14 ਨਵੰ 2025·8 ਮਿੰਟ
ਰੀਡ ਰੈਪਲਿਕੇਸ ਕਿਉਂ ਮੌਜੂਦ ਹਨ ਅਤੇ ਉਹ ਕਦੋਂ ਅਸਲ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ
ਜਾਣੋ ਕਿ ਰੀਡ ਰੈਪਲਿਕੇਸ ਕਿਉਂ ਮੌਜੂਦ ਹਨ, ਕਿਹੜੀਆਂ ਸਮੱਸਿਆਵਾਂ ਉਹ ਹੱਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਉਹ ਕਦੋਂ ਮਦਦਗਾਰ ਜਾਂ ਨੁਕਸਾਨਦਾਇਕ ਹੁੰਦੇ ਹਨ। ਆਮ ਵਰਤੇ ਕੇਸ, ਸੀਮਾਵਾਂ ਅਤੇ ਵਿਹੰਗਮ ਨਿਰਣਏ-ਸਲਾਹਾਂ ਸ਼ਾਮਲ ਹਨ।
ਜਾਣੋ ਕਿ ਰੀਡ ਰੈਪਲਿਕੇਸ ਕਿਉਂ ਮੌਜੂਦ ਹਨ, ਕਿਹੜੀਆਂ ਸਮੱਸਿਆਵਾਂ ਉਹ ਹੱਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਉਹ ਕਦੋਂ ਮਦਦਗਾਰ ਜਾਂ ਨੁਕਸਾਨਦਾਇਕ ਹੁੰਦੇ ਹਨ। ਆਮ ਵਰਤੇ ਕੇਸ, ਸੀਮਾਵਾਂ ਅਤੇ ਵਿਹੰਗਮ ਨਿਰਣਏ-ਸਲਾਹਾਂ ਸ਼ਾਮਲ ਹਨ।
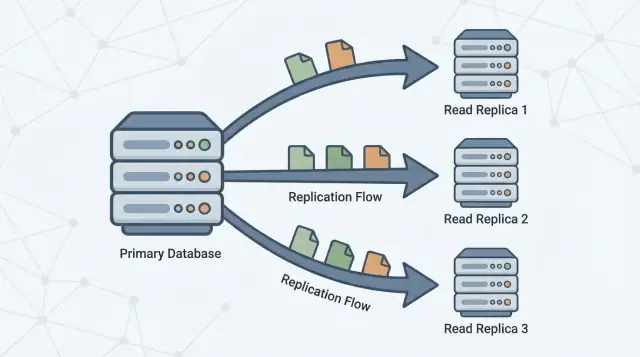
ਇੱਕ ਰੀਡ ਰੈਪਲਿਕਾ ਤੁਹਾਡੇ ਮੁੱਖ ਡੇਟਾਬੇਸ (ਅਕਸਰ primary ਕਹਿੰਦੇ ਹਨ) ਦੀ ਇੱਕ ਨਕਲ ਹੁੰਦੀ ਹੈ ਜੋ ਲਗਾਤਾਰ ਉਸ ਤੋਂ ਬਦਲਾਅ ਪ੍ਰਾਪਤ ਕਰਦੀ ਰਹਿੰਦੀ ਹੈ। ਤੁਹਾਡੀ ਐਪlicaਸ਼ਨ ਰੈਪਲਿਕਾ ਨੂੰ ਸਿਰਫ਼ ਪੜ੍ਹਨ ਵਾਲੀਆਂ ਕਵੇਰੀਆਂ (ਜਿਵੇਂ ਕਿ SELECT) ਭੇਜ ਸਕਦੀ ਹੈ, ਜਦਕਿ ਪ੍ਰਾਇਮਰੀ ਸਾਰੇ ਲਿਖਣ (ਜਿਵੇਂ INSERT, UPDATE, DELETE) ਸੰਭਾਲਦਾ ਰਹਿੰਦਾ ਹੈ।
ਵਾਅਦਾ ਸਾਦਾ ਹੈ: ਅਤੇ ਪੜ੍ਹਨਾਂ ਦੀ ਸਮਰੱਥਾ ਵਧਾਓ ਬਿਨਾਂ ਪ੍ਰਾਇਮਰੀ ਉੱਤੇ ਹੋਰ ਦਬਾਅ ਪਾਉਂਦੇ।
ਜੇ ਤੁਹਾਡੇ ਐਪ ਤੇ ਕਈ “ਫੈਚ” ਟ੍ਰੈਫਿਕ ਹੈ—ਹੋਮਪੇਜ, ਪ੍ਰੋਡਕਟ ਪੇਜ, ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ, ਡੈਸ਼ਬੋਰਡ—ਤਾਂ ਇਨ੍ਹਾਂ ਵਿੱਚੋਂ ਕੁਝ ਪੜ੍ਹਨ ਰੈਪਲਿਕਿਆਂ ਵੱਲ ਮੂਹਾਂ ਕਰਵਾ ਕੇ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਲਿਖਾਈ ਅਤੇ ਜ਼ਰੂਰੀ ਪੜ੍ਹਨਾਂ ਲਈ ਖੁੱਲ੍ਹਾ ਰੱਖਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸੈਟਅੱਪਾਂ ਵਿੱਚ ਇਹ ਕੰਮ ਘੱਟ ਐਪਲੀਕੇਸ਼ਨ ਬਦਲਾਅ ਨਾਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ: ਇੱਕ ਡੇਟਾਬੇਸ ਨੂੰ ਸੱਚਾਈ ਦਾ ਸਰੋਤ ਰੱਖੋ ਅਤੇ ਰੈਪਲਿਕਾ ਜੋੜੋ ਜਿੱਥੇ ਰਿਕਵੇਸਟ ਕਰਨੀ ਹੋਵੇ।
ਰੀਡ ਰੈਪਲਿਕਾ ਲਾਭਦਾਇਕ ਹਨ, ਪਰ ਇਹ ਕੋਈ ਜਾਦੂਈ ਸਮੱਸਿਆ ਹੱਲ ਨਹੀਂ ਹਨ। ਇਹ ਨਹੀਂ ਕਰਦੇ:
ਰੀਪਲਿਕਿਆਂ ਨੂੰ ਇੱਕ ਪੜ੍ਹਨ-ਸਕੇਲਿੰਗ ਟੂਲ ਜਿਸਦੇ ਨਾਲ ਟਰੇਡ-ਆਫ਼ ਹੁੰਦੇ ਵਜੋਂ ਸੋਚੋ। ਇਸ ਆਲੇ-ਦੁਆਲੇ ਦੇ ਹਿੱਸੇ ਵਿੱਚ ਵਿਆਖਿਆ ਕੀਤੀ ਹੈ ਕਿ ਇਹ ਕਦੋਂ ਵਾਸਤਵ ਵਿਚ ਮਦਦ ਕਰਦੇ ਹਨ, ਕਿਹੜਿਆਂ ਤਰੀਕਿਆਂ ਨਾਲ ਇਹ ਗਲਤ ਹੋ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਕਿਵੇਂ ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਅਤੇ ਅੰਤਿਮ ਸਥਿਰਤਾ ਉਪਭੋਗਤਾਂ ਨੂੰ ਪ੍ਰਭਾਵਤ ਕਰ ਸਕਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਪ੍ਰਾਇਮਰੀ ਦੀ ਬਜਾਏ ਨਕਲ ਤੋਂ ਪੜ੍ਹਨਾ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ।
ਇੱਕ ਇਕਲਾ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਸਰਵਰ ਸ਼ੁਰੂ ਵਿੱਚ “ਕਾਫ਼ੀ ਵੱਡਾ” ਲੱਗ ਸਕਦਾ ਹੈ। ਇਹ ਲਿਖਾਈਆਂ (inserts, updates, deletes) ਸੰਭਾਲਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੇ ਐਪ, ਡੈਸ਼ਬੋਰਡ ਅਤੇ ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਦੀਆਂ ਹਰ ਪੜ੍ਹਨ ਦੀ ਅਗਵਾਈ ਕਰਦਾ ਹੈ।
ਜਿਵੇਂ-ਜਿਵੇਂ ਇਸਤੇਮਾਲ ਵਧਦਾ ਹੈ, ਪੜ੍ਹਨ ਆਮ ਤੌਰ 'ਤੇ ਲਿਖਾਈਆਂ ਨਾਲੋਂ ਤੇਜ਼ੀ ਨਾਲ ਵਧਦੇ ਹਨ: ਹਰ ਪੇਜ-ਵਿਊ ਕੁਝ ਕਵੇਰੀਆਂ ਚਲਾ ਸਕਦੀ ਹੈ, ਖੋਜ ਸਕਰੀਨਾਂ ਕਈ ਲੁਕਅਪ ਖੋਲ ਸਕਦੀਆਂ ਹਨ, ਅਤੇ ਐਨਾਲਿਟਿਕਸ-ਸਟਾਈਲ ਕਵੇਰੀਆਂ ਕਈ ਰਿਕਾਰਡਾਂ ਨੂੰ ਸਕੈਨ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਭਾਵੇਂ ਤੁਹਾਡੀ ਲਿਖਤ ਦੀ ਮਾਤਰਾ ਮੱਡੀ ਹੋਵੇ, ਪ੍ਰਾਇਮਰੀ ਫਿਰ ਵੀ ਬੋਤਲਨੇਕ ਬਣ ਸਕਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਇਕੱਠੇ ਦੋ ਕੰਮ ਕਰ ਰਿਹਾ ਹੁੰਦਾ ਹੈ: ਤਬਦੀਲੀਆਂ ਨੂੰ ਬੇਹਤਰ ਢੰਗ ਨਾਲ ਸਵੀਕਾਰ ਕਰਨਾ, ਅਤੇ ਥੋੜ੍ਹੇ ਹੀ ਲਾਟੈਂਸੀ ਨਾਲ ਵੱਧ ਰਹੀ ਪੜ੍ਹਨ ਟ੍ਰੈਫਿਕ ਨੂੰ ਸੇਵਾ ਦੇਣਾ।
ਰੀਡ ਰੈਪਲਿਕਾ ਉਸੇ ਕੰਮ ਨੂੰ ਵੰਡਣ ਲਈ ਹੋਂਦੇ ਹਨ। ਪ੍ਰਾਇਮਰੀ ਲਿਖਤਾਂ ਅਤੇ “ਸੱਚਾਈ ਦਾ ਸਰੋਤ” ਤੇ ਧਿਆਨ ਰੱਖਦਾ ਹੈ, ਜਦਕਿ ਇੱਕ ਜਾਂ ਵੱਧ ਰੈਪਲਿਕਾ ਪੜ੍ਹਨ-ਮਾਤਰ ਕਵੇਰੀਆਂ ਸੰਭਾਲਦੇ ਹਨ। ਜਦੋਂ ਤੁਹਾਡੀ ਐਪ ਕੁਝ ਕਵੇਰੀਆਂ ਨੂੰ ਰੈਪਲਿਕਿਆਂ ਵੱਲ ਰੂਟ ਕਰ ਸਕਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਪ੍ਰਾਇਮਰੀ 'ਤੇ CPU, ਮੈਮੋਰੀ ਅਤੇ I/O ਦਾ ਦਬਾਅ ਘਟਾ ਸਕਦੇ ਹੋ। ਇਸ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਸੁਝਾਅ ਅਤੇ ਲਿਖਤ ਸਪੀਕ ਹੌਲ ਨੂੰ ਸੁਧਾਰ ਮਿਲਦੀ ਹੈ।
ਰਿਪਲਿਕੇਸ਼ਨ ਉਹ ਤਰੀਕਾ ਹੈ ਜੋ ਰੈਪਲਿਕਿਆਂ ਨੂੰ ਅਪ-ਟੂ-ਡੇਟ ਰੱਖਦਾ ਹੈ—ਇਹ ਪ੍ਰਾਇਮਰੀ ਤੋਂ ਬਦਲਾਅ ਨਕਲ ਕਰਦਾ ਹੈ। ਪ੍ਰਾਇਮਰੀ ਤਬਦੀਲੀਆਂ ਨੂੰ ਰਿਕਾਰਡ ਕਰਦਾ ਹੈ, ਅਤੇ ਰੈਪਲਿਕੇਤ ਉਹ ਬਦਲਾਅ ਲਗਾਤਾਰ ਲਾਗੂ ਕਰਦੇ ਹਨ ਤਾਂ ਜੋ ਉਹ ਲਗਭਗ ਇੱਕੋ ਹੀ ਡੇਟਾ 'ਤੇ ਕਵੇਰੀਆਂ ਦਾ ਜਵਾਬ ਦੇ ਸਕਣ।
ਇਹ ਪੈਟਰਨ ਕਈ ਡੇਟਾਬੇਸ ਸਿਸਟਮਾਂ ਅਤੇ managed ਸੇਵਾਵਾਂ ਵਿੱਚ ਆਮ ਹੈ (ਉਦਾਹਰਨ ਲਈ PostgreSQL, MySQL ਅਤੇ ਕਲਾਉਡ-ਹੋਸਟਡ ਵਰਜਨ)। ਲਾਗੂ ਕਰਨ ਦਾ ਤਰੀਕਾ ਵੱਖਰਾ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਮਕਸਦ ਇੱਕੋ-ਹੀ ਹੈ: ਰੀਡ ਸਮਰੱਥਾ ਵਧਾਉਣਾ ਬਿਨਾਂ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਕਦੇ-ਕਦੇ ਉਰਧਵ ਤੌਰ 'ਤੇ ਸਕੇਲ ਕਰਨ ਦੇ।
ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਨੂੰ “ਸੱਚਾਈ ਦਾ ਸਰੋਤ” ਸਮਝੋ। ਇਹ ਹਰ ਲਿਖਤ ਨੂੰ ਸਵੀਕਾਰ ਕਰਦਾ—ਆਰਡਰ ਬਣਾਉਣਾ, ਪ੍ਰੋਫਾਈਲ ਅਪਡੇਟ ਕਰਨਾ, ਭੁਗਤਾਨ ਦਰਜ ਕਰਨਾ—ਅਤੇ ਉਹਨਾਂ ਤਬਦੀਲੀਆਂ ਨੂੰ ਇੱਕ ਨਿਸ਼ਚਿਤ ਕ੍ਰਮ ਦਿੰਦਾ ਹੈ।
ਇੱਕ ਜਾਂ ਵੱਧ ਰੀਡ ਰੈਪਲਿਕਾ ਫਿਰ ਪ੍ਰਾਇਮਰੀ ਦਾ ਪਾਲਣ ਕਰਦੇ ਹਨ, ਉਹਨਾਂ ਬਦਲਾਅ ਨੂੰ ਨਕਲ ਕਰਦੇ ਹਨ ਤਾਂ ਜੋ ਉਹ ਪੜ੍ਹਨ ਦੀਆਂ ਕਵੇਰੀਆਂ (ਜਿਵੇਂ “ਮੇਰਾ ਆਰਡਰ ਇਤਿਹਾਸ ਵਿਖਾਓ”) ਦਾ ਜਵਾਬ ਦੇ ਸਕਨ ਬਿਨਾਂ ਪ੍ਰਾਇਮਰੀ 'ਤੇ ਹੋਰ ਭਾਰ ਪਾਉਂਦੇ।
ਪੜ੍ਹਨ ਰੈਪਲਿਕਿਆਂ ਤੋਂ ਸੇਵਾ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ ਲਿਖਤ ਅਜੇ ਵੀ ਪ੍ਰਾਇਮਰੀ 'ਤੇ ਜਾਂਦੇ ਹਨ।
ਰਿਪਲਿਕੇਸ਼ਨ ਦੋ ਮੁੱਖ ਮੋਡਾਂ ਵਿੱਚ ਹੋ ਸਕਦੀ ਹੈ:
ਉਹ ਦੇਰੀ—ਜਿੱਥੇ ਰੈਪਲਿਕੇਸ ਪ੍ਰਾਇਮਰੀ ਤੋਂ ਪਿੱਛੇ ਰਹਿ ਜਾਂਦੀਆਂ ਹਨ—ਨੂੰ ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਕਹਿੰਦੇ ਹਨ। ਇਹ ਆਪਣੇ ਆਪ ਵਿੱਚ ਅਸਫਲਤਾ ਨਹੀਂ ਹੈ; ਇਹ ਅਕਸਰ ਪੜ੍ਹਨ ਨੂੰ ਸਕੇਲ ਕਰਨ ਲਈ ਨਾਮਜ਼ਦ ਟਰੇਡ-ਆਫ਼ ਹੁੰਦਾ ਹੈ।
ਉਪਭੋਗਤਾਵਾਂ ਲਈ, ਲੈਗ ਅੰਤਿਮ ਸਥਿਰਤਾ ਵਜੋਂ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ: ਤੁਸੀਂ ਕੋਈ ਚੀਜ਼ ਬਦਲਦੇ ਹੋ, ਸਿਸਟਮ ਅੰਤ ਵਿੱਚ ਸਾਰੇ ਥਾਵਾਂ ਤੇ ਸਥਿਰ ਹੋ ਜਾਵੇਗਾ, ਪਰ ਫੁਰਤਿ ਨਾਲ ਨਹੀਂ।
ਉਦਾਹਰਨ: ਤੁਸੀਂ ਆਪਣਾ ਈਮੇਲ ਪਤਾ ਅਪਡੇਟ ਕਰਦੇ ਹੋ ਅਤੇ ਆਪਣੀ ਪ੍ਰੋਫਾਈਲ ਪੇਜ ਰੀਫਰੈਸ਼ ਕਰਦੇ ਹੋ। ਜੇ ਪੇਜ ਕਿਸੇ ਰੈਪਲਿਕਾ ਤੋਂ ਸੇਵਾ ਹੋ ਰਿਹਾ ਹੈ ਜੋ ਕੁਝ ਸਕਿੰਟ ਪਿੱਛੇ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਥੋੜ੍ਹੇ ਸਮੇਂ ਲਈ ਪੁਰਾਣਾ ਈਮੇਲ ਦੇਖ ਸਕਦੇ ਹੋ—ਜਦ ਤੱਕ ਰੈਪਲਿਕਾ ਅਪਡੇਟ ਲਾਗੂ ਨਹੀਂ ਕਰ ਲੈਂਦੀ।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਉਦੋਂ ਮਦਦਗਾਰ ਹੁੰਦੀਆਂ ਹਨ ਜਦੋਂ ਤੁਹਾਡਾ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਲਿਖਤਾਂ ਲਈ ਸਿਹਤਮੰਦ ਹੋ ਪਰ ਪੜ੍ਹਨ ਟ੍ਰੈਫਿਕ ਦੀ ਸੇਵਾ ਕਰਕੇ ਥੱਕ ਜਾਂਦਾ ਹੈ। ਇਹ ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਬਿਨਾਂ ਡੇਟਾ ਲਿਖਣ ਦੇ ਤਰੀਕੇ ਬਦਲੇ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਹਿੱਸਾ SELECT ਲੋਡ ਨੂੰ ਆਫਲੋਡ ਕਰ ਸਕੋ।
ਇਹਨਾਂ ਨਮੂਨਿਆਂ ਨੂੰ ਦੇਖੋ:
SELECT ਕਵੇਰੀਆਂ ਦਾ ਅਸਧਾਰਨ ਅਨੁਪਾਤ INSERT/UPDATE/DELETE ਨਾਲਰੈਪਲਿਕੇਸ ਜੋੜਨ ਤੋਂ ਪਹਿਲਾਂ ਕੁਝ ठੋਸ ਸਿਗਨਲ ਚੈੱਕ ਕਰੋ:
SELECT ਬਿਆਨਾਂ 'ਤੇ ਲਾਈ ਟਾਈਮ ਦਾ ਅਨੁਸ਼ਤਰ (ਸਲੋ ਕ੍ਵੈਰੀ ਲੌਗ/APM)ਅਕਸਰ ਪਹਿਲਾ ਚੰਗਾ ਕਦਮ ਟਿਊਨਿੰਗ ਹੁੰਦੀ ਹੈ: ਠੀਕ ਇੰਡੈਕਸ ਜੋੜੋ, ਇੱਕ ਕਵੇਰੀ ਦੁਬਾਰਾ ਲਿਖੋ, N+1 ਕਾਲਾਂ ਘਟਾਓ, ਜਾਂ ਹਾਟ ਰੀਡਾਂ ਨੂੰ ਕੈਸ਼ ਕਰੋ। ਇਹ ਤਬਦੀਲੀਆਂ ਰੈਪਲਿਕੇਸ ਚਲਾਉਣ ਨਾਲੋਂ ਤੇਜ਼ ਅਤੇ ਸਸਤੇ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਰੈਪਲਿਕੇਸ ਚੁਣੋ ਜੇ:
ਟਿਊਨਿੰਗ ਪਹਿਲਾਂ ਚੁਣੋ ਜੇ:
ਰੀਡ ਰੈਪਲਿਕੇਸ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਵਿੱਚ ਮੂਲ-ਮੁੱਲੀ ਹਨ ਜਿੱਥੇ ਤੁਹਾਡਾ ਪ੍ਰਾਇਮਰੀ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਨੂੰ ਸੰਭਾਲ ਰਿਹਾ ਹੈ (ਚੈਕਆਉਟ, ਸਾਈਨ-ਅੱਪ, ਅਪਡੇਟ), ਪਰ ਟ੍ਰੈਫਿਕ ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਪੜ੍ਹਨ-ਭਾਰ ਵਾਲਾ ਹੈ। ਪ੍ਰਾਇਮਰੀ–ਰੈਪਲਿਕਾ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ, ਠੀਕ ਕਵੇਰੀਆਂ ਨੂੰ ਰੈਪਲਿਕਿਆਂ ਵੱਲ ਭੇਜ ਕੇ ਡੇਟਾਬੇਸ ਪ੍ਰਦਰਸ਼ਨ ਨੂੰ ਬਿਨਾਂ ਐਪ ਫੀਚਰਾਂ ਦੇ ਬਦਲਾਅ ਵਧਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
ਡੈਸ਼ਬੋਰਡ ਅਕਸਰ ਲੰਬੀਆਂ ਕਵੇਰੀਆਂ ਚਲਾਉਂਦੇ ਹਨ: ਗਰੂਪਿੰਗ, ਵੱਡੇ ਰੇਂਜਾਂ 'ਤੇ ਫਿਲਟਰ, ਇੱਕ-ਤੋਂ-ਅਧਿਕ ਟੇਬਲਾਂ ਦੇ ਜੋਇਨ। ਇਹ ਕਵੇਰੀਆਂ ਟਰਾਂਜ਼ੈਕਸ਼ਨਲ ਕੰਮ ਨਾਲ CPU, ਮੈਮੋਰੀ ਅਤੇ ਕੇਸ਼ ਲਈ ਮੁਕਾਬਲਾ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਰੀਡ ਰੈਪਲਿਕਾ ਚੰਗੀ ਥਾਂ ਹੋ ਸਕਦੀ ਹੈ:
ਤੁਸੀਂ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਤੇਜ਼, ਪੇਸ਼ਗੀ ਰੱਖਦਿਆਂ ਐਨਾਲਿਟਿਕਸ ਪੜ੍ਹਨਾਂ ਨੂੰ ਅਲੱਗ ਸਕੇਲ ਕਰ ਸਕਦੇ ਹੋ।
ਕੈਟਾਲੌਗ ਬ੍ਰਾਊਜ਼ਿੰਗ, ਯੂਜ਼ਰ ਪ੍ਰੋਫਾਈਲ ਅਤੇ ਕੰਟੈਂਟ ਫੀਡਸ ਇੱਕੋ ਜਿਹੀਆਂ ਕਈ ਕਵੇਰੀਆਂ ਪੈਦਾ ਕਰ ਸਕਦੇ ਹਨ। ਜਦੋਂ ਉਹ ਪੜ੍ਹਨ ਸਕੇਲਿੰਗ ਦਬਾਅ ਬੋਤਲਨੇਕ ਬਣਦਾ ਹੈ, ਰੈਪਲਿਕੇਸ ਟ੍ਰੈਫਿਕ ਪੀਦਾ ਕਰਕੇ ਲੈਟੈਂਸੀ ਸਪਾਈਕ ਨੂੰ ਘਟਾ ਸਕਦੀਆਂ ਹਨ।
ਇਹ ਉਹਦੇਗੇ ਜਦੋਂ ਪੜ੍ਹਨ ਕੇਸ਼-ਮਿਸ-ਹੈਵੀ ਹੋ (ਕਈ ਵਿਲੱਖਣ ਕਵੇਰੀਆਂ) ਜਾਂ ਜਦੋਂ ਤੁਸੀਂ ਸਿਰਫ਼ ਐਪਲੀਕੇਸ਼ਨ ਕੈਸ਼ 'ਤੇ ਨਿਰਭਰ ਨਹੀਂ ਹੋ ਸਕਦੇ।
ਐਕਸਪੋਰਟ, ਬੈਕਫਿਲ, ਸਾਰੀ ਸੰਖੇਪਾਂ ਨੂੰ ਦੁਬਾਰਾ ਗਣਨਾ ਕਰਨਾ, ਅਤੇ "ਜੇਕਰ X ਹੋਵੇ ਤਾਂ ਹਰ ਰਿਕਾਰਡ ਲੱਭੋ" ਵਾਲੇ ਜੋਬਜ਼ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਥੱਕਾ ਸਕਦੇ ਹਨ। ఈ ਸਕੈਨਾਂ ਨੂੰ ਰੈਪਲਿਕਾ 'ਤੇ ਚਲਾਉਣਾ ਅਕਸਰ ਸੁਰੱਖਿਅਤ ਹੁੰਦਾ ਹੈ।
ਸਿਰਫ਼ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਜੋਬ eventual consistency ਸਹਿੰਦਾ ਹੈ: ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਕਾਰਨ ਉਹ ਨਵੇਂ ਅਪਡੇਟ ਨਹੀਂ ਦੇਖ ਸਕੇਗਾ।
ਜੇ ਤੁਸੀਂ ਵਿਸ਼ਵ ਭਰ ਵਿੱਚ ਯੂਜ਼ਰ ਸੇਵਾ ਕਰਦੇ ਹੋ, ਤਾਂ ਰੀਡ ਰੈਪਲਿਕਾ ਉਨ੍ਹਾਂ ਦੇ ਨਜ਼ਦੀਕ ਰੱਖ ਕੇ ਰਾਊਂਡ-ਟ੍ਰਿਪ ਟਾਈਮ ਘਟਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। ਟਰੇਡ-ਆਫ਼ ਇਹ ਹੈ ਕਿ ਲੈਗ ਜਾਂ ਨੈਟਵਰਕ ਸਮੱਸਿਆਵਾਂ ਦੌਰਾਨ stale ਪੜ੍ਹਨ ਦੀ ਸੰਭਾਵਨਾ ਵੱਧ ਜਾਂਦੀ ਹੈ, ਇਸ ਲਈ ਇਹ ਉਨ੍ਹਾਂ ਪੇਜਾਂ ਲਈ ਵਧੀਆ ਹੈ ਜਿੱਥੇ "ਲੱਗਭਗ ਤਾਜ਼ਾ" ਕਾਫ਼ੀ ਹੈ (ਬ੍ਰਾਊਜ਼, ਰਿਕਮੈਂਡੇਸ਼ਨ, ਪਬਲਿਕ ਕੰਟੈਂਟ)।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਵਧੀਆ ਹਨ ਜਦੋਂ "ਤੀਕਹੀ ਹੋਣ" ਚੰਗਾ ਹੈ। ਉਹ ਨੁਕਸਾਨ ਪਹੁੰਚਾਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਤੁਹਾਡੀ ਪ੍ਰੋਡਕਟ ਖਾਮੋਸ਼ੀ ਨਾਲ ਧਾਰਨਾ ਕਰਦੀ ਹੈ ਕਿ ਹਰ ਪੜ੍ਹਨ ਹਮੇਸ਼ਾ ਨਵੀਂ ਲਿਖਤ ਨੂੰ ਦਰਸਾਏਗੀ।
ਯੂਜ਼ਰ ਆਪਣੀ ਪ੍ਰੋਫਾਈਲ ਅਪਡੇਟ ਕਰਦਾ ਹੈ, ਫਾਰਮ ਸਬਮਿਟ ਕਰਦਾ ਹੈ ਜਾ ਸੈਟਿੰਗ ਬਦਲਦਾ ਹੈ—ਅਗਲੀ ਪੇਜ ਲੋਡ ਕਿਸੇ ਰੈਪਲਿਕਾ ਤੋਂ ਹੋ ਰਹੀ ਹੈ ਜੋ ਕੁਝ ਸਕਿੰਟ ਪਿੱਛੇ ਹੈ। ਅਪਡੇਟ ਸਫਲ ਹੋਇਆ, ਪਰ ਯੂਜ਼ਰ ਪੁਰਾਣਾ ਡੇਟਾ ਵੇਖਦਾ ਹੈ ਅਤੇ ਦੁਹਰਾਉਂਦਾ ਹੈ, ਡਬਲ-ਸਬਮਿਟ ਕਰਦਾ ਹੈ ਜਾਂ ਭਰੋਸਾ ਖੋ ਦਿੰਦਾ ਹੈ।
ਇਹ ਉਹ ਫਲੋਜ਼ ਵਿੱਚ ਖਾਸ ਤੋਰ ਤੇ ਦਰਦਨਾਕ ਹੈ ਜਿੱਥੇ ਯੂਜ਼ਰ ਤੁਰੰਤ ਪੁਸ਼ਟੀ ਦੀ ਉਮੀਦ ਕਰਦੇ ਹਨ: ਈਮੇਲ ਬਦਲਣਾ, ਪ੍ਰਾਥਮਿਕਤਾਵਾਂ ਟੌਗਲ ਕਰਨਾ, ਡੌਕਯੂਮੈਂਟ ਅਪਲੋਡ ਕਰਨਾ, ਜਾਂ ਕਮੈਂਟ post ਕਰਕੇ ਵਾਪਸ ਰੀਡਾਇਰੈਕਟ ਹੋਣਾ।
ਕੁਝ ਪੜ੍ਹਨ ਮੁਸੱਲਮਾਨਤਾ ਸਹਿਣ ਨਹੀਂ ਸਕਦੇ, ਭੀੜ ਭੀੜੇ:
ਜੇ ਰੈਪਲਿਕਾ ਪਿੱਛੇ ਹੈ, ਤੁਸੀਂ ਗਲਤ ਕਾਰਟ ਟੋਟਲ ਦਿਖਾ ਸਕਦੇ ਹੋ, ਜ਼ਿਆਦਾ ਸਟਾਕ ਵੇਚ ਸਕਦੇ ਹੋ ਜਾਂ ਪੁਰਾਣਾ ਬੈਲੈਂਸ ਦਿਖਾ ਸਕਦੇ ਹੋ। ਭਾਵੇਂ ਸਿਸਟਮ ਬਾਅਦ ਵਿੱਚ ਸਹੀ ਕਰ ਦੇਵੇ, ਯੂਜ਼ਰ ਅਨੁਭਵ (ਅਤੇ ਸਪੋਰਟ ਵੋਲਿਊਮ) ਪ੍ਰਭਾਵਿਤ ਹੁੰਦੇ ਹਨ।
ਅੰਦਰੂਨੀ ਡੈਸ਼ਬੋਰਡ ਅਕਸਰ ਅਸਲ ਫੈਸਲੇ ਲੈਂਦੇ ਹਨ: ਫ੍ਰੌਡ ਰਿਵਿਊ, ਕਸਟਮਰ ਸਪੋਰਟ, ਆਰਡਰ ਫ਼ਲਫਿਲਮੈਂਟ, ਮਾਡਰੇਸ਼ਨ, ਅਤੇ ਘਟਨਾ ਪ੍ਰਤੀਕਿਰਿਆ। ਜੇ ਇੱਕ ਐਡਮਿਨ ਟੂਲ ਰੈਪਲਿਕਿਆਂ ਤੋਂ ਪੜ੍ਹਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਅਨਪੂਰਨ ਡੇਟਾ ਤੇ ਕਾਰਵਾਈ ਕਰਨ ਦਾ ਖਤਰਾ ਲੈ ਰਹੇ ਹੋ—ਉਦਾਹਰਨ ਲਈ, ਪਹਿਲਾਂ ਹੀ ਰਿਫੰਡ ਕੀਤੀ ਆਰਡਰ ਨੂੰ ਫਿਰ ਰਿਫੰਡ ਕਰਨਾ, ਜਾਂ ਨਵੇਂ ਸਟੇਟਸ ਚੇਂਜ ਨੂੰ ਮੁੱਕ ਗਇਆ ਹੈ ਪਰ ਤੁਸੀਂ ਨਹੀਂ ਦੇਖਦੇ।
ਇੱਕ ਆਮ ਪੈਟਰਨ ਸ਼ਰਤ-ਅਨੁਸਾਰ ਰੂਟਿੰਗ ਹੈ:
ਇਸ ਨਾਲ ਰੈਪਲਿਕਿਆਂ ਦੇ ਫਾਇਦੇ ਬਚ ਜਾਂਦੇ ਹਨ, ਬਿਨਾਂ ਸਥਿਰਤਾ ਨੂੰ ਇੱਕ ਅਨੁਮਾਨੀ ਖੇਡ ਬਣਾਉਣ ਦੇ।
ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਉਹ ਦੇਰੀ ਹੈ ਜੋ ਲਿਖਤ ਦੇ ਪ੍ਰਾਇਮਰੀ 'ਤੇ ਕਮਿਟ ਹੋਣ ਅਤੇ ਉਹੀ ਬਦਲਾਅ ਰੈਪਲਿਕਾ 'ਤੇ ਦਿੱਖਣ ਵਿੱਚ ਹੁੰਦੀ ਹੈ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਉਸ ਸਮੇਂ ਰੈਪਲਿਕਾ ਤੋਂ ਪੜ੍ਹਦੀ ਹੈ, ਤਾਂ ਇਹ "ਸਟੇਲ" ਨਤੀਜੇ ਦੇ ਸਕਦੀ ਹੈ—ਉਹ ਡੇਟਾ ਜੋ ਕੁਝ ਪਲ ਪਹਿਲਾਂ ਸਹੀ ਸੀ ਪਰ ਹੁਣ ਨਹੀਂ।
ਲੈਗ ਆਮ ਗੱਲ ਹੈ, ਅਤੇ ਇਹ ਜ਼ਿਆਦਤਰ ਦਬਾਅ ਹੇਠਾਂ ਵੱਧਦਾ ਹੈ। ਆਮ ਕਾਰਨਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਲੈਗ ਸਿਰਫ਼ "ਤਾਜ਼ਗੀ" ਨੂੰ ਪ੍ਰਭਾਵਤ ਨਹੀਂ ਕਰਦਾ—ਇਹ ਯੂਜ਼ਰ ਪਰਸਪੈਕਟਿਵ ਤੋਂ ਸਹੀਤਾ ਨੂੰ ਪ੍ਰਭਾਵਤ ਕਰਦਾ ਹੈ:
ਪਹਿਲਾਂ ਇਹ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਫੀਚਰ ਕੀ ਸਹਿਣਸ਼ੀਲਤਾ ਕਰ ਸਕਦੀ ਹੈ:
ਰੈਪਲਿਕਾ ਲੈਗ (ਸਮਾਂ/ਬਾਈਟ), ਰੈਪਲਿਕਾ ਅਪਲਾਈ ਦਰ, ਰਿਪਲਿਕੇਸ਼ਨ ਤਰੁਟੀਆਂ, ਅਤੇ ਰੈਪਲਿਕਾ CPU/ਡਿਸਕ I/O ਟਰੈਕ ਕਰੋ। ਜਦੋਂ ਲੈਗ ਤੁਹਾਡੇ ਟੋਲਰੈਂਸ ਤੋਂ ਵੱਧ ਜਾਵੇ (ਉਦਾਹਰਣ ਲਈ 5s, 30s, 2m) ਤਾਂ ਅਲਰਟ ਬਣਾਓ ਅਤੇ ਜੇ ਲੈਗ ਲਗਾਤਾਰ ਵੱਧਦਾ ਜਾਵੇ ਤਾਂ ਇੰਟਰਵੇਂਸ਼ਨ ਕਰੋ।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਰੀਡ ਸਕੇਲਿੰਗ ਲਈ ਟੂਲ ਹਨ: ਹੋਰ ਸਥਾਨ ਜੋ SELECT ਕਵੇਰੀਆਂ ਸਰਵ ਕਰ ਸਕਦੇ ਹਨ। ਇਹ ਰਾਈਟ ਸਕੇਲਿੰਗ ਲਈ ਨਹੀਂ ਹਨ: ਇਸ ਨਾਲ ਤੁਹਾਡੀ ਸਿਸਟਮ ਦੀ ਲਿਖਤ ਸਮਰੱਥਾ ਨਹੀਂ ਵੱਧਦੀ।
ਰੈਪਲਿਕੇਸ ਜੋੜ ਕੇ ਤੁਸੀਂ ਰੀਡ ਸਮਰੱਥਾ ਵਧਾਉਂਦੇ ਹੋ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਪੜ੍ਹਨ-ਹੈਵੀ ਏਂਡਪੋਇੰਟਸ (ਪ੍ਰੋਡਕਟ ਪੇਜ, ਫੀਡ, ਲੁਕਅਪ) 'ਤੇ ਬੋਤਲਨੇਕ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਉਹਨਾਂ ਕਵੇਰੀਆਂ ਨੂੰ ਕਈ ਮਸ਼ੀਨਾਂ 'ਤੇ ਫੈਲਾ ਸਕਦੇ ਹੋ।
ਇਸ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਸੁਧਾਰ ਹੁੰਦੇ ਹਨ:
ਆਮ ਗਲਤ ਧਾਰਣਾ ਹੈ ਕਿ "ਵਧ ਰੈਪਲਿਕੇਸ = ਵੱਧ ਲਿਖਤ ਥਰੂਪੁੱਟ"। ਆਮ ਪ੍ਰਾਇਮਰੀ–ਰੈਪਲਿਕਾ ਸੈਟਅੱਪ ਵਿੱਚ, ਸਾਰੇ ਲਿਖਤ ਹਮੇਸ਼ਾ ਪ੍ਰਾਇਮਰੀ ਤੇ ਹੀ ਜਾਂਦੇ ਹਨ। ਅਸਲ ਵਿੱਚ, ਹੋਰ ਰੈਪਲਿਕੇਸ ਪ੍ਰਾਇਮਰੀ ਲਈ ਥੋੜ੍ਹਾ ਓਵਰਹੈੱਡ ਵੀ ਵਧਾ ਸਕਦੇ ਹਨ, ਕਿਉਂਕਿ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਹਰ ਰੈਪਲਿਕਾ ਲਈ ਰਿਪਲਿਕੇਸ਼ਨ ਡੇਟਾ ਬਣਾਉਣਾ ਅਤੇ ਭੇਜਣਾ ਪੈਂਦਾ ਹੈ।
ਜੇ ਤੁਹਾਡੀ ਮੁੱਖ ਸਮੱਸਿਆ ਲਿਖਤ ਦੀ ਸਥਿਤੀ ਹੈ, ਤਾਂ ਰੈਪਲਿਕੇਸ ਇਸਨੂੰ ਠੀਕ ਨਹੀਂ ਕਰਨਗੇ। ਤੁਹਾਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਹੋਰ ਤਰੀਕੇ ਚਾਹੀਦੇ ਹਨ (ਕਵੇਰੀ/ਇੰਡੈਕਸ ਟਿਊਨਿੰਗ, ਬੈਚਿੰਗ, ਪਾਰਟੀਸ਼ਨਿੰਗ/ਸ਼ਾਰਡਿੰਗ, ਜਾਂ ਡੇਟਾ ਮਾਡਲ ਬਦਲਣਾ)।
ਚਾਹੇ ਰੈਪਲਿਕੇਸ ਤੁਹਾਨੂੰ ਹੋਰ ਪੜ੍ਹਨ CPU ਦੇਣ, ਤੁਸੀਂ ਫਿਰ ਵੀ ਕਨੈਕਸ਼ਨ ਸੀਮਾਵਾਂ 'ਤੇ ਫਸ ਸਕਦੇ ਹੋ। ਹਰ ਡੇਟਾਬੇਸ ਨੋਡ ਦੀ ਇੱਕ ਮੈਕਸਿਮਮ concurrent connections ਹੁੰਦੀ ਹੈ, ਅਤੇ ਰੈਪਲਿਕੇਸ ਜੋੜਣ ਨਾਲ ਤੁਹਾਡੇ ਐਪ ਲਈ ਕਨੈਕਸ਼ਨਾਂ ਦੀ ਸੰਭਾਵਨਾ ਵਧ ਜਾਂਦੀ—ਬਿਨਾਂ ਕੁੱਲ ਮੰਗ ਘਟਾਉਂਦੇ।
ਵਿਵਹਾਰਕ ਨਿਯਮ: ਕਨੈਕਸ਼ਨ ਪੂਲਿੰਗ (ਜਾਂ ਇੱਕ ਪੂਲਰ) ਵਰਤੋ ਅਤੇ ਆਪਣੇ ਪ੍ਰਤੀ-ਸੇਵਾ ਕਨੈਕਸ਼ਨ ਗਿਣਤੀ ਨੂੰ ਸੋਚ ਸਮਝ ਕੇ ਰੱਖੋ। ਨਹੀਂ ਤਾਂ, ਰੈਪਲਿਕੇਸ ਸਿਰਫ਼ "ਹੋਰ ਡੇਟਾਬੇਸ" ਬਣकर ਅਸਾਣੀ ਨਾਲ ਓਵਰਲੋਡ ਹੋ ਸਕਦੇ ਹਨ।
ਰੈਪਲਿਕੇਸ ਨਾਲ ਅਸਲ ਖ਼ਰਚ ਆਉਂਦਾ ਹੈ:
ਟਰੇਡ-ਆਫ਼ ਸਾਦਾ ਹੈ: ਰੈਪਲਿਕੇਸ ਤੁਹਾਨੂੰ ਪੜ੍ਹਨ ਹੇਡਰੂਮ ਅਤੇ ਆਇਸੋਲੇਸ਼ਨ ਖਰੀਦ ਦੇਂਦੀਆਂ ਹਨ, ਪਰ ਉਹ ਜਾਂਚ-ਪੜਤਾਲ ਅਤੇ ਲਿਖਤ ਛੱਤ ਨੂੰ ਨਹੀਂ ਹਿਲਾਉਂਦੀਆਂ।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਪੜ੍ਹਨ ਉਪਲਬਧਤਾ ਨੂੰ ਸੁਧਾਰ ਸਕਦੀਆਂ ਹਨ: ਜੇ ਤੁਹਾਡਾ ਪ੍ਰਾਇਮਰੀ ਓਵਰਲੋਡ ਜਾਂ ਥੋੜ੍ਹੀ ਦੇਰ ਲਈ ਅਣਉਪਲਬਧ ਹੋ ਜਾਵੇ, ਤਾਂ ਤੁਸੀਂ ਕੁਝ ਪੜ੍ਹਨ-ਮਾਤਰ ਟ੍ਰੈਫਿਕ ਨੂੰ ਰੈਪਲਿਕਿਆਂ ਤੋਂ ਸੇਵਾ ਕਰ ਸਕਦੇ ਹੋ। ਇਹ ਗਾਹਕ-ਸਮ੍ਮੁਖ ਪੇਜਾਂ ਨੂੰ ਜ਼ਿੰਦਾ ਰੱਖ ਸਕਦਾ ਹੈ (ਉਹ ਵੀ ਥੋੜ੍ਹੇ stale ਡੇਟਾ ਲਈ) ਅਤੇ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਘਟਨਾ ਦਾ ਨੁਕਸਾਨ ਘਟਾ ਸਕਦਾ ਹੈ।
ਜੋ ਰੈਪਲਿਕੇਸ ਇਕੱਲੇ ਪੂਰਾ ਹਾਈ-ਅਵੇਲੇਬਿਲਟੀ ਯੋਜਨਾ ਨਹੀਂ ਦਿੰਦੀਆਂ। ਇੱਕ ਰੈਪਲਿਕਾ ਆਮ ਤੌਰ 'ਤੇ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਲਿਖਤ ਸਵੀਕਾਰ ਕਰਨ ਲਈ ਤਿਆਰ ਨਹੀਂ ਹੁੰਦੀ, ਅਤੇ "ਪੜ੍ਹਨਯੋਗ ਨਕਲ ਮੌਜੂਦ ਹੈ" ਨੂੰ "ਸਿਸਟਮ ਤੇਜ਼ੀ ਨਾਲ ਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਦੁਬਾਰਾ ਲਿਖਤ ਸਵੀਕਾਰ ਕਰ ਸਕਦਾ ਹੈ" ਨਾਲ ਮਿਲਾਉਣਾ ਵੱਖਰਾ ਹੈ।
ਫੇਲਓਵਰ ਆਮ ਤੌਰ 'ਤੇ ਇਸਦਾ ਮਤਲਬ ਹੈ: ਪ੍ਰਾਇਮਰੀ ਫੇਲ → ਇੱਕ ਰੈਪਲਿਕਾ ਚੁਣੋ → ਉਸਨੂੰ ਨਵੇਂ ਪ੍ਰਾਇਮਰੀ ਵਜੋਂ promote ਕਰੋ → ਲਿਖਤਾਂ ਨੂੰ ਨਵੇਂ ਨੋਡ ਵੱਲ ਰੀਡਾਇਰੈਕਟ ਕਰੋ।
ਕੁਝ managed ਡੇਟਾਬੇਸ ਇਹਨਾਂ ਵਿੱਚੋਂ ਜ਼ਿਆਦਾਤਰ ਕੰਮ ਆਟੋਮੈਟ ਕਰ ਦਿੰਦੇ ਹਨ, ਪਰ ਮੂਲ ਵਿਚਾਰ ਉਹੀ ਰਹਿੰਦਾ ਹੈ: ਤੁਸੀਂ ਇਹ ਬਦਲਦੇ ਹੋ ਕਿ ਕੌਣ ਲਿਖਤ ਸਵੀਕਾਰ ਕਰਨ ਦੀ ਆਗਿਆ ਰੱਖਦਾ ਹੈ।
ਫੇਲਓਵਰ ਨੂੰ ਅਭਿਆਸ ਸਮਝੋ। ਸਟੇਜਿੰਗ ਵਿੱਚ game-day ਟੈਸਟ ਚਲਾਓ (ਅਤੇ ਸੰਭਾਲ ਕੇ ਪ੍ਰੋਡਕਸ਼ਨ ਵਿੱਚ ਛੋਟੇ ਜੋਖਿਮ ਵਾਲੇ ਵਿੰਡੋਜ਼ ਦੌਰਾਨ): ਪ੍ਰਾਇਮਰੀ ਖੋ ਜਾਣ ਦੀ ਨਕਲ ਕਰੋ, ਰਿਕਵਰੀ ਸਮਾਂ ਮਾਪੋ, ਰਾਊਟਿੰਗ ਦੀ ਜਾਂਚ ਕਰੋ, ਅਤੇ ਪੱਕਾ ਕਰੋ ਕਿ ਤੁਹਾਡੀ ਐਪ ਰੀਡ-ਮਾਤਰ ਅਵਧੀ ਅਤੇ ਰੀ-/ਕਨੈਕਸ਼ਨ ਨੂੰ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਸੰਭਾਲਦੀ ਹੈ।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਸਿਰਫ਼ ਉਸ ਸਮੇਂ ਮਦਦ ਕਰਦੀਆਂ ਹਨ ਜਦੋਂ ਤੁਹਾਡਾ ਟ੍ਰੈਫਿਕ ਅਸਲ ਵਿੱਚ ਉਨ੍ਹਾਂ ਤੱਕ ਪਹੁੰਚਦਾ ਹੈ। "ਰੀਡ/ਰਾਈਟ ਸਪਲਿੱਟਿੰਗ" ਉਹ ਨਿਯਮਾਂ ਦਾ ਸਮੂਹ ਹੈ ਜੋ ਲਿਖਤਾਂ ਨੂੰ ਪ੍ਰਾਇਮਰੀ ਵੱਲ ਅਤੇ ਉਚਿਤ ਰੀਡਾਂ ਨੂੰ ਰੈਪਲਿਕਿਆਂ ਵੱਲ ਭੇਜਦਾ ਹੈ—ਬਿਨਾਂ ਸਹੀਤਾ ਨੂੰ ਤੋੜੇ।
ਸਭ ਤੋਂ ਸਧਾਰਨ ਤਰੀਕਾ ਤੁਹਾਡੇ ਡੇਟਾ ਐਕਸੈਸ ਲੇਅਰ ਵਿੱਚ ਸਪਸ਼ਟ ਰਾਊਟਿੰਗ ਹੈ:
INSERT/UPDATE/DELETE, schema ਬਦਲਾਅ) ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਜਾਂਦੇ ਹਨ।ਇਹ ਸੋਚਣ ਵਿੱਚ ਆਸਾਨ ਅਤੇ ਰੀਵਰਸ ਕਰਨ ਵਿੱਚ ਵੀ ਆਸਾਨ ਹੈ। ਇੱਥੇ ਤੁਸੀਂ ਕਾਰੋਬਾਰੀ ਨਿਯਮਾਂ ਨੂੰ encode ਕਰ ਸਕਦੇ ਹੋ ਜਿਵੇਂ “ਚੈਕਆਉਟ ਤੋਂ ਬਾਅਦ, ਥੋੜੇ ਸਮੇਂ ਲਈ ਆਰਡਰ ਸਥਿਤੀ ਪ੍ਰਾਇਮਰੀ ਤੋਂ ਪੜ੍ਹੋ।”
ਕੁਝ ਟੀਮ ਇੱਕ ਡੇਟਾਬੇਸ ਪ੍ਰਾਕਸੀ ਜਾਂ ਸਮਾਰਟ ਡ੍ਰਾਈਵਰ ਪਸੰਦ ਕਰਦੀਆਂ ਹਨ ਜੋ "primary vs replica" endpoints ਨੂੰ ਸਮਝਦਾ ਹੈ ਅਤੇ ਕਵੇਰੀ ਕਿਸਮ ਜਾਂ ਕਨੈਕਸ਼ਨ ਸੈਟਿੰਗ ਅਨੁਸਾਰ ਰੂਟ ਕਰਦਾ ਹੈ। ਇਸ ਨਾਲ ਐਪ ਕੋਡ ਬਦਲਣ ਘੱਟ ਹੁੰਦੇ ਹਨ, ਪਰ ਧਿਆਨ ਰੱਖੋ: ਪ੍ਰਾਕਸੀ ਇਹ ਨਹੀਂ ਜਾਣ ਸਕਦੀ ਕਿ ਕਿਸ ਪੜ੍ਹਨ ਨੂੰ ਨੂੰ “ਸੁਰੱਖਿਅਤ” ਸਮਝਣਾ ਚਾਹੀਦਾ ਹੈ ਉਤਨੇ ਹੀ ਪ੍ਰੋਡਕਟ-ਦ੍ਰਿਸ਼ਟੀਕੋਣ ਤੋਂ।
ਚੰਗੇ ਉਮੀਦਵਾਰ:
ਉਨ੍ਹਾਂ ਪੜ੍ਹਨਾਂ ਨੂੰ ਰੈਪਲਿਕਿਆਂ ਵੱਲ ਨਾ ਭੇਜੋ ਜੋ ਯੂਜ਼ਰ ਲਿਖਤ ਦੇ ਤੁਰੰਤ ਬਾਅਦ ਆਉਂਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ: "ਪ੍ਰੋਫਾਈਲ ਅਪਡੇਟ → ਪ੍ਰੋਫਾਈਲ ਰੀਲੋਡ") ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ consistency ਰਣਨੀਤੀ ਨਹੀਂ ਹੈ।
ਇਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਦੇ ਅੰਦਰ, ਸਾਰੇ ਪੜ੍ਹਨ ਪ੍ਰਾਇਮਰੀ 'ਤੇ ਰੱਖੋ।
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਤੋਂ ਬਾਹਰ, "read-your-writes" ਸੈਸ਼ਨ ਬਾਰੇ ਸੋਚੋ: ਲਿਖਤ ਤੋਂ ਬਾਅਦ ਕਿਸੇ ਯੂਜ਼ਰ/ਸੈਸ਼ਨ ਨੂੰ ਛੋਟੀ TTL ਲਈ ਪ੍ਰਾਇਮਰੀ ਤੇ ਪਿਨ ਕਰੋ, ਜਾਂ ਨਿਰਦਿਸ਼ਟ ਅਨੁਕੂਲ ਫਾਲੋ-ਅਪ ਕਵੇਰੀਆਂ ਨੂੰ ਪ੍ਰਾਇਮਰੀ ਵੱਲ ਰੂਟ ਕਰੋ।
ਇੱਕ ਰੈਪਲਿਕਾ ਜੋੜੋ, ਸਮੇਤਿਤ ਕੁਰਚੀ-ਸੀਮਿਤ ਏਂਡਪੋਇੰਟ/ਕਵੇਰੀਆਂ ਨੂੰ ਰੀਪਲਿਕਿਆਂ ਵੱਲ ਰੂਟ ਕਰੋ, ਅਤੇ ਪਹਿਲਾਂ-ਬਾਅਦ ਦੀ ਤੁਲਨਾ ਕਰੋ:
ਜਦੋਂ ਪ੍ਰਭਾਵ ਸਪਸ਼ਟ ਅਤੇ ਸੁਰੱਖਿਅਤ ਹੋਵੇ ਤਾਂ ਹੀ ਰਾਊਟਿੰਗ ਵਧਾਓ।
ਰੀਡ ਰੈਪਲਿਕੇਸ "ਸੈਟ ਅਤੇ ਭੁੱਲ ਜਾ" ਨਹੀਂ ਹੁੰਦੀਆਂ। ਉਹ ਹੋਰ ਡੇਟਾਬੇਸ ਸਰਵਰ ਹਨ ਜਿਨ੍ਹਾਂ ਦੀਆਂ ਆਪਣੀਆਂ ਪ੍ਰਦਰਸ਼ਨ ਸੀਮਾਵਾਂ, ਫੇਲ-ਮੋਡ ਅਤੇ ਰੋਜ਼ਾਨਾ ਰੁਟੀਨਾਂ ਹੁੰਦੀਆਂ ਹਨ। ਥੋੜ੍ਹੀ ਮੋਨੀਟਰਿੰਗ ਵਿੱਚ ਦਿਸੀਪਲਿਨ ਅਕਸਰ ਇਹ ਫਰਕ ਬਣਾਉਂਦੀ ਹੈ ਕਿ "ਰੈਪਲਿਕਿਆਂ ਨੇ ਮਦਦ ਕੀਤੀ" ਜਾਂ "ਰੈਪਲਿਕਿਆਂ ਨੇ ਗੁੰਝਲ ਪੈਦਾ ਕੀਤਾ"।
ਉਹ ਸੁਚਕ ਹਨ ਜੋ ਉਪਭੋਗਤਾ-ਸਮਖੀ ਲੱਛਣਾਂ ਨੂੰ ਸਮਝਾਉਂਦੇ ਹਨ:
ਰੀਡਾਂ ਆਫਲੋਡ ਕਰਨ ਲਈ ਇੱਕ ਰੈਪਲਿਕਾ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ। ਹੋਰਾਂ ਨੂੰ ਜੋੜੋ ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਸਪੱਸ਼ਟ ਬੰਧਨ ਹੋਵੇ:
ਵਿਵਹਾਰਕ ਨਿਯਮ: ਰੈਪਲਿਕਿਆਂ ਨੂੰ ਸਿਰਫ਼ ਉਸ ਵੇਲੇ ਸਕੇਲ ਕਰੋ ਜਦੋਂ ਤੁਸੀਂ ਪੁਸ਼ਟੀ ਕਰ ਚੁੱਕੇ ਹੋ ਕਿ ਪੜ੍ਹਨ ਹੀ ਬੋਤਲਨੇਕ ਹੈ (ਨ ਕਿ ਇੰਡੈਕਸ, ਧੀਮੀ ਕਵੇਰੀ, ਜਾਂ ਐਪ ਕੈਸ਼)।
ਰੀਡ ਰੈਪਲਿਕੇਸ ਰੀਡ ਸਕੇਲਿੰਗ ਲਈ ਇੱਕ ਸੰਦ ਹਨ, ਪਰ ਉਹ ਅਕਸਰ ਪਹਿਲਾ ਸਬਕ ਨਹੀਂ। ਓਪਰੇਸ਼ਨਲ ਜਟਿਲਤਾ ਜੋੜਣ ਤੋਂ ਪਹਿਲਾਂ ਚੈੱਕ ਕਰੋ ਕਿ ਸਧਾਰਨ ਸੁਧਾਰ ਤੁਹਾਨੂੰ ਇਕੋ ਨਤੀਜਾ ਦੇ ਸਕਦੇ ਹਨ।
ਕੈਸ਼ਿੰਗ ਤੁਹਾਡੇ ਡੇਟਾਬੇਸ ਤੋਂ ਪੂਰੀਆਂ ਪੜ੍ਹਨਾਂ ਨੂੰ ਹਟਾ ਸਕਦੀ ਹੈ। "ਰੀਡ-ਮੋਸਟਲੀ" ਪੰਨਿਆਂ (ਪ੍ਰੋਡਕਟ ਵੇਰਵੇ, ਸਾਹਮਣਾ ਪ੍ਰੋਫਾਈਲ, ਸੰਰਚਨਾ) ਲਈ ਐਪ ਕੈਸ਼ ਜਾਂ CDN ਟ੍ਰੈਫਿਕ ਨੂੰ ਘਟਾ ਸਕਦਾ ਹੈ—ਬਿਨਾਂ ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਜੋੜੇ।
ਇੰਡੈਕਸ ਅਤੇ ਕਵੇਰੀ ਅਪਟੀਮਾਈਜ਼ੇਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਰੈਪਲਿਕਿਆਂ ਨਾਲੋਂ ਵੱਧ ਫਾਇਦਾ ਦਿੰਦੇ ਹਨ: ਕੁਝ ਮਹਿੰਗੀਆਂ ਕਵੇਰੀਜ਼ CPU ਖਾ ਰਹੀਆਂ ਹਨ। ਠੀਕ ਇੰਡੈਕਸ ਜੋੜਨਾ, SELECT ਕਾਲਮਾਂ ਘੱਟ ਕਰਨਾ, N+1 ਸਮੱਸਿਆ ਨੂੰ ਠੀਕ ਕਰਨਾ, ਅਤੇ ਬੁਰੇ ਜੋਇਨ ਨਹੀਂ ਕਰਨਾਂ ਬਹੁਤ ਵੱਡੀ ਜਿੱਤ ਹੋ ਸਕਦੀ ਹੈ।
ਮੈਟੀਰੀਅਲਾਈਜ਼ਡ ਵਿਉਜ਼ / ਪ੍ਰੀ-ਅਗਰੀਗੇਸ਼ਨ ਉਹ ਸਮੇਂ ਕਾਰਗਰ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਵਰਕਲੋਡ ਪ੍ਰਾਭਾਵੀ ਤੌਰ 'ਤੇ ਭਾਰੀ ਹੋ (ਐਨਾਲਿਟਿਕਸ, ਡੈਸ਼ਬੋਰਡ). ਸੰਕੁਚਿਤ ਨਤੀਜੇ ਸਟੋਰ ਕਰੋ ਅਤੇ ਸਮੇਂ-ਸਮੇਂ 'ਤੇ ਰਿਫ੍ਰੈਸ਼ ਕਰੋ।
ਜੇ ਤੁਹਾਡੇ ਲਿਖਣ ਬੋਤਲਨੇਕ ਹਨ (ਹਾਟ ਰੋਜ਼, ਲਾਕ ਕੰਟੈਂਸ਼ਨ, ਲਿਖਤ IOPS ਸੀਮਾ), ਰੈਪਲਿਕੇਸ ਮਦਦਗਾਰ ਨਹੀਂ ਹੋਣਗੇ। ਅਜਿਹੇ ਵੇਲੇ ਟੇਬਲਾਂ ਨੂੰ ਸਮੇਂ/ਟੈਨੈਂਟ ਮੁਤਾਬਕ ਪਾਰਟੀਸ਼ਨਿੰਗ ਜਾਂ ਗ੍ਰਾਹਕ ਆਧਾਰਿਤ ਸ਼ਾਰਡਿੰਗ ਨਾਲ ਲਿਖਤ ਲੋਡ ਨੂੰ ਫੈਲਾਉਣਾ ਜ਼ਰੂਰੀ ਹੋ ਸਕਦਾ ਹੈ। ਇਹ ਵੱਡੀ ਆਰਕੀਟੈਕਚਰਲ ਕਦਮ ਹੈ, ਪਰ ਇਹ ਅਸਲ ਸੀਮਿਤੀ ਨੂੰ ਹੀ ਨਿਬਟਦਾ ਹੈ।
ਆਪਣੇ ਆਪ ਨੂੰ ਚਾਰ ਸਵਾਲ ਪੁੱਛੋ:
ਜੇ ਤੁਸੀਂ ਨਵੇਂ ਉਤਪਾਦ ਦੀ ਪ੍ਰੋਟੋਟਾਈਪ ਕਰ ਰਹੇ ਹੋ ਜਾਂ ਤੇਜ਼ੀ ਨਾਲ ਸੇਵਾ ਸ਼ੁਰੂ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇਨ੍ਹਾਂ ਸੀਮਾਵਾਂ ਨੂੰ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ ਪਹਿਲਾਂ ਤੋਂ ਹੀ ਸਮਾ ਲੈਣਾ ਮਦਦਗਾਰ ਹੁੰਦਾ ਹੈ। ਉਦਾਹਰਨ ਵਜੋਂ, ਟੀਮਾਂ ਜੋ Koder.ai 'ਤੇ ਬਣ ਰਹੀਆਂ ਹਨ (ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਜੋ Chat ਇੰਟਰਫੇਸ ਤੋਂ React ਐਪਸ ਨਾਲ Go + PostgreSQL ਬੈਕਐਂਡ ਜਨਰੇਟ ਕਰਦਾ ਹੈ) ਅਕਸਰ ਸਰਲਤਾ ਲਈ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੀਆਂ ਹਨ, ਫਿਰ ਜਦੋਂ ਡੈਸ਼ਬੋਰਡ, ਫੀਡ ਜਾਂ ਅੰਦਰੂਨੀ ਰਿਪੋਰਟਿੰਗ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਟ੍ਰੈਫਿਕ ਨਾਲ ਮੁਕਾਬਲਾ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰ ਦਿੰਦੇ ਹਨ, ਤਾਂ ਰੈਪਲਿਕਿਆਂ ਤੱਕ ਪਹੁੰਚਦੀਆਂ ਹਨ। ਯੋਜਨਾ-ਪਹਿਲਾਂ ਵਰਕਫਲੋ ਨੇ ਇਸ ਗੱਲ ਨੂੰ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ ਕਿ ਪਹਿਲਾਂ ਹੀ ਓਸੇ ਕਿਹੜੇ ਏਂਡਪੋਇੰਟ stale reads ਸਹਿਣਗੇ ਅਤੇ ਕਿਹੜੇ "read-your-writes" ਲਈ ਪ੍ਰਾਇਮਰੀ ਚਾਹੀਦਾ।
ਜੇ ਤੁਸੀਂ ਰਾਹ-ਚੁਣਨ ਵਿੱਚ ਮਦਦ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ /pricing ਲਈ ਵਿਕਲਪ ਵੇਖੋ, ਜਾਂ /blog ਵਿੱਚ ਸਬੰਧਤ ਗਾਈਡਾਂ ਨੂੰ ਬ੍ਰਾਊਜ਼ ਕਰੋ।
ਰੀਡ ਰੈਪਲਿਕਾ ਤੁਹਾਡੇ ਮੁੱਖ (primary) ਡੇਟਾਬੇਸ ਦੀ ਇੱਕ ਨਕਲ ਹੈ ਜੋ ਲਗਾਤਾਰ ਬਦਲਾਅ ਪ੍ਰਾਪਤ ਕਰਦੀ ਰਹਿੰਦੀ ਹੈ ਅਤੇ ਪੜ੍ਹਨ-ਮਾਤਰ ਕਵੇਰੀਆਂ (ਉਦਾਹਰਨ ਲਈ SELECT) ਦਾ ਜਵਾਬ ਦੇ ਸਕਦੀ ਹੈ। ਇਹ ਪ੍ਰਾਇਮਰੀ ਉੱਤੇ ਪੜ੍ਹਨ ਵਾਲੇ ਭਾਰ ਨੂੰ ਘੱਟ ਕਰਕੇ ਤੁਹਾਨੂੰ ਵੱਧ ਪੜ੍ਹਨ ਸਮਰੱਥਾ ਦੇਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ।
ਨਹੀਂ। ਆਮ ਪ੍ਰਾਇਮਰੀ–ਰੈਪਲਿਕਾ ਸੈਟਅੱਪ ਵਿੱਚ ਸਾਰੇ ਲਿਖਣ ਵਾਲੇ (writes) ਅਜੇ ਵੀ ਪ੍ਰਾਇਮਰੀ ਤੇ ਹੀ ਜਾਂਦੇ ਹਨ। ਰੈਪਲਿਕੇਸ ਪਰ ਨਜ਼ਦੀਕੀ ਤੌਰ ਤੇ ਥੋੜ੍ਹਾ ਓਵਰਹੈੱਡ ਵੱਧਾ ਸਕਦੇ ਹਨ ਕਿਉਂਕਿ ਪ੍ਰਾਇਮਰੀ ਨੂੰ ਹਰ ਰੈਪਲਿਕਾ ਨੂੰ ਬਦਲਾਅ ਭੇਜਣੇ ਪੈਂਦੇ ਹਨ।
ਉਹ ਉਦੋਂ ਵਧੀਆ ਕੰਮ ਕਰਦੇ ਹਨ ਜਦੋਂ ਤੁਸੀਂ ਰੀਡ-ਬਾਊਂਡ ਹੋ: ਬਹੁਤ ਸਾਰੇ SELECT ਟ੍ਰੈਫਿਕ ਪ੍ਰਾਇਮਰੀ ਤੇ CPU/I/O ਜਾਂ ਕਨੈਕਸ਼ਨ ਦਬਾਅ ਪੈਦਾ ਕਰ ਰਹੇ ਹਨ, ਜਦੋਂ ਕਿ ਲਿਖਣ ਸਥਿਰ ਹਨ। ਇਹ ਭਾਰੀ ਪੜ੍ਹਨਾਂ (ਰਿਪੋਰਟਿੰਗ, ਐਕਸਪੋਰਟ) ਨੂੰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਕੰਮ ਤੋਂ ਅਲੱਗ ਕਰਕੇ ਮਦਦ ਕਰਦੇ ਹਨ।
ਜ਼ਰੂਰੀ ਨਹੀਂ। ਜੇ ਕੋਈ ਕਵੇਰੀ ਇਨਡੈਕਸਾਂ ਦੀ ਘਾਟ, ਖਰਾਬ ਜੋਇਨ ਪੈਟਰਨ ਜਾਂ ਬਹੁਤ ਵੱਡੇ ਸਕੈਨ ਕਰਨ ਕਾਰਨ ਧੀਮੀ ਹੈ, ਤਾਂ ਉਹ ਰੈਪਲਿਕਾ 'ਤੇ ਵੀ ਧੀਮੀ ਰਹੇਗੀ—ਸਿਰਫ਼ ਕਿਸੇ ਹੋਰ ਸਥਾਨ 'ਤੇ। ਪਹਿਲਾਂ ਕਵੇਰੀਆਂ ਅਤੇ ਇੰਡੈਕਸ ਟਿਊਨ ਕਰੋ ਜਦੋਂ ਕੁਝ ਹੀ ਕਵੇਰੀਜ਼ ਕੁੱਲ ਸਮੇਂ ਦਾ ਵੱਡਾ ਹਿੱਸਾ ਲੈ ਰਹੀਆਂ ਹਨ।
ਰਿਪਲਿਕੇਸ਼ਨ ਲੈਗ ਉਹ ਦੇਰੀ ਹੈ ਜੋ ਕਿਸੇ ਲਿਖਤ ਦੇ ਪ੍ਰਾਇਮਰੀ 'ਤੇ ਕੰਮ ਹੋਣ ਅਤੇ ਉਸ ਬਦਲਾਅ ਦੇ ਰੈਪਲਿਕਾ 'ਤੇ ਦਿੱਖਣ ਵਿੱਚ ਹੁੰਦੀ ਹੈ। ਲੈਗ ਦੌਰਾਨ, ਰੈਪਲਿਕਾ ਤੋਂ ਕੀਤੇ ਪੜ੍ਹਨ stale ਹੋ ਸਕਦੇ ਹਨ, ਇਸ ਲਈ ਰੈਪਲਿਕੇਸ਼ਨ ਪਾਰ ਅਕਸਰ ਕੁਝ ਪੜ੍ਹਨਾਂ ਲਈ ਅੰਤਿਮ ਸਥਿਰਤਾ (eventual consistency) ਲਿਆਉਂਦੇ ਹਨ।
ਆਮ ਕਾਰਨ ਹਨ:
ਉਹ ਪੜ੍ਹਨ ਜੋ ਤੁਰੰਤ ਲਿਖਤ ਨੂੰ ਦਰਸਾਉਣ ਜ਼ਰੂਰੀ ਹਨ—ਉਦਾਹਰਨ ਲਈ:
ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਪਾਠਾਂ ਲਈ ਪ੍ਰਾਇਮਰੀ ਤੋਂ ਪੜ੍ਹੋ।
ਇੱਕ read-your-writes ਰਣਨੀਤੀ ਵਰਤੋ:
ਮੁੱਖ ਸੰਕੇਤਾਂ ਤੇ ਨਜ਼ਰ ਰੱਖੋ:
ਜਦੋਂ ਲੈਗ ਤੁਹਾਡੇ ਉਚਿਤ ਟੋਲਰੈਂਸ ਤੋਂ ਵੱਧ ਹੋਵੇ (ਜਿਵੇਂ 5s/30s/2m), ਆਲਾਰਮ ਬਣਾ ਲਵੋ।
ਵਿਕਲਪ ਹੋ ਸਕਦੇ ਹਨ:
ਰੈਪਲਿਕੇਸ ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਹਨ ਜਿੱਥੇ ਪੜ੍ਹਨ ਪਹਿਲਾਂ ਹੀ ਕਾਫ਼ੀ ਅਪਟੀਮਾਈਜ਼ਡ ਹਨ ਅਤੇ ਤੁਸੀਂ ਕੁਝ ਸਟੇਲੇ ਨਾਲ ਜੀ ਲੈ ਸਕਦੇ ਹੋ।