"Distributed SQL" ਦਾ ਸਧਾਰਨ ਮਤਲਬ (ਬਿਨਾ ਛੋਟੇ-ਮੋਟੇ ਸ਼ਬਦਾਂ ਦੇ)
"Distributed SQL" ਇੱਕ ਐਸਾ ਡੇਟਾਬੇਸ ਹੈ ਜੋ ਪਰੰਪਰਾਗਤ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਵਾਂਗ ਦਿੱਸਦਾ ਅਤੇ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ—ਟੇਬਲ, ਰੋਜ਼, ਜੋਇਨ, ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਤੇ SQL—ਪਰ ਇਹ ਕਲੱਸਟਰ ਵਜੋਂ ਕਈ ਮਸ਼ੀਨਾਂ (ਅਕਸਰ ਕਈ ਰੀਜਨਾਂ) 'ਤੇ ਚਲਾਉਣ ਲਈ ਡਿਜ਼ਾਇਨ ਕੀਤਾ ਗਿਆ ਹੈ ਅਤੇ ਫਿਰ ਵੀ ਇੱਕ ਲਾਜ਼ਮੀ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਦੀ ਤਰ੍ਹਾਂ ਵਰਤਦਾ ਹੈ।
ਇਹ ਸੰਯੋਗ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇਕੋ ਸਮੇਂ ਤਿੰਨ ਚੀਜਾਂ ਦੇ ਮਿਸ਼ਰਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ:
- SQL ਅਤੇ ਰਿਲੇਸ਼ਨਲ ਮਾਡਲਿੰਗ: ਜਾਣਪਛਾਣ ਵਾਲੇ ਸਕੀਮਾ, constraints ਅਤੇ ਕਵੈਰੀ tooling।
- Scale-out: ਸਮਰੱਥਾ ਵੱਧਾਉਣ ਲਈ ਨੋਡ ਸ਼ਾਮਲ ਕਰੋ, “ਵੱਡਾ ਸਰਵਰ ਖਰੀਦੋ” ਦੇ ਬਦਲੇ।
- ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ: ਜਦੋਂ ਡੇਟਾ ਫੈਲਾ ਹੋਵੇ ਤਾਂ ਵੀ ਰੀਡ ਅਤੇ ਲਿਖਤ ਸਪਸ਼ਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨਿਯਮਾਂ ਨੂੰ ਫਾਲੋ ਕਰਦੇ ਹਨ।
ਕਲਾਸਿਕ RDBMS ਅਤੇ NoSQL ਦੇ ਵਿਚਕਾਰ
ਇੱਕ ਕਲਾਸਿਕ RDBMS (ਜਿਵੇਂ PostgreSQL ਜਾਂ MySQL) ਆਮ ਤੌਰ 'ਤੇ ਸਭ ਕੁਝ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਨੋਡ 'ਤੇ ਰਹਿਣ 'ਤੇ ਚਲਾਉਣ ਲਈ ਸਭ ਤੋਂ ਆਸਾਨ ਹੁੰਦਾ ਹੈ। ਤੁਸੀਂ ਰੀਡਾਂ ਨੂੰ ਰੈਪਲਿਕਾਸ ਨਾਲ ਸਕੇਲ ਕਰ ਸਕਦੇ ਹੋ, ਪਰ ਲਿਖਤਾਂ ਨੂੰ ਸਕੇਲ ਕਰਨਾ ਅਤੇ ਰੀਜਨਲ ਆਊਟੇਜ ਤੋਂ ਬਚਣਾ ਅਕਸਰ ਵੱਖਰੀ ਆਰਕੀਟੈਕਚਰ (ਸ਼ਾਰਡਿੰਗ, ਮੈਨੂਅਲ ਫੇਲਓਵਰ ਅਤੇ ਧਿਆਨ ਨਾਲ ਐਪਲੀਕੇਸ਼ਨ ਲੌਜਿਕ) ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ।
ਕਈ NoSQL ਸਿਸਟਮ ਵੱਲੋਂ ਵਰਤਿਆ ਗਿਆ ਰੁਖ ਉਲਟ ਸੀ: ਪਹਿਲਾਂ ਸਕੇਲ ਅਤੇ ਉਪਲਬਧਤਾ ਅਤੇ ਕਈ ਵਾਰੀ consistency ਗੈਰੰਟੀ ਨੂੰ ਢੀਲਾ ਕਰਕੇ ਜਾਂ ਸਧਾਰਨ ਕਵੈਰੀ ਮਾਡਲ ਦੇ ਕੇ।
Distributed SQL ਇੱਕ ਦਰਮਿਆਨੀ ਰਾਹ ਲੱਭਦਾ ਹੈ: ਰਿਲੇਸ਼ਨਲ ਮਾਡਲ ਅਤੇ ACID ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਰੱਖੋ, ਪਰ ਡੇਟਾ ਨੂੰ ਆਪੋ-ਆਪਣੇ ਵੰਡ ਕੇ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਅਤੇ ਫੇਲਿਅਰ ਨੂੰ ਸੰਭਾਲੋ।
ਇਹ ਕੀ ਹੱਲ ਕਰਨਾ ਚਾਹੁੰਦਾ ਹੈ
Distributed SQL ਡੇਟਾਬੇਸ ਉਹ ਸਮੱਸਿਆਵਾਂ ਲਈ ਬਣਾਏ ਜਾਂਦੇ ਹਨ ਜਿਵੇਂ:
- ਗਲੋਬਲ ਐਪਲੀਕੇਸ਼ਨ ਜਿਨ੍ਹਾਂ ਦੇ ਯੂਜ਼ਰ ਕਈ ਰੀਜਨਾਂ ਵਿੱਚ ਹਨ, ਜਿੱਥੇ latency ਅਤੇ uptime ਦੋਹਾਂ ਮਹੱਤਵ ਰੱਖਦੇ ਹਨ।
- ਉੱਚ ਉਪਲਬਧਤਾ ਬਿਨਾ ਜਟਿਲ, ਮੈਨੂਅਲ ਫੇਲਓਵਰ ਪ੍ਰਕਿਰਿਆਵਾਂ ਦੇ।
- ਸਮਾਂ ਦੇ ਨਾਲ ਵਾਧਾ, ਜਿੱਥੇ ਤੁਸੀਂ ਸਮਰੱਥਾ ਕਦਮ-ਬ-ਕਦਮ ਵਧਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਅਤੇ ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ ਇੰਟਰਨਫੇਸ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ।
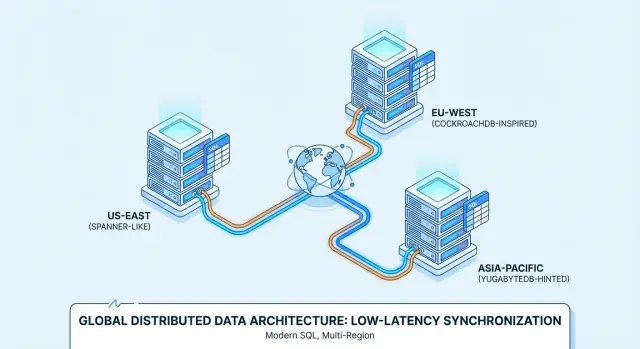
ਇਸੇ ਲਈ Google Spanner, CockroachDB ਅਤੇ YugabyteDB ਵਰਗੇ ਪ੍ਰੋਡਕਟ ਆਮ ਤੌਰ 'ਤੇ ਮਲਟੀ-ਰੀਜਨ ਤੈਨਾਤੀ ਅਤੇ ਹਮੇਸ਼ਾ-ਚਾਲੂ ਸਰਵਿਸਾਂ ਲਈ ਮੁਲਾਂਕਣ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਉਮੀਦਾਂ ਸੈੱਟ ਕਰੋ (ਇਹ ਡਿਫੌਲਟ ਨਹੀਂ)
Distributed SQL ਆਪੋ-ਆਪ ਵਿੱਚ “ਉੱਪਰਲੇ” ਨਹੀਂ ਹੈ। ਤੁਸੀਂ ਹੋਰ ਹਿੱਸਿਆਂ ਅਤੇ ਵੱਖਰੇ ਪ੍ਰਦਰਸ਼ਨ ਹਕੀਕਤਾਂ (ਨੈੱਟਵਰਕ ਹਾਪ, ਕਨਸੈਂਸਸ, ਕਰਾਸ-ਰੀਜਨ ਲੈਟੈਂਸੀ) ਨੂੰ ਸਵੀਕਾਰ ਕਰ ਰਹੇ ਹੋ ਬਦਲੇ ਵਿੱਚ resilience ਅਤੇ ਸਕੇਲ ਮਿਲਦੀ ਹੈ।
ਜੇ ਤੁਹਾਡਾ ਵਰਕਲੋਡ ਇੱਕ ਖੱਚੇ ਤਰੀਕੇ ਨਾਲ ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ 'ਤੇ ਆ ਸਕਦਾ ਹੈ ਅਤੇ ਇੱਕ ਸਿੱਧਾ replication ਸੈਟਅੱਪ ਨਾਲ ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਤਾੰ ਪਰੰਪਰਾਗਤ RDBMS ਸਧਾਰਨ ਅਤੇ ਸਸਤਾ ਹੋ ਸਕਦਾ ਹੈ। Distributed SQL ਉਸ ਵੇਲੇ ਆਪਣੇ ਲਈ ਓਕਾ ਵਜੀਫਾ ਦਿਖਾਉਂਦਾ ਹੈ ਜਦੋਂ ਵਿਕਲਪ ਮੈਨੂਅਲ ਸ਼ਾਰਡਿੰਗ, ਜਟਿਲ ਫੇਲਓਵਰ, ਜਾਂ ਬਿਜ਼ਨਸ ਲੋੜਾਂ ਹਨ ਜਿਹਨਾਂ ਨੂੰ ਬਹੁ-ਖੇਤਰ ਸਥਿਰਤਾ ਅਤੇ uptime ਦੀ ਲੋੜ ਹੈ।
Distributed SQL ਅੰਦਰੋਂ ਕਿਵੇਂ ਕੰਮ ਕਰਦਾ ਹੈ
Distributed SQL ਇਸ ਤਰ੍ਹਾਂ ਬਣਾਇਆ ਜਾਂਦਾ ਹੈ ਕਿ ਇਹ ਇੱਕ ਜਾਣਪਛਾਣ-ਯੋਗ SQL ਡੇਟਾਬੇਸ ਵਾਂਗ ਮਹਿਸੂਸ ਹੋਵੇ ਪਰ ਡੇਟਾ ਕਈ ਮਸ਼ੀਨਾਂ (ਅਕਸਰ ਕਈ ਰੀਜਨਾਂ) 'ਤੇ ਸਟੋਰ ਹੋਵੇ। ਔਖਾ ਕੰਮ ਇਹ ਹੈ ਕਿ ਕਈ ਕੰਪਿਊਟਰਾਂ ਨੂੰ ਐਸਾ ਕੋਆਰਡੀਨੇਟ ਕਰਨਾ ਤਾਂ ਕਿ ਉਹ ਇੱਕ ਭਰੋਸੇਮੰਦ ਸਿਸਟਮ ਵਾਂਗ ਵਤੀਰਾ ਕਰਨ।
ਰੀਪਲੀਕੇਸ਼ਨ + ਕਨਸੈਂਸਸ: ਨੋਡ ਕਿਵੇਂ ਇਕੱਠੇ ਸਹਿਮਤ ਹੁੰਦੇ ਹਨ
ਹਰ ਡੇਟਾ ਦਾ ਹਿੱਸਾ ਆਮ ਤੌਰ 'ਤੇ ਕਈ ਨੋਡਾਂ 'ਤੇ ਨਕਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ (ਰੀਪਲੀਕੇਸ਼ਨ)। ਜੇ ਇੱਕ ਨੋਡ ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਦੂਜੀ ਨਕਲ ਫਿਰ ਵੀ ਰੀਡ ਦੇ ਸਕਦੀ ਹੈ ਅਤੇ ਲਿਖਤ ਸਵੀਕਾਰ ਕਰ ਸਕਦੀ ਹੈ।
ਰੈਪਲਿਕਾ ਦੀਆਂ ਗਲਤੀਆਂ ਨੂੰ ਰੋਕਣ ਲਈ Distributed SQL ਸਿਸਟਮਾਂ ਕਨਸੈਂਸਸ ਪ੍ਰੋਟੋਕੋਲ ਵਰਤਦੇ ਹਨ—ਸਭ ਤੋਂ ਆਮ ਤੌਰ 'ਤੇ Raft (CockroachDB, YugabyteDB) ਜਾਂ Paxos (Spanner)। ਉੱਪਰਲੀ ਸਤਰ 'ਤੇ, ਕਨਸੈਂਸਸ ਦਾ ਮਤਲਬ ਹੁੰਦਾ ਹੈ:
- ਇੱਕ ਰੈਪਲਿਕਾ ਇੱਕ ਗਰੁੱਪ ਲਈ "ਲੀਡਰ" ਵਜੋਂ ਕੰਮ ਕਰਦੀ ਹੈ।
- ਲਿਖਤਾਂਲੀਦਰ ਕੋਲ ਜਾਂਦੀਆਂ ਹਨ।
- ਲੀਡਰ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਲਿਖਤ ਦੀ ਪੁਸ਼ਟੀ ਕਰਦਾ ਹੈ ਜਦੋਂ ਰੈਪਲਿਕਿਆਂ ਦੀ ਬਹੁਭਾਗ ਉਨ੍ਹਾਂ ਨੂੰ ਸੁਵੀਕਾਰ ਕਰ ਲੈਂਦੀ ਹੈ।
ਉਹ "ਬਹੁਭਾਗ ਵੋਟ" ਹੀ ਤੁਹਾਨੂੰ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਦਿੰਦਾ ਹੈ: ਇਕ ਵਾਰੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ commit ਹੋ ਜਾਵੇ, ਹੋਰ ਕਲਾਇੰਟ ਪੁਰਾਣੀ ਵਰਜਨ ਨਹੀਂ ਦੇਖਣਗੇ।
ਸ਼ਾਰਡਿੰਗ/ਪਾਰਟੀਸ਼ਨਿੰਗ: ਡੇਟਾ ਕਿੱਥੇ ਰਹਿੰਦਾ ਹੈ
ਕੋਈ ਇਕ ਨੋਡ ਸਭ ਕੁਝ ਨਹੀਂ ਰੱਖ ਸਕਦਾ, ਇਸ ਲਈ ਟੇਬਲਾਂ ਨੂੰ ਛੋਟੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ shards/partitions ਕਿਹਾ ਜਾਂਦਾ ਹੈ (Spanner ਉਨ੍ਹਾਂ ਨੂੰ splits ਕਹਿੰਦਾ ਹੈ; CockroachDB ਉਹਨਾਂ ਨੂੰ ranges ਕਹਿੰਦਾ ਹੈ; YugabyteDB ਉਨ੍ਹਾਂ ਨੂੰ tablets ਕਹਿੰਦਾ ਹੈ)।
ਹਰ ਪਾਰਟੀਸ਼ਨ ਰੀਪਲੀਕੇਟ ਹੁੰਦੀ ਹੈ (ਕਨਸੈਂਸਸ ਦੇ ਨਾਲ) ਅਤੇ ਖਾਸ ਨੋਡਾਂ 'ਤੇ ਰੱਖੀ ਜਾਂਦੀ ਹੈ। ਪਲੈਸਮੈਂਟ ਬੇਤਰਤੀਬੀ ਨਾਲ ਨਹੀਂ ਹੁੰਦਾ: ਤੁਸੀਂ ਪਾਲਿਸੀਆਂ ਰਾਹੀਂ ਪ੍ਰਭਾਵ ਪਾ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ, EU ਗ੍ਰਾਹਕਾਂ ਦੇ ਰਿਕਾਰਡ EU ਰੀਜਨਾਂ 'ਚ ਰੱਖੋ, ਜਾਂ ਗਰਮ partitions ਨਜ਼ਦੀਕੀ ਤੇਜ਼ ਨੋਡਾਂ 'ਤੇ ਰੱਖੋ)। ਚੰਗਾ ਪਲੈਸਮੈਂਟ ਕਰਾਸ-ਨੈੱਟਵਰਕ ਯਾਤਰਾਵਾਂ ਨੂੰ ਘਟਾਉਂਦਾ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਅਨੁਮਾਨਕ ਰੱਖਦਾ ਹੈ।
ਨੋਡਾਂ 'ਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ (ਅਤੇ ਕਿਉਂ ਇਹ ਲੈਟੈਂਸੀ ਵਧਾਉਂਦਾ ਹੈ)
ਇੱਕ ਸਿੰਗਲ-ਨੋਡ ਡੇਟਾਬੇਸ ਨਾਲ, ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਕਸਰ ਸਥਾਨਕ ਡਿਸਕ ਕੰਮ ਨਾਲ commit ਹੋ ਸਕਦੀ ਹੈ। Distributed SQL ਵਿੱਚ, ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਕਈ ਪਾਰਟੀਸ਼ਨਾਂ ਨੂੰ ਛੂਹ ਸਕਦਾ ਹੈ—ਸੰਭਵ ਹੈ ਵੱਖ-ਵੱਖ ਨੋਡਾਂ 'ਤੇ।
ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ commit ਕਰਨ ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਵੱਧ ਸਮਨਵੇਯਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
- ਸ਼ਾਮਲ ਪਾਰਟੀਸ਼ਨਾਂ 'ਤੇ ਡੇਟਾ ਲਾਕ/ਵੈਰੀਫਾਈ ਕਰਨਾ
- ਲਿਖਤਾਂ ਨੂੰ ਕਨਸੈਂਸਸ ਰਾਹੀਂ ਰੀਪਲੀਕੇਟ ਕਰਨਾ (ਬਹੁਭਾਗ ਪੁਸ਼ਟੀ)
- ਇੱਕ ਆਖਰੀ commit ਫੈਸਲਾ ਕਰਨਾ ਤਾਂ ਜੋ ਸਾਰੇ ਭਾਗੀਦਾਰ ਸਹਿਮਤ ਹੋਣ
ਇਹ ਕਦਮ ਨੈੱਟਵਰਕ ਰਾਊਂਡ ਟ੍ਰਿਪ ਲਿਆਉਂਦੇ ਹਨ, ਇਸ ਲਈ ਵਿਸ਼ੇਸ਼ ਕਰਕੇ ਜਦੋਂ ਡੇਟਾ ਰੀਜਨਾਂ 'ਚ ਫੈਲਿਆ ਹੋਵੇ, distributed ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲੈਟੈਂਸੀ ਵਧਾਉਂਦੇ ਹਨ।
ਬਹੁ-ਖੇਤਰ ਵਰਤਾਰਾ: ਲੋਕੈਲਟੀ-ਅਵੇਅਰ ਰੀਡ ਅਤੇ ਰਾਈਟ
ਜਦੋਂ ਤੈਨਾਤੀ ਰੀਜਨਾਂ 'ਚ ਫੈਲਦੀ ਹੈ, ਸਿਸਟਮ ਇਹ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ ਕਿ ਓਪਰੇਸ਼ਨਾਂ ਨੂੰ ਯੂਜ਼ਰਾਂ ਦੇ "ਨੇੜੇ" ਰੱਖਣ:
- ਲੋਕੈਲਟੀ-ਅਵੇਅਰ ਰੀਡਸ ਸੁਰੱਖਿਅਤ ਹੋਣ 'ਤੇ ਨੇੜੇ ਰੈਪਲਿਕਾ ਤੋਂ ਸੇਵਾ ਕਰ ਸਕਦੀਆਂ ਹਨ।
- ਲੋਕੈਲਟੀ-ਅਵੇਅਰ ਰਾਈਟਸ ਲੀਡਰਾਂ ਨੂੰ ਕਿਸੇ ਚੁਣੀ ਹੋਈ ਰੀਜਨ ਵਿਚ ਰੂਟ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਜਾਂ ਪ੍ਰਾਇਮਰੀ ਲਿਖਤਕਾਰਾਂ ਨੇੜੇ ਲੀਡਰ ਰੱਖ ਸਕਦੀਆਂ ਹਨ।
ਇਹ ਬਹੁ-ਖੇਤਰ ਸੰਤੁਲਨ ਦਾ ਮੁੱਖ ਮਾਪਦੰਡ ਹੈ: ਤੁਸੀਂ ਸਥਾਨਕ ਪ੍ਰਤੀਕਿਰਿਆ ਲਈ Optimize ਕਰ ਸਕਦੇ ਹੋ, ਪਰ ਲੰਬੀ ਦੂਰੀ ਉੱਤੇ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਹਮੇਸ਼ਾ ਨੈੱਟਵਰਕ ਖਰਚ ਚੁਕਾਏਗੀ।
ਜਦੋਂ ਤੁਹਾਨੂੰ ਸੱਚਮੁੱਚ ਲੋੜ ਹੁੰਦੀ ਹੈ (ਅਤੇ ਕਦੋ ਨਹੀਂ)
Distributed SQL ਦੀ ਵਰਤੋਂ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਆਪਣੇ ਬੇਸਲਾਈਨ ਲੋੜਾਂ ਦੀ ਤਸਦੀਕ ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਸਿੰਗਲ ਪ੍ਰਾਇਮਰੀ ਰੀਜਨ ਹੈ, ਪੈਟਰਨ ਲੋਡ ਹੈ, ਅਤੇ ਓਪਰੇਸ਼ਨਾਂ ਦੀ ਗਿਣਤੀ ਘੱਟ ਹੈ, ਤਾੰ ਇੱਕ ਪਰੰਪਰਾਗਤ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ (ਜਾਂ ਮੈਨੇਜਡ Postgres/MySQL) ਅਕਸਰ ਫੀਚਰ ਤੇਜ਼ੀ ਨਾਲ ਸ਼ਿਪ ਕਰਨ ਦਾ ਸਾਦਾ ਤਰੀਕਾ ਹੈ। ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਸਿੰਗਲ-ਰੀਜਨ ਸੈਟਅੱਪ ਨੂੰ ਰੀਡ ਰੈਪਲਿਕਾਸ, ਕੇਸ਼ਿੰਗ ਅਤੇ ਧਿਆਨ-ਪੂਰਵਕ ਸਕੀਮਾ/ਇੰਡੈਕਸ ਕੰਮ ਨਾਲ ਕਾਫ਼ੀ ਦੂਰ ਤੱਕ ਖਿੱਚ ਸਕਦੇ ਹੋ।
ਸਪਸ਼ਟ ਟ੍ਰਿਗਰ: ਜਦੋਂ distributed SQL ਲਾਭਕਾਰੀ ਹੈ
Distributed SQL ਨੂੰ ਗੰਭੀਰ ਵਿਚਾਰ ਕਰਨ ਲਾਇਕ ਬਣਾਉਂਦੇ ਹਨ ਜਦੋਂ ਇੱਕ ( ਜਾਂ ਵੱਧ) ਹੇਠਾਂ ਸੱਚ ਹੋਵੇ:
- ਤੁਹਾਡੇ ਕੋਲ ਕਈ ਰੀਜਨਾਂ ਵਿੱਚ ਹਕੀਕਤੀ ਯੂਜ਼ਰ ਹਨ ਅਤੇ ਤੁਸੀਂ ਡੇਟਾਬੇਸ ਨੂੰ ਉਨ੍ਹਾਂ ਦੇ ਨੇੜੇ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਬਿਨਾ ਐਪ-ਲੇਅਰ ਸ਼ਾਰਡਿੰਗ ਬਣਾਉਣ ਦੇ।
- ਉਪਲਬਧਤਾ ਦੀਆਂ ਲੋੜਾਂ ਉੱਚੀਆਂ ਹਨ (ਜਿਵੇਂ ਕਿ ਜ਼ੋਨ/ਰੀਜਨ ਫੇਲਿਅਰ ਸਹਿਣਾ ਜ਼ਰੂਰੀ) ਅਤੇ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਰੀਜਨ ਅਣੁਕੂਲ ਜੋਖਮ ਹੈ।
- ਡੇਟਾ ਵਾਲੀਅਮ ਜਾਂ ਲਿਖਤ ਥਰੂਪੁੱਟ ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਤੋਂ ਬਾਹਰ ਜਾ ਰਹੀ ਹੈ, ਅਤੇ ਤੁਸੀਂ SQL ਸੈਮਾਂਟਿਕਸ ਰੱਖਦੇ ਹੋਏ ਹੋਰੀਜ਼ੋਂਟਲ ਸਕੇਲ ਚਾਹੁੰਦੇ ਹੋ।
- ਤੁਹਾਨੂੰ ਨੋਡ/ਰੀਜਨਾਂ ਵਿੱਚ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਚਾਹੀਦੀ ਹੈ ਮੁੱਖ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ (ਆਰਡਰ, ਬੈਲੈਂਸ, ਰਿਜ਼ਰਵੇਸ਼ਨ) ਲਈ ਬਿਨਾ ਵੱਖ-ਵੱਖ ਸਿਸਟਮ ਜੋੜਣ ਦੇ।
- ਕੰਪਲਾਇੰਸ ਜਿਓਗ੍ਰਾਫਿਕ ਪਲੇਸਮੈਂਟ ਮੰਗਦਾ ਹੈ (ਡੇਟਾ ਰਿਹਾਇਸ਼) ਫਿਰ ਵੀ ਇੱਕ ਲਾਜਿਕਲ ਡੇਟਾਬੇਸ ਚਾਹੀਦਾ ਹੈ।
ਐਂਟੀ-ਟ੍ਰਿਗਰ: ਜਦੋਂ ਅਕਸਰ ਇਹ ਸਹੀ ਫੈਸਲਾ ਨਹੀਂ
Distributed ਸਿਸਟਮ ਜਟਿਲਤਾ ਅਤੇ ਲਾਗਤ ਜੋੜਦੇ ਹਨ। ਸਾਵਧਾਨ ਰਹੋ ਜੇ:
- ਤੁਹਾਡੀ ਟੀਮ ਛੋਟੀ ਹੈ ਅਤੇ ਕੋਲ ਨਵੇਂ ਫੇਲਰ ਮੋਡਾਂ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਪੈਟਰਨਾਂ ਨੂੰ ਸਿੱਖਣ ਦਾ ਸਮਾਂ ਨਹੀਂ ਹੈ।
- ਟ੍ਰੈਫਿਕ ਘੱਟ ਜਾਂ ਅਸਮਾਨ ਹੈ ਅਤੇ ਤੁਹਾਨੂੰ ਜ਼ਰੂਰਤ ਨਹੀਂ ਕਿ ਜਲਦੀ ਹੀ ਇਕ ਸਿੰਗਲ-ਰੀਜਨ ਡੇਟਾਬੇਸ ਤੋਂ ਬਾਹਰ ਜਾਈਏ।
- ਤੁਹਾਡੇ ਲਈ ਸਿੰਗਲ-ਕੀ ਲਿਖਤਾਂ ਲਈ ਲੈਟੈਂਸੀ ਬਹੁਤ ਕੱਟੀ ਹੈ ਅਤੇ ਤੁਸੀਂ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਦੀ ਕਾਰਨ ਹੋਣ ਵਾਲੇ ਸਹਿਯੋਗ ਓਵਰਹੈੱਡ ਨੂੰ ਬਰਦਾਸ਼ਤ ਨਹੀਂ ਕਰ ਸਕਦੇ।
- ਤੁਹਾਡੇ ਵਰਕਲੋਡ ਵਿੱਚ ਐਨਾਲਿਟਿਕਸ ਭਾਰੀ ਹੈ (ਵੱਡੇ ਸਕੈਨ, ਜਟਿਲ ਰਿਪੋਰਟਾਂ)। ਤੁਸੀਂ OLTP ਨੂੰ ਐਨਾਲਿਟਿਕਸ ਤੋਂ ਵੱਖ ਕਰਨਾ ਬੇਹਤਰ ਹੋ ਸਕਦਾ ਹੈ।
ਤੇਜ਼ ਫੈਸਲਾ ਚੈੱਕਲਿਸਟ
ਜੇ ਤੁਸੀਂ ਦੋ ਜਾਂ ਵੱਧ ਪ੍ਰਸ਼ਨਾਂ ਦਾ ਜਵਾਬ "ਹਾਂ" ਦੇ ਸਕਦੇ ਹੋ, ਤਾਂ distributed SQL ਦੀ ਮੁਲਾਂਕਣ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ:
- ਕੀ ਤੁਹਾਨੂੰ ਬਹੁ-ਖੇਤਰ ਯੂਜ਼ਰ ਚਾਹੀਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਨਾਲ ਡੇਟਾ ਸਥਿਰ ਰਹੇ?
- ਕੀ ਤੁਹਾਨੂੰ ਆਟੋਮੈਟਿਕ ਫੇਲਓਵਰ ਚਾਹੀਦਾ ਹੈ ਜੋ ਜੋਨ/ਰੀਜਨ ਤੱਕ ਫੈਲਦਾ ਹੈ?
- ਕੀ ਸਕੇਲਿੰਗ ਲਗਾਤਾਰ ਸੰਗਰਸ਼ ਬਣ ਰਹੀ ਹੈ?
- ਕੀ ਸ਼ਾਰਡਿੰਗ ਤੁਹਾਡੇ ਲਈ ਵੱਧ ਇੰਜੀਨੀਅਰਿੰਗ ਮਿਹਨਤ ਬਣ ਜਾਂਦੀ ਹੈ?
- ਕੀ ਤੁਹਾਨੂੰ ਡੇਟਾ ਰਿਹਾਇਸ਼ ਇੱਕ ਹੀ ਓਪਰੇਸ਼ਨਲ ਮਾਡਲ ਨਾਲ ਲਾਗੂ ਕਰਨੀ ਹੈ?
ਸਥਿਰਤਾ, ਉਪਲਬਧਤਾ, ਅਤੇ ਲੈਟੈਂਸੀ: ਮੁੱਖ ਤਰਜੀਹਾਂ
Distributed SQL ਆਡੀਓ "ਸਭ ਕੁਝ ਇਕੱਠੇ ਲੋ" ਜਿਹਾ ਲੱਗਦਾ ਹੈ, ਪਰ ਅਸਲ ਸਿਸਟਮ ਚੋਣਾਂ ਲਿਆਉਂਦੇ ਹਨ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਰੀਜਨਾਂ ਦੇ ਵਿਚਕਾਰ ਕੁਨੈਕਸ਼ਨ ਭਰੋਸੇਯੋਗ ਨਹੀਂ ਹੁੰਦੀ।
CAP, ਉਤਪਾਦਿਕ ਫੈਸਲਿਆਂ ਲਈ ਸਮਝਾਇਆ ਗਿਆ
ਨੈੱਟਵਰਕ partition ਨੂੰ ਸੋਚੋ ਜਿਵੇਂ "ਰੀਜਨਾਂ ਦੇ ਵਿਚਕਾਰ ਕਨੈਕਸ਼ਨ ਝਟਕਾਂ ਜਾਂ ਡਾਊਨ ਹੈ"। ਇਸ ਸਮੇਂ, ਡੇਟਾਬੇਸ ਤਰਜੀਹ ਦੇ ਸਕਦਾ ਹੈ:
- Consistency: ਹਰ ਕੋਈ ਇੱਕੋ-ਆਧੁਨਿਕ, ਅਪ-ਟੂ-ਡੇਟ ਜਵਾਬ ਵੇਖਦਾ ਹੈ (ਜਾਂ ਓਪਰੇਸ਼ਨ fail ਹੋ ਜਾਂਦਾ ਹੈ)।
- Availability: ਐਪ ਹਰ ਰੀਜਨ ਵਿੱਚ ਰੀਡ/ਰਾਈਟ ਸਵੀਕਾਰ ਕਰਦੀ ਰਹੇ (ਭਾਵੇਂ ਜਵਾਬ ਕੁਝ ਸਮੇਂ ਲਈ ਫੈਰ ਹੋ ਸਕਦੇ ਹਨ)।
Distributed SQL ਸਿਸਟਮ ਆਮ ਤੌਰ 'ਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲਈ consistency ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹਨ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇਹੀ ਚਾਹੁੰਦੀਆਂ ਹਨ—ਜਦ ਤੱਕ partition ਦੌਰਾਨ ਕੁਝ ਓਪਰੇਸ਼ਨਾਂ ਨੂੰ ਰੋਕਣਾ ਜਾਂ fail ਹੋਣਾ ਪਵੇ।
ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ (ਅਤੇ ਕਿਉਂ ਪੈਸਾ ਅਤੇ ਇਨਵੈਂਟਰੀ ਲਈ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ)
ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਵਾਰੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ commit ਹੋ ਗਿਆ, ਕੋਈ ਵੀ ਬਾਅਦ ਵਾਲੀ ਰੀਡ ਉਸ commit ਕੀਤੇ ਮੁੱਲ ਨੂੰ ਵਾਪਸ ਕਰੇਗੀ—ਕੋਈ "ਇੱਕ ਰੀਜਨ 'ਚ ਚਲਿਆ ਪਰ ਦੂਜੇ 'ਚ ਨਹੀਂ" ਵਾਲੀ ਸਥਿਤੀ ਨਹੀਂ। ਇਹ ਇਨ੍ਹਾਂ ਚੀਜ਼ਾਂ ਲਈ ਬਹੁਤ ਮਹੱਤਵਪੂਰਨ ਹੈ:
- ਭੁਗਤਾਨ ਅਤੇ ਬੈਲੈਂਸ (double-spend ਜਾਂ ਗਲਤ totals ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ)
- ਇਨਵੈਂਟਰੀ / ਰਿਜ਼ਰਵੇਸ਼ਨ (ਅੰਤੀਮ ਚੀਜ਼ ਨੂੰ oversell ਕਰਨ ਤੋਂ ਰੋਕਦਾ ਹੈ)
ਜੇ ਤੁਹਾਡੀ ਉਤਪਾਦੀ ਗਾਰੰਟੀ ਹੈ "ਜਦੋਂ ਅਸੀਂ ਪੁਸ਼ਟੀ ਕਰੀਏ, ਉਹ ਅਸਲ ਹੈ", ਤਾਂ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਇੱਕ ਫੀਚਰ ਹੈ, ਨ ਕਿ ਇੱਕ ਲਕਜ਼ਰੀ।
ਰੀਡ-ਯੋਰ-ਰਾਈਟਸ ਅਤੇ ਆਈਸੋਲੇਸ਼ਨ ਹਕੀਕਤੀਆਂ
ਦੋ ਅਮਲਿਕ ਵਿਹਾਰ ਮਹੱਤਵਪੂਰਨ ਹਨ:
- Read-your-writes: ਜਦੋਂ ਇੱਕ ਯੂਜ਼ਰ ਆਪਣਾ ਪ੍ਰੋਫਾਈਲ ਅੱਪਡੇਟ ਕਰਦਾ ਹੈ (ਜਾਂ ਆਰਡਰ ਦਿੰਦਾ ਹੈ), ਅਗਲੀ ਸਕ੍ਰੀਨ ਨੂੰ ਨਵੀਂ ਹਾਲਤ ਦਿਖਣੀ ਚਾਹੀਦੀ ਹੈ, ਨਾ ਕਿ ਕੋਈ ਪੁਰਾਣਾ ਰੈਪਲਿਕਾ।
- ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਆਈਸੋਲੇਸ਼ਨ: ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਕਿ ਇਕੱਠੇ concurrent ਇਕਸ਼ਨਾਂ ਕਿਵੇਂ ਪ੍ਰਭਾਵਤ ਹੁੰਦੇ ਹਨ। ਮਜ਼ਬੂਤ ਆਈਸੋਲੇਸ਼ਨ ਨਾਲ, ਤੁਸੀਂ ਠੰਡੇ ਕ੍ਰੋਮ-ਬਗਜ਼ ਤੋਂ ਬਚ ਸਕਦੇ ਹੋ ਜਿਵੇਂ ਕਿ ਦੋ ਗ੍ਰਾਹਕ ਇੱਕੋ ਹੀ ਸੀਟ ਬੁੱਕ ਕਰ ਲੈਂ।
ਕਰਾਸ-ਰੀਜਨ ਕਨਸੈਨਸਸ ਦੀ ਲੈਟੈਂਸੀ ਲਾਗਤ
ਰੀਜਨਾਂ 'ਚ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਆਮ ਤੌਰ 'ਤੇ ਕਨਸੈਂਸਸ ਦੀ ਲੋੜ ਰੱਖਦੀ ਹੈ (ਕਈ ਰੈਪਲਿਕਾ commit ਤੋਂ ਪਹਿਲਾਂ ਸਹਿਮਤ ਹੋਣੇ ਚਾਹੀਦੇ)। ਜੇ ਰੈਪਲਿਕਾ ਮਹਾਂਦੀਪਾਂ ਵਿਚ ਫੈਲੇ ਹਨ, ਤਾਂ ਰੌਂਡ-ਟ੍ਰਿਪ ਸਮਾਂ ਲੈਟੈਂਸੀ ਦੇ ਉਪਰ ਅੰਕਿਤ ਹੋ ਜਾਦਾ ਹੈ: ਹਰ ਕਰਾਸ-ਰੀਜਨ ਲਿਖਤ ਵਿੱਚ ਦਸਾਂ ਤੋਂ ਸੈਂਕੜੇ ਮਿਲੀਸੈਕੰਡ ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ।
ਟ੍ਰੇਡ-ਆਫ਼ ਸਧਾਰਣ ਹੈ: ਜਿਆਦਾ ਭੌਗੋਲਿਕ ਸੁਰੱਖਿਆ ਅਤੇ ਸਹੀਤਾ ਅਕਸਰ ਉੱਚੀ ਲਿਖਤ ਲੈਟੈਂਸੀ ਨਾਲ ਆਉਂਦੀ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ ਧਿਆਨ ਨਾਲ ਫੈਸਲਾ ਨਾਂ ਕਰੋ ਕਿ ਡੇਟਾ ਕਿੱਥੇ ਰਹੇ ਅਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਕਿੱਥੇ commit ਹੋਣਗੇ।
Spanner বনမ္ਵ CockroachDB বনਮ YugabyteDB: ਪ੍ਰੈਟਿਕਲ ਓਵਰਵਿਊ
Google Spanner ਇੱਕ distributed SQL ਡੇਟਾਬੇਸ ਹੈ ਜੋ ਮੁੱਖ ਤੌਰ 'ਤੇ Google Cloud 'ਤੇ managed service ਵਜੋਂ ਦਿੰਦਾ ਹੈ। ਇਹ ਮਲਟੀ-ਰੀਜਨ ਤੈਨਾਤੀ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ ਜਿਥੇ ਤੁਸੀਂ ਇੱਕ ਲਾਜ਼ਮੀ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਚਾਹੁੰਦੇ ਹੋ ਜਿਸ ਦਾ ਡੇਟਾ ਨੋਡਾਂ ਅਤੇ ਰੀਜਨਾਂ 'ਚ ਰੀਪਲੀਕੇਟ ਹੁੰਦਾ ਹੈ। Spanner ਦੋ SQL ਡਾਇਲੈਕਟ ਵਿਕਲਪ ਦਿੰਦਾ ਹੈ—GoogleSQL (ਇਸਦਾ ਨੈਟਿਵ ਡਾਇਲੈਕਟ) ਅਤੇ ਇੱਕ PostgreSQL-ਕੰਪੈਟਿਬਲ ਡਾਇਲੈਕਟ—ਇਸ ਲਈ ਪੋਰਟੇਬਿਲਟੀ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿਹੜਾ ਚੁਣਦੇ ਹੋ ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਕਿਸ ਫੀਚਰ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ।
CockroachDB ਇੱਕ distributed SQL ਡੇਟਾਬੇਸ ਹੈ ਜੋ PostgreSQL ਨਾਲ ਜਾਣੂ ਟੀਮਾਂ ਲਈ ਮਾਸੂਸ ਹਨ। ਇਹ PostgreSQL ਵਾਇਰ ਪ੍ਰੋਟੋਕੋਲ ਵਰਤਦਾ ਹੈ ਅਤੇ PostgreSQL-ਸਟਾਈਲ SQL ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਸਪੋਰਟ ਕਰਦਾ ਹੈ, ਪਰ ਇਹ Postgres ਦਾ ਇੱਕ-ਇੱਕ ਅਨੁਕੂਲ ਨਕਲ ਨਹੀਂ ਹੈ (ਕੁਝ ਐਕਸਟੈਂਸ਼ਨ ਅਤੇ ਐਜ਼-ਕੇਸ ਬਿਹੇਵਿਅਰ ਵੱਖਰੇ ਹੋ ਸਕਦੇ ਹਨ)। ਤੁਸੀਂ ਇਸ ਨੂੰ managed service (CockroachDB Cloud) ਵਜੋਂ ਚਲਾ ਸਕਦੇ ਹੋ ਜਾਂ ਖੁਦ-ਹੋਸਟ ਕਰ ਸਕਦੇ ਹੋ।
YugabyteDB ਇੱਕ distributed ਡੇਟਾਬੇਸ ਹੈ ਜਿਸ ਦਾ PostgreSQL-ਕੰਪੈਟਿਬਲ SQL API (YSQL) ਹੈ ਅਤੇ ਇਕ ਵਾਧੂ Cassandra-ਕੰਪੈਟਿਬਲ API (YCQL) ਵੀ ਰੱਖਦਾ ਹੈ। CockroachDB ਵਰਗੇ, ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਟੀਮਾਂ ਦੁਆਰਾ ਮੁਲਾਂਕਣ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਜੋ Postgres-ਵਾਂਗ ਵਿਕਾਸਕ ਅਨੁਭਵ ਚਾਹੁੰਦੇ ਹਨ ਪਰ ਨੋਡਾਂ ਅਤੇ ਰੀਜਨਾਂ ਵਿੱਚ ਸਕੇਲ ਆਉਣ ਚਾਹੁੰਦੇ ਹਨ। ਇਹ self-hosted ਅਤੇ managed (YugabyteDB Managed) ਦੋਹਾਂ ਉਪਲਬਧ ਹੈ, ਆਮ ਤੌਰ 'ਤੇ single-region HA ਤੋਂ multi-region ਸੈਟਅੱਪ ਤੱਕ।
Managed vs self-hosted: ਕੀ ਬਦਲਦਾ ਹੈ
Managed ਸੇਵਾਵਾਂ ਆਮ ਤੌਰ 'ਤੇ ਓਪਰੇਸ਼ਨਲ ਕੰਮ (ਅਪਗਰੇਡ, ਬੈਕਅਪ, ਮਾਨੀਟਰਨਿੰਗ ਇੰਟੀਗ੍ਰੇਸ਼ਨ) ਘਟਾ ਦਿੰਦੀਆਂ ਹਨ, ਜਦ ਕਿ self-hosting ਨੈੱਟਵਰਕਿੰਗ, ਇੰਸਟੰਸ ਟਾਈਪ ਅਤੇ ਡੇਟਾ ਕਿੱਥੇ ਚੱਲਦਾ ਹੈ ਤੇ ਵੱਧ ਕੰਟਰੋਲ ਦਿੰਦਾ ਹੈ। Spanner ਆਮ ਤੌਰ 'ਤੇ GCP ਤੇ managed ਰੂਪ ਵਿੱਚ ਖਪਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ; CockroachDB ਅਤੇ YugabyteDB ਦੋਹਾਂ managed ਅਤੇ self-hosted ਦੋਹਾਂ ਵਿੱਚ ਆਮ ਹਨ, ਜਿੰਨਾਂ ਵਿੱਚ multi-cloud ਅਤੇ on-prem ਵਿਕਲਪ ਸ਼ਾਮਲ ਹਨ।
ਅਮਲੀ SQL ਕਮਪੈਟਿਬਿਲਟੀ
ਤਿੰਨੋ "SQL" ਬੋਲਦੇ ਹਨ, ਪਰ ਦੈਨਦਿਨ ਕੰਪੈਟਿਬਿਲਟੀ ਡਾਇਲੈਕਟ ਚੋਣ (Spanner), Postgres ਫੀਚਰ ਕਵਰੇਜ (CockroachDB/YugabyteDB), ਅਤੇ ਤੁਸੀਂ ਕਿਸ Postgres ਐਕਸਟੈਂਸ਼ਨ/ਫੰਕਸ਼ਨ/ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੈਮਾਂਟਿਕਸ 'ਤੇ ਨਿਰਭਰ ਹੋ ਰਹੇ ਹੋ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ।
ਇੱਥੇ ਸਮੇਂ ਪਹਿਲਾਂ ਟੈਸਟ ਕਰਨਾ ਫਾਇਦੇਮੰਦ ਹੈ: ਆਪਣੀਆਂ ਕਵੈਰੀਆਂ, ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ, ਅਤੇ ORM ਵਿਵਹਾਰ ਨੂੰ ਜਲਦੀ ਜਾਂਚੋ, ਬਿਨਾ ਇਹ ਮੰਨਣ ਦੇ ਕਿ ਇਹ drop-in ਬਰਾਬਰੀ ਹੈ।
ਵਰਤੋਂ ਦੇ ਕੇਸ: ਖੇਤਰੀ ਯੂਜ਼ਰਾਂ ਵਾਲਾ ਗਲੋਬਲ SaaS
ਆਪਣੀ ਟੋਪੋਲੋਜੀ ਯੋਜਨਾ ਬਣਾਓ
ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ ਖੇਤਰਾਂ, ਟੈਨੈਂਟ ਅਤੇ ਡੇਟਾ ਰਿਹਾਇਸ਼ ਨਿਯਮ ਨਕਸ਼ਾ ਬਣਾਓ।
Distributed SQL ਲਈ ਇੱਕ ਕਲਾਸਿਕ ਸੂਟ B2B SaaS ਉਤਪਾਦ ਹੈ ਜਿਸਦੇ ਗ੍ਰਾਹਕ ਨਾਰਥ ਅਮਰੀਕਾ, ਯੂਰਪ ਅਤੇ APAC ਵਿੱਚ ਫੈਲੇ ਹੋਏ ਹਨ—ਸੋਚੋ ਸਪੋਰਟ ਟੂਲ, HR ਪਲੇਟਫਾਰਮ, ਐਨਾਲਿਟਿਕਸ ਡੈਸ਼ਬੋਰਡ ਜਾਂ ਮਾਰਕੇਟਪਲੇਸ।
ਬਿਜ਼ਨਸ ਲੋੜ ਸਧਾਰਨ ਹੈ: ਯੂਜ਼ਰਾਂ ਨੂੰ "ਲੋਕਲ ਐਪ" ਦੀ ਪ੍ਰਤੀਕਿਰਿਆ ਚਾਹੀਦੀ ਹੈ, ਜਿੱਥੇ ਕੰਪਨੀ ਇੱਕ ਹੀ ਲਾਜ਼ਮੀ ਡੇਟਾਬੇਸ ਚਾਹੁੰਦੀ ਹੈ ਜੋ ਹਮੇਸ਼ਾ ਉਪਲਬਧ ਹੋਵੇ।
ਡੇਟਾ ਰਿਹਾਇਸ਼ ਅਤੇ ਪ੍ਰਤੀ-ਟੈਨੈਂਟ ਪਲੇਸਮੈਂਟ
ਕਈ SaaS ਟੀਮਾਂ ਅੰਤ ਵਿਚ ਮਿਲੇ-ਜੁਲੇ ਲੋੜਾਂ ਨਾਲ ਖਤਮ ਹੁੰਦੀਆਂ ਹਨ:
- EU ਗ੍ਰਾਹਕ ਚਾਹੁੰਦੇ ਹਨ ਕਿ ਉਹਨਾਂ ਦਾ ਡੇਟਾ EU ਵਿੱਚ ਹੀ ਰਹੇ (GDPR, ਠੇਕੇ ਦੀਆਂ ਵਚਨਾਂ)।
- ਕੁਝ ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਦੇਸ਼-ਅੰਦਰ ਸਟੋਰੇਜ ਲੋੜੀਦਾ ਹੈ (ਉਦਾਹਰਣ: ਜਰਮਨੀ, ਆਸਟ੍ਰੇਲੀਆ, ਸਿੰਗਾਪੁਰ)।
- ਹੋਰ ਗ੍ਰਾਹਕਾਂ ਨੂੰ ਫ਼ਰਕ ਨਹੀਂ ਪੈਂਦਾ, ਪਰ ਫਿਰ ਵੀ ਤੇਜ਼ ਲੈਟੈਂਸੀ ਜਾਂਦੀ ਹੈ।
Distributed SQL ਇਸਨੂੰ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਮਾਡਲ ਕਰ ਸਕਦਾ ਹੈ ਪਰ-ਟੈਨੈਂਟ ਲੋਕੈਲਟੀ ਨਾਲ: ਹਰ ਟੈਨੈਂਟ ਦਾ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾ ਇੱਕ ਖਾਸ ਰੀਜਨ (ਜਾਂ ਰੀਜਨਾਂ ਦਾ ਸੈੱਟ) ਵਿੱਚ ਰੱਖੋ ਜਦੋਂ ਕਿ ਪੂਰੇ ਸਿਸਟਮ 'ਚ ਸਕੀਮਾ ਅਤੇ ਕਵੈਰੀ ਮਾਡਲ ਇੱਕੋ ਜਿਹੇ ਰਹਿੰਦੇ ਹਨ। ਇਸ ਨਾਲ ਤੁਸੀਂ "ਹਰ ਰੀਜਨ ਲਈ ਇੱਕ ਡੇਟਾਬੇਸ" ਦੇ ਫੈਲਾਅ ਤੋਂ ਬਚ ਸਕਦੇ ਹੋ ਪਰ ਫਿਰ ਵੀ ਰਿਹਾਇਸ਼ ਦੀਆਂ ਲੋੜਾਂ ਪੂਰੀਆਂ ਹੋ ਜਾਂਦੀਆਂ ਹਨ।
ਲੈਟੈਂਸੀ ਘਟਾਉਣਾ: ਖੇਤਰੀ ਰੀਡ ਅਤੇ ਲਿਖਤ ਪਲੇਸਮੈਂਟ
ਐਪ ਨੂੰ ਤੇਜ਼ ਰੱਖਣ ਲਈ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਲਕੜੀ ਚਾਹੁੰਦੇ ਹੋ:
- ਖੇਤਰੀ ਰੀਡਸ: ਰੀਡ-ਹੈਵੀ ਕਵੈਰੀਆਂ ਨੂੰ ਯੂਜ਼ਰ ਦੇ ਨੇੜੇ ਰੈਪਲਿਕਾ ਤੋਂ ਸੇਵ ਕਰੋ।
- ਲਿਖਤ ਪਲੇਸਮੈਂਟ: ਲਿਖਤ ਲੀਡਰ (ਜਾਂ ਪ੍ਰਾਇਮਰੀ ਰੈਪਲਿਕਾ ਸੈੱਟ) ਉਸ ਰੀਜਨ 'ਚ ਰੱਖੋ ਜਿੱਥੇ ਟੈਨੈਂਟ ਦੀਆਂ ਲਿਖਤਾਂ ਅਕਸਰ ਹੁੰਦੀਆਂ ਹਨ।
ਇਹ ਆਮ ਹੈ ਕਿਉਂਕਿ ਕਰਾਸ-ਰੀਜਨ ਰਾਊਂਡ ਟ੍ਰਿਪ ਯੂਜ਼ਰ-ਅਨੁਭਵ ਵੱਲੋਂ ਸਭ ਤੋਂ ਵੱਡਾ ਪ੍ਰਭਾਵਕਾਰਕ ਹੁੰਦਾ ਹੈ। ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਦੇ ਨਾਲ ਵੀ, ਚੰਗੀ ਲੋਕੈਲਟੀ ਡਿਜ਼ਾਇਨ ਯਕੀਨੀ ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਜ਼ਿਆਦੀ ਬੇਨਤੀ ਇੰਟਰਕਾਂਟੀਨੈਂਟਲ ਨੈੱਟਵਰਕ ਖਰਚ ਨਹੀਂ ਭੁਗਤਦੀ।
ਓਪਰੇਸ਼ਨਲ ਹਕੀਕਤਾਂ
ਤਕਨੀਕੀ ਫ਼ਾਇਦੇ ਹੀ ਮਾਇਨੇ ਰੱਖਦੇ ਹਨ ਜੇ ਓਪਰੇਸ਼ਨ ਮੈਨੇਜ ਕਰਨਯੋਗ ਰਹੇ। ਗਲੋਬਲ SaaS ਲਈ ਯੋਜ਼ਨਾ ਬਣਾਓ:
- ਆਨਲਾਈਨ ਸਕੀਮਾ ਬਦਲਾਅ ਜੋ ਖੇਤਰਾਂ 'ਚ ਟੇਬਲਾਂ ਨੂੰ ਲੌਕ ਨਾ ਕਰੇ।
- ਟੈਨੈਂਟ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ (ਇੱਕ ਟੈਨੈਂਟ ਨੂੰ ਇੱਕ ਰੀਜਨ ਤੋਂ ਦੂਜੇ ਰੀਜਨ 'ਚ ਘੱਟ-ਡਾਊਨਟਾਈਮ ਨਾਲ ਮੂਵ ਕਰਨਾ)।
- ਮਾਨੀਟਰਨਿੰਗ ਅਤੇ ਅਲਰਟਿੰਗ replication ਲੈਗ, hotspots, slow queries, ਅਤੇ ਰੀਜਨ-ਪੱਧਰੀ ਘਟਨਾਵਾਂ ਲਈ।
ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਕੀਤਿਆ ਹੋਵੇ ਤਾਂ distributed SQL ਤੁਹਾਨੂੰ ਇੱਕ ਏਸਾ ਉਤਪਾਦ ਅਨੁਭਵ ਦੇ ਸਕਦਾ ਹੈ ਜੋ ਅਜੇ ਵੀ ਸਥਾਨਕ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ—ਬਿਨਾ ਇਹਦੇ ਕਿ ਤੁਹਾਡੀ ਇੰਜੀਨੀਅਰਿੰਗ ਟੀਮ "EU ਸਟੈਕ" ਅਤੇ "APAC ਸਟੈਕ" ਵਿਚ ਵੰਡ ਜਾਵੇ।
ਵਰਤੋਂ ਦਾ ਕੇਸ: ਵਿੱਤੀ ਵਰਕਫ਼ਲੋਜ਼ ਅਤੇ ਲੈਜ਼ਰ
ਵਿੱਤੀ ਸਿਸਟਮ ਉਹ ਜਗ੍ਹਾ ਹਨ ਜਿੱਥੇ "ਇਵੇਂਚੁਅਲੀ ਕਨਸਿਸਟੈਂਸੀ" ਅਸਲ ਪੈਸੇ ਦੇ ਨੁਕਸਾਨ ਵਿੱਚ ਬਦਲ ਸਕਦੀ ਹੈ। ਜੇ ਇੱਕ ਗ੍ਰਾਹਕ ਆਰਡਰ ਰੱਖਦਾ ਹੈ, ਪੇਮੈਂਟ ਆਥਰਾਈਜ਼ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਬੈਲੈਂਸ ਅੱਪਡੇਟ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਇਹ ਸਟਪਾਂ ਇਕ-ਦੂਜੇ ਨਾਲ ਤੁਰੰਤ ਸਹਿਮਤ ਹੋਣੀਆਂ ਚਾਹੀਦੀ ਹਨ।
ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਇਸ ਲਈ ਜ਼ਰੂਰੀ ਹੈ ਕਿਉਂਕਿ ਇਹ ਦੋ ਵੱਖ-ਵੱਖ ਰੀਜਨਾਂ (ਜਾਂ ਦੋ ਵੱਖ-ਵੱਖ ਸਰਵਿਸਾਂ) ਨੂੰ ਇਕੋ "ਰੈਸ਼ਨਲ" ਫੈਸਲਾ ਕਰਨ ਤੋਂ ਰੋਕਦਾ ਹੈ ਜੋ ਲੈਜ਼ਰ ਨੂੰ ਗਲਤ ਕਰਦਾ ਹੈ।
ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਨਾ-ਪਹੁੰਚਣਯੋਗ ਨਹੀਂ
ਆਮ ਵਰਕਫਲੋ—ਆਰਡਰ ਬਣਾਓ → ਫੰਡ ਰਿਜ਼ਰਵ ਕਰੋ → ਪੇਮੈਂਟ ਕੈਪਚਰ ਕਰੋ → ਬੈਲੈਂਸ/ਲੈਜ਼ਰ ਅੱਪਡੇਟ—ਤੁਹਾਨੂੰ ਗਾਰੰਟੀ ਚਾਹੀਦੀ ਹੈ ਜਿਵੇਂ:
- ਜੇ ਪੇਮੈਂਟ ਕੈਪਚਰ ਨਹੀਂ ਹੋਇਆ ਤਾਂ ਆਰਡਰ "paid" ਨਹੀਂ ਹੋ ਸਕਦਾ।
- ਦੋ ਟਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੇ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਰੇਸ ਕਰਕੇ ਬੈਲੈਂਸ ਨੂੰ ਨੈਗੇਟਿਵ ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ।
- ਦੁਬਾਰਾ-ਭੁਗਤਾਨ ਨੂੰ ਦੋ ਵਾਰੀ ਲਾਗੂ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ।
Distributed SQL ਇਥੇ ਫਿੱਟ ਬੈਠਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਨੋਡਾਂ (ਅਕਸਰ ਰੀਜਨਾਂ) 'ਚ ACID ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਅਤੇ constraints ਦਿੰਦਾ ਹੈ, ਇਸਲਈ ਲੈਜ਼ਰ invariants ਫੇਲਿਅਰ ਦੌਰਾਨ ਵੀ ਰੱਖੇ ਜਾਂਦੇ ਹਨ।
Idempotency ਅਤੇ "ਡਬਲ ਚਾਰਜ ਨਹੀਂ" ਪੈਟਰਨ
ਜ਼ਿਆਦਾਤਰ ਪੇਮੈਂਟ ਇੰਟੀਗ੍ਰੇਸ਼ਨਾਂ ਰੀਟ੍ਰਾਈ-ਭਰੀਆਂ ਹੁੰਦੀਆਂ ਹਨ: ਟਾਈਮਆਉਟ, webhook ਰੀਟ੍ਰਾਈ, ਅਤੇ ਜੌਬ ਰੀ-ਪ੍ਰੋਸੈਸਿੰਗ ਆਮ ਹਨ। ਡੇਟਾਬੇਸ ਨੂੰ ਤੁਹਾਨੂੰ ਰੀਟ੍ਰਾਈਜ਼ ਸੁਰੱਖਿਅਤ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਵਿੱਥਾ ਐਪ-ਲੇਵਲ idempotency_key ਨੂੰ ਡੇਟਾਬੇਸ-ਨਿਯੰਤਰਿਤ ਅਨੋਖੇ ਨਿਯਮਾਂ ਨਾਲ ਜੋੜਨਾ ਹੈ:
- ਹਰ ਗਾਹਕ/ਭੁਗਤਾਨ ਯਤਨ ਲਈ ਇੱਕ
idempotency_key ਸਟੋਰ ਕਰੋ।
(account_id, idempotency_key) 'ਤੇ unique constraint ਸ਼ਾਮਲ ਕਰੋ।- "ਪੇਮੈਂਟ ਰਿਕਾਰਡ ਬਣਾਓ + ਲੈਜ਼ਰ ਐਂਟਰੀ ਲਗਾਓ" ਨੂੰ ਇੱਕ ਹੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਪਕੜੋ।
ਇਸ ਤਰ੍ਹਾਂ, ਦੂਜੀ ਕੋਸ਼ਿਸ਼ ਇੱਕ ਨੋ-ਓਪ ਬਣ ਜਾਂਦੀ ਹੈ ਨਾ ਕਿ ਦੋਹਰਾ ਚਾਰਜ।
ਸਪੀਕਸ ਨੂੰ ਸੰਭਾਲਣਾ ਬਿਨਾ ਸਹੀਤਾ ਟੁੱਟੇ
ਸੇਲ ਇਵੈਂਟਸ ਅਤੇ ਪੇਰੋਲ ਚਲਾਣੇ ਅਚਾਨਕ ਲਿਖਤ ਬਰਸਟ ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ (ਆਥਰਾਈਜ਼ੇਸ਼ਨ, ਕੈਪਚਰ, ਟਰਾਂਸਫਰ)। Distributed SQL ਨਾਲ, ਤੁਸੀਂ ਨੋਡ ਵਧਾ ਕੇ ਲਿਖਤ ਥਰੂਪੁੱਟ ਨੂੰ ਵਧਾ ਸਕਦੇ ਹੋ ਜਦੋਂ ਕਿ ਉਹੀ ਸਥਿਰਤਾ ਮਾਡਲ ਰੱਖਿਆ ਜਾਵੇ।
ਕੁੰਜੀ ਹੈ hot keys (ਉਦਾਹਰਣ ਲਈ, ਇੱਕ ਵਪਾਰੀ ਖਾਤਾ ਜਿਸ ਨੂੰ ਸਾਰੀ ਟ੍ਰੈਫਿਕ ਮਿਲਦੀ ਹੈ) ਦੇ ਲਈ ਯੋਜਨਾ ਬਣਾਉਣਾ ਅਤੇ ਸਕੀਮਾ ਪੈਟਰਨ ਵਰਤਨਾ ਜੋ ਲੋਡ ਨੂੰ ਵੰਡਦੇ ਹਨ।
ਕੰਪਲਾਇੰਸ, ਆਡਿਟ, ਅਤੇ ਰੇਟੇਨਸ਼ਨ
ਵਿੱਤੀ ਵਰਕਫਲੋਜ਼ ਆਮ ਤੌਰ 'ਤੇ immutable audit trails, traceability (ਕੌਣ/ਕੀ/ਕਦੋਂ), ਅਤੇ ਭਰੋਸੇਯੋਗ retention ਨੀਤੀਆਂ ਦੀ ਮੰਗ ਕਰਦੇ ਹਨ। ਨਾ-ਨਾਮ ਕਰਕੇ ਧਾਰੋ ਕਿ ਤੁਹਾਨੂੰ ਲੋੜ ਹੋਏਗੀ: append-only ਲੈਜ਼ਰ ਐਂਟ੍ਰੀਜ਼, ਟਾਈਮ-ਸਟੈਂਪ ਰਿਕਾਰਡ, ਨਿਯੰਤਰਿਤ ਪਹੁੰਚ, ਅਤੇ ਰਿਟੇਂਸ਼ਨ/ਆਰਕਾਈਵ ਰੂਲ ਜੋ ਆਡੀਟੇਬਿਲਟੀ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਨਾ ਕਰਨ।
ਵਰਤੋਂ ਦਾ ਕੇਸ: ਇਨਵੈਂਟਰੀ, ਬੁਕਿੰਗ ਅਤੇ ਰਿਜ਼ਰਵੇਸ਼ਨ
ਸੁੁਰੱਖਿਅਤ ਰੀਟ੍ਰਾਈਜ਼ ਡਿਜ਼ਾਇਨ ਕਰੋ
ਕੋਈ idempotent ਪੇਮেন্ট ਜਾਂ ਪ੍ਰੋਵੀਜ਼ਨਿੰਗ ਫਲੋ ਬਣਾਓ, ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ constraints ਅਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨਾਲ।
ਇਨਵੈਂਟਰੀ ਅਤੇ ਰਿਜ਼ਰਵੇਸ਼ਨ ਆਸਾਨ ਲੱਗਦੇ ਹਨ ਜਦ ਤੱਕ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕੋ ਹੀ ਦੁਨੀਆ ਭਰ 'ਚ ਬੇਚਣ ਵਾਲਾ ਇਕ ਸੀਮਤ ਸਰੋਤ ਨਹੀਂ ਹੁੰਦਾ: ਆਖਰੀ ਕਾਨਸਰਟ ਸੀਟ, "ਲਿਮਿਟਿਡ ਡ੍ਰੌਪ" ਪ੍ਰੋਡਕਟ, ਜਾਂ ਇੱਕ ਹੋਟਲ ਰੂਮ ਕਿਸੇ ਨਿਰਧਾਰਤ ਰਾਤ ਲਈ।
ਮੁਸ਼ਕਲ ਗੱਲ ਪੁੱਠ ਨਹੀਂ ਲੋੜ ਪੜ੍ਹਨਾ—ਇਹ ਹੈ ਦੋ ਲੋਕਾਂ ਨੂੰ ਉਹੀ ਹੀ ਆਈਟਮ ਇੱਕੋ ਵਾਰ ਮਿਲ ਜਾਣਾ।
ਟੱਕਰ ਕਿੱਥੋਂ ਆਉਂਦੇ ਹਨ
ਇੱਕ ਮਲਟੀ-ਰੀਜਨ ਸੈਟਅੱਪ ਵਿੱਚ ਜੇ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਨਾ ਹੋਵੇ, ਤਾਂ ਹਰ ਰੀਜਨ ਕੁਝ ਸਮੇਂ ਲਈ ਥੋੜਾ ਪੁਰਾਣਾ ਡੇਟਾ ਦੇਖ ਕੇ ਉਪਲਬਧਤਾ ਨੂੰ ਸਵੀਕਾਰ ਕਰ ਸਕਦੀ ਹੈ। ਦੋ ਯੂਜ਼ਰ ਵੱਖ-ਵੱਖ ਰੀਜਨਾਂ 'ਚ ਚੈੱਕਆਉਟ ਕਰਨ 'ਤੇ, ਦੋਹਾਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਸਥਾਨਕ ਤੌਰ 'ਤੇ ਮਨਜ਼ੂਰ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਮਿਲਾਪ ਦੌਰਾਨ ਕਾਨਫ਼ਲਿਕਟ ਬਣ ਸਕਦਾ ਹੈ।
ਇਹੀ ਹੈ ਕਿ ਕਰਾਸ-ਰੀਜਨ oversell ਕਿਵੇਂ ਹੁੰਦਾ ਹੈ: ਸਿਸਟਮ "ਗਲਤ" ਇਸ ਲਈ ਨਹੀਂ ਹੁੰਦਾ ਕਿ ਇਸਨੇ ਗਲਤ ਫੈਸਲਾ ਕੀਤਾ—ਬਲਕਿ ਇਸਨੇ ਥੋੜੇ ਸਮੇਂ ਲਈ ਵੱਖਰੇ ਸਚਾਈਆਂ ਆਗਿਆ ਕੀਤੀਆਂ।
Distributed SQL ਡੇਟਾਬੇਸ ਅਕਸਰ ਇੱਥੇ ਚੁਣੇ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਇਹ ਲਿਖਤ-ਭਰਤੀ ਸਮੇਂ ਇਕ ਇੱਕ ਅਧਿਕਾਰਕ ਨਤੀਜਾ ਲਾਗੂ ਕਰ ਸਕਦੇ ਹਨ—ਇਸ ਤਰ੍ਹਾਂ "ਆਖਰੀ ਸੀਟ" ਵਾਕਈ ਇੱਕ ਵਾਰੀ ਹੀ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ, ਭਾਵੇਂ ਬੇਨਤੀਆਂ ਵੱਖ-ਵੱਖ ਮਹਾਂਦੀਪਾਂ ਤੋਂ ਆ ਰਹੀਆਂ ਹਨ।
ठੋਸ ਉਦਾਹਰਣ
- ਸੀਟ ਬੁਕਿੰਗ: ਦੋ ਯੂਜ਼ਰ ਇੱਕੋ ਸੀਟ 'ਤੇ ਕਲਿੱਕ ਕਰਦੇ ਹਨ। ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਨਾਲ ਸਿਰਫ਼ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ commit ਹੁੰਦੀ ਹੈ; ਦੂਜੀ ਫ਼ੌਰਨ fail ਹੋ ਜਾਂਦੀ ਹੈ ਅਤੇ UI ਨੂੰ ਰੀਫ੍ਰੈਸ਼ ਲਈ ਕਹਿ ਸਕਦਾ ਹੈ।
- ਲਿਮਿਟਿਡ ਡ੍ਰੌਪਸ: 500 ਆਈਟਮ ਜ਼ਿੰਦਾ ਹੁੰਦੇ ਹਨ ਅਤੇ ਹਜ਼ਾਰਾਂ ਚੈੱਕਆਉਟ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ। ਤੁਹਾਨੂੰ ਐਟੌਮਿਕ decrement-and-allocate ਚਾਹੀਦਾ ਹੈ, ਨਾ ਕਿ ਬਾ�p�ੈ ṣ�ਦ ਬੇਹਤਰੀਨ ਕੋਸ਼ਿਸ਼ ਅਤੇ ਬਾਅਦ ਵਿਚ ਰੇਫੰਡ।
- ਹੋਟਲ ਰਿਜ਼ਰਵੇਸ਼ਨ: ਇਨਵੈਂਟਰੀ ਇਕਾਈ ਸਿਰਫ਼ ਰੂਮ ਨਹੀਂ ਬਲਕਿ ਰੂਮ-ਨਾਈਟ ਹੈ। ਡੇਟ ਰੇਂਜ 'ਤੇ ਡਬਲ-ਬੁਕਿੰਗ ਮਹਿੰਗੀ ਅਤੇ ਮੁਸ਼ਕਲ ਤੋਂ ਮੁਸ਼ਕਲ ਹੈ।
ਆਮ ਪੈਟਰਨ ਜੋ Distributed SQL ਨਾਲ ਚੰਗੇ ਜੁੜਦੇ ਹਨ
Hold + confirm: ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਅਸਥਾਈ ਹੋਲਡ ਰੱਖੋ (ਇੱਕ reservation ਰਿਕਾਰਡ), ਫਿਰ ਦੂਜੇ ਕਦਮ ਵਿੱਚ ਪੇਮੈਂਟ ਪੁਸ਼ਟੀ ਕਰੋ।
ਅਵਧੀ-ਅਧਾਰਿਤ ਖ਼ਤਮੀਆਂ: ਹੋਲਡ ਆਪਣੇ ਆਪ expire ਹੋ ਜਾਣੇ ਚਾਹੀਦੇ ਹਨ (ਉਦਾਹਰਨ ਲਈ 10 ਮਿੰਟ) ਤਾਂ ਕਿ ਜੇ ਯੂਜ਼ਰ ਚੈੱਕਆਉਟ ਛੱਡ ਦੇਵੇ ਤਾਂ ਇਨਵੈਂਟਰੀ ਅਟਕੀ ਨਾ ਰਹੇ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਆਊਟਬਾਕਸ: ਜਦੋਂ ਰਿਜ਼ਰਵੇਸ਼ਨ ਪੁਸ਼ਟੀ ਹੋ ਜਾਵੇ, ਉਸੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ "ਭੇਜਣ ਲਈ ਇਕ ਇਵੈਂਟ" ਰਿਕਾਰਡ ਲਿਖੋ, ਫਿਰ ਇਸਨੂੰ ਆਸਿੰਕ੍ਰੋਨਸ ਤਰੀਕੇ ਨਾਲ email, ਫ਼ਲਫ਼ਿਲਮੈਂਟ, ਐਨਾਲਿਟਿਕਸ ਜਾਂ message bus ਨੂੰ ਭੇਜੋ—ਇਸ ਤਰ੍ਹਾਂ "ਬੁੱਕ ਹੋ ਗਿਆ ਪਰ ਪੁਸ਼ਟੀ ਨਹੀਂ ਭੇਜੀ" ਵਾਲਾ ਫੈਕਟ ਘਟਦਾ ਹੈ।
ਨਿੱਕ ਨਤੀਜਾ: ਜੇ ਤੁਹਾਡਾ ਬਿਜ਼ਨਸ ਕਰਾਸ-ਰੀਜਨ ਦੁਆਰਾ ਡਬਲ-ਹਵਾਲਾ ਬਰਦਾਸ਼ਤ ਨਹੀਂ ਕਰ ਸਕਦਾ, ਤਾਂ ਮਜ਼ਬੂਤ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਗਾਰੰਟੀਆਂ ਇੱਕ ਉਤਪਾਦੀ ਫੀਚਰ ਬਣ ਜਾਂਦੀਆਂ ਹਨ।
ਵਰਤੋਂ ਦਾ ਕੇਸ: ਉੱਚ ਉਪਲਬਧਤਾ ਅਤੇ ਡਿਜਾਸਟਰ ਰਿਕਵਰੀ
ਉੱਚ ਉਪਲਬਧਤਾ (HA) Distributed SQL ਲਈ ਉਚਿਤ ਹੈ ਜਦੋਂ ਡਾਊਨਟਾਈਮ ਮਹਿੰਗਾ ਹੋਵੇ, ਅਣਨਿਯਤ ਆਊਟੇਜ ਮਨਜ਼ੂਰ ਨਹੀਂ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਮੇਂਟੇਨੈਂਸ ਸੁਸਤ ਹੋਵੇ।
ਮਕਸਦ "ਕਦੇ ਵੀ ਫੇਲ ਨਾ ਹੋਵੇ" ਨਹੀਂ—ਇਹ ਸਪਸ਼ਟ SLOs (ਜਿਵੇਂ 99.9% ਜਾਂ 99.99% uptime) ਨੂੰ ਪੂਰਾ ਕਰਨਾ ਹੈ, ਭਾਵੇਂ ਨੋਡ ਡਾਊਨ ਹੋਣ, ਜ਼ੋਨ ਗੂਜ ਹੋ ਜਾਣ ਜਾਂ ਅਪਗਰੇਡ ਲੱਗ ਰਹੇ ਹੋਣ।
"ਹਮੇਸ਼ਾਂ-ਚਾਲੂ" ਅਮਲ ਵਿੱਚ: SLOs, ਮੇਂਟੇਨੈਂਸ, ਫੇਲਿਅਰ
"ਹਮੇਸ਼ਾਂ-ਚਾਲੂ" ਨੂੰ ਮਾਪਯੋਗ ਉਮੀਦਾਂ ਵਿੱਚ ਬਦਲੋ: ਮਹੀਨੇ ਦੀ ਅਧੀਆਤਮ ਡਾਊਨਟਾਈਮ, recovery time objective (RTO), ਅਤੇ recovery point objective (RPO)।
Distributed SQL ਸਿਸਟਮ ਬਹੁਤ ਆਮ ਫੇਲਿਅਰਾਂ ਦੌਰਾਨ ਰੀਡ/ਰਾਈਟ ਸੇਵਾ ਜਾਰੀ ਰੱਖ ਸਕਦੇ ਹਨ, ਪਰ ਸਿਰਫ਼ ਜਦੋਂ ਤੁਹਾਡੀ ਟੋਪੋਲੋਜੀ ਤੁਹਾਡੇ SLO ਨੂੰ ਮਿਲਦੀ ਹੋਵੇ ਅਤੇ ਤੁਹਾਡੀ ਐਪ ਦ੍ ਰਿਪਟੀਅਲ ਕ੍ਰਿਯਾਵਾਂ (ਰੀਟ੍ਰਾਈਜ਼, idempotency) ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਹੇਅਲ ਕਰੇ।
ਪਲੈਨਡ ਮੇਂਟੇਨੈਂਸ ਵੀ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ। ਰੋਲਿੰਗ ਅਪਗਰੇਡ ਅਤੇ ਇੰਸਟੰਸ ਬਦਲਣ ਜਦੋਂ ਡੇਟਾਬੇਸ ਲੀਡਰਸ਼ਿਪ/ਰੈਪਲਿਕਾ ਪ੍ਰਭਾਵਤ ਨੋਡਾਂ ਤੋਂ ਦੂਰ ਮੋਵ ਕਰਨ ਦੀ ਯੋਗਤਾ ਰੱਖੇ ਤਾਂ ਆਸਾਨ ਹੁੰਦੇ ਹਨ—ਬਿਨਾ ਪੂਰੇ ਕਲੱਸਟਰ ਨੂੰ ਆਫਲਾਈਨ ਕਰਨ ਦੇ।
ਮੁਲਟੀ-ਜ਼ੋਨ ਵਿਰੁੱਧ ਮੁਲਟੀ-ਰੀਜਨ redundancy
ਮਲਟੀ-ਜ਼ੋਨ ਤੈਨਾਤੀ ਤੁਹਾਨੂੰ ਇੱਕ AZ/ਜੋਨ ਆਊਟੇਜ ਅਤੇ ਕਈ ਹਾਰਡਵੇਅਰ ਫੇਲਿਅਰਾਂ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ, ਆਮ ਤੌਰ 'ਤੇ ਘੱਟ ਲੈਟੈਂਸੀ ਅਤੇ ਕਾਸਟ ਨਾਲ। ਇਹ ਅਕਸਰ ਕਾਫੀ ਹੁੰਦੀ ਹੈ ਜੇ ਤੁਹਾਡੀ ਕੰਪਲਾਇੰਸ ਅਤੇ ਯੂਜ਼ਰ ਬੇਸ ਜ਼ਿਆਦਾਤਰ ਇੱਕ ਹੀ ਰੀਜਨ ਵਿੱਚ ਹੈ।
ਮਲਟੀ-ਰੀਜਨ ਤੈਨਾਤੀ ਤੁਹਾਨੂੰ ਇੱਕ ਪੂਰੇ ਰੀਜਨ ਆਊਟੇਜ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ ਅਤੇ ਰੀਜਨਲ ਫੇਲਓਵਰ ਸਹਾਇਕ ਹੈ। ਟਰੇਡ-ਆਫ਼ ਇਹ ਹੈ ਕਿ ਮਜ਼ਬੂਤ ਸਥਿਰ ਲਿਖਤਾਂ ਲਈ ਉੱਚੀ ਲੈਟੈਂਸੀ ਅਤੇ ਹੋਰ ਕੌਂਪਲੈਕਸ CAPEX/ਓPEX ਯੋਜਨਾ ਬਣਾਉਣੀ ਪੈਂਦੀ ਹੈ।
ਫੇਲਓਵਰ ਦੀਆਂ ਉਮੀਦਾਂ (ਅਤੇ game days ਨਾਲ ਟੈਸਟਿੰਗ)
ਫੇਲਓਵਰ ਨੂੰ ਫੌਰਨ ਜਾਂ ਅਦਿੱਖਾ ਨਾ ਮੰਨੋ। ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ "ਫੇਲਓਵਰ" ਤੁਹਾਡੀ ਸੇਵਾ ਲਈ ਕੀ ਮਤਲਬ ਰਖਦਾ ਹੈ: ਛੋਟੇ error spikes? read-only ਦੌਰਾਨ? ਕੁਝ ਸਕਿੰਟਾਂ ਦੀ ਵਧੀ ਲੈਟੈਂਸੀ?
"ਗੇਮ ਡੇਜ਼" ਚਲਾਓ ਤਾਂ ਜੋ ਇਹ ਸਾਬਤ ਹੋਵੇ:
- ਇੱਕ ਨੋਡ ਨੂੰ ਮਾਰੋ, ਫਿਰ ਇੱਕ ਜ਼ੋਨ; ਆਪਣੇ SLO ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਕਲਾਇੰਟ ਐਰਰ ਬਜਟ ਨੂੰ ਵੇਰੀਫਾਈ ਕਰੋ।
- ਨੈੱਟਵਰਕ partitions ਸਿਮੁਲੇਟ ਕਰੋ ਅਤੇ ਲੀਡਰ/ਰੈਪਲਿਕਾ ਵਿਵਹਾਰ ਦੀ ਜਾਂਚ ਕਰੋ।
- ਰੀਜਨ ਖਾਲੀ ਕਰਨ ਦਾ ਅਭਿਆਸ ਕਰੋ ਅਤੇ ਅਸਲੀ RTO ਮਾਪੋ।
ਰੀਪਲੀਕੇਸ਼ਨ ਬੈਕਅੱਪ ਨਹੀਂ
ਸਿੰਕ੍ਰੋਨਸ ਰੀਪਲੀਕੇਸ਼ਨ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਬੈਕਅੱਪ ਰੱਖੋ ਅਤੇ ਰੀਸਟੋਰ ਅਭਿਆਸ ਕਰੋ। ਬੈਕਅੱਪ ਨਹਿਰਤੀਆਂ ਕ੍ਰਿਯਾਵਾਂ (ਖਰਾਬ ਮਾਈਗ੍ਰੇਸ਼ਨ, ਅਕਸਮਿਕ ਡਿਲੀਟ), ਐਪ ਬੱਗ, ਅਤੇ ਕੋਰਪਸ਼ਨ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ, ਜੋ ਰੀਪਲੀਕੇਸ਼ਨ ਨਾਲ ਵੀ ਫੈਲ ਸਕਦੀ ਹੈ।
point-in-time recovery (ਜੇ ਉਪਲਬਧ) ਦੀ ਜਾਂਚ ਕਰੋ, ਰੀਸਟੋਰ ਸਪੀਡ ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਨੂੰ ਛੁਹੇ ਬਿਨਾਂ ਸਾਫ਼ ਵਾਤਾਵਰਨ ਵਿੱਚ ਰੀਕਵਰੀ ਯੋਗਤਾ ਨੂੰ ਪ੍ਰਮਾਣਿਤ ਕਰੋ।
ਵਰਤੋਂ ਦਾ ਕੇਸ: ਡੇਟਾ ਰਿਹਾਇਸ਼ ਅਤੇ ਕੰਪਲਾਇੰਸ-ਡ੍ਰਿਵਨ ਆਰਕੀਟੈਕਚਰ
ਡੇਟਾ ਰਿਹਾਇਸ਼ ਦੀਆਂ ਲੋੜਾਂ ਉਹਨਾਂ੍ਹ ਵੇਲੇ ਆਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਨਿਯਮ, ਠੇਕੇ, ਜਾਂ ਅੰਦਰੂਨੀ ਨੀਤੀਆਂ ਕਹਿਣ ਕਿ ਕੁਝ ਰਿਕਾਰਡ ਖਾਸ ਦੇਸ਼ ਜਾਂ ਰੀਜਨ ਵਿੱਚ ਸਟੋਰ (ਅਤੇ ਕਈ ਵਾਰੀ ਪ੍ਰੋਸੈੱਸ) ਹੋਣ।
ਇਹ ਨਿੱਜੀ ਡੇਟਾ, ਸਿਹਤ ਸੰਬੰਧੀ ਜਾਣਕਾਰੀ, ਪੇਮੈਂਟ ਡੇਟਾ, ਸਰਕਾਰੀ ਵਰਕਲੋਡ ਜਾਂ "ਗਾਹਕ-ਮਲਕੀਅਤ" ਡੇਟਾਸੈਟਾਂ 'ਤੇ ਲਾਗੂ ਹੋ ਸਕਦਾ ਹੈ ਜਿੱਥੇ ਕਲਾਇੰਟ ਠੇਕੇ ਨਾਲ ਨਿਰਧਾਰਿਤ ਕਰਦਾ ਹੈ ਕਿ ਉਹਨਾਂ ਦਾ ਡੇਟਾ ਕਿੱਥੇ ਹੋਵੇ।
Distributed SQL ਇੱਥੇ ਆਮ ਤੌਰ 'ਤੇ ਸੋਚਿਆ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਹੀ ਲਾਜ਼ਮੀ ਲੌਜਿਕਲ ਡੇਟਾਬੇਸ ਰੱਖ ਕੇ ਫਿਜ਼ਿਕਲ ਤੌਰ 'ਤੇ ਡੇਟਾ ਨੂੰ ਵੱਖ-ਵੱਖ ਰੀਜਨਾਂ ਵਿੱਚ ਰੱਖ ਸਕਦਾ ਹੈ—ਬਿਨਾ ਇਹਦੇ ਕਿ ਤੁਹਾਨੂੰ ਹਰ ਜਿਓਗ੍ਰਾਫੀ ਲਈ ਪੂਰਾ ਵੱਖਰਾ ਐਪਲੀਕੇਸ਼ਨ ਸਟੈਕ ਚਲਾਉਣਾ ਪਵੇ।
ਕਿਉਂ ਰਿਹਾਇਸ਼ ਨਿਯਮ ਡੇਟਾਬੇਸ ਡਿਜ਼ਾਇਨ ਨੂੰ ਬਦਲ ਦਿੰਦੇ ਹਨ
ਜੇ ਕੋਈ ਨਿਯਮਕ ਜਾਂ ਗ੍ਰਾਹਕ-ਠੇਕਾ "ਡੇਟਾ ਖੇਤਰ ਵਿੱਚ ਰਹੇ" ਦੀ ਮੰਗ ਕਰਦਾ ਹੈ, ਤਾਂ ਸਿਰਫ਼ ਨੇੜੇ ਰੈਪਲਿਕਾ ਹੋਣਾ ਕਾਫੀ ਨਹੀਂ। ਤੁਹਾਨੂੰ ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਪੈ ਸਕਦਾ ਹੈ ਕਿ:
- ਕੁਝ ਡੇਟਾ ਦੀ ਪ੍ਰਾਇਮਰੀ ਨਕਲ (ਜਾਂ ਸਾਰੀਆਂ ਨਕਲਾਂ) ਸਿਰਫ਼ ਮਨਜ਼ੂਰ ਰੀਜਨਾਂ ਵਿੱਚ ਸਟੋਰ ਕੀਤੀ ਜਾਂਦੀ ਹੈ
- ਬੈਕਅੱਪ ਅਤੇ ਸਨੈਪਸ਼ਾਟ ਉਹੇ ਨਿਯਮ ਫੋਲੋ ਕਰਦੇ ਹਨ
- ਰੀਜਨ ਤੋਂ ਬਾਹਰ ਦੇ ਓਪਰੇਟਿਵ ਲੋਕ/ਸੇਵਾਵਾਂ_raw ডੇਟਾ ਤੱਕ ਪਹੁੰਚ ਨਹੀਂ ਰੱਖਦੀਆਂ
ਇਸ ਨਾਲ ਟੀਮਾਂ ਨੂੰ ਉਹ ਆਰਕੀਟੈਕਚਰ ਵੱਲ ਧੱਕ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ ਜਿਸ ਵਿੱਚ ਲੋਕੈਸ਼ਨ ਇਕ ਪਹਿਲੀ-ਸ਼੍ਰੇਣੀ ਚਿੰਤਾ ਹੁੰਦੀ ਹੈ, ਨਾ ਕਿ ਇੱਕ ਬਾਅਦ ਵਾਲੀ ਸੋਚ।
ਪਰ-ਗਾਹਕ ਪਲੇਸਮੈਂਟ ਅਤੇ ਪਹੁੰਚ ਨਿਯੰਤਰਣ (ਊਪਰਲੀ ਸਤਰ)
SaaS ਵਿੱਚ ਇੱਕ ਆਮ ਪੈਟਰਨ ਪਰ-ਟੈਨੈਂਟ ਡੇਟਾ ਪਲੇਸਮੈਂਟ ਹੈ। ਉਦਾਹਰਣ ਲਈ: EU ਗਾਹਕਾਂ ਦੀਆਂ ਰੋਜ਼ਾਂ/ਪਾਰਟੀਸ਼ਨਾਂ ਨੂੰ EU ਰੀਜਨ ਵਿੱਚ ਪਿਨ ਕਰੋ, US ਗਾਹਕਾਂ ਲਈ US ਰੀਜਨ।
ਉੱਚ-ਸਤਰ 'ਤੇ, ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਜੁੜਦੇ ਹੋ:
- ਡੇਟਾ ਪਲੇਸਮੈਂਟ ਨੀਤੀਆਂ (ਇੱਕ ਟੈਨੈਂਟ ਦਾ ਡੇਟਾ ਕਿੱਥੇ ਰਹਿ ਸਕਦਾ ਹੈ)
- ਆਈਡੈਂਟੀਟੀ ਅਤੇ ਪਹੁੰਚ ਨਿਯੰਤਰਣ (ਕਿਹੜੀਆਂ ਸਰਵਿਸਾਂ ਅਤੇ ਮਨੁੱਖ ਪੜ੍ਹ ਸਕਦੇ ਹਨ)
- ਇਨਕ੍ਰਿਪਸ਼ਨ ਅਤੇ ਕੀ മാനੇਜਮੈਂਟ (ਕਈ ਵਾਰੀ ਰੀਜਨ-ਬਾਊਂਡ ਕੀਜ਼)
ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਓਪਰੇਸ਼ਨਲ ਪਹੁੰਚ, ਬੈਕਅੱਪ ਰੀਸਟੋਰ ਜਾਂ ਕਰਾਸ-ਰੀਜਨ ਰੀਪਲੀਕੇਸ਼ਨ ਦੇ ਜ਼ਰੀਏ ਅਕਸਮਾਤ ਤੌਰ 'ਤੇ ਰਿਹਾਇਸ਼ ਉਲੰਘਣ ਹੋਣ ਨੂੰ ਮੁਸ਼ਕਲ ਬਣਾਇਆ ਜਾਵੇ।
ਕਾਨੂੰਨੀ ਲੋੜਾਂ ਵਾਰੀਫਾਈ ਕਰੋ—ਸਲਾਹਕਾਰ ਸ਼ਾਮਲ ਕਰੋ
ਰਿਹਾਇਸ਼ ਅਤੇ ਕੰਪਲਾਇੰਸ ਦੀਆਂ ਜ਼ਰੂਰਤਾਂ ਦੇਸ਼, ਉਦਯੋਗ ਅਤੇ ਠੇਕੇ ਅਨੁਸਾਰ ਵੱਖ-ਵੱਖ ਹੁੰਦੀਆਂ ਹਨ। ਇਹ ਵੀ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲਦੀਆਂ ਹਨ।
ਡੇਟਾਬੇਸ ਟੋਪੋਲੋਜੀ ਨੂੰ ਆਪਣੇ ਕੰਪਲਾਇੰਸ ਪ੍ਰੋਗ੍ਰਾਮ ਦਾ ਹਿੱਸਾ ਮੰਨੋ, ਅਤੇ ਯੋਗ ਕਾਨੂੰਨੀ ਸਲਾਹਕਾਰ ਅਤੇ ਜੇ ਲੋੜ ਹੋਵੇ ਤਾਂ ਤੁਸੀਂ ਆਪਣੇ ਆਡਿਟਰ ਨਾਲ ਆਪਣੀਆਂ ਸਮਝੌਤੀਆਂ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ।
ਕਿਵੇਂ ਮਲਟੀ-ਰੀਜਨ ਟੋਪੋਲੋਜੀ ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਐਨਾਲੇਟਿਕਸ 'ਤੇ ਅਸਰ ਪਾਂਦੀ ਹੈ
ਰਿਹਾਇਸ਼-ਫਰੈਂਡਲੀ ਟੋਪੋਲੋਜੀ "ਗਲੋਬਲ ਵਿਊ" ਨੂੰ ਜਟਿਲ ਕਰ ਸਕਦੀ ਹੈ। ਜੇ ਗਾਹਕ ਡੇਟਾ ਇਰਾਦਾ-ਪੂਰਵਕ ਵੱਖ-ਵੱਖ ਰੀਜਨਾਂ ਵਿੱਚ ਰੱਖਿਆ ਗਿਆ ਹੈ, ਤਾਂ ਐਨਾਲਿਟਿਕਸ ਅਤੇ ਰਿਪੋਰਟਿੰਗ:
- ਖੇਤਰੀ ਰਿਪੋਰਟਿੰਗ ਪਾਈਪਲਾਈਨ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ (ਕੰਪਿ�ੂਟ ਉਥੇ ਚਲਾਇਆ ਜਾਂਦਾ ਹੈ ਜਿੱਥੇ ਡੇਟਾ ਮੌਜੂਦ ਹੈ)
- ਸੰਘ੍ਰਿਤ ਐਕਸਪੋਰਟ ਵਰਤਿਆ ਜਾ ਸਕਦਾ ਹੈ (ਸਿਰਫ਼ ਮਨਜ਼ੂਰ ਕੀਤੇ ਮੈਟਰਿਕਸ ਰੀਜਨ ਤੋਂ ਬਾਹਰ ਜਾ ਸਕਦੇ ਹਨ)
- ਗਲੋਬਲ ਡੈਸ਼ਬੋਰਡ ਲਈ ਉੱਚ ਲੈਟੈਂਸੀ ਮਨਜ਼ੂਰ ਕਰਨ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ, ਕਿਉਂਕਿ ਗਲੋਬਲ ਕਵੈਰੀਆਂ ਰੀਜਨਾਂ ਨੂੰ ਕਵਰ ਕਰਦੀਆਂ ਹਨ ਜਾਂ ਡੈਰੀਵਡ ਡੇਟਾਸੈਟ 'ਤੇ ਨਿਰਭਰ ਰਹਿੰਦੀਆਂ ਹਨ
ਅਮਲੀ ਤੌਰ 'ਤੇ, ਕਈ ਟੀਮਾਂ ਆਪਰੇਸ਼ਨਲ ਵਰਕਲੋਡ (ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ, ਰਿਹਾਇਸ਼-ਅਵੇਅਰ) ਨੂੰ ਐਨਾਲਿਟਿਕਸ (ਰੀਜਨ-ਸਕੋਪਡ ਵੇਅਰਹਾਊਸਜ਼ ਜਾਂ ਵਰਤੋ-ਨਿਯੰਤਰਿਤ ਐਗਰੀਗੇਟ ਡੇਟਾਸੈਟ) ਤੋਂ ਵੱਖ ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਕਿ ਕੰਪਲਾਇੰਸ ਸੰਭਾਲਣ ਜੋਗੇ ਰਹੇ ਬਿਨਾ ਰੋਜ਼ਾਨਾ ਪ੍ਰੋਡਕਟ ਰਿਪੋਰਟਿੰਗ ਨੂੰ දිਲਣੇ।
Distributed SQL ਲਈ ਲਾਗਤ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਯੋਜਨਾ
ਨਜ਼ਰੀਏ ਨੂੰ ਅੰਕਾਂ 'ਚ ਬਦਲੋ
ਲੇਖਾਂ ਨੂੰ ਨੰਬਰਾਂ ਵਿੱਚ ਬਦਲੋ — ਇੱਕ ਮੈਜ਼ਰੇਬਲ ਬੈਂਚਮਾਰਕ ਐਪ ਬਣਾਓ ਜੋ ਤੁਸੀਂ ਚਲਾ ਕੇ ਸੱਜਾ ਸਕੋਂ।
Distributed SQL ਤੁਹਾਨੂੰ ਦਰਦਨਾਕ ਆਊਟੇਜ ਅਤੇ ਰੀਜਨਲ ਸੀਮਾਵਾਂ ਤੋਂ ਬਚਾ ਸਕਦਾ ਹੈ, ਪਰ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਖ਼ਰਚ ਬਚਾਉਂਦਾ ਨਹੀਂ। ਅਗੇ-ਆਉਂਦੇ ਸੋਚ-ਵਿਚਾਰ ਨਾਲ ਤੁਸੀਂ ਅਣਜਾਣੇ "ਬੀਮਾ" ਲਈ ਪੈਸਾ ਨਾਂ ਦੇਵੋ।
ਮੁੱਖ ਖ਼ਰਚ ਕਾਰਕ
ਜ਼ਿਆਦਾਤਰ ਬਜਟ ਚਾਰ ਬਕੈਟਾਂ ਵਿੱਚ ਵੰਡਦੇ ਹਨ:
- ਨੋਡ (ਕੰਪਿਊਟ): ਤੁਸੀਂ ਕਈ ਰੈਪਲਿਕਾ ਰੱਖਣ ਦੇ ਲਈ ਅਕਸਰ ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ—ਅਕਸਰ ਹਰ ਰੀਜਨ ਵਿੱਚ 3+—ਅਤੇ ਫੇਲਓਵਰ ਲਈ ਵਾਧੂ ਕੈਪਿਸਿਟੀ। ਮਲਟੀ-ਰੀਜਨ ਡਿਜ਼ਾਈਨ ਆਮ ਤੌਰ 'ਤੇ single-region Postgres ਨਾਲੋਂ ਵੱਧ headroom ਮੰਗਦੇ ਹਨ।
- ਸਟੋਰੇਜ: ਰੀਪਲੀਕੇਸ਼ਨ ਡੇਟਾ ਸਾਈਜ਼ ਨੂੰ ਗੁਣਾ ਕਰ ਦਿੰਦੀ ਹੈ। 2 TB ਡੇਟਾਸੈਟ ਤਿੰਨ ਰੈਪਲਿਕਾ ਨਾਲ ~6 TB ਬਣ ਜਾਂਦਾ ਹੈ ਬਿਨਾ ਬੈਕਅੱਪ ਅਤੇ ਇੰਡੈਕਸ overhead ਦੇ।
- ਇੰਟਰ-ਰੀਜਨ ਟ੍ਰੈਫਿਕ: ਕਰਾਸ-ਰੀਜਨ ਰੀਪਲੀਕੇਸ਼ਨ, ਰੀਡਸ, ਅਤੇ ਕਲਾਇੰਟ ਟ੍ਰੈਫਿਕ ਮਹੱਤਵਪੂਰਨ ਲਾਈਨ ਆਈਟਮ ਹੋ ਸਕਦੇ ਹਨ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਪਹਿਲੀ "ਹੈਰਾਨੀ" ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ active-active ਬਣਦੇ ਹੋ।
- ਓਪਸ ਸਮਾਂ: ਭਾਵੇਂ managed ਪੇਸ਼ਕਸ਼ਾਂ ਹੋਣ, ਕੰਮ ਘਟਦਾ ਨਹੀਂ: ਸਕੀਮਾ ਅਤੇ ਕਵੈਰੀ ਟਿਊਨਿੰਗ, ਇੰਸੀਡੈਂਟ ਰਿਸਪਾਂਸ, ਕੈਪਿਸਿਟੀ ਪਲੈਨਿੰਗ, ਅਪਗਰੇਡ ਟੈਸਟਿੰਗ, ਅਤੇ ਗਵਰਨੈਂਸ (ਖਾਸ ਕਰਕੇ ਰਿਹਾਇਸ਼/ਕੰਪਲਾਇੰਸ) ਵੇਖਣਾ ਪੈਂਦਾ ਹੈ।
ਅਸਲੀ ਯੂਜ਼ਰ ਯਾਤਰਾਵਾਂ 'ਤੇ ਲੈਟੈਂਸੀ ਪ੍ਰਭਾਵ ਅੰਦਾਜ਼ਾ ਲਗਾਉਣਾ
Distributed SQL ਸਿਸਟਮ ਕੋਆਰਡੀਨੇਸ਼ਨ ਵਧਾਉਂਦੇ ਹਨ—ਖਾਸ ਕਰਕੇ ਮਜ਼ਬੂਤ ਸਥਿਰਤਾ ਵਾਲੇ ਲਿਖਤਾਂ ਲਈ ਜੋ quorum ਦੁਆਰਾ ਪੁਸ਼ਟੀ ਕੀਤੇ ਜਾਣੇ ਚਾਹੀਦੇ ਹਨ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕ ਤਰੀਕਾ ਪ੍ਰਭਾਵ ਅੰਦਾਜ਼ਾ ਲਗਾਉਣ ਲਈ:
- 2–3 ਕੁੰਜੀ ਯਾਤਰਾਵਾਂ (checkout, booking, "save changes") ਚੁਣੋ।
- ਮਹੱਤਵਪੂਰਨ ਰਾਹ 'ਚ ਕਿੰਨੀ ਲਿਖਤ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਅਤੇ ਰੀਡ-ਆਫਟਰ-ਰਾਈਟ ਕਦਮ ਹਨ, ਉਹ ਗਿਣੋ।
- ਹਰ ਕਦਮ ਲਈ, ਅਨੁਮਾਨ ਲਗਾਓ ਕਿ ਜਦੋਂ ਕੋਆਰਡੀਨੇਸ਼ਨ ਲੋੜੀਂਦੀ ਹੋਵੇ ਤਾਂ ਇੱਕ ਮਲਟੀ-ਰੀਜਨ ਰਾਊਂਡ-ਟ੍ਰਿਪ ਹੋ ਸਕਦਾ ਹੈ। ਜੇ ਕਰਾਸ-ਰੀਜਨ RTT 80–120 ms ਹੈ, ਤਾਂ ਦੋ ਕ੍ਰਮਵਾਰ ਲਿਖਤ ਕਦਮ 160–240 ms ਐਪਲੀਕੇਸ਼ਨ ਟਾਈਮ ਵਿੱਚ ਜੋੜ ਸਕਦੇ ਹਨ।
ਇਸਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ "ਇਸਦੀ ਵਰਤੋਂ ਨਾ ਕਰੋ", ਪਰ ਇਹ ਤੁਹਾਨੂੰ ਯਾਤਰਾਵਾਂ ਨੂੰ ਘੱਟ ਕਰਕੇ Sequential writes ਘਟਾਉਣ (ਬੈਚਿੰਗ, idempotent ਰੀਟ੍ਰਾਈਜ਼, ਘੱਟ ਚੈਟੀਆਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ) ਲਈ ਡਿਜ਼ਾਇਨ ਕਰਨ ਲਈ ਭੇਟ ਦੇਂਦਾ ਹੈ।
ਜਟਿਲਤਾ ਵਿਰੁੱਧ ਸਧਾਰਨ ਵਿਕਲਪ
ਜੇ ਤੁਹਾਡੇ ਯੂਜ਼ਰ ਜ਼ਿਆਦਾਤਰ ਇੱਕ ਹੀ ਰੀਜਨ ਵਿੱਚ ਹਨ, ਤਾਂ ਇੱਕ-ਰੀਜਨ Postgres ਰੀਡ ਰੈਪਲਿਕਾਸ, ਸ਼ਾਨਦਾਰ ਬੈਕਅਪ, ਅਤੇ ਟੈਸਟ ਕੀਤੀ ਫੇਲਓਵਰ ਯੋਜਨਾ ਨਾਲ ਸਸਤੀ ਅਤੇ ਸਾਦੀ ਹੋ ਸਕਦੀ ਹੈ—ਅਤੇ ਤੇਜ਼।
Distributed SQL ਉਹ ਖ਼ਰਚ ਬਰਦਾਸ਼ਤ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਵਾਕਈ ਮਲਟੀ-ਰੀਜਨ ਲਿਖਤਾਂ, ਕਠੋਰ RPO/RTO, ਜਾਂ ਰਿਹਾਇਸ਼-ਅਵੇਅਰ ਪਲੇਸਮੈਂਟ ਦੀ ਲੋੜ ਹੋਵੇ।
ਇੱਕ ਸਧਾਰਣ ROI ਝਲਕ
ਖ਼ਰਚ ਨੂੰ ਇਕ ਤਰਪਦਾ ਵਾਰٹا ਸਮਝੋ:
- ਜੋखिम ਟਾਲਿਆ ਗਿਆ: ਘੱਟ ਰੇਵਨਿਊ ਪ੍ਰਭਾਵ ਵਾਲੇ ਆਊਟੇਜ, ਘੱਟ ਡੇਟਾ-ਲਾਸ, "ਗਲੋਬਲ ਇੰਸੀਡੈਂਟ" ਹਫ਼ਤੇ ਦੇ ਕੰਮ ਘੱਟ।
- ਬਚਾਇਆ ਰੇਵਨਿਊ: ਖੇਤਰੀ ਯੂਜ਼ਰ ਲਈ ਘੱਟ ਲੈਟੈਂਸੀ ਨਾਲ ਬੇਤਰ ਕਨਵਰਸ਼ਨ, ਵੱਡੇ ਉਦਯੋਗਕ ਲਾਇਨ (SLA, ਕੰਪਲਾਇੰਸ)।
- ਖ਼ਰਚ: ਬੇਸਲਾਈਨ ਕਲੱਸਟਰ + ਰੀਪਲੀਕੇਸ਼ਨ ਓਵਰਹੈੱਡ + ਟ੍ਰੈਫਿਕ + ਇੰਜੀਨੀਅਰਿੰਗ ਸਮਾਂ।
ਜੇ ਟਾਲਿਆ ਗਿਆ ਨੁਕਸਾਨ (ਡਾਊਨਟਾਈਮ + ਚਰਨ + ਕੰਪਲਾਇੰਸ ਜੋਖਮ) ongoing ਪ੍ਰੀਮੀਅਮ ਤੋਂ ਵੱਡਾ ਹੈ, ਤਾਂ ਮਲਟੀ-ਰੀਜਨ ਡਿਜ਼ਾਈਨ ਵਾਜ਼ਬ ਹੈ। ਨਹੀਂ ਤਾਂ, ਆਸਾਨੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ—ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਵਿਕਸਿਤ ਹੋਵਣ ਦਾ ਰਸਤਾ ਰੱਖੋ।
ਅਪਡਾਪਸ਼ਨ ਚੈੱਕਲਿਸਟ ਅਤੇ ਅੱਗੇ ਕਦਮ
Distributed SQL ਨੂੰ ਅਪਨਾਉਣਾ ਡੇਟਾਬੇਸ ਨੂੰ "ਉੱਠਾ ਕੇ ਬਦਲਣਾ" ਨਹੀਂ ਹੈ—ਇਹ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਇਹ ਸਾਬਤ ਕਰਨ ਲਈ ਕਿ ਤੁਹਾਡਾ ਨਿਰਦਿਸ਼ਟ ਵਰਕਲੋਡ ਖਰਾ ਹੈ ਜਦੋਂ ਡੇਟਾ ਅਤੇ ਕਨਸੈਂਸਸ ਨੋਡਾਂ (ਅਤੇ ਸੰਭਵ ਹੈ ਕਿ ਰੀਜਨਾਂ) 'ਚ ਵੰਡੇ ਹੋਏ ਹਨ। ਇੱਕ ਹਲਕਾ ਯੋਜਨਾ ਤੁਹਾਡੇ ਨੂੰ ਅਣਚਾਹੀਆਂ ਗਲਤੀਆਂ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ।
ਫੋਕਸਡ ਪ੍ਰੂਫ-ਆਫ-ਕਾਂਸੈਪਟ (PoC)
ਇੱਕ ਇੱਕ ਵਰਕਲੋਡ ਚੁਣੋ ਜੋ ਅਸਲ ਦਰਦ ਦਰਸਾਉਂਦਾ ਹੈ: ਉਦਾਹਰਣ ਲਈ checkout/booking, account provisioning, ਜਾਂ ledger posting।
ਸਫਲਤਾ ਮੈਟਰਿਕ ਪਹਿਲਾਂ ਤੋਂ ਨਿਰਧਾਰਤ ਕਰੋ:
- Correctness: ਕੋਈ double-bookings ਨਹੀਂ, ਕੋਈ lost updates ਨਹੀਂ, predictable transaction ਵਿਵਹਾਰ
- Latency SLOs: ਸਿਖਰ 3 ਕਵੈਰੀਆਂ ਲਈ p50/p95 (ਜੋ ਕ੍ਰਾਸ-ਰੀਜਨ ਟਾਰਗੇਟ ਵੀ ਸ਼ਾਮਲ ਕਰਨ)
- Throughput: peak 'ਤੇ sustained QPS + ਸੁਰੱਖਿਆ ਮਾਰਜਿਨ (ਅਕਸਰ 2–3×)
- Resilience: ਨੋਡ ਫੇਲਿਅਰ ਅਤੇ (ਜੇ ਲਾਗੂ ਹੋਵੇ) ਰੀਜਨ ਲਾਸ ਦੌਰਾਨ ਵਿਵਹਾਰ
- Operational effort: ਨਕਲੀ ਘਟਨਾ ਤੋਂ ਪਤਾ ਲਗਾਉਣ, ਡਾਇਗਨੋਜ਼ ਅਤੇ ਰੀਕਵਰ ਕਰਨ ਦਾ ਸਮਾਂ
ਜੇ ਤੁਸੀਂ PoC ਦੌਰਾਨ ਤੇਜ਼ੀ ਨਾਲ ਅੱਗੇ ਵਧਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਛੋਟੀ "ਅਸਲੀ" ਐਪ ਸਤਹ (API + UI) ਬਣਾਉਣਾ ਸਹਾਇਕ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਸਿਰਫ਼ ਸਿੰਥੇਟਿਕ ਬੈਂਚਮਾਰਕ। ਉਦਾਹਰਣ ਵਜੋਂ, ਟੀਮਾਂ ਕਈ ਵਾਰੀ Koder.ai ਵਰਗੇ ਉਪਕਰਨ ਵਰਤ ਕੇ ਇੱਕ ਹਲਕਾ React + Go + PostgreSQL ਬੇਸਲਾਈਨ ਐਪ ਤੇਜ਼ੀ ਨਾਲ ਗੜ੍ਹਦੇ ਹਨ, ਫਿਰ ਡੇਟਾਬੇਸ ਲੇਅਰ ਨੂੰ CockroachDB/YugabyteDB ਨਾਲ ਬਦਲ ਕੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪੈਟਰਨ, ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਫੇਲਿਅਰ ਵਿਵਹਾਰ ਨੂੰ end-to-end ਟੈਸਟ ਕਰਦੇ ਹਨ। ਮਕਸਦ ਸਟਾਰਟਰ ਸਟੈਕ ਨਹੀਂ—"ਆਈਡੀਆ" ਤੋਂ "ਤੁਸੀਂ ਮਾਪ ਸਕਣ ਵਾਲਾ ਵਰਕਲੋਡ" ਤੱਕ ਲੂਪ ਛੋਟਾ ਕਰਨਾ ਹੈ।
ਡਿਜ਼ਾਈਨ ਚੈੱਕਲਿਸਟ (ਉਹ ਚੀਜ਼ਾਂ ਜੋ ਬਾਅਦ ਵਿੱਚ ਚਬਾਉਂਦੀਆਂ ਹਨ)
- ਸਕੀਮਾ: ਪ੍ਰਾਇਮਰੀ ਕੀਜ਼ ਚੁਣੋ ਜੋ ਲਿਖਤਾਂ ਨੂੰ ਵੰਡਦੀਆਂ ਹਨ; ਕ੍ਰਮਿਕ "ਹੋਟ" ਕੀਜ਼ ਤੋਂ ਬਚੋ
- ਇੰਡੈਕਸ: ਜਿਨ੍ਹਾਂ ਦੀ ਲੋੜ ਹੈ ਸਿਰਫ਼ ਰੱਖੋ; ਸੈਕੰਡਰੀ ਇੰਡੈਕਸਾਂ ਕਾਰਨ write amplification ਸਮਝੋ
- ਪਾਰਟੀਸ਼ਨਿੰਗ/ਪਲੈਸਮੈਂਟ: ਪਾਰਟੀਸ਼ਨ ਕੀਜ਼ ਅਤੇ ਕਿਸੇ ਜੀਓ/ਜ਼ੋਨ ਨਿਯਮਾਂ ਦਾ ਫੈਸਲਾ ਕਰੋ access ਪੈਟਰਨ ਅਨੁਸਾਰ
- ਹੋਟ ਸਪੋਟਸ: "ਸੈਲੇਬ੍ਰਿਟੀ ਰੋਜ਼" (ਗਲੋਬਲ ਕਾਊਂਟਰ, ਸਿੰਗਲ-ਟੈਨੈਂਟ ਟੇਬਲ) ਦੀ ਪਹਿਚਾਣ ਕਰੋ ਅਤੇ ਪਹਿਲਾਂ ਹੀ redesign ਕਰੋ
- ਮਾਈਗ੍ਰੇਸ਼ਨ: ਆਨਲਾਈਨ ਸਕੀਮਾ ਬਦਲਾਵ ਅਤੇ ਬੈਕਫਿਲਸ ਦੀ ਯੋਜਨਾ ਬਣਾਓ; ਰੋਲਬੈਕ ਰਾਹਾਂ ਟੈਸਟ ਕਰੋ
ਦਿਨ ਇਕ ਤੋਂ ਹੀ ਓਪਰੇਸ਼ਨਾਂ ਦੀਆਂ ਮੂਲ ਚੀਜ਼ਾਂ
ਮਾਨੀਟਰਨਿੰਗ ਅਤੇ ਰਨਬੁੱਕਸ SQL ਵਾਂਗ ਹੀ ਮਹੱਤਵਪੂਰਨ ਹਨ:
- ਲੈਟੈਂਸੀ, ਰੀਟ੍ਰਾਈਜ਼, contention, replication/consensus ਹੇਲਥ, ਡਿਸਕ ਅਤੇ compactions ਲਈ ਡੈਸ਼ਬੋਰਡ
- ਇੰਸੀਡੈਂਟ ਰਨਬੁੱਕ: slow queries, node restarts, failing replicas, uneven load
- ਲੋਡ ਟੈਸਟ ਜੋ ਪ੍ਰੋਡਕਸ਼ਨ ਨੂੰ ਨਕਲ ਕਰੇ (read/write mix, bursts, ਲੰਬੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ)
- ਬੈਕਅੱਪ + ਰੀਸਟੋਰ ਡ੍ਰਿਲ (ਜਿੱਥੇ point-in-time recovery ਸਹਾਇਕ ਹੋਵੇ)
ਅੱਗੇ ਕਦਮ
PoC ਸਪ੍ਰਿੰਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਫਿਰ ਪ੍ਰੋਡਕਸ਼ਨ ਰੈਡੀਨੈਸ ਸਮੀਖਿਆ ਅਤੇ ਧੀਰੇ-ਧੀਰੇ ਕਟਓਵਰ (ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ ਦੋਹਾਂ-ਤਰਫੇ ਲਿਖਤ ਜਾਂ ਸ਼ੈਡੋ ਰੀਡ) ਲਈ ਸਮਾਂ ਰੱਖੋ।
ਜੇ ਤੁਸੀਂ ਆਪਣੀਆਂ PoC ਨਤੀਜਿਆਂ, ਆਰਕੀਟੈਕਚਰ ਟਰੇਡਆਫ਼ਸ, ਜਾਂ ਮਾਈਗ੍ਰੇਸ਼ਨ ਸਬਕਾਂ ਦੀ ਡੌਕਯੂਮੈਂਟੇਸ਼ਨ ਕਰਦੇ ਹੋ, ਤਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਆਪਣੀ ਟੀਮ ਨਾਲ (ਅਤੇ ਜਨਤਕ ਰੂਪ ਵਿੱਚ ਜੇ ਸੰਭਵ ਹੋਵੇ) ਸਾਂਝਾ ਕਰਨ 'ਤੇ ਵਿਚਾਰ ਕਰੋ: ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਇੱਥੇ ਵੀ ਉਹਨਾਂ ਨੂੰ ਮਦਦਗਾਰ ਸਮੱਗਰੀ ਬਣਾਉਣ ਜਾਂ ਹੋਰ ਬਿਲਡਰਾਂ ਦਾ ਰੈਫ੍ਰਲ ਕਰਨ 'ਤੇ ਕਰੈਡਿਟ ਲੈਣ ਦੇ ਤਰੀਕੇ ਭੀ ਦਿੰਦੇ ਹਨ, ਜੋ ਤੁਸੀਂ ਮੁਲਾਂਕਣ ਦੌਰਾਨ ਪ੍ਰਯੋਗਾਂ ਦੀ ਲਾਗਤ ਘਟਾ ਸਕਦੇ ਹੋ।