06 ਅਗ 2025·8 ਮਿੰਟ
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਕੰਟਰੋਲ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਸਿੱਖੋ ਕਿ ਇੱਕ ਐਸਾ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਡਿਜ਼ਾਈਨ ਅਤੇ ਬਣਾਇਆ ਜਾਵੇ ਜੋ ਚੈਨਲਾਂ 'ਚੋਂ ਨੋਟੀਫਿਕੇਸ਼ਨਾਂ ਨੂੰ ਕੇਂਦਰੀਕ੍ਰਿਤ ਕਰੇ—ਰਾਊਟਿੰਗ ਨਿਯਮ, ਟੈਂਪਲੇਟ, ਯੂਜ਼ਰ ਪਸੰਦਾਂ ਅਤੇ ਡਿਲਿਵਰੀ ਟ੍ਰੈਕਿੰਗ ਸਮੇਤ।
ਸਿੱਖੋ ਕਿ ਇੱਕ ਐਸਾ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਡਿਜ਼ਾਈਨ ਅਤੇ ਬਣਾਇਆ ਜਾਵੇ ਜੋ ਚੈਨਲਾਂ 'ਚੋਂ ਨੋਟੀਫਿਕੇਸ਼ਨਾਂ ਨੂੰ ਕੇਂਦਰੀਕ੍ਰਿਤ ਕਰੇ—ਰਾਊਟਿੰਗ ਨਿਯਮ, ਟੈਂਪਲੇਟ, ਯੂਜ਼ਰ ਪਸੰਦਾਂ ਅਤੇ ਡਿਲਿਵਰੀ ਟ੍ਰੈਕਿੰਗ ਸਮੇਤ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਮੈਨੇਜਮੈਂਟ ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਹਾਡੇ ਪ੍ਰੋਡਕਟ ਵੱਲੋਂ ਭੇਜੇ ਜਾਣ ਵਾਲੇ ਹਰ ਸੁਨੇਹੇ — ਈਮੇਲ, SMS, ਪੁਸ਼, ਇਨ-ਐਪ ਬੈਨਰ, Slack/Teams, webhook callbacks — ਇੱਕ ਹੀ ਸਹਯੋਗੀ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਵੱਜੋਂ ਵੇਖੇ ਜਾਣ।
ਹਰ ਫੀਚਰ ਟੀਮ ਆਪਣਾ “ਮੇਸੇਜ ਭੇਜੋ” ਲੋਜਿਕ ਬਣਾਉਣ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਇੱਕ ਐਸੀ ਜਗ੍ਹਾ ਬਣਾਉਂਦੇ ਹੋ ਜਿੱਥੇ ਇਵੈਂਟ ਆਉਂਦੇ ਹਨ, ਨਿਯਮ ਫੈਸਲਾ ਕਰਦੇ ਹਨ ਕਿ ਕੀ ਹੋਵੇ, ਅਤੇ ਡਿਲਿਵਰੀਆਂ ਆਖਿਰ ਤੱਕ ਟ੍ਰੈਕ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ।
ਜਦੋਂ ਨੋਟੀਫਿਕੇਸ਼ਨ ਸੇਵਾਵਾਂ ਅਤੇ ਕੋਡਬੇਸਾਂ ਵਿੱਚ ਫੈਲੇ ਹੋਏ ਹੁੰਦੇ ਹਨ, ਤੇਜ਼ੀ ਨਾਲ ਇੱਕੋ ਹੀ ਸਮੱਸਿਆਵਾਂ ਵਾਪਰਦੀਆਂ ਹਨ:
ਕੇਂਦਰੀਕ੍ਰਿਤੀਕਰਨ ਅਡ-ਹਾਕ ਭੇਜਣ ਨੂੰ ਇੱਕ ਸਥਿਰ ਵਰਕਫਲੋ ਨਾਲ ਬਦਲ ਦਿੰਦਾ ਹੈ: ਇੱਕ ਇਵੈਂਟ ਬਣਾਉ, ਪਸੰਦਾਂ ਅਤੇ ਨਿਯਮ ਲਗਾਓ, ਟੈਂਪਲੇਟ ਚੁਣੋ, ਚੈਨਲ ਰਾਹੀਂ ਡਿਲਿਵਰ ਕਰੋ, ਅਤੇ ਨਤੀਜੇ ਦਰਜ ਕਰੋ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਆਮ ਤੌਰ 'ਤੇ ਸੇਵਾ ਕਰਦਾ ਹੈ:
ਤੁਸੀਂ ਜਾਣੋਗੇ ਕਿ ਰਵਾਇਤ ਕੰਮ ਕਰ ਰਹੀ ਹੈ ਜਦੋਂ:
ਆਰਕੀਟੈਕਚਰ ਤਿਆਰ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸੰਗਠਨ ਲਈ “ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਕੰਟਰੋਲ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਸਪਸ਼ਟ ਲੋੜਾਂ ਪਹਿਲੀ ਵਰਜਨ ਨੂੰ ਫੋਕਸਡ ਰੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਹੱਬ ਨੂੰ ਅਧ-ਬਣੇ CRM ਵਿੱਚ ਤਬਦੀਲ ਹੋਣ ਤੋਂ ਰੋਕਦੀਆਂ ਹਨ।
ਜੋ ਸ਼੍ਰੇਣੀਆਂ ਤੁਸੀਂ ਸਹਾਇਤਾ ਕਰੋਂਗੇ, ਉਹ ਸੂਚੀਬੱਧ ਕਰੋ, ਕਿਉਂਕਿ ਇਹ ਨਿਯਮ, ਟੈਂਪਲੇਟ ਅਤੇ ਕਨਪਲਾਇੰਸ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀਆਂ ਹਨ:
ਹਰ ਸੁਨੇਹੇ ਦੀ ਸ਼੍ਰੇਣੀ ਸਪਸ਼ਟ ਰਖੋ—ਇਹ ਬਾਅਦ ਵਿੱਚ “ਮਾਰਕੇਟਿੰਗ ਨੂੰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਵੱਲ ਛਲਕੇ” ਤੋਂ ਬਚਾਏਗਾ।
ਇੱਕ ਛੋਟਾ ਸਮੂਹ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਦਿਨ ਇਕ ਤੋਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਚਲਾ ਸਕੋ, ਅਤੇ “ਬਾਅਦ” ਦੇ ਚੈਨਲ ਲਿਖੋ ਤਾਂ ਕਿ ਤੁਹਾਡਾ ਡਾਟਾ ਮਾਡਲ ਉਨ੍ਹਾਂ ਨੂੰ ਰੋਕੇ ਨਾ।
ਹੁਣ ਸਹਾਇਤਾ (ਆਮ MVP): email + ਇੱਕ real-time ਚੈਨਲ (push ਜਾਂ in-app) ਜਾਂ SMS ਜੇ ਤੁਹਾਡਾ ਉਤਪਾਦ ਇਸ ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
ਬਾਅਦ ਵਿੱਚ ਸਹਾਇਤਾ: chat tools (Slack/Teams), WhatsApp, voice, postal, partner webhooks.
ਚੈਨਲ ਸੀਮਾਵਾਂ ਵੀ ਦਰਜ ਕਰੋ: rate limits, deliverability ਲੋੜਾਂ, sender identities (ਡੋਮੇਨ, ਫੋਨ ਨੰਬਰ), ਅਤੇ per-send ਲਾਗਤ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਮੈਨੇਜਮੈਂਟ ਦਾ ਮਤਲਬ “ਗਾਹਕ ਸੰਬੰਧੀ ਹਰ ਚੀਜ਼” ਨਹੀਂ। ਆਮ non-goals:
ਨਿਯਮ ਸ਼ੁਰੂ ਤੋਂ ਕੈਪਚਰ ਕਰੋ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ retro-fit ਨਾ ਕਰੋ:
ਜੇ ਪਹਿਲਾਂ ਹੀ ਨੀਤੀਆਂ ਹਨ, ਉਨ੍ਹਾਂ ਨੂੰ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਦਰਜ ਕਰੋ (ਉਦਾਹਰਨ ਲਈ: /security, /privacy) ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ MVP ਲਈ acceptance criteria ਵਜੋਂ ਵਰਤੋ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਨੂੰ ਇੱਕ ਪਾਈਪਲਾਈਨ ਵਜੋਂ ਸਮਝਣਾ ਸਭ ਤੋਂ ਆਸਾਨ ਹੈ: ਇਵੈਂਟ ਅੰਦਰ ਜਾਂਦੇ ਹਨ, ਸੁਨੇਹੇ ਬਾਹਰ ਆਉਂਦੇ ਹਨ, ਅਤੇ ਹਰ ਕਦਮ ਨੂੰ ਦੇਖਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਜਿੰਨਾਂ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਨੂੰ ਵੱਖਰਾ ਰੱਖੋਗੇ, ਉਨ੍ਹਾਂ ਚੈਨਲਾਂ (SMS, WhatsApp, push) ਨੂੰ ਬਾਅਦ ਵਿੱਚ ਜੋੜਨਾ ਉਤਨਾ ਹੀ ਸੌਖਾ ਰਹੇਗਾ।
1) Event intake (API + connectors). ਤੁਹਾਡੀ ਐਪ, ਸੇਵਾਵਾਂ, ਜਾਂ ਬਾਹਰੀ ਭਾਗੀਦਾਰ “ਕੁਝ ਹੋਇਆ” ਇਵੈਂਟ ਇੱਕ ਸਿੰਗਲ ਐਂਟਰੀ ਪੁਆਇੰਟ ਨੂੰ ਭੇਜਦੇ ਹਨ। ਆਮ intake ਰਾਹ REST endpoint, webhooks, ਜਾਂ ਸਿੱਧੇ SDK calls ਹੁੰਦੇ ਹਨ।
2) Routing engine. ਹੱਬ ਫ਼ੈਸਲਾ ਕਰਦਾ ਹੈ ਕਿ ਕਿਸਨੂੰ ਸੂਚਿਤ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਕਿਹੜੇ ਚੈਨਲ(ਜ਼) ਰਾਹੀਂ, ਅਤੇ ਕਦੋਂ। ਇਹ ਲੇਅਰ ਪ੍ਰਾਪਤਕਰਤਾ ਡੈਟਾ ਅਤੇ ਪਸੰਦਾਂ ਨੂੰ ਪੜ੍ਹਦੀ ਹੈ, ਨਿਯਮਾਂ ਦਾ ਮੁਲਾਂਕਣ ਕਰਦੀ ਹੈ, ਅਤੇ ਇੱਕ delivery plan ਬਾਹਰ ਦਿੱੰਦੀ ਹੈ।
3) Templating + personalization. ਇੱਕ delivery plan ਦੇ ਆਧਾਰ 'ਤੇ, ਹੱਬ ਚੈਨਲ-ਖਾਸ ਸੁਨੇਹਾ (email HTML, SMS ਟੈਕਸਟ, push ਪੇਲੋਡ) ਰੈਂਡਰ ਕਰਦਾ ਹੈ ਟੈਂਪਲੇਟ ਅਤੇ ਵੇਰੀਏਬਲ ਦੀ ਵਰਤੋਂ ਕਰਕੇ।
4) Delivery workers. ਇਹ provider (SendGrid, Twilio, Slack, ਆਦਿ) ਨਾਲ ਇੰਟੀਗਰੇਟ ਕਰਦੇ ਹਨ, retries ਸੰਭਾਲਦੇ ਹਨ, ਅਤੇ rate limits ਦਾ ਧਿਆਨ ਰੱਖਦੇ ਹਨ।
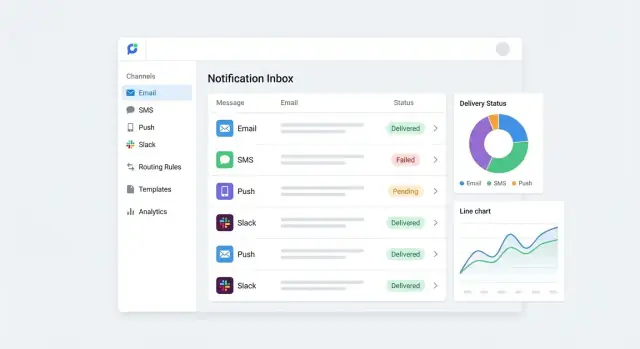
5) Tracking + reporting. ਹਰ ਕੋਸ਼ਿਸ਼ ਦਰਜ ਕੀਤੀ ਜਾਂਦੀ ਹੈ: accepted, sent, delivered, failed, opened/clicked (ਜਦੋਂ ਉਪਲਬਧ)। ਇਹ admin ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਆਡਿਟ ਟਰੇਲ ਨੂੰ ਚਲਾਉਂਦਾ ਹੈ।
ਸੰਖੇਪ ਤੌਰ 'ਤੇ ਵਰਤੋਂ ਲਈ synchronous ਪ੍ਰੋਸੈਸਿੰਗ ਕਿਵੇਂ ਵਰਤਣੀ ਚਾਹੀਦੀ ਹੈ (ਜਿਵੇਂ validate ਕਰਕੇ 202 Accepted ਵਾਪਸ ਦੇਣਾ)। ਬਹੁਤ ਸਾਰੇ ਅਸਲ ਸਿਸਟਮਾਂ ਲਈ, route ਅਤੇ deliver asynchronous ਰੱਖੋ:
ਸ਼ੁਰੂ ਵਿੱਚ dev/staging/prod ਲਈ ਯੋਜਨਾ ਬਣਾਓ। provider credentials, rate limits, ਅਤੇ feature flags environment-specific configuration ਵਿੱਚ ਰੱਖੋ (ਟੈਂਪਲੇਟਾਂ ਵਿੱਚ ਨਹੀਂ)। ਟੈਂਪਲੇਟਾਂ ਨੂੰ versioned ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ staging 'ਚ ਪਰਖ ਸਕੋ ਪਹਿਲਾਂ ਕਿ ਉਹ production 'ਤੇ ਪ੍ਰਭਾਵ ਪਾਵੇ।
ਇਕ ਉਪਯੋਗੀ ਵੰਡ ਇਹ ਹੋ ਸਕਦੀ ਹੈ:
ਇਹ ਆਰਕੀਟੈਕਚਰ ਤੁਹਾਨੂੰ ਇੱਕ ਸਥਿਰ ਬੈਕਬੋਨ ਦਿੰਦਾ ਹੈ ਜਦਕਿ ਦਿਨ-प्रतिदਿਨ ਸੁਨੇਹਾ ਬਦਲਾਅ deployment cycles ਤੋਂ ਬਿਨਾਂ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਮੈਨੇਜਮੈਂਟ ਸਿਸਟਮ ਦੀ ਜ਼ਿੰਦਗੀ ਉਸ ਦੀਆਂ ਇਵੈਂਟਾਂ ਦੀ ਗੁਣਵੱਤਾ 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀ ਹੈ। ਜੇ ਤੁਹਾਡੇ ਉਤਪਾਦ ਦੇ ਵੱਖ-ਵੱਖ ਹਿੱਸੇ ਇੱਕੋ ਚੀਜ਼ ਨੂੰ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਨਾਲ ਵਰਣਨ ਕਰਦੇ ਹਨ, ਤਾਂ ਤੁਹਾਡਾ ਹੱਬ ਸਾਰਾ ਸਮਾਂ translate, guess, ਅਤੇ break ਕਰਨ ਵਿੱਚ ਬਤੀਤ ਕਰੇਗਾ।
ਛੋਟੇ, ਸਪਸ਼ਟ contract ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜਿਸ ਦਾ ਹਰ producer ਪਾਲਣਾ ਕਰ ਸਕੇ। ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਬੇਸਲਾਈਨ ਇਸ ਤਰ੍ਹਾਂ ਹੋ ਸਕਦੀ ਹੈ:
invoice.paid, comment.mentioned)ਇਹ ਢਾਂਚਾ event-driven notifications ਨੂੰ ਸਮਝਣਯੋਗ ਰੱਖਦਾ ਹੈ ਅਤੇ routing rules, templates, ਅਤੇ delivery tracking ਦਾ ਸਮਰਥਨ ਕਰਦਾ ਹੈ।
ਇਵੈਂਟ ਵਿਕਸਤ ਹੁੰਦੇ ਹਨ। ਉਹਨਾਂ ਦੀ ਤਬਦੀਲੀ ਤੋਂ ਬਚਾਅ ਲਈ ਉਦਾਹਰਨ ਵਜੋਂ schema_version: 1 ਵਰਗਾ ਵਰਜਨ ਸ਼ਾਮਲ ਕਰੋ। ਜਦੋਂ ਵੱਡਾ ਬ੍ਰੇਕਿੰਗ ਚੇਜ਼ ਆਵੇ, ਨਵਾਂ ਵਰਜਨ ਜਾਰੀ ਕਰੋ ਅਤੇ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਪੀਰੀਅਡ ਦੌਰਾਨ ਦੋਹਾਂ ਨੂੰ ਸਹਾਇਕ ਰੱਖੋ। ਇਹ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਮਾਇਨੇ ਰੱਖਦਾ ਹੈ ਜਦੋਂ ਕਈ producers (backend services, webhooks, scheduled jobs) ਇੱਕ ਹੱਬ ਨੂੰ feed ਕਰਦੇ ਹਨ।
ਆਉਣ ਵਾਲੇ ਇਵੈਂਟਾਂ ਨੂੰ ਅਣ-ਭਰੋਸੇਯੋਗ ਇਨਪੁਟ ਵਜੋਂ ਦੇਖੋ, ਭਾਵੇਂ ਉਹ ਤੁਹਾਡੇ ਆਪਣੇ ਸਿਸਟਮ ਤੋਂ ਆ ਰਹੇ ਹੋਣ:
idempotency_key: invoice_123_paid) ਤਾਂ ਜੋ retries ਮਲਟੀ-ਚੈਨਲ ਸੁਨੇਹਿਆਂ 'ਚ duplicate sends ਨਾ ਬਣਣ।ਮਜ਼ਬੂਤ ਡਾਟਾ contracts support tickets ਘਟਾਉਂਦੇ ਹਨ, ਇੰਟੀਗਰੇਸ਼ਨ ਤੇਜ਼ ਕਰਦੇ ਹਨ, ਅਤੇ ਰਿਪੋਰਟਿੰਗ/ਆਡਿਟ ਲਾਗਜ਼ ਨੂੰ ਬਹੁਤ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ तभी ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਇਹ ਜਾਣੇ ਕਿ ਕੌਣ ਹੈ, ਕਿਵੇਂ ਉਸ ਤੱਕ ਪੁਹੁੰਚਣਾ ਹੈ, ਅਤੇ ਉਸ ਨੇ ਕੀ ਸਹਿਮਤੀ ਦਿੱਤੀ ਹੈ। identity, contact data, ਅਤੇ preferences ਨੂੰ first-class objects ਵਜੋਂ ਵਰਤੋ—ਉਪਭੋਗਤਾ record 'ਤੇ ਬੇਇੰਤਿਹਾਂ ਫੀਲਡ ਨਹੀਂ।
ਇੱਕ User (ਲੌਗਿਨ ਕਰਨ ਵਾਲਾ ਖਾਤਾ) ਨੂੰ Recipient (ਇੱਕ ਐਸਾ ਇਕਾਈ ਜੋ ਸੁਨੇਹੇ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੀ ਹੈ) ਤੋਂ ਵੱਖ ਕਰੋ:
ਹਰ contact point ਲਈ ਇਹ ਰੱਖੋ: value (ਉਦਾਹਰਨ: email), channel type, label, owner, ਅਤੇ verification status (unverified/verified/blocked). ਨਾਲ ਹੀ metadata ਜਿਵੇਂ last verified time ਅਤੇ verification method (link, code, OAuth) ਰੱਖੋ।
ਪਸੰਦਾਂ ਨੂੰ expressive ਪਰ predictable ਰੱਖੋ:
ਇਸ ਨੂੰ layered defaults ਨਾਲ ਮਾਡਲ ਕਰੋ: organization → team → user → recipient, ਜਿੱਥੇ ਨੀਚਲੇ ਪੱਧਰ ਉੱਪਰਲੇ ਪੱਧਰ ਨੂੰ override ਕਰਦੇ ਹਨ। ਇਸ ਨਾਲ admins ਸਮਝਦਾਰੀ ਨਾਲ baseline ਸੈਟ ਕਰ ਸਕਦੇ ਹਨ ਤੇ ਵਿਅਕਤੀਆਂ ਆਪਣੀ ਸੰਚਾਰ ਢੰਗ ਮੈਟਰਿਕ ਕਰ ਸਕਦੇ ਹਨ।
ਸਹਿਮਤੀ ਸਿਰਫ਼ ਇੱਕ ਚੈਕਬਾਕਸ ਨਹੀਂ ਹੈ। ਰੱਖੋ:
ਸਹਿਮਤੀ ਬਦਲਾਅ auditable ਅਤੇ ਇੱਕ ਸਥਾਨ ਤੋਂ exportable ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ (ਉਦਾਹਰਣ: /settings/notifications), ਕਿਉਂਕਿ support teams ਨੂੰ ਇਹ ਲੋੜ ਵੇਲੇ ਪੁੱਛਿਆ ਜਾ ਸਕਦਾ ਹੈ “ਮੈਨੂੰ ਇਹ ਕਿਉਂ ਮਿਲਿਆ?” ਜਾਂ “ਮੈਨੂੰ ਇਹ ਕਿਉਂ ਨਹੀਂ ਮਿਲਿਆ?”
Routing rules centralized notification hub ਦਾ “ਦਿਮਾਗ” ਹੁੰਦੇ ਹਨ: ਇਹ ਫੈਸਲਾ ਕਰਦੇ ਹਨ ਕਿ ਕਿਸ ਪ੍ਰਾਪਤਕਰਤਾ ਨੂੰ ਸੂਚਿਤ ਕੀਤਾ ਜਾਵੇ, ਕਿਹੜੇ ਚੈਨਲ ਰਾਹੀਂ, ਅਤੇ ਕਿਸ ਹਾਲਤ 'ਚ। ਚੰਗੀ ਰਾਊਟਿੰਗ ਸ਼ੋਰ ਘਟਾਉਂਦੀ ਹੈ ਬਿਨਾਂ ਅਹੰਕਾਰਕ ਅਲਰਟਸ ਨੂੰ ਗੁਮ ਕਰਨ ਦੇ।
ਉਹ inputs ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ ਜੋ ਤੁਹਾਡੇ ਨਿਯਮ ਮੁਲਾਂਕਣ ਕਰ ਸਕਦੇ ਹਨ। ਪਹਿਲੀ ਵਰਜਨ ਨੂੰ ਛੋਟਾ ਪਰ expressive ਰੱਖੋ:
invoice.overdue, deployment.failed, comment.mentioned)ਇਹ inputs ਤੁਹਾਡੇ event contract ਤੋਂ ਨਿਕਲਣੇ ਚਾਹੀਦੇ ਹਨ, ਨਾ ਕਿ admins ਦੁਆਰਾ ਹਰ ਨੋਟੀਫਿਕੇਸ਼ਨ ਲਈ ਹੱਥੋਂ ਟਾਈਪ ਕੀਤੇ ਜਾਣ।
Actions delivery ਵਰਤਾਰਾ ਨਿਰਧਾਰਤ ਕਰਦੀਆਂ ਹਨ:
ਹਰ rule ਲਈ explicit priority ਅਤੇ fallback order ਨਿਰਧਾਰਤ ਕਰੋ। ਉਦਾਹਰਨ: ਪਹਿਲਾਂ push ਕੋਸ਼ਿਸ਼ ਕਰੋ, ਜੇ push fail ਹੋਵੇ ਤਾਂ SMS, ਫਿਰ email ਆਖਰੀ ਰਾਹ।
fallback ਨੂੰ ਅਸਲ delivery ਸਿਗਨਲ (bounced, provider error, device unreachable) ਨਾਲ ਜੋੜੋ, ਅਤੇ retry loops ਨੂੰ clear caps ਨਾਲ ਰੋਕੋ।
Rules ਨੂੰ guided UI (dropdowns, previews, ਅਤੇ warnings) ਰਾਹੀਂ ਸੋਧਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਜਿਨ੍ਹਾਂ ਵਿੱਚ:
ਟੈਂਪਲੇਟ ਉਹ ਜਗ੍ਹਾ ਹਨ ਜਿੱਥੇ centralized management “ਕਈ ਸੁਨੇਹਿਆਂ” ਨੂੰ ਇੱਕ ਰੁਪ ਵਿੱਚ ਬਦਲਦਾ ਹੈ। ਚੰਗੀ template ਪ੍ਰਣਾਲੀ ਟੋਨ ਸਥਿਰ ਰੱਖਦੀ ਹੈ, ਗਲਤੀਆਂ ਘਟਾਉਂਦੀ ਹੈ, ਅਤੇ ਮਲਟੀ-ਚੈਨਲ ਡਿਲਿਵਰੀ (email, SMS, push, in-app) ਨੂੰ ਸਹੀ ਮਹਿਸੂਸ ਕਰਾਉਂਦੀ ਹੈ।
ਟੈਂਪਲੇਟ ਨੂੰ ਇੱਕ structured asset ਵਜੋਂ ਰੱਖੋ, ਨਾ ਕਿ ਸਿਰਫ਼ text blob। ਘੱਟੋ-ਘੱਟ ਰੱਖੋ:
{{first_name}}, {{order_id}}, {{amount}})Variables ਨੂੰ explicit schema ਨਾਲ ਰੱਖੋ ਤਾਂ ਕਿ ਸਿਸਟਮ validate ਕਰ ਸਕੇ ਕਿ event payload ਸਾਰੀ ਲੋੜੀਂਦੀ ਜਾਣਕਾਰੀ ਦਿੰਦਾ ਹੈ। ਇਸ ਨਾਲ ਅਧੂਰੇ-rendered messages ਜਿਵੇਂ “Hi {{name}}” ਭੇਜਣ ਤੋਂ ਰੋਕਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਆਪਣੀ ਪ੍ਰਾਪਤਕਰਤਾ ਦੀ locale ਕਿਵੇਂ ਚੁਣੀ ਜਾਂਦੀ ਹੈ ਦਰਜ ਕਰੋ: user preference ਪਹਿਲਾਂ, ਫਿਰ account/org setting, ਫਿਰ default (ਅਕਸਰ en). ਹਰ ਟੈਂਪਲੇਟ ਲਈ locale ਮੁਤਾਬਕ translations ਰੱਖੋ ਅਤੇ fallback policy ਸਪਸ਼ਟ ਰੱਖੋ:
fr-CA ਮੌਜੂਦ ਨਹੀਂ, ਤਾਂ fr ਨੂੰ fallback ਕਰੋ।fr ਮੌਜੂਦ ਨਹੀਂ, ਤਾਂ template ਦੀ default locale ਨੂੰ fallback ਕਰੋ।ਇਸ ਨਾਲ missing translations রিপোর্টਿੰਗ ਵਿੱਚ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ ਨਾ ਕਿ ਚੁਪਚਾਪ degrade।
ਇੱਕ template preview ਸਕ੍ਰੀਨ ਦਿਓ ਜੋ admin ਨੂੰ ਆਗਿਆ ਦੇਵੇ:
ਆਖਰੀ ਸੁਨੇਹਾ ਸਭ ਕੁਝ ਵਾਸਤੇ ਉੱਤੇ render ਕਰੋ, ਸਮੇਤ link rewriting ਅਤੇ truncation rules। ਇੱਕ test-send add ਕਰੋ ਜੋ safe “sandbox recipient list” ਨੂੰ ਟਾਰਗੇਟ ਕਰੇ ਤਾਂ ਕਿ ਗਾਹਕਾਂ ਨੂੰ ਅਚਾਨਕ ਸੁਨੇਹਾ ਨਾ ਜਾਵੇ।
ਟੈਂਪਲੇਟਾਂ ਨੂੰ code ਵਾਂਗ versioned ਰੱਖੋ: ਹਰ ਬਦਲਾਅ ਇੱਕ ਨਵਾਂ immutable version ਬਣਾਉਂਦਾ ਹੈ। statuses ਵਰਗੇ Draft → In review → Approved → Active ਵਰਤੋ, role-based approvals ਵਿਕਲਪੀ ਹੋ ਸਕਦੇ ਹਨ। Rollbacks ਇੱਕ ਕਲਿੱਕ ਚੀਜ਼ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ।
ਆਡਿਟ ਲਈ ਦਰਜ ਕਰੋ ਕਿ ਕਿਸਨੇ ਕੀ ਬਦਲਿਆ, ਕਦੋਂ ਅਤੇ ਕਿਉਂ, ਅਤੇ ਡਿਲਿਵਰੀ ਨਤੀਜਿਆਂ ਨਾਲ ਜੋੜੋ ਤਾਂ ਕਿ ਤੁਸੀਂ failures spikes ਨੂੰ template edits ਨਾਲ correlate ਕਰ ਸਕੋ (see also /blog/audit-logs-for-notifications).
ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਦੀ last mile ਹੀ ਉਸਦੀ dependability ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ: ਉਹ ਚੈਨਲ ਪ੍ਰੋਵਾਇਡਰ ਜੋ ਅਸਲ ਵਿੱਚ email, SMS, ਅਤੇ push ਭੇਜਦੇ ਹਨ। ਲਕਸ਼ ਹੈ ਕਿ ਹਰ provider ਨੂੰ “plug-in” ਮਹਿਸੂਸ ਕਰਵਾਉਣਾ, ਜਦਕਿ ਡਿਲਿਵਰੀ ਵਰਤਾਰਾ ਹਰ ਚੈਨਲ 'ਚ consistent ਰਹੇ।
ਹਰ ਚੈਨਲ ਲਈ ਇੱਕ single, ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਹਾਇਤਾ ਪ੍ਰਾਪਤ provider ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ—ਉਦਾਹਰਨ ਲਈ SMTP ਜਾਂ email API, ਇੱਕ SMS gateway, ਅਤੇ ਇੱਕ push service (APNs/FCM vendor ਰਾਹੀਂ)। ਇੰਟੀਗਰੇਸ਼ਨਾਂ ਨੂੰ ਇੱਕ common interface ਦੇ ਪਿਛੇ ਰੱਖੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ providers ਬਦਲ ਜਾਂ ਜੋੜ ਸਕੋ ਬਿਨਾਂ ਬਿਜ਼ਨਸ ਲੋਜਿਕ rewrite ਕੀਤੇ।
ਹਰ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਨੂੰ ਇਹ ਕੰਮ ਕਰਨੇ ਚਾਹੀਦੇ ਹਨ:
“send notification” ਨੂੰ ਇੱਕ pipeline ਵਜੋਂ ਮੰਨੋ: enqueue → prepare → send → record result. ਭਾਵੇਂ ਤੁਹਾਡੀ ਐਪ ਛੋਟੀ ਹੋਵੇ, queue-based worker model slow provider calls ਨੂੰ blocking ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ retries ਲਾਗੂ ਕਰਨ ਲਈ ਇੱਕ ਥਾਂ ਦਿੰਦਾ ਹੈ।
پRACTICAL approach:
Providers ਬਹੁਤ ਵੱਖਰੇ responses ਦਿੰਦੇ ਹਨ। ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ internal status model ਵਿੱਚ normalize ਕਰੋ ਜਿਵੇਂ: queued, sent, delivered, failed, bounced, suppressed, throttled।
ਡਿਬੱਗ ਕਰਨ ਲਈ raw provider payload ਸਟੋਰ ਕਰੋ, ਪਰ dashboards ਅਤੇ alerts normalized status 'ਤੇ ਆਧਾਰਿਤ ਹੋਣ।
exponential backoff ਅਤੇ maximum attempt limit ਨਾਲ retries ਲਗਾਓ। ਸਿਰਫ਼ transient failures (timeouts, 5xx, throttling) ਨੂੰ retry ਕਰੋ, permanent failures (invalid number, hard bounce) ਨੂੰ ਨਹੀਂ।
provider rate limits ਦਾ ਸਮਮਾਨ ਕਰਨ ਲਈ per-provider throttling ਲਗਾਓ। High-volume events ਲਈ, ਜਿੱਥੇ provider ਨੇ support ਦਿੱਤਾ ਹੈ, batching ਕਰੋ (ਉਦਾਹਰਨ: bulk email API calls) ਤਾਂ ਕਿ ਲਾਗਤ ਘਟੇ ਅਤੇ throughput ਵਧੇ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਦੀ ਭਰੋਸੇਮੰਦੀ ਇਸਦੀ visibility 'ਤੇ ਨਿਰਭਰ ਹੁੰਦੀ ਹੈ। ਜਦੋਂ ਗਾਹਕ ਕਹਿੰਦਾ ਹੈ “ਮੈਨੂੰ ਉਹੀ ਈਮੇਲ ਨਹੀਂ ਮਿਲੀ”, ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਜਵਾਬ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ: ਕੀ ਭੇਜਿਆ ਗਿਆ, ਕਿਸ ਚੈਨਲ ਰਾਹੀਂ, ਅਤੇ ਅੱਗੇ ਕੀ ਹੋਇਆ।
ਚੈਨਲਾਂ ਵਿੱਚ ਰਿਪੋਰਟਿੰਗ consistent ਰਹੇ ਇਸ ਲਈ ਛੋਟੀ ਸੈੱਟ ਦੇ delivery states standardize ਕਰੋ। ਪ੍ਰਯੋਗਿਕ ਬੇਸਲਾਈਨ:
ਇਨ੍ਹਾਂ ਨੂੰ ਇੱਕ timeline ਵਜੋਂ ਦੇਖੋ, ਨਾ ਕਿ ਇੱਕ ਇੱਕਲੋਤਾ ਮੁੱਲ—ਹਰ message attempt multiple status updates ਜਾਰੀ ਕਰ ਸਕਦੀ ਹੈ।
ਇੱਕ message log ਬਣਾਓ ਜੋ support ਅਤੇ operations ਲਈ ਵਰਤਣਾ ਆਸਾਨ ਹੋਵੇ। ਘੱਟੋ-ਘੱਟ, ਇਹ searchable ਹੋ:
invoice.paid, password.reset)ਮੁੱਖ ਵੇਰਵੇ ਸ਼ਾਮਲ ਕਰੋ: channel, template name/version, locale, provider, error codes, ਅਤੇ retry count। Default ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਬਣਾਓ: ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡਾਂ ਨੂੰ mask ਕਰੋ (ਜਿਵੇਂ ਆਧਾ-ਰੇਡੈਕਟ email/phone) ਅਤੇ roles ਦੇ ਆਧਾਰ 'ਤੇ ਪ੍ਰਵੇਸ਼ ਸੀਮਿਤ ਕਰੋ।
ਹਰ notification ਨੂੰ triggering action (checkout, admin update, webhook) ਨਾਲ ਜੋੜਨ ਲਈ trace IDs ਸ਼ਾਮਲ ਕਰੋ। ਇੱਕੋ trace ID ਵਰਤੋ:
ਇਸ ਨਾਲ “ਕੀ ਹੋਇਆ?” ਇੱਕ ਸਿੰਗਲ ਫਿਲਟਡ ਵਿਊ ਬਣ ਜਾਂਦੀ ਹੈ ਨਾ ਕਿ ਕਈ ਸਿਸਟਮਾਂ ਵਿੱਚ ਖੋਜ।
ਡੈਸ਼ਬੋਰਡ ਨੂੰ ਫੈਸਲਿਆਂ ਤੇ ਕੇਂਦ੍ਰਿਤ ਰੱਖੋ, ਸਫ਼ਲੀ metrics ਉੱਤੇ ਨਹੀਂ:
ਚਾਰਟਾਂ ਤੋਂ underlying message log ਵਿੱਚ drill-down add ਕਰੋ ਤਾਂ ਕਿ ਹਰ ਮੈਟ੍ਰਿਕ ਵੱਖ-ਵੱਖ ਸਮਝਾਇਆ ਜਾ ਸਕੇ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਗਾਹਕੀ ਡੇਟਾ, provider credentials, ਅਤੇ ਮੇਸੇਜ ਸਮੱਗਰੀ ਨੂੰ ਛੁਹਦਾ ਹੈ—ਇਸ ਲਈ security ਸ਼ੁਰੂ ਵਿੱਚ ਹੀ ਡਿਜ਼ਾਈਨ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ। ਲਕਸ਼ ਸਾਦਾ ਹੈ: ਸਹੀ ਲੋਕ ਹੀ ਵ行为 ਬਦਲ ਸਕਣ, secrets ਸੁਰੱਖਿਅਤ ਰਹਿਣ, ਅਤੇ ਹਰ ਬਦਲਾਅ ਟ੍ਰੇਸ ਕਰਨਯੋਗ ਹੋਵੇ।
ਛੋਟੇ roles ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਉਨ੍ਹਾਂ ਕਾਰਵਾਈਆਂ ਨਾਲ ਮੈਪ ਕਰੋ ਜੋ ਮਾਇਨੇ ਰੱਖਦੀਆਂ ਹਨ:
least privilege defaults ਵਰਤੋਂ: ਨਵੇਂ ਯੂਜ਼ਰਾਂ ਨੂੰ rule ਜਾਂ credentials edit ਕਰਨ ਦੀ permission ਨਾ ਦਿਓ ਜਦ ਤੱਕ ਉਹ ਖਾਸ ਤੌਰ 'ਤੇ ਨਹੀਂ ਦਿੱਤੀ ਗਈ ।
Provider keys, webhook signing secrets, ਅਤੇ API tokens ਨੂੰ end-to-end secrets ਵਜੋਂ treat ਕਰੋ:
ਹਰ configuration change ਇੱਕ immutable audit event ਲਿਖਣਾ ਚਾਹੀਦਾ ਹੈ: ਕਿਸਨੇ ਕੀ ਬਦਲਿਆ, ਕਦੋਂ, ਕਿੱਥੇ ਤੋਂ (IP/device), ਅਤੇ before/after values (secret fields masked). Routing rules, templates, provider keys, ਅਤੇ permission assignments 'ਤੇ ਬਦਲਾਅ ਟਰੈਕ ਕਰੋ। compliance reviews ਲਈ CSV/JSON export ਆਸਾਨ ਬਣਾਓ।
ਹਰ ਡੇਟਾ ਟਾਈਪ (events, delivery attempts, content, audit logs) ਲਈ retention define ਕਰੋ ਅਤੇ UI ਵਿੱਚ ਦਸਤਾਵੇਜ਼ ਕਰੋ। ਜਿੱਥੇ ਵਰਤੋਂਯੋਗ ਹੋਵੇ, deletion requests support ਕਰੋ: recipient identifiers remove ਜਾਂ anonymize ਕਰੋ, ਜਦਕਿ aggregate delivery metrics ਅਤੇ masked audit records ਰੱਖੋ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਦੀ ਕਾਮਯਾਬੀ ਯੂਜ਼ਬਿਲਟੀ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ। ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਹਰ ਰੋਜ਼ “ਨੋਟੀਫਿਕੇਸ਼ਨ manage” ਨਹੀਂ ਕਰਦੀਆਂ—ਜਦ ਤੱਕ ਕੁਝ ਟੁੱਟਦਾ ਨਹੀਂ। UI ਨੂੰ ਤੇਜ਼ ਸਕੈਨਿੰਗ, ਸੁਰੱਖਿਅਤ ਬਦਲਾਅ, ਅਤੇ ਸਪਸ਼ਟ ਨਤੀਜੇ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ।
Rules ਨੂੰ ਕੋਡ ਵਾਂਗ ਨਹੀਂ ਪਰ policies ਵਾਂਗ ਪੜ੍ਹੇ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। “IF event… THEN send…” phrasing ਨਾਲ ਇੱਕ ਟੇਬਲ ਵਰਤੋਂ, ਚੈਨਲ ਲਈ chips (Email/SMS/Push/Slack) ਅਤੇ simulator ਸ਼ਾਮਲ ਕਰੋ: ਇੱਕ ਇਵੈਂਟ ਚੁਣੋ ਅਤੇ ਵੇਖੋ ਕਿ ਕੌਣ, ਕਿਥੇ, ਅਤੇ ਕਦੋਂ ਸੁਚਿਤ ਹੋਵੇਗਾ।
Templates ਲਈ side-by-side editor ਅਤੇ preview ਦਿਓ। admin ਨੂੰ locale, channel, ਅਤੇ sample data toggle ਕਰਨ ਦਿਓ। template versioning ਅਤੇ “publish” step ਨਾਲ ਇੱਕ-ਕਲਿੱਕ rollback ਦੇਸ਼ੋ।
Recipients individuals ਅਤੇ groups (teams, roles, segments) ਦੋਹਾਂ ਲਈ ਸਹਿਯੋਗ ਕਰੋ। membership ਦਿੱਖਾਓ (“Alex On-call ਵਿੱਚ ਕਿਉਂ ਹੈ?”) ਅਤੇ ਦਿਖਾਓ ਕਿ ਕਿਸ rule 'ਚ recipient ਕਿੱਥੇ referenced ਹੈ।
Provider health ਨਜ਼ਰ ਵਿੱਚ ਰੱਖੋ: delivery latency, error rate, queue depth, ਅਤੇ last incident। ਹਰ issue ਨੂੰ human-readable explanation ਅਤੇ next actions ਨਾਲ ਲਿੰਕ ਕਰੋ (ਉਦਾਹਰਨ: “Twilio auth failed—check API key permissions”).
ਪਸੰਦਾਂ ਨੂੰ ਹਲਕੇ ਰੱਖੋ: channel opt-ins, quiet hours, ਅਤੇ topic/category toggles (ਉਦਾਹਰਨ: “Billing,” “Security,” “Product updates”)। ਸਕ੍ਰੀਨ ਦੇ ਉੱਪਰ ਇੱਕ ਸਧਾਰਨ-ਭਾਸ਼ਾਈ ਸੰਖੇਪ ਦਿਖਾਓ (“You’ll get security alerts by SMS, anytime”).
unsubscribe flows respectful ਅਤੇ compliant ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ: marketing ਲਈ ਇੱਕ-ਕਲਿੱਕ unsubscribe, ਅਤੇ ਜ਼ਰੂਰੀ alerts ਕਦੇ-ਕਦੇ off ਨਾ ਕੀਤੀਆਂ ਜਾ ਸਕਣ—ਇਸ ਦੀ ਸਾਫ਼ ਜਾਣਕਾਰੀ। ਜੇ ਯੂਜ਼ਰ ਇੱਕ ਚੈਨਲ disable ਕਰਦਾ ਹੈ, ਤਦ ਪਕਸ਼ ਦਿਓ ਕਿ ਕੀ ਬਦਲਿਆ (“No more SMS; email remains enabled”).
Operators ਨੂੰ ਅਜਿਹੇ ਟੂਲ ਚਾਹੀਦੇ ਹਨ ਜੋ pressure 'ਚ ਸੁਰੱਖਿਅਤ ਰਹਿਣ:
Empty states setup guide ਕਰਨ ("No rules yet—create your first routing rule") ਅਤੇ next step ਨਾਲ link ਦਿਓ (ਉਦਾਹਰਨ: /rules/new)। Error messages ਦੱਸਣ ਯੋਗ ਹੋਣ: ਕੀ ਹੋਇਆ, ਇਸ ਨਾਲ ਕੀ ਪ੍ਰਭਾਵ ਪਿਆ, ਅਤੇ ਅਗਲਾ ਕਦਮ—ਬਿਨਾਂ ਅੰਦਰੂਨੀ jargon ਦੇ। ਜੇ ਸੰਭਵ ਹੋਵੇ ਤਾਂ quick fix ("Reconnect provider") ਅਤੇ support tickets ਲਈ “copy details” ਬਟਨ ਦਿਓ।
ਕੇਂਦਰੀਕ੍ਰਿਤ ਨੋਟੀਫਿਕੇਸ਼ਨ ਹੱਬ ਵੱਡਾ ਪਲੇਟਫਾਰਮ ਬਣ ਸਕਦਾ ਹੈ, ਪਰ ਸ਼ੁਰੂ ਛੋਟਾ ਰਹੋ। MVP ਦਾ ਲਕਸ਼ end-to-end flow (event → routing → template → send → track) ਸਾਬਤ ਕਰਨਾ ਹੈ, ਘਟ ਤੋਂ ਘਟ ਹਿੱਸਿਆਂ ਨਾਲ, ਫਿਰ ਸੁਰੱਖਿਅਤ ਵਾਧਾ ਕਰੋ।
ਜੇ ਤੁਸੀਂ ਪਹਿਲਾ ਵਰਕਿੰਗ ਵਰਜਨ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗਾ ਇਕ vibe-coding ਪਲੇਟਫਾਰਮ ਤੁਹਾਡੀ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ: React-based UI, Go backend with PostgreSQL ਬਣਾਓ, ਅਤੇ chat-driven workflow ਵਿੱਚ iterate ਕਰੋ—ਫਿਰ planning mode, snapshots, ਅਤੇ rollback ਵਰਗੀਆਂ ਸੁਵਿਧਾਵਾਂ ਨਾਲ rule, templates, ਅਤੇ audit logs ਨੂੰ safe ਰੱਖੋ।
ਪਹਿਲੀ ਰਿਲੀਜ਼ ਜਾਣ-ਬੂਝ ਕੇ ਸਿੱਧੀ ਰੱਖੋ:
ਇਹ MVP ਇਹ ਸਵਾਲ ਜਵਾਬ ਕਰੇ: “ਕੀ ਅਸੀਂ ਸਹੀ ਸੁਨੇਹਾ ਸਹੀ ਪ੍ਰਾਪਤਕਰਤਾ ਨੂੰ ਭੇਜ ਸਕਦੇ ਹਾਂ ਅਤੇ ਦੇਖ ਸਕਦੇ ਹਾਂ ਕਿ ਕੀ ਹੋਇਆ?”
ਨੋਟੀਫਿਕੇਸ਼ਨ ਯੂਜ਼ਰ-ਸਾਮ੍ਹਣੇ ਅਤੇ ਸਮੇਂ-ਸੰਵੇਦਨਸ਼ੀਲ ਹਨ, ਇਸ ਲਈ automated tests ਜਲਦੀ ਫਾਇਦੇਦਾਰ ਹੁੰਦੇ ਹਨ। ਤਿਹਾਂ ਖੇਤਰਾਂ ਤੇ ਧਿਆਨ ਦਿਓ:
CI ਵਿੱਚ sandbox provider account ਨੂੰ use ਕਰਕੇ ਕੁਝ end-to-end tests ਚਲਾਉ।
staged deployment ਵਰਤੋ:
ਜਿਵੇਂ ਹੀ ਸਥਿਰ ਹੋ ਜਾਓ, ਸਪਸ਼ਟ ਕਦਮਾਂ ਵਿੱਚ ਵਧਾਓ: ਚੈਨਲ ਜੋੜੋ (SMS, push, in-app), richer routing, improved template tooling, ਅਤੇ deeper analytics (delivery rates, time-to-deliver, opt-out trends)।
Centralized notification management is a single system that ingests events (e.g., invoice.paid), applies preferences and routing rules, renders templates per channel, delivers via providers (email/SMS/push/etc.), and records outcomes end to end.
It replaces ad-hoc “send an email here” logic with a consistent pipeline you can operate and audit.
Common early signals include:
If these are recurring, a hub usually pays for itself quickly.
Start with a small set you can operate reliably:
Document “later” channels (Slack/Teams, webhooks, WhatsApp) so your data model can extend without breaking changes, but avoid integrating them in the MVP.
A practical MVP proves the full loop (event → route → template → deliver → track) with minimal complexity:
queued/sent/failed at minimumThe goal is reliability and observability, not feature breadth.
Use a small, explicit event contract so routing and templates don’t rely on guesswork:
event_name (stable)actor (who triggered it)recipient (who it’s for)Idempotency prevents duplicate sends when producers retry or when the hub retries.
Practical approach:
idempotency_key per event (e.g., invoice_123_paid)This is especially important for multi-channel and retry-heavy flows.
Separate identity from contact points:
Track verification status per recipient (unverified/verified/blocked) and use layered defaults for preferences (org → team → user → recipient).
Model consent per channel and notification type, and make it auditable:
Keep a single exportable view of consent history so support can answer “why did I get this?” reliably.
Normalize provider-specific outcomes into a consistent internal state machine:
queued, sent, delivered, failed, bounced, suppressed, throttledUse safe operations patterns and guardrails:
Back everything with immutable audit logs of who changed what and when.
payloadmetadata (tenant, timestamp, source, locale hints)Add schema_version and an idempotency key so retries don’t create duplicates.
Store raw provider responses for debugging, but drive dashboards and alerts off normalized statuses. Treat status as a timeline (multiple updates per attempt), not a single final value.