21 ਸਤੰ 2025·8 ਮਿੰਟ
ਘੱਟ ਲੈਟੈਂਸੀ ਲਈ Disruptor ਪੈਟਰਨ: ਪੇਸ਼ਗੋਈਯੋਗ ਰੀਅਲ-ਟਾਈਮ ਡਿਜ਼ਾਇਨ
ਘੱਟ ਲੈਟੈਂਸੀ ਲਈ Disruptor ਪੈਟਰਨ ਸਿੱਖੋ ਤੇ ਜਾਣੋ ਕਿ ਕਿਵੇਂ ਕਿਊਂ, ਯਾਦਦਾਸ਼ਤ ਅਤੇ ਆਰਕੀਟੈਕਚਰ ਚੋਣਾਂ ਨਾਲ ਰੀਅਲ-ਟਾਈਮ ਸਿਸਟਮ ਪੇਸ਼ਗੋਈਯੋਗ ਰਿਸਪਾਂਸ ਟਾਈਮ ਤੇ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਘੱਟ ਲੈਟੈਂਸੀ ਲਈ Disruptor ਪੈਟਰਨ ਸਿੱਖੋ ਤੇ ਜਾਣੋ ਕਿ ਕਿਵੇਂ ਕਿਊਂ, ਯਾਦਦਾਸ਼ਤ ਅਤੇ ਆਰਕੀਟੈਕਚਰ ਚੋਣਾਂ ਨਾਲ ਰੀਅਲ-ਟਾਈਮ ਸਿਸਟਮ ਪੇਸ਼ਗੋਈਯੋਗ ਰਿਸਪਾਂਸ ਟਾਈਮ ਤੇ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਤੁਰੰਤਤਾ ਦੇ ਦੋ ਪਹਿਲੂ ਹੁੰਦੇ ਹਨ: throughput ਅਤੇ latency। throughput ਦੱਸਦਾ ਹੈ ਤੁਸੀਂ ਇਕ ਸਕਿੰਟ ਵਿੱਚ ਕਿੰਨਾ ਕੰਮ ਮੁੱਕਦੇ ਹੋ। latency ਦੱਸਦੀ ਹੈ ਇੱਕ ਨਿਰਧਾਰਤ ਇਕਾਈ ਕੰਮ ਸ਼ੁਰੂ ਤੋਂ ਲੈ ਕੇ ਖਤਮ ਹੋਣ ਤੱਕ ਕਿੰਨਾ ਸਮਾਂ ਲੈਂਦੀ ਹੈ।
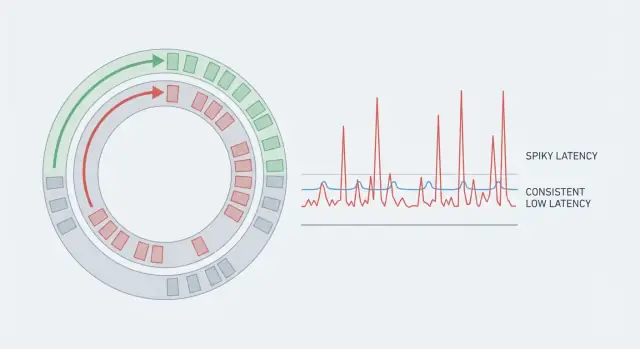
ਇੱਕ ਸਿਸਟਮ ਦੀ throughput ਵਧੀਆ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਫਿਰ ਵੀ ਇਹ ਧੀਮਾ ਮਹਿਸੂਸ ਹੋਵੇ ਜੇ ਕੁਝ ਰਿਕਵੇਸਟਾਂ ਹੋਰਾਂ ਨਾਲੋਂ ਬਹੁਤ ਜ਼ਿਆਦਾ ਸਮਾਂ ਲੈਂਦੀਆਂ ਹਨ। ਇਸ ਲਈ ਔਸਤ ਲੋਕ-ਮਿਥਕਦੀ ਗଲਤ ਹੈ। ਜੇ 99 ਕਾਰਵਾਈਆਂ 5 ms ਲੈਂਦੀਆਂ ਹਨ ਪਰ ਇਕ ਕਾਰਵਾਈ 80 ms ਲੈਂਦੀ ਹੈ, ਤਾਂ ਔਸਤ ਠੀਕ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ ਪਰ ਜਿਸ ਯੂਜ਼ਰ ਨੂੰ 80 ms ਮਿਲਿਆ ਉਹ ਅਨੁਭਵ ਦੂਰ-ਦੂਰ ਮਹਿਸੂਸ ਕਰੇਗਾ। ਰੀਅਲ-ਟਾਈਮ ਸਿਸਟਮਾਂ ਵਿੱਚ ਇਹ ਰੇਅਰ ਸਪਾਇਕਸ ਮੁੱਖ ਗੱਲ ਹਨ ਕਿਉਂਕਿ ਉਹ ਰਿਦਮ ਨੂੰ ਤੋੜਦੇ ਹਨ।
ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਤੁਸੀਂ ਸਿਰਫ਼ ਘੱਟ ਔਸਤ ਚਾਹੁੰਦੇ ਹੋ। ਤੁਸੀਂ ਲਗਾਤਾਰਤਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਕਿ ਜ਼ਿਆਦਾਤਰ ਓਪਰੇਸ਼ਨਾਂ ਇੱਕ ਤੰਗ ਪਹਿਰੇ ਵਿੱਚ ਖਤਮ ਹੋ ਜਾਣ। ਇਸ ਲਈ ਟੀਮਾਂ "ਟੇਲ" (p95, p99) ਨੂੰ ਵੇਖਦੀਆਂ ਹਨ — ਓਥੇ ਹੀ ਰੁਕਾਵਟਾਂ ਛੁਪਦੀਆਂ ਹਨ।
50 ms ਦੀ ਇੱਕ ਛੋਟੀ ਚਾਲ ਜੀਵਨ-ਜੱਚਿਆਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਮਹੱਤਵਪੂਰਨ ਹੋ ਸਕਦੀ ਹੈ: ਆਡੀਓ/ਵੀਡੀਓ (ਆਡੀਓ ਗਲਿੱਟਚ), ਮਲਟੀਪਲੇਅਰ ਗੇਮ (ਰਬਰ-ਬੈਂਡਿੰਗ), ਰੀਅਲ-ਟਾਈਮ ਟਰੇਡਿੰਗ (ਕੰਮ ਛੱਡਣਾ), ਉਦਯੋਗਿਕ ਮੋਨੀਟਰਿੰਗ (ਦਿਰੀ ਲਾਗ), ਜਾਂ ਲਾਈਵ ਡੈਸ਼ਬੋਰਡ (ਨੰਬਰ ਛੇਕ-ਝਪਟ ਦੇਖਾਈ ਦੇਣ)।
ਸਾਦਾ ਉਦਾਹਰਨ: ਇੱਕ ਚੈਟ ਐਪ ਜ਼ਿਆਦਾਤਰ ਸਮੇਂ پیام ਤੁਰੰਤ ਦਿੰਦਾ ਹੈ। ਪਰ ਜੇ ਬੈਕਗ੍ਰਾਊਂਡ ਪੌਜ਼ ਇਕ ਸੁਨੇਹੇ ਨੂੰ 60 ms ਦੇਰੀ ਨਾਲ ਪਹੁੰਚਾਉਂਦੀ ਹੈ, ਤਾਂ ਟਾਈਪਿੰਗ ਇੰਡਿਕੇਟਰ ਝਲਕਦੇ ਹਨ ਅਤੇ ਗੱਲਬਾਤ ਧੀਮੀ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ ਭਾਵੇਂ ਸਰਵਰ ਔਸਤ ਦੇ ਰੂਪ ਵਿੱਚ "ਤੇਜ਼" ਲੱਗੇ।
ਜੇ ਤੁਸੀਂ ਰੀਅਲ-ਟਾਈਮ ਨੂੰ ਵਾਸਤਵਿਕ ਮਹਿਸੂਸ ਕਰਵਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਤੁਹਾਨੂੰ ਘੱਟ ਝਟਕੇ ਚਾਹੀਦੇ ਹਨ, ਸਿਰਫ਼ ਤੇਜ਼ ਕੋਡ ਨਹੀਂ।
ਜ਼ਿਆਦਾਤਰ ਰੀਅਲ-ਟਾਈਮ ਸਿਸਟਮ ਇਸ ਲਈ ਧੀਮੇ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ ਕਿਉਂਕਿ ਕੰਮ ਆਪਣੀ ਜ਼ਿਆਦਾਤਰ ਜ਼ਿੰਦਗੀ ਇੰਤਜ਼ਾਰ ਵਿੱਚ ਬਿਤਾਉਂਦਾ ਹੈ: ਸ਼ਡਿਊਲ ਹੋਣ ਦੀ ਉਡੀਕ, ਕਿਊ ਵਿੱਚ ਬੈਠਣਾ, ਨੈੱਟਵਰਕ ਦੀ ਉਡੀਕ, ਜਾਂ ਸਟੋਰੇਜ ਦੀ ਉਡੀਕ।
ਐਂਡ-ਟੂ-ਐਂਡ ਲੈਟੈਂਸੀ ਉਹ ਪੂਰਾ ਸਮਾਂ ਹੈ ਜੋ "ਕੁਝ ਘਟਿਆ" ਤੋਂ ਲੈ ਕੇ "ਯੂਜ਼ਰ ਨਤੀਜਾ ਵੇਖਦਾ ਹੈ" ਤੱਕ ਲੱਗਦਾ ਹੈ। ਭਾਵੇਂ ਤੁਹਾਡਾ ਹੈਂਡਲਰ 2 ms ਚਲੇ, ਰਿਕਵੇਸਟ ਫਿਰ ਵੀ 80 ms ਲੈ ਸਕਦੀ ਹੈ ਜੇ ਇਹ ਪੰਜ ਵੱਖ-ਵੱਖ ਜਗ੍ਹਾਂ 'ਤੇ ਰੁਕਦਾ ਹੈ।
ਇੱਕ ਲਾਭਦਾਇਕ ਤਰੀਕਾ ਰਸਤੇ ਨੂੰ ਟੁੱਟਣਾ ਹੈ:
ਇਹ ਉਡੀਕਾਂ ਇਕੱਠੀਆਂ ਹੋ ਜਾਂਦੀਆਂ ਹਨ। ਇੱਥੇ-ਓਥੇ ਕੁਝ ਮਿਲੀਸੈਕਿੰਡ ਵੀ ਇਕ "ਤੇਜ਼" ਕੋਡ ਪਾਥ ਨੂੰ ਧੀਮਾ ਅਨੁਭਵ ਬਣਾਉਂਦਾ ਹੈ।
ਟੇਲ ਲੈਟੈਂਸੀ ਉੱਥੇ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਸ਼ਿਕਾਇਤ ਕਰਦੇ ਹਨ। ਔਸਤ ਲੈਟੈਂਸੀ ਠੀਕ ਦਿਖ ਸਕਦੀ ਹੈ, ਪਰ p95 ਜਾਂ p99 ਦਾ ਮਤਲਬ ਹੈ ਸਭ ਤੋਂ ਲਈ 5% ਜਾਂ 1% ਰਿਕਵੇਸਟ। ਆਊਟਲਾਇਰ ਆਮ ਤੌਰ 'ਤੇ ਰੇਅਰ ਪੌਜ਼ਾਂ ਤੋਂ ਆਉਂਦੇ ਹਨ: GC ਸਾਈਕਲ, ਹੋਸਟ 'ਤੇ noisy neighbor, ਸੰਕੁਚਿਤ ਲਾਕ ਕੁੰਟੇਨਸ਼ਨ, ਕੈਸ਼ ਰੀਫ਼ਿਲ, ਜਾਂ ਬਰਸਟ ਜੋ ਇੱਕ ਕਿਊ ਬਣਾਉਂਦਾ ਹੈ।
ਠੋਸ ਉਦਾਹਰਨ: ਇੱਕ ਪ੍ਰਾਈਸ ਅਪਡੇਟ ਨੈੱਟਵਰਕ ਰਾਹੀਂ 5 ms ਵਿੱਚ ਆ ਸਕਦਾ ਹੈ, 10 ms ਇੱਕ ਬਿਜੀ ਵਰਕਰ ਲਈ ਉਡੀਕ ਕਰਦਾ ਹੈ, 15 ms ਹੋਰ ਇਵੈਂਟਾਂ ਦੇ ਪਿੱਛੇ ਬੈਠਦਾ ਹੈ, ਫਿਰ ਡੇਟਾਬੇਸ ਰੁਕਾਵਟ ਲਈ 30 ms ਲੈਂਦਾ ਹੈ। ਤੁਹਾਡਾ ਕੋਡ ਫਿਰ ਵੀ 2 ms ਚੱਲਿਆ, ਪਰ ਯੂਜ਼ਰ ਨੇ 62 ms ਉਡੀਕ ਕੀਤੀ। ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਹਰ ਕਦਮ ਪੇਸ਼ਗੋਈਯੋਗ ਬਣਾਓ, ਨਾਂ ਕਿ ਸਿਰਫ਼ ਗਣਨਾ ਤੇਜ਼ ਕਰੋ।
ਇੱਕ ਤੇਜ਼ ਅਲਗੋਰਿਥਮ ਫਿਰ ਵੀ ਧੀਮਾ ਮਹਿਸੂਸ ਕਰ ਸਕਦਾ ਹੈ ਜੇ ਹਰ ਰਿਕਵੇਸਟ ਦਾ ਸਮਾਂ ਘੁੰਮਦਾ-ਫਿਰਦਾ ਹੋਵੇ। ਯੂਜ਼ਰ ਸਪਾਇਕਸ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹਨ, ਨਾਂ ਕਿ ਔਸਤ। ਇਹ ਘੁੰਮਾਅ ਜਿਟਰ ਹੈ, ਅਤੇ ਅਕਸਰ ਉਹ ਚੀਜ਼ਾਂ ਜੋ ਤੁਹਾਡੇ ਕੋਡ ਦੇ ਵਲੋਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਕਾਬੂ 'ਚ ਨਹੀਂ ਹਨ ਉਹਨਾਂ ਤੋਂ ਆਉਂਦੀ ਹੈ।
CPU ਕੈਸ਼ ਅਤੇ ਮੈਮੋਰੀ ਵਿਵਹਾਰ ਛੁਪੇ ਹੋਏ ਖਰਚ ਹਨ। ਜੇ ਹਾਟ ਡੇਟਾ ਕੈਸ਼ ਵਿੱਚ ਫਿੱਟ ਨਹੀਂ ਹੁੰਦਾ, ਤਾਂ CPU RAM ਲਈ ਰੁਕਦਾ ਹੈ। ਆਬਜੈਕਟ-ਭਰੀ ਬਣਤਰਾਂ, ਫੈਲੀ ਯਾਦ, ਅਤੇ "ਇੱਕ ਹੋਰ ਲੁੱਕਅਪ" ਕਈ ਵਾਰੀ ਕਈ ਕੈਸ਼ ਮਿਸਾਂ ਬਣ ਜਾਂਦੇ ਹਨ।
ਮੈਮੋਰੀ ਐਲੋਕੇਸ਼ਨ ਆਪਣਾ ਅਲੱਗ ਬੇਲੇਂਸ ਬਣਾਉਂਦੀ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਛੋਟੀਆਂ ਅਸਥਾਈ ਵਸਤੂਆਂ ਬਣਾਉਣ ਨਾਲ heap 'ਤੇ ਦਬਾਅ ਵਧਦਾ ਹੈ, ਜੋ ਬਾਅਦ ਵਿੱਚ ਰੁਕਾਵਟਾਂ (GC) ਜਾਂ ਐਲੋਕੇਟਰ ਕੰਟੇਨਸ਼ਨ ਵਜੋਂ ਨਜ਼ਰ ਆਉਂਦੀਆਂ ਹਨ। GC ਨਾ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਅਕਸਰ ਐਲੋਕੇਸ਼ਨ ਯਾਦ ਨੂੰ ਖੰਡਿਤ ਕਰ ਸਕਦੀ ਹੈ ਅਤੇ ਲੋਕੈਲਟੀ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੀ ਹੈ।
ਥ੍ਰੈਡ ਸ਼ਡਿਊਲਿੰਗ ਇੱਕ ਹੋਰ ਆਮ ਸਰੋਤ ਹੈ। ਜਦੋਂ ਇੱਕ ਥ੍ਰੈਡ ਦੇਸਡਿਊਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਤੁਸੀਂ ਕਾਂਟੈਕਸਟ ਸਵਿੱਚ ਓਵਰਹੈੱਡ ਭੁਗਤਦੇ ਹੋ ਅਤੇ ਕੈਸ਼ ਵਾਰਮਥ ਘਟਾਉਂਦੇ ਹੋ। ਇੱਕ ਬਿਜੀ ਮਸ਼ੀਨ 'ਤੇ, ਤੁਹਾਡਾ "ਰੀਅਲ-ਟਾਈਮ" ਥ੍ਰੈਡ ਬਿਨਾਂ ਸੰਬੰਧਿਤ ਕੰਮ ਦੇ ਪਿੱਛੇ ਰੁਕ ਸਕਦਾ ਹੈ।
ਲਾਕ ਕੰਟੇਨਸ਼ਨ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਪੇਸ਼ਗੋਈਯੋਗ ਸਿਸਟਮ ਅਕਸਰ ਟੁੱਟਦੇ ਹਨ। ਇੱਕ ਲਾਕ ਜੋ "ਅਮੂਮਨ ਖਾਲੀ" ਹੁੰਦਾ ਹੈ ਉਹ ਇੱਕ ਕਨਵੋਏ ਵਿੱਚ ਬਦਲ ਸਕਦਾ ਹੈ: ਥ੍ਰੈਡ ਜਾਗਦੇ ਹਨ, ਲਾਕ ਲਈ ਲੜਦੇ ਹਨ, ਅਤੇ ਮੁੜ ਸੌਂ ਜਾਂਦੇ ਹਨ। ਕੰਮ ਫਿਰ ਵੀ ਹੋ ਜਾਂਦਾ ਹੈ, ਪਰ টੇਲ ਲੈਟੈਂਸੀ ਖਿੱਚ ਜਾਂਦੀ ਹੈ।
I/O ਉਡੀਕ ਸਭ ਕੁਝ ਛੱਡ ਦੇਂਦੀ ਹੈ। ਇੱਕ ਸਿੰਗਲ syscall, ਇੱਕ ਪੂਰਾ ਨੈੱਟਵਰਕ ਬਫਰ, TLS ਹੈਂਡਸ਼ੇਕ, ਡਿਸਕ ਫਲਸ਼, ਜਾਂ ਹੌਲੀ DNS ਲੁੱਕਅਪ ਇਕ ਤੀਬਰ ਸਪਾਇਕ ਬਣਾਉ ਸਕਦੇ ਹਨ ਜੋ ਕਿਸੇ ਵੀ ਮਿਆਰ-ਸਿਟੀ ਮਾਈਕੋ-ਓਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਨਾਲ ਠੀਕ ਨਹੀਂ ਹੁੰਦੇ।
ਜੇ ਤੁਸੀਂ ਜਿਟਰ ਦਾ ਸ਼ਿਕਾਰ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਕੈਸ਼-ਮਿਸ (ਅਕਸਰ ਪੁਆਇੰਟਰ-ਭਰੀ ਬਣਤਰਾਂ ਅਤੇ ਰੈਂਡਮ ਐਕਸੈਸ ਨਾਲ ਹੋਣ), ਬਾਰੰਬਾਰ ਐਲੋਕੇਸ਼ਨ, ਬਹੁਤ ਸਾਰੇ ਥ੍ਰੈਡਾਂ ਜਾਂ noisy neighbors ਕਾਰਨ context switches, ਲਾਕ ਕੰਟੇਨਸ਼ਨ, ਅਤੇ ਕਿਸੇ ਵੀ ਬਲਾਕਿੰਗ I/O (ਨੈੱਟਵਰਕ, ਡਿਸਕ, ਲੌਗਿੰਗ, ਸਿੰਕ੍ਰੋਨਸ ਕਾਲਾਂ) ਦੀ ਜਾਂਚ ਕਰੋ।
ਉਦਾਹਰਨ: ਇੱਕ ਪ੍ਰਾਈਸ-ਟਿਕਰ ਸਰਵਿਸ ਮਾਈਕ੍ਰੋਸੈਕਿੰਡ ਵਿੱਚ ਅਪਡੇਟਾਂ ਗਣਨਾ ਕਰ ਸਕਦੀ ਹੈ, ਪਰ ਇੱਕ synchronized ਲੌਗਰ ਕਾਲ ਜਾਂ ਇੱਕ ਕਾਂਟੇਨਸ਼ਡ ਮੈਟ੍ਰਿਕਸ ਲਾਕ ਕਈ ਵਾਰ ਦਸਾਂ ਮਿਲੀਸੈਕਿੰਡ ਜੋੜ ਸਕਦਾ ਹੈ।
Martin Thompson ਨੀਚਲੇ-ਲੈਟੈਂਸੀ ਇੰਜੀਨੀਅਰਿੰਗ ਵਿੱਚ ਇਸ ਗੱਲ ਲਈ ਜਾਣੇ ਜਾਂਦੇ ਹਨ ਕਿ ਉਹ ਦਿਖਾਉਂਦੇ ਹਨ ਕਿ ਸਿਸਟਮ ਦਬਾਅ ਹੇਠਾਂ ਕਿਵੇਂ ਵਰਤਦੇ ਹਨ: ਸਿਰਫ਼ ਔਸਤ ਨਹੀਂ, ਬਲਕਿ ਪੇਸ਼ਗੋਈਯੋਗ ਤੇਜ਼ੀ। LMAX ਟੀਮ ਦੇ ਨਾਲ, ਉਹ Disruptor ਪੈਟਰਨ ਨੂੰ ਲੋਕਪ੍ਰਿਯ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕੀਤੀ — ਇੱਕ ਸੰਦਰਭੀ ਢੰਗ ਜਿਸ ਨਾਲ ਇਵੈਂਟਾਂ ਨੂੰ ਸਿਸਟਮ ਰਾਹੀਂ ਛੋਟੀ ਤੇ ਸਥਿਰ ਦੇਰੀਆਂ ਨਾਲ ਲਿਜਾਇਆ ਜਾਂਦਾ ਹੈ।
Disruptor ਅਪ੍ਰੋਚ ਦਾ ਜਵਾਬ ਉਹਨਾਂ ਚੀਜ਼ਾਂ ਲਈ ਹੈ ਜੋ ਕਈ "ਤੇਜ਼" ਐਪਾਂ ਨੂੰ ਅਣਪੇਖਤ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਕੰਟੇਨਸ਼ਨ ਅਤੇ ਕੋਆਰਡੀਨੇਸ਼ਨ। ਆਮ ਕਿਊਜ਼ ਅਕਸਰ ਲਾਕ ਜਾਂ ਭਾਰੀ ਐਟਾਮਿਕਸ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀਆਂ ਹਨ, ਥ੍ਰੈਡਾਂ ਨੂੰ ਉਠਾਉਂਦੀਆਂ ਅਤੇ ਸੁਲਾਉਂਦੀਆਂ ਹਨ, ਅਤੇ ਪ੍ਰੋਡੀੂਸਰ-ਕੰਜ਼ਿਊਮਰ ਦੇ ਵਿਚਕਾਰ ਲੜਾਈ ਬਣਾਉਂਦੀਆਂ ਹਨ।
ਕਿਊ ਦੀ ਥਾਂ, Disruptor ਰਿੰਗ ਬਫਰ ਵਰਤਦਾ ਹੈ: ਇੱਕ ਨਿਸ਼ਚਿਤ-ਆਕਾਰ ਦਾ ਸਰਕੁਲਰ ਐਰੇ ਜੋ ਸਲਾਟਾਂ ਵਿੱਚ ਇਵੈਂਟ ਰੱਖਦਾ ਹੈ। ਪ੍ਰੋਡੀੂਸਰ ਅਗਲਾ ਸਲਾਟ ਕਲੇਮ ਕਰਦਾ ਹੈ, ਡੇਟਾ ਲਿਖਦਾ ਹੈ, ਫਿਰ ਇੱਕ ਸੀਕੁਐਂਸ ਨੰਬਰ ਪਬਲਿਸ਼ ਕਰਦਾ ਹੈ। ਕੰਜ਼ਿਊਮਰ ਉਸ ਸੀਕੁਐਂਸ ਦਾ ਅਨੁਸਰਣ ਕਰਕੇ ਕ੍ਰਮ ਵਿੱਚ ਪੜ੍ਹਦੇ ਹਨ। ਕਿਉਂਕਿ ਬਫਰ ਪ੍ਰੀਅਲੋਕੇਟ ਹੈ, ਤੁਸੀਂ ਬਾਰ-ਬਾਰ ਐਲੋਕੇਸ਼ਨ ਤੋਂ ਬਚਦੇ ਹੋ ਅਤੇ ਗਾਰਬੇਜ ਕਲੇਕਟਰ 'ਤੇ ਦਬਾਅ ਘੱਟ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਮੁੱਖ ਵਿਚਾਰ ਸਿੰਗਲ-ਰਾਈਟਰ ਸਿਧਾਂਤ ਹੈ: ਇਕ ਹੀ ਕੰਪੋਨੈਂਟ ਕਿਸੇ ਸਾਂਝੇ ਸਟੇਟ (ਉਦਾਹਰਣ ਲਈ, ਰਿੰਗ ਦੀ ਅਗਵਾਈ ਕਰਣ ਵਾਲਾ ਕਰਸਰ) ਦਾ ਜ਼ਿੰਮੇਵਾਰ ਹੋਵੇ। ਘੱਟ ਲੇਖਕਾਂ ਦਾ ਮਤਲਬ ਘੱਟ "ਅਗਲਾ ਕੌਣ ਹੈ?" ਵਾਲੇ ਪਲ।
ਬੈਕਪ੍ਰੈਸ਼ਰ ਸਪੱਸ਼ਟ ਹੁੰਦਾ ਹੈ। ਜਦੋਂ ਕੰਜ਼ਿਊਮਰ ਪਿੱਛੇ ਰਹਿ ਜਾਂਦੇ ਹਨ, ਪ੍ਰੋਡੀੂਸਰ ਆਖ਼ਿਰਕਾਰ ਇੱਕ ਐਸੇ ਸਲਾਟ 'ਤੇ ਪਹੁੰਚਦਾ ਹੈ ਜੋ ਅਜੇ ਵੀ ਵਰਤ ਵਿੱਚ ਹੈ। ਇਸ ਵੇਲੇ ਸਿਸਟਮ ਨੂੰ ਰੁਕਣਾ, ਡ੍ਰਾਪ ਕਰਨਾ ਜਾਂ ਧੀਮਾ ਕਰਨਾ ਪੈ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਇੱਕ ਨਿਯੰਤਰਿਤ, ਦਿੱਖਣਯੋਗ ਤਰੀਕੇ ਨਾਲ ਹੁੰਦਾ ਹੈ ਨਾ ਕਿ ਵਧ ਰਹੀ ਕਿਊ ਅੰਦਰ ਸਮੱਸਿਆ ਨੂੰ ਛੁਪਾਉਂਦਾ।
Disruptor-ਸਟਾਈਲ ਡਿਜ਼ਾਇਨਾਂ ਨੂੰ ਤੇਜ਼ ਬਣਾਉਂਣ ਵਾਲੀ ਚੀਜ਼ ਕੋਈ ਚਤੁਰ ਮਾਈਕ੍ਰੋ-ਓਪਟੀਮਾਈਜੇਸ਼ਨ ਨਹੀਂ ਹੈ। ਇਹ ਉਹ ਅਣਪੇਖਤ ਰੁਕਾਵਟਾਂ ਦੂਰ ਕਰਨ 'ਤੇ ਧਿਆਨ ਦਿੰਦਾ ਹੈ ਜੋ سਿਸਟਮ ਆਪਣੇ ਹੀ ਹਿਲਦੇ-ਡੁਲਦੇ ਹਿੱਸਿਆਂ ਨਾਲ ਲੜਾਈ ਕਰਦਿਆਂ ਹੁੰਦੀਆਂ ਹਨ: ਐਲੋਕੇਸ਼ਨ, ਕੈਸ਼-ਮਿਸ, ਲਾਕ ਕੰਟੇਨਸ਼ਨ, ਅਤੇ ਹਾਟ ਪਾਥ ਵਿੱਚ ਮਿਲੀ ਹੋਈ ਧੀਮੀ ਕੰਮ।
ਇੱਕ ਲਾਭਦਾਇਕ ਮਾਨਸਿਕ ਮਾਡਲ ਇੱਕ ਅਸੈਂਬਲੀ ਲਾਈਨ ਦਾ ਹੈ। ਇਵੈਂਟ ਇੱਕ ਨਿਸ਼ਚਿਤ ਰੂਟ ਰਾਹੀਂ ਚੱਲਦੇ ਹਨ ਜਿਸ ਨਾਲ ਸਪੱਸ਼ਟ ਹੈਂਡਆਫ਼ ਹੁੰਦੇ ਹਨ। ਇਹ ਸਾਂਝੇ ਸਟੇਟ ਘੱਟ ਕਰਦਾ ਹੈ ਅਤੇ ਹਰ ਕਦਮ ਨੂੰ ਆਸਾਨ ਅਤੇ ਮਾਪਣਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਤੇਜ਼ ਸਿਸਟਮ ਅਚਾਨਕ ਐਲੋਕੇਸ਼ਨ ਤੋਂ ਬਚਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਬਫਰ ਪ੍ਰੀ-ਅਲੋਕੇਟ ਕਰਦੇ ਹੋ ਅਤੇ ਸੁਨੇਹੇ ਆਬਜੈਕਟ ਦੁਹਰਾਉਂਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ GC, heap ਵਾਧਾ, ਅਤੇ ਐਲੋਕੇਟਰ ਲਾਕਾਂ ਕਾਰਨ ਹੋਣ ਵਾਲੇ "ਕਦੇ-ਕਦੇ" ਸਪਾਇਕਸ ਘੱਟ ਕਰ ਦਿੰਦੇ ਹੋ।
ਇਹ ਵੀ ਮਦਦਗਾਰ ਹੈ ਕਿ ਸੁਨੇਹੇ ਛੋਟੇ ਅਤੇ ਸਥਿਰ ਰਹਿਣ। ਜਦੋਂ ਹਰ ਇਵੈਂਟ ਦੇ ਨਾਲ ਤੁਸੀਂ ਜਿੰਨਾ ਡੇਟਾ ਛੂੰਹਦੇ ਹੋ ਉਹ CPU ਕੈਸ਼ ਵਿੱਚ ਫਿੱਟ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਮੈਮੋਰੀ ਲਈ ਘੱਟ ਉਡੀਕ ਕਰਦੇ ਹੋ।
ਅਮਲੀ ਰੂਪ ਵਿੱਚ, ਆਮ ਨਿਬੇੜੇ ਜੋ ਅਕਸਰ ਸਭ ਤੋਂ ਜਿਆਦਾ ਅਹਮ ਹੋਂਦੇ ਹਨ: ਪ੍ਰਤੀ-ਇਵੈਂਟ ਨਵੇਂ ਆਬਜੈਕਟ ਬਣਾਉਣ ਦੀ ਥਾਂ ਆਬਜੈਕਟ ਦੁਹਰਾਉ, ਇਵੈਂਟ ਡੇਟਾ ਕਾਂਪੈਕਟ ਰੱਖੋ, ਸਾਂਝੇ ਸਟੇਟ ਲਈ ਇੱਕ-ਲੇਖਕ ਨੂੰ ਤਰਜੀਹ ਦਿਓ, ਅਤੇ ਸਮਝਦਾਰੀ ਨਾਲ ਬੈਚਿੰਗ ਕਰੋ ਤਾਂ ਕਿ ਤੁਹਾਨੂੰ ਕੋਆਰਡੀਨੇਸ਼ਨ ਖਰਚ ਘੱਟ ਵੇਲੇ ਤੇ ਭੁਗਤਣਾ ਪਏ।
ਰੀਅਲ-ਟਾਈਮ ਐਪਾਂ ਨੂੰ ਅਕਸਰ ਲੌਗਿੰਗ, ਮੈਟ੍ਰਿਕਸ, ਰੀਟ੍ਰਾਈ, ਜਾਂ ਡੇਟਾਬੇਸ ਲਿਖਤਾਂ ਵਰਗੀਆਂ ਵਾਧੂ ਚੀਜ਼ਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। Disruptor ਮਨੋਵ੍ਰਤੀ ਇਹ ਹੈ ਕਿ ਇਨ੍ਹਾਂ ਨੂੰ ਕੋਰ ਲੂਪ ਤੋਂ ਅਲੱਗ ਰੱਖੋ ਤਾਂ ਜੋ ਇਹ ਉਸ ਨੂੰ ਬਲਾਕ ਨਾ ਕਰ ਸਕਣ।
ਇੱਕ ਲਾਈਵ ਪ੍ਰਾਈਸਿੰਗ ਫੀਡ ਵਿੱਚ, ਹਾਟ ਪਾਥ ਸਿਰਫ਼ ਇੱਕ ਟਿਕ ਨੂੰ ਵੈਧ ਕਰਕੇ ਅਗਲਾ ਪ੍ਰਾਈਸ ਸਨੇਪਸ਼ਾਟ ਪਬਲਿਸ਼ ਕਰ ਸਕਦਾ ਹੈ। ਜੋ ਕੁਝ ਵੀ ਰੁਕ ਸਕਦਾ ਹੈ (ਡਿਸਕ, ਨੈੱਟਵਰਕ ਕਾਲ, ਭਾਰੀ ਸੀਰੀਅਲਾਈਜ਼ੇਸ਼ਨ) ਨੂੰ ਇੱਕ ਵੱਖਰੇ ਕੰਜ਼ਿਊਮਰ ਜਾਂ ਸਾਈਡ ਚੈਨਲ ਵਿੱਚ ਢੁਕੇਲ ਦਿਓ, ਤਾਂ ਜੋ predictable ਪਾਥ predictable ਹੀ ਰਹੇ।
ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਜ਼ਿਆਦਾਤਰ ਇੱਕ ਆਰਕੀਟੈਕਚਰ ਸਮੱਸਿਆ ਹੈ। ਤੁਸੀਂ ਤੇਜ਼ ਕੋਡ ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਫਿਰ ਵੀ ਤੇਜ਼ੀ-ਝਟਕਿਆਂ ਹੋ ਸਕਦੇ ਹਨ ਜੇ ਬਹੁਤ ਸਾਰੇ ਥ੍ਰੈਡ ਇੱਕੋ ਜਿਹੇ ਡੇਟਾ 'ਤੇ ਲੜਦੇ ਹੋ, ਜਾਂ ਸੁਨੇਹੇ ਬੇਕਾਰ ਨੈੱਟਵਰਕ ਹੋਪਸ 'ਤੇ ਛਲਕਦੇ ਹਨ।
ਸ਼ੁਰੂ ਕਰੋ ਇਹ ਫੈਸਲਾ ਕਰ ਕੇ ਕਿ ਕਿੰਨੇ ਲੇਖਕ ਅਤੇ ਪਾਠਕ ਇੱਕੋ ਕਿਊ ਜਾਂ ਬਫਰ ਨੂੰ ਛੂੰਹਦੇ ਹਨ। ਇੱਕ ਸਿੰਗਲ ਪ੍ਰੋਡੀੂਸਰ ਨੂੰ ਸੁਗਮ ਰੱਖਣਾ ਅਸਾਨ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਕੋਆਰਡੀਨੇਸ਼ਨ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ। ਬਹੁ-ਪ੍ਰੋਡੀੂਸਰ ਸੈਟਅਪ throughput ਵਧਾ ਸਕਦੇ ਹਨ, ਪਰ ਅਕਸਰ ਕੰਟੇਨਸ਼ਨ ਵਧਾ ਕੇ ਬੇਹਤਰੀਨ-ਕੇਸ ਟਾਈਮਿੰਗ ਨੂੰ ਘੁੰਮਾਦਾਰ ਬਣਾਉਂਦੇ ਹਨ। ਜੇ ਤੁਹਾਨੂੰ ਕਈ ਪ੍ਰੋਡੀਊਸਰ ਚਾਹੀਦੇ ਹਨ, ਤਾਂ ਸਾਂਝੇ ਲਿਖਤਾਂ ਨੂੰ ਘੱਟ ਕਰਨ ਲਈ ਇਵੈਂਟਾਂ ਨੂੰ ਕੁੰਜੀ ਅਨੁਸਾਰ ਸ਼ਾਰਡ ਕਰੋ (ਉਦਾਹਰਣ: userId ਜਾਂ instrumentId) ਤਾਂ ਕਿ ਹਰ ਸ਼ਾਰਡ ਦਾ ਆਪਣਾ ਹੌਟ ਪਾਥ ਹੋਵੇ।
ਕੰਜ਼ਿਊਮਰ ਪਾਸੇ, ਜੇ ਆਰਡਰ ਮਹੱਤਵਪੂਰਨ ਹੈ ਤਾਂ ਇੱਕ ਸਿੰਗਲ ਕੰਜ਼ਿਊਮਰ ਸਭ ਤੋਂ ਸਥਿਰ ਸਮਾਂ ਦਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਸਟੇਟ ਇੱਕ ਥ੍ਰੈਡ ਵਿੱਚ ਰਹਿੰਦਾ ਹੈ। ਵਰਕਰ ਪੁਲ ਉਹਨਾਂ ਕੰਮਾਂ ਲਈ ਮਦਦਗਾਰ ਹਨ ਜੋ ਸਤਾਂਤ੍ਰ ਹਨ, ਪਰ ਉਹ ਸ਼ਡਿਊਲਿੰਗ ਦੇਰਾਂ ਜੋੜਦੇ ਹਨ ਅਤੇ ਕੰਮ ਨੂੰ ਬਿਨਾ ਧਿਆਨ ਦੇ reorder ਕਰ ਸਕਦੇ ਹਨ।
ਬੈਚਿੰਗ ਇੱਕ ਹੋਰ ਵਪਾਰ-ਬਦਲੀ ਹੈ। ਛੋਟੇ ਬੈਚ ਓਵਰਹੈੱਡ ਕਟਦੇ ਹਨ (ਘੱਟ wakeups, ਘੱਟ ਕੈਸ਼ ਮਿਸ), ਪਰ ਬੈਚਿੰਗ ਰਹਿਣ ਲਈ ਇਵੈਂਟਾਂ ਨੂੰ ਰੋਕ ਸਕਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਰੀਅਲ-ਟਾਈਮ ਸਿਸਟਮ ਵਿੱਚ ਬੈਚ ਕਰਦੇ ਹੋ, ਤਾਂ ਬੈਚ ਭਰਨ ਦੀ ਉਡੀਕ 'ਤੇ ਇੱਕ ਸੀਮਾ ਰੱਖੋ (ਉਦਾਹਰਣ: "16 ਇਵੈਂਟਾਂ ਤੱਕ ਜਾਂ 200 ਮਾਈਕ੍ਰੋਸੈਕਿੰਡ, ਜੋ ਵੀ ਪਹਿਲਾਂ ਪੂਰਾ ਹੋਵੇ")।
ਸੇਵਾ ਸੀਮਾਵਾਂ ਮਹੱਤਵਪੂਰਨ ਹਨ। ਨਜ਼ਦੀਕੀ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਸੰਦੇਸ਼ ਭੇਜਣਾ ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਚੰਗਾ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਕਿੱਟ ਲੈਟੈਂਸੀ ਚਾਹੀਦੀ ਹੋਵੇ। ਸਕੇਲਿੰਗ ਲਈ ਨੈੱਟਵਰਕ ਹੋਪ ਕਦਰਯੋਗ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਹਰ ਹੋਪ ਕਿਊਜ਼, ਰੀਟ੍ਰਾਈ, ਅਤੇ ਵਰੀਏਬਲ ਦਿਰੀ ਜੋੜਦਾ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਇੱਕ ਹੋਪ ਚਾਹੀਦਾ ਹੈ, ਤਾਂ ਪ੍ਰੋਟੋਕਾਲ ਨੂੰ ਸੌਖਾ ਰੱਖੋ ਅਤੇ ਹਾਟ ਪਾਥ ਵਿੱਚ fan-out ਤੋਂ ਬਚੋ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਨਿਯਮ-ਸੈਟ: ਜਦੋਂ ਸੰਭਵ ਹੋਵੇ ਤਾਂ ਪ੍ਰਤੀ-ਸ਼ਾਰਡ ਇੱਕ-ਲੇਖਕ ਪਾਥ ਰੱਖੋ, ਇੱਕ ਹੌਟ ਕਿਊ ਨੂੰ ਸਾਂਝਾ ਕਰਨ ਦੀ ਥਾਂ ਸ਼ਾਰਡਿੰਗ ਨਾਲ ਸਕੇਲ ਕਰੋ, ਸਖਤ ਸਮੇਂ-ਸੀਮਾ ਨਾਲ ਹੀ ਬੈਚ ਕਰੋ, ਸਿਰਫ਼ ਸੁਤੰਤਰ ਕੰਮ ਲਈ ਵਰਕਰ ਪੁਲ ਜੋੜੋ, ਅਤੇ ਹਰ ਨੈੱਟਵਰਕ ਹੋਪ ਨੂੰ ਮਾਪਣ ਤੱਕ ਸੰਭਾਵਿਤ ਜਿਟਰ ਸਰੋਤ ਸਮਝੋ।
ਕੋਡ ਛੂਹਣ ਤੋਂ ਪਹਿਲਾਂ ਲਿਖਤੀ ਲੈਟੈਂਸੀ ਬਜਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਇੱਕ ਟਾਰਗੇਟ ਚੁਣੋ ("ਚੰਗਾ" ਕਿੱਦਾ ਮਹਿਸੂਸ ਕਰਦਾ ਹੈ) ਅਤੇ ਇੱਕ p99 ਜੋ ਤੁਹਾਨੂੰ ਲਈ ਠੀਕ ਰਹੇ। ਉਸ ਨੰਬਰ ਨੂੰ ਇਨਪੁੱਟ, ਵੈਲਿਡੇਸ਼ਨ, ਮੈਚਿੰਗ, ਪਾਇਲਟ, ਅਤੇ ਆਉਟਬਾਊਂਡ ਅਪਡੇਟ ਵਰਗੇ ਸਟੇਜਾਂ ਵਿੱਚ ਵੰਡੋ। ਜੇ ਕਿਸੇ ਸਟੇਜ ਲਈ ਬਜਟ ਨਹੀਂ ਹੈ, ਤਾਂ ਉਸਦਾ ਕੋਈ ਸੀਮਾ ਨਹੀਂ।
ਅਗਲਾ ਕਦਮ: ਪੂਰੇ ਡੇਟਾ ਫਲੋ ਨੂੰ ਡਰਾਇੰਗ ਕਰੋ ਅਤੇ ਹਰ ਹੈਂਡਆਫ਼ ਨੂੰ ਨਿਸ਼ਾਨ ਲਗਾਓ: ਥ੍ਰੈਡ ਬਾਉਂਡਰੀਜ਼, ਕਿਊਜ਼, ਨੈੱਟਵਰਕ ਹੋਪ, ਅਤੇ ਸਟੋਰੇਜ਼ ਕਾਲਾਂ। ਹਰ ਹੈਂਡਆਫ਼ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਜਿਟਰ ਛੁਪਿਆ ਹੋ ਸਕਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਵੇਖ ਸਕਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਘਟਾ ਸਕਦੇ ਹੋ।
ਇੱਕ ਡਿਜ਼ਾਇਨ ਵਰਕਫਲੋ ਜੋ ਡਿਜ਼ਾਇਨਾਂ ਨੂੰ ਇਮਾਨਦਾਰ ਬਣਾਉਂਦਾ ਹੈ:
ਫਿਰ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਕੁਝ ਅਸਿੰਕਰੇਨਸ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਯੂਜ਼ਰ ਅਨੁਭਵ ਨੂੰ ਤੋੜੇ। ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: ਜੋ ਕੁਝ "ਹੁਣ" ਦਿੱਖਦਾ ਹੈ ਉਹ ਕ੍ਰਿਟਿਕਲ ਪਾਥ 'ਤੇ ਰਹੇ, ਬਾਕੀ ਸਾਈਡ-ਪਾਥ ਤੇ ਭੇਜੋ।
ਐਨਾਲਿਟਿਕਸ, ਆਡਿਟ ਲੌਗ, ਅਤੇ ਸਕੈਂਡਰੀ ਇੰਡੈਕਸਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਹੌਟ ਪਾਥ ਤੋਂ ਬਾਹਰ ਧੱਕੇ ਜਾ ਸਕਦੇ ਹਨ। ਵੈਲਿਡੇਸ਼ਨ, ਆਰਡਰਿੰਗ, ਅਤੇ ਉਹ ਕਦਮ ਜੋ ਅਗਲਾ ਸਟੇਟ ਉਤਪੰਨ ਕਰਨ ਲਈ ਲਾਜ਼ਮੀ ਹਨ ਸਧਾਰਨਤ: ਕ੍ਰਿਟਿਕਲ ਪਾਥ 'ਤੇ ਰਹਿਣ।
ਤੇਜ਼ ਕੋਡ ਫਿਰ ਵੀ ਧੀਮਾ ਮਹਿਸੂਸ ਹੋ ਸਕਦਾ ਹੈ ਜਦੋਂ ਰਨਟਾਈਮ ਜਾਂ OS ਤੁਹਾਡਾ ਕੰਮ ਗਲਤ ਸਮੇਂ 'ਤੇ ਰੋਕ ਦੇਂਦੇ ਹਨ। ਮਕਸਦ ਸਿਰਫ਼ ਉੱਚ throughput ਨਹੀਂ; ਇਹ ਸਭ ਤੋਂ ਧੀਮੀ 1% ਰਿਕਵੇਸਟਾਂ ਵਿੱਚ ਘੱਟ ਅਚਾਨਕਤਾ ਹੈ।
ਗਾਰਬੇਜ ਕਲੇਕਟ ਕੀਤੀਆਂ ਭਾਸ਼ਾਵਾਂ (JVM, Go, .NET) ਉਤਪਾਦਕਤਾ ਲਈ ਵਧੀਆ ਹਨ, ਪਰ ਜਦੋਂ ਯਾਦ ਸਾਫ਼ ਕਰਨ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ ਤਾਂ ਪੌਜ਼ ਆ ਸਕਦੇ ਹਨ। ਆਧੁਨਿਕ ਕਲੇਕਟਰ ਪਹਿਲਾਂ ਨਾਲੋਂ ਬਿਹਤਰ ਹਨ, ਪਰ ਜੇ ਤੁਸੀਂ ਲੋਡ ਹੇਠਾਂ ਬਹੁਤ ਛੋਟੀਆਂ ਅਸਥਾਈ ਵਸਤੂਆਂ ਬਣਾਉਂਦੇ ਹੋ ਤਾਂ ਟੇਲ ਲੈਟੈਂਸੀ ਫਿਰ ਵੀ ਛੱਲ ਸਕਦੀ ਹੈ। ਗੈਰ-GC ਭਾਸ਼ਾਵਾਂ (Rust, C, C++) GC ਪੌਜ਼ ਤੋਂ ਬਚਾਉਂਦੀਆਂ ਹਨ, ਪਰ ਇਹ ਹੱਥ-ਆਧਾਰਤ ਮੈਮੋਰੀ ਨਿਯਮ ਲਿਆਉਂਦੀਆਂ ਹਨ।
ਕਾਰਗਰ ਆਦਤ: ਜਿੱਥੇ ਐਲੋਕੇਸ਼ਨ ਹੁੰਦੀ ਹੈ ਉਸ ਨੂੰ ਲਭੋ ਅਤੇ ਉਹਨੂੰ ਸੁਚਾਰੂ ਬਣਾਓ। ਆਬਜੈਕਟ ਦੁਹਰਾਓ, ਬਫਰ ਪਹਿਲਾਂ ਤੋਂ ਸਾਈਜ਼ ਕਰੋ, ਅਤੇ ਹਾਟ-ਪਾਥ ਡੇਟਾ ਨੂੰ ਅਸਥਾਈ ਸਤਰਿੰਗਾਂ ਜਾਂ ਮੈਪਾਂ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਬਚੋ।
ਥ੍ਰੈਡਿੰਗ ਫੈਸਲੇ ਵੀ ਜਿਟਰ ਵਜੋਂ ਨਜ਼ਰ ਆਂਦੇ ਹਨ। ਹਰ ਇੱਕ ਵਾਧੂ ਕਿਊ, ਐਸਿੰਕ ਹੋਪ, ਜਾਂ ਥ੍ਰੈਡ ਪੂਲ ਹੈਂਡਆਫ਼ ਇੰਤਜ਼ਾਰ ਜੋੜਦਾ ਹੈ ਅਤੇ ਵਿਵਿਧਤਾ ਵਧਾਉਂਦਾ ਹੈ। ਛੋਟੇ ਅਤੇ ਲੰਬੇ-ਜੀਵਨ ਵਾਲੇ ਥ੍ਰੈਡਾਂ ਦੀ ਵਰਤੋਂ ਕਰੋ, ਪ੍ਰੋਡੀਊਸਰ-ਕੰਜ਼ਿਊਮਰ ਬਾਉਂਡਰੀਆਂ ਸਪੱਸ਼ਟ ਰੱਖੋ, ਅਤੇ ਹਾਟ ਪਾਥ 'ਤੇ ਬਲਾਕਿੰਗ ਕਾਲਾਂ ਤੋਂ ਬਚੋ।
ਕੁਝ OS ਅਤੇ ਕੰਟੇਨਰ ਸੈਟਿੰਗਾਂ ਅਕਸਰ ਫ਼ੈਸਲਾ ਕਰਦੀਆਂ ਹਨ ਕਿ ਤੁਹਾਡਾ ਟੇਲ ਸਾਫ਼ ਰਹੇਗਾ ਜਾਂ ਚਿੱਟਾ ਹੋ ਜਾਵੇਗਾ: CPU throttling, shared host 'ਤੇ noisy neighbors, ਅਤੇ ਗਲਤ ਢੰਗ ਨਾਲ ਰੱਖੇ ਲੌਗਿੰਗ ਜਾਂ ਮੈਟ੍ਰਿਕਸ। ਜੇ ਤੁਸੀਂ ਕੇਵਲ ਇੱਕ ਚੀਜ਼ ਬਦਲੋ ਤਾਂ
ਪਹਿਲਾਂ ਲੈਟੈਂਸੀ ਸਪਾਇਕਸ ਦੌਰਾਨ ਐਲੋਕੇਸ਼ਨ ਰੇਟ ਅਤੇ ਕਾਂਟੈਕਸਟ ਸਵਿੱਚ ਮਾਪੋ।
ਕਈ ਲੈਟੈਂਸੀ ਸਪਾਇਕਸ "ਧੀਮਾ ਕੋਡ" ਨਹੀਂ ਹੁੰਦੀਆਂ। ਉਹ ਅਣਪੇਖਤ ਉਡੀਕਾਂ ਹਨ: ਡੇਟਾਬੇਸ ਲਾਕ, ਰੀਟ੍ਰਾਈ ਸਟੌਮ, ਇੱਕ ਕ੍ਰਾਸ-ਸੇਵਾ ਕਾਲ ਜੋ ਰੁਕ ਜਾਂਦੀ ਹੈ, ਜਾਂ ਇੱਕ ਕੈਸ਼ ਮਿਸ ਜਿਸ ਨੇ ਪੂਰਾ ਰਾਊਂਡ-ਟ੍ਰਿਪ ਬਣਾਇਆ।
ਕ੍ਰਿਟਿਕਲ ਪਾਥ ਛੋਟਾ ਰੱਖੋ। ਹਰ ਹੋਪ ਸ਼ਡਿਊਲਿੰਗ, ਸੀਰੀਅਲਾਈਜ਼ੇਸ਼ਨ, ਨੈੱਟਵਰਕ ਕਿਊਜ਼, ਅਤੇ ਹੋਰ ਬਲਾਕਿੰਗ ਜਗ੍ਹਾਂ ਜੋੜਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਇੱਕ ਪ੍ਰੋਸੈਸ ਅਤੇ ਇੱਕ ਡੇਟਾ ਸਟੋਰ ਤੋਂ ਉੱਤਰ ਦੇ ਸਕਦੇ ਹੋ ਤਾਂ ਪਹਿਲਾਂ ਉਹ ਕਰੋ। ਸੇਵਾਵਾਂ ਵਿੱਚ ਵੰਡਾਂ ਕੇਵਲ ਤਦੋਂ ਕਰੋ ਜਦੋਂ ਹਰ ਕਾਲ ਵਿਕਲਪਿਕ ਜਾਂ ਸੀਮਤ ਹੋਵੇ।
ਬਾਊਂਡਡ ਇੰਤਜ਼ਾਰ ਤੇਜ਼ ਔਸਤ ਅਤੇ ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਵਿੱਚ ਫਰਕ ਬਣਾਉਂਦਾ ਹੈ। ਦੂਜਿਆਂ ਕਾਲਾਂ 'ਤੇ ਕਠੋਰ ਟਾਇਮਆਊਟ ਲਗਾਓ, ਅਤੇ ਜਦੋਂ ਡਿਪੈਂਡੈਂਸੀ ਅਣਹੈਲਥੀ ਹੋਵੇ ਤਾਂ ਤੇਜ਼ੀ ਨਾਲ ਫੇਲ ਕਰੋ। ਸਰਕਿਟ ਬ੍ਰੇਕਰ ਸਿਰਫ ਸਰਵਰਾਂ ਨੂੰ ਬਚਾਉਣ ਲਈ ਨਹੀਂ। ਉਹ ਯੂਜ਼ਰਾਂ ਲਈ ਫਸਨ ਦੀ ਲੰਬਾਈ ਸੀਮਤ ਕਰਦੇ ਹਨ।
ਜਦੋਂ ਡੇਟਾ ਪਹੁੰਚ ਰੋਕਦੀ ਹੈ, ਤਾਂ ਰਾਹ ਵੱਖਰੇ ਕਰੋ। ਪੜ੍ਹਨ ਨੂੰ ਅਕਸਰ ਇੰਡੈਕਸਡ, ਡਿਨੋਰਮਲਾਈਜ਼ਡ, ਕੈਸ਼-ਫ੍ਰੈੰਡਲੀ ਆਕਾਰ ਚਾਹੀਦਾ ਹੈ। ਲਿਖਤਾਂ ਨੂੰ ਟਿਕਾਊਣ ਅਤੇ ਆਰਡਰਿੰਗ ਲਈ ਅਲੱਗ ਰੱਖਣਾ contention ਘਟਾ ਸਕਦਾ ਹੈ। ਜੇ ਤੁਹਾਡੀਆਂ ਸਥਿਰਤਾ ਜ਼ਰੂਰਤਾਂ ਆਗਿਆ ਦਿੰਦੀਆਂ ਹਨ, ਤਾਂ ਐਪੈਂਡ-ਓਨਲੀ ਰਿਕਾਰਡਾਂ (ਇਵੈਂਟ ਲੌਗ) ਆਮ ਤੌਰ 'ਤੇ ਥਾਂ-ਅੱਪਡੇਟਾਂ ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਪੇਸ਼ਗੋਈਯੋਗ ਹੋ ਸਕਦੇ ਹਨ।
ਰੀਅਲ-ਟਾਈਮ ਐਪਾਂ ਲਈ ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: persistence ਨੂੰ ਕ੍ਰਿਟਿਕਲ ਪਾਥ 'ਤੇ ਨਾ ਰੱਖੋ ਜਦ تک ਇਹ correctness ਲਈ ਲਾਜ਼ਮੀ ਨਾ ਹੋਵੇ। ਬਹੁਤ ਵਾਰ ਵਧੀਆ ਰੂਪ ਇਹ ਹੈ: ਮੈਮੋਰੀ ਵਿੱਚ ਅਪਡੇਟ ਕਰੋ, ਜਵਾਬ ਦਿਓ, ਫਿਰ ਐਸਿੰਕ ਤੌਰ 'ਤੇ ਪERSIST ਕਰੋ ਨਾਲ ਰੀਪਲੇ ਮਕੈਨਿਜ਼ਮ (ਜਿਵੇਂ ਆਉਟਬਾਕਸ ਜਾਂ ਵ੍ਰਾਈਟ-ਅਹੈੱਡ ਲੌਗ)।
ਕਈ ਰਿੰਗ-ਬਫਰ ਪਾਈਪਲਾਈਨਾਂ ਵਿੱਚ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਹੋਂਦਾ ਹੈ: ਇਨ-ਮੈਮੋਰੀ ਬਫਰ ਨੂੰ ਪਬਲਿਸ਼ ਕਰੋ, ਸਟੇਟ ਅਪਡੇਟ ਕਰੋ, ਜਵਾਬ ਦਿਓ, ਫਿਰ ਇੱਕ ਵੱਖਰਾ ਕੰਜ਼ਿਊਮਰ PostgreSQL 'ਤੇ ਬੈਚ ਲਿਖਤਾਂ ਕਰੇ।
ਇੱਕ ਲਾਈਵ ਕੋਲੈਬਰੇਸ਼ਨ ਐਪ (ਜਾਂ ਇੱਕ ਛੋਟਾ ਮਲਟੀਪਲੇਅਰ ਗੇਮ) ਸੋਚੋ ਜੋ ਹਰ 16 ms (ਲਗਭਗ 60 ਗੁਣਾ) ਅਪਡੇਟ ਭੇਜਦਾ ਹੈ। ਮਕਸਦ "ਔਸਤ ਤੇਜ਼" ਨਹੀਂ, ਬਲਕਿ "ਅਕਸਰ 16 ms ਤੋਂ ਘੱਟ" ਹੋਣਾ ਹੈ, ਭਾਵੇਂ ਕਿਸੇ ਯੂਜ਼ਰ ਦੀ ਕਨੈਕਸ਼ਨ ਖਰਾਬ ਹੋਵੇ।
ਸਧਾਰਨ Disruptor-ਸਟਾਈਲ ਫਲੋ ਇਉਂ ਦਿਖਦਾ ਹੈ: ਯੂਜ਼ਰ ਇਨਪੁੱਟ ਇੱਕ ਛੋਟੀ ਇਵੈਂਟ ਬਣ ਜਾਦੀ ਹੈ, ਇਹ ਪ੍ਰੀ-ਅਲੋਕੇਟ ਰਿੰਗ ਬਫਰ ਵਿੱਚ ਪਬਲਿਸ਼ ਹੁੰਦੀ ਹੈ, ਫਿਰ ਇੱਕ ਨਿਰਧਾਰਤ ਹੈਂਡਲਰ ਸੈੱਟ ਦੁਆਰਾ ਕ੍ਰਮ ਵਿੱਚ ਪ੍ਰੋਸੈਸ ਹੁੰਦੀ ਹੈ (validate -> apply -> prepare outbound messages), ਅਤੇ ਆਖਿਰ ਵਿੱਚ ਕਲਾਇੰਟਾਂ ਨੂੰ ਬ੍ਰੌਡਕਾਸਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਬੈਚਿੰਗ ਕਿਨਾਰਿਆਂ 'ਤੇ ਮਦਦ ਕਰ ਸਕਦੀ ਹੈ। ਉਦਾਹਰਣ ਲਈ, ਪ੍ਰਤੀ-ਕਲਾਇੰਟ ਆਉਟਬਾਉਂਡ ਲਿਖਤਾਂ ਨੂੰ ਹਰ ਟਿਕ 'ਤੇ ਬੈਚ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਨੈੱਟਵਰਕ ਲੇਅਰ ਨੂੰ ਘੱਟ ਵਾਰ ਕਾਲ ਕਰੋ। ਪਰ ਹਾਟ ਪਾਥ ਅੰਦਰ ਐਸਾ ਬੈਚ ਨਾ ਕਰੋ ਜਿੰਨਾਂ ਨਾਲ ਤੁਸੀਂ ਹੋਰ "ਥੋੜ੍ਹਾ ਜਿਹਾ ਹੋਰ" ਦੇ ਲਈ ਇੰਤਜ਼ਾਰ ਕਰੋ — ਇੰਤਜ਼ਾਰ ਕਰਨਾ ਹੀ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ ਟਿਕ ਨੂੰ ਗਵਾਂ ਬੈਠਦੇ ਹੋ।
ਜਦੋਂ ਕੋਈ ਚੀਜ਼ ਹੌਲੀ ਹੋ ਜਾਂਦੀ ਹੈ, ਉਸਨੂੰ containment ਸਮੱਸਿਆ ਵਾਂਗਿਊਂ ਤੱਕ ਲਓ। ਜੇ ਇੱਕ ਹੈਂਡਲਰ ਹੌਲਾ ਹੋ ਜਾਵੇ ਤਾਂ ਉਸਨੂੰ ਆਪਣੇ ਬਫਰ ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਅਤੇ ਮੁੱਖ ਲੂਪ ਨੂੰ ਬਲਾਕ ਨਾ ਕਰੋ — ਬਲਕਿ ਇੱਕ ਹਲਕਾ ਵਰਕ ਆਈਟਮ ਪਬਲਿਸ਼ ਕਰੋ। ਜੇ ਇੱਕ ਕਲਾਇੰਟ ਹੌਲਾ ਹੈ ਤਾਂ ਬ੍ਰੌਡਕਾਸਟਰ ਨੂੰ ਉਸ ਨਾਲ ਪਿੱਛੇ ਨਾ ਰੱਖੋ; ਹਰ ਕਲਾਇੰਟ ਨੂੰ ਇੱਕ ਛੋਟੀ ਸੈਂਡ ਕਿਊ ਦਿਓ ਅਤੇ ਪੁਰਾਣੀਆਂ ਅਪਡੇਟਾਂ ਨੂੰ ਡ੍ਰਾਪ ਜਾਂ ਕੋਆਲੇਸ ਕਰੋ ਤਾਂ ਕਿ ਤੁਹਾਡੇ ਕੋਲ ਤਾਜ਼ਾ ਸਟੇਟ ਰਹੇ। ਜੇ ਬਫਰ ਡੈਪਥ ਵਧੇ ਤਾਂ ਐਜ 'ਤੇ ਬੈਕਪ੍ਰੈਸ਼ਰ ਲਗਾਓ (ਉਸ ਟਿਕ ਲਈ ਹੋਰ ਇਨਪੁੱਟ ਰੋਕੋ, ਜਾਂ ਫੀਚਰ ਘਟਾਓ)।
ਤੁਹਾਨੂੰ ਪਤਾ ਲੱਗਦਾ ਹੈ ਕਿ ਇਹ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਜਦੋਂ ਨੰਬਰ ਬੋਰੀਂਗ ਰਹਿੰਦੇ ਹਨ: ਬੈਕਲੌਗ ਡੈਪਥ ਨਜਦੀਕੀ ਜ਼ੀਰੋ ਤੇ ਟਿਕਦੀ ਹੈ, ਡ੍ਰਾਪ/ਕੋਆਲੇਸ ਹੋਣਾ ਨਿਰਵਚਿਤ ਅਤੇ ਕਮ ਹੀ ਹੁੰਦਾ ਹੈ, ਅਤੇ p99 ਤੁਹਾਡੇ ਟਿਕ ਬਜਟ ਤੋਂ ਹੇਠਾਂ ਰਹਿੰਦਾ ਹੈ ਵਰਤਮਾਨ ਲੋਡ 'ਤੇ।
ਜ਼ਿਆਦਾਤਰ ਲੈਟੈਂਸੀ ਸਪਾਇਕ ਸਵੈ-ਨਿਰਮਿਤ ਹੁੰਦੇ ਹਨ। ਕੋਡ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਸਿਸਟਮ ਫਿਰ ਵੀ ਰੁਕ ਜਾਂਦਾ ਹੈ ਜਦੋਂ ਇਹ ਹੋਰ ਥ੍ਰੈਡਾਂ, OS, ਜਾਂ CPU ਕੈਸ਼ ਦੇ ਬਾਹਰ ਕੁਝ ਚੀਜ਼ਾਂ ਦੀ ਉਡੀਕ ਕਰਦਾ ਹੈ।
ਕੁਝ ਆਮ ਗਲਤੀਆਂ ਜੋ ਮੁੜ-ਮੁੜ ਦਿਖਦੀਆਂ ਹਨ:
ਜਲਦੀ ਸੁਧਾਰ ਲਈ: ਇੰਤਜ਼ਾਰਾਂ ਨੂੰ ਦਿੱਖਣਯੋਗ ਅਤੇ ਸੀਮਿਤ ਬਣਾਓ। ਹੌਲੀ ਕੰਮ ਨੂੰ ਅਲੱਗ ਰਾਹ 'ਤੇ ਰੱਖੋ, ਕਿਊਜ਼ ਨੂੰ ਸੀਮਿਤ ਕਰੋ, ਅਤੇ ਪੂਰੇ ਹੋਣ 'ਤੇ ਕੀ ਕਰਨਾ ਹੈ ਉਸਦਾ ਫੈਸਲਾ ਪਹਿਲਾਂ ਤੋਂ ਲਵੋ (ਡ੍ਰਾਪ, ਸ਼ੈਡ, ਕੋਆਲੇਸ, ਜਾਂ ਬੈਕਪ੍ਰੈਸ਼ਰ)।
ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਫੀਚਰ ਵਾਂਗ ਸਮਝੋ। ਕੋਡ ਟਿਊਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਸਿਸਟਮ ਦੇ ਲਈ ਸਪਸ਼ਟ ਲਕਸ਼ ਅਤੇ ਗਾਰਡਰੈਲ ਹਨ।
ਸਧਾਰਨ ਟੈਸਟ: ਇੱਕ ਬਰਸਟ ਸਿਮੁਲੇਟ ਕਰੋ (ਮੁਆਮ ਟ੍ਰੈਫਿਕ ਦਾ 10x ਲਈ 30 ਸਕਿੰਡ)। ਜੇ p99 ਫਟਕਦਾ ਹੈ, ਤਾਂ ਪੁੱਛੋ ਕਿ ਇੰਤਜ਼ਾਰ ਕਿੱਥੇ ਹੋ ਰਿਹਾ ਹੈ: ਵਧ ਰਹੀਆਂ ਕਿਊਜ਼, ਇੱਕ ਹੌਲਾ ਕੰਜ਼ਿਊਮਰ, GC ਪੌਜ਼, ਜਾਂ ਸਾਂਝਾ ਸਰੋਤ।
Disruptor ਪੈਟਰਨ ਨੂੰ ਇੱਕ ਲਾਇਬ੍ਰੇਰੀ ਚੋਣ ਵਜੋਂ ਨਹੀਂ, ਬਲਕਿ ਇੱਕ ਵਰਕਫਲੋ ਵਜੋਂ ਦੇਖੋ। ਇੱਕ ਪਤਲਾ ਸਲਾਈਸ ਨਾਲ ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਸਾਬਤ ਕਰੋ ਪਹਿਲਾਂ, ਫਿਰ ਫੀਚਰ ਜੋੜੋ।
ਇਕ ਤਰੀਕਾ ਜੋ ਅਕਸਰ ਕੰਮ ਕਰਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ Koder.ai (koder.ai) ਉੱਤੇ ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ ਪਹਿਲਾਂ ਇਵੈਂਟ ਫਲੋ ਨੂੰ Planning Mode ਵਿੱਚ ਨਕਸ਼ਾ ਬਣਾਉਣਾ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ ਤਾਂ ਕਿ ਕਿਊਜ਼, ਲਾਕ, ਅਤੇ ਸੇਵਾ ਸੀਮਾਵਾਂ ਗਲਤੀ ਨਾਲ ਨਾ ਆ ਜਾਣ। Snapshots ਅਤੇ rollback ਦੁਹਰਾਏ ਪ੍ਰਯੋਗ ਔਸਾਨ ਬਣਾ ਦਿੰਦੇ ਹਨ ਅਤੇ ਐਸੇ ਬਦਲਾਅ ਜੋ throughput ਨੂੰ ਵਧਾਉਂਦੇ ਹਨ ਪਰ p99 ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੇ ਹਨ, ਉਹਨਾਂ ਨੂੰ ਵਾਪਸ ਲਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਨਿਭਰਦੇ ਰਹੋ: ਮਾਪਣ ਇਮਾਨਦਾਰ ਰੱਖੋ। ਇੱਕ ਫਿਕਸਡ ਟੈਸਟ ਸਕ੍ਰਿਪਟ ਵਰਤੋ, ਸਿਸਟਮ ਨੂੰ ਵਾਰਮ-ਅਪ ਕਰੋ, ਅਤੇ throughput ਅਤੇ ਲੈਟੈਂਸੀ ਦੋਹਾਂ ਰਿਕਾਰਡ ਕਰੋ। ਜਦੋਂ p99 ਲੋਡ ਨਾਲ ਵੱਧਦਾ ਹੈ, ਤੁਰੰਤ ਕੋਡ 'ਉਤਕਰਸ਼' ਕਰਨ ਦੀ ਥਾਂ GC, noisy neighbors, ਲੌਗਿੰਗ ਬਰਸਟ, ਥ੍ਰੈਡ ਸ਼ਡਿਊਲਿੰਗ, ਜਾਂ ਲੁਕਿਆ ਹੋਇਆ ਬਲਾਕਿੰਗ ਕਾਲ ਲੱਭੋ।
ਔਸਤਾਂ ਦੂਰ ਕਰਨੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਦਰਅਸਲ ਅਪਰੇਸ਼ਨਾਂ ਦੇ ਕਦੇ ਕਦੇ ਹੋਣ ਵਾਲੇ ਰੁਕਾਵਟਾਂ ਨੂੰ ਛੁਪਾਉਂਦੀਆਂ ਹਨ। ਜੇ ਜ਼ਿਆਦਾਤਰ ਕਾਰਜ ਤੇਜ਼ ਹਨ ਪਰ ਕੁਝ ਬਹੁਤ ਲੰਮੇ ਚੱਲਦੇ ਹਨ, ਤਾਂ ਉਪਭੋਗਤਾ ਉਹ ਮੋੜ-ਮੋੜ ਦੇ ਹੱਥਬਾਲੇ ਤਜਰਬੇ ਨੂੰ 'ਲੈਗ' ਵਜੋਂ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ ਵਾਸਤਵਿਕ-ਸਮਾਂ ਪ੍ਰਵਾਹਾਂ ਵਿੱਚ ਜਿੱਥੇ ਰਿਦਮ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੀ ਹੈ।
ਪੇਲਾਂ ਟੇਲ ਲੈਟੈਂਸੀ (ਜਿਵੇਂ p95/p99) ਨੂੰ ਟਰੈਕ ਕਰੋ ਕਿਉਂਕਿ ਨਜ਼ਰਅੰਦਾਜ਼ ਕੀਤੇ ਜਾਣ ਵਾਲੇ ਰੁਕਾਵਟਾਂ ਓਥੇ ਰਹਿੰਦੀਆਂ ਹਨ।
ਥਰੂਪੁਟ ਉਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇੱਕ ਸਕਿੰਟ ਵਿੱਚ ਕਿੰਨਾ ਕੰਮ ਖਤਮ ਕਰਦੇ ਹੋ। ਲੈਟੈਂਸੀ ਉਹ ਸਮਾਂ ਹੈ ਜੋ ਇੱਕ ਇਕਾਈ ਕੰਮ ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਅਖੀਰ ਤੱਕ ਲੱਗਦਾ ਹੈ।
ਤੁਸੀਂ ਉੱਚ throughput ਹੋ ਸਕਦੇ ਹੋ ਅਤੇ ਫਿਰ ਵੀ ਵੇਲੇ-ਵੇਲੇ ਲੰਬੇ ਰੁਕਾਵਟਾਂ ਦਾ ਸਾਹਮਣਾ ਕਰ ਸਕਦੇ ਹੋ, ਅਤੇ ਓਹੀ ਰੁਕਾਵਟਾਂ ਵਾਸਤਵਿਕ-ਸਮਾਂ ਐਪਾਂ ਨੂੰ ਧੀਮਾ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੀਆਂ ਹਨ।
ਟੇਲ ਲੈਟੈਂਸੀ (p95/p99) ਸਭ ਤੋਂ ਸੋਨੇ-ਚੰਗੇ ਬੇਨਿਯਾ ਕਾਰਜਾਂ ਨੂੰ ਮਾਪਦੀ ਹੈ, ਨਾ ਕਿ ਆਮ। p99 ਦਾ ਮਤਲਬ ਹੈ ਕਿ 1% ਓਪਰੇਸ਼ਨਾਂ ਉਸ ਨੰਬਰ ਤੋਂ ਲੰਬਾ ਸਮਾਂ ਲੈਂਦੀਆਂ ਹਨ।
ਰੀਅਲ-ਟਾਈਮ ਐਪਾਂ ਵਿੱਚ, ਉਹ 1% ਅਕਸਰ ਨਜ਼ਰ ਆਉਂਦੇ ਜਿਟਰ ਵਜੋਂ ਦਿਖਾਈ ਦਿੰਦੇ ਹਨ: ਆਡੀਓ ਵਿੱਚ ਪਾਪ, ਗੇਮ ਵਿੱਚ ਰਬਰ-ਬੈਂਡਿੰਗ, ਇੰਡਿਕੇਟਰਾਂ ਦਾ ਫਿੱਕਰਨਾ, ਜਾਂ ਟਿਕ ਛੁੱਟ ਜਾਣਾ।
ਜਿਆਦातर ਸਮਾਂ ਗਣਨਾ ਕਰਨ ਵਿੱਚ ਨਹੀਂ, ਬਲਕਿ ਇੰਤਜ਼ਾਰ ਵਿੱਚ ਲੰਘ ਜਾਂਦਾ ਹੈ:
ਇੱਕ 2 ms ਹੈਂਡਲਰ ਵੀ ਕੁਝ ਆਪਣੀਆਂ ਜਗ੍ਹਾਂ 'ਤੇ ਰੁਕਣ ਨਾਲ 60–80 ms ਦਾ ਸਮਾਂ ਲਗਾ ਸਕਦਾ ਹੈ।
ਆਮ ਜਿਟਰ ਸਰੋਤਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਡਿਬੱਗ ਕਰਨ ਲਈ, ਓਹਨਾਂ ਸਮਿਆਂ ਨਾਲ ਐਲੋਕੇਸ਼ਨ ਰੇਟ, ਕਾਂਟੈਕਸਟ ਸਵਿੱਚ, ਅਤੇ ਕਿਊ ਡੈਪਥ ਦਾ ਸਬੰਧ ਜ਼ਰੂਰ ਦੇਖੋ।
Disruptor ਇੱਕ ਢੰਗ ਹੈ ਜਿਸ ਨਾਲ ਇਵੈਂਟਾਂ ਨੂੰ ਇੱਕ ਪਾਈਪਲਾਈਨ ਵਿੱਚ ਛੋਟੇ ਤੇ ਸਥਿਰ ਦੇਰੀ ਨਾਲ ਲਿਜਾਇਆ ਜਾਂਦਾ ਹੈ। ਇਹ ਇਕ ਪ੍ਰੀ-ਅਲੋਕੇਟ ਕੀਤਾ ਰਿੰਗ ਬਫਰ ਅਤੇ ਸੀਕੁਐਂਸ ਨੰਬਰਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ ਸਾਂਝੀ ਕਿਊ ਦੀ ਥਾਂ।
ਮਕਸਦ ਐਲੋਕੇਸ਼ਨ, ਕੰਟੇਨਸ਼ਨ ਅਤੇ ਓੁੱਪ-ਅਤੇ-ਡਾਊਨ ਵੈਕਅੱਪ ਤੋਂ ਹੋਣ ਵਾਲੇ ਅਣਪੇਖੇ ਰੁਕਾਵਟਾਂ ਨੂੰ ਘਟਾ ਕੇ ਲੈਟੈਂਸੀ ਨੂੰ ‘‘ਬੋਰਿੰਗ’’ ਰੱਖਣਾ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ ਔਸਤ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਕਰਨਾ।
ਹੋਟ ਲੂਪ ਵਿੱਚ ਆਬਜੈਕਟ/ਬਫਰ ਪ੍ਰੀ-ਅਲੋਕੇਟ ਅਤੇ ਦੁਹਰਾਓ। ਇਹ ਘਟਾਉਂਦਾ ਹੈ:
ਉਸਦੇ ਨਾਲ-ਨਾਲ ਇਵੈਂਟ ਡੇਟਾ ਕਾਂਪੈਕਟ ਰੱਖੋ ਤਾਂ ਕਿ CPU ਹਰ ਇਵੈਂਟ ਲਈ ਘੱਟ ਮੈਮੋਰੀ ਛੁਏ (ਬਿਹਤਰ ਕੈਸ਼ ਬਿਹੇਵਿਅਰ)।
ਇੱਕ-ਥ੍ਰੈਡ ਲੂਪ ਸਾਧਾਰਨ ਤੌਰ 'ਤੇ ਚੰਗਾ ਹੈ ਜਦੋਂ ਆਰਡਰ ਮਹੱਤਵਪੂਰਨ ਹੋਵੇ ਕਿਉਂਕਿ ਸਟੇਟ ਇੱਕ ਹੀ ਥ੍ਰੈੱਡ ਦੇ ਕੋਲ ਰਹਿੰਦਾ ਹੈ। ਸ਼ਾਰਡਿੰਗ ਰਾਹੀਂ ਸਕੇਲ ਕਰਨਾ (ਉਦਾਹਰਣ: userId ਜਾਂ instrumentId ਦੇ ਮੁਤਾਬਕ) ਅਕਸਰ ਬਿਹਤਰ ਹੈ ਬਜਾਏ ਇਕ ਹੌਟ ਕਿਊ 'ਤੇ ਬਹੁਤ ਸਾਰੇ ਰਾਈਟਰਾਂ ਦੇ।
ਵਰਕਰ ਪੂਲ ਉਹਨਾਂ ਕੰਮਾਂ ਲਈ ਵਰਤੋਂ ਜਦੋਂ ਅਸਲ ਵਿੱਚ ਕੰਮ ਸੁਤੰਤਰ ਹੋਵੇ; ਨਹੀਂ ਤਾਂ ਤੁਸੀਂ throughput ਲਈ tail latency ਖੋ ਸਕਦੇ ਹੋ ਅਤੇ ਡੀਬੱਗਿੰਗ ਮੁਸ਼ਕਲ ਹੋ ਜਾਏਗੀ।
ਬੈਚਿੰਗ ਓਵਰਹੈੱਡ ਘਟਾਉਂਦੀ ਹੈ, ਪਰ ਜੇ ਤੁਸੀਂ ਘਟਨਾ ਭਰਨ ਲਈ ਇਵੈਂਟਾਂ ਨੂੰ ਰੋਕਦੇ ਹੋ ਤਾਂ ਇਹ ਰੁਕਣਾ ਵਧਾ ਸਕਦੀ ਹੈ।
ਵਿਵਹਾਰਕ ਨਿਯਮ: ਬੈਚਿੰਗ ਨੂੰ ਸਮੇਂ ਅਤੇ ਆਕਾਰ ਦੁੰਨੋਂ ਨਾਲ ਸੀਮਤ ਕਰੋ (ਉਦਾਹਰਣ: "ਵੱਧ ਤੋਂ ਵੱਧ N ਇਵੈਂਟ ਜਾਂ T ਮਾਈਕ੍ਰੋਸੈਕਿੰਡ, ਜੋ ਵੀ ਪਹਿਲਾਂ ਪੂਰਾ ਹੋਏ") ਤਾਂ ਕਿ ਬੈਚਿੰਗ ਲੈਟੈਂਸੀ ਬਜਟ ਨੂੰ ਅਚਾਨਕ ਨਾ ਤੋੜੇ।
ਇੱਕ ਲਿਖਤੀ ਲੈਟੈਂਸੀ ਬਜਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਇੱਕ ਟਾਰਗੇਟ ਚੁਣੋ (ਕਿਹੜਾ "ਚੰਗਾ" ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ) ਅਤੇ ਇੱਕ p99 ਜਿਨ੍ਹਾਂ ਦੇ ਅੰਦਰ ਤੁਹਾਨੂੰ ਰਹਿਣਾ ਲਾਜ਼ਮੀ ਹੈ। ਉਸ ਨੰਬਰ ਨੂੰ ਇਨਪੁੱਟ, ਵੈਲਿਡੇਸ਼ਨ, ਮਿਲਾਣ, ਪਾਇਲਟ, ਅਤੇ ਆਉਟਬਾਊਂਡ ਅਪਡੇਟਾਂ ਵਰਗੇ ਪੜਾਅ ਵਿੱਚ ਵੰਡੋ।
ਇੱਕ ਵਾਰ ਪੜਾਅਾਂ ਦੀ ਲਿਸਟ ਹੋ ਜਾਵੇ, ਹਰ ਹੈਂਡਆਫ਼ (ਥ੍ਰੈਡ ਬਾਉਂਡਰੀ, ਕਿਊ, ਨੈੱਟਵਰਕ ਹੋਪ, ਸਟੋਰੇਜ਼ ਕਾਲ) ਨੂੰ ਨਿਸ਼ਾਨ ਲਗਾਓ — ਇਹ ਓਹ ਜਗ੍ਹਾਂ ਹਨ ਜਿੱਥੇ ਜਿਟਰ ਛੁਪਦਾ ਹੈ।
ਕदम-ਬ-ਕਦਮ ਵਰਕਫਲੋ:
ਗਾਰਬੇਜ-ਕਲੇਕਟ ਕੀਤੇ ਰੰਟਾਈਮ (JVM, Go, .NET) ਉਤਪਾਦਕਤਾ ਲਈ ਵਧੀਆ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਜਦੋਂ ਯਾਦ ਸ਼ਾਮਲ ਹੋਣੀ ਪੈਂਦੀ ਹੈ ਤਾਂ ਪੌਜ਼ ਹੋ ਸਕਦੇ ਹਨ। ਆਧੁਨਿਕ ਕਲੇਕਟਰ ਪਹਿਲਾਂ ਨਾਲੋਂ ਬਿਹਤਰ ਹਨ, ਪਰ ਲੋਡ ਹੇਠਾਂ ਬਹੁਤ ਸਾਰੀਆਂ ਛੋਟੀਆਂ ਅਸਥਾਈ ਵਸਤੂਆਂ ਬਣਾਉਣ ਨਾਲ ਟੇਲ ਲੈਟੈਂਸੀ ਵੱਧ ਸਕਦੀ ਹੈ।
ਗੈਰ-GC ਭਾਸ਼ਾਵਾਂ (Rust, C, C++) GC ਪੌਜ਼ ਤੋਂ ਬਚਦੀਆਂ ਹਨ, ਪਰ ਲੈਣ-ਦੇਣ ਅਤੇ ਐਲੋਕੇਸ਼ਨ ਨਿਯਮਾਂ ਨੂੰ ਹੱਥੋਂ ਸੰਭਾਲਣ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਕਾਰਗਰ ਆਦਤ: ਜਿੱਥੇ ਐਲੋਕੇਸ਼ਨ ਹੁੰਦੀ ਹੈ ਉਸ ਨੂੰ ਪਤਾ ਲਗਾਓ ਅਤੇ ਓਥੇ ਰੁਟੀਨ ਬਣਾਓ। ਆਬਜੈਕਟ ਦੁਹਰਾਓ, ਬਫਰ ਪਹਲੇ ਹੀ ਸਾਈਜ਼ ਕਰੋ, ਅਤੇ ਹਾਟ-ਪਾਥ ਡੇਟਾ ਨੂੰ ਅਸਥਾਈ ਸਤਰਿੰਗਾਂ ਜਾਂ ਨਕਸ਼ਿਆਂ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਬਚੋ।
ਥ੍ਰੈਡਿੰਗ ਫੈਸਲੇ ਵੀ ਜਿਟਰ ਵਜੋਂ ਨਜ਼ਰ ਆਉਂਦੇ ਹਨ—ਹਰ ਵਾਧੂ ਕਿਊ, ਐਸਿੰਕ ਹੋਪ ਜਾਂ ਥ੍ਰੈਡ ਪੂਲ ਹੈਂਡਆਫ਼ ਇੰਤਜ਼ਾਰ ਜੋੜਦੇ ਹਨ ਅਤੇ ਵੈਰੀਅੰਸ ਵਧਾਉਂਦੇ ਹਨ। ਛੋਟੇ ਅਤੇ ਲੰਬੇ-ਜੀਵਨ ਵਾਲੇ ਥ੍ਰੈਡਾਂ ਦੀ ਵਰਤੋਂ ਕਰੋ, ਪ੍ਰੋਡੀੂਸਰ-ਕੰਜ਼ਿਊਮਰ ਬਾਊਂਡਰੀਆਂ ਸਾਫ਼ ਰੱਖੋ, ਅਤੇ ਹਾਟ ਪਾਥ 'ਤੇ ਬਲਾਕਿੰਗ ਕਾਲਾਂ ਤੋਂ ਬਚੋ।
ਬਹੁਤ ਸਾਰੀਆਂ ਲੈਟੈਂਸੀ ਸਪਾਇਕਸ 'ਧੀਮਾ ਕੋਡ' ਨਹੀਂ ਹੁੰਦੀਆਂ — ਉਹ ਅਣਉਮੀਦਤ ਇੰਤਜ਼ਾਰ ਹੁੰਦੇ ਹਨ: ਡੇਟਾਬੇਸ ਲਾਕ, ਰੀਟ੍ਰਾਈ ਝੁੰਡ, ਕ੍ਰਾਸ-ਸੇਵਾ ਕਾਲ ਜਿਹੜੀ ਰੁਕੀ, ਜਾਂ ਕੈਸ਼ ਮਿਸ ਜਿਸਦਾ ਪੂਰਾ ਰਾਉਂਡ-ਟ੍ਰਿਪ ਬਣ ਜਾਂਦਾ ਹੈ।
ਕ੍ਰਿਟਿਕਲ ਪਾਥ ਛੋਟਾ ਰੱਖੋ। ਹਰੇਕ ਹੋਪ ਨੇ ਸ਼ਡਿਊਲਿੰਗ, ਸੀਰੀਅਲਾਈਜ਼ੇਸ਼ਨ, ਨੈੱਟਵਰਕ ਕਿਊਜ਼ ਅਤੇ ਹੋਰ ਬਲਾਕਿੰਗ ਦੀ ਸੰਭਾਵਨਾ ਜੋੜਦੀ ਹੈ। ਜੇ ਇਕ ਪ੍ਰੋਸੈਸ ਅਤੇ ਇਕ ਡੇਟਾ ਸਟੋਰ ਤੋਂ ਰਿਸਪਾਂਸ ਦਿੱਤਾ ਜਾ ਸਕਦਾ ਹੈ ਤਾਂ ਪਹਿਲਾਂ ਉਹ ਕਰੋ। ਸੇਵਾਵਾਂ ਨੂੰ ਵੰਡੋ ਕੇਵਲ ਜਦੋਂ ਹਰ ਕਾਲ ਵਿਕਲਪਿਕ ਜਾਂ ਸੀਮਿਤ ਹੋਵੇ।
ਸੀਮਤ ਇੰਤਜ਼ਾਰ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਤੇਜ਼ ਠੀਕ-ਥਾਣੇ ਟਾਇਮਆਊਟ ਰੱਖੋ ਅਤੇ ਜੇ ਡਿਪੈਂਡੈਂਸੀ ਗਲਤ ਹੋਵੇ ਤਾਂ ਤੇਜ਼ੀ ਨਾਲ ਫੇਲ ਕਰੋ। ਸਰਕਿਟ ਬ੍ਰੇਕਰ ਸਿਰਫ ਸਰਵਰਾਂ ਨੂੰ ਬਚਾਉਣ ਲਈ ਨਹੀਂ — ਉਹ ਇਸ ਗੱਲ ਨੂੰ ਵੀ ਸੀਮਤ ਕਰਦੇ ਹਨ ਕਿ ਯੂਜ਼ਰ ਕਿੰਨੀ ਦੇਰ ਲਈ ਫਸ ਸਕਦਾ ਹੈ।
ਪੜ੍ਹਨ ਲਈ, ਪੜ੍ਹਨ ਦੀਆਂ ਬੇਨਤੀਆਂ ਅਕਸਰ ਇੰਡੈਕਸਡ, ਡਿਨੋਰਮਲਾਈਜ਼ਡ ਅਤੇ ਕੈਸ਼-ਫ੍ਰੈਂਡਲੀ ਆਕਾਰ ਚਾਹੁੰਦੀਆਂ ਹਨ; ਲਿਖਤਾਂ ਨੂੰ ਟਿਕਾਉਣ ਅਤੇ ਆਰਡਰਿੰਗ ਲਈ ਸਖ਼ਤਤਾ ਚਾਹੀਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਹੋਰ ਖਰਾਬੀ ਮਨਜੂਰ ਕਰ ਸਕਦੇ ਹੋ ਤਾਂ ਐਪੈਂਡ-ਓਨਲੀ ਰਿਕਾਰਡ (ਇਵੈਂਟ ਲੌਗ) ਅਕਸਰ ਜ਼ਿਆਦਾ ਪੇਸ਼ਗੋਈਯੋਗ ਵਤੀਰੇ ਦਿਖਾਉਂਦੇ ਹਨ।
ਇੱਕ ਸਧਾਰਨ ਨਿਯਮ: ਪਹੁੰਚ ਰੀਅਲ-ਟਾਈਮ ਐਪ ਵਿੱਚ ਪERSISTENCE ਸਿਰਫ਼ ਉਸ ਸਮੇਂ ਕ੍ਰਿਟਿਕਲ ਹੋਵੇ ਜਦੋਂ ਇਹ ਸਹੀਤਾ ਲਈ ਲਾਜ਼ਮੀ ਹੋਵੇ। ਬਹੁਤ ਵਾਰੀ ਬੇਹਤਰ ਰੂਪ: ਪਹਿਲਾਂ ਮੈਮੋਰੀ ਵਿੱਚ ਅਪਡੇਟ, ਫਿਰ ਰਿਸਪਾਂਡ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਐਸਿੰਕ ਨਾਲ ਪERSIST ਕਰੋ (ਜਿਵੇਂ ਆਉਟਬਾਕਸ ਜਾਂ ਰਾਈਟ-ਅਹੈੱਡ ਲੌਗ)।
ਕਲਪਨਾ ਕਰੋ ਇੱਕ ਲਾਈਵ ਸਹਿ-ਕਾਰੀ ਐਪ ਜਾਂ ਛੋਟਾ ਮਲਟੀਪਲੇਅਰ ਗੇਮ ਜੋ ਹਰ 16 ms (ਲਗਭਗ 60Hz) ਅਪਡੇਟ ਪুশ ਕਰਦਾ ਹੈ। ਮਕਸਦ 'ਔਸਤ ਤੇਜ਼' ਨਹੀਂ, ਸਗੋਂ 'ਅਕਸਰ 16 ms ਤੋਂ ਘੱਟ' ਹੋਣਾ ਹੈ, ਭਾਵੇਂ ਕਿਸੇ ਯੂਜ਼ਰ ਦੀ ਕਨੈਕਸ਼ਨ ਖਰਾਬ ਹੋਵੇ।
ਸਧਾਰਨ Disruptor-ਸਟਾਈਲ ਫਲੋ:
ਏਦਾਂ ਦੇ ਡਿਜ਼ਾਇਨ ਵਿੱਚ, ਜੇ ਕੋਈ ਹੈਂਡਲਰ ਹੌਲੀ ਹੋ ਜਾਏ ਤਾਂ ਉਸਨੂੰ ਆਪਣੇ ਬਫਰ ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਅਤੇ ਮූਲ ਲੂਪ ਨੂੰ ਬਲਾਕ ਨਾ ਕਰੋ; ਮੁਢਲੇ ਲੂਪ ਵਿੱਚ ਇੱਕ ਹਲਕਾ ਵਰਕ ਆਈਟਮ ਪਬਲਿਸ਼ ਕਰੋ। ਹਰੇਕ ਕਲਾਇੰਟ ਲਈ ਛੋਟੀ ਸੈਂਡ ਕਿਊ ਰੱਖੋ ਅਤੇ ਓਲਡ ਅਪਡੇਟ ਡ੍ਰਾਪ ਜਾਂ ਕੋਆਲੇਸ ਕਰ ਦਿਓ ਤਾਂ ਜੋ ਤਾਜ਼ਾ ਸਟੇਟ ਰਹੇ। ਜੇ ਬਫਰ ਡੈਥ ਵਧਦੀ ਹੈ ਤਾਂ ਐਜ 'ਤੇ ਬੈਕਪ੍ਰੈਸ਼ਰ ਲਗਾਓ (ਉਸ ਟਿਕ ਲਈ ਹੋਰ ਇਨਪੁੱਟ ਰੋਕੋ ਜਾਂ ਫੀਚਰ ਘਟਾਓ)।
ਕਿਸੇ ਵੀ ਸਿਸਟਮ ਦੇ ਵੱਡੇ ਭਾਗ ਖੁਦ ਕੀਤਾ ਹੁੰਦੇ ਹਨ। ਕਈ ਵਾਰੀ ਕੋਡ ਤੇਜ਼ ਹੁੰਦਾ ਹੈ ਪਰ ਸਿਸਟਮ ਹੋਰ ਥ੍ਰੈਡਾਂ, OS ਜਾਂ CPU ਕੈਸ਼ ਦੇ ਬਾਹਰ ਕੁਝ 'ਉਹ' ਚੀਜ਼ਾਂ ਦੇ ਇੰਤਜ਼ਾਰ ਕਰਦੀ ਹੈ।
ਆਮ ਗਲਤੀਆਂ:
ਪੇਸ਼ਗੋਈਯੋਗ ਲੈਟੈਂਸੀ ਨੂੰ ਇੱਕ ਪ੍ਰੋਡਕਟ ਫੀਚਰ ਵਾਂਗ ਦੇਖੋ, ਨਾ ਕਿ ਕਿਸੇ ਕੌਸ਼ਿਸ਼ ਦਾ ਨਤੀਜਾ। ਕੋਡ ਟਿਊਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਸਿਸਟਮ ਲਈ ਸਾਫ਼ ਲਕਸ਼ ਪਾ ਲਵੋ ਅਤੇ ਗਰਡਰੈਲ ਤੈਅ ਕਰੋ।
ਸਧਾਰਨ ਟੈਸਟ: ਇੱਕ ਬਰਸਟ ਦੀ ਨਕਲ ਕਰੋ (ਮੁਆਮ ਟ੍ਰੈਫਿਕ ਦੇ 10x ਲਈ 30 ਸੈਕਿੰਡ)। ਜੇ p99 ਵਿਸਫੋਟਕ ਹੋ ਜਾਏ, ਤਾਂ ਪੁੱਛੋ ਕਿ ਇੰਤਜ਼ਾਰ ਕਿੱਥੇ ਹੋ ਰਿਹਾ ਹੈ: ਵਧ ਰਹੀਆਂ ਕਿਊਜ਼, ਇੱਕ ਹੌਲਾ ਕਨਜ਼ਿਊਮਰ, ਇੱਕ GC ਪੌਜ਼, ਜਾਂ ਕੋਈ ਸਾਂਝਾ ਸਰੋਤ।
Disruptor ਪੈਟਰਨ ਨੂੰ ਇੱਕ ਲਾਇਬ੍ਰੇਰੀ ਚੋਣ ਵਜੋਂ ਨਹੀਂ, ਬਲਕਿ ਇੱਕ ਵਰਕਫਲੋ ਵਜੋਂ ਦੇਖੋ। ਇੱਕ ਪਤਲਾ ਸਲਾਈਸ ਸਬੂਤ ਕਰੋ ਕਿ ਲੈਟੈਂਸੀ ਪੇਸ਼ਗੋਈਯੋਗ ਹੈ ਪਹਿਲਾਂ, ਫਿਰ ਫੀਚਰ ਸ਼ਾਮਲ ਕਰੋ।
ਨਾਲੀਕ੍ਰਮ ਜੋ ਆਮ ਤੌਰ 'ਤੇ ਕੰਮ ਕਰਦਾ ਹੈ:
ਜੇ ਤੁਸੀਂ Koder.ai (koder.ai) 'ਤੇ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਪਹਿਲਾਂ ਇਵੈਂਟ ਫਲੋ ਦਾ ਨਕਸ਼ਾ ਬਣਾਉਣਾ ਮਦਦਗਾਰ ਹੈ ਤਾਂ ਕਿ ਕਿਊਜ਼, ਲਾਕ ਅਤੇ ਸੇਵਾ ਸੀਮਾਵਾਂ ਗਲਤੀ ਨਾਲ ਨਾ ਆ ਜਾਣ। Snapshots ਅਤੇ rollback ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਲੈਟੈਂਸੀ ਪ੍ਰਯੋਗਾਂ ਨੂੰ ਚਲਾਉਣ ਅਤੇ ਉਹ ਚੀਜ਼ਾਂ ਵਾਪਸ ਲੈਣ ਵਿੱਚ ਸਹਾਇਕ ਹੁੰਦੇ ਹਨ ਜੋ throughput ਨੂੰ ਵਧਾਉਂਦੀਆਂ ਹਨ ਪਰ p99 ਨੂੰ ਖਰਾਬ ਕਰਦੀਆਂ ਹਨ।
ਫਿਰ ਤੈਅ ਕਰੋ ਕਿ ਕੀ ਕੁਝ ਅਸਿੰਕਰੇਨਸ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਯੂਜ਼ਰ ਅਨੁਭਵ ਬਦਲੇ। ਇਕ ਸਧਾਰਨ ਨਿਯਮ: ਜੋ ਕੁਝ 'ਹੁਣ' ਵੇਖਾਉਂਦਾ ਹੈ ਉਹ ਕ੍ਰਿਟਿਕਲ ਪਾਥ 'ਤੇ ਰਹੇ, ਬਾਕੀ ਸਾਈਡ-ਪਾਥ ਤੇ ਭੇਜੋ।
ਤੁਸੀਂ ਜਾਣ ਲਓ ਕਿ ਇਹ ਕੰਮ ਕਰ ਰਿਹਾ ਹੈ ਜਦੋਂ ਬੈਕਲੌਗ ਡੈਪਥ ਨਜ਼ਦੀਕੀ ਜ਼ੀਰੋ 'ਤੇ ਟਿਕੀ ਰਹਿੰਦੀ ਹੈ, ਡ੍ਰਾਪ/ਕੋਆਲੇਸ ਹੋਣਾ ਅਨੁਮਾਨਯੋਗ ਅਤੇ ਥੋੜ੍ਹਾ-ਬਹੁਤ ਹੁੰਦਾ ਹੈ, ਅਤੇ p99 ਤੁਹਾਡੇ ਟਿਕ ਬਜਟ ਤੋਂ ਹੇਠਾਂ ਰਹਿੰਦਾ ਹੈ।
ਜਲਦੀ ਸੁਧਾਰ ਲਈ: ਇੰਤਜ਼ਾਰਾਂ ਨੂੰ ਦਿੱਖਣਯੋਗ ਅਤੇ ਸੀਮਿਤ ਬਣਾਓ। ਹੌਲੀ ਕੰਮ ਨੂੰ ਅਲੱਗ ਰਾਹ 'ਤੇ ਰੱਖੋ, ਕਿਊਜ਼ ਨੂੰ ਸੀਮਿਤ ਕਰੋ, ਅਤੇ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਪੂਰਾ ਹੋਣ 'ਤੇ ਕੀ ਕਰਨਾ ਹੈ (ਡ੍ਰਾਪ, ਲੋਡ ਸ਼ੈਡ, ਕੋਆਲੇਸ ਜਾਂ ਬੈਕਪ੍ਰੈਸ਼ਰ)।
ਮਾਪਣਾਂ ਨੂੰ ਇਮਾਨਦਾਰ ਰੱਖੋ: ਇੱਕ ਫਿਕਸਡ ਟੈਸਟ ਸਕ੍ਰਿਪਟ ਵਰਤੋ, ਸਿਸਟਮ ਨੂੰ ਵਾਰਮ-ਅਪ ਕਰੋ, ਅਤੇ ਦੋਹਾਂ throughput ਅਤੇ ਲੈਟੈਂਸੀ ਰਿਕਾਰਡ ਕਰੋ। ਜਦੋਂ p99 ਲੋਡ ਨਾਲ ਛੱਲਾਂ ਮਾਰਦਾ ਹੈ, ਤੁਰੰਤ ਕੋਡ 'ਓਪਟੀਮਾਈਜ਼' ਕਰਨ ਦੀ ਬਜਾਏ GC, noisy neighbors, ਲੌਗਿੰਗ ਬਰਸਟ, ਥ੍ਰੈਡ ਸ਼ਡਿਊਲਿੰਗ, ਜਾਂ ਲੁਕਿਆ ਹੋਇਆ ਬਲਾਕਿੰਗ ਕਾਲ ਖੋਜੋ।