21 ਜੁਲਾ 2025·8 ਮਿੰਟ
ਇੰਸਿਡੈਂਟ ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਵੈੱਬ ਐਪ ਬਣਾਉਣਾ — ਕਦਮ ਦਰ ਕਦਮ
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਈਨ ਤੇ ਬਣਾਈ ਜਾਵੇ ਜੋ ਸਰਵਿਸ ਨਿਰਭਰਤਾਵਾਂ, ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ ਸਿਗਨਲਾਂ ਅਤੇ ਸਪਸ਼ਟ ਡੈਸ਼ਬੋਰਡਾਂ ਨਾਲ ਇੰਸਿਡੈਂਟ ਪ੍ਰਭਾਵ ਗਣਨਾ ਕਰੇ।
ਸਿੱਖੋ ਕਿ ਕਿਵੇਂ ਇੱਕ ਵੈੱਬ ਐਪ ਡਿਜ਼ਾਈਨ ਤੇ ਬਣਾਈ ਜਾਵੇ ਜੋ ਸਰਵਿਸ ਨਿਰਭਰਤਾਵਾਂ, ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ ਸਿਗਨਲਾਂ ਅਤੇ ਸਪਸ਼ਟ ਡੈਸ਼ਬੋਰਡਾਂ ਨਾਲ ਇੰਸਿਡੈਂਟ ਪ੍ਰਭਾਵ ਗਣਨਾ ਕਰੇ।
ਕੈਲਕੁਲੇਸ਼ਨ ਜਾਂ ਡੈਸ਼ਬੋਰਡ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸੰਸਥਾਨ ਵਿੱਚ “ਪ੍ਰਭਾਵ” ਦਾ ਅਰਥ ਕੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਹ ਕਦਮ ਛੱਡ ਦਿਓਗੇ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਅਜਿਹਾ ਸਕੋਰ ਰਹਿ ਜਾਵੇਗਾ ਜੋ ਵਿਗਿਆਨਿਕ ਲੱਗਦਾ ਹੈ ਪਰ ਕਿਸੇ ਦੀ ਮਦਦ ਨਹੀਂ ਕਰਦਾ।
ਪ੍ਰਭਾਵ ਇੱਕ ਇੰਸਿਡੈਂਟ ਦਾ ਮਾਪਯੋਗ ਨਤੀਜਾ ਹੈ ਜੋ ਕਾਰੋਬਾਰ ਲਈ ਮਹੱਤਵਪੂਰਕ ਚੀਜ਼ 'ਤੇ ਪੈਂਦਾ ਹੈ। ਆਮ ਪੱਖ ਇਹ ਹਨ:
2–4 ਮੁੱਖ ਪੈਮਾਨਿਆਂ ਨੂੰ ਚੁਣੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਖੁੱਲ੍ਹੇ ਲਿਖੋ। ਉਦਾਹਰਣ ਵਜੋਂ: “ਪ੍ਰਭਾਵ = ਪ੍ਰਭਾਵਿਤ ਭਰੇ ਹੋਏ ਗਾਹਕ + SLA ਮਿੰਟ ਜੋ ਖ਼ਤਰੇ 'ਚ” — ਨਾ ਕਿ “ਪ੍ਰਭਾਵ = ਗ੍ਰਾਫ਼ਾਂ 'ਤੇ ਜੋ ਵੀ ਖ਼ਰਾਬ ਲੱਗੇ।”
ਵੱਖ-ਵੱਖ ਭੂਮਿਕਾਵਾਂ ਵੱਖ-ਵੱਖ ਫੈਸਲੇ ਲੈਂਦੀਆਂ ਹਨ:
“ਪ੍ਰਭਾਵ” ਆਉਟਪੁੱਟ ਐਸੇ ਡਿਜ਼ਾਈਨ ਕਰੋ ਤਾਂ ਜੋ ਹਰ ਪਰਦੇਸ਼ਕ ਆਪਣਾ ਮੁੱਖ ਸਵਾਲ ਬਿਨਾਂ ਮੈਟਰਿਕ ਦਾ ਅਨੁਵਾਦ ਕੀਤੇ ਜਵਾਬ ਦੇ ਸਕੇ।
ਕਿਸੀ ਲੋਚੇ ਨੂੰ ਕਿਹੜੀ ਲੇਟੰਸੀ ਮਨਜ਼ੂਰ ਹੈ ਇਹ ਫੈਸਲਾ ਕਰੋ। “ਰੀਅਲ-ਟਾਈਮ” ਮਹਿੰਗਾ ਹੈ ਅਤੇ ਅਕਸਰ ਜ਼ਰੂਰੀ ਨਹੀਂ ਹੁੰਦਾ; ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ (ਉਦਾਹਰਨ ਵਜੋਂ 1–5 ਮਿੰਟ) ਕਈ ਵਾਰੀ ਫੈਸਲਾ ਕਰਨ ਲਈ ਕਾਫ਼ੀ ਹੁੰਦਾ ਹੈ।
ਇਹ ਗੱਲ ਇੱਕ ਪ੍ਰੋਡਕਟ ਲੋੜ ਵੱਜੋਂ ਲਿਖੋ ਕਿਉਂਕਿ ਇਹ ਇਨਜੈਸ਼ਨ, ਕੈਸ਼ਿੰਗ, ਅਤੇ UI 'ਤੇ ਅਸਰ ਪਾਉਂਦਾ ਹੈ।
ਤੁਹਾਡਾ MVP ਸਿੱਧਾ ਉਸ ਤਰ੍ਹਾਂ ਦੀਆਂ ਕਾਰਵਾਈਆਂ ਦਾ ਸਮਰਥਨ ਕਰੇ ਜੋ ਨੀਵੇਂ ਹਨ, ਜਿਵੇਂ:
ਜੇ ਕੋਈ ਮੈਟਰਿਕ ਫੈਸਲਾ ਨਹੀਂ ਬਦਲਦੀ, ਤਾਂ ਉਹ ਸੰਭਵਤ: “ਪ੍ਰਭਾਵ” ਨਹੀਂ—ਸਿਰਫ਼ ਟੈਲੀਮੇਟਰੀ ਹੈ।
ਸਕ੍ਰੀਨ ਡਿਜ਼ਾਈਨ ਕਰਨ ਜਾਂ ਡੇਟਾਬੇਸ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਲਿਖੋ ਕਿ ਇੰਸਿਡੈਂਟ ਦੌਰਾਨ “ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ” ਨੇ ਕੀ-ਕੀ ਜਵਾਬ ਦੇਣੇ ਹਨ। ਲਕਸ਼ਅਦ ਨੁਕਸ ਇਹ ਨਹੀਂ ਕਿ ਪਹਿਲੇ ਦਿਨੋਂ ਹੀ ਬਹੁਤ ਸੁਧਾਰ ਹੋਵੇ—ਲਕਸ਼ਅਦ ਇਹ ਹੈ ਕਿ ਨਤੀਜੇ ਸਥਿਰ, ਸਮਝਣਯੋਗ ਅਤੇ ਰਿਸਪਾਂਡਰਾਂ ਲਈ ਭਰੋਸੇਯੋਗ ਹੋਣ।
ਉਹ ਡਾਟਾ ਜਿਸਨੂੰ ਤੁਸੀਂ ਇਨਜੈਸਟ ਜਾਂ ਰੇਫਰੈਂਸ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਪ੍ਰਭਾਵ ਗਣਨਾ ਕੀਤੀ ਜਾ ਸਕੇ:
ਅਕਸਰ ਟੀਮਾਂ ਕੋਲ ਦਿਨ ਏਕ 'ਤੇ ਪੂਰਾ dependency ਜਾਂ customer mapping ਨਹੀਂ ਹੁੰਦੀ। ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਲੋਕਾਂ ਨੂੰ ਹੱਥ ਨਾਲ ਦਾਖਲ ਕਰਨ ਦੀ ਆਗਿਆ ਕਿਵੇਂ ਦਿਓਗੇ ਤਾਂ ਐਪ ਫਾਇਦੇਮੰਦ ਰਹੇ:
ਇਨ੍ਹਾਂ ਨੂੰ ਖੁੱਲ੍ਹੇ ਫੀਲਡ ਵਜੋਂ ਡਿਜ਼ਾਈਨ ਕਰੋ (ਹੈਰਾਨੀ ਦੇ ਨੋਟਸ ਨਹੀਂ) ਤਾਂ ਜੋ ਉਹ ਬਾਅਦ ਵਿੱਚ ਕ੍ਵੈਰੀ ਕਰਨ ਯੋਗ ਹੋਣ।
ਤੁਹਾਡੀ ਪਹਿਲੀ ਰਿਲੀਜ਼ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਇਹਨੂੰ ਜਨਰੇਟ ਕਰੇ:
ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਇੱਕ ਫੈਸਲਾ ਸੰਦ ਹੈ, ਇਸ ਲਈ ਸੀਮਾਵਾਂ ਮਾਇਨੇ ਰੱਖਦੀਆਂ ਹਨ:
ਇਹ ਲੋੜਾਂ ਟੈਸਟੇਬਲ ਬਿਆਨ ਵਜੋਂ ਲਿਖੋ। ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਵੇਰਫ਼ਾਈ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਤੁਸੀਂ ਆਊਟੇਜ ਦੌਰਾਨ ਇਸ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕਰ ਸਕਦੇ।
ਤੁਹਾਡਾ ਡਾਟਾ ਮਾਡਲ ਇਨਜੈਸ਼ਨ, ਕੈਲਕੁਲੇਸ਼ਨ ਅਤੇ UI ਵਿਚਾਲੇ ਕਾਂਟਰੈਕਟ ਹੈ। ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਠੀਕ ਬਣਾਉਂਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਟੂਲਿੰਗ ਸਰੋਤ ਬਦਲ ਸਕੋਗੇ, ਸਕੋਰਿੰਗ ਸੁਧਾਰ ਸਕੋਗੇ, ਅਤੇ ਫਿਰ ਵੀ ਉਹੋ ਜਿਹੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇ ਸਕੋਗੇ: “ਕੀ ਟੁੱਟਿਆ?”, “ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੈ?”, ਅਤੇ “ਕਿੰਨੀ ਦੇਰ ਲਈ?”
ਘੱਟੋ-ਘੱਟ, ਇਹਨਾਂ ਨੂੰ ਫਰਸਟ-ਕਲਾਸ ਰਿਕਾਰਡ ਵਜੋਂ ਮਾਡਲ ਕਰੋ:
IDs ਸਥਿਰ ਅਤੇ ਸਦਾਭਾਰ ਹੋਣ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਸਰਵਿਸ ਕੈਟਾਲੌਗ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਸਰੋਤ-ਅਫ-ਸਚ ਮੰਨੋ ਅਤੇ ਬਾਹਰੀ ਟੂਲਾਂ ਦੇ identifiers ਨੂੰ ਉਸ ਵਿੱਚ ਮੈਪ ਕਰੋ।
ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਸਮਰਥਨ ਲਈ ਇੰਸਿਡੈਂਟ 'ਤੇ ਕਈ ਟਾਈਮਸਟੈਂਪ ਸਟੋਰ ਕਰੋ:
ਸਾਥ ਹੀ ਗਣਨਾ ਕੀਤੀਆਂ ਟਾਈਮ ਵਿੰਡੋਜ਼ ਵੀ ਰੱਖੋ (ਉਦਾਹਰਨ: 5-ਮਿੰਟ ਬੱਕੇਟ) ਤਾਂ ਜੋ ਰੀਪਲੇ ਅਤੇ ਤੁਲਨਾਵਾਂ ਸਿੱਧੀਆਂ ਹੋਣ।
ਦੋ ਮੁੱਖ ਗ੍ਰਾਫ਼ ਮਾਡਲ ਕਰੋ:
ਇਕ ਸਧਾਰਨ ਪੈਟਰਨ ਹੈ customer_service_usage(customer_id, service_id, weight, last_seen_at) ਤਾਂ ਜੋ ਤੁਸੀਂ “ਕਿੰਨਾ ਗਾਹਕ ਉਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ” ਦੇ ਅਧਾਰ 'ਤੇ ਪ੍ਰਭਾਵ ਨੂੰ ਦਰਜ ਕਰ ਸਕੋ।
Dependencies ਤਬਦੀਲ ਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ ਪ੍ਰਭਾਵ ਗਣਨਾਵਾਂ ਨੂੰ ਉਸ ਸਮੇਂ ਦੀ ਸੱਚਾਈ ਦਰਸਾਉਣੀ ਚਾਹੀਦੀ ਹੈ। ਐਜ ਆਫ dependency(valid_from, valid_to) ਵਰਗੇ effectived dating ਨੂੰ ਐਜ edges 'ਤੇ ਸ਼ਾਮਿਲ ਕਰੋ:
dependency(valid_from, valid_to)ਇਹੀ ਰਵਾਇਤ ਗਾਹਕ ਦੀਆਂ ਸਬਸਕ੍ਰਿਪਸ਼ਨਾਂ ਅਤੇ ਵਰਤੋਂ ਸਨੇਪਸ਼ਾਟਾਂ ਲਈ ਵੀ ਕਰੋ। ਇਤਿਹਾਸਕ ਵਰਜ਼ਨਾਂ ਨਾਲ, ਤੁਸੀਂ ਪੋਸਟ-ਇੰਸਿਡੈਂਟ ਰਿਵਿਊ ਦੌਰਾਨ ਪਿਛਲੇ ਇੰਸਿਡੈਂਟਾਂ ਨੂੰ ਸਹੀ ਤੌਰ 'ਤੇ ਦੁਬਾਰਾ ਚਲਾ ਸਕਦੇ ਹੋ ਅਤੇ SLA ਰਿਪੋਰਟਿੰਗ ਲਈ ਅ਼ਕੂਰੇਟ ਨਤੀਜੇ ਨਿਕਾਲ ਸਕਦੇ ਹੋ।
ਤੁਹਾਡਾ ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਸਿਰਫ਼ ਉਹਨਾਂ ਇਨਪੁੱਟਸ ਜਿੰਨਾਂ 'ਤੇ ਉਹ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਉਨ੍ਹਾਂ ਦੀ ਗੁਣਵੱਤਾ 'ਤੇ ਹੀ ਚਲਦਾ ਹੈ। ਲਕਸ਼ ਹੈ: ਉਹ ਸਿਗਨਲ ਖਿੱਚੋ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤਦੇ ਹੋ, ਫਿਰ ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਇਕਸਾਰ ਇਵੈਂਟ ਸਟ੍ਰੀਮ ਵਿੱਚ ਬਦਲੋ ਜਿਸਨੂੰ ਤੁਹਾਡੀ ਐਪ ਸਮਝ ਸਕੇ।
ਇੱਕ ਛੋਟੀ ਸੂਚੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਬਰਾਬਰ “ਕੁਝ ਬਦਲਿਆ” ਨੂੰ ਦਰਸਾਉਂਦੀ ਹੈ ਦੌਰਾਨ ਇੱਕ ਇੰਸਿਡੈਂਟ:
ਹੋਰ ਸਭ ਕੁਝ ਇਕ ਵਾਰੀ ਵਿੱਚ ਇਨਜੈਸਟ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਾ ਕਰੋ। ਉਹ ਸਰੋਤ ਚੁਣੋ ਜੋ ਡਿਟੈਕਸ਼ਨ, ਐਸਕਲੇਸ਼ਨ ਅਤੇ ਪੁਸ਼ਟੀ ਕਵਰ ਕਰਦੇ ਹੋਣ।
ਵੱਖ-ਵੱਖ ਟੂਲ ਵੱਖ-ਵੱਖ ਇੱਕੀਕਰਨ ਪੈਟਰਨ ਹਨੀਤ ਕਰਦੇ ਹਨ:
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਯੋਜਨਾ ਹੈ: ਅਹੰਕਾਰ ਸਿਗਨਲ ਲਈ webhooks, ਅਤੇ ਗੈਪ ਪੂਰੇ ਕਰਨ ਲਈ batch imports।
ਹਰ ਆਉਣ ਵਾਲੀ ਆਈਟਮ ਨੂੰ ਇੱਕੋ “ਇਵੈਂਟ” ਆਕਾਰ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ, ਭਾਵੇਂ ਸਰੋਤ ਉਹਨੂੰ ਅਲਰਟ, ਇੰਸਿਡੈਂਟ, ਜਾਂ ਐਨੋਟੇਸ਼ਨ ਕਹੇ। ਘੱਟੋ-ਘੱਟ ਮਾਪਦੰਡ ਸਟੈਂਡਰਡ ਕਰੋ:
ਗੰਦੇ ਡਾਟੇ ਦੀ ਉਮੀਦ ਕਰੋ। idempotency keys (source + external_id) ਨਾਲ ਡੁਪਲਿਕੇਟ ਨੂੰ ਹਟਾਓ, ਆਏ-ਆਰਡਰ ਵਿੱਚ ਆਉਣ ਵਾਲੇ ਇਵੈਂਟਸ ਨੂੰ occurred_at 'ਤੇ ਆਧਾਰਿਤ ਕਰਕੇ ਸੰਭਾਲੋ (arrival time 'ਤੇ ਨਹੀਂ), ਅਤੇ ਫੀਲਡ ਗੁੰਮ ਹੋਣ 'ਤੇ ਸੁਰੱਖਿਅਤ ਡਿਫੌਲਟ ਲਗਾਓ — ਪਰ ਉਹਨਾਂ ਨੂੰ ਸਮੀਖਿਆ ਲਈ ਝੰਡਾ ਲਗਾਓ।
UI ਵਿੱਚ ਇੱਕ ਛੋਟਾ “unmatched service” ਕਿਊ ਟਿਕਟ ਚੁੱਕਣ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੀ ਪ੍ਰਭਾਵ ਨਤੀਜਿਆਂ 'ਤੇ ਭਰੋਸਾ ਰੱਖਦਾ ਹੈ।
ਜੇ ਤੁਹਾਡਾ dependency ਮੈਪ ਗਲਤ ਹੈ, ਤਾਂ ਤੁਹਾਡਾ ਬਲਾਸਟ-ਰੇਡੀਅਸ ਗਲਤ ਹੋਵੇਗਾ — ਚਾਹੇ ਤੁਹਾਡੇ ਸਿਗਨਲ ਅਤੇ ਸਕੋਰਿੰਗ ਪਰਫੈਕਟ ਹੀ ਕਿਉਂ ਨਾ ਹੋਵਣ। ਲਕਸ਼ ਹੈ ਇੱਕ dependency ਗ੍ਰਾਫ ਬਣਾਉਣਾ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਇੰਸਿਡੈਂਟ ਦੌਰਾਨ ਅਤੇ ਬਾਅਦ ਦੋਹਾਂ ਵਿਸ਼ਵਾਸ ਕਰ ਸਕੋ।
ਐਜ edges ਆਕਾਰ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਨੋਡ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਹਰ ਉਸ ਸਿਸਟਮ ਲਈ ਇੱਕ ਸਰਵਿਸ ਕੈਟਾਲੌਗ ਐਨਟਰੀ ਬਣਾਓ ਜੋ ਤੁਸੀਂ ਇੰਸਿਡੈਂਟ 'ਚ ਹਵਾਲਾ ਦੇ ਸਕਦੇ ਹੋ: APIs, background workers, ਡੇਟਾ ਸਟੋਰ, third-party vendors, ਅਤੇ ਹੋਰ ਮਹੱਤਵਪੂਰਨ ਸਾਂਝੇ ਕੰਪੋਨੈਂਟ।
ਹਰ ਸਰਵਿਸ ਵਿੱਚ ਘੱਟੋ-ਘੱਟ ਇਹ ਸ਼ਾਮਿਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: owner/team, tier/criticality (ਉਦਾਹਰਨ ਲਈ: customer-facing vs internal), SLA/SLO ਟਾਰਗੇਟ, ਅਤੇ ਰਨਬੁੱਕ/on-call ਡੌਕਾਂ ਲਈ ਲਿੰਕ (ਉਦਾਹਰਨ: /runbooks/payments-timeouts)।
ਦੋ ਪੂਰਕ ਸਰੋਤ ਵਰਤੋ:
ਇਨ੍ਹਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਐਜ ਕਿਸਮਾਂ ਵਜੋਂ ਰੱਖੋ ਤਾਂ ਜੋ ਲੋਕ ਵਿਸ਼ਵਾਸ ਦੀ ਸਮਝ ਰੱਖ ਸਕਣ: “ਟੀਮ ਵੱਲੋਂ घोषित” vs “ਪਿਛਲੇ 7 ਦਿਨਾਂ ਵਿੱਚ ਨਜ਼ਰ ਆਇਆ।”
Dependencies ਨੂੰ ਦਿਸ਼ਾਦਰਸ਼ੀ ਰੱਖੋ: Checkout → Payments ਉਹੋ ਹੀ ਨਹੀਂ ਜੋ Payments → Checkout। ਦਿਸ਼ਾ ਸੋਚ ਨੂੰ ਚਲਾਉਂਦੀ ਹੈ (“ਜੇ Payments ਖ਼ਰਾਬ ਹੋਵੇ, ਤਾਂ ਕਿਹੜੇ upstreams ਫੇਲ ਹੋ ਸਕਦੇ ਹਨ?”)।
ਹਾਰਡ vs ਸੌਫਟ dependencies ਵੀ ਮਾਡਲ ਕਰੋ:
ਇਹ ਫਰਕ ਪ੍ਰਭਾਵ ਨੂੰ ਬਹੁਤ ਵੱਧ ਨਹੀਂ ਦਰਸਾਉਣ ਦਿੰਦਾ ਅਤੇ ਰਿਸਪਾਂਡਰਾਂ ਨੂੰ ਪ੍ਰਾਥਮਿਕਤਾ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
ਤੁਹਾਡੀ ਆਰਕੀਟੈਕਚਰ ਹਫ਼ਤੇ-ਹਫ਼ਤੇ ਬਦਲਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਸਨੇਪਸ਼ਾਟ ਸੰਭਾਲਦੇ ਨਹੀਂ, ਤਾਂ ਤੁਸੀਂ ਦੋ ਮਹੀਨੇ ਪਹਿਲਾਂ ਦੇ ਇੰਸਿਡੈਂਟ ਦੀ ਸਹੀ ਤਰ੍ਹਾਂ ਵਿਸ਼ਲੇਸ਼ਣ ਨਹੀਂ ਕਰ ਸਕੋਗੇ।
ਡੀਪੈਂਡੇੰਸੀ ਗ੍ਰਾਫ ਦੇ ਵਰਜ਼ਨਾਂ ਨੂੰ ਸਮੇਂ-ਸਮੇਂ 'ਤੇ ਸਟੋਰ ਕਰੋ (ਰੋਜ਼ਾਨਾ, per deploy, ਜਾਂ ਜਦੋਂ ਤਬਦੀਲੀ ਹੋਵੇ)। ਜਦ ਬਲਾਸਟ-ਰੇਡੀਅਸ ਕੈਲਕੁਲੇਟ ਕੀਤਾ ਜਾਵੇ, ਤਾਂ ਇੰਸਿਡੈਂਟ ਟਾਈਮਸਟੈਂਪ ਨੂੰ ਸਭ ਤੋਂ ਨੇੜਲੇ ਗ੍ਰਾਫ ਸਨੇਪਸ਼ਾਟ 'ਤੇ ਰਿਜ਼ਾਲਵ ਕਰੋ, ਤਾਂ ਜੋ “ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਸੀ” ਉਸ ਸਮੇਂ ਦੀ ਹਕੀਕਤ ਨੂੰ ਦਰਸਾਏ — ਅੱਜ ਦੀ ਆਰਕੀਟੈਕਚਰ ਨਹੀਂ।
ਜਦ ਤੁਸੀਂ ਸਿਗਨਲ (ਅਲਰਟਸ, SLO ਬਰਨ, synthetic checks, ਗਾਹਕ ਟਿਕਟ) ਇਨਜੈਸਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਐਪ ਨੂੰ ਇੱਕ ਸਕੰਚਿਤ ਤਰੀਕੇ ਦੀ ਲੋੜ ਹੈ ਜੋ ਗੰਦੀਆਂ ਇਨਪੁੱਟਸ ਨੂੰ ਸਾਫ਼ ਬਿਆਨ ਵਿੱਚ ਬਦਲੇ: ਕੀ ਟੁੱਟਿਆ ਹੈ, ਕਿੰਨਾ ਬੁਰਾ ਹੈ, ਅਤੇ ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੈ?
ਤੁਸੀਂ ਕਿਸੇ ਵੀ ਹੇਠਾਂ ਦਿੱਤੇ ਪੈਟਰਨ ਨਾਲ ਇੱਕ ਵਰਤਣਯੋਗ MVP ਤਿਆਰ ਕਰ ਸਕਦੇ ਹੋ:
ਜੋ ਵੀ ਢੰਗ ਤੁਸੀਂ ਚੁਣੋ, ਇੰਟਰਮੀਡੀਏਟ ਮੁੱਲ ਸੰਭਾਲੋ (threshold hit, weights, tier) ਤਾਂ ਜੋ ਲੋਕ ਦੇਖ ਸਕਣ ਕਿ ਸਕੋਰ ਕਿਉਂ ਬਣਿਆ।
ਸਭ ਕੁਝ ਇਕ ਨੰਬਰ ਵਿੱਚ ਜ਼ਲਦੀ ਨਾ ਗੁਸਦੇ ਹੋਵੋ। ਕੁਝ ਡਾਇਮੈਨਸ਼ਨਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਟਰੈਕ ਕਰੋ, ਫਿਰ ਇੱਕ ਕੁੱਲ severity ਨਿਕਾਲੋ:
ਇਸ ਨਾਲ ਰਿਸਪਾਂਡਰਾਂ ਨੂੰ ਤਕਨੀਕੀ ਤੌਰ 'ਤੇ ਸਹੀ ਤਰ੍ਹਾਂ ਅਨੁਵਾਦ ਕਰਨ ਵਿੱਚ ਮਦਦ ਮਿਲਦੀ ਹੈ (ਉਦਾਹਰਨ: “ਉਪਲਬਧ ਹੈ ਪਰ ਧੀਮਾ” ਬਣਾਮ “ਗਲਤ ਨਤੀਜੇ”)।
ਪ੍ਰਭਾਵ ਸਿਰਫ਼ ਸਰਵਿਸ ਹੈਲਥ ਨਹੀਂ — ਇਹ ਹੈ ਕਿ ਕਿਸ ਨੇ ਇਹ ਮਹਿਸੂਸ ਕੀਤਾ।
ਵਰਤੋਂ ਨਕਸ਼ਾ (tenant → service, customer plan → features, user traffic → endpoint) ਵਰਤ ਕੇ ਅਤੇ ਇੱਕ ਟਾਈਮ ਵਿੰਡੋ ਅਨੁਸਾਰ ਪ੍ਰਭਾਵਿਤ ਗਾਹਕਾਂ ਦੀ ਗਿਣਤੀ ਗਣੋ (start time, mitigation time, ਅਤੇ ਕੋਈ backfill ਪੀਰੀਅਡ)।
ਅਨੁਮਾਨਾਂ ਦੇ ਬਾਰੇ ਸਪਸ਼ਟ ਰਹੋ: sampled logs, ਅੰਦਾਜ਼ਾ ਟ੍ਰੈਫਿਕ, ਜਾਂ ਪਾਰਸ਼ਲ ਟੈਲੀਮੇਟਰੀ।
ਅਪਰੇਟਰਾਂ ਨੂੰ ਓਵਰਰਾਈਡ ਕਰਨ ਦੀ ਲੋੜ ਪਵੇਗੀ: ਇੱਕ false-positive alert, partial rollout, ਜਾਂ ਜਾਣਿਆ ਹੋਇਆ subset of tenants।
Severity, dimensions, ਅਤੇ ਪ੍ਰਭਾਵਿਤ ਗਾਹਕਾਂ ਨੂੰ ਮੈਨੁਅਲ ਤੌਰ 'ਤੇ ਸੋਧਣ ਦੀ ਆਗਿਆ ਦਿਓ, ਪਰ ਲੋੜੀਂਦਾ ਹੋਵੇ:
ਇਹ ਆਡਿਟ ਟਰੇਲ ਡੈਸ਼ਬੋਰਡ ਵਿੱਚ ਭਰੋਸਾ ਬਣਾਉਂਦੀ ਹੈ ਅਤੇ ਪੋਸਟ-ਇੰਸਿਡੈਂਟ ਰਿਵਿਊ ਤੇਜ਼ ਬਣਾਉਂਦੀ ਹੈ।
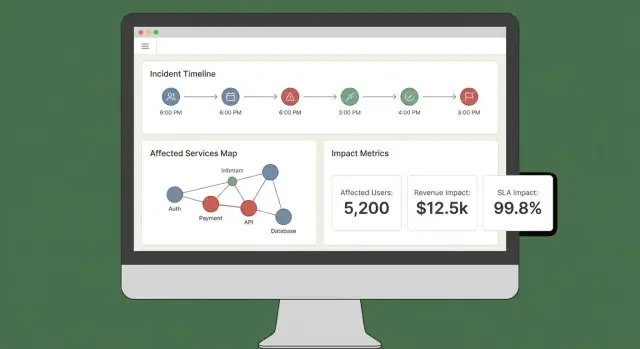
ਇੱਕ ਵਧੀਆ ਪ੍ਰਭਾਵ ਡੈਸ਼ਬੋਰਡ ਤਿੰਨ ਸਵਾਲਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇਂਦਾ ਹੈ: ਕੀ ਪ੍ਰਭਾਵਿਤ ਹੈ? ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੋਇਆ? ਸਾਨੂੰ ਕਿੰਨੀ ਯਕੀਨ ਹੈ? ਜੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਇਹ ਜਾਣਨ ਲਈ ਪੰਜ ਟੈਬ ਖੋਲ੍ਹਣੇ ਪੈਂਦੇ ਹਨ, ਤਾਂ ਉਹ ਆਉਟਪੁੱਟ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕਰਨਗੇ—ਅਤੇ ਨਾਹ ਹੀ ਐਕਸ਼ਨ ਲੈਣਗੇ।
ਛੋਟੇ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਅਸਲ ਇੰਸਿਡੈਂਟ ਵਰਕਫਲੋਜ਼ ਨਾਲ ਮੈਪ ਹੁੰਦੇ ਹਨ:
ਬਿਨਾਂ ਵਜ੍ਹੇ ਦੇ ਪ੍ਰਭਾਵ ਸਕੋਰ ਅਰਗੁਮੇਂਟਲ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ। ਹਰ ਸਕੋਰ ਨੂੰ ਇਨਪੁੱਟਸ ਅਤੇ ਨਿਯਮਾਂ ਨਾਲ ਜੋੜ ਕੇ ਦਰਸਾਇਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ:
ਇੱਕ ਸਧਾਰਣ “Explain impact” ਡਰਾਅਰ ਜਾਂ ਪੈਨਲ ਮੁੱਖ ਵਿਊ ਨੂੰ ਬੇਕ ਨਹੀਂ ਕਰਦਾ।
ਅਸਾਨੀ ਨਾਲ ਪ੍ਰਭਾਵ ਨੂੰ ਸਰਵਿਸ, ਖੇਤਰ, ਗਾਹਕ ਟੀਅਰ, ਅਤੇ ਟਾਈਮ ਰੇਂਜ ਅਨੁਸਾਰ slice ਕਰਨ ਦਿਓ। ਯੂਜ਼ਰਾਂ ਨੂੰ ਹਰ ਚਾਰ্ট ਪਾਇੰਟ ਜਾਂ ਰੋ ਫ਼ਤੇ 'ਤੇ ਕਲਿੱਕ ਕਰਕੇ ਕੱਚਾ ਸਬੂਤ (ਉਹੀ ਮਾਨੀਟਰ, ਲੌਗ, ਜਾਂ ਇਵੈਂਟ) ਦੇਖਣ ਦੀ ਆਗਿਆ ਦਿਓ ਜੋ ਬਦਲਾਅ ਚਲਾਉਂਦੇ ਹਨ।
ਇੱਕ ਸਰਗਰਮ ਇੰਸਿਡੈਂਟ ਦੌਰਾਨ ਲੋਕਾਂ ਨੂੰ ਪੋਰਟੇਬਲ ਅੱਪਡੇਟ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਸ਼ਾਮਿਲ ਕਰੋ:
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਇੱਕ ਸਟੇਟਸ ਪੇਜ ਹੈ, ਤਾਂ ਉਸਨੂੰ ਸਨਬੰਧਿਤ ਰਸਤੇ /status ਰਾਹੀਂ ਲਿੰਕ ਕਰੋ ਤਾ ਕਿ ਕਮਿਊਨੀਕੇਸ਼ਨ ਟੀਮਜ਼ ਤੇਜ਼ੀ ਨਾਲ cross-reference ਕਰ ਸਕਣ।
ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਕੇਵਲ ਤਾਂ ਹੀ ਲਾਭਦਾਇਕ ਹੈ ਜਦ ਲੋਕ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰਨ — ਜਿਸਦਾ ਮਤਲਬ ਹੈ ਕਿਸ ਨੇ ਕੀ ਵੇਖ ਸਕਦਾ/ਸੰਪਾਦਿਤ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਬਦਲਾਅ ਦੀ ਸਪਸ਼ਟ ਰਿਕਾਰਡ ਰੱਖਣਾ।
ਛੋਟੀ ਭੂਮਿਕਾਵਾਂ ਦੀ ਵਿਆਖਿਆ ਕਰੋ ਜੋ ਅਸਲ ਜੀਵਨ ਵਿੱਚ ਇੰਸਿਡੈਂਟ ਚਲਾਉਂਦੀਆਂ ਹਨ:
ਅਧਿਕਾਰਾਂ ਨੂੰ ਜ਼ਿਆਦਾ ਤੌਰ 'ਤੇ ਕਰਮਕਾਂਡਾਂ ਨਾਲ ਮਿਲਾਓ, ਨਾਂ ਕਿ ਨੌਕਰੀਆਂ ਦੇ ਨਾਂ ਨਾਲ। ਉਦਾਹਰਨ ਵਜੋਂ, “ਗਾਹਕ ਪ੍ਰਭਾਵ ਰਿਪੋਰਟ ਐਕਸਪੋਰਟ ਕਰਨ ਦੀ ਆਗਿਆ” ਇੱਕ ਅਧਿਕਾਰ ਹੈ ਜੋ ਤੁਸੀਂ commandਰਾਂ ਅਤੇ ਘੱਟ ਸੰਗਿਆਤadmins ਨੂੰ ਦੇ ਸਕਦੇ ਹੋ।
ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਆਮ ਤੌਰ 'ਤੇ ਗਾਹਕ ਦੇ ਪਰਛਿੱਡ, ਠੇਕੇਦਾਰੀ ਟੀਅਰ ਅਤੇ ਕਈ ਵਾਰ ਸੰਪਰਕ ਵੇਰਵੇ ਛੂਹਦਾ ਹੈ। ਵੀਰਤਾ ਦੇ ਸਿਧਾਂਤ (least privilege) ਲਗਾਓ:
ਮੁੱਖ ਕਾਰਵਾਈਆਂ ਨੂੰ ਕਨ੍ਹਾਂ ਦਾ ਪ੍ਰਸੰਗ ਦੇ ਨਾਲ ਲਾਗ ਕਰੋ ਤਾਂ ਜੋ ਸਮੀਖਿਆ ਲਈ ਯੋਗ ਹੋਵਾਂ:
ਆਡਿਟ ਲੌਗ ਪ੍ਰਤਿ-ਵਧਦੇ ਰੂਪ ਵਿੱਚ ਸਟੋਰ ਕਰੋ, ਟਾਈਮਸਟੈਂਪ ਅਤੇ ਕਿਰਿਆ ਕਰਨ ਵਾਲੇ ਦੀ ਪਛਾਣ ਸਮੇਤ। ਉਨ੍ਹਾਂ ਨੂੰ ਇੰਸੀਡੈਂਟ ਅਨੁਸਾਰ ਖੋਜਯੋਗ ਬਣਾਓ ਤਾਂ ਜੋ ਪੋਸਟ-ਇੰਸਿਡੈਂਟ ਰਿਵਿਊ ਦੌਰਾਨ ਵਰਤੀ ਜਾ ਸਕਣ।
ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਕੋਲ ਹੁਣ ਕੀ ਸਮਰਥਨ ਹੈ—ਰਿਟੇਨਸ਼ਨ ਮਿਆਦ, ਪਹੁੰਚ ਨਿਯੰਤਰਣ, ਇਨਕ੍ਰਿਪਸ਼ਨ, ਅਤੇ ਆਡਿਟ ਕਵਰੇਜ਼—ਅਤੇ ਕੀ ਰੋਡਮੈਪ 'ਤੇ ਹੈ।
ਐਪ ਵਿੱਚ ਇੱਕ ਛੋਟੀ “Security & Audit” ਪੇਜ (ਉਦਾਹਰਨ: /security) ਉਮੀਦਾਂ ਸੈੱਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਅਤੇ ਸੰਘਰਮ ਰੂਪ ਵਿੱਚ ਆਉਣ ਵਾਲੇ ਪ੍ਰਸ਼ਨਾਂ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ।
ਪ੍ਰਭਾਵ ਵਿਸ਼ਲੇਸ਼ਣ ਸਿਰਫ਼ ਤਦ ਉਪਯੋਗੀ ਹੈ ਜਦ ਇਹ ਅਗਲੇ ਕਦਮ ਚਲਾਉਂਦਾ ਹੈ। ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਇੰਸੀਡੈਂਟ ਚੈਨਲ ਲਈ “ਕੋ-ਪਾਇਲਟ” ਵਾਂਗ ਚੱਲਣਾ ਚਾਹੀਦਾ ਹੈ: ਇਹ ਆ ਰਹੇ ਸਿਗਨਲਾਂ ਨੂੰ ਸਸਪਸ਼ਟ ਅੱਪਡੇਟਾਂ ਵਿੱਚ ਬਦਲਦੀ ਹੈ ਅਤੇ ਲੋਕਾਂ ਨੂੰ ਅਨੁਕੂਲਤਾੋਂ ਦਿੰਦੀ ਹੈ ਜਦੋਂ ਪ੍ਰਭਾਵ ਮਹੱਤਵਪੂਰਨ ਤੌਰ 'ਤੇ ਬਦਲਦਾ ਹੈ।
ਸੌਖਾ ਸ਼ੁਰੂਆਤ ਉਹਨਾਂ ਥਾਵਾਂ ਨਾਲ ਇੰਟਿਗ੍ਰੇਟ ਕਰਨਾ ਹੈ ਜਿੱਥੇ ਰਿਸਪਾਂਡਰ ਪਹਿਲਾਂ ਹੀ ਕੰਮ ਕਰਦੇ ਹਨ (ਅਕਸਰ Slack, Microsoft Teams, ਜਾਂ ਇੱਕ ਸਮਰਪਿਤ ਇੰਸਿਡੈਂਟ ਟੂਲ)। ਲਕਸ਼ ਇਹ ਨਹੀਂ ਕਿ ਚੈਨਲ ਨੂੰ ਬਦਲਣਾ—ਬਲਕਿ ਪ੍ਰਸੰਗ-ਸਹਿਤ ਅੱਪਡੇਟ ਪੋਸਟ ਕਰਨਾ ਅਤੇ ਸਾਂਝੀ ਰਿਕਾਰਡ ਰੱਖਣਾ ਹੈ।
ਪ੍ਰਯੋਗਿਕ ਪੈਟਰਨ ਇਹ ਹੈ ਕਿ ਇੰਸੀਡੈਂਟ ਚੈਨਲ ਨੂੰ ਦੋਹਾਂ ਇਨਪੁੱਟ ਅਤੇ ਆਉਟਪੁੱਟ ਵਜੋਂ ਵਰਤੋ:
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਪਹਿਲਾਂ end-to-end ਵਰਕਫਲੋ (incident view → summarize → notify) ਬਣਾਓ ਫਿਰ ਸਕੋਰਿੰਗ 'ਤੇ ਪਰਫੈਕਟ ਕਰੋ। ਪਲੇਟਫਾਰਮ ਜਿਵੇਂ Koder.ai ਇੱਥੇ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ: ਤੁਸੀਂ React ਡੈਸ਼ਬੋਰਡ ਅਤੇ Go/PostgreSQL ਬੈਕਐਂਡ 'ਤੇ ਚੈਟ-ਚਲਿਤ ਵਰਕਫਲੋ ਰਾਹੀਂ ਦੁਹਰਾਈ ਕਰ ਸਕਦੇ ਹੋ, ਫਿਰ ਜਦ ਟੀਮ UX ਨੂੰ ਮਨਜ਼ੂਰ ਕਰ ਲੈਂਦੀ ਹੈ ਤਾਂ ਸਰੋਤ ਕੋਡ ਨਿਰਯਾਤ ਕਰੋ।
ਪ੍ਰਭਾਵ ਇੱਕ ਇੰਸਿਡੈਂਟ ਦਾ ਮਾਪਯੋਗ ਨਤੀਜਾ ਹੈ ਜੋ ਕਾਰੋਬਾਰ-ਮਹੱਤਵਪੂਰਨ ਨਤੀਜਿਆਂ `ਤੇ ਪੈਂਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਪਰਿਭਾਸ਼ਾ 2–4 ਮੁੱਖ ਪੈਮਾਨਿਆਂ (ਜਿਵੇਂ ਭਰੇ ਹੋਏ ਗਾਹਕ + SLA ਮਿੰਟ ਜੋ ਖ਼ਤਰੇ 'ਚ ਹਨ) ਨੂੰ ਨਿਰਧਾਰਿਤ ਕਰਦੀ ਹੈ ਅਤੇ “ਗਰਾਫ਼ਾਂ 'ਤੇ ਜੋ ਵੀ ਅਚਾਨਕ ਖ਼ਰਾਬ ਦਿਖੇ” ਨੂੰ ਬਾਹਰ ਰੱਖਦੀ ਹੈ। ਇਸ ਨਾਲ ਆਉਟਪੁੱਟ ਫੈਸਲਿਆਂ ਨਾਲ ਜੁੜੀ ਰਹਿੰਦੀ ਹੈ, ਸਿਰਫ਼ ਟੈਲੀਮੇਟਰੀ ਨਾਲ ਨਹੀਂ।
ਉਹ ਪੈਮਾਨੇ ਚੁਣੋ ਜੋ ਪਹਿਲੀਆਂ 10 ਮਿੰਟਾਂ ਵਿੱਚ ਤੁਹਾਡੀ ਟੀਮਾਂ ਦੇ فیصلਿਆਂ ਨਾਲ ਮਿਲਦੇ ਹਨ।
ਆਮ, MVP-ਮਿੱਤਰ ਪੈਮਾਨੇ:
ਹੋ ਸਕਦਾ ਹੈ ਕਿ 2–4 ਤੱਕ ਸੀਮਿਤ ਰੱਖੋ ਤਾਂ ਜੋ ਸਕੋਰ ਸਮਝਾਉਣ ਲਈ ਆਸਾਨ ਰਹੇ।
ਆਉਟਪੁੱਟ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਹਰ ਭੂਮਿਕਾ ਆਪਣਾ ਮੁੱਖ ਸਵਾਲ ਬਿਨਾਂ ਮੈਟਰਿਕਸ ਦਾ ਅਨੁਵਾਦ ਕੀਤੇ ਜਵਾਬ ਦੇ ਸਕੇ:
ਜੇ ਕੋਈ ਮੈਟਰਿਕ ਕਿਸੇ ਵੀ ਇਨ ਆਡੀਅੰਸ ਲਈ ਵਰਤੋਂਯੋਗ ਨਹੀਂ ਹੈ, ਤਾਂ ਉਹ ਸੰਭਵਤ: “ਪ੍ਰਭਾਵ” ਨਹੀਂ ਹੈ।
“ਰੀਅਲ-ਟਾਈਮ” ਮਹਿੰਗਾ ਹੋ ਸਕਦਾ ਹੈ; ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਨੇਅਰ-ਰੀਅਲ-ਟਾਈਮ (1–5 ਮਿੰਟ) ਨਾਲ ਠੀਕ ਰਹਿੰਦੀਆਂ ਹਨ।
ਇਹ ਲੇਟੰਸੀ ਨਿਸ਼ਾਨਾ ਇੱਕ ਲੋੜ ਦੇ ਤੌਰ ਤੇ ਲਿਖੋ ਕਿਉਂਕਿ ਇਹ ਪ੍ਰਭਾਵ ਪਾਉਂਦਾ ਹੈ:
UI ਵਿੱਚ ਵੀ ਤਾਜ਼ਗੀ ਦਿਖਾਉ (ਉਦਾਹਰਨ: “ਡਾਟਾ 2 ਮਿੰਟ ਪਹਿਲਾਂ ਤੱਕ ਤਾਜ਼ਾ”)।
ਪਹਿਲਾਂ ਉਹ ਫੈਸਲੇ ਲਿਸਟ ਕਰੋ ਜੋ ਰਿਸਪਾਂਡਰਾਂ ਨੂੰ ਕਰਨੇ ਲਾਜ਼ਮੀ ਹੁੰਦੇ ਹਨ, ਫਿਰ ਇਹ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ ਆਉਟਪੁੱਟ ਇੱਕ ਫੈਸਲੇ ਦਾ ਸਮਰਥਨ ਕਰਦਾ ਹੈ:
ਜੇ ਕੋਈ ਮੈਟਰਿਕ ਫੈਸਲੇ ਨੂੰ ਬਦਲਦਾ ਨਹੀਂ, ਤਾਂ ਉਹ ਟੈਲੀਮੇਟਰੀ ਹੀ ਰਹੇ।
ਆਮ ਤੌਰ 'ਤੇ ਘੱਟੋ-ਘੱਟ ਲੋੜੀਂਦੇ ਇਨਪੁੱਟ ਸ਼ਾਮਿਲ ਹਨ:
ਇਹਨਾਂ ਲਈ ਖੁੱਲ੍ਹੇ, ਕ਼ੁਏਰੀਏਬਲ ਮੈਨੁਅਲ ਫੀਲਡ ਆਸਾਨ ਬਣਾਓ ਤਾਂ ਕਿ ਡਾਟਾ ਗਾਇਬ ਹੋਣ 'ਤੇ ਵੀ ਐਪ ਲਾਭਕਾਰੀ ਰਹੇ:
ਸਾਰਥਕ ਆਡਿਟ ਟਰੇਲ ਲਈ “ਕੌਣ/ਕਦੋਂ/ਕਿਉਂ” ਲਾਜ਼ਮੀ ਰੱਖੋ।
ਇੱਕ ਭਰੋਸੇਯੋਗ MVP ਨੂੰ ਸਥਿਰ ਤੌਰ 'ਤੇ ਨਿਰੀਅਤ ਕਰਨ ਲਈ ਲੋੜੀਂਦੇ ਆਉਟਪੁੱਟ ਪੈਦਾ ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ:
ਵਿਕਲਪਿਕ: ਲਾਗਤ ਅੰਦਾਜ਼ਾ (SLA ਕ੍ਰੈਡਿਟ, ਸਪੋਰਟ ਲੋਡ, ਰੈਵੇਨਿਊ ਜੋਖਮ) ਵਿਸ਼ਵਾਸ ਰੇਂਜਾਂ ਨਾਲ ਵਧੀਆ ਹੈ।
ਹਰ ਸੋਰਸ ਨੂੰ ਇੱਕ ਇਕਸਾਰ “ਇਵੈਂਟ” ਆਕਾਰ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ ਤਾਂ ਕਿ ਕੈਲਕੁਲੇਸ਼ਨ ਸੰਗਠਿਤ ਰਹਿਣ।
ਘੱਟੋ-ਘੱਟ ਇਹਨਾਂ ਨੂੰ ਇੱਕਸਾਰ ਕਰੋ:
ਸਧਾਰਣ ਅਤੇ ਸਮਝਣਯੋਗ ਬਣਾਉਣ ਨਾਲ ਤੁਸੀਂ MVP ਲਈ ਬਹੁਤ ਕੁਝ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ:
ਸਕੋਰਿੰਗ ਪੈਟਰਨ ਜੋ MVP ਲਈ ਚੰਗੇ ਹਨ:
ਜੋ ਵੀ ਤਰੀਕਾ ਤੁਸੀਂ ਚੁਣੋ, ਇੰਟਰਮੀਡੀਏਟ ਵੈਲਿਊਜ਼ ਸੰਭਾਲੋ (ਥ੍ਰੈਸ਼ਹੋਲਡ ਹਿਟ, weights, tier) ਤਾਂ ਜੋ ਲੋਕ ਸਮਝ ਸਕਣ ਕਿ ਸਕੋਰ ਕਿਉਂ ਬਣਿਆ।
ਇਹ ਸੈੱਟ ਇਹ ਗਿਣ ਸਕਦਾ ਹੈ ਕਿ “ਕੀ ਟੁੱਟਿਆ”, “ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੋਇਆ”, ਅਤੇ “ਕਿੰਨੀ ਦੇਰ ਲਈ”।
ਗੰਦੇ ਡਾਟਾ ਨਾਲ ਨਜਿੱਠਣ ਲਈ idempotency keys (source + external_id) ਵਰਤੋ, ਆਉਟ-ਆਫ-ਆਰਡਰ ਇਵੈਂਟਸ ਨੂੰ occurred_at 'ਤੇ ਅਨੁਕ੍ਰਮਿਤ ਕਰੋ, ਅਤੇ ਗੁੰਮ ਖੇਤਰਾਂ ਲਈ ਸੁਰੱਖਿਅਤ ਡਿਫ਼ਾਲਟ ਲਗਾਓ।