06 ਮਈ 2025·8 ਮਿੰਟ
ਕੈਸ਼ਿੰਗ, ਸੈਸ਼ਨ, ਅਤੇ ਤੇਜ਼ ਲੁੱਕਅਪ ਲਈ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ
ਜਾਣੋ ਕਿ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਕਿਵੇਂ caching, user sessions ਅਤੇ ਤੇਜ਼ ਲੁੱਕਅਪ ਚਲਾਉਂਦੇ ਹਨ—TTL, eviction, ਸਕੇਲਿੰਗ ਵਿਕਲਪ ਅਤੇ ਵ੍ਹਰਤੋਂ ਵਾਲੀਆਂ ਵਪਾਰ-ਟਰੇਡਆਫ਼ਾਂ ਸਮੇਤ।
ਜਾਣੋ ਕਿ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਕਿਵੇਂ caching, user sessions ਅਤੇ ਤੇਜ਼ ਲੁੱਕਅਪ ਚਲਾਉਂਦੇ ਹਨ—TTL, eviction, ਸਕੇਲਿੰਗ ਵਿਕਲਪ ਅਤੇ ਵ੍ਹਰਤੋਂ ਵਾਲੀਆਂ ਵਪਾਰ-ਟਰੇਡਆਫ਼ਾਂ ਸਮੇਤ।
ਮੁੱਖ ਮਕਸਦ ਸਧਾਰਨ ਹੈ: end users ਲਈ ਲੇਟੈਂਸੀ ਘਟਾਉਣਾ ਅਤੇ ਤੁਹਾਡੇ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ 'ਤੇ ਲੋਡ ਘਟਾਉਣਾ। ਇਕੋ ਮਹਿੰਗੀ ਕਵੇਰੀ ਨੂੰ ਮੁੜ ਤੱਕਣਾ ਜਾਂ ਇਕੋ ਨਤੀਜੇ ਨੂੰ ਮੁੜ-ਗਣਨਾ ਬਦਲੇ, ਤੁਹਾਡੀ ਐਪ ਇੱਕ ਪਹਿਲਾਂ ਤੋਂ ਪ੍ਰੀਕੰਪਿੳੁਟ ਕੀਤੀ ਮੁੱਲ ਇਕ ਹੀ, ਪੇਸ਼ਗੀ ਭਰੋਸੇਯੋਗ ਕਦਮ ਵਿੱਚ ਲੈ ਸਕਦੀ ਹੈ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਇੱਕ ਹੀ ਓਪਰੇਸ਼ਨ ਲਈ ਅਨੁਕੂਲਤ ਹੁੰਦੇ ਹਨ: “ਇਸ ਕੁੰਜੀ ਨੂੰ ਦੇ ਕੇ ਮੁੱਲ ਵਾਪਸ ਕਰੋ।” ਇਹ ਤंग ਫੋਕਸ ਬਹੁਤ ਛੋਟੀ critical path ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ।
ਕਈ ਸਿਸਟਮਾਂ ਵਿੱਚ ਇੱਕ ਲੁੱਕਅਪ ਅਕਸਰ ਇਨ੍ਹਾਂ ਨਾਲ ਹੱਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ:
ਨਤੀਜਾ ਘੱਟ ਅਤੇ ਅਨੁਕੂਲ ਜਵਾਬ ਸਮਾਂ ਹੈ—ਇਹੀ ਤੁਸੀਂ caching, session storage ਅਤੇ ਹੋਰ high-speed lookups ਲਈ ਚਾਹੁੰਦੇ ਹੋ।
ਚਾਹੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਸਹੀ ਤਰ੍ਹਾਂ ਟਿਊਨ ਕੀਤਾ ਹੋਵੇ, ਫਿਰ ਵੀ ਉਹਨਾਂ ਨੂੰ ਕੁਏਰੀ ਪਾਰਸ ਕਰਣੀ ਪੈਂਦੀ ਹੈ, ਪਲੈਨ ਬਣਾਉਣਾ ਪੈਂਦਾ ਹੈ, ਇੰਡੈਕਸ ਪੜ੍ਹਨੇ ਪੈਂਦੇ ਹਨ ਅਤੇ concurrency ਕੋਆਰਡੀਨੇਟ ਕਰਨਾ ਪੈਂਦਾ ਹੈ। ਜੇ ਹਜ਼ਾਰਾਂ ਬੇਨਤੀਆਂ ਇੱਕੋ “ਟਾਪ ਪ੍ਰੋਡਕਟਸ” ਲਿਸਟ ਲਈ ਪੁੱਛਦੀਆਂ ਹਨ, ਉਹ ਦੁਹਰਾਈ ਹੋਈ ਕੰਮ ਬਹੁਤ ਹੋ ਜਾਂਦਾ ਹੈ।
ਇੱਕ key-value cache ਉਹ ਦੁਹਰਾਈ ਪੜ੍ਹਾਈ ਟ੍ਰੈਫਿਕ ਨੂੰ ਡੇਟਾਬੇਸ ਤੋਂ ਹਟਾ ਦਿੰਦਾ ਹੈ। ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਉਹਨਾਂ ਰਿਕਵੇਸਟਾਂ ਲਈ ਵਧੇਰੇ ਸਮਾਂ ਬਣਾ ਸਕਦਾ ਹੈ ਜੋ ਸੱਚਮੁਚ ਇਸ ਦੀ ਲੋੜ ਰੱਖਦੀਆਂ ਹਨ: ਲਿਖਤਾਂ, ਜਟਿਲ joins, ਰਿਪੋਰਟਿੰਗ ਅਤੇ consistency-ਨਿਰਭਰ ਪੜ੍ਹਾਈਆਂ।
ਤੇਜ਼ੀ ਮੁਫਤ ਨਹੀਂ ਹੁੰਦੀ। ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਆਮ ਤੌਰ 'ਤੇ ਸਮਝਦਾਰ ਕੁਐਰੀਆਂ (filters, joins) ਨੂੰ ਤਿਆਗ ਦਿੰਦੇ ਹਨ ਅਤੇ ਕਨਫਿਗਰੇਸ਼ਨ ਦੇ ਆਧਾਰ 'ਤੇ persistence ਅਤੇ consistency ਦੇ ਵੱਖਰੇ ਗੈਰੰਟੀ ਹੋ ਸਕਦੇ ਹਨ।
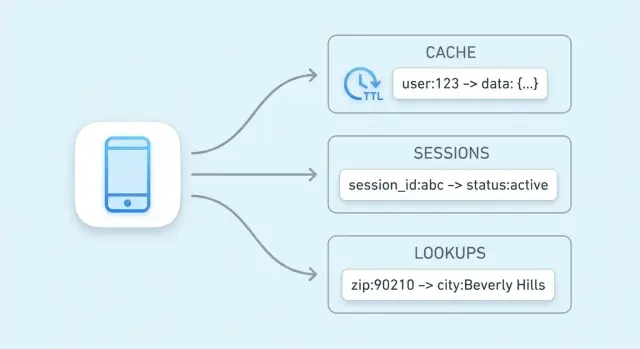
ਉਹ ਵਧੀਆ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਇੱਕ ਸਪષ્ટ ਕੁੰਜੀ ਨਾਲ ਨਾਮ ਦੇ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਣ: user:123, cart:abc) ਅਤੇ ਤੇਜ਼ ਰਿਟਰੀਵਲ ਚਾਹੁੰਦੇ ਹੋ। ਜੇ ਤੁਸੀਂ ਅਕਸਰ “X ਵਾਲੀਆਂ ਸਾਰੀਆਂ ਆਈਟਮ ਲੱਭੋ” ਦੀ ਲੋੜ ਰੱਖਦੇ ਹੋ, ਤਾਂ ਰਿਲੇਸ਼ਨਲ ਜਾਂ ਡਾਕਯੂਮੈਂਟ ਡੇਟਾਬੇਸ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਚੰਗਾ ਪ੍ਰਾਇਮਰੀ ਸਟੋਰ ਹੈ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਸਭ ਤੋਂ ਸਧਾਰਨ ਕਿਸਮ ਦੀ ਡੇਟਾਬੇਸ ਹੈ: ਤੁਸੀਂ ਇੱਕ ਮੁੱਲ (ਕੋਈ ਡੇਟਾ) ਇਕ ਵਿਲੱਖਣ ਕੁੰਜੀ (ਲੇਬਲ) ਹੇਠਾਂ ਸਟੋਰ ਕਰਦੇ ਹੋ, ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਤੁਸੀਂ ਕੁੰਜੀ ਦਿੰਦੇ ਹੋ ਕੇ ਮੁੱਲ ਫੈਚ ਕਰਦੇ ਹੋ।
ਕੁੰਜੀ ਨੂੰ ਇੱਕ ਪਛਾਣਕਰਤਾ ਸੋਚੋ ਜੋ ਬਿਲਕੁਲ ਵਾਪਸ ਦਿੱਤਾ ਜਾ ਸਕੇ, ਅਤੇ ਮੁੱਲ ਉਹ ਚੀਜ਼ ਜੋ ਤੁਸੀਂ ਵਾਪਸ ਚਾਹੁੰਦੇ ਹੋ।
ਕੁੰਜੀਆਂ ਆਮ ਤੌਰ 'ਤੇ ਛੋਟੀ ਸਤਰਾਂ ਹੁੰਦੀਆਂ ਹਨ (ਜਿਵੇਂ user:1234 ਜਾਂ session:9f2a...). ਮੁੱਲ ਛੋਟੇ (ਇੱਕounter) ਜਾਂ ਵੱਡੇ (JSON ਬਲੌਬ) ਹੋ ਸਕਦੇ ਹਨ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ "ਇਸ ਕੁੰਜੀ ਲਈ ਮੁੱਲ ਦਿਓ" ਪ੍ਰਸ਼ਨਾਂ ਲਈ ਬਣਾਏ ਜਾਂਦੇ ਹਨ। ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ, ਕਈਆਂ ਵਿੱਚ ਇੱਕ ਢਾਂਚਾ ਹੈ ਜੋ hash table ਵਰਗਾ ਹੋ ਸਕਦਾ ਹੈ: ਕੁੰਜੀ ਨੂੰ ਇੱਕ ਐਸੇ ਸਥਾਨ 'ਤੇ ਬਦਲਿਆ ਜਾਂਦਾ ਹੈ ਜਿੱਥੇ ਮੁੱਲ ਤੇਜ਼ੀ ਨਾਲ ਮਿਲ ਸਕੇ।
ਇਸ ਲਈ ਤੁਸੀਂ ਅਕਸਰ ਸੁਣੋਗੇ constant-time lookups (ਅਕਸਰ O(1) ਲਿਖਿਆ ਜਾਂਦਾ ਹੈ): ਪ੍ਰਦਰਸ਼ਨ ਜ਼ਿਆਦਾ ਹਿਸਾਬ ਨਾਲ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਕਿੰਨੀਆਂ ਰਿਕਵੇਸਟਾਂ ਤੁਸੀਂ ਕਰ ਰਹੇ ਹੋ ਨਾ ਕਿ ਕਿੰਨੇ ਰਿਕਾਰਡ ਮੌਜੂਦ ਹਨ। ਇਹ ਜਾਦੂ ਨਹੀਂ—ਕੋਲਾਈਜ਼ਨ ਅਤੇ ਮੈਮੋਰੀ ਸੀਮਾਵਾਂ ਅਜੇ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹਨ—ਪਰ ਆਮ cache/session ਵਰਤੋਂ ਲਈ ਇਹ ਬਹੁਤ ਤੇਜ਼ ਹੈ।
ਗਰਮ ਡੇਟਾ ਉਹ ਛੋਟਾ ਸਲਾਇਸ ਹੁੰਦਾ ਹੈ ਜੋ ਵਾਰ-ਵਾਰ ਮੰਗਿਆ ਜਾਂਦਾ ਹੈ (ਪ੍ਰਸਿੱਧ ਉਤਪਾਦ ਪੇਜ, ਸਰਗਰਮ sessions, rate-limit ਕਾਊਂਟਰ). ਗਰਮ ਡੇਟਾ ਨੂੰ ਇੱਕ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਵਿੱਚ—ਖਾਸ ਕਰਕੇ memory ਵਿੱਚ—ਰੱਖਣਾ slows ਡੇਟਾਬੇਸ ਕੁਏਰੀਆਂ ਤੋਂ ਬਚਾਉਂਦਾ ਹੈ ਅਤੇ ਲੋਡ ਅਧੀਨ ਜਵਾਬ ਸਮਾਂ ਨਿਯਤ ਰੱਖਦਾ ਹੈ।
Caching ਦਾ ਮਤਲਬ ਹੈ ਲੋੜੀਂਦੇ ਡੇਟਾ ਦੀ ਇੱਕ ਨਕਲ ਉਸ ਜਗ੍ਹਾ ਉੱਤੇ ਰੱਖਣਾ ਜੋ ਮੂਲ ਸਰੋਤ ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਪਹੁੰਚਯੋਗ ਹੋਵੇ। ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਇਸ ਲਈ ਆਮ ਥਾਂ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਕੁੰਜੀ ਨਾਲ ਇੱਕ ਸਿੰਗਲ ਲੁੱਕਅਪ ਵਿੱਚ ਮੁੱਲ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ, ਅਕਸਰ ਕੁਝ ਮਿਲੀਸੈਕਿੰਡਾਂ ਵਿੱਚ।
Caching ਉਹ ਵੇਲੇ ਮਹਾਨ ਹੈ ਜਦੋਂ ਇੱਕੋ-ਹੋਇਆਂ ਸਵਾਲ ਲਗਾਤਾਰ ਪੁੱਛੇ ਜਾਂਦੇ ਹਨ: ਪ੍ਰਸਿੱਧ ਪੇਜ, ਮੁੜ-ਮੁੜ ਖੋਜਾਂ, ਆਮ API ਕਾਲਾਂ, ਜਾਂ ਮਹਿੰਗੀਆਂ ਗਣਨਾਵਾਂ। ਜਦੋਂ ਮੁੱਖ ਸਰੋਤ ਧੀਮਾ ਜਾਂ rate-limited ਹੋਵੇ—ਜਿਵੇਂ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਭਾਰੀ ਲੋਡ 'ਤੇ ਹੋਵੇ ਜਾਂ ਤੀਸਰੇ ਪੱਖੀ API ਹਰ ਬੇਨਤੀ 'ਤੇ ਖਰਚਾ ਲੱਗਾਈ—ਤਾਂ ਵੀ кеш ਸਹਾਇਕ ਹੁੰਦਾ ਹੈ।
ਚੰਗੀ ਉਮੀਦ ਵਾਲੇ ਪਦਾਰਥ ਉਹ ਹਨ ਜਿਹੜੇ ਅਕਸਰ ਪੜ੍ਹੇ ਜਾਂਦੇ ਹਨ ਅਤੇ ਜਿਨ੍ਹਾਂ ਨੂੰ ਜੇ ਲੋੜ ਪਈ ਤਾਂ ਮੁੜ-ਤਿਆਰ ਕੀਤਾ ਜਾ ਸਕਦਾ:
ਸਿਧਾ ਨਿਯਮ: ਉਹ ਨਤੀਜੇ ਕੈਸ਼ ਕਰੋ ਜੋ ਤੁਸੀਂ ਮੁੜ-ਤਿਆਰ ਕਰ ਸਕਦੇ ਹੋ। ਜੇ ਡੇਟਾ ਲਗਾਤਾਰ ਬਦਲਦਾ ਹੈ ਜਾਂ ਹਰ ਪੜ੍ਹਾਈ 'ਤੇ consistent ਰਹਿਣਾ ਜ਼ਰੂਰੀ ਹੈ (ਉਦਾਹਰਣ: ਬੈਂਕ ਬੈਲੇਂਸ), ਤਾਂ ਕੈਸ਼ ਕਰਨ ਤੋਂ ਬਚੋ।
ਬਿਨਾਂ caching ਦੇ, ਹਰ ਪੇਜ ਵਿਊ ਵਿੱਚ ਕਈ ਡੇਟਾਬੇਸ ਕੁਏਰੀਆਂ ਜਾਂ API ਕਾਲਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇੱਕ cache ਨਾਲ, ਐਪਲਿਕੇਸ਼ਨ ਬਹੁਤ ਸਾਰੀਆਂ ਬੇਨਤੀਆਂ key-value ਸਟੋਰ ਤੋਂ ਸਰਵ ਕਰ ਸਕਦੀ ਹੈ ਅਤੇ ਸਿਰਫ਼ cache miss ਤੇ ਹੀ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ/API ਨੂੰ fallback ਕਰਦੀ ਹੈ। ਇਸ ਨਾਲ ਕੁਏਰੀਆਂ ਦੀ ਸੰਖਿਆ ਘਟਦੀ ਹੈ, ਕਨੈਕਸ਼ਨ contention ਘਟਦਾ ਹੈ, ਅਤੇ ਟਰੈਫਿਕ spike ਦੌਰਾਨ ਭਰੋਸੇਯੋਗਤਾ ਸੁਧਰਦੀ ਹੈ।
ਕੈਸ਼ਿੰਗ ਤਾਜ਼ਗੀ ਨੂੰ ਤੇਜ਼ੀ ਲਈ ਤਿਆਗ ਕਰਦੀ ਹੈ। ਜੇ cached ਮੁੱਲ ਜਲਦੀ ਅਪਡੇਟ ਨਹੀਂ ਕੀਤੇ ਜਾਂਦੇ, ਤਾਂ ਯੂਜ਼ਰ stale ਜਾਣਕਾਰੀ ਦੇਖ ਸਕਦੇ ਹਨ। ਡਿਸਟ੍ਰਿਬਿਊਟਡ ਸਿਸਟਮਾਂ ਵਿੱਚ ਦੋ ਰਿਕਵੇਸਟ ਵੱਖ-ਵੱਖ ਸੰਸਕਰਣ ਪੜ੍ਹ ਸਕਦੀਆਂ ਹਨ।
ਤੁਸੀਂ ਇਹ ਜੋਖਮ TTLs ਚੁਣ ਕੇ, ਇਹ ਫੈਸਲਾ ਕਰ ਕੇ ਕਿ ਕਿਹੜਾ ਡੇਟਾ "ਥੋੜ੍ਹਾ ਪੁਰਾਣਾ" ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਆਪਣੀ ਐਪਲੀਕੇਸ਼ਨ ਨੂੰ ਕਈ ਵਾਰ cache misses ਜਾਂ ਰਿਫਰੇਸ਼ ਦੀ ਦੇਰੀ ਸਹਿਣਯੋਗ ਬਣਾਕੇ ਨਿਯੰਤਰਿਤ ਕਰਦੇ ਹੋ।
ਇੱਕ cache “pattern” ਉਹ ਦੁਹਰਾਉਣਯੋਗ ਵਰਕਫਲੋ ਹੈ ਜਿਸ ਵਿੱਚ ਤੁਹਾਡੀ ਐਪ cache ਸ਼ਾਮਿਲ ਹੋਣ 'ਤੇ ਡਾਟਾ ਪੜ੍ਹਦੀ ਅਤੇ ਲਿਖਦੀ ਹੈ। ਸਹੀ ਚੋਣ ਟੂਲ (Redis, Memcached ਆਦਿ) ਤੋਂ ਘੱਟ, underlying ਡੇਟਾ ਕਿੰਨੀ ਵਾਰੀ ਬਦਲਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਕਿੰਨੀ stale ਡੇਟਾ ਸਹਿਣ ਕਰ ਸਕਦੇ ਹੋ, ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ।
Cache-aside ਵਿੱਚ ਤੁਹਾਡੀ ਐਪ cache ਨੂੰ ਸਪਸ਼ਟ ਤਰੀਕੇ ਨਾਲ ਕੰਟਰੋਲ ਕਰਦੀ ਹੈ:
ਸਹੀ ਫਿਟ: ਉਹ ਡੇਟਾ ਜੋ ਅਕਸਰ ਪੜ੍ਹਿਆ ਜਾਂਦਾ ਹੈ ਪਰ ਘੱਟ-ਕਦਰ ਬਦਲਦਾ ਹੈ (ਉਤਪਾਦ ਪੇਜ, configuration, ਪਬਲਿਕ ਪ੍ਰੋਫਾਈਲ). ਇਹ ਇੱਕ ਵਧੀਆ ਡਿਫੌਲਟ ਵੀ ਹੈ ਕਿਉਂਕਿ ਫੇਲਿਓਰ graceful ਡਿਗਰੇਡ ਕਰਦੇ ਹਨ: ਜੇ cache ਖਾਲੀ ਹੈ ਤਾਂ ਵੀ ਤੁਸੀਂ database ਤੋਂ ਪੜ੍ਹ ਸਕਦੇ ਹੋ।
Read-through ਦਾ ਮਤਲਬ ਹੈ ਕਿ cache ਟੀਅਰ miss 'ਤੇ database ਤੋਂ ਲੋਡ ਕਰ ਲੈਂਦਾ ਹੈ (ਤੁਹਾਡੀ ਐਪ "cache ਤੋਂ" ਪੜ੍ਹਦੀ ਹੈ, ਅਤੇ cache ਨੂੰ ਲੋਡ ਕਰਨ ਦਾ ਢੰਗ ਪਤਾ ਹੁੰਦਾ ਹੈ). ਇਹ ਐਪ ਕੋਡ ਨੂੰ ਸਧਾਰਨ ਬਣਾਉਂਦਾ ਹੈ, ਪਰ cache ਟੀਅਰ ਵਿੱਚ ਇੱਕ ਲੋਡਰ ਇੰਟੀਗਰੇਸ਼ਨ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ।
Write-through ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਹਰ ਲਿਖਤ synchronous ਤੌਰ 'ਤੇ cache ਅਤੇ database ਦੋਹਾਂ ਨੂੰ ਜਾਦੋਂ ਕਰਦੀ ਹੈ। ਪੜ੍ਹਾਈ ਆਮ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਅਤੇ consistent ਹੁੰਦੀ ਹੈ, ਪਰ ਲਿਖਤਾਂ ਹੌਲੀ ਹੁੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਦੋ ਓਪਰੇਸ਼ਨ ਪੂਰੇ ਹੋਣੇ ਲਾਜ਼ਮੀ ਹਨ।
ਸਹੀ ਫਿਟ: ਉਹ ਡੇਟਾ ਜਿੱਥੇ ਤੁਸੀਂ ਘੱਟ cache misses ਅਤੇ ਸਧਾਰਨ ਪੜ੍ਹਾਈ consistency ਚਾਹੁੰਦੇ ਹੋ (ਉਦਾਹਰਣ: user settings, feature flags), ਅਤੇ ਜਿੱਥੇ ਲਿਖਤ ਲੈਟੈਂਸੀ ਕਬੂਲਯੋਗ ਹੈ।
Write-back ਵਿੱਚ, ਤੁਹਾਡੀ ਐਪ ਪਹਿਲਾਂ cache ਨੂੰ ਲਿਖਦੀ ਹੈ, ਅਤੇ cache ਬਾਅਦ ਵਿੱਚ (ਅਕਸਰ బ్యాచਾਂ ਵਿੱਚ) database ਤੇ flush ਕਰਦਾ ਹੈ।
ਫਾਇਦੇ: ਤੇਜ਼ ਲਿਖਤਾਂ ਅਤੇ ਘੱਟ ਡੇਟਾਬੇਸ ਲੋਡ।
ਰਿਸਕ: ਜੇ cache ਨੋਡ flush ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਫੇਲ ਹੋ ਜਾਵੇ, ਤਾਂ ਤੁਹਾਨੂੰ ਡੇਟਾ ਘਟ ਸਕਦਾ ਹੈ। ਇਸਨੂੰ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਵਰਤੋ ਜਦੋਂ ਤੁਸੀਂ ਗੁਆਉਣ ਸਹਿਣ ਕਰ ਸਕਦੇ ਹੋ ਜਾਂ ਮਜ਼ਬੂਤ durability ਮਕੈਨਿਜ਼ਮ ਹੋਣ।
ਜੇ ਡੇਟਾ ਘੱਟ ਬਦਲਦਾ ਹੈ, ਤਾਂ cache-aside ਇੱਕ ਸਮਝਦਾਰ TTL ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਕਾਫੀ ਹੁੰਦਾ ਹੈ। ਜੇ ਡੇਟਾ ਬਹੁਤ ਵਾਰ ਬਦਲਦਾ ਹੈ ਅਤੇ stale ਰੀਡਸ ਦੁੱਖਦਾਇਕ ਹਨ, ਤਾਂ write-through (ਜਾਂ ਬਹੁਤ ਛੋਟੇ TTLs ਨਾਲ explicit invalidation) 'ਤੇ ਵਿਚਾਰ ਕਰੋ। ਜੇ ਲਿਖਤ ਵਾਲੀ ਮਾਤਰਾ ਅਤਿ-ਵੱਡੀ ਹੈ ਅਤੇ ਦਫਾ-ਦਫਾ ਗੁਆਉਣਾ ਮਨਜ਼ੂਰ ਹੈ, ਤਾਂ write-behind ਲਾਭਦਾਇਕ ਹੋ ਸਕਦਾ ਹੈ।
cached ਡੇਟਾ "ਉਚਿਤ ਤੌਰ 'ਤੇ ਤਾਜ਼ਾ" ਰੱਖਣਾ ਹਰ ਕੁੰਜੀ ਲਈ ਸਹੀ expiration ਰਣਨੀਤੀ ਚੁਣਨ ਬਾਰੇ ਹੈ। ਲਕਸ਼ ਨਿਰਪੱਖਤਾ ਨਹੀਂ—ਉਦੇਸ਼ ਹੈ ਕਿ stale ਨਤੀਜੇ ਯੂਜ਼ਰਾਂ ਨੂੰ ਹੈਰਾਨ ਨਾ ਕਰਨ ਅਤੇ ਫਿਰ ਵੀ caching ਤੋਂ ਹੋਣ ਵਾਲੇ ਗਤੇ ਉਫ਼ਦੇ ਹੋਣ।
TTL (time to live) ਇੱਕ ਕੁੰਜੀ 'ਤੇ ਆਟੋਮੈਟਿਕ ਮਿਆਦ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਤਾਂ ਕਿ ਉਹ ਇੱਕ ਸਮਾਂ ਬਾਅਦ ਉੱਡ ਜਾਂਦੀ/ਅਣਉਪਲਬਧ ਹੋ ਜਾਂਦੀ ਹੈ। ਛੋਟੇ TTL stale ਰਿਸਕ ਘਟਾਉਂਦੇ ਹਨ ਪਰ cache misses ਅਤੇ backend ਲੋਡ ਵਧਾਉਂਦੇ ਹਨ। ਲੰਮੇ TTLs hit rate ਵਧਾਉਂਦੇ ਹਨ ਪਰ outdated ਮੁੱਲ ਸਰਵ ਕਰਨ ਦਾ ਜੋਖਮ ਵਧਾਉਂਦੇ ਹਨ।
ਅਮਲੀ ਢੰਗ TTL ਚੁਣਨ ਦਾ:
TTL passive ਹੁੰਦੀ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਜਾਣਦੇ ਹੋ ਕਿ ਡੇਟਾ ਬਦਲ ਗਿਆ ਹੈ, ਤਾਂ ਅਕਸਰ ਇਹ ਵਧੀਆ ਹੁੰਦਾ ਹੈ ਕਿ actively invalidate ਕਰੋ: ਪੁਰਾਣੀ ਕੁੰਜੀ ਹਟਾਓ ਜਾਂ ਨਵਾਂ ਮੁੱਲ ਤੁਰੰਤ ਲਿਖੋ।
ਉਦਾਹਰਣ: ਯੂਜ਼ਰ ਨੇ ਆਪਣੀ ਈਮੇਲ ਅੱਪਡੇਟ ਕੀਤੀ, ਤਾਂ user:123:profile ਹਟਾਓ ਜਾਂ cache ਵਿੱਚ ਤੁਰੰਤ ਅਪਡੇਟ ਕਰੋ। Active invalidation stale windows ਘਟਾਉਂਦੀ ਹੈ, ਪਰ ਇਹ ਲਾਜ਼ਮੀ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਤੁਹਾਡੀ ਐਪ ਿਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ cache ਅਪਡੇਟ ਕਰੇ।
ਪੁਰਾਣੀ ਕੁੰਜੀ ਹਟਾਉਣ ਦੀ ਬਜਾਇ, ਕੁੰਜੀ ਦੇ ਨਾਮ ਵਿੱਚ ਇੱਕ ਵਰਜ਼ਨ ਸ਼ਾਮਿਲ ਕਰੋ, ਜਿਵੇਂ product:987:v42। ਜਦੋਂ ਉਤਪਾਦ ਬਦਲੇ, ਵਰਜ਼ਨ ਵਧਾ ਕੇ product:987:v43 ਪੜ੍ਹੋ/ਲਿਖੋ। ਪੁਰਾਣੀਆਂ ਵਰਜ਼ਨਾਂ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਦੇਰ ਨਾਲ expire ਹੋ ਜਾਂਦੀਆਂ ਹਨ। ਇਸ ਨਾਲ ਉਹ ਦੌੜ-ਭੇਦ ਟਾਲੇ ਜਾਂਦੀਆਂ ਹਨ ਜਿੱਥੇ ਇੱਕ ਸਰਵਰ ਇੱਕ ਕੁੰਜੀ ਮਿਟਾ ਰਿਹਾ ਹੋ ਅਤੇ ਦੂਜਾ ਲਿਖ ਰਿਹਾ ਹੋਵੇ।
ਜਿਵੇਂ ਪਹਿਲਾਂ ਵਰਣਨ ਕੀਤਾ ਗਿਆ: request coalescing/locking, stale serve ਵੀ-ਰਿਵੈਲਡਿੰਗ ਦੌਰਾਨ, ਅਤੇ early refresh ਖਾਸ hot keys ਲਈ ਸਭ ਆਮ ਹੱਲ ਹਨ।
Session ਡੇਟਾ ਉਹ ਛੋਟਾ ਬੰਡਲ ਹੈ ਜੋ ਤੁਹਾਡੀ ਐਪ ਨੂੰ ਵਾਪਸ ਆ ਰਹੇ ਬਰਾਊਜ਼ਰ ਜਾਂ ਮੋਬਾਇਲ ਕਲਾਇੰਟ ਨੂੰ ਪਛਾਣਨ ਲਈ ਚਾਹੀਦਾ ਹੁੰਦਾ ਹੈ। ਘੱਟੋ-ਘੱਟ, ਇਹ ਇੱਕ session ID (ਜਾਂ ਟੋਕਨ) ਹੈ ਜੋ ਸਰਵਰ-ਸਾਈਡ ਸਟੇਟ ਨਾਲ ਮੈਪ ਹੁੰਦੀ ਹੈ। ਉਤਪਾਦ ਦੇ ਅਨੁਸਾਰ, ਇਸ ਵਿੱਚ user state (logged-in flag, roles, CSRF nonce), ਅਸਥਾਈ ਪਸੰਦਾਂ ਅਤੇ ਕਾਰਟ ਸਮੱਗਰੀ ਜਾਂ ਚੈੱਕਆਉਟ ਸਟੀਪ ਜਿਹੇ ਸਮੇਂ-ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਹੋ ਸਕਦੇ ਹਨ।
Session reads ਅਤੇ writes ਸਧਾਰਨ ਹਨ: token ਨਾਲ ਲੱਭੋ, ਮੁੱਲ ਲੋ, ਅਪਡੇਟ ਕਰੋ, ਅਤੇ expiration ਲਗਾਓ। TTL ਲਗਾਉਣ ਨਾਲ inactive sessions ਆਪਣੇ ਆਪ ਹਟ ਜਾਂਦੇ ਹਨ, ਸਟੋਰੇਜ ਸਾਫ਼ ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਟੋਕਨ ਲੀਕ ਹੋਣ 'ਤੇ ਜੋਖਮ ਘਟਦਾ ਹੈ।
ਆਮ ਫਲੋ:
ਸਾਫ਼, ਸਕੋਪਡ ਕੁੰਜੀਆਂ ਰੱਖੋ ਅਤੇ ਮੁੱਲ ਛੋਟਾ ਰੱਖੋ:
sess:<token> ਜਾਂ sess:v2:<token> (versioning ਭਵਿੱਖੀ ਤਬਦੀਲੀਆਂ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ)।user_sess:<userId> -> <token> ਰੱਖੋ ਤਾਂ ਕਿ "ਇੱਕ active session ਪ੍ਰਤੀ user" ਨੂੰ ਲਾਗੂ ਕੀਤਾ ਜਾ ਸਕੇ ਜਾਂ user ਵੱਲੋਂ ਸੈਸ਼ਨਾਂ ਨੂੰ ਰੱਦ ਕੀਤਾ ਜਾ ਸਕੇ।ਲੌਗਆਉਟ ਨੂੰ session ਕੁੰਜੀ ਅਤੇ ਕੋਈ ਸਬੰਧਤ ਇੰਡੈਕਸ (ਜਿਵੇਂ user_sess:<userId>) ਤੁਰੰਤ ਹਟਾਈ ਜਾਣੀ ਚਾਹੀਦੀ ਹੈ। ਰੋਟੇਸ਼ਨ (ਜੋ ਕਿ ਲੌਗਿਨ, privilege ਬਦਲਾਅ ਜਾਂ ਨਿਯਮਤ ਰੂਪ ਵਿੱਚ ਸਿਫਾਰਿਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ) ਲਈ ਨਵਾਂ ਟੋਕਨ ਬਣਾਓ, ਨਵਾਂ session ਲਿਖੋ, ਫਿਰ ਪੁਰਾਣੀ ਕੁੰਜੀ ਹਟਾਓ। ਇਹ stolen token ਦੇ ਵਰਤੋਂਯੋਗ ਰਹਿਣ ਦੀ ਝਿੜੀ ਘਟਾਉਂਦਾ ਹੈ।
Caching ਸਭ ਤੋਂ ਆਮ ਵਰਤੋਂ ਮਾਮਲਾ ਹੈ, ਪਰ ਇਹ ਇਕੱਲਾ ਤਰੀਕਾ ਨਹੀਂ ਜਿਸ ਨਾਲ ਇੱਕ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਤੇਜ਼ ਕਰ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੀਆਂ ਐਪਸ ਛੋਟੀ-ਛੋਟੀ, ਅਕਸਰ ਦੋਵਾਰ-ਚੈੱਕ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਸਥਿਤੀਆਂ ਲਈ ਤੇਜ਼ ਰੀਡਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀਆਂ ਹਨ—ਜੋ “source of truth adjacent” ਹਨ ਅਤੇ ਲਗਭਗ ਹਰ ਰਿਕਵੇਸਟ 'ਤੇ ਚੈੱਕ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
Authorization checks ਆਮ ਤੌਰ 'ਤੇ critical path 'ਤੇ ਹੁੰਦੀਆਂ ਹਨ: ਹਰ API ਕਾਲ ਨੂੰ ਪੜ੍ਹਨਾ ਪੈਂਦਾ ਹੈ “ਕੀ ਇਹ ਯੂਜ਼ਰ ਇਹ ਕਰਨ ਦੇ ਲਈ ਅਨੁਮਤ ਹੈ?” relational database ਤੋਂ ਹਰ ਰਿਕਵੈਸਟ 'ਤੇ permissions ਲੈਣਾ ਲੇਟੈਂਸੀ ਅਤੇ ਲੋਡ ਵਧਾ ਸਕਦਾ ਹੈ।
ਇੱਕ key-value ਸਟੋਰ compacto authorization ਡੇਟਾ ਰੱਖ ਸਕਦਾ ਹੈ ਤੇਜ਼ ਲੁੱਕਅਪ ਲਈ, ਉਦਾਹਰਣ:
perm:user:123 → permission ਕੋਡਾਂ ਦੀ ਸੂਚੀ/ਸੈੱਟentitlement:org:45 → enabled plan featuresਇਹ ਉਨ੍ਹਾਂ ਸਿਸਟਮਾਂ ਲਈ ਖਾਸ ਹੋਣਦਾ ਹੈ ਜਿੱਥੇ permissions read-heavy ਹਨ ਅਤੇ ਸਪੀਂਘ-ਘੱਟ ਬਦਲਦੀ ਹੈ। ਜਦੋਂ permissions ਬਦਲਦੀਆਂ ਹਨ (role updates, plan upgrades), ਤੁਸੀਂ ਇੱਕ ਛੋਟੀ ਕੁੰਜੀ ਸਮੂਹ ਨੂੰ ਅਪਡੇਟ/invalidate ਕਰ ਸਕਦੇ ਹੋ ਤਾਂ ਕਿ ਅਗਲੀ ਬੇਨਤੀ ਨਵੇਂ access ਨਿਯਮਾਂ ਨੂੰ ਦਰਸਾਏ।
Feature flags ਛੋਟੇ, ਅਕਸਰ ਪੜ੍ਹੇ ਜਾਣ ਵਾਲੇ ਮੁੱਲ ਹਨ ਜੋ ਤੇਜ਼ੀ ਨਾਲ ਅਤੇ ਸਮਾਂ-ਸੁਚਿਤ ਤਰੀਕੇ ਨਾਲ ਉਪਲਬਧ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।
ਆਮ ਪੈਟਰਨ:
flag:new-checkout → true/falseconfig:tax:region:EU → JSON ਬਲੌਬ ਜਾਂ versioned configਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਇੱਥੇ ਚੰਗੇ ਹਨ ਕਿਉਂਕਿ ਰੀਡਸ ਸਧਾਰਨ, ਪੇਸ਼ਗੋਈਯੋਗ ਅਤੇ ਤੇਜ਼ ਹੁੰਦੀਆਂ ਹਨ। ਤੁਸੀਂ ਮੁੱਲਾਂ ਨੂੰ ਵਰਜਨ ਵੀ ਕਰ ਸਕਦੇ ਹੋ (ਜਿਵੇਂ config:v27:...) ਤਾਂ ਕਿ rollouts ਸੁਰੱਖਿਅਤ ਰਹਿਣ ਅਤੇ ਤੇਜ਼ rollback ਸੰਭਵ ਹੋਵੇ।
Rate limiting ਅਕਸਰ user, API key, ਜਾਂ IP ਪਤੇ ਪ੍ਰਤੀ counters ਤੱਕ ਘੱਟ ਹੁੰਦੀ ਹੈ। ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਆਮ ਤੌਰ 'ਤੇ atomic operations ਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹਨ, ਜੋ ਤੁਹਾਨੂੰ concurrency ਦੇ ਦੌਰਾਨ ਵੀ ਕਾਉਂਟਰ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਵਧਾਉਣ ਦਿੰਦੇ ਹਨ।
ਤੁਸੀਂ ਟਰੈਕ ਕਰ ਸਕਦੇ ਹੋ:
rl:user:123:minute → ਹਰ ਰਿਕਵੇਸਟ 'ਤੇ increment ਕਰਨਾ, 60 ਸਕਿੰਟ ਬਾਅਦ expirerl:ip:203.0.113.10:second → ਛੋਟੇ-ਵਿੰਡੋ ਬਰਸਟ ਨਿਯੰਤਰਣਹਰ ਕਾਉਂਟਰ ਕੁੰਜੀ 'ਤੇ TTL ਲਗਾ ਕੇ, ਲਿਮਿਟ ਬਗੈਰ ਕੋਈ ਬੈਕਗ੍ਰਾਊਂਡ ਜਾਪ ਦੇ ਆਪ-ਕਾਰ ਠੀਕ ਹੋ ਜਾਂਦੀ ਹੈ। ਇਹ ਲੌਗਿਨ ਕੋਸ਼ਿਸ਼ਾਂ ਨੂੰ ਪ੍ਰੋਟੈਕਟ ਕਰਨ, ਮਹਿੰਗੇ ਐਂਡਪੋਇੰਟਸ ਦੀ ਰੱਖਿਆ ਕਰਨ ਜਾਂ ਯੋਜਨਾਵਾਂ-ਅਨੁਸਾਰ ਕੋਟਾ ਲਾਗੂ ਕਰਨ ਲਈ ਅਮਲ ਵਿੱਚ ਆੰਦਾ ਹੈ।
ਭੁਗਤਾਨ ਅਤੇ ਹੋਰ "ਇੱਕ ਵਾਰੀ ਹੀ ਕਰਨੇ" ਓਪਰੇਸ਼ਨ retries (ਟਾਈਮਆਉਟ, ਕਲਾਇੰਟ retries, ਜਾਂ message re-delivery) ਤੋਂ ਰੱਖਣ ਲਈ idempotency keys ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ idempotency keys ਰਿਕਾਰਡ ਕਰ ਸਕਦਾ ਹੈ:
idem:pay:order_789:clientKey_abc → ਸਟੋਰ ਕੀਤਾ ਨਤੀਜਾ ਜਾਂ ਸਥਿਤੀਪਹਿਲੀ ਬੇਨਤੀ 'ਤੇ, ਤੁਸੀਂ ਉਸ ਨਤੀਜੇ ਨੂੰ پروਸੈਸ ਕਰਕੇ TTL ਨਾਲ ਸਟੋਰ ਕਰਦੇ ਹੋ। ਬਾਅਦੀ retries 'ਤੇ ਤੁਸੀਂ ਸਟੋਰ ਕੀਤਾ ਨਤੀਜਾ ਵਾਪਸ ਕਰ ਦਿਓਗੇ ਬਜਾਏ ਫਿਰੋਂ ਓਪਰੇਸ਼ਨ ਚਲਾਉਣ ਦੇ। TTL ਅਣ-ਮਾਪੀ ਵਧਨ ਤੋਂ ਰੋਕਦਾ ਹੈ ਅਤੇ ਹਕੀਕਤੀ retry ਵਿੰਡੋ ਨੂੰ ਕਵਰ ਕਰਦਾ ਹੈ।
ਇਹ ਵਰਤੋਂ "ਕੈਸ਼ਿੰਗ" ਦੀ ਕਲਾਸਿਕ ਮਹੱਤਤਾ ਨਹੀਂ ਹਨ; ਇਹ high-frequency reads ਅਤੇ coordination primitives ਲਈ ਤੇਜ਼ੀ ਅਤੇ atomicity ਰੱਖਣ ਬਾਰੇ ਹਨ।
"ਕੀ-ਵੈਲਯੂ ਸਟੋਰ" ਹਮੇਸ਼ਾਂ "string in, string out" ਨਹੀਂ ਹੁੰਦੇ। ਕਈ ਸਿਸਟਮ ਸਮਰੱਥ ਡਾਟਾ ਸਟਰੱਕਚਰ ਦਿੰਦੇ ਹਨ ਜੋ ਤੁਹਾਨੂੰ ਆਮ ਜਰੂਰਤਾਂ ਨੂੰ ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਸਟੋਰ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ—ਅਕਸਰ ਤੇਜ਼ੀ ਨਾਲ ਅਤੇ ਘੱਟ ਕੋਡ ਨਾਲ।
Hashes (maps) ਓਹੇ ਸਮਾਂ ਲਈ ਆਦਰਸ਼ ਹਨ ਜਦ ਤੁਸੀਂ ਇੱਕ ਹੀ "ਚੀਜ਼" ਦੇ ਕਈ ਸਬੰਧਤ ਗੁਣ ਰੱਖਦੇ ਹੋ। ਇੱਕ-ਇਕ user:123:name, user:123:plan, user:123:last_seen ਦੇ ਬਦਲੇ, ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ user:123 ਹੇਠਾਂ ਫੀਲਡਾਂ ਵਜੋਂ ਰੱਖ ਸਕਦੇ ਹੋ।
ਇਸ ਨਾਲ key sprawl ਘਟਦੀ ਹੈ ਅਤੇ ਤੁਸੀਂ ਸਿਰਫ਼ ਲੋੜੀਂਦਾ ਫੀਲਡ ਫੈਚ ਜਾਂ ਬਦਲ ਸਕਦੇ ਹੋ—profiles, feature flags, ਜਾਂ ਛੋਟੇ config ਬਲੌਬ ਲਈ ਉਪਯੋਗੀ।
Sets "ਕੀ X ਸਮੂਹ ਦਾ ਮੈਂਬਰ ਹੈ?" ਦੇ ਸਵਾਲਾਂ ਲਈ ਵਧੀਆ ਹਨ:
Sorted sets ਵਿੱਚ ordering score ਦੇ ਨਾਲ ਹੁੰਦੀ ਹੈ, ਜੋ leaderboards, "ਟੌਪ N" ਸੂਚੀਆਂ ਅਤੇ ਸਮਾਂ/ਲੋਕਪ੍ਰਿਯਤਾ ਅਨੁਸਾਰ ਰੈਂਕਿੰਗ ਲਈ ਫਿੱਟ ਹੈ। ਤੁਸੀਂ ਸਕੋਰ ਵਜੋਂ view counts ਜਾਂ timestamps ਰੱਖ ਕੇ ਤੇਜ਼ੀ ਨਾਲ top items ਪੜ੍ਹ ਸਕਦੇ ਹੋ।
Concurrency ਸਮੱਸਿਆ ਆਮ ਤੌਰ 'ਤੇ counters, quotas, ਇੱਕ-ਵਾਰੀ ਕਾਰਵਾਈਆਂ, ਅਤੇ rate limits ਵਿੱਚ ਦਿਸਦੀ ਹੈ। ਜੇ ਦੋ ਰਿਕਵੇਸਟ ਇਕੱਠੇ ਆ ਕੇ "read → add 1 → write" ਕਰਦੇ ਹਨ, ਤਾਂ ਤੁਸੀਂ ਅਪਡੇਟ ਗੁਆ ਸਕਦੇ ਹੋ।
Atomic operations ਇਸਨੂੰ ਇਕੇ, ਅਟੂਟ ਕਦਮ ਦੇ ਤੌਰ 'ਤੇ store ਦੇ ਅੰਦਰ ਕਰਨ ਦਿੰਦੀਆਂ ਹਨ:
Atomic increments ਨਾਲ ਤੁਹਾਨੂੰ locks ਜਾਂ ਵੱਖ-ਵੱਖ ਸਰਵਰਾਂ ਵਿਚਕਾਰ ਜ਼ਿਆਦਾ ਸਮਨਵਯ ਦੀ ਲੋੜ ਨਹੀਂ ਰਹਿੰਦੀ। ਇਸ ਨਾਲ race conditions ਘਟਦੀਆਂ, ਕੋਡ ਪਾਥ ਸਧਾਰਨ ਹੁੰਦੇ ਹਨ, ਅਤੇ ਲੋਡ ਹੇਠਾਂ ਪੇਸ਼ਗੀ ਪਹੁੰਚ ਹੋਰ ਭਵਿੱਖ-ਯੋਗ ਹੁੰਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ rate limiting ਅਤੇ quota ਜਿੱਥੇ "ਕੁਝ-ਲਗਭਗ-ਸਹੀ" ਗ਼ਲਤ ਹੋ ਸਕਦਾ ਹੈ।
ਜਦੋਂ ਕੋਈ key-value ਸਟੋਰ ਗੰਭੀਰ ਟਰੈਫਿਕ ਸੰਭਾਲਣਾ ਸ਼ੁਰੂ ਕਰਦਾ ਹੈ, "ਇਸਨੂੰ ਤੇਜ਼ ਬਣਾਉਣਾ" ਆਮ ਤੌਰ 'ਤੇ "ਇਸਨੂੰ ਵਿਆਪਕ ਬਣਾਉਣਾ" ਹੁੰਦਾ ਹੈ: ਪੜ੍ਹਾਈਆਂ ਅਤੇ ਲਿਖਤਾਂ ਨੂੰ ਕਈ ਨੋਡਾਂ ਵਿੱਚ ਫੈਲਾਉਣਾ ਜਦੋਂ ਕਿ ਫੇਲਿਅਰ ਹਾਲਤ 'ਚ ਪ੍ਰਬੰਧਿਤ ਰਹੇ।
Replication ਇੱਕੋ ਡੇਟਾ ਦੀਆਂ ਕਈ ਨਕਲਾਂ ਰੱਖਦਾ ਹੈ।
Sharding ਕਿ-ਸਪੇਸ ਨੂੰ ਨੋਡਾਂ 'ਤੇ ਵੰਡ ਦਿੰਦਾ ਹੈ।
ਬਹੁਤ ਸਾਰੀਆਂ ਤਤਪਕ ਡਿਪਲੋਇਮੈਂਟ ਦੋਹਾਂ ਨੂੰ ਮਿਲਾਂਦੀਆਂ ਹਨ: throughput ਲਈ shards, availability ਲਈ ਹਰ shard 'ਤੇ replicas।
"High availability" ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਯਕੀਨ ਕਰਾਉਂਦੀ ਹੈ ਕਿ cache/session ਲੇਅਰ ਨੋਡ ਫੇਲ ਹੋਣ `ਤੇ ਵੀ ਬੇਨਤੀਆਂ ਸਰਵ ਕਰਦੀ ਰਹੇ।
Client-side routing ਵਿੱਚ, ਤੁਹਾਡੀ ਐਪ (ਜਾਂ ਉਸਦੀ ਲਾਇਬ੍ਰੇਰੀ) ਗਣਨਾ ਕਰਦੀ ਹੈ ਕਿ ਕਿਹੜਾ ਨੋਡ ਕਿਸ ਕੁੰਜੀ ਦਾ ਮਾਲਕ ਹੈ (consistent hashing ਨਾਲ). ਇਹ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ clients ਨੂੰ topology ਤਬਦੀਲੀਆਂ ਬਾਰੇ ਜਾਣਕਾਰ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
Server-side routing ਵਿੱਚ, ਤੁਸੀਂ ਇੱਕ proxy ਜਾਂ cluster endpoint ਨੂੰ ਰਿਕਵੇਸਟ ਭੇਜਦੇ ਹੋ ਜੋ ਠੀਕ ਨੋਡ ਨੂੰ ਅੱਗੇ ਭੇਜਦਾ ਹੈ। ਇਹ clients ਨੂੰ ਸਰਲ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ rollouts ਸੌਖੇ ਕਰਦਾ ਹੈ, ਪਰ ਇੱਕ ਹੋਰ hop ਜੋੜਦਾ ਹੈ।
ਉਪਰੋਂ नीचे ਤੱਕ ਮੈਮੋਰੀ ਦੀ ਯੋਜਨਾ ਬਣਾਓ:
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਗਰਮ ਡੇਟਾ memory ਵਿੱਚ ਰੱਖ ਕੇ ਅਤੇ ਤੇਜ਼ reads/writes ਲਈ optimize ਕਰਕੇ "ਤੁਰੰਤ" ਦਿੱਸਦੇ ਹਨ। ਇਸ ਤੇਜ਼ੀ ਦੀ ਕੀਮਤ ਹੈ: ਤੁਸੀਂ ਅਕਸਰ ਪ੍ਰਦਰਸ਼ਨ, durability, ਅਤੇ consistency ਵਿੱਚੋਂ ਕਿਸੇ ਦੇ ਨਾਲ ਸਮਝੌਤਾ ਕਰ ਰਹੇ ਹੋ। ਪਹਿਲਾਂ ਹੀ ਇਹ ਟਰੇਡ-ਆਫ ਸਮਝ ਲੈਣ ਨਾਲ ਭਵਿੱਖ ਵਿੱਚ ਦਰਦਨਾਕ ਹੈਰਾਨੀ ਤੋਂ ਬਚਾਅ ਹੁੰਦਾ ਹੈ।
ਕਈ ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਵੱਖ-ਵੱਖ persistence ਮੋਡ ਵਿੱਚ ਚਲ ਸਕਦੇ ਹਨ:
ਜੋ ਮੋਡ ਤੁਸੀਂ ਚੁਣਦੇ ਹੋ ਉਹ ਡੇਟਾ ਦੇ ਉਦੇਸ਼ ਨਾਲ ਮਿਲਣਾ ਚਾਹੀਦਾ ਹੈ: caches ਖੋਣਾ ਸਹਿਣ ਕਰ ਸਕਦੇ ਹਨ; session storage ਨੂੰ ਅਕਸਰ ਹੋਰ ਧਿਆਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਡਿਸਟ੍ਰਿਬਿਊਟਡ ਸੈਟਅਪ ਵਿੱਚ, ਤੁਸੀਂ eventual consistency ਵੇਖ ਸਕਦੇ ਹੋ—ਖਾਸ ਕਰਕੇ failover ਜਾਂ replication lag ਦੌਰਾਨ reads ਥੋੜ੍ਹਾ ਪੁਰਾਣਾ ਮੁੱਲ ਵਾਪਸ ਦੇ ਸਕਦੇ ਹਨ। ਜ਼ਿਆਦਾ ਮਜ਼ਬੂਤ consistency (ਉਦਾਹਰਣ ਲਈ, ਕਈ ਨੋਡਾਂ ਤੋਂ acknowledgements ਦੀ ਲੋੜ) anomalies ਘਟਾਉਂਦਾ ਹੈ ਪਰ latency ਵਧਾਉਂਦਾ ਹੈ ਅਤੇ ਨੈਟਵਰਕ ਸਮੱਸਿਆਵਾਂ ਦੌਰਾਨ availability ਘਟਾ ਸਕਦਾ ਹੈ।
Caches ਭਰ ਜਾਂਦੇ ਹਨ। Eviction policy ਫੈਸਲਾ ਕਰਦੀ ਹੈ ਕਿ ਕੀ ਹਟਾਇਆ ਜਾਵੇ: least-recently-used (LRU), least-frequently-used (LFU), random, ਜਾਂ "no-evict" (ਜੋ ਮੈਮੋਰੀ ਭਰਨ 'ਤੇ ਲਿਖਤ ਫੇਲ ਕਰਾਉਂਦਾ ਹੈ). ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ missing cache entries ਨੂੰ ਤਰਜੀਹ ਦਿਓਗੇ ਜਾਂ pressure 'ਤੇ errors।
ਮੰਨੋ ਕਿ outages ਹੁੰਦੀਆਂ ਹਨ। ਆਮ fallback ਵਿੱਚ:
ਇਨ੍ਹਾਂ ਵਿਹਾਰਾਂ ਨੂੰ ਜਾਣ-ਬੂਝ ਕੇ ਡਿਜ਼ਾਇਨ ਕਰਨਾ ਹੀ ਸਿਸਟਮ ਨੂੰ ਯੂਜ਼ਰਾਂ ਲਈ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਅਕਸਰ ਤੁਹਾਡੀ ਐਪ ਦੇ "ਹਾਟ ਪਾਥ" 'ਤੇ ਹੁੰਦੇ ਹਨ। ਇਸ ਨਾਲ ਉਹ ਸੰਵੇਦਨਸ਼ੀਲ (ਉਹਨਾਂ ਵਿੱਚ session tokens ਜਾਂ user identifiers ਹੋ ਸਕਦੇ ਹਨ) ਅਤੇ ਮਹਿੰਗੇ (ਜ਼ਿਆਦਾਤਰ memory-ਭਾਰ) ਹੋ ਜਾਂਦੇ ਹਨ। ਸ਼ੁਰੂ ਅਤ ਜ਼ਰੂਰੀ ਮੂਢੀ ਚੀਜ਼ਾਂ ਸਹੀ ਰੱਖਣ ਨਾਲ ਬਾਅਦ ਵਾਲੀਆਂ ਘਟਨਾਵਾਂ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਨਿਯਤ ਨੈੱਟਵਰਕ ਸੀਮਾਵਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: ਸਟੋਰ ਨੂੰ ਇੱਕ private subnet/VPC ਸেগਮੈਂਟ ਵਿੱਚ ਰੱਖੋ, ਅਤੇ ਸਿੱਫ਼ ਉਹੀ ਐਪਲਿਕੇਸ਼ਨ ਸਰਵਿਸਾਂ ਜੋ ਸੱਚਮੁਚ ਜਰੂਰੀ ਹਨ, ਟ੍ਰੈਫਿਕ ਦੀ ਆਗਿਆ ਦਿਓ।
ਜੇ ਪ੍ਰੋਡਕਟ ਸਮਰਥਨ ਕਰਦਾ ਹੈ ਤਾਂ authentication ਵਰਤੋ, ਅਤੇ least privilege ਦੀ ਪਾਲਣਾ ਕਰੋ: apps, admins, automation ਲਈ ਵੱਖ-ਵੱਖ credentials; secrets rotate ਕਰੋ; shared “root” tokens ਤੋਂ ਬਚੋ।
ਟ੍ਰੈਫਿਕ ਨੂੰ transit ਵਿੱਚ (TLS) encrypt ਕਰੋ ਜਦੋਂ ਸੰਭਵ ਹੋ—ਖਾਸ ਕਰਕੇ ਜੇ ਟ੍ਰੈਫਿਕ ਹੋਸਟਾਂ ਜਾਂ ਜ਼ੋਨਜ਼ ਨੂੰ ਪਾਰ ਕਰਦਾ ਹੈ। rest ਤੇ encryption ਪ੍ਰੋਡਕਟ ਅਤੇ ਡਿਪਲੋਇਮੈਂਟ-ਨਿਰਭਰ ਹੁੰਦਾ ਹੈ; managed services ਲਈ ਇਹ enable ਕਰੋ ਅਤੇ ਬੈਕਅੱਪ encryption ਵੀ ਚੈੱਕ ਕਰੋ।
ਕੁਝ metrics ਤੁਹਾਨੂੰ ਦੱਸਦੇ ਹਨ ਕਿ cache ਮਦਦ ਕਰ ਰਿਹਾ ਹੈ ਜਾਂ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਰਿਹਾ ਹੈ:
ਹਠਾਓ sudden changes ਲਈ alerts, ਨਾ ਕੇਵਲ absolute thresholds, ਅਤੇ ਕੀ-ਓਪਰੇਸ਼ਨਾਂ ਨੂੰ ਧਿਆਨ ਨਾਲ ਲਾਜ਼ਮੀ ਲਾਗ ਕਰੋ (ਸੰਵੇਦਨਸ਼ੀਲ ਮੁੱਲ ਲਾਗ ਕਰਨ ਤੋਂ ਬਚੋ)।
ਸਭ ਤੋਂ ਵੱਡੇ ਚਾਲਕ ਹਨ:
ਇੱਕ ਵਰਤਮਾਨੀ ਲਾਗਤ-ਕੰਟਰੋਲ value size ਘਟਾਉਣਾ ਅਤੇ ਹਕੀਕਤ-ਅਨੁਸਾਰ TTLs ਸੈਟ ਕਰਨ ਨਾਲ ਹੁੰਦਾ ਹੈ, ਤਾਂ ਕਿ ਸਟੋਰ ਸਿਰਫ਼ ਉਹੀ ਰੱਖੇ ਜੋ ਐਕਟਿਵਲੀ ਲੋੜੀਂਦਾ ਹੈ।
###ਪ੍ਰਯੋਗਿਕ ਰੋਲਆਉਟ ਚੈੱਕਲਿਸਟ
ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਕੀ ਨਿਮਿੰਗ ਨੂੰ ਮਿਆਰੀਕ੍ਰਿਤ ਕਰੋ ਤਾਂ ਕਿ ਤੁਹਾਡੇ cache ਅਤੇ session keys ਪੇਸ਼ਗੀ-ਅਨੁਮਾਨਯੋਗ, searchable, ਅਤੇ bulk-ਉੱਤੇ ਸੁਰੱਖਿਅਤ ਓਪਰੇਸ਼ਨ ਲਈ ਸਹਿਮਤ ਹੋਣ। ਇੱਕ ਸਧਾਰਨ Convention ਜਿਵੇਂ app:env:feature:id (ਉਦਾਹਰਣ: shop:prod:cart:USER123) ਟਕਰਾਅ ਤੋਂ ਬਚਾਉਂਦਾ ਅਤੇ ਡੀਬੱਗ ਤੇਜ਼ ਕਰਦਾ ਹੈ।
ਇੱਕ TTL ਰਣਨੀਤੀ ਸ਼ਿਪ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਪਰਿਭਾਸ਼ਿਤ ਕਰੋ। ਫ਼ੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜਾ ਡੇਟਾ ਤੇਜ਼ੀ ਨਾਲ expire ਹੋ ਸਕਦਾ ਹੈ (ਸਕਿੰਟ/ਮਿੰਟ), ਕੀ ਲੰਮੀ ਉਮਰ ਚਾਹੀਦੀ ਹੈ (ਘੰਟੇ), ਅਤੇ ਕੀ ਕੇਵਲ ਕਦੇ ਵੀ ਕੈਸ਼ ਨਹੀ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ। ਜੇ ਤੁਸੀਂ ਡੇਟਾਬੇਸ ਰੋਜ਼ rows cache ਕਰ ਰਹੇ ਹੋ, ਤਾਂ TTLs ਨੂੰ underlying ਡੇਟਾ ਦੇ ਬਦਲਣ ਨਾਲ align ਕਰੋ।
ਹਰ cached item type ਲਈ ਇੱਕ invalidation ਯੋਜਨਾ ਲਿਖੋ:
product:v3:123) ਜਦ ਤੁਸੀਂ ਢਾਂਚਾਕ੍ਰਮਿਕ "ਸਭ ਨੂੰ invalidate ਕਰੋ" ਵਰਤਣਾ ਚਾਹੁੰਦੇ ਹੋਸ਼ੁਰੂ ਤੋਂ ਹੀ ਕੁਝ success metrics ਚੁਣੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਟ੍ਰੈਕ ਕਰੋ:
eviction counts ਅਤੇ memory usage ਵੀ ਮਾਨੀਟਰ ਕਰੋ ਤਾਂ ਕਿ ਕੈਸ਼ ਸਹੀ ਸਾਈਜ਼ ਕੀਤਾ ਗਿਆ ਹੈ।
ਵੱਡੇ ਮੁੱਲ ਨੈੱਟਵਰਕ ਸਮਾਂ ਅਤੇ memory-ਦਬਾਅ ਵਧਾਉਂਦੇ ਹਨ—ਛੋਟੇ, precomputed fragments cache ਕਰਨਾ ਪਸੰਦ ਕਰੋ। TTLs ਨੂੰ ਨਾ ਭੁੱਲੋ (stale ਡੇਟਾ ਅਤੇ memory leaks) ਅਤੇ ਅਨੰਤ ਕੁੰਜੀ ਵਾਧਾ (ਉਦਾਹਰਣ: ਹਰ search query ਨੂੰ ਸਦਾ ਲਈ cache ਕਰਨਾ) ਤੋਂ ਬਚੋ। ਸਾਂਝੇ ਕੁੰਜੀਆਂ ਹੇਠਾਂ ਯੂਜ਼ਰ-ਖਾਸ ਡੇਟਾ cache ਕਰਨ ਵਿੱਚ ਸਾਵਧਾਨ ਰਹੋ।
ਜੇ ਤੁਸੀਂ ਵਿਕਲਪ ਮੁਲਾਂਕਣ ਕਰ ਰਹੇ ਹੋ, local in-process cache ਅਤੇ distributed cache ਦੀ ਤੁਲਨਾ ਕਰੋ ਅਤੇ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ consistency ਕਿੱਥੇ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੈ। Implementation ਵਿਸ਼ੇਸ਼ ਅਤੇ অপਰੇਸ਼ਨਲ ਮਾਰਗਦਰਸ਼ਨ ਲਈ, /docs ਵੇਖੋ। Capacity ਯੋਜਨਾ ਜਾਂ ਕੀਮਤ ਅਨੁਮਾਨ ਲਈ, /pricing ਵੇਖੋ।
ਜੇ ਤੁਸੀਂ ਨਵਾਂ ਉਤਪਾਦ ਬਣਾ ਰਹੇ ਹੋ (ਜਾਂ ਮੌਜੂਦਾ ਨੂੰ ਨਵੀਨਤਮ ਕਰ ਰਹੇ ਹੋ), ਤਦ caching ਅਤੇ session storage ਨੂੰ ਸ਼ੁਰੂ ਤੋਂ ਪਹਿਲਾਂ-ਕਲਾਸ concerns ਵਜੋਂ ਡਿਜ਼ਾਈਨ ਕਰਨਾ ਮਦਦਗਾਰ ਰਹਿੰਦਾ ਹੈ। Koder.ai 'ਤੇ, ਟੀਮਾਂ ਅਕਸਰ ਇੱਕ end-to-end ਐਪ ਪ੍ਰੋਟੋਟਾਈਪ (React ਵੈਬ, Go ਸਰਵਿਸز ਨਾਲ PostgreSQL, ਅਤੇ ਵਿਕਲਪਕ ਤੌਰ 'ਤੇ Flutter ਮੋਬਾਇਲ) ਬਣਾਂਦੀਆਂ ਹਨ ਅਤੇ ਫਿਰ cache-aside, TTLs ਅਤੇ rate-limiting counters ਵਰਗੇ ਪੈਟਰਨਾਂ ਨਾਲ ਪ੍ਰਦਰਸ਼ਨ ਤੇ ਇਟਰੇਟ ਕਰਦੀਆਂ ਹਨ। Planning mode, snapshots, ਅਤੇ rollback ਵਰਗੀਆਂ ਖਾਸੀਅਤਾਂ cache key ਡਿਜ਼ਾਈਨ ਅਤੇ invalidation ਨੀਤੀਆਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਟੈਸਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ, ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਤਿਆਰ ਹੋ ਤਾਂ ਤੁਸੀਂ ਸੋਰਸ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰ ਸਕਦੇ ਹੋ।
ਕੀ-ਵੈਲਯੂ ਸਟੋਰ ਇੱਕ ਹੀ ਓਪਰੇਸ਼ਨ ਲਈ ਅਨੁਕੂਲਿਤ ਹੁੰਦੇ ਹਨ: ਇਸ ਕੁੰਜੀ ਨੂੰ ਦੇ ਕੇ ਮੁੱਲ ਵਾਪਸ ਕਰੋ। ਇਸ ਤੰਗ ਧਿਆਨ ਨਾਲ ਹੀ in-memory ਇੰਡੈਕਸਿੰਗ ਅਤੇ ਹੈਸ਼ਿੰਗ ਵਰਗੀਆਂ ਤੇਜ਼ ਰਸਤੇ мөмкин ਹੋ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਆਮ-ਉਦੇਸ਼ ਵਾਲੇ ਡੇਟਾਬੇਸ ਦੇ ਤੁਲਨਾਤਮਕ ਤੌਰ 'ਤੇ ਘੱਟ ਕੁਆਰੀ ਪਲੈਨਿੰਗ ਲੋੜੀਦੀ ਹੈ।
ਉਹ ਅਪਣੇ ਸਿਸਟਮ ਨੂੰ ਅਲੱਗ ਤਰੀਕੇ ਨਾਲ ਵੀ ਤੇਜ਼ ਕਰਦਿਆਂ ਹਨ: ਕਈ ਵਾਰੀ ਪੁੱਛੀਆਂ ਜਾਣ ਵਾਲੀਆਂ ਗੱਲਾਂ (ਪ੍ਰਸਿੱਧ ਪੇਜ, ਆਮ API ਜਵਾਬ) ਨੂੰ ਹਟਾ ਕੇ ਉਹ ਤੁਹਾਡੇ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਨੂੰ ਲਿਖਾਈਆਂ ਅਤੇ ਜਟਿਲ ਕੁਐਰੀਆਂ ਲਈ ਸਮਾਂ ਦੇ ਸਕਦੇ ਹਨ।
ਇੱਕ ਕੁੰਜੀ ਇੱਕ ਐਸਾ ਵਿਲੱਖਣ ਪਹਿਚਾਣਕਰਤਾ ਹੈ ਜੋ ਤੁਸੀਂ ਰੀਪੀਟ ਕਰ ਸਕਦੇ ਹੋ (ਅਕਸਰ ਇੱਕ ਸਤਰ ਜਿਵੇਂ user:123 ਜਾਂ sess:<token>). ਮੁੱਲ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਤੁਸੀਂ ਵਾਪਸ ਲੈਣਾ ਚਾਹੁੰਦੇ ਹੋ—ਛੋਟੇ ਗਿਣਤੀ ਤੋਂ ਲੈ ਕੇ ਇੱਕ JSON ਬਲੌਬ ਤੱਕ ਕੁੱਝ ਵੀ ਹੋ ਸਕਦਾ ਹੈ।
ਚੰਗੀਆਂ ਕੁੰਜੀਆਂ ਸਥਿਰ, ਸਕੋਪਡ, ਅਤੇ ਪੇਸ਼ਗੀ-ਅਨੁਮਾਨਯੋਗ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ, ਜਿਸ ਨਾਲ caching, sessions ਅਤੇ lookups ਸਾਫ਼ਸਫ਼ਾਯੀ ਨਾਲ ਕੰਮ ਕਰਦੇ ਹਨ ਤੇ ਡੀਬੱਗ ਕਰਨਾ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
ਉਹ ਨਤੀਜੇ cache ਕਰੋ ਜੋ ਅਕਸਰ ਪੜ੍ਹੇ ਜਾਂਦੇ ਹਨ ਅਤੇ ਜੇ ਲੋੜ ਪਈ ਤਾਂ ਮੁੜ-ਤਿਆਰ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
ਆਮ ਉਦਾਹਰਣ:
ਜੋ ਚੀਜ਼ ਸਦਾ ਤਾਜ਼ਾ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ (ਉਦਾਹਰਣ ਲਈ ਵਿੱਤੀ ਬੈਲੇਂਸ), ਉਹ ਕੈਸ਼ ਕਰਨ ਤੋਂ ਬਚੋ ਜਦ ਤੱਕ ਤੁਹਾਡੇ ਕੋਲ ਮਜ਼ਬੂਤ invalidation ਯੋਜਨਾ ਨਾ ਹੋਵੇ।
Cache-aside (ਲੈਜ਼ੀ ਲੋਡਿੰਗ) ਆਮ ਤੌਰ 'ਤੇ ਡਿਫਾਲਟ ਹੁੰਦਾ ਹੈ:
ਇਹ gracefully degrade ਕਰਦਾ ਹੈ: ਜੇ cache ਖਾਲੀ ਜਾਂ ਡਾਊਨ ਹੋ ਜਾਵੇ ਤਾਂ ਵੀ ਤੁਸੀਂ database ਤੋਂ ਰਿਕਵੇਸਟ ਸਰਵ ਕਰ ਸਕਦੇ ਹੋ (ਉਚਿਤ ਸੁਰੱਖਿਆ-ਚੇਤਾਵਨੀ ਨਾਲ)।
ਤੁਸੀਂ read-through ਵਰਤੋਂ ਜਦੋਂ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ cache ਮਿਸ 'ਤੇ ਆਪੋ-ਆਪ ਵਲੋਂ ਲੋਡ ਕਰ ਲਵੇ (ਐਪ ਕੋਡ ਸਧਾਰਨ ਰਹਿੰਦਾ ਹੈ, cache ਟੀਅਰ ਵਿੱਚ ਇੱਕ ਲੋਡਰ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਲੋੜੀਂਦੀ ਹੈ).
Write-through ਤਦ ਵਰਤੋ ਜਦੋਂ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ ਕਿ ਹਰ ਲਿਖਤ cache ਅਤੇ database ਦੋਹਾਂ ਨੂੰ ਸਮਕਾਲੀ ਤੌਰ 'ਤੇ ਅਪਡੇਟ ਕਰੇ—ਇਸ ਨਾਲ ਪੜ੍ਹਾਈ ਆਮ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਅਤੇ consistent ਰਹਿੰਦੀ ਹੈ, ਪਰ ਲਿਖਤ ਦੀ ਲੈਟੈਂਸੀ ਵਧਦੀ ਹੈ।
ਉਹਨਾਂ ਨੂੰ ਉਸ ਵੇਲੇ ਚੁਣੋ ਜਦੋਂ ਤੁਸੀਂ ਓਪਰੇਸ਼ਨਲ ਕੱਠਿਨਾਈ (read-through) ਜਾਂ ਵੱਧ ਲਿਖਤ ਸਮਾਂ (write-through) ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ।
TTL ਇੱਕ ਕਿੰਨੀ ਦੇਰ ਲਈ ਕੀ-ਨੂੰ ਜੀਵਿਤ ਰੱਖਣਾ ਹੈ ਇਹ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ। ਛੋਟੇ TTL ਨਾਲ stale ਹੋਣ ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਹੁੰਦੀ ਹੈ ਪਰ miss ਦਰ ਵੱਧਦੀ ਹੈ; ਲੰਮੇ TTL ਨਾਲ hit rate ਵਧਦਾ ਹੈ ਪਰ purane ਮੁੱਲ ਸਰਵ ਹੋਣ ਦਾ ਜੋਖਮ ਵਧ ਜਾਂਦਾ ਹੈ।
ਅਮਲੀ ਸੁਝਾਵ:
Cache stampede ਉਹ ਵੇਲਾ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਕੋਈ ਗਰਮ ਕੁੰਜੀ expire ਹੋ ਜਾਵੇ ਅਤੇ ਕਈ ਰਿਕਵੇਸਟ ਇਕੱਠੇ ਹੋਕੇ ਉਸ ਨੂੰ ਦੁਬਾਰਾ ਬਣਾਈਂ।
ਆਮ ਰੋਕਥਾਮ:
Sessions ਲਈ key-value ਸਟੋਰ ਇੱਕ ਸੁਭਾਵਿਕ ਮਿਲਾਪ ਹੈ ਕਿਉਂਕਿ read/write ਸਰਲ ਹਨ: ਟੋਕਨ ਨਾਲ ਲੱਭੋ, ਮੁੱਲ ਲਓ, ਅਪਡੇਟ ਕਰੋ ਅਤੇ ਮਿਆਦ ਸੈੱਟ ਕਰੋ। TTL ਲਗਾਉਣ ਨਾਲ inactive sessions ਆਪਣੇ ਆਪ ਹਟ ਜਾਂਦੇ ਹਨ, ਜੋ ਸਟੋਰੇਜ ਸਾਫ਼ ਰੱਖਣ ਅਤੇ ਲੀਕ ਹੋਈ ਟੋਕਨ ਦੇ ਜੋਖਮ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ।
ਅਮਲੀ ਫਲੋ ਇਕਸਾਰ ਹੁੰਦਾ ਹੈ:
ਕਈ key-value ਸਟੋਰ atomic increment ਵਰਗੀਆਂ ਗਤਿਵਿਧੀਆਂ ਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹਨ, ਜਿਸ ਨਾਲ concurrency ਦੌਰਾਨ ਕਾਊਂਟਰ ਸੁਰੱਖਿਅਤ ਰਹਿੰਦੇ ਹਨ।
ਆਮ ਪੈਟਰਨ:
rl:user:123:minute → ਹਰ ਰਿਕਵੇਸਟ 'ਤੇ increment ਕਰੋਜੇ ਕਾਊਂਟਰ ਤੁਹਾਡੇ ਥ੍ਰੈਸ਼ਹੋਲਡ ਤੋਂ ਵੱਧ ਜਾਵੇ ਤਾਂ ਰਿਕਵੇਸਟ ਨੂੰ throttle ਜਾਂ reject ਕਰੋ। TTL-ਅਧਾਰਿਤ expiration ਬੈਕਗ੍ਰਾਊਂਡ ਜਾਬਾਂ ਨੂੰ ਬਿਨਾਂ ਸੈਟਿੰਗ ਲਈ ਲਿਮਿਟ ਰੀਸੈਟ ਕਰ ਦੇਂਦੀ ਹੈ।
ਮੁੱਖ ਟਰੇਡ-ਆਫ਼ ਜੋ ਤੁਹਾਨੂੰ ਯੋਜਨਾ ਬਣਾਉਣ ਸਮੇਂ ਸਮਝਣੇ ਚਾਹੀਦੇ ਹਨ:
ਡਿਜ਼ਾਇਨ ਕਰੋ ਕਿ degraded ਮੋਡ 'ਚ ਕਿੱਵੇਂ ਵਰਤੋਂਕਾਰਾਂ ਲਈ ਅਨੁਭਵ ਰਹੇਗਾ—cache ਬਾਇਪਾਸ, ਥੋੜ੍ਹਾ stale ਸੇਵਾ, ਜਾਂ ਸੰਵੇਦਨਸ਼ੀਲ ਓਪਰੇਸ਼ਨਾਂ ਲਈ fail-closed।