ਅਸੀਂ ਪਹਿਲਾਂ ਵੈੱਬ, ਮੋਬਾਈਲ ਅਤੇ ਬੈਕਐਂਡ ਨਾਲ ਕੀ ਮਤਲਬ ਲੈਂਦੇ ਸੀ
ਕਈ ਸਾਲਾਂ ਤੱਕ, “ਵੈੱਬ”, “ਮੋਬਾਈਲ”, ਅਤੇ “ਬੈਕਐਂਡ” ਸਿਰਫ਼ ਲੇਬਲ ਨਹੀਂ ਸਨ—ਉਹ ਹੱਦਾਂ ਸਨ ਜਿਨ੍ਹਾਂ ਨੇ ਟੀਮਾਂ ਦੇ ਸਾਫਟਵੇਅਰ ਬਣਾਉਣ ਦੇ ਤਰੀਕੇ ਨੂੰ ਆਕਾਰ ਦਿਤਾ।
ਪਰੰਪਰागत ਵੰਡ
ਵੈੱਬ ਆਮ ਤੌਰ 'ਤੇ ਉਹ ਸਭ ਕੁਝ ਸੀ ਜੋ ਬ੍ਰਾਊਜ਼ਰ 'ਚ ਚਲਦਾ: ਪੇਜ, ਕੰਪੋਨੇਟ, ਸਟੇਟ ਮੈਨੇਜਮੈਂਟ ਅਤੇ UI ਲਾਜਿਕ ਜੋ ਸਕ੍ਰੀਨਾਂ ਨੂੰ ਇੰਟਰੈਕਟਿਵ ਬਣਾਉਂਦਾ। ਵੈੱਬ ਟੀਮਾਂ ਤੇਜ਼ iteration, responsive ਲੇਆਉਟ ਅਤੇ ਬ੍ਰਾਊਜ਼ਰ ਅਨੁਕੂਲਤਾ ਲਈ ਅਪਟਿਮਾਈਜ਼ ਕਰਦੀਆਂ ਸਨ।
ਮੋਬਾਈਲ ਦਾ مطلب ਨੈਟਿਵ iOS ਅਤੇ Android ਐਪਸ ਸੀ (ਫਿਰ ਬਾਅਦ ਵਿੱਚ cross-platform ਫਰੇਮਵਰਕ). ਮੋਬਾਈਲ ਡੈਵੈਲਪਰਨਾਂ ਨੂੰ app store ਰਿਲੀਜ਼, ਡਿਵਾਈਸ ਪਰਫੌਰਮੈਂਸ, ਆਫਲਾਈਨ ਬਿਹੇਵਿਯਰ, ਪੁਸ਼ ਨੋਟੀਫਿਕੇਸ਼ਨ ਅਤੇ ਪਲੇਟਫਾਰਮ-ਵਿਸ਼ੇਸ਼ UI ਪੈਟਰਨ ਦੀ ਚਿੰਤਾ ਹੁੰਦੀ ਸੀ।
ਬੈਕਐਂਡ ਦਾ ਮਤਲਬ ਸੀ ਪਿੱਛੇ ਵਾਲੀਆਂ ਸੇਵਾਵਾਂ: ਡਾਟਾਬੇਸ, ਬਿਜ਼ਨੈਸ ਰੂਲਜ਼, authentication, ਇੰਟਿਗ੍ਰੇਸ਼ਨ, queues ਅਤੇ ਉਹ APIs ਜੋ ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ ਨੂੰ ਫੀਡ ਕਰਦੇ। ਬੈਕਐਂਡ ਕੰਮ ਅਕਸਰ ਭਰੋਸੇਯੋਗਤਾ, ਡਾਟਾ ਇੱਕਸਾਰਤਾ, ਸਕੇਲਬਿਲਟੀ ਅਤੇ ਸਾਂਝੇ ਲਾਜਿਕ 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਹੁੰਦਾ ਸੀ।
ਟੀਮਾਂ ਨੇ ਇਹ ਵੰਡ ਕਿਉਂ ਬਣਾਈ
ਇਹ ਵੰਡ ਸਹਿਕਾਰਤਾ ਦੇ ਓਹਲੇ ਘਟਾਉਂਦੀ ਸੀ ਕਿਉਂਕਿ ਹਰ ਲੇਅਰ ਦੀ ਆਪਣੀ ਟੁਲਚੇਨ, ਰਿਲੀਜ਼ ਸਾਈਕਲ ਅਤੇ ਵਿਸ਼ੇਸ਼ ਗਿਆਨ ਹੁੰਦਾ ਸੀ। ਟੀਮਾਂ ਅਕਸਰ ਇਸ ਹਕੀਕਤ ਦੀ ਪਰਤ ਹੁੰਦੀਆਂ ਸਨ:
- ਵੱਖ-ਵੱਖ ਰੀਪੋ (ਵੈੱਬ ਐਪ, iOS ਐਪ, Android ਐਪ, ਬੈਕਐਂਡ)
- ਵੱਖਰੇ ਡਿਪਲੋਇਮੈਂਟ ਪਾਈਪਲਾਈਨ (app stores ਵਿਰੁੱਧ ਸਰਵਰ ਡਿਪਲੋਇਸ)
- ਵੱਖ-ਵੱਖ ਹੁਨਰ-ਸੈੱਟ (UI/UX ਇੰਪਲੀਮੇਟੇਸ਼ਨ ਵਿਰੁੱਧ ਡਿਸਟ੍ਰੀਬਿਊਟਡ ਸਿਸਟਮ)
ਇਸ ਨਾਲ ਮਾਲਕੀ ਵੀ ਸਾਫ਼ ਹੁੰਦੀ ਸੀ: ਜੇ ਲੌਗਿਨ ਸਕ੍ਰੀਨ ਟੁੱਟ ਗਿਆ ਤਾਂ ਉਹ “ਵੈੱਬ” ਜਾਂ “ਮੋਬਾਈਲ” ਸੀ; ਜੇ ਲੌਗਿਨ API ਫੇਲ ਹੋਇਆ ਤਾਂ ਉਹ “ਬੈਕਐਂਡ” ਸੀ।
ਰੋਜ਼ਾਨਾ ਜੀਵਨ ਵਿੱਚ "ਹੱਦਾਂ ਧੁੰਦਲੀ" ਹੋਣ ਦਾ ਮਤਲਬ
ਧੁੰਦਲੀ ਹੋਣਾ ਇਸ ਗੱਲ ਦਾ ਇਸ਼ਾਰਾ ਹੈ ਕਿ ਇਹ ਲੇਅਰ ਮਿਟ ਜਾਂਦੇ ਹਨ, ਨਹੀਂ—ਪਰ ਕੰਮ ਹੁਣ ਪਹਿਲਾਂ ਦੀ ਤਰ੍ਹਾਂ ਸਾਫ਼-ਸਲਾਈਸ ਨਹੀਂ।
ਇੱਕ ਹੀ ਉਤਪਾਦ ਬਦਲਾਅ—ਜਿਵੇਂ “onboarding ਨੂੰ ਸੁਧਾਰੋ”—ਅਕਸਰ UI, API ਆਕਾਰ, ਡਾਟਾ ਟਰੇਕਿੰਗ ਅਤੇ ਐਕਸਪੇਰੀਮੈਂਟਸ ਨੂੰ ਇੱਕ ਬੰਡਲ ਵਜੋਂ ਛੂਹਦਾ ਹੈ। ਹਦਾਂ ਮੌਜੂਦ ਹਨ, ਪਰ ਉਹ ਘੱਟ ਕਠੋਰ ਮਹਿਸੂਸ ਹੁੰਦੀਆਂ ਹਨ: ਜ਼ਿਆਦਾ ਸਾਂਝਾ ਕੋਡ, ਜ਼ਿਆਦਾ ਸਾਂਝੇ ਟੂਲਿੰਗ, ਅਤੇ ਇਕੋ ਲੋਕਾਂ ਵੱਲੋਂ ਵੱਖ-ਵੱਖ ਲੇਅਰਾਂ 'ਤੇ ਤੇਜ਼ ਤਬਦੀਲੀਆਂ।
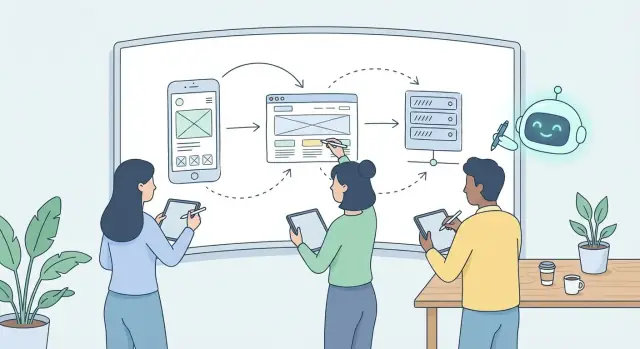
ਕਿਵੇਂ AI ਲੇਅਰਾਂ ਦੇ ਥਾਂ ਫੀਚਰਾਂ ਤਕ ਕੰਮ ਦੀ ਇਕਾਈ ਬਦਲਦਾ ਹੈ
ਕਈ ਸਾਲਾਂ ਤੱਕ ਟੀਮਾਂ ਨੇ ਕੰਮ ਨੂੰ ਲੇਅਰਾਂ ਅਨੁਸਾਰ ਆਯੋਜਿਤ ਕੀਤਾ: “ਵੈੱਬ ਪੇਜ ਲਿਖਦਾ ਹੈ”, “ਮੋਬਾਈਲ ਸਕ੍ਰੀਨ ਬਣਾਉਂਦਾ ਹੈ”, “ਬੈਕਐਂਡ endpoint ਜੋੜਦਾ ਹੈ”, “ਡਾਟਾ ਟੀਮ ਟੇਬਲ ਬਣਾਉਂਦੀ ਹੈ।” ਇਹ ਤਰਕ ਉਸ ਵੇਲੇ ਠੀਕ ਸੀ ਜਦੋਂ ਹਰ ਲੇਅਰ ਨੂੰ ਵੱਖਰੇ ਟੂਲ, ਡੂੰਘਾ ਸੰਦਰਭ ਅਤੇ ਬਹੁਤ ਸਾਰੀ ਮੈਨੂਅਲ ਗਲੁ ਚਾਹੀਦੀ ਸੀ।
AI-ਸਹਾਇਤਾ ਵਾਲਾ ਵਿਕਾਸ ਕੰਮ ਦੀ ਇਕਾਈ ਨੂੰ ਉੱਪਰ ਵਧਾਉਂਦਾ ਹੈ—ਲੇਅਰਾਂ ਤੋਂ ਫੀਚਰਾਂ ਤੱਕ।
“ਇਕ ਸਕ੍ਰੀਨ ਲਿਖੋ” ਤੋਂ “ਪੂਰਾ ਫੀਚਰ ਬਣਾਓ” ਤੱਕ ਪ੍ਰੌਮਪਟਸ
ਜਦੋਂ ਤੁਸੀਂ AI ਟੂਲ ਨੂੰ ਕਹਿੰਦੇ ਹੋ “ਇੱਕ checkout ਸਕ੍ਰੀਨ ਜੋੜੋ”, ਇਹ ਅਕਸਰ ਇੱਕ UI ਫਾਈਲ ਤੇ ਹੀ ਰੁੱਕਦਾ ਨਹੀਂ। ਚੰਗਾ ਪ੍ਰੌਮਪਟ ਕੁਦਰਤੀ ਤੌਰ ਤੇ ਇਰੇਟ ਹੁੰਦਾ ਹੈ: ਉਦੇਸ਼ ਕੀ ਹੈ, ਯੂਜ਼ਰ ਕੀ ਕਰਨਾ ਚਾਹੁੰਦਾ ਹੈ, ਸਫਲਤਾ ਜਾਂ ਨਾਕامی 'ਤੇ ਕੀ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਕਿਵੇਂ ਇਹ ਸਟੋਰ ਹੋਏਗਾ।
ਇਸ ਨਾਲ ਲੋਕ ਇਨ੍ਹਾਂ ਤਰ੍ਹਾਂ ਦੇ ਪ੍ਰੌਮਪਟ ਵੱਲ ਧੱਕੇ ਜਾਂਦੇ ਹਨ:
- “'Save for later' ਫੀਚਰ end-to-end ਬਣਾਉ, UI, API ਅਤੇ persistence ਸਮੇਤ।”
ਮਿਲੇ-ਜੁਲੇ ਨਤੀਜੇ ਡਿਫੌਲਟ ਹੁੰਦੇ ਹਨ
AI ਦੇ ਨਤੀਜੇ ਅਕਸਰ ਇਕੱਠੇ ਪਹੁੰਚਦੇ ਹਨ: ਇੱਕ UI ਕੰਪੋਨੇਟ, ਇੱਕ API ਰੂਟ, ਇੱਕ ਵੈਰੀਡੇਸ਼ਨ ਰੂਲ, ਅਤੇ ਇੱਕ ਡਾਟਾਬੇਸ ਬਦਲ—ਕਈ ਵਾਰੀ ਇੱਕ ਮਾਈਗਰੇਸ਼ਨ ਸਕ੍ਰਿਪਟ ਅਤੇ ਇੱਕ ਬੁਨਿਆਦੀ ਟੈਸਟ ਵੀ। ਇਹ “ਜ਼ਿਆਦਾ ਚਤੁਰ” ਨਹੀਂ ਹੈ; ਇਹ ਉਸ ਤਰੀਕੇ ਦੀ ਨਕਲ ਕਰ ਰਿਹਾ ਹੈ ਜਿਸ ਤਰ੍ਹਾਂ ਇੱਕ ਫੀਚਰ ਅਸਲ ਵਿੱਚ ਕੰਮ ਕਰਦਾ ਹੈ।
ਇਸ ਲਈ AI ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਫੀਚਰ-ਕੇਂਦਰਿਤ ਹੁੰਦਾ ਹੈ, ਨਾ ਕਿ ਲੇਅਰ-ਕੇਂਦਰਿਤ: ਇਹ ਇੱਕ ਯੂਜ਼ਰ ਸਟੋਰੀ ਨੂੰ click → request → logic → storage → response → render ਤੱਕ ਫਾਲੋ ਕਰਦਾ ਹੈ।
ਸਕੋਪਿੰਗ ਅਤੇ ਹੈਂਡਫ ਵਿੱਚ ਕੀ ਬਦਲਦਾ ਹੈ
ਕੰਮ ਦੀ ਯੋਜਨਾ “ਲੇਅਰ ਪ੍ਰਤੀ ਟਿਕਟ” ਤੋਂ “ਇੱਕ ਫੀਚਰ ਸਲਾਈਸ ਜਿਸ ਦੀ ਸਪਸ਼ਟ ਕਬੂਲੀਅਤ ਹੈ” ਵੱਲ ਬਦਲਦੀ ਹੈ। ਤਿੰਨ ਵੱਖਰੇ ਹੈਂਡਫ (ਵੈੱਬ → ਬੈਕਐਂਡ → ਡਾਟਾ) ਦੀ ਥਾਂ, ਟੀਮਾਂ ਇੱਕ ਸਿੰਗਲ ਮਾਲਿਕ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੀਆਂ ਹਨ ਜੋ ਫੀਚਰ ਦੇ ਪਾਰ ਕਰਕੇ ਚਲਾਉਂਦਾ ਹੈ, ਜਦਕਿ ਵਿਸ਼ੇਸ਼ਗਿਆਨੀ ਉਹ ਹਿੱਸੇ ਸਮੀਖਿਆ ਕਰਦੇ ਹਨ ਜੋ ਜੋਖਮ-ਭਰੇ ਹਨ।
ਅਮਲੀ ਨਤੀਜਾ: ਘੱਟ ਸਹਿਕਾਰਤਾ ਦੀ ਦੇਰੀ, ਪਰ clarity ਲਈ ਉੱਚੇ ਉਮੀਦਾਂ। ਜੇ ਫੀਚਰ ਵਧੀਆ ਤਰ੍ਹਾਂ ਪਰਿਭਾਸ਼ਿਤ ਨਹੀਂ ਹੈ (edge cases, permissions, error states), ਤਾਂ AI ਅਕਸਰ ਐਸਾ ਕੋਡ ਜਨਰੇਟ ਕਰੇਗਾ ਜੋ ਲੱਗਦਾ ਤਾਂ ਪੂਰਾ ਹੈ ਪਰ ਅਸਲ ਲੋੜਾਂ ਘੱਟ ਰਹਿ ਜਾਵੇ।
ਟੈਕ ਸਟੈਕ: ਸਾਂਝੇ ਕੋਡ ਅਤੇ ਟੂਲਿੰਗ ਵੱਲ ਸ਼ਿਫਟ
AI-ਸਹਾਇਤਾ ਵਿਕਾਸ "ਵੱਖ-ਵੱਖ ਸਟੈਕ" (ਵੈੱਬ, ਮੋਬਾਈਲ, ਬੈਕਐਂਡ) ਤੋਂ ਸਾਂਝੇ ਬਣਾਉਣ ਵਾਲੇ ਬਿਲਡਿੰਗ ਬਲਾਕ ਵੱਲ ਗਤੀ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ। ਜਦੋਂ ਕੋਡ ਤੇਜ਼ੀ ਨਾਲ ਡਰਾਫਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਤਦ ਬੋਟਲਨੈਕ consistency ਬਣ ਜਾਂਦਾ ਹੈ: ਕੀ ਸਾਰੇ ਚੈਨਲ ਇੱਕੋ ਨਿਯਮ, ਇੱਕੋ ਡੇਟਾ ਆਕਾਰ ਅਤੇ ਇੱਕੋ UI ਪੈਟਰਨ ਵਰਤ ਰਹੇ ਹਨ?
ਇੱਕ JavaScript/TypeScript ਟੂਲਚੇਨ ਸਾਮਨੇ ਅਤੇ ਪਿਛੋਕੜ ਦੋਹਾਂ ਲਈ
ਟੀਮਾਂ TypeScript 'ਤੇ ਜ਼ਿਆਦਾ ਇਕਸਾਰ ਹੁੰਦੀਆਂ ਹਨ, ਸਿਰਫ਼ ਟਰੈਂਡੀ ਹੋਣ ਕਰਕੇ ਨਹੀਂ, ਬਲਕਿ ਇਸ ਲਈ ਕਿ ਇਹ ਸਾਂਝੇ ਵਰਤਣ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਂਦਾ ਹੈ। ਇੱਕੋ ਹੀ types API response ਨੂੰ ਵੇਰਵਾ ਕਰ ਸਕਦੇ ਹਨ, ਬੈਕਐਂਡ ਵੈਰੀਡੇਸ਼ਨ ਚਲਾ ਸਕਦੇ ਹਨ, ਅਤੇ ਫਰੰਟਐਂਡ ਫਾਰਮਾਂ ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ।
ਟੂਲਿੰਗ ਵੀ ਇਕਠੀ ਹੁੰਦੀ ਹੈ: ਫਾਰਮੈਟਿੰਗ, linting, ਅਤੇ testing ਨੂੰ ਇੱਕਜੁਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਤਾਂ ਜੋ ਬਦਲਾਅ ਇੱਕ ਹਿੱਸੇ ਨੂੰ ਤੋੜਨ ਬਿਨਾਂ ਦੂਜੇ ਹੋਰ ਜਗ੍ਹਾ 'ਚ "ਪਾਸ" ਦਿਖੇ।
Monorepos ਅਤੇ ਸਾਂਝੇ ਪੈਕੇਜ ਡਿਫੌਲਟ
Monorepos ਸਾਂਝੇ ਕੋਡ ਨੂੰ ਕਾਰਗਰ ਬਣਾਉਂਦੇ ਹਨ। ਲਾਜ਼ਮੀ ਤਰ੍ਹਾਂ ਲਾਜਿਕ ਨੂੰ ਕਾਪੀ ਕਰਨ ਦੀ ਥਾਂ, ਟੀਮਾਂ reusable packages ਨਿਕਾਲਦੀਆਂ ਹਨ:
- Types ਅਤੇ schemas (ਕਿਹੜਾ "User" ਜਾਂ "Order" ਦਿਖਦਾ ਹੈ)
- Validators (ਇਹ ਸੁਨਿਸ਼ਚਿਤ ਕਰਨਾ ਕਿ inputs ਹਰ ਥਾਂ ਨਿਯਮਾਂ ਨੂੰ ਮਿਲਦੇ ਹਨ)
- UI components (ਬਟਨ, ਫਾਰਮ ਕੰਟਰੋਲ ਅਤੇ ਲੇਆਉਟ ਪ੍ਰਿਮਿਟਿਵ)
ਇਸ ਨਾਲ drift ਘਟਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ AI ਕਈ ਥਾਵਾਂ 'ਤੇ ਕੋਡ ਜਨਰੇਟ ਕਰਦਾ ਹੈ। ਇੱਕ ਸਾਂਝਾ ਪੈਕੇਜ generated ਕੋਡ ਨੂੰ aligned ਰੱਖ ਸਕਦਾ ਹੈ।
ਕ੍ਰਾਸ-ਪਲੈਟਫਾਰਮ UI ਫਰੇਮਵਰਕ ਅਤੇ ਡਿਜ਼ਾਈਨ ਸਿਸਟਮ
ਕ੍ਰਾਸ-ਪਲੈਟਫਾਰਮ ਫਰੇਮਵਰਕ ਅਤੇ ਡਿਜ਼ਾਈਨ ਸਿਸਟਮ UI ਲੇਅਰ 'ਤੇ ਉਹੀ ਵਿਚਾਰ ਧਕੇਦੇ ਹਨ: ਇਕ ਵਾਰ ਕੰਪੋਨੇਟ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ, ਫਿਰ ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ 'ਤੇ ਦੁਬਾਰਾ ਵਰਤੋਂ। ਭਾਵੇਂ ਵੱਖ-ਵੱਖ ਐਪ ਰਹਿਣ, ਪਰ ਸਾਂਝੇ tokens (ਰੰਗ, spacing, typography) ਅਤੇ component APIs ਨਾਲ ਫੀਚਰਾਂ ਨੂੰ ਲਗਾਤਾਰ ਲਾਗੂ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਸਰੋਤ-ਏ-ਸੱਚਾਈ ਤੋਂ ਜਨਰੇਟ ਕੀਤੇ API clients
ਹੋਰ ਵੱਡਾ ਬਦਲਾਅ ਇਹ ਹੈ ਕਿ API clients ਆਟੋਮੇਟਿਕ ਤੌਰ 'ਤੇ (ਅਕਸਰ OpenAPI ਜਾਂ ਸਮਾਨ специ) ਤੋਂ ਜਨਰੇਟ ਕੀਤੇ ਜਾਂਦੇ ਹਨ। ਹਰੇਕ ਪਲੇਟਫਾਰਮ 'ਤੇ network calls ਨੂੰ ਹੱਥੋਂ ਲਿਖਣ ਦੀ ਥਾਂ, ਟੀਮਾਂ typed clients ਜਨਰੇਟ ਕਰਦੀਆਂ ਹਨ ਤਾਂ ਜੋ ਵੈੱਬ, ਮੋਬਾਈਲ ਅਤੇ ਬੈਕਐਂਡ contracts synchronization ਵਿੱਚ ਰਹਿਣ।
ਜਦੋਂ ਹੱਦਾਂ ਧੁੰਦਲੀ ਹੁੰਦੀਆਂ ਹਨ, "ਸਟੈਕ" ਟੈਕਨੋਲੋਜੀਜ਼ ਬਾਰੇ ਘੱਟ ਹੁੰਦਾ ਹੈ ਅਤੇ ਜ਼ਿਆਦਾ ਗੱਲ shared primitives—types, schemas, components, ਅਤੇ generated clients—ਦੇ ਬਾਰੇ ਹੁੰਦੀ ਹੈ ਜੋ ਫੀਚਰ ਨੂੰ end-to-end ਘੱਟ ਹੈਂਡਫਾਂ ਤੇ ਤੇਜ਼ੀ ਨਾਲ ਭੇਜਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
AI ਹਰ ਕਿਸੇ ਨੂੰ ਹਿਸਾ-ਭਾਗੀ ਫੁੱਲ-ਸਟੈਕ ਡੈਵੈਲਪਰ ਬਣਾਉਂਦਾ ਹੈ
AI-ਸਹਾਇਤਾ ਵਿਕਾਸ ਲੋਕਾਂ ਨੂੰ ਆਪਣੀ "leine" ਤੋਂ ਬਾਹਰ ਧੱਕਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਘਾਟੇ ਸੰਦਰਭ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਭਰ ਸਕਦਾ ਹੈ।
ਇੱਕ ਫਰੰਟ-ਐਂਡ ਡੈਵੈਲਪਰ "add caching with ETags and rate limiting" ਪੁੱਛ ਸਕਦਾ ਹੈ ਅਤੇ ਸਰਵਰ-ਸਾਈਡ ਬਦਲਾਅ ਵੀ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦਾ ਹੈ, ਜਦਕਿ ਬੈਕਐਂਡ ਡੈਵੈਲਪਰ "ਇਸ ਸਕ੍ਰੀਨ ਨੂੰ ਤੇਜ਼ ਮਹਿਸੂਸ ਕਰਵਾਓ" ਪੁੱਛੇ ਤਾਂ skeleton loading, optimistic UI ਅਤੇ retry ਬਿਹੇਵਿਅਰ ਜਿਹੜੇ ਸੁਝਾਅ ਮਿਲ ਸਕਦੇ ਹਨ।
ਫਰੰਟ-ਐਂਡ ਡੈਵੈਲਪਰ ਹੁਣ caching, auth, ਅਤੇ rate limits 'ਤੇ ਹੱਥ ਫੜਦੇ ਹਨ
ਜਦੋਂ AI ਸਕਿੰਨੇ ਸੈਕਿੰਡਾਂ ਵਿੱਚ middleware ਜਾਂ API gateway ਰੂਲ ਡਰਾਫਟ ਕਰ ਸਕਦਾ ਹੈ, "ਮੈਂ ਬੈਕਐਂਡ ਕੋਡ ਨਹੀਂ ਲਿਖਦਾ" ਵਾਲੀ ਰੁਕਾਵਟ ਘਟ ਜਾਂਦੀ ਹੈ। ਇਸ ਨਾਲ ਫਰੰਟ-ਐਂਡ ਦਾ ਕੰਮ ਹੁਣ ਇਸ ਤਰ੍ਹਾਂ ਦਿਖਦਾ ਹੈ:
- Caching:
Cache-Control, ETags, ਜਾਂ client-side cache invalidation ਜੋ UI ਪਰਫੋਰਮੈਂਸ ਟਾਸਕ ਦਾ ਹਿੱਸਾ ਬਣ ਜਾਂਦੇ ਹਨ
- Auth: token refresh, secure cookie settings, ਅਤੇ "401 ਤੇ ਕੀ ਹੁੰਦਾ ਹੈ" ਨੂੰ ਦੋਹਾਂ ਪਾਸਿਆਂ 'ਤੇ ਅਮਲ ਕਰਨਾ
- Rate limits: ਜੇ infinite scroll API ਨੂੰ ਝੱਟਾ ਮਾਰ ਰਿਹਾ ਹੈ, ਠੀਕ ਕਰਨ ਵਿੱਚ UI throttling, server-side limits ਅਤੇ ਸਮਝਦਾਰ error responses ਆ ਸਕਦੇ ਹਨ
ਬੈਕਐਂਡ ਡੈਵੈਲਪਰ ਹੁਣ UX ਅਤੇ ਲੋਡਿੰਗ ਸਟੇਟਾਂ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਉਂਦੇ ਹਨ
ਬੈਕਐਂਡ ਫੈਸਲੇ ਯੂਜ਼ਰ ਅਨੁਭਵ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ: response times, partial failures, ਅਤੇ ਕੀ ਡਾਟਾ ਜਲਦੀ ਈਰਲੀ ਸਟ੍ਰੀਮ ਹੋ ਸਕਦਾ ਹੈ। AI ਨਾਲ ਬੈਕਐਂਡ ਡੈਵੈਲਪਰ UX-ਜਾਗਰੂਕ ਬਦਲਾਅ ਇਸ਼ਤਿਹਾਰ ਕਰਕੇ ਲਾਗੂ ਕਰਨ ਦੀ ਸਮਰੱਥਾ ਹੋ ਜਾਂਦੀ ਹੈ, ਜਿਵੇਂ:
- partial results ਦੇਣਾ ਜਿਨ੍ਹਾਂ ਵਿੱਚ
warnings ਫੀਲਡ ਹੋ ਸਕਦੀ ਹੈ
- cursor-based pagination ਸਹਾਇਤਾ ਕਰਨਾ ਤਾਕਿ smoother scrolling ਹੋਵੇ
- lightweight “summary” responses ਭੇਜ ਕੇ initial render ਤੇ ਫਿਰ details ਫੈਚ ਕਰਨਾ
ਇੱਕ ਫੀਚਰ, ਕਈ ਲੇਅਰ: pagination, validation, error handling
Pagination ਚੰਗਾ ਉਦਾਹਰਣ ਹੈ। API ਨੂੰ stable cursors ਅਤੇ predictable ordering ਚਾਹੀਦੀ ਹੈ; UI ਨੂੰ “no more results”, retries, ਅਤੇ ਤੇਜ਼ back/forward navigation ਨੂੰ ਸੰਭਾਲਣਾ ਪੈਂਦਾ ਹੈ।
Validation ਵੀ ਮਿਲਦੀ ਜੁਲਦੀ ਹੈ: ਸਰਵਰ-ਸਾਈਡ ਨਿਯਮ authoritative ਹੋਣਗੇ, ਪਰ UI ਨੂੰ ਉਨ੍ਹਾਂ ਨਾਲ ਮਿਲਦਾ-ਜੁਲਦਾ ਫੀਡਬੈਕ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ। AI ਅਕਸਰ ਦੋਵਾਂ ਪਾਸਿਆਂ ਨੂੰ ਇੱਕੱਠੇ ਜਨਰੇਟ ਕਰਦਾ ਹੈ—shared schemas, consistent error codes, ਅਤੇ ਐਸਾ ਮੈਸੇਜ ਜੋ ਫਾਰਮ ਫੀਲਡਾਂ ਨਾਲ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਮੇਲ ਖਾਂਦੇ ਹੋਣ।
Error handling ਵੀ ਕ੍ਰਾਸ-ਲੇਅਰ ਬਣ ਜਾਂਦੀ ਹੈ: ਇੱਕ 429 (rate limited) ਸਿਰਫ਼ ਇੱਕ status code ਨਹੀਂ ਰਹਿਣਾ; ਇਹ UI ਸਟੇਟ ਨੂੰ ਪੈਦਾ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ (“30 ਸਕਿੰਟ ਵਿੱਚ ਮੁੜ ਕੋਸ਼ਿਸ਼ ਕਰੋ”) ਅਤੇ ਸ਼ਾਇਦ ਇੱਕ backoff strategy ਵੀ ਹੋਵੇ।
ਐਸਟਿਮੇਸ਼ਨ ਅਤੇ ਮਾਲਕੀ 'ਤੇ ਇਸਦਾ ਪ੍ਰਭਾਵ
ਜਦੋਂ ਇੱਕ “frontend” ਟਾਸਕ ਚੁਪਕੇ ਨਾਲ API tweaks, caching headers, ਅਤੇ auth edge cases ਸ਼ਾਮਲ ਕਰਦਾ ਹੈ, ਹੁਣਲੇ ਐਸਟਿਮੇਟ ਪੁਰਾਣੀਆਂ ਹੱਦਾਂ ਅਨੁਸਾਰ ਠੀਕ ਨਹੀਂ ਰਹਿੰਦੇ।
ਟੀਮਾਂ ਵਧੀਆ ਕਰਦੀਆਂ ਹਨ ਜਦownership ਫੀਚਰ ਨਤੀਜਿਆਂ (ਉਦਾਹਰਣ: “search ਤੁਰੰਤ ਅਤੇ ਭਰੋਸੇਯੋਗ ਮਹਿਸੂਸ ਕਰੇ”) ਦੁਆਰਾ ਨਿਰਧਾਰਤ ਹੁੰਦੀ ਹੈ ਅਤੇ checklists ਵਿੱਚ ਕ੍ਰਾਸ-ਲੇਅਰ ਮੁੱਦਿਆਂ ਨੂੰ ਸ਼ਾਮਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਭਾਵੇਂ ਵੱਖ-ਵੱਖ ਲੋਕ ਵੱਖ-ਵੱਖ ਹਿੱਸੇ ਲਾਗੂ ਕਰਨ।
ਬੈਕਐਂਡ-ਫੋਰ-ਫਰੰਟਐਂਡ ਅਤੇ UI-ਆਕਾਰ APIs ਦਾ ਉਭਾਰ
ਜੋ ਕੋਡ ਤੁਸੀਂ ਜਨਰੇਟ ਕਰੋ ਉਹਨਾਂ ਨੂੰ ਆਪਣਾ ਬਣਾਓ
ਜਦੋਂ ਤੁਸੀਂ ਸਮੀਖਿਆ ਕਰਨੀ ਹੋ ਜਾਂ ਦੂਜੇ ਥਾਂ ਲਿਜਾਣਾ ਹੋਵੇ, ਤਦ ਆਪਣਾ ਜਨਰੇਟ ਕੀਤਾ ਸੋర్స్ ਕੋਡ ਨਿਕਾਲ ਕੇ ਰੱਖੋ।
Backend-for-Frontend (BFF) ਇੱਕ ਪਤਲਾ ਸਰਵਰ ਲੇਅਰ ਹੈ ਜੋ ਖਾਸ ਤੌਰ 'ਤੇ ਇੱਕ ਗਾਹਕ ਅਨੁਭਵ ਲਈ ਬਣਾਈ ਜਾਂਦੀ ਹੈ—ਅਕਸਰ ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ ਲਈ ਵੱਖ-ਵੱਖ। ਸਾਰੇ ਐਪਾਂ ਨੂੰ ਇੱਕ “ਜਨਰਿਕ” API ਨੂੰ ਕਾਲ ਕਰਨ ਦੀ ਬਜਾਏ, BFF endpoints ਉਹੀ ਸਪੁਰਦਗੀਆਂ ਦੇਂਦੇ ਹਨ ਜੋ UI ਨੂੰ ਚਾਹੀਦੀ ਹੈ।
BFF ਵੈੱਬ + ਮੋਬਾਈਲ ਨਾਲ ਲੋਕਪਰੀਅ ਕਿਉਂ ਹੈ
ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ ਸਕ੍ਰੀਨ ਅਕਸਰ ਧਾਰਨਾਤਮਕ ਤੌਰ 'ਤੇ ਇੱਕੋ ਹੀ ਹਨ ਪਰ ਵੇਰਵੇ ਵਿੱਚ ਵੱਖਰੇ: pagination rules, caching, offline ਬਿਹੇਵਿਅਰ, ਅਤੇ ਇਹ ਵੀ ਕਿ “ਤੇਜ਼” ਕੀਹ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਇੱਕ BFF ਹਰ client ਨੂੰ ਉਸਦੀ ਲੋੜ ਅਨੁਸਾਰ ਮੰਗਣ ਦੀ ਆਜ਼ਾਦੀ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਇੱਕ-size-fits-all API ਵਿੱਚ ਸਮਝੌਤਾ ਕਰਨ ਦੇ।
ਉਤਪਾਦ ਟੀਮਾਂ ਲਈ, ਇਹ ਰਿਲੀਜ਼ ਨੂੰ ਵੀ ਸਧਾਰਨ ਕਰ ਸਕਦਾ ਹੈ: UI ਬਦਲਾਅ ਇੱਕ ਛੋਟੇ BFF ਅੱਪਡੇਟ ਨਾਲ ਜਾ ਸਕਦਾ ਹੈ, ਬੇਸ਼ੱਕ ਹਰ ਵਾਰੀ ਇੱਕ ਵਿਆਪਕ ਪਲੇਟਫਾਰਮ ਸੌਦਾ ਕਰਨ ਦੀ ਲੋੜ ਨਾ ਹੋਵੇ।
UI-ਫਰਮਾਏਡ endpoints ਨੂੰ AI ਜਨਰੇਟ ਕਰਨਾ
AI-ਸਹਾਇਤਾ ਨਾਲ ਟੀਮਾਂ ਅਕਸਰ UI ਲੋੜਾਂ ਤੋਂ ਸਿੱਧਾ endpoints ਜਨਰੇਟ ਕਰਦੀਆਂ ਹਨ: “checkout summary ਨੂੰ totals, shipping options, ਅਤੇ payment methods ਇਕ ਕਾਲ ਵਿੱਚ ਚਾਹੀਦੇ ਹਨ।” ਇਸ ਨਾਲ UI-ਆਕਾਰ APIs ਨੂੰ ਉਤਸ਼ਾਹ ਮਿਲਦਾ ਹੈ—ਐਂਡਪੌਇੰਟਸ ਜੋ ਇੱਕ ਸਕ੍ਰੀਨ ਜਾਂ ਯੂਜ਼ਰ ਯਾਤਰਾ ਦੇ ਇर्द-ਗਿਦ ਹੀ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਜਾਂਦੇ ਹਨ ਨਾ ਕਿ ਸਿਰਫ਼ ਡੋਮੇਨ ਇੰਟੀਟੀ ਦੇ ਆਧਾਰ 'ਤੇ।
ਇਹ ਫਾਇਦਾ ਦੇ ਸਕਦਾ ਹੈ ਜਦੋਂ round trips ਘੱਟ ਹੁੰਦੇ ਹਨ ਅਤੇ client ਕੋਡ ਛੋਟਾ ਰਹਿੰਦਾ ਹੈ। ਜੋਖਮ ਇਹ ਹੈ ਕਿ API ਵਰਤਮਾਨ UI ਦਾ ਦਿੱਪਲੈਕਸ ਬਣ ਸਕਦੀ ਹੈ, ਜਿਸ ਨਾਲ ਭਵਿੱਖ ਦੀਆਂ redesigns ਮਹਿੰਗੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜੇ BFF ਬਿਨਾਂ ਸਟਰਕਚਰ ਦੇ ਵੱਡੀ ਹੋ ਜਾਏ।
ਵਪਾਰ-ਬਦਲੇ: ਗਤੀ ਵਿਰੁੱਧ ਡੁਪਲਿਕੇਟ ਲਾਜਿਕ
BFF ਵਿਕਾਸ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਇਹ ਡੁਪਲੀਕੇਟ ਲਾਜਿਕ ਵੀ ਲੈ ਕੇ ਆ ਸਕਦਾ ਹੈ:
- validation ਅਤੇ formatting ਵੇਖ-ਵੱਖ BFFs ਵਿੱਚ ਦੁਹਰਾਵੇ ਹੋ ਸਕਦੇ ਹਨ
- ਸਮਾਨ aggregation ਕੋਡ ਕਈ ਥਾਵਾਂ 'ਤੇ ਬਣਾਈ ਜਾ ਸਕਦੀ ਹੈ
- ਜੇ ਬਿਜ਼ਨੈਸ ਰੂਲਜ਼ ਕੋਰ ਸਰਵਿਸਿਜ਼ ਤੋਂ BFF ਤੱਕ ਲੀਕ ਹੋ ਜਾਂਦੇ ਹਨ ਤਾਂ multiple “sources of truth” ਬਣ ਸਕਦੀਆਂ ਹਨ
ਵਧੀਆ ਨਿਯਮ ਇਹ ਹੈ ਕਿ BFF ਡੇਟਾ ਨੂੰ ਆਕੀਟ੍ਰੇਟ ਅਤੇ ਆਕਾਰ ਦੇਵੇ, ਨ ਕਿ ਕੋਰ ਬਿਜ਼ਨੈਸ ਵਿਹਾਰ ਨੂੰ ਦੁਬਾਰਾ ਪਰਿਭਾਸ਼ਿਤ ਕਰੇ।
BFF ਕਦੋਂ ਜੋੜਣਾ (ਜਾਂ ਬਚਣਾ)
BFF ਜੋੜੋ ਜਦੋਂ:
- ਤੁਹਾਡੇ ਕੋਲ ਜਟਿਲ ਸਕ੍ਰੀਨ-ਖ਼ਾਸ ਕੰਪੋਜ਼ੀਸ਼ਨ ਹੋਵੇ
- ਪ੍ਰਤੀ-ਦ੍ਰਿਸ਼ ਵਿੱਚ ਕਈ ਨੈਟਵਰਕ ਕਾਲਾਂ ਹੋ ਰਹੀਆਂ ਹੋਣ
- ਵੱਖ-ਵੱਖ ਕਲਾਇੰਟ ਲੋੜਾਂ ਲਗਾਤਾਰ ਟਕਰਾਉਂਦੀਆਂ ਹੋਣ
ਬਚੋ ਜਾਂ ਘੱਟ ਰੱਖੋ ਜਦੋਂ:
- ਤੁਹਾਡਾ ਉਤਪਾਦ ਛੋਟਾ ਹੋਵੇ
- UI ਅਜੇ ਅਟੱਲ ਨਾ ਹੋਵੇ
- ਜਾਂ ਤੁਸੀਂ ਇੱਕ ਚੰਗੀ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਇਨ ਕੀਤੀ APIs ਅਤੇ ਹਲਕੀ client-side composition ਨਾਲ ਲੋੜ ਪੂਰੀ ਕਰ ਸਕਦੇ ਹੋ
ਜੇ ਤੁਸੀਂ BFF ਸ਼ਾਮਲ ਕਰਦੇ ਹੋ, ਤਾਂ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਹੱਦਾਂ ਨਿਰਧਾਰਤ ਕਰੋ: ਸਾਂਝੇ ਬਿਜ਼ਨੈਸ ਨਿਯਮ ਕੋਰ ਸਰਵਿਸਿਜ਼ ਵਿੱਚ ਰਹਿਣ; BFF UI-ਮਿੱਤਰ ਅਗਰੇਗੇਸ਼ਨ, caching ਅਤੇ authorization-aware data shaping 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਰਹੇ।
ਕੋਡ ਸਮੀਖਿਆ ਸਟੈਕ ਭਰ 'ਚ ਮੁੱਖ ਹੁਨਰ ਬਣ ਜਾਂਦੀ ਹੈ
ਜਦੋਂ AI ਸਹਾਇਕ ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ React ਕੰਪੋਨੇਟ, ਮੋਬਾਈਲ ਸਕ੍ਰੀਨ, ਅਤੇ ਡਾਟਾਬੇਸ ਕੁਏਰੀ ਜਨਰੇਟ ਕਰ ਸਕਦਾ ਹੈ, "ਕੋਡ ਲਿਖਣ" ਦਾ ਰੁਝਾਨ ਬਦਲ ਕੇ "ਕੋਡ ਦੀ ਸਮੀਖਿਆ" ਹੋ ਜਾਂਦਾ ਹੈ। throughput ਵੱਧ ਜਾਂਦਾ ਹੈ, ਪਰ ਸਮੇਤ ਵਿੱਚ ਨਾਜ਼ੁਕ ਗਲਤੀਆਂ ਦਾ ਜੋਖਮ ਵੀ ਵੱਧ ਜਾਂਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਜਦੋਂ ਬਦਲਾਅ UI, API, ਅਤੇ ਡਾਟਾ ਲੇਅਰਾਂ ਨੂੰ ਛੂਹਦੇ ਹਨ।
ਸਮੀਖਿਆ ਹੁਣ syntax ਤੋਂ ਬਿਨਾਂ ਸਿਸਟਮ ਵਿਹਾਰ ਬਾਰੇ ਹੈ
AI ਅਕਸਰ ਪੜ੍ਹਨਯੋਗ ਕੋਡ ਬਣਾਉਣ ਵਿੱਚ ਠੀਕ ਹੁੰਦਾ ਹੈ। ਉੱਚ ਮੂਲ ਰਿਵਿਊ ਪ੍ਰਸ਼ਨ ਹੁੰਦੇ ਹਨ:
- ਕੀ ਇਹ ਬਦਲਾਅ ਉਤਪਾਦ ਦੇ ਉਦੇਸ਼ ਅਤੇ edge cases ਨਾਲ ਮਿਲਦਾ ਹੈ?
- ਕੀ ਇਹ ਅਸਲ ਡਾਟਾ, ਅਸਲੀ ਲੇਟੈਂਸੀ, ਅਤੇ ਅਸਲ ਯੂਜ਼ਰਾਂ ਨਾਲ ਠੀਕ ਚਲੇਗਾ?
- ਕੀ ਅਸੀਂ ਅਕਸਮਾਤ ਸੁਰੱਖਿਆ ਜਾਂ ਪ੍ਰਾਈਵੇਸੀ ਨੁਕਸਾਨ ਪੈਦਾ ਕਰ ਦਿੱਤਾ ਹੈ?
ਲਗਾਤਾਰ ਹਰ-ਲੇਅਰ ਨੂੰ ਜੋੜ ਸਕਣ ਵਾਲਾ ਸਮੀਖਿਆਕਾਰ ਉਹਨਾਂ ਲੋਕਾਂ ਨਾਲੋਂ ਵੱਧ ਕੀਮਤੀ ਹੈ ਜੋ ਸਿਰਫ਼ style ਨੂੰ polish ਕਰਦੇ ਹਨ।
ਲੇਅਰਾਂ 'ਤੇ ਕੀ ਸਮੀਖਿਆ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ
ਕੁਝ ਮੁੜ ਆਉਣ ਵਾਲੇ ਫੇਲ-ਪੁਆਇੰਟਾਂ 'ਤੇ ਧਿਆਨ ਦਿਓ:
- ਡਾਟਾ ਐਕਸੈਸ: N+1 queries, missing indexes, over-fetching, ਅਤੇ payload bloat
- ਸੁਰੱਖਿਆ: auth checks ਸਹੀ ਬਾਊਂਡਰੀ 'ਤੇ ਹਨ ਕਿ ਨਹੀਂ, permission checks ਹਰ operation ਲਈ, tokenਾਂ ਦੀ ਸੁਰੱਖਿਅਤ ਹੈਂਡਲਿੰਗ, input validation, ਅਤੇ rate limiting ਅਨੁਮਾਨ
- UX edge cases: loading ਅਤੇ empty states, ਆਫਲਾਈਨ/ਖਰਾਬ ਨੈਟਵਰਕ ਬਿਹੋਜ, error messages ਜੋ ਯੂਜ਼ਰ ਨੂੰ ਰੀਕਵਰ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨ, ਅਤੇ accessibility ਬੁਨਿਆਦੀ ਚੀਜ਼ਾਂ
- API contracts: backward compatibility, consistent naming, ਅਤੇ responses ਜੋ UI ਨੂੰ ਦੇਸਤੀ ਕਰਦੀਆਂ ਹਨ ਬਗੈਰ internal tables ਛੱਡਣ
ਗਤੀ ਨਾਲ ਸਮਰੱਥ ਕਰਨ ਲਈ checklists ਅਤੇ ਟੈਸਟ
ਤੇਜ਼ ਨਿਕਾਸੀ ਲਈ tighter guardrails ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। PRs ਵਿੱਚ ਹਲਕੀ-ਫੁੱਲਕੀ checklists ਸਮੀਖਿਆਕਾਰਾਂ ਨੂੰ consistent ਰਹਿਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ, ਜਦਕਿ automated tests ਉਹ ਚੀਜ਼ਾਂ ਫੜ ਲੈਂਦੇ ਹਨ ਜੋ ਮਨੁੱਖ ਛੱਡ ਦਿੰਦੇ ਹਨ।
ਚੰਗੇ “AI-speed” ਮੁਕਾਬਲਿਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
- APIs ਅਤੇ schema ਬਦਲਾਅ ਲਈ contract tests
- ਕਈ ਮਹੱਤਵਪੂਰਨ end-to-end flows
- CI ਵਿੱਚ linting/formatting ਅਤੇ ਸੁਰੱਖਿਆ ਸਕੈਨ
ਜੋੜ-ਜੋੜ: ਮਨੁੱਖੀ ਡੋਮੇਨ ਗਿਆਨ + AI ਦੀ ਗਤੀ
ਇੱਕ ਸਿੱਧਾ ਨਮੂਨਾ ਇਹ ਹੈ ਕਿ ਇੱਕ domain expert (product, compliance, ਜਾਂ platform) ਨੂੰ builder ਨਾਲ ਜੋੜਿਆ ਜਾਵੇ ਜੋ AI ਚਲਾਉਂਦਾ ਹੈ। builder ਤੇਜ਼ੀ ਨਾਲ ਜਨਰੇਟ ਅਤੇ iteration ਕਰਦਾ ਹੈ; domain expert ਉਹ ਗੁੱਲ-ਪ੍ਰਸ਼ਨ ਪੁੱਛਦਾ ਹੈ: “ਜੇ ਯੂਜ਼ਰ suspended ਹੈ ਤਾਂ ਕੀ ਹੁੰਦਾ?” “ਕਿਹੜਾ ਡਾਟਾ ਸੰਵੇਦਨਸ਼ੀਲ ਹੈ?” “ਇਹ ਮਾਰਕੀਟ ਵਿੱਚ lagu ਹੈ?”
ਇਹ ਜੋੜ ਕੋਡ ਸਮੀਖਿਆ ਨੂੰ ਇੱਕ ਕ੍ਰਾਸ-ਸਟੈਕ ਗੁਣਵੱਤਾ ਅਭਿਆਸ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ, ਨਾ ਕਿ ਇੱਕ ਰੁਕਾਵਟ।
ਜਦੋਂ ਹੱਦਾਂ ਧੁੰਦਲੀ ਹੁੰਦੀਆਂ ਹਨ ਤਾਂ ਸੁਰੱਖਿਆ ਅਤੇ ਡਾਟਾ ਸੰਬੰਧੀ ਚਿੰਤਾਵਾਂ
ਜਦੋਂ AI ਤੁਹਾਨੂੰ ਇੱਕ "ਫੀਚਰ" ਤੁਰੰਤ ਬਣਾਕੇ ਦੇ ਸਕਦਾ ਹੈ ਜੋ UI, API, ਅਤੇ ਸਟੋਰੇਜ ਨੂੰ ਇਕੱਠੇ ਛੂਹਦਾ ਹੈ, ਤਾਂ ਸੁਰੱਖਿਆ ਮੁੱਦਿਆਂ ਨੂੰ ਹੁਣ ਕਿਸੇ ਹੋਰ ਦਾ مسئلہ ਨਹੀਂ ਰਹਿਣਾ। ਜੋਖਮ ਇਹ ਨਹੀਂ ਕਿ ਟੀਮਾਂ ਸੁਰੱਖਿਆ ਭੁੱਲ ਜਾਂਦੀਆਂ ਹਨ—ਬਲਕਿ ਛੋਟੀਆਂ ਗਲਤੀਆਂ ਫਿਸਲ ਸਕਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਹੁਣ ਕੋਈ ਇਕ ਲੇਅਰ boundary—ਦਾ ਮਾਲਕ ਨਹੀਂ ਹੁੰਦਾ।
ਕ੍ਰਾਸ-ਲੇਅਰ ਜੋਖਮ ਜਿਨ੍ਹਾਂ ਉੱਤੇ ਧਿਆਨ ਰੱਖੋ
ਕਈ ਸਮੱਸਿਆਵਾਂ ਅਕਸਰ ਦੁਹਰਾਈਆਂ ਜਾਂਦੀਆਂ ਹਨ ਜਦੋਂ AI-ਜਨਰੇਟ ਕੀਤੇ ਬਦਲਾਅ ਕਈ ਲੇਅਰਾਂ ਨੂੰ ਛੂਹਦੇ ਹਨ:
- Secrets ਲੀਕ ਹੋਣਾ: API keys ਕਲਾਇੰਟ ਕੋਡ ਵਿੱਚ, example
.env ਮੁੱਲ commit ਹੋ ਜਾਣ, ਜਾਂ ਟੋਕਨ logs ਵਿੱਚ print ਹੋ ਜਾਣ
- ਕਮਜ਼ੋਰ authentication/authorization: endpoints ਬਿਨਾਂ ਯੂਜ਼ਰ ਪਛਾਣ ਜਾਂ server-side checks ਦੇ ਬਣਾਉਣਾ, ਜਾਂ UI gating ਨੂੰ ਅਸਲ access control ਸਮਝ ਲੈਣਾ
- Injection bugs: SQL/NoSQL injection, unsafe string interpolation, ਅਤੇ SSRF ਜਦ inputs ਸੇਵਾਵਾਂ ਵਿਚ ਅੱਗੇ ਭੇਜੇ ਜਾਂਦੇ ਹਨ
ਡਾਟਾ ਹੈਂਡਲਿੰਗ ਦੀਆਂ ਮੂਲ ਗਲਤੀਆਂ ਜੋ ਛੱਡ ਜਾਂਦੀਆਂ ਹਨ
ਧੁੰਦਲੀ ਹੱਦਾਂ ਨਾਲ ਇਹ ਵੀ ਧੁੰਦਲਾ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿ "ਡਾਟਾ" ਕੀ ਹੈ। ਇਹਨਾਂ ਨੂੰ ਪਹਿਲੀ-ਕਤੀ ਫੈਸਲੇ ਵਜੋਂ ਦੇਖੋ:
- PII: ਕੀ ਸ਼ਾਮਲ ਹੈ (email, phone, ਨਜ਼ਦੀਕੀ ਸਥਾਨ, device IDs) ਅਤੇ ਕਿੱਥੇ ਇਹ ਪੇਸ਼ ਹੋ ਸਕਦਾ ਹੈ
- ਲੌਗਿੰਗ: ਪੇਲੋਡ ਡਿਫੌਲਟ ਅਨੁਸਾਰ ਲੌਗ ਨਾ ਕਰੋ; identifiers ਅਤੇ tokens redact ਕਰੋ; ਲੌਗ ਲੈਵਲ ਸਪਸ਼ਟ ਕਰੋ
- Analytics events: ਕੱਚਾ ਯੂਜ਼ਰ ਸਮੱਗਰੀ ਇਵੈਂਟ ਪ੍ਰਾਪਰਟੀਜ਼ ਵਜੋਂ ਨਾ ਭੇਜੋ; schemas explicit ਰੱਖੋ
- Retention: ਡਾਟਾ ਕਿੰਨੀ ਦੇਰ ਤੱਕ ਰੱਖਿਆ ਜਾਵੇਗਾ, ਬੈਕਅਪ ਸਮੇਤ, ਅਤੇ ਕੌਣ ਇਸ ਤੱਕ ਪਹੁੰਚ ਸਕਦਾ ਹੈ
AI-ਸਹਾਇਤਾ ਕੰਮ ਨਾਲ ਮਿਲਦੇ-ਜੁਲਦੇ ਸੁਰੱਖਿਆ-ਤਿਆਰ ਡਿਫੌਲਟ
“ਡਿਫਾਲਟ ਪਾਥ” ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਓ ਤਾਂ ਜੋ AI-ਜਨਰੇਟ ਕੋਡ ਘੱਟ ਗਲਤੀਆਂ ਕਰੇ:
- Least privilege: scoped tokens, ਘੱਟੋ-ਘੱਟ IAM ਰੋਲ, ਜਿੱਥੇ ਸੰਭਵ read-only
- Input validation: API boundary 'ਤੇ validation; unknown fields reject ਕਰੋ; size limits ਲਗਾਓ
- Dependency hygiene: lockfiles, automated audits, ਅਤੇ ਨਵੇਂ ਪੈਕੇਜ ਜੋੜਨ ਦੀ ਨੀਤੀ
ਸੁਰੱਖਿਆ-ਤਿਆਰ ਪ੍ਰੌਮਪਟ + ਸਮੀਖਿਆ ਚੈੱਕਲਿਸਟ
AI ਨੂੰ ਕ੍ਰਾਸ-ਲੇਅਰ ਬਦਲਾਅ ਜਨਰੇਟ ਕਰਨ ਲਈ ਪੁੱਛਣ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਸਟੈਂਡਰਡ ਪ੍ਰੌਮਪਟ ਵਰਤੋ:
Before generating code: list required authZ checks, input validation rules, sensitive data fields, logging/redaction rules, and any new dependencies. Do not place secrets in client code. Ensure APIs enforce permissions server-side.
ਫਿਰ ਹੇਠਾਂ ਦਿੱਤੇ ਛੋਟੇ ਚੈੱਕਲਿਸਟ ਨਾਲ ਸਮੀਖਿਆ ਕਰੋ: server 'ਤੇ authZ ਲਾਗੂ ਹੈ, secrets ਬਾਹਰ ਨਹੀਂ ਆਏ, inputs validated ਅਤੇ encoded ਹਨ, logs/events redact ਕੀਤੇ ਗਏ ਹਨ, ਅਤੇ ਨਵੇਂ dependencies ਜ਼ਰੂਰੀ ਹਨ।
ਪਰੋਜੈਕਟ ਮੈਨੇਜਮੈਂਟ: ਐਸਟਿਮੇਸ਼ਨ, ਮਾਲਕੀ ਅਤੇ ਰਿਲੀਜ਼
ਆਪਣਾ ਯੋਜਨਾ ਚੁਣੋ
ਜਦੋਂ ਤੁਸੀਂ ਵਰਕਫਲੋ ਨੂੰ ਸਕੇਲ ਕਰਨ ਲਈ ਤਿਆਰ ਹੋਵੋਗੇ ਤਾਂ Free, Pro, Business, ਜਾਂ Enterprise ਚੁਣੋ।
AI-ਸਹਾਇਤਾ ਵਿਕਾਸ ਬੋਰਡ 'ਤੇ ਕੰਮ ਦੇ ਦਿਖਾਈ ਦੇਣ ਦੇ ਢੰਗ ਨੂੰ ਬਦਲ ਦਿੰਦਾ ਹੈ। ਇੱਕ ਫੀਚਰ ਅਕਸਰ ਮੋਬਾਈਲ ਸਕ੍ਰੀਨ, ਵੈੱਬ ਫਲੋ, ਇੱਕ API endpoint, analytics event ਅਤੇ permission rule ਨੂੰ ਛੂਹਦਾ ਹੈ—ਅਕਸਰ ਇੱਕੋ ਹੀ PR ਵਿੱਚ।
ਇਸ ਨਾਲ ਇਹ ਟ੍ਰੈਕ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ ਕਿ ਸਮਾਂ ਕਿੱਥੇ ਗਿਆ, ਕਿਉਂਕਿ "frontend" ਅਤੇ "backend" ਟਾਸਕ ਹੁਣ ਸਾਫ਼-ਤੌਰ 'ਤੇ ਵੰਡੇ ਨਹੀਂ ਜਾ ਸਕਦੇ।
ਲੇਅਰਾਂ ਨੂੰ ਛੁੰਨ ਵਾਲੇ ਫੀਚਰਾਂ ਦੀ ਐਸਟਿਮੇਸ਼ਨ
ਜਦੋਂ ਫੀਚਰ ਲੇਅਰਾਂ ਨੂੰ ਛੂਹਦਾ ਹੈ, “ਕਿੰਨੇ endpoints” ਜਾਂ “ਕਿੰਨੇ screens” ਆਧਾਰਿਤ ਅੰਦਾਜ਼ੇ ਅਕਸਰ ਅਸਲੀ ਮਿਹਨਤ ਨੂੰ ਮਿਸ ਕਰਦੇ ਹਨ: ਇੰਟੀਗ੍ਰੇਸ਼ਨ, edge cases, ਅਤੇ validation। ਇੱਕ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਤਰੀਕਾ ਹੈ ਯੂਜ਼ਰ ਪ੍ਰਭਾਵ ਅਤੇ ਜੋਖਮ ਦੁਆਰਾ ਅੰਦਾਜ਼ਾ ਲੱਗਾਉਣਾ।
ਇੱਕ ਵਰਤੋਂਯੋਗ ਪੈਟਰਨ:
- ਕੰਮ ਨੂੰ ਉਹਨਾਂ ਸਲਾਈਸਾਂ ਵਿੱਚ ਤੋੜੋ ਜੋ ਯੂਜ਼ਰ ਯਾਤਰਾ ਦਾ ਇੱਕ ਪੂਰਾ ਕਦਮ ਪਹੁੰਚਾਉਂਦੀਆਂ ਹਨ
- integration ਅਤੇ rollout ਲਈ explicit ਸਮਾਂ ਜੋੜੋ (feature flags, migrations, app store review)
- “ਅਣਜਾਣੀਆਂ” ਨੂੰ ਪਹਿਲੇ-ਕਦਮ ਦੇ ਟਾਸਕ ਮੰਨੋ: ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਹਿੱਸੇ ਦੀ prototype ਬਣਾਓ, ਫਿਰ ਦੁਬਾਰਾ ਅੰਦਾਜ਼ਾ ਲਗਾਓ
ਨਤੀਜਿਆਂ ਦੇ ਆਧਾਰ 'ਤੇ ਮਾਲਕੀ
ਕੰਪੋਨੈਂਟਾਂ ਦੁਆਰਾ ownership ਨਿਰਧਾਰਿਤ ਕਰਨ ਦੀ ਥਾਂ (ਵੈੱਬ ਵੈੱਬ ਦਾ ਮਾਲਿਕ, ਬੈਕਐਂਡ ਬੈਕਐਂਡ ਦਾ) ownership ਨਤੀਜਿਆਂ ਦੁਆਰਾ ਨਿਰਧਾਰਤ ਕਰੋ: ਇੱਕ ਯੂਜ਼ਰ ਯਾਤਰਾ ਜਾਂ ਉਤਪਾਦ ਲੱਖਾ। ਇੱਕ ਟੀਮ (ਜਾਂ ਇੱਕ ਡਾਇਰੈਕਟਰੀ ਜਵਾਬਦੇਹ ਵਿਅਕਤੀ) end-to-end ਅਨੁਭਵ ਲਈ ਮਾਲਿਕ ਹੋਵੇ, ਜਿਸ ਵਿੱਚ success metrics, error handling, ਅਤੇ support readiness ਸ਼ਾਮਲ ਹੋ।
ਇਸ ਨਾਲ specialists ਦੀ ਜਰੂਰਤ ਖਤਮ ਨਹੀਂ ਹੁੰਦੀ—ਪਰ accountability ਸਪਸ਼ਟ ਹੁੰਦੀ ਹੈ। ਵਿਸ਼ੇਸ਼ਗਿਆਨੀ ਅਜੇ ਵੀ ਸਮੀਖਿਆ ਅਤੇ ਮਾਰਗ-ਦਰਸ਼ਨ ਦੇਂਦੇ ਹਨ, ਪਰ feature owner ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਸਾਰੇ ਹਿੱਸੇ ਇਕੱਠੇ ਭੇਜੇ ਜਾਣ।
ਚੰਗੇ ਟਿਕਟ: "ਮੁਕੰਮਲ" ਦਾ ਅਸਲ ਮਤਲਬ
ਜਿਵੇਂ ਹੱਦਾਂ ਧੁੰਦਲੀ ਹੁੰਦੀਆਂ ਹਨ, ਟਿਕਟਾਂ ਨੂੰ ਹੋਰ ਤੀਖ੍ਹਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਵਧੀਆ ਟਿਕਟਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
- Acceptance criteria ਯੂਜ਼ਰ-ਦਿੱਖਣ ਵਾਲੇ ਵਿਹਾਰ ਵਜੋਂ ਲਿਖੇ ਹੋਣ
- Error states (ਧੀਮੀ ਨੈਟਵਰਕ, ਗਲਤ ਇਨਪੁਟ, parcਸੀ ਮੱਖਲ਼੍ਹ) ਦਾ ਵਰਣਨ
- ਪ੍ਰਦਰਸ਼ਨ ਟਾਰਗੇਟ (ਜਿਵੇਂ page load time, API latency, battery ਪ੍ਰਭਾਵ)
- Logging/analytics ਉਮੀਦਾਂ (events, dashboards, alerts)
ਵੈੱਬ, ਮੋਬਾਈਲ, ਬੈਕਐਂਡ 'ਤੇ ਰਿਲੀਜ਼ ਅਤੇ ਵਰਜ਼ਨਿੰਗ
ਕ੍ਰਾਸ-ਲੇਅਰ ਕੰਮ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਰਿਲੀਜ਼ ਸਮੇਂ ਫੇਲ ਹੁੰਦਾ ਹੈ। ਵਰਜ਼ਨਿੰਗ ਅਤੇ ਰਿਲੀਜ਼ ਕਦਮ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਕਮਿਊਨੀਕੇਟ ਕਰੋ: ਕਿਹੜੇ ਬੈਕਐਂਡ ਬਦਲਾਅ ਪਹਿਲਾਂ deploy ਕਰਨੇ ਹਨ, API backward-compatible ਹੈ ਜਾਂ ਨਹੀਂ, ਅਤੇ ਮੋਬਾਈਲ ਲਈ ਘੱਟੋ-ਘੱਟ ਵਰਜ਼ਨ ਕੀ ਹੈ।
ਇੱਕ ਸਧਾਰਣ ਰਿਲੀਜ਼ ਚੈੱਕਲਿਸਟ ਮਦਦਗਾਰ ਹੁੰਦੀ ਹੈ: feature flag ਯੋਜਨਾ, rollout ਕ੍ਰਮ, ਮਾਨੀਟਰਿੰਗ ਸਿਗਨਲ, ਅਤੇ rollback ਕਦਮ—ਜੋ ਵੈੱਬ, ਮੋਬਾਈਲ ਅਤੇ ਬੈਕਐਂਡ ਵਿੱਚ ਸਾਂਝੇ ਹੋਣ ਤਾਂ ਜੋ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਕਿਸੇ ਨੂੰ ਹੈਰਾਨੀ ਨਾ ਹੋਵੇ।
ਟੈਸਟਿੰਗ ਅਤੇ ਨਿਰੀਖਣ: ਕ੍ਰਾਸ-ਲੇਅਰ ਬਦਲਾਅ ਲਈ
ਜਦੋਂ AI ਤੁਹਾਨੂੰ UI, ਮੋਬਾਈਲ ਸਕ੍ਰੀਨਾਂ, ਅਤੇ ਬੈਕਐਂਡ endpoints ਜੋੜਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, ਤਦ ਅਸਾਨੀ ਨਾਲ ਕੁਝ ਐਸਾ ਭੇਜਿਆ ਜਾ ਸਕਦਾ ਹੈ ਜੋ "ਲੱਗਦਾ" ਤਾਂ ਮੁਕੰਮਲ ਹੈ ਪਰ ਸਿਲਫ਼ਿλ ਕੰਨੈੱਮ ਬਣਾਉਂਦਾ ਹੈ।
ਤੇਜ਼ ਟੀਮਾਂ ਟੈਸਟਿੰਗ ਅਤੇ ਨਿਰੀਖਣ ਨੂੰ ਇੱਕ ਪ੍ਰਣালী ਵਜੋਂ ਮੰਨਦੀਆਂ ਹਨ: ਟੈਸਟ predictable ਤੋੜ-ਟੋੜ ਨੂੰ ਫੜਦੇ ਹਨ; ਨਿਰੀਖਣ ਅਜਿਹੀਆਂ ਗਲਤੀਆਂ ਨੂੰ ਸਮਝਾਉਂਦਾ ਹੈ ਜੋ ਅਚਾਨਕ ਆਉਂਦੀਆਂ ਹਨ।
ਕਿੱਥੇ ਬੱਗ ਲੁਕਦੇ ਹਨ ਜਦੋਂ AI "ਗਲੂ" ਬਣਾਉਂਦਾ ਹੈ
AI adapters ਬਣਾਉਣ ਵਿੱਚ ਬੇਹੱਦ ਚੰਗਾ ਹੁੰਦਾ ਹੈ—ਫੀਲਡ ਨਕਲ ਕਰਨਾ, JSON ਨੂੰ reshaping ਕਰਨਾ, dates ਨੂੰ convert ਕਰਨਾ, callbacks ਨੂੰ ਵਾਇਰ ਕਰਨਾ। ਇਹੀ ਥਾਂ ਹੈ ਜਿੱਥੇ ਨਾਜ਼ੁਕ ਖਾਮੀਆਂ ਰਹਿ ਜਾਂਦੀਆਂ ਹਨ:
- ਕਲਾਇੰਟ 'ਚ ਇੱਕ ਫੀਲਡ ਦਾ ਨਾਮ ਬਦਲ ਗਿਆ ਹੈ, ਪਰ API ਅਜੇ ਵੀ ਪੁਰਾਣਾ ਨਾਮ ਭੇਜਦਾ ਹੈ
- null/empty ਸੰਭਾਲ ਵੈੱਬ ਅਤੇ ਮੋਬਾਈਲ ਵਿੱਚ ਵੱਖਰੀ ਹੁੰਦੀ ਹੈ
- ਸਮਾਂ-ਜ਼ੋਨ, ਮੁਦਰਾ ਫਾਰਮੈਟਿੰਗ, ਅਤੇ rounding ਲੇਅਰਾਂ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਵਰਤਦੇ ਹਨ
- error states consistent ਨਹੀਂ ਹੁੰਦੀਆਂ (ਉਦਾਹਰਣ: ਮੋਬਾਈਲ code ਦੀ ਉਮੀਦ ਕਰਦਾ ਹੈ ਪਰ ਬੈਕਐਂਡ message ਭੇਜਦਾ ਹੈ)
ਇਹ ਮੁੱਦੇ ਅਕਸਰ ਯੂਨਿਟ ਟੈਸਟ ਨੂੰ ਬਾਈਪਾਸ ਕਰ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਹਰ ਲੇਅਰ ਆਪਣੇ ਟੈਸਟ ਪਾਸ ਕਰਦਾ ਹੈ ਪਰ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਵਿੱਚ ਸੁੱਕਾ drift ਹੋ ਜਾਂਦਾ ਹੈ।
client ਅਤੇ API ਵਿਚਕਾਰ contract tests ਜੋੜੋ
Contract tests “ਹੱਥ ਮਿਲਾਉਣ” ਵਾਲੇ ਟੈਸਟ ਹਨ: ਇਹ ਜਾਂਚਦੇ ਹਨ ਕਿ client ਅਤੇ API ਅਜੇ ਵੀ request/response shapes ਅਤੇ ਮੁੱਖ ਵਿਵਹਾਰਾਂ 'ਤੇ ਰਾਜ਼ੀ ਹਨ।
ਇਨ੍ਹਾਂ ਨੂੰ ਕੇਂਦਰਿਤ ਰੱਖੋ:
- ਲਾਜ਼ਮੀ ਫੀਲਡ, types, ਅਤੇ ਆਮ error responses ਨੂੰ validate ਕਰੋ
- versioning ਨਿਯਮਾਂ ਨੂੰ ਕਵਰ ਕਰੋ (ਕਿਹੜੀਆਂ ਚੀਜ਼ਾਂ ਬਦਲੀ ਜਾ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ clients ਤੋੜੇ)
- ਹਰ ਬਦਲਾਅ 'ਤੇ CI ਵਿੱਚ contracts ਚਲਾਓ, ਚਾਹੇ ਉਹ client ਵੱਲੋਂ ਹੋਵੇ ਜਾਂ server ਵੱਲੋਂ
ਇਹ ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਜ਼ਰੂਰੀ ਹੈ ਜਦੋਂ AI ambiguous ਪ੍ਰੌਮਪਟਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਕੋਡ refactor ਕਰਦਾ ਜਾਂ ਨਵੇਂ endpoints ਜਨਰੇਟ ਕਰਦਾ ਹੈ।
ਮਹੱਤਵਪੂਰਨ ਯੂਜ਼ਰ ਫਲੋਜ਼ ਲਈ end-to-end ਟੈਸਟ ਵਰਤੋ
ਕੁਝ revenue- ਜਾਂ trust-critical flows ਚੁਣੋ (signup, checkout, password reset) ਅਤੇ ਉਹਨਾਂ ਦੀਆਂ end-to-end ਟੈਸਟ ਚਲਾਓ ਜੋ ਵੈੱਬ/ਮੋਬਾਈਲ + ਬੈਕਐਂਡ + ਡਾਟਾਬੇਸ ਨੂੰ ਕਵਰ ਕਰਦੀਆਂ ਹਨ।
100% E2E coverage ਦਾ ਲਕੜੀ ਟੀਚਾ ਨਾ ਰੱਖੋ—ਉਤਨਾਂ ਜਗ੍ਹਾ ਤੇ ਭਰੋਸਾ ਉੱਚਾ ਰੱਖੋ ਜਿੱਥੇ ਅਸਫਲਤਾ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਨੁਕਸਾਨ ਕਰਦੀ ਹੈ।
ਨਿਰੀਖਣ: ਫੀਚਰ-ਆਧਾਰਤ logs, metrics, traces
ਜਦੋਂ ਹੱਦਾਂ ਧੁੰਦਲੀ ਹੁੰਦੀਆਂ ਹਨ, “ਕਿਸ ਟੀਮ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ” ਦੇ ਆਧਾਰ 'ਤੇ ਡੀਬੱਗ ਕਰਨਾ ਟੁੱਟ ਜਾਂਦਾ ਹੈ। ਫੀਚਰ ਅਨੁਸਾਰ ਇੰਸਟ੍ਰੂਮੈਂਟ ਕਰੋ:
- Logs consistent identifiers (user/session/request/feature flag) ਨਾਲ
- Metrics success rate, latency, ਅਤੇ error rate ਹਰ endpoint ਅਤੇ flow ਲਈ
- Traces ਜੋ client → API → ਸੇਵਾਵਾਂ ਵਿੱਚ ਇੱਕ ਯੂਜ਼ਰ ਐਕਸ਼ਨ ਦਿਖਾਉਂਦੇ ਹਨ
ਜੇ ਤੁਸੀਂ ਇਹ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹੋ: “ਕੀ ਬਦਲਿਆ, ਕੌਣ ਪ੍ਰਭਾਵਿਤ ਹੈ, ਅਤੇ ਕਿੱਥੇ ਫੇਲ ਹੋ ਰਿਹਾ ਹੈ” ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ, ਤਾਂ ਕ੍ਰਾਸ-ਲੇਅਰ ਵਿਕਾਸ ਤੇਜ਼ ਰਹਿੰਦਾ ਹੈ ਬਗੈਰ ਗਲਤੀ ਵਧਣ ਦੇ।
ਆਰਕੀਟੈਕਚਰ ਪੈਟਰਨ ਜੋ AI-ਸਹਾਇਤਾ ਟੀਮਾਂ ਨਾਲ ਚੰਗੇ ਕੰਮ ਕਰਦੇ ਹਨ
ਪ੍ਰੋਡਕਸ਼ਨ-ਜੈਸੀ ਸੈਟਅੱਪ ਵਿੱਚ ਵੈਧਤਾ ਕਰੋ
ਇਡਿਆ ਤੋਂ ਹੋਸਟਡ ਐਪ ਤੱਕ ਜਾਓ ਤਾਂ ਜੋ ਤੁਸੀਂ ਅਸਲੀ ਯੂਜ਼ਰ ਫਲੋ ਨੂੰ ਜਲਦੀ ਟੈਸਟ ਕਰ ਸਕੋ।
AI ਟੂਲ ਬਹੁਤ ਆਸਾਨੀ ਨਾਲ ਕਈ ਲੇਅਰਾਂ ਨੂੰ ਬਦਲ ਸਕਦੇ ਹਨ, ਜੋ ਤੇਜ਼ੀ ਲਈ ਬਿਹਤਰ ਹੈ—ਪਰ ਸੰਗਠਨ ਲਈ ਖਤਰਾ ਵੀ। ਵਧੀਆ ਨਮੂਨੇ ਇਸ ਗੱਲ ਨੂੰ ਨਹੀਂ ਰੋਕਦੇ; ਉਹ ਇਸਨੂੰ ਐਸੇ ਸਪਸ਼ਟ ਸੀਮਾਂ ਤੱਕ ਰਾਹ ਦਿੰਦੇ ਹਨ ਜੋ ਮਨੁੱਖ ਅਜੇ ਵੀ ਸੰਝ ਸਕਦੇ ਹਨ।
API-first, schema-first, feature-first
API-first endpoints ਅਤੇ contracts ਤੋਂ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ, ਫਿਰ clients ਅਤੇ servers ਉਨ੍ਹਾਂ ਦੇ ਆਸ-ਪਾਸ ਇੰਪਲੀਮੈਂਟ ਹੁੰਦੇ ਹਨ। ਜੇਕਰ ਤੁਹਾਡੇ ਕੋਲ ਕਈ ਉਪਭੋਗਤਾ ਹਨ (ਵੈੱਬ, ਮੋਬਾਈਲ, ਪਾਰਟਨਰ) ਤਾਂ ਇਹ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੈ।
Schema-first data model ਅਤੇ operations ਨੂੰ ਇੱਕ ਸਾਂਝੇ schema (OpenAPI ਜਾਂ GraphQL) ਵਿੱਚ ਪਹਿਲਾਂ define ਕਰਦਾ ਹੈ, ਫਿਰ clients, stubs, ਅਤੇ docs ਜਨਰੇਟ ਹੁੰਦੇ ਹਨ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ AI-ਸਹਾਇਤਾ ਟੀਮਾਂ ਲਈ sweet spot ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ schema ਇੱਕ single source of truth ਬਣ ਜਾਂਦਾ ਹੈ ਜਿਸਨੂੰ AI ਭਰੋਸੇ ਨਾਲ ਫਾਲੋ ਕਰ ਸਕਦਾ ਹੈ।
Feature-first ਕੰਮ ਨੂੰ ਯੂਜ਼ਰ ਨਤੀਜੇ (ਜਿਵੇਂ “checkout” ਜਾਂ “profile editing”) ਦੇ ਆਸ-ਪਾਸ ਆਯੋਜਿਤ ਕਰਦਾ ਹੈ ਅਤੇ ਕ੍ਰਾਸ-ਲੇਅਰ ਬਦਲਾਅ ਨੂੰ ਇੱਕ ਜ਼ਿੰਮੇਵਾਰ ਸਰਫ਼ੇਸ ਦੇ ਪਿੱਛੇ ਬੰਧ ਕਰਦਾ ਹੈ। ਇਹ AI ਦੇ ਨੈਚਰ ਨਾਲ ਵੀ ਮਿਲਦਾ ਹੈ: ਇੱਕ ਫੀਚਰ ਦੇ ਪ੍ਰੌਮਪਟ ਆਮ ਤੌਰ 'ਤੇ UI, API, ਅਤੇ ਡਾਟਾ ਨੂੰ ਛੂਹਦਾ ਹੈ।
ਇੱਕ ਅਮਲੀ ਰਵੱਈਆ ਇਹ ਹੈ: feature-first delivery ਨਾਲ schema-first contracts ਹੇਠਾਂ।
ਸਾਂਝੇ schemas ਕ੍ਰਾਸ-ਟੀਮ friction ਘਟਾਉਂਦੇ ਹਨ
ਜਦੋਂ ਹਰ ਕੋਈ ਇੱਕੋ contract ਨੂੰ ਨਿਸ਼ਾਨਾ ਬਣਾਉਂਦਾ ਹੈ, “ਇਹ ਫੀਲਡ ਕੀ ਮਤਲਬ ਹੈ?” ਵਾਲੇ ਬਹਸ ਘੱਟ ਹੁੰਦੇ ਹਨ। OpenAPI/GraphQL schemas ਨਾਲ ਤੁਸੀਂ ਆਸਾਨੀ ਨਾਲ:
- typed clients web ਅਤੇ mobile ਲਈ ਜਨਰੇਟ ਕਰੋ
- requests/responses ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ validate ਕਰੋ
- docs ਸਹੀ ਰੱਖੋ ਬਿਨਾਂ ਹੱਥ ਨਾਲ ਦੁਬਾਰਾ ਲੇਖਨ ਦੀ
ਕੁੰਜੀ ਇਹ ਹੈ ਕਿ schema ਨੂੰ versioned product surface ਵਜੋਂ ਟ੍ਰੀਟ ਕਰੋ, ਨਾ ਕਿ ਇੱਕ ਬਾਅਦ ਵਿੱਚ ਸੋਚੀ ਜਾਣ ਵਾਲੀ ਚੀਜ਼।
ਮਾਡਿਊਲ, ਡੋਮੇਨਾਂ, ਅਤੇ ਇੰਟਰਫੇਸ ਨਾਲ ਹੱਦਾਂ ਸਪਸ਼ਟ ਰੱਖੋ
ਧੁੰਦਲੀ ਟੀਮ ਲਾਈਨਾਂ ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਕੋਡ ਧੁੰਦਲਾ ਹੋ ਜਾਏ। ਸਪਸ਼ਟਤਾ ਇਹਨਾਂ ਤਰੀਕਿਆਂ ਨਾਲ ਬਰਕਰਾਰ ਰੱਖੋ:
- Domain modules: ਕੋਡ ਨੂੰ ਬਿਜ਼ਨੈਸ ਸਮਰੱਥਾ (Payments, Catalog) ਅਨੁਸਾਰ ਗਰੁੱਪ ਕਰੋ, ਨ ਕਿ “frontend/backend” ਅਨੁਸਾਰ
- Explicit interfaces: ਚੰਗੇ ਨਾਮ ਵਾਲੇ service interfaces ਅਤੇ API contracts ਰਾਹੀਂ ਕੈਪਬਿਲਿਟੀਜ਼ ਦਿਖਾਓ
- Dependency direction: domains UI ਵੇਰਵੇ 'ਤੇ ਨਿਰਭਰ ਨਾ ਹੋਣ; UIs domain services 'ਤੇ ਨਿਰਭਰ ਹੋਣ
ਇਸ ਨਾਲ AI-ਜਨਰੇਟ ਬਦਲਾਅ ਇੱਕ “ਡੱਬੇ” ਵਿੱਚ ਰਹਿਣਗੇ, ਸਮੀਖਿਆ ਤੇਜ਼ ਹੋਵੇਗੀ ਅਤੇ regressions ਘੱਟ ਹੋਣਗੀਆਂ।
ਤੇਜ਼ੀ ਨਾਲ ਚਲੋ ਬਿਨਾਂ ਘਨ੍ਹੇ coupling ਦੇ
ਫੀਚਰ-ਫਰਸਟ ਕੰਮ ਨੂੰ ਗੁੰਝਲਦਾਰ ਕੋਡ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਬਚਾਉਣ ਲਈ:
- composition ਨੂੰ shared global utilities ਤੋਂ ਤਰਜੀਹ ਦਿਓ
- UI-shaped APIs ਨੂੰ ਤੇਰ (BFF ਜਾਂ gateway) ਤੇ ਰੱਖੋ, ਕੋਰ ਡੋਮੇਨਾਂ ਵਿਚ ਨਹੀਂ
- contract tests ਲਾਗੂ ਕਰੋ ਤਾਂ ਕਿ ਲੇਅਰਾਂ ਵਿੱਚ ਬਦਲਾਅ ਜਲਦੀ ਫੇਲ ਹੋ
ਮੁਕੱਦਮ ਦਾ ਲਕਾ: ਸਖਤ ਵੰਡ ਨਹੀਂ—ਇੱਕ ਅਨੁਮਾਨਯੋਗ ਸੰਪਰਕ ਬਿੰਦੂ ਜੋ AI ਫਾਲੋ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਮਨੁੱਖ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ।
ਗੁਣਵੱਤਾ ਗੁਆਏ ਬਿਨਾਂ ਆਪਣੀ ਟੀਮ ਨੂੰ ਕਿਵੇਂ ਰੂਪਾਂਤਰਿਤ ਕਰੀਏ
AI ਟੀਮਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਬਿਨਾਂ guardrails ਦੇ ਤੇਜ਼ੀ ਮੁੜ-ਕੰਮ ਵਿੱਚ ਬਦਲ ਸਕਦੀ ਹੈ। ਮਕਸਦ ਇਹ ਨਹੀਂ ਕਿ ਹਰ ਕੋਈ “ਸਭ ਕੁਝ ਕਰੇ”। ਮਕਸਦ ਇਹ ਹੈ ਕਿ ਕ੍ਰਾਸ-ਲੇਅਰ ਬਦਲਾਅ ਸੁਰੱਖਿਅਤ, ਸਮੀਖਿਆਯੋਗ, ਅਤੇ ਰੀਪਟੀਬਲ ਬਣੇ—ਚਾਹੇ ਫੀਚਰ UI, API ਅਤੇ ਡਾਟਾ ਨੂੰ ਛੂਹੇ ਜਾਂ ਸਿਰਫ਼ ਇੱਕ ਛੋਟਾ ਕਿਨਾਰਾ।
ਵਿਕਸਿਤ ਕਰਨ ਲਾਇਕ ਹੁਨਰ (ਜੋ scalable ਹਨ)
ਜਦੋਂ ਹੱਦਾਂ ਧੁੰਦਲੀ ਹੁੰਦੀਆਂ ਹਨ, specialists ਫਿਰ ਵੀ ਜ਼ਰੂਰੀ ਹਨ, ਪਰ ਕੁਝ ਸਾਂਝੇ ਹੁਨਰ ਸਹਿਯੋਗ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ:
- Product thinking: ਯੂਜ਼ਰ ਮਕਸਦ ਅਤੇ trade-offs (latency, reliability, accessibility) ਨੂੰ ਕੋਡ ਲਿਖਣ ਤੋਂ ਪਹਿਲਾਂ ਸਮਝਣਾ
- Debugging across layers: UI → API → database ਤੱਕ ਇੱਕ ਬੇਨਤੀ follow ਕਰਨਾ, ਅਤੇ ਇਹ ਜਾਣਨਾ ਕਿ ਕਿਸ ਤਰ੍ਹਾਂ ਘੱਟਾਓ
- Reading unfamiliar code: ਹੋਰ ਰੀਪੋ ਜਾਂ ਪਲੇਟਫਾਰਮ ਵਿੱਚ ਪੈਟਰਨ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪੜ੍ਹਕੇ ਸੁਰੱਖਿਅਤ ਸਥਾਨਕ ਤਬਦੀਲੀਆਂ ਕਰਨਾ
ਇਹ “ਹਰ ਇੱਕ ਦੇ ਹੁਨਰ” ਹਨ ਜੋ ਹੇਡ-ਆਫ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ AI-ਜਨਰੇਟ ਸੁਝਾਅਾਂ ਨੂੰ ਮਨੁੱਖੀ ਤੌਰ 'ਤੇ ਸਹੀ ਕਰਨ ਯੋਗ ਬਣਾ ਦਿੰਦੇ ਹਨ।
ਗੁਣਵੱਤਾ drift ਰੋਕਣ ਲਈ ਟੀਮ ਆਦਤਾਂ
AI output ਵਧਾਉਂਦਾ ਹੈ; ਤੁਹਾਡੇ ਆਦਤ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੀਆਂ ਹਨ ਕਿ ਉਹ output consistent ਹੈ।
ਸ਼ੁਰੂ ਕਰੋ ਇੱਕ ਸਾਂਝੀ Definition of Done ਨਾਲ ਜੋ ਇਹ ਕਵਰ ਕਰੇ:
- tests (ਕਿਸ ਤਰ੍ਹਾਂ, ਕਿੱਥੇ ਰਹਿਣ, ਅਤੇ ਘੱਟੋ-ਘੱਟ coverage ਉਮੀਦਾਂ)
- error handling ਅਤੇ logging
- documentation ਅੱਪਡੇਟ (ਝਿੱਲੀਆਂ ਵੀ)
- performance ਅਤੇ accessibility checks ਜਿੱਥੇ ਲੋੜ
ਹਲਕੇ templates ਜੁੜੋ: PR checklist, feature spec one-pager, ਅਤੇ API changes ਵੇਰਵਾ ਕਰਨ ਦਾ ਸਟੈਂਡਰਡ ਤਰੀਕਾ। ਸੰਕਲਿਤ ਢਾਂਚਾ ਸਮੀਖਿਆ ઝડપી ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਗਲਤਫਹਮੀ ਘਟਾਉਂਦਾ ਹੈ।
ਪ੍ਰਮਾਣੀਕਰਣ ਲਈ ਟੂਲਿੰਗ (ਤਾਕਿ ਗੁਣਵੱਤਾ ਵਿਕਲਪਤ ਨਾ ਰਹੇ)
Standardization ਯਾਦ 'ਤੇ ਨਹੀਂ ਰਹਿਣੀ ਚਾਹੀਦੀ—ਉਸਨੂੰ automation ਵਿੱਚ ਰੱਖੋ:
- Linters ਅਤੇ formatters ਸਾਰੇ ਰੀਪੋ ਵਿੱਚ (ਉਹੀ ਨਿਯਮ, ਉਹੀ ਆਉਟਪੁੱਟ)
- CI checks ਜੋ tests, type checks, ਅਤੇ build steps ਹਰ ਬਦਲਾਅ 'ਤੇ ਚਲਾਉਣ
- Dependency ਅਤੇ secret scanning ਜੋ ਖਤਰਨਾਕ packages ਅਤੇ ਅਕਸਿਮਤ credential leaks ਜਲਦੀ ਫੜ ਲੈਂ
ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਇਹ ਪਹਿਲਾਂ ਹੀ ਹਨ, ਉਹਨਾਂ ਨੂੰ ਘੱਟ-ਘੱਟ ਕਦਮਾਂ ਨਾਲ ਝੱਕੋ—ਸਭ ਥਾਂ ਇਕੱਠੇ ਸਖਤ ਨਿਯਮ ਚਾਲੂ ਨਾ ਕਰੋ।
ਇੱਕ ਵਜ੍ਹਾ ਕਿ AI-ਸਹਾਇਤਾ ਵਰਕਫਲੋਜ਼ 'ਤੇ ਪਲੇਟਫਾਰਮ ਉਭਰ ਰਹੇ ਹਨ, ਉਹ ਇਹ ਹੈ ਕਿ ਇਹ “ਫੀਚਰ-ਫਰਸਟ” ਬਦਲਾਅ ਨੂੰ ਅੰਤ-ਤੱਕ coherent ਮਹਿਸੂਸ ਕਰਵਾਉਣ; ਉਦਾਹਰਣ ਲਈ, Koder.ai ਨੂੰ ਇਸ ਤਰੀਕੇ ਨਾਲ ਬਣਾਇਆ ਗਿਆ ਹੈ ਕਿ chat ਰਾਹੀਂ ਪੂਰੇ ਫੀਚਰ ਜਨਰੇਟ ਅਤੇ iterate ਕੀਤਾ ਜਾ ਸਕੇ (ਸਿਰਫ snippets ਨਹੀਂ), ਪਰ ਉਹਨਾਂ ਪਰੈਕਟਿਸਾਂ ਦਾ ਵੀ ਸਹਾਰਾ ਮਿਲਦਾ ਹੈ ਜਿਨ੍ਹਾਂ 'ਤੇ ਟੀਮਾਂ ਭਰੋਸਾ ਕਰਦੀਆਂ ਹਨ—ਜਿਵੇਂ planning mode, deploy/hosting, ਅਤੇ source code export. ਅਮਲੀ ਤੌਰ 'ਤੇ, ਇਹ boundary-blurring ਹਕੀਕਤ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ: ਤੁਸੀਂ ਅਕਸਰ ਇੱਕ ਵਰਕਫਲੋ ਚਾਹੋਗੇ ਜੋ React ਵੈੱਬ, ਬੈਕਐਂਡ ਸਰਵਿਸਿਜ਼, ਅਤੇ ਡਾਟਾ ਬਦਲਾਅ ਨੂੰ ਛੂਹ ਸਕੇ ਬਿਨਾਂ coordination ਨੂੰ ਬੋਟਲਨੈਕ ਬਣਾਏ।
ਇੱਕ ਅਮਲੀ ਅਪਨਾਉਣ ਯੋਜਨਾ: ਛੋਟਾ ਸ਼ੁਰੂ ਕਰੋ, ਮਾਪੋ, ਦੁਹਰਾਓ
ਇੱਕ ਇੱਕ ਫੀਚਰ ਚੁਣੋ ਜੋ ਇੱਕ ਤੋਂ ਵੱਧ ਲੇਅਰ ਨੂੰ ਛੂਹਦਾ ਹੈ (ਉਦਾਹਰਣ: ਇੱਕ ਨਵਾਂ settings toggle ਜਿਸਨੂੰ UI, ਇੱਕ API ਫੀਲਡ, ਅਤੇ ਡਾਟਾ ਸਟੋਰੇਜ ਦੀ ਲੋੜ ਹੈ)। ਸਫਲਤਾ ਮੈਟਰਿਕ ਪੇਸ਼ ਕਰੋ: cycle time, defect rate, ਅਤੇ ਕਿੰਨੀ ਵਾਰ ਫੀਚਰ ਨੂੰ follow-up fix ਦੀ ਲੋੜ ਪਈ।
ਇਕ sprint ਲਈ ਪ੍ਰਯੋਗ ਚਲਾਓ, ਫਿਰ ਜੋ ਟੁੱਟਿਆ ਜਾਂ ਧੀਮਾ ਹੋਇਆ ਉਸ ਅਨੁਸਾਰ standards, templates, ਅਤੇ CI ਸੋਧੋ। ਅਗਲੇ ਫੀਚਰ ਨਾਲ ਦੁਹਰਾਓ।
ਇਸ ਤਰ੍ਹਾਂ AI ਅਪਨਾਉਣ ਨਤੀਜਿਆਂ 'ਤੇ ਆਧਾਰਿਤ ਰਹਿੰਦਾ ਹੈ, hype 'ਤੇ ਨਹੀਂ—ਤੇ ਤੁਹਾਡੀ ਵਰਕਫਲੋ ਵਿਕਸਤ ਹੁੰਦਿਆਂ ਗੁਣਵੱਤਾ ਬਚੀ ਰਹਿੰਦੀ ਹੈ।