ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਦਾ ਮਤਲਬ (ਬਿਨਾਂ ਜਾਰਗਨ ਦੇ)
“Consistency” ਇੱਕ ਸਧਾਰਣ ਸਵਾਲ ਹੈ: ਜੇ ਦੋ ਲੋਕ ਇੱਕੋ ਹੀ ਡੇਟਾ ਵੇਖਦੇ ਹਨ, ਤਾਂ ਕੀ ਉਹ ਉਸੇ ਸਮੇਂ ਉਹੀ ਚੀਜ਼ ਦੇਖਦੇ ਹਨ? ਉਦਾਹਰਨ ਲਈ, ਜੇ ਤੁਸੀਂ ਆਪਣਾ ਸ਼ਿਪਿੰਗ ਐਡਰੈੱਸ ਬਦਲਦੇ ਹੋ, ਕੀ ਤੁਹਾਡਾ ਪ੍ਰੋਫਾਈਲ ਪੇਜ, ਚੈਕਆਊਟ ਪੇਜ ਅਤੇ ਕਸਟਮਰ ਸਪੋਰਟ ਸਕ੍ਰੀਨ ਸਭ ਤੁਰੰਤ ਨਵਾਂ ਐਡਰੈੱਸ ਦਿਖਾਏਂਗੇ?
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ (eventual consistency) ਦੇ ਨਾਲ, ਜਵਾਬ ਇਹ ਹੈ: ਹਰ ਵਾਰ ਤੁਰੰਤ ਨਹੀਂ—ਪਰ ਅੰਤ ਵਿੱਚ ਇਹ ਮਿਲ ਜਾਵੇਗਾ. ਸਿਸਟਮ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਇਨ ਕੀਤਾ ਹੁੰਦਾ ਹੈ ਕਿ ਕੁਝ ਘੱਟ ਸਮੇਂ ਬਾਅਦ ਹਰ ਨਕਲ ਇੱਕੋ ਨਵੀਨਤਮ ਮੁੱਲ 'ਤੇ ਠਹਿਰ ਜਾਵੇ।
“ਅੰਤਿਮ” ਦਾ ਅਸਲ ਮਤਲਬ
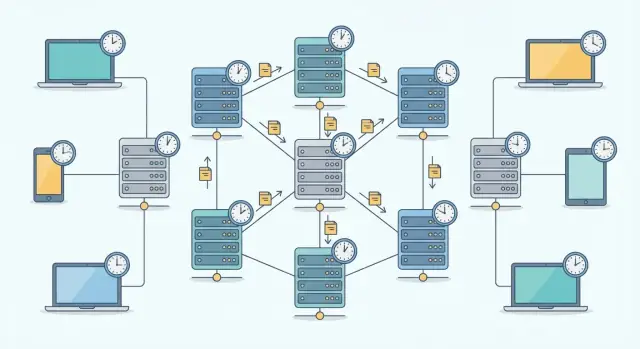
ਜਦੋਂ ਤੁਸੀਂ ਕੋਈ ਬਦਲਾਅ ਸੇਵ ਕਰਦੇ ਹੋ, ਉਸ ਅਪਡੇਟ ਨੂੰ ਘੁੰਮਣਾ ਪੈਂਦਾ ਹੈ। ਵੱਡੀਆਂ ਐਪਸ ਵਿੱਚ ਡੇਟਾ ਸਿਰਫ਼ ਇਕ ਹੀ ਥਾਂ 'ਤੇ ਨਹੀਂ ਰੱਖਿਆ ਹੁੰਦਾ। ਇਹ ਨਕਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ—ਇੱਕੋ ਡੇਟਾ ਦੀਆਂ ਕਈ ਨਕਲਾਂ (ਜਿਨ੍ਹਾਂ ਨੂੰ replicas ਕਹਿੰਦੇ ਹਨ) ਵੱਖ-ਵੱਖ ਸਰਵਰਾਂ ਜਾਂ ਖੇਤਰਾਂ ਵਿੱਚ ਰੱਖੀਆਂ ਹੁੰਦੀਆਂ ਹਨ।
ਨਕਲ ਕਿਉਂ ਰੱਖਦੇ ਹਨ?
- ਜਦੋਂ ਕੋਈ ਸਰਵਰ ਜਾਂ ਡੇਟਾ ਸੈਂਟਰ ਸਮੱਸਿਆ ਵਿੱਚ ਹੋਵੇ ਤਾਂ ਓਪਲੇ ਰਹਿਣ ਲਈ
- ਨੇੜੇ ਸਥਿਤ ਲੋਕਾਂ ਨੂੰ ਤੇਜ਼ ਸੇਵਾ ਦੇਣ ਲਈ
- ਭਾਰੀ ਟ੍ਰੈਫਿਕ ਨੂੰ ਹੈਂਡਲ ਕਰਨ ਲਈ ਤਾਂ ਕਿ ਸਭ ਕੁਝ ਬੋਤਲਨੇਕ ਨਾ ਹੋਵੇ
ਉਹ ਨਕਲ ਪੂਰੀ ਤਰ੍ਹਾਂ ਇਕ-ਸਮੇਂ ਅਪਡੇਟ ਨਹੀਂ ਹੁੰਦੀਆਂ। ਜੇ ਤੁਸੀਂ ਆਪਣਾ ਯੂਜ਼ਰਨੇਮ ਬਦਲਦੇ ਹੋ, ਇਕ ਨਕਲ ਤੁਰੰਤ ਬਦਲ ਸਕਦੀ ਹੈ ਤੇ ਦੂਜੀ ਥੋੜ੍ਹਾ ਦੇਰ ਬਾਅਦ। ਉਸ ਵਿੰਡੋ ਦੌਰਾਨ, ਕੁਝ ਯੂਜ਼ਰ (ਜਾਂ ਅਨਿਆ ਸਕ੍ਰੀਨ ਤੋਂ ਤੁਸੀਂ ਖੁਦ) ਥੋੜ੍ਹੇ ਸਮੇਂ ਲਈ ਪੁਰਾਣੀ ਵੈਲੂ ਦੇਖ ਸਕਦੇ ਹਨ।
“ਤੁਰੰਤ ਨਹੀਂ” ਦਾ ਮਤਲਬ “ਗਲਤ” ਨਹੀਂ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਸ਼ੱਕ ਲਿਆ ਸਕਦੀ ਹੈ ਕਿਉਂਕਿ ਅਸੀਂ ਇਸ ਗੱਲ ਦੇ ਆਦਤ-ਪ੍ਰੇਰਿਤ ਹਾਂ ਕਿ ਕੰਪਿਊਟਰ ਸਹੀ ਹੋਣਗੇ। ਪਰ ਸਿਸਟਮ ਤੁਹਾਡਾ ਅਪਡੇਟ ਗੁਆ ਨਹੀਂ ਰਿਹਾ—ਇਹ ਉਪਲਬਧਤਾ ਅਤੇ ਤੇਜ਼ੀ ਨੂੰ ਤਰਜੀਹ ਦੇ ਰਿਹਾ ਹੈ, ਫਿਰ ਬਾਕੀ ਨਕਲਾਂ ਨੂੰ ਕੈਚ-ਅਪ ਹੋਣ ਦਿੰਦਾ ਹੈ।
ਕਾਰਗਰ ਫਰੇਮਿੰਗ ਇਹ ਹੈ:
- Strong consistency: “ਸਭ ਤੁਰੰਤ ਸਹਿਮਤ ਹਨ.”
- Eventual consistency: “ਸਭ ਜਲਦੀ ਹੀ ਸਹਿਮਤ ਹੋ ਜਾਣਗੇ.”
ਉਹ "ਜਲਦੀ" ਮਿਲੀਸੈਕੰਡ, ਸਕਿੰਟ ਚ ਹੋ ਸਕਦਾ ਹੈ, ਜਾਂ ਬੇ-ਕਦਰ ਲੋਡ ਜਾਂ ਆਉਟੇਜ ਦੌਰਾਨ ਕਦੇ ਵੱਧ ਕਿੱਕ। ਚੰਗੀ ਪ੍ਰਾਡਕਟ ਡਿਜ਼ਾਇਨ ਇਸ ਦੇਰੀ ਨੂੰ ਸਮਝਦਾਰ ਤੇ ਸਿਆਹੀ ਵਾਲਾ ਬਣਾਉਂਦੀ ਹੈ ਤਾਂ ਜੋ ਆਮਤੌਰ 'ਤੇ ਇਹ ਨਜ਼ਰ ਨਾ ਆਵੇ।
ਕਿਉਂ ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ ਤੁਰੰਤ ਸਹਿਮਤੀ ਵੇਖਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਹੀਂ ਕਰਦੇ
ਤੁਰੰਤ ਸਹਿਮਤੀ ਆਦਰਸ਼ ਜਾਪਦੀ ਹੈ: ਹਰ ਸਰਵਰ, ਹਰ ਖੇਤਰ ਵਿੱਚ, ਇੱਕੋ ਸਮੇਂ ਤੇ ਇੱਕੋ ਹੀ ਡੇਟਾ ਦੇਖਾਉਣਾ। ਛੋਟੇ, ਇੱਕ-ਡੇਟਾਬੇਸ ਵਾਲੇ ਐਪ ਲਈ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਮੁਮਕਿਨ ਹੁੰਦਾ ਹੈ। ਪਰ ਜਿਵੇਂ-ਜਿਵੇਂ ਉਤਪਾਦ ਵੱਧਦੇ ਹਨ—ਵੱਧ ਯੂਜ਼ਰ, ਵੱਧ ਸਰਵਰ, ਵੱਧ ਸਥਾਨ—“ਹਰ ਥਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਸਿੰਕ” ਮਹਿੰਗਾ ਅਤੇ ਕਦੇ-ਕਦੇ ਅਵਾਸਥਿਤ ਹੋ ਜਾਂਦਾ ਹੈ।
ਡੇਟਾ ਜਿੱਥੇ-ਜਿੱਥੇ ਸਟੋਰ ਹੁੰਦਾ ਹੈ, ਉੱਥੇ ਇੰਤਜ਼ਾਰ ਵਾਲੇ ਮੌਕੇ ਵੱਧ ਜਾਂਦੇ ਹਨ
ਜਦੋਂ ਐਪ ਕਈ ਸਰਵਰਾਂ ਜਾਂ ਖੇਤਰਾਂ 'ਚ ਚੱਲਦੀ ਹੈ, ਡੇਟਾ ਨੂੰ ਨੈੱਟਵਰਕ ਰਾਹੀਂ ਭੇਜਣਾ ਪੈਂਦਾ ਹੈ ਜਿਹੜਾ ਦੇਰ ਅਤੇ ਕਦੇ-ਕਦੇ ਅਸਫਲਤਾ ਲੈ ਕੇ ਆਉਂਦਾ ਹੈ। ਜੇਕਰ ਜ਼ਿਆਦਾਤਰ ਬੇਨਤੀ ਤੇਜ਼ ਹਨ, ਤਾਂ ਸਭ ਤੋਂ ਹੌਲੀ ਕੜੀ (ਜਾਂ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਅਨਪਹੁੰਚ ਰੀਜਨ) ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ “ਸਭ ਕੋਲ ਨਵਾਂ ਅਪਡੇਟ” ਪੁੱਜਣ ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗੇਗਾ।
ਜੇ ਸਿਸਟਮ ਤੁਰੰਤ ਸਹਿਮਤੀ 'ਤੇ ਜ਼ੋਰ ਦਿੰਦਾ ਹੈ, ਤਾਂ ਇਹ ਕਰਨਾ ਪੈ ਸਕਦਾ ਹੈ:
- ਲਿਖਤ ਨੂੰ ਪੁਸ਼ਟੀ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਦੂਰਦਰਾਜ ਨਕਲਾਂ ਦੀ ਉਡੀਕ ਕਰਨੀ
- ਨੈੱਟਵਰਕ ਹਿਕਅਪ ਦੌਰਾਨ ਅਪਡੇਟ ਰੋਕਣਾ
- ਨਾ-ਸਹਿਮਤੀ ਦੇ ਖਤਰੇ ਕਰਕੇ ਬੇਨਤੀਆਂ ਠੁਕਰਾਉਣਾ
ਇਸ ਨਾਲ ਇੱਕ ਨਿਰਮਲ ਨੈੱਟਵਰਕ ਸਮੱਸਿਆ ਵੀ ਯੂਜ਼ਰ ਲਈ ਵੱਡੀ ਸਮੱਸਿਆ ਬਣ ਸਕਦੀ ਹੈ।
ਕੋਆਰਡੀਨੇਸ਼ਨ ਸਹੀਪਣ ਦੀ ਗਾਰੰਟੀ ਦਿੰਦੀ ਹੈ, ਪਰ tail latency ਵਧਾ ਦੇਂਦੀ ਹੈ
ਤੁਰੰਤ consistency ਦੀ ਗਾਰੰਟੀ ਦੇਣ ਲਈ ਕਈ ਡਿਜ਼ਾਈਨ ਕੋਆਰਡੀਨੇਸ਼ਨ ਦੀ ਲੋੜ ਪੈਂਦੇ ਹਨ—ਅਸਲ ਵਿੱਚ ਇੱਕ ਗਰੁੱਪ ਫੈਸਲਾ—ਆਪ੍ਰੇਸ਼ਨ ਕਮੀਟ ਮੰਨਿਆਂ ਜਾਣ ਤੋਂ ਪਹਿਲਾਂ। ਕੋਆਰਡੀਨੇਸ਼ਨ ਤਾਕਤਵਰ ਹੈ, ਪਰ ਇਹ ਰਾਊਂਡ-ਟ੍ਰਿਪ ਵਧਾਂਦਾ ਹੈ ਅਤੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਘੱਟ ਭਵਿੱਖਬਾਣੀਯੋਗ ਬਣਾਉਂਦਾ ਹੈ। ਜੇ ਕੋਈ ਮੁੱਖ ਨਕਲ ਹੌਲੀ ਹੈ, ਤਾਂ ਸਾਰੀ ਓਪਰੇਸ਼ਨ ਉਸਦੇ ਨਾਲ ਹੌਲੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਬਦਲਾ CAP theorem ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਵਿਆਖਿਆ ਕੀਤਾ ਜਾਂਦਾ ਹੈ: ਨੈੱਟਵਰਕ partitions ਹੇਠਾਂ, ਸਿਸਟਮਾਂ ਨੂੰ ਉਪਲਬਧ ਰਹਿਣਾ (availability) ਜਾਂ ਸਖਤ consistency ਵਿੱਚੋਂ ਇੱਕ ਚੁਣਨਾ ਪੈਂਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਅਸਲ ਐਪਸ ਰਿਸਪਾਂਸਿਵ ਰਹਿਣ ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੀਆਂ ਹਨ।
ਨਕਲ ਸਿਰਫ਼ ਸਕੇਲ ਲਈ ਨਹੀਂ, ਉਪਲਬਧਤਾ ਲਈ ਵੀ ਹੁੰਦੀ ਹੈ
ਨਕਲ ਕਰਨਾ ਸਿਰਫ਼ ਵੱਧ ਟ੍ਰੈਫਿਕ ਸੰਭਾਲਣ ਲਈ ਨਹੀਂ ਹੁੰਦਾ; ਇਹ ਫੇਲ੍ਹਰ ਦੇ ਖਿਲਾਫ਼ ਬੀਮਾ ਵੀ ਹੈ: ਸਰਵਰ ਕਰੈਸ਼ ਹੁੰਦੇ ਹਨ, ਖੇਤਰ degrade ਹੋ ਜਾਂਦੇ ਹਨ, deployment ਗਲਤ ਹੋ ਸਕਦੇ ਹਨ। ਨਕਲਾਂ ਨਾਲ ਐਪ ਇੱਕ ਹਿੱਸੇ ਦੀ ਬਿਮਾਰਤਾ ਦੇ ਬਾਵਜੂਦ ਆਰਡਰ, ਮੈਸੇਜ, ਅਤੇ ਅੱਪਲੋਡ ਸਵੀਕਾਰ ਕਰਨਾ ਜਾਰੀ ਰੱਖ ਸਕਦੀ ਹੈ।
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਚੁਣਨਾ ਅਕਸਰ ਇੱਕ ਜਾਣ-ਬੁਝ ਕੇ ਫੈਸਲਾ ਹੁੰਦਾ ਹੈ:
- ਗਤੀ ਅਤੇ ਉਪਟਾਈਮ: ਉਪਭੋਗਤਾ ਰੁਕਵਟਾਂ ਦੌਰਾਨ ਵੀ ਕੰਮ ਕਰ ਸਕਦੇ ਹਨ
- ਤੁਰੰਤ ਸਹਿਮਤੀ ਹਰ ਥਾਂ: ਹਰ ਰੀਡ ਗਲੋਬਲ ਤੌਰ 'ਤੇ ਨਵੀਂ ਲਿਖਤ ਦਰਸਾਵੇ
ਕਈ ਟੀਮਾਂ ਛੋਟੀ-ਅਵਧੀ ਦੇ ਫ਼ਰਕ ਨੂੰ ਕਬੂਲ ਕਰ ਲੈਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਵਿੱਕਲਪ ਤੇਜ਼ੀ ਜਾਂ ਆਉਟੇਜ ਤੋਂੋਂ ਬਿਹਤਰ ਹੋ ਸਕਦਾ ਹੈ—ਖ਼ਾਸਕਰ ਪੀਕ ਟ੍ਰੈਫਿਕ, ਪ੍ਰੋਮੋਸ਼ਨ, ਜਾਂ ਇੰਸੀਡੈਂਟ ਦੌਰਾਨ।
ਯੂਜ਼ਰਾਂ ਲਈ ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਕਿਵੇਂ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਉਸ ਸਮੇਂ ਆਸਾਨੀ ਨਾਲ ਨਜ਼ਰ ਆਉਂਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇੱਕੋ ਐਪ ਨੂੰ ਇੱਕ ਤੋਂ ਵੱਧ ਥਾਂ ਤੋਂ ਵਰਤਦੇ ਹੋ।
ਇੱਕ ਸਧਾਰਨ, ਜਾਣ-ਪਛਾਣ ਵਾਲਾ ਦ੍ਰਿਸ਼
ਤੁਸੀਂ ਆਪਣੇ ਫੋਨ ਤੇ ਕਿਸੇ ਪੋਸਟ ਨੂੰ “ਲਾਈਕ” ਕਰਦੇ ਹੋ। ਹਾਰਟ ਆਈਕਨ ਤੁਰੰਤ ਭਰ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਲਾਈਕ ਗਿਣਤੀ 10 ਤੋਂ 11 ਹੋ ਸਕਦੀ ਹੈ।
ਇੱਕ ਮਿੰਟ ਬਾਅਦ, ਤੁਸੀਂ ਉਹੀ ਪੋਸਟ ਆਪਣੇ ਲੈਪਟਾਪ 'ਤੇ ਖੋਲ੍ਹਦੇ ਹੋ ਅਤੇ… ਇਹ ਅਜੇ ਵੀ 10 ਦਿਖਾ ਸਕਦੀ ਹੈ। ਜਾਂ ਹਾਰਟ ਅਜੇ ਭਰਿਆ ਨਹੀਂ। ਲੰਬੀ ਮਿਆਦ ਵਿੱਚ ਕੁਝ “ਟੁੱਟਿਆ” ਨਹੀਂ—ਸਿਰਫ਼ ਅਪਡੇਟ ਹਰ ਨਕਲ ਤੱਕ ਨਹੀਂ ਪੁੱਜੀ।
ਅਕਸਰ ਇਹ ਦੇਰੀਆਂ ਛੋਟੀ ਹੁੰਦੀਆਂ ਹਨ (ਅਕਸਰ ਅੰਸ਼-ਸੈਕੰੜ). ਪਰ ਜਦੋਂ ਨੈੱਟਵਰਕ ਹੌਲਾ ਹੋਵੇ, ਡੇਟਾ ਸੈਂਟਰ ਅਣਪਹੁੰਚ ਹੋ ਜਾਵੇ, ਜਾਂ ਸੇਵਾ ਉੱਚਾ ਟ੍ਰੈਫਿਕ ਸੰਭਾਲ ਰਹੀ ਹੋਵੇ, ਇਹ spike ਕਰ ਸਕਦਾ ਹੈ। ਉਹ ਸਮੇਂ, ਸਿਸਟਮ ਦੇ ਵੱਖ-ਵੱਖ ਹਿੱਸੇ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਅਸਹਿਮਤ ਹੋ ਸਕਦੇ ਹਨ।
ਯੂਜ਼ਰ ਅਸਲ ਵਿੱਚ ਕੀ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ
ਉਪਭੋਗਤਾ ਨਜ਼ਰੀਏ ਤੋਂ, ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਆਮ ਤੌਰ 'ਤੇ ਇਨ੍ਹਾਂ ਰੂਪਾਂ ਵਿੱਚ ਵਿਆਖਿਆ ਹੋਣੀ ਹੈ:
- Stale reads: ਤੁਸੀਂ ਰਿਫ੍ਰੇਸ਼ ਕਰਦੇ ਹੋ ਪਰ ਕੁਝ ਸਮੇਂ ਲਈ ਪੁਰਾਣੀ ਵੈਲੂ ਹੀ ਵੇਖਦੇ ਹੋ
- Temporary mismatches: ਤੁਹਾਡਾ ਫੋਨ “Liked” ਦਿਖਾਉਂਦਾ ਹੈ, ਜਦਕਿ ਲੈਪਟਾਪ ਨਹੀਂ
- Out-of-order updates (reordering): ਕਾਰਵਾਈਆਂ ਵੱਖ-ਵੱਖ ਡਿਵਾਈਸਾਂ 'ਤੇ ਥੋੜ੍ਹੇ ਵੱਖਰੇ ਕ੍ਰਮ ਵਿੱਚ nazar ਆ ਸਕਦੀਆਂ ਹਨ—for example, ਇੱਕ comment ਪਹਿਲਾਂ ਆਉਂਦਾ ਹੈ ਅਤੇ “edited” ਲੇਬਲ ਥੋੜ੍ਹਾ ਬਾਅਦ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ
ਇਹ ਪ੍ਰਭਾਵ counters (likes, views), activity feeds, notifications, ਅਤੇ search results ਜਿਹੇ ਇਲਾਕਿਆਂ 'ਚ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਨਜ਼ਰ ਆਉਂਦੇ ਹਨ—ਜਿੱਥੇ ਡੇਟਾ ਤੇਜ਼ੀ ਲਈ ਚੌੜੇ ਪੱਧਰ 'ਤੇ ਨਕਲ ਹੁੰਦਾ ਹੈ।
ਮੁੱਖ ਖਿਆਲ: convergence
Eventual consistency ਦਾ ਮਤਲਬ “ਕੀਛ ਵੀ ਚੱਲਦਾ ਰਹੇ” ਨਹੀਂ ਹੈ। ਮਤਲਬ ਹੈ ਕਿ ਸਿਸਟਮ ਨੂੰ ਮਿਲ ਕੇ ਠਹਿਰਾਉਣ ਲਈ ਡਿਜ਼ਾਇਨ ਕੀਤਾ ਗਿਆ ਹੈ: ਜਦ ਤੱਕ ਅਸਥਾਈ ਰੁਕਾਵਟ ਦੂਰ ਨਹੀਂ ਹੁੰਦੀ ਅਤੇ ਅਪਡੇਟਾਂ ਨੂੰ ਫੈਲਣ ਦਾ ਸਮਾਂ ਮਿਲ ਜਾਂਦਾ ਹੈ, ਹਰ ਨਕਲ ਆਖ਼ਿਰਕਾਰ ਇੱਕੋ ਅੰਤਿਮ ਸਥਿਤੀ 'ਤੇ ਠਹਿਰ ਜਾਵੇਗੀ।
“ਲਾਈਕ” ਉਦਾਹਰਨ ਵਿੱਚ, ਦੋਹਾਂ ਡਿਵਾਈਸ ਆਖ਼ਿਰਕਾਰ ਸਹਿਮਤ ਹੋ ਜਾਣਗੇ ਕਿ ਤੁਸੀਂ ਪੋਸਟ ਨੂੰ ਲਾਈਕ ਕੀਤਾ ਅਤੇ ਗਿਣਤੀ 11 ਹੈ। ਸਮਾਂ ਵੱਖ-ਵੱਖ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਮੰਜ਼ਿਲ ਇੱਕੋ ਹੈ।
ਜਦੋਂ ਐਪ ਇਹ ਛੋਟੀ-ਅਵਧੀ ਅਸਹਿਮਤੀਆਂ ਸੋਚ-ਸਮਝ ਕੇ ਹੈਂਡਲ ਕਰਦੇ ਹਨ—ਸਾਫ UI ਫੀਡਬੈਕ, ਸਮਝਦਾਰ refresh ਵਰਤਾਰ, ਅਤੇ ਡਰਾਅਉਣ ਵਾਲੇ ਐਰਰ ਸੁਨੇਹਿਆਂ ਤੋਂ ਬਚਣਾ—ਅਕਸਰ ਯੂਜ਼ਰ ਇਹਨਾਂ ਗੱਲਾਂ ਨੂੰ ਮਹਿਸੂਸ ਹੀ ਨਹੀਂ ਕਰਦੇ।
ਕਾਰਗਰ ਫਾਇਦੇ: ਉਪਟਾਈਮ, ਤੇਜ਼ੀ, ਅਤੇ ਸਕੇਲ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਇੱਕ ਤਰਜੀਹ ਹੈ: ਸਿਸਟਮ ਕੁਝ ਸਮੇਂ ਲਈ ਵੱਖ-ਵੱਖ ਡੇਟਾ ਦਿਖਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਨੂੰ ਬਹੁਤ ਹੀ ਪ੍ਰਯੋਗਿਕ ਫਾਇਦੇ ਦਿੰਦੀ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਉਤਪਾਦਾਂ ਲਈ, ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਖੇਤਰਾਂ ਵਿੱਚ ਉਪਭੋਗਤਾ ਅਤੇ ਕਈ ਨਕਲ ਹਨ, ਉਹ ਫਾਇਦੇ ਤੁਰੰਤ ਸਹਿਮਤੀ ਨਾਲੋਂ ਮਹੱਤਵਪੂਰਣ ਹੋ ਜਾਂਦੇ ਹਨ।
ਜਦੋਂ ਹਿੱਸੇ ਫੇਲ੍ਹ ਹੋਣ ਤੇ ਉੱਚੀ ਉਪਲਬਧਤਾ
ਨਕਲਾਂ ਨਾਲ, ਡੇਟਾ ਇਕ ਤੋਂ ਵੱਧ ਥਾਂ 'ਤੇ ਰਹਿੰਦਾ ਹੈ। ਜੇ ਇਕ ਨੋਡ ਜਾਂ ਪੂਰਾ ਖੇਤਰ ਸਮੱਸਿਆ 'ਚ ਹੋ ਜਾਵੇ, ਹੋਰ ਨਕਲਾਂ ਰੀਡਸ ਸੇਵਾ ਜਾਰੀ ਰੱਖ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਲਿਖਤ ਸਵੀਕਾਰ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਨਤੀਜਾ: ਘੱਟ “ਸਖ਼ਤ ਡਾਊਨ” ਘਟਨਾਵਾਂ ਅਤੇ ਘੱਟ ਫੀਚਰ ਬ੍ਰੇਕ ਹੋਣ।
ਸਭ ਨੂੰ ਰੋਕ ਕੇ ਹਰ ਨਕਲ ਦੀ ਸਹਿਮਤੀ ਦੀ ਉਡੀਕ ਕਰਨ ਦੀ ਬਜਾਇ, ਐਪ ਕੰਮ ਕਰਦੀ ਰਹਿੰਦੀ ਅਤੇ ਬਾਅਦ ਵਿੱਚ convergent ਹੋ ਜਾਂਦੀ ਹੈ।
ਨਿਯੂਨਤਮ ਲੈਟੈਂਸੀ: ਯੂਜ਼ਰ ਦੇ ਨੇੜੇ ਤੇਜ਼ ਇੰਟਰੈਕਸ਼ਨ
ਹਰ ਲਿਖਤ ਨੂੰ ਦੂਰ-ਦੂਰ ਸਰਵਰਾਂ ਵਿੱਚ coordinate ਕਰਨ ਨਾਲ ਦੇਰ ਆਉਂਦੀ ਹੈ। ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਉਸ ਕੋਆਰਡੀਨੇਸ਼ਨ ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ, ਇਸ ਲਈ ਸਿਸਟਮ ਅਕਸਰ:
- ਨੇੜੇ ਨਕਲ ਤੇ ਲਿਖ ਕੇ ਤੇਜ਼ੀ ਨਾਲ ਪੁਸ਼ਟੀ ਕਰਦਾ ਹੈ
- ਨੇੜੇ ਨਕਲ ਤੋਂ ਪੜ੍ਹਦਾ ਹੈ (ਭਾਵੇਂ ਉਹ ਥੋੜ੍ਹਾ ਪਿੱਛੇ ਹੋਵੇ)
ਨਤੀਜਾ ਇੱਕ ਜ਼ਿਆਦਾ ਤੁਰੰਤ ਮਹਿਸੂਸ: ਪੇਜ ਲੋਡ, ਟਾਇਮਲਾਈਨ ਰਿਫ੍ਰੈਸ਼, “ਲਾਈਕ” ਗਿਣਤੀ ਅਤੇ ਇਨਵੈਂਟਰੀ ਲੁੱਕਅੱਪ ਘੱਟ ਲੈਟੈਂਸੀ ਨਾਲ ਦਿੱਤੇ ਜਾ ਸਕਦੇ ਹਨ। ਹਾਂ, ਇਸ ਨਾਲ stale reads ਹੋ ਸਕਦੇ ਹਨ, ਪਰ UX ਪੈਟਰਨ ਆਮ ਤੌਰ 'ਤੇ ਧੀਰੇ ਬਲਾਕ ਕਰਨ ਵਾਲੀ ਬੇਨਤੀ ਨਾਲੋਂ ਸਮਭਾਲਣ ਵਿੱਚ ਅਸਾਨ ਹੁੰਦੇ ਹਨ।
ਬਿਹਤਰ ਸਕੇਲਿੰਗ ਬਿਨਾਂ ਸਿੰਗਲ ਬੌਟਲਨੇਕ
ਜਿਵੇਂ ਟ੍ਰੈਫਿਕ ਵਧਦਾ ਹੈ, ਸਖਤ ਗਲੋਬਲ ਸਹਿਮਤੀ coordination ਨੂੰ ਬੌਟਲਨੇਕ ਬਣਾਉ ਸਕਦੀ ਹੈ। ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਨਾਲ, ਨਕਲ ਵਰਕਲੋਡ ਸਾਂਝਾ ਕਰਦੇ ਹਨ: ਰੀਡ ਟ੍ਰੈਫਿਕ ਫੈਲ ਜਾਂਦਾ ਹੈ, ਤੇ ਲਿਖਤ throughput ਸੁਧਾਰ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਨੋਡ ਹਮੇਸ਼ਾ cross-region ਪੁਸ਼ਟੀ ਦੀ ਉਡੀਕ ਨਹੀਂ ਕਰਦੇ।
ਸਕੇਲ ਤੇ, ਇਹ ਫਰਕ ਹੈ “ਹੋਰ ਸਰਵਰ ਜੋੜੋ ਤੇ ਤੇਜ਼ ਹੋ ਜਾਏ” ਅਤੇ “ਹੋਰ ਸਰਵਰ ਜੋੜੋ ਤੇ ਕੋਆਰਡੀਨੇਸ਼ਨ ਮੁਸ਼ਕਲ ਹੋ ਜਾਵੇ” ਦੇ ਵਿਚਕਾਰ।
ਲਾਗਤ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਸਾਦਗੀ ਸਕੇਲ ਤੇ
ਸਦਾ-ਗਲੋਬਲ ਕੋਆਰਡੀਨੇਸ਼ਨ ਮਹਿੰਗੀ ਇਨਫ੍ਰਾਸਟ੍ਰਕਚਰ ਅਤੇ ਨਜ਼ਦੀਕੀ ਟਿਊਨਿੰਗ ਮੰਗ ਸਕਦੀ ਹੈ (ਸੋਚੋ ਗਲੋਬਲ ਲਾਕਸ ਅਤੇ synchronous replication ਹਰ ਜਗ੍ਹਾ)। ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਤੁਹਾਨੂੰ ਸਧਾਰਣ replication ਯੁਕਤੀਆਂ ਵਰਤਣ ਅਤੇ ਘੱਟ “ਹਰ ਕੋਈ ਹੁਣੇ ਹੀ ਸਹਿਮਤ” ਮਿਕੈਨਿਜ਼ਮ ਵਰਤਣ ਦੀ ਆਜ਼ਾਦੀ ਦੇ ਕੇ ਲਾਗਤ ਘਟਾ ਸਕਦੀ ਹੈ।
ਘੱਟ ਕੋਆਰਡੀਨੇਸ਼ਨ ਦੀ ਲੋੜ ਨਾਲ ਹੀ debug ਕਰਨ ਲਈ failure modes ਵੀ ਘੱਟ ਹੋ ਸਕਦੇ ਹਨ—ਜੋ ਤੁਹਾਡੇ ਨੂੰ ਵਧਣ ਵੇਲੇ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਪਹਿਚਾਨਣ ਵਿੱਚ ਅਸਾਨੀ ਦਿੰਦਾ ਹੈ।
ਅਸਲੀ ਵਰਤੋਂ-ਕੇਸ ਜਿੱਥੇ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਠੀਕ ਰਹਿੰਦਾ ਹੈ
ਹਰ ਫੀਚਰ ਲਈ consistency ਨਕਸ਼ਾ ਬਣਾਓ
ਚੈਟ ਵਿੱਚ ਆਪਣੀਆਂ consistency ਲੋੜਾਂ ਬਿਆਨ ਕਰੋ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਇਕ ਸੇਵਾ ਬਣਾਓ.
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਉਹਨਾਂ ਹਾਲਤਾਂ ਵਿੱਚ ਸਭ ਤੋਂ ਵਧੀਆ ਹੁੰਦੀ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ “ਮੈਂ ਨੇ ਕੀਤਾ” ਅਤੇ “ਹਰ ਕੋਈ ਵੇਖਦਾ” ਵਿਚਕਾਰ ਥੋੜ੍ਹੀ ਦੇਰ ਸਹਿ ਸਕਦਾ ਹੈ, ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਡੇਟਾ ਉੱਚ-ਮਾਤਰਾ ਵਾਲਾ ਅਤੇ ਸੁਰੱਖਿਆ-ਸੰਬੰਧੀ ਨਹੀਂ ਹੋਵੇ।
ਸੋਸ਼ਲ ਫੀਡ ਅਤੇ ਕਾਂਟਰ
ਲਾਈਕਾਂ, ਵਿਊਜ਼, ਫਾਲੋਅਰ ਗਿਣਤੀ ਅਤੇ ਪੋਸਟ ਇੰਪ੍ਰੈਸ਼ਨ ਇਸਦੀਆਂ ਕਲਾਸਿਕ ਉਦਾਹਰਨ ਹਨ। ਜੇ ਤੁਸੀਂ “ਲਾਈਕ” ਕਰਦੇ ਹੋ ਅਤੇ ਗਿਣਤੀ ਤੁਹਾਡੇ ਲਈ ਤੁਰੰਤ ਅੱਪਡੇਟ ਹੋ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਠੀਕ ਹੁੰਦਾ ਹੈ ਕਿ ਦੂਜਾ ਬੰਦਾ ਕੁਝ ਸਕਿੰਟ (ਜਾਂ ਬਹੁਤ ਜ਼ਿਆਦਾ ਟ੍ਰੈਫਿਕ ਦੌਰਾਨ ਮਿੰਟ) ਲਈ ਪੁਰਾਣੀ ਗਿਣਤੀ ਵੇਖੇ।
ਇਹ ਕਾਂਟਰ ਅਕਸਰ ਬੈਚਾਂ ਵਿੱਚ ਜਾਂ asynchronous ਪ੍ਰੋਸੈਸਿੰਗ ਰਾਹੀਂ ਅਪਡੇਟ ਕੀਤੇ ਜਾਂਦੇ ਹਨ ਤਾਂ ਕਿ ਐਪ ਤੇਜ਼ ਰਹੇ। ਮੁੱਖ ਗੱਲ ਇਹ ਹੈ ਕਿ ਥੋੜ੍ਹਾ-ਜਿਹਾ ਗਲਤ ਹੋਣਾ ਜ਼ਿਆਦਾਤਰ ਵਾਰ ਯੂਜ਼ਰ ਦੇ ਫੈਸਲੇ 'ਤੇ ਪ੍ਰਭਾਵ ਨਹੀਂ ਪਾਂਦਾ।
ਮੈਸੇਜਿੰਗ ਅਤੇ ਨੋਟੀਫਿਕੇਸ਼ਨ
ਮੈਸੇਜਿੰਗ ਸਿਸਟਮ ਅਕਸਰ ਡਿਲਿਵਰੀ ਰਸੀਦਾਂ (“sent,” “delivered,” “read”) ਨੂੰ ਨੈੱਟਵਰਕ ਡਿਲਿਵਰੀ ਦੇ ਸਮੇਂ ਤੋਂ ਅਲਗ ਰੱਖਦੇ ਹਨ। ਇੱਕ ਮੈਸੇਜ ਤੁਹਾਡੇ ਫੋਨ ਤੇ ਤੁਰੰਤ “sent” ਦਿਖਾ ਸਕਦਾ ਹੈ, ਜਦਕਿ ਪ੍ਰਾਪਤਕਰਤਾ ਦੀ ਡਿਵਾਈਸ ਕੁਝ ਸਮੇਂ ਬਾਅਦ ਮਿਲ ਸਕਦੀ ਹੈ connectivity, background restrictions, ਜਾਂ routing ਦੇ ਕਾਰਨ।
ਇਸੇ ਤਰ੍ਹਾਂ, push notifications ਦੇਰੀ ਨਾਲ ਜਾਂ ਆਊਟ-ਆਫ-ਆਰਡਰ ਆ ਸਕਦੇ ਹਨ, ਜੇਕਰ underlying message ਐਪ ਵਿੱਚ ਪਹਿਲਾਂ ਹੀ ਲਭਦਾ ਹੋਵੇ। ਯੂਜ਼ਰ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਨੂੰ ਨਾਰਮਲ ਮੰਨਦੇ ਹਨ, ਜੇਕਰ ਐਪ ਅਖ਼ਿਰਕਾਰ convergent ਹੋਵੇ ਤੇ ਡਿਊਪਲੀਕੇਟ ਜਾਂ ਗੁੰਮ ਹੋਏ ਮੈਸੇਜ ਨਾ ਹੋਣ।
ਖੋਜ ਅਤੇ ਸਿਫ਼ਾਰਸ਼ਾਂ
Search results ਅਤੇ recommendation carousels ਅਕਸਰ indexes 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ ਜੋ ਲਿਖਤਾਂ ਤੋਂ ਬਾਅਦ ਰਿਫਰੇਸ਼ ਹੁੰਦੇ ਹਨ। ਤੁਸੀਂ ਇੱਕ ਪ੍ਰੋਡਕਟ ਪਬਲਿਸ਼ ਕਰ ਸਕਦੇ ਹੋ, ਪ੍ਰੋਫਾਈਲ ਅਪਡੇਟ ਕਰ ਸਕਦੇ ਹੋ ਜਾਂ ਪੋਸਟ ਐਡੀਟ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਉਹ ਤੁਰੰਤ ਖੋਜ ਵਿੱਚ ਨਾ ਦਿਖੇ।
ਇਹ ਦੇਰੀ ਆਮ ਤੌਰ 'ਤੇ ਮਨਜ਼ੂਰਯੋਗ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ ਯੂਜ਼ਰ ਖੋਜ ਨੂੰ “ਜਲਦੀ ਅਪਡੇਟ ਹੋਵੇਗਾ” ਵਜੋਂ ਸਮਝਦੇ ਹਨ, ਨਾ ਕਿ “ਫੌਰਨ-ਪਰਫੈਕਟ”। ਸਿਸਟਮ ਤੇਜ਼ ਲਿਖਤ ਅਤੇ ਬਿਹਤਰ ਸਕੇਲਿੰਗ ਲਈ ਥੋੜ੍ਹਾ ਤਾਜ਼ਗੀ-ਫੇਰ ਛੱਡ ਦਿੰਦਾ ਹੈ।
ਐਨਾਲਿਟਿਕਸ ਡੈਸ਼ਬੋਰਡ
ਐਨਾਲਿਟਿਕਸ ਅਕਸਰ ਨਿਯਤ ਅੰਤਰਾਲਾਂ 'ਤੇ ਪ੍ਰੋਸੈਸ ਕੀਤੀ ਜਾਂਦੀ ਹੈ: ਹਰ ਮਿੰਟ, ਘੰਟਾ, ਜਾਂ ਦਿਨ। ਡੈਸ਼ਬੋਰਡ "last updated at…" ਦਿਖਾ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਸਚ-ਮੁੱਕ-ਟਾਈਮ ਨੰਬਰ ਮਹਿੰਗੇ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਲੋੜੀਂਦੇ ਨਹੀਂ ਹੁੰਦੇ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਲਈ, ਇਹ ਠੀਕ ਹੁੰਦਾ ਹੈ ਕਿ ਚਾਰਟ ਹਕੀਕਤ ਤੋਂ ਕੁਝ ਪਿੱਛੇ ਰਹਿ ਜਾਵੇ—ਬਸ ਇਹ਼ ਸਪਸ਼ਟ ਹੋਵੇ ਅਤੇ ਰੁਝਾਨਾਂ ਅਤੇ ਫੈਸਲੇ ਲਈ ਕਾਫ਼ੀ ਲਗਾਤਾਰ ਹੋਵੇ।
ਜਦੋਂ ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਮਨਜ਼ੂਰ ਨਹੀਂ ਹੁੰਦੀ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਉਹ ਵੇਲੇ ਉਚਿਤ ਨਹੀਂ ਜਦੋਂ “ਥੋੜ੍ਹੀ ਦੇਰ” ਨਾਲ ਹੋਣਾ ਨਤੀਜੇ کو ਬਦਲ ਸਕਦਾ ਹੈ। ਕੁਝ ਫੀਚਰਾਂ ਵਿੱਚ ਸਖਤ ਸੁਰੱਖਿਆ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: ਸਿਸਟਮ ਨੂੰ ਹੁਣੇ ਹੀ ਸਹਿਮਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਾ ਕਿ ਬਾਅਦ ਵਿੱਚ। ਇਨ੍ਹਾਂ ਹਾਲਤਾਂ ਵਿੱਚ stale read ਸਿਰਫ਼ ਭ੍ਰਮ ਨਹੀਂ—ਇਹ ਅਸਲ ਨੁਕਸਾਨ ਪੈਦਾ ਕਰ ਸਕਦੀ ਹੈ।
ਪੈਸਾ-ਸੰਬੰਧੀ ਲੈਣ-ਦੇਣ ਅਤੇ ਬੈਲੇਂਸ
Payments, transfers ਅਤੇ stored-value balances “ਇਹ ਆਖੜੇ ਤੇ settle ਹੋਏਗਾ” 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਜੇ ਦੋ ਨਕਲ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਵੱਖ-ਵੱਖ ਹੋਣ, ਤਾਂ double-spend (ਇੱਕੋ ਫੰਡ ਦੋ ਵਾਰੀ ਵਰਤੇ ਜਾਣ) ਜਾਂ ਗਲਤ ਓਵਰਡ੍ਰਾਫਟ ਦਾ ਜੋਖਮ ਹੋ ਸਕਦਾ ਹੈ। ਯੂਜ਼ਰ ਇਕ ਬੈਲੇਂਸ ਵੇਖ ਸਕਦੇ ਹਨ ਜੋ ਖਰੀਦ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਜਦਕਿ ਪੈਸੇ ਪਹਿਲਾਂ ਹੀ ਕਿੱਥੇ ਹੋਰ commit ਹੋ ਗਏ ਹੋਣ।
ਜਿਸ ਵੀ ਚੀਜ਼ ਨਾਲ ਮੋਨੀਟਰੀ ਸਟੇਟ ਬਦਲਦਾ ਹੈ, ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ strong consistency, serializable transactions, ਜਾਂ ਇੱਕ single authoritative ledger service ਵਰਤਦੀਆਂ ਹਨ ਜਿਸ ਵਿੱਚ ਸਖਤ ordering ਹੁੰਦੀ ਹੈ।
ਚੈੱਕਆਊਟ 'ਤੇ ਇਨਵੈਂਟਰੀ
ਕੈਟਾਲੌਗ ਨੂੰ ਵੇਖਣਾ ਥੋੜ੍ਹਾ stale ਸਹਿ ਸਕਦਾ ਹੈ, ਪਰ checkout ਨੀਹ-ਨਹੀਂ। ਜੇ ਸਿਸਟਮ outdated ਨਕਲਾਂ ਅਧਾਰ 'ਤੇ “in stock” ਦਿਖਾਵੇ, ਤਾਂ ਤੁਸੀਂ oversell ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਫਿਰ ਕੈਂਸਲਵੇਸ਼ਨ, ਰਿਫੰਡ ਅਤੇ ਸਪੋਰਟ ਟਿਕਟਾਂ ਨਾਲ ਸਾਮਣਾ ਕਰਨਾ ਪੈ ਸਕਦਾ ਹੈ।
ਆਮ ਰੀਖਾ ਇਹ ਹੈ: product pages ਲਈ eventual consistency, ਪਰ checkout 'ਤੇ confirmed reservation (ਜਾਂ atomic decrement) ਲਈ strong consistency।
ਸੁਰੱਖਿਆ ਅਤੇ ਪਰਮੀਸ਼ਨ
ਐਕਸੇਸ ਕੰਟਰੋਲ ਲਈ ਬਰਦਾਸ਼ਤ ਕੀਤੀ ਜਾਣ ਵਾਲੀ ਦੇਰ ਛੋਟੀ ਹੁੰਦੀ—ਅਕਸਰ ਵਾਸਤੀ ਤੌਰ 'ਤੇ ਜ਼ੀਰੋ। ਜੇ ਕਿਸੇ ਉਪਭੋਗਤਾ ਦੀ ਐਕਸੇਸ revoke ਕੀਤੀ ਗਈ, ਤਾਂ ਇਹ ਰਿਵੋਕੇਸ਼ਨ ਤੁਰੰਤ ਲਾਗੂ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਨਹੀਂ ਤਾਂ ਇੱਕ ਵਿੰਡੋ ਰਹਿ ਜਾਂਦਾ ਹੈ ਜਿਸ ਦੌਰਾਨ ਕੋਈ ਅਜੇ ਵੀ ਡਾਟਾ ਡਾਊਨਲੋਡ, ਸੈਟਿੰਗਸ ਐਡੀਟ ਜਾਂ ਐਡਮਿਨ ਕਾਰਵਾਈ ਕਰ ਸਕਦਾ ਹੈ।
ਇਸ ਵਿੱਚ password resets, token revocation, role changes ਅਤੇ account suspensions ਸ਼ਾਮਿਲ ਹਨ।
ਕਾਂਪਲਾਇੰਸ ਅਤੇ ਆਡਿਟ ਲਾਗਜ਼
ਆਡਿਟ ਟਰੇਲਾਂ ਅਤੇ ਕਾਂਪਲਾਇੰਸ ਰਿਕਾਰਡ ਅਕਸਰ ਸਖਤ ordering ਅਤੇ immutable ਰਿਕਾਰਡ ਦੀ ਮੰਗ ਕਰਦੇ ਹਨ। ਇੱਕ ਲਾਗ ਜੋ “ਅੰਤ ਵਿੱਚ” ਇੱਕ ਕਾਰਵਾਈ ਦਰਸਾਉਂਦਾ ਹੈ, ਜਾਂ ਰੀਜਨਾਂ ਵਿੱਚ ਈਵੇਂਟਸ ਨੂੰ reorder ਕਰਦਾ ਹੈ, ਜਾਂਚਾਂ ਅਤੇ ਨਿਯਮਾਂ ਦੀ ਲੰਗਣ ਕਰ ਸਕਦਾ ਹੈ।
ਇਨ੍ਹਾਂ ਹਾਲਤਾਂ ਵਿੱਚ, ਟੀਮਾਂ append-only storage, tamper-evident logs, ਅਤੇ consistent timestamps/sequence numbers ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੀਆਂ ਹਨ।
ਪ੍ਰਾਇਟਿਕਲ ਰੁਲ ਆਫ਼ ਥੰਬ
ਜੇ ਇੱਕ ਅਸਥਾਈ mismatch irreversible ਨਤੀਜੇ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ (ਪੈਸਾ ਭੇਜਿਆ ਗਿਆ, ਮਾਲ ਭੇਜਿਆ ਗਿਆ, ਐਕਸੇਸ ਦਿੱਤੀ ਗਈ, ਕਾਨੂੰਨੀ ਰਿਕਾਰਡ ਬਦਲਿਆ ਗਿਆ), ਤਾਂ source-of-truth ਲਈ eventual consistency ਮਨਜ਼ੂਰ ਨਾ ਕਰੋ। ਇਸ ਨੂੰ ਸਿਰਫ਼ derived views — ਜਿਵੇਂ dashboards, recommendations ਜਾਂ search indexes — ਲਈ ਵਰਤੋ ਜਿੱਥੇ ਥੋੜ੍ਹਾ ਪਿੱਛੇ ਰਹਿਣਾ ਠੀਕ ਹੈ।
ਡਿਜ਼ਾਈਨ ਪੈਟਰਨ ਜਿਹੜੇ ਇਸਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੇ ਹਨ
Eventual consistency ਨੂੰ ਯੂਜ਼ਰਾਂ ਲਈ “ਬੇਤਰਤੀਬ” محسوس ਨਹੀਂ ਕਰਵਾਉਣਾ ਚਾਹੀਦਾ। ਚਾਲ ਇਹ ਹੈ ਕਿ ਪ੍ਰੋਡਕਟ ਅਤੇ APIs ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਇਨ ਕੀਤੇ ਜਾਣ ਕਿ ਅਸਥਾਈ ਅਸਹਿਮਤੀ ਉਮੀਦ ਵਿੱਚ ਹੋਵੇ, ਦਿਖਾਈ ਦੇ ਅਤੇ ਦੁਬਾਰਾ ਸਹੀ ਹੋ ਸਕੇ। ਜਦੋਂ ਲੋਕ ਸਮਝਦੇ ਹਨ ਕਿ ਕੀ ਹੋ ਰਿਹਾ ਹੈ—ਅਤੇ ਸਿਸਟਮ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ retry ਕਰ ਸਕਦਾ ਹੈ—ਭਰੋਸਾ ਵਧਦਾ ਹੈ ਭਾਵੇਂ ਡੇਟਾ ਪਿੱਛੇ ਹੀ ਕਿਉਂ ਨਾ ਹੋਵੇ।
ਸਰਲ UI ਰਾਜ਼ਦਾਰੀ ਨਾਲ ਪ੍ਰਗਤੀ ਦਿਖਾਓ
ਛੋਟਾ ਸੰਦੈਸ਼ ਕਾਫੀ ਸਪੋਰਟ ਟਿਕਟਾਂ ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ। ਦੋਸਤਾਨਾ ਸਥਿਤੀ ਸਿਗਨਲ ਵਰਤੋ ਜਿਵੇਂ “Saving…”, “Updated just now”, ਜਾਂ “May take a moment.”
ਇਹ ਸਭ ਤੋਂ ਵਧੀਆ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦ UI ਵਿਚ ਇਹ ਵੱਖਰੇ ਰਾਜ਼ ਦਰਸਾਏ ਜਾਣ:
- Local success (ਤੁਹਾਡੀ ਕਾਰਵਾਈ ਸਵੀਕਾਰ ਹੋ ਗਈ)
- Global success (ਸਭ ਕੋਲ ਇਹ ਵੇਖਣਗੇ)
ਉਦਾਹਰਨ ਵਜੋਂ, ਐਡਰੈੱਸ ਬਦਲਣ ਤੋਂ ਬਾਅਦ ਤੁਸੀਂ “Saved—syncing to all devices” ਦਿਖਾ ਸਕਦੇ ਹੋ ਬਜਾਏ ਇਸਦੇ ਕਿ ਅੰਦਰ ਦੀ ਗਲਤੀ ਨੂੰ ਤੁਰੰਤ ਜ਼ੋਰ ਦਿੱਤੇ ਜਾਏ।
Optimistic UI ਨਾਲ ਪੁਸ਼ਟੀ (ਤੇ ਨਰਮ ਰੋਲਬੈਕ)
Optimistic UI ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਅਮਲ ਹੋਣ ਦੀ ਉਮੀਦ ਕਰਕੇ ਨਤੀਜਾ ਤੁਰੰਤ ਦਿਖਾਉਂਦੇ ਹੋ—ਕਿਉਂਕਿ ਜ਼ਿਆਦਾਤਰ ਹਾਲਾਤਾਂ ਵਿੱਚ ਉਹ ਸਹੀ ਹੋਵੇਗਾ। ਇਹ replication ਕੁਝ ਸਕਿੰਟ ਲੈਂਦੀ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਇਹ ਐਪ ਨੂੰ ਤੇਜ਼ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦਾ ਹੈ।
ਇਸ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਣ ਲਈ:
- Background ਵਿੱਚ ਪੁਸ਼ਟੀ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ, ਜਦ ਸਰਵਰ ਪੁਸ਼ਟੀ ਕਰੇ ਤਾਂ “Saving…” ਨੂੰ “Updated just now” ਨਾਲ ਬਦਲੋ)
- ਜਰੂਰੀ ਹੋਣ 'ਤੇ ਵਾਪਸ ਘੁਮਾਉ (ਉਦਾਹਰਨ: “Couldn’t save. Tap to retry.”)
ਮੁੱਦ੍ਹਾ optimism ਹੀ ਨਹੀਂ—ਮੁੱਖ ਗੱਲ ਇੱਕ ਦਿੱਖੀ ਰਸੀਦ ਹੈ ਜੋ ਥੋੜ੍ਹੇ ਸਮੇਂ ਵਿੱਚ ਆਉਂਦੀ ਹੈ।
Idempotent actions: retries ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਓ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਨਾਲ, timeouts ਅਤੇ retries ਆਮ ਗੱਲ ਹਨ। ਜੇ ਯੂਜ਼ਰ “Pay” ਬਟਨ ਦੋ ਵਾਰੀ ਦਬਾਉਂਦਾ ਹੈ ਜਾਂ ਮੋਬਾਈਲ ਐਪ ਸਿਗਨਲ ਖੋ ਜਾਣ 'ਤੇ ਰੀਟ੍ਰਾਈ ਕਰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ duplicate charges ਜਾਂ duplicate orders ਨਹੀਂ ਚਾਹੁੰਦੇ।
Idempotent actions retries ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦੇ ਹਨ ਤਾਂ ਕਿ “ਉਹੇ ਬੇਨਤੀ ਫਿਰ ਭੇਜੋ” ਦਾ ਅਰਥ ਇਕੋ ਨਤੀਜਾ ਹੋਵੇ। ਆਮ ਤਰੀਕੇ:
- ਹਰ ਯੂਜ਼ਰ ਐਕਸ਼ਨ ਲਈ ਇੱਕ ਵਿਲੱਖਣ request ID
- ਸਰਵਰ-ਸਾਈਡ deduplication ਉਸ ID ਦੇ ਨਾਲ਼
ਇਸ ਨਾਲ ਤੁਸੀਂ ਨਿਸ਼ਚਤ ਹੋ ਕੇ retry ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਯੂਜ਼ਰ ਨੂੰ ਡਰਾਇਆ-ਡਰਾਇਆ ਮਹਿਸੂਸ ਕਰਾਏ।
Conflict handling: ਟਕਰਾਅ ਹੋਣ 'ਤੇ ਫੈਸਲਾ ਕਰੋ
ਜਦੋਂ ਸਿਸਟਮ ਅਜੇ ਸਹਿਮਤ ਨਹੀਂ ਹੋਇਆ ਤੇ ਦੋ ਤਬਦੀਲੀਆਂ ਆ ਜਾਂਦੀਆਂ ਹਨ—ਜਿਵੇਂ ਦੋ ਲੋਕ ਇਕੋ ਸਮੇਂ ਕਿਸੇ ਪ੍ਰੋਫਾਈਲ ਫੀਲਡ ਨੂੰ ਸੋਧ ਰਹੇ ਹਨ—ਤੋਂ conflicts ਪੈਦਾ ਹੁੰਦੇ ਹਨ।
ਆਮ ਤੌਰ 'ਤੇ ਤਿੰਨ ਵਿਕਲਪ ਹਨ:
- Last write wins ਘੱਟ-ਸਟੇਕ ਫੀਲਡ ਲਈ (ਜਿਵੇਂ display name)
- Merge rules ਸੰਰਚਿਤ ਡੇਟਾ ਲਈ (ਜਿਵੇਂ ਲਿਸਟਾਂ ਨੂੰ ਜੋੜਨਾ)
- ਯੂਜ਼ਰ ਨੂੰ ਪੁੱਛੋ ਜਦੋਂ ਚੋਣ ਮਹੱਤਵਪੂਰਨ ਹੋਵੇ (ਜਿਵੇਂ “ਸਾਨੂੰ ਦੋ ਵਰਜਨ ਮਿਲੇ—ਕਿਹੜਾ ਚਾਹੁੰਦੇ ਹੋ?”)
ਜੋ ਵੀ ਚੁਣੋ, ਵਰਤਾਰ predictable ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਯੂਜ਼ਰ ਦੇ ਲਈ ਦੇਰੀ ਸਹਿਣਯੋਗ ਹੈ; ਅਚਾਨਕੀ ਹੈਰਾਨੀ ਉਨ੍ਹਾਂ ਲਈ ਮੁਸ਼ਕਲ ਹੈ।
ਗਲਤਫ਼ਹਮੀ ਘਟਾਉਣ ਵਾਲੇ ਤਰੀਕੇ: Read-Your-Writes ਅਤੇ ਹੋਰ
ਬਿਨਾਂ ਖਤਰੇ ਦੇ ਵਿਕਲਪ ਅਜ਼ਮਾਓ
ਸਹੂਲਤ ਨਾਲ coordination ਅਤੇ availability ਦੇ ਵਿਕਲਪ ਅਜ਼ਮਾਓ, ਫਿਰ ਜੇ ਮਨ ਨਹੀਂ ਭਾਵੇ ਤਾਂ ਰੋਲਬੈਕ ਕਰੋ.
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਆਮ ਤੌਰ 'ਤੇ ਮਨਜ਼ੂਰਯੋਗ ਹੈ—ਪਰ ਸਿਰਫ਼ ਜੇ ਯੂਜ਼ਰ ਐਸਾ ਮਹਿਸੂਸ ਨਾ ਕਰੇ ਕਿ ਐਪ "ਉਸ ਨੇ ਜੋ ਕੀਤਾ ਭੁੱਲ ਗਿਆ"। ਮਕਸਦ ਸਧਾਰਣ ਹੈ: ਜੋ ਯੂਜ਼ਰ ਉਮੀਦ ਕਰਦਾ ਹੈ ਉਹੀ ਸਿਸਟਮ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਗਾਰੰਟੀ ਕਰ ਸਕੇ।
Read-your-writes: ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਵਾਅਦਾ
ਜੇ ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ ਸੋਧਦਾ ਹੈ, ਟਿੱਪਣੀ ਪੋਸਟ ਕਰਦਾ ਹੈ, ਜਾਂ ਐਡਰੈੱਸ ਅਪਡੇਟ ਕਰਦਾ ਹੈ, ਤਾਂ ਅਗਲੀ ਸਕਰਿਨ ਤੇ ਉਹ ਆਪਣੀ ਹੀ ਲਿਖਤ ਵੇਖੇ—ਇਹ read-your-writes ਦਾ ਖਿਆਲ ਹੈ।
ਟੀਮ ਆਮ ਤੌਰ 'ਤੇ ਇਸਨੂੰ ਲਾਗੂ ਕਰਨ ਲਈ:
- ਉਸੇ ਸਥਾਨ ਤੋਂ ਪੜ੍ਹਨਾ ਜਿਸਨੇ ਲਿਖਤ ਸਵੀਕਾਰ ਕੀਤੀ
- ਜਸਟ-ਲਿਖੀ ਹੋਈ ਵੈਲੂ ਲਈ session-aware cache ਤੋਂ ਫ਼ਿਲਹਾਲ ਸੇਵਾ
- replication catch-up ਹੋਣ ਤੱਕ ਯੂਜ਼ਰ ਲਈ ਤਾਜ਼ਾ ਨਕਲ ਹੇਠਾਂ ਰਾਹਦਾਰੀ
Session consistency: ਹਰ ਯੂਜ਼ਰ ਲਈ ਇੱਕ ਸੰਗਤ ਕਹਾਣੀ
ਭਾਵੇਂ ਸਿਸਟਮ ਹਰ ਕਿਸੇ ਨੂੰ ਤੁਰੰਤ ਨਹੀਂ ਬਣਾ ਸਕਦਾ, ਇਹ ਇੱਕ ਯੂਜ਼ਰ ਲਈ ਉਸਦੀ session ਦੌਰਾਨ ਸੰਗਤ ਦ੍ਰਿਸ਼ ਪ੍ਰਦਾਨ ਕਰ ਸਕਦਾ ਹੈ।
ਉਦਾਹਰਨ ਲਈ, ਜਦ ਤੁਸੀਂ ਕਿਸੇ ਪੋਸਟ ਨੂੰ “ਲਾਈਕ” ਕਰਦੇ ਹੋ, ਤੁਹਾਡੀ session ਨੂੰ liked/unliked ਦੇ ਵਿਚਕਾਰ ਫਿਰ-ਫਿਰ ਨਾ ਕਰਨਾ ਚਾਹੀਦਾ—ਜਿਵੇਂ ਵੱਖ-ਵੱਖ ਨਕਲ ਦੇ ਥੋੜ੍ਹੇ-ਜਿਹੇ ਅੰਤਰ ਕਰ ਸਕਦੇ ਹਨ।
Sticky sessions ਅਤੇ replica-aware routing
ਜਦੋਂ ਸੰਭਵ ਹੋਵੇ, ਯੂਜ਼ਰ ਦੀਆਂ ਬੇਨਤੀਆਂ ਨੂੰ ਉਸ ਨਕਲ ਤੱਕ ਰੂਟ ਕਰੋ ਜੋ ਉਹਨਾਂ ਦੀ ਹਾਲੀਆ ਲਿਖਤ ਨੂੰ ਹੈਂਡਲ ਕਰ ਚੁੱਕੀ ਹੈ। ਇਸਨੂੰ ਕਈ ਵਾਰੀ sticky sessions ਕਿਹਾ ਜਾਂਦਾ ਹੈ।
ਇਹ ਡੇਟਾਬੇਸ ਨੂੰ ਤੁਰੰਤ ਸਮਰਥ ਨਹੀਂ ਬਣਾਉਂਦਾ, ਪਰ ਉਹ ਨਕਲਾਂ ਦੇ ਵਿਚਕਾਰ ਅਚਾਨਕ hops ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਜੋ ਵਿਰੋਧ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ।
ਹੱਦਾਂ ਬਾਰੇ ਇਮਾਨਦਾਰ ਰਹੋ
ਇਹ ਤਕਨੀਕਾਂ ਧਾਰਣਾ ਨੂੰ ਸੁਧਾਰਦੀਆਂ ਹਨ ਤੇ ਗਲਤਫ਼ਹਮੀ ਘਟਾਉਂਦੀਆਂ ਹਨ, ਪਰ ਹਰ ਮਾਮਲੇ ਦਾ ਹੱਲ ਨਹੀਂ। ਜੇ ਯੂਜ਼ਰ ਹੋਰ ਡਿਵਾਈਸ ਤੇ ਲੋਗਿਨ ਕਰਦਾ ਹੈ, ਕਿਸੇ ਹੋਰ ਨੂੰ ਲਿੰਕ ਭੇਜਦਾ ਹੈ, ਜਾਂ failover ਤੋਂ ਬਾਅਦ refresh ਕਰਦਾ ਹੈ, ਉਹ ਵੀ ਕੁਝ ਸਮੇਂ ਲਈ ਪੁਰਾਣਾ ਡੇਟਾ ਵੇਖ ਸਕਦਾ ਹੈ।
ਛੋਟਾ-ਜਿਹਾ ਪ੍ਰੋਡਕਟ ਡਿਜ਼ਾਈਨ ਵੀ ਮਦਦਗਾਰ ਹੈ: “Saved” ਪੁਸ਼ਟੀ ਦਿਖਾਓ, optimistic UI ਨੂੰ ਧਿਆਨ ਨਾਲ ਵਰਤੋਂ, ਅਤੇ ਇਸ ਤਰ੍ਹਾਂ ਦੀ ਬਿਆਨਬਾਜ਼ੀ ਤੋਂ ਬਚੋ ਕਿ “ਹਰ ਕੋਈ ਤੁਰੰਤ ਦੇਖੇਗਾ” ਜਦੋਂ ਉਹ ਗਰੰਟੀ ਨਹੀਂ ਹੈ।
ਟੀਮਾਂ ਕਿਸ ਤਰ੍ਹਾਂ consistency ਖਤਰਾ ਮੋਨੀਟਰ ਅਤੇ ਕੰ트੍ਰੋਲ ਕਰਦੀਆਂ ਹਨ
ਆਖ਼ਿਰਕਾਰ, ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ "ਸੈਟ-ਇਟ-ਅਨ-ਭੁੱਲ ਜਾਓ" ਨਹੀਂ ਹੈ। ਜਿਹੜੀਆਂ ਟੀਮਾਂ ਇਸ 'ਤੇ ਨਿਰਭਰ ਹਨ ਉਹ consistency ਨੂੰ ਇੱਕ ਮਾਪਣ ਯੋਗ ਭਰੋਸੇਯੋਗਤਾ ਖਾਸੀਅਤ ਮੰਨਦੇ ਹਨ: ਉਹ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੇ ਹਨ ਕਿ “ਤਾਜ਼ਾ ਕਿੰਨਾ ਕਾਫ਼ੀ” ਹੈ, ਜਦ ਅਸਲੀਅਤ ਉਸ ਲਕੜੀ ਤੋਂ ਭਟਕਦੀ ਹੈ, ਅਤੇ ਜਦ ਸਿਸਟਮ ਪਿੱਛੇ ਰਹਿ ਜਾਂਦਾ ਹੈ ਤਾਂ ਕੀ ਕਰਣਾ ਹੈ।
ਤਾਜ਼ਗੀ ਟਾਰਗਟ (SLOs) ਸੈੱਟ ਕਰੋ
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸ਼ੁਰੂਆਤ propagation delay ਲਈ SLO ਹੈ—ਇਕ ਲਿਖਤ ਇੱਕ ਥਾਂ 'ਤੇ ਹੋਣ ਤੋਂ ਬਾਅਦ ਕਿੰਨੀ ਦੇਰ ਵਿੱਚ ਹਰ ਥਾਂ ਦਿਖਾਈ ਦੇਵੇਗੀ। ਟੀਮਾਂ ਅਕਸਰ ਸਰਵ-ਪਾਇੰਟਾਈਲਜ਼ (p50/p95/p99) ਵਰਤਦੀਆਂ ਹਨ averages ਦੀ ਬਜਾਏ, ਕਿਉਂਕਿ long tail ਉਹੀ ਹੈ ਜੋ ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰਦਾ ਹੈ।
ਉਦਾਹਰਨ: “95% ਅਪਡੇਟ 2 ਸਕਿੰਟ ਦੇ ਅੰਦਰ ਖੇਤਰਾਂ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦੇ ਹਨ, 99% 10 ਸਕਿੰਟ ਦੇ ਅੰਦਰ।” ਇਹ ਨੰਬਰ ਇੰਜੀਨੀਅਰਿੰਗ ਫੈਸਲਿਆਂ (batching, retry ਨੀਤੀਆਂ, queue sizing) ਅਤੇ ਪ੍ਰਾਡਕਟ ਫੈਸਲਿਆਂ ਦਾ ਮਾਰਗਦਰਸ਼ਨ ਕਰਦੇ ਹਨ (ਜਿਵੇਂ “syncing” ਸੂਚਕ ਦਿਖਾਉਣਾ)।
ਲੈਗ, conflicts, ਅਤੇ retries ਨੂੰ ਮਾਪੋ
ਸਿਸਟਮ ਨੂੰ ਉੱਚਾ ਰੱਖਣ ਲਈ, ਟੀਮਾਂ ਲਗਾਤਾਰ ਲੌਗ ਅਤੇ ਮੈਟ੍ਰਿਕਸ ਰੱਖਦੀਆਂ ਹਨ:
- replication lag (ਕਿੰਨਾ followers leaders ਤੋਂ ਪਿੱਛੇ ਹਨ)
- conflict rates (ਕਿੰਨੀ ਵਾਰ concurrent updates ਨੂੰ resolution ਦੀ ਲੋੜ ਪਈ)
- stale-read rates (ਕਿੰਨੀ ਵਾਰ ਇੱਕ ਰੀਡ ਉਮੀਦ ਤੋਂ ਪੁਰਾਣੀ ਡੇਟਾ ਦਿੰਦੀ ਹੈ)
ਇਹ ਮੈਟ੍ਰਿਕਸ ਸਧਾਰਨ ਦੇਰੀ ਨੂੰ ਗੰਭੀਰ ਸਮੱਸਿਆ (ਜਿਵੇਂ stuck consumer, overloaded queue, ਜਾਂ failing network link) ਤੋਂ ਵੱਖ ਕਰਦੇ ਹਨ।
ਤਕਲੀਫ਼ ਦੇ ਪਹਿਲੇ ਨਿਸ਼ਾਨਾਂ ਤੇ ਅਲਰਟ ਕਰੋ
ਚੰਗੇ ਅਲਰਟ ਉਹ ਪੈਟਰਨਾਂ 'ਤੇ ਫੋਕਸ ਕਰਦੇ ਹਨ ਜੋ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰਦੇ ਹਨ:
- ਨਕਲਾਂ ਦਰਮਿਆਨ ਅਸਾਮਾਨਤਾ ਵਿੱਚ ਅਸਧਾਰਨ ਵਾਧਾ
- replication ਜਾਂ event queues ਵਿੱਚ backlog ਦੀ ਵਾਧਾ
- retry storms (ਕਈ ਕੰਪੋਨੇਟ ਬਾਰ-ਬਾਰ ਫੇਲ ਹੋ ਕੇ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੇ)
ਉਦੇਸ਼ ਇਹ ਹੈ ਕਿ “ਅਸੀਂ ਪਿੱਛੇ ਹੋ ਰਹੇ ਹਾਂ” ਨੂੰ “ਯੂਜ਼ਰ ਵੱਖ-ਵੱਖ ਸਟੇਟ ਵੇਖ ਰਹੇ ਹਨ” ਤੋਂ ਪਹਿਲਾਂ ਪਕੜ ਲਿਆ ਜਾਵੇ।
ਇੰਸੀਡੈਂਟ playbooks ਤਿਆਰ ਰੱਖੋ
ਟੀਮਾਂ partitions ਦੌਰਾਨ graceful degrade ਕਰਨ ਦੀ ਯੋਜਨਾ ਵੀ ਬਣਾਉਂਦੀਆਂ ਹਨ: ਪੜ੍ਹਾਈ ਨੂੰ “ਸਭ ਤੋਂ ਸੰਭਵ ਤਾਜ਼ਾ” ਨਕਲ ਵੱਲ ਰਾਉਟ ਕਰੋ, risky multi-step flows ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਅਣ-ਚਾਲੂ ਕਰੋ, ਜਾਂ ਸਪਸ਼ਟ ਸਥਿਤੀ ਦਿਖਾਓ ਜਿਵੇਂ “Changes may take a moment to appear.” Playbooks ਇਨ੍ਹਾਂ ਫੈਸਲਿਆਂ ਨੂੰ ਦਬਾਅ ਹੇਠਾਂ ਰਿਪੀਟੇਬਲ ਬਣਾਉਂਦੇ ਹਨ, ਨਾ ਕਿ ਘੜੀ-ਵਾਰ improvisation।
ਹਰ ਫੀਚਰ ਲਈ ਠੀਕ consistency ਮਾਡਲ ਚੁਣਨਾ
ਪ੍ਰੋਡਕਸ਼ਨ-ਨੁਮਾ ਮਹੋਲ ਵਿੱਚ ਟੈਸਟ ਕਰੋ
ਚੈਟ ਤੋਂ ਹੋਸਟ ਕੀਤੀ ਐਪ ਤੱਕ ਜਾਓ ਤਾਂ ਜੋ ਤੁਸੀਂ ਅਸਲੀ ਦੁਨੀਆ ਦੇ ਲੈਗ ਅਤੇ ਵਿਵਹਾਰ ਦੀ ਟੈਸਟਿੰਗ ਕਰ ਸਕੋ.
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਇੱਕ ਪੂਰਨ-ਪੂਰਵ ਨਾਂ ਕੀਤੇ ਗਏ ਚੋਣ ਨਹੀਂ ਹੈ ਜੋ ਤੁਸੀਂ ਪੂਰੇ ਉਤਪਾਦ ਲਈ ਕਰਦੇ ਹੋ। ਸਭ ਤੋਂ ਵਧੀਆ ਐਪਸ ਮਿਕਸ ਮਾਡਲ ਵਰਤਦੀਆਂ ਹਨ: ਕੁਝ ਕਾਰਵਾਈਆਂ ਤੁਰੰਤ ਸਹਿਮਤੀ ਦੀ ਮੰਗ ਕਰਦੀਆਂ ਹਨ, ਜਦਕਿ ਦੂਜੀਆਂ ਕੁਝ ਸਕਿੰਟ ਬਾਅਦ settle ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਇਨਫ਼੍ਰਾਸਟ੍ਰਕਚਰ ਨਹੀਂ, ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ
ਇੱਕ ਕਾਰਗਰ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਪੁੱਛੋ: ਥੋੜ੍ਹਾ ਗਲਤ ਹੋਣ ਦਾ ਅਸਲ ਖ਼ਰਚਾ ਕੀ ਹੈ?
ਜੇ ਯੂਜ਼ਰ ਨੂੰ ਥੋੜ੍ਹਾ ਪੁਰਾਣਾ likes ਦੀ ਗਿਣਤੀ ਦੇਖ ਕੇ ਫੈਸਲਾ ਬਦਲਨਾ ਸੰਭਵ ਨਹੀਂ ਹੈ, ਤਾਂ ਘੱਟ ਨੁਕਸਾਨ ਹੈ। ਜੇ ਉਹ ਓਵਰਡਰਾਫਟ ਦੇਖ ਕੇ ਪੈਨਿਕ ਹੋ ਸਕਦਾ ਹੈ, ਤਾਂ nuksan ਭਾਰੀ ਹੋ ਸਕਦਾ ਹੈ।
ਸਧਾਰਨ ਫੈਸਲਾ ਚੈੱਕਲਿਸਟ
ਫੀਚਰ ਦਾ ਮੁਲਾਂਕਣ ਕਰਦਿਆਂ, ਚਾਰ ਸਵਾਲਾਂ 'ਤੇ ਜਾਓ:
- Safety: ਕੀ ਗਲਤ ਹੋਣਾ ਕਿਸੇ ਨੂੰ ਜ਼ਖਮੀ ਕਰ ਸਕਦਾ ਹੈ ਜਾਂ ਸੁਰੱਖਿਆ ਖ਼ਤਰਾ ਬਣ ਸਕਦਾ ਹੈ? (e.g., access control)
- Money: ਕੀ ਇਹ ਗਲਤ ਚਾਰਜ, double-bill, ਜਾਂ payment miss ਕਰ ਸਕਦਾ ਹੈ?
- Trust: ਜੇ ਯੂਜ਼ਰ mismatch ਵੇਖਦਾ ਹੈ ਤਾਂ کیا وہ اعتماد کھو ਦੇ گا؟
- Reversibility: ਜੇ ਕੁਝ ਗਲਤ ਹੋ ਜਾਂਦਾ ਹੈ, ਕੀ ਤੁਸੀਂ ਆਸਾਨੀ ਨਾਲ ਇਸਨੂੰ ਅਨਡੂ/ਰਿਫੰਡ/ਰੀਟ੍ਰਾਈ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਮੈਨੂਅਲ ਦਖਲ ਦੇ?
ਜੇ safety/money/trust 'ਤੇ ਜਵਾਬ "ਹਾਂ" ਹੈ, ਤਾਂ ਉਸ ਵਿਸ਼ੇਸ਼ ਓਪਰੇਸ਼ਨ ਲਈ strong consistency ਵੱਲ ਝੁਕੋ (ਜਾਂ ਘੱਟੋ-ਘੱਟ commit ਕਦਮ ਲਈ)। ਜੇ reversibility ਵਧੀਆ ਹੈ ਅਤੇ ਪ੍ਰਭਾਵ ਘੱਟ ਹੈ, ਤਾਂ eventual consistency ਆਮ ਤੌਰ 'ਤੇ ਚੰਗਾ ਵਪਾਰ ਹੈ।
ਮਿਲਾ-ਜੁਲਾ ਉਦਾਹਰਨ
ਆਮ ਪੈਟਰਨ ਇਹ ਹੈ ਕਿ ਮੁੱਖ ਲੈਣ-ਦੇਣ ਨੂੰ strong ਰੱਖੋ, ਪਰ ਆਸ-ਪਾਸ ਵਾਲੀਆਂ ਵਿਉਜ਼ ਨੂੰ eventual ਰੱਖੋ:
- Checkout: “order placed” ਅਤੇ payment capture ਲਈ strong, ਪਰ “order history sorting” ਜਾਂ “recommendations” ਲਈ eventual
- Messaging: “message sent” acknowledgement ਲਈ strong, ਪਰ “unread counts” devices ਵਿਚ sync ਕਰਨ ਲਈ eventual
ਫੈਸਲਾ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਤਾਂ ਜੋ ਟੀਮਾਂ aligned ਰਹਿਣ
ਜਦ ਤੁਸੀਂ ਫੈਸਲਾ ਕਰ ਲੈਂਦੇ ਹੋ, ਉਸਨੂੰ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਲਿਖੋ: ਕੀ stale ਹੋ ਸਕਦਾ ਹੈ, ਕਿੰਨੀ ਦੇਰ ਲਈ, ਅਤੇ ਉਪਭੋਗਤਾ ਨੂੰ ਉਸ ਦੇ ਦੌਰਾਨ ਕੀ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਹ ਪ੍ਰੋਡਕਟ, ਸਪੋਰਟ ਅਤੇ QA ਨੂੰ ਇੱਕਸਾਰ ਰੀਸਪਾਂਸ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ (ਅਤੇ “ਇਹ ਬੱਗ ਹੈ” ਬਨਾਮ “ਇਹ ਬਾਅਦ ਵਿੱਚ ਕੈਚ-ਅਪ ਹੋ ਜਾਵੇਗਾ” ਨੂੰ ਅਨੁਮਾਨ ਨਾ ਰਹਿ ਜਾਣ ਦਿੰਦਾ)।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਅੱਗੇ ਵਧ ਰਹੇ ਹੋ, ਤਾਂ ਐਸੀਆਂ ਫੈਸਲਾਂ ਨੂੰ ਪਹਿਲਾਂ ਤੋਂ ਮਿਆਰੀਕਿਤ ਕਰਨਾ ਵੀ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ। ਉਦਾਹਰਨ ਵਜੋਂ, ਜਦ ਟੀਮਾਂ Koder.ai ਵਰਤਦੀਆਂ ਹਨ ਨਵੇਂ ਸਰਵਿਸਜ਼ ਲਈ vibe-code ਬਣਾਉਣ ਲਈ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਯੋਜ਼ਨਾ ਵਿੱਚ ਵਰਣਨ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ ਕਿ ਕਿਹੜੇ endpoints strongly consistent ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ (payments, permissions) ਅਤੇ ਕਿਹੜੇ eventual ਹੋ ਸਕਦੇ ਹਨ (feeds, analytics). ਪਹਿਲਾਂ ਤੋਂ ਲਿਖੀ ਇਹ contract ਸਹੀ ਪੈਟਰਨ ਜਨਰੇਟ ਕਰਨ ਵਿੱਚ ਆਸਾਨੀ ਕਰਦੀ ਹੈ—ਜਿਵੇਂ idempotency keys, retry-safe handlers, ਅਤੇ ਸਪષ્ટ UI “syncing” states—ਜਦੋਂ ਤੁਸੀਂ scale ਕਰਦੇ ਹੋ।
ਨਤੀਜਾ: consistency ਬਾਰੇ ਇੱਕ ਪ੍ਰਯੋਗਿਕ, ਯੂਜ਼ਰ-ਕੇਂਦਰਤ ਨਜ਼ਰੀਆ
ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ “ਘਟੀਆ consistency” ਨਹੀਂ ਹੈ—ਇਹ ਇੱਕ ਜਾਣ-ਬੁਝ ਕੇ ਫੈਸਲਾ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਫੀਚਰਾਂ ਲਈ, ਇਹ ਅਨੁਭਵ ਨੂੰ ਸੱਚਮੁਚ ਬਿਹਤਰ ਕਰ ਸਕਦੀ ਹੈ: ਪੇਜ ਤੇਜ਼ ਲੋਡ ਹੁੰਦੇ ਹਨ, ਕਾਰਵਾਈਆਂ ਕਮ ਫੇਲ ਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ ਐਪ ਉਸ ਵੇਲੇ ਉਪਲਬਧ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਤਣਾਓ 'ਚ ਹਨ। ਯੂਜ਼ਰ ਆਮ ਤੌਰ 'ਤੇ “ਇਹ ਚੰਗਾ ਹੈ ਅਤੇ ਤੇਜ਼ ਹੈ” ਨੂੰ “ਹਰ ਸਕ੍ਰੀਨ ਫੌਰਨ ਅਪਡੇਟ ਹੋਵੇ” ਨਾਲੋਂ ਜ਼ਿਆਦਾ ਮੁੱਲ ਦਿੰਦੇ ਹਨ, ਜੇਕਰ ਉਤਪਾਦ predictable ਤਰੀਕੇ ਨਾਲ ਵਰਤਦਾ ਹੋਵੇ।
ਜਿੱਥੇ ਮਜ਼ਬੂਤ consistency ਰੱਖਣੀ ਜ਼ਰੂਰੀ ਹੈ
ਕੁਝ ਸ਼੍ਰੇਣੀਆਂ ਨੂੰ ਸਖਤ ਨਿਯਮਾਂ ਦੀ ਲੋੜ ਹੈ ਕਿਉਂਕਿ ਗਲਤ ਹੋਣ ਦਾ ਖ਼ਰਚ ਉਚਾ ਹੈ। ਇਨ੍ਹਾਂ ਲਈ strong consistency ਜਾਂ ਕਾਬੂਵੰਦ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਰਤੋ:
- ਪੈਸਾ-ਸੰਬੰਧੀ ਲੈਣ-ਦੇਣ, ਬੈਲੇੰਸ, ਇਨਵਾਇਸ
- ਐਕਸੇਸ ਕੰਟਰੋਲ ਅਤੇ permission changes
- ਸੁਰੱਖਿਆ-ਜ਼ਰੂਰੀ ਸਟੇਟ (password resets, MFA settings)
- ਇਨਵੈਂਟਰੀ ਜਾਂ quotas ਜਿੱਥੇ overselling/over-allocation ਅਸਵੀਕਾਰ ਹੋ
ਹਰ ਹੋਰ ਚੀਜ਼—feeds, view counts, search results, analytics, recommendations—ਲਈ ਅੰਤਿਮ ਸਮਾਂਜਸਤਾ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਹੱਕਦਾਰ ਡਿਫੌਲਟ ਹੈ।
ਡਿਜ਼ਾਈਨ ਕਰੋ ਅਤੇ ਮਾਪੋ, ਫਰਜ਼ ਨਾ ਕਰੋ
ਸਭ ਤੋਂ ਵੱਡੀ ਗਲਤੀ ਉਹ ਹੈ ਜਦ ਟੀਮਾਂ consistency ਬਿਹੇਵਿਅਰ ਬਿਨਾਂ ਪਰਿਭਾਸ਼ਤ ਕੀਤੇ ਮੰਨ ਲੈੰਦੀਆਂ ਹਨ। ਹਰੇਕ ਫੀਚਰ ਲਈ ਇਹ ਪਰਿਭਾਸ਼ਤ ਕਰੋ ਕਿ “ਠੀਕ” ਕੀ ਹੈ: ਮਨਜ਼ੂਰਯੋਗ ਦੇਰ, ਯੂਜ਼ਰ ਨੂੰ ਉਸ ਦੇ ਦੌਰਾਨ ਕੀ ਵੇਖਾਉਣਾ ਹੈ, ਅਤੇ ਅਪਡੇਟ ਆਉਣ 'ਤੇ ਆਊਟ-ਆਫ-ਆਰਡਰ ਹੋਣ ਤੇ ਕੀ ਹੋਵੇਗਾ।
ਫਿਰ ਇਸਨੂੰ ਮਾਪੋ। ਅਸਲ replication delay, stale reads, conflict rates, ਅਤੇ ਯੂਜ਼ਰ-ਨਜ਼ਰ ਵਾਲੇ mismatches ਨੂੰ ਟਰੈਕ ਕਰੋ। ਮਾਨੀਟਰਿੰਗ “ਸ਼ਾਇਦ ਠੀਕ” ਨੂੰ ਇੱਕ ਨਿਯੰਤਰਿਤ, ਟੈਸਟ ਕਰਨ ਯੋਗ ਫੈਸਲੇ ਵਿੱਚ ਬਦਲ ਦਿੰਦੀ ਹੈ।
ਅਗਲੇ ਕਦਮ
ਇਸਨੂੰ ਪ੍ਰਯੋਗਿਕ ਬਣਾਉਣ ਲਈ, ਆਪਣੇ ਉਤਪਾਦ ਫੀਚਰਾਂ ਨੂੰ ਉਹਨਾਂ ਦੀ consistency ਲੋੜਾਂ ਨਾਲ ਮੈਪ ਕਰੋ, ਫੈਸਲੇ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰੋ, ਅਤੇ guardrails ਜੋੜੋ:
- ਇੱਕ ਸਧਾਰਣ ਫੀਚਰ-ਵਾਈਜ਼ consistency ਮੈਟ੍ਰਿਕਸ
- “ਅਪਡੇਟ ਹੋ ਰਿਹਾ ਹੈ” ਜਾਂ “ਸਿੰਕ ਹੋ ਰਿਹਾ ਹੈ” ਲਈ ਸਪਸ਼ਟ UX ਰਾਜ
- consistency ਰਿਸਕ ਲਈ ਅਲਰਟ ਅਤੇ ਡੈਸ਼ਬੋਰਡ
Consistency ਇੱਕ-ਸਾਈਜ਼-ਫਿਟ-ਸਭ ਲਈ ਚੋਣ ਨਹੀਂ ਹੈ। ਲਕੜੀ ਇਹ ਹੈ ਕਿ ਸਿਸਟਮ ਯੂਜ਼ਰਾਂ ਲਈ ਭਰੋਸੇਯੋਗ ਹੋਵੇ—ਜਿੱਥੇ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ ਉਥੇ ਤੇਜ਼, ਅਤੇ ਜਿੱਥੇ ਸਖਤੀ ਲਾਜ਼ਮੀ ਹੈ ਉਥੇ ਸਖਤ।