂ ਆਏ।
ਇਸ ਕਰਕੇ ਦੋ CPU ਜਿਨ੍ਹਾਂ ਦੇ ISA ਵੱਖਰੇ ਹਨ ਉਹਨਾਂ ਦੀ ਪ੍ਰਦਰਸ਼ਨ ਅਕਸਰ ਨੇੜੇ-ਨੇੜੇ ਹੋ ਸਕਦੀ ਹੈ ਜੇਕਰ ਉਹਨਾਂ ਦੀ ਮਾਈਕ੍ਰੋਆਰਕੀਟੈਕਚਰ, ਕੈਸ਼ ਸਾਈਜ਼, ਬ੍ਰਾਂਚ ਪ੍ਰਿਡਿਕਸ਼ਨ, ਅਤੇ ਨਿਰਮਾਣ ਪ੍ਰਕਿਰਿਆ ਵੱਖਰੀ ਹੋਵੇ। ISA ਨਿਯਮ ਬਣਾਉਂਦੀ ਹੈ; ਮਾਈਕ੍ਰੋਆਰਕੀਟੈਕਚਰ ਉਸ ਨਿਯਮ 'ਚ ਖੇਡ ਖੇਡਦਾ ਹੈ।
ਪੈਟਰਸਨ-ਕਾਲ ਦੀ ਇੱਕ ਮੁੱਖ ਬਦਲਾਅ ਇਹ ਸੀ ਕਿ ਡਿਜ਼ਾਈਨ ਡੇਟਾ ਤੋਂ ਕੀਤਾ ਜਾਵੇ, ਅਨੁਮਾਨਾਂ ਤੋਂ ਨਹੀਂ। ਨਿਰਦੇਸ਼ ਜੋ "ਲਗਦਾ" ਕਿ ਮਦਦਗਾਰ ਹਨ, ਉਹ ਸ਼ਾਇਦ ਅਸਲ ਕੋਡ ਵਿੱਚ ਘੱਟ ਹੀ ਵਰਤੇ ਜਾਂ। ਇਸ ਲਈ Berkeley RISC ਮਾਪ-ਅਧਾਰਤ ਪਹੁੰਚ ਨੂੰ ਤਰਜੀਹ ਦਿੱਤੀ—ਗਰਮ ਰਾਹਾਂ ਨੂੰ ਪਛਾਣੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਤੇਜ਼ ਕਰੋ।
ਇਹ ਮਨਸੂਬਾ ਅਕਸਰ "ਫੀਚਰ-ਚਲਿਤ" ਡਿਜ਼ਾਈਨ ਤੋਂ ਬਿਹਤਰ ਨਿਕਲਿਆ, ਜਿੱਥੇ ਜਟਿਲਤਾ ਲਾਭ ਤੋਂ ਤੇਜ਼ ਵਧਦੀ। ਇਹ ਟਰੇਡ-ਆਫ ਸਪਸ਼ਟ ਕਰਦਾ ਹੈ: ਇੱਕ ਹਦਾਇਤ ਜੋ ਕੁਝ ਲਾਈਨਾਂ ਕੋਡ ਬਚਾਂਦੀ ਹੈ, ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਵੱਧ ਸਾਈਕਲ, ਊਰਜਾ, ਜਾਂ ਚਿਪ ਥਾਂ ਲੈ ਜਾਵੇ—ਅਤੇ ਉਹ ਲਾਗਤ ਹਰ ਥਾਂ ਤੇ ਦਿਖਾਈ ਦੇਵੇਗੀ।
RISC ਸੋਚ ਨੇ ਸਿਰਫ਼ “RISC ਚਿਪਾਂ” ਨੂੰ ਪੂਰਾ ਤੌਰ 'ਤੇ ਰੂਪ ਨਹੀਂ ਦਿੱਤਾ। ਸਮੇਂ ਦੇ ਨਾਲ, ਕਈ CISC CPUਆਂ ਨੇ RISC-ਸਮਾਨ ਅੰਦਰੂਨੀ ਤਕਨੀਕਾਂ ਅਪਣਾਈਆਂ (ਉਦਾਹਰਣ ਲਈ, ਜਟਿਲ ਹਦਾਇਤਾਂ ਨੂੰ ਅੰਦਰੂਨੀ ਸਧਾਰਨ ਓਪਸ ਵਿੱਚ ਤਬਦੀਲ ਕਰਨਾ) ਪਰ ਉਹਨਾਂ ਦਾ ਪੁਰਾਣਾ ISA ਰੱਖਿਆ।
ਇਸ ਲਈ ਨਤੀਜਾ ਇਹ ਨਹੀਂ ਸੀ ਕਿ “RISC ਨੇ CISC ਨੂੰ ਹਰਾਇਆ।” ਇਹ ਇੱਕ ਵਿਕਾਸ ਸੀ ਜੋ ਮਾਪ, ਪੇਸ਼ਗੀ, ਅਤੇ ਘਣ-ਹਾਰਡਵੇਅਰ-ਸੌਫਟਵੇਅਰ ਕੋਆਰਡੀਨੇਸ਼ਨ ਨੂੰ ਮਹੱਤਵ ਦਿੰਦਾ—ਭਾਵੇਂ ISA 'ਤੇ ਕੌਣ ਸਰਕਾਰੀ ਨਿਸ਼ਾਨ ਹੋਵੇ।
RISC ਲੈਬ ਤੋਂ ਬਾਹਰ ਵੀ ਰਿਹਾ। ਸ਼ੁਰੂਆਤੀ ਖੋਜ ਤੋਂ ਆਧੁਨਿਕ ਅਮਲ ਵਿੱਚ ਇੱਕ ਸਪਸ਼ਟ ਰੇਖਾ MIPS ਤੋਂ RISC-V ਵੱਲ ਦਿਖਦੀ ਹੈ—ਦੋ ISA ਜੋ ਸਧਾਰਤਾ ਅਤੇ ਸਪਸਟਤਾ ਨੂੰ ਇੱਕ ਫੀਚਰ ਵਜੋਂ ਰੱਖਦੀਆਂ ਹਨ।
MIPS ਨੂੰ ਅਕਸਰ ਇੱਕ ਸਿਖਲਾਈ ISA ਵਜੋਂ ਯਾਦ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਵਜ੍ਹਾ ਸਿੱਧਾ ਹੈ: ਨਿਯਮ ਆਸਾਨ ਹਨ, ਨਿਰਦੇਸ਼ ਫਾਰਮੈਟ ਲਗਾਤਾਰ ਹਨ, ਅਤੇ ਬੇਸਿਕ ਲੋਡ/ਸਟੋਰ ਮਾਡਲ ਕੰਪਾਇਲਰ ਦਾ ਰਸਤਾ ਸਾਫ਼ ਰੱਖਦਾ ਹੈ।
ਇਹ ਸਾਫ਼ਾਈ ਸਿਰਫ਼ ਅਕਾਦਮਿਕ ਨਹੀਂ ਰਹੀ। MIPS ਪ੍ਰੋਸੈਸਰ ਸਾਲਾਂ ਤੱਕ ਅਸਲ ਉਤਪਾਦਾਂ ਵਿੱਚ ਚਲੇ (ਵਰਕਸਟੇਸ਼ਨ ਤੋਂ ਏੰਬੇਡਡ ਸਿਸਟਮ), ਹਿੱਸੇ ਵਜੋਂ ਕਿ ਸਪੱਖਾ ISA ਛੇਤੀ ਪਾਈਪਲਾਈਨ, ਪੇਸ਼ਗੀਯੋਗ ਕੰਪਾਇਲਰ ਅਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਟੂਲਚੇਨਾਂ ਬਣਾਉਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ। ਜਦੋਂ ਹਾਰਡਵੇਅਰ ਵਰਤਾਰੂ ਵਰਤਾਰੂ ਹੋਵੇ, ਸਾਫ਼ ਸੋਫਟਵੇਅਰ ਉਸਦੇ ਆਸਪਾਸ ਯੋਜਨਾ ਬਣਾ ਸਕਦਾ ਹੈ।
RISC-V ਨੇ RISC ਸੋਚ ਨੂੰ ਨਵੀਂ ਜਿੰਦ ਦਿੱਤੀ ਇਕ ਮੁੱਖ ਕਦਮ ਨਾਲ ਜੋ MIPS ਨੇ ਨਹੀਂ ਕੀਤਾ: ਇਹ ਇੱਕ ਖੁੱਲ੍ਹਾ ISA ਹੈ। ਇਸ ਨਾਲ ਪ੍ਰੇਰਕ ਤੱਥ ਬਦਲ ਜਾਂਦੇ ਹਨ। ਯੂਨੀਵਰਸਿਟੀਆਂ, ਸਟਾਰਟਅਪ ਅਤੇ ਵੱਡੀਆਂ ਕੰਪਨੀਆਂ ਅਜ਼ਮਾਇਆ, ਚਿਪ ਬਜਾਰ ਕਰ ਸਕਦੀਆਂ ਅਤੇ ਟੂਲਿੰਗ ਸਾਂਝਾ ਕਰ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ ISA 'ਤੇ ਪਹੁੰਚ ਲਈ ਸਮਝੌਤੇ ਕੀਤੇ।
ਕੋ‑ਡਿਜ਼ਾਈਨ ਲਈ ਇਹ ਖੁੱਲ੍ਹਾ ਹੋਣਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ “ਸੌਫਟਵੇਅਰ ਪਾਸਾ” (ਕੰਪਾਇਲਰ, OS, ਰਨਟਾਈਮ) ਪਬਲਿਕ ਤੌਰ 'ਤੇ ਹਾਰਡਵੇਅਰ ਪਾਸੇ ਨਾਲ ਇੱਕੱਠੇ ਵਿਕਸਤ ਹੋ ਸਕਦਾ ਹੈ, ਘੱਟ ਰੋਕ-ਟੋਕ ਨਾਲ।
RISC-V ਇੱਕ ਹੋਰ ਕਾਰਨ ਨਾਲ ਕੋ‑ਡਿਜ਼ਾਈਨ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਜੁੜਦਾ ਹੈ: ਇਸਦਾ ਮਾਡਿਊਲਰ ਤਰੀਕਾ। ਤੁਸੀਂ ਛੋਟੇ ਬੇਸ ISA ਤੋਂ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ, ਫਿਰ ਵੱਖ-ਵੱਖ ਲੋੜਾਂ ਲਈ ਐਕਸਟੇੰਸ਼ਨ ਜੋੜਦੇ ਹੋ—ਜਿਵੇਂ ਵੈਕਟਰ ਗਣਿਤ, ਏੰਬੇਡਡ ਸੀਮਾਵਾਂ, ਜਾਂ ਸੁਰੱਖਿਆ ਫੀਚਰ।
ਇਸ ਨਾਲ ਇੱਕ ਜ਼ਿੰਦਾ ਟਰੇਡ-ਆਫ ਉਤਸ਼ਾਹਿਤ ਹੁੰਦਾ ਹੈ: ਇੱਕ ਵੱਡੇ ਮੋਨੋਲਿਥਿਕ ਡਿਜ਼ਾਈਨ ਵਿੱਚ ਹਰ ਸੰਭਵ ਫੀਚਰ ਨਾ ਭਰੋ, ਬਲਕਿ ਟੀਮਾਂ ਹਾਰਡਵੇਅਰ ਫੀਚਰਾਂ ਨੂੰ ਉਸ ਸੌਫਟਵੇਅਰ ਨਾਲ ਮਿਲਾਉਂਦੀਆਂ ਹਨ ਜੋ ਉਹ ਅਸਲ ਵਿੱਚ ਚਲਾਉਂਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਡੀਪ ਪ੍ਰਾਈਮਰ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ /blog/what-is-risc-v ਵੇਖੋ।
ਕੋ‑ਡਿਜ਼ਾਈਨ RISC ਯੁੱਗ ਦਾ ਇਤਿਹਾਸਕ ਪੈਰੋਕਾਰ ਨਹੀਂ—ਇਹ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਆਧੁਨਿਕ ਕੰਪਿਊਟਿੰਗ ਤੇਜ਼ੀ ਅਤੇ ਕੁਸ਼ਲਤਾ ਹਾਸਲ ਕਰਦੀ ਰਹਿੰਦੀ ਹੈ। ਮੁੱਖ ਵਿਚਾਰ ਅਜੇ ਵੀ ਪੈਟਰਸਨ-ਸਟਾਈਲ ਹੈ: ਤੁਸੀਂ ਸਿਰਫ਼ ਹਾਰਡਵੇਅਰ ਨਾਲ ਨਹੀਂ ਜਿੱਤ ਸਕਦੇ, ਨਾ ਹੀ ਸਿਰਫ਼ ਸੌਫਟਵੇਅਰ ਨਾਲ। ਜਿੱਤ ਉਸ ਵੇਲੇ ਮਿਲਦੀ ਹੈ ਜਦੋਂ ਦੋਨੋਂ ਇਕ ਦੂਜੇ ਦੀਆਂ ਤਾਕਤਾਂ ਅਤੇ ਸੀਮਤੀਆਂ ਨੂੰ ਮੇਲ ਕਰਦੇ ਹਨ।
ਸਮਾਰਟਫੋਨ ਅਤੇ ਬਹੁਤ-ਸਾਰੇ ਐਂਬੇਡਡ ਡਿਵਾਈਸ RISC ਸਿਧਾਂਤਾਂ (ਅਕਸਰ ARM-ਅਧਾਰਿਤ) 'ਤੇ ਭਰੋਸਾ ਕਰਦੇ ਹਨ: ਸਧਾਰਨ ਹਦਾਇਤਾਂ, ਪੇਸ਼ਗੀਯੋਗ ਕਾਰਜ, ਅਤੇ ਊਰਜਾ ਦੀ ਬਚਤ ਤੇ ਜ਼ੋਰ।
ਇਹ ਪੇਸ਼ਗੀ ਕੰਪਾਇਲਰਾਂ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਕੋਡ ਜਨਰੇਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ ਅਤੇ ਡਿਜ਼ਾਈਨਰਾਂ ਨੂੰ ਐਸੇ ਕੋਰ ਬਣਾਉਣ ਦਿੰਦੀ ਹੈ ਜੋ ਸਕ੍ਰੋਲਿੰਗ ਦੌਰਾਨ ਘੱਟ ਪਾਵਰ ਖਾਂਦੇ ਹਨ, ਪਰ מצליח ਤਤਕਾਲੀ ਬਰਸਤ ਵੀ ਕਰ ਸਕਦੇ ਹਨ ਜਿਵੇਂ ਕਿ ਕੈਮਰਾ ਪਾਈਪਲਾਈਨ ਜਾਂ ਗੇਮ।
ਲੈਪਟਾਪ ਅਤੇ ਸਰਵਰ ਵੀ ਵਧ-ਚੜ੍ਹਕੇ ਉਹੇ ਲਕੜੀ ਦੀ ਤਲਾਸ਼ ਕਰ ਰਹੇ ਹਨ—ਖ਼ਾਸ ਕਰਕੇ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਲਈ। ਭਾਵੇਂ ISA ਪ੍ਰਚਲਿਤ ਤੌਰ 'ਤੇ “RISC” ਨਾ ਹੋਵੇ, ਬਹੁਤ ਸਾਰੇ ਅੰਦਰੂਨੀ ਡਿਜ਼ਾਈਨ ਚੋਣਾਂ RISC-ਸਮਾਨ ਕੁਸ਼ਲਤਾ ਨੂੰ ਨਿਸ਼ਾਨਾ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਡੀਪ ਪਾਈਪਲਾਈਨਿੰਗ, ਵਾਈਡ ਐਕਜ਼ੀਕਿਊਸ਼ਨ, ਅਤੇ ਆਗ੍ਰੈਸਿਵ ਪਾਵਰ ਮੈਨੇਜਮੈਂਟ ਜੋ ਅਸਲ ਸੌਫਟਵੇਅਰ ਵਿਹਾਰ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖ ਕੇ ਟਿਊਨ ਹੁੰਦੇ ਹਨ।
GPUs, AI ਐਕਸਿਲਰੇਟਰ (TPUs/NPUs), ਅਤੇ ਮੀਡੀਆ ਏਂਜਿਨ ਇੱਕ ਪ੍ਰਯੋਗਾਤਮਕ ਰੂਪ ਹਨ ਕੋ‑ਡਿਜ਼ਾਈਨ ਦੇ: ਇਸਦੇ ਬਦਲੇ ਕਿ ਸਾਰਾ ਕੰਮ ਜਨਰਲ-ਪਰਪਜ਼ CPU ਰਾਹੀਂ ਹੋਵੇ, ਪਲੇਟਫਾਰਮ ਉਹ ਹਾਰਡਵੇਅਰ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ ਜੋ ਆਮ ਗਣਨਾ ਪੈਟਰਨਾਂ ਨਾਲ ਮਿਲਦਾ ਹੈ।
ਇਹ ਕੋ‑ਡਿਜ਼ਾਈਨ ਕਿਉਂ ਹੈ (ਸਿਰਫ਼ "ਵਾਧੂ ਹਾਰਡਵੇਅਰ" ਨਹੀਂ) ਇਹ ਇਸ ਲਈ ਹੈ ਕਿ ਦੇਸ਼-ਕਰ-ਵਾਰ ਸੌਫਟਵੇਅਰ ਸਟੈਕ ਵੀ ਆਰਥਿਕ ਹੋ:
ਜੇ ਸੌਫਟਵੇਅਰ ਐਕਸਿਲਰੇਟਰ ਨੂੰ ਟਾਰਗਟ ਨਹੀਂ ਕਰਦੀ, ਤਾਂ ਥੀਓਰਟਿਕਲ ਤੇਜ਼ੀ ਹੀ ਥੀਓਰਟੀਕਲ ਰਹਿ ਜਾਂਦੀ ਹੈ।
ਦੋ ਪਲੇਟਫਾਰਮ ਜਿਨ੍ਹਾਂ ਦੇ ਸਮਾਨ ਸਪੈੱਕ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਅਨੁਭਵ ਵੱਖਰਾ ਲੱਗ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ “ਅਸਲ ਉਤਪਾਦ” ਵਿੱਚ ਕੰਪਾਇਲਰ, ਲਾਇਬਰੇਰੀਆਂ ਅਤੇ ਫਰੇਮਵਰਕ ਵੀ ਸ਼ਾਮਲ ਹੁੰਦੇ ਹਨ। ਇੱਕ ਚੰਗੀ-ਅਪਟੀਮਾਈਜ਼ਡ ਮੈਥ ਲਾਇਬਰੇਰੀ (BLAS), ਇੱਕ ਵਧੀਆ JIT, ਜਾਂ ਇੱਕ ਸਮਰੱਥ ਕੰਪਾਇਲਰ ਚਿੱਪ ਬਦਲਣ ਤੋਂ ਬਿਨਾਂ ਵੱਡੇ ਨਤੀਜੇ ਦੇ ਸਕਦੇ ਹਨ।
ਇਸ ਲਈ ਆਧੁਨਿਕ CPU ਡਿਜ਼ਾਈਨ ਅਕਸਰ ਬੈਂਚਮਾਰਕ-ਚਲਿਤ ਹੁੰਦੀ ਹੈ: ਹਾਰਡਵੇਅਰ ਟੀਮਾਂ ਦੇਖਦੀਆਂ ਹਨ ਕਿ ਕੰਪਾਇਲਰ ਅਤੇ ਵਰਕਲੋਡ ਅਸਲ ਵਿੱਚ ਕੀ ਕਰਦੇ ਹਨ, ਫਿਰ ਫੀਚਰ (ਕੈਸ਼, ਬ੍ਰਾਂਚ ਪ੍ਰਿਡਿਕਸ਼ਨ, ਵੈਕਟਰ ਹੁਕਮ, ਪ੍ਰੀਫੈਚਿੰਗ) ਨੂੰ ਐਲੇਨ ਕਰਦੇ ਹਨ ਤਾਂ ਕਿ ਆਮ ਕੇਸ ਤੇਜ਼ ਹੋਵੇ।
ਜਦੋਂ ਤੁਸੀਂ ਕਿਸੇ ਪਲੇਟਫਾਰਮ ਦਾ ਅਕਲ-ਮੁਲਾਂਕਣ ਕਰਦੇ ਹੋ (ਫੋਨ, ਲੈਪਟਾਪ, ਸਰਵਰ, ਜਾਂ ਏੱਮਬੇਡਡ ਬੋਰਡ), ਕੋ‑ਡਿਜ਼ਾਈਨ ਦੇ ਨਿਸ਼ਾਨੇ ਖੋਜੋ:
ਆਧੁਨਿਕ ਕੰਪਿਊਟਿੰਗ ਤਰੱਕੀ ਇੱਕ ਇਕੱਲੇ “ਤੇਜ਼ CPU” ਵਾਰੇ ਘੱਟ ਹੈ ਅਤੇ ਜ਼ਿਆਦਾ ਹੈ ਉਸ ਸਾਰੇ ਹਾਰਡਵੇਅਰ‑ਪਲੱਸ‑ਸੌਫਟਵੇਅਰ ਸਿਸਟਮ ਬਾਰੇ ਜੋ ਮਾਪਿਆ ਗਿਆ ਤੇ ਫਿਰ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ—ਅਸਲ ਵਰਕਲੋਡਾਂ ਦੇ ਆਧਾਰ 'ਤੇ।
RISC ਸੋਚ ਅਤੇ ਪੈਟਰਸਨ ਦਾ ਵਿਸ਼ਾਲ ਸੁਨੇਹਾ ਕੁਝ ਟਿਕਾਊ ਸਿੱਖਿਆਵਾਂ ਵਿੱਚ ਸੰਕੁਚਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ: ਜੋ ਚੀਜ਼ ਤੇਜ਼ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਉਸ ਨੂੰ ਸਧਾਰਨ ਕਰੋ, ਅਸਲ ਵਿੱਚ ਕੀ ਹੁੰਦਾ ਹੈ ਉਨ੍ਹਾਂ ਨੂੰ ਮਾਪੋ, ਅਤੇ ਹਾਰਡਵੇਅਰ ਅਤੇ ਸੌਫਟਵੇਅਰ ਨੂੰ ਇੱਕ ਸਿਸਟਮ ਵਜੋਂ ਦੇਖੋ—ਕਿਉਂਕਿ ਯੂਜ਼ਰ ਪੂਰੇ ਤਜਰਬੇ ਨੂੰ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ, ਅਲੱਗ-ਅਲੱਗ ਹਿੱਸਿਆਂ ਨੂੰ ਨਹੀਂ।
ਪਹਿਲਾਂ, ਸਧਾਰਨਤਾ ਇੱਕ ਰਣਨੀਤੀ ਹੈ, ਸੁੰਦਰਤਾ ਨਹੀਂ। ਇੱਕ ਸਾਫ਼ ISA ਅਤੇ ਪੇਸ਼ਗੀਯੋਗ ਪ੍ਰਦਰਸ਼ਨ ਕੰਪਾਇਲਰਾਂ ਲਈ ਚੰਗਾ ਕੋਡ ਜਨਰੇਟ ਕਰਨਾ ਅਤੇ CPU ਲਈ ਉਸ ਕੋਡ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਚਲਾਉਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਦੂਜਾ, ਮਾਪਣ ਅਨੁਮਾਨ ਨੂੰ ਹਰ ਵਾਰੀ ਹਰਾ ਦਿੰਦਾ ਹੈ। ਪ੍ਰਤੀਨਿਧੀ ਵਰਕਲੋਡਾਂ ਨਾਲ ਬੈਂਚਮਾਰਕ ਕਰੋ, ਪ੍ਰੋਫਾਈਲਿੰਗ ਡੇਟਾ ਇਕੱਠਾ ਕਰੋ, ਅਤੇ ਅਸਲ ਬੋਤਲਨੇਕਸ ਨੂੰ ਡਿਜ਼ਾਈਨ ਫੈਸਲੇਆں ਦੇ ਮਾਰਗਦਰਸ਼ਨ ਲਈ ਵਰਤੋ—ਚਾਹੇ ਤੁਸੀਂ ਕੰਪਾਇਲਰ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਟਿਊਨ ਕਰ ਰਹੇ ਹੋ, CPU SKU ਚੁਣ ਰਹੇ ਹੋ, ਜਾਂ ਇੱਕ ਮੁੱਖ ਹਿੱਸੇ ਦਾ ਨਵਾਂ ਡਿਜ਼ਾਈਨ ਕਰ ਰਹੇ ਹੋ।
ਤੀਸਰਾ, ਕੋ‑ਡਿਜ਼ਾਈਨ ਹੈ ਜਿੱਥੇ ਨਤੀਜੇ ਇਕੱਠੇ ਹੁੰਦੇ ਹਨ। ਪਾਈਪਲਾਈਨ-ਫ੍ਰੈਂਡਲੀ ਕੋਡ, ਕੈਸ਼-ਸੁਚੇਤ ਡੇਟਾ ਸਟਰੱਕਚਰ, ਅਤੇ ਅਸਲ ਪ੍ਰਦਰਸ਼ਨ‑ਪ੍ਰਤੀ‑ਵਾਟ ਲਕੜੀ ਅਕਸਰ ਥਿਊਰਟੀਕਲ ਚੋਟੀ ਦੀ ਦਰ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਅਮਲੀ ਤੇਜ਼ੀ ਦਿੰਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ ਪਲੇਟਫਾਰਮ (x86, ARM, ਜਾਂ RISC-V ਆਧਾਰਤ) ਚੁਣ ਰਹੇ ਹੋ, ਤਾਂ ਇਸਨੂੰ ਆਪਣੇ ਯੂਜ਼ਰਾਂ ਦੇ ਤਰੀਕੇ ਨਾਲ ਮೌಲਾਂਕਣ ਕਰੋ:
ਜੇ ਤੁਹਾਡਾ ਕੰਮ ਇਹ ਮਾਪਣ ਸ਼ਿਪ ਕੀਤੇ ਸੌਫਟਵੇਅਰ ਵਿੱਚ ਬਦਲਣਾ ਹੈ, ਤਾਂ ਬਿਲਡ–ਮਾਪ ਲੂਪ ਨੂੰ ਛੋਟਾ ਕਰਨ ਨਾਲ ਮਦਦ ਮਿਲਦੀ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਟੀਮਾਂ Koder.ai ਵਰਤਦੀਆਂ ਹਨ ਤਾਂ ਜੋ ਚੈਟ-ਚਲਾਈ ਗਈ ਵਰਕਫਲੋ ਦੇ ਰਾਹੀਂ ਵਾਸਤਵਿਕ ਐਪਲਿਕੇਸ਼ਨਾਂ ਦਾ ਪ੍ਰੋਟੋਟਾਈਪ ਤੇ ਤਬਦੀਲੀ ਕਰ ਸਕਣ (web, backend, mobile), ਫਿਰ ਹਰ ਬਦਲਾਅ ਤੋਂ ਬਾਅਦ ਉਹੀ ਅੰਤ-ਤੱਕ ਬੈਂਚਮਾਰਕ ਰੀ-ਰਨ ਕਰਦੇ ਹਨ। ਯੋਜਨਾ ਮੋਡ, ਸнэਪਸ਼ਾਟ ਅਤੇ ਰੋਲਬੈਕ ਵਰਗੀਆਂ ਫੀਚਰਾਂ ਉਹੀ “ਮਾਪੋ, ਫਿਰ ਡਿਜ਼ਾਈਨ ਕਰੋ” ਅਨੁਸ਼ਾਸਨ ਨੂੰ ਅਧੁਨਿਕ ਪ੍ਰੋਡਕਟ ਵਿਕਾਸ 'ਤੇ ਲਗਾਉਂਦੀਆਂ ਹਨ।
ਗਹਿਰਾਈ ਲਈ /blog/performance-per-watt-basics ਵੇਖੋ। ਜੇ ਤੁਸੀਂ ਵਾਤਾਵਰਨਾਂ ਦੀ ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ ਅਤੇ ਲਾਗਤ/ਪ੍ਰਦਰਸ਼ਨ ਟਰੇਡ-ਆਫ ਦਾ ਇੱਕ ਸਾਦਾ ਅੰਦਾਜ਼ਾ ਚਾਹੀਦਾ ਹੈ, ਤਾਂ /pricing ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ।
ਇਹ ਲੰਬੇ ਸਮੇਂ ਵਾਲੀ ਸਿੱਖ: ਸਧਾਰਨਤਾ, ਮਾਪਣ, ਅਤੇ ਕੋ‑ਡਿਜ਼ਾਈਨ ਦੇ ਵਿਚਾਰ ਸਤਤੀ ਫਾਇਦੇ ਦੇ ਰਹਿੰਦੇ ਹਨ, ਭਾਵੇਂ ਨਿਰਮਾਣ MIPS-ਯੁੱਗ ਦੀਆਂ ਪਾਈਪਲਾਈਨਾਂ ਤੋਂ ਆਧੁਨਿਕ ਹਿਟਮੌਰਫਿਕ ਕੋਰਾਂ ਅਤੇ ਨਵੇਂ ISA ਜਿਵੇਂ RISC-V ਤੱਕ ਬਦਲ ਰਹੇ ਹੋਣ।
RISC (Reduced Instruction Set Computing) ਛੋਟੀ, ਸਧਾਰਨ ਤੇ ਨਿਯਮਤ ਹੁੰਦੀਆਂ ਹਦਾਇਤਾਂ 'ਤੇ ਜੋਰ ਦਿੰਦਾ ਹੈ ਜੋ ਪਾਈਪਲਾਈਨ ਕਰਨ ਅਤੇ ਅਪਟੀਮਾਈਜ਼ ਕਰਨ ਵਿੱਚ ਆਸਾਨ ਹਨ। ਮਕਸਦ “ਘੱਟ ਸਮਰੱਥਾ” ਨਹੀਂ, ਬਲਕਿ ਉਹ ਹੈ ਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮ ਜਿਹੜੀਆਂ ਓਪਰੇਸ਼ਨ ਜ਼ਿਆਦਾ ਵਰਤਦੇ ਹਨ (ਲੋਡ/ਸਟੋਰ, ਗਣਿਤ, ਬ੍ਰਾਂਚ) ਉਨਾਂ ਤੇ ਹੋਰ ਪੇਸ਼ਗੀ ਅਤੇ ਕੁਸ਼ਲਤਾ ਨਾਲ ਚਲਾਇਆ ਜਾਵੇ।
CISC ਬਹੁਤ ਸਾਰੇ ਜਟਿਲ, ਵਿਸ਼ੇਸ਼ ਹਦਾਇਤਾਂ ਦੇ ਕੇ ਇੱਕ ਹੀ ਕਦਮ ਵਿੱਚ ਕਈ ਕੰਮ ਕਰਵਾ ਦੇਂਦਾ ਹੈ। RISC ਸਧਾਰਨ ਬਿਲਡਿੰਗ ਬਲਾਕ ਵਰਤਦਾ ਹੈ (ਅਕਸਰ ਲੋਡ/ਸਟੋਰ + ALU ਆਪਰੇਸ਼ਨ) ਅਤੇ ਕੰਪਾਇਲਰ 'ਤੇ ਇਨ੍ਹਾ ਬਲਾਕਾਂ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ালী ਢੰਗ ਨਾਲ ਮਿਲਾਉਣ ਦਾ ਭਾਰ ਰੱਖਦਾ ਹੈ। ਆਧੁਨਿਕ CPUਆਂ ਵਿੱਚ ਇਹ ਲਕੀਰ ਧੁੰਦਲੀ ਹੈ ਕਿਉਂਕਿ ਕਈ CISC ਚਿਪਾਂ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਜਟਿਲ ਹਦਾਇਤਾਂ ਨੂੰ ਸਧਾਰਨ ਅੰਦਰੂਨੀ ਓਪਸ ਵਿੱਚ ਤਬਦੀਲ ਕਰ ਦਿੰਦੇ ਹਨ।
ਸਧਾਰਨ, ਹੋਰ ਇੱਕਸਾਰ ਹਦਾਇਤਾਂ ਬਣਾਉਂਦੀਆਂ ਹਨ ਕਿ ਪਾਈਪਲਾਈਨ (ਹਰ ਸਟੇਜ ਇੱਕੋ ਜਿਹਾ ਕੰਮ) ਨੂੰ ਬਣਾਈ ਰੱਖਣਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ। ਇਸ ਨਾਲ ਆਊਟਪੁੱਟ ਦਰ ਬਹਿਸ਼ਤ ਤੱਕ ਸੁਧਰ ਸਕਦੀ ਹੈ (ਲਗਭਗ ਇੱਕ ਹਦਾਇਤ ਪ੍ਰਤੀ ਸਾਈਕਲ) ਅਤੇ ਵਿਸ਼ੇਸ਼ ਕੇਸਾਂ ਨੂੰ ਸੰਭਾਲਣ 'ਤੇ ਘੱਟ ਸਮਾਂ ਲੱਗਦਾ ਹੈ — ਜੋ ਪ੍ਰਦਰਸ਼ਨ ਅਤੇ ਊਰਜਾ ਦੋਹਾਂ ਲਈ ਫਾਇਦੇਮੰਦ ਹੋ ਸਕਦਾ ਹੈ।
ਇਕ ਪਹੁੰਚਣਯੋਗ ISA ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਮਾਡਲ ਕੰਪਾਇਲਰ ਨੂੰ ਇਹ ਯਕੀਨੀ ਬਣਾਉਣ ਦਿੰਦੇ ਹਨ ਕਿ ਉਹ:
ਇਸ ਨਾਲ ਪਾਈਪਲਾਈਨ ਬਬਲ ਘੱਟ ਹੁੰਦੇ ਹਨ ਅਤੇ ਬੇਕਾਰ ਕੰਮ ਘਟਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਅਸਲ ਪ੍ਰਦਰਸ਼ਨ ਸੁਧਾਰਦਾ ਹੈ ਬਿਨਾਂ ਇੰਝੀਨੀਅਰਿੰਗ ਖਰਚੇ ਨਾਲ ਜਟਿਲ ਹਾਰਡਵੇਅਰ ਜੋੜੇ।
ਹਾਰਡਵੇਅਰ-ਸੌਫਟਵੇਅਰ ਕੋ‑ਡਿਜ਼ਾਈਨ ਇੱਕ ਇਟਰੇਟਿਵ ਲੂਪ ਹੈ ਜਿਥੇ ISA ਚੋਣਾਂ, ਕੰਪਾਇਲਰ ਰਣਨੀਤੀਆਂ ਅਤੇ ਅਸਲ ਵਰਕਲੋਡਾਂ ਦੇ ਮਾਪ-ਨੇਤੀਜੇ ਇੱਕ ਦੂਜੇ ਨੂੰ ਪ੍ਰਭਾਵਤ ਕਰਦੇ ਹਨ। CPU ਨੂੰ ਅਲੱਗ ਢੰਗ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕਰਨ ਦੀ ਬਜਾਏ, ਟੀਮਾਂ ਹਾਰਡਵੇਅਰ, ਟੂਲਚੇਨ ਅਤੇ ਕਈ ਵਾਰ OS/runtime ਨੂੰ ਇਕੱਠੇ ਟਿਊਨ ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮ ਤੇਜ਼ ਅਤੇ ਕੁਸ਼ਲ ਚੱਲਣ।
ਪਾਈਪਲਾਈਨ ਉਹਨਾਂ ਸਥਿਤੀਆਂ 'ਤੇ ਰੁਕਦਾ ਹੈ ਜਦੋਂ ਅੱਗੇ ਵਾਲੀ ਸਟੇਜ ਨੂੰ ਕਿਸੇ ਚੀਜ਼ ਦੀ ਉਡੀਕ ਹੋਵੇ:
RISC-ਸ਼ੈਲੀ ਦੀ ਪੇਸ਼ਗੀ ਹਾਰਡਵੇਅਰ ਅਤੇ ਕੰਪਾਇਲਰ ਦੋਹਾਂ ਨੂੰ ਇਨ੍ਹਾਂ ਰੁਕਾਵਟਾਂ ਦੀ ਆਵ੍ਰਿਤੀ ਅਤੇ ਲਾਗਤ ਘਟਾਉਣ ਵਿਚ ਮਦਦ ਕਰਦੀ ਹੈ।
“ਮੇਮੋਰੀ ਵਾਲ” ਤੇਜ਼ CPU ਅਤੇ ਢੀਲਾ ਮੈਨ-ਮੈਮੋਰੀ (DRAM) ਪਹੁੰਚ ਦਰਮਿਆਨ ਵਧ ਰਹੀ ਖਾਈ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਕੈਸ਼ (L1/L2/L3) ਇਸਨੂੰ ਘਟਾਉਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਅਸਲ ਪ੍ਰੋਗਰਾਮਾਂ ਵਿੱਚ ਟੈਮਪੋਰਲ ਅਤੇ ਸਪੈਸ਼ਲ ਲੋਕੈਲਿਟੀ ਹੁੰਦੀ ਹੈ। ਫਿਰ ਵੀ ਕੈਸ਼ ਮਿਸਜ਼ ਅਕਸਰ ਰਨਟਾਈਮ ਨੂੰ ਡੋਮੀਨੇਟ ਕਰ ਸਕਦੀਆਂ ਹਨ—ਇਸ ਲਈ ਅਕਸਰ ਪ੍ਰੋਗਰਾਮ ਬਹੁਤ ਤੇਜ਼ ਕੋਰ ਵੀ ਹੋਣ 'ਤੇ ਮੈਮੋਰੀ-ਬਾਊਂਡ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ।
ਇਹ ਇੱਕ ਕੁਸ਼ਲਤਾ ਮੈਟ੍ਰਿਕ ਹੈ: ਤੁਹਾਨੂੰ ਇੱਕ ਇਕਾਈ ਉਰਜਾ 'ਤੇ ਕਿੰਨਾ ਲਾਭਦਾਇਕ ਕੰਮ ਮਿਲਦਾ ਹੈ। ਅਮਲੀ ਜੀਵਨ ਵਿੱਚ ਇਹ ਬੈਟਰੀ ਲਾਈਫ, ਗਰਮੀ, ਫੈਨ ਸ਼ੋਰ, ਅਤੇ ਡੇਟਾ-ਸੈਂਟਰ ਦੇ ਪਾਵਰ/ਕੂਲਿੰਗ ਖਰਚੇ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ।RISC-ਵਿੱਚਾਰਧਾਰਾ ਵਾਲੀਆਂ ਡਿਜ਼ਾਈਨ ਅਕਸਰ ਹੋਰ ਬੇਕਾਰ ਬਿਟ-ਟੋਗਲਿੰਗ ਘਟਾਉਂਦੀਆਂ ਹਨ ਅਤੇ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਪ੍ਰਭਾਵ ਦੇ ਕੇ ਪ੍ਰਦਰਸ਼ਨ ਪ੍ਰਤੀ ਵਾਟ ਸੁਧਾਰ ਸਕਦੀਆਂ ਹਨ।
ਕਈ CISC ਡਿਜ਼ਾਈਨਾਂ ਨੇ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ RISC-ਸਮਾਨ ਤਕਨੀਕਾਂ (ਪਾਈਪਲਾਈਨਿੰਗ, ਅੰਦਰੂਨੀ ਮਾਈਕਰੋ-ਓਪਸ ਵਗੈਰਾ) ਅਪਣਾਈਆਂ ਪਰ ਆਪਣਾ ਥੱਲਾ ISA ਰੱਖਿਆ। ਲੰਬੇ ਸਮੇਂ ਦੀ ਜਿੱਤ ਕਿਸੇ ਇਕ ਧਾਰਨਾ ਦੀ ਨਹੀਂ ਸੀ—ਬਲਕਿ ਮਾਪ-ਏਂਧਣ, ਪੇਸ਼ਗੀ ਅਤੇ ਹਾਰਡਵੇਅਰ-ਸੌਫਟਵੇਅਰ ਸੰਗਠਨ ਦੀ ਸੋਚ ਨੇ ਅਹਿਮ ਭੂਮਿਕਾ ਨਿਭਾਈ।
RISC-V ਇੱਕ ਖੁੱਲ੍ਹਾ ISA ਹੈ ਜਿਸਦਾ ਛੋਟਾ ਬੇਸ ਅਤੇ ਮਾਡਿਊਲਰ ਐਕਸਟੇੰਸ਼ਨ ਕੋ‑ਡਿਜ਼ਾਈਨ ਲਈ ਅਨੁਕੂਲ ਬਣਾਉਂਦੇ ਹਨ: ਯੂਨੀਵਰਸਿਟੀਆਂ, ਸਟਾਰਟਅਪ ਅਤੇ ਕੰਪਨੀਆਂ ਬਿਨਾਂ ਰੋਕ-ਟੋਕ ਦੇ ਅਜ਼ਮਾਇਸ਼ ਅਤੇ ਸਾਂਝਾ ਕਰਨ ਦੇ ਯੋਗ ਹੋਦੀਆਂ ਹਨ।ਇਹ ਪਹੁੰਚ “ਸਧਾਰਨ ਕੋਰ + ਮਜ਼ਬੂਤ ਟੂਲ + ਮਾਪ” ਵਾਲੀ ਸੋਚ ਨੂੰ ਅੱਗੇ ਲੈ ਜਾਂਦੀ ਹੈ।
ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਵਧ ਰਹੀ ਪ੍ਰਥਾ ਹੈ: ਅਕਸਰ ਐਕਸਿਲਰੇਟਰ (GPU, TPU/NPUs, ਮੀਡੀਆ ਏਂਜਿਨ) ਇੱਕ ਖਾਸ ਕਿਸਮ ਦੇ ਕੰਪਿਊਟੇਸ਼ਨ ਲਈ ਹਾਰਡਵੇਅਰ ਮੁਹੱਈਆ ਕਰਵਾਉਂਦੇ ਹਨ।ਪਰ ਇਹ ਸਿਰਫ ਹਾਰਡਵੇਅਰ ਨਹੀਂ — ਉਹਨਾਂ ਨਾਲ ਜੁੜੀ ਸੌਫਟਵੇਅਰ ਸਟੈਕ (ਕੰਪਾਇਲਰ, ਰਨਟਾਈਮ, APIs) ਵੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਕਿ ਅਸਲ ਵਿਚ ਤੇਜ਼ੀ ਮਿਲੇ।