07 ਨਵੰ 2025·8 ਮਿੰਟ
Geoffrey Hinton ਦੀਆਂ ਨਿਊਰਲ ਨੈੱਟਵਰਕ ਖੋਜਾਂ ਦੀ ਵਿਆਖਿਆ
Geoffrey Hinton ਦੀਆਂ ਮੁੱਖ ਵਿਚਾਰਧਾਰਾਵਾਂ—backprop ਅਤੇ Boltzmann machines ਤੋਂ ਲੈ ਕੇ deep nets ਅਤੇ AlexNet ਤੱਕ—ਸਪੱਠ ਪੰਜਾਬੀ ਵਿੱਚ ਸਮਝਾਏ ਗਏ ਅਤੇ ਇਹ ਕਿ ਓਹ ਆਧੁਨਿਕ AI ਨੂੰ ਕਿਵੇਂ ਆਕਾਰ ਦਿੱਤਾ।
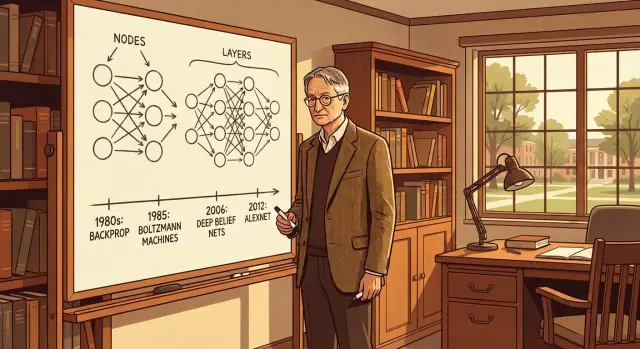
Geoffrey Hinton ਦੀਆਂ ਮੁੱਖ ਵਿਚਾਰਧਾਰਾਵਾਂ—backprop ਅਤੇ Boltzmann machines ਤੋਂ ਲੈ ਕੇ deep nets ਅਤੇ AlexNet ਤੱਕ—ਸਪੱਠ ਪੰਜਾਬੀ ਵਿੱਚ ਸਮਝਾਏ ਗਏ ਅਤੇ ਇਹ ਕਿ ਓਹ ਆਧੁਨਿਕ AI ਨੂੰ ਕਿਵੇਂ ਆਕਾਰ ਦਿੱਤਾ।
ਇਹ ਗਾਈਡ ਉਹਨਾਂ ਦਿਲਚਸਪ, ਗੈਰ-ਟੈਕਨੀਕਲ ਪੜ੍ਹਨ ਵਾਲਿਆਂ ਲਈ ਹੈ ਜੋ ਹਮੇਸ਼ਾਂ ਸੁਣਦੇ ਹਨ ਕਿ “ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੇ ਸବ ਕੁਜ਼ ਬਦਲ ਦਿੱਤਾ” ਅਤੇ ਉਹ ਜਾਣਨਾ ਚਾਹੁੰਦੇ ਹਨ ਕਿ ਅਸਲ ਵਿੱਚ ਇਹ ਕੀ ਮਤਲਬ ਹੈ—ਬਿਨਾਂ ਕੈਲਕੁਲਸ ਜਾਂ ਪ੍ਰੋਗਰਾਮਿੰਗ ਦੇ।
ਤੁਸੀਂ Geoffrey Hinton ਵੱਲੋਂ ਅੱਗੇ ਵਧਾਏ ਗਏ ਵਿਚਾਰਾਂ ਦੀ ਸਾਫ਼-ਸੁਧੀ ਵਿਆਖਿਆ ਮਿਲੇਗੀ, ਉਹ ਉਸ ਵੇਲੇ ਕਿਉਂ ਮਹੱਤਵਪੂਰਨ ਸਨ, ਅਤੇ ਉਹ ਅੱਜ ਦੇ AI ਟੂਲਾਂ ਨਾਲ ਕਿਸ ਤਰ੍ਹਾਂ ਜੁੜਦੇ ਹਨ। ਇਸਨੂੰ ਸਮਝੋ ਜਿਵੇਂ ਕੰਪਿਊਟਰਾਂ ਨੂੰ ਉਦਾਹਰਨਾਂ ਤੋਂ ਸਿੱਖਾ ਕੇ ਪੈਟਰਨ—ਸ਼ਬਦ, ਹੋਂਦ-ਚਿੱਤਰ, ਆਵਾਜ਼—ਪਛਾਣਨ ਦੇ ਬੇਹਤਰ ਤਰੀਕੇ ਦੀ ਇਕ ਕਹਾਣੀ।
Hinton ਨੇ "AI ਦੀ ਖੋਜ" ਨਹੀਂ ਕੀਤੀ, ਅਤੇ ਕੋਈ ਇਕ ਵਿਅਕਤੀ ਆਧੁਨਿਕ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਦਾ ਰਚੇਤਾ ਨਹੀਂ ਹੈ। ਉਸਦੀ ਮਹੱਤਤਾ ਇਹ ਹੈ ਕਿ ਉਸਨੇ ਕਈ ਵਾਰ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਅਮਲ ਵਿੱਚ ਕੰਮ ਕਰਵਾਇਆ ਜਦੋਂ ਕਈ ਖੋਜਕਰਤਾ ਉਨ੍ਹਾਂ ਨੂੰ ਨਾਮੁਮਕਿਨ ਸਮਝਦੇ ਸਨ। ਉਸਦਾ ਯੋਗਦਾਨ ਕੁੰਜੀ ਧਾਰਨਾਵਾਂ, ਪ੍ਰਯੋਗਾਂ ਅਤੇ ਇੱਕ ਅਜਿਹੇ ਖੋਜ-ਸੱਭਿਆਚਾਰ ਦਾ ਰੂਪ ਹੈ ਜਿਸਨੇ representation (ਅੰਦਰੂਨੀ ਫੀਚਰ) ਸਿੱਖਣ ਨੂੰ ਕੇਂਦਰ ਬਣਾਇਆ—ਬਜਾਏ ਹੱਥੋਂ-ਹੱਥ ਨਿਯਮ ਲਿਖਣ ਦੇ।
ਅਗਲੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਅਸੀਂ ਖੋਲਾਸਾ ਕਰਾਂਗੇ:
ਇਸ ਲੇਖ ਵਿੱਚ, ਬ੍ਰੇਕਥਰੂ ਉਹ ਪਰਿਵਰਤਨ ਹੈ ਜੋ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਵਧੇਰੇ ਉਪਯੋਗੀ ਬਣਾਉਂਦਾ: ਉਹ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਟਰੇਨ ਹੋਣ, ਬਿਹਤਰ ਫੀਚਰ ਸਿੱਖਣ, ਨਵੇਂ ਡਾਟਾ 'ਤੇ ਵਧੀਆ ਜਨਰਲਾਈਜ਼ ਕਰਨ ਜਾਂ ਵੱਡੇ ਟਾਸਕਾਂ ਤੱਕ ਸਕੇਲ ਕਰਨ ਯੋਗ ਹੋ ਜਾਣ। ਇਹ ਕਿਸੇ ਇਕ ਚਮਕਦਾਰ ਡੈਮੋ ਬਾਰੇ ਨਹੀਂ; ਇਹ ਇੱਕ ਵਿਚਾਰ ਨੂੰ ਭਰੋਸੇਯੋਗ ਵਿਧੀ ਵਿੱਚ ਬਦਲਣ ਬਾਰੇ ਹੈ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ "ਪ੍ਰੋਗਰਾਮਰਾਂ ਦੀ ਥਾਂ" ਬਣਾਉਣ ਲਈ ਨਹੀਂ ਬਣਾਇਆ ਗਿਆ ਸੀ। ਉਹਨਾਂ ਦਾ ਅਸਲ ਵਾਅਦਾ ਇਹ ਸੀ ਕਿ ਮਸ਼ੀਨਾਂ ਅਜਿਹੇ ਅੰਦਰੂਨੀ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖ ਸਕਣ ਜੋ ਗੰਦੇ ਅਸਲ-ਦੁਨੀਆ ਇਨਪੁਟ—ਤਸਵੀਰਾਂ, ਬੋਲਚਾਲ, ਟੈਕਸਟ—ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਮਦਦ ਕਰਣ, ਬਿਨਾਂ ਹਰ ਨਿਯਮ ਨੂੰ ਇੰਜੀਨੀਅਰਾਂ ਨੇ ਹੱਥੋਂ-ਹੱਥ ਲਿਖਿਆ ਹੋਵੇ।
ਇੱਕ ਫੋਟੋ ਸਿਰਫ਼ ਮਿਲੀਅਨ ਪਿਕਸਲ ਮੁੱਲ ਹੁੰਦੀ ਹੈ। ਇੱਕ ਆਵਾਜ਼ ਰਿਕਾਰਡਿੰਗ ਦਬਾਅ ਮਾਪਾਂ ਦੀ ਲੜੀ ਹੁੰਦੀ ਹੈ। ਚੁਣੌਤੀ ਇਹ ਹੈ ਕਿ ਉਹਨਾਂ ਕੱਚੇ ਅੰਕੜਿਆਂ ਨੂੰ ਉਹਨਾਂ ਸੰਕਲਪਾਂ ਵਿੱਚ ਬਦਲਣਾ ਜੋ ਲੋਕਾਂ ਲਈ ਅਹਮ ਹਨ: ਕਿਨਾਰੇ, ਆਕਾਰ, ਫੋਨੀਮ, ਸ਼ਬਦ, ਵਸਤੂ, ਮਨਸ਼ਾ।
ਜਦੋਂ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਪ੍ਰਾਇਕਟਿਕਲ ਨਹੀਂ ਸਨ, ਬਹੁਤ ਸਿਸਟਮ ਹੱਥੋਂ-ਤਿਆਰ ਫੀਚਰਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ—ਜਿਵੇਂ edge detectors ਜਾਂ texture descriptors। ਇਹ ਕੁਝ ਹੱਦ ਤੱਕ ਚੰਗਾ ਕੰਮ ਕਰਦਾ, ਪਰ ਰੋਸ਼ਨੀ ਬਦਲੇ ਜਾਂ ਉਚਾਰਣ ਵੱਖਰਾ ਹੋਵੇ ਤਾਂ ਇਹ ਅਕਸਰ ਟੁੱਟ ਜਾਂਦਾ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਦਾ ਮਕਸਦ ਇਹ ਸੀ ਕਿ ਮਾਡਲ ਪਰਤ ਦਰ ਪਰਤ ਫੀਚਰ ਆਪਣੇ ਆਪ ਸਿੱਖ ਲਵੇ। ਜੇ ਸਿਸਟਮ ਖੁਦ ਠੀਕ ਮੱਧਵਤੀ ਬਿਲਡਿੰਗ ਬਲਾਕ ਲੱਭ ਸਕੇ, ਤਾਂ ਉਹ ਘੱਟ ਮਨੋਰੰਜਨ ਇੰਜੀਨੀਅਰਿੰਗ ਨਾਲ ਨਵੇਂ ਟਾਸਕਾਂ 'ਤੇ ਚੰਗੀ ਤਰ੍ਹਾਂ ਜਨਰਲਾਈਜ਼ ਕਰ ਸਕਦਾ ਹੈ।
ਇਹ ਵਿਚਾਰ ਆਕਰਸ਼ਕ ਸੀ, ਪਰ ਕਈ ਰੁਕਾਵਟਾਂ ਨੇ ਨਿューਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਕਾਮਯਾਬ ਨਹੀਂ ਹੋਣ ਦਿੱਤਾ:
ਜਦੋਂ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਧੜਕ ਰਹੇ ਸਨ—ਖ਼ਾਸ ਕਰਕੇ 1990s ਅਤੇ 2000s ਦੇ ਸ਼ੁਰੂਆਤ ਵਿੱਚ—Geoffrey Hinton ਵਰਗੇ ਖੋਜਕਰਤਾ representation learning 'ਤੇ ਅਡਿੱਠ ਰਹੇ। ਉਹ 1980s ਦੇ ਮਧ ਤੋਂ ਵਿਚਾਰ ਪ੍ਰਸਤਾਵਿਤ ਕਰਦੇ ਰਹੇ ਅਤੇ ਪੁਰਾਣੀਆਂ ਧਾਰਣਾਵਾਂ (ਜਿਵੇਂ energy-based models) ਨੂੰ ਮੁੜ-ਦੇਖਦੇ ਰਹੇ ਜਦ ਤੱਕ ਕਿ ਹਾਰਡਵੇਅਰ, ਡਾਟਾ ਅਤੇ ਢੰਗਾ ਮਿਲ ਕੇ ਕੰਮ ਕਰਨ ਲੱਗੇ।
ਇਹ ਜ਼ਿੰਦਗੀ ਰੱਖਣ ਵਾਲੀ ਲਗਨ ਮੁੱਖ ਲਕੜੀ ਨੂੰ ਜਿੰਦਾ ਰੱਖਣ ਵਿੱਚ ਮਦਦਗਾਰ ਸੀ: ਮਸ਼ੀਨਾਂ ਜੋ ਸਹੀ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਕੇਵਲ ਅੱਖਰੀ ਜਵਾਬ।
Backpropagation (ਅਕਸਰ "backprop" ਕਹਿੰਦੇ ਹਨ) ਉਹ ਤਰੀਕਾ ਹੈ ਜੋ ਨੈੱਟਵਰਕ ਨੂੰ ਆਪਣੀਆਂ ਗਲਤੀਆਂ ਤੋਂ ਸਿੱਖਣ ਦਿੰਦਾ ਹੈ। ਨੈੱਟਵਰਕ ਅਨੁਮਾਨ ਲਗਾਉਂਦਾ, ਅਸੀਂ ਮਾਪਦੇ ਹਾਂ ਕਿ ਇਹ ਕਿੰਨਾ ਗਲਤ ਸੀ, ਫਿਰ ਅਸੀਂ ਨੈੱਟਵਰਕ ਦੇ ਅੰਦਰੂਨੀ "ਨਾਬ" (weights) ਨੂੰ ਠੀਕ ਕਰਦੇ ਹਾਂ ਤਾਂ ਜੋ ਅਗਲੀ ਵਾਰ ਇਹ ਬਿਹਤਰ ਕਰੇ।
ਕੱਲਪਨਾ ਕਰੋ ਕਿ ਇੱਕ ਨੈੱਟਵਰਕ ਇੱਕ ਤਸਵੀਰ ਨੂੰ "cat" ਜਾਂ "dog" ਲੇਬਲ ਦੇ ਰਿਹਾ ਹੈ। ਇਹ "cat" ਕਹਿੰਦਾ, ਪਰ ਸਹੀ ਜਵਾਬ "dog" ਹੈ। Backprop ਇਸ ਆਖਰੀ ਗਲਤੀ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦਾ ਅਤੇ ਨੈੱਟਵਰਕ ਦੀਆਂ ਪਰਤਾਂ ਰਾਹੀਂ ਵਾਪਸ ਜਾ ਕੇ ਇਹ ਪਤਾ ਲਗਾਂਦਾ ਕਿ ਹਰ ਇੱਕ ਵਜ਼ਨ ਨੇ ਗਲਤ ਜਵਾਬ ਵਿੱਚ ਕਿੰਨਾ ਯੋਗਦਾਨ ਦਿੱਤਾ।
ਇਕ ਪ੍ਰਯੋਗਕਰ ਯਾਦਗਾਰ ਤਰੀਕਾ:
ਇਹ ਨੁੱਡਜ ਆਮ ਤੌਰ 'ਤੇ gradient descent ਨਾਲ ਹੁੰਦੇ ਹਨ, ਜੋ ਕਿ "ਐਰਰ ਤੇ ਥੱਲੇ ਵੱਲ ਛੋਟੇ ਕਦਮ" ਲੈਣ ਦਾ ਮਤਲਬ ਹੈ।
ਬੈਕਪ੍ਰੋਪ ਨੂੰ ਵਿਸ਼ਾਲ ਪੱਧਰ 'ਤੇ ਅਪਣਾਇਆ ਜਾਣ ਤੋਂ ਪਹਿਲਾਂ, ਮਲਟੀ-ਲੇਅਰ ਨੈੱਟਵਰਕਸ ਨੂੰ ਟ੍ਰੇਨ ਕਰਨਾ ਅਨਿਸ਼ਚਿਤ ਅਤੇ ਹੌਲਾ ਸੀ। ਬੈਕਪ੍ਰੋਪ ਨੇ ਕਈ ਪਰਤਾਂ ਨੂੰ ਇੱਕ-ਸਮੇਂ ਵਿੱਚ ਟਿਊਨ ਕਰਨ ਦਾ ਇੱਕ ਵਿਧੀਬੱਧ, ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਤਰੀਕਾ ਦਿਤਾ—ਜਿਸ ਨਾਲ ਸਿਰਫ਼ ਅੰਤਿਮ ਪਰਤ ਨੂੰ ਜਿੱਤੀਂ ਤਬਦੀਲ ਕਰਨ ਜਾਂ ਅਨੁਮਾਨ ਲਗਾਉਣ ਦੀ ਥਾਂ ਬਹੁਤ ਸਾਰੇ ਪਰਤ ਇੱਕਠੇ ਸੁਧਾਰ ਸਕਦੇ।
ਇਹ ਬਦਲਾਅ ਅਗਲੇ ਬ੍ਰੇਕਥਰੂਜ਼ ਲਈ ਮਹੱਤਵਪੂਰਨ ਸੀ: ਜਦੋਂ ਤੁਸੀਂ ਕਈ ਪਰਤਾਂ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਟਰੇਨ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ ਨੈੱਟਵਰਕ ਜ਼ਿਆਦਾ ਰਿਸ਼ਤੇਦਾਰ ਫੀਚਰ ਸਿੱਖ ਸਕਦੇ ਹਨ (ਕਿਨਾਰੇ → ਆਕਾਰ → ਵਸਤੂ, ਉਦਾਹਰਨ ਲਈ)।
Backprop ਨੈੱਟਵਰਕ ਦਾ "ਸੋਚਣਾ" ਨਹੀਂ ਹੈ। ਇਹ ਗਣਿਤ-ਚਲਿਤ ਫੀਡਬੈਕ ਹੈ: ਪੈਰਾਮੀਟਰਾਂ ਨੂੰ ਉਦਾਹਰਨਾਂ ਨਾਲ ਮਿਲਾਉਣ ਲਈ ਢੰਗ।
ਅਤੇ, backprop ਕਿਸੇ ਇਕ ਮਾਡਲ ਨੂੰ ਦਰਸਾਉਂਦਾ ਨਹੀਂ; ਇਹ ਇੱਕ ਟ੍ਰੇਨਿੰਗ ਵਿਧੀ ਹੈ ਜੋ ਕਈ ਕਿਸਮਾਂ ਦੇ ਨੈੱਟਵਰਕਸ 'ਤੇ ਵਰਤੀ ਜਾ ਸਕਦੀ ਹੈ।
If you want a gentle deeper dive on how networks are structured, see /blog/neural-networks-explained.
Boltzmann machines Geoffrey Hinton ਦੇ ਉਹਨਾਂ ਮੋਹੜਿਆਂ ਵਿੱਚੋਂ ਇੱਕ ਸਨ ਜਿਨ੍ਹਾਂ ਨੇ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਉਪਯੋਗੀ ਅੰਦਰੂਨੀ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖਣ ਲਈ ਅੱਗੇ ਵਧਾਇਆ।
Boltzmann machine ਸਰਲ ਯੂਨਿਟਾਂ ਦਾ ਇੱਕ ਨੈੱਟਵਰਕ ਹੁੰਦੀ ਹੈ ਜੋ on/off ਰਹਿੰਦੀਆਂ ਹਨ (ਜਾਂ ਆਧੁਨਿਕ ਵਰਜਨਾਂ ਵਿੱਚ ਰੀਅਲ ਮੁੱਲ ਲੈ ਸਕਦੀਆਂ)। ਇਹ ਸਿੱਧਾ ਅਉਟਪੁਟ ਦੀ ਭਵਿੱਖਵਾਣੀ ਕਰਨ ਦੀ ਥਾਂ ਹਰ ਇਕ ਯੂਨਿਟ ਕੰਫਿਗਰੇਸ਼ਨ ਨੂੰ ਇੱਕ energy ਦੇਂਦੀ ਹੈ। ਘੱਟ energy ਦਾ ਮਤਲਬ ਹੈ "ਇਹ ਕੰਫਿਗਰੇਸ਼ਨ ਮੰਨਯੋਗ ਹੈ।"
ਇੱਕ ਸਹਾਇਕ ਤુલਨਾ ਇੱਕ ਮੇਜ਼ ਨਾਲ ਹੈ ਜਿਸ 'ਤੇ ਛੋਟੀਆਂ ਖੱਡਾਂ ਅਤੇ ਘਾਟ ਹਨ। ਜੇ ਤੁਸੀਂ ਉੱਤੇ ਕੋਈ ਮਾਰਬਲ ਛੱਡੋ, ਇਹ ਰੋਲ ਕਰਕੇ ਘੱਟ ਪੁਆਇੰਟ 'ਤੇ ਠਹਿਰ ਜਾਵੇਗਾ। Boltzmann machines ਕੁਝ ਇਸੇ ਤਰ੍ਹਾਂ ਕਰਦੀਆਂ ਹਨ: ਜਦੋਂ ਕੁਝ ਵੇਖਣਯੋਗ ਯੂਨਿਟ ਡਾਟਾ ਦੁਆਰਾ ਸੈੱਟ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਨੈੱਟਵਰਕ ਅੰਦਰੂਨੀ ਯੂਨਿਟਾਂ ਨੂੰ "ਵਿਗਲ" (wiggle) ਕਰਵਾਉਂਦਾ ਹੈ ਜਦ ਤੱਕ ਉਹ ਉਹਨਾਂ ਹਾਲਤਾਂ ਵਿੱਚ ਨਹੀਂ ਠਹਿਰਦੇ ਜਿਨ੍ਹਾਂ ਨੂੰ ਇਸ ਨੇ ਘੱਟ energy ਵਜੋਂ ਸਿੱਖਿਆ ਹੈ।
ਪੁਰਾਣੇ Boltzmann machines ਦੀ ਟ੍ਰੇਨਿੰਗ ਵਿੱਚ ਮਾਡਲ ਦੀ ਮੰਨਤਾ ਅਤੇ ਡਾਟਾ ਦਰਮਿਆਨ ਅੰਤਰ ਦਾ ਅੰਦਾਜ਼ ਲਗਾਉਣ ਲਈ ਬਾਰ-ਬਾਰ ਹਰ ਸੰਭਾਵਨਾ ਤੋਂ ਨਮੂਨਾ ਲੈਣਾ ਸ਼ਾਮਲ ਸੀ। ਇਹ ਸੈਂਪਲਿੰਗ ਵੱਡੇ ਨੈੱਟਵਰਕ ਲਈ ਬਹੁਤ ਹੌਲੀ ਹੋ ਸਕਦੀ ਹੈ।
ਫਿਰ ਵੀ, ਇਹ ਪਹੁੰਚ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਸੀ ਕਿਉਂਕਿ ਇਸ ਨੇ:
ਅੱਜ-ਕੱਲ੍ਹ ਜ਼ਿਆਦਾਤਰ ਉਤਪਾਦ ਫੀਡਫਾਰਵਰਡ ਡੀਪ ਨੈੱਟਵਰਕਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਜੋ backpropagation ਨਾਲ ਟ੍ਰੇਨ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਉਹ ਤੇਜ਼ ਅਤੇ ਅਸਾਨੀ ਨਾਲ ਸਕੇਲ ਹੁੰਦੇ ਹਨ।
Boltzmann machines ਦੀ ਵਿਰਾਸਤ ਜ਼ਿਆਦਾਤਰ ਸਾਰਥਕਤਾ ਵਿੱਚ ਨਾ ਰਹਿ ਕੇ ਧਾਰਨਾਤਮਕ ਹੈ: ਇਹ ਵਿਚਾਰ ਕਿ ਚੰਗੇ ਮਾਡਲ ਦੁਨੀਆ ਦੇ "ਪਸੰਦੀਦਾ ਹਾਲਤਾਂ" ਸਿੱਖਦੇ ਹਨ—ਅਤੇ ਸਿੱਖਣਾ ਇਸ energy ਢਾਂਚੇ ਵਿੱਚ ਸੰਭਾਵਨਾ ਨੂੰ ਘਟਾਉਣ ਜਿੱਤੋਂ ਵਧਾਉਣ ਦੇ ਰੂਪ ਵਿੱਚ ਦੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਸਿਰਫ਼ ਵਧੀਆ ਕර්ਵ ਫਿੱਟ ਕਰਨਾ ਨਹੀਂ ਸਿੱਖੇ—ਉਹਨਾਂ ਨੇ ਸਹੀ ਫੀਚਰ ਬਣਾਉਣਾ ਸਿੱਖਿਆ। ਇਹੀ representation learning ਦਾ ਮਤਲਬ ਹੈ: ਮਾਡਲ ਖੁਦ ਅੰਦਰੂਨੀ ਵਰਣਨ (representations) ਬਣਾਉਂਦਾ ਜੋ ਟਾਸਕ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ, ਨਾ ਕਿ ਰੋਜ਼ਗਾਰੀਆਂ ਦੁਆਰਾ ਹੱਥੋਂ-ਹੱਥ ਤਿਆਰ ਕੀਤੇ ਗਏ।
ਇੱਕ representation ਮਾਡਲ ਦਾ ਆਪਣੇ ਆਪ ਇਨਪੁਟ ਨੂੰ ਸੰਖੇਪ ਕਰ ਦੇਣ ਦਾ ਢੰਗ ਹੈ। ਇਹ ਅਜੇ ਲੇਬਲ "cat" ਨਹੀਂ ਹੈ; ਇਹ ਉਹ ਵਿਚਾਰ ਹੈ ਜੋ ਲੇਬਲ ਤੱਕ ਜਾਣ 'ਤੇ ਮਦਦ ਕਰਦਾ—ਉਹ ਰਚਨਾ ਜੋ ਕਾਮ ਆਉਂਦੀ ਹੈ। ਸ਼ੁਰੂਆਤੀ ਪਰਤਾਂ ਸਧਾਰਨ ਸਿਗਨਲਾਂ 'ਤੇ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਜਦਕਿ ਬਾਅਦੀ ਪਰਤਾਂ ਉਹਨਾਂ ਨੂੰ ਜ਼ਿਆਦਾ ਅਰਥਪੂਰਨ ਧਾਰਨਾਵਾਂ ਵਿੱਚ ਜੋੜ ਦਿੰਦੀਆਂ ਹਨ।
ਇਸ ਤਬਦੀਲੀ ਤੋਂ ਪਹਿਲਾਂ, ਕਈ ਸਿਸਟਮ ਮਾਹਿਰ-ਤਿਆਰ ਫੀਚਰਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਸਨ: ਇਮੇਜ ਲਈ edge detectors, speech ਲਈ ਹੱਥੋਂ-ਤਰਤੀਬ ਆਡੀਓ ਸੁਚਕ, ਜਾਂ ਟੈਕਸਟ ਲਈ ਨਿਰਧਾਰਤ ਅੰਕੜੇ। ਇਹ ਫੀਚਰ ਕੰਮ ਕਰਦੇ ਸਨ, ਪਰ ਜਦੋਂ ਹਾਲਾਤ ਬਦਲਦੇ (ਰੋਸ਼ਨੀ, ਉਚਾਰਣ, ਸ਼ਬਦਬੰਦੀ) ਤਾਂ ਉਹ ਅਕਸਰ ਟੁੱਟ ਜਾਂਦੇ।
Representation learning ਮਾਡਲਾਂ ਨੂੰ ਡਾਟਾ ਅਨੁਸਾਰ ਫੀਚਰ ਅਡਜਸਟ ਕਰਨ ਦਿੰਦਾ, ਜਿਸ ਨਾਲ ਸਹੀਅਤੀ ਦਰੁਸਤਗੀ ਮਿਲਦੀ ਅਤੇ ਸਿਸਟਮ ਵੱਖ-ਵੱਖ ਹਾਲਾਤਾਂ 'ਚ ਵੱਧ ਢੰਗ ਨਾਲ ਕੰਮ ਕਰਦੇ ਹਨ।
ਸਾਰ ਸੁਤਰ ਇਹ ਹੈ: ਹਾਇਰਾਰਕੀ—ਸਧਾਰਨ ਪੈਟਰਨ ਮਿਲ ਕੇ ਬਦਲੇ ਹੋਏ, ਰਿਚ ਪੈਟਰਨ ਬਣਾਉਂਦੇ ਹਨ।
ਇਮੇਜ ਰਿਕਗਨੀਸ਼ਨ ਵਿੱਚ, ਇੱਕ ਨੈੱਟਵਰਕ ਪਹਿਲਾਂ edge-ਜਿਹੇ ਪੈਟਰਨ ਸਿੱਖ ਸਕਦਾ ਹੈ। ਫਿਰ ਇਹ edges ਨੂੰ ਮਿਲਾ ਕੇ ਕੋਰਨਰ ਅਤੇ ਘੁੰਮਾਅ ਬਣਾਉਂਦਾ, ਬਾਅਦ ਵਿੱਚ ਉਹਨਾਂ ਨੂੰ ਹਿੱਸਿਆਂ (ਜਿਵੇਂ ਪਹੀਆ ਜਾਂ ਅੱਖ) ਵਿੱਚ ਜੋੜਦਾ ਅਤੇ ਅੰਤ ਵਿੱਚ ਪੂਰੀ ਵਸਤੂ (ਜਿਵੇਂ "ਸਾਈਕਲ" ਜਾਂ "ਚਿਹਰਾ") ਬਣਾਉਂਦਾ।
Hinton ਦੀਆਂ ਖੋਜਾਂ ਨੇ ਇਸ ਪਰਤ-ਵਾਰ ਫੀਚਰ-ਬਿਲਡਿੰਗ ਨੂੰ ਪ੍ਰਾਇਕਟਿਕਲ ਬਣਾਇਆ—ਅਤੇ ਇਹ ਇੱਕ ਵੱਡਾ ਕਾਰਨ ਹੈ ਕਿ ਡੀਪ ਲਰਨਿੰਗ ਅਸਲ-ਦੁਨੀਆ ਟਾਸਕਾਂ ਤੇ ਜਿੱਤਣ ਲੱਗੀ।
Deep belief networks (DBNs) ਡੀਪਰ ਨੈੱਟਵਰਕਸ ਵੱਲ ਰਸਤਾ ਬਣਾਉਣ ਵਿੱਚ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਕਦਮ ਸਨ। ਇਕ DBN ਉੱਪਰ-ਉੱਪਰ ਲੇਅਰਾਂ ਦੀ ਇੱਕ ਸਟੈਕ ਹੁੰਦੀ ਹੈ, ਜਿੱਥੇ ਹਰ ਪਰਤ ਹੇਠਾਂ ਵਾਲੀ ਪਰਤ ਦੀ ਨੁਕਤਚੀਨੀ (representation) ਸਿੱਖਦੀ—ਕੱਚੇ ਇਨਪੁਟ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦਿਆਂ ਧੀਰੇ-ਧੀਰੇ ਹੋਰ ਜਟਿਲ "ਅਰਥ" ਤੱਕ।
ਕੱਲਪਨਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਇੱਕ ਸਿਸਟਮ ਨੂੰ ਹੱਥ-ਲਿਖਾਈ ਪਛਾਣਨੀਆਂ ਸਿੱਖਾ ਰਹੇ ਹੋ। ਇਕ DBN ਸਿੱਧਾ ਸਭ ਕੁਝ ਇਕੱਠੇ ਸਿੱਖਣ ਦੀ ਥਾਂ ਪਹਿਲਾਂ ਸਧਾਰਨ ਪੈਟਰਨ (ਜਿਵੇਂ edges ਅਤੇ strokes) ਸਿੱਖੇਗਾ, ਫਿਰ ਉਹਨਾਂ ਪੈਟਰਨਾਂ ਦੇ ਜੋੜ (ਲੂਪ, ਕੋਰਨਰ) ਅਤੇ ਆਖ਼ਰਕਾਰ ਹੱਥ-ਲਿਖੇ ਅੰਕਾਂ ਦੇ ਉਪਰਲੇ-ਪੱਧਰੀ ਹਿੱਸਿਆਂ ਜਿਹੇ ਆਕਾਰ ਸਿੱਖੇਗਾ।
ਮੁੱਖ ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ ਹਰ ਪਰਤ ਆਪਣੇ ਇਨਪੁਟ ਵਿੱਚ ਮੌਜੂਦ ਪੈਟਰਨਾਂ ਨੂੰ ਬਿਨਾ ਸਿੱਟੇ ਜਾਂਦੇ ਬਿਨਾਂ-ਲਿਖੇ ਸਿੱਖਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੀ। ਫਿਰ, ਜਦ ਸਟੈਕ ਨੇ ਇਹ ਵਧ ਰਹੀਆਂ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖ ਲਈਆਂ ਹਨ, ਤੁਸੀਂ ਪੂਰੇ ਨੈੱਟਵਰਕ ਨੂੰ ਕਿਸੇ ਵਿਸ਼ੇਸ਼ ਟਾਸਕ ਲਈ ਫਾਇਨ-ਟਿਊਨ ਕਰ ਸਕਦੇ ਹੋ—ਜਿਵੇਂ classification।
ਛੇਤੀ ਗੱਲ ਇਹ ਹੈ ਕਿ ਪਹਿਲਾਂ ਦੇ ਡੀਪਰ ਨੈੱਟਵਰਕ ਅਕਸਰ ਰੈਂਡਮ ਤੌਰ 'ਤੇ initialize ਹੋਣ 'ਤੇ ਚੰਗੀ ਤਰ੍ਹਾਂ ਟ੍ਰੇਨ ਨਹੀਂ ਹੁੰਦੇ ਸਨ। ਟਰੇਨਿੰਗ ਸਿਗਨਲ ਕਈ ਪਰਤਾਂ ਵਿੱਚ ਜਾ ਕੇ ਕਮਜ਼ੋਰ ਜਾਂ ਅਸਥਿਰ ਹੋ ਸਕਦਾ ਸੀ, ਅਤੇ ਨੈੱਟਵਰਕ ਅਣਉਪਯੋਗ ਸੈਟਿੰਗਜ਼ ‘ਤੇ ਅਟਕ ਸਕਦਾ ਸੀ।
ਪਰਤ-ਦਰ-ਪਰਤ pretraining ਮਾਡਲ ਨੂੰ ਇੱਕ "ਵਾਰਮ ਸਟਾਰਟ" ਦਿੰਦਾ। ਹਰ ਪਰਤ ਡਾਟਾ ਦੀ ਬਣਤਰ ਬਾਰੇ ਇੱਕ ਠੀਕ ਸਮਝ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀ, ਇਸ ਲਈ ਪੂਰਾ ਨੈੱਟਵਰਕ ਅੰਧੇ ਤਰ੍ਹਾਂ ਖੋਜ ਨਹੀਂ ਕਰ ਰਿਹਾ।
Pretraining ਹਰ ਸਮੱਸਿਆ ਦਾ ਜਾਦੂਈ ਹੱਲ ਨਹੀਂ ਸੀ, ਪਰ ਇਸ ਨੇ ਉਦੋਂ ਦੀਆਂ ਸੀਮਤ ਡਾਟਾ, ਹਾਰਡਵੇਅਰ ਅਤੇ ਟ੍ਰੇਨਿੰਗ ਟ੍ਰਿਕਸ ਵਾਲੀ ਹਾਲਤ ਵਿੱਚ ਡੈਪਥ ਨੂੰ ਪ੍ਰਾਇਕਟਿਕਲ ਬਣਾਇਆ।
DBNs ਨੇ ਦਿਖਾਇਆ ਕਿ ਕਈ ਪਰਤਾਂ 'ਚ ਚੰਗੀਆਂ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖਣਾ ਕੰਮ ਕਰ ਸਕਦਾ—ਅਤੇ ਡੈਪਥ ਸਿਰਫ਼ ਸਿਧਾਂਤ ਨਹੀਂ, ਇੱਕ ਵਰਤੋਂਯੋਗ ਰਾਹ ਹੈ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਕਈ ਵਾਰ "ਟੈਸਟ ਲਈ ਪੜ੍ਹਨਾ" ਇਸ ਢੰਗ ਨਾਲ ਕਰ ਲੈਂਦੇ ਹਨ ਕਿ ਉਹ ਸਿਰਫ਼ ਟਰੇਨਿੰਗ ਡਾਟਾ ਨੂੰ ਯਾਦ ਕਰ ਲੈਂਦੇ ਹਨ—ਇਸ ਸਮੱਸਿਆ ਨੂੰ overfitting ਕਹਿੰਦੇ ਹਨ। ਇਹ ਉਸ ਸਮੇਂ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ ਜਦ ਮਾਡਲ ਟਰੇਨਿੰਗ ਵਿੱਚ ਸ਼ਾਨਦਾਰ ਹੁੰਦਾ ਪਰ ਨਵੇਂ, ਅਸਲ-ਦੁਨੀਆ ਇਨਪੁਟ 'ਤੇ ਠੀਕ ਨਹੀਂ ਕਰਦਾ।
ਕੱਲਪਨਾ ਕਰੋ ਤੁਸੀਂ ਡ੍ਰਾਈਵਿੰਗ ਦੀ ਟੈਸਟ ਲਈ ਉਹੀ ਰਸਤਾ ਯਾਦ ਕਰ ਰਹੇ ਹੋ ਜੋ ਅਗਲੀ ਵਾਰੀ ਦਿੱਤਾ ਗਿਆ—ਹਰ ਮੋੜ, ਹਰ ਸਾਇਨ, ਹਰ ਗਡ੍ਹਾ। ਜੇ ਟੈਸਟ ਰਸਤਾ ਬਦਲ ਜਾਵੇ, ਤੁਸੀਂ ਘੱਟ ਸਕੋਰ ਕਰੋਗੇ ਕਿਉਂਕਿ ਤੁਸੀਂ ਆਮ ਡ੍ਰਾਈਵਿੰਗ ਕੁਸ਼ਲ ਨਹੀਂ ਸਿੱਖੀ; ਤੁਸੀਂ ਇਕ ਖਾਸ ਸਕ੍ਰਿਪਟ ਯਾਦ ਕੀਤੀ।
ਇਹ overfitting ਹੈ: ਜਾਣੇ-ਪਛਾਣੇ ਉਦਾਹਰਣਾਂ 'ਤੇ ਉਚੀ ਐਕੁਰਸੀ, ਨਵਿਆਂ 'ਤੇ ਕਮਜ਼ੋਰ ਨਤੀਜੇ।
Dropout ਨੂੰ Geoffrey Hinton ਅਤੇ ਉਸਦੇ ਸਹਯੋਗੀਆਂ ਨੇ ਪ੍ਰਸਿੱਧ ਕੀਤਾ। ਟਰੇਨਿੰਗ ਦੌਰਾਨ ਨੈੱਟਵਰਕ ਰੈਂਡਮ ਤੌਰ 'ਤੇ ਕੁਝ ਯੂਨਿਟ ਠੱਠੇ ਕਰ ਦਿੰਦਾ।
ਇਸ ਨਾਲ ਮਾਡਲ ਕਿਸੇ ਇੱਕ ਪਾਥਵੇ ਜਾਂ "ਪਸੰਦੀਦਾ" ਫੀਚਰ-ਸੈੱਟ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਰਹਿੰਦਾ; ਓਹਨਾਂ ਨੂੰ ਜਾਣ-ਪਛਾਣ ਵੱਖ-ਵੱਖ ਕਨੈਕਸ਼ਨਾਂ 'ਤੇ ਫੈਲਾਉਣਾ ਪੈਂਦਾ ਅਤੇ ਐਸੇ ਪੈਟਰਨ ਸਿੱਖਣੇ ਪੈਂਦੇ ਜੋ ਮਾਡਲ ਦੇ ਕੁਝ ਹਿੱਸੇ ਗਾਇਬ ਹੋਣ 'ਤੇ ਵੀ ਕੰਮ ਕਰਨ।
ਇੱਕ ਮਦਦਗਾਰ ਸੋਚ: ਇਹ ਉਸੇ ਵਰਗਾ ਹੈ ਜਿਥੇ ਤੁਸੀਂ ਕਈ ਵਾਰੀ ਆਪਣੀਆਂ ਨੋਟਸ ਦੇ ਰੈਂਡਮ ਪੰਨੇ ਗਵਾ ਬੈਠਦੇ ਹੋ—ਤੁਸੀਂ ਇੱਕ ਵਿਸ਼ਾ ਨੂੰ ਸਮਝਣ ਲਈ ਮਜ਼ਬੂਤੀ ਨਾਲ ਤਿਆਰ ਹੁੰਦੇ ਹੋ ਨਾ ਕਿ ਕਿਸੇ ਇਕ ਲਫ਼ਜ਼-ਪੈਰਾਗ੍ਰਾਫ ਨੂੰ ਯਾਦ ਕਰਨ ਲਈ।
ਮੁੱਖ ਨਤੀਜਾ ਬਿਹਤਰ ਜਨਰਲਾਈਜ਼ੇਸ਼ਨ ਹੈ: ਨੈੱਟਵਰਕ ਨਵੇਂ ਡਾਟਾ 'ਤੇ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਹੋ ਜਾਂਦਾ। ਪ੍ਰਯੋਗਕ ਤੌਰ 'ਤੇ, dropout ਨੇ ਵੱਡੇ ਨੈੱਟਵਰਕਸ ਨੂੰ ਟ੍ਰੇਨ ਕਰਨ ਵੱਲ ਸਹਾਇਤਾ ਕੀਤੀ ਬਿਨਾਂ ਉਹ ਸਿਰਫ਼ ਯਾਦ ਕਰਨ ਲੱਗਣ, ਅਤੇ ਇਹ ਬਹੁਤ ਸਾਰੇ ਡੀਪ ਲਰਨਿੰਗ ਸੈੱਟਅੱਪਸ 'ਚ ਇੱਕ ਸਟੈਂਡਰਡ ਟੂਲ ਬਣ ਗਿਆ।
AlexNet ਤੋਂ ਪਹਿਲਾਂ, "ਇਮੇਜ ਰਿਕਗਨੀਸ਼ਨ" ਸਿਰਫ਼ ਇੱਕ ਕੂਲ ਡੈਮੋ ਨਹੀਂ ਸੀ—ਇਹ ਇੱਕ ਨਾਪ-ਤੋਲ ਹੋਈ ਮੁਕਾਬਲਾ ਸੀ। ImageNet ਵਰਗੇ ਬੈਂਚਮਾਰਕ ਪੁੱਛਦੇ ਸਨ: ਇੱਕ ਫੋਟੋ ਦੇ ਦਿੱਤੀ ਜਾਣ 'ਤੇ ਤੁਹਾਡੀ ਸਿਸਟਮ ਉਸ ਵਿੱਚ ਕੀ ਹੈ ਇਹ ਨਾਮ ਕਰ ਸਕਦੀ ਹੈ?
ਮੁੱਦਾ ਸਕੇਲ ਦਾ ਸੀ: ਮਿਲੀਅਨ ਫੋਟੋਆਂ ਅਤੇ ਹਜ਼ਾਰਾਂ ਸ਼੍ਰੇਣੀਆਂ। ਇਹ ਆਕਾਰ ਇਸ ਗੱਲ ਨੂੰ ਵੱਖਰਾ ਕਰਦਾ ਕਿ ਕਿਹੜੇ ਵਿਚਾਰ ਛੋਟੇ ਪਰਖਾਂ ਵਿੱਚ ਚੰਗੇ ਲੱਗਦੇ ਹਨ ਅਤੇ ਕਿਹੜੇ ਵਿਧੀਆਂ ਅਜੇ ਵੀ ਅਸਲ-ਦੁਨੀਆ ਵਿੱਚ ਟਿਕ ਸਕਦੀਆਂ ਹਨ।
ਅਕਸਰ ਲੀਡਰਬੋਰਡ ਉੱਤੇ ਪ੍ਰਗਤੀ ਹੌਲੀ ਹੁੰਦੀ। ਪਰ ਜਦ AlexNet (Alex Krizhevsky, Ilya Sutskever, ਅਤੇ Geoffrey Hinton ਵੱਲੋਂ ਬਣਾਇਆ) ਆਇਆ, ਤਦ ਨਤੀਜੇ ਵਿੱਚ ਇੱਕ ਵੱਡਾ ਬਦਲਾਅ ਮਹਿਸੂਸ ਹੋਇਆ।
AlexNet ਨੇ ਦਿਖਾਇਆ ਕਿ ਇੱਕ ਡੀਪ convolutional ਨੈੱਟਵਰਕ ਸਭ ਤੋਂ ਵਧੀਆ ਰਵਾਇਤੀ ਕੰਪਿਊਟਰ-ਵਿਜ਼ਨ ਪਾਈਪਲਾਈਨਸ ਨੂੰ ਹਰਾ ਸਕਦਾ ਹੈ ਜਦੋਂ ਤਿੰਨ ਗੁਣਾਂ ਨੂੰ ਜੋੜਿਆ ਜਾਵੇ:
ਇਹ ਕੇਵਲ "ਵੱਡਾ ਮਾਡਲ" ਨਹੀਂ ਸੀ—ਇਹ ਡੀਪ ਨੈੱਟਸ ਨੂੰ ਅਸਲ-ਦੁਨੀਆ ਟਾਸਕਾਂ ਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਟ੍ਰੇਨ ਕਰਨ ਦੀ ਇੱਕ ਪ੍ਰਯੋਗਕ ਨੁਸਖਾ ਸੀ।
ਕੱਲਪਨਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਇੱਕ ਛੋਟਾ "ਖਿੜਕੀ" ਫੋਟੋ 'ਤੇ ਘੁਮਾਉਂਦੇ ਹੋ—ਜਿਵੇਂ ਇੱਕ ਡਾਕ ਟਿਕਟ ਦੀ ਤਰ੍ਹਾਂ। ਉਸ ਖਿੜਕੀ ਦੇ ਅੰਦਰ, ਨੈੱਟਵਰਕ ਕਿਸੇ ਸਧਾਰਨ ਪੈਟਰਨ ਨੂੰ ਦੇਖਦਾ ਹੈ: ਇੱਕ ਕਿਨਾਰਾ, ਇਕ ਕੋਣ, ਇਕ ਧਾਰ। ਇਹੀ ਪੈਟਰਨ-ਚੈੱਕਰ ਤਸਵੀਰ ਦੇ ਹਰ ਹਿੱਸੇ 'ਚ ਦੁਹਰਾਇਆ ਜਾਂਦਾ ਹੈ, ਇਸ ਲਈ ਇਹ ਕਿਤੇ ਵੀ ਕਿਨਾਰਾ ਜਿਹੇ ਚੀਜ਼ਾਂ ਲੱਭ ਸਕਦਾ ਹੈ।
ਇਹ ਪਰਤਾਂ ਕਾਫੀ ਸਟੈਕ ਹੋਣ 'ਤੇ ਇੱਕ ਹਾਇਰਾਰਕੀ ਬਣਦੀ ਹੈ: edges textures ਵਿੱਚ ਬਦਲਦੇ ਹਨ, textures ਹਿੱਸਿਆਂ ਵਿੱਚ, ਅਤੇ ਹਿੱਸੇ ਵਸਤੂਆਂ ਵਿੱਚ।
AlexNet ਨੇ ਡੀਪ ਲਰਨਿੰਗ ਨੂੰ ਭਰੋਸੇਯੋਗ ਅਤੇ ਨਿਵੇਸ਼ਯੋਗ ਮਹਿਸੂਸ ਕਰਵਾਇਆ। ਜੇ ਡੀਪ ਨੈੱਟਸ ਇੱਕ ਮੁਸ਼ਕਲ, ਪਬਲਿਕ ਬੈਂਚਮਾਰਕ 'ਤੇ ਡੋਮੀਨੇਟ ਕਰ ਸਕਦੇ, ਤਾਂ ਉਹ ਸੰਭਵਤ: ਸਰਚ, ਫੋਟੋ ਟੈਗਿੰਗ, ਕੈਮਰਾ ਫੀਚਰ, ਪਹੁੰਚਯੋਗਤਾ ਟੂਲਾਂ ਵਰਗੇ ਉਤਪਾਦਾਂ ਨੂੰ ਵੀ ਸੁਧਾਰ ਸਕਦੇ।
ਇਸ ਨੇ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ "ਪ੍ਰੋਮੀਸਿੰਗ ਰਿਸਰਚ" ਤੋਂ ਵਾਸਤਵਿਕ ਉਤਪਾਦ ਨਿਰਮਾਣ ਦੀ ਦਿਸ਼ਾ ਵੱਲ ਧੱਕਿਆ।
ਡੀਪ ਲਰਨਿੰਗ "ਇਕ ਛੋਕੇ ਵਿੱਚ ਨਹੀਂ ਆਈ।" ਇਹ ਉਸ ਵੇਲੇ ਨਜ਼ਰ ਆਈ ਜਦ ਕੁਝ ਜ਼ਰੂਰੀ ਤੱਤ ਮਿਲ ਕੇ ਕੰਮ ਕਰਨ ਲੱਗੇ—ਕੁਝ ਸਾਲਾਂ ਦੀ ਪੂਰਵ ਕੰਮ ਨੇ ਇਹ ਦਿਖਾ ਦਿੱਤਾ ਸੀ ਕਿ ਵਿਚਾਰ ਵਧੀਆ ਹਨ ਪਰ ਸਕੇਲ ਕਰਨਾ ਔਖਾ ਹੈ।
ਜ਼ਿਆਦਾ ਡਾਟਾ. ਵੈੱਬ, ਸਮਾਰਟਫੋਨ ਅਤੇ ਵੱਡੇ ਲੇਬਲਡ ਡੈਟਾਸੈੱਟ (ImageNet ਵਰਗੇ) ਨੇ ਨੈੱਟਵਰਕਸ ਨੂੰ ਮਿਲੀਅਨ ਉਦਾਹਰਣਾਂ ਤੋਂ ਸਿੱਖਣ ਯੋਗ ਬਣਾਇਆ। ਛੋਟੇ ਡੈਟਾਸੈੱਟ ਨਾਲ, ਵੱਡੇ ਮਾਡਲ ਅਕਸਰ ਯਾਦ ਕਰ ਲੈਂਦੇ।
ਜ਼ਿਆਦਾ ਕੰਪਿਊਟ (ਖ਼ਾਸ ਕਰਕੇ GPUs). ਡੀਪ ਮਾਡਲ ਟ੍ਰੇਨ ਕਰਨ ਲਈ ਬਹੁਤ ਸਾਰਾ ਇਕੋ ਹੀ ਗਣਿਤ ਦੁਹਰਾਉਣਾ ਪੈਂਦਾ ਹੈ। GPUs ਨੇ ਇਹ ਪ੍ਰਕਿਰਿਆ ਤੇਜ਼ ਅਤੇ ਸਸਤੀ ਬਣਾਈ, ਜਿਸ ਨਾਲ ਜੋਸ਼ੀਲੇ ਵਿਦਿਆਰਥੀ ਹੋਰ ਆਰਕੀਟੈਕਚਰਾਂ、ਹਾਇਪਰਪੈਰامیਟਰਾਂ試 ਕਰ ਸਕੇ।
ਵਧੀਆ ਟ੍ਰੇਨਿੰਗ ਟ੍ਰਿਕਸ. ਪ੍ਰੈਕਟਿਕਲ ਸੁਧਾਰਾਂ ਨੇ "ਇਹ ਟ੍ਰੇਨ ਹੋਵੇਗਾ… ਜਾਂ ਨਹੀਂ" ਵਾਲੀ ਬੇਕਾਬੂ ਫਿੱਲ ਹੁੰਦੀ ਦੀ ਘੱਟੀ:
ਇਨ੍ਹਾਂ ਨੇ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਦੇ ਮੂਲ ਵਿਚਾਰ ਨੂੰ ਨਹੀਂ ਬਦਲਿਆ; ਇਹਨਾਂ ਨੇ ਉਨ੍ਹਾਂ ਨੂੰ ਕੰਮ ਕਰਵਾਉਣ ਵਿੱਚ ਭਰੋਸੇਯੋਗ ਬਣਾਇਆ।
ਜਦੋਂ ਕੰਪਿਊਟ ਅਤੇ ਡਾਟਾ ਇੱਕ ਮਿਆਰ ਤੱਕ ਪਹੁੰਚ ਗਏ, ਤਦੋਂ ਨਤੀਜੇ ਇੱਕ-ਦੂਜੇ 'ਤੇ ਚੜ੍ਹਨ ਲੱਗੇ। ਵਧੀਆ ਨਤੀਜੇ ਹੋਰ ਨਿਵੇਸ਼ ਖਿੱਚਦੇ, ਜੋ ਵੱਡੇ ਡਾਟਾਸੈੱਟ ਅਤੇ ਤੇਜ਼ ਹਾਰਡਵੇਅਰ ਨੂੰ ਫੰਡ ਕਰਦੇ, ਜੋ ਕਿ ਹੋਰ ਵਧੀਆ ਨਤੀਜੇ ਲਿਆਂਦੇ। ਬਾਹਰੋਂ ਇਹ ਇੱਕ ਛਾਲ ਵਾਂਗ ਲੱਗਦਾ ਹੈ; ਅੰਦਰੋਂ ਇਹ ਇੱਕ ਧੀਮੇ-ਧੀਮੇ ਬਣਨ ਵਾਲੀ ਪ੍ਰਕਿਰਿਆ ਹੈ।
ਸਕੇਲ ਕਰਨ ਨਾਲ ਅਸਲੀ ਲਾਗਤ ਆਉਂਦੀ ਹੈ: ਵੱਧ ਊਰਜਾ ਖਪਤ, ਮਹਿੰਗੇ ਟ੍ਰੇਨਿੰਗ ਰਨ, ਅਤੇ ਡਿਪਲੋਯਮੈਂਟ ਲਈ ਹੋਰ mehnat। ਇਸ ਨਾਲ ਛੋਟੀ ਟੀਮ ਦੇ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾਉਣ ਅਤੇ ਸਿਰਫ਼ ਚੁਣੇ ਹੋਏ ਲੈਬਾਂ ਦੇ ਸਪਸ਼ਟ ਫਰਕ ਨੂੰ ਵਧਾਉਂਦਾ ਹੈ।
Hinton ਦੇ ਫੰਡਾਮੈਂਟਲ ਵਿਚਾਰ—ਡਾਟਾ ਤੋਂ ਲਾਭਦਾਇਕ ਪ੍ਰਤਿਨਿਧੀਆਂ ਸਿੱਖਣਾ, ਡੀਪ ਨੈੱਟਵਰਕਸ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਟ੍ਰੇਨ ਕਰਨਾ, ਅਤੇ overfitting ਨਾਲ ਲੜਨਾ—ਉਹ "ਫੀਚਰ" ਨਹੀਂ ਹਨ ਜੋ ਤੁਸੀਂ ਐਪ ਵਿੱਚ ਦਿਖਾ ਸਕੋ। ਪਰ ਇਹ ਉਹ ਕਾਰਨ ਹਨ ਕਿ ਕਈ ਰੋਜ਼ਮਰਾ ਵਾਲੀਆਂ ਸੁਵਿਧਾਂ ਤੇਜ਼, ਜ਼ਿਆਦਾ ਸਹੀ ਅਤੇ ਘੱਟ ਨਿਰਾਸ਼ ਕਰਨ ਵਾਲੀਆਂ ਮਹਿਸੂਸ ਹੁੰਦੀਆਂ ਹਨ।
ਆਧੁਨਿਕ ਸਰਚ ਸਿਸਟਮ ਸਿਰਫ਼ keywords ਨੂੰ ਮੇਲ ਨਹੀਂ ਕਰਦੇ। ਉਹ ਖੋਜ ਅਤੇ ਸਮੱਗਰੀ ਦੀ ਪ੍ਰਤਿਨਿਧੀ ਸਿੱਖਦੇ ਹਨ ਤਾਂ ਕਿ "best noise-canceling headphones" ਵਰਗੇ ਕੁਝ ਕਈ ਵਾਰ ਅਜਿਹੇ ਪੇਜਾਂ ਨੂੰ ਵੀ ਉੱਪਰ ਲਿਆ ਸਕਣ ਜੋ ਠੀਕ ਵਾਕਾਂਸ਼ ਨਹੀਂ ਦਿਖਾਉਂਦੇ। ਇਹੀ representation learning ਰਿਕਮੈਂਡੇਸ਼ਨ ਫੀਡਜ਼ ਨੂੰ ਵੀ ਸਮਝਾਰੀ ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਦੋ ਆਈਟਮ ਇਕ-ਦੂਜੇ ਨਾਲ ਕਿਵੇਂ ਮਿਲਦੇ ਹਨ ਭਾਵੇਂ ਉਹਨਾਂ ਦੇ ਵਰਣਨ ਵੱਖ-ਵੱਖ ਹੋਣ।
ਜਦੋਂ ਮਾਡਲ ਪੈਰ-ਪੈਰ ਪੈਟਰਨ (ਅੱਖਰ → ਸ਼ਬਦ → ਅਰਥ) ਸਿੱਖਣ ਵਿੱਚ ਬਿਹਤਰ ਹੋਏ ਤਾਂ ਮਸ਼ੀਨੀ ਅਨੁਵਾਦ ਵਿੱਚ ਵੱਡੀ ਸੁਧਾਰ ਆਈ। ਹਾਲਾਂਕਿ ਮਾਡਲ ਕਿਸਮਾਂ ਵਿਕਸਤ ਹੋ ਚੁੱਕੀਆਂ ਹਨ, ਪਰ ਟ੍ਰੇਨਿੰਗ ਦਾ ਖੇਡ-ਪਲਾਨ—ਵੱਡੇ ਡਾਟਾ, ਧਿਆਨਪੂਰਵਕ optimization ਅਤੇ regularization—ਅਜੇ ਵੀ ਭਰੋਸੇਯੋਗ ਭਾਸ਼ਾ ਫੀਚਰ ਬਣਾਉਣ ਵਿੱਚ ਮੇਹਤਵਪੂਰਨ ਹੈ।
ਵੋਇਸ ਅਸਿਸਟੈਂਟਸ ਅਤੇ ਡਿਕਟੇਸ਼ਨ ਉਹ ਨੈੱਟਵਰਕਸ ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਜੋ ਗੰਦੇ ਆਡੀਓ ਨੂੰ ਸਾਫ਼ ਟੈਕਸਟ ਵਿੱਚ ਮੈਪ ਕਰਦੇ ਹਨ। Backpropagation ਇਹਨਾਂ ਮਾਡਲਾਂ ਨੂੰ ਟਿਊਨ ਕਰਨ ਵਾਲਾ ਮੁੱਖ ਕਾਰਜ ਹੈ, ਜਦਕਿ dropout ਵਰਗੀਆਂ ਤਕਨੀਕਾਂ ਉਹਨਾਂ ਨੂੰ ਕਿਸੇ ਖਾਸ ਬੋਲਣ ਵਾਲੇ ਜਾਂ ਮਾਈਕ ਦੀ ਵਿਸ਼ੇਸ਼ਤਾ ਯਾਦ ਕਰਨ ਤੋਂ ਰੋਕਦੀਆਂ ਹਨ।
ਫੋਟੋ ਐਪਸ ਚਿਹਰੇ ਪਛਾਣ ਸਕਦੀਆਂ, ਮਿਲਦੇ-ਜੁਲਦੇ ਦ੍ਰਿਸ਼ ਗਰੂਪ ਕਰਦੀਆਂ ਅਤੇ "beach" ਵਰਗਾ ਖੋਜ ਬਿਨਾਂ ਮੈਨੂਅਲ ਟੈਗਿੰਗ ਦੇ ਕੰਮ ਕਰਾਉਂਦੀਆਂ ਹਨ। ਇਹ representation learning ਦਾ ਨਤੀਜਾ ਹੈ: ਸਿਸਟਮ ਵਿਜ਼ੂਅਲ ਫੀਚਰ (edges → textures → objects) ਸਿੱਖਦਾ ਹੈ ਜੋ ਟੈਗਿੰਗ ਅਤੇ retrieval ਨੂੰ ਸਕੇਲ 'ਤੇ ਕੰਮ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਚਾਹੇ ਤੁਸੀਂ ਮਾਡਲ ਸਿਰਫ਼ ਪ੍ਰਿਟ੍ਰੇਨ ਕੀਤੇ ਹੋਏ ਵਰਤ ਰਹੇ ਹੋ, ਫੈਲਾਉਂਦੇ ਹੋ, ਜਾਂ ਨਵਾਂ ਤਿਆਰ ਕਰ ਰਹੇ ਹੋ—ਇਹ ਸਿਧਾਂਤ ਰੋਜ਼ਮਰਾ ਉਤਪਾਦ ਕੰਮ ਵਿੱਚ ਆਉਂਦੇ ਹਨ: ਪਹਿਲਾਂ ਚੰਗੀ ਪ੍ਰਤਿਨਿਧੀ, ਫਿਰ ਟ੍ਰੇਨਿੰਗ ਅਤੇ ਮੁਲਿਆਂਕਣ ਨੂੰ ਸਥਿਰ ਕਰੋ, ਅਤੇ ਜਦ ਮਾਡਲ ਬੈਂਚਮਾਰਕ ਨੂੰ ਯਾਦ ਕਰਨ ਲੱਗੇ ਤਾਂ regularization ਵਰਤੋ।
ਇਸੇ ਕਾਰਨ ਆਧੁਨਿਕ “vibe-coding” ਟੂਲਜ਼ ਭੀ ਬਹੁਤ ਯੋਗ ਮਹਿਸੂਸ ਹੋ ਸਕਦੇ ਹਨ। Platforms like Koder.ai ਵਰਤਮਾਨ ਪੀੜ੍ਹੀ ਦੇ LLMs ਅਤੇ agent workflows ਉੱਤੇ ਟਿਕਕੇ ਹੋਏ ਹਨ ਤਾਂ ਜੋ ਟੀਮਾਂ ਸਧਾਰਨ-ਭਾਸ਼ਾ ਵਾਲੇ ਨਿਰਦੇਸ਼ਾਂ ਨੂੰ ਵੈਬ, ਬੈਕਐਂਡ, ਜਾਂ ਮੋਬਾਈਲ ਐਪਾਂ ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਣ—ਅਕਸਰ ਪਰੰਪਰਾਗਤ ਪਾਇਪਲਾਈਨਾਂ ਨਾਲੋਂ ਤੇਜ਼—ਅਤੇ ਫਿਰ ਵੀ ਤੁਹਾਨੂੰ ਸੋর্স ਕੋਡ ਐਕਸਪੋਰਟ ਕਰਨ ਅਤੇ ਇੱਕ ਆਮ ਇੰਜੀਨੀਅਰਿੰਗ ਟੀਮ ਵਾਂਗ ਤੈਨਾਤ ਕਰਨ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦੇ ਹਨ।
If you want the high-level training intuition, see /blog/backpropagation-explained.
ਵੱਡੀਆਂ ਖੋਜਾਂ ਅਕਸਰ ਸੌਖੇ ਕਹਾਣੀਆਂ ਵਿੱਚ ਬਦਲ ਦਿੱਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ। ਇਹ ਯਾਦ ਰੱਖਣ ਲਈ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ—ਪਰ ਇਹ ਉਹਨਾਂ ਸੱਚੀਆਂ ਗੱਲਾਂ ਨੂੰ ਲੁਕਾਉਂਦਾ ਹੈ ਜੋ ਵਾਸਤਵ ਵਿੱਚ ਹੋਇਆ ਅਤੇ ਅਜੇ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹੈ।
Hinton ਇੱਕ ਕੇਂਦਰੀ ਅੰਸ਼ ਹੈ, ਪਰ ਆਧੁਨਿਕ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਕਈ ਦਹਾਕਿਆਂ ਦੀ ਨੂੰਸ਼ੀਲਤਾ ਦਾ ਨਤੀਜਾ ਹਨ: optimization ਵਿਧੀਆਂ ਬਣਾਉਣ ਵਾਲੇ ਖੋਜਕਰਤਾ, ਡੈਟਾਸੈੱਟ ਬਣਾਉਣ ਵਾਲੇ ਲੋਕ, GPUs ਨੂੰ ਪ੍ਰ-yੋਗ ਕਰਨ ਵਾਲੇ ਇੰਜੀਨੀਅਰ, ਅਤੇ ਆਯੋਗਾਂ ਜਿਨ੍ਹਾਂ ਨੇ ਵਿਚਾਰਾਂ ਨੂੰ ਸਕੇਲ 'ਤੇ ਸਿੱਧ ਕੀਤਾ।
Hinton ਦੇ ਕੰਮ ਵਿੱਚ ਵੀ, ਉਸਦੇ ਵਿਦਿਆਰਥੀ ਅਤੇ ਸਹਯੋਗੀਆਂ ਨੇ ਵੱਡਾ ਯੋਗਦਾਨ ਦਿੱਤਾ। ਅਸਲ ਕਹਾਣੀ ਕਈ ਯੋਗਦਾਨਾਂ ਦੀ ਲੜੀ ਹੈ ਜੋ ਆਖ਼ਰਕਾਰ ਇਕੱਠੇ ਮਿਲੇ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਮੱਧ-20ਵੀਂ ਸਦੀ ਤੋਂ ਅਧਿਐਨ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਉਤਸਾਹ ਅਤੇ ਨਿਰਾਸ਼ਾ ਦੋਹਾਂ ਦੇ ਦੌਰ ਆਏ। ਜੋ ਬਦਲਿਆ ਉਹ ਨਹੀਂ ਕਿ ਸਿਧਾਂਤ ਮੌਜੂਦ ਨਹੀਂ ਸੀ, ਪਰ ਹੁਣ ਉਹਨਾਂ ਨੂੰ ਵੱਡੇ ਮਾਡਲ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਟ੍ਰੇਨ ਕਰਨ ਦੀ ਸਮਰੱਥਾ ਆ ਗਈ ਅਤੇ ਅਸਲ ਸਮੱਸਿਆਵਾਂ 'ਤੇ ਸਪਸ਼ਟ ਜਿੱਤ dikhane ਲੱਗੇ।
ਡਿਪਰ ਮਾਡਲ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਉਹ ਜਾਦੂ ਨਹੀਂ ਹਨ। ਟਰੇਨਿੰਗ ਸਮਾਂ, ਲਾਗਤ, ਡਾਟਾ ਦੀ ਗੁਣਵੱਤਾ ਅਤੇ diminishing returns ਸੱਚੇ ਰੁਕਾਵਟ ਹਨ। ਕਈ ਵਾਰ ਛੋਟੇ ਮਾਡਲ ਵੱਡੇ ਮਾਡਲ ਨਾਲੋਂ ਚੰਗੇ ਪਰਿਣਾਮ ਦਿੰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹਨਾਂ ਨੂੰ ਟਿਊਨ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ, ਉਹ ਸ਼ੋਰ-ਸਹਿਣਸ਼ੀਲ ਨਹੀਂ ਹੁੰਦੇ, ਜਾਂ ਟਾਸਕ ਲਈ ਬਿਹਤਰ ਮਿਲਦੇ ਹਨ।
Backpropagation ਪੈਰਾਮੀਟਰਾਂ ਨੂੰ ਲੇਬਲਡ ਫੀਡਬੈਕ ਦੇ ਕੇ ਸਹੀ ਕਰਨ ਦੀ ਪ੍ਰਯੋਗਕ ਵਿਧੀ ਹੈ। ਮਨੁੱਖ ਘੱਟ ਉਦਾਹਰਣਾਂ ਤੋਂ ਸਿੱਖਦੇ ਹਨ, ਵਿਸ਼ਾਲ prior knowledge ਵਰਤਦੇ ਹਨ, ਅਤੇ ਇੱਕੋ ਤਰ੍ਹਾਂ ਦੇ ਸਪਸ਼ਟ error signals 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਹੁੰਦੇ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕ ਜੀਵ ਵਿਗਿਆਨ ਤੋਂ ਪ੍ਰੇਰਿਤ ਹੋ ਸਕਦੇ ਹਨ ਪਰ ਉਹ ਦਿਮਾਗ ਦੇ ਸਹੀ ਨਕਸ਼ੇ ਨਹੀਂ ਹਨ।
Hinton ਦੀ ਕਹਾਣੀ ਸਿਰਫ਼ ਖੋਜਾਂ ਦੀ ਲੜੀ ਨਹੀਂ—ਇਹ ਇੱਕ ਨਮੂਨਾ ਹੈ: ਇੱਕ ਸਧਾਰਨ ਸਿੱਖਣ ਵਾਲੀ ਧਾਰਨਾ ਰੱਖੋ, ਉਸਦੀ ਕੜੀ-ਕੜੀ ਜਾਂਚ ਕਰੋ, ਅਤੇ ਆਲੇ-ਦੁਆਲੇ ਵਾਲੇ ਤੱਤ (ਡਾਟਾ, ਕੰਪਿਊਟ, ਟ੍ਰੇਨਿੰਗ ਨੁਸਖੇ) ਨੂੰ ਅਪਗਰੇਡ ਕਰੋ ਜਦੋਂ ਤੱਕ ਇਹ ਸਕੇਲ 'ਤੇ ਕੰਮ ਨਾ ਕਰਨ ਲੱਗੇ।
ਪਰੇਗਟ ਤਰੀਕਿਆਂ ਵਿੱਚੋਂ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਅੰਸ਼-ਅਨੁਕੂਲ ਆਦਤਾਂ ਪ੍ਰਾਇਕਟਿਕਲ ਹਨ:
ਸਿਰਫ਼ "ਵੱਡੇ ਮਾਡਲ ਜਿੱਤਦੇ ਹਨ" ਨੂੰ ਸਰਸਰ ਲੈਣ ਤੋਂ ਬਚੋ। ਇਹ ਅਧੂਰਾ ਹੈ।
ਬਿਨਾ ਸਾਫ਼ ਲਕੜੇ ਦੇ ਸਿਰਫ਼ ਆਕਾਰ ਦੀ ਪਿੱਛਾ ਕਰਨ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ:
ਇੱਕ ਚੰਗਾ ਡੀਫੌਲਟ ਹੈ: ਛੋਟੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਵੈਲਿਊ ਸਾਬਤ ਕਰੋ, ਫਿਰ ਸਕੇਲ ਕਰੋ—ਅਤੇ ਸਿਰਫ਼ ਉਸ ਹਿੱਸੇ ਨੂੰ ਸਕੇਲ ਕਰੋ ਜੋ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਪ੍ਰਦਰਸ਼ਨ ਰੋਕ ਰਿਹਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਹ ਸਬਕ ਦਿਨ-ਪ੍ਰਤੀਦਿਨ ਅਮਲ ਵਿੱਚ ਲਿਆਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਇਹ ਅਗਲੇ ਲਿੰਕ ਭਲੇਬੁੱਧੀ ਹੁੰਦੇ ਹਨ:
Backprop ਦੇ ਮੁੱਖ ਸਿੱਖਣ ਨਿਯਮ ਤੋਂ ਲੈ ਕੇ, ਡਾਟਾ ਤੋਂ ਅਰਥਪੂਰਨ ਪ੍ਰਤਿਨਿਧੀਆਂ ਤਿਆਰ ਕਰਨ, Dropout ਵਰਗੇ ਪ੍ਰਯੋਗਕ ਤਰੀਕੇ, ਅਤੇ AlexNet ਵਰਗਾ ਇੱਕ ਬ੍ਰੇਕਥਰੂ ਡੈਮੋ—ਕਹਾਣੀ ਇੱਕੋ ਹੀ ਰਹਿੰਦੀ: ਡਾਟਾ ਤੋਂ ਲਾਭਦਾਇਕ ਫੀਚਰ ਸਿੱਖੋ, ਟ੍ਰੇਨਿੰਗ ਨੂੰ ਸਥਿਰ ਬਣਾਓ, ਅਤੇ ਅਸਲ ਨਤੀਜਿਆਂ ਨਾਲ ਤਰੱਕੀ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ।
ਇਹੀ ਖੇਡ-ਪਲਾਨ ਯੋਗ ਹੈ।
Geoffrey Hinton ਇਸ ਲਈ ਮਿਆਨੀ ਹੈ ਕਿਉਂਕਿ ਉਸ ਨੇ ਵਾਰ-ਵਾਰ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਨੂੰ ਅਮਲ ਵਿੱਚ ਕੰਮ ਕਰਵਾਇਆ ਜਦੋਂ ਕਈ ਖੋਜਕਰਤਾ ਇਨ੍ਹਾਂ ਨੂੰ ਬੁਝੇ ਹੋਏ ਰਾਹ ਸਮਝਦੇ ਸਨ.
ਉਸ ਨੇ "AI ਦਾ ਆਵਿਸਕਾਰ" ਨਹੀ ਕੀਤਾ; ਉਹਨਾਂ ਦਾ ਪ੍ਰਭਾਵ ਇਸ ਗੱਲ 'ਤੇ ਹੈ ਕਿ ਉਹ representation learning ਨੂੰ ਅੱਗੇ ਵਧਾਉਂਦੇ ਰਹੇ, ਟ੍ਰੇਨਿੰਗ ਤਰੀਕਿਆਂ ਨੂੰ ਸੁਧਾਰਿਆ ਅਤੇ ਇੱਕ ਖੋਜ ਸੱਭਿਆਚਾਰ ਬਣਾਇਆ ਜਿਸ ਨੇ ਡਾਟਾ ਤੋਂ ਫੀਚਰ ਸਿੱਖਣ ਨੂੰ ਮੱਧ-ਬਿੰਦੂ ਬਣਾਇਆ ਨਾ ਕਿ ਹੱਥ ਨਾਲ ਨਿਯਮ ਲਿਖਣ ਨੂੰ।
ਇੱਥੇ "breakthrough" ਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਹੋਰ ਭਰੋਸੇਯੋਗ ਅਤੇ ਉਪਯੋਗੀ ਬਣ ਗਏ: ਉਹ ਘੱਟ-ਅਸਥਿਰ ਤਰੀਕੇ ਨਾਲ ਟਰੇਨ ਹੁੰਦੇ, ਅੰਦਰੂਨੀ ਫੀਚਰ ਬਿਹਤਰ ਸਿੱਖਦੇ, ਨਵਾਂ ਡਾਟਾ ਤੇ ਵਧੀਆ ਜਨਰਲਾਈਜ਼ ਕਰਦੇ ਜਾਂ ਮੁਸ਼ਕਲ ਟਾਸਕਾਂ ਤੱਕ ਸਕੇਲ ਕਰਦੇ।
ਇਹ ਕਿਸੇ ਚਮਕਦਾਰ ਡੈਮੋ ਤੋਂ ਵੱਧ ਹੈ—ਜ਼ਿਆਦਾ ਤੋਰ 'ਤੇ ਇਹ ਇੱਕ ਵਿਚਾਰ ਨੂੰ ਇੱਕ ਦੁਹਰਾਏ ਜਾਣਯੋਗ ਤਰੀਕੇ ਵਿੱਚ ਬਦਲਨਾ ਹੈ ਜਿਸ ਉੱਤੇ ਟੀਮਾਂ ਭਰੋਸਾ ਕਰ ਸਕਣ।
ਨਿਊਰਲ ਨੈੱਟਵਰਕਸ ਦਾ ਮਕਸਦ ਗੰਦੇ ਰੋਅ ਡਾਟਾ (ਪਿਕਸਲ, ਆਡੀਓ ਵੇਵਫਾਰਮ, ਟੈਕਸਟ ਟੋਕਨ) ਨੂੰ ਲਾਭਦਾਇਕ ਪ੍ਰਤਿਨਿਧੀਆਂ ਵਿੱਚ ਬਦਲਣਾ ਹੈ—ਅੰਦਰੂਨੀ ਫੀਚਰ ਜੋ ਮਹੱਤਵਪੂਰਨ ਚੀਜ਼ਾਂ ਨੂੰ ਕੈਪਚਰ ਕਰਦੇ ਹਨ.
ਇਹਨਾਂ ਮਾਡਲਾਂ ਨਾਲ ਇੰਜੀਨੀਅਰਾਂ ਨੂੰ ਹਰ ਇਕ ਫੀਚਰ ਹੱਥੋਂ-ਹੱਥ ਤਿਆਰ ਕਰਨ ਦੀ ਲੋੜ ਘਟ ਜਾਂਦੀ ਹੈ; ਮਾਡਲ ਖੁਦ ਡਾਟਾ ਤੋਂ ਪਰਤਾਂ ਵਾਰ ਫੀਚਰ ਸਿੱਖ ਲੈਂਦਾ ਹੈ, ਜੋ ਹਕੀਕਤ ਵਾਲੇ ਪਰਿਛਾਵਾਂ ਵਿੱਚ ਜ਼ਿਆਦਾ ਮਜ਼ਬੂਤ ਹੁੰਦਾ ਹੈ।
ਬੈਕਪ੍ਰੋਪਾਗੇਸ਼ਨ ਇੱਕ ਟ੍ਰੇਨਿੰਗ ਢੰਗ ਹੈ ਜੋ ਨੈੱਟਵਰਕ ਨੂੰ ਗਲਤੀਆਂ ਤੋਂ ਸਿੱਖਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ:
ਇਹ gradient descent ਵਰਗੇ ਅਲਗੋਰਿਦਮਾਂ ਨਾਲ ਕੰਮ ਕਰਦਾ ਹੈ, ਜੋ ਡਿੱਗਦੇ ਹੋਏ ਏਰਰ ਮੁੱਲ ਨੂੰ ਘਟਾਉਣ ਲਈ ਛੋਟੇ ਕਦਮ ਲੈਂਦੇ ਹਨ।
ਬੈਕਪ੍ਰੋਪ ਨੇ ਇੱਕ ਹੀ ਵਾਰੀ ਕਈ ਪਰਤਾਂ ਨੂੰ ਸੁਚੱਜੇ ਢੰਗ ਨਾਲ ਟਿਊਨ ਕਰਨ ਯੋਗ ਬਣਾਇਆ।
ਇਸ ਦਾ ਅਰਥ ਇਹ ਹੈ ਕਿ ਡੀਪਰ ਨੈੱਟਵਰਕ ਫੀਚਰ ਹਾਇਰਾਰਕੀ ਬਣਾਉ ਸਕਦੇ (ਜਿਵੇਂ ਕਿ edges → shapes → objects)। ਬਿਨਾ ਇੱਕ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਦੇ, ਕਈ ਸਮੇਂ ਡੈਪਥ ਵਰਕ ਨਹੀਂ ਕਰਦੀ।
Boltzmann machines ਹਰ ਸੰਭਾਵਨਾ ਵਾਲੀ ਕਾਂਫਿਗਰੇਸ਼ਨ ਨੂੰ ਇੱਕ energy ਸਕੋਰ ਦੇ ਕੇ ਸਿੱਖਦੀਆਂ ਹਨ; ਘੱਟ energy دا ਮਤਲਬ ਹੈ "ਇਹ ਕਾਂਫਿਗਰੇਸ਼ਨ ਮੰਨਯੋਗ ਹੈ।"
ਇਹ ਢਾਂਚਾ ਮਹੱਤਵਪੂਰਨ ਸੀ ਕਿਉਂਕਿ ਇਸ ਨੇ:
ਅੱਜ ਕੱਲ੍ਹ ਦੇ ਫੀਡਫਾਰਵਰਡ ਡੀਪ ਨੈੱਟਸ ਤੇਜ਼ ਅਤੇ ਸਕੇਲ ਕਰਨ ਯੋਗ ਹੋਣ ਕਰਕੇ ਵੱਧ ਵਰਤੇ ਜਾਂਦੇ ਹਨ, ਪਰ Boltzmann machines ਦੀ ਵਿਰਾਸਤ ਬਹਿਸ਼ਤੀ ਧਾਰਣਾ ਵਿੱਚ ਰਹੀ।
Representation learning ਦਾ ਮਤਲਬ ਹੈ ਮਾਡਲ ਆਪਣੇ ਹੀ ਅੰਦਰੂਨੀ ਫੀਚਰ ਸਿੱਖ ਲੈਂਦਾ ਹੈ ਜੋ ਟਾਸਕ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ, ਬਜਾਏ ਇਸਦੇ ਕਿ ਉਦਯੋਗ-ਵਿਸ਼ੇਸ਼ਜਰੀਆਂ ਨੂੰ ਹਰ ਫੀਚਰ ਹੱਥੋਂ-ਹੱਥ ਤਿਆਰ ਕਰਨਾ ਪਵੇ।
ਇਸ ਨਾਲ ਅਮਲ ਵਿੱਚ ਨਤੀਜੇ ਬਿਹਤਰ ਅਤੇ ਜ਼ਿਆਦਾ ਰੋਬਸਟ ਹੋ ਜਾਂਦੇ ਹਨ, ਕਿਉਂਕਿ ਸਿੱਖੇ ਹੋਏ ਫੀਚਰ ਅਸਲੀ ਡਾਟਾ ਵਿੱਚ ਆਉਣ ਵਾਲੀਆਂ ਬਦਲਾਵਾਂ (ਰੋਸ਼ਨੀ, ਮਾਈਕ, ਅੱਕਸੇਟ) ਦੇ ਅਨੁਕੂਲ ਹੋ ਸਕਦੇ ਹਨ।
Deep belief networks (DBNs) ਨੇ layer-by-layer pretraining ਰਾਹੀਂ ਡੈਪਥ ਨੂੰ ਵਾਸਤਵਿਕ ਬਣਾਇਆ।
ਹਰ ਪਰਤ ਪਹਿਲਾਂ ਆਪਣੇ ਇਨਪੁਟ ਦੀ ਬਣਤਰ ਸਿੱਖਦੀ (ਅਕਸਰ ਬਿਨਾ ਲੇਬਲਾਂ ਦੇ), ਜਿਸ ਨਾਲ ਪੂਰੀ ਸਟੈਕ ਨੂੰ ਇੱਕ "ਵਾਰਮ ਸਟਾਰਟ" ਮਿਲਦਾ। ਫਿਰ ਸਟੈਕ ਨੂੰ ਕਿਸੇ ਨਿਰਧਾਰਤ ਕੰਮ ਲਈ ਫਾਇਨ-ਟਿਊਨ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
Dropout ਟਰੇਨਿੰਗ ਦੌਰਾਨ ਕੁਝ units ਨੂੰ ਰੈਂਡਮ ਤੌਰ 'ਤੇ "ਬੰਦ" ਕਰ ਦੇਂਦਾ ਹੈ।
ਇਸ ਨਾਲ ਨੈੱਟਵਰਕ ਕਿਸੇ ਇੱਕ ਰਸਤੇ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਰਹਿੰਦਾ ਅਤੇ ਉਹ ਅਜਿਹੇ ਫੀਚਰ ਸਿੱਖਦਾ ਹੈ ਜੋ ਮਾਡਲ ਦੇ ਕਿਸੇ ਹਿੱਸੇ ਦੇ ਗਾਇਬ ਹੋਣ 'ਤੇ ਵੀ ਕੰਮ ਕਰਨ। ਇਹ ਅਮਲ ਵਿੱਚ ਜਨਰਲਾਈਜ਼ੇਸ਼ਨ ਨੂੰ ਸੁਧਾਰਦਾ ਹੈ ਅਤੇ overfitting ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ।
AlexNet ਨੇ ਝਟਕੇ ਵਾਲਾ ਪ੍ਰਭਾਵ ਪਾਇਆ ਕਿਉਂਕਿ ਉਸ ਨੇ ਦਿਖਾਇਆ ਕਿ ਇੱਕ ਡੀਪ convolutional ਨੈੱਟਵਰਕ ਆਮ ਤਰੀਕਿਆਂ ਨੂੰ ਹਰਾ ਸਕਦਾ ਹੈ ਜਦੋਂ ਤਿੰਨ ਚੀਜ਼ਾਂ ਇਕੱਠੀਆਂ ਹੋਵਣ:
ਇਸ ਨਤੀਜੇ ਨੇ ਉਦਯੋਗੀ ਧਿਆਨ ਖਿੱਚਿਆ ਅਤੇ ਡੀਪ ਲਰਨਿੰਗ ਨੂੰ ਇੱਕ ਪ੍ਰਾਇਕਟਿਕਲ ਰਾਹ ਵਜੋਂ ਮੰਨਵਾਇਆ।