Claude Shannon ਦੇ ਸੂਚਨਾ ਸਿਧਾਂਤ ਦਾ ਅਧੁਨਿਕ ਡਿਜੀਟਲ ਟੈਕ 'ਤੇ ਪ੍ਰਭਾਵ
Claude Shannon ਦੇ ਮੁੱਖ ਵਿਚਾਰ—ਬਿਟ, ਐਨਟਰਪੀ, ਅਤੇ ਚੈਨਲ ਸਮਰੱਥਾ—ਸਿੱਖੋ ਅਤੇ ਜਾਣੋ ਕਿ ਇਹ ਕੰਪ੍ਰੈਸ਼ਨ, ਤ੍ਰੁੱਟੀ-ਸੁਧਾਰ, ਭਰੋਸੇਯੋਗ ਨੈਟਵਰਕਿੰਗ ਅਤੇ ਆਧੁਨਿਕ ਡਿਜੀਟਲ ਮੀਡੀਆ ਵਿੱਚ ਕਿਵੇਂ ਕੰਮ ਕਰਦੇ ਹਨ।
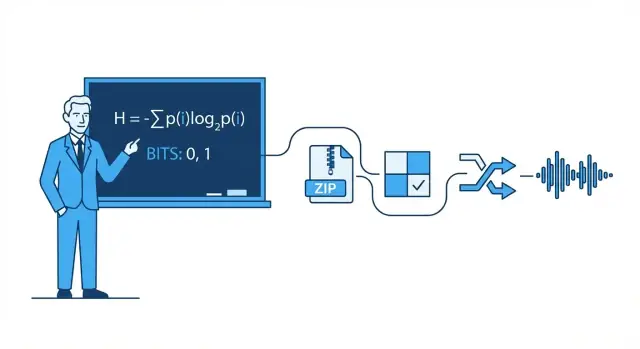
Shannon ਅਜੇ ਵੀ ਰੋਜ਼ਾਨਾ ਤਕਨਾਲੋਜੀ ਲਈ ਕਿਉਂ ਮਹੱਤਵਪੂਰਨ ਹੈ
ਤੁਸੀਂ Claude Shannon ਦੇ ਵਿਚਾਰ ਹਰ ਵਾਰ ਵਰਤਦੇ ਹੋ ਜਦੋਂ ਤੁਸੀਂ ਇਕ ਟੈਕਸਟ ਭੇਜਦੇ ਹੋ, ਵੀਡੀਓ ਦੇਖਦੇ ਹੋ, ਜਾਂ Wi‑Fi ਨਾਲ ਜੁੜਦੇ ਹੋ। ਇਹ ਇਸ ਲਈ ਨਹੀਂ ਕਿ ਤੁਹਾਡਾ ਫੋਨ “Shannon ਨੂੰ ਜਾਣਦਾ” ਹੈ, ਬਲਕਿ ਇਸ ਲਈ ਕਿ ਆਧੁਨਿਕ ਡਿਜੀਟਲ ਸਿਸਟਮ ਇੱਕ ਸਧਾਰਣ ਵਾਅਦੇ 'ਤੇ ਬਣੇ ਹਨ: ਅਸੀਂ ਗੰਦੇ-ਰੇਅਲ-ਵਰਲ্ড ਸੁਨੇਹਿਆਂ ਨੂੰ ਬਿੱਟਾਂ ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਾਂ, ਉਹ ਬਿੱਟ ਅਪਰਿਪੂਰਾ ਚੈਨਲਾਂ ਰਾਹੀਂ ਭੇਜ ਸਕਦੇ ਹਾਂ, ਅਤੇ ਫਿਰ ਵੀ ਮੂਲ ਸਮੱਗਰੀ ਨੂੰ ਉੱਚ ਭਰੋਸੇਯੋਗਤਾਪੂਰਕ ਰੀਕਵਰ ਕਰ ਸਕਦੇ ਹਾਂ।
ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ ਸੂਚਨਾ ਸਿਧਾਂਤ
ਸੂਚਨਾ ਸਿਧਾਂਤ ਸੁਨੇਹਿਆਂ ਦੀ ਗਣਿਤ ਹੈ: ਕਿਸ ਹੱਦ ਤੱਕ ਇੱਕ ਸੁਨੇਹਾ ਚੋਣ (ਅਣਿਸ਼ਚਿਤਤਾ) ਰੱਖਦਾ ਹੈ, ਇਸਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਅਤੇ ਸ਼ੋਰ, ਹਸਤਖੇਪ, ਅਤੇ ਭੀੜ-ਭਾੜ ਦੇ ਸਮੇਂ ਇਸਨੂੰ ਕਿਵੇਂ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਭੇਜਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇਸ ਦੇ ਪਿੱਛੇ ਗਣਿਤ ਹੈ, ਪਰ ਵਿਵਹਾਰਿਕ ਸੂਝ-ਬੂਝ ਲਈ ਗਣਿਤਜ್ಞ ਹੋਣ ਦੀ ਲੋੜ ਨਹੀਂ। ਅਸੀਂ ਹਰ-ਰੋਜ਼ ਦੇ ਉਦਾਹਰਣ ਵਰਤਾਂਗੇ—ਜਿਵੇਂ ਕਿ ਕੁਝ ਫੋਟੋ ਕਿਉਂ ਬਿਹਤਰ compress ਹੁੰਦੀਆਂ ਹਨ, ਜਾਂ ਜਦੋਂ ਸਿਗਨਲ ਕਮਜ਼ੋਰ ਹੁੰਦਾ ਹੈ ਤਾਂ ਤੁਹਾਡੀ ਕਾਲ ਕਿਵੇਂ ਠੀਕ ਸੁਣਾਈ ਦਿੰਦੀ ਹੈ—ਤਾਕਿ ਗੰਭੀਰ ਫਾਰਮੂਲਾਂ ਤੋਂ ਬਿਨਾਂ ਵਿਚਾਰ ਸਪੱਸ਼ਟ ਹੋਣ।
ਉਹ ਚਾਰ ਅਸਾਸ ਜੋ ਤੁਸੀਂ ਹਰ ਥਾਂ ਵੇਖੋਂਗੇ
ਇਹ ਲੇਖ਼ ਚਾਰ Shannon-ਪ੍ਰੇਰਿਤ ਅਸਾਸਾਂ ਤੇ ਕੇਂਦਰਿਤ ਹੈ ਜੋ ਆਧੁਨਿਕ ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਵਿਆਪਕ ਹਨ:
- ਕੰਪ੍ਰੈਸ਼ਨ: ਡਾਟਾ (ਆਡੀਓ, ਵੀਡੀਓ, ਫਾਇਲਾਂ) ਨੂੰ ਛੋਟਾ ਕਰਨਾ ਬਿਨਾਂ ਜ਼ਰੂਰੀ ਗੱਲਾਂ ਗੁਆਓ।
- ਤ੍ਰੁੱਟੀ-ਸੁਧਾਰ: ਥੋੜ੍ਹੇ ਜ਼ਿਆਦਾ ਬਿੱਟ ਜੋੜ ਕੇ ਮੁਲ ਵਿੱਚ ਹੋਈਆਂ ਗਲਤੀਆਂ ਪਛਾਣਨਾ ਅਤੇ ਠੀਕ ਕਰਨਾ।
- ਨੈਟਵਰਕ ਭਰੋਸੇਯੋਗਤਾ: ਡ੍ਰਾਪ ਕੀਤੀਆਂ ਪੈਕਟਾਂ ਨੂੰ retries, ordering, ਅਤੇ throughput tradeoffs ਨਾਲ ਸੰਭਾਲਨਾ।
- ਅੰਤ-ਤੋਂ-ਅੰਤ ਡਿਜੀਟਲ ਸੰਚਾਰ: ਸਰੋਤ (ਤੁਹਾਡਾ ਸੁਨੇਹਾ) ਤੋਂ ਚੈਨਲ (Wi‑Fi, ਸੈੱਲੁਲਰ, ਫਾਈਬਰ) ਤੱਕ ਪੂਰੇ ਚੈਨ ਨੂੰ ਦੇਖਣਾ ਅਤੇ ਵਾਪਸ ਆਉਣਾ।
ਅਖੀਰ ਵਿੱਚ ਤੁਸੀਂ ਕਿਹੜੀਆਂ ਚੀਜ਼ਾਂ ਬਾਰੇ ਸੋਚ ਸਕੋਗੇ
ਅਖੀਰ ਤੇ, ਤੁਸੀਂ ਸਪੱਸ਼ਟ ਤੌਰ 'ਤੇ ਸੋਚ ਸਕੋਗੇ ਕਿ: ਉੱਚ ਵੀਡੀਓ ਕੁਆਲਿਟੀ ਲਈ ਵਧੇਰੇ ਬੈਂਡਵਿਡਥ ਕਿਉਂ ਲੋੜਦੀ ਹੈ, "ਜਿਆਦਾ ਬਾਰਾਂ" ਹਮੇਸ਼ਾਂ ਤੇਜ਼ ਇੰਟਰਨੈੱਟ ਨਹੀਂ ਦਾਦਾ ਕਰਦੀਆਂ, ਕੁਝ ਐਪਸ ਤੁਰੰਤ ਕਿਉਂ ਮਹਿਸੂਸ ਹੁੰਦੀਆਂ ਹਨ ਜਦਕਿ ਦੂਜੇ buffer ਕਰਦੇ ਹਨ, ਅਤੇ ਹਰ ਸਿਸਟਮ ਆਪਣੀਆਂ ਸੀਮਾਵਾਂ 'ਚ ਕਿਵੇਂ ਫਸ ਜਾਂਦਾ ਹੈ—ਖਾਸ ਕਰਕੇ ਮਸ਼ਹੂਰ Shannon limit।
Claude Shannon ਇੱਕ ਪੇਜ਼ ਵਿੱਚ: ਵੱਡਾ ਖ਼ਿਆਲ
1948 ਵਿੱਚ, ਗਣਿਤਜ्ञ ਅਤੇ ਇੰਜੀਨੀਅਰ Claude Shannon ਨੇ ਇੱਕ ਕਾਗਜ਼ ਛਪਾਇਆ ਜਿਸਦਾ ਸਿਰਲੇਖ ਨਿੱਜੀ ਤੌਰ 'ਤੇ ਸਧਾਰਣ ਸੀ—A Mathematical Theory of Communication—ਜਿਸਨੇ ਸ਼ਾਂਤੀ ਨਾਲ ਇਹ ਸੋਚ ਬਦਲ ਦਿੱਤੀ ਕਿ ਡਾਟਾ ਭੇਜਣ ਬਾਰੇ ਕਿਵੇਂ ਸੋਚਿਆ ਜਾਵੇ। ਰਚਨਾ ਨੂੰ ਇੱਕ ਕਲਾ ਵਜੋਂ ਦੇਖਣ ਦੀ ਬਜਾਏ, ਉਸਨੇ ਸੁਨੇਹਿਆਂ ਨੂੰ ਇੱਕ ਇੰਜੀਨੀਅਰਿੰਗ ਸਮੱਸਿਆ ਵਜੋਂ ਦੇਖਿਆ: ਇੱਕ ਸਰੋਤ ਸੁਨੇਹੇ ਬਣਾ ਰਿਹਾ ਹੈ, ਇੱਕ ਚੈਨਲ ਉਨਾਂ ਨੂੰ ਲੈ ਕੇ ਜਾਂਦਾ ਹੈ, ਸ਼ੋਰ ਉਹਨਾਂ ਨੂੰ ਖ਼ਰਾਬ ਕਰਦਾ ਹੈ, ਅਤੇ ਇੱਕ ਰਿਸੀਵਰ ਜੋ ਭੇਜਿਆ ਗਿਆ ਸੀ ਉਸਨੂੰ ਮੁੜ ਤਿਆਰ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ।
ਸੂਚਨਾ "ਅਰਥ" ਨਹੀਂ, "ਘਟਾਈ ਗਈ ਅਣਿਸ਼ਚਿਤਤਾ" ਹੈ
Shannon ਦਾ ਮੁੱਖ ਫੈਸਲਾ ਇਹ ਸੀ ਕਿ ਸੂਚਨਾ ਨੂੰ ਇਸ ਤਰੀਕੇ ਨਾਲ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਜਾਵੇ ਜੋ ਮਾਪਯੋਗ ਅਤੇ ਮਸ਼ੀਨਾਂ ਲਈ ਉਪਯੋਗੀ ਹੋਵੇ। ਉਸਦੇ ਫਰੇਮਵਰਕ ਵਿੱਚ, ਸੂਚਨਾ ਇਸ ਗੱਲ ਬਾਰੇ ਨਹੀਂ ਕਿ ਸੁਨੇਹਾ ਕਿੰਨਾ ਮਹੱਤਵਪੂਰਨ ਲੱਗਦਾ ਹੈ ਜਾਂ ਇਸਦਾ ਕੀ ਅਰਥ ਹੈ। ਇਹ ਇਸ ਗੱਲ ਬਾਰੇ ਹੈ ਕਿ ਉਹ ਕਿੰਨਾ ਹਰਾਨ ਕਰਦਾ ਹੈ—ਜਦ ਤੁਸੀਂ ਨਤੀਜਾ ਜਾਣਦੇ ਹੋ ਤਾਂ ਕਿੰਨੀ ਅਣਿਸ਼ਚਿਤਤਾ ਘਟਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਜਾਣਦੇ ਹੋ ਕਿ ਕੀ ਹੋਵੇਗਾ, ਤਾਂ ਸੁਨੇਹਾ ਲਗਭਗ ਕੋਈ ਜਾਣਕਾਰੀ ਨਹੀਂ ਦਿੰਦਾ। ਜੇ ਤੁਸੀਂ ਸੱਚਮੁੱਚ ਅਣਪਛਾਣ ਹੋ, ਨਤੀਜੇ ਨੂੰ ਜਾਣਨਾ ਵਧੇਰੇ ਜਾਣਕਾਰੀ ਦਿੰਦਾ ਹੈ।
ਬਿਟ: ਸਭ ਤੋਂ ਸਧਾਰਣ ਇਕਾਈ ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਗਿਨ ਸਕਦੇ ਹੋ
ਸੂਚਨਾ ਮਾਪਣ ਲਈ, Shannon ਨੇ ਬਿਟ (binary digit) ਨੂੰ ਲੋਕਪ੍ਰਿਯ ਕੀਤਾ। ਇੱਕ ਬਿਟ ਉਹ ਮਾਤਰਾ ਹੈ ਜੋ ਇੱਕ ਸਧਾਰਣ ਹਾਂ/ਨਹੀਂ ਅਣਿਸ਼ਚਿਤਤਾ ਨੂੰ ਹੱਲ ਕਰਨ ਲਈ ਚਾਹੀਦੀ ਹੁੰਦੀ ਹੈ।
ਉਦਾਹਰਨ: ਜੇ ਮੈਂ ਪੁੱਛਾਂ "ਲਾਈਟ ਚਾਲੂ ਹੈ?" ਅਤੇ ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ ਕੁਝ ਪਤਾ ਨਹੀਂ ਹੈ, ਤਾਂ ਜਵਾਬ (ਹਾਂ ਜਾਂ ਨਹੀਂ) ਨੂੰ 1 ਬਿਟ ਜਾਣਕਾਰੀ ਸਮਝਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਬਹੁਤ ਸਾਰੇ ਅਸਲ ਸੁਨੇਹੇ ਇਨ੍ਹਾਂ ਬਾਈਨਰੀ ਚੋਣਾਂ ਦੀ ਲੰਬੀ ਲੜੀ ਵਿੱਚ ਟੁੱਟ ਸਕਦੇ ਹਨ, ਇਸ ਲਈ ਟੈਕਸਟ ਤੋਂ ਲੈ ਕੇ ਫੋਟੋ ਅਤੇ ਆਡੀਓ ਤੱਕ ਸਾਰਾ ਕੁਝ ਬਿੱਟਾਂ ਵਜੋਂ ਸਟੋਰ ਅਤੇ ਭੇਜਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇਸ ਪੋਸਟ ਵਿੱਚ ਕੀ ਕਰਾਂਗੇ (ਅਤੇ ਕੀ ਨਹੀਂ)
ਇਹ ਲੇਖ਼ Shannon ਦੇ ਵਿਚਾਰਾਂ ਦੇ ਪ੍ਰਯੋਗਿਕ ਸੂਝ-ਬੂਝ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਦਾ ਹੈ ਅਤੇ ਦੱਸਦਾ ਹੈ ਕਿ ਉਹ ਕਿਉਂ ਹਰ ਥਾਂ ਪ੍ਰਗਟ ਹੁੰਦੇ ਹਨ: ਕੰਪ੍ਰੈਸ਼ਨ, ਤ੍ਰੁੱਟੀ-ਸੁਧਾਰ, ਨੈਟਵਰਕ ਭਰੋਸੇਯੋਗਤਾ, ਅਤੇ ਚੈਨਲ ਸਮਰੱਥਾ।
ਇਹ ਭਾਰੀ ਪ੍ਰਮਾਣ-ਸਬੂਤਾਂ 'ਚ ਨਹੀਂ ਜਾਵੇਗਾ। ਤੁਹਾਨੂੰ ਨਤੀਜਾ ਸਮਝਣ ਲਈ ਉੱਚ ਗਣਿਤ ਦੀ ਲੋੜ ਨਹੀਂ: ਜਦ ਤੁਸੀਂ ਸੂਚਨਾ ਨੂੰ ਮਾਪ ਸਕਦੇ ਹੋ, ਤਦ ਤੁਸੀਂ ਉਹ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਸੰਭਵ ਤੌਰ 'ਤੇ ਸਭ ਤੋਂ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੋ—ਅਕਸਰ Shannon ਦੁਆਰਾ ਦਰਸਾਏ ਗਿਆ ਸਿਧਾਂਤਿਕ ਸੀਮਾ ਬਹੁਤ ਨੇੜੇ ਤੱਕ।
ਬਿੱਟ, ਚਿੰਨ੍ਹ, ਅਤੇ ਕੋਡ: ਇੱਕ ਵਰਤੋਂਯੋਗ ਸ਼ਬਦਾਵਲੀ
ਐਨਟਰਪੀ, ਕੰਪ੍ਰੈਸ਼ਨ, ਜਾਂ ਤ੍ਰੁੱਟੀ-ਸੁਧਾਰ ਬਾਰੇ ਗੱਲ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਕੁਝ ਰੋਜ਼ਾਨਾ ਸ਼ਬਦ ਨਿਰਧਾਰਤ ਕਰਨਾ ਮਦਦਗਾਰ ਰਹੇਗਾ। Shannon ਦੇ ਵਿਚਾਰ ਉਹਨਾਂ ਟੁਕੜਿਆਂ ਨੂੰ ਨਾਮ ਦੇ ਕੇ ਆਸਾਨ ਹੋ ਜਾਂਦੇ ਹਨ।
ਚਿੰਨ੍ਹ, ਅੱਖਰਮਾਲਾ, ਅਤੇ ਸੁਨੇਹੇ
ਇੱਕ ਚਿੰਨ੍ਹ ਉਹ ਇੱਕ "ਟੋਕਨ" ਹੈ ਜੋ ਤੁਸੀਂ ਸਹਿਮਤ ਹੋ ਕਿ ਵਰਤੋਂਗੇ। ਉਹ ਸੈਟ ਅੱਖਰਮਾਲਾ ਹੈ। ਅੰਗ੍ਰੇਜ਼ੀ ਟੈਕਸਟ ਵਿੱਚ, ਅੱਖਰਮਾਲਾ ਹੋ ਸਕਦੀ ਹੈ ਅੱਖਰ (ਖਾਲੀ ਥਾਂ ਅਤੇ ਵਿਰਾਮ-ਚਿੰਨ੍ਹ ਸਮੇਤ)। ਕੰਪਿਊਟਰ ਫਾਇਲ ਵਿੱਚ, ਅੱਖਰਮਾਲਾ 0–255 ਬਾਈਟ ਮੁੱਲ ਹੋ ਸਕਦੀ ਹੈ।
ਇੱਕ ਸੁਨੇਹਾ ਉਸ ਅੱਖਰਮਾਲਾ ਤੋਂ ਚਿੰਨ੍ਹਾਂ ਦੀ ਲੜੀ ਹੁੰਦਾ ਹੈ: ਇੱਕ ਸ਼ਬਦ, ਇੱਕ ਵਾਕ, ਇੱਕ ਫੋਟੋ ਫਾਇਲ, ਜਾਂ ਆਡੀਓ ਨਮੂਨਿਆਂ ਦੀ ਸਟ੍ਰੀਮ।
Concrete ਰੂਪ ਵਿੱਚ ਸੋਚੋ, ਇੱਕ ਛੋਟੀ ਅੱਖਰਮਾਲਾ ਕਲਪਨਾ ਕਰੋ: {A, B, C}. ਇੱਕ ਸੁਨੇਹਾ ਹੋ ਸਕਦਾ ਹੈ:
A A B C A B A ...
ਬਿੱਟ ਅਤੇ ਕੋਡ
ਇੱਕ ਬਿਟ ਇਕ ਬਾਈਨਰੀ ਅੰਕ ਹੈ: 0 ਜਾਂ 1. ਕੰਪਿਊਟਰ ਭੰਡਾਰਣ ਅਤੇ ਪ੍ਰਸारण ਲਈ ਬਿੱਟਾਂ ਨੂੰ ਇਸ ਲਈ ਸਟੋਰ ਕਰਦੇ ਹਨ ਕਿਉਂਕਿ ਹਾਰਡਵੇਅਰ ਦੋ ਹਾਲਤਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਅਲੱਗ ਕਰ ਸਕਦਾ ਹੈ।
ਇੱਕ ਕੋਡ ਉਹ ਨਿਯਮ ਹੈ ਜੋ ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਬਿੱਟਾਂ (ਜਾਂ ਹੋਰ ਚਿੰਨ੍ਹਾਂ) ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਦਰਸਾਉਂਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਸਾਡੇ {A, B, C} ਅੱਖਰਮਾਲਾ ਲਈ, ਇੱਕ ਸੰਭਵ ਬਾਈਨਰੀ ਕੋਡ ਹੈ:
- A → 0
- B → 10
- C → 11
ਹੁਣ ਕੋਈ ਵੀ ਸੁਨੇਹਾ ਜੋ A/B/C ਤੇ ਬਣਿਆ ਹੈ, ਉਹ ਬਿੱਟਾਂ ਦੀ ਇੱਕ ਸਟ੍ਰੀਮ ਵਿੱਚ ਬਦਲਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਐਨਕੋਡਿੰਗ vs. ਕੰਪ੍ਰੈਸ਼ਨ vs. ਇਨਕ੍ਰਿਪਸ਼ਨ
ਇਹ ਸ਼ਬਦ ਅਕਸਰ ਮਿਲਾ-ਝੁਲਾ ਵਰਤੇ ਜਾਂਦੇ ਹਨ:
- ਐਨਕੋਡਿੰਗ: ਡੇਟਾ ਨੂੰ ਇੱਕ ਚੁਣੇ ਹੋਏ ਫਾਰਮੈਟ ਵਿੱਚ ਬਦਲਨਾ ਤਾਂ ਜੋ ਇਸਨੂੰ ਸਟੋਰ/ਟ੍ਰਾਂਸਮਿਟ/ਪ੍ਰੋਸੈਸ ਕੀਤਾ ਜਾ ਸਕੇ (ਜਿਵੇਂ A/B/C ਨੂੰ ਬਿੱਟਾਂ ਵਿੱਚ ਮੈਪ ਕਰਨਾ, ਜਾਂ UTF‑8 ਵਿੱਚ ਟੈਕਸਟ ਬਦਲਣਾ)।
- ਕੰਪ੍ਰੈਸ਼ਨ: ਐਨਕੋਡਿੰਗ ਜੋ ਪੈਟਰਨ ਅਤੇ ਅਸਮਾਨ ਆਵਿਰਤੀ ਨੂੰ ਵਰਤ ਕੇ ਔਸਤ ਵਿੱਚ ਘੱਟ ਬਿੱਟ ਵਰਤਦੀ ਹੈ।
- ਇਨਕ੍ਰਿਪਸ਼ਨ: ਇੱਕ ਕੀ ਨਾਲ ਡੇਟਾ ਨੂੰ ਰੱਦਭਾਸ਼ਾ ਕਰਨਾ ਤਾਂ ਜੋ ਬਾਹਰੀ ਲੋਕ ਪੜ੍ਹ ਨਾ ਸਕਣ; ਇਹ ਗੁਪਤਤਾ ਨਾਲ਼ ਸਬੰਧਤ ਹੈ, ਆਕਾਰ ਨਾਲ ਨਹੀਂ।
ਇੱਕ ਛੋਟੀ ਸੰਭਾਵਨਾ ਸੂਝ-ਬੂਝ
ਅਸਲ ਸੁਨੇਹੇ ਬੇਕਾਰ ਨਹੀਂ ਹੁੰਦੇ: ਕੁਝ ਚਿੰਨ੍ਹ ਹੋਰਾਂ ਦੇ ਮੁਕਾਬਲੇ ਵੱਧ ਵਾਰ ਆਉਂਦੇ ਹਨ। ਮੰਨੋ A 70% ਵਾਰੀ ਆਉਂਦਾ ਹੈ, B 20%, C 10%. ਇੱਕ ਚੰਗੀ ਕੰਪ੍ਰੈਸ਼ਨ ਸਕੀਮ ਆਮ ਤੌਰ 'ਤੇ ਆਮ ਚਿੰਨ੍ਹਾਂ (A) ਨੂੰ ਛੋਟੇ ਬਿੱਟ ਪੈਟਰਨ ਦੇਵੇਗੀ ਅਤੇ ਦਰਿ rare ਚਿੰਨ੍ਹਾਂ (C) ਨੂੰ ਲੰਮੇ। ਉਹ "ਅਸਮਾਨਤਾ" ਹੀ ਹੈ ਜਿਸਨੂੰ ਅਗਲੇ ਭਾਗ ਐਨਟਰਪੀ ਨਾਲ ਮਾਪੇਗਾ।
ਐਨਟਰਪੀ: ਹੈਰਾਨੀ ਦਾ ਮਾਪ (ਅਤੇ ਇਹ ਕੰਪ੍ਰੈਸ਼ਬਿਲਟੀ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਿਉਂ ਕਰਦਾ ਹੈ)
Shannon ਦਾ ਸਭ ਤੋਂ ਮਸ਼ਹੂਰ ਵਿਚਾਰ ਐਨਟਰਪੀ ਹੈ: ਇੱਕ ਸਰੋਤ ਵਿੱਚ ਕਿੰਨੀ "ਹੈਰਾਨੀ" ਹੈ, ਇਹ ਮਾਪਣ ਦਾ ਤਰੀਕਾ। ਇੱਥੇ ਹੈਰਾਨੀ ਭਾਵਨਾਤਮਕ ਨਹੀਂ—ਹੈਰਾਨੀ ਇਕ ਅਣਪੇਖੀਤਾ ਹੈ। ਜਿੰਨਾ ਅਣਪੇਖੀਤ ਹੋਏਗਾ, ਅਗਲਾ ਚਿੰਨ੍ਹ ਆਉਣ 'ਤੇ ਉਸਦੇ ਨਾਲ ਜ਼ਿਆਦਾ ਜਾਣਕਾਰੀ ਮਿਲੇਗੀ।
ਐਨਟਰਪੀ ਨੂੰ "ਔਸਤ ਹੈਰਾਨੀ" ਵਜੋਂ ਦੇਖਣਾ
ਕੋਈ ਸਿੱਕਾ ਉਲਟਦੇ ਦੇਖੋ।
- ਨਿਆਇਕ ਸਿੱਕਾ (50/50 heads ਜਾਂ tails): ਹਰ ਉਲਟਣਾ ਅਨੁਮਾਨ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੈ। Heads ਅਤੇ tails ਇੱਕੋ ਜਿਹੇ ਸੰਭਾਵਨਾਵਾਂ ਹਨ, ਇਸ ਲਈ ਤੁਸੀਂ ਹਰ ਵਾਰ "ਹੈਰਾਨ" ਹੋ ਸਕਦੇ ਹੋ। ਇਹ ਉੱਚ ਅਣਪੇਖੀਤਾ ਦਾ ਮਤਲਬ ਹੈ—ਉੱਚ ਐਨਟਰਪੀ।
- ਭਾਰਤ-ਭਰੇ ਸਿੱਕੇ (ਜਿਵੇਂ 95% heads, 5% tails): ਅਧਿਕ ਭਾਗ heads ਹੁੰਦੇ ਹਨ। ਥੋੜ੍ਹੇ ਹੀ ਉਲਟਣਾਂ ਤੋਂ ਬਾਅਦ ਤੁਸੀਂ heads ਦੀ ਉਮੀਦ ਕਰ ਲੈਂਦੇ ਹੋ, ਇਸ ਲਈ heads ਦੇ ਆਉਣ 'ਤੇ ਘੱਟ ਨਵੀਂ ਜਾਣਕਾਰੀ ਮਿਲਦੀ ਹੈ। ਸਿਰਫ਼ ਕਦਰੇ rare tails ਹੈ ਜੋ ਹੈਰਾਨੀ ਲਿਆਉਂਦਾ ਹੈ। ਔਸਤ ਤੌਰ 'ਤੇ ਇਹ ਘੱਟ ਐਨਟਰਪੀ ਵਾਲੀ ਸਟ੍ਰੀਮ ਹੈ।
ਇਹ "ਔਸਤ ਹੈਰਾਨੀ" ਵਾਲਾ ਫ੍ਰੇਮਵਰਕ ਰੋਜ਼ਾਨਾ ਪੈਟਰਨਾਂ ਨਾਲ ਮੇਲ ਖਾਂਦਾ ਹੈ: ਇੱਕ ਟੈਕਸਟ ਫਾਇਲ ਜਿਸ ਵਿੱਚ ਦੁਹਰਾਏ ਗਏ spaces ਅਤੇ ਆਮ ਸ਼ਬਦ ਹਨ ਉਹ random ਅੱਖਰਾਂ ਵਾਲੀ ਫਾਇਲ ਨਾਲੋਂ ਅਸਾਨੀ ਨਾਲ ਪੇਸ਼ਗੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਕਿਉਂ ਅਨੁਮਾਨਯੋਗਤਾ ਕੰਪ੍ਰੈਸ਼ਬਿਲਟੀ ਮਤਲਬ ਹੈ
ਕੰਪ੍ਰੈਸ਼ਨ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਲਈ ਕੰਮ ਕਰਦੀ ਹੈ ਕਿ ਇਹ ਆਮ ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਛੋਟੇ ਕੋਡ ਅਤੇ rare ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਲੰਮੇ ਕੋਡ ਦੇਂਦੀ ਹੈ। ਜੇ ਸਰੋਤ ਅਨੁਮਾਨਯੋਗ (ਘੱਟ ਐਨਟਰਪੀ) ਹੈ, ਤਾਂ ਤੁਸੀਂ ਜ਼ਿਆਦਾਤਰ ਵਾਰ ਛੋਟੇ ਕੋਡਾਂ 'ਤੇ ਨਿਰਭਰ ਹੋ ਸਕਦੇ ਹੋ ਅਤੇ ਥਾਂ ਬਚਾ ਸਕਦੇ ਹੋ। ਜੇ ਇਹ ਲਗਭਗ random-ਨੁਮਾ (ਉੱਚ ਐਨਟਰਪੀ) ਹੈ, ਤਾਂ ਘੱਟ ਸਮੱਸਾ ਹੈ ਕਿ ਤੁਸੀਂ ਘਟਾ ਸਕੋਂਗੇ ਕਿਉਂਕਿ ਕੁਝ ਵੀ ਬਹਾਲ ਹੀ ਇੰਨੇ ਵਾਰ ਨਹੀਂ ਆਉਂਦਾ ਜਿਸ ਨੂੰ ਫਾਇਦਾ ਹੋਵੇ।
ਐਨਟਰਪੀ ਅਤੇ ਔਸਤ ਕੋਡ ਲੰਬਾਈ ਲਈ ਸਭ ਤੋਂ ਵਧੀਆ ਸੀਮਾ
Shannon ਨੇ ਦਰਸਾਇਆ ਕਿ ਐਨਟਰਪੀ ਇੱਕ ਸੰਕਲਪਿਕ ਬੰਧਨ ਹੈ: ਇਹ ਉਹ ਭੇਟਾਂ ਪ੍ਰਤੀ ਚਿੰਨ੍ਹ ਔਸਤ ਬਿਟਾਂ ਦੀ ਸਭ ਤੋਂ ਵਧੀਆ ਨੀਵ ਹੈ ਜੋ ਤੁਸੀਂ ਉਸ ਸਰੋਤ ਦੇ ਡੇਟਾ ਨੂੰ ਐਨਕੋਡ ਕਰਕੇ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ।
ਜ਼ਰੂਰੀ: ਐਨਟਰਪੀ ਕੋਈ ਕੰਪ੍ਰੈਸ਼ਨ ਐਲਗੋਰਿਦਮ ਨਹੀਂ ਹੈ। ਇਹ ਤੁਹਾਨੂੰ ਦੱਸਦੀ ਹੈ ਕਿ ਸਿਧਾਂਤੀ ਤੌਰ 'ਤੇ ਕੀ ਸੰਭਵ ਹੈ—ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਸੀਮਾ ਦੇ ਨੇੜੇ ਹੋ।
ਕੰਪ੍ਰੈਸ਼ਨ: ਐਨਟਰਪੀ ਨੂੰ ਛੋਟੇ ਫਾਇਲਾਂ ਵਿੱਚ ਬਦਲਣਾ
ਕੰਪ੍ਰੈਸ਼ਨ ਉਹ ਹੁੰਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਸੁਨੇਹਾ ਲੈਂਦੇ ਹੋ ਜੋ ਘੱਟ ਬਿੱਟਾਂ ਵਿੱਚ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਇਸਨੂੰ ਘਟਾਉਂਦੇ ਹੋ। Shannon ਦੀ ਮੁੱਖ ਸੂਝ ਇਹ ਹੈ ਕਿ ਨੀਵ ਐਨਟਰਪੀ ਵਾਲੇ ਡੇਟਾ (ਜ਼ਿਆਦਾ ਅਨੁਮਾਨਯੋਗ) ਕੋਲ "ਘੱਟ ਹੋਣ ਦੀ ਜਗ੍ਹਾ" ਹੁੰਦੀ ਹੈ, ਜਦਕਿ ਉੱਚ-ਐਨਟਰਪੀ ਡੇਟਾ ਕੋਲ ਨਹੀਂ।
ਕਿਉਂ ਪੈਟਰਨ ਅਤੇ ਅਸਮਾਨ ਆਵਿਰਤੀ ਵਧੀਆ compress ਹੁੰਦੇ ਹਨ
ਦੁਹਰਾਏ ਪੈਟਰਨ ਸਪੱਸ਼ਟ ਫਾਇਦੇ ਹਨ: ਜੇ ਇੱਕ ਫਾਇਲ ਵਿੱਚ ਇੱਕੋ-ਹੀ ਕ੍ਰਮ ਕਈ ਵਾਰ ਆਉਂਦਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਉਸ ਕ੍ਰਮ ਨੂੰ ਇੱਕ ਵਾਰੀ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਕਈ ਵਾਰੀ ਹਵਾਲਾ ਦੇ ਸਕਦੇ ਹੋ। ਪਰ ਸਪਸ਼ਟ ਦੁਹਰਾਵਾਂ ਤੋਂ ਬਿਨਾਂ ਵੀ, ਪੱਖੀ ਆਵਿਰਤੀ ਮਦਦ ਕਰਦੀ ਹੈ।
ਜੇ ਇਕ ਟੈਕਸਟ 'ਚ "e" ਬਹੁਤ ਵਾਰੀ ਆਉਂਦਾ ਹੈ ਪਰ "z" ਕਮ ਆਉਂਦਾ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਹਰ ਚਰਿੱਤਰ 'ਤੇ ਇਕੋ ਜਿਹੇ ਬਿੱਟਾਂ ਦੀ ਲੋੜ ਨਹੀਂ। ਜਿੰਨਾ ਜ਼ਿਆਦਾ ਅਸਮਾਨ ਆਵਿਰਤੀ ਹੈ, ਉਤਨਾ ਵਧੇਰਾ predictability ਅਤੇ compressibility।
ਵੈਰੀਏਬਲ-ਲੰਬਾਈ ਕੋਡਿੰਗ (ਮੁੱਖ ਸੂਝ)
ਅਸਮਾਨ ਆਵਿਰਤੀ ਦਾ ਲਾਭ ਉਠਾਉਣ ਦਾ ਇੱਕ ਅਮਲੀ ਤਰੀਕਾ ਵੈਰੀਏਬਲ-ਲੰਬਾਈ ਕੋਡਿੰਗ ਹੈ:
- ਆਮ ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਛੋਟੇ ਕੋਡ ਮਿਲਦੇ ਹਨ
- ਦੁਰਲਭ ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਲੰਮੇ ਕੋਡ ਮਿਲਦੇ ਹਨ
ਯਥਾਰਥ ਵਿੱਚ, ਇਹ ਔਸਤ ਬਿੱਟ ਪ੍ਰਤੀ ਚਿੰਨ੍ਹ ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ ਬਿਨਾਂ ਜਾਣਕਾਰੀ ਗਵਾਉਂਦੇ।
ਅਸਲ ਦਿਨ-ਚੱਲ ਹਕੀਕਤ ਦੇ lossless compressors ਕਈ ਵਿਚਾਰ ਮਿਲਾਕੇ ਵਰਤਦੇ ਹਨ, ਪਰ ਆਮ ਤੌਰ 'ਤੇ ਤੁਸੀਂ ਇਹ ਪਰਿਵਾਰ ਸੁਣੋਗੇ:
- Huffman coding: ਇੱਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ "ਅਮੂਕ-ਲਈ-ਛੋਟਾ" ਕੋਡਬੁੱਕ ਬਣਾਉਂਦਾ ਹੈ
- Arithmetic coding: ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਭਾਗੀ-ਰੈਂਜ 'ਚ ਪੈਕ ਕਰਦਾ ਹੈ, ਅਕਸਰ ਐਨਟਰਪੀ ਸੀਮਾ ਦੇ ਨੇੜੇ ਪਹੁੰਚਦਾ ਹੈ
- LZ (Lempel–Ziv) ਵਿਧੀਆਂ: ਦੁਹਰਾਏ substrings ਲੱਭ ਕੇ ਉਹਨਾਂ ਨੂੰ ਰੈਫਰੰਸ ਨਾਲ ਬਦਲ ਦਿੰਦੀਆਂ ਹਨ (ਬਹੁਤ ਸਾਰੇ ZIP-ਸਟਾਈਲ ਫਾਰਮੈਟਾਂ ਵਿੱਚ ਵਰਤਿਆ ਜਾਂਦਾ)
ਲੌਸਲੇਸ vs. ਲੌਸੀ (ZIP vs. JPEG/MP3)
Lossless compression ਅਸਲ ਨੂੰ ਪੂਰੀ ਤਰ੍ਹਾਂ ਦੁਹਰਾਉਂਦਾ ਹੈ (ਉਦਾਹਰਨ: ZIP, PNG)। ਇਹ ਸਾਫਟਵੇਅਰ, ਦਸਤਾਵੇਜ਼, ਅਤੇ ਕਿਸੇ ਵੀ ਚੀਜ਼ ਲਈ ਜ਼ਰੂਰੀ ਹੈ ਜਿੱਥੇ ਇੱਕ ਵੀ ਗਲਤ ਬਿੱਟ ਮਹੱਤਵ ਰੱਖਦੀ ਹੈ।
Lossy compression ਜਾਣਬੂਝ ਕੇ ਉਹ ਜਾਣਕਾਰੀ ਕੱਡ ਦਿੰਦਾ ਹੈ ਜੋ ਲੋਕ ਆਮ ਤੌਰ 'ਤੇ ਮਹਿਸੂਸ ਨਹੀਂ ਕਰਦੇ (ਉਦਾਹਰਨ: JPEG ਫੋਟੋ, MP3/AAC ਆਡੀਓ)। ਉਦਦੇਸ਼ ਹੁੰਦਾ ਹੈ "ਉਹੀ ਅਨੁਭਵ" ਬਣਾਇਆ ਜਾਏ, ਅਕਸਰ ਬਹੁਤ ਛੋਟੀਆਂ ਫਾਇਲਾਂ ਪ੍ਰਾਪਤ ਕਰਨ ਲਈ ਦ੍ਰਿਸ਼ਟੀਗਤ ਨਿੱਕੀਆਂ ਵਿਸਥਾਰ ਹਟਾ ਕੇ।
ਗਲਤੀਆਂ ਹੁੰਦੀਆਂ ਹਨ: ਕਿਉਂ redundancy ਲਾਭਦਾਇਕ ਹੈ
ਹਰ ਡਿਜੀਟਲ ਸਿਸਟਮ ਇੱਕ ਨਾਜ਼ੁਕ ਧਾਰਨਾ 'ਤੇ ਖੜ੍ਹਾ ਹੈ: ਇੱਕ 0 ਇੱਕ 0 ਹੀ ਰਹਿਣੀ ਚਾਹੀਦੀ ਹੈ, ਅਤੇ ਇੱਕ 1 ਇੱਕ 1। ਅਸਲ ਵਿਚ, ਬਿੱਟਾਂ ਫਲਿੱਪ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਗਲਤੀਆਂ ਕਿੱਥੋਂ ਆਉਂਦੀਆਂ ਹਨ
ਟ੍ਰਾਂਸਮਿਸ਼ਨ 'ਚ, ਬਿਜਲੀ ਹਸਤਖੇਪ, ਕਮਜ਼ੋਰ Wi‑Fi ਸਿਗਨਲ, ਜਾਂ ਰੇਡੀਓ ਸ਼ੋਰ ਇੱਕ ਸਿਗਨਲ ਨੂੰ ਥੋੜ੍ਹਾ-ਬਹੁਤ ਬਦਲ ਸਕਦੇ ਹਨ ਤਾਂ ਜੋ ਰਿਸੀਵਰ ਗਲਤ ਤਰੀਕੇ ਨਾਲinterpret ਕਰ ਲਵੇ। ਸਟੋਰੇਜ ਵਿੱਚ, ਛੋਟੇ ਭੌਤਿਕ ਪ੍ਰਭਾਵ—ਫਲੈਸ਼ ਮੈਮੋਰੀ ਦੀ ਘਿਸਾਈ, optical ਮੀਡੀਆ 'ਤੇ ਖ਼ਰੋਸ਼, ਜਾਂ ਇੱਛਾ ਰਹਿਤ ਰੇਡੀਏਸ਼ਨ—ਭੰਡਾਰਤ ਪ੍ਰਭਾਵ ਬਦਲ ਸਕਦੇ ਹਨ।
ਕਿਉਂਕਿ ਗਲਤੀਆਂ ਅਣਿਵਾਰਯ ਹਨ, ਇੰਜੀਨੀਅਰ ਜ਼ਰੂਰਤ ਮੁਤਾਬਕ redundancy ਜੋੜਦੇ ਹਨ: ਵਾਧੂ ਬਿੱਟ ਜੋ "ਨਵੀਂ" ਜਾਣਕਾਰੀ ਨਹੀਂ ਲਿਆਉਂਦੇ, ਪਰ ਨੁਕਸਾਨ ਦਾ ਪਤਾ ਲਗਾਉਣ ਜਾਂ ਉਸਨੂੰ ਠੀਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਸਧਾਰਨ redundancy ਜੋ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤੀ ਹੈ
Parity bit (ਫ਼ੁੱਟਕ ਨਿਰਧਾਰਨ). ਇਕ ਵਾਧੂ ਬਿੱਟ ਜੋ ਕੁੱਲ 1s ਦੀ ਗਿਣਤੀ even (ਜੋੜੀ) ਜਾਂ odd ਰਹੇ—ਇਸ ਨਾਲ ਇੱਕ ਸਿੰਗਲ ਬਿੱਟ ਦੀ ਗਲਤੀ ਹੋਣ 'ਤੇ parity ਚੈਕ fail ਕਰ ਜਾਉਂਦਾ ਹੈ।
- ਫਾਇਦਾ: ਸਸਤਾ ਅਤੇ ਤੇਜ਼।
- ਹੱਦ: ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਦੱਸ ਨਹੀਂ ਸਕਦਾ ਕਿ ਕਿਹੜੀ ਬਿੱਟ ਗਲਤ ਹੈ, ਅਤੇ ਦੋ ਫਲਿੱਪ ਇਕੱਠੇ ਹੋਕੇ ਸਹੀ ਲੱਗ ਸਕਦੇ ਹਨ।
Checksum (ਬਲਾਕ ਲਈ ਬਿਹਤਰ ਪਤਾ ਲਾਉਣਾ). ਇਕ ਪੈਕੇਟ ਜਾਂ ਫਾਈਲ ਤੋਂ ਇਕ ਛੋਟੀ ਸੰਖਿਆਗਤ ਸੰਖੇਪ ਰਚਨਾ (ਉਦਾਹਰਨ: ਜੋੜ-ਸੰਖਿਆ checksum, CRC)। ਰਿਸੀਵਰ ਦੁਬਾਰਾ ਗਣਨਾ ਕਰਦਾ ਹੈ ਅਤੇ ਤੁਲਨਾ ਕਰਦਾ ਹੈ।
- ਫਾਇਦਾ: ਬਹੁਤ ਸਾਰੀਆਂ ਬਲਾਕ-ਵਿਆਪੀ ਗਲਤੀਆਂ ਨੂੰ ਪਕੜਦਾ ਹੈ।
- ਹੱਦ: ਫੇਰ ਵੀ ਸਿਰਫ਼ ਪਤਾ ਲਗਾਉਂਦਾ ਹੈ; ਜੇ ਇਹ fail ਹੋ ਜਾਏ ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ retry ਜਾਂ ਬੈਕਅਪ ਨਕਲ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
Repetition code (ਸਧਾਰਣ ਸੁਧਾਰ). ਹਰ ਬਿੱਟ ਨੂੰ ਤਿੰਨ ਵਾਰੀ ਭੇਜੋ: 0 → 000, 1 → 111। ਰਿਸੀਵਰ majority vote ਵਰਤਦਾ ਹੈ।
- ਫਾਇਦਾ: ਹਰ ਤਿੰਨ ਦੇ ਗਰੁੱਪ ਵਿੱਚ ਇੱਕ ਫਲਿੱਪ ਨੂੰ ਠੀਕ ਕਰ ਸਕਦਾ ਹੈ।
- ਹੱਦ: ਬਹੁਤ ਅਣੁਪਯੋਗ—ਡੇਟਾ ਤਿੰਨ ਗੁਣਾ ਹੋ ਜਾਂਦਾ ਹੈ।
ਪਤਾ ਲਗਾਉਣਾ vs. ਸੁਧਾਰ (ਅਤੇ ਤੁਸੀਂ ਕਦੋਂ ਹਰ ਇਕ ਵਰਤਦੇ ਹੋ)
Error detection ਦਾ ਜਵਾਬ ਹੁੰਦਾ ਹੈ: "ਕੁਝ ਗਲਤ ਹੋਇਆ?" ਜਦੋਂ retries ਸਸਤੇ ਹੁੰਦੇ ਹਨ—ਜਿਵੇਂ ਨੈੱਟਵਰਕ ਪੈਕੇਟ—ਤਦ ਇਹ ਆਮ ਹੁੰਦਾ ਹੈ।
Error correction ਦਾ ਜਵਾਬ ਹੁੰਦਾ ਹੈ: "ਮੂਲ ਬਿੱਟ ਕੀ ਸੀ?" ਜਦੋਂ retries ਮਹਿੰਗੇ ਜਾਂ ਅਸੰਭਵ ਹੁੰਦੇ ਹਨ—ਜਿਵੇਂ streaming ਆਡੀਓ noisy link 'ਤੇ, deep-space communication, ਜਾਂ ਸਟੋਰੇਜ਼ ਜਿੱਥੇ ਦੁਬਾਰਾ ਪੜ੍ਹਨਾ ਵੀ ਗਲਤੀਆਂ ਦੇ ਸਕਦਾ ਹੈ—ਤਦ ਇਹ ਵਰਤੀ ਜਾਂਦੀ ਹੈ।
Redundancy ਵੇਖਣ ਵਿੱਚ ਵਿਅਰਥ ਲੱਗਦੀ ਹੈ, ਪਰ ਇਹੀ ਕਾਰਨ ਹੈ ਕਿ ਆਧੁਨਿਕ ਸਿਸਟਮ ਖ਼ਰਾਬ ਹਾਰਡਵੇਅਰ ਅਤੇ ਸ਼ੋਰ ਵਾਲੇ ਚੈਨਲਾਂ ਦੇ ਬਾਵਜੂਦ ਤੇਜ਼ ਅਤੇ ਭਰੋਸੇਯੋਗ ਹੋ ਸਕਦੇ ਹਨ।
ਚੈਨਲ ਸਮਰੱਥਾ ਅਤੇ Shannon ਸੀਮਾ (ਭਾਰੀ ਗਣਿਤ ਤੋਂ ਬਿਨਾਂ)
ਜਦ ਤੁਸੀਂ ਹਕੀਕਤੀ ਚੈਨਲ 'ਤੇ ਡੇਟਾ ਭੇਜਦੇ ਹੋ—Wi‑Fi, ਸੈੱਲੁਲਰ, USB ਕੇਬਲ, ਇੱਥੋਂ ਤੱਕ ਕਿ ਇੱਕ ਹਾਰਡ ਡਰਾਈਵ—ਸ਼ੋਰ ਅਤੇ ਹਸਤਖੇਪ ਬਿੱਟਾਂ ਨੂੰ ਫਲਿੱਪ ਕਰ ਸਕਦੇ ਹਨ ਜਾਂ ਚਿੰਨ੍ਹਾਂ ਨੂੰ ਧੁੰਦਲਾ ਕਰ ਸਕਦੇ ਹਨ। Shannon ਦਾ ਵੱਡਾ ਵਾਅਦਾ ਹੈ: ਭਰੋਸੇਯੋਗ ਸੰਚਾਰ ਸੰਭਵ ਹੈ, ਇਥੇ ਤੱਕ ਕਿ noisy ਚੈਨਲ ਵੀ ਵਿਕਰਾਲੀ ਦਰੀਆਂ ਰੱਖ ਕੇ, ਜੇ ਤੁਸੀਂ ਬਹੁਤ ਜਿਆਦਾ ਜਾਣਕਾਰੀ ਨਹੀਂ ਧੱਕਦੇ।
ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ ਚੈਨਲ ਸਮਰੱਥਾ
Channel capacity ਚੈਨਲ ਦੀ "ਗਤੀ ਸੀਮਾ" ਹੈ: ਉਹ ਵੱਧ ਤੋਂ ਵੱਧ ਦਰ (bits per second) ਜੋ ਤੁਸੀਂ ਭੇਜ ਸਕਦੇ ਹੋ ਇਸ ਨਾਲ ਕਿ errors ਨੂੰ ਲਗਭਗ-ਨੂੰਨਾਂ ਤੱਕ ਘਟਾਇਆ ਜਾ ਸਕੇ, ਚੈਨਲ ਦੇ ਸ਼ੋਰ ਲੈਵਲ ਅਤੇ ਬੈਂਡਵਿਡਥ/ਪਾਵਰ ਵਰਗੀਆਂ ਪਾਬੰਦੀਆਂ ਦੇ ਮੱਦੇਨਜ਼ਰ।
ਇਹ ਕੱਚੇ symbol rate (ਤੁਸੀਂ ਸਿਗਨਲ ਕਿਵੇਂ ਤੇਜ਼ੀ ਨਾਲ ਟੌਗਲ ਕਰਦੇ ਹੋ) ਦੇ ਬਰਾਬਰ ਨਹੀਂ ਹੈ। ਇਹ ਇਸ ਬਾਰੇ ਹੈ ਕਿ ਸ਼ੋਰ ਦੇ ਬਾਅਦ ਕਿੰਨੀ ਮਾਇਨੇਦਾਰ ਜਾਣਕਾਰੀ ਬਚਦੀ ਹੈ—ਜਦ ਤੁਸੀਂ ਸਮਾਰਟ ਐਨਕੋਡਿੰਗ, redundancy, ਅਤੇ ਡਿਕੋਡਿੰਗ ਸ਼ਾਮਲ ਕਰਦੇ ਹੋ।
Shannon limit: ਅੰਜਨੀਆਂ ਦੇਖਣ ਵਾਲੀ ਸੀਮਾ
Shannon limit ਉਹ ਅਮਲੀ ਨਾਮ ਹੈ ਜੋ ਲੋਕ ਇਸ ਬੰਧਨ ਨੂੰ ਦਿੰਦੇ ਹਨ: ਇਸ ਤੋਂ ਹੇਠਾਂ ਤੁਹਾਨੂੰ ਚਾਹੀਦਾ ਹੈ ਕਿ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ, ਤੁਸੀਂ ਸੰਚਾਰ ਨੂੰ ਜਿੰਨਾ ਚਾਹੋ ਭਰੋਸੇਯੋਗ ਬਣਾ ਸਕਦੇ ਹੋ; ਇਸ ਤੋਂ ਉੱਪਰ, ਤੁਸੀਂ ਨਹੀਂ ਕਰ ਸਕਦੇ—ਗਲਤੀਆਂ ਕਿਸੇ ਵੀ ਡਿਜ਼ਾਈਨ ਨਾਲ ਰੁਕਦੀਆਂ ਨਹੀਂ।
ਇੰਜੀਨੀਅਰ ਇਸ ਸੀਮਾ ਦੇ ਨੇੜੇ ਪਹੁੰਚਣ ਲਈ modulation ਅਤੇ error-correcting ਕੋਡਾਂ ਨਾਲ ਬਹੁਤ ਮਹਿਨਤ ਕਰਦੇ ਹਨ। ਆਧੁਨਿਕ ਸਿਸਟਮ ਜਿਵੇਂ LTE/5G ਅਤੇ Wi‑Fi ਪ੍ਰਗਟਕੋਡਿੰਗ ਵਰਤਦੇ ਹਨ ਤਾਂ ਕਿ ਉਹ ਇਸ ਹੱਦ ਦੇ ਨੇੜੇ ਕੰਮ ਕਰ ਸਕਣ ਨਾ ਕਿ ਬਹੁਤ ਸਿਗਨਲ ਪਾਵਰ ਜਾਂ ਬੈਂਡਵਿਡਥ ਖ਼ਰਚਾਂ।
ਮੁੱਖ ਟਰੇਡਆਫ਼ (ਰੇਟ vs. error probability)
ਇਸਨੂੰ ਇੱਕ ਹਿਲਦੇ-ਡੁੱਲਦੇ ਰਸਤੇ 'ਤੇ ਵਸਤੂਆਂ ਪੈਕ ਕਰਨ ਵਾਲੀ ਟਰੱਕ ਵਜੋਂ ਸੋਚੋ:
- ਬਹੁਤ ਤੰਗ ਪੈਕ ਕਰੋ (rate capacity ਤੋਂ ਉੱਪਰ), ਅਤੇ ਕੁਝ ਵਸਤੂਆਂ ਹਮੇਸ਼ਾਂ ਟੁੱਟਣਗੀਆਂ (nonzero error floor)।
- ਥੋੜ੍ਹੀ ਜਗ੍ਹਾ ਅਤੇ padding ਨਾਲ ਪੈਕ ਕਰੋ (rate capacity ਤੋਂ ਹੇਠਾਂ), ਅਤੇ ਤੁਸੀਂ ਟੁੱਟਣ ਬਹੁਤ ਹੀ ਘੱਟ ਕਰ ਸਕਦੇ ਹੋ—ਪਰ throughput ਘਟ ਜਾਂਦੀ ਹੈ ਜਾਂ redundancy ਵੱਧ ਜਾਦੀ ਹੈ।
Shannon ਨੇ ਕੋਈ ਇਕ "ਸਭ ਤੋਂ ਵਧੀਆ ਕੋਡ" ਨਹੀਂ ਦਿੱਤਾ, ਪਰ ਉਸਨੇ ਸਬੂਤ ਦਿੱਤਾ ਕਿ ਸੀਮਾ ਮੌਜੂਦ ਹੈ—ਅਤੇ ਇਸਦੇ ਨੇੜੇ ਜਾਣ ਲਈ ਮਹਨਤ ਕਰਨੀ ਲਾਇਕ ਹੈ।
ਅਸਲ ਸਿਸਟਮਾਂ ਵਿੱਚ Error-Correcting Codes
Shannon ਦੀ noisy-channel theorem ਅਕਸਰ ਇਹ ਵਾਅਦਾ ਕਰਦੀ ਹੈ: ਜੇ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਇੱਕ ਚੈਨਲ ਦੀ ਸਮਰੱਥਾ ਤੋਂ ਘੱਟ ਦਰ 'ਤੇ ਭੇਜਦੇ ਹੋ, ਤਾਂ ਅਜਿਹੇ ਕੋਡ ਮੌਜੂਦ ਹਨ ਜੋ errors ਨੂੰ ਇੱਛਿਤ ਤੌਰ 'ਤੇ ਬਹੁਤ ਘੱਟ ਕਰ ਸਕਦੇ ਹਨ। ਅਸਲ ਇੰਜੀਨੀਅਰਿੰਗ ਇਸ "ਮੌਜੂਦਗੀ ਸਬੂਤ" ਨੂੰ ਅਮਲੀ ਸਕੀਮਾਂ ਵਿੱਚ ਬਦਲਣ ਬਾਰੇ ਹੈ ਜੋ ਚਿਪ, ਬੈਟਰੀ, ਅਤੇ ਡੈਡਲਾਈਨ ਵਿੱਚ ਫਿੱਟ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਪ੍ਰਯੋਗਿਕ ਟੂਲਕਿਟ: ਬਲਾਕ, interleaving, ਅਤੇ ਵਧੀਆ ਅਨੁਮਾਨ
ਜਿਆਦਾਤਰ ਵਾਸਤਵਿਕ ਸਿਸਟਮ block codes (ਇੱਕ ਚੁੰਕ ਬਿੱਟਾਂ ਦੀ ਰਕਿਅਤ) ਜਾਂ stream-oriented codes (ਲਗਾਤਾਰ ਲੜੀ ਦੀ ਰੱਖਿਆ) ਵਰਤਦੇ ਹਨ।
Block codes ਨਾਲ, ਤੁਸੀਂ ਹਰ ਬਲਾਕ ਵਿੱਚ ਨਿਆਪੂਰਨ redundancy ਜੋੜਦੇ ਹੋ ਤਾਂ ਕਿ ਰਿਸੀਵਰ ਗਲਤੀਆਂ ਪਛਾਣ ਅਤੇ ਠੀਕ ਕਰ ਸਕੇ। Interleaving ਨਾਲ ਤੁਸੀਂ ਭੇਜੇ ਗਏ ਬਿੱਟਾਂ/ਚਿੰਨ੍ਹਾਂ ਦੀ ਕ੍ਰਮ-ਵਿਨਯਾਸ ਨੂੰ ਦੁਬਾਰਾ ਰੱਖਦੇ ਹੋ ਤਾਂ ਜੋ ਸ਼ੋਰ ਦੇ ਇੱਕ ਬਰਸਟ (ਕਈ ਲਗਾਤਾਰ ਗਲਤੀਆਂ) ਨੂੰ ਕਈ ਬਲਾਕਾਂ ਵਿੱਚ ਫੈਲਾ ਦਿੱਤਾ ਜਾਵੇ—ਜੇਹੜਾ wireless ਅਤੇ ਸਟੋਰੇਜ ਲਈ ਬਹੁਤ ਜ਼ਰੂਰੀ ਹੈ।
ਹੋਰ ਵੱਡਾ ਫਰਕ ਇਹ ਹੈ ਕਿ ਰਿਸੀਵਰ "ਫੈਸਲਾ" ਕਿਵੇਂ ਕਰਦਾ ਹੈ:
- Hard decisions: ਹਰ ਪ੍ਰਾਪਤ ਸਿਗਨਲ ਨੂੰ ਤੁਰੰਤ 0 ਜਾਂ 1 ਬਣਾਇਆ ਜਾਂਦਾ ਹੈ।
- Soft decisions: ਰਿਸੀਵਰ confidence ਵੀ ਰੱਖਦਾ ਹੈ (ਜਿਵੇਂ "ਇਹ ਸੰਭਵਤ: 1 ਹੈ, ਪਰ ਮੈਂ ਪੱਕਾ ਨਹੀਂ ਹਾਂ").
Soft decisions decoder ਨੂੰ ਹੋਰ ਜਾਣਕਾਰੀ ਦਿੰਦੀਆਂ ਹਨ ਅਤੇ ਵਿਸ਼ੇਸ਼ਤੌਰ 'ਤੇ Wi‑Fi ਅਤੇ ਸੈੱਲੁਲਰ ਵਿੱਚ ਭਰੋਸੇਯੋਗਤਾ ਵਿੱਚ ਕਾਫੀ ਸੁਧਾਰ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਉਹ ਕੋਡ ਜਿਹੜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤੇ ਹਨ
- Reed–Solomon: ਸਿੰਬਲਾਂ 'ਤੇ ਕੰਮ ਕਰਦੇ ਹਨ (ਬਿੱਟਾਂ 'ਤੇ ਨਹੀਂ) ਅਤੇ bursts ਦੇ ਖ਼ਿਲਾਫ਼ ਉੱਤਮ ਹਨ। ਇਹ QR codes, CD/DVD, ਅਤੇ ਕੁਝ ਪ੍ਰਸਾਰਣ/ਸਟੋਰੇਜ ਸਿਸਟਮਾਂ ਵਿੱਚ ਵਰਤੇ ਜਾਂਦੇ ਹਨ।
- Convolutional ਕੋਡ: ਲਗਾਤਾਰ ਸਟ੍ਰੀਮ ਲਈ ਕਲਾਸਿਕ ਚੋਣ; ਇਤਿਹਾਸਕ ਤੌਰ 'ਤੇ satellite links ਵਿੱਚ ਆਮ।
- Turbo ਕੋਡ: 1990s ਵਿੱਚ ਇੱਕ ਵੱਡਾ ਉੱਪਰਾਲ, ਜੋ 3G/4G ਵਿੱਚ ਵਿਸ਼ਾਲ ਰੂਪ ਵਿੱਚ ਵਰਤੇ ਗਏ।
- LDPC (Low-Density Parity-Check) ਕੋਡ: ਆਧੁਨਿਕ ਹਾਈ-ਕੁਸ਼ਲਤਾ ਵਾਲੇ ਬਲਾਕ ਕੋਡ, Wi‑Fi, 5G, ਅਤੇ ਨਾਣੇ-ਹਾਈ-ਥਰੂਪੁੱਟ ਸਿਸਟਮਾਂ ਵਿੱਚ ਵਰਤੋਂ ਵਿੱਚ।
ਇਹ ਕਿੱਥੇ ਮਹੱਤਵ ਰੱਖਦੇ ਹਨ
Deep-space communication ਤੋਂ ਲੈ ਕੇ ਉਪਗ੍ਰਹਿ, Wi‑Fi, ਅਤੇ 5G ਤੱਕ, error-correcting codes Shannon ਦੇ ਸਿਧਾਂਤ ਅਤੇ noisy ਚੈਨਲ ਦੀ ਹਕੀਕਤ ਦੇ ਵਿਚਕਾਰ ਅਮਲੀ ਪੁਲ ਹਨ—ਇਨਸਾਨਾਂ ਤੋਂ ਵੱਧ ਬਿੱਟ ਅਤੇ ਗਣਨਾ ਦੇ ਵਚਨ ਦੇ ਬਦਲੇ ਘੱਟ ਡ੍ਰਾਪਡ ਕਾਲਾਂ, ਤੇਜ਼ ਡਾਊਨਲੋਡ, ਅਤੇ ਹੋਰ ਭਰੋਸੇਯੋਗ ਲਿੰਕ ਪ੍ਰਾਪਤ ਕਰਨ ਲਈ।
ਨੈਟਵਰਕ ਭਰੋਸੇਯੋਗਤਾ: ਪੈਕਟ, retries, ਅਤੇ throughput
ਇੰਟਰਨੈੱਟ ਕੰਮ ਕਰਦਾ ਹੈ ਭਾਵੇਂ ਕਿ ਹਰ ਇੱਕ ਲਿੰਕ ਪਰਫੈਕਟ ਨਾ ਹੋਵੇ। Wi‑Fi fade ਹੁੰਦੀ ਹੈ, ਮੋਬਾਈਲ ਸਿਗਨਲ ਰੁਕ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਤਾਰਾਂ ਅਤੇ ਫਾਇਬਰ ਵੀ ਸ਼ੋਰ ਅਤੇ ਕਈ ਵਾਰ ਗਲਤੀਆਂ ਭੁਗਤਦੇ ਹਨ। Shannon ਦਾ ਮੁੱਖ ਸੁਨੇਹਾ—ਸ਼ੋਰ ਅਣਿਵਾਰਯ ਹੈ, ਪਰ ਭਰੋਸੇਯੋਗਤਾ ਹਾਸਲ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ—ਨੈਟਵਰਕਿੰਗ ਵਿੱਚ error detection/correction ਅਤੇ retransmission ਦੇ ਮਿਲੇ-ਜੁਲੇ ਯੂਜ਼ ਦੀ ਰਚਨਾ ਵਜੋਂ ਉਭਰਦਾ ਹੈ।
ਪੈਕਟ: ਇਕ ਵੱਡੇ ਜੋਖਮ ਦੀ ਬਜਾਏ ਛੋਟੇ ਦਾਅਵ
ਡਾਟਾ ਨੂੰ ਪੈਕਟਾਂ ਵਿੱਚ ਵੰਡਿਆ ਜਾਂਦਾ ਹੈ ਤਾਂ ਕਿ ਨੈੱਟਵਰਕ ਮੁਸ਼ਕਲ ਘੜੀਆਂ ਤੋਂ ਰਾਹ ਲੱਭ ਸਕੇ ਅਤੇ ਖੋਹ-ਪੋਹ ਤੋਂ ਬਿਨਾਂ ਬਹਾਲ ਹੋ ਸਕੇ। ਹਰ ਪੈਕਟ ਵਿੱਚ ਵਾਧੂ ਬਿੱਟ (headers ਅਤੇ checks) ਹੁੰਦੇ ਹਨ ਜੋ ਰਿਸੀਵਰ ਨੂੰ ਫੈਸਲਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ ਕਿ ਜੋ ਆਇਆ ਉਹ ਭਰੋਸੇਯੋਗ ਹੈ ਜਾਂ ਨਹੀਂ।
ARAQ (Automatic Repeat reQuest) ਇੱਕ ਆਮ ਪੈਟਰਨ ਹੈ:
- ਰਿਸੀਵਰ ਪੈਕਟ ਦੀ ਜਾਂਚ ਕਰਦਾ ਹੈ (ਆਮ ਤੌਰ 'ਤੇ checksum/CRC)।
- ਜੇ ਠੀਕ ਲੱਗੇ ਤਾਂ ਉਹ acknowledgment (ACK) ਭੇਜਦਾ ਹੈ।
- ਜੇ ਇਹ ਗੁੰਮ ਜਾਂ ਖਰਾਬ ਹੋਵੇ, ਤਾਂ ਭੇਜਣ ਵਾਲਾ timeout ਤੋਂ ਬਾਅਦ ਦੁਬਾਰਾ ਭੇਜਦਾ ਹੈ (ਜਾਂ negative acknowledgment ਤੇ)।
ਠੀਕ ਕਰਨਾ vs. ਦੁਬਾਰਾ ਭੇਜਣਾ: latency ਟਰੇਡਆਫ਼
ਜਦੋਂ ਇਕ ਪੈਕਟ ਗਲਤ ਆਉਂਦਾ ਹੈ, ਤੁਹਾਡੇ ਕੋਲ ਮੁੱਖ ਤੌਰ 'ਤੇ ਦੋ ਚੋਣਾਂ ਹੁੰਦੀਆਂ ਹਨ:
- ਹੁਣੇ ਹੀ ਇਸਨੂੰ fixed ਕਰੋ ਵਰਤ ਕੇ forward error correction (FEC): ਐਨਾ redundancy ਦਿਓ ਕਿ ਰਿਸੀਵਰ ਬਿਨਾਂ ਦੁਬਾਰਾ ਭੇਜੇ ਕੁਝ ਗਲਤੀਆਂ ਸਿੱਧਾ ਠੀਕ ਕਰ ਸਕੇ।
- ARQ ਵਰਤੋ ਅਤੇ ਦੁਬਾਰਾ ਭੇਜੋ: ਸ਼ੁਰੂ ਵਿੱਚ ਘੱਟ redundancy ਭੇਜੋ, ਪਰ ਗਲਤ ਹੋਣ 'ਤੇ ਵਧੇਰੇ ਸਮਾਂ ਖਰਚ ਕਰੋ।
FEC ਉਨ੍ਹਾਂ ਲਿੰਕਾਂ 'ਤੇ latency ਘਟਾ ਸਕਦਾ ਹੈ ਜਿੱਥੇ retransmissions ਮਹਿੰਗੇ ਹਨ (ਉੱਚ latency, ਬਿਨਾ ਲਗਾਤਾਰ ਕਨੈਕਸ਼ਨ), ਜਦਕਿ ARQ ਉਹਨਾਂ ਸਮੇਂ ਪ੍ਰਭਾਵਸ਼ালী ਹੈ ਜਦੋਂ ਹਾਨੀਅਰ੍ਹਿੰਗ ਘੱਟ ਹੋਵੇ, ਕਿਉਂਕਿ ਤੁਸੀਂ ਹਰ ਪੈਕਟ 'ਤੇ ਭਾਰੀ redundancy ਨਹੀਂ ਜੋੜਦੇ।
throughput, congestion, ਅਤੇ ਕਿਉਂ ਭਰੋਸੇਯੋਗਤਾ ਮੁਫ਼ਤ ਨਹੀਂ ਹੁੰਦੀ
ਭਰੋਸੇਯੋਗਤਾ ਯੰਤ੍ਰਣ capacity ਖਪਤ ਕਰਦੇ ਹਨ: ਵਾਧੂ ਬਿੱਟ, ਵਾਧੂ ਪੈਕਟ, ਅਤੇ ਵਾਧੂ ਉਡੀਕ। Retransmissions ਲੋਡ ਵਧਾਉਂਦੀਆਂ ਹਨ, ਜੋ congestion ਨੂੰ ਬੁਝਾਉ ਸਕਦੀ ਹੈ; congestion ਫਿਰ delay ਅਤੇ loss ਵਧਾਉਂਦੀ ਹੈ, ਜੋ ਹੋਰ retries ਨੂੰ ਚੇਤੇ ਕਰਵਾਉਂਦੀ ਹੈ।
ਅਚਛੀ ਨੈਟਵਰਕ ਡਿਜ਼ਾਈਨ ਇਕ ਸਤੁਲਨ ਦੇ ਖੋਜ ਵਿੱਚ ਹੁੰਦੀ ਹੈ: ਕਾਫ਼ੀ ਭਰੋਸੇਯੋਗਤਾ ਤਾਂ ਜੋ ਡੇਟਾ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਦਿੱਤਾ ਜਾ ਸਕੇ, ਪਰ ਓਵਹੈੱਡ ਘੱਟ ਤਾਂ ਕਿ ਨੈੱਟਵਰਕ ਵੱਖ-ਵੱਖ ਹਾਲਤਾਂ ਵਿੱਚ ਸਿਹਤਮੰਦ throughput ਰੱਖ ਸਕੇ।
ਸੋਸਰ-ਤੋ-ਚੈਨਲ ਅੰਤ-ਤੱਕ ਡਿਜੀਟਲ ਸੰਚਾਰ
ਆਧੁਨਿਕ ਡਿਜੀਟਲ ਸਿਸਟਮਾਂ ਨੂੰ ਇੱਕ ਪਾਈਪਲਾਈਨ ਵਜੋਂ ਸਮਝਣਾ ਲਾਭਦਾਇਕ ਹੈ ਜਿਸਦੇ ਦੋ ਕੰਮ ਹਨ: ਸੁਨੇਹਾ ਛੋਟਾ ਬਣਾਉਣਾ ਅਤੇ ਸੁਨੇਹਾ ਯਾਤਰਾ ਬਚਣਾ। Shannon ਦੀ ਮੁੱਖ ਸੂਝ ਇਹ ਹੈ ਕਿ ਅਕਸਰ ਤੁਸੀਂ ਇਨ੍ਹਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਪਰਤਾਂ ਵਜੋਂ ਸੋਚ ਸਕਦੇ ਹੋ—ਹਾਲਾਂਕਿ ਅਸਲ ਉਤਪਾਦ ਕਈ ਵਾਰ ਇਹਨਾਂ ਨੂੰ ਮਿਲਾ ਦੇਂਦੇ ਹਨ।
ਕਦਮ 1: ਸੋਰਸ ਕੋਡਿੰਗ (ਕੰਪ੍ਰੈਸ਼ਨ)
ਤੁਸੀਂ ਇੱਕ "ਸੋਰਸ" ਨਾਲ ਸ਼ੁਰੂ ਕਰਦੇ ਹੋ: ਟੈਕਸਟ, ਆਡੀਓ, ਵੀਡੀਓ, ਸੈਂਸਰ ਰੀਡਿੰਗ। Source coding ਅਣਪੇਖੀ ਢਾਂਚਾ ਹਟਾਉਂਦੀ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਬੇਕਾਰ ਬਿੱਟਾਂ ਨੂੰ ਖਰਚ ਨਾ ਕਰੋ। ਉਹ ZIP ਫਾਇਲਾਂ ਲਈ ਹੋ ਸਕਦਾ ਹੈ, AAC/Opus ਆਡੀਓ ਲਈ, ਜਾਂ H.264/AV1 ਵੀਡੀਓ ਲਈ।
ਕੰਪ੍ਰੈਸ਼ਨ ਇੱਥੇ ਐਨਟਰਪੀ ਨੂੰ ਕਾਰਜਕਾਰੀ ਰੂਪ ਵਿੱਚ ਲਿਆਉਂਦੀ ਹੈ: ਜਿੰਨਾ ਅਨੁਮਾਨਯੋਗ ਸਮੱਗਰੀ, ਉਤਨੇ ਘੱਟ ਬਿੱਟਾਂ ਦੀ ਲੋੜ ਆਮ ਤੌਰ 'ਤੇ ਹੋਵੇਗੀ।
ਕਦਮ 2: ਚੈਨਲ ਕੋਡਿੰਗ (ਤ੍ਰੁੱਟੀ-ਸੁਧਾਰ)
ਫਿਰ ਕੰਪ੍ਰੈੱਸ ਕੀਤੇ ਬਿੱਟਾਂ ਨੂੰ ਇੱਕ noisy ਚੈਨਲ ਤੋਂ ਲੈ ਕੇ ਜਾਣਾ ਪੈਂਦਾ ਹੈ: Wi‑Fi, ਸੈੱਲੁਲਰ, ਫਾਇਬਰ, USB ਕੇਬਲ। Channel coding ਧਿਆਨ ਨਾਲ redundancy ਜੋੜਦੀ ਹੈ ਤਾਂ ਕਿ ਰਿਸੀਵਰ ਗਲਤੀਆਂ ਪਛਾਣ ਅਤੇ ਠੀਕ ਕਰ ਸਕੇ। ਇਹ CRCs, Reed–Solomon, LDPC, ਅਤੇ ਹੋਰ forward error correction (FEC) ਤਕਨੀਕਾਂ ਦੀ ਦੁਨੀਆਂ ਹੈ।
Shannon ਦੀ "ਪ੍ਰਿਥਕਤਾ" ਸੋਚ (ਇੱਕ ਲਾਭਦਾਇਕ ਮਨੋਦਰਸ਼ਨ)
Shannon ਨੇ ਦਿਖਾਇਆ ਕਿ ਸਿਧਾਂਤ ਵਿੱਚ ਤੁਸੀਂ source coding ਨੂੰ ਸਭ ਤੋਂ ਚੰਗੀ ਕੰਪ੍ਰੈਸ਼ਨ ਦੇ ਨੇੜੇ ਅਤੇ channel coding ਨੂੰ ਚੈਨਲ ਸਮਰੱਥਾ ਤੱਕ ਭਰੋਸੇਯੋਗਤਾ ਦੇ ਨੇੜੇ ਅਜ਼ਾਦੀ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕਰ ਸਕਦੇ ਹੋ—ਆਪਸ ਵਿੱਚ।
ਅਸਲ ਵਿੱਚ, ਇਹ ਪ੍ਰਿਥਕਤਾ ਇੱਕ ਚੰਗਾ ਤਰੀਕਾ ਹੈ ਡੀਬੱਗ ਕਰਨ ਲਈ: ਜੇ ਪ੍ਰਦਰਸ਼ਨ ਖਰਾਬ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਪੁੱਛ ਸਕਦੇ ਹੋ ਕਿ ਕੀ ਤੁਸੀਂ ਕੰਪ੍ਰੈਸ਼ਨ (source coding) ਵਿੱਚ ਕੁਝ ਗੁਆ ਰਹੇ ਹੋ, ਲਿੰਕ (channel coding) 'ਤੇ ਭਰੋਸੇਯੋਗਤਾ ਘਟ ਰਹੀ ਹੈ, ਜਾਂ retries ਅਤੇ buffering ਨਾਲ ਬਹੁਤਾ ਲੇਟੇੰਸ ਖਾ ਰਹੇ ਹੋ।
konkreਟ ਉਦਾਹਰਨ: Wi‑Fi 'ਤੇ ਵੀਡੀਓ streaming
ਜਦ ਤੁਸੀਂ ਵੀਡੀਓ stream ਕਰ ਰਹੇ ਹੋ, ਐਪ ਇੱਕ codec ਵਰਤ ਕੇ ਫਰੇਮਾਂ ਨੂੰ ਕੰਪ੍ਰੈੱਸ ਕਰਦਾ ਹੈ। Wi‑Fi 'ਤੇ, ਪੈਕਟ ਲੌਸਟ ਜਾਂ ਖਰਾਬ ਹੋ ਸਕਦੇ ਹਨ, ਇਸ ਲਈ ਸਿਸਟਮ error detection, ਕਦੇ-ਕਦੇ FEC, ਅਤੇ ਫਿਰ ਲੋੜ ਪੈਣ 'ਤੇ retries (ARQ) ਵਰਤਦਾ ਹੈ। ਜੇ ਕਨੈਕਸ਼ਨ ਮਾੜਾ ਹੋ ਜਾਂਦਾ ਹੈ, ਤਾਂ player ਘੱਟ bitrate ਸਟ੍ਰੀਮ 'ਤੇ ਸਵਿੱਚ ਕਰ ਸਕਦਾ ਹੈ।
ਅਸਲ ਸਿਸਟਮਾਂ separation ਨੂੰ ਮੁਹੱਈਆ ਕਰਦੇ ਹਨ ਪਰ ਜ਼ਿਆਦਾਤਰ ਵਾਰੀ ਸਮੇਂ ਦੀ ਲੋੜ ਕਾਰਨ ਇਨ੍ਹਾਂ ਨੂੰ ਮਿਲਾ ਦੇਂਦੇ ਹਨ: retries ਲਈ ਉਡੀਕ buffering ਦਾ ਕਾਰਨ ਬਣੇਗੀ, ਅਤੇ wireless ਹਾਲਤ ਤੇਜ਼ੀ ਨਾਲ ਬਦਲ ਸਕਦੀ ਹੈ। ਇਸੀ ਲਈ streaming stack ਕੰਪ੍ਰੈਸ਼ਨ ਚੋਣਾਂ, redundancy, ਅਤੇ adaptation ਨੂੰ ਇਕੱਠੇ ਮਿਲਾ ਕੇ ਚਲਾਉਂਦਾ ਹੈ—ਸਭ ਕੁਝ ਪੂਰਨ ਤੌਰ 'ਤੇ ਵੱਖ-ਵੱਖ ਨਹੀਂ, ਪਰ Shannon ਦੇ ਮਾਡਲ ਨਾਲ ਹੁਕਮਿਤ।
ਆਮ ਗਲਤਫਹਿਮੀਆਂ ਅਤੇ ਪ੍ਰਾਇਗਮਿਕ ਟਰੇਡਆਫ਼
ਸੂਚਨਾ ਸਿਧਾਂਤ ਬਹੁਤ ਵਾਰੀ ਉਲੇਖਤ ਹੁੰਦਾ ਹੈ, ਅਤੇ ਕੁਝ ਵਿਚਾਰ ਸਧਾਰਨਕਰਨ ਦੀ ਘਲਤੀਆਂ ਨਾਲ ਆਉਂਦੇ ਹਨ। ਹੇਠਾਂ ਕੁਝ ਆਮ ਗਲਤ ਫਹਿਮੀਆਂ ਦਿੱਤੀਆਂ ਹਨ—ਅਤੇ ਅਸਲ ਟਰੇਡਆਫ਼ ਜੋ ਇੰਜੀਨੀਅਰ ਬਣਾਉਂਦੇ ਹਨ ਜਦ ਸਿਸਟਮ ਤਿਆਰ ਕਰ ਰਹੇ ਹੁੰਦੇ ਹਨ।
ਗਲਤਫਹਮੀ 1: "ਐਨਟਰਪੀ ਦਾ ਅਰਥ randomness ਹੈ"
ਰੋਜ਼ਾਨਾ ਬੋਲਚਾਲ ਵਿੱਚ, "random" ਦਾ ਮਤਲਬ "ਗੁੰਝਲਦਾਰ" ਜਾਂ "ਅਣਪੇਖੀਤ" ਹੋ ਸਕਦਾ ਹੈ। Shannon ਐਨਟਰਪੀ ਥੋੜ੍ਹਾ ਨਿਰਾਲਾ ਹੈ: ਇਹ ਹੈਰਾਨੀ ਨੂੰ ਮਾਪਦਾ ਹੈ ਦਿੱਤੇ probability ਮਾਡਲ ਦੇ ਆਧਾਰ 'ਤੇ।
- ਪੂਰੀ ਤਰ੍ਹਾਂ predictable stream (ਜਿਵੇਂ ਸਾਰੇ zeros) ਵਿੱਚ ਘੱਟ ਐਨਟਰਪੀ ਹੁੰਦੀ ਹੈ।
- ਉਹ stream ਜੋ ਤੁਹਾਡੇ ਗਿਆਨ ਦੇ ਅਨੁਸਾਰ ਮੁਸ਼ਕਲ ਹੈ ਉਸਦੀ ਐਨਟਰਪੀ ਵੱਧ ਹੁੰਦੀ ਹੈ।
ਇਸ ਲਈ ਐਨਟਰਪੀ ਅਹਿਸਾਸ ਨਹੀਂ; ਇਹ assumptions ਬਾਰੇ ਸੰਖਿਆਤਮਕ ਨੰਬਰ ਹੁੰਦਾ ਹੈ।
ਗਲਤਫਹਮੀ 2: "ਹਮੇਸ਼ਾਂ ਵੱਧ ਕੰਪ੍ਰੈਸ਼ਨ ਚੰਗਾ ਹੈ"
ਕੰਪ੍ਰੈਸ਼ਨ redundancy ਨੂੰ ਹਟਾਉਂਦੀ ਹੈ। Error correction ਅਕਸਰ ਮੱਕਸਦ ਕਰਕੇ redundancy ਜੋੜਦਾ ਹੈ ਤਾਂ ਜੋ ਰਿਸੀਵਰ ਨੁਕਸਾਨ ਤੋਂ ਬਚ ਸਕੇ।
ਇਸ ਨਾਲ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਟਕਰਾਅ ਪੈਦਾ ਹੁੰਦਾ ਹੈ:
- ਜੇ ਤੁਸੀਂ ਜਿਆਦਾ ਅੱਗਰਸਿਵ ਤੌਰ 'ਤੇ compress ਕਰਦੇ ਹੋ ਅਤੇ ਫਿਰ noisy ਚੈਨਲ 'ਤੇ ਡੇਟਾ ਭੇਜਦੇ ਹੋ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ recovery ਲਈ ਘੱਟ "ਗੁਣਾ" ਰਹਿੰਦਾ ਹੈ।
- ਚੰਗੇ ਤਰੀਕੇ ਨਾਲ ਡਿਜ਼ਾਇਨ ਕੀਤੇ ਗਏ ਸਿਸਟਮ ਪਹਿਲਾਂ compress ਕਰਦੇ ਹਨ (ਅਣਪੇਖੀਤਾ ਹਟਾਉਂਦੇ) ਅਤੇ ਫਿਰ ਚੈਨਲ ਲਈ ਸੁਚੱਜੀ redundancy ਜੋੜਦੇ ਹਨ।
ਗਲਤਫਹਮੀ 3: "ਅਸੀਂ ਕਿਸੇ ਵੀ ਰਫ਼ਤਾਰ 'ਤੇ ਪੂਰੀ ਤਰ੍ਹਾਂ ਭਰੋਸੇਯੋਗ ਹੋ ਸਕਦੇ ਹਾਂ"
Shannon ਦੀ ਚੈਨਲ ਸਮਰੱਥਾ ਕਹਿੰਦੀ ਹੈ ਕਿ ਹਰ ਚੈਨਲ ਦੀ ਇੱਕ ਅਧਿਕਤਮ ਭਰੋਸੇਯੋਗ throughput ਮੁਕਰਰ ਹੈ ਦਿੱਤੀ ਸ਼ੋਰ ਹਾਲਤਾਂ ਵਿੱਚ। ਉਸ ਸੀਮਾ ਤੋਂ ਹੇਠਾਂ, ਸਹੀ ਕੋਡਿੰਗ ਨਾਲ error ਦਰ ਨੂੰ ਬਹੁਤ ਘੱਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ; ਉਸ ਤੋਂ ਉੱਪਰ, ਗਲਤੀਆਂ ਕਿਸੇ ਵੀ ਤਰਕ ਨਾਲ ਰੋਕਣਯੋਗ ਨਹੀਂ।
ਇਸ ਲਈ "ਕਿਸੇ ਵੀ ਰਫ਼ਤਾਰ 'ਤੇ ਪੂਰਨ ਭਰੋਸੇਯੋਗਤਾ" ਸੰਭਵ ਨਹੀਂ: ਰਫ਼ਤਾਰ ਵਧਾਉਣਾ ਅਕਸਰ ਮਤਲਬ ਹੈ ਉੱਚ error probability, ਜ਼ਿਆਦਾ ਲੇਟੇੰਸ (ਹੋਰ retransmissions), ਜਾਂ ਵਧੇਰੇ ਓਵਰਹੈੱਡ (ਮਜ਼ਬੂਤ ਕੋਡਿੰਗ)।
ਅਸਲ ਸਿਸਟਮਾਂ ਲਈ ਇੱਕ ਸੌਖਾ ਚੱਲਣ-ਯੋਗ ਚੈਕਲਿਸਟ
ਉਤਪਾਦ ਜਾਂ ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਅੰਕਲਨ ਕਰਦਿਆਂ ਪੁੱਛੋ:
- Source stats: ਡੇਟਾ ਅਨੁਮਾਨਯੋਗ ਹੈ (text, logs) ਜਾਂ ਪਹਿਲਾਂ ਹੀ ਲਗਭਗ random (encrypted, compressed)?
- Noise: ਕੀ ਇਸਨੂੰ ਖ਼ਰਾਬ ਕਰ ਸਕਦਾ ਹੈ—wireless ਹਸਤਖੇਪ, bit rot, packet loss?
- Latency budget: ਕੀ ਤੁਸੀਂ retries ਅਤੇ buffering ਬਰਦਾਸ਼ਤ ਕਰ ਸਕਦੇ ਹੋ, ਜਾਂ ਇਹ ਰੀਅਲ-ਟਾਈਮ ਹੋਣਾ ਲਾਜ਼ਮੀ ਹੈ?
- Overhead choice: ਕੀ ਤੁਸੀਂ bits ਖਪਤ ਸੇਵਿੰਗ, error correction, retransmissions, ਜਾਂ ਕੋਈ ਮਿਕਸ 'ਤੇ ਖਰਚ ਕਰ ਰਹੇ ਹੋ?
ਇਹਨਾਂ ਚਾਰਾਂ ਨੂੰ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਸੈਟ ਕਰਨਾ ਫਾਰਮੂਲ ਯਾਦ ਕਰਨ ਤੋਂ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੈ।
ਮੁੱਖ ਸਿੱਖਣਯੋਗ ਗੱਲਾਂ ਅਤੇ ਅੱਗੇ ਕਿੱਥੇ ਜਾਵੇਂ
Shannon ਦਾ ਮੁੱਖ ਸੁਨੇਹਾ ਇਹ ਹੈ ਕਿ ਸੂਚਨਾ ਨੂੰ ਮਾਪਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਬਚਾਇਆ ਜਾ ਸਕਦਾ ਹੈ, ਅਤੇ ਇੱਕ ਛੋਟੇ ਸੈਟ ਵਿਚਾਰਾਂ ਵਰਤ ਕੇ compress ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
- ਇੱਕ ਬਿਟ ਸਾਂਝੀ ਕਰੰਸੀ ਹੈ ਜੋ ਟੈਕਸਟ, ਆਡੀਓ, ਵੀਡੀਓ, ਅਤੇ ਸੈਂਸਰ ਡੇਟਾ ਨੂੰ ਇੱਕੋ ਰੂਪ 'ਤੇ ਚਿਕਿਤਸਾ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦੀ ਹੈ।
- ਐਨਟਰਪੀ ਮਾਪਦੀ ਹੈ ਕਿ ਇੱਕ ਸਰੋਤ ਕਿੰਨਾ ਅਣਪੇਖੀਤ ਹੈ, ਅਤੇ ਇਹ predict ਕਰਦੀ ਹੈ ਕਿ ਡੇਟਾ ਕਿੰਨਾ ਚੰਗਾ compress ਹੋ ਸਕਦਾ ਹੈ।
- ਸ਼ੋਰ ਅਤੇ ਨੁਕਸਾਨ ਅਣਿਵਾਰਯ ਹਨ, ਇਸਲਈ ਭਰੋਸੇਯੋਗ ਸਿਸਟਮ redundancy ਜੋੜਦੇ ਹਨ error detection ਅਤੇ error-correcting codes ਰਾਹੀਂ।
- ਚੈਨਲ ਸਮਰੱਥਾ ਇੱਕ ਅਸਲ ਛੱਤ ਵਜੋਂ ਕੰਮ ਕਰਦੀ ਹੈ: ਇੱਕ ਨਿਰਧਾਰਤ ਦਰ ਤੋਂ ਉੱਪਰ ਤੁਸੀਂ ਹੋਰ "ਕਠੋਰ" ਕੋਸ਼ਿਸ਼ਾਂ ਨਾਲ ਭੀ ਭਰੋਸੇਯੋਗ ਨਹੀਂ ਹੋ ਸਕਦੇ; ਤੁਹਾਨੂੰ ਰੇਟ ਘਟਾਉਣੀ ਪਏਗੀ, ਚੈਨਲ ਸੋਧਣਾ ਪਏਗਾ, ਜਾਂ ਕੋਡਿੰਗ ਬਦਲਣੀ ਪਏਗੀ।
ਆਧੁਨਿਕ ਨੈੱਟਵਰਕ ਅਤੇ ਸਟੋਰੇਜ ਸਿਸਟਮ ਮੁੱਢਲੀ ਤੌਰ 'ਤੇ rate, ਭਰੋਸੇਯੋਗਤਾ, ਲੇਟੇੰਸ, ਅਤੇ ਗਣਨਾ ਦੇ ਤਰਲ-ਟਰੇਡਆਫ਼ ਹਨ।
ਨਿਰਮਾਤਾਵਾਂ ਲਈ ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਨੋਟ
ਜੇ ਤੁਸੀਂ ਅਸਲ ਉਤਪਾਦ—APIs, streaming ਫੀਚਰ, ਮੋਬਾਈਲ ਐਪਸ, telemetry ਪਾਈਪਲਾਈਨਾਂ—ਬਣਾ ਰਹੇ ਹੋ, ਤਾਂ Shannon ਦਾ ਫਰੇਮਵਰਕ ਇੱਕ ਉਪਯੋਗੀ ਡਿਜ਼ਾਈਨ ਚੈਕਲਿਸਟ ਹੈ: ਜੋ compress ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਉਸਨੂੰ compress ਕਰੋ; ਜੋ ਜ਼ਰੂਰੀ ਹੈ ਉਸਨੂੰ ਸੁਰੱਖਿਅਤ ਕਰੋ; ਅਤੇ latency/throughput ਬਜਟ ਬਾਰੇ ਸਪਸ਼ਟ ਰਹੋ। ਇੱਕ ਤੁਰੰਤ ਦਰਸ਼ਨ ਇਹ ਹੈ ਕਿ ਜਦੋਂ ਤੁਸੀਂ end-to-end ਸਿਸਟਮ ਦਾ ਪ੍ਰੋਟੋਟਾਈਪ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਂਦੇ ਹੋ ਅਤੇ ਫਿਰ iteration ਕਰਦੇ ਹੋ: ਵਰਗਾ ਝੁਕਾਅ-ਕੋਡਿੰਗ ਪਲੇਟਫਾਰਮ Koder.ai, ਟੀਮਾਂ ਨੂੰ ਇੱਕ chat-driven spec ਤੋਂ React web app, Go backend ਨਾਲ PostgreSQL, ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ ਇੱਕ Flutter mobile client ਤੱਕ spin up ਕਰਨ ਦੀ ਆਸਾਨੀ ਦਿੰਦਾ ਹੈ, ਫਿਰ ਹਕੀਕਤੀ ਵਰਲ্ড ਟਰੇਡਆਫ਼ (payload size, retries, buffering behavior) ਨੂੰ ਜਲਦੀ ਟੈਸਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ। planning mode, snapshots, ਅਤੇ rollback ਵਰਗੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਨਾਲ ਤੁਸੀਂ "ਮਜ਼ਬੂਤ ਭਰੋਸੇਯੋਗਤਾ vs ਘੱਟ ਓਵਰਹੈਡ" ਬਦਲ ਵੇਖ ਕੇ ਦੋਹਰਾਉਣ ਕਰ ਸਕਦੇ ਹੋ ਬਿਨਾਂ ਰੁਕਾਵਟ ਦੇ।
ਕੌਣ ਅੱਗੇ ਖੋਜ ਕਰੇ
ਹੋਰ ਪੜ੍ਹਾਈ ਕਿਸੇ ਹੋਰ ਲਾਗਤ ਵਾਲੀ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਲਾਭਦਾਇਕ ਹੈ:
- ਵਿਦਿਆਰਥੀ ਜੋ probability ਨੂੰ ਕੰਪ੍ਰੈਸ਼ਨ ਅਤੇ ਕੋਡਿੰਗ ਨਾਲ ਜੋੜਨ ਵਾਲਾ ਸਾਫ਼ ਮਨੋ-ਮਾਡਲ ਚਾਹੁੰਦੇ ਹਨ
- ਪ੍ਰੋਡਕਟ ਮੈਨੇਜਰ ਜੋ ਕੁਆਲਿਟੀ, ਲੇਟੇੰਸ, ਬੈਂਡਵਿਡਥ, ਅਤੇ ਲਾਗਤ ਵਿੱਚ ਟਰੇਡਆਫ਼ ਬਣਾਉਂਦੇ ਹਨ
- ਇੰਜੀਨੀਆਂ ਜੋ ਨੈਟਵਰਕਿੰਗ, ਮੀਡੀਆ codecs, ਸਟੋਰੇਜ, telemetry, ਜਾਂ ML ਡੇਟਾ ਪਾਈਪਲਾਈਨਾਂ 'ਤੇ ਕੰਮ ਕਰ ਰਹੇ ਹਨ
ਅੱਗੇ ਵਧਣ ਲਈ, related explainers in /blog ਦੇਖੋ, ਫਿਰ /docs ਵਿੱਚ ਪਾਓ ਕਿ ਸਾਡਾ product ਸੰਚਾਰ ਅਤੇ ਕੰਪ੍ਰੈਸ਼ਨ-ਸੰਬੰਧੀ settings ਅਤੇ APIs ਕਿਵੇਂ ਦਿਖਾਉਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ plans ਜਾਂ throughput limits ਦੀ tulna ਕਰ ਰਹੇ ਹੋ, /pricing agla ਕਦਮ ਹੈ।
ਅਕਸਰ ਪੁੱਛੇ ਜਾਣ ਵਾਲੇ ਸਵਾਲ
Claude Shannon ਨੇ ਸਾਡੇ ਸੰਚਾਰ ਦੇ ਸੋਚਣ ਦੇ ਢੰਗ ਵਿੱਚ ਅਸਲ ਵਿੱਚ ਕੀ ਬਦਲਾਅ ਲਿਆਏ?
Shannon ਦਾ ਮੁੱਖ ਬਦਲਾਅ ਇਹ ਸੀ ਕਿ ਉਸਨੇ ਸੂਚਨਾ ਨੂੰ ਘਟਾਈ ਗਈ ਅਣਿਸ਼ਚਿਤਤਾ ਵਜੋਂ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ—ਮਤਲਬ ਕਿ ਇਹ ਮਾਇਨੇ ਜਾਂ ਮਹੱਤਤਾ ਨਹੀਂ, ਬਲਕਿ ਉਹ ਹੈ ਜੋ ਪਤਾ ਲਗਣ ਨਾਲ ਅਣਿਸ਼ਚਿਤਤਾ ਘਟਦੀ ਹੈ। ਇਸ ਤੋਂ ਇੰਜੀਨੀਅਰ ਉਹ ਸਿਸਟਮ ਡਿਜ਼ਾਈਨ ਕਰ ਸਕਦੇ ਹਨ ਜੋ:
- ਸੁਨੇਹਿਆਂ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਦਰਸਾਉਂਦੇ ਹਨ (ਕੰਪ੍ਰੈਸ਼ਨ)
- ਸ਼ੋਰ ਅਤੇ ਰੁਕਾਵਟ ਨੂੰ ਬਰਦਾਸ਼ਤ ਕਰਕੇ ਟਿਕਾਊ ਬਣਾਉਂਦੇ ਹਨ (error detection/correction)
- ਭੌਤਿਕ ਸੀਮਾਵਾਂ ਦਾ ਆਦਰ ਕਰਦੇ ਹਨ (channel capacity / the Shannon limit)
ਅਮਲੀ ਤੌਰ 'ਤੇ "ਬਿਟ" ਕੀ ਹੁੰਦਾ ਹੈ ਅਤੇ ਇਹ ਕਿਉਂ ਇੰਨਾ ਵਿਸ਼ਵਵਿਆਪੀ ਹੈ?
ਇੱਕ ਬਿਟ ਉਸ ਜਾਣਕਾਰੀ ਦੀ ਮਾਤਰਾ ਹੈ ਜੋ ਇੱਕ ਹਾਂ/ਨਹੀਂ ਅਣਿਸ਼ਚਿਤਤਾ ਨੂੰ ਸੁਲਝਾਉਣ ਲਈ ਲੋੜੀਂਦੀ ਹੁੰਦੀ ਹੈ। ਡਿਜੀਟਲ ਹਾਰਡਵੇਅਰ ਦੋ ਹਾਲਤਾਂ ਨੂੰ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਅਲੱਗ ਕਰ ਸਕਦਾ ਹੈ, ਇਸ ਲਈ ਕਈ ਕਿਸਮਾਂ ਦੇ ਡਾਟਾ ਨੂੰ ਲੰਮੇ 0 ਅਤੇ 1 ਦੀ ਲੜੀ ਵਿੱਚ ਬਦਲ ਕੇ ਇਕਸਾਰ ਰੂਪ ਵਿੱਚ ਸਟੋਰ ਅਤੇ ਭੇਜਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਐਨਟਰਪੀ ਕੀ ਹੈ, ਅਤੇ ਇਹ ਮੈਨੂੰ ਕੰਪ੍ਰੈਸ਼ਨ ਬਾਰੇ ਕੀ ਦੱਸਦੀ ਹੈ?
ਐਨਟਰਪੀ ਕਿਸੇ ਸਰੋਤ ਦੀ ਔਸਤ ਅਣਪੇਖੀਤਾ ਦਾ ਮਾਪ ਹੈ। ਇਹ ਕੰਪ੍ਰੈਸ਼ਨ ਲਈ ਇਹ ਦੱਸਦਾ ਹੈ ਕਿ ਕਿੰਨਾ ਘਟਾਇਆ ਜਾ ਸਕਦਾ ਹੈ:
- ਘੱਟ ਐਨਟਰਪੀ (ਪੂਰੇ ਤਰ੍ਹਾਂ ਅਣਪੇਖੀਤ): ਆਮ ਤੌਰ 'ਤੇ ਚੰਗੀ ਤਰ੍ਹਾਂ compress ਹੋ ਜਾਂਦਾ ਹੈ।
- ਉੱਚ ਐਨਟਰਪੀ (ਜਰਦੀ-ਹਾਲਤ-ਨੁਮਾ ਡਾਟਾ): ਘੱਟ ਕਮ ਕਰਨ ਦੀ ਜਗ੍ਹਾ ਹੁੰਦੀ ਹੈ।
ਐਨਟਰਪੀ ਕਿਸੇ ਕੰਪ੍ਰੈੱਸਰ ਨਹੀਂ ਹੈ; ਇਹ ਇੱਕ ਮਿਆਰੀ ਹੈ ਜੋ ਦਰਸਾਉਂਦਾ ਹੈ ਕਿ ਔਸਤ ਤੇ ਕੀ ਸੰਭਵ ਹੈ।
ਕਿਉਂ ਕੁਝ ਫਾਇਲਾਂ ਬਹੁਤ ਕੰਪ੍ਰੈਸ ਹੁੰਦੀਆਂ ਹਨ ਅਤੇ ਕੁਝ ਥੋੜ੍ਹੀਆਂ?
ਕੰਪ੍ਰੈਸ਼ਨ ਆਕਾਰ ਘਟਾਉਂਦੀ ਹੈ ਜਿਸ ਨਾਲ ਪੈਟਰਨ ਅਤੇ ਅਸਮਾਨ ਆਵਿਰਤੀ ਦਾ ਫਾਇਦਾ ਲੈ ਕੇ ਡੇਟਾ ਨੂੰ ਘੱਟ ਬਿੱਟਾਂ 'ਚ ਦਰਸਾਇਆ ਜਾਂਦਾ ਹੈ।
- ਜੇ ਕੁਝ ਚੀਜ਼ਾਂ ਬਹੁਤ ਵਾਰੀ ਆਉਂਦੀਆਂ ਹਨ ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਛੋਟੇ ਪ੍ਰਤੀਨਿਧੀ ਬਿਟ ਪੈਟਰਨ ਦਿੱਤੇ ਜਾ ਸਕਦੇ ਹਨ।
- ਜੇ substrings ਵਾਰ-ਵਾਰ ਆਉਂਦੀਆਂ ਹਨ ਤਾਂ ਉਹਨਾਂ ਨੂੰ ਰੈਫਰੰਸ ਨਾਲ ਬਦਲਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਇਸ ਲਈ text, logs, ਅਤੇ ਸਰਲ ਗ੍ਰਾਫਿਕਸ ਆਮ ਤੌਰ 'ਤੇ ਚੰਗੀਆਂ ਤਰ੍ਹਾਂ compress ਹੁੰਦੇ ਹਨ; encrypted ਜਾਂ ਪਹਿਲਾਂ ਤੋਂ compress ਕੀਤੇ ਡਾਟਾ ਅਕਸਰ ਬਹੁਤ ਘੱਟ ਘਟਦੇ ਹਨ।
Encoding, compression, ਅਤੇ encryption ਵਿੱਚ ਕੀ ਫਰਕ ਹੈ?
Encoding ਸਿਰਫ਼ ਡੇਟਾ ਨੂੰ ਇੱਕ ਚੁਣੀ ਹੋਈ ਰੂਪ ਵਿੱਚ ਬਦਲਣਾ ਹੈ (ਉਦਾਹਰਨ ਲਈ UTF‑8)।
Compression ਇੱਕ ਐਸੀ encoding ਹੈ ਜੋ ਅਸਮਾਨ ਆਵਿਰਤੀ ਨੂੰ ਵਰਤ ਕੇ ਔਸਤ ਬਿਟਾਂ ਦੀ ਗਿਣਤੀ ਘਟਾਉਂਦੀ ਹੈ।
Encryption ਡੇਟਾ ਨੂੰ ਇੱਕ কী ਨਾਲ ਗੁੰਝੀਲਾ ਕਰ ਦੇਂਦਾ ਹੈ ਤਾਂ ਕਿ ਬਾਹਰਲੇ ਲੋਕ ਪੜ੍ਹ ਨਾ ਸਕਣ; ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਡੇਟਾ ਨੂੰ “ਰੈਂਡਮ-ਨੁਮਾ” ਬਣਾਉਂਦਾ ਹੈ, ਜਿਸ ਨਾਲ compress ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੋ ਜਾਂਦਾ ਹੈ।
ਅਸੀਂ redundancy ਕਿਉਂ ਜੋੜਦੇ ਹਾਂ ਜਦੋਂ ਲਕਸ਼ ਹੈ ਕਿਫਾਇਤੀ ਹੋਣਾ?
ਕਿਉਂਕਿ ਹਕੀਕਤ ਵਿੱਚ ਚੈਨਲ ਅਤੇ ਸਟੋਰੇਜ ਪਰਫੈਕਟ ਨਹੀਂ ਹੁੰਦੇ। ਟੈਲੀਫੋਨੀ, Wi‑Fi ਸ਼ੋਰ, ਫਲੈਸ਼ ਮੈਮੋਰੀ ਦੀ ਘੱਸਾਟ ਆਦਿ ਕਾਰਨ 0 ਅਤੇ 1 ਕਦੇ-ਕਦੇ ਉਲਟ ਸਕਦੇ ਹਨ। ਇੰਜੀਨੀਅਰ redundancy ਜੋੜਦੇ ਹਨ ਤਾਂ ਜੋ ਰਿਸੀਵਰ:
- ਖਰਾਬੀ ਦਾ ਪਤਾ ਲਗਾ ਸਕੇ (ਉਦਾਹਰਨ: parity, CRC)
- ਕੁਝ ਗ਼ਲਤੀਆਂ ਨੂੰ ਬਿਨਾਂ ਦੁਬਾਰਾ ਭੇਜੇ ਠੀਕ ਕਰ ਸਕੇ (FEC ਕੋਡ)
ਇਹ “ਵਾਧੂ” ਡੇਟਾ ਭਰੋਸੇਮੰਦੀ ਨੂੰ ਖਰੀਦਦੇ ਹਨ।
error detection ਅਤੇ error correction ਵਿੱਚ ਕੀ ਅੰਤਰ ਹੈ, ਅਤੇ ਅਸੀਂ ਕਿਸ ਵੇਲੇ ਹਰ ਇਕ ਵਰਤਦੇ ਹਾਂ?
Error detection ਤੁਹਾਨੂੰ ਦੱਸਦੀ ਹੈ ਕਿ "ਕੁਝ ਗਲਤ ਹੋਇਆ ਹੈ" (ਜਦੋਂ retransmit ਸੰਭਵ ਹੋਵੇ)।
Error correction ਤੁਹਾਨੂੰ ਉਹ ਦੱਸਦੀ ਹੈ "ਅਸਲ ਡੇਟਾ ਕੀ ਸੀ" (ਜਦੋਂ retransmit ਮਹਿੰਗਾ ਜਾਂ ਅਸੰਭਵ ਹੋਵੇ)।
ਬਹੁਤ ਸਾਰੀਆਂ ਸਿਸਟਮ ਮਿਲਾ ਕੇ ਵਰਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ: ਪਹਿਲਾਂ detect ਕਰੋ, ਕੁਝ ਗਲਤੀਆਂ لوਕਲ طور 'ਤੇ correct ਕਰੋ, ਅਤੇ ਜਰੂਰਤ ਪੈਣ 'ਤੇ retransmit ਕਰੋ।
Channel capacity ਅਤੇ Shannon limit ਆਮ ਸ਼ਾਬਦਾਂ ਵਿੱਚ ਕੀ ਹਨ?
Channel capacity ਉਹ ਉੱਚਤਮ ਦਰ (bits/sec) ਹੈ ਜਿਸ 'ਤੇ ਤੁਸੀਂ noise ਦੀ ਦਿੱਤੀ ਸਤਰ ਅਤੇ bandwidth/power ਵਰਗੀਆਂ ਪਾਬੰਦੀਆਂ ਦੇ ਹੇਠਾਂ errors ਨੂੰ ਲਗਭਗ-ਨੂੰਨਾਂ (arbitrarily close to zero) ਤੱਕ ਘਟਾ ਸਕਦੇ ਹੋ।
Shannon limit ਇੱਕ ਅਮਲੀ “ਗਤੀ ਸੀਮਾ” ਹੈ: ਇਸ ਤੋਂ ਹੇਠਾਂ ਹੋ ਕੇ ਸੰਚਾਰ ਬਹੁਤ ਭਰੋਸੇਯੋਗ ਬਣਾਇਆ ਜਾ ਸਕਦਾ ਹੈ; ਇਸ ਤੋਂ ਉੱਪਰ ਕਿਸੇ ਵੀ ਤਰਕ ਨਾਲ errors ਲਾਜ਼ਮੀ ਹਨ।
ਜੇ packets ਗੁਮ ਜਾਂ ਖਰਾਬ ਹੋ ਜਾਂਦੇ ਹਨ ਤਾਂ ਇੰਟਰਨੈੱਟ ਕਿਵੇਂ ਭਰੋਸੇਯੋਗ ਰਹਿੰਦਾ ਹੈ?
ਨੈਟਵਰਕ ਡੇਟਾ ਨੂੰ ਛੋਟੇ-ਛੋਟੇ packets ਵਿੱਚ ਤੋੜਦੇ ਹਨ ਅਤੇ ਮਿਲੀ-ਗਈ ਵਿਧੀਆਂ ਵਰਤਦੇ ਹਨ:
- corrupted packets ਨੂੰ detect ਕਰਨ ਲਈ checksums/CRCs
- losses ਨੂੰ recover ਕਰਨ ਲਈ ACKs ਅਤੇ retransmissions (ARQ)
- ਜਦੋਂ latency ਮਹਿੰਗੀ ਹੋਵੇ ਤਾਂ ਕਦੇ-ਕਦੇ FEC ਵੀ ਵਰਤੇ ਜਾਂਦੇ ਹਨ
ਇਸ ਤਰ੍ਹਾਂ ਇੰਟਰਨੈੱਟ ਭਾਵੇਂ ਕਿ ਕੁਝ ਲਿੰਕ ਖ਼ਰਾਬ ਹੋ ਜਾਂਦੇ ਹਨ, ਫਿਰ ਵੀ ਭਰੋਸੇਯੋਗ ਬਣਿਆ ਰਹਿੰਦਾ ਹੈ।
Streaming ਐਪਸ buffering ਕਿਉਂ ਕਰਦੀਆਂ ਹਨ, ਅਤੇ ਇਹ Shannon ਦੇ ਵਿਚਾਰਾਂ ਨਾਲ ਕਿਵੇਂ ਜੁੜਿਆ ਹੈ?
ਕਿਉਂਕਿ ਤੁਸੀਂ ਰੇਟ, ਭਰੋਸੇਮੰਦੀ, ਲੇਟੇੰਸ, ਅਤੇ ਓਵਰਹੈੱਡ ਦੇ ਵਿਚਕਾਰ ਵਪਾਰ ਕਰ ਰਹੇ ਹੋ:
- ਵਧੀਆ ਕੁਆਲਿਟੀ (ਵੱਧ ਬਿੱਟ) ਵਧੇਰੇ bandwidth ਮੰਗਦੀ ਹੈ।
- ਜ਼ਿਆਦਾ ਸੁਰੱਖਿਆ (ਵਧੀਕ redundancy) ਗਲਤੀਆਂ ਘਟਾਉਂਦੀ ਹੈ ਪਰ throughput ਘਟਾਉਂਦੀ ਹੈ।
- Retries ਸਹੀਨੂੰ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ ਪਰ delay ਅਤੇ buffering ਵਧਾ ਸਕਦੇ ਹਨ।
ਇਸ ਲਈ streaming ਸਿਸਟਮ ਅਕਸਰ bitrate ਅਤੇ protection ਨੂੰ Wi‑Fi/cellular ਹਾਲਤਾਂ ਅਨੁਸਾਰ ਅਡਾਪਟ ਕਰਦੇ ਹਨ ਤਾਂ ਜੋ ਉਹ ਸਭ ਤੋਂ ਚੰਗੇ ਟਰੇਡਆਫ਼ 'ਤੇ ਰਹਿਣ।