29 ਅਕਤੂ 2025·8 ਮਿੰਟ
ਵੈੱਬ, ਮੋਬਾਈਲ ਅਤੇ APIs ਲਈ ਇੱਕ AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡਬੇਸ
ਦੇਖੋ ਕਿ ਇਕ ਹੀ AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡਬੇਸ ਕਿਵੇਂ web ਐਪ, ਮੋਬਾਈਲ ਐਪ ਅਤੇ APIs ਨੂੰ ਸਾਂਝੇ ਲਾਜ਼ਿਕ, consistent ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਸੁਰੱਖਿਅਤ releases ਨਾਲ ਚਲਾ ਸਕਦਾ ਹੈ।
ਦੇਖੋ ਕਿ ਇਕ ਹੀ AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡਬੇਸ ਕਿਵੇਂ web ਐਪ, ਮੋਬਾਈਲ ਐਪ ਅਤੇ APIs ਨੂੰ ਸਾਂਝੇ ਲਾਜ਼ਿਕ, consistent ਡੇਟਾ ਮਾਡਲ ਅਤੇ ਸੁਰੱਖਿਅਤ releases ਨਾਲ ਚਲਾ ਸਕਦਾ ਹੈ।
“ਇੱਕ ਕੋਡਬੇਸ” ਦਾ ਅਰਥ ਅਕਸਰ ਹਰ ਥਾਂ ਇੱਕੋ UI ਨਹੀਂ ਹੁੰਦਾ। ਅਮਲ ਵਿੱਚ, ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਰਿਪੋ ਅਤੇ ਸਾਂਝੇ ਨਿਯਮਾਂ ਦਾ ਇੱਕ ਸੈੱਟ ਹੁੰਦਾ ਹੈ—ਜਿਸ ਦੇ ਨਾਲ ਵੱਖਰੇ delivery surfaces (web app, mobile app, API) ਹੁੰਦੇ ਹਨ ਜੋ ਸਭੇ नीचे ਇੱਕੋ ਬਿਜ਼ਨੈਸ ਫੈਸਲਿਆਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ।
ਇਕ ਉਪਯੋਗੀ ਮਨੋਵੈज्ञानिक ਮਾਡਲ ਇਹ ਹੈ ਕਿ ਉਹ ਹਿੱਸੇ ਸਾਂਝੇ ਕਰੋ ਜੋ ਕਦੇ ਵੱਖਰੀਆਂ ਨਹੀਂ ਹੋਣੇ ਚਾਹੀਦੇ:
ਇਸ ਦੇ ਨਾਲ, ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ UI ਲੇਅਰ ਨੂੰ ਪੂਰੀ ਤਰ੍ਹਾਂ ਸਾਂਝਾ ਨਹੀਂ ਕਰਦੇ। ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ ਦੇ navigation pattern, accessibility ਉਮੀਦਾਂ, performance ਸੀਮਾਵਾਂ ਅਤੇ ਪਲੇਟਫਾਰਮ ਦੇ ਯੋਗਤਾਵਾਂ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ। ਕੁਝ ਹਾਲਤਾਂ 'ਚ UI ਸਾਂਝਾ ਕਰਨਾ ਲਾਭਦਾਇਕ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ "ਇੱਕ ਕੋਡਬੇਸ" ਦੀ ਪਰਿਭਾਸ਼ਾ ਨਹੀਂ ਹੈ।
AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ ਬਹੁਤ ਤੇਜ਼ੀ ਨਾਲ ਸਕੈਫੋਲਡਿੰਗ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ:
ਪਰ AI ਆਪਣੇ ਆਪ ਵਿੱਚ ਇਕ ਸੰਗਠਿਤ ਆਰਕੀਟੈਕਚਰ ਨਹੀਂ ਬਣਾਉਂਦਾ। ਬਿਨਾਂ ਸਪੱਸ਼ਟ ਹੱਦਾਂ ਦੇ, ਇਹ ਅਕਸਰ ਲੋਜਿਕ ਨੂੰ ਦੁਹਰਾਉਂਦਾ ਹੈ, concerns ਮਿਲਾ ਦਿੰਦਾ ਹੈ (UI ਸਿੱਧਾ DB ਕੋਡ ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ), ਅਤੇ ਕਈ ਥਾਵਾਂ 'ਤੇ “लगभग वही” validations ਬਣ ਜਾਂਦੀਆਂ ਹਨ। ਲਾਭ ਤਾਂ ਉਸ ਵੇਲੇ ਆਉਂਦਾ ਹੈ ਜਦੋਂ ਪਹਿਲਾਂ structure ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਜਾਏ—ਫਿਰ AI ਨੂੰ ਰੀਪਿਟੇਟਿਵ ਹਿੱਸਿਆਂ ਨੂੰ ਭਰਨ ਲਈ ਵਰਤਿਆ ਜਾਵੇ।
ਇੱਕ AI-ਸਹਾਇਤ ਕੋਡਬੇਸ ਸਫਲ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਹ:
ਇੱਕ ਹੀ ਕੋਡਬੇਸ ਸਿਰਫ ਉਸ ਵੇਲੇ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਪਤਾ ਹੋਵੇ ਕਿ ਇਸ ਨੂੰ ਕੀ ਹਾਸਲ ਕਰਨਾ ਹੈ—ਅਤੇ ਕੀ ਚੀਜ਼ਾਂ ਨੂੰ ਮਿਆਰ ਬਣਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਹੀਂ ਕਰਨੀ ਚਾਹੀਦੀ। ਵੈੱਬ, ਮੋਬਾਈਲ, ਅਤੇ APIs ਵੱਖ-ਵੱਖ ਦਰਸ਼ਕਾਂ ਅਤੇ ਉਪਯੋਗ ਪੈਟਰਨਾਂ ਨੂੰ ਸੇਵਾ ਦਿੰਦੇ ਹਨ, ਭਾਵੇਂ ਉਹ ਇੱਕੋ ਬਿਜ਼ਨੈਸ ਨਿਯਮ ਸਾਂਝੇ ਕਰਦੇ ਹੋਣ।
ਅਧਿਕਤਰ ਉਤਪਾਦਾਂ ਕੋਲ ਘੱਟੋ-ਘੱਟ ਤਿੰਨ “ਫਰੰਟ ਡੋਰ” ਹੁੰਦੇ ਹਨ:
ਲਕ਼ਸ਼ ਹੈ ਵਰਤੋਂ ਵਿੱਚ ਇੱਕਸਰਤਾ (rules, permissions, calculations)—ਨਾ ਕਿ ਇਕੋ ਜਿਹੀ ਅਨੁਭਵ।
ਆਮ ਨੁਕਸਾਨ ਇਹ ਹੈ ਕਿ “single codebase” ਨੂੰ “single UI” ਵਜੋਂ ਲੈ ਲਿਆ ਜਾਵੇ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ web-like mobile app ਜਾਂ mobile-like web app ਬਣਾਉਂਦਾ ਹੈ—ਦੋਹਾਂ ਹੀ ਸੁਸਤ ਕਰਨ ਵਾਲੇ।
ਬਦਲੇ ਵਿੱਚ, ਇਹਨਾਂ ਉਦੇਸ਼ਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ:
Offline mode: ਮੋਬਾਈਲ ਨੂੰ ਅਕਸਰ ਨੈੱਟਵਰਕ ਬਿਨਾਂ read access (ਅਤੇ ਕਈ ਵਾਰੀ writes) ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਇਸ ਲਈ local storage, sync ਰਣਨੀਤੀਆਂ, conflict handling, ਅਤੇ ਸਪਸ਼ਟ “source of truth” ਨਿਯਮ ਲਾਜ਼ਮੀ ਹੋ ਜਾਂਦੇ ਹਨ।
Performance: ਵੈੱਬ bundle size ਅਤੇ time-to-interactive ਦੀ ਪਰਵਾਹ ਕਰਦਾ ਹੈ; ਮੋਬਾਈਲ startup time ਅਤੇ network efficiency; APIs latency ਅਤੇ throughput। ਕੋਡ ਸਾਂਝਾ ਕਰਨਾ ਇਹ ਨਹੀਂ ਥਾਪਣਾ ਕਿ ਹਰ client ਨੂੰ ਅਣਜਰੂਰੀ modules ਭੇਜੇ ਜਾਣ।
Security and compliance: Authentication, authorization, audit trails, encryption, ਅਤੇ data retention ਸਭ surfaces 'ਤੇ consistent ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ regulated ਖੇਤਰ ਵਿੱਚ ਕੰਮ ਕਰਦੇ ਹੋ, ਤਾਂ logging, consent, ਅਤੇ least-privilege access ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਸ਼ਾਮਲ ਕਰੋ—ਬਾਅਦ ਵਿੱਚ ਪੈਚ ਵਾਂਗ ਨਹੀਂ।
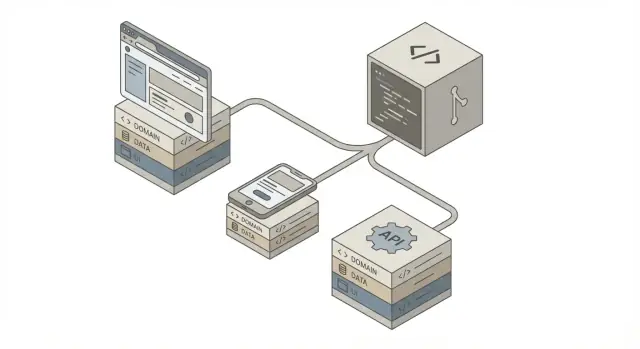
ਇੱਕ ਹੀ ਕੋਡਬੇਸ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਸਪਸ਼ਟ ਲੇਅਰਾਂ ਵਿੱਚ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਅੰਗਠਿਤ ਹੋਵੇ। ਇਹ ਢਾਂਚਾ AI-ਜਨਰੇਟ ਕੀਤੇ ਕੋਡ ਨੂੰ ਅਸਾਨੀ ਨਾਲ review, test, ਅਤੇ ਬਿਨਾਂ ਅਣਚਾਹੇ ਪ੍ਰਭਾਵ ਦੇ ਬਦਲਣ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਇਹ ਉਹ ਬੁਨਿਆਦੀ ਆਕਾਰ ਹੈ ਜਿਸ 'ਤੇ ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇਕਠੀਆਂ ਹੁੰਦੀਆਂ ਹਨ:
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
ਮੁੱਖ ਵਿਚਾਰ: ਯੂਜ਼ਰ ਇੰਟਰਫੇਸ ਅਤੇ ਟ੍ਰਾਂਸਪੋਰਟ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਕਿਨਾਰੇ ਬੈਠਦੀਆਂ ਹਨ, ਜਦਕਿ ਬਿਜ਼ਨੈਸ ਨਿਯਮ ਕੇਂਦਰ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ।
“Shareable core” ਉਹ ਸਭ ਕੁਝ ਹੈ ਜੋ ਹਰ ਜਗ੍ਹਾ ਇੱਕੋ ਤਰ੍ਹਾਂ ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ:
ਜਦੋਂ AI ਨਵੀਆਂ ਫੀਚਰ ਜਨਰੇਟ ਕਰਦਾ ਹੈ, ਸਭ ਤੋਂ ਵਧੀਆ ਨਤੀਜਾ ਹੈ: ਇੱਕ ਵਾਰੀ domain rules update ਹੁੰਦੇ ਹਨ, ਅਤੇ ਹਰ client ਆਪਣੇ-ਆਪ ਨੇ ਲਾਭ ਪਾਂਦਾ ਹੈ।
ਕੁਝ ਕੋਡ ਸਾਂਝੇ abstraction ਵਿੱਚ ਪਾ ਦੇਣਾ ਮਹਿੰਗਾ (ਅਤੇ ਖਤਰਨਾਕ) ਹੋ ਸਕਦਾ ਹੈ:
ਵਿਆਵਹਾਰਿਕ ਨਿਯਮ: ਜੇ ਯੂਜ਼ਰ ਇਸਨੂੰ ਦੇਖ ਸਕਦਾ ਹੈ ਜਾਂ OS ਇਸਨੂੰ ਤੋੜ ਸਕਦਾ ਹੈ, ਤਾਂ ਇਸਨੂੰ app-specific ਰੱਖੋ। ਜੇ ਇਹ ਕੋਈ ਬਿਜ਼ਨੈਸ ਫੈਸਲਾ ਹੈ, ਤਾਂ ਡੋਮੇਨ ਵਿੱਚ ਰੱਖੋ।
ਸਾਂਝੀ ਡੋਮੇਨ ਲੇਅਰ ਉਸ ਕੋਡ ਦਾ ਹਿੱਸਾ ਹੈ ਜੋ "boring" ਜਿਹਾ ਮਹਿਸੂਸ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: predictable, testable, ਅਤੇ ਹਰ ਜਗ੍ਹਾ reuse ਯੋਗ। ਜੇ AI ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਬਣਾਉਣ ਵਿੱਚ ਸਹਾਇਤਾ ਕਰ ਰਿਹਾ ਹੈ, ਤਾਂ ਇਹ ਲੇਅਰ ਉਹ ਜ਼ਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਪ੍ਰੋਜੈਕਟ ਦੀ ਮੀਨਿੰਗ ਐਂਕਰ ਕਰਦੇ ਹੋ—ਤਾਂ ਜੋ web screens, mobile flows, ਅਤੇ API endpoints ਸਭ ਇੱਕੋ ਨਿਯਮ ਦਰਸਾਉਣ।
ਆਪਣੇ ਉਤਪਾਦ ਦੀਆਂ ਮੁੱਖ ਸੰਕਲਪਨਾਵਾਂ ਨੂੰ define ਕਰੋ ਜਿਵੇਂ entities (ਪਛਾਣ ਵਾਲੀਆਂ ਚੀਜ਼ਾਂ, ਜਿਵੇਂ Account, Order, Subscription) ਅਤੇ value objects (Money, EmailAddress, DateRange)। ਫਿਰ ਬਿਹੈਵਿਅਰ ਨੂੰ capture ਕਰੋ use cases (ਕਈ ਵਾਰੀ application services ਕਹਿੰਦੇ ਹਨ): “Create order,” “Cancel subscription,” “Change email.”
ਇਸ ਢਾਂਚੇ ਨਾਲ ਡੋਮੇਨ ਨਾਨ-ਸਪੈਸ਼ਲਿਸਟਾਂ ਲਈ ਵੀ ਸਮਝਣਯੋਗ ਰਹਿੰਦਾ ਹੈ: nouns ਦੱਸਦੇ ਹਨ ਕਿ ਕੀ ਮੌਜੂਦ ਹੈ, verbs ਦੱਸਦੇ ਹਨ ਕਿ ਸਿਸਟਮ ਕੀ ਕਰਦਾ ਹੈ।
ਬਿਜ਼ਨੈਸ ਲੋਜਿਕ ਨੂੰ ਇਹ ਨਹੀਂ ਪਤਾ ਹੋਣਾ ਚਾਹੀਦਾ ਕਿ ਇਹ ਕਿਸ ਤਰ੍ਹਾਂ trigger ਹੋਇਆ: button tap, web form submit, ਜਾਂ API request। ਬਹੁਤ ਸੋਹਣੇ ਤੌਰ ਤੇ ਇਸਦਾ ਅਰਥ:
ਜਦੋਂ AI ਕੋਡ ਜਨਰੇਟ ਕਰਦਾ ਹੈ, ਇਹ ਵਿਛਿੱਤੀ ਹੋ ਸਕਦਾ ਹੈ—models ਨੂੰ UI concerns ਨਾਲ ਭਰ ਦਿੱਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਇਸ ਨੂੰ refactor ਟ੍ਰਿਗਰ ਸਮਝੋ।
Validation ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਪ੍ਰੋਡਕਟ ਅਕਸਰ ਭਟਕ ਜਾਂਦੇ ਹਨ: web ਕੁਝ allow ਕਰਦਾ ਹੈ ਜੋ API reject ਕਰਦਾ ਹੈ, ਜਾਂ mobile ਵੱਖਰਾ validate ਕਰਦਾ ਹੈ। Validation ਨੂੰ domain layer (ਜਾਂ shared validation module) ਵਿੱਚ ਰੱਖੋ ਤਾਂ ਕਿ ਹਰ surface ਇੱਕੋ ਨਿਯਮ ਲਾਗੂ ਕਰੇ।
Examples:
EmailAddress ਇੱਕ ਵਾਰੀ ਫਾਰਮੈਟ validate ਜਾਵੇ, web/mobile/API 'ਚ reuseMoney negative totals ਰੋਕੇ, ਜਿੱਥੇ ਤੋਂ ਵੀ value ਆਈਜੇ ਤੁਸੀਂ ਇਹ ਚੰਗੀ ਤਰ੍ਹਾਂ ਕਰ ਲੈਂਦੇ ਹੋ, ਤਾਂ API layer translator ਬਣ ਜਾਦਾ ਹੈ, ਅਤੇ web/mobile presenters ਬਣਦੇ ਹਨ—ਜਦਕਿ domain layer single source of truth ਰਹਿੰਦਾ ਹੈ।
API layer ਤੁਹਾਡੇ ਸਿਸਟਮ ਦਾ “ਪਬਲਿਕ ਚਿਹਰਾ” ਹੈ—ਅਤੇ ਇੱਕ ਹੀ AI-ਜਨਰੇਟ ਕੀਤੇ ਕੋਡਬੇਸ ਵਿੱਚ, ਇਹ ਉਹ ਹਿੱਸਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜੋ ਹੋਰ ਸਭ ਚੀਜ਼ਾਂ ਨੂੰ anchor ਕਰੇ। ਜੇ contract ਸਪਸ਼ਟ ਹੋਵੇ, ਤਾਂ web app, mobile app, ਅਤੇ ਇੰਟਰਨਲ ਸਰਵਿਸਿਜ਼ ਇਕੋ ਸੋਰਸ ਤੋਂ generate ਅਤੇ validate ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
contract define ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ handlers ਜਾਂ UI wiring generate ਨਾ ਕਰੋ:
/users, /orders/{id}), predictable filtering ਅਤੇ sorting।/v1/... ਜਾਂ header-based) ਅਤੇ deprecation ਨਿਯਮ ਦਸਤਾਵੇਜ਼ ਕਰੋ।OpenAPI (ਜਾਂ schema-first tool ਜਿਵੇਂ GraphQL SDL) ਨੂੰ canonical artifact ਬਣਾਓ। ਇਸ ਤੋਂ generate ਕਰੋ:
ਇਹ AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ: ਮਾਡਲ ਤੇਜ਼ੀ ਨਾਲ ਬਹੁਤ ਕੋਡ ਤਿਆਰ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ schema ਇਸਨੂੰ aligned ਰੱਖਦੀ ਹੈ।
ਕੁਝ non-negotiables ਰੱਖੋ:
snake_case ਜਾਂ camelCase, ਦੋਹਾਂ ਨਹੀਂ; JSON ਅਤੇ generated types 'ਚ ਮਿਲਾਓ।Idempotency-Key ਲਾਜ਼ਮੀ ਕਰੋ, ਅਤੇ retry behavior define ਕਰੋ।API contract ਨੂੰ ਇੱਕ ਉਤਪਾਦ ਵਾਂਗ treat ਕਰੋ। ਜਦ ਇਹ stable ਹੁੰਦਾ ਹੈ, ਹੋਰ ਸਭ ਕੁਝ generate, test, ਅਤੇ ship ਕਰਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ।
Web app ਸਾਂਝੀ ਬਿਜ਼ਨੈਸ ਲੋਜਿਕ ਤੋਂ ਬਹੁਤ ਲਾਭ ਲੈਂਦੀ ਹੈ—ਪਰ ਜਦੋਂ ਉਹ ਲੋਜਿਕ UI concerns ਨਾਲ ਗੂੰਝ ਜਾਂਦੀ ਹੈ ਤਾਂ ਨੁਕਸਾਨ ਹੁੰਦਾ ਹੈ। ਕੁੰਜੀ ਇਹ ਹੈ ਕਿ ਸਾਂਝੀ ਡੋਮੇਨ ਲੇਅਰ ਨੂੰ "headless" engine ਵਾਂਗ treat ਕੀਤਾ ਜਾਵੇ: ਇਹ ਨਿਯਮ, validation, ਅਤੇ workflows ਜਾਣਦਾ ਹੈ, ਪਰ components, routes, ਜਾਂ browser APIs ਬਾਰੇ ਕੁਝ ਨਹੀਂ ਜਾਣਦਾ।
ਜੇ ਤੁਸੀਂ SSR (server-side rendering) ਵਰਤਦੇ ਹੋ, ਤਾਂ ਸਾਂਝਾ ਕੋਡ ਸਰਵਰ 'ਤੇ safe ਤਰੀਕੇ ਨਾਲ ਦੌੜਨ ਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਕੋਈ direct window, document, ਜਾਂ browser storage calls ਨਾ ਹੋਣ। ਇਹ ਇੱਕ ਚੰਗੀ ਬਲਦਾਈ ਹੈ: browser-dependent ਵਿਹਾਰ ਨੂੰ ਇੱਕ ਬਾਰੀਕ web adapter ਲੇਅਰ ਵਿੱਚ ਰੱਖੋ।
CSR (client-side rendering) ਨਾਲ ਤੁਹਾਡੇ ਕੋਲ ਹੋਰ ਆਜ਼ਾਦੀ ਹੁੰਦੀ ਹੈ, ਪਰ ਇੱਕੋ ਅਨੁਸ਼ਾਸਨ ਫਾਇਦੇਮੰਦ ਹੁੰਦਾ ਹੈ। CSR-only projects ਅਕਸਰ “ਅਣਚਾਹੇ ਤਰੀਕੇ” ਨਾਲ UI ਕੋਡ ਨੂੰ domain modules ਵਿੱਚ import ਕਰ ਲੈਂਦੇ ਹਨ ਕਿਉਂਕਿ ਸਭ ਕੁਝ browser ਵਿੱਚ ਦੌਰਦਾ ਹੈ—ਇਹ ਤਦ ਤਕ ਠੀਕ ਲੱਗਦਾ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ SSR, edge rendering, ਜਾਂ Node ਵਿੱਚ ਦੌੜਨ ਵਾਲੇ tests ਜੋੜਦੇ ਨਹੀਂ।
ਇੱਕ ਪ੍ਰਸੰਗਿਕ ਨਿਯਮ: shared modules deterministic ਅਤੇ environment-agnostic ਹੋਣ; ਜੋ ਕੁਝ cookies, localStorage, ਜਾਂ URL ਨੂੰ ਛੋਹਦਾ ਹੈ, ਉਹ web app layer ਵਿੱਚ ਹੋਵੇ।
Shared logic domain state (ਉਦਾਹਰਣ: order totals, eligibility, derived flags) ਸਧਾਰਨ objects ਅਤੇ pure functions ਰਾਹੀਂ expose ਕਰ ਸਕਦਾ ਹੈ। Web app ਨੂੰ UI state ਦਾ ਮਾਲਕ ਬਣਨਾ ਚਾਹੀਦਾ ਹੈ: loading spinners, form focus, optimistic animations, modal visibility।
ਇਸ ਨਾਲ React/Vue ਦੀ state management ਲਚਕੀਲੀ ਰਹਿੰਦੀ ਹੈ: ਤੁਸੀਂ libraries ਬਦਲ ਸਕਦੇ ਹੋ ਬਿਨਾਂ business rules ਦੁਬਾਰਾ ਲਿਖੇ।
Web layer ਇਹ ਸੰਭਾਲੇ:
localStorage, caching)Web app ਨੂੰ ਇੱਕ adapter ਸਮਝੋ ਜੋ user interactions ਨੂੰ domain commands ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ—ਅਤੇ domain outcomes ਨੂੰ accessible screens ਵਿੱਚ ਤਬਦੀਲ ਕਰਦਾ ਹੈ।
Mobile app shared domain layer ਤੋਂ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲਾਭ ਉਠਾਂਦੀ ਹੈ: pricing, eligibility, validation, ਅਤੇ workflows web ਅਤੇ API ਵਰਗੇ ਹੀ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। Mobile UI ਫਿਰ shared logic ਦੇ ਆਲੇ-ਦੁਆਲੇ ਇੱਕ “shell” ਬਣਦਾ ਹੈ—touch, intermittent connectivity, ਅਤੇ device features ਲਈ optimize ਕੀਤਾ ਹੋਇਆ।
ਭਾਵੇਂ shared business logic ਹੋਵੇ, mobile ਦੇ ਕੁਝ ਪੈਟਰਨ ਹਨ ਜੋ ਸ਼ਾਮਿਲ ਨਹੀਂ ਹੁੰਦੇ:
ਜੇ ਤੁਸੀਂ ਅਸਲੀ ਮੋਬਾਈਲ ਉਪਯੋਗ ਦੀ ਉਮੀਦ ਕਰਦੇ ਹੋ, ਤਾਂ offline assume ਕਰੋ:
ਇੱਕ "single codebase" ਤੁਰੰਤ ਟੁੱਟ ਸਕਦੀ ਹੈ ਜੇ ਤੁਹਾਡੇ web app, mobile app, ਅਤੇ API ਹਰ ਇੱਕ ਆਪਣੀਆਂ data shapes ਅਤੇ security rules ਨਿਰਧਾਰਤ ਕਰਨ। ਸੁਧਾਰ ਇਹ ਹੈ ਕਿ models, authentication, ਅਤੇ authorization ਨੂੰ shared product ਫੈਸਲਿਆਂ ਵਜੋਂ treat ਕਰੋ ਅਤੇ ਇੱਕ ਵਾਰੀ encode ਕਰੋ।
ਇੱਕ ਥਾਂ ਚੁਣੋ ਜਿੱਥੇ models ਰਹਿਣਗੀਆਂ, ਅਤੇ ਹੋਰ ਸਭ ਕੁਝ ਉਸ ਤੋਂ derive ਹੋਵੇ। ਆਮ ਵਿਕਲਪ:
ਮੁੱਖ ਗੱਲ ਟੂਲ ਨਹੀਂ—ਇਕਸਾਰਤਾ ਹੈ। ਜੇ “OrderStatus” ਇੱਕ client ਵਿੱਚ ਪੰਜ values ਅਤੇ ਦੂਜੇ ਵਿੱਚ ਛੇ, ਤਾਂ AI-ਜਨਰੇਟ ਕੀਤਾ ਕੋਡ ਖੁਸ਼ ਹੋ ਕੇ compile ਕਰੇਗਾ ਪਰ bugs ship ਹੋਣਗੇ।
Authentication ਉਪਭੋਗਤਾ ਨੂੰ ਇੱਕੋ ਜਿਹਾ ਲੱਗਣਾ ਚਾਹੀਦਾ ਹੈ, ਪਰ mechanics surface ਅਨੁਸਾਰ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ:
ਇੱਕ ਇੱਕ(flow) ਡਿਜ਼ਾਈਨ ਕਰੋ: login → short-lived access → refresh ਜਦ ਲੋੜ ਹੋਏ → logout ਜੋ server-side state invalidate ਕਰੇ। Mobile 'ਚ secrets Keychain/Keystore ਵਿੱਚ ਰੱਖੋ, ਸਧਾਰਨ preferences ਵਿੱਚ ਨਹੀਂ। Web 'ਚ httpOnly cookies ਨੂੰ ਤਰਜੀਹ ਦਿਓ ਤਾਂ ਜੋ tokens JavaScript ਤੋਂ exposure ਤੋਂ ਬਚੇ ਰਹਿਣ।
Permissions ਇੱਕ ਵਾਰੀ define ਕਰੋ—ਆਈਡੀਅਲੀ ਤੌਰ 'ਤੇ business rules ਦੇ ਨੇੜੇ—ਫਿਰ ਸਭ ਥਾਂ ਲਾਗੂ ਕਰੋ।
canApproveInvoice(user, invoice))।ਇਸ ਨਾਲ “mobile 'ਤੇ ਚਲਦਾ ਹੈ ਪਰ web 'ਤੇ ਨਹੀਂ” ਵਾਲੀ drift ਰੋਕੀ ਜਾਂਦੀ ਹੈ ਅਤੇ AI code generation ਲਈ ਇੱਕ ਸਪਸ਼ਟ, testable contract ਮਿਲਦੀ ਹੈ।
ਇੱਕ unified codebase ਉਸ ਵੇਲੇ ਹੀ ਇਕਠੀ ਰਹਿੰਦੀ ਹੈ ਜਦੋਂ builds ਅਤੇ releases predictable ਹੋਣ। ਲਕ਼ਸ਼ ਇਹ ਹੈ ਕਿ ਟੀਮਾਂ API, web app, ਅਤੇ mobile apps ਨੂੰ independent ਤਰੀਕੇ ਨਾਲ ship ਕਰ ਸਕਣ—ਬਿਨਾਂ logic fork ਕੀਤੇ ਜਾਂ environments ਲਈ special casing ਕੀਤੇ।
Monorepo (ਇੱਕ repo, multiple packages/apps) ਇੱਕ single codebase ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ ਕਿਉਂਕਿ shared domain logic, API contracts, ਅਤੇ UI clients ਇਕੱਠੇ evolve ਹੁੰਦੇ ਹਨ। ਤੁਹਾਨੂੰ atomic changes ਮਿਲਦੇ ਹਨ (ਇੱਕ PR ਇੱਕ contract ਅਤੇ ਸਾਰੇ consumers ਨੂੰ update ਕਰਦਾ ਹੈ) ਅਤੇ ਸਾਦਾ refactors।
Multi-repo ਵੀ ਇੱਕਤਾ ਬਣਾਈ ਰੱਖ ਸਕਦਾ ਹੈ, ਪਰ coordination ਦੀ ਕੀਮਤ ਚੁਕਾਉਣੀ ਪੈਂਦੀ ਹੈ: shared packages ਦੀ versioning, artifacts publish ਕਰਨਾ, ਅਤੇ breaking changes synchronize ਕਰਨਾ। multi-repo ਤਦ ਹੀ ਚੁਣੋ ਜੇ org boundaries, security rules, ਜਾਂ scale monorepo ਨੂੰ ਗੁੰਝਲਦਾਰ ਬਣਾ ਦੇਣ।
ਹਰ surface ਨੂੰ ਇਕ ਵੱਖਰਾ build target ਸਮਝੋ ਜੋ shared packages consume ਕਰਦਾ ਹੈ:
Build outputs explicit ਅਤੇ reproducible ਰੱਖੋ (lockfiles, pinned toolchains, deterministic builds)।
ਆਮ pipeline: lint → typecheck → unit tests → contract tests → build → security scan → deploy।
ਕੋਨਫਿਗ ਨੂੰ ਕੋਡ ਤੋਂ ਵੱਖਰਾ ਰੱਖੋ: environment variables ਅਤੇ secrets CI/CD ਅਤੇ secret manager ਵਿੱਚ ਰਹਿਣ, repo ਵਿੱਚ ਨਹੀਂ। dev/stage/prod overlays ਵਰਤੋ ਤਾਂ ਜੋ ਇਕੋ artifact ਨੂੰ promote ਕੀਤਾ ਜਾ ਸਕੇ bina rebuild—ਖ਼ਾਸ ਕਰਕੇ API ਅਤੇ web runtime ਲਈ।
ਜਦ web, mobile, ਅਤੇ API ਇਕੋ codebase ਤੋਂ ship ਹੁੰਦੇ ਹਨ, testing “ਇਕ ਹੋਰ ਚੈੱਕਬਾਕਸ” ਨਹੀਂ ਰਹਿੰਦੀ—ਇਹ ਉਹ ਮਕੈਨਿਜ਼ਮ ਬਣ ਜਾਂਦਾ ਹੈ ਜੋ ਛੋਟਾ ਬਦਲਾਅ ਤਿੰਨ ਉਤਪਾਦਾਂ ਨੂੰ ਇਕੱਠੇ ਤੋੜਨ ਤੋਂ ਰੋਕੇ। ਲਕ਼ਸ਼ ਸਧਾਰਨ ਹੈ: ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਉਹ ਜਗ੍ਹਾ ਪਤਾ ਲਗਾਓ ਜਿੱਥੇ ਠੀਕ ਕਰਨਾ ਸਭ ਤੋਂ ਸਸਤਾ ਹੈ, ਅਤੇ ਖਤਰਨਾਕ ਬਦਲਾਵਾਂ ਨੂੰ users ਤੱਕ ਪਹੁੰਚਣ ਤੋਂ ਪਹਿਲਾਂ ਬਲਾਕ ਕਰੋ।
ਸਾਂਝੀ ਡੋਮੇਨ 'ਤੇ ਸ਼ੁਰੂ ਕਰੋ (ਤੁਹਾਡੀ business logic) ਕਿਉਂਕਿ ਇਹ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ reuse ਹੁੰਦੀ ਹੈ ਅਤੇ infrastructure ਤੋਂ ਬਿਨਾਂ test ਕਰਨਾ ਆਸਾਨ ਹੈ।
ਇਹ ਢਾਂਚਾ ਬਹੁਤ ਸਾਰਾ ਭਰੋਸਾ shared logic 'ਚ ਰੱਖਦਾ ਹੈ, ਜਦਕਿ layers ਮਿਲਣ ਵਾਲੀਆਂ wiring issues ਨੂੰ ਵੀ ਫੜਦਾ ਹੈ।
Monorepo ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਆਸਾਨੀ ਨਾਲ API ਉਸ ਤਰੀਕੇ ਨਾਲ ਬਦਲ ਸਕਦਾ ਹੈ ਜੋ compile ਤਾਂ ਹੋਵੇ ਪਰ user experience ਤੋੜ ਦੇਵੇ। Contract tests ਇਸ silent drift ਨੂੰ ਰੋਕਦੇ ਹਨ।
ਚੰਗੇ tests ਮਹੱਤਵਪੂਰਨ ਹਨ, ਪਰ ਉਹਨਾਂ ਦੇ ਆਲੇ-ਦਲੇ ਨਿਯਮ ਵੀ ਜ਼ਰੂਰੀ ਹਨ।
ਇਨ੍ਹਾਂ gates ਨਾਲ, AI-assisted changes ਵਾਰੰ-ਵਾਰ ਹੋ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ fragile ਹੋਏ।
AI single codebase ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਸਿਰਫ ਉਦੋਂ ਜਦੋਂ ਇਸਨੂੰ ਤੇਜ਼ ਜੂਨੀਅਰ ਇੰਜੀਨੀਅਰ ਵਾਂਗ treat ਕੀਤਾ ਜਾਵੇ: drafts ਲਈ ਵਧੀਆ, merge ਤੋਂ ਪਹਿਲਾਂ review ਲਾਜ਼ਮੀ। ਲਕ਼ਸ਼ ਇਹ ਹੈ ਕਿ AI ਨੂੰ speed ਲਈ ਵਰਤੋਂ, ਪਰ humans architecture, contracts, ਅਤੇ long-term coherence ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਰਹਿਣ।
AI ਨੂੰ ਉਹਨਾਂ "first versions" ਲਈ ਵਰਤੋ ਜੋ ਤੁਸੀਂ ਬਹੁਤ mechanistically Likely ਲਿਖਦੇ:
ਇੱਕ ਚੰਗਾ ਨਿਯਮ: AI ਉਹ ਕੋਡ ਤਿਆਰ ਕਰੇ ਜੋ ਪੜ੍ਹ ਕੇ ਜਾਂ tests ਚਲਾ ਕੇ ਅਸਾਨੀ ਨਾਲ verify ਕੀਤਾ ਜਾ ਸਕੇ, ਨਾ ਕਿ ਉਹ ਕੋਡ ਜੋ silently business meaning ਬਦਲ ਦੇਵੇ।
AI output ਨੂੰ explicit ਨਿਯਮਾਂ ਨਾਲ ਸੀਮਤ ਕਰੋ, ਨਾ ਕਿ vague ਹਦਾਇਤਾਂ ਨਾਲ। ਇਹ ਨਿਯਮ ਕੋਡ ਵਿੱਚ ਰਖੋ:
ਜੇ AI shortcut ਸੁਝਾਏ ਜੋ boundaries violate ਕਰਦਾ ਹੈ, ਤਾਂ ਉਹਨੂੰ ਮਨਜ਼ੂਰ ਨਾ ਕਰੋ—even if it compiles।
ਖ਼ਤਰਾ ਸਿਰਫ खराब ਕੋਡ ਨਹੀਂ—ਅਣਟ੍ਰੈਕ ਕੀਤੀਆਂ ਫੈਸਲਾਂ ਵੀ ਹਨ। audit trail ਰੱਖੋ:
AI ਸਭ ਤੋਂ ਵਧੀਆ ਉਹ ਵੇਲੇ ਮੁੱਲ ਰੱਖਦਾ ਹੈ ਜਦੋਂ ਇਹ repeatable ਹੋ: ਟੀਮ ਦੇਖ ਸਕੇ ਕਿ ਕਿਉਂ ਕੁਝ generate ਕੀਤਾ ਗਿਆ, verify ਕਰ ਸਕੇ, ਅਤੇ ਜ਼ਰੂਰਤ ਪੈਣ 'ਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਦੁਬਾਰਾ generate ਕਰ ਸਕੇ।
ਜੇ ਤੁਸੀਂ AI-assisted development ਨੂੰ system-ਪੱਧਰ ਤੇ ਲੈ ਕੇ ਜਾ ਰਹੇ ਹੋ (web + API + mobile), ਤਾਂ ਸਭ ਤੋਂ ਮਹत्त्वਪੂਰਨ “ਫੀਚਰ” raw generation speed ਨਹੀਂ—ਇਹ ਹੈ outputs ਨੂੰ ਤੁਹਾਡੇ contracts ਅਤੇ layering ਨਾਲ aligned ਰੱਖਣ ਦੀ ਸਮਰੱਥਾ।
ਉਦਾਹਰਣ ਵਜੋਂ, Koder.ai ਇੱਕ vibe-coding platform ਹੈ ਜੋ teams ਨੂੰ chat interface ਰਾਹੀਂ web, server, ਅਤੇ mobile applications ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ—ਜਦੋਂ ਕੇ ਅਜੇ ਵੀ real, exportable source code ਪੈਦਾ ਹੁੰਦੀ ਹੈ। ਅਮਲੀ ਤੌਰ 'ਤੇ, ਇਹ ਲੇਖ ਵਿਚ ਵਰਣਿਤ workflow ਲਈ ਲਾਭਦਾਇਕ ਹੈ: ਤੁਸੀਂ ਇੱਕ API contract ਅਤੇ domain rules define ਕਰ ਸਕਦੇ ਹੋ, ਫਿਰ React-based web surfaces, Go + PostgreSQL backends, ਅਤੇ Flutter mobile apps 'ਤੇ ਤੇਜ਼ੀ ਨਾਲ iterate ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ architecture boundaries ਨੂੰ ਖੋ ਦਿੱਤੇ। planning mode, snapshots, ਅਤੇ rollback ਵਰਗੀਆਂ features "generate → verify → promote" release discipline ਨਾਲ ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ।
ਇੱਕ single codebase duplication ਘਟਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ default "best" ਚੋਣ ਨਹੀਂ। ਜਦ shared code awkward UX ਲਈ ਮਜ਼ਬੂਰ ਕਰਦਾ ਹੈ, releases धीਮੇ ਕਰਦਾ ਹੈ, ਜਾਂ platform differences ਚੁੱਪ ਕਰ ਦਿੰਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ architecture 'ਤੇ ਸੋਚ-ਵਟਾਂਦਰਾ ਕਰਨ ਵਿੱਚ ਜ਼ਿਆਦਾ ਸਮਾਂ ਖਰਚ ਕਰੋਂਗੇ।
ਵੱਖ-ਵੱਖ codebases (ਜਾਂ ਘੱਟੋ-ਘੱਟ ਵੱਖਰੀ UI layers) ਅਕਸਰ ਉਚਿਤ ਹੁੰਦੇ ਹਨ ਜਦ:
ਇਹ ਸਵਾਲ ਪੁੱਛੋ ਪਹਿਲਾਂ ਕਿ single codebase 'ਤੇ ਫੈਸਲਾ ਕਰੋ:
ਜੇ ਤੁਸੀਂ ਚੇਤਾਵਨੀ ਨਿਸ਼ਾਨੇ ਦੇਖ ਰਹੇ ਹੋ, ਇੱਕ ਪ੍ਰਯੋਗਾਤਮਕ ਵਿਕਲਪ ਹੈ shared domain + API contracts, ਪਰ ਵੱਖ web ਅਤੇ mobile apps। shared code ਨੁੰ ਬਿਜ਼ਨੈਸ ਨਿਯਮ ਅਤੇ validation 'ਤੇ ਕੇਂਦਰਿਤ ਰੱਖੋ, ਅਤੇ ਹਰ client ਨੂੰ UX ਅਤੇ platform integrations ਦਾ ਮਾਲਕ ਬਣਾਓ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਰਸਤਾ ਚੁਣਨ ਵਿੱਚ ਮਦਦ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ /pricing 'ਤੇ ਵਿਕਲਪ ਤੁਲਨਾ ਕਰੋ ਜਾਂ /blog 'ਤੇ ਸਮੰਬੰਧਤ ਆਰਕੀਟੈਕਚਰ ਪੈਟਰਨਾਂ ਦੇਖੋ।
ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਰਿਪੋਜ਼ਿਟਰੀ ਅਤੇ ਇੱਕ ਸੈੱਟ ਨਿਯਮ ਹੋਣ ਦਾ ਮਤਲਬ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਹਰ ਥਾਂ ਇੱਕੋ ਜਿਹਾ ਐਪ।
ਅਮਲੀ ਤੌਰ 'ਤੇ, ਵੈੱਬ, ਮੋਬਾਈਲ ਅਤੇ API ਇੱਕ ਡੋਮੇਨ ਲੇਅਰ (ਬਿਜ਼ਨੈਸ ਨਿਯਮ, validation, use cases) ਅਤੇ ਅਕਸਰ ਇੱਕ ਸਾਂਝੇ API contract ਸਾਂਝੇ ਕਰਦੇ ਹਨ, ਜਦਕਿ ਹਰ ਪਲੇਟਫਾਰਮ ਆਪਣੀ UI ਅਤੇ ਪਲੇਟਫਾਰਮ ਇੰਟੀਗਰੇਸ਼ਨ ਰੱਖਦਾ ਹੈ।
ਉਹ ਚੀਜ਼ਾਂ ਸਾਂਝੀਆਂ ਕਰੋ ਜੋ ਕਦੇ ਵੱਖਰੀ ਨਹੀਂ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ:
UI components, navigation, ਅਤੇ device/browser ਇੰਟੀਗਰੇਸ਼ਨ ਪਲੇਟਫਾਰਮ-ਨਿੱਜੀ ਰੱਖੋ।
AI scaffolding ਅਤੇ ਰੀਪਿਟੇਟਿਵ ਕੰਮ ਤੇਜ਼ ਕਰਦਾ ਹੈ (CRUD, clients, tests), ਪਰ ਇਹ ਬਿਨਾਂ ਇਰਾਦੇ ਵਾਲੀ ਆਰਕੀਟੈਕਚਰ ਤੋਂ ਚੰਗੀਆਂ ਸਿੱਧੀਆਂ ਬਣਾ ਕੇ ਨਹੀਂ ਦੇਵੇਗਾ।
ਬਿਨਾਂ ਸਪੱਸ਼ਟ ਹੱਦਾਂ ਦੇ, AI ਅਕਸਰ:
AI ਨੂੰ ਉਹਨਾਂ ਪਰਤਾਂ 'ਚ ਵਰਤੋ ਜਿਨ੍ਹਾਂ ਦੀ ਤੁਸੀਂ ਪਹਿਲਾਂ ਢਾਂਚਾ ਤੈਅ ਕਰ ਚੁੱਕੇ ਹੋ।
ਇੱਕ ਆਸਾਨ, ਭਰੋਸੇਯੋਗ ਫਲੋ ਇਹ ਹੈ:
ਇਸ ਨਾਲ ਬਿਜ਼ਨੈਸ ਨਿਯਮ ਕੇਂਦਰੀ ਹੋ ਜਾਂਦੇ ਹਨ ਅਤੇ testing ਅਤੇ AI-ਜਨਰੇਟ ਕੀਤੇ ਜੋੜੇ ਆਸਾਨੀ ਨਾਲ ਸਮੀਖਿਆਯੋਗ ਬਣਦੇ ਹਨ।
Validation ਇਕ ਹੀ ਥਾਂ ਪਾਓ (domain ਜਾਂ shared validation ਮੋਡੀਊਲ) ਅਤੇ ਜ਼ਿਆਦਾ ਸਾਰੇ ਖੰਡਾਂ 'ਚ reuse ਕਰੋ।
ਵਿਆਹਿਕ ਰੁਝਾਨ:
EmailAddress ਇਕ ਵਾਰੀ validate ਕਰੋ ਅਤੇ web/mobile/API 'ਚ reuse ਕਰੋMoney negative totals ਨੂੰ ਰੋਕੇ, ਜਿੱਥੇ ਤੋਂ ਵੀ ਆਇਆਇਸ ਤਰ੍ਹਾਂ API ਇੱਕ translator ਬਣ ਜਾਂਦਾ ਹੈ ਅਤੇ web/mobile presenters ਹੁੰਦੇ ਹਨ—ਡੋਮੇਨ ਲੇਅਰ ਸਿੰਗਲ ਸੋਸ ਆਫ਼ ਟਰੂਥ ਰਹਿੰਦਾ ਹੈ।
ਇੱਕ canonical schema ਵਰਤੋ ਜਿਵੇਂ OpenAPI (ਜਾਂ GraphQL SDL) ਅਤੇ ਇਸ ਤੋਂ generate ਕਰੋ:
ਫਿਰ contract tests ਜੋ schema-breaking changes ਨੂੰ CI ਵਿੱਚ fail ਕਰਾਵੇਂ ਤਾਂ clients ਅਤੇ API aligned ਰਹਿਣਗੇ।
Offline ਨੂੰ ਇਰਾਦੇ ਨਾਲ ਡਿਜ਼ਾਇਨ ਕਰੋ:
Offline storage ਅਤੇ sync mobile app layer 'ਚ ਰੱਖੋ; ਬਿਜ਼ਨੈਸ ਨਿਯਮ shared domain code 'ਚ ਰਹਿਣ।
ਇੱਕ ਹੀ ਸੰਕਲਪਿਕ flow ਬਣਾਓ, ਪਰ surface ਅਨੁਸਾਰ implement ਕਰੋ:
Authorization rules centrally define ਕਰੋ (ਉਦਾਹਰਣ: canApproveInvoice) ਅਤੇ API 'ਤੇ enforce ਕਰੋ; UI ਸਿਰਫ actions ਨੂੰ hide/disable ਕਰਨ ਲਈ mirror ਕਰੇ।
ਹਰ surface ਨੂੰ ਇੱਕ ਵੱਖਰਾ build target ਸਮਝੋ ਜੋ shared packages consume ਕਰਦਾ ਹੈ:
CI/CD ਵਿੱਚ: lint → typecheck → unit tests → contract tests → build → security scan → deploy, ਅਤੇ secrets/config repo ਵਿੱਚ ਨਾ ਰੱਖੋ।
AI ਨੂੰ ਇੱਕ ਤੇਜ਼ ਜੂਨੀਅਰ ਇੰਜੀਨੀਅਰ ਵਾਂਗ ਵਰਤੋ: drafts ਲਈ ਵਧੀਆ, merge ਤੋਂ ਪਹਿਲਾਂ ਸਦੀ ਕਬੂਲ ਨਹੀਂ।
ਚੰਗੇ guardrails:
ਜੇ AI output architecture ਨਿਯਮਾਂ ਨੂੰ ਤੋੜਦਾ ਹੈ, ਤਾਂ ਉਸ ਨੂੰ رد ਕਰੋ ਭਾਵੇਂ ਉਹ compile ਕਰ ਲਏ।