21 ਸਤੰ 2025·8 ਮਿੰਟ
ਤੁਹਾਡੇ ਐਪਸ ਵਿੱਚ ਤੁਰੰਤ ਸਰਵਰ-ਸਾਈਡ ਖੋਜ ਲਈ Meilisearch
ਸਿੱਖੋ ਕਿ Meilisearch ਨੂੰ ਆਪਣੇ ਬੈਕਐਂਡ ਵਿੱਚ ਕਿਵੇਂ ਸ਼ਾਮِل ਕੀਤਾ ਜਾਵੇ ਤਾਂ ਜੋ ਤੇਜ਼, ਗਲਤੀ-ਸਹਿਣਸ਼ੀਲ ਖੋਜ ਮਿਲੇ: ਸੈਟਅਪ, ਇੰਡੈਕਸਿੰਗ, ਰੈਂਕਿੰਗ, ਫਿਲਟਰ, ਸੁਰੱਖਿਆ ਅਤੇ ਸਕੇਲਿੰਗ ਦੀਆਂ ਬੁਨਿਆਦੀ ਗੱਲਾਂ।
ਸਿੱਖੋ ਕਿ Meilisearch ਨੂੰ ਆਪਣੇ ਬੈਕਐਂਡ ਵਿੱਚ ਕਿਵੇਂ ਸ਼ਾਮِل ਕੀਤਾ ਜਾਵੇ ਤਾਂ ਜੋ ਤੇਜ਼, ਗਲਤੀ-ਸਹਿਣਸ਼ੀਲ ਖੋਜ ਮਿਲੇ: ਸੈਟਅਪ, ਇੰਡੈਕਸਿੰਗ, ਰੈਂਕਿੰਗ, ਫਿਲਟਰ, ਸੁਰੱਖਿਆ ਅਤੇ ਸਕੇਲਿੰਗ ਦੀਆਂ ਬੁਨਿਆਦੀ ਗੱਲਾਂ।
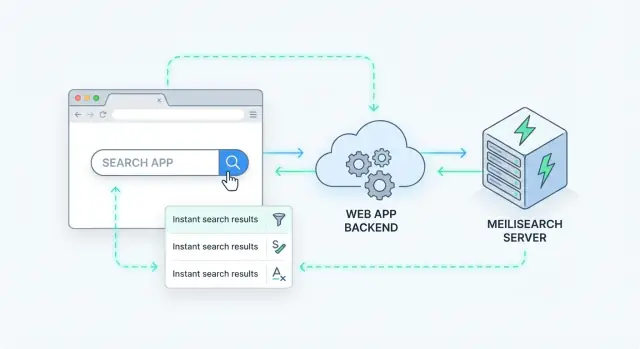
Server-side search ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਕੁਇਰੀ ਤੁਹਾਡੇ ਸਰਵਰ (ਜਾਂ ਇੱਕ ਸਮਰਪਿਤ search ਸੇਵਾ) 'ਤੇ ਪ੍ਰੋਸੈੱਸ ਹੁੰਦੀ ਹੈ—ਬਰਾਊਜ਼ਰ ਵਿੱਚ ਨਹੀਂ। ਤੁਹਾਡੀ ਐਪ ਇੱਕ ਖੋਜ ਬੇਨਤੀ ਭੇਜੇਗੀ, ਸਰਵਰ ਉਸਨੂੰ ਇੰਡੈਕਸ 'ਤੇ ਚਲਾਏਗਾ ਅਤੇ ਰੈਂਕ ਕੀਤੇ ਨਤੀਜੇ ਵਾਪਸ ਕਰੇਗਾ।
ਇਹ ਉਹ ਸਮੇਂ ਮਹੱਤਵਪੂਰਨ ਹੁੰਦਾ ਹੈ ਜਦੋਂ ਤੁਹਾਡਾ ਡੇਟਾਸੈਟ ਕਲਾਇੰਟ ਨੂੰ ਭੇਜਣ ਵਾਲਾ ਨਹੀਂ ਰਹਿੰਦਾ, ਜਦੋਂ ਤੁਹਾਨੂੰ ਪਲੇਟਫਾਰਮਾਂ ਵਿੱਚ ਸਥਿਰ relevancy ਚਾਹੀਦੀ ਹੈ, ਜਾਂ ਜਦੋਂ access control ਲਾਜ਼ਮੀ ਹੋ (ਉਦਾਹਰਣ ਲਈ, ਅੰਦਰੂਨੀ ਟੂਲ ਜਿੱਥੇ ਉਪਭੋਗਤারা ਸਿਰਫ ਉਹੀ ਵੇਖ ਸਕਣ ਜੋ ਉਹਨਾਂ ਦੀ ਆਗਿਆ ਹੈ)। ਇਹ ਉਹ ਡਿਫਾਲਟ ਚੋਣ ਵੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਐਨਾਲਿਟਿਕਸ, ਲੌਗਿੰਗ ਅਤੇ ਪੂਰਵ-ਨਿਰਧਾਰਤ ਪ੍ਰਦਰਸ਼ਨ ਚਾਹੁੰਦੇ ਹੋ।
ਲੋਕ ਖੋਜ ਇੰਜਣਾਂ ਬਾਰੇ ਨਹੀਂ ਸੋਚਦੇ—ਉਹ ਅਨੁਭਵ ਦਾ ਮੌਲ-ਅੰਕੜਾ ਲੈ ਕੇ ਫੈਸਲਾ ਕਰਦੇ ਹਨ। ਇਕ ਚੰਗੀ “ਤੁਰੰਤ” ਖੋਜ ਰੋਅ ਅਮੂਮਨ ਇਹ ਦਿੰਦੀ ਹੈ:
ਜੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਵੀ ਗੁਣ गायਬ ਹੋਵੇ, ਯੂਜ਼ਰ ਵੱਖ-ਵੱਖ ਕੁਇਰੀਆਂ ਆਜ਼ਮਾਉਂਦੇ ਹਨ, ਜ਼ਿਆਦਾ ਸਕ੍ਰੋਲ ਕਰਦੇ ਹਨ ਜਾਂ ਖੋਜ ਨੂੰ ਛੱਡ ਦਿੰਦੇ ਹਨ।
ਇਹ ਲੇਖ ਤੁਹਾਨੂੰ Meilisearch ਨਾਲ ਉਹ ਅਨੁਭਵ ਬਣਾਉਣ ਲਈ ਇੱਕ ਪ੍ਰਾਇਕਟਿਕਲ ਵਾਕਥਰੂ ਦੇਵੇਗਾ। ਅਸੀਂ ਦਿਖਾਵਾਂਗੇ ਕਿ ਇਸਨੂੰ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਕਿਵੇਂ ਸੈਟਅਪ ਕਰਨਾ ਹੈ, ਆਪਣੇ ਇੰਡੈਕਸਡ ਡੇਟਾ ਨੂੰ ਕਿਵੇਂ ਬਣਾਉਣਾ ਅਤੇ ਸਿੰਕ ਰੱਖਣਾ ਹੈ, relevancy ਅਤੇ ਰੈਂਕਿੰਗ ਨਿਯਮ ਕਿਵੇਂ ਟਿਊਨ ਕਰਨੇ ਹਨ, ਫਿਲਟਰ/ਸੌਰਟ/ਫੈਸਿਟ ਕਿਵੇਂ ਜੋੜਣੇ ਹਨ, ਅਤੇ ਸੁਰੱਖਿਆ ਅਤੇ ਸਕੇਲਿੰਗ ਬਾਰੇ ਕਿਵੇਂ ਸੋਚਣਾ ਹੈ ਤਾਂ ਜੋ ਤੁਸੀਂ ਵਧਦੇ ਐਪ ਦੇ ਨਾਲ ਨਾਲ ਖੋਜ ਨੂੰ ਤੇਜ਼ ਰੱਖ ਸਕੋ।
Meilisearch ਇਹਨਾਂ ਲਈ ਬਿਹਤਰ ਹੈ:
ਸਾਰੇ ਸਮੇਂ ਹਮੇਸ਼ਾ ਮਕਸਦ: ਨਤੀਜੇ ਜੋ ਤੁਰੰਤ, ਸਹੀ ਅਤੇ ਭਰੋਸੇਯੋਗ ਮਹਿਸੂਸ ਹੋਣ—ਬਿਨਾਂ ਇਸਦੇ ਕਿ ਖੋਜ ਇੱਕ ਵੱਡਾ ਇੰਜੀਨੀਅਰਿੰਗ ਪ੍ਰੋਜੈਕਟ ਬਣ ਜਾਏ।
Meilisearch ਇੱਕ search engine ਹੈ ਜੋ ਤੁਸੀਂ ਆਪਣੀ ਐਪ ਦੇ ਨਾਲ ਚਲਾਉਂਦੇ ਹੋ। ਤੁਸੀਂ ਇਸਨੂੰ ਦਸਤਾਵੇਜ਼ (ਜਿਵੇਂ products, articles, users, support tickets) ਭੇਜਦੇ ਹੋ, ਅਤੇ ਇਹ ਤੇਜ਼ ਖੋਜ ਲਈ optimized ਇੱਕ ਇੰਡੈਕਸ ਬਣਾਉਂਦਾ ਹੈ। ਤੁਹਾਡਾ ਬੈਕਐਂਡ (ਜਾਂ ਫਰੰਟਐਂਡ) ਫਿਰ Meilisearch ਨੂੰ ਇੱਕ ਸਧਾਰਨ HTTP API ਰਾਹੀਂ ਕਾਲ ਕਰਦਾ ਹੈ ਅਤੇ ਮਿਲੀਸੈਕੰਡਾਂ ਵਿੱਚ ਰੈਂਕ ਕੀਤੇ ਨਤੀਜੇ ਪ੍ਰਾਪਤ ਕਰਦਾ ਹੈ।
Meilisearch ਆਧੁਨਿਕ ਖੋਜ ਲਈ ਜੋ ਲੋਕ ਉਮੀਦ ਕਰਦੇ ਹਨ ਉਹ ਮੁਹੱਈਆ ਕਰਦਾ ਹੈ:
ਇਸਨੂੰ ਇਸ ਤਰੀਕੇ ਨਾਲ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਹੈ ਕਿ ਇਹ ਛੋਟੀ ਕੁਇਰੀਆਂ, ਥੋੜ੍ਹੀ ਗਲਤੀਆਂ ਜਾਂ ਅਸਪਸ਼ਟਤਾ ਹੋਣ ਦੇ ਬਾਵਜੂਦ responsive ਅਤੇ forgiving ਮਹਿਸੂਸ ਕਰਵਾਏ।
Meilisearch ਤੁਹਾਡੇ ਪ੍ਰਾਇਮਰੀ ਡੇਟਾਬੇਸ ਦੀ ਬਦਲੀ ਨਹੀਂ ਹੈ। ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਲਿਖਤਾਂ, ਟ੍ਰਾਂਜ਼ੈਕਸ਼ਨਾਂ ਅਤੇ constraints ਲਈ ਸਰੋਤ ਰਹੇਗਾ। Meilisearch ਉਹਨਾਂ ਫੀਲਡਾਂ ਦੀ ਨਕਲ ਰੱਖਦਾ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ ਤੁਸੀਂ searchable, filterable ਜਾਂ displayable ਬਣਾਉਂਦੇ ਹੋ।
ਇੱਕ ਵਧੀਆ ਮੈਨਟਲ ਮਾਡਲ: ਡੇਟਾਬੇਸ ਲਈ ਡਾਟਾ ਸਟੋਰ ਅਤੇ ਅਪਡੇਟ, Meilisearch ਲਈ ਤੇਜ਼ੀ ਨਾਲ ਲੱਭਣਾ।
Meilisearch ਬਹੁਤ ਤੇਜ਼ ਹੋ ਸਕਦਾ ਹੈ, ਪਰ ਨਤੀਜੇ ਕੁਝ ਹਕੀਕਤੀਆਂ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ:
ਛੋਟੇ ਤੋਂ ਮੱਧਮ ਡੇਟਾ ਲਈ, ਅਕਸਰ ਇੱਕ ਹੀ ਮਸ਼ੀਨ ਤੇ ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। ਜਿਵੇਂ-जਿਵੇਂ ਤੁਹਾਡਾ ਇੰਡੈਕਸ ਵੱਧਦਾ ਹੈ, ਤੁਸੀਂ ਸੋਚ-ਸਮਝ ਕੇ ਫੈਸਲਾ ਕਰੋ ਕਿ ਕਿਹੜਾ ਡੇਟਾ ਇੰਡੈਕਸ ਕਰਨਾ ਹੈ ਅਤੇ ਕਿਵੇਂ ਅਪਡੇਟ ਰੱਖਣਾ ਹੈ—ਇਹ ਵਿਸ਼ੇ ਅੱਗੇ ਵਾਲੇ ਸੈਕਸ਼ਨਾਂ ਵਿੱਚ ਕਵਰ ਕੀਤੇ ਗਏ ਹਨ।
ਕਿਸੇ ਚੀਜ਼ ਨੂੰ ਇੰਸਟਾਲ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਅਸਲ ਵਿੱਚ ਕੀ ਖੋਜਣਾ ਚਾਹੁੰਦੇ ਹੋ। Meilisearch ਤਦ ਹੀ “ਤੁਰੰਤ” ਮਹਿਸੂਸ ਹੋਵੇਗਾ ਜਦੋਂ ਤੁਹਾਡੇ ਇੰਡੈਕਸ ਅਤੇ ਦਸਤਾਵੇਜ਼ ਉਹੀ ਹੋਣਗੇ ਜਿਥੇ ਲੋਕ ਤੁਹਾਡੀ ਐਪ ਵੇਖਦੇ ਹਨ।
ਆਪਣੇ searchable entities ਦੀ ਲਿਸਟ ਬਣਾਓ—ਆਮ ਤੌਰ 'ਤੇ products, articles, users, help docs, locations ਆਦਿ। ਬਹੁਤ ਸਾਰੀਆਂ ਐਪਸ ਵਿੱਚ, ਸਭ ਤੋਂ ਸਾਫ਼ ਤਰੀਕਾ ਹਰ entity type ਲਈ ਇੱਕ ਇੰਡੈਕਸ ਹੁੰਦਾ ਹੈ (ਜਿਵੇਂ products, articles)। ਇਸ ਨਾਲ ranking rules ਅਤੇ filters predictable ਰਹਿੰਦੇ ਹਨ।
ਜੇ ਤੁਹਾਡੀ UX ਇੱਕ ਹੀ ਖਾਣੇ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਕਿਸਮਾਂ 'ਤੇ ਖੋਜ ਕਰਦੀ ਹੈ (“search everything”), ਤਾਂ ਤੁਸੀਂ ਫਿਰ ਵੀ ਵੱਖ-ਵੱਖ ਇੰਡੈਕਸ ਰੱਖ ਸਕਦੇ ਹੋ ਅਤੇ ਨਤੀਜੇ ਬੈਕਐਂਡ ਵਿੱਚ ਮਿਲਾ ਸਕਦੇ ਹੋ, ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਇੱਕ dedicated “global” index ਬਣਾਉ। ਸਿਰਫ਼ ਸਾਰਿਆਂ ਨੂੰ ਇੱਕ ਇੰਡੈਕਸ ਵਿੱਚ ਬਲਦ ਕਰਨ ਦੀ ਜ਼ਰੂਰਤ ਨਹੀਂ ਜਦ ਤਕ ਫੀਲਡ ਅਤੇ ਫਿਲਟਰ ਸੱਚਮੁੱਚ aligned ਨਹੀਂ ਹੁੰਦੇ।
ਹਰ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਇੱਕ ਸਥਿਰ identifier (primary key) ਚਾਹੀਦਾ ਹੈ। ਕੁਝ ਹੋਈਆਂ ਗੱਲਾਂ ਜੋ ਚੁਣੋ:
id, sku, slug)ਦਸਤਾਵੇਜ਼ ਦੀ ਰਚਨਾ ਲਈ, ਜੇ ਹੋ ਸਕੇ ਤਾਂ flat fields ਨੂੰ ਤਰਜੀਹ ਦਿਓ। ਫਲੈਟ ਸਟ੍ਰਕਚਰ ਫਿਲਟਰ ਅਤੇ ਸੌਰਟ ਲਈ ਆਸਾਨ ਹੁੰਦੇ ਹਨ। ਨੇਸਟਡ ਫੀਲਡ ਠੀਕ ਹਨ ਜੇ ਉਹ ਇੱਕ ਕੱਸ ਪੈਕੇਜ ਦਰਸਾਉਂਦੇ ਹਨ (ਉਦਾਹਰਣ: author object), ਪਰ ਡੀਪ ਨੇਸਟਿੰਗ ਤੋਂ ਬਚੋ ਜੋ ਤੁਹਾਡੇ ਪੂਰੇ ਰਿਲੇਸ਼ਨਲ ਸਕੀਮਾ ਦੀ ਨਕਲ ਕਰਦੀ ਹੋਵੇ—ਖੋਜ ਦਸਤਾਵੇਜ਼ read-optimized ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ, database-shaped ਨਹੀਂ।
ਇੱਕ ਪ੍ਰਾਇਕਟਿਕਲ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ ਹਰ ਫੀਲਡ ਨੂੰ ਇੱਕ ਭੂਮਿਕਾ ਦੇਵੋ:
ਇਸ ਨਾਲ ਇੱਕ ਆਮ ਗਲਤੀ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕਦਾ ਹੈ: “ਭਵਿੱਖ ਦੇ ਲਈ” ਕਿਸੇ ਫੀਲਡ ਨੂੰ ਇੰਡੈਕਸ ਕਰਨਾ ਅਤੇ ਬਾਅਦ ਵਿੱਚ ਹੈਰਾਨ ਹੋਣਾ ਕਿ ਨਤੀਜੇ noisy ਹਨ ਜਾਂ ਫਿਲਟਰ slow ਹਨ।
“Language” ਤੁਹਾਡੇ ਡੇਟਾ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਮਤਲਬ ਰੱਖ ਸਕਦਾ ਹੈ:
lang: "en")ਪਹਿਲਾਂ ਫੈਸਲਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਭਾਸ਼ਾ-ਹਿਸਾਬ ਨਾਲ ਵੱਖ-ਵੱਖ ਇੰਡੈਕਸ ਵਰਤੋਗੇ (ਸਧਾਰਣ ਅਤੇ predictable) ਜਾਂ ਇਕਲੈ ਕੀਤੇ ਇੰਡੈਕਸ ਨਾਲ ਭਾਸ਼ਾ ਫੀਲਡ (ਘੱਟ ਇੰਡੈਕਸ, ਵਧੇਰੇ ਲਾਜਿਕ)। ਸਹੀ ਜਵਾਬ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਯੂਜ਼ਰ ਇੱਕ ਸਮੇਂ ਵਿੱਚ ਇੱਕ ਭਾਸ਼ਾ ਵਿੱਚ ਖੋਜ ਕਰਦੇ ਹਨ ਜਾਂ ਨਹੀਂ ਅਤੇ ਤੁਸੀਂ ਅਨੁਵਾਦ ਕਿਵੇਂ ਸਟੋਰ ਕਰਦੇ ਹੋ।
Meilisearch ਚਲਾਉਣਾ ਸੀਧਾ ਹੈ, ਪਰ “default ਵਿੱਚ ਸੁਰੱਖਿਅਤ” ਬਣਾਉਣ ਲਈ ਕੁਝ ਧਿਆਨ ਦੇਣੇ ਪੈਂਦੇ ਹਨ: ਕਿੱਥੇ deploy ਕਰਨਾ ਹੈ, ਡੇਟਾ ਕਿਵੇਂ persist ਰੱਖਣਾ ਹੈ, ਅਤੇ master key ਦਾ ਹਾਲਾਂ।
Storage: Meilisearch ਆਪਣਾ ਇੰਡੈਕਸ ਡਿਸਕ 'ਤੇ ਲਿਖਦਾ ਹੈ। data directory ਨੂੰ ਭਰੋਸੇਯੋਗ, persistent storage ਉੱਤੇ ਰੱਖੋ (ephemeral container storage ਨਹੀਂ)। ਵਧਣ ਲਈ capacity ਦੀ ਯੋਜਨਾ ਬਣਾਓ: ਵੱਡੇ ਟੈਕਸਟ ਫੀਲਡਾਂ ਅਤੇ ਬਹੁਤ ਸਾਰੇ attributes ਨਾਲ indexes ਤੇਜ਼ੀ ਨਾਲ ਵਧ ਸਕਦੇ ਹਨ।
Memory: ਲੋਡ ਹੇਠ search responsive ਰੱਖਣ ਲਈ ਕਾਫ਼ੀ RAM ਦੇਵੋ। ਜੇ ਤੁਸੀਂ swapping ਵੇਖਦੇ ਹੋ, ਤਾਂ performance ਪ੍ਰਭਾਵਿਤ ਹੋਵੇਗੀ।
Backups: Meilisearch data directory ਦਾ backup ਲਓ (ਜਾਂ storage layer 'ਤੇ snapshots ਵਰਤੋ)। ਘੱਟੋ-ਘੱਟ ਇੱਕ ਵਾਰੀ restore ਟੈਸਟ ਕਰੋ; ਇੱਕ ਅਜਿਹਾ backup ਜੋ restore ਨੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਉਦੋਂ ਸਿਰਫ਼ ਇੱਕ ਫਾਈਲ ਹੈ।
Monitoring: CPU, RAM, disk ਵਰਤੋਂ ਅਤੇ disk I/O ਟਰੈਕ ਕਰੋ। ਪ੍ਰੋਸੈਸ health ਅਤੇ ਲੌਗ errors ਵੀ ਮੌਨੀਟਰ ਕਰੋ। ਘੱਟੋ-ਘੱਟ, ਸੇਵਾ ਬੰਦ ਹੋਣ ਜਾਂ ਡਿਸਕ ਸਪੇਸ ਘੱਟ ਹੋਣ 'ਤੇ alert ਰੱਖੋ।
ਲੋਕਲ ਡਿਵੈਲਪਮੈਂਟ ਤੋਂ ਇਲਾਵਾ ਹਮੇਸ਼ਾ Meilisearch master key ਨਾਲ ਚਲਾਓ। ਇਸਨੂੰ secret manager ਜਾਂ encrypted environment variable store ਵਿੱਚ ਰੱਖੋ (Git ਵਿੱਚ ਨਹੀਂ, ਨਾ ਹੀ plain-text .env ਜੋ repo ਵਿੱਚ commit ਹੋ)।
Example (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
ਨੈੱਟਵਰਕ ਨਿਯਮਾਂ ਬਾਰੇ ਵੀ ਸੋਚੋ: ਕਿਸੇ ਪ੍ਰਾਈਵੇਟ ਇੰਟਰਫੇਸ 'ਤੇ bind ਕਰੋ ਜਾਂ inbound access ਸੀਮਤ ਕਰੋ ਤਾਂ ਜੋ ਸਿਰਫ਼ ਤੁਹਾਡਾ ਬੈਕਐਂਡ Meilisearch ਤੱਕ ਪਹੁੰਚ ਸਕੇ।
curl -s http://localhost:7700/version
Meilisearch ਇੰਡੈਕਸਿੰਗ ਅਸਿੰਕ੍ਰੋਨਸ ਹੈ: ਤੁਸੀਂ ਦਸਤਾਵੇਜ਼ ਭੇਜਦੇ ਹੋ, Meilisearch ਇੱਕ ਟਾਸਕ ਕਤਾਰ ਵਿੱਚ ਰੱਖਦਾ ਹੈ, ਅਤੇ ਉਸ ਟਾਸਕ ਦੇ ਸਫਲ ਹੋਣ ਤੋਂ ਬਾਅਦ ਹੀ ਉਹ ਦਸਤਾਵੇਜ਼ ਖੋਜ ਜੋਗ ਬਣਦੇ ਹਨ। ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਇੱਕ job system ਵਾਂਗ ਸੋਚੋ, ਇੱਕ single request ਵਾਂਗ ਨਹੀਂ।
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid ਹੁੰਦਾ ਹੈ। ਇਸਨੂੰ poll ਕਰੋ ਜਦ ਤੱਕ ਇਹ succeeded (ਜਾਂ failed) ਨਹੀਂ ਹੋ ਜਾਂਦਾ।curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
ਜੇ ਗਿਣਤੀਆਂ ਮਿਲਦੀਆਂ ਨਹੀਂ, ਤਾਂ ਅਨੁਮਾਨ ਨਾ ਲਗਾਓ—ਸਭ ਤੋਂ ਪਹਿਲਾਂ task error details ਚੈੱਕ ਕਰੋ।
Batching ਦਾ ਮਕਸਦ tasks ਨੂੰ predictable ਅਤੇ recoverable ਬਣਾਉਣਾ ਹੈ।
addDocuments ਇੱਕ upsert ਵਾਂਗ ਕੰਮ ਕਰਦਾ ਹੈ: ਇੱਕੋ primary key ਵਾਲੇ ਦਸਤਾਵੇਜ਼ update ਹੁੰਦੇ ਹਨ, ਨਵੇਂ ਦਸਤਾਵੇਜ਼ insert ਹੁੰਦੇ ਹਨ। ਇਹ ਨੌਰਮਲ ਅਪਡੇਟ ਲਈ ਵਰਤੋ।
ਤੁਸੀਂ ਇੱਕ ਪੂਰਾ reindex ਕਰੋ ਜਦੋਂ:
ਹਟਾਉਣ ਲਈ, ਖਾਸ ਤੌਰ 'ਤੇ deleteDocument(s) ਕਾਲ ਕਰੋ; ਨਹੀਂ ਤਾਂ ਪੁਰਾਣੇ ਰਿਕਾਰਡ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਰਹਿ ਸਕਦੇ ਹਨ।
ਇੰਡੈਕਸਿੰਗ ਨੂੰ retryable ਬਣਾਉ। ਮੁੱਖ ਚੀਜ਼ ਹੈ ਸਥਿਰ document ids।
taskUid ਨੂੰ ਆਪਣੇ batch/job id ਨਾਲ ਇੱਕਠਾ ਸੰਭਾਲੋ, ਅਤੇ task status ਦੇ ਆਧਾਰ 'ਤੇ retry ਕਰੋ।ਪ੍ਰੋਡਕਸ਼ਨ ਡੇਟਾ ਤੋਂ ਪਹਿਲਾਂ, ਇੱਕ ਛੋਟਾ dataset (200–500 ਆਈਟਮ) ਇੰਡੈਕਸ ਕਰੋ ਜੋ ਤੁਹਾਡੇ ਅਸਲੀ ਫੀਲਡਾਂ ਨਾਲ ਮਿਲਦਾ-ਜੁਲਦਾ ਹੋਵੇ। ਉਦਾਹਰਣ: ਇੱਕ products ਸੈਟ ਜਿਸ ਵਿੱਚ id, name, description, category, brand, price, inStock, createdAt ਹੋਣ। ਇਹ task flow, counts, ਅਤੇ update/delete ਉਹਵਾਰਤ ਨੂੰ validate ਕਰਨ ਲਈ ਕਾਫ਼ੀ ਹੈ—ਬਿਨਾਂ ਵੱਡੀ import ਦੀ ਉਡੀਕ ਕੀਤੇ।
Search “relevancy” ਸਧਾਰਨ ਤੌਰ 'ਤੇ ਹੈ: ਕੀ ਪਹਿਲਾਂ ਦਿਖਾਇਆ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਕਿਉਂ। Meilisearch ਇਸਨੂੰ adjustable ਬਣਾਉਂਦਾ ਹੈ ਬਿਨਾਂ ਤੁਹਾਨੂੰ ਆਪਣਾ scoring system ਬਣਾਉਣ ਲਈ ਮਜਬੂਰ ਕੀਤੇ।
ਦੋ settings ਇਹ ਨਿਰਧਾਰਤ ਕਰਦੀਆਂ ਹਨ ਕਿ Meilisearch ਤੁਹਾਡੇ ਸਮੱਗਰੀ ਨਾਲ ਕੀ ਕਰ ਸਕਦਾ ਹੈ:
searchableAttributes: ਉਹ ਫੀਲਡਾਂ ਜੋ Meilisearch ਯੂਜ਼ਰ ਦੀ ਕੁਇਰੀ 'ਤੇ ਵੇਖਦਾ ਹੈ (ਉਦਾਹਰਣ: title, summary, tags)। order ਮਹੱਤਵ ਰੱਖਦਾ ਹੈ: ਪਹਿਲੇ ਫੀਲਡਾਂ ਨੂੰ ਜ਼ਿਆਦਾ ਮਹੱਤਵ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ।displayedAttributes: ਉਹ ਫੀਲਡਾਂ ਜੋ ਜਵਾਬ ਵਿੱਚ ਵਾਪਸ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ। ਇਹ privacy ਅਤੇ payload ਸਾਈਜ਼ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ—ਜੇ ਕੋਈ ਫੀਲਡ displayed ਨਹੀਂ ਹੈ ਤਾਂ ਉਹ ਵਾਪਸ ਨਹੀਂ ਭੇਜੀ ਜਾਵੇਗੀ।ਇੱਕ ਪ੍ਰਾਇਕਟਿਕਲ baseline ਹੈ ਕਿ ਕੁਝ high-signal ਫੀਲਡ searchable ਬਣਾਓ (title, key text), ਅਤੇ displayed fields ਨੂੰ UI ਦੀ ਲੋੜ ਤੱਕ ਹੀ ਰੱਖੋ।
Meilisearch matching documents ਨੂੰ ranking rules ਦੀ ਲੜੀ ਨਾਲ ਸਾਰਟ ਕਰਦਾ ਹੈ—ਇਕ pipeline of “tie-breakers.” ਝਟਕਾ ਤੌਰ ਤੇ ਇਹ ਤਰਜੀਹ ਦਿੰਦਾ ਹੈ:
ਤੁਹਾਨੂੰ internals ਯਾਦ ਰੱਖਣ ਦੀ ਲੋੜ ਨਹੀਂ—ਤੁਸੀਂ ਮੁੱਖਤੌਰ ਤੇ ਇਹ ਚੁਣਦੇ ਹੋ ਕਿ ਕਿਹੜੇ ਫੀਲਡ ਜ਼ਿਆਦਾ ਗੁਰਤਵਪੂਰਨ ਹਨ ਅਤੇ ਕਦੋਂ custom sorting ਲਗਾਉਣੀ ਹੈ।
Goal: “Title matches should win.” title ਨੂੰ ਪਹਿਲਾਂ ਰੱਖੋ:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Goal: “Newer content should appear first.” ਇੱਕ sort ਨਿਯਮ ਜੋੜੋ ਅਤੇ query ਸਮੇਂ ਸੌਰਟ ਕਰੋ (ਜਾਂ custom ranking ਸੈਟ):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
ਫਿਰ ਬੇਨਤੀ ਕਰੋ:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Goal: “Promote popular items.” popularity ਨੂੰ sortable ਬਣਾਓ ਅਤੇ ਜਦ ਲੋੜ ਹੋਵੇ ਉਸ ਦੇ ਆਧਾਰ 'ਤੇ ਸੌਰਟ ਕਰੋ।
5–10 ਅਸਲੀ ਕੁਇਰੀਆਂ ਚੁਣੋ ਜੋ ਯੂਜ਼ਰ ਟਾਈਪ ਕਰਦੇ ਹਨ। ਬਦਲਾਅ ਤੋਂ ਪਹਿਲਾਂ ਟਾਪ ਫਲਾਂ ਨੂੰ ਸੇਵ ਕਰੋ, ਫਿਰ ਬਾਦ ਦੀ ਤੁਲਨਾ ਕਰੋ।
ਉਦਾਹਰਣ:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerਜੇ “ਬਾਦ” ਦੀ ਸੂਚੀ ਯੂਜ਼ਰ ਦੀ ਨੀਅਤ ਨਾਲ ਵਧੀਆ ਮਿਲਦੀ ਹੈ, ਤਾਂ ਉਹ ਸੈਟਿੰਗ ਰੱਖੋ। ਜੇ ਇਹ ਕਿਨਾਰੇ ਮਾਮਲਿਆਂ ਨੂੰ ਨੁਕਸਾਨ ਪਹੁੰਚਾਏ, ਤਾਂ ਇੱਕ-ਇਕ ਚੀਜ਼ ਬਦਲੋ (attribute order, ਫਿਰ ranking rules) ਤਾਂ ਜੋ ਤੁਹਾਨੂੰ ਪਤਾ ਲੱਗੇ ਕਿ ਸੁਧਾਰ ਕਿਹੜੀ ਚੀਜ਼ ਨੇ ਕੀਤਾ।
ਇੱਕ ਚੰਗਾ search ਬਾਕਸ ਸਿਰਫ਼ “ਸ਼ਬਦ ਟਾਈਪ ਕਰੋ, ਮੇਲ ਪਾਓ” ਨਹੀਂ ਹੁੰਦਾ। ਲੋਕ ਨਤੀਜੇ ਸੰਕੁਚਿਤ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹਨ (“ਸਿਰਫ ਉਪਲਬਧ ਆਈਟਮ”) ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਆਰਡਰ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ (“ਸਭ ਤੋਂ ਸਸਤੀ ਪਹਿਲਾਂ”)। Meilisearch ਵਿੱਚ ਤੁਸੀਂ ਇਹ filters, sorting, ਅਤੇ facets ਨਾਲ ਕਰਦੇ ਹੋ।
ਇੱਕ filter ਨਤੀਜੇ ਸੈੱਟ 'ਤੇ ਲਗਾਈ ਇੱਕ rule ਹੈ। ਇੱਕ facet UI ਵਿੱਚ ਉਹ ਚੀਜ਼ ਹੈ ਜੋ ਯੂਜ਼ਰਾਂ ਨੂੰ ਉਹ rule ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ (ਅਕਸਰ ਚੈਕਬੌਕਸ ਜਾਂ ਗਿਣਤੀਆਂ ਦੇ ਰੂਪ ਵਿੱਚ)।
ਗੈਰ-ਟੈਕਨੀਕਲ ਉਦਾਹਰਣ:
ਇਸ ਤਰ੍ਹਾਂ ਇੱਕ ਯੂਜ਼ਰ “running” ਖੋਜ ਸਕਦਾ ਹੈ ਅਤੇ ਫਿਰ category = Shoes ਅਤੇ status = in_stock ਨਾਲ ਫਿਲਟਰ ਕਰ ਸਕਦਾ ਹੈ। ਫੈਸਿਟਸ counts ਵੇਖਾ ਕੇ ਦਿਖਾ ਸਕਦੇ ਹਨ “Shoes (128)” ਅਤੇ “Jackets (42)” ਤਾਂ ਜੋ ਯੂਜ਼ਰ ਜਾਣ ਸਕਣ ਕਿ ਕੀ ਉਪਲਬਧ ਹੈ।
Meilisearch ਨੂੰ ਤੁਹਾਨੂੰ ਉਹ ਫੀਲਡਾਂ ਖਾਸ ਤੌਰ 'ਤੇ ਅਨੁਮਤ ਕਰਨੀ ਪੈਂਦੀਆਂ ਹਨ ਜੋ ਤੁਸੀਂ ਫਿਲਟਰ ਜਾਂ ਸੌਰਟ ਲਈ ਵਰਤੋਂਗੇ।
category, status, brand, price, created_at (ਜੇ ਤੁਸੀਂ ਸਮੇਂ ਨਾਲ filter ਕਰੋ), tenant_id (ਜੇ ਤੁਸੀਂ customers ਨੂੰ ਜਾਂਚਦੇ ਹੋ)।price, rating, created_at, popularity।ਇਸ ਸੂਚੀ ਨੂੰ ਥੋੜੀ ਰੱਖੋ। ਹਰ ਚੀਜ਼ ਨੂੰ filterable/sortable ਬਣਾਉਣ ਨਾਲ ਇੰਡੈਕਸ ਆਕਾਰ ਵੱਧ ਸਕਦਾ ਹੈ ਅਤੇ ਅਪਡੇਟ ਰੁਕ ਸਕਦੇ ਹਨ।
ਭਾਵੇਂ ਤੁਹਾਡੇ ਕੋਲ 50,000 ਮਿਲਦਾ ਹੋਵੇ, ਯੂਜ਼ਰ ਸਿਰਫ ਪਹਿਲਾ ਪੇਜ ਵੇਖਦੇ ਹਨ। ਛੋਟੇ pages ਵਰਤੋਂ (ਅਕਸਰ 20–50 ਨਤੀਜੇ), sensible limit ਸੈਟ ਕਰੋ, ਅਤੇ offset ਨਾਲ paginate ਕਰੋ (ਜਾਂ ਜੇ ਤੁਹਾਨੂੰ ਨਵੇਂ pagination features ਚਾਹੀਦੇ ਹਨ ਤਾਂ ਉਹ ਵਰਤੋਂ)। ਆਪਣੀ ਐਪ ਵਿੱਚ page depth ਨੂੰ cap ਕਰੋ ਤਾਂ ਜੋ ਮਹਿੰਗੇ “page 400” ਬੇਨਤੀਆਂ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
ਸਰਵਰ-ਸਾਈਡ search ਜੋੜਨ ਦਾ ਸਾਫ਼ ਤਰੀਕਾ ਇਹ ਹੈ ਕਿ Meilisearch ਨੂੰ ਆਪਣੇ API ਦੇ ਪਿੱਛੇ ਇੱਕ ਵਿਸ਼ੇਸ਼ ਡੇਟਾ ਸੇਵਾ ਵਾਂਗ ਰੱਖੋ। ਤੁਹਾਡੀ ਐਪ ਇੱਕ search ਬੇਨਤੀ ਪ੍ਰਾਪਤ ਕਰਦੀ ਹੈ, Meilisearch ਨੂੰ ਕਾਲ ਕਰਦੀ ਹੈ, ਫਿਰ ਇੱਕ curated ਜਵਾਬ ਕਲਾਇੰਟ ਨੂੰ ਦਿੰਦੀ ਹੈ।
ਜ਼ਿਆਦਾਤਰ ਟੀਮਾਂ ਇਹ ਫਲੋ ਅਪਣਾਉਂਦੀਆਂ ਹਨ:
GET /api/search?q=wireless+headphones&limit=20).ਇਹ pattern Meilisearch ਨੂੰ replaceable ਰੱਖਦਾ ਹੈ ਅਤੇ front-end ਕੋਡ ਨੂੰ index internals ਉੱਤੇ ਨਿਰਭਰ ਹੋਣ ਤੋਂ ਰੋਕਦਾ ਹੈ।
ਜੇ ਤੁਸੀਂ ਨਵੀਂ ਐਪ ਬਣਾ ਰਹੇ ਹੋ (ਜਾਂ ਇਕ ਅੰਦਰੂਨੀ ਟੂਲ ਦੁਬਾਰਾ ਬਣਾਉਂਦੇ ਹੋ) ਅਤੇ ਇਸ pattern ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਲਾਗੂ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ Koder.ai ਵਰਗਾ ਇੱਕ vibe-coding ਪਲੇਟਫਾਰਮ ਤੁਹਾਡੀ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ—React UI, ਇੱਕ Go backend, ਅਤੇ PostgreSQL scaffold ਕਰ ਸਕਦਾ ਹੈ—ਫਿਰ Meilisearch ਨੂੰ ਇੱਕ single /api/search endpoint ਦੇ ਪਿੱਛੇ ਇੰਟੀਗ੍ਰੇਟ ਕਰੋ ਤਾਂ ਕਿ client ਸਿਮਪਲ ਰਹੇ ਅਤੇ permissions ਸਰਵਰ-ਸਾਈਡ ਰਹਿਣ।
Meilisearch client-side querying ਨੂੰ ਸਮਰਥਨ ਕਰਦਾ ਹੈ, ਪਰ backend querying ਆਮ ਤੌਰ 'ਤੇ ਸੁਰੱਖਿਅਤ ਹੈ ਕਿਉਂਕਿ:
ਪਬਲਿਕ ਡੇਟਾ ਲਈ client-side querying ਕੰਮ ਕਰ ਸਕਦੀ ਹੈ restricted keys ਦੇ ਨਾਲ, ਪਰ ਜੇ ਕੋਈ user-specific visibility rule ਹੈ ਤਾਂ search ਨੂੰ ਆਪਣੀ ਸਰਵਰ ਰਾਹੀਂ ਰੂਟ ਕਰੋ।
ਖੋਜ ਟ੍ਰੈਫਿਕ ਅਕਸਰ ਦੋਹਰਾਇਆ ਜਾਂਦਾ ਹੈ (“iphone case”, “return policy”)। ਆਪਣੀ API ਲੇਅਰ 'ਤੇ caching ਜੋੜੋ:
search ਨੂੰ public-facing endpoint ਸਮਝੋ:
limit ਅਤੇ maximum query length ਸੈੱਟ ਕਰੋ।Meilisearch ਮੁੱਖ ਤੌਰ 'ਤੇ ਤੁਹਾਡੇ ਐਪ ਦੇ “ਪਿੱਛੇ” ਰੱਖਿਆ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਇਹ ਸੰਵੇਦਨਸ਼ੀਲ ਡੇਟਾ ਤੇਜ਼ੀ ਨਾਲ ਵਾਪਸ ਕਰ ਸਕਦਾ ਹੈ। ਇਸਨੂੰ ਡੇਟਾਬੇਸ ਵਾਂਗ ਲੌਕ ਕਰੋ: ਇਸਨੂੰ restrict ਕਰੋ, ਅਤੇ ਸਿਰਫ਼ ਉਹੀ expose ਕਰੋ ਜੋ ਹਰ caller ਦੇਖ ਸਕਦਾ ਹੈ।
Meilisearch ਦਾ master key ਸਭ ਕੁਝ ਕਰ ਸਕਦਾ: ਇੰਡੈਕਸ ਬਣਾਉਣਾ/ਹਟਾਉਣਾ, settings update ਕਰਨਾ, ਅਤੇ read/write documents। ਇਸਨੂੰ ਸਿਰਫ਼ ਸਰਵਰ-ਅੰਦਰ ਰੱਖੋ।
ਆਪਲੀਕੇਸ਼ਨਾਂ ਲਈ ਸੀਮਤ ਕਾਰਵਾਈਆਂ ਅਤੇ ਸੀਮਤ ਇੰਡੈਕਸਾਂ ਵਾਲੇ API keys ਬਣਾਓ। ਇੱਕ ਆਮ ਢਾਂਚਾ:
least privilege ਦਾ ਮਤਲਬ ਹੈ ਕਿ leaked key data ਨੂੰ delete ਨਹੀਂ ਕਰ ਸਕਦੀ ਜਾਂ ਅਣਸਬੰਧਤ ਇੰਡੈਕਸਾਂ ਤੋਂ ਪੜ੍ਹ ਨਹੀਂ ਸਕਦੀ।
ਜੇ ਤੁਸੀਂ ਕਈ customers (tenants) ਨੂੰ ਸੇਵਾ ਦਿੰਦੇ ਹੋ, ਤਾਂ ਤੁਹਾਡੇ ਕੋਲ ਦੋ ਮੁੱਖ ਵਿਕਲਪ ਹਨ:
1) ਹਰ tenant ਲਈ ਇੱਕ ਇੰਡੈਕਸ।
ਸੋਚਣ ਵਿੱਚ ਸਾਦਾ ਅਤੇ cross-tenant access ਦਾ ਖਤਰਾ ਘੱਟ। ਨੁਕਸਾਨ: ਜ਼ਿਆਦਾ ਇੰਡੈਕਸਾਂ ਨੂੰ manage ਕਰਨਾ ਅਤੇ settings ਅਪਡੇਟ ਕੁਝ ਹਥਿਆਰਾਂ 'ਤੇ ਲਗਾਤਾਰ ਲਾਉਣੇ ਪੈਂਦੇ ਹਨ।
2) Shared index + tenant filter.
ਹਰ ਦਸਤਾਵੇਜ਼ 'ਤੇ tenantId ਫੀਲਡ ਰੱਖੋ ਅਤੇ ਸਾਰੇ searches ਲਈ ਇੱਕ filter ਲਾਜ਼ਮੀ ਕਰੋ ਜਿਵੇਂ tenantId = "t_123"। ਇਹ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਕੇਲ ਕਰ ਸਕਦਾ ਹੈ, ਪਰ ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਹਰ ਬੇਨਤੀ 'ਤੇ ਇਹ filter ਲਗਦਾ ਹੈ (ਇੱਥੇ scoped key ਵਰਤਣਾ ਚੰਗਾ ਹੈ ਤਾਂ callers ਇਸਨੂੰ ਹਟਾ ਨਾ ਸਕਣ)।
ਭਾਵੇਂ search ਸਹੀ ਹੋਵੇ, ਨਤੀਜੇ ਉਹ ਫੀਲਡ ਲੀਕ ਕਰ ਸਕਦੇ ਹਨ ਜੋ ਤੁਸੀਂ ਦਰਸਾਉਣਾ ਨਹੀਂ ਚਾਹੁੰਦੇ (emails, internal notes, cost prices)। ਕੀ retrievable ਹੈ ਉਸਦੀ ਨਿਗਰਾਨੀ ਕਰੋ:
ਇੱਕ quick “worst-case” ਟੈਸਟ ਕਰੋ: ਇੱਕ ਆਮ ਸ਼ਬਦ ਲਈ ਖੋਜ ਕਰੋ ਅਤੇ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਕੋਈ ਨਿੱਜੀ ਫੀਲਡ ਨਜ਼ਰ ਨਹੀਂ ਆਉਂਦਾ।
ਜੇ ਤੁਹਾਨੂੰ ਸ਼ੱਕ ਹੋ ਕਿ ਕੀ ਕੋਈ key client-side ਹੋਣੀ ਚਾਹੀਦੀ ਹੈ, ਤਾਂ “ਨਹੀਂ” ਸੋਚੋ ਅਤੇ search ਨੂੰ server-side ਰੱਖੋ।
Meilisearch ਤੇਜ਼ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਦੋ workloads ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋ: indexing (writing) ਅਤੇ search queries (reading)। ਜ਼ਿਆਦਾਤਰ “ਅਣਜਾਣੀ ਮੰਦਗੀ” ਬਸ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਇਹਨਾਂ ਵਿੱਚੋਂ ਕੋਈ ਇੱਕ CPU, RAM, ਜਾਂ disk ਲਈ ਮੁਕਾਬਲਾ ਕਰ ਰਿਹਾ ਹੈ।
Indexing load spike ਹੋ ਸਕਦੀ ਹੈ ਜਦੋਂ ਤੁਸੀਂ ਵੱਡੇ ਬੈਚ import ਕਰਦੇ ਹੋ, frequent updates ਚਲਾਉਂਦੇ ਹੋ, ਜਾਂ ਬਹੁਤ ਸਾਰੇ searchable fields ਜੋੜਦੇ ਹੋ। ਇੰਡੈਕਸਿੰਗ background task ਹੈ, ਪਰ ਇਹ ਫਿਰ ਵੀ CPU ਅਤੇ disk bandwidth ਵਰਤਦਾ ਹੈ। ਜੇ ਤੁਹਾਡੀ task queue ਵਧੇ, ਤਾਂ searches slow ਲੱਗ ਸਕਦੀਆਂ ਹਨ ਭਾਵੇਂ query volume ਇੱਕੋ ਜਿਹਾ ਹੋਵੇ।
Query load ਟ੍ਰੈਫਿਕ ਨਾਲ ਵਧਦੀ ਹੈ, ਪਰ features ਨਾਲ ਵੀ—ਜਿਆਦਾ filters, facets, ਵੱਡੇ result sets, ਅਤੇ ਵਧੀਕ typo tolerance ਪ੍ਰਤੀ ਬੇਨਤੀ ਕੰਮ ਵਧਾ ਸਕਦੇ ਹਨ।
Disk I/O ਅਕਸਰ ਚੁਪ-ਚਾਪ ਮੁੱਦਾ ਹੁੰਦੀ ਹੈ। ਸੁਸਤ ਡਿਸਕ (ਜਾਂ shared volumes 'ਤੇ noisy neighbors) “ਤੁਰੰਤ” ਨੂੰ “ਅਖੀਰਕਾਰ” ਵਿੱਚ ਬਦਲ ਸਕਦੇ ਹਨ। ਪ੍ਰੋਡਕਸ਼ਨ ਲਈ NVMe/SSD ਆਮ ਬੇਸਲਾਈਨ ਹੁੰਦਾ ਹੈ।
ਸਧਾਰਨ sizing ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ: Meilisearch ਨੂੰ ਕਾਫੀ RAM ਦੇਵੋ ਤਾਂ ਕਿ ਇੰਡੈਕਸ hot ਰਹਿ ਸਕੇ ਅਤੇ ਕਾਫੀ CPU peak QPS ਨੂੰ ਸੰਭਾਲਣ ਲਈ। ਫਿਰ ਚਿੰਤਾਵਾਂ ਨੂੰ ਵੱਖ-ਵੱਖ ਕਰੋ:
ਕੁਝ ਸੰਕੇਤ ਟਰੈਕ ਕਰੋ:
Backups routine ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ। Meilisearch ਦੀ snapshot ਫੀਚਰ ਨਿਯਮਤ ਅਨੁਸਾਰ ਵਰਤੋ, snapshots ਨੂੰ ਬਾਹਰ ਸਟੋਰ ਕਰੋ, ਅਤੇ ਸਮੇਂ-ਸਮੇਂ 'ਤੇ restore ਟੈਸਟ ਕਰੋ। ਅਪਗਰੇਡ ਲਈ release notes ਪੜ੍ਹੋ, non-prod environment ਵਿੱਚ stage ਕਰੋ, ਅਤੇ reindexing ਲਈ ਸਮਾਂ ਯੋਜਨਾ ਬਣਾਓ ਜੇ ਕਿਸੇ version change ਨਾਲ indexing behavior ਪ੍ਰਭਾਵਿਤ ਹੋ ਸਕਦੀ ਹੈ।
ਜੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ environment snapshots ਅਤੇ rollback ਵਰਤਦੇ ਹੋ (ਉਦਾਹਰਣ: Koder.ai ਦੇ snapshots/rollback workflow), ਤਾਂ ਆਪਣੇ search rollout ਨੂੰ ਉਸੇ ਅਨੁਸ਼ਾਸਨ ਨਾਲ align ਰੱਖੋ: ਬਦਲਾਵਾਂ ਤੋਂ ਪਹਿਲਾਂ snapshot ਲਵੋ, health checks verify ਕਰੋ ਅਤੇ known-good state ਤੱਕ ਤੇਜ਼ੀ ਨਾਲ ਵਾਪਸ ਜਾਣ ਦਾ ਰਸਤਾ ਰੱਖੋ।
ਸਾਫ਼ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਦੇ ਬਾਵਜੂਦ, search ਸਮੱਸਿਆਵਾਂ ਕੁਝ ਆਮ ਸ਼੍ਰੇਣੀਆਂ ਵਿੱਚ ਆਉਂਦੀਆਂ ਹਨ। ਚੰਗੀ ਗੱਲ ਇਹ ਹੈ: Meilisearch ਤੁਹਾਨੂੰ ਕਾਫੀ visibility (tasks, logs, deterministic settings) ਦਿੰਦਾ ਹੈ ਤਾਂ ਕਿ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਡੀਬੱਗ ਕਰ ਸਕੋ—ਜੇ ਤੁਸੀਂ ਸਿਸਟਮੈਟਿਕ ਤਰੀਕੇ ਨਾਲ ਨਜ਼ਰੀਆ ਰੱਖੋ।
filterableAttributes ਵਿੱਚ ਨਹੀਂ ਜੋੜਿਆ ਗਿਆ, ਜਾਂ ਦਸਤਾਵੇਜ਼ ਉਸਨੂੰ ਅਣਉਮੀਦ shape (string vs array vs nested) ਵਿੱਚ ਰੱਖਦੇ ਹਨ।sortableAttributes/rankingRules ਦੀ ਕਮੀ ਗਲਤ ਆਈਟਮ ਨੂੰ ਅੱਗੇ ਲਾ ਰਹੀ ਹੈ।ਪਹਿਲਾਂ ਜਾਂਚ ਕਰੋ ਕਿ Meilisearch ਨੇ ਤੁਸੀਂ ਕੀਤਾ ਆਖਰੀ ਬਦਲਾਅ ਸਫਲਤਾਪੂਰਵਕ ਲਾਗੂ ਕੀਤਾ ਕਿ ਨਹੀਂ।
filter, ਫਿਰ sort, ਫਿਰ facets।ਜੇ ਤੁਹਾਨੂੰ ਨਤੀਜੇ ਸਮਝ ਨਹੀਂ ਆ ਰਹੇ, ਤਾਂ ਆਪਣੀ configuration ਨੂੰ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਘਟਾਓ: synonyms ਹਟਾਓ, ranking tweaks ਘਟਾਓ, ਅਤੇ ਇੱਕ ਛੋਟੇ dataset ਤੇ ਟੈਸਟ ਕਰੋ। ਜਟਿਲ relevance ਸਮੱਸਿਆਵਾਂ 50 ਦਸਤਾਵੇਜ਼ਾਂ 'ਤੇ 5 ਮਿਲੀਅਨ ਨਾਲੋਂ ਆਸਾਨੀ ਨਾਲ ਦਿਖਾਈ ਦਿੰਦੀਆਂ ਹਨ।
your_index_v2 ਨੂੰ ਪੈਰਲਲ ਬਣਾਓ, settings ਲਗਾਓ, ਅਤੇ production queries ਦਾ ਨਮੂਨਾ replay ਕਰੋ।filterableAttributes ਅਤੇ sortableAttributes ਤੁਹਾਡੇ UI ਦੀ ਲੋੜਾਂ ਨਾਲ ਮਿਲਦੇ ਹਨ।Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
Server-side search ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਕੁਇਰੀ ਤੁਹਾਡੇ ਬੈਕਐਂਡ (ਜਾਂ ਇੱਕ ਸਮਰਪਿਤ search ਸੇਵਾ) ਤੇ ਚਲਦੀ ਹੈ—ਬਰਾਊਜ਼ਰ ਦੇ ਵਿੱਚ ਨਹੀਂ। ਇਹ ਠੀਕ ਚੋਣ ਹੈ ਜਦੋਂ:
ਉਪਭੋਗਤਾ ਚਾਰ ਗੱਲਾਂ ਨੂੰ ਤੁਰੰਤ ਮਹਿਸੂਸ ਕਰਦੇ ਹਨ:
ਜੇ ਇਹਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਗੈਰ ਮੌਜੂਦ ਹੋਵੇ, ਲੋਕ ਕੁਇਰੀਆਂ ਦੁਬਾਰਾ ਲਿਖਦੇ ਹਨ, ਜ਼ਿਆਦਾ ਸਕ੍ਰੋਲ ਕਰਦੇ ਹਨ, ਜਾਂ ਖੋਜ ਛੱਡ ਦਿੰਦੇ ਹਨ।
ਇਸਨੂੰ search index ਵਾਂਗ ਟਰੀਟ ਕਰੋ—ਨਹੀਂ ਕਿ ਤੁਹਾਡਾ ਸਾਰਥਿਕ ਡੇਟਾ ਸਟਰੋਰ। ਤੁਹਾਡੀ ਡੇਟਾਬੇਸ ਲਿਖਾਈ, ਟ੍ਰਾਂਜੇਕਸ਼ਨ ਅਤੇ constraints ਸੰਭਾਲਦੀ ਰਹੇਗੀ; Meilisearch ਉਹਨਾਂ ਫੀਲਡਾਂ ਦੀ ਇੱਕ ਨਕਲ ਰੱਖਦਾ ਹੈ ਜੋ ਤੇਜ਼ ਤਰੀਕੇ ਨਾਲ ਖੋਜ ਲਈ optimized ਹੁੰਦੀਆਂ ਹਨ।
ਇਕ ਲਾਹੇਵੰਤ ਮਾਡਲ:
ਅਕਸਰ ਡਿਫ਼ਾਲਟ ਇਹ ਹੁੰਦਾ ਹੈ ਕਿ ਹਰ entity type ਲਈ ਇੱਕ ਇੰਡੈਕਸ (ਜਿਵੇਂ products, articles)। ਇਸ ਨਾਲ:
ਜੇ ਤੁਸੀਂ “ਸਭ ਕੁਝ ਖੋਜੋ” ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ ਤੁਸੀਂ ਇੱਕ ਕਈ ਇੰਡੈਕਸਾਂ ਦੀ ਕੁਇਰੀ ਕਰਕੇ ਨਤੀਜੇ ਬੈਕਐਂਡ ਵਿੱਚ ਮਿਲਾ ਸਕਦੇ ਹੋ ਜਾਂ ਬਾਅਦ ਵਿੱਚ ਇੱਕ global index ਬਣਾਉ।
ਇੱਕ primary key ਚੁਣੋ ਜੋ:
id, sku, slug)ਸਥਿਰ IDs ਇੰਡੈਕਸਿੰਗ ਨੂੰ idempotent ਬਣਾ ਦਿੰਦੇ ਹਨ: ਜੇ ਤੁਸੀਂ ਅਪਲੋਡ ਦੁਹਰਾਉਂਦੇ ਹੋ ਤਾਂ duplicates ਨਹੀਂ ਬਣਦੇ ਕਿਉਂਕਿ updates ਬਚਾਓ ਿਂਉਸਰ-ਅੱਪਸਰਟ ਹੁੰਦੇ ਹਨ।
ਹਰ ਫੀਲਡ ਨੂੰ ਇੱਕ ਰੋਲ ਦੇ ਕੇ ਫੈਸਲਾ ਕਰੋ ਤਾਂ ਕਿ ਤੁਸੀਂ ਬੇਸਹਰ ਹੋ ਕੇ ਇੰਡੈਕਸ ਨਾ ਕਰੋਂ:
ਇਹ ਰੋਲ ਸਪਸ਼ਟ ਰੱਖਣ ਨਾਲ noisy ਨਤੀਜੇ ਘਟਦੇ ਹਨ ਅਤੇ ਇੰਡੈਕਸ ਫੁੱਲ/ਭਾਰ ਹੌਲਿਆਂ ਤੋਂ ਰਿਹਾ ਜਾਂਦਾ ਹੈ।
ਇੰਡੈਕਸਿੰਗ ਅਸਿੰਕ੍ਰੋਨਸ ਹੁੰਦੀ ਹੈ: ਦਸਤਾਵੇਜ਼ਾਂ ਦੀ ਅਪਲੋਡ ਇੱਕ task ਬਣਾਉਂਦੀ ਹੈ, ਅਤੇ ਦਸਤਾਵੇਜ਼ ਉਸ ਟਾਸਕ ਦੇ succeeded ਹੋਣ ਦੇ ਬਾਅਦ ਹੀ ਖੋਜ ਜੋਗ ਹੁੰਦੇ ਹਨ।
ਇੱਕ ਭਰੋਸੇਮੰਦ ਫਲੋ:
ਛੋਟੇ-ਛੋਟੇ batches ਬਹੁਤ ਵਧੀਆ ਹਨ। ਸ਼ੁਰੂ ਕਰਨ ਲਈ:
ਛੋਟੇ ਬੈਚ ਦੁਬਾਰਾ-ਕੋਸ਼ਿਸ਼ ਕਰਨ, ਡੀਬੱਗ ਕਰਨ ਅਤੇ ਗਲਤ ਰਿਕਾਰਡ ਲੱਭਣ ਵਿੱਚ ਆਸਾਨ ਹੁੰਦੇ ਹਨ।
ਦੋ ਉੱਚ- ਪ੍ਰਭਾਵ ਵਾਲੇ ਲੀਵਰ ਹਨ:
searchableAttributes: ਕਿਹੜੇ ਫੀਲਡ ਖੋਜੇ ਜਾਣਗੇ, ਅਤੇ ਕਿਹੜੇ ਤਰਤੀਬ ਵਿੱਚ (ਜਿੰਨੀ ਉੱਚੀ precedence, ਉਨ੍ਹਾਂ ਦੇ ਮੈਚਾਂ ਨੂੰ ਵੱਧ ਮਹੱਤਵ ਮਿਲਦਾ ਹੈ)publishedAt, price, ਜਾਂ popularity ਵਰਗੇ ਫੀਲਡਾਂ ਨਾਲ ਸੌਰਟ ਕਰਨ ਦਿੰਦੇ ਹੋਪ੍ਰਯੋਗ: 5–10 ਅਸਲੀ ਯੂਜ਼ਰ ਕੁਇਰੀ ਲਓ, ਪਹਿਲਾਂ ਦੇ ਨਤੀਜੇ ਸਟੋਰ ਕਰੋ, ਇੱਕ ਸੈਟਿੰਗ ਬਦਲੋ, ਫਿਰ ਨਤੀਜਿਆਂ ਦੀ ਤੁਲਨਾ ਕਰੋ।
ਅਕਸਰ ਫਿਲਟਰ/ਸੌਰਟ ਸਮੱਸਿਆਵਾਂ configuration ਦੀ ਕਮੀ ਕਰਕੇ ਹੁੰਦੀਆਂ ਹਨ:
filterableAttributes ਵਿੱਚ ਸ਼ਾਮِل ਕਰੋsortableAttributes ਵਿੱਚ ਸ਼ਾਮِل ਕਰੋਇਲਾਵਾ, ਦਸਤਾਵੇਜ਼ਾਂ ਵਿੱਚ ਫੀਲਡ ਦਾ shape/type (string vs array vs nested object) ਚੈੱਕ ਕਰੋ। ਜੇ ਫਿਲਟਰ ਫੇਲ ਹੋ ਰਿਹਾ ਹੈ ਤਾਂ ਆਖਰੀ settings/task status ਵੇਖੋ ਅਤੇ ਪੁਸ਼ਟੀ ਕਰੋ ਕਿ ਇੰਡੈਕਸ ਕੀਤੇ ਦਸਤਾਵੇਜ਼ਾਂ ਵਿੱਚ ਉਮੀਦ ਕੀਤਾ ਗਿਆ ਮੁੱਲ ਹੈ।
taskUidsucceededfailedਜੇ ਨਤੀਜੇ ਪੁਰਾਣੇ ਲੱਗਦੇ ਹਨ ਤਾਂ ਪਹਿਲਾਂ ਟਾਸਕ ਸਥਿਤੀ ਚੈੱਕ ਕਰੋ।