21 ਮਈ 2025·8 ਮਿੰਟ
ਕੇਂਦਰੀਕ੍ਰਿਤ ਕਲਾਇੰਟ SLA ਰਿਪੋਰਟਿੰਗ ਲਈ ਵੈਬ ਐਪ ਬਣਾਓ
ਸਿੱਖੋ ਕਿ ਕਿਸ ਤਰ੍ਹਾਂ ਇੱਕ ਮੁਲਟੀ-ਕਲਾਇੰਟ ਵੈਬ ਐਪ ਯੋਜਨਾ, ਬਣਾਉਣ ਅਤੇ ਲਾਂਚ ਕੀਤਾ ਜਾਵੇ ਜੋ SLA ਡੇਟਾ ਇਕੱਠਾ ਕਰਦਾ, ਮੈਟਰਿਕਸ ਨਾਰਮਲਾਈਜ਼ ਕਰਦਾ, ਅਤੇ ਡੈਸ਼ਬੋਰਡ, ਅਲਰਟ ਅਤੇ ਐਕਸਪੋਰਟਯੋਗ ਰਿਪੋਰਟਾਂ ਦਿੰਦਾ ਹੈ।
ਸਿੱਖੋ ਕਿ ਕਿਸ ਤਰ੍ਹਾਂ ਇੱਕ ਮੁਲਟੀ-ਕਲਾਇੰਟ ਵੈਬ ਐਪ ਯੋਜਨਾ, ਬਣਾਉਣ ਅਤੇ ਲਾਂਚ ਕੀਤਾ ਜਾਵੇ ਜੋ SLA ਡੇਟਾ ਇਕੱਠਾ ਕਰਦਾ, ਮੈਟਰਿਕਸ ਨਾਰਮਲਾਈਜ਼ ਕਰਦਾ, ਅਤੇ ਡੈਸ਼ਬੋਰਡ, ਅਲਰਟ ਅਤੇ ਐਕਸਪੋਰਟਯੋਗ ਰਿਪੋਰਟਾਂ ਦਿੰਦਾ ਹੈ।
ਕੇਂਦਰੀਕ੍ਰਿਤ SLA ਰਿਪੋਰਟਿੰਗ ਇਸ ਲਈ ਅਵਸ਼્યਕ ਹੈ ਕਿਉਂਕਿ SLA ਸਬੂਤ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਜਗ੍ਹਾ ਤੇ ਨਹੀਂ ਮਿਲਦੇ। ਉਪਟਾਈਮ ਕਿਸੇ ਮਾਨੀਟਰਿੰਗ ਟੂਲ ਵਿੱਚ ਹੋ ਸਕਦਾ ਹੈ, ਇੰਸੀਡੈਂਟ ਇੱਕ ਸਟੇਟਸ ਪੇਜ਼ 'ਤੇ, ਟਿਕਟਸ ਕਿਸੇ helpdesk ਵਿੱਚ ਅਤੇ ਏਸਕਲੇਸ਼ਨ ਨੋਟਾਂ ਈਮੇਲ ਜਾਂ ਚੈਟ ਵਿੱਚ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਜਦੋਂ ਹਰ ਕਲਾਇੰਟ ਦਾ ਸਟੈਕ ਥੋੜ੍ਹਾ ਵੱਖਰਾ ਹੁੰਦਾ ਹੈ (ਜਾਂ ਨਾਮਕਾਰਣ ਦੇ ਭਿੰਨ ਨਿਯਮ), ਤਾਂ ਮਹੀਨਾਵਾਰ ਰਿਪੋਰਟਿੰਗ ਹੁੱਥਾਂ ਨਾਲ ਭਰਿਆ ਹੋਇਆ ਸਪ੍ਰੈਡਸ਼ੀਟ ਕੰਮ ਬਣ ਜਾਂਦੀ ਹੈ—ਅਤੇ “ਅਸਲ ਵਿਚ ਕੀ ਹੋਇਆ” ਬਾਰੇ ਜ਼ਿਆਦਾ ਗੱਲਬਾਤ ਹੁੰਦੀ ਹੈ।
ਇੱਕ ਵਧੀਆ SLA ਰਿਪੋਰਟਿੰਗ ਵੈਬ ਐਪ ਵੱਖ-ਵੱਖ ਦਰਸ਼ਕਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਮਕਸਦ ਲਈ ਸੇਵਾ ਦਿੰਦੀ ਹੈ:
ਐਪ ਨੂੰ ਹਰ ਰੋਲ ਲਈ ਵੱਖਰੇ ਵੇਰਵੇ 'ਤੇ ਇੱਕੋ ਹੀ ਅਸਲ ਸਚ ਪੇਸ਼ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।
ਕੇਂਦਰੀਕ੍ਰਿਤ SLA ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਇਹ ਦਿੱਤੀਆਂ ਚੀਜ਼ਾਂ ਦੇਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ:
ਅਮਲ ਵਿੱਚ, ਹਰ SLA ਨੰਬਰ ਨੂੰ ਰੌ ਬੇਅਵੈਂਟ (ਅਲਰਟ, ਟਿਕਟ, ਇੰਸੀਡੈਂਟ ਟਾਈਮਲਾਈਨ) ਨਾਲ ਟਾਈਮਸਟੈਂਪ ਅਤੇ ਮਾਲਕੀ ਵਿਵਰਣ ਸਮੇਤ ਟਰੈਸ ਕਰ ਸਕਣਾ ਚਾਹੀਦਾ ਹੈ।
ਕਿਸੇ ਵੀ ਚੀਜ਼ ਦੀ ਨਿਰਮਾਣ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ ਕੀ in scope ਹੈ ਅਤੇ ਕੀ out of scope ਹੈ। ਉਦਾਹਰਨ:
ਸਪਸ਼ਟ ਸੀਮਾਵਾਂ ਬਾਅਦ ਵਿੱਚ ਝਗੜਿਆਂ ਨੂੰ ਰੋਕਦੀਆਂ ਹਨ ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਕਲਾਇੰਟਾਂ ਵਿੱਚ ਲਗਾਤਾਰ ਰੱਖਦੀਆਂ ਹਨ।
ਘੱਟੋ-ਘੱਟ, ਕੇਂਦਰੀ SLA ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਇਹ ਪੰਜ ਵਰਕਫਲੋਜ਼ ਸਹਿਯੋਗ ਦੇਣੇ ਚਾਹੀਦੇ ਹਨ:
ਇਨ੍ਹਾਂ ਵਰਕਫਲੋਜ਼ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਡਿਜ਼ਾਇਨ ਕਰੋ ਤਾ ਕਿ ਸਿਸਟਮ (ਡੇਟਾ ਮਾਡਲ, ਇੰਟੀਗ੍ਰੇਸ਼ਨ, UX) ਅਸਲੀ ਰਿਪੋਰਟਿੰਗ ਦੀਆਂ ਲੋੜਾਂ ਨਾਲ ਮੇਲ ਖਾਂਵੇ।
ਸਕ੍ਰੀਨਾਂ ਜਾਂ ਪਾਈਪਲਾਈਨਾਂ ਬਣਾਉਣ ਤੋਂ ਪਹਿਲਾਂ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਐਪ ਕੀ ਨਾਪੇਗੀ ਅਤੇ ਉਹ ਨੰਬਰਾਂ ਨੂੰ ਕਿਵੇਂ ਵਿਆਖਿਆ ਕੀਤਾ ਜਾਏਗਾ। مقصد ਇੱਕਸਾਰਤਾ ਹੈ: ਇੱਕੋ ਰਿਪੋਰਟ ਵੇਖ ਕੇ ਦੋ ਲੋਕਾਂ ਨੂੰ ਇੱਕੋ ਨਤੀਜਾ ਮਿਲਣਾ ਚਾਹੀਦਾ ਹੈ।
ਥੋੜ੍ਹੇ ਸੈਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਜ਼ਿਆਦਾਤਰ ਕਲਾਇੰਟਾਂ ਲਈ ਜਾਣਪਛਾਣਯੋਗ ਹੋਂ:
ਹਰ ਮੈਟਰਿਕ ਬਾਰੇ ਖੁੱਲ੍ਹ ਕੇ ਲਿਖੋ ਕਿ ਉਹ ਕੀ ਮਾਪਦਾ ਹੈ ਅਤੇ ਕੀ ਨਹੀਂ। UI ਵਿੱਚ ਛੋਟੀ ਪਹਚਾਣ ਪੈਨਲ (ਅਤੇ /help/sla-definitions ਦੀ ਜ਼ਿਕਰ) ਗਲਤਫਹਿਮੀਆਂ ਰੋਕਦੀ ਹੈ।
ਨਿਯਮ ਉਹ ਥਾਂ ਹੈ ਜਿੱਥੇ SLA ਰਿਪੋਰਟਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਟੁੱਟਦੀ ਹੈ। ਪਹਿਲਾਂ ਉਹ ਸਜਾਵਟ ਭਾਸ਼ਾ ਵਿੱਚ ਦਸਤਾਵੇਜ਼ ਬਣਾਓ ਜੋ ਕਲਾਇੰਟ ਵੱਲੋਂ ਵੈਰੀਫਾਈ ਕੀਤੀ ਜਾ ਸਕੇ, ਫਿਰ ਉਨ੍ਹਾਂ ਨੂੰ ਲਾਜਿਕ ਵਿੱਚ ਤਰਜਮਾ ਕਰੋ।
ਮੁੱਢਲੇ ਪੱਦ:
ਡਿਫਾਲਟ ਅਵਧੀਆਂ ਚੁਣੋ (ਮਹੀਨਾਵਾਰ ਅਤੇ ਤਿਮਾਹੀ ਆਮ ਹਨ) ਅਤੇ ਦੇਖੋ ਕਿ ਕੀ ਤੁਸੀਂ ਕਸਟਮ ਰੇਂਜ ਸਹਿਯੋਗ ਕਰੋਂਗੇ। ਕਟਆਫ਼ ਲਈ ਟਾਈਮਜ਼ੋਨ ਸਪਸ਼ਟ ਕਰੋ।
ਬ੍ਰੀਚ ਲਈ, ਨਿਰਧਾਰਤ ਕਰੋ:
ਹਰ ਮੈਟਰਿਕ ਲਈ ਲੋੜੀਂਦੇ ਇਨਪੁੱਟ (ਮਾਨੀਟਰਿੰਗ ਘਟਨਾਵਾਂ, ਇੰਸੀਡੈਂਟ ਰਿਕਾਰਡ, ਟਿਕਟ ਟਾਈਮਸੈਂਪ, ਰੱਖ-ਰਖਾਅ ਵਿੰਡੋ) ਦੀ ਸੂਚੀ ਬਣਾਓ। ਇਹ ਤੁਹਾਡੇ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਡੇਟਾ ਕੁਆਲਟੀ ਚੈੱਕ ਲਈ ਨਕਸ਼ਾ ਬਣੇਗੀ।
ਡੈਸ਼ਬੋਰਡ ਜਾਂ KPI ਡਿਜ਼ਾਇਨ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਸਪਸ਼ਟ ਕਰੋ ਕਿ SLA ਸਬੂਤ ਅਸਲ ਵਿੱਚ ਕਿੱਥੇ ਰਹਿੰਦੇ ਹਨ। ਬਹੁਤ ਸਾਰੀਆਂ ਟੀਮਾਂ ਪਤਾ ਲਗਾਉਂਦੀਆਂ ਹਨ ਕਿ ਉਹਨਾਂ ਦਾ “SLA ਡੇਟਾ” ਟੂਲਾਂ ਵਿੱਚ ਵੰਡਿਆ ਹੋਇਆ ਹੈ, ਵੱਖ-ਵੱਖ ਸਮੂਹਾਂ ਦੇ ਦੁਆਰਾ ਮਾਲਕੀ ਹੈ, ਅਤੇ ਥੋੜ੍ਹੇ ਵੱਖਰੇ ਅਰਥਾਂ ਨਾਲ ਦਰਜ ਕੀਤਾ ਗਿਆ ਹੈ।
ਹਰ ਕਲਾਇੰਟ (ਅਤੇ ਹਰ ਸੇਵਾ) ਲਈ ਇੱਕ ਸਧਾਰਨ ਸੂਚੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਹਰ ਸਿਸਟਮ ਲਈ, ਮਾਲਕ, ਰਿਟੇਨਸ਼ਨ ਪੀਰੀਅਡ, API ਸੀਮਾਵਾਂ, ਟਾਈਮ ਰਿਜ਼ੋਲੂਸ਼ਨ (Seconds vs Minutes), ਅਤੇ ਕੀ ਡੇਟਾ ਕਲਾਇੰਟ-ਸਕੋਪਡ ਹੈ ਜਾਂ ਸ਼ੇਅਰਡ, ਇਹ ਨੋਟ ਕਰੋ।
ਜ਼ਿਆਦਾਤਰ SLA ਰਿਪੋਰਟਿੰਗ ਐਪ ਇੱਕ ਸੰਯੋਗ ਵਰਤਦੇ ਹਨ:
ਇੱਕ ਪ੍ਰਾਇਗਮੈਟਿਕ ਨਿਯਮ: ਜਿੱਥੇ ਤਾਜਗੀ ਮਹੱਤਵਪੂਰਨ ਹੋਵੇ ਉੱਥੇ webhooks ਵਰਤੋ, ਅਤੇ ਜਿੱਥੇ ਪੂਰਨਤਾ ਜ਼ਰੂਰੀ ਹੋਵੇ ਉੱਥੇ API pulls ਵਰਤੋ।
ਵੱਖ-ਵੱਖ ਟੂਲ ਇਕੋ ਚੀਜ਼ ਨੂੰ ਵੱਖਰੇ ਤਰੀਕਿਆਂ ਨਾਲ ਵਰਣਨ ਕਰਦੇ ਹਨ। ਇੱਕ ਛੋਟੀ ਸੈਟ ਵਿੱਚ ਨਾਰਮਲਾਈਜ਼ ਕਰੋ, ਜਿਵੇਂ:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedਲਗਾਤਾਰ ਫੀਲਡ ਸ਼ਾਮਿਲ ਕਰੋ: client_id, service_id, source_system, external_id, severity, ਅਤੇ ਟਾਈਮਸਟੈਂਪ।
ਸਾਰੇ ਟਾਈਮਸਟੈਂਪ UTC ਵਿੱਚ ਸਟੋਰ ਕਰੋ, ਅਤੇ ਡਿਸਪਲੇ ਵਿੱਚ ਕਲਾਇੰਟ ਦੀ ਪਸੰਦੀਦਾ ਟਾਈਮਜ਼ੋਨ ਦੇ ਅਨੁਸਾਰ ਰੂਪਾਂਤਰਿਤ ਕਰੋ (ਖਾਸ ਕਰਕੇ ਮਹੀਨਾਵਾਰ ਰਿਪੋਰਟਿੰਗ ਕਟਆਫ਼ ਲਈ)।
ਫਾਲਤੂ ਢਾਂਚਿਆਂ ਦੀ ਯੋਜਨਾ ਵੀ ਬਣਾਓ: ਕੁਝ ਕਲਾਇੰਟਾਂ ਕੋਲ ਸਟੇਟਸ ਪੇਜ ਨਹੀਂ ਹੋਵੇਗਾ, ਕੁਝ ਸੇਵਾਵਾਂ 24/7 ਮਾਨੀਟਰਡ ਨਹੀਂ ਹੋਣਗੀਆਂ, ਅਤੇ ਕੁਝ ਟੂਲ ਇਵੈਂਟ ਗੁਆ ਸਕਦੇ ਹਨ। ਰਿਪੋਰਟਾਂ ਵਿੱਚ “ਆਰਾਸ਼ ਲੋੜੀਂਦੇ ਡੇਟਾ ਉਪਲਬਧ ਨਹੀਂ ਸੀ X ਘੰਟੇ” ਵਰਗਾ ਨੋਟ ਦਿਖਾਉ ਤਾਂ ਜੋ SLA ਨਤੀਜੇ ਭੁਲਾਵੇ ਵਾਲੇ ਨਾ ਲੱਗਣ।
ਜੇ ਤੁਹਾਡੀ ਐਪ ਬਹੁਤ ਸਾਰੇ ਗਾਹਕਾਂ ਲਈ SLA ਰਿਪੋਰਟਿੰਗ ਕਰਦੀ ਹੈ, ਤਾਂ ਆਰਕੀਟੈਕਚਰ ਫੈਸਲੇ ਇਹ ਦਿਸ਼ਾ ਦਿੰਦੇ ਹਨ ਕਿ ਤੁਸੀਂ ਬਿਨਾਂ ਕਲਾਇੰਟ-ਡੇਟਾ ਲੀਕ ਦੇ ਕਿਵੇਂ ਸਕੇਲ ਕਰ ਸਕਦੇ ਹੋ।
ਉਹ ਪਰਤਾਂ ਨਾਮੋ ਨਿਰਧਾਰਤ ਕਰੋ ਜੋ ਤੁਹਾਨੂੰ ਲੋੜੀਂਦੀਆਂ ਹਨ। ਇੱਕ “ਕਲਾਇੰਟ” ਹੋ ਸਕਦਾ ਹੈ:
ਇਹ ਸਭ ਪਹਿਲਾਂ ਲਿਖੋ, ਕਿਉਂਕਿ ਇਹ ਪਰਮੀਸ਼ਨ, ਫਿਲਟਰ, ਅਤੇ ਸੰਰਚਨਾ ਸਟੋਰ ਕਰਨ 'ਤੇ ਅਸਰ ਪਾਂਦੇ ਹਨ।
ਜ਼ਿਆਦਾਤਰ SLA ਰਿਪੋਰਟਿੰਗ ਐਪ ਇਹਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਚੁਣਦੇ ਹਨ:
tenant_id ਨਾਲ ਟੈਗ ਕੀਤਾ। ਕਿਫਾਇਤੀ ਅਤੇ ਸੌਖਾ ਹੈ, ਪਰ ਸਖ਼ਤ ਕਵੈਰੀ ਅਨੁਸ਼ਾਸਨ ਦੀ ਲੋੜ ਹੈ।ਆਮ ਸਮਝੌਤਾ: ਬਹੁਤ ਸਾਰੇ ਟੇਨੈਂਟਾਂ ਲਈ ਸ਼ੇਅਰਡ DB ਅਤੇ “ਐਂਟਰਪ੍ਰਾਈਜ਼” ਗਾਹਕਾਂ ਲਈ ਡੈਡੀਕੇਟਡ DB।
ਆਈਸੋਲੇਸ਼ਨ ਨੂੰ ਇਹਨਾਂ ਸਭ 'ਤੇ ਲਾਗੂ ਕਰੋ:
tenant_id ਲੈ ਕੇ ਚੱਲਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਕਿ ਨਤੀਜੇ ਗਲਤ ਟੈਨੈਂਟ ਵਿੱਚ ਨਾ ਲਿਖੇ ਜਾਣਗਾਰਡਰੇਲਸ ਵਰਗੇ row-level security, ਜ਼ਰੂਰੀ ਕਵੈਰੀ ਸਕੋਪ, ਅਤੇ ਟੈਨੈਂਟ ਬਾਊਂਡਰੀਆਂ ਲਈ ਆਟੋਮੈਟਿਕ ਟੈਸਟ ਵਰਤੋ।
ਵੱਖ-ਵੱਖ ਕਲਾਇੰਟਾਂ ਦੇ ਟਾਰਗੇਟ ਅਤੇ ਪਰਿਭਾਸ਼ਾਵਾਂ ਵੱਖ-ਵੱਖ ਹੋਣਗੀਆਂ। ਪ੍ਰਤੀ-ਟੇਨੈਂਟ ਸੈਟਿੰਗਾਂ ਲਈ ਯੋਜਨਾ ਬਣਾਓ ਜਿਵੇਂ:
ਆਪਣੇ ਅੰਦਰੂਨੀ ਯੂਜ਼ਰਾਂ ਨੂੰ ਅਕਸਰ “ਇੰਪਰਸੋਨੇਟ” ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਹੋਵੇਗੀ। ਇਕ ਸੋਚ-ਵਿਚਾਰ ਕੇ ਸਵਿੱਚ ਲਾਗੂ ਕਰੋ (ਫ੍ਰੀ-ਫਾਰਮ ਫਿਲਟਰ ਨਹੀਂ), ਐਕਟਿਵ ਟੈਨੈਂਟ ਬੜੇ ਅੱਖਰਾਂ ਨਾਲ ਦਿਖਾਓ, ਸਵਿੱਚਾਂ ਦੀ ਲਾਗਿੰਗ ਕਰੋ ਅਤੇ ਲਿੰਕਾਂ ਨੂੰ ਰੋਕੋ ਜੋ ਟੈਨੈਂਟ ਚੈੱਕਾਂ ਨੂੰ ਬਾਈਪਾਸ ਕਰ ਸਕਦੇ ਹਨ।
ਕੇਂਦਰੀ SLA ਰਿਪੋਰਟਿੰਗ ਵੈਬ ਐਪ ਆਪਣੀ ਡੇਟਾ ਮਾਡਲ 'ਤੇ ਜੀਉਂਦਾ ਜਾਂ ਮਰ ਜਾਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ “ਮਹੀਨੇ-ਦਰ-ਮਹੀਨਾ SLA %” ਮਾਡਲ ਕਰੋਗੇ ਤਾਂ ਤੁਸੀਂ ਨਤੀਜਿਆਂ ਦੀ ਵਿਵਰਣ ਕਰਨ, ਵਿਵਾਦਾਂ ਨੂੰ ਸੰਭਾਲਣ ਜਾਂ ਗਣਨਾਵਾਂ ਬਦਲਣ ਵਿੱਚ ਮੁਸ਼ਕਲ ਵਿੱਚ ਪੈ ਜਾਓਗੇ। ਜੇ ਤੁਸੀਂ ਸਿਰਫ ਰਾ ਇਵੈਂਟਸ ਮਾਡਲ ਕਰਦੇ ਹੋ ਤਾਂ ਰਿਪੋਰਟਿੰਗ ਜ਼ਰੂਰੀ ਤੌਰ 'ਤੇ ਧੀਮੀ ਅਤੇ ਮਹਿੰਗੀ ਹੋ ਸਕਦੀ ਹੈ। ਲਕੜੀ ਦਾ ਮਕਸਦ ਦੋਹਾਂ ਦਾ ਸਹਿਯੋਗ ਕਰਨਾ ਹੈ: ਟਰੇਸੇਬਲ ਰਾ ਸਬੂਤ ਅਤੇ ਤੇਜ਼, ਕਲਾਇੰਟ-ਤਿਆਰ ਰੋਲਅਪਸ।
ਸਪਸ਼ਟ ਵੰਡ ਰੱਖੋ ਕਿ ਕੌਣ ਦੀ ਰਿਪੋਰਟਿੰਗ ਹੋ ਰਹੀ ਹੈ, ਕੀ ਮਾਪਿਆ ਜਾ ਰਿਹਾ ਹੈ, ਅਤੇ ਕਿਵੇਂ ਗਣਨਾ ਕੀਤੀ ਗਈ ਹੈ:
ਟੇਬਲਾਂ (ਜਾਂ ਕਲੈਕਸ਼ਨ) ਡਿਜ਼ਾਇਨ ਕਰੋ:
SLA ਲਾਜਿਕ ਬਦਲਦੀ ਹੈ: ਬਿਜ਼ਨਸ ਘੰਟੇ ਅੱਪਡੇਟ, exclusions ਸਪਸ਼ਟ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ, rounding ਨਿਯਮ ਵਿਕਸਤ ਹੁੰਦੇ ਹਨ। ਹਰcomputed result 'ਤੇ calculation_version (ਅਤੇ ਸੰਭਵ ਤੌਰ 'ਤੇ “rule set” ਸੰਦਰਭ) ਜੋੜੋ। ਇਸ ਤਰ੍ਹਾਂ ਪੁਰਾਣੀਆਂ ਰਿਪੋਰਟਾਂ ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਬਿਲਕੁਲ ਦੁਹਰਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ, ਆਡਿਟ ਫੀਲਡ ਸ਼ਾਮਿਲ ਕਰੋ:
ਕਲਾਇੰਟ ਅਕਸਰ ਪੁੱਛਦੇ ਹਨ “ਮੈਨੂੰ ਦਿਖਾਓ ਕਿਉਂ”। ਸਬੂਤ ਲਈ ਸਕੀਮਾ ਯੋਜਨਾ ਕਰੋ:
ਇਹ ਢਾਂਚਾ ਐਪ ਨੂੰ ਸਮਝਣਯੋਗ, ਦੁਹਰਾਣਯੋਗ, ਅਤੇ ਤੇਜ਼ ਰੱਖਦਾ ਹੈ—ਬਿਨਾਂ ਅਸਲੀ ਸਬੂਤ ਨੂੰ ਖੋ ਦੇ।
ਜੇ ਤੁਹਾਡੇ ਇਨਪੁੱਟ ਗੰਦੇ ਹਨ, ਤਾਂ ਤੁਹਾਡਾ SLA ਡੈਸ਼ਬੋਰਡ ਵੀ ਗੰਦਾ ਹੋਵੇਗਾ। ਇਕ ਭਰੋਸੇਯੋਗ ਪਾਈਪਲਾਈਨ ਇੰਸੀਡੈਂਟ ਅਤੇ ਟਿਕਟ ਡੇਟਾ ਨੂੰ ਕਈ ਟੂਲਾਂ ਤੋਂ ਲੈ ਕੇ ਇੱਕਸਾਰ, ਆਡਿਟੇਬਲ SLA ਨਤੀਜਿਆਂ ਵਿੱਚ ਬਦਲਦਾ ਹੈ—ਬਿਨਾਂ ਦੁਹਰਾਉਂਦਿਆਂ, ਖਾਲੀ ਪੈਲਿਆਂ, ਜਾਂ ਚੁਪਕੇ ਨਾਲ ਫੇਲ ਹੋਣ ਦੇ।
ਇਨਜੈਸ਼ਨ, ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਅਤੇ rollups ਨੂੰ ਅਲੱਗ-ਅਲੱਗ ਸਟੇਜ ਮੰਨੋ। ਉਹਨਾਂ ਨੂੰ ਬੈਕਗ੍ਰਾਉਂਡ ਜੌਬਸ ਵਜੋਂ ਚਲਾਓ ਤਾਂ ਕਿ UI ਤੇਜ਼ ਰਹੇ ਅਤੇ ਤੁਸੀਂ ਸੁਰੱਖਿਅਤ ਰੀਟਰਾ�ੀ ਕਰ ਸਕੋ।
ਇਹ ਵੰਡ ਇਸ ਗੱਲ ਵਿੱਚ ਵੀ ਮਦਦ ਕਰਦੀ ਹੈ ਕਿ ਜਦੋਂ ਕਿਸੇ ਇੱਕ ਕਲਾਇੰਟ ਦਾ ਸਰੋਤ ਡਾਊਨ ਹੋਵੇ: ingestion ਫੇਲ ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਮੌਜੂਦਾ ਗਣਨਾਵਾਂ ਨੂੰ ਖਰਾਬ ਨਹੀਂ ਕਰਦਾ।
ਬਾਹਰੀ APIs ਟਾਈਮਆਊਟ ਹੋ ਜਾਂਦੇ ਹਨ। Webhooks ਦੁਬਾਰਾ ਭੇਜੇ ਜਾ ਸਕਦੇ ਹਨ। ਤੁਹਾਡੀ ਪਾਈਪਲਾਈਨ idempotent ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ: ਇੱਕੋ ਇਨਪੁੱਟ ਨੂੰ ਇੱਕ ਤੋਂ ਵੱਧ ਵਾਰ ਪ੍ਰੋਸੈਸ ਕਰਨ ਨਾਲ ਨਤੀਜਾ ਨਹੀਂ ਬਦਲਣਾ ਚਾਹੀਦਾ।
ਆਮ ਤਰੀਕੇ:
ਕਲਾਇੰਟਾਂ ਅਤੇ ਟੂਲਾਂ ਦੇ ਪਾਰ, “P1,” “Critical,” ਅਤੇ “Urgent” ਇੱਕੋ ਹੀ ਪ੍ਰਾਇਰਟੀ ਹੋ ਸਕਦੇ ਹਨ—ਜਾਂ ਨਹੀਂ। ਇੱਕ ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਲੇਅਰ ਬਣਾਓ ਜੋ ਮਿਆਰੀਕਰਨ ਕਰੇ:
ਟ੍ਰੇਸੇਬਿਲਟੀ ਲਈ ਅਸਲੀ ਮੁੱਲ ਅਤੇ ਨਾਰਮਲਾਈਜ਼ਡ ਮੁੱਲ ਦੋਹਾਂ ਨੂੰ ਸਟੋਰ ਕਰੋ।
ਵੈਧਤਾ ਨਿਯਮ ਜੋੜੋ (ਗੁੰਮ ਹੋਏ ਟਾਈਮਸਟੈਂਪ, ਨਕਾਰਾਤਮਕ ਦੈਰਿਆਂ, ਅਸੰਭਵ ਸਥਿਤੀ ਤਬਦੀਲੀਆਂ)। ਬੁਰੇ ਡੇਟਾ ਨੂੰ ਚੁਪਕੇ ਨਾਲ ਫਿੱਕ ਨਾ ਕਰੋ—ਉਹਨਾਂ ਨੂੰ ਇੱਕ ਕਵਾਰੰਟਾਈਨ ਕਿਊ ਵਿੱਚ ਭੇਜੋ ਜਿਸ 'ਚ ਕਾਰਨ ਅਤੇ “fix or map” ਵਰਕਫਲੋ ਹੋਵੇ।
ਹਰ ਕਲਾਇੰਟ ਅਤੇ ਸਰੋਤ ਲਈ “last successful sync”, “oldest unprocessed event”, ਅਤੇ “rollup up-to date through” ਗਿਣੋ। ਇਸ ਨੂੰ ਸਧਾਰਨ data freshness indicator ਵਜੋਂ ਦਿਖਾਓ ਤਾਂ ਕਿ ਕਲਾਇੰਟ ਸੰਖਿਆਵਾਂ 'ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਣ ਅਤੇ ਤੁਹਾਡੀ ਟੀਮ ਸਮੱਸਿਆਵਾਂ ਜਲਦੀ ਦੇਖ ਸਕੇ।
ਜੇ ਕਲਾਇੰਟ ਤੁਹਾਡੇ ਪੋਰਟਲ ਨੂੰ SLA ਪ੍ਰਦਰਸ਼ਨ ਵੇਖਣ ਲਈ ਵਰਤਦੇ ਹਨ, ਤਾਂ authentication ਅਤੇ permissions SLA ਗਣਿਤ ਦੀ ਤਰ੍ਹਾਂ ਹੀ ਧਿਆਨ ਨਾਲ ਡਿਜ਼ਾਇਨ ਕੀਤੀਆਂ ਜਾਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ। ਮਕਸਦ ਸਧਾਰਨ ਹੈ: ਹਰ ਯੂਜ਼ਰ ਸਿਰਫ ਉਹੀ ਵੇਖੇ ਜੋ ਉਹ ਦੇਖਣਾ ਚਾਹੀਦਾ—ਅਤੇ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਇਸਦਾ ਸਬੂਤ ਦੇ ਸਕੋ।
ਸ্মਾਲ, ਸਪਸ਼ਟ ਰੋਲਜ਼ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਤਦ ਹੀ ਵਧਾਓ:
Least privilege ਨੂੰ ਡੀਫੌਲਟ ਰੱਖੋ: ਨਵੇਂ ਖਾਤੇ viewer ਮੋਡ ਵਿੱਚ ਆਉਣ ਚਾਹੀਦੇ ਹਨ ਜਦ ਤੱਕ ਉਨ੍ਹਾਂ ਨੂੰ ਸੁਨੇਹਾ ਦੇ ਕੇ promote ਨਾ ਕੀਤਾ ਜਾਵੇ।
ਅੰਦਰੂਨੀ ਟੀਮਾਂ ਲਈ, SSO account sprawl ਅਤੇ offboarding ਖਤਰੇ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ। OIDC (Google Workspace/Azure AD/Okta ਸਮੇਤ) ਅਤੇ ਜਿੱਥੇ ਲੋੜ ਹੋਵੇ SAML ਸਹਿਯੋਗ ਕਰੋ।
ਕਲਾਇੰਟਾਂ ਲਈ, SSO ਅੱਪਗ੍ਰੇਡ ਰੂਪ ਵਿੱਚ ਦਿਓ, ਪਰ ਛੋਟੇ ਸੰਗਠਨਾਂ ਲਈ email/password ਨਾਲ MFA ਦੀ ਚੋਣ ਵੀ ਰੱਖੋ।
ਹਰ ਪੱਧਰ 'ਤੇ ਟੈਨੈਂਟ ਬਾਊਂਡਰੀਆਂ ਲਾਗੂ ਕਰੋ:
ਸੰਵੇਦਨਸ਼ੀਲ ਪੇਜ਼ਾਂ ਅਤੇ ਡਾਊਨਲੋਡਸ ਦੀ ਪਹੁੰਚ ਲੌਗ ਕਰੋ: ਕਿਸ ਨੇ ਕਿੰਨੇ ਵੇਲੇ ਤੇ ਕਿੱਥੇ ਤੋਂ ਐਕਸੈੱਸ ਕੀਤਾ। ਇਹ ਕੰਪਲਾਇੰਸ ਅਤੇ ਕਲਾਇੰਟ ਭਰੋਸੇ ਲਈ ਮਦਦਗਾਰ ਹੈ।
ਇੱਕ ਓनਬੋਰਡਿੰਗ ਫਲੋ ਬਣਾਓ ਜਿਸ ਵਿੱਚ admins ਜਾਂ client editors ਯੂਜ਼ਰਾਂ ਨੂੰ invite ਕਰ ਸਕਣ, ਰੋਲ ਸੈੱਟ ਕਰ ਸਕਣ, email verification ਮੰਗ ਸਕਣ, ਅਤੇ ਜਦੋਂ ਕੋਈ ਜ਼ਰੂਰੀ ਹੋਵੇ ਤੁਰੰਤ ਪਹੁੰਚ ਰੱਦ ਕਰ ਸਕਣ।
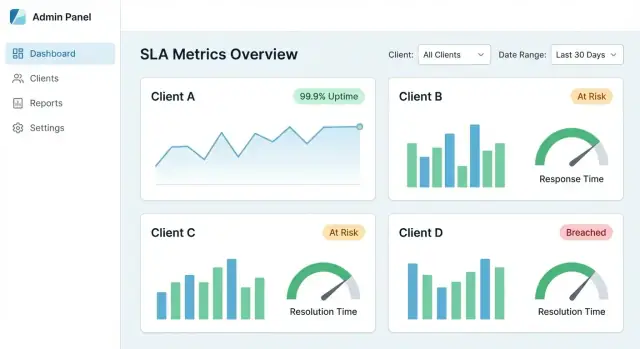
ਕੇਂਦਰੀ SLA ਡੈਸ਼ਬੋਰਡ ਉਸ ਵੇਲੇ کامیاب ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇੱਕ ਕਲਾਇੰਟ ਤਿੰਨ ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਇੱਕ ਮਿੰਟ ਤੋਂ ਘੱਟ ਵਿੱਚ ਲੱਭ ਸਕੇ: ਕੀ ਅਸੀਂ SLA ਪੂਰੇ ਕਰ ਰਹੇ ਹਾਂ? ਕੀ ਤਬਦੀਲੀ ਆਈ? ਮਿਸ ਹੋਣ ਦੇ ਕਾਰਨ ਕੀ ਸੀ? ਤੁਹਾਡੀ UX ਉਨ੍ਹਾਂ ਨੂੰ ਉੱਚ-ਸਤਰ ਦੇ ਦਰਸ਼ਨ ਤੋਂ ਸਬੂਤ ਤੱਕ ਰਹਿਤ ਨਾ ਕਰਦੀ ਹੋਵੇ।
ਛੋਟੇ ਟਾਇਲਾਂ ਅਤੇ ਚਾਰਟਸ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਆਮ SLA ਗੱਲਬਾਤਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦੇ ਹਨ:
ਹਰ ਕਾਰਡ ਨੂੰ ਕਲਿਕਯੋਗ ਬਣਾਓ ਤਾਂ ਕਿ ਉਹ ਡੀਟੇਲ ਵੱਲ ਦਰਵਾਜ਼ਾ ਬਣੇ।
ਫਿਲਟਰ ਸਾਰਿਆਂ ਪੇਜਜ਼ 'ਤੇ ਲਗਾਤਾਰ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ ਅਤੇ ਨੈਵੀਗੇਸ਼ਨ ਦੌਰਾਨ “stick” ਰਹਿਣ।
ਸਿਫਾਰਸ਼ੀ ਡਿਫੌਲਟ:
ਸਰੋਤ ਸਕ੍ਰੀਨ 'ਤੇ active filter chips ਦਿਖਾਓ ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਹਮੇਸ਼ਾ ਸਮਝ ਸਕਣ ਉਹ ਕੀ ਵੇਖ ਰਹੇ ਹਨ।
ਹਰ ਮੈਟਰਿਕ ਲਈ “ਕਿਉਂ” ਦਾ ਰਸਤਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਕ ਮਜ਼ਬੂਤ ਡ੍ਰਿਲ-ਡਾਊਨ ਪ੍ਰਵਾਹ:
ਜੇ ਕਿਸੇ ਨੰਬਰ ਨੂੰ ਸਬੂਤ ਨਾਲ ਸਮਝਾਇਆ ਨਾ ਜਾ ਸਕੇ, ਉਹ QBR ਦੌਰਾਨ ਸਵਾਲ ਕੀਤਾ ਜਾਵੇਗਾ।
ਹਰ KPI ਲਈ ਟੂਲਟਿਪ ਜਾਂ “info” ਪੈਨਲ ਸ਼ਾਮਿਲ ਕਰੋ: ਇਹ ਕਿਵੇਂ ਗਣਨਾ ਹੁੰਦਾ, exclusions, ਟਾਈਮਜ਼ੋਨ, ਅਤੇ ਡੇਟਾ ਤਾਜਗੀ। ਉਦਾਹਰਨ ਸ਼ਾਮਿਲ ਕਰੋ ਜਿਵੇਂ “Maintenance windows excluded” ਜਾਂ “Uptime measured at the API gateway.”
ਫਿਲਟਰ ਕੀਤੇ ਵਿਊਜ਼ ਨੂੰ ਸਥਿਰ URLs ਰਾਹੀਂ ਸਾਂਝਾ ਕਰਨ ਯੋਗ ਬਣਾਓ (ਉਦਾਹਰਨ: /reports/sla?client=acme&service=api&range=30d). ਇਹ ਤੁਹਾਡੇ ਕੇਂਦਰੀ SLA ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਕਲਾਇੰਟ-ਤਿਆਰ ਰਿਪੋਰਟਿੰਗ ਪੋਰਟਲ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਨਿਯਮਤ ਚੈੱਕ-ਇਨ ਅਤੇ ਆਡਿਟ ਟ੍ਰੇਲ ਲਈ ਉਪਯੋਗੀ ਹੈ।
ਕੇਂਦਰੀ SLA ਡੈਸ਼ਬੋਰਡ ਦਿਨ-ਪ੍ਰਤੀਦਿਨ ਲਈ ਲਾਭਦਾਇਕ ਹੈ, ਪਰ ਕਲਾਇੰਟਾਂ ਨੂੰ ਅਕਸਰ ਇੱਕ ਐਸੀ ਚੀਜ਼ ਚਾਹੀਦੀ ਹੈ ਜੋ ਉਹ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਫਾਰਵਰਡ ਕਰ ਸਕਣ: ਲੀਡਰਸ਼ਿੱਪ ਲਈ PDF, ਵਿਸ਼ਲੇਸ਼ਣ ਲਈ CSV, ਅਤੇ ਇੱਕ ਲਿੰਕ ਜੋ ਉਹ ਬੁੱਕਮਾਰਕ ਕਰ ਸਕਣ।
ਉਹੀ SLA ਨਤੀਜਿਆਂ ਤੋਂ ਤਿੰਨ ਆਉਟਪੁੱਟ ਸਪੋਰਟ ਕਰੋ:
ਲਿੰਕ-ਆਧਾਰਿਤ ਰਿਪੋਰਟਾਂ ਲਈ ਫਿਲਟਰ ਸਪਸ਼ਟ ਰੱਖੋ (date range, service, severity) ਤਾਂ ਕਿ ਕਲਾਇੰਟ ਨੰਬਰਾਂ ਦਾ ਸ਼ੁੱਧ ਅਰਥ ਸਮਝ ਸਕੇ।
ਹਰ ਕਲਾਇੰਟ ਲਈ ਸ਼ੈਡਿਊਲਿੰਗ ਜੋੜੋ ਤਾਂ ਜੋ ਉਹ ਸਵੈਚਾਲਿਤ ਰਿਪੋਰਟ weekly, monthly, ਅਤੇ quarterly ਪ੍ਰਾਪਤ ਕਰ ਸਕਣ—ਕਲਾਇੰਟ-ਪ੍ਰਤੀ-ਅਨੁਕੂਲ ਸੂਚੀ ਜਾਂ ਸਾਂਝਾ ਇਨਬਾਕਸ ਨੂੰ ਭੇਜੀ ਜਾ ਸਕਦੀ ਹੈ। ਸ਼ਡਿਊਲ ਟੇਨੈਂਟ-ਸਕੋਪਡ ਅਤੇ ਆਡਿਟੇਬਲ ਰੱਖੋ (ਕਿਸ ਨੇ ਬਣਾਇਆ, ਆਖਰੀ ਵਾਰੀ ਭੇਜਿਆ ਗਿਆ, ਅਗਲੇ ਚਲਾਨ ਦਾ ਸਮਾਂ)।
ਸਰਲ ਸ਼ੁਰੂਆਤ ਲਈ, /reports ਤੋਂ “ਮਹੀਨਾਵਾਰ ਸਮਰੀ” ਅਤੇ ਇਕ-ਕਲਿੱਕ ਡਾਊਨਲੋਡ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ।
ਟੇਮਪਲੇਟ ਬਨਾਓ ਜੋ QBR/MBR ਸਲਾਈਡਾਂ ਵਾਂਗ ਲਿਖੇ ਹੋਣ:
ਅਸਲ SLA ਵਿੱਚ ਛੋਟਾਂ ਸ਼ਾਮਿਲ ਹੁੰਦੀਆਂ ਹਨ (maintenance windows, third-party outages). ਯੂਜ਼ਰਾਂ ਨੂੰ compliance notes ਜੋੜਨ ਦਿਓ ਅਤੇ ਉਹਨਾਂ ਛੋਟਾਂ ਨੂੰ approval ਲਈ ਫਲੈਗ ਕਰੋ, ਮਨਜ਼ੂਰੀ ਟਰੇਲ ਨਾਲ।
ਐਕਸਪੋਰਟਸ ਨੂੰ ਟੈਨੈਂਟ ਆਈਸੋਲੇਸ਼ਨ ਅਤੇ ਰੋਲ ਪਰਮੀਸ਼ਨਾਂ ਦਾ ਪਾਲਣ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਕ ਯੂਜ਼ਰ ਸਿਰਫ ਉਹਨਾਂ ਕਲਾਇੰਟਾਂ, ਸੇਵਾਵਾਂ, ਅਤੇ ਸਮੇਂ ਵਾਲੀਆਂ ਪੀਰੀਅਡਾਂ ਨੂੰ export ਕਰ ਸਕੇ ਜੋ ਉਹ ਦੇਖਣ ਲਈ ਅਧਿਕਾਰਤ ਹੈ—ਅਤੇ ਐਕਸਪੋਰਟ ਪੋਰਟਲ ਵਿਊ ਨਾਲ ਬਿਲਕੁਲ ਮਿਲੇ (ਕੋਈ ਵਾਧੂ ਕਾਲਮ ਜੋ ਲੁਕਾਉਂਦਾ ਡੇਟਾ ਲੀਕ ਕਰਦਾ ਹੋ) ਨਾ ਹੋਵੇ।
ਅਲਰਟਸ ਉਹ ਥਾਂ ਹਨ ਜਿਥੇ SLA ਰਿਪੋਰਟਿੰਗ ਐਪ “ਦਿਲਚਸਪ ਡੈਸ਼ਬੋਰਡ” ਤੋਂ ਇੱਕ ਆਪਰੇਸ਼ਨਲ ਟੂਲ ਬਣ ਜਾਂਦਾ ਹੈ। ਮਕਸਦ ਜ਼ਿਆਦਾ ਸੁਨੇਹੇ ਭੇਜਣਾ ਨਹੀਂ—ਸਹੀ ਲੋਕਾਂ ਨੂੰ ਜਲਦੀ ਰੀਐਕਟ ਕਰਨ, ਜੋ ਹੋਇਆ ਉਸ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰਨ, ਅਤੇ ਕਲਾਇੰਟਾਂ ਨੂੰ ਜਾਣੂ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਨਾ ਹੈ।
ਤਿੰਨ ਸ਼੍ਰੇਣੀਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
ਹਰ ਅਲਰਟ ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਪਰਿਭਾਸ਼ਾ (ਮੈਟਰਿਕ, ਟਾਈਮਵਿੰਡੋ, ਥ੍ਰੇਸ਼ਹੋਲਡ, ਕਲਾਇੰਟ ਸਕੋਪ) ਨਾਲ ਜੋੜੋ ਤਾਂ ਕਿ ਪ੍ਰਾਪਤ ਕਰਨ ਵਾਲੇ ਇਸ 'ਤੇ ਭਰੋਸਾ ਕਰ ਸਕਣ।
ਕਈ ਡਿਲਿਵਰੀ ਵਿਕਲਪ ਦਿਓ ਤਾਂ ਜੋ ਟੀਮਾਂ ਕਲਾਇੰਟਾਂ ਦੇ ਮੈਥਿod ਨਾਲ ਮਿਲ ਸਕਣ:
ਮਲਟੀ-ਕਲਾਇੰਟ ਰਿਪੋਰਟਿੰਗ ਲਈ, ਨੋਟੀਫਿਕੇਸ਼ਨ ਨੂੰ ਟੈਨੈਂਟ ਨਿਯਮਾਂ ਨਾਲ ਰੂਟ ਕਰੋ (ਉਦਾਹਰਨ: “Client A breaches Channel A ਨੂੰ ਜਾਵੇ; internal breaches on-call ਨੂੰ ਜਾਵੇ”). ਸਾਂਝੇ ਚੈਨਲਾਂ ਨੂੰ ਕਲਾਇੰਟ-ਵਿਸ਼ੇਸ਼ ਵੇਰਵੇ ਨਾ ਭੇਜੋ।
ਅਲਰਟ fatigue ਦ੍ਵਾਰਾ ਆਪਣੇ ਉਪਭੋਗਤਾ ਖਤਮ ਹੋ ਜਾਣਗੇ। ਇਹ ਲਾਗੂ ਕਰੋ:
ਹਰ ਅਲਰਟ ਨੂੰ ਸਮਰੱਥ ਕਰੋ:
ਇਸ ਨਾਲ ਇਕ ਹਲਕਾ ਜਿਹਾ ਆਡੀਟ ਟਰੇਲ ਬਣਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਕਲਾਇੰਟ-ਤਿਆਰ ਸਮਰੀ ਵਿੱਚ ਦੁਬਾਰਾ ਵਰਤ ਸਕਦੇ ਹੋ।
ਪ੍ਰਤੀ-ਕਲਾਇੰਟ ਥ੍ਰੇਸ਼ਹੋਲਡ ਅਤੇ ਰੂਟਿੰਗ ਲਈ ਇੱਕ ਮੂਲ ਰੂਲਸ ਐਡੀਟਰ ਦਿਓ (ਬਿਨਾਂ ਕਠਿਨ ਕੈਵਰੀ ਲੌਜਿਕ ਦਿਖਾਉਣ ਦੇ)। ਗਾਰਡਰੇਲਸ ਮਦਦਗਾਰ ਹਨ: ਡਿਫੌਲਟ, ਵੈਧਤਾ, ਅਤੇ ਪ੍ਰਿਵਿਊ (“ਇਹ ਨਿਯਮ ਪਿਛਲੇ ਮਹੀਨੇ ਵਿੱਚ 3 ਵਾਰੀ ਟ੍ਰਿਗਰ ਹੁੰਦਾ”)।
ਇੱਕ ਕੇਂਦਰੀ SLA ਰਿਪੋਰਟਿੰਗ ਐਪ ਤੇਜ਼ੀ ਨਾਲ ਮਿਸ਼ਨ-ਕ੍ਰਿਟੀਕਲ ਬਣ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਕਲਾਇੰਟ ਇਸਨੂੰ ਸੇਵਾ ਗੁਣਵੱਤਾ ਮਾਪਣ ਲਈ ਵਰਤਦੇ ਹਨ। ਇਸ ਲਈ ਸਪੀਡ, ਸੁਰੱਖਿਆ, ਅਤੇ ਆਡਿਟ ਲਈ ਸਬੂਤ ਚਾਰਟਾਂ ਨੂੰ ਵੀ ਚਾਰਟਾਂ ਵਰਗਾ ਜਿੰਨਾ ਮਹੱਤਵਪੂਰਨ ਸਮਝੋ।
ਵੱਡੇ ਕਲਾਇੰਟ ਮਿਲੀਅਨਾਂ ਟਿਕਟ, ਇੰਸੀਡੈਂਟ ਅਤੇ ਮਾਨੀਟਰਿੰਗ ਇਵੈਂਟ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹਨ। ਪੇਜ਼ਾਂ ਨੂੰ ਜ਼ਿੰਦਾ ਰੱਖਣ ਲਈ:
ਰਾ ਇਵੈਂਟਜ਼ ਖੋਜ ਜਾਂ ਛੇੜਛਾੜ ਲਈ ਕੀਮਤੀ ਹਨ, ਪਰ ਹਰ ਚੀਜ਼ ਨੂੰ ਸਦਾ ਲਈ ਰੱਖਣਾ ਲਾਗਤ ਅਤੇ ਖਤਰੇ ਵਧਾਉਂਦਾ ਹੈ。
ਨਿਯਮ ਬਣਾਓ:
ਕੋਈ ਵੀ ਕਲਾਇੰਟ ਰਿਪੋਰਟਿੰਗ ਪੋਰਟਲ ਸੰਵੇਦਨਸ਼ੀਲ ਸਮਗਰੀ ਹੋ ਸਕਦੀ ਹੈ: ਗਾਹਕ ਦੇ ਨਾਮ, ਟਾਈਮਸਟੈਂਪ, ਟਿਕਟ ਨੋਟਸ, ਅਤੇ ਕਈ ਵਾਰ PII।
ਭਾਵੇਂ ਤੁਸੀਂ ਕਿਸੇ ਖਾਸ ਮਿਆਰ ਲਈ ਨਹੀਂ ਜਾ ਰਹੇ, ਚੰਗੇ ਓਪਰੇਸ਼ਨਲ ਸਬੂਤ ਭਰੋਸਾ ਬਣਾਉਂਦੇ ਹਨ।
ਇੱਕ SLA ਰਿਪੋਰਟਿੰਗ ਵੈਬ ਐਪ ਲਾਂਚ ਕਰਨਾ ਵੱਡੀ ਰਿਲੀਜ਼ ਦੀ ਥਾਂ ਅਕਸਰ accuracy ਪਰ ਸਾਬਿਤ ਕਰਨ ਅਤੇ ਫਿਰ ਦੁਹਰਾਉਣਯੋਗ ਤਰੀਕੇ ਨਾਲ ਸਕੇਲ ਕਰਨ ਬਾਰੇ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਮਜ਼ਬੂਤ ਲਾਂਚ ਯੋਜਨਾ ਝਗੜਿਆਂ ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ ਕਿਉਂਕਿ ਨਤੀਜੇ ਆਸਾਨੀ ਨਾਲVerify ਅਤੇ ਦੁਹਰਾਏ ਜਾ ਸਕਦੇ ਹਨ।
ਇੱਕ ਐਸਾ ਕਲਾਇੰਟ ਚੁਣੋ ਜਿਸਦਾ ਸੇਟ ਸੇਵਾਵਾਂ ਅਤੇ ਡੇਟਾ ਸੋਸز manageable ਹੋਵੇ। ਆਪਣੀ ਐਪ ਦੀ SLA ਗਣਨਾਵਾਂ ਨੂੰ ਉਨ੍ਹਾਂ ਦੇ ਮੌਜੂਦਾ ਸਪ੍ਰੈਡਸ਼ੀਟ, ਟਿਕਟ ਐਕਸਪੋਰਟ, ਜਾਂ vendor portal ਰਿਪੋਰਟਾਂ ਦੇ ਨਾਲ ਪੈਰਲੇਲ ਵਿੱਚ ਚਲਾਓ।
ਆਮ ਮਿਲਤੀਆਂ ਮੁੱਦਿਆਂ 'ਤੇ ਧਿਆਨ:
ਫਰਕਾਂ ਨੂੰ ਦਸਤਾਵੇਜ਼ ਕਰੋ ਅਤੇ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕੀ ਐਪ ਨੂੰ ਕਲਾਇੰਟ ਦੀ ਮੌਜੂਦਾ ਪদ্ধਤੀ ਨਾਲ ਮੇਲ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਜਾਂ ਇਸਨੂੰ ਇੱਕ ਸਪਸ਼ਟ ਮਿਆਰ ਨਾਲ ਬਦਲਣਾ ਚਾਹੀਦਾ ਹੈ।
ਇੱਕ ਦੁਹਰਾਏਜੋਗ ਓਨਬੋਰਡਿੰਗ ਚੈਕਲਿਸਟ ਬਣਾਓ ਤਾਂ ਕਿ ਹਰ ਨਵੇਂ ਕਲਾਇੰਟ ਦਾ ਤਜਰਬਾ ਪੇਸ਼ਗੀ ਤੌਰ 'ਤੇ ਅਨੁਮਾਨਯੋਗ ਹੋਵੇ:
ਇੱਕ ਚੈਕਲਿਸਟ ਤੁਹਾਨੂੰ ਕੋਸ਼ਿਸ਼ ਦਿਲਾਉਂਦੀ ਹੈ ਅਤੇ /pricing ਉੱਤੇ ਨਿਰੱਕਣ ਚਰਚਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
SLA ਡੈਸ਼ਬੋਰਡ ਤਦ ਹੀ ਭਰੋਸੇਯੋਗ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਉਹ ਤਾਜਾ ਅਤੇ ਪੂਰਾ ਹੁੰਦਾ ਹੈ। ਨਿਮਨਲਿੱਖਤ ਚੀਜ਼ਾਂ ਲਈ ਮਾਨੀਟਰਿੰਗ ਜੋੜੋ:
ਪਹਿਲਾਂ ਆਤੰਤਰਿਕ ਅਲਰਟ ਭੇਜੋ; ਇਕ ਵਾਰ ਸਥਿਰ ਹੋਣ 'ਤੇ, ਤੁਸੀਂ ਕਲਾਇੰਟ-ਦਿੱਖ ਵਾਲੇ ਸਟੇਟਸ ਨੋਟਾਂ ਸਥਾਪਿਤ ਕਰ ਸਕਦੇ ਹੋ।
Feedback ਇਕੱਠਾ ਕਰੋ ਕਿ ਕਿੱਥੇ ਗਲਤਫਹਿਮੀ ਹੁੰਦੀ ਹੈ: ਪਰਿਭਾਸ਼ਾਵਾਂ, ਵਿਵਾਦ (“ਇਹ ਬ੍ਰੀਚ ਕਿਉਂ ਹੈ?”), ਅਤੇ “ਪਿਛਲੇ ਮਹੀਨੇ ਤੋਂ ਕੀ ਬਦਲਿਆ?”। ਅਹਿਮਿਤ ਦੇ ਧੁੱਨ ਵਿੱਚ ਛੋਟੇ UX ਸੁਧਾਰ ਨੂੰ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿਓ ਜਿਵੇਂ ਟੂਲਟਿਪਸ, ਚੇਨਜ ਲੌਗ, ਅਤੇ exclusions ਦੇ ਨੋਟਸ।
ਜੇ ਤੁਸੀਂ ਇੱਕ ਅੰਦਰੂਨੀ MVP (tenant model, integrations, dashboards, exports) ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਰਿਲੀਜ਼ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਬਿਨਾਂ ਹਫਤਿਆਂ boilerplate 'ਤੇ ਖਰਚ ਕੀਤੇ, ਤਾਂ vibe-coding ਦੇ ਤਰੀਕੇ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ। ਉਦਾਹਰਨ ਲਈ, Koder.ai ਟੀਮਾਂ ਨੂੰ chat ਰਾਹੀਂ ਇੱਕ multi-tenant ਵੈਬ ਐਪ ਦਾ ਰੁਪਰੇਖਾ ਤਿਆਰ ਕਰਨ ਅਤੇ ਫਿਰ سورਸ ਕੋਡ export ਕਰਨ ਦੀ ਆਸਾਨੀ ਦਿੰਦਾ ਹੈ। ਇਹ SLA ਰਿਪੋਰਟਿੰਗ ਉਤਪਾਦਾਂ ਲਈ ਵਾਸਤਵਿਕ ਫਿਟ ਹੈ, ਜਿੱਥੇ ਮੁੱਖ ਜਟਿਲਤਾ ਡੋਮੇਨ ਨਿਯਮ ਅਤੇ ਡੇਟਾ ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਹੈ ਨਾਂ ਕਿ ਯੂਆਈ ਸਕੈਫੋਲਡਿੰਗ।
ਤੁਸੀਂ Koder.ai ਦੇ planning mode ਨੂੰ tenants, services, SLA definitions, events, rollups ਵਰਗੀਆਂ ਏਨਟਿਟੀਜ਼ ਦਾ ਖਾਕਾ ਬਣਾਉਣ ਲਈ ਵਰਤ ਸਕਦੇ ਹੋ, ਫਿਰ ਇੱਕ React UI ਅਤੇ Go/PostgreSQL ਬੈਕਐਂਡ ਨਿਰਧਾਰਿਤ ਆਧਾਰ generate ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਆਪਣੇ ਖਾਸ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਅਤੇ ਗਣਨਾ ਲਾਜਿਕ ਨਾਲ ਵਧਾ ਸਕਦੇ ਹੋ।
ਅਗਲੇ ਕਦਮਾਂ ਦੀ ਇੱਕ ਜੀਵੰਤ ਦਸਤਾਵੇਜ਼ ਰੱਖੋ: ਨਵੇਂ ਇੰਟੀਗ੍ਰੇਸ਼ਨ, ਐਕਸਪੋਰਟ ਫਾਰਮੈਟ, ਅਤੇ ਆਡਿਟ ਟਰੇਲ। /blog 'ਤੇ ਸਬੰਧਤ ਗਾਈਡਾਂ ਨਾਲ ਲਿੰਕ ਕਰੋ ਤਾਂ ਕਿ ਕਲਾਇੰਟ ਅਤੇ ਟੀਮ ਮੈਂਬਰ ਖੁਦ ਸੇਵਾਉਰ ਕਰ ਸਕਣ।
Centralized SLA reporting should create one source of truth by pulling uptime, incidents, and ticket timelines into a single, traceable view.
Practically, it should:
Start with a small set most clients recognize, then expand only when you can explain and audit them.
Common starting metrics:
For each metric, document what it measures, what it excludes, and the data sources required.
Write rules in plain language first, then convert them into logic.
You typically need to define:
If two people can’t agree on the sentence version, the code version will be disputed later.
Store all timestamps in UTC, then convert for display using the tenant’s reporting time zone.
Also decide upfront:
Be explicit in the UI (e.g., “Reporting period cutoffs are in America/New_York”).
Use a mix of integration methods based on freshness vs completeness:
A practical rule: use webhooks where freshness matters, API pulls where completeness matters.
Define a small canonical set of normalized events so different tools map to the same concepts.
Examples:
incident_opened / incident_closedPick a multi-tenancy model and enforce isolation beyond the UI.
Key protections:
tenant_idAssume exports and background jobs are the easiest places to accidentally leak data if you don’t design for tenant context.
Store both raw events and derived results so you can be fast and explainable.
A practical split:
Make the pipeline staged and idempotent:
For reliability:
Include three alert categories so the system is operational, not just a dashboard:
Reduce noise with deduplication, quiet hours, and escalation, and make each alert actionable with acknowledgment and resolution notes.
downtime_started / downtime_endedticket_created / first_response / resolvedInclude consistent fields like tenant_id, service_id, source_system, external_id, severity, and UTC timestamps.
Add a calculation_version so past reports can be reproduced exactly after rule changes.