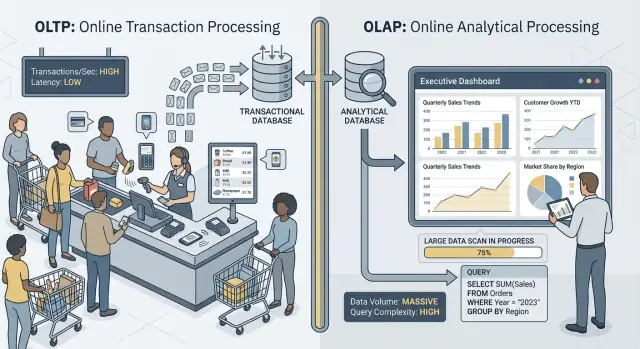
OLTP vs OLAP: ਬਿਨਾਂ ਜ਼ਿਆਦਾ ਜਾਰਗਨ ਦੇ ਕੀ ਹੁੰਦਾ ਹੈ
ਜਦੋਂ ਲੋਕ “OLTP” ਅਤੇ “OLAP” ਬਾਰੇ ਗੱਲ ਕਰਦੇ ਹਨ, ਉਹ ਦੱਸ ਰਹੇ ਹੁੰਦੇ ਹਨ ਕਿ ਡੇਟਾਬੇਸ ਕਿਸ ਤਰ੍ਹਾਂ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ—ਅਤੇ ਦੋ ਬਿਲਕੁਲ ਵੱਖਰੇ ਢੰਗ ਹਨ।
OLTP: ਉਹ ਡੇਟਾਬੇਸ ਜੋ ਵਿਅਵਸਾਇਆ ਚਲਾਉਂਦਾ ਹੈ
OLTP (Online Transaction Processing) ਉਹ ਵਰਕਲੋਡ ਹੈ ਜੋ ਰੋਜ਼ਮਰਾ ਦੇ ਕਾਮਾਂ ਲਈ ਹੁੰਦਾ ਹੈ — ਤੇਜ਼ ਅਤੇ ਸਹੀ ਹੋਣਾ ਲਾਜ਼ਮੀ ਹੁੰਦਾ ਹੈ। ਸੋਚੋ: “ਇਸ ਤਰ੍ਹਾਂ ਦਾ ਬਦਲਾਅ ਅੱਜ ਹੀ ਸੇਵ ਕਰੋ।”
ਆਮ OLTP ਟਾਸਕਾਂ ਵਿੱਚ ਆਰਡਰ ਬਣਾਉਣਾ, ਇਨਵੈਂਟਰੀ ਅਪਡੇਟ ਕਰਨਾ, ਭੁਗਤਾਨ ਦਰਜ ਕਰਨਾ ਜਾਂ ਗਾਹਕ ਦਾ ਪਤਾ ਬਦਲਣਾ ਸ਼ਾਮِل ਹੁੰਦਾ ਹੈ। ਇਹ ਫ਼ਰਮੂਲਾਈਟੀਆਂ ਛੋਟੇ (ਕੁਝ ਹੀ ਪੰਗਤੀਆਂ), ਬਹੁਤ ਵਾਰ ਹੁੰਦੀਆਂ ਅਤੇ ਮਿਲੀਸੈਕਿੰਡਾਂ ਵਿੱਚ ਜਵਾਬ ਦੇਣੀਆਂ ਲਾਜ਼ਮੀ ਹੁੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਕਿਸੇ ਵਿਅਕਤੀ ਜਾਂ ਹੋਰ ਸਿਸਟਮ ਦਾ ਇੰਤਜ਼ਾਰ ਹੁੰਦਾ ਹੈ।
OLAP: ਉਹ ਡੇਟਾਬੇਸ ਜੋ ਕਾਰੋਬਾਰ ਨੂੰ ਸਮਝਾਂਦਾ ਹੈ
OLAP (Online Analytical Processing) ਉਹ ਵਰਕਲੋਡ ਹੈ ਜੋ ਇਹ ਦੱਸਦਾ ਹੈ ਕਿ ਕੀ ਹੋਇਆ ਅਤੇ ਕਿਉਂ। ਸੋਚੋ: “ਕਾਫ਼ੀ ਡੇਟਾ ਸਕੈਨ ਕਰ ਕੇ ਸਾਰ ਦਿੱਤਾ ਜਾਵੇ।”
ਆਮ OLAP ਟਾਸਕਾਂ ਵਿੱਚ ਡੈਸ਼ਬੋਰਡ, ਰੁਝਾਨੀ ਰਿਪੋਰਟਾਂ, ਕੋਹੋਰਟ ਵਿਸ਼ਲੇਸ਼ਣ, ਅਨੁਮਾਨ ਅਤੇ "ਕਟ-ਤੋ-ਕਟ" ਪ੍ਰਸ਼ਨ ਹੁੰਦੇ ਹਨ; ਉਦਾਹਰਨ ਲਈ: “ਆਖ਼ਰੀ 18 ਮਹੀਨਿਆਂ ਵਿੱਚ ਖੇਤਰ ਅਤੇ ਉਤਪਾਦ ਸ਼੍ਰੇਣੀ ਅਨੁਸਾਰ ਰੈਵਨਿਊ ਕਿਵੇਂ ਬਦਲਿਆ?” ਇਹ ਕੁਝ ਦਿਨਾਂ ਜਾਂ ਮਿੰਟਾਂ ਤੱਕ ਚਲ ਸਕਦੇ ਹਨ ਅਤੇ ਗਲਤ ਨਹੀਂ ਮੰਨੇ ਜਾਂਦੇ।
ਇੱਕੋ ਡੇਟਾ, ਵੱਖਰੇ ਮਕਸਦ—ਅਤੇ ਵੱਖਰੀਆਂ ਲੋੜਾਂ
ਮੁੱਖ ਵਿਚਾਰ ਸਧਾਰਨ ਹੈ: OLTP ਤੇਜ਼, ਸਹੀ ਲਿਖਾਈਆਂ ਅਤੇ ਛੋਟੇ ਰੀਡ ਲਈ ਅਪਟੀਮਾਈਜ਼ ਕਰਦਾ ਹੈ, ਜਦਕਿ OLAP ਵੱਡੀਆਂ ਰੀਡ ਅਤੇ ਜਟਿਲ ਹਿਸਾਬਾਂ ਲਈ ਅਪਟੀਮਾਈਜ਼ ਕਰਦਾ ਹੈ। ਲਕੜੀ-ਲੱਕੜੀ ਲੋੜਾਂ ਦੀ ਵਜ੍ਹਾ ਨਾਲ ਸਰੋਤਾਂ, ਇੰਡੈਕਸ, ਸਟੋਰੇਜ ਅਤੇ ਸਕੇਲਿੰਗ ਦੇ ਤਰੀਕੇ ਵੱਖਰੇ ਹੋ ਜਾਂਦੇ ਹਨ।
ਇੱਥੇ ਸ਼ਬਦ 'ਅਕਸਰ' ਵਰਤਿਆ ਗਿਆ ਹੈ—'ਕਦੀ ਨਹੀਂ' ਨਹੀਂ। ਕੁਝ ਛੋਟੀ ਟੀਮਾਂ ਇੱਕ ਹੀ ਡੇਟਾਬੇਸ ਸਾਂਝਾ ਕਰ ਸਕਦੀਆਂ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ ਜਦ ਡੇਟਾ ਘੱਟ ਹੋਵੇ ਅਤੇ ਪੂਰੀ ਚੇਤਨੀ ਨਾਲ કਵੇਰੀਆਂ ਚਲਾਈਆਂ ਜਾਣ। ਅਗਲੇ ਸਕੈਕਸ਼ਨਾਂ ਵਿੱਚ ਵੇਖਾਂਗੇ ਕਿ ਪਹਿਲਾਂ ਕੀ ਤੋੜਦਾ ਹੈ, ਆਮ ਵੱਖਰੇ ਪੈਟਰਨ ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਤੋਂ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਸਰਫ਼ ਕਰਕੇ ਕਿਵੇਂ ਹਟਾਇਆ ਜਾ ਸਕਦਾ ਹੈ।
ਤੇਜ਼ ਉਦਾਹਰਨ
- Checkout (OLTP): ਗਾਹਕ “Pay” ਤੇ ਕਲਿਕ ਕਰਦਾ ਹੈ, ਤੇ ਤੁਹਾਡੀ ਐਪ ਆਰਡਰ, ਭੁਗਤਾਨ ਸਥਿਤੀ ਅਤੇ ਇਨਵੈਂਟਰੀ ਅਪਡੇਟ ਲਿਖਦੀ ਹੈ।
- Reporting dashboard (OLAP): ਮੈਨੇਜਰ ਇੱਕ ਡੈਸ਼ਬੋਰਡ ਖੋਲਦਾ ਹੈ ਜੋ ਹਜ਼ਾਰਾਂ (ਜਾਂ ਲੱਖਾਂ) ਆਰਡਰਾਂ ਨੂੰ ਇੱਕਠਾ ਕਰਕੇ ਕੰਵਰਜਨ ਦਰ, ਔਸਤ ਆਰਡਰ ਮੁੱਲ ਅਤੇ ਹਫਤਾਵਾਰੀ ਰੁਝਾਨ ਦਿਖਾਉਂਦਾ ਹੈ।
ਵੱਖਰੇ ਮਕਸਦ, ਵੱਖਰੇ ਸਫਲਤਾ ਮੈਟ੍ਰਿਕਸ
OLTP ਅਤੇ OLAP ਦੋਹਾਂ "SQL ਵਰਤਦੇ" ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਉਹ ਵੱਖਰੇ ਕੰਮਾਂ ਲਈ ਅਪਟੀਮਾਈਜ਼ ਹੁੰਦੇ ਹਨ—ਤੇ ਇਹ ਇਸ ਗੱਲ 'ਤੇ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ ਕਿ ਹਰ ਇੱਕ ਕੀ ਗੱਲ ਸਫਲਤਾ ਮੰਨਦਾ ਹੈ।
OLTP: ਸਪੀਡ, concurrency, ਅਤੇ ਸਹੀਪਣ
OLTP (ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ) ਸਿਸਟਮ ਦਿਨ-ਪ੍ਰਤੀਦਿਨ ਦੇ ਕਾਰਜ ਚਲਾਉਂਦੇ ਹਨ: ਚੈਕਆਉਟ ਫਲੋਜ਼, ਖਾਤੇ ਅਪਡੇਟ, ਰਿਜ਼ਰਵੇਸ਼ਨ, ਸਹਾਇਤਾ ਟੂਲ। ਪ੍ਰਾਥਮਿਕਤਾਵਾਂ ਸਪਸ਼ਟ ਹਨ:
- ਛੋਟੇ ਰੀਡ/ਰਾਈਟ ਲਈ ਤੇਜ਼ ਜਵਾਬ (ਮਿਲੀਸੈਕਿੰਡਾਂ ਦਰਜੇ)
- ਬਹੁਤ ਸਾਰੇ ਸਾਥੀ ਉਪਭੋਗੀ ਬਿਨਾਂ ਸਲੋਡਾਊਨਾਂ ਦੇ
- ਸਹੀਪਣਾ ਅਤੇ ਸਾਂਤਲਤਾ, ਕਿਉਂਕਿ ਗਲਤ ਬੈਲੈਂਸ ਜਾਂ ਡੁਪਲਿਕੇਟ ਆਰਡਰ ਵਪਾਰ ਲਈ ਵੱਡਾ ਸੰਕਟ ਹੈ
ਸਫਲਤਾ ਆਮ ਤੌਰ 'ਤੇ latency ਮੈਟ੍ਰਿਕਸ (ਜਿਵੇਂ p95/p99), error rate ਅਤੇ peak concurrency ਹਲਾਤਾਂ ਅਨੁਸਾਰ ਮਾਪੀ ਜਾਂਦੀ ਹੈ।
OLAP: ਸਕੈਨਿੰਗ, ਅੱਗਰੀਕਰਨ ਅਤੇ ਲਚਕੀਲਾਪਣ
OLAP (ਐਨਾਲਿਟਿਕਸ) ਸਿਸਟਮ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦਿੰਦੇ ਹਨ ਜਿਵੇਂ “ਇਸ ਕਵਾਰਟਰ 'ਚ ਕੀ ਬਦਲਿਆ?” ਜਾਂ “ਕਿਸ ਸੈਗਮੈਂਟ ਨੇ ਨਵੀਂ ਕੀਮਤ ਦੇ ਬਾਅਦ churn ਕੀਤਾ?” ਇਹ ਕੁਆਰੀਆਂ ਅਕਸਰ:
- ਵੱਡੀ ਮਾਤਰਾ ਦਾ ਡੇਟਾ ਸਕੈਨ ਕਰਦੀਆਂ
- ਅੱਗ੍ਰੈਗੇਸ਼ਨ (SUM, COUNT, ਪ੍ਰਤੀਸ਼ਤਿਕ), ਅਤੇ ਜੋਇਨ ਕਰਦੀਆਂ
- ਅਕਸਰ ਬਦਲਦੀਆਂ ਹਨ ਜਦ ਵਿਸ਼ਲੇਸ਼ਕ ਖੋਜ ਕਰਦੇ ਹਨ
ਇਥੇ ਸਫਲਤਾ ਕੁਆਰੀ throughput, time-to-insight ਅਤੇ ਬਿਨਾਂ ਹੱਥ-ਟਿਆਰ ਕਰਨ ਵਾਲੀਆਂ जਟਿਲ ਕੁਆਰੀਆਂ ਚਲਾਉਣ ਦੀ ਯੋਗਤਾ ਵਗੈਰਾ ਨਾਲ ਹੋਵੇਗੀ।
"ਸਭ ਕੁਝ ਲਈ ਇੱਕ ਸਿਸਟਮ" ਕਿਉਂ ਸਮਝੌਤਾ ਬਣਾਉਂਦਾ ਹੈ
ਜਦ ਤੁਸੀਂ ਦੋਹਾਂ ਵਰਕਲੋਡ ਇਕੇ ਡੇਟਾਬੇਸ 'ਤੇ ਜ਼ਬਰਦਸਤ ਕਰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਉਸਨੂੰ ਇਕੋ-ਸਮੇਂ ਛੋਟੇ ਤੇਜ਼ ਲੈਣ-ਦੇਣ ਅਤੇ ਵੱਡੇ ਐਕਸਪਲੋਰੇਟਰੀ ਸਕੈਨ ਦੋਹਾਂ ਚੰਗੇ ਬਣਾਉਣ ਦੀ ਉਮੀਦ ਕਰ ਰਹੇ ਹੋ। ਨਤੀਜਾ ਆਮ ਤੌਰ 'ਤੇ ਸਮਝੌਤਾ ਹੁੰਦਾ ਹੈ: OLTP ਨੂੰ ਲੈਟੈਂਸੀ ਅਣਪੇਸ਼ਗੁਈ ਮਿਲਦੀ ਹੈ, OLAP ਨੂੰ ਪ੍ਰੋਟੈਕਟ ਕਰਨ ਲਈ throttle ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਟੀਮਾਂ ਤੇ ਦਲੀਲ ਹੋਂਦੀਆਂ ਹਨ ਕਿ ਕੌਣ ਦੀਆਂ ਕੁਆਰੀਆਂ "ਅਨੁਮਤ" ਹਨ। ਵੱਖਰੇ ਲਕੜੀ-ਲੱਕੜੀ ਲਈ ਵੱਖਰੇ ਮਾਪਦੰਡ ਲੋੜੀਂਦੇ ਹਨ—ਅਕਸਰ ਵੱਖਰੇ ਸਿਸਟਮ ਵੀ।
ਸਰੋਤਾਂ ਦੀ ਟਕਰਾਅ: ਜਦ ਐਨਾਲਿਟਿਕਸ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਤੋਂ ਚੋਰੀ ਕਰ ਲੈਂਦਾ ਹੈ
ਜਦ OLTP (ਤੁਹਾਡੇ ਐਪ ਦੇ ਦੈਨਿਕ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ) ਅਤੇ OLAP (ਰਿਪੋਰਟਿੰਗ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ) ਇੱਕੇ ਡੇਟਾਬੇਸ 'ਤੇ ਦੌੜਦੇ ਹਨ, ਉਹ ਇੱਕੋ ਸੀਮਿਤ ਸਰੋਤਾਂ ਲਈ ਲੜਦੇ ਹਨ। ਨਤੀਜਾ ਸਿਰਫ਼ "ਰਿਪੋਰਟਿੰਗ ਧੀਮੀ" ਨਹੀਂ ਹੁੰਦਾ—ਅਕਸਰ ਚੈਕਆਉਟ ਸਲੋ ਹੋ ਜਾਂਦੇ ਹਨ, ਲੌਗਿਨ ਰੁਕ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਐਪ ਅਣਪੇਸ਼ਗੁਈ ਤਰ੍ਹਾਂ ਕੰਮ ਕਰਦਾ ਹੈ।
CPU ਅਤੇ ਮੈਮੋਰੀ: ਲੰਮੀ ਕੁਆਰੀਆਂ ਬਨਾਮ ਛੋਟੀਆਂ ਕੁਆਰੀਆਂ
ਐਨਾਲਿਟਿਕਲ ਕੁਆਰੀਆਂ ਆਮ ਤੌਰ 'ਤੇ ਲੰਬੀਆਂ ਅਤੇ ਭਾਰੀ ਹੁੰਦੀਆਂ ਹਨ: ਵੱਡੀਆਂ ਟੇਬਲਾਂ 'ਤੇ ਜੋਇਨ, ਅੱਗ੍ਰੈਗੇਸ਼ਨ, ਸਾਰਟਿੰਗ ਅਤੇ ਗਰੁੱਪਿੰਗ। ਉਹ CPU ਕੋਰ ਅਤੇ ਮੈਮੋਰੀ (ਹੈਸ਼ ਜੋਇਨ ਅਤੇ ਸਾਰਟ ਬਫਰ) 'ਤੇ ਕਬਜ਼ਾ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਦੂਜੇ ਪਾਸੇ, ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਕੁਆਰੀਆਂ ਛੋਟੀਆਂ ਪਰ latency-ਸਂਵੇਦਨਸ਼ੀਲ ਹੁੰਦੀਆਂ ਹਨ। ਜੇ CPU ਭਰ ਜਾਵੇ ਜਾਂ ਮੈਮੋਰੀ ਕਿੱਲ੍ਹੇ ਜਾਂ eviction ਹੋਵੇ, ਉਹ ਛੋਟੀਆਂ ਕੁਆਰੀਆਂ ਵੱਡੀਆਂ ਦੇ ਪਿੱਛੇ ਇੰਤਜ਼ਾਰ ਕਰਨ ਲੱਗਦੀਆਂ ਹਨ—ਭਾਵੇਂ ਹਰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਨੂੰ ਅਸਲ ਵਿੱਚ ਕੁਝ ਮਿਲੀਸੈਕਿੰਡ ਹੀ ਲੱਗਦੇ ਹੋਣ।
ਡਿਸਕ I/O: ਵੱਡੇ ਸਕੈਨ ਬਨਾਮ ਬਹੁਤ ਛੋਟੇ ਰੀਡ/ਰਾਈਟ
ਐਨਾਲਿਟਿਕਸ ਅਕਸਰ ਵੱਡੇ ਟੇਬਲ ਸਕੈਨ ਖਿੱਚਦੀ ਹੈ ਅਤੇ ਕਈ ਪੇਜਾਂ ਸੀਕੁਐੰਸ਼ਲੀ ਪੜ੍ਹਦੀ ਹੈ। OLTP ਉਲਟ ਕਰਦਾ ਹੈ: ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ ਰੈਂਡਮ ਰੀਡ ਤੇ ਲਿਖਾਈਆਂ, ਤੇ ਇੰਡੈਕਸ ਅਤੇ ਲੌਗ ਲਿਖਾਈਆਂ ਮੁੜ-ਮੁੜ।
ਜਦ ਦੋਹਾਂ ਮਿਲਦੇ ਹਨ, ਸਟੋਰੇਜ ਸਬਸਿਸਟਮ ਵੱਖ-ਵੱਖ ਪਹੁੰਚ ਪੈਟਰਨਾਂ ਨੂੰ ਸੰਭਾਲਣਾ ਪੈਂਦਾ ਹੈ। ਕੈਸ਼ ਜੋ OLTP ਨੂੰ ਫਾਇਦਾ ਦੇ ਰਿਹਾ ਸੀ, ਉਹ ਐਨਾਲਿਟਿਕਸ ਸਕੈਨਾਂ ਨਾਲ "ਵਾਸ਼ ਆਊਟ" ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਡਿਸਕ ਉੱਤੇ ਲੇਟੈਂਸੀ ਵਧ ਸਕਦੀ ਹੈ ਜਦ ਰਿਪੋਰਟਿੰਗ ਲਈ ਡੇਟਾ ਸਟਰੀਮ ਕੀਤਾ ਜਾ ਰਿਹਾ ਹੋਵੇ।
ਕਨੈਕਸ਼ਨ ਪੂਲ ਦਬਾਅ ਅਤੇ ਕਤਾਰਬੰਦੀ
ਕੁਝ ਵਿਸ਼ਲੇਸ਼ਕ ਵੱਡੀਆਂ ਕੁਆਰੀਆਂ ਚਲਾਉਂਦੇ ਹਨ ਜੋ ਮਿਨਟਾਂ ਲਈ ਕਨੈਕਸ਼ਨਾਂ ਨੂੰ ਬੰਨ੍ਹ ਸਕਦੀਆਂ ਹਨ। ਜੇ ਤੁਹਾਡੀ ਐਪ ਸਥਿਰ-ਅਕਾਰ ਪੂਲ ਵਰਤਦੀ ਹੈ, ਤਾਂ ਬੇਨਤੀ ਇੱਕ ਫ੍ਰੀ ਕਨੈਕਸ਼ਨ ਦੀ ਉਡੀਕ ਕਰਦੀਆਂ ਹਨ। ਇਹ ਕਤਾਰਬੰਦੀ ਤਰਤੀਬ ਸਿਹਤਮੰਦ ਸਿਸਟਮ ਨੂੰ ਟੁੱਟਿਆ ਹੋਇਆ ਮਹਿਸੂਸ ਕਰਵਾ ਸਕਦੀ ਹੈ: ਔਸਤ latency ਠੀਕ ਲੱਗ ਸਕਦੀ ਹੈ, ਪਰ tail latencies (p95/p99) ਦੁਖਦਾਈ ਹੋ ਜਾਂਦੀਆਂ ਹਨ।
ਉਪਭੋਗੀ ਕੀ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ
ਬਾਹਰੋਂ, ਇਹ সময়-ਆਉਂਦੀਆਂ timeout, ਧੀਮਾ ਚੈੱਕਆਉਟ, ਦੇਰੀ ਨਾਲ ਖੋਜ ਨਤੀਜੇ ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਅਸਥਿਰ ਵਿਹਾਰ ਵਜੋਂ ਨਜ਼ਰ ਆਉਂਦਾ ਹੈ—ਅਕਸਰ "ਸਿਰਫ ਰਿਪੋਰਟਿੰਗ ਦੌਰਾਨ" ਜਾਂ "ਸਿਰਫ ਮਹੀਨੇ ਦੇ ਅੰਤ ਵਿੱਚ"। ਐਪ ਟੀਮ errors ਵੇਖਦੀ ਹੈ; ਐਨਾਲਿਟਿਕਸ ਟੀਮ ਕੁਆਰੀਆਂ ਨੂੰ ਧੀਮੀਆਂ ਵੇਖਦੀ ਹੈ; ਅਸਲ ਸਮੱਸਿਆ ਸਾਂਝੀ ਟਕਰਾਅ ਹੀ ਹੁੰਦੀ ਹੈ।
ਡੇਟਾ ਲੇਆਊਟ ਅਤੇ ਇੰਡੈਕਸਿੰਗ ਦੀਆਂ ਲੋੜਾਂ ਵੱਖ-ਵੱਖ ਦਿਸ਼ਾਵਾਂ ਵਿੱਚ ਖਿੱਚਦੀਆਂ ਹਨ
OLTP ਅਤੇ OLAP ਸਿਰਫ "ਡੇਟਾਬੇਸ ਵੱਖਰੇ ਢੰਗ ਨਾਲ ਵਰਤਦੇ" ਨਹੀਂ—ਉਹ ਵਿਰੋਧੀ ਫਿਜ਼ਿਕਲ ਡਿਜ਼ਾਈਨਾਂ ਨੂੰ ਇਨਾਮ ਦਿੰਦੇ ਹਨ। ਜਦ ਤੁਸੀਂ ਦੋਹਾਂ ਦੀ ਪੂਰੀ ਤਰ੍ਹਾਂ ਪੂਰੀ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਐਸਾ ਸਮਝੌਤਾ ਹੁੰਦਾ ਹੈ ਜੋ ਮਹਿੰਗਾ ਵੀ ਹੋ ਸਕਦਾ ਹੈ ਅਤੇ ਫਿਰ ਵੀ ਠੀਕ ਨਹੀਂ ਚੱਲਦਾ।
OLTP: ਤੇਜ਼, ਚੁਣਿੰਦਗੀ ਲੁੱਕਅਪ ਲਈ ਅਪਟੀਮਾਈਜ਼
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਵਰਕਲੋਡ ਛੋਟੇ queries ਨਾਲ ਡੋਮੀਨਟ ਹੁੰਦਾ ਹੈ: ਇੱਕ ਆਰਡਰ ਲਿਆਓ, ਇੱਕ ਇਨਵੈਂਟਰੀ ਪੰਗਤੀ ਅਪਡੇਟ ਕਰੋ, ਇੱਕ ਯੂਜ਼ਰ ਲਈ ਆਖਰੀ 20 ਇਵੈਂਟ ਲਿਸਟ ਕਰੋ।
ਇਹ OLTP schema ਨੂੰ row-oriented ਸਟੋਰੇਜ ਅਤੇ ਇੰਡੈਕਸਾਂ ਵੱਲ ਧਕਲਦਾ ਹੈ ਜੋ point lookups ਅਤੇ ਛੋਟੇ range scans ਲਈ ਸਹਾਇਕ ਹੁੰਦੇ ਹਨ (ਅਕਸਰ primary keys, foreign keys ਅਤੇ ਕੁਝ ਉੱਚ ਮੁੱਲ ਵਾਲੇ secondary indexes)। ਲਕੜੀ ਮਕਸਦ predictible, ਘੱਟ latency—ਖ਼ਾਸ ਕਰਕੇ ਲਿਖਾਈਆਂ ਲਈ।
OLAP: ਸਕੈਨਿੰਗ, ਗਰੁੱਪਿੰਗ, ਅਤੇ ਸਾਰਾਂਸ਼ ਲਈ ਅਪਟੀਮਾਈਜ਼
ਐਨਾਲਿਟਿਕਸ ਅਕਸਰ ਕਈ ਪੰਗਤੀਆਂ ਪੜ੍ਹਦਾ ਹੈ ਪਰ ਥੋੜੇ ਕਾਲਮ: “ਹਫਤੇ ਅਨੁਸਾਰ ਖੇਤਰ ਮੁਤਾਬਕ ਰੈਵਨਿਊ,” “ਕੈਂਪੇਨ ਮੁਤਾਬਕ ਕੰਵਰਜਨ,” “ਮਾਰਜਿਨ ਮੁਤਾਬਕ ਸਿਖਰ ਦੇ ਉਤਪਾਦ।”
OLAP ਸਿਸਟਮ columnar storage (ਸਿਰਫ਼ ਲੋੜੀਂਦੇ ਕਾਲਮ ਪੜ੍ਹਨ ਲਈ), partitioning (ਪੁਰਾਣਾ/ਅਣਲੱਗ ਡੇਟਾ ਛੇਤੀ prune ਕਰਨ ਲਈ), ਅਤੇ pre-aggregation (materialized views, rollups, summary tables) ਤੋਂ ਲਾਭ ਲੈਂਦੇ ਹਨ ਤਾਂ ਕਿ ਰਿਪੋਰਟਾਂ ਵਾਰ-ਵਾਰ ਇਕੋ-ਇਹ totals ਦੁਬਾਰਾ ਨਾ ਗਣਿਆ ਕਰਨ।
"ਹਰ ਚੀਜ਼ ਲਈ ਇੰਡੈਕਸ" ਕਿਉਂ ਵਾਪਸੀ ਕਰਦਾ ਹੈ
ਆਮ ਰਿਆਕਸ਼ਨ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਹਰ ਡੈਸ਼ਬੋਰਡ ਤੇਜ਼ ਹੋਵੇ ਇਹਦੇ ਲਈ ਇੰਡੈਕਸ ਵਧਾਏ ਜਾਣ। ਪਰ ਹਰ ਵੱਧ ਇੰਡੈਕਸ ਨਾਲ ਲਿਖਣ ਦੀ ਲਾਗਤ ਵੱਧਦੀ ਹੈ: inserts, updates, deletes ਹੁਣ ਹੋਰ ਬਣਤਰਾਂ ਨੂੰ ਵੀ maintain ਕਰਦੇ ਹਨ। ਇਹ ਸਟੋਰੇਜ ਵਧਾਉਂਦਾ ਹੈ ਅਤੇ vacuuming, reindexing ਅਤੇ ਬੈਕਅੱਪ ਵਰਗੀਆਂ ਮੇਨਟੇਨੈਂਸ ਟਾਸਕਾਂ ਨੂੰ ਵੀ ਧੀਮਾ ਕਰਦਾ ਹੈ।
ਕੁਆਰੀ ਪਲੈਨਰ ਅਤੇ ਅੰਕੜਿਆਂ ਦਾ ਡ੍ਰਿਫਟ (ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ)
ਡੇਟਾਬੇਸ ਕੁਆਰੀ ਪਲੈਨਜ਼ ਅੰਕੜਿਆਂ ਦੇ ਆਧਾਰ ਤੇ ਚੁਣਦੇ ਹਨ—ਇਹ ਅੰਦਾਜ਼ਾ ਹੁੰਦਾ ਹੈ ਕਿ ਕਿਸ ਫਿਲਟਰ ਲਈ ਕਿੰਨੀ ਰੋਜ਼ ਮਿਲਣਗੀਆਂ, ਕਿੰਨਾ ਸਿਲੈਕਟਿਵ ਇੰਡੈਕਸ ਹੈ, ਅਤੇ ਡੇਟਾ ਕਿਵੇਂ ਫੈਲਿਆ ਹੋਇਆ ਹੈ। OLTP ਡੇਟਾ ਲਗਾਤਾਰ ਬਦਲਦਾ ਹੈ। ਜਿਵੇਂ ਜਿਵੇਂ ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ ਬਦਲਦੇ ਹਨ, ਅੰਕੜੇ ਡ੍ਰਿਫਟ ਕਰਦੇ ਹਨ, ਅਤੇ ਪਲੈਨਰ ਅਜਿਹਾ ਪਲਾਨ ਚੁਣ ਸਕਦਾ ਹੈ ਜੋ ਕੱਲ੍ਹ ਲਈ ਵਧੀਆ ਸੀ ਪਰ ਅਜ ਲਈ ਧੀਮਾ ਹੈ।
ਭਾਰੀ OLAP ਕੁਆਰੀਆਂ ਜਦ ਮਿਲਦੀਆਂ ਹਨ ਜੋ ਵੱਡੀਆਂ ਟੇਬਲਾਂ ਨੂੰ ਸਕੈਨ ਅਤੇ ਜੋਇਨ ਕਰਦੀਆਂ ਹਨ, ਤਾਂ ਵੱਖਰਾ ਰਿਹਾ variability ਆਉਂਦਾ ਹੈ: "ਸਭ ਤੋਂ ਵਧੀਆ ਪਲਾਨ" ਅਣਪ੍ਰਡਿਕਟੇਬਲ ਹੋ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਇੱਕ ਵਰਕਲੋਡ ਲਈ ਟਿਊਨ ਕਰਨ ਨਾਲ ਦੂਜੇ ਨੂੰ ਨੁਕਸਾਨ ਹੋ ਸਕਦਾ ਹੈ।
ਲਾਕਿੰਗ, MVCC, ਅਤੇ ਮੇਨਟੇਨੈਂਸ ਸਾਈਡ ਐਫੈਕਟ
Protect production from dashboards
Set a clear reporting boundary so dashboards do not slow checkouts.
ਇਹ ਵੀ ਕਿ ਜੇ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ "ਕਨਕਰਨਸੀ ਦਾ ਸਮਰਥਨ" ਕਰਦਾ ਹੈ, ਭਾਰੀ ਰਿਪੋਰਟਿੰਗ ਨਾਲ ਲਾਈਵ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਮਿਲਾਉਂਦੇ ਹੋਏ ਸੁਖਦਾਈ ਬਣਾਉਂਦਾ ਹੈ—ਤੇ ਇਹ ਸੁਥਰ ਪੈਦਾ ਕਰਦਾ ਹੈ ਜੋ ਅਣਪ੍ਰਡਿਕਟੇਬਲ ਹੁੰਦੇ ਹਨ ਅਤੇ ਗਾਹਕ ਨੂੰ ਸਮਝਾਉਣਾ ਮੁਸ਼ਕਲ ਹੁੰਦਾ ਹੈ।
ਲੰਬੀਆਂ ਕੁਆਰੀਆਂ ਹਾਲਾਂਕਿ ਲਾਕ ਸਮੱਸਿਆ ਪੈਦਾ ਕਰਦੀਆਂ ਹਨ
OLAP-ਸਟਾਈਲ ਕੁਆਰੀਆਂ ਅਕਸਰ ਬਹੁਤ ਸਾਰੀਆਂ ਰੋਜ਼ਾਂ ਨੂੰ ਸਕੈਨ ਕਰਦੀਆਂ, ਕਈ ਟੇਬਲਾਂ ਨੂੰ ਜੋਇਨ ਕਰਦੀਆਂ ਅਤੇ ਸਕਿੰਟਾਂ ਜਾਂ ਮਿੰਟਾਂ ਲਈ ਚਲਦੀਆਂ। ਇਸ ਦੌਰਾਨ ਉਹ ਲਾਕ ਰੱਖ ਸਕਦੀਆਂ ਹਨ (ਉਦਾਹਰਨ ਲਈ schema objects ਤੇ, ਜਾਂ ਜਦ ਉਹ temp structures ਵਿੱਚ ਸਾਰਟ/ਅੱਗ੍ਰੈਗੇਟ ਕਰਦੇ ਹਨ) ਅਤੇ ਅਕਸਰ ਉਹ ਬਹੁਤ ਸਾਰੀਆਂ ਰੋਜ਼ਾਂ ਨੂੰ "ਚਲਣ ਵਿਚ" ਰੱਖ ਕੇ ਪਰੋਸੇ ਸਰੋਤੇ ਤੇ ਲਾਕ contention ਬਢ੍ਹਾ ਦਿੰਦੇ ਹਨ।
MVCC (multi-version concurrency control) ਦੇ ਨਾਲ ਵੀ, ਡੇਟਾਬੇਸ ਨੂੰ ਇੱਕੋ ਹੀ ਰੋਜ਼ ਦੇ ਕਈ ਵਰਜਨਾਂ ਨੂੰ ਟਰੈਕ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਤਾਂ ਕਿ readers ਅਤੇ writers ਇੱਕ ਦੂਜੇ ਨੂੰ ਬਲੌਕ ਨਾ ਕਰਨ। ਇਹ ਮਦਦ ਕਰਦਾ ਹੈ, ਪਰ ਇਹ contention ਖਤਮ ਨਹੀਂ ਕਰਦਾ—ਖ਼ਾਸ ਕਰਕੇ ਜਦ queries hot tables ਨੂੰ ਛੂਹਦੇ ਹਨ ਜੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਲਗਾਤਾਰ ਅਪਡੇਟ ਕਰਦੇ ਹਨ।
MVCC ਦੀ ਛੁਪਈ ਲਾਗਤ: ਕਲੀਨਅਪ ਔਖਾ ਹੋ ਜਾਂਦਾ ਹੈ
MVCC ਦਾ ਅਰਥ ਹੈ ਕਿ ਪੁਰਾਣੇ row versions ਤੱਕ ਡੇਟਾਬੇਸ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਹਟਾਉਣ ਤੱਕ ਰੱਖਿਆ ਜਾਣਾ। ਇੱਕ ਲੰਬੀ ਰਿਪੋਰਟ ਪੁਰਾਣਾ snapshot open ਰੱਖ ਸਕਦੀ ਹੈ, ਜੋ cleanup ਨੂੰ space ਮੁੜ-ਹਾਸਲ ਕਰਨ ਤੋਂ ਰੋਕਦੀ ਹੈ।
ਇਸ ਤੋਂ ਪ੍ਰਭਾਵ ਹੁੰਦੇ ਹਨ:
- Vacuum/garbage collection: dead tuples/versions ਤੁਰੰਤ ਹਟ ਨਹੀਂ ਹੋ ਸਕਦੇ।
- Bloat/fragmentation: ਸਟੋਰੇਜ ਵੱਧਦਾ ਹੈ, ਇੰਡੈਕਸ ਘੱਟ ਪ੍ਰਭਾਵਸ਼ালী ਹੋ ਜਾਂਦੇ ਹਨ, ਅਤੇ caches ਘੱਟ ਕੰਮ ਕਰਨਗੇ।
- Compaction pressure: ਕੁਝ ਇੰਜਣ background ਵਿੱਚ ਵੱਧ ਕੰਮ ਕਰਦੇ ਹਨ ਜੋ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਤੋਂ I/O ਅਤੇ CPU ਚੋਰੀ ਕਰ ਲੈਂਦੇ ਹਨ।
ਨਤੀਜਾ ਇੱਕ ਡਬਲ ਹਿੱਟ ਹੈ: ਰਿਪੋਰਟਿੰਗ ਡੇਟਾਬੇਸ ਨੂੰ ਵੱਧ ਮਹਨਤ ਕਰਵਾਉਂਦੀ ਹੈ ਅਤੇ ਸਮੇਂ ਨਾਲ ਸਿਸਟਮ ਨੂੰ ਧੀਮਾ ਕਰ ਦਿੰਦੀ ਹੈ।
ਆਈਸੋਲੇਸ਼ਨ ਲੈਵਲ latency ਦੀ ਬੇਅਥਾਦ ਤਬਦੀਲੀ ਵਧਾਉਂਦੇ ਹਨ
ਰਿਪੋਰਟਿੰਗ ਟੂਲ ਅਕਸਰ ਹੋਰ ਮਜ਼ਬੂਤ ਆਈਸੋਲੇਸ਼ਨ ਮੰਗਦੇ ਹਨ (ਜਾਂ ਗਲਤੀ ਨਾਲ ਲੰਬੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਚਲਦੇ ਹਨ)। ਉੱਚ ਆਈਸੋਲੇਸ਼ਨ ਲਾਕ ਉੱਤੇ ਇੰਤਜ਼ਾਰ ਵਧਾ ਸਕਦਾ ਹੈ ਅਤੇ engine ਨੂੰ manage ਕਰਨ ਲਈ ਹੋਰ ਵਰਜ਼ਨਾਂ ਦੀ ਲੋੜ ਪੈਦਾ ਕਰਦਾ ਹੈ। OLTP ਪਾਸੇ, ਤੁਸੀਂ ਇਹ ਅਣਪੇਸ਼ਗੁਈ spike ਵਜੋਂ ਵੇਖਦੇ ਹੋ: ਜ਼ਿਆਦਾਤਰ ਆਰਡਰ ਤੇਜ਼ੀ ਨਾਲ ਲਿਖਦੇ ਹਨ, ਪਰ ਕੁਝ ਵਾਰ achanak stunt ਹੋ ਜਾਂਦੇ ਹਨ।
ਪ੍ਰੈਕਟੀਕਲ ਉਦਾਹਰਨ: ਮਹੀਨੇ ਦੇ ਅੰਤ ਦੀ ਰਿਪੋਰਟਿੰਗ ਆਰਡਰਾਂ ਨੂੰ ਧੀਮਾ ਕਰ ਦਿੰਦੀ ਹੈ
ਮਹੀਨੇ ਦੇ ਅੰਤ 'ਤੇ, ਫਾਇਨੈਂਸ ਇੱਕ "ਪ੍ਰੋਡਕਟ ਮੁਤਾਬਕ ਰੈਵਨਿਊ" ਕੁਆਰੀ ਚਲਾਉਂਦਾ ਹੈ ਜੋ ਸਾਰੇ ਮਹੀਨੇ ਦੇ ਆਰਡਰ ਅਤੇ ਲਾਈਨ ਆਈਟਮਾਂ ਨੂੰ ਸਕੈਨ ਕਰਦੀ ਹੈ। ਜਦ ਇਹ ਚੱਲਦੀ ਹੈ, ਨਵੇਂ ਆਰਡਰ ਲਿਖੇ ਤਾਂ ਜਾ ਸਕਦੇ ਹਨ, ਪਰ vacuum ਪੁਰਾਣੀਆਂ ਵਰਜ਼ਨਾਂ ਨੂੰ ਮੁੜ-ਹਾਸਲ ਨਹੀਂ ਕਰ ਸਕਦਾ ਅਤੇ ਇੰਡੈਕਸ churn ਹੋ ਜਾਂਦੇ ਹਨ। ਆਰਡਰ API ਕਈ ਵਾਰੀ timeout ਦੇਖਣ ਲੱਗਦੀ ਹੈ—ਇਸ ਲਈ ਨਹੀਂ ਕਿ ਸਿਸਟਮ "ਡਾਊਨ" ਹੈ, ਸਗੋਂ ਕਿਉਂਕਿ contention ਅਤੇ ਕਲੀਨਅਪ ਓਵਰਹੈੱਡ ਚੁਪਚਾਪ latency ਨੂੰ ਤੁਹਾਡੇ ਲਿਮਿਟ ਤੋਂ ਉੱਪਰ ਧੱਕ ਦਿੰਦੇ ਹਨ।
ਵਰਕਲੋਡ ਦਾ ਉੱਪਰ-ਥੱਲਾ ਅਤੇ ਅਣਪ੍ਰਡਿਕਟੇਬਲ ਲੈਟੈਂਸੀ
OLTP ਸਿਸਟਮ predictability 'ਤੇ ਜਿੰਦਾ ਰਹਿੰਦੇ ਹਨ। ਇੱਕ ਚੈਕਆਉਟ, ਸਪੋਰਟ ਟਿਕਟ, ਜਾਂ ਬੈਲੈਂਸ ਅਪਡੇਟ "ਜ਼ਿਆਦਾਤਰ ਠੀਕ" ਹੋਣਾ ਕਾਫੀ ਨਹੀਂ—ਉਪਭੋਗੀ ਢੀਮੇ ਪਲ ਨੂੰ ਵੇਖਦੇ ਹਨ। OLAP ਅਕਸਰ ਬਰਸਟਿਆ ਹੁੰਦਾ ਹੈ: ਕੁਝ ਭਾਰੀ ਕੁਆਰੀਆਂ ਘੰਟਿਆਂ ਤੱਕ ਬਹੁਤ ਘੱਟ ਚਲਦੀਆਂ ਹਨ ਅਤੇ ਫਿਰ ਇੱਕ ਦਫ਼ਾ ਵੱਡਾ ਲੋਡ ਲੈ ਲੈਂਦੀਆਂ ਹਨ।
ਸਧਾਰਨ ਕਾਰਜਾਂ ਲਈ spike ਆਮ ਹਨ
ਐਨਾਲਿਟਿਕਸ ਟ੍ਰੈਫਿਕ ਆਮ ਤੌਰ 'ਤੇ ਰੁਟੀਨਾਂ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਇਕੱਠ ਹੋ ਜਾਂਦਾ ਹੈ:
- ਸਵੇਰੇ "standup dashboards" ਜਿੱਥੇ ਕਈ ਲੋਕ ਇੱਕੋ ਚਾਰਟ ਰਿੱਫਰੇਸ਼ ਕਰਦੇ ਹਨ
- ਨਿਯਤ ਰਿਪੋਰਟ ਜੋ ਘੰਟੇ ਦੀ ਸ਼ੁਰੂਆਤ 'ਤੇ ਇੱਕਸਾਰ ਚਲਦੀਆਂ ਹਨ
- ਮਹੀਨੇ-ਅੰਤ ਬੰਦ ਅਤੇ ਤਿਮਾਹੀ ਸਮੀਖਿਆ ਜੋ ਲੰਬੇ ਸਕੈਨ ਅਤੇ ਜੋਇਨ ਕਿਕ ਕਰਦੇ ਹਨ
ਦੂਜੇ ਪਾਸੇ, OLTP ਟਰੈਫਿਕ ਆਮ ਤੌਰ 'ਤੇ ਜ਼ਿਆਦਾ ਸਥਿਰ ਰਹਿੰਦਾ ਹੈ। ਜਦ ਦੋਹਾਂ ਇੱਕੇ ਡੇਟਾਬੇਸ ਨੂੰ ਸਾਂਝਾ ਕਰਦੇ ਹਨ, ਉਹ ਐਨਾਲਿਟਿਕਸ spikes ਨੂੰ ਟਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲਈ ਅਣਪ੍ਰਡਿਕਟੇਬਲ ਲੈਟੈਂਸੀ ਵਿੱਚ ਤਬਦੀਲ ਕਰ ਦਿੰਦੇ ਹਨ—timeouts, ਧੀਮੀ ਪੇਜ਼ ਲੋਡ, ਅਤੇ ਵਾਧੂ ਰੀਟ੍ਰਾਈਜ਼ ਜੋ ਹੋਰ ਲੋਡ ਪੈਦਾ ਕਰਦੇ ਹਨ।
ਸੀਮਾਵਾਂ ਅਤੇ ਸ਼ਡਿਊਲਿੰਗ ਕਿਉਂ ਮਦਦ ਕਰਦੀਆਂ ਹਨ—ਪਰ ਮੁੱਲ ਨਾਹੀ ਹਟਾਉਂਦੀਆਂ
ਤੁਸੀਂ ਨੁਕਸਾਨ ਘਟਾ ਸਕਦੇ ਹੋ ਜਿਵੇਂ ਰਿਪੋਰਟਿੰਗ ਨੂੰ ਰਾਤ ਨੂੰ ਚਲਾਉਣਾ, concurrency ਸੀਮਿਤ ਕਰਨਾ, statement timeouts ਲਗਾਉਣਾ, ਜਾਂ query cost caps ਸੈੱਟ ਕਰਨਾ। ਇਹ guardrails ਕੀਮਤੀ ਹੁੰਦੇ ਹਨ, ਖ਼ਾਸ ਕਰਕੇ "ਪ੍ਰੋਡਕਸ਼ਨ 'ਤੇ ਰਿਪੋਰਟਿੰਗ" ਲਈ।
ਪਰ ਇਹਨਾਂ ਨਾਲ ਮੂਲ ਤਣਾਅ ਹਟਦਾ ਨਹੀਂ: OLAP ਕੁਆਰੀਆਂ ਵੱਡੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਲਈ ਬਹੁਤ ਸਰੋਤ ਵਰਤਣ ਲਈ ਤਿਆਰ ਹੋਦੀਆਂ ਹਨ, ਜਦਕਿ OLTP ਨੂੰ ਦਿਨ ਭਰ ਛੋਟੇ ਤੇਜ਼ ਸਰੋਤ ਟੁਕੜੇ ਚਾਹੀਦੇ ਹਨ। ਜਦ ਇੱਕ ਅਣਅਨੁਮਤ ਡੈਸ਼ਬੋਰਡ ਰਿੱਫਰੇਸ਼, ਐਡ-ਹੌਕ ਕੁਆਰੀ, ਜਾਂ ਬੈਕਫਿਲਡ ਰਿਪੋਰਟ ਹੋ ਜਾਂਦੀ ਹੈ, ਤਾੰ ਸਾਂਝਾ ਡੇਟਾਬੇਸ ਮੁੜ ਖਤਰੇ ਵਿੱਚ ਆ ਜਾਂਦਾ ਹੈ।
noisy neighbor ਸਮੱਸਿਆ
ਸਾਂਝੇ ਇੰਫ੍ਰਾਸਟਰਕਚਰ 'ਤੇ, ਇੱਕ "ਸ਼ੋਰ ਮਚਾਉਣ ਵਾਲਾ" ਐਨਾਲਿਟਿਕਸ ਯੂਜ਼ਰ ਜਾਂ ਨੌਕਰੀ cache, disk ਜਾਂ CPU scheduling 'ਤੇ ਕਬਜ਼ਾ ਕਰ ਸਕਦੀ ਹੈ—ਬਿਨਾਂ ਕਿਸੇ ਗਲਤੀ ਦੇ। OLTP ਵਰਕਲੋਡ collateral damage ਬਣ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਸਭ ਤੋਂ ਮੁਸ਼ਕਲ ਗੱਲ ਇਹ ਹੈ ਕਿ ਫੇਲ੍ਹ੍ਹੀਅਰ ਸ random latency spikes ਵਾਂਗ ਦਿਖਦੀਆਂ ਹਨ: ਸਪਸ਼ਟ, ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ errors ਨਹੀਂ।
ਡੇਟਾਬੇਸ ਓਪਰੇਸ਼ਨ: ਬੈਕਅੱਪ, ਸੁਰੱਖਿਆ, ਅਤੇ क्षमता ਯੋਜਨਾ ਬਣਾਉਣ ਦੀ ਜਟਿਲਤਾ
Start a transactional app fast
Create a React plus Go backend app from chat, ready for transactional workloads.
OLTP ਅਤੇ OLAP ਮਿਲਾਉਣਾ ਸਿਰਫ਼ ਕਾਰਗੁਜ਼ਾਰੀ ਦਿੱਖ ਨਹੀਂ ਪੈਦਾ ਕਰਦਾ—ਇਹ ਦੈਨੀਕ ਓਪਰੇਸ਼ਨ ਨੂੰ ਵੀ ਮੁਸ਼ਕਲ ਬਣਾ ਦਿੰਦਾ ਹੈ। ਡੇਟਾਬੇਸ ਇੱਕ "ਸਭ ਕੁਝ ਬਕਸਾ" ਬਣ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਹਰ ਓਪਰੇਸ਼ਨਲ ਟਾਸਕ ਦੋਹਾਂ ਵਰਕਲੋਡਾਂ ਦੇ ਜੋਖਮ ਸਾਂਝੇ ਕਰ ਲੈਂਦਾ ਹੈ।
ਬੈਕਅੱਪ, ਰੀਸਟੋਰ ਅਤੇ ਡਿਜਾਸਟਰ ਰਿਕਵਰੀ ਧੀਮੇ ਹੋ ਜਾਂਦੇ ਹਨ
ਐਨਾਲਿਟਿਕਸ ਟੇਬਲ ਆਮ ਤੌਰ 'ਤੇ ਚੌੜੀਆਂ ਅਤੇ ਤੇਜ਼ੀ ਨਾਲ ਵਧਦੀਆਂ ਹਨ (ਵਧੀਕ ਇਤਿਹਾਸ, ਵੱਧ ਕਾਲਮ, ਵੱਧ rollups)। ਇਹ ਵਾਧਾ ਤੁਹਾਡੇ recovery ਕਹਾਣੀ ਨੂੰ ਬਦਲਦਾ ਹੈ।
ਫੁੱਲ ਬੈਕਅੱਪ ਲੰਮਾ ਲੱਗਦਾ, ਵੱਧ ਸਟੋਰੇਜ ਲੈਂਦਾ, ਅਤੇ ਬੈਕਅੱਪ ਵਿੰਡੋ ਗੁਆਣੇ ਦਾ ਖਤਰਾ ਵਧਦਾ ਹੈ। ਰੀਸਟੋਰ ਹੋਰ ਵੀ ਖਰਾਬ: ਜਦ ਤੁਹਾਨੂੰ ਤੇਜ਼ੀ ਨਾਲ recover ਕਰਨਾ ਹੁੰਦਾ ਹੈ, ਤੁਸੀਂ ਨਾ ਸਿਰਫ਼ ٽ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਡੇਟਾ ਬਹਾਲ ਕਰ ਰਹੇ ਹੋ, ਬਲਕਿ ਵੱਡੇ ਐਨਾਲਿਟਿਕਲ ਡੇਟਾਸੇੱਟ ਵੀ ਜੋ بزنس ਚਲਾਉਣ ਲਈ ਜ਼ਰੂਰੀ ਨਹੀਂ। ਡਿਜਾਸਟਰ ਰਿਕਵਰੀ ਟੈਸਟ ਵੀ ਲੰਮੇ ਹੁੰਦੇ ਹਨ, ਇਸ ਲਈ ਘੱਟ ਕਰਕੇ ਟੈਸਟ ਕੀਤੇ ਜਾਂਦੇ ਹਨ—ਇਹ ਖਾਸ ਕਰਕੇ ਉਲਟ ਹੈ ਜੋ ਤੁਸੀਂ ਚਾਹੁੰਦੇ ਹੋ।
ظرفیت ਯੋਜਨਾ ਅਣਨਿਯਤ ਹੋ ਜਾਂਦੀ ਹੈ
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਵਾਧਾ ਆਮ ਤੌਰ 'ਤੇ ਅਨੁਮਾਨਯੋਗ ਹੁੰਦਾ ਹੈ: ਵੱਧ ਗਾਹਕ, ਵੱਧ ਆਰਡਰ, ਵੱਧ ਰੋਜ਼। ਐਨਾਲਿਟਿਕਸ ਵਾਧਾ ਅਕਸਰ ਬੇਤਹਾ: ਇੱਕ ਨਵਾਂ ਡੈਸ਼ਬੋਰਡ, ਇੱਕ ਨਵਾਂ retention policy, ਜਾਂ ਇੱਕ ਟੀਮ ਦੇਸ਼ਾਂ 'ਚ "ਹੋਰ ਇੱਕ ਸਾਲ" ਰਾਹਤ ਰੱਖਣ ਦੀ ਫੈਸਲਾ ਕਰ ਸਕਦੀ ਹੈ।
ਜਦ ਦੋਹਾਂ ਇਕੱਠੇ ਰਹਿੰਦੀਆਂ ਹਨ, ਤੁਹਾਨੂੰ ਅੰਸਰ-ਅਨੁਮਾਨ ਨਹੀਂ ਲੱਗਦਾ:
- ਕੀ ਅਸੀਂ ਵਧ ਰਹੇ ਹਾਂ ਕਿਉਂਕਿ ਪ੍ਰੋਡਕਟ ਸਫਲ ਹੈ, ਜਾਂ ਕਿਉਂਕਿ ਰਿਪੋਰਟਾਂ ਵੱਧ ਇਤਿਹਾਸ ਰੱਖਦੀਆਂ ਹਨ?
- ਕੀ ਸਾਨੂੰ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਲਈ ਤੇਜ਼ ਸਟੋਰੇਜ ਚਾਹੀਦਾ ਹੈ, ਜਾਂ ਐਨਾਲਿਟਿਕਸ ਲਈ ਸਸਤਾ ਸਟੋਰੇਜ?
ਇਹ ਅਣਪ੍ਰਡਿਕਟੇਬਿਲਟੀ overprovisioning (ਅਣਉਚਿਤ ਭੁਗਤਾਨ) ਜਾਂ underprovisioning (ਅਚਾਨਕ ਆਊਟੇਜ) ਵੱਲ ਲੈ ਕੇ ਜਾਂਦੀ ਹੈ।
guardrails ਨੂੰ ਨਿਆਂ ਨਾਲ ਲਾਗੂ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੈ
ਸਾਂਝੇ ਡੇਟਾਬੇਸ 'ਚ, ਇੱਕ "ਬੇਦੋਸ਼" ਕੁਆਰੀ incident ਬਣ ਸਕਦੀ ਹੈ। ਤੁਸੀਂ guardrails ਲਗਾਉਂਦੇ ਹੋ: query timeouts, workload quotas, scheduled reporting windows, ਜਾਂ workload management ਨਿਯਮ। ਇਹ ਮਦਦ ਕਰਦੇ ਹਨ, ਪਰ brittle ਹੁੰਦੇ ਹਨ: ਐਪ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਕ ਹੁਣ ਇਕੋ ਹੀ ਸੀਮਾਵਾਂ ਲਈ ਮੁਕਾਬਲਾ ਕਰ ਰਹੇ ਹਨ, ਅਤੇ ਇੱਕ ਗਰੁੱਪ ਲਈ ਨੀਤੀ ਬਦਲਣ ਨਾਲ ਦੂਜੇ ਨੂੰ ਤੋੜ ਸਕਦੀ ਹੈ।
ਸੁਰੱਖਿਆ ਅਤੇ ਐਕਸੈੱਸ ਕੰਟਰੋਲ ਗੁੰਝਲਦਾਰ ਹੋ ਜਾਂਦੇ ਹਨ
ਐਪਲੀਕੇਸ਼ਨਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਸੁੰਕੜੇ, ਮਕਸਦ-ਨਿਰਧਾਰਤ ਅਧਿਕਾਰਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਵਿਸ਼ਲੇਸ਼ਕਾਂ ਨੂੰ ਅਕਸਰ ਵਿਸ਼ਾਲ read access ਚਾਹੀਦਾ ਹੈ, ਕਈ ਟੇਬਲਾਂ 'ਤੇ, ਤांकि ਉਹ ਜਾਂਚ ਅਤੇ ਵੈਰੀਫਾਈ ਕਰ ਸਕਣ। ਦੋਹਾਂ ਇਕੇ ਡੇਟਾਬੇਸ 'ਤੇ ਰੱਖਣ ਨਾਲ ਚੋਣ ਵਧਦੀ ਹੈ ਕਿ ਰਿਪੋਰਟ ਚੱਲਣ ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਵੱਡੇ ਅਧਿਕਾਰ ਦਿੱਤੇ ਜਾਣ—ਇਸ ਨਾਲ ਗਲਤੀ ਦਾ blast radius ਵਧਦਾ ਅਤੇ ਉਹਨਾਂ ਲੋਕਾਂ ਦੀ ਗਿਣਤੀ ਵਧਦੀ ਜੋ ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਵੇਖ ਸਕਦੇ ਹਨ।
ਸਕੇਲਿੰਗ ਅਤੇ ਲਾਗਤ: ਤੁਸੀਂ ਦੋ ਵਾਰੀ (ਜਾਂ ਉਸ ਤੋਂ ਵੱਧ) ਭੁਗਤਾਨ ਕਰਦੇ ਹੋ
OLTP ਅਤੇ OLAP ਇੱਕੋ ਡੇਟਾਬੇਸ 'ਤੇ ਚਲਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਅਕਸਰ ਸਸਤੀ ਲੱਗਦੀ ਹੈ—ਜਦ ਤਕ ਤੁਸੀਂ ਸਕੇਲ ਕਰਦੇ ਨਹੀਂ। ਸਮੱਸਿਆ ਸਿਰਫ਼ ਕਾਰਗੁਜ਼ਾਰੀ ਨਹੀਂ। ਹਰ ਵਰਕਲੋਡ ਨੂੰ ਸਕੇਲ ਕਰਨ ਦਾ "ਸਹੀ" ਤਰੀਕਾ ਵੱਖਰਾ ਇੰਫ੍ਰਾਸਟਰਕਚਰ ਵੱਲ ਧਕਲਦਾ ਹੈ, ਅਤੇ ਮਿ੍ਰਿਤ ਕਰਨ ਨਾਲ ਮਹਿੰਗੇ ਸਮਝੌਤੇ ਹੋ ਜਾਂਦੇ ਹਨ।
OLTP ਸਕੇਲਿੰਗ ਲਿਖਾਈ-ਚਲਿਤ ਹੁੰਦੀ ਹੈ (ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਦੁਖਦਾਇਕ)
ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਲ ਸਿਸਟਮ ਲਿਖਾਈਆਂ ਦੁਆਰਾ ਸੀਮਿਤ ਹੁੰਦੇ ਹਨ: ਬਹੁਤ ਸਾਰੇ ਛੋਟੇ ਅਪਡੇਟ, ਸਖ਼ਤ latency, ਅਤੇ ਬਰਸਟ ਜੋ ਤੁਰੰਤ absorb ਕਰਣੇ ਪੈਂਦੇ ਹਨ। OLTP ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ vertical scaling (ਵੱਡੀ CPU, ਤੇਜ਼ ਡਿਸਕ, ਵੱਧ ਮੈਮੋਰੀ) ਨਾਲ ਸਕੇਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ write-heavy ਵਰਕਲੋਡ ਆਸਾਨੀ ਨਾਲ fan-out ਨਹੀਂ ਹੁੰਦੇ।
ਜਦ vertical ਸਿਮਤਾਂ ਪਹੁੰਚ ਜਾਂਦੀਆਂ ਹਨ, ਤੁਸੀਂ sharding ਜਾਂ ਹੋਰ write-scaling ਪੈਟਰਨਾਂ ਵੱਲ ਦੇਖਦੇ ਹੋ। ਇਹ ਇੰਜੀਨੀਅਰਿੰਗ ਖ਼ਰਚ ਵਧਾਉਂਦਾ ਹੈ ਅਤੇ ਅਕਸਰ ਐਪਲੀਕੇਸ਼ਨ ਵਿੱਚ ਸੋਚ-ਵਿਚਾਰ ਵਾਲੇ ਬਦਲਾਵ ਲਿਆਉਂਦਾ ਹੈ।
OLAP ਸਕੇਲਿੰਗ compute-ਚਲਿਤ ਹੁੰਦੀ ਹੈ (ਅਕਸਰ elastic)
ਐਨਾਲਿਟਿਕਸ ਵਰਕਲੋਡ ਵੱਖਰਾ ਤਰੀਕੇ ਨਾਲ ਸਕੇਲ ਕਰਦੇ ਹਨ: ਲੰਬੇ ਸਕੈਨ, ਭਾਰੀ ਅੱਗ੍ਰੈਗੇਸ਼ਨ, ਅਤੇ ਰੀਡ throughput। OLAP ਸਿਸਟਮ ਆਮ ਤੌਰ 'ਤੇ distributed compute ਵਧਾ ਕੇ ਸਕੇਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਕਈ ਮੌਡਰਨ ਸੈਟਅਪ compute ਨੂੰ storage ਤੋਂ ਅਲੱਗ ਰੱਖਦੇ ਹਨ ਤਾਂ ਕਿ ਤੁਸੀਂ ਕਵਾਟਰ horsepower ਬਿਨਾਂ ਡੇਟਾ ਮੂਵ ਕੀਤੇ ਉਸ ਨੂੰ ਵਧਾ ਸਕੋ।
ਜੇ OLAP OLTP ਡੇਟਾਬੇਸ ਸਾਂਝਾ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਐਨਾਲਿਟਿਕਸ ਨੂੰ ਅਲੱਗ ਹੀ ਸਕੇਲ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਤੁਹਾਨੂੰ ਪੂਰੇ ਡੇਟਾਬੇਸ ਨੂੰ ਸਕੇਲ ਕਰਨਾ ਪਏਗਾ—even ਜੇ ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨ ਠੀਕ ਨੇ।
ਲੁਕਿਆ ਬਿੱਲ: ਐਨਾਲਿਟਿਕਸ ਲਈ OLTP-ਗ੍ਰੇਡ ਸਰੋਤਾਂ ਦੀ ਭੁਗਤਾਨੀ
ਚੈਕਆਉਟ ਤੇਜ਼ ਰੱਖਣ ਲਈ ਅਤੇ ਰਿਪੋਰਟ ਚਲਾਉਣ ਦੌਰਾਨ ਪ੍ਰੋਡਕਸ਼ਨ ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖਣ ਲਈ ਟੀਮਾਂ ਪ੍ਰੋਡਕਸ਼ਨ ਡੇਟਾਬੇਸ ਨੂੰ ਅਧਿਕ ਪ੍ਰੋਵਿਸ਼ਨ ਕਰਦੀਆਂ ਹਨ: ਵਾਧੂ CPU headroom, high-end storage, ਅਤੇ ਵੱਡੇ ਇੰਸਟਾਂਸ "ਸਿਰਫ਼ ਕਿਸੇ ਵੀ ਸਥਿਤੀ ਲਈ"। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ OLAP ਵਿਹਾਰ ਚਲਾਉਣ ਲਈ OLTP ਕੀਮਤਾਂ ਭਰ ਰਹੇ ਹੋ।
ਵੱਖਰਾ ਕਰਨ ਨਾਲ over-provisioning ਘਟਦਾ ਹੈ ਕਿਉਂਕਿ ਹਰ ਇੱਕ ਸਿਸਟਮ ਆਪਣੀ ਜਾਬ ਲਈ ਸਾਇਜ਼ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ: OLTP ਲਈ predictible low-latency writes, OLAP ਲਈ bursty heavy reads. ਨਤੀਜਾ ਆਮ ਤੌਰ 'ਤੇ ਕੁੱਲ ਖਰਚੇ ਵਿੱਚ ਘਟੋਤਰੀ ਹੁੰਦਾ ਹੈ—ਭਾਵੇਂ ਇਹ "ਦੋ ਸਿਸਟਮ" ਹੋਣ ਦੇ ਬਾਵਜੂਦ—ਕਿਉਂਕਿ ਤੁਸੀਂ ਪ੍ਰੀਮੀਅਮ transactional capacity ਰਿੱਲ ਨਹੀਂ ਖਰੀਦ ਰਹੇ ਜੋ ਰਿਪੋਰਟਿੰਗ ਚਲਾਉਣ ਲਈ ਲੋੜੀਂਦੀ ਹੈ।
ਆਮ ਆਰਕੀਟੈਕਚਰ ਜੋ OLTP ਅਤੇ OLAP ਨੂੰ ਵੱਖ ਰੱਖਦੇ ਹਨ
Recover quickly from schema changes
Use snapshots and rollback when a migration or query change causes surprises.
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ transactional workload (OLTP) ਅਤੇ analytics workload (OLAP) ਨੂੰ ਵੱਖ ਕਰਨ ਲਈ ਦੂਜਾ "ਰੀਡ-ਓਰੀਐਂਟਿਡ" ਸਿਸਟਮ ਸ਼ਾਮِل ਕਰਦੀਆਂ ਹਨ ਨਾਰ ਕਿ ਇਕੇ ਡੇਟਾਬੇਸ ਨੂੰ ਦੋਹਾਂ ਲਈ ਮਜ਼ਬੂਰ ਕਰਨ।
ਪੈਟਰਨ 1: ਰਿਪੋਰਟਿੰਗ ਲਈ read replica
ਸਭ ਤੋਂ ਆਮ ਪਹਿਲਾ ਕਦਮ ਇੱਕ read replica (ਜਾਂ follower) ਬਣਾਉਣਾ ਹੈ OLTP ਡੇਟਾਬੇਸ ਦਾ, ਜਿੱਥੇ BI ਟੂਲ ਕੁਆਰੀਆਂ ਚਲਾਉਂਦੇ ਹਨ。
ਫਾਹਿਦੇ: ਘੱਟ ਐਪ ਚੇਨਜ, ਪਰਚੇ ਜਾਣ ਵਾਲੀ SQL, ਤੇਜ਼ ਸੈਟਅਪ。
ਨੁਕਸਾਨ: ਇਹ ਫਿਰ ਵੀ ਇੱਕੋ ਇੰਜਣ ਅਤੇ schema ਹੁੰਦਾ ਹੈ, ਇਸ ਲਈ ਭਾਰੀ ਰਿਪੋਰਟਾਂ replica CPU/I/O ਨੂੰ saturate ਕਰ ਸਕਦੀਆਂ ਹਨ; ਕੁਝ ਰਿਪੋਰਟਾਂ ਕੋਲ replica 'ਤੇ ਵਰਤੋਂਲਾਈ ਜੋੜੇ ਨਾ ਹੋਣਗੇ; ਅਤੇ replication lag ਦਾ ਮਤਲਬ ਨਤੀਜੇ ਕਈ ਮਿੰਟ ਪਿੱਛੇ ਹੋ ਸਕਦੇ ਹਨ। Lag ਵੀ incidents ਦੌਰਾਨ ਕਾਨਫ਼ਿਊਜ਼ਨ ਪੈਦਾ ਕਰਦਾ ਹੈ।
ਵਧੀਆ ਫਿੱਟ: ਛੋਟੀ ਟੀਮਾਂ, ਨੌਨ-ਵੱਡਾ ਡੇਟਾ ਵਾਲੇ, “near-real-time” ਚੰਗਾ ਹੈ ਪਰ ਜ਼ਰੂਰੀ ਨਹੀਂ, ਅਤੇ ਰਿਪੋਰਟਿੰਗ ਕੁਆਰੀਆਂ ਕਾਬੂ ਵਿੱਚ ਹਨ।
ਪੈਟਰਨ 2: ਸਮਰਪਿਤ ਡੇਟਾ ਵੇਅਰਹਾਊਸ / ਐਨਾਲਿਟਿਕਸ ਡੇਟਾਬੇਸ
ਇੱਥੇ OLTP ਲਿਖਾਈਆਂ ਲਈ ਅਪਟੀਮਾਈਜ਼ਡ ਰਹਿੰਦਾ ਹੈ ਅਤੇ ਐਨਾਲਿਟਿਕਸ ਨੂੰ ਇੱਕ ਡੇਟਾ ਵੇਅਰਹਾਊਸ (ਜਾਂ columnar analytics DB) 'ਤੇ ਰੱਖਿਆ ਜਾਂਦਾ ਹੈ ਜੋ ਸਕੈਨ, ਕੁੰਪ੍ਰੈਸ਼ਨ ਅਤੇ ਵੱਡੀਆਂ ਅੱਗ੍ਰੈਗੇਸ਼ਨ ਲਈ ਬਣਿਆ ਹੁੰਦਾ ਹੈ。
ਫਾਹਿਦੇ: predictible OLTP ਕਾਰਗੁਜ਼ਾਰੀ, ਤੇਜ਼ ਡੈਸ਼ਬੋਰਡ, ਵਿਸ਼ਲੇਸ਼ਕਾਂ ਲਈ ਵਧੀਆ concurrency, ਅਤੇ ਸਪਸ਼ਟ ਖ਼ਰਚ/ਕਾਰਗੁਜ਼ਾਰੀ ਟਿਊਨਿੰਗ。
ਨੁਕਸਾਨ: ਤੁਸੀਂ ਹੁਣ ਹੋਰ ਸਿਸਟਮ ਚਲਾਉਂਦੇ ਹੋ ਅਤੇ ਇੱਕ analytics-friendly ਡੇਟਾ ਮਾਡਲ (ਅਕਸਰ star schema) ਬਣਾਉਣ ਦੀ ਲੋੜ ਹੋਵੇਗੀ।
ਵਧੀਆ ਫਿੱਟ: ਡੇਟਾ ਵਧ ਰਿਹਾ ਹੈ, ਬਹੁਤ ਸਾਰੇ stakeholder ਹਨ, ਜਟਿਲ ਰਿਪੋਰਟਿੰਗ ਜਾਂ ਸਖ਼ਤ OLTP latency ਦੀ ਲੋੜ ਹੈ।
ਪੈਟਰਨ 3: CDC-ਅਧਾਰਤ ਪਾਈਪਲਾਈਨ into analytics
ਪਰਿਯੋਗਿਕ ETL ਦੀ ਥਾਂ, ਤੁਸੀਂ CDC (change data capture) ਨੂੰ OLTP ਲਾਗ ਤੋਂ ਵਹਾਉਂਦੇ ਹੋ ਅਤੇ ਵੇਅਰਹਾਊਸ ਵਿੱਚ ਸਟਰੀਮ ਕਰਦੇ ਹੋ (ਅਕਸਰ ELT ਨਾਲ)।
ਫਾਹਿਦੇ: ताजा ਡੇਟਾ ਨਾਲ ਘੱਟ OLTP ਲੋਡ, ਇੰਕ੍ਰੀਮੈਂਟਲ ਪ੍ਰੋਸੈਸਿੰਗ ਆਸਾਨ, ਅਤੇ ਬਹਤਰ ਆਡੀਟੇਬਿਲਟੀ।
ਨੁਕਸਾਨ: ਹੋਰ moving parts ਅਤੇ schema ਬਦਲਾਵਾਂ ਦੀ ਸੰਭਾਲ।
ਵਧੀਆ ਫਿੱਟ: ਵੱਡੀ ਮਾਤਰਾ, ਹਾਈ ਫ੍ਰੈਸ਼ਨੈਸ ਜ਼ਰੂਰਤ, ਅਤੇ ਟੀਮਾਂ ਜੋ ਡੇਟਾ ਪਾਈਪਲਾਈਨਸ ਲਈ ਤਿਆਰ ਹਨ।
OLTP ਤੋਂ OLAP ਤਕ ਡੇਟਾ ਭੇਜਣ ਦੀ ਸੁਰੱਖਿਅਤ ਤਰੀਕਾ
ਤੁਹਾਡੇ transactional ਡੇਟਾਬੇਸ (OLTP) ਤੋਂ analytics ਸਿਸਟਮ (OLAP) ਨੂੰ ਡੇਟਾ ਭੇਜਣਾ ਸਿਰਫ਼ "ਟੇਬਲਾਂ ਦੀ ਨਕਲ" ਨਹੀਂ—ਇਹ ਭਰੋਸੇਯੋਗ, ਘੱਟ-ਇੰਪੈਕਟ ਵਾਲੀ ਪਾਈਪਲਾਈਨ ਬਣਾਉਣ ਬਾਰੇ ਹੈ। ਹਦਫ਼ ਸਧਾਰਨ ਹੈ: ਐਨਾਲਿਟਿਕਸ ਨੂੰ ਜੋ ਚਾਹੀਦਾ ਹੈ ਮਿਲੇ, ਪ੍ਰੋਡਕਸ਼ਨ ਟ੍ਰੈਫਿਕ ਨੂੰ ਖ਼ਤਰੇ ਵਿੱਚ ਨਾ ਪਾਉਂਦੇ ਹੋਏ।
ETL vs ELT (ਸਧਾਰਣ ਪੰਜਾਬੀ)
ETL (Extract, Transform, Load) ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਵੇਅਰਹਾਊਸ 'ਚ ਪੂਰਨ ਤਰ੍ਹਾਂ ਰੱਖਣ ਤੋਂ ਪਹਿਲਾਂ ਸਾਫ਼ ਅਤੇ ਰੀਸ਼ੇਪ ਕਰਦੇ ਹੋ। ਜਦ ਵੇਅਰਹਾਊਸ ਵਿੱਚ ਗਣਨਾ ਮਹਿੰਗੀ ਹੋ, ਜਾਂ ਤੁਸੀਂ ਜੋ ਸਟੋਰ ਕਰੋ ਉਸ 'ਤੇ ਸਖ਼ਤ ਨਿਯੰਤਰਣ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇਹ ਵਰਤੋਂਯੋਗ ਹੈ।
ELT (Extract, Load, Transform) ਸਭ ਤੋਂ ਪਹਿਲਾਂ ਕੱਚਾ-ਜਿਹਾ ਡੇਟਾ ਲੋਡ ਕਰਦਾ ਹੈ, ਫਿਰ ਵੇਅਰਹਾਊਸ ਦੇ ਅੰਦਰ ਤਬਦੀਲੀ ਕਰਦਾ ਹੈ। ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਤਿਆਰ ਕਰਨ ਵਿੱਚ ਤੇਜ਼ ਅਤੇ ਬਦਲਦਿਆਂ ਨਾਲ ਵਧਣ ਵਿੱਚ ਆਸਾਨ ਹੁੰਦਾ ਹੈ: ਤੁਸੀਂ ਸਾਰਾ ਇਤਿਹਾਸ ਰੱਖ ਸਕਦੇ ਹੋ ਅਤੇ ਜਦ ਲੋੜ ਬਦਲੇ ਤਾਂ transformation ਨੂਂ ਸੋਧ ਸਕਦੇ ਹੋ।
ਇੱਕ ਪ੍ਰੈਕਟੀਕਲ ਨਿਯਮ: ਜੇ ਬਿਜ਼ਨਸ ਲੋਜਿਕ ਬਹੁਤ ਵਾਰ ਬਦਲਦੀ ਹੈ, ELT rework ਘਟਾਉਂਦਾ ਹੈ; ਜੇ governance ਨਾਲ ਸਿਰਫ curated ਡੇਟਾ ਸਟੋਰ ਕਰਨੀ ਹੈ, ਤਾਂ ETL ਬਿਹਤਰ ਹੋ ਸਕਦਾ ਹੈ।
CDC ਮੂਲ ਗੱਲਾਂ: ਭਾਰੀ ਕੁਆਰੀਆਂ ਬਿਨਾਂ ਬਦਲਾਅ ਪਕੜਨਾ
Change Data Capture (CDC) OLTP ਤੋਂ inserts/updates/deletes ਨੂੰ ਸਟ੍ਰੀਮ ਕਰਦਾ ਹੈ (ਅਕਸਰ ਡੇਟਾਬੇਸ ਲੌਗ ਤੋਂ) ਤੇ ਤੁਹਾਡੇ analytics ਸਿਸਟਮ 'ਚ ਭੇਜਦਾ ਹੈ। ਵੱਡੀਆਂ ਟੇਬਲਾਂ ਨੂੰ ਮੁੜ-ਸਕੈਨ ਕਰਨ ਦੀ ਥਾਂ ਤੁਸੀਂ ਸਿਰਫ਼ ਜੋ ਬਦਲਿਆ ਉਹ ਹੀ ਘੁਮਾਉਂਦੇ ਹੋ।
ਇਹ ਜਿਸ<|end_of_text|>