04 ਜੂਨ 2025·4 ਮਿੰਟ
ਹੋਰਾਈਜ਼ੋਨਟਲ ਸਕੇਲਿੰਗ ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਨਾਲੋਂ ਕਿਉਂ ਜ਼ਿਆਦਾ ਔਖੀ ਹੈ
ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਸਿਰਫ CPU/RAM ਵਧਾਉਣਾ ਹੁੰਦਾ ਹੈ। ਹੋਰਾਈਜ਼ੋਨਟਲ ਸਕੇਲਿੰਗ ਵਿਚ ਕੋਆਰਡੀਨੇਸ਼ਨ, ਪਾਰਟੀਸ਼ਨਿੰਗ, ਕੰਸਿਸਟੈਂਸੀ ਅਤੇ ਵੱਧ ਓਪਰੇਸ਼ਨਲ ਕੰਮ ਲੱਗਦਾ ਹੈ—ਇਸੇ ਲਈ ਇਹ ਔਖਾ ਹੈ।
ਸਕੇਲਿੰਗ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ
ਸਕੇਲਿੰਗ ਦਾ ਮਤਲਬ ਹੈ “ਛੰਡੇ ਬਿਨਾ ਹੋਰ ਸੰਭਾਲਨਾ।” ਇਹ “ਹੋਰ” ਹੋ ਸਕਦਾ ਹੈ:
- ਇੱਕੋ ਸਮੇਂ ਜਿਆਦਾ ਯੂਜ਼ਰ ਪ੍ਰੋਡਕਟ ਵਰਤ ਰਹੇ ਹੋਣ
- API ਕਾਲਾਂ ਦੀ ਰਫਤਾਰ ਵੱਧਣਾ (requests per second)
- ਸਟੋਰ ਕੀਤੀ ਅਤੇ ਕਵੈਰੀ ਕੀਤੀ ਜਾਣ ਵਾਲੀ ਡੇਟਾ ਵਧਣਾ
- ਬੈਕਗ੍ਰਾਊਂਡ ਕੰਮ (ਈਮੇਲ, ਵੀਡੀਓ ਪ੍ਰੋਸੇਸਿੰਗ, ਰਿਪੋਰਟ) ਵਧ ਜਾਣਾ
ਜਦੋਂ ਲੋਕ ਸਕੇਲਿੰਗ ਦੀ ਗੱਲ ਕਰਦੇ ਹਨ, ਉਹ ਆਮ ਤੌਰ 'ਤੇ ਇਨ੍ਹਾਂ ਵਿਚੋਂ ਕਿਸੇ ਨੂੰ ਬਿਹਤਰ ਬਣਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹਨ:
- ਸਮਰੱਥਾ: ਸਿਸਟਮ ਕਿੰਨਾ ਟ੍ਰੈਫਿਕ ਜਾਂ ਡੇਟਾ ਸਹਰ ਸਕਦਾ ਹੈ।
- ਗਤੀ: ਲੋਡ ਹੇਠ ਲੈਂਦੇ ਵਿੱਚ ਸਿਸਟਮ ਕਿੰਨਾ ਤੇਜ਼ ਜਵਾਬ ਦਿੰਦਾ ਹੈ।
- ਭਰੋਸੇਮੰਦਤਾ: ਕੁਝ ਟੁੱਟਣ ਤੇ ਵੀ ਸਿਸਟਮ ਕਿਵੇਂ ਕੰਮ ਕਰਦਾ ਰਹਿੰਦਾ ਹੈ।
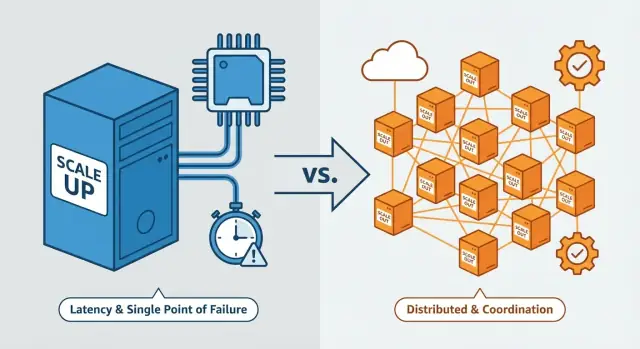
ਇਨਾਂ ਵਿੱਚੋਂ ਬਹੁਤ ਕੁਝ ਇੱਕ ਹੀ ਥੀਮ 'ਤੇ ਆਉਂਦਾ ਹੈ: ਸਕੇਲ ਅੱਪ ਇੱਕ “ਇੱਕ-ਸਿਸਟਮ” ਦਾ ਅਹਿਸਾਸ ਬਰਕਰਾਰ ਰੱਖਦਾ ਹੈ, ਜਦਕਿ ਸਕੇਲ ਆਊਟ ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਕਈ ਸੁਤੰਤਰ ਮਸ਼ੀਨਾਂ ਦੇ ਸਮਹੂ ਬਣਾਉਂਦਾ ਹੈ—ਅਤੇ ਇਹੀ ਸਮਨਵਯ ਹੀ ਮੁਸ਼ਕਿਲੀ ਨੂੰ ਬੜ੍ਹਾ ਦਿੰਦਾ ਹੈ।
ਵਰਟੀਕਲ vs ਹੋਰਾਈਜ਼ੋਨਟਲ ਸਕੇਲਿੰਗ (ਛੋਟੀ ਵਿਆਖਿਆ)
ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ (scale up)
ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਦਾ ਮਤਲਬ ਇੱਕ ਹੀ ਮਸ਼ੀਨ ਨੂੰ ਮਜ਼ਬੂਤ ਕਰਨਾ ਹੈ। ਆਰਕੀਟੈਕਚਰ ਵਹੀ ਰਹਿੰਦੀ, ਪਰ ਸਰਵਰ (ਜਾਂ VM) ਨੂੰ ਅੱਪਗਰੇਡ ਕੀਤਾ ਜਾਂਦਾ ਹੈ: ਵੱਧ CPU ਕੋਰ, ਵੱਧ RAM, ਤੇਜ਼ ਡਿਸਕ, ਉੱਚ ਨੈੱਟਵਰਕ ਥਰੂਪੁੱਟ।
ਇਸਨੂੰ ਵੱਡੀ ਟਰੱਕ ਖਰੀਦਣ ਵਾਂਗ ਸਮਝੋ: ਇੱਕ ਚਾਲਕ ਅਤੇ ਇੱਕ ਵਾਹਨ ਹੀ ਹੈ, ਪਰ ਇਹ ਜ਼ਿਆਦਾ ਲੋਡ ਢੋ ਸਕਦਾ ਹੈ।
ਹੋਰਾਈਜ਼ੋਨਟਲ ਸਕੇਲਿੰਗ (scale out)
ਹੋਰਾਈਜ਼ੋਨਟਲ ਸਕੇਲਿੰਗ ਦਾ ਮਤਲਬ ਹੋਰ ਮਸ਼ੀਨਾਂ ਜੋੜਨਾ ਅਤੇ ਕੰਮ ਵੰਡਣਾ ਹੁੰਦਾ ਹੈ—ਅਕਸਰ ਲੋਡ ਬੈਲੈਂਸਰ ਪਿੱਛੇ। ਇੱਕ ਵੱਡੇ ਸਰਵਰ ਦੀ ਥਾਂ ਤੁਸੀਂ ਕਈ ਸਰਵਰ ਚਲਾ ਰਹੇ ਹੁੰਦੇ ਹੋ।
ਇਹ ਇਕ ਤੋਂ ਵੱਧ ਟਰੱਕ ਵਰਗਾ ਹੈ: ਤੁਸੀਂ ਕੁੱਲ ਮਿਲਾ ਕੇ ਜ਼ਿਆਦਾ ਸਮਾਨ ਹਿਲਾ ਸਕਦੇ ਹੋ, ਪਰ ਹੁਣ ਸ਼ਡਿਊਲਿੰਗ, ਰੂਟਿੰਗ ਅਤੇ ਕੋਰਡੀਨੇਸ਼ਨ ਦੀ ਚਿੰਤਾ ਵੀ ਹੁੰਦੀ ਹੈ।
ਆਮ ਤੌਰ 'ਤੇ ਕਿਹੜੀਆਂ ਸਥਿਤੀਆਂ ਇਹਨਾਂ ਚੋਣ ਨੂੰ ਮਜ਼ਬੂਰ ਕਰਦੀਆਂ ਹਨ?
ਆਮ ਟ੍ਰਿੱਗਰ:
- ਟ੍ਰੈਫਿਕ ਦੇ ਝਟਕੇ (ਮਾਰਕੇਟਿੰਗ, ਸੀਜ਼ਨਲ ਤੇਜ਼ੀ, ਵਾਇਰਲ ਗ੍ਰੋਥ)
- ਮਹੀਨਿਆਂ ਜਾਂ ਸਾਲਾਂ ਦੀ ਲਗਾਤਾਰ ਉੱਗ
- ਵੱਡੇ ਡੇਟਾਸੇਟ (ਵੱਧ ਗਾਹਕ, ਵੱਧ ইਵੈਂਟ, ਸਟੋਰੇਜ ਲਈ ਜ਼ਿਆਦਾ ਇਤਿਹਾਸ)
ਇਕ ਜ਼ਰੂਰੀ ਨੁਆੰਸ: ਅਸਲੀ ਸਿਸਟਮ ਦੋਹਾਂ ਵਰਤਦੇ ਹਨ
ਟੀਮ ਪਹਿਲਾਂ ਆਮ ਤੌਰ 'ਤੇ scale up ਕਰਦੀ ਹੈ ਕਿਉਂਕਿ ਇਹ ਤੇਜ਼ ਹੈ (ਬੌਕਸ ਅੱਪਗਰੇਡ ਕਰੋ), ਫਿਰ scale out ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਇੱਕ ਮਸ਼ੀਨ ਸੀਮਿਤ ਹੋ ਜਾਂਦੀ ਹੈ ਜਾਂ ਉਚੀ ਉਪਲਬਧਤਾ ਚਾਹੀਦੀ ਹੁੰਦੀ ਹੈ। ਪੱਕੀ ਆਰਕੀਟੈਕਚਰ ਅਕਸਰ ਦੋਹਾਂ ਮਿਲਾਉਂਦੀ ਹੈ: ਵੱਡੇ ਨੋਡ ਅਤੇ ਵੱਧ ਨੋਡ, ਬੋਤਲਨੇਕ ਦੇ ਅਧਾਰ 'ਤੇ।
ਕਿਉਂ ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਅਸਾਨ ਮਹਿਸੂਸ ਹੁੰਦੀ ਹੈ
ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਆਕਰਸ਼ਕ ਹੈ ਕਿਉਂਕਿ ਇਹ ਤੁਹਾਡੇ ਸਿਸਟਮ ਨੂੰ ਇੱਕ ਥਾਂ 'ਤੇ ਰੱਖਦੀ ਹੈ। ਇੱਕ ਨੋਡ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਰੀਮੈਂਬਰੀ ਤੇ ਲੋਕਲ ਸਟੇਟ ਦਾ ਇੱਕ ਸਰੋਤ ਹੁੰਦਾ ਹੈ। ਇੱਕ ਪ੍ਰੋਸੈਸ in-memory cache, job queue, session store (ਜੇ ਸੈਸ਼ਨ ਮੈਮੋਰੀ ਵਿੱਚ ਹਨ) ਅਤੇ ਟੈਂਪ ਫਾਇਲਾਂ ਦਾ ਮਾਲਕ ਹੁੰਦਾ ਹੈ।
ਘੱਟ ਹਿਲਦੇ-ਚਲਦੇ ਹਿੱਸੇ
ਇੱਕ ਸਰਵਰ 'ਤੇ ਜ਼ਿਆਦਾਤਰ ਆਪਰੇਸ਼ਨ ਸਿੱਧੇ ਹੁੰਦੇ ਹਨ ਕਿਉਂਕਿ ਇੰਟਰ-ਨੋਡ ਕੋਆਰਡੀਨੇਸ਼ਨ ਘੱਟ ਹੁੰਦੀ:
- ਡੀਬੱਗਿੰਗ ਆਸਾਨ ਹੁੰਦੀ ਹੈ ਕਿਉਂਕਿ ਲੌਗਸ ਅਤੇ ਮੈਟ੍ਰਿਕਸ ਇਕੱਠੇ ਹੋਂਦੇ ਹਨ।
- ਫੇਲਰ ਸਪਸ਼ਟ ਹੁੰਦੇ ਹਨ: ਯਾ ਮਸ਼ੀਨ ਠੀਕ ਹੈ ਜਾਂ ਨਹੀਂ।
- ਬਹੁਤ ਸਾਰੀਆਂ ਬੋਤਲਨੇਕ ਸਥਾਨਕ ਅਤੇ ਮਾਪਯੋਗ ਹੁੰਦੀਆਂ ਹਨ।
ਪਰਫਾਰਮੈਂਸ ਟਿਊਨਿੰਗ “ਲੋਕਲ” ਰਹਿੰਦੀ ਹੈ
ਜਦੋਂ ਤੁਸੀਂ scale up ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਜਾਣੂ ਲੀਵਰ ਖਿੱਚਦੇ ਹੋ: CPU/RAM ਵਧਾਓ, ਤੇਜ਼ ਸਟੋਰੇਜ ਵਰਤੋ, ਇੰਡੈਕਸ ਸੁਧਾਰੋ, ਕ੍ਵੈਰੀاں ਟਿਊਨ ਕਰੋ। ਤੁਹਾਨੂੰ ਡੇਟਾ ਵੰਡਣ ਜਾਂ ਕਈ ਨੋਡਾਂ ਵਿਚ “ਅਗਲਾ ਕੀ ਹੋਵੇ” ਉੱਤੇ ਮੁੜ-ਡਿਜ਼ਾਇਨ ਨਹੀਂ ਕਰਨਾ ਪੈਂਦਾ।
ਜੋ ਤਰਜੀਹਾਂ ਤੁਸੀਂ ਸਵੀਕਾਰਦੇ ਹੋ
ਵਰਟੀਕਲ ਸਕੇਲਿੰਗ ਮੁਫ਼ਤ ਨਹੀਂ ਹੈ—ਪਰ ਇਹ ਜਟਿਲਤਾ ਨੂੰ ਸੰਗ੍ਰਹਿਤ ਰੱਖਦੀ ਹੈ। ਆਖਿਰਕਾਰ ਤੁਹਾਨੂੰ ਸੀਮਾਵਾਂ ਮਿਲਦੀਆਂ ਹਨ: ਜਿਸ ਸਭ ਤੋਂ ਵੱਡੇ ਇੰਸਟੈਂਸ ਨੂੰ ਤੁਸੀਂ ਕਿਰਾਏ 'ਤੇ ਲੈ ਸਕਦੇ ਹੋ, ਘਟਦੀ ਲੋਭਦਾਇਕ ਲਾਭ, ਜਾਂ ਉੱਚ ਖ਼ਰਚ। ਇੱਕ ਵੱਡੀ ਮਸ਼ੀਨ ਨਿਗਰਾਨੀ/ਮੇਟੇਨੈਂਸ ਲਈ ਡਾਊਨਟਾਈਮ ਜੋਖਮ ਵੀ ਵਧਾ ਸਕਦੀ ਹੈ ਜੇ ਤੁਸੀਂ redundancy ਨਹੀਂ ਜੋੜੀ।
ਕੋਆਰਡੀਨੇਸ਼ਨ ਓਵਰਹੈਡ: ਜਿਣ੍ਹਾਂ ਨੋਡ ਵੱਧ, ਨਿਯਮ ਵੱਧ
ਜਦੋਂ ਤੁਸੀਂ scale out ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਸਿਰਫ਼ “ਜ਼ਿਆਦਾ ਸਰਵਰ” ਨਹੀਂ ਪਾਉਂਦੇ। ਤੁਸੀਂ ਹੋਰ ਸੁਤੰਤਰ ਕਿਰਦਾਰ ਪਾਉਂਦੇ ਹੋ ਜੋ ਇਹ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ ਕਿਹੜਾ ਨੋਡ ਕਿਸ ਕੰਮ ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਹੈ, ਕਦੋਂ ਅਤੇ ਕਿਹੜੇ ਡੇਟਾ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ।
ਇੱਕ ਮਸ਼ੀਨ ਨਾਲ ਕੋਆਰਡੀਨੇਸ਼ਨ ਅਕਸਰ ਨਿਰਦੇਸ਼ਤ ਨਹੀਂ ਹੁੰਦੀ: ਇੱਕ ਮੈਮੋਰੀ ਸਪੇਸ, ਇੱਕ ਪ੍ਰੋਸੈਸ, ਇੱਕ ਸਥਾਨ। ਕਈ ਮਸ਼ੀਨਾਂ ਨਾਲ, ਕੋਆਰਡੀਨੇਸ਼ਨ ਇੱਕ ਫੀਚਰ ਬਣ ਜਾਂਦੀ ਹੈ ਜੋ ਤੁਹਾਨੂੰ ਡਿਜ਼ਾਇਨ ਕਰਨੀ ਪੈਂਦੀ ਹੈ।
ਕੋਆਰਡੀਨੇਸ਼ਨ ਅਮਲ ਵਿੱਚ ਕਿਸ ਤਰ੍ਹਾਂ ਦਿਖਦੀ ਹੈ
ਆਮ ਟੂਲ ਅਤੇ ਪੈਟਰਨ:
- ਲੀਡਰ ਚੋਣ: ਇਕ ਨੋਡ ਫੈਸਲੇ ਕਰਦਾ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਅਗਲਾ ਜੌਬ ਕਿਹੜਾ ਵਰਕਰ ਪੜੇਗਾ)। ਜੇ ਲੀਡਰ ਡਾਟਾ ਹੈ, ਤਾਂ ਸਭ ਨੂੰ ਇੱਕ ਬਦਲੀਆ ਲੀਡਰ 'ਤੇ ਮਿਲ ਕੇ ਰਾਜੀ ਹੋਣਾ ਪੈਂਦਾ ਹੈ।
- ਲੌਕ/ਲੀਜ਼: ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ ਕਿ ਇੱਕ ਸਮੇਂ ਸਿਰਫ਼ ਇਕ ਨੋਡ ਕੰਮ ਕਰੇ (ਜਿਵੇਂ ਬਿਲਿੰਗ ਈਮੇਲ ਭੇਜਣਾ)। ਲੀਜ਼ ਮੁਕਾਦਮਾ ਹੁੰਦੇ ਹਨ, ਘੜੀਆਂ ਡ੍ਰਿਫਟ ਹੁੰਦੀਆਂ ਹਨ, ਅਤੇ “ਕੌਣ ਲੌਕ ਰੱਖਦਾ ਹੈ” ਗੁੰਝਲਦਾਰ ਹੋ ਸਕਦਾ ਹੈ।
- ਕਨਸੈਨਸ ਸਿਸਟਮ: ਇਕ ਛੋਟਾ ਗਰੁੱਪ ਖਾਸ ਸਟੇਟ (ਕਨਫਿਗ, ਮੈਂਬਰਸ਼ਿਪ, ਲੀਡਰਸ਼ਿਪ) ਦੇ ਉੱਤੇ ਸਹਿਮਤ ਰਹਿੰਦਾ ਹੈ। ਬਲਦਿਅਰ—ਪਰ ਆਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ ਮੰਗਲਾ।
ਜਦੋਂ ਕੋਆਰਡੀਨੇਸ਼ਨ ਗਲਤ ਹੋ ਜਾਂਦੀ ਹੈ ਤਾਂ ਲਛਣ
ਕੋਆਰਡੀਨੇਸ਼ਨ ਬੱਗ ਆਮ ਤੌਰ 'ਤੇ ਸਾਫ਼ क्रੈਸ਼ ਵਰਗੇ ਨਹੀਂ ਹੁੰਦੇ। ਜ਼ਿਆਦातर ਤੁਸੀਂ ਵੇਖਦੇ ਹੋ:
- ਰੇਸ ਕੰਡੀਸ਼ਨ: ਦੋ ਨੋਡ ਇੱਕੋ ਡੇਟਾ 'ਤੇ ਗਲਤ ਕ੍ਰਮ ਵਿੱਚ ਕਾਰਵਾਈ ਕਰਦੇ ਹਨ।
- ਡੁਪਲਿਕੇਟ ਕੰਮ: ਉਹੀ ਜੌਬ ਦੋ ਵਾਰੀ ਚੱਲ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਦੋ ਵਰਕਰਾਂ ਨੂੰ ਲਗਦਾ ਹੈ ਕਿ ਇਹ ਅਣਕਲੇਮਡ ਹੈ।
- ਸਪਲਿੱਟ-ਬ੍ਰੇਨ: ਇਕ ਨੈੱਟਵਰਕ ਹਿਕਅਪ ਦੋ ਲੀਡਰ ਬਣਾਉ ਸਕਦਾ ਹੈ, ਦੋਹਾਂ ਵੱਖ-ਵੱਖ ਫੈਸਲੇ ਲੈਂਦੇ ਹਨ।
ਇਹ ਮੁੱਦੇ ਅਕਸਰ ਸਿਰਫ਼ ਅਸਲ ਲੋਡ ਹੇਠ, ਡਿਪਲੋਇਮੈਂਟਾਂ ਦੌਰਾਨ, ਜਾਂ ਜਦੋਂ ਅੰਸ਼ਿਕ ਫੇਲਅਰ ਹੁੰਦਾ ਹੈ, ਵੇਖਣ ਨੂੰ ਮਿਲਦੇ ਹਨ। ਸਿਸਟਮ ਠੀਕ ਲੱਗਦਾ ਹੈ—ਜਦ ਤੱਕ ਦਬਾਅ ਨਹੀਂ ਆਉਂਦਾ।
ਡੇਟਾ ਪਾਰਟੀਸ਼ਨਿੰਗ ਅਤੇ ਸ਼ਾਰਡਿੰਗ ਸਹੀ ਬਣਾਉਣਾ ਔਖਾ ਹੈ
Own the Codebase
Keep moving with full source code export when you want your own workflow.
ਜਦੋਂ ਤੁਸੀਂ scale out ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਅਕਸਰ ਸਾਰਾ ਡੇਟਾ ਇਕ ਥਾਂ ਨਹੀਂ ਰੱਖ ਸਕਦੇ। ਤੁਸੀਂ ਇਸਨੂੰ ਮਸ਼ੀਨਾਂ ਵਿੱਚ ਵੰਡਦੇ ਹੋ (ਸ਼ਾਰਡ) ਤਾਂ ਜੋ ਬਹੁਤ ਸਾਰੇ ਨੋਡ ਪੈਰਲਲ ਵਿੱਚ ਸੇਵਾ ਦੇ ਸਕਣ। ਇਹ ਵੰਡ ਹੀ ਮੁਸ਼ਕਲੀਆਂ ਦਾ ਸਿਰੋਤ ਬਣਦੀ ਹੈ: ਹਰ ਰੀਡ/ਰਾਈਟ ਤੇ ਇਹ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ “ਕਿਹੜਾ ਸ਼ਾਰਡ ਇਹ ਰਿਕਾਰਡ ਰੱਖਦਾ ਹੈ?”
ਆਮ ਰਣਨੀਤੀਆਂ: ਰੇਂਜ vs ਹੈਸ਼
ਰੇਂਜ ਪਾਰਟੀਸ਼ਨਿੰਗ ਡੇਟਾ ਨੂੰ ਇੱਕ ਕ੍ਰਮਵਾਰ ਕੀ ਦੇ ਆਧਾਰ ਤੇ ਗਰੁੱਪ ਕਰਦੀ ਹੈ (ਉਦਾਹਰਨ ਲਈ, ਯੂਜ਼ਰ A–F ਸ਼ਾਰਡ 1 ਤੇ, G–M ਸ਼ਾਰਡ 2 ਤੇ)। ਇਹ ਸਮਝਣ ਵਿੱਚ ਆਸਾਨ ਹੈ ਤੇ ਰੇਂਜ ਕ્વੈਰੀਆਂ ਲਈ ਵਧੀਆ ਹੈ। ਘਾਟ ਇਹ ਹੈ ਕਿ ਲੋਡ ਅਨਸਮਾਨ ਹੋ ਸਕਦਾ ਹੈ: ਜੇ ਇੱਕ ਰੇਂਜ ਪਾਪੁਲਰ ਹੋ ਜਾਵੇ ਤਾਂ ਉਹ ਸ਼ਾਰਡ ਬੋਤਲਨੇਕ ਬਣ ਜਾਂਦਾ ਹੈ।
ਹੈਸ਼ ਪਾਰਟੀਸ਼ਨਿੰਗ ਇੱਕ ਕੀ ਨੂੰ ਹੈਸ਼ ਕਰਦੀ ਹੈ ਅਤੇ ਨਤੀਜਿਆਂ ਨੂੰ ਸ਼ਾਰਡਾਂ 'ਤੇ ਵੰਡ ਦਿੰਦੀ ਹੈ। ਇਹ ਟ੍ਰੈਫਿਕ ਨੂੰ ਅੱਧਿਕਤਮ ਤੌਰ 'ਤੇ ਸਮਾਨ ਤਰ੍ਹਾਂ ਫੈਲਾਂਦੀ ਹੈ, ਪਰ ਰੇਂਜ ਕਵੈਰੀਆਂ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਸੰਬੰਧਿਤ ਰਿਕਾਰਡ ਬਿਖਰੇ ਹੋ ਜਾਂਦੇ ਹਨ।
ਰੀਬੈਲੈਂਸਿੰਗ मुफ਼ਤ ਨਹੀਂ ਹੁੰਦੀ
ਨੋਡ ਸ਼ਾਮਲ ਕਰੋ ਅਤੇ ਤੁਸੀਂ ਉਸਨੂੰ ਵਰਤਣਾ ਚਾਹੁੰਦੇ ਹੋ—ਅਰਥਾਤ ਕੁਝ ਡੇਟਾ ਖਿਸਕਣਾ ਪੈਂਦਾ ਹੈ। ਨੋਡ ਹਟਾਉ (ਯੋਜਨਾਬੱਧ ਜਾਂ ਫੇਲ) ਅਤੇ ਹੋਰ ਸ਼ਾਰਡਾਂ ਨੂੰ ਕਵਰ ਕਰਨਾ ਪਏਗਾ। ਰੀਬੈਲੈਂਸਿੰਗ ਵੱਡੇ ਟ੍ਰਾਂਸਫਰ, ਕੈਸ਼ ਵਾਰਮ-ਅਪ, ਅਤੇ ਅਸਥਾਈ ਪਰਫਾਰਮੈਂਸ ਘਟਾਉਂਦੀਆਂ ਲਿਆ ਸਕਦੀ ਹੈ। ਮੂਵ ਦੌਰਾਨ ਤੁਹਾਨੂੰ ਸਟੇਲ ਰੀਡ ਅਤੇ ਗਲਤ ਰਾਹਤ ਵਾਲੀਆਂ ਰਾਈਟਸ ਨੂੰ ਰੋਕਣਾ ਪੈਂਦਾ ਹੈ।
ਹਾਟ ਪਾਰਟੀਸ਼ਨ ਅਤੇ ਸਕਿਊ
ਹੈਸ਼ ਦੇ ਬਾਵਜੂਦ, ਅਸਲੀ ਟ੍ਰੈਫਿਕ ਇਕਸਾਰ ਨਹੀਂ ਹੁੰਦਾ। ਕਿਸੇ ਸੇਲਿਬ੍ਰਿਟੀ ਖਾਤੇ, ਲੋਕਪ੍ਰਿਯ ਪ੍ਰੋਡਕਟ ਜਾਂ ਸਮੇਂ-ਅਧਾਰਿਤ ਪਹੁੰਚ ਪੈਟਰਨ ਇੱਕ ਸ਼ਾਰਡ 'ਤੇ ਲੋਡ ਗਠਾ ਸਕਦੇ ਹਨ। ਇੱਕ ਹਾਟ ਸ਼ਾਰਡ ਸਾਰੇ ਸਿਸਟਮ ਦੀ ਥਰੂਪੁੱਟ ਨੂੰ ਸੀਮਿਤ ਕਰ ਸਕਦਾ ਹੈ।
ਆਪਰੇਸ਼ਨਲ ਕੰਮ ਜੋ ਤੁਸੀਂ ਨਜ਼ਰਅੰਦਾਜ਼ ਨਹੀਂ ਕਰ ਸਕਦੇ
ਸ਼ਾਰਡਿੰਗ ਲਗਾਤਾਰ ਜ਼ਿੰਮੇਵਾਰੀਆਂ ਲਿਆਉਂਦੀ ਹੈ: ਰਾਊਟਿੰਗ ਨਿਯਮਾਂ ਰੱਖਣਾ, ਮਾਈਗ੍ਰੇਸ਼ਨ ਚਲਾਉਣਾ, ਸਕੀਮਾ ਬਦਲਣ 'ਤੋਂ ਬਾਅਦ ਬੈਕਫਿਲ ਕਰਨਾ, ਅਤੇ ਕਲਾਇੈਂਟਾਂ ਨੂੰ ਟੁੱਟਣ ਤੋਂ ਬਿਨਾਂ ਸਪਲਿਟ/ਮਰਜ ਯੋਜਨਾ ਬਣਾਉਣ।
ਰਾਜ: ਸੈਸ਼ਨ, ਕੈਸ਼ ਅਤੇ ਬੈਕਗ੍ਰਾਊਂਡ ਵਰਕ
Get to a Live Environment
Deploy and host your app when you are ready to share or load test.
ਜਦੋਂ ਤੁਸੀਂ scale out ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਸਿਰਫ਼ ਹੋਰ ਸਰਵਰ ਨਹੀਂ ਜੋੜਦੇ—ਤੁਸੀਂ ਆਪਣੀ ਐਪ ਦੀਆਂ ਹੋਰ ਨਕਲਾਂ ਜੋੜਦੇ ਹੋ। ਮੁਸ਼ਕਲ ਪਾਸਾ ਹੈ ਸਟੇਟ: ਕੁਝ ਵੀ ਜੋ ਤੁਹਾਡੀ ਐਪ 'ਰਿਕਾਲ' ਕਰਦੀ ਹੈ ਬੀਚ-ਬੀਚ ਵਿੱਚ ਜਾਂ ਕੰਮ ਦੌਰਾਨ।
ਸੈਸ਼ਨ: ਲੌਗਿਨ ਕਿੱਥੇ ਰੱਖਿਆ ਹੈ?
ਜੇ ਇੱਕ ਯੂਜ਼ਰ ਸਰਵਰ A 'ਤੇ ਲੌਗਿਨ ਕਰਦਾ ਹੈ ਪਰ ਉਨ੍ਹਾਂ ਦੀ ਅਗਲੀ ਰੀਕਵੇਸਟ ਸਰਵਰ B ਤੇ ਜਾਂਦੀ ਹੈ, ਤਾਂ B ਨੂੰ ਕੀ ਪਤਾ ਹੈ ਕਿ ਉਹ ਕੋਣ ਹੈ?
- ਸਟਿੱਕੀ ਸੈਸ਼ਨ ਯੂਜ਼ਰ ਨੂੰ ਇੱਕੋ ਸਰਵਰ ਤੇ ਭੇਜਦੇ ਰਹਿੰਦੇ ਹਨ। ਸਧਾਰਨ, ਪਰ ਨਾਜ਼ੁਕ: ਰੀਸਟਾਰਟ ਅਤੇ ਅਨਸਮਾਨ ਲੋਡ ਯੂਜ਼ਰ-ਦੇਖੇ ਸਮੱਸਿਆਵਾਂ ਬਣ ਸਕਦੇ ਹਨ।
- ਸ਼ੇਅਰਡ ਸੈਸ਼ਨ ਸਟੋਰ (Redis ਜਾਂ ਡੇਟਾਬੇਸ) ਕਿਸੇ ਵੀ ਸਰਵਰ ਨੂੰ ਕਿਸੇ ਵੀ ਰੀਕਵੇਸਟ ਨੂੰ ਹੈਂਡਲ ਕਰਨ ਦਿੰਦਾ ਹੈ। ਜ਼ਿਆਦਾ ਭਰੋਸੇਮੰਦ—ਪਰ ਇਹ ਖ਼ਰਚ ਅਤੇ ਇੱਕ ਨਿਰਭਰਤਾ ਜੋੜਦਾ ਹੈ। ਜੇ ਸੈਸ਼ਨ ਸਟੋਰ ਸਲੋ ਹੋ ਜਾਵੇ, ਸਾਰੀ ਐਪ ਸੁਸਤ ਮਹਿਸੂਸ ਕਰੇਗੀ।
ਕੈਸ਼: ਤੇਜ਼ ਪਰ ਜਦੋਂ ਬੇਇਤਬਾਰ ਹੋ ਜਾਵੇ
ਕੈਸ਼ ਚੀਜ਼ਾਂ ਨੂੰ ਤੇਜ਼ ਕਰਦੇ ਹਨ, ਪਰ ਕਈ ਸਰਵਰਾਂ ਦਾ ਮਤਲਬ ਕਈ ਕੈਸ਼ਾਂ। ਹੁਣ ਤੁਸੀਂ ਨਿਪਟਦੇ ਹੋ:
- ਇਨਵੈਲੀਡੇਸ਼ਨ: ਜਦ ਡੇਟਾ ਬਦਲਦਾ ਹੈ, ਤੁਸੀਂ ਹਰ ਕੈਸ਼ ਨੂੰ ਪੁਰਾਣਾ ਮೌಲ ਤੋਂ ਰੋਕਣ ਲਈ ਕਿਵੇਂ ਕਰਦੇ ਹੋ?
- ਕੋਹੀਰੈਂਸ: ਨੋਡ ਛੋਟੇ ਸਮੇਂ ਲਈ ਸਹਿਮਤ ਨਹੀਂ ਹੋ ਸਕਦੇ।
- ਅਨਸਮਾਨ ਹਿਟ ਰੇਟ: ਇੱਕ ਸਰਵਰ ਵਾਰਮ ਹੈ ਤੇ ਦੂਜਾ ਕੋਲਡ—ਫਰਕ 퍼ਫਾਰਮੈਂਸ ਬਣਦਾ ਹੈ।
ਬੈਕਗ੍ਰਾਊਂਡ ਵਰਕ: ਡਬਲ ਪ੍ਰੋਸੈਸਿੰਗ ਤੋਂ ਬਚਾਓ
ਕਈ ਵਰਕਰਾਂ ਨਾਲ, ਬੈਕਗ੍ਰਾਊਂਡ ਜੌਬ ਦੋ ਵਾਰੀ ਚੱਲ ਸਕਦੇ ਹਨ ਜਦ ਤੱਕ ਤੁਸੀਂ ਇਸ ਲਈ ਡਿਜ਼ਾਇਨ ਨਹੀਂ ਕਰਦੇ। ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ ਕਿਉਂਕਿ queue, ਲੀਜ਼/ਲੌਕ, ਜਾਂ idempotent ਨੌਕਰੀ ਲਾਜ਼ਮੀ ਹੁੰਦੀ ਹੈ ਤਾਂ ਕਿ “ਇਨਵਾਇਸ ਭੇਜੋ” ਜਾਂ “ਕਾਰਡ ਚਾਰਜ ਕਰੋ” ਵਾਰੀ ਵਾਰੀ ਨਾ ਹੋਵੇ—ਖਾਸ ਕਰਕੇ retries ਅਤੇ ਰੀਸਟਾਰਟ ਦੌਰਾਨ।
ਕੰਸਿਸਟੈਂਸੀ ਅਤੇ ਕਨਕਰਨਸੀ ਦੀਆਂ ਸਮੱਸਿਆਵਾਂ ਵੱਧ ਰਹੀਆਂ ਹਨ
ਇੱਕ ਹੀ ਨੋਡ (ਜਾਂ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਡੀਬੀ) ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਸਪਸ਼ਟ “ਸਚਾਈ ਦਾ ਸਰੋਤ” ਹੁੰਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ scale out ਕਰਦੇ ਹੋ, ਡੇਟਾ ਅਤੇ ਰੀਕਵੇਸਟ ਕਈ ਮਸ਼ੀਨਾਂ ਵਿਚ ਫੈਲ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਹਰ ਕੋਈ ਸਿੰਕ ਰਹਿਣਾ ਇੱਕ ਲਗਾਤਾਰ ਚਿੰਤਾ ਬਣਦੀ ਹੈ।
ਮਜ਼ਬੂਤ vs ਆਖ਼ਰੀ ਅਣੁਕੂਲਤਾ (ਸਧਾਰਨ ਭਾਸ਼ਾ)
- ਮਜ਼ਬੂਤ ਕੰਸਿਸਟੈਂਸੀ: ਜਦ ਇੱਕ ਲਿਖਤ ਸਫਲ ਹੋ ਜਾਂਦੀ ਹੈ, ਹਰ ਰੀਡਰ ਨੂੰ ਤੁਰੰਤ ਨਵਾਂ ਮੱਲ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ।
- ਆਖ਼ਰੀ ਅਣੁਕੂਲਤਾ: ਅਪਡੇਟ ਪ੍ਰਸਾਰਿਤ ਹੁੰਦੇ ਹਨ, ਪਰ ਛੋਟੇ ਸਮੇਂ ਲਈ ਕੁਝ ਰੀਡਰ ਪੁਰਾਣਾ ਵੇਖ ਸਕਦੇ ਹਨ।
ਆਖ਼ਰੀ ਅਣੁਕੂਲਤਾ ਅਕਸਰ ਤੇਜ਼ ਅਤੇ ਸਸਤੀ ਹੁੰਦੀ ਹੈ ਵੱਡੇ ਪੱਧਰ 'ਤੇ, ਪਰ ਇਹ ਹੈਰਾਨ ਕਰਨ ਵਾਲੇ ਐਜ ਕੇਸ ਲਿਆ ਸਕਦੀ ਹੈ।
ਅਸਲੀ ਸਿਸਟਮਾਂ ਵਿੱਚ ਕੀ ਗਲਤ ਹੁੰਦਾ ਹੈ
ਆਮ ਮੁੱਦੇ:
- ਸਟੇਲ ਰੀਡਸ: ਯੂਜ਼ਰ ਆਪਣਾ ਐਡਰੈੱਸ ਅਪਡੇਟ ਕਰਦਾ ਹੈ ਪਰ ਰੀਫਰੇਸ਼ 'ਤੇ ਵੀ ਪੁਰਾਣਾ ਵੇਖਦਾ ਹੈ।
- ਰਾਈਟ ਕਨਫਲਿਕਟਸ: ਦੋ ਅਪਡੇਟ ਲਗਭਗ ਇਕੋ ਸਮੇਂ ਹੁੰਦੇ ਹਨ ਅਤੇ ਇਕ ਦੂਜੇ ਨੂੰ ਓਵਰਰਾਈਟ ਕਰ ਦਿੰਦੇ ਹਨ।
- ਲਾਸਟ ਅਪਡੇਟ ਲੰਘਣਾ: “ਆਖ਼ਰੀ ਲਿਖਤ ਜਿੱਤਦੀ” ਕਿਸੇ ਬਦਲਾਅ ਨੂੰ ਮਿਟਾ ਦੇਂਦੀ ਹੈ ਜੋ ਮਿੱਲ ਕੇ ਮਰਜ ਹੋਣਾ ਚਾਹੀਦਾ ਸੀ।
ਨੁਕਸਾਨ ਘਟਾਉਣ ਵਾਲੇ ਪੈਟਰਨ
ਤੁਸੀਂ ਫੇਲਿਅਰਾਂ ਨੂੰ ਖ਼ਤਮ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਪਰ ਤੁਸੀਂ ਉਹਨਾਂ ਲਈ ਡਿਜ਼ਾਇਨ ਕਰ ਸਕਦੇ ਹੋ:
- Idempotency keys: “ਪੇਮੈਂਟ ਬਣਾਉ” ਦੀ retries ਦੁਆਰਾ ਡਬਲ-ਚਾਰਜ ਨਾ ਹੋਵੇ।
- ਬੈਕਆਫ ਨਾਲ ਰੀਟ੍ਰਾਈ: 200ms, ਫਿਰ 400ms, ਫਿਰ 800ms (ਜਿੱਟਰ ਨਾਲ) ਤਾਂ ਜੋ stampede ਨਾ ਹੋਵੇ।
- ਡਿਡੁਪਲੀਕੇਸ਼ਨ: ਜਦ 메시ਜ ਦੋ ਵਾਰੀ ਆਉਂਦੇ ਹਨ, ਇਕ ਵਾਰੀ ਹੀ ਪ੍ਰੋਸੈਸ ਕਰੋ।
ਕਿਉਂ ਵੰਡੇ ਹੋਏ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਮਸ਼ਕਲ ਹਨ
ਸਰਵਿਸਾਂ ਦੇ ਦਰਮਿਆਨ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ (order + inventory + payment) ਚਾਹੀਦਾ ਹੈ ਕਿ ਕਈ ਸਿਸਟਮ ਸਹਿਮਤ ਹੋਣ। ਜੇ ਇੱਕ ਕਦਮ ਅੱਧ ਰਾਹ 'ਤੇ ਫੇਲ ਹੋ ਜਾਵੇ, ਤਾਂ ਤੁਹਾਨੂੰ ਮੁਆਵਜਾ ਕਾਰਵਾਈਆਂ ਅਤੇ ਨਜ਼ਦੀਕੀ ਲੇਖਾ-ਰਖਾ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ। ਨੈੱਟਵਰਕ ਅਤੇ ਨੋਡਾਂ ਦੇ ਅਲੱਗ-ਅਲੱਗ ਫੇਲ ਹੋਣ 'ਤੇ
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
What’s the difference between vertical scaling and horizontal scaling?
Vertical scaling means making a single machine bigger (more CPU/RAM/faster disk). Horizontal scaling means adding more machines and spreading work across them.
Vertical often feels simpler because your app still behaves like “one system,” while horizontal requires multiple systems to coordinate and stay consistent.
Why does horizontal scaling introduce more complexity than vertical scaling?
Because the moment you have multiple nodes, you need explicit coordination:
- deciding who handles which work
- preventing duplicate processing
- handling network delays and partial outages
A single machine avoids many of these distributed-system problems by default.
What is “coordination overhead” in a scaled-out system?
It’s the time and logic spent making multiple machines behave like one:
- leader election and failover rules
- locks/leases and clock drift issues
- avoiding split-brain situations
Even if each node is simple, the system behavior gets harder to reason about under load and failure.
Why are sharding and data partitioning so difficult to get right?
Sharding (partitioning) splits data across nodes so no single machine has to store/serve everything. It’s hard because you must:
- route every read/write to the correct shard
- rebalance data when adding/removing capacity
- handle hot partitions where one shard becomes the bottleneck
It also increases operational work (migrations, backfills, shard maps).
What does “state” mean, and why does it matter for scaling out?
State is anything your app “remembers” between requests or while work is in progress (sessions, in-memory caches, temporary files, job progress).
With horizontal scaling, requests may land on different servers, so you typically need shared state (e.g., Redis/db) or you accept trade-offs like sticky sessions.
How do you prevent background jobs from running twice when scaling out?
If multiple workers can pick up the same job (or a job is retried), you can end up charging twice or sending duplicate emails.
Common mitigations:
- idempotent job handlers
- locks/leases around job claims
- deduplication using unique job IDs
- careful retry policies with backoff
What’s the practical difference between strong and eventual consistency?
Strong consistency means once a write succeeds, all readers immediately see it. Eventual consistency means updates propagate over time, so some readers may see stale data briefly.
Use strong consistency for correctness-critical data (payments, balances, inventory). Use eventual consistency where small delays are acceptable (analytics, recommendations).
Why do timeouts and retries become a bigger deal with horizontal scaling?
In a distributed system, calls become network calls, which adds latency, jitter, and failure modes.
Basics that usually matter most:
- set timeouts so requests don’t hang
- limit retries and add exponential backoff + jitter
- retry only safe (idempotent) operations to avoid duplicate effects
What is “partial failure,” and why is it normal at scale?
Partial failure means some components are broken or slow while others are fine. The system can be “up” but still produce errors, timeouts, or inconsistent behavior.
Design responses include replication, quorums, multi-zone deployments, circuit breakers, and graceful degradation so failures don’t cascade.
How do you debug issues when your app runs on many servers?
Across many machines, evidence is fragmented: logs, metrics, and traces live on different nodes.
Practical steps:
- use correlation IDs end-to-end
- adopt distributed tracing to see request paths
- alert on saturation signals (CPU, queue depth, connection pools), not just error rates