05 ਮਈ 2025·5 ਮਿੰਟ
ਗਾਹਕ ਐਸਕਲੇਸ਼ਨ ਦੀਆਂ ਟਾਈਮਲਾਈਨਾਂ ਨੂੰ ਮੈਨੇਜ ਕਰਨ ਲਈ ਵੈੱਬ ਐਪ ਬਣਾਓ
ਸਟੈਪ-ਬਾਇ-ਸਟੈਪ ਯੋਜਨਾ: ਇੱਕ ਐਸਕਲੇਸ਼ਨ ਟਾਈਮਲਾਈਨ ਟ੍ਰੈਕ ਕਰਨ ਵਾਲੀ ਵੈੱਬ ਐਪ ਬਣਾਓ—ਡੈਡਲਾਈਨ, SLA, ਮਲਕੀਅਤ, ਅਲਰਟ, ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਸਮੇਤ।
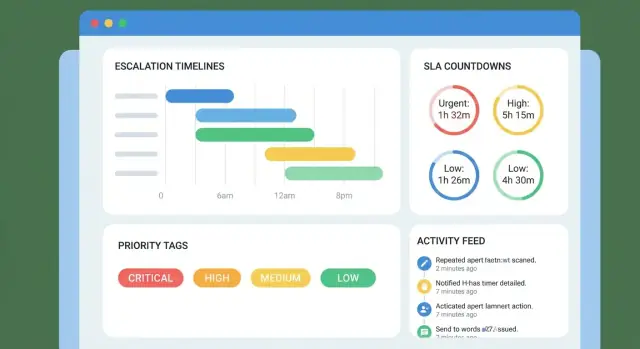
ਸਟੈਪ-ਬਾਇ-ਸਟੈਪ ਯੋਜਨਾ: ਇੱਕ ਐਸਕਲੇਸ਼ਨ ਟਾਈਮਲਾਈਨ ਟ੍ਰੈਕ ਕਰਨ ਵਾਲੀ ਵੈੱਬ ਐਪ ਬਣਾਓ—ਡੈਡਲਾਈਨ, SLA, ਮਲਕੀਅਤ, ਅਲਰਟ, ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਸਮੇਤ।
ਸਕ੍ਰੀਨਾਂ ਡਿਜ਼ਾਇਨ ਕਰਨ ਜਾਂ ਟੈਕ ਸਟੈਕ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ, ਇਹ ਵਜ੍ਹਾ ਸਪਸ਼ਟ ਕਰੋ ਕਿ ਤੁਹਾਡੇ ਸੰਗਠਨ ਵਿੱਚ “ਏਸਕਲੇਸ਼ਨ” ਦਾ ਕੀ ਮਤਲਬ ਹੈ। ਕੀ ਇਹ ਇਕ ਸਪੋਰਟ ਕੇਸ ਹੈ ਜੋ ਪੁਰਾਣਾ ਹੋ ਰਿਹਾ ਹੈ, ਕੋਈ ਇਨਸਿਡੈਂਟ ਜੋ ਉਪਟਾਈਮ ਨੂੰ ਖ਼ਤਰਾ ਦਿੰਦਾ ਹੈ, ਕਿਸੇ ਮੁੱਖ ਖਾਤੇ ਦੀ ਸ਼ਿਕਾਇਤ, ਜਾਂ ਕੋਈ ਵੀ ਬੇਨਤੀ ਜੋ ਸੰਵੇਦਨਸ਼ੀਲਤਾ ਸਤਰ ਪਾਰ ਕਰਦੀ ਹੈ? ਜੇ ਵੱਖ-ਵੱਖ ਟੀਮਾਂ ਇਹ ਸ਼ਬਦ ਵੱਖ-ਵੱਖ ਤਰ੍ਹਾਂ ਵਰਤਦੀਆਂ ਹਨ, ਤਾਂ ਤੁਹਾਡੀ ਐਪ ਗਲਤਫ਼ਹਮੀਆਂ ਦਾ ਰਿਕਾਰਡ ਕਰੇਗੀ।
ਇੱਕ ਵਾਕ ਦਾ ਪਰਿਭਾਸ਼ਾ ਲਿਖੋ ਜਿਸ ਤੇ ਪੂਰੀ ਟੀਮ ਸਹਿਮਤ ਹੋ ਸਕੇ, ਫਿਰ ਕੁਝ ਉਦਾਹਰਣ ਸ਼ਾਮਲ ਕਰੋ। ਉਦਾਹਰਨ ਵਜੋਂ: “ਇੱਕ escalation ਉਹ ਕੋਈ ਵੀ ਗਾਹਕ ਮੁੱਦਾ ਹੈ ਜੋ ਉੱਚ ਸਹਾਇਤਾ ਸਤਰ ਜਾਂ ਪ੍ਰਬੰਧਕੀ ਸ਼ਾਮਿਲਤਾ ਦੀ ਲੋੜ ਰੱਖਦਾ ਹੈ, ਅਤੇ ਜਿਸ ਲਈ ਸਮੇਂ-ਸੀਮਾ ਵਾਲੀ ਜ਼ਿੰਮੇਵਾਰੀ ਹੈ।”
ਇਹ ਵੀ ਨਿਰਧਾਰਿਤ ਕਰੋ ਕਿ ਕੀ ਗਿਣਤੀ ਨਹੀਂ ਹੁੰਦੀ (ਜਿਵੇਂ ਰੁਟੀਨ ਟਿਕਟ, ਅੰਦਰੂਨੀ ਕੰਮ) ਤਾਂ ਕਿ v1 ਵਿੱਚ ਬੇਕਾਰ ਚੀਜ਼ਾਂ ਨਾ ਆ ਜ਼ਿਆਦਤ ਹੋਣ।
ਸਫਲਤਾ ਦੇ ਮਾਪਦੰਡ ਉਸ ਗੱਲ ਨੂੰ ਦਰਸਾਉਣੇ ਚਾਹੀਦੇ ਹਨ ਜੋ ਤੁਸੀਂ ਸੁਧਾਰਨਾ ਚਾਹੁੰਦੇ ਹੋ—ਸਿਰਫ਼ ਜੋ ਤੁਸੀਂ ਬਣਾਉਣਾ ਚਾਹੁੰਦੇ ਹੋ ਨਹੀਂ। ਆਮ ਕੋਰ ਨਤੀਜੇ ਸ਼ਾਮਲ ਹਨ:
ਦਿਨ ਇਕ ਤੋਂ ਹੀ 2–4 ਮੈਟ੍ਰਿਕਸ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਟ੍ਰੈਕ ਕਰ ਸਕਦੇ ਹੋ (ਉਦਾਹਰਨ ਲਈ, breach rate, ਹਰ ਐਸਕਲੇਸ਼ਨ ਸਟੇਜ ਵਿਚ ਸਮਾਂ, reassignment ਗਿਣਤੀ)।
ਪ੍ਰਾਇਮਰੀ ਯੂਜ਼ਰਾਂ (ਏਜੰਟ, ਟੀਮ ਲੀਡ, ਮੈਨੇਜਰ) ਅਤੇ ਸੈਕੰਡਰੀ ਸਟੇਕਹੋਲਡਰਾਂ (ਅਕਾਉਂਟ ਮੈਨੇਜਰ, ਇੰਜੀਨੀਅਰਿੰਗ on-call) ਨੂੰ ਲਿਸਟ ਕਰੋ। ਹਰ ਇੱਕ ਲਈ ਨੋਟ ਕਰੋ ਕਿ ਉਹਨਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਕੀ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ: ਮਲਕੀਅਤ ਲੈਣਾ, ਕਾਰਨ ਪੇਸ਼ ਕਰਕੇ ਡੈਡਲਾਈਨ ਵਧਾਉਣਾ, ਅਗਲੇ ਕਦਮ ਦੇਖਣਾ, ਜਾਂ ਗਾਹਕ ਲਈ ਸਥਿਤੀ ਸਾਰਾਂਸ਼ ਤਿਆਰ ਕਰਨਾ।
ਮੌਜੂਦਾ ਫੇਲਿਯਰ ਮੋਡਜ਼ ਨੂੰ ਵਿਸ਼ੇਸ਼ ਕਹਾਣੀਆਂ ਨਾਲ ਕੈਪਚਰ ਕਰੋ: ਟੀਅਰਾਂ ਦਰਮਿਆਨ ਛੁੱਟਣ ਵਾਲੀ ਗਲਤੀ, ਰੀਅਸਾਈਨਮੈਂਟ ਤੋਂ ਬਾਅਦ ਅਣਸਪਸ਼ਟ ਡਿਊ ਟਾਈਮ, “ਕਿਸਨੇ ਐਕਸਟੈਂਸ਼ਨ ਮਨਜ਼ੂਰ ਕੀਤੀ?” ਦੀਆਂ बहसਾਂ।
ਇਹ ਕਹਾਣੀਆਂ ਇਸ ਗੱਲ ਵਿੱਚ ਮਦਦ ਕਰਨਗੀਆਂ ਕਿ ਕੀਜ਼ ਮੁਸਟ-ਹੈਵਜ਼ ਹਨ (ਟਾਈਮਲਾਈਨ + ਮਲਕੀਅਤ + ਆਡਿਟੇਬਲਟੀ) ਅਤੇ ਕੀ ਬਾਅਦ ਵਿਚ ਸ਼ਾਮਲ ਕੀਤਾ ਜਾਵੇ (ਉਨਤ ਡੈਸ਼ਬੋਰਡ, ਜਟਿਲ ਆਟੋਮੇਸ਼ਨ)।
ਮਕਸਦ ਸਾਫ਼ ਹੋਣ ਤੇ, ਲਿਖੋ ਕਿ ਇੱਕ escalation ਤੁਹਾਡੀ ਟੀਮ ਵਿੱਚ ਕਿਵੇਂ ਚਲਦੀ ਹੈ। ਇੱਕ ਸਾਂਝੀ ਵਰਕਫਲੋ “ਖਾਸ ਮੁਾਮਲਿਆਂ” ਨੂੰ ਨਿਰੰਤਰ ਦੁਰੁਸਤ ਕਰਨ ਅਤੇ SLA ਮਿਸ ਹੋਣ ਤੋਂ ਰੋਕਦੀ ਹੈ।
ਸਧਾਰਣ ਸਟੇਜ ਅਤੇ ਮਨਜ਼ੂਰਸ਼ੁਦਾ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ:
ਦਸਤਾਵੇਜ਼ ਕਰੋ ਕਿ ਹਰ ਸਟੇਜ ਦਾ ਕੀ ਮਤਲਬ ਹੈ (ਐਂਟਰੀ ਮਾਪਦੰਡ) ਅਤੇ ਕਿਹੜੀ ਸ਼ਰਤ ਪੂਰੀ ਹੋਣ 'ਤੇ ਉਥੋਂ ਨਿਕਲਿਆ ਜਾ ਸਕਦਾ ਹੈ (ਏਗਜ਼ਿਟ ਮਾਪਦੰਡ)। ਇਥੇ ਹੀ ਤੁਸੀਂ "Resolved ਪਰ ਫਿਰ ਵੀ ਗਾਹਕ ਦੀ ਉਡੀਕ" ਵਰਗੀ ਅੰਧਕਾਰਪੂਰਣ ਗੱਲਾਂ ਤੋਂ ਬਚ ਸਕਦੇ ਹੋ।
Escalation ਨਿਯਮ ਇਕ ਵਾਕ ਵਿੱਚ ਸਮਝਾਏ ਜਾ ਸਕਣੇ ਚਾਹੀਦੇ ਹਨ। ਆਮ ਟ੍ਰਿਗਰ ਸ਼ਾਮਲ ਹਨ:
ਫੈਸਲਾ ਕਰੋ ਕਿ ਟ੍ਰਿਗਰ ਸਵੈਚਾਲਿਤ ਤੌਰ 'ਤੇ escalation ਬਣਾਉਂਦੇ ਹਨ, ਏਜੰਟ ਨੂੰ ਸੁਝਾਅ ਦਿੰਦੇ ਹਨ, ਜਾਂ ਮਨਜ਼ੂਰੀ ਦੀ ਲੋੜ ਰੱਖਦੇ ਹਨ।
ਤੁਹਾਡੀ ਟਾਈਮਲਾਈਨ ਉਹਨਾ ਇਵੈਂਟਾਂ ਉੱਤੇ ਹੀ ਨਿਰਭਰ ਹੈ ਜੋ ਤੁਸੀਂ ਕੈਪਚਰ ਕਰਦੇ ਹੋ। ਘੱਟੋ-ਘੱਟ ਰਿਕਾਰਡ ਕਰੋ:
ਮਲਕੀਅਤ ਬਦਲਾਅ ਲਈ ਨੀਅਮ ਲਿਖੋ: ਕੌਣ reassign ਕਰ ਸਕਦਾ ਹੈ, ਕਦੋਂ approvals ਚਾਹੀਦੇ ਹਨ (ਉਦਾਹਰਨ: cross-team ਜਾਂ vendor handoff), ਅਤੇ ਜੇ ਮਾਲਕ ਸ਼ਿਫਟ ਤੋਂ ਬਾਹਰ ਹੋ ਜਾਵੇ ਤਾਂ ਕੀ ਹੁੰਦਾ ਹੈ।
ਅਖੀਰਕਾਰ, ਉਹ dependencies ਨਕਸ਼ਾ ਕਰੋ ਜੋ ਟਾਈਮਿੰਗ ਨੂੰ ਪ੍ਰਭਾਵਤ ਕਰਦੀਆਂ ਹਨ: on-call schedules, tier levels (T1/T2/T3), ਅਤੇ external vendors (ਉਨ੍ਹਾਂ ਦੀ ਪਰਤੀਕਿਰਿਆ ਵਿੰਡੋ ਸਮੇਤ)। ਇਹ ਤੁਹਾਡੇ ਟਾਈਮਲਾਈਨ ਗਣਨਾਵਾਂ ਅਤੇ ਏਸਕਲੇਸ਼ਨ ਮੈਟ੍ਰਿਕਸ ਨੂੰ ਸੰਜੋਏਗਾ।
ਇੱਕ ਭਰੋਸੇਯੋਗ ਐਸਕਲੇਸ਼ਨ ਐਪ ਮੁੱਖ ਤੌਰ 'ਤੇ ਡੇਟਾ ਸਮੱਸਿਆ ਹੈ। ਜੇ ਟਾਈਮਲਾਈਨ, SLA ਅਤੇ ਇਤਿਹਾਸ ਸਾਫ਼ ਤਰੀਕੇ ਨਾਲ ਮਾਡਲ ਨਹੀਂ ਕੀਤੇ ਗਏ, ਤਾਂ UI ਅਤੇ ਨੋਟੀਫਿਕੇਸ਼ਨ ਹਮੇਸ਼ਾ "ਗਲਤ" ਮਹਿਲੂਸ ਹੋਣਗੇ। ਕੋਰ ਇਹਟਾਈਟੀਆਂ ਅਤੇ ਰਿਸ਼ਤੇ ਦੀ ਨਾਂਕੀ ਤੋਂ ਸ਼ੁਰੂ ਕਰੋ।
ਘੱਟੋ-ਘੱਟ ਯੋਜਨਾ ਕਰੋ:
ਹਰ ਮਾਈਲਸਟੋਨ ਨੂੰ ਇੱਕ ਟਾਈਮਰ ਵਜੋਂ ਵਰਤੋ ਜਿਸ ਵਿੱਚ:
start_at (ਜਦੋਂ ਘੜੀ ਚਲਦੀ ਹੈ)due_at (ਹਿਸਾਬ ਕੀਤਾ ਗਿਆ ਡੈਡਲਾਈਨ)paused_at / pause_reason (ਵਿਕਲਪਿਕ)completed_at (ਜਦੋਂ ਪੂਰਾ ਹੋਇਆ)ਯਾਦ ਰੱਖੋ ਕਿ ਤੁਸੀਂ ਕਿਉਂ ਇੱਕ ਡਿਊ ਡੇਟ ਰੱਖਦੇ ਹੋ (ਕਿਹੜਾ ਨਿਯਮ) ਨਾ ਕਿ ਸਿਰਫ਼ ਕੈਲਕੁਲੇਟ ਕੀਤਾ ਸਮਾਂ। ਇਸ ਨਾਲ ਬਾਅਦ ਵਿੱਚ ਵਿਵਾਦ ਸੌਲਝਾਉਣ ਆਸਾਨ ਹੁੰਦਾ ਹੈ।
SLA ਅਕਸਰ "ਹਮੇਸ਼ਾ" ਨਹੀਂ ਹੁੰਦੇ। ਹਰ SLA ਪਾਲਿਸੀ ਲਈ ਇੱਕ ਕੈਲੰਡਰ ਮਾਡਲ ਕਰੋ: ਬਿਜ਼ਨਸ ਘੰਟੇ vs 24/7, ਛੁੱਟੀਆਂ, ਅਤੇ ਖੇਤਰ-ਨਿਰਧਾਰਤ ਸਮਾਂ।
ਡੈਡਲਾਈਨਾਂ ਨੂੰ ਇਕ ਰੂਪ ਵਿੱਚ ਸਰਵਰ ਟਾਈਮ (UTC) ਵਿੱਚ ਗਿਣੋ, ਪਰ ਸਦੀਆਂ ਲਈ ਕੇਸ ਟਾਈਮਜ਼ੋਨ (ਜਾ ਗਾਹਕ ਟਾਈਮਜ਼ੋਨ) ਸੰਭਾਲੋ ਤਾਂ ਕਿ UI ਡੈਡਲਾਈਨਾਂ ਸਹੀ ਤਰੀਕੇ ਨਾਲ ਦਿਖਾ ਸਕੇ।
ਸ਼ੁਰੂ ਵਿੱਚ ਇਹ ਫੈਸਲਾ ਕਰੋ:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), ਜਾਂਕੰਪਲਾਇੰਸ ਅਤੇ ਜ਼ਿੰਮੇਵਾਰੀ ਲਈ, ਇੱਕ event log ਨੂੰ ਤਰਜੀਹ ਦਿਓ (ਜੇਕਰਕਿ ਤੁਸੀਂ ਪ੍ਰਦਰਸ਼ਨ ਲਈ current state ਕਾਲਮ ਵੀ ਰੱਖ ਸਕਦੇ ਹੋ)। ਹਰ ਬਦਲਾਅ ਰਿਕਾਰਡ ਕਰੇ ਕਿ ਕਿਸਨੇ, ਕੀ ਬਦਲਿਆ, ਕਦੋਂ, ਅਤੇ ਸਰੋਤ (UI, API, automation), ਨਾਲ ਇੱਕ correlation ID ਟ੍ਰੇਸਿੰਗ ਲਈ।
ਅਨੁਮਤੀਆਂ ਉਹ ਜਗ੍ਹਾ ਹਨ ਜਿੱਥੇ ਐਸਕਲੇਸ਼ਨ ਟੂਲ ਭਰੋਸਾ ਕਮਾਉਂਦੇ ਹਨ—ਯਾ ਸਾਇਡ ਸਪ੍ਰੈਡਸ਼ੀਟਾਂ ਨਾਲ ਬਾਈਪਾਸ ਹੋ ਜਾਂਦੇ ਹਨ। ਸ਼ੁਰੂ ਵਿੱਚ ਇਹ ਨਿਰਧਾਰਤ ਕਰੋ ਕਿ ਕੌਣ ਕੀ ਕਰ ਸਕਦਾ ਹੈ, ਫਿਰ UI, API, ਅਤੇ ਐਕਸਪੋਰਟਾਂ 'ਤੇ ਇਸ ਨੂੰ ਲਾਗੂ ਕਰੋ।
v1 ਸਧਾਰਨ ਰੱਖੋ ਜੋ ਸਹਾਇਤਾ ਟੀਮਾਂ ਦੇ ਹਕੀਕਤੀ ਕੰਮ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹਨ:
ਉਤਪਾਦ ਵਿੱਚ ਰੋਲ ਚੈੱਕ ਸਪੱਸ਼ਟ ਕਰੋ: ਕੰਟਰੋਲਾਂ ਨੂੰ disabled ਦਿਖਾਓ ਨਾ ਕਿ ਯੂਜ਼ਰ ਨੂੰ ਗਲਤੀ 'ਤੇ ਕਲਿੱਕ ਕਰਨ ਦਿਓ।
Escalations ਅਕਸਰ ਕਈ ਗਰੁੱਪਾਂ ਨੂੰ ਪਾਰ ਕਰਦੀਆਂ ਹਨ (Tier 1, Tier 2, CSM, incident response)।visibility ਲਈ ਇੱਕ ਜਾਂ ਵੱਧ ਆਯਾਮਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ multi-team ਸਹਾਇਤਾ ਦੀ ਯੋਜਨਾ ਬਣਾਓ:
ਇੱਕ ਚੰਗਾ ਡੀਫਾਲਟ: ਯੂਜ਼ਰ ਉਹਨਾਂ ਕੇਸਾਂ ਤੱਕ ਪੁੱਜ ਸਕਦੇ ਹਨ ਜਿੱਥੇ ਉਹ assignee, watcher, ਜਾਂ owning team ਦਾ ਹਿੱਸਾ ਹਨ—ਨਾਲ ਹੀ ਉਹ ਅਕਾਉਂਟ ਜੋ ਖਾਸ ਤੌਰ 'ਤੇ ਉਨ੍ਹਾਂ ਨਾਲ ਸਾਂਝੇ ਕੀਤੇ ਗਏ ਹਨ।
ਸਭ ਡੇਟਾ ਹਰ ਕਿਸੇ ਲਈ ਦਿਖਾਈ ਨਾ ਦੇਵੇ। ਆਮ ਸੰਵੇਦਨਸ਼ੀਲ ਫੀਲਡਾਂ ਵਿੱਚ ਗਾਹਕ PII, ਠੇਕਾ ਵੇਰਵੇ, ਅਤੇ ਅੰਦਰੂਨੀ ਨੋਟ ਸ਼ਾਮਲ ਹਨ। ਫੀਲਡ-ਲੈਵਲ ਅਨੁਮਤੀਆਂ ਲਾਗੂ ਕਰੋ ਜਿਵੇਂ:
v1 ਲਈ, email/password ਨਾਲ MFA support ਆਮ ਤੌਰ 'ਤੇ ਕਾਫ਼ੀ ਹੁੰਦੀ ਹੈ। ਯੂਜ਼ਰ ਮodel ਇੰਝ ਡਿਜ਼ਾਇਨ ਕਰੋ ਕਿ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ SSO (SAML/OIDC) ਜੋੜ ਸਕੋ ਬਿਨਾਂ permissions ਦੁਬਾਰਾ ਲਿਖੇ (ਉਦਾਹਰਨ ਲਈ, roles/teams ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ store ਕਰੋ, SSO groups login 'ਤੇ map ਕਰੋ)।
ਅਨੁਮਤੀ ਬਦਲਾਅ ਨੂੰ auditable ਕਾਰਵਾਈ ਵਜੋਂ ਸਲੋ। ਘਟਨਾਵਾਂ ਨੂੰ ਰਿਕਾਰਡ ਕਰੋ ਜਿਵੇਂ role updates, team reassignment, export downloads, ਅਤੇ configuration edits—ਕਿਸਨੇ ਕੀਤਾ, ਕਦੋਂ, ਅਤੇ ਕੀ ਬਦਲਿਆ। ਇਹ INCIDENTS ਦੌਰਾਨ ਤੁਹਾਡੀ ਸਹਾਇਤਾ ਕਰੇਗਾ ਅਤੇ access reviews ਨੂੰ ਆਸਾਨ ਬਣਾਏਗਾ।
ਤੁਹਾਡੀ ਐਸਕਲੇਸ਼ਨ ਐਪ ਆਪਣੀ ਹਰ-ਰੋਜ਼ ਦੀ ਸਕ੍ਰੀਨਾਂ 'ਤੇ ਹੀ ਅਸਫਲ ਜਾਂ ਕਾਮਯਾਬ ਹੁੰਦੀ ਹੈ: ਸਹਾਇਤਾ ਲੀਡ ਪਹਿਲਾਂ ਕੀ ਦੇਖਦਾ ਹੈ, ਉਹ ਕਿੰਨੀ ਤੇਜ਼ੀ ਨਾਲ ਕੇਸ ਸਮਝ ਸਕਦਾ ਹੈ, ਅਤੇ ਕੀ ਅਗਲਾ ਡੈਡਲਾਈਨ ਨਜ਼ਰਅੰਦਾਜ਼ ਹੋਣਾ ਅਸੰਭਵ ਹੈ।
ਛੋਟੀ ਸਕੱਦ ਦੀਆਂ ਪੰਨੀਆਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਜੋ 90% ਕੰਮ ਕਵਰ ਕਰਦੀਆਂ ਹਨ:
ਨੇਵੀਗੇਸ਼ਨ ਨੂੰ ਪ੍ਰਡਿਕਟੇਬਲ ਰੱਖੋ: ਖੱਬੇ sidebar ਜਾਂ ਸਿਖਰ tabs ਨਾਲ “Queue”, “My Cases”, “Reports”। Queue ਨੂੰ default landing page ਬਣਾਓ।
ਕੇਸ ਸੂਚੀ ਵਿੱਚ ਸਿਰਫ ਉਹ ਫੀਲਡ ਦਿਖਾਓ ਜੋ ਕਿਸੇ ਨੂੰ ਫ਼ੈਸਲਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ ਕਿ ਅਗਲਾ ਕਦਮ ਕੀ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ। ਇੱਕ ਚੰਗੀ ਡੈਫਾਲਟ ਰੋ ਵਿੱਚ ਸ਼ਾਮਲ ਹੋਵੈ: customer, priority, current owner, status, next due date, ਅਤੇ warning indicator (ਜਿਵੇਂ “Due in 2h” ਜਾਂ “Overdue by 1d”)।
ਤੇਜ਼, ਪ੍ਰਯੋਗਿਕ ਫਿਲਟਰਿੰਗ ਅਤੇ ਖੋਜ ਸ਼ਾਮਲ ਕਰੋ:
ਸਕੈਨਿੰਗ ਲਈ ਡਿਜ਼ਾਇਨ ਕਰੋ: ਸਥਿਰ column widths, ਸਾਫ status chips, ਅਤੇ urgency ਲਈ ਇਕ ਹੀ ਹਾਈਲਾਈਟ ਰੰਗ।
ਕੇਸ ਵਿਊ ਇਕ ਨਜ਼ਰ ਵਿੱਚ ਇਹ ਉੱਤਰ ਦੇਣਾ ਚਾਹੀਦਾ ਹੈ:
ਫਾਸਟ actions ਸਿਖਰ 'ਤੇ ਰੱਖੋ (ਮੇਨੂ ਵਿੱਚ ਛੁਪਾਏ ਨਹੀਂ): Reassign, Escalate, Add milestone, Add note, Set next deadline. ਹਰ ਕਾਰਵਾਈ ਇਹ ਪੁਸ਼ਟੀ ਕਰੇ ਕਿ ਕੀ ਬਦਲਿਆ ਅਤੇ ਟਾਈਮਲਾਈਨ ਤੁਰੰਤ ਅੱਪਡੇਟ ਹੋ ਜਾਏ।
ਤੁਹਾਡੀ ਟਾਈਮਲਾਈਨ ਕਮਿਟਮੈਂਟਾਂ ਦੇ ਇੱਕ ਸਪਸ਼ਟ ਕ੍ਰਮ ਵਾਂਗ ਪੜ੍ਹਨੀ ਚਾਹੀਦੀ ਹੈ। ਸ਼ਾਮਲ ਕਰੋ:
ਪ੍ਰੋਗਰੈਸੀਵ ਡਿਸਕਲੋਜ਼ਰ ਵਰਤੋ: ਨਵੀਨਤਮ ਇਵੈਂਟ ਪਹਿਲਾਂ ਦਿਖਾਓ, ਪੁਰਾਣੀ ਹਸਤੀ ਵੇਖਣ ਲਈ ਵਿਸਥਾਰ ਦਾ ਵਿਕਲਪ ਰਹੇ। ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਆਡਿਟ ਟਰੇਲ ਹੈ, ਤਾਂ ਟਾਈਮਲਾਈਨ ਤੋਂ
Start with a one-sentence definition everyone agrees on (plus a few examples). Include explicit non-examples (routine tickets, internal tasks) so v1 doesn’t turn into a general ticketing system.
Then write 2–4 success metrics you can measure immediately, like SLA breach rate, time in each stage, or reassignment count.
Pick outcomes that reflect operational improvement, not feature completion. Practical v1 metrics include:
Choose a small set you can compute from day-one timestamps.
Use a small shared set of stages with clear entry/exit criteria, such as:
Write what must be true to enter and to leave each stage. This prevents ambiguity like “Resolved but still waiting on customer.”
Capture the minimum events needed to reconstruct the timeline and defend SLA decisions:
If you can’t explain how a timestamp is used, don’t collect it in v1.
Model each milestone as a timer with:
start_atdue_at (computed)paused_at and pause_reason (optional)completed_atAlso store the rule that produced (policy + calendar + reason). That makes audits and disputes far easier than storing only the final deadline.
Store timestamps in UTC, but keep a case/customer time zone for display and user reasoning. Model SLA calendars explicitly (24/7 vs business hours, holidays, region schedules).
Test edge cases like daylight saving changes, cases created near business close, and “pause starts exactly at the boundary.”
Keep v1 roles simple and aligned with real workflows:
Add scoping rules (team/region/account) and field-level controls for sensitive data like internal notes and PII.
Design the “everyday” screens first:
Optimize for scanning and reduce context switching—fast actions should not be buried in menus.
Start with a small set of high-signal notifications:
Pick 1–2 channels for v1 (usually in-app + email), then add an escalation matrix with clear thresholds (T–2h, T–0h, T+1h). Prevent fatigue with dedupe, batching, and quiet hours, and make acknowledge/snooze auditable.
Integrate only what keeps timelines accurate:
If you do two-way sync, define a source of truth per field and conflict rules (avoid “last write wins”). Publish a minimal versioned API contract so integrations don’t break. For more on automation patterns, see /blog/workflow-automation-basics; for packaging considerations, see /pricing.
due_at