ਇਸ ਲੇਖ ਵਿੱਚ “Document Database” ਦਾ ਕੀ ਮਤਲਬ ਹੈ
ਇੱਕ document database ਡੇਟਾ ਨੂੰ ਆਪਣੇ-ਅੰਦਰ ਮੁਕੰਮਲ “ਦਸਤਾਵੇਜ਼” ਵਜੋਂ ਸਟੋਰ ਕਰਦੀ ਹੈ, ਆਮ ਤੌਰ 'ਤੇ JSON-ਵਰਗੇ ਫਾਰਮੈਟ ਵਿੱਚ। ਇੱਕ ਕਾਰੋਬਾਰੀ ਵਸਤੂ ਨੂੰ ਕਈ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡਣ ਦੀ ਬਜਾਏ, ਇਕੱਲਾ ਦਸਤਾਵੇਜ਼ ਉਸ ਦੀਆਂ ਸਾਰੀਆਂ ਜਾਣਕਾਰੀਆਂ ਰੱਖ ਸਕਦਾ ਹੈ—ਫੀਲਡ, ਸਬ-ਫੀਲਡ, ਅਤੇ ਐਰੇ—ਜਿਵੇਂ ਬਹੁਤ ਸਾਰੇ ਐਪ ਕੋਡ ਵਿੱਚ ਪਹਿਲਾਂ ਹੀ ਡੇਟਾ ਦਰਸਾਉਂਦੇ ਹਨ।
ਦਸਤਾਵੇਜ਼ ਅਤੇ ਕਲੈਕਸ਼ੰਸ (ਸਧਾਰਣ ਭਾਸ਼ਾ)
- Document: ਇਕ ਰਿਕਾਰਡ ਜੋ ਤੁਸੀਂ ਪੂਰੇ ਤਰੀਕੇ ਨਾਲ ਪੜ੍ਹ ਜਾਂ ਲਿਖ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਨ ਵਜੋਂ, ਇਕ ਗਾਹਕ, ਇਕ ਆਰਡਰ, ਇਕ ਸਪੋਰਟ ਟਿਕਟ)।
- Collection: ਸਮਾਨ ਦਸਤਾਵੇਜ਼ਾਂ ਦਾ ਸਮੂਹ (ਉਦਾਹਰਨ ਵਜੋਂ,
users ਕਲੈਕਸ਼ਨ ਜਾਂ orders ਕਲੈਕਸ਼ਨ)।
ਇੱਕੋ ਕਲੈਕਸ਼ਨ ਵਿੱਚ ਰਹਿਣ ਵਾਲੇ ਦਸਤਾਵੇਜ਼ ਇਕੋ ਜਿਹੇ ਹੋਣ ਲਾਜ਼ਮੀ ਨਹੀਂ। ਇਕ user ਦਸਤਾਵੇਜ਼ ਕੋਲ 12 ਫੀਲਡ ਹੋ ਸਕਦਿਆਂ ਹਨ, ਦੂਜੇ ਕੋਲ 18 — ਅਤੇ ਦੋਹਾਂ ਇਕੱਠੇ ਰਹਿ ਸਕਦੇ ਹਨ।
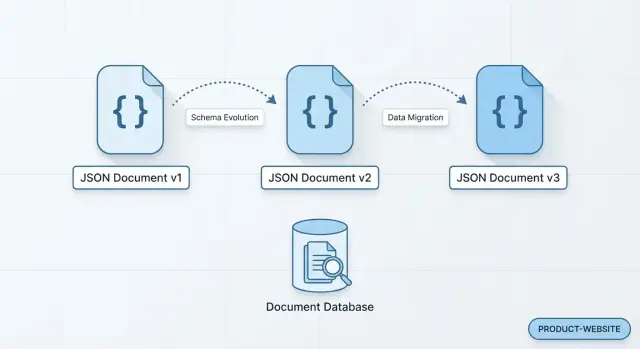
“ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦਾ ਡੇਟਾ ਮਾਡਲ” ਦਿਖਦਾ ਕਿਵੇਂ ਹੈ
ਇਕ ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ ਦੀ ਕਲਪਨਾ ਕਰੋ। ਤੁਸੀਂ ਸ਼ੁਰੂ ਵਿੱਚ name ਅਤੇ email ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ। ਅਗਲੇ ਮਹੀਨੇ, ਮਾਰਕੀਟਿੰਗ preferred_language ਚਾਹੁੰਦੀ ਹੈ। ਫਿਰ ਕਸਟਮਰ ਸੱਕਸੈਸ timezone ਅਤੇ subscription_status ਮੰਗਦਾ ਹੈ। ਬਾਅਦ ਵਿੱਚ ਤੁਸੀਂ social_links (ਇੱਕ ਐਰੇ) ਅਤੇ privacy_settings (ਇਕ ਨੈਸਟਡ ऑਬਜੈਕਟ) ਜੋੜਦੇ ਹੋ।
ਡਾਕੂਮੈਂਟ ਡੇਟਾਬੇਸ ਵਿੱਚ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਨਵੇਂ ਫੀਲਡ ਲਿਖਣਾ ਫੌਰاً ਸ਼ੁਰੂ ਕਰ ਸਕਦੇ ਹੋ। ਪੁਰਾਣੇ ਦਸਤਾਵੇਜ਼ ਜਿਵੇਂ ਹਨ ਰਹਿ ਸਕਦੇ ਹਨ ਜਿਥੋਂ ਤੱਕ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਬੈਕਫਿਲ ਕਰਨ ਜਾਂ ਨਾ ਕਰਨ ਦਾ ਫੈਸਲਾ ਕਰੋ।
ਲਚਕੀਲੇਪਣ—ਪਰ ਨੁਕਸਾਨ ਵੀ ਹਨ
ਇਹ ਲਚਕੀਲੇਪਣ ਉਤਪਾਦੀ ਕੰਮ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਜ਼ਿੰਮੇਵਾਰੀ ਟੀਮ ਅਤੇ ਐਪਲੀਕੇਸ਼ਨ 'ਤੇ ਸਥਾਂਤਰਿਤ ਕਰਦਾ ਹੈ: ਤੁਹਾਨੂੰ ਸਾਫ਼ ਰੱਖਣ ਲਈ ਰੀਤ-ਰਿਵਾਜ, ਚੋਣੀਏ ਵੈਧਤਾ ਨਿਯਮ ਅਤੇ ਸੋਚ-ਵਿਚਾਰ ਵਾਲੀ ਕਵੇਰੀ ਡਿਜ਼ਾਈਨ ਦੀ ਲੋੜ ਪਵੇਗੀ ਤਾਂ ਜੋ ਅਣ-ਸਮਝਦਾਰ, ਵਿਵਸਥਿਤ ਨਾ ਹੋਏ ਡੇਟਾ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
ਤੁਸੀਂ ਇਸ ਲੇਖ ਵਿੱਚ ਕੀ ਸਿੱਖੋਗੇ
ਅਗਲੇ ਹਿੱਸੇ ਵਿੱਚ ਅਸੀਂ ਦੇਖਾਂਗੇ ਕਿ ਕਿਉਂ ਕੁਝ ਮਾਡਲ ਇੰਨੇ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦੇ ਹਨ, ਲਚਕੀਲੇ ਸਕੀਮਾ ਘਟਾ ਕਿਸ-ਤਰ੍ਹਾਂ ਘਰਾਈ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ, ਦਸਤਾਵੇਜ਼ ਕਿਵੇਂ ਅਸਲ ਐਪликੇਸ਼ਨ ਕਵੇਰੀਆਂ ਨਾਲ ਮਿਲਦੇ ਹਨ, ਅਤੇ ਦਸਤਾਵੇਜ਼ ਸਟੋਰੇਜ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਕਿਹੜੇ ਵਪਾਰ-ਬੇਲਾਂਸਾਂ ਨੂੰ ਤੌਜ਼ੀ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
ਕਿਉਂ ਕੁਝ ਡੇਟਾ ਮਾਡਲ ਅਕਸਰ ਬਦਲਦੇ ਰਹਿੰਦੇ ਹਨ
ਡੇਟਾ ਮਾਡਲ ਕਦੇ ਵੀ ਸਥਿਰ ਨਹੀਂ ਰਹਿੰਦੇ ਕਿਉਂਕਿ ਉਤਪਾਦ ਕਦੇ ਵਾਰ ਨਹੀਂ ਰਹਿੰਦਾ। ਜੋ “ਸਿਰਫ਼ ਇੱਕ ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ ਸਟੋਰ ਕਰੋ” ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ, ਉਹ ਜਲਦੀ ਹੀ ਪ੍ਰਿਫਰੈਂਸ, ਨੋਟੀਫਿਕੇਸ਼ਨ, ਬਿਲਿੰਗ ਮੈਟਾਡੇਟਾ, ਡਿਵਾਈਸ ਜਾਣਕਾਰੀ, ਸਹਿਮਤੀ ਫਲੈਗ ਅਤੇ ਹੋਰ ਬਹੁਤ ਸਾਰੇ ਵੇਰਵੇ ਜੋ ਪਹਿਲੀ ਵਰਜਨ ਵਿੱਚ ਨਹੀਂ ਸਨ ਵਿੱਚ ਤਬਦੀਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਉਤਪਾਦ ਦੀ ਵਾਧੀ ਨਵੇਂ ਗੁਣ ਜੋੜਦੀ ਹੈ
ਜ਼ਿਆਦਾਤਰ ਮਾਡਲ ਚਰਨ ਸਿੱਖਣ ਦੇ ਨਤੀਜੇ ਹਨ। ਟੀਮਾਂ ਟੀਚੇ ਜਦੋਂ ਜੋੜਦੀਆਂ ਹਨ:
- ਨਵੇਂ ਫੀਚਰ ਉਤਾਰਦਿਆਂ (ਜਿਵੇਂ ਲੋਇਲਟੀ ਟੀਅਰ, ਸਬਸਕ੍ਰਿਪਸ਼ਨ, ਰੋਲ)
- ਪ੍ਰਯੋਗ ਜੋ ਨਵੇਂ ਟਰੈਕਿੰਗ ਪ੍ਰੋਪਰਟੀ ਲੈਂਦੇ ਹਨ
- ਅਨੁਭਵ ਨਿੱਜੀਕਰਨ ਲਈ ਵੱਧ ਸੰਦਰਭ ਇਕੱਤਰ ਕਰਦੇ ਹਨ
ਇਹ ਬਦਲਾਅ ਅਕਸਰ ਛੋਟੇ ਅਤੇ ਘਨੇ-ਘਨੇ ਹੁੰਦੇ ਹਨ—ਛੋਟੇ ਜੋੜ ਜੋ ਅਕਸਰ ਵੱਡੀਆਂ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਵਜੋਂ ਸ਼ਡਿਊਲ ਕਰਨਾ ਔਖਾ ਹੁੰਦਾ ਹੈ।
ਇੱਕੋ ਏਕਾਈ ਦੇ ਵੱਖ-ਵੱਖ ਵਰਜਨ ਸਾਥ-ਸਾਥ ਰਹਿੰਦੇ ਹਨ
ਅਸਲ ਡੇਟਾਬੇਸ ਇਤਿਹਾਸ ਰੱਖਦੇ ਹਨ। ਪੁਰਾਣੇ ਰਿਕਾਰਡ ਉਹੀ ਆਕਾਰ ਰੱਖਦੇ ਹਨ ਜਿਸ ਨਾਲ ਉਹ ਲਿਖੇ ਗਏ ਸਨ, ਜਦਕਿ ਨਵੇਂ ਰਿਕਾਰਡ ਨਵੀਂ ਆਕਾਰ ਅਪਣਾਉਂਦੇ ਹਨ। ਤੁਸੀਂ ਐਸੇ ਗਾਹਕ ਹੋ ਸਕਦੇ ਹੋ ਜੋ marketing_opt_in ਦੇ ਆਉਣ ਤੋਂ ਪਹਿਲਾਂ ਬਣੇ ਹੋ, ਆਰਡਰ ਜੋ delivery_instructions ਦੇ ਸਹਿਯੋਗ ਤੋਂ ਪਹਿਲਾਂ ਬਣੇ, ਜਾਂ ਇਵੈਂਟ ਜੋ ਨਵੇਂ source ਫੀਲਡ ਤੋਂ ਪਹਿਲਾਂ ਲੌਗ ਕੀਤੇ ਗਏ।
ਇਸ ਲਈ ਤੁਸੀਂ "ਇੱਕ ਮਾਡਲ ਨਹੀਂ ਬਦਲ ਰਹੇ"—ਤੁਸੀਂ ਕਈ ਵਰਜਨਾਂ ਨੂੰ ਇੱਕੱਠੇ ਸਹਿਯੋਗ ਦੇ ਰਹੇ ਹੋ, ਕਈ ਵਾਰ ਮਹੀਨਿਆਂ ਲਈ।
ਪੈਰੱਲਲ ਟੀਮਾਂ ਅਤੇ ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਬਦਲਾਅ ਨੂੰ ਤੇਜ਼ ਕਰਦੇ ਹਨ
ਜਦੋਂ ਕਈ ਟੀਮਾਂ ਇਕੱਠੇ ਸ਼ਿਪ ਕਰਦੀਆਂ ਹਨ, ਡੇਟਾ ਮਾਡਲ ਇੱਕ ਸਾਂਝਾ ਸਤਹ ਬਣ ਜਾਂਦਾ ਹੈ। ਭੁਗਤਾਨ ਟੀਮ ਫ੍ਰੌਡ ਸਿਗਨਲਾਂ ਜੋੜ ਸਕਦੀ ਹੈ ਜਦੋਂ ਕਿ ਗ੍ਰੋਥ ਟੀਮ attribution ਡੇਟਾ ਜੋੜਦੀ ਹੈ। ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਵਿੱਚ, ਹਰ ਸੇਵਾ "customer" ਸੰਕਲਪ ਨੂੰ ਵੱਖਰੇ ਢੰਗ ਨਾਲ ਰੱਖ ਸਕਦੀ ਹੈ, ਅਤੇ ਉਹ ਲੋੜਾਂ ਆਜ਼ਾਦੀ ਨਾਲ ਤਬਦੀਲ ਹੁੰਦੀਆਂ ਹਨ।
ਬਿਨਾਂ ਸਹਿਯੋਗ ਦੇ, "ਇੱਕ ਸੋਹਣਾ ਸਕੀਮਾ" ਇੱਕ ਰੁਕਾਵਟ ਬਣ ਜਾਂਦਾ ਹੈ।
ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਨੇਸਟਡ, ਅਰਧ‑ਸੰਰਚਿਤ ਡੇਟਾ
ਬਾਹਰੀ ਸਿਸਟਮ ਅਕਸਰ ਪੇਲੋਡ ਭੇਜਦੇ ਹਨ ਜੋ ਅਨੋਖੇ, ਨੇਸਟਡ ਜਾਂ ਅਸਮਰਥਿਤ ਹੁੰਦੇ ਹਨ: webhook ਇਵੈਂਟ, ਪਾਰਟਨਰ ਮੈਟਾਡੇਟਾ, ਫਾਰਮ ਸਬਮਿਸ਼ਨ, ਡਿਵਾਈਸ ਟੈਲਿਮੈਟਰੀ। ਜਦੋਂ ਤੁਸੀਂ ਮਹੱਤਵਪੂਰਨ ਟੁਕੜੇ ਨਾਰਮਲਾਈਜ਼ ਕਰ ਲੈਂਦੇ ਹੋ, ਤਦ ਵੀ ਅਕਸਰ ਤੁਸੀਂ ਆਊਟਪੁੱਟ ਦੀ ਮੂਲ ਸਰਚਨਾ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ—ਆਡਿਟ, ਡਿਬੱਗਿੰਗ ਜਾਂ ਭਵਿੱਖ ਲਈ।
ਇਹ ਸਾਰੀਆਂ ਤਾਕਤਾਂ ਉਹਨਾਂ ਟੀਮਾਂ ਨੂੰ ਐਸੇ ਸਟੋਰੇਜ ਵੱਲ ਧੱਕਦੀਆਂ ਹਨ ਜੋ ਬਦਲਾਅ ਨੂੰ ਸਹਿਣਸ਼ੀਲ ਢੰਗ ਨਾਲ ਸਹਿਯੋਗ ਕਰਦੇ ਹਨ—ਖਾਸ ਤੌਰ 'ਤੇ ਜਦੋਂ ਸ਼ਿਪਿੰਗ ਤੇਜ਼ੀ ਮਹੱਤਵਪੂਰਨ ਹੋਵੇ।
ਜਦੋਂ ਲੋੜ ਬਦਲਦੀ ਹੈ ਤਾਂ ਲਚਕੀਲੇ ਸਕੀਮਾ ਘਟਾ ਨੂੰ ਕਿਵੇਂ ਘਟਾਉਂਦੇ ਹਨ
ਜਦੋਂ ਇੱਕ ਉਤਪਾਦ ਆਪਣੀ ਸ਼ਕਲ ਲੱਭ ਰਿਹਾ ਹੁੰਦਾ ਹੈ, ਡੇਟਾ ਮਾਡਲ ਕਦੇ ਡਨ ਨਹੀਂ ਹੁੰਦਾ। ਨਵੇਂ ਫੀਲਡ ਆਉਂਦੇ ਹਨ, ਪੁਰਾਣੇ ਫੀਲਡ ਜ਼ਰੂਰੀ ਨਹੀਂ ਰਹਿੰਦੇ, ਅਤੇ ਵੱਖ-ਵੱਖ ਗਾਹਕ ਥੋੜ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹਾ ਵੱਖਰਾ ਜਾਣਕਾਰੀ ਚਾਹੁੰਦੇ ਹਨ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਇਨ੍ਹਾਂ ਪਲਾਂ ਵਿੱਚ ਪਸੰਦ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਤੁਹਾਨੂੰ ਡੇਟਾ ਨੂੰ ਅਜ਼ਾਜ਼ਾ ਨਾਲ ਵਿਕਸਤ ਕਰਨ ਦਿੰਦੇ ਹਨ ਬਿਨਾਂ ਹਰ ਬਦਲਾਅ ਨੂੰ ਡੇਟਾਬੇਸ ਮਾਈਗ੍ਰੇਸ਼ਨ ਪ੍ਰੋਜੈਕਟ ਬਣਾਉਣ ਦੇ।
ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਨਵੇਂ ਫੀਲਡ ਜੋੜੋ (ਟੇਬਲ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਨਹੀਂ)
JSON ਦਸਤਾਵੇਜ਼ਾਂ ਨਾਲ, ਨਵੀਂ ਪ੍ਰਾਪਰਟੀ ਜੋੜਨਾ ਨਵੇਂ ਰਿਕਾਰਡਾਂ 'ਤੇ ਲਿਖਣ ਵਜੋਂ ਸਧਾਰਨ ਹੋ ਸਕਦਾ ਹੈ। ਮੌਜੂਦਾ ਦਸਤਾਵੇਜ਼ ਤੱਕ ਜਿਥੇ ਤਕ ਤੁਸੀਂ ਬੈਕਫਿਲ ਕਰਨ ਦੀ ਚਾਹ ਨਾ ਰੱਖੋ, ਉਹ ਓਹੋ ਰਹਿ ਸਕਦੇ ਹਨ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਛੋਟਾ ਪ੍ਰਯੋਗ—ਜਿਵੇਂ ਨਵੀਂ ਪ੍ਰਿਫਰੈਂਸ ਸੈਟਿੰਗ ਇਕੱਠੀ ਕਰਨੀ—ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਹਰ ਵਾਰ ਸਕੀਮਾ ਦੁਹਾਈ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਪੈਂਦੀ।
ਜਦੋਂ संभव ਹੋਵੇ, ਦਸਤਾਵੇਜ਼ ‘ਸ਼ੇਪ’ ਮਿਲਾਉ
ਕਈ ਵਾਰ ਤੁਹਾਡੇ ਕੋਲ ਵੈਰੀਐਂਟ ਹੁੰਦੇ ਹਨ: “free” ਖਾਤਾ ਵਿੱਚ ਘੱਟ ਸੈਟਿੰਗ ਹੋ ਸਕਦੀਆਂ ਹਨ, “enterprise” ਖਾਤੇ ਵਿੱਚ ਵੱਧ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਵਿੱਚ, ਇੱਕੋ ਕਲੈਕਸ਼ਨ ਦੇ ਦਸਤਾਵੇਜ਼ ਵੱਖ-ਵੱਖ ਆਕਾਰ ਦੇ ਹੋ ਸਕਦੇ ਹਨ, ਜੇ ਤੁਹਾਡੀ ਐਪਲੀਕੇਸ਼ਨ ਉਹਨਾਂ ਨੂੰ ਸਮਝ ਸਕੇ।
ਇਸਦੀ ਬਜਾਏ ਕਿ ਹਰ ਚੀਜ਼ ਨੂੰ ਇੱਕ ਰਿਗਿਡ ਸਟਰਕਚਰ ਵਿੱਚ ਫ਼ੋਰਸ ਕੀਤਾ ਜਾਵੇ, ਤੁਸੀਂ ਰੱਖ ਸਕਦੇ ਹੋ:
- ਸਾਂਝੇ ਫੀਲਡ ਸਥਿਰ (ਜਿਵੇਂ
id, userId, createdAt)
- ਵੈਰੀਐਂਟ ਫੀਲਡ ਸਿਰਫ਼ ਜਿੱਥੇ ਲੋੜੀਂਦੇ ਰਹਿਣ
ਡਿਫਾਲਟ + ਐਪ ਲੌਜਿਕ ਗੈਪਾਂ ਨੂੰ ਭਰਦੇ ਹਨ
ਲਚਕੀਲੇ ਸਕੀਮਾ ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ "ਕੋਈ ਨਿਯਮ ਨਹੀਂ"। ਆਮ ਪੈਟਰਨ ਇਹ ਹੈ ਕਿ ਗੈਪ ਫੀਲਡਾਂ ਨੂੰ "ਡਿਫਾਲਟ ਵਰਗੇ" ਮੰਨਿਆ ਜਾਂਦਾ ਹੈ। ਤੁਹਾਡੀ ਐਪ ਪੜ੍ਹਦੇ ਸਮੇਂ ਸੈਂਸਿਬਲ ਡਿਫਾਲਟ ਲਗਾ ਸਕਦੀ ਹੈ (ਜਾਂ ਲਿਖਣ ਸਮੇਂ ਸੈਟ ਕਰ ਸਕਦੀ ਹੈ), ਤਾਂ ਕਿ ਪੁਰਾਣੇ ਦਸਤਾਵੇਜ਼ ਵੀ ਠੀਕ ਕੰਮ ਕਰਨ।
ਤੇਜ਼ ਪ੍ਰਯੋਗ ਅਤੇ ਫੀਚਰ ਫਲੈਗ
ਫੀਚਰ ਫਲੈਗ ਅਕਸਰ ਅਸਥਾਈ ਫੀਲਡ ਅਤੇ ਅੰਸ਼ਕ ਰੋਲਆਊਟ ਪੈਦਾ ਕਰਦੇ ਹਨ। ਲਚਕੀਲੇ ਸਕੀਮਾ ਇਕ ਛੋਟੀ ਕੋਹੋਰਟ ਲਈ ਚੀਜ਼ ਸ਼ਿਪ ਕਰਨ, ਸਿਰਫ਼ ਫਲੈਗ ਕੀਤੇ ਯੂਜ਼ਰਾਂ ਲਈ ਵਧੂ ਸਟੇਟ ਰੱਖਣ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਦੁਹਰਾਉਣ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ—ਬਿਨਾਂ ਇਸਦੇ ਕਿ ਖਰਾਬ ਸਕੀਮਾ ਕੰਮ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਰੁੱਕ ਜਾਵੇ।
ਦਸਤਾਵੇਜ਼ ਬਹੁਤ ਸਾਰੀਆਂ ਐਪ ਦੀ ਸੋਚ ਨਾਲ ਮਿਲਦੇ ਹਨ
ਬਹੁਤ ਸਾਰੀ ਪ੍ਰੋਡਕਟ ਟੀਮਾਂ ਕੁਦਰਤੀ ਤੌਰ ਤੇ “ਉਹ ਵਸਤੂ ਜੋ ਯੂਜ਼ਰ ਸਕਰੀਨ 'ਤੇ ਵੇਖਦਾ ਹੈ” ਦੇ ਵਿਚਾਰ ਵਿੱਚ ਸੋਚਦੀਆਂ ਹਨ। ਇਕ ਪ੍ਰੋਫਾਈਲ ਪੇਜ, ਆਰਡਰ ਡੀਟੇਲ ਵਿਊ, ਪ੍ਰੋਜੈਕਟ ਡੈਸ਼ਬੋਰਡ—ਹਰ ਇੱਕ ਆਮ ਤੌਰ 'ਤੇ ਇਕ ਐਪ ਅਬਜੈਕਟ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਇਸ ਮਾਨਸਿਕ ਮਾਡਲ ਨੂੰ ਸਹਾਰਾ ਦਿੰਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਤੁਹਾਨੂੰ ਓਹੋ ਅਬਜੈਕਟ ਨੂੰ ਇਕੱਲੇ JSON ਦਸਤਾਵੇਜ਼ ਵਜੋਂ ਸਟੋਰ ਕਰਨ ਦਿੰਦੇ ਹਨ, ਜਿਸ ਨਾਲ ਐਪ ਕੋਡ ਅਤੇ ਸਟੋਰੇਜ ਦੇ ਵਿਚਕਾਰ ਘੱਟ ਤਬਦੀਲੀਆਂ ਰਹਿ ਜਾਂਦੀਆਂ ਹਨ।
ਐਪ ਆਬਜੈਕਟ ਤੋਂ JSON ਤੱਕ ਘੱਟ ਹੱਥ-ਓੜਕ
ਰਿਲੇਸ਼ਨਲ ਟੇਬਲਾਂ ਨਾਲ, ਇੱਕ ਫੀਚਰ ਅਕਸਰ ਕਈ ਟੇਬਲਾਂ, ਫੋਰਿੰਨ ਕੀਜ਼ ਅਤੇ JOIN ਲਾਜ਼ਿਕ ਵਿੱਚ ਵੰਡਿਆ ਹੁੰਦਾ ਹੈ। ਇਹ ਸਚ ਹੈ ਪਰ ਜਦੋਂ ਐਪ ਪਹਿਲਾਂ ਤੋਂ ਹੀ ਨੇਸਟਡ ਆਬਜੈਕਟ ਰੱਖਦਾ ਹੈ ਤਾਂ ਇਹ ਵਿਅੰਗ ਮਹਿਸੂਸ ਹੋ ਸਕਦਾ ਹੈ।
ਇੱਕ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਵਿੱਚ, ਤੁਸੀਂ ਬਹੁਤ ਵਾਰ ਆਬਜੈਕਟ ਨੂੰ ਲਗਭਗ ਉਸੇ ਰੂਪ ਵਿੱਚ ਪਰਸਿਸਟ ਕਰ ਸਕਦੇ ਹੋ:
- ਇੱਕ
user ਦਸਤਾਵੇਜ਼ ਜੋ ਤੁਹਾਡੇ User ਕਲਾਸ/ਟਾਈਪ ਨਾਲ ਮਿਲਦਾ ਹੈ
- ਇੱਕ
project ਦਸਤਾਵੇਜ਼ ਜੋ ਤੁਹਾਡੇ Project ਸਟੇਟ ਮਾਡਲ ਨਾਲ ਮਿਲਦਾ ਹੈ
ਘੱਟ ਤਬਦੀਲੀ ਅਕਸਰ ਘੱਟ ਮੈਪਿੰਗ ਬੱਗ ਅਤੇ ਫੀਲਡ ਬਦਲਾਅ ਵੇਲੇ ਤੇਜ਼ ਦੁਹਰਾਈ ਦਾ ਮਤਲਬ ਹੁੰਦੀ ਹੈ।
ਨੇਸਟਡ ਡੇਟਾ ਇਕੱਠੇ ਰਹਿੰਦਾ ਹੈ
ਅਸਲ ਐਪ ਡੇਟਾ ਕਦੇ ਫਲੈਟ ਨਹੀਂ ਹੁੰਦਾ। ਪਤੇ, ਪ੍ਰਿਫਰੈਂਸ, ਨੋਟੀਫਿਕੇਸ਼ਨ ਸੈਟਿੰਗ, ਸੇਵਡ ਫਿਲਟਰ, UI ਫਲੈਗ—ਇਹ ਸਾਰੇ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਨੇਸਟਡ ਹੁੰਦੇ ਹਨ।
ਮਾਪੇ ਦਸਤਾਵੇਜ਼ ਵਿੱਚ ਨੇਸਟਡ ਉবਜੈਕਟ ਰੱਖਣਾ ਸੰਬੰਧਿਤ ਮੁੱਲਾਂ ਨੂੰ ਨੇੜੇ ਰੱਖਦਾ ਹੈ, ਜੋ "ਇੱਕ ਰਿਕਾਰਡ = ਇੱਕ ਸਕਰੀਨ" ਕਵੇਰੀਆਂ ਲਈ ਮਦਦਗਾਰ ਹੈ: ਇਕ ਦਸਤਾਵੇਜ਼ ਫੈਚ ਕਰੋ, ਇਕ ਵਿਊ ਰੈਂਡਰ ਕਰੋ। ਇਸ ਨਾਲ JOIN ਦੀ ਲੋੜ ਅਤੇ ਉਨ੍ਹਾਂ ਨਾਲ ਜੁੜੀਆਂ ਪ੍ਰਦਰਸ਼ਨ ਆਸ਼ਯਾਂ ਘੱਟ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਟੀਮਾਂ ਦੇ ਅੰਦਰ ਸਪੱਸ਼ਟ ਮਾਲਕੀ
ਜਦੋਂ ਹਰ ਫੀਚਰ ਟੀਮ ਆਪਣੇ ਦਸਤਾਵੇਜ਼ ਦੇ ਆਕਾਰ ਦੀ ਮਾਲਕੀ ਕਰਦੀ ਹੈ, ਤਾਂ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਸਪੱਸ਼ਟ ਹੋ ਜਾਂਦੀਆਂ ਹਨ: ਜਿਸ ਟੀਮ ਨੇ ਫੀਚਰ ਸ਼ਿੱਪ ਕੀਤਾ ਉਹ ਅਪਣਾ ਡੇਟਾ ਮਾਡਲ ਵੀ ਵਿਕਸਤ ਕਰਦੀ ਹੈ। ਇਹ ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਜਾਂ ਮਾਡਯੂਲਰ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ, ਜਿੱਥੇ ਆਜ਼ਾਦੀ ਨਾਲ ਬਦਲਾਅ ਆਮ ਹਰਮਿੱਤਾਂ ਹਨ।
ਤੇਜ਼ ਉਤਪਾਦੀ ਦੁਹਰਾਈ ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ ਪੈਟਰਨ
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਉਹਨਾਂ ਟੀਮਾਂ ਲਈ ਢੰਗ ਬਣਦੇ ਹਨ ਜੋ ਬਾਰ-ਬਾਰ ਸ਼ਿਪ ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਛੋਟੇ ਡੇਟਾ ਜੋੜ ਆਮ ਤੌਰ 'ਤੇ ਕੋਆਰਡੀਨੇਟ ਕੀਤੇ "ਰੋਕੋ ਸੰਸਾਰ" ਡੇਟਾਬੇਸ ਬਦਲਾਅ ਦੀ ਲੋੜ ਨਹੀਂ ਰੱਖਦੇ।
ਤੇਜ਼ ਦੁਹਰਾਈਆਂ ਘੱਟ ਰੁਕਾਵਟਾਂ ਨਾਲ
ਜੇ ਪ੍ਰੋਡਕਟ ਮੈਨੇਜਰ "ਸਿਰਫ ਇੱਕ ਹੋਰ ਐਟਰਿਬਿਊਟ" ਮੰਗਦਾ ਹੈ (ਜਿਵੇਂ preferredLanguage ਜਾਂ marketingConsentSource), ਤਾਂ ਦਸਤਾਵੇਜ਼ ਮਾਡਲ ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ ਉਸ ਫੀਲਡ ਨੂੰ ਤੁਰੰਤ ਲਿਖਣਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ। ਤੁਹਾਨੂੰ ਹਮੇਸ਼ਾਂ ਇੱਕ ਮਾਈਗ੍ਰੇਸ਼ਨ ਸੈਡਿਊਲ ਕਰਨ ਦੀ, ਟੇਬਲ ਲੌਕ ਕਰਨ ਜਾਂ ਕਈ ਸੇਵਾਵਾਂ 'ਚ ਰੀਲੀਜ਼ ਵਿੰਡੋ ਮਿਲਾਉਣ ਦੀ ਲੋੜ ਨਹੀਂ ਹੁੰਦੀ।
ਇਸ ਨਾਲ ਸਪ੍ਰਿੰਟ ਨੂੰ ਰੋਕਣ ਵਾਲੇ ਕੰਮਾਂ ਦੀ ਗਿਣਤੀ ਘਟਦੀ ਹੈ: ਜਦੋਂ ਐਪ ਵਿਕਸਤ ਹੁੰਦੀ ਹੈ ਡੇਟਾਬੇਸ ਵਰਤਣਯੋਗ ਰਹਿੰਦਾ ਹੈ।
ਫੀਲਡ ਜੋੜਣ ਵੇਲੇ ਸਧਾਰਣ ਡਿਪਲੋਇਮੈਂਟ
JSON-ਵਰਗੇ ਦਸਤਾਵੇਜ਼ਾਂ ਵਿੱਚ ਸਨੇਹੀ ਫੀਲਡਾਂ ਜੋੜਨਾ ਆਮ ਤੌਰ 'ਤੇ ਬੈਕਵਰਡ-ਕੰਪੈਟਿਬਲ ਹੁੰਦਾ ਹੈ:
- ਪੁਰਾਣੇ ਰਿਕਾਰਡ ਸਿਰਫ ਨਵੇਂ ਫੀਲਡ ਨੂੰ ਨਹੀਂ ਰੱਖਦੇ।
- ਨਵੇਂ ਰਿਕਾਰਡ ਇਸਨੂੰ ਸ਼ਾਮਿਲ ਕਰਦੇ ਹਨ।
- ਰੀਡਰ "ਮਿਸਿੰਗ" ਨੂੰ ਇੱਕ ਨਾਰਮਲ ਕੇਸ ਵਜੋਂ ਲੈ ਸਕਦੇ ਹਨ।
ਇਹ ਪੈਟਰਨ ਡਿਪਲੋਇਮੈਂਟ ਨੂੰ ਸ਼ਾਂਤ ਬਣਾਉਂਦਾ ਹੈ: ਤੁਸੀਂ ਪਹਿਲਾਂ ਲਿਖਣ ਵਾਲਾ ਰਾਹ ਰੋਲ-ਆਊਟ ਕਰ ਸਕਦੇ ਹੋ (ਨਵਾਂ ਫੀਲਡ ਸਟੋਰ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰੋ), ਫਿਰ ਬਾਅਦ ਵਿੱਚ ਰੀਡ ਰਾਹ ਅਤੇ UI ਨੂੰ ਅਪਡੇਟ ਕਰੋ—ਬਿਨਾਂ ਹਰ ਮੌਜੂਦਾ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਤੁਰੰਤ ਅਪਡੇਟ ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਦੇ।
ਵੱਖ-ਵੱਖ ਐਪ ਵਰਜਨਾਂ ਦਾ ਸਮਰਥਨ
ਅਸਲ ਸਿਸਟਮ ਕਦੇ ਵੀ ਸਾਰੇ ਕਲਾਇੰਟ ਇਕੱਠੇ ਅੱਪਗਰੇਡ ਨਹੀਂ ਕਰਦੇ। ਤੁਹਾਡੇ ਕੋਲ ਹੋ ਸਕਦਾ ਹੈ:
- ਪੁਰਾਣੇ ਵਰਜਨਾਂ ਉੱਤੇ ਮੋਬਾਈਲ ਐਪ ਕਈ ਹਫ਼ਤੇ ਰਹਿਣ
- A/B ਟੈਸਟ ਅਤੇ ਕੈਨੇਰੀ ਰਿਲੀਜ਼
- ਕਈ ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਆਜ਼ਾਦੀ ਨਾਲ ਡਿਪਲੋਾਇ
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਨਾਲ ਟੀਮਾਂ ਅਕਸਰ "ਮਿਕਸਡ ਵਰਜਨ" ਲਈ ਡਿਜ਼ਾਈਨ ਕਰਦੀਆਂ ਹਨ, ਫੀਲਡਾਂ ਨੂੰ ਜੋੜਤੀਆਂ ਅਤੇ ਵਿਕਲਪਕ ਬਣਾਕੇ। ਨਵੇਂ ਲੇਖਨਕ data ਜੋੜ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਪੁਰਾਣੇ ਰੀਡਰ ਨੂੰ ਤੋੜੇ।
ਇੱਕ ਆਮ ਪ੍ਰੈਕਟਿਸ: ਨਵੇਂ ਫੀਲਡ ਲਿਖੋ, ਫਾਲਬੈਕ ਨਾਲ ਪੜ੍ਹੋ
ਇੱਕ ਵਰਤੋਂਯੋਗ ਡਿਪਲੋਇਮੈਂਟ ਪੈਟਰਨ ਇਉਂ ਹੁੰਦਾ ਹੈ:
- Write ਨਵਾਂ ਫੀਲਡ ਨਵੀਨਤਮ ਐਪ/ਸੇਵਾ ਵਰਜਨ ਵਿੱਚ ਲਿਖੋ।
- Read ਫਾਲਬੈਕ ਨਿਯਮ ਨਾਲ: "ਜੇ ਫੀਲਡ ਮੌਜੂਦ ਨਹੀਂ, ਤਾਂ ਪੁਰਾਣਾ ਮੁੱਲ ਜਾਂ ਡਿਫਾਲਟ ਵਰਤੋ।"
- ਜੇ ਲੋੜ ਹੋਵੇ ਤਾਂ ਬਾਅਦ ਵਿੱਚ ਪਿਛੋਕੜ ਬੈਕਫਿਲ ਚਲਾਓ।
ਇਹ ਤਰੀਕਾ ਤੇਜ਼ੀ ਨੂੰ ਉੱਚ ਰੱਖਦਾ ਹੈ ਜਦੋਂ ਕਿ ਡੇਟਾਬੇਸ ਬਦਲਾਅ ਅਤੇ ਐਪ ਰਿਲੀਜ਼ਾਂ ਵਿਚਕਾਰ ਸਮਨਵੇਯ ਘਟਦਾ ਹੈ।
ਅਸਲ-ਦੁਨੀਆ ਦੀਆਂ ਕਵੇਰੀਆਂ ਲਈ ਰੀਡ-ਫ੍ਰੈਂਡਲੀ ਮਾਡਲਿੰਗ
Try a hybrid approach
Build a relational core with flexible JSONB fields in PostgreSQL without slowing releases.
ਇੱਕ ਕਾਰਨ ਜਿਸ ਕਰਕੇ ਟੀਮਾਂ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਨੂੰ ਪਸੰਦ ਕਰਦੀਆਂ ਹਨ ਉਹ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਉਸ ਤਰੀਕੇ ਨਾਲ ਮਾਡਲ ਕਰ ਸਕਦੇ ਹੋ ਜਿਸ ਤਰੀਕਾ ਨਾਲ ਤੁਹਾਡੀ ਐਪ ਬਹੁਤ ਅਕਸਰ ਪੜ੍ਹਦੀ ਹੈ। ਥੋੜ੍ਹੇ-ਜਿਹੇ ਕਾਨਸੈਪਟ ਨੂੰ ਕਈ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡਣ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਇਕੱਠਾ ਕਰਨ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ ਇੱਕ "ਪੂਰਾ" ऑਬਜੈਕਟ (ਅਕਸਰ JSON ਦਸਤਾਵੇਜ਼) ਇੱਕ ਥਾਂ 'ਤੇ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹੋ।
ਡੇਨੋਰਮਲਾਈਜ਼ੇਸ਼ਨ: ਸੰਬੰਧਿਤ ਡੇਟਾ ਇਕੱਠੇ ਰੱਖੋ
ਡੇਨੋਰਮਲਾਈਜ਼ੇਸ਼ਨ ਦਾ ਮਤਲਬ ਹੈ ਸੰਬੰਧਿਤ ਫੀਲਡਾਂ ਨੂੰ ਨਕਲ ਜਾਂ ਐਂਬੈੱਡ ਕਰਨਾ ਤਾਂ ਜੋ ਆਮ ਕਵੇਰੀਆਂ ਇੱਕ ਦਸਤਾਵੇਜ਼ ਪੜ੍ਹ ਕੇ ਜਵਾਬ ਦੇ ਸਕਣ।
ਉਦਾਹਰਨ ਵਜੋਂ, ਇਕ ਆਰਡਰ ਦਸਤਾਵੇਜ਼ ਗਾਹਕ ਸਨੈਪਸ਼ਾਟ ਫੀਲਡ (ਉਸ ਸਮੇਂ ਦਾ ਨਾਮ, ਈਮੇਲ) ਅਤੇ ਲਾਈਨ ਆਇਟਮਾਂ ਦੀ ਐਂਬੈੱਡ ਕੀਤੀ ਐਰੇ ਰੱਖ ਸਕਦਾ ਹੈ। ਇਹ ਡਿਜ਼ਾਈਨ "ਮੇਰੇ ਆਖਰੀ 10 ਆਰਡਰ ਦਿਖਾਓ" ਵਰਗੀਆਂ ਕਵੇਰੀਆਂ ਨੂੰ ਤੇਜ਼ ਅਤੇ ਸਧਾਰਣ ਬਣਾਉਂਦਾ ਹੈ, ਕਿਉਂਕਿ UI ਨੂੰ ਇੱਕ ਪੰਨੇ ਨੂੰ ਰੈਂਡਰ ਕਰਨ ਲਈ ਕਈ ਲੁੱਕਅੱਪ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ।
ਆਮ ਪ੍ਰਦਰਸ਼ਨ ਫਾਇਦੇ (ਅਤੇ ਇਹ ਕਿਉਂ ਹੁੰਦੇ ਹਨ)
ਜਦੋਂ ਇੱਕ ਸਕਰੀਨ ਜਾਂ API ਰਿਸਪਾਂਸ ਲਈ ਡੇਟਾ ਇੱਕ ਦਸਤਾਵੇਜ਼ ਵਿੱਚ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਮਿਲਦਾ ਹੈ:
- ਐਪ ਅਤੇ ਡੇਟਾਬੇਸ ਦੇ ਵਿਚਕਾਰ ਘੱਟ ਨੈਟਵਰਕ ਰਾਊਂਡ ਟ੍ਰਿਪ
- ਨਤੀਜੇ ਇਕੱਠੇ ਕਰਨ ਲਈ ਘੱਟ ਸਰਵਰ-ਸਾਈਡ ਜੋਇਨ
ਇਸ ਨਾਲ ਪੜ੍ਹਾਈ-ਭਾਰੀ ਰਾਹਾਂ ਲਈ ਲੇਟੈਂਸੀ ਘਟਦੀ ਹੈ—ਖਾਸ ਕਰਕੇ ਉਤਪਾਦ ਫੀਡ, ਪ੍ਰੋਫਾਈਲ, ਕਾਰਟ ਅਤੇ ਡੈਸ਼ਬੋਰਡ ਵਿੱਚ।
ਐਂਬੈਡਿੰਗ vs ਰੇਫਰੰਸਿੰਗ: ਇੱਕ ਵਿਹਾਰਕ ਨਿਯਮ
ਐਂਬੈਡਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹੁੰਦੀ ਹੈ ਜਦੋਂ:
- ਐਂਬੈਡ ਕੀਤੀ ਡੇਟਾ ਆਮ ਤੌਰ 'ਤੇ ਮਾਤਾ ਦੇ ਨਾਲ ਪੜ੍ਹੀ ਜਾਂਦੀ ਹੈ
- ਐਂਬੈਡ ਕੀਤੀ ਡੇਟਾ ਦਾ ਆਕਾਰ ਸੀਮਿਤ ਹੋਵੇ (ਜਿਵੇਂ “ਤਕ 20 ਆਈਟਮ”)
- ਤੁਸੀਂ ਇਸਨੂੰ ਮਾਤਾ ਦਸਤਾਵੇਜ਼ ਦੇ ਹਿੱਸੇ ਵਜੋਂ ਅਪਡੇਟ ਕਰਨ ਨੂੰ ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ
ਰੇਫਰੰਸਿੰਗ ਅਕਸਰ ਵਧੀਆ ਹੁੰਦੀ ਹੈ ਜਦੋਂ:
- ਸੰਬੰਧਿਤ ਐਂਟਿਟੀ ਵੱਡੀ ਜਾਂ ਅਨਬਾਊਂਡ ਹੋਵੇ (ਜਿਵੇਂ “ਸਾਰੇ ਕਮੈਂਟਸ ਕਦੇ ਵੀ”)
- ਬਹੁਤ ਸਾਰੇ ਮਾਤਾ ਇੱਕੋ ਹੀ ਚਾਈਲਡ ਨੂੰ ਪੋਇੰਟ ਕਰਦੇ ਹੋ
- ਚਾਈਲਡ ਬਹੁਤ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਕਈ ਦਸਤਾਵੇਜ਼ ਅਪਡੇਟ ਨਹੀਂ ਕਰਨਾ ਚਾਹੁੰਦੇ
ਪ੍ਰਦਰਸ਼ਨ ਪਹੁੰਚ ਪੈਟਰਨਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ
ਕੋਈ ਸਰਬੋਤਮ "ਦਸਤਾਵੇਜ਼ ਆਕਾਰ" ਨਹੀਂ ਹੈ। ਇੱਕ ਮਾਡਲ ਜੋ ਇਕ ਕਵੇਰੀ ਲਈ ਉਤਕ੍ਰਿਸ਼ਟ ਹੈ, ਦੂਜੇ ਲਈ ਸੁਸਤ (ਜਾਂ ਅੱਪਡੇਟ ਲਈ ਮਹਿੰਗਾ) ਹੋ ਸਕਦਾ ਹੈ। ਸਭ ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਆਪਣੀਆਂ ਅਸਲ ਕਵੇਰੀਆਂ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ—ਤੁਹਾਡੀ ਐਪ ਅਸਲ ਵਿੱਚ ਕੀ ਪੜ੍ਹਦੀ ਹੈ—ਅਤੇ ਫਿਰ ਡੇਟਾ ਨੂੰ ਉਹਨਾਂ ਪਾਠਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਸ਼ੇਪ ਕਰੋ, ਅਤੇ ਵਰਤੋਂ ਦੇ ਨਾਲ-ਨਾਲ মਾਡਲ ਦੀ ਦੁਬਾਰਾ ਸਮੀਖਿਆ ਕਰੋ।
schema-on-read ਅਤੇ ਵਿਕਲਪਕ ਵੈਧਤਾ
schema-on-read ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਹਾਨੂੰ ਹਰ ਫੀਲਡ ਅਤੇ ਟੇਬਲ ਆਕਾਰ ਪਹਿਲਾਂ ਤੋਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ। ਇਸ ਦੀ ਬਜਾਏ, ਤੁਹਾਡੀ ਐਪ (ਜਾਂ ਿਐਨਾਲਿਟਿਕਸ ਕਵੇਰੀ) ਹਰ ਦਸਤਾਵੇਜ਼ ਦੀ ਸਰਚਨਾ ਨੂੰ ਪੜ੍ਹਦੇ ਸਮੇਂ ਸਮਝਦੀ ਹੈ। ਪ੍ਰਯੋਗਿਕ ਤੌਰ 'ਤੇ, ਇਹ ਤੁਹਾਨੂੰ ਇੱਕ ਨਵੀਂ ਫੀਚਰ ਜੋੜਨ ਦਿੰਦਾ ਹੈ ਜਿਵੇਂ preferredPronouns ਜਾਂ ਇਕ ਨਵਾਂ ਨੇਸਟਡ shipping.instructions ਬਿਨਾਂ ਪਹਿਲਾਂ ਡੇਟਾਬੇਸ ਮਾਈਗ੍ਰੇਸ਼ਨ ਦੇ।
ਰੋਜ਼ਾਨਾ ਜ਼ਿੰਦਗੀ ਵਿੱਚ schema-on-read ਕਿਵੇਂ ਦਿਖਦਾ ਹੈ
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਕੋਲ ਫਿਰ ਵੀ ਇੱਕ "ਉਮੀਦ ਕੀਤੀ ਆਕਾਰ" ਹੋਂਦੀ ਹੈ—ਸਿਰਫ਼ ਇਹ enforcement ਬਾਅਦ ਵਿੱਚ ਅਤੇ ਚੁਣੀਦਾ ਢੰਗ ਨਾਲ ਹੁੰਦੀ ਹੈ। ਇਕ ਗਾਹਕ ਦਸਤਾਵੇਜ਼ ਕੋਲ phone ਹੋ ਸਕਦਾ ਹੈ, ਦੂਜੇ ਕੋਲ ਨਹੀਂ। ਇਕ ਪੁਰਾਣਾ ਆਰਡਰ discountCode ਨੂੰ ਸਤਰਿੰਗ ਵਜੋਂ ਰੱਖ ਸਕਦਾ ਹੈ, ਜਦਕਿ ਨਵੇਂ ਆਰਡਰ ਇੱਕ ਵਧੇਰੇ ਧਨਾਢ discount ਆਬਜੈਕਟ ਰੱਖਦੇ ਹਨ।
ਭਾਰੀ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਤੋਂ ਬਿਨਾਂ ਗਲਤ ਡੇਟਾ ਰੋਕਣਾ
ਲਚਕੀਲੇਪਣ ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਹੰਗਾਮਾ ਹੋਵੇ। ਆਮ ਤਰੀਕੇ:
- ਡੇਟਾਬੇਸ ਵਿੱਚ ਵੈਧਤਾ ਨਿਯਮ (ਜਿੱਥੇ ਸਹਿਯੋਗ ਹੈ): ਮਹੱਤਵਪੂਰਨ ਫੀਲਡਾਂ ਜਿਵੇਂ
id, createdAt, ਜਾਂ status ਲਾਜ਼ਮੀ ਕਰੋ ਅਤੇ ਉੱਚ-ਖਤਰੇ ਵਾਲੇ ਫੀਲਡਾਂ ਲਈ ਕਿਸਮਾਂ ਨੂੰ ਸੀਮਿਤ ਕਰੋ।
- ਐਪਲੀਕੇਸ਼ਨ-ਸਤਰ ਦੀ ਜਾਂਚ: ਲਿਖਣ ਸਮੇਂ (API ਲੇਅਰ) ਇਨਪੁੱਟ ਨੂੰ ਵੈਧ ਕਰੋ, ਅਤੇ ਅਣ-ਉਮੀਦ ਕੀਤੀਆਂ ਮੁੱਲਾਂ ਨੂੰ ਰੱਦ ਜਾਂ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ।
- ਪਿਛੋਕੜ “ਡੇਟਾ ਹਾਈਜੀਨ” ਨੌਕਰੀਆਂ: ਸਮੇਂ-ਸਮੇਂ ਤੇ ਆਊਟਲਾਇਰਾਂ ਲਈ ਸਕੈਨ ਕਰੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਠੀਕ ਜਾਂ ਫਲੈਗ ਕਰੋ।
ਹਲਕੀ-ਫੁਲਕੀ ਗਵਰਨੈਂਸ ਜੋ ਸਕੇਲ ਕਰਦੀ ਹੈ
ਥੋੜ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹ੍ਹੀ ਇੱਕਸਾਰਤਾ ਬਹੁਤ ਲੰਮੇ ਸਮੇਂ ਤੱਕ ਕੰਮ ਕਰਦੀ ਹੈ:
- ਨਾਮਕਰਨ ਰਿਵਾਜ (ਜਿਵੇਂ
camelCase, ISO-8601 ਵਿੱਚ ਟਾਈਮਸਟੈਂਪ)
- ਦਸਤਾਵੇਜ਼ ਦੇ ਕੁਝ ਲਾਜ਼ਮੀ ਫੀਲਡ
- ਦਸਤਾਵੇਜ਼ ਵਰਜਨਿੰਗ (ਉਦਾਹਰਨ:
schemaVersion: 3) ਤਾਂ ਕਿ ਪੜ੍ਹਨ ਵਾਲੇ ਪੁਰਾਣੇ ਅਤੇ ਨਵੇਂ ਆਕਾਰ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਸੰਭਾਲ ਸਕਣ
ਕਦੋਂ ਵੈਧਤਾ ਕੜੀ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ
ਜਿਵੇਂ ਜਿਵੇਂ ਮਾਡਲ ਸਥਿਰ ਹੁੰਦਾ ਹੈ—ਆਮਤੌਰ 'ਤੇ ਜਦੋਂ ਤੁਸੀਂ ਇਹ ਸਿੱਖ ਲੈਂਦੇ ਹੋ ਕਿ ਕਿਹੜੇ ਫੀਲਡ ਸੱਚਮੁੱਚ ਕੋਰ ਹਨ—ਉਹਨਾਂ ਫੀਲਡਾਂ ਅਤੇ ਅਹਿਮ ਸੰਬੰਧਾਂ 'ਤੇ ਕੜੀ ਵੈਧਤਾ ਲਗਾਓ। ਪ੍ਰਯੋਗਾਤਮਕ ਜਾਂ ਵਿਕਲਪਕ ਫੀਲਡਾਂ ਨੂੰ ਲਚਕੀਲਾ ਰੱਖੋ ਤਾਂ ਕਿ ਡੇਟਾਬੇਸ ਤੀਜ਼ੀ ਨਾਲ ਦੁਹਰਾਉ ਨੂੰ ਸਮਰਥਨ ਕਰੇ ਬਿਨਾਂ ਹਮੇਸ਼ਾਂ ਮਾਈਗ੍ਰੇਸ਼ਨ ਦੀ ਲੋੜ ਥਾਪਣ ਦੇ।
ਬਦਲਾਅ ਇਤਿਹਾਸ ਅਤੇ ਵਿਕਸਿਤ ਹੋ ਰਹੇ ਇਵੈਂਟਸ ਨੂੰ ਹੇਠਾਂ ਲਿਆਉਣਾ
Refactor with confidence
Use snapshots and rollback when a new data shape needs a quick revert.
ਜਦੋਂ ਤੁਹਾਡਾ ਉਤਪਾਦ ਹਫ਼ਤੇ-ਹਫ਼ਤੇ ਬਦਲਦਾ ਹੈ, ਤਾਂ ਸਿਰਫ਼ ਮੌਜੂਦਾ ਆਕਾਰ ਹੀ ਮਹੱਤਵਪੂਰਨ ਨਹੀਂ ਹੈ—ਤੁਹਾਨੂੰ ਇਹ ਵੀ ਚਾਹੀਦਾ ਹੈ ਕਿ ਇਹ ਕਿਵੇਂ ਆਇਆ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਬਦਲਾਅ ਇਤਿਹਾਸ ਰੱਖਣ ਲਈ ਕੁਦਰਤੀ ਤਰੀਕਾ ਹਨ ਕਿਉਂਕਿ ਉਹ ਆਪਣੇ-ਅੰਦਰ ਮੁਕੰਮਲ ਰਿਕਾਰਡ ਸਟੋਰ ਕਰਦੇ ਹਨ ਜੋ ਪੁਰਾਣੀਆਂ ਰਿਕਾਰਡਾਂ ਨੂੰ ਮੁੜ-ਲਿਖਣ ਲਈ ਮਜ਼ਬੂਰੀ ਨਹੀਂ ਕਰਦੇ।
ਐਪੈਂਡ-ਓਨਲੀ ਇਵੈਂਟ ਦਸਤਾਵੇਜ਼
ਇਕ ਆਮ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਚੇਂਜ ਨੂੰ ਇਕ ਇਵੈਂਟ ਸਟ੍ਰੀਮ ਵਜੋਂ ਰੱਖਿਆ ਜਾਵੇ: ਹਰ ਇਵੈਂਟ ਇੱਕ ਨਵਾਂ ਦਸਤਾਵੇਜ਼ ਹੈ ਜੋ ਤੁਸੀਂ ਐਪੈਂਡ ਕਰਦੇ ਹੋ (ਪੁਰਾਣੇ ਰਿਕਾਰਡਾਂ ਨੂੰ ਅੱਪਡੇਟ ਕਰਨ ਦੀ ਬਜਾਏ)। ਉਦਾਹਰਨ: UserEmailChanged, PlanUpgraded, ਜਾਂ AddressAdded।
ਕਿਉਂਕਿ ਹਰ ਇਵੈਂਟ ਆਪਣੀ JSON ਦਸਤਾਵੇਜ਼ ਹੁੰਦੀ ਹੈ, ਤੁਸੀਂ ਉਸ ਸਮੇਂ ਦੀ ਪੂਰੀ ਸੰਦੇਸ਼ਭੂਮਿ ਰੱਖ ਸਕਦੇ ਹੋ—ਕਿਸ ਨੇ ਕੀਤਾ, ਕੀ ਟ੍ਰਿਗਰ ਕੀਤਾ, ਅਤੇ ਕੋਈ ਵੀ ਮੈਟਾਡੇਟਾ ਜੋ ਬਾਅਦ ਵਿੱਚ ਚਾਹੀਦਾ ਹੋ ਸਕਦਾ ਹੈ।
ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ-ਲਿਖਣ ਤੋਂ ਬਿਨਾਂ ਨਵੇਂ ਫੀਲਡ ਜੋੜਨਾ
ਇਵੈਂਟ ਪਰिभਾਸ਼ਾਵਾਂ ਅਕਸਰ ਸਥਿਰ ਨਹੀਂ ਰਹਿੰਦੀਆਂ। ਤੁਸੀਂ source="mobile", experimentVariant, ਜਾਂ ਇੱਕ ਨਵਾਂ ਨੇਸਟਡ ਆਬਜੈਕਟ ਜਿਵੇਂ paymentRiskSignals ਜੋੜ ਸਕਦੇ ਹੋ। ਦਸਤਾਵੇਜ਼ ਸਟੋਰੇਜ ਨਾਲ, ਪੁਰਾਣੇ ਇਵੈਂਟ ਸਿਰਫ਼ ਉਹਨਾਂ ਫੀਲਡਾਂ ਨੂੰ ਛੱਡ ਸਕਦੇ ਹਨ, ਤੇ ਨਵੇਂ ਇਵੈਂਟ ਉਹਨਾਂ ਨੂੰ ਸ਼ਾਮਿਲ ਕਰ ਸਕਦੇ ਹਨ।
ਤੁਹਾਡੇ ਰੀਡਰ (ਸੇਵਾਵਾਂ, ਜੌਬ, ਡੈਸ਼ਬੋਰਡ) ਮਿਸਿੰਗ ਫੀਲਡਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਡਿਫਾਲਟ ਅਨੁਸਾਰ ਹਾਲ ਕਰ ਸਕਦੇ ਹਨ, ਬਜਾਏ ਦੇ ਲੱਖਾਂ ਇਤਿਹਾਸਕ ਰਿਕਾਰਡਾਂ ਨੂੰ ਮਾਈਗ੍ਰੇਟ ਕਰਨ ਦੇ ਕੇਵਲ ਇੱਕ ਵੱਧ ਫੀਲਡ ਲਿਆਉਣ ਲਈ।
ধੀਰੇ-ਧੀਰੇ ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਲਈ ਵਰਜਨਿੰਗ
ਉਪਭੋਗਤਾਵਾਂ ਨੂੰ ਪੇਸ਼ਗੋਈ ਬਣਾਈ ਰੱਖਣ ਲਈ, ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਹਰ ਦਸਤਾਵੇਜ਼ ਵਿੱਚ schemaVersion (ਜਾਂ eventVersion) ਸ਼ਾਮਿਲ ਕਰਦੀਆਂ ਹਨ। ਇਸ ਨਾਲ ਧੀਰੇ-ਧੀਰੇ ਰੋਲਆਊਟ ਸੰਭਵ ਹੁੰਦਾ ਹੈ:
- ਪ੍ਰੋਡੀਉਸਰ ਵਰਜਨ 2 ਇਵੈਂਟ ਲਿਖਣਾ ਸ਼ੁਰੂ ਕਰਦੇ ਹਨ
- ਕਨਸੁਮਰ ਦੋਹਾਂ v1 ਅਤੇ v2 ਪੜ੍ਹਦੇ ਹਨ ਕੁਝ ਸਮੇਂ ਲਈ
- ਤੁਸੀਂ ਪੁਰਾਣੀਆਂ ਵਰਜਨਾਂ ਨੂੰ ਜਦੋਂ ਸੁਵਿਧਾ ਹੋਵੇ ਤਾਂ ਮਾਈਗ੍ਰੇਟ ਜਾਂ ਰਿਟਾਇਰ ਕਰ ਦਿੰਦੇ ਹੋ
ਸਮੇਂ ਦੇ ਨਾਲ ਬਿਹਤਰ ਐਨਾਲਿਟਿਕਸ ਅਤੇ ਡਿਬੱਗਿੰਗ
ਕਿਸੇ "ਕੀ ਹੋਇਆ" ਦੀ ਦਿਰਘਕਾਲੀ ਇਤਿਹਾਸ ਆਡਿਟਾਂ ਤੋਂ ਪਰੇ ਵੀ ਲਾਭਦਾਇਕ ਹੈ। ਐਨਾਲਿਟਿਕਸ ਟੀਮਾਂ ਕਿਸੇ ਵੀ ਸਮੇਂ ਪੁਣਾਬੀਅ ਸਥਿਤੀ ਦੁਬਾਰਾ ਬਣਾਉਣ ਲਈ ਰੀਪਲੇ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਅਤੇ ਸਪੋਰਟ ਇੰਜੀਨੀਅਰਜ਼ ਬੱਗ ਨੂੰ ਪਿਛੇ-ਪਿੱਛੇ ਖੋਜਣ ਲਈ ਇਵੈਂਟ ਰੀਪਲੇ ਜਾਂ ਨਿਰققPayload ਦੀ ਜਾਂਚ ਕਰ ਸਕਦੇ ਹਨ। ਮਹੀਨਿਆਂ ਵਿੱਚ, ਇਸ ਨਾਲ ਰੂਟ-ਕੌਜ਼ ਵਿਸ਼ਲੇਸ਼ਣ ਤੇਜ਼ ਹੁੰਦੀ ਹੈ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਬਣਦੀ ਹੈ।
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਜਾਣਨ ਯੋਗ ਟਰੇਡ-ਆਫ
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਬਦਲਾਅ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ, ਪਰ ਉਹ ਡਿਜ਼ਾਈਨ ਕੰਮ ਨੂੰ ਹਟਾਊਂਦੇ ਨਹੀਂ—ਉਹ ਇਸ ਨੂੰ ਸਥਾਨਾਂਤਰਤ ਕਰਦੇ ਹਨ। ਫੈਸਲਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇਹ ਜਾਣਨਾ ਅਚ্ছে ਹੈ ਕਿ ਤੁਸੀਂ ਉਸ ਲਚਕੀਲੇਪਣ ਲਈ ਕੀ ਤਿਆਗ ਰਹੇ ਹੋ।
ਕਈ ਏਨਟੀਟੀਆਂ 'ਤੇ ਟ੍ਰਾਂਜੇਕਸ਼ਨ ਔਖੇ ਹੋ ਸਕਦੇ ਹਨ
ਕਈ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜੇਕਸ਼ਨਾਂ ਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹਨ, ਪਰ ਮਲਟੀ-ਡੌਕੁਮੈਂਟ ਟ੍ਰਾਂਜੇਕਸ਼ਨ ਸੀਮਤ, धीਮੇ ਜਾਂ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਦੀ ਤੁਲਨਾ ਵਿੱਚ ਮਹਿੰਗੇ ਹੋ ਸਕਦੇ ਹਨ—ਖਾਸ ਕਰਕੇ ਉੱਚ ਸਕੇਲ 'ਤੇ। ਜੇ ਤੁਹਾਡੀ ਮੁੱਖ ਵਰਕਫਲੋ "ਕਈ ਰਿਕਾਰਡਾਂ" 'ਤੇ ਆਲ-ਅਰ-ਨਥਿੰਗ ਅਪਡੇਟ ਦੀ ਮੰਗ ਕਰਦੀ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਆਰਡਰ, ਇਨਵੈਂਟਰੀ, ਅਤੇ ਲੈਜਰ ਐਂਟਰੀ ਨੂੰ ਇੱਕੱਠੇ ਅਪਡੇਟ ਕਰਨਾ), ਤਾਂ ਆਪਣੇ ਡੇਟਾਬੇਸ ਦੇ ਇਸ ਨਿਪਟਾਰੇ ਨੂੰ ਚੈੱਕ ਕਰੋ ਅਤੇ ਇਹ ਦੇਖੋ ਕਿ ਇਸਦਾ ਪ੍ਰਦਰਸ਼ਨ ਜਾਂ ਜਟਿਲਤਾ ਕਿਸ ਤਰ੍ਹਾਂ ਪ੍ਰਭਾਵਿਤ ਹੋਵੇਗਾ।
ਲਚਕੀਲੇਪਣ ਅਸਿੰਘਤ ਆਕਾਰ ਬਣਾਉ ਸਕਦੀ ਹੈ
ਕਿਉਂਕਿ ਫੀਲਡ ਵਿੱਖ-ਚੁਣਨਯੋਗ ਹੁੰਦੇ ਹਨ, ਟੀਮਾਂ ਗਲਤੀ ਨਾਲ ਇੱਕੋ ਸੰਕਲਪ ਦੇ ਕਈ "ਵਰਜਨ" ਬਣਾਉ ਸਕਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ ਲਈ, address.zip vs address.postalCode)। ਇਹ ਡਾਊਨਸਟ੍ਰੀਮ ਫੀਚਰਾਂ ਨੂੰ ਟੋੜ ਸਕਦਾ ਹੈ ਅਤੇ ਬੱਗਾਂ ਨੂੰ ਲੱਭਣਾ ਔਖਾ ਕਰ ਸਕਦਾ ਹੈ। ਇਕ ਵਿਹਾਰਕ ਨਿਵਾਰਣ ਇਹ ਹੈ ਕਿ ਕੁਝ ਮੁੱਖ ਦਸਤਾਵੇਜ਼ ਟਾਈਪਾਂ ਲਈ ਇੱਕ ਸਾਂਝਾ ਕਾਂਟ੍ਰੈਕਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਭਾਵੇਂ ਹਲਕਾ) ਅਤੇ ਜਿੱਥੇ ਜ਼ਰੂਰੀ ਹੋਵੇ ਉਥੇ ਚੋਣੀਏ ਵੈਧਤਾ ਨਿਯਮ ਜੋੜੋ—ਜਿਵੇਂ ਭੁਗਤਾਨ ਸਥਿਤੀ, ਕੀਮਤ, ਜਾਂ ਅਧਿਕਾਰ।
ਐਡ‑ਹਾਕ ਰਿਪੋਰਟਿੰਗ ਬਿਨਾਂ ਇੱਕਸਾਰਤਾ ਮੁਸ਼ਕਲ ਹੋ ਸਕਦੀ ਹੈ
ਜੇ ਦਸਤਾਵੇਜ਼ ਆਜ਼ਾਦੀ ਨਾਲ ਵਿਕਸਿਤ ਹੁੰਦੇ ਹਨ, ਤਾਂ ਐਨਾਲਿਸਟਾਂ ਨੂੰ ਕਈ ਫੀਲਡ ਨਾਮਾਂ ਅਤੇ ਮਿਸਿੰਗ ਵੈਲਿਊਜ਼ ਲਈ ਲੌਜਿਕ ਲਿਖਣਾ ਪੈ ਸਕਦਾ ਹੈ। ਉਹਨਾਂ ਟੀਮਾਂ ਲਈ ਜੋ ਭਾਰੀ ਰਿਪੋਰਟਿੰਗ 'ਤੇ ਨਿਰਭਰ ਹਨ, ਤੁਸੀਂ ਇੱਕ ਯੋਜਨਾ ਰੱਖੋ ਜਿਵੇਂ:
- “ਰਿਪੋਰਟਿੰਗ-ਫ੍ਰੈਂਡਲੀ” ਫੀਲਡਾਂ ਨੂੰ ਮਿਆਰੀ ਬਣਾਉਣਾ
- ਵਾਹ ਰੱਖਿਆ ਗਿਆ ਡੈਟਾ ਵਰਹਾਓ (export) ਕਰੋ ਵੇਅਰਹਾਊਸ ਵਿੱਚ
- ਐਨਾਲਾਇਟਿਕਸ ਲਈ ਕੁਰੇਟ ਕੀਤੇ ਹੋਏ ਰੀਡ ਮਾਡਲ ਬਣਾਓ
ਡੇਨੋਰਮਲਾਈਜ਼ੇਸ਼ਨ ਨਕਲ ਅਤੇ ਅਪਡੇਟ ਜਟਿਲਤਾ ਪੈਦਾ ਕਰਦੀ ਹੈ
ਸੰਬੰਧਿਤ ਡੇਟਾ (ਜਿਵੇਂ ਆਰਡਰ ਦੇ ਅੰਦਰ ਗਾਹਕ ਸਨੈਪਸ਼ਾਟ) ਨੂੰ ਐਂਬੈੱਡ ਕਰਨਾ ਪੜ੍ਹ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ, ਪਰ ਡੇਟਾ ਨਕਲ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਸਾਂਝਾ ਡਾਟਾ ਬਦਲਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਫੈਸਲਾ ਕਰਨਾ ਪੈندا ਹੈ: ਸਭਥਾਵਾਂ ਨੂੰ ਅਪਡੇਟ ਕਰੋ, ਇਤਿਹਾਸ ਰੱਖੋ, ਜਾਂ ਅਸਥਾਈ ਅਸਮਰਥਤਾ ਬਰਦਾਸ਼ਤ ਕਰੋ। ਇਹ ਫੈਸਲਾ ਇਰਾਦੇ ਨਾਲ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ—ਨਹੀਂ ਤਾਂ ਤੁਸੀਂ ਸੁੱਝਣਹਾਰ ਡੇਟਾ ਡ੍ਰਿਫਟ ਨੂੰ ਜੋਖਮ ਵਿੱਚ ਪਾ ਸਕਦੇ ਹੋ।
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਟੀਮਾਂ ਲਈ ਵਧੀਆ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਬਦਲਾਅ ਬਾਰੰਬਾਰ ਹੁੰਦਾ ਹੈ, ਪਰ ਉਹ ਟੀਮਾਂ ਨੂੰ ਇਨਾਮ ਦਿੰਦੇ ਹਨ ਜੋ ਮਾਡਲਿੰਗ, ਨਾਮਕਰਨ, ਅਤੇ ਵੈਧਤਾ ਨੂੰ ਲਗਾਤਾਰ ਉਤਪਾਦ ਕੰਮ ਵਜੋਂ ਮੰਨਦੇ ਹਨ—ਨਾ ਕਿ ਇਕ ਵਾਰੀ ਦਾ ਕੰਮ।
ਆਮ ਵਰਤੋਂ ਕੇਸ ਜਿੱਥੇ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਚਮਕਦੇ ਹਨ
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ JSON ਦਸਤਾਵੇਜ਼ ਵਜੋਂ ਡੇਟਾ ਸਟੋਰ ਕਰਦੇ ਹਨ, ਜੋ ਉਨ੍ਹਾਂ ਨੂੰ ਕੁਦਰਤੀ ਢੰਗ ਨਾਲ ਉਸ ਵੇਲੇ ਮੰਗਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਡੇ ਫੀਲਡ ਵਿਕਲਪਕ ਹਨ, ਅਕਸਰ ਬਦਲਦੇ ਹਨ, ਜਾਂ ਗਾਹਕ/ਡਿਵਾਈਸ/ਉਤਪਾਦ ਲਾਈਨ ਦੇ ਹਿਸਾਬ ਨਾਲ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ। ਇਕੋ ਹੀ ਕਠੋਰ ਟੇਬਲ ਸ਼ੇਪ ਵਿੱਚ ਹਰ ਰਿਕਾਰਡ ਨੂੰ ਮਜ਼ਬੂਰ ਕਰਨ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ ਧੀਰੇ-ਧੀਰੇ ਡੇਟਾ ਮਾਡਲ ਨੂੰ ਵਿਕਸਤ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਟੀਮਾਂ ਨੂੰ ਆਗੇ ਵਧਣ ਰਹਿਣ ਦਿੰਦੇ ਹੋ।
ਈ‑ਕਾਮਰਸ ਕੈਟਾਲਾਗ ਜਿੱਥੇ ਗੁਣ ਬਦਲਦੇ ਰਹਿੰਦੇ ਹਨ
ਉਤਪਾਦ ਡੇਟਾ ਕਮ ਹੀ ਸਥਿਰ ਰਹਿੰਦੀ ਹੈ: ਨਵੀਂ ਸਾਈਜ਼, ਮੈਟੀਰੀਅਲ, ਕੰਪਲਾਇੰਸ ਫਲੈਗ, ਬੰਡਲ, ਖੇਤਰੀ ਵੇਰਵੇ, ਅਤੇ ਮਾਰਕੀਟਪਲੇਸ-ਨਿਰਧਾਰਤ ਫੀਲਡ ਹਰ ਵੇਲੇ ਆਉਂਦੇ ਹਨ। JSON ਦਸਤਾਵੇਜ਼ਾਂ ਵਿੱਚ ਨੇਸਟਡ ਡੇਟਾ ਨਾਲ, ਇਕ "product" ਮੂਲ ਫੀਲਡ (SKU, price) ਰੱਖ ਸਕਦਾ ਹੈ ਅਤੇ ਸ਼੍ਰੇਣੀ-ਖਾਸ ਐਟਰਿਬਿਊਟਾਂ ਨੂੰ ਬਿਨਾਂ ਹਫ਼ਤਿਆਂ ਦੇ ਸਕੀਮਾ ਰੀ-ਡਿਜ਼ਾਈਨ ਦੇ ਆਸਾਨੀ ਨਾਲ ਸਮਰਥਨ ਕਰ ਸਕਦਾ ਹੈ।
ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ ਅਤੇ ਪ੍ਰਿਫਰੈਂਸਾਂ ਜਿੱਥੇ ਫੀਲਡ ਵਿਕਲਪਕ ਹੁੰਦੇ ਹਨ
ਪ੍ਰੋਫਾਈਲ ਆਮ ਤੌਰ 'ਤੇ ਛੋਟੇ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੇ ਹਨ ਅਤੇ ਵੱਧਦੇ ਹਨ: ਨੋਟੀਫਿਕੇਸ਼ਨ ਸੈਟਿੰਗ, ਮਾਰਕੀਟਿੰਗ ਸਹਿਮਤੀਆਂ, ਓਨਬੋਰਡਿੰਗ ਦੇ ਜਵਾਬ, ਫੀਚਰ ਫਲੈਗ, ਅਤੇ ਨਿੱਜੀਕਰਨ ਇਨਸਾਇਟ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਵਿੱਚ, ਯੂਜ਼ਰ ਵੱਖ-ਵੱਖ ਫੀਲਡ ਸੈੱਟ ਰੱਖ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਮੌਜੂਦਾ ਪੜ੍ਹਾਈ ਨੂੰ ਤੋੜੇ। ਇਹ ਸਕੀਮਾ ਲਚਕੀਲੇਪਣ ਵੀ ਚੁਸਤ ਵਿਕਾਸ ਨੂੰ ਮਦਦ ਕਰਦਾ ਹੈ, ਜਿੱਥੇ ਪ੍ਰਯੋਗ ਤੇਜ਼ੀ ਨਾਲ ਫੀਲਡ ਜੋੜਦੇ ਜਾਂ ਹਟਾਂਦੇ ਹਨ।
ਸਮਗਰੀ ਪ੍ਰਬੰਧਨ ਜੋ ਸਮੇਂ ਨਾਲ ਵਿਕਸਿਤ ਹੁੰਦੀ ਹੈ
ਆਧੁਨਿਕ CMS ਸਮਾਨ ਤੌਰ 'ਤੇ ਸਿਰਫ਼ "ਇੱਕ ਪੇਜ" ਨਹੀਂ ਹੁੰਦੀ। ਇਹ ਬਲੌਕ ਅਤੇ ਕੰਪੋਨੈਂਟਾਂ ਦਾ ਮਿਲਾਪ ਹੈ—ਹੀਰੋ ਸੈਕਸ਼ਨ, FAQ, ਉਤਪਾਦ ਕੈਰੋਸੇਲ, ਐਂਬੈਡ—ਹਰੇਕ ਦੀ ਆਪਣੀ ਸਰਚਨਾ ਹੁੰਦੀ ਹੈ। ਪੰਨਿਆਂ ਨੂੰ JSON ਦਸਤਾਵੇਜ਼ ਵਜੋਂ ਰੱਖਣਾ ਸੰਪਾਦਕਾਂ ਅਤੇ ਵਿਕਸਾਕਾਂ ਨੂੰ ਨਵੇਂ ਕੰਪੋਨੈਂਟ ਕਿਸਮਾਂ ਰੱਖਣ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਹਰ ਇਤਿਹਾਸਿਕ ਪੇਜ ਨੂੰ ਤੁਰੰਤ ਮਾਈਗ੍ਰੇਟ ਕੀਤੇ।
IoT ਅਤੇ ਟੈਲਿਮੈਟਰੀ ਜਿੱਥੇ ਡਿਵਾਈਸ-ਖਾਸ ਪੇਲੋਡ ਹੁੰਦੇ ਹਨ
ਟੈਲਿਮੈਟਰੀ ਅਕਸਰ ਫਰਮਵੇਅਰ ਵਰਜਨ, ਸੈਂਸਰ ਪੈਕੇਜ, ਜਾਂ ਨਿਰਮਾਤਾ ਅਨੁਸਾਰ ਵੱਖਰਾ ਹੁੰਦਾ ਹੈ। ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਇਹ ਬਦਲਦੇ ਡੇਟਾ ਮਾਡਲਾਂ ਨੂੰ ਵਧੀਆ ਢੰਗ ਨਾਲ ਹੋਲਡ ਕਰਦੇ ਹਨ: ਹਰ ਘਟਨਾ ਸਿਰਫ਼ ਉਹੀ ਸ਼ਾਮਿਲ ਕਰ ਸਕਦੀ ਹੈ ਜੋ ਡਿਵਾਈਸ ਜਾਣਦਾ ਹੈ, ਜਦਕਿ schema-on-read ਨਾਲ ਐਨਾਲਿਟਿਕਸ ਟੂਲਾਂ ਮੌਜੂਦ ਫੀਲਡ ਨੂੰ ਪੜ੍ਹਕੇ ਸਮਝ ਸਕਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ NoSQL ਅਤੇ SQL ਵਿਚਕਾਰ ਫ਼ੈਸਲਾ ਕਰ ਰਹੇ ਹੋ, ਇਹ ਉਹ ਸਥਿਤੀਆਂ ਹਨ ਜਿੱਥੇ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਤੇਜ਼ ਢੁਕਵਾਂ ਦੁਹਰਾਈ ਤੇ ਘੱਟ ਘਟਾ ਨਾਲ ਨਤੀਜੇ ਦਿੰਦੇ ਹਨ।
ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦੇ ਮਾਡਲਾਂ ਲਈ ਵਿਆਵਹਾਰਕ ਮਾਡਲਿੰਗ ਸੁਝਾਅ
Keep control of your code
Generate the app, then export source code so your team can extend it freely.
ਜਦੋਂ ਤੁਹਾਡਾ ਡੇਟਾ ਮਾਡਲ ਹਜੇ ਸੈਟਲ ਹੋ ਰਿਹਾ ਹੋਵੇ, ਤਾਂ "ਕਾਫੀ ਚੰਗਾ ਅਤੇ ਆਸਾਨ ਬਦਲਣਯੋਗ" ਕਾਗਜ਼ ਤੇ "ਪਰਫੈਕਟ" ਤੋਂ ਵਧੀਆ ਹੁੰਦਾ ਹੈ। ਇਹ ਪ੍ਰੈਟਿਕਲ ਆਦਤਾਂ ਤੁਹਾਨੂੰ ਗਤੀ ਬਣਾਈ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ ਬਿਨਾਂ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਨੂੰ ਡੈਂਜਰਜ਼ ਭਰੀ ਵਿਚਾਰ ਕਮਰੇ ਵਿੱਚ ਬਦਲਣ ਦਿੱਤੇ।
1) ਇਕਸੈਸ ਪੈਟਰਨਾਂ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਐਨਟੀਟੀਆਂ ਤੋਂ ਨਹੀਂ
ਹਰ ਫੀਚਰ ਦੀ ਸ਼ੁਰੂਆਤ ਉਸਦੀ ਸਿਖਲਾਈ ਨਾਲ ਕਰੋ ਜੋ ਤੁਸੀਂ ਉਤਪਾਦ ਵਿੱਚ ਅਸਲ ਵਿੱਚ ਪੜ੍ਹੋਗੇ ਅਤੇ ਲਿਖੋਗੇ: ਉਹ ਸਕਰੀਨ ਜੋ ਤੁਸੀਂ ਰੈਂਡਰ ਕਰੋਗੇ, API ਰਿਸਪਾਂਸ ਜੋ ਤੁਸੀਂ ਵਾਪਸ ਕਰੋਗੇ, ਅਤੇ ਉਹ ਅਪਡੇਟ ਜੋ ਤੁਸੀਂ ਸਭ ਤੋਂ ਵੱਧ ਕਰੋਂਗੇ।
ਜੇ ਇਕ ਉਪਭੋਗਤਾ ਕਾਰਵਾਈ ਆਮ ਤੌਰ 'ਤੇ "order + items + shipping address" ਚਾਹੀਦੀ ਹੈ, ਤਾਂ ਇਕ ਐਸਾ ਦਸਤਾਵੇਜ਼ ਮਾਡਲ ਕਰੋ ਜੋ ਉਹ ਪੜ੍ਹਾਈ ਘੱਟ ਤੋਂ ਘੱਟ ਫੇਚਿੰਗ ਨਾਲ ਦੇ ਸਕੇ। ਜੇ ਇਕ ਹੋਰ ਕਾਰਵਾਈ "status ਅਨੁਸਾਰ ਸਾਰੇ ਆਰਡਰ" ਚਾਹੀਦੀ ਹੈ, ਤਾਂ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਤੁਸੀਂ ਉਸ ਪਾਥ ਲਈ ਕਵੇਰੀ ਜਾਂ ਇੰਡੈਕਸ ਕਰ ਸਕਦੇ ਹੋ।
2) ਐਂਬੈਡਿੰਗ ਵਿਰੋਧ ਰੇਫਰੰਸਿੰਗ 'ਤੇ ਫੈਸਲਾ ਜਲਦੀ ਕਰੋ
ਐਂਬੈਡਿੰਗ (ਨੇਸਟਡ) ਡੇਟਾ ਉਹਨਾਂ ਹਾਲਾਤਾਂ ਵਿੱਚ ਵਧੀਆ ਹੈ ਜਦੋਂ:
- ਚਾਈਲਡ ਡੇਟਾ ਆਮ ਤੌਰ 'ਤੇ ਮਾਤਾ ਨਾਲ ਪੜ੍ਹੀ ਜਾਂਦੀ ਹੈ
- ਚਾਈਲਡ ਸੈੱਟ ਸੀਮਿਤ ਹੈ (1–20 ਆਈਟਮ)
ਰੇਫਰੰਸਿੰਗ ਸੁਰੱਖਿਅਤ ਹੁੰਦੀ ਹੈ ਜਦੋਂ:
- ਚਾਈਲਡ ਕਲੇਕਸ਼ਨ ਵੱਡੀ ਜਾਂ ਅਨਬਾਊਂਡ ਹੋ ਸਕਦੀ ਹੈ
- ਚਾਈਲਡ ਕਈ ਮਾਤਾਵਾਂ ਦੁਆਰਾ ਸਾਂਝੀ ਹੈ (ਜਿਵੇਂ ਕਿਸੇ ਕੈਟਾਲਾਗ ਉਤਪਾਦ)
- ਚਾਈਲਡ ਬਹੁਤ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਕਈ ਦਸਤਾਵੇਜ਼ ਅਪਡੇਟ ਨਹੀਂ ਕਰਨਾ ਚਾਹੁੰਦੇ
ਤੁਸੀਂ ਦੋਹਾਂ ਮਿਲਾ ਸਕਦੇ ਹੋ: ਤੇਜ਼ ਪੜ੍ਹ ਲਈ ਇੱਕ ਸਨੈਪਸ਼ਾਟ ਐਂਬੈਡ ਕਰੋ ਅਤੇ ਅਪਡੇਟ ਲਈ ਸੋਰਸ ਓਫ ਟਰੂਥ ਨੂੰ ਰੇਫਰੈਂਸ ਰੱਖੋ।
3) ਘੱਟੋ-ਘੱਟ ਗਾਰਡਰੇਲ: ਵੈਧਤਾ + ਵਰਜਨਿੰਗ ਜੋੜੋ
ਸਕੀਮਾ ਲਚਕੀਲੇ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਉਹ ਫੀਲਡਾਂ ਲਈ ਹਲਕੀ-ਫੁਲਕੀ ਨਿਯਮ ਜੋ ਤੁਹਾਡੇ ਡਿਪੇਂਡੇਬਲ ਹਨ (ਟਾਈਪ, ਲਾਜ਼ਮੀ ID, ਅਨੁਮਤ ਸਥਿਤੀਆਂ) ਜੋੜੋ। ਇਕ schemaVersion (ਜਾਂ docVersion) ਫੀਲਡ ਸ਼ਾਮਿਲ ਕਰੋ ਤਾਂ ਕਿ ਤੁਹਾਡੀ ਐਪ ਪੁਰਾਣੇ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਸੰਭਾਲ ਸਕੇ ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ ਉਨ੍ਹਾਂ ਨੂੰ ਮਾਈਗ੍ਰੇਟ ਕਰ ਸਕੇ।
4) ਸਫਾਈ ਅਤੇ ਮਾਈਗ੍ਰੇਸ਼ਨ ਨੂੰ ਇਕ ਨਿਯਮਤ ਰੁਟੀਨ ਬਣਾਓ
ਮਾਈਗ੍ਰੇਸ਼ਨਾਂ ਨੂੰ ਇੱਕ ਪੀਰਿਯੋਡਿਕ ਰੱਖ-ਰੱਖਾਅ ਸਮਝੋ, ਨਾ ਕਿ ਇਕ ਵਾਰੀ ਦਾ ਕੰਮ। ਜਿਵੇਂ ਮਾਡਲ ਪੱਕਾ ਹੁੰਦਾ ਹੈ, ਛੋਟੇ ਬੈਕਫਿਲ ਅਤੇ ਸਫਾਈ ਕੰਮ (ਗੈਰ-ਉਪਯੋਗੀ ਫੀਲਡ, ਨਾਂ-ਬਦਲੇ ਹੋਏ ਕੀ) ਸ਼ਡਿਊਲ ਕਰੋ ਅਤੇ ਪ੍ਰਭਾਵ ਮਿਟਾਓ। ਇੱਕ ਸਧਾਰਨ ਚੈੱਕਲਿਸਟ ਅਤੇ ਹਲਕੀ ਮਾਈਗ੍ਰੇਸ਼ਨ ਸਕ੍ਰਿਪਟ ਬਹੁਤ ਮਦਦਗਾਰ ਹੁੰਦੇ ਹਨ।
ਕਿਵੇਂ ਫੈਸਲਾ ਕਰੀਏ: ਦਸਤਾਵੇਜ਼ vs ਰਿਲੇਸ਼ਨਲ (ਅਤੇ ਹਾਈਬ੍ਰਿਡ)
ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਅਤੇ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਵਿੱਚ ਚੋਣ ਕਰਨਾ "ਕਿਹੜਾ ਬਿਹਤਰ ਹੈ" ਦੇ ਬਜਾਏ ਇਹ ਦੇ ਉੱਪਰ ਨਿਰਭਰ ਹੈ ਕਿ ਤੁਹਾਡਾ ਉਤਪਾਦ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਕਿਸ ਤਰ੍ਹਾਂ ਬਦਲਦਾ ਹੈ।
ਜਦੋਂ ਲਚਕੀਲਾਪਣ ਅਤੇ ਗਤੀ ਸਭ ਤੋਂ ਜ਼ਰੂਰੀ ਹੋਣ, ਦਸਤਾਵੇਜ਼ ਚੁਣੋ
ਜਦੋਂ ਤੁਹਾਡੇ ਡੇਟਾ ਦਾ ਆਕਾਰ ਬਾਰੰਬਾਰ ਬਦਲਦਾ ਹੈ, ਵੱਖ-ਵੱਖ ਰਿਕਾਰਡ ਵੱਖ-ਵੱਖ ਫੀਲਡ ਰੱਖ ਸਕਦੇ ਹਨ, ਜਾਂ ਟੀਮਾਂ ਹਰ ਸਪ੍ਰਿੰਟ ਦੇ ਨਾਲ-ਨਾਲ ਫੀਚਰ ਸ਼ਿਪ ਕਰਨਾ ਚਾਹੁੰਦੀਆਂ ਹਨ ਤਾਂ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ ਉਚਿਤ ਰਹਿੰਦੇ ਹਨ।
ਇਹ ਉਹਨਾਂ ਐਪਾਂ ਲਈ ਵੀ ਅਚ্ছে ਹਨ ਜਿੱਥੇ ਐਪ ਆਮ ਤੌਰ 'ਤੇ "ਹੁਣੇ-ਪੂਰੇ ਆਬਜੈਕਟ" ਨਾਲ ਕੰਮ ਕਰਦੀ ਹੈ, ਜਿਵੇਂ: ਇੱਕ ਆਰਡਰ (ਗਾਹਕ ਜਾਣਕਾਰੀ + ਆਈਟਮ + ਡਿਲਿਵਰੀ ਨੋਟ) ਜਾਂ ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ (ਸੈਟਿੰਗਾਂ + ਪ੍ਰਿਫਰੈਂਸ + ਡਿਵਾਈਸ ਜਾਣਕਾਰੀ) ਜੋ ਇੱਕਠੇ JSON ਦਸਤਾਵੇਜ਼ ਵਿੱਚ ਸਟੋਰ ਕੀਤੇ ਹਨ।
ਜਦੋਂ ਸਖਤ ਇੱਕਸਾਰਤਾ ਅਤੇ ਜੋਇਨ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੋਣ, ਰਿਲੇਸ਼ਨਲ ਚੁਣੋ
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਉਹ ਵੇਲੇ ਚਮਕਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਨੂੰ:
- ਮਜ਼ਬੂਤ, ਪਾਬੰਦੀ ਨਾਲ ਲਾਗੂ ਕੀਤੇ ਗਏ ਸੇਟਰਕਚਰ ਦੀ ਲੋੜ ਹੋਵੇ
- ਕਈ ਸਦਸਿਆਂ 'ਤੇ ਕਠਿਨ ਰਿਪੋਰਟਿੰਗ (ਬਹੁਤ ਜੋਇਨ) ਦੀ ਲੋੜ ਹੋਵੇ
- ਟ੍ਰਾਂਜੇਕਸ਼ਨ ਜਿਹੜੀਆਂ ਕਈ ਟੇਬਲਾਂ ਨੂੰ ਪਾਰ ਕਰਦੀਆਂ ਹਨ ਉਹਨਾਂ ਨੂੰ ਬਿਲਕੁਲ ਸਥਿਰ ਰਹਿਣਾ ਲਾਜ਼ਮੀ ਹੋਵੇ
ਜੇ ਤੁਹਾਡੀ ਟੀਮ ਬਹੁਤ ਜ਼ਿਆਦਾ ক্রਾਸ-ਟੇਬਲ ਕਵੇਰੀਆਂ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ 'ਤੇ ਕੰਮ ਕਰਦੀ ਹੈ, SQL ਆਮ ਤੌਰ 'ਤੇ ਲੰਬੇ ਸਮੇਂ ਲਈ ਸਧਾਰਨ घर ਹੁੰਦਾ ਹੈ।
ਜਦੋਂ ਹਕੀਕਤ ਮਿਲੀ-ਝੁਲੀ ਹੋਵੇ ਤਾਂ ਹਾਈਬ੍ਰਿਡ ਸੋਚੋ
ਕਈ ਟੀਮਾਂ ਦੋਹਾਂ ਵਰਤਦੀਆਂ ਹਨ: ਰਿਲੇਸ਼ਨਲ "ਕੋਰ ਸਿਸਟਮ ਆਫ ਰਿਕਾਰਡ" ਲਈ (ਬਿਲਿੰਗ, ਇਨਵੈਂਟਰੀ, ਅਧਿਕਾਰ) ਅਤੇ ਦਸਤਾਵੇਜ਼ ਸਟੋਰ ਤੇਜ਼-ਬਦਲਦੇ ਜਾਂ ਰੀਡ-ਓਪਟਿਮਾਈਜ਼ਡ ਵਿਊਜ਼ ਲਈ (ਪ੍ਰੋਫਾਈਲ, ਸਮਗਰੀ ਮੈਟਾਡੇਟਾ, ਉਤਪਾਦ ਕੈਟਾਲੋਗ)। ਮਾਈਕ੍ਰੋਸਰਵਿਸਜ਼ ਵਿੱਚ, ਇਹ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਮਿਲ ਸਕਦਾ ਹੈ: ਹਰ ਸੇਵਾ ਆਪਣੇ ਬਾਊਂਡਰੀਜ਼ ਲਈ ਸਟੋਰੇਜ ਮਾਡਲ ਚੁਣਦੀ ਹੈ।
ਇਹ ਵੀ ਯਾਦ ਰੱਖਣ ਲਾਇਕ ਹੈ ਕਿ "ਹਾਈਬ੍ਰਿਡ" ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਦੇ ਅੰਦਰ ਵੀ ਹੋ ਸਕਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, PostgreSQL ਅਜੇ ਵੀ JSON/JSONB ਵਰਗੇ ਅਰਧ-ਸੰਰਚਿਤ ਫੀਲਡ ਸਟੋਰ ਕਰ ਸਕਦਾ ਹੈ ਨਾਲ ਹੀ ਮੁਕੰਮਲ-ਟਾਈਪਡ ਕਾਲਮ—ਜਦੋਂ ਤੁਸੀਂ ਟ੍ਰਾਂਜੇਕਸ਼ਨਲ ਇਕਸਾਰਤਾ ਅਤੇ ਵਿਕਸਤ ਐਟਰਿਬਿਊਟ ਲਈ ਥਾਂ ਚਾਹੁੰਦੇ ਹੋ।
Koder.ai ਕਿੱਥੇ ਫਿੱਟ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਦੁਹਰਾਉਂਦੇ ਹੋ
ਜੇ ਤੁਹਾਡਾ ਸਕੀਮਾ ਹਫ਼ਤੇ-ਹਫ਼ਤੇ ਬਦਲ ਰਿਹਾ ਹੈ, ਤਾਂ ਬੋਤਲ-ਨੈਕ ਅਕਸਰ ਐਂਡ-ਟੂ-ਐਂਡ ਲੂਪ ਹੁੰਦਾ ਹੈ: ਮਾਡਲ ਅਪਡੇਟ ਕਰਨਾ, API, UI, ਮਾਈਗ੍ਰੇਸ਼ਨ (ਜੇ ਕੋਈ) ਅਤੇ ਬਦਲਾਅ ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੀਲੀਜ਼ ਕਰਨਾ। Koder.ai ਉਸ ਤਰ੍ਹਾਂ ਦੀ ਦੁਹਰਾਈ ਲਈ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਹੈ। ਤੁਸੀਂ ਚੈਟ ਵਿੱਚ ਫੀਚਰ ਅਤੇ ਡੇਟਾ ਆਕਾਰ ਵੇਰਵਾ ਕਰ ਸਕਦੇ ਹੋ, ਇੱਕ ਕੰਮ ਕਰ ਰਹੀ ਵੈੱਬ/ਬੈਕਇੰਡ/ਮੋਬਾਈਲ ਇਮਪਲੀਮੇੰਟੇਸ਼ਨ ਤਿਆਰ ਕਰਵਾ ਸਕਦੇ ਹੋ, ਅਤੇ ਫਿਰ ਜਿਵੇਂ- ਜਿਵੇਂ ਲੋੜ ਹੋਵੇ ਸੁਧਾਰ ਕਰ ਸਕਦੇ ਹੋ।
ਵ-Practice ਵਿੱਚ, ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਰਿਲੇਸ਼ਨਲ ਕੋਰ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ (Koder.ai ਦਾ ਬੈਕਇੰਡ ਸਟੈਕ Go ਨਾਲ PostgreSQL ਹੈ) ਅਤੇ ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ ਦਸਤਾਵੇਜ਼-ਸਟਾਈਲ ਪੈਟਰਨ ਵਰਤਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ ਲਈ, ਲਚਕੀਲੇ ਐਟਰੀਬਿਊਟ ਲਈ JSONB ਜਾਂ ਇਵੈਂਟ ਪੇਲੋਡ)। Koder.ai ਦੀਆਂ ਸਨੈਪਸ਼ਾਟਸ ਅਤੇ ਰੋਲਬੈਕ ਵੀ ਮਦਦਗਾਰ ਹੁੰਦੀਆਂ ਹਨ ਜਦੋਂ ਕਿਸੇ ਪ੍ਰਯੋਗਾਤਮਕ ਡਾਟਾ ਆਕਾਰ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਵਾਪਸ ਲੈਣਾ ਹੋਵੇ।
ਅਗਲੇ ਕਦਮ: ਇੱਕ ਛੋਟਾ ਪਾਇਲਟ ਦੌੜਾਓ
ਕਮੇਟ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਛੋਟਾ ਮੂਲਿਆਂਕਣ ਚਲਾਓ:
- 5–10 ਅਸਲੀ ਕਵੇਰੀਆਂ ਲਿਖੋ ਜੋ ਉਤਪਾਦ ਨੂੰ ਚਾਹੀਦੀਆਂ ਹਨ (ਕੁਝ ਅਨੁਮਾਨੀ ਨਹੀਂ)।
- ਇੱਕੋ ਫੀਚਰ ਨੂੰ ਦੋਹਾਂ ਪਹੁੰਚਾਂ ਵਿੱਚ ਮਾਡਲ ਕਰੋ।
- ਦੁਹਰਾਈ ਦੀ ਗਤੀ ਮਾਪੋ: ਦੂਜੇ ਬਦਲਾਅ ਦੀ ਬੇਦਰੀ ਹੋਣ ਦੀ ਦਰਦ ਕਿੰਨੀ ਸੀ?
- ਆਪਰੇਸ਼ਨਲ ਲੋੜਾਂ ਦੀ ਪੁਸ਼ਟੀ ਕਰੋ (ਬੈਕਅੱਪ, ਮਾਨਿਟਰਿੰਗ, ਐਕਸੈਸ ਕੰਟਰੋਲ)।
ਜੇ ਤੁਸੀਂ ਵਿਕਲਪਾਂ ਦੀ ਤੁਲਨਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਸਕੋਪ ਤੰਗ ਰੱਖੋ ਅਤੇ ਟਾਈਮ-ਬਾਕਸ ਕਰੋ—ਫਿਰ ਜਿਸ ਮਾਡਲ ਨਾਲ ਘੱਟ ਅਚਾਨਕਤਾ ਨਾਲ ਸ਼ਿਪ ਹੋ ਰਿਹਾ ਹੈ ਉਸ ਨੂੰ ਵੱਧਾਇਆ ਜਾਵੇ। For more on evaluating storage trade-offs, see /blog/document-vs-relational-checklist.