15 ਮਈ 2025·8 ਮਿੰਟ
ਗਾਹਕ ਡੇਟਾ ਐਨਰਿਚਮੈਂਟ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਈਏ ਜੋ ਗਾਹਕ ਰਿਕਾਰਡਾਂ ਨੂੰ ਐਨਰਿਚ ਕਰੇ: ਆਰਕੀਟੈਕਚਰ, ਇੰਟੇਗਰੇਸ਼ਨ, ਮੇਚਿੰਗ, ਵੈਲੀਡੇਸ਼ਨ, ਪ੍ਰਾਈਵੇਸੀ, ਨਿਗਰਾਨੀ ਅਤੇ ਰੋਲਆਉਟ ਟਿੱਪਸ।
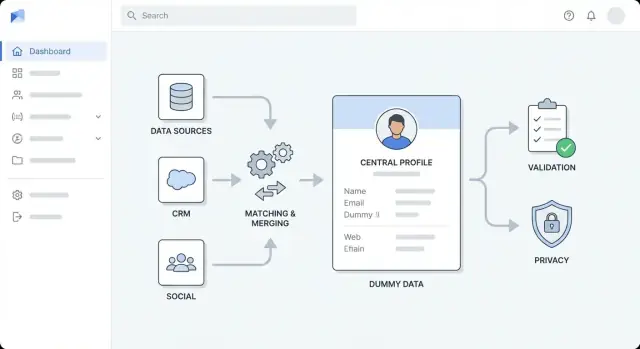
ਲਕਸ਼, ਯੂਜ਼ਰ ਅਤੇ ਐਨਰਿਚਮੈਂਟ ਰੇਂਜ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਕਿਸੇ ਵੀ ਟੂਲ ਚੁਣਨ ਜਾਂ ਆਰਕੀਟੈਕਚਰ ਡਾਇਗ੍ਰਾਮ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਲਈ “ਐਨਰਿਚਮੈਂਟ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਟੀਮਾਂ ਅਕਸਰ ਕਈ ਕਿਸਮਾਂ ਦੇ ਐਨਰਿਚਮੈਂਟ ਮਿਲਾ ਦਿੰਦੇ ਹਨ ਅਤੇ ਫਿਰ ਪ੍ਰਗਟਤ ਮਾਪ-ਦੰਡ ਮਾਪਣ ਜਾਂ ਇਹ ਨਿਰਣੈ ਕਰਨ ਵਿੱਚ ਮੁਸ਼ਕਲ ਮਹਿਸੂਸ ਕਰਦੀਆਂ ਹਨ ਕਿ ਕੰਮ ਕਦੋਂ ਮੁਕੰਮਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਐਨਰਿਚਮੈਂਟ ਵਿੱਚ ਕੀ ਗਿਣਿਆ ਜਾਂਦਾ ਹੈ?
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਉਹ ਫੀਲਡ ਸ਼੍ਰੇਣੀਆਂ ਨਾਮ ਦੀ ਲਿਖੋ ਜੋ ਤੁਸੀਂ ਸੁਧਾਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਅਤੇ ਕਿਉਂ:
- Firmographic: ਕੰਪਨੀ ਦਾ ਆਕਾਰ, ਉਦਯੋਗ, HQ ਟਿਕਾਣਾ, ਫੰਡਿੰਗ ਸਟੇਜ਼
- Contact: ਜੌਬ ਟਾਈਟਲ, ਵੈਰੀਫਾਇਡ ਈਮੇਲ/ਫ਼ੋਨ, ਸੀਨੀਅਰਟੀ, ਭੂਮਿਕਾ
- Behavioral: ਉਤਪਾਦ ਉਪਯੋਗ ਦੇ ਸਿਗਨਲ, ਇੰਟੈਂਟ, এনਗੇਜਮੈਂਟ ਸਕੋਰ
- Custom fields: ਅੰਤਰਿਕ ਟੈਰੀਟਰੀ, ਖਾਤੇ ਦੀ ਟੀਅਰ, ICP ਫਿਟ ਸਕੋਰ
ਲਿਖੋ ਕਿ ਕਿਹੜੇ ਫੀਲਡ ਜ਼ਰੂਰੀ ਹਨ, ਕਿਹੜੇ ਚੰਗੇ-ਹੋਂਦਿਆਂ ਹਨ, ਅਤੇ ਕਿਹੜੇ ਕਦੇ ਵੀ ਐਨਰਿਚ ਨਹੀਂ ਹੋਣੇ ਚਾਹੀਦੇ (ਉਦਾਹਰਨ ਲਈ ਸੰਵੇਦਨਸ਼ੀਲ ਗੁਣਾਂ)।
ਐਪ ਨੂੰ ਕੌਣ ਵਰਤੇਗਾ—ਅਤੇ ਕਿਸ ਲਈ?
ਆਪਣੇ ਪ੍ਰਾਥਮਿਕ ਯੂਜ਼ਰ ਸਮੂਹ ਅਤੇ ਉਹਨਾਂ ਦੇ ਮੁੱਖ ਕੰਮ ਵੱਲ ਧਿਆਨ ਦਿਓ:
- Sales ops: ਡੁਪਲਿਕੇਟ ਘਟਾਉਣਾ, ਖਾਤਿਆਂ ਨੂੰ ਸਟੈਂਡਰਡ ਕਰਨਾ, ਰੂਟਿੰਗ ਸੁਧਾਰਨਾ
- Marketing ops: ਲੀਡਜ਼ ਨੂੰ ਸਿਗਮੈਂਟੇਸ਼ਨ ਲਈ ਐਨਰਿਚ ਕਰਨਾ ਅਤੇ ਟਾਰਗੇਟਿੰਗ ਸੁਧਾਰਨਾ
- Support: ਟਿਕਟਾਂ ਦੌਰਾਨ ਖਾਤੇ ਦਾ ਸੰਦਰਭ ਦਿਖਾਉਣਾ
- Analysts: ਰਿਪੋਰਟਿੰਗ ਲਈ ਭਰੋਸੇਯੋਗ ਡੇਟਾਸੈੱਟ
ਹਰ ਯੂਜ਼ਰ ਗਰੁੱਪ ਅਕਸਰ ਵੱਖਰਾ ਵਰਕਫਲੋ (bulk processing বনਾਮ single-record review) ਚਾਹੁੰਦਾ ਹੈ, ਇਸ ਲਈ ਉਹਨਾਂ ਦੀਆਂ ਲੋੜਾਂ ਪਹਿਲਾਂ ਹੀ ਦਰਜ ਕਰੋ।
ਨਤੀਜੇ, ਸਕੋਪ ਸੀਮਾਵਾਂ ਅਤੇ ਸਫ਼ਲਤਾ ਮੈਟ੍ਰਿਕਸ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਨਤੀਜਿਆਂ ਨੂੰ ਮਾਪਣਯੋਗ ਸਰੂਪ ਵਿੱਚ ਲਿਸਟ ਕਰੋ: ਵਧੀ ਹੋਈ match rate, ਘੱਟ ਡੁਪਲਿਕੇਟ, ਤੇਜ਼ lead/account ਰੂਟਿੰਗ, ਜਾਂ ਸਿਗਮੈਂਟੇਸ਼ਨ ਕਾਰਗੁਜ਼ਾਰੀ ਵਿੱਚ ਸੁਧਾਰ।
ਸਪਸ਼ਟ ਸੀਮਾਵਾਂ ਤੈਅ ਕਰੋ: ਕਿਹੜੇ ਸਿਸਟਮ ਸਕੋਪ ਵਿੱਚ ਹਨ (CRM, ਬਿਲਿੰਗ, ਪ੍ਰੋਡਕਟ ਐਨਾਲਿਟਿਕਸ, ਸਪੋਰਟ ਡੈਸਕ) ਅਤੇ ਕਿਹੜੇ ਨਹੀਂ—ਵਿਸ਼ੇਸ਼ਤੌਰ 'ਤੇ ਪਹਿਲੀ ਰਿਲੀਜ਼ ਲਈ।
ਆਖ਼ਿਰਕਾਰ, ਸਫ਼ਲਤਾ ਮੈਟਰਿਕਸ ਅਤੇ ਮਨਜ਼ੂਰਯੋਗ ਐਰਰ ਦਰਾਂ 'ਤੇ ਸਹਿਮਤੀ ਕਰੋ (ਜਿਵੇਂ ਐਨਰਿਚਮੈਂਟ ਕਵਰੇਜ, ਵੈਰੀਫਿਕੇਸ਼ਨ ਰੇਟ, ਡੁਪਲਿਕੇਟ ਰੇਟ, ਅਤੇ "ਸੇਫ ਫੇਲਯਰ" ਨਿਯਮ ਜਦੋਂ ਐਨਰਿਚਮੈਂਟ ਅਨਿਸ਼ਚਿਤ ਹੋ)। ਇਹ ਤੁਹਾਡੇ ਬਾਕੀ ਬਿਲਡ ਲਈ ਨੋਰਥ ਸਟਾਰ ਬਣ ਜਾਂਦਾ ਹੈ।
ਆਪਣੇ ਗਾਹਕ ਡੇਟਾ ਦਾ ਮਾਡਲ ਬਣਾਓ ਅਤੇ ਗੈਪਾਂ ਦੀ ਪਹਚਾਨ ਕਰੋ
ਕਿਸੇ ਵੀ ਚੀਜ਼ ਨੂੰ ਐਨਰਿਚ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸਿਸਟਮ ਵਿੱਚ “ਇੱਕ ਗਾਹਕ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ—ਅਤੇ ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ ਹੀ ਉਹਨਾਂ ਬਾਰੇ ਕੀ ਪਤਾ ਹੈ। ਇਹ ਉਸ ਐਨਰਿਚਮੈਂਟ 'ਤੇ ਪੈਸਾ ਖਰਚ ਕਰਨ ਤੋਂ ਰੋਕਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਸਟੋਰ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਗਲਤ ਮਰਜਾਂ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
ਆਪਣੀਆਂ ਮੌਜੂਦਾ ਫੀਲਡਾਂ ਅਤੇ ਸਰੋਤਾਂ ਦੀ ਇਨਵੈਂਟਰੀ ਕਰੋ
ਸਧਾਰਨ ਫੀਲਡ ਕੈਟਲੌਗ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ (ਉਦਾਹਰਨ: ਨਾਮ, ਈਮੇਲ, ਕੰਪਨੀ, ਡੋਮੇਨ, ਫ਼ੋਨ, ਪਤਾ, ਜੌਬ ਟਾਈਟਲ, ਉਦਯੋਗ)। ਹਰ ਫੀਲਡ ਲਈ ਦਰਜ ਕਰੋ ਕਿ ਇਹ ਕਿੱਥੋਂ ਆ ਰਹੀ ਹੈ: ਯੂਜ਼ਰ ਇਨਪੁੱਟ, CRM ਇੰਪੋਰਟ, ਬਿਲਿੰਗ ਸਿਸਟਮ, ਸਪੋਰਟ ਟੂਲ, ਪ੍ਰੋਡਕਟ ਸਾਈਨ-ਅੱਪ ਫਾਰਮ, ਜਾਂ ਕਿਸੇ ਐਨਰਿਚਮੈਂਟ ਪ੍ਰੋਵਾਈਡਰ ਤੋਂ।
ਇਸ ਦੇ ਨਾਲ ਇਹ ਭੀ ਦਰਜ ਕਰੋ ਕਿ ਇਹ ਕਿਵੇਂ ਇਕੱਠਾ ਹੁੰਦਾ ਹੈ (ਜ਼ਰੂਰੀ বনਾਮ ਵਿਕਲਪਿਕ) ਅਤੇ ਕਿੰਨੇ ਅਕਸਰ ਬਦਲਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਜੌਬ ਟਾਈਟਲ ਅਤੇ ਕੰਪਨੀ ਆਕਾਰ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲਦੇ ਰਹਿੰਦੇ ਹਨ, ਜਦੋਂ ਕਿ ਇੱਕ ਅੰਦਰੂਨੀ ਗਾਹਕ ID ਕਦੇ ਨਹੀਂ ਬਦਲਣਾ ਚਾਹੀਦਾ।
ਆਪਣਾ identity ਮਾਡਲ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਵਿਅਕਤੀ, ਕੰਪਨੀ, ਖਾਤਾ
ਜ਼ਿਆਦਾਤਰ ਐਨਰਿਚਮੈਂਟ ਵਰਕਫਲੋ ਵਿੱਚ ਘੱਟੋ-ਘੱਟ ਦੋ ਇਕਾਈਆਂ ਸ਼ਾਮਿਲ ਹੁੰਦੀਆਂ ਹਨ:
- Person (contact/lead): ਇੱਕ ਵਿਅਕਤੀ ਜਿਸਦੇ ਈਮੇਲ, ਫ਼ੋਨ, ਭੂਮਿਕਾਵਾਂ ਹੁੰਦੀਆਂ ਹਨ
- Company (organization): ਇੱਕ ਕਾਰੋਬਾਰ ਜਿਸਦਾ ਡੋਮੇਨ, ਟਿਕਾਣਾ, firmographics ਹੁੰਦੇ ਹਨ
ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਤੁਹਾਨੂੰ ਇੱਕ Account ਵੀ ਚਾਹੀਦਾ ਹੈ (ਵਪਾਰਕ ਰਿਸ਼ਤਾ) ਜੋ ਕਈ ਲੋਕਾਂ ਨੂੰ ਇੱਕ ਕੰਪਨੀ ਨਾਲ ਜੋੜ ਸਕਦਾ ਹੈ ਅਤੇ(plan, contract dates, status) ਵਰਗੇ ਗੁਣ ਰੱਖਦਾ ਹੈ।
ਉਹ ਰਿਸ਼ਤੇ ਲਿਖੋ ਜੋ ਤੁਸੀਂ ਸਪੋਰਟ ਕਰੋਗੇ (ਜਿਵੇਂ、多 ਲੋਕ → ਇੱਕ ਕੰਪਨੀ; ਇੱਕ ਵਿਅਕਤੀ → ਵਕਤ ਦੇ ਨਾਲ ਕਈ ਕੰਪਨੀਆਂ)।
ਆਮ ਡੇਟਾ ਸਮੱਸਿਆਵਾਂ ਦਾ ਦਸਤਾਵੇਜ਼ ਬਣਾਓ
ਉਹ ਮੁੱਦੇ ਲਿਸਟ ਕਰੋ ਜੋ ਅਕਸਰ ਆਉਂਦੇ ਹਨ: ਮਿਸਿੰਗ ਵੈਲਿਊਜ਼, ਬੇਹਮਤਲਫ਼ ਫਾਰਮੇਟ ("US" vs "United States"), ਇੰਪੋਰਟਸ ਕਰਕੇ ਬਣੇ duplicates, stale ਰਿਕਾਰਡ, ਅਤੇ conflicting ਸਰੋਤ (ਬਿਲਿੰਗ ਐਡਰੈੱਸ vs CRM ਐਡਰੈੱਸ)।
ਲੋੜੀਂਦੇ ਕੁੰਜੀਆਂ ਚੁਣੋ ਅਤੇ ਟਰੱਸਟ ਲੈਵਲ ਤੈਅ ਕਰੋ
ਉਹ identifiers ਚੁਣੋ ਜੋ ਤੁਸੀਂ matching ਅਤੇ updates ਲਈ ਵਰਤੋਂਗੇ—ਆਮ ਤੌਰ 'ਤੇ ਈਮੇਲ, ਡੋਮੇਨ, ਫ਼ੋਨ, ਅਤੇ ਇੱਕ ਅੰਦਰੂਨੀ customer ID।
ਹਰ ਇੱਕ ਨੂੰ ਇਕ ਟਰੱਸਟ ਲੈਵਲ ਦੇਵੋ: ਕਿਹੜੀਆਂ ਕੁੰਜੀਆਂ authoritative ਹਨ, ਕਿਹੜੀਆਂ “best effort” ਹਨ, ਅਤੇ ਕਿਹੜੀਆਂ ਨੂੰ ਕਦੇ ਓਵਰਰਾਈਟ ਨਾ ਕੀਤਾ ਜਾਵੇ।
ਮਾਲਕੀ ਅਤੇ ਸੰਪਾਦਨ ਅਧਿਕਾਰ ਸਪਸ਼ਟ ਕਰੋ
ਤੈਅ ਕਰੋ ਕਿ ਕੌਣ ਕਿਹੜੇ ਫੀਲਡਾਂ ਦਾ ਮਾਲਕ ਹੈ (Sales ops, Support, Marketing, Customer success) ਅਤੇ ਐਡਿਟ ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: ਇੱਕ ਮਨੁੱਖ ਕੀ ਬਦਲ ਸਕਦਾ ਹੈ, automation ਕੀ ਬਦਲ ਸਕਦੀ ਹੈ, ਅਤੇ ਕਿਹੜੀਆਂ ਚੀਜ਼ਾਂ ਲਈ ਮਨਜ਼ੂਰੀ ਲੋੜੀਂਦੀ ਹੈ।
ਇਹ ਗਵਰਨੈਂਸ ਐਨਰਿਚਮੈਂਟ ਨਤੀਜਿਆਂ ਦੇ ਟਕਰਾਅ 'ਚ ਸਮਾਂ ਬਚਾਉਂਦੀ ਹੈ।
ਐਨਰਿਚਮੈਂਟ ਸਰੋਤ ਅਤੇ ਡੇਟਾ ਕੰਟ੍ਰੈਕਟ ਚੁਣੋ
ਇੰਟੇਗ੍ਰੇਸ਼ਨ ਕੋਡ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ, ਤੈਅ ਕਰੋ ਕਿ ਐਨਰਿਚਮੈਂਟ ਡੇਟਾ ਕਿੱਥੋਂ ਆਏਗਾ ਅਤੇ ਤੁਸੀਂ ਉਸਦੇ ਨਾਲ ਕੀ ਕਰਨ ਲਈ ਅਧਿਕਾਰਤ ਹੋ। ਇਹ ਇੱਕ ਆਮ ਫੇਲਯਰ ਮੋਡ ਰੋਕਦਾ ਹੈ: ਤਕਨੀਕੀ ਤੌਰ ਤੇ ਕੰਮ ਕਰਨ ਵਾਲੀ ਫੀਚਰ ਨੂੰ ਰਿਲੀਜ਼ ਕਰਨਾ ਜੋ ਲਾਗਤ, ਭਰੋਸੇਯੋਗਤਾ, ਜਾਂ ਕੰਪਲਾਇਅੰਸ ਉਮੀਦਾਂ ਨੂੰ ਤੋੜ ਦੇਵੇ।
ਆਮ ਐਨਰਿਚਮੈਂਟ ਸਰੋਤ
ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਕਈ ਇਨਪੁੱਟ ਮਿਲਾ ਕੇ ਵਰਤੋਂਗੇ:
- ਅੰਦਰੂਨੀ ਸਿਸਟਮ: CRM, ਬਿਲਿੰਗ, ਸਪੋਰਟ ਟਿਕਟ, ਪ੍ਰੋਡਕਟ ਐਨਾਲਿਟਿਕਸ, ਈਮੇਲ ਪਲੇਟਫਾਰਮ, ਡੇਟਾ ਵੇਅਰਹਾਊਸ
- ਤੀਜੀ-ਪੱਖੀ APIs: ਕੰਪਨੀ firmographics, contact validation, industry codes, technographics, risk signals
- ਅਪਲੋਡ ਕੀਤੇ ਗਏ ਲਿਸਟਾਂ: sales, events, partners, ਜਾਂ data providers ਵੱਲੋਂ CSV
- Webhooks: ਉਹ ਟੂਲ ਜੋ ਤੁਰੰਤ ਅਪਡੇਟ ਦਿੰਦੇ ਹਨ (ਉਦਾਹਰਨ ਲਈ email verification, identity providers)
ਸਰੋਤਾਂ ਦਾ ਮੁਲਾਂਕਣ ਕਿਵੇਂ ਕਰਨਾ ਹੈ
ਹਰ ਸਰੋਤ ਲਈ ਉਸਨੂੰ coverage (ਕਿੰਨੀ ਵਾਰ ਇਹ ਕੁਝ ਉਪਯੋਗੀ ਲੈਂਦਾ ਹੈ), freshness (ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਇਹ ਅਪਡੇਟ ਹੁੰਦਾ ਹੈ), ਲਾਗਤ (per call/per record), rate limits, ਅਤੇ terms of use (ਤੁਸੀਂ ਕੀ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹੋ, ਕਿੰਨੀ ਦੇਰ, ਅਤੇ ਕਿਸ ਉਦੇਸ਼ ਲਈ) 'ਤੇ ਸਕੋਰ ਕਰੋ।
ਇਸ ਦੇ ਨਾਲ ਜਾਂਚੋ ਕਿ ਪ੍ਰੋਵਾਈਡਰ confidence scores ਤੇ ਸਾਫ਼ provenance (ਕਿਹੜੇ ਸਰੋਤ ਤੋਂ ਫੀਲਡ ਆਈ) ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ ਕਿ ਨਹੀਂ।
ਡੇਟਾ ਕੰਟ੍ਰੈਕਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਹਰ ਸਰੋਤ ਨੂੰ ਇੱਕ contract ਵਾਂਗ ਵਿਵਹਾਰ ਕਰੋ ਜੋ ਫੀਲਡ ਨਾਂ ਅਤੇ ਫਾਰਮੇਟ, required vs optional ਫੀਲਡ, ਅਪਡੇਟ ਫ੍ਰਿਕੁਐਂਸੀ, ਉਮੀਦ ਕੀਤੀ ਲੇਟੇੰਸੀ, error ਕੋਡ, ਅਤੇ confidence semantics ਦੱਸਦਾ ਹੋਵੇ।
ਇੱਕ ਸਪਸ਼ਟ ਮੈਪਿੰਗ ਸ਼ਾਮਿਲ ਕਰੋ ("provider field → ਤੁਹਾਡੀ canonical field") ਨਾਲ null ਅਤੇ conflicting values ਲਈ ਨਿਯਮ।
fallback ਅਤੇ ਸਟੋਰੇਜ ਫੈਸਲੇ
ਇਹ ਯੋਜਨਾ ਬਣਾਓ ਕਿ ਜਦੋਂ ਇੱਕ ਸਰੋਤ ਉਪਲਬਧ ਨਹੀਂ ਹੈ ਜਾਂ ਨੀਵਾਂ-confidence ਨਤੀਜੇ ਦਿੰਦਾ ਹੈ ਤਾਂ ਕੀ ਹੋਵੇ: backoff ਨਾਲ retry, ਬਾਅਦ ਲਈ queue, ਜਾਂ secondary source ਤੇ fallback।
ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਕੀ ਸਟੋਰ ਕਰੋਗੇ (ਢੁਕਵਾਂ ਗੁਣ ਜੋ search/reporting ਲਈ ਲੋੜੀਂਦੇ ਹਨ) ਅਤੇ ਕੀ ਤੁਸੀਂ on demand ਲੈਕੇ ਕੈਲਕੁਲੈਟ ਕਰੋਗੇ (ਮਹਿੰਗੇ ਜਾਂ ਸਮੇਂ-ਸੰਵੇਦਨਸ਼ੀਲ ਲੁੱਕਅਪ)।
ਆਖਿਰਕਾਰ, ਸੰਵੇਦਨਸ਼ੀਲ ਗੁਣਾਂ (ਜਿਵੇਂ ਨਿੱਜੀ ਪਛਾਣ ਪੱਤਰ, ਅਨੁਮਾਨਿਤ ਲੋਕ-ਗਣਨਾ) ਸਟੋਰ ਕਰਨ 'ਤੇ ਰੋਕਾਂ ਅਤੇ retention ਨੀਤੀਆਂ ਦਸਤਾਵੇਜ਼ ਕਰੋ।
ਉੱਚ-ਸਤਰ ਆਰਕੀਟੈਕਚਰ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਟੂਲ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਐਪ ਕਿਸ ਤਰ੍ਹਾਂ ਬਣਿਆ ਹੋਇਆ ਹੋਵੇਗਾ। ਸਪਸ਼ਟ ਉੱਚ-ਸਤਰ ਆਰਕੀਟੈਕਚਰ ਐਨਰਿਚਮੈਂਟ ਕੰਮ ਨੂੰ ਪੇਸ਼ਗੀ ਅਨੁਮਾਨਕਾਰੀ ਰੱਖਦੀ ਹੈ, "quick fixes" ਨੂੰ ਸਥਾਈ ਗੁੰਦੇ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਰੋਕਦੀ ਹੈ, ਅਤੇ ਟੀਮ ਨੂੰ ਕੋਸ਼ਿਸ਼ ਦਾ ਅੰਦਾਜ਼ਾ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
ਆਪਣੀ ਟੀਮ ਲਈ ਫਿੱਟ ਆਰਕੀਟੈਕਚਰ ਸ਼ੈਲੀ ਚੁਣੋ
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਲਈ, ਇੱਕ modular monolith ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਇੱਕ deployable ਐਪ, ਪਰ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਵੱਖ-ਵੱਖ ਮਾਡਿਊਲ (ingestion, matching, enrichment, UI) ਵਿੱਚ ਵੰਡਿਆ ਹੋਇਆ। ਇਹ ਬਣਾਉਣ, ਟੈਸਟ ਕਰਨ ਅਤੇ ਡੀਬੱਗ ਕਰਨ ਲਈ ਸਧਾਰਨ ਹੈ।
ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਸਪਸ਼ਟ ਕਾਰਨ ਹੋਵੇ ਤਾਂ separate services ਤੇ ਜਾਓ—ਉਦਾਹਰਨ ਲਈ enrichment throughput ਉੱਚਾ ਹੈ, ਤੁਹਾਨੂੰ ਅਲੱਗ-ਅਲੱਗ scaling ਚਾਹੀਦੀ ਹੈ, ਜਾਂ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਵੱਖ-ਵੱਖ ਹਿੱਸਿਆਂ ਦੀ ਮਾਲਕੀ ਰੱਖਦੀਆਂ ਹਨ। ਇੱਕ ਆਮ ਵੰਡ ਹੈ:
- API service (sync requests, auth, record CRUD)
- Worker service (async enrichment, retries)
- UI (review, approvals, bulk actions)
ਚਿੰਤਾਵਾਂ ਨੂੰ ਲੇਅਰਾਂ 'ਚ ਵੱਖਰਾ ਕਰੋ
ਬਦਲਾਵਾਂ ਦੀ ਲਹਿਰਾਂ ਨੂੰ ਰੋਕਣ ਲਈ ਹੱਦਾਂ ਸਪਸ਼ਟ ਰੱਖੋ:
- Ingestion layer: CRM/ਫਾਈਲਾਂ ਤੋਂ imports ਅਤੇ inputs ਨੂੰ normalize ਕਰਨਾ
- Enrichment layer: vendors/ਅੰਦਰੂਨੀ ਸਰੋਤਾਂ ਨੂੰ ਕਾਲ ਕਰਨਾ ਅਤੇ ਨਤੀਜੇ ਸਟੋਰ ਕਰਨਾ
- Validation layer: ਡੇਟਾ ਗੁਣਵੱਤਾ ਨਿਯਮ ਲਗਾਉਣਾ ਅਤੇ exceptions ਨੂੰ ਫਲੈਗ ਕਰਨਾ
- Storage layer: customer profiles, raw source payloads, audit history
- Presentation layer: UI views, review queues, approvals
ਪਹਿਲੇ ਦਿਨ ਤੋਂ async enrichment ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਐਨਰਿਚਮੈਂਟ ਧੀਮਾ ਅਤੇ ਫੇਲ-ਪੂਰਕ ਹੁੰਦਾ ਹੈ (rate limits, timeouts, partial data)। ਐਨਰਿਚਮੈਂਟ ਨੂੰ jobs ਵਜੋਂ ਰਵਾਇਆ ਕਰੋ:
- API ਇੱਕ job ਬਣਾਂਦਾ ਅਤੇ ਤੁਰੰਤ ਜਵਾਬ ਦਿੰਦਾ ਹੈ
- Workers jobs ਨੂੰ queue ਰਾਹੀਂ process ਕਰਦੇ ਹਨ (retries ਅਤੇ backoff ਨਾਲ)
- UI job status ਦਿਖਾਉਂਦੀ ਅਤੇ ਜ਼ਰੂਰਤ 'ਤੇ re-run ਦੀ ਆਗਿਆ ਦਿੰਦੀ ਹੈ
Environments ਅਤੇ configuration ਦੀ ਯੋਜਨਾ ਬਣਾਓ
ਸ਼ੁਰੂ ਤੋਂ dev/staging/prod ਸੈਟ ਕਰੋ। vendor keys, thresholds, ਅਤੇ feature flags ਨੂੰ configuration ਵਿੱਚ ਰੱਖੋ (ਕੋਡ ਵਿੱਚ ਨਹੀਂ), ਅਤੇ per-environment providers swap ਕਰਨਾ ਆਸਾਨ ਬਣਾਓ।
ਇੱਕ-ਪੰਨੇ ਦੀ ਡਾਇਗ੍ਰਾਮ ਨਾਲ ਸਹਿਮਤੀ ਕਰੋ
ਇੱਕ ਸਰਲ ਡਾਇਗ੍ਰਾਮ ਸਕੈਚ ਕਰੋ ਜੋ ਦਿਖਾਉਂਦਾ ਹੈ: UI → API → database, ਨਾਲ ਹੀ queue → workers → enrichment providers। ਇਸਨੂੰ ਰਿਵਿਊਜ਼ ਵਿੱਚ ਵਰਤੋ ਤਾਂ ਜੋ ਸਭ Implementation ਤੋਂ ਪਹਿਲਾਂ ਜ਼ਿੰਮੇਵਾਰੀਆਂ 'ਤੇ ਸਹਿਮਤ ਹੋਣ।
ਤੇਜ਼-ਪੱਥ ਪ੍ਰੋਟੋਟਾਈਪ (ਚੋਣੀਕ)
ਜੇ ਤੁਹਾਡਾ ਲਕਸ਼ ਵਰਕਫਲੋਅ ਅਤੇ review ਸਕਰੀਨਾਂ ਨੂੰ ਵੇਰਜ਼ੀਫਾਈ ਕਰਨਾ ਹੈ ਤਾਂ ਫੁੱਲ ਇੰਜੀਨियरਿੰਗ ਸਾਈਕਲ ਵਿੱਚ ਪੈਸਾ ਲਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ ਮੁੱਢਲੀ ਐਪ ਜਲਦੀ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: React-based UI review/approvals ਲਈ, Go API ਲੇਅਰ, ਅਤੇ PostgreSQL ਬੈਕਡ storage.
ਇਹ ਖਾਸ ਕਰਕੇ job ਮਾਡਲ (async enrichment with retries), audit history, ਅਤੇ role-based access patterns ਨੂੰ ਪ੍ਰਮਾਣਿਤ ਕਰਨ ਲਈ ਲਾਭਦਾਇਕ ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ productionize ਕਰਨ ਲਈ ਤਿਆਰ ਹੋਵੋਗੇ ਤਾਂ ਸਰੋਤ ਕੋਡ export ਕਰਨ ਦੀ ਵੀ ਸਹੂਲਤ ਰੱਖਦਾ ਹੈ।
ਸਟੋਰੇਜ, ਕਿਊਜ਼ ਅਤੇ ਸਹਾਇਕ ਸੇਵਾਵਾਂ ਸੈਟ ਕਰੋ
ਐਨਰਿਚਮੈਂਟ ਪ੍ਰੋਵਾਈਡਰਾਂ ਨੂੰ ਵਾਇਰਿੰਗ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ “ਪਲੰਬਿੰਗ” ਸਹੀ ਰੱਖੋ। ਸਟੋਰੇਜ ਅਤੇ background processing ਦੇ ਫੈਸਲੇ ਬਾਅਦ ਵਿੱਚ ਬਦਲਣਾ ਔਖਾ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਇਹ ਭਰੋਸੇਯੋਗਤਾ, ਲਾਗਤ, ਅਤੇ ਆਡੀਟਬਿਲਿਟੀ 'ਤੇ ਸਿੱਧਾ ਪ੍ਰਭਾਵ ਪਾਂਉਦੇ ਹਨ।
ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ: ਪ੍ਰੋਫਾਈਲ + ਇਤਿਹਾਸ
ਗਾਹਕ ਪ੍ਰੋਫਾਈਲਾਂ ਲਈ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਚੁਣੋ ਜੋ structured ਡੇਟਾ ਅਤੇ ਲਚਕੀਲੇ attributes ਨੂੰ ਸਮਰਥਨ ਕਰਦਾ ਹੋਵੇ। Postgres ਇੱਕ ਆਮ ਚੋਣ ਹੈ ਕਿਉਂਕਿ ਇਹ ਕੋਰ ਫੀਲਡ (ਨਾਂ, ਡੋਮੇਨ, ਉਦਯੋਗ) ਨਾਲ-ਨਾਲ semi-structured enrichment fields (JSON) ਰੱਖ ਸਕਦਾ ਹੈ।
ਇਸ ਤੋਂ ਵਧ ਕੇ: change history ਸਟੋਰ ਕਰੋ। ਮਨਹਰਾਇਤ ਤੌਰ 'ਤੇ ਮੁੱਲਾਂ ਨੂੰ ਖਾਮੋਸ਼ੀ ਨਾਲ overwrite ਕਰਨ ਦੀ ਬਜਾਏ, ਦਰਜ ਕਰੋ ਕਿ ਕਿਸਨੇ/ਕਿਸ ਚੀਜ਼ ਨੇ ਇੱਕ ਫੀਲਡ ਬਦਲਿਆ, ਕਦੋਂ, ਅਤੇ ਕਿਉਂ (ਉದਾਹਰਨ: "vendor_refresh", "manual_approval")। ਇਸ ਨਾਲ approvals ਆਸਾਨ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਅਤੇ rollbacks ਦੌਰਾਨ ਤੁਹਾਡੀ ਸੁਰੱਖਿਆ ਬਰਕਰਾਰ ਰਹਿੰਦੀ ਹੈ।
Queue: enrichment ਅਤੇ retries
ਐਨਰਿਚਮੈਂਟ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ asynchronous ਹੈ: APIs rate-limit ਕਰਦੇ ਹਨ, ਨੈਟਵਰਕ fail ਹੁੰਦੇ ਹਨ, ਅਤੇ ਕੁਝ vendors ਹੌਲੀ ਜਵਾਬ ਦੇਦੇ ਹਨ। background ਕੰਮ ਲਈ job queue ਸ਼ਾਮਿਲ ਕਰੋ:
- Enrichment requests (single record ਅਤੇ bulk)
- Retries with backoff
- Scheduled refresh (ਉਦਾਹਰਨ: ਹਰ 30/90 ਦਿਨ)
- Dead-letter handling ਉਹ jobs ਲਈ ਜੋ ਨਹੀਂ ਠੀਕ ਹੁੰਦੀਆਂ
ਇਹ ਤੁਹਾਡੇ UI ਨੂੰ ਪ੍ਰਭਾਵੀ ਰੱਖਦਾ ਹੈ ਅਤੇ vendor hiccups ਨੂੰ ਐਪ ਡਾਊਨ ਕਰਨ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ।
Cache: ਤੇਜ਼ ਲੁਕਅਪ ਅਤੇ rate-limit ਟਰੈਕਿੰਗ
ਇੱਕ ਛੋਟਾ cache (ਅਕਸਰ Redis) ਬਾਰ-ਬਾਰ ਵਾਲੇ ਲੁਕਅਪ ਲਈ (ਉਦਾਹਰਨ: "ਡੋਮੇਨ ਨਾਲ ਕੰਪਨੀ") ਅਤੇ vendor rate limits ਅਤੇ cooldown windows ਟਰੈਕ ਕਰਨ ਲਈ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ। ਇਹ idempotency keys ਲਈ ਵੀ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ ਤਾਂ ਕਿ ਦੁਹਰਾਈਆਂ imports duplicate enrichment ਨੂੰ ਟਰIGGER ਨਾ ਕਰਨ।
ਫ਼ਾਇਲ ਸਟੋਰੇਜ ਅਤੇ retention
CSV imports/exports, error reports, ਅਤੇ review flows ਵਿੱਚ ਵਰਤੋਂ ਲਈ "diff" ਫ਼ਾਈਲਾਂ ਲਈ object storage ਦੀ ਯੋਜਨਾ ਬਣਾਓ।
ਰetention ਨਿਯਮ ਪਹਿਲਾਂ ਤੈਅ ਕਰੋ: raw vendor payloads ਸਿਰਫ ਡਿਬੱਗਿੰਗ ਅਤੇ audits ਲਈ ਉਸ ਸਮੇਂ ਤਕ ਰੱਖੋ ਜਿੰਨਾ ਲੋੜੀਂਦਾ ਹੈ, ਅਤੇ logs ਨੂੰ compliance ਨੀਤੀ ਅਨੁਸਾਰ expire ਕਰੋ।
ਇਨਜੇਸ਼ਨ ਅਤੇ ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਪਾਈਪਲਾਈਨ ਬਣਾਓ
ਮੂਲ ਐਪ ਤੁਰੰਤ ਬਣਾਓ
ਇੱਕ ਹੀ ਥਾਂ ਤੇ React review UI, Go API ਅਤੇ PostgreSQL ਬੈਕਅਫਿਸ ਬਣਾਓ।
ਤੁਹਾਡੀ ਐਨਰਿਚਮੈਂਟ ਐਪ ਉਸ ਡੇਟਾ ਦੇ ਬਰਾਬਰ ਹੀ ਉਪਯੋਗੀ ਹੈ ਜੋ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਭੇਜਦੇ ਹੋ। ingestion ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਫੈਸਲਾ ਕਰਦੇ ਹੋ ਕਿ ਜਾਣਕਾਰੀ ਸਿਸਟਮ ਵਿੱਚ ਕਿਵੇਂ ਆਏਗੀ, ਅਤੇ normalization ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਉਸ ਜਾਣਕਾਰੀ ਨੂੰ ਮਿਲਾ-ਕੇ ਮਿਲਦੀ-ਜੁਲਦੀ ਬਣਾਇਆ ਜਾਂਦਾ ਹੈ ਤਾਂ ਜੋ match, enrich, ਅਤੇ report ਕੀਤਾ ਜਾ ਸਕੇ।
ਡੇਟਾ ਕਿਵੇਂ ਐਂਟਰੀ ਕਰਦਾ ਹੈ, ਇਹ ਤੈਅ ਕਰੋ
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਨੂੰ mix of entry points ਚਾਹੀਦੇ ਹਨ:
- API endpoints ਤੁਹਾਡੇ ਉਤਪਾਦ ਜਾਂ ਅੰਦਰੂਨੀ ਟੂਲਜ਼ ਲਈ ਨਵੇਂ/ਅਪਡੇਟ ਗਾਹਕ push ਕਰਨ ਲਈ
- Webhooks CRM ਜਾਂ billing ਸਿਸਟਮ ਤੋਂ near-real-time changes ਲਈ
- Scheduled pulls (ਰਾਤ ਭਰ syncs) ਉਹ ਸਿਸਟਮਾਂ ਲਈ ਜੋ push ਸਮਰਥਨ ਨਹੀਂ ਕਰਦੇ
- CSV imports backfills ਅਤੇ ਇੱਕ-ਵਾਰੀ uploads ਲਈ
ਜੋ ਵੀ ਤੁਸੀਂ ਸਹਿਯੋਗ ਕਰੋ, "raw ingest" ਕਦਮ ਨੂੰ ਹਲਕਾ ਰੱਖੋ: ਡੇਟਾ ਸਵੀਕਾਰ ਕਰੋ, authenticate ਕਰੋ, metadata ਲਾਗ ਕਰੋ, ਅਤੇ processing ਲਈ work enqueue ਕਰੋ।
ਜਲਦੀ ਨਾਰਮਲਾਈਜ਼ ਅਤੇ ਸਟੈਂਡਰਡਾਈਜ਼ ਕਰੋ
ਇੱਕ normalization layer ਬਣਾਓ ਜੋ ਗੰਦੇ ਇਨਪੁੱਟ ਨੂੰ ਇੱਕ ਲਗਾਤਾਰ internal ਸਾਕੇ ਵਿੱਚ ਬਦਲ ਦੇਵੇ:
- ਨਾਂ: whitespace trim ਕਰੋ, ਜਿਤੋ ਤੱਕ ਹੋ ਸਕੇ full names split ਕਰੋ, casingManage ਕਰੋ
- ਫ਼ੋਨ: E.164 ਫਾਰਮੈਟ ਵਿੱਚ ਬਦਲੋ ਅਤੇ ਦੇਸ਼ ਦੀ ਅਟਕਲ ਸਪਸ਼ਟ ਰੱਖੋ
- ਪਤੇ: fields standardize ਕਰੋ (street, locality, region, postal code) ਅਤੇ ਮੂਲ ਟੈਕਸਟ ਰੱਖੋ
- ਡੋਮੇਨ/ਈਮੇਲ: lowercase ਕਰੋ, URLs ਤੋਂ tracking parameters ਹਟਾਓ, syntax validate ਕਰੋ
Validate, quarantine, ਅਤੇ idempotent ਰਹੋ
ਰਿਕਾਰਡ ਟਾਈਪ ਮੁਤਾਬਕ required fields ਤੈਅ ਕਰੋ ਅਤੇ ਜਿਨ੍ਹਾਂ ਚੈਕਾਂ 'ਤੇ ਨਾਕਾਮ ਹੋਵੰਦੇ ਹਨ ਉਹਨਾਂ ਨੂੰ reject ਜਾਂ quarantine ਕਰੋ (ਉਦਾਹਰਨ: company matching ਲਈ missing email/domain)। Quarantined items UI ਵਿੱਚ ਵੇਖਣਯੋਗ ਅਤੇ ਠੀਕ ਕਰਨ ਯੋਗ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।
Idempotency keys ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਜੋ retries ਹੋਣ ਤੇ duplicate processing ਨਾ ਹੋਵੇ (webhooks ਅਤੇ flaky networks ਨਾਲ ਆਮ)। ਇੱਕ ਸਧਾਰਨ ਢੰਗ hash(source_system, external_id, event_type, event_timestamp) ਵਰਗਾ ਹੈ।
ਪ੍ਰਤੀ ਫੀਲਡ lineage ਟਰੈਕ ਕਰੋ
ਹਰ ਰਿਕਾਰਡ ਅਤੇ ਸੰਭਵ ਤੌਰ 'ਤੇ ਹਰ ਫੀਲਡ ਲਈ provenance ਸਟੋਰ ਕਰੋ: source, ingestion time, ਅਤੇ transformation version। ਇਸ ਨਾਲ ਬਾਅਦ ਵਿੱਚ ਸਵਾਲਾਂ ਦੇ ਉੱਤਰ ਮਿਲਦੇ ਹਨ: "ਇਹ ਫ਼ੋਨ ਨੰਬਰ ਕਿਉਂ ਬਦਲਿਆ?" ਜਾਂ "ਕਿਹੜੀ import ਨੇ ਇਹ ਮੁੱਲ ਪੈਦਾ ਕੀਤਾ?"
ਮੇਚਿੰਗ, ਡुपਲਿਕੇਸ਼ਨ, ਅਤੇ ਮਰਜਿੰਗ ਲਾਗਿਕ ਲਾਗੂ ਕਰੋ
ਐਨਰਿਚਮੈਂਟ ਸਹੀ ਹੋਣ ਲਈ ਇਹ ਜਾਣਨਾ ਜ਼ਰੂਰੀ ਹੈ ਕਿ "ਕੌਣ ਕੌਣ ਹੈ"। ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਸਪਸ਼ਟ matching ਨਿਯਮ, ਪੇਸ਼ਗੀ merge ਵਿਹਾਰ, ਅਤੇ ਜਦੋਂ ਸਿਸਟਮ ਸ਼ੱਕ ਕਰੇ ਤਾਂ ਸੁਰੱਖਿਆ ਨੈੱਟ ਚਾਹੀਦਾ ਹੈ।
matching ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਅਤੇ confidence thresholds)
ਪਹਿਲਾਂ deterministic identifiers ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
- Exact keys: ਈਮੇਲ (lowercase), customer ID, tax/VAT ID, ਜਾਂ verified domain
ਫਿਰ ਉਹਨਾਂ ਮਾਮਲਿਆਂ ਲਈ probabilistic matching ਸ਼ਾਮਿਲ ਕਰੋ ਜਿੱਥੇ exact keys ਮੌਜੂਦ ਨਹੀਂ ਹਨ:
- Fuzzy matches: name + company domain, name + location, phone similarity
ਇੱਕ match score ਦਿਓ ਅਤੇ thresholds ਤੈਅ ਕਰੋ, ਉਦਾਹਰਨ:
- Auto-merge ਸਿਰਫ਼ ਉਚੇ threshold ਤੋਂ ਉਪਰ
- Manual review ਲਈ queue "ਸ਼ਾਇਦ" ਰੇਂਜ ਵਿੱਚ
- Reject ਨੀਵਲੇ threshold ਤੋਂ ਹੇਠਾਂ
deduplication ਅਤੇ merge logic ਦੀ ਯੋਜਨਾ ਬਣਾਓ
ਜਦੋਂ ਦੋ ਰਿਕਾਰਡ ਇਕੋ ਗਾਹਕ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਫੀਲਡ ਕਿਹੜੇ ਚੁਣੇ ਜਾਣਗੇ:
- Field precedence: "verified email unverified ਤੇ ਹਮੇਸ਼ਾਂ ਉੱਪਰ", "ਨਵਾਂ timestamp ਜਿੱਤਦਾ ਹੈ", "CRM enrichment ਲਈ contact owner ਨੂੰ override ਕਰਦਾ ਹੈ"
- Source trust scores: ਸਰੋਤਾਂ ਨੂੰ rank ਕਰੋ (CRM, billing, enrichment providers) ਤਾ ਕਿ conflicts ਹੱਲ ਹੋ ਸਕਣ
- Conflict handling: ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ ਦੋਹਾਂ ਮੁੱਲ ਰੱਖੋ (ਉਦਾਹਰਨ: ਕਈ ਫ਼ੋਨ ਨੰਬਰ), ਜਾਂ ਹਰਾਰੂ value history ਵਿੱਚ ਰੱਖੋ
ਆਡੀਟ ਟ੍ਰੇਲ ਅਤੇ review workflow
ਹਰ merge ਨੂੰ ਇੱਕ audit event ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ: ਕਿਸਨੇ/ਕਿਸ ਚੀਜ਼ ਨੇ ਉਸਨੂੰ trigger ਕੀਤਾ, before/after ਮੁੱਲ, match score, ਅਤੇ ਸ਼ਾਮਿਲ record IDs।
ਅੰਬੀਗ੍ਯੂਅਸ matches ਲਈ, ਇੱਕ review screen ਦਿਓ side-by-side comparison ਅਤੇ "merge / don't merge / ਹੋਰ ਡਾਟਾ ਮੰਗੋ" ਜਿਹਾ ਵਿਕਲਪ।
ਗਲਤੀ ਨਾਲ mass merges ਤੋਂ ਸੁਰੱਖਿਆ
ਬਲੌਕ merges ਲਈ ਵਾਧੂ ਪੁਸ਼ਟੀ ਲੋੜੀਦਾ ਕਰੋ, ਇੱਕ ਜੋਬ ਵਿੱਚ merges ਦੀ ਕੁੱਲ ਸੀਮਾ ਲਗਾਓ, ਅਤੇ "dry run" previews ਦਾ ਸਮਰਥਨ ਦਿਓ।
ਇਸ ਦੇ ਨਾਲ ਇੱਕ undo ਰਾਹ (ਜਾਂ merge reversal) audit history ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਰੱਖੋ ਤਾਂ ਕਿ ਗਲਤੀਆਂ ਸਥਾਈ ਨਾ ਬਣਣ।
ਐਨਰਿਚਮੈਂਟ APIs ਨੂੰ ਇੰਟੇਗਰੇਟ ਕਰੋ ਅਤੇ ਭਰੋਸੇਯੋਗਤਾ ਸੰਭਾਲੋ
ਐਨਰਿਚਮੈਂਟ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਬਾਹਰਲੇ ਸੰਸਾਰ ਨਾਲ ਜੋੜਦੀ ਹੈ—ਕਈ ਪ੍ਰੋਵਾਈਡਰ, ਅਸੰਗਤ ਜਵਾਬ, ਅਤੇ ਅਣਪੇक्षित ਉਪਲਬਧਤਾ। ਹਰ ਪ੍ਰੋਵਾਈਡਰ ਨੂੰ ਇੱਕ plug-in "connector" ਵਜੋਂ ਤਰਤੀਬ ਦਿਓ ਤਾਂ ਜੋ ਤੁਸੀਂ ਸਰੋਤ ਜੋੜ, ਬਦਲ, ਜਾਂ disable ਕਰ ਸਕੋ ਬਿਨਾਂ ਬਾਕੀ ਪਾਈਪਲਾਈਨ ਨੂੰ ਛੇੜੇ।
provider connectors ਬਣਾਓ (auth, retries, error mapping)
ਹਰ enrichment provider ਲਈ ਇੱਕ connector ਬਣਾਓ ਜਿਸਦਾ ਇੱਕ consistent interface ਹੋਵੇ (ਉਦਾਹਰਨ: enrichPerson(), enrichCompany())। provider-specific logic connector ਵਿੱਚ ਰੱਖੋ:
- Authentication (API keys, OAuth tokens, token refresh)
- Transient failures ਲਈ standardized retries
- Error mapping (provider errors ਨੂੰ ਤੁਹਾਡੇ ਆਪਣੀਆਂ ਸ਼੍ਰੇਣੀਆਂ ਵਿੱਚ ਬਦਲੋ ਜਿਵੇਂ
invalid_request,not_found,rate_limited,provider_down)
ਇਸ ਨਾਲ downstream workflows ਸਧਾਰਨ ਹੁੰਦੇ ਹਨ: ਉਹ ਤੁਹਾਡੇ error types ਨੂੰ ਹੈਂਡਲ ਕਰਦੇ ਹਨ, ਹਰ provider ਦੇ quirky errors ਨੂੰ ਨਹੀਂ।
rate limits ਨੂੰ throttling ਅਤੇ backoff ਨਾਲ ਹੈਂਡਲ ਕਰੋ
ਜ਼ਿਆਦਾਤਰ enrichment APIs quotas ਲਗਾਉਂਦੇ ਹਨ। ਹਰ provider (ਅਤੇ ਕਈ ਵਾਰੀ ਹਰ endpoint) ਲਈ throttling ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਕਿ requests limits ਅੰਦਰ ਰਹਿਣ।
ਜਦੋਂ limit ਟਰਿੱਗਰ ਹੋਵੇ, exponential backoff with jitter ਵਰਤੋ ਅਤੇ Retry-After headers ਦਾ ਆਦਰ ਕਰੋ।
"Slow failure" ਦੀ ਯੋਜਨਾ ਵੀ ਬਣਾਓ: timeouts ਅਤੇ partial responses ਨੂੰ retriable events ਵਜੋਂ ਸਮਭਾਲੋ, silent drops ਵਜੋਂ ਨਹੀਂ।
confidence ਅਤੇ evidence ਸਟੋਰ ਕਰੋ (policy ਅਨੁਸਾਰ)
ਐਨਰਿਚਮੈਂਟ ਨਤੀਜੇ ਕਦੇ ਵੀ ਪੂਰੀ ਤਰ੍ਹਾਂ ਨਿਸ਼ਚਿਤ ਨਹੀਂ ਹੁੰਦੇ। ਜਦੋਂ ਉਪਲਬਧ ਹੋਵੇ ਤਾਂ provider confidence scores ਅਤੇ ਤੁਹਾਡਾ ਆਪਣਾ score based on match quality ਅਤੇ field completeness ਸਟੋਰ ਕਰੋ।
ਜਿੱਥੇ contract ਅਤੇ privacy policy ਮਨਜ਼ੂਰ ਕਰਦੇ ਹਨ, raw evidence (source URLs, identifiers, timestamps) ਸਟੋਰ ਕਰੋ ਤਾਂ ਜੋ auditing ਅਤੇ ਯੂਜ਼ਰ ਭਰੋਸਾ ਸਹੀ ਢੰਗ ਨਾਲ ਦਿੱਤਾ ਜਾ ਸਕੇ।
multi-provider ਰਣਨੀਤੀ: "best available" ਚੋਣ
ਕਈ providers ਦਾ ਸਮਰਥਨ ਕਰੋ ਤੇ selection rules ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ: cheapest-first, highest-confidence, ਜਾਂ field-by-field "best available"।
ਰਿਕਾਰਡ ਕਰੋ ਕਿ ਕਿਹੜੇ provider ਨੇ ਹਰ attribute ਦਿੱਤਾ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਦਲਾਅ ਵਿਆਖਿਆ ਕਰ ਸਕੋ ਅਤੇ ਜ਼ਰੂਰਤ 'ਤੇ rollback ਕਰ ਸਕੋ।
scheduled refresh ਨੀਤੀ
ਐਨਰਿਚਮੈਂਟ ਪੁਰਾਣਾ ਹੋ ਜਾਂਦਾ ਹੈ। refresh ਨੀਤੀਆਂ ਜਿਵੇਂ "ਹਰ 90 ਦਿਨ re-enrich", "ਮੁੱਖ ਫੀਲਡ ਬਦਲਣ 'ਤੇ refresh", ਜਾਂ "ਸਿਰਫ ਜੇ confidence ਘੱਟ ਹੋਵੇ ਤਾਂ refresh" ਲਾਗੂ ਕਰੋ।
ਇਹchedules per customer ਅਤੇ per data type configurable ਰੱਖੋ ਤਾਂ ਕਿ ਲਾਗਤ ਅਤੇ ਨੌਇਜ਼ ਕੰਟਰੋਲ ਹੋ ਸਕੇ।
ਡੇਟਾ ਗੁਣਵੱਤਾ ਨਿਯਮ ਅਤੇ ਵੈਰੀਫਿਕੇਸ਼ਨ ਸ਼ਾਮਿਲ ਕਰੋ
ਆਪਣੇ ਬਣਾਉਣ ਦੀ ਲਾਗਤ ਘਟਾਓ
ਆਪਣਾ ਬਣਾਇਆ ਹੋਇਆ ਕੁਝ ਸਾਂਝਾ ਕਰਕੇ ਜਾਂ ਟੀਮ-mates ਨੂੰ ਬੁਲਾ ਕੇ credits ਪ੍ਰਾਪਤ ਕਰੋ ਅਤੇ ਆਪਣੀ ਬਣਟਾਈ ਦੀ ਕੀਮਤ ਘਟਾਓ।
ਨਵਾ ਮੁੱਲ ਤਦ ਹੀ ਫਾਇਦੇਮੰਦ ਹੈ ਜਦੋਂ ਉਹ ਭਰੋਸੇਯੋਗ ਹੋ। validation ਨੂੰ ਪਹਿਲਾ ਦਰਜਾ ਦਿਓ: ਇਹ messy imports, unreliable third-party responses, ਅਤੇ merges ਦੌਰਾਨ ਸੰਭਵ ਨੁਕਸਾਨ ਤੋਂ ਯੂਜ਼ਰਾਂ ਨੂੰ ਬਚਾਉਂਦੀ ਹੈ।
ਫੀਲਡ-ਸਤਰ validation ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ
ਹਰ ਫੀਲਡ ਲਈ ਇੱਕ ਸਧਾਰਨ "rules catalog" ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ UI forms, ingestion pipelines, ਅਤੇ public APIs ਦੁਆਰਾ ਸਾਂਝਾ ਹੋਵੇ।
ਆਮ ਨਿਯਮਾਂ ਵਿੱਚ format checks (email, phone, postal code), allowed values (country codes, industry lists), ranges (employee count, revenue bands), ਅਤੇ required dependencies (ਜੇ country = US ਤਾਂ state ਜਰੂਰੀ) ਸ਼ਾਮਿਲ ਹਨ।
ਨਿਯਮ versioned ਰੱਖੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਸਮੇਂ ਦੇ ਨਾਲ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਬਦਲ ਸਕੋ।
ਹਕੀਕਤੀ ਉਪਯੋਗ ਨੂੰ ਦਰਸਾਉਂਦੇ quality checks ਸ਼ਾਮਿਲ ਕਰੋ
ਮੁਢਲੇ validation ਤੋਂ ਅੱਗੇ, ਉਹ data quality checks ਚਲਾਓ ਜੋ ਕਾਰੋਬਾਰੀ ਪ੍ਰਸ਼ਨਾਂ ਦਾ ਜਵਾਬ ਦਿੰਦੇ ਹਨ:
- Completeness: ਕੀ ਸਾਡੇ ਕੋਲ record ਵਰਤਣ ਲਈ ਘੱਟੋ ਘੱਟ ਫੀਲਡ ਹਨ?
- Uniqueness: ਕੀ "unique" identifiers (domain, tax ID) duplicate ਹਨ?
- Consistency: ਕੀ ਸੰਬੰਧਤ ਫੀਲਡ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਮੇਲ ਖਾਂਦੇ ਹਨ (country vs. phone prefix)?
- Timeliness: ਇੱਕ ਮੁੱਲ ਕਿੰਨਾ ਪੁਰਾਣਾ ਹੈ, ਅਤੇ ਕੀ ਇਹ refresh ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ?
records ਅਤੇ sources ਨੂੰ ਸਕੋਰ ਕਰੋ
ਚੈੱਕਾਂ ਨੂੰ ਸਕੋਰਕਾਰਡ ਵਿੱਚ ਬਦਲੋ: per record (ਸਰਵਜਨੀਨ health) ਅਤੇ per source (ਕਿੰਨੀ ਵਾਰ ਇਹ valid, ਨਵਾਂ ਮੁੱਲ ਦਿੰਦਾ ਹੈ)।
ਇਸ ਸਕੋਰ ਦੀ ਵਰਤੋਂ automation ਨੂੰ ਰਾਹ ਦਿਖਾਉਣ ਲਈ ਕਰੋ—ਉਦਾਹਰਨ: ਸਿਰਫ਼ ਇੱਕ ਥ੍ਰੇਸ਼ਹੋਲਡ ਤੋਂ ਉਪਰ ਵਾਲੀ enrichments ਨੂੰ auto-apply ਕਰੋ।
failures ਨੂੰ predictable ਰਾਹ 'ਤੇ ਰੂਟ ਕਰੋ
ਜਦੋਂ ਕੋਈ record validation ਫੇਲ ਕਰ ਜਾਵੇ, ਉਸਨੂੰ ਨਾਂ ਛੱਡੋ।
ਇਹ ਨੂੰ "data-quality" queue ਵਿੱਚ ਭੇਜੋ retry (transient issues) ਜਾਂ manual review (bad input) ਲਈ। failed payload, rule violations, ਅਤੇ suggested fixes ਸਟੋਰ ਕਰੋ।
errors ਨੂੰ ਸਮਝਣਯੋਗ ਬਣਾਓ
Imports ਅਤੇ API clients ਲਈ ਸਪਸ਼ਟ, actionable messages ਵਾਪਸ ਕਰੋ: ਕਿਹੜਾ ਫੀਲਡ fail ਹੋਇਆ, ਕਿਉਂ, ਅਤੇ ਵਰਤੋਂ ਲਈ ਇੱਕ ਉਦਾਹਰਨ।
ਇਸ ਨਾਲ support ਲੋਡ ਘਟਦਾ ਹੈ ਅਤੇ cleanup ਤੇਜ਼ ਹੁੰਦੀ ਹੈ।
Review, Approvals, ਅਤੇ Bulk Work ਲਈ UI ਬਣਾਓ
ਤੁਹਾਡੀ ਐਨਰਿਚਮੈਂਟ ਪਾਈਪਲਾਈਨ ਉਸ ਵੇਲੇ ਮੱਲੀ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਲੋਕ ਵੇਖ ਸਕਣ ਕਿ ਕੀ ਬਦਲਿਆ, ਕਿਉਂ, ਅਤੇ ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ। UI ਨੂੰ ਇਹ ਸਪਸ਼ਟ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ: "ਕੀ ਹੋਇਆ, ਕਿਉਂ, ਅਤੇ ਮੈਨੂੰ ਅਗਲਾ ਕੀ ਕਰਨਾ ਹੈ?"
ਡਿਜ਼ਾਈਨ ਕਰਨ ਲਈ ਮੁੱਖ ਸਕਰੀਨ
Customer profile ਹੋਮ ਬੇਸ ਹੈ। ਮੁੱਖ identifiers (ਈਮੇਲ, ਡੋਮੇਨ, ਕੰਪਨੀ ਦਾ ਨਾਮ), ਮੌਜੂਦਾ ਫੀਲਡ ਮੁੱਲ, ਅਤੇ ਇੱਕ enrichment status ਬੈਜ ਦਿਖਾਓ (ਉਦਾਹਰਨ: Not enriched, In progress, Needs review, Approved, Rejected)।
ਇੱਕ change history timeline ਸ਼ਾਮਿਲ ਕਰੋ ਜੋ updates ਨੂੰ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਵਿਆਖਿਆ ਕਰੇ: "Company size 11–50 ਤੋਂ 51–200 ਹੋ ਗਈ"। ਹਰ エਂਟਰੀ clickable ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਕਿ ਵੇਰਵੇ ਵੇਖੇ ਜਾ ਸਕਣ।
ਡੁਪਲਿਕੇਟ ਪਾਇਆ ਜਾਣ 'ਤੇ merge suggestions ਦਿਖਾਓ। ਦੋ (ਜਾਂ ਵੱਧ) candidate records side-by-side ਦਿਖਾਓ ਅਤੇ recommended “survivor” record ਅਤੇ merged result ਦੀ preview ਦਿਖਾਓ।
ਬੁਲਕ ਕਾਰਜ ਜੋ ਅਸਲ ਓਪਰੇਸ਼ਨ ਨਾਲ ਮਿਲਦੇ ਹੋ
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਬੈਚ ਵਿੱਚ ਕੰਮ ਕਰਦੀਆਂ ਹਨ। bulk actions ਸ਼ਾਮਿਲ ਕਰੋ ਜਿਵੇਂ:
- ਚੁਣੇ ਹੋਏ records ਨੂੰ enrich ਕਰੋ (ਜਾਂ ਰਾਤ ਲਈ enqueue ਕਰੋ)
- suggested merges approve/reject ਕਰੋ
- ਨਤੀਜੇ export (CSV) ਕਰੋ audits ਜਾਂ offline review ਲਈ
destructive actions (merge, overwrite) ਲਈ ਸਪਸ਼ਟ confirmation step ਰੱਖੋ ਅਤੇ ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ "undo" window ਦਿਓ।
ਤੇਜ਼ search, filters, ਅਤੇ field-level provenance
ਗਲੋਬਲ search ਅਤੇ filters ਦਿਓ by email, domain, company, status, ਅਤੇ quality score।
ਉਪਯੋਗਕਰਤਾਵਾਂ ਨੂੰ views save ਕਰਨ ਦਿਓ ਜਿਵੇਂ "Needs review" ਜਾਂ "Low confidence updates"।
ਹਰ enriched ਫੀਲਡ ਲਈ provenance ਦਿਖਾਓ: source, timestamp, ਅਤੇ confidence।
ਇੱਕ ਸਰਲ "Why this value?" ਪੈਨਲ ਭਰੋਸਾ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਬੈਕ-ਅੰ-ਫੋਰਥ ਘੱਟ ਕਰਦਾ ਹੈ।
ਗੈਰ-ਟੈਕਨੀਕੀ ਯੂਜ਼ਰਾਂ ਲਈ guided workflows
ਫੈਸਲੇ binary ਅਤੇ guided ਰੱਖੋ: "Accept suggested value", "Keep existing", ਜਾਂ "Edit manually"। ਜੇ ਤੁਹਾਨੂੰ ਡੂੰਘੀ ਕੰਟ੍ਰੋਲ ਦੀ ਲੋੜ ਹੋਵੇ ਤਾਂ ਇਸਨੂੰ "Advanced" toggle ਦੇ ਪਿੱਛੇ ਰੱਖੋ ਤਾਂ ਕਿ ਇਹ ਡਿਫਾਲਟ ਨਾ ਬਣੇ।
ਸੁਰੱਖਿਆ, ਪ੍ਰਾਈਵੇਸੀ, ਅਤੇ ਕੰਪਲਾਇਅੰਸ ਬੁਨਿਆਦੀ ਗੱਲਾਂ
ਸਾਫ਼ ਪਾਈਪਲਾਈਨ ਭੇਜੋ
ਇਕੋ ਹੀ ਪ੍ਰੋਜੈਕਟ ਵਿੱਚ ingestion, normalization, ਅਤੇ validation flows ਡਰਾਫਟ ਕਰੋ ਅਤੇ ਦੌਰਾਨ-ਦੌਰਾਨ ਵਿਕਸਤ ਕਰੋ।
ਗਾਹਕ enrichment ਐਪ PII (ਈਮੇਲ, ਫ਼ੋਨ ਨੰਬਰ, ਕੰਪਨੀ ਵੇਰਵੇ) ਨੂੰ ਛੂਹਦੀ ਹੈ ਅਤੇ ਅਕਸਰ ਤੀਜੀ-ਪੱਖੀ ਸਰੋਤਾਂ ਤੋਂ ਡੇਟਾ ਲੈਂਦੀ ਹੈ। ਸੁਰੱਖਿਆ ਅਤੇ ਪ੍ਰਾਈਵੇਸੀ ਨੂੰ ਮੂਲ ਫੀਚਰ ਮੰਨੋ, "ਬਾਅਦ" ਦੇ ਕੰਮ ਨਹੀਂ।
Role-based access control (RBAC)
ਸ਼ੁਰੂ ਕਰੋ ਸਪਸ਼ਟ roles ਅਤੇ least-privilege defaults ਨਾਲ:
- Admin: ਯੂਜ਼ਰ, roles, connectors, retention policies ਪ੍ਰਬੰਧਨ
- Ops: enrichment jobs ਚਲਾਉਣਾ, conflicts ਹੱਲ ਕਰਨਾ, merges approve ਕਰਨਾ
- Viewer: ਰਿਪੋਰਟਿੰਗ ਅਤੇ support ਲਈ read-only access
Permissions granular ਰੱਖੋ (ਉਦਾਹਰਨ: "export data", "view PII", "approve merges"), ਅਤੇ environments ਅਲੱਗ ਰੱਖੋ ਤਾਂ ਕਿ production ਡੇਟਾ dev ਵਿੱਚ ਉਪਲਬਧ ਨਾ ਹੋਵੇ।
ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਦੀ ਰੱਖਿਆ
ਸਾਰੇ ਟ੍ਰੈਫਿਕ ਲਈ TLS ਵਰਤੋ ਅਤੇ databases/object storage ਲਈ encryption at rest ਲੱਗਾਓ।
API keys secrets manager ਵਿੱਚ ਰੱਖੋ (env files ਵਿੱਚ ਨਾ), ਉਹਨਾਂ ਨੂੰ ਨਿਯਮਤ ਤੌਰ 'ਤੇ rotate ਕਰੋ, ਅਤੇ per-environment scope ਕਰੋ।
ਜੇ ਤੁਸੀਂ UI ਵਿੱਚ PII ਦਿਖਾਉਂਦੇ ਹੋ ਤਾਂ safe defaults ਜਿਵੇਂ masked fields (ਅੰਤਮ 2–4 ਅੰਕ ਦਿਖਾਓ) ਅਤੇ ਪੂਰੇ ਮੁੱਲ ਵਿਖਾਉਣ ਲਈ explicit permission ਲੋੜੀਦਾ ਕਰੋ।
consent ਅਤੇ ਡੇਟਾ-ਵਰਤੋਂ ਦੀਆਂ ਸੀਮਾਵਾਂ
ਜੇ ਐਨਰਿਚਮੈਂਟ consent ਜਾਂ ਵਿਸ਼ੇਸ਼ contractual terms 'ਤੇ ਨਿਰਭਰ ਹੈ, ਤਾਂ ਉਹ constraints workflow ਵਿੱਚ encode ਕਰੋ:
- ਹਰ ਫੀਲਡ ਲਈ data source, purpose, ਅਤੇ allowed uses ਟਰੈਕ ਕਰੋ
- ਜੋ ਤੁਸੀਂ ਸਟੋਰ ਕਰਦੇ ਹੋ ਅਤੇ ਕਿਉਂ (ਛੋਟੀ internal policy ਜਿਵੇਂ /privacy ਜਾਂ /docs/data-handling) ਦਸਤਾਵੇਜ਼ ਕਰੋ
- ਉਹ ਫੀਲਡ ਨਾ ਇਕੱਠਾ ਕਰੋ ਜੋ ਤੁਸੀਂ ਨਹੀਂ ਚਾਹੁੰਦੇ—ਘੱਟ ਡੇਟਾ ਘੱਟ ਰਿਸਕ
Auditing, retention, ਅਤੇ deletion
Access ਅਤੇ changes ਦੋਹਾਂ ਲਈ audit trail ਬਣਾਓ:
- ਕੌਣ record ਵੇਖਿਆ/ਐਕਸਪੋਰਟ ਕੀਤਾ ਲਾਗ ਕਰੋ
- ਕਿਸਨੇ ਕੀ ਅਤੇ ਕਦੋਂ badਲਿਆ (before/after, job ID, enrichment provider) ਲਾਗ ਕਰੋ
ਅਖੀਰਕਾਰ, privacy requests ਲਈ ਹਸਤੀ ਟੂਲਿੰਗ ਦਿਓ: retention schedules, record deletion, ਅਤੇ “forget” workflows ਜੋ ਲਾਗਾਂ, caches, ਅਤੇ backups ਵਿੱਚ ਨਕਲਾਂ ਨੂੰ ਵੀ purge ਕਰਨ ਜਾਂ expiry ਲਈ ਨਿਸ਼ਾਨ ਲਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਨਿਗਰਾਨੀ, ਐਨਾਲਿਟਿਕਸ, ਅਤੇ ਆਪਰੇਸ਼ਨਲ ਕন্ট્રોલ
ਮਾਨੀਟਰਿੰਗ ਸਿਰਫ uptime ਲਈ ਨਹੀਂ—ਇਹ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ enrichment ਨੂੰ ਭਰੋਸੇਯੋਗ ਰੱਖਦੇ ਹੋ ਜਿਵੇਂ volumes, providers, ਅਤੇ rules ਬਦਲਦੇ ਹਨ।
ਹਰ enrichment run ਨੂੰ ਇੱਕ measurable job ਵਜੋਂ ਸਬੰਧਤ ਸਿਗਨਲਾਂ ਨਾਲ ਟਰੈਕ ਕਰੋ।
ਮੈਟ੍ਰਿਕਸ ਜੋ ਅਸਲ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ
ਛੋਟੀ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਨਤੀਜਿਆਂ ਨਾਲ ਜੁੜੇ ਹੋਣ:
- Job throughput (records/min) ਅਤੇ time-to-complete ਪ੍ਰਤੀ run
- Success rate vs failure rate, failure type ਦੇ ਅਨੁਸਾਰ (validation, matching, provider)
- Provider latency (p50/p95) ਅਤੇ enrichment source ਮੁਤਾਬਕ timeouts
- Match rate (ਕਿੰਨੀ ਵਾਰ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਐਨਰਿਚਮੇੰਟ ਜੋੜਦੇ ਹੋ)
- Duplicates prevented (ਕਿੰਨਾਂ merges ਰੋਕੇ ਗਏ)
ਇਹ ਨੰਬਰ ਜਵਾਬ ਦਿੰਦੇ ਹਨ: "ਕੀ ਅਸੀਂ ਡੇਟਾ ਸੁਧਾਰ ਰਹੇ ਹਾਂ, ਜਾਂ ਸਿਰਫ਼ ਇਸਨੂੰ ਹਿਲਾ ਰਹੇ ਹਾਂ?"
alerts ਅਤੇ guardrails
ਬੇਕਾਰ noise ਵਾਲੇ alerts ਨਾ ਬਣਾਓ—ਅਸਲ ਬਦਲਾਵ 'ਤੇ alerts ਰੱਖੋ:
- failures ਜਾਂ quarantined records ਵਿੱਚ spike
- queue backlogs ਜਾਂ slow consumers (pipeline stuck ਹੋਣ ਦਾ ਸੰਕੇਤ)
- provider error bursts (429/5xx), ਤੇਜ਼ latency, ਜਾਂ ਵੱਧ timeouts
alerts ਨੂੰ concrete actions ਨਾਲ ਜੋੜੋ, ਜਿਵੇਂ provider ਨੂੰ pause ਕਰਨਾ, concurrency ਘਟਾਉਣਾ, ਜਾਂ cached/stale data 'ਤੇ switch ਕਰਨਾ।
operators ਲਈ admin dashboard
ਤਾਜ਼ਾ runs ਲਈ ਇੱਕ admin view ਦਿਓ: status, counts, retries, ਅਤੇ quarantined records ਦੀ list ਕਾਰਨ ਸਮੇਤ।
"replay" controls ਅਤੇ safe bulk actions ਸ਼ਾਮਿਲ ਕਰੋ (retry all provider timeouts, re-run matching only)।
logs ਨਾਲ traceability
structured logs ਅਤੇ ਇੱਕ correlation ID ਵਰਤੋ ਜੋ ਇੱਕ record end-to-end follow ਕਰੇ (ingestion → match → enrichment → merge)।
ਇਸ ਨਾਲ customer support ਅਤੇ incident debugging ਤੇਜ਼ ਹੋ ਜਾਂਦੀ ਹੈ।
incident playbooks ਅਤੇ rollback
ਛੋਟੇ playbooks ਲਿਖੋ: provider degrade ਹੋਣ ਤੇ ਕੀ ਕਰਨਾ, match rate ਝਟਕੇ ਨਾਲ ਘਟਣ ਤੇ, ਜਾਂ duplicates ਪਾਸ ਹੋਣ 'ਤੇ ਕੀ ਕਰਨਾ।
rollback option ਰੱਖੋ (ਉਦਾਹਰਨ: merges ਨੂੰ ਇੱਕ ਸਮਾਂ-ਵਿੰਡੋ ਲਈ revert), ਅਤੇ ਇਸਨੂੰ /runbooks ਤੇ ਦਸਤਾਵੇਜ਼ ਕਰੋ।
ਟੈਸਟਿੰਗ, ਰੋਲਆਉਟ, ਅਤੇ ਇਟਰੇਸ਼ਨ ਯੋਜਨਾ
ਟੈਸਟਿੰਗ ਅਤੇ rollout ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਇੱਕ enrichment ਐਪ ਭਰੋਸੇਯੋਗ ਬਣਦਾ ਹੈ। ਲਕਸ਼ "ਜ਼ਿਆਦਾ ਟੈਸਟ" ਨਹੀਂ, ਬਲਕਿ ਇਹ ਹੈ ਕਿ matching, merging, ਅਤੇ validation messy real-world data ਹੇਠਾਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰਨ।
ਸਭ ਤੋਂ ਫ਼ਰਕਿਦਾਰ ਹਿੱਸਿਆਂ ਦੀ ਟੈਸਟਿੰਗ ਪਹਿਲਾਂ ਕਰੋ
ਉਹ ਲਾਜ਼ਮੀ ਤਰ੍ਹਾਂ ਟੈਸਟ ਕਰੋ ਜੋ records ਨੂੰ ਖ਼ਾਮੋਸ਼ੀ ਨਾਲ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਸਕਦੇ ਹਨ:
- Matching rules: exact, fuzzy, ਅਤੇ composite matches ਲਈ unit tests (ਉਦਾਹਰਨ: email + company domain)। near-duplicates ਅਤੇ swapped fields ਸ਼ਾਮਿਲ ਕਰੋ।
- Merge outcomes: field precedence (source priority), conflict handling, ਅਤੇ "do not overwrite" ਨਿਯਮ ਟੈਸਟ ਕਰੋ।
- Validation edge cases: malformed emails, international phone formats, missing country, duplicate identifiers, ਅਤੇ "unknown" values
ਸਿੰਥੇਟਿਕ datasets ਵਰਤੋ (ਜਨਰੇਟ ਕੀਤੇ ਨਾਂ, ਡੋਮੇਨ, ਪਤੇ) ਤਾਂ ਕਿ accuracy validate ਕਰ ਸਕੋ ਬਿਨਾਂ ਅਸਲੀ ਗਾਹਕ ਡੇਟਾ ਨੂੰ ਖਤਰੇ ਵਿੱਚ ਪਾਏ।
ਇੱਕ versioned "golden set" ਰੱਖੋ ਜਿਸਦੇ expected match/merge outputs ਹੋਣ ਤਾਂ ਕਿ regressions ਸਾਡੇ ਲਈ ਸਾਫ਼ ਹੋਣ।
rollout ਨੂੰ stage ਕਰੋ ਤਾਂ ਕਿ blast radius ਘੱਟ ਰਹੇ
ਛੋਟੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਫਿਰ ਵਧਾਓ:
- Pilot scope: ਇੱਕ ਟੀਮ ਜਾਂ ਇੱਕ ਸੈਗਮੈਂਟ (ਉਦਾਹਰਨ: ਸਿਰਫ SMB leads)
- Limited actions: ਪਹਿਲਾਂ "suggested updates" ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ CRM 'ਤੇ ਲਿਖਣ ਲਈ approval ਲੋੜੀਂਦਾ ਹੈ
- Ramp up: record volume ਵਧਾਓ, ਫਿਰ ਘੱਟ-ਰਿਸਕ ਫੀਲਡਾਂ ਲਈ automated writes enable ਕਰੋ
ਰੋਲਆਉਟ ਤੋਂ ਪਹਿਲਾਂ success metrics ਤੈਅ ਕਰੋ (match precision, approval rate, manual edits ਵਿੱਚ ਕਟੌਤੀ, ਅਤੇ time-to-enrich)।
workflows ਅਤੇ integration ਚੈੱਕਲਿਸਟ ਦਸਤਾਵੇਜ਼ ਕਰੋ
ਯੂਜ਼ਰਾਂ ਅਤੇ ਇੰਟਿਗਰੇਟਰਾਂ ਲਈ ਛੋਟੀ docs ਬਣਾਓ (ਉਸਨੂੰ product area ਜਾਂ /pricing ਤੋਂ ਲਿੰਕ ਕਰੋ ਜੇ ਤੁਸੀਂ features gate ਕਰਦੇ ਹੋ)। ਇੱਕ integration checklist ਸ਼ਾਮਿਲ ਕਰੋ:
- API auth method, rate limits, ਅਤੇ retry behavior
- enrichment requests ਲਈ required fields
- Webhook/event payloads (ਅਤੇ versioning)
- Error codes ਅਤੇ "partial enrichment" ਨਿਯਮ
- Audit log ਉਮੀਦਾਂ ਅਤੇ data retention
ਚੰਗੇ ਸੁਧਾਰ ਲਈ ਇੱਕ ਹਲਕੀ review cadence ਸ਼ੈਡਿਊਲ ਕਰੋ: failed validations, frequent manual overrides, ਅਤੇ mismatches ਵਿਸ਼ਲੇਸ਼ਣ ਕਰੋ, ਫਿਰ rules ਅਪਡੇਟ ਕਰੋ ਅਤੇ tests ਜੋੜੋ।
ਇੱਕ ਪ੍ਰਯੋਗਕਰ ਰੈਫਰੈਂਸ: /blog/data-quality-checklist.
Build vs. accelerate: ਇੱਕ ਪ੍ਰਾਇਕਟੀਕਲ ਨੋਟ
ਜੇ ਤੁਸੀਂ ਆਪਣੇ target workflows ਨੂੰ ਜਾਣਦੇ ਹੋ ਪਰ spec → ਕੰਮ ਕਰਨ ਵਾਲੀ ਐਪ ਦਾ ਸਮਾਂ ਘੱਟ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗੀਆਂ ਸੇਵਾਵਾਂ ਨੂੰ ਵਰਤਣਾ ਸੋਚੋ ਤਾਂ ਜੋ ਇੱਕ ਮੁੱਢਲਾ implementation (React UI, Go services, PostgreSQL storage) structured chat-based plan ਤੋਂ ਜਨਰੇਟ ਕੀਤਾ ਜਾ ਸਕੇ।
ਟੀਮਾਂ ਅਕਸਰ ਇਸ ਤਰੀਕੇ ਨਾਲ review UI, job processing, ਅਤੇ audit history ਨੂੰ ਜਲਦੀ ਉੱਠਾਉਂਦੀਆਂ ਹਨ—ਫਿਰ planning mode, snapshots, ਅਤੇ rollback ਵਰਗੇ features ਨਾਲ requirements ਬਦਲਦੇ ਹੀ iterate ਕਰਦੀਆਂ ਹਨ। ਜਦੋਂ ਤੁਹਾਨੂੰ ਪੂਰਾ ਕੰਟਰੋਲ ਚਾਹੀਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਸਰੋਤ ਕੋਡ export ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਆਪਣੇ ਮੌਜੂਦਾ pipeline ਵਿੱਚ ਅੱਗੇ ਵਧ ਸਕਦੇ ਹੋ। Koder.ai free, pro, business, ਅਤੇ enterprise tiers ਦਿੰਦਾ ਹੈ ਜੋ experimentation ਤੇ production ਦੀ ਜ਼ਰੂਰਤਾਂ ਦੇ ਅਨੁਸਾਰ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ।