26 ਨਵੰ 2025·8 ਮਿੰਟ
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਰਿਸ਼ਤਿਆਂ 'ਚ ਕਿਉਂ ਮਾਹਿਰ ਹਨ — ਹਰ ਚੀਜ਼ ਲਈ ਨਹੀਂ
ਜੇ ਤੁਹਾਡੇ ਸਵਾਲ ਕੁਨੈਕਸ਼ਨਾਂ 'ਤੇ ਧਿਆਨ ਰੱਖਦੇ ਹਨ ਤਾਂ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਚਮਕਦੇ ਹਨ। ਸਭ ਤੋਂ ਵਧੀਆ ਵਰਤੋਂ-ਕੇਸ, ਨੁਕਸਾਨ ਅਤੇ ਜਦੋਂ ਰਿਲੇਸ਼ਨਲ ਜਾਂ ਡੌਕਯੂਮੈਂਟ ਡੇਟਾਬੇਸ ਵਧੀਆ ਫਿੱਟ ਹੁੰਦੇ ਹਨ, ਇਹ ਜਾਣੋ।
ਜੇ ਤੁਹਾਡੇ ਸਵਾਲ ਕੁਨੈਕਸ਼ਨਾਂ 'ਤੇ ਧਿਆਨ ਰੱਖਦੇ ਹਨ ਤਾਂ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਚਮਕਦੇ ਹਨ। ਸਭ ਤੋਂ ਵਧੀਆ ਵਰਤੋਂ-ਕੇਸ, ਨੁਕਸਾਨ ਅਤੇ ਜਦੋਂ ਰਿਲੇਸ਼ਨਲ ਜਾਂ ਡੌਕਯੂਮੈਂਟ ਡੇਟਾਬੇਸ ਵਧੀਆ ਫਿੱਟ ਹੁੰਦੇ ਹਨ, ਇਹ ਜਾਣੋ।
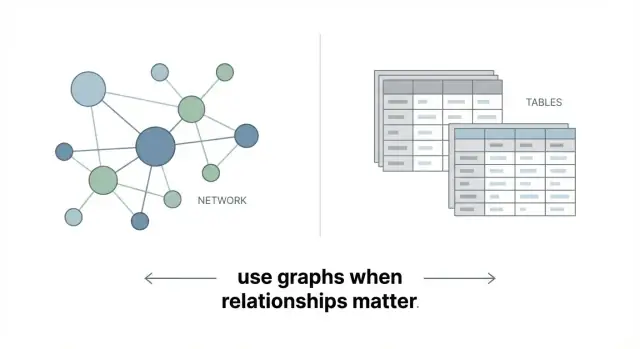
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਡੇਟਾ ਨੂੰ ਟੇਬਲਾਂ ਦੀ ਥਾਂ ਨੈੱਟਵਰਕ ਵਜੋਂ ਸਟੋਰ ਕਰਦੇ ਹਨ। ਮੁੱਖ ਵਿਚਾਰ ਸਿੱਧਾ ਹੈ:
ਇਨਾ ਦਾ ਮਤਲਬ: ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਜੁੜੇ ਹੋਏ ਡੇਟਾ ਨੂੰ ਦਰਸਾਂਦੇ ਹਨ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਵਿੱਚ, ਰਿਸ਼ਤੇ ਸੋਚ-ਵਿਚਾਰ ਦੀ ਦੇਰ ਨਹੀਂ ਹੁੰਦੇ—ਉਹ ਅਸਲ, ਕਿਵੇਂ-ਪੜ੍ਹੇ ਜਾ ਸਕਣ ਵਾਲੇ ਆਬਜੈਕਟ ਹੋਦੇ ਹਨ। ਇੱਕ ਰਿਸ਼ਤਾ ਆਪਣੀਆਂ ਪ੍ਰੌਪਰਟੀਜ਼ ਰੱਖ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਇੱਕ PURCHASED ਰਿਸ਼ਤਾ ਤਾਰੀਖ, ਚੈਨਲ, ਅਤੇ ਛੁਟ ਰੱਖ ਸਕਦਾ ਹੈ), ਅਤੇ ਤੁਸੀਂ ਇੱਕ ਨੋਡ ਤੋਂ ਦੂਜੇ ਨੋਡ ਤਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਚੱਲ ਸਕਦੇ ਹੋ।
ਇਹ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਬਹੁਤ ਸਾਰੇ ਕਾਰੋਬਾਰੀ ਸਵਾਲ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਰਸਤੇ ਅਤੇ ਕੁਨੈਕਸ਼ਨਾਂ ਬਾਰੇ ਹੁੰਦੇ ਹਨ: “ਕੌਣ ਕਿਸ ਨਾਲ ਜੁੜਿਆ ਹੈ?”, “ਇਹ ਘਟਨਾ ਕਿੰਨੇ ਕਦਮ ਦੂਰ ਹੈ?”, ਜਾਂ “ਇਨ੍ਹਾਂ ਦੋ ਚੀਜ਼ਾਂ ਦੇ ਵਿਚਕਾਰ ਸਾਂਝੇ ਲਿੰਕ ਕੀ ਹਨ?”
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਸ ਬਣੇ ਹਨ ਢਾਂਚਾਬੱਧ ਰਿਕਾਰਡਾਂ ਲਈ: ਗਾਹਕ, ਆਰਡਰ, ਚਲਾਨ। ਉਥੇ ਵੀ ਰਿਸ਼ਤੇ ਹੁੰਦੇ ਹਨ, ਪਰ ਅਕਸਰ ਉਹ ਫਾਰਨ-ਕੀਜ਼ ਰਾਹੀਂ ਅਪਰੋਕਸ਼ ਤੌਰ 'ਤੇ ਦਰਸਾਏ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕਈ ਕਦਮ ਜੋੜਨ ਲਈ ਕਈ ਟੇਬਲਾਂ 'ਤੇ ਜੋਇਨ ਲਿਖਣੇ ਪੈਂਦੇ ਹਨ।
ਗ੍ਰਾਫ ਜੁੜੇ ਹੋਏ ਡੇਟਾ ਨੂੰ ਸਿੱਧੇ-ਸਿੱਧਾ ਨਾਲ ਰੱਖਦੇ ਹਨ, ਇਸ ਲਈ ਬਹੁ-ਕਦਮੀ ਰਿਸ਼ਤਿਆਂ ਦੀ ਤਫਸੀਲ ਮਾਡਲ ਅਤੇ ਕਵੈਰੀ ਦੋਹਾਂ ਲਈ ਆਸਾਨ ਹੁੰਦੀ ਹੈ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਤਮ ਨੇ ਜਦੋਂ ਰਿਸ਼ਤੇ ਮੁੱਖ ਮਕਸਦ ਹੋਣ—ਸਿਫਾਰਿਸ਼ਾਂ, ਧੋਖਾਧੜੀ ਦੇ ਗਰੁੱਪ, ਨਿਰਭਰਤਾ ਮੈਪਿੰਗ, ਨੋਲੇਜ ਗ੍ਰਾਫ। ਉਹ ਸਧਾਰਨ ਰਿਪੋਰਟਿੰਗ, ਟੋਟਲ, ਜਾਂ ਬਹੁਤ ਟੇਬੂਲਰ ਵਰਕਲੋਡ ਲਈ ਆਪਣੇ ਆਪ ਬਿਹਤਰ ਨਹੀਂ ਹੁੰਦੇ। ਮਕਸਦ ਹਰ ਡੇਟਾਬੇਸ ਨੂੰ ਬਦਲਣਾ ਨਹੀਂ, ਸਗੋਂ ਜਿੱਥੇ ਕੁਨੈਕਟਿਵਟੀ ਮੁੱਲ ਬਣਾਉਂਦੀ ਹੈ ਉੱਥੇ ਗ੍ਰਾਫ ਵਰਤਣਾ ਹੈ।
ਜਿਆਦਾਤਰ ਕਾਰੋਬਾਰੀ ਸਵਾਲ ਇਕੱਲੇ ਰਿਕਾਰਡਾਂ ਬਾਰੇ ਨਹੀਂ ਹੁੰਦੇ—ਉਹ ਇਸ ਗੱਲ ਬਾਰੇ ਹੁੰਦੇ ਹਨ ਕਿ ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਜੁੜੀਆਂ ਹਨ।
ਇੱਕ ਗਾਹਕ ਸਿਰਫ਼ ਇੱਕ ਰੋ ਨਹੀਂ; ਉਹ ਆਰਡਰਾਂ, ਡਿਵਾਈਸਾਂ, ਪਤੇ, ਸਹਾਇਤਾ ਟਿਕਟ, ਰੈਫਰਲ ਅਤੇ ਕਈ ਵਾਰ ਹੋਰ ਗਾਹਕਾਂ ਨਾਲ ਜੁੜਿਆ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਲੈਣ-ਦੇਣ ਸਿਰਫ਼ ਇੱਕ ਘਟਨਾ ਨਹੀਂ; ਇਹ ਇੱਕ ਵਪਾਰੀ, ਭੁਗਤਾਨ ਮਾਧਿਅਮ, ਸਥਾਨ, ਸਮੇਂ ਦੀ ਵਿੰਡੋ ਅਤੇ ਸੰਬੰਧਿਤ ਗਤਿਵਿਧੀ ਦੀ ਲੜੀ ਨਾਲ ਜੁੜਿਆ ਹੁੰਦਾ ਹੈ। ਜਦੋਂ ਸਵਾਲ ਹੈ “ਕੌਣ/ਕਿਹੜਾ ਕਿਸ ਨਾਲ ਜੁੜਿਆ ਹੈ, ਅਤੇ ਕਿਵੇਂ?”, ਰਿਸ਼ਤਾ ਡੇਟਾ ਮੁੱਖ ਕਿਰਦਾਰ ਬਣ ਜਾਂਦਾ ਹੈ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ traversals ਲਈ ਬਣਾਏ ਗਏ ਹਨ: ਤੁਸੀਂ ਇੱਕ ਨੋਡ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ ਅਤੇ ਐਜ਼ ਨੂੰ ਫਾਲੋ ਕਰਦੇ ਹੋ ਕੇ ਨੈੱਟਵਰਕ 'ਚ “ਚੱਲਦੇ” ਹੋ।
ਬਦਲੇ ਵਿੱਚ ਟੇਬਲਾਂ ਨੂੰ ਵਾਰੀ-ਵਾਰੀ ਜੋੜਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਉਹ ਰਾਹ ਦਰਸਾਉਂਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਜਾਣਾ ਚਾਹੁੰਦੇ ਹੋ: Customer → Device → Login → IP Address → Other Customers. ਇਹ ਕਦਮ-ਦਰ-ਕਦਮ ਫਰੇਮ ਲੋਕਾਂ ਦੇ ਤਰੀਕੇ ਨਾਲ ਮਿਲਦਾ ਹੈ ਕਿ ਉਹ ਧੋਖਾਧੜੀ ਦੀ ਜਾਂਚ ਕਿਵੇਂ ਕਰਦੇ ਹਨ, ਨਿਰਭਰਤਾਵਾਂ ਦੀ ਪਛਾਣ ਕਰਦੇ ਹਨ, ਜਾਂ ਸਿਫਾਰਿਸ਼ਾਂ ਦੀ ਵਿਆਖਿਆ ਕਰਦੇ ਹਨ।
ਅਸਲ ਫਰਕ ਉਹਤੋਂ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਕਈ ਕਦਮ ਚਾਹੀਦੇ ਹੁੰਦੇ ਹਨ (2, 3, 5 ਕਦਮ) ਅਤੇ ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ ਕਿ ਦਿਲਚਸਪ ਕਨੈਕਸ਼ਨ ਕਿੱਥੇ ਆਉਣਗੇ।
ਰਿਲੇਸ਼ਨਲ ਮਾਡਲ ਵਿੱਚ, ਬਹੁ-ਕਦਮੀ ਸਵਾਲ ਅਕਸਰ ਲੰਬੀਆਂ ਜੋਇਨ ਚੇਨਾਂ ਅਤੇ ਦੁਹਰਾਵਾਂ ਤੋਂ ਬਚਣ ਲਈ ਵਾਧੂ ਲਾਜਿਕ ਵਿੱਚ ਬਦਲ ਜਾਂਦੇ ਹਨ। ਗ੍ਰਾਫ ਵਿੱਚ, “ਮੇਨੂੰ N ਕਦਮ ਤੱਕ ਸਾਰੇ ਰਾਹ ਲੱਭੋ” ਇੱਕ ਆਮ, ਪਾਠਯੋਗ ਪੈਟਰਨ ਹੈ—ਖਾਸ ਤੌਰ 'ਤੇ property graph ਮਾਡਲ ਵਿੱਚ ਜੋ ਬਹੁਤ ਸਾਰੇ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਵਰਤਦੇ ਹਨ।
ਐਜ਼ ਸਿਰਫ ਲਾਈਨਾਂ ਨਹੀਂ; ਉਹ ਡੇਟਾ ਵੀ ਰੱਖ ਸਕਦੀਆਂ ਹਨ:
ਇਹ ਪ੍ਰੌਪਰਟੀਜ਼ ਤੁਹਾਨੂੰ ਬਿਹਤਰ ਸਵਾਲ ਪੁੱਛਣ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦੀਆਂ ਹਨ: “ਪਿਛਲੇ 30 ਦਿਨਾਂ ਵਿੱਚ ਜੁੜੇ”, “ਸਬ ਤੋਂ ਮਜ਼ਬੂਤ ਟਾਈਜ਼”, ਜਾਂ “ਉਹ ਰਾਹ ਜੋ ਉੱਚ-ਰਿਸਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਸ਼ਾਮِل ਕਰਦੇ ਹਨ”—ਬਿਨਾਂ ਹਰ ਚੀਜ਼ ਨੂੰ ਵੱਖ-ਵੱਖ ਲੁਕਅੱਪ ਟੇਬਲਾਂ ਵਿੱਚ ਫਿਰਾਉਣ ਦੇ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚਮਕਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਡੇ ਸਵਾਲ ਕੁਨੈਕਟਿਵਟੀ 'ਤੇ ਨਿਰਭਰ ਹੋਣ: “ਕੌਣ ਕਿਸ ਨਾਲ ਜੁੜਿਆ ਹੈ, ਕਿਸ ਰਾਹ ਦੇ ਰਾਹੀਂ, ਅਤੇ ਕਿੰਨੇ ਕਦਮ ਦੂਰ?” ਜੇ ਤੁਹਾਡੇ ਡੇਟਾ ਦੀ ਕੀਮਤ ਰਿਸ਼ਤਾ ਡੇਟਾ ਵਿੱਚ ਹੈ (ਸਿਰਫ਼ ਐਟ੍ਰਿਬਿਊਟ ਵਾਲੀਆਂ ਕਤਾਰਾਂ ਨਹੀਂ), ਤਾਂ ਗ੍ਰਾਫ ਮਾਡਲ ਡੇਟਾ ਮਾਡਲਿੰਗ ਅਤੇ ਕਵੇਰੀ ਦੋਹਾਂ ਨੂੰ ਕੁਦਰਤੀ ਬਣਾਉਂਦਾ ਹੈ।
ਜੀਹੜਾ ਕੁਝ ਨੈੱਟਵਰਕ ਦੀ ਸ਼ਕਲ ਦਾ ਹੁੰਦਾ ਹੈ—ਮਿਤ੍ਰ, ਫਾਲੋਅਰ, ਸਹਿਕਰਮੀ, ਟੀਮ, ਰੈਫਰਲ—ਉਹ ਸਾਫ਼ ਤੌਰ 'ਤੇ ਨੋਡਾਂ ਅਤੇ ਰਿਸ਼ਤਿਆਂ 'ਤੇ ਮੈਪ ਹੋ ਜਾਂਦਾ ਹੈ। ਆਮ ਸਵਾਲਾਂ ਵਿੱਚ “ਪਰਸਪਰ ਕਨੈਕਸ਼ਨ”, “ਕਿਸੀ ਵਿਅਕਤੀ ਤੱਕ ਸਭ ਤੋਂ ਛੋਟਾ ਰਾਹ”, ਜਾਂ “ਇਹ ਦੋ ਸਮੂਹਾਂ ਨੂੰ ਕੌਣ ਜੋੜਦਾ ਹੈ?” ਹੁੰਦੇ ਹਨ। ਇਹ ਕਵੇਰੀਆਂ ਬਹੁਤ ਵਾਰੀ ਜੋਇਨਾਂ ਨਾਲ ਜਬਰਦਸਤ ਜਾਂ ਧੀਮੀ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਸਿਫਾਰਿਸ਼ ਇੰਜਣ ਅਕਸਰ ਬਹੁ-ਕਦਮੀ ਕਨੈਕਸ਼ਨਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ: user → item → category → similar items → other users. ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ “ਜਿਨ੍ਹਾਂ ਨੇ X ਨੂੰ ਲਿਆ ਉਹ Y ਨੂੰ ਵੀ ਲਿਆ” ਜਾਂ “ਅਕਸਰ ਇਕੱਠੇ ਵੇਖੇ ਜਾਂਦੇ ਉਤਪਾਦ” ਵਰਗੀਆਂ ਗੱਲਾਂ ਲਈ ਢੰਗ ਨਾਲ ਮਲਦੇ ਹਨ। ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਜਦੋਂ ਸਿਗਨਲ ਵੱਖ-ਵੱਖ ਹੋਣ ਅਤੇ ਤੁਸੀਂ ਨਵੇਂ ਰਿਸ਼ਤੇ ਸ਼ਾਮਲ ਕਰਦੇ ਰਹਿੰਦੇ ਹੋ, ਤਾਂ ਇਹ ਲਾਭਦਾਇਕ ਹੁੰਦਾ ਹੈ।
ਧੋਖਾਧੜੀ ਪਛਾਣ ਗ੍ਰਾਫ ਚੰਗੇ ਕੰਮ ਕਰਦੇ ਹਨ ਕਿਉਂਕਿ ਸੰਦੇਹਸਪਦ ਵਰਤੋਂ ਹਮੇਸ਼ਾ ਇਕੱਲੀ ਨਹੀਂ ਹੁੰਦੀ। ਖਾਤੇ, ਡਿਵਾਈਸ, ਲੈਣ-ਦੇਣ, ਫ਼ੋਨ ਨੰਬਰ, ਈਮੇਲ ਅਤੇ ਪتے ਸਾਂਝੇ ਪਹਿਚਾਨਾਂ ਦੇ ਜਾਲ ਬਣਾਉਂਦੇ ਹਨ। ਗ੍ਰਾਫ ਰਿੰਗਾਂ, ਦੁਹਰਾਏ ਹੋਏ ਪੈਟਰਨ ਅਤੇ ਅਪਰੋਕਸ਼ ਲਿੰਕਾਂ (ਉਦਾਹਰਨ: ਦੋ “ਬੇਸੰਤ” ਖਾਤੇ ਇੱਕ ਹੀ ਡਿਵਾਈਸ ਰਾਹੀਂ ਜੁੜੇ ਹੋਏ) ਨੂੰ ਦੇਖਣ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
ਸੇਵਾਵਾਂ, ਹੋਸਟਾਂ, APIs, ਕਾਲਾਂ ਅਤੇ ਮਾਲਕੀਅਤ ਲਈ, ਮੁੱਖ ਸਵਾਲ ਨਿਰਭਰਤਾ ਹੋਂਦੀ ਹੈ: “ਜੇ ਇਹ ਬਦਲੇ ਤਾਂ ਕੀ ਟੁੱਟੇਗਾ?” ਗ੍ਰਾਫ ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ, ਰੂਟ-ਕਾਜ਼ ਖੋਜ, ਅਤੇ “ਬਲਾਸਟ ਰੇਡੀਅਸ” ਕਵੇਰੀਆਂ ਲਈ ਮਦਦਗਾਰ ਹਨ ਜਦੋਂ ਸਿਸਟਮ ਇਕ ਦੂਜੇ ਨਾਲ ਜੁੜੇ ਹੋਂਦੇ ਹਨ।
ਨੋਲੇਜ ਗ੍ਰਾਫ ਸੱਧਾਂਤਾਂ (ਲੋਗ, ਕੰਪਨੀਆਂ, ਉਤਪਾਦ, ਦਸਤਾਵੇਜ਼) ਨੂੰ ਫੈਕਟਾਂ ਅਤੇ ਸੋਤਰਾਂ ਨਾਲ ਜੋੜਦੇ ਹਨ। ਇਹ ਖੋਜ, ਇੰਟੀਟੀ ਰੈਜ਼ੋਲੂਸ਼ਨ, ਅਤੇ ਇਹ ਦਰਸਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਕਿ ਕਿਸ ਤਰ੍ਹਾਂ ਕੋਈ ਫੈਕਟ ਜਾਣਿਆ ਗਿਆ (provenance) ਕਈ ਲਿੰਕ ਕੀਤੇ ਸਰੋਤਾਂ ਦੇ ਰਾਹੀਂ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਸਵਾਲਾਂ ਲਈ ਸ਼ਾਨਦਾਰ ਹਨ ਜੋ ਅਸਲ ਵਿੱਚ ਕੁਨੈਕਸ਼ਨਾਂ ਬਾਰੇ ਹੁੰਦੇ ਹਨ: ਕੌਣ ਕਿਸ ਨਾਲ ਜੁੜਿਆ ਹੈ, ਕਿਸ ਰਾਹ ਦੁਆਰਾ, ਅਤੇ ਕਿਹੜੇ ਪੈਟਰਨ ਦੋਹਰਾਏ ਜਾ ਰਹੇ ਹਨ। ਟੇਬਲਾਂ ਨੂੰ ਮੁੜ-ਮੁੜ ਜੋੜਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਸਿੱਧਾ ਰਿਸ਼ਤੇ ਦਾ ਸਵਾਲ ਪੁੱਛਦੇ ਹੋ ਅਤੇ ਜਿਵੇਂ ਜਾਲ ਵੱਡਾ ਹੁੰਦਾ ਹੈ, ਕਵੇਰੀ ਪਾਠਯੋਗ ਰਹਿੰਦੀ ਹੈ।
ਆਮ ਸਵਾਲ:
ਇਹ ਗਾਹਕ ਸਹਾਇਤਾ (“ਅਸੀਂ ਇਹ ਸੁਝਾਅ ਕਿਉਂ ਕੀਤਾ?”), ਅਨੁਕੂਲਤਾ (“ਮਾਲਕੀ ਲੜੀ ਦਿਖਾਓ”), ਅਤੇ ਜਾਂਚਾਂ (“ਇਹ ਕਿਵੇਂ ਫੈਲਿਆ?”) ਲਈ ਮਦਦਗਾਰ ਹੈ।
ਗ੍ਰਾਫ ਤੁਹਾਨੂੰ ਕੁਦਰਤੀ ਗਰੁੱਪਿੰਗ ਦਿਖਾਉਂਦੇ ਹਨ:
ਤੁਸੀਂ ਇਸ ਨੂੰ ਯੂਜ਼ਰ ਸੈਗਮੈਂਟ ਕਰਨ, ਧੋਖਾਧੜੀ ਟੀਮਾਂ ਲੱਭਣ, ਜਾਂ ਉਤਪਾਦਾਂ ਦੇ ਆਪਸੀ ਖਰੀਦੀ ਦੇ ਤਰੀਕੇ ਸਮਝਣ ਲਈ ਵਰਤ ਸਕਦੇ ਹੋ। ਅਹਮ ਗੱਲ ਇਹ ਹੈ ਕਿ “ਗਰੁੱਪ” ਨੂੰ ਇਹ ਦਰਸਾਉਂਦਾ ਹੈ ਕਿ ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਜੁੜੀਆਂ ਹਨ, ਨਾ ਕਿ ਕਿਸੇ ਇੱਕ ਕਾਲਮ ਦੁਆਰਾ।
ਕਈ ਵਾਰ ਸਵਾਲ ਸਿਰਫ “ਕੌਣ ਜੁੜਿਆ ਹੈ” ਨਹੀਂ ਹੁੰਦਾ, ਬਲਕਿ “ਕੌਣ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਹੈ”:
ਇਹ ਕੇਂਦਰੀ ਨੋਡ ਆਮ ਤੌਰ 'ਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ, ਨਾਜ਼ੁਕ ਢਾਂਚਾ, ਜਾਂ ਮੋੜ-ਬਿੰਦੂ ਦਰਸਾਉਂਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਦੀ ਨਿਗਰਾਨੀ ਲੋੜ ਹੈ।
ਗ੍ਰਾਫ ਦੋਹਰਾਏ ਜਾਣ ਵਾਲੇ ਆਕਾਰਾਂ ਦੀ ਖੋਜ ਵਿੱਚ ਸ਼ਾਨਦਾਰ ਹਨ:
Cypher (ਇੱਕ ਆਮ ਗ੍ਰਾਫ ਕਵੇਰੀ ਭਾਸ਼ਾ) ਵਿੱਚ, ਇੱਕ ਤਿਕੋਣ ਪੈਟਰਨ ਇਸ ਤਰ੍ਹਾਂ ਲੱਗ ਸਕਦੀ ਹੈ:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
ਭਾਵੇਂ ਤੁਸੀਂ ਖੁਦ Cypher ਨਾ ਲਿਖੋ, ਇਹ ਦਿਖਾਉਂਦਾ ਹੈ ਕਿਉਂ ਗ੍ਰਾਫ ਪਹੁੰਚਯੋਗ ਹਨ: ਕਵੇਰੀ ਉਸ ਤਸਵੀਰ ਨਾਲ ਮਿਲਦੀ ਹੈ ਜੋ ਤੁਹਾਡੇ ਦਿਮਾਗ ਵਿੱਚ ਹੈ।
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਉਹ ਚੀਜ਼ਾਂ ਲਈ ਸ਼ਾਨਦਾਰ ਹਨ ਜਿਨ੍ਹਾਂ ਲਈ ਉਹ ਬਣਾਏ ਗਏ ਸਨ: ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਅਤੇ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸੰਜੋਇਆ ਹੋਇਆ ਰਿਕਾਰਡ। ਜੇ ਤੁਹਾਡੇ ਡੇਟਾ ਨੂੰ ਟੇਬਲਾਂ ਵਿੱਚ ਠੀਕ ਫਿੱਟ ਹੁੰਦਾ ਹੈ (ਗਾਹਕ, ਆਰਡਰ, ਚਲਾਨ) ਅਤੇ ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ID, ਫਿਲਟਰ, ਅਤੇ ਅਨੇਕ ਗਣਨਾਵਾਂ ਨਾਲ ਪ੍ਰਾਪਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮ ਅਕਸਰ ਸਭ ਤੋਂ ਸਧਾਰਨ, ਸੁਰੱਖਿਅਤ ਚੋਣ ਹੁੰਦੇ ਹਨ।
ਜਦੋਂ ਜੋਇਨ ਕਦੇ-ਕਦੇ ਅਤੇ ਥੋੜੇ ਹੋਂਦੇ ਹਨ ਤਾਂ ਉਹ ਠੀਕ ਹਨ। ਮੁਸ਼ਕਲ ਉਹ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਸਵਾਲ ਹਮੇਸ਼ਾਂ ਬਹੁਤ ਸਾਰੇ ਜੋਇਨਾਂ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ।
ਉਦਾਹਰਨ:
SQL ਵਿੱਚ, ਇਹ ਲੰਬੀਆਂ ਕਵੇਰੀਆਂ ਵਿਚ ਬਦਲ ਸਕਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਦੁਹਰਾਵਾਂ ਸੈਲਫ-ਜੋਇਨ ਅਤੇ ਜਟਿਲ ਲਾਜਿਕ ਹੋ ਸਕਦੀ ਹੈ। ਜਦੋਂ ਰਿਸ਼ਤੇ ਦੀ ਡੇਪਥ ਵਧਦੀ ਹੈ, ਉਹਨਾਂ ਨੂੰ ਟਿਊਨ ਕਰਨਾ ਵੀ ਮੁਸ਼ਕਿਲ ਹੋ ਸਕਦਾ ਹੈ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਸਟੋਰ ਕਰਦੇ ਹਨ, ਇਸ ਲਈ ਕਈ ਕਦਮਾਂ ਦੀ ਯਾਤਰਾ ਕੁਦਰਤੀ ਹੈ। ਟੇਬਲਾਂ ਨੂੰ ਕਵੇਰੀ ਸਮੇਂ ਜੁੜਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਜੁੜੇ ਹੋਏ ਨੋਡ ਅਤੇ ਐਜ਼ਾਂ ਨੂੰ ਤਰਵਰਸ ਕਰਦੇ ਹੋ।
ਇਸਦਾ ਅਰਥ ਆਮ ਤੌਰ 'ਤੇ:
ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਅਕਸਰ ਬਹੁ-ਹੋਪ ਸਵਾਲ ਪੁੱਛਦੀ ਹੈ—“ਜੁੜਿਆ ਹੋਇਆ,” “ਦਰਮਿਆਨ ਰਾਹ,” “ਉਸੇ ਨੈੱਟਵਰਕ ਵਿੱਚ”—ਤਾਂ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ 'ਤੇ ਵਿਚਾਰ ਕਰਨ ਯੋਗ ਹੈ।
ਜੇ ਤੁਹਾਡਾ ਮੁੱਖ ਵਰਕਲੋਡ ਉੱਚ-ਵਾਲਿਊਮ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ, ਕੜੀ schema, ਰਿਪੋਰਟਿੰਗ, ਅਤੇ ਸਧਾਰਨ ਜੋਇਨ ਹਨ, ਤਾਂ ਰਿਲੇਸ਼ਨਲ ਅਕਸਰ ਡਿਫਾਲਟ ਚੰਗੀ ਚੋਣ ਹੁੰਦਾ ਹੈ। ਬਹੁਤ ਸਿਸਟਮ ਦੋਹਾਂ ਵਰਤਦੇ ਹਨ; ਵੇਖੋ /blog/practical-architecture-graph-alongside-other-databases.
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਹ ਵੇਲੇ ਚੰਗੇ ਹਨ ਜਦੋਂ ਰਿਸ਼ਤੇ “ਮੁੱਖ ਪ੍ਰਸਤੁਤੀ” ਹੋਣ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਦੀ ਕੀਮਤ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਆਧਾਰ ਨਹੀਂ ਹੁੰਦੀ (ਕੌਣ-ਜਾਣ-ਕੌਣ, ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਸੰਬੰਧਿਤ ਹਨ, ਰਾਸਤੇ, ਪੜੋਸ), ਤਾਂ ਗ੍ਰਾਫ ਵਿਚ ਸਮਾਂ ਅਤੇ ਜਟਿਲਤਾ ਵੱਧ ਸਕਦੀ ਹੈ ਬਿਨਾਂ ਖਾਸ ਲਾਭ ਦੇ।
ਜੇ ਜ਼ਿਆਦਾਤਰ ਬੇਨਤੀ “ID ਰਾਹੀਂ ਯੂਜ਼ਰ ਲੱਭੋ,” “ਪ੍ਰੋਫਾਇਲ ਅਪਡੇਟ ਕਰੋ,” “ਆਰਡਰ ਬਣਾਓ” ਹਨ ਅਤੇ ਜ਼ਰੂਰੀ ਡੇਟਾ ਇੱਕ ਰਿਕਾਰਡ (ਜਾਂ ਥੋੜ੍ਹੇ ਟੇਬਲ) ਵਿੱਚ ਰਹਿੰਦਾ ਹੈ, ਤਾਂ ਗ੍ਰਾਫ ਅਕਸਰ ਗੈਰਜ਼ਰੂਰੀ ਹੈ। ਤੁਸੀਂ ਨੋਡ ਅਤੇ ਐਜ਼ ਮਾਡਲ ਕਰਨ, traversals ਨੂੰ ਟਿਊਨ ਕਰਨ, ਅਤੇ ਨਵੀਂ ਕਵੇਰੀ ਸ਼ੈਲੀ ਸਿੱਖਣ ਵਿੱਚ ਸਮਾਂ ਲਗਾਉਗੇ—ਜਦਕਿ ਰਿਲੇਸ਼ਨਲ ਇਸ ਪੈਟਰਨ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਅਤੇ ਜਾਣੂ ਟੂਲਿੰਗ ਨਾਲ ਸੰਭਾਲਦਾ ਹੈ।
ਜੋ ਡੈਸ਼ਬੋਰਡ ਟੋਟਲ, ਔਸਤ, ਅਤੇ ਗਰੂਪ ਕੀਤੇ ਮੈਟ੍ਰਿਕਸ 'ਤੇ ਅਧਾਰਿਤ ਹਨ (ਮਹੀਨੇ ਵਾਰ ਰੇਵਿਨਿਊ, ਖੇਤਰ ਵਾਰ ਆਰਡਰ, ਚੈਨਲ ਵਾਰ ਕਨਵਰਜ਼ਨ ਰੇਟ) ਆਮ ਤੌਰ 'ਤੇ SQL ਅਤੇ ਕਾਲਮਾਰ ਅਨੈਲਿਟਿਕਸ ਲਈ ਵਧੀਆ ਫਿੱਟ ਹੁੰਦੇ ਹਨ। ਗ੍ਰਾਫ ਇੰਜਨ ਕੁਝ aggregates ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਨ, ਪਰ ਭਾਰੀ OLAP-ਸ਼ੈਲੀ ਵਰਕਲੋਡ ਲਈ ਉਹ ਕਦੇ-ਕਦੇ ਸਭ ਤੋਂ ਆਸਾਨ ਜਾਂ ਤੇਜ਼ ਰਾਹ ਨਹੀਂ ਹੁੰਦੇ।
ਜਦੋਂ ਤੁਸੀਂ ਪੱਕੇ SQL ਫੀਚਰਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹੋ—ਜੱਟਿਲ ਜੋਇਨ, ਕਸਰਤੀ ਪਾਬੰਦੀਆਂ, ਐਡਵਾਂਸਡ ਇੰਡੈਕਸਿੰਗ, ਸਟੋਰਡ ਪ੍ਰੋਸੀਜਰ, ਜਾਂ ਪੱਕੇ ACID ਪੈਟਰਨ—ਤਾਂ ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮ ਆਮ ਤੌਰ 'ਤੇ ਕੁਦਰਤੀ ਫਿੱਟ ਹੁੰਦੇ ਹਨ। ਬਹੁਤ ਸਾਰੇ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ سپੋਰਟ ਕਰਦੇ ਹਨ, ਪਰ ਆਸ پاس ਦਾ ਇਕੋਸਿਸਟਮ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਪੈਟਰਨ ਤੁਹਾਡੇ ਟੀਮ ਦੀ ਆਮ ਵਰਤੋਂ ਨਾਲ ਮੇਲ ਨਹੀਂ ਖਾਂਦੇ।
ਜੇ ਤੁਹਾਡਾ ਡੇਟਾ ਬਹੁਤ ਹੱਦ ਤੱਕ ਆਜ਼ਾਦ ਘਟਨਾਵਾਂ (ਟਿਕਟ, ਚਲਾਨ, ਸੈੰਸਰ ਰੀਡਿੰਗ) ਦਾ ਸੈੱਟ ਹੈ ਜਿਸ ਵਿੱਚ ਘੱਟ-ਮਾਣ ਵਾਲੇ ਕਨੈਕਸ਼ਨ ਹਨ, ਤਾਂ ਗ੍ਰਾਫ ਮਾਡਲ ਜ਼ਬਰਦਸਤ ਮਹਿਸ਼ੂਸ ਹੋ ਸਕਦਾ ਹੈ। ਐਸੇ ਕੇਸਾਂ ਵਿੱਚ, ਇੱਕ ਸਾਫ਼ ਰਿਲੇਸ਼ਨਲ ਸਕੀਮਾ (ਜਾਂ ਡੌਕਯੂਮੈਂਟ ਮਾਡਲ) 'ਤੇ ਧਿਆਨ ਦਿਓ ਅਤੇ ਕਿਵੇਂ-ਕਦੋਂ ਗ੍ਰਾਫ ਦੀ ਲੋੜ ਹੋਵੇ ਉਹ ਬਾਅਦ ਵਿੱਚ ਸੋਚੋ।
ਇੱਕ ਚੰਗਾ ਨਿਯਮ: ਜੇ ਤੁਸੀਂ ਆਪਣੇ ਟاپ ਕਵੇਰੀਆਂ ਨੂੰ ਉਹਦੇ ਬਿਨਾਂ ਬਿਆਨ ਕਰ ਸਕਦੇ ਹੋ ਜਿਵੇਂ “connected,” “path,” “neighborhood,” ਜਾਂ “recommend” ਵਰਤੇ ਬਿਨਾਂ, ਤਾਂ ਸ਼ੁਰੂਆਤ ਲਈ ਗ੍ਰਾਫ ਸਹੀ ਚੋਣ ਨਹੀਂ ਹੋ ਸਕਦੀ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਸ ਵੇਲੇ ਚਮਕਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਨੂੰ ਜ਼ਲਦੀ ਕੁਨੈਕਸ਼ਨਾਂ ਦਾ ਪਿੱਛਾ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇ—ਪਰ ਇਸ ਤਾਕਤ ਦੀ ਕੀਮਤ ਹੁੰਦੀ ਹੈ। ਫ਼ੈਸਲਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਸਮਝਣਾ ਫਾਇਦੇਮੰਦ ਹੈ ਕਿ ਗ੍ਰਾਫ ਕਿੱਥੇ ਘੱਟ ਕੁਸ਼ਲ, ਮਹਿੰਗੇ, ਜਾਂ ਰੋਜ਼ਾਨਾ ਚਲਾਉਣ ਵਿੱਚ ਵੱਖਰੇ ਹੋ ਸਕਦੇ ਹਨ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਅਕਸਰ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਤੇਜ਼ ਬਣਾਈ ਰੱਖਣ ਲਈ ਇਸ ਤਰ੍ਹਾਂ ਸਟੋਰ ਅਤੇ ਇੰਡੈਕਸ ਕਰਦੇ ਹਨ ਕਿ “ਹੋਪ” ਤੇਜ਼ ਹੋਣ। ਟਰੇਡ-ਆਫ ਇਹ ਹੈ ਕਿ ਉਹ ਸਾਡੀ ਤੁਲਨਾ ਵਿੱਚ ਮੈਮਰੀ ਅਤੇ ਸਟੋਰੇਜ 'ਤੇ ਵੱਧ ਲਾਗਤ ਕਰ ਸਕਦੇ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਤੁਸੀਂ ਆਮ ਲੁਕਅੱਪ ਲਈ ਇੰਡੈਕਸ ਜੋੜਦੇ ਹੋ ਅਤੇ ਰਿਸ਼ਤਾ ਡੇਟਾ ਤੁਰੰਤ ਉਪਲਬਧ ਰੱਖਦੇ ਹੋ।
ਜੇ ਤੁਹਾਡਾ ਵਰਕਲੋਡ ਇੱਕ ਸਪ੍ਰੈਡਸ਼ੀਟ ਵਾਂਗ ਹੈ—ਵੱਡੇ ਟੇਬਲ-ਤਕਨੀਕੀ ਸਕੈਨ, ਮਿਲੀਅਨਾਂ ਰਿਕਾਰਡਾਂ 'ਤੇ ਰਿਪੋਰਟਿੰਗ, ਜਾਂ ਭਾਰੀ aggregates—ਤਾਂ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਇੱਕੋ ਨਤੀਜੇ ਲਈ ਧੀਮੇ ਜਾਂ ਮਹਿੰਗੇ ਹੋ ਸਕਦੇ ਹਨ। ਗ੍ਰਾਫ traversals ਲਈ optimize ਹਨ (“ਕੌਣ ਕਿਸ ਨਾਲ ਜੁੜਿਆ?”), ਨਾ ਕਿ ਵੱਡੇ ਬੈਚਾਂ ਦੇ ਅੰਕੜਿਆਂ ਨੂੰ crunch ਕਰਨ ਲਈ।
ਉਪਚਾਰਕ ਜਟਿਲਤਾ ਇੱਕ ਅਸਲ ਕਾਰਕ ਹੋ ਸਕਦੀ ਹੈ। ਬੈਕਅਪ, ਸਕੇਲਿੰਗ, ਅਤੇ ਮਾਨੀਟਰਿੰਗ ਉਹੋ ਚੀਜ਼ਾਂ ਨਹੀਂ ਹਨ ਜੋ ਬਹੁਤ ਟੀਮਾਂ ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮਾਂ ਨਾਲ ਆਦਤ ਕਰ ਚੁੱਕੀਆਂ ਹਨ। ਕੁਝ ਗ੍ਰਾਫ ਪਲੇਟਫਾਰਮ ਅੱਛੀ ਤਰ੍ਹਾਂ scale-up ਕਰਦੇ ਹਨ (ਵੱਡੀਆਂ ਮਸ਼ੀਨਾਂ), ਜਿਵੇਂ ਹੋਰ scale-out ਨੂੰ ਸਹਾਇਤਾ ਦਿੰਦੇ ਹਨ ਪਰ ਸੰਗਤਤਾ, ਰਿਪਲੀਕੇਸ਼ਨ, ਅਤੇ ਕਵੇਰੀ ਪੈਟਰਨਾਂ ਲਈ ਸਾਵਧਾਨ ਯੋਜਨਾ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ।
ਤੁਹਾਡੀ ਟੀਮ ਨੂੰ ਨਵੇਂ ਮਾਡਲਿੰਗ ਪੈਟਰਨ ਅਤੇ ਕਵੇਰੀ ਤਰੀਕਿਆਂ (ਉਦਾਹਰਨ ਲਈ property graph ਮਾਡਲ ਅਤੇ ਭਾਸ਼ਾਵਾਂ ਜਿਵੇਂ Cypher) ਸਿੱਖਣ ਲਈ ਸਮਾਂ ਚਾਹੀਦਾ ਹੋ ਸਕਦਾ ਹੈ। ਲਰਣਿੰਗ ਕਰਵ ਇੱਕ ਪ੍ਰਬੰਧਨਯੋਗ ਲਾਗਤ ਹੈ, ਪਰ ਖ਼ਾਸ ਕਰਕੇ ਜੇ ਤੁਸੀਂ ਮੈਚੂਅਰ SQL-ਆਧਾਰਿਤ ਰਿਪੋਰਟਿੰਗ ਵਰਕਫਲੋਜ਼ ਨੂੰ ਬਦਲ ਰਹੇ ਹੋ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕਲ ਰਵੱਈਆ ਇਹ ਹੈ ਕਿ ਗ੍ਰਾਫ ਨੂੰ ਉੱਥੇ ਵਰਤੋ ਜਿੱਥੇ ਰਿਸ਼ਤੇ ਉਤਪਾਦ ਹਨ, ਅਤੇ ਰਿਪੋਰਟਿੰਗ, ਐਗਰੀਗੇਸ਼ਨ, ਅਤੇ ਟੇਬੂਲਰ ਐਨਾਲਿਟਿਕਸ ਲਈ ਮੌਜੂਦਾ ਸਿਸਟਮ ਰੱਖੋ।
ਗ੍ਰਾਫ ਮਾਡਲਿੰਗ ਬਾਰੇ ਸੋਚਣ ਦਾ ਇੱਕ ਲਾਭਦਾਇਕ ਤਰੀਕਾ ਸਧਾਰਨ ਹੈ: ਨੋਡ ਚੀਜ਼ਾਂ ਹਨ, ਅਤੇ ਐਜ਼ ਚੀਜ਼ਾਂ ਦਰਮਿਆਨ ਰਿਸ਼ਤੇ ਹਨ। ਲੋਕ, ਖਾਤੇ, ਡਿਵਾਈਸ, ਆਰਡਰ, ਉਤਪਾਦ, ਸਥਾਨ—ਇਹ ਨੋਡ ਹਨ। “Bought”, “logged in from”, “works with”, “is parent of”—ਇਹ ਐਜ਼ ਹਨ।
ਜ਼ਿਆਦਾਤਰ ਪ੍ਰੋਡਕਟ-ਕੇਂਦਰਤ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ property graph ਮਾਡਲ ਵਰਤਦੇ ਹਨ: ਨੋਡ ਅਤੇ ਐਜ਼ ਦੋਹਾਂ ਕੋਲ ਪ੍ਰੌਪਰਟੀਜ਼ (ਕੀ–ਵੈਲਯੂ ਫੀਲਡ) ਹੋ ਸਕਦੀਆਂ ਹਨ। ਉਦਾਹਰਨ ਲਈ, ਇੱਕ PURCHASED ਐਜ਼ date, amount, ਅਤੇ channel ਰੱਖ ਸਕਦਾ ਹੈ। ਇਹ “ਵੇਰਵਾ ਨਾਲ ਰਿਸ਼ਤੇ” ਮਾਡਲ ਕਰਨਾ ਕੁਦਰਤੀ ਬਣਾਉਂਦਾ ਹੈ।
RDF ਗਿਆਨ ਨੂੰ ਟ੍ਰਿਪਲਜ਼ ਵਜੋਂ ਦਰਸਾਉਂਦਾ ਹੈ: subject – predicate – object. ਇਹ ਸਿਸਟਮਾਂ ਦੇ ਦਰਮਿਆਨ ਇੰਟਰਓਪਰੇਬਿਲਟੀ ਅਤੇ ਵਕੈਬੁਲਰੀਜ਼ ਲਈ ਵਧੀਆ ਹੈ, ਪਰ ਅਕਸਰ “ਰਿਸ਼ਤੇ ਦੇ ਵੇਰਵੇ” ਨੂੰ ਵਾਧੂ ਨੋਡ/ਟ੍ਰਿਪਲਜ਼ ਵਿੱਚ ਪਾਈਡ਼ਾ ਕਰ ਦਿੰਦਾ ਹੈ। ਵਰਤੋਂਕਾਰੀ ਤੌਰ 'ਤੇ, RDF ਤੁਹਾਨੂੰ ਸਟੈਂਡਰਡ ਓਂਟੋਲੋਜੀ ਅਤੇ SPARQL ਪੈਟਰਨਾਂ ਵੱਲ ਧੱਕਦਾ ਹੈ, ਜਦੋਂ ਕਿ property graphs ਐਪਲੀਕੇਸ਼ਨ ਡੇਟਾ ਮਾਡਲਿੰਗ ਨੂੰ ਨੇੜੇ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ।
ਸ਼ੁਰੂ ਕਰਨ ਲਈ syntax ਯਾਦ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ—ਅਹੰਕਾਰ ਇਹ ਹੈ ਕਿ ਗ੍ਰਾਫ ਕਵੇਰੀਆਂ ਆਮ ਤੌਰ 'ਤੇ ਰਾਹਾਂ ਅਤੇ ਪੈਟਰਨਾਂ ਵਜੋਂ ਦਰਸਾਈਆਂ ਜਾਂਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਟੇਬਲ ਜੋਇਨਾਂ ਵਜੋਂ।
ਗ੍ਰਾਫ ਅਕਸਰ ਸਕੀਮਾ-ਫਲੈਸਿਬਲ ਹੁੰਦੇ ਹਨ, ਜਿਸਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਨਵਾਂ ਨੋਡ ਲੇਬਲ ਜਾਂ ਪ੍ਰੌਪਰਟੀ ਬਿਨਾਂ ਭਾਰੀ ਮਾਈਗਰੇਸ਼ਨ ਦੇ ਜੋੜ ਸਕਦੇ ਹੋ। ਪਰ ਲਚਕੀਲੇਪਣ ਨੂੰ ਅਜੇ ਵੀ ਅਨੁਸ਼ਾਸਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: ਨਾਮਕਰਨ ਸਹਾਇਤਾਵਾਂ, ਲਾਜ਼ਮੀ ਪ੍ਰੌਪਰਟੀਜ਼ (ਉਦਾਹਰਨ: id), ਅਤੇ ਰਿਸ਼ਤਾ ਕਿਸਮਾਂ ਲਈ ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ।
ਉਨ੍ਹਾਂ ਰਿਸ਼ਤਾ ਕਿਸਮਾਂ ਦੀ ਚੋਣ ਕਰੋ ਜੋ ਮਤਲਬ ਸਪਸ਼ਟ ਕਰਦੀਆਂ ਹਨ (“FRIEND_OF” ਵਿਰੁੱਧ “CONNECTED”). ਅਨੇਕਤਾ ਨੂੰ স্পਸ਼ਟ ਕਰਨ ਲਈ ਦਿਸ਼ਾ ਵਰਤੋ (ਉਦਾਹਰਨ: follower ਤੋਂ creator ਵੱਲ FOLLOWS), ਅਤੇ ਐਜ਼ ਪ੍ਰੌਪਰਟੀਜ਼ ਸ਼ਾਮِل ਕਰੋ ਜਦੋਂ ਰਿਸ਼ਤੇ ਦੇ ਆਪਣੇ ਸੱਚ ਹੁੰਦਿਆਂ ਹੋਣ (ਸਮਾਂ, ਭਰੋਸਾ, ਰੋਲ, ਵਜ਼ਨ)।
ਜੇ ਮੁਸ਼ਕਲ ਇਹ ਨਹੀਂ ਕਿ ਰਿਕਾਰਡ ਸਟੋਰ کیسے ਹੁੰਦੇ ਹਨ—ਮੁਸ਼ਕਲ ਇਹ ਹੈ ਕਿ ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਜੁੜਦੀਆਂ ਹਨ ਅਤੇ ਉਹ ਰਾਹ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਲੈਂਦੇ ਹੋ ਉਹ ਮਤਲਬ ਕਿਵੇਂ ਬਦਲਦਾ ਹੈ—ਤਾਂ ਇਹ “ਰਿਸ਼ਤਾ-ਚਲਿਤ” ਪ੍ਰੋਬਲਮ ਹੈ।
ਸ਼ੁਰੂਆਤ ਆਪਣੇ ਟਾਪ 5–10 ਸਵਾਲ ਸਿੱਧੇ ਬੋਲ ਵਿੱਚ ਲਿਖ ਕੇ ਕਰੋ—ਉਹ ਜੋ stakeholder ਅਕਸਰ ਪੁੱਛਦੇ ਹਨ ਅਤੇ ਤੁਹਾਡੀ ਮੌਜੂਦਾ ਸਰਵਿਸ ਹੌਲੀ ਜਾਂ ਅਣ-ਇਨ੍ਹੇ ਤਰੀਕੇ ਨਾਲ ਜਵਾਬ ਦਿੰਦੀ ਹੈ। ਚੰਗੇ ਗ੍ਰਾਫ ਉਮੀਦਵਾਰਾਂ ਵਿੱਚ ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਬਦ ਹਨ: “connected,” “through,” “similar to,” “within N steps,” ਜਾਂ “who else.”
ਉਦਾਹਰਨ:
ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਸਵਾਲ ਹੋਣ, ਨਾਉਂਸ ਅਤੇ ਵਰਬ ਨੂੰ نقشਾ ਕਰੋ:
ਫਿਰ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਚੀਜ਼ ਰਿਸ਼ਤਾ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ ਜਾਂ ਨੋਡ। ਇੱਕ ਵਿਆਪਕ ਨਿਯਮ: ਜੇ ਕੁਝ ਆਪਣੇ attributes ਰੱਖਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਇਸਨੂੰ ਕਈ ਪੱਖਾਂ ਨਾਲ ਜੋੜੋਗੇ, ਤਾਂ ਉਸਨੂੰ ਨੋਡ ਬਣਾਓ (ਉਦਾਹਰਨ: Order ਜਾਂ Login event ਜਦੋਂ ਇਹ ਵੇਰਵੇ ਰੱਖਦਾ ਹੈ ਅਤੇ ਕਈ ਐਂਟੀਟੀਆਂ ਨਾਲ ਜੁੜਦਾ ਹੈ)।
ਉਹ ਪ੍ਰੌਪਰਟੀਜ਼ ਜੋ ਤੁਹਾਨੂੰ ਨਤੀਜੇ ਘੱਟ ਕਰਨ ਅਤੇ ਪ੍ਰਭਾਵਤਾ ਦਰਜ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ, ਜੋ ਇਨਟਰਨਲ ਜੋਇਨਾਂ ਜਾਂ ਬਾਅਦ-ਪ੍ਰੋਸੈਸਿੰਗ ਤੋਂ ਬਿਨਾਂ ਕਾਰਗਰ ਹਨ। ਆਮ ਮਹੱਤਵਪੂਰਨ ਪ੍ਰੌਪਰਟੀਜ਼ ਵਿੱਚ ਸਮਾਂ, ਰਕਮ, ਸਥਿਤੀ, ਚੈਨਲ, ਅਤੇ ਭਰੋਸਾ ਸਕੋਰ ਸ਼ਾਮِل ਹਨ।
ਜੇ ਤੁਹਾਡੇ ਜ਼ਿਆਦਾਤਰ ਸਵਾਲ ਬਹੁ-ਕਦਮੀਆਂ ਕਨੈਕਸ਼ਨਾਂ ਨਾਲ ਨਾਲ ਉਹਨਾਂ ਪ੍ਰੌਪਰਟੀਜ਼ ਦੁਆਰਾ ਫਿਲਟਰ ਕਰਨ ਅਤੇ ਰੈਂਕਿੰਗ ਕਰਨ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਸੰਭਵਤ: ਇੱਕ ਰਿਸ਼ਤਾ-ਚਲਿਤ ਸਮੱਸਿਆ ਨਾਲ ਨਜ਼ਦੀਕੀ ਹੋ ਜਾ ਰਹੇ ਹੋ ਜਿੱਥੇ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਚਮਕਦੇ ਹਨ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਸਾਰੇ ਕੁਝ ਗ੍ਰਾਫ ਨਾਲ ਨਹੀਂ ਬਦਲਦੀਆਂ। ਇੱਕ ਵਧੀਆ ਰਵੱਈਆ ਇਹ ਹੈ ਕਿ ਤੁਹਾਡਾ “ਸਿਸਟਮ ਆਫ ਰਿਕਾਰਡ” ਉਥੇ ਰਹੇ ਜਿੱਥੇ ਇਹ ਪਹਿਲਾਂ ਹੀ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ (ਅਕਸਰ SQL), ਅਤੇ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਨੂੰ ਇੱਕ ਵਿਸ਼ੇਸ਼ ਇੰਜਨ ਵਜੋਂ ਵਰਤੋ ਜੋ ਰਿਸ਼ਤਾ-ਭਾਰੀ ਸਵਾਲਾਂ ਲਈ ਹੈ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ, ਪਾਬੰਦੀਆਂ, ਅਤੇ ਕੈਨੋਨਿਕਲ ਐਂਟੀਟੀਆਂ ਲਈ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਵਰਤੋ (ਗਾਹਕ, ਆਰਡਰ, ਖਾਤੇ)। ਫਿਰ ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਵਿੱਚ ਇੱਕ ਰਿਸ਼ਤਾ ਦਿਖਾਵਾ ਪ੍ਰੋਜੇਕਟ ਕਰੋ—ਸਿਰਫ ਉਹ ਨੋਡ ਅਤੇ ਐਜ਼ ਜੋ ਤੁਹਾਨੂੰ_CONNECTED_QUERIES ਲਈ ਚਾਹੀਦੇ ਹਨ।
ਇਸ ਨਾਲ ਆਡਿਟਿੰਗ ਅਤੇ ਡੇਟਾ ਗਵਰਨੈਂਸ ਸਪਸ਼ਟ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ ਕਿ traversals ਤੇਜ਼ ਹੋ ਜਾਂਦੇ ਹਨ।
ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਸ ਸਮੇਂ ਚਮਕਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਸਪਸ਼ਟ ਸਕੋਪਡ ਫੀਚਰ ਲਈ ਇਸਨੂੰ ਲਗਾਉਂਦੇ ਹੋ, ਜਿਵੇਂ:
ਇੱਕ ਫੀਚਰ, ਇੱਕ ਟੀਮ, ਅਤੇ ਇੱਕ ਮਾਪਯੋਗ ਨਤੀਜੇ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਜੇ ਇਹ ਮੁੱਲ ਸਾਬਤ ਕਰੇ ਤਾਂ ਤੁਸੀਂ ਆਹੀਲੇ ਤੌਰ ਤੇ ਵਿਸਥਾਰ ਕਰ ਸਕਦੇ ਹੋ।
ਜੇ ਤੁਹਾਡੀ ਬੋਤਲਨੈਕ ਪ੍ਰੋਟੋਟਾਈਪ ਸ਼ਿਪ ਕਰਨ ਵਿੱਚ ਹੈ (ਮਾਡਲ 'ਤੇ ਬੈਠਕ ਨਹੀਂ), ਤਾਂ ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਜਿਵੇਂ Koder.ai ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਇੱਕ ਸਧਾਰਨ ਗ੍ਰਾਫ-ਪਾਵਰਡ ਐਪ ਖੜਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: ਤੁਸੀਂ ਚੈੱਟ ਵਿੱਚ ਫੀਚਰ ਵਰਣਨ ਕਰੋ, React UI ਅਤੇ Go/PostgreSQL ਬੈਕਐਂਡ ਜਨਰੇਟ ਕਰੋ, ਅਤੇ ਡੇਟਾ ਟੀਮ ਮਾਡਲ ਅਤੇ ਕਵੇਰੀਸ ਦੀ ਜਾਂਚ ਕਰੇ।
ਗ੍ਰਾਫ ਨੂੰ ਕਿੰਨਾ ਤਾਜ਼ਾ ਰੱਖਣਾ ਹੈ?
ਆਮ ਪੈਟਰਨ: ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ SQL ਵਿੱਚ ਲਿਖੋ → ਚੇਂਜ ਇਵੈਂਟ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰੋ → ਗ੍ਰਾਫ ਨੂੰ ਅਪਡੇਟ ਕਰੋ।
ID ਭਿੱਣੇ ਹੋ ਜਾਣ 'ਤੇ ਗ੍ਰਾਫ ਗੜਬੜ ਹੋ ਜਾਂਦੇ ਹਨ।
ਸਥਿਰ ਪਛਾਣਕਰਤਾ (ਉਦਾਹਰਨ: customer_id, account_id) ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਸਿਸਟਮਾਂ ਵਿੱਚ ਮਿਲਦੇ ਹਨ, ਅਤੇ ਦਸੋ ਕਿ ਹਰ ਫੀਲਡ ਅਤੇ ਰਿਸ਼ਤੇ ਦੀ “ਮਾਲਕੀ” ਕੌਣ ਰੱਖਦਾ ਹੈ। ਜੇ ਦੋ ਸਿਸਟਮ ਇੱਕੋ ਐਜ਼ ਬਣਾਉਂਦੇ ਹਨ (ਕਹੋ “knows”), ਤਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜਾ ਸਿਸਟਮ ਜਿੱਤੇਗਾ।
ਜੇ ਤੁਸੀਂ ਪਾਇਲਟ ਦੀ ਯੋਜਨਾ ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ /blog/getting-started-a-low-risk-pilot-plan ਨੂੰ ਵੇਖੋ।
ਇੱਕ ਗ੍ਰਾਫ ਪਾਇਲਟ ਇੱਕ ਤਜਰਬਾ ਵਾਂਗ ਮਹਿਸੂਸ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਮੁੜ-ਲਿਖਾਈ ਨਹੀਂ। ਮਕਸਦ ਇਹ ਸਾਬਤ ਕਰਨਾ ਹੈ (ਜਾਂ ਖੰਡਿਤ ਕਰਨਾ) ਕਿ ਰਿਸ਼ਤਾ-ਭਾਰੀ ਕਵੇਰੀਆਂ ਸਾਦੀਆਂ ਅਤੇ ਤੇਜ਼ ਹੋ ਜਾਂਦੀਆਂ ਹਨ—ਬਿਨਾਂ ਪੂਰੇ ਡੇਟਾ ਸਟੈਕ 'ਤੇ ਦਾਂਵ ਲਗਾਏ।
ਉਸ ਨੈਰੇ ਡੇਟਾਸੈਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਪਹਿਲਾਂ ਹੀ ਦਰਦ ਪੈਦਾ ਕਰਦਾ ਹੈ: ਬਹੁਤ ਸਾਰੇ JOINs, ਭੰਗੁਰ SQL, ਜਾਂ ਹੌਲੀ “ਕੌਣ ਕਿਸ ਨਾਲ ਜੁੜਿਆ?” ਸਵਾਲ। ਇਸਨੂੰ ਇੱਕ ਵਰਕਫਲੋ ਤੱਕ ਸਿਮਿਤ ਰੱਖੋ (ਉਦਾਹਰਨ: customer ↔ account ↔ device, ਜਾਂ user ↔ product ↔ interaction) ਅਤੇ ਕੁਝ ਕਵੇਰੀਆਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਤੁਸੀਂ end-to-end ਜਵਾਬ ਦੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ।
ਸਿਰਫ਼ ਰਫ਼ਤਾਰ ਮਾਪੋ ਨਾ:
ਜੇ ਤੁਸੀਂ “ਪਹਿਲਾਂ” ਨੰਬਰ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ “ਪਿੱਛੇ” ਨੰਬਰਾ ਨੂੰ ਭਰੋਸਾ ਨਹੀਂ ਕਰੋਗੇ।
ਸਭ ਕੁਝ ਨੋਡ ਅਤੇ ਐਜ਼ ਵਜੋਂ ਮਾਡਲ ਕਰਨ ਦੀ ਲਾਲਚ ਹੁੰਦੀ ਹੈ। ਇਸਦਾ ਵਿਰੋਧ ਕਰੋ। “ਗ੍ਰਾਫ ਸਪ੍ਰਾਲ”: ਬੇਸੂਦੀ ਨੋਡ/ਐਜ਼ ਕਿਸਮਾਂ ਜਿਨ੍ਹਾਂ ਦੀ ਕੋਈ ਸਪਸ਼ਟ ਕਵੇਰੀ ਲੋੜ ਨਹੀਂ। ਹਰ ਨਵਾਂ ਲੇਬਲ ਜਾਂ ਰਿਸ਼ਤਾ ਆਪਣੀ ਥਾਂ ਕਮਾਈ ਕਰੇ—ਇੱਕ ਅਸਲੀ ਸਵਾਲ ਨੂੰ ਯੋਗ ਬਣਾਕੇ।
ਰਾਜਨੀਤਿਕਤਾ, ਐਕਸੈਸ ਕੰਟਰੋਲ, ਅਤੇ ਡੇਟਾ ਰੀਟੈਨਸ਼ਨ ਲਈ ਪਹਿਲਾਂ ਯੋਜਨਾ ਬਣਾਓ। ਰਿਸ਼ਤਾ ਡੇਟਾ ਇੱਕਲੀਆਂ ਰਿਕਾਰਡਾਂ ਨਾਲੋਂ ਵੱਧ ਪ੍ਰਗਟ ਕਰ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ: ਅਜੇਹੇ ਕਨੈਕਸ਼ਨ ਜੋ ਵਰਤੋਂ ਦੀ ਸੂਚਨਾ ਦਿੰਦੇ ਹਨ)। ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕੌਣ ਕੀ ਕਵੇਰੀ ਕਰ ਸਕਦਾ ਹੈ, ਨਤੀਜਿਆਂ ਦੀ ਆਡਿਟ ਕਿਵੇਂ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਲੋੜੀਏ ਤੇ ਡੇਟਾ ਨੂੰ ਕਿਵੇਂ ਮਿਟਾਇਆ ਜਾਂਦਾ ਹੈ।
ਸਿੰਪਲ ਸਿੰਕ (ਬੈਚ ਜਾਂ ਸਟਰੀਮਿੰਗ) ਵਰਤ ਕੇ ਗ੍ਰਾਫ ਨੂੰ ਫੀਡ ਕਰੋ ਜਦੋਂ ਤੁਸੀਂ ਮੌਜੂਦਾ ਸਿਸਟਮ ਨੂੰ ਸਚਾਈ ਦਾ ਸਰੋਤ ਰੱਖਦੇ ਹੋ। ਜਦੋਂ ਪਾਇਲਟ ਮੁੱਲ ਸਾਬਤ ਕਰੇ, ਤੂੰਹਾਨੂੰ ਵੇਥੇ-ਵੈਥੇ ਸਕੇਲ-ਆਉਟ ਕਰ ਸਕਦੇ ਹੋ—ਧੀਰੇ, ਇੱਕ ਵਰਕਕੇਸ ਪ੍ਰਤੀ ਵਾਰ।
ਜੇ ਤੁਸੀਂ ਡੇਟਾਬੇਸ ਚੁਣ ਰਹੇ ਹੋ, ਤਕਨੀਕ ਨਾਲ ਨਹੀਂ—ਸਵਾਲਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਗ੍ਰਾਫ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚਮਕਦੇ ਹਨ ਜੇ ਤੁਹਾਡੇ ਸਭ ਤੋਂ ਔਖੇ ਸਮੱਸਿਆਵਾਂ ਕਨੈਕਸ਼ਨਾਂ ਅਤੇ ਰਾਹਾਂ ਬਾਰੇ ਹਨ, ਨਾ ਕਿ ਸਿਰਫ਼ ਰਿਕਾਰਡ ਸਟੋਰ ਕਰਨ ਬਾਰੇ।
ਜੇ ਤੁਸੀਂ ਅਧਿਕাংশ “ਹਾਂ” ਉੱਤਰ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਗ੍ਰਾਫ ਇੱਕ ਮਜ਼ਬੂਤ ਫਿੱਟ ਹੋ ਸਕਦਾ ਹੈ—ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਜਦੋਂ ਤੁਹਾਨੂੰ ਬਹੁ-ਹੋਪ ਪੈਟਰਨ ਮੈਚਿੰਗ ਦੀ ਲੋੜ ਹੋਵੇ:
ਜੇ ਤੁਹਾਡਾ ਕੰਮ ਪ੍ਰਧਾਨਕਤ: ਸਾਦਾ ਲੁੱਕਅੱਪ (ID/email ਦੁਆਰਾ) ਜਾਂ ਐਗਰੀਗੇਸ਼ਨ (“ਮਹੀਨੇ ਵਾਰ ਟੋਟਲ ਸੇਲਜ਼”), ਤਾਂ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਜਾਂ ਕੀ-ਵੈਲਯੂ/ਡੌਕਯੂਮੈਂਟ ਸਟੋਰ ਆਮ ਤੌਰ 'ਤੇ ਸਧਾਰਨ ਅਤੇ ਸਸਤਾ ਚਲਾਉਣਾ ਹੈ।
ਤੁਹਾਡੇ 10 ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਕਾਰੋਬਾਰੀ ਸਵਾਲ ਸਿੱਧੇ ਵਾਕਾਂ ਵਿੱਚ ਲਿਖੋ, ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਹਕੀਕਤੀ ਡੇਟਾ 'ਤੇ ਇੱਕ ਛੋਟੇ ਪਾਇਲਟ ਵਿੱਚ ਜाँचੋ। ਕਵੇਰੀਆਂ ਦਾ ਸਮਾਂ ਲਓ, ਜੋ ਕੁਝ ਦਰਦਦਾਇਕ ਹੈ ਉਹ ਨੋਟ ਕਰੋ, ਅਤੇ ਮਾਡਲ ਬਦਲਣਾਂ ਦੀ ਇੱਕ ਛੋਟੀ ਲਾਗ ਰੱਖੋ। ਜੇ ਤੁਹਾਡਾ ਪਾਇਲਟ ਜ਼ਿਆਦਾਤਰ “ਹੋਰ ਜੋਇਨ” ਜਾਂ “ਹੋਰ ਕੈਸ਼ਿੰਗ” ਬਣ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਗ੍ਰਾਫ ਦੇ ਲਾਭ ਸਪਸ਼ਟ ਹੋ ਸਕਦੇ ਹਨ। ਜੇ ਇਹ ਜਿਆਦਾਤਰ ਗਿਣਤੀ ਅਤੇ ਫਿਲਟਰ ਬਣ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਸੰਭਵਤ: ਇਹ ਨਹੀਂ ਚੁਣੋ।
A graph database stores data as nodes (entities) and relationships (connections) with properties on both. It’s optimized for questions like “how is A connected to B?” and “who is within N steps?”
Because relationships are stored as real, queryable objects (not just foreign-key values). You can traverse multiple hops efficiently and attach properties to the relationship itself (e.g., date, amount, risk_score), which makes connection-heavy questions easier to model and query.
Relational databases represent relationships indirectly (foreign keys) and often require multiple JOINs for multi-hop questions. Graph databases keep connections adjacent to the data, so variable-depth traversals (like 2–6 hops) are typically more direct to express and maintain.
Use a graph database when your core questions involve paths, neighborhoods, and patterns:
Common graph-friendly queries include:
Often when your workload is mostly:
In those cases, a relational or analytics system is usually simpler and cheaper.
Model a relationship as an edge when it primarily connects two entities and may carry its own properties (time, role, weight). Model it as a node when it’s an event or entity with multiple attributes that connects to many parties (e.g., an Order or Login event linked to user, device, IP, and time).
Typical trade-offs include:
Property graphs let nodes and relationships have properties (key–value fields) and are common for application-style modeling. RDF represents knowledge as triples (subject–predicate–object) and often aligns with shared vocabularies and SPARQL.
Pick based on whether you need app-centric relationship properties (property graph) or interoperable semantic modeling (RDF).
Keep your existing system (often SQL) as the source of truth, then project the relationship view into a graph for one scoped feature (recommendations, fraud, identity resolution). Sync via batch or streaming, use stable identifiers across systems, and measure success (latency, query complexity, developer time) before expanding. See /blog/practical-architecture-graph-alongside-other-databases and /blog/getting-started-a-low-risk-pilot-plan.