29 ਨਵੰ 2025·8 ਮਿੰਟ
ਗਾਹਕ ਫੀਡਬੈਕ ਲੂਪਾਂ ਨੂੰ ਪ੍ਰਬੰਧਿਤ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਇੱਕ ਵੈੱਬ ਐਪ ਦੀ ਡਿਜ਼ਾਈਨ ਅਤੇ ਨਿਰਮਾਣ ਸਿੱਖੋ ਜੋ ਗਾਹਕ ਫੀਡਬੈਕ ਇਕੱਠਾ, ਰੂਟ, ਟ੍ਰੈਕ ਅਤੇ ਲੂਪ ਬੰਦ ਕਰੇ—ਸਾਫ਼ ਵਰਕਫਲੋ, ਰੋਲ ਅਤੇ ਮੈਟ੍ਰਿਕਸ ਦੇ ਨਾਲ।
ਇੱਕ ਵੈੱਬ ਐਪ ਦੀ ਡਿਜ਼ਾਈਨ ਅਤੇ ਨਿਰਮਾਣ ਸਿੱਖੋ ਜੋ ਗਾਹਕ ਫੀਡਬੈਕ ਇਕੱਠਾ, ਰੂਟ, ਟ੍ਰੈਕ ਅਤੇ ਲੂਪ ਬੰਦ ਕਰੇ—ਸਾਫ਼ ਵਰਕਫਲੋ, ਰੋਲ ਅਤੇ ਮੈਟ੍ਰਿਕਸ ਦੇ ਨਾਲ।
ਫੀਡਬੈਕ ਮੈਨੇਜਮੈਂਟ ਐਪ صرف "ਸੰਦੇਸ਼ ਰੱਖਣ ਦੀ ਥਾਂ" ਨਹੀਂ ਹੈ। ਇਹ ਇੱਕ ਐਸਾ ਸਿਸਟਮ ਹੈ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਨੂੰ ਨਿਸ਼ਚਿਤ ਤਰੀਕੇ ਨਾਲ ਇਨਪੁਟ → ਕਾਰਵਾਈ → ਗਾਹਕ-ਦੇਖਣ ਯੋਗ ਫਾਲੋਅਪ ਵਿੱਚ ਲੈ ਗਿਆ ਅਤੇ ਫਿਰ ਕੀ ਹੋਇਆ ਉਸ ਤੋਂ ਸਿੱਖਣ ਵਿੱਚ ਸਹਾਇਤਾ ਕਰਦਾ ਹੈ।
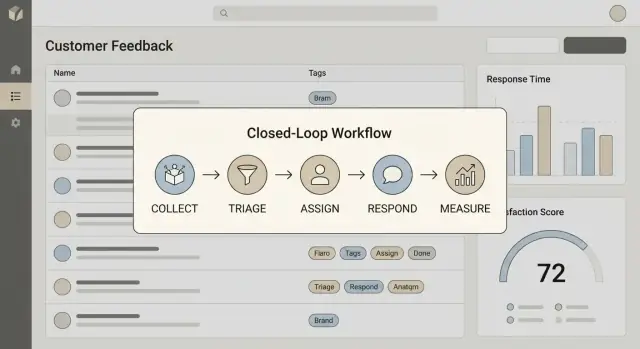
ਇੱਕ ਵਾਕ ਦਾ ਪਰਿਭਾਸ਼ਾ ਲਿਖੋ ਜੋ ਤੁਸੀਂ ਟੀਮ ਵਿੱਚ ਦੁਹਰਾ ਸਕੋਂ। ਜ਼ਿਆਦातर ਟੀਮਾਂ ਲਈ, ਲੂਪ ਬੰਦ ਕਰਨ ਵਿੱਚ ਚਾਰ ਕਦਮ ਸ਼ਾਮਲ ਹੁੰਦੇ ਹਨ:
ਜੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ ਕਦਮ ਗਾਇਬ ਹੋਵੇ, ਤਾਂ ਤੁਹਾਡੀ ਐਪ backlog ਦੀ ਸਮਾਨ ਹੋ ਜਾਏਗੀ।
ਤੁਹਾਡੀ ਪਹਿਲੀ ਵਰਜਨ ਨੂੰ ਦੈਣਿਕ ਕਿਰਿਆਕਲਾਪ ਵਾਲੇ ਰੋਲਾਂ ਦੀ ਸੇਵਾ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ:
“ਫੈਸਲੇ ਪਰ ਕਲਿਕ” ਬਾਰੇ ਵਿਸ਼ੇਸ਼ ਹੋਵੋ:
ਇਹ ਛੋਟੇ ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਜੋ ਤੇਜ਼ੀ ਅਤੇ ਗੁਣਵੱਤਾ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ, ਜਿਵੇਂ ਪਹਿਲੇ ਜਵਾਬ ਦਾ ਸਮਾਂ, ਸਮਾਧਾਨ ਦਰ, ਅਤੇ ਫਾਲੋਅਪ ਤੋਂ ਬਾਅਦ CSAT ਵਿੱਚ ਬਦਲਾਅ। ਇਹ ਤੁਹਾਡੇ ਬਾਅਦ ਵਾਲੇ ਡਿਜ਼ਾਈਨ ਫੈਸਲਿਆਂ ਲਈ ਨਾਰਥ ਸਟਾਰ ਬਣ ਜਾਉਂਦੇ ਹਨ।
ਸਕ੍ਰੀਨਾਂ ਡਿਜ਼ਾਈਨ ਕਰਨ ਜਾਂ ਡੇਟਾਬੇਸ ਚੁਣਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਨਕਸ਼ਾ ਬਣਾਓ ਕਿ ਫੀਡਬੈਕ ਬਣਨ ਤੋਂ ਲੈ ਕੇ ਜਵਾਬ ਦੇਣ ਤੱਕ ਕੀ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਸਧਾਰਣ ਯਾਤਰਾ ਮੈਪ ਟੀਮਾਂ ਨੂੰ “ਗਿਆਨ” ਤੇ ਸਹਿਮਤ ਰੱਖਦਾ ਹੈ ਅਤੇ ਉਹਨਾਂ ਫੀਚਰਾਂ ਨੂੰ ਤਿਆਰ ਕਰਨ ਤੋਂ ਰੋਕਦਾ ਹੈ ਜੋ ਅਸਲੀ ਕੰਮ ਲਈ ਨਹੀਂ ਫਿੱਟ ਹੁੰਦੇ।
ਆਪਣੇ ਫੀਡਬੈਕ ਸਰੋਤਾਂ ਦੀ ਲਿਸਟ ਬਣਾਓ ਅਤੇ ਦਰਜ ਕਰੋ ਕਿ ਹਰ ਇੱਕ ਕੀ ਡਾਟਾ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ:
ਚਾਹੇ ਇਨਪੁਟ ਵੱਖ-ਵੱਖ ਹੋਣ, ਤੁਹਾਡੀ ਐਪ ਨੇ ਉਹਨਾਂ ਨੂੰ ਇੱਕ ਸੰਗਤ “feedback item” ਰੂਪ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਕਿ ਟੀਮ ਸਭ ਕੁਝ ਇਕ ਥਾਂ ਤੇ ਤਿਆਰ ਕਰ ਸਕੇ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਪਹਿਲਾ ਮਾਡਲ ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਾਮਲ ਕਰਦਾ ਹੈ:
ਸ਼ੁਰੂ ਲਈ statuses: New → Triaged → Planned → In Progress → Shipped → Closed. status ਦੀ ਮੀਨਿੰਗ ਲਿਖੀ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਤਾਂ ਜੋ “Planned” ਕਿਸੇ ਇੱਕ ਟੀਮ ਲਈ “ਸ਼ਾਇਦ” ਨਾ ਹੋ ਜਾਵੇ ਅਤੇ ਦੂਜੇ ਲਈ “Committed” ਹੋਵੇ।
Duplicates ਅਟਲ ਹਨ। ਨਿਯਮ ਪਹਿਲਾਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ:
ਆਮ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਇੱਕ canonical feedback item ਰੱਖਿਆ ਜਾਵੇ ਅਤੇ ਹੋਰਾਂ ਨੂੰ duplicates ਵਜੋਂ ਲਿੰਕ ਕੀਤਾ ਜਾਵੇ, attribution ਸੰਭਾਲਦੇ ਹੋਏ (ਕੌਣ ਮੰਗਿਆ) ਬਿਨਾਂ ਕੰਮ ਨੂੰ ਟੁਕੜਾ ਕਰਨ ਦੇ।
ਇੱਕ ਫੀਡਬੈਕ ਲੂਪ ਐਪ ਦਿਨ ਇੱਕ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਲੋਕ feedback ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਸੈਸ ਕਰ ਸਕਦੇ ਹਨ ਕਿ ਨਹੀਂ। ਇੱਕ ਐਸਾ ਫਲੋ ਬਣਾਉਂ ਜੋ ਮਹਿਸੂਸ ਹੋਵੇ: “scan → decide → move on,” ਪਰ ਫਿਰ ਵੀ ਬਾਦ ਵਿੱਚ ਫੈਸਲਿਆਂ ਲਈ ਪ੍ਰਸੰਗ ਬਚਾ ਕੇ ਰੱਖੇ।
ਤੁਹਾਡਾ inbox ਟੀਮ ਦੀ ਸਾਂਝੀ queue ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਇਹ ਤੇਜ਼ triage ਲਈ ਛੋਟੇ ਪਰ ਪ੍ਰਬਲ ਫਿਲਟਰਾਂ ਦਾ ਸਹਾਰਾ ਦੇਵੇ:
“Saved views” ਜਲਦੀ ਸ਼ਾਮਲ ਕਰੋ (ਭਾਵੇਂ ਬੁਨਿਆਦੀ ਹੋਵਨ), ਕਿਉਂਕਿ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਸਕੈਨ ਕਰਦੀਆਂ ਹਨ: Support ਨੂੰ “urgent + paying” ਚਾਹੀਦਾ ਹੈ, Product ਨੂੰ “feature requests + high ARR”।
ਜਦੋਂ ਯੂਜ਼ਰ ਇਕ ਆਈਟਮ ਖੋਲ੍ਹਦਾ ਹੈ, ਉਹਨਾਂ ਨੂੰ ਇਹ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ:
ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਜਵਾਬ ਦੇਣ ਲਈ ਟੈਬ ਸਵੀਚ ਨਾ ਕਰਨੀ ਪਏ: “ਇਹ ਕੌਣ ਹੈ, ਉਹ ਕੀ ਮਤਲਬ ਲੈ ਰਿਹਾ ਸੀ, ਅਤੇ ਕੀ ਅਸੀਂ ਪਹਿਲਾਂ ਜਵਾਬ ਦਿੱਤਾ ਸੀ?”
Detail view ਤੋਂ triage ਹਰ ਫੈਸਲੇ ਲਈ ਇਕ ਕਲਿਕ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਤੁਹਾਨੂੰ ਸੰਭਵਤ: ਦੋ ਮੋਡਾਂ ਦੀ ਲੋੜ ਪਏਗੀ:
ਜੋ ਵੀ ਚੁਣੋ, “context ਦੇ ਨਾਲ reply” ਨੂੰ ਅੰਤਿਮ ਕਦਮ ਬਣਾਓ—ਤਾਂ ਕਿ ਲੂਪ ਬੰਦ ਕਰਨਾ workflow ਦਾ ਹਿੱਸਾ ਹੋਵੇ, ਕੋਈ ਬਾਹਰਲੇ ਕੰਮ ਵਜੋਂ ਨਹੀਂ।
ਫੀਡਬੈਕ ਐਪ ਤੇਜ਼ੀ ਨਾਲ shared system of record ਬਣ ਜਾਂਦੀ ਹੈ: product themes ਚਾਹੀਦੇ ਹਨ, support ਤੇਜ਼ ਜਵਾਬ ਚਾਹੁੰਦੀ ਹੈ, ਅਤੇ ਲੀਡਰਸ਼ਿਪ exports ਚਾਹੁੰਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਹ ਨਾ ਤੈਅ ਕਰੋ ਕਿ ਕੌਣ ਕੀ ਕਰ ਸਕਦਾ ਹੈ (ਅਤੇ ਕੀ ਹੋਇਆ ਇਹ ਸਾਬਤ ਕਰ ਸਕਣਾ), ਤਾਂ ਭਰੋਸਾ ਟੁੱਟ ਜਾਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਕਈ ਕੰਪਨੀਆਂ ਨੂੰ ਸੇਵਾ ਦਿਓਗੇ, ਤਾਂ ਹਰੇਕ workspace/org ਨੂੰ ਦਿਨ ਇੱਕ ਤੋਂ ਸਖ਼ਤ ਬਾਊਂਡਰੀ ਸਮਝੋ। ਹਰ core record (feedback item, customer, conversation, tags, reports) ਵਿੱਚ workspace_id ਸ਼ਾਮਲ ਕਰੋ, ਅਤੇ ਹਰ query ਨੂੰ ਇਸ ਤਹਿਤ ਸਕੋਪ ਕਰੋ।
ਇਹ ਸਿਰਫ਼ ਡੇਟਾਬੇਸ ਦੀ ਗੱਲ ਨਹੀਂ — ਇਹ URLs, invitations ਅਤੇ analytics ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ। ਇੱਕ ਸੁਰੱਖਿਅਤ ਡਿਫਾਲਟ: ਯੂਜ਼ਰ ਇੱਕ ਜਾਂ ਅਧਿਕ ਵਰਕਸਪੇਸ ਦੇ ਮੈਂਬਰ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਉਨ੍ਹਾਂ ਦੀਆਂ permissions ਪ੍ਰਤੀ ਵਰਕਸਪੇਸ ਮੁਲਾਂਕਣ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
ਪਹਿਲੀ ਵਰਜ਼ਨ ਸਧਾਰਣ ਰੱਖੋ:
ਫਿਰ permissions ਨੂੰ actions ਨਾਲ ਨਕਸ਼ਾ ਕਰੋ, ਨਾ ਕਿ ਸਕ੍ਰੀਨਾਂ ਨਾਲ: view vs. edit feedback, merge duplicates, change status, export data, ਅਤੇ send replies। ਇਸ ਨਾਲ ਆਉਣ ਵਾਲੀ ਸਮੇਂ “Read-only” ਰੋਲ ਸ਼ਾਮਲ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
“Audit log” ਇਹ ਰੋਕਦਾ ਹੈ ਕਿ “ਇਸਨੂੰ ਕਿਸ ਨੇ ਬਦਲਿਆ?” ਵਾਲੇ ਵਾਦ-ਵਿਵਾਦ ਹੋਣ। ਮਹੱਤਵਪੂਰਨ ਘਟਨਾਵਾਂ ਨੂੰ ਲਾਗ ਕਰੋ actor, timestamp, ਅਤੇ ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ before/after ਨਾਲ:
ਉਚਿਤ password ਨੀਤੀ ਲਾਗੂ ਕਰੋ, endpoints ਨੂੰ rate limiting ਨਾਲ ਸੁਰੱਖਿਅਤ ਕਰੋ (ਖ਼ਾਸ ਕਰਕੇ login ਅਤੇ ingestion), ਅਤੇ session handling ਸੁਰੱਖਿਅਤ ਰੱਖੋ।
SSO (SAML/OIDC) ਨੂੰ ਨਜ਼ਰ ਵਿੱਚ ਰੱਖਕੇ ਡਿਜ਼ਾਈਨ ਕਰੋ — ਭਾਵੇਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ship ਕਰੋ: identity provider ID ਸਟੋਰ ਕਰੋ ਅਤੇ account linking ਦੀ ਯੋਜਨਾ ਬਣਾਓ। ਇਸ ਨਾਲ enterprise ਦੀਆਂ ਬੇਨਤੀਆਂ ਤੁਹਾਨੂੰ painful refactor ਕਰਨ ਲਈ ਮਜਬੂਰ ਨਹੀਂ ਕਰਣਗੀਆਂ।
ਸ਼ੁਰੂਆਤ ਵਿੱਚ ਸਭ ਤੋਂ ਵੱਡਾ ਆਰਕੀਟੈਕਚਰ ਦਾ ਜੋਖਮ ਇਹ ਨਹੀਂ ਕਿ “ਕੀ ਇਹ scale ਹੋਵੇਗੀ?” — ਬਲਕਿ ਇਹ ਹੈ ਕਿ “ਕੀ ਅਸੀਂ ਇਸਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਦੇ ਹਾਂ ਬਿਨਾਂ ਚੀਜ਼ਾਂ ਤੋੜਦੇ?”। ਫੀਡਬੈਕ ਐਪ ਤੇਜ਼ੀ ਨਾਲ ਵਿਕਸਤ ਹੁੰਦੀ ਹੈ ਜਿਵੇਂ ਤੁਸੀਂ ਸਿੱਖਦੇ ਹੋ ਕਿ ਟੀਮਾਂ ਅਸਲ ਵਿੱਚ triage, route, ਅਤੇ respond ਕਿਵੇਂ ਕਰਦੀਆਂ ਹਨ।
ਇੱਕ modular monolith ਅਕਸਰ ਪਹਿਲੀ ਚੋਣ ਲਈ ਵਧੀਆ ਹੁੰਦਾ ਹੈ। ਤੁਹਾਡੇ ਕੋਲ ਇਕ deployable service, ਇਕ ਲੌਗ ਸੈੱਟ, ਅਤੇ ਸਧਾਰਣ debugੀੰਗ ਹੋਂਦੀ ਹੈ — ਫਿਰ ਵੀ ਕੋਡਬੇਸ ਨੂੰ ਢਾਂਚਾਬੱਧ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ module split ਇਸ ਤਰ੍ਹਾਂ ਦਿਖ ਸਕਦਾ ਹੈ:
“ਵੱਖ-ਵੱਖ ਫੋਲਡਰ ਅਤੇ ਇੰਟਰਫੇਸ” ਦੇ ਬਾਰੇ ਸੋਚੋ ਪਹਿਲਾਂ “ਵੱਖ-ਵੱਖ ਸੇਵਾਵਾਂ” ਦੇ ਬਾਰੇ। ਜੇ ਕੋਈ ਹੱਦਾ ਬਾਅਦ ਵਿੱਚ ਦੁਖਦਾਈ ਬਣਦੀ ਹੈ (ਜਿਵੇਂ ingestion ਦਾ ਵਧਦਾ ਬੋਝ), ਤਦੋਂ ਤੁਸੀਂ ਓਹਨੂੰ ਘੱਟ ਡਰਾਮੇ ਨਾਲ ਨਿਕਾਲ ਸਕੋਗੇ।
ਫਰੇਮਵਰਕ ਅਤੇ ਲਾਇਬ੍ਰੇਰੀਆਂ ਚੁਣੋ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਨਿਸ਼ਚਿੰਤ ਤਰੀਕੇ ਨਾਲ ship ਕਰ ਸਕੇ। ਇੱਕ ਸਧਾਰਣ, ਜ਼ਿਆਦਾ ਜਾਣਿਆ ਹੋਇਆ ਸਟੈਕ ਆਮ ਤੌਰ 'ਤੇ ਜਿੱਤਦਾ ਹੈ ਕਿਉਂਕਿ:
ਨਵੇਂ ਟੂਲਿੰਗ ਨੂੰ ਉਨ੍ਹਾਂ ਹਾਲਾਤਾਂ ਤੱਕ ਰੱਖੋ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਅਸਲ ਸੀਮਾਵਾਂ ਹੋਣ। ਇਸ ਤੱਕ, ਸਪੱਸ਼ਟਤਾ ਅਤੇ steady delivery ਲਈ optimize ਕਰੋ।
ਜ਼ਿਆਦਾਤਰ ਕੋਰ entities—feedback items, customers, accounts, tags, assignments—relational database ਵਿੱਚ ਸੁਭਾਵਿਕ ਤੌਰ 'ਤੇ ਫਿੱਟ ਹੁੰਦੇ ਹਨ। ਤੁਹਾਨੂੰ workflow changes ਲਈ ਚੰਗੀ querying, constraints, ਅਤੇ transactions ਚਾਹੀਦੀਆਂ ਹੋਣਗੀਆਂ।
ਜੇ full‑text search ਅਤੇ filtering ਮਹੱਤਵਪੂਰਨ ਬਣ ਜਾਂਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ dedicated search index ਬਾਅਦ ਵਿੱਚ ਜੋੜ ਸਕਦੇ ਹੋ (ਜਾਂ ਪਹਿਲਾਂ built‑in capabilities ਵਰਤ ਸਕਦੇ ਹੋ)। ਬਹੁਤ ਜਲਦੀ ਦੋ sources of truth ਬਣਾਉਣ ਤੋਂ ਬਚੋ।
ਫੀਡਬੈਕ ਸਿਸਟਮ ਜਲਦੀ “ਇਹ ਬਾਅਦ ਵਿੱਚ ਕਰੋ” ਵਾਲਾ ਕੰਮ ਇਕੱਤਰ ਕਰ ਲੈਂਦਾ ਹੈ: email replies ਭੇਜਣਾ, integrations sync, attachments process ਕਰਨਾ, digests generate ਕਰਨਾ, webhooks fire ਕਰਨਾ। ਸ਼ੁਰੂ ਤੋਂ ਇਹਨਾਂ ਨੂੰ queue/background worker ਸੈਟਅੱਪ ਵਿੱਚ ਰੱਖੋ।
ਇਸ ਨਾਲ UI responsive ਰਹਿੰਦੀ ਹੈ, timeouts ਘਟਦੇ ਹਨ, ਅਤੇ failures retryable ਬਣ ਜਾਂਦੇ ਹਨ — ਬਿਨਾਂ ਦਿਨ ਇੱਕ ਹੀ microservices ਵਿੱਚ ਜਾਣੇ ਦੇ।
ਜੇ ਤੁਹਾਡਾ ਮਕਸਦ workflow ਅਤੇ UI ਨੂੰ ਜਲਦੀ validate ਕਰਨਾ ਹੈ (inbox → triage → replies), ਤਾਂ Koder.ai ਵਰਗੇ vibe‑coding ਪਲੇਟਫਾਰਮ ਦੀ ਵਰਤੋਂ ਕਰਨ 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਇਹ ਤੁਹਾਨੂੰ structured chat spec ਤੋਂ ਪਹਿਲੀ ਵਰਜਨ ਖੜੀ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: React front end ਨਾਲ Go + PostgreSQL backend, planning mode ਵਿੱਚ ਤੇਜ਼ iteration, ਅਤੇ ਜਦੋਂ ਤਿਆਰ ਹੋਵੋ ਤਾਂ source code export ਕਰਨ ਦੀ ਸਹੂਲਤ।
ਤੁਹਾਡੀ storage ਲੇਅਰ ਇਹ ਫ਼ੈਸਲਾ ਕਰਦੀ ਹੈ ਕਿ ਤੁਹਾਡਾ ਫੀਡਬੈਕ ਲੂਪ ਤੇਜ਼ ਤੇ ਭਰੋਸੇਯੋਗ ਮਹਿਸੂਸ ਹੋਵੇਗਾ ਜਾਂ ਸੁਸਤ ਅਤੇ ਉਲਝਣ ਭਰਾ। ਇੱਕ schema ਦਾ ਟੀਚਾ ਰੱਖੋ ਜੋ ਦੈਣਿਕ ਕੰਮ (triage, assignment, status) ਲਈ ਢੁਕਵਾਂ query ਕਰਨ ਯੋਗ ਹੋਵੇ, ਪਰ ਕਾਫ਼ੀ raw ਵੇਰਵਾ ਵੀ ਰੱਖੇ ਜਾ ਸਕਣaudit ਕਰਨ ਲਈ।
MVP ਲਈ, ਤੁਸੀਂ ਕਈ ਜ਼ਰੂਰਤਾਂ ਇਕ ਛੋਟੀ ਟੇਬਲ/ਕਲੇਕਸ਼ਨ ਸੈੱਟ ਨਾਲ ਕਵਰ ਕਰ ਸਕਦੇ ਹੋ:
ਇੱਕ ਉਪਯੋਗਕੱਤਰ ਨਿਯਮ: feedback ਨੂੰ ਰੋਜ਼ਾਨਾ ਪ੍ਰਸ਼ਨ ਕਰਨ ਵਾਲੀਆਂ ਚੀਜ਼ਾਂ ਲਈ ਲੀਨ ਰੱਖੋ ਅਤੇ “ਬਾਕੀ ਸਭ” ਨੂੰ events ਅਤੇ channel-specific metadata ਵਿੱਚ ਧਕੋ।
ਜਦੋਂ ਟਿਕਟ email, chat, ਜਾਂ webhook ਰਾਹੀਂ ਆਉਂਦੀ ਹੈ, ਤਾਂ raw incoming payload ਨੂੰ ਠੀਕ ਉਹੀ ਵਜੋਂ ਸਟੋਰ ਕਰੋ ਜਿਵੇਂ ਮਿਲੀ (ਉਦਾਹਰਨ ਲਈ, ਮੂਲ email headers + body, ਜਾਂ webhook JSON)। ਇਸ ਨਾਲ ਤੁਸੀਂ:
ਆਮ ਪੈਟਰਨ: ਇਕ ingestions ਟੇਬਲ source, received_at, raw_payload (JSON/text/blob), ਅਤੇ ਬਣੇ/ਅਪਡੇਟ ਕੀਤੇ feedback_id ਨਾਲ।
ਜ਼ਿਆਦਾਤਰ ਸਕ੍ਰੀਨਾਂ ਕੁਝ predictable filters 'ਤੇ ਟਿਕੀਆਂ ਹੁੰਦੀਆਂ ਹਨ। ਸ਼ੁਰੂ ਵਿੱਚ ਇੰਡੈਕਸ ਸ਼ਾਮਲ ਕਰੋ:
(workspace_id, status) inbox/kanban views ਲਈ(workspace_id, assigned_to) “my items” ਲਈ(workspace_id, created_at) sorting ਅਤੇ date filters ਲਈ(tag_id, feedback_id) ਜਾਂ ਦੂਜਾ dedicated tag lookup indexਜੇ ਤੁਸੀਂ full‑text search ਸਪੋਰਟ ਕਰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਵੱਖਰਾ search index ਜਾਂ database ਦੀ built‑in text search ਵੇਖੋ, ਨਾ ਕਿ ਪੈਦਾਵਾਰੀ LIKE queries ਉੱਤੇ ਭਰੋ।
ਫੀਡਬੈਕ ਵਿੱਚ ਅਕਸਰ personal data ਹੁੰਦਾ ਹੈ। ਪਹਿਲਾਂ ਤੋਂ ਫੈਸਲਾ ਕਰੋ:
Retention ਨੂੰ ਹਰ workspace ਲਈ policy ਵਜੋਂ ਲਾਗੂ ਕਰੋ (ਉਦਾਹਰਨ: 90/180/365 ਦਿਨ) ਅਤੇ scheduled job ਨਾਲ enforce ਕਰੋ ਜੋ ਪਹਿਲਾਂ raw ingestions expire ਕਰਦਾ ਹੈ, ਫਿਰ ਜਰੂਰੀ ਹੋਣ 'ਤੇ ਪੁਰਾਣੇ events/replies expire ਕਰਦਾ ਹੈ।
Ingestion ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡਾ ਗਾਹਕ ਫੀਡਬੈਕ ਲੂਪ ਸਾਫ਼ ਅਤੇ ਉਪਯੋਗੀ ਰਹਿੰਦਾ ਹੈ ਜਾਂ ਗੰਦਲਾ ਹੋ ਕੇ ਰਹਿ ਜਾਂਦਾ ਹੈ। “ਭੇਜਣਾ ਆਸਾਨ, ਪ੍ਰੋਸੈਸ ਕਰਨਾ ਸਥਿਰ” ਨੂੰ ਲੱਛਣ ਬਣਾਓ। ਉਹ ਚੈਨਲਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਤੁਹਾਡੇ ਗਾਹਕ ਪਹਿਲਾਂ ਹੀ ਵਰਤਦੇ ਹਨ, ਫਿਰ ਵਧਾਓ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸ਼ੁਰੂਆਤੀ ਸੈੱਟ ਅਮੂਮਨ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ:
ਦਿਨ ਇੱਕ 'ਤੇ heavyweight filtering ਦੀ ਲੋੜ ਨਹੀਂ, ਪਰ ਬੁਨਿਆਦੀ ਸੁਰੱਖਿਆ ਲੋੜੀਂਦੀ ਹੈ:
ਹਰ ਇਕ event ਨੂੰ ਇਕ ਅੰਦਰੂਨੀ ਫਾਰਮੈਟ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ ਜਿਸ ਵਿੱਚ ਇਕੋ-ਪੋਸਟ ਫੀਲਡਾਂ ਹੋਣ:
ਦੋਹਾਂ raw payload ਅਤੇ normalized record ਰੱਖੋ ਤਾਂ ਜੋ ਬਾਅਦ ਵਿੱਚ parsing ਸੁਧਾਰ ਕੇ ਪੁਰਾਣੇ ਡੇਟਾ ਨੂੰ ਦੁਬਾਰਾ ਪ੍ਰੋਸੈਸ ਕੀਤਾ ਜਾ ਸਕੇ।
ਹਰ ਸੰਭਵ ਚੈਨਲ ਲਈ ਤੁਰੰਤ ਪੁਸ਼ਟੀ ਭੇਜੋ (email/API/widget): ਉਨ੍ਹਾਂ ਦਾ ਧੰਨਵਾਦ ਕਰੋ, ਦੱਸੋ ਅਗਲਾ ਕੀ ਹੋਵੇਗਾ, ਅਤੇ ਵਾਅਦੇ ਨਾ ਕਰੋ। ਉਦਾਹਰਨ: “ਅਸੀਂ ਹਰ ਸੁਨੇਹੇ ਦੀ ਸਮੀਖਿਆ ਕਰਦੇ ਹਾਂ। ਜੇ ਸਾਨੂੰ ਹੋਰ ਵੇਰਵੇ ਚਾਹੀਦੇ ਹੋਣਗੇ ਤਾਂ ਅਸੀਂ ਜਵਾਬ ਦੇਵਾਂਗੇ। ਅਸੀਂ ਹਰ ਬੇਨਤੀ ਨੂੰ ਵਿਅਕਤੀਗਤ ਤੌਰ 'ਤੇ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਪਰ ਤੁਹਾਡੀ ਫੀਡਬੈਕ ਟਰੈਕ ਕੀਤੀ ਜਾਂਦੀ ਹੈ।”
ਫੀਡਬੈਕ inbox ਤਦ ਤੱਕ ਉਪਯੋਗੀ ਰਹਿੰਦਾ ਹੈ ਜਦ ਤੱਕ ਟੀਮਾਂ ਤੇਜ਼ੀ ਨਾਲ ਇਹ ਤਿੰਨ ਸਵਾਲ ਜਵਾਬ ਦੇ ਸਕਦੀਆਂ ਹਨ: ਇਹ ਕੀ ਹੈ? ਇਹ ਕਿਸ ਦਾ ਮਾਮਲਾ ਹੈ? ਇਹ ਕਿੰਨਾ urgent ਹੈ? Triage ਉਹ ਹਿੱਸਾ ਹੈ ਜੋ raw messages ਨੂੰ ਵਿਵਸਥਿਤ ਕੰਮ ਵਿੱਚ ਬਦਲਦਾ ਹੈ।
Freeform tags ਲਚਕਦਾਰ ਲੱਗਦੇ ਹਨ ਪਰ ਜਲਦੀ ਟੁੱਟ ਜਾਂਦੇ ਹਨ (“login”, “log-in”, “signin”)। ਛੋਟੀ controlled taxonomy ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਤੁਹਾਡੇ product ਟੀਮਾਂ ਜਿਵੇਂ ਸੋਚਦੀਆਂ ਹਨ ਉਸਨੂੰ mirror ਕਰਦੀ ਹੋਵੇ:
ਯੂਜ਼ਰਾਂ ਨੂੰ ਨਵੇਂ tags ਸੁਝਾਉਣ ਦੀ ਆਗਿਆ ਦਿਓ, ਪਰ ਉਹਨਾਂ ਲਈ ਇਕ owner (ਉਦਾਹਰਨ: PM/Support lead) ਦੀ ਮਨਜ਼ੂਰੀ ਲਾਜ਼ਮੀ ਰੱਖੋ। ਇਸ ਨਾਲ reporting ਬਾਅਦ ਵਿੱਚ ਮਾਨਯੋਗ ਰਹਿੰਦੀ ਹੈ।
ਇੱਕ ਸਧਾਰਣ rules engine ਬਣਾਓ ਜੋ predictable signals ਦੇ ਆਧਾਰ 'ਤੇ feedback ਨੂੰ ਆਟੋਮੈਟਿਕ ਰੂਪ ਵਿੱਚ ਰੂਟ ਕਰ ਸਕੇ:
ਨਿਯਮਾਂ ਨੂੰ ਪਾਰਦਰਸ਼ੀ ਬਣਾਓ: “Routed because: Enterprise plan + keyword ‘SSO’.” ਟੀਮ automation 'ਤੇ ਭਰੋਸਾ ਤਾਂ ਕਰਦੀ ਜਦੋਂ ਉਹ audit ਕਰ ਸਕੇ।
ਹਰੇਕ ਆਈਟਮ ਅਤੇ ਹਰੇਕ queue 'ਤੇ SLA timers ਜੋੜੋ:
List view ਵਿੱਚ SLA status ਦਿਖਾਓ (“2h left”) ਅਤੇ detail page 'ਤੇ ਵੀ, ਤਾਂ ਕਿ urgency ਟੀਮ 'ਚ ਸਾਂਝੀ ਰਹੇ — ਕਿਸੇ ਇੱਕ ਸ਼ਖ਼ਸ ਦੇ ਦਿਮਾਗ਼ ਵਿੱਚ ਫੰਸੀ ਨਾ ਰਹੇ।
ਜਦੋਂ ਆਈਟਮ ਅਟਕ ਜਾਂਦੇ ਹਨ ਤਾਂ ਇੱਕ ਸਾਫ਼ ਰਸਤਾ ਬਣਾਓ: overdue queue, owners ਨੂੰ daily digests, ਅਤੇ ਇੱਕ ਸੌਖੀ escalation ladder (Support → Team lead → On-call/Manager). ਮਕਸਦ ਦਬਾਅ ਨਹੀਂ—ਮਹੱਤਵਪੂਰਨ ਗਾਹਕ ਫੀਡਬੈਕ ਨੂੰ ਚੁੱਪਚਾਪ expire ਹੋਣ ਤੋਂ ਰੋਕਣਾ ਹੈ।
ਲੂਪ ਬੰਦ ਕਰਨਾ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਫੀਡਬੈਕ ਪ੍ਰਬੰਧਨ ਸਿਸਟਮ “ਸੰਗ੍ਰਹਿ ਬਕਸਾ” ਬਣਨਾ ਬੰਦ ਕਰਕੇ ਭਰੋਸਾ ਬਣਾਉਣ ਵਾਲਾ ਔਜ਼ਾਰ ਬਣ ਜਾਂਦਾ ਹੈ। ਟੀਚਾ ਸਧਾਰਣ ਹੈ: ਹਰ ਫੀਡਬੈਕ ਆਈਟਮ ਕੰਮ ਨਾਲ ਜੋੜਿਆ ਜਾ ਸਕੇ, ਅਤੇ ਉਹ ਗਾਹਕ ਜੋ ਚਾਹੇ ਸਨ ਉਹਨਾਂ ਨੂੰ ਦੱਸਿਆ ਜਾ ਸਕੇ—ਬਿਨਾਂ ਮੈਨੂਅਲ spreadsheets ਦੇ।
ਸ਼ੁਰੂਆਤ ਲਈ, ਇਕ feedback item ਨੂੰ ਇੱਕ ਜਾਂ ਇੱਕ ਤੋਂ ਵੱਧ ਅੰਦਰੂਨੀ work objects (bug, task, feature request) ਨਾਲ ਜੋੜਨ ਦਿਓ। ਆਪਣਾ ਸਿਸਟਮ ਪੂਰੇ issue tracker ਨੂੰ mirror ਨਾ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੇ—halke references ਰੱਖੋ:
work_type (ਉਦਾਹਰਨ: issue/task/feature)external_system (ਉਦਾਹਰਨ: jira, linear, github)external_id ਅਤੇ ਵਿਕਲਪਿਕ ਤੌਰ 'ਤੇ external_urlਇਸ ਨਾਲ ਤੁਹਾਡਾ ਡਾਟਾ ਮਾਡਲ ਥਿਰ ਰਹਿੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਟੂਲ ਬਦਲਦੇ ਹੋ। ਇਹ “ਇਸ ਰਿਲੀਜ਼ ਨਾਲ ਜੁੜੇ ਸਾਰੇ ਗਾਹਕ ਫੀਡਬੈਕ ਦਿਖਾਓ” ਵਰਗੇ ਨਜ਼ਾਰੇ ਬਣਾਉਣਾ ਅਸਾਨ ਕਰਦਾ ਹੈ।
ਜਦੋਂ linked work Shipped (ਜਾਂ Done/Released) ਹੋ ਜਾਵੇ, ਤੁਹਾਡੀ ਐਪ ਸਭ ਜੁੜੇ ਗਾਹਕਾਂ ਨੂੰ notify ਕਰਨ ਯੋਗ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ।
ਟੈਮਪਲੇਟ ਕੀਤੇ ਸੁਨੇਹੇ ਵਰਤੋ ਜਿਸ ਵਿੱਚ ਸੁਰੱਖਿਅਤ placeholders ਹੋਣ (name, product area, summary, release notes link)। ਭੇਜਣ ਸਮੇਂ ਇਸਨੂੰ ਈਡੀਟ ਕਰਨ ਯੋਗ ਰੱਖੋ ਤਾਂ ਕਿ ਅਮਲ ਵਿੱਚ awkward wording ਨਾ ਹੋਵੇ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ public notes ਹਨ, ਤਾਂ ਉਹਨਾਂ ਨੂੰ relative path ਵਰਗੇ /releases ਨਾਲ ਲਿੰਕ ਕਰੋ।
ਸੇਟ‑ਅੱਪ ਉਹਨਾਂ ਚੈਨਲਾਂ ਨੂੰ ਸਪੋਰਟ ਕਰੋ ਜਿਹੜਿਆਂ ਤੋਂ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਭੇਜ ਸਕਦੇ ਹੋ:
ਜੋ ਵੀ ਚੁਣੋ, replies ਨੂੰ ਹਰ feedback item ਲਈ audit‑friendly timeline ਨਾਲ ਟਰੈਕ ਕਰੋ: sent_at, channel, author, template_id, ਅਤੇ delivery status। ਜੇ ਗਾਹਕ ਵਾਪਸ ਜਵਾਬ ਦੇਵੇ, inbound messages timestamps ਨਾਲ ਸਟੋਰ ਕਰੋ, ਤਾਂ ਜੋ ਟੀਮ ਸਾਬਤ ਕਰ ਸਕੇ ਕਿ ਲੂਪ ਅਸਲ ਵਿੱਚ ਬੰਦ ਹੋਇਆ — ਸਿਰਫ਼ “marked shipped” ਨਹੀਂ।
ਰਿਪੋਰਟਿੰਗ ਤਦ ਹੀ ਉਪਯੋਗੀ ਹੈ ਜਦੋਂ ਇਹ ਟੀਮਾਂ ਦੇ ਅਗਲੇ ਕਦਮ ਬਦੇਲ ਦੇਵੇ। ਕੁਝ ਦ੍ਰਿਸ਼ ਦਿਓ ਜੋ ਲੋਕ ਰੋਜ਼ਾਨਾ ਚੈੱਕ ਕਰ ਸਕਣ, ਫਿਰ ਜਦੋਂ workflow ਡਾਟਾ (status, tags, owners, timestamps) ਸਥਿਰ ਹੋ ਜਾਵੇ ਤਾਂ ਵਧਾਓ।
ਸੰਚਾਲਨਾਤਮਕ ਡੈਸ਼ਬੋਰਡ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ routing ਅਤੇ follow‑up ਦੀ ਸਹਾਇਤਾ ਕਰਦੇ ਹਨ:
ਚਾਰਟਸ ਸਧਾਰਣ ਅਤੇ clickable ਰੱਖੋ ਤਾਂ ਕਿ ਮੈਨੇਜਰ spike ਦੇ ਪਿੱਛੇ ਦੇ ਖਾਸ ਆਈਟਮ ਤੱਕ ਪਹੁੰਚ ਸਕੇ।
ਇੱਕ “customer 360” ਪੇਜ ਜੋ support ਅਤੇ success ਟੀਮਾਂ ਨੂੰ ਸੰਦਰਭ ਦੇ ਕੇ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ:
ਇਹ view duplicate questions ਘਟਾਉਂਦੀ ਹੈ ਅਤੇ follow‑ups ਨਿਯਤ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੀ ਹੈ।
ਟੀਮਾਂ ਜਲਦੀ exports ਮੰਗਣਗੀਆਂ। ਪ੍ਰਦਾਨ ਕਰੋ:
ਹਰ ਥਾਂ filtering consistent ਰੱਖੋ (ਉਹੇ tag names, date ranges, status definitions)। ਇਹ consistency “ਦੋ ਸੱਚਾਈਆਂ” ਹੋਣ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ।
ਕੇਵਲ activity (tickets created, tags added) ਮਾਪਣ ਵਾਲੀਆਂ ਡੈਸ਼ਬੋਰਡਸ ਛੱਡੋ। outcome metrics ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਜੋ action ਅਤੇ response ਨਾਲ ਜੁੜੇ ਹਨ: time to first reply, % of items that reached a decision, ਅਤੇ ਉਹ ਮੁੜ-ਅਰਥ ਰੱਖਣ ਵਾਲੇ issues ਜੋ ਅਸਲ ਵਿੱਚ address ਕੀਤੇ ਗਏ।
ਫੀਡਬੈਕ ਲੂਪ ਤਦ ਹੀ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਉਹਨਾਂ ਥਾਂਵਾਂ 'ਤੇ ਰਹੇ ਜਿਥੇ ਲੋਕ ਪਹਿਲਾਂ ਹੀ ਸਮਾਂ ਬਿਤਾਂਦੇ ਹਨ। ਇੰਟੀਗ੍ਰੇਸ਼ਨਸ copy‑pasting ਘਟਾਉਂਦੀਆਂ ਹਨ, ਕੰਟੈਕਸਟ ਨਜ਼ਦੀਕ ਰੱਖਦੀਆਂ ਹਨ, ਅਤੇ “ਲੂਪ ਬੰਦ ਕਰਨ” ਨੂੰ ਆਦਤ ਬਣਾਉਂਦੀਆਂ ਹਨ ਨਾ ਕਿ ਵਿਸ਼ੇਸ਼ ਪ੍ਰੋਜੈਕਟ।
ਉਹ ਸਿਸਟਮ ਪਹਿਲਾਂ ਤਰਜੀਹ ਦੇਵੋ ਜੋ ਤੁਹਾਡੀ ਟੀਮ ਸੰਚਾਰ, ਬਣਾਉਣ, ਅਤੇ ਗਾਹਕ ਟ੍ਰੈਕ ਲਈ ਵਰਤੀਦੀ ਹੈ:
ਪਹਿਲੀ ਵਰਜ਼ਨ ਨੂੰ ਸਧਾਰਣ ਰੱਖੋ: one‑way notifications + deep links back to your app, ਫਿਰ write‑back actions (ਉਦਾਹਰਨ: “Assign owner” from Slack) ਬਾਅਦ ਵਿੱਚ ਜੋੜੋ।
ਭਾਵੇਂ ਤੁਸੀਂ ਸਿਰਫ਼ ਕੁਝ native integrations ship ਕਰੋ, webhooks ਗਾਹਕਾਂ ਅਤੇ ਅੰਦਰੂਨੀ ਟੀਮਾਂ ਨੂੰ ਬਾਕੀ ਕੁਝ ਜੋੜਨ ਦਿੰਦੇ ਹਨ।
ਛੋਟੇ, ਸਥਿਰ events ਦੀ ਪੇਸ਼ਕਸ਼ ਕਰੋ:
feedback.createdfeedback.updatedfeedback.closedਇੱਕ idempotency key, timestamps, tenant/workspace id, ਅਤੇ ਇੱਕ ਨਿਊਨਤਮ payload ਨਾਲ ਇੱਕ URL ਸ਼ਾਮਲ ਕਰੋ ਜੋ full details ਲੈ ਸਕਦਾ ਹੋਵੇ। ਇਹ ਤੁਹਾਡੇ ਡਾਟਾ ਮਾਡਲ ਨੂੰ ਵਿਕਸਤ ਕਰਨ 'ਤੇ consumers ਨੂੰ ਤੋੜਨ ਤੋਂ ਬਚਾਏਗਾ।
Integrations ਲਾਜ਼ਮੀ ਤੌਰ 'ਤੇ fail ਹੁੰਦੀਆਂ ਹਨ: revoked tokens, rate limits, network issues, schema mismatches. ਪਹਿਲਾਂ ਤੋਂ ਇਸ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ:
ਜੇ ਤੁਸੀਂ ਇਹ ਉਤਪਾਦ ਵਜੋਂ ਪੈਕੇਜ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ integrations ਖਰੀਦ ਲਈ ਵੀ trigger ਹੁੰਦੀਆਂ ਹਨ। ਆਪਣੇ ਐਪ (ਅਤੇ marketing site) ਤੋਂ /pricing ਅਤੇ /contact ਲਈ ਸਪਸ਼ਟ next steps ਦਿਓ ਜਿਨ੍ਹਾਂ ਨੂੰ ਡੈਮੋ ਜਾਂ ਮਦਦ ਚਾਹੀਦੀ ਹੋਵੇ।
ਇੱਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਫੀਡਬੈਕ ਐਪ ਲਾਂਚ ਤੋਂ ਬਾਅਦ “ਪੂਰਾ” ਨਹੀਂ ਹੁੰਦਾ — ਇਹ ਉਸ ਤਰੀਕੇ ਨਾਲ ਸੰਵਾਰੇ ਜਾਂਦਾ ਹੈ ਜਿਸ ਤਰ੍ਹਾਂ ਟੀਮਾਂ ਅਸਲੀ ਵਿੱਚ triage, act, ਅਤੇ respond ਕਰਦੀਆਂ ਹਨ। ਤੁਹਾਡੀ ਪਹਿਲੀ ਰਿਲੀਜ਼ ਦਾ ਟੀਚਾ ਸਧਾਰਣ ਹੈ: workflow ਨੂੰ ਸਾਬਤ ਕਰੋ, ਮੈਨੂਅਲ ਮਿਹਨਤ ਘਟਾਓ, ਅਤੇ ਸਾਫ਼ ਡਾਟਾ ਕੈਪਚਰ ਕਰੋ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹੋ।
ਸਕੋਪ ਤੰਗ ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ship ਕਰ ਸਕੋ ਅਤੇ ਸਿੱਖ ਸਕੋ। ਇੱਕ ਪ੍ਰਯੋਗਿਕ MVP ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਾਮਲ ਹੁੰਦਾ ਹੈ:
ਜੇ ਕੋਈ feature ਟੀਮ ਨੂੰ end‑to‑end feedback process ਵਿੱਚ ਮਦਦ ਨਹੀਂ ਕਰਦਾ, ਤਾਂ ਉਹ ਬਾਅਦ ਲਈ ਰੱਖੋ।
ਸ਼ੁਰੂਆਤੀ ਯੂਜ਼ਰ missing features ਨੂੰ ਮਾਫ਼ ਕਰ ਦੇਣਗੇ, ਪਰ lost feedback ਜਾਂ ਗਲਤ routing ਨਹੀਂ। ਉਹ ਟੈਸਟ ਜਿੱਥੇ ਗਲਤੀਆਂ ਮਹਿੰਗੀਆਂ ਪੈ ਸਕਦੀਆਂ ਹਨ ਉਥੇ ਧਿਆਨ ਦਿਓ:
workflow ਵਿੱਚ ਭਰੋਸਾ ਲਈ confidence ਧਿਆਨ ਰੱਖੋ, ਨਾ ਕਿ perfect coverage।
ਇੱਕ MVP ਨੂੰ ਵੀ ਕੁਝ “ਬੋਰਿੰਗ” ਜਰੂਰੀ ਚੀਜ਼ਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
ਇੱਕ pilot ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਇੱਕ ਟੀਮ, ਸੀਮਿਤ ਚੈਨਲਾਂ ਦਾ ਸੈੱਟ, ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ success metric (ਉਦਾਹਰਨ: “90% high‑priority feedback 2 ਦਿਨਾਂ ਵਿੱਚ ਜਵਾਬ ਮਿਲ ਜਾਵੇ”). ਹਫ਼ਤੇਵਾਰ friction points ਇਕੱਠੇ ਕਰੋ ਅਤੇ workflow ਨੂੰ ਇਤਰੈਟ ਕਰੋ ਪਹਿਲਾਂ ਕਿ ਹੋਰ ਟੀਮਾਂ ਨੂੰ invite ਕਰੋ।
ਉਸਤੇ ਵਰਤੋਂ ਡਾਟਾ ਨੂੰ ਆਪਣੇ ਰੋਡਮੈਪ ਵਜੋਂ ਵਰਤੋ: ਲੋਕ ਕਿੱਥੇ ਕਲਿੱਕ ਕਰਦੇ ਹਨ, ਕਿੱਥੇ ਛੱਡਦੇ ਹਨ, ਕਿਹੜੇ tags unused ਰਹਿ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕਿਹੜੇ “workarounds” ਅਸਲ ਜਰੂਰਤਾਂ ਨੂੰ ਬਤਲਦੇ ਹਨ।
“ਲੂਪ ਬੰਦ ਕਰਨ” ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਨਿਸ਼ਚਿਤ ਤਰੀਕੇ ਨਾਲ Collect → Act → Reply → Learn ਦੇ ਚੱਕਰ ਨੂੰ ਪੂਰਾ ਕਰ ਸਕੋ। ਅਮਲ ਵਿੱਚ, ਹਰ feedback ਆਈਟਮ ਨੂੰ ਇੱਕ ਵਿਖਾਈ ਦੇਣ ਵਾਲੇ ਨਤੀਜੇ (shipped, declined, explained, ਜਾਂ queued) ਤੱਕ ਲੈ ਜਾਇਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ ਜੇ ਲੋੜ ਹੋਵੇ ਤਾਂ ਗਾਹਕ ਨੂੰ ਸਮੇਂ-ਸੀਮਾ ਸਹਿਤ ਇਕ ਬਾਹਰੀ ਜਵਾਬ ਦਿੱਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ।
ਉਹ ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਜੋ ਤੇਜ਼ੀ ਅਤੇ ਗੁਣਵੱਤਾ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ:
ਛੋਟੀ ਅਤੇ ਫੋਕਸ ਕੀਤੀ ਹੋਈ ਸੈੱਟ ਪਿਕ ਕਰੋ ਤਾਂ ਕਿ ਟੀਮਾਂ ਵੈਨਿਟੀ ਮੈਟ੍ਰਿਕਸ ਲਈ ਅਪਟੀਮਾਈਜ਼ ਨਾ ਕਰਨ।
ਸਭ ਨੂੰ ਇਕੋ “feedback item” ਸਿਰੇ ਨਾਲ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ, ਪਰ ਮੂਲ ਡਾਟਾ ਸੰਭਾਲ ਕੇ ਰੱਖੋ।
ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਤਰੀਕਾ:
ਇਸ ਨਾਲ triage ਸਥਿਰ ਰਹੇਗਾ ਅਤੇ ਜੇ parser ਵਿੱਚ ਸੁਧਾਰ ਹੋਵੇ ਤਾਂ ਪੁਰਾਣੀ ਮੈਸੇਜਾਂ ਨੂੰ ਦੁਬਾਰਾ ਪ੍ਰੋਸੈਸ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਮੂਲ ਮਾਡਲ ਸਧਾਰਣ ਅਤੇ query-friendly ਰੱਖੋ:
ਛੋਟੀ, ਸਾਂਝੀ status definitions ਲਿਖੋ ਅਤੇ ਲਕੀਰ ਵਾਲੀ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਹਰ status ਨੂੰ ਇਹ ਸਪੱਸ਼ਟ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਕਿ “ਅਗਲਾ ਕਦਮ ਕੀ ਹੈ?” ਅਤੇ “ਅਗਲਾ ਕਦਮ ਕਿਸ ਦਾ ਹੈ?” ਜੇ ਕਿਸੇ ਟੀਮ ਲਈ “Planned” ਦਾ ਮਤਲਬ ‘ਸ਼ਾਇਦ’ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਵੱਖਰਾ ਕਰੋ ਜਾਂ ਨਾਂ ਬਦਲੋ ਤਾਂ ਜੋ ਰਿਪੋਰਟਿੰਗ ਭਰੋਸੇਯੋਗ ਰਹੇ।
Duplicates ਨੂੰ “ਉਹੀ ਮੂਲ ਸਮੱਸਿਆ/ਬੇਨਤੀ” ਵਜੋਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਸਿਰਫ਼ ਟੈਕਸਟ ਦੀ ਸਮਾਨਤਾ ਤੇ ਨਹੀਂ।
ਸਧਾਰਣ workflow:
ਇਸ ਨਾਲ ਕੰਮ ਟੁੱਟਦਾ ਨਹੀਂ ਅਤੇ ਮੰਗ ਦਾ ਪੂਰਾ ਰਿਕਾਰਡ ਰਹਿੰਦਾ ਹੈ।
Automation ਨੂੰ ਸਧਾਰਣ ਅਤੇ audit-friendly ਰੱਖੋ:
ਹਮੇਸ਼ਾਂ ਦਿਖਾਓ “Routed because: …” ਤਾਂ ਕਿ ਮਨੁੱਖ ਇਸਨੂੰ ਵੇਖ ਕੇ ਭਰੋਸਾ ਕਰ ਸੱਕਣ ਅਤੇ ਲੋੜੀਂਦੇ ਤਬਦੀਲੀਆਂ ਕਰ ਸਕਣ। ਪਹਿਲਾਂ suggestions ਜਾਂ defaults ਦਿਓ, ਫਿਰ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ hard routing ਲਾਵੋ।
ਹਰ workspace ਨੂੰ ਇਕ ਸਖ਼ਤ ਬਾਊਂਡਰੀ ਮੰਨੋ:
workspace_id ਸ਼ਾਮਲ ਕਰੋworkspace_id ਦੇ ਤਹਿਤ ਸਕੋਪ ਕਰੋਫਿਰ roles ਨੂੰ actions (view/edit/merge/export/send replies) ਦੇ ਆਧਾਰ 'ਤੇ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਨਾ ਕਿ ਸਕ੍ਰੀਨਾਂ ਦੇ ਆਧਾਰ 'ਤੇ। Audit log ਪਹਿਲੇ ਤੋਂ ਹੀ ਸ਼ਾਮਲ ਕਰੋ ਤਾਂ ਕਿ status changes, merges, assignments ਅਤੇ replies ਟਰੇਸ ਕੀਤੇ ਜਾ ਸਕਣ।
ਮෝਨੋਲਿਥ (ਪਰ ਮਾਡਿਊਲਰ) ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਸਪੱਸ਼ਟ ਬਾਊਂਡਰੀਆਂ ਬਣਾਓ (auth/orgs, feedback, workflow, messaging, analytics). ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ workflow ਡਾਟਾ ਲਈ relational database ਵਰਤੋ.
Background jobs ਨੂੰ ਪਹਿਲੇ ਤੋਂ ਸ਼ਾਮਲ ਕਰੋ ਜਿਵੇਂ ਕਿ:
ਇਸ ਨਾਲ UI ਤੇਜ਼ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਅਸਥਾਈ ਨਿਕਾਸਾਂ ਨੂੰ retry ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਬਿਨਾਂ ਮਾਇਕਰੋਸਰਵਿਸਿਜ਼ ਦੇ ਪਹਿਲਾਂ ਹੀ ਵੰਡੇ ਹੋਏ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ ਜਾਣ ਦੇ।
external_system ਨੂੰ mirror ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਾ ਕਰੋ; ਥੋੜ੍ਹੇ lightweight references ਰੱਖੋ:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (ਅਤੇ ਵਿਵਿਕਲਪਕ external_url)ਜਦੋਂ linked work ਹੋ ਜਾਵੇ, ਤਾਂ ਟੈਮਪਲੇਟ ਕੀਤੀ ਮੈਸੇਜਿੰਗ ਨਾਲ ਸਭ ਜੁੜੇ ਗਾਹਕਾਂ ਨੂੰ notify ਕਰਨ ਦਾ workflow ਚਲਾਓ ਅਤੇ delivery status ਟਰੈਕ ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ public notes ਹਨ ਤਾਂ ਉਹਨਾਂ ਨੂੰ /releases ਵਰਗੇ relative path ਨਾਲ ਲਿੰਕ ਕਰੋ।
Auditability ਲਈ events timeline ਵਰਤੋਂ ਅਤੇ ਮੁੱਖ feedback ਰਿਕਾਰਡ 'ਤੇ ਬਹੁਤ ਸਾਰਾ ਭਾਰ ਨਾ ਪਾਓ।