13 ਨਵੰ 2025·8 ਮਿੰਟ
NoSQL ਡੇਟਾਬੇਸ ਕਿਵੇਂ ਉਭਰੇ—ਸਕੇਲਿੰਗ ਅਤੇ ਲਚੀਲਾਪਨ ਦਾ ਹੱਲ
ਜਾਣੋ ਕਿ NoSQL ਡੇਟਾਬੇਸ ਕਿਉਂ ਉਭਰੇ: ਵੈੱਬ ਦਾ ਸਕੇਲ, ਲਚਕੀਲੇ ਡੇਟਾ ਦੀ ਲੋੜ ਅਤੇ ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮਾਂ ਦੀਆਂ ਸੀਮਾਵਾਂ—ਨਾਲ ਹੀ ਮੁੱਖ ਮਾਡਲ ਅਤੇ ਟਰੇਡ‑ਆਫ।
ਜਾਣੋ ਕਿ NoSQL ਡੇਟਾਬੇਸ ਕਿਉਂ ਉਭਰੇ: ਵੈੱਬ ਦਾ ਸਕੇਲ, ਲਚਕੀਲੇ ਡੇਟਾ ਦੀ ਲੋੜ ਅਤੇ ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮਾਂ ਦੀਆਂ ਸੀਮਾਵਾਂ—ਨਾਲ ਹੀ ਮੁੱਖ ਮਾਡਲ ਅਤੇ ਟਰੇਡ‑ਆਫ।
NoSQL ਉੱਥੇ ਉਭਰਿਆ ਜਦੋਂ ਕਈ ਟੀਮਾਂ ਨੇ ਪਾਇਆ ਕਿ ਉਹਨਾਂ ਦੀਆਂ ਐਪਲੀਕੇਸ਼ਨਾਂ ਦੀਆਂ ਲੋੜਾਂ ਅਤੇ ਰਵਾਇਤੀ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸਾਂ (SQL ਡੇਟਾਬੇਸ) ਦੀਆਂ ਔਪਟੀਮਾਈਜ਼ੇਸ਼ਨਾਂ ਵਿਚਕਾਰ ਮੇਲ ਨਹੀਂ ਰਿਹਾ। SQL "ਫੇਲ" ਨਹੀਂ ਹੋਇਆ—ਪਰ ਵੈੱਬ ਸਕੇਲ 'ਤੇ ਕੁਝ ਟੀਮਾਂ ਨੇ ਵੱਖ-ਵੱਖ ਲਕੜੀਆਂ ਨੂੰ ਜ਼ਿਆਦਾ ਤਰਜੀਹ ਦਿੱਤੀ।
ਸਭ ਤੋਂ ਪਹਿਲਾਂ, ਸਕੇਲ। ਲੋਕਪ੍ਰਿਯ ਉਪਭੋਗੀ ਐਪਾਂ ਨੂੰ ਟ੍ਰੈਫਿਕ ਦੇ ਧੱਕੇ, ਲਗਾਤਾਰ ਲਿਖਾਈਆਂ ਅਤੇ ਵੱਡੇ ਪੈਮਾਨੇ 'ਤੇ ਯੁਜ਼ਰ-ਜਨਰੇਟਿਡ ਡਾਟਾ ਮਿਲਣ ਲੱਗਿਆ। ਇਨ੍ਹਾਂ ਵਰਕਲੋਡਾਂ ਲਈ، "ਸਿਰਫ਼ ਵੱਡਾ ਸਰਵਰ ਖਰੀਦੋ" ਮਹਿੰਗਾ, ਲਾਗੂ ਕਰਨ ਵਿੱਚ ਢੀਰ ਅਤੇ ਆਖ਼ਿਰਕਾਰ ਸਭ ਤੋਂ ਵੱਡੀ ਮਸ਼ੀਨ ਤੱਕ ਸੀਮਿਤ ਹੋ ਗਿਆ।
ਦੂਜਾ, ਬਦਲਾਅ। ਪ੍ਰੋਡਕਟ ਫੀਚਰ ਤੇਜ਼ੀ ਨਾਲ ਵਿਕਸਤ ਹੁੰਦੇ ਸਨ, ਅਤੇ ਉਹਨਾਂ ਦੇ ਮੂਹਰੇ ਡਾਟਾ ਹਮੇਸ਼ਾ ਇੱਕ ਕਠੋਰ ਟੇਬਲ ਸੈੱਟ ਵਿੱਚ ਫਿੱਟ ਨਹੀਂ ਕਰਦੇ। ਯੂਜ਼ਰ ਪ੍ਰੋਫ਼ਾਈਲ ਵਿੱਚ ਨਵੇਂ ਗੁਣ ਜੋੜਨਾ, ਕਈ ਈਵੈਂਟ ਕਿਸਮਾਂ ਸੰਭਾਲਣਾ, ਜਾਂ ਵੱਖ-ਵੱਖ ਸੋਰਸਾਂ ਤੋਂ ਅਰਧ-ਸੰਰਚਿਤ JSON ਲੈਣਾ ਅਕਸਰ ਵਾਰ-ਵਾਰ ਸਕੀਮਾ ਮਾਈਗ੍ਰੇਸ਼ਨ ਅਤੇ ਟੀਮ-ਸਹਯੋਗ ਮੰਗਦਾ।
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸਾਂ ਬਣਤਰ ਨੂੰ ਲਾਗੂ ਕਰਨ ਅਤੇ ਸੰਗੀਨ ਕਵੇਰੀਆਂ ਕਰਨ ਵਿੱਚ ਮਹਿਰ ਹਨ। ਪਰ ਕੁਝ ਹਾਈ-ਸਕੇਲ ਵਰਕਲੋਡ ਨੇ ਇਹ ਫਾਇਦੇ ਲੈਣਾ ਔਖਾ ਕਰ ਦਿੱਤਾ:
ਨਤੀਜਾ: ਕੁਝ ਟੀਮਾਂ ਨੇ ਇਹ ਸੋਚਿਆ ਕਿ ਕੁਝ ਗਾਰੰਟੀਜ਼ ਅਤੇ ਸਮਰੱਥਾਵਾਂ ਨੂੰ ਤਿਆਗ ਕੇ ਉਹਨਾਂ ਨੂੰ ਸਰਲ ਸਕੇਲਿੰਗ ਅਤੇ ਤੇਜ਼ ਇਟਰੇਸ਼ਨ ਮਿਲ ਸਕਦਾ ਹੈ।
NoSQL ਇੱਕ ਏਕ-ਡੇਟਾਬੇਸ ਜਾਂ ਡਿਜ਼ਾਈਨ ਨਹੀਂ ਹੈ। ਇਹ ਐਸੇ ਸਿਸਟਮਾਂ ਲਈ ਛਤਰੀ ਸ਼ਬਦ ਹੈ ਜੋ ਇਹਨਾਂ ਗੁਣਾਂ ਨੂੰ ਜ਼ੋਰ ਦਿੰਦੇ ਹਨ:
NoSQL ਕਦੇ ਵੀ SQL ਲਈ ਬਿਲਕੁਲ ਬਦਲ ਨਹੀਂ ਸੀ ਮੰਨਿਆ ਗਿਆ। ਇਹ ਟਰੇਡ-ਆਫ ਦਾ ਸਮੂਹ ਹੈ: ਤੁਸੀਂ ਸਕੇਲਿੰਗ ਜਾਂ ਸਕੀਮਾ ਲਚਕੀਲਾਪਨ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ, ਪਰ ਤੁਸੀਂ ਕਾਨਸਿਸਟੈਂਸੀ ਦੀਆਂ ਕਮਜ਼ੋਰੀਆਂ, ਘੱਟ-ਆਜ਼ਾਦ-ਕਵੇਰੀ ਵਿਕਲਪਾਂ, ਜਾਂ ਐਪ-ਪੱਧਰੀ ਡੇਟਾ ਮਾਡਲਿੰਗ ਵਿੱਚ ਵੱਧ ਜ਼ਿੰਮੇਵਾਰੀ ਨੂੰ ਸਵੀਕਾਰ ਕਰ ਸਕਦੇ ਹੋ।
ਸਾਲਾਂ ਲਈ, ਇੱਕ ਸਲੋ ਡੇਟਾਬੇਸ ਦਾ ਸਧਾਰਨ ਜਵਾਬ ਸਪਸ਼ਟ ਸੀ: ਵੱਡਾ ਸਰਵਰ ਖਰੀਦੋ। ਵਧੇਰੇ CPU, ਵੱਧ RAM, ਤੇਜ਼ ਡਿਸਕ, ਅਤੇ ਉਹੀ ਸਕੀਮਾ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਮਾਡਲ ਰੱਖੋ। ਇਹ "ਸਕੇਲ-ਅੱਪ" ਤਰੀਕਾ ਚੱਲਦਾ ਰਿਹਾ—ਜਦ ਤੱਕ ਇਹ ਪ੍ਰਯੋਗੀ ਨਹੀਂ ਰਿਹਾ।
ਉੱਚ-ਅੰਤ ਦੀਆਂ ਮਸ਼ੀਨیں ਜਲਦੀ ਮਹਿੰਗੀਆਂ ਹੋ ਜਾਂਦੀਆਂ ਹਨ, ਅਤੇ ਮੁੱਲ/ਪ੍ਰਦਰਸ਼ਨ ਘੱਟ ਹੋ ਜਾਂਦਾ ਹੈ। ਅਪਗਰੇਡ ਅਕਸਰ ਵੱਡੇ, ਘੱਟ-ਬਾਰੰਬਾਰ ਬਜਟ ਮਨਜ਼ੂਰੀਆਂ ਅਤੇ ਡਾਟਾ ਹਿਲਾਉਣ ਤੇ ਕੰਮ-ਕੱਟ ਕਰਨ ਲਈ ਮਾਇੰਟੇਨੈਂਸ ਵਿੰਡੋਆਂ ਮੰਗਦੇ ਹਨ। ਜੇ ਤੁਸੀਂ ਵੱਡਾ ਹਾਰਡਵੇਅਰ ਖਰੀਦ ਵੀ ਸਕਦੇ ਹੋ, ਇੱਕ ਇਕੱਲਾ ਸਰਵਰ ਫਿਰ ਵੀ ਇਕ ਸੀਲਿੰਗ ਹੋਵੇਗਾ: ਇੱਕ ਮੈਮੋਰੀ ਬੱਸ, ਇੱਕ ਸਟੋਰੇਜ ਸਿਸਟਮ, ਅਤੇ ਇੱਕ ਪ੍ਰਾਇਮਰੀ ਨੋਡ ਜੋ ਲਿਖਾਈ ਦੇ ਵੋਲੇਅਮ ਨੂੰ ਅਟੈਂਡ ਕਰਦਾ ਹੈ।
ਜਿਵੇਂ-ਜਿਵੇਂ ਪ੍ਰੋਡਕਟ ਵਧੇ, ਡੇਟਾਬੇਸ 24/7 ਪੜ੍ਹਾਈ/ਲਿਖਾਈ ਦੇ ਦਬਾਅ ਨਾਲ ਸਾਹਮਣਾ ਕਰਨ ਲੱਗੇ। ਟ੍ਰੈਫਿਕ ਸਚਮੁੱਚ ਸਥਿਰ ਹੋ ਗਿਆ, ਅਤੇ ਕੁਝ ਫੀਚਰ ਅਨੇਕ ਅਨੁਪਾਤੀ ਪਹੁੰਚ ਪੈਟਰਨ ਬਣਾਉਂਦੇ। ਕੁਝ ਘੱਟ-ਮਾਤਰਾ ਵਾਲੀਆਂ ਬਹੁਤ ਜ਼ਿਆਦਾ ਐਕਸੈੱਸ ਕੀਤੀਆਂ ਰੋਜ਼/ਪਾਰਟਿਸ਼ਨਾਂ ਸਾਰੇ ਟ੍ਰੈਫਿਕ ਨੂੰ ਘੇਰ ਸਕਦੀਆਂ ਹਨ, ਜਿਸ ਨਾਲ hot tables ਜਾਂ hot keys ਬਣਦੇ ਜੋ ਹੋਰ ਕੁਝ ਸੁਥਰੇ ਕੰਮ ਨੂੰ ਖਿੱਚਦੇ।
ਓਪਰੇਸ਼ਨਲ ਬੋਤਲਨੈਕ ਆਮ ਹੋ ਗਏ:
ਕਈ ਐਪਲੀਕੇਸ਼ਨਾਂ ਨੂੰ ਸਿਰਫ਼ ਇੱਕ ਡੇਟਾ ਸੈਂਟਰ ਵਿੱਚ ਤੇਜ਼ ਹੋਣ ਦੀ ਲੋੜ ਨਹੀਂ ਸੀ—ਉਹਨਾਂ ਨੂੰ ਕਈ ਖੇਤਰਾਂ ਵਿੱਚ ਉਪਲਬਧ ਹੋਣਾ ਲਾਜ਼ਮੀ ਸੀ। ਇੱਕ ਇਕੱਲਾ "ਮੁੱਖ" ਡੇਟਾਬੇਸ ਇੱਕ ਥਾਂ ਤੇ ਰੱਖਣਾ ਦੂਰੇ ਯੂਜ਼ਰਾਂ ਲਈ ਲੈਟੈਂਸੀ ਵਧਾਉਂਦਾ ਅਤੇ ਆਉਟੇਜ ਨੂੰ ਹੋਰ ਵੀ ਭਿਆਨਕ ਬਣਾਉਂਦਾ। ਸਵਾਲ ਬਦਲ ਗਿਆ: "ਅਸੀਂ ਵੱਡਾ ਬਾਕਸ ਕਿਵੇਂ ਖਰੀਦਾਂ?" ਦੀ ਥਾਂ "ਅਸੀਂ ਡੇਟਾਬੇਸ ਕਈ ਮਸ਼ੀਨਾਂ ਅਤੇ ਖੇਤਰਾਂ 'ਚ ਕਿਵੇਂ ਚਲਾਈਏ?"।
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਉਦੋਂ ਜ਼ਿਆਦਾ ਚਮਕਦੇ ਹਨ ਜਦੋਂ ਤੁਹਾਡਾ ਡੇਟਾ ਆਕਾਰ ਸਥਿਰ ਹੋਵੇ। ਪਰ ਕਈ ਆਧੁਨਿਕ ਉਤਪਾਦ ਇੱਕਥੈ ਨਹੀਂ ਰਹਿੰਦੇ। ਇੱਕ ਟੇਬਲ ਸਕੀਮਾ ਸਖਤ ਹੁੰਦਾ ਹੈ: ਹਰ ਚਰ ਰਹਿ ਇੱਕੋ ਹੀ ਕਾਲਮ, ਕਿਸਮਾਂ ਅਤੇ ਕੰਸਟ੍ਰੇੰਟ ਫੋਲੋ ਕਰਦੀ ਹੈ। ਇਹ ਪੇਸ਼ਗੀ ਕੀਮਤੀ ਹੈ—ਜਦ ਤੱਕ ਤੁਸੀਂ ਤੇਜ਼ੀ ਨਾਲ ਇਤਰੈਟ ਨਹੀਂ ਕਰ ਰਹੇ।
ਅਮਲੀ ਰੂਪ ਵਿੱਚ, ਬਾਰੰਬਾਰ ਸਕੀਮਾ ਬਦਲਾਅ ਮਹਿੰਗੇ ਹੋ ਸਕਦੇ ਹਨ। ਇੱਕ ਛੋਟਾ ਅਪਡੇਟ ਵੀ ਮਾਈਗ੍ਰੇਸ਼ਨ, ਬੈਕਫਿਲ, ਇੰਡੈਕਸ ਅਪਡੇਟ, ਕੋਆਰਡੀਨੇਟਡ ਡੀਪਲੋਇਮੈਂਟ ਸਮਾਂ, ਅਤੇ ਪੁਰਾਣੇ ਕੋਡ ਰਾਹਾਂ ਦੀ ਸੰਗਤਤਾ ਦੀ ਯੋਜਨਾ ਮੰਗ ਸਕਦਾ ਹੈ। ਵੱਡੇ ਟੇਬਲਾਂ 'ਤੇ ਕਾਲਮ ਜੋੜਨਾ ਜਾਂ ਕਿਸਮ ਬਦਲਣਾ ਜੰਚੀ ਕਾਰਵਾਈ ਬਣ ਸਕਦੀ ਹੈ ਜਿਸ ਵਿੱਚ ਵਾਸਤਵਿਕ ਓਪਰੇਸ਼ਨਲ ਜੋਖਮ ਹੁੰਦਾ ਹੈ।
ਇਹ ਘਰੜ ਟੀਮਾਂ ਨੂੰ ਬਦਲਾਅ ਦੈਰ ਕਰਨ, ਵਰਕਅਰਾਊਂਡ ਇਕੱਤਰ ਕਰਨ ਜਾਂ ਟੈਕਸਟ ਫੀਲਡਾਂ ਵਿੱਚ ਗੱਦੀ-ਭਰੀਆਂ ਬਲੋਬਾਂ ਸਟੋਰ ਕਰਨ ਵੱਲ ਧੱਕਦਾ—ਜੋ ਤੇਜ਼ ਇਟਰੇਸ਼ਨ ਲਈ ਆਦਰਸ਼ ਨਹੀਂ।
ਬਹੁਤ ਸਾਰਾ ਐਪਲੀਕੇਸ਼ਨ ਡੇਟਾ ਕੁਦਰਤੀ ਤੌਰ 'ਤੇ ਅਰਧ-ਸੰਰਚਿਤ ਹੁੰਦਾ ਹੈ: ਨੇਸਟਡ ਆਬਜੈਕਟਸ, ਵਿਕਲਪਿਕ ਫੀਲਡ, ਅਤੇ ਐਤਰੇ-ਟਾਈਮ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਗੁਣ।
ਉਦਾਹਰਣ ਲਈ, ਇੱਕ "user profile" ਸ਼ੁਰੂ ਵਿੱਚ ਨਾਂ ਅਤੇ ਈਮੇਲ ਨਾਲ ਹੋ ਸਕਦੀ ਹੈ, ਫਿਰ ਪREFERੇਰਨਸ, ਲਿੰਕ ਕੀਤੇ ਖਾਤੇ, ਸ਼ิปਿੰਗ ਪਤੇ, ਨੋਟੀਫਿਕੇਸ਼ਨ ਸੈਟਿੰਗਜ਼ ਅਤੇ ਐਕਸਪੇਰੀਮੈਂਟ ਫਲੈਗਸ ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ। ਹਰ ਯੂਜ਼ਰ ਕੋਲ ਹਰੇਕ ਫੀਲਡ ਨਹੀਂ ਹੁੰਦੀ ਅਤੇ ਨਵੇਂ ਫੀਲਡ ਧੀਰੇ-धीਰੇ ਆਉਂਦੇ ਹਨ। ਦਸਤਾਵੇਜ਼-ਸ਼ੈਲੀ ਮਾਡਲ ਨੇਸਟਡ ਅਤੇ ਅਸਮਾਨ ਸਾਝੇ ਰੂਪਾਂ ਨੂੰ ਸਿੱਧਾ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹਨ ਬਿਨਾਂ ਹਰ ਰਿਕਾਰਡ ਨੂੰ ਇੱਕ ਕਠੋਰ ਟੈਮਪਲੇਟ ਵਿਚ ਫ਼ਿੱਟ ਕਰਨ ਦੇ।
ਲਚਕ ਵੀ ਕੁਝ ਡੇਟਾ ਸ਼ੇਪਾਂ ਲਈ ਜਟਿਲ ਜੋਇਨਾਂ ਦੀ ਲੋੜ ਘਟਾਉਂਦਾ ਹੈ। ਜਦੋਂ ਇੱਕ ਸਕ੍ਰੀਨ ਨੂੰ ਇੱਕ ਰਚਿਆ ਗਿਆ ਆਬਜੈਕਟ (ਇੱਕ ਆਰਡਰ ਜਿਸ ਵਿੱਚ ਆਈਟਮ, ਸ਼ਿਪਿੰਗ ਜਾਣਕਾਰੀ, ਅਤੇ ਸਥਿਤੀ ਇਤਿਹਾਸ ਹੈ) ਦੀ ਲੋੜ ਹੋਵੇ, ਰਿਲੇਸ਼ਨਲ ਡਿਜ਼ਾਈਨ ਬਹੁਤ ਟੇਬਲਾਂ ਅਤੇ ਜੋਇਨਾਂ ਦੀ ਮੰਗ ਕਰ ਸਕਦਾ ਹੈ—ਅਤੇ ORM ਲੇਅਰ ਜੋ ਇਸ ਪੇਚੀਦਗੀ ਨੂੰ ਛੁਪਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਨ ਪਰ ਅਕਸਰ ਰੁਕਾਵਟ ਵਧਾਉਂਦੇ ਹਨ।
NoSQL ਵਿਕਲਪ ਡੇਟਾ ਨੂੰ ਇਸ ਤਰਾਂ ਮਾਪਦੇ ਹਨ ਜਿੰਨਾ ਕਿ ਐਪਲੀਕੇਸ਼ਨ ਪੜ੍ਹਦੀ/ਲਿਖਦੀ ਹੈ, ਜਿਸ ਨਾਲ ਟੀਮਾਂ ਤੇਜ਼ੀ ਨਾਲ ਚੀਜ਼ਾਂ ਜਾਰੀ ਕਰਦੀਆਂ ਹਨ।
ਵੈੱਬ ਐਪਸ ਸਿਰਫ਼ ਵੱਡੀਆਂ ਨਹੀਂ ਹੋਈਆਂ—ਉਹਨਾਂ ਦੀ ਰਚਨਾ ਵੀ ਬਦਲੀ। ਅੰਦਰੂਨੀ ਯੂਜ਼ਰਾਂ ਦੀ ਪੂਰੀ ਸੰਖਿਆ ਦੇ ਸਥਾਨ 'ਤੇ, ਉਤਪਾਦ ਮਿਲੀਅਨਾਂ ਗਲੋਬਲ ਯੂਜ਼ਰਾਂ ਨੂੰ 24/7 ਸਰਵ ਕਰਦੇ ਹਨ, ਜਿਸ ਦੇ ਨਾਲ ਲਾਂਚ, ਖ਼ਬਰਾਂ ਜਾਂ ਸੋਸ਼ਲ ਸ਼ੇਅਰਿੰਗ ਨਾਲ ਅਚਾਨਕ ਚਰਮਕਾਲ ਆ ਜਾਂਦੇ ਹਨ।
ਹਮੇਸ਼ਾ-ਚੱਲਦੀਆਂ ਉਮੀਦਾਂ ਨੇ ਰੁਕਾਵਟ ਦੀ ਭਾਵਨਾ ਤਿਆਰ ਕੀਤੀ: ਡਾਉਨਟਾਈਮ ਸਿਰਫ਼ ਅਸਹੂਲਤ ਨਹੀਂ ਰਹਿ ਗਿਆ। ਉਸੇ ਸਮੇਂ, ਟੀਮਾਂ ਨੂੰ ਜ਼ਿਆਦਾ ਤੇਜ਼ੀ ਨਾਲ ਫੀਚਰ ਲਗਾਉਣ ਲਈ ਕਿਹਾ ਗਿਆ—ਕਈ ਵਾਰੀ ਉਹ ਸਮੇਂ ਜਦੋਂ ਤੱਕ ਕਿਸੇ ਨੇ ਕਿਹਾ ਨਾ ਹੋਵੇ ਕਿ ਅੰਤਿਮ ਡੇਟਾ ਮਾਡਲ ਕੀ ਹੈ।
ਐਸੇ ਲਈ, ਇੱਕ ਇਕੱਲਾ ਡੇਟਾਬੇਸ ਸਰਵਰ ਨੂੰ ਵਧਾਉਣਾ ਕਾਫ਼ੀ ਨਹੀਂ ਸੀ। ਜਿੰਨੀ ਟ੍ਰੈਫਿਕ ਤੁਹਾਡੇ ਕੋਲ ਸੀ, ਤੁਹਾਨੂੰ ਐਸੀ ਸਮਰਥਾ ਚਾਹੀਦੀ ਸੀ ਜੋ ਤੁਸੀਂ ਕਦਮ-ਬਦਲ ਕੇ ਵਧਾ ਸਕੋ—ਹੋਰ ਨੋਡ ਜੋੜੋ, ਲੋਡ ਫੈਲਾਓ, ਫੇਲਿਅਰ ਨੂੰ ਅਲੱਗ ਕਰੋ।
ਇਸ ਨੇ ਆਰਕੀਟੈਕਚਰ ਨੂੰ ਕਈ ਮਸ਼ੀਨਾਂ ਦੀ ਓਰ ਧੱਕਿਆ ਅਤੇ ਟੀਮਾਂ ਦੀਆਂ ਉਮੀਦਾਂ ਡੇਟਾਬੇਸ ਤੋਂ ਬਦਲ ਦਿੱਤੀਆਂ: ਸਿਰਫ਼ ਸਹੀ ਨਤੀਜਾ ਨਹੀਂ, ਬਲਕਿ ਉੱਚ ਸਮਕਾਲਤਾ ਹੇਠ ਵਿਵਹਾਰ ਦੀ ਪੇਸ਼ਗੀ ਅਤੇ ਸਿਸਟਮ ਦੇ ਕੁਝ ਹਿੱਸੇ ਅਣਹੈਲਦੀ ਹੋਣ 'ਤੇ ਵੀ ਨਰਮ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰਨ ਦੀ ਯੋਗਤਾ।
"NoSQL" ਮੈਨਸਟਰੀਮ ਹੋਣ ਤੋਂ ਪਹਿਲਾਂ ਹੀ ਕਈ ਟੀਮਾਂ ਨੇ ਵੈੱਬ-ਸਕੇਲ ਹਕੀਕਤਾਂ ਲਈ ਪ੍ਰਣਾਲੀਆਂ ਨੂੰ ਮੋੜਣਾ ਸ਼ੁਰੂ ਕਰ ਦਿੱਤਾ ਸੀ:
ਇਹ ਤਕਨੀਕਾਂ ਕਾਮਯਾਬ ਰਹੀਆਂ, ਪਰ ਉਹਨਾਂ ਨੇ ਜਟਿਲਤਾ ਨੂੰ ਐਪਲੀਕੇਸ਼ਨ ਕੋਡ ਵਿੱਚ ਸਥਾਨਾਂਤਰਿਤ ਕੀਤਾ: ਕੈਸ਼ ਇਨਵੈਲਿਡੇਸ਼ਨ, ਡੁਪਲਿਕੇਟ ਡਾਟਾ ਨੂੰ ਸੰਕਲਿਤ ਰੱਖਣਾ, ਅਤੇ "ਚਲਾਣ-ਲਾਇਕ" ਰਿਕਾਰਡਸ ਲਈ ਪਾਈਪਲਾਈਨ ਬਣਾਉਣਾ।
ਜਿਵੇਂ-ਜਿਵੇਂ ਇਹ ਪੈਟਰਨ ਸਧਾਰਣ ਬਣੇ, ਡੇਟਾਬੇਸਾਂ ਨੂੰ ਡੇਟਾ ਨੂੰ ਮਸ਼ੀਨਾਂ 'ਤੇ ਵੰਡਣ, ਆੰਸ਼ਿਕ ਫੇਲਿਅਰ ਨੂੰ ਝੱਲਣ, ਉੱਚ ਲਿਖਾਈ ਵਾਲੀ ਬੋਲ ਭਾਰ ਸੰਭਾਲਣ ਅਤੇ ਵਿਕਸਿਤ ਹੋ ਰਹੀ ਡੇਟਾ ਨੂੰ ਸਾਫ਼-ਸੁਥਰੇ ਤਰੀਕੇ ਨਾਲ ਦਰਸਾਉਣ ਦੀ ਸਮਰੱਥਾ ਹੋਣੀ ਲਾਜ਼ਮੀ ਹੋ ਗਈ। NoSQL ਡੇਟਾਬੇਸ ਇਸਦਾ ਹਿੱਸਾ ਇਸ ਲਈ ਉਭਰੇ ਕਿ ਆਮ ਵੈੱਬ-ਸਕੇਲ ਰਣਨੀਤੀਆਂ ਨੂੰ ਨਿਰਮਾਣ-ਸਥਰ 'ਤੇ ਲਿਆ ਜਾ ਸਕੇ—ਨਕਲਾਂ ਅਤੇ ਹਮੇਸ਼ਾ ਕਰਨੀ ਪੈਂਦੀ ਕੰਮ-ਕੋਸ਼ਿਸ਼ਾਂ ਦੀ ਥਾਂ।
ਜਦੋਂ ਡੇਟਾ ਇੱਕ ਮਸ਼ੀਨ 'ਤੇ ਰਹਿੰਦਾ ਹੈ, ਨਿਯਮ ਸਧਾਰਨ ਮਹਿਸੂਸ ਹੁੰਦੇ ਹਨ: ਇੱਕ ਇਕੱਲਾ ਸੱਚ ਦਾ ਸਰੋਤ ਹੈ, ਅਤੇ ਹਰ ਰੀਡ ਜਾਂ ਰਾਈਟ ਨੂੰ ਤੁਰੰਤ ਚੈੱਕ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਪਰ ਜਦੋਂ ਤੁਸੀਂ ਡੇਟਾ ਨੂੰ ਸਰਵਰਾਂ ਵਿੱਚ ਫੈਲਾਉਂਦੇ ਹੋ (ਅਕਸਰ ਖੇਤਰਾਂ 'ਚ), ਤਾਂ ਇਕ ਨਵੀਂ ਹਕੀਕਤ ਉभरਦੀ ਹੈ: ਸੁਨੇਹੇ ਦੇਰੀ ਨਾਲ ਪਹੁੰਚ ਸਕਦੇ ਹਨ, ਨੋਡ ਫੇਲ ਹੋ ਸਕਦੇ ਹਨ, ਅਤੇ ਸਿਸਟਮ ਦੇ ਹਿੱਸੇ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਗੱਲਬਾਤ ਬੰਦ ਕਰ ਸਕਦੇ ਹਨ।
ਇੱਕ ਵਿਤਰਿਤ ਡੇਟਾਬੇਸ ਨੂੰ ਫੈਸਲਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਜੇ ਉਹਨਾਂ ਨੂੰ ਜਦੋਂ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਕੋਆਰਡੀਨੇਟ ਨਾ ਕੀਤਾ ਜਾ ਸਕੇ ਤਾਂ ਕੀ ਕਰਨਾ ਹੈ। ਕੀ ਇਹ ਸਰਵਿਸ ਦੇਣ ਜਾਰੀ ਰੱਖੇਗਾ ਤਾਂ ਜੋ ਐਪ "ਅਪ" ਰਹੇ, ਭਾਵੇਂ ਨਤੀਜੇ ਥੋੜ੍ਹੇ ਪੁਰਾਣੇ ਹੋ ਸਕਦੇ ਹਨ? ਜਾਂ ਕੀ ਇਹ ਕੁਝ ਆਪਰੇਸ਼ਨਾਂ ਨੂੰ ਰੱਦ ਕਰ ਦੇਵੇਗਾ ਜਦ ਤੱਕ ਇਹ ਰੀਪਲਿਕਾ ਦੀ ਸਹਿਮਤੀ ਪੱਕੀ ਨਹੀਂ ਕਰ ਲੈਂਦਾ, ਜੋ ਉਪਭੋਗਤਾਵਾਂ ਲਈ ਡਾਊਨਟਾਈਮ ਵਾਂਗ ਲੱਗ ਸਕਦਾ ਹੈ?
ਇਹ ਸਥਿਤੀਆਂ ਰਾਊਟਰ ਫੇਲਯਰ, ਓਵਰਲੋਡ ਨੈੱਟਵਰਕ, ਰੋਲਿੰਗ ਡੀਪਲੋਇਮੈਂਟ, ਫਾਇਰਵਾਲ ਮਿਸਕਨਫਿਗਰੇਸ਼ਨ, ਅਤੇ ਕ੍ਰਾਸ-ਰੀਜਨ ਰੀਪਲੀਕੇਸ਼ਨ ਦੇਰੀ ਦੌਰਾਨ ਹੁੰਦੀਆਂ ਹਨ।
CAP ਥਿਅਰਮ ਤਿੰਨ ਗੁਣਾਂ ਲਈ ਇੱਕ ਸੁਖੇ ਸਾਰ ਹੈ ਜੋ ਤੁਸੀਂ ਇੱਕੋ ਸਮੇਂ ਚਾਹੁੰਦੇ ਹੋ:
ਮੁੱਖ ਬਿੰਦੂ ਇਹ ਨਹੀਂ ਕਿ "ਹਮੇਸ਼ਾ ਦੋ ਚੁਣੋ"। ਇਹ ਹੈ: ਜਦੋਂ ਨੈੱਟਵਰਕ ਪਾਰਟੀਸ਼ਨ ਹੁੰਦੀ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਕਾਨੂੰਨੀ ਤਰੀਕੇ ਨਾਲ consistency ਅਤੇ availability ਵਿੱਚੋਂ ਇੱਕ ਚੁਣਨਾ ਪੈਂਦਾ ਹੈ। ਵੈੱਬ-ਸਕੇਲ ਸਿਸਟਮਾਂ ਵਿੱਚ ਪਾਰਟੀਸ਼ਨਾਂ ਨੂੰ ਅਣਿਵਾਰਯ ਮੰਨਿਆ ਜਾਂਦਾ ਹੈ—ਖ਼ਾਸ ਕਰਕੇ ਬਹੁ-ਖੇਤਰੀ ਸੈਟਅਪਾਂ ਵਿੱਚ।
ਕਲਪਨਾ ਕਰੋ ਤੁਹਾਡੀ ਐਪ ਦੋ ਖੇਤਰਾਂ 'ਚ ਚੱਲਦੀ ਹੈ। ਇਕ ਫਾਈਬਰ ਕੱਟ ਜਾਂ ਰਾਊਟਿੰਗ ਮੁੱਦਾ ਸਿੰਕ੍ਰੋਨਾਈਜ਼ੇਸ਼ਨ ਨੂੰ ਰੋਕਦਾ ਹੈ।
ਵੱਖ-ਵੱਖ NoSQL ਸਿਸਟਮ (ਅਤੇ ਇੱਕੋ ਹੀ ਸਿਸਟਮ ਦੀ ਵੱਖ-ਵੱਖ ਸੰਰਚਨਾਵਾਂ) ਵੱਖ-ਵੱਖ ਬਣਧਨ ਤਿਆਗਦੀਆਂ ਹਨ, ਇਹ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਕਿ ਕਿਹੜੀ ਚੀਜ਼ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਮਹੱਤਵਪੂਰਨ ਹੈ: ਫੇਲਿਅਰਾਂ ਦੌਰਾਨ ਯੂਜ਼ਰ ਅਨੁਭਵ, ਸਹੀਤਾ ਗਾਰੰਟੀਜ਼, ਓਪਰੇਸ਼ਨਲ ਸਧਾਰਣਤਾ, ਜਾਂ ਰਿਕਵਰੀ ਵਿਵਹਾਰ।
ਸਕੇਲ ਆਊਟ (ਹੋਰ ਮਸ਼ੀਨਾਂ ਜੋੜਕੇ) ਦਾ ਅਰਥ ਹੈ ਸਮਰਥਾ ਵਧਾਉਣ ਲਈ ਹੋਰ ਨੋਡ ਜੋੜੇ ਜਾਣ। ਕਈ ਟੀਮਾਂ ਲਈ ਇਹ ਆਰਥਿਕ ਅਤੇ ਓਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ ਦਰਪੇਸ਼ ਬਦਲਾਅ ਸੀ: ਕਾਮਮੀਡੀਟੀ ਨੋਡ ਸਟੈਪ-ਵਾਇਜ਼ ਜੋੜੇ ਜਾ ਸਕਦੇ ਸਨ, ਫੇਲਿਅਰ ਉਮੀਦਯੋਗ ਸੀ, ਅਤੇ ਵਾਧਾ ਖਤਰਨਾਕ "ਵੱਡੇ ਬਾਕਸ" ਮਾਈਗ੍ਰੇਸ਼ਨ नहीं ਮੰਗਦਾ ਸੀ।
ਕਈ ਨੋਡਸ ਨੂੰ ਕਾਰਗਰ ਬਣਾਉਣ ਲਈ NoSQL ਸਿਸਟਮ ਸ਼ਾਰਡਿੰਗ ਨੂੰ ਵਰਤੇ। ਇੱਕ ਪਾਰਟੀਸ਼ਨ ਕੀ (ਜਿਵੇਂ user_id) ਦੁਆਰਾ ਡਾਟਾ ਨੂੰ ਵੰਡਣਾ ਇੱਕ ਸਧਾਰਣ ਉਦਾਹਰਣ ਹੈ:
user_id 1–1,000,000 ਨੂੰ ਰੱਖਦਾ ਹੈuser_id 1,000,001–2,000,000 ਨੂੰ ਰੱਖਦਾ ਹੈਪੜ੍ਹਾਈਆਂ ਅਤੇ ਲਿਖਾਈਆਂ ਫੈਲ ਜਾਂਦੀਆਂ ਹਨ, ਹਾਟਸਪੌਟ ਘੱਟ ਹੁੰਦੇ ਹਨ ਅਤੇ ਨੋਡ ਜੋੜਨ ਨਾਲ ਥਰੂਪੁੱਟ ਵਧਦਾ ਹੈ। ਪਰ ਪਾਰਟੀਸ਼ਨ ਕੀ ਇੱਕ ਡਿਜ਼ਾਈਨ ਫੈਸਲਾ ਬਣ ਜਾਂਦੀ ਹੈ: ਐਗਰ ਤੁਸੀਂ ਖ਼ਰਾਬ ਕੀ ਚੁਣਦੇ ਹੋ ਤਾਂ ਇੱਕ ਹੀ ਸ਼ਾਰਡ ਵਿੱਚ ਜ਼ਿਆਦਾ ਟ੍ਰੈਫਿਕ ਜਾਂਦਾ ਹੈ।
ਰੀਪਲੀਕੇਸ਼ਨ ਦੇ ਅਰਥ ਹਨ ਇੱਕੋ ਡੇਟਾ ਦੀਆਂ ਕਈ ਨਕਲਾਂ ਵੱਖ-ਵੱਖ ਨੋਡਸ 'ਤੇ ਰੱਖਣਾ। ਇਹ ਵਧਾਉਂਦਾ ਹੈ:
ਰੀਪਲੀਕੇਸ਼ਨ ਡਾਟਾ ਨੂੰ ਰੈਕ ਜਾਂ ਖੇਤਰਾਂ ਵਿੱਚ ਫੈਲਾਉਣ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ ਤਾਂ ਜੋ ਲੋਕਲ ਆਉਟੇਜ ਤੋਂ ਬਚਿਆ ਜਾ ਸਕੇ।
ਸ਼ਾਰਡਿੰਗ ਅਤੇ ਰੀਪਲੀਕੇਸ਼ਨ ਚਲਾਉਣ ਯੋਗਤਾ ਦੇ ਨਾਲ ਲਗਾਤਾਰ ਓਪਰੇਸ਼ਨਲ ਕੰਮ ਲਿਆਉਂਦੇ ਹਨ। ਜਿਵੇਂ-जਿਵੇਂ ਡਾਟਾ ਵੱਧਦਾ ਜਾਂ ਨੋਡ ਬਦਲਦੇ ਹਨ, ਸਿਸਟਮ ਨੂੰ ਰੀਬੈਲੈਂਸ ਕਰਨਾ ਪੈਂਦਾ—ਪਾਰਟੀਸ਼ਨ ਲਿਜਾਣਾ ਅਤੇ ਹੁਣੇ-ਹੁਣੇ ਆਨਲਾਈਨ ਰਹਿਣਾ। ਜੇ ਇਹ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਨਹੀਂ ਕੀਤਾ ਗਿਆ ਤਾਂ ਰੀਬੈਲੈਂਸ ਦੌਰਾਨ ਲੈਟੈਂਸੀ ਸਪਾਈਕ, ਅਸਮਾਨ ਲੋਡ ਜਾਂ ਅਸਥਾਈ क्षमता ਘਾਟ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਮੁੱਖ ਟਰੇਡ-ਆਫ ਹੈ: ਮਸ਼ੀਨਾਂ ਦੁਆਰਾ ਸਸਤੇ ਸਕੇਲਿੰਗ ਬਦਲੇ ਵਿੱਚ ਵੰਡ, ਮਾਨੀਟਰਿੰਗ ਅਤੇ ਫੇਲਿਅਰ ਹੈਂਡਲਿੰਗ ਵਿੱਚ ਵੱਧ ਜਟਿਲਤਾ।
ਜਦੋਂ ਡੇਟਾ ਵਿਤਰਿਤ ਹੋ ਜਾਂਦਾ ਹੈ, ਇੱਕ ਡੇਟਾਬੇਸ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨਾ ਪੈਂਦਾ ਹੈ ਕਿ "ਸਹੀ" ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਜਦੋਂ ਸਮਕਾਲੀ ਅਪਡੇਟ, ਨੈੱਟਵਰਕ ਦੇਰੀ ਜਾਂ ਨੋਡਸ ਦੀ ਗੱਲਬਾਤ ਰੁਕੇ।
Strong consistency ਵਿਚ, ਜਿਵੇਂ ਹੀ ਇੱਕ ਲਿਖਾਈ ਮਨਜ਼ੂਰ ਹੋ ਜਾਵੇ, ਹਰ ਰੀਡਰ ਨੇ ਇਸ ਨੂੰ ਤੁਰੰਤ ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਹ "ਇਕ ਇਕੱਲਾ ਸੱਚ ਦਾ ਸਰੋਤ" ਦਾ ਅਨੁਭਵ ਦੇਂਦਾ ਹੈ ਜੋ ਬਹੁਤ ਲੋਕ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸਾਂ ਨਾਲ ਜੋੜਦੇ ਹਨ।
ਚੁਣੌਤੀ ਕੋਆਰਡੀਨੇਸ਼ਨ ਹੈ: ਨੋਡਸ ਵਿੱਚ ਸਖਤ ਗਾਰੰਟੀਜ਼ ਲਈ ਕਈ ਸੁਨੇਹੇ, ਜਵਾਬਾਂ ਦੀ ਉਡੀਕ ਅਤੇ ਫੇਲ-ਮਿਡ-ਫਲਾਈਟ ਹੈਂਡਲਿੰਗ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਜਦ Nੋਡਸ ਦੂਰੇ ਹੋਣ ਜਾਂ ਬਹੁਤ ਬਿਜੀ ਹੋਣ, ਤਾਂ ਹਰ ਲਿਖਾਈ 'ਤੇ ਵਧੀ ਲੈਟੈਂਸੀ ਆ ਸਕਦੀ ਹੈ।
Eventual consistency ਨੇ ਇਹ ਗਾਰੰਟੀ ਢੀਲੀ ਕੀਤੀ: ਇੱਕ ਲਿਖਾਈ ਤੋਂ ਬਾਅਦ ਵੱਖ-ਵੱਖ ਨੋਡ ਅਸਥਾਈ ਤੌਰ 'ਤੇ ਵੱਖ-ਵੱਖ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਨ, ਪਰ ਸਮੇਂ ਦੇ ਨਾਲ ਸਿਸਟਮ ਇਕੱਠਾ ਹੋ ਜਾਵੇਗਾ।
ਉਦਾਹਰਣ:
ਕਈ ਯੂਜ਼ਰ ਅਨੁਭਵਾਂ ਲਈ ਇਹ ਅਸਥਾਈ ਪਾਰਸਪਰਤਾ ਮੰਨਣਯੋਗ ਹੈ ਜੇ ਸਿਸਟਮ ਤੇਜ਼ ਅਤੇ ਉਪਲਬਧ ਰਹੇ।
ਜੇ ਦੋ ਰੀਪਲਿਕਾਜ਼ ਨੇ ਲਗਭਗ ਇੱਕੋ ਸਮੇਂ ਅਪਡੇਟ ਸਵੀਕਾਰ ਕੀਤੀ, ਤਾਂ ਡੇਟਾਬੇਸ ਨੂੰ ਮਿਲਾਉਣ ਵਾਲਾ ਨਿਯਮ ਚਾਹੀਦਾ ਹੈ।
ਆਮ ਪਹੁੰਚਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
Strong consistency ਉਹਨਾਂ ਸਥਿਤੀਆਂ ਲਈ ਮੁੱਖ ਹੈ ਜਿੱਥੇ ਦੋ ਅਸਥਾਈ ਸੱਚ ਨੁਕਸਾਨ ਪਹੁੰਚਾ ਸਕਦੇ ਹਨ: ਪੈਸੇ ਦੀਆਂ ਲੇਣ-ਦੇਣ, ਇਨਵੈਂਟਰੀ ਸੀਮਾਵਾਂ, ਯੂਨੀਕ ਯੂਜ਼ਰਨੇਮਜ਼, ਪਰਮਿਸ਼ਨ, ਅਤੇ ਕੋਈ ਵੀ ਵਰਕਫਲੋ ਜਿੱਥੇ ਉਤਪਾਦਨ 'ਚ ਦੋ ਸੱਚ ਸਮੇਂ-ਸ਼ਕਤੀ ਹੋਣ ਨਾਲ ਵੱਡਾ ਨੁਕਸਾਨ ਹੋਵੇ।
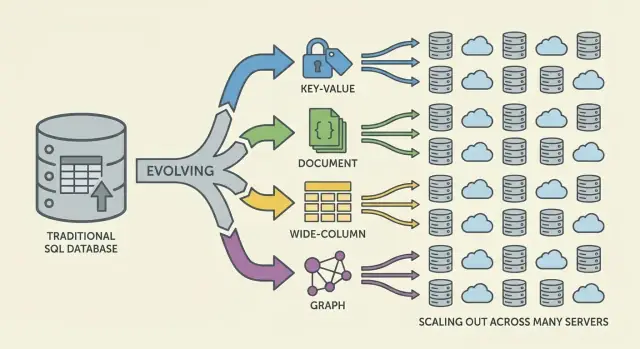
NoSQL ਵੱਖ-ਵੱਖ ਮਾਡਲਾਂ ਦਾ ਸੈੱਟ ਹੈ ਜੋ ਸਕੇਲ, ਲੈਟੈਂਸੀ, ਅਤੇ ਡੇਟਾ ਰੂਪ ਲਈ ਵੱਖ-ਵੱਖ ਟਰੇਡ-ਆਫ ਕਰਦੇ ਹਨ। ਪਰਿਵਾਰ ਨੂੰ ਸਮਝਣਾ ਤੁਹਾਨੂੰ ਪਤਾ ਲਗਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਕਿ ਕੀ ਤੇਜ਼ ਹੋਏਗਾ, ਕੀ ਦੁਖ ਦੈਵੇਗਾ, ਅਤੇ ਕਿਉਂ।
Key-value ਡੇਟਾਬੇਸ ਇੱਕ ਸਮਾਨ ਵਿਸ਼ਾਲ ਵਿਟਹੈਸ਼ਮੇਪ ਵਾਂਗ ਇੱਕ ਕੁੰਜੀ ਦੇ ਪਿੱਛੇ ਇੱਕ ਮੁੱਲ ਸਟੋਰ ਕਰਦੇ ਹਨ। ਕਿਉਂਕਿ ਐਕਸੈਸ ਪੈਟਰਨ ਆਮ ਤੌਰ 'ਤੇ "ਕੁੰਜੀ ਨਾਲ ਲਿਆਓ"/"ਕੁੰਜੀ ਨਾਲ ਸੈੱਟ ਕਰੋ" ਹੁੰਦਾ ਹੈ, ਉਹ ਬਹੁਤ ਤੇਜ਼ ਅਤੇ ਹੋਰੀਜ਼ੌਂਟਲ ਸਕੇਲ ਕਰਨ ਯੋਗ ਹੋ ਸਕਦੇ ਹਨ।
ਉਹ ਉਨ੍ਹਾਂ ਸਥਿਤੀਆਂ ਲਈ ਵਧੀਆ ਹਨ ਜਿਥੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਲੁੱਕਅਪ ਕੀ ਜਾਣਦੇ ਹੋ (sessions, caching, feature flags), ਪਰ ਵੱਖ-ਵੱਖ ਫੀਲਡਾਂ 'ਤੇ ਆਡ-ਹਾਕ ਕਵੇਰੀਆਂ ਲਈ ਉਹ ਘੱਟ ਬੇਨਤੀ ਵਾਲੇ ਹੁੰਦੇ ਹਨ।
Document databases JSON-ਵਾਂਗ ਦਸਤਾਵੇਜ਼ਾਂ ਨੂੰ (ਅਕਸਰ ਕਲੈਕਸ਼ਨਾਂ ਵਿੱਚ) ਸਟੋਰ ਕਰਦੇ ਹਨ। ਹਰ ਦਸਤਾਵੇਜ਼ ਦਾ ਢਾਂਚਾ ਥੋੜ੍ਹਾ ਵੱਖਰਾ ਹੋ ਸਕਦਾ ਹੈ, ਜੋ ਪ੍ਰੋਡਕਟ ਦੇ ਵਿਕਾਸ ਨੂੰ ਸਮਰਥਨ ਦਿੰਦਾ ਹੈ।
ਇਹ ਪੂਰੇ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਪੜ੍ਹਨ-ਲਿਖਨ ਅਤੇ ਉਸਦੇ ਅੰਦਰਲੇ ਫੀਲਡਾਂ 'ਤੇ ਕਵੇਰੀ ਕਰਨ ਲਈ ਓਪਟੀਮਾਈਜ਼ਡ ਹਨ—ਬਿਨਾਂ ਕਠੋਰ ਟੇਬਲਾਂ ਨੂੰ ਜ਼ਬਰਦستی ਕਰਨ ਦੇ। ਟਰੇਡ-ਆਫ: ਸੰਬੰਧਾਂ ਨੂੰ ਮਾਡਲ ਕਰਨਾ ਮੁਸ਼ਕਲ ਹੋ ਸਕਦਾ ਹੈ, ਅਤੇ ਜੋਇਨਾਂ (ਜੋ ਮੌਜੂਦ ਹੋਣ) ਰਿਲੇਸ਼ਨਲ ਸਿਸਟਮਾਂ ਨਾਲੋਂ ਘੱਟ ਹੋ ਸਕਦੇ ਹਨ।
Wide-column ਡੇਟਾਬੇਸ (Bigtable ਤੋਂ ਪ੍ਰਭਾਵਿਤ) ਡੇਟਾ ਨੂੰ ਰੋ ਕੁੰਜੀਆਂ ਵੱਲੋਂ ਸੰਗਠਿਤ ਕਰਦੇ ਹਨ, ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਹਰ ਰੋ ਲਈ ਬਹੁਤ ਸਾਰੇ ਕਾਲਮ ਹੋ ਸਕਦੇ ਹਨ। ਇਹ ਵੱਡੇ ਲਿਖਾਈ ਦਰਾਂ ਅਤੇ ਵਿਤਰਿਤ ਸਟੋਰੇਜ ਲਈ ਉਚਿਤ ਹਨ—ਟਾਈਮ-ਸੀਰੀਜ਼, ਈਵੈਂਟ ਅਤੇ ਲੌਗ ਵਰਕਲੋਡ ਲਈ ਮਜ਼ਬੂਤ ਫਿੱਟ।
ਇਹ ਅਕਸਰ ਪ੍ਰਧਾਨ ਕੀ ਅਤੇ ਕਲਸਟਰਿੰਗ ਨਿਯਮਾਂ ਦੇ ਆਧਾਰ 'ਤੇ ਕੁਸ਼ਲ ਪ੍ਰਸ਼ਨ ਕਰਨ ਨੂੰ ਇਨਾਮ ਦਿੰਦੇ ਹਨ, ਨਾ ਕਿ ਮਨਮਾਨੇ ਫਿਲਟਰਾਂ ਨੂੰ।
Graph databases ਰਿਸ਼ਤੀਆਂ ਨੂੰ ਪਹਿਲੀ ਜਨਤਕਤਾ ਵਜੋਂ ਮੰਨਦੇ ਹਨ। ਟੇਬਲਾਂ ਨੂੰ ਜ਼ੋਰ-ਜ਼ੋਰ ਜੋੜਨ ਦੀ ਥਾਂ, ਇਹ ਨੋਡਸ ਦੇ ਦਰਮਿਆਨ ਏਜਜ਼ ਦੀ ਯਾਤਰਾ ਕਰਦੇ ਹਨ, ਜਿਸ ਨਾਲ "ਇਹ ਚੀਜ਼ਾਂ ਕਿਵੇਂ ਜੁੜੀਆਂ ਹਨ?" ਤਰ੍ਹਾਂ ਦੀਆਂ ਕਵੇਰੀਆਂ ਕੂਦਰਤੀ ਅਤੇ ਤੇਜ਼ ਹੋ ਜਾਂਦੀਆਂ ਹਨ (ਧੋਖਾ-ਚਲਾਉਣ ਵਾਲੇ ਘਰੰਟ, ਸਿਫਾਰਸ਼ਾਂ, ਨਿਰਭਰਤਾ ਗ੍ਰਾਫ)।
ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸ ਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਨੂੰ ਪ੍ਰੋਤਸਾਹਿਤ ਕਰਦੇ ਹਨ: ਡੇਟਾ ਨੂੰ ਬਹੁਤ ਸਾਰੀਆਂ ਟੇਬਲਾਂ ਵਿੱਚ ਵੰਡੋ ਅਤੇ ਜਵਾਬ ਵੇਲੇ ਜੋਇਨਾਂ ਨਾਲ ਮੁੜ ਜੋੜੋ। کئی NoSQL ਸਿਸਟਮ ਤੁਹਾਨੂੰ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਐਕਸੈਸ ਪੈਟਰਨਸ ਦੇ ਆਲੇ-ਦੁਆਲੇ ਡਿਜ਼ਾਈਨ ਕਰਨ ਲਈ ਧੱਕਦੇ ਹਨ—ਝਣਕਤਾ ਤੇ ਨੀਤੀ-ਕਾਪੀ ਕਰਕੇ, ਜ਼ਿਆਦਾ ਨਕਲ ਕਰਨ ਦੇ ਮੁੱਲ 'ਤੇ—ਤਾਂ ਜੋ ਨੋਡਸ 'ਤੇ ਲੈਟੈਂਸੀ ਪੇਸ਼ਗੀ ਬਣੀ ਰਹੇ।
ਵਿਤਰਿਤ ਡੇਟਾਬੇਸਾਂ ਵਿੱਚ, ਇੱਕ ਜੋਇਨ ਨੂੰ ਕਈ ਪਾਰਟੀਸ਼ਨਾਂ ਜਾਂ ਮਸ਼ੀਨਾਂ ਤੋਂ ਡੇਟਾ ਖਿੱਚਣ ਦੀ ਲੋੜ ਪੈਂਦੀ ਹੈ। ਇਸ ਨਾਲ ਨੈੱਟਵਰਕ ਹਿਟਸ, ਕੋਆਰਡੀਨੇਸ਼ਨ, ਅਤੇ ਅਣਪ੍ਰੀਡਿਕਟੇਬਲ ਲੈਟੈਂਸੀ ਵਧਦੀ ਹੈ। ਡੇਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ (ਸੰਬੰਧਿਤ ਡੇਟਾ ਨੂੰ ਇਕੱਠੇ ਸਟੋਰ ਕਰਨਾ) ਰਾਊਂਡ-ਟ੍ਰਿਪ ਘਟਾਉਂਦਾ ਅਤੇ ਪੜ੍ਹਾਈ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ "ਲੋਕਲ" ਰੱਖਦਾ ਹੈ।
ਇੱਕ ਪ੍ਰਭਾਵੀ ਨਤੀਜਾ: ਤੁਸੀਂ orders ਰਿਕਾਰਡ ਵਿੱਚ ਇੱਕੋ ਹੀ ਖਰੀਦਦਾਰ ਦਾ ਨਾਮ ਸਟੋਰ ਕਰ ਸਕਦੇ ਹੋ, ਚਾਹੇ ਇਹ customers ਵਿੱਚ ਵੀ ਹੋਵੇ, ਕਿਉਂਕਿ "ਆਖਰੀ 20 orders" ਇੱਕ ਬੁਨਿਆਦੀ ਕਵੇਰੀ ਹੈ।
ਕਈ NoSQL ਡੇਟਾਬੇਸ ਸੀਮਤ ਜੋਇਨ (ਜਾਂ ਕੋਈ) ਸਮਰਥਨ ਕਰਦੇ ਹਨ, ਇਸ ਲਈ ਐਪਲੀਕੇਸ਼ਨ ਨੂੰ ਵਧੇਰੇ ਜ਼ਿੰਮੇਵਾਰੀ ਲੈਣੀ ਪੈਂਦੀ ਹੈ:
ਇਸ ਲਈ NoSQL ਮਾਡਲਿੰਗ ਆਮ ਤੌਰ 'ਤੇ ਇਹ ਪ੍ਰਸ਼ਨ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ: "ਸਾਡੇ ਨੂੰ ਕਿਹੜੇ ਸਕ੍ਰੀਨ ਲੋਡ ਕਰਨੇ ਹਨ?" ਅਤੇ "ਉਹਨਾਂ ਦੀਆਂ ਟਾਪ ਕਵੇਰੀਜ਼ ਕੀ ਹਨ?"
ਸੈਕੰਡਰੀ ਇੰਡੈਕਸ ਨਵੇਂ ਕਵੇਰੀਆਂ ਨੂੰ ਯੋਗ ਕਰ ਸਕਦੇ ਹਨ ("ইਮੇਲ ਰਾਹੀਂ ਯੂਜ਼ਰ ਲੱਭੋ"), ਪਰ ਉਹ ਮੁਫ਼ਤ ਨਹੀਂ ਹੁੰਦੇ। ਵਿੱਤ ਕੀਤਾ ਲਿਖਾਈ ਹਰ ਲਿਖਾਈ 'ਤੇ ਕਈ ਇੰਡੈਕਸ ਨੂੰ ਅਪਡੇਟ ਕਰਨਾ ਪੈਂਦਾ, ਜਿਸ ਨਾਲ:
user_profile_summary ਰਿਕਾਰਡ ਰੱਖੋ ਤਾਂ ਕਿ ਪ੍ਰੋਫ਼ਾਈਲ ਪੇਜ਼ ਬਿਨਾਂ ਪੋਸਟਸ, ਲਾਈਕਸ, ਫਾਲੋਜ਼ ਦੇ ਸਕੈਨ ਤੋਂserve ਹੋ ਜਾਵੇNoSQL ਇਸ ਲਈ ਗ੍ਰਹਿਣ ਨਹੀਂ ਕੀਤਾ ਗਿਆ ਕਿ ਇਹ ਹਮੇਸ਼ਾਂ "ਬਿਹਤਰ" ਸੀ। ਇਹ ਇਸ ਲਈ ਚੁਣਿਆ ਗਿਆ ਕਿ ਟੀਮਾਂ ਨੇ ਰਿਲੇਸ਼ਨਲ ਡੇਟਾਬੇਸਾਂ ਦੀਆਂ ਕੁਝ ਸੁਵਿਧਾਵਾਂ ਨੂੰ ਬਦਲੇ ਵਿੱਚ ਤੇਜ਼ੀ, ਸਕੇਲ ਅਤੇ ਲਚਕੀਲਾਪਨ ਲਈ ਤਿਆਗ ਦਿੱਤਾ।
ਡਿਜ਼ਾਈਨ ਅਨੁਸਾਰ ਸਕੇਲ-ਆਊਟ। ਕਈ NoSQL ਸਿਸਟਮਾਂ ਨੇ ਮਸ਼ੀਨਾਂ ਜੋੜ ਕੇ ਸਕੇਲ ਕਰਨਾ ਪ੍ਰਯੋਗੀ ਬਣਾਇਆ। ਸ਼ਾਰਡਿੰਗ ਅਤੇ ਰੀਪਲੀਕੇਸ਼ਨ ਮੁੱਖ ਸਮਰੱਥਾਵਾਂ ਬਣ ਗਈਆਂ।
ਲਚਕੀਲੇ ਸਕੀਮਾਂ। ਦਸਤਾਵੇਜ਼ ਅਤੇ ਕੀ-ਵੈਲਿਫ਼ ਸਿਸਟਮਾਂ ਨੇ ਐਪਲੀਕੇਸ਼ਨਾਂ ਨੂੰ ਹਰੇਕ ਫੀਲਡ ਬਦਲਾਅ ਲਈ ਕਠੋਰ ਟੇਬਲ ਡਿਫਿਨੀਸ਼ਨ ਰਾਹੀਂ ਗੁਜ਼ਰਨਾ ਘਟਾ ਦਿੱਤਾ, ਜੋ ਹਫ਼ਤਾਵਾਰੀ ਬਦਲਾਅ ਦੇ ਵੇਲੇ ਰੂਕਾਵਟ ਨੂੰ ਘਟਾਉਂਦਾ।
ਉਪਲਬਧਤਾ ਪੈਟਰਨ। ਨੋਡਸ ਅਤੇ ਖੇਤਰਾਂ 'ਚ ਰੀਪਲੀਕੇਸ਼ਨ ਨੇ ਸੇਵਾਵਾਂ ਨੂੰ ਹਾਰਡਵੇਅਰ ਫੇਲਿਅਰ ਜਾਂ ਮੈਂਟੇਨੈਂਸ ਦੌਰਾਨ ਚੱਲਦਿਆਂ ਰੱਖਣਾ ਆਸਾਨ ਕੀਤਾ।
ਡੇਟਾ ਨਕਲ ਅਤੇ ਡੇਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ। ਜੋਇਨਾਂ ਤੋਂ ਬਚਣ ਲਈ ਡਾਟਾ ਅਕਸਰ ਕ੍ਰਮੜੀ ਹੁੰਦੀ ਹੈ। ਇਸ ਨਾਲ ਰੀਡ ਪ੍ਰਦਰਸ਼ਨ ਸੁਧਰਦਾ ਹੈ ਪਰ ਸਟੋਰੇਜ ਵਧਦਾ ਅਤੇ "ਹਰ ਥਾਂ ਅੱਪਡੇਟ ਕਰੋ" ਦੀ ਜਟਿਲਤਾ ਹੈ।
ਕਾਂਸਿਸਟੈਂਸੀ ਦੇ ਆਸ਼ਚਰਜ। ਆਖ਼ਰੀ-ਤੱਕ-ਕਾਂਸਿਸਟੈਂਸੀ ਕਈ ਵਾਰੀ ਚਲ ਜਾਏ—ਜਦ ਤੱਕ ਇਹ ਨਹੀਂ ਹੁੰਦਾ। ਯੂਜ਼ਰ ਸਟੇਲ ਡੇਟਾ ਜਾਂ ਗੁੰਝਲਦਾਰ ਕੋਨੇ-ਕੋਨੇ ਦੇ ਕੇਸ ਵੇਖ ਸਕਦੇ ਹਨ ਜੇ ਐਪਲੀਕੇਸ਼ਨ ਠੀਕ ਤਰ੍ਹਾਂ ਨਹੀਂ ਡਿਜ਼ਾਈਨ ਕੀਤਾ।
ਕਦੇ-ਕਦੇ ਮੁਸ਼ਕਲ ਏਨਾਲਿਟਿਕਸ। ਕੁਝ NoSQL ਸਟੋਰ ਆਪਰੇਸ਼ਨਲ ਰੀਡ/ਰਾਈਟ ਵਿੱਚ ਬਹੁਤ ਚੰਗੇ ਹਨ ਪਰ ਐਡ-ਹਾਕ ਕਵੇਰੀ, ਰਿਪੋਰਟਿੰਗ, ਜਾਂ ਜਟਿਲ ਐਗਰੀਗੇਸ਼ਨਾਂ ਨੂੰ SQL-ਮੁੱਖ ਸਿਸਟਮਾਂ ਨਾਲੋਂ ਔਖਾ ਕਰ ਦਿੰਦੇ ਹਨ।
ਸ਼ੁਰੂਆਤੀ NoSQL ਅਪਨਾਵਟ ਨੇ ਅਕਸਰ ਕੋਸ਼ਿਸ਼ ਡੇਟਾਬੇਸ ਫੀਚਰਾਂ ਤੋਂ ਇੰਜੀਨੀਅਰਿੰਗ ਅਨੁਸ਼ਾਸਨ ਵੱਲ ਸ਼ਿਫਟ ਕੀਤੀ: ਰੀਪਲੀਕੇਸ਼ਨ ਮਾਨੀਟਰਿੰਗ, ਪਾਰਟੀਸ਼ਨਾਂ ਦਾ ਪ੍ਰਬੰਧ, ਕੰਪੈਕਸ਼ਨ ਚਲਾਉਣਾ, ਬੈਕਅਪ/ਰਿਸਟੋਰ ਯੋਜਨਾ, ਅਤੇ ਫੇਲਿਅਰ ਸੇਨੇਰੀਓਜ਼ ਲਈ ਲੋਡ-ਟੈਸਟਿੰਗ। ਓਪਰੇਸ਼ਨਲ ਮੁਹੱਈਆ থੀਮ ਵਾਲੀਆਂ ਟੀਮਾਂ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਲਾਭ ਉਠਾਉਂਦੀਆਂ ਹਨ।
ਲੋਡ ਕਰੋ: ਉਮੀਦ ਕੀਤੀ ਲੈਟੈਂਸੀ, ਚੋਟੀ ਦੀ ਥਰੂਪੁੱਟ, ਪ੍ਰਮੁੱਖ ਕਵੇਰੀ ਪੈਟਰਨ, ਪੁਰਾਣੇ-ਡੇਟਾ ਲਈ ਸਹਿਣਸ਼ੀਲਤਾ, ਅਤੇ ਰਿਕਵਰੀ ਦੀਆਂ ਲੋੜਾਂ (RPO/RTO)। ਸਹੀ NoSQL ਚੋਣ ਉਹ ਹੁੰਦੀ ਹੈ ਜੋ ਤੁਹਾਡੇ ਐਪਲੀਕੇਸ਼ਨ ਦੇ ਫੇਲ-ਸਿਸਟਮ, ਸਕੇਲ ਅਤੇ ਕਿਵੇਂ ਕਵੇਰੀ ਕਰਨਾ ਹੈ ਨਾਲ ਮੇਲ ਖਾਂਦੀ ਹੋਵੇ—ਨਹੀਂ ਕਿ ਜਿਸਦੇ ਕੋਲ ਸਭ ਤੋਂ ਸ਼ਾਨਦਾਰ ਚੈੱਕਲਿਸਟ ਹੋਵੇ।
NoSQL ਚੁਣਨਾ ਡੇਟਾਬੇਸ ਬਰਾਂਡਾਂ ਜਾਂ ਹਾਈਪ ਨਾਲ ਸ਼ੁਰੂ ਨਹੀਂ ਕਰਨਾ ਚਾਹੀਦਾ—ਇਹ ਤੁਹਾਡੇ ਐਪ ਦੀਆਂ ਜ਼ਰੂਰਤਾਂ, ਵਧਤ, ਅਤੇ ਯੂਜ਼ਰਾਂ ਲਈ "ਸਹੀ" ਦਾ ਕੀ ਮਤਲਬ ਹੈ ਨਾਲ ਸ਼ੁਰੂ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ।
ਡੇਟਾਸਟੋਰ ਚੁਣਨ ਤੋਂ ਪਹਿਲਾਂ ਲਿਖੋ:
ਜੇ ਤੁਸੀਂ ਆਪਣੀਆਂ ਐਕਸੈਸ ਪੈਟਰਨਸ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਨਹੀਂ ਲਿਖ ਸਕਦੇ, ਤਾਂ ਕੋਈ ਵੀ ਚੋਣ ਅਨੁਮਾਨੀ ਰਹੇਗੀ—ਖ਼ਾਸ ਕਰਕੇ NoSQL ਵਿੱਚ, ਜਿਥੇ ਮਾਡਲਿੰਗ ਅਕਸਰ ਪੜ੍ਹਨ/ਲਿਖਨ ਦੇ ਆਧਾਰ 'ਤੇ ਬਣਦੀ ਹੈ।
ਇੱਕ ਵਰਤਨੀਕ ਸੰਕੇਤ: ਜੇ ਤੁਹਾਡਾ "ਕੋਰ ਸੱਚ" (orders, payments, inventory) ਹਰ ਵੇਲੇ ਸਹੀ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ, ਤਾਂ ਉਸਨੂੰ SQL ਜਾਂ ਕਿਸੇ ਹੋਰ ਮਜ਼ਬੂਤ ਸਟੋਰ ਵਿੱਚ ਰੱਖੋ। ਜੇ ਤੁਸੀਂ ਉੱਚ-ਵਾਲੀਉ ਸੰਪੱਤੀ, sessions, caching, activity feeds, ਜਾਂ ਲਚਕੀਲੇ ਯੂਜ਼ਰ-ਜਨਰੇਟੇਡ ਡੇਟਾ ਸੇਵਾ ਕਰ ਰਹੇ ਹੋ, NoSQL ਚੰਗਾ ਫਿਟ ਹੋ ਸਕਦਾ ਹੈ।
ਕਈ ਟੀਮਾਂ ਕਈ ਸਟੋਰਾਂ ਨਾਲ ਸਫਲ ਹੁੰਦੀਆਂ ਹਨ: ਉਦਾਹਰਣ ਲਈ, ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਲਈ SQL, ਪ੍ਰੋਫਾਈਲ/ਕੰਟੈਂਟ ਲਈ ਦਸਤਾਵੇਜ਼ ਡੇਟਾਬੇਸ, ਅਤੇ sessions ਲਈ ਕੀ-ਵੈਲਿਫ਼ ਸਟੋਰ। ਮਕਸਦ ਸਿਰਫ਼ ਜਟਿਲਤਾ ਨਹੀਂ—ਹਰ ਵਰਕਲੋਡ ਨੂੰ ਉਸ ਟੂਲ ਨਾਲ ਮਿਲਾਉਣਾ ਹੈ ਜੋ ਉਸਨੂੰ ਸਾਫ਼ ਸੰਭਾਲੇ।
ਇਹ ਓਥੇ ਹੈ ਜਿੱਥੇ ਡਿਵੈਲਪਰ ਵਰਕਫਲੋ ਮਹੱਤਵਪੂਰਣ ਹੋਂਦਾ ਹੈ। ਜੇ ਤੁਸੀਂ ਆਰਕੀਟੈਕਚਰ 'ਤੇ ਇਤਰੈਟ ਕਰ ਰਹੇ ਹੋ, ਤਾਂ ਇਕ ਕਾਰਯਸ਼ੀਲ ਪ੍ਰੋਟੋਟਾਈਪ ਤੇਜ਼ੀ ਨਾਲ ਖੜਾ ਕਰਨਾ—API, ਡੇਟਾ ਮਾਡਲ, ਅਤੇ UI—ਫੈਸਲਿਆਂ ਨੂੰ ਘੱਟ ਜੋਖਿਮ ਵਾਲਾ ਬਣਾ ਸਕਦਾ ਹੈ। ਪਲੇਟਫਾਰਮਾਂ ਜਿਵੇਂ Koder.ai ਟੀਮਾਂ ਨੂੰ ਚੈਟ ਤੋਂ ਪੂਰਾ-ਸਟੈਕ ਐਪ ਜਨਰੇਟ ਕਰਕੇ ਇਹ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀਆਂ ਹਨ, ਆਮ ਤੌਰ 'ਤੇ React frontend ਅਤੇ Go + PostgreSQL backend ਨਾਲ, ਫਿਰ ਤੁਹਾਨੂੰ ਸਰੋਤ ਕੋਡ ਐਕਸਪੋਰਟ ਕਰਨ ਦਿੰਦੇ ਹਨ। ਭਾਵੇਂ ਤੁਸੀਂ ਬਾਅਦ ਵਿੱਚ ਨਿਯਮਤ NoSQL ਸਟੋਰ ਕਿਸੇ ਨਿਰਧਾਰਿਤ ਵਰਕਲੋਡ ਲਈ ਸ਼ਾਮਿਲ ਕਰੋ, ਪ੍ਰਮਾਣਿਤ SQL "ਸਿਸਟਮ ਆਫ ਰਿਕਾਰਡ" ਨਾਲ ਤੇਜ਼ ਪ੍ਰੋਟੋਟਾਈਪਿੰਗ, ਸਨੈਪਸ਼ਾਟਸ, ਅਤੇ ਰੋਲਬੈਕ ਪ੍ਰयोगਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਅਤੇ ਤੇਜ਼ ਬਣਾਉਂਦਾ ਹੈ।
ਜੋ ਵੀ ਤੁਸੀਂ ਚੁਣੋ, ਉਸ ਨੂੰ ਪਰਖੋ:
ਜੇ ਤੁਸੀਂ ਇਹ ਸਾਰੇ ਸੈਨੇਰੀਓ ਨਹੀਂ ਟੈਸਟ ਕਰ ਸਕਦੇ, ਤਾਂ ਤੁਹਾਡਾ ਡੇਟਾਬੇਸ ਫੈਸਲਾ ਥਿਓਰਟਿਕ ਹੀ ਰਹਿ ਜਾਵੇਗਾ—ਅਤੇ ਪ੍ਰੋਡਕਸ਼ਨ ਤੁਹਾਡੇ ਲਈ ਟੈਸਟ ਕਰੇਗਾ।
NoSQL ਨੇ ਦੋ ਆਮ ਦਬਾਵਾਂ ਦਾ ਹੱਲ ਲੱਭਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕੀਤੀ:
ਇਹ ਦੱਸਣਾ ਮੁੱਖ ਹੈ ਕਿ ਇਹ ਇਸ ਲਈ ਨਹੀਂ ਸੀ ਕਿ SQL "ਖਰਾਬ" ਸੀ—ਬੱਸ ਵੱਖ-ਵੱਖ ਵਰਕਲੋਡ ਵੱਖ-ਵੱਖ ਟਰੇਡ-ਆਫ ਨੂੰ ਤਰਜੀਹ ਦਿੰਦੇ ਹਨ।
ਪ੍ਰੰਪਰਾਗਤ "ਸਕੇਲ-ਅੱਪ" ਤਰਕ ਸਾਡੇ ਲਈ ਹੇਠਾਂ ਆ ਗਿਆ:
NoSQL ਸਿਸਟਮਾਂ ਨੇ ਬਾਕੀ ਦੇ ਢਾਂਚੇ 'ਤੇ ਨੋਡ ਜੋੜ ਕੇ ਸਕੇਲ ਆਊਟ ਦੀ ਔਖੀਨ ਨੂੰ ਸਵੀਕਾਰ ਕੀਤਾ।
ਰਿਲੇਸ਼ਨਲ ਸਕੀਮਾਂ ਜਾਣ-ਬਝ ਕੇ ਕਠੋਰ ਹੁੰਦੀਆਂ ਹਨ, ਜੋ ਸਥਿਰਤਾ ਲਈ ਬਹਿਲਾ ਹੈ ਪਰ ਤੇਜ਼ ਇਤਰੇਸ਼ਨ ਦੇ ਸਮੇਂ ਵਿੱਚ ਦੁਖਦਾਈ ਬਣ ਸਕਦਾ ਹੈ। ਵੱਡੇ ਟੇਬਲਾਂ 'ਤੇ ਇੱਕ ਛੋਟਾ ਬਦਲਾਅ ਵੀ:
Document-ਸਟਾਈਲ ਮਾਡਲ ਆਮ ਤੌਰ 'ਤੇ ਇਸ ਘਰੜ ਨੂੰ ਘਟਾਉਂਦੇ ਹਨ ਕਿਉਂਕਿ ਉਹ ਵਿਕਾਸਸ਼ੀਲ ਅਤੇ ਵਿਕਲਪਿਕ ਫੀਲਡਸ ਨੂੰ ਸਿੱਧਾ ਸਟੋਰ ਕਰ ਲੈਂਦੇ ਹਨ।
ਜ਼ਰੂਰੀ ਨਹੀਂ। ਬਹੁਤ ਸਾਰੇ SQL ਡੇਟਾਬੇਸ ਵੀ ਸਕੇਲ ਆਊਟ ਕਰ ਸਕਦੇ ਹਨ, ਪਰ ਇਹ ਓਪਰੇਸ਼ਨਲ ਤੌਰ 'ਤੇ ਔਖਾ ਹੋ ਸਕਦਾ ਹੈ (ਸ਼ਾਰਡਿੰਗ, ਕ੍ਰਾਸ-ਸ਼ਾਰਡ ਜੌਇਨ, ਵਿਤਰਿਤ ਲੈਣਦੇਣ).
NoSQL ਸਿਸਟਮਾਂ ਨੇ ਆਮ ਤੌਰ 'ਤੇ ਡਿਸਟ੍ਰੀਬਿਊਸ਼ਨ (ਪਾਰਟੀਸ਼ਨਿੰਗ + ਰੀਪਲੀਕੇਸ਼ਨ) ਨੂੰ ਪਹਿਲੀ ਪੰਗਤੀ ਵਜੋਂ ਕਾਇਮ ਕੀਤਾ ਅਤੇ ਖਾਸ, ਭਵਿੱਖਵਾਣੀ ਪੈਟਰਨ ਲਈ ਓਪਟੀਮਾਈਜ਼ ਕੀਤਾ।
ਡੇਟਾ ਨੂੰ ਉਸ ਰੂਪ ਵਿੱਚ ਰੱਖੋ ਜਿਸ ਤਰ੍ਹਾਂ ਤੁਸੀਂ ਉਸਨੂੰ ਪੜ੍ਹਦੇ ਹੋ—ਯਾਨੀ ਅਕਸਰ ਡੇਨਾਰਮਲਾਈਜ਼ੇਸ਼ਨ ਹੋਣੀ ਪੈਂਦੀ ਹੈ, ਜਿਸ ਨਾਲ ਇੱਕੋ-ਇੱਕ ਰੀਕਵੈਸਟ 'ਤੇ ਜਾਣ ਵਾਲੀ ਰਿਕਾਰਡ ਨੂੰ ਸਟੋਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਉਦਾਹਰਣ: orders ਰਿਕਾਰਡ ਵਿੱਚ ਗਾਹਕ ਦਾ ਨਾਮ ਰੱਖਣਾ ਤਾਂ ਜੋ "ਆਖਰੀ 20 orders" ਇੱਕ ਹੀ ਤੇਜ਼ ਪੜ੍ਹਾਈ ਵਿੱਚ ਮਿਲ ਜਾਵੇ।
ਇਸ ਦਾ ਟਰੇਡ-ਆਫ: ਅੱਪਡੇਟਾਂ ਨੂੰ ਹਰ ਥਾਂ ਸਹੀ ਰੱਖਣ ਲਈ ਐਪਲੀਕੇਸ਼ਨ ਲੌਜਿਕ ਜਾਂ ਪਾਈਪਲਾਈਨ ਬਨਾਉਣੇ ਪੈਂਦੇ ਹਨ।
ਨੈੱਟਵਰਕ ਪਾਰਟੀਸ਼ਨਾਂ ਦੇ ਸਮੇਂ, ਡੇਟਾਬੇਸ ਨੇ ਸੋਚਣਾ ਪੈਂਦਾ ਹੈ ਕਿ ਕਦੋਂ ਵੀ ਇਹ ਸਹੀ ਤੌਰ 'ਤੇ ਕੋਆਰਡੀਨੇਟ ਨਹੀਂ ਕਰ ਸਕਦਾ ਤਾਂ ਕੀ ਕਰੇ।
CAP ਸਾਨੂੰ ਯਾਦ ਦਿਲਾਉਂਦਾ ਹੈ ਕਿ ਪਾਰਟੀਸ਼ਨ ਦੇ ਦੌਰਾਨ ਤੁਸੀਂ ਇੱਕੋ-ਸਮੇਂ ਦੋਵਾਂ ਨੂੰ ਪੂਰਾ ਨਹੀਂ ਕਰ ਸਕਦੇ।
ਮਜ਼ਬੂਤ (strong) consistency ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਜਿਵੇਂ ਹੀ ਇੱਕ ਲਿਖਾਈ ਤਸਦੀਕ ਹੋ ਜਾਵੇ, ਸਾਰੇ ਰੀਡਰ ਉਸ ਨੂੰ ਤੁਰੰਤ ਵੇਖਣ। ਇਹ ਅਕਸਰ ਨੋਡਸ ਵਿੱਚ ਕੋਆਰਡੀਨੇਸ਼ਨ ਮੰਗਦਾ ਹੈ।
Eventual consistency ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਰੀਪਲਿਕਾ ਆਰੰਭਿਕ ਤੌਰ 'ਤੇ ਵੱਖਰੇ ਜਵਾਬ ਦੇ ਸਕਦੇ ਹਨ, ਪਰ ਕੁਝ ਸਮੇਂ ਬਾਅਦ ਸਿਸਟਮ ਮਿਲ ਜੁਲ ਕੇ ਸਮਾਨ ਹੋ ਜਾਏਗਾ। ਇਹ ਫੀਡਜ਼, ਕਾਊਂਟਰਜ਼ ਅਤੇ ਉੱਚ-ਉਪਲਬਧਤਾ ਵਾਲੀਆਂ ਯੂਜ਼ਰ ਅਨੁਭਵਾਂ ਲਈ ਕਾਫੀ ਹੁੰਦਾ ਹੈ—ਜੇ ਐਪਲੀਕੇਸ਼ਨ ਥੋੜ੍ਹੀ ਪੁਰਾਣੀ ਜਾਣਕਾਰੀ ਸਹਿਣ ਕਰ ਸਕਦੀ ਹੋਵੇ।
ਟਕਰਾਅ ਉਸ ਵੇਲੇ ਹੁੰਦੇ ਹਨ ਜਦੋਂ ਵੱਖ-ਵੱਖ ਰੀਪਲਿਕਾਜ਼ ਨੇ ਇਕੱਠੇ-ਇੱਕੋ ਸਮੇਂ ਅੱਪਡੇਟ ਸਵੀਕਾਰ ਲਿਆ। ਆਮ ਰਣਨੀਤੀਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
ਤੁਹਾਡਾ ਚੋਣ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰੇਗੀ ਕਿ ਕੀ ਮੱਧ-ਅਪਡੇਟ ਲੁੱਟ ਜਾਣਾ ਬਰਦਾਸ਼ਤ ਹੈ ਜਾਂ ਨਹੀਂ।
ਛੇਤੀ ਮੇਲ-ਮਿਲਾਪ ਲਈ ਇੱਕ ਤੇਜ਼ ਡਿਸਟ੍ਰੀਬਿਊਟਡ ਹੈਸ਼ਮੇਪ ਵਾਂਗ key-value ਸਟੋਰ ਬਣਾ ਦਿੰਦੇ ਹਨ।
ਇਹ ਉਹਥੇ ਚੰਗੇ ਹਨ ਜਿੱਥੇ ਤੁਸੀਂ ਪਹਿਲਾਂ ਹੀ ਲੁੱਕਅਪ ਕੀ ਜਾਣ ਹੋ (sessions, caching, feature flags), ਪਰ ਇਨ੍ਹਾਂ ਦਾ ਇरਾਦਾ ਅਕਸਰ ਕਈ ਫੀਲਡਾਂ 'ਤੇ ਫਿਲਟਰਿੰਗ ਨਹੀਂ ਹੁੰਦੀ।
ਆਪਣੀਆਂ ਡੋਮਿਨ-ਸਪੈਸੀਫਿਕ ਐਕਸੈਸ ਪੈਟਰਨਸ ਦੇ ਅਧਾਰ 'ਤੇ ਚੁਣੋ—ਨਾਮ ਹੀ ਨਹੀਂ।
ਆਪਣੀ ਲੋੜਾਂ ਨਾਲ ਸ਼ੁਰੂ ਕਰੋ ਅਤੇ ਹੋਰ ਕੀਮਤਾਂ/ਗ੍ਰੋਥ ਨਾਲ ਪ੍ਰਮਾਣਿਤ ਕਰੋ:
ਅਕਸਰ ਹਾਈਬ੍ਰਿਡ ਹੀ ਸਹੀ ਹੁੰਦਾ ਹੈ: SQL ਟਰਾਂਜ਼ੈਕਸ਼ਨ ਲਈ, NoSQL ਉੱਚ-ਵਾਲਿਊ ਜਾਂ ਲਚਕੀਲੇ ਡਾਟਾ ਲਈ।