09 ਜੁਲਾ 2025·8 ਮਿੰਟ
Joe Armstrong ਅਤੇ Erlang: ਭਰੋਸੇਯੋਗ ਪਲੇਟਫਾਰਮਾਂ ਲਈ Let It Crash
ਪਤਾ ਕਰੋ ਕਿ Joe Armstrong ਨੇ Erlang ਦੀ concurrency, supervision ਅਤੇ “let it crash” ਸੋਚ ਨੂੰ ਕਿਵੇਂ ਰੂਪ ਦਿੱਤਾ—ਉਹ ਵਿਚਾਰ ਅਜੇ ਵੀ ਭਰੋਸੇਯੋਗ ਰੀਅਲ-ਟਾਈਮ ਸੇਵਾਵਾਂ ਬਣਾਉਣ ਲਈ ਵਰਤੇ ਜਾਂਦੇ ਹਨ।
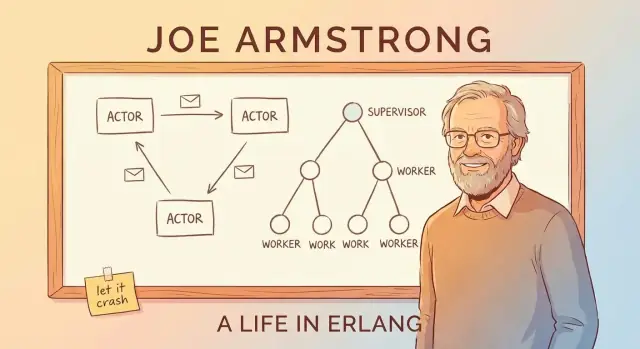
ਇਸ ਪੋਸਟ 'ਚ ਕੀ ਕਵਰ ਕੀਤਾ ਗਿਆ (ਅਤੇ ਇਹ ਅੱਜ ਵੀ ਕਿਉਂ ਮਹੱਤਵਪੂਰਨ ਹੈ)
Joe Armstrong ਨੇ ਸਿਰਫ Erlang ਬਣਾਇਆ ਹੀ ਨਹੀਂ — ਉਹ ਇਸਦਾ ਸਭ ਤੋਂ ਸਪਸ਼ਟ ਅਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਵਿਆਖਿਆਕਾਰ ਬਣ ਕੇ ਰਹਿ ਗਏ। ਟਾਕਸ, ਪੇਪਰਾਂ ਅਤੇ ਇੱਕ ਪ੍ਰਜ਼ਗਮੈਟਿਕ ਨਜ਼ਰੀਏ ਦੁਆਰਾ ਉਹਨਾ ਨੇ ਇੱਕ ਸਧਾਰਣ خیال ਨੂੰ ਲੋਕਪ੍ਰਿਯ ਕੀਤਾ: ਜੇ ਤੁਸੀਂ ਉਹ ਸੋਫਟਵੇਅਰ ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਚੱਲਦਾ ਰਹੇ, ਤਾਂ ਤਕਨਾਲੋਜੀ ਨੂੰ ਅਸਫਲਤਾ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ ਨਾ ਕਿ ਇਹ ਸੋਚੋ ਕਿ ਤੁਸੀਂ ਅਸਫਲਤਾ ਤੋਂ ਬਚ ਸਕੋਗੇ।
ਇਹ ਪੋਸਟ Erlang ਦੀ ਸੋਚ ਦਾ ਇੱਕ ਰਾਹ-ਦਰਸ਼ਨ ਹੈ ਅਤੇ ਦਿਖਾਉਂਦੀ ਹੈ ਕਿ ਜਦੋਂ ਤੁਸੀਂ ਭਰੋਸੇਯੋਗ ਰੀਅਲ-ਟਾਈਮ ਪਲੇਟਫਾਰਮ ਬਣਾਉਂਦੇ ਹੋ ਤਾਂ ਇਹ ਕਿਉਂ ਅਹਿਮ ਹੈ — ਜਿਵੇਂ ਕਿ ਚੈਟ ਸਿਸਟਮ, ਕਾਲ ਰੂਟਿੰਗ, ਲਾਈਵ ਨੋਟੀਫਿਕੇਸ਼ਨ, ਮਲਟੀਪਲੇਅਰ ਕੋਆਰਡੀਨੇਸ਼ਨ ਅਤੇ ਉਹ ਇੰਫ੍ਰਾਸਟਰੱਕਚਰ ਜੋ ਤੇਜ਼ੀ ਅਤੇ ਲਗਾਤਾਰ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਨ ਭਾਵੇਂ ਕੁਝ ਹਿੱਸੇ ਗਲਤ ਵਰਤੋਂ ਕਰ ਰਹੇ ਹੋਣ।
“ਰੀਅਲ-ਟਾਈਮ” ਆਮ ਭਾਸ਼ਾ ਵਿੱਚ
ਰੀਅਲ-ਟਾਈਮ ਹਰ ਵੇਲੇ “ਮਾਇਕ੍ਰੋਸੈਕਿੰਡ” ਜਾਂ “ਹਾਰਡ ਡੈੱਡਲਾਈਨ” ਨਹੀਂ ਹੁੰਦਾ। ਕਈ ਪ੍ਰੋਡਕਟਾਂ ਵਿੱਚ ਇਸਦਾ ਮਤਲਬ ਹੁੰਦਾ ਹੈ:
- ਤੇਜ਼ ਜਵਾਬ ਜੋ ਯੂਜ਼ਰ ਮਹਿਸੂਸ ਕਰ ਸਕਦੇ ਹਨ (ਕੋਈ ਅਚਾਨਕ ਰੁਕਾਵਟ ਨਹੀਂ)
- ਲੋਡ ਹੇਠਾਂ ਪੇਸ਼ਗੋਈ ਯੋਗ ਵਿਹਾਰ (ਸ਼ਾਇਦ ਧੀਮਾ ਹੋਵੇ, ਪਰ ਘੱਟੋ-ਘੱਟ ਭਰਭਰਾ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ)
- ਅੰਸ਼ਿਕ ਫੇਲ੍ਹਰ ਦੌਰਾਨ ਸੇਵਾ ਜਾਰੀ ਰਹਿਣਾ (ਇੱਕ ਖਰਾਬ ਕੰਪੋਨੈਂਟ ਸਾਰਾ ਸਿਸਟਮ ਡਾਊਨ ਨਹੀਂ ਲਿਆਣਾ ਚਾਹੀਦਾ)
Erlang ਟੈਲੀਕੋਮ ਸਿਸਟਮਾਂ ਲਈ ਬਣਾਇਆ ਗਿਆ ਸੀ ਜਿੱਥੇ ਇਹ ਉਮੀਦਾਂ ਬਿਨਾ ਗੱਲ-ਬਾਤ ਦੇ ਮੰਨੀਆਂ ਜਾਂਦੀਆਂ ਸਨ — ਅਤੇ ਇਹ ਦਬਾਅ ਇਸ ਦੇ ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਵਿਚਾਰਾਂ ਨੂੰ ਰੂਪ ਦਿੱਤਾ।
ਅਸੀਂ ਜਿਹੜੇ ਤਿੰਨ ਖੰਭਾਂ 'ਤੇ ਧਿਆਨ ਦੇਵਾਂਗੇ
ਸਿੰਟੈਕਸ ਵਿੱਚ ਡਿੱਠੇ ਬਿਨਾਂ, ਅਸੀਂ ਉਹ ਧਾਰਨਾਵਾਂ 'ਤੇ ਧਿਆਨ ਦੇਵਾਂਗੇ ਜਿਨ੍ਹਾਂ ਨੇ Erlang ਨੂੰ ਮਸ਼ਹੂਰ ਕੀਤਾ ਅਤੇ ਜੋ ਅਧੁਨਿਕ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਵਿੱਚ ਵਾਪਸ-ਵਾਪਸ ਆ ਰਹੀਆਂ ਹਨ:
- ਸਮਕਾਲੀਤਾ ਐਨ-ਡਿਫਾਲਟ: ਇੱਕ ਜਾਂ ਦੋ ਵੱਡੇ ਕੰਮਾਂ ਵਾਲੇ ਪ੍ਰੋਗਰਾਮ ਦੀ ਥਾਂ ਕਈ ਛੋਟੇ, ਅਲੱਗ ਵਰਕਰ ਬਣਾਓ।
- ਫੌਲਟ ਟੋਲਰੈਂਸ ਇੱਕ ਡਿਜ਼ਾਈਨ ਲਕਸ਼ਯ: ਮੰਨੋ ਕਿ ਬੱਗ, ਟਾਈਮਆਊਟ ਅਤੇ ਕਰੈਸ਼ ਹੋਣਗੇ—ਅਤੇ ਅੱਗੇ ਕੀ ਹੋਵੇਗਾ ਇਹ ਯੋਜਨਾ ਬਣਾਓ।
- “Let it crash”: ਹਰ ਲਾਈਨ ਕੋਡ ਦੀ ਬੇਹੱਦ ਰੱਖਿਆ ਨਾ ਕਰੋ; ਫੇਲ੍ਹ ਤੇਜ਼ੀ ਨਾਲ ਹੋਵੇ ਅਤੇ ਸਾਫ਼ ਸਥਿਤੀ ਵਿੱਚ ਵਾਪਸ ਆਓ, ਧੁੰਧਲੇ ਹੌਂਸਲੇ ਨਾਲ ਨਹੀਂ।
ਇਸ ਰਾਹ 'ਤੇ ਅਸੀਂ actor ਮਾਡਲ ਅਤੇ ਮੇਸੇਜ ਪਾਸਿੰਗ ਨਾਲ ਜੋੜਾਂਗੇ, ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀਆਂ ਅਤੇ OTP ਨੂੰ ਸਧਾਰਣ ਸ਼ਬਦਾਂ ਵਿੱਚ ਸਮਝਾਵਾਂਗੇ, ਅਤੇ ਦਿਖਾਵਾਂਗੇ ਕਿ BEAM VM ਸਾਰੇ ਤਰੀਕੇ ਨੂੰ ਪ੍ਰਾਇਕਟੀਕਲ ਕਿਵੇਂ ਬਣਾਉਂਦਾ ਹੈ।
ਭਾਵੇਂ ਤੁਸੀਂ Erlang ਨਹੀਂ ਵਰਤ ਰਹੇ (ਅਤੇ ਸ਼ਾਇਦ ਕਦੇ ਨਹੀਂ ਵਰਤੋਂਗੇ), Armstrong ਦੀ ਰੇਖਾ ਤੁਹਾਡੇ ਲਈ ਇੱਕ ਤਾਕਤਵਰ ਚੈਕਲਿਸਟ ਦਿੰਦੀ ਹੈ ਜੋ ਅਜਿਹੇ ਸਿਸਟਮ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ ਜੋ ਗੰਦੇ ਹਾਲਾਤਾਂ ਵਿੱਚ ਵੀ ਜਵਾਬਦੇਹ ਅਤੇ ਉਪਲਬਧ ਰਹਿੰਦੇ ਹਨ।
Joe Armstrong ਦੀ ਪ੍ਰੇਰਨਾ: ਐਸੇ ਸਿਸਟਮ ਬਣਾਉਣਾ ਜੋ ਚੱਲਦੇ ਰਹਿੰਦੇ ਹਨ
ਟੈਲੀਕੋਮ ਸੁਇਚਾਂ ਅਤੇ ਕਾਲ-ਰੂਟਿੰਗ ਪਲੇਟਫਾਰਮ ਉਹ ਨਹੀਂ ਜਿਹੜੇ "ਮੇਨਟੇਨੈਂਸ ਲਈ ਡਾਊਨ" ਹੋ ਸਕਦੇ। ਉਹਨਾਂ ਤੋਂ ਉਮੀਦ ਰਹਿੰਦੀ ਹੈ ਕਿ ਉਹ calls, billing events ਅਤੇ signaling ਟ੍ਰੈਫਿਕ ਨੂੰ ਰਾਤ-ਦਿਨ ਹੈਂਡਲ ਕਰਨ — ਅਕਸਰ availability ਅਤੇ ਪੇਸ਼ਗੋਈ ਯੋਗ ਜਵਾਬ ਸਮੇਂ ਲਈ ਕਠੋਰ ਮਾਪਦੰਡਾਂ ਦੇ ਨਾਲ।
Erlang 1980s ਦੇ ਆਖਰੀ ਦਹਾਕੇ ਵਿੱਚ Ericsson ਦੇ ਅੰਦਰ ਇੱਕ ਕੋਸ਼ਿਸ਼ ਵਜੋਂ ਸ਼ੁਰੂ ਹੋਇਆ ਸੀ ਜਿਸਦਾ ਮਕਸਦ ਇਹ ਅਸਲੀਅਤਾਂ ਸਾਫਟਵੇਅਰ ਨਾਲ ਮਿਲਕੇ ਪੂਰੀਆਂ ਕਰਨੀ ਸਨ, ਨਾ ਕਿ ਸਿਰਫ਼ ਵਿਸ਼ੇਸ਼ ਹਾਰਡਵੇਅਰ। Joe Armstrong ਤੇ ਉਸਦੇ ਸਹਯੋਗੀ ਸੁੰਦਰਤਾ ਲਈ ਨਹੀਂ, ਬਲਕਿ ਓਹ ਪਰਯਾਪਤ ਤੌਰ ਤੇ ਅਜਿਹੇ ਸਿਸਟਮ ਬਣਾਉਣ ਲਈ ਸੋਚ ਰਹੇ ਸਨ ਜਿਸ 'ਤੇ ਆਪਰੇਟर्स ਭਰੋਸਾ ਕਰ ਸਕਣ — ਲਗਾਤਾਰ ਲੋਡ, ਅੰਸ਼ਿਕ ਫੇਲ੍ਹਰ ਅਤੇ ਅਸਲੀ ਦੁਨੀਆ ਦੀ ਗੜਬੜ ਦੇ ਬਾਵਜੂਦ।
ਅਮਲ ਵਿੱਚ “ਰਿਲਾਇਬਲ” ਦਾ ਕੀ ਮਤਲਬ ਸੀ
ਸੋਚ ਵਿੱਚ ਇੱਕ ਮੁੱਖ ਬਦਲਾਅ ਇਹ ਸੀ ਕਿ ਯਕੀਨ ਨੂੰ "ਕਦੇ ਫੇਲ੍ਹ ਨਾ ਹੋਣਾ" ਦੇ ਨਾਲ ਸਮਾਨ ਨਾ ਕੀਤਾ ਜਾਵੇ। ਵੱਡੇ, ਲੰਬੇ ਚਲਣ ਵਾਲੇ ਸਿਸਟਮਾਂ ਵਿੱਚ ਕੁਝ ਨਾ ਕੁਝ ਫੇਲ੍ਹ ਹੋਵੇਗਾ: ਇੱਕ ਪ੍ਰੋਸੈਸ ਅਣਛਾਹੀ ਇਨਪੁਟ ਉੱਤੇ ਲੱਗ ਸਕਦਾ ਹੈ, ਇੱਕ ਨੋਡ ਰੀਬੂਟ ਹੋ ਸਕਦਾ ਹੈ, ਨੈੱਟਵਰਕ ਲਿੰਕ ਝਟਕਾ ਖਾ ਸਕਦੀ ਹੈ, ਜਾਂ ਇੱਕ ਡੀਪੈਂਡੇੰਸੀ ਸਟਾਲ ਹੋ ਸਕਦੀ ਹੈ।
ਤਾਂ ਲਕਸ਼ਯ ਬਣਦਾ ਹੈ:
- ਯੂਜ਼ਰਾਂ ਨੂੰ ਸਰਵ ਕਰਦੇ ਰਹੋ ਭਾਵੇਂ ਕੁਝ ਹਿੱਸੇ ਗਲਤ ਕਰ ਰਹੇ ਹੋਣ
- ਫੇਲ੍ਹਰਾਂ ਦਾ ਤੇਜ਼ ਪਤਾ ਲਗਾਓ
- ਘੱਟ ਤੋਂ ਘੱਟ ਮਨੁੱਖੀ ਹਸਤਖੇਪ ਨਾਲ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਰਿਕਵਰ ਕਰੋ
- ਫੌਲਟਾਂ ਨੂੰ ਅਲੱਗ ਰੱਖੋ ਤਾਂ ਕਿ ਇੱਕ ਬੱਗ ਸਾਰਾ ਕੁਝ ਨਹੀਂ ਲੈ ਜਾਏ
ਇਹੀ ਮਨੋਭਾਵ ਬਾਅਦ ਵਿੱਚ ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀਆਂ ਅਤੇ “let it crash” ਵਰਗੀਆਂ ਵਿਚਾਰਾਂ ਨੂੰ ਵਾਜਬ ਬਣਾਉਂਦਾ ਹੈ: ਤੁਸੀਂ ਅਸਫਲਤਾ ਨੂੰ ਇੱਕ ਆਮ ਘਟਨਾ ਮੰਨ ਕੇ ਡਿਜ਼ਾਈਨ ਕਰਦੇ ਹੋ, ਨਾ ਕਿ ਇੱਕ ਭਾਰੀ ਬਿਪਤਾ।
ਘੱਟ ਮਿਥ ਅਤੇ ਜ਼ਿਆਦਾ ਸਮੱਸਿਆ-ਹੱਲ
ਇਹ ਕਹਾਣੀ ਇੱਕ ਇੱਕਦਰਸ਼ ਮਹਾਨ ਵਿਜ਼ਨਰੀ ਦੀ ਉਪਲਬਧੀ ਵਾਂਗ ਨਹੀਂ ਦਿਸ਼ ਰਹੀ — ਬਦلے ਵਿੱਚ ਸਭ ਤੋਂ ਵਰਤੋਂਯੋਗ ਨਜ਼ਰੀਆ ਸਧਾਰਨ ਹੈ: ਟੈਲੀਕੋਮ ਦੀਆਂ ਮੰਗਾਂ ਨੇ ਵੱਖਰੇ ਤਰ੍ਹਾਂ ਦੇ ਟਰੇਡ-ਆਫ਼ਾਂ ਨੂੰ ਜਨਮ ਦਿੱਤਾ। Erlang ਨੇ concurrency, isolation ਅਤੇ recovery ਨੂੰ ਤਰਜੀਹ ਦਿੱਤੀ ਕਿਉਂਕਿ ਇਹ ਉਹ ਪ੍ਰਾਇਗਟਿਕ ਟੂਲ ਸਨ ਜੋ ਸੇਵਾਵਾਂ ਨੂੰ ਚੱਲਦੇ ਰੱਖਣ ਲਈ ਲੋਜ਼ਮੀ ਸਨ ਜਦੋਂ ਦੁਨੀਆ ਬਦਲ ਰਹੀ ਸੀ।
ਇਹ ਸਮੱਸਿਆ-ਪਹਿਲਾ ਫ੍ਰੇਮ Erlang ਦੇ ਸਬਕਾਂ ਨੂੰ ਅੱਜ ਵੀ ਬਹੁਤ ਜਗ੍ਹਾ ਵਰਤਣ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ—ਜਿੱਥੇ uptime ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਰਿਕਵਰੀ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦੇ ਹਨ।
ਡਿਫਾਲਟ ਵਜੋਂ ਸਮਕਾਲੀਤਾ: ਕਈ ਛੋਟੇ ਵਰਕਰ
Erlang ਦੀ ਇੱਕ ਮੁੱਖ ਧਾਰਣਾ ਇਹ ਹੈ ਕਿ "ਕਈ ਕੰਮ ਇੱਕਠੇ ਕਰਨਾ" ਕੋਈ ਖਾਸ ਫੀਚਰ ਨਹੀਂ ਜੋ ਤਦੋਂ ਜੋੜਿਆ ਜਾਵੇ — ਇਹ ਉਹ ਆਮ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ ਤੁਸੀਂ ਸਿਸਟਮ ਨੂੰ ਬਣਾਉਂਦੇ ਹੋ।
ਲਾਈਟਵੇਟ ਪ੍ਰੋਸੈਸ, ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ
Erlang ਵਿੱਚ ਕੰਮ ਨੂੰ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ “ਪ੍ਰੋਸੈਸ” ਵਿੱਚ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ। ਉਨ੍ਹਾਂ ਨੂੰ ਛੋਟੇ ਵਰਕਰ ਸੋਚੋ, ਹਰ ਇੱਕ ਇਕ ਕੰਮ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਲਈ: ਇੱਕ ਫੋਨ ਕਾਲ ਸੰਭਾਲਣਾ, ਇੱਕ ਚੈਟ ਸੈਸ਼ਨ ਟਰੈਕ ਕਰਨਾ, ਇੱਕ ਡਿਵਾਈਸ ਨਿਗਰਾਨੀ ਕਰਨਾ, ਪੇਮੈਂਟ ਨੂੰ ਰੀਟ੍ਰਾਈ ਕਰਨਾ, ਜਾਂ ਇੱਕ ਕਿਊ ਵੇਖਣਾ।
ਉਹ ਲਾਈਟਵੇਟ ਹੁੰਦੇ ਹਨ, ਜਿਸਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਬਿਨਾਂ ਵੱਡੇ ਹਾਰਡਵੇਅਰ ਦੀ ਲੋੜ ਦੇ ਬਹੁਤ ਸਾਰੇ ਪ੍ਰੋਸੈਸ ਚਲਾ ਸਕਦੇ ਹੋ। ਇੱਕ ਭਾਰੀ ਵਰਕਰ ਦੇ ਮੁਕਾਬਲੇ, ਤਤਕਾਲ ਸ਼ੁਰੂ ਹੋਣ, ਬੰਦ ਹੋਣ, ਅਤੇ ਬਦਲਣ ਦੀ ਯੋਗਤਾ ਨਾਲ ਤੁਹਾਨੂੰ ਘਣੇ ਧਿਆਨਕੇਂਦ੍ਰਿਤ ਵਰਕਰ ਮਿਲਦੇ ਹਨ।
“ਇੱਕ ਵੱਡਾ ਪ੍ਰੋਗਰਾਮ” ਕਿਉਂ ਵੱਖਰੇ ਤਰੀਕੇ ਨਾਲ ਟੁੱਟਦਾ ਹੈ
ਕਈ ਸਿਸਟਮ ਇਕ ਵੱਡੇ ਪ੍ਰੋਗਰਾਮ ਦੀ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਜਾਂਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਦੇ ਕਈ ਹਿੱਸੇ ਨੇੜੇ ਜੁੜੇ ਹੁੰਦੇ ਹਨ। ਜਦੋਂ ਐਸੇ ਸਿਸਟਮ ਨੂੰ ਕੋਈ ਗੰਭੀਰ ਬੱਗ, ਮੈਮੋਰੀ ਮੁੱਦਾ, ਜਾਂ ਬਲਾਕਿੰਗ ਆਪਰੇਸ਼ਨ ਮਿਲਦਾ ਹੈ, ਤਾਂ ਫੇਲ੍ਹ ਸਕਾਰਾਤਮਕ ਤਰੀਕੇ ਨਾਲ ਫੈਲ ਸਕਦਾ ਹੈ—ਜਿਵੇਂ ਇੱਕ ਬ੍ਰੇਕਰ ਦੇ ਝਟਕੇ ਨਾਲ ਸਾਰਾ ਬਿਲਡਿੰਗ ਬਲੈਕ ਆਉਟ ਹੋ ਜਾਵੇ।
Erlang ਵਿਰੋਧੀ ਦਿਸ਼ਾ ਦਿਖਾਉਂਦਾ ਹੈ: ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਨੂੰ ਅਲੱਗ ਕਰੋ। ਜੇ ਇੱਕ ਛੋਟਾ ਵਰਕਰ ਗਲਤ ਆਚਰਨ ਕਰਦਾ ਹੈ, ਤੁਸੀਂ ਉਸ ਨੂੰ ਬਿਨਾਂ ਅਸਬੰਧਤ ਕੰਮ ਨੂੰ ਡਾਊਨ ਕੀਤੇ ਬਦਲ ਸਕਦੇ ਹੋ।
ਮੇਸੇਜ ਪਾਸਿੰਗ ਨੂੰ "ਨੋਟ ਭੇਜਣਾ" ਸਮਝੋ
ਇਹ ਵਰਕਰ ਅਪਸ ਵਿੱਚ ਸਹੀ ਰੂਪ ਵਿੱਚ ਕਿਵੇਂ ਕੋਆਰਡੀਨੇਟ ਕਰਦੇ ਹਨ? ਉਹ ਇਕ ਦੂਜੇ ਦੀ ਅੰਦਰਲੀ ਸਥਿਤੀ ਵਿੱਚ ਦਖਲ ਨਹੀਂ ਦਿੰਦੇ। ਉਹ ਮੇਸੇਜ ਭੇਜਦੇ ਹਨ—ਇੱਕ ਗੱਲ-ਬਾਤ ਜਿਆਦਾ ਨੋਟ ਭੇਜਣ ਵਰਗੀ ਹੈ ਨਾ ਕਿ ਗਲਤ-ਭਰਿਆ ਵਾਈਟਬੋਰਡ ਚੇਤਾਵਨੀ।
ਇੱਕ ਵਰਕਰ ਕਹਿ ਸਕਦਾ ਹੈ, “ਇੱਕ ਨਵੀਂ ਬੇਨਤੀ ਹੈ,” “ਇਹ ਯੂਜ਼ਰ ਡਿਸਕਨੈਕਟ ਹੋ ਗਿਆ,” ਜਾਂ “5 ਸੈਕਿੰਡ ਵਿੱਚ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕਰੋ।” ਪ੍ਰਾਪਤ ਕਰਨ ਵਾਲਾ ਵਰਕਰ ਨੋਟ ਪੜ੍ਹਦਾ ਹੈ ਅਤੇ ਫੈਸਲਾ ਕਰਦਾ ਹੈ।
ਮੁੱਖ ਲਾਭ ਇਹ ਹੈ ਕਿ ਕਿਉਂਕਿ ਵਰਕਰ ਅਲੱਗ ਹਨ ਅਤੇ ਮੇਸੇਜ ਦੁਆਰਾ ਸੰਚਾਰ ਕਰਦੇ ਹਨ, ਫੇਲ੍ਹਰ ਸਾਰੇ ਸਿਸਟਮ ਵਿੱਚ ਵੱਧਣ ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੋ ਜਾਂਦੀ ਹੈ।
ਮੇਸੇਜ ਪਾਸਿੰਗ ਅਤੇ ਐਕਟਰ ਮਾਡਲ (ਜਰਾਗਨ ਦੇ ਬਿਨਾਂ)
Erlang ਦੇ “ਐਕਟਰ ਮਾਡਲ” ਨੂੰ ਸਮਝਣ ਦਾ ਇੱਕ ਸਧਾਰਣ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਸਿਸਟਮ ਨੂੰ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ, ਸੁਤੰਤਰ ਵਰਕਰਾਂ ਦੀ ਤਸਵੀਰ ਦੇ ਰੂਪ ਵਿੱਚ ਸੋਚੋ।
ਐਕਟਰ: ਨਿੱਕੇ ਵਰਕਰ ਜੋ ਸਿਰਫ ਮੇਸੇਜ ਭੇਜ ਕੇ ਗੱਲ ਕਰਦੇ ਹਨ
ਇਕ ਐਕਟਰ ਆਪਣੀ ਨਿੱਜੀ ਸਥਿਤੀ ਅਤੇ ਇੱਕ ਮੇਲਬਾਕਸ ਨਾਲ ਇੱਕ ਸੁਤੰਤਰ ਇਕਾਈ ਹੁੰਦਾ ਹੈ। ਇਹ ਤਿੰਨ ਮੁੱਖ ਕੰਮ ਕਰਦਾ ਹੈ:
- ਆਪਣੇ ਮੇਲਬਾਕਸ ਤੋਂ (ਇੱਕ-ਇੱਕ ਕਰ ਕੇ) ਮੇਸੇਜ ਪ੍ਰਾਪਤ ਕਰਦਾ ਹੈ
- ਆਪਣੀ ਅੰਦਰੂਨੀ ਸਥਿਤੀ ਅਪਡੇਟ ਕਰਦਾ ਹੈ
- ਹੋਰ ਐਕਟਰਾਂ ਨੂੰ ਮੇਸੇਜ ਭੇਜਦਾ ਹੈ
ਬਸ ਇੰਨਾ ਹੀ। ਕੋਈ ਛੁਪਿਆ ਹੋਇਆ ਸਾਂਝਾ ਵੇਰੀਏਬਲ ਨਹੀਂ, ਕੋਈ “ਦੂਜੇ ਵਰਕਰ ਦੀ ਮੈਮੋਰੀ ਵਿੱਚ ਦਾਖ਼ਲ” ਨਹੀਂ। ਜੇ ਇੱਕ ਐਕਟਰ ਨੂੰ ਦੂਜੇ ਤੋਂ ਕੁੱਝ ਚਾਹੀਦਾ ਹੈ, ਉਹ ਮੇਸੇਜ ਭੇਜ ਕੇ ਮੰਗਦਾ ਹੈ।
ਸਾਂਝੀ ਸਟੇਟ ਤੋਂ ਪਰਹੇਜ਼ ਕਿਉਂ ਬਹੁਤ ਸਾਰੇ ਬੱਗਾਂ ਨੂੰ ਖਤਮ ਕਰਦਾ ਹੈ
ਜਦੋਂ ਇਕੱਠੇ ਧਾਗੇ ਇੱਕੋ ਡੇਟਾ ਸਾਂਝਾ ਕਰਦੇ ਹਨ, ਤਦ ਸੀਮਾਂ 'ਤੇ race conditions ਆ ਸਕਦੀਆਂ ਹਨ: ਦੋ ਚੀਜ਼ਾਂ ਲਗਭਗ ਇਕੋ ਸਮੇਂ ਇੱਕੋ ਹੀ ਵੈਲਯੂ ਨੂੰ ਬਦਲ ਦਿੰਦੀਆਂ ਹਨ, ਅਤੇ ਨਤੀਜਾ ਸਮੇਂ ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਇਹ ਉਹਨਾਂ ਬੱਗਾਂ ਦਾ ਰੁਪ ਹੈ ਜੋ ਅਕਸਮਾਤ ਅਤੇ ਮੁਸ਼ਕਲ ਦੁਹਰਾਏ ਜਾਂਦੇ ਹਨ।
ਮੇਸੇਜ ਪਾਸਿੰਗ ਨਾਲ, ਹਰ ਐਕਟਰ ਆਪਣੇ ਡੇਟਾ ਦਾ ਮਾਲਿਕ ਹੁੰਦਾ ਹੈ। ਹੋਰ ਐਕਟਰ ਇਸ ਨੂੰ ਸਿੱਧਾ ਬਦਲ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਇਹ ਹਰ ਬੱਗ ਨਹੀਂ ਖਤਮ ਕਰਦਾ, ਪਰ ਇੱਕੋ ਹੀ ਟੁਕੜੇ ਸਟੇਟ ਦੀ ਸਮਕਾਲੀ ਪਹੁੰਚ ਕਾਰਨ ਹੋਣ ਵਾਲੇ ਮੁੱਦਿਆਂ ਨੂੰ ਬਹੁਤ ਘਟਾ ਦਿੰਦਾ ਹੈ।
ਬੈਕ-ਪ੍ਰੈਸ਼ਰ: ਕਾਫੀ ਕੁਝ ਗਰਾਹਕ ਵਾਲੇ ਕੌਫੀ-ਦੁਕਾਨ ਦੀ ਕਿਸਮ
ਮੇਸੇਜ "ਮੁਫ਼ਤ" ਨਹੀਂ ਆਉਂਦੇ। ਜੇ ਕੋਈ ਐਕਟਰ ਵੇਖਦਾ ਹੈ ਕਿ ਉਸ ਨੂੰ ਉਸਦੀ ਸਮਰੱਥਾ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਮੇਸੇਜ ਮਿਲ ਰਹੇ ਹਨ, ਤਾਂ ਉਸਦੀ ਮੇਲਬਾਕਸ (ਕਿਊ) ਵੱਧ ਜਾਂਦੀ ਹੈ। ਇਹੀ ਬੈਕ-ਪ੍ਰੈਸ਼ਰ ਹੈ: ਸਿਸਟਮ ਨਿਸ਼ਾਨਾ ਦਿੰਦਾ ਹੈ, “ਇਹ ਹਿੱਸਾ ਓਵਰਲੋਡ ਹੋ ਰਿਹਾ ਹੈ।”
ਅਮਲ ਵਿੱਚ, ਤੁਸੀਂ ਮੇਲਬਾਕਸ ਸਾਈਜ਼ ਦੀ ਨਿਗਰਾਨੀ ਕਰਦੇ ਹੋ ਅਤੇ ਸੀਮਾਵਾਂ ਬਣਾਉਂਦੇ ਹੋ: ਲੋਡ ਛੱਡਣਾ, ਬੈਚਿੰਗ, ਸੈਂਪਲਿੰਗ, ਜਾਂ ਕੰਮ ਨੂੰ ਹੋਰ ਵਰਕਰਾਂ 'ਤੇ ਧੱਕਣਾ ਤਾਂ ਕਿ ਕਿਊਆਂ ਅਨੰਤ ਤੱਕ ਨਾ ਵਧਣ।
ਇੱਕ ਖਾਸ ਉਦਾਹਰਣ: ਚੈਟ ਨੋਟੀਫਿਕੇਸ਼ਨ
ਇੱਕ ਚੈਟ ਐਪ ਦੀ ਕਲਪਨਾ ਕਰੋ। ਹਰ ਯੂਜ਼ਰ ਲਈ ਇੱਕ ਐਕਟਰ ਹੋ ਸਕਦਾ ਹੈ ਜੋ ਨੋਟੀਫਿਕੇਸ਼ਨਾਂ ਦੀ ਡਿਲਿਵਰੀ ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਹੁੰਦਾ ਹੈ। ਜਦੋਂ ਯੂਜ਼ਰ ਆਫ਼ਲਾਈਨ ਹੋ ਜਾਂਦਾ ਹੈ, ਸੁਨੇਹੇ ਆਉਂਦੇ ਰਹਿਣਗੇ—ਤਾਂ ਮੇਲਬਾਕਸ ਵਧੇਗਾ। ਇੱਕ ਚੰਗੀ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਸਿਸਟਮ ਕਿਊ ਦੀ ਸੀਮਾ ਲਗਾ ਸਕਦਾ ਹੈ, ਗੈਰ-ਜ਼ਰੂਰੀ ਨੋਟੀਫਿਕੇਸ਼ਨਾਂ ਨੂੰ ਡ੍ਰੌਪ ਕਰ ਸਕਦਾ ਹੈ, ਜਾਂ ਡਾਈਜੇਸਟ ਮੋਡ 'ਤੇ ਚਲ ਸਕਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਇੱਕ ਢੀਲਾ ਯੂਜ਼ਰ ਪੂਰੇ ਸਰਵਿਸ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਨਾ ਕਰੇ।
“Let It Crash” ਸਮਝਾਇਆ: ਤੇਜ਼ੀ ਨਾਲ ਫੇਲ੍ਹ ਹੋਵੋ, ਤੇਜ਼ੀ ਨਾਲ ਵਾਪਸ ਆਓ
“Let it crash” ਢੀਠ ਕੋਡਿੰਗ ਲਈ ਨਾਰੀ ਨਹੀ ਹੈ। ਇਹ ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਰਣਨੀਤੀ ਹੈ: ਜੇ ਕੋਈ ਹਿੱਸਾ ਬੁਰੇ ਜਾਂ ਅਣਉਮੀਦਿਤ ਸਟੇਟ 'ਚ ਪਹੁੰਚ ਜਾਵੇ, ਉਨ੍ਹੇ ਨੂੰ ਚੀੜ੍ਹ-ਚਿੜ੍ਹ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ ਅਤੇ ਚੰਗੇ ਤਰੀਕੇ ਨਾਲ ਮੁੜ ਪ੍ਰਾਪਤ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਇਸਦਾ ਅਸਲ ਮਤਲਬ
ਇੱਕ ਪ੍ਰੋਸੈਸ ਵਿੱਚ ਹਰ ਸੰਭਵ ਐਡਜ ਕੇਸ ਨੂੰ ਹੈਂਡਲ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਦੀ ਬਜਾਏ, Erlang ਹਰ ਵਰਕਰ ਨੂੰ ਛੋਟਾ ਅਤੇ ਕੇਂਦਰਿਤ ਰੱਖਣ ਦੀ ਹਿਮਾਇਤ ਕਰਦਾ ਹੈ। ਜੇ ਉਹ ਵਰਕਰ ਕਿਸੇ ਚੀਜ਼ ਦਾ ਸਾਹਮਣਾ ਕਰਦਾ ਹੈ ਜੋ ਵਾਸਤਵ ਵਿੱਚ ਉਹ ਸੰਭਾਲ ਨਹੀਂ ਸਕਦਾ (ਕੋਰੀਪਟ ਸਟੇਟ, ਟੁੱਟੀਆਂ ਧਾਰਨਾਵਾਂ, ਅਣਛਾਹੀ ਇਨਪੁਟ), ਤਾਂ ਉਹ ਬੰਦ ਹੋ ਜਾਂਦਾ ਹੈ। ਸਿਸਟਮ ਦਾ ਕੋਈ ਹੋਰ ਹਿੱਸਾ ਇਸ ਨੂੰ ਵਾਪਸ ਲਿਆਉਣ ਲ਼ਏ ਜ਼ਿੰਮੇਵਾਰ ਹੁੰਦਾ ਹੈ।
ਇਸ ਨਾਲ ਮੁੱਖ ਸਵਾਲ "ਅਸੀਂ ਅਸਫਲਤਾ ਨੂੰ ਕਿਵੇਂ ਰੋਕੀਏ?" ਤੋਂ ਬਦਲ ਕੇ "ਅਸੀਂ ਅਸਫਲਤਾ ਹੋਣ 'ਤੇ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਕਿਵੇਂ ਰਿਕਵਰ ਕਰੀਏ?" ਹੋ ਜਾਂਦਾ ਹੈ।
ਟਰੇਡ-ਆਫ਼: ਘੱਟ ਰੱਖਿਆ ਜਾਂਦੀ ਜਾਂਚ, ਵੱਧ ਸਾਫ਼ ਲਾਜਿਕ
ਹਰ ਜਗ੍ਹਾ defensive programming ਕਈ ਵਾਰ ਸਰਲ ਫਲੋਜ਼ ਨੂੰ ਕੰਡੇ ਦੀਆਂ ਸ਼ਰਤਾਂ, ਰੀਟ੍ਰਾਈਜ਼ ਅਤੇ ਅਧੂਰੇ ਸਟੇਟ ਵਿੱਚ ਬਦਲ ਦੇ ਦਿੰਦਾ ਹੈ। “Let it crash” ਕੁਝ ਅਦਾਲਤ-ਵਾਲੀ ਜਟਿਲਤਾ ਨੂੰ ਬਦਲ ਦਿੰਦਾ ਹੈ:
- ਸਰਲ, ਪਾਠਣਯੋਗ ਕੋਡ
- ਟੁੱਟੀਆਂ ਧਾਰਨਾਵਾਂ ਦਾ ਤੇਜ਼ ਪਤਾ
- ਕੇਂਦਰਿਤ ਰਿਕਵਰੀ (ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਥਾਂ 'ਤੇ ਹੈ) ਜੋ ਅਮਲ ਵਿੱਚ ਸਥਿਰ ਹੁੰਦੀ ਹੈ
ਵੱਡਾ ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ ਰਿਕਵਰੀ ਨੂੰ ਪੇਸ਼ਗੋਈਯੋਗ ਅਤੇ ਦੁਹਰਾਯੋਗ ਬਣਾਉਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਾ ਕਿ ਹਰ ਫੰਕਸ਼ਨ ਵਿੱਚ improvisation।
ਕਦੋਂ ਇਹ ਫਿੱਟ ਹੁੰਦਾ ਹੈ—ਅਤੇ ਕਦੋਂ ਨਹੀਂ
ਇਹ ਸਭ ਤੋਂ ਵਧੀਆ ਫਿੱਟ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਫੇਲ੍ਹਰ recoverable ਅਤੇ isolated ਹੁੰਦੇ ਹਨ: ਇੱਕ ਅਰੰਭਕ ਨੈੱਟਵਰਕ ਮੁੱਦਾ, ਖਰਾਬ ਰਿਕਵੇਸਟ, ਇੱਕ ਅਟੱਕਿਆ ਵਰਕਰ, ਜਾਂ ਤੀਸਰੇ-ਪਾਰਟੀ ਟਾਈਮਆਊਟ।
ਇਹ ਮਾੜੀਆਂ ਸਥਿਤੀਆਂ ਲਈ ਠੀਕ ਨਹੀਂ ਜਦੋਂ ਇੱਕ ਕਰੈਸ਼ ਅਮਾਨਯੋਗ ਨੁਕਸਾਨ ਪੈਦਾ ਕਰ ਸਕਦਾ ਹੈ, ਜਿਵੇਂ:
- ਡੇਟਾ ਲੋਸ ਜਦ ਤੱਕ ਇਸਦਾ ਦਾਇਮੀ ਸਰੋਤ ਨਹੀਂ ਹੋਵੇ
- ਸੇਫਟੀ-ਕ੍ਰਿਟਿਕਲ ਓਪਰੇਸ਼ਨ ਜਿੱਥੇ "ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰੋ" ਮਨਜ਼ੂਰ ਨਹੀਂ
ਤੇਜ਼ ਰੀਸਟਾਰਟ ਅਤੇ ਜਾਣਿਆ-ਹੁਇਆ ਸਥਿਤੀ
ਕਰੈਸ਼ ਸਿਰਫ ਇਸ ਵੇਲੇ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਮੁੜ ਆਉਣਾ ਤੇਜ਼ ਅਤੇ ਸੁਰੱਖਿਅਤ ਹੋਵੇ। ਅਮਲ ਵਿੱਚ, ਇਸਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਵਰਕਰਾਂ ਨੂੰ ਜਾਣਿਆ-ਪ੍ਰਮਾਣਿਤ ਸਥਿਤੀ ਵਿੱਚ ਰੀਸਟਾਰਟ ਕੀਤਾ ਜਾਵੇ—ਅਕਸਰ configuration reload ਕਰਕੇ, in-memory cache ਨੂੰ ਦਾਇਮੀ ਸਟੋਰੇਜ ਤੋਂ ਦੁਬਾਰਾ ਬਣਾਕੇ, ਅਤੇ ਕੰਮ ਨੂੰ ਬਿਨਾਂ ਖੋਏ ਜਾਰੀ ਰੱਖਣਾ।
ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀਜ਼: ਨਿਰਦੇਸ਼ਤ ਤੌਰ 'ਤੇ ਫੇਲ੍ਹ ਲਈ ਡਿਜ਼ਾਈਨ
ਉਹ ਚੀਜ਼ ਬਣਾਓ ਜੋ ਤੁਸੀਂ ਬਣਾਉਂਦੇ ਹੋ
ਜਦੋਂ ਤੁਸੀਂ ਚਾਹੋ ਤਾਂ ਸਰੋਤ ਕੋਡ export ਕਰਕੇ ਪੂਰਾ ਕੰਟਰੋਲ ਰੱਖੋ ਅਤੇ ਬਾਹਰ ਦੌੜਾਓ ਜਾਂ ਵਧਾਓ।
Erlang ਦਾ “let it crash” ਵਿਚਾਰ तभी ਕੰਮ ਕਰਦਾ ਹੈ ਜਦ ਕਾਰੈਸ਼ਾਂ ਨੂੰ ਮੌਕੇ 'ਤੇ ਛੱਡਿਆ ਨਹੀਂ ਜਾਂਦਾ। ਮੁੱਖ ਪੈਟਰਨ ਹੈ ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀ: ਇੱਕ ਹਾਇਰਾਰਕੀ ਜਿੱਥੇ ਸੁਪਰਵਾਈਜ਼ਰ ਮੈਨੇਜਰਾਂ ਵਾਂਗ ਕੰਮ ਕਰਦੇ ਹਨ ਅਤੇ वर्कਰ ਅਸਲ ਕੰਮ ਕਰਦੇ ਹਨ (ਕਾਲ ਸੰਭਾਲਣਾ, ਸੈਸ਼ਨ ਟਰੈਕ ਕਰਨਾ, ਕਿਊ ਖਪਤ ਕਰਨਾ ਆਦਿ)। ਜਦੋਂ ਕੋਈ ਵਰਕਰ ਗਲਤ ਆਚਰਣ ਕਰਦਾ ਹੈ, ਮੈਨੇਜਰ ਨੋਟਿਸ ਕਰਦਾ ਹੈ ਅਤੇ ਉਸ ਨੂੰ ਰੀਸਟਾਰਟ ਕਰਦਾ ਹੈ।
ਵਰਕਰਾਂ ਨੂੰ ਰੀਸਟਾਰਟ ਕਰਨ ਵਾਲੇ ਮੈਨੇਜਰ
ਇੱਕ ਸੁਪਰਵਾਈਜ਼ਰ ਟੁੱਟੇ ਹੋਏ ਵਰਕਰ ਨੂੰ ਜਗ੍ਹਾ 'ਤੇ “ਠੀਕ” ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਹੀਂ ਕਰਦਾ। ਇਸ ਦੀ ਬਜਾਏ, ਇਹ ਇੱਕ ਸਧਾਰਣ, ਸੂਚਿਤ ਨਿਯਮ ਲਗਾਉਂਦਾ ਹੈ: ਜੇ ਵਰਕਰ ਮਰ ਜਾਂਦਾ ਹੈ, ਨਵਾਂ ਵਰਕਰ ਸ਼ੁਰੂ ਕਰੋ। ਇਸ ਨਾਲ ਰਿਕਵਰੀ ਦਾ ਰਾਸ਼ਤਾ ਪੇਸ਼ਗੋਈਯੋਗ ਹੁੰਦਾ ਹੈ ਅਤੇ ਕੋਡ ਵਿੱਚ ਫੈਲ-ਹੈਂਡਲਿੰਗ ਨੂੰ ਘਟਾਇਆ ਜਾਂਦਾ ਹੈ।
ਉਹਨਾਂ ਲਈ ਵੀ ਜ਼ਰੂਰੀ ਹੈ ਕਿ ਸੁਪਰਵਾਈਜ਼ਰ ਇਹ ਵੀ ਫੈਸਲਾ ਕਰ ਸਕੇ ਕਿ ਕਦੋਂ ਰੀਸਟਾਰਟ ਨਾ ਕੀਤਾ ਜਾਵੇ—ਜੇ ਕੋਈ ਚੀਜ਼ ਬਹੁਤ ਵਾਰ ਕਰੈਸ਼ ਹੋ ਰਹੀ ਹੈ, ਤਾਂ ਇਹ ਕੋਈ ਡੂੰਘੀ ਸਮੱਸਿਆ ਦਰਸਾਉਂਦਾ ਹੈ, ਅਤੇ ਲਗਾਤਾਰ ਰੀਸਟਾਰਟ ਕਰਨਾ ਹਾਲਤ ਨੂੰ ਹੋਰ ਖਰਾਬ ਕਰ ਸਕਦਾ ਹੈ।
ਰੀਸਟਾਰਟ ਰਣਨੀਤੀਆਂ (ਉੱਚ-ਸਤਰ)
ਸੁਪਰਵਾਈਜ਼ਨ ਇੱਕ-ਸਾਈਜ਼-ਫਿੱਟ-ਸਭ ਨੂੰ ਨਹੀਂ ਹੈ। ਆਮ ਤੌਰ 'ਤੇ ਰਣਨੀਤੀਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
- One-for-one: ਸਿਰਫ ਫੇਲ੍ਹ ਹੋਏ ਵਰਕਰ ਨੂੰ ਰੀਸਟਾਰਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ ਖੁਦਮੁਖਤਿਆਰ ਕੰਮਾਂ ਲਈ ਢੰਗ ਹੈ ਜਿੱਥੇ ਇੱਕ ਫੇਲ੍ਹ ਹੋਰਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ।
- Group restarts: ਜੇ ਇੱਕ ਵਰਕਰ ਫੇਲ੍ਹ ਕਰਦਾ ਹੈ, ਇੱਕ ਸੰਬੰਧਤ ਸਮੂਹ ਨੂੰ ਇਕੱਠੇ ਰੀਸਟਾਰਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ ਉਹਨਾਂ tightly-coupled ਕੰਪੋਨੈਂਟਾਂ ਲਈ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ sync ਵਿੱਚ ਰਹਿਣਾ ਲਾਜ਼ਮੀ ਹੈ।
ਨਿਰਭਰਤਾਵਾਂ: ਜਿਸ 'ਤੇ ਤੁਹਾਨੂੰ ਸੋਚਣਾ ਪੈਂਦਾ ਹੈ
ਵਧੀਆ ਸੁਪਰਵਾਈਜ਼ਨ ਡਿਜ਼ਾਈਨ ਇੱਕ dependency map ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ: ਕਿਹੜੇ ਕੰਪੋਨੈਂਟ ਕਿਸ ਤੇ ਨਿਰਭਰ ਹਨ, ਅਤੇ "ਤਾਜ਼ਾ ਸ਼ੁਰੂ" ਉਨ੍ਹਾਂ ਲਈ ਕੀ ਅਰਥ ਰੱਖਦਾ ਹੈ।
ਜੇ ਇੱਕ ਸੈਸ਼ਨ ਹੈਂਡਲਰ ਇੱਕ cache ਪ੍ਰੋਸੈਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ, ਤਾਂ ਸਿਰਫ ਹੈਂਡਲਰ ਨੂੰ ਰੀਸਟਾਰਟ ਕਰਨਾ ਉਸ ਨੂੰ ਖਰਾਬ ਸਟੇਟ ਨਾਲ ਜੁੜਿਆ ਰਹਿ ਸਕਦਾ ਹੈ। ਉਚਿਤ ਸੁਪਰਵਾਈਜ਼ਰ ਹੇਠਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਗਰੁੱਪ ਕਰਨਾ (ਜਾਂ ਇਕੱਠੇ ਰੀਸਟਾਰਟ ਕਰਨਾ) ਗੰਦੇ ਫੇਲ੍ਹ ਮੋਡ ਨੂੰ ਲਾਜ਼ਮੀ ਅਤੇ ਦੁਹਰਾਯੋਗ ਰਿਕਵਰੀ ਵਿਹਾਰ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ।
OTP: ਭਰੋਸੇਯੋਗ ਸੇਵਾਵਾਂ ਲਈ ਦੁਹਰਾਏ ਜਾ ਸਕਣ ਵਾਲੇ ਬਿਲਡਿੰਗ ਬਲਾਕ
ਜੇ Erlang ਭਾਸ਼ਾ ਹੈ, ਤਾਂ OTP (Open Telecom Platform) ਉਹ ਪਾਰਟਸ ਦੀ ਕਿਟ ਹੈ ਜੋ “let it crash” ਨੂੰ ਇਕ ਐਸਾ ਚੀਜ਼ ਬਣਾਉਂਦੀ ਹੈ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਸਾਲਾਂ ਤੱਕ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਚਲਾ ਸਕਦੇ ਹੋ।
OTP ਇੱਕ ਟੂਲਬੌਕਸ ਵਜੋਂ — ਸਾਬਤ ਕੀਤੇ ਪੈਟਰਨ
OTP ਕੋਈ ਇਕ ਲਾਇਬ੍ਰੇਰੀ ਨਹੀਂ; ਇਹ ਰਵਾਇਤਾਂ ਅਤੇ ਤਿਆਰ-ਕਿਤੇ ਕੰਪੋਨੈਂਟਾਂ (ਜਿਨ੍ਹਾਂ ਨੂੰ behaviours ਕਿਹਾ ਜਾਂਦਾ ਹੈ) ਦਾ ਇੱਕ ਸੈਟ ਹੈ ਜੋ ਸਰਵਿਸਾਂ ਬਣਾਉਣ ਦੇ ਬੋਰੀੰਗ-ਪਰ-ਅਹਮ ਹਿੱਸਿਆਂ ਨੂੰ ਹੱਲ ਕਰਦਾ ਹੈ:
gen_serverਇੱਕ ਲੰਬੇ-ਚਲਦੇ ਵਰਕਰ ਲਈ ਜੋ ਸਟੇਟ ਰੱਖਦਾ ਹੈ ਅਤੇ ਇੱਕ-ਇੱਕ ਕਰਕੇ ਬੇਨਤੀਆਂ ਨੂੰ ਹੈਂਡਲ ਕਰਦਾ ਹੈsupervisorਫੇਲ੍ਹ ਹੋਏ ਵਰਕਰਾਂ ਨੂੰ ਸਪਸ਼ਟ ਨਿਯਮਾਂ ਅਨੁਸਾਰ ਆਟੋਮੈਟਿਕ ਰੀਸਟਾਰਟ ਕਰਦਾ ਹੈapplicationਪੂਰੇ ਸਰਵਿਸ ਦਾ ਸ਼ੁਰੂ/ਬੰਦ ਕਿਵੇਂ ਹੋਵੇ ਅਤੇ ਰਿਲੀਜ਼ ਵਿੱਚ ਕਿਵੇਂ ਫਿੱਟ ਕਰੇ, ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ
ਇਹ "ਜਾਦੂ" ਨਹੀਂ — ਇਹ ਟੈਮਪਲੇਟ ਹਨ ਜਿਨ੍ਹਾਂ ਦੇ ਸਪਸ਼ਟ callback ਹੋਂਦੇ ਹਨ, ਤਾਂ ਜੋ ਤੁਹਾਡਾ ਕੋਡ ਇੱਕ ਜਾਣੀ-ਪਹਚਾਣੀ ਸ਼ਕਲ ਵਿੱਚ ਫਿੱਟ ਹੋ ਜਾਵੇ ਨਾ ਕਿ ਹਰ ਪ੍ਰਾਜੈਕਟ ਵਿੱਚ ਨਵਾਂ ਫਰੇਮ ਬਣਾਉਣਾ ਪਵੇ।
ਸਟੈਂਡਰਡ ਪੈਟਰਨਾਂ ਕਿਉਂ ਕਸਟਮ ਫਰੇਮਵਰਕਾਂ ਨੂੰ ਹਰਾ ਦੇਂਦੇ ਹਨ
ਟੀਮਾਂ ਅਕਸਰ ਕਰਦੀ-ਕਰਦੀ ਬੈਕਗ੍ਰਾਊਂਡ ਵਰਕਰ, ਘਰੇਲੂ ਮੋਨੀਟਰਿੰਗ ਹੋਕ, ਅਤੇ ਇਕ-ਵੈਰੀ ਰੀਸਟਾਰਟ ਲੌਜਿਕ ਬਣਾਉਂਦੀਆਂ ਹਨ। ਇਹ ਕੰਮ ਕਰਦਾ ਹੈ—ਜਦ ਤੱਕ ਇਹ ਨਹੀਂ ਕਰਦਾ। OTP ਇਸ ਖਤਰੇ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਹਰ ਕਿਸੇ ਨੂੰ ਇੱਕੋ ਹੀ ਸ਼ਬਦਾਵਲੀ ਅਤੇ ਲਾਈਫਸਾਇਕਲ ਵੱਲ ਧਕाबिक ਕਰਦਾ ਹੈ। ਜਦ ਯੂ-ਇਕ ਨਵਾਂ ਇੰਜੀਨੀਅਰ ਜੋਇਨ ਕਰਦਾ ਹੈ, ਉਹ ਤੁਹਾਡੇ ਕਸਟਮ ਫਰੇਮਵਰਕ ਨੂੰ ਪਹਿਲਾਂ ਸਿੱਖਣ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ ਰੱਖਦਾ; ਉਹ Erlang ਇਕੋਸਿਸਟਮ ਵਿੱਚ ਵਿਆਪਕ ਤੌਰ 'ਤੇ ਸਮਝੇ ਜਾਂਦੇ ਪੈਟਰਨਾਂ ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਦਾ ਹੈ।
OTP ਦਿਨ-प्रतিদিন ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਕਿਵੇਂ ਦਿštਗਦੀ ਹੈ
OTP ਤੁਹਾਨੂੰ ਪ੍ਰੋਸੈਸ ਰੋਲਸ ਅਤੇ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਦੇ ਤਰੀਕੇ ਨਾਲ ਸੋਚਣ ਲਈ ਪ੍ਰੇਰਿਤ ਕਰਦਾ ਹੈ: ਇੱਕ ਵਰਕਰ ਕੀ ਹੈ, ਇੱਕ ਕੋਆਰਡੀਨੇਟਰ ਕੀ ਹੈ, ਕਿਹੜਾ ਕਿਸਨੂੰ ਰੀਸਟਾਰਟ ਕਰੇਗਾ, ਅਤੇ ਕਿਹੜਾ ਕਦੇ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਰੀਸਟਾਰਟ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ।
ਇਹ ਸਾਫ਼ ਨਾਂਕਰਨ, ਸਪਸ਼ਟ ਸ਼ੁਰੂਆਤ ਆਰਡਰ, ਪੇਸ਼ਗੋਈ ਸ਼ਟਡਾਊਨ, ਅਤੇ ਬਿਲਟ-ਇਨ ਮੋਨੀਟਰੀੰਗ ਸਿਗਨਲਾਂ ਨੂੰ ਵੀ ਉਤਸ਼ਾਹਿਤ ਕਰਦਾ ਹੈ। ਨਤੀਜਾ: ਐਸਾ ਸੌਫਟਵੇਅਰ ਜੋ ਲਗਾਤਾਰ ਚੱਲਣ ਲਈ ਬਣਿਆ ਹੁੰਦਾ ਹੈ—ਜੋ ਫੌਲਟ ਤੋਂ ਰਿਕਵਰ ਕਰ ਸਕਦਾ, ਸਮੇਂ ਦੇ ਨਾਲ ਵਿਕਸਤ ਹੋ ਸਕਦਾ, ਅਤੇ ਬਿਨਾਂ ਲਗਾਤਾਰ ਮਨੁੱਖੀ ਦੇਖਰੇਖ ਦੇ ਆਪਣਾ ਕੰਮ ਜਾਰੀ ਰੱਖ ਸਕਦਾ ਹੈ।
BEAM VM: ਉਹ ਰਨਟਾਈਮ ਜੋ ਮਾਡਲ ਨੂੰ ਪ੍ਰਾਇਕਟੀਕਲ ਬਣਾਉਂਦਾ ਹੈ
ਰੀਅਲ-ਟਾਈਮ ਪ੍ਰੋਟੋਟਾਈਪ ਬਣਾਓ
ਰਿਲਾਇਬਿਲਟੀ ਦੇ ਖਿਆਲਾਂ ਨੂੰ ਕੰਮ ਕਰਨ ਵਾਲੀ ਐਪ ਵਿੱਚ ਬਦਲੋ — Koder.ai ਵਿੱਚੋਂ ਇੱਕ ਚੈਟ ਪ੍ਰਾਂਪਟ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ।
Erlang ਦੇ ਵੱਡੇ ਵਿਚਾਰ—ਨਿੱਕੇ ਪ੍ਰੋਸੈਸ, ਮੇਸੇਜ ਪਾਸਿੰਗ, ਅਤੇ “let it crash”—BEAM virtual machine ਬਿਨਾਂ ਪੂਰੇ ਤੌਰ 'ਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਵਰਤਣ ਯੋਗ ਨਹੀਂ ਰਹਿੰਦੇ। BEAM ਉਹ ਰਨਟਾਈਮ ਹੈ ਜੋ ਇਹਨਾਂ ਪੈਟਰਨਾਂ ਨੂੰ ਨਾਜੁਕ ਨਹੀਂ, ਪਰ ਕੁਦਰਤੀ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦਾ ਹੈ।
ਸ਼ੈਡਿਯੂਲਿੰਗ: “ਇੱਕ ਵੱਡੇ ਥ੍ਰੈਡ” ਦੇ ਮੁਕਾਬਲੇ ਇਨਸਾਫ਼
BEAM ਦਾ ਨਿਰਮਾਣ ਵੱਡੀ ਗਿਣਤੀ ਵਿੱਚ ਲਾਈਟਵੇਟ ਪ੍ਰੋਸੈਸ ਚਲਾਉਣ ਲਈ ਕੀਤਾ ਗਿਆ ਹੈ। OS ਥ੍ਰੈਡਾਂ 'ਤੇ ਨਿਰਭਰ ਹੋਣ ਦੀ ਥਾਂ, BEAM ਖੁਦ Erlang ਪ੍ਰੋਸੈਸਾਂ ਨੂੰ ਸ਼ੈਡਿਯੂਲ ਕਰਦਾ ਹੈ।
ਅਮਲਿਕ ਲਾਭ ਇਹ ਹੈ ਕਿ ਲੋਡ ਹੇਠਾਂ ਰਿਸਪਾਂਸਿਵਨੈੱਸ: ਕੰਮ ਨੂੰ ਛੋਟੇ ਟੁਕੜਿਆਂ ਵਿੱਚ ਕੱਟਿਆ ਜਾਂਦਾ ਹੈ ਅਤੇ ਇਨਸਾਫ਼ ਨਾਲ ਰੋਟੇਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਜੋ ਕੋਈ ਵੀ ਅਤੀ-ਬੀਜੀ ਵਰਕਰ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਸਿਸਟਮ 'ਤੇ ਹਕ਼ ਨਹੀਂ ਜਮਾਂਦਾ। ਇਹ ਉਸ ਸਰਵਿਸ ਨਾਲ ਬਹੁਤ ਬਿਹਤਰ ਢੰਗ ਨਾਲ ਮਿਲਦਾ ਹੈ ਜੋ ਕਈ ਸੁਤੰਤਰ ਕਾਰਜਾਂ ਦਾ ਸਮੂਹ ਹੋਂਦਾ ਹੈ—ਹਰ ਇੱਕ ਥੋੜ੍ਹੀ ਕੰਮ ਕਰਦਾ ਹੈ, ਫਿਰ yield ਕਰਦਾ ਹੈ।
ਅਲੱਗ ਤੇ "ਪਰ-ਪ੍ਰੋਸੈਸ" ਮੈਮੋਰੀ ਕਲੀਨਅਪ
ਹਰ Erlang ਪ੍ਰੋਸੈਸ ਦੀ ਆਪਣੀ ਹੀ heap ਅਤੇ ਆਪਣੀ garbage collection ਹੁੰਦੀ ਹੈ। ਇਹ ਇੱਕ ਮੁੱਖ ਵੇਰਵਾ ਹੈ: ਇੱਕ ਪ੍ਰੋਸੈਸ ਵਿੱਚ ਮੈਮੋਰੀ ਸਾਫ਼ ਕਰਨ ਲਈ ਪੂਰੇ ਪ੍ਰੋਗਰਾਮ ਨੂੰ ਰੋਕਣਾ ਲੋੜੀਂਦਾ ਨਹੀਂ।
ਇਸੇ ਤਰ੍ਹਾਂ ਅਹੰਕਾਰਪੂਰਕ, ਪ੍ਰੋਸੈਸ ਆਈਸੋਲੇਟ ਰਹਿੰਦੇ ਹਨ। ਜੇ ਇਕ ਪ੍ਰੋਸੈਸ ਕਰੈਸ਼ ਕਰ ਜਾਂਦਾ ਹੈ, ਉਹ ਹੋਰਾਂ ਦੀ ਮੈਮੋਰੀ ਨੂੰ ਕਰੋਪਟ ਨਹੀਂ ਕਰਦਾ, ਅਤੇ VM ਜੀਊਂਦਾ ਰਹਿੰਦਾ ਹੈ। ਇਹ ਆਈਸੋਲੇਸ਼ਨ ਉਹ ਬੁਨਿਆਦ ਹੈ ਜੋ ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀਆਂ ਨੂੰ ਹਕੀਕਤ ਬਣਾਉਂਦਾ ਹੈ: ਫੇਲ੍ਹਰ ਨੁਕਸਾਨਤਮਕ ਢੰਗ ਨਾਲ ਰੋਕਿਆ ਜਾਂਦਾ ਹੈ, ਫਿਰ ਨੁਕਸਾਨ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਹੱਲ ਕਰਨ ਲਈ ਫੇਲ੍ਹ ਹਿੱਸੇ ਨੂੰ ਰੀਸਟਾਰਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ: ਬਹੁਤ ਸਾਰੇ ਨੋਡ, ਇੱਕ ਸਿਸਟਮ
BEAM ਸਪਲਾਈ ਕਰਨ ਵਿੱਚ ਵੀ ਆਸਾਨ ਸ਼ਬਦਾਂ ਵਿੱਚ ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ ਨੂੰ ਸਮਰਥਨ ਦਿੰਦਾ ਹੈ: ਤੁਸੀਂ ਕਈ Erlang ਨੋਡ (ਅਲੱਗ VM ਇੰਸਟੈਂਸ) ਚਲਾ ਸਕਦੇ ਹੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਮੇਸੇਜ ਭੇਜ ਕੇ ਗੱਲਬਾਤ ਕਰਨ ਦੇ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ “ਪ੍ਰੋਸੈਸ ਐਕਟਰਾਂ ਦੁਆਰਾ ਮੇਸੇਜ ਭੇਜਦੇ ਹਨ” ਨੂੰ ਸਮਝ ਲਿਆ ਹੈ, ਤਾਂ ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ ਉਹੀ ਵਿਚਾਰ ਦਾ ਇੱਕ ਵਿਸਥਾਰ ਹੈ—ਕੁਝ ਪ੍ਰੋਸੈਸ ਕਿਸੇ ਹੋਰ ਨੋਡ 'ਤੇ ਰਹਿੰਦੇ ਹਨ।
BEAM ਕੱਚੀ ਗਤੀ ਦੇ ਵਾਅਦਿਆਂ ਬਾਰੇ ਨਹੀਂ ਹੈ। ਇਹ concurrency, ਫੌਲਟ ਕੰਟੇਨਮੈਂਟ, ਅਤੇ ਰਿਕਵਰੀ ਨੂੰ ਡਿਫਾਲਟ ਬਣਾਉਂਦਾ ਹੈ, ਤਾਂ ਕਿ ਭਰੋਸੇਯੋਗਤਾ ਦੀ ਕਹਾਣੀ ਸਿਧੀ-ਸਾਦੀ ਨਾ ਰਹਿ ਕੇ ਅਮਲਯੋਗ ਬਣ ਜਾਵੇ।
ਸੀਸਟਮ ਨੂੰ ਰੋਕੇ ਬਗੈਰ ਅਪਡੇਟ (Hot Code, ਸਾਵਧਾਨੀ ਨਾਲ)
Erlang ਦੀਆਂ ਸਭ ਤੋਂ ਚਰਚਿਤ ਤਰਕੀਬਾਂ ਵਿੱਚੋਂ ਇੱਕ ਹੈ hot code swapping: ਰਨਿੰਗ ਸਿਸਟਮ ਦੇ ਹਿੱਸਿਆਂ ਨੂੰ ਘੱਟ-ਡਾਊਨਟਾਈਮ ਨਾਲ ਅਪਡੇਟ ਕਰਨਾ (ਜਿੱਥੇ ਰਨਟਾਈਮ ਅਤੇ ਟੂਲਿੰਗ ਇਸਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹਨ)। ਅਮਲਿਕ ਵਾਅਦਾ ਇਹ ਨਹੀਂ ਕਿ "ਕਦੇ ਵੀ ਰੀਸਟਾਰਟ ਨਾ ਕਰੋ", ਪਰ ਇਹ ਕਿ "ਇੱਕ ਛੋਟੇ ਬੱਗ ਨੂੰ ਲੰਬੇ ਆਊਟੇਜ ਵਿੱਚ ਨਹੀਂ ਬਦਲਣਾ"।
“ਹਾਟ ਕੋਡ” ਦਾ ਅਸਲ ਮਤਲਬ
Erlang/OTP ਵਿੱਚ, ਰਨਟਾਈਮ ਇੱਕ ਹੀ ਸਮੇਂ ਦੋ ਵਰਜ਼ਨਾਂ ਇੱਕ ਮੌਡੀਊਲ ਦੀ ਲੋਡ ਰੱਖ ਸਕਦਾ ਹੈ। ਮੌਜੂਦਾ ਪ੍ਰੋਸੈਸ ਪੁਰਾਣੇ ਵਰਜ਼ਨ ਨਾਲ ਕੰਮ ਮੁਕੰਮਲ ਕਰ ਸਕਦੇ ਹਨ ਜਦਕਿ ਨਵੀਆਂ ਬੇਨਤੀਆਂ ਨਵੇਂ ਵਰਜ਼ਨ ਨਾਲ ਸ਼ੁਰੂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇਸ ਨਾਲ ਤੁਹਾਨੂੰ ਬੱਗ ਪੈਚ ਕਰਨ, ਫੀਚਰ ਰੋਲ ਆਊਟ ਕਰਨ, ਜਾਂ ਵਿਵਹਾਰ ਸਹੀ ਕਰਨ ਲਈ ਥੋੜ੍ਹਾ ਸਮਾਂ ਮਿਲਦਾ ਹੈ ਬਿਨਾਂ ਸਭ ਨੂੰ ਨਿਕਾਸ ਕਰਨ ਦੇ।
ਚੰਗੀ ਤਰੀਕੇ ਨਾਲ ਕੀਤਾ ਗਿਆ, ਇਹ ਸਿੱਧਾ ਰਿਲਾਇਬਿਲਟੀ ਲਕਸ਼ਯਾਂ ਦੀ ਸਹਾਇਤਾ ਕਰਦਾ ਹੈ: ਘੱਟ ਪੂਰੇ-ਸਿਸਟਮ ਰੀਸਟਾਰਟ, ਛੋਟੀ ਮੈਨਟੇਨੈਂਸ ਵਿੰਡੋਜ਼, ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਕੁਝ ਗਲਤ ਹੋਣ 'ਤੇ ਤੇਜ਼ ਰਿਕਵਰੀ।
ਉਹ ਸੀਮਾਵਾਂ ਜਿਨ੍ਹਾਂ ਨੂੰ ਕਿਸੇ ਨੇ ਅਣਡੋਲ ਨਹੀਂ ਕਰਨਾ
ਹਰ ਬਦਲਾਅ ਨੂੰ ਲਾਈਵ ਵਿੱਚ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਸਵੈਪ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ। ਕੁਝ ਉਦਾਹਰਣ ਜਿਨ੍ਹਾਂ ਲਈ ਵੱਖਰੀ ਸਾਵਧਾਨੀ ਜਾਂ ਰੀਸਟਾਰਟ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ:
- ਸਟੇਟ ਆਕਾਰ (state shape) ਬਦਲਾਅ ਜਦੋਂ ਇਕ ਪ੍ਰੋਸੈਸ ਇੱਕ ਫਾਰਮੈਟ ਦੀ ਉਮੀਦ ਕਰਦਾ ਹੈ ਪਰ ਨਵਾਂ ਕੋਡ ਦੂਜਾ
- ਪ੍ਰੋਟੋਕਾਲ ਜਾਂ ਮੇਸੇਜ-ਫਾਰਮੈਟ ਬਦਲਾਅ ਜੋ ਸੇਵਾਵਾਂ ਵਿੱਚ ਅਨੁਕੂਲ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ
- schema migrations ਜੋ ਸਮਾਂ ਲੈ ਸਕਦੀਆਂ ਹਨ ਜਾਂ ਸਾਥੀ-ਸਹਿਯੋਗ ਦੀ ਲੋੜ ਰੱਖਦੀਆਂ ਹਨ
Erlang ਸੰਤੁਲਿਤ ਤਬਦੀਲੀਆਂ ਲਈ ਮਕੈਨਜ਼ਮ ਦਿੰਦਾ ਹੈ, ਪਰ ਤੁਹਾਨੂੰ ਅਜੇ ਵੀ ਅਪਗਰੇਡ ਪਾਥ ਡਿਜ਼ਾਈਨ ਕਰਨੀ ਪੈਂਦੀ ਹੈ।
ਮਨੋਭਾਵ: ਅਪਗਰੇਡਸ ਅਤੇ ਰੋਲਬੈਕ ਰੋਜ਼ਾਨਾ ਹੋਣ
ਹਾਟ ਅਪਗਰੇਡਸ ਸਭ ਤੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੇ ਹਨ ਜਦੋਂ ਅਪਗਰੇਡਸ ਅਤੇ ਰੋਲਬੈਕ ਰੋਜ਼ਾਨਾ ਅਪਰੇਸ਼ਨ ਮੰਨੇ ਜਾਂਦੇ ਹਨ, ਨ ਕਿ ਖਾਸ ਐਮਰਜੈਂਸੀ। ਇਸਦਾ ਮਤਲਬ ਵਰਜ਼ਨਿੰਗ, ਅਨੁਕੂਲਤਾ, ਅਤੇ ਇੱਕ ਸਪਸ਼ਟ “ਅਣਕਰ” ਰਸਤਾ ਸ਼ੁਰੂ ਤੋਂ ਹੀ ਯੋਜਿਤ ਹੋਵੇ। ਅਮਲ ਵਿੱਚ, ਟੀਮਾਂ ਲਾਈਵ-ਅਪਗਰੇਡ ਤਕਨੀਕਾਂ ਨੂੰ stagਡ ਰੋਲਆਊਟ, ਹੈਲਥ ਚੈਕ, ਅਤੇ ਸੁਪਰਵਾਈਜ਼ਨ-ਅਧਾਰਤ ਰਿਕਵਰੀ ਨਾਲ ਜੋੜਦੀਆਂ ਹਨ।
ਜੇ ਤੁਸੀਂ Erlang ਵਰਤਦੇ ਵੀ ਨਹੀਂ, ਤਾਂ ਸਬਕ ਇਹ ਹੈ: ਸਿਸਟਮਾਂ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕਰੋ ਕਿ ਉਹਨਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਬਦਲਣਾ ਪਹਿਲਾ-ਪ੍ਰਖਿਆਤ ਲਕਸ਼ਯ ਹੋਵੇ, ਨਾ ਕਿ ਇੱਕ ਬਾਅਦ-ਵਿੱਚਾਰ।
ਜਿੱਥੇ Erlang ਦੇ ਵਿਚਾਰ ਰੀਅਲ-ਟਾਈਮ ਪਲੇਟਫਾਰਮਾਂ ਵਿੱਚ ਚਮਕਦੇ ਹਨ
ਰੀਅਲ-ਟਾਈਮ ਪਲੇਟਫਾਰਮਾਂ ਦਾ ਸਬੰਧ ਪੂਰੀ ਤਰ੍ਹਾਂ ਸਪੀਡ ਨਾਲ ਨਹੀਂ, ਬਲਕਿ ਇਸ ਨਾਲ ਹੈ ਕਿ ਜਦੋਂ ਹਮੇਸ਼ਾ ਕੁਝ ਗਲਤ ਹੁੰਦਾ ਰਹੇ ਤਾ ਵੀ ਸਿਸਟਮ ਜਵਾਬਦੇਹ ਰਹੇ: ਨੈੱਟਵਰਕ ਹੰਝਦਾ ਹੈ, ਡੀਪੈਂਡੇੰਸੀਆਂ ਢੀਮੀਆਂ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਅਤੇ ਯੂਜ਼ਰ ਟ੍ਰੈਫਿਕ spike ਕਰ ਜਾਂਦਾ ਹੈ। Erlang ਦਾ ਡਿਜ਼ਾਈਨ—Joe Armstrong ਦੁਆਰਾ ਪ੍ਰਚਾਰਤ—ਇਸ ਹਕੀਕਤ ਨੂੰ ਮੰਨਦਾ ਹੈ ਅਤੇ concurrency ਨੂੰ ਅਸਧਾਰਨ ਨਹੀਂ, ਪਰ ਆਮ ਮੰਨਦਾ ਹੈ।
ਆਮ "ਰੀਅਲ-ਟਾਈਮ" ਵਰਤੋਂ ਕੇਸ
ਤੁਸੀਂ Erlang-ਸ਼ੈਲੀ ਸੋਚ ਨੂੰ ਹਰ ਥਾਂ ਵੇਖਦੇ ਹੋ ਜਿੱਥੇ ਬਹੁਤ ਸਾਰੀਆਂ ਸੁਤੰਤਰ ਗਤਿਵਿਧੀਆਂ ਇੱਕੋ ਸਮੇਂ ਹੋ ਰਹੀਆਂ ਹੁੰ:
- ਮੇਸেজਿੰਗ ਅਤੇ ਚੈਟ: ਲੱਖਾਂ ਨਿੱਕੀਆਂ ਗੱਲਬਾਤਾਂ, ਹਰ ਇੱਕ ਆਪਣੀ ਸਥਿਤੀ ਅਤੇ ਰੀਟ੍ਰਾਈਜ਼ ਨਾਲ।
- ਰੀਅਲ-ਟਾਈਮ ਕਮਿਊਨਿਕੇਸ਼ਨ: ਵਾਇਸ/ਵੀਡੀਓ signaling, ਪ੍ਰੇਜ਼ੈਂਸ ਅਪਡੇਟਸ, ਅਤੇ ਸੈਸ਼ਨ ਕੋਆਰਡੀਨੇਸ਼ਨ।
- IoT ਕੋਆਰਡੀਨੇਸ਼ਨ: ਡਿਵਾਈਸਾਂ ਦੀ ਫ਼ਲੋਕ ਜੋ ਅਕਸਰ ਚੇੱਕ-ਇਨ, ਡ੍ਰੌਪ-ਆਊਟ ਅਤੇ ਦੁਬਾਰਾ ਆਉਂਦੀਆਂ ਹਨ।
- ਪੇਮੈਂਟ ਵਰਕਫਲੋਜ਼: ਕਈ ਕਦਮ ਵਾਲੇ ਪ੍ਰੋਸੈਸ ਜਿੱਥੇ ਕੁਝ ਕਦਮ ਸਲੇਠ ਹੋ ਸਕਦੇ ਹਨ, ਉਪਲਬਧ ਨਹੀਂ, ਜਾਂ ਮੁਆਵਜ਼ਾ ਕਾਰਵਾਈਆਂ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ।
“ਸੌਫਟ ਰੀਅਲ-ਟਾਈਮ” ਆਮ ਤੌਰ 'ਤੇ ਕੀ ਮਤਲਬ ਹੁੰਦਾ ਹੈ
ਬਹੁਤ ਸਾਰੇ ਉਤਪਾਦਾਂ ਨੂੰ ਉਹ ਕਠੋਰ ਗਾਰੰਟੀ ਨਹੀਂ ਚਾਹੀਦੀ ਕਿ "ਹਰ ਐਕਸ਼ਨ 10ms ਵਿੱਚ ਪੂਰਾ ਹੋਵੇ"। ਉਹ ਚਾਹੁੰਦੇ ਹਨ ਸੌਫਟ ਰੀਅਲ-ਟਾਈਮ: ਆਮ ਬੇਨਤੀਆਂ ਲਈ ਲਗਾਤਾਰ ਘੱਟ latency, ਹਿੱਸੇ ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਤੇਜ਼ ਰਿਕਵਰੀ, ਅਤੇ ਉੱਚ ਉਪਲਬਧਤਾ ਤਾਂ ਜੋ ਯੂਜ਼ਰ INCIDENTS ਨੂੰ ਬਹੁਤ ਘੱਟ ਮਹਿਸੂਸ ਕਰਨ।
ਫੇਲ੍ਹਰ ਸਧਾਰਨ ਹਨ: ਇਸ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ
ਅਸਲ ਸਿਸਟਮ ਇਹ ਮੁੱਦੇ ਸਹਿਮਾਣੇ ਆਂਦੇ ਹਨ:
- ਡ੍ਰਾਪਡ ਕਨੈਕਸ਼ਨ (ਮੋਬਾਈਲ ਨੈੱਟਵਰਕ, Wi‑Fi ਹੈਂਡਆਫ)
- ਟਾਈਮਆਊਟ ਜਦੋਂ ਡਾਊਨਸਟ੍ਰੀਮ ਸਰਵਿਸ ਧੀਮੀ ਹੋ ਜਾ ਰਹੀ ਹੋ
- ਅੰਸ਼ਿਕ ਆਉਟੇਜ ਜਿੱਥੇ ਇੱਕ ਖੇਤਰ ਜਾਂ ਡੀਪੈਂਡੇੰਸੀ ਡਿਗਰੇਡ ਹੋ ਜਾਂਦੀ ਹੈ
Erlang ਦਾ ਮਾਡਲ ਹਰ ਗਤੀਵਿਧੀ ਨੂੰ ਅਲੱਗ ਕਰਨ ਦੀ ਹਿਮਾਇਤ ਕਰਦਾ ਹੈ (ਇੱਕ ਯੂਜ਼ਰ ਸੈਸ਼ਨ, ਇੱਕ ਡਿਵਾਈਸ, ਇੱਕ ਰੀਟ੍ਰਾਈ ਅਟੈਂਪ) ਤਾਂ ਕਿ ਇੱਕ ਫੇਲ੍ਹਰ ਫੈਲ੍ਹ ਨਾ ਹੋਵੇ। ਇੱਕ ਵੱਡੇ “ਸਭ ਕੁਝ ਸੰਭਾਲਣ ਦੀ” ਕੰਪੋਨੈਂਟ ਬਣਾਉਣ ਦੀ ਥਾਂ, ਟੀਮਾਂ ਛੋਟੇ ਯੂਨਿਟਾਂ 'ਤੇ ਸੋਚ ਸਕਦੀਆਂ ਹਨ: ਹਰ ਵਰਕਰ ਇੱਕ ਕੰਮ ਕਰਦਾ, ਮੇਸੇਜ ਰਾਹੀਂ ਗੱਲ ਕਰਦਾ, ਅਤੇ ਜੇ ਟੁੱਟਦਾ ਹੈ ਤਾਂ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਰੀਸਟਾਰਟ ਹੁੰਦਾ ਹੈ।
ਇਹ ਬਦਲਾਅ—"ਹਰ ਫੇਲ੍ਹ ਨੂੰ ਰੋਕਣ" ਤੋਂ "ਫੇਲ੍ਹ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸੀਮਿਤ ਅਤੇ ਰਿਕਵਰ ਕਰਨ"—ਅਕਸਰ ਉਹੀ ਗੱਲ ਹੈ ਜੋ ਰੀਅਲ-ਟਾਈਮ ਪਲੇਟਫਾਰਮਾਂ ਨੂੰ ਦਬਾਅ ਹੇਠਾਂ ਸਥਿਰ ਮਹਿਸੂਸ ਕਰਵਾਉਂਦੀ ਹੈ।
ਆਮ ਗਲਤਫ਼ਹਮੀਆਂ ਅਤੇ ਅਸਲੀ ਸੀਮਾਵਾਂ
ਰਿਲਾਇਬਿਲਟੀ ਨੂੰ ਆਦਤ ਬਣਾਓ
ਛੋਟੀਆਂ ਸਰਵਿਸਾਂ ਬਣਾਓ, ਫੇਲ੍ਹਰ ਨੂੰ ਅਲੱਗ ਰੱਖੋ, ਅਤੇ Koder.ai ਨੂੰ ਆਪਣਾ ਵਰਕਬੈਂਚ ਬਣਾਕੇ ਤੇਜ਼ੀ ਨਾਲ ਇਤਰੈਟ ਕਰੋ।
Erlang ਦੀ ਸ਼ੋਤਰੀ ਇਮেজ ਇੱਕ ਵਾਅਦੇ ਵਾਂਗ ਦਿਸਦੀ ਹੈ: ਸਿਸਟਮ ਜੋ ਕਦੇ ਡਾਊਨ ਨਹੀਂ ਹੁੰਦੇ ਕਿਉਂਕਿ ਉਹ ਸਿਰਫ ਰੀਸਟਾਰਟ ਕਰ ਲੈਂਦੇ ਹਨ। ਹਕੀਕਤ ਜ਼ਿਆਦਾ ਅਮਲਿਕ ਅਤੇ ਲਾਭਦਾਇਕ ਹੈ। “Let it crash” ਇਕ ਟੂਲ ਹੈ ਭਰੋਸੇਯੋਗ ਸੇਵਾਵਾਂ ਬਣਾਉਣ ਲਈ, ਨਾ ਕਿ ਮੁਸ਼ਕਲ ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਅਣਦੇਖਾ ਕਰਨ ਦੀ ਆਗਿਆ।
ਰੀਸਟਾਰਟ ਇੱਕ ਪੇਚਕਸ਼ ਦਵਾਈ ਨਹੀਂ
ਇੱਕ ਆਮ ਗਲਤੀ ਸੁਪਰਵਾਈਜ਼ਨ ਨੂੰ ਡੂੰਘੀਆਂ ਬੱਗੇ ਛੁਪਾਉਣ ਦੇ ਤਰੀਕੇ ਵਜੋਂ ਵਰਤਣਾ ਹੈ। ਜੇ ਇੱਕ ਪ੍ਰੋਸੈਸ ਤੁਰੰਤ ਸ਼ੁਰੂ ਹੋਣ ਤੋਂ ਬਾਅਦ ਕਰੈਸ਼ ਕਰਦਾ ਹੈ, ਤਾਂ ਸੁਪਰਵਾਈਜ਼ਰ ਉਸ ਨੂੰ ਲਗਾਤਾਰ ਰੀਸਟਾਰਟ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਇੱਕ ਕ੍ਰੈਸ਼ ਲੂਪ ਵਿੱਚ ਆ ਸਕਦੇ ਹੋ—CPU ਜ਼ਿਆਦਾ ਵਰਤਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਲੌਗ ਭਰ ਸਕਦੇ ਹਨ, ਅਤੇ ਸ਼ਾਇਦ ਮੁਢਲੀ ਬੱਗ ਨਾਲੋਂ ਵੱਡਾ ਆਊਟੇਜ ਬਣ ਜਾਏ।
ਚੰਗੇ ਸਿਸਟਮ backoff, restart intensity ਸੀਮਾਵਾਂ, ਅਤੇ "ਦਰਜਾ-ਉਠਾਓ" ਵਿਵਹਾਰ ਜੋੜਦੇ ਹਨ। ਰੀਸਟਾਰਟ ਸਿਹਤਮੰਦ ਓਪਰੇਸ਼ਨ ਨੂੰ بحال ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ, ਨ ਕਿ ਇੱਕ ਟੁੱਟੇ ਹੋਏ ਇਨਵੈਰੀਅੰਟ ਨੂੰ ਛੁਪਾਉਣਾ।
ਸਟੇਟ ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਹਿੱਸਾ ਹੈ
ਕਿਸੇ ਪ੍ਰੋਸੈਸ ਨੂੰ ਰੀਸਟਾਰਟ ਕਰਨਾ ਆਮ ਤੌਰ 'ਤੇ ਆਸਾਨ ਹੁੰਦਾ ਹੈ; ਸਹੀ ਸਟੇਟ ਨੂੰ ਮੁੜ ਪ੍ਰਾਪਤ ਕਰਨਾ ਵੱਡੀ ਗੱਲ ਹੈ। ਜੇ ਸਟੇਟ صرف memory ਵਿੱਚ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਇਹ ਫੈਸਲਾ ਕਰਨ ਦੀ ਲੋੜ ਹੈ ਕਿ ਕਰੈਸ਼ ਤੋਂ ਬਾਅਦ "ਸਹੀ" ਕੀ ਹੈ:
- ਕੀ ਤੁਸੀਂ ਇਸਨੂੰ ਇੱਕ ਦਾਇਮੀ ਸਟੋਰੇਜ ਤੋਂ ਦੁਬਾਰਾ ਬਣਾਉਗੇ?
- ਕੀ ਤੁਸੀਂ events ਨੂੰ ਦੁਬਾਰਾ ਖੇਡਕੇ idempotency ਨੂੰ ਯਕੀਨੀ ਬਣਾਓਗੇ?
- ਮਧਿਆਨ ਵਿੱਚ ਹੋ ਰਹੇ ਕੰਮ ਜਾਂ ਅਧੂਰੇ ਅਪਡੇਟਾਂ ਦਾ ਕੀ ਹੋਵੇਗਾ?
ਫੌਲਟ ਟੋਲਰੈਂਸ ਡੇਟਾ ਡਿਜ਼ਾਈਨ ਨੂੰ ਬਦਲਦਾ ਨਹੀਂ; ਇਹ ਤੁਹਾਨੂੰ ਇਸ ਬਾਰੇ ਸਪਸ਼ਟ ਹੋਣ ਲਈ ਬਲਦਾ ਹੈ।
ਤੁਸੀਂ ਅਜੇ ਵੀ ਨਿਗਰਾਨੀ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹੋ
ਕਰੈਸ਼ ਤਦ ਹੀ ਮਦਦਗਾਰ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਉਨ੍ਹਾਂ ਨੂੰ ਜਲਦੀ ਦੇਖ ਸਕੋ ਅਤੇ ਸਮਝ ਸਕੋ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਲੌਗਿੰਗ, ਮੈਟ੍ਰਿਕਸ, ਅਤੇ ਟਰੇਸਿੰਗ ਵਿੱਚ ਨਿਵੇਸ਼—ਨਾ ਕਿ ਸਿਰਫ "ਇਹ ਰੀਸਟਾਰਟ ਹੋ ਗਿਆ, ਸਾਨੂੰ ਚਿੰਤਾ ਨਹੀਂ"। ਤੁਸੀਂ ਰੀਸਟਾਰਟ ਦਰਾਂ, ਵਧ ਰਹੀ ਕਿਊਆਂ, ਅਤੇ ਧੀਮੇ ਡੀਪੈਂਡੇੰਸੀਜ਼ ਨੂੰ ਵੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਪਹਿਲਾਂ ਕਿ ਯੂਜ਼ਰਾਂ ਨੂੰ ਮਹਿਸੂਸ ਹੋਵੇ।
ਅਸਲੀ ਓਪਰੇਸ਼ਨਲ ਸੀਮਾਵਾਂ ਮੌਜੂਦ ਹਨ
BEAM ਦੀਆਂ ਤਾਕਤਾਂ ਦੇ ਬਾਵਜੂਦ, ਸਿਸਟਮ ਆਮ ਤੌਰ 'ਤੇ ਆਮ ਢੰਗ ਨਾਲ ਫੇਲ੍ਹ ਹੋ ਸਕਦੇ ਹਨ:
- ਮੈਮੋਰੀ ਵਾਧਾ ਲੀਕ, cache ਜਾਂ ਵੱਡੇ heaps ਕਰਕੇ
- ਮੇਲਬਾਕਸ ਬੈੱਕਲੌਗ ਜਦੋਂ ਪ੍ਰੋਡੀੂਸਰਸ consumers ਨਾਲੋਂ ਤੇਜ਼ ਹੋ ਜਾਂਦੇ ਹਨ (ਲੈਟेंसी spike ਅਤੇ ਟਾਈਮਆਊਟ)
- ਡਿਪੈਂਡੇੰਸੀ ਫੇਲ੍ਹਰ (ਡਾਟਾਬੇਸ, ਤੀਸਰੇ-ਪਾਰਟੀ APIs, DNS) ਜਿੱਥੇ ਰੀਸਟਾਰਟ ਤੁਹਾਡਾ ਕੋਡ ਮੂਲ ਕਾਰਨ ਨੂੰ ਠੀਕ ਨਹੀਂ ਕਰੇਗਾ
Erlang ਦਾ ਮਾਡਲ ਤੁਹਾਨੂੰ ਫੇਲ੍ਹਰ ਨੂੰ ਸੀਮਿਤ ਅਤੇ ਰਿਕਵਰ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ—ਪਰ ਇਹ ਉਨ੍ਹਾਂ ਨੂੰ ਹਟਾ ਨਹੀਂ ਸਕਦਾ।
ਅੱਜ ਕਿਵੇਂ ਇਹ ਸਬਕ ਲਾਗੂ ਕਰਨ (ਚਾਹੇ ਤੁਸੀਂ Erlang ਨਾ ਵਰਤੋਂ)
Erlang ਦੀ ਸਭ ਤੋਂ ਵੱਡੀ ਕਿਫ਼ਾਇਤ syntax ਨਹੀਂ ਹੈ—ਇਹ ਆਦਤਾਂ ਦਾ ਇੱਕ ਸੈੱਟ ਹੈ ਜੋ ਉਹ ਸੇਵਾਵਾਂ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ ਹਿੱਸਿਆਂ ਦੇ ਫੇਲ੍ਹ ਹੁੰਦੇ ਸਮੇਂ ਵੀ ਚੱਲਦੀਆਂ ਰਹਿੰਦੀਆਂ ਹਨ। ਤੁਸੀਂ ਉਹ ਆਦਤਾਂ ਲਗਭਗ ਕਿਸੇ ਵੀ ਟੈਕ ਸਟੈਕ ਵਿੱਚ ਲਾਗੂ ਕਰ ਸਕਦੇ ਹੋ।
ਵਿਚਾਰਾਂ ਨੂੰ ਤਹਿ-ਤਹਿ ਤੌਰ 'ਤੇ ਕਰਵਾਈਵਾਂ ਵਿੱਚ ਬਦਲੋ
ਸ਼ੁਰੂਆਤ failure boundaries ਨੂੰ ਸਪੱਸ਼ਟ ਬਣਾਉਣ ਨਾਲ ਕਰੋ। ਆਪਣੇ ਸਿਸਟਮ ਨੂੰ ਐਸੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਤੋੜੋ ਜੋ ਅਜ਼ਾਦੀ ਨਾਲ ਫੇਲ ਹੋ ਸਕਣ, ਅਤੇ ਹਰ ਹਿੱਸੇ ਲਈ ਇੱਕ ਸਪਸ਼ਟ ਕਾਂਟਰੈਕਟ (ਇਨਪੁਟ, ਆਉਟਪੁਟ, ਅਤੇ "ਖਰਾਬ" ਕੀ ਦਿਖਦਾ) ਪੱਕਾ ਕਰੋ।
ਫਿਰ recovery ਨੂੰ ਆਪਣੇ ਕੋਡ ਵਿੱਚ ਹਰ ਗਲਤੀ ਰੋਕਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਦੀ ਥਾਂ ਆਟੋਮੇਟ ਕਰੋ:
- ਕੰਪੋਨੈਂਟਾਂ ਨੂੰ ਅਲੱਗ ਰੱਖੋ: CPU-ਭਾਰ ਜਾਂ ਅਣ-ਭਰੋਸੇਯੋਗ ਕੰਮਾਂ ਲਈ ਵੱਖਰੀ ਪ੍ਰੋਸੈਸ/ਕੰਟੇਨਰ/ਸੇਵਾਵਾਂ ਚਲਾਓ
- ਬਾਰਡਰ ਰਖੋ: ਟਾਈਮਆਊਟ, ਬੈਕਆਫ ਦੇ ਨਾਲ ਰੀਟ੍ਰਾਈ, ਸਰਕਿਟ ਬਰੇਕਰ, ਅਤੇ ਬਲੁਕਹੈਡ cascading failures ਰੋੱਕਣ ਲਈ
- ਰਿਕਵਰੀ ਰੁਟੀਨ ਬਣਾਓ: ਹੈਲਥ ਚੈਕ, ਆਟੋ-ਰੀਸਟਾਰਟ, ਅਤੇ ਸੇਫ਼ ਡਿਫਾਲਟ ਤਾਂ ਜੋ ਸਿਸਟਮ ਤੇਜ਼ੀ ਨਾਲ ਜਾਣਿਆ-ਪ੍ਰਮਾਣਿਤ ਸਥਿਤੀ ਵਿੱਚ ਵਾਪਸ ਆ ਸਕੇ
ਇਹ ਆਦਤਾਂ tooling ਅਤੇ ਲਾਈਫਸਾਇਕਲ ਵਿੱਚ ਹੀ ਬੇਸ਼ਕ ਸ਼ਾਮਲ ਕਰੋ, ਨਾ ਕਿ ਸਿਰਫ਼ ਕੋਡ ਵਿੱਚ। ਉਦਾਹਰਣ ਲਈ, ਜਦੋਂ 팀 Koder.ai ਵਰਤਦੇ ਹਨ ਤਾਂ Planning Mode ਰੀਪੀਟੇਬਲ ਡਿਪਲੋਯਮੈਂਟ ਅਤੇ ਸਨੈਪਸ਼ੌਟ/ਰੋਲਬੈਕ ਦੀਆਂ ਪ੍ਰਕ੍ਰਿਯਾਵਾਂ ਨਾਲ ਉਹੀ ਓਪਰੇਸ਼ਨਲ ਸੋਚ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਆਉਂਦੀ ਹੈ: ਮੰਨੋ ਕਿ ਬਦਲਾਵ ਅਤੇ ਫੇਲ੍ਹ ਹੌਣਗੇ ਅਤੇ recovery ਨੂੰ ਰੋਜ਼ਮਰਾ ਦਾ ਹਿੱਸਾ ਬਣਾਓ।
Erlang ਤੋਂ ਬਾਹਰ ਸ਼ੁਰੂ ਕਰਨ ਵਾਲੇ ਪੌਂਡ ਪੁਆਇੰਟਸ
ਤੁਸੀਂ "ਸੁਪਰਵਾਈਜ਼ਨ" ਪੈਟਰਨ ਨੂੰ ਉਹ ਸੰਦਾਂ ਨਾਲ ਨਜ਼ਦੀਕੀ ਰੂਪ ਵਿੱਚ ਨਕਲ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤ ਰਹੇ ਹੋ:
- ਸੁਪਰਵਾਈਜ਼ਰ: systemd, Kubernetes Deployments, ਜਾਂ ਇੱਕ process manager (restart-on-failure, readiness probes)
- ਪ੍ਰੋਸੈਸ ਆਈਸੋਲੇਸ਼ਨ: CPU-ਭਾਰੀ ਜਾਂ ਅਣ-ਭਰੋਸੇਯੋਗ ਟਾਸਕਾਂ ਲਈ ਵੱਖ-ਵੱਖ ਵਰਕਰ ਸਰਵਿਸਾਂ
- ਮੇਸੇਜ ਪਾਸਿੰਗ: queues/streams (RabbitMQ, SQS, Kafka) ਪ੍ਰੋਡੀੂਸਰਸ ਅਤੇ consumers ਨੂੰ decouple ਅਤੇ spikes ਨੂੰ smooth ਕਰਨ ਲਈ
ਇੱਕ ਛੋਟਾ ਫੈਸਲਾ ਚੈੱਕਲਿਸਟ
ਇਹ ਪੈਟਰਨਾਂ ਨੂੰ ਨਕਲ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਨੂੰ ਅਸਲ ਵਿੱਚ ਕੀ ਚਾਹੀਦਾ ਹੈ:
- ਉਮੀਦ ਕੀਤੇ ਫੇਲ੍ਹ ਮੋਡ: ਓਵਰਲੋਡ, ਅੰਸ਼ਿਕ ਆਊਟੇਜ, ਧੀਮੀ ਡਿਪੈਂਡੇੰਸੀਜ਼, ਖਰਾਬ ਇਨਪੁਟ, ਮੈਮੋਰੀ ਲੀਕ
- ਲੈਟੈਂਸੀ ਦੀ ਲੋੜ: ਕੀ ਤੁਸੀਂ ਰੀਅਲ-ਟਾਈਮ ਜਵਾਬ ਚਾਹੀਦੇ ਹੋ, ਜਾਂ eventual processing ਠੀਕ ਹੈ?
- ਰਿਕਵਰੀ ਦਾ ਲਕਸ਼ਯ: ਤੇਜ਼ ਰੀਸਟਾਰਟ, ਗਰੇਸਫੁੱਲ ਡிகਰੇਡੇਸ਼ਨ, ਜਾਂ ਮੈਨੂਅਲ ਦਖਲਅੰਦਾਜ਼ੀ?
- ਟੀਮ ਸਕਿਲਜ਼ ਅਤੇ ਟੂਲਿੰਗ: ਕੌਣ on-call, observability, ਅਤੇ incident response ਨੂੰ ਸੰਭਾਲੇਗਾ?
ਜੇ ਤੁਸੀਂ ਪ੍ਰਯੋਗਾਤਮਕ ਅਗਲੇ ਕਦਮ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ /blog ਵਿੱਚ ਹੋਰ ਗਾਈਡ ਵੇਖੋ, /docs ਵਿੱਚ ਇੰਪਲੀਮੈਂਟੇਸ਼ਨ ਵੇਰਵਿਆਂ ਨੂੰ ਜाँचੋ (ਅਤੇ ਜੇ ਤੁਸੀਂ ਟੂਲਿੰਗ ਦਾ ਮੂਲਿਆੰਕਣ ਕਰ ਰਹੇ ਹੋ ਤਾਂ /pricing ਦੇ ਯੋਜਨਾਂ ਨੂੰ ਵੇਖੋ)।
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
Why is Joe Armstrong’s Erlang mindset still relevant today?
Erlang ਨੇ ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਰਿਲਾਇਬਿਲਟੀ ਸੋਚ ਮਸ਼ਹੂਰ ਕੀਤੀ: ਮੰਨੋ ਕਿ ਹਿੱਸੇ ਫੇਲ੍ਹ ਹੋਣਗੇ ਅਤੇ ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਅੱਗੇ ਕੀ ਹੋਏਗਾ ਇਹ ਡਿਜ਼ਾਈਨ ਕਰੋ।
ਹਰ ਇੱਕ ਕਰੈਸ਼ ਨੂੰ ਰੋਕਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਦੀ ਬਜਾਏ, ਇਹ ਜ਼ੋਰ ਦਿੰਦਾ ਹੈ ਫੌਲਟ ਆਈਸੋਲੇਸ਼ਨ, ਤੇਜ਼ ਪਤਾ ਲਗਾਉਣਾ, ਅਤੇ ਆਟੋਮੈਟਿਕ ਰਿਕਵਰੀ, ਜੋ ਚੈਟ, ਕਾਲ ਰੂਟਿੰਗ, ਨੋਟੀਫਿਕੇਸ਼ਨ ਅਤੇ ਕੋਆਰਡੀਨੇਸ਼ਨ ਸਰਵਿਸਾਂ ਵਰਗੀਆਂ ਰੀਅਲ-ਟਾਈਮ ਪਲੇਟਫਾਰਮਾਂ ਨਾਲ ਚੰਗੀ ਤਰ੍ਹਾਂ ਮਿਲਦਾ ਹੈ।
What does “real-time” mean in the post’s plain terms?
ਇਸ ਸੰਦਰਭ ਵਿੱਚ, “ਰੀਅਲ-ਟਾਈਮ” ਆਮਤੌਰ 'ਤੇ ਸੌਫਟ ਰੀਅਲ-ਟਾਈਮ ਦਾ ਮਤਲਬ ਰੱਖਦਾ ਹੈ:
- ਰਿਸਪਾਂਸ ਤੇਜ਼ ਅਤੇ ਸਥਿਰ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ
- ਲੋਡ ਹੇਠਾਂ ਵੀ ਵਤੀਰਾ ਪੇਸ਼ਿਖਾਰ ਰਹਿੰਦਾ ਹੈ
- ਸਿਸਟਮ ਅੰਸ਼ਿਕ ਫੇਲ੍ਹ ਦੀ ਦੌਰਾਨ ਕੰਮ ਕਰਦਾ ਰਹਿੰਦਾ ਹੈ
ਇਹ ਮਾਈਕ੍ਰੋਸੈਕਿੰਡ ਡੇਢਲਾਈਨਾਂ ਬਾਰੇ ਘੱਟ ਹੈ ਅਤੇ ਜ਼ਿਆਦਾ ਉਸ ਗੱਲ ਬਾਰੇ ਹੈ ਕਿ ਸਟਾਲ, ਸਪਾਇਰਲ ਅਤੇ ਕੈਸਕੇਡਿੰਗ ਆਊਟੇਜ ਤੋਂ ਬਚਿਆ ਜਾਵੇ।
What does “concurrency by default” mean in Erlang-style design?
ਕਨਕਰਨਸੀ-ਬਾਈ-ਡਿਫੌਲਟ ਦਾ ਮਤਲਬ ਹੈ ਸਿਸਟਮ ਨੂੰ ਘਣੇ ਛੋਟੇ, ਅਲੱਗ ਵਰਕਰਾਂ ਵਜੋਂ ਬਣਾਉਣਾ ਨਾ ਕਿ ਕੁਝ ਵੱਡੇ, ਅਜਿਹਾ-ਭਰੇ ਕੰਪੋਨੈਂਟਾਂ ਵਜੋਂ।
ਹਰ ਵਰਕਰ ਇੱਕ ਨਿੱਕੀ ਜ਼ਿੰਮੇਵਾਰੀ (ਇੱਕ ਸੈਸ਼ਨ, ਡਿਵਾਈਸ, ਕਾਲ, ਰੀਟ੍ਰਾਈ ਲੂਪ) ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਸਕੇਲਿੰਗ ਅਤੇ ਫੇਲ੍ਹਰ ਕੰਟੇਨਮੈਂਟ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ।
What are Erlang “lightweight processes,” and why do they matter?
ਲਾਈਟਵੇਟ ਪ੍ਰੋਸੈਸ ਉਹ ਨਿੱਕੇ ਸਵਤੰਤਰ ਵਰਕਰ ਹੁੰਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਵੱਡੇ ਗਿਣਤੀ ਵਿੱਚ ਬਣਾ ਸਕਦੇ ਹੋ।
ਅਮਲ ਵਿੱਚ, ਇਹ ਇਸ ਲਈ ਮਾਇਨੇ ਰੱਖਦੇ ਹਨ:
- ਤੁਸੀਂ ਹਰ “ਚੀਜ਼” ਲਈ ਇੱਕ ਪ੍ਰੋਸੈਸ ਮਾਡਲ ਕਰ ਸਕਦੇ ਹੋ (ਯੂਜ਼ਰ/ਸੈਸ਼ਨ/ਡਿਵਾਈਸ)
- ਫੇਲ੍ਹਰ ਸਿਰਫ ਇੱਕ ਵਰਕਰ ਤੱਕ ਸੀਮਤ ਰਹਿੰਦੇ ਹਨ
- ਵੱਖਰੇ ਢੰਗ ਨਾਲ ਰੀਸਟਾਰਟ ਕਰਨਾ ਮੋਨੋਲਿਥ ਰੀਬੂਟ ਨਾਲੋਂ ਸਸਤਾ ਹੈ
Why does Erlang prefer message passing over shared state?
ਮੇਸੇਜ ਪਾਸਿੰਗ ਸਹਿਯੋਗ ਲਈ ਮੇਸੇਜ ਭੇਜਣ ਹੈ, ਨਾ ਕਿ ਸਾਂਝੀ ਮਿਊਟੇਬਲ ਸਟੇਟ।
ਇਸ ਨਾਲ concurrency ਬੱਗਜ਼ (ਜਿਵੇਂ race conditions) ਦੇ ਬਹੁਤ ਸਾਰੇ ਕੇਸ ਘਟ ਜਾਂਦੇ ਹਨ ਕਿਉਂਕਿ ਹਰ ਵਰਕਰ ਆਪਣਾ ਡੇਟਾ ਮਾਲਿਕ ਹੈ; ਹੋਰ ਕੋਈ ਇਹਨੂੰ ਸਿੱਧਾ ਬਦਲ ਨਹੀਂ ਕਰ ਸਕਦਾ।
What is back-pressure in an actor/message system, and how do you handle it?
ਬੈਕ-ਪ੍ਰੈਸ਼ਰ ਉਹਦੇ ਸਮੇਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਕ ਵਰਕਰ ਨੂੰ ਉਸ ਦੀ ਸਮਰੱਥਾ ਤੋਂ ਤੇਜ਼ੀ ਨਾਲ ਮੇਸੇਜ ਮਿਲ ਰਹੇ ਹੁੰਦੇ ਹਨ ਅਤੇ ਉਸ ਦੀ ਮੇਲਬਾਕਸ ਵਧਦੀ ਹੈ।
ਅਮਲ ਵਿੱਚ ਮੁਕਾਬਲਾ ਕਰਨ ਦੇ ਤਰੀਕੇ:
- ਮੇਲਬਾਕਸ/ਕਿਊ ਆਕਾਰ ਦੀ ਨਿਗਰਾਨੀ
- ਸੀਮਾਵਾਂ ਲਗਾਉਣਾ (ਡ੍ਰੌਪ, ਸੈਂਪਲ, ਕੈਪ)
- ਵਧੇਰੇ ਵਰਕਰਾਂ 'ਤੇ ਲੋਡ ਵੰਡਣਾ
- ਗਰੇਸਫੁੱਲ ਡਿਗ੍ਰੇਡੇਸ਼ਨ (ਗੈਰ-ਜ਼ਰੂਰੀ ਨੋਟੀਫਿਕੇਸ਼ਨਾਂ ਲਈ ਡਾਈਜੇਸਟ)
What does “let it crash” actually mean (and what doesn’t it mean)?
“Let it crash” ਦਾ ਮਤਲਬ ਇਹ ਨਹੀਂ ਕਿ ਢਿੱਡੀ ਇੰਜੀਨੀਅਰਿੰਗ ਚਲਾਈ ਜਾਵੇ। ਇਹ ਇੱਕ ਰਿਲਾਇਬਿਲਟੀ ਨੀਤੀ ਹੈ: ਜਦੋਂ ਕੋਈ ਕੰਪੋਨੈਂਟ ਬਹੁਤ ਖਰਾਬ ਹਾਲਤ ਵਿੱਚ ਹੋਵੇ, ਉਹ ਤੇਜ਼ੀ ਨਾਲ ਰੁੱਕਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਕਿ ਢੀਠ ਸਾਹਮਣੇ ਨਾ ਪਏ।
ਰਿਕਵਰੀ ਫੈਸਲਾ ਸੁਪਰਵਾਈਜ਼ਨ ਰਚਨਾ ਦੁਆਰਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਕੋਡ ਸਾਫ਼ ਅਤੇ ਪਾਠਣਯੋਗ ਰਹਿੰਦਾ ਹੈ।
What are supervision trees, and why are they central to fault tolerance?
ਸੁਪਰਵਾਈਜ਼ਨ ਟਰੀ ਇੱਕ ਹਾਇਰਾਰਕੀ ਹੁੰਦੀ ਹੈ ਜਿੱਥੇ ਸੁਪਰਵਾਈਜ਼ਰ ਵਰਕਰਾਂ ਦੀ ਨਿਗਰਾਨੀ ਕਰਦੇ ਹਨ ਅਤੇ ਨਿਯਮਾਂ ਅਨੁਸਾਰ ਉਨ੍ਹਾਂ ਨੂੰ ਰੀਸਟਾਰਟ ਕਰਦੇ ਹਨ।
ਇਸ ਨਾਲ ਤੁਸੀਂ ਹਰ ਥਾਂ ਫੈਲ੍ਹਰ ਨੂੰ ਲਪੇਟਣ ਦੀ ਬਜਾਏ ਰਿਕਵਰੀ ਨੂੰ ਕੇਂਦਰਿਤ ਕਰ ਸਕਦੇ ਹੋ:
- ਫੈਸਲਾ ਕਰੋ ਕਿ ਫੇਲ੍ਹ ਹੋਣ 'ਤੇ ਕੀ ਰੀਸਟਾਰਟ ਹੁੰਦਾ ਹੈ
- ਬੈਕਆਫ/ਇੰਟੈਨਸਿਟੀ ਸੀਮਾਵਾਂ ਨਾਲ endess crash-loops ਰੋਕੋ
- ਜਦੋਂ ਲੋੜ ਹੋਵੇ ਤਾਂ ਸਮੂਹਿਕ ਰੀਸਟਾਰਟ ਕਰੋ ਤਾਂ ਕਿ ਕੁਝ tightly-coupled ਹਿੱਸੇ sync ਵਿੱਚ ਰਹਿਣ
What is OTP, and how does it help build reliable services?
OTP ਉਹ ਸਟੈਂਡਰਡ ਪੈਟਰਨ (behaviours) ਅਤੇ ਰਵਾਇਤੀ ਤਰੀਕੇ ਹਨ ਜੋ “let it crash” ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਚਲਾਉਣ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
ਆਮ ਬਿਲਡਿੰਗ ਬਲਾਕ ਸ਼ਾਮਲ ਹਨ:
gen_serverਲੰਬੇ-ਚਲਦੇ ਵਰਕਰ ਲਈ ਜੋ ਸਟੇਟ ਰੱਖਦਾ ਹੈ ਅਤੇ ਇੱਕ-ਇੱਕ ਕਰਕੇ ਬੇਨਤੀ ਹੈਂਡਲ ਕਰਦਾ ਹੈsupervisorਫੇਲ੍ਹ ਹੋਏ ਵਰਕਰਾਂ ਨੂੰ ਸਪਸ਼ਟ ਨਿਯਮਾਂ ਅਨੁਸਾਰ ਰੀਸਟਾਰਟ ਕਰਦਾ ਹੈapplicationਪੂਰੇ ਸਰਵਿਸ ਦੇ ਸ਼ੁਰੂ, ਬੰਦ ਅਤੇ ਰਿਲੀਜ਼ ਨਾਲ ਮਿਲਦਾ ਹੈ
ਇਹ ਪ੍ਰੋਜੈਕਟ-ਵਿਸ਼ੇਸ਼ ਫਰੇਮਵਰਕਾਂ ਨਾਲੋਂ ਸਾਂਝੇ ਪੈਟਰਨ ਦੇ ਨਾਲ ਕੰਮ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
How can I apply Erlang’s lessons if I’m not using Erlang?
ਤੁਸੀਂ ਉਹੀ ਨੀਤੀਆਂ ਹੋਰ ਸਟੈੱਕਾਂ ਵਿੱਚ ਵੀ ਲਾਗੂ ਕਰ ਸਕਦੇ ਹੋ: ਫੇਲ੍ਹਰ ਅਤੇ ਰਿਕਵਰੀ ਨੂੰ ਪਹਿਲੀ-ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ।
ਕੁਝ ਅਮਲ ਦੇ ਤਰੀਕੇ:
- ਜੋਖਿਮ ਵਾਲੇ ਕੰਮ ਨੂੰ ਇਕੱਲੇ ਪ੍ਰੋਸੈਸ/ਕੰਟੇਨਰ/ਸੇਵਾ ਵਿੱਚ ਚਲਾਓ
- ਟਾਈਮਆਊਟ, ਬੈਕਆਫ ਦੇ ਨਾਲ ਰੀਟ੍ਰਾਈ, ਸਰਕਿਟ ਬਰੇਕਰ, ਅਤੇ ਬਲੁਕਹੈਡ ਵਰਤੇ
- ਹੇਲਥ ਚੈਕ, ਆਟੋ-ਰੀਸਟਾਰਟ ਅਤੇ ਸੇਫ ਡਿਫਾਲਟ ਰੱਖੋ
ਇਕ ਉਦਾਹਰਣਤੌਰ 'ਤੇ, ਜਦੋਂ ਟੀਮਾਂ Koder.ai ਵਰਤਦੀਆਂ ਹਨ ਤਾਂ Planning Mode, ਰੀਪੀਟੇਬਲ ਡਿਪਲੋਯਮੈਂਟ ਅਤੇ ਸਨੈਪਸ਼ੌਟ/ਰੋਲਬੈਕ ਵਰਗੀਆਂ ਵਰਕਫਲੋਜ਼ ਉਹੀ ਆਪਰੇਸ਼ਨਲ ਸੋਚ ਨੈਚਰਲ ਤੌਰ 'ਤੇ ਉਤਪੰਨ ਕਰਦੀਆਂ ਹਨ: ਮੰਨੋ ਕਿ ਬਦਲਾਅ ਅਤੇ ਫੇਲ੍ਹ ਹੋਵੇਗਾ, ਅਤੇ ਰਿਕਵਰੀ ਨੂੰ ਬੋਰਿੰਗ ਬਣਾਓ।