22 ਸਤੰ 2025·8 ਮਿੰਟ
Kafka ਕੀ ਹੈ ਅਤੇ ਆਧੁਨਿਕ ਪ੍ਰਣਾਲੀਆਂ ਵਿੱਚ ਇਹ ਕਿਵੇਂ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ?
ਜਾਣੋ Apache Kafka ਕੀ ਹੈ, ਟਾਪਿਕਸ ਅਤੇ ਪਾਰਟੀਸ਼ਨਾਂ ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ, ਅਤੇ ਆਧੁਨਿਕ ਪ੍ਰਣਾਲੀਆਂ ਵਿੱਚ Kafka ਰੀਅਲ-ਟਾਈਮ ਇਵੈਂਟਸ, ਲੌਗਸ ਅਤੇ ਡੇਟਾ ਪਾਈਪਲਾਈਨਸ ਲਈ ਕਿੱਥੇ ਫਿੱਟ ਹੁੰਦਾ ਹੈ।
ਜਾਣੋ Apache Kafka ਕੀ ਹੈ, ਟਾਪਿਕਸ ਅਤੇ ਪਾਰਟੀਸ਼ਨਾਂ ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ, ਅਤੇ ਆਧੁਨਿਕ ਪ੍ਰਣਾਲੀਆਂ ਵਿੱਚ Kafka ਰੀਅਲ-ਟਾਈਮ ਇਵੈਂਟਸ, ਲੌਗਸ ਅਤੇ ਡੇਟਾ ਪਾਈਪਲਾਈਨਸ ਲਈ ਕਿੱਥੇ ਫਿੱਟ ਹੁੰਦਾ ਹੈ।
Apache Kafka ਇੱਕ ਵੰਡਿਆ ਹੋਇਆ ਇਵੈਂਟ ਸਟ੍ਰੀਮਿੰਗ ਪਲੇਟਫਾਰਮ ਹੈ। ਛੇਤੀ ਵਿੱਚ, ਇਹ ਇੱਕ ਸਾਂਝਾ, ਟਿਕਾਊ “ਪਾਇਪ” ਹੈ ਜੋ ਕਈ ਸਿਸਟਮਾਂ ਨੂੰ ਉਹਤੋਂ ਦੇਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਕਿ ਕੀ ਹੋਇਆ ਅਤੇ ਹੋਰ ਸਿਸਟਮ ਉਹਨਾਂ ਤੱਥਾਂ ਨੂੰ — ਤੇਜ਼ੀ ਨਾਲ, ਪੈਮਾਨੇ 'ਤੇ ਅਤੇ ਕ੍ਰਮ ਵਿੱਚ — ਪੜ੍ਹ ਸਕਦੇ ਹਨ।
ਟੀਮਾਂ Kafka ਨੂੰ ਇਸ ਵੇਲੇ ਵਰਤਦੀਆਂ ਹਨ ਜਦੋਂ ਡੇਟਾ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਸਿਸਟਮਾਂ ਵਿੱਚ ਲਿਜਾਣਾ ਹੁੰਦਾ ਹੈ ਬਿਨਾਂ ਕੜੇ ਤੌਰ 'ਤੇ ਜੁੜੇ ਹੋਏ। ਇਕ ਐਪ ਸਿੱਧਾ ਦੂਜੇ ਨੂੰ ਕਾਲ ਕਰਨ ਦੀ ਬਜਾਏ (ਅਤੇ ਜਦੋਂ ਉਹ ਡਾਊਨ ਜਾਂ ਧੀਮਾ ਹੋਵੇ ਤਾਂ ਫੇਲ ਹੋਣ ਦਾ ਖਤਰਾ), ਪ੍ਰੋਡਿਊਸਰ ਇਵੈਂਟਸ ਨੂੰ Kafka 'ਤੇ ਲਿਖਦੇ ਹਨ। ਕਨਜ਼ਿਊਮਰ ਜਦੋਂ ਤਿਆਰ ਹੁੰਦੇ ਹਨ ਉਹਨਾਂ ਨੂੰ ਪੜ੍ਹਦੇ ਹਨ। Kafka ਇਵੈਂਟਸ ਨੂੰ ਇੱਕ ਨਿਰਧਾਰਤ ਸਮੇਂ ਲਈ ਰੱਖਦਾ ਹੈ, ਇਸ ਲਈ ਸਿਸਟਮ ਆਉਟੇਜ਼ ਤੋਂ ਬਾਅਦ ਬਹਾਲ ਹੋ ਸਕਦੇ ਹਨ ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ-ਪ੍ਰੋਸੈਸ ਵੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਇਹ ਗਾਈਡ ਪ੍ਰੋਡਕਟ-ਮਨਸੂਬਾ ਇੰਜੀਨੀਅਰਾਂ, ਡੇਟਾ ਲੋਕਾਂ ਅਤੇ ਤਕਨੀਕੀ ਨੇਤਾਵਾਂ ਲਈ ਹੈ ਜੋ Kafka ਦਾ ਇੱਕ ਪ੍ਰਯੋਗਕ ਉਪਯੋਗੀ ਮਾਨਸਿਕ ਮਾਡਲ ਚਾਹੁੰਦੇ ਹਨ।
ਤੁਸੀਂ ਮੁੱਖ ਬਲਾਕ (ਪ੍ਰੋਡਿਊਸਰ, ਕਨਜ਼ਿਊਮਰ, ਟਾਪਿਕਸ, ਬ੍ਰੋਕਰ), ਪਾਰਟੀਸ਼ਨਾਂ ਨਾਲ Kafka ਕਿਵੇਂ ਸਕੇਲ ਹੁੰਦਾ ਹੈ, ਇਹ ਕਿਵੇਂ ਸਟੋਰ ਅਤੇ ਰੀਪਲੇ ਕਰਦਾ ਹੈ, ਅਤੇ ਇਵੈਂਟ-ਡਰਿਵਨ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ ਕਿੱਥੇ ਫਿੱਟ ਹੁੰਦਾ ਹੈ, ਇਹ ਸਭ ਸਿੱਖੋਗੇ। ਅਸੀਂ ਆਮ ਉਪਯੋਗ ਕੇਸ, ਡਿਲਿਵਰੀ ਗਾਰੰਟੀਜ਼, ਸੁਰੱਖਿਆ ਮੁਲ-ਤੱਤ, ਓਪਰੇਸ਼ਨ ਯੋਜਨਾ ਅਤੇ ਕਦੋਂ Kafka ਠੀਕ ਹੈ ਜਾਂ ਨਹੀਂ ਵੀ ਕਵਰ ਕਰਾਂਗੇ।
Kafka ਨੂੰ ਇੱਕ ਸਾਂਝੇ ਇਵੈਂਟ ਲੌਗ ਵਜੋਂ ਸਮਝਣਾ ਸਭ ਤੋਂ ਆਸਾਨ ਹੈ: ਐਪਲੀਕੇਸ਼ਨ ਇਸ 'ਤੇ ਇਵੈਂਟ ਲਿਖਦੇ ਹਨ, ਅਤੇ ਹੋਰ ਐਪਲੀਕੇਸ਼ਨ ਉਹਨਾਂ ਇਵੈਂਟਸ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਪੜ੍ਹਦੇ ਹਨ—ਅਕਸਰ ਰੀਅਲ-ਟਾਈਮ ਵਿੱਚ, ਕਈ ਵਾਰੀ ਘੰਟਿਆਂ ਜਾਂ ਦਿਨਾਂ ਬਾਅਦ।
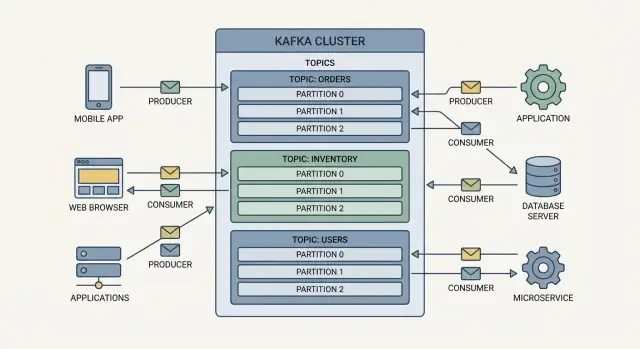
ਪ੍ਰੋਡਿਊਸਰ ਲਿਖਣ ਵਾਲੇ ਹਨ। ਇੱਕ ਪ੍ਰੋਡਿਊਸਰ “order placed”, “payment confirmed”, ਜਾਂ “temperature reading” ਵਰਗਾ ਇਕ ਇਵੈਂਟ ਪਬਲਿਸ਼ ਕਰ ਸਕਦਾ ਹੈ। ਪ੍ਰੋਡਿਊਸਰ ਇਵੈਂਟਸ ਨੂੰ ਸਿੱਧਾ ਕਿਸੇ ਖ਼ਾਸ ਐਪ ਨੂੰ ਨਹੀਂ ਭੇਜਦੇ—ਉਹਨਾਂ ਨੂੰ Kafka 'ਤੇ ਭੇਜਦੇ ਹਨ।
ਕਨਜ਼ਿਊਮਰ ਪੜ੍ਹਨ ਵਾਲੇ ਹਨ। ਇੱਕ ਕਨਜ਼ਿਊਮਰ ਡੈਸ਼ਬੋਰਡ ਚਲਾ ਸਕਦਾ ਹੈ, ਸ਼ਿਪਮੈਂਟ ਵਰਕਫਲੋ ਚਲਾਉਂਦਾ ਹੈ, ਜਾਂ ਡੇਟਾ ਨੂੰ ਐਨਾਲਿਟਿਕਸ ਵਿੱਚ ਲੋਡ ਕਰ ਸਕਦਾ ਹੈ। ਕਨਜ਼ਿਊਮਰ ਇਵੈਂਟਸ ਨਾਲ ਕੀ ਕਰਣਾ ਹੈ ਫੈਸਲਾ ਕਰਦੇ ਹਨ, ਅਤੇ ਉਹ ਆਪਣੇ ਰਫ਼ਤਾਰ 'ਤੇ ਪੜ੍ਹ ਸਕਦੇ ਹਨ।
Kafka ਵਿੱਚ ਇਵੈਂਟਸ ਨੂੰ ਟਾਪਿਕਸ ਵਿੱਚ ਸਮੂਹਬੱਧ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜੋ ਮੁਢਲਾ ਤੌਰ 'ਤੇ ਨਾਮਵਾਰ ਵਰਗ ਹਨ। ਉਦਾਹਰਨਾਂ:
orders = ਆਰਡਰ-ਸੰਬੰਧੀ ਇवੈਂਟਸpayments = ਭੁਗਤਾਨ ਇਵੈਂਟਸinventory = ਸਟਾਕ ਬਦਲਾਅਇੱਕ ਟਾਪਿਕ ਉਸ ਕਿਸਮ ਦੇ ਇਵੈਂਟ ਲਈ “ਸਰੋਤ-ਦਾ-ਸੱਚ” ਸਟ੍ਰੀਮ ਬਣ ਜਾਂਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਕਈ ਟੀਮਾਂ ਇਕ ਹੀ ਡੇਟਾ ਦੁਬਾਰਾ ਵਰਤ ਸਕਦੀਆਂ ਹਨ ਬਿਨਾਂ ਇੱਕ-ਵਾਰਗ ਇੰਟੇਗ੍ਰੇਸ਼ਨਾਂ ਦੇ।
ਬ੍ਰੋਕਰ ਇੱਕ Kafka ਸਰਵਰ ਹੈ ਜੋ ਇਵੈਂਟਸ ਨੂੰ ਸਟੋਰ ਕਰਦਾ ਅਤੇ ਕਨਜ਼ਿਊਮਰਾਂ ਨੂੰ ਸਰਵ ਕਰਦਾ ਹੈ। ਅਮਲ ਵਿੱਚ, Kafka ਇੱਕ ਕਲੱਸਟਰ (ਕਈ ਬ੍ਰੋਕਰ ਇਕੱਠੇ) ਵਜੋਂ ਚਲਦਾ ਹੈ ਤਾਂ ਜੋ ਜ਼ਿਆਦਾ ਟਰੈਫਿਕ ਨੂੰ ਹੈਂਡਲ ਕੀਤਾ ਜਾ ਸਕੇ ਅਤੇ ਜੇਕਰ ਕੋਈ ਮਸ਼ੀਨ ਫੇਲ ਹੋਵੇ ਤਾਂ ਸੇਵਾ ਚਲਦੀ ਰਹੇ।
ਕਨਜ਼ਿਊਮਰ ਅਕਸਰ ਇੱਕ ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ ਵਿੱਚ ਚੱਲਦੇ ਹਨ। Kafka ਗਰੂਪ ਵਿੱਚ ਪੜ੍ਹਨ ਦਾ ਕੰਮ ਵੰਡਦਾ ਹੈ, ਤਾਂ ਜੋ ਤੁਸੀਂ ਵੱਧ ਕਨਜ਼ਿਊਮਰ ਇੰਸਟੈਂਸ ਸ਼ਾਮਿਲ ਕਰਕੇ ਪ੍ਰੋਸੈਸਿੰਗ ਨੂੰ ਸਕੇਲ ਕਰ ਸਕੋ—ਬਿਨਾਂ ਹਰ ਇੰਸਟੈਂਸ ਦੇ ਉਹੀ ਕੰਮ ਕਰਨ ਦੇ।
Kafka ਟਾਪਿਕਸ (ਸੰਬੰਧਿਤ ਇਵੈਂਟਸ ਦੀਆਂ ਸਟ੍ਰੀਮਾਂ) ਨੂੰ ਵੰਡ ਕੇ ਅਤੇ ਹਰੇਕ ਟਾਪਿਕ ਨੂੰ ਪਾਰਟੀਸ਼ਨਾਂ (ਉਸ ਸਟ੍ਰੀਮ ਦੇ ਛੋਟੇ, ਸੁਤੰਤਰ ਟੁਕੜੇ) ਵਿੱਚ ਵੰਡ ਕੇ ਸਕੇਲ ਹੁੰਦਾ ਹੈ।
ਇੱਕ ਟਾਪਿਕ ਜਿਸ ਵਿੱਚ ਇਕ ਪਾਰਟੀਸ਼ਨ ਹੋਵੇ, ਉਹ ਇੱਕ ਸਮੇਂ ਵਿੱਚ ਗਰੂਪ ਦੇ ਇੱਕ ਹੀ ਕਨਜ਼ਿਊਮਰ ਦੁਆਰਾ ਹੀ ਪੜ੍ਹਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਹੋਰ ਪਾਰਟੀਸ਼ਨ ਜੋੜੋ, ਅਤੇ ਤੁਸੀਂ ਹੋਰ ਕਨਜ਼ਿਊਮਰ ਜੋੜ ਕੇ ਇਵੈਂਟਸ ਨੂੰ ਸਮਾਂਤਰੀ ਤੌਰ 'ਤੇ ਪ੍ਰੋਸੈਸ ਕਰ ਸਕਦੇ ਹੋ। ਇਹੀ ਤਰੀਕਾ ਹੈ ਜਿਸ ਨਾਲ Kafka ਉੱਚ-ਮਾਤਰਾ ਦੀ ਇਵੈਂਟ ਸਟ੍ਰੀਮਿੰਗ ਅਤੇ ਰੀਅਲ-ਟਾਈਮ ਡੇਟਾ ਪਾਈਪਲਾਈਨਸ ਨੂੰ ਸਹਾਰਦਾ ਹੈ ਬਿਨਾਂ ਹਰ ਸਿਸਟਮ ਨੂੰ ਬੋਤਲਨੈਕ ਬਣਾਏ।
ਪਾਰਟੀਸ਼ਨ ਲੋਡ ਨੂੰ ਬ੍ਰੋਕਰਾਂ 'ਤੇ ਵੰਡਣ ਵਿੱਚ ਵੀ ਮਦਦ ਕਰਦੇ ਹਨ। ਇਕ ਹੀ ਮਸ਼ੀਨ ਦੇ ਵਲੋਂ ਸਾਰੇ ਲਿਖਣ ਅਤੇ ਪੜ੍ਹਨ ਕੰਮ ਨਹੀਂ ਹੋਣੇ, ਬਲਕਿ ਕਈ ਬ੍ਰੋਕਰ ਵੱਖ-ਵੱਖ ਪਾਰਟੀਸ਼ਨਾਂ ਦੀ ਮਿਹਮਾਨੀ ਕਰ ਸਕਦੇ ਹਨ ਤੇ ਟਰੈਫਿਕ ਸਾਂਝਾ ਹੁੰਦਾ ਹੈ।
Kafka ਇੱਕ-ਪਾਰਟੀਸ਼ਨ ਦੇ ਅੰਦਰ ਕ੍ਰਮ ਦੀ ਗਾਰੰਟੀ ਦਿੰਦਾ ਹੈ। ਜੇ ਇਵੈਂਟ A, B, ਅਤੇ C ਇੱਕੋ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਉਸੀ ਕ੍ਰਮ ਵਿੱਚ ਲਿਖੇ ਗਏ ਹਨ, ਤਾਂ ਕਨਜ਼ਿਊਮਰ ਉਹਨਾਂ ਨੂੰ A → B → C ਢੰਗ ਨਾਲ ਪੜ੍ਹੇਗਾ।
ਪਾਰਟੀਸ਼ਨਾਂ ਦੇ ਪਾਰੋਂ ਕ੍ਰਮ ਗਾਰੰਟੀ ਨਹੀਂ ਹੁੰਦੀ। ਜੇ ਤੁਹਾਨੂੰ ਕਿਸੇ ਵਿਸ਼ੇਸ਼ ਇਕਾਈ (ਜਿਵੇਂ ਗਾਹਕ ਜਾਂ ਆਰਡਰ) ਲਈ ਸਖਤ ਕ੍ਰਮ ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹੋ ਕਿ ਉਸ ਇਕਾਈ ਦੇ ਸਾਰੇ ਇਵੈਂਟ ਇੱਕੋ ਹੀ ਪਾਰਟੀਸ਼ਨ ਨੂੰ ਜਾਂਦੇ ਹਨ।
ਜਦੋਂ ਪ੍ਰੋਡਿਊਸਰ ਇੱਕ ਇਵੈਂਟ ਭੇਜਦਾ ਹੈ, ਉਹ ਇੱਕ ਕੀ (ਉਦਾਹਰਨ ਲਈ, order_id) ਸ਼ਾਮਿਲ ਕਰ ਸਕਦਾ ਹੈ। Kafka ਕੀ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸੰਬੰਧਿਤ ਇਵੈਂਟਸ ਨੂੰ ਇੱਕੋ ਪਾਰਟੀਸ਼ਨ ਵੱਲ ਲਗਾਤਾਰ ਰੂਪ ਵਿੱਚ ਰੂਟ ਕਰਦਾ ਹੈ। ਇਸ ਨਾਲ ਉਸ ਕੀ ਲਈ ਪੂਰਵ-ਨਿਰਧਾਰਿਤ ਕ੍ਰਮ ਮਿਲਦਾ ਹੈ, ਜਦਕਿ ਕੁੱਲ ਮਿਲਾ ਕੇ ਟਾਪਿਕ ਕਈ ਪਾਰਟੀਸ਼ਨਾਂ 'ਤੇ ਫੈਲ ਸਕਦਾ ਹੈ।
ਹਰ ਪਾਰਟੀਸ਼ਨ ਨੂੰ ਹੋਰ ਬ੍ਰੋਕਰਾਂ 'ਤੇ ਰੇਪਲਿਕੇਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਜੇ ਕੋਈ ਬ੍ਰੋਕਰ ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਹੋਰ ਬ੍ਰੋਕਰ 'ਤੇ ਮੌਜੂਦ ਰੇਪਲਿਕਾ ਲੀਡਰ ਬਣ ਕੇ ਕੰਮ ਜਾਰੀ ਰੱਖ ਸਕਦਾ ਹੈ। ਰੈਪਲੀਕੇਸ਼ਨ ਹੀ ਮਨ-ਕਾਰਨ ਹੈ ਕਿ Kafka ਮਿਸ਼ਨ-ਕ੍ਰਿਟਿਕਲ ਸਿਸਟਮਾਂ ਲਈ ਭਰੋਸੇਯੋਗ ਹੈ: ਇਹ ਉਪਲਬਧਤਾ ਸੁਧਾਰਦਾ ਹੈ ਅਤੇ ਫਾਲਟ ਟੋਲਰੈਂਸ ਦਿੰਦਾ ਹੈ ਬਿਨਾਂ ਹਰ ਐਪ ਨੂੰ ਆਪਣੀ ਫੇਲਓਵਰ ਲਾਜ਼ਮੀ ਤੌਰ 'ਤੇ ਬਣਾਉਣ ਦੀ ਲੋੜ।
Apache Kafka ਵਿੱਚ ਇੱਕ ਮੁੱਖ ਵਿਚਾਰ ਇਹ ਹੈ ਕਿ ਇਵੈਂਟਸ ਸਿਰਫ ਅੱਗੇ-ਅੱਗੇ ਨਹੀਂ ਜਾਂਦੇ—ਉਹ ਡਿਸਕ 'ਤੇ ਲਿਖੇ ਜਾਂਦੇ ਹਨ, ਇਸ ਲਈ ਕਨਜ਼ਿਊਮਰ ਉਹਨਾਂ ਨੂੰ ਹੁਣ ਪੜ੍ਹ ਸਕਦੇ ਹਨ ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਵੀ। ਇਹ Kafka ਨੂੰ ਸਿਰਫ ਡੇਟਾ ਹਿਲਾਉਣ ਲਈ ਹੀ ਨਹੀਂ, ਬਲਕਿ ਹੋਣ ਵਾਲੀ ਘਟਨਾ ਦਾ ਟਿਕਾਊ ਇਤਿਹਾਸ ਰੱਖਣ ਲਈ ਵੀ ਵਰਤੋਂਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਜਦੋਂ ਇੱਕ ਪ੍ਰੋਡਿਊਸਰ ਟਾਪਿਕ 'ਤੇ ਇਵੈਂਟ ਭੇਜਦਾ ਹੈ, Kafka ਉਹਨੂੰ ਬ੍ਰੋਕਰ 'ਤੇ ਸਟੋਰੇਜ ਵਿੱਚ ਐਪੈਂਡ ਕਰਦਾ ਹੈ। ਫਿਰ ਕਨਜ਼ਿਊਮਰ ਉਸ ਸਟੋਰ ਕੀਤੇ ਲੌਗ ਤੋਂ ਆਪਣੀ ਰਫ਼ਤਾਰ 'ਤੇ ਪੜ੍ਹਦੇ ਹਨ। ਜੇ ਇੱਕ ਕਨਜ਼ਿਊਮਰ ਇਕ ਘੰਟੇ ਲਈ ਡਾਊਨ ਰਹਿੰਦਾ ਹੈ, ਤਾਂ ਵੀ ਇਵੈਂਟਸ ਮੌਜੂਦ ਹੁੰਦੇ ਹਨ ਅਤੇ ਉਹ ਬਰਾਮਦ ਹੋ ਕੇ ਕੈਚ-ਅੱਪ ਕਰ ਸਕਦਾ ਹੈ ਜਦੋਂ ਇਹ ਮੁੜ ਚੱਲ ਪੈਂਦਾ ਹੈ।
Kafka ਇਵੈਂਟਸ ਨੂੰ ਰਿਟੇਂਸ਼ਨ ਨੀਤੀਆਂ ਦੇ ਅਨੁਸਾਰ ਰੱਖਦਾ ਹੈ:
ਰਿਟੇਂਸ਼ਨ ਪ੍ਰਤੀ ਟਾਪਿਕ ਕਨਫਿਗਰ ਕੀਤੀ ਜਾਂਦੀ ਹੈ, ਇਸ ਲਈ ਤੁਸੀਂ “ਆਡਿਟ ਟਰੇਲ” ਵਾਲੇ ਟਾਪਿਕਾਂ ਨੂੰ ਵੱਖਰਾ ਇਲਾਜ ਦੇ ਸਕਦੇ ਹੋ ਹੌਰ-ਵਾਲੇ ਟੈਲੀਮੀਟਰੀ ਟਾਪਿਕਾਂ ਦੀ ਤੁਲਨਾ ਵਿੱਚ।
ਕਈ ਟਾਪਿਕ ਸਿਰਫ ਇਤਿਹਾਸਕ ਆਰਕਾਈਵ ਨਹੀਂ ਹੁੰਦੇ—ਉਹ ਚੇਂਜਲੌਗ ਵਾਂਗ ਹੋ ਸਕਦੇ ਹਨ, ਉਦਾਹਰਨ ਲਈ “ਮੌਜੂਦਾ ਗਾਹਕ ਸੈਟਿੰਗਜ਼।” ਲੌਗ ਕੰਪੈਕਸ਼ਨ ਘੱਟੋ-ਘੱਟ ਹਰ ਕੀ ਲਈ ਆਖਰੀ ਇਵੈਂਟ ਰੱਖਦੀ ਹੈ, ਜਦਕਿ ਪੁਰਾਣੇ ਓਲਟੇ-ਸਰੇ ਰਿਕਾਰਡ ਹਟਾਏ ਜਾ ਸਕਦੇ ਹਨ। ਇਸ ਨਾਲ ਤੁਹਾਨੂੰ ਹਮੇਸ਼ਾ ਤਾਜ਼ਾ ਸਥਿਤੀ ਲਈ ਇੱਕ ਟਿਕਾਊ ਸਰੋਤ ਮਿਲਦਾ ਹੈ ਬਿਨਾਂ ਬੇਅੰਤ ਵਾਧੇ ਦੇ।
ਕਿਉਂਕਿ ਇਵੈਂਟਸ ਸਟੋਰ ਕੀਤੇ ਰਹਿੰਦੇ ਹਨ, ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਮੁੜ-ਚਲਾ ਸਕਦੇ ਹੋ:
ਅਮਲ ਵਿੱਚ, ਰੀਪਲੇ ਇਸ 'ਤੇ ਨਿਯੰਤਰਿਤ ਹੁੰਦੀ ਹੈ ਕਿ ਇੱਕ ਕਨਜ਼ਿਊਮਰ "ਕਿੱਥੋਂ ਪੜ੍ਹਨਾ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ" (ਉਸਦਾ ਆਫਸੈੱਟ), ਜੋ ਟੀਮਾਂ ਨੂੰ ਪ੍ਰਣਾਲੀਆਂ ਬਦਲਣ ਦੇ ਸਮੇਂ ਇੱਕ ਤਾਕਤਵਰ ਸੇਫਟੀ ਨੈੱਟ ਦਿੰਦਾ ਹੈ।
Kafka ਇਸ ਤਰ੍ਹਾਂ ਬਣਾਇਆ ਗਿਆ ਹੈ ਕਿ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਫੇਲ ਹੋਣ 'ਤੇ ਵੀ ਡੇਟਾ ਬਹਿ ਰਹੇ। ਇਹ ਰੈਪਲੀਕੇਸ਼ਨ, ਹਰੇਕ ਪਾਰਟੀਸ਼ਨ ਲਈ “ਕੌਣ ਇੰਚਾਰਜ ਹੈ” ਦੇ ਸਾਫ਼ ਨਿਯਮਾਂ, ਅਤੇ ਕੰਫ਼ਿਗਰੇਬਲ ਲਿਖਾਈ ਪੁਸ਼ਟੀਕਰਨਾਂ (acknowledgments) ਨਾਲ ਹੁੰਦਾ ਹੈ।
ਹਰ ਟਾਪਿਕ ਪਾਰਟੀਸ਼ਨ ਦਾ ਇਕ ਲੀਡਰ ਬ੍ਰੋਕਰ ਹੁੰਦਾ ਹੈ ਅਤੇ ਇੱਕ ਜਾਂ ਵੱਧ ਫਾਲੋਅਰ ਰੇਪਲਿਕਾ ਹੋ ਸਕਦੇ ਹਨ। ਪ੍ਰੋਡਿਊਸਰ ਅਤੇ ਕਨਜ਼ਿਊਮਰ ਉਸ ਪਾਰਟੀਸ਼ਨ ਲਈ ਲੀਡਰ ਨਾਲ ਗੱਲ ਕਰਦੇ ਹਨ।
ਫਾਲੋਅਰ ਲੀਡਰ ਦਾ ਡੇਟਾ ਲਗਾਤਾਰ ਨਕਲ ਕਰਦੇ ਰਹਿੰਦੇ ਹਨ। ਜੇ ਲੀਡਰ ਡਾਊਨ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ Kafka ਇੱਕ ਅਪ-ਟੂ-ਡੇਟ ਫਾਲੋਅਰ ਨੂੰ ਨਵਾਂ ਲੀਡਰ ਬਣਾਉਣ ਲਈ ਪ੍ਰੋਮੋਟ ਕਰ ਸਕਦਾ ਹੈ, ਤਾਂ ਕਿ ਪਾਰਟੀਸ਼ਨ ਉਪਲਬਧ ਰਹੇ।
ਜੇਕਰ ਕੋਈ ਬ੍ਰੋਕਰ ਫੇਲ ਹੋ ਜਾਵੇ, ਤਾਂ ਜਿਹੜੀਆਂ ਪਾਰਟੀਸ਼ਨਾਂ ਉਸ ਨੇ ਲੀਡਰ ਵਜੋਂ ਹੋਸਟ ਕੀਤੀਆਂ ਸਨ ਉਹ थोੜ੍ਹੇ ਸਮੇਂ ਲਈ ਅਣਉਪਲਬਧ ਹੋ ਸਕਦੀਆਂ ਹਨ। Kafka ਦਾ ਕੰਟਰੋਲਰ ਫੇਲਯ ਨੂੰ ਡਿੱਟੈਕਟ ਕਰਦਾ ਹੈ ਅਤੇ ਉਹਨਾਂ ਪਾਰਟੀਸ਼ਨਾਂ ਲਈ ਲੀਡਰ ਚੁਣਾਅ ਚਲਾਉਂਦਾ ਹੈ।
ਜੇ ਘੱਟੋ-ਘੱਟ ਇਕ ਫਾਲੋਅਰ ਰੇਪਲਿਕਾ ਸੰਕਲਿਤ ਹੋਈ ਹੋਵੇ, ਤਾਂ ਉਹ ਲੀਡਰ ਬਣ ਸਕਦੀ ਅਤੇ ਕਲਾਇੰਟਸ ਲਿਖਨਾ/ਪੜ੍ਹਨਾ ਜਾਰੀ ਰੱਖ ਸਕਦੇ ਹਨ। ਜੇ ਕੋਈ ਇਨ-ਸਿੰਕ ਰੇਪਲਿਕਾ ਉਪਲਬਧ ਨਾ ਹੋਵੇ, ਤਾਂ Kafka ਤੁਹਾਡੇ ਸੈਟਿੰਗਜ਼ ਦੇ ਅਨੁਸਾਰ writes ਰੋਕ ਸਕਦਾ ਹੈ ਤਾਂ ਜੋ ਤੁਹਾਡੀ ਐਕਨਾਲਿਜ਼ਡ ਡੇਟਾ ਗੁੰਮ ਨਾ ਹੋਏ।
ਦੋ ਮੁੱਖ ਕਨਫ਼ਿਗਰੇਸ਼ਨ ਟਿਕਾਊਤਾ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀਆਂ ਹਨ:
ਸਧਾਰਨ ਪੱਧਰ ਤੇ:
ਰੀਟ੍ਰਾਈਜ਼ ਦੌਰਾਨ ਡੁਪਲੀਕੇਟ्स ਘਟਾਉਣ ਲਈ ਟੀਮਾਂ ਅਕਸਰ ਸੁਰੱਖਿਅਤ acks ਨਾਲ idempotent ਪ੍ਰੋਡਿਊਸਰ ਅਤੇ ਮਜ਼ਬੂਤ ਕਨਜ਼ਿਊਮਰ ਹੈਂਡਲਿੰਗ ਨੂੰ ਮਿਲਾਉਂਦੀਆਂ ਹਨ।
ਜ਼ਿਆਦਾ ਸੁਰੱਖਿਆ ਆਮ ਤੌਰ 'ਤੇ ਵੱਧ ਪੁਸ਼ਟੀਆਂ ਦੀ ਉਡੀਕ ਕਰਨ ਅਤੇ ਹੋਰ ਰੇਪਲਿਕਾਜ਼ ਨੂੰ ਸਿੰਕ ਰੱਖਣ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਜੋ ਕਿ ਲੇਟੈਂਸੀ ਵਧਾ ਸਕਦੀ ਹੈ ਅਤੇ ਚੋਟੀ ਦੀ ਥਰੂਪੁੱਟ ਘਟਾ ਸਕਦੀ ਹੈ。
ਘੱਟ ਲੇਟੈਂਸੀ ਸੈਟਿੰਗਜ਼ ਟੈਲੀਮੀਟਰੀ ਜਾਂ ਕਲਿਕਸਟ੍ਰੀਮ ਵਰਗੇ ਮਾਮਲਿਆਂ ਲਈ ਠੀਕ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਿੱਥੇ ਕਦਚਿੱਤ ਨੁੱਕਸਾਨ ਮਨਜ਼ੂਰ ਹੈ, ਪਰ ਭੁਗਤਾਨ, ਸਟਾਕ, ਅਤੇ ਆਡਿਟ ਲੋਗ ਆਮ ਤੌਰ 'ਤੇ ਵੱਧ ਸੁਰੱਖਿਆ ਦੀ ਮੰਗ ਕਰਦੇ ਹਨ।
ਇਵੈਂਟ-ਡਰਿਵਨ ਆਰਕੀਟੈਕਚਰ (EDA) ਉਹ ਤਰੀਕਾ ਹੈ ਜਿੱਥੇ ਕਾਰੋਬਾਰ ਵਿੱਚ ਹੋਣ ਵਾਲੀਆਂ ਘਟਨਾਵਾਂ—ਜਿਵੇਂ ਇਕ ਆਰਡਰ ਰੱਖਿਆ ਗਿਆ, ਭੁਗਤਾਨ ਪੁਸ਼ਟੀ ਹੋਈ, ਪੈਕੇਜ ਭੇਜਿਆ ਗਿਆ—ਇਹਨਾਂ ਨੂੰ ਇਵੈਂਟਸ ਵਜੋਂ ਦਰਸਾਇਆ ਜਾਂਦਾ ਹੈ ਜਿਨ੍ਹਾਂ 'ਤੇ ਸਿਸਟਮ ਦੇ ਹੋਰ ਹਿੱਸੇ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰ ਸਕਦੇ ਹਨ।
Kafka ਅਕਸਰ EDA ਦੇ ਕੇਂਦਰ ਵਿੱਚ ਏਕ ਸਾਂਝਾ “ਇਵੈਂਟ ਸਟ੍ਰੀਮ” ਵਜੋਂ ਖੜਾ ਹੁੰਦਾ ਹੈ। ਸੇਵਾ A ਸਿੱਧਾ ਸੇਵਾ B ਨੂੰ ਕਾਲ ਕਰਨ ਦੀ ਬਜਾਏ ਇੱਕ ਇवੈਂਟ (OrderCreated ਵਰਗਾ) ਇੱਕ Kafka ਟਾਪਿਕ 'ਤੇ ਪਬਲਿਸ਼ ਕਰਦੀ ਹੈ। ਕੋਈ ਵੀ ਗਿਣਤੀ ਸੇਵਾਵਾਂ ਉਸ ਇਵੈਂਟ ਨੂੰ ਕਨਜ਼ਿਊਮ ਕਰ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਕਾਰਵਾਈ ਕਰ ਸਕਦੀਆਂ ਹਨ—ਈਮੇਲ ਭੇਜੋ, ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵ ਕਰੋ, ਫਰਾਡ ਚੈੱਕ ਸ਼ੁਰੂ ਕਰੋ—ਬਿਨਾਂ ਸੇਵਾ A ਨੂੰ ਇਹ ਜ਼ਰੂਰਤ ਹੋਣ ਦੀ ਕਿ ਉਹ ਉਹਨਾਂ ਦੀ ਮੌਜੂਦਗੀ ਜਾਣਦੀ ਹੋਵੇ।
ਕਿਉਂਕਿ ਸੇਵਾਵਾਂ ਇਵੈਂਟਸ ਰਾਹੀਂ ਗੱਲ ਕਰਦੀਆਂ ਹਨ, ਉਨ੍ਹਾਂ ਨੂੰ ਹਰ ਇੰਟਰੈਕਸ਼ਨ ਲਈ ਰਿਕੁਏਸਟ/ਰਿਸਪਾਂਸ APIs ਦੀ ਸਹਿ-ਰਚਨਾ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ। ਇਸ ਨਾਲ ਟੀਮਾਂ ਦਰਮਿਆਨ ਕਠੋਰ ਨਿਰਭਰਤਾਵਾਂ ਘਟਦੀਆਂ ਹਨ ਅਤੇ ਨਵੀਆ ਫੀਚਰ ਜੋੜਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ: ਤੁਸੀਂ ਇੱਕ ਮੌਜੂਦਾ ਇਵੈਂਟ ਲਈ ਨਵਾਂ ਕਨਜ਼ਿਊਮਰ ਪੇਸ਼ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਪ੍ਰੋਡਿਊਸਰ ਨੂੰ ਬਦਲੇ।
EDA ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਅਸਿੰਕ੍ਰੋਨਸ ਹੁੰਦੀ ਹੈ: ਪ੍ਰੋਡਿਊਸਰ ਤੇਜ਼ੀ ਨਾਲ ਇਵੈਂਟ ਲਿਖਦੇ ਹਨ, ਅਤੇ ਕਨਜ਼ਿਊਮਰ ਉਹਨਾਂ ਨੂੰ ਆਪਣੇ ਰਫ਼ਤਾਰ 'ਤੇ ਪ੍ਰੋਸੈਸ ਕਰਦੇ ਹਨ। ਟ੍ਰੈਫਿਕ ਦੇ ਸਪਾਈਕ ਦੌਰਾਨ, Kafka ਬਫ਼ਰ ਵਾਂਗ ਕੰਮ ਕਰਕੇ ਝਟਕੇ ਨੂੰ ਨਿਮ੍ਹਾਉਂਦਾ ਹੈ ਤਾਂ ਜੋ ਡਾਊਨਸਟਰੀਮ ਸਿਸਟਮ ਤੁਰੰਤ ਢਹਿ ਨਾ ਜਾਣ। ਕਨਜ਼ਿਊਮਰ ਸਕੇਲ ਆਉਟ ਕਰ ਸਕਦੇ ਹਨ ਅਤੇ ਫੇਲ ਹੋਣ 'ਤੇ ਮੁੜ ਓਥੇੋਂ ਜਾਰੀ ਰੱਖ ਸਕਦੇ ਹਨ ਜਿੱਥੋਂ ਉਹ ਰੁਕੇ ਸਨ।
Kafka ਨੂੰ ਸਿਸਟਮ ਦਾ "ਐਕਟਿਵਿਟੀ ਫੀਡ" ਸੋਚੋ। ਪ੍ਰੋਡਿਊਸਰ ਤੱਥ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹਨ; ਕਨਜ਼ਿਊਮਰ ਉਹ ਤੱਥ subscribe ਕਰਦੇ ਹਨ ਜੋ ਉਹਨਾਂ ਨੂੰ ਚਾਹੀਦੇ ਹਨ। ਇਹ ਪੈਟਰਨ ਰੀਅਲ-ਟਾਈਮ ਡੇਟਾ ਪਾਈਪਲਾਈਨਜ਼ ਤੇ ਇਵੈਂਟ-ਡਰਿਵਨ ਵਰਕਫ਼ਲੋਸ ਨੂੰ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ ਜਦੋਂ ਕਿ ਸੇਵਾਵਾਂ ਸਾਦਾ ਅਤੇ ਸੁਤੰਤਰ ਰਹਿੰਦੀਆਂ ਹਨ।
Kafka ਉਹਥੇ ਆਉਂਦਾ ਹੈ ਜਿੱਥੇ ਟੀਮਾਂ ਨੂੰ ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ “ਹੋਈਆਂ ਗੱਲਾਂ” (ਇਵੈਂਟਸ) ਸਿਸਟਮਾਂ ਵਿਚਕਾਰ—ਤੇਜ਼ੀ ਨਾਲ, ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਅਤੇ ਇਸ ਤਰ੍ਹਾਂ ਕਿ ਕਈ ਕਨਜ਼ਿਊਮਰ ਇਕੋ ਡੇਟਾ ਦੁਬਾਰਾ ਵਰਤ ਸਕਣ—ਇਹਨਾਂ ਨੂੰ ਮੂਵ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਐਪਲੀਕੇਸ਼ਨਾਂ ਨੂੰ ਅਕਸਰ ਇੱਕ ਐਪੈਂਡ-ਓਨਲੀ ਇਤਿਹਾਸ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: ਯੂਜ਼ਰ ਸਾਈਨ-ਇਨਸ, ਪਰਮੀਸ਼ਨ ਬਦਲਾਅ, ਰਿਕਾਰਡ ਤਬਦੀਲੀਆਂ, ਜਾਂ ਐਡਮਿਨ ਕਾਰਵਾਈਆਂ। Kafka ਇਹਨਾਂ ਇਵੈਂਟਸ ਦਾ ਕੇਂਦਰੀ ਸਟ੍ਰੀਮ ਬਣ ਕੇ ਚੰਗੀ ਤਰ੍ਹਾਂ ਕੰਮ ਕਰਦਾ ਹੈ, ਤਾਂ ਕਿ ਸੁਰੱਖਿਆ ਟੂਲ, ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਕੰਪਲਾਇੰਸ ਐਕਸਪੋਰਟ ਸਾਰੇ ਇੱਕੋ ਸਰੋਤ ਤੋਂ ਪੜ੍ਹ ਸਕਣ ਬਿਨਾਂ ਪ੍ਰੋਡਕਸ਼ਨ ਡੇਟਾਬੇਸ 'ਤੇ ਟੀਚੇ ਦਾ ਵਾਧਾ ਕੀਤੇ। ਕਿਉਂਕਿ ਇਵੈਂਟਸ ਨਿਰਧਾਰਤ ਸਮੇਂ ਲਈ ਰੱਖੇ ਜਾਂਦੇ ਹਨ, ਤੁਸੀਂ ਬੱਗ ਜਾਂ ਸਕੀਮਾ ਬਦਲਾਅ ਤੋਂ ਬਾਅਦ ਵੀ ਇੱਕ ਆਡਿਟ ਵਿਊ ਮੁੜ-ਬਣਾਉਣ ਲਈ ਉਹਨਾਂ ਨੂੰ ਮੁੜ ਚਲਾ ਸਕਦੇ ਹੋ।
ਸੇਵਾਵਾਂ ਸਿੱਧਾ-ਸਿੱਧਾ ਇੱਕ ਦੂਜੇ ਨੂੰ ਕਾਲ ਕਰਨ ਦੀ ਬਜਾਏ "order created" ਜਾਂ "payment received" ਵਰਗੇ ਇਵੈਂਟ ਪਬਲਿਸ਼ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਹੋਰ ਸੇਵਾਵਾਂ ਸਬਸਕ੍ਰਾਈਬ ਕਰਕੇ ਆਪਣੇ ਸਮੇਂ 'ਤੇ ਪ੍ਰਤੀਕਿਰਿਆ ਕਰਦੀਆਂ ਹਨ। ਇਹ ਤੰਗ ਜੋੜ ਘਟਾਉਂਦਾ ਹੈ, ਭਾਗੀਦਾਰ ਨਿਰਭਰਤਾਵਾਂ ਦੌਰਾਨ ਸਿਸਟਮਾਂ ਨੂੰ ਕੰਮ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, ਅਤੇ ਨਵੀਆਂ ਸਮਰੱਥਾਵਾਂ (ਜਿਵੇਂ ਫਰਾਡ ਚੈੱਕ) ਜੋੜਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ।
Kafka ਆਮ ਤੌਰ 'ਤੇ ਓਪਰੇਸ਼ਨਲ ਸਿਸਟਮਾਂ ਤੋਂ ਐਨਾਲਿਟਿਕਸ ਪਲੇਟਫਾਰਮਾਂ ਤੱਕ ਡੇਟਾ ਲਿਜਾਣ ਲਈ ਬੈਕਬੋਨ ਹੁੰਦਾ ਹੈ। ਟੀਮਾਂ ਐਪਲੀਕੇਸ਼ਨ ਡੇਟਾਬੇਸ ਤੋਂ ਬਦਲਾਅ ਸਟ੍ਰੀਮ ਕਰਕੇ ਉਨ੍ਹਾਂ ਨੂੰ ਵੇਅਰਹਾਊਸ ਜਾਂ ਲੇਕ ਤੱਕ ਛੋਟੇ ਸਮੇਂ ਵਿੱਚ ਭੇਜ ਸਕਦੀਆਂ ਹਨ, ਜਦਕਿ ਪ੍ਰੋਡਕਸ਼ਨ ਐਪ ਨੂੰ ਭਾਰੀ ਐਨਾਲਿਟਿਕ ਸਵਾਲਾਂ ਤੋਂ ਅਲੱਗ ਰੱਖਦੇ ਹਨ।
ਸੈਂਸਰ, ਡਿਵਾਈਸ ਅਤੇ ਐਪ ਟੈਲੀਮੀਟਰੀ ਅਕਸਰ ਝਟਕੇ ਵਿੱਚ ਆਉਂਦੀ ਹੈ। Kafka ਬਰਸਟਾਂ ਨੂੰ ਅਬਜ਼ੌਰਬ ਕਰ ਸਕਦਾ ਹੈ, ਉਨ੍ਹਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਬਫ਼ਰ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਡਾਊਨਸਟਰੀਮ ਪ੍ਰੋਸੈਸਿੰਗ ਨੂੰ ਕੈਚ-ਅੱਪ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ—ਮਾਨੀਟਰਨਗ, ਅਲਰਟਿੰਗ ਅਤੇ ਲੰਬੇ ਸਮੇਂ ਲਈ ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ ਲਾਭਦਾਇਕ।
Kafka ਸਿਰਫ਼ ਬ੍ਰੋਕਰ ਅਤੇ ਟਾਪਿਕਸ ਹੀ ਨਹੀਂ ਹੈ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਉਹਨਾਂ ਸਾਥੀ ਟੂਲਾਂ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਦੈਨੀਕ ਡੇਟਾ ਮੂਵਮੈਂਟ, ਸਟ੍ਰੀਮ ਪ੍ਰੋਸੈਸਿੰਗ ਅਤੇ ਓਪਰੇਸ਼ਨ ਲਈ Kafka ਨੂੰ ਪ੍ਰਯੋਗਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
Kafka Connect Kafka ਦਾ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਫਰੇਮਵਰਕ ਹੈ ਜੋ ਡੇਟਾ ਨੂੰ Kafka ਵਿੱਚ (ਸੋਰਸ) ਅਤੇ Kafka ਤੋਂ ਬਾਹਰ (ਸਿੰਕ) ਲਿਜਾਣ ਲਈ ਵਰਤਿਆ ਜਾਂਦਾ ਹੈ। ਇਕ-ਵਾਰੀ ਪਾਈਪਲਾਈਨ ਬਣਾਉਣ ਅਤੇ ਸੰਭਾਲਣ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ Connect ਚਲਾਉਂਦੇ ਹੋ ਅਤੇ ਕਨੈਕਟਰਸ ਕਨਫਿਗਰ ਕਰਦੇ ਹੋ।
ਸਧਾਰਨ ਉਦਾਹਰਨਾਂ ਵਿੱਚ ਡੇਟਾਬੇਸ ਤੋਂ ਬਦਲਾਅ ਖਿੱਚਣਾ, SaaS ਇਵੈਂਟਸ ਆਉਂਦੇ ਲੈਣਾ, ਜਾਂ Kafka ਡੇਟਾ ਨੂੰ ਡੇਟਾ ਵੇਅਰਹਾਊਸ ਜਾਂ ਆਬਜੈਕਟ ਸਟੋਰੇਜ ਨੂੰ ਡਿਲਿਵਰ ਕਰਨਾ ਸ਼ਾਮਿਲ ਹੈ। Connect ਰੀਟ੍ਰਾਈਜ਼, ਆਫਸੈਟਸ, ਅਤੇ ਸਮਾਂਤਰੀਤਾ ਜਿਵੇਂ ਓਪਰੇਸ਼ਨਲ ਚਿੰਤਾਵਾਂ ਨੂੰ ਵੀ ਸਟੈਂਡਰਡ ਕਰਦਾ ਹੈ।
ਜੇ Connect ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਲਈ ਹੈ, ਤਾਂ Kafka Streams ਹਿਸਾਬ ਕਿਤਾਬ ਲਈ ਹੈ। ਇਹ ਇੱਕ ਲਾਇਬ੍ਰੇਰੀ ਹੈ ਜੋ ਤੁਸੀਂ ਆਪਣੀ ਐਪ ਵਿੱਚ ਸ਼ਾਮਿਲ ਕਰਦੇ ਹੋ ਤਾ ਕਿ ਸਟ੍ਰੀਮਾਂ ਨੂੰ ਰੀਅਲ-ਟਾਈਮ ਵਿੱਚ ਤਬਦੀਲ ਕੀਤਾ ਜਾ ਸਕੇ—ਇਵੈਂਟਸ ਨੂੰ ਫਿਲਟਰ ਕਰਨ, ਉਨ੍ਹਾਂ ਨੂੰ ਐਨਰਿਚ ਕਰਨ, ਸਟ੍ਰੀਮਾਂ ਨੂੰ ਜੋੜਨ ਅਤੇ ਐਗਰੀਗੇਟ ਬਣਾਉਣ (ਜਿਵੇਂ "ਪ੍ਰਤੀ ਮਿੰਟ ਆਰਡਰਾਂ")।
ਕਿਉਂਕਿ Streams ਐਪਸ ਟਾਪਿਕਸ ਤੋਂ ਪੜ੍ਹਦੀਆਂ ਅਤੇ ਟਾਪਿਕਸ 'ਤੇ ਲਿਖਦੀਆਂ ਹਨ, ਉਹ ਇਵੈਂਟ-ਡਰਿਵਨ ਸਿਸਟਮਾਂ ਵਿੱਚ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਫਿੱਟ ਹੁੰਦੀਆਂ ਹਨ ਅਤੇ ਹੋਰ ਇੰਸਟੈਂਸ ਸ਼ਾਮਿਲ ਕਰਕੇ ਸਕੇਲ ਕੀਤੀਆਂ ਜਾ ਸਕਦੀਆਂ ਹਨ।
ਜਦੋਂ ਕਈ ਟੀਮਾਂ ਇਵੈਂਟਸ ਪਬਲਿਸ਼ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਇੱਕਸਾਰਤਾ ਮਹੱਤਵਪੂਰਨ ਹੋ ਜਾਂਦੀ ਹੈ। ਸਕੀਮਾ ਪ੍ਰਬੰਧਨ (ਅਕਸਰ ਇੱਕ ਸਕੀਮਾ ਰਜਿਸਟਰੀ ਰਾਹੀਂ) ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰਦਾ ਹੈ ਕਿ ਇੱਕ ਇਵੈਂਟ ਵਿੱਚ ਕਿਹੜੇ ਫੀਲਡ ਹੋਣ ਚਾਹੀਦੇ ਹਨ ਅਤੇ ਉਹ ਕਿਵੇਂ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲਣਗੇ। ਇਸ ਨਾਲ ਉਹ ਖ਼ਤਰਾ ਘਟਦਾ ਹੈ ਕਿ ਇੱਕ ਪ੍ਰੋਡਿਊਸਰ ਇੱਕ ਫੀਲਡ ਦਾ ਨਾਮ ਬਦਲ ਦੇਵੇ ਜੋ ਕਿਸੇ ਕਨਜ਼ਿਊਮਰ 'ਤੇ ਨਿਰਭਰ ਹੈ।
Kafka ਓਪਰੇਸ਼ਨली ਸੰਵੇਦਨਸ਼ੀਲ ਹੈ, ਇਸ ਲਈ ਬੁਨਿਆਦੀ ਮੋਨੀਟਰਿੰਗ ਜ਼ਰੂਰੀ ਹੈ:
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਪ੍ਰਬੰਧਨ UI ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ, ਟਾਪਿਕ ਕੰਫਿਗਰੇਸ਼ਨ, ਅਤੇ ਐਕਸੈਸ ਕੰਟਰੋਲ ਨੀਤੀਆਂ ਲਈ ਆਟੋਮੇਸ਼ਨ ਵੀ ਵਰਤਦੀਆਂ ਹਨ (ਦੇਖੋ /blog/kafka-security-governance)।
Kafka ਨੂੰ ਅਕਸਰ “ਟਿਕਾਊ ਲੌਗ + ਕਨਜ਼ਿਊਮਰ” ਵਜੋਂ ਵਰਣਨ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਪਰ ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਦਰਅਸਲ ਪਤਾ ਲਾਉਣ ਲਈ ਚਾਹੁੰਦੀਆਂ ਹਨ: ਕੀ ਮੈਂ ਹਰ ਇਵੈਂਟ ਨੂੰ ਇਕ ਵਾਰੀ ਪ੍ਰੋਸੈਸ ਕਰਾਂਗਾ, ਅਤੇ ਕੁਝ ਫੇਲ ਹੋਣ 'ਤੇ ਕੀ ਹੁੰਦਾ ਹੈ? Kafka ਤੁਹਾਨੂੰ ਬਣਾਉਣ ਲਈ ਨਿਰਮਾਣ ਖੰਡ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਟਰੇਡ-ਅਫ਼ ਚੁਣਦੇ ਹੋ।
At-most-once ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਹੋ ਸਕਦਾ ਹੈ ਇਵੈਂਟਸ ਗੁਆ ਦਿਓ, ਪਰ ਤੁਸੀਂ ਡੁਪਲੀਕੇਟ ਪ੍ਰੋਸੈਸ ਨਹੀਂ ਕਰੋਗੇ। ਇਹ ਹੋ ਸਕਦਾ ਹੈ ਜੇ ਇੱਕ ਕਨਜ਼ਿਊਮਰ ਪਹਿਲਾਂ ਆਪਣੀ ਪੋਜ਼ੀਸ਼ਨ ਕਮੇਟ ਕਰ ਦੇਵੇ ਅਤੇ ਫਿਰ ਕੰਮ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਕਰੈਸ਼ ਹੋ ਜਾਵੇ।
At-least-once ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਇਵੈਂਟਸ ਗੁਆ ਨਹੀਂ ਕਰੋਗੇ, ਪਰ ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ (ਉਦਾਹਰਨ ਲਈ, ਕਨਜ਼ਿਊਮਰ ਇੱਕ ਇवੈਂਟ ਪ੍ਰੋਸੈਸ ਕਰਦਾ ਹੈ, ਫੇਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਫਿਰ ਰੀ-ਸਟਾਰਟ 'ਤੇ ਮੁੜ-ਪ੍ਰੋਸੈਸ ਕਰ ਲੈਂਦਾ ਹੈ)। ਇਹ ਸਭ ਤੋਂ ਆਮ ਡਿਫ਼ੋਲਟ ਪੈਟਰਨ ਹੈ।
Exactly-once ਦੁਨੀਆ-ਭਰ ਦਾ ਉਦੇਸ਼ ਹੈ ਜੋ ਇਵੈਂਟ-ਟੂ-ਇवੈਂਟ ਖਤਮ-ਤੱਕ ਨਾ ਹਾਰ ਅਤੇ ਨਾ ਡੁਪਲੀਕੇਟ ਹੋਵੇ। Kafka ਵਿੱਚ, ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਪ੍ਰੋਡਿਊਸਰਜ਼ ਅਤੇ ਮਿਲਦੇ-ਜੁਲਦੇ ਪ੍ਰੋਸੈਸਿੰਗ (ਅਕਸਰ Kafka Streams ਰਾਹੀਂ) ਨਾਲ ਹੁੰਦਾ ਹੈ। ਇਹ ਸ਼ਕਤੀਸ਼ালী ਹੈ, ਪਰ ਜ਼ਿਆਦਾ ਰੋਕ-ਟੋਕ ਵਾਲਾ ਅਤੇ ਧਿਆਨ ਨਾਲ ਸੈੱਟਅੱਪ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਅਮਲ ਵਿੱਚ, ਬਹੁਤ ਸਾਰੇ ਸਿਸਟਮ at-least-once ਨੂੰ ਗਲੇ ਲਗਾਉਂਦੇ ਹਨ ਅਤੇ ਸੁਰੱਖਿਆ ਲਈ ਕਦਮ ਜੋੜਦੇ ਹਨ:
ਕਨਜ਼ਿਊਮਰ ਆਫਸੈਟ ਇੱਕ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਆਖ਼ਰੀ ਪ੍ਰੋਸੈਸ ਰਿਕਾਰਡ ਦੀ ਪੋਜ਼ੀਸ਼ਨ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਆਫਸੈਟਸ ਕਮੇਟ ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਕਹਿ ਰਹੇ ਹੋ, "ਮੈਂ ਇਥੇ ਤੱਕ ਹੋ ਕੇ ਖਤਮ ਕੀਤਾ।" ਜਲਦੀ ਕਮੇਟ ਕਰੋ ਤਾਂ ਨੁਕਸਾਨ ਦਾ ਖਤਰਾ ਵੱਧ ਜਾਂਦਾ ਹੈ; ਦੇਰ ਨਾਲ ਕਮੇਟ ਕਰੋ ਤਾਂ ਫੇਲ੍ਹ ਤੋਂ ਬਾਅਦ ਡੁਪਲੀਕੇਟ ਵੱਧ ਹੋ ਸਕਦੇ ਹਨ।
ਰੀਟ੍ਰਾਈਜ਼ ਨੂੰ ਸੀਮਿਤ ਅਤੇ ਦਿਖਾਈ ਦੇਣਯੋਗ ਰਹਿਣਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਕ ਆਮ ਪੈਟਰਨ:
ਇਸ ਨਾਲ ਇੱਕ "ਪੋਇਜ਼ਨ ਮੈਸੇਜ" ਪੂਰੇ ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ ਨੂੰ ਰੋਕਦਾ ਨਹੀਂ, ਪਰ ਡੇਟਾ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਠੀਕ ਕਰਨ ਲਈ ਸੰਭਾਲਿਆ ਜਾ ਸਕਦਾ ਹੈ।
Kafka ਅਕਸਰ ਕਾਰੋਬਾਰੀ-ਮਹੱਤਵਪੂਰਨ ਇਵੈਂਟਸ (ਆਰਡਰ, ਭੁਗਤਾਨ, ਯੂਜ਼ਰ ਐਕਟਿਵਿਟੀ) ਢੋ ਰਹਾ ਹੁੰਦਾ ਹੈ। ਇਸ ਲਈ ਸੁਰੱਖਿਆ ਅਤੇ ਗਵਰਨੈਂਸ ਡਿਜ਼ਾਈਨ ਦਾ ਹਿੱਸਾ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ, ਨਾ ਕਿ ਬਾਅਦ ਵਿੱਚ ਸੋਚਿਆ ਜਾਣਾ।
ਪ੍ਰਮਾਣਿਕਤਾ ਇਹ ਸਵਾਲ ਉੱਤਰਦੀ ਹੈ "ਤੁਸੀਂ ਕੌਣ ਹੋ?"; ਅਥੋਰਾਈਜ਼ੇਸ਼ਨ ਇਹ ਪੁੱਛਦੀ ਹੈ "ਤੁਸੀਂ ਕੀ ਕਰ ਸਕਦੇ ਹੋ?" Kafka ਵਿੱਚ, ਪ੍ਰਮਾਣਿਕਤਾ ਅਕਸਰ SASL (ਉਦਾਹਰਨ ਲਈ, SCRAM ਜਾਂ Kerberos) ਨਾਲ ਕੀਤੀ ਜਾਂਦੀ ਹੈ, ਜਦਕਿ ਅਥੋਰਾਈਜ਼ੇਸ਼ਨ ਟਾਪਿਕ, ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ, ਅਤੇ ਕਲੱਸਟਰ ਸਤਰਾਂ 'ਤੇ ACLs ਨਾਲ ਲਾਗੂ ਕੀਤੀ ਜਾਂਦੀ ਹੈ।
ਇੱਕ ਪ੍ਰਯੋਗਕ ਨਮੂਨਾ ਘੱਟ-ਸਭ ਤੋਂ-ਅਧਿਕਾਰ (least privilege) ਹੈ: ਪ੍ਰੋਡਿਊਸਰ ਸਿਰਫ ਉਹਨਾਂ ਟਾਪਿਕਸ 'ਤੇ ਲਿਖ ਸਕਦੇ ਹਨ ਜੋ ਉਹਨਾਂ ਦੀ ਮਦਾਦ ਹਨ, ਅਤੇ কਨਜ਼ਿਊਮਰ ਸਿਰਫ ਉਹਨਾਂ ਟਾਪਿਕਸ ਨੂੰ ਪੜ੍ਹ ਸਕਦੇ ਹਨ ਜੋ ਉਹਨਾਂ ਨੂੰ ਚਾਹੀਦੇ ਹਨ। ਇਸ ਨਾਲ ਗੁਪਤ ਡੇਟਾ ਦੇ ਦਿੱਖਣ ਦੇ% ਘਟਾਉਂਦੇ ਹਨ ਅਤੇ ਜੇਕਰ ਕੁਝ ਅਕਸੁਲਟ ਹੋ ਜਾਂਦਾ ਹੈ ਤਾਂ ਨੁਕਸਾਨ ਦੀ ਰੇਂਜ ਸੀਮਿਤ ਰਹਿੰਦੀ ਹੈ।
TLS ਐਪਸ, ਬ੍ਰੋਕਰ, ਅਤੇ ਟੂਲਿੰਗ ਦਰਮਿਆਨ ਡੇਟਾ ਨੂੰ ਇੰਕ੍ਰਿਪਟ ਕਰਦਾ ਹੈ। ਬਿਨਾਂ TLS ਦੇ, ਇਵੈਂਟਸ ਅੰਦਰੂਨੀ ਨੈੱਟਵਰਕ 'ਤੇ ਵੀ ਇੰਟਰਸੈਪਟ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ, ਨਾ ਕੇਵਲ ਪਬਲਿਕ ਇੰਟਰਨੈੱਟ 'ਤੇ। TLS ਬ੍ਰੋਕਰਾਂ ਦੀ ਪਛਾਣ ਵੀ ਵੈਰੀਫਾਈ ਕਰਕੇ "ਮੈਨ-ਇਨ-ਦ-ਮਿਡਲ" ਹਮਲਿਆਂ ਤੋਂ ਰੋਕਦਾ ਹੈ।
ਜਦੋਂ ਕਈ ਟੀਮਾਂ ਇੱਕ ਕਲੱਸਟਰ ਸਾਂਝਾ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਗਾਰਡਰੇਲਜ਼ ਜ਼ਰੂਰੀ ਹਨ। ਸਾਫ਼ ਟਾਪਿਕ ਨੈਮਿੰਗ ਰਿਵਾਜ (ਉਦਾਹਰਣ ਲਈ, <team>.<domain>.<event>.<version>) ਮਲਕੀਅਤ ਨੂੰ ਸਪਸ਼ਟ ਬਣਾਉਂਦੇ ਹਨ ਅਤੇ ਟੂਲਿੰਗ ਨੂੰ ਨੀਤੀਆਂ ਲਗਾਉਣ ਵਿਚ ਸਹਾਇਤਾ ਦਿੰਦੇ ਹਨ।
ਨਾਮਕਰਨ ਦੇ ਨਾਲ ਕਵੋਟਾ ਅਤੇ ACL ਟੈਮਪਲੇਟ ਜੁੜੋ ਤਾਂ ਇੱਕ ਸ਼ੋਰ ਕਰੋਡ ਵਰਕਲੋਡ ਦੂਸਰਿਆਂ ਨੂੰ ਭੁੱਖਾ ਨਾ ਕਰੇ, ਅਤੇ ਨਵੀਆਂ ਸਰਵਿਸਾਂ ਸੁਰੱਖਿਅਤ ਡਿਫਾਲਟਸ ਨਾਲ ਸ਼ੁਰੂ ਹੋ ਜਾਣ।
ਜੇ ਇਵੈਂਟਸ ਵਿੱਚ PII ਸ਼ਾਮਿਲ ਹੈ, ਤਾਂ ਡੇਟਾ ਘਟਾਉਣਾ (IDs ਭੇਜੋ ਨਾ ਕਿ ਪੂਰੇ ਪ੍ਰੋਫਾਈਲ), ਫੀਲਡ-ਲੈਵਲ ਇੰਕ੍ਰਿਪਸ਼ਨ ਬਾਰੇ ਸੋਚੋ, ਅਤੇ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ ਕਿਹੜੇ ਟਾਪਿਕ ਸੰਵੇਦਨਸ਼ੀਲ ਹਨ।
ਰਿਟੇਂਸ਼ਨ ਸੈਟਿੰਗਜ਼ ਨੂੰ ਕਾਨੂੰਨੀ ਅਤੇ ਕਾਰੋਬਾਰੀ ਲੋੜਾਂ ਦੇ ਅਨੁਕੂਲ ਰੱਖੋ। ਜੇ ਨੀਤੀ ਕਹਿੰਦੀ ਹੈ "30 ਦਿਨਾਂ ਬਾਅਦ ਮਿਟਾ ਦਿਓ" ਤਾਂ 6 ਮਹੀਨੇ ਰੱਖਣਾ "ਸਿਰਫ਼ ਇਹੋ ਕੰਮ ਲਈ" ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ। ਨਿਯਮਤ ਸਮੀਖਿਆਵਾਂ ਅਤੇ ਆਡਿਟਸ ਨਾਲ ਕਨਫਿਗਰੇਸ਼ਨ ਨੂੰ ਅਨੁਕੂਲ ਰੱਖੋ ਜਿਵੇਂ ਸਿਸਟਮ ਵਿਕਸਿਤ ਹੁੰਦੇ ਹਨ।
Apache Kafka ਚਲਾਉਣਾ ਸਿਰਫ਼ "ਇੰਸਟਾਲ ਕਰਦੇ ਹੀ ਭੁੱਲੋ" ਵਾਲਾ ਕੰਮ ਨਹੀਂ। ਇਹ ਇਕ ਸਾਂਝੀ ਸੇਵਾ ਵਾਂਗ ਵਰਤਦੀ ਹੈ: ਕਈ ਟੀਮਾਂ ਇਸ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ ਛੋਟੀ ਗਲਤੀ ਵੀ ਡਾਊਨਸਟਰੀਮ ਐਪਸ 'ਤੇ ਪ੍ਰਭਾਵ ਪਾ ਸਕਦੀ ਹੈ।
Kafka ਦੀ ਸਮਰੱਥਾ ਜ਼ਿਆਦਾਤਰ ਗਣਿਤ ਦਾ ਮਸਲਾ ਹੈ ਜੋ ਤੁਸੀਂ ਨਿਯਮਤ ਰੂਪ ਵਿੱਚ ਮੁੜ-ਜਾਂਚਦੇ ਹੋ। ਸਭ ਤੋਂ ਵੱਡੇ ਲਿਵਰ ਹਨ ਪਾਰਟੀਸ਼ਨਾਂ (ਸਮਾਂਤਰੀਤਾ), ਥਰੂਪੁੱਟ (MB/s in ਅਤੇ out), ਅਤੇ ਸਟੋਰੇਜ ਫ਼ੈਲੋਥ (ਰਿਟੇਂਸ਼ਨ ਨਾਲ ਵਾਧਾ)।
ਜੇ ਟਰੈਫਿਕ ਦੋਗੁਣਾ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਲੋਡ ਵੰਡਣ ਲਈ ਹੋਰ ਪਾਰਟੀਸ਼ਨ, ਰਿਟੇਂਸ਼ਨ ਸਮੇਂ ਲਈ ਹੋਰ ਡਿਸ्क, ਅਤੇ ਰੈਪਲੀਕੇਸ਼ਨ ਲਈ ਨੈਟਵਰਕ ਹੈੱਡਰੂਮ ਦੀ ਲੋੜ ਪੈ ਸਕਦੀ ਹੈ। ਇੱਕ ਪ੍ਰਯੋਗਕ ਆਦਤ ਟੋਪਿਕ ਹੈ ਕਿ "ਪੀਕ" ਲਿਖਾਈ ਦਰ ਦਾ ਅੰਦਾਜ਼ਾ ਲਗਾਓ ਅਤੇ ਰਿਟੇਂਸ਼ਨ ਨਾਲ ਗੁਣਾ ਕਰੋ ਤਾਂ ਕਿ ਡਿਸਕ ਵਾਧੇ ਦਾ ਅੰਦਾਜ਼ਾ ਲਗੇ, ਫਿਰ ਰੈਪਲੀਕੇਸ਼ਨ ਅਤੇ "ਅਚਾਨਕ ਸਫਲਤਾ" ਲਈ ਬਫਰ ਸ਼ਾਮਿਲ ਕਰੋ।
ਸਰਵਰ ਚਲਾਉਣ ਤੋਂ ਅਲਾਵਾ, ਰੋਜ਼ਾਨਾ ਕੰਮ ਉਮੀਦ ਕਰੋ:
ਲਾਗਤਾਂ ਡਿਸਕ, ਨੈਟਵਰਕ ਏਗਰੈਸ, ਅਤੇ ਬ੍ਰੋਕਰਾਂ ਦੀ ਗਿਣਤੀ/ਸਾਈਜ਼ ਨਾਲ ਚਲਦੀਆਂ ਹਨ। ਮੈਨੇਜਡ Kafka ਸਟਾਫ਼ਿੰਗ ਓਵਰਹੈਡ ਘਟਾ ਸਕਦਾ ਹੈ ਅਤੇ ਅਪਗਰੇਡ ਸਧਾਰਨ ਕਰ ਸਕਦਾ ਹੈ, ਜਦਕਿ ਸਵੈ-ਹੋਸਟਿੰਗ ਵੱਡੇ ਪੈਮਾਨੇ 'ਤੇ ਸਸਤੀ ਹੋ ਸਕਦੀ ਹੈ ਜੇਕਰ ਤੁਸੀਂ ਅਨੁਭਵੀ ਓਪਰੇਟਰ ਰੱਖਦੇ ਹੋ। ਤਕਨੀਕੀ ਵਪਾਰ ਇਹ ਹੈ ਕਿ ਟਾਈਮ-ਟੂ-ਰੀਕਵਰੀ ਅਤੇ ਔਨ-ਕਾਲ ਭਾਰ ਬਿਨਾਂ ਮੈਨੇਜਡ ਵਿਕਲਪ ਦੇ ਵੱਧ ਹੋ ਸਕਦੇ ਹਨ।
ਟੀਮਾਂ ਆਮ ਤੌਰ 'ਤੇ ਨਿਗਰਾਨੀ ਕਰਦੀਆਂ ਹਨ:
ਚੰਗੀਆਂ ਡੈਸ਼ਬੋਰਡਜ਼ ਅਤੇ ਅਲਰਟਸ Kafka ਨੂੰ ਇਕ "ਰਹਸਮਈ ਡੱਬੇ" ਤੋਂ ਸਮਝਦਾਰ ਸੇਵਾ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ।
Kafka ਵਧੀਆ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਘਣੇ ਇਵੈਂਟਸ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਹਿਲਾਉਣੇ ਹੋਣ, ਉਨ੍ਹਾਂ ਨੂੰ ਕੁਝ ਸਮੇਂ ਲਈ ਰੱਖਣਾ ਹੋਵੇ, ਅਤੇ ਕਈ ਸਿਸਟਮ ਇਕੋ ਡੇਟਾ ਉਪਯੋਗ ਕਰ ਸਕਣ। ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਵੈਂਟਸ ਨੂੰ ਮੁੜ-ਚਲਾਉਣਾ ਲਾਜ਼ਮੀ ਹੋ (ਬੈਕਫਿਲ, ਆਡਿਟ, ਜਾਂ ਨਵੀਂ ਸੇਵਾ ਮੁੜ-ਤਿਆਰ ਕਰਨ ਲਈ) ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਉਮੀਦ ਕਰਦੇ ਹੋ ਕਿ ਅਗਲੇ ਸਮੇਂ ਹੋਰ ਪ੍ਰੋਡਿਊਸਰ/ਕਨਜ਼ਿਊਮਰ ਜੋੜੇ ਜਾਣਗੇ।
Kafka ਆਮ ਤੌਰ 'ਤੇ ਚਮਕਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ:
ਜੇ ਤੁਹਾਡੀਆਂ ਲੋੜਾਂ ਸਧਾਰਨ ਹਨ, ਤਾਂ Kafka ਓਵਰਕੀਲ ਹੋ ਸਕਦਾ ਹੈ:
ਇਨ੍ਹਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ, ਕਲੱਸਟਰ ਸਾਈਜ਼ਿੰਗ, ਅਪਗਰੇਡਜ਼, ਮੋਨੀਟਰਿੰਗ, ਅਤੇ ਔਨ-ਕਾਲ ਬੋਝ ਲਾਭ ਤੋਂ ਜ਼ਿਆਦਾ ਹੋ ਸਕਦੇ ਹਨ।
Kafka ਡੇਟਾਬੇਸ (ਰਿਕਾਰਡ ਦਾ ਸਿਸਟਮ), ਕੈਸ਼ (ਫਾਸਟ ਰੀਡ), ਅਤੇ ਬੈਚ ETL ਟੂਲਜ਼ (ਵੱਡੇ ਆਰੰਭਿਕ ਬਦਲਾਵ) ਦਾ ਬਦਲ ਨਹੀਂ, ਬਲਕਿ ਉਨ੍ਹਾਂ ਦੀ ਪੂਰਕਤਾ ਹੈ।
ਪੂਛੋ:
ਜੇ ਤੁਹਾਡਾ ਜਵਾਬ ਜ਼ਿਆਦਾਤਰ ਪ੍ਰਸ਼ਨਾਂ ਲਈ "ਹਾਂ" ਹੈ, ਤਾਂ Kafka ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਸੋਝੀਦਾਰ ਚੋਣ ਹੁੰਦੀ ਹੈ।
Kafka ਸਭ ਤੋਂ ਵਧੀਆ ਤਦੋਂ ਫਿੱਟ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਨੂੰ ਰੀਅਲ-ਟਾਈਮ ਇਵੈਂਟ ਸਟ੍ਰੀਮਾਂ ਲਈ ਇੱਕ ਸਾਂਝਾ "ਸਰੋਤ-ਦਾ-ਸੱਚ" ਚਾਹੀਦਾ ਹੈ: ਕਈ ਸਿਸਟਮ ਤੱਥ ਪੈਦਾ ਕਰਦੇ ਹਨ (orders created, payments authorized, inventory changed) ਅਤੇ ਕਈ ਸਿਸਟਮ ਉਹਨਾਂ ਤੱਥਾਂ ਨੂੰ ਉਪਭੋਗ ਕਰਦੇ ਹਨ ਪਾਈਪਲਾਈਨ, ਐਨਾਲਿਟਿਕਸ, ਅਤੇ ਪ੍ਰਤੀਕਿਰਿਆਸ਼ੀਲ ਫੀਚਰਾਂ ਲਈ।
ਇੱਕ ਸਾਰਥਕ, ਸੰਕੀर्ण ਫਲੋ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ—ਜਿਵੇਂ "OrderPlaced" ਇवੈਂਟਸ ਨੂੰ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਨਾ downstream ਸੇਵਾਵਾਂ (ਈਮੇਲ, ਫਰਾਡ ਚੈੱਕ, ਫਲਫਿਲਮੈਂਟ) ਲਈ। ਪਹਿਲੇ ਦਿਨ Kafka ਨੂੰ ਸਭ ਕੁਝ ਸਮੇਤ ਇੱਕ ਫਿਰ-ਚੌੱਕ ਕਿਊ ਬਣਾਉਣ ਤੋਂ ਬਚੋ।
ਲਿਖੋ:
ਸ਼ੁਰੂਆਤੀ ਸਕੀਮਾਂ ਸਧਾਰਨ ਅਤੇ ਸੰਗਤ ਰੱਖੋ (ਟਾਈਮਸਟੈਂਪ, IDs, ਅਤੇ ਸਾਫ਼ ਇਵੈਂਟ ਨਾਮ)। ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਸਕੀਮਾਂ ਨੂੰ ਪਹਿਲਾਂ ਤੋਂ ਲਾਗੂ ਕਰੋਗੇ ਜਾਂ ਸਮੇਂ-ਸਿਰ ਧੀਰੇ-ਧੀਰੇ ਵਿਕਸਤ ਕਰਨਗੇ।
Kafka ਉਸ ਵੇਲੇ ਸਫਲ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਕਿਸੇ ਕੋਲ ਮਲਕੀਅਤ ਹੁੰਦੀ ਹੈ:
ਫੁੱਲ-ਟੂ-ਅੰਤ ਮਾਨੀਟਰਿੰਗ (ਕਨਜ਼ਿਊਮਰ ਲੈਗ, ਬ੍ਰੋਕਰ ਸਿਹਤ, ਥਰੂਪੁੱਟ, ਐਰਰ ਰੇਟ) ਤੁਰੰਤ ਸ਼ੁਰੂ ਕਰੋ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਹੋਰਾਂ ਪليਟਫਾਰਮ ਟੀਮ ਨਹੀਂ ਹੈ, ਤਾਂ ਪਹਿਲਾਂ ਮੈਨੇਜਡ ਸੇਵਾ ਲੈਓ ਅਤੇ ਸਪੱਸ਼ਟ ਸੀਮਾ ਤੈਅ ਕਰੋ।
ਇੱਕ ਸਿਸਟਮ ਤੋਂ ਇਵੈਂਟਸ ਪੈਦਾ ਕਰੋ, ਇੱਕ ਜਗ੍ਹਾ ਤੇ ਉਹਨਾਂ ਨੂੰ ਕਨਜ਼ਿਊਮ ਕਰੋ, ਅਤੇ ਲੂਪ ਨੂੰ ਐਂਡ-ਟੂ-ਐਂਡ ਸਾਬਿਤ ਕਰੋ। ਫਿਰ ਹੀ ਹੋਰ ਕਨਜ਼ਿਊਮਰਾਂ, ਪਾਰਟੀਸ਼ਨਾਂ ਅਤੇ ਇੰਟégrੇਸ਼ਨਾਂ ਵੱਲ ਵਧੋ।
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ "ਵਿਚਾਰ" ਤੋਂ ਕੰਮ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗੇ ਟੂਲ ਤੁਹਾਨੂੰ ਆਲੇ-ਦੁਆਲੇ ਦੀ ਐਪ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ (React UI, Go ਬੈਕਐਂਡ, PostgreSQL) ਅਤੇ ਗੱਲ-ਬਾਤ-ਆਧਾਰਿਤ ਵਰਕਫਲੋ ਰਾਹੀਂ Kafka ਪ੍ਰੋਡਿਊਸਰ/ਕਨਜ਼ਿਊਮਰ ਜੋੜ ਸਕਦੇ ਹਨ। ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਅੰਦਰੂਨੀ ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਹਲਕੇ-ਫੁਲਕੇ ਸੇਵਾਵਾਂ ਲਈ ਲਾਭਦਾਇਕ ਹੈ, ਜਿਸ ਵਿੱਚ ਯੋਜਨਾ ਮੋਡ, ਸੋర్స్ ਕੋਡ ਐਕਸਪੋਰਟ, ਡਿਪਲੋਇਮੈਂਟ/ਹੋਸਟਿੰਗ, ਅਤੇ ਰੋਲੇਬੈਕ ਨਾਲ ਸਨੇਪਸ਼ਾਟ ਵਰਗੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਹਨ।
ਜੇ ਤੁਸੀਂ ਇਸਨੂੰ ਇੱਕ ਇਵੈਂਟ-ਡਰਿਵਨ ਪਹੁੰਚ ਵਿੱਚ ਨਕਸ਼ਾ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਵੇਖੋ /blog/event-driven-architecture। ਖ਼ਰਚਿਆਂ ਅਤੇ ਵਾਤਾਵਰਣਾਂ ਦੀ ਯੋਜਨਾ ਲਈ, ਦੇਖੋ /pricing.
Kafka ਇੱਕ ਵੰਡਿਆ ਹੋਇਆ ਇਵੈਂਟ-ਸਟ੍ਰੀਮਿੰਗ ਪਲੇਟਫਾਰਮ ਹੈ ਜੋ ਇਵੈਂਟਸ ਨੂੰ ਟਿਕਾਊ, ਐਪੈਂਡ-ਓਨਲੀ ਲੌਗਾਂ ਵਿੱਚ ਸਟੋਰ ਕਰਦਾ ਹੈ।
ਪ੍ਰੋਡਿਊਸਰ ਇਵੈਂਟਸ ਨੂੰ ਟਾਪਿਕਸ 'ਤੇ ਲਿਖਦੇ ਹਨ, ਅਤੇ ਕਨਜ਼ਿਊਮਰ ਉਹਨਾਂ ਨੂੰ ਸੁਤੰਤਰ ਰੂਪ ਵਿੱਚ ਪੜ੍ਹਦੇ ਹਨ (ਅਕਸਰ ਰੀਅਲ-ਟਾਈਮ ਵਿੱਚ, ਪਰ ਕਈ ਵਾਰੀ ਬਾਅਦ ਵੀ), ਕਿਉਂਕਿ Kafka ਜਾਣਕਾਰੀ ਨੂੰ ਨਿਰਧਾਰਤ ਸਮੇਂ ਲਈ ਰੱਖਦਾ ਹੈ।
ਜਦੋਂ ਕਈ ਸਿਸਟਮਾਂ ਨੂੰ ਇੱਕੋ ਹੀ ਇਵੈਂਟ ਸਟ੍ਰੀਮ ਦੀ ਲੋੜ ਹੋਵੇ, ਤੁਸੀਂ ਢਿੱਲੇ-ਢੰਗ ਨਾਲ ਜੋੜਤੋੜ ਚਾਹੁੰਦੇ ਹੋ, ਅਤੇ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ ਚਲਾਉਣ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ, ਤਾਂ Kafka ਵਰਤੋ।
ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਮਦਦਗਾਰ ਹੈ:
ਟਾਪਿਕ ਇਕ ਨਾਮਵਾਰ ਸ਼੍ਰੇਣੀ ਹੁੰਦੀ ਹੈ (ਜਿਵੇਂ orders ਜਾਂ payments)।
ਪਾਰਟੀਸ਼ਨ ਇੱਕ ਟਾਪਿਕ ਦੀ ਇੱਕ ਕੱਟ ਹੈ ਜੋ:
Kafka ਸਿਰਫ਼ ਇੱਕ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਕ੍ਰਮ ਨੂੰ ਗਾਰੰਟੀ ਕਰਦਾ ਹੈ।
Kafka ਰਿਕੌਰਡ ਕੀ (order_id ਵਰਗਾ) ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸੰਬੰਧਿਤ ਇਵੈਂਟਸ ਨੂੰ ਇੱਕੋ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਮੁਸੱਲਤ ਤੌਰ 'ਤੇ ਰੂਟ ਕਰਦਾ ਹੈ।
ਵਿਆਵਹਾਰਕ ਨਿਯਮ: ਜੇ ਤੁਹਾਨੂੰ ਪ੍ਰਤੀ-ਇਕਾਈ ਕ੍ਰਮ (ਜਿਵੇਂ ਇੱਕ ਆਰਡਰ/ਗਾਹਕ ਲਈ ਸਾਰੇ ਇਵੈਂਟਸ ਲੜੀਵਾਰ) ਦੀ ਲੋੜ ਹੈ, ਤਾਂ ਉਹੀ ਇਕਾਈ ਦਰਸਾਉਣ ਵਾਲਾ ਕੀ ਚੁਣੋ ਤਾਂ ਜੋ ਉਹ ਇਵੈਂਟਸ ਇੱਕ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਜਾ ਸਕਣ।
ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ ਉਹ ਕਨਜ਼ਿਊਮਰ ਇੰਸਟੈਂਸਾਂ ਦਾ ਸਮੂਹ ਹੈ ਜੋ ਇੱਕ ਟਾਪਿਕ ਲਈ ਕੰਮ ਸਾਂਝਾ ਕਰਦੇ ਹਨ।
ਇੱਕ ਗਰੂਪ ਦੇ ਅੰਦਰ:
ਜੇ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਦੋ ਵੱਖ-ਵੱਖ ਐਪ ਹਰ ਇਵੈਂਟ ਨੂੰ ਪ੍ਰਾਪਤ ਕਰਨ, ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ ਵਰਤਣੇ ਚਾਹੀਦੇ ਹਨ।
Kafka ਡਿਸਕ 'ਤੇ ਟਾਪਿਕ ਨੀਤੀਆਂ ਦੇ ਅਨੁਸਾਰ ਇਵੈਂਟਸ ਰੱਖਦਾ ਹੈ, ਤਾਂ ਜੋ ਕਨਜ਼ਿਊਮਰ ਡਾਊਨ ਹੋਣ 'ਤੇ ਵੀ ਕੈਚ ਅੱਪ ਕਰ ਸਕਣ ਜਾਂ ਇਤਿਹਾਸ ਨੂੰ ਮੁੜ ਪ੍ਰੋਸੈਸ ਕਰ ਸਕਣ।
ਆਮ ਰਿਟੇਂਸ਼ਨ ਕਿਸਮਾਂ:
ਰਿਟੇਂਸ਼ਨ ਪ੍ਰਤੀ-ਟਾਪਿਕ ਕਨਫਿਗਰ ਕੀਤੀ ਜਾਂਦੀ ਹੈ, ਇਸ ਲਈ ਆਡਿਟ ਟ੍ਰੇਲ ਵਰਗੇ ਟਾਪਿਕਜ਼ ਨੂੰ ਉੱਚ ਰਿਟੇਂਸ਼ਨ ਦਿੱਤੀ ਜਾ ਸਕਦੀ ਹੈ।
ਲੌਗ ਕੰਪੈਕਸ਼ਨ ਹਰ ਕੀ ਲਈ ਘੱਟੋ-ਘੱਟ ਨਾਲੋਂ ਨਵਾਂ ਰਿਕੌਰਡ ਰੱਖਦੀ ਹੈ, ਅਤੇ ਸਮੇਂ ਦੇ ਨਾਲ ਪੁਰਾਣੇ ਪ੍ਰਵਰਤਤ ਰਿਕੌਰਡ ਹਟਾਏ ਜਾ ਸਕਦੇ ਹਨ।
ਇਹ "ਮੌਜੂਦਾ ਸਥਿਤੀ" ਸਟ੍ਰੀਮਾਂ (ਜਿਵੇਂ ਸੈਟਿੰਗਜ਼ ਜਾਂ ਪ੍ਰੋਫਾਈਲ) ਲਈ ਵਧੀਆ ਹੈ ਜਿੱਥੇ ਤੁਹਾਨੂੰ ਹਰ ਇਤਿਹਾਸਿਕ ਬਦਲਾਅ ਦੀ ਲੋੜ ਨਹੀਂ, ਸਗੋਂ ਹਰ ਕੀ ਦਾ ਤਾਜ਼ਾ ਮੁੱਲ ਚਾਹੀਦਾ ਹੈ।
Kafka ਦਾ ਆਮ ਸਮਾਪਤੀ ਪੈਟਰਨ ਅਟ-ਲੀਸਟ-ਓਨਸ ਹੈ: ਤੁਸੀਂਈਵੈਂਟਸ ਖੋਵੋਗੇ ਨਹੀਂ, ਪਰ ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ।
ਇਸ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਉਣ ਲਈ:
ਆਫਸੈਟ ਇੱਕ ਪਾਰਟੀਸ਼ਨ ਵਿੱਚ ਆਖ਼ਰੀ ਪ੍ਰੋਸੈਸ ਕੀਤੇ ਰਿਕੌਰਡ ਦੀ ਪੋਜ਼ੀਸ਼ਨ ਹੁੰਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ ਆਫਸੈਟਸ ਬਹੁਤ ਜਲਦੀ ਕਮੇਟ ਕਰਦੇ ਹੋ ਤਾਂ ਕ੍ਰੈਸ਼ ਹੋਣ 'ਤੇ ਕੰਮ ਗੁੰਮ ਹੋ ਸਕਦਾ ਹੈ; ਬਹੁਤ ਦੇਰ ਨਾਲ ਕਮੇਟ ਕਰਨ 'ਤੇ ਰੀ-ਪ੍ਰੋਸੈਸ ਹੋਵੇਗਾ ਅਤੇ ਡੁਪਲੀਕੇਟ ਹੋ ਸਕਦੇ ਹਨ।
ਆਮ ਘਟਨਾ-ਹੱਲ: ਸੀਮਿਤ ਬੈਕਆਫ ਨਾਲ ਰੀਟ੍ਰਾਈਜ਼, ਫੇਲ ਹੋਣ ਵਾਲੇ ਰਿਕਾਰਡ ਨੂੰ ਇਕ ਡੈਡ-ਲੇਟਰ ਟਾਪਿਕ 'ਚ ਭੇਜੋ ਤਾਂ ਕਿ ਇੱਕ ਪੋਇਜ਼ਨ ਮੈਸੇਜ ਸਾਰੇ ਕਨਜ਼ਿਊਮਰ ਗਰੂਪ ਨੂੰ ਬਲਾਕ ਨਾ ਕਰੇ।
Kafka Connect ਡੇਟਾ ਨੂੰ Kafka ਵਿੱਚ ਲਿਆਉਣ ਅਤੇ Kafka ਤੋਂ ਬਾਹਰ ਭੇਜਣ ਲਈ ਕਨੈਕਟਰਾਂ ਨਾਲ ਇੱਕ ਇੰਟੇਗ੍ਰੇਸ਼ਨ ਫਰੇਮਵਰਕ ਹੈ—ਇਸ ਨਾਲ ਕਸਟਮ ਪਾਈਪਲਾਈਨ ਕੋਡ ਦੀ ਲੋੜ ਘੱਟ ਹੁੰਦੀ ਹੈ।
Kafka Streams ਇੱਕ ਲਾਇਬ੍ਰੇਰੀ ਹੈ ਜੋ ਤੁਹਾਡੇ ਐਪ ਵਿੱਚ ਰੀਅਲ-ਟਾਈਮ ਸਟ੍ਰੀਮ ਪ੍ਰੋਸੈਸਿੰਗ ਕਰਨ ਲਈ ਵਰਤੀ ਜਾਂਦੀ ਹੈ (ਫਿਲਟਰ, ਜੁੜਾਈ, ਐਨਰਿਚ, ਐਗਰੀਗੇਟ)।
ਸਰਲ ਨਿਯਮ: Connect ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਲਈ; Streams ਗਣਨਾ ਲਈ।