21 ਸਤੰ 2025·8 ਮਿੰਟ
Eric Brewer ਦੀ CAP ਸੋਚ: ਕਿਉਂ ਵੰਡੇ ਹੋਏ ਸਿਸਟਮ ਟਰੇਡਆਫ਼ ਕਰਦੇ ਹਨ
Eric Brewer ਦੇ CAP theorem ਨੂੰ ਇੱਕ व्यवहारਕ ਮਨੋਦਰਸ਼ਨ ਵਜੋਂ ਸਮਝੋ: consistency, availability ਅਤੇ partitions ਕਿਵੇਂ ਵੰਡੇ ਸਿਸਟਮ ਨਿਰਣਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
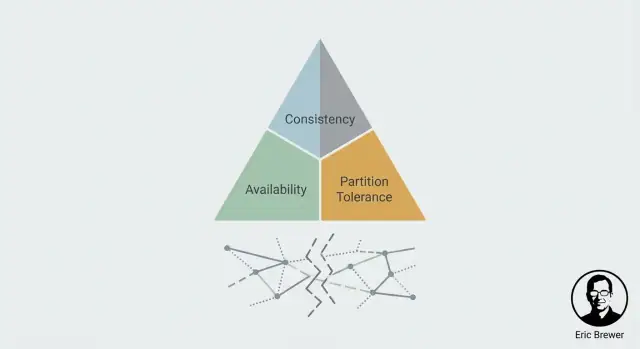
Eric Brewer ਦੇ CAP theorem ਨੂੰ ਇੱਕ व्यवहारਕ ਮਨੋਦਰਸ਼ਨ ਵਜੋਂ ਸਮਝੋ: consistency, availability ਅਤੇ partitions ਕਿਵੇਂ ਵੰਡੇ ਸਿਸਟਮ ਨਿਰਣਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ।
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕੋ ਡੇਟਾ ਨੂੰ ਇੱਕ ਤੋਂ ਵੱਧ ਮਸ਼ੀਨਾਂ 'ਤੇ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਅਤੇ ਤਰਤੀਬਦਾਰੀ ਮਿਲਦੀ ਹੈ—ਪਰ ਇਕ ਨਵੀਂ ਸਮੱਸਿਆ ਵੀ ਆਉਂਦੀ ਹੈ: ਅਸਹਿਮਤੀ. ਦੋ ਸਰਵਰ ਵੱਖ-ਵੱਖ ਅਪਡੇਟ ਲੈ ਸਕਦੇ ਹਨ, ਸੁਨੇਹੇ ਦੇਰੀ ਨਾਲ ਆ ਸਕਦੇ ਹਨ ਜਾਂ ਗੁੰਮ ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ ਯੂਜ਼ਰ ਨੂੰ ਵੱਖ-ਵੱਖ ਨਤੀਜੇ ਮਿਲ ਸਕਦੇ ਹਨ ਇਹ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਕੇ ਕਿ ਉਹ ਕਿਸ ਰੀਪਲਿਕਾ ਨੂੰ ਹਿੱਟ ਕਰਦੇ ਹਨ। CAP ਇਸ ਗੁੰਝਲਦਾਰ ਹਕੀਕਤ ਬਾਰੇ ਇੰਜੀਨੀਅਰਾਂ ਨੂੰ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਗੱਲ ਕਰਨ ਦਾ ਢੰਗ ਦਿੰਦਾ ਹੈ।
Eric Brewer ਨੇ 2000 ਵਿੱਚ ਇਸ ਮੁੱਖ ਵਿਚਾਰ ਨੂੰ ਰੀਪਲਿਕੇਟ ਕੀਤੇ ਸਿਸਟਮਾਂ ਵਿੱਚ ਫੇਲਿਅਰ ਹਾਲਤਾਂ ਬਾਰੇ ਇੱਕ ਪ੍ਰਾਇਗਮੈਟਿਕ ਬਿਆਨ ਵਜੋਂ ਪੇਸ਼ ਕੀਤਾ। ਇਹ ਤੇਜ਼ੀ ਨਾਲ ਫੈਲਿਆ ਕਿਉਂਕਿ ਇਹ ਉਸੇ ਤਜਰਬੇ ਨਾਲ ਮਿਲਦਾ ਸੀ ਜੋ ਟੀਮਾਂ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਦੇਖ ਰਹੀਆਂ ਸਨ: ਵੰਡੇ ਸਿਸਟਮ ਸਿਰਫ ਡਾਊਨ ਹੋ ਕੇ ਫੇਲ ਨਹੀਂ ਹੁੰਦੇ; ਉਹ ਵੰਡ ਕੇ ਫੇਲ ਹੁੰਦੇ ਹਨ।
CAP ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲਾਭਦਾਇਕ ਉਸ ਵੇਲੇ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਚੀਜ਼ਾਂ ਗਲਤ ਜਾਂਦੀਆਂ ਹਨ—ਖਾਸ ਕਰਕੇ ਜਦੋਂ ਨੈੱਟਵਰਕ ਬੁਰੀ ਤਰ੍ਹਾਂ ਵਰਤੋਂ ਨਹੀਂ ਕਰਦਾ। ਸਿਹਤਮੰਦ ਦਿਨ 'ਤੇ, ਬਹੁਤ ਸਿਸਟਮ ਇੱਕੋ ਸਮੇਂ ਕੁਝ ਹੱਦ ਤੱਕ consistent ਅਤੇ available ਦਿਖਾਈ ਦੇ ਸਕਦੇ ਹਨ। ਪ੍ਰੈਸ਼ਰ ਟੈਸਟ ਉਹ ਦਿਨ ਹੈ ਜਦੋਂ ਮਸ਼ੀਨਾਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਸੰਚਾਰ ਨਹੀਂ ਕਰ ਪਾਂਦੀਆਂ ਅਤੇ ਤੁਹਾਨੂੰ ਪੜ੍ਹਾਈਆਂ ਅਤੇ ਲਿਖਤਾਂ ਦੇ ਨਾਲ ਕੀ ਕਰਨਾ ਹੈ ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
ਇਹੀ ਫਰੇਮ CAP ਨੂੰ ਇੱਕ ਜ਼ਰੂਰੀ ਮਾਨਸਿਕ ਮਾਡਲ ਬਣਾਉਂਦਾ ਹੈ: ਇਹ ਬਣਦੇ ਜੀਵਨ-ਮੁੱਲ ਬਾਰੇ ਦੀਆਂ ਚਰਚਾਵਾਂ ਨੂੰ ਛੱਡ ਕੇ ਇੱਕ ਸਪਸ਼ਟ ਸਵਾਲ ਪੇਸ਼ ਕਰਦਾ—ਉਦੋਂ ਸਪਲਿੱਟ ਹੋਣ 'ਤੇ ਅਸੀਂ ਕੀ ਤਿਆਗਾਂਗੇ?
ਇਸ ਲੇਖ ਦੇ ਅੰਤ ਤੱਕ ਤੁਸੀਂ ਸਮਝ ਸਕੋਗੇ:
CAP ਇਸ ਲਈ ਲਾਗੂ ਰਹਿੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ "ਵੰਡਿਆ ਹੋਣਾ ਔਖਾ ਹੈ" वाली ਗੱਲ ਨੂੰ ਇੱਕ ਐਸਾ ਫੈਸਲਾ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਬਚਾਵ ਕਰ ਸਕਦੇ ਹੋ।
ਵੰਡਿਆ ਸਿਸਟਮ ਆਮ ਭਾਸ਼ਾ ਵਿੱਚ ਇਤਲਾ ਹੈ: ਕਈ ਕੰਪਿਊਟਰ ਇਕ-ਜਹੇ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੇ ਹਨ। ਤੁਹਾਡੇ ਕੋਲ ਵੱਖ-ਵੱਖ ਰੈਕ, ਰੀਜਨ ਜਾਂ ਕਲਾਡ ਜ਼ੋਨ ਵਿੱਚ ਬਹੁਤ ਸਾਰੇ ਸਰਵਰ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਯੂਜ਼ਰ ਲਈ ਇਹ "ਐਪ" ਜਾਂ "ਡਾਟਾਬੇਸ" ਹੈ।
ਵਾਸਤਵਿਕ ਸਕੇਲ 'ਤੇ ਸਾਂਝੇ ਸਿਸਟਮ ਨੂੰ ਚਲਾਉਣ ਲਈ ਅਸੀਂ ਆਮ ਤੌਰ ਤੇ ਨਕਲ ਰੱਖਦੇ ਹਾਂ: ਅਸੀਂ ਇਕੋ ਡੇਟਾ ਦੀਆਂ ਕਈ ਕਾਪੀਆਂ ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨਾਂ 'ਤੇ ਰੱਖਦੇ ਹਾਂ।
ਨਕਲ ਤਿੰਨ ප්ਰਾਯੋਗਿਕ ਕਾਰਨਾਂ ਕਰਕੇ ਲੋਕਪ੍ਰਿਯ ਹੈ:
ਪਰ ਨਕਲ ਇੱਕ ਨਵੀਂ ਜ਼ਿੰਮੇਵਾਰੀ ਲਿਆਉਂਦਾ ਹੈ: ਸਭ ਕਾਪੀਆਂ ਨੂੰ ਸਹਿਮਤ ਰੱਖਣਾ।
ਜੇ ਹਰ ਰੀਪਲਿਕਾ ਹਮੇਸ਼ਾ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਤੁਰੰਤ ਗੱਲ ਕਰ ਸਕਦੀ ਤਾਂ ਉਹ ਅਪਡੇਟਾਂ ਨੂੰ ਕੋਆਰਡੀਨੇਟ ਕਰਕੇ ਇੱਕੋ ਅਵਸਥਾ 'ਤੇ ਰਹਿ ਸਕਦੇ। ਪਰ ਅਸਲ ਨੈੱਟਵਰਕ ਆਦਰਸ਼ ਨਹੀਂ ਹੁੰਦੇ: ਸੁਨੇਹੇ ਦੇਰੀ ਨਾਲ ਆ ਸਕਦੇ ਹਨ, ਗੁੰਮ ਹੋ ਸਕਦੇ ਹਨ ਜਾਂ ਫੇਲ ਹੋ ਸਕਦੇ ਹਨ।
ਜਦੋਂ ਸੰਚਾਰ ਠੀਕ ਹੈ, ਰੀਪਲਿਕਾਜ਼ ਆਮ ਤੌਰ 'ਤੇ ਅਪਡੇਟਾਂ ਨੂੰ ਸਾਂਝਾ ਕਰਕੇ ਇਕੱਠੇ ਹੋ ਜਾਂਦੇ ਹਨ। ਪਰ ਜਦੋਂ ਸੰਚਾਰ ਟੁੱਟ ਜਾਂਦਾ ਹੈ (ਭਾਵੇਂ ਅਸਥਾਈ), ਤੁਸੀਂ ਦੋ "ਵੈਧ-ਲੱਗਣ ਵਾਲੀਆਂ" "ਸੱਚਾਈਆਂ" ਮਿਲ ਸਕਦੀਆਂ ਹਨ।
ਉਦਾਹਰਣ ਵਜੋਂ, ਇੱਕ ਯੂਜ਼ਰ ਆਪਣਾ ਸ਼ਿਪਿੰਗ ਐਡਰੈੱਸ ਬਦਲਦਾ ਹੈ। ਰੀਪਲਿਕਾ A ਅਪਡੇਟ ਪ੍ਰਾਪਤ ਕਰ ਲੈਂਦੀ ਹੈ, ਰੀਪਲਿਕਾ B ਨਹੀਂ। ਹੁਣ ਸਿਸਟਮ ਨੂੰ ਇੱਕ ਸਧਾਰਨ ਸਵਾਲ ਦਾ ਜਵਾਬ ਦੇਣਾ ਪੈਂਦਾ ਹੈ: ਹੁਣ ਐਡਰੈੱਸ ਕੀ ਹੈ?
ਇਹ ਫਰਕ ਇਹ ਹੈ:
CAP ਸੋਚ ਇੱਥੇ ਹੀ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ: ਇੱਕ ਵਾਰੀ ਨਕਲ ਮੌਜੂਦ ਹੈ, ਸੰਚਾਰ ਫੇਲਿਅਰ ਅਧੀਨ ਅਸਹਿਮਤੀ ਕੋਈ ਐਜ ਕੇਸ ਨਹੀਂ—ਇਹ ਕੇਂਦਰੀ ਡਿਜ਼ਾਇਨ ਸਮੱਸਿਆ ਹੈ।
CAP ਇੱਕ ਮੈਨਟਲ ਮਾਡਲ ਹੈ ਜੋ ਦੱਸਦਾ ਹੈ ਕਿ ਜਦੋਂ ਸਿਸਟਮ ਕਈ ਮਸ਼ੀਨਾਂ 'ਤੇ ਫੈਲਿਆ ਹੋਵੇ ਤਾਂ ਯੂਜ਼ਰ ਸਭ ਤੋਂ ਵੱਧ ਕੀ ਮਹਿਸੂਸ ਕਰਦਾ ਹੈ। ਇਹ "ਚੰਗਾ" ਜਾਂ "ਬੁਰਾ" ਸਿਸਟਮ ਨਹੀਂ ਦੱਸਦਾ—ਸਿਰਫ਼ ਟਨਸ਼ਨ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਮੈਨੇਜ ਕਰਨਾ ਹੈ।
Consistency ਬਾਰੇ ਸੋਚ ਇਸ ਗੱਲ ਨਾਲ ਹੈ ਕਿ ਜੇ ਤੁਸੀਂ ਕੁਝ ਅਪਡੇਟ ਕੀਤਾ, ਤਾਂ ਅਗਲੇ ਪੜ੍ਹਾਈ (ਕਿਸੇ ਵੀ ਰੀਪਲਿਕਾ ਤੋਂ) ਉਹੀ ਅਪਡੇਟ ਦਰਸਾਏਗੀ? ਯੂਜ਼ਰ ਲਈ ਇਹ ਉਸ ਫਰਕ ਵਰਗੀ ਹੈ: "ਮੈਂ ਅਜੇ ਬਦਲਿਆ, ਅਤੇ ਹਰ ਕੋਈ ਉਹੀ ਨਵਾਂ ਮੁੱਲ ਵੇਖਦਾ ਹੈ" ਬਨਾਮ "ਕੁਝ ਲੋਕ ਥੋੜ੍ਹੇ ਸਮੇਂ ਲਈ ਪੁਰਾਣਾ ਮੁੱਲ ਵੇਖਦੇ ਰਹਿੰਦੇ ਹਨ।"
Availability ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸਿਸਟਮ ਬੇਨਤੀਆਂ—ਪੜ੍ਹਾਈਆਂ ਅਤੇ ਲਿਖਤਾਂ—ਦਾ ਸਫਲ ਨਤੀਜਾ ਦਿੰਦਾ ਹੈ। ਨਾ ਕਿ "ਸਭ ਤੋਂ ਤੇਜ਼," ਪਰ "ਇਹ ਤੁਹਾਨੂੰ ਸੇਵਾ ਦੇਣ ਤੋਂ ਇਨਕਾਰ ਨਹੀਂ ਕਰਦਾ।"
ਸਮੱਸਿਆਂ ਦੇ ਦੌਰਾਨ (ਇੱਕ ਸਰਵਰ ਡਾਊਨ ਹੋਵੇ ਜਾਂ ਨੈੱਟਵਰਕ ਘੱਟ ਹੋਵੇ), ਇੱਕ ਉਪਲਬਧ ਸਿਸਟਮ ਬੇਨਤੀਆਂ ਲਈ ਜਵਾਬ ਦਿੰਦਾ ਰਹਿੰਦਾ ਹੈ, ਭਾਵੇਂ ਨਤੀਜੇ ਕੁਝ ਹੱਦ ਤੱਕ ਪੁਰਾਣੇ ਹੋ ਸਕਦੇ ਹਨ।
ਪਾਰਟੀਸ਼ਨ ਉਹ ਹੈ ਜਦੋਂ ਨੈੱਟਵਰਕ ਵੰਡ ਜਾਂਦੀ ਹੈ: ਮਸ਼ੀਨਾਂ ਚੱਲ ਰਹੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ, ਪਰ ਕੁਝ ਵਿਚਕਾਰ ਸੁਨੇਹੇ ਨਹੀਂ ਪਹੁੰਚ ਰਹੇ (ਜਾਂ ਬਹੁਤ ਦੇਰ ਨਾਲ ਪਹੁੰਚ ਰਹੇ)। ਵੰਡਾਂ ਨੂੰ ਅਨੁਮਾਨ ਲੱਗਾ ਕੇ ਨਾ ਦੇਖੋ—ਤੁਹਾਨੂੰ ਇਸ ਦੀ ਵਰਤੋਂ ਕਰਨ ਦੀ ਵਰਤੋਂ ਵੀ ਕਰਨੀ ਪੈਂਦੀ ਹੈ।
ਦੀਜੀਏ ਦੋ ਰੀਟੇਲ ਦੁਕਾਨਾਂ ਜੋ ਇੱਕੋ ਹੀ ਉਤਪਾਦ ਵੇਚਦੀਆਂ ਹਨ ਅਤੇ "1 ਇਨਵੈਂਟਰੀ ਗਿਣਤੀ" ਸਾਂਝੀ ਕਰਦੀਆਂ ਹਨ। ਗਾਹਕ Shop A ਤੋਂ ਆਖਰੀ ਆਈਟਮ ਖਰੀਦ ਲੈਂਦਾ ਹੈ, ਇਸ ਲਈ Shop A ਨੇ inventory = 0 ਲਿਖ ਦਿੱਤਾ। ਓਸੇ ਸਮੇਂ, ਨੈੱਟਵਰਕ ਪਾਰਟੀਸ਼ਨ ਕਾਰਨ Shop B ਨੂੰ ਇਹ ਜਾਣਕਾਰੀ ਨਹੀਂ ਮਿਲੀ।
ਜੇ Shop B ਉਪਲਬਧ ਰਹਿੰਦੀ ਹੈ, ਤਾਂ ਇਹ ਇਕ ਆਈਟਮ ਵੇਚ ਸਕਦੀ ਹੈ ਜੋ ਹੁਣ ਨਹੀਂ ਹੈ (ਬਿਨਾਂ ਜਾਣੂ ਹੋਏ ਸੇਲ ਕਰਨਾ)। ਜੇ Shop B ਸਥਿਰਤਾ ਲਾਗੂ ਕਰੇ, ਤਾਂ ਇਹ ਸੇਲ ਇਨਕਾਰ ਕਰ ਸਕਦੀ ਹੈ ਜਦ ਤੱਕ ਇਹ ਤਾਜ਼ਾ ਭੰਡਾਰ ਦੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰ ਲੈਂਦੀ (ਸਪਲਿੱਟ ਦੌਰਾਨ ਸੇਵਾ ਰੱਦ ਕਰਨਾ)।
"ਪਾਰਟੀਸ਼ਨ" ਸਿਰਫ਼ "ਇੰਟਰਨੈਟ ਡਾਊਨ ਹੈ" ਨਹੀਂ ਹੈ। ਇਹ ਕੋਈ ਵੀ ਸਥਿਤੀ ਹੈ ਜਿੱਥੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਗੱਲ ਨਹੀਂ ਕਰ ਸਕਦੇ—ਭਾਵੇਂ ਹਰ ਹਿੱਸਾ ਅਜੇ ਵੀ ਚੱਲ ਰਿਹਾ ਹੋਵੇ।
ਰਿਪਲਿਕੇਟ ਸਿਸਟਮ ਵਿੱਚ, ਨੋਡ ਲਗਾਤਾਰ ਸੁਨੇਹੇ ਬੇਝਦੇ-ਪ੍ਰਾਪਤ ਕਰਦੇ ਹਨ: ਲਿਖਤਾਂ, acknowlegdements, heartbeats, leader elections, read ਬੇਨਤੀਆਂ। ਪਾਰਟੀਸ਼ਨ ਉਸ ਸਮੇਂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਸੁਨੇਹੇ ਨਹੀਂ ਪਹੁੰਚਦੇ (ਜਾਂ ਬਹੁਤ ਦੇਰ ਨਾਲ ਪਹੁੰਚਦੇ) ਅਤੇ ਇਹ ਅਸਹਿਮਤੀ ਬਾਰੇ ਹਕੀਕਤ ਪੈਦਾ ਕਰਦਾ: "ਕੀ ਲਿਖਤ ਹੋਈ?" "ਕੌਣ ਲੀਡਰ ਹੈ?" "ਕੀ ਨੋਡ B ਜਿੰਦ ਹੈ?"
ਸੰਚਾਰ ਮੈਸਰੂਰੀ ਤੌਰ 'ਤੇ ਅਨੇਕ ਅੰਸ਼ਾਂ ਵਿੱਚ ਫੇਲ ਹੋ ਸਕਦਾ ਹੈ:
ਮੁੱਖ ਗੱਲ: partitions ਅਕਸਰ ਗਿਰਾਵਟ ਹੁੰਦੇ ਹਨ, ਨਾ ਕਿ ਸਾਫ਼ ਆਨ/ਆਫ਼ ਆਊਟੇਜ। ਐਪ ਲਈ, "ਕਾਫੀ ਧੀਮਾ" ਕਈ ਵਾਰ "ਡਾਊਨ" ਦੇ ਸਮਾਨ ਹੁੰਦਾ ਹੈ।
ਜਿਵੇਂ-ਜਿਵੇਂ ਤੁਸੀਂ ਹੋਰ ਮਸ਼ੀਨ, ਹੋਰ ਨੈੱਟਵਰਕ, ਹੋਰ ਰੀਜਨ ਅਤੇ ਹੋਰ ਹਿਲਦੇ-ਦੌਲਦੇ ਹਿੱਸੇ ਜੁੜਦੇ ਹੋ, ਸੰਚਾਰ ਟੁੱਟਣ ਲਈ ਹੋਰ ਮੌਕੇ ਬਣ ਜਾਂਦੇ ਹਨ। ਭਾਵੇਂ ਇਕੱਲੇ ਘਟਕ ਭਰੋਸੇਯੋਗ ਹੋਣ, ਕੁੱਲ ਸਿਸਟਮ ਫੇਲ ਹੁੰਦਾ ਹੈ ਕਿਉਂਕਿ ਇਸ ਦੇ ਵੱਧ ਡੀਪੈਂਡੈਂਸੀ ਅਤੇ ਵੱਧ ਨੋਡ-ਅੰਤਰਕਾਰ சங்க੍ਰਿਯਾ ਹਨ।
ਤੁਹਾਨੂੰ ਕਿਸੇ ਨਿਰਧਾਰਤ ਫੇਲਿਓਨ ਦਰ ਦੀ ਲੋੜ ਨਹੀਂ ਕਿ ਇਹ ਮੰਨਣ ਲਈ: ਜੇ ਤੁਹਾਡੀ ਸਿਸਟਮ ਕਾਫੀ ਲੰਬਾ ਚੱਲੇ ਅਤੇ ਕਾਫੀ ਢਾਂਚਾ ਫੈਲਾਏ, ਤਾਂ partitions ਜ਼ਰੂਰ ਹੋਣਗੇ।
Partition tolerance ਦਾ ਅਰਥ ਹੈ ਕਿ ਤੁਹਾਡੀ ਸਿਸਟਮ ਏਸ ਤਰ੍ਹਾਂ ਡਿਜ਼ਾਈਨ ਕੀਤੀ ਗਈ ਹੈ ਕਿ ਵੰਡ ਦੌਰਾਨ ਵੀ ਉਹ ਚੱਲਦੀ ਰਹੇ—ਭਾਵੇਂ ਨੋਡ ਇਕ-ਦੂਜੇ ਨਾਲ ਸਹਿਮਤ ਨਾ ਹੋ ਸਕਣ ਜਾਂ ਉਹਨਾਂ ਨੂੰ ਪੁਸ਼ਟੀ ਨਾ ਮਿਲ ਸਕੇ। ਇਹ ਇਕ ਚੋਣ ਕਰਵਾਉਂਦਾ ਹੈ: ਜਾਂ ਤਾਂ ਬੇਨਤੀਆਂ ਨੂੰ ਸੇਵਾ ਦੇਣਾ ਜਾਰੀ ਰੱਖੋ (ਜੋ inconsistent ਹੋ ਸਕਦਾ ਹੈ) ਜਾਂ ਕੁਝ ਬੇਨਤੀਆਂ ਨੂੰ ਰੋਕ/ਅਸਵੀਕਾਰ ਕਰੋ (consistency ਬਚਾਉਂਦੇ ਹੋਏ)।
ਇੱਕ ਵਾਰੀ ਤੁਹਾਡੇ ਕੋਲ ਨਕਲ ਹੋ ਜਾਵੇ, ਇੱਕ partition ਕਿਸੇ ਸੰਚਾਰ ਤਰੁੱਟੀ ਤੋਂ ਵੱਧ ਨਹੀਂ ਹੁੰਦੀ: ਸਿਸਟਮ ਦੇ ਦੋ ਹਿੱਸੇ ਇਕ-ਦੂਜੇ ਨਾਲ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਗੱਲ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਰੀਪਲਿਕਾਜ਼ ਹੋਰ ਵੀ ਚੱਲ ਰਹੀਆਂ ਹਨ, ਯੂਜ਼ਰ ਅਜੇ ਵੀ ਕਲਿੱਕ ਕਰ ਰਹੇ ਹਨ, ਤੇ ਤੁਹਾਡੀ ਸੇਵਾ ਬੇਨਤੀਆਂ ਪ੍ਰਾਪਤ ਕਰ ਰਹੀ ਹੈ—ਪਰ ਰੀਪਲਿਕਾਜ਼ ਤਾਜ਼ਾ ਸੱਚ 'ਤੇ ਸਹਿਮਤ ਨਹੀਂ ਹੋ ਸਕਦੇ।
ਇਹ CAP ਟਨਸ਼ਨ ਇੱਕ ਵਾਕ ਵਿੱਚ: ਪਾਰਟੀਸ਼ਨ ਦੌਰਾਨ, ਤੁਸੀਂ Consistency (C) ਜਾਂ Availability (A) ਨੂੰ ਤਰਜੀਹ ਦੇਣਾ ਹੋਵੇਗਾ। ਤੁਸੀਂ ਦੋਹਾਂ ਨੂੰ ਇੱਕੱਠੇ ਨਹੀਂ ਰੱਖ ਸਕਦੇ।
ਤੁਸੀਂ ਕਹਿ ਰਹੇ ਹੋ: "ਮੈਂ ਰਿਸਪਾਂਸ ਤੋ ਪਹਿਲਾਂ ਸਹੀ ਹੋਣਾ ਚਾਹੁੰਦਾ/ਚਾਹੁੰਦੀ ਹਾਂ।" ਜਦੋਂ ਸਿਸਟਮ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰ ਸਕਦੀ ਕਿ ਇੱਕ ਬੇਨਤੀ ਸਾਰੀਆਂ ਰੀਪਲਿਕਾਜ਼ ਨੂੰ ਇੱਕਸਾਰ ਰੱਖੇਗੀ, ਤਾਂ ਉਹ ਬੇਨਤੀ ਨੂੰ ਫੇਲ ਜਾਂ ਰੋਕ ਦੇਵੇਗੀ।
ਵਾਸਤਵਿਕ ਪ੍ਰਭਾਵ: ਕੁਝ ਯੂਜ਼ਰ ਐਰਰ, ਟਾਈਮਆਉਟ, ਜਾਂ "ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰੋ" ਦੇਖਣਗੇ—ਖਾਸ ਕਰਕੇ ਉਹ ਕਾਰਵਾਈਆਂ ਜਿਹੜੀਆਂ ਡੇਟਾ ਬਦਲਦੀਆਂ ਹਨ। ਇਹ ਆਮ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਦੁਹਰਾਈ ਚਾਰਜ ਦੇਣ ਦੀ ਥਾਂ ਰੁੱਖਣਾ ਚਾਹੁੰਦੇ ਹੋ ਜਾਂ ਸੀਟ ਰਿਜ਼ਰਵ ਕਰਦਿਆਂ oversell ਨੂੰ ਰੋਕਣਾ ਚਾਹੁੰਦੇ ਹੋ।
ਤੁਸੀਂ ਕਹਿ ਰਹੇ ਹੋ: "ਮੈਂ ਰਾਹਤ ਵਾਲਾ ਜਵਾਬ ਦੇਣਾ ਚਾਹੁੰਦਾ/ਚਾਹੁੰਦੀ ਹਾਂ।" partition ਦੇ ਦੋਹੀ ਪਾਸੇ ਬੇਨਤੀਆਂ ਕਬੂਲ ਹੁੰਦੀਆਂ ਰਹਿਣਗੀਆਂ, ਭਾਵੇਂ ਉਹ ਕੋਆਰਡੀਨੇਟ ਨਾ ਕਰ ਸਕਣ।
ਵਾਸਤਵਿਕ ਪ੍ਰਭਾਵ: ਯੂਜ਼ਰ ਸਫਲ ਜਵਾਬ ਪ੍ਰਾਪਤ ਕਰਦੇ ਹਨ, ਪਰ ਉਹਨਾਂ ਦੇ ਵੇਖਣ ਵਾਲੇ ਡੇਟਾ ਵਿੱਚ ਪੁਰਾਣਾਪਨ ਹੋ ਸਕਦਾ ਹੈ ਅਤੇ ਸਮਕਾਲੀ ਅਪਡੇਟ ਟਕਰਾਉਂਦੀਆਂ ਹਨ। ਫਿਰ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ reconciliation 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹੋ (merge ਨਿਯਮ, last-write-wins, ਮਨੁਅਲ ਰਿਵਿਊ ਆਦਿ)।
ਹਮੇਸ਼ਾ ਇਹ ਇਕ ਵਿਅਕਤੀਗਤ ਗਲੋਬਲ ਸੈਟਿੰਗ ਨਹੀਂ ਹੁੰਦੀ। ਬਹੁਤ ਉਤਪਾਦ ਰਣਨੀਤੀਆਂ ਮਿਲਾਉਂਦੇ ਹਨ:
ਮੁੱਦਾ ਇਹ ਹੈ ਕਿ ਪ੍ਰਤੀ ਓਪਰੇਸ਼ਨ ਫੈਸਲਾ ਕਰੋ: ਹੁਣ ਯੂਜ਼ਰ ਨੂੰ ਰੋਕਣਾ ਵੱਧ ਖਰਾਬ ਹੈ ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਸੱਚ ਨੂੰ ਠੀਕ ਕਰਨਾ?
"ਦੋ ਚੁਣੋ" ਵਾਲਾ ਨਾਅਰਾ ਯਾਦ ਰਹਿਣਯੋਗ ਹੈ, ਪਰ ਇਹ ਲੋਕਾਂ ਨੂੰ ਗਲਤ ਸਮਝ ਲਾਉਂਦਾ ਹੈ ਕਿ CAP ਇੱਕ ਤਿੰਨ-ਚੀਜ਼ਾਂ ਵਾਲਾ ਮੀਨੂ ਹੈ ਜਿੱਥੇ ਤੁਸੀਂ ਸਦਾ-ਸਦਾ ਦੋ ਹੀ ਰੱਖ ਸਕਦੇ ਹੋ। CAP ਇਸ ਗੱਲ ਬਾਰੇ ਹੈ ਕਿ ਜਦੋਂ ਨੈੱਟਵਰਕ ਸਹਿਯੋਗ ਨਹੀਂ ਕਰਦਾ: partition ਦੌਰਾਨ, ਤੁਹਾਨੂੰ consistent ਜਵਾਬਾਂ ਦੇਣ ਅਤੇ ਹਰ ਬੇਨਤੀ ਲਈ ਉਪਲਬਧ ਰਹਿਣ ਦੇ ਵਿਚਕਾਰ ਚੋਣ ਕਰਨੀ ਪੈਂਦੀ ਹੈ।
ਵਾਸਤਵਿਕ ਸਿਸਟਮਾਂ ਵਿੱਚ partitions ਇਕ ਐਸਾ ਸੈਟਿੰਗ ਨਹੀਂ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ ਬੰਦ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਤੁਹਾਡਾ ਸਿਸਟਮ ਮਸ਼ੀਨਾਂ, ਰੈਕ, ਜੋਨ ਜਾਂ ਰੀਜਨਾਂ 'ਚ ਫੈਲਿਆ ਹੈ, ਤਾਂ ਸੁਨੇਹੇ ਦੇਰੀ, ਡਰੌਪ ਜਾਂ ਗਲਤ ਆਰਡਰ ਹੋ ਸਕਦੇ ਹਨ। ਇਹ ਸਾਰੇ ਸਾਫ਼-ਸੁਥਰੇ ਪਾਰਟੀਸ਼ਨ ਦੀ ਭਾਵਨਾ ਤੋਂ ਇੱਕੋ ਨਤੀਜੇ ਦਾ ਕਾਰਨ ਬਣਦੇ ਹਨ: ਨੋਡ ਇੱਕ-ਦੂਜੇ ਨਾਲ ਸਹਿਮਤ ਨਹੀਂ ਹੋ ਸਕਦੇ।
ਕਈ ਹੋਰ ਫੇਲਿਅਰ—ਓਵਰਲੋਡ, GC ਪੌਜ਼, DNS ਹਿਕਅਪ—ਉਸੇ ਪ੍ਰਭਾਵ ਨੂੰ ਪੈਦਾ ਕਰਦੇ ਹਨ।
ਐਪਲਿਕੇਸ਼ਨ ਪਾਰਟੀਸ਼ਨ ਨੂੰ ਇੱਕ ਸਾਫ਼ ਦੂਅਲ-ਸਟੇਟ ਇਵੈਂਟ ਵਜੋਂ ਨਹੀਂ ਵੇਖਦੀਆਂ; ਉਹ latency spikes ਅਤੇ timeouts ਦੇ ਤੌਰ 'ਤੇ ਹੁੰਦੇ ਹਨ। ਜੇ ਇੱਕ ਬੇਨਤੀ 200ms ਤੋਂ ਬਾਅਦ time out ਹੁੰਦੀ ਹੈ, ਤਾਂ ਇਹ ਮਾਇਨੇ ਨਹੀਂ ਰੱਖਦਾ ਕਿ ਪੈਕਟ 201ms 'ਤੇ ਪਹੁੰਚਿਆ ਜਾਂ ਕਦੇ ਵੀ ਨਹੀਂ ਪਹੁੰਚਿਆ—ਐਪ ਨੂੰ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ। ਧੀਮੀ ਸੰਚਾਰ ਆਮ ਤੌਰ 'ਤੇ ਟੁੱਟੇ ਹੋਏ ਸੰਚਾਰ ਨਾਲ ਅਣਭੇਦਯ ਹੁੰਦਾ ਹੈ।
ਅਸਲੀ ਸਿਸਟਮਾਂ ਬਹੁਤ ਹੱਦ ਤੱਕ ਯਾ ਤਾਂ consistent ਜਾਂ available ਹੋ ਸਕਦੇ ਹਨ, ਵਿਸਥਾਰ ਅਤੇ ਰਣਨੀਤੀਆਂ ਦੇ ਆਧਾਰ 'ਤੇ। ਟਾਈਮਆਉਟ, retry ਨੀਤੀਆਂ, quorum ਆਕਾਰ, ਅਤੇ "read-your-writes" ਵਿਵਸਥਾਵਾਂ ਵਰਤਾਰਾ ਬਦਲ ਸਕਦੀਆਂ ਹਨ।
ਸਧਾਰਨ ਸਥਿਤੀਆਂ ਵਿੱਚ ਇੱਕ ਡੇਟਾਬੇਸ ਮਜ਼ਬੂਤ consistent ਲੱਗ ਸਕਦਾ ਹੈ; ਦਬਾਅ ਜਾਂ cross-region hiccup ਦੌਰਾਨ ਇਹ request fail ਕਰਨਾ ਸ਼ੁਰੂ ਕਰ ਸਕਦਾ ਹੈ (consistency ਨੂੰ ਤਰਜੀਹ ਦੇਨਾ) ਜਾਂ ਪੁਰਾਣਾ ਡੇਟਾ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ (availability ਨੂੰ ਤਰਜੀਹ ਦੇਣਾ)।
CAP ਨਿਰਧਾਰਨ ਕਰਨ ਵਾਲੇ ਪ੍ਰੋਡਕਟ ਲੇਬਲਾਂ ਬਾਰੇ ਨਹੀਂ—ਇਹ ਸਮਝਾਉਂਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਕਿਸ ਤਰ੍ਹਾਂ ਦਾ ਵਪਾਰ-ਫੈਸਲਾ ਕਰ ਰਹੇ ਹੋ ਜਦੋਂ ਅਸਹਿਮਤੀ ਹੋਵੇ।
CAP ਗੱਲਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਦੋ-ਟੁਕੜਿਆਂ ਵਾਲਾ ਦਿਖਾਇਆ ਜਾਂਦਾ ਹੈ: "ਪੂਰਾ" ਜਾਂ "ਕੋਈ ਰੋਕ ਨਹੀਂ"। ਪਰ ਅਸਲ ਸਿਸਟਮਾਂ ਵਿੱਚ ਕਈ ਗੁਆਰੰਟੀਜ਼ ਹਨ, ਹਰ ਇੱਕ ਦਾ ਵੱਖਰਾ ਯੂਜ਼ਰ ਅਨੁਭਵ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਰੀਪਲਿਕਾਜ਼ ਅਸਹਿਮਤ ਹੁੰਦੇ ਹਨ ਜਾਂ ਨੈੱਟਵਰਕ ਲਿੰਕ ਭੰਗ ਹੁੰਦਾ ਹੈ।
Strong consistency (ਅਕਸਰ "linearizable") ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇੱਕ ਲਿਖਤ ਦੀ ਪੁਸ਼ਟੀ ਹੋਣ ਤੋਂ ਬਾਅਦ ਹਰ ਆਉਣ ਵਾਲੀ ਪੜ੍ਹਾਈ—ਕਿਸੇ ਵੀ ਰੀਪਲਿਕਾ ਤੋਂ—ਉਸ ਲਿਖਤ ਨੂੰ ਵਾਪਸ ਕਰੇਗੀ।
ਕੀ ਮਿਲਦਾ ਹੈ: partition ਜਾਂ ਜਦੋਂ ਕੁਝ ਰੀਪਲਿਕਾਜ਼ ਅਪਹੁੰਚ ਰਹੀਆਂ ਹਨ, ਤਾਂ ਸਿਸਟਮ ਪੜ੍ਹਾਈ/ਲਿਖਤ ਨੂੰ ਰੋਕ ਜਾਂ ਭੁੱਲ ਸਕਦੀ ਹੈ ਤਾਂ ਜੋ conflicting ਸਥਿਤੀਆਂ ਨਾ ਬਣਨ। ਯੂਜ਼ਰ ਨੂੰ ਇਹ timeout, "ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰੋ" ਜਾਂ ਅਸਥਾਈ read-only ਵਰਤਾਰਾ ਵਜੋਂ ਮਹਿਸੂਸ ਹੋ ਸਕਦਾ ਹੈ।
Eventual consistency ਇਹ ਵਾਅਦਾ ਕਰਦੀ ਹੈ ਕਿ ਜੇ ਕੋਈ ਨਵੇਂ ਅਪਡੇਟ ਨਹੀਂ ਹੋਰਹੇ, ਤਾਂ ਸਾਰੀਆਂ ਰੀਪਲਿਕਾਜ਼ ਆਖ਼ਿਰਕਾਰ ਮਿਲ ਜਾਵੇਂਗੀਆਂ। ਇਹ ਇਹ ਨਹੀਂ ਕਹਿੰਦੀ ਕਿ ਦੋ यੂज़ਰ ਇੱਕੋ ਸਮੇਂ ਪੜ੍ਹਾਈ ਕਰਦੇ ਸਮੇਂ ਇੱਕੋ ਨਤੀਜਾ ਵੇਖਣਗੇ।
ਯੂਜ਼ਰ ਜੋ ਮਹਿਸੂਸ ਕਰ ਸਕਦੇ ਹਨ: ਇੱਕ ਹਾਲੀਆ ਅਪਡੇਟ ਕੀਤੀ ਪ੍ਰੋਫਾਈਲ ਫੋਟੋ "ਵਾਪਸ" ਹੋ ਜਾਂਦੀ ਹੈ, কাউਂਟਰ ਲੈਗ ਕਰਦੇ ਹਨ, ਜਾਂ ਭੇਜਿਆ ਗਿਆ ਸੁਨੇਹਾ ਦੂਜੇ ਡਿਵਾਈਸ 'ਤੇ ਕੁਝ ਸਮੇਂ ਲਈ ਨਹੀਂ ਦਿਖਾਈ ਦੇਣਾ।
ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਪੂਰੀ strong consistency ਦੀ ਲੋੜ ਬਿਨਾਂ ਵੀ ਬਿਹਤਰੀਨ ਅਨੁਭਵ ਖਰੀਦ ਸਕਦੇ ਹੋ:
ਇਹ ਗੁਆਰੰਟੀਜ਼ ਮਨੁੱਖੀ ਸੋਚ ਨਾਲ ਵਧੀਆ ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ ("ਮੇਰੀ ਆਪਣੀ ਬਦਲੀ ਮੈਨੂੰ ਦਿਖਾਈ ਦੇਣੀ ਚਾਹੀਦੀ ਹੈ") ਅਤੇ ਅਕਸਰ ਅਸਥਾਈ ਫੇਲਿਅਰ ਦੌਰਾਨ ਕਾਇਮ ਰੱਖਣ ਲਈ ਆਸਾਨ ਹੁੰਦੀਆਂ ਹਨ।
ਯੂਜ਼ਰ ਵਾਅਦੇ (promises) ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ, ਜargon ਨਾਲ ਨਹੀਂ:
Consistency ਇੱਕ ਉਤਪਾਦੀ ਚੋਣ ਹੈ: ਇਹ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਕਿ ਯੂਜ਼ਰ ਲਈ "ਗਲਤ" ਕੀ ਹੈ, ਫਿਰ ਉਹ ਸਭ ਤੋਂ ਕਮਜ਼ੋਰ ਗੁਆਰੰਟੀ ਚੁਣੋ ਜੋ ਉਸ ਗਲਤੀ ਨੂੰ ਰੋਕੇ।
CAP ਵਿੱਚ availability ਇੱਕ ਦਾਅਵਾ ਹੁੰਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਯੂਜ਼ਰਾਂ ਨੂੰ ਕਰਦੇ ਹੋ ਕਿ ਜਦੋਂ ਸਿਸਟਮ ਨਿਸ਼ਚਿਤ ਨਹੀਂ ਹੋ ਸਕਦਾ ਤਾਂ ਤੁਸੀਂ ਕੀ ਦਿਖਾਉਗੇ।
ਜਦੋਂ ਰੀਪਲਿਕਾਜ਼ ਸਹਿਮਤ ਨਹੀਂ ਹੋ ਸਕਦੀਆਂ, ਅਕਸਰ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ:
ਯੂਜ਼ਰ ਨੂੰ ਇਹ "ਐਪ ਚੱਲਦਾ ਹੈ" ਬਨਾਮ "ਐਪ ਸਹੀ ਹੈ" ਵਜੋਂ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ। ਕੋਈ ਇਕੱਲਾ ਸਦਾ-ਸ਼੍ਰੇਸ਼ਠ ਨਹੀਂ—ਸਹੀ ਚੋਣ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ "ਗਲਤ" ਦਾ ਕੀ ਮਤਲਬ ਹੈ।
ਅਣਿਸ਼ਚਿਤਤਾ ਦੌਰਾਨ ਦੋ ਆਮ ਵਿਹਾਰ:
ਇਹ ਸਿਰਫ਼ ਤਕਨੀਕੀ ਫੈਸਲਾ ਨਹੀਂ—ਇੱਕ ਨੀਤੀ-ਅਧਾਰਤ ਫੈਸਲਾ ਹੈ। ਉਤਪਾਦ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ ਕਿ ਕੀ ਦਿਖਾਉਣਾ ਮਨਜ਼ੂਰ ਹੈ ਅਤੇ ਕੀ ਕਦੇ ਵੀ ਅਨੁਮਾਨ ਨਹੀਂ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ।
ਉਪਲਬਧਤਾ ਬਹੁਤ ਘੱਟ-ਸਪਸ਼ਟ ਨਹੀਂ ਹੁੰਦੀ। ਇੱਕ ਸਪਲਿੱਟ ਦੌਰਾਨ ਤੁਸੀਂ ਭਾਗੀਦਾਰ ਉਪਲਬਧਤਾ ਦੇਖ ਸਕਦੇ ਹੋ: ਕੁਝ ਰੀਜਨਾਂ, ਨੈੱਟਵਰਕ ਜਾਂ ਯੂਜ਼ਰ ਗਰੁੱਪ ਸਫਲ ਹੋ ਸਕਦੇ ਹਨ ਜਦਕਿ ਹੋਰ fail। ਇਹ ਜਾਂ ਤਾਂ ਇਰਾਦਤੀ ਡਿਜ਼ਾਈਨ ਦਾ ਨਤੀਜਾ ਹੋ ਸਕਦਾ ਹੈ (ਜਿੱਥੇ ਲੋਕਲ ਰੀਪਲਿਕਾ ਸੇਵਾ ਜਾਰੀ ਰੱਖਦੀ ਹੈ) ਜਾਂ ਅਣਜਾਣਾ (routing imbalance, unequal quorum reach)।
ਇੱਕ ਕਾਰਗਰ ਦਰਮਿਆਨਾ ਰਵਾਇਤ degraded mode ਹੈ: ਸੁਰੱਖਿਅਤ ਕਾਰਵਾਈਆਂ ਜਾਰੀ ਰੱਖੋ ਅਤੇ ਜੋਖਮ ਵਾਲੀਆਂ ਨੂੰ ਸੀਮਤ ਕਰੋ। ਉਦਾਹਰਣ ਵਜੋਂ, browse ਅਤੇ search ਅਨੁਮਤ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ "fund transfer", "password change" ਵਰਗੀਆਂ ਕਾਰਵਾਈਆਂ ਨੂੰ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਨਿਰਧਾਰਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
CAP ਆਬਸਟ੍ਰੈਕਟ ਲੱਗਦਾ ਹੈ ਜਦ ਤੱਕ ਤੁਸੀਂ ਇਸਨੂੰ ਵੇਖਦੇ ਨਹੀਂ ਕਿ ਨੈੱਟਵਰਕ ਸਪਲਿੱਟ ਦੌਰਾਨ ਤੁਹਾਡੇ ਯੂਜ਼ਰਾਂ ਦੇ ਨਾਲ ਕੀ ਹੁੰਦਾ: ਤੁਹਾਨੂੰ ਪਸੰਦ ਹੈ ਕਿ ਸਿਸਟਮ ਜਾਰੀ ਰੱਖੇ ਜਾਂ ਰੁੱਕ ਕੇ conflicting ਡੇਟਾ ਨੂੰ ਰੋਕੇ?
ਜਿਵੇਂ ਦੋ ਡੇਟਾ ਸੈਂਟਰ ਇਕੋ ਸਮੇਂ orders ਕਬੂਲ ਕਰਦੇ ਹਨ:
ਪੈਸਾ ਆਮ ਤੌਰ 'ਤੇ "ਗਲਤ ਹੋਣਾ ਮਹਿੰਗਾ" ਵਲੋਂ ਹੁੰਦਾ ਹੈ। ਜੇ ਵੰਡ ਦੌਰਾਨ ਦੋ ਰੀਪਲਿਕਾਜ਼ ਅਲੱਗ ਅਲਗ ਵੱਧੋਂ-ਕਾਢੇ ਲੈ ਲੈਂਦੇ ਹਨ, ਤਾਂ ਇੱਕ ਅਕਾਊਂਟ ਨੇਗਟਿਵ ਹੋ ਸਕਦਾ ਹੈ।
ਇਸ ਲਈ ਬਹੁਤ ਸਿਸਟਮ ਅਹੰਕਾਰਤ: ਲਿਖਤਾਂ ਲਈ consistency ਤਰਜੀਹ ਦਿੰਦੀਆਂ ਹਨ; ਜੇ ਬੈਲੈਂਸ ਦੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਹੋ ਸਕਦੀ ਤਾਂ ਕਾਰਵਾਈ ਇਨਕਾਰ ਜਾਂ ਦੇਰੀ ਕਰ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ। ਤੁਸੀਂ ਕੁਝ ਉਪਲਬਧਤਾ (ਟੈਮਪ ਫੇਲ) ਤਬਦੀਲ ਕਰਦੇ ਹੋ ਪਰ ਸਹੀਤਾ, ਇੱਕੌਰਿਟੀ ਅਤੇ ਭਰੋਸੇ ਲਈ।
ਚੈਟ ਅਤੇ ਸੋਸ਼ਲ ਫੀਡਾਂ ਵਿੱਚ ਯੂਜ਼ਰ ਆਮ ਤੌਰ 'ਤੇ ਛੋਟੀ-ਮਿਆਦ ਦੀ ਅਸਹਿਮਤੀ ਸਹਿਣ ਕਰ ਲੈਂਦੇ ਹਨ: ਇੱਕ ਸੁਨੇਹਾ ਕੁਝ ਸਕਿੰਟ ਮਗਰੋਂ ਆਵੇ, ਲਾਈਕਾਂ ਦੀ ਗਿਣਤੀ ਥੋੜ੍ਹੀ ਵਿਲੰਬਤ ਹੋਵੇ।
ਇੱਥੇ, ਉਪਲਬਧਤਾ ਲਈ ਡਿਜ਼ਾਈਨ ਇੱਕ ਚੰਗੀ ਉਤਪਾਦੀ ਚੋਣ ਹੋ ਸਕਦੀ ਹੈ, ਜੇ ਤੱਕ ਤੁਸੀਂ ਸਪਸ਼ਟ ਹੋ ਕਿ ਕਿਹੜੇ ਤੱਤ "ਅੰਤਮ ਰੂਪ ਵਿੱਚ ਸਹੀ" ਹੋਣਗੇ ਅਤੇ ਤੁਸੀਂ ਅਪਡੇਟਾਂ ਨੂੰ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਮਿਲਾ ਸਕਦੇ ਹੋ।
"ਠੀਕ" CAP ਚੋਣ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਗਲਤ ਹੋਣ ਦੀ ਲਾਗਤ ਕਿੰਨੀ ਹੈ: ਰੀਫੰਡ, ਕਾਨੂੰਨੀ ਜ਼ਿੰਮੇਵਾਰੀ, ਯੂਜ਼ਰ ਭਰੋਸਾ, ਜਾਂ ਓਪਰੇਸ਼ਨਲ ਗੜਬੜ। ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕਿੱਥੇ ਤੁਸੀਂ ਅਸਥਾਈ ਸਟੇਲੇਨਸ ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ—ਅਤੇ ਕਿੱਥੇ ਤੁਹਾਨੂੰ fail-closed ਕਰਨਾ ਜ਼ਰੂਰੀ ਹੈ।
ਜਦੋਂ ਤੁਸੀਂ ਇਹ ਤੈਅ ਕਰ ਲੈਂਦੇ ਹੋ ਕਿ partition ਦੌਰਾਨ ਤੁਸੀਂ ਕੀ ਕਰੋਗੇ, ਤੁਹਾਨੂੰ ਐਸੀ ਮਕੈਨਿਜ਼ਮ ਚਾਹੀਦੀਆਂ ਹਨ ਜੋ ਉਸ ਚੋਣ ਨੂੰ ਅਸਲੀਅਤ ਬਣਾਉਣ। ਇਨ੍ਹਾਂ ਪੈਟਰਨਾਂ ਨੂੰ ਡਾਟਾਬੇਸ, ਮੈਸੇਜ ਸਿਸਟਮ ਅਤੇ APIs ਵਿੱਚ ਮਿਲਦਾ ਹੈ—ਭਾਵੇਂ ਉਤਪਾਦ ਕਿਸੇ ਵੀ ਨਾਮ ਨਾਲ CAP ਦਾ ਜ਼ਿਕਰ ਨਾ ਕਰੇ।
Quorum ਸੀਧਾ ਵਿਚਾਰ ਹੈ: ਜੇ ਤੁਹਾਡੇ ਕੋਲ 5 ਕਾਪੀਆਂ ਹਨ, majority 3 ਹੈ।
ਪੜ੍ਹਾਈਆਂ ਅਤੇ/ਜਾਂ ਲਿਖਤਾਂ ਲਈ majority ਦੀ ਲੋੜ ਰਖ ਕੇ ਤੁਸੀਂ stale ਜਾਂ conflicting ਡੇਟਾ ਘਟਾ ਸਕਦੇ ਹੋ। ਉਦਾਹਰਣ ਵਜੋਂ, ਜੇ ਲਿਖਤ ਨੂੰ 3 ਰੀਪਲਿਕਾ ਨਿਰਾਕਰਤਾ ਦੇਣੀ ਪੈਂਦੀ ਹੈ, ਤਾਂ ਦੋ ਅਲੱਗ ਗਰੁੱਪਾਂ ਦੁਆਰਾ ਵੱਖ-ਵੱਖ ਸੱਚਾਈਆਂ ਕਬੂਲ ਹੋਣ ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੋ ਜਾਂਦੀ ਹੈ।
ਟਰੇਡਆਫ਼: ਤੇਜ਼ੀ ਅਤੇ ਪਹੁੰਚ। ਜੇ ਤੁਹਾਨੂੰ majority ਤੱਕ ਪਹੁੰਚ ਨਹੀਂ ਮਿਲਦੀ, ਸਿਸਟਮ ਆਪਰੇਸ਼ਨ ਰੱਦ ਕਰ ਸਕਦਾ ਹੈ—consistency ਨੂੰ availability 'ਤੇ ਤਰਜੀਹ ਦੇਣਾ।
ਕਈ "ਉਪਲਬਧਤਾ" ਮੁੱਦੇ ਸਖ਼ਤ ਫੇਲਿਅਰ ਨਹੀਂ ਪਰ ਧੀਮੇ ਜਵਾਬ ਹਨ। ਛੋਟਾ timeout ਸਿਸਟਮ ਨੂੰ ਤੇਜ਼ ਮਹਿਸੂਸ ਕਰਾ ਸਕਦਾ ਹੈ, ਪਰ ਇਸ ਨਾਲ ਤੁਸੀਂ slow-successes ਨੂੰ ਫੇਲ ਮੰਨ ਲੈ ਸਕਦੇ ਹੋ।
Retries transient blips ਨੂੰ ਠੀਕ ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਜ਼ਬਰਦਸਤ retries ਪਹਿਲਾਂ ਹੀ ਸੰਘਣੇ ਸਰਵਿਸ ਨੂੰ ਓਵਰਲੋਡ ਕਰ ਸਕਦੇ ਹਨ। backoff (retryਾਂ ਵਿੱਚ ਵਧੇਰੇ ਦੇਰ) ਅਤੇ jitter (randomness) retries ਤੋਂ traffic spike ਨੂੰ ਰੋਕਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਮੁੱਖ ਗੱਲ: ਤੁਹਾਡੇ ਨਿਰਧਾਰਾਂ ਨੂੰ ਤੁਹਾਡੇ ਵਾਅਦੇ ਨਾਲ ਜੋੜੋ—"ਹਮੇਸ਼ਾ ਜਵਾਬ ਦੇਣਾ" ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਵਧੇਰੇ retries ਅਤੇ fallback ਲੋੜੀਂਦੇ ਹਨ; "ਕਦੇ ਵੀ ਝੂਠ ਨਹੀਂ" ਲਈ ਕਸਰਤੀਆਂ ਅਤੇ ਸਾਫ਼ ਐਰਰ ਚਾਹੀਦੇ ਹਨ।
ਜੇ ਤੁਸੀਂ partition ਦੌਰਾਨ ਉਪਲਬਧ ਰਹਿਣਾ ਚੁਣਦੇ ਹੋ, ਰੀਪਲਿਕਾਜ਼ ਵੱਖ-ਵੱਖ ਅਪਡੇਟ ਕਬੂਲ ਕਰ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ reconcile ਕਰਨਾ ਪੈਣਾ—ਆਮ ਤਰੀਕੇ:
Retries duplicates ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ: ਕਰਡ ਨੂੰ ਦੁਬਾਰਾ ਚਾਰਜ ਕਰਨਾ ਜਾਂ ਇੱਕੋ ਆਰਡਰ ਦੋ ਵਾਰੀ ਸਭਮਿਟ ਹੋ ਜਾਣਾ। Idempotency ਇਸਨੂੰ ਰੋਕਦੀ ਹੈ।
ਆਮ ਪੈਟਰਨ ਇੱਕ idempotency key (request ID) ਹੈ ਜੋ ਹਰ ਬੇਨਤੀ ਨਾਲ ਭੇਜਿਆ ਜਾਂਦਾ ਹੈ। ਸਰਵਰ ਪਹਿਲਾ ਨਤੀਜਾ ਸਟੋਰ ਕਰਦਾ ਹੈ ਅਤੇ ਮੁੜ ਆਉਣ 'ਤੇ ਉੱਕੇ ਨਤੀਜੇ ਨੂੰ ਵਾਪਸ ਕਰਦਾ ਹੈ—ਇਸ ਤਰ੍ਹਾਂ retries ਉਪਲਬਧਤਾ ਵਧਾਉਂਦੇ ਹਨ ਬਿਨਾਂ ਡੇਟਾ ਖਰਾਬ ਕੀਤੇ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ whiteboard 'ਤੇ CAP ਰੁਕਾਵਟ ਚੁਣ ਲੈਂਦੀਆਂ ਹਨ—ਫਿਰ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਪਤਾ ਲੱਗਦਾ ਹੈ ਕਿ ਸਿਸਟਮ ਦਬਾਅ ਹੇਠਾਂ ਵੱਖਰਾ ਵਿਹਾਰ ਕਰਦਾ ਹੈ। ਵੈਰੀਫਿਕੇਸ਼ਨ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਉਹ ਹਾਲਾਤ ਜਾਣ-ਬੁੱਝ ਕੇ ਬਣਾਓ ਜਿੱਥੇ CAP ਟਰੇਡਆਫਜ਼ ਝਲਕਦੇ ਹਨ ਅਤੇ ਦੇਖੋ ਕਿ ਤੁਹਾਡੀ ਸਿਸਟਮ ਡਿਜ਼ਾਇਨ ਮੁਤਾਬਕ ਵਰਤਦੀ ਹੈ ਕਿ ਨਹੀਂ।
ਤੁਹਾਨੂੰ ਕਿਸੇ ਅਸਲ ਕੇਬਲ ਕਟ ਦੀ ਲੋੜ ਨਹੀਂ: staging (ਅਤੇ ਸੰਭਲ ਕੇ production) ਵਿੱਚ ਨਿਯੰਤਰਿਤ fault injection ਨਾਲ partitions simulate ਕਰੋ:
ਲਕੜ ਦਾ ਮਕਸਦ ਸਪਸ਼ਟ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਲੈਣਾ ਹੈ: ਲਿਖਤ ਰੱਦ ਹੋ ਰਹੇ ਹਨ ਜਾਂ ਕਬੂਲ? ਪੜ੍ਹਾਈ stale ਹਨ? ਸਿਸਟਮ ਆਪਣੇ ਆਪ recover ਕਰਦਾ ਹੈ ਅਤੇ reconciliation ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਦਾ ਹੈ?
ਜੇ ਤੁਸੀਂ ਇਹ ਪ੍ਰਵਿਰਤੀ ਪਹਿਲਾਂ ਹੀ ਪਰਖਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਛੋਟਾ ਰੀਐਜ਼ ਲਈ prototype ਘੜ੍ਹਨਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ—ਕਈ ਟੀਮਾਂ Koder.ai ਵਰਤਦੇ ਹੋਏ ਤੁਰੰਤ Go + PostgreSQL + React sandbox ਬਣਾਉਂਦੀਆਂ ਹਨ ਅਤੇ retries, idempotency ਅਤੇ degraded-ਫਲੋ ਨੂੰ ਅਜਮਾਂਦੀਆਂ ਹਨ।
ਰਿਵਾਇਤੀ uptime checks "ਉਪਲਬਧ ਪਰ ਗਲਤ" ਵਿਹਾਰ ਪਕੜ ਨਹੀਂ ਪਾਉਂਦੇ। ਇਹ ਚੀਜ਼ਾਂ ਟਰੈਕ ਕਰੋ:
ਓਪਰੇਟਰਾਂ ਲਈ ਪਹਿਲਾਂ ਤੋਂ ਤੈਅ ਕੀਤੀਆਂ ਕਾਰਵਾਈਆਂ ਚਾਹੀਦੀਆਂ ਹਨ ਜਦੋਂ partition ਹੁੰਦਾ ਹੈ: ਕਦੋਂ writes freeze ਕਰਨੇ ਹਨ, ਕਦੋਂ fail over ਕਰਨਾ ਹੈ, ਕਦੋਂ features degrade ਕਰਨੇ ਹਨ, ਅਤੇ re-merge safety ਦੀ ਪੁਸ਼ਟੀ ਕਿਵੇਂ ਕਰਨੀ ਹੈ।
ਇਸ ਦੇ ਨਾਲ ਯੂਜ਼ਰ-ਦਿਖਾਈ ਜਾਣ ਵਾਲਾ ਰਵਾਇਤੀ ਸੰਸ਼ੇਧਨ ਵੀ ਯੋਜਿਤ ਕਰੋ। ਜੇ ਤੁਸੀਂ consistency ਚੁਣਦੇ ਹੋ, ਤਾਂ ਸੁਨੇਹਾ ਹੋ ਸਕਦਾ ਹੈ "ਅਸੀਂ ਤੁਹਾਡੀ ਅਪਡੇਟ ਦੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕਰ ਸਕਦੇ—ਕਿਰਪਾ ਕਰਕੇ ਫਿਰ ਕੋਸ਼ਿਸ਼ ਕਰੋ।" ਜੇ ਤੁਸੀਂ availability ਚੁਣਦੇ ਹੋ, ਤਾਂ ਸਪਸ਼ਟ ਹੋਵੋ: "ਤੁਹਾਡੀ ਅਪਡੇਟ ਕੁਝ ਮਿੰਟਾਂ ਵਿੱਚ ਹਰ ਜਗ੍ਹਾ ਦਿਖਾਈ ਦੇ ਸਕਦੀ ਹੈ।" ਸਾਫ਼ ਸ਼ਬਦਾਂ ਨਾਲ ਵਿਆਖਿਆ incidente ਬੋਝ ਘੱਟ ਕਰਦੀ ਹੈ ਅਤੇ ਭਰੋਸਾ ਬਚਾਉਂਦੀ ਹੈ।
CAP ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਤੁਰੰਤ "ਕੋਣ-ਸੀ ਚੀਜ਼ ਸਪਲਿੱਟ ਹੋਣ ਤੇ ਟੁੱਟੇਗੀ?" ਦੀ ਆਡੀਟ ਵਜੋਂ ਲਾਭਕਾਰੀ ਹੈ—ਨਕਲ ਦਰ ਥਿਆਰ ਜਾਣ-ਬਿਨਾਂ ਸਿਧਾਂਤਿਕ ਚਰਚਾ ਨਹੀਂ। ਇਸ ਚੈੱਕਲਿਸਟ ਨੂੰ ਡੇਟਾਬੇਸ ਫੀਚਰ, caching ਰਣਨੀਤੀਆਂ ਜਾਂ ਨਕਲ ਮੋਡ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਵਰਤੋ।
ਇਹਨਾਂ ਨੂੰ ਪਹਿਲੇ ਕ੍ਰਮ ਵਿੱਚ ਪੁੱਛੋ:
ਇਹ ਤੈਅ ਕਰਨ 'ਤੇ ਕਿ partition ਆ ਜਾਂਦਾ ਹੈ, ਤੁਸੀਂ ਇਹ ਨਿਰਧਾਰਤ ਕਰ ਰਹੇ ਹੋ ਕਿ ਪਹਿਲਾਂ ਕਿਹੜੀ ਚੀਜ਼ ਦੀ ਰੱਖਿਆ ਕਰਾਂ।
ਇੱਕ ਗਲੋਬਲ ਸੈਟਿੰਗ "ਅਸੀਂ AP ਹਾਂ" ਤੋਂ ਬਚੋ। ਇਸ ਦੀ ਥਾਂ, ਪ੍ਰਤੀ:
ਉਦਾਹਰਣ: ਇੱਕ ਸਪਲਿੱਟ ਦੌਰਾਨ ਤੁਸੀਂ payments ਲਈ writes ਰੋਕ ਸਕਦੇ ਹੋ (consistency ਪ੍ਰਭਵਤ) ਪਰ product_catalog ਲਈ cached reads ਉਪਲਬਧ ਰੱਖ ਸਕਦੇ ਹੋ।
ਉਹਨਾਂ ਚੀਜ਼ਾਂ ਨੂੰ ਲਿਖੋ ਜੋ ਤੁਸੀਂ ਸਹਣ ਕਰ ਸਕਦੇ ਹੋ, ਉਦਾਹਰਣਾਂ ਨਾਲ:
ਜੇ ਤੁਸੀਂ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਅਸਮਰਥਾ ਦੇ ਉਦਾਹਰਣ ਨਹੀਂ ਦੇ ਸਕਦੇ, ਤਾਂ ਉਸ ਨੂੰ ਟੈਸਟ ਕਰਨ ਅਤੇ ਘਟਨਾ ਸਮਝਾਉਣ ਵਿੱਚ ਮੁਸ਼ਕਲ ਆਏਗੀ।
ਅੱਗੇ ਪੜ੍ਹਨ ਲਈ ਉਪਯੁਕਤ ਵਿਸ਼ੇ: consensus, consistency models, ਅਤੇ SLOs/error budgets.
CAP ਇੱਕ मानसिक ਮਾਡਲ ਹੈ ਜੋ ਨਕਲ ਕੀਤੇ ਸਿਸਟਮਾਂ ਵਿੱਚ ਸੰਚਾਰ ਦੀ ਤਰੁੱਟੀ ਦੇ ਸਮੇਂ ਇੰਜੀਨੀਅਰਾਂ ਨੂੰ ਸੋਚਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਵਧ ਕੇ ਉਸ ਵੇਲੇ ਲਾਗੂ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਨੈੱਟਵਰਕ ਧੀਮਾ, ਪੈਕੇਟ ਗੁੰਮ ਜਾਂ ਵੰਡ-ਵਿੱਚਕਾਰ ਦੀ ਸਥਿਤੀ ਬਨੀ ਹੋਵੇ, ਕਿਉਂਕਿ ਉਸ ਵਕਤ ਰੀਪਲਿਕਾਜ਼ ਭਰੋਸੇਯੋਗ ਤੌਰ ਤੇ ਸਹਿਮਤ ਨਹੀਂ ਹੋ ਸਕਦੇ ਅਤੇ ਤੁਹਾਨੂੰ ਨੀਮਨਲਿਖਤ ਵਿੱਚੋਂ ਇਕ ਚੁਣਨਾ ਪੈਂਦਾ ਹੈ:
ਇਹ "ਵੰਡੇ ਹੋਣ" ਦੀ ਪਰਿਸਥਿਤੀ ਨੂੰ ਠੋਸ ਉਤਰੇਖੇ ਤੇ ਉਤਾਰਦਾ ਹੈ ਅਤੇ ਨਿਰਣਿਆਂ ਨੂੰ ਉਤਪਾਦ ਅਤੇ ਇੰਜੀਨੀਅਰਿੰਗ ਬਿੰਦੂ-ਨਜ਼ਰ ਤੋਂ ਸਪਸ਼ਟ ਕਰਦਾ ਹੈ।
ਇੱਕ ਅਸਲੀ CAP ਸਥਿਤੀ ਲਈ ਦੋ ਚੀਜ਼ਾਂ ਲਾਜ਼ਮੀ ਹਨ:
ਜੇ ਤੁਹਾਡੀ ਸਿਸਟਮ ਇਕਲੌਤਾ ਨੋਡ ਹੈ ਜਾਂ ਤੁਸੀਂ ਸਟੇਟ ਨੂੰ ਨਕਲ ਨਹੀਂ ਕਰਦੇ, ਤਾਂ CAP ਦੌਰਾਨ ਹੋਣ ਵਾਲੀਆਂ ਟਰੇਡ-ਆਫ਼ ਮੁੱਖ ਸਮੱਸਿਆ ਨਹੀਂ ਹੁੰਦੀਆਂ।
ਪਾਰਟੀਸ਼ਨ ਉਹ ਕੋਈ ਵੀ ਸਥਿਤੀ ਹੈ ਜਿੱਥੇ ਤੁਹਾਡੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਵਧੀਆ ਤਰ੍ਹਾਂ ਨਾਲ ਸੰਚਾਰ ਨਹੀਂ ਕਰ ਪਾ ਰਹੇ ਹੱਲਾਂ—ਭਾਵੇਂ ਹਰੇਕ ਮਸ਼ੀਨ ਚੱਲ ਰਹੀ ਹੋਵੇ।
ਅਮਲ ਵਿੱਚ, “ਪਾਰਟੀਸ਼ਨ” ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਤਰਾਂ ਦਿਖਾਈ ਦਿੰਦੀ ਹੈ:
ਐਪਲੀਕੇਸ਼ਨ ਦੇ ਲਈ, “ਬਹੁ ਜ਼ਿਆਦਾ ਦੇਰ” ਅਕਸਰ “ਡਾਊਨ” ਦੇ ਬਰਾਬਰ ਹੁੰਦੀ ਹੈ।
Consistency (C) ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਪੜ੍ਹਾਈ ਉਸ ਤਾਜ਼ਾ ਲਿਖਤ ਨੂੰ ਦਰਸਾਵੇ ਜੋ ਮੰਨਤਾ ਪ੍ਰਾਪਤ ਹੋ ਚੁੱਕੀ ਹੈ—ਯਾਨੀ ਤੁਸੀਂ ਇਹ ਮਹਿਸੂਸ ਕਰਦੇ ਹੋ "ਮੈਂ ਇਹ ਬਦਲਿਆ, ਅਤੇ ਹਰ ਕੋਈ ਇਹੀ ਨਵਾਂ ਮੁੱਲ ਵੇਖਦਾ ਹੈ।"
Availability (A) ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਹਰ ਬੇਨਤੀ ਨੂੰ ਇੱਕ ਸਫਲ ਜਵਾਬ ਮਿਲਦਾ ਹੈ (ਲੋੜੀ ਦਾ ਨਵੀਨਤਮ ਡੇਟਾ ਨਹੀਂ ਹੋ ਸਕਦਾ)। ਯੂਜ਼ਰ ਲਈ ਇਹ ਇਸ ਤਰ੍ਹਾਂ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ: "ਐਪ ਚੱਲਦਾ ਰਹਿੰਦਾ ਹੈ," ਬੇਸ਼ੱਕ ਨਤੀਜੇ ਥੋੜ੍ਹੇ ਪੁਰਾਣੇ ਹੋ ਸਕਦੇ ਹਨ।
ਪਾਰਟੀਸ਼ਨ ਦੌਰਾਨ, ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਦੋਹਾਂ ਨੂੰ ਇੱਕਸਮੇਂ ਸ਼ੁਰੂ ਨਹੀਂ ਰੱਖ ਸਕਦੇ।
ਕਿਉਂਕਿ ਜੇ ਤੁਸੀਂ ਡੇਟਾ ਨਕਲ ਕਰਦੇ ਹੋ ਤੇ ਸਿਸਟਮ ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨਾਂ, ਰੈਕ, ਜੋਨ ਜਾਂ ਰੀਜਨਾਂ 'ਚ ਫੈਲਿਆ ਹੈ, ਤਾਂ ਸੰਚਾਰ-ਤਰੁੱਟੀਆਂ unavoidable ਹਨ। ਨੋਡਾਂ ਵਿਚਾਲੇ ਪੈਕੇਟ ਦੇਰ ਨਾਲ ਆ ਸਕਦੇ ਹਨ, ਕਦੇ-ਕਦੇ ਗੁੰਮ ਹੋ ਜਾਂਦੇ ਹਨ ਜਾਂ ਦੁਬਾਰਾ ਆਰਡਰ ਹੋ ਜਾਂਦੇ ਹਨ।
ਇਸ ਲਈ “partition ਨੂੰ ਨਜ਼ਰਅੰਦਾਜ਼ ਕਰੋ” ਇੱਕ ਆਪਸ਼ਨ ਨਹੀਂ—ਤੁਹਾਨੂੰ ਤੈਅ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ partition ਹੋਣ ਤੇ ਸਿਸਟਮ ਕਿਵੇਂ ਵਰਤੇਗਾ: ਕੁਝ ਕਾਰਵਾਈਆਂ ਨੂੰ ਰੋਕੋ (consistency) ਜਾਂ ਬਿਹਤਰ-ਚੇਤਨਾ ਜਵਾਬ ਦਿਓ (availability)।
ਜੇ ਤੁਸੀਂ consistency ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਆਮ ਤੌਰ ਤੇ ਤੁਸੀਂ:
ਇਹ ਪੈਸਾ-ਅਪ੍ਰੇਸ਼ਨ, ਇਨਵੈਂਟਰੀ ਰਿਜ਼ਰਵੇਸ਼ਨ ਆਦਿ ਵਾਂਗ ਤਰਲ ਨਹੀਂ ਹੋ ਸਕਦੇ—ਇਹਨਾਂ ਵਿੱਚ ਗਲਤੀ ਮਹਿੰਗੀ ਪੈ ਸਕਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ availability ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਆਮ ਤੌਰ ਤੇ ਤੁਸੀਂ:
ਯੂਜ਼ਰ ਘੱਟ ਕਠੋਰ ਗਲਤੀਆਂ ਦੇਖਦੇ ਹਨ ਪਰ ਡੈਟਾ stale ਹੋ ਸਕਦਾ ਹੈ ਜਾਂ ਕਾਨਫ਼ਲਿਕਟ ਹੋ ਕੇ ਹੱਲ ਦੀ ਲੋੜ ਪੈ ਸਕਦੀ ਹੈ।
ਹਾਂ — ਤੁਸੀਂ endpoint ਜਾਂ ਡੇਟਾ-ਕਿਸਮ ਮੁਤਾਬਕ ਵੱਖਰੇ ਚੋਣ ਕਰ ਸਕਦੇ ਹੋ। ਆਮ ਮਿਕਸ ਰਣਨੀਤੀਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਇਸ ਤਰ੍ਹਾਂ ਇੱਕ ਗਲੋਬਲ "ਅਸੀਂ AP/CP ਹਾਂ" ਲੇਬਲ ਦੁਰੁਸਤ ਨਹੀਂ ਰਹਿੰਦਾ।
ਪ੍ਰਯੋਗੀ ਵਿਕਲਪਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਪ੍ਰਮਾਣਿਤ ਕਰਨ ਲਈ ਉਹਨਾਂ ਹਾਲਾਤਾਂ ਨੂੰ ਵੇਖੋ ਜਿੱਥੇ ਵਿਵਾਦ ਪਟਿਆ ਹੋ ਕੇ ਦਿਖਾਈ ਦੇਵੇ:
ਕੁਝ ਟੀਮਾਂ ਵਰਗੀਆਂ ਚੀਜ਼ਾਂ ਨੂੰ ਜਲਦੀ ਪਰਖਣ ਲਈ Koder.ai ਵਰਤਦੀਆਂ ਹਨ—ਇੱਕ ਛੋਟਾ Go ਬੈਕਐਂਡ PostgreSQL ਅਤੇ React UI ਤੁਰੰਤ ਖੜਾ ਕਰਕੇ retries, idempotency ਅਤੇ degraded-ਫਲੋ ਦਾ ਸੈਂਡਬਾਕਸ ਵਿੱਚ ਅਭਿਆਸ ਕਰ ਸਕਦੇ ਹਨ।
ਉਦੇਸ਼ ਇਹ ਹੈ ਕਿ ਉਹ ਸਭ ਤੋਂ ਕਮਜ਼ੋਰ ਗਾਰੰਟੀ ਚੁਣੋ ਜੋ ਯੂਜ਼ਰ-ਜ਼ਾਹਿਰ "ਗਲਤ" ਹੋਣ ਨੂੰ ਰੋਕਦੀ ਹੋ।