ਜਦੋਂ ਪੁਰਾਣੀਆਂ ਇੰਟੈਗ੍ਰੇਸ਼ਨਜ਼ ਟੀਮਾਂ ਨੂੰ ਰੁਕਾਵਟ 'ਚ ਪਾ ਦਿੰਦੀਆਂ ਹਨ
ਅਕਸਰ ਉਤਪਾਦ ਸਧਾਰਨ ਪੌਇੰਟ-ਟੂ-ਪੌਇੰਟ ਇੰਟੈਗ੍ਰੇਸ਼ਨਜ਼ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੇ ਹਨ: ਸਿਸਟਮ A ਸਿਸਟਮ B ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ, ਜਾਂ ਇੱਕ ਨਿੱਕੀ ਸਕ੍ਰਿਪਟ ਕਿਸੇ ਥਾਂ ਤੋਂ ਡੇਟਾ ਕਾਪੀ ਕਰਦੀ ਹੈ। ਇਹ ਤਦ ਤੱਕ ਠੀਕ ਰਹਿੰਦਾ ਹੈ ਜਦ ਤੱਕ ਉਤਪਾਦ ਵਧਦਾ ਹੈ, ਟੀਮਾਂ ਵੱਖ-ਵੱਖ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਅਤੇ ਕਨੈਕਸ਼ਨਾਂ ਦੀ ਗਿਣਤੀ ਬਹੁਤ ਹੋ ਜਾਂਦੀ ਹੈ। ਜਲਦੀ-ਜਲਦੀ ਹਰ ਬਦਲਾਅ ਲਈ ਕਈ ਸਰਵਿਸਜ਼ ਦੇ ਕੋਆਰਡੀਨੇਸ਼ਨ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ, ਕਿਉਂਕਿ ਇੱਕ ਛੋਟਾ ਖੇਤਰ ਜਾਂ ਸਥਿਤੀ ਅਪਡੇਟ ਨਿਰਭਰਤਾਵਾਂ ਦੀ ਲੜੀ 'ਚ ਰਿਪਲ ਹੋ ਸਕਦਾ ਹੈ।
ਪਹਿਲਾਂ ਤੇਜ਼ੀ ਆਮ ਤੌਰ 'ਤੇ ਟੁੱਟਦੀ ਹੈ। ਨਵੀਂ ਫੀਚਰ ਜੋੜਣ ਦਾ ਮਤਲਬ ਕਈ ਇੰਟੈਗ੍ਰੇਸ਼ਨਜ਼ ਅਪਡੇਟ ਕਰਨਾ, ਕਈ ਸਰਵਿਸਜ਼ ਰੀਡਿਪਲੋਇ ਕਰਨਾ, ਅਤੇ ਆਸ਼ਾ ਕਰਨਾ ਕਿ ਹੋਰ ਕੁਝ ਪੁਰਾਣੇ ਬਿਹੇਵਿਅਰ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਸੀ।
ਫਿਰ ਡੀਬੱਗਿੰਗ ਦਰਦਨਾਕ ਹੋ ਜਾਂਦੀ ਹੈ। ਜਦੋਂ UI 'ਚ ਕੁਝ ਗਲਤ ਲਗਦਾ ਹੈ, ਤਾਂ ਬੁਨਿਆਦੀ ਸਵਾਲ ਔਖੇ ਹੋ ਜਾਂਦੇ ਹਨ: ਕੀ ਹੋਇਆ ਸੀ, ਕਿਸ ਕ੍ਰਮ ਵਿੱਚ, ਅਤੇ ਤੁਹਾਨੂੰ ਜੋ ਮੁੱਲ ਦਿੱਖ ਰਿਹਾ ਹੈ ਉਹ ਕਿਸ ਸਿਸਟਮ ਨੇ ਲਿਖਿਆ ਸੀ?
ਅਕਸਰ ਗੁੰਮ ਹੁੰਦੀ ਚੀਜ਼ ਆਡਿਟ ਟ੍ਰੇਲ ਹੁੰਦੀ ਹੈ। ਜੇ ਡੇਟਾ ਇੱਕ ਡੈਟਾਬੇਸ ਤੋਂ ਦੂਜੇ ਨੂੰ ਸਿੱਧਾ ਪুশ ਕੀਤਾ ਜਾਂਦਾ ਹੈ (ਜਾਂ ਰਸਤੇ ਵਿੱਚ ਰੂਪਾਂਤਰਿਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ), ਤਾਂ ਤੁਸੀਂ ਇਤਿਹਾਸ ਖੋ ਦਿੰਦੇ ਹੋ। ਤੁਸੀਂ ਆਖਰੀ ਅਵਸਥਾ ਦੇਖ ਸਕਦੇ ਹੋ, ਪਰ ਉਹ ਘਟਨਾਵਾਂ ਦੀ ਲੜੀ ਨਹੀਂ ਜੋ ਉੱਥੇ ਲੈ ਕੇ ਗਈ। ਘਟਨਾ-ਸਮੀਖਿਆ ਅਤੇ ਗ੍ਰਾਹਕ ਸਹਾਇਤਾ ਦੋਹਾਂ ਪ੍ਰਭਾਵਿਤ ਹੁੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਤੁਸੀਂ ਬਦਲੇ ਹੋਏ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾਈਆਂ ਬਿਨਾਂ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰ ਸਕਦੇ ਕਿ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕਿਉਂ।
ਇਹੀ ਥਾਂ "ਕੌਣ ਸੱਚ ਦਾ ਮਾਲਕ ਹੈ" ਦਾ ਤਰਕ ਆਰੰਭ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਟੀਮ ਕਹਿੰਦੀ ਹੈ, “ਬਿਲਿੰਗ ਸਰਵਿਸੀ ਸੱਚ ਦਾ ਸਰੋਤ ਹੈ।” ਦੂਜੀ ਕਹਿੰਦੀ ਹੈ, “ਆਰਡਰ ਸਰਵਿਸ ਹੈ।” ਅਸਲ ਵਿੱਚ, ਹਰ ਸਿਸਟਮ ਦਾ ਇੱਕ ਆংশਿਕ ਨਜ਼ਾਰਾ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਪੌਇੰਟ-ਟੂ-ਪੌਇੰਟ ਇੰਟੈਗ੍ਰੇਸ਼ਨਜ਼ ਉਸ ਵਿਵਾਦ ਨੂੰ ਰੋਜ਼ਾਨਾ ਘੱਟੋ-ਘੱਟ ਘਟਾਉਂਦੀਆਂ ਹਨ।
ਇੱਕ ਸਧਾਰਨ ਉਦਾਹਰਣ: ਇੱਕ ਆਰਡਰ ਬਣਦਾ ਹੈ, ਫਿਰ ਭੁਗਤਾਨ ਹੁੰਦਾ ਹੈ, ਫਿਰ ਰੀਫੰਡ। ਜੇ ਤਿੰਨ ਸਿਸਟਮ ਇਕ-ਦੂਜੇ ਨੂੰ ਸਿੱਧਾ ਅਪਡੇਟ ਕਰਦੇ ਹਨ, ਤਾਂ retry, timeout, ਜਾਂ ਮੈਨੁਅਲ ਫਿਕਸ ਹੋਣ 'ਤੇ ਹਰ ਇੱਕ ਦੇ ਕੋਲ ਵੱਖ-ਵੱਖ ਕਹਾਣੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਉਹ ਮੁੱਖ ਡਿਜ਼ਾਈਨ ਸਵਾਲ ਹੈ ਜੋ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਦੇ ਪਿੱਛੇ ਖੜਾ ਹੈ: ਕੀ ਤੁਹਾਨੂੰ ਸਿਰਫ ਕੰਮ ਇੱਕ ਥਾਂ ਤੋਂ ਦੂਜੇ ਥਾਂ ਭੇਜਣਾ ਹੈ (ਇੱਕ ਕਿਊ), ਜਾਂ ਤੁਹਾਨੂੰ ਇੱਕ ਸਾਂਝਾ, ਟਿਕਾਉ ਰਿਕਾਰਡ ਚਾਹੀਦਾ ਹੈ ਜਿਸਨੂੰ ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ ਪੜ੍ਹ ਸਕਦੇ, ਵਾਪਸ ਲੈ ਸਕਦੇ, ਅਤੇ ਭਰੋਸਾ ਕਰ ਸਕਦੇ ਹਨ (ਇੱਕ ਲੌਗ)? ਇਹ ਜਵਾਬ ਬਦਲ ਦੇਂਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਆਪਣੀ ਸਿਸਟਮ ਨੂੰ ਕਿਵੇਂ ਬਣਾਉਂਦੇ, ਡੀਬੱਗ ਕਰਦੇ, ਅਤੇ ਵਿਕਸਤ ਕਰਦੇ ਹੋ।
Jay Kreps, Kafka, ਅਤੇ ਲੌਗ ਦਾ ਵਿਚਾਰ
Jay Kreps ਨੇ Kafka ਨੂੰ ਆਕਾਰ ਦਿੱਤਾ ਅਤੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਕ ਗੱਲ — ਕਈ ਟੀਮਾਂ ਨੂੰ ਡੇਟਾ ਹਿਲਾਉਣ ਬਾਰੇ ਸੋਚਣ ਦਾ ਤਰੀਕਾ ਬਦਲਿਆ। ਲਾਭਦਾਇਕ ਸੋਚਾਂ ਵਿੱਚ ਸਵਿੱਚ ਇਹ ਹੈ: ਸੁਨੇਹਿਆਂ ਨੂੰ ਇੱਕ ਵਾਰੀ ਦੀ ਡਿਲਿਵਰੀ ਵਜੋਂ ਨਹੀਂ ਦੇਖੋ, ਬਲਕਿ ਸਿਸਟਮ ਗਤਿਵਿਧੀ ਨੂੰ ਇੱਕ ਰਿਕਾਰਡ ਵਜੋਂ ਦੇਖੋ।
ਮੁੱਲ ਖਿਆਲ ਸਧਾਰਣ ਹੈ। ਮਹੱਤਵਪੂਰਣ ਬਦਲਾਵਾਂ ਨੂੰ ਅਟੱਲ ਤੱਥਾਂ ਦੀ ਇੱਕ ਸਟ੍ਰੀਮ ਵਜੋਂ ਮਾਡਲ ਕਰੋ:
- ਇੱਕ ਆਰਡਰ ਬਣਿਆ।
- ਇੱਕ ਭੁਗਤਾਨ ਮਨਜ਼ੂਰ ਹੋਇਆ।
- ਇੱਕ ਯੂਜ਼ਰ ਨੇ ਆਪਣਾ ਈਮੇਲ ਬਦਲਿਆ।
ਹਰ ਇਵੈਂਟ ਇੱਕ ਐਸਾ ਤੱਥ ਹੈ ਜੋ ਬਾਅਦ ਵਿੱਚ ਸੋਧਿਆ ਨਹੀਂ ਜਾਣਾ ਚਾਹੀਦਾ। ਜੇ ਬਾਅਦ ਵਿੱਚ ਕੁਝ ਬਦਲਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਨਵਾਂ ਇਵੈਂਟ ਜੋੜਦੇ ਹੋ ਜੋ ਨਵੀਂ ਸੱਚਾਈ ਦੱਸਦਾ ਹੈ। ਸਮੇਂ ਦੇ ਨਾਲ, ਉਹ ਤੱਥ ਇੱਕ ਲੌਗ ਬਣਾਉਂਦੇ ਹਨ: ਇੱਕ append-only ਤੁਹਾਡੀ ਸਿਸਟਮ ਦਾ ਇਤਿਹਾਸ।
ਇੱਥੇ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਆਮ ਮੈਸੇਜਿੰਗ ਸੈਟਅਪਸ ਤੋਂ ਵੱਖਰਾ ਹੈ। ਕਈ ਕਿਊਜ਼ "ਭੇਜੋ, ਪ੍ਰੋਸੈਸ ਕਰੋ, ਮਿਟਾ ਦਿਓ" ਦੇ ਆਸਪਾਸ ਬਣੇ ਹੁੰਦੇ ਹਨ। ਜਦੋਂ ਕੰਮ ਸਿਰਫ਼ ਹੇਅਡਾਫ ਹੈ, ਤਾਂ ਇਹ ਠੀਕ ਹੈ। ਲੌਗ ਦਾ ਨਜ਼ਰੀਆ ਕਹਿੰਦਾ ਹੈ, "ਇਤਿਹਾਸ ਰੱਖੋ ਤਾਂ ਜੋ ਕਈ ਕੰਜਿਊਮਰ ਹੁਣ ਅਤੇ ਭਵਿੱਖ 'ਚ ਇਸਨੂੰ ਵਰਤ ਸਕਣ।"
ਰੀਪਲੇਇੰਗ ਇਤਿਹਾਸ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਸੁਪਰਪਾਵਰ ਹੈ।
ਜੇ ਕਿਸੇ ਰਿਪੋਰਟ 'ਚ ਗਲਤੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਹੀ ਇਵੈਂਟ ਇਤਿਹਾਸ ਨੂੰ ਇੱਕ ਠੀਕ ਕੀਤੇ ਆਨਾਲਿਟਿਕਸ ਜੌਬ 'ਚ ਦੁਬਾਰਾ ਚਲਾ ਸਕਦੇ ਹੋ ਅਤੇ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਗਿਣਤੀ ਕਿੱਥੇ ਬਦਲੀ। ਜੇ ਕਿਸੇ ਬੱਗ ਨੇ ਗਲਤ ਈਮੇਲ ਭੇਜੇ, ਤਾਂ ਤੁਸੀਂ ਇਵੈਂਟਾਂ ਨੂੰ ਟੈਸਟ ਮਾਹੌਲ 'ਚ ਰੀਪਲੇ ਕਰਕੇ ਠੀਕ ਢੰਗ ਨਾਲ ਠੀਕ ਸਮਾਂ-ਰੇਖਾ ਦੁਹਰਾ ਸਕਦੇ ਹੋ। ਜੇ ਨਵੀਂ ਫੀਚਰ ਨੂੰ ਪੁਰਾਣਾ ਡੇਟਾ ਲੋੜੀਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਨਵਾਂ ਕੰਜਿਊਮਰ ਸ਼ੁਰੂ ਤੋਂ ਪੜ੍ਹ ਕੇ ਆਪਣੇ ਆਪ ਕੈਚ-ਅਪ ਕਰ ਸਕਦਾ ਹੈ।
ਇੱਕ ਵਿਅਰਥ ਉਦਾਹਰਣ: ਤੁਸੀਂ ਫਰਾਡ ਚੈਕਸ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਜੋੜਦੇ ਹੋ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਮਹੀਨਿਆਂ ਦੇ ਭੁਗਤਾਨ ਪਹਿਲਾਂ ਤੋਂ ਪ੍ਰੋਸੈਸ ਹੋ ਚੁੱਕੇ ਹਨ। ਭੁਗਤਾਨ ਅਤੇ ਅਕਾਉਂਟ ਇਵੈਂਟਾਂ ਦਾ ਇੱਕ ਲੌਗ ਹੋਣ ਨਾਲ, ਤੁਸੀਂ ਬੀਤੇ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾ ਕੇ ਅਸਲ ਕ੍ਰਮ 'ਤੇ ਨਿਯਮ ਸਿੱਖਾਉਣ ਜਾਂ ਕੈਲਿਬਰੇਟ ਕਰਨ, ਪੁਰਾਣੀਆਂ ਲੈਨ-ਦੇਨ ਲਈ ਰਿਸਕ ਸਕੋਰਾਂ ਦੀ ਗਣਨਾ ਕਰਨ, ਅਤੇ ਡੈਟਾਬੇਸ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖੇ ਬਿਨਾਂ "fraud_review_requested" ਇਵੈਂਟ ਬੈਕਫਿਲ ਕਰਨ ਯੋਗ ਹੋ।
ਧਿਆਨ ਦਿਓ ਕਿ ਇਹ ਤੁਹਾਨੂੰ ਕੀ ਕਰਨ ਲਈ ਮਜ਼ਬੂਰ ਕਰਦਾ ਹੈ। ਲੌਗ-ਅਧਾਰਿਤ ਰਵਈਆ ਤੁਹਾਨੂੰ ਇਵੈਂਟਾਂ ਨੂੰ ਸਾਫ਼ ਨਾਮ ਦੇਣ, ਉਨ੍ਹਾਂ ਨੂੰ ਸਥਿਰ ਰੱਖਣ, ਅਤੇ ਇਹ ਮੰਨਣ ਲਈ ਪ੍ਰੇਰਿਤ ਕਰਦਾ ਹੈ ਕਿ ਕਈ ਟੀਮਾਂ ਅਤੇ ਸਰਵਿਸਜ਼ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਹੋਣਗੀਆਂ। ਇਹ ਉਹਨਾਂ ਸਵਾਲਾਂ ਨੂੰ ਵੀ ਜਨਮ ਦਿੰਦਾ ਹੈ: ਸੱਚ ਦਾ ਸਰੋਤ ਕੀ ਹੈ? ਇਹ ਇਵੈਂਟ ਲੰਬੇ ਸਮੇਂ ਲਈ ਕੀ ਮਤਲਬ ਰੱਖਦਾ ਹੈ? ਜਦੋਂ ਅਸੀਂ ਗਲਤੀ ਕਰਦੇ ਹਾਂ ਤਾਂ ਕੀ ਕਰਾਂਗੇ?
ਮੁੱਲ ਵਿਅਕਤੀਗਤ ਨਹੀਂ ਹੈ। ਮੁੱਲ ਇਹ ਸਮਝਣਾ ਹੈ ਕਿ ਇੱਕ ਸਾਂਝਾ ਲੌਗ ਤੁਹਾਡੀ ਸਿਸਟਮ ਦੀ ਯਾਦ ਦੱਸੀ ਸਕਦਾ ਹੈ, ਅਤੇ ਯਾਦ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਸਿਸਟਮਾਂ ਨੂੰ ਬਿਨਾਂ ਟੁੱਟੇ ਵਧਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਨਵਾਂ ਕੰਜਿਊਮਰ ਜੋੜਦੇ ਹੋ।
ਕਿਊ ਵਿਰੁੱਧ ਲੌਗ: ਸਭ ਤੋਂ ਸਧਾਰਨ ਮਾਨਸਿਕ ਮਾਡਲ
ਇੱਕ ਮੇਸੇਜ ਕਿਊ ਤੁਹਾਡੇ ਸੌਫਟਵੇਅਰ ਲਈ ਟੂ-ਡੂ ਲਾਈਨ ਵਾਂਗ ਹੈ। ਪ੍ਰੋਡਿਊਸਰ ਕੰਮ ਲਾਈਨ ਵਿੱਚ ਰੱਖਦੇ ਹਨ, ਕੰਜਿਊਮਰ ਅਗਲਾ ਆਈਟਮ ਲੈਂਦੇ ਹਨ, ਕੰਮ ਕਰਦੇ ਹਨ, ਅਤੇ ਆਈਟਮ ਗਾਇਬ ਹੋ ਜਾਂਦਾ ਹੈ। ਸਿਸਟਮ ਦਾ ਮੁੱਖ ਮਕਸਦ ਹੈ ਹਰ ਟਾਸਕ ਨੂੰ ਜਲਦੀ ਸੰਭਾਲਣਾ ਅਤੇ ਇੱਕ ਵਾਰੀ ਸੰਭਾਲ ਲੈਣਾ।
ਲੌਗ ਵੱਖਰਾ ਹੈ। ਇਹ ਹੋਏ ਹੋਏ ਤੱਥਾਂ ਦਾ ਇੱਕ ਅਨੁਕ੍ਰਮਿਤ ਰਿਕਾਰਡ ਹੈ ਜੋ ਇੱਕ ਟਿਕਾਊ ਕ੍ਰਮ ਵਿੱਚ ਰੱਖਿਆ ਜਾਂਦਾ ਹੈ। ਕੰਜਿਊਮਰ ਇਵੈਂਟਾਂ ਨੂੰ "ਲੈ" ਕੇ ਨਹੀਂ ਲੈਂਦੇ; ਉਹ ਆਪਣੀ ਰਫ਼ਤਾਰ 'ਤੇ ਲੌਗ ਪੜ੍ਹਦੇ ਹਨ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਦੁਬਾਰਾ ਵੀ ਪੜ੍ਹ ਸਕਦੇ ਹਨ। Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਵਿੱਚ, ਉਹ ਲੌਗ ਮੁੱਖ ਵਿਚਾਰ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਤਰੀਕ ਯਾਦ ਰੱਖਣ ਲਈ:
- ਕਿਊ = ਕੀਤਾ ਜਾਣ ਵਾਲਾ ਕੰਮ। ਜਦੋਂ ਇੱਕ ਵਰਕਰ ਪੁਸ਼ਟੀ ਕਰਦਾ, ਇਹ ਗਾਇਬ ਹੋ ਜਾਂਦਾ ਹੈ।
- ਲੌਗ = ਜੋ ਹੋਇਆ ਉਸ ਦਾ ਇਤਿਹਾਸ। ਇਵੈਂਟ retention ਪੀਰੀਅਡ ਲਈ ਟਿਕੇ ਰਹਿੰਦੇ ਹਨ।
ਰੀਟੇਨਸ਼ਨ ਡਿਜ਼ਾਈਨ ਬਦਲ ਦਿੰਦਾ ਹੈ। ਕਿਊ ਨਾਲ, ਜੇ ਬਾਅਦ ਵਿੱਚ ਤੁਹਾਨੂੰ ਪੁਰانے ਸੁਨੇਹਿਆਂ 'ਤੇ ਨਿਰਭਰ ਕਰਨ ਵਾਲੀ ਨਵੀਂ ਫੀਚਰ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ (ਐਨਾਲਿਟਿਕਸ, ਫਰਾਡ ਚੈੱਕਸ, ਬੱਗ ਤੋਂ ਬਾਅਦ ਰੀਪਲੇ), ਤਾਂ ਅਕਸਰ ਤੁਹਾਨੂੰ ਇੱਕ ਵੱਖਰਾ ਡੈਟਾਬੇਸ ਜੋੜਨਾ ਪੈਂਦਾ ਹੈ ਜਾਂ ਹੋਰ ਕਾਪੀਆਂ ਕੈਪਚਰ ਕਰਨੀ ਪੈਂਦੀ ਹਨ। ਲੌਗ ਨਾਲ, ਰੀਪਲੇ ਸਧਾਰਨ ਹੈ: ਤੁਸੀਂ ਸ਼ੁਰੂ ਤੋਂ (ਜਾਂ ਜਾਣੇ-ਪਛਾਣ ਵਾਲੇ ਚੈਕਪੋਇੰਟ ਤੋਂ) ਪੜ੍ਹ ਕੇ ਰੀਬਿਲਡ ਕਰ ਸਕਦੇ ਹੋ।
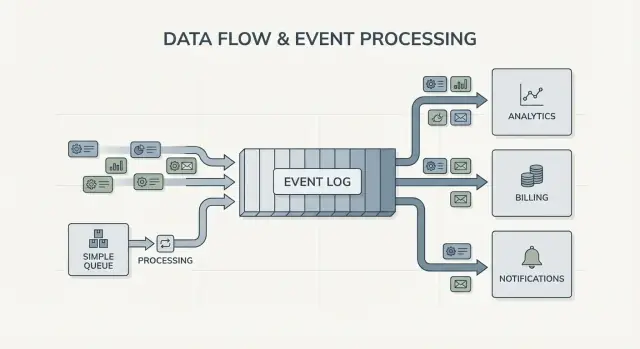
ਫੈਨ-ਆਉਟ ਵੀ ਇੱਕ ਵੱਡਾ ਫਰਕ ਹੈ। ਸੋਚੋ ਕਿ ਇੱਕ ਚੈਕਆਉਟ ਸਰਵਿਸ OrderPlaced ਜਾਰੀ ਕਰਦੀ ਹੈ। ਕਿਊ ਨਾਲ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਵਰਕਰ ਗਰੁੱਪ ਚੁਣਦੇ ਹੋ ਜਾਂ ਕਈ ਕਿਊਜ਼ 'ਤੇ ਕੰਮ ਨਕਲ ਕਰਦੇ ਹੋ। ਲੌਗ ਨਾਲ, billing, email, inventory, search indexing, ਅਤੇ analytics ਸਭ ਇੱਕੋ ਇਵੈਂਟ ਸਟਰੀਮ ਨੂੰ ਸੁਤੰਤਰ ਤਰੀਕੇ ਨਾਲ ਪੜ੍ਹ ਸਕਦੇ ਹਨ। ਹਰ ਟੀਮ ਆਪਣੀ ਗਤਿ ਨਾਲ ਚੱਲ ਸਕਦੀ ਹੈ, ਅਤੇ ਨਵਾਂ ਕੰਜਿਊਮਰ ਜੋੜਨਾ ਪ੍ਰੋਡਿਊਸਰ ਨੂੰ ਬਦਲਣ ਦੀ ਲੋੜ ਨਹੀਂ ਪਾਉਂਦਾ।
ਸੁਤੰਤਰ ਮਾਡਲ ਸਿਧਾ ਹੈ: ਜੇ ਤੁਸੀਂ ਕੰਮ ਹਿਲਾਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਕਿਊ ਵਰਤੋ; ਜੇ ਤੁਸੀਂ ਇवੈਂਟਾਂ ਨੂੰ ਦਰਜ ਕਰਕੇ ਰੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਕਈ ਹਿੱਸੇ ਭਵਿੱਖ ਵਿੱਚ ਪੜ੍ਹ ਸਕਣ, ਤਾਂ ਲੌਗ ਵਰਤੋ।
ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਵਿੱਚ ਕੀ ਬਦਲਦਾ ਹੈ
ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਮੁਲ ਪ੍ਰਸ਼ਨ ਨੂੰ ਉਲਟਦਾ ਹੈ। "ਮੈਨੂੰ ਇਹ ਸੁਨੇਹਾ ਕਿਸ ਨੂੰ ਭੇਜਣਾ ਚਾਹੀਦਾ ਹੈ?" ਪੁਛਣ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਸ਼ੁਰੂ ਕਰੋਗੇ "ਹੁਣ ਕੀ ਹੋਇਆ?" ਇਹ ਛੋਟੀ ਲੱਗਦੀ ਹੈ, ਪਰ ਇਹ ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਮਾਡਲ ਕਰਨ ਦਾ ਤਰੀਕਾ ਬਦਲ ਦਿੰਦੀ ਹੈ।
ਤੁਸੀਂ OrderPlaced ਜਾਂ PaymentFailed ਵਰਗੇ ਤੱਥ ਪਬਲਿਸ਼ ਕਰਦੇ ਹੋ, ਅਤੇ ਸਿਸਟਮ ਦੇ ਹੋਰ ਹਿੱਸੇ ਫੈਸਲਾ ਕਰਦੇ ਹਨ ਕਿ ਉਹ ਕਦੋਂ, ਕਿਵੇਂ ਅਤੇ ਕੀ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।
Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਨਾਲ, ਪ੍ਰੋਡਿਊਸਰਾਂ ਨੂੰ ਸਿੱਧਾ ਏਕ-ਏਕ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਦੀ ਲਿਸਟ ਰੱਖਣ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ। ਇੱਕ ਚੈਕਆਉਟ ਸਰਵਿਸ ਇੱਕ ਹੀ ਇਵੈਂਟ ਪਬਲਿਸ਼ ਕਰ ਸਕਦੀ ਹੈ ਅਤੇ ਇਹ ਜਾਣਨ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ ਕਿ analytics, email, fraud checks, ਜਾਂ ਭਵਿੱਖ ਦੀ recommendation ਸਰਵਿਸ ਇਸਨੂੰ ਵਰਤੇਗੀ ਜਾਂ ਨਹੀਂ। ਨਵੇਂ ਕੰਜਿਊਮਰ ਬਾਅਦ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ, ਪੁਰਾਣੇ ਰੋਕੇ ਜਾ ਸਕਦੇ ਹਨ, ਅਤੇ ਪ੍ਰੋਡਿਊਸਰ ਇੱਕੋ ਜਿਹਾ ਰਹਿੰਦਾ ਹੈ।
ਇਸ ਨਾਲ ਗਲਤੀਆਂ ਤੋਂ ਮੁਕਤੀ ਦਾ ਢੰਗ ਵੀ ਬਦਲ ਜਾਂਦਾ ਹੈ। ਸਿਰਫ ਮੇਸੇਜਿੰਗ ਦੀ ਦੁਨੀਆ ਵਿੱਚ, ਜਦ ਇੱਕ ਕੰਜਿਊਮਰ ਕੁਝ ਮਿਸ ਕਰਦਾ ਜਾਂ ਬੱਗ ਹੋ ਜਾਂਦਾ, ਤਾਂ ਡੇਟਾ ਅਕਸਰ "ਚਲੀ ਗਈ" ਮੰਨੀ ਜਾਂਦੀ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ ਖ਼ਾਸ ਬੈਕਅਪ ਨਹੀਂ ਬਣਾਏ। ਲੌਗ ਨਾਲ, ਤੁਸੀਂ ਕੋਡ ਠੀਕ ਕਰੋ ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾ ਕੇ ਸਹੀ ਅਵਸਥਾ ਬਣਾ ਸਕਦੇ ਹੋ। ਇਹ ਅਕਸਰ ਹਥਿਆਰ ਦੀ ਤਰ੍ਹਾਂ ਐਡ-ਹੌਕ ਡੈਟਾਬੇਸ ਐਡਿਟਸ ਜਾਂ ਅਣਭਰੋਸੇਯੋਗ ਸਕ੍ਰਿਪਟਾਂ ਤੋਂ ਵਧੀਆ ਹੁੰਦਾ ਹੈ।
ਅਮਲੀ ਤੌਰ 'ਤੇ, ਇਹ ਬਦਲਾਅ ਕੁਝ ਵਿਸ਼ਵਸਨੀਯ ਤਰੀਕਿਆਂ ਵਿੱਚ ਪ੍ਰਗਟ ਹੁੰਦੇ ਹਨ: ਤੁਸੀਂ ਇਵੈਂਟਾਂ ਨੂੰ ਟਿਕਾਉ ਰਿਕਾਰਡ ਵਜੋਂ ਮੰਨਦੇ ਹੋ, ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਨੂੰ ਜੋੜਨ ਲਈ ਪ੍ਰੋਡਿਊਸਰ ਨੂੰ ਸੋਧਣ ਦੀ ਥਾਂ subscribe ਕਰਦੇ ਹੋ, ਤੁਸੀਂ read models (ਖੋਜ ਇੰਡੈਕਸ, ਡੈਸ਼ਬੋਰਡ) ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਦੁਬਾਰਾ ਬਣਾ ਸਕਦੇ ਹੋ, ਅਤੇ ਤੁਹਾਨੂੰ ਕੇਸਾਂ ਦੀ ਸਾਫ਼ ਟਾਈਮਲਾਈਨ ਮਿਲਦੀ ਹੈ ਕਿ ਕੀ ਹੋਇਆ।
ਨਿਗਰਾਨੀ ਸੁਧਰਦੀ ਹੈ ਕਿਉਂਕਿ ਇਵੈਂਟ ਲੌਗ ਇੱਕ ਸਾਂਝਾ ਸੰਦਰਭ ਬਣ ਜਾਂਦਾ ਹੈ। ਜਦੋਂ ਕੁਝ ਗਲਤ ਹੋਵੇ, ਤੁਸੀਂ ਇੱਕ ਬਿਜ਼ਨਸ ਕ੍ਰਮ ਨੂੰ ਫਾਲੋ ਕਰ ਸਕਦੇ ਹੋ: ਆਰਡਰ ਬਣਿਆ, ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਹੋਈ, ਭੁਗਤਾਨ ਦੁਬਾਰਾ ਕੋਸ਼ਿਸ਼ ਕੀਤਾ ਗਿਆ, ਸ਼ਿਪਮੈਂਟ ਨਿਯਤ ਕੀਤਾ ਗਿਆ। ਇਹ ਟਾਈਮਲਾਈਨ ਅਕਸਰ ਵਿਖਰੇ ਐਪਲੀਕੇਸ਼ਨ ਲੋਗਾਂ ਨਾਲੋਂ ਸਮਝਣ ਵਿੱਚ ਆਸਾਨ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ ਇਹ ਬਿਜ਼ਨਸ ਤੱਥਾਂ 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਨਿਰਧਾਰਤ ਉਦਾਹਰਣ: ਜੇ ਇੱਕ ਡਿਸਕਾਊਂਟ ਬੱਗ ਨੇ ਦੋ ਘੰਟਿਆਂ ਲਈ ਆਰਡਰਾਂ ਦੀ ਕੀਮਤ ਗਲਤ ਕੀਤੀ, ਤੁਸੀਂ ਫਿਕਸ ਸ਼ਿਪ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਪ੍ਰਭਾਵਿਤ ਇਵੈਂਟਾਂ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾ ਕੇ ਟੋਟਲਾਂ ਦੁਬਾਰਾ ਗਣਨਾ, ਇਨਵੌਇਸ ਅਪਡੇਟ, ਅਤੇ ਐਨਾਲਿਟਿਕਸ ਰੀਫ੍ਰੈਸ਼ ਕਰ ਸਕਦੇ ਹੋ। ਤੁਸੀਂ ਨਤੀਜੇ ਦੁਬਾਰਾ ਉਤਪੰਨ ਕਰਕੇ ਸਹੀ ਕਰ ਰਹੇ ਹੋ, ਨਾ ਕਿ ਹੱਥੋ-ਹੱਥ ਦ੍ਰਿੜ੍ਹ ਟੇਬਲਾਂ ਨੂੰ ਪੈਚ ਕਰਕੇ।
ਜਦੋਂ ਇੱਕ ਸਧਾਰਨ ਕਿਊ ਕਾਫੀ ਹੁੰਦੀ ਹੈ
ਜਦੋਂ ਤੁਸੀਂ ਕੰਮ ਹਿਲਾ ਰਹੇ ਹੋ, ਨਾ ਕਿ ਲੰਬੇ ਸਮੇਂ ਦਾ ਰਿਕਾਰਡ ਬਣਾ ਰਹੇ ਹੋ, ਇੱਕ ਸਧਾਰਨ ਕਿਊ ਠੀਕ ਟੂਲ ਹੈ। ਲਕੜੀ ਦਾ ਮਕਸਦ ਇੱਕ ਵਰਕਰ ਨੂੰ ਟਾਸਕ ਹਵਾਲਾ ਕਰਨਾ, ਉਹ ਚਲਾ ਕੇ ਭੁੱਲ ਜਾਣਾ ਹੈ। ਜੇ ਕਿਸੇ ਨੂੰ ਪੁਰਾਣੀ ਇਤਿਹਾਸ ਨੂੰ ਰੀਪਲੇ ਕਰਨ, ਪੁਰਾਣੇ ਇਵੈਂਟਾਂ ਨੂੰ ਜਾਂਚਣ, ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਨਵੇਂ ਕੰਜਿਊਮਰ ਜੋੜਨ ਦੀ ਲੋੜ ਨਹੀਂ, ਤਾਂ ਕਿਊ ਸਧਾਰਨ ਰੱਖਦਾ ਹੈ।
ਕਿਊ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬਾਂ ਲਈ ਚਮਕਦਾਰ ਹੈ: ਸائنਅਪ ਈਮੇਲ ਭੇਜਣਾ, ਅਪਲੋਡ ਤੋਂ ਬਾਅਦ ਇਮੇਜ ਰੀਸਾਈਜ਼ ਕਰਨਾ, ਰਾਤੀਂ ਨਾਈਟਲੀ ਰਿਪੋਰਟ ਬਣਾਉਣਾ, ਜਾਂ ਬਾਹਰੀ API ਨੂੰ ਕਾਲ ਕਰਨਾ ਜੋ ਧੀਮਾ ਹੋ ਸਕਦਾ ਹੈ। ਇਨ੍ਹਾਂ ਕੇਸਾਂ ਵਿੱਚ ਸੁਨੇਹਾ ਸਿਰਫ਼ ਇੱਕ ਵਾਰਕ ਟਿਕਟ ਹੈ। ਜਦ ਇੱਕ ਵਰਕਰ ਕੰਮ ਮੁਕੰਮਲ ਕਰ ਲੈਂਦਾ, ਟਿਕਟ ਦਾ ਕੰਮ ਮੁਕੰਮਲ ਹੋ ਜਾਂਦਾ।
ਕਿਊ ਉਸ ਮਾਲਕੀ ਮਾਡਲ ਨਾਲ ਵੀ ਮੇਲ ਖਾਂਦਾ ਹੈ: ਇੱਕ ਕੰਜਿਊਮਰ ਗਰੁੱਪ ਕੰਮ ਦਾ ਜਿੰਮੇਵਾਰ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਹੋਰ ਸਰਵਿਸਜ਼ ਉਮੀਦ ਨਹੀਂ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਕਿ ਉਹ ਇਕੋ ਸੁਨੇਹਾ ਸੁਤੰਤਰ ਤਰੀਕੇ ਨਾਲ ਪੜ੍ਹਣ।
ਕਿਊ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਜ਼ਿਆਦਾਤਰ ਸੱਚ ਹੈ ਕਿ:
- ਡੇਟਾ ਦੀ ਵੈਲਿਊ ਛੇਤੀ ਖਤਮ ਹੋ ਜਾਂਦੀ ਹੈ।
- ਇੱਕ ਟੀਮ ਜਾਂ ਇੱਕ ਸਰਵਿਸ ਪੂਰੇ ਕੰਮ ਦੀ ਜ਼ਿੰਮੇਵਾਰੀ ਰੱਖਦੀ ਹੈ।
- ਰੀਪਲੇ ਅਤੇ ਲੰਬੀ ਰੀਟੇਨਸ਼ਨ ਜ਼ਰੂਰੀ ਨਹੀਂ।
- ਡੀਬੱਗਿੰਗ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਚਲਾਉਣ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਹੈ।
ਉਦਾਹਰਣ: ਇੱਕ ਉਤਪਾਦ ਯੂਜ਼ਰ ਫੋਟੋਅਪਲੋਡ ਹੁੰਦਾ ਹੈ। ਐਪ "resize image" ਟਾਸਕ ਨੂੰ ਕਿਊ 'ਚ ਲਿਖਦਾ ਹੈ। ਵਰਕਰ A ਇਸਨੂੰ ਲੈਂਦਾ ਹੈ, ਥੰਬਨੇਲ ਬਣਾ ਕਰ ਸਟੋਰ ਕਰਦਾ ਹੈ, ਅਤੇ ਟਾਸਕ ਨੂੰ ਮਾਰਕ ਕਰ ਦਿੰਦਾ ਹੈ। ਜੇ ਟਾਸਕ ਦੋ ਵਾਰੀ ਚੱਲੇ, ਨਤੀਜਾ ਇਕੋ ਰਹਿੰਦਾ (idempotent), ਇਸ ਲਈ at-least-once ਡਿਲਿਵਰੀ ਠੀਕ ਹੈ। ਕਿਸੇ ਹੋਰ ਸਰਵਿਸ ਨੂੰ ਉਸ ਟਾਸਕ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਪੜ੍ਹਨ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ।
ਜੇ ਤੁਹਾਡੀਆਂ ਲੋੜਾਂ ਸਾਂਝੇ ਤੱਥ (ਕਈ ਕੰਜਿਊਮਰ), ਰੀਪਲੇ, ਆਡਿਟ, ਜਾਂ "ਪਿਛਲੇ ਹਫ਼ਤੇ ਸਿਸਟਮ ਨੇ ਕੀ ਮੰਨਿਆ ਸੀ?" ਵੱਲ ਵਧਣ ਲੱਗਦੀਆਂ ਹਨ, ਤਾਂ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਅਤੇ ਲੌਗ-ਅਧਾਰਿਤ ਰਵਈਏ ਦੀ ਕੀਮਤ ਦਿੱਸਣ ਲੱਗਦੀ ਹੈ।
ਜਦੋਂ ਲੌਗ-ਅਧਾਰਿਤ ਤਰੀਕਾ ਲਾਭਦਾਇਕ ਹੁੰਦੀ ਹੈ
ਜਦੋਂ ਇਵੈਂਟ ਇੱਕ ਵਾਰੀ ਦੇ ਸੁਨੇਹੇ ਹੋਣ ਦੀ ਬਜਾਏ ਸਾਂਝਾ ਇਤਿਹਾਸ ਬਣ ਜਾਂਦੇ ਹਨ, ਲੌਗ-ਅਧਾਰਿਤ ਸਿਸਟਮ ਲਾਭਦਾਇਕ ਹੋ ਜਾਂਦਾ ਹੈ। "ਭੇਜੋ ਅਤੇ ਭੁੱਲ ਜਾਓ" ਦੀ ਥਾਂ, ਤੁਸੀਂ ਇੱਕ ਅਨੁਕ੍ਰਮਿਤ ਰਿਕਾਰਡ ਰੱਖਦੇ ਹੋ ਜਿਸ ਨੂੰ ਕਈ ਟੀਮਾਂ ਆਪਣੀ ਗਤੀ ਦੇ ਨਾਲ ਪੜ੍ਹ ਸਕਦੀਆਂ ਹਨ।
ਸਭ ਤੋਂ ਸਾਫ਼ ਸੰਕੇਤ ਕਈ ਕੰਜਿਊਮਰ ਹਨ। ਇੱਕ ਇਵੈਂਟ ਜਿਵੇਂ OrderPlaced billing, email, fraud checks, search indexing, ਅਤੇ analytics ਨੂੰ ਫੀਡ ਕਰ ਸਕਦਾ ਹੈ। ਲੌਗ ਨਾਲ, ਹਰ ਕੰਜਿਊਮਰ ਇੱਕੋ ਸਟ੍ਰੀਮ ਨੂੰ ਸੁਤੰਤਰ ਤੌਰ 'ਤੇ ਪੜ੍ਹਦਾ ਹੈ। ਤੁਹਾਨੂੰ ਇੱਕ ਕਸਟਮ ਫੈਨ-ਆਉਟ ਪਾਈਪਲਾਈਨ ਬਣਾਉਣ ਜਾਂ ਰਣਨੀਤੀ ਬਣਾਉਣ ਦੀ ਲੋੜ ਨਹੀਂ ਕਿ ਕਿਸਨੂੰ ਪਹਿਲਾਂ ਸੁਨੇਹਾ ਮਿਲੇ।
ਹੋਰ ਲਾਭ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ ਇਹ ਉੱਤਰ ਦੇ ਸਕਦੇ ਹੋ, "ਉਸ ਵੇਲੇ ਅਸੀਂ ਕੀ ਜਾਣਦੇ ਸੀ?" ਜੇ ਇੱਕ ਗਾਹਕ ਚਾਰਜ ਦੀ ਵਿਵਾਦ ਕਰਦਾ ਹੈ, ਜਾਂ ਸਿਫਾਰਸ਼ ਗਲਤ ਲੱਗੀ, ਤਾਂ append-only ਇਤਿਹਾਸ ਇਹ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਤੱਥਾਂ ਨੂੰ ਉਹਨਾਂ ਦੇ ਆਉਣ ਦੇ ਅਨੁਕ੍ਰਮ ਜਾਂ ਰੀਪਲੇ ਕਰ ਸਕੋ। ਇਹ ਆਡਿਟ ਟਰੇਲ ਇੱਕ ਸਧਾਰਨ ਕਿਊ 'ਤੇ ਪੋਸਟ-ਫੈਕਟੋਰੀ ਢੰਗ ਨਾਲ ਜੋੜਣਾ ਮੁਸ਼ਕਲ ਹੁੰਦਾ ਹੈ।
ਤੁਸੀਂ ਨਵੇਂ ਫੀਚਰ ਬਿਨਾਂ ਪੁਰਾਣੇ ਨੂੰ ਦੁਬਾਰਾ ਲਿਖੇ ਜੋੜ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਮਹੀਨਿਆਂ ਬਾਅਦ ਇੱਕ ਨਵੀਂ "shipping status" ਪੇਜ ਜੋੜਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਨਵੀਂ ਸਰਵਿਸ ਇਤਿਹਾਸ ਤੋਂ ਬੈਕਫਿਲ ਕਰ ਸਕਦੀ ਹੈ ਤਾ ਕਿ ਆਪਣੀ ਅਵਸਥਾ ਬਣਾਵੇ, ਬਜਾਏ ਕਿ ਹਰ ਉੱਪਸਟਰੀਮ ਟੀਮ ਨੂੰ ਐਕਸਪੋਰਟ ਮੰਗਣ।
ਲੌਗ-ਅਧਾਰਿਤ ਰਵਈਆ ਆਮ ਤੌਰ 'ਤੇ ਲਾਭਕਾਰੀ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇਹਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਜਾਂ ਵੱਧ ਲੱਭਦੇ ਹੋ:
- ਇਕੋ ਹੀ ਇवੈਂਟ ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮਾਂ ਨੂੰ ਫੀਡ ਕਰਨਾ ਹੁੰਦਾ ਹੈ (analytics, search, billing, support)।
- ਤੁਸੀਂ ਰੀਪਲੇ, ਆਡਿਟ ਜਾਂ ਪਿਛਲੇ ਤੱਥਾਂ ‘ਤੇ ਜਾਂਚ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹੋ।
- ਨਵੀਂ ਸਰਵਿਸਾਂ ਇਤਿਹਾਸ ਤੋਂ ਬੈਕਫਿਲ ਕਰਨੀਆਂ ਪੈਂਦੀਆਂ ਹਨ ਬਿਨਾਂ ਵੱਖ-ਵੱਖ ਇਕ-ਵਾਰੀ ਜੌਬਾਂ ਦੇ।
- ਹਰ ਇਕ ਧੜੇ ਲਈ (ਪਰ-ਆਈਟਮ) ਆਰਡਰਿੰਗ ਮਹੱਤਵਪੂਰਨ ਹੈ (ਉਦਾਹਰਣ: ਪਰ-order, ਪਰ-user)।
- ਇਵੈਂਟ ਫਾਰਮੈਟ ਵਿਚ ਵਿਕਾਸ ਹੋਵੇਗਾ ਅਤੇ ਤੁਹਾਨੂੰ ਵਰਜ਼ਨਿੰਗ ਨੂੰ ਸੰਭਾਲਣ ਦਾ ਇੱਕ ਨਿਯੰਤਰਿਤ ਤਰੀਕਾ ਚਾਹੀਦਾ ਹੈ।
ਇੱਕ ਆਮ ਨਮੂਨਾ ਇਹ ਹੈ ਕਿ ਉਤਪਾਦ orders ਅਤੇ emails ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦਾ ਹੈ। ਬਾਅਦ 'ਚ finance ਰੇਵੇਨਿਉ ਰਿਪੋਰਟ ਮੰਗਦਾ ਹੈ, product funnels ਚਾਹੁੰਦਾ ਹੈ, ਅਤੇ ops ਇੱਕ ਲਾਈਵ ਡੈਸ਼ਬੋਰਡ। ਜੇ ਹਰ ਨਵੀਂ ਲੋੜ ਤੁਹਾਨੂੰ ਡੇਟਾ ਨੂੰ ਨਵੇਂ ਪਾਈਪਲਾਈਨ ਰਾਹੀਂ ਨਕਲ ਕਰਨ 'ਤੇ ਮਜਬੂਰ ਕਰਦੀ ਹੈ, ਤਾਂ ਖਰਚ ਤੇਜ਼ੀ ਨਾਲ ਆ ਜਾਂਦਾ ਹੈ। ਇੱਕ ਸਾਂਝਾ ਇਵੈਂਟ ਲੌਗ ਟੀਮਾਂ ਨੂੰ ਇਕੋ ਸਰੋਤ 'ਤੇ ਬਣਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ, ਭਾਅਵੀ ਵਿੱਚ ਇਵੈਂਟ ਸ਼ਕਲ ਬਦਲਣ ਦੇ ਬਾਵਜੂਦ।
ਕਿਵੇਂ ਫੈਸਲਾ ਕਰਨਾ, ਕਦਮ-ਦਰ-কਦਮ
ਕਿਊ ਅਤੇ ਲੌਗ-ਅਧਾਰਿਤ ਤਰੀਕੇ ਵਿਚਕਾਰ ਚੋਣ ਇੱਕ ਉਤਪਾਦੀ ਫੈਸਲਾ ਵਾਂਗ ਆਸਾਨ ਹੁੰਦੀ ਹੈ। ਇੱਕ ਸਾਲ ਬਾਅਦ ਤੁਹਾਨੂੰ ਕੀ ਸੱਚ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਇਸ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਨਾ ਕਿ ਸਿਰਫ ਉਹ ਜੋ ਇਸ ਹਫ਼ਤੇ ਕੰਮ ਕਰਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਿਕ 5-ਕਦਮੀ ਫੈਸਲਾ
-
ਪ੍ਰਕਾਸ਼ਕ ਅਤੇ ਪਾਠਕ ਨਕਸ਼ਾ ਬਣਾਓ। ਲਿਖੋ ਕਿ ਅਜਿਹੇ ਕੌਣ ਇਵੈਂਟ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਅਜਿਹੇ ਕੌਣ ਅੱਜ ਉਹਨਾਂ ਨੂੰ ਪੜ੍ਹਦਾ ਹੈ, ਫਿਰ ਭਵਿੱਖ ਦੇ ਸੰਭਾਵਿਤ ਕੰਜਿਊਮਰ (analytics, search indexing, fraud checks, customer notifications) ਜੋੜੋ। ਜੇ ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ ਕਿ ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਇਕੋ ਇਵੈਂਟ ਨੂੰ ਸੁਤੰਤਰ ਤਰੀਕੇ ਨਾਲ ਪੜ੍ਹਨਗੀਆਂ, ਤਾਂ ਲੌਗ ਮਨਗਾ ਕਰਨ ਲੱਗਦੀ ਹੈ।
-
ਪੁੱਛੋ ਕਿ ਕੀ ਤੁਹਾਨੂੰ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਪੜ੍ਹਨ ਦੀ ਲੋੜ ਪਏਗੀ। ਵਾਜਬ ਕਾਰਨਾਂ ਦੀ ਵਿਦੇਸ਼ਣ ਕਰੋ: ਬੱਗ ਤੋਂ ਬਾਅਦ ਰੀਪਲੇ, ਬੈਕਫਿਲ, ਜਾਂ ਬੇ-ਸਮੇਂ ਕੰਜਿਊਮਰ ਜੋ ਵੱਖਰੀ ਰਫ਼ਤਾਰ 'ਤੇ ਪੜ੍ਹਦੇ ਹਨ। ਕਿਊਆਂ ਹੱਥ-ਫੱਟ ਕੰਮ ਲਈ ਬੇਹਤਰੀਨ ਹਨ; ਜਦੋਂ ਤੁਸੀਂ ਰਿਕਾਰਡ ਦੁਬਾਰਾ ਚਲਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਤਾਂ ਲੌਗ ਵਧੀਆ ਹੈ।
-
“ਮੁਕੰਮਲ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਉਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਕੁਝ ਵਰਕਫਲੋਜ਼ ਲਈ ਮੁਕੰਮਲ ਹੋਣਾ ਮਤਲਬ "ਜੌਬ ਚੱਲ ਗਿਆ" (ਈਮੇਲ ਭੇਜੋ, ਇਮੇਜ ਰੀਸਾਈਜ਼). ਹੋਰਾਂ ਲਈ, ਮੁਕੰਮਲ ਹੋਣਾ ਮਤਲਬ "ਇਵੈਂਟ ਇੱਕ ਟਿਕਾਊ ਤੱਥ ਹੈ" (ਇੱਕ ਆਰਡਰ ਰੱਖਿਆ ਗਿਆ, ਭੁਗਤਾਨ ਮਨਜ਼ੂਰ ਹੋਇਆ)। ਟਿਕਾਊ ਤੱਥ ਲੌਗ ਵੱਲ ਧਕੇਗਾ।
-
ਡਿਲਿਵਰੀ ਉਮੀਦਾਂ ਚੁਣੋ ਅਤੇ ਨਿਰਣਯ ਕਰੋ ਕਿ ਤੁਸੀਂ ਨਕਲਾਂ ਨਾਲ ਕਿਵੇਂ ਨਜਿੱਠੋਗੇ। at-least-once ਡਿਲਿਵਰੀ ਆਮ ਹੈ, ਜਿਸਦਾ ਮਤਲਬ ਇਹ ਹੈ ਕਿ ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ। ਜੇ ਇੱਕ ਡੁਪਲੀਕੇਟ ਨੁਕਸਾਨ ਕਰ ਸਕਦਾ ਹੈ (ਜਿਵੇਂ ਕਾਰਡ ਦਾ ਦੋ ਵਾਰੀ ਚਾਰਜ), ਤਾਂ idempotency ਲਈ ਯੋਜਨਾ ਬਣਾਓ: ਪ੍ਰੋਸੈਸਡ ਇਵੈਂਟ ID ਸਟੋਰ ਕਰੋ, ਯੂਨੀਕ ਕੰਸਟਰੈਂਟ ਵਰਤੋ, ਜਾਂ ਅਪਡੇਟਾਂ ਨੂੰ ਦੁਹਰਾਉਣ ਲਈ ਸੁਰੱਖਿਅਤ ਬਨਾਓ।
-
ਇੱਕ ਪਤਲਾ ਸਲਾਈਸ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਇੱਕ ਇਵੈਂਟ ਸਟਰੀਮ ਚੁਣੋ ਜੋ ਸੋਚਣ ਵਿੱਚ ਆਸਾਨ ਹੋਵੇ ਅਤੇ ਉਥੋਂ ਵਧੋ। ਜੇ ਤੁਸੀਂ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਨਾਲ ਜਾ ਰਹੇ ਹੋ, ਪਹਿਲਾ ਟਾਪਿਕ ਫੋਕਸਡ ਰੱਖੋ, ਇਵੈਂਟਾਂ ਨੂੰ ਸਪਸ਼ਟ ਨਾਂ ਦਿਓ, ਅਤੇ ਅਣਸੰਬੰਧਿਤ ਇਵੈਂਟ ਕਿਸੇ ਇੱਕ ਟਾਪਿਕ 'ਚ ਮਿਲਾਉਣ ਤੋਂ ਬਚੋ।
ਇੱਕ ਵਿਸ਼ੇਸ਼ ਉਦਾਹਰਣ: ਜੇ OrderPlaced ਬਾਅਦ ਵਿੱਚ shipping, invoicing, support, ਅਤੇ analytics ਨੂੰ ਫੀਡ ਕਰੇਗਾ, ਤਾਂ ਇੱਕ ਲੌਗ ਹਰ ਟੀਮ ਨੂੰ ਆਪਣੀ ਰਫ਼ਤਾਰ 'ਤੇ ਪੜ੍ਹਨ ਅਤੇ ਗਲਤੀਆਂ ਤੋਂ ਬਾਅਦ ਰੀਪਲੇ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ। ਜੇ ਤੁਹਾਨੂੰ ਸਿਰਫ਼ ਇੱਕ ਪਿਛੋਕੜ ਵਰਕਰ ਦੀ ਲੋੜ ਹੈ ਜੋ ਰਸੀਦ ਈਮੇਲ ਭੇਜੇ, ਤਾਂ ਇੱਕ ਸਧਾਰਨ ਕਿਊ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੈ।
ਉਦਾਹਰਣ: ਇੱਕ ਵਧਦੇ ਉਤਪਾਦ ਵਿੱਚ ਆਰਡਰ ਇਵੈਂਟ
ਇੱਕ ਛੋਟਾ ਆਨਲਾਈਨ ਸਟੋਰ ਸੋਚੋ। ਪਹਿਲਾਂ ਇਹ ਸਿਰਫ਼ ਆਰਡਰ ਲੈਣਾ, ਕਾਰਡ ਚਾਰਜ ਕਰਨਾ, ਅਤੇ ਇੱਕ ਸ਼ਿਪਿੰਗ ਬੇਨਤੀ ਬਣਾਉਣਾ ਚਾਹੁੰਦਾ ਹੈ। ਸਭ ਤੋਂ ਆਸਾਨ ਵਰਜਨ ਇਹ ਹੈ ਕਿ ਚੈਕਆਉਟ ਮਗਰੋਂ ਇੱਕ ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਚਲਾਓ: "process order." ਇਹ ਭੁਗਤਾਨ API ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ, ਆਰਡਰ ਰੋ ਨੂੰ ਅਪਡੇਟ ਕਰਦਾ ਹੈ, ਫਿਰ ਸ਼ਿਪਿੰਗ ਨੂੰ ਕਾਲ ਕਰਦਾ ਹੈ।
ਜਦ ਤੱਕ ਇੱਕ ਸਪਸ਼ਟ ਵਰਕਫਲੋ ਅਤੇ ਇੱਕ ਕੰਜਿਊਮਰ (ਵਰਕਰ) ਦੀ ਲੋੜ ਹੈ, ਅਤੇ retry/ਡੈੱਡ-ਲੈਟਰ ਮੌਕੇ ਜ਼ਿਆਦਾਤਰ ਫੇਅਰ ਕਰ ਲੈਂਦੇ ਹਨ, ਇਹ ਕਿਊ ਸਟਾਈਲ ਚੰਗਾ ਕੰਮ ਕਰਦਾ ਹੈ।
ਜਿਵੇਂ ਹੀ ਸਟੋਰ ਵਧਦਾ ਹੈ, ਇਹ ਦਰਦਨਾਕ ਹੋਣ ਲੱਗਦਾ ਹੈ। ਸਪੋਰਟ "ਮੇਰਾ ਆਰਡਰ ਕਿੱਥੇ ਹੈ?" ਅਪਡੇਟ ਚਾਹੁੰਦਾ ਹੈ। ਫਾਇਨੈਂਸ ਰੋਜ਼ਾਨਾ ਰੇਵੇਨਿਉ ਚਾਹੁੰਦਾ ਹੈ। ਪ੍ਰੋਡਕਟ ਟੀਮ ਗਾਹਕ ਈਮੇਲ ਚਾਹੁੰਦੀ ਹੈ। ਫਰਾਡ ਚੈਕ ਸ਼ਿਪਿੰਗ ਤੋਂ ਪਹਿਲਾਂ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਕੱਲੇ "process order" ਜੌਬ ਨਾਲ ਤੁਸੀਂ ਕੋਈ ਵਾਰ-ਵਾਰ ਉਹੀ ਵਰਕਰ ਸੋਧਦੇ ਰਹਿਣਾ ਪੈਂਦਾ ਹੈ, ਸਾਖਤਾਂ ਜੋੜਦੇ ਹੋ, ਅਤੇ ਮੁੱਖ ਫਲੋ ਵਿੱਚ ਨਵੇਂ ਬੱਗਾਂ ਖੜੇ ਹੋ ਜਾਂਦੇ ਹਨ।
ਲੌਗ-ਅਧਾਰਿਤ ਰਵਈਆ ਵਿੱਚ, ਚੈਕਆਉਟ ਛੋਟੇ ਤੱਥਾਂ ਨੂੰ ਇਵੈਂਟਾਂ ਵਜੋਂ ਜਾਰੀ ਕਰਦਾ ਹੈ, ਅਤੇ ਹਰ ਟੀਮ ਉਨ੍ਹਾਂ 'ਤੇ ਨਿਰਭਰ ਕਰ ਸਕਦੀ ਹੈ। ਆਮ ਇਵੈਂਟਾਂ ਇਸ ਤਰ੍ਹਾਂ ਲੱਗ ਸਕਦੀਆਂ ਹਨ:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
ਮੁੱਖ ਬਦਲਾਅ ਮਾਲਕੀ ਹੈ। ਚੈਕਆਉਟ ਸਰਵਿਸ OrderPlaced ਦੀ ਮਾਲਕ ਹੈ। ਭੁਗਤਾਨ ਸਰਵਿਸ PaymentConfirmed ਦੀ ਮਾਲਕ ਹੈ। ਸ਼ਿਪਿੰਗ ItemShipped ਦੀ। ਬਾਅਦ ਵਿੱਚ, ਨਵੇਂ ਕੰਜਿਊਮਰ ਪ੍ਰੋਡਿਊਸਰ ਨੂੰ ਬਦਲਣ ਬਿਨਾਂ ਆ ਸਕਦੇ ਹਨ: ਫਰਾਡ ਸਰਵਿਸ OrderPlaced ਅਤੇ PaymentConfirmed ਨੂੰ ਪੜ੍ਹ ਕੇ ਰਿਸਕ ਸਕੋਰ ਕਰਦੀ ਹੈ, ਇੱਕ ਈਮੇਲ ਸਰਵਿਸ ਰਸੀਦ ਭੇਜਦੀ ਹੈ, analytics funnel ਬਣਾਉਂਦਾ ਹੈ, ਅਤੇ ਸਪੋਰਟ ਟੂਲ ਇਕ ਟਾਈਮਲਾਈਨ ਰੱਖਦੇ ਹਨ।
ਇਹੀ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਦੀ ਕਦਰ ਹੈ: ਲੌਗ ਇਤਿਹਾਸ ਰੱਖਦਾ ਹੈ ਤਾਂ ਨਵੇਂ ਕੰਜਿਊਮਰ ਸ਼ੁਰੂ ਤੋਂ (ਜਾਂ ਜਾਣੇ-ਪਛਾਣ ਵਾਲੇ ਬਿੰਦੂ ਤੋਂ) ਰੀਵਾਈਂਡ ਕਰਕੇ ਕੈਚ-ਅਪ ਕਰ ਸਕਦੇ ਹਨ, ਬਜਾਏ ਕਿ ਹਰ ਉਪਸਟਰੀਮ ਟੀਮ ਨੂੰ ਹੋਰਨਾਂ ਵੈਬਹੁੱਕ ਜੋੜਨ ਲਈ ਕਹਿਣ।
ਲੌਗ ਤੁਹਾਡੇ ਡੈਟਾਬੇਸ ਦੀ ਥਾਂ ਨਹੀਂ ਲੈਂਦਾ। ਤੁਹਾਨੂੰ ਅਜੇ ਵੀ ਕਰੰਟ ਸਟੇਟ ਲਈ ਡੈਟਾਬੇਸ ਦੀ ਲੋੜ ਹੈ: ਆਖਰੀ ਆਰਡਰ ਸਥਿਤੀ, ਗ੍ਰਾਹਕ ਰਿਕਾਰਡ, ਸਟਾਕ ਗਿਣਤੀ, ਅਤੇ ਲੈਣ-ਦੇਣ ਨਿਯਮ (ਜਿਵੇਂ "ਪੈਮੈਂਟ ਪੁਸ਼ਟੀ ਤੋਂ ਬਿਨਾਂ ਭੇਜੋ ਨਾ"). ਲੌਗ ਨੂੰ ਬਦਲਾਵਾਂ ਦੇ ਰਿਕਾਰਡ ਵਜੋਂ ਸੋਚੋ ਅਤੇ ਡੈਟਾਬੇਸ ਨੂੰ ਉਹ ਜਗ੍ਹਾ ਸੋਚੋ ਜਿੱਥੇ ਤੁਸੀਂ "ਹੁਣ ਕੀ ਸੱਚ ਹੈ" ਪੁਛਦੇ ਹੋ।
ਆਮ ਗਲਤੀਆਂ ਅਤੇ ਫੰਦੇ
ਇਵੈਂਟ ਸਟ੍ਰੀਮਿੰਗ ਸਿਸਟਮਾਂ ਨੂੰ ਸਾਫ਼ ਮਹਿਸੂਸ ਕਰਵਾ ਸਕਦੀ ਹੈ, ਪਰ ਕੁਝ ਆਮ ਗਲਤੀਆਂ ਤੁਰੰਤ ਲਾਭ ਘਟਾ ਦਿੰਦੀਆਂ ਹਨ। ਜਿਆਦਾਤਰ ਉਹ ਇਸ ਗੱਲ ਤੋਂ ਆਉਂਦੀਆਂ ਹਨ ਕਿ ਲੋਕ ਲੌਗ ਨੂੰ ਇੱਕ ਰਿਕਾਰਡ ਦੀ ਥਾਂ ਰਿਮੋਟ ਕੰਟਰੋਲ ਵਾਂਗ ਵਰਤਦੇ ਹਨ।
ਇੱਕ ਆਮ ਫੰਨਾ ਹੈ ਇਵੈਂਟਾਂ ਨੂੰ ਕਮਾਂਡ ਵਾਂਗ ਲਿਖਣਾ, ਜਿਵੇਂ "SendWelcomeEmail" ਜਾਂ "ChargeCardNow." ਇਸ ਨਾਲ ਕੰਜਿਊਮਰ ਤੁਹਾਡੇ ਇਰਾਦੇ ਨਾਲ ਤੰਗ ਜੁੜ ਜਾਂਦੇ ਹਨ। ਇਵੈਂਟਾਂ ਤੱਥ ਵਜੋਂ ਜ਼ਿਆਦਾ ਵਧੀਆ ਕੰਮ ਕਰਦੀਆਂ ਹਨ: "UserSignedUp" ਜਾਂ "PaymentAuthorized." ਤੱਥ ਸਮੇਂ ਦੇ ਨਾਲ ਚੰਗੇ ਰਹਿੰਦੇ ਹਨ। ਨਵੀਆਂ ਟੀਮਾਂ ਬਿਨਾਂ ਅਣਗੋਲਣ ਦੇ ਉਨ੍ਹਾਂ ਨੂੰ ਦੁਬਾਰਾ ਵਰਤ ਸਕਦੀਆਂ ਹਨ।
ਡੁਪਲੀਕੇਟ ਅਤੇ ਰੀਟ੍ਰਾਈਜ਼ ਅਗਲਾ ਵੱਡਾ ਦਰਦ ਹੈ। ਅਸਲੀ ਸਿਸਟਮਾਂ ਵਿੱਚ, ਪ੍ਰੋਡਿਊਸਰ retry ਕਰਦੇ ਹਨ ਅਤੇ ਕੰਜਿਊਮਰ ਰੀ-ਪ੍ਰੋਸੈਸ ਕਰਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਇਸ ਲਈ ਯੋਜਨਾ ਨਹੀਂ ਬਣਾਉਂਦੇ, ਤਾਂ ਤੁਸੀਂ ਡਬਲ ਚਾਰਜ, ਡਬਲ ਈਮੇਲ, ਅਤੇ ਗੁੱਸੇ ਭਰੇ ਸਪੋਰਟ ਟਿਕਟਾਂ ਪਾਓਗੇ। ਇਸਦਾ ਸਮਾਧਾਨ ਨਵੀਂ ਚੀਜ਼ ਨਹੀਂ ਹੈ, ਪਰ ਇਹ ਇਰਾਦੇ ਨਾਲ ਕਰਨਾ ਪੈਂਦਾ ਹੈ: idempotent ਹੈਂਡਲਰ, ਸਥਿਰ ਇਵੈਂਟ ID, ਅਤੇ ਕਾਰੋਬਾਰ ਨਿਯਮ ਜੋ "ਪਹਿਲਾਂ ਹੀ ਲਾਗੂ" ਦਾ ਪਤਾ ਲਗਾ ਸਕਣ।
ਆਮ ਫੰਦੇ:
- ਕਮਾਂਡ-ਸਟਾਈਲ ਇਵੈਂਟ ਵਰਤਣਾ ਜੋ ਸੇਵਾਵਾਂ ਨੂੰ ਦੱਸਦੇ ਕਿ ਕੀ ਕਰਨਾ ਹੈ, ਨਾਂ ਕਿ ਜੋ ਹੋਇਆ ਉਹ ਦਰਜ ਕਰਨਾ।
- ਉਨ੍ਹਾਂ Consumers ਬਣਾਵਾਂ ਜੋ ਇੱਕੋ ਇਵੈਂਟ ਦੋ ਵਾਰੀ ਦੇਖਣ 'ਤੇ ਟੁੱਟ ਜਾਂਦੇ ਹਨ।
- ਬਹੁਤ ਜ਼ਲਦੀ streams ਨੂੰ ਵੰਡਣਾ, ਤਾਂ ਕਿ ਇਕ ਵਿਅਵਸਥਾ ਵੱਖ-ਵੱਖ ਟਾਪਿਕਾਂ 'ਚ ਤਰਸ਼ੀ ਹੋ ਜਾਏ।
- ਸਕੀਮਾ ਨਿਯਮਾਂ ਨੂੰ ਅਣਡੱਖਣਾ ਕਰਨਾ ਜਦ ਤੱਕ ਛੋਟਾ ਬਦਲਾਅ ਪੁਰਾਣੇ ਕੰਜਿਊਮਰਾਂ ਨੂੰ ਤੋੜ ਨਾ ਦੇਵੇ।
- ਸਟ੍ਰੀਮਿੰਗ ਨੂੰ ਚੰਗੇ ਡੈਟਾਬੇਸ ਡਿਜ਼ਾਈਨ ਦੀ ਥਾਂ ਮੰਨ ਲੈਣਾ।
ਸਕੀਮਾ ਅਤੇ ਵਰਜ਼ਨਿੰਗ ਨੂੰ ਖ਼ਾਸ ਧਿਆਨ ਚਾਹੀਦਾ ਹੈ। ਭਾਵੇਂ ਤੁਸੀਂ JSON ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਤੁਹਾਨੂੰ ਫਿਰ ਵੀ ਇੱਕ ਸਪਸ਼ਟ ਕਰਾਰ ਚਾਹੀਦਾ ਹੈ: ਲਾਜ਼ਮੀ ਫੀਲਡ, ਵਿਅਕਲਪਿਕ ਫੀਲਡ, ਅਤੇ ਬਦਲਾਅ ਕਿਵੇਂ ਰੋਲ ਆਊਟ ਹੋਣਗੇ। ਇੱਕ ਛੋਟਾ ਬਦਲਾਅ ਜਿਵੇਂ ਫੀਲਡ ਦਾ ਨਾਮ ਬਦਲਣਾ ਐਨਾਲਿਟਿਕਸ, ਬਿਲਿੰਗ, ਜਾਂ ਮੋਬਾਇਲ ਐਪ ਨੂੰ ਖਾਮੋਸ਼ੀ ਨਾਲ ਟੁੱਟ ਸਕਦਾ ਹੈ।
ਹੋਰ ਇੱਕ ਫੰਨਾ ਹੈ ਬਹੁਤ ਜ਼ਿਆਦਾ ਵੰਡਣਾ। ਟੀਮਾਂ ਕਈ ਵਾਰ ਹਰ ਫੀਚਰ ਲਈ ਨਵਾਂ ਸਟ੍ਰੀਮ ਬਣਾਉਂਦੀਆਂ ਹਨ। ਇੱਕ ਮਹੀਨੇ ਬਾਅਦ, ਕੋਈ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦਾ ਕਿ "ਆਰਡਰ ਦੀ ਵਰਤਮਾਨ ਸਥਿਤੀ ਕੀ ਹੈ?" ਕਿਉਂਕਿ ਕਹਾਣੀ ਬਹੁਤ ਸਾਰੀਆਂ ਜਗ੍ਹਾਂ 'ਤੇ ਫਿੱਲ ਹੋ ਗਈ ਹੈ।
ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਚੰਗੇ ਡੇਟਾ ਮਾਡਲਾਂ ਦੀ ਲੋੜ ਨੂੰ ਹਟਾਉਂਦੀ ਨਹੀਂ। ਤੁਹਾਨੂੰ ਅਜੇ ਵੀ ਉਹ ਡੈਟਾਬੇਸ ਚਾਹੀਦਾ ਹੈ ਜੋ ਵਰਤਮਾਨ ਸੱਚ ਦਾ ਪ੍ਰਤੀਨਿਧਤ ਕਰੇ। ਲੌਗ ਇਤਿਹਾਸ ਹੈ, ਤੁਹਾਡੀ ਸਾਰੀ ਐਪਲੀਕੇਸ਼ਨ ਨਹੀਂ।
ਤੇਜ਼ ਚੈੱਕਲਿਸਟ ਅਤੇ ਅਗਲੇ ਕਦਮ
ਜੇ ਤੁਸੀਂ ਕਿਊ ਅਤੇ Kafka ਇਵੈਂਟ ਸਟਰੀਮਿੰਗ ਵਿਚਕਾਰ ਫੈਸਲਾ ਨਹੀਂ ਕਰ ਪਾ ਰਹੇ, ਤਾਂ ਕੁਝ ਤੇਜ਼ ਜਾਂਚਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਉਹ ਤੁਹਾਨੂੰ ਦੱਸਣਗੇ ਕਿ ਤੁਹਾਨੂੰ ਸਿਰਫ ਇਕ ਸਧਾਰਨ ਹਾਨਡਪ ਚਾਹੀਦਾ ਹੈ ਜਾਂ ਇੱਕ ਲੌਗ ਜੋ ਤੁਹਾਡੇ ਲਈ ਸਾਲਾਂ ਵਰਤੋਂ ਯੋਗ ਰਹੇਗਾ।
ਤੇਜ਼ ਜਾਂਚ
- ਕੀ ਤੁਹਾਨੂੰ ਰੀਪਲੇ ਦੀ ਲੋੜ ਹੈ (ਬੈਕਫਿਲ, ਬੱਗ-ਫਿਕਸ, ਜਾਂ ਨਵੀਆਂ ਫੀਚਰਾਂ ਲਈ), ਅਤੇ ਕਿੰਨਾ ਪਿਛੇ ਜਾਣਾ ਪਵੇਗਾ?
- ਕੀ ਇੱਕੋ ਇਵੈਂਟ ਨੂੰ ਕਈ ਕੰਜਿਊਮਰਾਂ (analytics, search, email, fraud, billing) ਨੂੰ ਤੁਰੰਤ ਜਾਂ ਜਲਦੀ ਹੀ ਪੜ੍ਹਨ ਦੀ ਲੋੜ ਹੋਵੇਗੀ?
- ਕੀ ਤੁਹਾਨੂੰ ਰੀਟੇਨਸ਼ਨ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਕਿ ਟੀਮਾਂ ਇਤਿਹਾਸ ਨੂੰ ਦੁਬਾਰਾ ਪੜ੍ਹ ਸਕਣ ਬਿਨਾਂ ਪ੍ਰੋਡਿਊਸਰ ਨੂੰ ਦੁਬਾਰਾ ਭੇਜਣ ਨੂੰ ਕਹਿਣ ਦੇ?
- ਆਰਡਰਿੰਗ ਕਿੰਨੀ ਮਹੱਤਵਪੂਰਨ ਹੈ, ਅਤੇ ਕਿਸ ਪੱਧਰ 'ਤੇ: ਪ੍ਰਤੀ ਇਕਾਈ (ਪਰ-order, ਪਰ-user) ਜਾਂ ਸਭ-ਸਾਫ਼ ਗਲੋਬਲ?
- ਕੀ ਕੰਜਿਊਮਰ idempotent ਹੋ ਸਕਦੇ ਹਨ (ਉਹੇ ਇवੈਂਟ ਨੂੰ ਦੁਬਾਰਾ ਲਗਾਉਣ 'ਤੇ ਦੋ ਵਾਰੀ ਚਾਰਜ, ਦੋ ਵਾਰੀ ਈਮੇਲ, ਜਾਂ ਦੋ ਵਾਰੀ ਅਪਡੇਟ ਨਾ ਹੋਵੇ)?
ਜੇ ਤੁਸੀਂ "ਨਾਮ" ਦੇ ਉੱਤਰ ਦਿੱਤੇ "ਰੀਪਲੇ ਨਹੀਂ", "ਸਿਰਫ ਇੱਕ ਕੰਜਿਊਮਰ", ਅਤੇ "ਛੋਟੇ ਸਮੇਂ ਵਾਲੇ ਸੁਨੇਹੇ", ਤਾਂ ਇੱਕ ਬੁਨਿਆਦੀ ਕਿਊ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੁੰਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ "ਹਾਂ" ਕਿਹਾ ਰੀਪਲੇ, ਕਈ ਕੰਜਿਊਮਰ, ਜਾਂ ਲੰਬੀ ਰੀਟੇਨਸ਼ਨ ਲਈ, ਤਾਂ ਲੌਗ-ਅਧਾਰਿਤ ਤਰੀਕਾ ਅਕਸਰ ਮੁਨਾਫੇਦਾਇਕ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇਕ ਸਟ੍ਰੀਮ ਫੈਕਟਾਂ ਨੂੰ ਇੱਕ ਸਾਂਝੇ ਸਰੋਤ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ ਜਿਸ 'ਤੇ ਹੋਰ ਸਿਸਟਮ ਨਿਰਭਰ ਹੋ ਸਕਦੇ ਹਨ।
ਅਗਲੇ ਕਦਮ
ਉੱਤਰਾਂ ਨੂੰ ਇੱਕ ਛੋਟੀ, ਪਰਖਲਾਇਯੋਗ ਯੋਜਨਾ ਵਿੱਚ ਬਦਲੋ:
- 5-10 ਮੁੱਖ ਇਵੈਂਟ ਸਧੇ ਜ਼ਬਾਨੀ 'ਚ ਲਿਸਟ ਕਰੋ (ਉਦਾਹਰਣ:
OrderPlaced, PaymentAuthorized, OrderShipped) ਅਤੇ ਦਰਜ ਕਰੋ ਕਿ ਕੌਣ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦਾ ਅਤੇ ਕੌਣ ਲੈਂਦਾ ਹੈ।
- ਆਰਡਰਿੰਗ ਕੁੰਜੀ (ਅਕਸਰ ਪ੍ਰਤੀ ਇਕਾਈ, ਜਿਵੇਂ
orderId) ਚੁਣੋ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ "ਸਹੀ ਕ੍ਰਮ" ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
- ਹਰ ਇਕ ਕੰਜਿਊਮਰ ਲਈ idempotency ਨਿਯਮ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ (ਉਦਾਹਰਣ: ਪ੍ਰਤੀ ਆਰਡਰ ਆਖਰੀ ਪ੍ਰੋਸੈਸਡ ਇਵੈਂਟ ID ਸਟੋਰ ਕਰੋ)।
- ਆਪਣੀ ਲੋੜ ਮੁਤਾਬਕ ਰੀਟੇਨਸ਼ਨ ਟਾਰਗੇਟ ਚੁਣੋ (ਕਿਊ-ਸਟਾਈਲ ਵਰਕਫਲੋ ਲਈ ਦਿਨ, ਜਦੋਂ ਰੀਪਲੇ ਮਹੱਤਵਪੂਰਨ ਹੋ ਤਾਂ ਹਫ਼ਤੇ/ਮਹੀਨੇ)।
- ਫੈਸਲਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਇੱਕ ਸੈਂਡਬਾਕਸ 'ਚ ਇੱਕ ਅੰਤ-ਟੂ-ਅੰਤ ਸਲਾਈਸ ਚਲਾਓ।
ਜੇ ਤੁਸੀਂ ਪ੍ਰੋਟੋਟਾਈਪ ਤੇਜ਼ੀ ਨਾਲ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ Koder.ai planning mode 'ਚ ਇਵੈਂਟ ਫਲੋ ਸਕੈਚ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਡਿਜ਼ਾਈਨ 'ਤੇ ਇਟਰੇਟ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਇਵੈਂਟ ਨਾਂ ਅਤੇ ਰੀਟ੍ਰਾਈ ਨੀਯਮ ਫਿਕਸ ਕੀਤੇ। Koder.ai ਸੋਰਸ ਕੋਡ ਇੱਕਸਪੋਰਟ, ਸਨੈਪਸ਼ਾਟ, ਅਤੇ ਰੋਲਬੈਕ ਸਪੋਰਟ ਕਰਦਾ ਹੈ, ਇਸ ਲਈ ਇਕਲ-ਪ੍ਰੋਡਿਊਸਰ-ਕੰਜਿਊਮਰ ਸਲਾਈਸ ਨੂੰ ਟੈਸਟ ਕਰਨਾ ਅਤੇ ਇਵੈਂਟ ਸ਼ੇਪਾਂ ਨੂੰ ਠੀਕ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ ਬਿਨਾਂ ਸ਼ੁਰੂਆਤੀ ਪ੍ਰਯੋਗਾਂ ਨੂੰ ਪ੍ਰੋਡਕਸ਼ਨ ਕ਼ਰਜ਼ ਵਿੱਚ ਬਦਲਣ ਦੇ।