08 ਜੁਲਾ 2025·8 ਮਿੰਟ
ਕ੍ਰਾਸ-ਟੀਮ ਨਿਰਭਰਤਾਵਾਂ ਦੀ ਟ੍ਰੈਕਿੰਗ ਲਈ ਵੈੱਬ ਐਪ ਕਿਵੇਂ ਬਣਾਈਏ
ਕ੍ਰਾਸ-ਟੀਮ ਨਿਰਭਰਤਾਵਾਂ ਦੀ ਟ੍ਰੈਕਿੰਗ ਲਈ ਵੈੱਬ ਐਪ ਯੋਜਨਾ ਅਤੇ ਬਣਾਉਣ ਸਿੱਖੋ: ਡੇਟਾ ਮਾਡਲ, UX, ਵਰਕਫਲੋ, ਅਲਰਟ, ਇੰਟੈਗ੍ਰੇਸ਼ਨ ਅਤੇ ਰੋਲਆਊਟ ਕਦਮ।
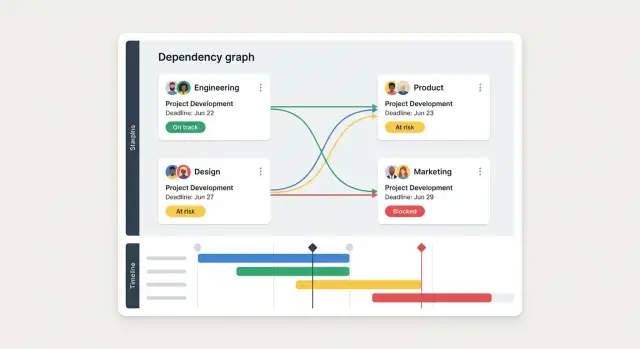
ਕ੍ਰਾਸ-ਟੀਮ ਨਿਰਭਰਤਾਵਾਂ ਦੀ ਟ੍ਰੈਕਿੰਗ ਲਈ ਵੈੱਬ ਐਪ ਯੋਜਨਾ ਅਤੇ ਬਣਾਉਣ ਸਿੱਖੋ: ਡੇਟਾ ਮਾਡਲ, UX, ਵਰਕਫਲੋ, ਅਲਰਟ, ਇੰਟੈਗ੍ਰੇਸ਼ਨ ਅਤੇ ਰੋਲਆਊਟ ਕਦਮ।
ਸਕ੍ਰੀਨਾਂ ਬਣਾਉਣ ਜਾਂ ਟੈਕ ਸਟੈਕ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਸਾਫ਼ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸੰਗਠਨ ਵਿੱਚ “dependency” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਜੇ ਲੋਕ ਇਹ ਸ਼ਬਦ ਹਰ ਚੀਜ਼ ਲਈ ਵਰਤਦੇ ਹਨ ਤਾਂ ਤੁਹਾਡੀ ਐਪ ਕੁਝ ਵੀ ਚੰਗੀ ਤਰ੍ਹਾਂ ਟ੍ਰੈਕ ਨਹੀ ਕਰੇਗੀ।
ਇੱਕ ਇੱਕ ਪੰੰਜੀ ਵਾਕ ਬਣਾਓ ਜੋ ਹਰ ਕੋਈ ਦੁਹਰਾ ਸਕੇ, ਫਿਰ ਯਹ ਲਿਖੋ ਕਿ ਕੀ ਅਰਜ਼ੀ ਦਿੰਦਾ ਹੈ। ਆਮ ਸ਼੍ਰੇਣੀਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹੋ ਸਕਦੀਆਂ ਹਨ:
ਇਹ ਵੀ ਲਿਖੋ ਕਿ ਕੀ ਨਹੀ dependency ਹੈ (ਉਦਾਹਰਨ ਲਈ, “ਹੋਰਨ ਘਟੀਆਂ ਸੁਧਾਰਾਂ”, ਆਮਖਤਰੇ ਜਾਂ ਅੰਦਰੂਨੀ ਕਾਰਜ ਜੋ ਦੂਜੀ ਟੀਮ ਨੂੰ ਰੋਕਦੇ ਨਹੀਂ)। ਇਹ ਪ੍ਰਣਾਲੀ ਨੂੰ ਸਾਫ਼ ਰੱਖਦਾ ਹੈ।
dependency ਟ੍ਰੈਕਿੰਗ ਅੱਸਫਲ ਹੋ ਜਾਂਦੀ ਜਦੋਂ ਇਹ ਸਿਰਫ PMs ਲਈ ਜਾਂ ਸਿਰਫ ਇੰਜੀਨੀਅਰਾਂ ਲਈ ਬਣਾਈ ਜਾਂਦੀ ਹੈ। ਆਪਣੀਆਂ ਪ੍ਰਮੁੱਖ ਯੂਜ਼ਰ ਕਿਸੇ 30 ਸਕਿੰਟ ਵਿੱਚ ਨਾਮਿਤ ਕਰੋ ਅਤੇ ਉਨ੍ਹਾਂ ਦੀਆਂ ਜਰੂਰਤਾਂ ਲਿਖੋ:
ਕੁਝ ਛੋਟੇ ਨਤੀਜੇ ਚੁਣੋ, ਜਿਵੇਂ:
ਜੋ ਸਮੱਸਿਆਵਾਂ ਤੁਹਾਡੀ ਐਪ ਦਿਨ-ਇੱਕ ਨੂੰ ਹੱਲ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ ਉਹ ਸੁਪਤ ਕਰੋ: ਜਰਾਖ਼ ਹੋਏ ਸਪ੍ਰੈਡਸ਼ੀਟ, ਅਸਪੱਸ਼ਟ ਮਾਲਕ, ਛੁੱਟੀਆਂ ਦੀਆਂ ਤਾਰੀਖਾਂ, ਲੁਕੇ ਹੋਏ ਖਤਰੇ, ਅਤੇ ਚੈਟ ਦੀਆਂ ਥ੍ਰੇਡਾਂ ਵਿੱਚ ਫੈਲੀ ਸਥਿਤੀ ਅੱਪਡੇਟਸ।
ਜਦੋਂ ਤੁਸੀਂ ਇਹ ਤੈਅ ਕਰ ਲੋ ਕਿ ਤੁਸੀਂ ਕੀ ਟ੍ਰੈਕ ਕਰ ਰਹੇ ਹੋ ਅਤੇ ਇਹ ਕਿਸ ਲਈ ਹੈ, ਤਾਂ ਸ਼ਬਦਾਵਲੀ ਅਤੇ ਲਾਇਫਸਾਇਕਲ ਨੂੰ ਲੌਕ ਕਰੋ। ਸਾਂਝੇ ਪਰਿਭਾਸ਼ਾਵਾਂ ਉਹ ਹਨ ਜੋ “ਟਿਕਟਾਂ ਦੀ ਸੂਚੀ” ਨੂੰ ਇੱਕ ਐਸੀ ਪ੍ਰਣਾਲੀ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜੋ ਰੋਕਾਵਟਾਂ ਘਟਾਵੇ।
ਉਹ ਛੋਟੀ ਜਿਹੀ ਕਿਸਮਾਂ ਚੁਣੋ ਜੋ ਜ਼ਿਆਦਾਤਰ ਹਾਲਤਾਂ ਨੂੰ ਕਵਰ ਕਰਦੀਆਂ ਹਨ ਅਤੇ ਹਰ ਕਿਸਮ ਨੂੰ ਪਛਾਣਣਾ ਆਸਾਨ ਰੱਖੋ:
ਲੱਖ ਇੱਕੋ ਜਿਹੇ ਰੂਪ: ਦੋ ਲੋਕ ਇੱਕੋ dependency ਨੂੰ ਇੱਕੋ ਤਰੀਕੇ ਨਾਲ ਵਰਗੀਕ੍ਰਿਤ ਕਰਨ।
ਇੱਕ dependency ਰਿਕਾਰਡ ਛੋਟਾ ਪਰ ਬਹੁਤ ਕੁਝ ਕਵਰ ਕਰਨ ਵਾਲਾ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ:
ਜੇ ਤੁਸੀਂ dependency ਬਣਾਉਣ ਦੇ ਸਮੇਂ owner team ਜਾਂ due date ਲਾਜ਼ਮੀ ਨਹੀਂ ਬਣਾਉਂਦੇ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ “ਚਿੰਤਾ ਟ੍ਰੈੱਕਰ” ਬਣਾ ਰਹੇ ਹੋ, ਨਾ ਕਿ ਕੋਆਰਡੀਨੇਸ਼ਨ ਟੂਲ।
ਇਕ ਸਧਾਰਣ ਸਟੇਟ ਮਾਡਲ ਵਰਤੋ ਜੋ ਟੀਮਾਂ ਦੇ ਅਸਲ ਕੰਮ ਨਾਲ ਮਿਲਦਾ ਜੁਲਦਾ ਹੋਵੇ:
Proposed → Accepted → In progress → Ready → Delivered/Closed, ਨਾਲ ਹੀ Rejected.
ਸਟੇਟ-ਚੇਂਜ ਨਿਯਮ ਲਿਖੋ। ਉਦਾਹਰਨ ਵਜੋਂ: “Accepted ਲਈ owner team ਅਤੇ ਸ਼ੁਰੂਆਤੀ ਟਾਰਗਟ ਤਾਰੀਖ ਲਾਜ਼ਮੀ ਹੈ,” ਜਾਂ “Ready ਲਈ ਸਬੂਤ ਲਾਜ਼ਮੀ ਹੈ।”
ਬੰਦ ਕਰਨ ਲਈ ਹੇਠਾਂ ਦਿੱਤੀਆਂ ਸਭ ਚੀਜ਼ਾਂ ਲਾਜ਼ਮੀ ਕਰੋ:
ਇਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਫਿਲਟਰਾਂ, ਰਿਮਾਈਂਡਰਾਂ, ਅਤੇ ਸਥਿਤੀ ਸਮੀਖਿਆਵਾਂ ਦੀ ਹੱਡੀ ਬਣ ਜਾਂਦੀਆਂ ਹਨ।
ਇੱਕ dependency ਟ੍ਰੈਕਰ ਦੀ ਸਫਲਤਾ ਇਸ ਗੱਲ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ ਕਿ ਲੋਕ ਟੂਲ ਨਾਲ ਲੜਤੋਂ ਬਿਨਾਂ ਹਕੀਕਤ ਨੂੰ ਵਰਣਨ ਕਰ ਸਕਣ। ਛੋਟੇ ਆਬਜੈਕਟ ਸੈੱਟ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਟੀਮਾਂ ਪਹਿਲਾਂ ਹੀ ਵਰਤਦੀਆਂ ਭਾਸ਼ਾ ਨਾਲ ਮਿਲਦੇ ਹਨ, ਫਿਰ ਠਹਿਰਾਅ ਲਿਓ ਜਿੱਥੇ ਢਾਂਚਾ ਗਲਤ ਫੈਸਲਿਆਂ ਤੋਂ ਬਚਾਂਦਾ ਹੈ।
ਕੁਝ ਮੁੱਖ ਰਿਕਾਰਡ ਵਰਤੋਂ:
ਹਰ ਐਜਕੇਸ ਲਈ ਵੱਖ-ਵੱਖ ਕਿਸਮਾਂ ਨਾ ਬਣਾਓ। ਸ਼ੁਰੂ ਵਿੱਚ ਕੁਝ ਫੀਲਡ ਜੋੜੋ (ਜਿਵੇਂ “type: data/API/approval”) ਨਾਲ ਮਾਡਲ ਨੂੰ ਵੰਡਣ ਦੀ ਬਜਾਏ।
Dependencies ਅਕਸਰ ਕਈ ਸਮੂਹਾਂ ਅਤੇ ਕਈ ਟਾਸਕਾਂ ਨਾਲ ਜੁੜੇ ਹੁੰਦੇ ਹਨ। ਇਸ ਨੂੰ ਸਪਸ਼ਟ ਮਾਡਲ ਕਰੋ:
ਇਸ ਨਾਲ “one dependency = one ticket” ਵਾਲੀ ਨਾਜ਼ੁਕ ਸੋਚ ਤੋਂ ਬਚਾਅ ਹੁੰਦਾ ਹੈ ਅਤੇ ਰੋਲ-ਅਪ ਰਿਪੋਰਟਿੰਗ ਸੰਭਵ ਹੁੰਦੀ ਹੈ।
ਹਰ ਮੁੱਖ ਆਬਜੈਕਟ ਵਿੱਚ ਆਡੀਟ ਫੀਲਡ ਹੋਣੀਆਂ ਚਾਹੀਦੀਆਂ ਹਨ:
ਹਰ dependency ਵਿੱਚ ਇੱਕ ਟੀਮ ਨਾ ਹੋਵੇ। ਇੱਕ Owner/Contact ਰਿਕਾਰਡ (ਨਾਂ, ਓਰੇਗਨਾਈਜ਼ੇਸ਼ਨ, ਈਮੇਲ/Slack, ਨੋਟ) ਜੋੜੋ ਅਤੇ dependencies ਨੂੰ ਇਸ ਦੀ طرف ਇਸ਼ਾਰਾ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿਓ। ਇਹ ਵੇਂਡਰ ਜਾਂ “ਹੋਰ ਵਿਭਾਗ” ਵਾਲੀਆਂ ਰੁਕਾਵਟਾਂ ਨੂੰ ਵਿਖਾਉਂਦਾ ਹੈ ਬਿਨਾਂ ਉਨ੍ਹਾਂ ਨੂੰ ਅੰਦਰੂਨੀ ਟੀਮ ਢਾਂਚੇ ਵਿੱਚ ਜ਼ਬਰਦਸਤੀ ਰੱਖਣ ਦੇ।
ਜੇ ਰੋਲ ਸਪਸ਼ਟ ਨਹੀਂ ਹਨ ਤਾਂ dependency tracking ਇੱਕ ਟਿੱਪਣੀ ਧਾਗੇ ਵਿੱਚ ਬਦਲ ਜਾਂਦੀ ਹੈ: ਹਰ ਕੋਈ ਸੋਚਦਾ ਹੈ ਕਿ ਕਿਸੇ ਹੋਰ ਨੇ ਜਵਾਬ ਦੇਣਾ ਹੈ, ਅਤੇ ਤਾਰੀਖਾਂ ਬਗੈਰ ਸੰਦਰਭ ਦੇ “ਸੰਤੁਲਿਤ” ਹੋ ਜਾਂਦੀਆਂ ਹਨ। ਇੱਕ ਸਪਸ਼ਟ ਰੋਲ ਮਾਡਲ ਐਪ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਣਾਉਂਦਾ ਅਤੇ ਐਸਕਲੇਸ਼ਨ ਨੂੰ ਪੇਸ਼ਗੋਈਯੋਗ ਬਣਾਉਂਦਾ ਹੈ।
ਚਾਰ ਰੋਜ਼ਾਨਾ ਰੋਲ ਅਤੇ ਇੱਕ ਪ੍ਰਸ਼ਾਸਕੀ ਰੋਲ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ:
Owner ਲਾਜ਼ਮੀ ਅਤੇ ਇਕਲ ਬਣਾਓ: ਇੱਕ dependency, ਇੱਕ accountable owner। ਤੁਸੀਂ ਫਿਰ ਵੀ collaborators (ਹੋਰ ਟੀਮਾਂ ਤੋਂ ਯੋਗਦਾਨਕਰਤਾ) ਸਹਾਇਤਾ ਦੇ ਸਕਦੇ ਹੋ, ਪਰ collaborators ਨੂੰ accountability ਦੀ ਥਾਂ ਨਹੀਂ ਰੱਖਣੀ ਚਾਹੀਦੀ।
ਜੇ Owner ਜਵਾਬ ਨਹੀਂ ਦਿੰਦਾ ਤਾਂ ਇੱਕ ਐਸਕਲੇਸ਼ਨ ਰਸਤਾ ਜੋੜੋ: ਪਹਿਲਾਂ Owner ਨੂੰ ਪਿੰਗ, ਫਿਰ ਉਸਦਾ ਮੈਨੇਜਰ (ਜਾਂ ਟੀਮ ਲੀਡ), ਫਿਰ ਇੱਕ ਪ੍ਰੋਗ੍ਰਾਮ/ਰਿਲੀਜ਼ ਮਾਲਕ — ਆਪਣੀ ਸੰਰਚਨਾ ਅਨੁਸਾਰ।
“ਡਿਟੇਲ ਸੋਧਣ” ਅਤੇ “ਵਚਨਬੱਧਤਾ ਬਦਲਣ” ਨੂੰ ਵੱਖ ਕਰੋ। ਇੱਕ ਵਿਆਵਹਾਰਿਕ ਡਿਫਾਲਟ:
ਜੇ ਤੁਸੀਂ private initiatives ਦਾ ਸਮਰਥਨ ਕਰਦੇ ਹੋ ਤਾਂ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕੌਣ ਉਹਨਾਂ ਨੂੰ ਦੇਖ ਸਕਦਾ ਹੈ (ਉਦਾਹਰਨ: ਸਿਰਫ ਸ਼ਾਮਲ ਟੀਮਾਂ + Admin)। “ਛੁਪੇ ਹੋਏ dependencies” ਤੋਂ ਬਚੋ ਜੋ ਡਿਲਿਵਰੀ ਟੀਮਾਂ ਨੂੰ ਹੈਰਾਨ ਕਰਦੇ ਹਨ।
ਜ਼ਿੰਮੇਵਾਰੀ ਨੂੰ ਨੀਤੀ ਦਸਤਾਵੇਜ਼ ਵਿੱਚ ਲੁਕਾਓ ਨਾ। ਹਰ dependency 'ਤੇ ਇਹ ਦਿਖਾਓ:
ਫਾਰਮ 'ਚ ਸਿੱਧਾ “Accountable vs Consulted” ਲੇਬਲ ਕਰਨਾ ਗਲਤ ਰਾਹ ਨੂੰ ਘਟਾਉਂਦਾ ਅਤੇ ਸਥਿਤੀ ਸਮੀਖਿਆਵਾਂ ਨੂੰ ਤੇਜ਼ ਕਰਦਾ ਹੈ।
ਇੱਕ dependency tracker ਸਿਰਫ਼ ਤਦ ਹੀ ਕੰਮ ਕਰਦਾ ਹੈ ਜਦੋਂ ਲੋਕ ਆਪਣੀਆਂ ਆਈਟਮਸ ਸੈਕਿੰਡਾਂ ਵਿੱਚ ਲੱਭ ਸਕਣ ਅਤੇ ਬਿਨਾਂ ਸੋਚੇ ਉਨ੍ਹਾਂ ਨੂੰ ਅਪਡੇਟ ਕਰ ਸਕਣ। ਡਿਜ਼ਾਇਨ ਉਹਨਾਂ ਸਵਾਲਾਂ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਕਰੋ: “ਮੈਂ ਕਿਸ ਨੂੰ ਰੋਕ ਰਿਹਾ ਹਾਂ?”, “ਕਿਹੜਾ ਮੈਨੂੰ ਰੋਕ ਰਿਹਾ ਹੈ?”, ਅਤੇ “ਕੀ ਕੋਈ ਚੀਜ਼ ਲੰਘਣ ਵਾਲੀ ਹੈ?”
ਛੋਟੀ ਪਰ ਪਯੋਗੀ ਦ੍ਰਿਸ਼ ਦੀ ਸ਼ੁਰੂਆਤ ਕਰੋ ਜੋ ਟੀਮਾਂ ਦੀ ਭਾਸ਼ਾ ਨਾਲ ਮਿਲਦੀ ਹੈ:
ਰੋਜ਼ਾਨਾ ਅਪਡੇਟਸ ਲਈ ਤੁਲਨਾਤਮਕ ਤੌਰ 'ਤੇ ਤੇਜ਼ ਬਣਾਉ:
ਰੰਗ + ਟੈਕਸਟ ਲੇਬਲ ਵਰਤੋਂ (ਕਦੇ ਵੀ ਸਿਰਫ਼ ਰੰਗ ਨਾ) ਅਤੇ ਸ਼ਬਦਾਵਲੀ ਨੂੰ ਇਕਸਾਰ ਰੱਖੋ। ਹਰ dependency 'ਤੇ ਇੱਕ ਉਜੱਗ “Last updated” ਟਾਈਮਸਟੈਪ ਜੋੜੋ, ਅਤੇ ਜਦੋਂ ਇਹ ਨਿਰਧਾਰਤ ਸਮੇਂ ਲਈ ਨਾ ਛੁਹਿਆ ਗਿਆ ਹੋਵੇ ਤਾਂ stale warning ਦਿਖਾਓ (ਉਦਾਹਰਨ: 7–14 ਦਿਨ)। ਇਹ ਹੌਲੀ-ਹੌਲੀ ਅਪਡੇਟ ਲਈ ਉਤਸ਼ਾਹਿਤ ਕਰਦਾ ਹੈ ਬਿਨਾਂ ਮੀਟਿੰਗਾਂ ਨੂੰ ਬਲੂ ਕਰਨ ਦੇ।
ਹਰ dependency ਕੋਲ ਇੱਕ ਸਿੰਗਲ ਥਰੈਡ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਜਿਸ ਵਿੱਚ:
ਜਦੋਂ ਡੀਟੇਲ ਪੰਨਾ ਪੂਰੀ ਕਹਾਣੀ ਦੱਸਦਾ ਹੈ, ਤਾਂ ਸਥਿਤੀ ਸਮੀਖਿਆਵਾਂ ਤੇਜ਼ ਹੋ ਜਾਂਦੀਆਂ ਹਨ—ਅਤੇ ਬਹੁਤ ਸਾਰੀਆਂ “ਤੁਰੰਤ ਮਿਲਣੀਆਂ” ਗਲਤਫਹਮੀ ਦੂਰ ਹੋ ਜਾਂਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਜਵਾਬ ਪਹਿਲਾਂ ਹੀ ਲਿਖਿਆ ਹੋਵੇ।
ਇੱਕ dependency tracker ਉਹ ਹਰਰੋਜ਼ ਦੀਆਂ ਕਾਰਵਾਈਆਂ 'ਤੇ ਸਫਲ ਜਾਂ ਅਸਫਲ ਹੁੰਦਾ ਹੈ ਜੋ ਉਹ ਸਹਾਇਤਾ ਕਰਦਾ ਹੈ। ਜੇ ਟੀਮ ਤੁਰੰਤ ਬੇਨਤੀ ਨਹੀਂ ਕਰ ਸਕਦੀਆਂ, ਸਾਫ਼ ਵਚਨਬੱਧਤਾ ਨਾਲ ਜਵਾਬ ਨਹੀਂ ਦਿੰਦੇ, ਅਤੇ ਸਬੂਤ ਦੇ ਕੇ ਲੂਪ ਬੰਦ ਨਹੀਂ ਕਰਦੇ, ਤਾਂ ਤੁਹਾਡੀ ਐਪ “FYI ਬੋਰਡ” ਬਣ ਜਾਵੇਗੀ ਨਾਕਿ ਕਾਰਜਕਾਰੀ ਟੂਲ।
ਇੱਕ single “Create request” ਫਲੋ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ ਪ੍ਰਦਾਨ ਕਰਨ ਵਾਲੀ ਟੀਮ ਤੋਂ ਕੀ ਡਿਲਿਵਰ ਕਰਨਾ ਹੈ, ਕਿਉਂ ਜਰੂਰੀ ਹੈ, ਅਤੇ ਕਦੋਂ ਲੋੜ ਹੈ, ਇਹ ਫ਼ਿਕਸ ਕਰੇ। ਇਸਨੂੰ ਸਟ੍ਰਕਚਰਡ ਰੱਖੋ: requested due date, acceptance criteria, ਅਤੇ ਸਬੰਧਤ epic/spec ਦਾ ਲਿੰਕ।
ਉਥੋਂ, ਇੱਕ ਸਪਸ਼ਟ ਰਿਸਪਾਂਸ ਸਟੇਟ ਲਾਜ਼ਮੀ ਕਰੋ:
ਇਸ ਨਾਲ ਸਭ ਤੋਂ ਆਮ ਨਾਕਾਮੀ ਨੂੰ ਬਚਾਇਆ ਜਾਂਦਾ ਹੈ: ਚੁੱਪ-ਚਾਪ “ਸ਼ਾਇਦ” dependencies ਜੋ ਠੀਕ ਲੱਗਦੀਆਂ ਹਨ ਪਰ ਬਾਅਦ ਵਿੱਚ ਫੱਟ ਜਾਂਦੀਆਂ ਹਨ।
ਵਰਕਫਲੋ ਵਿੱਚ ਹਲਕੇ-ਫੁਲਕੇ ਉਮੀਦਾਂ ਨਿਰਧਾਰਤ ਕਰੋ। ਉਦਾਹਰਨ:
ਲਕਸ਼ ਦਾ ਮਕਸਦ ਪਾਲਣਾ ਨਹੀਂ ਕਰਨਾ; ਇਹ ਹੈ ਕਿ ਵਚਨਬੱਧਤਾਵਾਂ ਹੁਣੇ-ਹੁਣੇ ਸਹੀ ਰਹਿਣ ਤਾਂ ਜੋ ਯੋਜਨਾ ਸਚੀ ਰਹੇ।
ਟੀਮਾਂ ਨੂੰ At risk ਸਥਿਤੀ ਸੈੱਟ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿਓ ਇੱਕ ਛੋਟੀ ਨੋਟ ਅਤੇ ਅਗਲੇ ਕਦਮ ਨਾਲ। ਜਦੋਂ ਕੋਈ due date ਜਾਂ status ਬਦਲਦਾ ਹੈ, ਤਾਂ ਇੱਕ ਕਾਰਨ ਲਾਜ਼ਮੀ ਕਰੋ (ਡ੍ਰੌਪਡਾਊਨ + ਖੁੱਲਾ ਟੈਕਸਟ)। ਇਹ ਇੱਕ ਆਡੀਟ ਟ੍ਰੇਲ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਰਿਟਰੋਸਪੈਕਟਿਵ ਅਤੇ ਐਸਕਲੇਸ਼ਨ ਨੂੰ ਤੱਥਪ੍ਰਧ ਬਣਾਉਂਦਾ ਹੈ, ਨਾ ਕਿ ਭਾਵਨਾਤਮਕ।
“Close” ਦਾ ਮਤਲਬ dependency ਪੂਰਾ ਹੋ ਗਿਆ। ਲਾਜ਼ਮੀ ਕਰੋ ਸਬੂਤ: ਮਰਜਡ PR, ਰਿਲੀਜ਼ਡ ਟਿਕਟ, ਦਸਤਾਵੇਜ਼, ਜਾਂ ਮਨਜ਼ੂਰੀ ਨੋਟ। ਜੇ ਕਲੋਜ਼ਰ ਅਸਪਸ਼ਟ ਹੈ, ਟੀਮ ਆਈਟਮਾਂ ਨੂੰ ਸ਼ੋਰ ਘਟਾਉਣ ਲਈ ਜਲਦੀ “ਹਰਾ” ਕਰ ਦੇਣਗੇ।
ਸਟੇਟਸ ਰਿਵਿਊਜ਼ ਦੌਰਾਨ ਬਲਕ ਅਪਡੇਟਸ ਦਾ ਸਮਰਥਨ ਕਰੋ: ਕਈ dependencies ਚੁਣੋ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਇੱਕੋ ਸਥਿਤੀ ਵਿੱਚ ਸੈੱਟ ਕਰੋ, ਇੱਕ ਸਾਂਝਾ ਨੋਟ ਜੋੜੋ (ਉਦਾਹਰਨ: “Q1 ਜ਼ਮੇਂ ਤੋਂ ਬਾਅਦ ਮੁੜ-ਯੋਜਿਤ”), ਜਾਂ ਅਪਡੇਟ ਮੰਗੋ। ਇਹ ਐਪ ਨੂੰ ਅਸਲ ਮੀਟਿੰਗਾਂ ਵਿੱਚ ਵਰਤਣ ਯੋਗ ਤੇਜ਼ ਰੱਖਦਾ ਹੈ, ਨਾਕਿ ਕੇਵਲ ਮੀਟਿੰਗਾਂ ਤੋਂ ਬਾਅਦ।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਡਿਲਿਵਰੀ ਦੀ ਰੱਖਿਆ ਕਰਨੇ ਚਾਹੀਦੀਆਂ ਹਨ, ਨਾ ਕਿ ਲੋਕਾਂ ਨੂੰ ਵਿਅਸਤ ਕਰਨ। ਹਰ ਕਿਸੇ ਨੂੰ ਹਰ ਚੀਜ਼ ਬਾਰੇ ਸੂਚਿਤ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰਨ ਦਾ ਆਸਾਨ ਤਰੀਕਾ ਹੈ। ਬਦਲੇ ਵਿੱਚ, ਸੂਚਨਾਵਾਂ ਨੂੰ ਫੈਸਲਾ-ਪੁਆਇੰਟਸ (ਕਿਸੇ ਨੂੰ ਕਾਰਵਾਈ ਦੀ ਲੋੜ) ਅਤੇ ਖਤਰੇ ਦੇ ਸੰਕੇਤ (ਕੁਝ ਡ੍ਰਿਫਟ ਕਰ ਰਿਹਾ ਹੈ) ਦੇ ਆਲੇ-ਦੁਆਲੇ ਡਿਜ਼ਾਈਨ ਕਰੋ।
ਪਹਿਲੀ ਕਿਰਤ ਵਿੱਚ ਉਹ ਘਟਨਾਵਾਂ ਰੱਖੋ ਜੋ ਯੋਜਨਾ ਬਦਲਦੀਆਂ ਹਨ ਜਾਂ ਸਪਸ਼ਟ ਜਵਾਬ ਦੀ ਲੋੜ ਹੈ:
ਹਰੇਕ ਟ੍ਰਿਗਰ ਦਾ ਅਗਲਾ ਕਦਮ ਸਪਸ਼ਟ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: accept/decline, ਨਵੀਂ ਤਾਰੀਖ ਪ੍ਰਸਤਾਵਿਤ ਕਰੋ, ਸੰਦਰਭ ਜੋੜੋ, ਜਾਂ ਐਸਕਲੇਟ ਕਰੋ।
ਡਿਫਾਲਟ ਨੂੰ in-app notifications 'ਤੇ ਰੱਖੋ (ਤਾਂ ਜੋ alerts dependency ਰਿਕਾਰਡ ਨਾਲ ਜੁੜੇ ਰਹਿਣ) ਅਤੇ ਜੋ ਵੀ ਤਤਕਾਲੀ ਹੋ ਉਸ ਲਈ ਈਮੇਲ।
ਔਪਸ਼ਨਲ ਚੈਟ ਇੰਟੈਗ੍ਰੇਸ਼ਨਾਂ—Slack ਜਾਂ Microsoft Teams—ਦਿਓ, ਪਰ ਉਨ੍ਹਾਂ ਨੂੰ ਸਿਸਟਮ ਆਫ਼ ਰਿਕਾਰਡ ਨਾ ਬਣਾਓ। ਚੈਟ ਸੁਨੇਹੇ ਆਈਟਮ ਨਾਲ ਡੀਪ-ਲിങ്ക ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ (ਉਦਾਹਰਨ, /dependencies/123) ਅਤੇ ਘੱਟੋ-ਘੱਟ ਸੰਦਰਭ ਸ਼ਾਮਲ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ: ਕਿਸ ਨੂੰ ਕਾਰਵਾਈ ਦੀ ਲੋੜ ਹੈ, ਕੀ ਬਦਲਿਆ, ਅਤੇ ਕਦੋਂ ਤੱਕ।
ਟੀਮ-ਲੈਵਲ ਅਤੇ ਯੂਜ਼ਰ-ਲੈਵਲ ਕੰਟਰੋਲ ਦਿਓ:
ਇਥੇ “watchers” ਮਾਮਲਾ ਮਹੱਤਵਪੂਰਣ ਹੈ: requester, owning team, ਅਤੇ ਖਾਸ ਸਟੀਕਹੋਲਡਰ ਨੋਟੀਫਾਈ ਕਰੋ—ਵਿਆਪਕ ਬਰਾਡਕਾਸਟਾਂ ਤੋਂ ਬਚੋ।
ਐਸਕਲੇਸ਼ਨ ਆਟੋਮੇਟਿਕ ਪਰ ਸੰਭਾਲ ਕੇ ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ: ਜਦੋਂ dependency overdue ਹੋਵੇ, ਜਦੋਂ due date बार-बार ਧਕਿਆ ਗਿਆ ਹੋਵੇ, ਜਾਂ ਜਦੋਂ blocked ਸਥਿਤੀ ਲਈ ਕੋਈ ਅਪਡੇਟ ਨ ਹੋਈ ਹੋਵੇ।
ਐਸਕਲੇਸ਼ਨਾਂ ਨੂੰ ਸਹੀ ਪੱਧਰ ਤੇ ਰਾਹੀਂ ਭੇਜੋ (ਟੀਮ ਲੀਡ, ਪ੍ਰੋਗ੍ਰਾਮ ਮੈਨੇਜਰ) ਅਤੇ ਇਤਿਹਾਸ ਸ਼ਾਮਲ ਕਰੋ ਤਾਂ ਕਿ ਪ੍ਰਾਪਤ ਕਰਨ ਵਾਲਾ ਵੇਰਵਾ ਜਾਣ ਕੇ ਤੇਜ਼ ਕਦਮ ਚੁੱਕ ਸਕੇ।
ਇੰਟੈਗ੍ਰੇਸ਼ਨਾਂ ਦਾ ਮਕਸਦ ਦੁਹਰਾਈ ਦਰਜ ਨਹੀਂ ਕਰਵਾਉਣਾ, ਬਲਕਿ ਕੰਫਿਗਰੇਸ਼ਨ ਓਵਰਹੈੱਡ ਨਾ ਵਧਾਉਣਾ ਹੈ। ਸਭ ਤੋਂ ਸੁਰੱਖਿਅਤ ਤਰੀਕਾ ਉਹ प्रणਾਲੀਆਂ ਚੁਣੋ ਜੋ ਟੀਮਾਂ ਪਹਿਲਾਂ ਹੀ ਭਰੋਸਾ ਕਰਦੀਆਂ ਹਨ (issue trackers, ਕੈਲੰਡਰ, ਅਤੇ ਆਈਡੈਂਟੀਟੀ), ਪਹਿਲਾਂ ਰੀਡ-ਓਨਲੀ ਜਾਂ ਇੱਕ-ਤਰੀਕੇ ਨਾਲ ਰੱਖੋ, ਫਿਰ ਵਧਾਓ ਜਦੋਂ ਲੋਕ ਇਸ ਤੇ ਨਿਰਭਰ ਹੋਣ।
ਇੱਕ ਪ੍ਰਾਥਮਿਕ ਟ੍ਰੈਕਰ (Jira, Linear, ਜਾਂ Azure DevOps) ਚੁਣੋ ਅਤੇ ਸਾਦਾ ਲਿੰਕ-ਪਹਿਲਾ ਫਲੋ ਸਹਾਇਤਾ ਦਿਓ:
PROJ-123).ਇਸ ਨਾਲ “ਦੋ ਸਰੋਤ ਸੱਚਾਈ ਦੇ” ਸਮੱਸਿਆ ਤੋਂ ਬਚਾਅ ਹੁੰਦਾ ਹੈ। ਬਾਅਦ ਵਿੱਚ, ਛੋਟੀ ਫੀਲਡ ਲਾਇਨ-ਵਿਭਿੰਨ (status, due date) ਲਈ ਵਿਕਲਪਿਕ ਦੋ-ਤਰਫ਼ਾ ਸਿੰਕ ਜੋੜੋ, ਸਪਸ਼ਟ ਸੰਘਰਸ਼ ਨਿਯਮਾਂ ਦੇ ਨਾਲ।
ਮਾਈਲਸਟੋਨ ਅਤੇ ਡੈਡਲਾਈਨ ਅਕਸਰ Google Calendar ਜਾਂ Microsoft Outlook ਵਿੱਚ ਮੈਨੇਜ ਹੁੰਦੇ ਹਨ। ਇਵੈਂਟਸ ਨੂੰ ਆਪਣੇ dependency timeline ਵਿੱਚ ਪੜ੍ਹਨਾ ਸ਼ੁਰੂ ਕਰੋ (ਉਦਾਹਰਨ, “Release Cutoff”, “UAT Window”) ਬਿਨਾਂ ਕੁਝ ਵਾਪਸ ਲਿਖੇ।
ਰੀਡ-ਓਨਲੀ ਕੈਲੰਡਰ ਸਿੰਕ ਟੀਮਾਂ ਨੂੰ ਜਿੱਥੇ ਪਹਿਲਾਂ ਹੀ ਯੋਜਨਾ ਬਣਾਉਂਦੀਆਂ ਹਨ ਉੱਥੇ ਬਣੇ ਰਹਿਣ ਦਿੰਦਾ ਹੈ, ਜਦਕਿ ਤੁਹਾਡੀ ਐਪ ਪ੍ਰਭਾਵ ਅਤੇ ਆਉਣ ਵਾਲੀਆਂ ਤਾਰੀਖਾਂ ਇੱਕ ਥਾਂ ਤੇ ਦਿਖਾਉਂਦੀ ਹੈ।
Single sign-on onboarding friction ਘਟਾਉਂਦਾ ਹੈ ਅਤੇ permissions drift ਨੂੰ ਘਟਾਉਂਦਾ ਹੈ। ਹਕੀਕਤ ਦੇ ਅਧਾਰ ਤੇ ਚੁਣੋ:
ਜੇ ਤੁਸੀਂ ਸ਼ੁਰੂਆਤੀ ਹੌਂ ਤਾਂ ਇੱਕ ਪ੍ਰਦਾਤਾ ਪਹਿਲਾਂ shipments ਕਰੋ ਅਤੇ ਦੱਸੋ ਕਿ ਹੋਰ ਕਿਵੇਂ ਮੰਗ ਸਕਦੇ ਹਨ।
ਅੰਦਰੂਨੀ ops ਵੀ ਆਟੋਮੇਟ ਕਰਨ ਦੇ ਲਾਭ ਲੈ ਸਕਦੇ ਹਨ। ਕੁਝ endpoints ਅਤੇ event hooks ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਨਕਲ-ਪੇਸਟ ਉਦਾਹਰਨ ਦਿਓ。
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H \"Authorization: Bearer $TOKEN\" \\
-d '{\"title\":\"API contract from Payments\",\"trackerUrl\":\"https://jira/.../PAY-77\"}'
Webhooks ਜਿਵੇਂ dependency.created ਅਤੇ dependency.status_changed ਟੀਮਾਂ ਨੂੰ ਅੰਦਰੂਨੀ ਟੂਲਾਂ ਨਾਲ ਜੋੜਨ ਲਈ ਆਸਾਨੀ ਦਿੰਦੇ ਹਨ। ਵੱਧ ਜਾਣਕਾਰੀ ਲਈ docs/integrations ਨੂੰ ਦੇਖੋ.
ਡੈਸ਼ਬੋਰਡ ਉਹ ਥਾਂ ਹਨ ਜਿੱਥੇ dependency ਐਪ ਆਪਣੀ ਵਰਤੋਂ ਦਾ ਮੁੱਲ ਸਾਬਤ ਕਰਦੀ ਹੈ: ਉਹ “ਮੈਨੂੰ ਲੱਗਦਾ ਹੈ ਕਿ ਅਸੀਂ ਰੁਕੇ ਹੋ” ਨੂੰ ਇੱਕ ਸਪਸ਼ਟ, ਸਾਂਝੇ ਚਿੱਤਰ ਵਿੱਚ ਬਦਲ ਦਿੰਦੇ ਹਨ ਜਿਸ ਨਾਲ ਅਗਲੀ ਚੈੱਕ-ਇਨ ਤੋਂ ਪਹਿਲਾਂ ਧਿਆਨ ਦੀ ਲੋੜ ਪਟਾਓਂਦੀ ਹੈ।
ਇੱਕ “ਸਭ ਲਈ ਇੱਕ” ਡੈਸ਼ਬੋਰਡ ਆਮ ਤੌਰ 'ਤੇ ਨਾਕਾਮ ਰਹਿੰਦਾ ਹੈ। ਇਸ ਦੀ ਬਜਾਏ, ਕੁਝ ਨਜ਼ਰੇ ਡਿਜ਼ਾਈਨ ਕਰੋ ਜੋ ਲੋਕ ਮੀਟਿੰਗ ਚਲਾਉਣ ਦੇ ਤਰੀਕੇ ਨਾਲ ਮਿਲਦੇ ਹਨ:
ਕੁਝ ਛੋਟੀ ਰਿਪੋਰਟਾਂ ਬਣਾਓ ਜੋ ਲੋਕ ਵਰਤਣਗੇ:
ਹਰ ਰਿਪੋਰਟ ਦਾ ਉਦੇਸ਼ ਹੋਵੇ: “ਅਗਲਾ ਕੌਣ ਕੀ ਕਰੇ?” ਮਾਲਕ, ਉਮੀਦਿਤ ਤਾਰੀਖ, ਅਤੇ ਆਖਰੀ ਅਪਡੇਟ ਸ਼ਾਮਲ ਕਰੋ।
ਫਿਲਟਰ ਤੇਜ਼ ਅਤੇ ਸਪਸ਼ਟ ਬਣਾਓ, ਕਿਉਂਕਿ ਜ਼ਿਆਦातर ਮੀਟਿੰਗਾਂ “ਸਿਰਫ਼ ਦਿਖਾਓ…” ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੀਆਂ ਹਨ।
ਹਰ ਕੋਈ ਐਪ ਵਿੱਚ ਹਰ ਵੇਲੇ ਨਹੀਂ ਰਹੇਗਾ। ਦਿਓ:
ਜੇ ਤੁਸੀਂ paid tier ਦਿੰਦੇ ਹੋ ਤਾਂ admin-friendly sharing controls ਰੱਖੋ ਅਤੇ pricing ਵੇਖਾਓ।
ਤੁਹਾਨੂੰ dependency tracking web app ਲਾਉਣ ਲਈ ਜਟਿਲ ਪਲੇਟਫਾਰਮ ਦੀ ਲੋੜ ਨਹੀਂ। ਇੱਕ MVP ਇੱਕ ਸਧਾਰਣ ਤਿੰਨ-ਭਾਗੀ ਸਿਸਟਮ ਹੋ ਸਕਦਾ ਹੈ: ਮਨੁੱਖਾਂ ਲਈ ਵੈੱਬ UI, ਨਿਯਮਾਂ ਅਤੇ ਇੰਟੈਗ੍ਰੇਸ਼ਨਾਂ ਲਈ API, ਅਤੇ ਸਚਾਈ ਲਈ ਡੇਟਾਬੇਸ। “ਸੌਖਾ ਬਦਲਣਾ” ਨੂੰ “ਪਰਫੈਕਟ” ਤੋਂ ਵੱਡੀ ਤਰਜੀਹ ਦਿਓ। ਅਸਲੀ ਵਰਤੋਂ ਤੋਂ ਤੁਸੀਂ ਮਹੱਤਵਪੂਰਨ ਸਿਖੋਗੇ।
ਇੱਕ Prattਮਿਕ ਸ਼ੁਰੂਆਤ ਇਹ ਹੋ ਸਕਦੀ ਹੈ:
ਜੇ ਤੁਸੀਂ ਜਲਦੀ Slack/Jira ਇੰਟੈਗ੍ਰੇਸ਼ਨ ਉਮੀਦ ਕਰਦੇ ਹੋ, ਤਾਂ ਇੰਟੈਗ੍ਰੇਸ਼ਨਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਮੋਡੀਊਲ/ਜੌਬਸ ਰੱਖੋ ਜੋ ਉਹੀ API ਵਰਤ ਕੇ ਗੱਲ ਕਰਨ, ਨਾ ਕਿ ਬਾਹਰੀ ਟੂਲਾਂ ਨੂੰ ਸਿੱਧਾ ਡੇਟਾਬੇਸ ਲਿਖਣ ਦਿਓ।
ਜਲਦੀ ਵਰਕਿੰਗ ਪ੍ਰੋਡਕਟ ਤੱਕ ਪਹੁੰਚ ਕਰਨ ਲਈ vibe-coding ਵਰਕਫਲੋ ਮਦਦਗਾਰ ਹੋ ਸਕਦਾ ਹੈ: ਉਦਾਹਰਨ ਲਈ, Koder.ai ਰੀਐਕਟ UI ਅਤੇ Go + PostgreSQL ਬੈਕਐਂਡ ఆਟੋ-ਜਨਰੇਟ ਕਰ ਸਕਦੀ ਹੈ ਚੈਟ-ਆਧਾਰਤ ਸਪੇਸ ਤੋਂ, ਫਿਰ planning mode, snapshots, ਅਤੇ rollback ਨਾਲ ਤੁਸੀਂ ਮੁੜ-ਦੌਰਾ ਕਰ ਸਕਦੇ ਹੋ। ਤੁਸੀਂ ਫਿਰ ਵੀ ਆਰਕੀਟੈਕਚਰ ਫੈਸਲੇ ਆਪਣੇ ਕੋਲ ਰੱਖਦੇ ਹੋ, ਪਰ requirements ਤੋਂ usable pilot ਤੱਕ ਦਾ ਰਸਤਾ ਛੋਟਾ ਹੋ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਤਿਆਰ ਹੋਵੋ ਤਾਂ ਸੋর্স ਕੋਡ Export ਕਰੋ।
ਜ਼ਿਆਦਾਤਰ ਸਕ੍ਰੀਨ ਲਿਸਟ ਵਿਊ ਹਨ: open dependencies, blockers by team, changes this week. ਇਸ ਲਈ ਡਿਜ਼ਾਈਨ ਕਰੋ:
Dependency ਡੇਟਾ ਵਿੱਚ ਸੰਵੇਦਨਸ਼ੀਲ ਵੇਰਵੇ ਹੋ ਸਕਦੇ ਹਨ। least-privilege access (ਟੀਮ-ਲੈਵਲ ਵਿਜ਼빌ਟੀ ਜਿੱਥੇ ਯੋਗ) ਵਰਤੋ ਅਤੇ ਸੋਧਾਂ ਲਈ audit logs ਰੱਖੋ—ਕਿਸ ਨੇ ਕੀ ਬਦਲਿਆ ਅਤੇ ਕਦੋਂ। ਉਹ ਆਡੀਟ ਟ੍ਰੇਲ ਸਥਿਤੀ ਸਮੀਖਿਆਵਾਂ ਵਿਚ ਵਾਦ-ਵਿਵਾਦ ਘਟਾਉਂਦੀ ਹੈ ਅਤੇ ਟੂਲ ਨੂੰ ਭਰੋਸੇਯੋਗ ਬਨਾਉਂਦੀ ਹੈ।
ਇੱਕ dependency tracking ਵੈੱਬ ਐਪ ਰੋਲਆਊਟ ਫੀਚਰਾਂ ਤੋਂ ਵੱਧ ਆਦਤਾਂ ਬਦਲਣ ਬਾਰੇ ਹੁੰਦਾ ਹੈ। rollout ਨੂੰ ਇੱਕ product launch ਵਾਂਗ ਸੋਚੋ: ਛੋਟੇ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ, ਮੁੱਲ ਸਾਬਤ ਕਰੋ, ਫਿਰ ਇੱਕ ਸਪਸ਼ਟ ਓਪਰੇਟਿੰਗ ਰਿਦਮ ਨਾਲ ਸਕੇਲ ਕਰੋ।
2–4 ਟੀਮਾਂ ਚੋਂ ਇੱਕ ਸ਼ੇਅਰਡ initiative (ਉਦਾਹਰਨ: ਇਕ release train ਜਾਂ ਇੱਕ customer program) ਚੁਣੋ। ਕੁਝ ਹਫ਼ਤਿਆਂ ਵਿੱਚ ਨਾਪੇ ਜਾ ਸਕਣ ਵਾਲੇ success criteria ਤੈਅ ਕਰੋ:
ਪਾਇਲਟ ਕੰਫਿਗਰੇਸ਼ਨ ਨੂੰ ਘੱਟ ਰੱਖੋ: ਕੇਵਲ ਉਹੀ ਫੀਲਡ ਅਤੇ ਦ੍ਰਿਸ਼ ਜਿੰਨ੍ਹਾਂ ਨਾਲ ਜਵਾਬ ਮਿਲੇ, “ਕੀ ਰੋਕਿਆ ਹੈ, ਕਿਸਨੇ ਅਤੇ ਕਦੋਂ?”
ਅਕਸਰ ਟੀਮਾਂ dependency spreadsheets ਵਿੱਚ ਰੱਖਦੀਆਂ ਹਨ। ਉਨ੍ਹਾਂ ਨੂੰ ਇੰਪੋਰਟ ਕਰੋ, ਪਰ ਧਿਆਨ ਨਾਲ:
ਇੱਕ ਛੋਟੀ “data QA” ਪਾਸ ਪਾਇਲਟ ਯੂਜ਼ਰਾਂ ਨਾਲ ਚਲਾਉ ਤਾਂ ਜੋ ਪਰਿਭਾਸ਼ਾਵਾਂ ਦੀ ਪੁਸ਼ਟੀ ਹੋ ਸਕੇ ਅਤੇ ambiguous entries ਠੀਕ ਕੀਤੀਆਂ ਜਾ ਸਕਣ।
ਅਡਾਪਸ਼ਨ ਉਸ ਵੇਲੇ ਟਿਕਦੀ ਹੈ ਜਦੋਂ ਐਪ ਮੌਜੂਦਾ ਰਿਦਮ ਨੂੰ ਸਹਾਇਤਾ ਕਰਦੀ ਹੈ। ਦਿਓ:
ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਬਣਾਉਣੀ ਹੋ (ਉਦਾਹਰਨ, pilot Koder.ai ਵਿੱਚ iterating), ਤਾਂ environments/snapshots ਵਰਤ ਕੇ required fields, states, ਅਤੇ dashboards ਦੀਆਂ ਬਦਲੀਆਂ ਟੈਸਟ ਕਰੋ—ਫਿਰ ਬਿਨਾਂ ਸਭ ਨੂੰ ਵਿਘਟਿਤ ਕੀਤੇ ਅੱਗੇ ਵਧੋ ਜਾਂ ਵਾਪਸ ਜਾਓ।
ਟ੍ਰੈਕ ਕਰੋ ਕਿ ਲੋਕ ਕਿੱਥੇ ਫਸਦੇ ਹਨ: ਗੁੰਝਲਦਾਰ ਫੀਲਡ, ਘੱਟ ਸਥਿਤੀਆਂ, ਜਾਂ ਦ੍ਰਿਸ਼ ਜੋ ਸਮੀਖਿਆ ਪ੍ਰਸ਼ਨ ਨੂੰ ਨਹੀਂ ਜਵਾਬ ਦਿੰਦੇ। ਪਾਇਲਟ ਦੌਰਾਨ ਹਫਤਾਵਾਰ ਫੀਡਬੈਕ ਸਮੀਖਿਆ ਕਰੋ, ਫਿਰ ਹੋਰ ਟੀਮਾਂ ਨੂੰ ਨਿਯੁਕਤ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਫੀਲਡ ਅਤੇ ਡਿਫਾਲਟ ਵਿਉਜ਼ ਨੂੰ ਅਪਡੇਟ ਕਰੋ। ਇੱਕ ਸਧਾਰਨ “Report an issue” link to /support ਰੱਖਣਾ ਲੂਪ ਤਿੱਖੀ ਰੱਖਦਾ ਹੈ।
ਜਦੋਂ ਤੁਹਾਡੀ dependency tracking ਐਪ ਲਾਈਵ ਹੁੰਦੀ ਹੈ, ਸਭ ਤੋਂ ਵੱਡੇ ਖ਼ਤਰੇ ਤਕਨੀਕੀ ਨਹੀਂ—ਉਹ ਵਰਤਾਰਕੀ ਹੁੰਦੇ ਹਨ। ਜ਼ਿਆਦातर ਟੀਮਾਂ ਟੂਲ ਛੱਡਦੇ ਨਹੀਂ ਕਿਉਂਕਿ ਉਹ “ਕਮਪਾ” ਨਹੀਂ ਕਰਦੇ, ਬਲਕਿ ਕਿਉਂਕਿ ਉਸ ਨੂੰ ਅਪਡੇਟ ਕਰਨਾ ਵਿਕਲਪਿਕ, ਗੁੰਝਲਦਾਰ, ਜਾਂ ਸ਼ੋਰ ਭਰਿਆ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ।
ਬਹੁਤ ਜ਼ਿਆਦਾ ਫੀਲਡ। ਜੇ dependency ਬਣਾਉਣਾ ਇੱਕ ਬਹੁਤ ਲੰਮਾ ਫਾਰਮ ਮਹਿਸੂਸ ਹੁੰਦਾ ਹੈ, ਲੋਕ ਇਸਨੂੰ ਟਾਲਣਗੇ। ਸ਼ੁਰੂ ਵਿੱਚ ਘੱਟ ਲਾਜ਼ਮੀ ਫੀਲਡ ਰੱਖੋ: title, requesting team, owning team, “next action,” due date, ਅਤੇ status.
ਅਸਪਸ਼ਟ ਮਾਲਕੀ. ਜੇ ਅਗਲਾ ਕਰਵਾਈ ਕਰਨ ਵਾਲਾ ਸਪਸ਼ਟ ਨਾ ਹੋਵੇ ਤਾਂ dependencies status threads ਬਣ ਜਾਂਦੇ ਹਨ। “owner” ਅਤੇ “next action owner” ਨੂੰ ਸਪਸ਼ਟ ਅਤੇ ਪ੍ਰਮੁੱਖ ਦਿਖਾਓ।
ਅਪਡੇਟ ਆਦਤਾਂ ਦੀ ਘਾਟ। ਇੱਕ ਵਧੀਆ UI ਵੀ ਅਸਫਲ ਹੁੰਦੀ ਹੈ ਜੇ ਆਈਟਮ stale ਹੋ ਜਾਏਂ। ਹੌਲੇ-ਹੌਲੇ ਨੋਟਿਸ ਦਿਓ: stale items ਨੂੰ ਹਾਈਲਾਈਟ ਕਰੋ, ਜਦੋਂ due date ਨੇੜੇ ਹੋ ਜਾਂ ਆਖਰੀ ਅਪਡੇਟ ਪੁਰਾਣਾ ਹੋਵੇ ਤਾਂ ਯਾਦ ਦਿਓ, ਅਤੇ ਅਪਡੇਟ ਨੂੰ ਆਸਾਨ ਬਣਾਓ (ਇੱਕ-ਕਲਿੱਕ status change + ਛੋਟੀ ਨੋਟ)।
ਨੋਟੀਫਿਕੇਸ਼ਨ ਓਵਰਲੋਡ। ਜੇ ਹਰ ਟਿੱਪਣੀ ਹਰ ਕਿਸੇ ਨੂੰ ਪਿੰਗ ਕਰੇ, ਯੂਜ਼ਰ ਸਿਸਟਮ ਨੂੰ ਮਿਊਟ ਕਰ ਦੇਣਗੇ। ਡਿਫਾਲਟ "watchers" ਜੋ ਆਪਚੌਣ ਕਰਦੇ ਹਨ, ਅਤੇ ਘੱਟ ਤਾਤਪਰਤਾ ਲਈ summaries ਭੇਜੋ।
“next action” ਨੂੰ ਇੱਕ ਮੁੱਖ ਫੀਲਡ ਦੇ ਤੌਰ 'ਤੇ ਜ਼ਿੰਮੇਵਾਰ ਰੱਖੋ: ਹਰ open dependency ਹਮੇਸ਼ਾ ਇੱਕ ਸਪਸ਼ਟ ਅਗਲਾ ਕਦਮ ਅਤੇ ਇੱਕ ਇਕਲ ਜਵਾਬਦੇਹ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਜੇ ਇਹ ਗੈਰਹਾਜ਼ਿਰ ਹੋਵੇ, آیਟਮ ਮੁੱਖ ਦ੍ਰਿਸ਼ ਵਿੱਚ “complete” ਨਹੀਂ ਲੱਗਣਾ ਚਾਹੀਦਾ।
ਇਸ ਤੋਂ ਇਲਾਵਾ, ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ “done” ਦਾ ਕੀ ਮਤਲਬ ਹੈ (ਉਦਾਹਰਨ: resolved, ਲੋੜ ਨਹੀਂ ਰਹੀ, ਜਾਂ ਕਿਸੇ ਹੋਰ ਟ੍ਰੈਕਰ ਵਿੱਚ ਮੂਵ ਕੀਤਾ) ਅਤੇ ਕਲੋਜ਼ਰ ਦਾ ਛੋਟਾ ਕਾਰਨ ਲਾਜ਼ਮੀ ਕਰੋ ਤਾਂ ਕਿ zombie items ਨਾ ਬਣਨ।
ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ tags, team list, ਅਤੇ categories ਦੀ ਮਾਲਕੀ ਕੌਣ ਕਰਦਾ ਹੈ। ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਇੱਕ ਪ੍ਰੋਗ੍ਰਾਮ ਮੈਨੇਜਰ ਜਾਂ ops ਰੋਲ ਹੁੰਦਾ ਹੈ ਜਿਸ ਕੋਲ ਹਲਕੀ-ਫੁਲਕੀ change control ਹੁੰਦੀ ਹੈ। ਸਧਾਰਣ ਰਿਟਾਇਰਮੈਂਟ ਨੀਤੀ ਰੱਖੋ: X ਦਿਨ ਬੰਦ ਰਹਿਣ 'ਤੇ ਪੁਰਾਣੇ initiatives ਆਟੋ-ਆਰਕਾਈਵ ਕਰੋ, ਅਤੇ ਵਰਤੋਂ-ਰਹਿਤ tags ਨੂੰ ਤिमਾਹੀ ਸਮੀਖਿਆ ਕਰੋ।
ਅਪਨਾਉਣ ਸਥਿਰ ਹੋਣ ਤੋਂ ਬਾਅਦ, ਐਸੇ ਅਪਗਰੇਡ ਦੇ ਬਾਰੇ ਸੋਚੋ ਜੋ ਮੁੱਲ ਵਧਾਉਂਦੇ ਹਨ ਬਿਨਾਂ ਰੁਕਾਵਟ ਵਧਾਏ:
ਜੇ ਤੁਹਾਨੂੰ ਸੁਚਿਤ ਢੰਗ ਨਾਲ ਪ੍ਰਾਥਮਿਕਤਾ ਦਿੰਨੀ ਹੋਵੇ, ਤਾਂ ਹਰ ਵਿਚਾਰ ਨੂੰ ਇੱਕ ਸਮੀਖਿਆ ਰਿਵਜ਼ (ਸाप्तਾਹਿਕ status meeting, release planning, incident retros) ਨਾਲ ਜੋੜੋ, ਤਾਂ ਜੋ ਸੁਧਾਰ ਅਸਲੀ ਵਰਤੋਂ 'ਤੇ ਆਧਾਰਤ ਹੋਣ ਨਾ ਕਿ ਅਨੁਮਾਨਾਂ 'ਤੇ।
Start with a one-sentence definition everyone can repeat, then list what qualifies (work item, deliverable, decision, environment/access).
Also write down what does not count (nice-to-haves, general risks, internal tasks that don’t block another team). This keeps the tool from becoming a vague “concern tracker.”
At minimum, design for:
If you build for only one group, the others won’t update it—and the system will go stale.
Use a small, consistent lifecycle such as:
Then define rules for state changes (e.g., “Accepted requires an owner team and a target date,” “Ready requires evidence”). Consistency matters more than complexity.
Require only what you need to coordinate:
If you allow missing owner or due date, you’ll collect items that can’t be acted on.
Make “done” provable. Require:
This prevents early “green status” updates just to reduce noise.
Define four everyday roles plus admin:
Keep “one dependency, one owner” to avoid ambiguity; use collaborators for helpers, not accountability.
Start with views that answer daily questions:
Optimize for fast updates: templates, inline editing, keyboard-friendly controls, and a prominent “Last updated.”
Alert only on decision points and risk signals:
Use watchers instead of broadcasting, support digest mode, and deduplicate notifications (one summary per dependency per time window).
Integrate to remove duplicate entry, not to create a second source of truth:
dependency.created, dependency.status_changed)Keep chat (Slack/Teams) as a delivery channel that deep-links back to the record, not the system of record.
Run a focused pilot before scaling:
Treat “no owner or due date” as incomplete, and iterate based on where users get stuck.