18 ਅਪ੍ਰੈ 2025·8 ਮਿੰਟ
Jim Gray, ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪ੍ਰੋਸੈਸਿੰਗ, ਅਤੇ ACID ਹਾਲੇ ਵੀ ਕਿਉਂ ਮਹੱਤਵਪੂਰਣ ਹੈ
Jim Gray ਦੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ-ਪ੍ਰੋਸੈਸਿੰਗ ਵਿਚਾਰਾਂ ਦਾ ਪ੍ਰਯੋਗਕ ਨਜ਼ਰੀਆ ਅਤੇ ਕਿਵੇਂ ACID ਪ੍ਰਿੰਸੀਪਲ ਬੈਂਕਿੰਗ, ਕੌਮਰਸ ਅਤੇ SaaS ਸਿਸਟਮਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
Jim Gray ਦੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ-ਪ੍ਰੋਸੈਸਿੰਗ ਵਿਚਾਰਾਂ ਦਾ ਪ੍ਰਯੋਗਕ ਨਜ਼ਰੀਆ ਅਤੇ ਕਿਵੇਂ ACID ਪ੍ਰਿੰਸੀਪਲ ਬੈਂਕਿੰਗ, ਕੌਮਰਸ ਅਤੇ SaaS ਸਿਸਟਮਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
Jim Gray ਇੱਕ ਕੰਪਿਊਟਰ ਵਿਗਿਆਨੀ ਸਨ ਜੋ ਇਕ ਬਹੁਤ ਸਧਾਰਨ ਪਰ ਮੁਸ਼ਕਲ ਸਵਾਲ 'ਤੇ ਜ਼ੋਰ ਦਿੰਦੇ ਸੀ: ਜਦੋਂ ਬਹੁਤ ਸਾਰੇ ਲੋਕ ਇੱਕ ਹੀ ਸਮੇਂ ਵਿੱਚ ਸਿਸਟਮ ਵਰਤ ਰਹੇ ਹੁੰਦੇ ਹਨ—ਅਤੇ ਫੇਲਿਅਰ ਲਾਜ਼ਮੀ ਹਨ—ਤਾਂ ਨਤੀਜੇ ਕਿਵੇਂ "ਸਹੀ" ਰੱਖੇ ਜਾਣ?
ਉਸਦਾ ਕੰਮ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪ੍ਰੋਸੈਸਿੰਗ ਨੇ ਡੇਟਾਬੇਸਾਂ ਨੂੰ "ਕਦੇ-ਕਦੇ ਠੀਕ, ਜੇ ਤੁਸੀਂ ਕਿਸਮਤ ਵਿੱਚ ਹੋ" ਤੋਂ ਉਹ ਇੰਫ੍ਰਾਸਟ੍ਰੱਕਚਰ ਬਣਾਇਆ ਜੋ ਆਪ ਕਾਰੋਬਾਰ ਦੇ ਆਧਾਰ ਤੇ ਤਿਆਰ ਕਰ ਸਕਦੇ ਹੋ। ਉਹਨਾਂ ਦੀਆਂ ਵਿਚਾਰਧਾਰਾਂ—ਖ਼ਾਸ ਕਰਕੇ ACID ਗੁਣ—ਹਰ ਜਗ੍ਹਾ ਨਜ਼ਰ ਆਉਂਦੀਆਂ ਹਨ, ਭਾਵੇਂ ਤੁਸੀਂ ਕਦੇ ਪ੍ਰੋਡਕਟ ਮੀਟਿੰਗ ਵਿੱਚ "ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ" ਸ਼ਬਦ ਨਾ ਵੀ ਵਰਤਿਆ ਹੋਵੇ।
ਭਰੋਸੇਯੋਗ ਸਿਸਟਮ ਉਹ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਸਕ੍ਰੀਨਾਂ ਦੇ ਮਗਰੋਂ ਨਤੀਜਿਆਂ 'ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ।
ਦੂਜੇ ਸ਼ਬਦਾਂ ਵਿੱਚ: ਸਹੀ ਬੈਲੈਂਸ, ਸਹੀ ਆਰਡਰ ਅਤੇ ਕੋਈ ਗੁੰਮ ਰਿਕਾਰਡ ਨਹੀਂ।
ਆਧੁਨਿਕ ਉਤਪਾਦ ਭੀ queues, microservices ਅਤੇ ਤੀਜੇ-ਪੱਖੀ ਭੁਗਤਾਨਾਂ ਨਾਲ ਹੋਣ ਦੇ ਬਾਵਜੂਦ ਮੁੱਖ ਪਲਾਂ 'ਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੋਚ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ।
ਅਸੀਂ ਸੰਕਲਪਾਂ ਨੂੰ ਪ੍ਰਯੋਗਕ ਦੇ ਰੂਪ ਵਿੱਚ ਰੱਖਾਂਗੇ: ACID ਕਿਨ੍ਹਾਂ ਚੀਜ਼ਾਂ ਨੂੰ ਬਚਾਉਂਦਾ ਹੈ, ਕੇਥੇ ਬੱਗ ਛੁਪਦੇ ਹਨ (ਇਸੋਲੇਸ਼ਨ ਅਤੇ concurrency), ਅਤੇ ਲੌਗ ਅਤੇ recovery ਫੇਲਿਅਰਾਂ ਨੂੰ ਕਿਵੇਂ ਸਹਿਣਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
ਅਸੀਂ ਆਧੁਨਿਕ ਟਰੇਡ-ਆਫਾਂ ਨੂੰ ਵੀ ਛੁਹਾਂਗੇ—ਤੁਸੀਂ ACID ਦੀਆਂ ਬਾਰਡਰਜ਼ ਕਿੱਥੇ ਰੱਖਦੇ ਹੋ, ਵੰਡੇ ਹੋਏ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲਈ ਕਦੋਂ ਵਧੀਆ ਹੈ, ਅਤੇ ਕਦੋਂ sagas, retries ਅਤੇ idempotency ਵਰਗੇ ਪੈਟਰਨ ਤੁਸੀਂ ਬਿਨਾਂ ਓਵਰਇੰਜੀਨੀਅਰਿੰਗ ਦੇ "ਕਾਫ਼ੀ ਚੰਗੇ" ਸਥਿਰਤਾ ਦਿੰਦੇ ਹਨ।
ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇੱਕ ਬਹੁ-ਕਦਮੀ ਕਾਰੋਬਾਰਕ ਕਾਰਵਾਈ ਨੂੰ ਇਕੱਲੇ "ਹਾਂ/ਨਾ" ਇਕਾਈ ਵਾਂਗ ਟਰੀਟ ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ। ਜੇ ਸਭ ਕੁਝ ਸਫਲ ਹੋਵੇ ਤਾਂ ਤੁਸੀਂ ਉਸਨੂੰ commit ਕਰਦੇ ਹੋ। ਜੇ ਕੁਝ ਵੀ ਗੜਬੜ ਹੋਵੇ ਤਾਂ ਤੁਸੀਂ ਉਸਨੂੰ roll back ਕਰਦੇ ਹੋ ਜਿਵੇਂ ਕਿ ਕਦੇ ਹੀ ਨਹੀਂ ਹੋਇਆ।
ਸੋਚੋ ਤੁਸੀਂ Checking ਤੋਂ Savings ਵਿੱਚ $50 ਭੇਜ ਰਹੇ ਹੋ। ਇਹ ਇਕ ਹੀ ਬਦਲਾਅ ਨਹੀਂ; ਇਹ ਘੱਟੋ-ਘੱਟ ਦੋ ਹੈ:
ਜੇ ਤੁਹਾਡੀ ਸਿਸਟਮ ਸਿਰਫ "ਇੱਕ-ਕਦਮ ਅਪਡੇਟ" ਕਰਦੀ ਹੈ, ਤਾਂ ਇਹ ਸੰਭਵ ਹੈ ਕਿ ਪੈਸਾ ਘਟਿਆ ਜਾਵੇ ਪਰ ਡੈਪਾਜ਼ਿਟ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ ਫੇਲ ਹੋ ਜਾਵੇ। ਹੁਣ ਗ੍ਰਾਹਕ ਕੋਲ $50 ਘਟ ਗਿਆ—ਅਤੇ ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਆਉਣ ਲੱਗਦੀਆਂ ਹਨ।
ਆਮ ਚੈਕਆਉਟ ਵਿੱਚ ਆਰਡਰ ਬਣਾਉਣ, ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਕਰਨ, ਭੁਗਤਾਨ ਨੂੰ ਅਥਾਰਾਈਜ਼ ਕਰਨ ਅਤੇ ਰਸੀਦ ਦਰਜ ਕਰਨ ਵਰਗੇ ਕਈ ਕਦਮ ਹੁੰਦੇ ਹਨ। ਹਰ ਕਦਮ ਵੱਖ-ਵੱਖ ਟੇਬਲਾਂ (ਜਾਂ ਅਲੱਗ ਸੇਵਾਵਾਂ) ਨੂੰ ਛੂਹਦਾ ਹੈ। ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੋਚ ਨਾ ਹੋਣ 'ਤੇ ਤੁਸੀਂ ਅਜਿਹੇ ਹਾਲਤਾਂ ਵਿੱਚ ਫਸ ਸਕਦੇ ਹੋ ਜਿਥੇ ਆਰਡਰ "paid" ਦਿਖਾਈ ਦੇ ਰਿਹਾ ਹੋਵੇ ਪਰ ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਨਾ ਹੋਈ ਹੋਵੇ—ਜਾਂ ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਹੋਈ ਹੋਵੇ ਪਰ ਆਰਡਰ ਕਦੇ ਬਣਿਆ ਹੀ ਨਾ ਹੋਵੇ।
ਫੇਲਿਅਰ ਆਮ ਤੌਰ 'ਤੇ ਸੁਖਦayi ਸਮਿਆਂ 'ਤੇ ਨਹੀਂ ਹੁੰਦੇ। ਆਮ ਟੁਟ-ਟੁਕ ਪਲ ਹਨ:
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪ੍ਰੋਸੈਸਿੰਗ ਇੱਕ ਸਧਾਰਨ ਵਾਅਦਾ ਯਕੀਨੀ ਬਣਾਉਂਦੀ ਹੈ: ਸੰਭਾਵਤ ਤੌਰ 'ਤੇ ਕਾਰੋਬਾਰਕ ਕਾਰਵਾਈ ਦੇ ਸਾਰੇ ਕਦਮ ਇਕੱਠੇ ਪ੍ਰਭਾਵ ਵਿੱਚ ਆਉਣ ਜਾਂ ਕੋਈ ਵੀ ਪ੍ਰਭਾਵ ਵਿੱਚ ਨਾ ਆਉਣ। ਇਹ ਵਾਅਦਾ ਭਰੋਸੇ ਦਾ ਬੁਨਿਆਦ ਹੈ—ਚਾਹੇ ਤੁਸੀਂ ਪੈਸਾ ਹਿਲਾ ਰਹੇ ਹੋ, ਆਰਡਰ ਦੇ ਰਹੇ ਹੋ ਜਾਂ subscription ਪਲੈਨ ਬਦਲ ਰਹੇ ਹੋ।
ACID ਉਹ ਚੈੱਕਲਿਸਟ ਹੈ ਜੋ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਭਰੋਸੇਯੋਗ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੀ। ਇਹ ਕੋਈ ਮਾਰਕੀਟਿੰਗ ਸ਼ਬਦ ਨਹੀਂ; ਇਹ ਉਹ ਵਾਅਦੇ ਹਨ ਜੋ ਮਹੱਤਵਪੂਰਨ ਡੇਟਾ ਬਦਲਣ ਤੇ ਹੁੰਦੇ ਹਨ।
Atomicity ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਜਾਂ ਤਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਪੂਰਾ ਹੁੰਦਾ ਹੈ ਜਾਂ ਕੋਈ ਨਿਸ਼ਾਨ ਨਹੀਂ ਰਹਿ ਜਾਂਦਾ।
ਬੈਂਕ ਟ੍ਰਾਂਸਫਰ ਸੋਚੋ: ਤੁਸੀਂ Account A ਤੋਂ $100 ਡੈਬਿਟ ਕਰਦੇ ਹੋ ਅਤੇ Account B ਨੂੰ $100 ਕਰੈਡਿਟ ਕਰਦੇ ਹੋ। ਜੇ ਸਿਸਟਮ ਡੈਬਿਟ ਤੋਂ ਬਾਅਦ ਪਰ ਕਰੈਡਿਟ ਤੋਂ ਪਹਿਲਾਂ crash ਕਰਦਾ ਹੈ, ਤਾਂ atomicity ਯਕੀਨੀ ਬਣਾਉਂਦੀ ਹੈ ਕਿ ਪੂਰਾ ਟਰਾਂਸਫਰ roll back ਹੋ ਜਾਵੇ ਜਾਂ ਪੂਰਾ ਟਰਾਂਸਫਰ ਖ਼ਤਮ ਹੋ ਜਾਵੇ। ਕੋਈ ਵੈਧ ਆਖਰੀ ਹਾਲਤ ਨਹੀਂ ਜਿੱਥੇ ਸਿਰਫ ਇੱਕ ਪਾਸਾ ਹੋਇਆ ਹੋਵੇ।
Consistency ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡੇ ਡੇਟਾ ਨਿਯਮ (constraints ਅਤੇ invariants) ਹਰੇਕ committed ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਤੋਂ ਬਾਅਦ ਠੀਕ ਰਹਿਣ।
ਉਦਾਹਰਣ: ਜੇ ਤੁਹਾਡਾ ਪ੍ਰੋਡਕਟ overdrafts ਮਨਾਂਦਾ ਹੈ ਤਾਂ ਬੈਲੈਂਸ ਨੈਗੇਟਿਵ ਨਹੀਂ ਹੋ ਸਕਦਾ; ਇੱਕ ਟ੍ਰਾਂਸਫਰ ਲਈ ਡੈਬਿਟ ਅਤੇ ਕਰੈਡਿਟ ਦਾ ਜੋੜ ਮਿਲਣਾ ਚਾਹੀਦਾ ਹੈ; ਆਰਡਰ ਟੋਟਲ ਨੂੰ line items ਅਤੇ ਟੈਕਸ ਮਿਲ ਕੇ ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ। Consistency ਹਿੱਸੇ-ਭਾਗ ਡੇਟਾਬੇਸ ਦਾ ਕੰਮ ਹੈ (constraints), ਅਤੇ ਹਿੱਸਾ ਐਪਲੀਕੇਸ਼ਨ ਦਾ ਕੰਮ (ਬਿਜ਼ਨਸ ਰੂਲ) ਹੈ।
Isolation ਤੁਹਾਨੂੰ ਇਸ ਵੇਲੇ ਬਚਾਉਂਦਾ ਹੈ ਜਦੋਂ ਕਈ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇੱਕੋ ਸਮੇਂ ਹੋ ਰਹੇ ਹੁੰਦੇ ਹਨ।
ਉਦਾਹਰਣ: ਦੋ ਗ੍ਰਾਹਕ ਆਖਰੀ ਇਕਾਈ ਖਰੀਦਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ। ਬਿਨਾਂ ਠੀਕ isolation ਦੇ, ਦੋਹਾਂ ਚੈਕਆਉਟ "inventory = 1" ਵੇਖ ਸਕਦੇ ਹਨ ਅਤੇ ਦੋਹਾਂ ਕੰਮਯਾਬ ਹੋ ਸਕਦੇ ਹਨ, ਜਿਸ ਨਾਲ inventory -1 ਜਾਂ ਮੈਨੂਅਲ ਸਹੀ ਕਰਨ ਵਾਲੀ ਗੜਬੜ ਹੋ ਸਕਦੀ ਹੈ।
Durability ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਜਦੋਂ ਤੁਸੀਂ "committed" ਦੇਖਦੇ ਹੋ, ਤਾਂ ਨਤੀਜਾ crash ਜਾਂ power loss ਤੋਂ ਬਾਅਦ ਖ਼ਤਮ ਨਹੀਂ ਹੋਵੇਗਾ। ਜੇ ਰਸੀਦ ਕਹਿੰਦੀ ਹੈ ਕਿ ਟਰਾਂਸਫਰ ਸਫਲ ਹੋਇਆ, ਤਾਂ ਲੈਜਰ ਨੂੰ reboot ਤੋਂ ਬਾਅਦ ਵੀ ਉਹੀ ਦਿਖਣਾ ਚਾਹੀਦਾ ਹੈ।
"ACID" ਇੱਕ ਸਵਿੱਚ ਨਹੀਂ ਹੈ। ਵੱਖ-ਵੱਖ ਸਿਸਟਮ ਅਤੇ isolation ਲੈਵਲ ਵੱਖ-ਵੱਖ ਗਰੰਟੀਜ਼ ਦਿੰਦੇ ਹਨ, ਅਤੇ ਅਕਸਰ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ ਕਿ ਕਿਹੜੀਆਂ ਸੁਰੱਖਿਆਵਾਂ ਕਿਹੜੀਆਂ ਕਾਰਵਾਈਆਂ 'ਤੇ ਲਾਗੂ ਕਰਨੀਆਂ ਹਨ।
ਜਦੋਂ ਲੋਕ "ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ" ਬਾਰੇ ਗੱਲ ਕਰਦੇ ਹਨ, ਬੈਂਕਿੰਗ ਸਭ ਤੋਂ ਸਾਫ਼ ਉਦਾਹਰਣ ਹੈ: ਯੂਜ਼ਰ ਉਮੀਦ ਕਰਦੇ ਹਨ ਕਿ ਬੈਲੈਂਸ ਹਮੇਸ਼ਾ ਸਹੀ ਹੋਵੇ। ਇੱਕ ਬੈਂਕਿੰਗ ਐਪ ਥੋੜ੍ਹਾ ਹੌਲੀ ਹੋ ਸਕਦੀ ਹੈ; ਪਰ ਉਹ ਗਲਤ ਨਹੀਂ ਹੋ ਸਕਦੀ। ਇੱਕ ਗਲਤ ਬੈਲੈਂਸ overdraft ਫੀਸਾਂ, ਮੁਕਤੀ ਅਦਾਇਗੀ ਦੀਆਂ ਗਲਤੀਆਂ ਅਤੇ ਲੰਬਾ ਮੈਨੂਅਲ ਕਾਰਜਕ੍ਰਮ ਲਿਆ ਸਕਦਾ ਹੈ।
ਇੱਕ ਸਧਾਰਨ ਬੈਂਕ ਟਰਾਂਸਫਰ ਇੱਕ ਕਾਰਵਾਈ ਨਹੀਂ—ਇਹ ਕਈ ਹਨ ਜੋ ਇਕੱਠੇ ਸਫਲ ਜਾਂ ਫੇਲ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ:
ACID ਸੋਚ ਇਹਨਾਂ ਨੂੰ ਇੱਕ ਹੀ ਯੂਨਿਟ ਵਜੋਂ ਦਿਖਦੀ ਹੈ। ਜੇ ਕੋਈ ਕਦਮ ਫੇਲ ਹੋਵੇ—ਨੈੱਟਵਰਕ ਹਿੱਕ, ਸਰਵਿਸ ਕ੍ਰੈਸ਼, validation error—ਤਾਂ ਸਿਸਟਮ ਨੂੰ ਆਧਾ-ਸਫਲ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ। ਨਹੀਂ ਤਾਂ ਤੁਹਾਨੂੰ A ਤੋਂ ਪੈਸਾ ਘੱਟ ਅਤੇ B 'ਤੇ ਨਾ ਦਿਖਾਈ ਦੇਣਾ, B 'ਤੇ ਪੈਸਾ ਬਿਨਾਂ matching ਡੈਬਿਟ ਦੇ, ਜਾਂ ਕੋਈ ਆਡਿਟ ਟਰੇਲ ਨਾ ਹੋਣ ਵਰਗੀਆਂ ਸਮੱਸਿਆਵਾਂ ਮਿਲਣਗੀਆਂ।
ਕਈ ਉਤਪਾਦਾਂ ਵਿੱਚ ਇੱਕ ਛੋਟੀ ਗਲਤਫ਼ਹਮੀ ਅਗਲੇ ਰਿਲੀਜ਼ ਵਿੱਚ ਠੀਕ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ। ਬੈਂਕਿੰਗ ਵਿੱਚ, "ਅਗਲੇ ਸਮੇਂ ਠੀਕ ਕਰੋ" ਨਾਲ ਵਿਵਾਦ, ਨਿਯਮਾਂ ਦੀ ਉਲੰਘਣਾ ਅਤੇ ਮੈਨੂਅਲ ਓਪਰੇਸ਼ਨਾਂ ਦਾ ਭਾਰ ਬਣ ਜਾਂਦਾ ਹੈ। ਸਹਾਇਤਾ ਟਿਕਟਾਂ ਵੱਧਦੀਆਂ ਹਨ, ਇੰਜਨੀਅਰ incident calls ਵਿੱਚ ਫਸਦੇ ਹਨ, ਅਤੇ ਓਪਸ ਟੀਮਾਂ ਘੰਟਿਆਂ ਵੇਖ ਕੇ records reconcile ਕਰਦੀਆਂ ਹਨ।
ਭਲੇ ਤੁਸੀਂ ਨੰਬਰ ਠੀਕ ਕਰ ਸਕਦੇ ਹੋ, ਤੁਹਾਨੂੰ ਫਿਰ ਵੀ ਇਤਿਹਾਸ ਨੂੰ ਸਮਝਾਉਣ ਦੀ ਲੋੜ ਪਵੇਗੀ।
ਇਸਲਈਆਂ ਬੈਂਕ ਲੈਜਰਾਂ ਅਤੇ append-only ਰਿਕਾਰਡਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ: ਇਤਿਹਾਸ ਨੂੰ overwrite ਕਰਨ ਦੀ ਬਜਾਏ, ਉਹ ਡੈਬਿਟ ਅਤੇ ਕਰੈਡਿਟ ਦੀ ਲੜੀ ਦਰਜ ਕਰਦੇ ਹਨ ਜੋ ਮਿਲਦੀ ਹੈ। immutable logs ਅਤੇ ਸਪੱਸ਼ਟ ਆਡਿਟ ਟਰੇਲ recovery ਅਤੇ investigation ਕਰਨਾ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
Reconciliation—ਅਜ਼ਾਦ ਸੋਰਸ-ਆਫ-ਟਰੂਥ ਦੀ ਤੁਲਨਾ—ਜਦੋਂ ਕੁਝ ਗਲਤ ਜਾਂਦਾ ਹੈ ਤਦ ਇੱਕ ਬੈਕਸਟਾਪ ਵਜੋਂ ਕੰਮ ਕਰਦਾ ਹੈ, ਟੀਮਾਂ ਨੂੰ ਪਤਾ ਲਗਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਕਿ divergence ਕਦੋਂ ਅਤੇ ਕਿੱਥੇ ਹੋਈ।
ਸਹੀ ਹੋਣਾ ਭਰੋਸਾ ਖਰੀਦਦਾ ਹੈ। ਇਹ ਸਹਾਇਤਾ ਵਾਲੀ ਘੰਟੀਆਂ ਘਟਾਉਂਦਾ ਅਤੇ ਸੁਲਝਾਉਣ ਤੇਜ਼ ਕਰਦਾ ਹੈ: ਜਦੋਂ ਕੋਈ ਸਮੱਸਿਆ ਆਉਂਦੀ ਹੈ, ਇੱਕ ਸਾਫ਼ ਆਡਿਟ ਟਰੇਲ ਅਤੇ consistent ਲੈਜਰ ਐਂਟਰੀਜ਼ ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ "ਕੀ ਹੋਇਆ?" ਦਾ ਉੱਤਰ ਦੇਣਗੇ ਅਤੇ ਬਿਨਾਂ ਅਨੁਮਾਨ ਦੇ ਠੀਕ ਕਰਨ ਦੀ ਯੋਗਤਾ ਦਿਵਾਉਣਗੇ।
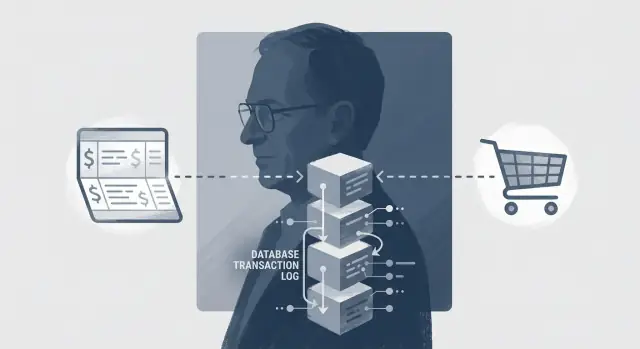
ਈ-ਕਾਮਰਸ ਸਾਦਾ ਲੱਗਦੀ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ peak traffic 'ਤੇ ਨਹੀਂ ਪਹੁੰਚਦੇ: ਉਹੀ ਆਖਰੀ ਆਇਟਮ ਦਸ carts ਵਿੱਚ ਹੋ ਸਕਦਾ ਹੈ, ਗ੍ਰਾਹਕ ਪੇਜ਼ ਰੀਫ੍ਰੈਸ਼ ਕਰਦੇ ਹਨ, ਅਤੇ ਤੁਹਾਡੇ payment provider ਦਾ timeout ਹੋ ਜਾਂਦਾ ਹੈ। ਇਹ ਥਾਂ ਹੈ ਜਿੱਥੇ Jim Gray ਦੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ-ਪ੍ਰੋਸੈਸਿੰਗ ਸੋਚ ਪ੍ਰਯੋਗਿਕ, ਨਿਰਮਲ ਤਰੀਕਿਆਂ ਵਿੱਚ ਆਉਂਦੀ ਹੈ।
ਆਮ ਚੈਕਆਉਟ ਕਈ state ਪੀਸਾਂ ਨੂੰ ਛੂਹਦਾ ਹੈ: inventory ਰਿਜ਼ਰਵ, ਆਰਡਰ ਬਣਾਉਣਾ, ਅਤੇ ਭੁਗਤਾਨ ਕੈਪਚਰ. ਉੱਚ concurrency ਹੇਠਾਂ, ਹਰ ਕਦਮ ਆਪਣੇ ਆਪ ਵਿੱਚ ਸਹੀ ਹੋ ਸਕਦਾ ਹੈ ਫਿਰ ਵੀ ਕੁੱਲ ਨਤੀਜਾ ਗਲਤ ਹੋ ਸਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਨਵੈਂਟਰੀ ਨੂੰ isolation ਦੇ ਬਗੈਰ ਘਟਾਉਂਦੇ ਹੋ, ਤਾਂ ਦੋ ਚੈਕਆਉਟ "1 ਬਚਿਆ" ਵੇਖ ਕੇ ਦੋਹਾਂ ਸਫਲ ਹੋ ਸਕਦੇ ਹਨ—overselling ਆ ਜਾਂਦੀ ਹੈ। ਜੇ ਤੁਸੀਂ ਭੁਗਤਾਨ ਕੈਪਚਰ ਕਰ ਦਿੰਦੇ ਹੋ ਅਤੇ ਫਿਰ ਆਰਡਰ ਬਣਾਉਣ ਵਿੱਚ ਫੇਲ ਹੋ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਗ੍ਰਾਹਕ ਤੋਂ ਪੈਸਾ ਵਸੂਲ ਕਰ ਚੁੱਕੇ ਹੋ ਪਰ ਭੇਜਣ ਲਈ ਕੋਈ ਚੀਜ਼ ਨਹੀਂ।
ACID ਡੇਟਾਬੇਸ ਬਾਰਡਰ 'ਤੇ ਵੱਧ ਤੌਰ 'ਤੇ ਮਦਦ ਕਰਦਾ ਹੈ: ਆਰਡਰ ਬਣਾਉਣਾ ਅਤੇ ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਇੱਕ ਇਕੱਲੇ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰੈਪ ਕਰੋ ਤਾਂ ਜੋ ਉਹ ਦੋਹਾਂ ਜਾਂ ਤਾਂ commit ਹੋਣ ਜਾਂ ਦੋਹਾਂ rollback ਹੋ ਜਾਣ। ਤੁਸੀਂ constraints ਨਾਲ correctness ਨੂੰ बलੀਬੱਧ ਵੀ ਕਰ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ ਲਈ, "inventory zero ਤੋਂ ਘੱਟ ਨਹੀਂ ਹੋ ਸਕਦੀ") ਤਾਂ ਕਿ ਡੇਟਾਬੇਸ ਅਸੰਭਵ ਹਾਲਤਾਂ ਨੂੰ ਰੱਦ ਕਰ ਦੇਵੇ ਭਾਵੇਂ ਐਪ ਕੋਡ ਗਲਤ ਕਰੇ।
ਨੈੱਟਵਰਕ ਜਵਾਬ ਕੱਟ ਦਿੰਦਾ, ਯੂਜ਼ਰ double-click ਕਰਦੇ ਹਨ, ਅਤੇ background jobs retry ਕਰਦੇ ਹਨ। ਇਸ ਲਈ ਸਿਸਟਮਾਂ 'ਚ "exactly once" ਪ੍ਰੋਸੈਸਿੰਗ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦੀ ਹੈ। ਲਕਸ਼ ਹੈ: ਪੈਸੇ ਦੀ ਹਰਕਤ ਲਈ at most once, ਅਤੇ ਹਰ ਥਾਂ safe retries।
ਆਪਣੇ payment processor ਨਾਲ idempotency keys ਦੀ ਵਰਤੋਂ ਕਰੋ ਅਤੇ ਆਪਣੀ ਆਰਡਰ ਨਾਲ ਜੁੜੀ durable "payment intent" ਰਿਕਾਰਡ ਸਟੋਰ ਕਰੋ। ਜੇ ਤੁਹਾਡੀ ਸੇਵਾ retry ਕਰਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ double-charge ਨਹੀਂ ਕਰੋਗੇ।
ਵਾਪਸੀ, ਅੰਸ਼ਕ ਰੀਫੰਡ ਅਤੇ chargebacks ਕਾਰੋਬਾਰੀ ਹਕੀਕਤਾਂ ਹਨ, ਐਡਜ-ਕੇਸ ਨਹੀਂ। ਸਪਸ਼ਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਬਾਰਡਰਜ਼ ਉਹਨਾਂ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦੇ ਹਨ: ਤੁਸੀਂ ਹਰ ਅਨੁਕੂਲਤਾ ਨੂੰ ਆਰਡਰ, ਭੁਗਤਾਨ ਅਤੇ ਆਡਿਟ ਟਰੇਲ ਨਾਲ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਜੋੜ ਸਕਦੇ ਹੋ—ਤਾਂ ਜੋ ਜਦੋਂ ਕੁਝ ਗਲਤ ਹੋਵੇ ਤਾਂ reconciliation ਸਮਝਣਯੋਗ ਹੋਵੇ।
SaaS ਕਾਰੋਬਾਰ ਇੱਕ ਵਾਅਦੇ 'ਤੇ ਜੀਉਂਦੇ ਹਨ: ਗਾਹਕ ਜੋ ਭੁਗਤਾਨ ਕਰਦਾ ਹੈ ਉਹੀ ਤੁਰੰਤ ਅਤੇ ਪੇਸ਼ਗੋਈਯੋਗ ਤਰੀਕੇ ਨਾਲ ਵਰਤ ਸਕਦਾ ਹੈ। ਇਹ ਸਧਾਰਨ ਲੱਗਦਾ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ plan upgrades, downgrades, mid-cycle proration, refunds ਅਤੇ asynchronous payment events ਨਾਲ ਮਿਲਾਉਂਦੇ ਹੋ। ACID-ਸਟਾਈਲ ਸੋਚ "billing truth" ਅਤੇ "product truth" ਨੂੰ aligned ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
ਇਕ ਪਲਾਨ ਬਦਲਾਅ ਅਕਸਰ ਕਈ ਕਾਰਵਾਈਆਂ ਚਲਾਉਂਦਾ ਹੈ: ਇਨਵੌਇਸ ਬਣਾਉਣਾ ਜਾਂ ਅਨੁਕੂਲ ਕਰਨਾ, proration ਦਰਜ ਕਰਨਾ, ਭੁਗਤਾਨ ਇਕੱਠਾ/ਕੋਸ਼ਿਸ਼ ਕਰਨਾ, ਅਤੇ entitlements (ਫੀਚਰ, ਸੀਟਾਂ, ਸੀਮਾਵਾਂ) ਅਪਡੇਟ ਕਰਨਾ। ਇਹਨਾਂ ਨੂੰ ਇੱਕ ਇਕਾਈ ਵਜੋਂ ਹੀ ਟਰੀਟ ਕਰੋ ਜਿਥੇ ਅੰਸ਼ਕ ਸਫਲਤਾ ਅਣੁਕੂਲ ਨਹੀਂ।
ਜੇ ਇੱਕ upgrade ਇਨਵੌਇਸ ਬਣ ਜਾਂਦੀ ਹੈ ਪਰ entitlements ਅਪਡੇਟ ਨਹੀਂ ਹੁੰਦੇ (ਜਾਂ ਉਲਟ), ਤਾਂ ਗਾਹਕ ਜਾਂ ਤਾਂ ਉਹ ਅਕਸੇਸ ਖੋ ਦੇਗਾ ਜਿਸਦਾ ਉਹ ਭੁگਤਾਨ ਕਰ ਚੁੱਕਾ ਹੈ ਜਾਂ ਅਜਿਹਾ ਅਕਸੇਸ ਮਿਲੇਗਾ ਜਿਸਦਾ ਉਹ ਅਧਿਕਾਰ ਨਹੀਂ ਰੱਖਦਾ।
ਇੱਕ ਪ੍ਰਯੋਗਕ ਪੈਟਰਨ ਇਹ ਹੈ ਕਿ billing ਫੈਸਲਾ (ਨਵਾਂ ਪਲਾਨ, effective date, proration ਲਾਈਨਾਂ) ਅਤੇ entitlement ਫੈਸਲਾ ਇਕੱਠੇ ਸਟੋਰ ਕਰੋ, ਫਿਰ downstream ਪ੍ਰੋਸੈਸ ਉਹCommitted record ਤੋਂ ਚਲਾਓ। ਜੇ ਭੁਗਤਾਨ ਦੀ ਪੁਸ਼ਟੀ ਬਾਅਦ ਵਿੱਚ ਆਵੇ, ਤਾਂ ਤੁਸੀਂ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ-ਲਿਖਣ ਬਿਨਾਂ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ state ਅੱਗੇ ਵਧਾ ਸਕਦੇ ਹੋ।
ਮਲਟੀ-ਟੇਨੰਟ ਸਿਸਟਮਾਂ ਵਿੱਚ isolation ਅਕਾਦਮਿਕ ਨਹੀਂ ਹੁੰਦਾ: ਇੱਕ ਗਾਹਕ ਦੀ ਭਾਰੀ ਸਰਗਰਮੀ ਕਿਸੇ ਹੋਰ ਨੂੰ ਰੋਕਣ ਜਾਂ ਗਲਤ ਕਰਨ ਨਾਲੋਂ ਬਚਾਉਣਾ ਚਾਹੀਦਾ ਹੈ। tenant-scoped keys, ਸਪੱਸ਼ਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਬਾਰਡਰ ਅਤੇ ਚੁਣੇ ਹੋਏ isolation ਲੈਵਲ ਵਰਤੋ ਤਾਂ ਜੋ Tenant A ਦੇ renewals ਦੇ ਬਰਸਟ ਤੋਂ Tenant B ਲਈ inconsistent reads ਨਾ ਬਣਨ।
ਸਹਾਇਤਾ ਟਿਕਟ ਆਮ ਤੌਰ 'ਤੇ "ਮੈਨੂੰ ਕਿਉਂ ਚਾਰਜ ਕੀਤਾ ਗਿਆ?" ਜਾਂ "ਮੈਂ X ਤੱਕ ਕਿਉਂ ਨਹੀਂ ਪਹੁੰਚ ਸਕਦਾ?" ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੀਆਂ ਹਨ। ਕਿਸ ਨੇ, ਕਦੋਂ ਅਤੇ ਕਿਵੇਂ ਬਦਲਾਅ ਕੀਤਾ—ਇਸ ਦਾ append-only ਆਡਿਟ ਲੌਗ ਰੱਖੋ ਅਤੇ ਇਸ ਨੂੰ ਇਨਵੌਇਸ ਅਤੇ entitlement transitions ਨਾਲ ਜੋੜੋ।
ਇਸ ਨਾਲ silent drift ਰੋਕੀ ਜਾਂਦੀ ਹੈ—ਜਿੱਥੇ ਇਨਵੌਇਸ "Pro" ਦਿਖਾਉਂਦਾ ਹੈ ਪਰ entitlements "Basic" ਦਰਸਾਉਂਦੀਆਂ ਹਨ—ਅਤੇ reconciliation ਇੱਕ ਕਵੇਰੀ ਬਣ ਜਾਂਦਾ ਹੈ, ਇੱਕ ਜਾਂਚ ਨਹੀਂ।
Isolation ACID ਦਾ "I" ਹੈ, ਅਤੇ ਇਹ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ ਸਿਸਟਮ ਸੁਬਕ, ਮਹਿੰਗੀਆਂ ਤਰੀਕਿਆਂ ਨਾਲ ਅਕਸਰ fail ਹੁੰਦੇ ਹਨ। ਮੁੱਖ ਵਿਚਾਰ ਸਧਾਰਨ ਹੈ: ਬਹੁਤ ਸਾਰੇ ਯੂਜ਼ਰ ਇਕੱਠੇ ਕਾਰਵਾਈ ਕਰਦੇ ਹਨ, ਪਰ ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਐਸਾ ਵਰਤਣਾ ਚਾਹੀਦਾ ਹੈ ਜਿਵੇਂ ਉਹ ਇਕੱਲਾ ਚੱਲ ਰਿਹਾ ਹੈ।
ਇੱਕ ਦੁਕਾਨ ਦੇਖੋ ਜਿਸ ਵਿੱਚ ਦੋ cashiers ਹਨ ਅਤੇ ਸ਼ੈਲਫ 'ਤੇ ਇੱਕ ਆਖਰੀ ਆਈਟਮ। ਜੇ ਦੋਹਾਂ cashiers ਇਕੋ ਸਮੇਂ ਸਟਾਕ ਚੈੱਕ ਕਰਦੇ ਹਨ ਅਤੇ ਦੋਹਾਂ "1 available" ਵੇਖਦੇ ਹਨ, ਤਾਂ ਦੋਹਾਂ ਆਈਟਮ ਵੇਚ ਸਕਦੇ ਹਨ। ਕੁਝ "crash" ਨਹੀਂ ਹੋਇਆ, ਪਰ ਨਤੀਜਾ ਗਲਤ ਹੈ—ਜਿਵੇਂ double-spend।
ਡੇਟਾਬੇਸਾਂ ਨੂੰ ਵੀ ਉਹੀ ਸਮੱਸਿਆ ਸਾਹਮਣੇ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਦੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਇਕੋ ਹੀ rows ਨੂੰ concurrency ਵਿੱਚ ਪੜ੍ਹਦੇ ਅਤੇ ਅਪਡੇਟ ਕਰਦੇ ਹਨ।
ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ safety ਅਤੇ throughput ਦੇ ਵਿਚਕਾਰ tradeoff ਲਈ ਇੱਕ isolation ਲੈਵਲ ਚੁਣਦੇ ਹਨ:
ਜੇ ਇੱਕ ਗਲਤੀ ਵਿਤੀਅਨ ਨੁਕਸਾਨ, ਕਾਨੂੰਨੀ ਖਤਰਾ ਜਾਂ ਗ੍ਰਾਹਕ-ਦਿਖਾਈ ਦੇਣ ਵਾਲੀ ਅਸੰਗਤਤਾ ਪੈਦਾ ਕਰਦੀ ਹੈ, ਤਾਂ ਮਜ਼ਬੂਤ isolation (ਜਾਂ explicit locking/constraints) ਵਲ ਝੁਕੋ। ਜੇ ਸਭ ਤੋਂ ਬੁਰਾ ਨਤੀਜਾ ਇੱਕ ਅਸਥਾਈ UI glitch ਹੈ, ਤਾਂ ਕਮਜ਼ੋਰ ਲੈਵਲ ਕਬੂਲਯੋਗ ਹੋ ਸਕਦਾ ਹੈ।
ਉੱਚ isolation throughput ਨੂੰ ਘਟਾ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਡੇਟਾਬੇਸ unsafe interleavings ਰੋਕਣ ਲਈ ਹੋਰ coordination—ਉਦਾਹਰਣ ਲਈ wait, lock, ਜਾਂ abort/retry—ਕਰਨਾ ਪੈਂਦਾ ਹੈ। ਲਾਗਤ ਵਾਸਤਵਿਕ ਹੈ, ਪਰ ਗਲਤ ਡੇਟਾ ਦੀ ਲਾਗਤ ਭੀ ਵਾਸਤਵਿਕ ਹੈ।
ਜਦੋਂ ਇੱਕ ਸਿਸਟਮ crash ਕਰਦਾ ਹੈ, ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਸਵਾਲ ਨਹੀਂ "ਕਿਉਂ crash ਹੋਇਆ?" ਪਰ "restart ਤੋਂ ਬਾਅਦ ਸਾਨੂੰ ਕਿਸ ਹਾਲਤ ਵਿੱਚ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ?" Jim Gray ਦੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪ੍ਰੋਸੈਸਿੰਗ ਨੇ ਇਸ ਦਾ ਜਵਾਬ ਪ੍ਰਯੋਗਯੋਗ بنایا: durability ਨਿਰਯਾਤੀ ਲੌਗਿੰਗ ਅਤੇ recovery ਨਾਲ ਪ੍ਰਾਪਤ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਲੌਗ (ਅਕਸਰ WAL ਕਹਾਉਂਦਾ) ਬਦਲਾਵਾਂ ਦਾ append-only ਰਿਕਾਰਡ ਹੁੰਦਾ ਹੈ। ਇਹ recovery ਲਈ ਕੇਂਦਰੀ ਹੈ ਕਿਉਂਕਿ ਇਹ ਅਦਾਲਤ ਅਤੇ ਅਪਡੇਟਾਂ ਦਾ ਆਦੇਸ਼ ਅਤੇ ਇਰਾਦਾ ਬਚਾ ਕੇ ਰੱਖਦਾ ਹੈ ਭਾਵੇਂ ਡੇਟਾਬੇਸ ਫਾਈਲਾਂ ਮਿਡ-ਰਾਈਟ ਹੋਣ ਸਮੇਂ power ਦੌਰਾਨ ਕੱਟ-ਫ਼ੜ ਹੋ ਜਾਵੇ।
restart ਦੌਰਾਨ, ਡੇਟਾਬੇਸ:
ਇਸੀ ਕਰਕੇ "ਅਸੀਂ commit ਕੀਤਾ" ਸਚ ਰਹਿ ਸਕਦਾ ਹੈ ਭਾਵੇਂ ਸਰਵਰ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਬੰਦ ਨਾ ਹੋਵੇ।
Write-ahead logging ਦਾ ਮਤਲਬ ਹੈ: ਲੌਗ ਨੂੰ durable storage ਤੇ ਲਿਖਿਆ ਅਤੇ flush ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਪਹਿਲਾਂ ਕਿ data pages ਨੂੰ ਲਿਖਣ ਦੀ ਆਗਿਆ ਦਿੱਤੀ ਜਾਵੇ। ਅਮਲੀ ਤੌਰ 'ਤੇ, "commit" ਉਸ ਸਮੇਂ ਜੁੜਿਆ ਹੁੰਦਾ ਹੈ ਜਦੋਂ relevant log records ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ ਡਿਸਕ 'ਤੇ ਹੋਵਨ।
ਜੇ crash commit ਦੇ ਬਹੁਤ ਜਲਦੀ ਬਾਅਦ ਹੁੰਦਾ ਹੈ, recovery ਲੌਗ ਨੂੰ replay ਕਰਕੇ committed state ਨੂੰ reconstruct ਕਰ ਸਕਦੀ ਹੈ। ਜੇ crash commit ਤੋਂ ਪਹਿਲਾਂ ਆਇਆ, ਤਾਂ ਲੌਗ rollback ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
ਬੈਕਅਪ ਇੱਕ snapshot ਹੈ। ਲੌਗ ਇੱਕ ਇਤਿਹਾਸ ਹੈ। ਬੈਕਅਪ catastrophic loss (ਬੁਰਾ deploy, ਡ੍ਰੌਪ ਕੀਤਾ ਟੇਬਲ, ransomware) ਦੇ ਹੱਲ ਲਈ ਹੈ। ਲੌਗ ਹਾਲੀਆ committed ਕੰਮ recover ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਅਤੇ point-in-time recovery ਸਪੋਰਟ ਕਰਦਾ ਹੈ: ਬੈਕਅਪ restore ਕਰੋ, ਫਿਰ ਲੌਗਸ replay ਕਰਕੇ ਚੁਣੀ ਹੋਈ ਮੋਮੈਂਟ ਤੱਕ ਜਾਓ।
ਜੋ ਬੈਕਅਪ ਤੁਸੀਂ ਕਦੇ restore ਨਹੀਂ ਕੀਤਾ ਉਹ ਆਸ ਹੈ, ਯੋਜਨਾ ਨਹੀਂ। ਨਿਯਮਤ ਰੂਪ ਵਿੱਚ restore drills ਸ਼ੈਡਿੰਗ ਵਿਚ ਕਰਨ, ਡੇਟਾ ਇੰਟੀਗ੍ਰਿਟੀ ਚੈੱਕਸ ਵੈਰੀਫਾਈ ਕਰਨ, ਅਤੇ recovery ਦਾ ਸਮਾਂ ਮਾਪੋ। ਜੇ ਇਹ ਤੁਹਾਡੇ RTO/RPO ਲੋੜਾਂ ਨੂੰ ਪੂਰਾ ਨਹੀਂ ਕਰਦਾ, ਤਾਂ retention, log shipping, ਜਾਂ backup cadence adjust ਕਰੋ ਪਹਿਲਾਂ ਕਿ ਕੋਈ incident ਤੁਹਾਨੂੰ ਸਿਖਾਏ।
ACID ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਇੱਕ ਡੇਟਾਬੇਸ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਲਈ "source of truth" ਹੋ ਸਕਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਕਾਰੋਬਾਰਕ ਕਾਰਵਾਈ ਨੂੰ ਕਈ ਸੇਵਾਵਾਂ (payments, inventory, email, analytics) ਵਿੱਚ ਫੈਲਾ ਦਿੰਦੇ ਹੋ, ਤਦ ਤੁਸੀਂ distributed systems ਖੇਤਰ ਵਿੱਚ ਦਾਖ਼ਲ ਹੋ—ਜਿੱਥੇ ਫੇਲਿਅਰ ਸਾਫ "ਸਫਲ" ਜਾਂ "ਗਲਤ" ਵਰਗੇ ਨਹੀਂ ਲੱਗਦੇ।
Distributed setup ਵਿੱਚ ਤੁਹਾਨੂੰ partial failures ਮਨਣੇ ਪੈਂਦੇ ਹਨ: ਇੱਕ ਸੇਵਾ commit ਕਰ ਸਕਦੀ ਹੈ ਜਦੋਂ ਦੂਜੀ crash ਹੋ ਜਾਵੇ, ਜਾਂ ਨੈੱਟਵਰਕ ਹਿੱਕ ਸੱਚੇ ਨਤੀਜੇ ਨੂੰ ਛੁਪਾ ਸਕਦੀ ਹੈ। ਹੋਰ ਖ਼ਰਾਬ ਗੱਲ ਇਹ ਹੈ ਕਿ timeouts ambiguous ਹੁੰਦੇ ਹਨ—ਦੂਜੇ ਪਾਸੇ fail ਹੋਇਆ ਕਿ ਢੀਰ ਹੋ ਰਿਹਾ ਹੈ?
ਉਹੀ ਅਸਪਸ਼ਟਤਾ double-charges, overselling ਅਤੇ missing entitlements ਨੂੰ ਜਨਮ ਦਿੰਦੀ ਹੈ।
Two-phase commit ਕਈ ਡੇਟਾਬੇਸਾਂ ਨੂੰ "ਇੱਕ ਵਾਂਗ" commit ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ।
2PC ਨੂੰ ਟੀਮਾਂ ਅਕਸਰ avoid ਕਰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ slow ਹੋ ਸਕਦੀ ਹੈ, locks ਲੰਬੇ ਸਮੇਂ ਲਈ ਰੱਖਦੀ ਹੈ (throughput ਘਟਦਾ ਹੈ), ਅਤੇ coordinator bottleneck ਬਣ ਸਕਦਾ ਹੈ। ਇਹ ਸਿਸਟਮਾਂ ਨੂੰ ਕੱਠਾ ਕਰਦਾ ਹੈ: ਸਾਰੇ participants protocol ਬੋਲਣੇ ਹੋਣਗੇ ਅਤੇ high availability ਬਣਾਈ ਰੱਖਣੀ ਹੋਵੇਗੀ।
ਆਮ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ACID ਬਾਰਡਰਜ਼ ਛੋਟੇ ਰੱਖੋ ਅਤੇ cross-service ਕੰਮ ਨੂੰ explicit ਤਰੀਕੇ ਨਾਲ manage ਕਰੋ:
ਜਿੱਥੇ ਸੰਭਵ ਹੋਵੇ, ਸਭ ਤੋਂ ਮਜ਼ਬੂਤ ਗਰੰਟੀ (ACID) ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ ਦੇ ਅੰਦਰ ਰੱਖੋ, ਅਤੇ ਉਸ ਬਾਰਡਰ ਤੋਂ ਬਾਹਰ ਦੀਆਂ ਚੀਜ਼ਾਂ ਨੂੰ retries, reconciliation, ਅਤੇ "ਜੇ ਇਹ ਕਦਮ ਫੇਲ ਹੋਇਆ ਤਾਂ ਕੀ ਹੋਏਗਾ?" ਦੇ ਸਪੱਸ਼ਟ ਬਰਤਾਓ ਨਾਲ ਟ੍ਰੀਟ ਕਰੋ।
ਫੇਲਿਅਰ ਸ਼ੁੱਧ "ਇਹ ਹੋਇਆ ਹੀ ਨਹੀਂ" ਵਰਗੇ ਨਹੀਂ ਹੁੰਦੇ। ਅਕਸਰ, ਇੱਕ ਰੀਕਵੇਸਟ ਅੰਸ਼ਿਕ ਤੌਰ 'ਤੇ ਸਫਲ ਹੋ ਜਾਂਦੀ ਹੈ, ਕਲਾਇੰਟ ਨੂੰ timeout ਮਿਲਦਾ ਹੈ, ਅਤੇ ਕੋਈ (browser, mobile app, job runner, ਜਾਂ partner system) retry ਕਰ ਦਿੰਦਾ ਹੈ।
ਸੁਰੱਖਿਆ ਦੇ ਬਿਨਾਂ, retries ਸਭ ਤੋਂ ਖ਼ਤਰਨਾਕ ਕਿਸਮ ਦਾ ਬਗ ਪੈਦਾ ਕਰਦੇ ਹਨ: ਢੁਕਵੇਂ ਕੋਡ ਜੋ ਕਦੇ-ਕਦੇ double-charge, double-ship, ਜਾਂ double-grant ਕਰ ਬੈਠਦਾ ਹੈ।
Idempotency ਉਹ ਗੁਣ ਹੈ ਕਿ ਇੱਕੋ ਓਪਰੇਸ਼ਨ ਨੂੰ ਕਈ ਵਾਰੀ ਕਰਨ ਨਾਲ ਅੰਤਿਮ ਨਤੀਜਾ ਇੱਕੋ ਹੀ ਰਹਿੰਦਾ ਹੈ ਜਿਵੇਂ ਕਿ ਤੁਸੀਂ ਉਸਨੂੰ ਇੱਕ ਵਾਰੀ ਕੀਤਾ ਹੋਵੇ। ਯੂਜ਼ਰ-ਮੁਖੀ ਸਿਸਟਮਾਂ ਲਈ ਇਹ "safe retries ਬਿਨਾਂ double effects" ਦਾ ਤਰੀਕਾ ਹੈ।
ਇੱਕ ਮਦਦਗਾਰ ਨਿਯਮ: GET ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ idempotent ਹੁੰਦਾ ਹੈ; ਬਹੁਤ ਸਾਰੇ POST ਕਰਵਾਈਆਂ idempotent ਨਹੀਂ ਹੁੰਦੀਆਂ ਜਦ ਤੱਕ ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਇਸਤਰਾਂ ਡਿਜ਼ਾਈਨ ਨਾ ਕਰੋ।
ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਕੁਝ ਮੈਕੈਨਿਜ਼ਮ ਮਿਲਾ ਕੇ ਵਰਤਦੇ ਹੋ:
Idempotency-Key: ...)। ਸਰਵਰ ਉਸ ਕੀ ਨਾਲ outcome ਸਟੋਰ ਕਰਦਾ ਹੈ ਅਤੇ ਦੁਹਰਾਅ 'ਤੇ ਉਹੀ ਨਤੀਜਾ ਵਾਪਸ ਕਰਦਾ ਹੈ।order_id ਲਈ ਇੱਕ ਹੀ payment)ਇਹ ਸਬ ਤੋਂ ਵਧੀਆ ਤੌਰ 'ਤੇ ਕੰਮ ਕਰਦੇ ਹਨ ਜਦੋਂ unique check ਅਤੇ ਅਸਰ ਇੱਕੋ ਹੀ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰਹਿੰਦੇ ਹਨ।
ਇੱਕ timeout ਇੱਥੇ ਮਤਲਬ ਨਹੀਂ ਕਿ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ rollback ਹੋ ਗਿਆ; ਇਹ committed ਹੋ ਸਕਦਾ ਹੈ ਪਰ response ਖੋ ਗਿਆ। ਇਸੀ ਲਈ retry logic ਨੂੰ ਇਹ ਧਾਰਨਾ ਰੱਖਣੀ ਚਾਹੀਦੀ ਹੈ ਕਿ ਸਰਵਰ ਸਫਲ ਹੋ ਸਕਦਾ ਹੈ।
ਆਮ ਪੈਟਰਨ: ਪਹਿਲਾਂ ਇੱਕ idempotency record ਲਿਖੋ (ਜਾਂ ਉਸਨੂੰ lock ਕਰੋ), side effects ਕਰੋ, ਫਿਰ ਉਸਨੂੰ पूरा marcar ਕਰੋ—ਜਦਕਿ ਸੰਭਵ ਹੋਵੇ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ। ਜੇ ਤੁਸੀਂ ਸਭ ਕੁਝ ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ 'ਚ ਨਹੀਂ ਪਾ ਸਕਦੇ (ਉਦਾਹਰਣ ਲਈ, payment gateway ਕਾਲ), ਤਾਂ ਇੱਕ durable "intent" ਸਟੋਰ ਕਰੋ ਅਤੇ ਬਾਅਦ ਵਿੱਚ reconcile ਕਰੋ।
ਜਦੋਂ ਸਿਸਟਮ "ਫਲੇਕੀ" ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ, ਮੂਲ ਕਾਰਨ ਅਕਸਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸੋਚ ਦੀ ਘਾਟ ਹੁੰਦੀ ਹੈ। ਆਮ ਲੱਛਣਾਂ ਵਿੱਚ ਫੈਂਟਮ ਆਰਡਰ ਜੋ ਕੋਈ ਮੈਚਿੰਗ ਭੁਗਤਾਨ ਨਹੀਂ ਰੱਖਦੇ, concurrency ਤੋਂ ਬਾਅਦ negative inventory, ਅਤੇ ਲੈਜਰ, ਇਨਵੌਇਸ ਅਤੇ analytics ਦੇ ਵਿਚਕਾਰ ਮਿਲਦੇ-ਜੁਲਦੇ totals ਨਹੀਂ ਹੁੰਦੇ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਆਪਣੇ invariants Plain English ਵਿੱਚ ਲਿਖੋ—ਉਹ ਸੱਚਾਈਆਂ ਜੋ ਹਮੇਸ਼ਾਂ ਸਹੀ ਰਹਿਣ। ਉਦਾਹਰਣ: "inventory ਕਦੇ zero ਤੋਂ ਘੱਟ ਨਹੀਂ ਹੋਣਾ चाहिए", "ਇੱਕ ਆਰਡਰ ਜਾਂ ਤਾਂ unpaid ਹੈ ਜਾਂ paid (ਦੋਹਾਂ ਨਹੀਂ)", "ਹਰ balance change ਦਾ matching ledger entry ਹੋਵੇ"।
ਫਿਰ ਉਹਨਾਂ invariants ਨੂੰ ਬਚਾਉਣ ਵਾਲੇ ਸਭ ਤੋਂ ਛੋਟੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਬਾਰਡਰਜ਼ define ਕਰੋ। ਜੇ ਇਕ ਵਰਤੋਂਕਾਰ ਦੀ ਕਾਰਵਾਈ ਕਈ rows/tables ਨੂੰ ਛੂਹਦੀ ਹੈ, ਤਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜੇ ਹਿੱਸੇ ਨੂੰ ਇਕੱਠੇ commit ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ ਕਿਹੜੇ ਹਿੱਸੇ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤੌਰ 'ਤੇ deferred ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਆਖਰ ਵਿੱਚ, ਤੈਅ ਕਰੋ ਕਿ load ਹੇਠਾਂ conflicts ਨੂੰ ਤੁਸੀਂ ਕਿਵੇਂ ਹੱਲ ਕਰੋਂਗੇ:
Concurrency bugs ਆਮ ਤੌਰ 'ਤੇ happy-path ਟੈਸਟਾਂ ਵਿੱਚ ਨਹੀਂ ਹੁੰਦੇ। ਉਹਨਾਂ ਨੂੰ ਫੜਨ ਲਈ ਟੈਸਟ ਸ਼ਾਮਲ ਕਰੋ ਜੋ ਦਬਾਅ ਬਣਾਉਂਦੇ ਹਨ:
ਤੁਸੀਂ ਉਸਦੀ ਰੱਖਿਆ ਨਹੀਂ ਕਰ ਸਕਦੇ ਜੋ ਤੁਸੀਂ measure ਨਹੀਂ ਕਰਦੇ। ਉਪਯੋਗੀ ਸੰਕੇਤਾਂ ਵਿੱਚ deadlocks, lock wait time, rollback ਦਰ (ਖ਼ਾਸ ਕਰਕੇ deploy ਤੋਂ ਬਾਅਦ spikes), ਅਤੇ reconciliation diffs (ledger vs balances, orders vs payments) ਸ਼ਾਮਲ ਹਨ। ਇਹ metrics ਅਕਸਰ ਤੁਹਾਨੂੰ ਹਫ਼ਤਿਆਂ ਪਹਿਲਾਂ ਚੇਤਾਵਨੀ ਦਿੰਦੇ ਹਨ ਜ਼ਦੋਂ ਗਾਹਕ "ਗੁੰਮ ਪੈਸਾ" ਜਾਂ inventory ਦੀ ਤੁੱਲੀ ਮਹਿਸੂਸ ਕਰਨਗੇ।
Jim Gray ਦਾ lasting ਯੋਗਦਾਨ ਸਿਰਫ ਗੁਣਾਂ ਦਾ ਸੈੱਟ ਨਹੀਂ ਸੀ—ਇਹ "ਕੀ ਗਲਤ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ" ਲਈ ਇੱਕ ਸਾਂਝਾ ਸ਼ਬਦ-ਭੰਡਾਰ ਸੀ। ਜਦੋਂ ਟੀਮਾਂ ਨਿਸ਼ਚਿਤ ਗਰੰਟੀ ਦਾ ਨਾਮ ਲੈ ਸਕਦੀਆਂ ਹਨ (atomicity, consistency, isolation, durability), ਤਾਂ correctness ਬਾਰੇ ਤਰਕ vague ਤੋਂ actionable ਬਣ ਜਾਂਦੇ ਹਨ ("ਇਹ ਨਿਰਭਰ ਹੋਣਾ ਚਾਹੀਦਾ" ਤੋਂ "ਇਹ update ਉਸ charge ਨਾਲ atomic ਹੋਣਾ ਚਾਹੀਦਾ")।
ਪੂਰੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਰਤੋਂ ਜਦੋਂ ਗਾਹਕ ਉਮੀਦ ਕਰੇ ਕਿ ਇੱਕ ਨਤੀਜਾ ਇੱਕਦਮ ਨਿਰਣਾਇਕ ਹੋਵੇ ਅਤੇ ਗਲਤੀਆਂ ਮਹਿੰਗੀਆਂ ਪੈਂ। ਉਦਾਹਰਣ:
ਇਥੇ, throughput ਲਈ ਗਰੰਟੀ ਹਲਕਾ ਕਰਨ ਨਾਲ ਅਕਸਰ ਸਹਾਇਤਾ ਟਿਕਟ, ਮੈਨੂਅਲ reconciliation, ਅਤੇ ਭਰੋਸੇ ਦਾ ਨੁਕਸਾਨ ਹੀ ਵਧਦਾ ਹੈ।
ਜਿੱਥੇ ਅਸਥਾਈ ਅਸੰਗਤਤਾ ਮਨਜ਼ੂਰਯੋਗ ਅਤੇ ਆਸਾਨੀ ਨਾਲ ਠੀਕ ਹੋ ਸਕਦੀ ਹੈ, ਓਥੇ ਗਰੰਟੀਆਂ ਹਲਕੀ ਕਰੋ:
ਚਾਲਾਕੀ ਇਹ ਹੈ ਕਿ ਇੱਕ ਸਪੱਸ਼ਟ ACID ਬਾਰਡਰ ਨੂੰ "source of truth" ਦੇ ਆਲੇ-ਦੁਆਲੇ ਰੱਖੋ, ਅਤੇ ਬਾਕੀ ਸਭ ਨੂੰ ਥੋੜ੍ਹਾ ਪਿੱਛੇ ਰਹਿਣ ਦਿਓ।
ਜੇ ਤੁਸੀਂ ਇਹ flows prototype ਕਰ ਰਹੇ ਹੋ (ਜਾਂ legacy pipeline ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਉਂਦੇ ਹੋ), ਤਾਂ ਇਕ ਐਸਾ stack ਚੁਣੋ ਜੋ transactions ਅਤੇ constraints ਨੂੰ ਪਹਿਲੀ-ਪ੍ਰਾਥਮਿਕਤਾ ਦੇਵੇ। ਉਦਾਹਰਣ ਲਈ, Koder.ai ਇੱਕ ਸਧਾਰਨ chat ਤੋਂ React front end ਅਤੇ Go + PostgreSQL backend generate ਕਰ ਸਕਦਾ ਹੈ, ਜੋ ਪ੍ਰਯੋਗਕ ਤੌਰ 'ਤੇ "ਅਸਲ" transaction ਬਾਰਡਰਜ਼ ਜਲਦੀ ਖੜੇ ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ (ਜਿਸ ਵਿੱਚ idempotency records, outbox tables, ਅਤੇ rollback-safe workflows ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ) ਪਹਿਲਾਂ ਕਿ ਤੁਸੀਂ ਪੂਰੇ microservices ਰੋਲਆਊਟ ਵਿੱਚ ਨਿਵੇਸ਼ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਹੋਰ ਪੈਟਰਨ ਅਤੇ ਚੈਕਲਿਸਟ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਉਨ੍ਹਾਂ ਉਮੀਦਾਂ ਨੂੰ /blog 'ਤੇ ਲਿੰਕ ਕਰੋ। ਜੇ ਤੁਸੀਂ tier ਦੁਆਰਾ reliability ਉਮੀਦਾਂ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਉਹਨਾਂ ਨੂੰ /pricing 'ਤੇ ਸਪੱਸ਼ਟ ਰੱਖੋ ਤਾਂ ਕਿ ਗਾਹਕ ਜਾਣ ਸਕਣ ਕਿ ਉਹ ਕਿਸ ਤਰ੍ਹਾਂ ਦੀ correctness ਗਰੰਟੀ ਖਰੀਦ ਰਹੇ ਹਨ।
Jim Gray ਇੱਕ ਕੰਪਿਊਟਰ ਵਿਗਿਆਨੀ ਸਨ ਜੀਂਹਨਾਂ ਝੜਪਾਂ ਅਤੇ ਅਣਜਾਣ ਹਾਲਾਤਾਂ ਹੇਠਾਂ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਪ੍ਰੋਸੈਸਿੰਗ ਨੂੰ ਪ੍ਰਯੋਗਯੋਗ ਅਤੇ ਸਮਝਣਯੋਗ ਬਣਾਇਆ। ਉਹਨਾਂ ਦੀ ਵਿਰਾਸਤ ਇਹ ਸੋਚ ਹੈ ਕਿ ਮਹੱਤਵਪੂਰਨ ਬਹੁ-ਕਦਮੀ ਕਾਰਵਾਈਆਂ (ਪੈਸੇ ਦੀ ਹਰਕਤ, ਚੈਕਆਉਟ, subscription ਬਦਲਾਅ) ਨੂੰ concurrency ਅਤੇ ਫੇਲਿਅਰਾਂ ਹੇਠਾਂ ਵੀ "ਸਹੀ ਨਤੀਜੇ" ਦੇਣੇ ਚਾਹੀਦੇ ਹਨ।
ਦਿਨ-ਇਨ-ਦਿਨ ਦੇ ਉਤਪਾਦੀ ਸ਼ਬਦਾਂ ਵਿੱਚ: ਘੱਟ “ਰਹੱਸਮਈ ਹਾਲਤਾਂ”, ਘੱਟ ਜੋੜ-ਤੋੜ ਦੀਆਂ ਅੱਗ-ਬੁਝਾਈਆਂ, ਅਤੇ ਇਹ ਸਪੱਸ਼ਟ ਗੈਰੰਟੀ ਕਿ "committed" ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
ਇੱਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਕਈ ਅਪਡੇਟਾਂ ਨੂੰ ਇਕੱਠੇ "ਸਭ-ਜਾਂ-ਕੋਈ ਨਹੀਂ" ਇਕਾਈ ਵਜੋਂ ਗਿਣਦਾ ਹੈ। ਜਦੋਂ ਸਭ ਕਦਮ ਸਫਲ ਹੁੰਦੇ ਹਨ ਤਾਂ ਤੁਸੀਂ commit ਕਰਦੇ ਹੋ; ਜੇ ਕੁਝ ਵੀ ਫੇਲ ਹੁੰਦਾ ਹੈ ਤਾਂ ਤੁਸੀਂ roll back ਕਰਦੇ ਹੋ।
ਆਮ ਉਦਾਹਰਣ:
ACID ਉਹ ਗਰੰਟੀਜ਼ ਹਨ ਜੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੀਆਂ ਹਨ:
ਇਹ ਕੋਈ ਇਕ ਸਵਿੱਚ ਨਹੀਂ—ਤੁਸੀਂ ਫੈਸਲਾ ਕਰਦੇ ਹੋ ਕਿ ਕਿੱਥੇ ਅਤੇ ਕਿੰਨੀ ਮਜ਼ਬੂਤੀ ਚਾਹੀਦੀ ਹੈ।
ਜਿਆਦਾਤਰ "ਸਿਰਫ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਹੁੰਦਾ ਹੈ" ਵਾਲੇ ਬੱਗ ਆਮ ਤੌਰ 'ਤੇ load ਹੇਠਾਂ ਕਮਜ਼ੋਰ isolation ਕਾਰਨ ਹੁੰਦੇ ਹਨ।
ਆਮ failure ਪੈਟਰਨ:
ਵਿਹਵਾਰਿਕ ਠੀਕ ਕਰਨ ਦਾ ਤਰੀਕਾ: ਵਪਾਰਕ ਖਤਰੇ ਦੇ ਅਧਾਰ 'ਤੇ isolation ਲੈਵਲ ਚੁਣੋ, ਅਤੇ ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ constraints ਜਾਂ locking ਨਾਲ backstop ਕਰੋ।
ਸਾਧਾਰਨ ਤੌਰ 'ਤੇ, ਪਹਿਲਾਂ ਪੰਜਾਬੇ ਵਿੱਚ ਆਪਣੀਆਂ ਇਨਵੇਰੀਐਂਟ ਲਿਖੋ (ਉਹ ਸੱਚਾਈਆਂ ਜੋ ਹਮੇਸ਼ਾ ਸੱਚ ਰਹਿਣ ਚਾਹੀਦੀਆਂ ਹਨ), ਫਿਰ ਉਹਨਾਂ ਨੂੰ ਘੱਟ ਤੋਂ ਘੱਟ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਸਕੋਪ ਵਿੱਚ ਬੰਦ ਕਰੋ।
ਵਧੀਆ ਮਿਲ ਕੇ ਕੰਮ ਕਰਨ ਵਾਲੇ ਮੈਕੈਨਿਜ਼ਮ:
ਜਦੋਂ ਐਪ ਕੋਡ concurrency ਗਲਤ ਕਰ ਦੇਵੇ, ਤਾਂ constraints ਇੱਕ ਸੁਰੱਖਿਆ ਨੈੱਟ ਵਜੋਂ ਕੰਮ ਕਰਦੇ ਹਨ।
Write-ahead logging (WAL) ਡੇਟਾਬੇਸਾਂ ਨੂੰ "commit" ਨੂੰ crash ਤੋਂ ਬਾਅਦ ਵੀ ਬਚਾਉਣ ਦਾ ਤਰੀਕਾ ਦਿੰਦਾ ਹੈ।
ਪ੍ਰਕਿਰਿਆਕ रूप से:
ਇਸ ਲਈ ਇੱਕ ਚੰਗਾ ਡਿਜ਼ਾਇਨ ਇਹ ਹੋ ਸਕਦਾ ਹੈ: ਜੇ ਕੁਝ committed ਸੀ ਤਾਂ ਉਹ power loss ਤੋਂ ਬਾਅਦ ਵੀ ਟਿਕਦਾ ਰਹੇਗਾ।
ਬੈਕਅਪ ਇੱਕ point-in-time snapshot ਹੈ; ਲੌਗ ਉਸ snapshot ਤੋਂ ਬਾਅਦ ਹੋਏ ਬਦਲਾਵਾਂ ਦਾ ਇਤਿਹਾਸ।
ਇੱਕ ਪ੍ਰੈਕਟਿਕਲ recovery ਰੂਪਰੇਖਾ:
ਜੇ ਤੁਸੀਂ ਕਦੇ restore ਨਹੀਂ ਕੀਤਾ, ਤਾਂ ਉਹ ਇੱਕ ਯੋਜਨਾ ਨਹੀਂ—ਸਿਰਫ ਇੱਕ ਆਸ ਹੈ।
Distributed ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਵਿੱਚ partial failures ਅਤੇ ambiguous timeouts ਹੁੰਦੇ ਹਨ—ਇਹੀ ਉਹ ਸਥਾਨ ਹੈ ਜਿੱਥੇ double-charges, overselling ਅਤੇ ਗੁੰਮ entitlements ਪੈਦਾ ਹੁੰਦੀਆਂ ਹਨ।
Two-phase commit (2PC) ਅਕਸਰ ਟੀਮਾਂ ਦੁਆਰਾ ਟਾਲਿਆ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ:
ਜਦੋਂ ਤੁਸੀਂ ਵਾਸਤਵ ਵਿੱਚ cross-system atomicity ਚਾਹੁੰਦੇ ਹੋ ਅਤੇ operational complexity ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ, ਤਾਂ ਹੀ 2PC ਵਰਤੋਂ।
ਸਧਾਰਨ ਨਿਯਮ: ਛੋਟੇ ਲੋਕਲ ACID ਸੀਮਾਵਾਂ ਨੂੰ ਰੱਖੋ ਅਤੇ ਸੇਵਾਵਾਂ ਦੇ ਵਿਚਕਾਰ ਸਪੱਸ਼ਟ ਕੋਆਰਡੀਨੇਸ਼ਨ ਕਰੋ।
ਆਮ ਪੈਟਰਨ:
ਇਹ ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਫੇਲਿਅਰ ਹਾਲਤਾਂ ਹੇਠਾਂ ਅਣੁਮਾਨਯੋਗ ਵਰਤਾਰਾਂ ਦਿੰਦੇ ਹਨ ਬਿਨਾਂ ਹਰ ਵਰਕਫਲੋ ਨੂੰ ਗਲੋਬਲ ਲੌਕ ਵਿਚ ਬਦਲਣ ਦੇ।
Failure ਅਕਸਰ ਇਸ ਤਰ੍ਹਾਂ ਹੁੰਦੀ ਹੈ: ਇਕ ਰੀਕਵੇਸਟ ਅੰਸ਼ਿਕ ਤੌਰ 'ਤੇ ਸਫਲ ਹੋ ਜਾਂਦੀ ਹੈ, ਕਲਾਇੰਟ ਨੂੰ timeout ਮਿਲਦਾ ਹੈ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ retry ਹੁੰਦੀ ਹੈ।
ਇਸਦੇ ਬਿਨਾਂ retries ਸਭ ਤੋਂ ਖ਼ਤਰਨਾਕ ਬਗ ਪੈਦਾ ਕਰਦੇ ਹਨ: ਦੋ-ਚਾਰਜ, ਦੋ-ਸ਼ਿਪ ਜਾਂ ਦੋ-ਵਾਰ ਐਕਸੈਸ ਮਿਲਣਾ।
ਰੋਕਥਾਮ ਲਈ ਉਪਾਇ:
order_id ਲਈ ਇੱਕ ਹੀ payment)ਜਿੰਨਾ ਹੋ ਸਕੇ dedupe ਚੈੱਕ ਅਤੇ ਅਸਰ ਇੱਕੋ ਹੀ ਡੇਟਾਬੇਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਵਿੱਚ ਰੱਖੋ।