14 ਅਕਤੂ 2025·7 ਮਿੰਟ
GraphQL ਕੀ ਹੈ? APIs ਅਤੇ ਡੇਟਾ ਫੈਚਿੰਗ ਲਈ ਸਪਸ਼ਟ ਗਾਈਡ
ਜਾਣੋ ਕਿ GraphQL ਕੀ ਹੈ, queries, mutations ਅਤੇ schemas ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ, ਅਤੇ ਕਦੋਂ ਇਸਨੂੰ REST ਦੀ ਥਾਂ ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ—ਵ੍ਯਵਹਾਰਿਕ ਫਾਇਦੇ, ਨੁਕਸਾਨ ਅਤੇ ਉਦਾਹਰਨਾਂ ਨਾਲ।
ਜਾਣੋ ਕਿ GraphQL ਕੀ ਹੈ, queries, mutations ਅਤੇ schemas ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ, ਅਤੇ ਕਦੋਂ ਇਸਨੂੰ REST ਦੀ ਥਾਂ ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ—ਵ੍ਯਵਹਾਰਿਕ ਫਾਇਦੇ, ਨੁਕਸਾਨ ਅਤੇ ਉਦਾਹਰਨਾਂ ਨਾਲ।
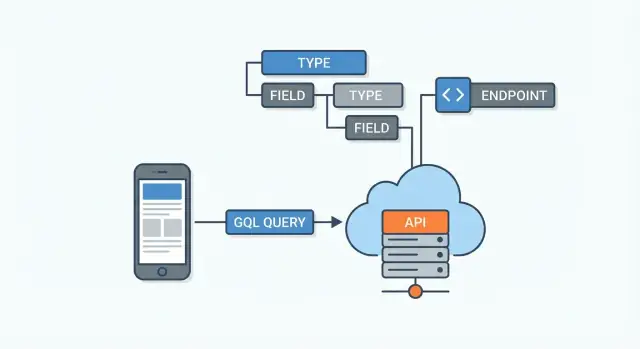
GraphQL ਇੱਕ query language ਅਤੇ APIs ਲਈ runtime ਹੈ। ਸਿੱਧੀ ਗੱਲ: ਇਹ ਇੱਕ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਇੱਕ ਐਪ (ਵੈੱਬ, ਮੋਬਾਈਲ, ਜਾਂ ਕੋਈ ਹੋਰ ਸਰਵਿਸ) API ਨੂੰ ਸਪਸ਼ਟ, ਸੰਰਚਿਤ ਬੇਨਤੀ ਭੇਜ ਕੇ ਡੇਟਾ ਮੰਗ ਸਕਦਾ ਹੈ—ਅਤੇ ਸਰਵਰ ਉਸ ਬੇਨਤੀ ਨਾਲ ਮਿਲਦਾ-ਜੁਲਦਾ ਜਵਾਬ ਵਾਪਸ ਕਰਦਾ ਹੈ।
ਬਹੁਤ ਸਾਰੇ APIs ਕਲਾਇਂਟ ਨੂੰ ਉਹੀ ਡਾਟਾ ਲੈਣ 'ਤੇ ਮਜਬੂਰ ਕਰਦੇ ਹਨ ਜੋ ਇੱਕ fix ਕੀਤਾ endpoint ਰਿਟਰਨ ਕਰਦਾ ਹੈ। ਇਸ ਨਾਲ ਅਕਸਰ ਦੋ ਮੁੱਦੇ ਵਾਪਰਦੇ ਹਨ:
GraphQL ਨਾਲ ਕਲਾਇਂਟ ਸਿਰਫ਼ ਉਹੀ ਖੇਤਰ ਮੰਗ ਸਕਦਾ ਹੈ ਜੋ ਉਸਨੂੰ ਚਾਹੀਦੇ ਹਨ—ਨਾ ਵੱਧ, ਨਾ ਘੱਟ। ਇਹ ਉਸ ਵੇਲੇ ਖਾਸ ਕਰਕੇ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਵੱਖ-ਵੱਖ ਸਕ੍ਰੀਨਾਂ ਜਾਂ ਐਪਾਂ ਨੂੰ ਇੱਕੋ underlying ਡੇਟਾ ਦੇ ਵੱਖ-ਵੱਖ “ਕਟ” ਚਾਹੀਦੇ ਹੁੰਦੇ ਹਨ।
GraphQL ਆਮਤੌਰ 'ਤੇ ਕਲਾਇਂਟ ਐਪਾਂ ਅਤੇ ਤੁਹਾਡੇ ਡੇਟਾ ਸਰੋਤਾਂ ਦੇ ਵਿਚਕਾਰ ਰਹਿੰਦਾ ਹੈ। ਉਹਨਾ ਡੇਟਾ ਸਰੋਤਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ:
GraphQL ਸਰਵਰ ਇੱਕ query ਪ੍ਰਾਪਤ ਕਰਦਾ ਹੈ, ਹਰ ਮੰਗੇ ਗਏ field ਨੂੰ ਠੀਕ ਸਥਾਨ ਤੋਂ ਲੈ ਕੇ ਆਉਣ ਦਾ ਤਰੀਕਾ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ, ਅਤੇ ਫਿਰ ਆਖਰੀ JSON ਜਵਾਬ ਜੋੜਦਾ ਹੈ।
GraphQL ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਸੋਚੋ ਕਿ ਤੁਸੀਂ ਇੱਕ "ਕਸਟਮ-ਆਕਾਰ" ਦਾ ਜਵਾਬ ਮੰਗ ਰਹੇ ਹੋ:
ਕੁਝ ਗੱਲਾਂ ਸਪਸ਼ਟ ਕਰਨ ਲਈ:
ਜੇ ਤੁਸੀਂ ਇਸ ਮੁੱਢਲੇ ਪਰਿਭਾਸ਼ਾ—query language + runtime for APIs—ਨੂੰ ਯਾਦ ਰੱਖੋ ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਬਾਕੀ ਸਾਰਾ ਠੀਕ ਨਿਰਮਾਣ ਹੋਵੇਗਾ।
GraphQL ਇਕ ਪ੍ਰਯੋਗਿਕ ਪ੍ਰੋਡਕਟ ਪ੍ਰਸ਼ਨ ਦਾ ਹੱਲ ਕਰਨ ਲਈ ਬਣਾਇਆ ਗਿਆ ਸੀ: ਟੀਮਾਂ APIs ਨੂੰ UI ਸਕ੍ਰੀਨਾਂ ਦੇ ਅਨੁਰੂਪ ਬਣਾਉਣ ਵਿੱਚ ਬਹੁਤ ਵਕਤ ਖਰਚ ਕਰ ਰਹੀਆਂ ਸਨ।
ਪਾਰੰਪਰਿਕ endpoint-ਅਧਾਰਤ APIs ਅਕਸਰ ਇਹ ਫ਼ੈਸਲਾ ਕਰਨ ਤੇ ਮਜ਼ਬੂਰ ਕਰਦੇ ਹਨ ਕਿ ਜਾਂ ਤਾਂ ਅਣਚਾਹੀ ਡਾਟਾ ਭੇਜੋ ਜਾਂ ਲੋੜੀਂਦਾ ਡਾਟਾ ਲੈਣ ਲਈ ਵੱਧ ਕਾਲਾਂ ਕਰੋ। ਜਿਵੇਂ-ਜਿਵੇਂ ਪ੍ਰੋਡਕਟ ਵਧਦੇ ਹਨ, ਇਹ ਘਟਨਾ ਪੇਜ਼ ਸਲੋ, ਕਲਾਇਂਟ ਕੋਡ ਜਟਿਲ ਅਤੇ ਫਰੰਟਐਂਡ-ਬੈਕਐਂਡ ਸਹਯੋਗ ਵਿੱਚ ਮੁਸ਼ਕਲਾਂ ਬਣਾਉਂਦੀ ਹੈ।
Over-fetching ਉਦਾਹਰਨ ਵਜੋਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇੱਕ endpoint "ਫੁੱਲ" ਆਬਜੈਕਟ ਰਿਟਰਨ ਕਰਦਾ ਹੈ ਜਦੋਂ ਕਿ ਇੱਕ ਸਕਰੀਨ ਨੂੰ ਸਿਰਫ਼ ਕੁਝ ਫੀਲਡ ਚਾਹੀਦੇ ਹਨ। ਮੋਬਾਈਲ ਪ੍ਰੋਫਾਈਲ ਦੇਖਾਉਣ ਲਈ ਸ਼ਾਇਦ ਸਿਰਫ਼ ਨਾਮ ਅਤੇ avatar ਚਾਹੀਦੇ ਹੋਣ, ਪਰ API addresses, preferences, audit fields ਆਦਿ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ—ਇਸ ਨਾਲ bandwidth ਬਰਬਾਦ ਹੋ ਸਕਦੀ ਹੈ ਅਤੇ ਯੂਜ਼ਰ ਤਜ਼ਰਬੇ 'ਤੇ ਅਸਰ ਪੈ ਸਕਦਾ ਹੈ।
Under-fetching ਵਿਰੋਧੀ ਸਥਿਤੀ ਹੈ: ਕਿਸੇ ਵੀ ਇੱਕ endpoint ਕੋਲ ਉਹ ਸਾਰੀ ਜਾਣਕਾਰੀ ਨਹੀਂ ਹੁੰਦੀ ਜੋ ਇੱਕ view ਨੂੰ ਚਾਹੀਦੀ ਹੈ, ਇਸ ਲਈ ਕਲਾਇਂਟ ਨੂੰ ਕਈ ਬੇਨਤੀਆਂ ਭੇਜਣੀਆਂ ਪੈਂਦੀਆਂ ਹਨ ਅਤੇ ਨਤੀਜੇ ਜੋੜਣੇ ਪੈਂਦੇ ਹਨ। ਇਸ ਨਾਲ latency ਵੱਧਦੀ ਹੈ ਅਤੇ partial failures ਦੀ ਸੰਭਾਵਨਾ ਬਣਦੀ ਹੈ।
ਬਹੁਤ REST-ਅਨੁਕੂਲ APIs ਬਦਲਾਵ ਦਾ ਜਵਾਬ ਨਵੇਂ endpoints ਜਾਂ versioning (v1, v2, v3) ਨਾਲ਼ ਦੇਂਦੇ ਹਨ। ਵਰਜ਼ਨਿੰਗ ਜ਼ਰੂਰੀ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਇਹ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਰੱਖ-ਰਖਾਵ ਦਾ ਕੰਮ ਬਣਾਉਂਦੀ ਹੈ: ਪੁਰਾਣੇ ਕਲਾਇਂਟ ਪੁਰਾਣੀਆਂ ਵਰਜ਼ਨਾਂ ਨੂੰ ਵਰਤਦੇ ਰਹਿੰਦੇ ਹਨ, ਜਦਕਿ ਨਵੀਆਂ ਫੀਚਰਸ ਕਿਤੇ ਹੋਰ ਇਕੱਠੇ ਹੋ ਜਾਂਦੀਆਂ ਹਨ।
GraphQL ਦਾ ਰਵੱਈਆ schema ਨੂੰ ਸਮੇਂ ਦੇ ਨਾਲ ਨਵੇਂ fields ਅਤੇ types ਜੋੜ ਕੇ ਵਿਕਸਤ ਕਰਨ ਦਾ ਹੈ, ਜਦਕਿ ਮੌਜੂਦਾ fields ਨੂੰ ਸਥਿਰ ਰਖਿਆ ਜਾਂਦਾ ਹੈ। ਇਸ ਨਾਲ ਅਕਸਰ "ਨਵੀਂ ਵਰਜ਼ਨ" ਬਣਾਉਣ ਦੇ ਦਬਾਅ ਨੂੰ ਘਟਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
ਆਧੁਨਿਕ ਪ੍ਰੋਡਕਟ ਬਹੁਤ ਵਾਰ ਸਿਰਫ ਇੱਕ consumer ਨਹੀਂ ਰੱਖਦੇ। ਵੈੱਬ, iOS, Android ਅਤੇ partner integrations ਵੱਖ-ਵੱਖ ਡੇਟਾ ਆਕਾਰ ਚਾਹੁੰਦੇ ਹਨ।
GraphQL ਇਸ ਤਰ੍ਹਾਂ ਬਣਾਇਆ ਗਿਆ ਕਿ ਹਰ ਕਲਾਇਂਟ ਬਿਲਕੁਲ ਉਹੀ fields ਮੰਗ ਸਕਦਾ ਹੈ ਜੋ ਉਸਨੂੰ ਲੋੜ ਹਨ—ਬਿਨਾਂ ਬੈਕਐਂਡ ਨੂੰ ਹਰ ਸਕ੍ਰੀਨ ਜਾਂ ਡਿਵਾਈਸ ਲਈ ਵੱਖ-ਵੱਖ endpoint ਬਣਾਉਣ ਦੀ ਲੋੜ ਪਏ।
GraphQL API ਦੀ ਪਰਿਭਾਸ਼ਾ ਉਸਦੀ schema ਨਾਲ ਹੁੰਦੀ ਹੈ। ਇਸਨੂੰ ਸਰਵਰ ਅਤੇ ਹਰ ਕਲਾਇਂਟ ਦੇ ਵਿਚਕਾਰ ਇਕ ਸਮਝੌਤਾ ਸਮਝੋ: ਇਹ ਦੱਸਦਾ ਹੈ ਕਿ ਡਾਟਾ ਕੀ ਹੈ, ਕਿਵੇਂ ਜੁੜਿਆ ਹੈ, ਅਤੇ ਕੀ ਮੰਗਿਆ ਜਾਂ ਸਕਦਾ ਹੈ ਜਾਂ ਬਦਲਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਕਲਾਇਂਟ endpoints ਦੀ ਅਨੁਮਾਨ ਨਹੀਂ ਲਗਾਉਂਦੇ—ਉਹ schema ਪੜ੍ਹਕੇ ਖਾਸ ਖੇਤਰ ਮੰਗਦੇ ਹਨ।
Schema types (ਜਿਵੇਂ User ਜਾਂ Post) ਅਤੇ fields (ਜਿਵੇਂ name ਜਾਂ title) ਨਾਲ ਬਣਦਾ ਹੈ। Fields ਹੋਰ types ਵੱਲ ਇਸ਼ਾਰਾ ਕਰ ਸਕਦੇ ਹਨ—ਇਸ ਤਰ੍ਹਾਂ GraphQL ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਮਾਡਲ ਕਰਦਾ ਹੈ।
ਹੇਠਾਂ Schema Definition Language (SDL) ਵਿੱਚ ਇੱਕ ਸਧਾਰਨ ਉਦਾਹਰਨ ਹੈ:
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
ਕਿਉਂਕਿ schema strongly typed ਹੁੰਦੀ ਹੈ, GraphQL ਇੱਕ request ਨੂੰ ਚਲਾਉਣ ਤੋਂ ਪਹਿਲਾਂ validate ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਕੋਈ ਕਲਾਇਂਟ ਕਿਸੇ ਅਜਿਹੇ ਫੀਲਡ ਨੂੰ ਮੰਗਦਾ ਹੈ ਜੋ ਮੌਜੂਦ ਨਹੀਂ (ਉਦਾਹਰਨ ਵਜੋਂ, Post.publishDate ਜਦੋਂ schema 'ਚ ਐਸੀ ਫੀਲਡ ਨਹੀਂ), ਤਾਂ ਸਰਵਰ ਬੇਨਤੀ ਨੂੰ reject ਕਰ ਸਕਦਾ ਹੈ ਜਾਂ ਹਿੱਸੇਦਾਰ ਤਰੀਕੇ ਨਾਲ ਭਰ ਸਕਦਾ ਹੈ—ਸਪਸ਼ਟ errors ਨਾਲ।
Schemas ਨੂੰ ਵਧਾਉਣ ਲਈ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਹੈ। ਤੁਸੀਂ ਆਮ ਤੌਰ ਤੇ ਨਵੇਂ fields (ਜਿਵੇਂ User.bio) ਸ਼ਾਮਲ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਮੌਜੂਦਾ ਕਲਾਇਂਟਾਂ ਨੂੰ ਤੋੜੇ—ਕਿਉਂਕਿ ਕਲਾਇਂਟ ਸਿਰਫ਼ ਉਹੀ ਪ੍ਰਾਪਤ ਕਰਦੇ ਹਨ ਜੋ ਉਹ ਮੰਗਦੇ ਹਨ। fields ਹਟਾਉਣਾ ਜਾਂ ਬਦਲਣਾ ਜ਼ਿਆਦਾ ਸੰਵੇਦਨਸ਼ੀਲ ਹੈ, ਇਸ ਲਈ ਟੀਮਾਂ ਅਕਸਰ ਪਹਿਲਾਂ fields ਨੂੰ deprecate ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਹੌਲੇ-ਹੌਲੇ ਕਲਾਇਂਟਸ ਨੂੰ migrate ਕਰਦੀਆਂ ਹਨ।
GraphQL API ਆਮਤੌਰ 'ਤੇ ਇੱਕ single endpoint ਰਾਹੀਂ ਪ੍ਰਦਾਨ ਕੀਤਾ ਜਾਂਦਾ ਹੈ (ਉਦਾਹਰਨ /graphql)। ਕਈ URLs (ਜਿਵੇਂ /users, /users/123, /users/123/posts) ਦੇ ਬਦਲੇ, ਤੁਸੀਂ ਇੱਕ query ਇੱਕ ਹੀ ਥਾਂ ਤੇ ਭੇਜ ਕੇ ਉਸ ਵਿੱਚ ਉਹ ਖੇਤਰ ਵੇਰਵਾ ਕਰਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਵਾਪਸ ਚਾਹੁੰਦੇ ਹੋ।
ਇੱਕ query ਬੁਨਿਆਦੀ ਤੌਰ ਤੇ ਖੇਤਰਾਂ ਦੀ "ਸ਼ਾਪਿੰਗ ਲਿਸਟ" ਹੁੰਦੀ ਹੈ। ਤੁਸੀਂ ਸਧਾਰਨ ਖੇਤਰ (ਜਿਵੇਂ id ਅਤੇ name) ਅਤੇ ਨੈਸਟਡ ਡੇਟਾ (ਜਿਵੇਂ ਇੱਕ ਯੂਜ਼ਰ ਦੇ ਹਾਲੀਆ posts) ਇੱਕੋ ਬੇਨਤੀ ਵਿੱਚ ਮੰਗ ਸਕਦੇ ਹੋ—ਬਿਨਾਂ ਵਾਧੂ ਫੀਲਡਾਂ ਨੂੰ ਡਾਊਨਲੋਡ ਕੀਤੇ।
ਇੱਕ ਛੋਟੀ ਉਦਾਹਰਨ:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
GraphQL responses predictable ਹੁੰਦੇ ਹਨ: ਜੋ JSON ਤੁਸੀਂ ਲੈਂਦੇ ਹੋ ਉਹ ਤੁਹਾਡੇ query ਦੀ ਸਾਂਝੀ ਰਚਨਾ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਇਹ ਫਰੰਟਐਂਡ 'ਤੇ ਕੰਮ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ, ਕਿਉਂਕਿ ਤੁਹਾਨੂੰ ਇਹ ਅਨੁਮਾਨ ਨਹੀਂ ਲਗਾਉਣਾ ਪੈਂਦਾ ਕਿ ਡੇਟਾ ਕਿੱਥੇ ਹੋਏਗਾ ਜਾਂ ਵੱਖ-ਵੱਖ ਫਾਰਮੈਟਾਂ ਨੂੰ parse ਕਰਨਾ ਪਵੇਗਾ।
ਸਧਾਰਨ ਅਉਟਲਾਈਨ ਸ਼ਾਇਦ ਇਸ ਤਰ੍ਹਾਂ ਲੱਗ ਸਕਦੀ ਹੈ:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
ਜੇ ਤੁਸੀਂ ਕਿਸੇ field ਦੀ ਮੰਗ ਨਹੀਂ ਕੀਤੀ, ਉਹ ਸ਼ਾਮਿਲ ਨਹੀਂ ਹੋਏਗਾ। ਜੇ ਤੁਸੀਂ ਮੰਗਿਆ, ਤਾਂ ਤੁਸੀਂ ਉਮੀਦ ਕਰ ਸਕਦੇ ਹੋ ਕਿ ਉਹ ਉਸੇ ਥਾਂ ਤੇ ਮਿਲੇਗਾ—ਇਸ ਨਾਲ GraphQL queries ਹਰ ਸਕਰੀਨ ਜਾਂ ਫੀਚਰ ਲਈ ਬਿਲਕੁਲ ਲੋੜੀਂਦਾ ਡਾਟਾ ਲੈਣ ਦਾ ਸਾਫ਼ ਤਰੀਕਾ ਬਣ ਜਾਂਦੇ ਹਨ।
Queries ਪੜ੍ਹਨ ਲਈ ਹੁੰਦੇ ਹਨ; mutations ਉਹ ਤਰੀਕਾ ਹਨ ਜਿਨ੍ਹਾਂ ਨਾਲ ਤੁਸੀਂ GraphQL API ਵਿੱਚ ਡੇਟਾ ਬਦਲਦੇ ਹੋ—ਬਣਾਉਣਾ, ਅੱਪਡੇਟ ਕਰਨਾ, ਜਾਂ ਹਟਾਉਣਾ।
ਜਿਆਦਾਤਰ mutations ਇੱਕੋ ਹੀ ਪੈਟਰਨ ਫਾਲੋ ਕਰਦੇ ਹਨ:
input object) ਭੇਜਦਾ ਹੈ, ਜਿਵੇਂ ਅੱਪਡੇਟ ਕਰਨ ਵਾਲੇ ਫੀਲਡ।GraphQL mutations ਆਮ ਤੌਰ 'ਤੇ ਉਦੇਸ਼ਪੂਰਕ ਤੌਰ 'ਤੇ ਡਾਟਾ ਵਾਪਸ ਕਰਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਸਿਰਫ਼ “success: true”। ਅੱਪਡੇਟ ਕੀਤੀ ਗਈ ਆਬਜੈਕਟ (ਜਾਂ ਘੱਟੋ-ਘੱਟ ਉਸਦੀ id ਅਤੇ ਮੁੱਖ ਫੀਲਡ) ਵਾਪਸ ਕਰਨ ਨਾਲ UI:
ਇੱਕ ਆਮ ਡਿਜ਼ਾਈਨ “payload” ਟਾਈਪ ਹੈ ਜੋ ਅੱਪਡੇਟਡ entity ਅਤੇ ਕੋਈ errors ਦੋਹਾਂ ਸ਼ਾਮਲ ਕਰਦਾ ਹੈ।
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
UI-ਚਲਿਤ APIs ਲਈ ਇੱਕ ਚੰਗਾ ਨਿਯਮ ਹੈ: ਅਗਲੇ ਸਟੇਟ ਨੂੰ ਰੈਨਡਰ ਕਰਨ ਲਈ ਜੋ ਚਾਹੀਦਾ ਹੈ ਉਹ ਵਾਪਸ ਕਰੋ (ਉਦਾਹਰਨ ਦੇ ਤੌਰ ਤੇ, ਅੱਪਡੇਟਡ user ਅਤੇ ਕੋਈ errors)। ਇਹ ਕਲਾਇਂਟ ਨੂੰ ਸਧਾਰਨ ਰੱਖਦਾ ਹੈ, ਬਦਲਾਅ ਬਾਰੇ ਅੰਦਾਜ਼ਾ ਕਰਨ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ, ਅਤੇ ਫੇਲ੍ਹ ਰਹੇ ਹਾਲਤਾਂ ਨੂੰ ਨਰਮਾਈ ਨਾਲ ਸੰਭਾਲਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
GraphQL schema ਇਹ ਦੱਸਦਾ ਹੈ ਕਿ ਕੀ ਮੰਗਿਆ ਜਾ ਸਕਦਾ ਹੈ। Resolvers ਦੱਸਦੇ ਹਨ ਕਿ ਅਸਲ ਵਿੱਚ ਉਸਨੂੰ ਕਿਵੇਂ ਲਿਆਉਣਾ ਹੈ। Resolver ਇੱਕ function ਹੁੰਦਾ ਹੈ ਜੋ schema ਵਿੱਚ ਕਿਸੇ ਖਾਸ field ਨਾਲ ਜੁੜਿਆ ਹੁੰਦਾ ਹੈ। ਜਦੋਂ ਕਲਾਇਂਟ ਉਹ field ਮੰਗਦਾ ਹੈ, GraphQL ਉਸ resolver ਨੂੰ ਚਲਾਉਂਦਾ ਹੈ ਤਾਂ ਕਿ ਮੁੱਲ fetch ਜਾਂ compute ਹੋ ਸਕੇ।
GraphQL query ਨੂੰ execute ਕਰਦਿਆਂ requested shape ਨੂੰ walk ਕਰਦਾ ਹੈ। ਹਰ field ਲਈ, ਉਹ matching resolver ਲੱਭਦਾ ਹੈ ਅਤੇ ਉਸਨੂੰ ਚਲਾਉਂਦਾ ਹੈ। ਕੁਝ resolvers ਸਿਰਫ਼ ਮੈਮੋਰੀ ਵਿੱਚ ਮੌਜੂਦ object ਦੀ property ਵਾਪਸ ਕਰਦੇ ਹਨ; ਹੋਰ ਕਿਸੇ ਡੇਟਾਬੇਸ, ਹੋਰ ਸਰਵਿਸ, ਜਾਂ ਕਈ ਸਰੋਤਾਂ ਨੂੰ ਜੋੜ ਕੇ ਮੁੱਲ ਨੂੰ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹਨ।
ਉਦਾਹਰਨ ਵਜੋਂ, ਜੇ schema 'ਚ User.posts ਹੈ, ਤਾਂ posts resolver userId ਨਾਲ posts ਟੇਬਲ ਨੂੰ query ਕਰ ਸਕਦਾ ਹੈ, ਜਾਂ ਅਲੱਗ Posts ਸਰਵਿਸ ਨੂੰ ਕਾਲ ਕਰ ਸਕਦਾ ਹੈ।
Resolvers schema ਅਤੇ ਤੁਹਾਡੇ ਅਸਲੀ ਸਿਸਟਮਾਂ ਵਿਚਕਾਰ glue ਹਨ:
ਇਹ mapping ਲਚਕੀਲਾ ਹੈ: ਤੁਸੀਂ ਬੈਕਐਂਡ implementation ਨੂੰ ਬਦਲ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਕਲਾਇਂਟ query shape ਬਦਲੇ—ਜਦ ਤਕ schema ਸਥਿਰ ਰਹਿੰਦੀ ਹੈ।
ਕਿਉਂਕਿ resolvers ਹਰ field ਅਤੇ ਸੂਚੀ ਦੇ item ਲਈ ਚੱਲ ਸਕਦੇ ਹਨ, ਬੜੀ ਆਸਾਨੀ ਨਾਲ ਬਹੁਤ ਸਾਰੀਆਂ ਛੋਟੀਆਂ ਕਾਲਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ: 100 users ਲਈ posts ਵੱਖ-ਵੱਖ 100 queries ਨਾਲ ਫੈਚ ਕਰਨਾ)। ਇਹ “N+1” ਪੈਟਰਨ ਜਵਾਬ ਨੂੰ ਹੌਲੀ ਕਰ ਸਕਦਾ ਹੈ।
ਆਮ ਸੋਧਾਂ ਵਿੱਚ batching ਅਤੇ caching ਸ਼ਾਮਲ ਹਨ (ਉਦਾਹਰਨ: IDs ਇਕੱਠੇ ਕਰ ਕੇ ਇੱਕ query), ਅਤੇ ਉਹਨਾਂ nested fields ਬਾਰੇ ਸੋਚ-ਵਿਚਾਰ ਕਰਨਾ ਜੋ ਤੁਸੀਂ clients ਨੂੰ ਅਪੀਲ ਕਰਨ ਲਈ ਪ੍ਰੋਤਸਾਹਿਤ ਕਰਦੇ ਹੋ।
Authorization ਅਕਸਰ resolvers (ਜਾਂ shared middleware) ਵਿੱਚ ਲਾਗੂ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ resolvers ਜਾਣਦੇ ਹਨ ਕੌਣ ਮੰਗ ਰਿਹਾ ਹੈ (context ਰਾਹੀਂ) ਅਤੇ ਕਿਹੜਾ ਡੇਟਾ ਉਹ ਐਕਸੇਸ ਕਰ ਰਿਹਾ ਹੈ। Validation ਆਮ ਤੌਰ 'ਤੇ ਦੋ ਸਤਰਾਂ 'ਤੇ ਹੁੰਦੀ ਹੈ: GraphQL ਤਰ੍ਹਾਂ ਦੀ/ਆਕਾਰ ਦੀ validation ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਕਰਦਾ ਹੈ, ਜਦਕਿ resolvers ਵਿਅਵਸਾਇਕ ਨਿਯਮ (ਜਿਵੇਂ "ਸਿਰਫ਼ admins ਇਹ field ਸੈਟ ਕਰ ਸਕਦੇ ਹਨ") ਨੂੰ ਲਾਗੂ ਕਰਦੇ ਹਨ।
GraphQL ਨਵੇਂ ਲੈਣ ਵਾਲਿਆਂ ਨੂੰ ਹੈਰਾਨ ਕਰਦਾ ਹੈ ਕਿ ਇੱਕ request "ਸਫ਼ਲ" ਹੋ ਸਕਦੀ ਹੈ ਅਤੇ ਫਿਰ ਵੀ errors ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ। ਇਹ ਇਸ ਲਈ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ GraphQL field-ਅਧਾਰਿਤ ਹੈ: ਜੇ ਕੁਝ fields resolve ਹੋ ਜਾਂਦੇ ਹਨ ਅਤੇ ਹੋਰ ਨਹੀਂ, ਤਾਂ ਤੁਹਾਨੂੰ partial data ਵਾਪਸ ਮਿਲ ਸਕਦਾ ਹੈ।
ਇੱਕ ਆਮ GraphQL response ਵਿੱਚ ਦੋਹਾਂ data ਅਤੇ errors array ਹੋ ਸਕਦੇ ਹਨ:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
ਇਹ ਲਾਭਦਾਇਕ ਹੈ: ਕਲਾਇਂਟ ਜੋ ਕੁਝ ਹੈ ਉਹ render ਕਰ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ ਲਈ, user profile) ਜਦਕਿ ਗੁੰਮ ਹੋਏ ਫੀਲਡ ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ।
data ਅਕਸਰ null ਹੁੰਦਾ ਹੈ।Error messages ਨੂੰ end user ਲਈ ਲਿਖੋ, debugging ਲਈ ਨਹੀਂ। stack traces, database names, ਜਾਂ ਅੰਦਰੂਨੀ IDs ਪ੍ਰਗਟ ਕਰਨ ਤੋਂ ਬਚੋ। ਚੰਗਾ ਪੈਟਰਨ ਇਹ ਹੈ:
messageextensions.coderetryable: true)ਵਿਸ਼ਤਾਰਤ error ਨੂੰ server-ਸਾਈਡ ਤੇ request ID ਨਾਲ ਲੌਗ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਿਨਾਂ ਅੰਦਰੂਨੀ ਜਾਣਕਾਰੀ ਖੋਲ੍ਹੇ ਜਾਂਚ ਕਰ ਸਕੋ।
ਆਪਣੇ web ਅਤੇ mobile apps ਲਈ ਇੱਕ ਛੋਟਾ error “contract”.define ਕਰੋ: ਆਮ extensions.code ਮੁੱਲ (ਜਿਵੇਂ UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), ਕਦੋਂ toast ਦਿਖਾਉਣਾ ਹੈ ਬਨਾਮ inline field errors, ਅਤੇ partial data ਨੂੰ ਕਿਵੇਂ handle ਕਰਨਾ ਹੈ। ਇੱਥੇ ਸਥਿਰਤਾ ਹਰ ਕਲਾਇਂਟ ਵੱਲੋਂ ਵੱਖਰੇ ਨਿਯਮ ਬਣਾਉਣ ਤੋਂ ਬਚਾਉਂਦੀ ਹੈ।
Subscriptions GraphQL ਦੀ ਢੰਗ ਹੈ ਜਿਸ ਨਾਲ ਕਲਾਇਂਟਾਂ ਨੂੰ ਜਿਵੇਂ-ਜਿਵੇਂ ਡੇਟਾ ਬਦਲਦਾ ਹੈ ਉਹ ਤੁਰੰਤ push ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਬਜਾਏ ਇਸਦੇ ਕਿ ਕਲਾਇਂਟ ਹਰ ਵਾਰੀ ਪੁੱਛੇ। ਇਹ ਆਮਤੌਰ 'ਤੇ persistent connection (ਜ਼ਿਆਦਾਤਰ ਵੈਬਸਾਕਟਸ) ਤੇ ਡਿਲਿਵਰ ਹੁੰਦੇ ਹਨ, ਤਾਂ ਜੋ ਸਰਵਰ ਤੁਰੰਤ events ਭੇਜ ਸਕੇ।
Subscription ਕਾਫੀ ਹਦ ਤੱਕ query ਵਰਗੀ ਹੀ ਹੁੰਦੀ ਹੈ, ਪਰ ਨਤੀਜਾ ਇੱਕ ਹੀ ਜਵਾਬ ਨਹੀਂ ਹੁੰਦਾ। ਇਹ ਇੱਕ results ਦੀ stream ਹੁੰਦੀ ਹੈ—ਹਰ ਇਕ event ਨੂੰ ਦਰਸਾਉਂਦੀ ਹੈ।
ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ, ਇੱਕ ਕਲਾਇਂਟ ਕਿਸੇ topic ਨੂੰ “subscribe” ਕਰਦਾ ਹੈ (ਉਦਾਹਰਨ: chat ਐਪ ਵਿੱਚ messageAdded)। ਜਦੋਂ ਸਰਵਰ event publish ਕਰਦਾ ਹੈ, ਕਿਸੇ ਵੀ connected subscribers ਨੂੰ subscription ਦੇ selection set ਨਾਲ ਮਿਲਦਾ payload ਭੇਜ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ।
Subscriptions ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਚਮਕਦਾਰ ਹੁੰਦੇ ਹਨ ਜਿੱਥੇ ਤਬਦੀਲੀਆਂ ਤੁਰੰਤ ਚਾਹੀਦੀਆਂ ਹਨ:
Polling ਵਿੱਚ ਕਲਾਇਂਟ ਹਰ N ਸਕਿੰਟਾਂ 'ਚ ਪੁੱਛਦਾ ਹੈ “ਕੋਈ ਨਵਾਂ ਹੈ?”। ਇਹ ਸਾਦਾ ਹੈ, ਪਰ ਜਦੋਂ ਕੁਝ ਵੀ ਬਦਲਦਾ ਨਹੀਂ ਤਾਂ ਬੇਕਾਰ ਬੇਨਤੀਆਂ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਅਜੇ ਵੀ ਦੇਰੀ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ।
Subscriptions ਨਾਲ ਸਰਵਰ ਤੁਰੰਤ ਕਹਿੰਦਾ ਹੈ “ਇਹ ਰਹਾ update”। ਇਸ ਨਾਲ ਬੇਕਾਰ ਟ੍ਰੈਫਿਕ ਘਟ ਸਕਦਾ ਹੈ ਅਤੇ ਮਹਿਸੂਸ ਕੀਤੀ ਤੇਜ਼ੀ ਵਧ ਸਕਦੀ ਹੈ—ਪਰ ਇਸਦਾ ਕੀਮਤ connections open ਰੱਖਣ ਅਤੇ real-time infrastructure ਨੂੰ manage ਕਰਨ 'ਚ ਹੁੰਦੀ ਹੈ।
Subscriptions ਹਮੇਸ਼ਾਂ ਲਾਭਕਾਰੀ ਨਹੀਂ ਹੁੰਦੇ। ਜੇ updates ਅਕਸਰ ਨਹੀਂ ਹੁੰਦੀਆਂ, ਸਮੇਂ-ਸੰਵੇਦਨਸ਼ੀਲ ਨਹੀਂ ਹਨ, ਜਾਂ ਆਸਾਨੀ ਨਾਲ batch ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ, ਤਾਂ polling (ਜਾਂ user actions ਤੋਂ ਬਾਅਦ re-fetch) ਕਾਫ਼ੀ ਹੋ ਸਕਦਾ ਹੈ।
ਉਹ<|vq_image_14639|><|vq_image_2326|><|vq_image_3432|><|vq_image_1293|><|vq_image_107|><|vq_image_107|><|vq_image_14702|><|vq_image_11960|><|vq_image_4436|><|vq_image_8986|><|vq_image_4660|><|vq_image_14202|><|vq_image_16104|><|vq_image_2490|><|vq_image_1425|><|vq_image_12662|><|vq_image_1176|><|vq_image_877|><|image_border_904|><|vq_image_11291|><|vq_image_8885|><|vq_image_1331|><|vq_image_11943|><|vq_image_6739|><|vq_image_2586|><|vq_image_9039|><|vq_image_6718|><|vq_image_14455|><|vq_image_14455|><|vq_image_8936|><|vq_image_9147|><|vq_image_6298|><|vq_image_16056|><|vq_image_1458|><|vq_image_1458|><|vq_image_1458|><|vq_image_638|><|vq_image_16311|><|vq_image_3364|><|vq_image_5096|><|vq_image_11847|><|vq_image_10130|><|vq_image_15138|><|vq_image_5764|><|vq_image_10117|><|vq_image_1204|><|vq_image_13925|><|vq_image_1984|><|vq_image_4190|><|vq_image_4744|><|vq_image_9289|><|vq_image_8590|><|vq_image_4171|><|vq_image_14466|><|vq_image_13825|><|vq_image_15482|><|vq_image_15482|><|vq_image_15482|><|vq_image_11070|><|vq_image_1500|><|vq_image_4144|><|vq_image_5504|><|vq_image_14369|><|vq_image_6384|><|vq_image_4012|><|vq_image_13212|><|vq_image_2213|><|image_border_905|><|vq_image_14455|><|vq_image_991|><|vq_image_9203|><|vq_image_14291|><|vq_image_11756|><|vq_image_5286|><|vq_image_14585|><|vq_image_7023|><|vq_image_6298|><|vq_image_1458|><|vq_image_12683|><|vq_image_12683|><|vq_image_10305|><|vq_image_10088|><|vq_image_9684|><|vq_image_15029|><|vq_image_3224|><|vq_image_13161|><|vq_image_5843|><|vq_image_12928|><|vq_image_11248|><|vq_image_7617|><|vq_image_1204|><|vq_image_12105|><|vq_image_4502|><|vq_image_53|><|vq_image_8338|><|vq_image_15437|><|vq_image_585|><|vq_image_15689|><|vq_image_8799|><|vq_image_1565|><|vq_image_9692|><|vq_image_8358|><|vq_image_1668|><|vq_image_1959|><|vq_image_3319|><|vq_image_1646|><|vq_image_15560|><|vq_image_2020|><|vq_image_15632|><|vq_image_10192|><|vq_image_5834|><|vq_image_3774|><|vq_image_3182|><|vq_image_9077|><|vq_image_7023|><|vq_image_1718|><|image_border_906 analysis>
GraphQL ਇੱਕ query language ਅਤੇ runtime for APIs ਹੈ। ਕਲਾਇਂਟ ਇੱਕ ਐਸਾ query ਭੇਜਦੇ ਹਨ ਜੋ ਉਨ੍ਹਾਂ ਦੀ ਲੋੜ ਵਾਲੇ ਖੇਤਰਾ(ਫ਼ੀਲਡ) ਨੂੰ ਵਿਆਖਿਆ ਕਰਦਾ ਹੈ, ਤੇ ਸਰਵਰ ਉਸੇ ਢਾਂਚੇ ਵਿੱਚ JSON ਜਵਾਬ ਵਾਪਸ ਕਰਦਾ ਹੈ।
ਇਹਨਾਂ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਸੋਚੋ: ਇਹ ਕਲਾਇਂਟਾਂ ਅਤੇ ਇੱਕ ਜਾਂ ਇਕੱਠੇ ਡੇਟਾ ਸਰੋਤਾਂ (ਡੇਟਾਬੇਸ, REST ਸੇਵਾਵਾਂ, third‑party APIs, microservices) ਦੇ ਵਿਚਕਾਰ ਇੱਕ ਪਰਤ ਹੈ।
GraphQL ਮੁੱਖ ਤੌਰ 'ਤੇ ਹੇਠਾਂ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਦਾ ਹੱਲ ਕਰਦਾ ਹੈ:
ਕਲਾਇਂਟ ਸਿਰਫ਼ ਉਨ੍ਹਾਂ ਖੇਤਾਂ ਨੂੰ ਮੰਗ ਸਕਦਾ ਹੈ ਜੋ ਉਸਨੂੰ ਚਾਹੀਦੇ ਹਨ (ਨੈਸਟਡ ਖੇਤਾਂ ਸਮੇਤ), ਜਿਸ ਨਾਲ ਬਿਆਨਖ਼ਰਚੀ ਘੱਟ ਹੁੰਦੀ ਹੈ ਅਤੇ ਕਲਾਇਂਟ ਕੋਡ ਸਧਾਰਨ ਹੁੰਦਾ ਹੈ।
GraphQL ਇਹ ਨਹੀਂ ਹੈ:
ਇਸਨੂੰ ਇੱਕ API contract + execution engine ਵਜੋਂ ਸਮਝੋ, ਨਾ ਕਿ ਸਟੋਰੇਜ ਜਾਂ ਪ੍ਰਦਰਸ਼ਨ ਦਾ ਜਾਦੂ।
ਬਹੁਤ ਸਾਰੇ GraphQL APIs ਇੱਕ single endpoint (ਅਕਸਰ /graphql)Expose ਕਰਦੇ ਹਨ। ਵੱਖ-ਵੱਖ URLs ਦੀ ਥਾਂ, ਤੁਸੀਂ ਵੱਖ-ਵੱਖ operations (queries/mutations) ਨੂੰ ਉਸ ਇੱਕ ਐਂਡਪੌਇੰਟ ਤੇ ਭੇਜਦੇ ਹੋ।
ਵਰਤੋਂ ਵਿੱਚ: caching ਅਤੇ observability ਆਮਤੌਰ 'ਤੇ operation name + variables ਤੇ ਨਿਰਭਰ ਹੁੰਦੇ ਹਨ, ਨਾ ਕਿ URL ਤੇ।
ਸchema ਇੱਕ API contract ਹੈ। ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ:
User, Post)User.name)User.posts)ਕਿਉਂਕਿ ਇਹ ਹੈ, ਸਰਵਰ execution ਤੋਂ ਪਹਿਲਾਂ queries ਨੂੰ validate ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਜੇ ਫੀਲਡ ਮੌਜੂਦ ਨਹੀਂ ਹੈ ਤਾਂ ਸਪਸ਼ਟ errors ਦੇ ਸਕਦਾ ਹੈ।
GraphQL queries read operations ਹਨ। ਤੁਸੀਂ ਉਹ fields specify ਕਰਦੇ ਹੋ ਜੋ ਤੁਹਾਨੂੰ ਚਾਹੀਦੇ ਹਨ, ਅਤੇ response JSON ਤੁਹਾਡੇ query ਦੇ ਢਾਂਚੇ ਨੂੰ mirror ਕਰਦਾ ਹੈ।
ਟਿਪਸ:
query GetUserWithPosts) ਤਾਂ ਜੋ debugging ਅਤੇ monitoring ਸੁਖਾਲੀ ਹੋਵੇ।posts(limit: 2))।Mutations write operations ਹਨ (create/update/delete)। ਆਮ ਪੈਟਰਨ:
input object ਭੇਜੋਡਾਟਾ ਵਾਪਸ ਭੇਜਣਾ (sirf success: true ਨਹੀਂ) UI ਨੂੰ turant ਅੱਪਡੇਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਅਤੇ caches ਨੂੰ consistent ਰੱਖਦਾ ਹੈ।
Resolvers ਉਹ field-level functions ਹਨ ਜੋ ਦੱਸਦੇ ਹਨ ਕਿ ਹਰ field ਨੂੰ ਕਿਵੇਂ fetch ਜਾਂ compute ਕਰਨਾ ਹੈ।
ਅਮਲ ਵਿੱਚ, resolvers:
ਅਧਿਕਾਰ (authorization) ਅਕਸਰ resolvers (ਜਾਂ ਨਿਰਧਾਰਿਤ middleware) ਵਿੱਚ ਲਾਭ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਓਹ ਜਾਣਦੇ ਹਨ ਕਿ ਕੌਣ ਕੀ ਮੰਗ ਰਿਹਾ ਹੈ।
ਆਮ ਤੌਰ 'ਤੇ N+1 pattern ਆਸਾਨੀ ਨਾਲ ਬਣ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ: 100 users ਲਈ আলੱਗ-আਲੱਗ posts ਲੋਡ ਕਰਨਾ)।
ਸੁਧਾਰ:
resolver timing ਮਾਪੋ ਅਤੇ ਇੱਕ request ਦੌਰਾਨ repeated downstream calls 'ਤੇ ਧਿਆਨ ਰੱਖੋ।
GraphQL partial data ਨੂੰ errors array ਨਾਲ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਕੁਝ fields resolve ਹੋ ਜਾਦੇ ਹਨ ਪਰ ਕੁਝ fail ਹੋ ਜਾਂਦੇ ਹਨ (ਉਦਾਹਰਨ: forbidden field ਜਾਂ downstream timeout)।
ਚੰਗੀਆਂ ਪ੍ਰੈਕਟਿਸਜ਼:
message ਦਿਓextensions.code ਵਰਤੋਂ (ਜਿਵੇਂ FORBIDDEN, BAD_USER_INPUT)ਕਲਾਇਂਟ ਇਹ ਨਿਰਣੈ ਕਰੇ ਕਿ partial data ਨੂੰ ਕਦੋਂ render ਕਰਨਾ ਹੈ ਅਤੇ ਕਦੋਂ ਪੂਰੇ operation ਨੂੰ ਅਸਫਲ ਮੰਨਣਾ ਹੈ।