03 ਨਵੰ 2025·8 ਮਿੰਟ
Leslie Lamport and Distributed Systems: ਸਮਾਂ, ਕ੍ਰਮ, ਸਹੀਅਤ
Lamport ਦੇ ਮੁੱਖ ਵਿਚਾਰ—ਲੌਜਿਕਲ ਘੜੀਆਂ, ਆਰਡਰਿੰਗ, consensus ਅਤੇ correctness—ਸੀਖੋ ਅਤੇ ਜਾਣੋ ਕਿ ਇਹ ਆਧੁਨਿਕ ਇੰਫਰਾਸਟ੍ਰਕਚਰ ਨੂੰ ਅਜੇ ਵੀ ਕਿਵੇਂ ਰਾਹਦਰਸ਼ਨ ਦਿੰਦے ਹਨ।
ਕਿਉਂ Lamport ਅਜੇ ਵੀ ਵੰਡੇ ਸਿਸਟਮਾਂ ਲਈ ਜ਼ਰੂਰੀ ਹੈ
Leslie Lamport ਉਹਨਾਂ ਕਮੀਯਾਬ ਖੋਜਕਾਰਾਂ ਵਿੱਚੋਂ ਇੱਕ ਹੈ ਜਿਹਨਾਂ ਦੇ “ਸਿਧਾਂਤਕ” ਕੰਮ ਹਰ ਵਾਰੀ ਅਸਲ ਸਿਸਟਮ ਡਿਪਲੌਇ ਕਰਨ ਵੇਲੇ ਸਾਹਮਣੇ ਆਉਂਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਕਦੇ ਡੇਟਾਬੇਸ ਕਲੱਸਟਰ, ਮੈਸੇਜ ਕਿਊ, ਵਰਕਫਲੋ ਇੰਜਣ ਜਾਂ ਕੋਈ ਵੀ ਐਸੀ ਚੀਜ਼ ਚਲਾਈ ਹੈ ਜੋ ਰੀਟ੍ਰਾਈ ਕਰਦੀ ਹੈ ਅਤੇ ਫੇਲਿਅਰ ਤੋਂ ਬਚਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਉਹਨਾਂ ਮੁਸ਼ਕਿਲਾਂ ਦੇ ਅੰਦਰ ਰਹੇ ਹੋ ਜਿਨ੍ਹਾਂ ਨੂੰ Lamport ਨੇ ਨਾਂ ਦਿੱਤਾ ਅਤੇ ਹੱਲ ਕੀਤੇ।
ਉਸ ਦੀਆਂ ਵਿਚਾਰਧਾਰਾਵਾਂ ਇਸ ਲਈ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਯਾਦ ਰਹਿੰਦੀਆਂ ਹਨ ਕਿਉਂਕਿ ਇਹ ਕਿਸੇ ਖਾਸ ਤਕਨੀਕ ਨਾਲ ਬੰਨ੍ਹੀਆਂ ਨਹੀਂ ਹਨ। ਇਹ ਉਹ ਕਠਿਨ ਹਕੀਕਤਾਂ ਬਿਆਨ ਕਰਦੀਆਂ ਹਨ ਜੋ ਹਰ ਵਾਰੀ ਸਾਹਮਣੇ ਆਉਂਦੀਆਂ ਹਨ ਜਦੋਂ ਕਈ ਮਸ਼ੀਨਾਂ ਇੱਕੋ ਸਿਸਟਮ ਵਾਂਗ ਕੰਮ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੀਆਂ ਹਨ: ਘੜੀਆਂ ਮਿਲਦੀਆਂ ਨਹੀਂ, ਨੈਟਵਰਕ ਸੁਨੇਹਿਆਂ ਨੂੰ ਰੋਕ ਜਾਂ ਲੇਟ ਕਰਦਾ ਹੈ, ਅਤੇ ਫੇਲਿਅਰ ਆਮ ਹਨ—ਨ ਕਿ ਅਪਵਾਦ।
ਤਿੰਨ ਥੀਮਾਂ ਜੋ ਅਸੀਂ ਪੂਰੇ ਲੇਖ ਵਿੱਚ ਵਰਤਾਂਗੇ
ਸਮਾਂ: ਵੰਡੇ ਸਿਸਟਮ ਵਿੱਚ “ਹੁਣ ਸਮਾਂ ਕਿੰਨਾ ਹੈ?” ਸਿੱਧਾ ਸਵਾਲ ਨਹੀਂ ਹੈ। ਫਿਜ਼ੀਕਲ ਘੜੀਆਂ ਡ੍ਰਿਫਟ ਕਰਦੀਆਂ ਹਨ, ਅਤੇ ਤੁਸੀਂ ਜੋ ਘਟਨਾ ਵੇਖਦੇ ਹੋ ਉਹ ਹਰ ਮਸ਼ੀਨ 'ਤੇ ਵੱਖਰੀ ਹੋ ਸਕਦੀ ਹੈ।
ਕ੍ਰਮ: ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਇਕਲ ਘੜੀ ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਦ ਤੁਹਾਨੂੰ ਇਹ ਦੱਸਣ ਲਈ ਹੋਰ ਤਰੀਕੇ ਚਾਹੀਦੇ ਹਨ ਕਿ ਕਿਹੜੀਆਂ ਘਟਨਾਵਾਂ ਪਹਿਲਾਂ ਹੋਈਆਂ—ਅਤੇ ਕਦੋਂ ਤੁਹਾਡੇ ਲਈ ਹਰ ਕਿਸੇ ਨੂੰ ਇਕੋ ਕ੍ਰਮ ਮੰਨਣਾ ਲਾਜ਼ਮੀ ਹੈ।
ਸਹੀਅਤ: “ਅਕਸਰ ਠੀਕ ਹੁੰਦਾ ਹੈ” ਇੱਕ ਡਿਜ਼ਾਈਨ ਨਹੀਂ ਹੈ। Lamport ਨੇ ਖੇਤਰ ਨੂੰ ਸਪਸ਼ਟ ਪਰਿਭਾਸ਼ਾਵਾਂ (safety vs. liveness) ਅਤੇ ਇਨ੍ਹਾਂ ਦੀਆਂ ਵਿਵਰਣਾਂ ਵੱਲ ਧੱਕ ਦਿੱਤਾ ਤਾਂ ਜੋ ਤੁਸੀਂ ਕੇਵਲ ਟੈਸਟ ਨਹੀਂ, ਬਲਕਿ ਵਿਚਾਰ ਕਰ ਸਕੋ।
ਕੀ ਉਮੀਦ ਕਰਨੀ ਚਾਹੀਦੀ ਹੈ (ਕੋਈ ਭਾਰੀ ਗਣਿਤ ਨਹੀਂ)
ਅਸੀਂ ਧਿਆਨ ਧਾਰਾਵਾਂ ਤੇ ਇੰਟੂਇਸ਼ਨ 'ਤੇ ਰੱਖਾਂਗੇ: ਮੁਸ਼ਕਿਲਾਂ, ਸੋਚਣ ਲਈ ਘੱਟੋ-ਘੱਟ ਸੰਦ, ਅਤੇ ਇਹ ਸੰਦ ਕਿਵੇਂ ਪ੍ਰਯੋਗਿਕ ਡਿਜ਼ਾਈਨਾਂ ਨੂੰ ਆਕਾਰ ਦਿੰਦੇ ਹਨ।
ਇੱਥੇ ਨਕਸ਼ਾ ਹੈ:
- ਕਿਉਂ ਕੋਈ ਸਾਂਝੀ ਘੜੀ ਨਹੀਂ ਹੋਣ ਕਾਰਨ ਇੱਕੋ ਗਲੋਬਲ ਕਹਾਣੀ ਮੌਜੂਦ ਨਹੀਂ ਹੋ ਸਕਦੀ
- ਕਿਵੇਂ ਕਾਰਨਾਤਮਕਤਾ ("happened-before") ਲਾਜਿਕਲ ਘੜੀਆਂ ਅਤੇ Lamport timestamps ਵੱਲ ਲੈ ਜਾਂਦੀ ਹੈ
- ਕਦੋਂ ਅੰਸ਼ਕ ਕ੍ਰਮ ਕਾਫ਼ੀ ਨਹੀਂ ਹੁੰਦਾ ਅਤੇ ਤੁਹਾਨੂੰ ਇੱਕ ਇਕੋ ਟਾਇਮਲਾਈਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ
- ਕਿਵੇਂ consensus ਅਤੇ Paxos ਇੱਕ ਕ੍ਰਮ 'ਤੇ ਸਹਿਮਤ ਹੋਣ ਨਾਲ ਜੁੜਦੇ ਹਨ
- ਕਿਉਂ state machine replication ਕੰਮ ਕਰਦੀ ਹੈ ਜਦੋਂ ਕ੍ਰਮ ਸਾਂਝਾ ਹੁੰਦਾ ਹੈ
- ਸਪੈਸ ਵਿੱਚ ਸਹੀਅਤ ਕਿਵੇਂ ਬਿਆਨ ਕਰੀਏ—ਅਤੇ TLA+ ਵਰਗੇ ਮਾਡਲਿੰਗ ਸੰਦ ਕਿਵੇਂ ਮਦਦਗਾਰ ਹੁੰਦੇ ਹਨ
ਮੁੱਖ ਸਮੱਸਿਆ: ਕੋਈ ਸਾਂਝੀ ਘੜੀ ਨਹੀਂ, ਕੋਈ ਇਕੱਲੀ ਹਕੀਕਤ ਨਹੀਂ
ਸਿਸਟਮ ਨੂੰ “ਵੰਡਿਆ” ਕਿਹਾ ਜਾਂਦਾ ਹੈ ਜਦੋਂ ਉਹ ਕਈ ਮਸ਼ੀਨਾਂ ਦਾ ਸਮੂਹ ਹੁੰਦਾ ਹੈ ਜੋ ਨੈਟਵਰਕ ਰਾਹੀਂ ਏਕ ਕੰਮ ਕਰਨ ਲਈ ਕੋਆਰਡੀਨেট ਕਰਦੀਆਂ ਹਨ। ਇਹ ਆਸਾਨ ਲੱਗਦਾ ਹੈ ਜਦ ਤਕ ਤੁਸੀਂ ਦੋ ਤੱਥ ਮੰਨ ਲੋ: ਮਸ਼ੀਨਾਂ ਅਲੱਗ-ਅਲੱਗ ਤਰੀਕੇ ਨਾਲ ਫੇਲ ਹੋ ਸਕਦੀਆਂ ਹਨ (ਅੰਸ਼ਿਕ ਫੇਲਿਅਰ), ਅਤੇ ਨੈਟਵਰਕ ਸੁਨੇਹਿਆਂ ਨੂੰ ਦੇਰੀ, ਗੁਆਚ ਜਾਂ ਦੁਹਰਾਓ, ਜਾਂ ਰੀਅਰੰਗ ਕਰ ਸਕਦਾ ਹੈ।
ਇਕੋ ਕੰਪਿਊਟਰ 'ਤੇ ਇਕ ਇਕਲ ਪ੍ਰੋਗਰਾਮ ਵਿੱਚ, ਤੁਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਕਹਿ ਸਕਦੇ ਹੋ “ਪਹਿਲਾਂ ਕੀ ਹੋਇਆ।” ਵੰਡੇ ਸਿਸਟਮ ਵਿੱਚ, ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨ ਵੱਖ-ਵੱਖ ਘਟਨਾਵਾਂ ਦੀ ਲੜੀ ਦੇਖ ਸਕਦੀਆਂ ਹਨ—ਅਤੇ ਦੋਹਾਂ ਆਪਣੀ-ਆਪਣੀ ਲੋਕਲ ਨਜ਼ਰ ਤੋਂ ਸਹੀ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਕਿਉਂ ਤੁਸੀਂ ਗਲੋਬਲ ਘੜੀ 'ਤੇ ਭਰੋਸਾ ਨਹੀਂ ਕਰ ਸਕਦੇ
ਸਹਿਜ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਹਰ ਚੀਜ਼ ਤੇ ਟਾਈਮਸਟੈਂਪ ਲਗਾ ਦਿਓ। ਪਰ ਮਸ਼ੀਨਾਂ ਵਿੱਚ ਕੋਈ ਇਕੋ ਘੜੀ ਨਹੀਂ ਹੈ ਜਿਸ 'ਤੇ ਤੁਸੀਂ ਹਮੇਸ਼ਾ ਭਰੋਸਾ ਕਰ ਸਕੋ:
- ਹਰ ਸਰਵਰ ਦੀ ਹਾਰਡਵੇਅਰ ਘੜੀ ਆਪਣੀ ਰਫਤਾਰ ਨਾਲ ਡ੍ਰਿਫਟ ਕਰਦੀ ਹੈ।
- ਘੜੀ ਸਿੰਕ੍ਰਨਾਈਜੇਸ਼ਨ (ਜਿਵੇਂ NTP) ਸਿਰਫ ਬੈਸਟ-ਐਫ਼ੋਰਟ ਹੰੂਦੀ ਹੈ, ਗਰੰਟੀ ਨਹੀਂ।
- ਵਰਚੁਅਲਾਈਜੇਸ਼ਨ, CPU ਲੋਡ, ਜਾਂ ਰੁਕਾਵਟਾਂ ਸਮਾਂ ਛਾਲਾਂ ਜਾਂ ਰੁਕਣ ਵਾਂਗ ਕਰ ਸਕਦੀਆਂ ਹਨ।
ਇਸ ਲਈ “ਇਵੈਂਟ A 10:01:05.123 'ਤੇ ਹੋਇਆ” ਇਕ ਹੋਸਟ 'ਤੇ ਹੋਰ ਹੋਸਟ ਦੇ “10:01:05.120” ਨਾਲ ਭਰੋਸੇਯੋਗ ਤੌਰ 'ਤੇ ਤੁਲਨਾ ਨਹੀਂ ਹੁੰਦੀ।
ਦੇਰੀਆਂ ਹਕੀਕਤ ਨੂੰ ਕਿਵੇਂ ਗੁੰਝਲਦਾਰ ਬਣਾਉਂਦੀਆਂ ਹਨ
ਨੈਟਵਰਕ ਦੇਰੀਆਂ ਉਹ ਗੱਲਾਂ ਉਲਟ-ਸਿੱਧਾ ਕਰ ਸਕਦੀਆਂ ਹਨ ਜੋ ਤੁਸੀਂ ਸੋਚਦੇ ਹੋ। ਇੱਕ ਲੇਖਣ ਪਹਿਲਾਂ ਭੇਜਿਆ ਗਿਆ ਹੋ ਸਕਦਾ ਹੈ ਪਰ ਬਾਅਦ ਵਿੱਚ ਪੱਜਣਾ। ਇੱਕ ਰੀਟ੍ਰਾਈ ਮੁਢਲੇ ਤੋਂ ਬਾਅਦ ਆ ਸਕਦਾ ਹੈ। ਦੋ ਡੇਟਾਸੈਂਟਰ ਇੱਕੋ ਬਿਨੈ ਨੂੰ ਉਲਟ ਕ੍ਰਮ ਵਿੱਚ ਪ੍ਰੋਸੈਸ ਕਰ ਸਕਦੇ ਹਨ।
ਇਸ ਨਾਲ ਡੀਬੱਗਿੰਗ ਇਕ ਵਿਲੱਖਣ ਤਰ੍ਹਾਂ ਗੁੰਝਲਦਾਰ ਹੋ ਜਾਂਦੀ ਹੈ: ਵੱਖ-ਵੱਖ ਮਸ਼ੀਨਾਂ ਦੇ ਲੌਗ ਸਹਿਮਤ ਨਹੀਂ ਕਰਦੇ, ਅਤੇ "ਟਾਈਮਸਟੈਂਪ ਦੇ ਮੁਤਾਬਕ ਛਾਂਟਣਾ" ਇੱਕ ਐਸੀ ਕਹਾਣੀ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਅਸਲ ਵਿੱਚ ਕਦੇ ਨਹੀਂ ਹੋਈ।
ਅਸਲ ਨੁਕਸਾਨ
ਜਦੋਂ ਤੁਸੀਂ ਇੱਕ ਇਕੱਲੀ ਟਾਈਮਲਾਈਨ ਮੰਨ ਲੈਂਦੇ ਹੋ ਜੋ ਮੌਜੂਦ ਨਹੀਂ, ਤਦ ਤੁਹਾਨੂੰ ਠੋਸ ਨੁਕਸਾਨ ਮਿਲਦੇ ਹਨ:
- ਡਬਲ ਪ੍ਰੋਸੈਸਿੰਗ (ਰੀਟ੍ਰਾਈਜ਼ ਤੋਂ ਬਾਅਦ ਦੋ ਵਾਰੀ ਭੁਗਤਾਨ ਹੋ ਜਾਣਾ)
- ਅਸੰਗਤੀਆਂ (ਦੋ ਯੂਜ਼ਰ ਦੋਹਾਂ "ਸਫਲ" ਢੰਗ ਨਾਲ ਆਖਰੀ ਆਈਟਮ ਦਾ ਦਾਅਵਾ ਕਰਨਾ)
- ਲੱਗਣ ਵਾਲੀ ਡਾਟਾ ਖੋਈ (ਬਾਅਦ ਵਿੱਚ ਆਉਣ ਵਾਲਾ ਅਪਡੇਟ ਨਵੇਂ ਨੂੰ ਓਵਰਰਾਈਟ ਕਰ ਦੇਂਦਾ ਹੈ)
Lamport ਦੀ ਮੁੱਖ ਦਿੱਖ ਇੱਥੇ ਤੋਂ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ: ਜੇ ਤੁਸੀਂ ਸਮਾਂ ਸਾਂਝਾ ਨਹੀਂ ਕਰ ਸਕਦੇ, ਤਾਂ ਤੁਹਾਨੂੰ ਕ੍ਰਮ ਬਾਰੇ ਵੱਖਰੇ ਤਰੀਕੇ ਨਾਲ ਸੋਚਣਾ ਪਵੇਗਾ।
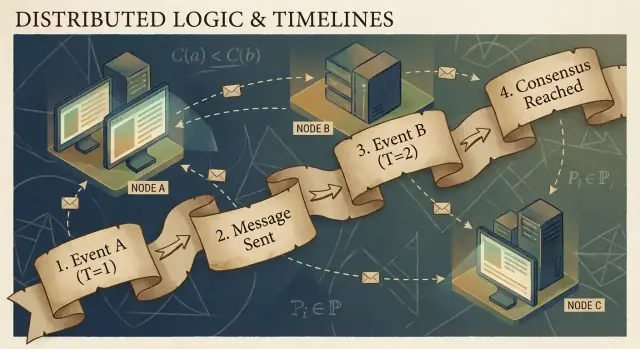
ਕਾਰਨਾਤਮਕਤਾ ਅਤੇ Happened-Before ਸੰਬੰਧ
ਵੰਡੇ ਪ੍ਰੋਗਰਾਮਾਂ ਨੂੰ ਘਟਨਾਵਾਂ ਬਣਾ ਕੇ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ: ਕੋਈ ਖਾਸ ਨੋਡ (ਪ੍ਰੋਸੈਸ, ਸਰਵਰ, ਜਾਂ ਥ੍ਰੈਡ) 'ਤੇ ਜੋ ਕੁਝ ਵੀ ਹੁੰਦਾ ਹੈ। ਉਦਾਹਰਣਾਂ ਵਿੱਚ “ਇੱਕ ਬੀਨੈ ਪ੍ਰਾਪਤ ਕੀਤਾ”, “ڈیਟਾਬੇਸ ਵਿੱਚ ਲਿਖਿਆ”, ਜਾਂ “ਸੁਨੇਹਾ ਭੇਜਿਆ” ਸ਼ਾਮਿਲ ਹਨ। ਇੱਕ ਸੁਨੇਹਾ ਨੋਡਾਂ ਨੂੰ ਜੋੜਦਾ ਹੈ: ਇਕ ਘਟਨਾ ਭੇਜੋ ਹੁੰਦੀ ਹੈ, ਦੂਜੀ ਪ੍ਰਾਪਤ.
Lamport ਦੀ ਮੁੱਖ ਸੁਝਾਵ ਇਹ ਹੈ ਕਿ ਵਿਸ਼ਵਾਸਯੋਗ ਸਾਂਝੀ ਘੜੀ ਨਾ ਹੋਣ ਉੱਤੇ ਸਭ ਤੋਂ ਭਰੋਸੇਯੋਗ ਚੀਜ਼ ਜੋ ਤੁਸੀਂ ਟਰੈਕ ਕਰ ਸਕਦੇ ਹੋ ਉਹ ਕਾਰਨਾਤਮਕਤਾ ਹੈ—ਕਿਹੜੀਆਂ ਘਟਨਾਵਾਂ ਦੂਜੀਆਂ 'ਤੇ ਅਸਰ ਕਰ ਸਕਦੀਆਂ ਹਨ।
happened-before ਸੰਬੰਧ (→)
Lamport ਨੇ ਇੱਕ ਸਧਾਰਣ ਨਿਯਮ define ਕੀਤਾ ਜਿਸਨੂੰ happened-before ਕਿਹਾ ਜਾਂਦਾ ਹੈ, ਜਿਸਨੂੰ A → B ਨਾਲ ਲਿਖਦੇ ਹਾਂ (ਘਟਨਾ A ਘਟਨਾ B ਤੋਂ ਪਹਿਲਾਂ ਹੋਈ):
- ਇੱਕੋ ਪ੍ਰੋਸੈਸ ਵਿੱਚ ਕ੍ਰਮ: ਜੇ A ਅਤੇ B ਇੱਕੋ ਮਸ਼ੀਨ/ਪ੍ਰੋਸੈਸ 'ਤੇ ਹੋਣ ਅਤੇ A ਉਸ ਪ੍ਰੋਸੈਸ ਵਿੱਚ ਪਹਿਲਾਂ ਆਵੇ, ਤਾਂ A → B।
- ਸੁਨੇਹਾ ਕ੍ਰਮ: ਜੇ A "ਸੁਨੇਹਾ m ਭੇਜਿਆ" ਹੈ ਅਤੇ B "ਉਹ ਸੁਨੇਹਾ ਪ੍ਰਾਪਤ ਕੀਤਾ", ਤਾਂ A → B।
- ਟ੍ਰਾਂਸਿਟਿਵਟੀ: ਜੇ A → B ਅਤੇ B → C, ਤਾਂ A → C।
ਇਹ ਸੰਬੰਧ ਤੁਹਾਨੂੰ ਇੱਕ ਅੰਸ਼ਕ ਕ੍ਰਮ ਦਿੰਦੀ ਹੈ: ਇਹ ਦੱਸਦੀ ਹੈ ਕਿ ਕੁਝ ਜੋੜੇ ਆਦੇਸ਼ਿਤ ਹਨ, ਪਰ ਸਾਰੇ ਨਹੀਂ।
ਇੱਕ ਵੀਵਰਨੀ ਕਹਾਣੀ: ਯੂਜ਼ਰ → ਬੇਨੈ → DB → cache
ਇੱਕ ਯੂਜ਼ਰ "Buy" 'ਤੇ ਕਲਿੱਕ ਕਰਦਾ ਹੈ। ਉਹ ਕਲਿੱਕ API ਸਰਵਰ ਨੂੰੋਂ ਇੱਕ ਬੇਨੈ ਦਿਲਵਾਉਂਦੀ ਹੈ (ਘਟਨਾ A). ਸਰਵਰ ਡੇਟਾਬੇਸ ਵਿੱਚ ਇੱਕ order ਰੋ ਦਿਖਾਉਂਦਾ ਹੈ (ਘਟਨਾ B). ਲਿਖਾਈ ਮੁਕੰਮਲ ਹੋਣ 'ਤੇ, ਸਰਵਰ "order created" ਸੁਨੇਹਾ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦਾ ਹੈ (ਘਟਨਾ C), ਅਤੇ cache ਸੇਵਾ ਇਸ ਨੂੰ ਪ੍ਰਾਪਤ ਕਰਕੇ cache ਅਪਡੇਟ ਕਰਦੀ ਹੈ (ਘਟਨਾ D).
ਇੱਥੇ, A → B → C → D। ਭਾਵੇਂ ਘੜੀਆਂ ਮਿਲਦੀਆਂ ਨਾ ਹੋਣ, ਸੁਨੇਹੇ ਅਤੇ ਪ੍ਰੋਗਰਾਮ ਬਣਤਰ ਹਕੀਕਤੀ ਕਾਰਨਾਤਮਕ ਲਿੰਕ ਬਣਾਂਦੀਆਂ ਹਨ।
"ਸਮਕਾਲੀ" ਦਾ ਅਸਲ ਮਤਲਬ
ਦੋ ਘਟਨਾਵਾਂ ਸਮਕਾਲੀ ਹੁੰਦੀਆਂ ਹਨ ਜਦੋਂ ਕੋਈ ਵੀ ਇੱਕ ਦੂਜੇ ਦਾ ਕਾਰਨ ਨਹੀਂ: ਨਾ (A → B) ਅਤੇ ਨਾ (B → A)। ਸਮਕਾਲੀ ਦਾ ਮਤਲਬ "ਇੱਕੋ ਸਮੇਂ" ਨਹੀਂ—ਇਹ ਮਤਲਬ ਹੈ "ਕੋਈ ਕਾਰਨਾਤਮਕ ਰਸਤਾ ਨਹੀਂ ਜੋ ਉਹਨਾਂ ਨੂੰ ਜੋੜਦਾ ਹੋਵੇ।" ਇਸੀ ਲਈ ਦੋ ਸਰਵਿਸਜ਼ ਇਕ-ਸਮੇਂ ਦਾਅਵਾ ਕਰ ਸਕਦੀਆਂ ਹਨ ਕਿ ਉਹ ਪਹਿਲਾਂ ਕਾਰਵਾਈ ਕੀਤੀ, ਅਤੇ ਦੋਹਾਂ ਸਹੀ ਹੋ ਸਕਦੀਆਂ ਹਨ ਜਦ ਤਕ ਤੁਸੀਂ ਕੋਈ ਆਰਡਰਿੰਗ ਨਿਯਮ ਨਹੀਂ ਲਾਉਂਦੇ।
ਲਾਜਿਕਲ ਘੜੀਆਂ: Lamport ਟਾਈਮਸਟੈਂਪ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ
ਜੇ ਤੁਸੀਂ ਕਦੇ ਕਈ ਮਸ਼ੀਨਾਂ 'ਚੋਂ "ਪਹਿਲਾਂ ਕੀ ਹੋਇਆ" ਨੂੰ ਮੁੜ reconstruct ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ़ ਕੀਤੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਬੁਨਿਆਦੀ ਸਮੱਸਿਆ ਨਾਲ ਜੂਝ ਚੁਕੇ ਹੋ: ਕੰਪਿਊਟਰਾਂ ਕੋਲ ਇੱਕ ਪਰਫੈਕਟ ਤੰਗ ਨਾਲ ਸਿੰਕਰੇਨਾਈਜ਼ਡ ਘੜੀ ਨਹੀਂ ਹੁੰਦੀ। Lamport ਦੀ ਚਾਲ ਹੈ ਕਿ ਪਰਫੈਕਟ ਸਮਾਂ ਦੇ ਪਿੱਛੇ ਨਾ ਭੱਜੋ ਅਤੇ ਬਜਾਏ ਉਸ ਦੀ ਥਾਂ ਕ੍ਰਮ ਨੂੰ ਟਰੈਕ ਕਰੋ।
ਵਿਚਾਰ: ਹਰ ਘਟਨਾ ਨਾਲ ਜੋੜਿਆ ਇੱਕ ਕਾਊਂਟਰ
Lamport ਟਾਈਮਸਟੈਂਪ ਸਿਰਫ ਇੱਕ ਨੰਬਰ ਹੈ ਜੋ ਤੁਸੀਂ ਹਰ ਸਮੇਂ ਦੀ ਘਟਨਾ ਨੂੰ ਇੱਕ ਪ੍ਰੋਸੈਸ 'ਤੇ (ਸਰਵਿਸ ਇੰਸਟੈਂਸ, ਨੋਡ, ਥ੍ਰੈਡ—ਜੋ ਵੀ ਤੁਸੀਂ ਚੁਣੋ) ਨਾਲ ਜੋੜਦੇ ਹੋ। ਇਸ ਨੂੰ ਇੱਕ "ਘਟਨਾ ਗਿਣਤੀ" ਵਾਂਗ ਸੋਚੋ ਜੋ ਤੁਹਾਨੂੰ ਇਹ ਕਹਿਣ ਦਾ ਸਥਿਰ ਤਰੀਕਾ ਦਿੰਦੀ ਹੈ, "ਇਹ ਘਟਨਾ ਉਸ ਘਟਨਾ ਤੋਂ ਪਹਿਲਾਂ ਹੋਈ," ਭਾਵੇਂ ਵਾਲ-ਕਲਾਕ਼ ਅਣਵਿਸ਼ਵਾਸਯੋਗ ਹੋਵੇ।
ਦੋ ਨਿਯਮ (ਅਤੇ ਇਹ واقعاً ਇਨੇ ਹੀ ਸਾਦੇ ਹਨ)
-
ਲੋਕਲ ਵਧਾਓ: ਕਿਸੇ ਘਟਨਾ ਨੂੰ ਰਿਕਾਰਡ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ (ਉਦਾਹਰਣ: "DB ਵਿੱਚ ਲਿਖਿਆ", "ਬੇਨੈ ਭੇਜੀ", "ਲੌਗ ਐਂਟਰੀ ਜੋੜੀ"), ਆਪਣੇ ਲੋਕਲ ਕਾਊਂਟਰ ਨੂੰ ਇੰਕਰੀਮੈਂਟ ਕਰੋ।
-
ਪ੍ਰਾਪਤ ਕਰਨ ਤੇ, max + 1 ਲੋਵੀ: ਜਦੋਂ ਤੁਸੀਂ ਉਹ ਸੁਨੇਹਾ ਪ੍ਰਾਪਤ ਕਰੋ ਜਿਸ ਵਿੱਚ ਭੇਜਣ ਵਾਲੇ ਦਾ ਟਾਈਮਸਟੈਂਪ ਸ਼ਾਮਲ ਹੈ, ਆਪਣੇ ਕਾਊਂਟਰ ਨੂੰ ਸੈੱਟ ਕਰੋ:
max(local_counter, received_counter) + 1
ਫਿਰ ਪ੍ਰਾਪਤ ਘਟਨਾ 'ਤੇ ਉਸ ਮੂਲ ਨੂੰ ਸਟੈਂਪ ਕਰੋ।
ਇਹ ਨਿਯਮ ਕਾਰਨਾਤਮਕਤਾ ਨੂੰ ਮਨਾਉਂਦੇ ਹਨ: ਜੇ ਘਟਨਾ A ਨੇ ਘਟਨਾ B ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕੀਤਾ ਹੋ ਸਕਦਾ ਹੈ (ਸੁਨੇਹਿਆਂ ਰਾਹੀਂ ਜਾਣਕਾਰੀ ਬਹੀ), ਤਾਂ A ਦਾ ਟਾਈਮਸਟੈਂਪ B ਤੋਂ ਛੋਟਾ ਹੋਵੇਗਾ।
Lamport ਟਾਈਮਸਟੈਂਪ ਤੁਹਾਨੂੰ ਕੀ ਦੱਸ ਸਕਦੇ ਹਨ—ਅਤੇ ਕੀ ਨਹੀਂ
ਉਹ ਕਾਰਨਾਤਮਕ ਆਰਡਰਿੰਗ ਬਾਰੇ ਦੱਸ ਸਕਦੇ ਹਨ:
- ਜੇ
TS(A)\u003cTS(B), ਤਾਂ A ਸ਼ਾਇਦ B ਤੋਂ ਪਹਿਲਾਂ ਹੋਇਆ। - ਜੇ A ਨੇ B ਦਾ ਕਾਰਨ ਕੀਤਾ (ਸਿੱਧਾ ਜਾਂ ਅਪਰੋਛ), ਤਾਂ ਨਿਸ਼ਚਿਤ ਤੌਰ 'ਤੇ
TS(A)\u003cTS(B)।
ਉਹ ਅਸਲ ਸਮੇਂ ਬਾਰੇ ਨਹੀਂ ਦੱਸ ਸਕਦੇ:
- ਇੱਕ ਛੋਟਾ ਟਾਈਮਸਟੈਂਪ ਇਸਦਾ ਮਤਲਬ ਨਹੀਂ ਕਿ "ਸੈਕੰਡਾਂ ਵਿੱਚ ਪਹਿਲਾਂ"।
- ਦੋ ਘਟਨਾਵਾਂ ਸਮਕਾਲੀ ਹੋ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਫਿਰ ਵੀ ਵੱਖ-ਵੱਖ ਟਾਈਮਸਟੈਂਪ ਹੋ ਸਕਦੇ ਹਨ ਸੁਨੇਹਾ ਪੈਟਰਨ ਕਾਰਨ।
ਇਸ ਲਈ Lamport ਟਾਈਮਸਟੈਂਪ ਆਰਡਰ ਕਰਨ ਲਈ ਵਧੀਆ ਹਨ, ਪਰ latency ਮਾਪਣ ਜਾਂ "ਕਿੰਨਾ ਸਮਾਂ ਸੀ" ਪੁੱਛਣ ਲਈ ਨਹੀਂ।
ਪ੍ਰਯੋਗਿਕ ਉਦਾਹਰਣ: ਸਰਵਿਸਾਂ 'ਚੋਂ ਲੌਗ ਐਂਟ੍ਰੀਆਂ ਨੂੰ ਕ੍ਰਮਤਬੱਧ ਕਰਨਾ
ਕਲਪਨਾ ਕਰੋ ਸਰਵਿਸ A ਸੇਵਾ B ਨੂੰ ਕਾਲ ਕਰਦੀ ਹੈ, ਅਤੇ ਦੋਹਾਂ ਆਡਿਟ ਲੌਗ ਲਿਖਦੇ ਹਨ। ਤੁਸੀਂ ਇੱਕ ਸੰਗਠਿਤ ਲੌਗ ਵਿਚਾਰਨਾ ਚਾਹੁੰਦੇ ਹੋ ਜੋ ਕਾਰਨ-ਅਤੇ-ਅਸਰ ਨੂੰ ਬਰਕਰਾਰ ਰੱਖੇ।
- ਸਰਵਿਸ A ਆਪਣਾ ਕਾਊਂਟਰ ਇੰਕਰੀਮੈਂਟ ਕਰਦੀ ਹੈ, "payment ਸ਼ੁਰੂ" ਲੌਗ ਕਰਦੀ ਹੈ, ਅਤੇ timestamp 42 ਵਾਲੇ ਨਾਲ B ਨੂੰ ਬੇਨੈ ਭੇਜਦੀ ਹੈ।
- ਸਰਵਿਸ B 42 ਨਾਲ ਬੇਨੈ ਪ੍ਰਾਪਤ ਕਰਦੀ ਹੈ, ਆਪਣੇ ਕਾਊਂਟਰ ਨੂੰ
max(local, 42) + 1ਸੈੱਟ ਕਰਦੀ ਹੈ—ਮੰਨਲੋ 43—ਅਤੇ "ਕਾਰਡ ਵੈਰੀਫਾਈ" ਲੌਗ ਕਰਦੀ ਹੈ। - B 44 ਨਾਲ ਜਵਾਬ ਭੇਜਦੀ ਹੈ; A 44 ਪ੍ਰਾਪਤ ਕਰਕੇ 45 'ਤੇ ਅਪਡੇਟ ਕਰਦੀ ਹੈ ਅਤੇ "payment ਪੂਰਾ" ਲੌਗ ਕਰਦੀ ਹੈ।
ਹੁਣ, ਜਦੋਂ ਤੁਸੀਂ ਦੋਹਾਂ ਸਰਵਿਸਾਂ ਤੋਂ ਲੌਗ ਇਕੱਠੇ ਕਰਦੇ ਹੋ, (lamport_timestamp, service_id) ਦੇ ਅਨੁਸਾਰ ਛਾਂਟਣਾ ਤੁਹਾਨੂੰ ਇੱਕ ਸਥਿਰ, ਵਿਆਖਿਆ-ਯੋਗ ਟਾਈਮਲਾਈਨ ਦੇਦਾ ਹੈ ਜੋ ਅਸਲ ਪ੍ਰਭਾਵ ਦੀ ਲੜੀ ਨਾਲ ਮੈਚ ਕਰਦਾ ਹੈ—ਭਾਵੇਂ ਵਾਲ-ਕਲੌਕ ਡ੍ਰਿਫਟ ਹੋ ਜਾਂ ਨੈਟਵਰਕ ਦੇਰੀ ਹੋਏ।
ਅੰਸ਼ਕ ਕ੍ਰਮ ਤੋਂ ਪੂਰਨ ਕ੍ਰਮ: ਜਦੋਂ ਤੁਹਾਨੂੰ ਇੱਕ ਟਾਈਮਲਾਈਨ ਚਾਹੀਦੀ ਹੈ
ਕਾਰਨਾਤਮਕਤਾ ਤੁਹਾਨੂੰ ਇੱਕ ਅੰਸ਼ਕ ਕ੍ਰਮ ਦਿੰਦੀ ਹੈ: ਕੁਝ ਘਟਨਾਵਾਂ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ "ਪਹਿਲਾਂ" ਹੋਣਗੀਆਂ (ਕਿਉਂਕਿ ਉਹਨਾਂ ਨੂੰ ਸੁਨੇਹਾ ਜਾਂ ਨਿਰਭਰਤਾ ਜੋੜਦੀ ਹੈ), ਪਰ ਬਹੁਤ ਸਾਰੀਆਂ ਘਟਨਾਵਾਂ ਸਿਰਫ ਸਮਕਾਲੀ ਹੁੰਦੀਆਂ ਹਨ। ਇਹ ਕੋਈ ਬ੍ਰੇਕ ਨਹੀਂ—ਇਹ ਵੰਡੇ ਹਕੀਕਤ ਦੀ ਕੁਦਰਤ ਹੈ।
ਅੰਸ਼ਕ ਕ੍ਰਮ: ਕਈ ਸਵਾਲਾਂ ਲਈ ਕਾਫ਼ੀ
ਜੇ ਤੁਸੀਂ ਡੀਬੱਗ ਕਰ ਰਹੇ ਹੋ "ਇਸਨੇ ਕਿਸ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕੀਤਾ ਹੋ ਸਕਦਾ ਹੈ?", ਜਾਂ ਐਸੇ ਨਿਯਮ ਲਗਾ ਰਹੇ ਹੋ "ਜਵਾਬ ਨੂੰ ਉਸਦੀ ਬੇਨੈ ਤੋਂ ਬਾਅਦ ਆਨਾ ਚਾਹੀਦਾ ਹੈ", ਤਾਂ ਅੰਸ਼ਕ ਕ੍ਰਮੇ ਸਹੀ ਹੈ। ਤੁਸੀਂ ਸਿਰਫ happened-before ਕਿਨਾਰਿਆਂ ਦਾ ਆਦਰ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ; ਬਾਕੀ ਸਭ ਨੂੰ ਸਤੰਤਰ ਮੰਨ ਸਕਦੇ ਹੋ।
ਪੂਰਨ ਕ੍ਰਮ: ਜਦੋਂ ਸਿਸਟਮ ਨੂੰ ਇੱਕ ਕਹਾਣੀ ਚਾਹੀਦੀ ਹੈ
ਕੁਝ ਸਿਸਟਮ "ਦੋ ਰਾਹ ਚੱਲ ਸਕਦੇ ਹਨ" ਨੂੰ ਸਹਿਣ ਨਹੀਂ ਕਰ ਸਕਦੇ। ਉਨ੍ਹਾਂ ਨੂੰ ਇੱਕ ਇੱਕਲੜੀ ਦੇ ਕਾਰਜਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਖ਼ਾਸ ਕਰਕੇ:
- ਸਾਂਝੇ ਓਬਜੈਕਟ ਨੂੰ ਲਿਖਣ ('set balance', 'update profile', 'append to log')
- ਹੁਕਮ ਜੋ ਹਰ ਥਾਂ ਇੱਕੋ ਤਰੀਕੇ ਨਾਲ ਲਾਗੂ ਹੋਣ (state machine replication)
- ਟਕਰਾਅ-ਨਿਵਾਰਨ ਜਿੱਥੇ "ਅਖੀਰਲਾ ਲਿਖਣਾ ਜੇਤੂ ਹੋਵੇ" ਦਾ ਇੱਕੋ ਮਤਲਬ ਹਰ ਨੋਡ ਲਈ ਹੋਵੇ
ਬਿਨਾਂ ਇਕੱਲੀ ਕ੍ਰਮ ਦੇ, ਦੋ ਰੇਪਲਿਕਾ ਲੋਕਲੀ "ਸਹੀ" ਹੋ ਸਕਦੇ ਹਨ ਪਰ ਗਲੋਬਲੀ ਵੱਖਰੇ ਹੋ ਸਕਦੇ ਹਨ: ਇੱਕ A ਫਿਰ B ਲਾਗੂ ਕਰ ਸਕਦਾ ਹੈ, ਦੂਜਾ B ਫਿਰ A; ਨਤੀਜਾ ਵੱਖਰਾ ਆਵੇਗਾ।
ਤੁਸੀਂ ਇੱਕ ਟਾਈਮਲਾਈਨ ਕਿਵੇਂ ਪ੍ਰਾਪਤ ਕਰੋ?
ਤੁਸੀਂ ਇਕ ਐਸਾ ਤੰਤਰ ਲਿਆਂਦੇ ਹੋ ਜੋ ਕ੍ਰਮ ਬਣਾਉਂਦਾ ਹੈ:
- ਇੱਕ sequencer/leader ਜੋ ਹਰ ਕਮਾਂਡ ਨੂੰ ਇੱਕ monotonic ਅਸਥਾਨ ਦਿੰਦਾ ਹੈ।
- ਜਾਂ consensus (ਜਿਵੇਂ Paxos-ਸਟਾਇਲ ਤਰੀਕੇ) ਤਾਂ ਜੋ ਕਲੱਸਟਰ ਅਗਲੇ ਲੌਗ ਐਂਟਰੀ ਤੇ ਸਹਿਮਤ ਹੋ ਜਾਵੇ ਭਾਵੇਂ ਦੇਰੀ ਜਾਂ ਫੇਲ ਹੋਵਣ।
ਉਹ ਟ੍ਰੇਡ-ਆਫ਼ ਜਿਹਨੂੰ ਤੁਸੀਂ ਬਚ ਨਹੀਂ ਸਕਦੇ
ਇੱਕ ਪੂਰਨ ਕ੍ਰਮ ਸ਼ਕਤੀਸ਼ਾਲੀ ਹੈ, ਪਰ ਇਹ ਕੁਝ ਕੀਮਤ ਲਿਆਉਂਦਾ ਹੈ:
- ਲੇਟੈਂਸੀ: ਕੋਆਰਡੀਨੇਸ਼ਨ ਲਈ ਤੁਸੀਂ ਕਦੀ-ਕਦੀ ਉਡੀਕ ਕਰੋਗੇ।
- ਥਰੂਪੁੱਟ: ਇੱਕ ਇਕੋ ਆਰਡਰਡ ਲੌਗ ਬੋਤਲ-ਨੈਕ ਬਣ ਸਕਦਾ ਹੈ।
- ਫੇਲਿਅਰ ਵਿੱਚ ਉਪਲਬਦੀਤਾ: ਜੇ ਤੁਸੀਂ ਕਾਫ਼ੀ ਨੋਡਾਂ ਤੱਕ ਨਹੀਂ ਪੁੱਜਦੇ ਤਾਂ ਤਰੱਕੀ ਰੁਕ ਸਕਦੀ ਹੈ ਤਾਕਿ ਸਹੀਅਤ ਸੁਰੱਖਿਅਤ ਰਹੇ।
ਡਿਜ਼ਾਈਨ ਚੋਣ ਸਪਸ਼ਟ ਹੈ: ਜਦੋਂ ਸਹੀਅਤ ਇੱਕ ਸਾਂਝੀ ਕਹਾਣੀ ਮੰਗਦੀ ਹੈ, ਤੁਸੀਂ ਇਸਨੂੰ ਪ੍ਰਾਪਤ ਕਰਨ ਲਈ ਕੋਆਰਡੀਨੇਸ਼ਨ ਦੀ ਕੀਮਤ ਭਰਦੇ ਹੋ।
Consensus: ਦੇਰੀ ਅਤੇ ਫੇਲਿਅਰ ਦੇ ਮੌਜੂਦ ਹੋਣ 'ਚ ਸਹਿਮਤੀ
Make retries safe
Idempotency ਕੀਜ਼ ਅਤੇ ਸਾਫ਼ request tracing ਨਾਲ ਇੱਕ retry-safe workflow ਸਰਵਿਸ ਤਿਆਰ ਕਰੋ।
Consensus ਉਹ ਸਮੱਸਿਆ ਹੈ ਜਿਸ ਵਿੱਚ ਕਈ ਮਸ਼ੀਨਾਂ ਇੱਕ ਫੈਸਲੇ 'ਤੇ ਸਹਿਮਤ ਹੋਣ—ਇੱਕ ਮੁੱਲ ਨੂੰ commit ਕਰਨ, ਇੱਕ ਲੀਡਰ ਨੂੰ ਮੰਨਣ, ਇੱਕ ਕੰਫਿਗਰੇਸ਼ਨ activate ਕਰਨ—ਜਦਕਿ ਹਰ ਨੋਡ ਸਿਰਫ ਆਪਣੀਆਂ ਲੋਕਲ ਘਟਨਾਵਾਂ ਅਤੇ ਜੋ ਸੁਨੇਹੇ ਮਿਲੇ ਉਨ੍ਹਾਂ ਨੂੰ ਹੀ ਵੇਖਦਾ।
ਇਹ ਸਧਾਰਣ ਲੱਗਦਾ ਹੈ ਜਦ ਤਕ ਤੁਸੀਂ ਯਾਦ ਰੱਖੋ ਕਿ ਵੰਡੇ ਸਿਸਟਮ ਨੂੰ ਕੀ ਕਰਨ ਦੀ ਆਗਿਆ ਹੈ: ਸੁਨੇਹੇ ਦੇਰੀ, ਨਕਲ, ਰੀਅਰੰਗ ਜਾਂ ਗੁਆਚ ਹੋ ਸਕਦੇ ਹਨ; ਮਸ਼ੀਨਾਂ crash ਕਰ ਸਕਦੀਆਂ ਹਨ ਅਤੇ ਰੀਸਟਾਰਟ ਹੋ ਸਕਦੀਆਂ ਹਨ; ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ ਇਹ ਪਤਾ ਨਹੀਂ ਹੁੰਦਾ ਕਿ "ਇਹ ਨੋਡ ਪੱਕੇ ਤੌਰ 'ਤੇ ਮੁਰਝਾ ਗਿਆ"। Consensus ਇਹ ਹੈ ਕਿ ਇਨਾਂ ਹਾਲਤਾਂ ਵਿੱਚ ਸਹਿਮਤੀ ਨੂੰ ਸੁਰੱਖਿਅਤ ਬਣਾਇਆ ਜਾਵੇ।
ਕਿਉਂ ਸਹਿਮਤੀ ਔਖੀ ਹੈ
ਜੇ ਦੋ ਨੋਡ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਗੱਲ ਨਹੀਂ ਕਰ ਸਕਦੇ (ਨੈਟਵਰਕ partition), ਤਾਂ ਹਰ ਪਾਸਾ ਆਪਣੀ ਤਰ੍ਹਾਂ "ਅੱਗੇ ਵਧਨ" ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰ ਸਕਦਾ ਹੈ। ਜੇ ਦੋਹਾਂ ਵੱਖ-ਵੱਖ ਮੁੱਲ ਫੈਸਲ ਕਰ ਲੈਂ, ਤਾਂ ਤੁਸੀਂ split-brain ਹਾਲਤ ਵਿੱਚ ਫਸ ਸਕਦੇ ਹੋ: ਦੋ ਲੀਡਰ, ਦੋ ਕੰਫਿਗਰੇਸ਼ਨ, ਜਾਂ ਦੋ ਮੁਕਾਬਲਾ ਇਤਿਹਾਸ।
Partition ਤੋਂ ਇਲਾਵਾ, ਕੇਵਲ ਦੇਰੀ ਵੀ ਮਸਲੇ ਪੈਦਾ ਕਰਦੀ ਹੈ। ਜਦ ਇੱਕ ਨੋਡ ਕਿਸੇ ਪ੍ਰਸਤਾਵ ਬਾਰੇ ਸੁਣਦਾ ਹੈ, ਹੋ ਸਕਦਾ ਹੈ ਹੋਰ ਨੋਡ ਪਹਿਲਾਂ ਹੀ ਅੱਗੇ ਹੋ ਚੁੱਕੇ ਹੋਣ। ਘੜੀ ਸਾਂਝੀ ਨਹੀਂ ਹੈ, ਇਸ ਲਈ ਤੁਸੀਂ ਭਰੋਸੇ ਨਾਲ ਨਹੀਂ ਕਹਿ ਸਕਦੇ "ਪ੍ਰਸਤਾਵ A ਪ੍ਰਸਤਾਵ B ਤੋਂ ਪਹਿਲਾਂ ਹੋਇਆ" ਸਿਰਫ ਇਸ ਲਈ ਕਿ A ਦਾ ਟਾਈਮਸਟੈਂਪ ਛੋਟਾ ਹੈ—physical time ਇਥੇ ਪ੍ਰਮਾਣਿਕ ਨਹੀਂ।
ਅਸੀਂ ਰੋਜ਼ਮਰ੍ਹਾ ਸਿਸਟਮਾਂ ਵਿੱਚ consensus ਕਿੱਥੇ ਵੇਖਦੇ ਹਾਂ
ਤੁਸੀਂ ਦਿਲ ਵਿੱਚ ਹਰ ਰੋਜ਼ consensus ਨਹੀਂ ਕਹੋਂਗੇ, ਪਰ ਇਹ ਆਮ ਬੁਨਿਆਦੀ ਢਾਂਚਿਆਂ ਵਿੱਚ ਆਉਂਦਾ ਹੈ:
- ਲੀਡਰ ਚੋਣ (ਹੁਣ ਕੌਣ ਮੁਖੀ ਹੈ?)
- ਨਕਲ-ਕਿਯਾ ਲੌਗ (ਸਾਂਝੇ ਇਤਿਹਾਸ ਵਿੱਚ ਅਗਲੀ ਐਂਟਰੀ ਕੀ ਹੈ?)
- ਕੰਫਿਗਰੇਸ਼ਨ ਬਦਲਾਅ (ਕਿਹੜਾ ਨੋਡਾਂ ਦਾ ਸੈੱਟ vote/commit ਕਰਨ ਲਈ ਅਧਿਕਾਰਤ ਹੈ?)
ਹਰ ਕੇਸ ਵਿੱਚ, ਸਿਸਟਮ ਨੂੰ ਇੱਕ ਇਕੱਲਾ ਨਤੀਜਾ ਚਾਹੀਦਾ ਹੈ ਜਿਸ 'ਤੇ ਹਰ ਕੋਈ ਕਿਸੇ ਸਾਡੇ ਨਿਯਮ ਅਨੁਸਾਰ ਇਕੱਠਾ ਹੋ ਸਕੇ, ਜਾਂ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਐਸਾ ਨਿਯਮ ਜੋ ਦੋ ਵੱਖਰੇ ਨਤੀਜਿਆਂ ਨੂੰ ਦੋਹਾਂ ਲਈ ਵੈਧ ਹੋਣ ਤੋਂ ਰੋਕੇ।
Paxos — Lamport ਦਾ ਜਵਾਬ
Lamport ਦਾ Paxos ਇਸ "ਸੁਰੱਖਿਅਤ ਸਹਿਮਤੀ" ਸਮੱਸਿਆ ਦਾ ਮੁੱਢਲੀ ਹੱਲ ਹੈ। ਮੁੱਖ ਵਿਚਾਰ ਕੋਈ ਜਾਦੂਈ timeout ਜਾਂ ਪੂਰਨ ਲੀਡਰ ਨਹੀਂ ਹੈ—ਇਹ ਨਿਯਮਾਂ ਦਾ ਇੱਕ ਸੈੱਟ ਹੈ ਜੋ ਇਹ ਯਕੀਨੀ ਬਣਾਂਦਾ ਹੈ ਕਿ ਇੱਕੋ ਮੁੱਲ ਹੀ ਚੁਣਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਭਾਵੇਂ ਸੁਨੇਹੇ ਦੇਰੀ ਹੋਣ ਜਾਂ ਨੋਡ ਫੇਲ ਹੋਣ।
Paxos safety ("ਕਦੇ ਵੀ ਦੋ ਵੱਖਰੇ ਮੁੱਲ ਨਹੀਂ ਚੁਣੇ ਜਾਣੇ") ਅਤੇ progress ("ਆਖਿਰਕਾਰ ਕੁਝ ਚੁਣਿਆ ਜਾਵੇ") ਨੂੰ ਵੱਖ-ਵੱਖ ਰੱਖਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਇਹ عملي ਬੇਸਲਾਈਨ ਬਣਦਾ ਹੈ: ਤੁਸੀਂ ਅਸਲੀ ਪਰਸਥਿਤੀਆਂ ਲਈ ਪ੍ਰਦਰਸ਼ਨ ਟਿਊਨ ਕਰ ਸਕਦੇ ਹੋ ਪਰ ਮੁੱਖ ਗਰੰਟੀ ਚੱਲਦੀ ਰਹਿੰਦੀ ਹੈ।
Paxos, ਸਿਰਦਰਦ ਤੋਂ ਬਿਨਾਂ: ਮੁੱਖ safety ਇੰਟੂਇਸ਼ਨ
Paxos ਨੂੰ ਪੜ੍ਹਨ ਦੀ ਮਸ਼ਕਲ ਇਸ ਲਈ ਹੈ ਕਿ "Paxos" ਇੱਕ ਹੀ ਸਰਲ algorithm ਨਹੀਂ—ਇਹ ਨਜ਼ਦੀਕੀ ਢੰਗਾਂ ਦੀ ਪਰਿਵਾਰ ਹੈ ਜੋ ਇੱਕ ਗਰੁੱਪ ਨੂੰ ਸਹਿਮਤ ਕਰਾਉਂਦੀ ਹੈ, ਭਾਵੇਂ ਸੁਨੇਹੇ ਲੇਟ, ਦੁਹਰਾਏ ਜਾਂ ਮਸ਼ੀਨ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਫੇਲ ਹੋਣ।
ਕਾਸਟ: proposers, acceptors, ਅਤੇ quorums
ਇੱਕ ਮਦਦਗਾਰ ਮਾਨਸਿਕ ਮਾਡਲ ਇਹ ਹੈ ਕਿ ਕੌਣ ਸੁਝਾਅ ਦਿੰਦਾ ਅਤੇ ਕੌਣ ਪੱਕਾ ਕਰਦਾ/ਵੀਟਾ ਕਰਦਾ ਨੂੰ ਵੱਖਰਾ ਕਰੋ।
- Proposers ਉਹ ਹਨ ਜੋ ਕਿਸੇ ਮੁੱਲ ਨੂੰ ਚੁਣਵਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ (ਜਿਵੇਂ: "ਅਗਲੀ ਲੌਗ ਐਂਟਰੀ X ਹੈ").
- Acceptors ਪ੍ਰਸਤਾਵਾਂ 'ਤੇ ਵੋਟ ਕਰਦੇ ਹਨ।
- ਕੁਆਂਰਮ "ਕਾਫ਼ੀ acceptors" ਹੁੰਦੇ ਹਨ ਤਾਕਿ ਤਰੱਕੀ ਹੋ ਸਕੇ—ਆਮ ਤੌਰ 'ਤੇ ਇੱਕ ਵੱਡੀ ਭਾਗੈਦਾਰੀ (majority)।
ਇੱਕ ਢਾਂਚੇਵਾਦੀ ਵਿਚਾਰ ਇਹ ਹੈ: ਕੋਈ ਵੀ ਦੋ majorities ਮੇਲ ਖਾਂਦੀਆਂ ਹਨ। ਇਹੀ ਓਵਰਲੈਪ ਹੈ ਜਿੱਥੇ safety ਟਿਕੀ ਰਹਿੰਦੀ ਹੈ।
safety ਲਛਣ: ਦੋ ਵੱਖਰੇ ਮੁੱਲ ਕਦੇ ਫੈਸਲ ਨਾ ਹੋਣ
Paxos safety ਆਸਾਨੀ ਨਾਲ ਬਿਆਨ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ: ਜਦੋਂ ਸਿਸਟਮ ਕਿਸੇ ਮੁੱਲ ਦਾ ਫੈਸਲਾ ਕਰ ਲੈਂਦਾ ਹੈ, ਉਹ ਮੁੱਲ ਕਦੇ ਬਦਲਿਆ ਨਹੀਂ ਜਾ ਸਕਦਾ—ਕੋਈ split-brain ਫੈਸਲਾ ਨਹੀਂ।
ਮੁੱਖ ਇੰਟੂਇਸ਼ਨ ਇਹ ਹੈ ਕਿ ਪ੍ਰਸਤਾਵਾਂ ਨਾਲ ਨੰਬਰ ਹੁੰਦੇ ਹਨ (ਬਾਲਟ IDs ਸਮਝੋ)। Acceptors ਵਾਅਦਾ ਕਰਦੇ ਹਨ ਕਿ ਉਹ ਪੁਰਾਣੇ-ਨੰਬਰ ਵਾਲੇ ਪ੍ਰਸਤਾਵਾਂ ਨੂੰ ਨਕਾਰ ਦੇਣਗੇ ਜਦੋਂ ਉਹ ਨਵੇਂ ਨੰਬਰ ਦੇਖ ਲੈਂਦੇ ਹਨ। ਅਤੇ ਜਦੋਂ ਇੱਕ proposer ਨਵੇਂ ਨੰਬਰ ਨਾਲ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ, ਉਹ ਪਹਿਲਾਂ ਇੱਕ ਕੁਵੋਰਮ ਤੋਂ ਪੁੱਛਦਾ ਹੈ ਕਿ ਉਨ੍ਹਾਂ ਨੇ ਪਹਿਲਾਂ ਕੀ ਸੁਵੀਕਾਰ ਕੀਤਾ।
ਕੁਆਂਰਮ ਓਵਰਲੈਪ ਕਾਰਨ, ਨਵੇਂ proposer ਨੂੰ ਜਰੂਰ ਇੱਕ ਐਸੇ acceptor ਤੋਂ ਜਵਾਬ ਮਿਲੇਗਾ ਜੋ "ਸਭ ਤੋਂ ਹਾਲੀਆ ਤੌਰ 'ਤੇ ਮਨਜ਼ੂਰ ਕੀਤਾ ਹੋਇਆ ਮੁੱਲ" ਯਾਦ ਰੱਖਦਾ ਹੈ। ਨਿਯਮ ਇਹ ਹੈ: ਜੇ ਕੁਆਂਰਮ ਵਿੱਚ ਕਿਸੇ ਨੇ ਕੁਝ ਮਨਜ਼ੂਰ ਕੀਤਾ ਹੈ ਤਾਂ ਤੁਸੀਂ ਉਹੀ ਮੁੱਲ propose ਕਰੋ (ਜਾਂ ਉਨ੍ਹਾਂ ਵਿੱਚੋਂ ਸਭ ਤੋਂ ਨਵਾਂ)। ਇਹ ਪਾਬੰਦੀ ਦੋ ਵੱਖਰੇ ਮੁੱਲ ਚੁਣਨ ਤੋਂ ਰੋਕਦੀ ਹੈ।
लਾਈਵਨੈਸ, ਇੱਕ ਉਚੇ ਸਤਰ ਤੇ
Liveness ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਸਿਸਟਮ ਅੰਤ ਵਿੱਚ ਕੁਝ ਫੈਸਲਾ ਕਰੇਗਾ ਜੇ ਹਾਲਾਤ ਠੀਕ ਹਨ (ਮਿਸਾਲ ਲਈ, ਇੱਕ ਸਥਿਰ leader ਉਭਰੇ ਅਤੇ ਨੈਟਵਰਕ ਆਖਿਰਕਾਰ ਸੁਨੇਹੇ ਡਿਲਿਵਰ ਕਰੇ)। Paxos ਤਬੱਯਨ ਤੇਜ਼ੀ ਦਾ ਵਾਅਦਾ ਨਹੀਂ ਕਰਦਾ; ਇਹ correctness ਦਾ ਵਾਅਦਾ ਕਰਦਾ ਹੈ, ਅਤੇ ਜਦੋਂ ਹਾਲਾਤ ਸ਼ਾਂਤ ਹੋਂਦੀਆਂ ਹਨ ਤਦ ਤਰੱਕੀ।
State Machine Replication: ਸਾਂਝੇ ਆਰਡਰਿੰਗ ਰਾਹੀਂ ਸਹੀਅਤ
Keep full ownership
ਜਦੋਂ ਡਿਜ਼ਾਇਨ ਠੀਕ ਲੱਗੇ ਤਾਂ ਜਨਰੇਟ ਕੀਤਾ ਗਿਆ ਸੋਰਸ ਕੋਡ ਆਪਣੇ ਰਿਪੋ ਵਿੱਚ ਭੇਜੋ।
State machine replication (SMR) ਉਹ ਨੁਮਾਇੰਦਾ ਢਾਂਚਾ ਹੈ ਜੋ ਕਈ “ਉਪਲਬਧ” ਸਿਸਟਮਾਂ ਦੇ ਪਿੱਛੇ ਖੜ੍ਹਾ ਹੈ: ਇੱਕ ਸਰਵਰ ਫੈਸਲੇ ਕਰਨ ਦੀ ਥਾਂ, ਤੁਸੀਂ ਕਈ ਰੇਪਲਿਕਾ ਚਲਾਉਂਦੇ ਹੋ ਜੋ ਸਾਰੇ ਇਕੋ ਕ੍ਰਮ ਦੇ ਹੁਕਮ ਪ੍ਰੋਸੈਸ ਕਰਦੇ ਹਨ।
ਨਕਲ-ਕੀਆ ਲੌਗ ਦਾ ਵਿਚਾਰ
ਕੇਂਦਰ 'ਚ ਇੱਕ ਰਿਪਲਿਕੇਟਡ ਲੌਗ ਹੁੰਦੀ ਹੈ: ਹੁਕਮਾਂ ਦੀ ਇੱਕ ਕ੍ਰਮਤ ਲਿਸਟ ਜਿਵੇਂ "put key=K value=V" ਜਾਂ "A ਤੋਂ B ਨੂੰ $10 ਤਬਾਦਲਾ"। ਕਲਾਇੰਟ ਸਭ ਰੇਪਲਿਕਾ ਨੂੰ ਹੁਕਮ ਨਹੀਂ ਭੇਜਦੇ ਅਤੇ ਉਮੀਦ ਨਹੀਂ ਰੱਖਦੇ; ਉਹ ਗਰੁੱਪ ਨੂੰ ਹੁਕਮ ਭੇਜਦੇ ਹਨ, ਅਤੇ ਸਿਸਟਮ उन ਹੁਕਮਾਂ ਲਈ ਇੱਕ ਕ੍ਰਮ 'ਤੇ ਸਹਿਮਤ ਹੁੰਦਾ ਹੈ, ਫਿਰ ਹਰ ਰੇਪਲਿਕਾ ਉਹਨਾਂ ਨੂੰ ਲੋਕਲੀ ਲਾਗੂ ਕਰਦੀ ਹੈ।
ਕ੍ਰਮ ਕਿਉਂ ਤੁਹਾਨੂੰ ਸਹੀਅਤ ਦਿੰਦਾ ਹੈ
ਜੇ ਹਰ ਰੇਪਲਿਕਾ ਇੱਕੋ ਸ਼ੁਰੂਆਤੀ ਅਵਸਥਾ ਤੋਂ ਸ਼ੁਰੂ ਕਰਦੀ ਹੈ ਅਤੇ ਇਕੋ ਹੁਕਮਾਂ ਨੂੰ ਇਕੋ ਕ੍ਰਮ ਵਿੱਚ ਚਲਾਉਂਦੀ ਹੈ, ਤਾਂ ਉਹ ਇੱਕੋ ਅਵਸਥਾ ਵਿੱਚ ਪੁੱਜਣਗੇ। ਇਹ ਮੁੱਖ safety ਇੰਟੂਇਸ਼ਨ ਹੈ: ਤੁਸੀਂ ਕਈ ਮਸ਼ੀਨਾਂ ਨੂੰ ਸਮਾਂ ਨਾਲ ਸਿੰਕ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਨਹੀਂ ਕਰ ਰਹੇ; ਤੁਸੀਂ deterministic ਅਤੇ ਸਾਂਝੇ ਕ੍ਰਮ ਰਾਹੀਂ ਉਨਾਂ ਨੂੰ ਇੱਕੋ ਜਿਹਾ ਬਣਾਉਂਦੇ ਹੋ।
ਇਸੀ ਲਈ consensus (Paxos/Raft-ਸਟਾਇਲ) ਅਕਸਰ SMR ਨਾਲ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ: consensus ਅਗਲੀ ਲੌਗ ਐਂਟਰੀ ਦਾ ਫੈਸਲਾ ਕਰਦਾ ਹੈ, ਅਤੇ SMR ਉਸ ਫੈਸਲੇ ਨੂੰ ਰੇਪਲਿਕਾਂ 'ਚ ਇਕਸਾਰ ਅਵਸਥਾ ਵਿੱਚ ਬਦਲ ਦਿੰਦਾ ਹੈ।
ਕਿੱਥੇ ਤੁਸੀਂ ਇਸਨੂੰ ਵੇਖਦੇ ਹੋ
- ਕੋਆਰਡੀਨੇਸ਼ਨ ਸਰਵਿਸਜ਼ (ਜਿਵੇਂ ਕੰਫਿਗਰੇਸ਼ਨ ਅਤੇ ਲੀਡਰ ਚੋਣ)
- ਰਿਪਲਿਕੇਟਡ write-ahead logs ਵਾਲੇ ਡੇਟਾਬੇਸ
- ਮੈਸੇਜ ਸਿਸਟਮ ਜਿੰਨਾ ਨੂੰ ਕਠੋਰ partition ordering ਚਾਹੀਦੀ ਹੈ
ਇੰਜੀਨੀਅਰਾਂ ਲਈ ਪ੍ਰਾਇਕਟਿਕਲ ਚਿੰਤਾਵਾਂ
ਲੌਗ ਹਮੇਸ਼ਾ ਵਧਦਾ ਰਹੇਗਾ ਜਦ ਤੱਕ ਤੁਸੀਂ ਉਸ ਨੂੰ ਮੇਨੇਜ ਨਹੀਂ ਕਰਦੇ:
- Snapshots: ਸਮੇਂ-ਸਮੇਂ ਤੇ ਮੌਜੂਦਾ ਸਟੇਟ ਕੈਪਚਰ ਕਰੋ ਤਾਂ ਕਿ ਨਵੇਂ ਨੋਡ ਪੂਰੇ ਇਤਿਹਾਸ ਨੂੰ ਰੀਪਲੇ ਕਰਨ ਦੇ ਬਿਨਾਂ catch up ਕਰ ਸਕਣ।
- ਲੌਗ ਕੰਪੈਕਸ਼ਨ: ਉਹਨਾਂ ਪੁਰਾਣੀਆਂ ਐਂਟਰੀ ਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਹਟਾਓ ਜੋ snapshot ਵਿੱਚ ਲਾਪਤਾ ਹੋ ਚੁੱਕੀਆਂ ਹਨ ਅਤੇ ਹੁਣ ਲੋੜੀਂਦੀਆਂ ਨਹੀਂ।
- ਮੈਂਬਰਸ਼ਿਪ ਬਦਲਾਅ: ਰੇਪਲਿਕਾ ਜੋੜਨਾ ਜਾਂ ਹਟਾਉਣਾ ਵੀ ਆਰਡਰ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਨਹੀਂ ਤਾਂ ਵੱਖ-ਵੱਖ ਨੋਡ ਇਹ ਫੈਸਲਾ ਕਰ ਸਕਦੇ ਹਨ ਕਿ ਕਿਸੇ ਗਰੁੱਪ ਦਾ ਹਿੱਸਾ ਕੌਣ ਹੈ ਅਤੇ split-brain ਹੋ ਸਕਦਾ ਹੈ।
SMR ਜਾਦੂ ਨਹੀਂ; ਇਹ ਕੜੀ ਅਨੁਸ਼ਾਸਨ ਹੈ ਜੋ "ਕ੍ਰਮ 'ਤੇ ਸਹਿਮਤੀ" ਨੂੰ "ਸਟੇਟ 'ਤੇ ਸਹਿਮਤੀ" ਵਿੱਚ ਬਦਲ ਦਿੰਦੀ ਹੈ।
ਸਹੀਅਤ: Safety, Liveness, ਅਤੇ ਇੱਕ ਸਪੱਸ਼ਟ ਸਪੈਕ ਲਿਖਣਾ
ਵੰਡੇ ਸਿਸਟਮ ਅਜਿਹੇ ਢੰਗ ਨਾਲ ਫੇਲ ਹੁੰਦੇ ਹਨ ਜੋ ਅਨੋਖੇ ਹਨ: ਸੁਨੇਹੇ ਦੇਰੀ ਨਾਲ ਆਉਂਦੇ, ਨੋਡ ਰੀਸਟਾਰਟ ਹੁੰਦੇ, ਘੜੀਆਂ ਨਹੀਂ ਮਿਲਦੀਆਂ, ਅਤੇ ਨੈੱਟਵਰਕ ਟੁੱਟਦਾ ਹੈ। "ਸਹੀਅਤ" ਇਕ ਭਾਵ ਨਹੀਂ—ਇਹ ਅਜਿਹੇ ਵਾਅਦੇ ਹਨ ਜੋ ਤੁਸੀਂ ਨਿਸ਼ਚਿਤ ਤੌਰ 'ਤੇ ਬਿਆਨ ਕਰ ਸਕਦੇ ਹੋ ਅਤੇ ਫਿਰ ਹਰ ਹਾਲਤ, ਸਮੇਤ ਫੇਲਿਅਰਾਂ ਦੇ ਖਿਲਾਫ ਜਾਂਚ ਸਕਦੇ ਹੋ।
Safety vs. liveness (ਕਾਂਕਰਟ ਉਦਾਹਰਣਾਂ ਨਾਲ)
Safety ਦਾ ਮਤਲਬ ਹੈ "ਕਦੇ ਵੀ ਕੋਈ ਜ਼ਹਿਰੀਲਾ ਹਾਲਤ ਨਾ ਹੋਵੇ"। ਉਦਾਹਰਣ: ਇੱਕ ਰਿਪਲਿਕੇਟਡ key-value ਸਟੋਰ ਵਿੱਚ, ਇੱਕੋ ਲੌਗ ਇੰਡੈਕਸ ਲਈ ਕਦੇ ਦੋ ਵੱਖਰੇ ਮੁੱਲ commit ਨਹੀ́ ਹੋਣੇ ਚਾਹੀਦੇ। ਹੋਰ: ਇੱਕ ਲਾਕ ਸੇਵਾ ਨੂੰ ਕਦੇ ਇੱਕੋ ਸਮੇਂ ਦੋ ਕਲਾਇੰਟਾਂ ਨੂੰ ਉਹੀ ਲਾਕ ਨਹੀਂ ਦੇਣੀ ਚਾਹੀਦੀ।
Liveness ਦਾ ਮਤਲਬ ਹੈ "ਕੁਝ ਚੰਗਾ ਅੰਤ ਵਿੱਚ ਹੋਵੇ"। ਉਦਾਹਰਣ: ਜੇ ਜ਼ਿਆਦਾਤਰ ਰੇਪਲਿਕਾ ਚਾਲੂ ਹਨ ਅਤੇ ਨੈਟਵਰਕ ਆਖਿਰਕਾਰ ਸੁਨੇਹੇ ਪਹੁੰਚਾਉਂਦਾ ਹੈ, ਤਾਂ ਇੱਕ write ਬੇਨੈ ਅੰਤ ਵਿੱਚ ਪੂਰੀ ਹੋ ਜਾਂਦੀ ਹੈ। ਇੱਕ ਲਾਕ ਬੇਨੈ ਨੂੰ ਆਖਿਰਕਾਰ ਹਾਂ ਜਾਂ ਨਾ ਮਿਲਣਾ ਚਾਹੀਦਾ (ਅਨੰਤ ਉਡੀਕ ਨਹੀਂ)।
Safety contradictions ਰੋਕਣ ਬਾਰੇ ਹੈ; liveness ਹਮੇਸ਼ਾ ਰੁਕਾਵਟਾਂ ਤੋਂ ਬਚਣ ਬਾਰੇ।
Invariants: ਤੁਹਾਡੇ ਨਾਨ-ਨੈਗੋਸ਼ੀਏਬਲ
ਇੱਕ invariant ਇੱਕ ਸ਼ਰਤ ਹੈ ਜੋ ਹਮੇਸ਼ਾ ਹਰ ਪਹੁੰਚਣ ਯੋਗ ਸਥਿਤੀ ਵਿੱਚ ਸਹੀ ਰਹਿਣੀ ਚਾਹੀਦੀ ਹੈ। ਉਦਾਹਰਣਾਂ:
- "ਹਰ ਲੌਗ ਇੰਡੈਕਸ ਲਈ ਘੱਟ ਤੋਂ ਘੱਟ ਇੱਕ ਹੀ committed value ਹੋ ਸਕਦੀ ਹੈ।"
- "ਲੀਡਰ ਦਾ ਤਰਮ ਨੰਬਰ ਕਦੇ ਘਟਦਾ ਨਹੀਂ।"
ਜੇ ਕੋਈ invariant crash, timeout, retry, ਜਾਂ partition ਦੌਰਾਨ ਲੰਘਦੀ ਜਾਵੇ, ਤਾਂ ਇਹ ਲਾਗੂ ਨਹੀਂ ਕੀਤੀ ਗਈ।
ਇੱਥੇ 'ਪ੍ਰੂਫ' ਦਾ ਕੀ ਮਤਲਬ ਹੈ
ਇੱਕ ਪ੍ਰੂਫ ਉਹ ਤਰਕ ਹੈ ਜੋ ਸਭ ਸੰਭਾਵੀ ਕਿਰਿਆਵਲੀਆਂ ਨੂੰ ਕਵਰ ਕਰਦਾ ਹੈ, ਕੇਵਲ "ਸਧਾਰਨ ਰਸਤੇ" ਨੂੰ ਨਹੀਂ। ਤੁਸੀਂ ਹਰ ਕੇਸ 'ਤੇ ਵਿਚਾਰ ਕਰਦੇ ਹੋ: ਸੁਨੇਹਾ ਗੁਆਚ, ਨਕਲ, ਰੀਅਰੰਗ; ਨੋਡ ਦੇ crash ਅਤੇ ਰੀਸਟਾਰਟ; ਮੁਕਾਬਲਾ ਕਰਨ ਵਾਲੇ ਲੀਡਰ; ਕਲਾਇੰਟ ਰੀਟ੍ਰਾਈ।
ਸੁਪੱਸ਼ਟ ਸਪੈਕ ਐਨਿਆਨਕ ਨੂੰ ਰੋਕਦਾ ਹੈ
ਇੱਕ ਸਾਫ਼ ਸਪੈਕ ਸਟੇਟ, ਮਨਜ਼ੂਰ ਕੀਤੀਆਂ ਕਾਰਵਾਈਆਂ, ਅਤੇ ਲੋੜੀਂਦੇ ਗੁਣਾਂ ਨੂੰ ਪਰਿਭਾਸ਼ਤ ਕਰਦਾ ਹੈ। ਇਹ ਅਸਪਸ਼ਟ ਮੰਗਾਂ ਜਿਵੇਂ "ਸਿਸਟਮ consistent ਹੋਣਾ ਚਾਹੀਦਾ" ਨੂੰ ਮੁਟਭੇਦਾਂ ਵਿੱਚ ਬਦਲਣ ਤੋਂ ਰੋਕਦਾ ਹੈ। ਸਪੈਕ ਤੁਹਾਨੂੰ ਬਤਾਉਂਦਾ ਹੈ ਕਿ partition ਦੌਰਾਨ ਕੀ ਹੋਵੇਗਾ, "commit" ਦਾ ਕੀ ਮਤਲਬ ਹੈ, ਅਤੇ ਕਲਾਇੰਟ ਕਿਸ 'ਤੇ ਨਿਰਭਰ ਕਰ ਸਕਦਾ ਹੈ—ਉਤਪਾਦਣ ਤੋਂ ਪਹਿਲਾਂ।
ਸਿਧਾਂਤ ਤੋਂ ਅਮਲ: TLA+ ਨਾਲ ਮਾਡਲਿੰਗ
Lamport ਦੀ ਸਭ ਤੋਂ ਪ੍ਰਯੋਗਿਕ ਸਿਖਿਆ ਇਹ ਹੈ ਕਿ ਤੁਸੀਂ (ਅਤੇ ਆਮ ਤੌਰ 'ਤੇ ਤੁਹਾਨੂੰ) ਡਿਸਟ੍ਰਿਬਿਊਟਿਡ ਪ੍ਰੋਟੋਕੋਲ ਨੂੰ ਕੋਡ ਤੋਂ ਉੱਚੇ ਪੱਧਰ 'ਤੇ ਡਿਜ਼ਾਈਨ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ। ਧਾਗੇ, RPCs, ਅਤੇ ਰੀਟ੍ਰਾਈ ਲੂਪ ਦੀ ਚਿੰਤਾ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਤੁਸੀਂ ਸਿਸਟਮ ਦੇ ਨਿਯਮ ਲਿਖ ਸਕਦੇ ਹੋ: ਕਿਹੜੇ ਕਾਰਵਾਈਆਂ ਮਨਜ਼ੂਰ ਹਨ, ਕਿਹੜੀ ਸਥਿਤੀ ਬਦਲ ਸਕਦੀ ਹੈ, ਅਤੇ ਕੀ ਕਦੇ ਨਹੀਂ ਹੋਣਾ ਚਾਹੀਦਾ।
TLA+ ਕਿੰਨੇ ਲਈ ਹੈ
TLA+ ਇੱਕ ਵਿਸ਼ੇਸ਼ਣ ਭਾਸ਼ਾ ਅਤੇ ਮਾਡਲ-ਚੈਕਿੰਗ ਟੂਲਕਿਟ ਹੈ ਜੋ concurrent ਅਤੇ distributed ਸਿਸਟਮਾਂ ਨੂੰ ਵਰਣਨ ਕਰਨ ਲਈ ਬਣਾਇਆ ਗਿਆ ਹੈ। ਤੁਸੀਂ ਆਪਣਾ ਸਿਸਟਮ ਇੱਕ ਸਧਾਰਨ, ਗਣਿਤ-ਅਨੁਕੂਲ ਮਾਡਲ ਵਿੱਚ ਲਿਖਦੇ ਹੋ—ਸਟੇਟ ਅਤੇ ਟ੍ਰਾਂਜ਼ਿਸ਼ਨ—ਅਤੇ ਉਹ ਗੁਣ ਜੋ ਤੁਹਾਨੂੰ ਚਾਹੀਦੇ ਹਨ (ਉਦਾਹਰਨ: "ਘੱਟ ਤੋਂ ਘੱਟ ਇੱਕ ਲੀਡਰ" ਜਾਂ "commit ਕੀਤੀ ਐਂਟਰੀ ਨਿਕਲ ਨਹੀਂ ਸਕਦੀ")।
ਫਿਰ ਮਾਡਲ-ਚੈੱਕਰ ਸੰਭਾਵੀ ਇੰਟਰਲੀਵਿੰਗ, ਸੁਨੇਹਾ ਲੇਟ, ਅਤੇ ਫੇਲਿਅਰਾਂ ਨੂੰ ਖੰਗਾਲਦਾ ਹੈ ਅਤੇ ਇੱਕ ਕਾਊਂਟਰਏਗਜ਼ੈਂਪਲ ਦਿੰਦਾ ਹੈ: ਹਕੀਕਤੀ ਕਦਮਾਂ ਦੀ ਇੱਕ ਲੜੀ ਜੋ ਤੁਹਾਡੇ ਗੁਣ ਨੂੰ ਤੋੜ ਦਿੰਦੀ ਹੈ। ਮੇਟਿੰਗਾਂ ਵਿੱਚ ਕਟਿ-ਬਹਿਸ ਕਰਨ ਦੀ ਬਜਾਏ, ਤੁਹਾਨੂੰ ਇੱਕ ਕਾਰਜਕਾਰੀ ਦਲੀਲ ਮਿਲਦੀ ਹੈ।
ਇੱਕ ਕੀੜਾ ਜੋ ਮਾਡਲ ਫੜ ਸਕਦਾ ਹੈ
ਧਾਰਨਾ ਕਰੋ ਕਿ ਇੱਕ replicated ਲੌਗ ਵਿੱਚ "commit" ਕਦਮ ਹੈ। ਕੋਡ ਵਿੱਚ ਅਸਾਨੀ ਨਾਲ ਗਲਤੀ ਹੋ ਸਕਦੀ ਹੈ ਜੋ ਵੱਖ-ਵੱਖ ਨੋਡਾਂ ਨੂੰ ਇੱਕੋ ਇੰਡੈਕਸ ਤੇ ਦੋ ਵੱਖਰੇ ਐਂਟਰੀਜ਼ commit ਕਰਨ ਦੀ ਆਗਿਆ ਦੇ ਦੇਵੇ—ਇਹ ਕਦੇ-ਕਦੇ ਹੀ ਉਤਪਨ ਹੋ ਸਕਦਾ ਹੈ।
ਇੱਕ TLA+ ਮਾਡਲ ਇਹ ਟਰੇਸ ਦਰਸਾ ਸਕਦਾ ਹੈ:
- ਨੋਡ A quorum ਤੋਂ ਸੁਣ ਕੇ ਐਂਟਰੀ X ਨੂੰ ਇੰਡੈਕਸ 10 'ਤੇ commit ਕਰ ਦਿੰਦਾ ਹੈ।
- ਨੋਡ B (ਸਭਾੰਪੂਰਕ ਡੇਟਾ ਨਾਲ) ਵੀ ਇੱਕ quorum ਬਣਾ ਕੇ ਐਂਟਰੀ Y ਨੂੰ ਇੰਡੈਕਸ 10 'ਤੇ commit ਕਰ ਲੈਂਦਾ ਹੈ।
ਇਹ duplicate commit ਹੈ—ਇੱਕ safety ਉਲੰਘਣਾ ਜੋ ਪ੍ਰਭਾਵਤ ਤੌਰ 'ਤੇ ਮਹੀਨੇ ਵਿੱਚ ਇਕ ਵਾਰੀ ਹੀ ਪੈਦਾ ਹੋ ਸਕਦੀ ਹੈ, ਪਰ exhaustive search ਵਿੱਚ ਜਲਦੀ ਪਤਾ ਲੱਗ ਜਾਂਦਾ ਹੈ। ਐਸੇ ਮਾਡਲ ਅਕਸਰ lost updates, double-applies, ਜਾਂ "ack ਪਰ durable ਨਹੀਂ" ਵਰਗੀਆਂ ਸਮੱਸਿਆਵਾਂ ਫੜ ਲੈਂਦੇ ਹਨ।
ਕਦੋਂ ਮਾਡਲ ਬਣਾਉਣਾ ਮੁੱਨਤੀ ਹੁੰਦਾ ਹੈ
TLA+ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਕੀਮਤੀ ਹੈ ਨਾਜੁਕ ਕੋਆਰਡੀਨੇਸ਼ਨ ਲਾਜਿਕ ਲਈ: ਲੀਡਰ ਚੋਣ, ਮੈਂਬਰਸ਼ਿਪ ਬਦਲਾਵ, consensus-ਜਿਹੇ ਪ੍ਰਵਾਹ, ਅਤੇ ਕੋਈ ਵੀ ਪ੍ਰੋਟੋਕੋਲ ਜਿਸ ਵਿੱਚ ਕ੍ਰਮ ਅਤੇ ਫੇਲ ਹੈਂਡਲਿੰਗ ਇਕੱਠੇ ਕਿਰਿਆ ਕਰਦੇ ਹਨ। ਜੇ ਕੋਈ ਬੱਗ ਡਾਟਾ ਨੂੰ ਖ਼राब ਕਰੇਗਾ ਜਾਂ ਹੱਥੋਂ-ਹੱਥ ਬਹਾਲੀ ਮੰਗੇਗਾ, ਤਾਂ ਇੱਕ ਛੋਟਾ ਮਾਡਲ ਆਮ ਤੌਰ 'ਤੇ ਬਾਅਦ ਵਿੱਚ ਡੀਬੱਗ ਕਰਨ ਨਾਲ ਸਸਤਾ ਪੈਂਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਇਨ੍ਹਾਂ ਵਿਚਾਰਾਂ 'ਤੇ ਅਧਾਰਿਤ ਅੰਦਰੂਨੀ ਟੂਲ ਬਣਾਉਣੇ ਹੋ, ਇੱਕ ਪ੍ਰਯੋਗਿਕ ਵਰਕਫਲੋ ਇਹ ਹੈ: ਇੱਕ ਹਲਕਾ-ਫੁਲਕਾ ਸਪੈਕ ਉੱਤੇ ਲਿਖੋ (ਅਝਿਹਾ ਹੀ), ਫਿਰ ਸਿਸਟਮ ਇੰਪਲੀਮੈਂਟ ਕਰੋ ਅਤੇ ਸਪੈਕ ਦੇ invariants ਤੋਂ ਟੈਸਟ ਨਿਰਪਦ ਕਰੋ। Koder.ai ਵਰਗੇ ਪਲੇਟਫਾਰਮ ਇੱਥੇ ਮਦਦਗਾਰ ਹੋ ਸਕਦੇ ਹਨ: ਤੁਸੀਂ ਆਰਡਰਿੰਗ/consensus ਬਿਹੇਵਿਯਰ ਨੂੰ ਸਧਾਰਨ ਭਾਸ਼ਾ ਵਿੱਚ ਵੇਰਵਾ ਕਰਕੇ ਸਰਵਿਸ scaffolding ਤੇਜ਼ੀ ਨਾਲ ਜਨਰੇਟ ਕਰ ਸਕਦੇ ਹੋ (React ਫਰੰਟਐਂਡ, Go ਬੈਕਏਂਡ ਨਾਲ PostgreSQL, ਜਾਂ Flutter ਕਲਾਇੰਟ), ਅਤੇ ਜਦੋਂ ਤੁਸੀਂ ਸ਼ਿਪ ਕਰੋ ਤਾਂ "ਕਦੇ ਨਹੀਂ ਹੋਣਾ" ਵਾਲੀ ਗੱਲ ਸਪਸ਼ਟ ਰਹਿੰਦੀ ਹੈ।
ਭਰੋਸੇਯੋਗ ਸਿਸਟਮ ਬਣਾਉਣ ਅਤੇ ਚਲਾਉਣ ਲਈ ਪ੍ਰਯੋਗਿਕ ਨੁਕਤੇ
Build an ordering demo
ਆਪਣੇ ਕ੍ਰਮ-ਅਨੁਕ੍ਰਮ ਵਿਚਾਰਾਂ ਨੂੰ ਇੱਕ ਕਾਰगर Go ਸੇਵਾ ਵਿੱਚ ਬਦਲੋ ਅਤੇ ਸਾਦਾ ਚੈਟ ਤੋਂ ਅੱਗੇ ਵਧੋ।
Lamport ਦਾ ਵੱਡਾ ਤੋਹਫਾ ਪ੍ਰੈਕਟਿਸ ਲਈ ਇੱਕ ਸੋਚ ਹੈ: ਸਮਾਂ ਅਤੇ ਆਰਡਰਿੰਗ ਨੂੰ ਉਹ ਡੇਟਾ ਸਮਝੋ ਜੋ ਤੁਸੀਂ ਮਾਡਲ ਕਰਦੇ ਹੋ, ਨਾ ਕਿ ਕਲਾਕ-ਘੜੀ ਤੋਂ ਪ੍ਰਾਪਤ ਕੀਤੇ ਨਿਰਧਾਰਿਤ ਧਾਰਨਾ। ਇਹ ਸੋਚ ਇੱਕ ਜੋੜੇ ਆਦਤਾਂ ਵਿੱਚ ਬਦਲ ਜਾਂਦੀ ਹੈ ਜੋ ਤੁਸੀਂ ਰੋਜ਼ਾਨਾ ਅਪਣਾ ਸਕਦੇ ਹੋ।
ਸਿਧਾਂਤ ਨੂੰ ਰੋਜ਼ਮਰ੍ਹਾ ਇੰਜੀਨੀਅਰਿੰਗ ਪ੍ਰੈਕਟਿਸ ਵਿੱਚ ਬਦਲੋ
ਜੇ ਸੁਨੇਹੇ ਦੇਰੀ, ਨਕਲ, ਜਾਂ ਬਾਹਰ-ਅਨੁਕ੍ਰਮ ਵਿੱਚ ਆ ਸਕਦੇ ਹਨ, ਤਾਂ ਹਰ ਇੰਟਰੈਕਸ਼ਨ ਨੂੰ ਇਨ੍ਹਾਂ ਹਾਲਤਾਂ ਤਹਿਤ ਸੁਰੱਖਿਅਤ ਬਣਾਓ।
- Idempotency ਮੂਲ ਵਿਚਾਰ: "ਦੋ ਵਾਰੀ ਕਰੋ" ਨੂੰ ਨੁਕਸਾਨ ਰਹਿਤ ਬਣਾਓ। ਭੁਗਤਾਨ, ਪ੍ਰੋਵਿਜਨਿੰਗ, ਜਾਂ ਕਿਸੇ ਵੀ ਲਿਖਤ ਲਈ idempotency keys ਵਰਤੋ।
- ਰੀਟ੍ਰਾਈ ਨਾਲ deduplication: ਰੀਟ੍ਰਾਈਜ਼ ਜ਼ਰੂਰੀ ਹਨ, ਪਰ ਬਿਨਾਂ dedup ਦੇ ਤੁਸੀਂ double-writes ਪੈਦਾ ਕਰੋਗੇ। request IDs ਟ੍ਰੈਕ ਕਰੋ ਅਤੇ "ਪਹਿਲਾਂ ਹੀ ਪ੍ਰੋਸੈਸ ਕੀਤਾ" ਨਿਸ਼ਾਨ ਰੱਖੋ।
- At-least-once delivery + exactly-once effects: ਮੰਨੋ ਨੈਟਵਰਕ ਦੋ ਵਾਰੀ ਡਿਲਿਵਰ ਕਰ ਸਕਦਾ ਹੈ; ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਤੁਹਾਡੇ state ਚੇਂਜ exactly-once ਪ੍ਰਭਾਵ ਰੱਖਦੇ ਹਨ।
ਟਾਈਮਆਊਟ ਅਤੇ ਘੜੀ ਨਾਲ ਸਾਵਧਾਨ ਰਹੋ
Timeouts ਸੱਚ ਨਹੀਂ; ਉਹ ਇੱਕ ਨੀਤੀ ਹੁੰਦੇ ਹਨ। ਇੱਕ timeout ਸਿਰਫ ਦੱਸਦਾ ਹੈ "ਮੈਨੂੰ ਸਮੇਂ ਵਿੱਚ ਜਵਾਬ ਨਹੀਂ ਮਿਲਿਆ", ਨਾ ਕਿ "ਦੂਜੇ ਪਾਸੇ ਨੇ ਕਾਰਵਾਈ ਨਹੀਂ ਕੀਤੀ"। ਦੋ ਨੁਕਸਾਨ:
- Timeout ਨੂੰ ਇੱਕ ਅੰਤੀਮ ਫੇਲਿਅਰ ਨਾ ਸਮਝੋ। ਮੁਆਵਜ਼ਾ ਅਤੇ reconciliation ਰਸਤੇ ਡਿਜ਼ਾਈਨ ਕਰੋ।
- ਨੋਡਾਂ ਵਿੱਚ ਘੜੀ ਸਮਾਂ ਦੀ ਆਧਾਰ 'ਤੇ ਆਰਡਰ ਨਿਰਧਾਰਤ ਕਰਨ ਤੋਂ ਬਚੋ। ਸਫਲਤਾ ਲਈ sequence numbers, monotonic counters, ਜਾਂ explicit causal metadata ਵਰਤੋ (ਉਦਾਹਰਣ: "ਇਹ ਅਪਡੇਟ ਵਰਜਨ X ਨੂੰ supersede ਕਰਦਾ ਹੈ")।
causality ਦਾ ਆਦਰ ਕਰਨ ਵਾਲੀ observability
ਚੰਗੀ ਡੀਬੱਗਿੰਗ ਸੰਦਾਂ ਸਿਰਫ timestamps ਨਹੀਂ, ਬਲਕਿ ਆਰਡਰਿੰਗEncode ਕਰਦੀਆਂ ਹਨ:
- Trace IDs ਹਰ ਜਗਾਹ: ਹਰ ਹੌਪ ਅਤੇ ਲੌਗ ਲਾਈਨ ਵਿੱਚ correlation/trace ID propagate ਕਰੋ।
- ਲੌਗ ਵਿੱਚ ਕਾਰਨਾਤਮਿਕ ਸੂਚਕ: message IDs, parent request IDs, ਅਤੇ "ਜਦ ਮੈਂ ਫੈਸਲਾ ਕੀਤਾ ਤਾਂ ਮੈਂ ਕਿਸ version ਨੂੰ latest ਸਮਝਦਾ ਸੀ" ਲੌਗ ਕਰੋ।
- ਨਿਰਧਾਰਤ ਰੀਪਲੇਜ਼: ਇਨਪੁਟ (ਹੁਕਮ) ਰਿਕਾਰਡ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ আচਰਨ ਨੂੰ ਰੀਪਲੇ ਕਰ ਸਕੋਂ ਅਤੇ_decide_ ਕਰ ਸਕੋਂ ਕਿ ਬੱਗ timing-dependent ਸੀ ਜਾਂ logic-dependent।
ਸਪਸ਼ਟ ਕਰਨ ਵਾਲੇ ਡਿਜ਼ਾਈਨ ਸਵਾਲ ਜਿਹੜੇ ਸ਼ਿਪ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ ਪੁੱਛੋ
ਕਿਸੇ ਵੰਡੇ ਫੀਚਰ ਨੂੰ ਸ਼ਾਮِل ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਕੁਝ ਸਵਾਲ ਲਾਜ਼ਮੀ ਪੁੱਛੋ:
- ਜੇ ਇਕੋ ਬੇਨੈ ਦੋ ਵਾਰੀ ਪ੍ਰੋਸੈਸ ਹੋ ਜਾਏ ਤਾਂ ਕੀ ਹੁੰਦਾ?
- ਸਾਨੂੰ ਕਿਸ ਕਿਸਮ ਦੀ ਆਰਡਰਿੰਗ ਦੀ ਲੋੜ ਹੈ, ਅਤੇ ਕਿੱਥੇ ਇਹ ਲਾਗੂ ਹੈ?
- ਕਿਹੜੇ ਫੇਲ"ਸੈਫ" ਹਨ (ਕੋਈ ਮਾੜੀ ਸਥਿਤੀ ਨਹੀਂ), ਕਿਹੜੇ "ਲਾਉਡ" (ਯੂਜ਼ਰ-ਦਿੱਖਣ ਵਾਲੇ), ਅਤੇ ਕਿਹੜੇ "ਚੁਪ" (ਛੁਪਾ ਖਰਾਬੀ)?
- ਅੰਸ਼ਿਕ outage ਜਾਂ ਨੈੱਟਵਰਕ ਸਪਲਿਟ ਤੋਂ ਬਾਅਦ recovery ਦਾ ਰਾਸਤਾ ਕੀ ਹੈ?
- پروਡਕਸ਼ਨ ਵਿੱਚ happened-before ਕਹਾਣੀ ਨੂੰ ਰੀਕਨਸ੍ਟ੍ਰਕਟ ਕਰਨ ਲਈ ਅਸੀਂ ਕੀ ਲੌਗ ਕਰਾਂਗੇ?
ਇਹ ਸਵਾਲ ਪੀਐਚਡੀ ਦੀ ਲੋੜ ਨਹੀਂ ਰੱਖਦੇ—ਸਿਰਫ਼ ਆਡਸ਼ਪਾ ਨਾਲ ਆਰਡਰਿੰਗ ਅਤੇ correctness ਨੂੰ ਪ੍ਰੋਡਕਟ ਮੰਗਾਂ ਵਾਂਗ ਪਹਿਲੀ-ਕਲਾਸ ਮੁੱਦੇ ਮੰਨੋ।
ਨਤੀਜਾ ਅਤੇ ਅਗਲੇ ਕਦਮ
Lamport ਦਾ ਲੰਬਾ-ਚੱਲਣ ਵਾਲਾ ਤੋਹਫਾ ਉਹ ਤਰੀਕਾ ਹੈ ਜੋ ਤੁਹਾਨੂੰ ਸਪਸ਼ਟ ਸੋਚ ਕਰਨ ਦਿੰਦਾ ਹੈ ਜਦੋਂ ਸਿਸਟਮ ਇੱਕੋ ਘੜੀ ਸਾਂਝੀ ਨਹੀਂ ਕਰਦੇ ਅਤੇ "ਕੀ ਹੋਇਆ" ਬਾਰੇ ਮੁੱਲ-ਲਗਾਤਾਰ ਸਹਿਮਤ ਨਹੀਂ ਹੁੰਦੀ। ਪਰਫੈਕਟ ਸਮਾਂ ਦੀ ਪਿੱਛੇ ਭੱਜਣ ਦੀ ਬਜਾਏ, ਤੁਸੀਂ ਕਾਰਨਾਤਮਕਤਾ ਟਰੈਕ ਕਰੋ (ਕਿਹੜਾ ਕਿਸ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦਾ ਸੀ), ਇਸਨੂੰ ਲਾਜਿਕਲ ਸਮਾਂ (Lamport timestamps) ਨਾਲ ਦਰਸਾਓ, ਅਤੇ—ਜਦੋਂ ਪ੍ਰੋਡਕਟ ਨੂੰ ਇੱਕ ਹੀ ਇਤਿਹਾਸ ਚਾਹੀਦਾ ਹੋ—ਸਹਿਮਤੀ (consensus) ਬਣਾਓ ਤਾਂ ਕਿ ਹਰ ਰੇਪਲਿਕਾ ਇਕੋ ਕ੍ਰਮ ਲਾਗੂ ਕਰੇ।
ਇਹ ਧਾਰਾ ਇਕ ਪ੍ਰਯੋਗਿਕ ਇੰਜੀਨੀਅਰਿੰਗ ਸੋਚ ਵੱਲ ਲੈ ਜਾਂਦਾ ਹੈ:
ਪਹਿਲਾਂ ਸਪੇਸਿਫਾਈ ਕਰੋ, ਫਿਰ ਬਣਾਓ
ਉਹ ਨਿਯਮ ਲਿਖੋ ਜੋ ਤੁਹਾਨੂੰ ਚਾਹੀਦੇ ਹਨ: ਕੀ ਕਦੇ ਨਹੀਂ ਹੋਣਾ (safety) ਅਤੇ ਕੀ ਆਖਿਰਕਾਰ ਹੋਣਾ ਚਾਹੀਦਾ (liveness)। ਫਿਰ ਉਸ ਸਪੇਕ ਦੇ ਅਨੁਸਾਰ ਇੰਪਲੀਮੈਂਟ ਕਰੋ ਅਤੇ ਸਿਸਟਮ ਨੂੰ ਦੇਰੀ, partition, ਰੀਟ੍ਰਾਈ, duplicate ਸੁਨੇਹੇ, ਅਤੇ ਨੋਡ ਰੀਸਟਾਰਟਾਂ ਹੇਠਾਂ ਟੈਸਟ ਕਰੋ। ਕਈ "ਰਹਸਮੀ outage" ਅਸਲ ਵਿੱਚ ਗੁਮ ਅਸਪਸ਼ਟ ਧਾਰਣਾਂ ਹਨ ਜਿਵੇਂ "ਇੱਕ ਬੇਨੈ ਦੋ ਵਾਰੀ پروਸੈਸ ਹੋ ਸਕਦੀ ਹੈ" ਜਾਂ "ਲੀਡਰ ਕਿਸੇ ਵੀ ਸਮੇਂ ਬਦਲ ਸਕਦਾ ਹੈ।"
ਅਗੇ ਸਿੱਖਣ ਲਈ ਫੋਕਸ ਕੀਤੇ ਗਏ ਕਦਮ
ਜੇ ਤੁਸੀਂ ਬਿਨਾਂ formalism ਵਿੱਚ ਡੁੱਬੇ ਹੋਰ ਜਾਣਨਾ ਚਾਹੁਂਦੇ ਹੋ:
- Lamport ਦਾ "Time, Clocks, and the Ordering of Events in a Distributed System" ਪੜ੍ਹੋ ਤਾਂ ਜੋ happened-before ਨੂੰ ਅੰਦਰੋਂ ਸਮਝ ਸਕੋ।
- "Paxos Made Simple" ਨੂੰ skim ਕਰੋ ਤਾਂ ਕਿ safety ਇੰਟੂਇਸ਼ਨ ਸਮਝ ਆ ਜਾਵੇ: ਜੇ ਇੱਕ ਮੁੱਲ ਚੁਣਿਆ ਗਿਆ, ਤਾਂ ਭਵੀਖ ਵਿੱਚ ਕੋਈ ਵੀ ਤਰੱਕੀ ਉਸ ਨਾਲ ਵਿਰੋਧ ਨਹੀ ਕਰ ਸਕਦੀ।
- ਇੱਕ TLA+ ਇंट੍ਰੋ ਟੌਕ ਦੇਖੋ, ਫਿਰ ਇੱਕ ਛੋਟੇ ਪ੍ਰੋਟੋਕੋਲ (ਜਿਵੇਂ lock ਸੇਵਾ ਜਾਂ ਦੋ-ਰੇਪਲਿਕਾ ਰਜਿਸਟਰ) ਦਾ ਮਾਡਲ ਬਣਾਕੇ ਚੈੱਕ ਕਰੋ।
ਇੱਕ ਹੱਥ-ਉੱਤੇ ਅਭਿਆਸ
ਆਪਣੇ ਸਮੇਤ ਕੋਈ ਇੱਕ ਕੰਪੋਨੈਂਟ ਚੁਣੋ ਅਤੇ ਇਕ ਪੰਨਾ "failure contract" ਲਿਖੋ: ਤੁਸੀਂ ਨੈਟਵਰਕ ਅਤੇ ਸਟੋਰੇਜ ਬਾਰੇ ਕਿਹੜੀਆਂ ਧਾਰਣਾਂ ਕਰਦੇ ਹੋ, ਕੀ ਆਪਰੇਸ਼ਨਾਂ idempotent ਹਨ, ਅਤੇ ਤੁਸੀਂ ਕਿਹੜੀਆਂ ਆਰਡਰਿੰਗ ਗਾਰੰਟੀ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹੋ।
ਜੇ ਤੁਸੀਂ ਇਸ ਅਭਿਆਸ ਨੂੰ ਹੋਰ ठਸ੍ਤ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਇੱਕ ਛੋਟੀ "ਆਰਡਰਿੰਗ ਡੈਮੋ" ਸਰਵਿਸ ਬਣਾਓ: ਇੱਕ request API ਜੋ ਹੁਕਮਾਂ ਨੂੰ ਲੌਗ 'ਤੇ ਜੋੜਦਾ ਹੈ, ਇੱਕ ਬੈਕਗ੍ਰਾਊਂਡ ਵਰਕਰ ਜੋ ਉਹਨਾਂ ਨੂੰ ਲਾਗੂ ਕਰਦਾ ਹੈ, ਅਤੇ ਇੱਕ ਐਡਮਿਨ ਵਿਊ ਜੋ causality metadata ਅਤੇ ਰੀਟ੍ਰਾਈਜ਼ ਦਿਖਾਉਂਦਾ ਹੈ। Koder.ai 'ਤੇ ਇਹ ਤੁਰੰਤ ਬਣਾਉਣਾ ਤੇਜ਼ ਤਰੀਕਾ ਹੋ ਸਕਦਾ ਹੈ—ਖ਼ਾਸ ਤੌਰ 'ਤੇ ਜੇ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ scaffolding, deployment/hosting, प्रयोगਾਂ ਲਈ snapshots/rollback, ਅਤੇ ਜਦੋਂ ਹਦ ਹੋ ਜਾਵੇ ਤਾਂ ਸੋਰਸ ਕੋਡ ਨਿਰਯਾਤ ਚਾਹੁੰਦੇ ਹੋ।
ਚੰਗੀ ਤਰੀਕੇ ਨਾਲ ਕੀਤਾ ਗਿਆ, ਇਹ ਵਿਚਾਰ outage ਘਟਾਉਂਦੇ ਹਨ ਕਿਉਂਕਿ ਘੱਟ ਵਿਚਾਰ implicit ਰਹਿਣਗੇ। ਇਹ reasoning ਵੀ ਸਹਿਜ ਬਣਾਉਂਦਾ ਹੈ: ਤੁਸੀਂ ਸਮੇਂ ਬਾਰੇ ਬਹਿਸ ਕਰਨਾ ਬੰਦ ਕਰ ਦਿੰਦੇ ਹੋ ਅਤੇ ਇਹ ਸਾਬਤ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰ ਦਿੰਦੇ ਹੋ कि ਆਰਡਰ, ਸਹਿਮਤੀ, ਅਤੇ correctness ਤੁਹਾਡੇ ਸਿਸਟਮ ਲਈ ਕੀ ਮਤਲਬ ਰੱਖਦੇ ਹਨ।